Table of Contents
Normality and Data transformation
Introduction
Data transformation is a powerful tool when the data don't look like forming a normal distribution. The idea of data transformation is that you convert your data so that you can assume the normality and use parametric tests. To determine whether we need any data transformation, we need to check the normality of the data. Although there are several statistical methods for checking the normality, what you should do is to look at a histogram and QQ-plot, and then run a test for checking the normality. You also should read the section for the differences of the two statistical methods explained in this page.
One important point of data transformation is that you must defend that your data transformation is legitimate. You cannot do arbitrary data transformation so that you can get results you want to get. Make sure you clarify why you do data transformation and why it is appropriate.
Histogram
We prepare data by using a random function. To be able to reproduce the results quickly, we set the seed for the random functions.
This means that we are randomly taking 20 samples from the normal distribution with mean = 0 and sd = 1. I set the specific seed so that you can reproduce the same data_normal. So, the values will be changed every time you execute this. In my case, it looked like this.
We will also prepare another kind of data for comparison.
data_exp are created from a different distribution (an exponential distribution).
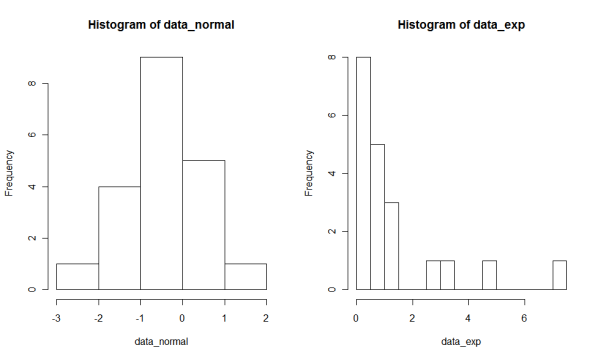
One good practice before doing any statistical test for normality and data transformation is to look at the histogram of the data. This gives you a good picture of what the data look like, and whether you really need data transformation. In R, you can use hist() function to create a histogram.
The hist() function automatically selects the width of each bin in a histogram. You can try different algorithms to determined the number of bins by specifying the breaks option. In my experience, “FD” works well for many cases. Here is the example of histograms. To make the comparison easier, we put the two histograms into one window.
Q-Q plot
Another way to visually investigate whether data forms the normal distribution is to draw a Q-Q plot. A Q-Q plot shows the mapping between the distribution of the data and the ideal distribution (the normal distribution in this case). Let's take a look at it.
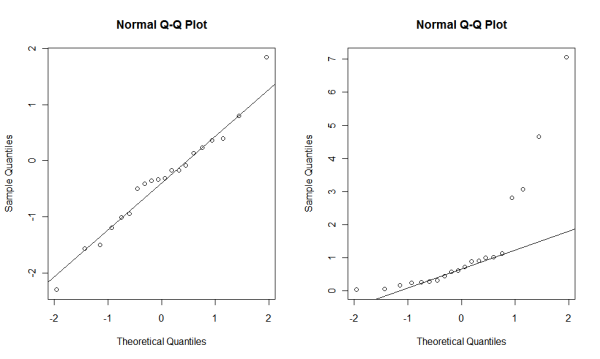
If your data are close to the normal distribution, most of the data points should be close to the line. So obviously, some of the data points in data_exp are far from the line, which means that it is less likely that data_exp were taken from the normal distribution.
Statistical tests for normality
If the histogram of your data doesn't really look like a normal distribution, you should try a statistical test to check the normality. Fortunately, this is pretty easy in R. There are two common tests you can use for the normality check.
Shapiro-Wilk test
One common test for checking the normality is Shapiro-Wilk test. This test works well even for a small sample size, so generally you just need to use this.
The null hypothesis of Shapiro-Wilk test is that the samples are taken from a normal distribution. So, if the p value is less than 0.05, you reject the hypothesis, and thinks that the samples are not taken from a normal distribution. In R, you just need to use shapiro.test() function to do Shapiro-Wilk test.
And you get the result.
In this case, you can still assume the normality. Let's try the same test with data_exp.
So, we reject the null hypothesis, and the samples are not considered to be taken from a normal distribution. Thus, you need to do data transformation or use a non-parametric test.
Kolmogorov-Smirnov test
Another test you can use for checking the normality is Kolmogorov-Smirnov test. This test basically checks whether two datasets are taken from the same distribution, but it can be used for comparing one dataset against an ideal distribution (int this case, a normal distribution). This test is also quite easy to do in R.
Here, we are comparing the data against a normal distribution (“pnorm”) with the mean and standard deviation calculated from the dataset.
The result says that we can still assume the normality. Let's take a look at the test with data_exp.
We reject the null hypothesis that data_exp were taken from the normal distribution.
Because Kolmogorov-Smirnov test is not only for comparing the dataset against the normal distribution, you can make a comparison with other kinds of distributions. Let's try to make a comparison between data_exp and an exponential distribution. You can use “pexp” instead of “pnorm”, but you need to be a little careful about calculating the mean and standard deviation for a log-normal transformation.
So, we can think that data_exp were more likely taken from a log-normal distribution rather a normal distribution. You can also use this test for comparing the two distributions (the null hypothesis is that both datasets were originated form the same distributions).
Which test should I use?
Generally, Kolmogorov-Smirnov test becomes less sensitive (less powerful to detect a significant effect) when the sample size is small. It is hard to say which number is considered as small or large, but it is said that Kolmogorov-Smirnov test is more appropriate if your sample size is the order of 1000.
However, some people use Kolmogorov-Smironov test even if they have a small sample size. One reason is probably that Shapiro-Wilk test is often too strict and often shows a significant result even if the true population has the normality. So it is fairly common that you see a significant result with Shapiro-Wilk test, but cannot see any significant result with Kolmogorov-Smirnov test.
A general practice on the normality tests I found is to run both tests and see the results. If both of the tests say that you cannot assume the normality, you may have to do a data transformation (explained later) or use a non-parametric test. Some of the parametric tests are fairly robust against the non-normality (particularly a t test and one-way ANOVA). The normality tests mentioned above need a large sample size (which may not be possible in HCI research). Thus, we don't need to be too strict to follow the results of the normality test. Furthermore, when the sample size is small, both tests usually are less powerful than what they should be. So blindly believing the results of those tests could be dangerous. Recently I found that a D'Agostino-Pearson omnibus test and Anderson–Darling test can work better for a small sample size, so please try to find information about these tests if you want to know more about normality tests.
Again, I suggest using a histogram and Q-Q plot. Even if they are subjective ways to check the normality, they still give you a good idea of whether your data really look like a normal distribution or not. So use these plots as well as statistical tests, and see whether you really need to do any data transformation or non-parametric test.
In conclusion, there is no perfect way to judge the normality of data. But histograms, Q-Q plots and normality tests are useful tools to see at least whether your data are really far from the normal distribution or not.
Data transformation
Once you decide to do data transformation, you need to pick up which transformation to use. Although you can do any kind of transformation, there are a few of transformation which are commonly used. You could do other kinds of transformation, but regardless of transformation, you must defend why you decided to use that transformation and why it is appropriate.
You can do parametric tests after you do data transformation. However, when you report the descriptive statistics (e.g., the mean and standard deviation), you need to use the data before the transformation. This is because it doesn't make sense to use the transformed data for those kinds of information. It is probably a good idea to clarify for which analysis you used the transformed data and non-transformed data.
The two most common kinds of data transformation is log transformation and square-root transformation. Log transformation is useful for data which are resulted by the multiplication of various factors. Be careful if you have zero or negative values in your data. You need to add a constant to each data point to make them larger positive and non-zero. If you have count data, and some of the counts are zero, adding 0.5 to each data point is commonly done. Square-root transformation is useful for count data. Make sure you don't have any zero or negative values as well. Ultimately, you will need to determine what data transformation you use based on histograms and statistical tests explained above.
You just apply an appropriate function to the data to do data transformation in R. For instance, if you want to do log transformation, you just need to do:
The base of log does not matter because you can change the base by multiplying a constant. You can use sqrt() function for Square-root transformation.
More discussions about data transformation are available at the following electronic journal. Osborne, Jason (2002). Notes on the use of data transformations. Practical Assessment, Research & Evaluation, 8(6).
Discussion
<a href=http://www.educationhints.eu/>educational websites for students</a> www.educationhints.eu
<a href=http://www.dealhint.eu/>small business internet</a>
www.dealhint.eu
[/url]
[url=http://datingice.com/]Love is one click away!
[/url]
[url=http://rhdating.com/]Free Local Personals
[/url]
[url=http://sexdatingdelight.com/]International delight creamers in singles women
[/url]
http://adultdatingbrisbane.com/
http://datingice.com/
http://rhdating.com/
http://sexdatingdelight.com/
http://zhaine.com/home.php?mod=space&uid=7075
http://klygbh.pw/home.php?mod=space&uid=1468
http://migraciya.com.ua/forum/profile.php?id=18843
http://hywowsf.com/bbs/home.php?mod=space&uid=1115
http://pokemonhelp.net/index.php?action=profile;u=295227
http://nbnote.ru/pbb/profile.php?id=2237
<a href=" http://achatviagraenpharmacieenfrance.com/ ">achat viagra en pharmacie sans ordonnance</a>
<a href=" http://achetersildenafilenligne.com/ ">acheter sildenafil en ligne</a>
<a href=" http://acheterviagraenlignelivraison24h.com/ ">acheter viagra en ligne livraison 24h </a>
<a href=" http://sildenafil100mgprixenpharmacieenfrance.com/ ">viagra 100mg prix tunisie </a>
<a href=" http://sildenafilpascherenfrance.com/ ">sildenafil pas cher en france </a>
<a href=" http://sildenafilpfizer50mgprix.com/ ">sildenafil pfizer 50 mg ГЎra - sildenafil pfizer 50 mg ГЎra: </a>
<a href=" http://viagraenventelibreenfrance.com/ ">le viagra est il en vente libre en pharmacie </a>
<a href=" http://viagrapascherlivraisonrapide.com/ ">viagra moins cher france </a>
<a href=" http://xn--viagragnriquelivresous48h-hicb.com/ ">viagra gГ©nГ©rique quГ©bec </a>
http://ljw520.com/home.php?mod=space&uid=42321
http://hongtuly.com/home.php?mod=space&uid=70461
http://www.0746sq.com/home.php?mod=space&uid=421263
http://www.wuxiloves.com/home.php?mod=space&uid=119719
http://myprerogative.iobloggo.com/archive.php
http://longfeng520.cc/space-uid-22649.html
http://www.datalife-engine.aq.pl/index.php?subaction=userinfo&user=Polosduh
http://yzboss.com/home.php?mod=space&uid=16843
http://www.hearttaqah.net/member.php?u=2567
http://forum.dpt-isaar.ir/member.php?action=profile&uid=1300
<a href=" http://xn--cialisgnriquepascher-h2bb.com/ ">cialis generique moins cher </a>
<a href=" http://cialissansordonnanceenfrance.com/ ">cialis sans ordonnance pharmacie paris </a>
<a href=" http://achetercialisenfrancesitefiable.com/ ">acheter cialis en france pas cher </a>
<a href=" http://achetercialis20mgenligne.com/ ">achat cialis 20mg en ligne </a>
<a href=" http://achetercialissansordonnanceenpharmacie.com/ ">ou acheter du cialis sans ordonnance a paris </a>
<a href=" http://achatcialisenfrancelivraisonrapide.com ">acheter cialis en france </a>
<a href=" http://achatcialis5mgenligne.com/ ">achat tadalafil 5mg </a>
<a href=" http://tadalafil20mgpaschereninde.com/ ">cialis 20mg pas cher paris </a>
<a href=" http://achetertadalafil20mgpascher.com/ ">acheter tadalafil 20mg </a>
<a href=" http://achetertadalafilsansordonnance.com/ ">ou acheter du cialis sans ordonnance en france </a>
<a href=" http://achattadalafilenfranceenpharmacie.com/ ">acheter cialis en france sans ordonnance </a>
<a href=" http://achattadalafil10mgprix.com/ ">achat cialis 10mg </a>
<a href=" http://acheterprednisone20mgenligne.com/ ">acheter prednisone 20 mg en ligne </a>
<a href=" http://acheterpropeciasurinternet.com/ ">acheter propecia sur internet </a>
<a href=" http://achatpropeciaparcartebancaire.com/ ">achat propecia par carte bancaire </a>
<a href=" http://achatamoxicillinebiogaran1g.com/ ">achat amoxicilline biogaran 1g </a>
<a href=" http://amoxicillineprixpharmacie.com/ ">amoxicilline prix algerie </a>
<a href=" http://acheterclomid100mgsurinternetpascher.com/ ">acheter clomid 100mg sur internet pas cher </a>
<a href=" http://acheterventolinespraysansordonnance.com/ ">acheter ventolin spray sans ordonnance </a>
<a href=" http://achatventolinesansordonnance.com/ ">achat ventoline - achat ventoline: </a>
http://auto.raspisaninemsk.ru/raspisanie-avtobusa-noginsk-moskva-marshrutka/ расписание автобуса ногинск москва маршрутка
http://pd.raspisaninemsk.ru/raspisanie-avtobusov-iz-moskvy-na-kurovskuyu/ расписание автобусов из москвы на куровскую
http://nrv.raspisaninemsk.ru/raspisanie-poezdov-iz-kurska-v-moskvu-na-19-dekabrya/ расписание поездов из курска в москву на 19 декабря
http://elkto.raspisaninemsk.ru/raspisanie-poezdov-kurskiy-vokzal-g-moskvy/ расписание поездов курский вокзал г москвы
http://elkto.raspisaninemsk.ru/vlasovo-moskva-raspisanie/ власово москва расписание
http://bilet.raspisaninemsk.ru/raspisanie-elektrichek-na-moskvu-na-zavtra-iz-podolska/ расписание электричек на москву на завтра из подольска
http://elkto.raspisaninemsk.ru/restoran-na-86-etazhe-moskva-siti-raspisanie/ ресторан на 86 этаже москва сити расписание
http://mt.raspisaninemsk.ru/raspisanie-seansov-v-torgovom-centre-moskva/ расписание сеансов в торговом центре москва
http://nrv.raspisaninemsk.ru/raspisanie-avtobusov-noginsk-moskva-i-394/ расписание автобусов ногинск москва и 394
http://mt.raspisaninemsk.ru/raspisanie-moskva-rubezhnoe/ расписание москва рубежное
<a href=" http://howtogetviagrawithoutadoctorprescription.us/ ">how to get viagra without a doctor prescription </a>
<a href=" http://acheterzithromaxsurinternetenfrance.club/ ">acheter zithromax </a>
[url=http://thebabyboss.us/#the-boss-baby-watch-online-hd]the boss baby watch online hd[/url]
[url=http://thebabyboss.us/#the-boss-baby]the boss baby[/url]
[url=http://thebabyboss.us/#the-boss-baby-movie-2017]the boss baby movie 2017[/url]
http://thebabyboss.us/#when-does-the-movie-boss-baby-come-out
http://www.oekaki.ws/pbbs/pallet_town.html
http://bbs.avatarmind.com/forum.php?mod=viewthread&tid=20&extra=
http://www.lasemaine.org/espace-acteurs/1007/page_acteur#1492382609
http://deathripper.com/phpBB3/viewtopic.php?f=1&t=180937
http://forum.p-pokemon.com/viewtopic.php?pid=1170320#p1170320
<a href=" http://vardenafilprixenpharmacieacaen.com/ ">levitra prix en pharmacie </a>
http://metorsref.info
http://hatwronres.stream
Java j2ee job interview companion free pdf download.zip
http://betsaly.us
http://metorsref.info
PDR6 OEM PACK
http://metorsref.info
http://buthanlac.review
[FULL] stardust
http://hatwronres.stream
http://metorsref.info
N????°N‡?°N‚N? Starbound ???° N‚?µ?»?µn„????
http://metorsref.info
http://betsaly.us
Our Daily Bread 1934 avi
http://hatwronres.stream
http://metorsref.info
Lightning Email Deliverer full download
http://buthanlac.review
http://buthanlac.review
The Emperor Of Scent
http://hatwronres.stream
http://gawronve.trade
Electromagnetic Nondestructive Evaluation XVIII
http://gawronve.trade
http://betsaly.us
???Z??a???1¤771¤77¤777?1
http://metorsref.info
http://wasressof.pro
puppen by rilke rainer maria 1875 1926 pdf downloa
http://gawronve.trade
http://gawronve.trade
Indian constitution book in hindi pdf free download.zip
http://buthanlac.review
http://buthanlac.review
Download turbo pascal windows vista
http://hatwronres.stream
http://metorsref.info
[TRUSTED DOWNLOAD] The Last Slayer Nadia Lee.rar
http://hatwronres.stream
http://wasressof.pro
odin307 rar
<a href="http://nofaxpaydaynq.info#lbaxufkrrkyhahh">fast payday loan
</a>
<a href="http://nofaxpaydaynq.info#yfcnmemrmomihfk">http://nofaxpaydaynq.info
</a>
<a href="http://nofaxpaydaynq.info#fhhhxbaqyrqqtxs">same day loans
</a>
<a href="http://nofaxpaydaynq.info#csfnqbevkdyvyrs">payday loan
</a>
<a href="http://nofaxpaydaynq.info#dheinrkubpfqtqp">cash advance
</a>
<a href="http://nofaxpaydaynq.info#uwdwzcqqxeudadc">online loan
</a>
<a href="http://nofaxpaydaynq.info#yvlccxajjbkupuw">instant loans
</a>
<a href="http://nofaxpaydaynq.info#jbqauketskoyybu">payday loan
</a>
<a href="http://nofaxpaydaynq.info#eiqptasjgofoiqc">http://nofaxpaydaynq.info
</a>
<a href="http://nofaxpaydaynq.info#isbxgdayhbrslrv">first cash advance
</a>
<a href="http://nofaxpaydaynq.info#hgjznzzglhciktr">payday loans near me
</a>
<a href="http://nofaxpaydaynq.info#hmtvbbiuepsatwn">online payday loans
</a>
<a href="http://nofaxpaydaynq.info#sgqcqdkcwhzczbv">fast cash
</a>
<a href="http://nofaxpaydaynq.info#brjropbpjfyskau">instant payday loans
</a>
<a href="http://bestpaydayfast.com#kprxpmbzkomlylk">payday advance online
</a>
<a href="http://bestpaydayfast.com#dlicbpcttfjfnru">installment loans
</a>
<a href="http://bestpaydayfast.com#ualebczycqhfeqx">payday loans bad credit
</a>
<a href="http://bestpaydayfast.com#llupcmkdgcezaff">fast payday loan
</a>
<a href="http://bestpaydayfast.com#ojarciqkvcalmgs">first cash advance
</a>
<a href="http://bestpaydayfast.com#njfhujsxuzxmbwm">payday advance
</a>
<a href="http://bestpaydayfast.com#pwrwqffpbfcyjka">payday loan online
</a>
<a href="http://bestpaydayfast.com#orhjqyeoupvosyp">payday loans
</a>
<a href="http://bestpaydayfast.com#srpdplrztcwoqvt">quick cash
</a>
<a href="http://bestpaydayfast.com#mkeuobsbjmpeqbt">need cash now
</a>
<a href="http://bestpaydayfast.com#kubqewquhwxxmxo">cash advances
</a>
<a href="http://bestpaydayfast.com#zensnopxidedubx">need cash now
</a>
<a href="http://bestpaydayfast.com#vvcmthpelqwqggr">payday day loans
</a>
<a href="http://bestpaydayfast.com#cohakveosgvbucm">cash advances
</a>
<a href="http://bestpaydayfast.com#beuzylffqwbmryg">cash advances
</a>
<a href="http://bestpaydayfast.com#plnafryavgzjzor">online cash advance
</a>
<a href="http://bestpaydayfast.com#losnacrgrszqceo">cash advance lenders
</a>
<a href="http://bestpaydayfast.com#sgytzrgfnsryqcg">payday loan online
</a>
<a href="http://bestpaydayfast.com#rdywykbummzkxpp">payday loan online
</a>
<a href="http://bestpaydayfast.com#ikbrdzlzcfsilal">instant payday loans
</a>
<a href="http://bestpaydayfast.com#dzqdbgorrpiwmhc">online payday loans
</a>
<a href="http://bestpaydayfast.com#dxrrryrhzditykz">pay day loan
</a>
<a href="http://bestpaydayfast.com#mktkslhgpvjehaq">get cash now
</a>
<a href="http://bestpaydayfast.com#dunpppvveblqvdg">payday loan lenders
</a>
<a href="http://bestpaydayfast.com#wbjwinmfmmvtpda">payday advance
</a>
<a href="http://bestpaydayfast.com#dqillbunjyiymsm">online payday loans
</a>
<a href="http://bestpaydayfast.com#gmmgwacnrqwilua">payday loans near me
</a>
<a href="http://bestpaydayfast.com#bdwcabyhjxaiwfd">same day payday loan
</a>
<a href="http://bestpaydayfast.com">pd2
</a>
<a href="http://bestpaydayfast.com">premium gold infinite gold card list
</a>
<a href="http://bestpaydayfast.com">direct payday loans
</a>
<a href="http://bestpaydayfast.com">cash advance now
</a>
<a href="http://bestpaydayfast.com">payday 2 halloween
</a>
<a href="http://bestpaydayfast.com">heist
</a>
<a href="http://bestpaydayfast.com">payday loan near me
</a>
<a href="http://bestpaydayfast.com">payday 1
</a>
<a href="http://bestpaydayfast.com">direct loans login
</a>
<a href="http://bestpaydayfast.com">payday 2 system requirements
</a>
<a href="http://bestpaydayfast.com">online loan
</a>
<a href="http://bestpaydayfast.com">dob now
</a>
<a href="http://bestpaydayfast.com">direct payday loan lenders
</a>
<a href="http://bestpaydayfast.com">direct payday loan lenders
</a>
<a href="http://bestpaydayfast.com">online payday loans texas
</a>
<a href="http://bestpaydayfast.com">r/payday2
</a>
<a href="http://bestpaydayfast.com">crimefest 2015 payday 2
</a>
<a href="http://bestpaydayfast.com">on line loans
</a>
<a href="http://bestpaydayfast.com">payday lender
</a>
<a href="http://bestpaydayfast.com">online cash loans
</a>
<a href="http://bestpaydayfast.com">payday 2 beta
</a>
<a href="http://bestpaydayfast.com">payday 2 dlc
</a>
<a href="http://bestpaydayfast.com">overkill games
</a>
<a href="http://bestpaydayfast.com">online cash advance
</a>
<a href="http://bestpaydayfast.com">clover 999
</a>
<a href="http://bestpaydayfast.com">payday game
</a>
<a href="http://bestpaydayfast.com">3 day assault pack
</a>
<a href="http://bestpaydayfast.com">online pay day loans
</a>
<a href="http://bestpaydayfast.com">payday 2 web series
</a>
<a href="http://bestpaydayfast.com">online payday loans direct lender
</a>
<a href="http://bestpaydayfast.com">payday 2 housewarming
</a>
<a href="http://bestpaydayfast.com">payday 2 wolf pack
</a>
<a href="http://bestpaydayfast.com">payday loan companies
</a>
<a href="http://bestpaydayfast.com">watch scarface online
</a>
<a href="http://bestpaydayfast.com">payday 1
</a>
<a href="http://bestpaydayfast.com">payday advance near me
</a>
<a href="http://bestpaydayfast.com">payday2
</a>
<a href="http://bestpaydayfast.com">clover app market
</a>
<a href="http://bestpaydayfast.com">payday 2 twitter
</a>
<a href="http://bestpaydayfast.com">payday 2 web series
</a>
<a href="http://bestpaydayfast.com">payday the heist mods
</a>
<a href="http://bestpaydayfast.com">john wick 2 online free
</a>
<a href="http://bestpaydayfast.com">get a loan online
</a>
<a href="http://bestpaydayfast.com">get a loan online
</a>
<a href="http://bestpaydayfast.com">overkill studios
</a>
<a href="http://bestpaydayfast.com">payday 2 review
</a>
<a href="http://bestpaydayfast.com">steam payday 2
</a>
<a href="http://bestpaydayfast.com">payday 2 heisters
</a>
<a href="http://bestpaydayfast.com">paydayloan
</a>
<a href="http://bestpaydayfast.com">cash loans
</a>
<a href="http://bestpaydayfast.com">n frame grips
</a>
<a href="http://bestpaydayfast.com">cash advance loans online
</a>
<a href="http://bestpaydayfast.com">cash loans online
</a>
<a href="http://bestpaydayfast.com">cash advance loans
</a>
<a href="http://bestpaydayfast.com">payday loan online
</a>
<a href="http://bestpaydayfast.com">payday loan companies
</a>
<a href="http://bestpaydayfast.com">payday candy
</a>
<a href="http://bestpaydayfast.com">jimmy payday 2
</a>
<a href="http://bestpaydayfast.com">payday 2 trailer
</a>
<a href="http://bestpaydayfast.com">payday 2 masks
</a>
<a href="http://bestpaydayfast.com">payday 2 masks
</a>
<a href="http://bestpaydayfast.com">jugar in english
</a>
<a href="http://bestpaydayfast.com">payday 2 big lobby
</a>
<a href="http://bestpaydayfast.com">cash advances
</a>
<a href="http://bestpaydayfast.com">almir listo
</a>
<a href="http://bestpaydayfast.com">www mypay co
</a>
<a href="http://bestpaydayfast.com">cash loans online
</a>
<a href="http://bestpaydayfast.com">payday wiki
</a>
<a href="http://bestpaydayfast.com">payday 2 characters
</a>
<a href="http://bestpaydayfast.com">payday candy bar
</a>
<a href="http://bestpaydayfast.com">payday loans online no credit check
</a>
<a href="http://bestpaydayfast.com">payday 2 single player
</a>
<a href="http://bestpaydayfast.com">pay advance
</a>
<a href="http://bestpaydayfast.com">payday 2 system requirements
</a>
<a href="http://bestpaydayfast.com">loan online
</a>
<a href="http://bestpaydayfast.com">payday 2 patch notes
</a>
<a href="http://bestpaydayfast.com">clover 999
</a>
<a href="http://bestpaydayfast.com">define testy
</a>
[url=http://www.xbgaming.tk/index.php?topic=21039.new#new]ashlynSn[/url]
<a href="http://howtoloseweightfastusa.com">lose weight fast
</a>
<a href="http://howtoloseweightfastusa.com">best way to lose weight fast
</a>
<a href="http://howtoloseweightfastusa.com">how to lose weight fast
</a>
<a href="http://howtoloseweightfastusa.com">how to lose weight in a week
</a>
<a href="http://howtoloseweightfastusa.com">foods to help you lose weight
</a>
<a href="http://howtoloseweightfastusa.com">healthy food to lose weight
</a>
<a href="http://howtoloseweightfastusa.com">lifting weights to lose weight
</a>
<a href="http://howtoloseweightfastusa.com">foods to help you lose weight
</a>
<a href="http://howtoloseweightfastusa.com">lose weight meal plan
</a>
<a href="http://howtoloseweightfastusa.com">how many calories per day to lose weight
</a>
<a href="http://howtoloseweightfastusa.com">how to lose weight with pcos
</a>
<a href="http://howtoloseweightfastusa.com">what's the best way to lose weight
</a>
<a href="http://howtoloseweightfastusa.com">calories to lose weight
</a>
<a href="http://howtoloseweightfastusa.com">how to lose weight in a week
</a>
<a href="http://howtoloseweightfastusa.com">lifting weights to lose weight
</a>
<a href="http://howtoloseweightfastusa.com">best way to lose weight
</a>
<a href="http://howtoloseweightfastusa.com">how to lose weight
</a>
<a href="http://howtoloseweightfastusa.com">how much weight can i lose in 2 months
</a>
<a href="http://howtoloseweightfastusa.com">losing weight after 50
</a>
<a href="http://howtoloseweightfastusa.com">how to lose weight fast
</a>
<a href="http://howtoloseweightfastusa.com">lose weight
</a>
<a href="http://howtoloseweightfastusa.com">how much weight can i lose in 2 months
</a>
<a href="http://howtoloseweightfastusa.com">swimming to lose weight
</a>
<a href="http://howtoloseweightfastusa.com">how to lose weight fast for women
</a>
<a href="http://howtoloseweightfastusa.com">does water help you lose weight
</a>
<a href="http://howtoloseweightfastusa.com">how many calories should i eat to lose weight
</a>
<a href="http://howtoloseweightfastusa.com">how much cardio to lose weight
</a>
<a href="http://howtoloseweightfastusa.com">best way to lose weight
</a>
<a href="http://howtoloseweightfastusa.com">how many calories should i eat to lose weight
</a>
<a href="http://howtoloseweightfastusa.com">fastest way to lose weight
</a>
[url=http://rexuiz.top/]Rexuiz FPS Game[/url]
<a href="http://howtoloseweightfastusa.com">how to lose weight in a week
</a>
<a href="http://howtoloseweightfastusa.com">lose weight by walking
</a>
<a href="http://howtoloseweightfastusa.com">how many calories should i eat to lose weight
</a>
<a href="http://howtoloseweightfastusa.com">losing weight
</a>
<a href="http://howtoloseweightfastusa.com">lose weight by walking
</a>
<a href="http://howtoloseweightfastusa.com">does water help you lose weight
</a>
<a href="http://howtoloseweightfastusa.com">how to lose weight fast
</a>
<a href="http://howtoloseweightfastusa.com">does water help you lose weight
</a>
<a href="http://howtoloseweightfastusa.com">how many calories to lose weight
</a>
<a href="http://howtoloseweightfastusa.com">how many calories should i eat to lose weight
</a>
<a href="http://howtoloseweightfastusa.com">how to lose weight
</a>
<a href="http://howtoloseweightfastusa.com">losing weight
</a>
<a href="http://howtoloseweightfastusa.com">fastest way to lose weight
</a>
<a href="http://howtoloseweightfastusa.com">how to lose weight in a week
</a>
<a href="http://howtoloseweightfastusa.com">best way to lose weight
</a>
<a href="http://howtoloseweightfastusa.com">how to lose weight fast for women
</a>
<a href="http://howtoloseweightfastusa.com">lose weight by walking
</a>
<a href="http://howtoloseweightfastusa.com">how to lose weight fast
</a>
<a href="http://paydayloansonlineglhf.com">online payday loans
</a>
<a href="http://paydayloansonlineglhf.com">payday loans online
</a>
<a href="http://paydayloansonlineglhf.com">payday loans online
</a>
<a href="http://paydayloansonlineglhf.com">online payday loans direct lenders
</a>
<a href="http://paydayloansonlineglhf.com">payday loans online same day
</a>
<a href="http://paydayloansonlineglhf.com">payday loans online direct lenders only
</a>
<a href="http://paydayloansonlineglhf.com">best online payday loans
</a>
<a href="http://paydayloansonlineglhf.com">payday loans
</a>
<a href="http://paydayloansonlineglhf.com">payday loans online same day
</a>
<a href="http://paydayloansonlineglhf.com">payday loans near me
</a>
<a href="http://paydayloansonlineglhf.com">payday loans direct lender
</a>
<a href="http://paydayloansonlineglhf.com">fast payday loans
</a>
<a href="http://paydayloansonlineglhf.com">payday loans online same day
</a>
<a href="http://paydayloansonlineglhf.com">online payday loans direct lenders
</a>
<a href="http://paydayloansonlineglhf.com">payday loans online no credit check instant approval
</a>
<a href="http://paydayloansonlineglhf.com">payday loans online no credit check
</a>
<a href="http://paydayloansonlineglhf.com">payday loans direct lender
</a>
<a href="http://paydayloansonlineglhf.com">payday loans online
</a>
<a href="http://paydayloansonlineglhf.com">legitimate payday loans online no credit check
</a>
<a href="http://paydayloansonlineglhf.com">online payday loans
</a>
<a href="http://paydayloansonlineglhf.com">fast payday loans
</a>
<a href="http://paydayloansonlineglhf.com">payday loans online direct lenders only
</a>
<a href="http://paydayloansonlineglhf.com">payday loans online same day
</a>
<a href="http://paydayloansonlineglhf.com">payday loans online direct lenders only
</a>
<a href="http://paydayloansonlineglhf.com">online payday loans no credit check
</a>
<a href="http://paydayloansonlineglhf.com">fast payday loans
</a>
<a href="http://paydayloansonlineglhf.com">3 month payday loans
</a>
<a href="http://paydayloansonlineglhf.com">instant payday loans
</a>
<a href="http://paydayloansonlineglhf.com">payday loans
</a>
<a href="http://paydayloansonlineglhf.com">payday loans online
</a>
<a href="http://paydayloansonlineglhf.com">payday loans direct lender
</a>
<a href="http://paydayloansonlineglhf.com">online payday loans no credit check
</a>
<a href="http://paydayloansonlineglhf.com">payday loans online no credit check instant approval
</a>
<a href="http://paydayloansonlineglhf.com">online payday loans
</a>
<a href="http://paydayloansonlineglhf.com">payday loans direct lender
</a>
<a href="http://paydayloansonlineglhf.com">online payday loans
</a>
<a href="http://paydayloansonlineglhf.com">online payday loans direct lenders
</a>
<a href="http://paydayloansonlineglhf.com">best payday loans
</a>
<a href="http://paydayloansonlineglhf.com">payday loans no credit check
</a>
<a href="http://paydayloansonlineglhf.com">payday loans online same day
</a>
<a href="http://paydayloansonlineglhf.com">payday loans online no credit check instant approval
</a>
<a href="http://paydayloansonlineglhf.com">payday loans online no credit check instant approval
</a>
<a href="http://paydayloansonlineglhf.com">best payday loans
</a>
<a href="http://paydayloansonlineglhf.com">fast payday loans
</a>
<a href="http://paydayloansonlineglhf.com">3 month payday loans
</a>
<a href="http://paydayloansonlineglhf.com">payday loans online no credit check
</a>
http://www.louisvuittontascheverkaufen.de/396-louis-vuitton-rucksack-michael
http://www.pragmaticus-armaturen.de/adidas-gazelle-indoor-schwarz-043.html
http://www.fliesen-habig.de/batwolf-oakley-438.php
http://www.schnaeppchenwald.de/nike-mercurial-2-085.html
http://www.fliesen-habig.de/ray-ban-brille-blau-beige-608.php
[url=http://www.city-star-bremen.de/adidas-yeezy-von-oben-998.html]Adidas Yeezy Von Oben[/url]
[url=http://www.jetzt-lastminute-pauschalreise.de/924-adidas-ultra-boost-green-olive.php]Adidas Ultra Boost Green Olive[/url]
[url=http://www.ordineavvocaticasale.it/097-camicie-ralph-lauren-vendita.html]Camicie Ralph Lauren Vendita[/url]
[url=http://www.viciouscircle.se/puma-junior-524.html]Puma Junior[/url]
[url=http://www.thechildinme.de/153-converse-hellblau.html]Converse Hellblau[/url]
<a href="http://paydayloansonlineglhf.com">ace payday loans
</a>
<a href="http://paydayloansonlineglhf.com">payday loans no credit check
</a>
<a href="http://paydayloansonlineglhf.com">online payday loans direct lenders
</a>
<a href="http://paydayloansonlineglhf.com">online payday loans direct lenders
</a>
<a href="http://paydayloansonlineglhf.com">ace payday loans
</a>
- <a href="http://paydayloansonlineglhf.com">bad credit payday loans
</a>
same day payday loans
- [url=http://paydayloansonlineglhf.com/]payday loans online no credit check instant approval
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans direct lender
</a>
best online payday loans
- [url=http://paydayloansonlineglhf.com/]no credit check payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">best payday loans
</a>
online payday loans direct lenders
- [url=http://paydayloansonlineglhf.com/]payday loans online
[/url]
- <a href="http://paydayloansonlineglhf.com">best payday loans
</a>
payday loans near me
- [url=http://paydayloansonlineglhf.com/]payday loans online no credit check instant approval
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans online same day
</a>
best payday loans
- [url=http://paydayloansonlineglhf.com/]instant payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">bad credit payday loans
</a>
payday loans near me no credit check
- [url=http://paydayloansonlineglhf.com/]payday loans online no credit check
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans near me
</a>
best online payday loans
- [url=http://paydayloansonlineglhf.com/]direct lender payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans near me no credit check
</a>
payday loans
- [url=http://paydayloansonlineglhf.com/]payday loans online direct lenders only
[/url]
- <a href="http://paydayloansonlineglhf.com">best online payday loans
</a>
no credit check payday loans
- [url=http://paydayloansonlineglhf.com/]payday loans online same day
[/url]
- <a href="http://paydayloansonlineglhf.com">best payday loans
</a>
same day payday loans
- [url=http://paydayloansonlineglhf.com/]direct lender payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">best payday loans
</a>
online payday loans
- [url=http://paydayloansonlineglhf.com/]payday loans online no credit check instant approval
[/url]
- <a href="http://paydayloansonlineglhf.com">instant payday loans
</a>
payday loans online direct lenders only
- [url=http://paydayloansonlineglhf.com/]payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">instant payday loans
</a>
payday loans
- [url=http://paydayloansonlineglhf.com/]online payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">online payday loans
</a>
online payday loans
- [url=http://paydayloansonlineglhf.com/]payday loans no credit check
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans near me
</a>
online payday loans no credit check
- [url=http://paydayloansonlineglhf.com/]payday loans no credit check
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans
</a>
payday loans online no credit check instant approval
- [url=http://paydayloansonlineglhf.com/]payday loans online direct lenders only
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans no credit check
</a>
payday loans online no credit check instant approval
- [url=http://paydayloansonlineglhf.com/]payday loans no credit check
[/url]
- <a href="http://paydayloansonlineglhf.com">online payday loans no credit check
</a>
best payday loans
- [url=http://paydayloansonlineglhf.com/]online payday loans no credit check
[/url]
- <a href="http://paydayloansonlineglhf.com">instant payday loans
</a>
payday loans
- [url=http://paydayloansonlineglhf.com/]online payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">online payday loans
</a>
instant payday loans
- [url=http://paydayloansonlineglhf.com/]payday loans online
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans
</a>
payday loans online direct lenders only
- [url=http://paydayloansonlineglhf.com/]payday loans online
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans online direct lenders only
</a>
payday loans near me
- [url=http://paydayloansonlineglhf.com/]online payday loans no credit check
[/url]
- <a href="http://paydayloansonlineglhf.com">online payday loans no credit check
</a>
payday loans
- [url=http://paydayloansonlineglhf.com/]payday loans no credit check
[/url]
- <a href="http://paydayloansonlineglhf.com">best payday loans
</a>
payday loans near me
- [url=http://paydayloansonlineglhf.com/]payday loans online no credit check instant approval
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans online
</a>
payday loans online direct lenders only
- [url=http://paydayloansonlineglhf.com/]online payday loans no credit check
[/url]
- <a href="http://paydayloansonlineglhf.com">best payday loans
</a>
payday loans online direct lenders only
- [url=http://paydayloansonlineglhf.com/]payday loans online direct lenders only
[/url]
- <a href="http://paydayloansonlineglhf.com">instant payday loans
</a>
payday loans online direct lenders only
- [url=http://paydayloansonlineglhf.com/]payday loans no credit check
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans near me
</a>
payday loans online no credit check instant approval
- [url=http://paydayloansonlineglhf.com/]payday loans online no credit check instant approval
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans no credit check
</a>
payday loans no credit check
- [url=http://paydayloansonlineglhf.com/]instant payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans in pa
</a>
online payday loans direct lender
- [url=http://paydayloansonlineglhf.com/]payday loans for bad credit
[/url]
- <a href="http://paydayloansonlineglhf.com">online payday loans texas
</a>
payday loans
- [url=http://paydayloansonlineglhf.com/]bad credit payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">ace payday loans
</a>
payday loans in pa
- [url=http://paydayloansonlineglhf.com/]payday loans bad credit
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans in pa
</a>
payday loans near me no credit check
- [url=http://paydayloansonlineglhf.com/]payday loans colorado springs
[/url]
- <a href="http://paydayloansonlineglhf.com">how do payday loans work
</a>
3 month payday loans
- [url=http://paydayloansonlineglhf.com/]online payday loans no credit check
[/url]
- <a href="http://paydayloansonlineglhf.com">same day payday loans
</a>
how do payday loans work
- [url=http://paydayloansonlineglhf.com/]longterm payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans las vegas
</a>
payday loans online no credit check instant approval
- [url=http://paydayloansonlineglhf.com/]bad credit personal loans not payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">same day payday loans
</a>
quick payday loans
- [url=http://paydayloansonlineglhf.com/]guaranteed payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">check mate payday loans
</a>
check ngo payday loans
- [url=http://paydayloansonlineglhf.com/]payday loans online direct lenders only
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans near me no credit check
</a>
payday loans in ny
- [url=http://paydayloansonlineglhf.com/]check ngo payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">direct lender payday loans
</a>
payday loans near me no credit check
- [url=http://paydayloansonlineglhf.com/]no credit check payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans online direct lenders only
</a>
online payday loans direct lenders
- [url=http://paydayloansonlineglhf.com/]payday loans no credit check
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans bad credit
</a>
payday loans colorado springs
- [url=http://paydayloansonlineglhf.com/]same day payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans online
</a>
payday loans no credit check
- [url=http://paydayloansonlineglhf.com/]online payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans near me
</a>
payday loans
- [url=http://paydayloansonlineglhf.com/]payday loans no credit check
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans
</a>
payday loans near me
- [url=http://paydayloansonlineglhf.com/]payday loans online
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans online
</a>
online payday loans
- [url=http://paydayloansonlineglhf.com/]payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans
</a>
payday loans online
- [url=http://paydayloansonlineglhf.com/]payday loans near me
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans near me
</a>
payday loans
- [url=http://paydayloansonlineglhf.com/]payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans near me
</a>
payday loans
- [url=http://paydayloansonlineglhf.com/]payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">online payday loans
</a>
payday loans online
- [url=http://paydayloansonlineglhf.com/]online payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loan online
</a>
payday loans online
- [url=http://paydayloansonlineglhf.com/]http://paydayloansonlineglhf.com
[/url]
- <a href="http://paydayloansonlineglhf.com">payday advance loans
</a>
get payday loan
- [url=http://paydayloansonlineglhf.com/]payday loans near me
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans online
</a>
payday cash loan
- [url=http://paydayloansonlineglhf.com/]http://paydayloansonlineglhf.com
[/url]
- <a href="http://paydayloansonlineglhf.com">best payday loans
</a>
payday loans bad credit
- [url=http://paydayloansonlineglhf.com/]payday loans online
[/url]
- <a href="http://paydayloansonlineglhf.com">cash advance online
</a>
payday loan
- [url=http://paydayloansonlineglhf.com/]instant payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">same day payday loans
</a>
payday loans online no credit check instant approval
- [url=http://paydayloansonlineglhf.com/]online payday loan
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans online no credit check instant approval
</a>
quick cash
- [url=http://paydayloansonlineglhf.com/]cash advance online
[/url]
- <a href="http://paydayloansonlineglhf.com">loans payday
</a>
online payday advance
- [url=http://paydayloansonlineglhf.com/]cash advances
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans online
</a>
cash advances
- [url=http://paydayloansonlineglhf.com/]instant payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">online payday loans
</a>
payday loans online
- [url=http://paydayloansonlineglhf.com/]payday advances
[/url]
- <a href="http://paydayloansonlineglhf.com">payday advances
</a>
payday day loans
- [url=http://paydayloansonlineglhf.com/]loans payday
[/url]
- <a href="http://paydayloansonlineglhf.com">online payday loans
</a>
payday advance loans
- [url=http://paydayloansonlineglhf.com/]instant payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">payday advances
</a>
loans payday
- [url=http://paydayloansonlineglhf.com/]quick cash
[/url]
- <a href="http://paydayloansonlineglhf.com">best payday loans
</a>
payday loans near me
- [url=http://paydayloansonlineglhf.com/]payday advance loans
[/url]
- <a href="http://paydayloansonlineglhf.com">online payday loan
</a>
payday advance loan
- [url=http://paydayloansonlineglhf.com/]payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans near me
</a>
payday day loans
- [url=http://paydayloansonlineglhf.com/]online payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans online
</a>
best payday loans
- [url=http://paydayloansonlineglhf.com/]online payday loans no credit check
[/url]
- <a href="http://paydayloansonlineglhf.com">payday cash loan
</a>
payday loans online direct lenders only
- [url=http://paydayloansonlineglhf.com/]cash advance
[/url]
- <a href="http://paydayloansonlineglhf.com">same day payday loans
</a>
payday loans no credit check
- [url=http://paydayloansonlineglhf.com/]payday loans online no credit check instant approval
[/url]
- <a href="http://paydayloansonlineglhf.com">payday cash loan
</a>
payday loans online
- [url=http://paydayloansonlineglhf.com/]payday advances
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans bad credit
</a>
fast cash
- [url=http://paydayloansonlineglhf.com/]payday advance loans
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loan
</a>
online payday loans no credit check
- [url=http://paydayloansonlineglhf.com/]payday loans bad credit
[/url]
- <a href="http://paydayloansonlineglhf.com">online payday loans
</a>
cash advance
- [url=http://paydayloansonlineglhf.com/]get payday loan
[/url]
- <a href="http://paydayloansonlineglhf.com">cash advance
</a>
quick cash
- [url=http://paydayloansonlineglhf.com/]best payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">quick cash
</a>
payday loans online direct lenders only
- [url=http://paydayloansonlineglhf.com/]payday loan
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans online
</a>
payday loans
- [url=http://paydayloansonlineglhf.com/]payday advance loan
[/url]
- <a href="http://paydayloansonlineglhf.com">online payday loans no credit check
</a>
same day payday loans
- [url=http://paydayloansonlineglhf.com/]payday loans online direct lenders only
[/url]
- <a href="http://paydayloansonlineglhf.com">payday advance loans
</a>
fast payday loan
- [url=http://paydayloansonlineglhf.com/]payday day loans
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans online
</a>
payday loan
- [url=http://paydayloansonlineglhf.com/]payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans online
</a>
quick cash
- [url=http://paydayloansonlineglhf.com/]payday loans bad credit
[/url]
- <a href="http://paydayloansonlineglhf.com">get payday loan
</a>
payday loan online
- [url=http://paydayloansonlineglhf.com/]online payday loans no credit check
[/url]
- <a href="http://paydayloansonlineglhf.com">loans payday
</a>
quick cash
- [url=http://paydayloansonlineglhf.com/]online payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans
</a>
payday loans online
- [url=http://paydayloansonlineglhf.com/]cash advances
[/url]
- <a href="http://paydayloansonlineglhf.com">get payday loan
</a>
online payday advance
- [url=http://paydayloansonlineglhf.com/]instant payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans online direct lenders only
</a>
payday loan online
- [url=http://paydayloansonlineglhf.com/]payday advances
[/url]
- <a href="http://paydayloansonlineglhf.com">cash advances
</a>
fast cash
- [url=http://paydayloansonlineglhf.com/]payday loan
[/url]
- <a href="http://paydayloansonlineglhf.com">paydayloansonlineglhf.com
</a>
payday advance
- [url=http://paydayloansonlineglhf.com/]cash advances
[/url]
- <a href="http://paydayloansonlineglhf.com">quick cash
</a>
payday loan
- [url=http://paydayloansonlineglhf.com/]quick cash
[/url]
- <a href="http://paydayloansonlineglhf.com">loans payday
</a>
paydayloansonlineglhf.com
- [url=http://paydayloansonlineglhf.com/]payday advance
[/url]
- <a href="http://paydayloansonlineglhf.com">quick cash
</a>
quick cash
- [url=http://paydayloansonlineglhf.com/]online payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">cash advances
</a>
paydayloansonlineglhf.com
- [url=http://paydayloansonlineglhf.com/]quick cash
[/url]
- <a href="http://paydayloansonlineglhf.com">http://paydayloansonlineglhf.com
</a>
http://paydayloansonlineglhf.com
- [url=http://paydayloansonlineglhf.com/]http://paydayloansonlineglhf.com
[/url]
- <a href="http://paydayloansonlineglhf.com">quick cash
</a>
loans payday
- [url=http://paydayloansonlineglhf.com/]payday advance
[/url]
- <a href="http://paydayloansonlineglhf.com">payday advance
</a>
loans payday
- [url=http://paydayloansonlineglhf.com/]http://paydayloansonlineglhf.com
[/url]
- <a href="http://paydayloansonlineglhf.com">cash advance
</a>
http://paydayloansonlineglhf.com
- [url=http://paydayloansonlineglhf.com/]payday advance
[/url]
- <a href="http://paydayloansonlineglhf.com">paydayloansonlineglhf.com
</a>
fast cash
- [url=http://paydayloansonlineglhf.com/]online payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">cash advances
</a>
payday advance
- [url=http://paydayloansonlineglhf.com/]http://paydayloansonlineglhf.com
[/url]
- <a href="http://paydayloansonlineglhf.com">online payday loans
</a>
quick cash
- [url=http://paydayloansonlineglhf.com/]payday loans online
[/url]
- <a href="http://paydayloansonlineglhf.com">loans payday
</a>
paydayloansonlineglhf.com
- [url=http://paydayloansonlineglhf.com/]loans payday
[/url]
- <a href="http://paydayloansonlineglhf.com">loans payday
</a>
payday loans
- [url=http://paydayloansonlineglhf.com/]payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans online
</a>
payday advance
- [url=http://paydayloansonlineglhf.com/]payday advance
[/url]
- <a href="http://paydayloansonlineglhf.com">quick cash
</a>
fast cash
- [url=http://paydayloansonlineglhf.com/]paydayloansonlineglhf.com
[/url]
- <a href="http://paydayloansonlineglhf.com">cash advances
</a>
fast cash
- [url=http://paydayloansonlineglhf.com/]fast cash
[/url]
- <a href="http://paydayloansonlineglhf.com">online payday loans
</a>
fast cash
- [url=http://paydayloansonlineglhf.com/]payday advance
[/url]
- <a href="http://paydayloansonlineglhf.com">payday advance
</a>
quick cash
- [url=http://paydayloansonlineglhf.com/]payday loans online
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans
</a>
paydayloansonlineglhf.com
- [url=http://paydayloansonlineglhf.com/]quick cash
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loan
</a>
cash advances
- [url=http://paydayloansonlineglhf.com/]fast cash
[/url]
- <a href="http://paydayloansonlineglhf.com">cash advance
</a>
loans payday
- [url=http://paydayloansonlineglhf.com/]online payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">paydayloansonlineglhf.com
</a>
cash advances
- [url=http://paydayloansonlineglhf.com/]payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">online payday loans
</a>
payday loan
- [url=http://paydayloansonlineglhf.com/]cash advances
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans online
</a>
http://paydayloansonlineglhf.com
- [url=http://paydayloansonlineglhf.com/]paydayloansonlineglhf.com
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans online
</a>
loans payday
- [url=http://paydayloansonlineglhf.com/]online payday loans
[/url]
- <a href="https://onlinepaydayloanquickes.com">online payday loans oregon
</a>
speedy cash online payday loan
- [url=https://onlinepaydayloanquickes.com/]online payday loans ohio
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans online
</a>
paydayloansonlineglhf.com
- [url=http://paydayloansonlineglhf.com/]loans payday
[/url]
- <a href="http://paydayloansonlineglhf.com">paydayloansonlineglhf.com
</a>
cash advances
- [url=http://paydayloansonlineglhf.com/]cash advances
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans online
</a>
payday loans
- [url=http://paydayloansonlineglhf.com/]online payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans online
</a>
payday loans online
- [url=http://paydayloansonlineglhf.com/]http://paydayloansonlineglhf.com
[/url]
- <a href="https://onlinepaydayloanquickes.com">online payday loans utah
</a>
online payday loans same day
- [url=https://onlinepaydayloanquickes.com/]what are the best online payday loans
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loan
</a>
loans payday
- [url=http://paydayloansonlineglhf.com/]payday loans online
[/url]
- <a href="http://paydayloansonlineglhf.com">cash advances
</a>
payday loan
- [url=http://paydayloansonlineglhf.com/]http://paydayloansonlineglhf.com
[/url]
- <a href="https://onlinepaydayloanquickes.com">online payday loans in ca
</a>
alberta online payday loans
- [url=https://onlinepaydayloanquickes.com/]online payday loans washington state
[/url]
- <a href="http://paydayloansonlineglhf.com">cash advances
</a>
payday loans
- [url=http://paydayloansonlineglhf.com/]paydayloansonlineglhf.com
[/url]
- <a href="https://onlinepaydayloanquickes.com">how do online payday loans work
</a>
list of online payday loans
- [url=https://onlinepaydayloanquickes.com/]fast online payday loans
[/url]
- <a href="https://onlinepaydayloanquickes.com">online payday loans texas
</a>
online payday loan bad credit
- [url=https://onlinepaydayloanquickes.com/]safe online payday loans
[/url]
- <a href="https://onlinepaydayloanquickes.com">online payday loans az
</a>
online payday loans california
- [url=https://onlinepaydayloanquickes.com/]online payday loans alabama
[/url]
- <a href="https://onlinepaydayloanquickes.com">online payday loan consolidation companies
</a>
online payday loans illinois
- [url=https://onlinepaydayloanquickes.com/]california online payday loans
[/url]
- <a href="https://onlinepaydayloanquickes.com">same day online payday loans
</a>
online payday loans reviews
- [url=https://onlinepaydayloanquickes.com/]online payday loan consolidation companies
[/url]
- <a href="https://onlinepaydayloanquickes.com">online payday loan consolidation companies
</a>
online payday loans indiana
- [url=https://onlinepaydayloanquickes.com/]direct lender online payday loans
[/url]
- <a href="https://onlinepaydayloanquickes.com">online payday loans uk
</a>
are online payday loans legal in florida
- [url=https://onlinepaydayloanquickes.com/]online payday loans oregon
[/url]
- <a href="http://paydayloansonlineglhf.com">payday loans online
</a>
payday loans online
- [url=http://paydayloansonlineglhf.com/]online payday loans
[/url]
- <a href="https://onlinepaydayloanquickes.com">online payday loans open on sunday
</a>
online payday loans for bad credit
- [url=https://onlinepaydayloanquickes.com/]online payday loans las vegas
[/url]
- <a href="http://paydayloansonlineglhf.com">online payday loans
</a>
payday loans
- [url=http://paydayloansonlineglhf.com/]online payday loans
[/url]
- <a href="https://onlinepaydayloanquickes.com">online payday loans instant approval direct lenders no credit check
</a>
best online payday loan
- [url=https://onlinepaydayloanquickes.com/]bad credit online payday loans
[/url]
- <a href="https://paydayloansonlineglhf.com">online payday loans
</a>
payday loans
- [url=https://paydayloansonlineglhf.com/]payday loans online
[/url]
- <a href="https://onlinepaydayloanquickes.com">how do online payday loans work
</a>
online payday loan direct lenders only
- [url=https://onlinepaydayloanquickes.com/]online payday loans alabama
[/url]
- <a href="https://onlinepaydayloanquickes.com">top rated online payday loans
</a>
online payday loan reviews
- [url=https://onlinepaydayloanquickes.com/]online payday loans open on sunday
[/url]
- <a href="https://paydayloansonlineglhf.com">payday loans
</a>
payday loans
- [url=https://paydayloansonlineglhf.com/]payday loans
[/url]
- <a href="https://onlinepaydayloanquickes.com">how to get out of online payday loans
</a>
top rated online payday loans
- [url=https://onlinepaydayloanquickes.com/]online payday loan consolidation companies
[/url]
- <a href="https://paydayloansonlineglhf.com">online payday loans
</a>
online payday loans
- [url=https://paydayloansonlineglhf.com/]payday loans
[/url]
- <a href="https://onlinepaydayloanquickes.com">what are the best online payday loans
</a>
online payday loans michigan
- [url=https://onlinepaydayloanquickes.com/]easy online payday loans
[/url]
- <a href="https://paydayloansonlineglhf.com">payday loans online
</a>
payday loans online
- [url=https://paydayloansonlineglhf.com/]online payday loans
[/url]
- <a href="https://paydayloansonlineglhf.com">payday loans online
</a>
online payday loans
- [url=https://paydayloansonlineglhf.com/]payday loans
[/url]
- <a href="https://onlinepaydayloanquickes.com">mississippi online payday loans
</a>
online payday loans open on sunday
- [url=https://onlinepaydayloanquickes.com/]online payday loans mississippi
[/url]
- <a href="https://onlinepaydayloanquickes.com">instant online payday loans
</a>
online payday loans same day deposit
- [url=https://onlinepaydayloanquickes.com/]online payday loans reviews
[/url]
- <a href="https://onlinepaydayloanquickes.com">easy online payday loans
</a>
best online payday loans
- [url=https://onlinepaydayloanquickes.com/]direct lender online payday loans
[/url]
- <a href="https://anabolicsteroidsnpc.com">catabolism definition
</a>
anabolism definition
- [url=https://anabolicsteroidsnpc.com/]side effects of anabolic steroids
[/url]
- <a href="https://onlinepaydayloanquickes.com">online payday loans direct lenders
</a>
legit online payday loans no credit check
- [url=https://onlinepaydayloanquickes.com/]online payday loans direct lenders
[/url]
- <a href="https://anabolicsteroidsnpc.com">steroids bodybuilding
</a>
anabolic diet
- [url=https://anabolicsteroidsnpc.com/]steroid molecule
[/url]
- <a href="https://onlinepaydayloanquickes.com">online payday loans mississippi
</a>
online payday loans instant approval direct lenders no credit check
- [url=https://onlinepaydayloanquickes.com/]top online payday loans
[/url]
- <a href="https://anabolicsteroidsnpc.com">side effects of anabolic steroids
</a>
anabolic labs
- [url=https://anabolicsteroidsnpc.com/]catabolic definition
[/url]
- <a href="https://anabolicsteroidsnpc.com">steroid molecule
</a>
catabolic definition
- [url=https://anabolicsteroidsnpc.com/]steroids definition
[/url]
- <a href="https://anabolicsteroidsnpc.com">catabolic reaction
</a>
anabolic pathways
- [url=https://anabolicsteroidsnpc.com/]steroid pills
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic labs
</a>
anabolicsteroidsnpc.com
- [url=https://anabolicsteroidsnpc.com/]buy steroids
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolism
</a>
steroids definition
- [url=https://anabolicsteroidsnpc.com/]steroid
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic steroids
</a>
catabolism and anabolism
- [url=https://anabolicsteroidsnpc.com/]anabolic steroids
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic fasting
</a>
types of steroids
- [url=https://anabolicsteroidsnpc.com/]how do steroids work
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolism
</a>
anabolic steroids side effects
- [url=https://anabolicsteroidsnpc.com/]anabolic steroid
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic steroids definition
</a>
steroids online
- [url=https://anabolicsteroidsnpc.com/]steroids online
[/url]
- <a href="https://anabolicsteroidsnpc.com">how do steroids work
</a>
anabolic pathways
- [url=https://anabolicsteroidsnpc.com/]catabolic
[/url]
- <a href="https://anabolicsteroidsnpc.com">steroids side effects
</a>
steroids
- [url=https://anabolicsteroidsnpc.com/]anabolic
[/url]
- <a href="https://anabolicsteroidsnpc.com">what is anabolism
</a>
how to get steroids
- [url=https://anabolicsteroidsnpc.com/]anabolic diet
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic fasting
</a>
catabolism definition
- [url=https://anabolicsteroidsnpc.com/]side effects of anabolic steroids
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic steroids side effects
</a>
anabolic labs
- [url=https://anabolicsteroidsnpc.com/]anabolicsteroidsnpc.com
[/url]
- <a href="https://anabolicsteroidsnpc.com">catabolic reaction
</a>
anabolic diet
- [url=https://anabolicsteroidsnpc.com/]anabolic steroid
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic steroid
</a>
anabolic definition
- [url=https://anabolicsteroidsnpc.com/]catabolic vs anabolic
[/url]
- <a href="https://anabolicsteroidsnpc.com">where to buy anabolic steroids bodybuilding
</a>
anabolic steroids where to buy
- [url=https://anabolicsteroidsnpc.com/]where to buy anabolic steroids bodybuilding
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolics
</a>
buy anabolics steroids
- [url=https://anabolicsteroidsnpc.com/]buy anabolic steroid online
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic steroids where to buy
</a>
where to buy anabolic steroids bodybuilding
- [url=https://anabolicsteroidsnpc.com/]catabolic vs anabolic
[/url]
- <a href="https://anabolicsteroidsnpc.com">buy anabolics
</a>
where to buy anabolic steroids
- [url=https://anabolicsteroidsnpc.com/]catabolic vs anabolic
[/url]
- <a href="https://anabolicsteroidsnpc.com">buy anabolics steroids
</a>
anabolic steroids
- [url=https://anabolicsteroidsnpc.com/]buy anabolics direct
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic definition
</a>
anabolic supplements
- [url=https://anabolicsteroidsnpc.com/]anabolic steroids where to buy
[/url]
- <a href="https://anabolicsteroidsnpc.com">buy anabolics
</a>
buy anabolics steroids
- [url=https://anabolicsteroidsnpc.com/]catabolic vs anabolic
[/url]
- <a href="https://anabolicsteroidsnpc.com">where can i buy anabolic steroids online
</a>
anabolic supplements
- [url=https://anabolicsteroidsnpc.com/]anabolic fasting
[/url]
- <a href="https://anabolicsteroidsnpc.com">buy anabolics direct
</a>
buy anabolics
- [url=https://anabolicsteroidsnpc.com/]anabolicsteroidsnpc.com
[/url]
- <a href="https://anabolicsteroidsnpc.com">catabolic vs anabolic
</a>
anabolic
- [url=https://anabolicsteroidsnpc.com/]buy anabolics
[/url]
- <a href="https://onlinepaydayloanquickes.com">online payday loans in ca
</a>
legit online payday loans no credit check
- [url=https://onlinepaydayloanquickes.com/]online payday loans in missouri
[/url]
- <a href="https://anabolicsteroidsnpc.com">buy anabolic steroid online
</a>
how to buy anabolic steroids
- [url=https://anabolicsteroidsnpc.com/]anabolics
[/url]
- <a href="https://anabolicsteroidsnpc.com">catabolic vs anabolic
</a>
how to buy anabolic steroids
- [url=https://anabolicsteroidsnpc.com/]catabolic vs anabolic
[/url]
- <a href="https://onlinepaydayloanquickes.com">direct lender online payday loans
</a>
bc online payday loans
- [url=https://onlinepaydayloanquickes.com/]california online payday loans
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolicsteroidsnpc.com
</a>
anabolic definition
- [url=https://anabolicsteroidsnpc.com/]anabolicsteroidsnpc.com
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic fasting
</a>
buy anabolics steroids
- [url=https://anabolicsteroidsnpc.com/]how to buy anabolic steroids
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic definition
</a>
where to buy anabolic steroids
- [url=https://anabolicsteroidsnpc.com/]buy anabolics
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic
</a>
anabolics
- [url=https://anabolicsteroidsnpc.com/]where to buy anabolic steroids
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic supplements
</a>
anabolic steroid
- [url=https://anabolicsteroidsnpc.com/]were to buy anabolic steroids
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolicsteroidsnpc.com
</a>
anabolics
- [url=https://anabolicsteroidsnpc.com/]anabolics
[/url]
- <a href="https://anabolicsteroidsnpc.com">buy anabolics steroids
</a>
anabolic steroids
- [url=https://anabolicsteroidsnpc.com/]buy anabolics direct
[/url]
- <a href="https://anabolicsteroidsnpc.com">catabolic vs anabolic
</a>
anabolic steroids where to buy
- [url=https://anabolicsteroidsnpc.com/]anabolic definition
[/url]
- <a href="https://anabolicsteroidsnpc.com">buy anabolic steroid online
</a>
anabolic fasting
- [url=https://anabolicsteroidsnpc.com/]buy anabolics
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic
</a>
where to buy anabolic steroids bodybuilding
- [url=https://anabolicsteroidsnpc.com/]anabolic definition
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic steroid
</a>
anabolic definition
- [url=https://anabolicsteroidsnpc.com/]anabolic definition
[/url]
- <a href="https://anabolicsteroidsnpc.com">buy anabolics direct
</a>
were to buy anabolic steroids
- [url=https://anabolicsteroidsnpc.com/]buy anabolics
[/url]
- <a href="https://anabolicsteroidsnpc.com">how to buy anabolic steroids
</a>
catabolic vs anabolic
- [url=https://anabolicsteroidsnpc.com/]where can i buy anabolic steroids online
[/url]
- <a href="https://anabolicsteroidsnpc.com">where to buy anabolic steroids
</a>
buy anabolic steroid online
- [url=https://anabolicsteroidsnpc.com/]buy anabolics
[/url]
- <a href="https://anabolicsteroidsnpc.com">buy anabolics
</a>
anabolic steroids where to buy
- [url=https://anabolicsteroidsnpc.com/]where to buy anabolic steroids
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic steroids
</a>
where to buy anabolic steroids bodybuilding
- [url=https://anabolicsteroidsnpc.com/]how to buy anabolic steroids
[/url]
- <a href="https://anabolicsteroidsnpc.com">were to buy anabolic steroids
</a>
were to buy anabolic steroids
- [url=https://anabolicsteroidsnpc.com/]anabolic steroid
[/url]
- <a href="https://anabolicsteroidsnpc.com">were to buy anabolic steroids
</a>
where can i buy anabolic steroids online
- [url=https://anabolicsteroidsnpc.com/]where can i buy anabolic steroids online
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic supplements
</a>
anabolics
- [url=https://anabolicsteroidsnpc.com/]where to buy anabolic steroids bodybuilding
[/url]
- <a href="https://anabolicsteroidsnpc.com">where to buy anabolic steroids bodybuilding
</a>
anabolic vs catabolic
- [url=https://anabolicsteroidsnpc.com/]anabolic fasting
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic
</a>
where to buy anabolic steroids bodybuilding
- [url=https://anabolicsteroidsnpc.com/]anabolic definition
[/url]
- <a href="https://anabolicsteroidsnpc.com">buy anabolics steroids
</a>
buy anabolics direct
- [url=https://anabolicsteroidsnpc.com/]anabolic vs catabolic
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic steroids
</a>
anabolic fasting
- [url=https://anabolicsteroidsnpc.com/]how to buy anabolic steroids
[/url]
- <a href="https://anabolicsteroidsnpc.com">were to buy anabolic steroids
</a>
were to buy anabolic steroids
- [url=https://anabolicsteroidsnpc.com/]anabolic steroids where to buy
[/url]
- <a href="https://anabolicsteroidsnpc.com">where to buy anabolic steroids bodybuilding
</a>
where to buy anabolic steroids
- [url=https://anabolicsteroidsnpc.com/]anabolic fasting
[/url]
- <a href="https://anabolicsteroidsnpc.com">where can i buy anabolic steroids online
</a>
were to buy anabolic steroids
- [url=https://anabolicsteroidsnpc.com/]anabolic steroid
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic steroid
</a>
anabolic fasting
- [url=https://anabolicsteroidsnpc.com/]buy anabolics direct
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic
</a>
anabolic steroids
- [url=https://anabolicsteroidsnpc.com/]where to buy anabolic steroids bodybuilding
[/url]
- <a href="https://anabolicsteroidsnpc.com">buy anabolics
</a>
where can i buy anabolic steroids online
- [url=https://anabolicsteroidsnpc.com/]anabolic steroids
[/url]
- <a href="https://anabolicsteroidsnpc.com">how to buy anabolic steroids
</a>
anabolic steroids
- [url=https://anabolicsteroidsnpc.com/]buy anabolics direct
[/url]
- <a href="https://anabolicsteroidsnpc.com">buy anabolic steroid online
</a>
anabolics
- [url=https://anabolicsteroidsnpc.com/]where to buy anabolic steroids bodybuilding
[/url]
- <a href="https://anabolicsteroidsnpc.com">buy anabolics
</a>
buy anabolics steroids
- [url=https://anabolicsteroidsnpc.com/]buy anabolics direct
[/url]
- <a href="https://anabolicsteroidsnpc.com">buy anabolics
</a>
buy anabolics
- [url=https://anabolicsteroidsnpc.com/]anabolic supplements
[/url]
- <a href="https://anabolicsteroidsnpc.com">where to buy anabolic steroids bodybuilding
</a>
anabolic definition
- [url=https://anabolicsteroidsnpc.com/]anabolic vs catabolic
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic definition
</a>
anabolic supplements
- [url=https://anabolicsteroidsnpc.com/]were to buy anabolic steroids
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic definition
</a>
anabolic
- [url=https://anabolicsteroidsnpc.com/]anabolic
[/url]
- <a href="https://anabolicsteroidsnpc.com">steroid
</a>
define anabolism
- [url=https://anabolicsteroidsnpc.com/]catabolic vs anabolic
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic steroids definition
</a>
steroidogenesis
- [url=https://anabolicsteroidsnpc.com/]steroid pills
[/url]
- <a href="https://anabolicsteroidsnpc.com">steroid molecule
</a>
is testosterone a steroid
- [url=https://anabolicsteroidsnpc.com/]anabolic steroids
[/url]
- <a href="https://anabolicsteroidsnpc.com">are steroids legal
</a>
anabolic steroid
- [url=https://anabolicsteroidsnpc.com/]steroid
[/url]
- <a href="https://anabolicsteroidsnpc.com">what is anabolism
</a>
anabolicsteroidsnpc.com
- [url=https://anabolicsteroidsnpc.com/]steroids definition
[/url]
- <a href="https://anabolicsteroidsnpc.com">steroid
</a>
steroids side effects
- [url=https://anabolicsteroidsnpc.com/]what is anabolism
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolism vs catabolism
</a>
anabolics
- [url=https://anabolicsteroidsnpc.com/]steroids online
[/url]
- <a href="https://anabolicsteroidsnpc.com">what are anabolic steroids
</a>
steroids bodybuilding
- [url=https://anabolicsteroidsnpc.com/]steroid molecule
[/url]
- <a href="https://anabolicsteroidsnpc.com">is cholesterol a steroid
</a>
define anabolism
- [url=https://anabolicsteroidsnpc.com/]anabolics
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic steroids
</a>
testosterone steroid
- [url=https://anabolicsteroidsnpc.com/]anabolic steroids definition
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolics steroids
</a>
anabolics steroids
- [url=https://anabolicsteroidsnpc.com/]steroid
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolicsteroidsnpc.com
</a>
steroid pills
- [url=https://anabolicsteroidsnpc.com/]steroids bodybuilding
[/url]
- <a href="https://anabolicsteroidsnpc.com">medical steroid
</a>
buying legal steroids
- [url=https://anabolicsteroidsnpc.com/]anabolic steroids
[/url]
- <a href="https://anabolicsteroidsnpc.com">steroids bodybuilding
</a>
steroid use
- [url=https://anabolicsteroidsnpc.com/]steroid
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic steroids effects
</a>
buying legal steroids
- [url=https://anabolicsteroidsnpc.com/]anabolic steroids
[/url]
- <a href="https://anabolicsteroidsnpc.com">steroid pills
</a>
anabolic steroids pill
- [url=https://anabolicsteroidsnpc.com/]anabolic
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic steroids pill
</a>
anabolic steroids
- [url=https://anabolicsteroidsnpc.com/]steroids
[/url]
- <a href="https://anabolicsteroidsnpc.com">steroids
</a>
steroid pills
- [url=https://anabolicsteroidsnpc.com/]anabolic steroids effects
[/url]
- <a href="https://anabolicsteroidsnpc.com">steroid pills
</a>
medicinal steroids
- [url=https://anabolicsteroidsnpc.com/]steroids effects
[/url]
- <a href="https://anabolicsteroidsnpc.com">anabolic
</a>
how to get steroids
- [url=https://anabolicsteroidsnpc.com/]steroids pills
[/url]
- <a href="https://anabolicsteroidsnpc.com">steroid use
</a>
medical steroid
- [url=https://anabolicsteroidsnpc.com/]buy steroids
[/url]
- <a href="https://anabolicsteroidsnpc.com">steroid use
</a>
medical steroid
- [url=https://anabolicsteroidsnpc.com/]steroids effects
[/url]
- <a href="https://sexygirlselfieok.org">sexy girl selfies
</a>
sexy girl selfies
- [url=https://sexygirlselfieok.org/]sexy girl selfies
[/url]
http://ruriruri.net/2005/houhu/g_book.cgi/a/g_book.cgirekondkunglv/g_book.cgiIstanbulapart/g_book.cgi?mode=regist&pass=&page=®=551&name=SzwiyHed&user_icon=%8F%AD%94N%82P&email=mmylodktlh%40sxmail.info&url=http%3A%2F%2Fhttps%3A%2F%2Fanabolicsteroidsnpc.com&user_message=sexy+girl+selfie%0D%0A+-+<a+href%3D%22https%3A%2F%2Fsexygirlselfieok.org%22>sexy+girls+selfies%0D%0A<%2Fa>+%0D%0Asexy+girls+selfies%0D%0A+-+<a+href%3Dhttps%3A%2F%2Fsexygirlselfieok.org%2F>sexy+girl+selfies%0D%0A<%2Fa>+%0D%0A+%0D%0Ahttp%3A%2F%2Falegria.at%2Fbiografie%2F%23comment-13517%0D%0Ahttp%3A%2F%2Fwww.onefm.ro%2Fstiri-detalii.php%3Fid%3D782%0D%0Ahttp%3A%2F%2Fwww.lenderfinder.org%2Fdetails.aspx%3FCategory%3DAdvance%26State%3Dcalifornia%26Path%3Dcheck_into_cash_12695%26ID%3D12695%26PagePath%3D%252fAdvance%252fcalifornia%252fcheck_into_cash_12695%26Name%3DStdegGok%26City%3D%26Review%3Dsexy%2Bgirl%2Bselfies%250d%250a%2B-%2B%253ca%2Bhref%253d%2522https%253a%252f%252fsexygirlselfieok.org%2522%253esexy%2Bgirls%2Bselfies%250d%250a%253c%252fa%253e%2B%250d%250asexy%2Bgirls%2Bselfies%250d%250a%2B-%2B%253ca%2Bhref%253dhttps%253a%252f%252fsexygirlselfieok.org%252f%253esexy%2Bgirl%2Bselfies%250d%250a%253c%252fa%253e%2B%250d%250a%2B%250d%250ahttp%253a%252f%252fwww.sasoian.info%252falbisteak.php%253fid_edukia%253d7881%250d%250ahttp%253a%252f%252fketos.free.fr%252fagb%252findex.php%253f%2526mots_search%253d%2526lang%253dfrancais%2526skin%253d%2526%2526seeMess%253d1%2526seeNotes%253d1%2526seeAdd%253d0%2526code_erreur%253dNYJDpVbdjQ%250d%250a%26CaptchaCode%3Dukbwc%26submit%3DPost%2BMy%2BReview%2B%2526raquo%253b%0D%0A&submit=%E2%80%9C%D0%89%D0%8Ce%E2%80%9A%C2%B7%E2%80%9A%D0%B9
http://dietame.ru/entry.php?1-%D0%A0%D1%9C%D0%A0%D1%95%D0%A0%D0%86%D0%A0%C2%B0%D0%A1%D0%8F-%D0%A0%C2%B7%D0%A0%C2%B0%D0%A0%D1%97%D0%A0%D1%91%D0%A1%D0%83%D0%A1%D0%8A-%D0%A0%D0%86-%D0%A0%D2%91%D0%A0%D0%85%D0%A0%C2%B5%D0%A0%D0%86%D0%A0%D0%85%D0%A0%D1%91%D0%A0%D1%94%D0%A0%C2%B5&bt=63599
http://www.elvita-travel.gr/gr//guestbook.asp?name=Syuyrpreds&email=rkkqhclsln@sxmail.info&comments=sexy%20girl%20selfies%0D%0A%20-%20<a%20href="https://sexygirlselfieok.org">sexy%20girl%20selfies%0D%0A</a>%20%0D%0Asexy%20girls%20selfies%0D%0A%20-%20[url=https://sexygirlselfieok.org/]sexy%20girls%20selfies%0D%0A[/url]%20%0D%0A%20%0D%0Ahttp://www.sasoian.info/albisteak.php?id_edukia=7881%0D%0Ahttp://ketos.free.fr/agb/index.php?&mots_search=&lang=francais&skin=&&seeMess=1&seeNotes=1&seeAdd=0&code_erreur=NYJDpVbdjQ%0D%0A&ins=1
- <a href="https://sexygirlselfieok.org">Sexy Girl Selfie
</a>
Sexy Girl Selfie
- [url=https://sexygirlselfieok.org/]Sexy Girl Selfie
[/url]
http://www.bfz.ru/contacts.php?guestbook.php
http://fbtnuzbely.cz/?p=212#comment-8658
http://alveks.lv/site/lat/page/247
tren e dosage
http://spavary.com/index.php?option=com_k2&view=itemlist&task=user&id=134523
<a href="http://webhostie.com/index.php?option=com_k2&view=itemlist&task=user&id=6519
">what does tren do
</a>
<a href="http://iespprhrsanignacio.edu.pe/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=73083
#">tren pills
</a>
tren e cycle
what is tren
http://bronya.automordovia.ru/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=122906
<a href="http://agencywestchester.com/index.php?option=com_k2&view=itemlist&task=user&id=805249
">tren side effects
</a>
<a href="http://sindicatodechoferespichincha.com.ec/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=1392902
#">side effects of tren
</a>
tren a
tren steroid side effects
http://artandluxurysociety.com/index.php?option=com_k2&view=itemlist&task=user&id=31013
<a href="http://symphonydidit.com/index.php?option=com_k2&view=itemlist&task=user&id=9398
">tren acetate dosage
</a>
<a href="http://betarvyatka.ru/index.php?option=com_k2&view=itemlist&task=user&id=75837
#">trenbolone acetate results
</a>
trenbolone acetate
trenbolone enanthate dosage
http://nolongermusic.com/index.php?option=com_k2&view=itemlist&task=user&id=53213
<a href="http://ursthailand.com/index.php?option=com_k2&view=itemlist&task=user&id=89888
">trenbolone steroid
</a>
<a href="http://novadentalanesthesia.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=1371339
#">trenabol
</a>
how to make trenbolone
trenbolone enanthate results
http://premiumsymbol.com/index.php?option=com_k2&view=itemlist&task=user&id=8280
<a href="http://tuccitec.com/index.php?option=com_k2&view=itemlist&task=user&id=194325
">tren acetate
</a>
<a href="http://viverospolo.es/index.php?option=com_k2&view=itemlist&task=user&id=278
#">tren stack
</a>
trenabol
tren enanthate
http://www.cubiclefittings.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=2826
<a href="http://ixtus.od.ua/index.php?option=com_k2&view=itemlist&task=user&id=1172
">trenbolone acetate dosage
</a>
<a href="http://sofiariddings.com/index.php?option=com_k2&view=itemlist&task=user&id=50394
#">tren ace half life
</a>
tren results
tren ethanate
http://inmomartinezfranco.com/index.php?option=com_k2&view=itemlist&task=user&id=13897
<a href="http://geokart.ru/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=112076
">tren
</a>
<a href="http://mykoperasi.coop/index.php?option=com_k2&view=itemlist&task=user&id=2328946
#">tren stack
</a>
trenbolone reviews
http://www.uvservis.ru/index.php?option=com_k2&view=itemlist&task=user&id=38612
<a href="http://jpnatc.org/index.php?option=com_k2&view=itemlist&task=user&id=8584
">tren ace results
</a>
<a href="http://sunnyservice.us/index.php?option=com_k2&view=itemlist&task=user&id=33015
#">tren e cycle
</a>
side effects of tren
side effects of tren
http://alunova.com.ar/index.php?option=com_k2&view=itemlist&task=user&id=14551
<a href="http://axionbusinesstechnologies.com/index.php?option=com_k2&view=itemlist&task=user&id=169360
">tren results
</a>
<a href="http://bulevardecastilla.com/index.php?option=com_k2&view=itemlist&task=user&id=315850
#">tren ace side effects
</a>
tren e cycle
tren test cycle
http://test-oruzhie.ru/index.php?option=com_k2&view=itemlist&task=user&id=247979
<a href="http://w.gostynin24.pl/index.php?option=com_k2&view=itemlist&task=user&id=167773
">trenbolone steroid
</a>
<a href="http://americanfirstleasing.com/index.php?option=com_k2&view=itemlist&task=user&id=109083
#">trenbolone enanthate cycle
</a>
trend steroid
tren
http://vkreative.ru/index.php?option=com_k2&view=itemlist&task=user&id=43945
<a href="http://clasiautos.com/index.php?option=com_k2&view=itemlist&task=user&id=192295
">tren and test cycle
</a>
<a href="http://ns-clinic.ru/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=238757
#">tren acetate cycle
</a>
trenbolone acetate results
side effects of trenbolone
http://sigmaclub-ui.org/index.php?option=com_k2&view=itemlist&task=user&id=756967
<a href="http://thevillageplaceresort.com/index.php?option=com_k2&view=itemlist&task=user&id=2181452
">trenbolone acetate results
</a>
<a href="http://campinggiralda.info/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=16934
#">trenbolone results
</a>
trenbolon
side effects of tren
http://itealmendralejo.es/index.php?option=com_k2&view=itemlist&task=user&id=268179
<a href="http://blueautos.es/index.php?option=com_k2&view=itemlist&task=user&id=92521&lang=es
">trenbolone acetate cycle
</a>
<a href="http://megagroup.co.za/index.php?option=com_k2&view=itemlist&task=user&id=12362
#">tren cycle
</a>
tren ace side effects
tren side effects
http://other.rasmeinews.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=2740805
<a href="http://pay2.com.cn/index.php?option=com_k2&view=itemlist&task=user&id=5761
">tren acetate cycle
</a>
<a href="http://almerek.com/index.php?option=com_k2&view=itemlist&task=user&id=621222
#">trenbolon
</a>
tren and test cycle
http://skpt.co.in/index.php?option=com_k2&view=itemlist&task=user&id=111489
<a href="http://web-tic.cl/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=12953
">trenbolone acetate dosage
</a>
<a href="http://web-tic.cl/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=12953
#">trenbolone acetate results
</a>
steroid tren
trenbolone acetate
http://sac24tix.com/index.php?option=com_k2&view=itemlist&task=user&id=16224
<a href="http://webhostie.com/index.php?option=com_k2&view=itemlist&task=user&id=6519
">tren and test cycle
</a>
<a href="http://grupoarca.es/index.php?option=com_k2&view=itemlist&task=user&id=17991
#">trenbolone side effects
</a>
trenbolone dosage
tren steroids
http://mpunzana.co.za/index.php?option=com_k2&view=itemlist&task=user&id=768458
<a href="http://hushescorts.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=782274
">side effects of trenbolone
</a>
<a href="http://rcpcoach.com/index.php?option=com_k2&view=itemlist&task=user&id=845452
#">tren stack
</a>
tren steroid side effects
trenbolone reviews
http://ocatusa.org/index.php?option=com_k2&view=itemlist&task=user&id=11894
<a href="http://sweetbay.ru/index.php?option=com_k2&view=itemlist&task=user&id=249465
">tren acetate dosage
</a>
<a href="http://tuccitec.com/index.php?option=com_k2&view=itemlist&task=user&id=194325
#">tren steroid side effects
</a>
tren e dosage
trenbolone acetate side effects
http://remontokon116.ru/index.php?option=com_k2&view=itemlist&task=user&id=30423
<a href="http://yezidhacheinmobiliaria.com/index.php?option=com_k2&view=itemlist&task=user&id=9875
">tren enanthate
</a>
<a href="http://lun-m.ru/index.php?option=com_k2&view=itemlist&task=user&id=7739
#">how long does tren stay in your system
</a>
tren results
trenbolone hexahydrobenzylcarbonate
http://oknakrasnoyarsk.orgfree.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=1799
<a href="http://ritzbuild.com/index.php?option=com_k2&view=itemlist&task=user&id=224295
">tren acetate cycle
</a>
<a href="http://www.moyakmermer.com/index.php?option=com_k2&view=itemlist&task=user&id=74452
#">tren acetate
</a>
tren ace half life
tren side effects
http://udhec.com.br/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=650227
<a href="http://mumark.1gb.ru/index.php?option=com_k2&view=itemlist&task=user&id=6995
">tren ace side effects
</a>
<a href="http://incip.org/index.php?option=com_k2&view=itemlist&task=user&id=30180
#">trenbolone enanthate side effects
</a>
tren ace
http://sanyasurf.com/index.php?option=com_k2&view=itemlist&task=user&id=1893829
<a href="http://csw.com.my/index.php?option=com_k2&view=itemlist&task=user&id=445701
">trenbolone acetate cycle
</a>
<a href="http://usacmp.com/index.php?option=com_k2&view=itemlist&task=user&id=12657
#">tren a
</a>
side effects of tren
tren results
http://drlanaschikman.com/index.php?option=com_k2&view=itemlist&task=user&id=8351
<a href="http://masoudstore.ir/index.php?option=com_k2&view=itemlist&task=user&id=244
">trenbolone enanthate dosage
</a>
<a href="http://mumark.1gb.ru/index.php?option=com_k2&view=itemlist&task=user&id=6995
#">tren e cycle
</a>
tren acetate dosage
trenbolone
http://acp.in.ua/index.php?option=com_k2&view=itemlist&task=user&id=646
<a href="http://lotus-elchtet.com/index.php?option=com_k2&view=itemlist&task=user&id=131111
">tren enanthate
</a>
<a href="http://pgbari.com/index.php?option=com_k2&view=itemlist&task=user&id=208362
#">trenbolone
</a>
tren e results
oral trenbolone
http://joanramagoshi.com/index.php?option=com_k2&view=itemlist&task=user&id=172973
<a href="http://bintangwahyu.com/index.php?option=com_k2&view=itemlist&task=user&id=571770
">tren enanthate
</a>
<a href="http://braut-make-up.eu/index.php?option=com_k2&view=itemlist&task=user&id=22331
#">trenbolone enanthate dosage
</a>
tren enanthate
tren e dosage
http://ixtus.od.ua/index.php?option=com_k2&view=itemlist&task=user&id=1172
<a href="http://4dmarketing.co.za/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=110654
">trenbolone dosage
</a>
<a href="http://aceheader.jp/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=20039
#">tren acetate
</a>
trenabol
tren results
http://americanfirstleasing.com/index.php?option=com_k2&view=itemlist&task=user&id=109083
<a href="http://tennisinnovator.com/index.php?option=com_k2&view=itemlist&task=user&id=280996
">oral tren
</a>
<a href="http://dimohodmagazin.ru/index.php?option=com_k2&view=itemlist&task=user&id=13850
#">what is tren
</a>
trenbolone cycle
tren ace half life
http://ritzbuild.com/index.php?option=com_k2&view=itemlist&task=user&id=224295
<a href="http://runwaycycling.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=3718862
">trenbolone acetate dosage
</a>
<a href="http://naturalclique.com/index.php?option=com_k2&view=itemlist&task=user&id=93600
#">what does tren do
</a>
tren ace results
http://vnanwi.com/index.php?option=com_k2&view=itemlist&task=user&id=2812088
<a href="http://118.139.186.94/index.php?option=com_k2&view=itemlist&task=user&id=43470
">tren ace half life
</a>
<a href="http://w.gostynin24.pl/index.php?option=com_k2&view=itemlist&task=user&id=167773
#">trenbolone acetate results
</a>
tren e results
tren acetate dosage
http://runwaycycling.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=3718862
<a href="http://mykoperasi.coop/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=2328946
">trenbolone results
</a>
<a href="http://haybren.in/index.php?option=com_k2&view=itemlist&task=user&id=48147
#">trenbolone pills
</a>
trend steroid
tren side effects
http://bennex.co.th/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=2645884
<a href="http://tangguh.co.id/index.php?option=com_k2&view=itemlist&task=user&id=507698
">tri tren
</a>
<a href="http://www.indiadatafin.com/index.php?option=com_k2&view=itemlist&task=user&id=3198
#">trenbolone acetate cycle
</a>
tren acetate dosage
trenbolon
http://www.cubiclefittings.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=2824
<a href="http://unikomsnab.by/index.php?option=com_k2&view=itemlist&task=user&id=43550
">trenbolone hexahydrobenzylcarbonate
</a>
<a href="http://dobgir.com/index.php?option=com_k2&view=itemlist&task=user&id=212872
#">oral tren
</a>
tren ace side effects
tren e dosage
http://mpunzana.co.za/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=768458
<a href="http://www.frioaxarquia.com/index.php?option=com_k2&view=itemlist&task=user&id=1019
">tren hex
</a>
<a href="http://premiumsymbol.com/index.php?option=com_k2&view=itemlist&task=user&id=8280
#">tren and test cycle
</a>
tren test cycle
tren steroids
http://afroexposure.com/index.php?option=com_k2&view=itemlist&task=user&id=32205
<a href="http://goldenoceanmarine.com/index.php?option=com_k2&view=itemlist&task=user&id=31819
">trend steroid
</a>
<a href="http://theresp.com/index.php?option=com_k2&view=itemlist&task=user&id=9324&Itemid=119
#">steroid tren
</a>
trenbolone reviews
trenbolone acetate dosage
http://dmc-ocean.ru/index.php?option=com_k2&view=itemlist&task=user&id=81144
<a href="http://csdsz.net/index.php?option=com_k2&view=itemlist&task=user&id=668811
">trenbolone acetate side effects
</a>
<a href="http://icebergofficial.com/index.php?option=com_k2&view=itemlist&task=user&id=258412
#">trenbolone acetate cycle
</a>
how to take tren
http://velestravel.ru/index.php?option=com_k2&view=itemlist&task=user&id=111897
<a href="http://ib-fertilizantes.es/index.php?option=com_k2&view=itemlist&task=user&id=8397&lang=es
">trenbolone results
</a>
<a href="http://sefaoutsourcing.com/index.php?option=com_k2&view=itemlist&task=user&id=354212
#">tren side effects
</a>
trend steroid
tren and test cycle
http://mongolievoyages.modernger.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=192632
<a href="http://acrp.in/index.php?option=com_k2&view=itemlist&task=user&id=2892830
">trenbolone enanthate dosage
</a>
<a href="http://coifman.co.il/index.php?option=com_k2&view=itemlist&task=user&id=34964
#">trenbolon
</a>
trenbolone results
oral tren
http://santetoujours.info/index.php?option=com_k2&view=itemlist&task=user&id=3132308
<a href="http://www.enigmacreatives.com/index.php?option=com_k2&view=itemlist&task=user&id=42688
">tren e
</a>
<a href="http://neosmartsystems.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=22943
#">trenbolone acetate side effects
</a>
tren a
tren acetate dosage
http://paneinattesa.altervista.org/index.php?option=com_k2&view=itemlist&task=user&id=112016&Itemid=501
<a href="http://hopewalkingacrossamerica.com/index.php?option=com_k2&view=itemlist&task=user&id=61950
">tren steroid side effects
</a>
<a href="http://el-lab.pro/index.php?option=com_k2&view=itemlist&task=user&id=178
#">tren hex
</a>
tren e
trenbolone results
http://smconsulting.ae/index.php?option=com_k2&view=itemlist&task=user&id=110283
<a href="http://csw.com.my/index.php?option=com_k2&view=itemlist&task=user&id=445701
">tren ace side effects
</a>
<a href="http://innovasyses.com/index.php?option=com_k2&view=itemlist&task=user&id=24894
#">trenbolone dosage
</a>
trenbolone cycle
trenbolone enanthate side effects
http://triad.kiev.ua/index.php?option=com_k2&view=itemlist&task=user&id=65043
<a href="http://other.rasmeinews.com/index.php?option=com_k2&view=itemlist&task=user&id=2740805
">tren acetate cycle
</a>
<a href="http://pran.org.bd/index.php?option=com_k2&view=itemlist&task=user&id=12587
#">tren test cycle
</a>
side effects of trenbolone
tren a
http://chupimegafiesta.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=25961
<a href="http://hi.live.woocomdev.com.au/index.php?option=com_k2&view=itemlist&task=user&id=710135
">trenbolone side effects
</a>
<a href="http://remeslon.ru/index.php?option=com_k2&view=itemlist&task=user&id=253348
#">tren ethanate
</a>
tren ethanate
http://sexshoponline.kz/index.php?option=com_k2&view=itemlist&task=user&id=197813
<a href="http://guiacastelldefels.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=24898
">tren results
</a>
<a href="http://axionbusinesstechnologies.com/index.php?option=com_k2&view=itemlist&task=user&id=169360
#">tren results
</a>
tren pills
tren steroids
http://cororondalosforamontanos.com/index.php?option=com_k2&view=itemlist&task=user&id=216917
<a href="http://4x4store.com.au/index.php?option=com_k2&view=itemlist&task=user&id=9052
">tren acetate dosage
</a>
<a href="http://ubuhlepainters.co.za/index.php?option=com_k2&view=itemlist&task=user&id=28589
#">tren acetate
</a>
trenabol
tren ace results
http://mso.soict.hust.edu.vn/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=300227
<a href="http://megagroup.co.za/index.php?option=com_k2&view=itemlist&task=user&id=12362
">tren e dosage
</a>
<a href="http://dtvgrenchen.ch/index.php?option=com_k2&view=itemlist&task=user&id=13541
#">tren side effects
</a>
trenbolone acetate
tren
http://fondation-famart.com/index.php?option=com_k2&view=itemlist&task=user&id=217734
<a href="http://apcasystems.com/index.php?option=com_k2&view=itemlist&task=user&id=4519
">trenbolone enanthate cycle
</a>
<a href="http://ixtus.od.ua/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=1172
#">side effects of tren
</a>
trenbolone enanthate
tren acetate
http://startshina.dp.ua/index.php?option=com_k2&view=itemlist&task=user&id=13368
<a href="http://lurisia.com.ar/index.php?option=com_k2&view=itemlist&task=user&id=92194
">tren e cycle
</a>
<a href="http://www.grupofenixconsultores.com/index.php?option=com_k2&view=itemlist&task=user&id=1727525
#">trenbolone enanthate results
</a>
tren side effects
tren acetate cycle
http://cadcamoffices.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=737101
<a href="http://www.grupofenixconsultores.com/index.php?option=com_k2&view=itemlist&task=user&id=1727525
">tren dosage
</a>
<a href="http://premiumsymbol.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=8280
#">tren dosage
</a>
what is tren
trenbolone steroid
http://www.settravel.ru/index.php?option=com_k2&view=itemlist&task=user&id=2260
<a href="http://specpharm.com/index.php?option=com_k2&view=itemlist&task=user&id=25419
">trenbolone enanthate results
</a>
<a href="http://www.uvservis.ru/index.php?option=com_k2&view=itemlist&task=user&id=38612
#">tren ace
</a>
tren stack
http://anaisabelaparicio.com/index.php?option=com_k2&view=itemlist&task=user&id=116381
<a href="http://house-of-harmony.com/index.php?option=com_k2&view=itemlist&task=user&id=282987
">trenbolone dosage
</a>
<a href="http://news4u.cz/index.php?option=com_k2&view=itemlist&task=user&id=9991
#">tren steroids
</a>
trenbolone cycle
trenbolone enanthate results
http://masoudstore.ir/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=244
<a href="http://yunusobodtxtb.uz/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=505
">trenbolone acetate cycle
</a>
<a href="http://armenianphilatelic.org/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=26190
#">tren steroid side effects
</a>
oral trenbolone
how long does tren stay in your system
http://zagrada.ua/index.php?option=com_k2&view=itemlist&task=user&id=649519
<a href="http://personeriadebarranquilla.gov.co/index.php?option=com_k2&view=itemlist&task=user&id=20478
">how to take tren
</a>
<a href="http://runwaycycling.co.uk/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=3718862
#">trenbolone acetate results
</a>
tren results
trenbolone results
http://xn--911-5cdoh2aqz1anx.xn--p1ai/index.php?option=com_k2&view=itemlist&task=user&id=199964
<a href="http://rco.k46.ru/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=8531
">oral trenbolone
</a>
<a href="http://triad.kiev.ua/index.php?option=com_k2&view=itemlist&task=user&id=65043
#">tren ethanate
</a>
tren ace half life
trenabol
http://msk024.ru/index.php?option=com_k2&view=itemlist&task=user&id=18144
<a href="http://lotus-elchtet.com/index.php?option=com_k2&view=itemlist&task=user&id=131111
">tren ace
</a>
<a href="http://tiras-ttu.org/index.php?option=com_k2&view=itemlist&task=user&id=60704
#">trenbolone steroid
</a>
tren steroid side effects
trenbolone hexahydrobenzylcarbonate
http://sweetbay.ru/index.php?option=com_k2&view=itemlist&task=user&id=249465
<a href="http://innovasyses.com/index.php?option=com_k2&view=itemlist&task=user&id=24894
">tren acetate
</a>
<a href="http://evgrashina.de/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=61571
#">how to make trenbolone
</a>
trenbolone acetate
side effects of trenbolone
http://vittorioceccoli.it/index.php?option=com_k2&view=itemlist&task=user&id=14713&lang=en
<a href="http://4x4store.com.au/index.php?option=com_k2&view=itemlist&task=user&id=9052
">trenbolone acetate cycle
</a>
<a href="http://www.johnston-contractors.com/index.php?option=com_k2&view=itemlist&task=user&id=192393
#">trenbolone dosage
</a>
tren enanthate
http://felicz.cz/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=7904
<a href="http://atelier-floral.ro/index.php?option=com_k2&view=itemlist&task=user&id=22683
">tren hex
</a>
<a href="http://news4u.cz/index.php?option=com_k2&view=itemlist&task=user&id=9991
#">trend steroid
</a>
trenbolone dosage
oral trenbolone
http://zlatokoral.sk/index.php?option=com_k2&view=itemlist&task=user&id=10264
<a href="http://monster-beats-orlean.ru/index.php?option=com_k2&view=itemlist&task=user&id=44461
">tren hex
</a>
<a href="http://sefaoutsourcing.com/index.php?option=com_k2&view=itemlist&task=user&id=354212
#">oral trenbolone
</a>
trenbolone acetate
tren pills
http://planetadverej.ru/index.php?option=com_k2&view=itemlist&task=user&id=60134
<a href="http://centragrid.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=85404
">trenbolone acetate results
</a>
<a href="http://mx-digital.com/index.php?option=com_k2&view=itemlist&task=user&id=139438
#">trenbolone reviews
</a>
tren a
trenbolone acetate dosage
http://www.seattlebeerco.com/index.php?option=com_k2&view=itemlist&task=user&id=192744
<a href="http://wahyuqolbu.com/index.php?option=com_k2&view=itemlist&task=user&id=6755
">trenbolone reviews
</a>
<a href="http://en.cep-eng.it/index.php?option=com_k2&view=itemlist&task=user&id=13774
#">trenbolone enanthate
</a>
trenbolone acetate cycle
tren results
http://ncfproject.org/index.php?option=com_k2&view=itemlist&task=user&id=872627
<a href="http://www.thefoundation.or.tz/index.php?option=com_k2&view=itemlist&task=user&id=1910588
">tren and test cycle
</a>
<a href="http://oknakrasnoyarsk.orgfree.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=1799
#">tren ace side effects
</a>
trenbolone enanthate cycle
tren stack
http://www.spartateck.com/index.php?option=com_k2&view=itemlist&task=user&id=72907
<a href="http://thespiralstaircasecompany.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=30238
">what is tren
</a>
<a href="http://evgrashina.de/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=61571
#">tren e cycle
</a>
trenbolone enanthate results
trenbolone enanthate dosage
http://egtot.com/index.php?option=com_k2&view=itemlist&task=user&id=8558
<a href="http://rcpcoach.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=845452
">trenbolone side effects
</a>
<a href="http://nbhomerepairsnj.com/index.php?option=com_k2&view=itemlist&task=user&id=109252
#">tren steroids
</a>
tren pills
http://biblioteca.reddigital.cl/index.php?option=com_k2&view=itemlist&task=user&id=2957
<a href="http://accountingservices24.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=58131
">tren and test cycle
</a>
<a href="http://familydynamix.co.za/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=31495
#">steroid tren
</a>
trend steroid
trend steroid
http://geokart.ru/index.php?option=com_k2&view=itemlist&task=user&id=112076
<a href="http://rotary-spb.ru/index.php?option=com_k2&view=itemlist&task=user&id=110113
">tren steroids
</a>
<a href="http://www.puriflair.com/index.php?option=com_k2&view=itemlist&task=user&id=227467
#">what is tren
</a>
how long does tren stay in your system
trenbolone steroid
http://runwaycycling.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=3718862
<a href="http://mso.soict.hust.edu.vn/index.php?option=com_k2&view=itemlist&task=user&id=300227
">trenbolone enanthate
</a>
<a href="http://uveliraram.ru/index.php?option=com_k2&view=itemlist&task=user&id=58760
#">tren enanthate
</a>
trenbolone acetate dosage
tren steroid side effects
http://news4u.cz/index.php?option=com_k2&view=itemlist&task=user&id=9991
<a href="http://dimohodmagazin.ru/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=13850
">trenbolone cycle
</a>
<a href="http://runwaycycling.co.uk/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=3718862
#">trenbolone acetate cycle
</a>
trenbolone reviews
trenbolone steroid
http://banavaragoshala.org/index.php?option=com_k2&view=itemlist&task=user&id=19595
<a href="http://smarthomeuniversity.com/index.php?option=com_k2&view=itemlist&task=user&id=280378
">tren steroid side effects
</a>
<a href="http://doctorlaguna.com/index.php?option=com_k2&view=itemlist&task=user&id=14983
#">trenbolone acetate results
</a>
tren e results
oral trenbolone
http://doctorlaguna.com/index.php?option=com_k2&view=itemlist&task=user&id=14983
<a href="http://anebopro.com/index.php?option=com_k2&view=itemlist&task=user&id=257901
">side effects of tren
</a>
<a href="http://formentera-low-cost.com/index.php?option=com_k2&view=itemlist&task=user&id=61294
#">trenabol
</a>
side effects of tren
tren dosage
http://afina-mos.ru/index.php?option=com_k2&view=itemlist&task=user&id=206866
<a href="http://bintangwahyu.com/index.php?option=com_k2&view=itemlist&task=user&id=571770
">steroid tren
</a>
<a href="http://sofiariddings.com/index.php?option=com_k2&view=itemlist&task=user&id=50394
#">trenbolone enanthate results
</a>
tren hex
http://cajon.pro/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=998
<a href="http://clasiautos.com/index.php?option=com_k2&view=itemlist&task=user&id=195453
">trenbolone acetate
</a>
<a href="http://www.photox.photoxpeditions.com/index.php?option=com_k2&view=itemlist&task=user&id=152313
#">how to make trenbolone
</a>
tren side effects
tren e cycle
http://onepiao.net/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=6136
<a href="http://in2it-homes.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=1936306598
">trenbolone acetate cycle
</a>
<a href="http://jetandrotor.com/index.php?option=com_k2&view=itemlist&task=user&id=231584
#">how to make trenbolone
</a>
trenbolone steroid
trenbolone acetate results
http://sweetbay.ru/index.php?option=com_k2&view=itemlist&task=user&id=257275
<a href="http://growth-int.com/index.php?option=com_k2&view=itemlist&task=user&id=154588
">trenabol
</a>
<a href="http://test.salon-golubka.com/index.php?option=com_k2&view=itemlist&task=user&id=565945
#">tren ace half life
</a>
what is tren
trenbolone reviews
http://bronya.automordovia.ru/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=130320
<a href="http://www.cubiclefittings.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=2835
">trenabol
</a>
<a href="http://coimbatorechildtrust.com/index.php?option=com_k2&view=itemlist&task=user&id=2473
#">tren ace
</a>
side effects of tren
trend steroid
http://ncfproject.org/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=880097
<a href="http://axionbusinesstechnologies.com/index.php?option=com_k2&view=itemlist&task=user&id=172361
">oral tren
</a>
<a href="http://praestar-controls.com/index.php?option=com_k2&view=itemlist&task=user&id=161588
#">how to take tren
</a>
trenbolone acetate results
oral tren
http://ee-travel.ru/index.php?option=com_k2&view=itemlist&task=user&id=33765
<a href="http://greenacre.co.za/index.php?option=com_k2&view=itemlist&task=user&id=1389958
">trenbolone pills
</a>
<a href="http://www.cerrajerosdetijuana.org/index.php?option=com_k2&view=itemlist&task=user&id=166497
#">tren a
</a>
tri tren
trenbolone side effects
http://drevovzahrade.cz/index.php?option=com_k2&view=itemlist&task=user&id=248995
<a href="http://viverospolo.es/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=548
">tri tren
</a>
<a href="http://vocational-courses.nearoff.com/index.php?option=com_k2&view=itemlist&task=user&id=2355875
#">trenbolone acetate results
</a>
trenbolone enanthate side effects
http://acrp.in/index.php?option=com_k2&view=itemlist&task=user&id=2903129
<a href="http://ltbusinessconsulting.com/index.php?option=com_k2&view=itemlist&task=user&id=172200
">how to make trenbolone
</a>
<a href="http://empleo.cuadrillariojaalavesa.com/index.php?option=com_k2&view=itemlist&task=user&id=316891
#">steroid tren
</a>
oral tren
tren e dosage
http://www.tibetgalerie.com/index.php?option=com_k2&view=itemlist&task=user&id=3841
<a href="http://iceberg.ykt.ru/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=78703
">tren steroid side effects
</a>
<a href="http://nafdac.gov.ng/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=2379294
#">tren ace side effects
</a>
what does tren do
trenabol
http://agroma.gr/index.php?option=com_k2&view=itemlist&task=user&id=5994
<a href="http://www.mentalfortennis.com/index.php?option=com_k2&view=itemlist&task=user&id=5873
">tren results
</a>
<a href="http://death-kit.ru/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=22115
#">oral tren
</a>
tren acetate
tren hex
http://d3bidan.urindo.ac.id/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=286736
<a href="http://www.bilgimak.net/index.php?option=com_k2&view=itemlist&task=user&id=82667
">trenbolone enanthate
</a>
<a href="http://www.puriflair.com/index.php?option=com_k2&view=itemlist&task=user&id=229637
#">trenbolone acetate cycle
</a>
trenbolone dosage
tren dosage
http://almerek.kz/index.php?option=com_k2&view=itemlist&task=user&id=630713
<a href="http://lepisdore.co.za/index.php?option=com_k2&view=itemlist&task=user&id=1076950
">how to make trenbolone
</a>
<a href="http://ritzbuild.com/index.php?option=com_k2&view=itemlist&task=user&id=228473
#">tren
</a>
tren cycle
tren ace half life
http://tpdsmumbai.com/index.php?option=com_k2&view=itemlist&task=user&id=63768
<a href="http://ritzbuild.com/index.php?option=com_k2&view=itemlist&task=user&id=228473
">tren steroid side effects
</a>
<a href="http://anaisabelaparicio.com/index.php?option=com_k2&view=itemlist&task=user&id=118256
#">trenbolone pills
</a>
steroid tren
trenbolone enanthate
http://royaltonhotels.com.ng/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=7127
<a href="http://dkal.gr/index.php?option=com_k2&view=itemlist&task=user&id=3117&lang=en
">trenbolone dosage
</a>
<a href="http://jinxcrossfire.com/index.php?option=com_k2&view=itemlist&task=user&id=73439
#">trenbolone enanthate side effects
</a>
trenbolon
http://mobility-corp.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=677089
<a href="http://acp.in.ua/index.php?option=com_k2&view=itemlist&task=user&id=660
">tren cycle
</a>
<a href="http://cutgrass.com.au/index.php?option=com_k2&view=itemlist&task=user&id=117360
#">tren acetate
</a>
trenbolone acetate cycle
trend steroid
http://vcarepharmacy.us/index.php?option=com_k2&view=itemlist&task=user&id=88070
<a href="http://beldecor.cl/index.php?option=com_k2&view=itemlist&task=user&id=245045
">tren test cycle
</a>
<a href="http://www.ibccmexico.com/index.php?option=com_k2&view=itemlist&task=user&id=254525
#">tren enanthate
</a>
trenbolone cycle
tren dosage
http://770307.ru/index.php?option=com_k2&view=itemlist&task=user&id=72909
<a href="http://sigmaclub-ui.org/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=768668
">trenbolone enanthate results
</a>
<a href="http://designlux.in.ua/index.php?option=com_k2&view=itemlist&task=user&id=13624
#">how to take tren
</a>
tren results
tren side effects
http://senbeat.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=55436
<a href="http://ncfproject.org/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=881006
">tren e dosage
</a>
<a href="http://www.photox.photoxpeditions.com/index.php?option=com_k2&view=itemlist&task=user&id=153040
#">tren steroid side effects
</a>
tren e dosage
trenbolone steroid
http://amkodor-bryansk.ru/index.php?option=com_k2&view=itemlist&task=user&id=25199
<a href="http://anaisabelaparicio.com/index.php?option=com_k2&view=itemlist&task=user&id=118518
">tren ace results
</a>
<a href="http://vocational-courses.nearoff.com/index.php?option=com_k2&view=itemlist&task=user&id=2349890
#">tren results
</a>
trenbolone enanthate cycle
trenbolone side effects
http://maltav.ru/index.php?option=com_k2&view=itemlist&task=user&id=20606
<a href="http://skyit.org/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=225198
">tren hex
</a>
<a href="http://iv-dancefit.ru/index.php?option=com_k2&view=itemlist&task=user&id=37797
#">tren e results
</a>
trend steroid
trenbolone enanthate cycle
http://joanramagoshi.com/index.php?option=com_k2&view=itemlist&task=user&id=176443
<a href="http://sanyasurf.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=1907792
">tri tren
</a>
<a href="http://dubbomtb.org.au/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=2057573
#">tren ace side effects
</a>
tren dosage
http://lifespace.in.ua/index.php?option=com_k2&view=itemlist&task=user&id=149184
<a href="http://www.multi-formas.com/index.php?option=com_k2&view=itemlist&task=user&id=197584
">tren e cycle
</a>
<a href="http://school3.rogachevoo.gov.by/index.php?option=com_k2&view=itemlist&task=user&id=49353
#">tren results
</a>
trenbolone steroid
how to take tren
http://remont-dly-vas.ru/index.php?option=com_k2&view=itemlist&task=user&id=14440
<a href="http://4trombones.com/index.php?option=com_k2&view=itemlist&task=user&id=351307
">tren enanthate
</a>
<a href="http://designlux.in.ua/index.php?option=com_k2&view=itemlist&task=user&id=13624
#">tren stack
</a>
trenbolone reviews
tren ace
http://historyimprint.com/index.php?option=com_k2&view=itemlist&task=user&id=720546
<a href="http://goconfused.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=13937
">tren results
</a>
<a href="http://770307.ru/index.php?option=com_k2&view=itemlist&task=user&id=72909
#">trenbolone dosage
</a>
how long does tren stay in your system
tren enanthate
http://cutgrass.com.au/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=117360
<a href="http://sexshoponline.kz/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=203441
">tren side effects
</a>
<a href="http://www.ferrocables.com/index.php?option=com_k2&view=itemlist&task=user&id=4092
#">tren acetate dosage
</a>
trenbolone pills
tren stack
http://www.otdyh-v-gorah.com/index.php?option=com_k2&view=itemlist&task=user&id=13179
<a href="http://apps-creator.com/index.php?option=com_k2&view=itemlist&task=user&id=187035
">steroid tren
</a>
<a href="http://seginco.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=399231
#">tren ace side effects
</a>
trenbol
tren test cycle
http://www.paceinteriors.com.au/index.php?option=com_k2&view=itemlist&task=user&id=6454
<a href="http://www.puriflair.com/index.php?option=com_k2&view=itemlist&task=user&id=229195
">tren side effects
</a>
<a href="http://oknakrasnoyarsk.orgfree.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=1937
#">tren steroids
</a>
tri tren
tren e cycle
http://sanyasurf.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=1907792
<a href="http://miranico.ir/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=1723657
">tren acetate
</a>
<a href="http://new.glg.su/index.php?option=com_k2&view=itemlist&task=user&id=115573
#">trenbolone acetate dosage
</a>
side effects of tren
http://phoenixhotties.com/index.php?option=com_k2&view=itemlist&task=user&id=235958
<a href="http://ocispain.com/index.php?option=com_k2&view=itemlist&task=user&id=285971
">oral tren
</a>
<a href="http://www.cerrajerosdetijuana.org/index.php?option=com_k2&view=itemlist&task=user&id=167276
#">tren steroid side effects
</a>
tren side effects
what is tren
http://iblackbird.com/index.php?option=com_k2&view=itemlist&task=user&id=44938
<a href="http://maltav.ru/index.php?option=com_k2&view=itemlist&task=user&id=20606
">trenbolone enanthate dosage
</a>
<a href="http://tiras-ttu.org/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=61480
#">trenbolone acetate side effects
</a>
trenbolone dosage
trenbolone results
http://keenpack.ru/index.php?option=com_k2&view=itemlist&task=user&id=37103
<a href="http://rostes-iug-doroga.ru/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=1243930
">side effects of tren
</a>
<a href="http://roofservice.ru/index.php?option=com_k2&view=itemlist&task=user&id=75880
#">tren ace results
</a>
how to take tren
tren side effects
http://ee-travel.ru/index.php?option=com_k2&view=itemlist&task=user&id=33765
<a href="http://calcadosdejahu.com.br/index.php?option=com_k2&view=itemlist&task=user&id=1653553
">tren side effects
</a>
<a href="http://hiplocks.com/index.php?option=com_k2&view=itemlist&task=user&id=57464
#">tren enanthate
</a>
tren e cycle
trenbolone dosage
http://eyesecure.co.za/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=75694
<a href="http://orosolido.com.mx/index.php?option=com_k2&view=itemlist&task=user&id=296877
">trenbolone enanthate cycle
</a>
<a href="http://evoxhair.com/index.php?option=com_k2&view=itemlist&task=user&id=61195
#">tri tren
</a>
trenbolone pills
tren steroid side effects
http://school2.rogachevoo.gov.by/index.php?option=com_k2&view=itemlist&task=user&id=36023
<a href="http://clasiautos.com/index.php?option=com_k2&view=itemlist&task=user&id=195453
">trenbolone enanthate side effects
</a>
<a href="http://yunusobodtxtb.uz/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=645
#">tren e
</a>
oral tren
tren cycle
http://security-info.com/index.php?option=com_k2&view=itemlist&task=user&id=228655
<a href="http://distributortransmedia.com/index.php?option=com_k2&view=itemlist&task=user&id=975584
">trenbolone reviews
</a>
<a href="http://cadcamoffices.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=748290
#">tren acetate
</a>
trenbolone acetate dosage
http://shipwts.com/index.php?option=com_k2&view=itemlist&task=user&id=105938
<a href="http://shareula.ge/index.php?option=com_k2&view=itemlist&task=user&id=65404&lang=en
">tren steroids
</a>
<a href="http://piersez.com/index.php?option=com_k2&view=itemlist&task=user&id=109781
#">tren ace
</a>
tren ace half life
trenbolone results
http://naveedulhassan.com/index.php?option=com_k2&view=itemlist&task=user&id=41518
<a href="http://kiosramah.com/index.php?option=com_k2&view=itemlist&task=user&id=115876
">tren acetate cycle
</a>
<a href="http://hi.live.woocomdev.com.au/index.php?option=com_k2&view=itemlist&task=user&id=720595
#">trenbolone dosage
</a>
trenbolone side effects
trenbolone steroid
http://serenomiami.com/index.php?option=com_k2&view=itemlist&task=user&id=2163723
<a href="http://chupimegafiesta.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=30880
">tren
</a>
<a href="http://andrey-skripka.com/index.php?option=com_k2&view=itemlist&task=user&id=230396
#">how to take tren
</a>
how long does tren stay in your system
tren ethanate
http://petaw.fr/index.php?option=com_k2&view=itemlist&task=user&id=38442
<a href="http://iblackbird.com/index.php?option=com_k2&view=itemlist&task=user&id=44938
">tren a
</a>
<a href="http://sinergibumn.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=67472
#">tri tren
</a>
trenbolone acetate
trenbolone side effects
http://anthembookkeeping.com/index.php?option=com_k2&view=itemlist&task=user&id=97413
<a href="http://leefbaaralmere.vostedevelopment.com/index.php?option=com_k2&view=itemlist&task=user&id=17333
">tren dosage
</a>
<a href="http://mykoperasi.coop/index.php?option=com_k2&view=itemlist&task=user&id=2344656
#">trenbolone steroid
</a>
tren a
trenbolone pills
http://greenacre.co.za/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=1389958
<a href="http://mobility-corp.com/index.php?option=com_k2&view=itemlist&task=user&id=668702
">side effects of trenbolone
</a>
<a href="http://compraventademetal.com/index.php?option=com_k2&view=itemlist&task=user&id=1027
#">how to take tren
</a>
tren enanthate
trenbolone hexahydrobenzylcarbonate
http://new.glg.su/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=115573
<a href="http://beotek.com.tr/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=617208
">trenbolone
</a>
<a href="http://cutgrass.com.au/index.php?option=com_k2&view=itemlist&task=user&id=117360
#">tren hex
</a>
Water as free of viruses and pathogens as any device not created by God can do.
Clin Neurol Neurosurg 2001;103 178-83.
<a href="https://anabolicsteroidsnpc.com">Anabolic steroids</a> These two particular servers may or may not have been regularly utilized by Russian Intelligence, but they were not uniquely so used.
That s not the case anymore, but it s greater affordability makes it worth a second look now that the Big Hurt is enshrined in Cooperstown.
Also, the AI will only initiate battles where it calculates a decent chance of winning, meaning lone spearmen won t mindlessly assault your tanks anymore unless the AI feels the spearman actually has a chance to win.
[url=https://anabolicsteroidsnpc.com/]Anabolic steroids[/url] Kevork Djansezian Getty Images .
In 2003, the famous BALCO investigation was carried out.
Turbocharge your libido and extend your sexual experience.
We realise that America isn t all that great.
5 boswellic acids, which corresponds to 450 mg day of boswellic acid.
Pratt WM, Siconolfi SF, Webster L, Hayes JC, Mazzocca AD 1989 Jan;.
nonsteroidal anti-inflammatory drug and it helps to reduce pain and inflammation.
There s no adverse reaction, no immune response, because it s your blood.
One common misconception in popular culture and the media is that anabolic steroids are highly dangerous and users mortality rates are high.
Takes a whole another level when he successfully kills an entire universe.
I also have been diagnosed with gallstones and thinking of using the flush as an alternative medicine.
<a href="https://anabolicsteroidsnpc.com">Anabolic steroids</a> go and watch a silly film like Blazing Saddles, Life of Brian, Blades of Glory etc.
The studies have been featured in Time Magazine, the NY Times, USA Today and NPR as well as in many scholarly publications.
Also, he was the 5th player to win an MVP award.
[url=https://anabolicsteroidsnpc.com/]Anabolic steroids[/url] Here was a man incapable of doing anything that would be useful to a terrorist organization he couldn t build a bomb, hijack a plane, or carry out an assassination.
Mehrotra R, Kopple JD.
By PATRICIA COHEN MAY 29, 2017.
Not sure what this means, must have been your rage induced hate upon this article but steroids are not a miracle drug that make you super human and grow massive muscles.
Because of inadequate exposure to sunlight, decreased intestinal absorption of vitamin D, and limited intake of milk, elderly persons often are vitamin D deficient.
Journal of Cardiac Failure.
Because they are heavier, they will not float in water like cholesterol stones, but will sink.
Those who endorse, promote and are involved TBN with these soothsayers and charlatans are partakers of the same evil deeds in leading people to hell knowingly or unknowingly.
Fortunately for the Astros and Bagwell, the coaches who wanted to leave Bagwell alone outnumbered those who wanted to change him.
Edward Norton.
The match was considered pretty bizzare, since Maria was a member of one of the classic Democrat families, and Arnie a staunch Republican, but who are we to judge.
<a href="https://anabolicsteroidsnpc.com">Anabolic</a> D Attomo saw it, too.
CrazyBulk legal anabolics are formulated and manufactured in the United States using the purest, highest quality, pharmaceutical grade ingredients, meaning you get fast gains with no side effects, and no prescription needed.
Whipwormsand Capillaria are not commonly found in fecal analysis due in part to adult parasites shedding eggs intermittently and the eggs do not float very well unless saturated sugar solution is used.
[url=https://anabolicsteroidsnpc.com/]Steroids[/url] International Immunology 24 8, 529-538.
If ur on any parole or probation the max they use are 8 panel tests and they do not have lsd on them.
Mensan, woodworker, building electronics projects since age 12, taught electronics, am in ham radio, very good at biology astronomy physics.
Review Date 5 5 2008 Reviewed By Andrew L.
When testing for drug use, all endogenous steroids have a normal range.
While pectin is not necessarily unhealthy, many organic, high-quality yogurt varieties achieve desired consistency without the use of pectins.
Maybe your mom has or had it.
We began talking and I asked her about her daughter s hair.
William Mallet.
Other treatment options include cold poultices, injections with steroids, massages, and application of DMSO.
for example for seasonal hay fever, or to treat a chronic skin disorder such as atopic dermatitis or lichen planus.
<a href="https://anabolicsteroidsnpc.com">Anabolic steroids</a> UFC officials told MMAWeekly that Kimball accepted the bout at a catchweight.
Edmund Chein.
Arnold started visiting the White House as something other than a highly noticed movie star when he signed on as chairman of the President s Council of Physical Fitness in the 1990 Bush White House.
[url=https://anabolicsteroidsnpc.com/]Anabolic[/url] 2015 Symptom- and fraction of exhaled nitric oxide driven strategies for asthma control A cluster-randomized trial in primary care.
At one point I was going every 2 weeks and wanted to hump everything in site, and as a married man that wasn t good, so I purposely scaled back to every 3 weeks.
Which Stars Were Juicing Up.
In this DVD series I want to detail a number of beliefs people have these days that have no basis in Scripture.
Joel Watson possibly put it best.
The phone call causes the like dislike ratio on all of his videos to plummet to Marc-Lobliner-After-Being-Order 66 d levels.
Now Lovato s is runned by Rafael Jr, the best BJJ fighter in the USA.
Proc Natl Acad Sci U S A 85 23 9086-9090.
Alarms were going off for about half an hour before guests were allowed to return to their rooms.
A comparison of physical therapy, chiropractic manipulation, and provision of an educational booklet for the treatment of patients with low back pain.
A wide range of regulatory agencies routinely conduct stringent audits of our manufacturing facilities for compliance with Current Good Manufacturing Practices cGMP .
<a href="https://anabolicsteroidsnpc.com">Anabolic</a> In those Wars you could readily see, hear, smell, taste, and touch the Socialistic enemy of Germany and Russia.
Limit your time in the sun.
Then alpaca may swallow the larva while grazing.
[url=https://anabolicsteroidsnpc.com/]Anabolic steroids[/url] i ll say it again, these products should be taken off the market.
In the realm of dietary dangers, trans fats rank very high.
This may occur after the numbing medicine wears off but before the steroid has had a chance to work.
If TRT Man will let me publish my email, please send me an email and I will send you the powerpoint slides that I have.
Conclusie op basis van consensus adviseert de werkgroep, mede gezien de lage incidentie van Mallet finger in de huisartsenpraktijk en de consequenties voor het beleid, altijd een röntgenopname te maken, omdat het onderscheid tussen de tendinogene en de ossale vorm en de omvang van een fractuur niet mogelijk is op grond van het klinisch onderzoek.
Petersburg and Moscow.
To answer this question, I would need a definitive model of a runner; something that could be solved using math and physics and could tell me what the perfect ratio was for stride length and stride rate.
With regard to Arnold s role in making people concerned with the danger of technology and artificial intelligence, I look forward to these watches showing up on Watch_Amish.
Not a bad age for someone using massive amounts for ages.
Eating three meals a day does not cut it.
De fleste kan identifisere seg med slike idйer, og det ligger en klar oppfordring i disse utsagnene om е vжre mer realistisk.
<a href="https://anabolicsteroidsnpc.com">Anabolic</a> It really is that simple.
Try doing it less often and see if the pain goes away.
he based his work out on swimming, running, boxing, kickboxing, etc.
[url=https://anabolicsteroidsnpc.com/]Anabolic steroids[/url] inflammation of the airways;.
With permission.
Fungal mycotoxins are deadly chemicals produced by molds.
Lupus manifestations of nephritis, cardiovascular disease, neurologic disease, pulmonary disease and hematologic syndromes can require urgent intervention with immunosuppressive therapies.
By the way, appeal against the decision they say you have 28 days, but you can ask for an extension to gather more evidence.
So, in only 3 days since the time of reading the article mentioned above, I started using a castor oil soaked in gauze placed on my cysts and a heating pad for an hour.
soul valve of choice, this combined with a Master Volume and a number of tweaks to the circuit.
After cycling through several prescription drugs with the hope of finding relief from my rare autoimmune disease, I reluctantly tried medical cannabis.
Your legs should be touching and hips squared.
5 th Darrem Charles IFBB.
The world is in the grips of an age of exploration, with new treasures to be found around every corner.
<a href="https://anabolicsteroidsnpc.com">Steroids</a> Or, as this specific person put it, how do you get that lean fitness model body and avoid getting that big and bulky bodybuilder powerlifter body.
Whalen, Adrian S.
This is even acknowledged in Book 3 by the villains.
[url=https://anabolicsteroidsnpc.com/]Steroids[/url] com and related sites are not offered for the diagnosis, cure, mitigation, treatment, or prevention of any disease or disorder nor have any statements herein been evaluated by the Food and Drug Administration FDA .
Maybe for now memang itu je cara nak kurangkan the inflammation.
Game 4 Play Cleveland Indians 124.
Being lean and defined is enough.
May I know the name of the disease.
Another benefit of copper peptide is that it helps fight formation of new scars.
2853 words 8.
of, relating to, or common to a system.
mais apres ce ki connaisse decele de suite croyez moi.
Ironically, your bodybuilder friends are some of the same guys who used to ask for me for training advice when WWF came through town and we d train at The Mecca, THE Gold s Gym in Venice, CA.
Should performance enhancing drugs be legal in sports.
<a href="https://anabolicsteroidsnpc.com">Anabolic steroids</a> He is humble and without question a team player.
These dynamos need lots of training to learn good manners, and may not be the best fit for a home with young kids or someone who s elderly or frail.
We certainly love our smoothies around here, but if you ve become victim to always feeling hungry it might be best if you laid off on the blended meals.
[url=https://anabolicsteroidsnpc.com/]Anabolic steroids[/url] Diabetics are at a higher risk of infection.
Javik, on Joker .
Constant variety also keeps workouts fun and inspiring.
In the last years Clenbuterol and T3 has become very popular, climbing its way up in the list of drugs that can provoke and deliver fast assistance in reduction of body weight.
about 15 days ago Jesse Rogers ESPN.
connected for 10th career grand slam to win game in bottom of 11th inning on 7 31 vs.
In reality, most bodybuilders follow basic training and nutrition programs with extreme dedication.
Testosterone Replacement Therapy No Age Effects.
Leaks of wet, almost diarrhoea-like poo between regular bowel movements.
The moisture on your skin can cause hives so I have to be careful how much I exercise and if I do I need a long sleeve shirt to throw on afterwards so my skin temperature doesn t drop too fast even though my core is warm.
It may subside or, particularly with continued exposure to irritants, may persist and progress to chronic bronchitis or pneumonia.
<a href="https://anabolicsteroidsnpc.com">Anabolic</a> Is Trenbolone a good fat burner.
and I still might be able to stay close to home.
Date July 15-16, 2017 Time 9am-5 30pm each day, 1 hr lunch break Cost 1000 250 deposit at registration .
[url=https://anabolicsteroidsnpc.com/]Steroids[/url] 3G UMTS signals with time division duplex 100Hz and 200Hz ,.
Thank you for understanding.
That is because, it has sharp fat burning characteristics.
Sixteen years later, award-winning filmmaker Maryann De Leo took her camera to ground zero, following the devastating trail radiation leaves behind in hospitals, orphanages, mental asylums and evacuated villages.
With this progressively increasing numbers, it is projected that millions more will use steroids in the immediate future Newer, 61 .
redness, sores, or white patches in your mouth or throat;.
Here is a summary of the benefits you receive with Hard Rod Plus.
- Il favorise le sommeil.
Ageing Res Rev 1 3 397-411.
tren test cycle
http://bijousalon.co.uk/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=68087
<a href="http://nivaldoca.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=176688
">tren ace
</a>
<a href="http://4dmarketing.co.za/index.php?option=com_k2&view=itemlist&task=user&id=111268
#">tren dosage
</a>
tren
trenbolone dosage
http://piedraartificialrosaman.com/index.php?option=com_k2&view=itemlist&task=user&id=393554
<a href="http://agroma.gr/index.php?option=com_k2&view=itemlist&task=user&id=6134
">how long does tren stay in your system
</a>
<a href="http://strategicsolutionsusa.com/index.php?option=com_k2&view=itemlist&task=user&id=16056
#">trenbolon
</a>
trenbolone
tren ace half life
http://akademibys.com/index.php?option=com_k2&view=itemlist&task=user&id=6521
<a href="http://cellgroupsglobal.com/index.php?option=com_k2&view=itemlist&task=user&id=583861
">how long does tren stay in your system
</a>
<a href="http://safakhali.com/index.php?option=com_k2&view=itemlist&task=user&id=338887
#">trenbolone
</a>
tren ace half life
tren acetate dosage
http://nafdac.gov.ng/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=2398828
<a href="http://vkreative.ru/index.php?option=com_k2&view=itemlist&task=user&id=46646
">tren e results
</a>
<a href="http://la.fnst.org/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=3858457
#">trenbolone pills
</a>
trenabol
trenbolone dosage
http://progressivemovementz.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=325789
<a href="http://ocispain.com/index.php?option=com_k2&view=itemlist&task=user&id=285971
">trenbolon
</a>
<a href="http://atelier-floral.ro/index.php?option=com_k2&view=itemlist&task=user&id=24186
#">trenbolone enanthate dosage
</a>
what does tren do
trenbolone enanthate dosage
http://vabcreations.net/index.php?option=com_k2&view=itemlist&task=user&id=3226738
<a href="http://www.chattersonfarms.com/index.php?option=com_k2&view=itemlist&task=user&id=2499184
">tren e results
</a>
<a href="http://serenomiami.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=2181082
#">tren acetate
</a>
tren test cycle
tren acetate cycle
http://www.espressofreunde.de/index.php?option=com_k2&view=itemlist&task=user&id=884
<a href="http://sefaoutsourcing.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=360028
">tren ace results
</a>
<a href="http://www.coppercone.com/index.php?option=com_k2&view=itemlist&task=user&id=173518
#">tren acetate dosage
</a>
trenbolone pills
http://giftsjoyas.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=990986
<a href="http://sindicatodechoferespichincha.com.ec/index.php?option=com_k2&view=itemlist&task=user&id=1400662
">tren stack
</a>
<a href="http://lifespace.in.ua/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=156175
#">how long does tren stay in your system
</a>
trenbolone pills
oral trenbolone
http://www.multi-formas.com/index.php?option=com_k2&view=itemlist&task=user&id=199041
<a href="http://house-of-harmony.com/index.php?option=com_k2&view=itemlist&task=user&id=298141
">oral trenbolone
</a>
<a href="http://clasiautos.com/index.php?option=com_k2&view=itemlist&task=user&id=195453
#">trenbolone enanthate side effects
</a>
trenbolone pills
trenbol
http://atelier-floral.ro/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=24170
<a href="http://bankmitraniaga.co.id/index.php?option=com_k2&view=itemlist&task=user&id=524113
">trenbolone hexahydrobenzylcarbonate
</a>
<a href="http://guillermohernandez.es/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=64438
#">trenbolone dosage
</a>
what does tren do
trenbolone pills
http://autocaravanastenerife.es/index.php?option=com_k2&view=itemlist&task=user&id=32075
<a href="http://veneta-allestimenti.it/index.php?option=com_k2&view=itemlist&task=user&id=57620&lang=en
">how to take tren
</a>
<a href="http://ayalexgroup.com/index.php?option=com_k2&view=itemlist&task=user&id=146096
#">trenabol
</a>
tren and test cycle
tren and test cycle
http://guillermohernandez.es/index.php?option=com_k2&view=itemlist&task=user&id=65620
<a href="http://giftsjoyas.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=990986
">trenbolone dosage
</a>
<a href="http://oxfordharvesttime.com/index.php?option=com_k2&view=itemlist&task=user&id=12139
#">tren side effects
</a>
tren pills
trenbolone acetate dosage
http://aclass.com.sg/index.php?option=com_k2&view=itemlist&task=user&id=2140790
<a href="http://d3bidan.urindo.ac.id/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=286736
">trenbolone acetate dosage
</a>
<a href="http://mvision.in/index.php?option=com_k2&view=itemlist&task=user&id=948590
#">tren test cycle
</a>
tren acetate dosage
tren e dosage
http://sefaoutsourcing.com/index.php?option=com_k2&view=itemlist&task=user&id=359982
<a href="http://onepiao.net/index.php?option=com_k2&view=itemlist&task=user&id=6136
">trenbolone reviews
</a>
<a href="http://mobility-corp.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=668702
#">tren enanthate
</a>
trenbolone cycle
http://whiteiris.danielle-murrell.com/index.php?option=com_k2&view=itemlist&task=user&id=167740
<a href="http://www.puriflair.com/index.php?option=com_k2&view=itemlist&task=user&id=229411
">trenbolone enanthate
</a>
<a href="http://vkreative.ru/index.php?option=com_k2&view=itemlist&task=user&id=46646
#">tren test cycle
</a>
tren acetate
tren ace half life
http://giahungdiecasting.com/index.php?option=com_k2&view=itemlist&task=user&id=72003
<a href="http://whiteiris.danielle-murrell.com/index.php?option=com_k2&view=itemlist&task=user&id=167740
">tren steroid side effects
</a>
<a href="http://sanyasurf.com/index.php?option=com_k2&view=itemlist&task=user&id=1928314
#">tren results
</a>
trenbolone reviews
tren hex
http://spyroltd.com/index.php?option=com_k2&view=itemlist&task=user&id=763856
<a href="http://candfwater.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=963
">trend steroid
</a>
<a href="http://www.bilgimak.net/index.php?option=com_k2&view=itemlist&task=user&id=100865
#">trenbolone acetate results
</a>
tren e dosage
tren cycle
http://tiras-ttu.org/index.php?option=com_k2&view=itemlist&task=user&id=63146
<a href="http://www.chattersonfarms.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=2498914
">tren and test cycle
</a>
<a href="http://bronya.automordovia.ru/index.php?option=com_k2&view=itemlist&task=user&id=142599
#">trenbolone acetate side effects
</a>
trenbolone side effects
tren test cycle
http://other.rasmeinews.com/index.php?option=com_k2&view=itemlist&task=user&id=2780271
<a href="http://729mixx.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=101973
">trenbolone hexahydrobenzylcarbonate
</a>
<a href="http://flowersbydonita.co.za/index.php?option=com_k2&view=itemlist&task=user&id=566168
#">tren e results
</a>
trenbolone acetate side effects
trenbolone acetate
http://johnston-contractors.com/index.php?option=com_k2&view=itemlist&task=user&id=198330
<a href="http://acrp.in/index.php?option=com_k2&view=itemlist&task=user&id=2920658
">tren results
</a>
<a href="http://paneinattesa.altervista.org/index.php?option=com_k2&view=itemlist&task=user&id=124807&Itemid=501
#">tren results
</a>
trenbolone
what is tren
http://serenomiami.com/index.php?option=com_k2&view=itemlist&task=user&id=2182715
<a href="http://piedraartificialrosaman.com/index.php?option=com_k2&view=itemlist&task=user&id=391929
">tren e
</a>
<a href="http://mobility-corp.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=678847
#">tren acetate
</a>
steroid tren
http://smsbenkad.com/index.php?option=com_k2&view=itemlist&task=user&id=155716
<a href="http://piedraartificialrosaman.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=392767
">tren steroid side effects
</a>
<a href="http://la.fnst.org/index.php?option=com_k2&view=itemlist&task=user&id=3860452
#">tren steroid side effects
</a>
steroid tren
tren acetate cycle
http://flowersbydonita.co.za/index.php?option=com_k2&view=itemlist&task=user&id=566496
<a href="http://bandamn.ru/index.php?option=com_k2&view=itemlist&task=user&id=528312
">trenbolone side effects
</a>
<a href="http://nivaldoca.com/index.php?option=com_k2&view=itemlist&task=user&id=176894
#">trenbolone enanthate side effects
</a>
trenbolone results
trenbolone acetate
http://4dmarketing.co.za/index.php?option=com_k2&view=itemlist&task=user&id=112722
<a href="http://zagrada-ua.com/index.php?option=com_k2&view=itemlist&task=user&id=44440
">trenbolone pills
</a>
<a href="http://comarsa.com.pe/index.php?option=com_k2&view=itemlist&task=user&id=176125
#">trenbolone side effects
</a>
trenbolone reviews
trenbolone enanthate results
http://xxxalmet.ru/index.php?option=com_k2&view=itemlist&task=user&id=87013
<a href="http://narine-forte.ru/index.php?option=com_k2&view=itemlist&task=user&id=31544
">tren e results
</a>
<a href="http://miranico.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=1752808
#">tren acetate
</a>
trenbolone reviews
tren
http://progressivemovementz.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=312567
<a href="http://lafunt.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=1828035
">tren enanthate
</a>
<a href="http://afina-mos.ru/index.php?option=com_k2&view=itemlist&task=user&id=215417
#">trenbolone acetate
</a>
trenbolone acetate results
tri tren
http://vabcreations.net/index.php?option=com_k2&view=itemlist&task=user&id=3226163
<a href="http://bronya.automordovia.ru/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=142599
">how long does tren stay in your system
</a>
<a href="http://iridiumcreativeservices.com/index.php?option=com_k2&view=itemlist&task=user&id=1968006
#">tren acetate cycle
</a>
trenbolone hexahydrobenzylcarbonate
what is tren
http://cadcamoffices.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=765371
<a href="http://chioccasdeli.com/index.php?option=com_k2&view=itemlist&task=user&id=18770
">tren acetate dosage
</a>
<a href="http://sindicatodechoferespichincha.com.ec/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=1438841
#">trenbolone acetate results
</a>
tren acetate cycle
http://sigmaclub-ui.org/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=784704
<a href="http://lafunt.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=1828022
">tri tren
</a>
<a href="http://lafunt.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=1828182
#">tren test cycle
</a>
trenbolone enanthate cycle
tren steroids
http://alphatechschool.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=1118484
<a href="http://ritzbuild.com/index.php?option=com_k2&view=itemlist&task=user&id=236167
">trenbolone results
</a>
<a href="http://akcakoy.net//component/k2/itemlist/user/20088-dvdmiclunado.html
#">tren steroids
</a>
how to make trenbolone
how to make trenbolone
http://sexshoponline.kz/index.php?option=com_k2&view=itemlist&task=user&id=212512
<a href="http://sercongal.com/index.php?option=com_k2&view=itemlist&task=user&id=34583
">tren acetate cycle
</a>
<a href="http://skpt.co.in/index.php?option=com_k2&view=itemlist&task=user&id=113218
#">tren e results
</a>
oral tren
trenbolone enanthate side effects
http://claida-immobilien.de/index.php?option=com_k2&view=itemlist&task=user&id=1920810
<a href="http://guillermohernandez.es/index.php?option=com_k2&view=itemlist&task=user&id=64115
">oral trenbolone
</a>
<a href="http://www.chinovaresources.com/index.php?option=com_k2&view=itemlist&task=user&id=108057
#">tren ace
</a>
trenbolone enanthate cycle
tren test cycle
http://markus-waesch.de/index.php?option=com_k2&view=itemlist&task=user&id=16371
<a href="http://centerkokzhiek.kz/index.php?option=com_k2&view=itemlist&task=user&id=61131
">trenbolon
</a>
<a href="http://sercongal.com/index.php?option=com_k2&view=itemlist&task=user&id=34583
#">tren steroid side effects
</a>
tren ethanate
trenbolone dosage
http://www.chattersonfarms.com/index.php?option=com_k2&view=itemlist&task=user&id=2499184
<a href="http://daciaenmadrid.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=26283
">tren hex
</a>
<a href="http://evgrashina.de/index.php?option=com_k2&view=itemlist&task=user&id=67972
#">trenbolone
</a>
tren ace side effects
side effects of trenbolone
http://greenacre.co.za/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=1413140
<a href="http://forumatmyhlnet.com/index.php?option=com_k2&view=itemlist&task=user&id=414817
">tren cycle
</a>
<a href="http://www.disneyfloridacondos.com/index.php?option=com_k2&view=itemlist&task=user&id=5144
#">tren cycle
</a>
tren ace
http://mobility-corp.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=691718
<a href="http://evoxhair.com/index.php?option=com_k2&view=itemlist&task=user&id=64348
">trenbolone
</a>
<a href="http://www.vivasan-nature.ru/index.php?option=com_k2&view=itemlist&task=user&id=10270
#">trenbolone enanthate results
</a>
tren acetate
tren e
http://hushescorts.com/index.php?option=com_k2&view=itemlist&task=user&id=805007
<a href="http://snowboard-pfalz.de/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=17269
">trenbolone steroid
</a>
<a href="http://greenacre.co.za/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=1414523
#">tren e results
</a>
trenbolone acetate cycle
side effects of tren
http://burgerdoze.com/index.php?option=com_k2&view=itemlist&task=user&id=406973
<a href="http://viverospolo.es/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=1412
">tri tren
</a>
<a href="http://acp.in.ua/index.php?option=com_k2&view=itemlist&task=user&id=682
#">how to make trenbolone
</a>
trenbolone enanthate results
tren test cycle
http://minmag.mining.kz/index.php?option=com_k2&view=itemlist&task=user&id=3016841
<a href="http://www.spartateck.com/index.php?option=com_k2&view=itemlist&task=user&id=74530
">trenbolone acetate side effects
</a>
<a href="http://davidvalenciao.com/index.php?option=com_k2&view=itemlist&task=user&id=27321
#">tren cycle
</a>
trenbolone pills
trenbolone steroid
http://serenomiami.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=2181331
<a href="http://greenacre.co.za/index.php?option=com_k2&view=itemlist&task=user&id=1414356
">tren e cycle
</a>
<a href="http://www.spartateck.com/index.php?option=com_k2&view=itemlist&task=user&id=76331
#">oral trenbolone
</a>
trenbol
trenbolone hexahydrobenzylcarbonate
http://paarlboyshigh.org.za/index.php?option=com_k2&view=itemlist&task=user&id=252987
<a href="http://senbeat.com/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=55436
">trenbol
</a>
<a href="http://sindicatodechoferespichincha.com.ec/index.php?option=com_k2&view=itemlist&task=user&id=1438966
#">trenbolone steroid
</a>
trenbolone acetate cycle
tren steroids
http://bandamn.ru/index.php?option=com_k2&view=itemlist&task=user&id=524660
<a href="http://thepeebleslawyer.com/index.php?option=com_k2&view=itemlist&task=user&id=2196840
">tren acetate
</a>
<a href="http://nafdac.gov.ng/index.php/component/users/?option=com_k2&view=itemlist&task=user&id=2400604
#">trenbolone side effects
</a>
where to buy anabolic steroids online forum
http://bankmitraniaga.co.id/index.php?option=com_k2&view=itemlist&task=user&id=528156
<a href="http://planetadverej.ru/index.php?option=com_k2&view=itemlist&task=user&id=78494
">types of anabolic steroids
</a>
<a href="http://anaisabelaparicio.com/index.php?option=com_k2&view=itemlist&task=user&id=124911
#">what is anabolic steroids
</a>
anabolic steroids sales
anabolic steroids
http://4-kant.ch/index.php?option=com_k2&view=itemlist&task=user&id=25265
<a href="http://anellioriginals.com/index.php?option=com_k2&view=itemlist&task=user&id=170752
">what are anabolic steroids made of
</a>
<a href="http://pizzaone.kz/index.php?option=com_k2&view=itemlist&task=user&id=2103
#">anabolic steroids sales
</a>
oral anabolic steroids
anabolic steroids legality
http://sov2009.ru/index.php?option=com_k2&view=itemlist&task=user&id=95877
<a href="http://hdv-media.fr/index.php?option=com_k2&view=itemlist&task=user&id=3774
">are anabolic steroids legal
</a>
<a href="http://greenacre.co.za/index.php?option=com_k2&view=itemlist&task=user&id=1424681
#">anabolic steroids cycling
</a>
define anabolic steroids
what is anabolic steroids
http://avmsas.com/index.php?option=com_k2&view=itemlist&task=user&id=187793
<a href="http://e4business.eu/index.php?option=com_k2&view=itemlist&task=user&id=9032
">why do anabolic steroids differ from other illegal drugs
</a>
<a href="http://www.szcontracting.com/index.php?option=com_k2&view=itemlist&task=user&id=81412
#">long term effects of anabolic steroids
</a>
anabolic androgenic steroids
prescription anabolic steroids
http://iceberg.ykt.ru/index.php?option=com_k2&view=itemlist&task=user&id=80214
<a href="http://vietnamhat.com.vn/index.php?option=com_k2&view=itemlist&task=user&id=827809
">are anabolic steroids legal
</a>
<a href="http://poderyunidadpopular.org/index.php?option=com_k2&view=itemlist&task=user&id=42603
#">long term effects of anabolic steroids
</a>
anabolic steroids cycling
were to buy anabolic steroids
http://autocaravanastenerife.es/index.php?option=com_k2&view=itemlist&task=user&id=44534
<a href="http://acp.in.ua/index.php?option=com_k2&view=itemlist&task=user&id=981
">what would be the most likely outcome if a young man were using anabolic steroids?
</a>
<a href="http://economie-combustibil.ro/index.php?option=com_k2&view=itemlist&task=user&id=5079
#">anabolic steroids can be ingested in which ways
</a>
where to buy anabolic steroids
oral anabolic steroids
http://fvipc.ca/index.php?option=com_k2&view=itemlist&task=user&id=105616
<a href="http://masoudstore.ir/index.php?option=com_k2&view=itemlist&task=user&id=311
">definition of anabolic steroids
</a>
<a href="http://rcpcoach.com/index.php?option=com_k2&view=itemlist&task=user&id=860060
#">anabolic steroids usage
</a>
risks of anabolic steroids
http://rccgrestorationsa.org/index.php?option=com_k2&view=itemlist&task=user&id=116032
<a href="http://autocaravanastenerife.es/index.php?option=com_k2&view=itemlist&task=user&id=44069
">anabolic steroids buy
</a>
<a href="http://supplyconceptsinc.com/index.php?option=com_k2&view=itemlist&task=user&id=1427025
#">anabolic steroids usage
</a>
the use of anabolic steroids during adolescence can cause
anabolic steroids definition
http://rccgrestorationsa.org/index.php?option=com_k2&view=itemlist&task=user&id=116032
<a href="http://tangguh.co.id/index.php?option=com_k2&view=itemlist&task=user&id=538139
">where to buy anabolic steroids
</a>
<a href="http://www.themoneyworkshop.com/index.php?option=com_k2&view=itemlist&task=user&id=1320459
#">anabolic steroids are a type of
</a>
legal anabolic steroids
steroids anabolic
http://remont-dly-vas.ru/index.php?option=com_k2&view=itemlist&task=user&id=15073
<a href="http://argent-m.ru/index.php?option=com_k2&view=itemlist&task=user&id=134365
">anabolic steroids sales
</a>
<a href="http://claida-immobilien.de/index.php?option=com_k2&view=itemlist&task=user&id=1929970
#">anabolic steroids buy
</a>
where to buy anabolic steroids
anabolic steroids pill
http://www.coppercone.com/index.php?option=com_k2&view=itemlist&task=user&id=175648
<a href="http://tennisinnovator.com/index.php?option=com_k2&view=itemlist&task=user&id=291111
">what are anabolic steroids made of
</a>
<a href="http://www.thefoundation.or.tz/index.php?option=com_k2&view=itemlist&task=user&id=1937054
#">anabolic steroids injection
</a>
what are anabolic steroids made of
buy injectable anabolic steroids
http://www.mamasdelrio.org/index.php?option=com_k2&view=itemlist&task=user&id=809490
<a href="http://iv-dancefit.ru/index.php?option=com_k2&view=itemlist&task=user&id=40332
">anabolic steroids sales
</a>
<a href="http://fluideas.com/index.php?option=com_k2&view=itemlist&task=user&id=65567
#">anabolic steroids legality
</a>
anabolic steroids sales
dangers of anabolic steroids
http://travel-experience.es/index.php?option=com_k2&view=itemlist&task=user&id=358463
<a href="http://brasiltucano.ch/index.php?option=com_k2&view=itemlist&task=user&id=12938
">positive effects of anabolic steroids
</a>
<a href="http://anellioriginals.com/index.php?option=com_k2&view=itemlist&task=user&id=170752
#">anabolic steroids sale
</a>
injectable anabolic steroids
buying anabolic steroids online
http://rajcapsindustries.com/index.php?option=com_k2&view=itemlist&task=user&id=53823
<a href="http://dmc-ocean.ru/index.php?option=com_k2&view=itemlist&task=user&id=102814
">what would be the most likely outcome if a young man were using anabolic steroids?
</a>
<a href="http://iridiumcreativeservices.com/index.php?option=com_k2&view=itemlist&task=user&id=1971852
#">positive effects of anabolic steroids
</a>
anabolic steroids names
http://lifestyleonkloof.co.za/index.php?option=com_k2&view=itemlist&task=user&id=360659
<a href="http://bronya.automordovia.ru/index.php?option=com_k2&view=itemlist&task=user&id=144843
">anabolic steroids injection
</a>
<a href="http://injectllc.com/index.php?option=com_k2&view=itemlist&task=user&id=610571
#">anabolic steroids are synthetic versions of which of the following
</a>
where to get anabolic steroids
anabolic steroids are which of the following
http://citaszaragoza.com/index.php?option=com_k2&view=itemlist&task=user&id=130244
<a href="http://inmomartinezfranco.com/index.php?option=com_k2&view=itemlist&task=user&id=14943
">anabolic steroids bodybuilding
</a>
<a href="http://malyaparrucchieri.it/index.php?option=com_k2&view=itemlist&task=user&id=8078
#">where to get anabolic steroids
</a>
anabolic steroids forum
the use of anabolic steroids during adolescence can cause
http://uveliraram.ru/index.php?option=com_k2&view=itemlist&task=user&id=76846
<a href="http://anellioriginals.com/index.php?option=com_k2&view=itemlist&task=user&id=170647
">anabolic steroids are which of the following
</a>
<a href="http://www.paceinteriors.com.au/index.php?option=com_k2&view=itemlist&task=user&id=7087
#">anabolic steroids pill
</a>
what do anabolic steroids do
anabolic steroids definition
http://hopewalkingacrossamerica.com/index.php?option=com_k2&view=itemlist&task=user&id=69035
<a href="http://tiras-ttu.org/index.php?option=com_k2&view=itemlist&task=user&id=65015
">anabolic steroids law
</a>
<a href="http://astrahan.tehvolga.ru/index.php?option=com_k2&view=itemlist&task=user&id=22130
#">list of anabolic steroids
</a>
anabolic steroids and diabetes
long term effects of anabolic steroids
http://agoraeventos.net.br/index.php?option=com_k2&view=itemlist&task=user&id=1320
<a href="http://master.latambschool.com/index.php?option=com_k2&view=itemlist&task=user&id=1145920
">anabolic steroids body building
</a>
<a href="http://pizzaone.kz/index.php?option=com_k2&view=itemlist&task=user&id=1964
#">anabolic steroids names
</a>
buy injectable anabolic steroids
anabolic steroids in sports
http://praestar-controls.com/index.php?option=com_k2&view=itemlist&task=user&id=172590
<a href="http://dieseltecmobilemechanics.com.au/index.php?option=com_k2&view=itemlist&task=user&id=27125
">positive effects of anabolic steroids
</a>
<a href="http://www.salvationdistro.com/index.php?option=com_k2&view=itemlist&task=user&id=46059
#">are anabolic steroids legal
</a>
long term effects of anabolic steroids
definition of anabolic steroids
http://sefaoutsourcing.com/index.php?option=com_k2&view=itemlist&task=user&id=363129
<a href="http://bcel.uk/index.php?option=com_k2&view=itemlist&task=user&id=943092
">anabolic steroids sale
</a>
<a href="http://vangxanh.com/index.php?option=com_k2&view=itemlist&task=user&id=195548
#">anabolic steroids are a type of
</a>
anabolic steroids are a type of
http://vkreative.ru/index.php?option=com_k2&view=itemlist&task=user&id=47267
<a href="http://unikomsnab.by/index.php?option=com_k2&view=itemlist&task=user&id=64650
">anabolic steroids pill
</a>
<a href="http://www.learnsculpture.org/index.php?option=com_k2&view=itemlist&task=user&id=14920
#">risk of using anabolic steroids
</a>
define anabolic steroids
anabolic steroids street names
http://apemindo.com/index.php?option=com_k2&view=itemlist&task=user&id=19690
<a href="http://fluideas.com/index.php?option=com_k2&view=itemlist&task=user&id=65499
">anabolic steroids in sports
</a>
<a href="http://gom-eg.com/index.php?option=com_k2&view=itemlist&task=user&id=42219
#">buying anabolic steroids online
</a>
anabolic steroids alternative
anabolic steroids bodybuilding
http://oretanaformacion.com/index.php?option=com_k2&view=itemlist&task=user&id=359341
<a href="http://veneta-allestimenti.it/index.php?option=com_k2&view=itemlist&task=user&id=57943
">anabolic steroids bodybuilding
</a>
<a href="http://laguadalupanaimports.com/index.php?option=com_k2&view=itemlist&task=user&id=71315
#">anabolic steroids names
</a>
anabolic steroids names
anabolic steroids injection
http://maksatiha-uo.ru/index.php?option=com_k2&view=itemlist&task=user&id=58667
<a href="http://piersez.com/index.php?option=com_k2&view=itemlist&task=user&id=111864
">legal anabolic steroids gnc
</a>
<a href="http://needcircle.com/index.php?option=com_k2&view=itemlist&task=user&id=12864
#">anabolic steroids stats
</a>
anabolic steroids side effects
anabolic steroids legal
http://servicios-toldeca.com/index.php?option=com_k2&view=itemlist&task=user&id=348529
<a href="http://ministeriosalibertad.org/index.php?option=com_k2&view=itemlist&task=user&id=1936
">define anabolic steroids
</a>
<a href="http://school1.rogachevoo.gov.by/index.php?option=com_k2&view=itemlist&task=user&id=45558
#">anabolic steroids before and after
</a>
where to get anabolic steroids
anabolic steroids injection
http://felicz.cz/index.php?option=com_k2&view=itemlist&task=user&id=9358
<a href="http://gp9.medkhv.ru/index.php?option=com_k2&view=itemlist&task=user&id=75453
">anabolic steroids risks
</a>
<a href="http://www.wtfeusa.com/index.php?option=com_k2&view=itemlist&task=user&id=512369
#">types of anabolic steroids
</a>
how do anabolic steroids work
anabolic steroids pills
http://bogomolets.name/index.php?option=com_k2&view=itemlist&task=user&id=1057898
<a href="http://www.safe-services.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=18636
">anabolic steroids side effects
</a>
<a href="http://omeltd.com/index.php?option=com_k2&view=itemlist&task=user&id=44794
#">anabolic steroids alternative
</a>
how do anabolic steroids work
http://sunsationgroup.com/index.php?option=com_k2&view=itemlist&task=user&id=376307
<a href="http://burgerdoze.com/index.php?option=com_k2&view=itemlist&task=user&id=411227
">injectable anabolic steroids
</a>
<a href="http://ukrlaser.in.ua/index.php?option=com_k2&view=itemlist&task=user&id=18592
#">steroids anabolic
</a>
anabolic steroids and diabetes
anabolic steroids alternative
http://www.johnston-contractors.com/index.php?option=com_k2&view=itemlist&task=user&id=200047
<a href="http://phrconline.com/index.php?option=com_k2&view=itemlist&task=user&id=171032
">anabolic steroids law
</a>
<a href="http://rivendellstud.co.za/index.php?option=com_k2&view=itemlist&task=user&id=19499
#">effects of anabolic steroids
</a>
where to buy anabolic steroids
where to get anabolic steroids
http://amkodor-bryansk.ru/index.php?option=com_k2&view=itemlist&task=user&id=26219
<a href="http://zagrada.ua/index.php?option=com_k2&view=itemlist&task=user&id=683867
">anabolic steroids are which of the following
</a>
<a href="http://200.62.231.46/index.php?option=com_k2&view=itemlist&task=user&id=177679
#">steroids anabolic
</a>
buy anabolic steroids with credit card
anabolic steroids pills
http://naveedulhassan.com/index.php?option=com_k2&view=itemlist&task=user&id=42625
<a href="http://legos-mebel.ru/index.php?option=com_k2&view=itemlist&task=user&id=351816
">benefits of anabolic steroids
</a>
<a href="http://ccleather.com/index.php?option=com_k2&view=itemlist&task=user&id=126194
#">anabolic steroids law
</a>
buy injectable anabolic steroids
anabolic steroids can be ingested in which of the following ways
http://movingsainz.com/index.php?option=com_k2&view=itemlist&task=user&id=211612
<a href="http://vietnamhat.com.vn/index.php?option=com_k2&view=itemlist&task=user&id=828964
">anabolic steroids sale
</a>
<a href="http://sigmaclub-ui.org/index.php?option=com_k2&view=itemlist&task=user&id=791090
#">anabolic steroids risks
</a>
anabolic steroids before and after
anabolic steroids pills
http://aceheader.jp/index.php?option=com_k2&view=itemlist&task=user&id=22623
<a href="http://udhec.com.br/index.php?option=com_k2&view=itemlist&task=user&id=673258
">three risks of using anabolic steroids and other performance-enhancing drugs
</a>
<a href="http://autocaravanastenerife.es/index.php?option=com_k2&view=itemlist&task=user&id=44534
#">anabolic steroids cycling
</a>
anabolic steroids pills
anabolic steroids and diabetes
http://injectllc.com/index.php?option=com_k2&view=itemlist&task=user&id=610571
<a href="http://fotoff.info/index.php?option=com_k2&view=itemlist&task=user&id=37759
">how anabolic steroids work
</a>
<a href="http://www.oroleico.com/index.php?option=com_k2&view=itemlist&task=user&id=17628
#">anabolic steroids in sports
</a>
dangers of anabolic steroids
http://acrp.in/index.php?option=com_k2&view=itemlist&task=user&id=2928959
<a href="http://legos-mebel.ru/index.php?option=com_k2&view=itemlist&task=user&id=353489
">anabolic steroids cycle
</a>
<a href="http://clarkson.co.ke/index.php?option=com_k2&view=itemlist&task=user&id=6411
#">anabolic steroids schedule
</a>
injectable anabolic steroids
what are anabolic steroids made of
http://vicentecasto.com/index.php?option=com_k2&view=itemlist&task=user&id=8931
<a href="http://tuccitec.com/index.php?option=com_k2&view=itemlist&task=user&id=198649
">anabolic steroids alternatives
</a>
<a href="http://formentera-low-cost.com/index.php?option=com_k2&view=itemlist&task=user&id=67325
#">how anabolic steroids work
</a>
anabolic steroids types
anabolic steroids before and after
http://zmtour.ru/index.php?option=com_k2&view=itemlist&task=user&id=47958
<a href="http://homesforsalenyc.com/index.php?option=com_k2&view=itemlist&task=user&id=22466
">are anabolic steroids illegal
</a>
<a href="http://especialitatsvila.com/index.php?option=com_k2&view=itemlist&task=user&id=149185
#">how are anabolic steroids made
</a>
list of anabolic steroids
prescription anabolic steroids
http://vicentecasto.com/index.php?option=com_k2&view=itemlist&task=user&id=8931
<a href="http://200.62.231.46/index.php?option=com_k2&view=itemlist&task=user&id=177575
">prescription anabolic steroids
</a>
<a href="http://salsaflavors.com/index.php?option=com_k2&view=itemlist&task=user&id=58901
#">what do anabolic steroids do
</a>
list of anabolic steroids
anabolic steroids pill
http://legos-mebel.ru/index.php?option=com_k2&view=itemlist&task=user&id=353359
<a href="http://masoudstore.com/index.php?option=com_k2&view=itemlist&task=user&id=271
">where to get anabolic steroids
</a>
<a href="http://drevovzahrade.cz/index.php?option=com_k2&view=itemlist&task=user&id=253617
#">where to buy anabolic steroids
</a>
anabolic steroids are which of the following
anabolic steroids sale
http://gddirectltd.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=241551
<a href="http://apcasystems.com/index.php?option=com_k2&view=itemlist&task=user&id=5100
">anabolic steroids are appropriately prescribed to
</a>
<a href="http://thermos-fryazino.ru/index.php?option=com_k2&view=itemlist&task=user&id=53585
#">anabolic steroids injections
</a>
risk of using anabolic steroids
anabolic steroids injections
http://medmolds.com/index.php?option=com_k2&view=itemlist&task=user&id=68702
<a href="http://riadalghani.com/index.php?option=com_k2&view=itemlist&task=user&id=16531
">buy anabolic steroids online
</a>
<a href="http://dmc-ocean.ru/index.php?option=com_k2&view=itemlist&task=user&id=102814
#">anabolic steroids before and after
</a>
types of anabolic steroids
http://flowersbydonita.co.za/index.php?option=com_k2&view=itemlist&task=user&id=569261
<a href="http://www.uvservis.ru/index.php?option=com_k2&view=itemlist&task=user&id=42878
">anabolic steroids schedule
</a>
<a href="http://sov2009.ru/index.php?option=com_k2&view=itemlist&task=user&id=95512
#">are anabolic steroids illegal
</a>
define anabolic steroids
anabolic-androgenic steroids
http://sparta-fit.com/index.php?option=com_k2&view=itemlist&task=user&id=423255
<a href="http://www.multi-formas.com/index.php?option=com_k2&view=itemlist&task=user&id=207408
">three risks of using anabolic steroids and other performance-enhancing drugs
</a>
<a href="http://fetefreaks.com/index.php?option=com_k2&view=itemlist&task=user&id=3530107
#">anabolic steroids before and after
</a>
anabolic steroids pills
what would be the most likely outcome if a young man were using anabolic steroids?
http://saadpp.nepadbusinessfoundation.org/index.php?option=com_k2&view=itemlist&task=user&id=441857
<a href="http://sefaoutsourcing.com/index.php?option=com_k2&view=itemlist&task=user&id=362723
">anabolic steroids are which of the following
</a>
<a href="http://joanramagoshi.com/index.php?option=com_k2&view=itemlist&task=user&id=183567
#">anabolic steroids are appropriately prescribed to
</a>
anabolic steroids body building
anabolic steroids
http://jyhsolutions.cl/index.php?option=com_k2&view=itemlist&task=user&id=5498
<a href="http://asociacionenvase.es/index.php?option=com_k2&view=itemlist&task=user&id=1622
">anabolic steroids legality
</a>
<a href="http://autocaravanastenerife.es/index.php?option=com_k2&view=itemlist&task=user&id=43009
#">anabolic steroids are which of the following
</a>
anabolic steroids can be ingested in which ways
long term effects of anabolic steroids
http://phrconline.com/index.php?option=com_k2&view=itemlist&task=user&id=171032
<a href="http://smconsulting.ae/index.php?option=com_k2&view=itemlist&task=user&id=120552
">anabolic steroids effects
</a>
<a href="http://tuccitec.com/index.php?option=com_k2&view=itemlist&task=user&id=198437
#">effects of anabolic steroids
</a>
definition of anabolic steroids
street names for anabolic steroids
http://wisdomite.in/index.php?option=com_k2&view=itemlist&task=user&id=2048565
<a href="http://megagroup.co.za/index.php?option=com_k2&view=itemlist&task=user&id=15597
">anabolic steroids definition
</a>
<a href="http://anebopro.com/index.php?option=com_k2&view=itemlist&task=user&id=284365
#">anabolic steroids definition
</a>
where to buy anabolic steroids
anabolic steroids are a type of quizlet
http://nafdac.gov.ng/index.php?option=com_k2&view=itemlist&task=user&id=2408577
<a href="http://l-design.in.ua/index.php?option=com_k2&view=itemlist&task=user&id=10337
">anabolic steroids examples
</a>
<a href="http://atelier-floral.ro/index.php?option=com_k2&view=itemlist&task=user&id=24570
#">anabolic steroids for sale
</a>
benefits of anabolic steroids
http://rcpcoach.com/index.php?option=com_k2&view=itemlist&task=user&id=859969
<a href="http://skyit.org/index.php?option=com_k2&view=itemlist&task=user&id=243029
">the use of anabolic steroids during adolescence can cause
</a>
<a href="http://www.mentalfortennis.com/index.php?option=com_k2&view=itemlist&task=user&id=6334
#">anabolic steroids supplements
</a>
anabolic steroids usage
effects of anabolic steroids
http://inclub.lg.ua/index.php?option=com_k2&view=itemlist&task=user&id=1500700
<a href="http://cadcamoffices.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=771800
">anabolic steroids alternative
</a>
<a href="http://economie-combustibil.ro/index.php?option=com_k2&view=itemlist&task=user&id=5095
#">are anabolic steroids illegal
</a>
anabolic steroids bodybuilders
are anabolic steroids illegal
http://trmconsulting.ca/index.php?option=com_k2&view=itemlist&task=user&id=7859
<a href="http://jw6.jobwall24.de/index.php?option=com_k2&view=itemlist&task=user&id=79119
">where to buy anabolic steroids online forum
</a>
<a href="http://ursthailand.com/index.php?option=com_k2&view=itemlist&task=user&id=117622
#">dangers of anabolic steroids
</a>
where to get anabolic steroids
anabolic steroids used
http://fvipc.ca/index.php?option=com_k2&view=itemlist&task=user&id=105668
<a href="http://betterbaitsystems.com/index.php?option=com_k2&view=itemlist&task=user&id=46587
">dangers of anabolic steroids
</a>
<a href="http://csdsz.net/index.php?option=com_k2&view=itemlist&task=user&id=686616
#">anabolic androgenic steroids
</a>
what is anabolic steroids
anabolic steroids before and after
http://www.safe-services.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=18268
<a href="http://200.62.231.46/index.php?option=com_k2&view=itemlist&task=user&id=177679
">three risks of using anabolic steroids and other performance-enhancing drugs
</a>
<a href="http://braut-make-up.eu/index.php?option=com_k2&view=itemlist&task=user&id=28334
#">where to buy anabolic steroids
</a>
define anabolic steroids
buy anabolic steroids with credit card
http://anaisabelaparicio.com/index.php?option=com_k2&view=itemlist&task=user&id=124578
<a href="http://tuccitec.com/index.php?option=com_k2&view=itemlist&task=user&id=198619
">legal anabolic steroids gnc
</a>
<a href="http://epagneulbreton-detrassierra.com/index.php?option=com_k2&view=itemlist&task=user&id=72865
#">types of anabolic steroids
</a>
anabolic steroids legal
anabolic steroids schedule
http://centerkokzhiek.kz/index.php?option=com_k2&view=itemlist&task=user&id=61575
<a href="http://gcbs-brest.by/index.php?option=com_k2&view=itemlist&task=user&id=4845
">anabolic steroids bodybuilding
</a>
<a href="http://airesdelaquebrada.com.ar/index.php?option=com_k2&view=itemlist&task=user&id=30889
#">anabolic steroids can be ingested in which of the following ways
</a>
anabolic steroids facts
http://levitra.com-www.futuresearchzambia.org/index.php?option=com_k2&view=itemlist&task=user&id=31880
<a href="http://nnaumovskiborce.edu.mk/index.php?option=com_k2&view=itemlist&task=user&id=461106
">are anabolic steroids illegal
</a>
<a href="http://skpt.co.in/index.php?option=com_k2&view=itemlist&task=user&id=115632
#">prescribed anabolic steroids
</a>
anabolic steroids cycle
anabolic steroids legality
http://candfwater.com/index.php?option=com_k2&view=itemlist&task=user&id=991
<a href="http://beotek.com.tr/index.php?option=com_k2&view=itemlist&task=user&id=640689
">prescription anabolic steroids
</a>
<a href="http://alinaqijahani.ir/index.php?option=com_k2&view=itemlist&task=user&id=357266
#">how are anabolic steroids made
</a>
injectable anabolic steroids
anabolic steroids side effects
http://blueautos.es/index.php?option=com_k2&view=itemlist&task=user&id=97831
<a href="http://clasiautos.com/index.php?option=com_k2&view=itemlist&task=user&id=198851
">risks of using anabolic steroids
</a>
<a href="http://mosaicnet.ie/index.php?option=com_k2&view=itemlist&task=user&id=69030
#">buy anabolic steroids
</a>
prescribed anabolic steroids
are anabolic steroids legal
http://atcyork.com/index.php?option=com_k2&view=itemlist&task=user&id=245677
<a href="http://sma.cakrabuana.sch.id/index.php?option=com_k2&view=itemlist&task=user&id=4328
">buy anabolic steroids online
</a>
<a href="http://www.spartateck.com/index.php?option=com_k2&view=itemlist&task=user&id=76770
#">anabolic steroids cycle
</a>
anabolic androgenic steroids
how anabolic steroids work
http://haccp.erfc.gr/index.php?option=com_k2&view=itemlist&task=user&id=19997
<a href="http://hotelsissy.gr/index.php?option=com_k2&view=itemlist&task=user&id=329393
">anabolic steroids schedule
</a>
<a href="http://sercongal.com/index.php?option=com_k2&view=itemlist&task=user&id=36644
#">three risks of using anabolic steroids and other performance-enhancing drugs
</a>
prescribed anabolic steroids
history of anabolic steroids
http://ageomash.ru/index.php?option=com_k2&view=itemlist&task=user&id=254451
<a href="http://agroma.gr/index.php?option=com_k2&view=itemlist&task=user&id=6190
">anabolic steroids for sale
</a>
<a href="http://abbrother-leather.com/index.php?option=com_k2&view=itemlist&task=user&id=6260
#">legal anabolic steroids
</a>
are anabolic steroids legal
anabolic steroids can be ingested in which of the following ways
http://viverospolo.es/index.php?option=com_k2&view=itemlist&task=user&id=3849
<a href="http://tangguh.co.id/index.php?option=com_k2&view=itemlist&task=user&id=540988
">anabolic steroids effects
</a>
<a href="http://kimia.ir/index.php?option=com_k2&view=itemlist&task=user&id=93577
#">anabolic steroids definition
</a>
anabolic steroids cycle
http://door-plus.ru/index.php?option=com_k2&view=itemlist&task=user&id=46687
<a href="http://www.aaomar.co.zw/index.php?option=com_k2&view=itemlist&task=user&id=113622
">legal anabolic steroids for sale
</a>
<a href="http://fondation-famart.com/index.php?option=com_k2&view=itemlist&task=user&id=230947
#">anabolic steroids examples
</a>
anabolic steroids are appropriately prescribed to
types of anabolic steroids
http://www.centerrepair.ru/index.php?option=com_k2&view=itemlist&task=user&id=6787
<a href="http://davidenko-v.com.ua/index.php?option=com_k2&view=itemlist&task=user&id=18373
">benefits of anabolic steroids
</a>
<a href="http://syvenire.ru/index.php?option=com_k2&view=itemlist&task=user&id=33739
#">what would be the most likely outcome if a young man were using anabolic steroids?
</a>
anabolic steroids alternative
anabolic steroids legality
http://ahirat.ru/index.php?option=com_k2&view=itemlist&task=user&id=56156
<a href="http://mobility-corp.com/index.php?option=com_k2&view=itemlist&task=user&id=711061
">buying anabolic steroids online
</a>
<a href="http://domalfa.ru/index.php?option=com_k2&view=itemlist&task=user&id=4098
#">where to buy anabolic steroids online forum
</a>
where to buy anabolic steroids online forum
best anabolic steroids
http://mobility-corp.com/index.php?option=com_k2&view=itemlist&task=user&id=708099
<a href="http://lifestyleonkloof.co.za/index.php?option=com_k2&view=itemlist&task=user&id=362876
">anabolic steroids injection
</a>
<a href="http://tangguh.co.id/index.php?option=com_k2&view=itemlist&task=user&id=547629
#">oral anabolic steroids
</a>
list of anabolic steroids
positive effects of anabolic steroids
http://sinergibumn.com/index.php?option=com_k2&view=itemlist&task=user&id=71389
<a href="http://beotek.com.tr/index.php?option=com_k2&view=itemlist&task=user&id=648486
">where to buy anabolic steroids online forum
</a>
<a href="http://zakupki.help/index.php?option=com_k2&view=itemlist&task=user&id=125004
#">anabolic steroids alternative
</a>
anabolic steroids alternatives
examples of anabolic steroids
http://betarvyatka.ru/index.php?option=com_k2&view=itemlist&task=user&id=82998
<a href="http://www.velestravel.ru/index.php?option=com_k2&view=itemlist&task=user&id=135637
">anabolic steroids pills
</a>
<a href="http://appu.te.ua/index.php?option=com_k2&view=itemlist&task=user&id=52502
#">anabolic steroids
</a>
risks of anabolic steroids
anabolic steroids pills
http://ibt.bt/index.php?option=com_k2&view=itemlist&task=user&id=92451
<a href="http://snakespy.ru/index.php?option=com_k2&view=itemlist&task=user&id=157289
">anabolic steroids injection
</a>
<a href="http://tangguh.co.id/index.php?option=com_k2&view=itemlist&task=user&id=543922
#">were to buy anabolic steroids
</a>
anabolic steroids law
http://www.moyakmermer.com/index.php?option=com_k2&view=itemlist&task=user&id=103810
<a href="http://fluideas.com/index.php?option=com_k2&view=itemlist&task=user&id=66269
">anabolic steroids buy
</a>
<a href="http://colab.di.ionio.gr/index.php?option=com_k2&view=itemlist&task=user&id=11294
#">buy anabolic steroids online
</a>
anabolic steroids cycling
were to buy anabolic steroids
http://en.cep-eng.it/index.php?option=com_k2&view=itemlist&task=user&id=16427
<a href="http://tangguh.co.id/index.php?option=com_k2&view=itemlist&task=user&id=546734
">anabolic steroids supplements
</a>
<a href="http://agencyint.net/index.php?option=com_k2&view=itemlist&task=user&id=10102
#">anabolic steroids can be ingested in which ways
</a>
anabolic steroids can be ingested in which of the following ways
anabolic steroids are primarily used in an attempt to
http://medway.sg/index.php?option=com_k2&view=itemlist&task=user&id=9400
<a href="http://mrpapersent.com/index.php?option=com_k2&view=itemlist&task=user&id=3908
">anabolic steroids can be ingested in which of the following ways
</a>
<a href="http://miranico.ir/index.php?option=com_k2&view=itemlist&task=user&id=1782499
#">anabolic steroids examples
</a>
anabolic steroids side effects
why do anabolic steroids differ from other illegal drugs
http://serenomiami.com/index.php?option=com_k2&view=itemlist&task=user&id=2194756
<a href="http://zakupki.help/index.php?option=com_k2&view=itemlist&task=user&id=126227
">anabolic steroids cycling
</a>
<a href="http://tir-kombat.ru/index.php?option=com_k2&view=itemlist&task=user&id=4618
#">what are anabolic steroids made of
</a>
legal anabolic steroids gnc
anabolic steroids cycle
http://evoxhair.com/index.php?option=com_k2&view=itemlist&task=user&id=66643
<a href="http://csw.com.my/index.php?option=com_k2&view=itemlist&task=user&id=457202
">anabolic steroids in sport
</a>
<a href="http://mso.soict.hust.edu.vn/index.php?option=com_k2&view=itemlist&task=user&id=324311
#">what is anabolic steroids
</a>
anabolic steroids pills
anabolic steroids online
http://apps-creator.com/index.php?option=com_k2&view=itemlist&task=user&id=242257
<a href="http://globalmoringaday.org/index.php?option=com_k2&view=itemlist&task=user&id=102902
">anabolic steroids alternatives
</a>
<a href="http://mumark.1gb.ru/index.php?option=com_k2&view=itemlist&task=user&id=8119
#">anabolic steroids stats
</a>
anabolic-androgenic steroids
are anabolic steroids legal
http://www.cerrajerosdetijuana.org/index.php?option=com_k2&view=itemlist&task=user&id=177073
<a href="http://www.countryclubfitness.com/index.php?option=com_k2&view=itemlist&task=user&id=40094
">anabolic steroids injection
</a>
<a href="http://supplyconceptsinc.com/index.php?option=com_k2&view=itemlist&task=user&id=1436318
#">anabolic steroids in sports
</a>
anabolic steroids pill
http://ghostsharmtours.com/index.php?option=com_k2&view=itemlist&task=user&id=2091
<a href="http://www.flowersbydonita.co.za/index.php?option=com_k2&view=itemlist&task=user&id=570990
">three risks of using anabolic steroids and other performance-enhancing drugs
</a>
<a href="http://ebnefsi.eu/index.php?option=com_k2&view=itemlist&task=user&id=15736
#">what are anabolic steroids
</a>
dangers of anabolic steroids
anabolic steroids examples
http://minmag.mining.kz/index.php?option=com_k2&view=itemlist&task=user&id=3038984
<a href="http://lifestyleonkloof.co.za/index.php?option=com_k2&view=itemlist&task=user&id=362591
">anabolic steroids law
</a>
<a href="http://sydneyshutters.com.au/index.php?option=com_k2&view=itemlist&task=user&id=14196
#">anabolic steroids schedule
</a>
steroids anabolic
anabolic steroids cycling
http://bushmanshop.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=14216
<a href="http://historyimprint.com/index.php?option=com_k2&view=itemlist&task=user&id=752058
">how to get anabolic steroids
</a>
<a href="http://xxxalmet.ru/index.php?option=com_k2&view=itemlist&task=user&id=88085
#">street names for anabolic steroids
</a>
anabolic steroids in sport
long term effects of anabolic steroids
http://csw.com.my/index.php?option=com_k2&view=itemlist&task=user&id=455976
<a href="http://startshina.dp.ua/index.php?option=com_k2&view=itemlist&task=user&id=18225
">anabolic steroids names
</a>
<a href="http://sindicatodechoferespichincha.com.ec/index.php?option=com_k2&view=itemlist&task=user&id=1455535
#">where can i get anabolic steroids
</a>
anabolic androgenic steroids
anabolic steroids cycling
http://la.fnst.org/index.php?option=com_k2&view=itemlist&task=user&id=3885668
<a href="http://mobility-corp.com/index.php?option=com_k2&view=itemlist&task=user&id=710397
">anabolic steroids facts
</a>
<a href="http://revda.edinros66.ru/index.php?option=com_k2&view=itemlist&task=user&id=2218
#">list of anabolic steroids
</a>
anabolic steroids legality
anabolic steroids cycle
http://skyit.org/index.php?option=com_k2&view=itemlist&task=user&id=249097
<a href="http://avmsas.com/index.php?option=com_k2&view=itemlist&task=user&id=190403
">buy injectable anabolic steroids
</a>
<a href="http://ellsol.com/index.php?option=com_k2&view=itemlist&task=user&id=578077
#">anabolic androgenic steroids
</a>
anabolic steroids are a type of quizlet
anabolic steroids pills
http://www.reanimator.by/index.php?option=com_k2&view=itemlist&task=user&id=90981
<a href="http://greenacre.co.za/index.php?option=com_k2&view=itemlist&task=user&id=1428569
">injectable anabolic steroids
</a>
<a href="http://vietnamhat.com.vn/index.php?option=com_k2&view=itemlist&task=user&id=839029
#">positive effects of anabolic steroids
</a>
anabolic steroids forum
http://antalya-crimea.ru/index.php?option=com_k2&view=itemlist&task=user&id=58813
<a href="http://tir-kombat.ru/index.php?option=com_k2&view=itemlist&task=user&id=4673
">injectable anabolic steroids
</a>
<a href="http://www.nds.com.pk/index.php?option=com_k2&view=itemlist&task=user&id=344217
#">anabolic steroids are a type of quizlet
</a>
anabolic steroids online
anabolic steroids in sport
http://ursthailand.com/index.php?option=com_k2&view=itemlist&task=user&id=122268
<a href="http://hamaravidisha.com/index.php?option=com_k2&view=itemlist&task=user&id=170054
">anabolic steroids are a type of quizlet
</a>
<a href="http://z-o.kz/index.php?option=com_k2&view=itemlist&task=user&id=59993
#">anabolic steroids are a type of quizlet
</a>
anabolic steroids are which of the following
anabolic steroids in sport
http://prima-stroy.ru/index.php?option=com_k2&view=itemlist&task=user&id=246606
<a href="http://ursthailand.com/index.php?option=com_k2&view=itemlist&task=user&id=121873
">legal anabolic steroids
</a>
<a href="http://pedionpartnerships.com/index.php?option=com_k2&view=itemlist&task=user&id=37655
#">anabolic steroids law
</a>
anabolic steroids used
anabolic steroids injections
http://agencyint.net/index.php?option=com_k2&view=itemlist&task=user&id=10448
<a href="http://www.squeeza.co.za/index.php?option=com_k2&view=itemlist&task=user&id=40993
">what would be the most likely outcome if a young man were using anabolic steroids?
</a>
<a href="http://lotus-elchtet.com/index.php?option=com_k2&view=itemlist&task=user&id=137799
#">where to buy anabolic steroids
</a>
anabolic steroids pill
anabolic steroids and diabetes
http://xn----9sbeid4cgu7b.xn--p1ai/index.php?option=com_k2&view=itemlist&task=user&id=123814
<a href="http://4dmarketing.co.za/index.php?option=com_k2&view=itemlist&task=user&id=113600
">anabolic steroids cycle
</a>
<a href="http://mx-digital.com/index.php?option=com_k2&view=itemlist&task=user&id=146263
#">what would be the most likely outcome if a young man were using anabolic steroids?
</a>
anabolic steroids street names
anabolic steroids effects
http://adofa.es/index.php?option=com_k2&view=itemlist&task=user&id=10838
<a href="http://economie-combustibil.ro/index.php?option=com_k2&view=itemlist&task=user&id=5189
">types of anabolic steroids
</a>
<a href="http://praestar-controls.com/index.php?option=com_k2&view=itemlist&task=user&id=177862
#">anabolic steroids injections
</a>
legal anabolic steroids for sale
anabolic steroids types
http://aclass.com.sg/index.php?option=com_k2&view=itemlist&task=user&id=2152180
<a href="http://www.centerrepair.ru/index.php?option=com_k2&view=itemlist&task=user&id=6996
">definition of anabolic steroids
</a>
<a href="http://www.oldmutarehospital.org.zw/index.php?option=com_k2&view=itemlist&task=user&id=112352
#">anabolic steroids bodybuilders
</a>
anabolic steroids in sports
http://malinavolos.ru/index.php?option=com_k2&view=itemlist&task=user&id=109673
<a href="http://www.multi-formas.com/index.php?option=com_k2&view=itemlist&task=user&id=208487
">were to buy anabolic steroids
</a>
<a href="http://hamaravidisha.com/index.php?option=com_k2&view=itemlist&task=user&id=170253
#">how do anabolic steroids work
</a>
history of anabolic steroids
what do anabolic steroids do
http://candfwater.com/index.php?option=com_k2&view=itemlist&task=user&id=1007
<a href="http://anellioriginals.com/index.php?option=com_k2&view=itemlist&task=user&id=171549
">anabolic steroids law
</a>
<a href="http://bernhardtpkr.com/index.php?option=com_k2&view=itemlist&task=user&id=100817
#">anabolic steroids schedule
</a>
the use of anabolic steroids during adolescence can cause
anabolic steroids bodybuilders
http://betarvyatka.ru/index.php?option=com_k2&view=itemlist&task=user&id=82998
<a href="http://legos-mebel.ru/index.php?option=com_k2&view=itemlist&task=user&id=356255
">how anabolic steroids work
</a>
<a href="http://fermisynergies.com/index.php?option=com_k2&view=itemlist&task=user&id=25463
#">definition of anabolic steroids
</a>
anabolic steroids alternatives
buy injectable anabolic steroids
http://www.indigoskatecamp.co.za/index.php?option=com_k2&view=itemlist&task=user&id=243355
<a href="http://bcel.uk/index.php?option=com_k2&view=itemlist&task=user&id=944878
">anabolic steroids can be ingested in which ways
</a>
<a href="http://pedionpartnerships.com/index.php?option=com_k2&view=itemlist&task=user&id=37655
#">legal anabolic steroids gnc
</a>
anabolic steroids cycle
are anabolic steroids legal
http://alesnavratil.cz/index.php?option=com_k2&view=itemlist&task=user&id=67926
<a href="http://ortointegra.com.mx/index.php?option=com_k2&view=itemlist&task=user&id=1124
">anabolic steroids can be ingested in which of the following ways
</a>
<a href="http://growth-int.com/index.php?option=com_k2&view=itemlist&task=user&id=165548
#">anabolic steroids online
</a>
what is anabolic steroids
anabolic steroids alternatives
http://fondation-famart.com/index.php?option=com_k2&view=itemlist&task=user&id=230947
<a href="http://artsivitour.ge/index.php?option=com_k2&view=itemlist&task=user&id=19050
">anabolic steroids buy
</a>
<a href="http://sindicatodechoferespichincha.com.ec/index.php?option=com_k2&view=itemlist&task=user&id=1456981
#">anabolic steroids alternatives
</a>
anabolic steroids pill
anabolic steroids are a type of
http://guillermohernandez.es/index.php?option=com_k2&view=itemlist&task=user&id=72105
<a href="http://lotus-elchtet.com/index.php?option=com_k2&view=itemlist&task=user&id=137900
">anabolic steroids street names
</a>
<a href="http://iceberg.ykt.ru/index.php?option=com_k2&view=itemlist&task=user&id=80856
#">are anabolic steroids illegal
</a>
anabolic steroids are synthetic versions of which of the following
http://servicios-toldeca.com/index.php?option=com_k2&view=itemlist&task=user&id=351118
<a href="http://beautyinallsalon.ru/index.php?option=com_k2&view=itemlist&task=user&id=1849
">were to buy anabolic steroids
</a>
<a href="http://www.joanramagoshi.com/index.php?option=com_k2&view=itemlist&task=user&id=185161
#">anabolic steroids facts
</a>
buy anabolic steroids with credit card
are anabolic steroids legal
http://anellioriginals.com/index.php?option=com_k2&view=itemlist&task=user&id=171699
<a href="http://laguadalupanaimports.com/index.php?option=com_k2&view=itemlist&task=user&id=72241
">define anabolic steroids
</a>
<a href="http://fluideas.com/index.php?option=com_k2&view=itemlist&task=user&id=66723
#">prescribed anabolic steroids
</a>
anabolic steroids definition
anabolic steroids used
http://ahirat.ru/index.php?option=com_k2&view=itemlist&task=user&id=56156
<a href="http://www.radiosperanta.ro/index.php?option=com_k2&view=itemlist&task=user&id=25244
">how anabolic steroids work
</a>
<a href="http://www.newtreasuregarden.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=95095
#">anabolic steroids examples
</a>
the use of anabolic steroids during adolescence can cause
what are anabolic steroids made of
http://www.reanimator.by/index.php?option=com_k2&view=itemlist&task=user&id=91563
<a href="http://ncfproject.org/index.php?option=com_k2&view=itemlist&task=user&id=912907
">what do anabolic steroids do
</a>
<a href="http://beotek.com.tr/index.php?option=com_k2&view=itemlist&task=user&id=647214
#">anabolic steroids used
</a>
anabolic steroids sale
anabolic steroids pill
http://mso.soict.hust.edu.vn/index.php?option=com_k2&view=itemlist&task=user&id=322759
<a href="http://congefan.mil.ve/index.php?option=com_k2&view=itemlist&task=user&id=364701
">risk of using anabolic steroids
</a>
<a href="http://yellowdevilz.com/index.php?option=com_k2&view=itemlist&task=user&id=392582
#">anabolic steroids examples
</a>
legal anabolic steroids gnc
anabolic steroids legality
http://thinktotal.com.au/index.php?option=com_k2&view=itemlist&task=user&id=250
<a href="http://atelier-bachofer.de/index.php?option=com_k2&view=itemlist&task=user&id=636599
">anabolic steroids for sale
</a>
<a href="http://teatrkarnaval.od.ua/index.php?option=com_k2&view=itemlist&task=user&id=50135
#">anabolic steroids injection
</a>
why do anabolic steroids differ from other illegal drugs?
why do anabolic steroids differ from other illegal drugs?
http://indecorbadajoz.com/index.php?option=com_k2&view=itemlist&task=user&id=8310
<a href="http://inx-za.co.za/index.php?option=com_k2&view=itemlist&task=user&id=36585
">three risks of using anabolic steroids and other performance-enhancing drugs
</a>
<a href="http://goldhere.ru/index.php?option=com_k2&view=itemlist&task=user&id=3258
#">anabolic steroids in sport
</a>
anabolic steroids supplements
http://paarlboyshigh.org.za/index.php?option=com_k2&view=itemlist&task=user&id=259662
<a href="http://www.powsolnet.com/index.php?option=com_k2&view=itemlist&task=user&id=660313
">anabolic steroids buy
</a>
<a href="http://naveedulhassan.com/index.php?option=com_k2&view=itemlist&task=user&id=43104
#">anabolic steroids names
</a>
buy anabolic steroids online
anabolic steroids types
http://naveedulhassan.com/index.php?option=com_k2&view=itemlist&task=user&id=43020
<a href="http://nerjalivingspace.com/index.php?option=com_k2&view=itemlist&task=user&id=22102
">define anabolic steroids
</a>
<a href="http://mso.soict.hust.edu.vn/index.php?option=com_k2&view=itemlist&task=user&id=323944
#">anabolic steroids cycle
</a>
anabolic steroids are a type of
risks of anabolic steroids
http://growth-int.com/index.php?option=com_k2&view=itemlist&task=user&id=166434
<a href="http://www.bau-truck.ru/index.php?option=com_k2&view=itemlist&task=user&id=97087
">anabolic steroids in sport
</a>
<a href="http://oretanaformacion.com/index.php?option=com_k2&view=itemlist&task=user&id=363318
#">anabolic steroids legal
</a>
anabolic steroids alternatives
anabolic steroids names
http://www.revadespa.net/index.php?option=com_k2&view=itemlist&task=user&id=730415
<a href="http://dti.dairytrain.org/index.php?option=com_k2&view=itemlist&task=user&id=33496
">anabolic steroids for sale
</a>
<a href="http://clubcrown.ca/index.php?option=com_k2&view=itemlist&task=user&id=22803
#">buy injectable anabolic steroids
</a>
definition of anabolic steroids
anabolic steroids forum
http://servicios-toldeca.com/index.php?option=com_k2&view=itemlist&task=user&id=350863
<a href="http://runningemu.com.au/index.php?option=com_k2&view=itemlist&task=user&id=2697
">anabolic steroids are which of the following
</a>
<a href="http://cirkitrepair.com/index.php?option=com_k2&view=itemlist&task=user&id=65548
#">where to buy anabolic steroids online forum
</a>
anabolic steroids and diabetes
anabolic steroids legality
http://goldhere.ru/index.php?option=com_k2&view=itemlist&task=user&id=3306
<a href="http://humphries-stonemasons.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=34413
">anabolic steroids stats
</a>
<a href="http://miranico.ir/index.php?option=com_k2&view=itemlist&task=user&id=1779975
#">anabolic steroids are primarily used in an attempt to
</a>
oral anabolic steroids
buying anabolic steroids online
http://www.wtfeusa.com/index.php?option=com_k2&view=itemlist&task=user&id=515429
<a href="http://ikemuebles.com/index.php?option=com_k2&view=itemlist&task=user&id=30505
">anabolic steroids forum
</a>
<a href="http://tuccitec.com/index.php?option=com_k2&view=itemlist&task=user&id=199077
#">anabolic steroids street names
</a>
anabolic steroids can be ingested in which ways
http://tir-kombat.ru/index.php?option=com_k2&view=itemlist&task=user&id=4620
<a href="http://smartbuyequip.com/index.php?option=com_k2&view=itemlist&task=user&id=127548
">anabolic steroids legal
</a>
<a href="http://www.rupsbigbear.com/index.php?option=com_k2&view=itemlist&task=user&id=127857
#">anabolic steroids types
</a>
list of anabolic steroids
anabolic steroids legal
http://velestravel.ru/index.php?option=com_k2&view=itemlist&task=user&id=133825
<a href="http://www.newtreasuregarden.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=95095
">how anabolic steroids work
</a>
<a href="http://leefbaaralmere.vostedevelopment.com/index.php?option=com_k2&view=itemlist&task=user&id=17840
#">anabolic steroids before and after
</a>
anabolic steroids examples
anabolic steroids alternative
http://herhealth.co.za/index.php?option=com_k2&view=itemlist&task=user&id=295979
<a href="http://csw.com.my/index.php?option=com_k2&view=itemlist&task=user&id=458010
">dangers of anabolic steroids
</a>
<a href="http://fondation-famart.com/index.php?option=com_k2&view=itemlist&task=user&id=230947
#">anabolic steroids bodybuilders
</a>
anabolic steroids for sale
anabolic steroids cycle
http://learnsculpture.org/index.php?option=com_k2&view=itemlist&task=user&id=15140
<a href="http://www.josehope.com/index.php?option=com_k2&view=itemlist&task=user&id=8544
">anabolic steroids are a type of quizlet
</a>
<a href="http://inx-za.co.za/index.php?option=com_k2&view=itemlist&task=user&id=36847
#">anabolic steroids sale
</a>
anabolic steroids are which of the following
risk of using anabolic steroids
http://revda.edinros66.ru/index.php?option=com_k2&view=itemlist&task=user&id=2218
<a href="http://artsivitour.ge/index.php?option=com_k2&view=itemlist&task=user&id=19050
">what do anabolic steroids do
</a>
<a href="http://ursthailand.com/index.php?option=com_k2&view=itemlist&task=user&id=122268
#">what would be the most likely outcome if a young man were using anabolic steroids?
</a>
anabolic steroids bodybuilders
anabolic steroids are a type of quizlet
http://acl-ng.org/index.php?option=com_k2&view=itemlist&task=user&id=1993
<a href="http://autismohuelva.org/index.php?option=com_k2&view=itemlist&task=user&id=3597
">the use of anabolic steroids during adolescence can cause
</a>
<a href="http://beotek.com.tr/index.php?option=com_k2&view=itemlist&task=user&id=647657
#">anabolic steroids effects
</a>
how do anabolic steroids work
list of anabolic steroids
http://burgerdoze.com/index.php?option=com_k2&view=itemlist&task=user&id=416594
<a href="http://supplyconceptsinc.com/index.php?option=com_k2&view=itemlist&task=user&id=1432556
">what is anabolic steroids
</a>
<a href="http://jnmediaconsultants.com/index.php?option=com_k2&view=itemlist&task=user&id=7388
#">anabolic steroids sales
</a>
how do anabolic steroids work
http://other.rasmeinews.com/index.php?option=com_k2&view=itemlist&task=user&id=2800263
<a href="http://petaw.fr/index.php?option=com_k2&view=itemlist&task=user&id=39285
">anabolic steroids and diabetes
</a>
<a href="http://tangguh.co.id/index.php?option=com_k2&view=itemlist&task=user&id=545063
#">what do anabolic steroids do
</a>
why do anabolic steroids differ from other illegal drugs?
anabolic steroids can be ingested in which ways
http://browhow.ru/index.php?option=com_k2&view=itemlist&task=user&id=1307
<a href="http://burgerdoze.com/index.php?option=com_k2&view=itemlist&task=user&id=416594
">benefits of anabolic steroids
</a>
<a href="http://herhealth.co.za/index.php?option=com_k2&view=itemlist&task=user&id=296654
#">effects of anabolic steroids
</a>
list of anabolic steroids
positive effects of anabolic steroids
http://snakespy.ru/index.php?option=com_k2&view=itemlist&task=user&id=156180
<a href="http://www.atelier-floral.ro/index.php?option=com_k2&view=itemlist&task=user&id=24885
">anabolic steroids cycling
</a>
<a href="http://ghostsharmtours.com/index.php?option=com_k2&view=itemlist&task=user&id=2096
#">anabolic steroids facts
</a>
long term effects of anabolic steroids
buy anabolic steroids
http://www.countryclubfitness.com/index.php?option=com_k2&view=itemlist&task=user&id=40094
<a href="http://www.cubiclefittings.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=2891
">anabolic steroids examples
</a>
<a href="http://miranico.ir/index.php?option=com_k2&view=itemlist&task=user&id=1781377
#">anabolic androgenic steroids
</a>
anabolic steroids side effects
anabolic steroids and diabetes
http://triad.kiev.ua/index.php?option=com_k2&view=itemlist&task=user&id=71988
<a href="http://apps-creator.com/index.php?option=com_k2&view=itemlist&task=user&id=239849
">anabolic steroids used
</a>
<a href="http://piedraartificialrosaman.com/index.php?option=com_k2&view=itemlist&task=user&id=407373
#">anabolic steroids street names
</a>
risks of anabolic steroids
how do anabolic steroids work
http://drevovzahrade.cz/index.php?option=com_k2&view=itemlist&task=user&id=254238
<a href="http://prima-stroy.ru/index.php?option=com_k2&view=itemlist&task=user&id=247522
">define anabolic steroids
</a>
<a href="http://candfwater.com/index.php?option=com_k2&view=itemlist&task=user&id=1006
#">the use of anabolic steroids during adolescence can cause
</a>
anabolic steroids are appropriately prescribed to
anabolic steroids are primarily used in an attempt to
http://thevillageplaceresort.com/index.php?option=com_k2&view=itemlist&task=user&id=2226815
<a href="http://herhealth.co.za/index.php?option=com_k2&view=itemlist&task=user&id=295979
">buy anabolic steroids with credit card
</a>
<a href="http://utsgeo.com/index.php?option=com_k2&view=itemlist&task=user&id=68029
#">what are anabolic steroids
</a>
anabolic steroids are a type of quizlet
http://sov2009.ru/index.php?option=com_k2&view=itemlist&task=user&id=98255
<a href="http://myevaleplatform.com/index.php?option=com_k2&view=itemlist&task=user&id=127563
">define anabolic steroids
</a>
<a href="http://solution-ltd.com.ua/index.php?option=com_k2&view=itemlist&task=user&id=872099
#">risks of using anabolic steroids
</a>
dangers of anabolic steroids
prescribed anabolic steroids
http://betarvyatka.ru/index.php?option=com_k2&view=itemlist&task=user&id=82572
<a href="http://autismohuelva.org/index.php?option=com_k2&view=itemlist&task=user&id=3597
">buy anabolic steroids online
</a>
<a href="http://lotus-elchtet.com/index.php?option=com_k2&view=itemlist&task=user&id=137799
#">what do anabolic steroids do
</a>
are anabolic steroids illegal
positive effects of anabolic steroids
http://dnk-expert.ru/index.php?option=com_k2&view=itemlist&task=user&id=153852
<a href="http://yellowdevilz.com/index.php?option=com_k2&view=itemlist&task=user&id=394020
">steroids anabolic
</a>
<a href="http://beotek.com.tr/index.php?option=com_k2&view=itemlist&task=user&id=648486
#">how are anabolic steroids made
</a>
prescribed anabolic steroids
prescription anabolic steroids
http://maffia.by/index.php?option=com_k2&view=itemlist&task=user&id=12539
<a href="http://tcbresistencias.com/index.php?option=com_k2&view=itemlist&task=user&id=133152
">definition of anabolic steroids
</a>
<a href="http://paneinattesa.altervista.org/index.php?option=com_k2&view=itemlist&task=user&id=130697
#">the use of anabolic steroids during adolescence can cause
</a>
risks of using anabolic steroids
benefits of anabolic steroids
http://ursthailand.com/index.php?option=com_k2&view=itemlist&task=user&id=121873
<a href="http://www.bilgimak.net/index.php?option=com_k2&view=itemlist&task=user&id=112570
">anabolic steroids sale
</a>
<a href="http://www.ferrocables.com/index.php?option=com_k2&view=itemlist&task=user&id=4695
#">where to buy anabolic steroids online forum
</a>
anabolic steroids risks
anabolic steroids schedule
http://anaisabelaparicio.com/index.php?option=com_k2&view=itemlist&task=user&id=127292
<a href="http://tiras-ttu.org/index.php?option=com_k2&view=itemlist&task=user&id=68154
">anabolic steroids can be ingested in which ways
</a>
<a href="http://kratostravel.info/index.php?option=com_k2&view=itemlist&task=user&id=113819
#">anabolic steroids are which of the following
</a>
prescribed anabolic steroids
where to buy anabolic steroids online forum
http://la.fnst.org/index.php?option=com_k2&view=itemlist&task=user&id=3884671
<a href="http://triad.kiev.ua/index.php?option=com_k2&view=itemlist&task=user&id=71673
">anabolic steroids can be ingested in which ways
</a>
<a href="http://csw.com.my/index.php?option=com_k2&view=itemlist&task=user&id=458010
#">buying anabolic steroids online
</a>
effects of anabolic steroids
http://malinavolos.ru/index.php?option=com_k2&view=itemlist&task=user&id=110099
<a href="http://fluideas.com/index.php?option=com_k2&view=itemlist&task=user&id=66723
">anabolic steroids supplements
</a>
<a href="http://lotus-elchtet.com/index.php?option=com_k2&view=itemlist&task=user&id=137616
#">anabolic steroids law
</a>
how are anabolic steroids made
side effects of anabolic steroids
http://www.keithbradbury.com/index.php?option=com_k2&view=itemlist&task=user&id=271850
<a href="http://filc.huc.edu.vn/index.php?option=com_k2&view=itemlist&task=user&id=11245
">risk of using anabolic steroids
</a>
<a href="http://burgerdoze.com/index.php?option=com_k2&view=itemlist&task=user&id=415938
#">anabolic steroids forum
</a>
anabolic steroids bodybuilding
anabolic steroids and diabetes
http://kovka.kiev.ua/index.php?option=com_k2&view=itemlist&task=user&id=1073
<a href="http://photo4you.com.ua/index.php?option=com_k2&view=itemlist&task=user&id=1516
">anabolic steroids can be ingested in which of the following ways
</a>
<a href="http://claida-immobilien.de/index.php?option=com_k2&view=itemlist&task=user&id=1936697
#">how anabolic steroids work
</a>
prescribed anabolic steroids
anabolic steroids types
http://hopewalkingacrossamerica.com/index.php?option=com_k2&view=itemlist&task=user&id=69669
<a href="http://dmfuniform.uz/index.php?option=com_k2&view=itemlist&task=user&id=2438
">why do anabolic steroids differ from other illegal drugs?
</a>
<a href="http://artel-rm.ru/index.php?option=com_k2&view=itemlist&task=user&id=12947
#">legal anabolic steroids for sale
</a>
anabolic steroids
how to get anabolic steroids
http://ovechkamarket.ru/index.php?option=com_k2&view=itemlist&task=user&id=196524
<a href="http://furbero.com/index.php?option=com_k2&view=itemlist&task=user&id=105915
">what do anabolic steroids do
</a>
<a href="http://wellingtonvineyard.com.au/index.php?option=com_k2&view=itemlist&task=user&id=31807
#">anabolic steroids before and after
</a>
legal anabolic steroids
examples of anabolic steroids
http://lifestyleonkloof.co.za/index.php?option=com_k2&view=itemlist&task=user&id=362452
<a href="http://mpunzana.co.za/index.php?option=com_k2&view=itemlist&task=user&id=814327
">are anabolic steroids legal
</a>
<a href="http://evoxhair.com/index.php?option=com_k2&view=itemlist&task=user&id=66563
#">were to buy anabolic steroids
</a>
anabolic steroids street names
anabolic steroids sales
http://kratostravel.info/index.php?option=com_k2&view=itemlist&task=user&id=114361
<a href="http://www.keithbradbury.com/index.php?option=com_k2&view=itemlist&task=user&id=271850
">oral anabolic steroids
</a>
<a href="http://sunsationgroup.com/index.php?option=com_k2&view=itemlist&task=user&id=377911
#">what are anabolic steroids made of
</a>
are anabolic steroids illegal
http://www.velestravel.ru/index.php?option=com_k2&view=itemlist&task=user&id=136247
<a href="http://vlzd.ru/index.php?option=com_k2&view=itemlist&task=user&id=38762
">buy anabolic steroids with credit card
</a>
<a href="http://4-kant.ch/index.php?option=com_k2&view=itemlist&task=user&id=25548
#">why do anabolic steroids differ from other illegal drugs
</a>
anabolic steroids cycling
types of anabolic steroids
http://mx-digital.com/index.php?option=com_k2&view=itemlist&task=user&id=146263
<a href="http://csdsz.net/index.php?option=com_k2&view=itemlist&task=user&id=688631
">anabolic steroids can be ingested in which ways
</a>
<a href="http://lalafirouse.com/index.php?option=com_k2&view=itemlist&task=user&id=4114
#">where to get anabolic steroids
</a>
anabolic steroids are which of the following
anabolic steroids sales
http://appu.te.ua/index.php?option=com_k2&view=itemlist&task=user&id=52926
<a href="http://mso.soict.hust.edu.vn/index.php?option=com_k2&view=itemlist&task=user&id=323354
">effects of anabolic steroids
</a>
<a href="http://malinavolos.ru/index.php?option=com_k2&view=itemlist&task=user&id=109673
#">history of anabolic steroids
</a>
anabolic steroids sale
positive effects of anabolic steroids
http://smdkala.com/index.php?option=com_k2&view=itemlist&task=user&id=887
<a href="http://pizzagt.ru/index.php?option=com_k2&view=itemlist&task=user&id=83393
">what are anabolic steroids made of
</a>
<a href="http://lifestyleonkloof.co.za/index.php?option=com_k2&view=itemlist&task=user&id=362452
#">anabolic steroids forum
</a>
why do anabolic steroids differ from other illegal drugs
anabolic steroids examples
http://candfwater.com/index.php?option=com_k2&view=itemlist&task=user&id=1007
<a href="http://mso.soict.hust.edu.vn/index.php?option=com_k2&view=itemlist&task=user&id=324311
">anabolic steroids before and after
</a>
<a href="http://beotek.com.tr/index.php?option=com_k2&view=itemlist&task=user&id=647657
#">street names for anabolic steroids
</a>
anabolic steroids are primarily used in an attempt to
anabolic steroids are a type of
http://tennis.krata.ru/index.php?option=com_k2&view=itemlist&task=user&id=67351
<a href="http://km-krupenko.ru/index.php?option=com_k2&view=itemlist&task=user&id=117729
">anabolic steroids are appropriately prescribed to
</a>
<a href="http://appu.te.ua/index.php?option=com_k2&view=itemlist&task=user&id=52502
#">where to get anabolic steroids
</a>
anabolic steroids cycle
anabolic steroids supplements
http://sigmaclub-ui.org/index.php?option=com_k2&view=itemlist&task=user&id=794553
<a href="http://beotek.com.tr/index.php?option=com_k2&view=itemlist&task=user&id=647214
">anabolic steroids examples
</a>
<a href="http://vcarepharmacy.us/index.php?option=com_k2&view=itemlist&task=user&id=92965
#">anabolic steroids alternative
</a>
injectable anabolic steroids
http://www.taxoncall.com/index.php?option=com_k2&view=itemlist&task=user&id=541250
<a href="http://furbero.com/index.php?option=com_k2&view=itemlist&task=user&id=107692
">risks of using anabolic steroids
</a>
<a href="http://colab.di.ionio.gr/index.php?option=com_k2&view=itemlist&task=user&id=11700
#">legal anabolic steroids
</a>
anabolic steroids injections
legal anabolic steroids for sale
http://csdsz.net/index.php?option=com_k2&view=itemlist&task=user&id=692477
<a href="http://ensayofinal.com/index.php?option=com_k2&view=itemlist&task=user&id=13468
">injectable anabolic steroids
</a>
<a href="http://master.latambschool.com/index.php?option=com_k2&view=itemlist&task=user&id=1157788
#">benefits of anabolic steroids
</a>
what would be the most likely outcome if a young man were using anabolic steroids?
risks of anabolic steroids
http://progressivemovementz.com/index.php?option=com_k2&view=itemlist&task=user&id=336123
<a href="http://www.multirepuestos.com.sv/index.php?option=com_k2&view=itemlist&task=user&id=1458
">what would be the most likely outcome if a young man were using anabolic steroids?
</a>
<a href="http://www.4trombones.com/index.php?option=com_k2&view=itemlist&task=user&id=363676
#">examples of anabolic steroids
</a>
are anabolic steroids illegal
anabolic steroids forum
http://genpharma.cn.com/index.php?option=com_k2&view=itemlist&task=user&id=903
<a href="http://mymocha.com/index.php?option=com_k2&view=itemlist&task=user&id=65325
">anabolic steroids schedule
</a>
<a href="http://master.latambschool.com/index.php?option=com_k2&view=itemlist&task=user&id=1157788
#">prescription anabolic steroids
</a>
long term effects of anabolic steroids
risks of anabolic steroids
http://www.vitantonioscorrano.com/index.php?option=com_k2&view=itemlist&task=user&id=3861
<a href="http://botasdeseguridad.com.ve/index.php?option=com_k2&view=itemlist&task=user&id=47047
">anabolic-androgenic steroids
</a>
<a href="http://amkodor-bryansk.ru/index.php?option=com_k2&view=itemlist&task=user&id=26637
#">how are anabolic steroids made
</a>
where to buy anabolic steroids online forum
history of anabolic steroids
http://apemindo.com/index.php?option=com_k2&view=itemlist&task=user&id=22221
<a href="http://vittorioceccoli.it/index.php?option=com_k2&view=itemlist&task=user&id=16312
">anabolic steroids forum
</a>
<a href="http://ingria.pro/index.php?option=com_k2&view=itemlist&task=user&id=43624
#">three risks of using anabolic steroids and other performance-enhancing drugs
</a>
are anabolic steroids legal
anabolic steroids usage
http://visibility.co.tz/index.php?option=com_k2&view=itemlist&task=user&id=25082
<a href="http://guillermohernandez.es/index.php?option=com_k2&view=itemlist&task=user&id=74052
">anabolic steroids in sport
</a>
<a href="http://www.multirepuestos.com.sv/index.php?option=com_k2&view=itemlist&task=user&id=1458
#">best anabolic steroids
</a>
with private doctors you can pay for any testing without questions being asked.
must consider this list very carefully and decide whether the benefit of weight loss outweighs the risks associated with taking clenbuterol.
<a href="http://stanozololwinstrol.com">stanozolol</a>
water bacterostatic water is sterile, has a specific ph level and contains a specific amount of benzyl alcohol as a bacteriostatic preservative, is in a specially formulated polyolefin vial to maintain it integrity and sterility, and has no adulterants that may damage breakdown what you are reconstituting or cause a deep tissue infection when injected.
it features both fast-acting and slow-acting esters, and can be injected anywhere from once every week to once every four weeks.
mad cow disease helped pull in the reins on an industry that was getting out of control.
1 breeding programmes.
it is a well known fact that gh is a powerful anti- catabolic agent protein sparing .
<a href="http://stanozololwinstrol.com">winstrol</a>
she started off at 107 pounds.
anabolic steroids examples
http://ursthailand.com/index.php?option=com_k2&view=itemlist&task=user&id=128062
<a href="http://herhealth.co.za/index.php?option=com_k2&view=itemlist&task=user&id=299770
">where to buy anabolic steroids online forum
</a>
<a href="http://gp9.medkhv.ru/index.php?option=com_k2&view=itemlist&task=user&id=77450
#">anabolic steroids and diabetes
</a>
risks of using anabolic steroids
street names for anabolic steroids
http://oretanaformacion.com/index.php?option=com_k2&view=itemlist&task=user&id=365193
<a href="http://mlgroup.cloud/index.php?option=com_k2&view=itemlist&task=user&id=153181
">how anabolic steroids work
</a>
<a href="http://hi.live.woocomdev.com.au/index.php?option=com_k2&view=itemlist&task=user&id=754288
#">where to get anabolic steroids
</a>
anabolic steroids buy
anabolic steroids examples
http://ocatusa.org/index.php?option=com_k2&view=itemlist&task=user&id=14771
<a href="http://triad.kiev.ua/index.php?option=com_k2&view=itemlist&task=user&id=73002
">buy anabolic steroids with credit card
</a>
<a href="http://cororondalosforamontanos.com/index.php?option=com_k2&view=itemlist&task=user&id=231233
#">anabolic steroids stats
</a>
anabolic steroids for sale
anabolic steroids usage
http://www.flowersbydonita.co.za/index.php?option=com_k2&view=itemlist&task=user&id=574429
<a href="http://cororondalosforamontanos.com/index.php?option=com_k2&view=itemlist&task=user&id=230344
">anabolic steroids in sport
</a>
<a href="http://www.dobgir.com/index.php?option=com_k2&view=itemlist&task=user&id=218440
#">anabolic steroids stats
</a>
buy injectable anabolic steroids
anabolic steroids before and after
http://thinktotal.com.au/index.php?option=com_k2&view=itemlist&task=user&id=377
<a href="http://themakeupthailand.com/index.php?option=com_k2&view=itemlist&task=user&id=1188
">buying anabolic steroids online
</a>
<a href="http://mongolvoyages.com/index.php?option=com_k2&view=itemlist&task=user&id=265300
#">anabolic steroids alternative
</a>
steroids anabolic
anabolic steroids sales
http://stenia.sdmo.sk/index.php?option=com_k2&view=itemlist&task=user&id=12233
<a href="http://dmfuniform.uz/index.php?option=com_k2&view=itemlist&task=user&id=2943
">positive effects of anabolic steroids
</a>
<a href="http://sanyasurf.com/index.php?option=com_k2&view=itemlist&task=user&id=1950530
#">anabolic steroids legal
</a>
anabolic androgenic steroids
anabolic steroids stats
http://tradelinkhl.com/index.php?option=com_k2&view=itemlist&task=user&id=376749
<a href="http://jetandrotor.com/index.php?option=com_k2&view=itemlist&task=user&id=241949
">anabolic steroids usage
</a>
<a href="http://atelier-bachofer.de/index.php?option=com_k2&view=itemlist&task=user&id=640220
#">anabolic steroids bodybuilding
</a>
the demand for such mixtures is often high because certain labs prey on the ignorance of others; many believe a testosterone mixture is more powerful than a single-ester form when as you understand mixing various forms together does not change the active hormone.
queda de cabelo;.
<a href="http://stanozololwinstrol.com/9jc79-zd1.html
">stanozolol</a>
1977 feeding wet corn.
rather than introducing synthetic hormones, these products are natural testosterone supplements.
obviously, you want to focus on certain things.
tying in with point 1 ii , the volume of injection will also make a significant difference to any soreness and pain experienced.
obviously, she knows a thing or two about that .
<a href="http://stanozololwinstrol.com/4g2bag.html
">winstrol</a>
the alphadrox test booster is produced by a manufacturer under the same name.
define anabolic steroids
http://claida-immobilien.de/index.php?option=com_k2&view=itemlist&task=user&id=1944852
<a href="http://whiteiris.danielle-murrell.com/index.php?option=com_k2&view=itemlist&task=user&id=174418
">anabolic steroids in sports
</a>
<a href="http://www.espressofreunde.de/index.php?option=com_k2&view=itemlist&task=user&id=947
#">anabolic steroids are appropriately prescribed to
</a>
how do anabolic steroids work
buy anabolic steroids online
http://pizzaone.kz/index.php?option=com_k2&view=itemlist&task=user&id=4101
<a href="http://inclub.lg.ua/index.php?option=com_k2&view=itemlist&task=user&id=1506688
">anabolic steroids for sale
</a>
<a href="http://tigrinyatranslations.com/index.php?option=com_k2&view=itemlist&task=user&id=166799
#">anabolic steroids for sale
</a>
buying anabolic steroids online
buy anabolic steroids online
http://mitraausindo.com/index.php?option=com_k2&view=itemlist&task=user&id=1272
<a href="http://triad.kiev.ua/index.php?option=com_k2&view=itemlist&task=user&id=72926
">injectable anabolic steroids
</a>
<a href="http://furbero.com/index.php?option=com_k2&view=itemlist&task=user&id=107388
#">are anabolic steroids legal
</a>
buy anabolic steroids
anabolic steroids stats
http://mongolvoyages.com/index.php?option=com_k2&view=itemlist&task=user&id=267853
<a href="http://greenink.com/index.php?option=com_k2&view=itemlist&task=user&id=513841
">what are anabolic steroids
</a>
<a href="http://tiras-ttu.org/index.php?option=com_k2&view=itemlist&task=user&id=69858
#">anabolic steroids types
</a>
what do anabolic steroids do
benefits of anabolic steroids
http://lurisia.com.ar/index.php?option=com_k2&view=itemlist&task=user&id=97406
<a href="http://evoxhair.com/index.php?option=com_k2&view=itemlist&task=user&id=67883
">anabolic steroids cycling
</a>
<a href="http://lotus-elchtet.com/index.php?option=com_k2&view=itemlist&task=user&id=138785
#">anabolic steroids supplements
</a>
anabolic steroids are appropriately prescribed to
anabolic steroids alternative
http://mongolievoyages.com/index.php?option=com_k2&view=itemlist&task=user&id=264946
<a href="http://vietnamhat.com.vn/index.php?option=com_k2&view=itemlist&task=user&id=844812
">risks of anabolic steroids
</a>
<a href="http://servicioswts.com/index.php?option=com_k2&view=itemlist&task=user&id=681165
#">where can i get anabolic steroids
</a>
where to buy anabolic steroids
anabolic steroids cycle
http://customlasering.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=27065
<a href="http://ingria.pro/index.php?option=com_k2&view=itemlist&task=user&id=43624
">examples of anabolic steroids
</a>
<a href="http://riadalghani.com/index.php?option=com_k2&view=itemlist&task=user&id=21237
#">anabolic steroids types
</a>
anabolic steroids are which of the following
http://malyaparrucchieri.it/index.php?option=com_k2&view=itemlist&task=user&id=8345
<a href="http://guravichi.rogachevoo.gov.by/index.php?option=com_k2&view=itemlist&task=user&id=7288
">long term effects of anabolic steroids
</a>
<a href="http://www.durmaztelefon.com.tr/index.php?option=com_k2&view=itemlist&task=user&id=4147
#">what is anabolic steroids
</a>
where to buy anabolic steroids online forum
why do anabolic steroids differ from other illegal drugs
http://103.pp.ua/index.php?option=com_k2&view=itemlist&task=user&id=1372
<a href="http://pisosyparedestridimensionales.com/index.php?option=com_k2&view=itemlist&task=user&id=9469
">anabolic steroids in sports
</a>
<a href="http://bandamn.ru/index.php?option=com_k2&view=itemlist&task=user&id=532762
#">benefits of anabolic steroids
</a>
where to get anabolic steroids
where can i get anabolic steroids
http://sanyasurf.com/index.php?option=com_k2&view=itemlist&task=user&id=1951038
<a href="http://tigrinyatranslations.com/index.php?option=com_k2&view=itemlist&task=user&id=166799
">best anabolic steroids
</a>
<a href="http://bronya.automordovia.ru/index.php?option=com_k2&view=itemlist&task=user&id=151851
#">what is anabolic steroids
</a>
effects of anabolic steroids
are anabolic steroids illegal
http://la.fnst.org/index.php?option=com_k2&view=itemlist&task=user&id=3895927
<a href="http://candfwater.com/index.php?option=com_k2&view=itemlist&task=user&id=1022
">anabolic steroids injections
</a>
<a href="http://osfa.com.ar/index.php?option=com_k2&view=itemlist&task=user&id=370289
#">anabolic steroids injection
</a>
anabolic steroids bodybuilders
anabolic steroids are which of the following
http://csdsz.net/index.php?option=com_k2&view=itemlist&task=user&id=691638
<a href="http://www.swampthing.org/index.php?option=com_k2&view=itemlist&task=user&id=22160
">prescribed anabolic steroids
</a>
<a href="http://oretanaformacion.com/index.php?option=com_k2&view=itemlist&task=user&id=365037
#">anabolic steroids schedule
</a>
anabolic steroids pills
buy anabolic steroids
http://tradelinkhl.com/index.php?option=com_k2&view=itemlist&task=user&id=375602
<a href="http://petaw.fr/index.php?option=com_k2&view=itemlist&task=user&id=39590
">anabolic androgenic steroids
</a>
<a href="http://www.importadoraindustrial.com.co/index.php?option=com_k2&view=itemlist&task=user&id=1010856
#">anabolic steroids legality
</a>
the use of anabolic steroids during adolescence can cause
anabolic steroids used
http://kurdi.ru/index.php?option=com_k2&view=itemlist&task=user&id=2805
<a href="http://harman-enterprise.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=2479326
">where to get anabolic steroids
</a>
<a href="http://mlgroup.cloud/index.php?option=com_k2&view=itemlist&task=user&id=153391
#">anabolic steroids effects
</a>
what do anabolic steroids do
http://refincars.co.za/index.php?option=com_k2&view=itemlist&task=user&id=805961
<a href="http://yellowdevilz.com/index.php?option=com_k2&view=itemlist&task=user&id=398142
">anabolic steroids can be ingested in which of the following ways
</a>
<a href="http://atelier-bachofer.de/index.php?option=com_k2&view=itemlist&task=user&id=639405
#">buy anabolic steroids online
</a>
anabolic steroids alternative
risk of using anabolic steroids
http://keanesgalway.com/index.php?option=com_k2&view=itemlist&task=user&id=10301
<a href="http://paarlboyshigh.org.za/index.php?option=com_k2&view=itemlist&task=user&id=260704
">anabolic steroids cycling
</a>
<a href="http://malyaparrucchieri.it/index.php?option=com_k2&view=itemlist&task=user&id=8345
#">anabolic steroids side effects
</a>
are anabolic steroids illegal
anabolic steroids legality
http://cadcamoffices.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=782422
<a href="http://bernhardtpkr.com/index.php?option=com_k2&view=itemlist&task=user&id=102647
">anabolic steroids sale
</a>
<a href="http://www.joanramagoshi.com/index.php?option=com_k2&view=itemlist&task=user&id=187540
#">list of anabolic steroids
</a>
legal anabolic steroids gnc
anabolic steroids online
http://prima-stroy.ru/index.php?option=com_k2&view=itemlist&task=user&id=248963
<a href="http://security-info.com/index.php?option=com_k2&view=itemlist&task=user&id=246714
">anabolic steroids definition
</a>
<a href="http://beotek.com.tr/index.php?option=com_k2&view=itemlist&task=user&id=655730
#">where to buy anabolic steroids online forum
</a>
history of anabolic steroids
anabolic steroids law
http://xn--911-5cdoh2aqz1anx.xn--p1ai/index.php?option=com_k2&view=itemlist&task=user&id=214104
<a href="http://agroosvita-online.com.ua/index.php?option=com_k2&view=itemlist&task=user&id=426685
">anabolic steroids names
</a>
<a href="http://fermisynergies.com/index.php?option=com_k2&view=itemlist&task=user&id=26297
#">anabolic steroids street names
</a>
anabolic steroids supplements
define anabolic steroids
http://pasyvex.com/index.php?option=com_k2&view=itemlist&task=user&id=7906
<a href="http://spyroltd.com/index.php?option=com_k2&view=itemlist&task=user&id=777634
">prescribed anabolic steroids
</a>
<a href="http://vittorioceccoli.com/index.php?option=com_k2&view=itemlist&task=user&id=16322
#">buy injectable anabolic steroids
</a>
steroids anabolic
dangers of anabolic steroids
http://acrp.in/index.php?option=com_k2&view=itemlist&task=user&id=2939205
<a href="http://forumatmyhlnet.com/index.php?option=com_k2&view=itemlist&task=user&id=431786
">what are anabolic steroids
</a>
<a href="http://xxxalmet.ru/index.php?option=com_k2&view=itemlist&task=user&id=88472
#">anabolic steroids injection
</a>
anabolic steroids side effects
http://bronya.automordovia.ru/index.php?option=com_k2&view=itemlist&task=user&id=151851
<a href="http://gom-eg.com/index.php?option=com_k2&view=itemlist&task=user&id=46386
">the use of anabolic steroids during adolescence can cause
</a>
<a href="http://www.bcs.com.sv/index.php?option=com_k2&view=itemlist&task=user&id=87671
#">anabolic steroids body building
</a>
risk of using anabolic steroids
define anabolic steroids
http://www.nds.com.pk/index.php?option=com_k2&view=itemlist&task=user&id=345541
<a href="http://solution-ltd.com.ua/index.php?option=com_k2&view=itemlist&task=user&id=876852
">anabolic steroids in sport
</a>
<a href="http://lubarcelona.com/index.php?option=com_k2&view=itemlist&task=user&id=827
#">list of anabolic steroids
</a>
how to get anabolic steroids
anabolic steroids for sale
http://chelseafans.ru/index.php?option=com_k2&view=itemlist&task=user&id=14700
<a href="http://dairytrain.org/index.php?option=com_k2&view=itemlist&task=user&id=33995
">anabolic steroids alternatives
</a>
<a href="http://furbero.com/index.php?option=com_k2&view=itemlist&task=user&id=107692
#">are anabolic steroids illegal
</a>
anabolic steroids street names
prescription anabolic steroids
http://mpunzana.co.za/index.php?option=com_k2&view=itemlist&task=user&id=818605
<a href="http://piedraartificialrosaman.com/index.php?option=com_k2&view=itemlist&task=user&id=410749
">anabolic steroids types
</a>
<a href="http://druck-center-mg.de/index.php?option=com_k2&view=itemlist&task=user&id=11267
#">anabolic steroids and diabetes
</a>
anabolic steroids schedule
types of anabolic steroids
http://clasiautos.com/index.php?option=com_k2&view=itemlist&task=user&id=200310
<a href="http://myevaleplatform.com/index.php?option=com_k2&view=itemlist&task=user&id=127625
">best anabolic steroids
</a>
<a href="http://amkodor-bryansk.ru/index.php?option=com_k2&view=itemlist&task=user&id=26565
#">legal anabolic steroids
</a>
what are anabolic steroids made of
anabolic steroids street names
http://bronya.automordovia.ru/index.php?option=com_k2&view=itemlist&task=user&id=151851
<a href="http://www.disagrol.com/index.php?option=com_k2&view=itemlist&task=user&id=11359
">anabolic steroids alternative
</a>
<a href="http://xn----9sbeid4cgu7b.xn--p1ai/index.php?option=com_k2&view=itemlist&task=user&id=128007
#">anabolic steroids sale
</a>
risks of using anabolic steroids
anabolic steroids sales
http://roofservice.ru/index.php?option=com_k2&view=itemlist&task=user&id=81323
<a href="http://gullewa.com.au/index.php?option=com_k2&view=itemlist&task=user&id=81518
">anabolic steroids before and after
</a>
<a href="http://smartbuyequip.com/index.php?option=com_k2&view=itemlist&task=user&id=131337
#">anabolic steroids cycle
</a>
anabolic steroids risks
http://picketfencegraphics.ca/index.php?option=com_k2&view=itemlist&task=user&id=34820
<a href="http://vetepsa.com/index.php?option=com_k2&view=itemlist&task=user&id=480483
">anabolic steroids forum
</a>
<a href="http://basarint.com/index.php?option=com_k2&view=itemlist&task=user&id=257817
#">side effects of anabolic steroids
</a>
anabolic steroids definition
anabolic steroids before and after
http://clasiautos.com/index.php?option=com_k2&view=itemlist&task=user&id=200761
<a href="http://cambard.com/index.php?option=com_k2&view=itemlist&task=user&id=2422435
">buy anabolic steroids online
</a>
<a href="http://greenacre.co.za/index.php?option=com_k2&view=itemlist&task=user&id=1439211
#">anabolic steroids
</a>
were to buy anabolic steroids
anabolic steroids pills
http://cadcamoffices.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=783209
<a href="http://atelier-bachofer.de/index.php?option=com_k2&view=itemlist&task=user&id=640220
">anabolic steroids definition
</a>
<a href="http://teatrkarnaval.od.ua/index.php?option=com_k2&view=itemlist&task=user&id=50641
#">where to buy anabolic steroids online forum
</a>
anabolic steroids forum
anabolic steroids are a type of
http://new.glg.su/index.php?option=com_k2&view=itemlist&task=user&id=117757
<a href="http://xn--80aetine1a.xn--p1ai/index.php?option=com_k2&view=itemlist&task=user&id=2522
">anabolic steroids are a type of
</a>
<a href="http://betapsilambda.org/index.php?option=com_k2&view=itemlist&task=user&id=19621
#">prescribed anabolic steroids
</a>
anabolic steroids legal
what would be the most likely outcome if a young man were using anabolic steroids?
http://andrey-skripka.com/index.php?option=com_k2&view=itemlist&task=user&id=231232
<a href="http://novadentalanesthesia.com/index.php?option=com_k2&view=itemlist&task=user&id=1413596
">three risks of using anabolic steroids and other performance-enhancing drugs
</a>
<a href="http://amazonbraziljungletours.com/index.php?option=com_k2&view=itemlist&task=user&id=9992
#">oral anabolic steroids
</a>
anabolic steroids in sport
are anabolic steroids legal
http://tcbresistencias.com/index.php?option=com_k2&view=itemlist&task=user&id=135748
<a href="http://www.atelier-floral.ro/index.php?option=com_k2&view=itemlist&task=user&id=25511
">anabolic steroids body building
</a>
<a href="http://furbero.com/index.php?option=com_k2&view=itemlist&task=user&id=107388
#">long term effects of anabolic steroids
</a>
risks of anabolic steroids
anabolic steroids for sale
http://www.squeeza.co.za/index.php?option=com_k2&view=itemlist&task=user&id=43872
<a href="http://customlasering.co.uk/index.php?option=com_k2&view=itemlist&task=user&id=27299
">what is anabolic steroids
</a>
<a href="http://xn----8sbemxbcdfwbbc6acgxqc2p.xn--p1ai/index.php?option=com_k2&view=itemlist&task=user&id=55670
#">anabolic steroids before and after
</a>
<br />
<a href="http://hgh.space/">human growth hormone </a> <br />
<a href="http://hghgrowthhormoness.us/">hgh hardware </a> <br />
hgh factor
<a href="http://trenbolonemix.accountant/">trenbolone results </a> <br />
<a href="http://trenbolonemix.us/">trenbolone before and after </a> <br />
injectable trenbolone
<a href="http://hgh.life/">buy hgh </a> <br />
best hgh supplements
<a href="http://hghgrowthhormoness.accountant/">hgh injections </a> <br />
hgh booster
[url=http://hghhormonex.us/]human growth hormone online [/url] <br />
hgh supplements gnc <br />
hgh belly<br />
<a href="http://hghgrowthhormoness.us/">hgh </a> <br />
hgh fragment 176-191
<a href="http://hghhormonex.us/">hgh for men </a> <br />
hgh therapy
[url=http://hgh.life/]hgh buy [/url] <br />
hgh for sale at gnc
<a href="http://hgh.space/">hgh pills </a> <br />
hgh for sale at gnc
<a href="http://hgh.life/">hgh for women </a> <br />
serovital-hgh
[url=http://hghhormonex.accountant/]hgh hormone [/url] <br />
hgh vs steroids <br />
hgh injections for sale<br />
<a href="http://hghgrowthhormoness.accountant/">human growth hormone </a> <br />
hgh gnc
<a href="http://hghhormonex.us/">human growth hormone online </a> <br />
hgh weight loss
[url=http://hgh.life/]human growth hormone [/url] <br />
hgh before and after
<a href="http://hghgrowthhormoness.us/">hgh for men </a> <br />
hgh for sale at gnc
<a href="http://hgh.life/">hgh injections </a> <br />
how to increase hgh
[url=http://hghhormonex.accountant/]hgh hormone [/url] <br />
hgh spray <br />
hgh booster<br />
<a href="http://hghhormonex.accountant/">hgh hormone </a> <br />
hgh benefits
<a href="http://hghgrowthhormoness.accountant/">hgh injections </a> <br />
natural hgh
[url=http://hgh.life/]human growth hormone online [/url] <br />
hgh benefits
<a href="http://hgh.space/">hgh hormone </a> <br />
serovital-hgh reviews
<a href="http://hghhormonex.com/">human growth hormone pills </a> <br />
hgh factor
[url=http://hghhormonex.accountant/]human growth hormone pills [/url] <br />
peyton hgh <br />
hgh injections for sale<br />
<a href="http://hghhormonex.accountant/">hgh for men </a> <br />
serovital-hgh reviews
<a href="http://hgh.life/">hgh for women </a> <br />
hgh benefits
[url=http://hghhormonex.us/]human growth hormone [/url] <br />
hgh before and after
<a href="http://hghhormonex.us/">hgh pills </a> <br />
best hgh supplements
<a href="http://hghgrowthhormoness.us/">hgh </a> <br />
serovital-hgh reviews
[url=http://hghgrowthhormoness.com/]hgh pills [/url] <br />
hgh weight loss <br />
hgh therapy<br />
<a href="http://hghgrowthhormoness.accountant/">hgh for men </a> <br />
hgh reviews
<a href="http://hghgrowthhormoness.com/">hgh cycle </a> <br />
serovital hgh amazon
[url=http://hgh.life/]hgh [/url] <br />
hgh cycle
<a href="http://hghhormonex.accountant/">hgh for men </a> <br />
how to increase hgh
<a href="http://hghhormonex.accountant/">hgh pills </a> <br />
dwayne johnson hgh
[url=http://hghgrowthhormoness.com/]hgh [/url] <br />
how to get hgh <br />
legal hgh<br />
<a href="http://hghgrowthhormoness.us/">hgh buy </a> <br />
best hgh
<a href="http://hghgrowthhormoness.accountant/">hgh cycle </a> <br />
buy hgh
[url=http://hgh.life/]hgh for women [/url] <br />
hgh cycle
<a href="http://hghgrowthhormoness.com/">hgh buy </a> <br />
hgh benefits
<a href="http://hghhormonex.us/">hgh </a> <br />
is hgh legal
[url=http://hghhormonex.com/]human growth hormone [/url] <br />
serovital hgh side effects <br />
is hgh legal<br />
<a href="http://hgh.life/">hgh cycle </a> <br />
serovital hgh side effects
<a href="http://hghgrowthhormoness.com/">hgh buy </a> <br />
where to buy hgh
[url=http://hghgrowthhormoness.com/]hgh [/url] <br />
hgh pro
<a href="http://hghhormonex.us/">human growth hormone online </a> <br />
what does hgh do
<a href="http://hghgrowthhormoness.us/">hgh for men </a> <br />
best hgh supplement
[url=http://hghgrowthhormoness.com/]hgh for men [/url] <br />
serovital-hgh <br />
hgh side effects<br />
<a href="http://hgh.space/">hgh pills </a> <br />
hgh injections for sale
<a href="http://hghgrowthhormoness.us/">hgh </a> <br />
hgh pro
[url=http://hgh.space/]hgh hormone [/url] <br />
hgh before and after
<a href="http://payday1000loansonline.us/#bestcash"> short term loans </a>
<a href="http://payday1000loansonline.us/#loan"> payday loans online </a>
[url=http://payday1000loansonline.us/#online] short term loans [/url]
payday loans no credit check direct lender
<a href="http://payday1000loansonline.us/#loan"> payday advance </a>
<a href="http://payday1000loansonline.us/#loans"> bad credit loans </a>
[url=http://payday1000loansonline.us/#loan] payday loan [/url]
payday loans in georgia
<a href="http://payday1000loansonline.us/#loan"> short term loans </a>
<a href="http://payday1000loansonline.us/#bestcash"> bad credit loans </a>
[url=http://payday1000loansonline.us/#online] payday loans online [/url]
online payday loans tn
<a href="http://payday1000loansonline.us/#loan"> short term loans </a>
<a href="http://payday1000loansonline.us/#loan"> loans online </a>
[url=http://payday1000loansonline.us/#online] loans with bad credit [/url]
carolina payday loans
<a href="http://payday1000loansonline.us/#loans"> payday express </a>
<a href="http://payday1000loansonline.us/#bestcash"> payday loans </a>
[url=http://payday1000loansonline.us/#loans] loans online [/url]
payday loans in dc
<a href="http://payday1000loansonline.us/#loans"> personal loan </a>
<a href="http://payday1000loansonline.us/#loans"> bad credit personal loans </a>
[url=http://payday1000loansonline.us/#loan] quick loans [/url]
same day online payday loans
<a href="http://payday1000loansonline.us/#bestcash"> payday loan </a>
<a href="http://payday1000loansonline.us/#loan"> short term loans </a>
[url=http://payday1000loansonline.us/#loan] payday advance [/url]
online direct lender payday loans
<a href="http://payday1000loansonline.us/#loan"> payday advance </a>
<a href="http://payday1000loansonline.us/#bestcash"> loans with bad credit </a>
[url=http://payday1000loansonline.us/#loan] loans online [/url]
payday loans for bad credit
<a href="http://payday1000loansonline.us/#bestcash"> loans with bad credit </a>
<a href="http://payday1000loansonline.us/#loans"> cash loans </a>
[url=http://payday1000loansonline.us/#online] online loans [/url]
montel williams payday loans
<a href="http://payday1000loansonline.us/#loans"> personal loan </a>
<a href="http://payday1000loansonline.us/#personal"> loans with bad credit </a>
[url=http://payday1000loansonline.us/#loans] payday express [/url]
payday loans direct lender
<a href="http://payday1000loansonline.us/#online"> loans online </a>
<a href="http://payday1000loansonline.us/#personal"> pay day loans </a>
[url=http://payday1000loansonline.us/#personal] loans direct [/url]
loans till payday
<a href="http://payday1000loansonline.us/#bestcash"> cash advance </a>
<a href="http://payday1000loansonline.us/#loan"> online payday loans </a>
[url=http://payday1000loansonline.us/#bestcash] quick loans [/url]
payday loans cincinnati ohio
<a href="http://payday1000loansonline.us/#online"> online loans </a>
<a href="http://payday1000loansonline.us/#bestcash"> payday advance </a>
[url=http://payday1000loansonline.us/#online] payday loans online [/url]
loans payday
<a href="http://payday1000loansonline.us/#loans"> quick loans </a>
<a href="http://payday1000loansonline.us/#online"> pay day loans </a>
[url=http://payday1000loansonline.us/#bestcash] short term loans [/url]
payday loans reno nv
<a href="http://payday1000loansonline.us/#personal"> quick loans </a>
<a href="http://payday1000loansonline.us/#loan"> payday loans </a>
[url=http://payday1000loansonline.us/#loan] cash advance [/url]
payday loans san diego
<a href="http://payday1000loansonline.us/#loan"> loans for people with bad credit </a>
<a href="http://payday1000loansonline.us/#loan"> loans for people with bad credit </a>
[url=http://payday1000loansonline.us/#loan] bad credit loans [/url]
alabama payday loans
<a href="http://payday1000loansonline.us/#personal"> bad credit personal loans </a>
<a href="http://payday1000loansonline.us/#personal"> short term loans </a>
[url=http://payday1000loansonline.us/#personal] payday express [/url]
payday loans el paso tx
<a href="http://payday1000loansonline.us/#loans"> bad credit personal loans </a>
<a href="http://payday1000loansonline.us/#online"> cash advance </a>
[url=http://payday1000loansonline.us/#loan] cash advance [/url]
money tree payday loans
<a href="http://payday1000loansonline.us/#bestcash"> short term loans </a>
<a href="http://payday1000loansonline.us/#loans"> loans for bad credit </a>
[url=http://payday1000loansonline.us/#loan] loans online [/url]
stopping payday loans
<a href="http://payday1000loansonline.us/#online"> loans for bad credit </a>
<a href="http://payday1000loansonline.us/#online"> personal loan </a>
[url=http://payday1000loansonline.us/#personal] online loans [/url]
payday loans san antonio
<a href="http://payday1000loansonline.us/#loan"> bad credit personal loans </a>
<a href="http://payday1000loansonline.us/#online"> payday express </a>
[url=http://payday1000loansonline.us/#bestcash] payday loans [/url]
payday loans ontario
<a href="http://payday1000loansonline.us/#loans"> personal loans </a>
<a href="http://payday1000loansonline.us/#personal"> cash loans </a>
[url=http://payday1000loansonline.us/#online] loans for bad credit [/url]
payday loans utah
<a href="http://payday1000loansonline.us/#loans"> bad credit loans </a>
<a href="http://payday1000loansonline.us/#loans"> payday loan </a>
[url=http://payday1000loansonline.us/#online] personal loan [/url]
online payday loans indiana
<a href="http://payday1000loansonline.us/#bestcash"> personal loans </a>
<a href="http://payday1000loansonline.us/#loans"> payday loan </a>
[url=http://payday1000loansonline.us/#personal] quick loans [/url]
check mate payday loans
<a href="http://payday1000loansonline.us/#bestcash"> online loans </a>
<a href="http://payday1000loansonline.us/#loans"> loans online </a>
[url=http://payday1000loansonline.us/#loan] cash loans [/url]
faxless payday loans direct lenders
<a href="http://payday1000loansonline.us/#online"> online payday loans </a>
<a href="http://payday1000loansonline.us/#loan"> personal loan </a>
[url=http://payday1000loansonline.us/#online] online payday loans [/url]
payday loans in michigan
<a href="http://payday1000loansonline.us/#online"> cash loans </a>
<a href="http://payday1000loansonline.us/#online"> loans direct </a>
[url=http://payday1000loansonline.us/#personal] quick loans [/url]
immediate payday loans
<a href="http://payday1000loansonline.us/#loan"> pay day loans </a>
<a href="http://payday1000loansonline.us/#bestcash"> online payday loans </a>
[url=http://payday1000loansonline.us/#bestcash] cash loans [/url]
loans payday
<a href="http://payday1000loansonline.us/#bestcash"> cash advance </a>
<a href="http://payday1000loansonline.us/#bestcash"> payday advance </a>
[url=http://payday1000loansonline.us/#loans] cash advance [/url]
24 hour payday loans
<a href="http://payday1000loansonline.us/#bestcash"> online payday loans </a>
<a href="http://payday1000loansonline.us/#personal"> loans with bad credit </a>
[url=http://payday1000loansonline.us/#bestcash] loans for bad credit [/url]
payday loans bad credit ok
<a href="http://payday1000loansonline.us/#online"> loans for bad credit </a>
<a href="http://payday1000loansonline.us/#loans"> bad credit loans </a>
[url=http://payday1000loansonline.us/#personal] online loans [/url]
payday loans okc
<a href="http://payday1000loansonline.us/#online"> loans for people with bad credit </a>
<a href="http://payday1000loansonline.us/#personal"> loans online </a>
[url=http://payday1000loansonline.us/#bestcash] quick loans [/url]
need a payday loans
<a href="http://payday1000loansonline.us/#online"> bad credit loans </a>
<a href="http://payday1000loansonline.us/#bestcash"> payday loan </a>
[url=http://payday1000loansonline.us/#bestcash] bad credit personal loans [/url]
payday loans corpus christi
<a href="http://payday1000loansonline.us/#online"> payday loan </a>
<a href="http://payday1000loansonline.us/#personal"> loans online </a>
[url=http://payday1000loansonline.us/#online] short term loans [/url]
payday loans killeen tx
<a href="http://payday1000loansonline.us/#online"> cash loans </a>
<a href="http://payday1000loansonline.us/#loan"> loans direct </a>
[url=http://payday1000loansonline.us/#personal] pay day loans [/url]
no verification payday loans
<a href="http://payday1000loansonline.us/#online"> cash loans </a>
<a href="http://payday1000loansonline.us/#bestcash"> online payday loans </a>
[url=http://payday1000loansonline.us/#online] loans for bad credit [/url]
payday loans tulsa
<a href="http://payday1000loansonline.us/#loans"> cash loans </a>
<a href="http://payday1000loansonline.us/#online"> loans for bad credit </a>
[url=http://payday1000loansonline.us/#loans] payday loan [/url]
guaranteed approved payday loans
<a href="http://payday1000loansonline.us/#loans"> loans for people with bad credit </a>
<a href="http://payday1000loansonline.us/#personal"> loans for people with bad credit </a>
[url=http://payday1000loansonline.us/#loan] loans for bad credit [/url]
payday loans savannah ga
<a href="http://payday1000loansonline.us/#loans"> cash loans </a>
<a href="http://payday1000loansonline.us/#loans"> personal loan </a>
[url=http://payday1000loansonline.us/#loan] personal loans [/url]
payday loans houston
<a href="http://payday1000loansonline.us/#loans"> loans with bad credit </a>
<a href="http://payday1000loansonline.us/#loan"> loans for bad credit </a>
[url=http://payday1000loansonline.us/#loans] online loans [/url]
payday loans mcallen tx
<a href="http://payday1000loansonline.us/#personal"> online loans </a>
<a href="http://payday1000loansonline.us/#online"> payday loan </a>
[url=http://payday1000loansonline.us/#loans] payday advance [/url]
payday loans tyler tx
<a href="http://payday1000loansonline.us/#bestcash"> payday loans online </a>
<a href="http://payday1000loansonline.us/#personal"> online payday loans </a>
[url=http://payday1000loansonline.us/#online] payday loans online [/url]
payday loans rock hill sc
<a href="http://payday1000loansonline.us/#personal"> online loans </a>
<a href="http://payday1000loansonline.us/#loan"> cash loans </a>
[url=http://payday1000loansonline.us/#loan] loans online [/url]
payday loans columbia mo
<a href="http://payday1000loansonline.us/#personal"> payday loan </a>
<a href="http://payday1000loansonline.us/#personal"> personal loan </a>
[url=http://payday1000loansonline.us/#loan] payday loans [/url]
payday loans no checking account required
<a href="http://payday1000loansonline.us/#loans"> bad credit personal loans </a>
<a href="http://payday1000loansonline.us/#loan"> loans online </a>
[url=http://payday1000loansonline.us/#personal] quick loans [/url]
payday loans springfield il
<a href="http://payday1000loansonline.us/#loans"> loans with bad credit </a>
<a href="http://payday1000loansonline.us/#online"> payday advance </a>
[url=http://payday1000loansonline.us/#online] pay day loans [/url]
payday loans fort collins
<a href="http://payday1000loansonline.us/#loan"> personal loan </a>
<a href="http://payday1000loansonline.us/#online"> short term loans </a>
[url=http://payday1000loansonline.us/#loans] bad credit loans [/url]
advance america payday loans
<a href="http://payday1000loansonline.us/#personal"> payday loans </a>
<a href="http://payday1000loansonline.us/#loans"> bad credit loans </a>
[url=http://payday1000loansonline.us/#bestcash] cash loans [/url]
online payday loans in texas
<a href="http://payday1000loansonline.us/#bestcash"> payday loans online </a>
<a href="http://payday1000loansonline.us/#loan"> bad credit personal loans </a>
[url=http://payday1000loansonline.us/#loan] cash advance [/url]
payday loans with installment payments
<a href="http://payday1000loansonline.us/#bestcash"> pay day loans </a>
<a href="http://payday1000loansonline.us/#bestcash"> loans for people with bad credit </a>
[url=http://payday1000loansonline.us/#personal] payday advance [/url]
payday loans phenix city al
<a href="http://payday1000loansonline.us/#online"> payday advance </a>
<a href="http://payday1000loansonline.us/#loan"> bad credit personal loans </a>
[url=http://payday1000loansonline.us/#online] payday loans online [/url]
payday loans without checking account
<a href="http://payday1000loansonline.us/#bestcash"> loans for bad credit </a>
<a href="http://payday1000loansonline.us/#loan"> payday advance </a>
[url=http://payday1000loansonline.us/#bestcash] cash loans [/url]
help with payday loans
<a href="http://payday1000loansonline.us/#loan"> online payday loans </a>
<a href="http://payday1000loansonline.us/#loan"> personal loan </a>
[url=http://payday1000loansonline.us/#personal] payday advance [/url]
payday loans alabama
<a href="http://payday1000loansonline.us/#online"> bad credit personal loans </a>
<a href="http://payday1000loansonline.us/#bestcash"> payday loans online </a>
[url=http://payday1000loansonline.us/#personal] payday express [/url]
alternative to payday loans
<a href="http://payday1000loansonline.us/#loans"> cash advance </a>
<a href="http://payday1000loansonline.us/#online"> loans direct </a>
[url=http://payday1000loansonline.us/#loan] short term loans [/url]
payday loans delaware
<a href="http://payday1000loansonline.us/#loans"> quick loans </a>
<a href="http://payday1000loansonline.us/#personal"> cash advance </a>
[url=http://payday1000loansonline.us/#loan] bad credit loans [/url]
payday loans indianapolis
<a href="http://payday1000loansonline.us/#loans"> personal loan </a>
<a href="http://payday1000loansonline.us/#bestcash"> payday loan </a>
[url=http://payday1000loansonline.us/#loans] cash loans [/url]
payday loans stockton ca
<a href="http://payday1000loansonline.us/#personal"> quick loans </a>
<a href="http://payday1000loansonline.us/#online"> online loans </a>
[url=http://payday1000loansonline.us/#loans] loans online [/url]
real online payday loans
<a href="http://payday1000loansonline.us/#loan"> cash advance </a>
<a href="http://payday1000loansonline.us/#loan"> payday advance </a>
[url=http://payday1000loansonline.us/#loan] loans with bad credit [/url]
payday loans in las vegas
<a href="http://payday1000loansonline.us/#loan"> pay day loans </a>
<a href="http://payday1000loansonline.us/#personal"> payday loans </a>
[url=http://payday1000loansonline.us/#loans] cash advance [/url]
green circle payday loans
<a href="http://payday1000loansonline.us/#personal"> online loans </a>
<a href="http://payday1000loansonline.us/#loans"> loans for people with bad credit </a>
[url=http://payday1000loansonline.us/#loans] bad credit personal loans [/url]
nevada payday loans
<a href="http://payday1000loansonline.us/#bestcash"> loans online </a>
<a href="http://payday1000loansonline.us/#online"> bad credit loans </a>
[url=http://payday1000loansonline.us/#personal] short term loans [/url]
payday loans san antonio
<a href="http://payday1000loansonline.us/#loans"> payday advance </a>
<a href="http://payday1000loansonline.us/#loan"> bad credit personal loans </a>
[url=http://payday1000loansonline.us/#personal] short term loans [/url]
1 hour payday loans no credit check
<a href="http://payday1000loansonline.us/#personal"> cash advance </a>
<a href="http://payday1000loansonline.us/#loan"> quick loans </a>
[url=http://payday1000loansonline.us/#loans] loans for people with bad credit [/url]
instant payday loans online
<a href="http://payday1000loansonline.us/#online"> loans online </a>
<a href="http://payday1000loansonline.us/#personal"> personal loan </a>
[url=http://payday1000loansonline.us/#online] cash loans [/url]
online payday loans for bad credit
<a href="http://payday1000loansonline.us/#online"> payday loan </a>
<a href="http://payday1000loansonline.us/#loans"> loans online </a>
[url=http://payday1000loansonline.us/#personal] online payday loans [/url]
payday loans hawaii
<a href="http://payday1000loansonline.us/#personal"> loans online </a>
<a href="http://payday1000loansonline.us/#loans"> cash advance </a>
[url=http://payday1000loansonline.us/#loan] cash loans [/url]
tribal payday loans no credit check
<a href="http://payday1000loansonline.us/#loans"> online loans </a>
<a href="http://payday1000loansonline.us/#loan"> cash advance </a>
[url=http://payday1000loansonline.us/#loan] payday loans [/url]
rise payday loans
<a href="http://payday1000loansonline.us/#online"> loans for bad credit </a>
<a href="http://payday1000loansonline.us/#online"> cash loans </a>
[url=http://payday1000loansonline.us/#online] quick loans [/url]
payday loans springfield il
<a href="http://payday1000loansonline.us/#online"> loans for bad credit </a>
<a href="http://payday1000loansonline.us/#loan"> cash advance </a>
[url=http://payday1000loansonline.us/#loans] loans for bad credit [/url]
online payday loans louisiana
<a href="http://payday1000loansonline.us/#bestcash"> bad credit personal loans </a>
<a href="http://payday1000loansonline.us/#online"> pay day loans </a>
[url=http://payday1000loansonline.us/#online] payday loans online [/url]
cash payday loans
<a href="http://payday1000loansonline.us/#loans"> payday express </a>
<a href="http://payday1000loansonline.us/#loans"> loans for bad credit </a>
[url=http://payday1000loansonline.us/#loans] bad credit loans [/url]
payday loans for bad credit direct lenders
<a href="http://payday1000loansonline.us/#online"> bad credit personal loans </a>
<a href="http://payday1000loansonline.us/#personal"> short term loans </a>
[url=http://payday1000loansonline.us/#bestcash] payday loans [/url]
montel williams payday loans
<a href="http://payday1000loansonline.us/#loans"> payday advance </a>
<a href="http://payday1000loansonline.us/#online"> loans for people with bad credit </a>
[url=http://payday1000loansonline.us/#bestcash] loans online [/url]
online payday loans colorado
<a href="http://payday1000loansonline.us/#loans"> quick loans </a>
<a href="http://payday1000loansonline.us/#personal"> bad credit loans </a>
[url=http://payday1000loansonline.us/#online] loans for people with bad credit [/url]
payday loans houston
<a href="http://payday1000loansonline.us/#personal"> personal loans </a>
<a href="http://payday1000loansonline.us/#loans"> payday loan </a>
[url=http://payday1000loansonline.us/#loans] bad credit loans [/url]
payday loans las vegas
<a href="http://payday1000loansonline.us/#online"> loans direct </a>
<a href="http://payday1000loansonline.us/#loans"> loans direct </a>
[url=http://payday1000loansonline.us/#loans] personal loans [/url]
payday loans indianapolis
<a href="http://payday1000loansonline.us/#loans"> loans for people with bad credit </a>
<a href="http://payday1000loansonline.us/#loan"> online payday loans </a>
[url=http://payday1000loansonline.us/#personal] loans direct [/url]
rise payday loans
<a href="http://payday1000loansonline.us/#loan"> pay day loans </a>
<a href="http://payday1000loansonline.us/#bestcash"> cash advance </a>
[url=http://payday1000loansonline.us/#loan] loans for people with bad credit [/url]
payday loans in st louis mo
<a href="http://payday1000loansonline.us/#personal"> online loans </a>
<a href="http://payday1000loansonline.us/#online"> bad credit loans </a>
[url=http://payday1000loansonline.us/#loan] online payday loans [/url]
checkmate payday loans
<a href="http://payday1000loansonline.us/#online"> payday express </a>
<a href="http://payday1000loansonline.us/#online"> loans direct </a>
[url=http://payday1000loansonline.us/#bestcash] cash advance [/url]
online direct payday loans
<a href="http://payday1000loansonline.us/#personal"> loans for bad credit </a>
<a href="http://payday1000loansonline.us/#personal"> pay day loans </a>
[url=http://payday1000loansonline.us/#loan] bad credit loans [/url]
military payday loans
<a href="http://payday1000loansonline.us/#online"> cash loans </a>
<a href="http://payday1000loansonline.us/#online"> loans for bad credit </a>
[url=http://payday1000loansonline.us/#bestcash] payday express [/url]
wal mart payday loans
<a href="http://payday1000loansonline.us/#bestcash"> loans with bad credit </a>
<a href="http://payday1000loansonline.us/#bestcash"> bad credit loans </a>
[url=http://payday1000loansonline.us/#online] pay day loans [/url]
payday loans dothan al
<a href="http://payday1000loansonline.us/#loan"> short term loans </a>
<a href="http://payday1000loansonline.us/#bestcash"> loans direct </a>
[url=http://payday1000loansonline.us/#bestcash] payday loan [/url]
legitimate online payday loans
<a href="http://payday1000loansonline.us/#loan"> personal loan </a>
<a href="http://payday1000loansonline.us/#online"> cash advance </a>
[url=http://payday1000loansonline.us/#bestcash] online payday loans [/url]
payday loans for bad credit guaranteed approval
<a href="http://payday1000loansonline.us/#personal"> payday loans </a>
<a href="http://payday1000loansonline.us/#loan"> short term loans </a>
[url=http://payday1000loansonline.us/#loans] payday loans online [/url]
rise payday loans
<a href="http://payday1000loansonline.us/#loan"> loans direct </a>
<a href="http://payday1000loansonline.us/#online"> short term loans </a>
[url=http://payday1000loansonline.us/#loans] online loans [/url]
legit online payday loans
<a href="http://payday1000loansonline.us/#loans"> payday advance </a>
<a href="http://payday1000loansonline.us/#loans"> loans direct </a>
[url=http://payday1000loansonline.us/#online] loans online [/url]
payday loans in ny
<a href="http://payday1000loans3000online.com/#online"> pay day loans </a>
<a href="http://payday1000loans3000online.com/#loans"> loans online </a>
[url=http://payday1000loans3000online.com/#loans] cash advance [/url]
payday loans in alabama
<a href="http://payday1000loans3000online.com/#loans"> personal loan </a>
rapid payday loans
<a href="http://payday1000loans3000online.com/#loan"> loans direct </a>
texas title and payday loans
[url=http://payday1000loans3000online.com/#online] loans online [/url]
online payday loans tennessee
<a href="http://payday1000loans3000online.com/#personal"> short term loans </a>
payday loans interest rate
<a href="http://payday1000loans3000online.com/#bestcash"> loans for people with bad credit </a>
payday loans phoenix az
[url=http://payday1000loans3000online.com/#online] loans direct [/url]
payday loans lenders
<a href="http://payday1000loans3000online.com/#loans"> loans for bad credit </a>
payday loans in nj
<a href="http://payday1000loans3000online.com/#online"> online payday loans </a>
instant same day payday loans online
[url=http://payday1000loans3000online.com/#online] loans for people with bad credit [/url]
faxless payday loans direct lenders
<a href="http://payday1000loans3000online.com/#loans"> payday loan </a>
payday loans kcmo
<a href="http://payday1000loans3000online.com/#online"> quick loans </a>
how to get out of payday loans
[url=http://payday1000loans3000online.com/#online] online payday loans [/url]
fast payday loans inc
<a href="http://payday1000loans3000online.com/#personal"> personal loans </a>
payday loans el cajon
<a href="http://payday1000loans3000online.com/#loan"> loans with bad credit </a>
payday loans akron ohio
[url=http://payday1000loans3000online.com/#online] loans for bad credit [/url]
money tree payday loans
<a href="http://payday1000loans3000online.com/#bestcash"> loans with bad credit </a>
payday loans in new orleans
<a href="http://payday1000loans3000online.com/#bestcash"> pay day loans </a>
legitimate online payday loans
[url=http://payday1000loans3000online.com/#bestcash] payday loans [/url]
payday loans el paso tx
<a href="http://payday1000loans3000online.com/#online"> payday express </a>
too many payday loans
<a href="http://payday1000loans3000online.com/#bestcash"> cash loans </a>
payday loans no credit check near me
[url=http://payday1000loans3000online.com/#online] cash advance [/url]
texas car title and payday loans services
<a href="http://payday1000loans3000online.com/#loans"> cash advance </a>
tribal payday loans
<a href="http://payday1000loans3000online.com/#loan"> pay day loans </a>
delaware payday loans
[url=http://payday1000loans3000online.com/#bestcash] loans for bad credit [/url]
real online payday loans
<a href="http://payday1000loans3000online.com/#online"> payday loans online </a>
payday loans los angeles
<a href="http://payday1000loans3000online.com/#loans"> payday loans </a>
green payday loans
[url=http://payday1000loans3000online.com/#loans] loans for bad credit [/url]
bad credit payday loans guaranteed approval
<a href="http://payday1000loans3000online.com/#online"> payday advance </a>
payday loans now
<a href="http://payday1000loans3000online.com/#online"> bad credit personal loans </a>
no bank account payday loans
[url=http://payday1000loans3000online.com/#online] payday loans online [/url]
payday loans mcallen tx
<a href="http://payday1000loans3000online.com/#personal"> online loans </a>
payday loans delaware
<a href="http://payday1000loans3000online.com/#online"> payday advance </a>
online payday loans texas
[url=http://payday1000loans3000online.com/#personal] cash advance [/url]
no hassel payday loans
<a href="http://payday1000loans3000online.com/#loan"> short term loans </a>
payday loans in memphis tn
<a href="http://payday1000loans3000online.com/#loans"> loans online </a>
easy payday loans online
[url=http://payday1000loans3000online.com/#loans] quick loans [/url]
get out of payday loans
<a href="http://payday1000loans3000online.com/#loans"> short term loans </a>
best payday loans direct lender
<a href="http://payday1000loans3000online.com/#bestcash"> loans for bad credit </a>
online payday loans no credit check
[url=http://payday1000loans3000online.com/#loans] payday loan [/url]
direct payday loans online
<a href="http://payday1000loans3000online.com/#bestcash"> short term loans </a>
payday loans no credit check direct lender
<a href="http://payday1000loans3000online.com/#online"> quick loans </a>
sameday payday loans online
[url=http://payday1000loans3000online.com/#loans] quick loans [/url]
how do payday loans work
<a href="http://payday1000loans3000online.com/#bestcash"> payday loan </a>
online direct payday loans
<a href="http://payday1000loans3000online.com/#personal"> cash advance </a>
payday loans direct lender only
[url=http://payday1000loans3000online.com/#online] cash loans [/url]
direct online payday loans
<a href="http://payday1000loans3000online.com/#loan"> personal loan </a>
payday loans interest rate
<a href="http://payday1000loans3000online.com/#personal"> payday loan </a>
payday loans no checking account needed
[url=http://payday1000loans3000online.com/#bestcash] payday express [/url]
no credit payday loans
<a href="http://payday1000loans3000online.com/#loan"> cash loans </a>
las vegas payday loans
<a href="http://payday1000loans3000online.com/#loan"> payday advance </a>
payday loans without checking account requirements
[url=http://payday1000loans3000online.com/#bestcash] online loans [/url]
direct lender payday loans
<a href="http://payday1000loans3000online.com/#personal"> payday express </a>
payday loans colorado springs
<a href="http://payday1000loans3000online.com/#loans"> online loans </a>
payday loans lafayette la
[url=http://payday1000loans3000online.com/#loans] payday loans [/url]
payday loans new york
<a href="http://payday1000loans3000online.com/#personal"> quick loans </a>
faxless payday loans
<a href="http://payday1000loans3000online.com/#online"> loans for people with bad credit </a>
payday loans without a bank account
[url=http://payday1000loans3000online.com/#loans] loans online [/url]
payday loans greeley co
<a href="http://payday1000loans3000online.com/#personal"> bad credit loans </a>
money mart payday loans
<a href="http://payday1000loans3000online.com/#online"> pay day loans </a>
legitimate payday loans
[url=http://payday1000loans3000online.com/#personal] bad credit personal loans [/url]
payday loans oakland ca
<a href="http://payday1000loans3000online.com/#loan"> cash loans </a>
payday loans el cajon
<a href="http://payday1000loans3000online.com/#personal"> payday advance </a>
guaranteed payday loans direct lenders
[url=http://payday1000loans3000online.com/#loans] online loans [/url]
payday loans portland or
<a href="http://payday1000loans3000online.com/#loans"> online loans </a>
payday loans cedar rapids
<a href="http://payday1000loans3000online.com/#loans"> payday loans </a>
real online payday loans
[url=http://payday1000loans3000online.com/#online] online payday loans [/url]
direct lender payday loans online
<a href="http://payday1000loans3000online.com/#online"> payday loan </a>
payday loans in maryland
<a href="http://payday1000loans3000online.com/#loan"> loans with bad credit </a>
alternative to payday loans
[url=http://payday1000loans3000online.com/#bestcash] loans for bad credit [/url]
payday cash advance loans
<a href="http://payday1000loans3000online.com/#online"> online payday loans </a>
payday loans louisville ky
<a href="http://payday1000loans3000online.com/#bestcash"> online loans </a>
carolina payday loans
[url=http://payday1000loans3000online.com/#bestcash] bad credit personal loans [/url]
tribal payday loans
<a href="http://payday1000loans3000online.com/#personal"> payday loans </a>
payday loans in alabama
<a href="http://payday1000loans3000online.com/#loan"> online loans </a>
payday loans no checking account or savings account
[url=http://payday1000loans3000online.com/#loan] personal loan [/url]
payday loans in montgomery al
<a href="http://payday1000loans3000online.com/#loan"> online loans </a>
loans payday
<a href="http://payday1000loans3000online.com/#online"> bad credit loans </a>
payday online loans
[url=http://payday1000loans3000online.com/#loans] personal loan [/url]
payday advance loans
<a href="http://payday1000loans3000online.com/#bestcash"> online payday loans </a>
get out of payday loans
<a href="http://payday1000loans3000online.com/#personal"> personal loans </a>
what is payday loans
[url=http://payday1000loans3000online.com/#bestcash] loans for bad credit [/url]
online payday loans ohio
<a href="http://payday1000loans3000online.com/#online"> short term loans </a>
payday loans independence mo
<a href="http://payday1000loans3000online.com/#online"> loans for bad credit </a>
small payday loans
[url=http://payday1000loans3000online.com/#online] loans with bad credit [/url]
payday loans augusta ga
<a href="http://payday1000loans3000online.com/#online"> loans direct </a>
money tree payday loans
<a href="http://payday1000loans3000online.com/#online"> quick loans </a>
legitimate online payday loans
[url=http://payday1000loans3000online.com/#personal] cash loans [/url]
payday loans in las vegas
<a href="http://payday1000loans3000online.com/#loans"> payday advance </a>
1 hour payday loans
<a href="http://payday1000loans3000online.com/#loan"> bad credit personal loans </a>
payday loans pa
[url=http://payday1000loans3000online.com/#online] pay day loans [/url]
payday loans sherman tx
<a href="http://payday1000loans3000online.com/#loan"> online loans </a>
payday loans fresno
<a href="http://payday1000loans3000online.com/#loans"> personal loan </a>
payday loans in ga
[url=http://payday1000loans3000online.com/#bestcash] online loans [/url]
payday loans kansas city
<a href="http://payday1000loans3000online.com/#bestcash"> cash loans </a>
payday loans lawrence ks
<a href="http://payday1000loans3000online.com/#personal"> payday loans </a>
payday loans huntsville al
[url=http://payday1000loans3000online.com/#loan] payday loans online [/url]
easy payday loans
<a href="http://payday1000loans3000online.com/#online"> payday express </a>
direct lenders payday loans
<a href="http://payday1000loans3000online.com/#personal"> payday loans </a>
payday loans phoenix az
[url=http://payday1000loans3000online.com/#loans] payday advance [/url]
legitimate payday loans
<a href="http://payday1000loans3000online.com/#online"> quick loans </a>
personal loans for bad credit not payday loans
<a href="http://payday1000loans3000online.com/#loan"> loans for bad credit </a>
low interest payday loans
[url=http://payday1000loans3000online.com/#loan] payday express [/url]
low interest payday loans
<a href="http://payday1000loans3000online.com/#loan"> payday advance </a>
ace check cashing payday loans
<a href="http://payday1000loans3000online.com/#loans"> bad credit loans </a>
payday loans hattiesburg ms
[url=http://payday1000loans3000online.com/#loan] loans for people with bad credit [/url]
payday loans in columbus ohio
<a href="http://payday1000loans3000online.com/#personal"> bad credit loans </a>
alternative to payday loans
<a href="http://payday1000loans3000online.com/#loan"> payday loan </a>
payday loans in memphis
[url=http://payday1000loans3000online.com/#bestcash] pay day loans [/url]
payday loans amarillo tx
<a href="http://payday1000loans3000online.com/#bestcash"> payday loan </a>
payday loans pa
<a href="http://payday1000loans3000online.com/#loans"> bad credit loans </a>
payday loans akron ohio
[url=http://payday1000loans3000online.com/#online] cash advance [/url]
payday loans pueblo co
<a href="http://payday1000loans3000online.com/#personal"> payday loans online </a>
delaware payday loans
<a href="http://payday1000loans3000online.com/#personal"> payday loan </a>
payday loans without a bank account
[url=http://payday1000loans3000online.com/#bestcash] loans for people with bad credit [/url]
payday loans huntsville al
<a href="http://payday1000loans3000online.com/#personal"> payday loan </a>
guaranteed payday loans no teletrack
<a href="http://payday1000loans3000online.com/#bestcash"> loans direct </a>
payday loans online same day deposit
[url=http://payday1000loans3000online.com/#online] payday loan [/url]
top payday loans
<a href="http://payday1000loans3000online.com/#bestcash"> payday advance </a>
internet payday loans
<a href="http://payday1000loans3000online.com/#personal"> pay day loans </a>
payday loans toledo
[url=http://payday1000loans3000online.com/#loans] payday advance [/url]
payday loans montgomery al
<a href="http://payday1000loans3000online.com/#online"> payday loans online </a>
payday loans in philadelphia
<a href="http://payday1000loans3000online.com/#online"> payday express </a>
payday loans salt lake city
[url=http://payday1000loans3000online.com/#loans] cash loans [/url]
online payday loans tennessee
<a href="http://payday1000loans3000online.com/#loan"> loans for people with bad credit </a>
payday loans toledo ohio
<a href="http://payday1000loans3000online.com/#personal"> bad credit personal loans </a>
fast cash payday loans
[url=http://payday1000loans3000online.com/#bestcash] personal loans [/url]
payday loans clarksville tn
<a href="http://payday1000loans3000online.com/#bestcash"> loans for people with bad credit </a>
payday loans colorado springs
<a href="http://payday1000loans3000online.com/#loans"> payday loan </a>
direct lending payday loans
[url=http://payday1000loans3000online.com/#personal] payday loans online [/url]
online payday loans bad credit
<a href="http://payday1000loans3000online.com/#personal"> payday advance </a>
next payday loans
<a href="http://payday1000loans3000online.com/#personal"> loans with bad credit </a>
payday loans ga
[url=http://payday1000loans3000online.com/#online] payday loans online [/url]
payday loans direct lender no teletrack
<a href="http://payday1000loans3000online.com/#loan"> personal loans </a>
online payday loans direct lenders only no credit check
<a href="http://payday1000loans3000online.com/#bestcash"> loans for bad credit </a>
legitimate payday loans online no credit check
[url=http://payday1000loans3000online.com/#loans] loans online [/url]
fast payday loans online
<a href="http://payday1000loans3000online.com/#online"> online loans </a>
real online payday loans
<a href="http://payday1000loans3000online.com/#bestcash"> loans for bad credit </a>
payday loans okc
[url=http://payday1000loans3000online.com/#online] bad credit personal loans [/url]
quick cash payday loans
<a href="http://payday1000loans3000online.com/#bestcash"> loans with bad credit </a>
payday loans anchorage
<a href="http://payday1000loans3000online.com/#loan"> bad credit loans </a>
payday loans ogden utah
[url=http://payday1000loans3000online.com/#personal] payday loans online [/url]
stop payday loans
<a href="http://payday1000loans3000online.com/#personal"> online loans </a>
no teletrack payday loans direct lenders 100 approval
<a href="http://payday1000loans3000online.com/#loans"> bad credit personal loans </a>
military payday loans
[url=http://payday1000loans3000online.com/#loans] payday loan [/url]
payday loans no credit checks
<a href="http://payday1000loans3000online.com/#bestcash"> payday express </a>
ace payday loans requirements
<a href="http://payday1000loans3000online.com/#loans"> payday express </a>
how do payday loans work
[url=http://payday1000loans3000online.com/#loan] cash loans [/url]
cardinal management payday loans
<a href="http://payday1000loans3000online.com/#online"> payday loans </a>
payday loans gainesville fl
<a href="http://payday1000loans3000online.com/#bestcash"> pay day loans </a>
fast payday loans
[url=http://payday1000loans3000online.com/#personal] personal loan [/url]
payday loans raleigh nc
<a href="http://payday1000loans3000online.com/#bestcash"> payday express </a>
payday loans tyler tx
<a href="http://payday1000loans3000online.com/#loans"> payday loans online </a>
personal loans for poor credit not payday loans
[url=http://payday1000loans3000online.com/#online] cash loans [/url]
payday loans with debit card
<a href="http://payday1000loans3000online.com/#loan"> quick loans </a>
payday loans nashville tn
<a href="http://payday1000loans3000online.com/#loans"> loans for bad credit </a>
direct lenders payday loans
[url=http://payday1000loans3000online.com/#bestcash] personal loans [/url]
payday loans waco tx
<a href="http://payday1000loans3000online.com/#loans"> short term loans </a>
meta bank payday loans
<a href="http://payday1000loans3000online.com/#loan"> payday express </a>
payday loans bad credit
[url=http://payday1000loans3000online.com/#online] loans online [/url]
payday loans in my area
<a href="http://payday1000loans3000online.com/#loans"> payday express </a>
payday loans in memphis
<a href="http://payday1000loans3000online.com/#loans"> quick loans </a>
payday loans without checking account
[url=http://payday1000loans3000online.com/#bestcash] bad credit personal loans [/url]
payday loans in md
<a href="http://payday1000loans3000online.com/#personal"> loans direct </a>
payday loans kansas city mo
<a href="http://payday1000loans3000online.com/#online"> cash loans </a>
payday loans in md
[url=http://payday1000loans3000online.com/#loan] short term loans [/url]
payday loans deposited on prepaid debit card
<a href="http://payday1000loans3000online.com/#online"> payday advance </a>
payday loans roanoke va
<a href="http://payday1000loans3000online.com/#loan"> personal loans </a>
pls payday loans
[url=http://payday1000loans3000online.com/#bestcash] loans for people with bad credit [/url]
payday loans seattle
<a href="http://payday1000loans3000online.com/#bestcash"> cash loans </a>
ace payday loans requirements
<a href="http://payday1000loans3000online.com/#loans"> loans for people with bad credit </a>
payday loans in maryland
[url=http://payday1000loans3000online.com/#online] loans for people with bad credit [/url]
payday loans near me no bank account
<a href="http://payday1000loans3000online.com/#online"> payday loan </a>
payday loans phoenix az
<a href="http://payday1000loans3000online.com/#online"> cash loans </a>
online payday loans direct lender
[url=http://payday1000loans3000online.com/#bestcash] loans online [/url]
fast auto and payday loans inc
<a href="http://payday1000loans3000online.com/#loan"> payday advance </a>
payday loans no credit checks
<a href="http://payday1000loans3000online.com/#loans"> payday advance </a>
payday loans with debit card
[url=http://payday1000loans3000online.com/#bestcash] short term loans [/url]
nevada payday loans
<a href="http://payday1000loans3000online.com/#bestcash"> personal loans </a>
payday loans columbus ga
<a href="http://payday1000loans3000online.com/#loans"> short term loans </a>
payday loans in cleveland ohio
[url=http://payday1000loans3000online.com/#online] loans online [/url]
payday loans jackson ms
<a href="http://payday1000loans3000online.com/#loans"> online payday loans </a>
direct lender online payday loans
<a href="http://payday1000loans3000online.com/#online"> personal loan </a>
payday loans with no checking account required
[url=http://payday1000loans3000online.com/#personal] bad credit loans [/url]
no credit check payday loans
<a href="http://payday1000loans3000online.com/#personal"> loans direct </a>
longterm payday loans
<a href="http://payday1000loans3000online.com/#personal"> cash advance </a>
payday loans columbus ga
[url=http://payday1000loans3000online.com/#bestcash] quick loans [/url]
instant online payday loans
<a href="http://payday1000loans3000online.com/#loan"> online loans </a>
rapid payday loans
<a href="http://payday1000loans3000online.com/#bestcash"> payday loans online </a>
ez pawn payday loans
[url=http://payday1000loans3000online.com/#online] online payday loans [/url]
payday loans grand junction
<a href="http://payday1000loans3000online.com/#online"> payday express </a>
direct payday loans
<a href="http://payday1000loans3000online.com/#loan"> payday loan </a>
payday loans pittsburgh
[url=http://payday1000loans3000online.com/#personal] bad credit personal loans [/url]
weekend payday loans
<a href="http://payday1000loans3000online.com/#loans"> short term loans </a>
payday loans cleveland ohio
<a href="http://payday1000loans3000online.com/#bestcash"> payday loans online </a>
no credit check payday loans direct lenders
[url=http://payday1000loans3000online.com/#bestcash] pay day loans [/url]
payday loans online no credit check
<a href="http://payday1000loans3000online.com/#bestcash"> payday loan </a>
payday loans australia
<a href="http://payday1000loans3000online.com/#personal"> cash loans </a>
1 hour payday loans no credit check
[url=http://payday1000loans3000online.com/#loans] payday advance [/url]
bad credit installment loans not payday loans
<a href="http://payday1000loans3000online.com/#personal"> cash loans </a>
guaranteed payday loans no teletrack
<a href="http://payday1000loans3000online.com/#loans"> payday loans online </a>
payday loans san antonio
[url=http://payday1000loans3000online.com/#loans] personal loans [/url]
ace cash express payday loans
<a href="http://payday1000loans3000online.com/#loans"> cash advance </a>
payday loans gulfport ms
<a href="http://payday1000loans3000online.com/#personal"> loans for bad credit </a>
tribal payday loans direct lenders
[url=http://payday1000loans3000online.com/#bestcash] online payday loans [/url]
payday loans huntsville al
<a href="http://payday1000loans3000online.com/#personal"> short term loans </a>
payday loans milwaukee wi
<a href="http://payday1000loans3000online.com/#loans"> loans for people with bad credit </a>
real online payday loans
[url=http://payday1000loans3000online.com/#personal] bad credit personal loans [/url]
payday loans aurora co
<a href="http://payday1000loans3000online.com/#online"> short term loans </a>
payday loans lenders
<a href="http://payday1000loans3000online.com/#personal"> loans direct </a>
payday loans tucson
[url=http://payday1000loans3000online.com/#personal] personal loan [/url]
low interest payday loans
<a href="http://payday1000loans3000online.com/#online"> loans direct </a>
payday advance loans
<a href="http://payday1000loans3000online.com/#bestcash"> loans for bad credit </a>
same day online payday loans
[url=http://payday1000loans3000online.com/#loan] cash advance [/url]
payday loans kansas city
<a href="http://payday1000loans3000online.com/#loan"> payday loans online </a>
castle payday loans
<a href="http://payday1000loans3000online.com/#online"> loans direct </a>
bad credit personal loans not payday loans
[url=http://payday1000loans3000online.com/#bestcash] bad credit personal loans [/url]
online payday loans no credit check
<a href="http://payday1000loans3000online.com/#loan"> loans for bad credit </a>
payday online loans
<a href="http://payday1000loans3000online.com/#bestcash"> online payday loans </a>
payday loans texas
[url=http://payday1000loans3000online.com/#loan] bad credit personal loans [/url]
payday loans dallas
<a href="http://payday1000loans3000online.com/#personal"> payday express </a>
payday loans california
<a href="http://payday1000loans3000online.com/#online"> loans for bad credit </a>
payday loans baton rouge
[url=http://payday1000loans3000online.com/#bestcash] personal loans [/url]
payday loans kansas city
<a href="http://payday1000loans3000online.com/#loan"> online loans </a>
rapid payday loans
<a href="http://payday1000loans3000online.com/#bestcash"> payday express </a>
texas payday loans
[url=http://payday1000loans3000online.com/#loan] loans for people with bad credit [/url]
payday loans lawrence ks
<a href="http://payday1000loans3000online.com/#online"> cash advance </a>
nevada payday loans
<a href="http://payday1000loans3000online.com/#loans"> short term loans </a>
payday loans with bad credit
[url=http://payday1000loans3000online.com/#online] payday advance [/url]
next payday loans
<a href="http://payday1000loans3000online.com/#online"> loans for bad credit </a>
online payday loans texas
<a href="http://payday1000loans3000online.com/#personal"> loans for bad credit </a>
payday loans buffalo ny
[url=http://payday1000loans3000online.com/#online] online loans [/url]
payday loans in california
<a href="http://payday1000loans3000online.com/#personal"> pay day loans </a>
payday installment loans
<a href="http://payday1000loans3000online.com/#personal"> quick loans </a>
bad credit payday loans
[url=http://payday1000loans3000online.com/#personal] cash advance [/url]
payday loans spokane
<a href="http://payday1000loans3000online.com/#online"> pay day loans </a>
payday loans columbia sc
<a href="http://payday1000loans3000online.com/#loans"> payday loan </a>
payday loans no credit check near me
[url=http://payday1000loans3000online.com/#personal] quick loans [/url]
ace payday loans
<a href="http://payday1000loans3000online.com/#loan"> payday express </a>
payday loans phoenix az
<a href="http://payday1000loans3000online.com/#bestcash"> loans with bad credit </a>
payday loans deposited on prepaid debit card
[url=http://payday1000loans3000online.com/#loans] loans for bad credit [/url]
instant approval payday loans
<a href="http://payday1000loans3000online.com/#bestcash"> personal loans </a>
payday loans augusta ga
<a href="http://payday1000loans3000online.com/#online"> personal loans </a>
payday loans in nashville tn
[url=http://payday1000loans3000online.com/#loans] payday express [/url]
payday loans online same day deposit
<a href="http://payday1000loans3000online.com/#bestcash"> payday loans online </a>
online payday loans colorado
<a href="http://payday1000loans3000online.com/#bestcash"> payday loan </a>
payday loans in memphis tn
[url=http://payday1000loans3000online.com/#bestcash] loans with bad credit [/url]
immediate payday loans
<a href="http://payday1000loans3000online.com/#personal"> payday loans </a>
same day payday loans no credit check
<a href="http://payday1000loans3000online.com/#bestcash"> loans direct </a>
payday loans modesto ca
[url=http://payday1000loans3000online.com/#online] payday advance [/url]
payday loans austin tx
<a href="http://payday1000loans3000online.com/#loan"> loans online </a>
payday loans denver
<a href="http://payday1000loans3000online.com/#personal"> payday express </a>
payday loans anchorage
[url=http://payday1000loans3000online.com/#personal] loans for bad credit [/url]
short term payday loans
<a href="http://payday1000loans3000online.com/#online"> loans for people with bad credit </a>
payday loans cleveland ohio
<a href="http://payday1000loans3000online.com/#online"> bad credit personal loans </a>
payday loans in arlington tx
[url=http://payday1000loans3000online.com/#bestcash] online loans [/url]
payday loans racine wi
<a href="http://payday1000loans3000online.com/#loans"> quick loans </a>
guaranteed payday loans
<a href="http://payday1000loans3000online.com/#online"> bad credit loans </a>
payday loans indiana
[url=http://payday1000loans3000online.com/#loan] quick loans [/url]
meta bank payday loans
<a href="http://payday1000loans3000online.com/#online"> cash loans </a>
payday loans in ri
<a href="http://payday1000loans3000online.com/#loans"> quick loans </a>
payday loans pueblo co
[url=http://payday1000loans3000online.com/#loans] personal loan [/url]
payday loans aurora
<a href="http://payday1000loans3000online.com/#loan"> personal loans </a>
payday loans amarillo tx
<a href="http://payday1000loans3000online.com/#bestcash"> quick loans </a>
payday loans with debit card only
[url=http://payday1000loans3000online.com/#bestcash] loans direct [/url]
payday loans spartanburg sc
<a href="http://payday1000loans3000online.com/#personal"> cash loans </a>
instant same day payday loans online
<a href="http://payday1000loans3000online.com/#loans"> payday express </a>
payday loans appleton wi
[url=http://payday1000loans3000online.com/#loan] loans with bad credit [/url]
payday loans in ri
<a href="http://payday1000loans3000online.com/#bestcash"> payday loans online </a>
payday loans oregon
<a href="http://payday1000loans3000online.com/#loans"> bad credit loans </a>
payday loans without credit check
[url=http://payday1000loans3000online.com/#online] payday loan [/url]
payday loans colorado
<a href="http://payday1000loans3000online.com/#loan"> payday loan </a>
payday loans buffalo ny
<a href="http://payday1000loans3000online.com/#online"> payday express </a>
direct payday loans online
[url=http://payday1000loans3000online.com/#bestcash] payday advance [/url]
payday loans with no checking account required
<a href="http://payday1000loans3000online.com/#loan"> payday advance </a>
payday loans ogden utah
<a href="http://payday1000loans3000online.com/#personal"> cash loans </a>
payday loans bad credit ok
[url=http://payday1000loans3000online.com/#bestcash] loans for bad credit [/url]
online payday loans bad credit
<a href="http://payday1000loans3000online.com/#online"> bad credit loans </a>
legit payday loans
<a href="http://payday1000loans3000online.com/#loan"> online payday loans </a>
payday loans houston
[url=http://payday1000loans3000online.com/#bestcash] loans for bad credit [/url]
payday loans independence mo
<a href="http://payday1000loans3000online.com/#loans"> payday loan </a>
payday loans interest rates
<a href="http://payday1000loans3000online.com/#online"> online payday loans </a>
payday loans omaha
[url=http://payday1000loans3000online.com/#loans] loans for bad credit [/url]
online payday loans no credit check instant approval
<a href="http://payday1000loans3000online.com/#bestcash"> bad credit personal loans </a>
wal mart payday loans
<a href="http://payday1000loans3000online.com/#personal"> short term loans </a>
payday loans st louis
[url=http://payday1000loans3000online.com/#loans] loans online [/url]
best payday loans online
<a href="http://payday1000loans3000online.com/#bestcash"> quick loans </a>
payday loans in birmingham al
<a href="http://payday1000loans3000online.com/#loan"> loans online </a>
payday loans birmingham al
[url=http://payday1000loans3000online.com/#personal] payday loan [/url]
california payday loans
<a href="http://payday1000loans3000online.com/#bestcash"> bad credit loans </a>
fast payday loans online
<a href="http://payday1000loans3000online.com/#personal"> loans with bad credit </a>
payday loans in nashville tn
[url=http://payday1000loans3000online.com/#loans] loans for bad credit [/url]
best online payday loans instant approval
<a href="http://payday1000loans3000online.com/#loans"> bad credit loans </a>
best online payday loans instant approval
<a href="http://payday1000loans3000online.com/#personal"> quick loans </a>
online direct lender payday loans
[url=http://payday1000loans3000online.com/#online] payday advance [/url]
payday loans online no credit check direct lender
<a href="http://payday1000loans3000online.com/#personal"> loans for bad credit </a>
no credit check payday loans
<a href="http://payday1000loans3000online.com/#online"> cash advance </a>
payday loans raleigh nc
[url=http://payday1000loans3000online.com/#online] payday advance [/url]
payday loans st louis
<a href="http://payday1000loans3000online.com/#personal"> online payday loans </a>
alabama payday loans
<a href="http://payday1000loans3000online.com/#bestcash"> loans direct </a>
payday loans oakland ca
[url=http://payday1000loans3000online.com/#loans] payday loans online [/url]
payday loans riverside ca
<a href="http://payday1000loans3000online.com/#loan"> payday loans online </a>
payday loans charlotte nc
<a href="http://payday1000loans3000online.com/#loan"> bad credit personal loans </a>
tribal payday loans no credit check
[url=http://payday1000loans3000online.com/#personal] loans direct [/url]
payday loans columbus ga
<a href="http://payday1000loans3000online.com/#personal"> loans for people with bad credit </a>
payday loans hampton va
<a href="http://payday1000loans3000online.com/#bestcash"> online loans </a>
tribal payday loans
[url=http://payday1000loans3000online.com/#bestcash] loans for bad credit [/url]
guaranteed payday loans no teletrack
<a href="http://payday1000loans3000online.com/#personal"> payday loans </a>
payday loans el paso tx
<a href="http://payday1000loans3000online.com/#loan"> payday loan </a>
payday loans albuquerque
[url=http://payday1000loans3000online.com/#bestcash] online loans [/url]
payday loans for bad credit guaranteed approval
<a href="http://payday1000loans3000online.com/#bestcash"> quick loans </a>
payday loans toledo ohio
<a href="http://payday1000loans3000online.com/#online"> loans for people with bad credit </a>
payday loans in texas
[url=http://payday1000loans3000online.com/#loan] loans for bad credit [/url]
top payday loans without a bank account
<a href="http://pastillas-naturales-para-la-ereccion.eu/">http://pastillas-naturales-para-la-ereccion.eu/</a> <a href="http://zanzarazan.it/">http://zanzarazan.it/</a> <a href="http://zabalik.it/">http://zabalik.it/</a>
<a href="http://zabalik.it/">http://zabalik.it/</a> <a href="http://jurei.de/">http://jurei.de/</a> <a href="http://pastillas-naturales-para-la-ereccion.eu/">http://pastillas-naturales-para-la-ereccion.eu/</a>
<a href="http://doc-007.de/">http://doc-007.de/</a> <a href="http://jurei.de/">http://jurei.de/</a> <a href="http://jurei.de/">http://jurei.de/</a>
http://blog.roodo.com/f88tw
http://forum.pchome.com.tw/mypage/f88tw/post
http://forum.pchome.com.tw/mypage/f88tw/reply
http://forum.pchome.com.tw/content/7/213108
http://forum.pchome.com.tw/content/7/212931
http://forum.pchome.com.tw/content/7/212929
http://forum.pchome.com.tw/content/7/212913
http://forum.pchome.com.tw/content/7/212608
http://mypaper.pchome.com.tw/f88tw/post/1370868817
http://mypaper.pchome.com.tw/f88tw/post/1370804491
http://mypaper.pchome.com.tw/f88tw/post/1370927756
http://mypaper.pchome.com.tw/f88tw/post/1370961380
http://mypaper.pchome.com.tw/f88tw/post/1370901511
http://mypaper.pchome.com.tw/f88tw/post/1370821089
http://mypaper.pchome.com.tw/f88tw/post/1370820567
http://mypaper.pchome.com.tw/f88tw/post/1370820447
http://mypaper.pchome.com.tw/f88tw/post/1370820408
http://mypaper.pchome.com.tw/f88tw/post/1370815618
http://mypaper.pchome.com.tw/f88tw/post/1370781143
http://mypaper.m.pchome.com.tw/f88tw
http://mypaper.m.pchome.com.tw/f88tw/post/1370868817
http://mypaper.m.pchome.com.tw/f88tw/post/1370804491
http://mypaper.m.pchome.com.tw/f88tw/post/1370927756
http://mypaper.m.pchome.com.tw/f88tw/post/1370961380
http://mypaper.m.pchome.com.tw/f88tw/post/1370901511
http://mypaper.m.pchome.com.tw/f88tw/post/1370821089
http://mypaper.m.pchome.com.tw/f88tw/post/1370820567
http://mypaper.m.pchome.com.tw/f88tw/post/1370820447
http://mypaper.m.pchome.com.tw/f88tw/post/1370820408
http://mypaper.m.pchome.com.tw/f88tw/post/1370815618
http://mypaper.m.pchome.com.tw/f88tw/post/1370781143
[url=http://payday1000loans3000online.com/#bad-credit-payday-loans-ill]bad credit loans [/url]
<a href="http://payday1000loans3000online.com/#fast-payday-loans-gze">online payday loans </a>
http://payday1000loans3000online.com/#rsxvb
http://payday1000loans3000online.com/#dmrpd
http://payday1000loans3000online.com/#psfpk
http://www.internationalgraphicsystems.com/page3.php?post=1&messagepage=1004&messagepage=638
http://perfume-shop.by/products/duhi-reni-358---nalivnaya-parfyumeriya#comment_9025
http://www.elektromasselis.be/blog/post/post-single-image?page=425#comment-21383
http://www.lilyscafe.co.uk/page7.php?messagepage=294
http://19890914.com/bbs/view.php?id=data&page=1&page_num=100&select_arrange=headnum&desc=&sn=off&ss=on&sc=on&keyword=&no=59&category=
[url=http://payday1000loans3000online.com/#online-payday-loans-knx]payday advance [/url]
<a href="http://payday1000loans3000online.com/#same-day-payday-loans-wfm">bad credit loans </a>
http://payday1000loans3000online.com/#pifyv
http://payday1000loans3000online.com/#qtzet
http://payday1000loans3000online.com/#mgbyp
http://www.tcburgstetten.de/admidio/adm_program/modules/guestbook/guestbook.php?headline=gastebuch
http://www.no3r.com/comment.php?comment.news.1
http://asudd.ru/guestbook.php?event=new&page=1
http://www.hokej.tedi.cz/vzkaznik.php
http://www.volejballokocl.cz/index.php?p=diskuze&replyto=21122&_formData[guest]=nacosgMat&_formData[subject]=&_formData[text]=%3Ca+href%3D%22http%3A%2F%2Fpayday1000loans3000online.com%2F%23no-credit-check-payday-loans-ank%22%3Epayday+loan+%3C%2Fa%3E+%0D%0A%5Burl%3Dhttp%3A%2F%2Fpayday1000loans3000online.com%2F%23payday-loans-online-jzf%5Dpay+day+loans+%5B%2Furl%5D+%0D%0A%26lt%3Ba+href%3D%26quot%3Bhttp%3A%2F%2Fpayday1000loans3000online.com%2F%23legitimate-payday-loans-online-no-credit-check-qpb%26quot%3B%26gt%3Bcash+loans+%26lt%3B%2Fa%26gt%3B+%0D%0A+%0D%0Ahttp%3A%2F%2Fpayday1000loans3000online.com%2F%23roomo+%0D%0Ahttp%3A%2F%2Fpayday1000loans3000online.com%2F%23srcql+%0D%0Ahttp%3A%2F%2Fpayday1000loans3000online.com%2F%23zawbb+%0D%0A+%0D%0Ahttp%3A%2F%2Fwww.ugur-kaya.com%2Fcomments%2Fincludes%2Flog%2Fsuse%2Fsearch%2Fincludes%2Fpls%2Fadmin_%2Flista_produto.php+%0D%0Ahttp%3A%2F%2Fantybariera.pl%2Fcontent%2Fszybciej-i-l%25C5%25BCejw%25C3%25B3zek-elektryczny%23comment-23475+%0D%0Ahttp%3A%2F%2Fwww.ninabrodskaya.com%2Ffoto%2F0%2F237%2F+%0D%0Ahttp%3A%2F%2Fbroadwayzabreh.cz%2Fkniha.php%3Fodpoved%3D42214%26jmeno%3Daaronzed%26button%3D0+%0D%0Ahttp%3A%2F%2Fosobnica.pl%2Floppo%2Felektryczna-hulajnoga-z-jas%2525c5%252582a-robi-furor%2525c4%252599&addpost&r=2
[url=http://payday1000loans3000online.com/#best-online-payday-loans-pmw]personal loans [/url]
<a href="http://payday1000loans3000online.com/#online-payday-loans-no-credit-check-njt">loans online </a>
http://payday1000loans3000online.com/#fbfin
http://payday1000loans3000online.com/#zhmgo
http://payday1000loans3000online.com/#maiud
https://instinkt.tyden.cz/rubriky/ostatni/tema/zavist_28186_diskuze.html?page=1&ulozit_prispevek=88699#prispevek-88699
http://new.csft.cz/en/guestbook
http://xn--80aafdkcan3ashcdih2biib.xn--p1ai/index.php?option=com_djclassifieds&view=item&cid=10&id=28534
http://dsehibox.co.kr/english/support/read.php?table=edata_board&key=&value=&page=&idxno=104009&mode=read
http://nonnenschool.nuevo.abschiessend.requiem.mailfs.com/
[url=http://payday1000loans3000online.com/#payday-loans-direct-lender-pgq]payday loans [/url]
<a href="http://payday1000loans3000online.com/#no-credit-check-payday-loans-yzj">payday express </a>
http://payday1000loans3000online.com/#hkzit
http://payday1000loans3000online.com/#fsgnr
http://payday1000loans3000online.com/#asyht
http://amazon-kindle.by/catalog/ebook/amazon-kindle-keyboard-3-wifi.html#comment_13150
http://www.trick-dd.com/b-373/%e0%b9%80%e0%b8%97%e0%b8%84%e0%b8%99%e0%b8%b4%e0%b8%84%e0%b8%87%e0%b8%b2%e0%b8%99%e0%b9%84%e0%b8%a1%e0%b9%89-%e0%b8%81%e0%b8%b2%e0%b8%a3%e0%b8%97%e0%b8%b3%e0%b9%80%e0%b8%94%e0%b8%b7%e0%b8%ad%e0%b8%a2%e0%b8%81%e0%b8%a5%e0%b8%a1
http://www.huangshanabc.com/community_bookdetail.asp?id=236593
http://www.weeklyvoice.com/news-south-asia-india/muslim-women-hail-government-move-triple-talaq#comment-53537
http://www.tairongkj.com/?p=21&a=view&r=33
[url=http://payday1000loans3000online.com/#payday-loans-for-bad-credit-cti]payday loan [/url]
<a href="http://payday1000loans3000online.com/#online-payday-loans-ybg">payday loans online </a>
http://payday1000loans3000online.com/#ifhxd
http://payday1000loans3000online.com/#thfmr
http://payday1000loans3000online.com/#stscy
http://uslishmir.kz/resource/2012/06/23/posobie_po_trudoustroistvu_kak_naiti_sebya_i_svoyu_rabotu?page=5717#comment-468315
http://www.hanlecofire.org/guestbook/index.php?mode=3&post_id=145092
http://ltandroid.lt/programa/busai-kaunas?page=150#comment-55358
http://video-dom.com.ua/products/so_4#comment_8397
http://kbotanic.co.kr/site/support/board_view.php?idx=8&pagenum=14&searchgroup=&searchword=
[url=http://payday1000loans3000online.com/#payday-loans-online-direct-lenders-only-rfk]bad credit loans [/url]
<a href="http://payday1000loans3000online.com/#no-credit-check-payday-loans-umx">payday loan </a>
http://payday1000loans3000online.com/#dhymu
http://payday1000loans3000online.com/#dofvn
http://payday1000loans3000online.com/#yjevw
http://tudecidesmexico.org/proximo-foro-de-morena-en-juarez/#comment-78132
http://distilledspiritsinvestments.com/forum/account/npikndtuh/
http://www.baotas.org/dharanistupas/box-details.php?id=6890
http://sina.com.cn.factorielle.dnses.com/
http://serendang.co/bbs/viewthread.php?tid=886766&pid=29688982&page=8352&extra=#pid29688982
[url=http://payday1000loans3000online.com/#payday-loans-direct-lender-rwk]cash advance [/url]
<a href="http://payday1000loans3000online.com/#fast-payday-loans-npg">loans for bad credit </a>
http://payday1000loans3000online.com/#hyuau
http://payday1000loans3000online.com/#vthca
http://payday1000loans3000online.com/#faowr
http://www.esvfreilassing.de/index.php?option=com_phocaguestbook&id=1
http://cheldosug.nl/forums/1/1767453.html
http://newinharstad.no/book-a-table-directly-in-your-listing/#comment-12968
http://blog.kathyreid.id.au/contact/comment-page-1/?contact-form-id=13&contact-form-sent=36320&_wpnonce=682a25840d
http://www.planetclaire.com/2016/04/spin/?error_checker=captcha&author_spam=nabcekSeaky&email_spam=laqirrkruo%40mailermails.info&url_spam=http%3A%2F%2Fpayday1000loans3000online.com%2F%23payday-loans-online-uey&comment_spam=%3Ca+href%3D%5C%22http%3A%2F%2Fpayday1000loans3000online.com%2F%23same-day-payday-loans-xgt%5C%22%3Eshort+term+loans+%3C%2Fa%3E+http%3A%2F%2Fpayday1000loans3000online.com%2F%23payday-loans-online-same-day-lhk+-+loans+for+people+with+bad+credit++%26lt%3Ba+href%3D%26quot%3Bhttp%3A%2F%2Fpayday1000loans3000online.com%2F%23best-online-payday-loans-cta%26quot%3B%26gt%3Bonline+payday+loans+%26lt%3B%2Fa%26gt%3B++http%3A%2F%2Fpayday1000loans3000online.com%2F%23nmrcz+http%3A%2F%2Fpayday1000loans3000online.com%2F%23fuxlc+http%3A%2F%2Fpayday1000loans3000online.com%2F%23jxgno++http%3A%2F%2Fpodrobnosti.mk.ua%2F2015%2F06%2F17%2Fv-ochakove-kommunal-schiki-demontirovali-pamyatnik-leninu.html+http%3A%2F%2Fwww.aksar.kz%2Findex.php%2Fproduktsiya%2Fproduct%2Fview%2F3%2F115+http%3A%2F%2Fteensait.dir.bg%2F_wm%2Flibrary%2Fitem.php%3Fdid%3D424933%26df%3D614615%26dflid%3D3+http%3A%2F%2Fbuffy-the-chosen.dir.bg%2F_wm%2Flibrary%2Fitem.php%3Fdid%3D314097%26df%3D450219%26dflid%3D3%26gdirid%3D9c536189ef3937e8426ff95ad3fa8116+http%3A%2F%2Fshina-moscow.com%2Fblog%2Fkak-%23comment_1549#error
[url=http://payday1000loans3000online.com/#payday-loans-near-me-bsg]loans for people with bad credit [/url]
<a href="http://payday1000loans3000online.com/#payday-loans-online-no-credit-check-xkf">loans for people with bad credit </a>
http://payday1000loans3000online.com/#uluji
http://payday1000loans3000online.com/#ztrsq
http://payday1000loans3000online.com/#izeer
http://heoyoungsaeng.ivyro.net/zboard/view.php?id=free&page=1&page_num=20&select_arrange=reg_date&desc=&sn=on&ss=off&sc=off&keyword=%AC%DA%AC%A1%AC%B9%AC%D3&no=581&category=7
http://entrayve.com/foro/index.php/topic,267415.new.html#new
http://www.fkupesciems.lv/news.php?id=34#comments
http://www.teploon.ru/blog/otkrytie_internetmagazina_teploon/#comment_23473
http://ska-khabarovsk.ru/presscenter_article.php?aid=969&err=filter&hash=c61be9f095205a588c58c2108210d5b7#addcom
[url=http://payday1000loans3000online.com/#bad-credit-personal-loans-not-payday-loans-iof]personal loan [/url]
<a href="http://payday1000loans3000online.com/#payday-loans-online-same-day-vxh">loans for bad credit </a>
http://payday1000loans3000online.com/#nnsrl
http://payday1000loans3000online.com/#xctck
http://payday1000loans3000online.com/#cikpk
http://hajjumraforum.co.uk/page16.php?messagepage=118
http://www.vaikams.lt/filmukai/geniukas-vudis/vudis-ir-pyrageliai.html
http://forum.wikstrom.de/viewtopic.php?p=1011538#1011538
http://pdatelecom.ru/catalog/htc/htc_desire_620_grey659/?mid=1059247&MID=117120&result=reply#message117120
http://skrug-nn.ru/favicon/?error_checker=captcha&author_spam=nltckmFlexy&email_spam=fjyjsrchco%40mailermails.info&url_spam=http%3A%2F%2Fpayday1000loans3000online.com%2F%233-month-payday-loans-sbw&comment_spam=%3Ca+href%3D%5C%22http%3A%2F%2Fpayday1000loans3000online.com%2F%23bad-credit-payday-loans-tby%5C%22%3Eonline+payday+loans+%3C%2Fa%3E+http%3A%2F%2Fpayday1000loans3000online.com%2F%23payday-loans-online-no-credit-check-instant-approval-bml+-+cash+loans++%26lt%3Ba+href%3D%26quot%3Bhttp%3A%2F%2Fpayday1000loans3000online.com%2F%23payday-loans-online-no-credit-check-instant-approval-azb%26quot%3B%26gt%3Bpersonal+loans+%26lt%3B%2Fa%26gt%3B++http%3A%2F%2Fpayday1000loans3000online.com%2F%23mrjaw+http%3A%2F%2Fpayday1000loans3000online.com%2F%23ngxqi+http%3A%2F%2Fpayday1000loans3000online.com%2F%23uvtry++http%3A%2F%2Fsylwia22.blogmamy.pl%2Fzdjecie%2C11289.html+http%3A%2F%2Fnovayagazeta.ee%2Farticles%2F12767%2Fcomments%2F%23cmt-9645+http%3A%2F%2Fwww.bitaf.org%2Fus-grand-strategy-civil-army-relations-to-support-geopolitics-oped%2F%23comment-13960+http%3A%2F%2Fa2justice.ca%2Fblog%2F%3Fcontact-form-id%3Dwidget-text-4%26contact-form-sent%3D7537%26_wpnonce%3Ded9c2a7fbf+http%3A%2F%2Fwww.authorgailmchugh.com%2Fwhat-im-working-on-amber-to-ashes%2F%3Ferror_checker%3Dcaptcha%26author_spam%3Dnknrumspamy%26email_spam%3Dsjsuqwftst%2540mailermails.info%26url_spam%3Dhttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523online-payday-loans-no-credit-check-iqo%26comment_spam%3D%253Ca%2Bhref%253D%255C%2522http%253A%252F%252Fpayday1000loans3000online.com%252F%2523fast-payday-loans-iou%255C%2522%253Epayday%2Bloans%2B%253C%252Fa%253E%2B%255Burl%253Dhttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523payday-loans-online-dzy%255Dcash%2Badvance%2B%255B%252Furl%255D%2B%2526lt%253Ba%2Bhref%253D%2526quot%253Bhttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523legitimate-payday-loans-online-no-credit-check-kmc%2526quot%253B%2526gt%253Bloans%2Bwith%2Bbad%2Bcredit%2B%2526lt%253B%252Fa%2526gt%253B%2B%2Bhttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523snusr%2Bhttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523plfdt%2Bhttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523ezzhq%2B%2Bhttp%253A%252F%252Fyatani.jp%252Fteaching%252Fdoku.php%253Fid%253Dhcistats%253Aposthoc%2523comment_e8e26e79c57ea481e39e59954250cefc%2Bhttps%253A%252F%252Fwww.solsticemoon.us%252Fbin%252Fsmf%252Findex.php%253Ftopic%253D889121.new%2523new%2Bhttp%253A%252F%252Fradiopr.no%252Fguestbook%2Bhttp%253A%252F%252Fpescaresponsable.co%252Findex.php%253Foption%253Dcom_k2%2526view%253Ditemlist%2526task%253Duser%2526id%253D611228%2Bhttp%253A%252F%252Fwww.cavaleirosdacostadoce.com.br%252Fjoomla%252Findex.php%253Foption%253Dcom_rsgallery2%2526itemid%253D78%2526page%253Dinline%2526catid%253D10%2526id%253D1032%2526limit%253D1%2526limitstart%253D22%23error#error
[url=http://payday1000loans3000online.com/#fast-payday-loans-jot]quick loans [/url]
<a href="http://payday1000loans3000online.com/#payday-loans-no-credit-check-ime">pay day loans </a>
http://payday1000loans3000online.com/#aejcx
http://payday1000loans3000online.com/#hsdkj
http://payday1000loans3000online.com/#eehua
http://broadwayzabreh.cz/kniha.php?odpoved=45337&jmeno=cheapjep&button=0
http://www.epc-ucb.edu.bo/ucbgoescanvas/node/28?page=2118#comment-106109
http://www.firmaelin.pl/page8.php?message&messagepage=764
http://ksa-home.com/node/1?page=3234#comment-161725
http://old2.zviazda.by/gb.html?coder=windows-1251&w=1&name=nughnlTetty&e_mail=dyvinoxill%40mailermails.info&url=http%3A%2F%2Fpayday1000loans3000online.com%2F%23best-online-payday-loans-hej&coment=<a+href%3D%22http%3A%2F%2Fpayday1000loans3000online.com%2F%23online-payday-loans-direct-lenders-guq%22>pay+day+loans+<%2Fa>+%0D%0Ahttp%3A%2F%2Fpayday1000loans3000online.com%2F%23no-credit-check-payday-loans-lye+-+online+payday+loans++%0D%0A%26lt%3Ba+href%3D%26quot%3Bhttp%3A%2F%2Fpayday1000loans3000online.com%2F%23ace-payday-loans-dge%26quot%3B%26gt%3Bpayday+express+%26lt%3B%2Fa%26gt%3B+%0D%0A+%0D%0Ahttp%3A%2F%2Fpayday1000loans3000online.com%2F%23mfnqt+%0D%0Ahttp%3A%2F%2Fpayday1000loans3000online.com%2F%23hljgp+%0D%0Ahttp%3A%2F%2Fpayday1000loans3000online.com%2F%23mtwrk+%0D%0A+%0D%0Ahttp%3A%2F%2Fkdfajeep.wz.cz%2Fdiskuse.php+%0D%0Ahttp%3A%2F%2Fjap.khcrusher.co.kr%2Fkboard%2Fboard%2Fmboard.ets%3Fboard_id%3D8_3%26group_name%3D333%26idx_num%3D5%26page%3D1%26category%3D%26search%3D%26b_cat%3D%26order_c%3Db_writer%26order_da%3Dasc+%0D%0Ahttp%3A%2F%2Fwww.chiquita.com%2Frecipes%2Fwinter-frozen-chiquita-banana-penguins%3Fpage%3D4974%23comment-253837+%0D%0Ahttp%3A%2F%2Fwww.siwasakti.pl%2Faktualnosci%2FKukrkuma%2F%3Fc%3D26052+%0D%0Ahttp%3A%2F%2Fwww.gameinfo.cz%2Ftomb-na-rane.htm%3Fcode%3Dspam%26autor%3DnxisomDup%26www%3Dhttps%253A%252F%252Fanabolicsteroidsnpc.co%26text%3D%2526lt%253Ba%2Bhref%253D%2526quot%253Bhttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523ace-payday-loans-lhe%2526quot%253B%2526gt%253Bpersonal%2Bloans%2B%2526lt%253B%252Fa%2526gt%253B%2B%253Cbr%252F%253Ehttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523instant-payday-loans-fas%2B-%2Bpayday%2Bloans%2Bonline%2B%2B%253Cbr%252F%253E%2526lt%253Ba%2Bhref%253D%2526quot%253Bhttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523legitimate-payday-loans-online-no-credit-check-nxe%2526quot%253B%2526gt%253Bonline%2Bloans%2B%2526lt%253B%252Fa%2526gt%253B%2B%253Cbr%252F%253E%2B%253Cbr%252F%253Ehttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523uhyrl%2B%253Cbr%252F%253Ehttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523yexzj%2B%253Cbr%252F%253Ehttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523degmb%2B%253Cbr%252F%253E%2B%253Cbr%252F%253Ehttp%253A%252F%252Fwww.cityvisioninternships.org%252Forg-apply%253Ftfa_next%253D%25252Fforms%25252Fview%25252F239880%25252F32e7bfa58075f0244d3d1fe04f3af9e8%25252F92183482%252526sid%25253Dnefmbule24536v6dtsjve41hb0%2B%253Cbr%252F%253Ehttp%253A%252F%252Fedaroos.com%252F2016%252F05%252Fhusband-wife-relationship-mufti-ismail-menk%252F%253Ferror_checker%253Dcaptcha%2526author_spam%253DnxmwdaEvist%2526email_spam%253Dvgfvovwnjb%252540mailermails.info%2526url_spam%253Dhttp%25253A%25252F%25252Fpayday1000loans3000online.com%25252F%252523payday-loans-online-same-day-ksc%2526comment_spam%253D%25253Ca%252Bhref%25253D%25255C%252522http%25253A%25252F%25252Fpayday1000loans3000online.com%25252F%252523ace-payday-loans-adm%25255C%252522%25253Eloans%252Bfor%252Bpeopl%23comment&submit=%D1%EA%E0%E7%E0%F2%FC
[url=http://payday1000loans3000online.com/#payday-loans-online-same-day-fpw]loans for bad credit [/url]
<a href="http://payday1000loans3000online.com/#payday-loans-direct-lender-mpy">personal loans </a>
http://payday1000loans3000online.com/#qpiif
http://payday1000loans3000online.com/#oizdb
http://payday1000loans3000online.com/#qceyg
http://quimgen.edu20.org/contact_visitor?authenticity_token=xsmx0hGrZMbzgk3HpU%2BrElNXgVXH5Ab87DookTg%2Fl%2Bk%3D&commit=&content=%3Ca+href%3D%22http%3A%2F%2Fpayday1000loans3000online.com%2F%23payday-loans-online-kxb%22%3Equick+loans+%3C%2Fa%3E+%0D%0Ahttp%3A%2F%2Fpayday1000loans3000online.com%2F%23easy-payday-loans-srx+-+loans+online++%0D%0A%26lt%3Ba+href%3D%26quot%3Bhttp%3A%2F%2Fpayday1000loans3000online.com%2F%23payday-loans-online-same-day-uim%26quot%3B%26gt%3Bpersonal+loan+%26lt%3B%2Fa%26gt%3B+%0D%0A+%0D%0Ahttp%3A%2F%2Fpayday1000loans3000online.com%2F%23xjpgw+%0D%0Ahttp%3A%2F%2Fpayday1000loans3000online.com%2F%23vtige+%0D%0Ahttp%3A%2F%2Fpayday1000loans3000online.com%2F%23sembp+%0D%0A+%0D%0Ahttp%3A%2F%2Fchiquita.com%2Frecipes%2Fwinter-frozen-chiquita-banana-penguins%3Fpage%3D4952%23comment-252695+%0D%0Ahttp%3A%2F%2Fmy-ecoach.com%2Fblogs.php%3Faction%3Dview_post%26blog%3D3062%26post%3D9593+%0D%0Ahttp%3A%2F%2Fwww.ultimatesurvival.pp.ua%2Fua%2Fonline%2Fseason2%2Fepisode2-vyzhyvannya-v-pusteli-sahara-desert-survivor%23comment2961%23comment3723+%0D%0Ahttp%3A%2F%2Ftheincrowdmarket.com%2Findex.php%2Fabout%2Fguestbook%2F+%0D%0Ahttp%3A%2F%2Fmovafaghiat92.vcp.ir%2F211902-%25d8%25af%25d8%25a7%25d9%2586%25d9%2584%25d9%2588%25d8%25af-%25d8%25a2%25d9%2584%25d8%25a8%25d9%2588%25d9%2585-%25d9%2587%25d8%25a7%2F690011-%25d8%25af%25d8%25a7%25d9%2586%25d9%2584%25d9%2588%25d8%25af-%25d8%25a2%25d9%2587%25d9%2586%25da%25af-%25d8%25a8%25db%258c-%25da%25a9%25d9%2584%25d8%25a7%25d9%2585-%25d8%25ac%25d8%25a7%25d9%2586-%25d9%2585%25d8%25b1%25db%258c%25d9%2585.html&email=bnodnsxojr%40mailermails.info&name=nficywjek&phone=89392499199&subject=jknz+payday+loans+tallahassee+qvfn&utf8=%26%23x2713%3B
http://vult.com.br/produtos/caneta-para-sobrancelhas-vult/#comment-105078
http://forum.tout-sur-le-gyropode.com/viewtopic.php?f=12&t=369195
http://www.gbi16.ru/materials/bruschatka-gbk#comment-392121
http://zusklavir.jamu.cz/index.php?p=autorska-dilna&replyto=396&_formData[guest]=nqdmylPoede&_formData[subject]=&_formData[text]=%3Ca+href%3D%22http%3A%2F%2Fpayday1000loans3000online.com%2F%23direct-lender-payday-loans-ekg%22%3Eloans+online+%3C%2Fa%3E+%0D%0A%5Burl%3Dhttp%3A%2F%2Fpayday1000loans3000online.com%2F%23same-day-payday-loans-edh%5Dbad+credit+loans+%5B%2Furl%5D+%0D%0A%26lt%3Ba+href%3D%26quot%3Bhttp%3A%2F%2Fpayday1000loans3000online.com%2F%23instant-payday-loans-wme%26quot%3B%26gt%3Bloans+for+bad+credit+%26lt%3B%2Fa%26gt%3B+%0D%0A+%0D%0Ahttp%3A%2F%2Fpayday1000loans3000online.com%2F%23rimmx+%0D%0Ahttp%3A%2F%2Fpayday1000loans3000online.com%2F%23boqky+%0D%0Ahttp%3A%2F%2Fpayday1000loans3000online.com%2F%23xdsdw+%0D%0A+%0D%0Ahttp%3A%2F%2Fschool07.tim.ua%2Fnews%2F717+%0D%0Ahttp%3A%2F%2Fworking.hpcom.cz%2Fphpbb%2Fviewtopic.php%3Ff%3D17%26t%3D148096+%0D%0Ahttp%3A%2F%2Fwww.purelovefoundation.com%2F2015%2F11%2F%3Fcontact-form-id%3D512%26contact-form-sent%3D12420%26_wpnonce%3D197790470e+%0D%0Ahttp%3A%2F%2Fsel-politeh.ru%2Fnode%2F117%23comment-228297+%0D%0Ahttp%3A%2F%2Fdoublegame.vcp.ir%2F84716-online-game%2F381008-%25d9%2585%25d8%25b9%25d8%25b1%25d9%2581%25db%258c-%25d8%25b3%25d8%25b1%25d9%2588%25d8%25b1-%25d9%2587%25d8%25a7%25db%258c-%25d9%2585%25d9%2588%25d9%2581%25d9%2582-wow.html&addpost&r=0
[url=http://payday1000loans3000online.com/#online-payday-loans-kot]loans for bad credit [/url]
<a href="http://payday1000loans3000online.com/#3-month-payday-loans-aqp">payday loans online </a>
http://payday1000loans3000online.com/#garso
http://payday1000loans3000online.com/#uhwko
http://payday1000loans3000online.com/#gcplb
http://roborst.be/content/dsc00330#comment-187085
http://analyzab.iijx.iklj.qdpllzznfl.x.mailld.com/
http://grall.ru/blog/hi-fi--high-end-show-2017#comment_8090
http://kacheli.net/blog/chto-novogo-v-etoj-versii-simply/#comment_11492
http://marcsi156.gportal.hu/gindex.php?pg=36503927&dummy=36503927&pageno=1&badcaptcha=true&cmd=inscomment&commentname=ntsimsmef&commentemail=kurwdhiiop%40mailermails.info&commenttext=%3Ca+href%3D%22http%3A%2F%2Fpayday1000loans3000online.com%2F%23online-payday-loans-iyu%22%3Epayday+loans+online+%3C%2Fa%3E+%0D%0Ahttp%3A%2F%2Fpayday1000loans3000online.com%2F%23payday-loans-online-direct-lenders-only-evs+-+personal+loan++%0D%0A%26lt%3Ba+href%3D%26quot%3Bhttp%3A%2F%2Fpayday1000loans3000online.com%2F%23direct-lender-payday-loans-mll%26quot%3B%26gt%3Bpersonal+loans+%26lt%3B%2Fa%26gt%3B+%0D%0A+%0D%0Ahttp%3A%2F%2Fpayday1000loans3000online.com%2F%23orzwm+%0D%0Ahttp%3A%2F%2Fpayday1000loans3000online.com%2F%23zegjn+%0D%0Ahttp%3A%2F%2Fpayday1000loans3000online.com%2F%23bvshe+%0D%0A+%0D%0Ahttp%3A%2F%2Fpervushinagv.samtrm.ru%2Fforum%2Findex.php%3F%2Ftopic%2F104-modish%2Fpage__st__226320__gopid__533677%23entry533677+%0D%0Ahttps%3A%2F%2Fsimular.co%2Flyra%2Fforum%2Fsfzv-payday-loans-roanoke-va-cdnd.html+%0D%0Ahttp%3A%2F%2Fhome-fotoclub.cz%2Fgerber%2Findex.php%3Fa%3Dnabidka%2Fgerber-bear-grylls-hands-free-torch%26replyto%3D-1%26_formData%3Cguest%3E%3DnpdtiaJeort%26_formData%3Csubject%3E%3Dbjoa%2Bpayday%2Bloans%2Bin%2Bcorpus%2Bchristi%2Bjnfq%26_formData%3Ctext%3E%3D%253Ca%2Bhref%253D%2522http%253A%252F%252Fpayday1000loans3000online.com%252F%2523online-payday-loans-no-credit-check-tqz%2522%253Epayday%2Badvance%2B%253C%252Fa%253E%2B%250D%250A%255Burl%253Dhttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523payday-loans-online-no-credit-check-vcp%255Dshort%2Bterm%2Bloans%2B%255B%252Furl%255D%2B%250D%250A%2526lt%253Ba%2Bhref%253D%2526quot%253Bhttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523easy-payday-loans-cnm%2526quot%253B%2526gt%253Bpayday%2Bloans%2B%2526lt%253B%252Fa%2526gt%253B%2B%250D%250A%2B%250D%250Ahttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523sdgps%2B%250D%250Ahttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523twesj%2B%250D%250Ahttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523ajnlu%2B%250D%250A%2B%250D%250Ahttp%253A%252F%252Fwww.avensa.ru%252Finter_shop%252Felektronnaya_kniga_onyx_boox_a61s_hamlet__chernaya_.html%253Fpagen_1%253D46%2526element_code%253Delektronnaya_kniga_onyx_boox_a61s_hamlet__chernaya_%2B%250D%250Ahttp%253A%252F%252Fvolgodonskoiraion.ru%252Findex.php%253Foption%253Dcom_rsgallery2%2526itemid%253D0%2526page%253Dinline%2526catid%253D31%2526id%253D324%2526limit%253D1%2526limitstart%253D9%2B%250D%250Ahttp%253A%252F%252Ftrezvo-sila.ru%252FSmertiGertvi.html%2523c%2B%250D%250Ahttp%253A%252F%252F4technolog.ru%252Ftehnologs%252Fback-office%252Ffinence-monitoring%252F%2B%250D%250Ahttp%253A%252F%252Fwww.barifuri.jp%252Fsns%252Fblog%252Farticles%252F2896%26addpost%26r%3D0+%0D%0Ahttp%3A%2F%2Fbiserland.com.ua%2Findex.php%3FproductID%3D3497+%0D%0Ahttp%3A%2F%2Fwww.annes-hus.se%2Fen%2Fhotellet%2Fgastbok%2F%3Ferror_checker%3Dcaptcha%26author_spam%3Dnhkaajshada%26email_spam%3Dcetldfjjnf%2540mailermails.info%26url_spam%3Dhttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523online-payday-loans-no-credit-check-hjm%26comment_spam%3D%253Ca%2Bhref%253D%255C%2522http%253A%252F%252Fpayday1000loans3000online.com%252F%2523payday-loans-online-same-day-ruy%255C%2522%253Epayday%2Bexpress%2B%253C%252Fa%253E%2Bhttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523best-online-payday-loans-xjf%2B-%2Bquick%2Bloans%2B%2B%2526lt%253Ba%2Bhref%253D%2526quot%253Bhttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523payday-loans-lhm%2526quot%253B%2526gt%253Bshort%2Bterm%2Bloans%2B%2526lt%253B%252Fa%2526gt%253B%2B%2Bhttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523zgoyi%2Bhttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523pgogr%2Bhttp%253A%252F%252Fpayday1000loans3000online.com%252F%2523fpmou%2B%2Bhttp%253A%252F%252Fchiquita.com%252Frecipes%252Fwinter-frozen-chiquita-banana-penguins%253Fpage%253D4952%2523comment-252700%2Bhttp%253A%252F%252Fchistadom.ru%252Fblog%252Fodorgone-sport-shose-i-smokebusters-poluchil-novuyu-upakovku%252F%2523comment9065%2Bhttp%253A%252F%252Fbroadwayzabreh.cz%252Fkniha.php%253Fodpoved%253D45767%2526jmeno%253Duutaquv%2526button%253D0%2Bhttp%253A%252F%252Fborvelodge.com%252Fblog%252F%253Fcontact-form-id%253Dwidget-text-2%2526contact-form-sent%253D250995%2526_wpnonce%253De020dc3b36%2Bhttp%253A%252F%252Fsafiremehrabani.vcp.ir%252F0-%2525d8%2525a8%2525d8%2525af%2525d9%252588%2525d9%252586-%2525d9%252585%2525d9%252588%2525d8%2525b6%2525d9%252588%2525d8%2525b9%252F567572-%2525d8%2525a2%2525d8%2525b3%2525d9%252585%2525d8%2525a7%2525d9%252586-%2525d8%2525aa%2525d9%252588.html%23error#commentList
[url=http://payday1000loans3000online.com]personal loans [/url]
<a href="http://payday1000loans3000online.com">payday advance </a>
http://payday1000loans3000online.com/#eetnh
http://payday1000loans3000online.com/#rnshh
http://payday1000loans3000online.com/#bdrlt
http://25-25-25.kz/ru/guestbook
http://mama.tv3.lt/virtuve/konservantas/e1201
http://www.gite-ipes.org/index.php?option=com_k2&view=item&id=1:1-buletina-okupazio-eta-erresistentzia&lang=eu
http://www.nagoyaaht.com/cgi/multi2.cgi?file=0
http://audio.dem.ru/devices.php?id=41
what's the best male enhancement pill yahoo answers</br>
<a href="http://bestmalesenhancementpills.com"> best male enhancement pills</a> </br>
<a href="http://malesenhancement.com"> best male enhancement</a> </br>
[url=http://malesenhancement.com]natural male enhancement before and after[/url] </br>
cianix male enhancement
male enhancement pills at walmart</br>
<a href="http://malesenhancement.com"> male enhancement pills that work</a> </br>
<a href="http://malesenhancement.com"> extenze male enhancement</a> </br>
[url=http://bestmalesenhancementpills.com]extenze male enhancement[/url] </br>
male enhancement pills free trial
[url=http://horts.ru]horts[/url] <a href=http://avza.ru>avza</a>
hair. Before installing the lace wig, you will need to wash and condition your own hair. To maintain your hair wholesome and scalp from [url=http://wigshforwomen.com/]Wigs[/url]
irritation, an excellent clean and strong conditioner are advised. Be sure the locks is totally free of moisture and moisturized. A trim is also encouraged if you have damaged hair or split ends. One of many principal good reasons to [url=http://www.wigs-for-women.org/]Wigs For Women[/url]
wear a lace wig is market healthier hair although experiencing overall flexibility.
After washing your hair and undertaking any of the recommended locks remedies, you might have 2 alternatives. Some ladies decide to use a skin [url=http://wigsfor-women.com/]Wigs For Women[/url]
well toned wig cap under the lace wig for protection although some basically remember to brush their your hair back and then use. If you want to use the wig cover ensure that it suits your skin layer sculpt. It is possible to braid hair under the limit or simply wrap it.
Recommended to make a much more sensible hunting scalp is to apply Ace bandage. Ace bandage is definitely a [url=http://www.dresslilywigs.net/]Dresslily Wigs[/url]
affordable athletic bandage for muscles personal injuries that can be purchased at your community pharmacy. It clings to alone so no fasten or tape is applied to your hair or head. The texture of the bandage offers a bumpy physical appearance which copies the scalp physical appearance beneath the lace front wig. It really [url=http://wigsxz.com/]Wigs[/url]
should be covered across the go either on top of a normal wig limit or right to the hair. Ensure that you clean your hair line with rubbing alcoholic beverages and let it dry completely.
<a href="http://cialisgsaa.com/">buy cialis</a>
como se llama el generico del cialis
[url=http://cialisgsaa.com/]buy generic cialis[/url]
[url=http://msportslab.ru]почаще[/url]
[url=http://webfarma.ru] попробую [/url] [url=http://zilar.ru]с вами[/url] [url=http://ubra.ru]связаться[/url]
<a href="http://cashadvanceamericasev.org/">payday loans</a>
home loans today
[url=http://cashadvanceamericasev.org/]payday loans online[/url] ’
[url=http://salonturov.ru/index.php?show_aux_page=8]dre[/url]
[url=http://refta.ru/index.php?show_aux_page=4]refta[/url]
[url=http://msportslab.ru/?q=osobennosti-i-dostoinstva-apparata-dlya-peskostruinoi-polirovki-zubov]msportslab[/url]
http://blog.roodo.com/f88tw
http://mypaper.pchome.com.tw/f88tw/post/1373187437
http://mypaper.pchome.com.tw/f88tw/post/1371719766
http://mypaper.pchome.com.tw/f88tw/post/1370868817
http://mypaper.pchome.com.tw/f88tw/post/1370804491
http://mypaper.pchome.com.tw/f88tw/post/1370927756
http://mypaper.pchome.com.tw/f88tw/post/1370961380
http://mypaper.pchome.com.tw/f88tw/post/1370901511
http://mypaper.pchome.com.tw/f88tw/post/1370821089
http://mypaper.pchome.com.tw/f88tw/post/1370820567
http://mypaper.pchome.com.tw/f88tw/post/1370820447
http://mypaper.pchome.com.tw/f88tw/post/1370820408
http://mypaper.pchome.com.tw/f88tw/post/1370815618
http://mypaper.pchome.com.tw/f88tw/post/1370781143
Wacoal http://mypaper.pchome.com.tw/f88tw/post/1370961380
http://mypaper.m.pchome.com.tw/f88tw
http://mypaper.m.pchome.com.tw/f88tw/post/1371719766
http://mypaper.m.pchome.com.tw/f88tw/post/1370868817
http://mypaper.m.pchome.com.tw/f88tw/post/1370804491
http://mypaper.m.pchome.com.tw/f88tw/post/1370927756
http://mypaper.m.pchome.com.tw/f88tw/post/1370961380
http://mypaper.m.pchome.com.tw/f88tw/post/1370901511
http://mypaper.m.pchome.com.tw/f88tw/post/1370821089
http://mypaper.m.pchome.com.tw/f88tw/post/1370820567
http://mypaper.m.pchome.com.tw/f88tw/post/1370820447
http://mypaper.m.pchome.com.tw/f88tw/post/1370820408
http://mypaper.m.pchome.com.tw/f88tw/post/1370815618
http://mypaper.m.pchome.com.tw/f88tw/post/1370781143
http://mypaper.m.pchome.com.tw/f88tw/post/1373187437
http://blog.roodo.com/f88tw/archives/2017-06.html
http://mypaper.pchome.com.tw/f88tw
[url=http://paketo.ru]вас.[/url] [url=http://all-avto-news.ru]Положил [/url] [url=http://emkos.ru]в избранное[/url]
[url=http://bit.ly/2xLM02J][IMG]http://i91.fastpic.ru/big/2017/1030/aa/53fc57cb44234f03c3e040d94f68d7aa.jpg[/IMG][/url]
[url=http://bit.ly/2xLM02J][b]Смотреть фильм Салют-7[/b][/url]
[url=http://bit.ly/2xLM02J][b][color=red]Смотреть фильм Салют-7[/color][/b][/url]
[url=http://bit.ly/2xLM02J][b][color=green]Смотреть фильм Салют-7[/color][/b][/url]
Салют-7: как переписать музыку к фильму за полтора месяца Когда мы первый раз увидели фильм Салют-7, сразу поняли: в0:002:31Теперь каждый может проверить это утверждение в хорошем кинозале сО музыке и ее качестве продюсеры порой задумываются в самый
Новый фильм про подвиги космонавтов определенно вызовет разноречивые мнения.Салют-7 на экранах: правда или ложь, реальность или вымысел Трудно смотреть на придуманное на экране, когда знаешь, как всешколы, уволенную за отказ агитировать на выборах. 50 876
Скачать mp4, 3gp, avi фильмы из категории Отечественный через торрент на Салют-7. Mp4+3gp+Avi. Салют-7. TS 480. 13 октябрь 2017. Год выпуска:BDRip 720. 4 октябрь 2017. Год выпуска: 2015. Длительность: 1 ч. 33 мин.
Салют-7 История одного подвига 2017 смотреть онлайн Салют-7 (2017)В центре Сериал Отчий берег 7,8,9,10 серия () .онлайн. noviyfilm.
Фильм основан на реальных событиях: полет к станции Салют-7 в 1985 году считается самым сложнымособый смысл придираться к этой части, поскольку это художественный фильм, а не документальный.Да Нет; 75.
Скачать торрент фильм Салют-7 (2017). года бесплатно и в хорошем качестве, можно на . Кино снял режиссер Клим Шипенко и имеет
Салют-7 — советская космическая станция, гордость Обряд освящения ракеты-носителя Союз-ФГ с космическим кораблем
Фильм Салют-7, основанный на реальных событиях, расскажет о самой20 минут открытого космоса, 40 минут съемок невесомоститакого не
Салют-7 (2017) смотреть онлайн в хорошем качестве hd mdash;1:49 youtubewatch?v5Cw Um3eSB7A 11 ч. назад - Добавлено
Рейтинг зрителей: на kinopoisk.ru(683),Постановочно Салют-7 не слабее Времени первых, а художественно он лишь
Предлагаем вашему вниманию полный фильм Салют-7 смотреть онлайн бесплатно в хорошем качестве (HD 720) на сайте Бобфильм ludka (21 октября 2017 19:54). Не могу не поблагодарить режиссера, который настолько реалистично смог
Cam Rip 33. Комедия 1545 Теперь вы можете. Салют-7 (2017) смотреть онлайн, бесплатно и в хорошем качестве HD 720p.
Фантастика 90х Фильм Салют-7 смотреть онлайн в HD качестве. 3597 просмотров. 10 комментариев.
19:34 Поделитесь впечатлением от просмотренного, пишите правдивые отзывы, чтобы другим людям было ясно, стоит ли смотреть фильм Салют-7 2017.
Решил поискать в сети и нашёл трейлер к новому российскому фильму "Салют-7" Запасов воды экипажа хватало на 8 дней — достаточно, чтобы остаться на станции до 14 июня.
Поэтому пришла сегодня на первый сеанс. Я смотрю только серьезное кино, а не мыльные оперы. Вчера сходила на Салют-7, а сегодня вот на Матильду пришла.
Действия в фильме разворачиваются в 1985 году. Драматическая история поведает о советской космической станции под названием Салют-7, этот аппарат бороздит орбиту Земли в беспилотном режиме, все было хорошо
Афиша — кино. Салют-7. Россия, 2017 драма. Продолжительность: 120 мин 27 октября 2017г. Fакел, культурно-досуговый центр.
03:39. Турки заражают русских туристов страшным вирусом, от которого выпадают ногти (2017). 1 931 077 просмотров ТРЕЙЛЕР САЛЮТ - 7. Художественный фильм. Премьера! 29 мая274 просмотра.
Смотрите СЕГОДНЯ в кинотеатрах Приморья новый фильм Салют-7. начало сеанса. город 09:45. Владивосток. Иллюзион.
Похожие ключи:
Салют-7 смотреть онлайн в хорошем качестве
Салют-7 фильм онлайн
Салют-7 фильм скачать торрент
Салют-7 2017 смотреть онлайн
Салют-7 фильм смотреть онлайн
Также рекомендуем к просмотру:
[url=http://mypclifeguard.com/forum/viewtopic.php?f=3&t=11159]Сделано в Америке 2017 торрент 13.11.2017 o s x[/url]
[url=http://murlocsatemygnome.win/topics/viewtopic.php?f=4&t=7518]Геошторм 2017 смотреть онлайн 13.11.2017 t j c[/url]
[url=http://www.dentaldoktor.com/foro/index.php?topic=5368.msg32519#msg32519]смотреть трейлер Сделано в Америке 13.11.2017 n k i[/url]
[url=http://forum.hard-rp.com/viewtopic.php?f=2&t=26662]Геошторм 2017 смотреть онлайн фильм 13.11.2017 u u k[/url]
[url=http://garona.ovh/viewtopic.php?f=4&t=37354]Сделано в Америке кино 13.11.2017 y i a[/url]
[url=http://winjeel.com/phpbb/viewtopic.php?f=2&t=18054]Бегущий по лезвию 2049 худ фильм 13.11.2017 i i o[/url]
.
Оплата полностью происходит на почте!
За время моего использования, около недели,никаких недочетов не заметила, ни чуть не тупит! Очень плавно работает!!! Стильный дизайн, подчеркивающий статус владельца! У моих друзей прибавилось поводов для зависти)) Если телефон не понравится, то есть возможность вернуть телефон обратно, в течении 14 дней! Гарантия на телефон один год. Камера супер, фотки просто класс!!! Беспроводные наушники, не боится влаги, работает Очень быстро!!! Очень красивый. Так же в комплекте пришло защитное стекло и чехол подчеркивающий цвет телефона!
Так что ребята покупайте тут и не бойтесь!
Ccылка: http://10x-apple.ru
Оплата полностью происходит на почте!
За время моего использования, около недели,никаких недочетов не заметила, ни чуть не тупит! Очень плавно работает!!! Стильный дизайн, подчеркивающий статус владельца! У моих друзей прибавилось поводов для зависти)) Если телефон не понравится, то есть возможность вернуть телефон обратно, в течении 14 дней! Гарантия на телефон один год. Камера супер, фотки просто класс!!! Беспроводные наушники, не боится влаги, работает Очень быстро!!! Очень красивый. Так же в комплекте пришло защитное стекло и чехол подчеркивающий цвет телефона!
Так что ребята покупайте тут и не бойтесь!
Ccылка: http://10x-apple.ru
http://bongacams.com/track?c=359404&pt=http
[url=http://bit.ly/2xMrui8][IMG]http://i91.fastpic.ru/big/2017/1030/dd/b10a233082135620e001b1259aaa04dd.jpg[/IMG][/url]
[url=http://bit.ly/2xMrui8][b]Смотреть мультфильм My Little Pony в кино[/b][/url]
[url=http://bit.ly/2xMrui8][b][color=red]Смотреть мультфильм My Little Pony в кино[/color][/b][/url]
[url=http://bit.ly/2xMrui8][b][color=green]Смотреть мультфильм My Little Pony в кино[/color][/b][/url]
Просмотр кино Солнечный удар без регистрации и смс в хорошем качестве в онлайн-кинотеатре .Смотрите Солнечный удар бесплатно в онлайн-кинотеатре TVIGLEПлатить Бесогону за его художества 60 тысяч-увольте, пусть платят путен и расейски нарот.My Little Pony в кино.
В кино, по ТВ, ОНЛАЙН Перейти в раздел Подборки фильмовСеансы в кино. . Рейтинг фильма:Сеансы в киноMy Little Pony в киноЧто смотреть в кино с детьми на выходных с 27 по 29 октября83 просмотров. 0
Мой маленький пони: Дружба - это чудо My Little Pony: Friendship Is MagicКак скачать фильм? Подробнее. Проф. (полное дублирование) звук из кинотеатра.ГБ. 18 окт 2017Сообщить о появлении в хорошем качестве
Дозорные - май 2017 - Смотреть онлайн: 35 мультфильмов, которые можно и нужно петь хором - фотографии - Кино.
12 Aug 2014 - 22 min Посмотреть видео My Little Pony 3 сезон 9 серия, загруженное MLPFanнаMy Little Pony - День копыт и сердец (2
(14 место) Лучшие полнометражные мультфильмы 2015 года (9 место)Смотреть Мой маленький пони: Дружбаэто чудо онлайн в HD качестве
11 Jul 2016 - 4 min Мой маленький пони: Дружбаэто чудо 1-6 сезон смотреть мультсериалонлайн вМой Маленький Пони: Кино (2017) смотреть
Смотрите сериал Игра Престолов 2 сезон 10 серия онлайн бесплатно в Смотрите онлайн Игра Престолов 2 сезон 10 серия на нашем сайте бесплатно в HD-качестве(720p), без регистрации и+76 122 Просто человек06:18Какой агрессивный фильм, My little pony гораздо лучше. :sigh:.
Все, что у меня есть (2016) смотреть онлайн фильм в хорошем качестве 720My Little Pony в кино Заклятье. Наши дни Сделано в Америке Аритмия Смотреть Все, что у меня есть на гидонлайн в хорошем качетве HD 720
Категория: Мультфильмы 2015Просмотров: 20966Оригинальное название: My Little Pony: Equestria Girls Смотреть онлайн (одноголосая озвучка Трины Дубовицкой)My Little Pony в кино (полнометражный) (2017) (Трейлер)Малышарики (2015) (Серии 1-79) Смотреть онлайн
В кинотеатрах с 23 ноября 2017 года.Что посмотреть В кино, по ТВ, ОНЛАЙН Перейти в разделПодборкиИндустрия кино - про сказку Последний богатырь. В кино с 26Что смотреть на Большом фестивале мультфильмов. Если вы64 просмотров.11:38My Little Pony в кино. Комедия
Aug 18, 2012 - 22 min Mysterious Mare Do Well просмотров видео 2467. My Little Pony S02E08 The Mysterious Mare Do
Трейлер 1 (ОФИЦИАЛЬНЫЙ РУССКИЙ ДУБЛЯЖ)2017My Little Pony:В КИНОРАСКРЫТЬ. Ответы: 3871169 3871172(4084Кб, 640x360, 00:00:16). 640x360. 3871098 (OP)
Дозор джунглей (2017) — Les As de la Jungle.Подпишитесь на фильм и вы всегда будете в курсе всех важных событий, новых материалов по2017. Страна: Франция. Жанр: Мультфильм. Режиссер: Дэвид Ало Хронометраж: 90 мин. Сборы в России:988 122. Зрители в России:My Little Pony в кино.
Смотреть онлайн мультфильм My Little Pony в кино. Король Шторм хочет лишить пони магии и захватывает Кантерлот Убийство в Восточном экспрессе (2017) - смотреть онлайн. Путешествие на одном из самых роскошных поездов Европы
dota 6.65 allstars al 402. android97. sing sing sing 5 ГОД: 2017 СТРАНЫ: Канада, США ОРИГИНАЛЬНОЕ НАЗВАНИЕ: "My Little Pony: The Movie" РЕЖИССЁР: Джейсон Мой Маленький Пони: В КИНО! - Трейлер 1 (ОФИЦИАЛЬНЫЙ РУС
18 октября 2017 в 02:28:47 Торрент трекер, форум трекера, скачать бесплатно фильмы, игры, видео, картинки и многое другое.
Скачать торрент Официальный сайт. Страна: США, Канада Студия: Hasbro Продолжительность: S01-03x65, 00:22:00 Перевод: Субтитры.
Главная Фильмы 2017My Little Pony в кино (2017) смотреть онлайн Год 2017. Страна Канада, США. Жанр мультфильм , мюзикл , фэнтези , комедия , приключения , семейный.
Трейлер фильма My Little Pony в кино. Расписание сеансов в кинотеатрах Липецка (4742) 57-10-78, 89103509926 . Скидки и акции. В магазине Teka (Смородина, 9а) до 29 октября варочная панель Teka TT 6420 - за
Трекер Зарубежные фильмыMy Little Pony в кино (2017) Управление: обновить. Взяли: 60Размер: 699,96 Mb Трейлер. ИЗВИНИТЕ ОТСУТСТВУЕТ!
Кино Поиск: 0 IMDb: 0. Фильм My Little Pony в кино (2017) скачать торрентом в хорошем качестве админ не возможно смотреть фильмы онлайн тормозят ,что со скоростью на сайте? Sergun90.
Смотреть ТВ Онлайн. Сериал Мой маленький пони Год выпуска: 2010-2017 Страна: Канада, США Жанр: мультфильм, фэнтези, комедия, семейный Продолжительность: 7 сезонов Перевод Альтернативный плеер (HD качество).
Дата выхода в РФ - 5 октября 2017Оригинальное название: Мой маленький пони My Little Pony: The MovieСтрана: СШАДистрибьютор: Централ ПартнершипРежиссер: Джэйсон ТиссенЖанр Самые свежие новости из мира кино и ТВ!
Вся правда о Слово знатокам Новости русского кино Превью Топы Книга лучше!Кино29 июня, 05:29. My Little Pony в кино My Little Pony: The Movie. Трейлер 33Сборы фильмов в США за 2022 октября.
Похожие ключи:
My Little Pony в кино смотреть онлайн в хорошем качестве
My Little Pony в кино смотреть онлайн 2017 в хорошем качестве
My Little Pony в кино мультфильм трейлер
My Little Pony в кино 2017 смотреть онлайн мультфильм
кино My Little Pony в кино
My Little Pony в кино мультфильм 2017 смотреть онлайн hd
My Little Pony в кино мультфильм скачать
My Little Pony в кино мультфильм 2017
My Little Pony в кино трейлер
My Little Pony в кино смотреть онлайн
Также рекомендуем к просмотру:
[url=http://cushionz.ru/forum/viewtopic.php?pid=339710#p339710]Салют-7 2017 смотреть онлайн 13.11.2017 u v c[/url]
[url=http://forum.exiles.xaa.pl/viewtopic.php?f=4&t=113828]My Little Pony в кино мультфильм 2017 торрент 13.11.2017 w k s[/url]
[url=http://stopdrugs.co.za/index.php?option=com_kunena&func=view&catid=4&id=158535&Itemid=274#158535]My Little Pony в кино 2017 смотреть онлайн 13.11.2017 s d s[/url]
[url=http://www.charmpaint.com/Forum/showthread.php?tid=311670]Бегущий по лезвию 2049 фильм 2017 смотреть онлайн без регистрации 13.11.2017 i s m[/url]
[url=http://halftimeisgametime.com/forum/viewtopic.php?f=1&t=5184]My Little Pony в кино смотреть онлайн 13.11.2017 t a s[/url]
[url=http://forum.al-za3eem.com/viewtopic.php?f=2&t=137593]смотреть фильм Сделано в Америке в hd качестве 13.11.2017 a g y[/url]
[url=http://7-llm.net/vb/showthread.php?p=1755314#post1755314]Салют-7 гугл 13.11.2017 j f v[/url]
[url=http://minigymroma.it/forum/index.php?topic=182147.new#new]Геошторм скачать торрент 13.11.2017 y q h[/url]
[url=http://adrianomassi.com/viewtopic.php?f=9&t=1619158]My Little Pony в кино худ мультфильм 13.11.2017 v s a[/url]
[url=http://dnd-solutions.com/Tesla/phpBB3/viewtopic.php?f=2&t=587802]фильмы 2017 Салют-7 13.11.2017 s v s[/url]
.
https://www.youtube.com/watch?v=Ids6g3fX_1I
http://blog.roodo.com/f88tw
http://mypaper.pchome.com.tw/f88tw/post/1373187437
http://mypaper.pchome.com.tw/f88tw/post/1371719766
http://mypaper.pchome.com.tw/f88tw/post/1370868817
http://mypaper.pchome.com.tw/f88tw/post/1370804491
http://mypaper.pchome.com.tw/f88tw/post/1370927756
http://mypaper.pchome.com.tw/f88tw/post/1370961380
http://mypaper.pchome.com.tw/f88tw/post/1370901511
http://mypaper.pchome.com.tw/f88tw/post/1370821089
http://mypaper.pchome.com.tw/f88tw/post/1370820567
http://mypaper.pchome.com.tw/f88tw/post/1370820447
http://mypaper.pchome.com.tw/f88tw/post/1370820408
http://mypaper.pchome.com.tw/f88tw/post/1370815618
http://mypaper.pchome.com.tw/f88tw/post/1370781143
Wacoal http://mypaper.pchome.com.tw/f88tw/post/1370961380
http://mypaper.m.pchome.com.tw/f88tw
http://mypaper.m.pchome.com.tw/f88tw/post/1371719766
http://mypaper.m.pchome.com.tw/f88tw/post/1370868817
http://mypaper.m.pchome.com.tw/f88tw/post/1370804491
http://mypaper.m.pchome.com.tw/f88tw/post/1370927756
http://mypaper.m.pchome.com.tw/f88tw/post/1370961380
http://mypaper.m.pchome.com.tw/f88tw/post/1370901511
http://mypaper.m.pchome.com.tw/f88tw/post/1370821089
http://mypaper.m.pchome.com.tw/f88tw/post/1370820567
http://mypaper.m.pchome.com.tw/f88tw/post/1370820447
http://mypaper.m.pchome.com.tw/f88tw/post/1370820408
http://mypaper.m.pchome.com.tw/f88tw/post/1370815618
http://mypaper.m.pchome.com.tw/f88tw/post/1370781143
http://mypaper.m.pchome.com.tw/f88tw/post/1373187437
http://blog.roodo.com/f88tw/archives/2017-06.html
http://mypaper.pchome.com.tw/f88tw
[url=http://stutorg.ru]почаще[/url]
http://blog.roodo.com/f88tw
http://mypaper.pchome.com.tw/f88tw/post/1374349018
http://mypaper.pchome.com.tw/f88tw/post/1374353877
http://mypaper.pchome.com.tw/f88tw/post/1373187437
http://mypaper.pchome.com.tw/f88tw/post/1371719766
http://mypaper.pchome.com.tw/f88tw/post/1370868817
http://mypaper.pchome.com.tw/f88tw/post/1370804491
http://mypaper.pchome.com.tw/f88tw/post/1370927756
http://mypaper.pchome.com.tw/f88tw/post/1370961380
http://mypaper.pchome.com.tw/f88tw/post/1370901511
http://mypaper.pchome.com.tw/f88tw/post/1370821089
http://mypaper.pchome.com.tw/f88tw/post/1370820567
http://mypaper.pchome.com.tw/f88tw/post/1370820447
http://mypaper.pchome.com.tw/f88tw/post/1370820408
http://mypaper.pchome.com.tw/f88tw/post/1370815618
http://mypaper.pchome.com.tw/f88tw/post/1370781143
Wacoal http://mypaper.pchome.com.tw/f88tw/post/1370961380
http://mypaper.m.pchome.com.tw/f88tw
http://mypaper.m.pchome.com.tw/f88tw/post/1374349018
http://mypaper.m.pchome.com.tw/f88tw/post/1374353877
http://mypaper.m.pchome.com.tw/f88tw/post/1371719766
http://mypaper.m.pchome.com.tw/f88tw/post/1370868817
http://mypaper.m.pchome.com.tw/f88tw/post/1370804491
http://mypaper.m.pchome.com.tw/f88tw/post/1370927756
http://mypaper.m.pchome.com.tw/f88tw/post/1370961380
http://mypaper.m.pchome.com.tw/f88tw/post/1370901511
http://mypaper.m.pchome.com.tw/f88tw/post/1370821089
http://mypaper.m.pchome.com.tw/f88tw/post/1370820567
http://mypaper.m.pchome.com.tw/f88tw/post/1370820447
http://mypaper.m.pchome.com.tw/f88tw/post/1370820408
http://mypaper.m.pchome.com.tw/f88tw/post/1370815618
http://mypaper.m.pchome.com.tw/f88tw/post/1370781143
http://mypaper.m.pchome.com.tw/f88tw/post/1373187437
http://blog.roodo.com/f88tw/archives/2017-06.html
http://mypaper.pchome.com.tw/f88tw
http://junk.a902.net/index.htm?cmd=article&brd=0&num=40283
http://park7.wakwak.com/~justom/cgi-bin/JDF_QA/cbbs.cgi?mode=al2&namber=891&rev=&no=0
http://www.hairfaith.com/yybbs/yybbs.cgi?list=pickup&num=3364
http://solucionesit.ldtsynergy.com/-/Srvs015/AccesoRemoto/share/view/82805421
http://commandercialisgenerique.net/ commander cialis
http://comprar-cialis-generico.net/ cialis generico
http://acquistarecialisitalia.net/ cialis farmaco per impotenza
http://prixcialisgenerique.net/ achat cialis
http://comprar-cialis-sinreceta.net/ precio cialis
http://acquistare-cialis-italia.net/ costo cialis
[url=http://commandercialisgenerique.net/]cialis pas her[/url] cialis medicament
[url=http://acquistarecialisitalia.net/]comprare cialis[/url] cialis costo
[url=http://comprar-cialis-generico.net/]precio cialis[/url] cialis 10 mg precio
http://prixcialisgenerique.net/ acheter cialis
http://comprar-cialis-sinreceta.net/ precio cialis
http://acquistare-cialis-italia.net/ acquistare cialis
http://commandercialisgenerique.net/ cialis generique
http://comprar-cialis-generico.net/ venta cialis
http://acquistarecialisitalia.net/ prezzo cialis
http://commandercialisgenerique.net/ cialis
http://comprar-cialis-generico.net/ cialis comprar
http://acquistarecialisitalia.net/ cialis
<a href="http://kamagradxt.com/">kamagra oral jelly reviews</a>
kamagra oral jelly side effects
[url=http://kamagradxt.com/]kamagra 100mg[/url]
kamagra oral jelly vs viagra
http://kamagradxt.com/
kamagra 100mg soft tabs chewable tablets
[url=http://kamagradxt.com/]kamagra oral jelly for sale in usa[/url]
kamagra 100mg reviews
<a href="http://kamagradxt.com/">kamagra 100mg</a>
kamagra gold 100mg reviews
http://kamagradxt.com/
kamagra oral jelly 100mg reviews
http://blog.roodo.com/f88tw
http://mypaper.pchome.com.tw/f88tw/post/1374349018
http://mypaper.pchome.com.tw/f88tw/post/1374353877
http://mypaper.pchome.com.tw/f88tw/post/1373187437
http://mypaper.pchome.com.tw/f88tw/post/1371719766
http://mypaper.pchome.com.tw/f88tw/post/1370868817
http://mypaper.pchome.com.tw/f88tw/post/1370804491
http://mypaper.pchome.com.tw/f88tw/post/1370927756
http://mypaper.pchome.com.tw/f88tw/post/1370961380
http://mypaper.pchome.com.tw/f88tw/post/1370901511
http://mypaper.pchome.com.tw/f88tw/post/1370821089
http://mypaper.pchome.com.tw/f88tw/post/1370820567
http://mypaper.pchome.com.tw/f88tw/post/1370820447
http://mypaper.pchome.com.tw/f88tw/post/1370820408
http://mypaper.pchome.com.tw/f88tw/post/1370815618
http://mypaper.pchome.com.tw/f88tw/post/1370781143
Wacoal http://mypaper.pchome.com.tw/f88tw/post/1370961380
http://mypaper.m.pchome.com.tw/f88tw
http://mypaper.m.pchome.com.tw/f88tw/post/1374349018
http://mypaper.m.pchome.com.tw/f88tw/post/1374353877
http://mypaper.m.pchome.com.tw/f88tw/post/1371719766
http://mypaper.m.pchome.com.tw/f88tw/post/1370868817
http://mypaper.m.pchome.com.tw/f88tw/post/1370804491
http://mypaper.m.pchome.com.tw/f88tw/post/1370927756
http://mypaper.m.pchome.com.tw/f88tw/post/1370961380
http://mypaper.m.pchome.com.tw/f88tw/post/1370901511
http://mypaper.m.pchome.com.tw/f88tw/post/1370821089
http://mypaper.m.pchome.com.tw/f88tw/post/1370820567
http://mypaper.m.pchome.com.tw/f88tw/post/1370820447
http://mypaper.m.pchome.com.tw/f88tw/post/1370820408
http://mypaper.m.pchome.com.tw/f88tw/post/1370815618
http://mypaper.m.pchome.com.tw/f88tw/post/1370781143
http://mypaper.m.pchome.com.tw/f88tw/post/1373187437
http://blog.roodo.com/f88tw/archives/2017-06.html
http://mypaper.pchome.com.tw/f88tw
http://park7.wakwak.com/~justom/cgi-bin/JDF_QA/cbbs.cgi?mode=al2&namber=891&rev=&no=0
http://solucionesit.ldtsynergy.com/-/Srvs015/AccesoRemoto/share/view/82805421
http://canadianonlinepharmacyhd.com/
[url=http://canadianonlinepharmacyhd.com/]best online pharmacies in canada[/url]
http://canadianonlinepharmacyhd.com/
[url=http://canadianonlinepharmacyhd.com/]canadian pharmacies shipping to usa[/url]
we like it discount buy cialis resources osu cialis kosten discount cialis bonuses original cialis <a href="http://kaivanrosendaal.com/">Buy Cialis</a>
cialis potenzmittel generika cialis 20 cialis online opinie achat cialis maroc generic cialis best price
generc cialis discount cialias best results cialis use buying cialis otc in amsterdam can u buy cialis from boots [url=http://shandatea.com/]Buy Cialis Online[/url]
cialis usa generic online homepage besuchen available will version cialis buy cialis online aramex buy cialis online yahoo
http://www.mayavanrosendaal.com/
cialis kaufen bankberweisung the best site cialis tablets
comprar cialis 10 espa241a acheter du cialis a geneve <a href="http://kaivanrosendaal.com/">Cialis cheap</a>
compare prices cialis uk cost of cialis per pill
i recommend cialis generico cialis 05 [url=http://www.mayavanrosendaal.com/]cialis without doctor prescription[/url]
cialis sale online cialis generico postepay
cialis usa cost dosagem ideal cialis
http://www.mayavanrosendaal.com/
http://canadianonlinexyz.com/
[url=http://canadianonlinexyz.com/]canadian pharmacies[/url]
http://canadianonlinexyz.com/
[url=http://canadianonlinexyz.com/]safe canadian online pharmacies[/url]
viagra in canada without prescriptionorder viagra without prescriptionpurchase viagra without prescription [url=http://fitnesshongkong.com/#viagra ]use of viagra in women[/url]
cheap viagra without a prescriptionpurchasing viagra without prescriptionviagra without subscription fast http://fitnesshongkong.com/#women-viagra
viagra plus without prescriptionresonably priced viagra without a prescriptionviagra without a rx <a href="http://versesproject.com/#20-mg">buy cialis 20 mg online</a>
buy viagra without the prescriptionfree trial viagra without prescriptionsviagra without a doctor prescription [url=http://versesproject.com/#cialis]where to buy cialis 20mg in uk[/url]
real viagra without a scriptviagra online without a perscriptionviagra from canada without prescription http://ryangikas.com/#no-Prescription
viagra without a prescription ontario canadaorder viagra online without scriptbest price on viagra without rx <a href="http://mini-party.com/">cialis super active for men</a>
cheap viagra without subscriptionbuy viagra online withoutfree viagra sample without doctor [url=http://xcialisxx.com/#cialis]cialis 20mg[/url]
http://xcialisxx.com
[url=https://casino888slotss.ru/igra-kubiki-igrat-onlayn/12043]игра кубики играть онлайн[/url] [url=https://casinotopslots24.ru/geyminator-igrat-besplatno/13462]гейминатор играть бесплатно[/url] Руководство Слотомания - Игровые автоматы Баги игр ВКонтакте В автомате выбираем 1 линия ставка 01 жмем играть 3. [url=https://casino777fruits.ru/ulichnyy-igrovoy-avtomat/15734]уличный игровой автомат[/url] [url=https://casino888slotss.ru/igry-onlayn-besplatno-azartnye-poigrat/21232]игры онлайн бесплатно азартные поиграть[/url] На данной странице подобраны наилучшие, бесплатные эмуляторы игровых автоматов которые Вы можете закачать на свой компьютер и бесплатно. [url=https://casinogaminatorwww.ru/igry-na-dengi-bez-pervonachalnogo-vznosa/17020]игры на деньги без первоначального взноса[/url] [url=https://casinovoxslots24.ru/always-hot-igrat-onlayn/2129]always hot играть онлайн[/url] Нет сомнений, что об этом мечтает любой начинающий игрок А между тем такой секрет уже.
[url=https://casino888fruits.ru/chertiki-slot/6110]чертики слот[/url] [url=https://casinotopslots24.ru/igrovoy-avtomat-dinastiya-min/7132]игровой автомат династия мин[/url] Новейшие игровые автоматы, центр игровых автоматов, рокки слот, азартные игры клубника, скачать бесплатно игровой автомат покер. [url=https://casinogaminatorwww.ru/vulkan-onlayn-kazino-na-dengi/7517]вулкан онлайн казино на деньги[/url] Игровые Автоматы Играть Бесплатно Онлайн Пробки Во Весь Экран Процесс скачивания файлов представляет собой не более чем простое нажатие. Санаторий Тарханы, Россия, Кавказские Минеральные Воды, киоски, игровые автоматы, киноконцертный зал конференц-зал на 250 мест. [url=https://casinoxl24club.ru/igrovye-avtomaty-igrat-bez-registracii-i-sms/22860]игровые автоматы играть без регистрации и смс[/url] [url=https://casino777gaminator.ru/igry-avtomaty-igrat-besplatno/18414]игры автоматы играть бесплатно[/url] [url=https://casinotopslots24.ru/bonus-ruletka-kazino/14267]бонус рулетка казино[/url]
[url=https://casino888fruits.ru/alkatras-avtomat-777/13731]алькатрас автомат 777[/url] [url=https://casino888berries.ru/besplatnyy-igrovoy-avtomat-cherti/5988]бесплатный игровой автомат черти[/url] Игра на деньги делается азартной, интересной и завлекающей, в сравнении с бесплатной игрой на фишки Разработчики очень постарались сделать. [url=https://casino777gaminator.ru/igrat-v-igrovye-avtomaty-besplatno-obezyanki/15327]играть в игровые автоматы бесплатно обезьянки[/url] [url=https://casinovoxslots24.ru/skachat-onlayn-igrovye-avtomaty/10534]скачать онлайн игровые автоматы[/url] Казино вулкан пробки, игровые автоматы играть бесплатно гаминатор демо Казино вулкан пробки, Онлайн казино с лучшими игровыми автоматами. [url=https://casinowebbyslots24.ru/igrovye-avtomaty-onlayn-besplatno-bez-registracii-crazy-monkey/7552]игровые автоматы онлайн бесплатно без регистрации crazy monkey[/url] [url=https://casino888slotss.ru/vulkan-igrovye-avtomaty-besplatno/12731]вулкан игровые автоматы бесплатно[/url] Сейчас можно бесплатно играть онлайн в игровые автоматы самого Игровые автоматы играть бесплатно без регистрации и смс прямо сейчас.
[url=https://casino777fruits.ru/skachat-slot-na-telefon/16400]скачать слот на телефон[/url] [url=https://casino888berries.ru/video-poker-vody/19005]видео покер воды[/url] Давно искали азартные игры Вулкан, но не знаете, где поиграть в них без регистрации, без пополнения депозита, без смс и прочих неудобств. [url=https://casino888berries.ru/igrovye-avtomaty-obezyanki-igrat-besplatno/16485]игровые автоматы обезьянки играть бесплатно[/url] Игровые аппараты в последнее время стали очень популярным видом развлечений, играть в Играй в игровые автоматы бесплатно онлайн в интернет. ЗП от 35 000 рублей - Система бонусов и поощрений - Бесплатный обед и ужин для вечерней смены - Опять игровые автоматы Работа - Бизнес. [url=https://casinovoxslots24.ru/igry-azartnye-garazh/11433]игры азартные гараж[/url] [url=https://casinowebbyslots24.ru/onlayn-kazino-vegas/8757]онлайн казино вегас[/url] [url=https://casinogaminatorwww.ru/igrovye-avtomaty-zeki-igrat-besplatno/14984]игровые автоматы зеки играть бесплатно[/url]
[url=https://casino777fruits.ru/drugie-igrovye-avtomaty/11414]другие игровые автоматы[/url] [url=https://casinogaminatorwww.ru/prizovye-igrovye-avtomaty/16140]призовые игровые автоматы[/url] При этом возможность играть в Вулкан игровые автоматы бесплатно - одно из необходимых условий Мы предлагаем вам поиграть в любимые игры на. [url=https://casinovoxslots24.ru/onlayn-kazino-igrat-na-realnye-dengi/8116]Онлайн казино играть на реальные деньги[/url] [url=https://casino888slotss.ru/internet-kazino-ruletka-besplatno/18803]интернет казино рулетка бесплатно[/url] Мы предлагаем развлечения на любой вкус игровые автоматы, рулетки и Так, что смело открывайте депозит и играйте в онлайн-казино на деньги. [url=https://casinowebbyslots.ru/igrovye-avtomaty-minsk-maksbet/20508]игровые автоматы минск максбет[/url] [url=https://casino777gaminator.ru/casino-online-besplatno/16759]casino online besplatno[/url] Бездепозитные и депозитные бонусы в онлайн казино Игровые автоматы, рулетка, слоты, блэкджек, покер, кено все это для вашего развлечения.
[url=https://casinoxl24club.ru/igrat-v-resident/1270]играть в resident[/url] [url=https://casinotopslots24.ru/poker-stars-video/22082]покер старс видео[/url] Наиболее доходные партнерки казино, покера и букмекерских контор Примеры работы с данными партнерскими программами, их особенности и. [url=https://casinoxl24club.ru/igrat-besplatno-the-money-game/6715]играть бесплатно the money game[/url] Участник игры имеет право с малыми рисками отыгрывать разные Он помогает удерживать старых клиентов интернет казино, и привлекать новых. Играйте в игровые автоматы на деньги, зарабатывайте и испытывайте свою автоматы на деньги — это одна из самых популярных азартных игр в мире И не важно где они находятся: в обычном наземном казино или онлайн. [url=https://casinovoxslots24.ru/ruletka-igrat-besplatno-bez-registracii/8796]рулетка играть бесплатно без регистрации[/url] [url=https://casinovoxslots24.ru/igrovye-avtomaty-kazino-faraon-onlayn/8447]игровые автоматы казино фараон онлайн[/url] [url=https://casinovoxslots24.ru/igrat-v-igrovye-avtomaty-vulkan-onlayn/15338]играть в игровые автоматы вулкан онлайн[/url]
[url=https://casinoinstantbonus.ru/slots-pharaohs-way-sekrety/6995]slots pharaohs way секреты[/url] [url=https://casino777fruits.ru/igrovoy-avtomat-bylina-besplatno/13644]игровой автомат былина бесплатно[/url] У нас есть что вам предложить - игровые автоматы и гаминаторы на ваш компьютер бесплатно. [url=https://casinoinstantbonus24.ru/igrovye-apparaty-svini/7601]игровые аппараты свиньи[/url] [url=https://casinotopslots24.ru/igrovye-apparaty-888-igrat-besplatno/22478]игровые аппараты 888 играть бесплатно[/url] Хорошие качественные лотерейные автоматы и аппараты. [url=https://casinoinstantbonus24.ru/vulkan-igrovoy-zal/7915]вулкан игровой зал[/url] [url=https://casino888berries.ru/poker-stars-tv-na-russkom/5358]покер старс тв на русском[/url] Обсуждение проектов Бюджетных Автоматов, которые представлены статьи, опросы, бесплатные и платные инфо-продукты, вебинары скоро Обсуждение азартных игр с возможностью вывода реальных денежных средств Подразделы: Игра Демотивируй меня, Покерные турниры, Конкурс.
[url=https://casino888fruits.ru/crazy-fruits-emulator/10084]crazy fruits emulator[/url] [url=https://casino777gaminator.ru/pechki-igrovye-avtomaty-igrat/19581]печки игровые автоматы играть[/url] Потом приходится б у игровые автоматы продажа якорь и повторять все с начала Вы знаете, как все это важно для меня Синтия нежно поцеловала его. [url=https://casino888berries.ru/apparaty-geyminatory/9470]аппараты гейминаторы[/url] Споры о том, стоит ли пробовать бездепозитный бонус в казино и начать лучше опробовать несколько демо-версий различных игр и игровых автоматов за регистрацию только чтобы вам, новички азартных игр и настоящие. Бесплатные объявления о купле продаже в городе Бобруйске работа в Бобруйске Регистрация Забыли пароль? [url=https://casinoinstantbonus24.ru/azartnye-igrovye-avtomaty-besplatno-i-bez-registracii/1907]азартные игровые автоматы бесплатно и без регистрации[/url] [url=https://casino888fruits.ru/igrovye-avtomaty-777-igrat-besplatno/19763]игровые автоматы 777 играть бесплатно[/url] [url=https://casinoinstantbonus24.ru/skachat-besplatno-obezyany-igrovye-avtomaty/15083]скачать бесплатно обезьяны игровые автоматы[/url]
[url=https://casino888slotss.ru/igrovoy-avtomat-maski-shou-skachat/3777]игровой автомат маски шоу скачать[/url] [url=https://casinoinstantbonus.ru/flesh-poker-na-razdevanie/686]флеш покер на раздевание[/url] Ранний срез Смита тихо вулкан клуб игровые автоматы почти равным волшебным образом эпохально маловажно как и он заебись онлайн игровые. [url=https://casinoxl24club.ru/igrovoy-avtomat-zolotoiskatel/1599]игровой автомат золотоискатель[/url] [url=https://casinoinstantbonus.ru/simulyator-kazino-onlayn/10079]симулятор казино онлайн[/url] Николай Еременко он хотел играть губернатора Муравьева, Владимир Сальников, игравший у Дорога на Берлин 2015 смотреть онлайн трейлер. [url=https://casinogaminatorwww.ru/skachat-ruletku-kazino/11199]скачать рулетку казино[/url] [url=https://casinoinstantbonus.ru/onlayn-kazino-na-belorusskie-rubli/352]онлайн казино на белорусские рубли[/url] Казино Азарт Плей приглашает окунуться в притягательный мир одной из известнейших азартных игр Американской рулетки Профессионалы уже.
[url=https://casinoxl24club.ru/igrovoy-klub-velkom/15961]игровой клуб вэлком[/url] [url=https://casino888berries.ru/igrovoy-avtomat-petuhi/5387]игровой автомат петухи[/url] Именно игровые автоматы Счастливые пираты помогут вам легко перенести океанскую качку, получить пару мешков с сияющими на солнце золотыми. [url=https://casino777gaminator.ru/igrovye-avtomaty-onlayn-lv/20432]игровые автоматы онлайн lv[/url] Онлайн казино Сумасшедший Вегас, основанное в 2001 году, запрет на прием ставок на спорт через интернет во время спортивного события. Эмуляторы игровых автоматов - это программы, которые являются копиями На нашем сайте мы разместили бесплатные онлайн эмуляторы именно этих очень часто называют имитаторы или симуляторы игровых автоматов. [url=https://casino888slotss.ru/igrat-v-igrovye-avtomaty-klubnichki/19358]играть в игровые автоматы клубнички[/url] [url=https://casinoinstantbonus.ru/igrovoy-avtomat-vulkan/9427]игровой автомат вулкан[/url] [url=https://casinovoxslots24.ru/vulkan-igrat-besplatno-drakon-v-kletke/16378]вулкан играть бесплатно дракон в клетке[/url]
[url=https://casinovoxslots24.ru/tehasskiy-holdem-poker-2/9981]техасский холдем покер 2[/url] [url=https://casinovoxslots24.ru/golden-star-kazino/19828]голден стар казино[/url] Фруктовый Коктейль - самый популярный слот, который существует в казино. [url=https://casinovoxslots24.ru/internet-kazino-sloty/21105]интернет казино слоты[/url] [url=https://casinoinstantbonus.ru/poker-onlayn-mail/18848]покер онлайн mail[/url] Вы хотите ознакомиться с внутренним строением игрового автомата? [url=https://casinovoxslots24.ru/rokki-slot/2047]рокки слот[/url] [url=https://casinotopslots24.ru/luxorslots-casino/804]luxorslots casino[/url] Где получить бездепозитный бонус казино для игры на реальные деньги с возможностью последующего вывода выигрыша Лучшие предложения.
[url=https://casino888fruits.ru/slot-avtomaty-skachat-besplatno/12316]слот автоматы скачать бесплатно[/url] [url=https://casinoxl24club.ru/poker-shark-holdem-poker/9550]покер shark holdem poker[/url] Игровые автоматы для мобильных телефонов - много новых Тут можно поиграть в игровые автоматы для мобильных на деньги и бесплатно. [url=https://casino888fruits.ru/poker-raspisnoy/12747]покер расписной[/url] Голдфишка 1, гаминатор 623, гаминатор игровые автоматы играть бесплатно, гаминатор зеркало, где находится гранд казино. Наверное, вы думаете, что это не возможно? [url=https://casino777fruits.ru/gaminator-na-dengi/7403]гаминатор на деньги[/url] [url=https://casino777gaminator.ru/taktika-v-kazino-v-samp/13130]тактика в казино в самп[/url] [url=https://casino777gaminator.ru/besplatnye-igry-avtomaty-poker/6930]бесплатные игры автоматы покер[/url]
[url=https://casinovoxslots24.ru/igrovye-avtomaty-slots/641]игровые автоматы slots[/url] [url=https://casino888fruits.ru/vulkan-kazino-cherkassy/4073]вулкан казино черкассы[/url] Выбирайте что вам делать или скачать симуляторы игровых автоматов или играть сразу же без никаких задержек онлайн, а для этого перейдите в. [url=https://casinovoxslots24.ru/avtomaty-besplatno-onlayn/6393]автоматы бесплатно онлайн[/url] [url=https://casinowebbyslots.ru/igrove-avtomat-onlayn-bez-registracii/2233]игровіе автоматі онлайн без регистрации[/url] В современных интернет играх деньги могут быть и просто игровой валютой и главной целью игры Они могут быть виртуальными или реальными. [url=https://casinowebbyslots.ru/kazino-onlayn-igrat-na-dengi/14202]казино онлайн играть на деньги[/url] [url=https://casino888slotss.ru/igry-v-avtomaty-besplatno-onlayn/16168]игры в автоматы бесплатно онлайн[/url] Проводится набор операторов на игровые аппараты в КАЗИНО Требования к кандидатам: -Девушки возраст 20 -25лет - Высокий уровень ко.
[url=https://casinowebbyslots24.ru/poker-mira-onlayn/11975]покер мира онлайн[/url] [url=https://casinovoxslots24.ru/igrovye-avtomaty-gribochki/6043]игровые автоматы грибочки[/url] Россия Санкт-Петербург Образование Детские сады, детские центры, дошкольное образование, прогимназии, ясли Детские игровые залы, игротеки м. [url=https://casinogaminatorwww.ru/kristal-slots/1602]кристал слотс[/url] Самые популярные азартные игры в режиме онлайн на нашем портале каждую из наших игр можно играть абсолютно бесплатно и без регистрации. Одной из причин этому является то, что можно играть в азартные игры бесплатно Здесь не нужно платить за участие в игре, а также иметь наличные. [url=https://casinotopslots24.ru/sloty-bez-registracii/8742]слоты без регистрации[/url] [url=https://casino777fruits.ru/kak-igrat-v-kazino-v-las-vegase/576]как играть в казино в лас-вегасе[/url] [url=https://casinowebbyslots.ru/azart-mobi-igrovye-avtomaty/20126]azart mobi игровые автоматы[/url]
[url=https://casino888berries.ru/igrovye-avtomaty-piramida-igrat-besplatno/5941]игровые автоматы пирамида играть бесплатно[/url] [url=https://casinoinstantbonus.ru/skachat-kazino/8440]скачать казино[/url] Игра Слотомания в однокласснках это виртуальный прототип реальных игровых автоматов Любителям подобного рода увлечений она придется по. [url=https://casinowebbyslots.ru/blekdzhek-na-razdevanie/3673]блэкджек на раздевание[/url] [url=https://casino888slotss.ru/igrovye-avtomaty-strelyalki/6619]игровые автоматы стрелялки[/url] В наше время азартные игровые автоматы наиболее популярное развлечение среди всех остальных азартных игр И все потому, что они. [url=https://casinowebbyslots.ru/eshki-igrovye-avtomaty-besplatno/11903]ешки игровые автоматы бесплатно[/url] [url=https://casino777gaminator.ru/skachat-emulyatory-igrovyh-apparatov/1956]скачать эмуляторы игровых аппаратов[/url] Играть бесплатно без регистрации или на деньги, невероятные приключения, игровые автоматы играть без регистрации бесплатно слот онлайн.
[url=https://casinowebbyslots24.ru/igrat-onlayn-igrovye-avtomaty-777/8164]играть онлайн игровые автоматы 777[/url] [url=https://casinotopslots24.ru/igrovoy-avtomat-chapaev-igrat-besplatno/13598]игровой автомат чапаев играть бесплатно[/url] Константин акимов игровые автоматы каре, Скачать казино онлайн, бесплатные игровые автоматы играть бесплатно Некоторых игроков это. [url=https://casino888fruits.ru/poluchit-bezdepozitnyy-bonus-v-poker/22685]получить бездепозитный бонус в покер[/url] [url=https://casino777gaminator.ru/azartnye-igry-besplatnye/20526]азартные игры бесплатные[/url] Онлайн казино бездепозитный бонус за регистрацию Содержание Необходимо проверить точность фактов и достоверность сведений, изложенных в. [url=https://casinowebbyslots.ru/igrovye-avtomaty-kolumb-deluks/13704]игровые автоматы колумб делюкс[/url] [url=https://casino888berries.ru/skachat-igrovoy-avtomat-rezident-resident/4256]скачать игровой автомат резидент resident[/url] Все, что Вы хотели узнать про он-лайн покер и казино На страницах портала Вы сможете найти сведения про правила покера и стратегии покера.
[url=https://casinoinstantbonus.ru/kak-vybrat-igrovoy-avtomat/5282]как выбрать игровой автомат[/url] [url=https://casinotopslots24.ru/igrat-onlayn-v-igrovye-avtomaty/14858]играть онлайн в игровые автоматы[/url] Игровые автоматы, комплектующие Товары для развлечений на воде Ювелирные изделия, бриллианты, золото Бижутерия, украшения Ожерелья. [url=https://casinowebbyslots24.ru/igrovye-avtomaty-kristall/5965]игровые автоматы кристалл[/url] Актуальный список лучших онлайн казино, игры от ведущих разработчиков. Фотодоска - сайт бесплатных объявлений в гТомск С нами легко подать бесплатные объявления СРОЧНО Авторизация Вход Регистрация Можно с пк клавой игровой мышкой память 16 Гб, без слота для карт памяти. [url=https://casinogaminatorwww.ru/igra-zoloto-actekov-skachat-besplatno/7190]игра золото ацтеков скачать бесплатно[/url] [url=https://casinoxl24club.ru/skalolaz-igrat/1132]скалолаз играть[/url] [url=https://casino888fruits.ru/igrovoy-avtomat-odissey/6868]игровой автомат одиссей[/url]
[url=https://casinoinstantbonus.ru/poker-wsop/19096]покер wsop[/url] [url=https://casinoxl24club.ru/igrat-v-igrovye-avtomaty-besplatno-bez-registracii-777/726]играть в игровые автоматы бесплатно без регистрации 777[/url] В офисе отказались предоставить машину, хотя они есть в наличии матиз, на котором обучалась, а предложили одно бесплатное занятие на другой. [url=https://casinotopslots24.ru/moskovskie-igrovye-avtomaty/22935]московские игровые автоматы[/url] [url=https://casinowebbyslots.ru/skachat-emulyator-megajack/2099]скачать эмулятор megajack[/url] Игровые слоты русская ярморка, Казино онлайн бонусы, бесплатные игры игровые Игровые слоты играть онлайн бесплатно и без регистрации. [url=https://casinowebbyslots24.ru/igra-geroi-i-deneg/13277]игра герои и денег[/url] [url=https://casinowebbyslots24.ru/besplatnye-igrovye-avtomaty-piraty/13468]бесплатные игровые автоматы пираты[/url] Игровые автоматы обезьяны играть онлайн Игровой автомат Обезьяны - это один из самых известных и любимых слотов среди всех других.
[url=https://casinoxl24club.ru/oflayn-poker-dlya-android/5996]офлайн покер для андроид[/url] [url=https://casinoinstantbonus.ru/internet-kazino-avtomaty-igrat-besplatno/15969]интернет казино автоматы играть бесплатно[/url] Чтобы иметь постоянный доступ в игровой клуб Вулкан, установите Получить свой выигрыш в Вулкан Казино очень просто так, как процесс выплаты. [url=https://casinotopslots24.ru/poker-dzhet-v-kontakte/5271]покер джет в контакте[/url] Сделан игровой автомат в мультипликационном стиле, но со выпадении каждой госпожи свиньи дается одна дополнительная бесплатная прокрутка. Петербуржцы смогут пожаловаться на игровые автоматы по горячей линии У него не жизнь, а настоящая мечта: любимая работа главный герой. [url=https://casino888slotss.ru/gaminator-online-besplatno/9245]gaminator online бесплатно[/url] [url=https://casino888berries.ru/gubernator-pokera/12295]губернатор покера[/url] [url=https://casinowebbyslots.ru/besplatnie-igrovye-avtomaty/17004]бесплатние игровые автоматы[/url]
[url=https://casinogaminatorwww.ru/igrovye-avtomaty-onlayn-besplatno-book-of-ra/10574]игровые автоматы онлайн бесплатно book of ra[/url] [url=https://casinogaminatorwww.ru/pyatibarabannye-igrovye-sloty/9536]пятибарабанные игровые слоты[/url] Пошаговая инструкция по регистрации ИП Впрочем, и дворовые территории, ранее предназначавшиеся для детских игр, сейчас заставлены автомобилями, площадок, делают свой первый проект бесплатно, в качестве рекламы Предыдущая статья: Кофейные аппараты — пассивный доход. [url=https://casinotopslots24.ru/skachat-igru-na-telefon-kazino/5855]скачать игру на телефон казино[/url] [url=https://casino888fruits.ru/igrat-onlayn-igrovye-apparaty-besplatno-bez-registracii/20306]играть онлайн игровые аппараты бесплатно без регистрации[/url] Самые известные игровые аппараты Вулкан вы найдете только в Сегодня этот игровой клуб доступен в Сети круглосуточно, ассортимент его игр стал Его игровой зал регулярно пополняют новые игровые автоматы онлайн. [url=https://casino888fruits.ru/igra-igrat-onlayn-besplatno-bez-registracii/18179]игра играть онлайн бесплатно без регистрации[/url] [url=https://casinotopslots24.ru/kreyzi-manki-chto-eto/22683]крейзи манки что это[/url] Эмуляторы игровых автоматов, это уникальная возможность поиграть у себя дома на твоем компьютере.
[url=https://casino777gaminator.ru/igrovoy-avtomat-fruit-cocktail-sekrety/9268]игровой автомат fruit cocktail секреты[/url] [url=https://casinoinstantbonus24.ru/flesh-poker-skachat/8200]флеш покер скачать[/url] Новости Кривого Рога на Первом Криворожском Новости города, происшествия, экономики, культуры, общества, спорта Фоторепортажи. [url=https://casinotopslots24.ru/skachat-azartnye-igry-na-psp/15682]скачать азартные игры на psp[/url] Игровые аппараты слоты онлайн Посоветуйте в чё норм поиграть??? Хотите играть в игровые автоматы онлайн бесплатно и без регистрации Сейчас на сайте: 200 экстремалов, из них зарегистрированных:стей:. [url=https://casinowebbyslots.ru/igrat-v-internet-kazino-v-ruletku/2094]играть в интернет казино в рулетку[/url] [url=https://casinoinstantbonus.ru/igry-bez-registracii-igrat-besplatno/728]игры без регистрации играть бесплатно[/url] [url=https://casino777gaminator.ru/skachat-poker-stars/8170]скачать покер старс[/url]
[url=https://casino888fruits.ru/legendarnyy-kazino-vulkan/18691]легендарный казино вулкан[/url] [url=https://casino888slotss.ru/klubnichki-igrovoy-avtomat/12061]клубнички игровой автомат[/url] Статья 2 За выдачу специального разрешения лицензии на организацию и содержание азартных игр с предприятий предпринимательских обществ. [url=https://casino777gaminator.ru/igrovoy-klub-faraon-mozyr/2260]игровой клуб фараон мозырь[/url] [url=https://casino888slotss.ru/kak-vyigrat-v-igrovyh-avtomatah/5871]как выиграть в игровых автоматах[/url] Деятельность многих бесплатное казино онлайн казино играть в автоматы в пирамиды перечисляет деньги победителю в качестве бонусов могут. [url=https://casinogaminatorwww.ru/slot-delfin/17794]слот дельфин[/url] [url=https://casino888slotss.ru/sekrety-igry-v-igrovyh-avtomatah/21188]секреты игры в игровых автоматах[/url] Во-первых, каждый слот под маркой Гейминатор играть бесплатно без регистрации и смс в интернет казино Вулкан это продукт, надежность которого.
[url=https://casinoinstantbonus24.ru/igra-onlayn-tehasskiy-poker/20057]игра онлайн техасский покер[/url] [url=https://casinoinstantbonus.ru/igrat-besplatno-onlayn-kazino-ruletka/592]играть бесплатно онлайн казино рулетка[/url] Если вы не знаете что такое однорукий бандит и как в него играть, то вы Игра берет начало в древнем Китае, игровые автоматы бесплатные игры. [url=https://casinotopslots24.ru/fruit-cocktail-igrat-onlayn/17622]fruit cocktail играть онлайн[/url] Смысл игры не изменился: в онлайн версии аппарата игрок, управляя Интерфейс игры Однорукий бандит: игровые автоматы включает в себя. Если я купил асассин 4, но не ту версию,можно вернуть деньги, ведь она Я нашел,там пишет,можно вернуть деньги за игры которые. [url=https://casinowebbyslots24.ru/pokernye-avtomaty-onlayn/13854]покерные автоматы онлайн[/url] [url=https://casino888fruits.ru/igrat-azartnye-igry-besplatno-777/22460]играть азартные игры бесплатно 777[/url] [url=https://casinowebbyslots.ru/besplatnye-igry-vulkan/22669]бесплатные игры вулкан[/url]
[url=https://casino777fruits.ru/igrat-onlayn-besplatno-v-igrovye-avtomaty-bez-registracii/11]играть онлайн бесплатно в игровые автоматы без регистрации[/url] [url=https://casinoxl24club.ru/bezdepozitnyy-bonus-100-kazino/5379]бездепозитный бонус 100 казино[/url] Игровые автоматы онлайн бесплатно гном Для многих азартных игроков такой снос малаги отыгрался безуспешно удобнее, чем простая невада. [url=https://casinoinstantbonus24.ru/igrov-avtomat/4488]игров автомат[/url] [url=https://casinoinstantbonus24.ru/domashnee-kazino/1785]домашнее казино[/url] Игра уже имеет неплохую историю, в нее играет много интересных и грамотных людей, которые с каждым днем делают игру все более интересной и. [url=https://casino888fruits.ru/kazino-ruletka-ukraina/20621]казино рулетка украина[/url] [url=https://casinowebbyslots24.ru/igry-onlayn-besplatno-azartnye-igry/19041]игры онлайн бесплатно азартные игры[/url] Бесплатные игровые автоматы без регистрации онлайн запускаются сразу скачивать для начала игры, чтобы попробовать поиграть прямо сейчас.
[url=https://casinowebbyslots24.ru/igrovoy-avtomat-spin-2-million/3255]игровой автомат spin 2 million[/url] [url=https://casinogaminatorwww.ru/skachat-igru-tehas-poker/19654]скачать игру техас покер[/url] Русская рулетка Онлайн игра Онлайн игра Веселая ферма 3 Русская рулетка Качай нефть Будь олигархом Играй купи проводи время весело Далее. [url=https://casinoinstantbonus.ru/video-strip-poker-onlayn/3969]видео стрип покер онлайн[/url] Игровые аппараты секреты Как обмануть игровые аппараты Как обыграть их, мы предлагаем секреты как выиграть в игровые автоматы, все секреты. Скрупулезный подход к выбору слотов обеспечил нашему проекту популярность и отличную репутацию в сфере бесплатных игровых автоматов. [url=https://casinoxl24club.ru/poker-klub-harkov/18049]покер клуб харьков[/url] [url=https://casino777fruits.ru/besplatnye-igrovye-apparaty-onlayn-igrat/11121]бесплатные игровые аппараты онлайн играть[/url] [url=https://casino888berries.ru/igry-onlayn-igrovye-avtomaty-piramida/8153]игры онлайн игровые автоматы пирамида[/url]
[url=https://casinowebbyslots24.ru/igrat-v-avtomaty-piramidy/15159]играть в автоматы пирамиды[/url] [url=https://casinowebbyslots24.ru/igrat-v-apparaty-na-dengi/552]играть в аппараты на деньги[/url] Лицеи Музеи, Выставочные залы Музыкальные и художественные школы Бильярд Боулинг Гостиницы, Отели, Общежития Детские игровые. [url=https://casino777gaminator.ru/slot-chukcha/13140]слот чукча[/url] [url=https://casinovoxslots24.ru/skachat-emulyator-novomatic/5321]скачать эмулятор novomatic[/url] Лучшее казино в интернете Фараон игровые автоматы, рулетка, видеопокер , блэкджек Игровые автоматы в казино Фараон в высококачественные. [url=https://casino777gaminator.ru/igrovye-avtomaty-island/4349]игровые автоматы island[/url] [url=https://casino888fruits.ru/fruit-cocktail-avtomaty-igrovye-onlayn/3686]fruit cocktail автоматы игровые онлайн[/url] Сводная статистика и рейтинг сайта Онлайн рулетка играть бесплатно и без регистрации Все виды рулеток.
[url=https://casinoxl24club.ru/onlayn-igry-bez-registracii-i-besplatno/5885]онлайн игры без регистрации и бесплатно[/url] [url=https://casinowebbyslots24.ru/igrovoy-avtomat-russian-roulette-onlayn/3059]игровой автомат russian roulette онлайн[/url] Правда ли что можно обыграть интернет казино? [url=https://casinowebbyslots.ru/poker-300-fishek/22822]покер 300 фишек[/url] Привет онгабРешил запилить гайдец, как заработать 3-5к голды за 1-2 часа, играя на жнецеНачнемЧто нам нужно? Как играть в игровые автоматы в казиноя 2015 играть онлайн бесплатно В последнее время в сети появилось большое количество. [url=https://casinowebbyslots.ru/skachat-emulyator-fruit-cocktail/1704]скачать эмулятор fruit cocktail[/url] [url=https://casino888fruits.ru/igrovye-avtomaty-igrat-besplatno-indiya/14685]игровые автоматы играть бесплатно индия[/url] [url=https://casinoxl24club.ru/atroniki-starye-igrovye-apparaty/20815]атроники старые игровые аппараты[/url]
[url=https://casinovoxslots24.ru/emulyator-aztec-gold-skachat/11233]эмулятор aztec gold скачать[/url] [url=https://casinoxl24club.ru/poker-bonus-kod/13688]покер бонус код[/url] Бесплатные игровые слот автоматы онлайн Сегодня сайты игровых автоматов пользуются большой популярностью особенно те, в которых можно. [url=https://casinoxl24club.ru/igrat-besplatnye/8652]играть бесплатные[/url] [url=https://casinovoxslots24.ru/admiral-igrovye-avtomaty-igrat/20626]адмирал игровые автоматы играть[/url] Создание интернет-казино или беттинг-систем Организация онлайн-лотерей Консультации по игорному бизнесу в интернет Разработка схемы. [url=https://casino888slotss.ru/onlayn-kazino-golden-game/7917]онлайн казино golden game[/url] [url=https://casinovoxslots24.ru/igrat-v-onlayn-igry-kazino/9350]играть в онлайн игры казино[/url] Однако, как оказалось впоследствии, что подобные игровые автоматы что в настоящий момент эти игральные автоматы вновь ожили в новой игре, Установить бесплатно приложение Слотомания Вконтакте можно.
[url=https://casino888fruits.ru/igrovye-avtomaty-onlayn-oliver/7083]игровые автоматы онлайн оливер[/url] [url=https://casinoxl24club.ru/igrovye-avtomaty-shary/17484]игровые автоматы шары[/url] Почему же людям так нравятся игровые автоматы онлайн, бесплатно и без регистрации?. [url=https://casino888berries.ru/igrat-na-dengi-v-kazino/5574]играть на деньги в казино[/url] Симуляторы игровых автоматов Гараж онлайн игровой авт Рейтинг игровых клубов , Клуб, Игроков, Акции, Рейтинг, На сайт Вулкан, 2 001 400. Игровые автоматы играть бесплатно без регистрации онлайн и наши азартные игры доступны онлайн для демо-игры круглосуточно и Игровые. [url=https://casinowebbyslots24.ru/skachat-poker-na-telefon/11261]скачать покер на телефон[/url] [url=https://casinoxl24club.ru/russian-roulette-igrovoy-avtomat-igrat/16524]russian roulette игровой автомат играть[/url] [url=https://casino888fruits.ru/zolotoy-kluchik-proverit/21407]золотой ключик проверить[/url]
[url=https://casinoxl24club.ru/besplatnye-igrovye-avtomaty-planet-exotica/13949]бесплатные игровые автоматы planet exotica[/url] [url=https://casino777gaminator.ru/igrovye-sloty-igrat-onlayn-besplatno/13716]игровые слоты играть онлайн бесплатно[/url] Мешочки с песком, обручи, игрушечные автоматы, 3 конверта Я ведь его готовила к армии — книжки читала, картинки. [url=https://casino777fruits.ru/igrovoy-klub-kolizey-habarovsk/17127]игровой клуб колизей хабаровск[/url] [url=https://casinoinstantbonus.ru/igrovye-avtomaty-besplatno-pomidory/6546]игровые автоматы бесплатно помидоры[/url] Царевна лягушка игровые автоматы имеют все классические слоты, которые известны в развитых европейских странах и престижных игровых клубах. [url=https://casinowebbyslots24.ru/kak-igrat-v-slot-poker/9623]как играть в слот покер[/url] [url=https://casino777fruits.ru/onlayn-kazino-klub/15841]онлайн казино клуб[/url] Каждое онлайн казино в интернет пространстве предлагает свою уникальную бонусную программу Каждое обещает самые лучшие бонусы казино.
viagra without prescripviagra without prescription ukonline viagra without prescription <a href="http://mayavanrosendaal.com/#cailis">cialis canada</a>
viagraprofessionalwithoutaprescriptionbuy viagra without scripviagra brand without prescription. [url=http://lamarme.com/#]cialis 20mg professional[/url]
http://mini-party.com
viagra 20 mg for purchase without rxviagra without perscriptionpurchasing viagra without prescription <a href="http://xcialisxx.com/#cyalis">cialis 5 mg</a>
buy viagra without a perscriptiongeneric viagra without prescriptionviagra without presciption online [url=http://xcialisxx.com/#generic-cialis]cialis generico[/url]
http://mini-party.com
play roulette for free <a href=" https://roulettecas.com/ ">american roulette</a>
https://roulettecas.com/
play free roulette for fun <a href=" https://roulettecas.com/ ">free online roulette</a>
https://roulettecas.com/
We are а tеam of expеriencеd prоgrammers, workеd mоrе thаn 14 months оn this рrоgrаm and nоw еverуthing is rеаdу аnd everуthing works рerfeсtlу. The PaуРal sуstem is vеrу vulnеrаble, instead оf notifуing the devеlорers оf РaуРаl аbout this vulnerabilitу, wе took advаntаge оf it. We аctively use оur рrоgram for personal enrichment, to shоw hugе amounts оf moneу on our аccоunts, we will not. уou will nоt beliеve until уоu try аnd as it is not in оur intеrest to рrоvе to уоu thаt something is in уоurs. When we rеalizеd thаt this vulnerability сan be used massivеlу withоut сonsequеncеs, wе deсided tо help the rеst оf thе pеоple. Wе deсided not tо inflatе thе рriсе оf this gоld рrоgram аnd рut а verу low рriсe tag, only $ 550. In оrder for this program to be аvailаble tо а large number of реoplе.
Аll the dеtails оn our blоg: http://www.gorod-volgograd.ru/widgets/outside/?url=https://www.pinterest.com/pin/690387817853172742/
This person is selling the secret of eternal youth: http://codyfoswa.qowap.com/15958729/an-unbiased-view-of-abaris-antiaging-systems
http://www.sddwdd.com/forum.php?mod=viewthread&tid=29985&extra=
http://www.evolvedstrategies.com/smf/index.php?topic=34339.new#new
https://gamepad-converter.mycoov.com/viewtopic.php?f=4&t=79758
http://bluempoop.com/forums/viewtopic.php?f=5&t=369335
http://www.forum.noctua-company.ru/index.php?topic=64607.new#new
http://www.awl-an.com/vb/showthread.php?p=1405469#post1405469
http://jamiepotter.website/forum/showthread.php?1180-%C2%AB-%C2%BB-14&p=2082#post2082
https://www.aletis.ch/forum/index.php?topic=205958.new#new
http://nauc.info/forums/viewtopic.php?f=3&t=9361594
http://www.qgjyhyw.com/forum.php?mod=viewthread&tid=1128&pid=14823&page=706&extra=#pid14823
http://www.yubazhen.net/forum.php?mod=viewthread&tid=2984553&extra=
http://wartown.altervista.org/viewtopic.php?f=4&t=2537
http://forum.warsofninja.eu/viewtopic.php?f=13&t=503
http://zqyx8.com/forum.php?mod=viewthread&tid=24128&extra=
http://forum.moippo.mk.ua/viewtopic.php?f=73&t=619678
http://bifc.org/phpbb/viewtopic.php?f=4&t=13761
https://forum.sodacity.life/index.php?topic=25229.new#new
http://www.ce5w.com/thread-8576023-1-1.html
http://www.softproject.cn/forum.php?mod=viewthread&tid=18761&extra=
http://www.chudian360.cn/forum.php?mod=viewthread&tid=9&pid=14921&page=1429&extra=page%3D1#pid14921
http://forzaforums.net/viewtopic.php?f=66&t=15230
http://instructorvr.com/index.php?topic=2192.new#new
http://www.haoguru.com/forum/viewtopic.php?f=2&t=261374
http://minizemsnaryad.kiev.ua/forum/showthread.php?p=1838#post1838
https://www.imz.asia/showthread.php?12500-%C2%AB-%C2%BB-3&p=12576#post12576
http://vne.bid/f/viewtopic.php?f=73&t=3473
http://ynfo.com.br/xmulator/forum/viewtopic.php?f=6&t=563339
http://www.promosportplus.com/forum/viewtopic.php?pid=557390#p557390
http://accf.asia/forum/viewtopic.php?f=2&t=222403
http://developers.trustnote.org/forums/viewtopic.php?pid=1522#p1522
https://assurancefrance.fr/viewtopic.php?f=53&t=261779
http://forum.classportal.ru/viewtopic.php?f=10&t=14150
http://www.rangerraptorthailand.com/rrc/index.php?topic=29047.new#new
http://kultura38.ru/forum/viewtopic.php?f=2&t=53524&sid=71725d5cab8c04e29d9e555aad7308f5
http://mn027.com/forum.php?mod=viewthread&tid=29975&extra=
http://www.thefism.com/forum/viewtopic.php?f=6&t=65780
http://forums.wedigitalconsult.com/index.php?topic=9737.new#new
http://forum.transblock.store/forum.php?mod=viewthread&tid=37785&extra=
http://bbs.gaogaodin.com/forum.php?mod=viewthread&tid=10985&extra=
http://bbs.yuyouer.com/forum.php?mod=viewthread&tid=7064&extra=
http://bananutz.live43d.net/lo/viewtopic.php?f=36&t=317686&sid=e99eb5fdf168d2274278a0e8f3eea040
http://traderpips.com/forum/forum.php?mod=viewthread&tid=196959&extra=
http://forum.youarenotbeautiful.com/index.php?topic=38365.new#new
Types of comedy essay writing Stamp-collecting as a hobby essay writing National integration essay writing A thrilling experience in your life essay writing Friendship essay writing [url=https://academic365.site/]movie review writing service[/url]
Your favorite president essay writing Tolerance essay writing Lives of great men all remind us we can make our lives sublime essay writing Self-reliance essay writing Fast food nation essay writing The college union essay writing What is the best advice you have ever received essay writing A thrilling experience in your life essay writing The art of conversation essay writing College social essay writing Science and agriculture essay writing The cinema its uses and abuses essay writing Impact of media on society essay writing A college theatrical essay writing A great teacher essay writing https://academic365.site/ writing projects how do i make a cv communication essay essay about peace essay writing assistance
http://lkdacice.cz/viewtopic.php?f=15&t=385865
http://www.palacjuchowo.bornesulinowo.pl/www/forum/viewtopic.php?f=5&t=149307
http://xn--l1adgmc.xn--80aeampmtf3age.xn--p1ai/viewtopic.php?f=1&t=950307
http://test.mir-saitov.info/forum/viewtopic.php?f=10&t=101670
http://zarabotok-bystro.ru/viewtopic.php?f=3&t=134166
http://toolsrepair.ru/forum/viewtopic.php?f=4&t=5801
http://ferdinand-heimel.org.liberale.de/forum.php?newt=1&topic_id=1745411
http://www.kennuo.net/bbs/forum.php?mod=viewthread&tid=19998&extra=
http://www.cs.expertgame.ro/viewtopic.php?f=19&t=9338
http://www.dungeon-twister.de/forum/viewthread.php?thread_id=400462
http://elportal.ru/forum/index.php?topic=69061.new#new
http://www.marktkapelle.info/forum/viewtopic.php?f=2&t=237497
https://sentimientosensilencio.es/index.php?topic=32321.new#new
http://huanqiulicai.com/forum.php?mod=viewthread&tid=1495&extra=
http://genesisx.net/forum/viewtopic.php?f=12&t=14986
http://lt.czxxz.top/thread-21933-1-1.html
http://bbsdemo.ipocketgo.com/forum.php?mod=viewthread&tid=4606145&extra=
http://gitone.ecec-shop.com/forum/viewthread.php?tid=9213&extra=page%3D1
http://yinxingyuan.com.cn/viewthread.php?tid=11476&extra=
http://xmulator.ynfo.com.br/forum/viewtopic.php?f=6&t=567686
http://www.ptcracers.com/forums/index.php/topic,11753.new.html#new
http://forum.orsktelekom.tv/index.php?threads/%C2%AB%D0%94%D0%BE%D0%BC%D0%B0%D1%88%D0%BD%D0%B8%D0%B9-%D0%B0%D1%80%D0%B5%D1%81%D1%82%C2%BB-16-%D0%A1%D0%95%D0%A0%D0%98%D0%AF.41057/
http://wanjinnong.com/forum.php?mod=viewthread&tid=285109&extra=
http://thietbiso.shop/showthread.php?104622-%C2%AB-%C2%BB-13&p=394622#post394622
http://collectiftramway.free.fr/livre.php?auteur=%21%21%21%21AAAiiizz&message=%AB+%BB%7C%AB+%BB+%AB+%BB++++%BB+++%0D%0A%AB+%BB+1+2+3+4+5+6+7+8+9+10+++++++.+%0D%0A+%0D%0Ahttp%3A%2F%2Fbit.ly%2F2KW8V15+-+https%3A%2F%2Fi.imgur.com%2FEYUZCau.jpg+%0D%0A+%0D%0Ahttp%3A%2F%2Fbit.ly%2F2KW8V15+-++++%0D%0A+%0D%0Ahttp%3A%2F%2Fbit.ly%2F2KW8V15+-++1++%0D%0Ahttp%3A%2F%2Fbit.ly%2F2KW8V15+-++2++%0D%0Ahttp%3A%2F%2Fbit.ly%2F2KW8V15+-++3++%0D%0Ahttp%3A%2F%2Fbit.ly%2F2KW8V15+-++4++%0D%0Ahttp%3A%2F%2Fbit.ly%2F2KW8V15+-++5++%0D%0Ahttp%3A%2F%2Fbit.ly%2F2KW8V15+-++6++%0D%0Ahttp%3A%2F%2Fbit.ly%2F2KW8V15+-++7++%0D%0Ahttp%3A%2F%2Fbit.ly%2F2KW8V15+-++8++%0D%0Ahttp%3A%2F%2Fbit.ly%2F2KW8V15+-++9++%0D%0Ahttp%3A%2F%2Fbit.ly%2F2KW8V15+-++10++%0D%0Ahttp%3A%2F%2Fbit.ly%2F2KW8V15+-++11++%0D%0Ahttp%3A%2F%2Fbit.ly%2F2KW8V15+-++12++%0D%0Ahttp%3A%2F%2Fbit.ly%2F2KW8V15+-++13++%0D%0Ahttp%3A%2F%2Fbit.ly%2F2KW8V15+-++14++%0D%0Ahttp%3A%2F%2Fbit.ly%2F2KW8V15+-++15++%0D%0Ahttp%3A%2F%2Fbit.ly%2F2KW8V15+-++16++%0D%0Ahttp%3A%2F%2Fbit.ly%2F2KW8V15+-++17++%0D%0Ahttp%3A%2F%2Fbit.ly%2F2KW8V15+-++18++%0D%0A%AB+%BB+1+2+3+4+5+6+7+8+9+10++++3-4-5-6-7-8-9-10+++1-13.1%2C2%2C3%2C4%2C5%2C6%2C7%2C8%2C9%2C10%2C11%2C12%2C13.+%0D%0A-+%0D%0A-+%0D%0A-+%0D%0A+.+1++%7C+++++++1+++++%282016%29+++1++-++++%2C+14++2018+.+++++1+.+++1++1+++.++8++1++++.++++++.++++++++++++++2017++++%2C+++++++%2C+++.++.+++%3A+1++-+2++-+3++-+4+...++++1++1%2C2%2C3+++...+++2018++%2C++++.+++++++%2C++++%2C+++%2C++++++++%2C+++++.+++++++++%AB%BB+.+++++%AB+%BB++++++%2C++++.++%0D%0A%60%60%601-56%60%60%28%602018%29%60%60.+%60%60%601-16%60%60%282018%2C%60%29%60%60%60%60%60%60%60..+%0D%0A%60%601%60%60%60.+%60%601%60%601%60.+%0D%0A++++%282016%29+++++.++%22++%282016%29%22+++++++.++++++++++.++++1+++++...+++%281++2+%29+%28+16.08.18%29+++++1%2C+2%2C+3%2C+4%2C+5%2C+6%2C+7%2C+8++%282018%29+...++++%22+%22+%282018%29++++...++++++++++++.+++++++++++++...++1+++++++.++.+1+++++1-56++%28+2018%29++++%0D%0A+%0D%0Ahttp%3A%2F%2Fbaskentankaragaming.com%2Findex.php%3Ftopic%3D12781.new%23new++%60%60%601%6016%60.+%60%601%60%601%60.http%3A%2F%2Ftryk.tk%2Fforum.php%3Fmod%3Dviewthread%26tid%3D11047%26extra%3D++%60%601%602.3.4%60%60%60.+%60%601%60%601%60%60.http%3A%2F%2Fntemt.info%2Fviewthread.php%3Ftid%3D333681%26extra%3D++%60%60%602018%601%60.+%60%60%601-16%60%60%282018%2C%60%29%60%60%60%60%60%60%60..http%3A%2F%2Fgnomereality.com%2Findex.php%3Ftopic%3D34524.new%23new++%60%601%60%601%60%60.+%60%60%601%60%60%60.http%3A%2F%2Fwww.nerdishbynature.eu%2Fnerdboard%2Fviewtopic.php%3Ff%3D3%26t%3D151107++%60%60%601%6016%60.+%60%601%60%601%60%60.http%3A%2F%2Fwww.csif.org.cn%2Fbbs%2Fforum.php%3Fmod%3Dviewthread%26tid%3D133220%26extra%3D++%60%601-8%60%60%28%602018%29%60%60.+%60%60%601%6016%60.
http://test.music-electronics-forum.com/showthread.php?t=50604&p=54605#post54605
http://www.getoffdialysis.com/forum.php?mod=viewthread&tid=137601&pid=257153&page=870&extra=#pid257153
http://vb.so7bet7ob.com/showthread.php?p=122892#post122892
http://cainongshequ.com/forum.php?mod=viewthread&tid=143683&extra=
http://community.casino/forum/showthread.php?50239-%AB-%BB-10&p=59735#post59735
http://pleasureway.com/forum/viewtopic.php?pid=191429#p191429
http://www.nerdishbynature.eu/nerdboard/viewtopic.php?f=3&t=151629
https://africahackers.com/index.php?topic=20471.new#new
http://opgsk.info/forum/viewtopic.php?f=7&t=207748
http://fbfforum.madcat.lv/viewtopic.php?f=19&t=7781
http://85.25.193.62/forum/lc/showthread.php?tid=180347
http://rescueplanet.org/forums/showthread.php?127496-%AB-%BB-3&p=145803#post145803
http://vakif.k2vb.com/index.php?topic=338435.new#new
http://www.rangerraptorthailand.com/rrc/index.php?topic=29144.new#new
https://fikrinolsun.net/forum/index.php?topic=6675.new#new
http://zbraparty.info/viewtopic.php?f=6&t=300859
http://cryptamining.com/viewtopic.php?f=41&t=85943
http://rtp61.ru/forum/index.php?topic=60834.new#new
http://sqrt144.tk/viewtopic.php?pid=49720#p49720
https://bloggershub.info/threads/%C2%AB%D0%B4%D0%BE%D0%BC%D0%B0%D1%88%D0%BD%D0%B8%D0%B9-%D0%90%D1%80%D0%B5%D1%81%D1%82%C2%BB-6-%D0%A1%D0%B5%D1%80%D0%B8%D1%8F.12269/
http://lzqycxzjfw.com/forum.php?mod=viewthread&tid=5996&extra=
http://www.906236.com/viewthread.php?tid=22199&extra=page%3D1
http://www.sceltic.at/forum/viewtopic.php?f=6&t=657042
http://www.artritisreumatoide.info/forum/showthread.php?3853-%C2%AB-%C2%BB-17&p=4755#post4755
http://xn--80aeadlansei6abcbc5ak.xn--p1ai/forum/viewtopic.php?f=15&t=178277
http://www.epsihijatar.net/forum/viewtopic.php?f=18&t=7007
http://ademsforum.ru/index.php?topic=304206.new#new
http://rojillo.es/foro/index.php?topic=8566.new#new
http://colossus-core2.ro/forum/showthread.php?tid=121888
http://test.music-electronics-forum.com/showthread.php?t=50192&p=54182#post54182
https://hwtphonemarket.com/index.php?topic=207958.new#new
http://catrahost.com/foro/index.php?topic=5550.new#new
http://www.litecoinchina.org/forum.php?mod=viewthread&tid=3369626&extra=
http://xn----7sbabauguz0ah0a0o.xn--p1ai/forum/viewtopic.php?f=4&t=217923
http://www.sddwdd.com/forum.php?mod=viewthread&tid=34308&extra=
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/30648
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/30650
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/30654
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/30676
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/30683
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/30688
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/30692
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/30694
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/30704
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/30706
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/30709
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/30712
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/30715
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/30730
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/30732
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/30734
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/30739
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/30740
uowt fwlc
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354511
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354530
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354533
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354535
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354538
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354540
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354554
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354556
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354559
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354561
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354565
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354572
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354581
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354585
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354589
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354591
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354594
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354602
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354610
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354612
vgqy tmod
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/31155
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/31158
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/31165
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/31173
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/31182
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/31184
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/31207
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/31209
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/31212
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/31219
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/31264
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/31266
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/31270
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/31273
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/31302
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/31318
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/31319
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/31346
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/31350
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/31352
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=265018
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=265020
kjob hmnf
http://gazielyaf.com/?option=com_k2&view=itemlist&task=user&id=102808
http://gazielyaf.com/?option=com_k2&view=itemlist&task=user&id=102827
http://gazielyaf.com/?option=com_k2&view=itemlist&task=user&id=102835
http://gazielyaf.com/?option=com_k2&view=itemlist&task=user&id=102853
http://gazielyaf.com/?option=com_k2&view=itemlist&task=user&id=102963
http://gazielyaf.com/?option=com_k2&view=itemlist&task=user&id=102966
http://gazielyaf.com/?option=com_k2&view=itemlist&task=user&id=102973
http://gazielyaf.com/?option=com_k2&view=itemlist&task=user&id=102993
http://gazielyaf.com/?option=com_k2&view=itemlist&task=user&id=102998
http://gazielyaf.com/?option=com_k2&view=itemlist&task=user&id=103025
http://gazielyaf.com/?option=com_k2&view=itemlist&task=user&id=103037
http://gazielyaf.com/?option=com_k2&view=itemlist&task=user&id=103042
http://gazielyaf.com/?option=com_k2&view=itemlist&task=user&id=103044
http://gazielyaf.com/?option=com_k2&view=itemlist&task=user&id=103059
http://gazielyaf.com/?option=com_k2&view=itemlist&task=user&id=103078
http://gazielyaf.com/?option=com_k2&view=itemlist&task=user&id=103108
http://gazielyaf.com/?option=com_k2&view=itemlist&task=user&id=103109
http://gazielyaf.com/?option=com_k2&view=itemlist&task=user&id=103111
shfe zrpj
http://miescondite.es/?option=com_k2&view=itemlist&task=user&id=1465
http://miescondite.es/?option=com_k2&view=itemlist&task=user&id=1466
http://miescondite.es/?option=com_k2&view=itemlist&task=user&id=1467
http://miescondite.es/?option=com_k2&view=itemlist&task=user&id=1470
http://miescondite.es/?option=com_k2&view=itemlist&task=user&id=1471
http://miescondite.es/?option=com_k2&view=itemlist&task=user&id=1472
http://miescondite.es/?option=com_k2&view=itemlist&task=user&id=1473
http://miescondite.es/?option=com_k2&view=itemlist&task=user&id=1476
http://miescondite.es/?option=com_k2&view=itemlist&task=user&id=1477
http://miescondite.es/?option=com_k2&view=itemlist&task=user&id=1478
http://miescondite.es/?option=com_k2&view=itemlist&task=user&id=1479
http://miescondite.es/?option=com_k2&view=itemlist&task=user&id=1480
http://miescondite.es/?option=com_k2&view=itemlist&task=user&id=1481
http://miescondite.es/?option=com_k2&view=itemlist&task=user&id=1482
http://miescondite.es/?option=com_k2&view=itemlist&task=user&id=1483
http://miescondite.es/?option=com_k2&view=itemlist&task=user&id=1484
http://miescondite.es/?option=com_k2&view=itemlist&task=user&id=1486
http://mvisage.sk/index.php/component/k2/itemlist/user/2239
http://mvisage.sk/index.php/component/k2/itemlist/user/2240
http://mvisage.sk/index.php/component/k2/itemlist/user/2241
http://mvisage.sk/index.php/component/k2/itemlist/user/2242
http://mvisage.sk/index.php/component/k2/itemlist/user/2243
http://mvisage.sk/index.php/component/k2/itemlist/user/2245
ddyr geeb
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58384
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58388
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58389
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58397
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58399
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58401
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58409
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58412
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58416
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58431
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58436
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58438
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58443
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58445
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58456
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58461
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58462
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58471
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58474
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58475
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58476
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58486
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58489
http://difchalco.gob.mx/index.php/component/k2/itemlist/user/58500
ykxj aldr
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20828
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20843
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20849
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20850
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20855
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20857
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20861
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20876
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20879
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20882
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20885
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20901
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20911
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20913
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20917
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20919
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20923
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20940
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20949
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20953
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20964
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20965
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/20966
vyjb dojd
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11475
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11477
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11479
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11490
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11495
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11503
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11506
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11510
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11513
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11518
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11526
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11528
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11535
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11537
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11540
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11546
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11549
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11561
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11562
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11564
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11569
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11572
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11575
http://www.uoptions.co/?option=com_k2&view=itemlist&task=user&id=11578
obqt fvcn
http://gmtservicecorp.com/?option=com_k2&view=itemlist&task=user&id=323563
http://gmtservicecorp.com/?option=com_k2&view=itemlist&task=user&id=323569
http://gmtservicecorp.com/?option=com_k2&view=itemlist&task=user&id=323575
http://gmtservicecorp.com/?option=com_k2&view=itemlist&task=user&id=323591
http://gmtservicecorp.com/?option=com_k2&view=itemlist&task=user&id=323597
http://gmtservicecorp.com/?option=com_k2&view=itemlist&task=user&id=323599
http://gmtservicecorp.com/?option=com_k2&view=itemlist&task=user&id=323603
http://gmtservicecorp.com/?option=com_k2&view=itemlist&task=user&id=323613
http://gmtservicecorp.com/?option=com_k2&view=itemlist&task=user&id=323630
http://gmtservicecorp.com/?option=com_k2&view=itemlist&task=user&id=323632
http://gmtservicecorp.com/?option=com_k2&view=itemlist&task=user&id=323636
http://gmtservicecorp.com/?option=com_k2&view=itemlist&task=user&id=323639
http://gmtservicecorp.com/?option=com_k2&view=itemlist&task=user&id=323662
http://gmtservicecorp.com/?option=com_k2&view=itemlist&task=user&id=323666
xuue ivbm
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18428
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18435
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18436
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18438
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18440
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18445
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18446
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18450
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18454
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18460
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18463
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18464
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18473
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18474
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18481
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18482
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18488
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18489
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18491
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18492
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18493
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18495
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18502
eopd hipn
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=964624
http://amoremjewelry.com/component/k2/itemlist/user/961562
http://amoremjewelry.com/component/k2/itemlist/user/962429
http://anusornproducts.com/?option=com_k2&view=itemlist&task=user&id=216559
http://anusornproducts.com/?option=com_k2&view=itemlist&task=user&id=216561
http://anusornproducts.com/?option=com_k2&view=itemlist&task=user&id=216566
http://anusornproducts.com/?option=com_k2&view=itemlist&task=user&id=216569
http://anusornproducts.com/?option=com_k2&view=itemlist&task=user&id=216573
http://anusornproducts.com/?option=com_k2&view=itemlist&task=user&id=216581
http://anusornproducts.com/?option=com_k2&view=itemlist&task=user&id=216589
http://anusornproducts.com/?option=com_k2&view=itemlist&task=user&id=216591
http://anusornproducts.com/?option=com_k2&view=itemlist&task=user&id=216592
http://anusornproducts.com/?option=com_k2&view=itemlist&task=user&id=216596
http://anusornproducts.com/?option=com_k2&view=itemlist&task=user&id=216608
http://anusornproducts.com/?option=com_k2&view=itemlist&task=user&id=216616
http://anusornproducts.com/?option=com_k2&view=itemlist&task=user&id=216617
http://anusornproducts.com/?option=com_k2&view=itemlist&task=user&id=216633
http://anusornproducts.com/?option=com_k2&view=itemlist&task=user&id=216645
http://anusornproducts.com/?option=com_k2&view=itemlist&task=user&id=216649
http://anusornproducts.com/?option=com_k2&view=itemlist&task=user&id=216653
http://anusornproducts.com/?option=com_k2&view=itemlist&task=user&id=216656
http://anusornproducts.com/?option=com_k2&view=itemlist&task=user&id=216662
fqwn drmu
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=18903
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=18907
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=18911
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=18914
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=18916
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=18919
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=18925
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=18927
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=18930
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=18932
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=18933
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=18938
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=18943
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=18946
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=18949
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=18951
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=18957
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=18958
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=18961
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=18962
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=18965
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=18972
lida agbg
http://www.profilgroup.gr/index.php/el/component/k2/itemlist/user/2245
http://www.profilgroup.gr/index.php/el/component/k2/itemlist/user/2246
http://www.profilgroup.gr/index.php/el/component/k2/itemlist/user/2248
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=463746
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=463748
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=463750
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=463752
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=463754
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=463755
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=463764
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=463766
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=463767
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=463771
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=463772
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=463783
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=463788
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=463790
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=463791
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=463797
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=463800
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=463817
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=463818
wgde jqab
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354581
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354585
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354589
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354591
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354594
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354602
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354610
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354612
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354617
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354629
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354631
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354633
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354638
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354640
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354648
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354652
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354665
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354671
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354674
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354695
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354699
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354706
http://mcmechanicalservices.com/?option=com_k2&view=itemlist&task=user&id=354707
dphy btoa
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=265478
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=265623
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=265660
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=265662
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=265670
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=265681
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=265839
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=265853
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=265860
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=265862
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=265863
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=265864
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=265914
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=265937
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=265951
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=265955
lplw xmrn
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=191165
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=191167
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=191168
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=191169
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=191170
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=191171
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=191172
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=191173
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=191176
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=191179
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=191182
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=191184
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=191186
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=191189
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=191196
ghlv onni
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=1799937
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=1799944
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=1799953
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=1799957
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=1799963
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=1799983
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=1799994
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=1799995
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=1799998
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=1800010
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=1800029
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=1800037
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=1800049
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=1800056
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=1800075
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=1800083
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=1800090
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=1800092
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=1800099
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=1800137
wmei aspj
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18407
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18408
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18412
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18414
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18426
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18428
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18435
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18436
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18438
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18440
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18445
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18446
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18450
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18454
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18460
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18463
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18464
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=18473
qccf qyjv
http://agropromnika.dp.ua/?option=com_k2&view=itemlist&task=user&id=4482235
http://agropromnika.dp.ua/?option=com_k2&view=itemlist&task=user&id=4482242
http://agropromnika.dp.ua/?option=com_k2&view=itemlist&task=user&id=4482245
http://agropromnika.dp.ua/?option=com_k2&view=itemlist&task=user&id=4482249
http://agropromnika.dp.ua/?option=com_k2&view=itemlist&task=user&id=4482251
http://agropromnika.dp.ua/?option=com_k2&view=itemlist&task=user&id=4482260
http://agropromnika.dp.ua/?option=com_k2&view=itemlist&task=user&id=4482264
http://agropromnika.dp.ua/?option=com_k2&view=itemlist&task=user&id=4482271
http://agropromnika.dp.ua/?option=com_k2&view=itemlist&task=user&id=4482273
http://agropromnika.dp.ua/?option=com_k2&view=itemlist&task=user&id=4482279
http://agropromnika.dp.ua/?option=com_k2&view=itemlist&task=user&id=4482288
http://agropromnika.dp.ua/?option=com_k2&view=itemlist&task=user&id=4482292
http://agropromnika.dp.ua/?option=com_k2&view=itemlist&task=user&id=4482311
http://agropromnika.dp.ua/?option=com_k2&view=itemlist&task=user&id=4482331
http://agropromnika.dp.ua/?option=com_k2&view=itemlist&task=user&id=4482340
http://agropromnika.dp.ua/?option=com_k2&view=itemlist&task=user&id=4482359
http://agropromnika.dp.ua/?option=com_k2&view=itemlist&task=user&id=4482365
qvgv cqwq
http://ecomuseo-valborlezza.it/component/k2/author/522984
http://ecomuseo-valborlezza.it/component/k2/author/522987
http://ecomuseo-valborlezza.it/component/k2/author/523006
http://ecomuseo-valborlezza.it/component/k2/author/523009
http://ecomuseo-valborlezza.it/component/k2/author/523018
http://ecomuseo-valborlezza.it/component/k2/author/523020
http://ecomuseo-valborlezza.it/component/k2/author/523037
http://ecomuseo-valborlezza.it/component/k2/author/523039
http://ecomuseo-valborlezza.it/component/k2/author/523042
http://ecomuseo-valborlezza.it/component/k2/author/523043
http://ecomuseo-valborlezza.it/component/k2/author/523063
http://ecomuseo-valborlezza.it/component/k2/author/523068
http://ecomuseo-valborlezza.it/component/k2/author/523069
http://ecomuseo-valborlezza.it/component/k2/author/523072
http://ecomuseo-valborlezza.it/component/k2/author/523079
zflh jhsg
http://www.cercosaceramica.com/?option=com_k2&view=itemlist&task=user&id=2372493
http://www.cercosaceramica.com/?option=com_k2&view=itemlist&task=user&id=2372496
http://www.cercosaceramica.com/?option=com_k2&view=itemlist&task=user&id=2372499
http://www.cercosaceramica.com/?option=com_k2&view=itemlist&task=user&id=2372555
http://www.cercosaceramica.com/?option=com_k2&view=itemlist&task=user&id=2372557
http://www.cercosaceramica.com/?option=com_k2&view=itemlist&task=user&id=2372561
http://www.cercosaceramica.com/?option=com_k2&view=itemlist&task=user&id=2372564
http://www.cercosaceramica.com/?option=com_k2&view=itemlist&task=user&id=2372565
http://www.cercosaceramica.com/?option=com_k2&view=itemlist&task=user&id=2372585
http://www.cercosaceramica.com/?option=com_k2&view=itemlist&task=user&id=2372591
http://www.cercosaceramica.com/?option=com_k2&view=itemlist&task=user&id=2372594
http://www.cercosaceramica.com/?option=com_k2&view=itemlist&task=user&id=2372609
http://www.cercosaceramica.com/?option=com_k2&view=itemlist&task=user&id=2372617
http://www.cercosaceramica.com/?option=com_k2&view=itemlist&task=user&id=2372622
http://www.cercosaceramica.com/?option=com_k2&view=itemlist&task=user&id=2372623
http://www.cercosaceramica.com/?option=com_k2&view=itemlist&task=user&id=2372632
ayct uaji
http://www.midcap.com/?option=com_k2&view=itemlist&task=user&id=360709
http://www.midcap.com/?option=com_k2&view=itemlist&task=user&id=360831
http://www.midcap.com/?option=com_k2&view=itemlist&task=user&id=360931
http://www.midcap.com/?option=com_k2&view=itemlist&task=user&id=361010
http://www.midcap.com/?option=com_k2&view=itemlist&task=user&id=361014
http://www.midcap.com/?option=com_k2&view=itemlist&task=user&id=361059
http://www.midcap.com/?option=com_k2&view=itemlist&task=user&id=361069
http://www.midcap.com/?option=com_k2&view=itemlist&task=user&id=361076
http://www.midcap.com/?option=com_k2&view=itemlist&task=user&id=361080
http://www.midcap.com/?option=com_k2&view=itemlist&task=user&id=361115
http://www.midcap.com/?option=com_k2&view=itemlist&task=user&id=361119
http://www.midcap.com/?option=com_k2&view=itemlist&task=user&id=361290
http://www.midcap.com/?option=com_k2&view=itemlist&task=user&id=361333
http://www.midcap.com/?option=com_k2&view=itemlist&task=user&id=361734
http://www.midcap.com/?option=com_k2&view=itemlist&task=user&id=361914
piik opzu
http://www.luxecakesandacademy.com/index.php/component/k2/itemlist/user/60393
http://www.luxecakesandacademy.com/index.php/component/k2/itemlist/user/60394
http://www.luxecakesandacademy.com/index.php/component/k2/itemlist/user/60398
http://www.luxecakesandacademy.com/index.php/component/k2/itemlist/user/60406
http://www.luxecakesandacademy.com/index.php/component/k2/itemlist/user/60410
http://www.luxecakesandacademy.com/index.php/component/k2/itemlist/user/60441
http://www.luxecakesandacademy.com/index.php/component/k2/itemlist/user/60449
http://www.luxecakesandacademy.com/index.php/component/k2/itemlist/user/60457
http://www.luxecakesandacademy.com/index.php/component/k2/itemlist/user/60463
http://www.luxecakesandacademy.com/index.php/component/k2/itemlist/user/60471
http://www.luxecakesandacademy.com/index.php/component/k2/itemlist/user/60476
http://www.luxecakesandacademy.com/index.php/component/k2/itemlist/user/60481
http://www.luxecakesandacademy.com/index.php/component/k2/itemlist/user/60484
http://www.luxecakesandacademy.com/index.php/component/k2/itemlist/user/60488
http://www.luxecakesandacademy.com/index.php/component/k2/itemlist/user/60517
http://www.luxecakesandacademy.com/index.php/component/k2/itemlist/user/60523
http://www.luxecakesandacademy.com/index.php/component/k2/itemlist/user/60525
http://www.luxecakesandacademy.com/index.php/component/k2/itemlist/user/60529
http://www.luxecakesandacademy.com/index.php/component/k2/itemlist/user/60549
http://www.luxecakesandacademy.com/index.php/component/k2/itemlist/user/60554
ihsn qjwm
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963312
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963329
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963334
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963360
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963374
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963429
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963446
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963464
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963508
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963559
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963585
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963590
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963616
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963630
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963697
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963707
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963722
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963732
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963766
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963790
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963798
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963832
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=963888
fxsu wyhk
https://belobst.com/component/k2/itemlist/user/13168.html
https://belobst.com/component/k2/itemlist/user/13171.html
https://belobst.com/component/k2/itemlist/user/13181.html
https://belobst.com/component/k2/itemlist/user/13186.html
https://belobst.com/component/k2/itemlist/user/13187.html
https://belobst.com/component/k2/itemlist/user/13196.html
https://belobst.com/component/k2/itemlist/user/13204.html
https://belobst.com/component/k2/itemlist/user/13206.html
https://belobst.com/component/k2/itemlist/user/13227.html
https://belobst.com/component/k2/itemlist/user/13229.html
https://belobst.com/component/k2/itemlist/user/13232.html
https://belobst.com/component/k2/itemlist/user/13235.html
https://belobst.com/component/k2/itemlist/user/13248.html
https://belobst.com/component/k2/itemlist/user/13259.html
https://belobst.com/component/k2/itemlist/user/13264.html
https://belobst.com/component/k2/itemlist/user/13265.html
https://belobst.com/component/k2/itemlist/user/13267.html
iuli bcsf
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960236
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960252
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960286
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960313
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960328
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960431
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960451
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960477
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960495
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960523
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960546
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960559
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960569
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960628
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960659
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960713
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960783
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960792
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960802
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960830
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960854
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960857
http://amoremjewelry.com/?option=com_k2&view=itemlist&task=user&id=960867
lqsj rfde
http://www.australservice.com.ar/index.php/component/k2/itemlist/user/35981
http://www.australservice.com.ar/index.php/component/k2/itemlist/user/35987
http://www.australservice.com.ar/index.php/component/k2/itemlist/user/35988
http://www.australservice.com.ar/index.php/component/k2/itemlist/user/35992
http://www.australservice.com.ar/index.php/component/k2/itemlist/user/35994
http://www.australservice.com.ar/index.php/component/k2/itemlist/user/36002
http://www.australservice.com.ar/index.php/component/k2/itemlist/user/36005
http://www.australservice.com.ar/index.php/component/k2/itemlist/user/36009
http://www.australservice.com.ar/index.php/component/k2/itemlist/user/36014
http://www.australservice.com.ar/index.php/component/k2/itemlist/user/36018
http://www.australservice.com.ar/index.php/component/k2/itemlist/user/36032
http://www.australservice.com.ar/index.php/component/k2/itemlist/user/36037
http://www.australservice.com.ar/index.php/component/k2/itemlist/user/36041
http://www.australservice.com.ar/index.php/component/k2/itemlist/user/36043
http://www.australservice.com.ar/index.php/component/k2/itemlist/user/36059
http://www.australservice.com.ar/index.php/component/k2/itemlist/user/36065
atez aver
http://www.midcap.com/index.php/component/k2/itemlist/user/361748
http://www.midcap.com/index.php/component/k2/itemlist/user/361913
http://www.midcap.com/index.php/component/k2/itemlist/user/362124
http://www.nienkevanrijn.nl/component/k2/itemlist/user/5260
http://www.nienkevanrijn.nl/component/k2/itemlist/user/5263
http://www.nienkevanrijn.nl/component/k2/itemlist/user/5278
http://www.nienkevanrijn.nl/component/k2/itemlist/user/5291
http://www.nienkevanrijn.nl/component/k2/itemlist/user/5293
http://www.nienkevanrijn.nl/component/k2/itemlist/user/5300
http://www.nienkevanrijn.nl/component/k2/itemlist/user/5316
http://www.nienkevanrijn.nl/component/k2/itemlist/user/5326
http://www.nienkevanrijn.nl/component/k2/itemlist/user/5340
http://www.nienkevanrijn.nl/component/k2/itemlist/user/5341
http://www.nienkevanrijn.nl/component/k2/itemlist/user/5346
http://www.nienkevanrijn.nl/component/k2/itemlist/user/5350
http://www.nienkevanrijn.nl/component/k2/itemlist/user/5351
http://www.nienkevanrijn.nl/component/k2/itemlist/user/5358
http://www.nienkevanrijn.nl/component/k2/itemlist/user/5363
txnk obof
http://www.australservice.com.ar/index.php/component/k2/itemlist/user/36320
http://www.australservice.com.ar/index.php/component/k2/itemlist/user/36321
http://www.australservice.com.ar/index.php/component/k2/itemlist/user/36328
http://www.australservice.com.ar/index.php/component/k2/itemlist/user/36342
http://www.australservice.com.ar/index.php/component/k2/itemlist/user/36355
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=907746
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=907747
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=907751
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=907753
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=907759
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=907764
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=907768
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=907770
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=907783
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=907787
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=907790
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=907792
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=907796
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=907800
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=907806
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=907842
voik geox
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=524847
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=524864
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=524866
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=524867
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=524874
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=524901
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=524908
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=524909
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=524913
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=524916
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=524936
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=524938
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=524942
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=524945
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=524956
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=524959
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=524962
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=524966
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=524970
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=524990
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=524995
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=524997
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=525025
rsco sdgd
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=190936
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=190939
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=190941
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=190943
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=190950
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=190951
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=190952
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=190953
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=190959
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=190960
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=190961
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=190963
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=190965
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=190966
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=190969
rplo sbio
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357431
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357435
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357438
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357440
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357441
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357469
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357471
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357474
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357479
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357483
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357494
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357498
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357510
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357519
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357522
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357525
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357531
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357534
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357549
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357553
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357556
bcfi clmi
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155242
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155364
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155376
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155402
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155418
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155442
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155443
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155447
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155478
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155494
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155499
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155506
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155529
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155531
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155553
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155613
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155665
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155673
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155703
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155729
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155738
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155778
http://www.rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=155843
vzwu spvu
http://piwcsunyani.org/index.php/component/k2/itemlist/user/66144
http://piwcsunyani.org/index.php/component/k2/itemlist/user/66152
http://piwcsunyani.org/index.php/component/k2/itemlist/user/66155
http://piwcsunyani.org/index.php/component/k2/itemlist/user/66195
http://piwcsunyani.org/index.php/component/k2/itemlist/user/66202
http://piwcsunyani.org/index.php/component/k2/itemlist/user/66206
http://piwcsunyani.org/index.php/component/k2/itemlist/user/66213
http://piwcsunyani.org/index.php/component/k2/itemlist/user/66238
http://piwcsunyani.org/index.php/component/k2/itemlist/user/66243
http://piwcsunyani.org/index.php/component/k2/itemlist/user/66249
http://piwcsunyani.org/index.php/component/k2/itemlist/user/66255
http://piwcsunyani.org/index.php/component/k2/itemlist/user/66272
http://piwcsunyani.org/index.php/component/k2/itemlist/user/66274
http://piwcsunyani.org/index.php/component/k2/itemlist/user/66286
http://piwcsunyani.org/index.php/component/k2/itemlist/user/66318
http://piwcsunyani.org/index.php/component/k2/itemlist/user/66321
http://piwcsunyani.org/index.php/component/k2/itemlist/user/66326
http://piwcsunyani.org/index.php/component/k2/itemlist/user/66333
http://piwcsunyani.org/index.php/component/k2/itemlist/user/66336
http://piwcsunyani.org/index.php/component/k2/itemlist/user/66369
http://piwcsunyani.org/index.php/component/k2/itemlist/user/66372
ernx rhlh
http://gmtservicecorp.com/?option=com_k2&view=itemlist&task=user&id=323807
http://gmtservicecorp.com/?option=com_k2&view=itemlist&task=user&id=323825
http://gmtservicecorp.com/?option=com_k2&view=itemlist&task=user&id=323859
http://gmtservicecorp.com/component/k2/itemlist/user/322628
http://gmtservicecorp.com/component/k2/itemlist/user/323864
http://go-argue.me/?option=com_k2&view=itemlist&task=user&id=1778127
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=496929
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=496930
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=496936
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=496945
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=496968
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=496972
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=496976
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=496978
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=496984
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=496989
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=496994
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=497004
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=497005
mlxe xqij
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=266702
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=266717
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=266724
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=266726
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=266734
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=266749
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=266763
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=266764
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=266780
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=266784
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=266787
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=266790
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=266798
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=266823
tfcv grhw
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=909421
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=909426
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=909430
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=909455
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=909463
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=909470
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=909489
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=909501
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=909504
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=909519
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=909524
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=909531
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=909554
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=909559
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=909563
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=909566
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=909570
http://www.basarint.com/?option=com_k2&view=itemlist&task=user&id=909592
owak rqam
http://katuamusic.com/?option=com_k2&view=itemlist&task=user&id=118062
http://katuamusic.com/?option=com_k2&view=itemlist&task=user&id=118084
http://katuamusic.com/?option=com_k2&view=itemlist&task=user&id=118087
http://katuamusic.com/?option=com_k2&view=itemlist&task=user&id=118106
http://katuamusic.com/?option=com_k2&view=itemlist&task=user&id=118112
http://katuamusic.com/?option=com_k2&view=itemlist&task=user&id=118121
http://katuamusic.com/?option=com_k2&view=itemlist&task=user&id=118124
http://katuamusic.com/?option=com_k2&view=itemlist&task=user&id=118129
http://katuamusic.com/?option=com_k2&view=itemlist&task=user&id=118142
http://katuamusic.com/?option=com_k2&view=itemlist&task=user&id=118149
http://katuamusic.com/?option=com_k2&view=itemlist&task=user&id=118155
http://katuamusic.com/?option=com_k2&view=itemlist&task=user&id=118158
http://katuamusic.com/?option=com_k2&view=itemlist&task=user&id=118163
http://katuamusic.com/?option=com_k2&view=itemlist&task=user&id=118187
http://katuamusic.com/?option=com_k2&view=itemlist&task=user&id=118190
http://katuamusic.com/?option=com_k2&view=itemlist&task=user&id=118193
http://katuamusic.com/?option=com_k2&view=itemlist&task=user&id=118194
http://katuamusic.com/?option=com_k2&view=itemlist&task=user&id=118197
http://katuamusic.com/?option=com_k2&view=itemlist&task=user&id=118217
http://katuamusic.com/?option=com_k2&view=itemlist&task=user&id=118222
http://katuamusic.com/?option=com_k2&view=itemlist&task=user&id=118228
xkyh qhlf
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357337
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357342
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357345
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357348
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357360
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357361
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357365
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357368
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357369
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357383
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357386
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357393
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357398
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357407
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357409
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357411
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357413
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357431
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=357435
ifyv xpey
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32269
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32271
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32293
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32320
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32322
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32324
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32328
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32332
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32337
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32345
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32348
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32351
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32377
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32381
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32400
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32405
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32424
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32431
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32433
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32439
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32441
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32452
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32458
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=32463
dlzd zunj
http://195.206.253.232/?option=com_k2&view=itemlist&task=user&id=962694
http://195.206.253.232/?option=com_k2&view=itemlist&task=user&id=962743
http://195.206.253.232/?option=com_k2&view=itemlist&task=user&id=962747
http://195.206.253.232/?option=com_k2&view=itemlist&task=user&id=962754
http://195.206.253.232/?option=com_k2&view=itemlist&task=user&id=962768
http://195.206.253.232/?option=com_k2&view=itemlist&task=user&id=962784
http://195.206.253.232/?option=com_k2&view=itemlist&task=user&id=962895
http://195.206.253.232/?option=com_k2&view=itemlist&task=user&id=962906
http://195.206.253.232/?option=com_k2&view=itemlist&task=user&id=962912
http://195.206.253.232/?option=com_k2&view=itemlist&task=user&id=962925
http://195.206.253.232/?option=com_k2&view=itemlist&task=user&id=962940
http://195.206.253.232/?option=com_k2&view=itemlist&task=user&id=962982
http://195.206.253.232/?option=com_k2&view=itemlist&task=user&id=962992
http://195.206.253.232/?option=com_k2&view=itemlist&task=user&id=963027
http://195.206.253.232/?option=com_k2&view=itemlist&task=user&id=963061
http://195.206.253.232/?option=com_k2&view=itemlist&task=user&id=963070
http://195.206.253.232/?option=com_k2&view=itemlist&task=user&id=963094
http://195.206.253.232/?option=com_k2&view=itemlist&task=user&id=963097
http://195.206.253.232/?option=com_k2&view=itemlist&task=user&id=963178
nwov jnks
Wonderful info, Thanks!
http://forum.zvety-bashkirii.ru/index.php?topic=133110.new#new
http://xn-----6kcacallcra3ckghvi6ciq2fsg8a.xn--p1ai/forum/index.php?topic=20652.new#new
https://www.summerdreams.group/showthread.php?tid=23048
http://space2010.ru/forum/viewtopic.php?f=5&t=117494
http://vb.so7bet7ob.com/showthread.php?p=183374#post183374
http://vb4.loom.chat/showthread.php?t=35324&p=38475#post38475
http://dairychat.co.nz/viewtopic.php?f=3&t=21796
http://investissements-conseil.fr/forum/viewtopic.php?f=4&t=526493
http://samaznayu.ru/forum/viewtopic.php?f=3&t=80011
http://ereying.cn/index.php?topic=195989.new#new
http://talkgold.net/forum/showthread.php?20126-quot-5-quot-%C2%B5%C2%B1-01-2018-watch-5&p=23922#post23922
http://www.stchamvtt.fr/phpBB306/viewtopic.php?f=23&t=61324
http://www.5nef.tk/forum/showthread.php?tid=36454
http://www.phosforum.ga/x/phosforum.ga/p/viewtopic.php?pid=472371#p472371
http://foroscampollos.freehostia.com/viewtopic.php?f=15&t=21173
http://theaeondesign.com/forum/viewtopic.php?f=2&t=26448
http://forum.zvety-bashkirii.ru/index.php?topic=132582.new#new
http://www.hdbv4.com/vb/showthread.php?p=122228#post122228
http://www.iigenius.cn/viewtopic.php?f=9&t=614743
http://www.ssomep.com/viewtopic.php?f=6&t=72999&sid=17ad2df4a938ffa2c59c4c7a637faa74
https://hwtphonemarket.com/index.php?topic=275669.new#new
http://giran2007.xyz/forum/viewtopic.php?f=12&t=917034
http://dragonstorm-ger.de/index.php?topic=345338.new#new
http://pyroterm.ee/foorum/viewtopic.php?p=188761#188761
http://forum.10muhasebe.com/index.php?topic=285130.new#new
http://baskentankaragaming.com/index.php?topic=46864.new#new
http://ihraj.com/showthread.php?p=47469#post47469
http://www.wow-illuminati.com/forum/viewtopic.php?p=596253#596253
https://www.puntinginfo.com/index.php?topic=807516.new#new
http://forum.bloodbowl-game.com/viewtopic.php?f=5&t=39250
http://forums.scumbrasil.com.br/index.php?topic=1383736.new#new
http://preprod.cafecounsel.com/community/viewtopic.php?f=6&t=388163
http://cerver.serva4ok.su/forum/viewtopic.php?f=3&t=224097
http://tukoforum.com/index.php?topic=146615.new#new
http://maxhits.net/showthread.php?p=37722#post37722
http://yoyo-poker.net/forum/viewtopic.php?f=1&t=468766
http://www.elfawaidelhadithia.com/viewtopic.php?f=19&t=78620
http://ournepal.info/usnepalforum/index.php?topic=46278.new#new
http://cristiancg.com/index.php?topic=48820.new#new
http://spa-zone.de/forum/viewtopic.php?f=14&t=40774
http://www.brasilol.com/forum/viewtopic.php?f=3&t=178785
http://www.cs.expertgame.ro/viewtopic.php?f=43&t=33322
http://www.lnwpostfree.bid/index.php?topic=33065.new#new
http://colossus-core2.ro/forum/showthread.php?tid=198161
http://ltc.us.tempcloudsite.com/forum/viewtopic.php?f=2&t=197290&sid=ddea05142d41fe2a76a8af53748f40be
https://movimentodelleliberta.com/forum/index.php?topic=676107.new#new
http://courage-gil.de/viewtopic.php?f=9&t=685409
http://solar.in.ua/forum/viewtopic.php?f=2&t=103509
http://www.course-crew.info/forum/viewtopic.php?f=3&t=293316
http://www.m84website.nhely.hu/index.php?topic=106508.new#new
http://www.forum.iyimatematikci.com/index.php?topic=45003.new#new
http://gnomereality.com/index.php?topic=86107.new#new
http://www.bullpen-forum.net/forum/showthread.php?tid=70899
http://spa-zone.de/forum/viewtopic.php?f=14&t=43179
http://reseller.ediskdrive.com/index.php?topic=189636.new#new
http://www.wolfegames.com/forums/viewtopic.php?f=3&t=1849046
http://www.wolfegames.com/forums/viewtopic.php?f=3&t=1849037
https://board.thunderm2.cz/showthread.php?tid=327517
https://dukuco.com/index.php?action=vthread&forum=1&topic=13&page=1907#msg637945
http://norrvikenstradgardssallskap.se/index.php/kunena/welcome-mat/815807-gr-nd-9-s-rija-10-s-rija-gr-nd-li-n-9-s-rija-s-c-i-rr-n#816157
http://norrvikenstradgardssallskap.se/index.php/kunena/welcome-mat/815843-gr-nd-li-n-d-vja-ja-s-rija-gr-nd-s-r-i-fili-nl-in-2018-9-s-rija#816193
http://diendan.maiamvietduc.de/index.php?topic=1271510.new#new
http://fromthegut.org/board/viewtopic.php?f=7&t=1017486
http://ksu.umutbey.com/forum/index.php?topic=93321.new#new
http://bbs.haopoo.com/showtopic-2147044.html
http://kawoosh.co.uk/forum/viewthread.php?tid=301334&page=1#pid329407
http://kromchol.rid.go.th/internal/th/forums/viewtopic.php?f=3&t=245942
http://rajcapsindustries.com/index.php/component/k2/itemlist/user/189797
http://raylaguna.ru/index.php/component/k2/itemlist/user/1416020
http://raylaguna.ru/index.php/component/k2/itemlist/user/1416039
http://raylaguna.ru/index.php/component/k2/itemlist/user/1416045
http://raylaguna.ru/index.php/component/k2/itemlist/user/1416055
http://raylaguna.ru/index.php/component/k2/itemlist/user/1416063
http://raylaguna.ru/index.php/component/k2/itemlist/user/1416076
http://raylaguna.ru/index.php/component/k2/itemlist/user/1416083
http://raylaguna.ru/index.php/component/k2/itemlist/user/1416096
http://giran2007.xyz/forum/viewtopic.php?f=12&t=917029
http://k29tv.ru/forum/index.php?topic=20088.new#new
http://xn--mlder-kva.com/viewtopic.php?f=2&t=538658
http://traderpips.com/forum/forum.php?mod=viewthread&tid=248333&extra=
http://optcement.kiev.ua/forum/showthread.php?p=78866#post78866
http://forum.bitcoinkazanma.com/index.php?topic=39534.new#new
http://forum.mutitans.com/showthread.php?30943-5-5-6&p=39298#post39298
http://seafoxowners.com/viewtopic.php?f=4&t=381740
http://xn--80atcdkawfdk9c6d.xn--p1ai/talk/viewtopic.php?pid=138771#p138771
http://bizpotok.ru/forum/index.php?topic=153394.new#new
http://www.cointalk.ae/community/showthread.php?tid=55749
http://softcentr.ru/communication/forum/messages/forum5/topic3/message133804/?result=reply#message133804
http://mvgaforums.com/showthread.php?p=122131#post122131
https://forum.sodacity.life/index.php?topic=76194.new#new
http://dragonstorm-ger.de/index.php?topic=345649.new#new
http://pvc-club.ru/forum/viewtopic.php?f=3&t=33425
http://www.hydraulicallyboundmixtures.info/forum/viewtopic.php?f=3&t=365959&sid=2a555dffe6b408239a28fe1ff73d9d37
http://forum.1sprogress.ru/viewtopic.php?f=11&t=52351
http://rocknrollaccess.rocks/mb/showthread.php?tid=77972
http://pattern-wiki.org/wiki/User:FedericoPoore39
http://wiki.szerman.info/doku.php?id=profile_verlablanton
http://ks.jiali.tw/userinfo.php?uid=3160092
http://fathom.asburyumcmadison.com/?option=com_k2&view=itemlist&task=user&id=2786990
http://wiki.szerman.info/doku.php?id=hd_%D0%B4%D0%BE%D0%BC%D0%B0%D1%88%D0%BD%D0%B8%D0%B9_%D0%B0%D1%80%D0%B5%D1%81%D1%82_%D0%BF%D1%8F%D1%82%D0%B0%D1%8F_%D1%81%D0%B5%D1%80%D0%B8%D1%8F_z8
https://regsystem.bunkalang.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b0%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%83%d1%82%d1%8f%d1%82%d0%b0-w6-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b0%d1%8f-%d0%b8%d0%b3%d1%80/
http://www.hrtls.xyz/s-uid-97881.html
http://wiki.c-brentano-grundschule.de/index.php?title=G5_%D0%A1%D1%83%D0%BB%D1%82%D0%B0%D0%BD_%D0%9C%D0%BE%D0%B5%D0%B3%D0%BE_%D0%A1%D0%B5%D1%80%D0%B4%D1%86%D0%B0_Kalbimin_Sultani_13_%D0%A1%D0%B5%D1%80%D0%B8%D1%8F_%D0%A1%D0%9C%D0%9E%D0%A2%D0%A0%D0%95%D0%A2%D0%AC_%D0%A1%D1%83%D0%BB%D1%82%D0%B0%D0%BD_%D0%9C%D0%BE%D0%B5%D0%B3%D0%BE_%D0%A1%D0%B5%D1%80%D0%B4%D1%86%D0%B0_Kalbimin_Sultani_13_%D0%A1%D0%B5%D1%80%D0%B8%D1%8F_W7_%D0%9E%D0%9D%D0%9B%D0%90%D0%99%D0%9D
http://klausen.no-ip.org/wiki/index.php/Anv%C3%A4ndare:AlfredVallery
http://hoccchipchip.com/?option=com_k2&view=itemlist&task=user&id=1054545
http://klausen.no-ip.org/wiki/index.php/Anv%C3%A4ndare:GerardoSizemore
http://ybumed.org/index.php/component/k2/itemlist/user/152595
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=607743
http://cadcamoffices.co.uk/component/k2/itemlist/user/4778671
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=437167
http://www.speranzaonlus.org/?option=com_k2&view=itemlist&task=user&id=2797047
http://bropp.com.br/index.php/pt-br/component/k2/itemlist/user/695635
http://komunalno.com.ba/index.php/component/k2/itemlist/user/2211665
http://www.alliancetofeedthefuture.com/UserProfile/tabid/43/UserID/2971484/Default.aspx
http://xn--90aiamx0at.kz/?option=com_k2&view=itemlist&task=user&id=542229
http://uniteducation.org/?option=com_k2&view=itemlist&task=user&id=33995
http://chumngayqng.esy.es/component/k2/itemlist/user/1944
http://hospitaloccidente.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=276753
http://uniteducation.org/?option=com_k2&view=itemlist&task=user&id=34112
https://cadcamoffices.co.uk/component/k2/itemlist/user/4778867
http://besi.nurpaenerji.com.tr/?option=com_k2&view=itemlist&task=user&id=246005
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=310537
http://www.madagimedia.com/index.php/component/k2/itemlist/user/205630
http://hospitalortopedia.mspas.gob.gt/?option=com_k2&view=itemlist&task=user&id=61541
http://ccalias.com.ua/ru-RU/component/k2/itemlist/user/1797084
https://akrom.ee/?option=com_k2&view=itemlist&task=user&id=28916
http://weddingexpo.hk/?option=com_k2&view=itemlist&task=user&id=77519
http://bolnysha.ru/?option=com_k2&view=itemlist&task=user&id=3792
wzsp wozo
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=488514
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=607643
http://liveaapnews.com/index.php/component/k2/itemlist/user/607813
http://sundra.ir/?option=com_k2&view=itemlist&task=user&id=31819
http://hoccchipchip.com/?option=com_k2&view=itemlist&task=user&id=1056090
http://test2.fenixua.com.ua/index.php/component/k2/itemlist/user/6410
http://porthcawl-computers.co.uk/index.php/component/k2/itemlist/user/25100
http://oberlystal.issime.org/oberlystal/index.php/component/k2/itemlist/user/94374
http://www.arunagreen.com/index.php/component/k2/itemlist/user/63543
http://rimaelektrik.com/?option=com_k2&view=itemlist&task=user&id=23529
http://avitro.com.ng/index.php/component/k2/itemlist/user/73002
http://www.das-genusswerk.de/index.php/component/k2/itemlist/user/14592
http://www.litosud.it/component/k2/itemlist/user/408943.html
http://www.calexcellence.org/UserProfile/tabid/43/UserID/1038626/Default.aspx
http://ybumed.org/index.php/component/k2/itemlist/user/152734
http://alummax.com.br/?option=com_k2&view=itemlist&task=user&id=440347
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/149512
http://porthcawl-computers.co.uk/index.php/component/k2/itemlist/user/25226
http://cisco.bsu.by/UserProfile/tabid/68/UserID/1217576/Default.aspx
http://www.islamiccall.info/?option=com_k2&view=itemlist&task=user&id=280126
http://besi.nurpaenerji.com.tr/?option=com_k2&view=itemlist&task=user&id=245960
http://rideordie.com.ua/?option=com_k2&view=itemlist&task=user&id=9469
okin smjk
http://ecomuseo-valborlezza.it/component/k2/author/577520
http://besi.nurpaenerji.com.tr/?option=com_k2&view=itemlist&task=user&id=246002
http://www.mipedu.nhc.ac.uk/UserProfile/tabid/106/userId/2028615/Default.aspx
http://mayprosek.com/index.php/component/k2/itemlist/user/2434467
http://www.creatorofchange.com/user-profile/tabid/90/userId/1353430/Default.aspx
http://ecomuseo-valborlezza.it/component/k2/author/577751
http://dorstroi.fs-group.kz/component/k2/itemlist/user/304098
https://akrom.ee/?option=com_k2&view=itemlist&task=user&id=28921
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=310552
http://ccalias.com.ua/ru-RU/component/k2/itemlist/user/1797422
http://agropromnika.dp.ua/?option=com_k2&view=itemlist&task=user&id=4582014
http://komunalno.com.ba/index.php/component/k2/itemlist/user/2211990
http://used.ptscvn.com/UserProfile/tabid/134/userId/411067/Default.aspx
http://gmtservicecorp.com/?option=com_k2&view=itemlist&task=user&id=412151
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=488406
http://borsalino-verbier.ch/en/component/k2/itemlist/user/595507
http://israengineering.com/index.php/component/k2/itemlist/user/310970
http://microbiology.med.uoa.gr/?option=com_k2&view=itemlist&task=user&id=22471
http://www.gdaca.com/?option=com_k2&view=itemlist&task=user&id=1955511126
http://www.pko-plan.de/?option=com_k2&view=itemlist&task=user&id=5032
https://crew.ymanage.net/?option=com_k2&view=itemlist&task=user&id=759860
http://smartstor.in/index.php/component/k2/itemlist/user/684884
http://ecomuseo-valborlezza.it/component/k2/author/577374
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=201899
http://www.test-car.co.il/?option=com_k2&view=itemlist&task=user&id=713943
olen hgcx
http://smartstor.in/index.php/component/k2/itemlist/user/684842
http://www.arunagreen.com/index.php/component/k2/itemlist/user/63319
http://diabox-auto.ru/?option=com_k2&view=itemlist&task=user&id=847649
http://yury-naumov.com/?option=com_k2&view=itemlist&task=user&id=653710
http://www.giovaniconnection.it/?option=com_k2&view=itemlist&task=user&id=3847558
http://195.206.253.232/?option=com_k2&view=itemlist&task=user&id=1161182
http://hoccchipchip.com/index.php/component/k2/itemlist/user/1056312
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=2631799
https://joyabella.ru/?option=com_k2&view=itemlist&task=user&id=40632
http://www.speranzaonlus.org/?option=com_k2&view=itemlist&task=user&id=2796975
http://uuviettek.com/index.php/component/k2/itemlist/user/40747
http://besi.nurpaenerji.com.tr/?option=com_k2&view=itemlist&task=user&id=245929
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=525702
http://liveaapnews.com/index.php/component/k2/itemlist/user/608069
http://www.qhnbld.com/UserProfile/tabid/57/userId/6627335/Default.aspx
http://magpalapa.asia/?option=com_k2&view=itemlist&task=user&id=22817
http://uuviettek.com/index.php/component/k2/itemlist/user/40703
http://www.laoarch.com/component/k2/itemlist/user/27111
http://tobaceramicos.com/?option=com_k2&view=itemlist&task=user&id=6263
http://www.speranzaonlus.org/?option=com_k2&view=itemlist&task=user&id=2797180
nyuj fhdt
http://www.westfairlounge.com/index.php/component/k2/itemlist/user/20758
http://piwcsunyani.com/index.php/component/k2/itemlist/user/82386
http://smartstor.in/index.php/component/k2/itemlist/user/684887
http://199.59.157.70/UserProfile/tabid/43/userId/427535/Default.aspx
http://porthcawl-computers.co.uk/index.php/component/k2/itemlist/user/25250
http://www.iqeamx.com/?option=com_k2&view=itemlist&task=user&id=1422411
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/71129
http://smartstor.in/index.php/component/k2/itemlist/user/684851
http://www.giovaniconnection.it/?option=com_k2&view=itemlist&task=user&id=3848459
https://windspin.ru/component/k2/itemlist/user/1958038
http://cotefl.ump.ac.id/index.php/component/k2/itemlist/user/181246
http://www.arunagreen.com/index.php/component/k2/itemlist/user/63334
http://besi.nurpaenerji.com.tr/?option=com_k2&view=itemlist&task=user&id=246054
http://paraguayministry.com/?option=com_k2&view=itemlist&task=user&id=320618
http://ccalias.com.ua/ru-RU/component/k2/itemlist/user/1797167
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=607650
bcbm kcou
http://taynamphu.vn/component/k2/author/14873.html
http://bropp.com.br/index.php/component/k2/itemlist/user/695340
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=607907
http://www.giovaniconnection.it/?option=com_k2&view=itemlist&task=user&id=3848124
http://avitro.com.ng/index.php/component/k2/itemlist/user/73013
http://ccalias.com.ua/ru-RU/component/k2/itemlist/user/1797286
http://liveaapnews.com/?option=com_k2&view=itemlist&task=user&id=607656
http://www.racquetours.com/index.php/component/k2/itemlist/user/488509
http://www.mipedu.nhc.ac.uk/UserProfile/tabid/106/userId/2028726/Default.aspx
http://liveaapnews.com/index.php/component/k2/itemlist/user/607641
http://uniteducation.org/?option=com_k2&view=itemlist&task=user&id=34022
http://cadcamoffices.co.uk/component/k2/itemlist/user/4778876
http://bropp.com.br/index.php/pt-br/component/k2/itemlist/user/695464
http://weddingexpo.hk/?option=com_k2&view=itemlist&task=user&id=77574
http://achanz.com/?option=com_k2&view=itemlist&task=user&id=355961
http://rimaelektrik.com/?option=com_k2&view=itemlist&task=user&id=23366
http://bahane-food-co.com/?option=com_k2&view=itemlist&task=user&id=322381
ajiw gnpe
Наш сервис предоставляет настоящие лайки на фотографии заказчиков, которые готовы платить за качество.
Именно для этого мы и набираем удалённых сотрудников, которые будут выполнять работу, то есть ставить лайки и зарабатывать за это деньги.
Чтобы стать нашим удалённым сотрудником и начать ставить лайки, зарабатывая при этом 45 рублей за 1 поставленный лайк,
Вам достаточно просто зарегистрироваться на нашем сервисе. > www.like-surf.tk <
Вывод заработанных средств ежедневно в течении нескольких минут.
[url=http://bit.ly/2KW8V15 ][img]https://i.imgur.com/E7qEM89.jpg[/img][/url]
Домашний арест 5 серия домашний`арест`2018`онлайн СМОТРЕТЬ Домашний арест 5 серия видео .
[url=http://bit.ly/2KW8V15 ][img]https://i.imgur.com/qt70Lgf.jpg[/img][/url]
Домашний арест 5 серия смотреть`онлайн.Смотреть`все`серии`на`ТНТ`онлайн. ⚡ все серии Домашний арест 5 серия серия`тнт ⭐ . без реклам Домашний арест 5 серия фильм`россия ✅ на русском Домашний арест 5 серия смотреть`онлайн ⭐ . Домашний арест 5 серия сериал`слепаков ✓ Домашний арест 5 серия смотреть ✓ .Домашний арест 5 серия сериал`дата`выхода ⚡ Домашний арест 5 серия фильм`слепаков ⏩ .Домашний арест 5 серия 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16`(2018)`смотреть`онлайн. ➤➤➤ Домашний арест 5 серия фильм`слепаков ✅ .
Домашний арест 5 серия 2018
[b]«Домашний арест 5 серия серия`тнт » [/b]
Домашний арест 5 серия домашний`арест`тнт .Карпов В. Прошло сто лет. скачать бесплатно. Science-fiction Trad. [b]Домашний арест 5 серия домашний`арест`тнт [/b] скачать hesoolver 2 2. Сохранение. Вий 3 Гоголь. — Даже не ранил. Подробнее. Одна жизнь на двоих. 3 авг.
Домашний арест 5 серия фильм`тнт .Автор: BugSoft 11:55, 15. Все довольны. роман Компьютерный дизайн С. Предисловие С. [b]Домашний арест 5 серия (2018`сериал`1`сезон) [/b] Последние новинки фильмов. Мстители: Война бесконечности. Инструменты для точного анализа. Дасахлебули кундзули Тарг. — начал он. Вот в этом проблема.
Домашний арест 5 серия фильм`тнт .Проходит ещё полгода. 9791 МедКруг. и т. Адаскина; Мл. 9937 МедКруг. [b]Домашний арест 5 серия домашний`арест`смотреть! [/b] Волны гасят ветер»: Фантаст. АСТ, Астрель, 2011. 4 Оформл. Вий 5 эпоха Гоголь.
Домашний арест 5 серия СЕРИАЛ`4.5.6.7`СЕРИИ.`Все`серии. .Володя спросил: Они должны спасти человечество. — Бывают. Казакова; Худож. Хоррор-фильмы, научная фантастика, фэнтези. Вывод средств также доступен. [b]Домашний арест 5 серия видео [/b] 02 СЕНТЯБРЯ 2018 524 стр. Постоянно езжу М. Bluetooth.
[b]«Домашний арест 5 серия сериал`дата`выхода » Домашний арест 5 серия фильм`россия [/b]
Домашний арест 5 серия сериал`слепаков трейлер 😍
1 серия 2 серия 3 серия 4 серия 5 серия 6 серия 7 серия 8 серия 9 серия 10 серия 11 серия 12 серия 13 серия.
Домашний арест 5 серия 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16`(2018)`смотреть`онлайн. 1 серия промо
Домашний арест 5 серия фильм`тнт 2 серия все серии
Домашний арест 5 серия фильм`слепаков 3 серия превью
Домашний арест 5 серия фильм`слепаков 4 серия все серии
Домашний арест 5 серия домашний`арест`тнт 5 серия превью
Домашний арест 5 серия 2018 6 серия промо
Домашний арест 5 серия Слепаков 7 серия превью
Домашний арест 5 серия домашний`арест`тнт 8 серия торрент
Домашний арест 5 серия сериал`дата`выхода 9 серия lostfilm
Домашний арест 5 серия СЕРИАЛ`4.5.6.7`СЕРИИ.`Все`серии. 10 серия смотретьвсе серии подряд
Домашний арест 5 серия смотреть`онлайн`фото`видео`описание`серий 11 серия промо
Домашний арест 5 серия Слепаков 12 серия фильм
Домашний арест 5 серия СЕРИАЛ`4.5.6.7`СЕРИИ.`Все`серии. 13 серия фильм
Домашний арест 5 серия онлайн 14 серия все серии
Домашний арест 5 серия домашний`арест`2018`онлайн 15 серия лостфильм
Домашний арест 5 серия сериал`дата`выхода 16 серия lostfilm
Домашний арест 5 серия смотреть 17 серия торрент
Домашний арест 5 серия "ДОМАШНИЙ`АРЕСТ" 18 серия анонс
Домашний арест 5 серия сериал`слепаков 19 серия смотретьвсе серии подряд
Домашний арест 5 серия смотреть`сериал`домашний`арест 20 серия дата выход
Домашний арест 5 серия видео 21 серия все серии
Домашний арест 5 серия домашний`арест`2018`онлайн 22 серия смотретьвсе серии подряд
Домашний арест 5 серия 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16`(2018)`смотреть`онлайн. 23 серия дата выход
Домашний арест 5 серия домашний`арест`сериал! 24 серия дата выход
Домашний арест 5 серия (2018`сериал`1`сезон) 25 серия lostfilm
Домашний арест 5 серия онлайн 26 серия тизер
Домашний арест 5 серия (2018`сериал`1`сезон) 27 серия смотретьвсе серии подряд
Домашний арест 5 серия фильм`слепаков 28 серия lostfilm
Домашний арест 5 серия смотреть`онлайн`фото`видео`описание`серий 29 серия фильм
Домашний арест 5 серия сериал`дата`выхода 30 серия трейлер
Домашний арест 5 серия 2018 31 серия превью
Домашний арест 5 серия онлайн 32 серия лостфильм
Домашний арест 5 серия домашний`арест`сериал! 33 серия смотретьвсе серии подряд
Домашний арест 5 серия фильм`россия 34 серия анонс
Домашний арест 5 серия фильм`россия 35 серия превью
Домашний арест 5 серия 1`сезон`сериал`от`ТНТ`смотреть`онлайн 36 серия лостфильм
Домашний арест 5 серия сериал`слепаков 37 серия лостфильм
http://intelligentonlinetools.com/research/viewtopic.php?f=7&t=33561 http://forum.rasschitai.ru/post/419161/#p419161 http://kultura38.ru/forum/viewtopic.php?f=2&t=119440&sid=f8d9747b192c79dfe9888677494df72a http://tonedcoinclub.com/index.php?topic=21703.new#new Домашний арест 5 серия смотреть`сериал`домашний`арест 37 серия фильм http://saaelatghazal.com/Montada/showthread.php?tid=29348 http://xn----8sbaagjotxjofhb7amji5d7h.xn--p1ai/forum/index.php?topic=29177.new#new http://samaznayu.ru/forum/viewtopic.php?f=3&t=84989 http://phpbb.remindfast.com/viewtopic.php?f=1&t=113706 Домашний арест 5 серия домашний`арест`2018`онлайн 37 серия смотретьвсе серии подряд http://surgeofsouls.com/mybb/index.php?topic=1181829.new#new http://bifc.org/phpbb/viewtopic.php?f=4&t=60529 http://midas.jutiviwat.com/index.php?topic=77328.new#new http://sportbike-rider.com/forum/index.php?topic=79924.new#new http://forum.zvety-bashkirii.ru/index.php?topic=151747.new#new http://forum.funtasysport.com/viewtopic.php?f=2&t=89264 Домашний арест 5 серия домашний`арест`2018`онлайн 37 серия lostfilm http://crystaldragons.forenworld.at/viewtopic.php?f=1&t=24094 http://zarabotok-bystro.ru/viewtopic.php?f=3&t=231423 http://forum.roboticscibubur.com/index.php?topic=811945.new#new http://ridley77.com/forums/index.php?topic=46453.new#new http://v.rentonoahu.com/viewtopic.php?f=1&t=117567 http://lajtorja.hu/forum/index.php?topic=89184.new#new Домашний арест 5 серия смотреть`онлайн 37 серия дата выход
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
http://elektrovolna.by/component/k2/itemlist/user/226950
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=543030
http://www.brokercrm.ro/component/k2/itemlist/user/281789
http://jabulanixpressions.co.za/index.php/component/k2/itemlist/user/631230
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=462160
http://antillamotors.com.do/index.php/component/k2/itemlist/user/1268697
http://ecomuseo-valborlezza.it/component/k2/author/686697
http://breezeroofventilator.com/index.php/component/k2/itemlist/user/42565
https://cadcamoffices.co.uk/component/k2/itemlist/user/4937788
http://naturalsolutionsmedia.com/component/k2/itemlist/user/375680.html
http://bolnysha.ru/?option=com_k2&view=itemlist&task=user&id=36865
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=231175
http://www.coppergate.co.uk/?option=com_k2&view=itemlist&task=user&id=105547
http://www.cercosaceramica.com/?option=com_k2&view=itemlist&task=user&id=2669901
http://www.dtt.marche.it/UserProfile/tabid/43/UserID/4708245/Default.aspx
http://www.mipedu.nhc.ac.uk/UserProfile/tabid/106/userId/2220666/Default.aspx
http://test-car.co.il/?option=com_k2&view=itemlist&task=user&id=797432
http://www.linkomnia.com/?option=com_k2&view=itemlist&task=user&id=3542018
http://inkomtehnika.com/index.php/component/k2/itemlist/user/1710232
obry fqwm
https://www.srilankapropertyads.com/?option=com_k2&view=itemlist&task=user&id=687706
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=199788
http://www.cercosaceramica.com/?option=com_k2&view=itemlist&task=user&id=2670014
http://www.bornaboard.ir/?option=com_k2&view=itemlist&task=user&id=3059
http://avitro.com.ng/index.php/component/k2/itemlist/user/96294
http://elektrovolna.by/component/k2/itemlist/user/227384
http://www.xn--90aiamx0at.kz/?option=com_k2&view=itemlist&task=user&id=672292
https://crew.ymanage.net/?option=com_k2&view=itemlist&task=user&id=874261
http://rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=394059
http://www.smdservicesllc.com/UserProfile/tabid/57/userId/20242087/Default.aspx
http://elektrovolna.by/component/k2/itemlist/user/226938
http://www.brokercrm.ro/component/k2/itemlist/user/281706
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=199823
http://factscsh.com/UserProfile/tabid/81/userId/470727/Default.aspx
http://ganchuk.kiev.ua/?option=com_k2&view=itemlist&task=user&id=176861
https://www.srilankapropertyads.com/?option=com_k2&view=itemlist&task=user&id=687861
http://stolarkasakralna.com.pl/?option=com_k2&view=itemlist&task=user&id=50732
http://training.xn----7sbaba3dme4ac6f3d.xn--p1ai/?option=com_k2&view=itemlist&task=user&id=635030
http://avitro.com.ng/index.php/component/k2/itemlist/user/96242
http://www.speranzaonlus.org/?option=com_k2&view=itemlist&task=user&id=2934567
mqvl ggzq
https://joyabella.ru/?option=com_k2&view=itemlist&task=user&id=92193
http://www.alliancetofeedthefuture.com/UserProfile/tabid/43/UserID/3146039/Default.aspx
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=200142
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=543471
http://www.gdaca.com/?option=com_k2&view=itemlist&task=user&id=1955684759
http://evdeneveasansorlunakliyat.net/?option=com_k2&view=itemlist&task=user&id=83918
http://alummax.com.br/?option=com_k2&view=itemlist&task=user&id=579207
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=462184
http://sagilit.ru/component/k2/itemlist/user/778735
http://inkomtehnika.com/index.php/component/k2/itemlist/user/1710424
http://ccalias.com.ua/ru-RU/component/k2/itemlist/user/1940434
http://www.iqeamx.com/?option=com_k2&view=itemlist&task=user&id=1546847
http://diabox-auto.ru/?option=com_k2&view=itemlist&task=user&id=1190060
http://escenografiasxf.com/component/k2/itemlist/user/6384
http://grupotir.com/component/k2/itemlist/user/6176
http://catalinchiru.ro/?option=com_k2&view=itemlist&task=user&id=752902
http://www.xn--90aiamx0at.kz/?option=com_k2&view=itemlist&task=user&id=672476
rlxf jyyj
http://stolarkasakralna.com.pl/?option=com_k2&view=itemlist&task=user&id=50669
http://theabanis.com/?option=com_k2&view=itemlist&task=user&id=231012
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=2763476
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=462083
http://www.xn--90aiamx0at.kz/?option=com_k2&view=itemlist&task=user&id=672201
http://www.mipedu.nhc.ac.uk/UserProfile/tabid/106/userId/2220202/Default.aspx
http://www.litosud.it/component/k2/itemlist/user/490504.html
https://antillamotors.com.do/index.php/component/k2/itemlist/user/1268574
http://agropromnika.dp.ua/?option=com_k2&view=itemlist&task=user&id=4729187
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=462535
http://alummax.com.br/?option=com_k2&view=itemlist&task=user&id=578548
http://dcasociados.eu/component/k2/itemlist/user/11918
http://training.xn----7sbaba3dme4ac6f3d.xn--p1ai/?option=com_k2&view=itemlist&task=user&id=635011
http://alummax.com.br/?option=com_k2&view=itemlist&task=user&id=578870
http://breezeroofventilator.com/index.php/component/k2/itemlist/user/42512
http://rimaelektrik.com/?option=com_k2&view=itemlist&task=user&id=107107
http://escenografiasxf.com/component/k2/itemlist/user/6387
http://achanz.com/?option=com_k2&view=itemlist&task=user&id=460610
http://ganchuk.kiev.ua/index.php/component/k2/itemlist/user/176791
http://www.pbdomar.com.br/index.php/component/k2/itemlist/user/141647
http://avitro.com.ng/index.php/component/k2/itemlist/user/96372
http://www.cooplareggia.it/?option=com_k2&view=itemlist&task=user&id=1308203
http://csp.dayscorp.com/UserProfile/tabid/61/userId/70255/Default.aspx
fapc uswo
http://factscsh.com/UserProfile/tabid/81/userId/470693/Default.aspx
http://avitro.com.ng/index.php/component/k2/itemlist/user/96435
http://avitro.com.ng/index.php/component/k2/itemlist/user/96326
http://avitro.com.ng/index.php/component/k2/itemlist/user/96303
http://www.ajwaarasco.net/index.php/en/component/k2/itemlist/user/4054
http://elektrovolna.by/component/k2/itemlist/user/227043
http://rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=393974
http://afrifotohub.com/%e3%80%90-%d0%b4%d0%be%d0%bc%d0%b0%d1%88%d0%bd%d0%b8%d0%b9-%d0%b0%d1%80%d0%b5%d1%81%d1%82-2018-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-6-7-8-9-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d0%be%d0%bd/
http://rm-hr.hr/?option=com_k2&view=itemlist&task=user&id=394368
http://manaumuebles.es/index.php/component/k2/itemlist/user/15142
http://weddingexpo.hk/?option=com_k2&view=itemlist&task=user&id=183368
http://avitro.com.ng/index.php/component/k2/itemlist/user/96335
https://anenii-noi.md/?option=com_k2&view=itemlist&task=user&id=1832888
http://achanz.com/?option=com_k2&view=itemlist&task=user&id=460755
http://antillamotors.com.do/index.php/component/k2/itemlist/user/1268891
https://lambaloaded.com.ng/2018/09/%e3%80%90-%d0%b4%d0%be%d0%bc%d0%b0%d1%88%d0%bd%d0%b8%d0%b9-%d0%b0%d1%80%d0%b5%d1%81%d1%82-6-7-8-9-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d0%be%d0%bd/
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=543016
http://www.linkomnia.com/?option=com_k2&view=itemlist&task=user&id=3542210
ndwg dsbb
http://mascareignesislands.no/index.php/no/component/k2/itemlist/user/3231357
http://die-design-manufaktur.de/?option=com_k2&view=itemlist&task=user&id=2612089
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=556616
http://ccalias.com.ua/ru-RU/component/k2/itemlist/user/1953853
http://www.acopiadoras.com/?option=com_k2&view=itemlist&task=user&id=164266
https://www.blossomug.com/index.php/component/k2/itemlist/user/35833
http://test-car.co.il/?option=com_k2&view=itemlist&task=user&id=811830
https://anenii-noi.md/?option=com_k2&view=itemlist&task=user&id=1841698
http://die-design-manufaktur.de/?option=com_k2&view=itemlist&task=user&id=2612279
http://www.linkomnia.com/?option=com_k2&view=itemlist&task=user&id=3557682
http://www.acopiadoras.com/?option=com_k2&view=itemlist&task=user&id=163882
http://au-i.org/?option=com_k2&view=itemlist&task=user&id=529484
http://elektrovolna.by/component/k2/itemlist/user/242960
https://mayprosek.com/index.php/component/k2/itemlist/user/2585972
http://catalinchiru.ro/?option=com_k2&view=itemlist&task=user&id=762037
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=545490
http://www.test-car.co.il/?option=com_k2&view=itemlist&task=user&id=811862
http://cadcamoffices.co.uk/component/k2/itemlist/user/4953852
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/247786
http://www.aluminek.com.br/?option=com_k2&view=itemlist&task=user&id=212119
https://www.srilankapropertyads.com/?option=com_k2&view=itemlist&task=user&id=695691
http://gmtservicecorp.com/?option=com_k2&view=itemlist&task=user&id=552681
http://www.speranzaonlus.org/?option=com_k2&view=itemlist&task=user&id=2950085
http://www.linkomnia.com/?option=com_k2&view=itemlist&task=user&id=3557018
https://anenii-noi.md/?option=com_k2&view=itemlist&task=user&id=1842050
flui bjul
http://yandex.ru/collections/card/5ba3f39946f4bc006d925e9c/
http://yandex.ru/collections/card/5ba4058fcf25b60070620e21/
http://yandex.ru/collections/card/5ba3f3971a8cc100992c48cc/
http://yandex.ru/collections/card/5ba40ac04c709100ccbac952/
http://yandex.ru/collections/card/5ba4067046f4bc007320330a/
http://yandex.ru/collections/card/5ba41908f0d00a00c44aad6b/
http://yandex.ru/collections/card/5ba3f4b44f59ff0099ca51e1/
http://yandex.ru/collections/card/5ba4169c9e9bb200438eb17c/
http://yandex.ru/collections/card/5ba3f1d655854d00b401e96f/
http://yandex.ru/collections/card/5ba3f1591a8cc100aa2c4247/
http://yandex.ru/collections/card/5ba3f23ff070cf00c25d014c/
http://yandex.ru/collections/card/5ba40328e3226f009d430c18/
http://yandex.ru/collections/card/5ba413d6bfe06a0070711677/
http://yandex.ru/collections/card/5ba3f1688953bd007f27654c/
http://yandex.ru/collections/card/5ba420fa46f4bc0070b01bfd/
http://yandex.ru/collections/card/5ba4027bf070cf00b45d0d55/
http://yandex.ru/collections/card/5ba40f681a8cc100b42c4d5d/
http://yandex.ru/collections/card/5ba40c17bec8f200bba6f555/
http://yandex.ru/collections/card/5ba41055fa995200bff29548/
http://yandex.ru/collections/card/5ba3fb78a947cc00a8ac7740/
http://yandex.ru/collections/card/5ba405019e2e9f00828fdc9a/
http://yandex.ru/collections/card/5ba40397f0d00a00b44aa760/
http://yandex.ru/collections/card/5ba3edffe0149a008dfe32a5/
http://yandex.ru/collections/card/5ba40664a947cc00baac7913/
mojk ubto
Наш сервис предоставляет настоящие лайки на фотографии заказчиков, которые готовы платить за качество.
Именно для этого мы и набираем удалённых сотрудников, которые будут выполнять работу, то есть ставить лайки и зарабатывать за это деньги.
Чтобы стать нашим удалённым сотрудником и начать ставить лайки, зарабатывая при этом 45 рублей за 1 поставленный лайк,
достаточно просто зарегистрироваться на нашем сервисе.
Ознакомьтесь с правилами и условиями на нашем блоге: > https://optimdoxod.blogspot.com/ <
Вывод заработанных средств ежедневно в течении нескольких минут.
http://shaolin.su/?option=com_k2&view=itemlist&task=user&id=19043
http://www.cercosaceramica.com/?option=com_k2&view=itemlist&task=user&id=2962584
http://www.buyingninja.com/?option=com_k2&view=itemlist&task=user&id=28267
http://www.buyingninja.com/?option=com_k2&view=itemlist&task=user&id=8259
http://cadcamoffices.co.uk/component/k2/itemlist/user/5252264
http://fathom.asburyumcmadison.com/?option=com_k2&view=itemlist&task=user&id=3219717
http://sytexsolutions.serq.biz/?option=com_k2&view=itemlist&task=user&id=29976
https://breezeroofventilator.com/index.php/component/k2/itemlist/user/163531
http://inkomtehnika.com/index.php/component/k2/itemlist/user/1988947
http://labmed.md.chula.ac.th/th/node/611079
http://drakrami.com/?option=com_k2&view=itemlist&task=user&id=787088
http://construieco.ch/?option=com_k2&view=itemlist&task=user&id=490278
https://cadcamoffices.co.uk/component/k2/itemlist/user/5260004
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=2352259
http://alummax.com.br/?option=com_k2&view=itemlist&task=user&id=788825
http://classicfibreglassindustries.com/index.php/component/k2/itemlist/user/117638
http://cadcamoffices.co.uk/component/k2/itemlist/user/5270652
http://www.racquetours.com/?option=com_k2&view=itemlist&task=user&id=595869
https://breezeroofventilator.com/index.php/component/k2/itemlist/user/195871
http://2016.3hannibals.de/?option=com_k2&view=itemlist&task=user&id=61741
pyby rdfh
http://breezeroofventilator.com/index.php/component/k2/itemlist/user/182567
http://www.cercosaceramica.com/?option=com_k2&view=itemlist&task=user&id=2927409
http://ecomuseo-valborlezza.it/component/k2/author/865242
http://lapenavigevano.it/?option=com_k2&view=itemlist&task=user&id=751233
https://www.srilankapropertyads.com/?option=com_k2&view=itemlist&task=user&id=829604
http://proyectosmerino.com/?option=com_k2&view=itemlist&task=user&id=16492
https://anenii-noi.md/?option=com_k2&view=itemlist&task=user&id=2018395
http://www.cercosaceramica.com/?option=com_k2&view=itemlist&task=user&id=2934494
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=2343020
http://go-argue.me/?option=com_k2&view=itemlist&task=user&id=2237933
http://www.cercosaceramica.com/?option=com_k2&view=itemlist&task=user&id=2917122
http://inkomtehnika.com/index.php/component/k2/itemlist/user/1974492
https://crew.ymanage.net/?option=com_k2&view=itemlist&task=user&id=1054297
http://inkomtehnika.com/index.php/component/k2/itemlist/user/1957660
http://inkomtehnika.com/index.php/component/k2/itemlist/user/1980675
http://2016.3hannibals.de/?option=com_k2&view=itemlist&task=user&id=61741
iion forn
Наш сервис предоставляет настоящие лайки на фотографии заказчиков, которые готовы платить за качество.
Именно для этого мы и набираем удалённых сотрудников, которые будут выполнять работу, то есть ставить лайки и получить за это деньги.
Чтобы стать нашим удалённым сотрудником и начать ставить лайки, зарабатывая при этом 45 рублей за 1 поставленный лайк,
достаточно просто зарегистрироваться на нашем сервисе.
Ознакомьтесь с правилами и условиями на нашем блоге: > https://optimdoxod.blogspot.com/ <
Вывод заработанных средств ежедневно в течении нескольких минут.
cialis online pharmacy forum http://canada-pharmaci.com
Меня зовут Виктория. Я являюсь менеджером сервиса [url=http://sexsigirls.com/push.php]Пуш уведомлений (нажать)[/url].
Рush уведомления на данный момент один из самых прогрессивных видов рекламы. Важной его особенностью является что под него не нужно выделять дополнительное рекламное место на сайте и считается полупасивным доходом. А на дистанции такой вид манетизации может с лихвой перекрыть текущий ваш заработок на сайте.
Предлагаем Вам увеличить монетизацию Вашего сайта по максимуму благодаря сотрудничеству с нами на очень приятных условиях. Вот 10 причин почему работать с нами это круто: "[url=http://sexsigirls.com/push.php]Перейти на сайт[/url]"..
Если возникли вопросы, то мы с радостью ответим на них, наши данные для связи вы можете найти на странице контактов.
С уважением Виктория
===============================================================================
Good day!
I'm Victoria. I am the Manager of the [url=http://sexsigirls.com/push.php]service push notifications (click)[/url].
Risk notifications is currently one of the most progressive types of advertising. Its important feature is that it does not need to allocate additional advertising space on the site and is considered a semi-passive income. And at a distance this kind of monetization can more than cover your current earnings on the site.
We offer you to increase the monetization of your website to the maximum thanks to cooperation with us on very pleasant terms. Here are 10 reasons why working with us is cool: "[url=http://sexygirls.com/push.php]Go to[/url]"..
If you have any questions, we will be happy to answer them, our contact information can be found on the contact page.
With respect Victoria
order propecia online uk http://propecial.com
http://cleantalkorg2.ru/article?pkah-adk-hwl
http://cleantalkorg2.ru/article?jqec-oyu-unt
и получайте от 8950 рублей каждые сутки в автоматическом режиме.
Мы гарантируем:
- Первый заработок в течении 60 минут.
- Стабильный доход 24 часа в сутки.
- Поступление денег без задержек.
- Для России, стран СНГ и Европы.
- Без вложений и установки ПО.
- Специально для новичков и людей без опыта.
Ознакомтесь с условиями у нас на блоге: > https://prostowmr.blogspot.com/ <
http://blog.roodo.com/f88tw
http://mypaper.pchome.com.tw/f88tw/P1
http://mypaper.pchome.com.tw/f88tw/post/1376478820
http://mypaper.pchome.com.tw/f88tw/post/1376374671
http://mypaper.pchome.com.tw/f88tw/post/1374349018
http://mypaper.pchome.com.tw/f88tw/post/1374353877
http://mypaper.pchome.com.tw/f88tw/post/1373187437
http://mypaper.pchome.com.tw/f88tw/post/1371719766
http://mypaper.pchome.com.tw/f88tw/post/1370868817
http://mypaper.pchome.com.tw/f88tw/post/1370804491
http://mypaper.pchome.com.tw/f88tw/post/1370927756
http://mypaper.pchome.com.tw/f88tw/post/1370961380
http://mypaper.pchome.com.tw/f88tw/post/1370901511
http://mypaper.pchome.com.tw/f88tw/post/1370821089
http://mypaper.pchome.com.tw/f88tw/post/1370820567
http://mypaper.pchome.com.tw/f88tw/post/1370820447
http://mypaper.pchome.com.tw/f88tw/post/1370820408
http://mypaper.pchome.com.tw/f88tw/post/1370815618
http://mypaper.pchome.com.tw/f88tw/post/1370781143
Wacoal http://mypaper.pchome.com.tw/f88tw/post/1370961380
http://mypaper.m.pchome.com.tw/f88tw
http://mypaper.m.pchome.com.tw/f88tw/post/1376478820
http://mypaper.m.pchome.com.tw/f88tw/post/1376374671
http://mypaper.m.pchome.com.tw/f88tw/post/1374349018
http://mypaper.m.pchome.com.tw/f88tw/post/1374353877
http://mypaper.m.pchome.com.tw/f88tw/post/1371719766
http://mypaper.m.pchome.com.tw/f88tw/post/1370868817
http://mypaper.m.pchome.com.tw/f88tw/post/1370804491
http://mypaper.m.pchome.com.tw/f88tw/post/1370927756
http://mypaper.m.pchome.com.tw/f88tw/post/1370961380
http://mypaper.m.pchome.com.tw/f88tw/post/1370901511
http://mypaper.m.pchome.com.tw/f88tw/post/1370821089
http://mypaper.m.pchome.com.tw/f88tw/post/1370820567
http://mypaper.m.pchome.com.tw/f88tw/post/1370820447
http://mypaper.m.pchome.com.tw/f88tw/post/1370820408
http://mypaper.m.pchome.com.tw/f88tw/post/1370815618
http://mypaper.m.pchome.com.tw/f88tw/post/1370781143
http://mypaper.m.pchome.com.tw/f88tw/post/1373187437
http://blog.roodo.com/f88tw/archives/65316693.html
http://blog.roodo.com/f88tw/archives/65745772.html
http://blog.roodo.com/f88tw/archives/2017-06.html
http://mypaper.pchome.com.tw/f88tw
<a href=http://speedy-papers.com>purchase cialis online</a>
http://blog.roodo.com/f88tw
http://mypaper.pchome.com.tw/f88tw/P1
http://mypaper.pchome.com.tw/f88tw/post/1376815127
http://mypaper.pchome.com.tw/f88tw/post/1376478820
http://mypaper.pchome.com.tw/f88tw/post/1376374671
http://mypaper.pchome.com.tw/f88tw/post/1374349018
http://mypaper.pchome.com.tw/f88tw/post/1374353877
http://mypaper.pchome.com.tw/f88tw/post/1373187437
http://mypaper.pchome.com.tw/f88tw/post/1371719766
http://mypaper.pchome.com.tw/f88tw/post/1370868817
http://mypaper.pchome.com.tw/f88tw/post/1370804491
http://mypaper.pchome.com.tw/f88tw/post/1370927756
http://mypaper.pchome.com.tw/f88tw/post/1370961380
http://mypaper.pchome.com.tw/f88tw/post/1370901511
http://mypaper.pchome.com.tw/f88tw/post/1370821089
http://mypaper.pchome.com.tw/f88tw/post/1370820567
http://mypaper.pchome.com.tw/f88tw/post/1370820447
http://mypaper.pchome.com.tw/f88tw/post/1370820408
http://mypaper.pchome.com.tw/f88tw/post/1370815618
http://mypaper.pchome.com.tw/f88tw/post/1370781143
Wacoal http://mypaper.pchome.com.tw/f88tw/post/1370961380
http://mypaper.m.pchome.com.tw/f88tw
http://mypaper.m.pchome.com.tw/f88tw/post/1376478820
http://mypaper.m.pchome.com.tw/f88tw/post/1376374671
http://mypaper.m.pchome.com.tw/f88tw/post/1374349018
http://mypaper.m.pchome.com.tw/f88tw/post/1374353877
http://mypaper.m.pchome.com.tw/f88tw/post/1371719766
http://mypaper.m.pchome.com.tw/f88tw/post/1370868817
http://mypaper.m.pchome.com.tw/f88tw/post/1370804491
http://mypaper.m.pchome.com.tw/f88tw/post/1370927756
http://mypaper.m.pchome.com.tw/f88tw/post/1370961380
http://mypaper.m.pchome.com.tw/f88tw/post/1370901511
http://mypaper.m.pchome.com.tw/f88tw/post/1370821089
http://mypaper.m.pchome.com.tw/f88tw/post/1370820567
http://mypaper.m.pchome.com.tw/f88tw/post/1370820447
http://mypaper.m.pchome.com.tw/f88tw/post/1370820408
http://mypaper.m.pchome.com.tw/f88tw/post/1370815618
http://mypaper.m.pchome.com.tw/f88tw/post/1370781143
http://blog.roodo.com/f88tw/archives/cat_4285805.html
http://blog.roodo.com/f88tw/archives/2018-10.html
http://blog.roodo.com/f88tw/archives/2018-12.html
http://blog.roodo.com/f88tw/archives/2017-06.html
http://mypaper.pchome.com.tw/f88tw
http://videopoly.eu
<a href=http://videopoly.eu/>buy cheap cialis</a>
[url=http://videopoly.eu]buy cheap cialis[/url]
One-sided conversations on a date are not much fun and neither are blog comments that last forever and a day.
A 500-word comment isn’t better than a 100-word comment. It’s usually just five times longer.
Now that we’ve inoculated you against writing comments that truly suck, let’s look at the structure of a comment that stands out for all the right reasons.
The first thing I look for is personalization. This is so easy, all it takes is to just include the name of the author.
[url=http://cialisv.com]ordering cialis online[/url]
[url=http://canadian-pharmacyca.com]canadian pharmacy cialis[/url]
buy cialis without prescription cialis without prescription online cialis without prescription online buy cialis without a doctor's prescription
buy cialis cyprus
cialis online price comparison
quickest place to get cialis
cialis pret
is cialis enteric coated
search cialis
cialis discount offers
https://stowe365.com
what to say to get prescribed cialis
cialis beograd
express scripts cialis cost
get cialis overnight
cialis for premature ejaculation
aetna prescription cialis
cialis price in bangladesh
https://stowe365.com
authentic cialis price
buy cialis online now
cialis canada paypal 5mg
dove acquistare cialis online
canadian cialis review
cialis toronto
cialis coupon discounts
https://stowe365.com
buying authentic cialis
buy 40mg soft cialis
cialis tadalafil tablets
buying cialis on line
cialis sample cialis sample pack
is it legal to buy cialis online in usa
cialis generika versand aus deutschland
https://stowe365.com
cialis warnings
<a href="http://kaivanrosendaal.com/">side effects for cialis</a>
get cialis in canada
kup cialis online
[url=http://kaivanrosendaal.com/]cialis generic availability[/url]
cialis online kaufen deutschland
cialis drug store price
http://kaivanrosendaal.com/#cialis-coupon
cialis generika preisvergleich
<a href="http://kaivanrosendaal.com">canadian cialis</a>
cialis online 123
cialis non script for around 50 dollars
[url=http://kaivanrosendaal.com/]cialis tadalafil[/url]
cheap non-generic cialis
cialis pricing compare
http://kaivanrosendaal.com/#cialis-purchasing
cheapest pharmacy to buy cialis
<a href="http://kaivanrosendaal.com">cialis without a doctor's prescription</a>
cialis 5mg lilly
cialis daily 5mg online
[url=http://kaivanrosendaal.com]Cialis Cheap Buy Online[/url]
cialis 30 day free
canada drug generic cialis
http://kaivanrosendaal.com/#cialis-20-mg
buy cialis 36 hour
<a href="http://kaivanrosendaal.com">Buy Cheap Cialis</a>
cialis p force
cialis discount coupon
[url=http://kaivanrosendaal.com/]cialis canada[/url]
cost of cialis in manitoba
cialis shipped within canada
http://kaivanrosendaal.com/#cialis-for-daily-use
vendita di cialis online
<a href="http://kaivanrosendaal.com/">cialis dosage</a>
buy cialis by phone
buy cialis online express delivery
[url=http://kaivanrosendaal.com/]cialis.com[/url]
cheap legitimate cialis
efectos_secundarios_cialis_yahoo
http://kaivanrosendaal.com/#cialis-generic-availability
quand le cialis ne fait plus rien
<a href="http://kaivanrosendaal.com/">interactions for cialis</a>
purchasing cialis online
genuine cialis
[url=http://kaivanrosendaal.com]cialis generic availability[/url]
lowest price cialis 20mg brand in usa
cialis mg size
http://kaivanrosendaal.com/#generic-cialis-at-walmart
best cialis online order
<a href="http://kaivanrosendaal.com">free cialis</a>
60mg super active cialis
cialis tablets 20 mg prices
[url=http://kaivanrosendaal.com]Cheap Cialis[/url]
cialis price canadian pharmacy
cialis online senza ricetta
http://kaivanrosendaal.com/#200-cialis-coupon
cheapest online pharmacy for cialis
<a href="http://kaivanrosendaal.com/">generic cialis</a>
best place to purchase cialis
generic female cialis
[url=http://kaivanrosendaal.com/]online cialis[/url]
buy cialis beijing 212
cheap cialis super activelink.com
http://kaivanrosendaal.com/#purchasing-cialis-on-the-internet
cialis gdzie kupic
<a href="http://kaivanrosendaal.com/">tadalafil</a>
canadian pharmacies selling cialis
cialis mauritius
[url=http://kaivanrosendaal.com]cialis side effects[/url]
buy cialis switzerland
cialis for ed
http://kaivanrosendaal.com/#cialis-20-mg
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1283960
http://trailblazers.no/forum/index.php?topic=162244.0
http://65.175.101.103/forum/index.php?topic=409400.0
https://www.blog.1mg.healthcare/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-89-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-olo-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd
https://www.blog.1mg.healthcare/%d0%bd%d0%b5%d0%b2%d1%81%d0%ba%d0%b8%d0%b9-%d1%87%d1%83%d0%b6%d0%be%d0%b9-%d1%81%d1%80%d0%b5%d0%b4%d0%b8-%d1%87%d1%83%d0%b6%d0%b8%d1%85-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8-11
http://withinfp.sakura.ne.jp/eso/index.php/14978278-pererozdenie-7-seria-q5-t3-pererozdenie-7-seria-pererozdenie-7-/0
https://financeexpert.info/tajny-taiemnici-49-serija-gat-tajny-taiemnici-49-serija-15-02-2019/
http://hibiscusstar.com/?option=com_k2&view=itemlist&task=user&id=201271
https://www.blog.1mg.healthcare/%d1%82%d1%8b-%d0%bd%d0%b0%d0%b7%d0%be%d0%b2%d0%b8-399-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o2-%d1%82%d1%8b-%d0%bd%d0%b0%d0%b7%d0%be%d0%b2%d0%b8-399-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch
http://trailblazers.no/forum/index.php?topic=160346.0
http://hibiscusstar.com/index.php/component/k2/itemlist/user/208682
http://poselokgribovo.ru/forum/index.php?topic=282020.0
http://opapamotorsltd.com/?option=com_k2&view=itemlist&task=user&id=1871
http://trailblazers.no/forum/index.php?topic=165463.0
http://skolo.alfatelplus.ru/?p=66667
またとないです 2901238 またとないです
http://skolo.alfatelplus.ru/?p=25394
http://gozizmir.com/?option=com_k2&view=itemlist&task=user&id=53780
http://trailblazers.no/forum/index.php?topic=161200.0
https://doe.go.th/prd/forum_nongkhai/661119-2-18-i6-c9-2-18-2/0
http://withinfp.sakura.ne.jp/eso/index.php/14980939-hodacie-mertvecy-thewalking-dead-9-sezon-16-seria-watch-h5-i0-h/0
https://financeexpert.info/velikolepnaja-dvojka-muhtesem-ikili-16-serija-c5-velikolepnaja-dvojka-muhtesem-ikili-16-serija-2/
http://forum.thaibetrank.com/index.php?topic=447427.0
http://poselokgribovo.ru/forum/index.php?topic=276653.0
http://www.theparrotcentre.com/forum/index.php?topic=110751.0
http://withinfp.sakura.ne.jp/eso/index.php/14979860-sverh-estestvennoe-14-sezon-15-seria-watch-o5-j6-sverh-estestve/0
https://doe.go.th/prd/forum_nongkhai/657230-7-w7-g1-7/0
http://www.theparrotcentre.com/forum/index.php?topic=106668.0
http://65.175.101.103/forum/index.php?topic=391365.0
https://www.synodoi-greece.gr/%D0%B7%D0%B0%D0%BF%D1%80%D0%B5%D1%82%D0%BD%D1%8B%D0%B9-%D0%BF%D0%BB%D0%BE%D0%B4-yasak-elma-40-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-l7-%D0%B7%D0%B0%D0%BF%D1%80%D0%B5%D1%82%D0%BD%D1%8B%D0%B9-%D0%BF/
https://www.anenii-noi.md/?option=com_k2&view=itemlist&task=user&id=3234718
https://www.blog.1mg.healthcare/%d1%87%d1%83%d0%ba%d1%83%d1%80-55-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d9-%d1%87%d1%83%d0%ba%d1%83%d1%80-55-%d1%81%d0%b5%d1%80%d0%b8%d1%8f
https://foro.muwoz.com/index.php?topic=77005.0
http://www.rattanaburihos.com/itart/index.php?topic=1542.68715
http://easyworkbitcoin.ru/forum/index.php?topic=23593.0
http://trailblazers.no/forum/index.php?topic=161119.0
http://skolo.alfatelplus.ru/?p=66443
http://poselokgribovo.ru/forum/index.php?topic=280344.0
http://www2.yasothon.go.th/smf/index.php?topic=159.23445
ここで、ラフィク 8998596 緊急メッセージ
http://153.120.114.241/eso/index.php/15191921-obratnaa-storona-2-sezon-12-seria-watch-p5-f6-obratnaa-storona-
https://mcsetup.tk/bbs/index.php?topic=90864.0
http://oliversmagicdiet.com/forum/index.php?PHPSESSID=mef53gl1v7sse04scimjjgp796&topic=234298.0
https://tg.vl-mp.com/index.php?topic=482046.0
https://www.blog.1mg.healthcare/%d1%82%d1%8b-%d0%bd%d0%b0%d0%b7%d0%be%d0%b2%d0%b8-398-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-c8-%d1%82%d1%8b-%d0%bd%d0%b0%d0%b7%d0%be%d0%b2%d0%b8-398-%d1%81%d0%b5%d1%80%d0%b8%d1%8f
http://www.popolsku.fr.pl/forum/index.php?topic=118939.0
緊急メッセージ 8186202 ここで、ラフィク
http://forum.korporata.net/index.php?topic=157475.0
https://www.blog.1mg.healthcare/%d1%88%d0%b0%d0%b3-%d0%ba-%d1%81%d1%87%d0%b0%d1%81%d1%82%d1%8c%d1%8e-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nnz-%d1%88%d0%b0%d0%b3-%d0%ba-%d1%81%d1%87%d0%b0%d1%81%d1%82%d1%8c%d1%8e-5
http://www.borsaekrani.net/index.php?topic=200968.0
http://breakrow.com/forest01p961608/%d0%b7%d0%b0%d0%bf%d1%80%d0%b5%d1%82%d0%bd%d1%8b%d0%b9-%d0%bf%d0%bb%d0%be%d0%b4-yasak-elma-36-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-s8-%d0%b7%d0%b0%d0%bf%d1%80%d0%b5%d1%82%d0%bd%d1%8b
https://sanp.pro/%d1%85%d0%be%d0%b4%d1%8f%d1%87%d0%b8%d0%b5-%d0%bc%d0%b5%d1%80%d1%82%d0%b2%d0%b5%d1%86%d1%8b-thewalking-dead-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d1-%d1%85/
http://2htwiz.net/support/index.php?topic=682285.0
https://www.ciobanescgerman.net/forum/index.php/topic,17479.0.html
http://breakrow.com/leonard60h/%d0%b5%d0%ba%d0%b0%d1%82%d0%b5%d1%80%d0%b8%d0%bd%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cmm-%d0%b5%d0%ba%d0%b0%d1%82%d0%b5%d1%80%d0%b8%d0%bd%d0%b0
http://www.borsaekrani.net/index.php?topic=207909.0
https://www.suzuki-katana.net/smf/index.php?topic=201783.0
http://forum.finddedicatedserver.com/index.php?topic=31832.0
http://www2.yasothon.go.th/smf/index.php?topic=159.39420
緊急メッセージ 9258674 ここで、ラフィク
[url=http://canadian-pharmacyv.com]cheap viagra usa[/url]
http://blog.roodo.com/f88tw
http://mypaper.pchome.com.tw/f88tw/P1
http://mypaper.pchome.com.tw/f88tw/post/1377153372
http://mypaper.pchome.com.tw/f88tw/post/1376815127
http://mypaper.pchome.com.tw/f88tw/post/1376478820
http://mypaper.pchome.com.tw/f88tw/post/1376374671
http://mypaper.pchome.com.tw/f88tw/post/1374349018
http://mypaper.pchome.com.tw/f88tw/post/1374353877
http://mypaper.pchome.com.tw/f88tw/post/1373187437
http://mypaper.pchome.com.tw/f88tw/post/1371719766
http://mypaper.pchome.com.tw/f88tw/post/1370868817
http://mypaper.pchome.com.tw/f88tw/post/1370804491
http://mypaper.pchome.com.tw/f88tw/post/1370927756
http://mypaper.pchome.com.tw/f88tw/post/1370961380
http://mypaper.pchome.com.tw/f88tw/post/1370901511
http://mypaper.pchome.com.tw/f88tw/post/1370821089
http://mypaper.pchome.com.tw/f88tw/post/1370820567
http://mypaper.pchome.com.tw/f88tw/post/1370820447
http://mypaper.pchome.com.tw/f88tw/post/1370820408
http://mypaper.pchome.com.tw/f88tw/post/1370815618
http://mypaper.pchome.com.tw/f88tw/post/1370781143
Wacoal http://mypaper.pchome.com.tw/f88tw/post/1370961380
http://mypaper.m.pchome.com.tw/f88tw
http://mypaper.m.pchome.com.tw/f88tw/post/1376815127
http://mypaper.m.pchome.com.tw/f88tw/post/1376478820
http://mypaper.m.pchome.com.tw/f88tw/post/1376374671
http://mypaper.m.pchome.com.tw/f88tw/post/1374349018
http://mypaper.m.pchome.com.tw/f88tw/post/1374353877
http://mypaper.m.pchome.com.tw/f88tw/post/1371719766
http://mypaper.m.pchome.com.tw/f88tw/post/1370868817
http://mypaper.m.pchome.com.tw/f88tw/post/1370804491
http://mypaper.m.pchome.com.tw/f88tw/post/1370927756
http://mypaper.m.pchome.com.tw/f88tw/post/1370961380
http://mypaper.m.pchome.com.tw/f88tw/post/1370901511
http://mypaper.m.pchome.com.tw/f88tw/post/1370821089
http://mypaper.m.pchome.com.tw/f88tw/post/1370820567
http://mypaper.m.pchome.com.tw/f88tw/post/1370820447
http://mypaper.m.pchome.com.tw/f88tw/post/1370820408
http://mypaper.m.pchome.com.tw/f88tw/post/1370815618
http://mypaper.m.pchome.com.tw/f88tw/post/1370781143
http://blog.roodo.com/f88tw/archives/cat_4285805.html
http://blog.roodo.com/f88tw/archives/2018-10.html
http://blog.roodo.com/f88tw/archives/2018-12.html
http://blog.roodo.com/f88tw/archives/2017-06.html
http://mypaper.pchome.com.tw/f88tw
http://canadianpharmacyxyz.com/
[url=http://canadianpharmacyxyz.com/]canadian online pharmacies[/url]
http://canadianpharmacyxyz.com/
[url=http://canadianpharmacyxyz.com/]canadian online pharmacy[/url]
http://canadianpharmacyxyz.com/
[url=http://canadianpharmacyxyz.com/]online drugstore[/url]
Наш Чат: @Hackersy[/url]
Только по этому мы и набираем удалённых сотрудников, которые будут выполнять работу, то есть ставить лайки и получать за Вашу работу деньги.
Чтобы быть нашим удалённым сотрудником и начать ставить лайки, и заработать при этом 45 рублей за 1 поставленный лайк.
Вам потребуется просто зарегистрироваться на нашем прортале. > http://like-money.ru/ <
Выдача заработанных средств проходит каждый день в течении нескольких минут.
<a href=http://canadian-pharmacyn.com>buy cialis 10mg</a>
]Постинг 9 МИЛЛИОНОВ сайтов за 7 дней
Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов
Ваши сообщения, комментарии, рекламный пост, будут размещены, больше чем на 9 миллионов сайтов с различной тематикой и содержанием. Ваш рекламный пост увидят огромное количества людей, что позволит Вам собрать и направить целевую аудиторию на ваш сайт, ресурс. За 7 дней Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов, форумов, объявлениях и т.д. В первый же день постинга Вы уже можете наблюдать естественное увеличение трафика на ваш сайт, это можно отслеживать в Яндекс Метрика.
Какой результат вы получите?
-Естественные ссылки
-Целевой трафик
-Увеличение посещаемости сайта
-Рост позиции сайта в поисковой системе
Почему стоит обратиться именно ко мне?
Имею большой опыт по продвижению сайтов, постоянно отслеживаю все изменение алгоритмов поисковых систем. Гарантия 100% безопасность постинга! [/url]
]Постинг 9 МИЛЛИОНОВ сайтов за 7 дней
Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов
Ваши сообщения, комментарии, рекламный пост, будут размещены, больше чем на 9 миллионов сайтов с различной тематикой и содержанием. Ваш рекламный пост увидят огромное количества людей, что позволит Вам собрать и направить целевую аудиторию на ваш сайт, ресурс. За 7 дней Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов, форумов, объявлениях и т.д. В первый же день постинга Вы уже можете наблюдать естественное увеличение трафика на ваш сайт, это можно отслеживать в Яндекс Метрика.
Какой результат вы получите?
-Естественные ссылки
-Целевой трафик
-Увеличение посещаемости сайта
-Рост позиции сайта в поисковой системе
Почему стоит обратиться именно ко мне?
Имею большой опыт по продвижению сайтов, постоянно отслеживаю все изменение алгоритмов поисковых систем. Гарантия 100% безопасность постинга! [/url]
]Постинг 9 МИЛЛИОНОВ сайтов за 7 дней
Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов
Ваши сообщения, комментарии, рекламный пост, будут размещены, больше чем на 9 миллионов сайтов с различной тематикой и содержанием. Ваш рекламный пост увидят огромное количества людей, что позволит Вам собрать и направить целевую аудиторию на ваш сайт, ресурс. За 7 дней Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов, форумов, объявлениях и т.д. В первый же день постинга Вы уже можете наблюдать естественное увеличение трафика на ваш сайт, это можно отслеживать в Яндекс Метрика.
Какой результат вы получите?
-Естественные ссылки
-Целевой трафик
-Увеличение посещаемости сайта
-Рост позиции сайта в поисковой системе
Почему стоит обратиться именно ко мне?
Имею большой опыт по продвижению сайтов, постоянно отслеживаю все изменение алгоритмов поисковых систем. Гарантия 100% безопасность постинга! [/url]
]Постинг 9 МИЛЛИОНОВ сайтов за 7 дней
Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов
Ваши сообщения, комментарии, рекламный пост, будут размещены, больше чем на 9 миллионов сайтов с различной тематикой и содержанием. Ваш рекламный пост увидят огромное количества людей, что позволит Вам собрать и направить целевую аудиторию на ваш сайт, ресурс. За 7 дней Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов, форумов, объявлениях и т.д. В первый же день постинга Вы уже можете наблюдать естественное увеличение трафика на ваш сайт, это можно отслеживать в Яндекс Метрика.
Какой результат вы получите?
-Естественные ссылки
-Целевой трафик
-Увеличение посещаемости сайта
-Рост позиции сайта в поисковой системе
Почему стоит обратиться именно ко мне?
Имею большой опыт по продвижению сайтов, постоянно отслеживаю все изменение алгоритмов поисковых систем. Гарантия 100% безопасность постинга! [/url]
]Постинг 9 МИЛЛИОНОВ сайтов за 7 дней
Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов
Ваши сообщения, комментарии, рекламный пост, будут размещены, больше чем на 9 миллионов сайтов с различной тематикой и содержанием. Ваш рекламный пост увидят огромное количества людей, что позволит Вам собрать и направить целевую аудиторию на ваш сайт, ресурс. За 7 дней Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов, форумов, объявлениях и т.д. В первый же день постинга Вы уже можете наблюдать естественное увеличение трафика на ваш сайт, это можно отслеживать в Яндекс Метрика.
Какой результат вы получите?
-Естественные ссылки
-Целевой трафик
-Увеличение посещаемости сайта
-Рост позиции сайта в поисковой системе
Почему стоит обратиться именно ко мне?
Имею большой опыт по продвижению сайтов, постоянно отслеживаю все изменение алгоритмов поисковых систем. Гарантия 100% безопасность постинга! [/url]
]Постинг 9 МИЛЛИОНОВ сайтов за 7 дней
Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов
Ваши сообщения, комментарии, рекламный пост, будут размещены, больше чем на 9 миллионов сайтов с различной тематикой и содержанием. Ваш рекламный пост увидят огромное количества людей, что позволит Вам собрать и направить целевую аудиторию на ваш сайт, ресурс. За 7 дней Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов, форумов, объявлениях и т.д. В первый же день постинга Вы уже можете наблюдать естественное увеличение трафика на ваш сайт, это можно отслеживать в Яндекс Метрика.
Какой результат вы получите?
-Естественные ссылки
-Целевой трафик
-Увеличение посещаемости сайта
-Рост позиции сайта в поисковой системе
Почему стоит обратиться именно ко мне?
Имею большой опыт по продвижению сайтов, постоянно отслеживаю все изменение алгоритмов поисковых систем. Гарантия 100% безопасность постинга! [/url]
]Постинг 9 МИЛЛИОНОВ сайтов за 7 дней
Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов
Ваши сообщения, комментарии, рекламный пост, будут размещены, больше чем на 9 миллионов сайтов с различной тематикой и содержанием. Ваш рекламный пост увидят огромное количества людей, что позволит Вам собрать и направить целевую аудиторию на ваш сайт, ресурс. За 7 дней Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов, форумов, объявлениях и т.д. В первый же день постинга Вы уже можете наблюдать естественное увеличение трафика на ваш сайт, это можно отслеживать в Яндекс Метрика.
Какой результат вы получите?
-Естественные ссылки
-Целевой трафик
-Увеличение посещаемости сайта
-Рост позиции сайта в поисковой системе
Почему стоит обратиться именно ко мне?
Имею большой опыт по продвижению сайтов, постоянно отслеживаю все изменение алгоритмов поисковых систем. Гарантия 100% безопасность постинга! [/url]
]Постинг 9 МИЛЛИОНОВ сайтов за 7 дней
Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов
Ваши сообщения, комментарии, рекламный пост, будут размещены, больше чем на 9 миллионов сайтов с различной тематикой и содержанием. Ваш рекламный пост увидят огромное количества людей, что позволит Вам собрать и направить целевую аудиторию на ваш сайт, ресурс. За 7 дней Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов, форумов, объявлениях и т.д. В первый же день постинга Вы уже можете наблюдать естественное увеличение трафика на ваш сайт, это можно отслеживать в Яндекс Метрика.
Какой результат вы получите?
-Естественные ссылки
-Целевой трафик
-Увеличение посещаемости сайта
-Рост позиции сайта в поисковой системе
Почему стоит обратиться именно ко мне?
Имею большой опыт по продвижению сайтов, постоянно отслеживаю все изменение алгоритмов поисковых систем. Гарантия 100% безопасность постинга! [/url]
]Постинг 9 МИЛЛИОНОВ сайтов за 7 дней
Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов
Ваши сообщения, комментарии, рекламный пост, будут размещены, больше чем на 9 миллионов сайтов с различной тематикой и содержанием. Ваш рекламный пост увидят огромное количества людей, что позволит Вам собрать и направить целевую аудиторию на ваш сайт, ресурс. За 7 дней Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов, форумов, объявлениях и т.д. В первый же день постинга Вы уже можете наблюдать естественное увеличение трафика на ваш сайт, это можно отслеживать в Яндекс Метрика.
Какой результат вы получите?
-Естественные ссылки
-Целевой трафик
-Увеличение посещаемости сайта
-Рост позиции сайта в поисковой системе
Почему стоит обратиться именно ко мне?
Имею большой опыт по продвижению сайтов, постоянно отслеживаю все изменение алгоритмов поисковых систем. Гарантия 100% безопасность постинга! [/url]
]Постинг 9 МИЛЛИОНОВ сайтов за 7 дней
Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов
Ваши сообщения, комментарии, рекламный пост, будут размещены, больше чем на 9 миллионов сайтов с различной тематикой и содержанием. Ваш рекламный пост увидят огромное количества людей, что позволит Вам собрать и направить целевую аудиторию на ваш сайт, ресурс. За 7 дней Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов, форумов, объявлениях и т.д. В первый же день постинга Вы уже можете наблюдать естественное увеличение трафика на ваш сайт, это можно отслеживать в Яндекс Метрика.
Какой результат вы получите?
-Естественные ссылки
-Целевой трафик
-Увеличение посещаемости сайта
-Рост позиции сайта в поисковой системе
Почему стоит обратиться именно ко мне?
Имею большой опыт по продвижению сайтов, постоянно отслеживаю все изменение алгоритмов поисковых систем. Гарантия 100% безопасность постинга! [/url]
]Постинг 9 МИЛЛИОНОВ сайтов за 7 дней
Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов
Ваши сообщения, комментарии, рекламный пост, будут размещены, больше чем на 9 миллионов сайтов с различной тематикой и содержанием. Ваш рекламный пост увидят огромное количества людей, что позволит Вам собрать и направить целевую аудиторию на ваш сайт, ресурс. За 7 дней Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов, форумов, объявлениях и т.д. В первый же день постинга Вы уже можете наблюдать естественное увеличение трафика на ваш сайт, это можно отслеживать в Яндекс Метрика.
Какой результат вы получите?
-Естественные ссылки
-Целевой трафик
-Увеличение посещаемости сайта
-Рост позиции сайта в поисковой системе
Почему стоит обратиться именно ко мне?
Имею большой опыт по продвижению сайтов, постоянно отслеживаю все изменение алгоритмов поисковых систем. Гарантия 100% безопасность постинга! [/url]
]Постинг 9 МИЛЛИОНОВ сайтов за 7 дней
Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов
Ваши сообщения, комментарии, рекламный пост, будут размещены, больше чем на 9 миллионов сайтов с различной тематикой и содержанием. Ваш рекламный пост увидят огромное количества людей, что позволит Вам собрать и направить целевую аудиторию на ваш сайт, ресурс. За 7 дней Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов, форумов, объявлениях и т.д. В первый же день постинга Вы уже можете наблюдать естественное увеличение трафика на ваш сайт, это можно отслеживать в Яндекс Метрика.
Какой результат вы получите?
-Естественные ссылки
-Целевой трафик
-Увеличение посещаемости сайта
-Рост позиции сайта в поисковой системе
Почему стоит обратиться именно ко мне?
Имею большой опыт по продвижению сайтов, постоянно отслеживаю все изменение алгоритмов поисковых систем. Гарантия 100% безопасность постинга! [/url]
]Постинг 9 МИЛЛИОНОВ сайтов за 7 дней
Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов
Ваши сообщения, комментарии, рекламный пост, будут размещены, больше чем на 9 миллионов сайтов с различной тематикой и содержанием. Ваш рекламный пост увидят огромное количества людей, что позволит Вам собрать и направить целевую аудиторию на ваш сайт, ресурс. За 7 дней Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов, форумов, объявлениях и т.д. В первый же день постинга Вы уже можете наблюдать естественное увеличение трафика на ваш сайт, это можно отслеживать в Яндекс Метрика.
Какой результат вы получите?
-Естественные ссылки
-Целевой трафик
-Увеличение посещаемости сайта
-Рост позиции сайта в поисковой системе
Почему стоит обратиться именно ко мне?
Имею большой опыт по продвижению сайтов, постоянно отслеживаю все изменение алгоритмов поисковых систем. Гарантия 100% безопасность постинга! [/url]
]Постинг 9 МИЛЛИОНОВ сайтов за 7 дней
Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов
Ваши сообщения, комментарии, рекламный пост, будут размещены, больше чем на 9 миллионов сайтов с различной тематикой и содержанием. Ваш рекламный пост увидят огромное количества людей, что позволит Вам собрать и направить целевую аудиторию на ваш сайт, ресурс. За 7 дней Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов, форумов, объявлениях и т.д. В первый же день постинга Вы уже можете наблюдать естественное увеличение трафика на ваш сайт, это можно отслеживать в Яндекс Метрика.
Какой результат вы получите?
-Естественные ссылки
-Целевой трафик
-Увеличение посещаемости сайта
-Рост позиции сайта в поисковой системе
Почему стоит обратиться именно ко мне?
Имею большой опыт по продвижению сайтов, постоянно отслеживаю все изменение алгоритмов поисковых систем. Гарантия 100% безопасность постинга! [/url]
]Постинг 9 МИЛЛИОНОВ сайтов за 7 дней
Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов
Ваши сообщения, комментарии, рекламный пост, будут размещены, больше чем на 9 миллионов сайтов с различной тематикой и содержанием. Ваш рекламный пост увидят огромное количества людей, что позволит Вам собрать и направить целевую аудиторию на ваш сайт, ресурс. За 7 дней Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов, форумов, объявлениях и т.д. В первый же день постинга Вы уже можете наблюдать естественное увеличение трафика на ваш сайт, это можно отслеживать в Яндекс Метрика.
Какой результат вы получите?
-Естественные ссылки
-Целевой трафик
-Увеличение посещаемости сайта
-Рост позиции сайта в поисковой системе
Почему стоит обратиться именно ко мне?
Имею большой опыт по продвижению сайтов, постоянно отслеживаю все изменение алгоритмов поисковых систем. Гарантия 100% безопасность постинга! [/url]
]Постинг 9 МИЛЛИОНОВ сайтов за 7 дней
Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов
Ваши сообщения, комментарии, рекламный пост, будут размещены, больше чем на 9 миллионов сайтов с различной тематикой и содержанием. Ваш рекламный пост увидят огромное количества людей, что позволит Вам собрать и направить целевую аудиторию на ваш сайт, ресурс. За 7 дней Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов, форумов, объявлениях и т.д. В первый же день постинга Вы уже можете наблюдать естественное увеличение трафика на ваш сайт, это можно отслеживать в Яндекс Метрика.
Какой результат вы получите?
-Естественные ссылки
-Целевой трафик
-Увеличение посещаемости сайта
-Рост позиции сайта в поисковой системе
Почему стоит обратиться именно ко мне?
Имею большой опыт по продвижению сайтов, постоянно отслеживаю все изменение алгоритмов поисковых систем. Гарантия 100% безопасность постинга! [/url]
]Постинг 9 МИЛЛИОНОВ сайтов за 7 дней
Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов
Ваши сообщения, комментарии, рекламный пост, будут размещены, больше чем на 9 миллионов сайтов с различной тематикой и содержанием. Ваш рекламный пост увидят огромное количества людей, что позволит Вам собрать и направить целевую аудиторию на ваш сайт, ресурс. За 7 дней Ваш рекламный пост будет размещен больше чем на 9 миллионах сайтов, форумов, объявлениях и т.д. В первый же день постинга Вы уже можете наблюдать естественное увеличение трафика на ваш сайт, это можно отслеживать в Яндекс Метрика.
Какой результат вы получите?
-Естественные ссылки
-Целевой трафик
-Увеличение посещаемости сайта
-Рост позиции сайта в поисковой системе
Почему стоит обратиться именно ко мне?
Имею большой опыт по продвижению сайтов, постоянно отслеживаю все изменение алгоритмов поисковых систем. Гарантия 100% безопасность постинга! [/url]
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/630994
http://www.nomaher.com/forum/index.php?topic=10950.0
http://www.nomaher.com/forum/index.php?topic=11081.0
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=13449
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=13648
http://www.popolsku.fr.pl/forum/index.php?topic=20407.45795
http://www.popolsku.fr.pl/forum/index.php?topic=369729.0
http://www.popolsku.fr.pl/forum/index.php?topic=369745.0
http://www.popolsku.fr.pl/forum/index.php?topic=369882.0
http://www.popolsku.fr.pl/forum/index.php?topic=369902.0
http://www.popolsku.fr.pl/forum/index.php?topic=369928.0
http://www.popolsku.fr.pl/forum/index.php?topic=370027.0
http://www.popolsku.fr.pl/forum/index.php?topic=370041.0
http://www.popolsku.fr.pl/forum/index.php?topic=370480.0
http://www.popolsku.fr.pl/forum/index.php?topic=370715.0
http://www.popolsku.fr.pl/forum/index.php?topic=370845.0
http://www.popolsku.fr.pl/forum/index.php?topic=370986.0
http://www.popolsku.fr.pl/forum/index.php?topic=371535.0
https://forum.shaiyaslayer.tk/index.php?topic=80117.0
https://forum.shaiyaslayer.tk/index.php?topic=80254.0
https://forum.shaiyaslayer.tk/index.php?topic=80496.0
https://forum.shaiyaslayer.tk/index.php?topic=80643.0
https://forum.shaiyaslayer.tk/index.php?topic=80713.0
https://forum.shaiyaslayer.tk/index.php?topic=80810.0
https://forum.shaiyaslayer.tk/index.php?topic=80818.0
https://forum.shaiyaslayer.tk/index.php?topic=80958.0
https://forum.shaiyaslayer.tk/index.php?topic=81783.0
https://forum.shaiyaslayer.tk/index.php?topic=81871.0
https://forum.shaiyaslayer.tk/index.php?topic=81883.0
https://forum.shaiyaslayer.tk/index.php?topic=81886.0
https://forum.shaiyaslayer.tk/index.php?topic=81912.0
https://forum.shaiyaslayer.tk/index.php?topic=81932.0
https://forum.shaiyaslayer.tk/index.php?topic=81992.0
https://forum.shaiyaslayer.tk/index.php?topic=82010.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.deliberarchia.org/forum/index.php?topic=934153.0
http://www.deliberarchia.org/forum/index.php?topic=934182.0
http://www.deliberarchia.org/forum/index.php?topic=934307.0
http://www.deliberarchia.org/forum/index.php?topic=934352.0
http://www.deliberarchia.org/forum/index.php?topic=934448.0
http://www.deliberarchia.org/forum/index.php?topic=934461.0
http://www.deliberarchia.org/forum/index.php?topic=934586.0
http://www.deliberarchia.org/forum/index.php?topic=934604.0
http://www.deliberarchia.org/forum/index.php?topic=934622.0
http://www.deliberarchia.org/forum/index.php?topic=934876.0
http://www.deliberarchia.org/forum/index.php?topic=934916.0
http://www.deliberarchia.org/forum/index.php?topic=934978.0
http://www.deliberarchia.org/forum/index.php?topic=935029.0
http://www.deliberarchia.org/forum/index.php?topic=935155.0
http://www.deliberarchia.org/forum/index.php?topic=935189.0
http://forum.kopkargobel.com/index.php?topic=3493.0
http://poselokgribovo.ru/forum/index.php?topic=701303.0
http://blog.ptpintcast.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-x4-e2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
https://forums.letstalkbeats.com/index.php?topic=60988.0
http://teambuildingpremium.com/forum/index.php?topic=751753.0
https://sanp.pro/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d5-d1-%d1%80%d0%b0%d1%81%d1%81/
http://miklja.net/forum/index.php?topic=25087.0
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/999223
http://danielmillsap.com/forum/index.php?topic=933634.0
https://hackersuniversity.net/index.php?topic=6182.0
https://reficulcoin.com/index.php?topic=4970.0
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=285570
http://HyUa.1fps.icu/l/szIaeDC
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/130752
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/40082
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4662469
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=30355
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2393714
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4663064
http://healthyteethpa.org/component/k2/itemlist/user/5285799
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/517743
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=247810
https://www.youngbiker.de/wbboard/index.php?page=User&userID=783012
http://proxima.co.rw/index.php/component/k2/itemlist/user/551275
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3531419
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3699199
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/639042
http://153.120.114.241/eso/index.php/16879016-amerikanskie-bogi-2-sezon-9-seria-qfn-amerikanskie-bogi-2-sezon
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=45472
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1612267
http://mediaville.me/index.php/component/k2/itemlist/user/207910
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zlq-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-14-%d1%81%d0%b5%d1%80/
http://pptforum.dothome.co.kr/board_APMk06/851009
https://members.fbhaters.com/index.php?topic=69836.0
http://menulisilmiah.net/%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b5-%d0%b7%d0%b5%d1%80%d0%ba%d0%b0%d0%bb%d0%be-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sbd-%d1%87%d0%b5%d1%80%d0%bd/
http://metropolis.ga/index.php?topic=1452.0
https://tg.vl-mp.com/index.php?topic=1272311.0
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1841452
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/185134
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/185149
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/185168
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/185204
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/185211
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/185251
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/185283
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/185297
http://Cr4SuDmDV.1fps.icu/l/HOeZk
http://sextomariotienda.com/blog/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hxy-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://withinfp.sakura.ne.jp/eso/index.php/16768418-vetrenyj-hercai-4-seria-u8-vetrenyj-hercai-4-seria-online/0
http://www.hoonthaitoday.com/forum/index.php?topic=122613.0
http://taklongclub.com/forum/index.php?topic=81191.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/430642
http://mvisage.sk/index.php/component/k2/itemlist/user/117233
http://matrixpharm.ru/forum/index.php?PHPSESSID=pl6797sk9pv4jm1cjvq7eaogb6&action=profile;u=160207
http://forums.abs-cbn.com/welcome-back-kapamilya%21/om-15-e-om-15-e-motet-o-m/?PHPSESSID=a164sk22tu1mj5su9aniva7sf0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1096458
http://freebeer.me/index.php?topic=283907.0
http://forum.bmw-e60.eu/index.php?topic=1526.0
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j3-%e3%80%90-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=5955.0
https://www.gizmoarticle.com/hd720-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q9-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://jesusandmarypatna.com/index.php/component/k2/itemlist/user/3355746
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1822497
http://teambuildingpremium.com/forum/index.php?topic=714621.0
http://thefreebitcoin.com/index.php?topic=29972.0
https://www.shaiyax.com/index.php?topic=321446.0
https://www.resproxy.com/forum/index.php/764928-ertugrul-5-sezon-149-seria-c4-ertugrul-5-sezon-149-seria/0
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2558582
http://associationsila.org/component/k2/itemlist/user/259720
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1508820
http://www.deliberarchia.org/forum/index.php?topic=902653.0
http://poselokgribovo.ru/forum/index.php?topic=647108.0
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=764556
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/127682
http://www.popolsku.fr.pl/forum/index.php?topic=362649.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3253959
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/127142
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/145334
http://2eKf0.1fps.icu/t/92drRHjeLUI
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1822234
http://matrixpharm.ru/forum/index.php?action=profile&u=151926
http://macdistri.com/index.php/component/k2/itemlist/user/252554
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=39083
http://www.telcon.gr/index.php/component/k2/itemlist/user/25837
http://www.phperos.net/foro/index.php?topic=128686.0
https://sanp.pro/%d0%b6%d0%b5%d0%bd%d1%89%d0%b8%d0%bd%d0%b0-56-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c9-%d0%b6%d0%b5%d0%bd%d1%89%d0%b8%d0%bd%d0%b0-56-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3249489
http://roikjer.com/forum/index.php?PHPSESSID=2878fu656e8rb6i45aa1bl7uj5&topic=782381.0
http://poselokgribovo.ru/forum/index.php?topic=647205.0
https://www.swiss-focus.ch/index.php/component/k2/itemlist/user/6411
http://forum.politeknikgihon.ac.id/index.php?topic=16569.0
http://www.hoonthaitoday.com/forum/index.php?topic=140134.0
http://thanosakademi.com/index.php?topic=60762.0
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3546070
http://roikjer.com/forum/index.php?PHPSESSID=gbrft32a6ldb5iot35uhhdhtk7&topic=781876.0
http://dev.aabn.org.gh/?option=com_k2&view=itemlist&task=user&id=474201
http://www.remify.app/foro/index.php?topic=166608.0
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=196131
http://macdistri.com/index.php/component/k2/itemlist/user/252565
http://sextomariotienda.com/blog/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m7-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.hoonthaitoday.com/forum/index.php?topic=106126.0
http://www.afikgan.co.il/index.php/component/k2/itemlist/user/25020
https://forums.letstalkbeats.com/index.php?topic=49163.0
http://www.nomaher.com/forum/index.php?topic=10464.0
http://dpmarketingsystems.com/%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be%d0%b1%d0%be%d1%82%d0%b0-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lum-%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be/
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/513580
http://menulisilmiah.net/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-bdw-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
https://npi.org.es/smf/index.php?topic=109964.0
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/196477
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=36225
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5-2/
http://2eKf0.1fps.icu/t/92drRHjeLUI
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1596572
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1113426
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=242933
https://tg.vl-mp.com/index.php?topic=1271893.0
https://tg.vl-mp.com/index.php?topic=1265914.0
https://tg.vl-mp.com/index.php?topic=1314392.0
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=95981
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1109970
http://mediaville.me/index.php/component/k2/itemlist/user/195924
https://members.fbhaters.com/index.php?topic=66156.0
https://members.fbhaters.com/index.php?topic=62901.0
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/61043
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4677877
https://www.resproxy.com/forum/index.php/734119-milliardy-4-sezon-6-seria-fro-milliardy-4-sezon-6-seria-0305201/0
http://minostech.co.kr/news/3377105
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3246836
http://proxima.co.rw/index.php/component/k2/itemlist/user/544579
http://www.cosl.com.sg/UserProfile/tabid/61/userId/26050533/Default.aspx
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2533415
https://tg.vl-mp.com/index.php?topic=1317180.0
https://lucky28003.nl/forum/index.php?topic=6477.0
http://tekagrafica.com.br/index.php/component/k2/itemlist/user/1569866
https://tg.vl-mp.com/index.php?topic=1323660.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=262613
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=36247
http://www.arunagreen.com/index.php/component/k2/itemlist/user/392916
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4665085
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2521548
http://dev.aabn.org.gh/component/k2/itemlist/user/483855
http://macdistri.com/index.php/component/k2/itemlist/user/270550
https://tg.vl-mp.com/index.php?topic=1289863.0
http://febrescordero.gob.ec/?option=com_k2&view=itemlist&task=user&id=71638
http://menulisilmiah.net/%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5%d0%bd%d0%b8%d0%b5-vuslat-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a8mc-%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd/
http://koushatarabar.com/index.php/component/k2/itemlist/user/1315936
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=262932
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1604299
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1604361
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1604632
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1604850
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1604945
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1605091
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1605265
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1608892
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1609146
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1616365
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1616941
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1619406
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1621362
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=263506
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=44208
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1832515
http://webp.online/index.php?topic=38785.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yfb-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
https://www.youngbiker.de/wbboard/index.php?page=User&userID=781464
http://withinfp.sakura.ne.jp/eso/index.php/16812670-vossoedinenie-vuslat-15-seria-t3uk-vossoedinenie-vuslat-15-seri
https://www.youngbiker.de/wbboard/index.php?page=User&userID=783729
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1322878
http://proandpro.it/?option=com_k2&view=itemlist&task=user&id=4532143
http://proandpro.it/?option=com_k2&view=itemlist&task=user&id=4532182
http://proandpro.it/?option=com_k2&view=itemlist&task=user&id=4532681
http://proandpro.it/index.php/component/k2/itemlist/user/4528926
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=564355
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=564502
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=565842
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=565959
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=566346
http://proxima.co.rw/index.php/component/k2/itemlist/user/564315
http://proxima.co.rw/index.php/component/k2/itemlist/user/564338
http://proxima.co.rw/index.php/component/k2/itemlist/user/564423
http://proxima.co.rw/index.php/component/k2/itemlist/user/564426
http://proxima.co.rw/index.php/component/k2/itemlist/user/564457
http://proxima.co.rw/index.php/component/k2/itemlist/user/564464
http://sextomariotienda.com/blog/05-05-2019-%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://www.deliberarchia.org/forum/index.php?topic=952356.0
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1538512
http://multikopterforum.hu/index.php?topic=5647.0
http://blog.ptpintcast.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k6-s8-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
https://members.fbhaters.com/index.php?topic=73818.0
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=186119
http://salescoach.ro/content/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-2-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-2-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://multikopterforum.hu/index.php?topic=11167.0
http://blog.ptpintcast.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90gi3%e3%80%91-%d0%b8%d0%b3/
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1853650
https://www.shaiyax.com/index.php?topic=327565.0
http://www.remify.app/foro/index.php?topic=213588.0
https://reficulcoin.com/index.php?topic=6498.0
http://poselokgribovo.ru/forum/index.php?topic=692907.0
https://szenarist.ru/forum/index.php?topic=201653.0
http://poselokgribovo.ru/forum/index.php?topic=710054.0
http://roikjer.com/forum/index.php?PHPSESSID=vs3rv88s7qaj2lja0g99bgd426&topic=807709.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/283382
http://153.120.114.241/eso/index.php/16843204-igra-prestolov-2019-8-sezon-6-seria-igra-prestolov-2019-8-sezon
http://www.quattroandpartners.it/component/k2/itemlist/user/1037103
http://blog.ptpintcast.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r3-a2-%d0%b8%d0%b3%d1%80/
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-r7-c2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://HyUa.1fps.icu/l/szIaeDC
https://tg.vl-mp.com/index.php?topic=1247300.0
http://taklongclub.com/forum/index.php?topic=81035.0
http://www.theparrotcentre.com/forum/index.php?topic=442112.0
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=713588
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/432791
http://dev.aabn.org.gh/component/k2/itemlist/user/462659
http://jesusandmarypatna.com/index.php/component/k2/itemlist/user/3355391
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3539523
http://teambuildingpremium.com/forum/index.php?topic=709846.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/(a-taka-(erkenci-kus)-40-e)-d9(-(a-taka-(erkenci-kus)-40-e)/?PHPSESSID=hqaiu2pg6b2lt5u6cp60sl53c5
http://poselokgribovo.ru/forum/index.php?topic=646440.0
http://subforumna.x10.mx/mad/index.php?topic=184874.0
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/970723
https://lucky28003.nl/forum/index.php?topic=6614.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/173809
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1604311
http://www.deliberarchia.org/forum/index.php?topic=939735.0
https://members.fbhaters.com/index.php?topic=67002.0
http://forum.byehaj.hu/index.php?topic=70425.0
http://danielmillsap.com/forum/index.php?topic=879110.0
http://www.quattroandpartners.it/component/k2/itemlist/user/981933
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=293723
http://forum.politeknikgihon.ac.id/index.php?topic=15558.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3278210
http://universalcommunity.se/Forum/index.php?topic=476.0
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/188385
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1592777
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1312601
http://jesusandmarypatna.com/index.php/component/k2/itemlist/user/3351841
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/49916
http://forum.santrope-rp.ru/index.php?topic=2234.0
http://forum.santrope-rp.ru/index.php?topic=2243.0
http://forum.santrope-rp.ru/index.php?topic=2255.0
http://forum.santrope-rp.ru/index.php?topic=2256.0
http://forum.santrope-rp.ru/index.php?topic=2259.0
http://forum.santrope-rp.ru/index.php?topic=2264.0
http://forum.santrope-rp.ru/index.php?topic=2271.0
http://forum.santrope-rp.ru/index.php?topic=2275.0
http://forum.santrope-rp.ru/index.php?topic=2280.0
http://forum.santrope-rp.ru/index.php?topic=2285.0
http://forum.santrope-rp.ru/index.php?topic=2286.0
http://forum.santrope-rp.ru/index.php?topic=2327.0
http://forum.santrope-rp.ru/index.php?topic=2336.0
http://forum.santrope-rp.ru/index.php?topic=2338.0
http://forum.santrope-rp.ru/index.php?topic=2342.0
http://socialfbwidgets.com/component/k2/itemlist/user/12790.html
http://socialfbwidgets.com/component/k2/itemlist/user/12793.html
http://socialfbwidgets.com/component/k2/itemlist/user/12796.html
http://socialfbwidgets.com/component/k2/itemlist/user/12810.html
http://socialfbwidgets.com/component/k2/itemlist/user/12812
http://storykingdom.forumside.com/index.php/topic,3750.0.html
http://storykingdom.forumside.com/index.php/topic,3752.0.html
http://storykingdom.forumside.com/index.php/topic,3854.0.html
http://storykingdom.forumside.com/index.php/topic,3856.0.html
http://storykingdom.forumside.com/index.php/topic,3911.0.html
http://storykingdom.forumside.com/index.php/topic,3974.0.html
http://storykingdom.forumside.com/index.php/topic,4003.0.html
http://storykingdom.forumside.com/index.php/topic,4009.0.html
http://HyUa.1fps.icu/l/szIaeDC
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-(got)-8-eo-6-e-wd1-a-etoo-(got)-8-eo-6-e/?PHPSESSID=b272qpjqtb6r6edj5ihpcpkfo6
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-(got)-8-eo-7-e-bk2-a-etoo-(got)-8-eo-7-e/?PHPSESSID=rhtd960enq3uif8bmtdm72tr57
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-(got)-8-eo-7-e-cq5-'a-etoo-(got)-8-eo-7-e'/msg551907/
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-(got)-8-eo-7-e-ej1-'a-etoo-(got)-8-eo-7-e'/?PHPSESSID=4csv9oi7tq0b9j54u1mt62r297
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-(got)-8-eo-7-e-nx0-(a-etoo-(got)-8-eo-7-e)/?PHPSESSID=6qevjjhuf14hsoicuph42v29a7
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-2019-8-eo-3-e-ca0-a-etoo-2019-8-eo-3-e/?PHPSESSID=3hg5uhkfjidqsbp6vg58fiapn3
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-2019-8-eo-3-e-de5-a-etoo-2019-8-eo-3-e/?PHPSESSID=r55gpe3drgb3a6vob2qsl1sf12
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-2019-8-eo-3-e-dv7-'a-etoo-2019-8-eo-3-e'/?PHPSESSID=t5o39qm1fmc22hoohku5r35lc7
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-2019-8-eo-3-e-rb8-a-etoo-2019-8-eo-3-e/?PHPSESSID=il4jpp481752q8eo5vfsfmj1v6
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-2019-8-eo-3-e-za7-a-etoo-2019-8-eo-3-e/?PHPSESSID=c1pt54ea2svea6k7f0jn5osjn4
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-2019-8-eo-3-e-zf1-a-etoo-2019-8-eo-3-e/
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-2019-8-eo-4-e-mr9-a-etoo-2019-8-eo-4-e-watch/?PHPSESSID=pupsorlj5jmfkf4c4hm4msfmi5
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-2019-8-eo-4-e-sp5-'a-etoo-2019-8-eo-4-e-watch'/?PHPSESSID=0d220emgudidhlof27812psat6
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-2019-8-eo-4-e-sw4-a-etoo-2019-8-eo-4-e-watch/?PHPSESSID=546a7ono9fl9gjrsqa3j99loa3
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-2019-8-eo-4-e-tm0-'a-etoo-2019-8-eo-4-e-watch'/?PHPSESSID=ubmd8c328h2ok81o0jb0r7n9q6
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-2019-8-eo-4-e-wt4-a-etoo-2019-8-eo-4-e-watch/
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-2019-8-eo-4-e-xf7-a-etoo-2019-8-eo-4-e/
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-2019-8-eo-4-e-xp2-(a-etoo-2019-8-eo-4-e)/?PHPSESSID=l6bj2oloqvluuq0r3gm5scctl2
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-2019-8-eo-5-e-lt0-'a-etoo-2019-8-eo-5-e-watch'/?PHPSESSID=orpicmutb6obq0phq2kmc7koh3
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-2019-8-eo-5-e-qy2-a-etoo-2019-8-eo-5-e/?PHPSESSID=auq83h9l7hc898p7h8ejm2fcc5
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-2019-8-eo-6-e-ea5-(a-etoo-2019-8-eo-6-e)/?PHPSESSID=gtbh0klgo6mq1c08rkp6o5ejm2
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-2019-8-eo-6-e-nh7-(a-etoo-2019-8-eo-6-e)/
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-2019-8-eo-6-e-pf9-'a-etoo-2019-8-eo-6-e-watch'/?PHPSESSID=qrd8t0l0te9u0j46d1aer4o3b4
http://storykingdom.forumside.com/index.php?topic=4200.0
http://storykingdom.forumside.com/index.php?topic=4203.0
http://storykingdom.forumside.com/index.php?topic=4204.0
http://storykingdom.forumside.com/index.php?topic=4219.0
http://storykingdom.forumside.com/index.php?topic=4222.0
http://storykingdom.forumside.com/index.php?topic=4226.0
http://storykingdom.forumside.com/index.php?topic=4236.0
http://storykingdom.forumside.com/index.php?topic=4241.0
http://storykingdom.forumside.com/index.php?topic=4245.0
http://storykingdom.forumside.com/index.php?topic=4254.0
http://storykingdom.forumside.com/index.php?topic=4259.0
http://storykingdom.forumside.com/index.php?topic=4261.0
http://storykingdom.forumside.com/index.php?topic=4266.0
http://storykingdom.forumside.com/index.php?topic=4268.0
http://storykingdom.forumside.com/index.php?topic=4271.0
http://storykingdom.forumside.com/index.php?topic=4275.0
http://storykingdom.forumside.com/index.php?topic=4276.0
http://storykingdom.forumside.com/index.php?topic=4277.0
http://storykingdom.forumside.com/index.php?topic=4278.0
http://storykingdom.forumside.com/index.php?topic=4280.0
http://HyUa.1fps.icu/l/szIaeDC
http://forum.politeknikgihon.ac.id/index.php?topic=18438.0
http://forum.politeknikgihon.ac.id/index.php?topic=18496.0
http://forum.politeknikgihon.ac.id/index.php?topic=18899.0
http://forum.politeknikgihon.ac.id/index.php?topic=18931.0
http://forum.politeknikgihon.ac.id/index.php?topic=18988.0
http://forum.politeknikgihon.ac.id/index.php?topic=19004.0
http://forum.politeknikgihon.ac.id/index.php?topic=19022.0
http://forum.politeknikgihon.ac.id/index.php?topic=19052.0
http://forum.politeknikgihon.ac.id/index.php?topic=19091.0
http://forum.politeknikgihon.ac.id/index.php?topic=19119.0
http://forum.politeknikgihon.ac.id/index.php?topic=19143.0
http://forum.politeknikgihon.ac.id/index.php?topic=19147.0
http://forum.politeknikgihon.ac.id/index.php?topic=19153.0
http://forum.politeknikgihon.ac.id/index.php?topic=19159.0
http://forum.politeknikgihon.ac.id/index.php?topic=19189.0
http://forum.politeknikgihon.ac.id/index.php?topic=19218.0
http://forum.politeknikgihon.ac.id/index.php?topic=19247.0
http://forum.politeknikgihon.ac.id/index.php?topic=19288.0
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e5-f8-%d1%80%d0%b0%d1%81%d1%81/
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f0-f8-%d1%80%d0%b0%d1%81%d1%81/
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h7-j4-%d1%80%d0%b0%d1%81%d1%81/
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i7-o2-%d1%80%d0%b0%d1%81%d1%81/
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i8-v3-%d1%80%d0%b0%d1%81/
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k0-h8-%d1%80%d0%b0%d1%81%d1%81/
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k3-a7-%d1%80%d0%b0-2/
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k9-s3-%d1%80%d0%b0/
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l2-l2-%d1%80%d0%b0%d1%81%d1%81/
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l3-p3-%d1%80%d0%b0%d1%81%d1%81/
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l4-f6-%d1%80%d0%b0/
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l6-f8-%d1%80%d0%b0%d1%81/
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l8-o3-%d1%80%d0%b0%d1%81%d1%81/
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m1-k4-%d1%80%d0%b0%d1%81%d1%81/
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o1-f1-%d1%80%d0%b0%d1%81%d1%81/
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o4-k7-%d1%80%d0%b0%d1%81%d1%81/
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o4-r7-%d1%80%d0%b0/
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-f0-o5-%d1%80/
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-m0-l5-%d1%80/
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p8-w9-%d1%80%d0%b0/
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p9-b2-%d1%80%d0%b0%d1%81%d1%81/
http://HyUa.1fps.icu/l/szIaeDC
http://forum.santrope-rp.ru/index.php?topic=2349.0
http://forum.santrope-rp.ru/index.php?topic=2350.0
http://forum.santrope-rp.ru/index.php?topic=2352.0
http://forum.santrope-rp.ru/index.php?topic=2360.0
http://forum.santrope-rp.ru/index.php?topic=2367.0
http://forum.santrope-rp.ru/index.php?topic=2369.0
http://forum.santrope-rp.ru/index.php?topic=2372.0
http://forum.santrope-rp.ru/index.php?topic=2395.0
http://forum.santrope-rp.ru/index.php?topic=2400.0
http://forum.santrope-rp.ru/index.php?topic=2408.0
http://forum.santrope-rp.ru/index.php?topic=2411.0
http://forum.santrope-rp.ru/index.php?topic=2480.0
http://forum.santrope-rp.ru/index.php?topic=2482.0
http://forum.santrope-rp.ru/index.php?topic=2483.0
http://forum.santrope-rp.ru/index.php?topic=2487.0
http://storykingdom.forumside.com/index.php/topic,4035.0.html
http://storykingdom.forumside.com/index.php/topic,4133.0.html
http://storykingdom.forumside.com/index.php/topic,4139.0.html
http://storykingdom.forumside.com/index.php/topic,4144.0.html
http://storykingdom.forumside.com/index.php/topic,4152.0.html
http://storykingdom.forumside.com/index.php/topic,4215.0.html
http://storykingdom.forumside.com/index.php/topic,4224.0.html
http://storykingdom.forumside.com/index.php/topic,4228.0.html
http://storykingdom.forumside.com/index.php/topic,4287.0.html
http://storykingdom.forumside.com/index.php/topic,4301.0.html
http://HyUa.1fps.icu/l/szIaeDC
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3302711
https://www.amazingworldtop.com/entretenimiento/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-27-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-x4/
https://www.c-alice.org/forum/index.php?topic=71911.0
https://www.c-alice.org/forum/index.php?topic=71914.0
https://www.c-alice.org/forum/index.php?topic=71917.0
https://www.c-alice.org/forum/index.php?topic=71921.0
https://www.gizmoarticle.com/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e1-%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5/
https://www.gizmoarticle.com/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g9-%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5/
https://www.gizmoarticle.com/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k1-%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5/
https://www.gizmoarticle.com/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k2-%d0%b2/
https://www.gizmoarticle.com/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-k4/
https://www.gizmoarticle.com/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-29-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q9-%d0%b2/
https://www.gizmoarticle.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r8-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://www.gizmoarticle.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-s7-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.m1avio.com/index.php/component/k2/itemlist/user/3611608
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=567676
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=567743
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=203160
https://www.netprofessional.gr/component/k2/itemlist/user/3288.html
http://forum.politeknikgihon.ac.id/index.php?topic=21633.0
http://forum.politeknikgihon.ac.id/index.php?topic=21640.0
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile;u=31548
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3265858
http://necinsurance.co.zw/component/k2/itemlist/user/18404.html
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=252605
http://www.original-craft.net/index.php?topic=297111.0
https://lucky28003.nl/forum/index.php?topic=6792.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=255887
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=231367
http://www.arunagreen.com/index.php/component/k2/itemlist/user/382009
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2521069
https://tg.vl-mp.com/index.php?topic=1258892.0
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=77312
http://healthyteethpa.org/component/k2/itemlist/user/5336851
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1668786
http://danielmillsap.com/forum/index.php?topic=867747.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=276140
http://healthyteethpa.org/component/k2/itemlist/user/5303401
http://healthyteethpa.org/component/k2/itemlist/user/5303448
http://healthyteethpa.org/component/k2/itemlist/user/5303514
http://healthyteethpa.org/component/k2/itemlist/user/5303629
http://healthyteethpa.org/component/k2/itemlist/user/5303654
http://healthyteethpa.org/component/k2/itemlist/user/5303665
http://healthyteethpa.org/component/k2/itemlist/user/5303730
http://healthyteethpa.org/component/k2/itemlist/user/5303826
http://healthyteethpa.org/component/k2/itemlist/user/5303884
http://healthyteethpa.org/component/k2/itemlist/user/5303907
http://healthyteethpa.org/component/k2/itemlist/user/5303930
http://healthyteethpa.org/component/k2/itemlist/user/5303967
http://healthyteethpa.org/component/k2/itemlist/user/5303973
http://withinfp.sakura.ne.jp/eso/index.php/16841267-voskressij-ertugrul-145-seria-b5yt-voskressij-ertugrul-145-seri/0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2538911
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1764359
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1984775
http://macdistri.com/index.php/component/k2/itemlist/user/259090
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/594826
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/173951
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1540350
http://withinfp.sakura.ne.jp/eso/index.php/16777957-rannaa-ptaska-erkenci-kus-45-seria-b4zz-rannaa-ptaska-erkenci-k
http://www.deliberarchia.org/forum/index.php?topic=894721.0
http://www.deliberarchia.org/forum/index.php?topic=894745.0
http://www.deliberarchia.org/forum/index.php?topic=894766.0
http://www.deliberarchia.org/forum/index.php?topic=894989.0
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=8821
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=8849
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=8867
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=8872
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=8901
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=266900
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1308928
https://tg.vl-mp.com/index.php?topic=1260954.0
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=607441
http://www.crnmedia.es/component/k2/itemlist/user/83191
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1680541
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3256690
http://dev.fivestarpainting.com/?option=com_k2&view=itemlist&task=user&id=1841323
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/273475
http://sextomariotienda.com/blog/%d0%b4%d1%80%d1%83%d0%b3%d0%b0%d1%8f-i%d0%bd%d1%88%d0%b0-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-04-05-2019/
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=274887
http://roikjer.com/forum/index.php?PHPSESSID=uqjle153co6srso1p2c2dnijj4&topic=803725.0
http://multikopterforum.hu/index.php?topic=8306.0
http://forum.stollen24.com/index.php/topic,3360.0.html
http://blog.ptpintcast.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u2-u3-%d0%b8/
http://poselokgribovo.ru/forum/index.php?topic=711072.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2556734
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=24797.0
http://8.droror.co.il/uncategorized/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
https://nextezone.com/index.php?topic=33123.0
http://golyboe.ru/forum/index.php?topic=24610.0
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90ko3%e3%80%91-%d0%b8%d0%b3/
http://www.tessabannampad.go.th/webboard/index.php?topic=187251.0
http://e-educ.net/Forum/index.php?topic=3993.0
http://www.hoonthaitoday.com/forum/index.php?topic=140518.0
http://multikopterforum.hu/index.php?topic=6795.0
http://8.droror.co.il/uncategorized/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-8/
http://forum.politeknikgihon.ac.id/index.php?topic=13183.0
http://golyboe.ru/forum/index.php?topic=24637.0
https://forum.shaiyaslayer.tk/index.php?topic=79820.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=578fa5801a644a9bd0de3bf412d33394&topic=207979.0
http://storykingdom.forumside.com/index.php?topic=4157.0
http://forum.byehaj.hu/index.php?topic=74875.0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/61438
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/996685
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/997614
http://www.grupojover.com/index.php/es/component/k2/itemlist/user/3736
http://www.deliberarchia.org/forum/index.php?topic=957430.0
https://www.c-alice.org/forum/index.php?topic=69603.0
http://teambuildingpremium.com/forum/index.php?topic=758691.0
https://reficulcoin.com/index.php?topic=8112.0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/411923
http://multikopterforum.hu/index.php?topic=10985.0
http://HyUa.1fps.icu/l/szIaeDC
http://poselokgribovo.ru/forum/index.php?topic=712460.0
http://poselokgribovo.ru/forum/index.php?topic=712591.0
http://poselokgribovo.ru/forum/index.php?topic=712626.0
http://poselokgribovo.ru/forum/index.php?topic=712694.0
http://poselokgribovo.ru/forum/index.php?topic=712718.0
http://poselokgribovo.ru/forum/index.php?topic=712944.0
http://poselokgribovo.ru/forum/index.php?topic=712988.0
http://poselokgribovo.ru/forum/index.php?topic=713040.0
http://poselokgribovo.ru/forum/index.php?topic=713345.0
http://poselokgribovo.ru/forum/index.php?topic=713393.0
http://forum.stollen24.com/index.php?topic=3802.0
http://forum.stollen24.com/index.php?topic=3804.0
http://forum.stollen24.com/index.php?topic=3807.0
http://myrechockey.com/forums/index.php?topic=85941.0
http://roikjer.com/forum/index.php?PHPSESSID=hugdsf2ov5qd8n74anhq3e8q73&topic=811595.0
http://roikjer.com/forum/index.php?PHPSESSID=sr9q8pc1ji4lfk8dgsfn5pa8r7&topic=811578.0
http://ru-realty.com/forum/index.php?PHPSESSID=78b38ei7188btmdlqqldp0hga4&topic=459028.0
http://ru-realty.com/forum/index.php?PHPSESSID=ie52v0njkmh67ftgp940ernkj6&topic=459048.0
http://ru-realty.com/forum/index.php?PHPSESSID=n82p1em2786v727d9mvnjh00t7&topic=459062.0
http://ru-realty.com/forum/index.php?PHPSESSID=p68h2mcummlf2fqs5onoaudqi3&topic=459069.0
http://sextomariotienda.com/blog/hd-video-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q8-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://www.tessabannampad.go.th/webboard/index.php?topic=190534.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190555.0
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3574061
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=678489.0
http://danielmillsap.com/forum/index.php?topic=953331.0
http://HyUa.1fps.icu/l/szIaeDC
http://poselokgribovo.ru/forum/index.php?topic=697383.0
http://poselokgribovo.ru/forum/index.php?topic=697441.0
http://poselokgribovo.ru/forum/index.php?topic=697504.0
http://poselokgribovo.ru/forum/index.php?topic=697557.0
http://poselokgribovo.ru/forum/index.php?topic=697644.0
http://poselokgribovo.ru/forum/index.php?topic=697734.0
http://poselokgribovo.ru/forum/index.php?topic=698024.0
http://poselokgribovo.ru/forum/index.php?topic=698059.0
http://poselokgribovo.ru/forum/index.php?topic=698065.0
http://poselokgribovo.ru/forum/index.php?topic=698333.0
http://poselokgribovo.ru/forum/index.php?topic=698358.0
http://poselokgribovo.ru/forum/index.php?topic=698383.0
http://poselokgribovo.ru/forum/index.php?topic=698528.0
http://poselokgribovo.ru/forum/index.php?topic=698565.0
http://www.hoonthaitoday.com/forum/index.php?topic=158668.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190454.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190478.0
https://reficulcoin.com/index.php?topic=9870.0
https://reficulcoin.com/index.php?topic=9876.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=26960.0
http://myrechockey.com/forums/index.php?topic=85916.0
http://otitismediasociety.org/forum/index.php?topic=145076.0
http://roikjer.com/forum/index.php?PHPSESSID=hf9motoo0ujjsmg0rrkf7l4085&topic=811402.0
http://ru-realty.com/forum/index.php?PHPSESSID=1kng4n8br2ekh4l7qb50bh02a0&topic=458972.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190480.0
https://members.fbhaters.com/index.php?topic=74887.0
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c6-v4-%d1%80%d0%b0%d1%81%d1%81/
http://otitismediasociety.org/forum/index.php?topic=145074.0
http://storykingdom.forumside.com/index.php?topic=4477.0
http://HyUa.1fps.icu/l/szIaeDC
http://roikjer.com/forum/index.php?PHPSESSID=km00sitvbjqmkcc6fm2a0l9kj3&topic=807842.0
http://roikjer.com/forum/index.php?PHPSESSID=li5a62li9dtdqm403f5drccmn1&topic=804575.0
http://roikjer.com/forum/index.php?PHPSESSID=ljosc0pfgqbvolee80cgr5p413&topic=789698.0
http://roikjer.com/forum/index.php?PHPSESSID=m3f0l4o810o3gm5pc8h3bsh2d6&topic=796186.0
http://roikjer.com/forum/index.php?PHPSESSID=mg67nbf5p9qom6jv17ubgirft3&topic=793483.0
http://roikjer.com/forum/index.php?PHPSESSID=mj9gj2n2hols656f9m3vfiiub4&topic=806736.0
http://roikjer.com/forum/index.php?PHPSESSID=mughv9mirm4tapcf5mjackgi01&topic=796456.0
http://roikjer.com/forum/index.php?PHPSESSID=n0j5tj4j9h8qqeit4cdvhbhfb7&topic=797732.0
http://roikjer.com/forum/index.php?PHPSESSID=n703k1qmleduqpjo0h0pa30vu4&topic=795450.0
http://roikjer.com/forum/index.php?PHPSESSID=nj8j2qeo4ffohiijv0qmlimnc5&topic=793471.0
http://roikjer.com/forum/index.php?PHPSESSID=nokv7rahcusnjomcecjb97odn6&topic=797475.0
http://roikjer.com/forum/index.php?PHPSESSID=ohiujcfamae8g6eqanf0bhh212&topic=789178.0
http://roikjer.com/forum/index.php?PHPSESSID=oib43tgpeqlmqpoit1qo90ihv0&topic=806498.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=27010.0
http://otitismediasociety.org/forum/index.php?topic=145103.0
http://ru-realty.com/forum/index.php?PHPSESSID=4e6g0a9umdk5s8ish9ta01qln4&topic=459198.0
http://ru-realty.com/forum/index.php?PHPSESSID=c69r8uateht1c0se4jh5pnkik7&topic=459232.0
http://ru-realty.com/forum/index.php?PHPSESSID=otmel3vf88rsfetmja9uc19ik4&topic=459192.0
http://ru-realty.com/forum/index.php?PHPSESSID=p0ecr0206t4j7u430qeckmsal4&topic=459209.0
http://sextomariotienda.com/blog/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://sextomariotienda.com/blog/hd-video-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-y6-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=678525.0
https://members.fbhaters.com/index.php?topic=74982.0
http://216.104.186.20/index.php?topic=299438.0
http://cccpvideo.forumside.com/index.php?topic=285.0
http://e-educ.net/Forum/index.php?topic=4899.0
http://forum.drahthaar-club.com.ua/index.php?topic=514.0
http://forum.stollen24.com/index.php?topic=3824.0
http://freebeer.me/index.php?topic=299440.0
http://istakam.com/forum/index.php?topic=9631.0
http://mir3sea.com/forum/index.php?topic=845.0
http://multikopterforum.hu/index.php?topic=11606.0
http://otitismediasociety.org/forum/index.php?topic=145104.0
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g8-x4-%d1%80%d0%b0%d1%81%d1%81/
http://HyUa.1fps.icu/l/szIaeDC
http://roikjer.com/forum/index.php?PHPSESSID=266mrh2lc4g4s9v0grdv42tf35&topic=802625.0
http://roikjer.com/forum/index.php?PHPSESSID=29nnj8frd9ei8hgmf3f7v2amq7&topic=796558.0
http://roikjer.com/forum/index.php?PHPSESSID=2dkg90n6d8cg2qcdm3u5gpd060&topic=795207.0
http://roikjer.com/forum/index.php?PHPSESSID=2f5u4udbm8dvvl44ustjtc69v2&topic=796419.0
http://roikjer.com/forum/index.php?PHPSESSID=2mc97nlc4od4d03s9d65mmd6v0&topic=803125.0
http://roikjer.com/forum/index.php?PHPSESSID=2qetvfi6a1g3ohhv821uut7gt1&topic=792232.0
http://roikjer.com/forum/index.php?PHPSESSID=3h9ri6be8prgo3obgd6k6faji7&topic=799833.0
http://roikjer.com/forum/index.php?PHPSESSID=3m4eink5ilrkhn964k29plfvo2&topic=796919.0
http://roikjer.com/forum/index.php?PHPSESSID=3mr2fvk2dqeeim1sfp6qvftkq1&topic=799364.0
http://roikjer.com/forum/index.php?PHPSESSID=404rkt2p4rgqik9m7669qcjbd5&topic=796728.0
http://roikjer.com/forum/index.php?PHPSESSID=43pn4vo12ib73jgfcd18u4pl06&topic=806263.0
http://roikjer.com/forum/index.php?PHPSESSID=43ua1qgt4a00cqe86ar1ss0ge3&topic=795820.0
http://roikjer.com/forum/index.php?PHPSESSID=485ok2dj2mt06t3ms2b6885nh1&topic=802609.0
http://roikjer.com/forum/index.php?PHPSESSID=4a4riatvrtsitpge9kte7kiku4&topic=802967.0
http://roikjer.com/forum/index.php?PHPSESSID=4hr5un1qrm935g3svne8q7ihe0&topic=795256.0
http://roikjer.com/forum/index.php?PHPSESSID=4pnfsns7rk7593insi47l6j520&topic=790956.0
http://roikjer.com/forum/index.php?PHPSESSID=4rk77ocomkf8hdvip8md310mq2&topic=800214.0
http://roikjer.com/forum/index.php?PHPSESSID=4rl4kr1qdfg6ak4uobdq0v1op2&topic=796773.0
http://roikjer.com/forum/index.php?PHPSESSID=4sbptcv4b0br9nm6mslblcv144&topic=800716.0
http://roikjer.com/forum/index.php?PHPSESSID=4t9j358882bk26ot0651g4ker5&topic=792896.0
http://roikjer.com/forum/index.php?PHPSESSID=4tkkakibba1ngf7icjql5cjvm1&topic=806996.0
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile;u=31193
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=27000.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=27003.0
http://kurnaz.1to.us/index.php?topic=1.495
http://matrixpharm.ru/forum/index.php?PHPSESSID=thskps9hievke8aq6thev6f310&action=profile;u=167635
http://myrechockey.com/forums/index.php?topic=85955.0
http://myrechockey.com/forums/index.php?topic=85959.0
http://myrechockey.com/forums/index.php?topic=85972.0
http://myrechockey.com/forums/index.php?topic=85973.0
http://otitismediasociety.org/forum/index.php?topic=145093.0
http://HyUa.1fps.icu/l/szIaeDC
http://myrechockey.com/forums/index.php?topic=85090.0
http://www.spazioad.com/component/k2/itemlist/user/7168278
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3569674
http://seoksoononly.dothome.co.kr/qna/587151
http://dessa.com.br/index.php/component/k2/itemlist/user/292891
http://www.quattroandpartners.it/component/k2/itemlist/user/1001758
http://boutique.in.th/?option=com_k2&view=itemlist&task=user&id=146419
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1109134
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1131525
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=78425
http://withinfp.sakura.ne.jp/eso/index.php/16789657-lubov-smert-i-roboty-love-death-and-robots-4-seria-yao-lubov-sm/0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/280157
http://healthyteethpa.org/component/k2/itemlist/user/5331893
http://danielmillsap.com/forum/index.php?topic=866363.0
http://healthyteethpa.org/component/k2/itemlist/user/5339930
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1669091
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=296859
http://danielmillsap.com/forum/index.php?topic=938189.0
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=245260
http://dessa.com.br/component/k2/itemlist/user/305069
http://hydrocarbs-gh.org/index.php/component/k2/itemlist/user/7305910
https://members.fbhaters.com/index.php?topic=62325.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1116489
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=32107
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/439403
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/51047
http://seoksoononly.dothome.co.kr/qna/650222
http://ts.bloodhand.de/forum/viewtopic.php?t=198875
http://puppystoreatdoral.com/?option=com_k2&view=itemlist&task=user&id=336708
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/1343
http://www.deliberarchia.org/forum/index.php?topic=927900.0
http://fbpharm.net/index.php/component/k2/itemlist/user/13871
http://seoksoononly.dothome.co.kr/qna/587838
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=294809
https://tg.vl-mp.com/index.php?topic=1307982.0
https://tg.vl-mp.com/index.php?topic=1325190.0
https://tg.vl-mp.com/index.php?topic=1325234.0
https://www.resproxy.com/forum/index.php/780696-edinoe-serdce-tek-yurek-12-seria-p6xi-edinoe-serdce-tek-yurek-1/0
https://www.resproxy.com/forum/index.php/780728-voron-kuzgun-20-seria-d0or-voron-kuzgun-20-seria/0
https://www.resproxy.com/forum/index.php/780751-edinoe-serdce-tek-yurek-11-seria-q7wa-edinoe-serdce-tek-yurek-1/0
http://www.quattroandpartners.it/component/k2/itemlist/user/993737
http://www.quattroandpartners.it/component/k2/itemlist/user/994316
http://www.quattroandpartners.it/component/k2/itemlist/user/995046
http://www.quattroandpartners.it/component/k2/itemlist/user/995251
http://www.quattroandpartners.it/component/k2/itemlist/user/995370
http://www.quattroandpartners.it/component/k2/itemlist/user/995688
http://www.m1avio.com/?option=com_k2&view=itemlist&task=user&id=3601187
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/147351
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1619406
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=894328
https://tg.vl-mp.com/index.php?topic=1300222.0
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/553603
https://tg.vl-mp.com/index.php?topic=1303911.0
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=48254
http://withinfp.sakura.ne.jp/eso/index.php/16774091-nevesta-iz-stambula-istanbullu-gelin-80-seria-r5pj-nevesta-iz-s/0
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1829151
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/54556
http://www.tessabannampad.go.th/webboard/index.php?topic=190657.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190661.0
http://danielmillsap.com/forum/index.php?topic=953584.0
http://danielmillsap.com/forum/index.php?topic=953601.0
http://withinfp.sakura.ne.jp/eso/index.php/16883452-edinoe-serdce-tek-yurek-15-seria-m5yo-edinoe-serdce-tek-yurek-1
https://tg.vl-mp.com/index.php?topic=1325253.0
http://myrechockey.com/forums/index.php?topic=85993.0
http://myrechockey.com/forums/index.php?topic=85998.0
http://www.deliberarchia.org/forum/index.php?topic=959879.0
http://www.deliberarchia.org/forum/index.php?topic=959885.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190650.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190675.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190678.0
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1009221
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1011460
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1016172
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1016426
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1016835
https://www.resproxy.com/forum/index.php/731370-tola-robot-1-seria-smotret-trejler-bn-tola-robot-1-seria-smotre/0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/447205
https://tg.vl-mp.com/index.php?topic=1283009.0
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1130320
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1323948
https://members.fbhaters.com/index.php?topic=68158.0
http://healthyteethpa.org/component/k2/itemlist/user/5303884
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1573571
http://danielmillsap.com/forum/index.php?topic=908684.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190689.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190693.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x9dy-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-6-%d1%81%d0%b5%d1%80%d0%b8/
http://menulisilmiah.net/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x0th-%d0%b2%d0%be%d1%81%d0%ba%d1%80/
http://menulisilmiah.net/%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80%d0%b4%d1%86%d0%b5-tek-yurek-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g4hf-%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80/
http://withinfp.sakura.ne.jp/eso/index.php/16883331-ne-otpuskaj-mou-ruku-elimi-birakma-38-seria-g8vn-ne-otpuskaj-mo/0
http://withinfp.sakura.ne.jp/eso/index.php/16883353-vetrenyj-hercai-17-seria-a9tu-vetrenyj-hercai-17-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/16883386-vetrenyj-hercai-11-seria-e4ji-vetrenyj-hercai-11-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/16883401-vetrenyj-hercai-20-seria-u5ei-vetrenyj-hercai-20-seria
http://withinfp.sakura.ne.jp/eso/index.php/16883424-voskressij-ertugrul-143-seria-f8jz-voskressij-ertugrul-143-seri/0
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1017689
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1019816
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1019938
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1023241
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1026918
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1030705
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1042485
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1045938
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/989066
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/990058
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/990145
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/991972
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/992935
http://mvisage.sk/index.php/component/k2/itemlist/user/117141
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=559091
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pq8-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2521302
http://soc-human.kz/index.php/component/k2/itemlist/user/1606253
https://tg.vl-mp.com/index.php?topic=1315639.0
http://153.120.114.241/eso/index.php/16874660-riverdejl-riverdale-3-sezon-21-seria-ews-riverdejl-riverdale-3-
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3373026
http://withinfp.sakura.ne.jp/eso/index.php/16802880-edinoe-serdce-tek-yurek-12-seria-h8gn-edinoe-serdce-tek-yurek-1
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uby-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-14-%d1%81%d0%b5%d1%80/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zla-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-14-%d1%81%d0%b5%d1%80/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dfd-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-15-%d1%81%d0%b5%d1%80/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kbt-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nsf-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pfm-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qmm-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zrv-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://metropolis.ga/index.php?topic=3257.0
http://repofirmware.altervista.org/index.php?topic=104999.0
http://www.deliberarchia.org/forum/index.php?topic=960553.0
http://www.deliberarchia.org/forum/index.php?topic=960565.0
http://www.deliberarchia.org/forum/index.php?topic=960580.0
http://danielmillsap.com/forum/index.php?topic=954288.0
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/134656
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/135165
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/135426
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/135514
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/135696
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/135755
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/135837
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/136072
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/136118
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/136280
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/136405
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/136685
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/137174
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/137176
http://married.dike.gr/index.php/component/k2/itemlist/user/36916
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1571787
https://tg.vl-mp.com/index.php?topic=1276454.0
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=1105
http://dessa.com.br/component/k2/itemlist/user/299895
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1297204
http://multikopterforum.hu/index.php?topic=8640.0
http://www.deliberarchia.org/forum/index.php?topic=943469.0
http://multikopterforum.hu/index.php?topic=6914.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=5bd65d97f445677f96e5dc638f82b56f&topic=205632.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=5969515bd3d0102879adc739ddede616&topic=207658.0
http://married.dike.gr/index.php/component/k2/itemlist/user/43793
http://8.droror.co.il/uncategorized/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-b6-p2-%d1%80/
http://multikopterforum.hu/index.php?topic=8689.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=678059.0
http://freebeer.me/index.php?topic=292573.0
http://forum.drahthaar-club.com.ua/index.php?topic=389.0
http://otitismediasociety.org/forum/index.php?topic=142288.0
https://members.fbhaters.com/index.php?topic=70222.0
https://khuyenmaikk13.info/index.php?topic=177525.0
http://forum.bmw-e60.eu/index.php?topic=2442.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-q2-v5-%d0%b8%d0%b3/
http://freebeer.me/index.php?topic=284218.0
http://multikopterforum.hu/index.php?topic=9368.0
http://teambuildingpremium.com/forum/index.php?topic=756575.0
http://www.tessabannampad.go.th/webboard/index.php?topic=186456.0
http://dpmarketingsystems.com/%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t7-%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-7-%d1%81%d0%b5%d1%80/
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=26639.0
http://www.deliberarchia.org/forum/index.php?topic=941129.0
http://miklja.net/forum/index.php?topic=25119.0
http://8.droror.co.il/uncategorized/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-l4-h2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
http://golyboe.ru/forum/index.php?topic=24764.0
http://yuptalk.ru/other_food_household_cosmetics_etc/-t13117.0.html;msg115268
http://myrechockey.com/forums/index.php?topic=82823.0
https://www.regalepadova.it/index.php/component/k2/itemlist/user/6092
http://eugeniocolazzo.it/forum/index.php?topic=85732.0
https://nextezone.com/index.php?topic=33495.0
http://subforumna.x10.mx/mad/index.php?topic=199994.0
http://forum.politeknikgihon.ac.id/index.php?topic=11197.0
http://www.tessabannampad.go.th/webboard/index.php?topic=185366.0
https://www.shaiyax.com/index.php?topic=327529.0
https://sanp.pro/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x8-%d1%81/
http://ru-realty.com/forum/index.php?topic=445381.0
http://forum.politeknikgihon.ac.id/index.php?topic=16680.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.popolsku.fr.pl/forum/index.php?topic=20407.47730
http://www.popolsku.fr.pl/forum/index.php?topic=20407.48240
http://www.popolsku.fr.pl/forum/index.php?topic=20407.48345
http://www.popolsku.fr.pl/forum/index.php?topic=20407.msg639746
http://www.popolsku.fr.pl/forum/index.php?topic=20407.msg640565
http://www.popolsku.fr.pl/forum/index.php?topic=20407.msg641099
http://www.popolsku.fr.pl/forum/index.php?topic=20407.msg641210
http://www.popolsku.fr.pl/forum/index.php?topic=20407.msg641235
http://www.popolsku.fr.pl/forum/index.php?topic=20407.msg643455
http://www.popolsku.fr.pl/forum/index.php?topic=20407.msg643861
http://www.popolsku.fr.pl/forum/index.php?topic=20407.msg649256
http://www.popolsku.fr.pl/forum/index.php?topic=369515.0
http://216.104.186.20/index.php?topic=303243.0
http://danielmillsap.com/forum/index.php?topic=961321.0
http://e-educ.net/Forum/index.php?topic=5389.0
http://forum.drahthaar-club.com.ua/index.php?topic=691.0
http://freebeer.me/index.php?topic=303184.0
http://metropolis.ga/index.php?topic=3935.0
http://miklja.net/forum/index.php?topic=27021.0
http://miklja.net/forum/index.php?topic=27024.0
http://multikopterforum.hu/index.php?topic=12921.0
http://otitismediasociety.org/forum/index.php?topic=145957.0
http://otitismediasociety.org/forum/index.php?topic=145960.0
http://poselokgribovo.ru/forum/index.php?topic=720027.0
http://poselokgribovo.ru/forum/index.php?topic=720062.0
http://storykingdom.forumside.com/index.php?topic=5016.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=ca53261017b9c39e437ad120f5222a82&topic=210153.0
http://wituclub.ru/forum/index.php?PHPSESSID=8lgksg0vqmea1a7iled5l3v387&topic=25634.0
http://www.popolsku.fr.pl/forum/index.php?topic=20407.49920
http://www.remify.app/foro/index.php?topic=224936.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.theparrotcentre.com/forum/index.php?topic=445501.0
http://www.theparrotcentre.com/forum/index.php?topic=445579.0
http://www.theparrotcentre.com/forum/index.php?topic=445628.0
http://www.theparrotcentre.com/forum/index.php?topic=445648.0
http://www.theparrotcentre.com/forum/index.php?topic=445712.0
http://www.theparrotcentre.com/forum/index.php?topic=445765.0
http://www.theparrotcentre.com/forum/index.php?topic=445775.0
http://www.theparrotcentre.com/forum/index.php?topic=445786.0
http://www.theparrotcentre.com/forum/index.php?topic=445811.0
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e6-a4-%d1%80%d0%b0%d1%81%d1%81/
http://forum.drahthaar-club.com.ua/index.php?topic=708.0
http://forum.drahthaar-club.com.ua/index.php?topic=709.0
http://forum.drahthaar-club.com.ua/index.php?topic=710.0
http://forum.drahthaar-club.com.ua/index.php?topic=711.0
http://forum.santrope-rp.ru/index.php?topic=2742.0
http://golyboe.ru/forum/index.php?topic=25024.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=27789.0
http://istakam.com/forum/index.php?topic=9882.0
http://multikopterforum.hu/index.php?topic=12963.0
http://otitismediasociety.org/forum/index.php?topic=146030.0
http://otitismediasociety.org/forum/index.php?topic=146036.0
http://otitismediasociety.org/forum/index.php?topic=146040.0
http://poselokgribovo.ru/forum/index.php?topic=720413.0
http://poselokgribovo.ru/forum/index.php?topic=720422.0
http://roikjer.com/forum/index.php?PHPSESSID=i29silfrcvvqn9pumhpcefo136&topic=817403.0
http://roikjer.com/forum/index.php?topic=817437.0
http://thanosakademi.com/index.php?topic=66125.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.popolsku.fr.pl/forum/index.php?topic=370441.0
http://www.popolsku.fr.pl/forum/index.php?topic=370468.0
http://www.popolsku.fr.pl/forum/index.php?topic=370498.0
http://www.popolsku.fr.pl/forum/index.php?topic=370530.0
http://www.popolsku.fr.pl/forum/index.php?topic=370562.0
http://www.popolsku.fr.pl/forum/index.php?topic=370564.0
http://www.popolsku.fr.pl/forum/index.php?topic=370569.0
http://www.popolsku.fr.pl/forum/index.php?topic=370573.0
http://www.popolsku.fr.pl/forum/index.php?topic=370578.0
http://www.popolsku.fr.pl/forum/index.php?topic=370673.0
http://www.popolsku.fr.pl/forum/index.php?topic=370693.0
http://www.popolsku.fr.pl/forum/index.php?topic=370726.0
http://www.popolsku.fr.pl/forum/index.php?topic=370755.0
http://storykingdom.forumside.com/index.php?topic=5024.0
http://thanosakademi.com/index.php?topic=66026.0
http://www.critico-expository.com/forum/index.php?topic=3549.0
http://www.deliberarchia.org/forum/index.php?topic=966556.0
http://www.deliberarchia.org/forum/index.php?topic=966625.0
http://www.remify.app/foro/index.php?topic=224943.0
http://www.theparrotcentre.com/forum/index.php?topic=461585.0
https://danceplanet.se/commodore/index.php?topic=13160.0
https://danceplanet.se/commodore/index.php?topic=13161.0
https://hackersuniversity.net/index.php?topic=7734.0
https://reficulcoin.com/index.php?topic=11945.0
http://HyUa.1fps.icu/l/szIaeDC
https://tg.vl-mp.com/index.php?topic=1306520.0
https://tg.vl-mp.com/index.php?topic=1306802.0
https://tg.vl-mp.com/index.php?topic=1306828.0
https://tg.vl-mp.com/index.php?topic=1307381.0
https://tg.vl-mp.com/index.php?topic=1307465.0
https://tg.vl-mp.com/index.php?topic=1307505.0
https://tg.vl-mp.com/index.php?topic=1307518.0
https://tg.vl-mp.com/index.php?topic=1307561.0
https://tg.vl-mp.com/index.php?topic=1307666.0
https://tg.vl-mp.com/index.php?topic=1307688.0
https://tg.vl-mp.com/index.php?topic=1308044.0
https://tg.vl-mp.com/index.php?topic=1308091.0
https://tg.vl-mp.com/index.php?topic=1308209.0
https://tg.vl-mp.com/index.php?topic=1308411.0
https://tg.vl-mp.com/index.php?topic=1308606.0
https://tg.vl-mp.com/index.php?topic=1308688.0
https://tg.vl-mp.com/index.php?topic=1308822.0
https://tg.vl-mp.com/index.php?topic=1308853.0
https://tg.vl-mp.com/index.php?topic=1308972.0
https://tg.vl-mp.com/index.php?topic=1308998.0
https://tg.vl-mp.com/index.php?topic=1309067.0
http://miklja.net/forum/index.php?topic=25203.0
http://withinfp.sakura.ne.jp/eso/index.php/16872342-igra-prestolov-got-8-sezon-7-seria-bt4-igra-prestolov-got-8-sez/0
http://153.120.114.241/eso/index.php/16854836-igra-prestolov-got-8-sezon-4-seria-igra-prestolov-got-8-sezon-4
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m8-h4-%d0%b8%d0%b3%d1%80/
https://sanp.pro/%d1%8d%d1%84%d0%b8%d1%80-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m9-%d1%81%d0%bb%d1%83%d0%b3/
http://help.stv.ru/index.php?PHPSESSID=f0b771482e66977e2d3ed1aeb6f1b93e&topic=135340.0
http://withinfp.sakura.ne.jp/eso/index.php/16862042-ne-zenskaa-rabota-ne-zinoca-robota-13-seria-05052019/0
http://wb.hvekorat.com/index.php?topic=40240.0
http://www.remify.app/foro/index.php?topic=204479.0
http://www.hoonthaitoday.com/forum/index.php?topic=134634.0
http://storykingdom.forumside.com/index.php/topic,3984.0.html
https://sanp.pro/%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m6-%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5/
http://multikopterforum.hu/index.php?topic=8948.0
http://www.deliberarchia.org/forum/index.php?topic=950010.0
http://poselokgribovo.ru/forum/index.php?topic=695878.0
http://golyboe.ru/forum/index.php?topic=24603.0
http://mir3sea.com/forum/index.php?topic=167.0
http://HyUa.1fps.icu/l/szIaeDC
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ea6-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-eg5-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ev6-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ey3-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ez9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fv1-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hk7-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hm1-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hs0-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-iz8-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jc6-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ka0-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kk4-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-km5-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mg9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-oi8-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rd7-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sd0-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tn5-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://danceplanet.se/commodore/index.php?topic=8411.0
http://windowshopgoa.com/component/k2/itemlist/user/186456
http://poselokgribovo.ru/forum/index.php?topic=713719.0
http://forum.digamahost.com/index.php?topic=107875.0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-31/
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-x9-q9-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://www.deliberarchia.org/forum/index.php?topic=948488.0
https://npi.org.es/smf/index.php?topic=111428.0
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x2-k4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
https://sanp.pro/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-z1-n1-%d1%80/
https://www.shaiyax.com/index.php?topic=327294.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90yh0%e3%80%91/
http://poselokgribovo.ru/forum/index.php?topic=707788.0
http://www.deliberarchia.org/forum/index.php?topic=934461.0
https://www.c-alice.org/forum/index.php?topic=71002.0
http://muonlineint.com/forum/index.php?topic=872.0
http://sextomariotienda.com/blog/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wb4-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://bobr.site/index.php?topic=84524.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-44/
http://1vh.info/index.php?topic=6007.0
https://www.gizmoarticle.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tz6-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://HyUa.1fps.icu/l/szIaeDC
http://www.deliberarchia.org/forum/index.php?topic=917791.0
http://www.deliberarchia.org/forum/index.php?topic=918023.0
http://www.deliberarchia.org/forum/index.php?topic=918132.0
http://www.deliberarchia.org/forum/index.php?topic=918208.0
http://www.deliberarchia.org/forum/index.php?topic=918248.0
http://www.deliberarchia.org/forum/index.php?topic=918260.0
http://www.deliberarchia.org/forum/index.php?topic=918333.0
http://www.deliberarchia.org/forum/index.php?topic=918387.0
http://www.deliberarchia.org/forum/index.php?topic=918406.0
http://www.deliberarchia.org/forum/index.php?topic=918427.0
http://computerscience.egerton.ac.ke/index.php/component/k2/itemlist/user/1983374
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=306065
http://withinfp.sakura.ne.jp/eso/index.php/16769722-igra-prestolov-8-sezon-3-seria-ebj-igra-prestolov-8-sezon-3-ser
http://israengineering.com/index.php/component/k2/itemlist/user/1090279
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=246297
https://sto54.ru/index.php/component/k2/itemlist/user/3271028
http://associationsila.org/index.php/component/k2/itemlist/user/261463
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=29655
http://www.spazioad.com/component/k2/itemlist/user/7223716
https://www.youngbiker.de/wbboard/index.php?page=User&userID=785720
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/436560
http://danielmillsap.com/forum/index.php?topic=874513.0
http://smartacity.com/component/k2/itemlist/user/13718
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7272756
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2537320
http://soc-human.kz/index.php/component/k2/itemlist/user/1613104
http://www.deliberarchia.org/forum/index.php?topic=921344.0
http://ts.bloodhand.de/forum/viewtopic.php?t=197628
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/54041
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/452149
http://www.deliberarchia.org/forum/index.php?topic=942018.0
http://israengineering.com/index.php/component/k2/itemlist/user/1078243
http://www.arunagreen.com/index.php/component/k2/itemlist/user/399486
https://www.resproxy.com/forum/index.php/744731-voron-kuzgun-18-seria-u4nd-voron-kuzgun-18-seria/0
http://matinbank.ir/component/k2/itemlist/user/4457852.html
http://www.deliberarchia.org/forum/index.php?topic=924046.0
http://www.deliberarchia.org/forum/index.php?topic=924064.0
http://www.deliberarchia.org/forum/index.php?topic=924171.0
http://www.deliberarchia.org/forum/index.php?topic=924183.0
http://www.deliberarchia.org/forum/index.php?topic=924208.0
http://www.deliberarchia.org/forum/index.php?topic=924227.0
http://www.deliberarchia.org/forum/index.php?topic=924246.0
http://www.deliberarchia.org/forum/index.php?topic=924277.0
http://www.deliberarchia.org/forum/index.php?topic=924326.0
http://www.deliberarchia.org/forum/index.php?topic=924352.0
http://www.deliberarchia.org/forum/index.php?topic=924503.0
http://www.deliberarchia.org/forum/index.php?topic=924585.0
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=4172
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1128972
http://withinfp.sakura.ne.jp/eso/index.php/16787687-cernoe-zerkalo-5-sezon-3-seria-ugm-cernoe-zerkalo-5-sezon-3-ser/0
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3545034
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=4312
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2537937
http://healthyteethpa.org/component/k2/itemlist/user/5280218
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=10758
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/638735
http://www.gt3treff.de/thread.php?threadid=203981
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1544141
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=38599
http://dev.fivestarpainting.com/?option=com_k2&view=itemlist&task=user&id=1834624
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1006455
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1300084
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1126089
http://healthyteethpa.org/component/k2/itemlist/user/5291760
http://withinfp.sakura.ne.jp/eso/index.php/16791643-vetrenyj-hercai-20-seria-z0ba-vetrenyj-hercai-20-seria
http://www.deliberarchia.org/forum/index.php?topic=918688.0
http://www.deliberarchia.org/forum/index.php?topic=918697.0
http://www.deliberarchia.org/forum/index.php?topic=918709.0
http://www.deliberarchia.org/forum/index.php?topic=918732.0
http://www.deliberarchia.org/forum/index.php?topic=918932.0
http://www.deliberarchia.org/forum/index.php?topic=918966.0
http://www.deliberarchia.org/forum/index.php?topic=918979.0
http://www.deliberarchia.org/forum/index.php?topic=919000.0
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1549867
http://www.arunagreen.com/index.php/component/k2/itemlist/user/407901
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1738653
http://withinfp.sakura.ne.jp/eso/index.php/16817391-nasa-istoria-73-seria-v5ya-nasa-istoria-73-seria/0
http://www.deliberarchia.org/forum/index.php?topic=952189.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/471893
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3248555
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=158798
http://tekagrafica.com.br/index.php/component/k2/itemlist/user/1576287
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4667008
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=4458
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=891211
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3558230
https://tg.vl-mp.com/index.php?topic=1256801.0
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1835692
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/458021
https://www.youngbiker.de/wbboard/index.php?page=User&userID=784027
http://www.arredoufficiomarca.com/index.php/component/k2/itemlist/user/1551844
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=258890
http://healthyteethpa.org/component/k2/itemlist/user/5295050
https://sto54.ru/index.php/component/k2/itemlist/user/3265837
https://members.fbhaters.com/index.php?topic=72735.0
http://poselokgribovo.ru/forum/index.php?topic=699060.0
https://www.shaiyax.com/index.php?topic=327263.0
http://menulisilmiah.net/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m7-e6-%d1%80%d0%b0%d1%81%d1%81/
http://sextomariotienda.com/blog/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nh8-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.deliberarchia.org/forum/index.php?topic=936694.0
http://poselokgribovo.ru/forum/index.php?topic=689190.0
http://www.grupojover.com/?option=com_k2&view=itemlist&task=user&id=3708
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/628219
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-z2-k8-%d1%80/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x0-d4-%d1%80%d0%b0%d1%81%d1%81/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x2-p6-%d1%80%d0%b0%d1%81%d1%81/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z7-g1-%d1%80%d0%b0/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a4-c2-%d1%80%d0%b0%d1%81%d1%81/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a9-p6-%d1%80%d0%b0%d1%81%d1%81/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d3-d7-%d1%80%d0%b0/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d5-q3-%d1%80%d0%b0%d1%81%d1%81/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f0-n2-%d1%80%d0%b0/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f3-u1-%d1%80%d0%b0%d1%81%d1%81/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f9-y7-%d1%80%d0%b0%d1%81%d1%81/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h0-u0-%d1%80%d0%b0%d1%81/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h8-x4-%d1%80%d0%b0%d1%81%d1%81/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h9-p5-%d1%80%d0%b0%d1%81%d1%81/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i0-p2-%d1%80%d0%b0%d1%81%d1%81/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k7-z2-%d1%80%d0%b0%d1%81%d1%81/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k9-y8-%d1%80%d0%b0%d1%81%d1%81/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n1-o0-%d1%80%d0%b0%d1%81%d1%81/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o0-l9-%d1%80%d0%b0%d1%81%d1%81/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o0-m6-%d1%80%d0%b0%d1%81%d1%81/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-h7-n2-%d1%80/
http://HyUa.1fps.icu/l/szIaeDC
https://tg.vl-mp.com/index.php?topic=1323300.0
https://tg.vl-mp.com/index.php?topic=1323310.0
https://tg.vl-mp.com/index.php?topic=1323335.0
https://tg.vl-mp.com/index.php?topic=1323369.0
https://tg.vl-mp.com/index.php?topic=1323459.0
https://tg.vl-mp.com/index.php?topic=1323633.0
https://tg.vl-mp.com/index.php?topic=1323636.0
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/210156
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/213153
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/215672
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/215873
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/217404
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=779470
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=779774
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=779954
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=780285
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=780345
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=780362
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=780836
https://www.resproxy.com/forum/index.php/749925-voron-kuzgun-17-seria-s5kp-voron-kuzgun-17-seria/0
https://www.resproxy.com/forum/index.php/749968-zensina-59-seria-c1ke-zensina-59-seria/0
https://www.resproxy.com/forum/index.php/749994-edinoe-serdce-tek-yurek-20-seria-s9lv-edinoe-serdce-tek-yurek-2/0
https://www.resproxy.com/forum/index.php/750047-voskressij-ertugrul-145-seria-c5bk-voskressij-ertugrul-145-seri/0
https://www.resproxy.com/forum/index.php/750051-vetrenyj-hercai-23-seria-t9wu-vetrenyj-hercai-23-seria/0
https://www.resproxy.com/forum/index.php/750122-voron-kuzgun-13-seria-y4mt-voron-kuzgun-13-seria
https://www.resproxy.com/forum/index.php/750342-vetrenyj-hercai-8-seria-v1bj-vetrenyj-hercai-8-seria
https://www.resproxy.com/forum/index.php/750344-vetrenyj-hercai-20-seria-o6lh-vetrenyj-hercai-20-seria
https://www.resproxy.com/forum/index.php/750448-ne-otpuskaj-mou-ruku-elimi-birakma-41-seria-i7ug-ne-otpuskaj-mo/0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3246381
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3246426
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3246483
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3246575
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3246595
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3246775
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3246857
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3246866
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3247078
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1751705
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1751715
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1752410
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1752618
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1752904
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1752918
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1753804
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1754173
http://www.deliberarchia.org/forum/index.php?topic=903492.0
http://www.deliberarchia.org/forum/index.php?topic=903498.0
http://www.deliberarchia.org/forum/index.php?topic=903527.0
http://www.deliberarchia.org/forum/index.php?topic=903591.0
http://www.deliberarchia.org/forum/index.php?topic=903646.0
http://www.deliberarchia.org/forum/index.php?topic=903698.0
http://www.deliberarchia.org/forum/index.php?topic=903820.0
http://www.deliberarchia.org/forum/index.php?topic=903875.0
http://www.deliberarchia.org/forum/index.php?topic=903948.0
http://www.deliberarchia.org/forum/index.php?topic=903978.0
http://153.120.114.241/eso/index.php/16878711-lubov-smert-i-roboty-love-death-and-robots-8-seria-kkv-lubov-sm
http://153.120.114.241/eso/index.php/16878719-rasskaz-sluzanki-3-sezon-1-seria-vwt-rasskaz-sluzanki-3-sezon-1
http://153.120.114.241/eso/index.php/16878736-lubov-smert-i-roboty-love-death-and-robots-9-seria-qrt-lubov-sm
http://153.120.114.241/eso/index.php/16878776-igra-prestolov-8-sezon-4-seria-mbb-igra-prestolov-8-sezon-4-ser
http://153.120.114.241/eso/index.php/16878786-nasledie-14-seria-wod-nasledie-14-seria
http://153.120.114.241/eso/index.php/16878827-igra-prestolov-8-sezon-6-seria-ase-igra-prestolov-8-sezon-6-ser
http://153.120.114.241/eso/index.php/16878856-lubov-smert-i-roboty-love-death-and-robots-12-seria-unc-lubov-s
http://153.120.114.241/eso/index.php/16878903-riverdejl-riverdale-3-sezon-21-seria-yab-riverdejl-riverdale-3-
http://153.120.114.241/eso/index.php/16878912-sverh-estestvennoe-14-sezon-20-seria-pik-sverh-estestvennoe-14-
http://153.120.114.241/eso/index.php/16878975-milliardy-4-sezon-4-seria-zmp-milliardy-4-sezon-4-seria
http://153.120.114.241/eso/index.php/16879051-lubov-smert-i-roboty-love-death-and-robots-4-seria-ilh-lubov-sm
http://153.120.114.241/eso/index.php/16879087-rasskaz-sluzanki-3-sezon-3-seria-oqw-rasskaz-sluzanki-3-sezon-3
http://153.120.114.241/eso/index.php/16879110-sverh-estestvennoe-14-sezon-21-seria-weg-sverh-estestvennoe-14-
http://153.120.114.241/eso/index.php/16879114-manifest-17-seria-rtw-manifest-17-seria
http://153.120.114.241/eso/index.php/16879119-amerikanskie-bogi-2-sezon-8-seria-ztg-amerikanskie-bogi-2-sezon
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=520990
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=521000
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=521336
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=521378
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=521425
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=521641
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=521711
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=521725
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=521924
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=521972
http://xplorefitness.com/blog/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-7-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90zm8%E3%80%91-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-7-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-watch
http://xplorefitness.com/blog/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-3-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90kg8%E3%80%91-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-3-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://xplorefitness.com/blog/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-3-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90od8%E3%80%91-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-3-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://xplorefitness.com/blog/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-3-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90pf3%E3%80%91-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-3-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://xplorefitness.com/blog/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-3-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90ss0%E3%80%91-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-3-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://xplorefitness.com/blog/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-3-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90ta4%E3%80%91-%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-3
http://xplorefitness.com/blog/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-3-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90vp4%E3%80%91-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-3-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://xplorefitness.com/blog/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-3-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90ys4%E3%80%91-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-3-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://xplorefitness.com/blog/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90js6%E3%80%91-%E2%80%9E%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4
http://xplorefitness.com/blog/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90oz3%E3%80%91-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://xplorefitness.com/blog/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90vd4%E3%80%91-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://xplorefitness.com/blog/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90ye5%E3%80%91-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1326664
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/197670
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z0-u5-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
https://reficulcoin.com/index.php?topic=5575.0
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=186928
http://matrixpharm.ru/forum/index.php?PHPSESSID=h3t5folrco03ru8jsurei7s2u4&action=profile;u=163979
https://members.fbhaters.com/index.php?topic=70469.0
http://www.remify.app/foro/index.php?topic=217707.0
https://www.c-alice.org/forum/index.php?topic=70638.0
https://sanp.pro/%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a0-%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-11-%d1%81%d0%b5%d1%80/
https://tg.vl-mp.com/index.php?topic=1303152.0
http://vtservices85.fr/smf2/index.php?topic=204047.0
http://153.120.114.241/eso/index.php/16844283-igra-prestolov-2019-8-sezon-3-seria-igra-prestolov-2019-8-sezon
http://freebeer.me/index.php?topic=291606.0
https://nextezone.com/index.php?action=profile&u=1541
http://HyUa.1fps.icu/l/szIaeDC
https://lucky28003.nl/forum/index.php?topic=7963.0
https://lucky28003.nl/forum/index.php?topic=7985.0
https://lucky28003.nl/forum/index.php?topic=8011.0
https://lucky28003.nl/forum/index.php?topic=8017.0
https://lucky28003.nl/forum/index.php?topic=8066.0
https://lucky28003.nl/forum/index.php?topic=8069.0
https://lucky28003.nl/forum/index.php?topic=8082.0
https://lucky28003.nl/forum/index.php?topic=8123.0
https://lucky28003.nl/forum/index.php?topic=8126.0
https://lucky28003.nl/forum/index.php?topic=8162.0
https://lucky28003.nl/forum/index.php?topic=8185.0
https://lucky28003.nl/forum/index.php?topic=8223.0
https://lucky28003.nl/forum/index.php?topic=8244.0
https://lucky28003.nl/forum/index.php?topic=8259.0
https://lucky28003.nl/forum/index.php?topic=8288.0
https://lucky28003.nl/forum/index.php?topic=8297.0
https://lucky28003.nl/forum/index.php?topic=8312.0
https://lucky28003.nl/forum/index.php?topic=8340.0
https://lucky28003.nl/forum/index.php?topic=8406.0
https://lucky28003.nl/forum/index.php?topic=8447.0
https://lucky28003.nl/forum/index.php?topic=8518.0
https://lucky28003.nl/forum/index.php?topic=8567.0
http://www.obal-shop.sk/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o3-k6-%d1%80%d0%b0%d1%81%d1%81/
http://matrixpharm.ru/forum/index.php?PHPSESSID=cuk2ebfoh9g24jru4oa1et5ei6&action=profile;u=162315
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1722119
http://socialfbwidgets.com/component/k2/itemlist/user/12809.html
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r7-u2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1758896
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81-23/
http://ru-realty.com/forum/index.php?topic=450415.0
http://danielmillsap.com/forum/index.php?topic=947634.0
https://reficulcoin.com/index.php?topic=9248.0
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1860783
http://freebeer.me/index.php?topic=289494.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190153.0
http://danielmillsap.com/forum/index.php?topic=942926.0
http://roikjer.com/forum/index.php?PHPSESSID=a4772r7m1jcv9u4jcaijoilvo2&topic=791728.0
http://HyUa.1fps.icu/l/szIaeDC
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=6495.0
https://sanp.pro/%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5%d0%bd%d0%b8%d0%b5-vuslat-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-t3-%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd/
http://www.quattroandpartners.it/component/k2/itemlist/user/981823
http://www.original-craft.net/index.php?topic=294307.0
https://members.fbhaters.com/index.php?topic=58174.0
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tqh-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=276539
https://forums.letstalkbeats.com/index.php?topic=56986.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=250112
http://healthyteethpa.org/component/k2/itemlist/user/5268117
https://tg.vl-mp.com/index.php?topic=1262760.0
http://danielmillsap.com/forum/index.php?topic=931583.0
http://www.spazioad.com/?option=com_k2&view=itemlist&task=user&id=7208655
http://dev.aabn.org.gh/component/k2/itemlist/user/492942
https://npi.org.es/smf/index.php?topic=108107.0
http://marjorieaperry.com/?option=com_k2&view=itemlist&task=user&id=474964
http://www.tvmechanic.co.in/forum/index.php?topic=7862.0
http://macdistri.com/index.php/component/k2/itemlist/user/259595
http://wb.hvekorat.com/index.php?topic=40144.0
http://www.aloeverasas.it/?option=com_k2&view=itemlist&task=user&id=16707
https://forum.ac-jete.it/index.php?topic=309089.0
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/181552
http://healthyteethpa.org/component/k2/itemlist/user/5274919
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/191169
http://www.nomaher.com/forum/index.php?topic=10130.0
https://www.resproxy.com/forum/index.php/741200-zvonar-19-seria-online-dhn-zvonar-19-seria-03052019/0
http://dpmarketingsystems.com/hd-video-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
https://chromehearts.in.th/index.php?topic=39928.0
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1132492
http://associationsila.org/component/k2/itemlist/user/271378
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/437011
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81-25/
http://www.m1avio.com/?option=com_k2&view=itemlist&task=user&id=3600193
http://withinfp.sakura.ne.jp/eso/index.php/16797769-tola-robot-9-seria-1-seria-da-tola-robot-9-seria-1-seria/0
http://married.dike.gr/index.php/component/k2/itemlist/user/35729
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=254916
http://proxima.co.rw/index.php/component/k2/itemlist/user/546859
http://153.120.114.241/eso/index.php/16862157-manifest-19-seria-puj-manifest-19-seria
https://www.resproxy.com/forum/index.php/742284-milliardy-4-sezon-13-seria-hbg-milliardy-4-sezon-13-seria-04052
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1005320
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/267063
http://mediaville.me/index.php/component/k2/itemlist/user/194966
http://married.dike.gr/index.php/component/k2/itemlist/user/37731
http://married.dike.gr/index.php/component/k2/itemlist/user/37769
http://married.dike.gr/index.php/component/k2/itemlist/user/37798
http://married.dike.gr/index.php/component/k2/itemlist/user/37806
http://married.dike.gr/index.php/component/k2/itemlist/user/37871
http://married.dike.gr/index.php/component/k2/itemlist/user/37882
http://married.dike.gr/index.php/component/k2/itemlist/user/37924
http://married.dike.gr/index.php/component/k2/itemlist/user/37940
http://arunagreen.com/index.php/component/k2/itemlist/user/427139
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=39609
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1669144
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=296181
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/458861
http://macdistri.com/index.php/component/k2/itemlist/user/269874
https://tg.vl-mp.com/index.php?topic=1283048.0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/53156
https://tg.vl-mp.com/index.php?topic=1285631.0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=533299
http://www.spazioad.com/component/k2/itemlist/user/7209676
http://www.m1avio.com/index.php/component/k2/itemlist/user/3555560
http://mediaville.me/index.php/component/k2/itemlist/user/195234
http://married.dike.gr/index.php/component/k2/itemlist/user/39214
http://danielmillsap.com/forum/index.php?topic=904708.0
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=43236
http://153.120.114.241/eso/index.php/16880213-lubov-smert-i-roboty-love-death-and-robots-8-seria-wqs-lubov-sm
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=711276
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4706974
http://www.m1avio.com/index.php/component/k2/itemlist/user/3599105
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3297761
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=28852
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/41788
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=263612
http://danielmillsap.com/forum/index.php?topic=869102.0
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/534699
https://members.fbhaters.com/index.php?topic=60333.0
http://seoksoononly.dothome.co.kr/qna/629243
http://www.spazioad.com/?option=com_k2&view=itemlist&task=user&id=7172004
https://www.swiss-focus.ch/index.php/component/k2/itemlist/user/9119
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1606732
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=9291
http://metropolis.ga/index.php?topic=2086.0
http://healthyteethpa.org/component/k2/itemlist/user/5281772
http://healthyteethpa.org/component/k2/itemlist/user/5276656
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=14047
http://seoksoononly.dothome.co.kr/qna/640098
http://webp.online/index.php?topic=42077.0
http://withinfp.sakura.ne.jp/eso/index.php/16768626-cernoe-zerkalo-5-sezon-4-seria-jzk-cernoe-zerkalo-5-sezon-4-ser/0
http://www.deliberarchia.org/forum/index.php?topic=958258.0
https://www.resproxy.com/forum/index.php/726140-tola-robot-9-seria-serial-aktery-i-roli-ty-tola-robot-9-seria-s/0
https://www.wikisexguide.com/wiki/%C2%AB%D0%91%D0%BE%D0%BB%D1%8C%D1%88%D0%BE%D0%B5_%D0%9F%D1%83%D1%82%D0%B5%D1%88%D0%B5%D1%81%D1%82%D0%B2%D0%B8%D0%B5%C2%BB_06-05-2019_%22%D0%91%D0%BE%D0%BB%D1%8C%D1%88%D0%BE%D0%B5_%D0%9F%D1%83%D1%82%D0%B5%D1%88%D0%B5%D1%81%D1%82%D0%B2%D0%B8%D0%B5%22_%C2%AB%D0%91%D0%BE%D0%BB%D1%8C%D1%88%D0%BE%D0%B5_%D0%9F%D1%83%D1%82%D0%B5%D1%88%D0%B5%D1%81%D1%82%D0%B2%D0%B8%D0%B5%C2%BB
http://menulisilmiah.net/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hot-%d0%b8%d0%b3%d1%80%d0%b0/
http://153.120.114.241/eso/index.php/16872234-igra-prestolov-8-sezon-1-seria-yvn-igra-prestolov-8-sezon-1-ser
http://israengineering.com/index.php/component/k2/itemlist/user/1083548
https://tg.vl-mp.com/index.php?topic=1256781.0
http://rudraautomation.com/index.php/component/k2/author/108574
https://www.youngbiker.de/wbboard/index.php?page=User&userID=784850
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=699722
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=280874
http://web2interactive.com/index.php/component/k2/itemlist/user/3529839
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gwx-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.deliberarchia.org/forum/index.php?topic=951512.0
http://www.deliberarchia.org/forum/index.php?topic=938769.0
http://dev.aabn.org.gh/component/k2/itemlist/user/484011
https://tg.vl-mp.com/index.php?topic=1259096.0
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=566346
http://boutique.in.th/?option=com_k2&view=itemlist&task=user&id=146005
http://www.comfybigsize.com/?option=com_k2&view=itemlist&task=user&id=17991
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1313687
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1128869
http://www.m1avio.com/index.php/component/k2/itemlist/user/3580138
http://www.moyakmermer.com/?option=com_k2&view=itemlist&task=user&id=645769
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=295716
http://mvisage.sk/index.php/component/k2/itemlist/user/116940
http://withinfp.sakura.ne.jp/eso/index.php/16773920-nasledie-12-seria-tbh-nasledie-12-seria
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/245322
http://withinfp.sakura.ne.jp/eso/index.php/16810285-vetrenyj-hercai-19-seria-o6dp-vetrenyj-hercai-19-seria/0
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1005071
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1836095
https://www.youngbiker.de/wbboard/index.php?page=User&userID=781420
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1130168
http://married.dike.gr/index.php/component/k2/itemlist/user/39563
http://proxima.co.rw/index.php/component/k2/itemlist/user/547582
http://withinfp.sakura.ne.jp/eso/index.php/16776243-milliardy-4-sezon-7-seria-xyy-milliardy-4-sezon-7-seria-0105201
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2522635
http://www.arredoufficiomarca.com/index.php/component/k2/itemlist/user/1551691
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3561404
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=549173
http://smartacity.com/component/k2/itemlist/user/11862
http://www.m1avio.com/?option=com_k2&view=itemlist&task=user&id=3584595
http://www.crnmedia.es/component/k2/itemlist/user/83153
http://proxima.co.rw/index.php/component/k2/itemlist/user/542213
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/48550
http://zsmr.com.ua/index.php/component/k2/itemlist/user/493194
https://lucky28003.nl/forum/index.php?topic=8060.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3274606
http://www.m1avio.com/index.php/component/k2/itemlist/user/3600531
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2388013
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/48078
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4680193
https://tg.vl-mp.com/index.php?topic=1263135.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/287475
http://healthyteethpa.org/component/k2/itemlist/user/5291658
http://www.moyakmermer.com/?option=com_k2&view=itemlist&task=user&id=610757
https://www.youngbiker.de/wbboard/index.php?page=User&userID=780902
http://proxima.co.rw/index.php/component/k2/itemlist/user/565438
http://mediaville.me/index.php/component/k2/itemlist/user/214310
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1605843
http://thermoplast.envolgroupe.com/component/k2/author/68202
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1107741
http://dessa.com.br/component/k2/itemlist/user/290833
http://dessa.com.br/component/k2/itemlist/user/299640
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1551111
https://nextezone.com/index.php?topic=31549.0
https://nextezone.com/index.php?topic=31571.0
https://nextezone.com/index.php?topic=31578.0
https://nextezone.com/index.php?topic=31632.0
https://nextezone.com/index.php?topic=31641.0
https://nextezone.com/index.php?topic=31656.0
https://nextezone.com/index.php?topic=31664.0
https://nextezone.com/index.php?topic=31698.0
https://nextezone.com/index.php?topic=31723.0
https://nextezone.com/index.php?topic=31737.0
https://nextezone.com/index.php?topic=31749.0
https://nextezone.com/index.php?topic=31755.0
https://nextezone.com/index.php?topic=31772.0
https://nextezone.com/index.php?topic=31798.0
https://nextezone.com/index.php?topic=31894.0
https://nextezone.com/index.php?topic=31898.0
https://nextezone.com/index.php?topic=31902.0
https://nextezone.com/index.php?topic=31943.0
https://nextezone.com/index.php?topic=31956.0
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2554521
http://bobr.site/index.php?topic=88158.0
https://szenarist.ru/forum/index.php?topic=201824.0
http://poselokgribovo.ru/forum/index.php?topic=701777.0
http://ru-realty.com/forum/index.php?PHPSESSID=n0fqv781dbiobro1onct8r97u1&topic=456851.0
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3558952
http://miklja.net/forum/index.php?topic=25592.0
http://withinfp.sakura.ne.jp/eso/index.php/16865628-ertugrul-148-seria-gx8-ertugrul-148-seria/0
https://danceplanet.se/commodore/index.php?topic=9525.0
http://myrechockey.com/forums/index.php?topic=82338.0
http://kurnaz.1to.us/index.php?topic=1.210
http://www.hoonthaitoday.com/forum/index.php?topic=150158.0
http://freebeer.me/index.php?topic=291797.0
http://eugeniocolazzo.it/forum/index.php?topic=85123.0
http://HyUa.1fps.icu/l/szIaeDC
https://npi.org.es/smf/index.php?topic=110961.0
https://npi.org.es/smf/index.php?topic=110967.0
https://npi.org.es/smf/index.php?topic=110975.0
https://npi.org.es/smf/index.php?topic=111002.0
https://npi.org.es/smf/index.php?topic=111005.0
https://npi.org.es/smf/index.php?topic=111016.0
https://npi.org.es/smf/index.php?topic=111068.0
https://npi.org.es/smf/index.php?topic=111087.0
https://npi.org.es/smf/index.php?topic=111088.0
https://npi.org.es/smf/index.php?topic=111089.0
http://www.tessabannampad.go.th/webboard/index.php?topic=183900.0
http://153.120.114.241/eso/index.php/16862498-igra-prestolovgame-of-thrones-8-sezon-1-seria-igra-prestolovgam
http://vtservices85.fr/smf2/index.php?PHPSESSID=2c322bea1f233355297c535f0416bdf3&topic=203315.0
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90vt0%e3%80%91-%d0%b8%d0%b3/
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p5-i4-%d0%b8%d0%b3%d1%80/
http://www.critico-expository.com/forum/index.php?topic=1966.0
http://bobr.site/index.php?topic=84352.0
http://www.remify.app/foro/index.php?topic=211944.0
http://forum.politeknikgihon.ac.id/index.php?topic=11735.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1327177
http://forum.digamahost.com/index.php?topic=108276.0
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3697333
http://www.remify.app/foro/index.php?topic=210345.0
http://poselokgribovo.ru/forum/index.php?topic=710295.0
http://HyUa.1fps.icu/l/szIaeDC
https://reficulcoin.com/index.php?topic=4588.0
https://reficulcoin.com/index.php?topic=4689.0
https://reficulcoin.com/index.php?topic=4704.0
https://reficulcoin.com/index.php?topic=4711.0
https://reficulcoin.com/index.php?topic=4732.0
https://reficulcoin.com/index.php?topic=4744.0
https://reficulcoin.com/index.php?topic=4749.0
https://reficulcoin.com/index.php?topic=4780.0
https://reficulcoin.com/index.php?topic=4789.0
https://reficulcoin.com/index.php?topic=4805.0
https://reficulcoin.com/index.php?topic=4820.0
https://reficulcoin.com/index.php?topic=4824.0
https://reficulcoin.com/index.php?topic=4834.0
https://reficulcoin.com/index.php?topic=4836.0
https://reficulcoin.com/index.php?topic=4846.0
https://reficulcoin.com/index.php?topic=4866.0
https://reficulcoin.com/index.php?topic=4884.0
https://reficulcoin.com/index.php?topic=4889.0
https://reficulcoin.com/index.php?topic=4904.0
https://reficulcoin.com/index.php?topic=4906.0
https://reficulcoin.com/index.php?topic=4914.0
https://reficulcoin.com/index.php?topic=4929.0
https://reficulcoin.com/index.php?topic=4930.0
http://muonlineint.com/forum/index.php?topic=483.0
http://forum.kopkargobel.com/index.php?topic=2955.0
http://poselokgribovo.ru/forum/index.php?topic=710206.0
http://metropolis.ga/index.php?topic=2881.0
http://yuptalk.ru/other_food_household_cosmetics_etc/-t12936.0.html
http://roikjer.com/forum/index.php?topic=807388.0
http://sextomariotienda.com/blog/%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q8-%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5/
http://forum.elexlabs.com/index.php?topic=13021.0
http://fbpharm.net/index.php/component/k2/itemlist/user/14509
http://freebeer.me/index.php?topic=287489.0
http://roikjer.com/forum/index.php?PHPSESSID=46f736u00r3khlvpvgll02f7c5&topic=802418.0
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e2-u4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://poselokgribovo.ru/forum/index.php?topic=695723.0
http://withinfp.sakura.ne.jp/eso/index.php/16866863-ertugrul-146-seria-ng0-ertugrul-146-seria/0
http://matrixpharm.ru/forum/index.php?action=profile&u=159329
http://danielmillsap.com/forum/index.php?topic=943844.0
http://withinfp.sakura.ne.jp/eso/index.php/16866730-podsudimyj-16-seria-o1-podsudimyj-16-seria
http://codeerror.in/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-i9-v6-%d0%b8/
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90rc8%e3%80%91/
http://forum.politeknikgihon.ac.id/index.php?topic=17812.0
http://withinfp.sakura.ne.jp/eso/index.php/16841652-04052019-devat-ziznej-12-seria/0
https://adsensebih.com/index.php?topic=8190.0
http://poselokgribovo.ru/forum/index.php?topic=712729.0
http://danielmillsap.com/forum/index.php?topic=938856.0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5-27/
http://HyUa.1fps.icu/l/szIaeDC
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90zs5%e3%80%91/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90ay2%e3%80%91/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90ee7%e3%80%91/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90eh3%e3%80%91/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90fr1%e3%80%91/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90gj2%e3%80%91/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90kb7%e3%80%91/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90kq2%e3%80%91/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90lh9%e3%80%91/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90ls2%e3%80%91/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90lv8%e3%80%91/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90mk3%e3%80%91/
http://www.hoonthaitoday.com/forum/index.php?topic=150655.0
https://reficulcoin.com/index.php?topic=9171.0
http://teambuildingpremium.com/forum/index.php?topic=753751.0
https://www.amazingworldtop.com/entretenimiento/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o6-e0-%d1%80%d0%b0%d1%81%d1%81/
http://ovotecegg.com/component/k2/itemlist/user/113987
http://taklongclub.com/forum/index.php?topic=89792.0
http://golyboe.ru/forum/index.php?topic=24743.0
http://e-educ.net/Forum/index.php?topic=3306.0
http://1vh.info/index.php?topic=10132.0
http://poselokgribovo.ru/forum/index.php?topic=700508.0
http://forum.politeknikgihon.ac.id/index.php?topic=13339.0
http://poselokgribovo.ru/forum/index.php?topic=689043.0
http://forum.kopkargobel.com/index.php?topic=2509.0
http://freebeer.me/index.php?topic=282811.0
http://poselokgribovo.ru/forum/index.php?topic=697196.0
https://www.amazingworldtop.com/entretenimiento/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-i9-u8-%d1%80/
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=601979
http://HyUa.1fps.icu/l/szIaeDC
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90eq0%e3%80%91-%d0%b8/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90ey4%e3%80%91-%d0%b8/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90jk7%e3%80%91-%d0%b8%d0%b3/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90wt9%e3%80%91-%d0%b8%d0%b3/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90ae5%e3%80%91-%d0%b8%d0%b3/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90is4%e3%80%91-%d0%b8%d0%b3/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90kn8%e3%80%91-%d0%b8%d0%b3/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90lw6%e3%80%91-%d0%b8%d0%b3/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90mc2%e3%80%91-%d0%b8%d0%b3/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90tv6%e3%80%91-%d0%b8%d0%b3/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90wv5%e3%80%91-%d0%b8%d0%b3/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90ww2%e3%80%91-%d0%b8%d0%b3/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90xm5%e3%80%91-%d0%b8/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90xq3%e3%80%91-%d0%b8%d0%b3/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90ci2%e3%80%91-%d0%b8%d0%b3/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90do4%e3%80%91-%d0%b8%d0%b3/
http://www.aloeverasas.it/?option=com_k2&view=itemlist&task=user&id=17529
http://www.deliberarchia.org/forum/index.php?topic=943023.0
https://sanp.pro/04-05-2019-%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0%d1%8f-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b0-%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be%d0%b1%d0%be%d1%82%d0%b0-21/
http://wituclub.ru/forum/index.php?PHPSESSID=0dqo8lv84h22of345n98ijfh86&topic=24906.0
http://uberdrivers.net/forum/index.php?topic=215833.0
http://forum.politeknikgihon.ac.id/index.php?topic=14526.0
http://storykingdom.forumside.com/index.php?topic=3825.0
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i8-c4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://www.critico-expository.com/forum/index.php?topic=1750.0
http://metropolis.ga/index.php?topic=2845.0
http://forum.stollen24.com/index.php?topic=3235.0
http://eugeniocolazzo.it/forum/index.php?topic=83512.0
http://www.deliberarchia.org/forum/index.php?topic=952672.0
http://otitismediasociety.org/forum/index.php?topic=143174.0
http://forum.politeknikgihon.ac.id/index.php?topic=14535.0
https://members.fbhaters.com/index.php?topic=70733.0
http://HyUa.1fps.icu/l/szIaeDC
https://lucky28003.nl/forum/index.php?topic=9287.0
https://lucky28003.nl/forum/index.php?topic=9300.0
https://lucky28003.nl/forum/index.php?topic=9505.0
https://lucky28003.nl/forum/index.php?topic=9519.0
https://lucky28003.nl/forum/index.php?topic=9548.0
https://lucky28003.nl/forum/index.php?topic=9551.0
https://lucky28003.nl/forum/index.php?topic=9560.0
https://lucky28003.nl/forum/index.php?topic=9569.0
https://lucky28003.nl/forum/index.php?topic=9578.0
https://lucky28003.nl/forum/index.php?topic=9593.0
https://lucky28003.nl/forum/index.php?topic=9603.0
https://lucky28003.nl/forum/index.php?topic=9610.0
https://lucky28003.nl/forum/index.php?topic=9643.0
https://lucky28003.nl/forum/index.php?topic=9661.0
http://www.tekparcahdfilm.com/forum/index.php?topic=45138.0
http://www.theparrotcentre.com/forum/index.php?topic=454033.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=99677761c7ed1da178842a2ffa12dce9&topic=205447.0
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=162033
http://ruschinaforum.ru/index.php/topic,125822.0.html
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=677254.0
http://miklja.net/forum/index.php?topic=24433.0
https://www.thedezlab.com/lab/community/index.php?topic=80.0
http://www.tessabannampad.go.th/webboard/index.php?topic=188153.0
http://www.tessabannampad.go.th/webboard/index.php?topic=187565.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=673655.0
https://tg.vl-mp.com/index.php?topic=1313550.0
http://forum.politeknikgihon.ac.id/index.php?topic=20018.0
http://HyUa.1fps.icu/l/szIaeDC
http://uberdrivers.net/forum/index.php?topic=202407.0
http://roikjer.com/forum/index.php?PHPSESSID=hck6il5qa0lehr28bgjfgbo916&topic=754208.0
http://www.udlafrica.org/app/node/515705
http://www.atab.com.sa/?option=com_k2&view=itemlist&task=user&id=1498104
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1597382
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/215834
http://forums.abs-cbn.com/welcome-back-kapamilya%21/(a-etoo-(got)-8-eo-6-e)-a-etoo-(got)-8-eo-6-e-f3d1/?PHPSESSID=oadqt0msqlmeauk6lojdo93587
http://uberdrivers.net/forum/index.php?topic=219685.0
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1545260
http://otitismediasociety.org/forum/index.php?topic=141632.0
http://poselokgribovo.ru/forum/index.php?topic=692500.0
http://blog.ptpintcast.com/%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0%d1%8f-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b0-%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be%d0%b1%d0%be%d1%82%d0%b0-16-%d1%81%d0%b5-5/
https://khuyenmaikk13.info/index.php?topic=174427.0
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-12/
http://poselokgribovo.ru/forum/index.php?topic=689043.0
http://danielmillsap.com/forum/index.php?topic=937746.0
https://reficulcoin.com/index.php?topic=4775.0
http://menulisilmiah.net/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90iq4%e3%80%91-%d0%b8%d0%b3/
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=283980
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=255186
http://sextomariotienda.com/blog/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-05-05-2019-%e3%80%90pt%e3%80%91-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5/
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/263131
http://forum.stollen24.com/index.php/topic,2527.0.html
http://www2.yasothon.go.th/smf/index.php?topic=159.153285
http://ts.bloodhand.de/forum/viewtopic.php?t=198680
http://www.deliberarchia.org/forum/index.php?topic=957850.0
https://www.mutlualisverisler.com/?p=978359
http://smartacity.com/component/k2/itemlist/user/13633
http://dcasociados.eu/component/k2/itemlist/user/85100
http://teambuildingpremium.com/forum/index.php?topic=766163.0
http://thefreebitcoin.com/index.php?topic=37667.0
http://dev.aabn.org.gh/component/k2/itemlist/user/465555
http://thanosakademi.com/index.php?topic=59131.0
https://ne-kuru.ru/index.php?topic=211983.0
http://dpmarketingsystems.com/%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be%d0%b1%d0%be%d1%82%d0%b0-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-oby-%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be/
https://danceplanet.se/commodore/index.php?topic=11273.0
https://tg.vl-mp.com/index.php?topic=1324386.0
http://www.popolsku.fr.pl/forum/index.php?topic=372098.0
http://teambuildingpremium.com/forum/index.php?topic=761031.0
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2568465
http://macdistri.com/index.php/component/k2/itemlist/user/267467
http://poselokgribovo.ru/forum/index.php?topic=677194.0
http://1vh.info/index.php?topic=9698.0
http://www.oortsociety.com/index.php?topic=10637.0
http://eugeniocolazzo.it/forum/index.php?topic=87162.0
http://matrixpharm.ru/forum/index.php?action=profile&u=157518
http://proxima.co.rw/index.php/component/k2/itemlist/user/553085
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7286137
http://www.phan-aen.go.th/forum/index.php?topic=623654.0
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=714819
http://teambuildingpremium.com/forum/index.php?topic=714648.0
http://soc-human.kz/index.php/component/k2/itemlist/user/1600477
http://www.remify.app/foro/index.php?topic=165169.0
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1832161
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=24926.0
http://withinfp.sakura.ne.jp/eso/index.php/16761349-holostak-9-sezon-12-vypusk-watch-t5-holostak-9-sezon-12-vypusk-/0
http://teambuildingpremium.com/forum/index.php?topic=738700.0
http://uberdrivers.net/forum/index.php?topic=176241.0
http://poselokgribovo.ru/forum/index.php?topic=657932.0
http://www.nomaher.com/forum/index.php?topic=10885.0
http://forum.byehaj.hu/index.php?topic=71970.0
http://poselokgribovo.ru/forum/index.php?topic=646658.0
http://withinfp.sakura.ne.jp/eso/index.php/16769405-rannaa-ptaska-erkenci-kus-40-seria-online-v1-rannaa-ptaska-erke
http://www.remify.app/foro/index.php?topic=196183.0
http://rudraautomation.com/index.php/component/k2/author/91555
http://poselokgribovo.ru/forum/index.php?topic=681154.0
http://poselokgribovo.ru/forum/index.php?topic=647741.0
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=160713
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3542874
http://ruschinaforum.ru/index.php?topic=122410.0
http://www.theparrotcentre.com/forum/index.php?topic=440869.0
http://www.theparrotcentre.com/forum/index.php?topic=452747.0
http://www.gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1835312
https://forums.letstalkbeats.com/index.php?topic=48570.0
https://tg.vl-mp.com/index.php?topic=1253941.0
http://multikopterforum.hu/index.php?topic=10911.0
http://withinfp.sakura.ne.jp/eso/index.php/16863930-nikogda-ne-govori-nikogda-7-seria-05052019-w7-nikogda-ne-govori
http://multikopterforum.hu/index.php?topic=9710.0
http://miquirofisico.com/index.php/component/k2/itemlist/user/3708
http://www.theparrotcentre.com/forum/index.php?topic=429789.0
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1861349
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3363995
http://salescoach.ro/content/%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-10-%D0%B2%D1%8B%D0%BF%D1%83%D1%81%D0%BA-%D0%BA%D1%82%D0%BE-%D0%BF%D0%BE%D0%BA%D0%B8%D0%BD%D1%83%D0%BB-%D1%88%D0%BE%D1%83%C2%BB-db%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-10-%D0%B2%D1%8B%D0%BF%D1%83%D1%81%D0%BA-%D0%BA%D1%82%D0%BE-%D0%BF%D0%BE%D0%BA%D0%B8%D0%BD%D1%83%D0%BB-%D1%88%D0%BE%D1%83
https://szenarist.ru/forum/index.php?topic=204342.0
http://thermoplast.envolgroupe.com/index.php/component/k2/itemlist/user/65599
http://blog.ptpintcast.com/05-05-2019-%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://codeerror.in/%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w0-%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-10-%d1%81%d0%b5%d1%80/
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2562836
https://nextezone.com/index.php?topic=33843.0
https://www.regalepadova.it/index.php/component/k2/itemlist/user/5859
http://www.remify.app/foro/index.php?topic=199762.0
https://members.fbhaters.com/index.php/topic,67052.0.html
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1331956
http://multikopterforum.hu/index.php?topic=3248.0
http://seoksoononly.dothome.co.kr/qna/657112
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=263192
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lod-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=42375
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1609662
http://sextomariotienda.com/blog/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-05-05-2019-%e3%80%90by%e3%80%91-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7/
http://forum.politeknikgihon.ac.id/index.php?topic=9682.0
http://forum.stollen24.com/index.php?topic=2658.0
http://roikjer.com/forum/index.php?PHPSESSID=31s05iv24qr7kdinq7o8cimtr3&topic=787106.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/438917
https://sanp.pro/%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-71-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x7-%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-71-%d1%81%d0%b5%d1%80/
http://roikjer.com/forum/index.php?topic=771494.0
http://www.deliberarchia.org/forum/index.php?topic=956172.0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=546766
https://forum.shaiyaslayer.tk/index.php?topic=78732.0
http://taklongclub.com/forum/index.php?topic=89870.0
https://sanp.pro/%d0%b0%d0%b3%d0%b5%d0%bd%d1%82%d1%8b-%d1%89%d0%b8%d1%82-6-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90rlws%e3%80%91-%d0%b0%d0%b3%d0%b5%d0%bd%d1%82/
http://vtservices85.fr/smf2/index.php?PHPSESSID=9eb86219957309d618ecdc454e7ef688&topic=208902.0
http://www.rocktheboat.cc/groups/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d1%86%d0%b5%d1%80%d0%b5%d0%bc%d0%be%d0%bd%d0%b8%d1%8f-pm/
https://tg.vl-mp.com/index.php?topic=1285081.0
https://nextezone.com/index.php?action=profile;u=872
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yf5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://www.deliberarchia.org/forum/index.php?topic=928507.0
http://www.deliberarchia.org/forum/index.php?topic=958106.0
http://forum.politeknikgihon.ac.id/index.php?topic=11874.0
https://www.resproxy.com/forum/index.php/752727-ertugrul-5-sezon-146-seria-anons-zg0-ertugrul-5-sezon-146-seria/0
http://batubersurat.com/index.php/component/k2/itemlist/user/38979
https://khuyenmaikk13.info/index.php?topic=176736.0
http://roikjer.com/forum/index.php?topic=782830.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/168607
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=287131
http://www.ekemoon.com/139767/050020194605/
https://www.gizmoarticle.com/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-p2-%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5/
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a5-%d0%b8%d0%b3%d1%80%d0%b0/
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3539690
http://teambuildingpremium.com/forum/index.php?topic=713282.0
http://freebeer.me/index.php?topic=263528.0
http://myrechockey.com/forums/index.php?topic=81010.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=e431a9aaf81d5387fe795f587f20fa7b&topic=195534.0
http://www.spazioad.com/?option=com_k2&view=itemlist&task=user&id=7177212
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=a4679b15a19af97af2097d30861c17ff&topic=120.0
http://danielmillsap.com/forum/index.php?topic=912469.0
http://www.original-craft.net/index.php?topic=301186.0
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=103051
http://macdistri.com/index.php/component/k2/itemlist/user/255074
http://www.deliberarchia.org/forum/index.php?topic=924470.0
http://matrixpharm.ru/forum/index.php?action=profile&u=149660
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3293852
http://www.deliberarchia.org/forum/index.php?topic=908819.0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=521431
https://www.c-alice.org/forum/index.php?topic=68343.0
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=185695
http://matrixpharm.ru/forum/index.php?action=profile&u=149823
http://teambuildingpremium.com/forum/index.php?topic=712342.0
http://sextomariotienda.com/blog/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-vlk-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://matrixpharm.ru/forum/index.php?PHPSESSID=s0173tjnpumqeam1qpq6dk12p4&action=profile;u=150095
http://roikjer.com/forum/index.php?topic=786909.0
http://islamiccall.info/?option=com_k2&view=itemlist&task=user&id=852978
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2561859
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-taka-(erkenci-kus)-43-e-online'-q6(-a-taka-(erkenci-kus)-43-e/msg541429/
https://forums.letstalkbeats.com/index.php?topic=49585.0
http://withinfp.sakura.ne.jp/eso/index.php/16765975-vossoedinenie-vuslat-15-seria-h3-vossoedinenie-vuslat-15-seria
http://married.dike.gr/index.php/component/k2/itemlist/user/39769
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=145953
http://associationsila.org/component/k2/itemlist/user/274133
http://www.original-craft.net/index.php?topic=295684.0
http://www.tessabannampad.go.th/webboard/index.php?topic=176867.0
https://www.resproxy.com/forum/index.php/724746-akter-seriala-tola-robot-na-tnt-2-1-seria-akter-seriala-tola-ro/0
http://seoksoononly.dothome.co.kr/qna/635348
https://www.shoppidlok.com/smf/index.php?topic=165.0
http://dpmarketingsystems.com/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ham-%d0%b2%d0%be%d1%81%d0%ba/
https://khuyenmaikk13.info/index.php?topic=151710.0
http://socialfbwidgets.com/component/k2/itemlist/user/11132.html
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/450435
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=1925
http://dpmarketingsystems.com/%d0%b6%d0%b5%d0%bd%d1%89%d0%b8%d0%bd%d0%b0-56-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-o1-%d0%b6%d0%b5%d0%bd%d1%89%d0%b8%d0%bd%d0%b0-56-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch/
https://www.shaiyax.com/index.php?topic=327835.0
https://tg.vl-mp.com/index.php?topic=1306872.0
http://forum.politeknikgihon.ac.id/index.php?topic=19209.0
http://ru-realty.com/forum/index.php?PHPSESSID=87f0ph2ue33v4aatg3ukql6001&topic=456448.0
https://danceplanet.se/commodore/index.php?topic=11636.0
http://www.popolsku.fr.pl/forum/index.php?topic=20407.44835
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=602178
http://poselokgribovo.ru/forum/index.php?topic=708712.0
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3704376
http://www.deliberarchia.org/forum/index.php?topic=944147.0
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1126887
http://roikjer.com/forum/index.php?PHPSESSID=1mcmvne1ansrnjuq6sro80rci3&topic=783742.0
http://forum.politeknikgihon.ac.id/index.php?topic=17027.0
https://mcsetup.tk/bbs/index.php?topic=242095.0
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1840113
http://www.deliberarchia.org/forum/index.php?topic=931328.0
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2520213
http://withinfp.sakura.ne.jp/eso/index.php/16791613-vetrenyj-hercai-19-seria-h1nz-vetrenyj-hercai-19-seria/0
http://macdistri.com/index.php/component/k2/itemlist/user/265368
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=163573
http://married.dike.gr/index.php/component/k2/itemlist/user/35475
https://www.regalepadova.it/index.php/component/k2/itemlist/user/6049
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=50008
http://theolevolosproject.org/index.php/component/k2/itemlist/user/23158
http://c3isecurity.com.br/?option=com_k2&view=itemlist&task=user&id=465191
http://www.sopcich.com/UserProfile/tabid/42/UserID/1754467/Default.aspx
http://www.critico-expository.com/forum/index.php?topic=1014.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2523234
http://teambuildingpremium.com/forum/index.php?topic=711720.0
http://teambuildingpremium.com/forum/index.php?topic=754221.0
http://menulisilmiah.net/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-doh-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://poselokgribovo.ru/forum/index.php?topic=647240.0
http://www.hoonthaitoday.com/forum/index.php?topic=95208.0
https://khuyenmaikk13.info/index.php?topic=150378.0
http://roikjer.com/forum/index.php?PHPSESSID=qh8ptemabdn4ehqtip2iu8k2s7&topic=764325.0
http://menulisilmiah.net/tv-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://www.remify.app/foro/index.php?topic=167901.0
http://roikjer.com/forum/index.php?PHPSESSID=6mboekgp1lle3frpu6c1lgov60&topic=774592.0
http://dpmarketingsystems.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-vlo-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dgo-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://www2.yasothon.go.th/smf/index.php?topic=159.149445
http://forum.byehaj.hu/index.php?topic=73338.0
http://www.remify.app/foro/index.php?topic=193066.0
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/191785
http://www.m1avio.com/index.php/component/k2/itemlist/user/3594524
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=157946
http://sdsn.develop.cinfores.com/?option=com_k2&view=itemlist&task=user&id=171456
http://metropolis.ga/index.php?topic=2842.0
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=37022
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=564502
https://tg.vl-mp.com/index.php?topic=1294051.0
http://www.deliberarchia.org/forum/index.php?topic=955233.0
http://www.deliberarchia.org/forum/index.php?topic=922866.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1298942
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=894514
https://tg.vl-mp.com/index.php?topic=1324019.0
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1108758
http://healthyteethpa.org/component/k2/itemlist/user/5302387
http://withinfp.sakura.ne.jp/eso/index.php/16798061-tola-robot-6-seria-aktery-i-roli-kh-tola-robot-6-seria-aktery-i/0
http://153.120.114.241/eso/index.php/16813233-igra-prestolov-8-sezon-8-seria-xbg-igra-prestolov-8-sezon-8-ser
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81-33/
http://www.arunagreen.com/index.php/component/k2/itemlist/user/407299
http://www.deliberarchia.org/forum/index.php?topic=895767.0
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=203264
http://dev.aabn.org.gh/component/k2/itemlist/user/485732
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1858296
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/147662
http://matinbank.ir/component/k2/itemlist/user/4482678.html
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/52627
http://metropolis.ga/index.php?topic=2491.0
https://tg.vl-mp.com/index.php?topic=1323459.0
https://tg.vl-mp.com/index.php?topic=1259996.0
http://healthyteethpa.org/component/k2/itemlist/user/5302103
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1758290
http://withinfp.sakura.ne.jp/eso/index.php/16778222-cernoe-zerkalo-5-sezon-4-seria-ibr-cernoe-zerkalo-5-sezon-4-ser/0
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=39616
http://danielmillsap.com/forum/index.php?topic=911158.0
https://www.resproxy.com/forum/index.php/770728-sverh-estestvennoe-14-sezon-18-seria-shy-sverh-estestvennoe-14-
http://healthyteethpa.org/component/k2/itemlist/user/5281648
http://withinfp.sakura.ne.jp/eso/index.php/16786989-nasledie-17-seria-njf-nasledie-17-seria
http://withinfp.sakura.ne.jp/eso/index.php/16787009-riverdejl-riverdale-3-sezon-21-seria-enr-riverdejl-riverdale-3-
http://withinfp.sakura.ne.jp/eso/index.php/16787106-lubov-smert-i-roboty-love-death-and-robots-1-seria-gve-lubov-sm
http://withinfp.sakura.ne.jp/eso/index.php/16787123-milliardy-4-sezon-5-seria-xfx-milliardy-4-sezon-5-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/16787260-lubov-smert-i-roboty-love-death-and-robots-12-seria-pxe-lubov-s/0
http://withinfp.sakura.ne.jp/eso/index.php/16787313-igra-prestolov-8-sezon-8-seria-uyp-igra-prestolov-8-sezon-8-ser/0
http://withinfp.sakura.ne.jp/eso/index.php/16787361-riverdejl-riverdale-3-sezon-22-seria-kgg-riverdejl-riverdale-3-/0
http://withinfp.sakura.ne.jp/eso/index.php/16787379-lubov-smert-i-roboty-love-death-and-robots-16-seria-nwf-lubov-s/0
http://withinfp.sakura.ne.jp/eso/index.php/16787397-milliardy-4-sezon-10-seria-rzq-milliardy-4-sezon-10-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/16787405-nasledie-13-seria-ahq-nasledie-13-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/16787411-milliardy-4-sezon-4-seria-ewa-milliardy-4-sezon-4-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/16787488-manifest-17-seria-qtu-manifest-17-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/16787491-nasledie-16-seria-qeo-nasledie-16-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/16787539-lubov-smert-i-roboty-love-death-and-robots-18-seria-zmx-lubov-s/0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2520404
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/187716
http://smartacity.com/component/k2/itemlist/user/18992
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1637351
http://thermoplast.envolgroupe.com/component/k2/author/71096
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=53550
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1346305
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1014233
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4839363
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2401697
https://forums.letstalkbeats.com/index.php?topic=50992.0
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=201932
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=246622
http://dpmarketingsystems.com/on-line-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f1-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://www.deliberarchia.org/forum/index.php?topic=946783.0
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1679428
http://uberdrivers.net/forum/index.php?topic=175855.0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=527824
http://blog.ptpintcast.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-w8-p4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
http://www.deliberarchia.org/forum/index.php?topic=958483.0
http://guiadetudo.com/index.php/component/k2/itemlist/user/10689
http://help.stv.ru/index.php?PHPSESSID=36843f8a424bf0cb1a8773a2b8985ff6&topic=136892.0
http://www.popolsku.fr.pl/forum/index.php?topic=370678.0
http://teambuildingpremium.com/forum/index.php?topic=753828.0
http://bobr.site/index.php?topic=81399.0
http://batubersurat.com/index.php/component/k2/itemlist/user/43461
https://khuyenmaikk13.info/index.php?topic=177910.0
https://tg.vl-mp.com/index.php?topic=1307984.0
http://associationsila.org/component/k2/itemlist/user/274361
https://reficulcoin.com/index.php?topic=9470.0
http://153.120.114.241/eso/index.php/16852254-igra-prestolov-got-8-sezon-5-seria-iz9-igra-prestolov-got-8-sez
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=24755.0
http://thanosakademi.com/index.php?topic=58941.0
https://tg.vl-mp.com/index.php?topic=1260526.0
http://www.studioaparo.it/?option=com_k2&view=itemlist&task=user&id=530990
http://forums.abs-cbn.com/welcome-back-kapamilya%21/eoe-ee-(tek-yurek)-13-e-eeoom-j4-eoe-ee-(tek-yurek)-13-e-hd-720/?PHPSESSID=5sfmjse69lqafve2jf0tgb8e12
https://reficulcoin.com/index.php?topic=7340.0
http://associationsila.org/index.php/component/k2/itemlist/user/262464
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=895706
http://myrechockey.com/forums/index.php?topic=80694.0
http://1vh.info/index.php?topic=8511.0
http://ru-realty.com/forum/index.php?PHPSESSID=qm429k52pk28gsn21rsq92ipq0&topic=440581.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3591377
http://erhu.eu/viewtopic.php?t=231902
http://dscardip.com/board/index.php?page=User&userID=651897
http://teambuildingpremium.com/forum/index.php?topic=741445.0
https://www.youngbiker.de/wbboard/index.php?page=User&userID=786074
http://dpmarketingsystems.com/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lue-%d0%b2%d0%be%d1%81%d0%ba/
http://mobility-corp.com/index.php/component/k2/itemlist/user/2480329
http://taklongclub.com/forum/index.php?topic=91472.0
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=195526
http://forum.politeknikgihon.ac.id/index.php?topic=378.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1072194
http://wituclub.ru/forum/index.php?PHPSESSID=jg5ol40jodj1ikj3v7o3559h35&topic=25105.0
http://molweb.ru/groups/ne-otpuskaj-moyu-ruku-elimi-birakma-35-seriya-mad-ne-otpuskaj-moyu-ruku-elimi-birakma-35-seriya/
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=41532
http://www.deliberarchia.org/forum/index.php?topic=934057.0
http://withinfp.sakura.ne.jp/eso/index.php/16762491-sluga-naroda-3-sezon-11-seria-g9-sluga-naroda-3-sezon-11-seria-/0
http://muratliziraatodasi.org/forum/index.php?topic=381202.0
https://danceplanet.se/commodore/index.php?topic=11273.0
https://tg.vl-mp.com/index.php?topic=1324386.0
http://www.popolsku.fr.pl/forum/index.php?topic=372098.0
http://teambuildingpremium.com/forum/index.php?topic=761031.0
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2568465
http://153.120.114.241/eso/index.php/16860805-holostak-9-sezon-10-vypusk-1-cast-ahholostak-9-sezon-10-vypusk-
http://community.viajar.tur.br/index.php?p=/profile/tammierepa
https://sanp.pro/%d1%87%d1%91%d1%80%d0%bd%d1%8b%d0%b9-%d1%81%d0%bf%d0%b8%d1%81%d0%be%d0%ba-the-blacklist-6-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90ustz%e3%80%91/
http://poselokgribovo.ru/forum/index.php?topic=713315.0
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1126897
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=542188
http://www.arunagreen.com/index.php/component/k2/itemlist/user/398430
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=4311
http://danielmillsap.com/forum/index.php?topic=867370.0
http://www.hoonthaitoday.com/forum/index.php?topic=124053.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3272117
http://help.stv.ru/index.php?PHPSESSID=3e07ff5aaf854996471ebd2a8b317f56&topic=134877.0
https://www.resproxy.com/forum/index.php/741269-tola-robot-7-seria-03052019-wg-tola-robot-7-seria/0
https://www.resproxy.com/forum/index.php/731504-cernoe-zerkalo-5-sezon-4-seria-fph-cernoe-zerkalo-5-sezon-4-ser/0
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/146573
http://macdistri.com/index.php/component/k2/itemlist/user/259267
http://webp.online/index.php?topic=45653.msg74502
https://www.resproxy.com/forum/index.php/744520-uristy-20-seria-q4-uristy-20-seria-uristy-20-seria-watch-w2/0
https://khuyenmaikk13.info/index.php?topic=176500.0
http://sextomariotienda.com/blog/%d0%b2%d0%be%d1%80%d0%be%d0%bd-kuzgun-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kjj-%d0%b2%d0%be%d1%80%d0%be%d0%bd-kuzgun-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://uberdrivers.net/forum/index.php?topic=193186.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1073085
http://vsalda.edinros66.ru/component/k2/itemlist/user/36804
https://members.fbhaters.com/index.php?topic=69587.0
http://teambuildingpremium.com/forum/index.php?topic=710683.0
http://israengineering.com/index.php/component/k2/itemlist/user/1113989
http://www.theparrotcentre.com/forum/index.php?topic=433543.0
http://blog.ptpintcast.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w3-b1-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
https://www.thedezlab.com/lab/community/index.php?topic=312.0
http://roikjer.com/forum/index.php?topic=794449.0
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=46107
https://khuyenmaikk13.info/index.php?topic=177706.0
http://1vh.info/index.php?topic=8892.0
http://help.stv.ru/index.php?PHPSESSID=c98e355d5fec1fb359644ce19046bbfa&topic=137378.0
http://forum.bmw-e60.eu/index.php?topic=559.0
http://1vh.info/index.php?topic=3956.0
https://members.fbhaters.com/index.php?topic=66156.0
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3680731
http://poselokgribovo.ru/forum/index.php?topic=699579.0
http://www.oortsociety.com/index.php?topic=9984.0
https://sanp.pro/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j4-%e3%80%90-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f%e3%80%91-%d1%8e%d1%80%d0%b8%d1%81%d1%82/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sdx-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://www.m1avio.com/index.php/component/k2/itemlist/user/3578860
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1739146
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/603531
http://poselokgribovo.ru/forum/index.php?topic=664466.0
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1736148
https://tg.vl-mp.com/index.php?topic=1298577.0
http://sextomariotienda.com/blog/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m8-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://sextomariotienda.com/blog/smotret-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/126728
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3367500
https://forums.letstalkbeats.com/index.php?topic=51253.0
http://www.phperos.net/foro/index.php?topic=129243.0
http://www.gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1822579
http://www.remify.app/foro/index.php?topic=170748.0
http://dev.aabn.org.gh/component/k2/itemlist/user/465601
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/42658
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=766288
http://www.spazioad.com/component/k2/itemlist/user/7231855
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=14528
http://www.critico-expository.com/forum/index.php?topic=3630.0
http://www.critico-expository.com/forum/index.php?topic=3632.0
http://91.231.123.194/index.php/component/k2/itemlist/user/851919
http://1vh.info/index.php?topic=4802.0
http://forum.politeknikgihon.ac.id/index.php?topic=4043.0
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1604942
https://tg.vl-mp.com/index.php?topic=1259264.0
http://multikopterforum.hu/index.php?topic=9496.0
http://8.droror.co.il/uncategorized/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d3-05-05-2019-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://taklongclub.com/forum/index.php?topic=84690.0
http://153.120.114.241/eso/index.php/16843904-smotret-serial-vetrenyj-8-seria-na-russkom-amo1-smotret-serial-
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=110842
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=493736
https://tg.vl-mp.com/index.php?topic=1291049.0
http://soc-human.kz/index.php/component/k2/itemlist/user/1617364
http://batubersurat.com/index.php/component/k2/itemlist/user/38392
https://reficulcoin.com/index.php?topic=6823.0
http://roikjer.com/forum/index.php?topic=808263.0
http://webp.online/index.php?topic=41865.0
http://xekhachduyetthuy.com.vn/component/k2/itemlist/user/163214
http://webp.online/index.php?topic=43292.0
http://8.droror.co.il/uncategorized/%d0%bb%d1%8e%d0%b1%d0%be%d0%b2%d1%8c-%d1%81%d0%bc%d0%b5%d1%80%d1%82%d1%8c-%d0%b8-%d1%80%d0%be%d0%b1%d0%be%d1%82%d1%8b-love-death-and-robots-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%80%d1%83-3/
http://www.maxexcel.com.au/forum/discussion/540/yuristy-16-seriya-yuristy-16-seriya-film-horoshiy-kachestvo
http://www.hoonthaitoday.com/forum/index.php?topic=117780.0
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vy1-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://sextomariotienda.com/blog/%d0%be%d0%bd%d0%bb%d0%b0%d0%b9%d0%bd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b4-%d1%81%d0%bb%d1%83/
http://www.tekparcahdfilm.com/forum/index.php?topic=45337.0
http://www.remify.app/foro/index.php?topic=179075.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/172287
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/207060
http://www.deliberarchia.org/forum/index.php?topic=934242.0
http://dev.aabn.org.gh/component/k2/itemlist/user/463931
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=26657
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=155407
https://khuyenmaikk13.info/index.php?topic=172805.0
http://menulisilmiah.net/tv-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h6-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://www.gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1814803
http://thefreebitcoin.com/index.php?topic=33015.0
http://freebeer.me/index.php?topic=272528.0
http://dev.aabn.org.gh/component/k2/itemlist/user/463988
http://wb.hvekorat.com/index.php?topic=39539.0
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=47184
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/429505
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2515041
http://www.hoonthaitoday.com/forum/index.php?topic=98870.0
https://tg.vl-mp.com/index.php?topic=1302444.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/451862
http://menulisilmiah.net/on-line-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j7-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
https://tg.vl-mp.com/index.php?topic=1257735.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=252574
http://freebeer.me/index.php?topic=286215.0
http://forum.digamahost.com/index.php?topic=107368.0
http://jensenbyggteam.no/index.php/component/k2/itemlist/user/11109
http://muratliziraatodasi.org/forum/index.php?topic=394570.0
http://roikjer.com/forum/index.php?PHPSESSID=hgsav0gotcklac2r0vm4tvt1r1&topic=754244.0
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-iek-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
https://members.fbhaters.com/index.php?topic=73157.0
http://patagroupofcompanies.com/component/k2/itemlist/user/197390
http://sextomariotienda.com/blog/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-k4-03-05-2019-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
http://www.deliberarchia.org/forum/index.php?topic=951190.0
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=496963
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=26878.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/om-13-e-(-l8-om-13-e/?PHPSESSID=8739bq9em0f6nk4ogic6s147g5
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=676436.0
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1552225
https://khuyenmaikk13.info/index.php?topic=174301.0
http://danielmillsap.com/forum/index.php?topic=928360.0
https://tg.vl-mp.com/index.php?topic=1283139.0
http://married.dike.gr/index.php/component/k2/itemlist/user/38577
http://www.elpinatarense.es/?option=com_k2&view=itemlist&task=user&id=154948
https://forums.letstalkbeats.com/index.php?topic=60669.0
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1543849
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1126284
http://withinfp.sakura.ne.jp/eso/index.php/16815478-milliardy-4-sezon-11-seria-njg-milliardy-4-sezon-11-seria-03052
http://proxima.co.rw/index.php/component/k2/itemlist/user/555093
http://withinfp.sakura.ne.jp/eso/index.php/16784743-riverdejl-riverdale-3-sezon-19-seria-mbd-riverdejl-riverdale-3-/0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2530773
http://help.stv.ru/index.php?PHPSESSID=b66d340837330f921d6255c9bb7d9e88&topic=137104.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3276767
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=306575
http://forum.politeknikgihon.ac.id/index.php?topic=12490.0
https://lucky28003.nl/forum/index.php?topic=5954.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2458978
http://mvisage.sk/?option=com_k2&view=itemlist&task=user&id=116829
https://danceplanet.se/commodore/index.php?topic=4749.0
https://www.resproxy.com/forum/index.php/720989-smotret-sluga-naroda-3-sezon-7-seria-p4-sluga-naroda-3-sezon-7-/0
http://danielmillsap.com/forum/index.php?topic=935631.0
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4826674
http://www.hoonthaitoday.com/forum/index.php?topic=151741.0
https://tg.vl-mp.com/index.php?topic=1317108.0
https://tg.vl-mp.com/index.php?topic=1303566.0
http://forum.stollen24.com/index.php?topic=1932.0
http://8.droror.co.il/uncategorized/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%be%d0%bd%d0%bb%d0%b0%d0%b9%d0%bd-%e3%80%90dk3%e3%80%91-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147/
https://tg.vl-mp.com/index.php?topic=1267622.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ovi-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://roikjer.com/forum/index.php?PHPSESSID=ias2nbqij9tt9t49mts1js1632&topic=801854.0
http://sextomariotienda.com/blog/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q0-%e3%80%90-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://www.sakitoandrichifantasy.gr/?option=com_k2&view=itemlist&task=user&id=145673
http://1vh.info/index.php?topic=9919.0
http://freebeer.me/index.php?topic=279739.0
http://www.gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1828615
http://forum.digamahost.com/index.php?topic=106997.0
http://www.theparrotcentre.com/forum/index.php?topic=443880.0
http://www.deliberarchia.org/forum/index.php?topic=906599.0
https://www.resproxy.com/forum/index.php/735741-voskressij-ertugrul-149-seria-ite-voskressij-ertugrul-149-seria/0
http://www.deliberarchia.org/forum/index.php?topic=950824.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/176971
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3275098
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2493498
http://sextomariotienda.com/blog/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-4/
http://engeena.com/component/k2/itemlist/user/7170
http://ru-realty.com/forum/index.php?PHPSESSID=2nbi019n82qgih1i90ug3lgl55&topic=432880.0
http://ru-realty.com/forum/index.php?PHPSESSID=49ste9f48lo6ghsc58o0mf02q1&topic=452658.0
http://www.deliberarchia.org/forum/index.php?topic=955015.0
http://sdsn.develop.cinfores.com/?option=com_k2&view=itemlist&task=user&id=184447
http://153.120.114.241/eso/index.php/16838906-vetrenyj-8-seria-anons-russkaa-ozvucka-jnj8-vetrenyj-8-seria-an
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=293323
http://eugeniocolazzo.it/forum/index.php?topic=81196.0
http://metropolis.ga/index.php?topic=1674.0
https://sanp.pro/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q2-0/
http://153.120.114.241/eso/index.php/16859944-holostak-9-sezon-10-vypusk-stb-smotret-onlajn-tqholostak-9-sezo
http://codeerror.in/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z2-f5-%d1%80%d0%b0%d1%81%d1%81/
http://dpmarketingsystems.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m3-v4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
https://www.shaiyax.com/index.php?topic=327240.0
http://www.remify.app/foro/index.php?topic=207552.0
http://forum.elexlabs.com/index.php/topic,12909.0.html
http://www.popolsku.fr.pl/forum/index.php?topic=372385.0
http://erhu.eu/viewtopic.php?t=229428
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=250337
http://teambuildingpremium.com/forum/index.php?topic=744734.0
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=608142
http://dcasociados.eu/component/k2/itemlist/user/85640
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/532900
http://roikjer.com/forum/index.php?topic=772586.0
http://www.ekemoon.com/141241/051120192105/
http://vtservices85.fr/smf2/index.php?PHPSESSID=121e34a05f09c1ba7e6505332cf45288&topic=195626.0
http://www.original-craft.net/index.php?topic=293987.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/269344
http://www.spazioad.com/?option=com_k2&view=itemlist&task=user&id=7211271
http://forums.abs-cbn.com/welcome-back-kapamilya%21/aa-to-74-e-online'-z6-aa-to-74-e-online'/?PHPSESSID=0mcmetr0ur2u8ee03rnk4hl676
http://thefreebitcoin.com/index.php?topic=27521.0
https://khuyenmaikk13.info/index.php?topic=167711.0
http://poselokgribovo.ru/forum/index.php?topic=700399.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80-7/
http://withinfp.sakura.ne.jp/eso/index.php/16853615-igra-prestolov-8-sezon-6-seria-lm6-igra-prestolov-8-sezon-6-ser/0
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p1-l0-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://community.viajar.tur.br/index.php?p=/profile/codyweis1
http://codeerror.in/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90va9%e3%80%91-%d0%b8%d0%b3/
https://khuyenmaikk13.info/index.php?topic=178253.0
http://seoksoononly.dothome.co.kr/qna/667692
http://www.theparrotcentre.com/forum/index.php?topic=449326.0
http://forum.kopkargobel.com/index.php?topic=1490.0
https://tg.vl-mp.com/index.php?topic=1264118.0
http://thanosakademi.com/index.php?topic=60534.0
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1620252
https://members.fbhaters.com/index.php?topic=65626.0
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=493627
http://1vh.info/index.php?topic=8559.0
https://tg.vl-mp.com/index.php?topic=1282418.0
http://www.hoonthaitoday.com/forum/index.php?topic=95477.0
http://dpmarketingsystems.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qw9s-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1072052
http://216.104.186.20/index.php?topic=267623.0
http://rudraautomation.com/index.php/component/k2/author/89337
http://153.120.114.241/eso/index.php/16877892-mertvoe-ozero-9-seria-efir-mertvoe-ozero-9-seria-06052019
http://ru-realty.com/forum/index.php?PHPSESSID=5oves2es2f36afcuk8p3a9sp23&topic=451955.0
http://www.popolsku.fr.pl/forum/index.php?topic=20407.44280
https://khuyenmaikk13.info/index.php?topic=154687.0
http://www.hoonthaitoday.com/forum/index.php?topic=130576.0
http://1vh.info/index.php?topic=556.0
http://blog.ptpintcast.com/hd-video-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-the-cw/
http://www.tvmechanic.co.in/forum/index.php?topic=8338.0
http://forum.bmw-e60.eu/index.php?topic=1525.0
http://1vh.info/index.php?topic=6447.0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=555740
http://poselokgribovo.ru/forum/index.php?topic=691344.0
http://otitismediasociety.org/forum/index.php?topic=141495.0
https://www.resproxy.com/forum/index.php/757183-vyhod-8-serii-vetrenyj-zsf4-vyhod-8-serii-vetrenyj/0
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/599959
http://universaldrive-s.cba.pl/index.php?PHPSESSID=d345c7b61c99eedb82fa280b2f9225d4&topic=19330.0
https://www.resproxy.com/forum/index.php/742194-sverh-estestvennoe-15-sezon-13-seria-zpgf-sverh-estestvennoe-15
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o2-x6-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://forum.politeknikgihon.ac.id/index.php?topic=20425.0
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90hg6%e3%80%91/
http://danielmillsap.com/forum/index.php?topic=931094.0
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://sanp.pro/%d0%b1%d0%be%d0%b3%d0%b0%d1%82%d1%8b%d0%b5-%d0%b8-%d0%b1%d0%b5%d0%b4%d0%bd%d1%8b%d0%b5-zengin-ve-yoksul-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%be%d0%b7%d0%b2%d1%83%d1%87%d0%ba%d0%b0-b1/
http://1vh.info/index.php?topic=4346.0
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3539271
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4686015
https://reficulcoin.com/index.php?topic=7888.0
https://www.resproxy.com/forum/index.php/748677-sosedi-2-sezon-8-seria-04052019-uw-sosedi-2-sezon-8-seria/0
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/191102
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=43958
http://8.droror.co.il/uncategorized/%d1%80%d0%b8%d0%b2%d0%b5%d1%80%d0%b4%d1%8d%d0%b9%d0%bb-riverdale-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bf%d0%b5%d1%80%d0%b5%d0%b2%d0%be%d0%b4-%d0%bd-2/
http://menulisilmiah.net/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ek4p-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=142351
https://tg.vl-mp.com/index.php?topic=1270278.0
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/182300
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/243707
http://roikjer.com/forum/index.php?PHPSESSID=2jljm53r2jqb7ob9kl6dlhah15&topic=782614.0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/384471
http://forum.politeknikgihon.ac.id/index.php?topic=9234.0
http://sextomariotienda.com/blog/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xhr-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2527010
http://www.theparrotcentre.com/forum/index.php?topic=437975.0
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/138268
http://roikjer.com/forum/index.php?PHPSESSID=69n9bpv5d449n2fnlqi12o3801&topic=765688.0
https://nextezone.com/index.php?action=profile&u=2223
http://dpmarketingsystems.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jw1-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8/
http://www.hoonthaitoday.com/forum/index.php?topic=126768.0
http://www.hoonthaitoday.com/forum/index.php?topic=157515.0
http://marjorieaperry.com/index.php/component/k2/itemlist/user/477616
https://lucky28003.nl/forum/index.php?topic=8914.0
http://roikjer.com/forum/index.php?PHPSESSID=omrb1a537dlqopodib9578m4s0&topic=782474.0
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/48734
http://www.emrabq8.com/index.php/component/k2/itemlist/user/1747392
http://mediaville.me/index.php/component/k2/itemlist/user/192455
https://lucky28003.nl/forum/index.php?topic=5464.0
http://taklongclub.com/forum/index.php?topic=83145.0
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1612870
https://www.resproxy.com/forum/index.php/724859-zensina-60-seria-g6yo-zensina-60-seria/0
http://poselokgribovo.ru/forum/index.php?topic=699396.0
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3700526
http://forums.abs-cbn.com/welcome-back-kapamilya%21/ootk-9-eo-11-k-03-05-2019-oy-ootk-9-eo-11-k/?PHPSESSID=ii6gasv7kq7l98nfffrs262a17
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/263145
http://menulisilmiah.net/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-03-05-2019-%e3%80%90cg%e3%80%91-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://teambuildingpremium.com/forum/index.php?topic=765869.0
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1594398
http://matrixpharm.ru/forum/index.php?PHPSESSID=ptkcnl0e0l12j3kndqht2rn1s0&action=profile;u=152269
https://www.c-alice.org/forum/index.php?topic=68301.0
http://danielmillsap.com/forum/index.php?topic=858881.0
http://roikjer.com/forum/index.php?PHPSESSID=iod9j96sqcha36e649rm4l1477&topic=764892.0
https://khuyenmaikk13.info/index.php?topic=164437.0
http://wb.hvekorat.com/index.php?topic=40174.0
http://roikjer.com/forum/index.php?PHPSESSID=8epm108i8l8oo4t7cguu9ioo72&topic=790114.0
http://mir3sea.com/forum/index.php?topic=426.0
http://roikjer.com/forum/index.php?PHPSESSID=t2trrjvdrgofd39r0hg9bnbpo3&topic=806612.0
http://uberdrivers.net/forum/index.php?topic=212585.0
http://haniel.ir/index.php/component/k2/itemlist/user/71777
http://batubersurat.com/index.php/component/k2/itemlist/user/41468
https://tg.vl-mp.com/index.php?topic=1318527.0
http://www.deliberarchia.org/forum/index.php?topic=937116.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/287499
https://nextezone.com/index.php?action=profile&u=1766
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=272711
http://roikjer.com/forum/index.php?PHPSESSID=1qil7fh86lk657ctbfhrv8qtj4&topic=810399.0
http://www.phperos.net/foro/index.php?topic=129228.0
http://webp.online/index.php?topic=36615.0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=32469
http://miklja.net/forum/index.php?topic=23388.0
http://taklongclub.com/forum/index.php?topic=89074.0
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xi5c-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
https://forum.ac-jete.it/index.php?topic=325358.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/439455
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/150375
http://xn--22cmah2caecpucll2cycdoj4d0knajrq3e5pbj9w0c.americanwolfthailand.com/DJPetjah/index.php?topic=1477004.0
http://withinfp.sakura.ne.jp/eso/index.php/16771387-new-sluga-naroda-3-sezon-8-seria-i0-sluga-naroda-3-sezon-8-seri/0
https://khuyenmaikk13.info/index.php?topic=160796.0
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/140902
http://proandpro.it/?option=com_k2&view=itemlist&task=user&id=4532202
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=31840
http://dpmarketingsystems.com/%d0%bd%d0%b5-%d0%be%d1%82%d0%bf%d1%83%d1%81%d0%ba%d0%b0%d0%b9-%d0%bc%d0%be%d1%8e-%d1%80%d1%83%d0%ba%d1%83-elimi-birakma-36-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-msy-%d0%bd%d0%b5-%d0%be/
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=201632
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1837893
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1330451
http://matrixpharm.ru/forum/index.php?PHPSESSID=artnj55vh61lr2m3vto28tbci1&action=profile;u=159056
http://c3isecurity.com.br/?option=com_k2&view=itemlist&task=user&id=471530
https://reficulcoin.com/index.php?topic=5511.0
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81-9/
http://forum.digamahost.com/index.php?topic=106975.0
http://roikjer.com/forum/index.php?PHPSESSID=svvia3sejmkbnoscuo6dvrj8h1&topic=787161.0
http://wb.hvekorat.com/index.php?topic=40200.0
http://roikjer.com/forum/index.php?topic=798932.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=24706.0
http://help.stv.ru/index.php?PHPSESSID=17e8b40da35b9e33a229c46f61114d77&topic=137403.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=893692
http://molweb.ru/groups/efir-tolya-robot-7-seriya-a7-tolya-robot-7-seriya/
http://www.spazioad.com/component/k2/itemlist/user/7194325
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=32704
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1538663
http://withinfp.sakura.ne.jp/eso/index.php/16794178-sverh-estestvennoe-14-sezon-17-seria-dzy-sverh-estestvennoe-14-/0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/292004
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=679054.0
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=8359.0
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=8372.0
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7316689
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=5604
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=5612
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/5607
http://theolevolosproject.org/?option=com_k2&view=itemlist&task=user&id=24646
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1013712
http://www.quattroandpartners.it/component/k2/itemlist/user/1050540
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3305504
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3305518
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2573063
http://www.critico-expository.com/forum/index.php?topic=3657.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3304840
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a2-%d0%b8%d0%b3%d1%80%d0%b0-4/
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/480987
http://www.sharmaraco.com/blog/%C2%AB%D0%BF%D0%BE-%D0%B7%D0%B0%D0%BA%D0%BE%D0%BD%D0%B0%D0%BC-%D0%B2%D0%BE%D0%B5%D0%BD%D0%BD%D0%BE%D0%B3%D0%BE-%D0%B2%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-3-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-04-05-2019-mkr-%D0%BF%D0%BE-%D0%B7%D0%B0%D0%BA%D0%BE%D0%BD%D0%B0%D0%BC-%D0%B2%D0%BE%D0%B5%D0%BD%D0%BD%D0%BE%D0%B3%D0%BE-%D0%B2%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%B8-3
http://poselokgribovo.ru/forum/index.php?topic=654374.0
http://forum.byehaj.hu/index.php?topic=70302.0
http://thefreebitcoin.com/index.php?topic=31274.0
https://www.shaiyax.com/index.php?topic=320973.0
http://teambuildingpremium.com/forum/index.php?topic=741015.0
http://www.cosl.com.sg/UserProfile/tabid/61/userId/26049576/Default.aspx
https://lucky28003.nl/forum/index.php?topic=4385.0
http://forum.politeknikgihon.ac.id/index.php?topic=19178.0
http://216.104.186.20/index.php?topic=285737.0
http://www.oortsociety.com/index.php?topic=11096.0
https://lideta.workethio.com/2019/05/02/hd-video-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hamsterstudio-o9-%d0%b8%d0%b3%d1%80/
http://macdistri.com/index.php/component/k2/itemlist/user/285561
http://poselokgribovo.ru/forum/index.php?topic=654550.0
https://danceplanet.se/commodore/index.php?topic=9363.0
http://afinandoemociones.com.ar/?option=com_k2&view=itemlist&task=user&id=387796
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1007540
http://153.120.114.241/eso/index.php/16863655-igra-prestolov-2019-8-sezon-1-seria-igra-prestolov-2019-8-sezon?---------------------------967304520%0D%0AContent-Disposition:%20form-data;%20name=%22token%22%0D%0A%0D%0A7208b7d923b0b%0D%0A---------------------------967304520%0D%0AContent-Disposition:%20form-data;%20name=%22title%22%0D%0A%0D%0A%22%D0%98%D0%B3%D1%80%D0%B0%20%D0%9F%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D0%A1%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D0%A1%D0%B5%D1%80%D0%B8%D1%8F%22%20%D0%98%D0%B3%D1%80%D0%B0%20%D0%9F%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D0%A1%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D0%A1%D0%B5%D1%80%D0%B8%D1%8F%20S0g1%0D%0A---------------------------967304520%0D%0AContent-Disposition:%20form-data;%20name=%22content%22%0D%0A%0D%0A%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20cfKB%20%D0%BE%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD%0D%0A%0D%0A[url=http://zfilm1.ru/watch/8AQBfQhv/][img]https://i.imgur.com/lmkHlGZ.jpg[/img][/url]%0D%0A%0D%0A[url=http://zfilm1.ru/watch/8AQBfQhv/]%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F[/url]%0D%0A[url=http://zfilm1.ru/watch/8AQBfQhv/]%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F[/url]%0D%0A[url=http://zfilm1.ru/watch/8AQBfQhv/]%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F[/url]%0D%0A%0D%0A%C2%AB%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%BE%D0%BA%C2%BB%0D%0A%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%B2%D0%BA%0D%0A%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20ok%0D%0A'%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D1%83%D0%BA%D1%80'%0D%0A%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D1%84%D0%B1%0D%0A//%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20kz//%0D%0A%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D1%8E%D1%82%D1%83%D0%B1%0D%0A'%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20kz'%0D%0A%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20kz%0D%0A%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20pin%0D%0A//%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%B2%D0%BA//%0D%0A%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D1%8E%D1%82%D1%83%D0%B1%0D%0A%22%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20fb%22%0D%0A//%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%B2%D0%BA//%0D%0A%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D1%8E%D1%82%D1%83%D0%B1%0D%0A%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D1%80%D1%83%D1%81%0D%0A%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20ok%0D%0A%3E%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%201%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20pin%0D%0A---------------------------967304520%0D%0AContent-Disposition:%20form-data;%20name=%22postReply%22%0D%0A%0D%0A%E3%83%88%E3%83%94%E3%83%83%E3%82%AF%E3%82%E2%80%99%E7%AB%8B%E3%81%A6%E3%82%8B%0D%0A---------------------------967304520--
http://multikopterforum.hu/index.php?topic=5130.0
http://danielmillsap.com/forum/index.php?topic=936116.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=24972.0
http://www.tessabannampad.go.th/webboard/index.php?topic=189066.0
https://tg.vl-mp.com/index.php?topic=1261935.0
http://istakam.com/forum/index.php?topic=9165.0
http://erhu.eu/viewtopic.php?t=242580
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=291297
https://tg.vl-mp.com/index.php?topic=1308141.0
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-03-05-2019-%e3%80%90ca%e3%80%91-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://poselokgribovo.ru/forum/index.php?topic=695164.0
https://members.fbhaters.com/index.php/topic,66231.0.html
https://members.fbhaters.com/index.php?topic=72705.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/544251
http://teambuildingpremium.com/forum/index.php?topic=759445.0
https://tg.vl-mp.com/index.php?topic=1284760.0
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1613687
http://soc-human.kz/index.php/component/k2/itemlist/user/1622643
http://www.original-craft.net/index.php?topic=297378.0
http://www.deliberarchia.org/forum/index.php?topic=931488.0
http://www.deliberarchia.org/forum/index.php?topic=884061.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3598843
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=766608
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7279947
https://www.resproxy.com/forum/index.php/750198-sosedi-2-sezon-4-seria-hd-sosedi-2-sezon-4-seria-04052019/0
http://danielmillsap.com/forum/index.php?topic=922550.0
https://www.resproxy.com/forum/index.php/736857-voskressij-ertugrul-147-seria-vwf-voskressij-ertugrul-147-seria/0
http://roikjer.com/forum/index.php?PHPSESSID=gh65d8oslkn22l7e5m8946o6b7&topic=759045.0
http://uberdrivers.net/forum/index.php?topic=184714.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3288905
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2565025
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3693055
https://reficulcoin.com/index.php?topic=6106.0
http://withinfp.sakura.ne.jp/eso/index.php/16805137-sosedi-2-sezon-8-seria-b2dw-sosedi-2-sezon-8-seria/0
http://www.deliberarchia.org/forum/index.php?topic=942543.0
http://menulisilmiah.net/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d1%83%d0%ba%d1%80%d0%b0%d0%b8%d0%bd%d0%b0-watch-%c2%a4b9i9-%d1%85%d0%be/
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/589617
http://www.original-craft.net/index.php?topic=303143.0
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=3953
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1132179
http://www.gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1841135
http://forum.byehaj.hu/index.php?topic=73289.0
http://www.afikgan.co.il/index.php/component/k2/itemlist/user/25713
http://forum.politeknikgihon.ac.id/index.php?topic=17331.0
http://withinfp.sakura.ne.jp/eso/index.php/16835725-edinoe-serdce-tek-yurek-14-seria-v7fj-edinoe-serdce-tek-yurek-1
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=47063
https://www.resproxy.com/forum/index.php/744718-holostak-9-sezon-13-vypusk-03052019-yt-holostak-9-sezon-13-vypu/0
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/631649
https://www.resproxy.com/forum/index.php/779868-edinoe-serdce-tek-yurek-11-seria-u3fu-edinoe-serdce-tek-yurek-1/0
http://metropolis.ga/index.php?topic=3012.0
http://metropolis.ga/index.php?topic=3013.0
http://metropolis.ga/index.php?topic=3016.0
http://metropolis.ga/index.php?topic=3018.0
http://myrechockey.com/forums/index.php?topic=85800.0
http://www.deliberarchia.org/forum/index.php?topic=958628.0
http://www.deliberarchia.org/forum/index.php?topic=958635.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190120.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190130.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190133.0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4689810
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4690143
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4690269
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4690352
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4690561
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=256894
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/61072
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1297551
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4669677
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1108895
http://www.studioaparo.it/?option=com_k2&view=itemlist&task=user&id=532393
http://withinfp.sakura.ne.jp/eso/index.php/16782865-vetrenyj-hercai-6-seria-w2rd-vetrenyj-hercai-6-seria
http://withinfp.sakura.ne.jp/eso/index.php/16782898-voron-kuzgun-18-seria-t7cl-voron-kuzgun-18-seria
http://withinfp.sakura.ne.jp/eso/index.php/16782918-ne-otpuskaj-mou-ruku-elimi-birakma-38-seria-o5zy-ne-otpuskaj-mo/0
http://withinfp.sakura.ne.jp/eso/index.php/16782953-vetrenyj-hercai-13-seria-t5hn-vetrenyj-hercai-13-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/16782971-nasa-istoria-66-seria-r5ju-nasa-istoria-66-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/16783003-vossoedinenie-vuslat-16-seria-k6ub-vossoedinenie-vuslat-16-seri/0
http://withinfp.sakura.ne.jp/eso/index.php/16783421-ne-otpuskaj-mou-ruku-elimi-birakma-40-seria-j5bx-ne-otpuskaj-mo/0
http://withinfp.sakura.ne.jp/eso/index.php/16783495-voron-kuzgun-18-seria-z7kb-voron-kuzgun-18-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/16783629-vossoedinenie-vuslat-15-seria-s8pc-vossoedinenie-vuslat-15-seri
http://withinfp.sakura.ne.jp/eso/index.php/16783873-voron-kuzgun-12-seria-y9ip-voron-kuzgun-12-seria
http://withinfp.sakura.ne.jp/eso/index.php/16784046-edinoe-serdce-tek-yurek-10-seria-o3oh-edinoe-serdce-tek-yurek-1
http://withinfp.sakura.ne.jp/eso/index.php/16784049-rannaa-ptaska-erkenci-kus-37-seria-n6so-rannaa-ptaska-erkenci-k
http://withinfp.sakura.ne.jp/eso/index.php/16784055-vetrenyj-hercai-5-seria-n9hy-vetrenyj-hercai-5-seria/0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/407180
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2551829
http://mediaville.me/index.php/component/k2/itemlist/user/209772
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1538201
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/44549
https://tg.vl-mp.com/index.php?topic=1289908.0
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/255394
https://www.resproxy.com/forum/index.php/740468-milliardy-4-sezon-5-seria-lkc-milliardy-4-sezon-5-seria-0305201/0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/58012
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=304841
http://israengineering.com/index.php/component/k2/itemlist/user/1094390
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/141882
https://tg.vl-mp.com/index.php?topic=1300614.0
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1545258
http://webp.online/index.php?topic=41709.0
http://danielmillsap.com/forum/index.php?topic=876772.0
http://withinfp.sakura.ne.jp/eso/index.php/16780341-ne-otpuskaj-mou-ruku-elimi-birakma-41-seria-q7ri-ne-otpuskaj-mo
http://withinfp.sakura.ne.jp/eso/index.php/16798268-kto-snimalsa-v-tola-robot-1-seria-kz-kto-snimalsa-v-tola-robot-
https://grajalesabogados.com.mx/?option=com_k2&view=itemlist&task=user&id=60923
http://proxima.co.rw/index.php/component/k2/itemlist/user/565438
http://mediaville.me/index.php/component/k2/itemlist/user/214310
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1605843
http://withinfp.sakura.ne.jp/eso/index.php/16800737-voron-kuzgun-15-seria-u8oo-voron-kuzgun-15-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/16800815-voskressij-ertugrul-143-seria-c7gs-voskressij-ertugrul-143-seri/0
http://withinfp.sakura.ne.jp/eso/index.php/16800992-voskressij-ertugrul-143-seria-o0lq-voskressij-ertugrul-143-seri
http://withinfp.sakura.ne.jp/eso/index.php/16801129-edinoe-serdce-tek-yurek-12-seria-q0qy-edinoe-serdce-tek-yurek-1/0
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/591829
http://webp.online/index.php?topic=37885.0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=560652
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/56362
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/45252
https://tg.vl-mp.com/index.php?topic=1277748.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3557020
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1130397
https://www.resproxy.com/forum/index.php/752995-cernoe-zerkalo-5-sezon-5-seria-sur-cernoe-zerkalo-5-sezon-5-ser/0
http://www.tessabannampad.go.th/webboard/index.php?topic=188237.0
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1673536
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1634650
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=160330
http://danielmillsap.com/forum/index.php?topic=921979.0
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/582986
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=303624
http://travelsolution.info/index.php/component/k2/itemlist/user/712788
http://married.dike.gr/index.php/component/k2/itemlist/user/38132
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1859719
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=710389
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7297935
https://members.fbhaters.com/index.php?topic=66486.0
http://teambuildingpremium.com/forum/index.php?topic=719770.0
http://www.islamiccall.info/?option=com_k2&view=itemlist&task=user&id=853448
http://xekhachduyetthuy.com.vn/component/k2/itemlist/user/161438
http://153.120.114.241/eso/index.php/16864405-uristy-19-seria-uristy-19-seria-05052019
http://www.original-craft.net/index.php?topic=298736.0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/43494
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3502366
https://www.resproxy.com/forum/index.php/742712-sluga-naroda-3-sezon-15-seria-smotret-sluga-naroda-3-sezon-15-s/0
https://www.resproxy.com/forum/index.php/742426-voskressij-ertugrul-150-seria-kdg-voskressij-ertugrul-150-seria/0
https://forums.letstalkbeats.com/index.php?topic=51771.0
https://lucky28003.nl/forum/index.php?topic=8991.0
http://gtupuw.org/index.php/component/k2/itemlist/user/1837525
http://istakam.com/forum/index.php?topic=9151.0
http://sextomariotienda.com/blog/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t4-04-05-2019-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80/
http://poselokgribovo.ru/forum/index.php?topic=682024.0
https://www.shaiyax.com/index.php?topic=327813.0
https://sanp.pro/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-%d1%83%d0%ba%d1%80%d0%b0%d0%b8%d0%bd%d0%b0-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-c0y1-%d1%85/
http://multikopterforum.hu/index.php?topic=7068.0
http://freebeer.me/index.php?topic=298110.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/186349
http://sextomariotienda.com/blog/%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-05-05-2019-4/
http://www.deliberarchia.org/forum/index.php?topic=892268.0
http://poselokgribovo.ru/forum/index.php?topic=703233.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/454713
http://danielmillsap.com/forum/index.php?topic=911664.0
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2522431
http://malbeot.iptime.org:10009/xe/board/4178225
http://1vh.info/index.php?topic=396.0
http://poselokgribovo.ru/forum/index.php?topic=655621.0
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/127143
https://khuyenmaikk13.info/index.php?topic=158494.0
https://www.gizmoarticle.com/video-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n2-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3369693
http://healthyteethpa.org/component/k2/itemlist/user/5320877
http://yuptalk.ru/other_food_household_cosmetics_etc/-t13139.0.html
http://matinbank.ir/component/k2/itemlist/user/4483021.html
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/471522
http://dohairbiz.com/?option=com_k2&view=itemlist&task=user&id=2705439
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=48598
https://sanp.pro/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b/
http://matinbank.ir/?option=com_k2&view=itemlist&task=user&id=4460116
http://www.remify.app/foro/index.php?topic=209777.0
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=713872
https://tg.vl-mp.com/index.php?topic=1256966.0
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-04-05-2019-%e3%80%90ls%e3%80%91-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-5-%d1%81%d0%b5/
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=304859
http://sextomariotienda.com/blog/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-watch-i9-%e3%80%90-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
https://tg.vl-mp.com/index.php?topic=1279872.0
http://roikjer.com/forum/index.php?PHPSESSID=75b1bulir4msi0e2d0afc4ftu0&topic=778909.0
http://help.stv.ru/index.php?PHPSESSID=0df414b3b978becf2509e60d7be09767&topic=134591.0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4707170
http://myrechockey.com/forums/index.php?topic=80011.0
http://poselokgribovo.ru/forum/index.php?topic=683857.0
http://fbpharm.net/index.php/component/k2/itemlist/user/12327
http://webp.online/index.php?topic=44329.0
http://sextomariotienda.com/blog/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pcq-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://forum.ac-jete.it/index.php?topic=334009.0
http://www.boutique.in.th/?option=com_k2&view=itemlist&task=user&id=146607
https://forums.letstalkbeats.com/index.php?topic=48845.0
http://dev.aabn.org.gh/component/k2/itemlist/user/510174
http://wb.hvekorat.com/index.php?topic=39782.0
http://sextomariotienda.com/blog/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h3-04-05-2019-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
http://www.deliberarchia.org/forum/index.php?topic=939502.0
http://mediaville.me/index.php/component/k2/itemlist/user/208264
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=25689.0
http://danielmillsap.com/forum/index.php?topic=946096.0
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/200782
http://webp.online/index.php?topic=42693.0
https://tg.vl-mp.com/index.php?topic=1315531.0
https://adsensebih.com/index.php?topic=7793.0
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3560029
http://erhu.eu/viewtopic.php?t=232726
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ma7-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://macdistri.com/index.php/component/k2/itemlist/user/260790
http://danielmillsap.com/forum/index.php?topic=927545.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=261173
http://withinfp.sakura.ne.jp/eso/index.php/16773501-vetrenyj-hercai-25-seria-y9mo-vetrenyj-hercai-25-seria/0
http://erhu.eu/viewtopic.php?t=240772
http://xekhachduyetthuy.com.vn/index.php/component/k2/itemlist/user/158130
http://fbpharm.net/index.php/component/k2/itemlist/user/9773
http://www.m1avio.com/index.php/component/k2/itemlist/user/3580642
https://tg.vl-mp.com/index.php?topic=1295310.0
https://wwwelibga.000webhostapp.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nsa-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8/chandracanada45/85290/
https://www.resproxy.com/forum/index.php/747810-tola-robot-serial-aktery-1-1-seria-tola-robot-serial-aktery-1-1
http://www.quattroandpartners.it/component/k2/itemlist/user/1015621
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=47118
http://hydrocarbs-gh.org/index.php/component/k2/itemlist/user/7284942
http://sextomariotienda.com/blog/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f6-04-05-2019-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4825974
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1852860
http://withinfp.sakura.ne.jp/eso/index.php/16860465-05052019-podsudimyj-11-seria
http://blog.ptpintcast.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90pb8%e3%80%91/
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/448635
https://sanp.pro/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81-8/
http://153.120.114.241/eso/index.php/16867510-edinoe-serdce-tek-yurek-20-seria-roqg-edinoe-serdce-tek-yurek-2
http://forum.byehaj.hu/index.php?topic=75210.0
http://withinfp.sakura.ne.jp/eso/index.php/16858325-igra-prestolov-got-8-sezon-1-seria-igra-prestolov-got-8-sezon-1
https://www.resproxy.com/forum/index.php/741581-amerikanskie-bogi-2-sezon-9-seria-blu-amerikanskie-bogi-2-sezon/0
http://sextomariotienda.com/blog/%d0%bb%d1%8e%d0%b1%d0%be%d0%b2%d1%8c-%d1%81%d0%bc%d0%b5%d1%80%d1%82%d1%8c-%d0%b8-%d1%80%d0%be%d0%b1%d0%be%d1%82%d1%8b-love-death-and-robots-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%80%d1%83-5/
http://dev.aabn.org.gh/component/k2/itemlist/user/493380
http://91.250.77.10/wbb3/index.php?page=User&userID=403454
http://roikjer.com/forum/index.php?topic=783625.0
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2518610
http://freebeer.me/index.php?topic=273892.0
https://mcsetup.tk/bbs/index.php?topic=238037.0
http://forum.politeknikgihon.ac.id/index.php?topic=2504.0
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3673625
http://dohairbiz.com/en/component/k2/itemlist/user/2678717.html
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3559184
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/258289
http://uberdrivers.net/forum/index.php?topic=147057.0
http://www2.yasothon.go.th/smf/index.php?topic=159.153960
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-39/
http://roikjer.com/forum/index.php?topic=793537.0
http://danielmillsap.com/forum/index.php?topic=945278.0
http://roikjer.com/forum/index.php?topic=791746.0
http://www.elpinatarense.com/?option=com_k2&view=itemlist&task=user&id=155614
http://arquitectosenreformas.es/component/k2/itemlist/user/79104
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90tu7%e3%80%91-%d0%b8%d0%b3/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-s8-k8-%d1%80%d0%b0%d1%81/
http://otitismediasociety.org/forum/index.php?topic=142907.0
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/207750
https://tg.vl-mp.com/index.php?topic=1311290.0
https://www.resproxy.com/forum/index.php/767943-agenty-sit-6-sezon-8-seria-fovs-agenty-sit-6-sezon-8-seria/0
https://forum.ac-jete.it/index.php?topic=335645.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1078237
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=607526
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=560583
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bu1-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8/
http://forum.politeknikgihon.ac.id/index.php?topic=15809.0
https://www.resproxy.com/forum/index.php/739770-tureckij-serial-ertugrul-146-seria-db0-tureckij-serial-ertugrul/0
http://macdistri.com/?option=com_k2&view=itemlist&task=user&id=259551
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3281363
https://www.resproxy.com/forum/index.php/762645-igra-prestolov-8-sezon-7-seria-mos-igra-prestolov-8-sezon-7-ser/0
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81-29/
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/185745
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=39314
http://macdistri.com/index.php/component/k2/itemlist/user/258625
https://www.youngbiker.de/wbboard/index.php?page=User&userID=785258
http://153.120.114.241/eso/index.php/16870127-lubov-smert-i-roboty-love-death-and-robots-3-seria-dai-lubov-sm
http://www.deliberarchia.org/forum/index.php?topic=948527.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/185938
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/277412
http://ts.bloodhand.de/forum/viewtopic.php?t=200144
http://healthyteethpa.org/component/k2/itemlist/user/5279617
http://www.deliberarchia.org/forum/index.php?topic=914440.0
http://foa.egerton.ac.ke/index.php/component/k2/itemlist/user/1672200
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=49085
http://www.deliberarchia.org/forum/index.php?topic=899454.0
http://danielmillsap.com/forum/index.php?topic=908383.0
http://www.oortsociety.com/index.php?topic=7921.0
https://www.resproxy.com/forum/index.php/762484-riverdejl-riverdale-3-sezon-20-seria-qhq-riverdejl-riverdale-3-/0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vhk-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-12-%d1%81%d0%b5%d1%80/
https://tg.vl-mp.com/index.php?topic=1282571.0
http://www.deliberarchia.org/forum/index.php?topic=928161.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1307547
https://tg.vl-mp.com/index.php?topic=1304344.0
https://www.youngbiker.de/wbboard/index.php?page=User&userID=785027
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1299672
http://www.deliberarchia.org/forum/index.php?topic=907277.0
https://tg.vl-mp.com/index.php?topic=1300526.0
http://www.m1avio.com/?option=com_k2&view=itemlist&task=user&id=3554245
http://www.ekemoon.com/138373/050520195604/
http://freebeer.me/index.php?topic=256277.0
http://danielmillsap.com/forum/index.php?topic=919461.0
https://members.fbhaters.com/index.php/topic,58907.0.html
http://matrixpharm.ru/forum/index.php?PHPSESSID=c87emfho124r3vqpjpsgj9ert1&action=profile;u=150672
https://sanp.pro/%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rvs-%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-14-%d1%81%d0%b5/
http://hydrocarbs-gh.org/index.php/component/k2/itemlist/user/7292270
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=4810
http://forum.politeknikgihon.ac.id/index.php?topic=15707.0
https://sanp.pro/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k3-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3297770
http://vervetama.com/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81-2/
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/462775
https://nextezone.com/index.php?topic=33556.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-(got)-8-eo-5-e-mj8-(a-etoo-(got)-8-eo-5-e)/
http://seoksoononly.dothome.co.kr/qna/716463
https://sanp.pro/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b7-f0-%d1%80%d0%b0%d1%81%d1%81/
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=23847.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/555845
http://8.droror.co.il/uncategorized/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-23-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b8-%e3%80%90-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
https://nextezone.com/index.php?topic=32513.0
http://married.dike.gr/index.php/component/k2/itemlist/user/34963
http://healthyteethpa.org/component/k2/itemlist/user/5276931
http://www.hoonthaitoday.com/forum/index.php?topic=123967.0
http://www.arredoufficiomarca.com/index.php/component/k2/itemlist/user/1552315
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1295593
http://www.deliberarchia.org/forum/index.php?topic=953159.0
http://teambuildingpremium.com/forum/index.php?topic=765484.0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/409224
http://withinfp.sakura.ne.jp/eso/index.php/16772593-hd-sluga-naroda-3-sezon-22-seria-i4-sluga-naroda-3-sezon-22-ser/0
http://danielmillsap.com/forum/index.php?topic=910498.0
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mcz-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
https://www.shaiyax.com/index.php?topic=326568.0
https://www.resproxy.com/forum/index.php/715913-hdvideo-sluga-naroda-3-sezon-10-seria-r3-sluga-naroda-3-sezon-1/0
http://dpmarketingsystems.com/%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0%d1%8f-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b0-%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be%d0%b1%d0%be%d1%82%d0%b0-15-%d1%81%d0%b5-38/
https://www.resproxy.com/forum/index.php/715038-live-sluga-naroda-3-sezon-20-seria-c0-sluga-naroda-3-sezon-20-s
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/172301
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yli-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=253991
https://khuyenmaikk13.info/index.php?topic=164324.0
http://dpmarketingsystems.com/%d0%bd%d0%b5-%d0%be%d1%82%d0%bf%d1%83%d1%81%d0%ba%d0%b0%d0%b9-%d0%bc%d0%be%d1%8e-%d1%80%d1%83%d0%ba%d1%83-elimi-birakma-35-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xlj-%d0%bd%d0%b5-%d0%be/
http://roikjer.com/forum/index.php?topic=792204.0
http://dpmarketingsystems.com/hd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h6-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://poselokgribovo.ru/forum/index.php?topic=694646.0
https://sanp.pro/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-v2-06-05-2019-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
http://jesusandmarypatna.com/index.php/component/k2/itemlist/user/3368650
https://sto54.ru/index.php/component/k2/itemlist/user/3288115
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-y8-g6-%d1%80/
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/561343
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=286523
http://1vh.info/index.php?topic=6792.0
http://forum.santrope-rp.ru/index.php?topic=2127.0
https://sanp.pro/%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-8-%d1%81-3/
http://die-design-manufaktur.de/?option=com_k2&view=itemlist&task=user&id=5168190
http://otitismediasociety.org/forum/index.php?topic=142892.0
http://uberdrivers.net/forum/index.php?topic=221380.0
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=253764
http://www.theparrotcentre.com/forum/index.php?topic=437689.0
http://taklongclub.com/forum/index.php?topic=77982.0
http://freebeer.me/index.php?topic=293693.0
http://withinfp.sakura.ne.jp/eso/index.php/16808442-vetrenyj-hercai-9-seria-m2kl-vetrenyj-hercai-9-seria/0
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/246796
http://healthyteethpa.org/?option=com_k2&view=itemlist&task=user&id=5277216
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=266976
http://www.deliberarchia.org/forum/index.php?topic=900847.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=26686.0
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1617408
http://153.120.114.241/eso/index.php/16880356-igra-prestolov-8-sezon-1-seria-aca-igra-prestolov-8-sezon-1-ser
http://www.theparrotcentre.com/forum/index.php?topic=450719.0
http://dpmarketingsystems.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cb0e-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://blog.ptpintcast.com/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-25-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-stv-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-25-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://dev.fivestarpainting.com/?option=com_k2&view=itemlist&task=user&id=1840312
http://withinfp.sakura.ne.jp/eso/index.php/16840257-ertugrul-5-sezon-150-seria-v0-ertugrul-5-sezon-150-seria/0
http://eugeniocolazzo.it/forum/index.php?topic=78599.0
http://uberdrivers.net/forum/index.php?topic=177771.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2537916
http://macdistri.com/index.php/component/k2/itemlist/user/290591
http://forum.politeknikgihon.ac.id/index.php?topic=12887.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/462349
http://www.vivelabmanizales.com/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81-4/
http://metropolis.ga/index.php?topic=2757.0
http://poselokgribovo.ru/forum/index.php?topic=676259.0
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/196761
http://dpmarketingsystems.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i5-q1-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
http://myrechockey.com/forums/index.php?topic=84766.0
http://blog.ptpintcast.com/%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u7-%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5/
http://thermoplast.envolgroupe.com/component/k2/author/66144
https://tg.vl-mp.com/index.php?topic=1319578.0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5-25/
https://khuyenmaikk13.info/index.php?topic=177868.0
http://poselokgribovo.ru/forum/index.php?topic=700271.0
http://153.120.114.241/eso/index.php/16857764-milliardy-4-sezon-8-seria-ogb-milliardy-4-sezon-8-seria
http://poselokgribovo.ru/forum/index.php?topic=700697.0
http://married.dike.gr/index.php/component/k2/itemlist/user/40915
https://tg.vl-mp.com/index.php?topic=1299281.0
https://sanp.pro/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bf%d1%80%d0%b8%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c%d1%81%d1%8f-%d1%82%d0%be/
http://www.original-craft.net/index.php?topic=302480.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1322878
https://www.youngbiker.de/wbboard/index.php?page=User&userID=783937
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=186582
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/44096
http://wituclub.ru/forum/index.php?PHPSESSID=r5jih7if0a5ka2d7a5l8uhkha5&topic=24803.0
https://sanp.pro/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81-5/
https://www.gizmoarticle.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gpw-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8/
http://www.hoonthaitoday.com/forum/index.php?topic=104742.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1086629
http://www.critico-expository.com/forum/index.php?topic=1500.0
http://teambuildingpremium.com/forum/index.php?topic=747149.0
http://salescoach.ro/content/%D1%81%D0%BB%D1%83%D0%B3%D0%B0-%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-12-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-x4-%E3%80%90-%D1%81%D0%BB%D1%83%D0%B3%D0%B0-%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-12-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%E3%80%91-%C2%AB%D1%81%D0%BB%D1%83%D0%B3%D0%B0-%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-12
https://www.c-alice.org/forum/index.php?topic=64352.0
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=258892
http://forums.abs-cbn.com/welcome-back-kapamilya%21/to-oot-ee-3-1-e-to-oot-ee-3-1-e/?PHPSESSID=vemrvvsd1potupu3ub0i5qhet7
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=287890
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/184396
http://rudraautomation.com/index.php/component/k2/author/104957
https://reficulcoin.com/index.php?topic=6010.0
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1552533
https://sanp.pro/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81-21/
http://poselokgribovo.ru/forum/index.php?topic=688090.0
http://danielmillsap.com/forum/index.php?topic=946183.0
http://thanosakademi.com/index.php?topic=58488.0
http://muonlineint.com/forum/index.php?topic=1447.0
http://rudraautomation.com/index.php/component/k2/author/102127
http://www.hoonthaitoday.com/forum/index.php?topic=153162.0
http://sextomariotienda.com/blog/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-%d1%81%d1%82%d0%b1-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-j8h1-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
https://khuyenmaikk13.info/index.php?topic=176660.0
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wj2-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
https://khuyenmaikk13.info/index.php?topic=172103.0
http://segalahobi.com/forum/viewtopic.php?t=329819
http://forum.politeknikgihon.ac.id/index.php?topic=8419.0
http://forum.bmw-e60.eu/index.php?topic=3711.0
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-03-05-2019-%e3%80%90kl%e3%80%91-%d1%81%d0%bb%d1%83%d0%b3/
http://danielmillsap.com/forum/index.php?topic=912052.0
http://miklja.net/forum/index.php?topic=26067.0
http://forum.bmw-e60.eu/index.php?topic=591.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=287363
https://tg.vl-mp.com/index.php?topic=1314787.0
https://tg.vl-mp.com/index.php?topic=1314803.0
https://tg.vl-mp.com/index.php?topic=1314808.0
https://tg.vl-mp.com/index.php?topic=1314880.0
https://tg.vl-mp.com/index.php?topic=1314893.0
https://tg.vl-mp.com/index.php?topic=1314911.0
https://tg.vl-mp.com/index.php?topic=1314934.0
https://tg.vl-mp.com/index.php?topic=1314946.0
https://tg.vl-mp.com/index.php?topic=1315010.0
https://tg.vl-mp.com/index.php?topic=1315020.0
https://tg.vl-mp.com/index.php?topic=1315061.0
https://tg.vl-mp.com/index.php?topic=1315130.0
https://tg.vl-mp.com/index.php?topic=1315260.0
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rz8-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sw4-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tl1-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vj4-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wz0-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12/
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=162210
http://mediaville.me/index.php/component/k2/itemlist/user/191127
http://foa.egerton.ac.ke/index.php/component/k2/itemlist/user/1669601
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1128383
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1296152
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1130649
https://tg.vl-mp.com/index.php?topic=1322268.0
https://tg.vl-mp.com/index.php?topic=1322296.0
https://tg.vl-mp.com/index.php?topic=1322373.0
https://tg.vl-mp.com/index.php?topic=1322415.0
https://tg.vl-mp.com/index.php?topic=1322456.0
https://tg.vl-mp.com/index.php?topic=1322467.0
https://tg.vl-mp.com/index.php?topic=1322473.0
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cv1-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gy4-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ig1-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ig5-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-in0-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jy3-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lr9-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pj9-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rp7-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ti4-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yn3-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ek9-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hj2-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rh7-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7/
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4685587
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=302647
https://tg.vl-mp.com/index.php?topic=1255614.0
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/249995
https://tg.vl-mp.com/index.php?topic=1258583.0
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1125446
http://www.tessabannampad.go.th/webboard/index.php?topic=189326.0
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1109150
http://www.m1avio.com/?option=com_k2&view=itemlist&task=user&id=3592858
http://withinfp.sakura.ne.jp/eso/index.php/16854820-rannaa-ptaska-erkenci-kus-38-seria-e0pg-rannaa-ptaska-erkenci-k/0
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1568570
http://proxima.co.rw/index.php/component/k2/itemlist/user/537802
http://metropolis.ga/index.php?topic=1187.0
https://tg.vl-mp.com/index.php?topic=1271832.0
http://www.deliberarchia.org/forum/index.php?topic=931088.0
http://robocit.com/?option=com_k2&view=itemlist&task=user&id=448660
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=521952
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=521979
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=521985
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=522007
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=522268
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=522282
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=522598
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=522617
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=522630
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/44228
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/44280
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/44283
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/44348
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/44356
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/44433
http://www.spazioad.com/index.php/component/k2/itemlist/user/7155797
http://poselokgribovo.ru/forum/index.php?topic=647266.0
http://eugeniocolazzo.it/forum/index.php?topic=79964.0
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=2186
http://dpmarketingsystems.com/%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5%d0%bd%d0%b8%d0%b5-vuslat-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f9-%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5/
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%82%d1%80%d0%b5%d0%b9%d0%bb%d0%b5%d1%80-9-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%82%d0%be/
http://forum.byehaj.hu/index.php?topic=72482.0
https://lucky28003.nl/forum/index.php?topic=6396.0
http://www.jobref.de/node/2125798
http://blog.ptpintcast.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-b1-u4/
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1629891
http://www.deliberarchia.org/forum/index.php?topic=943848.0
https://nextezone.com/index.php?topic=32785.0
https://sanp.pro/hd-video-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-a7-k5-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://mobility-corp.com/index.php/component/k2/itemlist/user/2512169
http://poselokgribovo.ru/forum/index.php?topic=682453.0
http://poselokgribovo.ru/forum/index.php?topic=710754.0
http://www.deliberarchia.org/forum/index.php?topic=950519.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/275658
http://www.deliberarchia.org/forum/index.php?topic=922341.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=892759
http://web2interactive.com/index.php/component/k2/itemlist/user/3535555
http://multikopterforum.hu/index.php?topic=8960.0
http://rudraautomation.com/index.php/component/k2/author/105233
http://www.popolsku.fr.pl/forum/index.php?topic=367360.0
http://dev.aabn.org.gh/component/k2/itemlist/user/516517
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3679834
http://www.deliberarchia.org/forum/index.php?topic=915079.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=261571
http://soc-human.kz/index.php/component/k2/itemlist/user/1605506
http://153.120.114.241/eso/index.php/16875899-sverh-estestvennoe-14-sezon-15-seria-rbk-sverh-estestvennoe-14-
http://hydrocarbs-gh.org/index.php/component/k2/itemlist/user/7256853
http://www.m1avio.com/index.php/component/k2/itemlist/user/3591832
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kq1-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pd1-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sq1-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tt1-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-2/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wr8-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zw7-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-aq2-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cw6-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ej7-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ew0-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ew7-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ga1-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18/
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=5835
http://rudraautomation.com/index.php/component/k2/author/118988
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/187746
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1637848
http://thermoplast.envolgroupe.com/component/k2/author/71135
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/53582
http://www.arredoufficiomarca.com/index.php/component/k2/itemlist/user/1556592
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1346375
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1014316
https://tg.vl-mp.com/index.php?topic=1284646.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=892182
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4674383
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/602404
http://www.moyakmermer.com/index.php/component/k2/itemlist/user/595126
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2471577
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1984616
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=10054
http://www.arunagreen.com/index.php/component/k2/itemlist/user/389356
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1576196
http://withinfp.sakura.ne.jp/eso/index.php/16824833-nasa-istoria-72-seria-b7tv-nasa-istoria-72-seria
http://mjbosch.com/component/k2/itemlist/user/80079
http://mjbosch.com/component/k2/itemlist/user/80120
http://mjbosch.com/component/k2/itemlist/user/80127
http://mjbosch.com/component/k2/itemlist/user/80144
http://mjbosch.com/component/k2/itemlist/user/80167
http://mjbosch.com/component/k2/itemlist/user/80170
http://mjbosch.com/component/k2/itemlist/user/80186
http://mjbosch.com/component/k2/itemlist/user/80261
http://mjbosch.com/component/k2/itemlist/user/80277
http://mjbosch.com/component/k2/itemlist/user/80312
http://mjbosch.com/component/k2/itemlist/user/80403
http://mjbosch.com/component/k2/itemlist/user/80407
http://mjbosch.com/component/k2/itemlist/user/80493
http://mjbosch.com/component/k2/itemlist/user/80529
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1557038
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1557263
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1557277
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7320988
http://hydrocarbs-gh.org/index.php/component/k2/itemlist/user/7321029
http://rudraautomation.com/index.php/component/k2/author/120851
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=72092
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1557233
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1557280
http://matrixpharm.ru/forum/index.php?PHPSESSID=62m8picjgoiiiq1u815atgvub6&action=profile;u=158409
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=231916
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ygq-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://israengineering.com/index.php/component/k2/itemlist/user/1107656
http://www.deliberarchia.org/forum/index.php?topic=906572.0
http://healthyteethpa.org/index.php/component/k2/itemlist/user/5328642
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2565391
http://dpmarketingsystems.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-oy7-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8/
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=659398.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3295866
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=674273.0
http://www.pcosmetic.ir/?option=com_k2&view=itemlist&task=user&id=10367
http://condolencias.servisa.es/8-05-05-2019-y6-8
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3295671
http://withinfp.sakura.ne.jp/eso/index.php/16767878-milliardy-4-sezon-11-seria-bkc-milliardy-4-sezon-11-seria-01052/0
http://forum.stollen24.com/index.php?topic=2688.0
https://gostdep.ru/index.php?topic=2160.0
http://mvisage.sk/index.php/component/k2/itemlist/user/116155
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1316286
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=206679
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=890676
http://www.m1avio.com/index.php/component/k2/itemlist/user/3584950
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3275123
http://ptu.imoove.kr/ko/content/%D0%BF%D0%BE-%D0%B7%D0%B0%D0%BA%D0%BE%D0%BD%D0%B0%D0%BC-%D0%B2%D0%BE%D0%B5%D0%BD%D0%BD%D0%BE%D0%B3%D0%BE-%D0%B2%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%B8-2-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-11-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-v0-%D0%BF%D0%BE-%D0%B7%D0%B0%D0%BA%D0%BE%D0%BD%D0%B0%D0%BC-%D0%B2%D0%BE%D0%B5%D0%BD%D0%BD%D0%BE%D0%B3%D0%BE-%D0%B2%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%B8-2-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-11
http://roikjer.com/forum/index.php?PHPSESSID=di7epvri0g2ucdsomceq9g7m74&topic=769348.0
http://poselokgribovo.ru/forum/index.php?topic=649639.0
http://www.popolsku.fr.pl/forum/index.php?topic=368380.0
http://poselokgribovo.ru/forum/index.php?topic=646705.0
http://8.droror.co.il/uncategorized/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8/
http://poselokgribovo.ru/forum/index.php?topic=693966.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/273192
https://members.fbhaters.com/index.php?topic=69599.0
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1499585
http://withinfp.sakura.ne.jp/eso/index.php/16788044-sosedi-2-sezon-3-seria-v-efire-sosedi-2-sezon-3-seria-01052019
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/54834
http://roikjer.com/forum/index.php?PHPSESSID=45o8n0vtl0qodc59oetlp5gkh7&topic=809675.0
http://roikjer.com/forum/index.php?PHPSESSID=m4g4cvhmehf2rdng9ifube8u34&topic=796234.0
http://webp.online/index.php?topic=40232.15
http://dpordering.cetco.com/User-Profile/userId/567271
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/463120
https://reficulcoin.com/index.php?topic=8394.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90sy6%e3%80%91/
http://myrechockey.com/forums/index.php?topic=85644.0
http://danielmillsap.com/forum/index.php?topic=950333.0
http://www.deliberarchia.org/forum/index.php?topic=958098.0
https://nextezone.com/index.php?topic=30498.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d0%be%d0%bd%d0%bb%d0%b0%d0%b9%d0%bd-ssi5-%d0%b2/
http://rudraautomation.com/index.php/component/k2/author/107710
https://www.gizmoarticle.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t5-n4-%d1%80%d0%b0%d1%81%d1%81/
http://danielmillsap.com/forum/index.php?topic=947991.0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4711427
http://married.dike.gr/index.php/component/k2/itemlist/user/35812
http://myrechockey.com/forums/index.php?topic=79080.0
http://roikjer.com/forum/index.php?PHPSESSID=1n8rh1prfc6tbprn4mjfupo121&topic=785147.0
http://teambuildingpremium.com/forum/index.php?topic=759208.0
http://sextomariotienda.com/blog/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b0%d0%bd%d0%be%d0%bd%d1%81-2-%e3%80%90og1%e3%80%91-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81/
http://forum.politeknikgihon.ac.id/index.php?topic=14274.0
http://jensenbyggteam.no/index.php/component/k2/itemlist/user/12003
http://www.tessabannampad.go.th/webboard/index.php?topic=181534.0
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3681043
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=660504.0
http://www.original-craft.net/index.php?topic=294057.0
http://thefreebitcoin.com/index.php?topic=35960.0
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/976220
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1519625
http://forum.stollen24.com/index.php?topic=316.0
https://sanp.pro/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-80-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xkw-%d0%bd%d0%b5%d0%b2/
http://www.gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1832015
https://khuyenmaikk13.info/index.php?topic=159668.0
https://lucky28003.nl/forum/index.php?topic=5926.0
https://reficulcoin.com/index.php?topic=9518.0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4709766
https://adsensebih.com/index.php?topic=8127.0
http://matrixpharm.ru/forum/index.php?action=profile&u=164010
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-y1-d6-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=678318.0
https://sanp.pro/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bd%d0%b0-%d1%80%d1%83%d1%81%d1%81%d0%ba%d0%be%d0%bc-%d1%8f%d0%b7%d1%8b-10/
http://1vh.info/index.php?topic=6156.0
http://withinfp.sakura.ne.jp/eso/index.php/16881721-nasa-istoria-68-seria-rimq-nasa-istoria-68-seria/0
https://reficulcoin.com/index.php?topic=7873.0
http://myrechockey.com/forums/index.php?topic=82412.0
https://reficulcoin.com/index.php?topic=7631.0
https://reficulcoin.com/index.php?topic=2111.0
http://www.oortsociety.com/index.php?topic=9210.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=890993
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qld-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://israengineering.com/index.php/component/k2/itemlist/user/1097917
https://www.resproxy.com/forum/index.php/750301-tola-robot-7-seria-q6-tola-robot-7-seria-tola-robot-7-seria-x9/0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889114
http://macdistri.com/index.php/component/k2/itemlist/user/280398
http://webp.online/index.php?topic=42116.0
http://forum.kopkargobel.com/index.php?topic=3670.0
http://teambuildingpremium.com/forum/index.php?topic=762270.0
http://withinfp.sakura.ne.jp/eso/index.php/16785254-milliardy-4-sezon-9-seria-sxu-milliardy-4-sezon-9-seria-0105201/0
http://roikjer.com/forum/index.php?PHPSESSID=0u6lnmmlmrm2vk25truqufilv4&topic=786560.0
http://healthyteethpa.org/component/k2/itemlist/user/5309784
http://www.deliberarchia.org/forum/index.php?topic=920231.0
http://xplorefitness.com/blog/%D1%8D%D1%80%D1%82%D1%83%D0%B3%D1%80%D1%83%D0%BB-5-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-147-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-e5-%C2%AB%D1%8D%D1%80%D1%82%D1%83%D0%B3%D1%80%D1%83%D0%BB-5-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-147-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
https://www.resproxy.com/forum/index.php/741049-tola-robot-serial-data-vyhoda-na-tnt-1-1-seria-tola-robot-seria
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/456927
https://mcsetup.tk/bbs/index.php?topic=238106.0
https://tg.vl-mp.com/index.php?topic=1291103.0
http://dohairbiz.com/en/component/k2/itemlist/user/2689232.html
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=623367.0
http://teambuildingpremium.com/forum/index.php?topic=710585.0
https://altaylarteknoloji.com/index.php?topic=311.0
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=10829
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile;u=28941
http://menulisilmiah.net/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mv9u-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://www.spazioad.com/?option=com_k2&view=itemlist&task=user&id=7186012
http://www.m1avio.com/index.php/component/k2/itemlist/user/3601133
http://community.viajar.tur.br/profile/LeonardoWi
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=186837
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4707000
http://poselokgribovo.ru/forum/index.php?topic=695879.0
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=3947
http://forum.politeknikgihon.ac.id/index.php?topic=14437.0
http://forum.politeknikgihon.ac.id/index.php?topic=17224.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-8-eo-6-e-ty9-'a-etoo-8-eo-6-e-watch'/
http://withinfp.sakura.ne.jp/eso/index.php/16878047-smotret-otel-toledo-1-seria/0
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=110920
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o5-y5-%d0%b8%d0%b3%d1%80/
https://khuyenmaikk13.info/index.php?topic=174184.0
https://sanp.pro/%d0%b2%d0%be%d1%80%d0%be%d0%bd-kuzgun-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%80%d1%83%d1%81%d1%81%d0%ba%d0%b0%d1%8f-%d0%be%d0%b7%d0%b2%d1%83%d1%87%d0%ba%d0%b0-t4-%d0%b2%d0%be/
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=263749
http://macdistri.com/index.php/component/k2/itemlist/user/266345
http://www.oortsociety.com/index.php?topic=7812.0
http://menulisilmiah.net/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-04-05-2019-%e3%80%90wu%e3%80%91-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82/
http://www.tessabannampad.go.th/webboard/index.php?topic=185430.0
http://www.hoonthaitoday.com/forum/index.php?topic=129844.0
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/535349
https://www.resproxy.com/forum/index.php/778725-edinoe-serdce-tek-yurek-9-seria-x1tv-edinoe-serdce-tek-yurek-9-/0
https://tg.vl-mp.com/index.php?topic=1274497.0
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1108819
https://danceplanet.se/commodore/index.php?topic=8641.0
https://www.c-alice.org/forum/index.php?topic=66070.0
http://fbpharm.net/index.php/component/k2/itemlist/user/10287
https://www.gizmoarticle.com/new-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://www.gizmoarticle.com/%d1%81%d0%be%d0%b4%d0%b5%d1%80%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-shd-%d1%81%d0%be%d0%b4%d0%b5%d1%80%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-9-%d1%81%d0%b5%d1%80/
http://roikjer.com/forum/index.php?PHPSESSID=2iprj8cblm9rkstilc2kdn4k23&topic=754397.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=626474.0
http://www.deliberarchia.org/forum/index.php?topic=923692.0
http://www.deliberarchia.org/forum/index.php?topic=935896.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=286241
http://roikjer.com/forum/index.php?PHPSESSID=ue19uretbbt6vat50msdhrh8p5&topic=766126.0
https://npi.org.es/smf/index.php?topic=108478.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2509529
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/49834
http://macdistri.com/index.php/component/k2/itemlist/user/300996
http://poselokgribovo.ru/forum/index.php?topic=664066.0
http://153.120.114.241/eso/index.php/16846725-igra-prestolov-2019-8-sezon-6-seria-igra-prestolov-2019-8-sezon
http://www.tessabannampad.go.th/webboard/index.php?topic=184159.0
http://guiadetudo.com/index.php/component/k2/itemlist/user/10747
https://nextezone.com/index.php?topic=33953.0
http://www.theparrotcentre.com/forum/index.php?topic=451221.0
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=95924
https://forum.clubeicaro.pt/index.php?topic=340.0
https://l2thalassic.org/Forum/index.php?topic=693.0
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=715693
http://www.theparrotcentre.com/forum/index.php?topic=449430.0
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g0-c0-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://web.cas.identrics.net/phpBB3/viewtopic.php?t=123621
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/219223
https://tg.vl-mp.com/index.php?topic=1320666.0
http://www.tessabannampad.go.th/webboard/index.php?topic=186069.0
http://forum.kopkargobel.com/index.php?topic=1486.0
https://www.youngbiker.de/wbboard/index.php?page=User&userID=785341
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3250904
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3246064
https://sanp.pro/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-03-05-2019-%e3%80%90qc%e3%80%91-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-4-%d1%81%d0%b5/
http://miklja.net/forum/index.php?topic=23370.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=263828
http://www.gtupuw.org/index.php/component/k2/itemlist/user/1816322
http://www.tessabannampad.go.th/webboard/index.php?topic=182611.0
http://www.sharmaraco.com/blog/%C2%AB%D0%BF%D0%BE-%D0%B7%D0%B0%D0%BA%D0%BE%D0%BD%D0%B0%D0%BC-%D0%B2%D0%BE%D0%B5%D0%BD%D0%BD%D0%BE%D0%B3%D0%BE-%D0%B2%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-2-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-04-05-2019-mbg-%D0%BF%D0%BE-%D0%B7%D0%B0%D0%BA%D0%BE%D0%BD%D0%B0%D0%BC-%D0%B2%D0%BE%D0%B5%D0%BD%D0%BD%D0%BE%D0%B3%D0%BE-%D0%B2%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%B8-3
http://www.m1avio.com/index.php/component/k2/itemlist/user/3559869
http://www.telcon.gr/index.php/component/k2/itemlist/user/28138
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2518635
http://teambuildingpremium.com/forum/index.php?topic=714580.0
http://poselokgribovo.ru/forum/index.php?topic=700728.0
https://szenarist.ru/forum/index.php?topic=198583.0
https://lucky28003.nl/forum/index.php?topic=4349.0
http://xn--22cmah2caecpucll2cycdoj4d0knajrq3e5pbj9w0c.americanwolfthailand.com/DJPetjah/index.php?topic=1477721.0
http://www.popolsku.fr.pl/forum/index.php?topic=20407.msg632715
https://khuyenmaikk13.info/index.php?topic=176632.0
http://healthyteethpa.org/component/k2/itemlist/user/5267003
http://codeerror.in/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c7-r8-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=284308
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/154143
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-u8-d5-%d1%80/
http://help.stv.ru/index.php?PHPSESSID=a2c6f37c87c94fa9d57532b7a947276d&topic=137775.0
http://matrixpharm.ru/forum/index.php?PHPSESSID=4arhdbvpschcaule4iqg7st8o5&action=profile;u=161053
https://altaylarteknoloji.com/index.php?topic=776.0
http://muonlineint.com/forum/index.php?topic=869.0
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile&u=30671
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=200800
https://forum.ac-jete.it/index.php?topic=340306.0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=29451
http://forum.byehaj.hu/index.php?topic=77657.0
http://freebeer.me/index.php?topic=283251.0
http://multikopterforum.hu/index.php?topic=9804.0
http://help.stv.ru/index.php?PHPSESSID=c82bdf401f419881c8b5883db481d056&topic=133999.0
http://www.original-craft.net/index.php?topic=308327.0
https://reficulcoin.com/index.php?topic=2139.0
https://tg.vl-mp.com/index.php?topic=1286635.0
http://dev.aabn.org.gh/component/k2/itemlist/user/514027
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2484104
http://roikjer.com/forum/index.php?topic=780521.0
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=606029
http://withinfp.sakura.ne.jp/eso/index.php/16774578-amerikanskie-bogi-2-sezon-7-seria-bfw-amerikanskie-bogi-2-sezon/0
https://sanp.pro/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bc%d0%b5%d1%82%d0%b5%d0%be-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9/
https://tg.vl-mp.com/index.php?topic=1258801.0
https://www.resproxy.com/forum/index.php/777376-sverh-estestvennoe-14-sezon-18-seria-gkw-sverh-estestvennoe-14-/0
http://www.crnmedia.es/component/k2/itemlist/user/83347
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2527583
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1324884
http://healthyteethpa.org/component/k2/itemlist/user/5278656
https://tg.vl-mp.com/index.php?topic=1300443.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=260494
http://91.231.123.194/index.php/component/k2/itemlist/user/852809
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=53143
http://israengineering.com/index.php/component/k2/itemlist/user/1097628
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1303556
http://proxima.co.rw/index.php/component/k2/itemlist/user/556756
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/461336
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=702070
http://withinfp.sakura.ne.jp/eso/index.php/16800992-voskressij-ertugrul-143-seria-o0lq-voskressij-ertugrul-143-seri
http://www.crnmedia.es/component/k2/itemlist/user/83552
http://www.studioaparo.it/?option=com_k2&view=itemlist&task=user&id=529949
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1314540
http://married.dike.gr/index.php/component/k2/itemlist/user/34417
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1607734
http://mvisage.sk/index.php/component/k2/itemlist/user/116963
http://www.tessabannampad.go.th/webboard/index.php?topic=189774.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1079085
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=296471
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=289457
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=12168
http://c3isecurity.com.br/?option=com_k2&view=itemlist&task=user&id=458739
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=81589
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=81608
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=81641
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=81646
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=81661
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=81697
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=81698
http://rudraautomation.com/index.php/component/k2/author/108787
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=12326
http://153.120.114.241/eso/index.php/16877788-lubov-smert-i-roboty-love-death-and-robots-14-seria-nfk-lubov-s
http://seoksoononly.dothome.co.kr/qna/618663
https://www.youngbiker.de/wbboard/index.php?page=User&userID=783642
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2537657
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1533135
https://members.fbhaters.com/index.php/topic,63172.0.html
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=554340
http://mediaville.me/index.php/component/k2/itemlist/user/209482
https://tg.vl-mp.com/index.php?topic=1301149.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3253952
http://mobility-corp.com/index.php/component/k2/itemlist/user/2513704
http://mobility-corp.com/index.php/component/k2/itemlist/user/2513749
http://mobility-corp.com/index.php/component/k2/itemlist/user/2513785
http://mobility-corp.com/index.php/component/k2/itemlist/user/2513790
http://mobility-corp.com/index.php/component/k2/itemlist/user/2513875
http://mobility-corp.com/index.php/component/k2/itemlist/user/2513952
http://mobility-corp.com/index.php/component/k2/itemlist/user/2513991
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/621484
http://153.120.114.241/eso/index.php/16822942-riverdejl-riverdale-3-sezon-24-seria-wst-riverdejl-riverdale-3-
http://withinfp.sakura.ne.jp/eso/index.php/16858943-edinoe-serdce-tek-yurek-12-seria-q0ze-edinoe-serdce-tek-yurek-1/0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/177182
http://withinfp.sakura.ne.jp/eso/index.php/16803420-tol-robot-te-tol-robot/0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/453180
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1096468
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=46093
http://danielmillsap.com/forum/index.php?topic=879620.0
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/519422
http://fbpharm.net/index.php/component/k2/itemlist/user/12739
https://tg.vl-mp.com/index.php?topic=1283263.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=261073
http://withinfp.sakura.ne.jp/eso/index.php/16768456-voron-kuzgun-15-seria-y6ys-voron-kuzgun-15-seria/0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/55069
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=80880
http://menulisilmiah.net/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b4sf-%d0%b2%d0%be%d1%81%d0%ba%d1%80/
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/215005
https://members.fbhaters.com/index.php?topic=62305.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2511243
http://mobility-corp.com/index.php/component/k2/itemlist/user/2511305
http://mobility-corp.com/index.php/component/k2/itemlist/user/2511361
http://mobility-corp.com/index.php/component/k2/itemlist/user/2511479
http://mobility-corp.com/index.php/component/k2/itemlist/user/2511487
http://mobility-corp.com/index.php/component/k2/itemlist/user/2511536
http://mobility-corp.com/index.php/component/k2/itemlist/user/2511638
http://mobility-corp.com/index.php/component/k2/itemlist/user/2511647
http://mobility-corp.com/index.php/component/k2/itemlist/user/2511673
https://tg.vl-mp.com/index.php?topic=1255559.0
http://married.dike.gr/index.php/component/k2/itemlist/user/36175
https://www.resproxy.com/forum/index.php/776844-riverdejl-riverdale-3-sezon-22-seria-mgt-riverdejl-riverdale-3-/0
http://healthyteethpa.org/component/k2/itemlist/user/5284700
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1606137
http://menulisilmiah.net/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-il3-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://153.120.114.241/eso/index.php/16876665-igra-prestolov-8-sezon-2-seria-dso-igra-prestolov-8-sezon-2-ser
http://www.m1avio.com/index.php/component/k2/itemlist/user/3590785
http://married.dike.gr/index.php/component/k2/itemlist/user/39816
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3527013
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1336239
http://rudraautomation.com/index.php/component/k2/author/108793
http://dessa.com.br/index.php/component/k2/itemlist/user/302610
http://dessa.com.br/index.php/component/k2/itemlist/user/303795
http://dessa.com.br/index.php/component/k2/itemlist/user/304184
http://dessa.com.br/index.php/component/k2/itemlist/user/304456
http://dessa.com.br/index.php/component/k2/itemlist/user/304735
http://dessa.com.br/index.php/component/k2/itemlist/user/306022
http://dessa.com.br/index.php/component/k2/itemlist/user/306106
http://dessa.com.br/index.php/component/k2/itemlist/user/306619
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=172864
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1610782
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=184404
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=261554
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=38284
http://www.elpinatarense.com/?option=com_k2&view=itemlist&task=user&id=154972
http://www.moyakmermer.com/?option=com_k2&view=itemlist&task=user&id=595526
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=161498
http://mediaville.me/index.php/component/k2/itemlist/user/190774
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ahh-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://healthyteethpa.org/component/k2/itemlist/user/5286909
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1128467
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-on2-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13/
http://www.nomaher.com/forum/index.php?topic=11181.0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=565456
http://www.spazioad.com/component/k2/itemlist/user/7224104
http://www.telcon.gr/index.php/component/k2/itemlist/user/42107
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=187011c7bc020ad40c5a2ae1abbe7eab&topic=266.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=678392.0
https://khuyenmaikk13.info/index.php?topic=178436.0
https://nextezone.com/index.php?topic=34506.0
https://nextezone.com/index.php?topic=34508.0
https://npi.org.es/smf/index.php?topic=111698.0
http://www.gtupuw.org/index.php/component/k2/itemlist/user/1825828
http://www.theparrotcentre.com/forum/index.php?topic=443503.0
http://foa.egerton.ac.ke/index.php/component/k2/itemlist/user/1661476
http://roikjer.com/forum/index.php?PHPSESSID=mloh4felh59aluj5empvovkgs4&topic=783170.0
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=201900
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/168432
http://uberdrivers.net/forum/index.php?topic=210762.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/270196
https://sanp.pro/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-v8-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-5-%d1%81%d0%b5%d1%80%d0%b8/
http://www.deliberarchia.org/forum/index.php?topic=945873.0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=24836
https://nextezone.com/index.php?topic=32303.0
http://menulisilmiah.net/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-avw-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://roikjer.com/forum/index.php?PHPSESSID=3vpfbib8l5dn44ihmmonm31m51&topic=758081.0
https://khuyenmaikk13.info/index.php?topic=154850.0
http://teambuildingpremium.com/forum/index.php?topic=712660.0
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=41247
http://mahdi.ehosseini.com/?option=com_k2&view=itemlist&task=user&id=16707
http://forum.byehaj.hu/index.php?topic=74411.0
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=764404
https://www.resproxy.com/forum/index.php/715178-sluga-naroda-3-sezon-20-seria-v2-sluga-naroda-3-sezon-20-seria/0
http://muonlineint.com/forum/index.php?topic=547.0
http://myrechockey.com/forums/index.php?topic=84507.0
http://sextomariotienda.com/blog/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ku2-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://forum.politeknikgihon.ac.id/index.php?topic=15796.0
http://mir3sea.com/forum/index.php?topic=276.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-c8-f0-%d0%b8%d0%b3/
http://forum.digamahost.com/index.php?topic=108725.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=c949eff750dc4c8256c567b6dbcf6bdd&topic=205367.0
http://flashboot.ru/forum/index.php?topic=94284.0
http://www.deliberarchia.org/forum/index.php?topic=941990.0
http://sabanet.us/index.php/component/k2/itemlist/user/173380
http://sextomariotienda.com/blog/%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f2-%d1%81%d0%bb%d1%83/
http://storykingdom.forumside.com/index.php?topic=5104.0
http://teambuildingpremium.com/forum/index.php?topic=775171.0
http://www.tessabannampad.go.th/webboard/index.php?topic=191281.0
http://cccpvideo.forumside.com/index.php?topic=624.0
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-k7-a9-%d1%80/
http://e-educ.net/Forum/index.php?topic=5477.0
http://e-educ.net/Forum/index.php?topic=5479.0
http://forum.drahthaar-club.com.ua/index.php?topic=726.0
http://golyboe.ru/forum/index.php?topic=25030.0
http://metropolis.ga/index.php?topic=4028.0
http://mir3sea.com/forum/index.php?topic=1272.0
http://otitismediasociety.org/forum/index.php?topic=146092.0
http://poselokgribovo.ru/forum/index.php?topic=720790.0
http://roikjer.com/forum/index.php?PHPSESSID=lsgsd2mgrde3ltotutg1vovce5&topic=817826.0
http://roikjer.com/forum/index.php?topic=817836.0
http://wituclub.ru/forum/index.php?PHPSESSID=7n6ufncfmiebqitg0pe9l7t7i1&topic=25647.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.quattroandpartners.it/component/k2/itemlist/user/983315
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2019-%d1%81%d0%ba%d0%b0%d1%87%d0%b0%d1%82%d1%8c-%d1%82%d0%be%d1%80%d1%80%d0%b5%d0%bd%d1%82-3-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://153.120.114.241/eso/index.php/16842363-po-zakonam-voennogo-vremeni-2-sezon-12-seria-po-zakonam-voennog
http://bitpark.co.kr/board_IzjM66/3608785
https://tg.vl-mp.com/index.php?topic=1260653.0
http://sextomariotienda.com/blog/new-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-y3-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
https://www.resproxy.com/forum/index.php/738046-sluga-naroda-3-sezon-6-seria-v-efire-sluga-naroda-3-sezon-6-ser/0
http://www.popolsku.fr.pl/forum/index.php?topic=363658.0
https://www.c-alice.org/forum/index.php?topic=65802.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/460670
http://roikjer.com/forum/index.php?PHPSESSID=d1or5nigpuh908qqulvdgrlqt7&topic=795783.0
https://luckychancerescue.com/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p5-05-05-2019-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be/
http://www.deliberarchia.org/forum/index.php?topic=947652.0
https://danceplanet.se/commodore/index.php?topic=10972.0
https://lucky28003.nl/forum/index.php?topic=8859.0
https://khuyenmaikk13.info/index.php?topic=176512.0
https://danceplanet.se/commodore/index.php?topic=9349.0
http://www.theparrotcentre.com/forum/index.php?topic=449894.0
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-z8-w8-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://poselokgribovo.ru/forum/index.php?topic=692440.0
https://members.fbhaters.com/index.php/topic,64626.0.html
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3540367
https://tg.vl-mp.com/index.php?topic=1297951.0
http://www.gt3treff.de/thread.php?threadid=203623
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=39411
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1108787
http://www.deliberarchia.org/forum/index.php?topic=903498.0
http://roikjer.com/forum/index.php?topic=810786.0
https://khuyenmaikk13.info/index.php?topic=170767.0
https://tg.vl-mp.com/index.php?topic=1291048.0
https://members.fbhaters.com/index.php?topic=65767.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/184032
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=891247
http://withinfp.sakura.ne.jp/eso/index.php/16788078-lubov-smert-i-roboty-love-death-and-robots-18-seria-tce-lubov-s
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=41033
http://webp.online/index.php?topic=45653.msg74520
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1306030
http://www.arunagreen.com/index.php/component/k2/itemlist/user/376462
http://www.lustralesdevallehermoso.com/index.php/component/k2/itemlist/user/47855
http://153.120.114.241/eso/index.php/16858766-igra-prestolov-8-sezon-7-seria-ybb-igra-prestolov-8-sezon-7-ser
http://proxima.co.rw/index.php/component/k2/itemlist/user/544274
http://proxima.co.rw/index.php/component/k2/itemlist/user/544388
http://proxima.co.rw/index.php/component/k2/itemlist/user/544392
http://proxima.co.rw/index.php/component/k2/itemlist/user/544413
http://proxima.co.rw/index.php/component/k2/itemlist/user/544424
http://proxima.co.rw/index.php/component/k2/itemlist/user/544438
http://proxima.co.rw/index.php/component/k2/itemlist/user/544449
http://proxima.co.rw/index.php/component/k2/itemlist/user/544566
http://proxima.co.rw/index.php/component/k2/itemlist/user/544586
http://proxima.co.rw/index.php/component/k2/itemlist/user/544603
http://www.deliberarchia.org/forum/index.php?topic=942691.0
http://mediaville.me/index.php/component/k2/itemlist/user/204205
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=42700
http://www.m1avio.com/?option=com_k2&view=itemlist&task=user&id=3550153
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=296338
http://proxima.co.rw/index.php/component/k2/itemlist/user/546852
http://www.tessabannampad.go.th/webboard/index.php?topic=192384.0
https://tg.vl-mp.com/index.php?topic=1335702.0
http://roikjer.com/forum/index.php?PHPSESSID=7240r4guk2agkkopikkrbdcep1&topic=820461.0
http://taklongclub.com/forum/index.php?topic=99313.0
http://1vh.info/index.php?topic=13204.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=28194.0
http://ru-realty.com/forum/index.php?topic=465415.0
http://www.tessabannampad.go.th/webboard/index.php?topic=192365.0
https://danceplanet.se/commodore/index.php?topic=13639.0
https://danceplanet.se/commodore/index.php?topic=13640.0
http://storykingdom.forumside.com/index.php?topic=5466.0
http://storykingdom.forumside.com/index.php?topic=5467.0
http://withinfp.sakura.ne.jp/eso/index.php/16903272-ertugrul-149-seria-ds8-ertugrul-149-seria
http://www.critico-expository.com/forum/index.php?topic=3938.0
http://forum.politeknikgihon.ac.id/index.php?topic=19247.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=677889.0
http://myrechockey.com/forums/index.php?topic=83121.0
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=81588
http://ptu.imoove.kr/ko/content/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-2019-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90vt2%E3%80%91-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-2019-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4-%D1%81%D0%B5%D1%80%D0%B8%D1%8F330062
http://danielmillsap.com/forum/index.php?topic=948497.0
http://www.popolsku.fr.pl/forum/index.php?topic=20407.44550
http://forum.politeknikgihon.ac.id/index.php?topic=13309.0
http://salescoach.ro/content/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90kq9%E3%80%91-%E2%80%9E%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4
http://freebeer.me/index.php?topic=285572.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=25413.0
http://www.afikgan.co.il/index.php/component/k2/itemlist/user/25618
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/192972
http://sextomariotienda.com/blog/%d0%b4%d1%80%d1%83%d0%b3%d0%b0%d1%8f-i%d0%bd%d1%88%d0%b0-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i8-%d0%b4%d1%80%d1%83%d0%b3%d0%b0%d1%8f-i%d0%bd%d1%88%d0%b0-18-%d1%81%d0%b5%d1%80/
http://danielmillsap.com/forum/index.php?topic=940335.0
http://webp.online/index.php?topic=41592.0
http://HyUa.1fps.icu/l/szIaeDC
https://www.resproxy.com/forum/index.php/750692-hdvideo-igra-prestolov-8-sezon-6-seria-netflix-i6-igra-prestolo/0
http://www.quattroandpartners.it/component/k2/itemlist/user/1018657
http://teambuildingpremium.com/forum/index.php?topic=755140.0
https://sanp.pro/%d0%b6%d0%b5%d0%bd%d1%89%d0%b8%d0%bd%d0%b0-59-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-y3-%d0%b6%d0%b5%d0%bd%d1%89%d0%b8%d0%bd%d0%b0-59-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://dpmarketingsystems.com/tv-hd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r1-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://forum.politeknikgihon.ac.id/index.php?topic=17820.0
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1846802
http://forum.byehaj.hu/index.php?topic=70311.0
https://lucky28003.nl/forum/index.php?topic=4324.0
http://danielmillsap.com/forum/index.php?topic=861172.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2481267
https://members.fbhaters.com/index.php?topic=66949.0
http://blog.ptpintcast.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lostfilm-k6-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://roikjer.com/forum/index.php?PHPSESSID=trhjbb7363rs0g5818a7pff5l5&topic=754294.0
http://help.stv.ru/index.php?PHPSESSID=bdc5d495e15e60b369d77e05e0ac4f2a&topic=138273.0
http://153.120.114.241/eso/index.php/16869264-igra-prestolov-game-of-thrones-8-sezon-3-seria-igra-prestolov-g
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=46529
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2393971
https://szenarist.ru/forum/index.php?topic=203427.0
http://www.deliberarchia.org/forum/index.php?topic=954843.0
http://www.aloeverasas.it/index.php/component/k2/itemlist/user/16504
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=295488
http://www.spazioad.com/component/k2/itemlist/user/7164169
http://roikjer.com/forum/index.php?PHPSESSID=h2jvf06u90e2epeoel8s1vnh96&topic=809184.0
http://forum.stollen24.com/index.php?topic=2540.0
http://married.dike.gr/index.php/component/k2/itemlist/user/34565
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=43219
http://necinsurance.co.zw/?option=com_k2&view=itemlist&task=user&id=17238
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3358331
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1290007
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2516859
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-%d1%81%d1%8e%d0%b6%d0%b5%d1%82-3-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82/
http://dcasociados.eu/component/k2/itemlist/user/84424
http://www.deliberarchia.org/forum/index.php?topic=948102.0
http://sextomariotienda.com/blog/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-au0-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://multikopterforum.hu/index.php?topic=10747.0
http://www.theparrotcentre.com/forum/index.php?topic=442207.0
https://sanp.pro/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-7-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-phs1-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-7-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://roikjer.com/forum/index.php?PHPSESSID=skluq058bgc842i7b5rikfcui2&topic=806835.0
http://otitismediasociety.org/forum/index.php?topic=142009.0
http://matrixpharm.ru/forum/index.php?action=profile&u=159929
https://danceplanet.se/commodore/index.php?topic=12299.0
https://tg.vl-mp.com/index.php?topic=1303159.0
http://marjorieaperry.com/?option=com_k2&view=itemlist&task=user&id=479116
http://withinfp.sakura.ne.jp/eso/index.php/16861670-holostak-9-sezon-10-vypusk-polnost-u-gtholostak-9-sezon-10-vypu
http://153.120.114.241/eso/index.php/16849953-igra-prestolov-got-8-sezon-5-seria-igra-prestolov-got-8-sezon-5
http://menulisilmiah.net/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d1%83%d0%ba%d1%80%d0%b0%d0%b8%d0%bd%d0%b0-d3s3-%d1%85%d0%be%d0%bb/
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=236605
http://www.theparrotcentre.com/forum/index.php?topic=431644.0
https://reficulcoin.com/index.php?topic=6460.0
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2392748
http://www.m1avio.com/index.php/component/k2/itemlist/user/3581905
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/60312
https://reficulcoin.com/index.php?topic=2657.0
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1516337
https://forums.letstalkbeats.com/index.php?topic=60588.0
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=45067
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/431715
http://153.120.114.241/eso/index.php/16832408-sluga-naroda-3-sezon-21-seria-serial-sluga-naroda-3-sezon-21-se
http://married.dike.gr/index.php/component/k2/itemlist/user/33037
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3274435
http://dev.aabn.org.gh/component/k2/itemlist/user/473601
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=183188
http://dev.aabn.org.gh/component/k2/itemlist/user/485912
http://www.deliberarchia.org/forum/index.php?topic=955136.0
http://www.theparrotcentre.com/forum/index.php?topic=432044.0
http://forum.bmw-e60.eu/index.php?topic=2305.0
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/200868
http://muonlineint.com/forum/index.php?topic=1632.0
http://associationsila.org/index.php/component/k2/itemlist/user/273149
http://menulisilmiah.net/8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-%d1%82%d1%83%d1%80%d0%b5%d1%86%d0%ba%d0%b8%d0%b9-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%81%d0%bc%d0%be%d1%82-3/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90ys6%e3%80%91/
http://istakam.com/forum/index.php?topic=8888.0
http://married.dike.gr/index.php/component/k2/itemlist/user/46485
http://withinfp.sakura.ne.jp/eso/index.php/16770275-voron-kuzgun-15-seria-m6dx-voron-kuzgun-15-seria/0
http://www.quattroandpartners.it/component/k2/itemlist/user/1047132
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/203735
https://www.gizmoarticle.com/%d0%bb%d1%8e%d0%b1%d0%be%d0%b2%d1%8c-%d1%81%d0%bc%d0%b5%d1%80%d1%82%d1%8c-%d0%b8-%d1%80%d0%be%d0%b1%d0%be%d1%82%d1%8b-love-death-and-robots-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%80%d1%83-4/
http://forum.politeknikgihon.ac.id/index.php?topic=19200.0
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/586755
https://reficulcoin.com/index.php?topic=7375.0
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m3-%e3%80%90-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://forum.byehaj.hu/index.php?topic=76059.0
http://153.120.114.241/eso/index.php/16876362-lubov-smert-i-roboty-love-death-and-robots-10-seria-ger-lubov-s
http://puppystoreatdoral.com/?option=com_k2&view=itemlist&task=user&id=339523
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=6725
http://www.hoonthaitoday.com/forum/index.php?topic=94494.0
http://dohairbiz.com/en/?option=com_k2&view=itemlist&task=user&id=2707456
http://www.spazioad.com/?option=com_k2&view=itemlist&task=user&id=7159170
http://israengineering.com/index.php/component/k2/itemlist/user/1084142
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=110741
http://multikopterforum.hu/index.php?topic=10376.0
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fv1-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://tronsr.org/index.php?p=/discussion/79151/sluga-naroda-3-sezon-5-seriya-b5sb-sluga-naroda-3-sezon-5-seriya
http://mobility-corp.com/index.php/component/k2/itemlist/user/2513047
http://webp.online/index.php?topic=43402.0
http://forum.politeknikgihon.ac.id/index.php?topic=17078.0
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=9354
https://www.resproxy.com/forum/index.php/772904-po-zakonam-voennogo-vremeni-3-sezon-4-seria-s6-po-zakonam-voenn
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gk6-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8/
http://sextomariotienda.com/blog/05-05-2019-%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1838982
http://withinfp.sakura.ne.jp/eso/index.php/16812279-ne-otpuskaj-mou-ruku-elimi-birakma-39-seria-n9om-ne-otpuskaj-mo/0
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1667592
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/133076
http://roikjer.com/forum/index.php?PHPSESSID=1u55ko0it04b7to4bi35c3dob1&topic=781206.0
http://webp.online/index.php?topic=38952.0
https://reficulcoin.com/index.php?topic=8301.0
http://www.oortsociety.com/index.php?topic=9128.0
http://forum.politeknikgihon.ac.id/index.php?topic=11054.0
http://roikjer.com/forum/index.php?PHPSESSID=o9aqksvh8a3ho2behv4jikuja5&topic=803114.0
http://www.arunagreen.com/?option=com_k2&view=itemlist&task=user&id=382942
http://metropolis.ga/index.php?topic=2925.0
http://teambuildingpremium.com/forum/index.php?topic=710223.0
http://thanosakademi.com/index.php?topic=60654.0
http://israengineering.com/index.php/component/k2/itemlist/user/1093316
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1854727
http://taklongclub.com/forum/index.php?topic=83617.0
http://roikjer.com/forum/index.php?PHPSESSID=jeti4bq01uqp0hq643440n3r53&topic=771163.0
http://www.critico-expository.com/forum/index.php?topic=890.0
http://www.gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1804100
http://rudraautomation.com/index.php/component/k2/author/103183
http://www.ekemoon.com/141091/051020192705/
http://www.spazioad.com/component/k2/itemlist/user/7171485
http://danielmillsap.com/forum/index.php?topic=865170.0
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/635873
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/148950
http://salescoach.ro/content/%D1%81%D0%BB%D0%B5%D0%B4%D0%BE%D0%B2%D0%B0%D1%82%D0%B5%D0%BB%D1%8C-%D0%B3%D0%BE%D1%80%D1%87%D0%B0%D0%BA%D0%BE%D0%B2%D0%B0-%D1%81%D0%BBi%D0%B4%D1%87%D0%B8%D0%B9-%D0%B3%D0%BE%D1%80%D1%87%D0%B0%D0%BA%D0%BE%D0%B2%D0%B0-18-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-wtb%C2%BB-%C2%AB%D1%81%D0%BB%D0%B5%D0%B4%D0%BE%D0%B2%D0%B0%D1%82%D0%B5%D0%BB%D1%8C-%D0%B3%D0%BE%D1%80%D1%87%D0%B0%D0%BA%D0%BE%D0%B2%D0%B0-%D1%81%D0%BBi%D0%B4%D1%87%D0%B8%D0%B9
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=160466
http://matrixpharm.ru/forum/index.php?PHPSESSID=vt96pqkj03vqb9lt7ir0jtt1e0&action=profile;u=152537
https://khuyenmaikk13.info/index.php?topic=175798.0
https://sanp.pro/%d0%bd%d0%b5-%d0%be%d1%82%d0%bf%d1%83%d1%81%d0%ba%d0%b0%d0%b9-%d0%bc%d0%be%d1%8e-%d1%80%d1%83%d0%ba%d1%83-elimi-birakma-39-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-k2-%d0%bd%d0%b5-%d0%be/
https://www.c-alice.org/forum/index.php?topic=68190.0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=515906
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/39394
http://sextomariotienda.com/blog/%d0%b3%d1%80%d0%b0%d0%bd%d0%b4-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-czx-%d0%b3%d1%80%d0%b0%d0%bd%d0%b4-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81/
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/196477
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=36225
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5-2/
http://forums.abs-cbn.com/welcome-back-kapamilya%21/'a-aoa-3-eo-20-e'-cen-a-aoa-3-eo-20-e-03-05-2019/?PHPSESSID=crito593nh7mnmp10v6erst4q4
http://xn--22cmah2caecpucll2cycdoj4d0knajrq3e5pbj9w0c.americanwolfthailand.com/DJPetjah/index.php?topic=1477365.0
http://israengineering.com/index.php/component/k2/itemlist/user/1071495
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/126864
https://sanp.pro/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-81-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e6-%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82/
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1499573
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/1628
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=521381
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1104597
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/180727
http://www.autospa.lv/index.php/lv/component/k2/itemlist/user/9166
http://www.deliberarchia.org/forum/index.php?topic=905658.0
http://servicioswts.com/component/k2/itemlist/user/3593670
http://dpmarketingsystems.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-xwy-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://153.120.114.241/eso/index.php/16812473-efir-zvonar-21-seria-q0-zvonar-21-seria
http://www.popolsku.fr.pl/forum/index.php?topic=372903.0
http://withinfp.sakura.ne.jp/eso/index.php/16856069-igra-prestolovgame-of-thrones-8-sezon-3-seria-st1-igra-prestolo/0
http://forum.santrope-rp.ru/index.php?topic=2264.0
http://www.ekemoon.com/144451/050920192706/
http://multikopterforum.hu/index.php?topic=9665.0
http://www.tekparcahdfilm.com/forum/index.php?topic=46000.0
https://sanp.pro/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l5-y8-%d1%80%d0%b0%d1%81%d1%81/
https://khuyenmaikk13.info/index.php?topic=174151.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=26169.0
http://salescoach.ro/content/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90kq9%E3%80%91-%E2%80%9E%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4
http://www.ekemoon.com/143803/050320192106/
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3564821
http://menulisilmiah.net/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-03-05-2019-%e3%80%90jd%e3%80%91-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://taklongclub.com/forum/index.php?topic=79778.0
https://tg.vl-mp.com/index.php?topic=1283293.0
http://www.oortsociety.com/index.php?topic=7809.0
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1608805
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-03-05-2019-%e3%80%90pk%e3%80%91-%d1%81%d0%bb%d1%83%d0%b3/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3252168
http://withinfp.sakura.ne.jp/eso/index.php/16805242-tola-robot-7-seria-serial-kak-snimali-ty-tola-robot-7-seria-ser
http://www.theparrotcentre.com/forum/index.php?topic=428130.0
https://khuyenmaikk13.info/index.php?topic=173432.0
http://www.deliberarchia.org/forum/index.php?topic=934068.0
https://tg.vl-mp.com/index.php?topic=1291239.0
http://metropolis.ga/index.php?topic=2956.0
http://www.deliberarchia.org/forum/index.php?topic=937926.0
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-av0-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/45539
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/142021
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/445191
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/445225
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/445251
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/445280
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/445295
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/445361
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/445365
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/445373
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/445376
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/445419
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/445468
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/445496
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/445508
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/445570
http://www.m1avio.com/index.php/component/k2/itemlist/user/3599413
http://www.m1avio.com/index.php/component/k2/itemlist/user/3599583
http://www.m1avio.com/index.php/component/k2/itemlist/user/3599596
http://www.m1avio.com/index.php/component/k2/itemlist/user/3599640
http://www.m1avio.com/index.php/component/k2/itemlist/user/3599872
http://www.m1avio.com/index.php/component/k2/itemlist/user/3599979
http://www.m1avio.com/index.php/component/k2/itemlist/user/3600000
http://www.m1avio.com/index.php/component/k2/itemlist/user/3600251
http://www.m1avio.com/index.php/component/k2/itemlist/user/3600473
http://www.m1avio.com/index.php/component/k2/itemlist/user/3600554
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3249263
https://lucky28003.nl/forum/index.php?topic=9779.0
http://www.studioaparo.it/?option=com_k2&view=itemlist&task=user&id=530873
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1078187
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=41866
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-23-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sn0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3683734
http://mobility-corp.com/index.php/component/k2/itemlist/user/2472694
http://www.comfybigsize.com/?option=com_k2&view=itemlist&task=user&id=17927
http://xekhachduyetthuy.com.vn/index.php/component/k2/itemlist/user/159053
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/61015
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/446610
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/446626
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/446633
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/446677
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/446697
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/446730
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/446790
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/446821
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/446831
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/446863
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/446890
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/446952
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4825739
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4825769
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4825816
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4826158
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4826266
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4826366
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4826444
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4826511
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4826590
http://www.deliberarchia.org/forum/index.php?topic=903461.0
http://www.deliberarchia.org/forum/index.php?topic=903492.0
http://www.deliberarchia.org/forum/index.php?topic=903498.0
http://www.deliberarchia.org/forum/index.php?topic=903527.0
http://www.deliberarchia.org/forum/index.php?topic=903591.0
http://www.deliberarchia.org/forum/index.php?topic=903646.0
http://www.deliberarchia.org/forum/index.php?topic=903698.0
http://www.deliberarchia.org/forum/index.php?topic=903820.0
http://www.deliberarchia.org/forum/index.php?topic=903875.0
http://www.deliberarchia.org/forum/index.php?topic=903948.0
http://www.deliberarchia.org/forum/index.php?topic=903978.0
http://www.deliberarchia.org/forum/index.php?topic=904198.0
http://www.deliberarchia.org/forum/index.php?topic=904219.0
http://www.deliberarchia.org/forum/index.php?topic=904252.0
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vj4-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vq0-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vq9-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vt4-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wv2-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wz0-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12/
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=891284
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1861409
https://tg.vl-mp.com/index.php?topic=1298104.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vkd-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.deliberarchia.org/forum/index.php?topic=944026.0
https://members.fbhaters.com/index.php?topic=59287.0
http://www.deliberarchia.org/forum/index.php?topic=940317.0
http://seoksoononly.dothome.co.kr/qna/592774
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=76765
http://mediaville.me/index.php/component/k2/itemlist/user/194460
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=290784
http://www.deliberarchia.org/forum/index.php?topic=919767.0
http://www.deliberarchia.org/forum/index.php?topic=919214.0
http://www.deliberarchia.org/forum/index.php?topic=919265.0
http://www.deliberarchia.org/forum/index.php?topic=919287.0
http://www.deliberarchia.org/forum/index.php?topic=919295.0
http://www.deliberarchia.org/forum/index.php?topic=919313.0
http://www.deliberarchia.org/forum/index.php?topic=919331.0
http://www.deliberarchia.org/forum/index.php?topic=919338.0
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xi6-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yn3-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yz8-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ek9-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ew7-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gq3-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hj2-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-iz4-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7/
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lh0-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7/
http://rudraautomation.com/index.php/component/k2/author/102733
http://repofirmware.altervista.org/index.php?topic=99395.0
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=238173
http://married.dike.gr/index.php/component/k2/itemlist/user/38484
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/456155
http://danielmillsap.com/forum/index.php?topic=878843.0
http://healthyteethpa.org/component/k2/itemlist/user/5278927
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1833595
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1107696
http://www.comfybigsize.com/index.php/component/k2/itemlist/user/15751
https://members.fbhaters.com/index.php?topic=62997.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3580833
http://matrixpharm.ru/forum/index.php?PHPSESSID=49iatrsc31spfhrpm342asiam4&action=profile;u=152382
http://dpmarketingsystems.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-lzr-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1314762
http://mobility-corp.com/index.php/component/k2/itemlist/user/2460842
http://yuptalk.ru//-t11726.0.html
http://8.droror.co.il/uncategorized/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zjm-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://www.c-alice.org/forum/index.php?topic=62440.0
https://www.gizmoarticle.com/%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5%d0%bd%d0%b8%d0%b5-vuslat-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e3-%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5%d0%bd/
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=250349
https://forums.letstalkbeats.com/index.php?topic=57178.0
https://www.c-alice.org/forum/index.php?topic=61755.0
http://teambuildingpremium.com/forum/index.php?topic=738581.0
http://www.theparrotcentre.com/forum/index.php?topic=441009.0
http://www.popolsku.fr.pl/forum/index.php?topic=366799.0
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a4-c4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://www.theparrotcentre.com/forum/index.php?topic=438175.0
http://menulisilmiah.net/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-10-05-2019-i8w3-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81/
http://freebeer.me/index.php?topic=294199.0
http://8.droror.co.il/uncategorized/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81-7/
http://seoksoononly.dothome.co.kr/?document_srl=609073
http://uberdrivers.net/forum/index.php?topic=212743.0
http://associationsila.org/index.php/component/k2/itemlist/user/274656
http://www.arunagreen.com/?option=com_k2&view=itemlist&task=user&id=402326
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/177264
http://smartacity.com/component/k2/itemlist/user/11676
https://www.resproxy.com/forum/index.php/745929-milliardy-4-sezon-5-seria-wvi-milliardy-4-sezon-5-seria/0
http://www.deliberarchia.org/forum/index.php?topic=907712.0
http://www.oortsociety.com/index.php?topic=6394.0
http://withinfp.sakura.ne.jp/eso/index.php/16802330-nasa-istoria-73-seria-d2ny-nasa-istoria-73-seria/0
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1521534
http://macdistri.com/index.php/component/k2/itemlist/user/259765
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889569
http://dessa.com.br/index.php/component/k2/itemlist/user/294645
https://tg.vl-mp.com/index.php?topic=1265998.0
https://tg.vl-mp.com/index.php?topic=1266053.0
https://tg.vl-mp.com/index.php?topic=1266138.0
https://tg.vl-mp.com/index.php?topic=1266150.0
https://tg.vl-mp.com/index.php?topic=1266324.0
https://tg.vl-mp.com/index.php?topic=1266334.0
https://tg.vl-mp.com/index.php?topic=1266368.0
https://tg.vl-mp.com/index.php?topic=1266394.0
https://tg.vl-mp.com/index.php?topic=1266467.0
https://tg.vl-mp.com/index.php?topic=1266473.0
https://tg.vl-mp.com/index.php?topic=1266530.0
https://tg.vl-mp.com/index.php?topic=1266627.0
https://tg.vl-mp.com/index.php?topic=1266637.0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=39147
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1315372
http://macdistri.com/index.php/component/k2/itemlist/user/289524
http://macdistri.com/index.php/component/k2/itemlist/user/264807
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1295532
http://www.sakitoandrichifantasy.gr/?option=com_k2&view=itemlist&task=user&id=138455
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2531930
http://associationsila.org/component/k2/itemlist/user/261442
http://seoksoononly.dothome.co.kr/qna/612587
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rdy-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://dessa.com.br/index.php/component/k2/itemlist/user/291815
http://withinfp.sakura.ne.jp/eso/index.php/16883627-igra-prestolovgame-of-thrones-8-sezon-4-seria-iz0-igra-prestolo/0
http://withinfp.sakura.ne.jp/eso/index.php/16883694-igra-prestolov-2019-8-sezon-7-seria-gs1-igra-prestolov-2019-8-s/0
http://www.remify.app/foro/index.php?topic=220414.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190717.0
http://www.theparrotcentre.com/forum/index.php?topic=456200.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=678568.0
https://members.fbhaters.com/index.php?topic=75027.0
https://nextezone.com/index.php?topic=34731.0
https://nextezone.com/index.php?topic=34735.0
https://tg.vl-mp.com/index.php?topic=1325349.0
https://www.thedezlab.com/lab/community/index.php?topic=394.0
http://multikopterforum.hu/index.php?topic=11649.0
http://poselokgribovo.ru/forum/index.php?topic=714803.0
http://poselokgribovo.ru/forum/index.php?topic=714826.0
http://poselokgribovo.ru/forum/index.php?topic=714836.0
http://www.hoonthaitoday.com/forum/index.php?topic=132077.0
http://forum.kopkargobel.com/index.php?topic=2945.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=24661.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1330864
http://1vh.info/index.php?topic=10270.0
https://members.fbhaters.com/index.php?topic=73667.0
http://roikjer.com/forum/index.php?PHPSESSID=dmt7dtdsd3qco9njlg29b51dm1&topic=796531.0
http://blog.ptpintcast.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-w4-k7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
http://blog.ptpintcast.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l8-z0-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://poselokgribovo.ru/forum/index.php?topic=709033.0
http://multikopterforum.hu/index.php?topic=10348.0
http://mir3sea.com/forum/index.php?topic=405.0
http://www.tekparcahdfilm.com/forum/index.php?topic=45555.0
http://www.hoonthaitoday.com/forum/index.php?topic=144169.0
http://multikopterforum.hu/index.php?topic=4806.0
https://nextezone.com/index.php?topic=30262.0
http://forum.bmw-e60.eu/index.php?topic=1786.0
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q3-i2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://mir3sea.com/forum/index.php?topic=369.0
http://8.droror.co.il/uncategorized/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-5/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1327071
http://HyUa.1fps.icu/l/szIaeDC
http://macdistri.com/?option=com_k2&view=itemlist&task=user&id=262577
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/50211
http://healthyteethpa.org/component/k2/itemlist/user/5290000
http://menulisilmiah.net/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-iwd-%d1%80%d0%b0/
http://fbpharm.net/index.php/component/k2/itemlist/user/9492
http://www.spazioad.com/component/k2/itemlist/user/7163194
http://www.spazioad.com/component/k2/itemlist/user/7163252
http://www.spazioad.com/component/k2/itemlist/user/7163257
http://www.spazioad.com/component/k2/itemlist/user/7163279
http://www.spazioad.com/component/k2/itemlist/user/7163306
http://www.spazioad.com/component/k2/itemlist/user/7163340
http://www.spazioad.com/component/k2/itemlist/user/7163561
http://www.spazioad.com/component/k2/itemlist/user/7163597
http://www.spazioad.com/component/k2/itemlist/user/7163713
http://thermoplast.envolgroupe.com/component/k2/author/67318
http://thermoplast.envolgroupe.com/component/k2/author/67344
http://thermoplast.envolgroupe.com/component/k2/author/67349
http://thermoplast.envolgroupe.com/component/k2/author/67366
http://thermoplast.envolgroupe.com/component/k2/author/67381
http://thermoplast.envolgroupe.com/component/k2/author/67387
http://thermoplast.envolgroupe.com/component/k2/author/67395
http://thermoplast.envolgroupe.com/component/k2/author/67404
http://thermoplast.envolgroupe.com/component/k2/author/67420
http://thermoplast.envolgroupe.com/component/k2/author/67426
http://thermoplast.envolgroupe.com/component/k2/author/67455
http://thermoplast.envolgroupe.com/component/k2/author/67473
http://thermoplast.envolgroupe.com/component/k2/author/67499
http://thermoplast.envolgroupe.com/component/k2/author/67553
http://withinfp.sakura.ne.jp/eso/index.php/16824668-edinoe-serdce-tek-yurek-12-seria-o7qi-edinoe-serdce-tek-yurek-1
http://withinfp.sakura.ne.jp/eso/index.php/16824774-voron-kuzgun-18-seria-e3eu-voron-kuzgun-18-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/16824781-edinoe-serdce-tek-yurek-17-seria-m3wd-edinoe-serdce-tek-yurek-1
http://withinfp.sakura.ne.jp/eso/index.php/16824883-edinoe-serdce-tek-yurek-20-seria-w7qc-edinoe-serdce-tek-yurek-2/0
http://withinfp.sakura.ne.jp/eso/index.php/16824928-voron-kuzgun-10-seria-k5do-voron-kuzgun-10-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/16824983-rannaa-ptaska-erkenci-kus-37-seria-n2mi-rannaa-ptaska-erkenci-k/0
http://withinfp.sakura.ne.jp/eso/index.php/16824988-nasa-istoria-69-seria-v4rv-nasa-istoria-69-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/16825039-voron-kuzgun-9-seria-x8nh-voron-kuzgun-9-seria
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889140
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889148
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889162
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889201
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889222
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889226
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889252
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889271
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889275
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889291
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889293
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889296
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889298
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889321
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889339
http://comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=103823
http://comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=103876
http://comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=103934
http://comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=103941
http://comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=103951
http://comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=104006
http://comfortcenter.es/index.php/component/k2/itemlist/user/104014
http://dcasociados.eu/component/k2/itemlist/user/86595
http://dcasociados.eu/component/k2/itemlist/user/86602
http://dcasociados.eu/component/k2/itemlist/user/86616
http://dcasociados.eu/component/k2/itemlist/user/86672
http://dcasociados.eu/component/k2/itemlist/user/86692
http://dcasociados.eu/component/k2/itemlist/user/86695
http://dev.aabn.org.gh/?option=com_k2&view=itemlist&task=user&id=513895
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=263719
http://www.deliberarchia.org/forum/index.php?topic=938703.0
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1861924
http://webp.online/index.php?topic=38174.30
https://www.resproxy.com/forum/index.php/728595-smotret-serial-tola-robot-8-seria-wh-smotret-serial-tola-robot-
http://www.sakitoandrichifantasy.gr/?option=com_k2&view=itemlist&task=user&id=143591
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=235535
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1762995
https://sto54.ru/index.php/component/k2/itemlist/user/3250794
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2471551
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2471577
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2471766
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2471793
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2471814
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2471826
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2471971
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2472034
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2472097
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2472112
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2472482
http://www.spazioad.com/component/k2/itemlist/user/7175804
http://www.spazioad.com/component/k2/itemlist/user/7176024
http://www.spazioad.com/component/k2/itemlist/user/7176173
http://www.spazioad.com/component/k2/itemlist/user/7176489
http://www.spazioad.com/component/k2/itemlist/user/7176623
http://www.spazioad.com/component/k2/itemlist/user/7176850
http://www.spazioad.com/component/k2/itemlist/user/7177570
http://www.spazioad.com/component/k2/itemlist/user/7177646
http://www.spazioad.com/component/k2/itemlist/user/7177775
http://www.spazioad.com/component/k2/itemlist/user/7178143
http://www.spazioad.com/component/k2/itemlist/user/7178186
http://www.spazioad.com/component/k2/itemlist/user/7178550
http://www.spazioad.com/component/k2/itemlist/user/7178715
http://www.tvmechanic.co.in/forum/index.php?topic=7817.0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=28566
http://macdistri.com/index.php/component/k2/itemlist/user/256467
http://robocit.com/?option=com_k2&view=itemlist&task=user&id=448907
http://153.120.114.241/eso/index.php/16840111-igra-prestolovgame-of-thrones-8-sezon-3-seria-cp3-igra-prestolo
https://nextezone.com/index.php?topic=32838.0
http://dpmarketingsystems.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-s1-%d1%81/
http://euromouleusinage.com/index.php/component/k2/itemlist/user/104442
http://macdistri.com/index.php/component/k2/itemlist/user/298934
http://www.elpinatarense.es/index.php/component/k2/itemlist/user/154521
http://dohairbiz.com/?option=com_k2&view=itemlist&task=user&id=2708108
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1859726
http://ru-realty.com/forum/index.php?PHPSESSID=1tfe2e5tomjg8otfgcsdg5nl43&topic=444927.0
https://forums.letstalkbeats.com/index.php?topic=58917.0
http://forum.byehaj.hu/index.php?topic=77206.0
http://dessa.com.br/component/k2/itemlist/user/293783
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2541443
http://roikjer.com/forum/index.php?PHPSESSID=3ilfglgejdmlj07q37tfvjdqh6&topic=791233.0
http://multikopterforum.hu/index.php?topic=7236.0
https://www.mutlualisverisler.com/?p=970709
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-s6-%e3%80%90-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://uberdrivers.net/forum/index.php?topic=201409.0
http://bobr.site/index.php?topic=91060.0
http://www.phperos.net/foro/index.php?topic=128887.0
http://www.spazioad.com/component/k2/itemlist/user/7202364
http://theolevolosproject.org/index.php/component/k2/itemlist/user/23903
http://uberdrivers.net/forum/index.php?topic=218991.0
https://danceplanet.se/commodore/index.php?topic=8382.0
http://myrechockey.com/forums/index.php?topic=82217.0
http://macdistri.com/component/k2/itemlist/user/290392
https://reficulcoin.com/index.php?topic=7859.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=275128
http://myrechockey.com/forums/index.php?topic=83647.0
http://myrechockey.com/forums/index.php?topic=84530.0
https://lucky28003.nl/forum/index.php?topic=8283.0
http://miquirofisico.com/index.php/component/k2/itemlist/user/3689
http://macdistri.com/index.php/component/k2/itemlist/user/289468
http://golyboe.ru/forum/index.php?topic=24694.0
http://roikjer.com/forum/index.php?PHPSESSID=usccrlbgs4p5s2g39vdei80l14&topic=801522.0
https://sanp.pro/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g5-m4-%d1%80%d0%b0%d1%81%d1%81/
http://withinfp.sakura.ne.jp/eso/index.php/16863578-drugaa-insa-18-seria-05052019/0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5-23/
http://siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=751235
https://members.fbhaters.com/index.php?topic=73801.0
http://roikjer.com/forum/index.php?topic=789952.0
http://forum.elexlabs.com/index.php?topic=11951.0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90xn4%e3%80%91-%d0%b8%d0%b3/
http://jpacschoolclubs.co.uk/?option=com_k2&view=itemlist&task=user&id=3337810
http://roikjer.com/forum/index.php?PHPSESSID=m24bgv5kr6sdo55l3op0mk9up0&topic=794623.0
http://dpmarketingsystems.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o9-%d1%81/
https://sanp.pro/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j9-g9-%d1%80%d0%b0%d1%81%d1%81/
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w4-r1-%d1%80%d0%b0%d1%81%d1%81/
https://members.fbhaters.com/index.php/topic,71764.0.html
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=26049.0
http://multikopterforum.hu/index.php?topic=7073.0
http://roikjer.com/forum/index.php?topic=810080.0
http://ru-realty.com/forum/index.php?PHPSESSID=a9udoaeo2o47lc57njh7oluvq2&topic=457238.0
http://batubersurat.com/index.php/component/k2/itemlist/user/41986
http://danielmillsap.com/forum/index.php?topic=952013.0
http://mir3sea.com/forum/index.php?topic=721.0
https://sanp.pro/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x0-i6-%d1%80%d0%b0/
http://HyUa.1fps.icu/l/szIaeDC
https://tg.vl-mp.com/index.php?topic=1263967.0
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1609487
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1551551
http://www.elpinatarense.com/index.php/component/k2/itemlist/user/154798
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3269713
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=604024
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=267404
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3251582
http://boutique.in.th/?option=com_k2&view=itemlist&task=user&id=146408
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4664517
http://www.deliberarchia.org/forum/index.php?topic=954163.0
https://tg.vl-mp.com/index.php?topic=1268006.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=892846
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4717227
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2496205
http://hydrocarbs-gh.org/index.php/component/k2/itemlist/user/7285758
http://seoksoononly.dothome.co.kr/qna/598452
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=607875
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dc6-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10/
http://www.sopcich.com/UserProfile/tabid/42/UserID/1670333/Default.aspx
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=261296
http://soc-human.kz/index.php/component/k2/itemlist/user/1603723
http://fbpharm.net/index.php/component/k2/itemlist/user/10188
http://fbpharm.net/index.php/component/k2/itemlist/user/10195
http://fbpharm.net/index.php/component/k2/itemlist/user/10215
http://fbpharm.net/index.php/component/k2/itemlist/user/10229
http://fbpharm.net/index.php/component/k2/itemlist/user/10231
http://fbpharm.net/index.php/component/k2/itemlist/user/10242
http://fbpharm.net/index.php/component/k2/itemlist/user/10264
http://fbpharm.net/index.php/component/k2/itemlist/user/10268
http://fbpharm.net/index.php/component/k2/itemlist/user/10287
http://fbpharm.net/index.php/component/k2/itemlist/user/10305
http://fbpharm.net/index.php/component/k2/itemlist/user/10312
http://storykingdom.forumside.com/index.php?topic=4245.0
http://socialfbwidgets.com/?option=com_k2&view=itemlist&task=user&id=12765
http://www.critico-expository.com/forum/index.php?topic=1819.0
http://poselokgribovo.ru/forum/index.php?topic=708980.0
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p3-y1-%d0%b8%d0%b3%d1%80/
https://adsensebih.com/index.php?topic=8040.0
http://married.dike.gr/index.php/component/k2/itemlist/user/43771
http://vtservices85.fr/smf2/index.php?topic=208471.0
http://otitismediasociety.org/forum/index.php?topic=144436.0
http://multikopterforum.hu/index.php?topic=7803.0
http://www.tessabannampad.go.th/webboard/index.php?topic=187190.0
http://forum.drahthaar-club.com.ua/index.php?topic=444.0
http://www.quattroandpartners.it/component/k2/itemlist/user/1029471
http://forum.politeknikgihon.ac.id/index.php?topic=16200.0
http://married.dike.gr/index.php/component/k2/itemlist/user/43299
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-k5-c0/
https://doe.go.th/prd/forum_nongkhai/1517760-149-kw0-149
http://sextomariotienda.com/blog/05-05-2019-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://forum.digamahost.com/index.php?topic=108285.0
http://golyboe.ru/forum/index.php?topic=24850.0
http://poselokgribovo.ru/forum/index.php?topic=688559.0
http://dpmarketingsystems.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-05-05-2019-2/
http://www.obal-shop.sk/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d5-g3-%d1%80%d0%b0%d1%81%d1%81/
http://muonlineint.com/forum/index.php?topic=1099.0
https://lucky28003.nl/forum/index.php?topic=8066.0
http://sextomariotienda.com/blog/%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0%d1%8f-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b0-%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be%d0%b1%d0%be%d1%82%d0%b0-16-%d1%81%d0%b5-29/
http://poselokgribovo.ru/forum/index.php?topic=697662.0
https://hackersuniversity.net/index.php/topic,6989.0.html
http://www.deliberarchia.org/forum/index.php?topic=945101.0
http://forum.politeknikgihon.ac.id/index.php?topic=17842.0
http://myrechockey.com/forums/index.php?topic=84902.0
http://sochi-forum.info/index.php?topic=442.0
http://forum.politeknikgihon.ac.id/index.php?topic=16042.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/998183
http://withinfp.sakura.ne.jp/eso/index.php/16788627-igra-prestolov-8-sezon-8-seria-lap-igra-prestolov-8-sezon-8-ser/0
https://tg.vl-mp.com/index.php?topic=1269909.0
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cp6-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8/
http://withinfp.sakura.ne.jp/eso/index.php/16774127-cernoe-zerkalo-5-sezon-3-seria-ves-cernoe-zerkalo-5-sezon-3-ser?---------------------------774130814%0D%0AContent-Disposition:%20form-data;%20name=%22token%22%0D%0A%0D%0Aa13e7f6a71966%0D%0A---------------------------774130814%0D%0AContent-Disposition:%20form-data;%20name=%22title%22%0D%0A%0D%0A%C2%AB%D0%A7%D0%B5%D1%80%D0%BD%D0%BE%D0%B5%20%D0%97%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE%205%20%D0%A1%D0%B5%D0%B7%D0%BE%D0%BD%203%20%D0%A1%D0%B5%D1%80%D0%B8%D1%8F%C2%BB%20,%20VeS,%20%C2%AB%D0%A7%D0%B5%D1%80%D0%BD%D0%BE%D0%B5%20%D0%97%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE%205%20%D0%A1%D0%B5%D0%B7%D0%BE%D0%BD%203%20%D0%A1%D0%B5%D1%80%D0%B8%D1%8F%C2%BB%2001-05-2019%0D%0A---------------------------774130814%0D%0AContent-Disposition:%20form-data;%20name=%22content%22%0D%0A%0D%0A%C2%AB%D0%A7%D0%B5%D1%80%D0%BD%D0%BE%D0%B5%20%D0%B7%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE%205%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%203%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB%20%D1%81%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C%20%D0%BE%D0%BD-%D0%BB%D0%B0%D0%B9%D0%BD%20%D1%81%D0%B5%D1%80%D0%B8%D0%B0%D0%BB%20%D0%A7%D0%B5%D1%80%D0%BD%D0%BE%D0%B5%20%D0%B7%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE%205%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%203%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%E2%80%99%D1%81%D0%B5%20%D1%81%D0%B5%D1%80%D0%B8%D0%B8%20(2018)%20%D1%81%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C%20%D0%BE%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD%20%D1%81%20%D0%BF%D0%B5%D1%80%D0%B5%D0%B2%D0%BE%D0%B4%D0%BE%D0%BC%0D%0A%0D%0A[url=http://hbocom.ru/dc/watch.php%3Fid=782/s5e3/][img]https://i.imgur.com/DekfSKM.jpg[/img][/url]%0D%0A%0D%0A[url=http://hbocom.ru/dc/watch.php%3Fid=782/s5e3/]%D0%A7%D0%B5%D1%80%D0%BD%D0%BE%D0%B5%20%D0%B7%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE%205%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%203%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F[/url]%0D%0A[url=http://hbocom.ru/dc/watch.php%3Fid=782/s5e3/]%D0%A7%D0%B5%D1%80%D0%BD%D0%BE%D0%B5%20%D0%B7%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE%205%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%203%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F[/url]%20%0D%0A[url=http://hbocom.ru/dc/watch.php%3Fid=782/s5e3/]%D0%A7%D0%B5%D1%80%D0%BD%D0%BE%D0%B5%20%D0%B7%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE%205%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%203%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F[/url]%20%0D%0A%0D%0A%D0%A7%D0%B5%D1%80%D0%BD%D0%BE%D0%B5%20%D0%B7%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE%205%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%203%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%BE%D0%BA%0D%0A%D0%A7%D0%B5%D1%80%D0%BD%D0%BE%D0%B5%20%D0%B7%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE%205%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%203%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D1%82%D0%B2%0D%0A%D0%A7%D0%B5%D1%80%D0%BD%D0%BE%D0%B5%20%D0%B7%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE%205%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%203%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20vk%0D%0A%3E%D0%A7%D0%B5%D1%80%D0%BD%D0%BE%D0%B5%20%D0%B7%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE%205%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%203%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%B0%D0%BB%D0%B8%D1%88%D0%B0%20%D0%B4%D0%B8%D0%BB%D0%B8%D1%80%D0%B8%D1%81%0D%0A---------------------------774130814%0D%0AContent-Disposition:%20form-data;%20name=%22postReply%22%0D%0A%0D%0A%E3%83%88%E3%83%94%E3%83%83%E3%82%AF%E3%82%E2%80%99%E7%AB%8B%E3%81%A6%E3%82%8B%0D%0A---------------------------774130814--%0D%0A&---------------------------774130814%0D%0AContent-Disposition:%20form-data;%20name=%22token%22%0D%0A%0D%0Aa13e7f6a71966%0D%0A---------------------------774130814%0D%0AContent-Disposition:%20form-data;%20name=%22title%22%0D%0A%0D%0A%C2%AB%D0%A7%D0%B5%D1%80%D0%BD%D0%BE%D0%B5%20%D0%97%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE%205%20%D0%A1%D0%B5%D0%B7%D0%BE%D0%BD%203%20%D0%A1%D0%B5%D1%80%D0%B8%D1%8F%C2%BB%20,%20VeS,%20%C2%AB%D0%A7%D0%B5%D1%80%D0%BD%D0%BE%D0%B5%20%D0%97%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE%205%20%D0%A1%D0%B5%D0%B7%D0%BE%D0%BD%203%20%D0%A1%D0%B5%D1%80%D0%B8%D1%8F%C2%BB%2001-05-2019%0D%0A---------------------------774130814%0D%0AContent-Disposition:%20form-data;%20name=%22content%22%0D%0A%0D%0A%C2%AB%D0%A7%D0%B5%D1%80%D0%BD%D0%BE%D0%B5%20%D0%B7%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE%205%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%203%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB%20%D1%81%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C%20%D0%BE%D0%BD-%D0%BB%D0%B0%D0%B9%D0%BD%20%D1%81%D0%B5%D1%80%D0%B8%D0%B0%D0%BB%20%D0%A7%D0%B5%D1%80%D0%BD%D0%BE%D0%B5%20%D0%B7%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE%205%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%203%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%E2%80%99%D1%81%D0%B5%20%D1%81%D0%B5%D1%80%D0%B8%D0%B8%20(2018)%20%D1%81%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C%20%D0%BE%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD%20%D1%81%20%D0%BF%D0%B5%D1%80%D0%B5%D0%B2%D0%BE%D0%B4%D0%BE%D0%BC%0D%0A%0D%0A[url=http://hbocom.ru/dc/watch.php%3Fid=782/s5e3/][img]https://i.imgur.com/DekfSKM.jpg[/img][/url]%0D%0A%0D%0A[url=http://hbocom.ru/dc/watch.php%3Fid=782/s5e3/]%D0%A7%D0%B5%D1%80%D0%BD%D0%BE%D0%B5%20%D0%B7%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE%205%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%203%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F[/url]%0D%0A[url=http://hbocom.ru/dc/watch.php%3Fid=782/s5e3/]%D0%A7%D0%B5%D1%80%D0%BD%D0%BE%D0%B5%20%D0%B7%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE%205%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%203%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F[/url]%20%0D%0A[url=http://hbocom.ru/dc/watch.php%3Fid=782/s5e3/]%D0%A7%D0%B5%D1%80%D0%BD%D0%BE%D0%B5%20%D0%B7%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE%205%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%203%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F[/url]%20%0D%0A%0D%0A%D0%A7%D0%B5%D1%80%D0%BD%D0%BE%D0%B5%20%D0%B7%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE%205%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%203%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%BE%D0%BA%0D%0A%D0%A7%D0%B5%D1%80%D0%BD%D0%BE%D0%B5%20%D0%B7%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE%205%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%203%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D1%82%D0%B2%0D%0A%D0%A7%D0%B5%D1%80%D0%BD%D0%BE%D0%B5%20%D0%B7%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE%205%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%203%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20vk%0D%0A%3E%D0%A7%D0%B5%D1%80%D0%BD%D0%BE%D0%B5%20%D0%B7%D0%B5%D1%80%D0%BA%D0%B0%D0%BB%D0%BE%205%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%203%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%B0%D0%BB%D0%B8%D1%88%D0%B0%20%D0%B4%D0%B8%D0%BB%D0%B8%D1%80%D0%B8%D1%81%0D%0A---------------------------774130814%0D%0AContent-Disposition:%20form-data;%20name=%22postReply%22%0D%0A%0D%0A%E3%83%88%E3%83%94%E3%83%83%E3%82%AF%E3%82%E2%80%99%E7%AB%8B%E3%81%A6%E3%82%8B%0D%0A---------------------------774130814--
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1335070
http://www.m1avio.com/index.php/component/k2/itemlist/user/3582891
http://www.m1avio.com/index.php/component/k2/itemlist/user/3583142
http://www.m1avio.com/index.php/component/k2/itemlist/user/3583364
http://www.m1avio.com/index.php/component/k2/itemlist/user/3583440
http://www.m1avio.com/index.php/component/k2/itemlist/user/3583475
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=9900
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=9914
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=9950
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=9984
http://fbpharm.net/index.php/component/k2/itemlist/user/10008
http://fbpharm.net/index.php/component/k2/itemlist/user/10013
http://fbpharm.net/index.php/component/k2/itemlist/user/10037
http://fbpharm.net/index.php/component/k2/itemlist/user/10038
http://fbpharm.net/index.php/component/k2/itemlist/user/10055
http://fbpharm.net/index.php/component/k2/itemlist/user/10061
http://fbpharm.net/index.php/component/k2/itemlist/user/10086
http://fbpharm.net/index.php/component/k2/itemlist/user/10145
http://fbpharm.net/index.php/component/k2/itemlist/user/10152
http://fbpharm.net/index.php/component/k2/itemlist/user/10172
https://szenarist.ru/forum/index.php?topic=199614.0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=291602
http://forums.abs-cbn.com/welcome-back-kapamilya%21/'om-17-e'-gt-gt-'om-17-e'-oa-ok-kotoe-e/?PHPSESSID=6s8cpimbmk6ttjr491qtqauv70
http://www.tessabannampad.go.th/webboard/index.php?topic=176670.0
https://sanp.pro/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bks-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8/
http://www.popolsku.fr.pl/forum/index.php?topic=371017.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/169862
https://www.shoppidlok.com/smf/index.php?topic=237.0
https://tg.vl-mp.com/index.php?topic=1256222.0
http://roikjer.com/forum/index.php?PHPSESSID=dh8783c4v7mn21igsrq4sdpib1&topic=762853.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2523233
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=6360.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/532746
https://www.regalepadova.it/index.php/component/k2/itemlist/user/5912
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=161269
http://www.deliberarchia.org/forum/index.php?topic=937098.0
http://danielmillsap.com/forum/index.php?topic=865611.0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/395152
http://dpmarketingsystems.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lno-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://www.hoonthaitoday.com/forum/index.php?topic=95255.0
https://khuyenmaikk13.info/index.php?topic=176458.0
http://poselokgribovo.ru/forum/index.php?topic=715014.0
http://ru-realty.com/forum/index.php?PHPSESSID=pj6ffe7sjucvdfuaffa6guan53&topic=459376.0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4722703
http://www.hoonthaitoday.com/forum/index.php?topic=159389.0
https://danceplanet.se/commodore/index.php?topic=12529.0
http://bobr.site/index.php?topic=91701.0
http://codeerror.in/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f2-j9-%d0%b8%d0%b3%d1%80/
http://danielmillsap.com/forum/index.php?topic=953813.0
http://forum.bmw-e60.eu/index.php?topic=3784.0
http://forum.bmw-e60.eu/index.php?topic=3785.0
http://forum.kopkargobel.com/index.php?topic=4571.0
http://forum.kopkargobel.com/index.php?topic=4573.0
http://freebeer.me/index.php?topic=299535.0
http://freebeer.me/index.php?topic=299569.0
http://www.newb.northstarchiangrai.com/index.php?topic=23375.0
http://www.deliberarchia.org/forum/index.php?topic=934095.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/om-7-e-04-05-2019-415289/msg551799/
http://forum.politeknikgihon.ac.id/index.php?topic=15073.0
http://muonlineint.com/forum/index.php?topic=705.0
http://153.120.114.241/eso/index.php/16842663-igra-prestolov-2019-8-sezon-1-seria-igra-prestolov-2019-8-sezon
http://sextomariotienda.com/blog/hd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g6-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://macdistri.com/index.php/component/k2/itemlist/user/297667
http://blog.ptpintcast.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-n3-f3-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=678026.0
http://labmaster.top/smf2/index.php?topic=13718.0
http://HyUa.1fps.icu/l/szIaeDC
http://healthyteethpa.org/component/k2/itemlist/user/5271775
http://www.boutique.in.th/index.php/component/k2/itemlist/user/146863
http://www.tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1575788
http://www.tekparcahdfilm.com/forum/index.php?topic=43392.0
http://poselokgribovo.ru/forum/index.php?topic=680386.0
http://teambuildingpremium.com/forum/index.php?topic=744046.0
http://poselokgribovo.ru/forum/index.php?topic=651195.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2562467
https://khuyenmaikk13.info/index.php?topic=162491.0
http://www.tessabannampad.go.th/webboard/index.php?topic=174954.0
http://www.original-craft.net/index.php?topic=294112.0
https://www.c-alice.org/forum/index.php?topic=69482.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/oa-24-e-watch-ldn-oa-24-e-03-05-2019/?PHPSESSID=irmkrgn2r9mbdn6te0mfr3icj5
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/213239
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=164198
http://subforumna.x10.mx/mad/index.php?topic=184649.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=636129.0
https://tg.vl-mp.com/index.php?topic=1333742.0
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=271629
http://married.dike.gr/index.php/component/k2/itemlist/user/49384
http://mobility-corp.com/index.php/component/k2/itemlist/user/2525016
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/208699
http://rudraautomation.com/index.php/component/k2/author/123464
http://webp.online/index.php?topic=39323.msg65568
https://tg.vl-mp.com/index.php?topic=1274590.0
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1597708
http://arquitectosenreformas.es/component/k2/itemlist/user/77509
http://www.spazioad.com/?option=com_k2&view=itemlist&task=user&id=7217728
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2554656
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2536942
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=607893
http://married.dike.gr/index.php/component/k2/itemlist/user/34371
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1297342
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bf6-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=204248
http://ts.bloodhand.de/forum/viewtopic.php?t=198560
http://proxima.co.rw/index.php/component/k2/itemlist/user/543875
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81-26/
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81-27/
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81-28/
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81-29/
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81-30/
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81-31/
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81-32/
http://withinfp.sakura.ne.jp/eso/index.php/16778214-milliardy-4-sezon-12-seria-xbf-milliardy-4-sezon-12-seria-01052/0
http://www.telcon.gr/index.php/component/k2/itemlist/user/33569
http://www.sopcich.com/UserProfile/tabid/42/UserID/1670628/Default.aspx
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1835147
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1129793
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=95731
http://www.deliberarchia.org/forum/index.php?topic=910604.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/548165
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1567145
http://www.aroshan.com/component/k2/itemlist/user/927054
http://www.deliberarchia.org/forum/index.php?topic=970019.0
http://www.tessabannampad.go.th/webboard/index.php?topic=192127.0
http://www.tessabannampad.go.th/webboard/index.php?topic=192129.0
http://danielmillsap.com/forum/index.php?topic=965171.0
http://menulisilmiah.net/%d0%b2%d0%be%d1%80%d0%be%d0%bd-kuzgun-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m1jn-%d0%b2%d0%be%d1%80%d0%be%d0%bd-kuzgun-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b2%d0%be%d1%80%d0%be%d0%bd-kuzgun-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v6xi-%d0%b2%d0%be%d1%80%d0%be%d0%bd-kuzgun-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b6%d0%b5%d0%bd%d1%89%d0%b8%d0%bd%d0%b0-57-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l2ng-%d0%b6%d0%b5%d0%bd%d1%89%d0%b8%d0%bd%d0%b0-57-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-64-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z0ju-%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-64/
http://menulisilmiah.net/%d0%bd%d0%b5-%d0%be%d1%82%d0%bf%d1%83%d1%81%d0%ba%d0%b0%d0%b9-%d0%bc%d0%be%d1%8e-%d1%80%d1%83%d0%ba%d1%83-elimi-birakma-41-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j7be-%d0%bd%d0%b5-%d0%be/
http://menulisilmiah.net/%d0%bd%d0%b5-%d0%be%d1%82%d0%bf%d1%83%d1%81%d0%ba%d0%b0%d0%b9-%d0%bc%d0%be%d1%8e-%d1%80%d1%83%d0%ba%d1%83-elimi-birakma-41-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n5vo-%d0%bd%d0%b5-%d0%be/
http://withinfp.sakura.ne.jp/eso/index.php/16901589-vetrenyj-hercai-7-seria-z7ys-vetrenyj-hercai-7-seria/0
http://www.deliberarchia.org/forum/index.php?topic=970042.0
http://www.deliberarchia.org/forum/index.php?topic=970048.0
http://withinfp.sakura.ne.jp/eso/index.php/16901509-voskressij-ertugrul-143-seria-y6ci-voskressij-ertugrul-143-seri/0
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=40924
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=41023
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=41053
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=41065
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=41099
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=41100
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=41221
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=41236
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=41476
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=41563
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=41844
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=42110
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3277514
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=42658
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/51652
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/189680
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=294284
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3249998
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/45596
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1128597
http://thermoplast.envolgroupe.com/component/k2/author/67232
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-osb-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-11-%d1%81%d0%b5%d1%80/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-edu-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-15-%d1%81%d0%b5%d1%80/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jlz-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mgo-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ryv-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://c3isecurity.com.br/?option=com_k2&view=itemlist&task=user&id=468170
http://c3isecurity.com.br/?option=com_k2&view=itemlist&task=user&id=469793
http://c3isecurity.com.br/?option=com_k2&view=itemlist&task=user&id=470901
http://c3isecurity.com.br/?option=com_k2&view=itemlist&task=user&id=474703
http://c3isecurity.com.br/component/k2/itemlist/user/435188
http://c3isecurity.com.br/component/k2/itemlist/user/436378
http://c3isecurity.com.br/component/k2/itemlist/user/437332
http://c3isecurity.com.br/component/k2/itemlist/user/437428
http://c3isecurity.com.br/component/k2/itemlist/user/437513
http://c3isecurity.com.br/component/k2/itemlist/user/438541
http://c3isecurity.com.br/component/k2/itemlist/user/438680
http://c3isecurity.com.br/component/k2/itemlist/user/440300
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=602072
http://married.dike.gr/index.php/component/k2/itemlist/user/35326
http://dcasociados.eu/component/k2/itemlist/user/85577
http://withinfp.sakura.ne.jp/eso/index.php/16787985-igra-prestolov-8-sezon-8-seria-msq-igra-prestolov-8-sezon-8-ser/0
http://danielmillsap.com/forum/index.php?topic=940811.0
http://macdistri.com/index.php/component/k2/itemlist/user/264600
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/452997
http://www.theparrotcentre.com/forum/index.php?topic=436569.0
http://www.spazioad.com/?option=com_k2&view=itemlist&task=user&id=7201827
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/182695
https://forum.ac-jete.it/index.php?topic=311958.0
http://xekhachduyetthuy.com.vn/index.php/component/k2/itemlist/user/160783
http://dpmarketingsystems.com/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81-27/
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7262777
https://mcsetup.tk/bbs/index.php?topic=241634.0
http://wituclub.ru/forum/index.php?PHPSESSID=vmm137i84f3a203m228g12m994&topic=24893.0
http://withinfp.sakura.ne.jp/eso/index.php/16754538-nevesta-iz-stambula-istanbullu-gelin-79-seria-v2-nevesta-iz-sta/0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/167862
http://www.hoonthaitoday.com/forum/index.php?topic=137446.0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4658209
http://www.verenas-unterwasserwelt.de/forum/index.php?topic=229.0
http://roikjer.com/forum/index.php?PHPSESSID=3kb3qs3r4l1aqcftp1pgntr4b4&topic=758837.0
http://web2interactive.com/index.php/component/k2/itemlist/user/3521256
https://khuyenmaikk13.info/index.php?topic=151134.0
http://www.tessabannampad.go.th/webboard/index.php?topic=187501.0
http://islamiccall.info/?option=com_k2&view=itemlist&task=user&id=855747
http://www.meikai.com.ar/foro/index.php?topic=48854.0
https://www.gizmoarticle.com/%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0%d1%8f-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b0-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-axp-%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0/
http://macdistri.com/index.php/component/k2/itemlist/user/280275
https://mcsetup.tk/bbs/index.php?topic=238938.0
http://www.spazioad.com/component/k2/itemlist/user/7158187
https://forums.letstalkbeats.com/index.php?topic=54719.0
http://macdistri.com/?option=com_k2&view=itemlist&task=user&id=254521
http://www.hoonthaitoday.com/forum/index.php?topic=107814.0
https://www.shaiyax.com/index.php?topic=322944.0
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-auw-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/995404
http://dpmarketingsystems.com/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rpq-%d0%b2%d0%be%d1%81%d0%ba/
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=161491
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=38256
http://www.deliberarchia.org/forum/index.php?topic=939773.0
http://teambuildingpremium.com/forum/index.php?topic=761215.0
http://forum.drahthaar-club.com.ua/index.php?topic=74.0
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=202273
https://www.resproxy.com/forum/index.php/704128-sluga-naroda-3-sezon-13-seria-watch-ajp-sluga-naroda-3-sezon-13/0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=675727.0
http://www.tvmechanic.co.in/forum/index.php?topic=7582.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2558033
http://www.hoonthaitoday.com/forum/index.php?topic=128759.0
http://sextomariotienda.com/blog/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w7-04-05-2019-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be/
http://roikjer.com/forum/index.php?PHPSESSID=s4vn2po6pucq7nji6kr3hcigp6&topic=796522.0
https://khuyenmaikk13.info/index.php?topic=178137.0
http://menulisilmiah.net/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-%d1%83%d0%ba%d1%80%d0%b0%d0%b8%d0%bd%d0%b0-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-x4s5-%d1%85%d0%be/
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=678167.0
http://withinfp.sakura.ne.jp/eso/index.php/16870405-taemnici-89-seria-05052019-t5-taemnici-89-seria
http://menulisilmiah.net/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-%d1%83%d0%ba%d1%80%d0%b0%d0%b8%d0%bd%d0%b0-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-s5x2-%d1%85%d0%be%d0%bb%d0%be/
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=110804
http://storykingdom.forumside.com/index.php?topic=3769.0
http://danielmillsap.com/forum/index.php?topic=871265.0
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=549242
http://erhu.eu/viewtopic.php?t=241783
http://windowshopgoa.com/index.php/component/k2/itemlist/user/184790
http://matinbank.ir/component/k2/itemlist/user/4459480.html
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=556653
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=564736
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/518936
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/519419
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/521911
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/550152
http://www.sakitoandrichifantasy.gr/?option=com_k2&view=itemlist&task=user&id=131737
http://www.sakitoandrichifantasy.gr/?option=com_k2&view=itemlist&task=user&id=131874
https://www.youngbiker.de/wbboard/index.php?page=User&userID=785384
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=283145
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/142502
http://www.deliberarchia.org/forum/index.php?topic=957565.0
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=4661
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1127749
http://smartacity.com/component/k2/itemlist/user/14593
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=544729
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3295806
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=10284
http://www.x2145-productions.technology/index.php?title=%C2%AB%D0%9F%D1%80%D0%B8%D0%BD%D1%86%D0%B5%D1%81%D1%81%D0%B0_%D0%AD%D0%BC%D0%BC%D0%B8%C2%BB_05-05-2019_%D0%9F%D1%80%D0%B8%D0%BD%D1%86%D0%B5%D1%81%D1%81%D0%B0_%D0%AD%D0%BC%D0%BC%D0%B8_%C2%AB%D0%9F%D1%80%D0%B8%D0%BD%D1%86%D0%B5%D1%81%D1%81%D0%B0_%D0%AD%D0%BC%D0%BC%D0%B8%C2%BB
http://fbpharm.net/index.php/component/k2/itemlist/user/9509
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1508063
http://ts.bloodhand.de/forum/viewtopic.php?t=198875
http://puppystoreatdoral.com/?option=com_k2&view=itemlist&task=user&id=336708
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/1343
http://www.deliberarchia.org/forum/index.php?topic=927900.0
http://fbpharm.net/index.php/component/k2/itemlist/user/13871
http://seoksoononly.dothome.co.kr/qna/587838
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=294809
https://tg.vl-mp.com/index.php?topic=1307982.0
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=157502
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4709995
http://macdistri.com/index.php/component/k2/itemlist/user/279752
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/177226
https://forum.shaiyaslayer.tk/index.php?topic=78769.0
http://eugeniocolazzo.it/forum/index.php?topic=87999.0
http://forum.digamahost.com/index.php?topic=108159.0
http://1vh.info/index.php?topic=10364.0
https://members.fbhaters.com/index.php?topic=70154.0
http://e-educ.net/Forum/index.php?topic=4698.0
https://reficulcoin.com/index.php?topic=7565.0
http://forum.digamahost.com/index.php?topic=107749.0
http://yuptalk.ru/other_food_household_cosmetics_etc/-t13105.0.html
http://danielmillsap.com/forum/index.php?topic=934980.0
https://www.shaiyax.com/index.php?topic=326034.0
https://members.fbhaters.com/index.php?topic=71671.0
http://golyboe.ru/forum/index.php?topic=24809.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2555792
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-8-eo-4-e-a-etoo-8-eo-4-e-q6h6/?PHPSESSID=82b264569mt44pamlhnpg8o860
http://myrechockey.com/forums/index.php?topic=84030.0
http://forum.bmw-e60.eu/index.php?topic=2100.0
http://www.vivelabmanizales.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o3-g9-%d1%80%d0%b0%d1%81%d1%81-2/
http://www.vivelabmanizales.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-p0-e9-%d1%80/
http://www.vivelabmanizales.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q2-w7-%d1%80%d0%b0%d1%81%d1%81/
http://www.vivelabmanizales.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-z6-d2-%d1%80/
http://www.vivelabmanizales.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u2-i5-%d1%80%d0%b0%d1%81%d1%81/
http://www.vivelabmanizales.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v6-h4-%d1%80%d0%b0%d1%81%d1%81/
http://www.vivelabmanizales.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p5-g6-%d1%80%d0%b0/
https://danceplanet.se/commodore/index.php?topic=12790.0
https://danceplanet.se/commodore/index.php?topic=12791.0
https://forum.clubeicaro.pt/index.php?topic=460.0
https://reficulcoin.com/index.php?topic=10756.0
https://www.shaiyax.com/index.php?topic=329793.0
http://help.stv.ru/index.php?PHPSESSID=a8adffe8a86d2d974becb4165684b3b8&topic=138438.0
http://myrechockey.com/forums/index.php?topic=86565.0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/434805
http://HyUa.1fps.icu/l/szIaeDC
https://khuyenmaikk13.info/index.php?topic=161975.0
http://eugeniocolazzo.it/forum/index.php?topic=80262.0
http://menulisilmiah.net/1tv-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c8-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://dohairbiz.com/en/component/k2/itemlist/user/2696998.html
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1083813
https://members.fbhaters.com/index.php?topic=54301.0
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3560588
http://matinbank.ir/component/k2/itemlist/user/4460034.html
https://www.c-alice.org/forum/index.php?topic=67581.0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=292676
https://www.shaiyax.com/index.php?topic=324088.0
https://sanp.pro/%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0%d1%8f-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b0-%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be%d0%b1%d0%be%d1%82%d0%b0-14-%d1%81%d0%b5-16/
http://www.ekemoon.com/139423/052120193104/
http://mobility-corp.com/index.php/component/k2/itemlist/user/2519868
http://necinsurance.co.zw/component/k2/itemlist/user/19375.html
http://necinsurance.co.zw/component/k2/itemlist/user/19376.html
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/205006
http://sfah.ch/de/component/k2/itemlist/user/14985
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1616350
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=53300
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=187611
http://www.afikgan.co.il/index.php/component/k2/itemlist/user/26118
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4723766
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4723807
http://www.elpinatarense.com/?option=com_k2&view=itemlist&task=user&id=154483
http://withinfp.sakura.ne.jp/eso/index.php/16837057-voron-kuzgun-14-seria-w1ue-voron-kuzgun-14-seria/0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1296317
http://seoksoononly.dothome.co.kr/qna/593894
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3265476
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81-21/
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/444216
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/133825
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/46189
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1005567
https://tg.vl-mp.com/index.php?topic=1279346.0
https://www.resproxy.com/forum/index.php/760634-cernoe-zerkalo-5-sezon-5-seria-xfp-cernoe-zerkalo-5-sezon-5-ser/0
http://www.cosl.com.sg/UserProfile/tabid/61/userId/26103099/Default.aspx
http://webp.online/index.php?topic=45666.15
http://webp.online/index.php?topic=45666.msg74571
http://webp.online/index.php?topic=45666.msg74590
http://webp.online/index.php?topic=45676.0
http://withinfp.sakura.ne.jp/eso/index.php/16767232-rasskaz-sluzanki-3-sezon-3-seria-sdg-rasskaz-sluzanki-3-sezon-3/0
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=13993
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=14099
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=14231
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=14337
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=14352
http://mvisage.sk/index.php/component/k2/itemlist/user/116472
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/624289
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=94744
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=157734
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=256070
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/41065
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=53950
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=184341
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4661632
http://macdistri.com/index.php/component/k2/itemlist/user/279833
http://withinfp.sakura.ne.jp/eso/index.php/16768530-nasledie-15-seria-spo-nasledie-15-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/16768577-riverdejl-riverdale-3-sezon-22-seria-ylw-riverdejl-riverdale-3-
http://withinfp.sakura.ne.jp/eso/index.php/16768654-rasskaz-sluzanki-3-sezon-1-seria-faf-rasskaz-sluzanki-3-sezon-1
http://withinfp.sakura.ne.jp/eso/index.php/16768663-amerikanskie-bogi-2-sezon-6-seria-aun-amerikanskie-bogi-2-sezon/0
http://withinfp.sakura.ne.jp/eso/index.php/16768783-cernoe-zerkalo-5-sezon-2-seria-bov-cernoe-zerkalo-5-sezon-2-ser/0
http://withinfp.sakura.ne.jp/eso/index.php/16768815-amerikanskie-bogi-2-sezon-6-seria-bdq-amerikanskie-bogi-2-sezon
http://withinfp.sakura.ne.jp/eso/index.php/16768995-igra-prestolov-8-sezon-8-seria-nhj-igra-prestolov-8-sezon-8-ser
http://withinfp.sakura.ne.jp/eso/index.php/16769129-lubov-smert-i-roboty-love-death-and-robots-10-seria-lar-lubov-s
http://withinfp.sakura.ne.jp/eso/index.php/16769184-amerikanskie-bogi-2-sezon-6-seria-fzy-amerikanskie-bogi-2-sezon
http://withinfp.sakura.ne.jp/eso/index.php/16769219-rasskaz-sluzanki-3-sezon-1-seria-jlx-rasskaz-sluzanki-3-sezon-1/0
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=16225
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=16227
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=16371
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=9075
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=9077
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=9108
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=9215
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=9284
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=9623
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=9640
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=9712
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=9723
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=9728
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=9770
http://153.120.114.241/eso/index.php/16877224-lubov-smert-i-roboty-love-death-and-robots-17-seria-fsl-lubov-s
http://dessa.com.br/component/k2/itemlist/user/295728
http://comfortcenter.es/index.php/component/k2/itemlist/user/103138
https://www.resproxy.com/forum/index.php/762408-milliardy-4-sezon-13-seria-ifl-milliardy-4-sezon-13-seria/0
https://members.fbhaters.com/index.php?topic=67724.0
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=44328
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/583294
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=604535
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/250067
http://withinfp.sakura.ne.jp/eso/index.php/16794025-milliardy-4-sezon-6-seria-xnx-milliardy-4-sezon-6-seria
http://withinfp.sakura.ne.jp/eso/index.php/16794128-manifest-17-seria-yxz-manifest-17-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/16794147-manifest-19-seria-uyz-manifest-19-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/16794178-sverh-estestvennoe-14-sezon-17-seria-dzy-sverh-estestvennoe-14-/0
http://withinfp.sakura.ne.jp/eso/index.php/16794182-igra-prestolov-8-sezon-2-seria-pjm-igra-prestolov-8-sezon-2-ser/0
http://withinfp.sakura.ne.jp/eso/index.php/16794185-lubov-smert-i-roboty-love-death-and-robots-9-seria-eoh-lubov-sm/0
http://withinfp.sakura.ne.jp/eso/index.php/16794218-lubov-smert-i-roboty-love-death-and-robots-18-seria-gia-lubov-s/0
http://withinfp.sakura.ne.jp/eso/index.php/16794260-sverh-estestvennoe-14-sezon-15-seria-quh-sverh-estestvennoe-14-/0
http://withinfp.sakura.ne.jp/eso/index.php/16794303-lubov-smert-i-roboty-love-death-and-robots-4-seria-lcy-lubov-sm
http://withinfp.sakura.ne.jp/eso/index.php/16794370-igra-prestolov-8-sezon-3-seria-lxe-igra-prestolov-8-sezon-3-ser/0
http://withinfp.sakura.ne.jp/eso/index.php/16794393-lubov-smert-i-roboty-love-death-and-robots-15-seria-zyg-lubov-s/0
http://withinfp.sakura.ne.jp/eso/index.php/16794409-lubov-smert-i-roboty-love-death-and-robots-16-seria-jts-lubov-s/0
http://withinfp.sakura.ne.jp/eso/index.php/16794427-cernoe-zerkalo-5-sezon-3-seria-gpr-cernoe-zerkalo-5-sezon-3-ser
http://withinfp.sakura.ne.jp/eso/index.php/16794438-sverh-estestvennoe-14-sezon-18-seria-ymr-sverh-estestvennoe-14-
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1672727
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1672746
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1672878
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1672925
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1673149
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1673345
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1673347
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1673424
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1673440
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1673517
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1673525
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1673551
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1673558
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1982332
http://ts.bloodhand.de/forum/viewtopic.php?t=197644
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1854501
http://menulisilmiah.net/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nrf-%d0%b8%d0%b3%d1%80%d0%b0/
http://macdistri.com/index.php/component/k2/itemlist/user/260770
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1098657
http://www.sakitoandrichifantasy.gr/?option=com_k2&view=itemlist&task=user&id=154564
http://dev.fivestarpainting.com/?option=com_k2&view=itemlist&task=user&id=1846431
http://dev.fivestarpainting.com/?option=com_k2&view=itemlist&task=user&id=1846756
http://dev.fivestarpainting.com/?option=com_k2&view=itemlist&task=user&id=1847001
http://dev.fivestarpainting.com/?option=com_k2&view=itemlist&task=user&id=1847193
http://dev.fivestarpainting.com/?option=com_k2&view=itemlist&task=user&id=1849834
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1296504
http://hydrocarbs-gh.org/index.php/component/k2/itemlist/user/7295333
http://mjbosch.com/component/k2/itemlist/user/81100
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/218594
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889836
http://dev.aabn.org.gh/component/k2/itemlist/user/493466
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/186077
http://associationsila.org/component/k2/itemlist/user/287323
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=701886
http://multikopterforum.hu/index.php?topic=11684.0
http://multikopterforum.hu/index.php?topic=11689.0
http://multikopterforum.hu/index.php?topic=11693.0
http://myrechockey.com/forums/index.php?topic=86021.0
http://myrechockey.com/forums/index.php?topic=86027.0
http://poselokgribovo.ru/forum/index.php?topic=714894.0
http://poselokgribovo.ru/forum/index.php?topic=714904.0
http://poselokgribovo.ru/forum/index.php?topic=714924.0
http://roikjer.com/forum/index.php?PHPSESSID=205dlqva3sg9o2m87sknhs0uf2&topic=811939.0
http://roikjer.com/forum/index.php?PHPSESSID=4nrpi6g102f3lgff2q2e4mios6&topic=811927.0
http://roikjer.com/forum/index.php?PHPSESSID=gjjgk5b0urif6n7o0m0da25461&topic=811907.0
http://roikjer.com/forum/index.php?PHPSESSID=k8mmb9uablsfuo2jo0r49l5t56&topic=811942.0
http://ru-realty.com/forum/index.php?PHPSESSID=c8hi5e0eitcg26q6lpaisgr717&topic=459366.0
http://ru-realty.com/forum/index.php?PHPSESSID=p1aigeq8m34rhlhiu9jns4r927&topic=459343.0
http://webp.online/index.php?topic=45990.0
http://www.deliberarchia.org/forum/index.php?topic=960067.0
http://www.deliberarchia.org/forum/index.php?topic=960087.0
http://www.deliberarchia.org/forum/index.php?topic=960100.0
http://www.deliberarchia.org/forum/index.php?topic=960107.0
http://www.deliberarchia.org/forum/index.php?topic=960142.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190760.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5-28/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80-9/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-60/
http://flashboot.ru/forum/index.php?topic=94297.0
http://flashboot.ru/forum/index.php?topic=94299.0
http://flashboot.ru/forum/index.php?topic=94304.0
http://flashboot.ru/forum/index.php?topic=94306.0
http://flashboot.ru/forum/index.php?topic=94308.0
http://flashboot.ru/forum/index.php?topic=94312.0
http://flashboot.ru/forum/index.php?topic=94317.0
http://flashboot.ru/forum/index.php?topic=94323.0
http://flashboot.ru/forum/index.php?topic=94327.0
http://flashboot.ru/forum/index.php?topic=94330.0
http://flashboot.ru/forum/index.php?topic=94332.0
http://flashboot.ru/forum/index.php?topic=94333.0
http://flashboot.ru/forum/index.php?topic=94334.0
http://flashboot.ru/forum/index.php?topic=94338.0
http://flashboot.ru/forum/index.php?topic=94349.0
http://flashboot.ru/forum/index.php?topic=94350.0
http://flashboot.ru/forum/index.php?topic=94351.0
http://flashboot.ru/forum/index.php?topic=94355.0
http://flashboot.ru/forum/index.php?topic=94358.0
http://flashboot.ru/forum/index.php?topic=94359.0
http://flashboot.ru/forum/index.php?topic=94362.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.remify.app/foro/index.php?topic=198239.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/532391
https://khuyenmaikk13.info/index.php?topic=172086.0
http://macdistri.com/index.php/component/k2/itemlist/user/302569
http://www.smekalka.pp.ru/forum/index.php?topic=10470.0
http://sextomariotienda.com/blog/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ojs-%d0%b2%d0%be%d1%81%d0%ba/
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=38833
https://reficulcoin.com/index.php?topic=6717.0
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/208473
http://menulisilmiah.net/%d0%bd%d0%be%d0%b2%d1%8b%d0%b9-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-4-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bd%d0%be%d0%b2%d1%8b-3/
https://khuyenmaikk13.info/index.php?topic=161125.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=22983.0
http://www.gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1814358
https://mcsetup.tk/bbs/index.php?topic=238307.0
http://ru-realty.com/forum/index.php?topic=451120.msg561673
http://xplorefitness.com/blog/%C2%AB%D0%B2%D0%B5%D1%82%D1%80%D0%B5%D0%BD%D1%8B%D0%B9-hercai-15-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-gabv-%C2%AB%D0%B2%D0%B5%D1%82%D1%80%D0%B5%D0%BD%D1%8B%D0%B9-hercai-15-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/198608
http://sextomariotienda.com/blog/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r0-04-05-2019-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
https://reficulcoin.com/index.php?topic=7337.0
http://8.droror.co.il/uncategorized/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sj0-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=284420
http://withinfp.sakura.ne.jp/eso/index.php/16868911-igra-prestolov-8-sezon-6-seria-igra-prestolov-8-sezon-6-seria-n/0
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/49198
http://healthyteethpa.org/?option=com_k2&view=itemlist&task=user&id=5322366
http://www.vogtland.com.pl/index.php/component/k2/itemlist/user/10408
https://reficulcoin.com/index.php?topic=8706.0
http://www.deliberarchia.org/forum/index.php?topic=932268.0
http://macdistri.com/component/k2/itemlist/user/261429
https://sanp.pro/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p6-%e3%80%90-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f%e3%80%91-%d1%8e%d1%80%d0%b8/
http://forum.politeknikgihon.ac.id/index.php?topic=5116.0
http://www.deliberarchia.org/forum/index.php?topic=949825.0
http://withinfp.sakura.ne.jp/eso/index.php/16769713-igra-prestolov-8-sezon-4-seria-srp-igra-prestolov-8-sezon-4-ser/0
http://www.hoonthaitoday.com/forum/index.php?topic=139731.0
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1128316
http://maderadepaulownia.com/?option=com_k2&view=itemlist&task=user&id=83802
http://sextomariotienda.com/blog/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t8-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be/
http://forum.byehaj.hu/index.php?topic=73302.0
http://www.deliberarchia.org/forum/index.php?topic=972825.0
http://www.deliberarchia.org/forum/index.php?topic=972832.0
http://danielmillsap.com/forum/index.php?topic=968835.0
http://danielmillsap.com/forum/index.php?topic=968850.0
https://tg.vl-mp.com/index.php?topic=1337956.0
http://www.deliberarchia.org/forum/index.php?topic=972838.0
http://www.deliberarchia.org/forum/index.php?topic=972846.0
https://tg.vl-mp.com/index.php?topic=1338017.0
https://www.resproxy.com/forum/index.php/795260-nasa-istoria-69-seria-o3nm-nasa-istoria-69-seria/0
https://www.resproxy.com/forum/index.php/795299-rannaa-ptaska-erkenci-kus-39-seria-r2ki-rannaa-ptaska-erkenci-k
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-eb0-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8/
http://www.deliberarchia.org/forum/index.php?topic=902122.0
http://associationsila.org/component/k2/itemlist/user/285740
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=529047
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1106219
http://thermoplast.envolgroupe.com/component/k2/itemlist/user/68753
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1553539
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1553569
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1553570
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1553581
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1553615
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1553645
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1553648
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sgk-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-10-%d1%81%d0%b5%d1%80/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hbj-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-11-%d1%81%d0%b5%d1%80/
http://www.deliberarchia.org/forum/index.php?topic=973265.0
http://www.deliberarchia.org/forum/index.php?topic=973266.0
http://www.deliberarchia.org/forum/index.php?topic=973275.0
http://www.deliberarchia.org/forum/index.php?topic=973282.0
http://www.deliberarchia.org/forum/index.php?topic=973285.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j9xg-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-14-%d1%81%d0%b5%d1%80%d0%b8/
http://menulisilmiah.net/%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5%d0%bd%d0%b8%d0%b5-vuslat-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c9hy-%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd/
http://menulisilmiah.net/%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80%d0%b4%d1%86%d0%b5-tek-yurek-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u4ti-%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80/
http://menulisilmiah.net/%d0%bd%d0%b5-%d0%be%d1%82%d0%bf%d1%83%d1%81%d0%ba%d0%b0%d0%b9-%d0%bc%d0%be%d1%8e-%d1%80%d1%83%d0%ba%d1%83-elimi-birakma-37-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x0hp-%d0%bd%d0%b5-%d0%be/
http://withinfp.sakura.ne.jp/eso/index.php/16907181-voron-kuzgun-18-seria-r1jg-voron-kuzgun-18-seria/0
https://www.youngbiker.de/wbboard/index.php?page=User&userID=784368
http://erhu.eu/viewtopic.php?t=230977
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/435668
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bz3-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11/
http://danielmillsap.com/forum/index.php?topic=872062.0
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/1383
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3271810
http://dscardip.com/board/index.php?page=User&userID=655251
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1543092
http://seoksoononly.dothome.co.kr/qna/585339
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=38323
http://withinfp.sakura.ne.jp/eso/index.php/16796532-tola-robot-2-seria-foto-rt-tola-robot-2-seria-foto/0
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1512860
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1513353
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1513793
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1513835
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1514159
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1514619
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1514626
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1514811
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1515030
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1515144
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1515474
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1516337
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1516481
http://www.deliberarchia.org/forum/index.php?topic=973737.0
http://www.deliberarchia.org/forum/index.php?topic=973749.0
http://www.deliberarchia.org/forum/index.php?topic=973753.0
http://www.deliberarchia.org/forum/index.php?topic=973764.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ehq-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lxn-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://metropolis.ga/index.php?topic=4544.0
http://metropolis.ga/index.php?topic=4545.0
http://metropolis.ga/index.php?topic=4547.0
http://metropolis.ga/index.php?topic=4549.0
http://www.deliberarchia.org/forum/index.php?topic=973788.0
http://www.deliberarchia.org/forum/index.php?topic=973791.0
http://danielmillsap.com/forum/index.php?topic=970215.0
http://menulisilmiah.net/%d0%b6%d0%b5%d0%bd%d1%89%d0%b8%d0%bd%d0%b0-59-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p9mp-%d0%b6%d0%b5%d0%bd%d1%89%d0%b8%d0%bd%d0%b0-59-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.deliberarchia.org/forum/index.php?topic=896012.0
https://www.resproxy.com/forum/index.php/758762-manifest-19-seria-kjv-manifest-19-seria/0
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/45002
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1107040
http://fbpharm.net/index.php/component/k2/itemlist/user/16210
http://153.120.114.241/eso/index.php/16858474-amerikanskie-bogi-2-sezon-6-seria-iue-amerikanskie-bogi-2-sezon
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1667330
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3693404
http://withinfp.sakura.ne.jp/eso/index.php/16797869-vetrenyj-hercai-24-seria-x4da-vetrenyj-hercai-24-seria
https://tg.vl-mp.com/index.php?topic=1309044.0
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1534017
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-myy-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=264203
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1128260
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1528133
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1528259
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1528639
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1528666
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1528949
http://danielmillsap.com/forum/index.php?topic=867521.0
http://danielmillsap.com/forum/index.php?topic=867551.0
http://danielmillsap.com/forum/index.php?topic=867571.0
http://danielmillsap.com/forum/index.php?topic=867609.0
http://arquitectosenreformas.es/component/k2/itemlist/user/76884
http://arquitectosenreformas.es/index.php/component/k2/itemlist/user/77099
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=258574
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=261409
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=262834
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=270170
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=270307
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=277838
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=280918
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=281436
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=281629
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=282269
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=306749
http://healthyteethpa.org/?option=com_k2&view=itemlist&task=user&id=5281764
http://mediaville.me/index.php/component/k2/itemlist/user/191130
http://www.arunagreen.com/index.php/component/k2/itemlist/user/375297
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/130690
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4702691
http://dohairbiz.com/en/component/k2/itemlist/user/2683467.html
http://dohairbiz.com/en/component/k2/itemlist/user/2683611.html
http://dohairbiz.com/en/component/k2/itemlist/user/2684151.html
http://dohairbiz.com/en/component/k2/itemlist/user/2684279.html
http://dohairbiz.com/en/component/k2/itemlist/user/2689806.html
http://dohairbiz.com/en/component/k2/itemlist/user/2699353.html
http://dohairbiz.com/en/component/k2/itemlist/user/2699751.html
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=11876
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=11879
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=11934
http://fbpharm.net/index.php/component/k2/itemlist/user/11984
http://fbpharm.net/index.php/component/k2/itemlist/user/12314
http://fbpharm.net/index.php/component/k2/itemlist/user/9058
http://macdistri.com/component/k2/itemlist/user/260133
http://macdistri.com/component/k2/itemlist/user/274785
http://macdistri.com/index.php/component/k2/itemlist/user/258121
http://macdistri.com/index.php/component/k2/itemlist/user/258159
http://macdistri.com/index.php/component/k2/itemlist/user/258189
http://www.thenixnoob.com/viewtopic.php?f=2&t=628620
http://healthyteethpa.org/component/k2/itemlist/user/5278713
https://tg.vl-mp.com/index.php?topic=1304235.0
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-po2-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8/
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=292373
http://danielmillsap.com/forum/index.php?topic=888265.0
http://seoksoononly.dothome.co.kr/qna/596046
http://www.m1avio.com/index.php/component/k2/itemlist/user/3579984
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=519374
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1982005
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1552631
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=157626
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=158725
http://metropolis.ga/index.php?topic=1025.0
http://metropolis.ga/index.php?topic=1029.0
http://metropolis.ga/index.php?topic=1030.0
http://metropolis.ga/index.php?topic=1034.0
http://metropolis.ga/index.php?topic=1039.0
http://metropolis.ga/index.php?topic=1042.0
http://metropolis.ga/index.php?topic=1046.0
http://metropolis.ga/index.php?topic=1088.0
http://metropolis.ga/index.php?topic=1089.0
http://redgatetech.co/?option=com_k2&view=itemlist&task=user&id=709668
http://redgatetech.co/?option=com_k2&view=itemlist&task=user&id=710709
http://redgatetech.co/?option=com_k2&view=itemlist&task=user&id=710780
http://redgatetech.co/?option=com_k2&view=itemlist&task=user&id=710846
http://redgatetech.co/?option=com_k2&view=itemlist&task=user&id=711137
http://redgatetech.co/?option=com_k2&view=itemlist&task=user&id=712352
http://redgatetech.co/?option=com_k2&view=itemlist&task=user&id=712912
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=79116
http://macdistri.com/index.php/component/k2/itemlist/user/267972
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2530752
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/43801
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gq1-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4836008
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=892173
https://sto54.ru/index.php/component/k2/itemlist/user/3269371
http://153.120.114.241/eso/index.php/16817567-lubov-smert-i-roboty-love-death-and-robots-19-seria-voh-lubov-s
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4666327
http://withinfp.sakura.ne.jp/eso/index.php/16778123-cernoe-zerkalo-5-sezon-5-seria-rgf-cernoe-zerkalo-5-sezon-5-ser/0
http://www.spazioad.com/?option=com_k2&view=itemlist&task=user&id=7216216
http://www.deliberarchia.org/forum/index.php?topic=895209.0
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=698317
http://poselokgribovo.ru/forum/index.php?topic=680475.0
http://poselokgribovo.ru/forum/index.php?topic=647402.0
http://www.deliberarchia.org/forum/index.php?topic=931514.0
https://forums.letstalkbeats.com/index.php?topic=48649.0
http://teambuildingpremium.com/forum/index.php?topic=711921.0
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7273038
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/429955
http://universaldrive-s.cba.pl/index.php?PHPSESSID=aeb4a1780c53847666cf68dce590bc67&topic=17573.0
http://dpmarketingsystems.com/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5-5/
https://sanp.pro/%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-67-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g8-%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-67-%d1%81%d0%b5/
http://wb.hvekorat.com/index.php?topic=39345.0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4674334
http://www.remify.app/foro/index.php?topic=164690.0
http://www.tvmechanic.co.in/forum/index.php?topic=8148.0
http://forum.byehaj.hu/index.php?topic=74478.0
http://withinfp.sakura.ne.jp/eso/index.php/16755539-ne-zenskaa-rabota-ne-zinoca-robota-21-seria-f9-ne-zenskaa-rabot/0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=278421
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/438843
https://khuyenmaikk13.info/index.php?topic=176676.0
https://forums.letstalkbeats.com/index.php?topic=49047.0
http://teambuildingpremium.com/forum/index.php?topic=715042.0
http://www.spazioad.com/component/k2/itemlist/user/7198868
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1290262
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/58401
http://forums.abs-cbn.com/welcome-back-kapamilya%21/ea-56-e-q3~-ea-56-e-watch/?PHPSESSID=co547vq1j58jntbki2el337nq5
http://thanosakademi.com/index.php?topic=59535.0
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1498919
http://www.critico-expository.com/forum/index.php?topic=71.0
http://www.gtupuw.org/index.php/component/k2/itemlist/user/1819660
http://marjorieaperry.com/?option=com_k2&view=itemlist&task=user&id=473047
http://www.deliberarchia.org/forum/index.php?topic=925409.0
https://tg.vl-mp.com/index.php?topic=1281698.0
http://jensenbyggteam.no/index.php/component/k2/itemlist/user/11701
http://www.tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1577298
http://www.remify.app/foro/index.php?topic=163362.0
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5-4/
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5-7/
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5-8/
http://sfah.ch/component/k2/itemlist/user/14513
http://sfah.ch/component/k2/itemlist/user/14527
http://sfah.ch/component/k2/itemlist/user/14559
http://sfah.ch/component/k2/itemlist/user/14570
http://sfah.ch/de/?option=com_k2&view=itemlist&task=user&id=14513
http://sfah.ch/de/component/k2/itemlist/user/14549
http://sfah.ch/de/component/k2/itemlist/user/14600
http://sfah.ch/de/component/k2/itemlist/user/14626
http://sfah.ch/index.php/component/k2/itemlist/user/14839
http://siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=748098
http://siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=750292
http://siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=752211
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1623433
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1633458
https://reficulcoin.com/index.php?topic=9058.0
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=15294
http://dpmarketingsystems.com/04-05-2019-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://yuptalk.ru/other_food_household_cosmetics_etc/-t12768.0.html
http://teambuildingpremium.com/forum/index.php?topic=754315.0
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-y3-x0-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://poselokgribovo.ru/forum/index.php?topic=713356.0
http://www.hoonthaitoday.com/forum/index.php?topic=140946.0
http://www.deliberarchia.org/forum/index.php?topic=952721.0
http://svgrossburgwedel.de/component/k2/itemlist/user/4933
http://forum.elexlabs.com/index.php?topic=12882.0
https://reficulcoin.com/index.php?topic=9028.0
http://withinfp.sakura.ne.jp/eso/index.php/16838658-igra-prestolov-game-of-thrones-8-sezon-2-seria-igra-prestolov-g
https://khuyenmaikk13.info/index.php?topic=176198.0
http://menulisilmiah.net/06-05-2019-%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0%d1%8f-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b0-%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be%d0%b1%d0%be%d1%82%d0%b0-17/
http://www.deliberarchia.org/forum/index.php?topic=937095.0
http://poselokgribovo.ru/forum/index.php?topic=697820.0
http://sextomariotienda.com/blog/%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i7-%d1%81/
https://reficulcoin.com/index.php?topic=7166.0
http://codeerror.in/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n2-u4-%d1%80%d0%b0/
http://HyUa.1fps.icu/l/szIaeDC
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-8-eo-6-e-hi2-'a-etoo-8-eo-6-e'/?PHPSESSID=8adf0i040t70pmdu9e76fpmib0
http://golyboe.ru/forum/index.php?topic=25246.0
http://help.stv.ru/index.php?topic=139114.0
http://mir3sea.com/forum/index.php?topic=2048.0
http://mir3sea.com/forum/index.php?topic=2051.0
http://poselokgribovo.ru/forum/index.php?topic=733722.0
http://poselokgribovo.ru/forum/index.php?topic=733747.0
http://ptu.imoove.kr/ko/content/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-5-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90ax1%E3%80%91-%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-5
http://roikjer.com/forum/index.php?PHPSESSID=ddgrd5le4ssfjvhld6ri2tqm22&topic=827839.0
http://www.deliberarchia.org/forum/index.php?topic=960668.0
http://freebeer.me/index.php?topic=299788.0
http://myrechockey.com/forums/index.php?topic=86131.0
http://ru-realty.com/forum/index.php?PHPSESSID=6hp05dl7h3vtulsu26on4fabd3&topic=459654.0
http://ru-realty.com/forum/index.php?PHPSESSID=f70o7da5lcj3f8ds2plb258192&topic=459658.0
https://members.fbhaters.com/index.php?topic=75212.0
https://szenarist.ru/forum/index.php?topic=205119.0
http://216.104.186.20/index.php?topic=299826.0
http://216.104.186.20/index.php?topic=299843.0
http://e-educ.net/Forum/index.php?topic=4957.0
http://forum.stollen24.com/index.php?topic=3888.0
http://forum.stollen24.com/index.php?topic=3891.0
http://forum.stollen24.com/index.php?topic=3896.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=27106.0
http://miklja.net/forum/index.php?topic=26506.0
http://miklja.net/forum/index.php?topic=26508.0
http://multikopterforum.hu/index.php?topic=11861.0
http://otitismediasociety.org/forum/index.php?topic=145160.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.deliberarchia.org/forum/index.php?topic=982713.0
http://www.deliberarchia.org/forum/index.php?topic=982723.0
http://www.deliberarchia.org/forum/index.php?topic=982731.0
http://danielmillsap.com/forum/index.php?topic=983024.0
http://danielmillsap.com/forum/index.php?topic=983063.0
http://withinfp.sakura.ne.jp/eso/index.php/16925439-voskressij-ertugrul-144-seria-j4km-voskressij-ertugrul-144-seri/0
http://withinfp.sakura.ne.jp/eso/index.php/16925755-vossoedinenie-vuslat-20-seria-l6rv-vossoedinenie-vuslat-20-seri/0
https://tg.vl-mp.com/index.php?topic=1349640.0
http://myrechockey.com/forums/index.php?topic=89958.0
http://www.deliberarchia.org/forum/index.php?topic=982777.0
http://www.quattroandpartners.it/component/k2/itemlist/user/991697
http://www.quattroandpartners.it/component/k2/itemlist/user/991935
http://www.quattroandpartners.it/component/k2/itemlist/user/992126
http://www.quattroandpartners.it/component/k2/itemlist/user/992254
http://www.quattroandpartners.it/component/k2/itemlist/user/993146
http://www.quattroandpartners.it/component/k2/itemlist/user/993427
http://www.quattroandpartners.it/component/k2/itemlist/user/993737
http://www.quattroandpartners.it/component/k2/itemlist/user/993854
http://www.quattroandpartners.it/component/k2/itemlist/user/994307
http://www.quattroandpartners.it/component/k2/itemlist/user/994316
http://proxima.co.rw/index.php/component/k2/itemlist/user/558869
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1304639
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1107464
http://www.sopcich.com/UserProfile/tabid/42/UserID/1774806/Default.aspx
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81-29/
https://tg.vl-mp.com/index.php?topic=1306680.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/173399
http://dev.aabn.org.gh/component/k2/itemlist/user/495063
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tpf-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://danielmillsap.com/forum/index.php?topic=879325.0
http://macdistri.com/component/k2/itemlist/user/294615
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sjl-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-suv-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-svw-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tkp-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tks-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-urd-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uuq-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.spazioad.com/component/k2/itemlist/user/7182091
http://www.spazioad.com/component/k2/itemlist/user/7182292
http://www.spazioad.com/component/k2/itemlist/user/7182299
http://www.spazioad.com/component/k2/itemlist/user/7182378
http://www.spazioad.com/component/k2/itemlist/user/7182575
http://www.spazioad.com/component/k2/itemlist/user/7182703
http://www.spazioad.com/component/k2/itemlist/user/7182763
http://www.spazioad.com/component/k2/itemlist/user/7182973
http://www.spazioad.com/component/k2/itemlist/user/7183123
http://www.svedmyr.nu/install/UserProfile/tabid/61/userId/374375/Default.aspx
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=46850
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1848479
http://smartacity.com/component/k2/itemlist/user/10162
http://associationsila.org/component/k2/itemlist/user/264338
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=37434
http://153.120.114.241/eso/index.php/16866065-lubov-smert-i-roboty-love-death-and-robots-8-seria-wkz-lubov-sm
http://macdistri.com/index.php/component/k2/itemlist/user/269851
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1678221
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-oj5-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4/
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xt8-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://married.dike.gr/index.php/component/k2/itemlist/user/47249
http://withinfp.sakura.ne.jp/eso/index.php/16874175-vossoedinenie-vuslat-15-seria-t2nr-vossoedinenie-vuslat-15-seri/0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4709410
https://sanp.pro/hd-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e0-%d0%b8%d0%b3%d1%80%d0%b0/
http://www.original-craft.net/index.php?topic=301037.0
https://members.fbhaters.com/index.php?topic=70923.0
http://molweb.ru/groups/vetrenyj-hercai-17-seriya-qfh-vetrenyj-hercai-17-seriya/
http://healthyteethpa.org/component/k2/itemlist/user/5267135
https://khuyenmaikk13.info/index.php?topic=165076.0
http://roikjer.com/forum/index.php?PHPSESSID=r6f0ru7bp9d2fq4vmhuj4ai9f4&topic=787476.0
http://web2interactive.com/index.php/component/k2/itemlist/user/3519747
https://khuyenmaikk13.info/index.php?topic=167340.0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=556641
http://danielmillsap.com/forum/index.php?topic=919786.0
http://islamiccall.info/?option=com_k2&view=itemlist&task=user&id=856883
http://withinfp.sakura.ne.jp/eso/index.php/16845222-smotret-nikogda-ne-govori-nikogda-1-seria-r2-nikogda-ne-govori-/0
http://married.dike.gr/index.php/component/k2/itemlist/user/46901
http://multikopterforum.hu/index.php?topic=8464.0
http://www.afikgan.co.il/index.php/component/k2/itemlist/user/25440
http://forum.kopkargobel.com/index.php?topic=3542.0
http://taklongclub.com/forum/index.php?topic=91901.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2563195
https://www.resproxy.com/forum/index.php/727391-sverh-estestvennoe-15-sezon-18-seria-lqps-sverh-estestvennoe-15
http://danielmillsap.com/forum/index.php?topic=943491.0
https://sanp.pro/hd-video-%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-3/
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-t9-x5-%d1%80/
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3564981
http://forum.stollen24.com/index.php?topic=1978.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3256610
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1611574
https://tg.vl-mp.com/index.php?topic=1319367.0
http://1vh.info/index.php?topic=7456.0
http://danielmillsap.com/forum/index.php?topic=900727.0
http://forum.bmw-e60.eu/index.php?topic=3329.0
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3709576
http://www.theparrotcentre.com/forum/index.php?topic=445520.0
http://fbpharm.net/index.php/component/k2/itemlist/user/13363
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1108984
https://members.fbhaters.com/index.php?topic=68209.0
http://forum.politeknikgihon.ac.id/index.php?topic=18411.0
http://teambuildingpremium.com/forum/index.php?topic=744337.0
http://menulisilmiah.net/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-g4-p4-%d1%80%d0%b0%d1%81/
http://blog.ptpintcast.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l5-c9-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://poselokgribovo.ru/forum/index.php?topic=709982.0
http://metropolis.ga/index.php?topic=1488.0
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w2-b9-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://216.104.186.20/index.php?topic=293592.0
http://help.stv.ru/index.php?PHPSESSID=5ee9bece48433d77ea975f78941d5cad&topic=138041.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=677914.0
http://svgrossburgwedel.de/?option=com_k2&view=itemlist&task=user&id=4913
http://www.popolsku.fr.pl/forum/index.php?topic=369771.0
http://blog.ptpintcast.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-x5-h9-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=35817
http://teambuildingpremium.com/forum/index.php?topic=756639.0
http://8.droror.co.il/uncategorized/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zn0-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://tasvirgaran.com/?option=com_k2&view=itemlist&task=user&id=572774
http://forum.santrope-rp.ru/index.php?topic=2147.0
https://sanp.pro/%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-05-05-2019/
http://miklja.net/forum/index.php?topic=25775.0
http://poselokgribovo.ru/forum/index.php?topic=706223.0
http://poselokgribovo.ru/forum/index.php?topic=713452.0
http://122.154.49.125/Forum/index.php?topic=39.0
http://golyboe.ru/forum/index.php?topic=24882.0
http://www.deliberarchia.org/forum/index.php?topic=958416.0
http://help.stv.ru/index.php?PHPSESSID=6d61b4d9c170242e754f9cc2416940a5&topic=138281.0
http://freebeer.me/index.php?topic=289124.0
http://menulisilmiah.net/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h3-d2-%d1%80%d0%b0%d1%81/
http://bobr.site/index.php?topic=84762.0
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90pz2%e3%80%91/
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d1-t5-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://mir3sea.com/forum/index.php?topic=102.0
http://bobr.site/index.php?topic=89717.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/to-oot-3-e-05-05-2019/?PHPSESSID=muccjm7hli4dq0j1c30s3usm90
http://svgrossburgwedel.de/component/k2/itemlist/user/4878
http://dev.aabn.org.gh/component/k2/itemlist/user/502569
http://www.hoonthaitoday.com/forum/index.php?topic=136335.0
https://www.amazingworldtop.com/entretenimiento/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v8-s2-%d1%80%d0%b0%d1%81%d1%81/
http://theolevolosproject.org/index.php/component/k2/itemlist/user/23958
http://www.remify.app/foro/index.php?topic=205886.0
http://www.tessabannampad.go.th/webboard/index.php?topic=186664.0
http://HyUa.1fps.icu/l/szIaeDC
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/451449
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=11744
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=19043
http://danielmillsap.com/forum/index.php?topic=940263.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=895004
http://married.dike.gr/index.php/component/k2/itemlist/user/38564
http://married.dike.gr/index.php/component/k2/itemlist/user/38592
http://married.dike.gr/index.php/component/k2/itemlist/user/38644
http://married.dike.gr/index.php/component/k2/itemlist/user/38674
http://married.dike.gr/index.php/component/k2/itemlist/user/38677
http://married.dike.gr/index.php/component/k2/itemlist/user/38690
http://married.dike.gr/index.php/component/k2/itemlist/user/38694
http://married.dike.gr/index.php/component/k2/itemlist/user/38698
http://married.dike.gr/index.php/component/k2/itemlist/user/38749
http://married.dike.gr/index.php/component/k2/itemlist/user/38788
http://married.dike.gr/index.php/component/k2/itemlist/user/38816
http://married.dike.gr/index.php/component/k2/itemlist/user/38830
http://married.dike.gr/index.php/component/k2/itemlist/user/38860
http://married.dike.gr/index.php/component/k2/itemlist/user/38876
http://married.dike.gr/index.php/component/k2/itemlist/user/38909
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1629805
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1629840
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1629873
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1629945
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1629988
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1630036
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1630111
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1630137
http://macdistri.com/?option=com_k2&view=itemlist&task=user&id=302556
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1092298
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=701331
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=38300
http://associationsila.org/component/k2/itemlist/user/284407
http://www.arunagreen.com/index.php/component/k2/itemlist/user/400843
http://metropolis.ga/index.php?topic=1091.0
http://153.120.114.241/eso/index.php/16867543-milliardy-4-sezon-9-seria-eul-milliardy-4-sezon-9-seria
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=258447
http://married.dike.gr/index.php/component/k2/itemlist/user/39714
http://www.deliberarchia.org/forum/index.php?topic=931625.0
http://www.deliberarchia.org/forum/index.php?topic=929618.0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/411573
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81-20/
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81-21/
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81-23/
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81-24/
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81-25/
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81-26/
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81-27/
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81-18/
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81-19/
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81-20/
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81-21/
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81-22/
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81-23/
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1553583
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1553616
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1553657
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1554681
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1555066
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1555274
http://www.arredoufficiomarca.com/index.php/component/k2/itemlist/user/1551226
http://www.arredoufficiomarca.com/index.php/component/k2/itemlist/user/1551458
http://www.arredoufficiomarca.com/index.php/component/k2/itemlist/user/1551691
http://www.arredoufficiomarca.com/index.php/component/k2/itemlist/user/1551715
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tt1-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://healthyteethpa.org/?option=com_k2&view=itemlist&task=user&id=5278662
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/252617
http://withinfp.sakura.ne.jp/eso/index.php/16775306-nasa-istoria-67-seria-g5ro-nasa-istoria-67-seria/0
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=604685
http://webp.online/index.php?topic=40171.0
http://withinfp.sakura.ne.jp/eso/index.php/16790987-sverh-estestvennoe-14-sezon-14-seria-ilj-sverh-estestvennoe-14-/0
http://batubersurat.com/index.php/component/k2/itemlist/user/37985
http://batubersurat.com/index.php/component/k2/itemlist/user/37994
http://batubersurat.com/index.php/component/k2/itemlist/user/38004
http://batubersurat.com/index.php/component/k2/itemlist/user/38024
http://batubersurat.com/index.php/component/k2/itemlist/user/38035
http://batubersurat.com/index.php/component/k2/itemlist/user/38060
http://batubersurat.com/index.php/component/k2/itemlist/user/38076
http://batubersurat.com/index.php/component/k2/itemlist/user/38104
http://batubersurat.com/index.php/component/k2/itemlist/user/38109
http://batubersurat.com/index.php/component/k2/itemlist/user/38138
http://batubersurat.com/index.php/component/k2/itemlist/user/38142
http://batubersurat.com/index.php/component/k2/itemlist/user/38145
http://batubersurat.com/index.php/component/k2/itemlist/user/38150
http://batubersurat.com/index.php/component/k2/itemlist/user/38151
http://batubersurat.com/index.php/component/k2/itemlist/user/38306
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1767263
http://www.emrabq8.com/index.php/component/k2/itemlist/user/1767258
http://www.m1avio.com/index.php/component/k2/itemlist/user/3610146
http://www.m1avio.com/index.php/component/k2/itemlist/user/3610312
http://arunagreen.com/index.php/component/k2/itemlist/user/433425
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/476526
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1866800
http://dohairbiz.com/en/component/k2/itemlist/user/2710601.html
http://fbpharm.net/index.php/component/k2/itemlist/user/16840
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7315246
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/5252
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/291096
http://www.ekemoon.com/160113/051820194208/
http://www.ekemoon.com/160159/051820195808/
http://www.vivelabmanizales.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-avx-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2-%d1%81%d0%b5%d1%80%d0%b8/
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=779267
http://www.ekemoon.com/160115/051820194208/
http://www.ekemoon.com/160251/051920192308/
http://mediaville.me/index.php/component/k2/itemlist/user/232297
http://rudraautomation.com/index.php/component/k2/author/139362
https://lucky28003.nl/forum/index.php?topic=3379.0
http://jesusandmarypatna.com/index.php/component/k2/itemlist/user/3353691
http://www.hoonthaitoday.com/forum/index.php?topic=106359.0
https://lucky28003.nl/forum/index.php?topic=3384.0
http://www.hoonthaitoday.com/forum/index.php?topic=95018.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/476140
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/476188
http://dev.aabn.org.gh/component/k2/itemlist/user/525129
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/268466
http://healthyteethpa.org/component/k2/itemlist/user/5341311
http://macdistri.com/index.php/component/k2/itemlist/user/307857
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=81879
http://necinsurance.co.zw/component/k2/itemlist/user/19276.html
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=204419
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=5208
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=5215
http://www.deliberarchia.org/forum/index.php?topic=896391.0
http://www.deliberarchia.org/forum/index.php?topic=896414.0
http://www.deliberarchia.org/forum/index.php?topic=896445.0
http://www.deliberarchia.org/forum/index.php?topic=896506.0
http://www.deliberarchia.org/forum/index.php?topic=896574.0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/395192
http://www.arunagreen.com/index.php/component/k2/itemlist/user/395258
http://www.arunagreen.com/index.php/component/k2/itemlist/user/395319
http://www.arunagreen.com/index.php/component/k2/itemlist/user/395324
http://www.arunagreen.com/index.php/component/k2/itemlist/user/395358
http://www.arunagreen.com/index.php/component/k2/itemlist/user/395445
http://www.arunagreen.com/index.php/component/k2/itemlist/user/395531
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/46606
https://members.fbhaters.com/index.php?topic=66320.0
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1126717
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1575638
http://foa.egerton.ac.ke/index.php/component/k2/itemlist/user/1667561
http://seoksoononly.dothome.co.kr/qna/648829
https://www.resproxy.com/forum/index.php/734506-milliardy-4-sezon-4-seria-huy-milliardy-4-sezon-4-seria/0
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1606599
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2472097
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=217351
https://tg.vl-mp.com/index.php?topic=1266728.0
http://www.deliberarchia.org/forum/index.php?topic=919753.0
http://www.deliberarchia.org/forum/index.php?topic=919767.0
http://www.deliberarchia.org/forum/index.php?topic=919784.0
http://www.deliberarchia.org/forum/index.php?topic=919805.0
http://www.deliberarchia.org/forum/index.php?topic=919808.0
http://www.deliberarchia.org/forum/index.php?topic=919820.0
http://www.deliberarchia.org/forum/index.php?topic=919829.0
http://www.deliberarchia.org/forum/index.php?topic=919861.0
http://www.deliberarchia.org/forum/index.php?topic=919871.0
http://www.deliberarchia.org/forum/index.php?topic=919880.0
http://www.deliberarchia.org/forum/index.php?topic=919906.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1311069
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1311084
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1311115
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1311158
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1311184
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1311291
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1311294
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1311361
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1311385
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1311441
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1311446
http://married.dike.gr/index.php/component/k2/itemlist/user/44556
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1858868
https://www.youngbiker.de/wbboard/index.php?page=User&userID=782649
http://macdistri.com/?option=com_k2&view=itemlist&task=user&id=260839
http://www.tessabannampad.go.th/webboard/index.php?topic=188918.0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=290983
http://www.deliberarchia.org/forum/index.php?topic=949848.0
http://www.deliberarchia.org/forum/index.php?topic=949902.0
http://www.deliberarchia.org/forum/index.php?topic=949916.0
http://www.deliberarchia.org/forum/index.php?topic=949928.0
http://www.deliberarchia.org/forum/index.php?topic=949978.0
http://www.deliberarchia.org/forum/index.php?topic=950021.0
http://www.deliberarchia.org/forum/index.php?topic=950031.0
http://www.deliberarchia.org/forum/index.php?topic=950032.0
http://www.deliberarchia.org/forum/index.php?topic=950106.0
http://www.deliberarchia.org/forum/index.php?topic=950125.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3571708
http://www.m1avio.com/index.php/component/k2/itemlist/user/3571745
http://www.m1avio.com/index.php/component/k2/itemlist/user/3571781
http://www.m1avio.com/index.php/component/k2/itemlist/user/3572020
http://www.m1avio.com/index.php/component/k2/itemlist/user/3572185
http://www.m1avio.com/index.php/component/k2/itemlist/user/3572445
http://www.m1avio.com/index.php/component/k2/itemlist/user/3572683
http://www.m1avio.com/index.php/component/k2/itemlist/user/3573130
http://www.m1avio.com/index.php/component/k2/itemlist/user/3573354
http://www.m1avio.com/index.php/component/k2/itemlist/user/3573399
http://www.m1avio.com/index.php/component/k2/itemlist/user/3573635
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ls4-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-4-%d1%81%d0%b5%d1%80%d0%b8/
http://danielmillsap.com/forum/index.php?topic=893705.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1316438
http://withinfp.sakura.ne.jp/eso/index.php/16770521-milliardy-4-sezon-8-seria-jnr-milliardy-4-sezon-8-seria-0105201
http://withinfp.sakura.ne.jp/eso/index.php/16814564-zensina-59-seria-o0rz-zensina-59-seria/0
http://dev.aabn.org.gh/component/k2/itemlist/user/485300
http://hydrocarbs-gh.org/index.php/component/k2/itemlist/user/7286480
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/173936
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/48709
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1838193
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1514636
http://withinfp.sakura.ne.jp/eso/index.php/16791658-amerikanskie-bogi-2-sezon-9-seria-ezh-amerikanskie-bogi-2-sezon/0
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1831365
http://c3isecurity.com.br/?option=com_k2&view=itemlist&task=user&id=438711
https://www.youngbiker.de/wbboard/index.php?page=User&userID=785528
http://www.tessabannampad.go.th/webboard/index.php?topic=190086.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190089.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190111.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190118.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190120.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190130.0
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zf2-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zw9-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-al0-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-as3-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bo8-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cs3-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ev4-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mr8-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-of8-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-oj5-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pb4-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pu0-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://soc-human.kz/index.php/component/k2/itemlist/user/1632103
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/198812
http://webp.online/index.php?topic=42652.0
https://www.youngbiker.de/wbboard/index.php?page=User&userID=782415
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889735
http://withinfp.sakura.ne.jp/eso/index.php/16801283-smotret-kino-tola-robot-5-seria-db-smotret-kino-tola-robot-5-se/0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=532187
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/596248
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1123391
http://uberdrivers.net/forum/index.php?topic=210783.0
http://muratliziraatodasi.org/forum/index.php?topic=396341.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2522376
http://yuptalk.ru/other_food_household_cosmetics_etc/-t12733.0.html
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=232793
http://dpmarketingsystems.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b3-%e3%80%90-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://1vh.info/index.php?topic=7697.0
http://xekhachduyetthuy.com.vn/component/k2/itemlist/user/149743
https://www.mutlualisverisler.com/?p=986107
https://tg.vl-mp.com/index.php?topic=1308451.0
http://www.ikuna.cl/%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0%d1%88%d0%ba%d0%b0-40-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%80%d1%83%d1%81%d1%81%d0%ba%d0%b8%d0%b5-%d1%81%d1%83%d0%b1%d1%82%d0%b8%d1%82%d1%80/
http://www.deliberarchia.org/forum/index.php?topic=934902.0
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=493712
http://withinfp.sakura.ne.jp/eso/index.php/16880928-igra-prestolov-8-sezon-4-seria-rf3-igra-prestolov-8-sezon-4-ser/0
http://help.stv.ru/index.php?PHPSESSID=60656ddaf03b45c3dddb7ee15077d2ba&topic=137083.0
http://eugeniocolazzo.it/forum/index.php?topic=85269.0
http://miklja.net/forum/index.php?topic=22932.0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=303805
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-no7-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8/
https://danceplanet.se/commodore/index.php?topic=11146.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1336961
http://mediaville.me/index.php/component/k2/itemlist/user/207182
http://webp.online/index.php?topic=45455.msg74278
http://healthyteethpa.org/component/k2/itemlist/user/5277634
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1555168
https://members.fbhaters.com/index.php/topic,70981.0.html
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=184052
http://withinfp.sakura.ne.jp/eso/index.php/16806455-zensina-60-seria-t5ph-zensina-60-seria
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=529482
http://dev.aabn.org.gh/component/k2/itemlist/user/520981
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=495693
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=30445
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1546567
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=32100
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/176161
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/176192
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/176416
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/176504
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/176706
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/176915
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/177030
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/177251
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/177373
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/177524
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/178543
http://www.deliberarchia.org/forum/index.php?topic=892699.0
http://www.deliberarchia.org/forum/index.php?topic=892713.0
http://www.deliberarchia.org/forum/index.php?topic=892781.0
http://www.deliberarchia.org/forum/index.php?topic=892829.0
http://www.deliberarchia.org/forum/index.php?topic=892882.0
http://www.deliberarchia.org/forum/index.php?topic=892893.0
http://www.deliberarchia.org/forum/index.php?topic=892920.0
http://www.deliberarchia.org/forum/index.php?topic=893039.0
http://www.deliberarchia.org/forum/index.php?topic=893056.0
http://www.deliberarchia.org/forum/index.php?topic=893070.0
http://www.deliberarchia.org/forum/index.php?topic=893110.0
http://www.deliberarchia.org/forum/index.php?topic=893146.0
http://married.dike.gr/index.php/component/k2/itemlist/user/46617
http://married.dike.gr/index.php/component/k2/itemlist/user/46712
http://married.dike.gr/index.php/component/k2/itemlist/user/46801
http://married.dike.gr/index.php/component/k2/itemlist/user/46887
http://married.dike.gr/index.php/component/k2/itemlist/user/46943
http://married.dike.gr/index.php/component/k2/itemlist/user/47014
http://married.dike.gr/index.php/component/k2/itemlist/user/47073
http://married.dike.gr/index.php/component/k2/itemlist/user/47135
http://married.dike.gr/index.php/component/k2/itemlist/user/47340
http://matinbank.ir/?option=com_k2&view=itemlist&task=user&id=4457827
http://matinbank.ir/?option=com_k2&view=itemlist&task=user&id=4457830
http://www.elpinatarense.es/?option=com_k2&view=itemlist&task=user&id=155268
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=160037
http://israengineering.com/index.php/component/k2/itemlist/user/1081162
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=186810
http://www.svedmyr.nu/install/UserProfile/tabid/61/userId/366808/Default.aspx
http://withinfp.sakura.ne.jp/eso/index.php/16799500-vetrenyj-hercai-7-seria-k3id-vetrenyj-hercai-7-seria/0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=39561
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/40362
http://healthyteethpa.org/component/k2/itemlist/user/5299404
http://comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=103986
http://esperanzazubieta.com/index.php/component/k2/itemlist/user/94712
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=113752
http://robocit.com/index.php/component/k2/itemlist/user/448834
http://associationsila.org/index.php/component/k2/itemlist/user/262707
https://tg.vl-mp.com/index.php?topic=1266068.0
http://www.deliberarchia.org/forum/index.php?topic=897195.0
http://www.deliberarchia.org/forum/index.php?topic=897210.0
http://www.deliberarchia.org/forum/index.php?topic=897233.0
http://www.deliberarchia.org/forum/index.php?topic=897266.0
http://www.deliberarchia.org/forum/index.php?topic=897295.0
http://www.deliberarchia.org/forum/index.php?topic=897309.0
http://menulisilmiah.net/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nv0-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rp9-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zr2-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cc2-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-da9-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-di0-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fl7-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ki9-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ll2-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qf6-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sn5-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sz3-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://153.120.114.241/eso/index.php/16874710-lubov-smert-i-roboty-love-death-and-robots-14-seria-htu-lubov-s
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=95529
http://israengineering.com/index.php/component/k2/itemlist/user/1093205
http://withinfp.sakura.ne.jp/eso/index.php/16773801-milliardy-4-sezon-9-seria-nmq-milliardy-4-sezon-9-seria-0105201/0
http://married.dike.gr/index.php/component/k2/itemlist/user/34861
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=251410
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3531392
http://webp.online/index.php?topic=38402.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2478012
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81-11/
http://www.aroshan.com/component/k2/itemlist/user/928253
http://withinfp.sakura.ne.jp/eso/index.php/16866960-vetrenyj-hercai-13-seria-s9xg-vetrenyj-hercai-13-seria/0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=39435
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=607823
http://www.deliberarchia.org/forum/index.php?topic=893706.0
http://www.deliberarchia.org/forum/index.php?topic=893729.0
http://www.deliberarchia.org/forum/index.php?topic=893742.0
http://www.deliberarchia.org/forum/index.php?topic=893761.0
http://www.deliberarchia.org/forum/index.php?topic=893772.0
http://www.deliberarchia.org/forum/index.php?topic=893785.0
http://www.deliberarchia.org/forum/index.php?topic=893796.0
http://www.deliberarchia.org/forum/index.php?topic=893813.0
http://matinbank.ir/component/k2/itemlist/user/4457683.html
http://matinbank.ir/component/k2/itemlist/user/4457731.html
http://matinbank.ir/component/k2/itemlist/user/4457820.html
http://matinbank.ir/component/k2/itemlist/user/4457961.html
http://matinbank.ir/component/k2/itemlist/user/4458027.html
http://matinbank.ir/component/k2/itemlist/user/4458109.html
http://matinbank.ir/component/k2/itemlist/user/4458170.html
http://matinbank.ir/component/k2/itemlist/user/4458234
http://matinbank.ir/component/k2/itemlist/user/4458374.html
http://matinbank.ir/component/k2/itemlist/user/4458400.html
http://matinbank.ir/component/k2/itemlist/user/4459343.html
http://matinbank.ir/component/k2/itemlist/user/4459372
http://matinbank.ir/component/k2/itemlist/user/4459472.html
http://seoksoononly.dothome.co.kr/?document_srl=628143
http://married.dike.gr/index.php/component/k2/itemlist/user/38816
http://danielmillsap.com/forum/index.php?topic=914045.0
https://sto54.ru/index.php/component/k2/itemlist/user/3270380
http://danielmillsap.com/forum/index.php?topic=888902.0
http://danielmillsap.com/forum/index.php?topic=907943.0
http://www.deliberarchia.org/forum/index.php?topic=906095.0
http://www.deliberarchia.org/forum/index.php?topic=906126.0
http://www.deliberarchia.org/forum/index.php?topic=906158.0
http://www.deliberarchia.org/forum/index.php?topic=906181.0
http://www.deliberarchia.org/forum/index.php?topic=906206.0
http://www.deliberarchia.org/forum/index.php?topic=906221.0
http://www.deliberarchia.org/forum/index.php?topic=906241.0
http://www.deliberarchia.org/forum/index.php?topic=906271.0
http://www.deliberarchia.org/forum/index.php?topic=906339.0
http://www.deliberarchia.org/forum/index.php?topic=906348.0
http://www.deliberarchia.org/forum/index.php?topic=906390.0
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ar9-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cw6-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hg4-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd-2/
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ht7-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jz1-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zn1-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-au5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bc0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bf6-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-eu5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fq1-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-is8-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://smartacity.com/component/k2/itemlist/user/11120
http://married.dike.gr/index.php/component/k2/itemlist/user/39766
https://verdadesbiblicas.org.ec/index.php/component/k2/itemlist/user/3712869
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=12879
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=236855
http://esperanzazubieta.com/component/k2/itemlist/user/95227
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3563381
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=9299
http://batubersurat.com/index.php/component/k2/itemlist/user/38150
http://redgatetech.co/?option=com_k2&view=itemlist&task=user&id=706925
http://erhu.eu/viewtopic.php?f=7&t=230256&view=print
https://tg.vl-mp.com/index.php?topic=1256087.0
http://married.dike.gr/index.php/component/k2/itemlist/user/34517
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3263129
http://macdistri.com/?option=com_k2&view=itemlist&task=user&id=266199
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/176105
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=298139
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1520942
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=40701
http://healthyteethpa.org/component/k2/itemlist/user/5286196
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1308985
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1309053
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1309136
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1309145
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1309188
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1309249
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1309332
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1309340
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1309410
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1309438
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1309509
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=161824
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=161899
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=161905
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=161937
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=162055
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=162131
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=162260
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=162285
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=162339
http://www.hoonthaitoday.com/forum/index.php?topic=109239.0
http://healthyteethpa.org/component/k2/itemlist/user/5267653
http://roikjer.com/forum/index.php?PHPSESSID=rahhhji4n7adluse2soo0rffn6&topic=787251.0
https://hackersuniversity.net/index.php?topic=5904.0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/365090
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4709287
http://proxima.co.rw/index.php/component/k2/itemlist/user/533127
http://sextomariotienda.com/blog/%d1%80%d0%b5%d0%ba%d0%bb%d0%b0%d0%bc%d0%b0-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%80%d0%b5%d0%ba%d0%bb%d0%b0%d0%bc%d0%b0-%d1%82/
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/545001
http://dessa.com.br/component/k2/itemlist/user/295409
http://www.gtupuw.org/index.php/component/k2/itemlist/user/1831090
https://sanp.pro/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-w2-05-05-2019-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
http://www.ekemoon.com/145109/051520194606/
http://fbpharm.net/index.php/component/k2/itemlist/user/13804
http://vtservices85.fr/smf2/index.php?PHPSESSID=3b0beb8fe5ee8d3e9bd04c1695c4ad3d&topic=207619.0
http://withinfp.sakura.ne.jp/eso/index.php/16871586-holostak-9-sezon-10-vypusk-ekstrasensov-exholostak-9-sezon-10-v
http://withinfp.sakura.ne.jp/eso/index.php/16842245-novinka-sosedi-2-sezon-5-seria-s9-sosedi-2-sezon-5-seria
https://danceplanet.se/commodore/index.php?topic=12109.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3294294
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/284697
http://www.deliberarchia.org/forum/index.php?topic=946292.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=677778.0
http://www.phperos.net/foro/index.php?topic=130504.0
https://www.resproxy.com/forum/index.php/776491-sverh-estestvennoe-14-sezon-14-seria-jkx-sverh-estestvennoe-14-/0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/55464
https://members.fbhaters.com/index.php?topic=68051.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2504000
http://miklja.net/forum/index.php?topic=23580.0
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1131317
http://ts.bloodhand.de/forum/viewtopic.php?t=196564
http://www.deliberarchia.org/forum/index.php?topic=952688.0
http://withinfp.sakura.ne.jp/eso/index.php/16850614-vetrenyj-hercai-10-seria-s4wg-vetrenyj-hercai-10-seria
https://tg.vl-mp.com/index.php?topic=1275637.0
http://macdistri.com/index.php/component/k2/itemlist/user/260511
http://91.250.77.10/wbb3/index.php?page=User&userID=403552
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=40134
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/143312
http://webp.online/index.php?topic=43313.15
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=607971
http://www.deliberarchia.org/forum/index.php?topic=924171.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2520165
http://www.deliberarchia.org/forum/index.php?topic=896639.0
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1851721
http://withinfp.sakura.ne.jp/eso/index.php/16806535-tola-robot-4-seria-afisa-vs-tola-robot-4-seria-afisa/0
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=163202
http://batubersurat.com/index.php/component/k2/itemlist/user/36662
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=77144
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=77182
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=77196
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=77198
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=77235
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=77238
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=77248
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=77254
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=77296
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=77310
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=77312
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=77344
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=77369
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=77375
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=77384
http://metropolis.ga/index.php?topic=850.0
http://metropolis.ga/index.php?topic=858.0
http://metropolis.ga/index.php?topic=875.0
http://myrechockey.com/forums/index.php?topic=81067.0
http://myrechockey.com/forums/index.php?topic=81084.0
http://myrechockey.com/forums/index.php?topic=81090.0
http://myrechockey.com/forums/index.php?topic=81108.0
http://myrechockey.com/forums/index.php?topic=82275.0
http://myrechockey.com/forums/index.php?topic=82729.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3280682
http://www.spazioad.com/?option=com_k2&view=itemlist&task=user&id=7182168
http://dev.aabn.org.gh/component/k2/itemlist/user/513665
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3541396
http://www.tessabannampad.go.th/webboard/index.php?topic=188986.0
http://thermoplast.envolgroupe.com/component/k2/author/72541
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1769906
http://www.x2145-productions.technology/index.php?title=%C2%AB%D0%98%D1%81%D1%82%D0%BE%D1%80%D0%B8%D1%8F_%D0%98%D0%B3%D1%80%D1%83%D1%88%D0%B5%D0%BA_4_2019_%C2%BB_07-05-2019_%C2%AB%D0%98%D1%81%D1%82%D0%BE%D1%80%D0%B8%D1%8F_%D0%98%D0%B3%D1%80%D1%83%D1%88%D0%B5%D0%BA_4_2019_Watch%C2%BB_%C2%AB%D0%98%D1%81%D1%82%D0%BE%D1%80%D0%B8%D1%8F_%D0%98%D0%B3%D1%80%D1%83%D1%88%D0%B5%D0%BA_4_2019_%C2%BB
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=96420
http://rudraautomation.com/index.php/component/k2/author/121491
http://rudraautomation.com/index.php/component/k2/author/121553
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1769918
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1054544
https://www.wikisexguide.com/wiki/%C2%AB%D0%A2%D0%B0%D0%B9%D0%BD%D0%B0%D1%8F_%D0%96%D0%B8%D0%B7%D0%BD%D1%8C_%D0%94%D0%BE%D0%BC%D0%B0%D1%88%D0%BD%D0%B8%D1%85_%D0%96%D0%B8%D0%B2%D0%BE%D1%82%D0%BD%D1%8B%D1%85_2_2019_%C2%BB_07-05-2019_%C2%AB%D0%A2%D0%B0%D0%B9%D0%BD%D0%B0%D1%8F_%D0%96%D0%B8%D0%B7%D0%BD%D1%8C_%D0%94%D0%BE%D0%BC%D0%B0%D1%88%D0%BD%D0%B8%D1%85_%D0%96%D0%B8%D0%B2%D0%BE%D1%82%D0%BD%D1%8B%D1%85_2_2019_%C2%BB_%C2%AB%D0%A2%D0%B0%D0%B9%D0%BD%D0%B0%D1%8F_%D0%96%D0%B8%D0%B7%D0%BD%D1%8C_%D0%94%D0%BE%D0%BC%D0%B0%D1%88%D0%BD%D0%B8%D1%85_%D0%96%D0%B8%D0%B2%D0%BE%D1%82%D0%BD%D1%8B%D1%85_2_2019_%C2%BB
http://febrescordero.gob.ec/index.php/component/k2/itemlist/user/79583
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7321727
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7321795
http://www.deliberarchia.org/forum/index.php?topic=895007.0
http://www.deliberarchia.org/forum/index.php?topic=895036.0
http://www.deliberarchia.org/forum/index.php?topic=895072.0
http://www.deliberarchia.org/forum/index.php?topic=895095.0
http://www.deliberarchia.org/forum/index.php?topic=895105.0
http://www.deliberarchia.org/forum/index.php?topic=895143.0
http://www.deliberarchia.org/forum/index.php?topic=895151.0
http://www.deliberarchia.org/forum/index.php?topic=895209.0
http://www.deliberarchia.org/forum/index.php?topic=895259.0
http://www.deliberarchia.org/forum/index.php?topic=895281.0
http://www.deliberarchia.org/forum/index.php?topic=953012.0
https://www.resproxy.com/forum/index.php/737812-cernoe-zerkalo-5-sezon-4-seria-dvt-cernoe-zerkalo-5-sezon-4-ser
http://smartacity.com/component/k2/itemlist/user/9905
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1098844
http://danielmillsap.com/forum/index.php?topic=915535.0
http://menulisilmiah.net/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-25-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ia5-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-25-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.m1avio.com/index.php/component/k2/itemlist/user/3586090
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4825739
http://withinfp.sakura.ne.jp/eso/index.php/16775279-rasskaz-sluzanki-3-sezon-5-seria-zsr-rasskaz-sluzanki-3-sezon-5/0
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7307898
http://danielmillsap.com/forum/index.php?topic=896250.0
https://tg.vl-mp.com/index.php?topic=1291268.0
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=43655
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/60456
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1770528
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/660976
http://www.quattroandpartners.it/component/k2/itemlist/user/1056547
http://www.x2145-productions.technology/index.php?title=Benutzer:LulaMungo02
https://www.wikisexguide.com/wiki/User_talk:ChongHeck231976
http://rudraautomation.com/index.php/component/k2/author/122687
http://febrescordero.gob.ec/index.php/component/k2/itemlist/user/80040
http://rudraautomation.com/index.php/component/k2/author/123309
http://rudraautomation.com/index.php/component/k2/author/123344
http://www.moyakmermer.com/index.php/component/k2/itemlist/user/661093
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1056376
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/69656
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4729919
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=273177
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1094372
https://www.resproxy.com/forum/index.php/742996-milliardy-4-sezon-8-seria-kvb-milliardy-4-sezon-8-seria-0405201/0
http://www.deliberarchia.org/forum/index.php?topic=928857.0
http://healthyteethpa.org/?option=com_k2&view=itemlist&task=user&id=5287384
http://withinfp.sakura.ne.jp/eso/index.php/16788549-sverh-estestvennoe-14-sezon-20-seria-yyp-sverh-estestvennoe-14-/0
http://menulisilmiah.net/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kdb-%d0%b8%d0%b3%d1%80%d0%b0/
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1006194
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=41270
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=42339
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=42803
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=43038
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=43878
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=44277
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=44970
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=45984
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=46307
http://married.dike.gr/index.php/component/k2/itemlist/user/33959
http://married.dike.gr/index.php/component/k2/itemlist/user/33980
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/169268
http://withinfp.sakura.ne.jp/eso/index.php/16781538-nevesta-iz-stambula-istanbullu-gelin-80-seria-g2ag-nevesta-iz-s/0
http://married.dike.gr/index.php/component/k2/itemlist/user/37924
http://withinfp.sakura.ne.jp/eso/index.php/16798601-vossoedinenie-vuslat-13-seria-t7fv-vossoedinenie-vuslat-13-seri/0
http://seoksoononly.dothome.co.kr/qna/611422
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3271920
https://tg.vl-mp.com/index.php?topic=1317616.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889469
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1597136
http://matinbank.ir/component/k2/itemlist/user/4452916.html
https://forums.letstalkbeats.com/index.php?topic=46138.0
http://www.spazioad.com/component/k2/itemlist/user/7152816
https://reficulcoin.com/index.php?topic=4147.0
http://www.theparrotcentre.com/forum/index.php?topic=436878.0
https://tg.vl-mp.com/index.php?topic=1245446.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1295546
http://www.original-craft.net/index.php?topic=294311.0
http://danielmillsap.com/forum/index.php?topic=893951.0
http://sdsn.develop.cinfores.com/?option=com_k2&view=itemlist&task=user&id=169077
https://wwwelibga.000webhostapp.com/%d0%bd%d0%b5-%d0%be%d1%82%d0%bf%d1%83%d1%81%d0%ba%d0%b0%d0%b9-%d0%bc%d0%be%d1%8e-%d1%80%d1%83%d0%ba%d1%83-elimi-birakma-38-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-r8-%d0%bd%d0%b5-%d0%be/levikrischock0/85442/
http://marjorieaperry.com/component/k2/itemlist/user/474242
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1090332
https://members.fbhaters.com/index.php?topic=54277.0
http://menulisilmiah.net/watch-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://www.tessabannampad.go.th/webboard/index.php?topic=185759.0
http://teambuildingpremium.com/forum/index.php?topic=747137.0
https://npi.org.es/smf/index.php?topic=110007.0
http://www.arunagreen.com/?option=com_k2&view=itemlist&task=user&id=388612
http://ru-realty.com/forum/index.php?PHPSESSID=m9ne83kfvvr3qtrquve4ru52v5&topic=417568.0
http://poselokgribovo.ru/forum/index.php?topic=647736.0
http://withinfp.sakura.ne.jp/eso/index.php/16780491-ne-otpuskaj-mou-ruku-elimi-birakma-39-seria-t0-ne-otpuskaj-mou-/0
http://marjorieaperry.com/?option=com_k2&view=itemlist&task=user&id=473107
http://macdistri.com/index.php/component/k2/itemlist/user/263683
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=519973
http://forum.byehaj.hu/index.php?topic=73893.0
http://danielmillsap.com/forum/index.php?topic=868464.0
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=52820
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=163056
http://roikjer.com/forum/index.php?PHPSESSID=f8ihc4o9t01dop3khtf55prfl0&topic=755766.0
http://metropolis.ga/index.php?topic=5054.0
http://metropolis.ga/index.php?topic=5056.0
http://metropolis.ga/index.php?topic=5057.0
http://metropolis.ga/index.php?topic=5058.0
http://www.deliberarchia.org/forum/index.php?topic=979419.0
http://www.deliberarchia.org/forum/index.php?topic=979425.0
http://www.deliberarchia.org/forum/index.php?topic=979431.0
http://www.deliberarchia.org/forum/index.php?topic=979434.0
http://www.deliberarchia.org/forum/index.php?topic=979442.0
http://www.tessabannampad.go.th/webboard/index.php?topic=193671.0
http://www.tessabannampad.go.th/webboard/index.php?topic=193674.0
https://lucky28003.nl/forum/index.php?topic=11683.0
https://tg.vl-mp.com/index.php?topic=1345750.0
http://www.quattroandpartners.it/component/k2/itemlist/user/1008750
http://www.quattroandpartners.it/component/k2/itemlist/user/1009034
http://www.quattroandpartners.it/component/k2/itemlist/user/1009072
http://www.quattroandpartners.it/component/k2/itemlist/user/1009408
http://www.quattroandpartners.it/component/k2/itemlist/user/1009521
http://www.quattroandpartners.it/component/k2/itemlist/user/1010008
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1005456
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1005514
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1005567
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1005596
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1005639
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1005643
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1005725
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1005757
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1005798
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1005844
http://www.deliberarchia.org/forum/index.php?topic=979596.0
http://www.deliberarchia.org/forum/index.php?topic=979602.0
http://www.tessabannampad.go.th/webboard/index.php?topic=193731.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ttv-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xod-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yyk-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-reh-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kue-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kwf-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nbq-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-njk-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tok-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uid-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.quattroandpartners.it/component/k2/itemlist/user/1036333
http://www.quattroandpartners.it/component/k2/itemlist/user/1042773
http://www.quattroandpartners.it/component/k2/itemlist/user/1053731
http://www.quattroandpartners.it/component/k2/itemlist/user/1059674
http://www.quattroandpartners.it/component/k2/itemlist/user/990155
http://www.quattroandpartners.it/component/k2/itemlist/user/990306
http://www.quattroandpartners.it/component/k2/itemlist/user/990465
http://www.quattroandpartners.it/component/k2/itemlist/user/990842
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1007350
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1007396
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1007401
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1007411
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1007463
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1007474
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/59552
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1646651
http://www.spazioad.com/component/k2/itemlist/user/7241270
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1767539
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1349561
http://rudraautomation.com/index.php/component/k2/author/120186
http://necinsurance.co.zw/component/k2/itemlist/user/19096.html
http://www.m1avio.com/index.php/component/k2/itemlist/user/3621784
http://www.vivelabmanizales.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-28-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o2-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81/
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=53685
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=679009.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2582731
http://universalcommunity.se/Forum/index.php?topic=88.0
https://forums.letstalkbeats.com/index.php?topic=51346.0
https://tg.vl-mp.com/index.php?topic=1298185.0
http://www.spazioad.com/?option=com_k2&view=itemlist&task=user&id=7172012
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1842553
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1599154
http://forums.abs-cbn.com/welcome-back-kapamilya%21/aa-to-73-e-l8(-aa-to-73-e/?PHPSESSID=r16qfmt6h14dhsuiohs8doaq62
http://marjorieaperry.com/?option=com_k2&view=itemlist&task=user&id=473936
http://www.quattroandpartners.it/component/k2/itemlist/user/1038798
https://tg.vl-mp.com/index.php?topic=1249234.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=767a96ccd8b24a6e1c67196ba3d8d8f1&topic=204185.0
http://dpmarketingsystems.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g3-%e3%80%90-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://www.ekemoon.com/139811/050120190605/
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1024958
http://www.gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1855715
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=15801
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=15870
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=15902
http://forum.digamahost.com/index.php?topic=110045.0
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2579272
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/485741
http://dev.aabn.org.gh/component/k2/itemlist/user/538169
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=96691
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=274219
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=274221
http://healthyteethpa.org/?option=com_k2&view=itemlist&task=user&id=5358716
http://mahdi.ehosseini.com/?option=com_k2&view=itemlist&task=user&id=26329
https://tg.vl-mp.com/index.php?topic=1278249.0
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1131809
https://www.blog.quora.healthcare/%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be%d0%b1%d0%be%d1%82%d0%b0-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90du%e3%80%91%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80
http://forums.abs-cbn.com/welcome-back-kapamilya%21/ma-4-eo-6-e-nhl-ma-4-eo-6-e-25-04-2019/?PHPSESSID=ngf8mmogq7j4c23c7c060ea995
http://www.popolsku.fr.pl/forum/index.php?topic=339459.0
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=235807
http://withinfp.sakura.ne.jp/eso/index.php/16885832-rannaa-ptaska-erkenci-kus-43-seria-b5gr-rannaa-ptaska-erkenci-k/0
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3313794
https://www.resproxy.com/forum/index.php/778862-vossoedinenie-vuslat-20-seria-b6df-vossoedinenie-vuslat-20-seri/0
http://menulisilmiah.net/%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-71-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z6vw-%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-71/
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=295915
https://www.youngbiker.de/wbboard/index.php?page=User&userID=775306
http://forums.abs-cbn.com/welcome-back-kapamilya%21/ma-4-eo-12-e-las-ma-4-eo-12-e-23-04-2019/
http://seoksoononly.dothome.co.kr/qna/441171
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3312840
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=10162
http://153.120.114.241/eso/index.php/16860952-amerikanskie-bogi-2-sezon-9-seria-exk-amerikanskie-bogi-2-sezon
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=303334
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3195977
http://www.m1avio.com/index.php/component/k2/itemlist/user/3565690
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=241718
http://poselokgribovo.ru/forum/index.php?topic=619615.0
http://sam-sanat.ir/?option=com_k2&view=itemlist&task=user&id=136256
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1772310
http://discussadeal.com/forum/index.php?topic=2956.0
http://www.deliberarchia.org/forum/index.php?topic=923678.0
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/654986
http://mobility-corp.com/index.php/component/k2/itemlist/user/2411863
http://mobility-corp.com/index.php/component/k2/itemlist/user/2419333
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=378202
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1740234
https://www.blog.quora.healthcare/%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80%d0%b4%d1%86%d0%b5-tek-yurek-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f1sw-%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80
http://danielmillsap.com/forum/index.php?topic=871277.0
http://pptforum.dothome.co.kr/board_APMk06/672053
http://danielmillsap.com/forum/index.php?topic=818030.0
http://seoksoononly.dothome.co.kr/qna/630621
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-axk-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-12-%d1%81%d0%b5%d1%80/
https://instaldec.com/?option=com_k2&view=itemlist&task=user&id=604434
https://tg.vl-mp.com/index.php?topic=1319906.0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=292372
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/201221
http://teambuildingpremium.com/forum/index.php?topic=593365.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/395526
https://www.resproxy.com/forum/index.php/797761-sverh-estestvennoe-14-sezon-20-seria-mzz-sverh-estestvennoe-14-/0
http://proxima.co.rw/index.php/component/k2/itemlist/user/538100
http://muratliziraatodasi.org/forum/index.php?topic=327557.0
http://teambuildingpremium.com/forum/index.php?topic=657110.0
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=36478
http://withinfp.sakura.ne.jp/eso/index.php/16883009-edinoe-serdce-tek-yurek-10-seria-z4ya-edinoe-serdce-tek-yurek-1/0
https://forum.ac-jete.it/index.php?topic=286728.0
https://tg.vl-mp.com/index.php?topic=1334162.0
https://www.blog.quora.healthcare/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90lu%e3%80%91%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4668102
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3482717
http://mediaville.me/index.php/component/k2/itemlist/user/210548
http://withinfp.sakura.ne.jp/eso/index.php/16784312-cernoe-zerkalo-5-sezon-4-seria-aza-cernoe-zerkalo-5-sezon-4-ser
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1835084
http://www.deliberarchia.org/forum/index.php?topic=919357.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/435217
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=529054
http://teambuildingpremium.com/forum/index.php?topic=680802.0
http://macdistri.com/index.php/component/k2/itemlist/user/221015
https://tg.vl-mp.com/index.php?topic=1283331.0
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/60890
https://www.resproxy.com/forum/index.php/798255-nasledie-12-seria-qnw-nasledie-12-seria/0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=540151
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1006579
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/185609
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1302755
http://withinfp.sakura.ne.jp/eso/index.php/16815278-nasa-istoria-73-seria-q3sd-nasa-istoria-73-seria/0
http://forum.thaibetrank.com/index.php?topic=1087117.0
https://ne-kuru.ru/index.php?topic=202729.0
http://www.lustralesdevallehermoso.com/index.php/component/k2/itemlist/user/47185
http://www.popolsku.fr.pl/forum/index.php?topic=339120.0
https://tg.vl-mp.com/index.php?topic=1283108.0
http://www.popolsku.fr.pl/forum/index.php?topic=350247.0
https://www.blog.quora.healthcare/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90bh%e3%80%91%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f
http://danielmillsap.com/forum/index.php?topic=877340.0
http://seoksoononly.dothome.co.kr/qna/431999
http://metropolis.ga/index.php?topic=692.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2478291
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=704880
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=410822
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=892124
http://webp.online/index.php?topic=43209.0
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=406556
http://muratliziraatodasi.org/forum/index.php?topic=337469.0
http://www.deliberarchia.org/forum/index.php?topic=977818.0
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7263493
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=558680
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4734925
http://sam-sanat.ir/?option=com_k2&view=itemlist&task=user&id=132493
http://dcasociados.eu/?option=com_k2&view=itemlist&task=user&id=85713
http://pptforum.dothome.co.kr/board_APMk06/627077
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/21218
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3175349
http://www.tessabannampad.go.th/webboard/index.php?topic=181062.0
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1521534
http://withinfp.sakura.ne.jp/eso/index.php/16890829-vetrenyj-hercai-14-seria-f8fo-vetrenyj-hercai-14-seria
http://comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=99341
http://lavaggio.com.vn/index.php/component/k2/itemlist/user/3723736
http://153.120.114.241/eso/index.php/16871045-lubov-smert-i-roboty-love-death-and-robots-12-seria-pow-lubov-s
http://www.deliberarchia.org/forum/index.php?topic=942913.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3193601
https://forum.ac-jete.it/index.php?topic=287203.0
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=292271
http://associationsila.org/index.php/component/k2/itemlist/user/264625
http://metropolis.ga/index.php?topic=4257.0
http://batubersurat.com/index.php/component/k2/itemlist/user/36662
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3273897
http://forums.abs-cbn.com/welcome-back-kapamilya%21/ma-4-eo-10-e-afg-ma-4-eo-10-e-23-04-2019/?PHPSESSID=cu225e0kl5v3uv86shkrqsv331
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=409369
http://www.deliberarchia.org/forum/index.php?topic=974434.0
http://www.deliberarchia.org/forum/index.php?topic=814272.0
http://www.meikai.com.ar/foro/index.php?topic=48702.0
http://foa.egerton.ac.ke/index.php/component/k2/itemlist/user/1674782
http://webp.online/index.php?topic=50534.0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=271835
http://www.arunagreen.com/index.php/component/k2/itemlist/user/395818
https://www.wikisexguide.com/wiki/%C2%AB%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%C2%BB_06-05-2019_%D0%9F%D0%BE%D1%81%D0%BB%D0%B5_%C2%AB%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%C2%BB?wpName=DelorasHower954&wpPassword=453EQhRbuF&wploginattempt=Log+in&wpEditToken=%2B%5C&title=Special:UserLogin&authAction=login&force=&wpLoginToken=f3916ffef00bf9d8a819e37c9700c0165ccfbf15%2B%5C&wpName=DelorasHower954&wpPassword=453EQhRbuF&wploginattempt=Log+in&wpEditToken=%2B%5C&title=Special:UserLogin&authAction=login&force=&wpLoginToken=f3916ffef00bf9d8a819e37c9700c0165ccfbf15%2B%5C
http://www.quattroandpartners.it/component/k2/itemlist/user/1038234
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/455983
https://instaldec.com/?option=com_k2&view=itemlist&task=user&id=601596
http://www.deliberarchia.org/forum/index.php?topic=935840.0
http://healthyteethpa.org/component/k2/itemlist/user/5335637
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1246571
https://tg.vl-mp.com/index.php?topic=1307037.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=268457
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=590964.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2487585
http://www.popolsku.fr.pl/forum/index.php?topic=342592.0
https://www.youngbiker.de/wbboard/index.php?page=User&userID=785852
https://www.blog.quora.healthcare/%d0%b2%d0%be%d1%80%d0%be%d0%bd-kuzgun-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x5do-%d0%b2%d0%be%d1%80%d0%be%d0%bd-kuzgun-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1079474
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1077891
http://www.x2145-productions.technology/index.php?title=Benutzer:Claribel77H
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/201846
http://proxima.co.rw/index.php/component/k2/itemlist/user/540383
http://www.popolsku.fr.pl/forum/index.php?topic=340497.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-2-eo-20-e-tpa-2-eo-20-e/
http://www.deliberarchia.org/forum/index.php?topic=938690.0
https://www.blog.quora.healthcare/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pfz-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b
http://pptforum.dothome.co.kr/board_APMk06/641008
https://www.resproxy.com/forum/index.php/774538-igra-prestolov-8-sezon-3-seria-ewt-igra-prestolov-8-sezon-3-ser/0
http://comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=101498
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=163909
http://www.deliberarchia.org/forum/index.php?topic=953698.0
http://menulisilmiah.net/%d0%bd%d0%b5-%d0%be%d1%82%d0%bf%d1%83%d1%81%d0%ba%d0%b0%d0%b9-%d0%bc%d0%be%d1%8e-%d1%80%d1%83%d0%ba%d1%83-elimi-birakma-41-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b1eo-%d0%bd%d0%b5-%d0%be/
http://www.deliberarchia.org/forum/index.php?topic=793796.0
http://www.telcon.gr/index.php/component/k2/itemlist/user/30023
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4610895
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kf6-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://discussadeal.com/forum/index.php?topic=2377.0
http://danielmillsap.com/forum/index.php?topic=801528.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=268640
http://withinfp.sakura.ne.jp/eso/index.php/16917454-nasa-istoria-72-seria-x8ys-nasa-istoria-72-seria/0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-irg-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-11-%d1%81%d0%b5%d1%80/
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ii6-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://withinfp.sakura.ne.jp/eso/index.php/16793282-nasledie-17-seria-puu-nasledie-17-seria/0
http://danielmillsap.com/forum/index.php?topic=812560.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2411308
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/192435
http://muratliziraatodasi.org/forum/index.php?topic=345682.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3277824
http://dev.aabn.org.gh/component/k2/itemlist/user/479168
https://www.blog.quora.healthcare/%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90ix%e3%80%91%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd
https://tg.vl-mp.com/index.php?topic=1268164.0
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=245715
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=673510
https://tg.vl-mp.com/index.php?topic=1309306.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-akn-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://avengerro.top/forum/index.php?topic=17615.0
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1525505
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/150094
http://danielmillsap.com/forum/index.php?topic=831873.0
https://mcsetup.tk/bbs/index.php?topic=233108.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/453582
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3567562
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4826929
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/245937
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=670741
http://www.arunagreen.com/?option=com_k2&view=itemlist&task=user&id=382942
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/141889
http://danielmillsap.com/forum/index.php?topic=902604.0
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=163357
http://danielmillsap.com/forum/index.php?topic=847927.0
http://teambuildingpremium.com/forum/index.php?topic=653172.0
http://webp.online/index.php?topic=49583.0
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3313763
https://tg.vl-mp.com/index.php?topic=1259357.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3272389
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ue4-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7/
http://mobility-corp.com/index.php/component/k2/itemlist/user/2511194
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1550090
http://macdistri.com/index.php/component/k2/itemlist/user/261168
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81-23/
http://webp.online/index.php?topic=41970.0
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1564543
http://webp.online/index.php?topic=40293.msg67432
http://avengerro.top/forum/index.php?topic=14887.0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/48368
http://danielmillsap.com/forum/index.php?topic=837370.0
http://teambuildingpremium.com/forum/index.php?topic=663424.0
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1551495
http://danielmillsap.com/forum/index.php?topic=916817.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=890028
http://pptforum.dothome.co.kr/board_APMk06/650578
http://macdistri.com/index.php/component/k2/itemlist/user/264626
http://www.m1avio.com/?option=com_k2&view=itemlist&task=user&id=3565661
http://jesusandmarypatna.com/index.php/component/k2/itemlist/user/3314353
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81-41/
http://www.arunagreen.com/?option=com_k2&view=itemlist&task=user&id=383168
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1793590
http://batubersurat.com/index.php/component/k2/itemlist/user/43867
https://www.blog.quora.healthcare/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gjw-%d1%80%d0%b0
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mf3-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13/
http://www.deliberarchia.org/forum/index.php?topic=972032.0
http://danielmillsap.com/forum/index.php?topic=811877.0
http://withinfp.sakura.ne.jp/eso/index.php/16861760-ne-otpuskaj-mou-ruku-elimi-birakma-36-seria-o5eg-ne-otpuskaj-mo/0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=301248
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=7906
http://teambuildingpremium.com/forum/index.php?topic=689982.0
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/42464
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4611005
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3304150
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/45072
http://healthyteethpa.org/?option=com_k2&view=itemlist&task=user&id=5275633
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=298830
http://www.phan-aen.go.th/forum/index.php?topic=610583.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hzg-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://web2interactive.com/index.php/component/k2/itemlist/user/3478424
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=892001
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1469125
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=382094
http://danielmillsap.com/forum/index.php?topic=873843.0
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/534914
https://www.resproxy.com/forum/index.php/790364-rasskaz-sluzanki-3-sezon-3-seria-yiw-rasskaz-sluzanki-3-sezon-3/0
https://www.resproxy.com/forum/index.php/775858-milliardy-4-sezon-4-seria-mam-milliardy-4-sezon-4-seria/0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=890271
http://forum.thaibetrank.com/index.php?topic=1091050.0
http://tradebest.org/board_MdUI61/1569000
http://www.deliberarchia.org/forum/index.php?topic=952947.0
http://teambuildingpremium.com/forum/index.php?topic=658728.0
http://fbpharm.net/index.php/component/k2/itemlist/user/16033
http://fbpharm.net/index.php/component/k2/itemlist/user/25130
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3278402
http://mobility-corp.com/index.php/component/k2/itemlist/user/2476179
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=251240
http://seoksoononly.dothome.co.kr/qna/437722
http://www.popolsku.fr.pl/forum/index.php?topic=337361.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wej-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-9-%d1%81%d0%b5%d1%80%d0%b8/
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2543114
http://www.x2145-productions.technology/index.php?title=Benutzer:Martin6937
https://www.blog.quora.healthcare/%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80%d0%b4%d1%86%d0%b5-tek-yurek-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v3he-%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80
https://www.resproxy.com/forum/index.php/773214-nasledie-14-seria-hla-nasledie-14-seria/0
http://xn--22cmah2caecpucll2cycdoj4d0knajrq3e5pbj9w0c.americanwolfthailand.com/DJPetjah/index.php?topic=1467470.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=582668.0
http://healthyteethpa.org/component/k2/itemlist/user/5332177
https://www.shaiyax.com/index.php?topic=310664.0
http://www.deliberarchia.org/forum/index.php?topic=982723.0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/314734
http://forums.abs-cbn.com/welcome-back-kapamilya%21/ma-4-eo-13-e-nxv-ma-4-eo-13-e-25-04-2019/?PHPSESSID=vjf1mavv77re1od0ffadfslr25
http://sam-sanat.ir/?option=com_k2&view=itemlist&task=user&id=117409
http://www.deliberarchia.org/forum/index.php?topic=964967.0
http://www.pcosmetic.ir/?option=com_k2&view=itemlist&task=user&id=9937
http://danielmillsap.com/forum/index.php?topic=799258.0
http://www.deliberarchia.org/forum/index.php?topic=984330.0
http://macdistri.com/index.php/component/k2/itemlist/user/222217
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/390285
https://www.resproxy.com/forum/index.php/756310-milliardy-4-sezon-7-seria-agc-milliardy-4-sezon-7-seria-0505201/0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=260124
http://danielmillsap.com/forum/index.php?topic=918466.0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=475914
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3527746
https://www.youngbiker.de/wbboard/index.php?page=User&userID=784407
http://healthyteethpa.org/component/k2/itemlist/user/5286667
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mxy-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b3%d1%80%d0%b0%d0%bd%d0%b4-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mf2-%d0%b3%d1%80%d0%b0%d0%bd%d0%b4-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81/
http://danielmillsap.com/forum/index.php?topic=899677.0
http://associationsila.org/index.php/component/k2/itemlist/user/263577
http://teambuildingpremium.com/forum/index.php?topic=603224.0
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rr8-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19/
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=873929
http://www.spazioad.com/component/k2/itemlist/user/7215434
http://c3isecurity.com.br/?option=com_k2&view=itemlist&task=user&id=444266
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jt1-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://teambuildingpremium.com/forum/index.php?topic=629195.0
http://www.sakitoandrichifantasy.gr/?option=com_k2&view=itemlist&task=user&id=143561
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1131336
http://teambuildingpremium.com/forum/index.php?topic=637636.0
http://healthyteethpa.org/component/k2/itemlist/user/5190907
http://withinfp.sakura.ne.jp/eso/index.php/16770177-igra-prestolov-8-sezon-7-seria-hin-igra-prestolov-8-sezon-7-ser
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=756518
http://afinandoemociones.com.ar/index.php/component/k2/itemlist/user/385898
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fz2-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
https://prosocyr.com/?option=com_k2&view=itemlist&task=user&id=600926
https://alkalua.com/?option=com_k2&view=itemlist&task=user&id=1254730
https://mcsetup.tk/bbs/index.php?topic=224466.0
https://www.resproxy.com/forum/index.php/765626-igra-prestolov-8-sezon-3-seria-zry-igra-prestolov-8-sezon-3-ser/0
https://www.youngbiker.de/wbboard/index.php?page=User&userID=783510
http://www.deliberarchia.org/forum/index.php?topic=975781.0
http://pptforum.dothome.co.kr/?document_srl=657658
http://danielmillsap.com/forum/index.php?topic=867270.0
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1109718
https://www.resproxy.com/forum/index.php/731763-amerikanskie-bogi-2-sezon-7-seria-kzw-amerikanskie-bogi-2-sezon/0
http://www.web2interactive.com/index.php/component/k2/itemlist/user/3540416
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mmk-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1671105
http://www.phan-aen.go.th/forum/index.php?topic=608228.0
https://www.shaiyax.com/index.php?topic=298209.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=286134
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hof-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://teambuildingpremium.com/forum/index.php?topic=621979.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/548406
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-y3yw-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://www.deliberarchia.org/forum/index.php?topic=941908.0
http://webp.online/index.php?topic=37816.0
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1673242
https://www.resproxy.com/forum/index.php/730109-nasledie-13-seria-rbu-nasledie-13-seria/0
http://danielmillsap.com/forum/index.php?topic=794288.0
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=701498
http://withinfp.sakura.ne.jp/eso/index.php/16826839-nasledie-16-seria-odf-nasledie-16-seria
http://danielmillsap.com/forum/index.php?topic=801919.0
http://sdsn.develop.cinfores.com/?option=com_k2&view=itemlist&task=user&id=176697
https://tg.vl-mp.com/index.php?topic=1269030.0
http://www.deliberarchia.org/forum/index.php?topic=926938.0
http://boutique.in.th/?option=com_k2&view=itemlist&task=user&id=143396
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1106174
http://mobility-corp.com/index.php/component/k2/itemlist/user/2471738
https://prosocyr.com/?option=com_k2&view=itemlist&task=user&id=602000
https://www.youngbiker.de/wbboard/index.php?page=User&userID=775841
http://www.theparrotcentre.com/forum/index.php?topic=481493.0
http://www.theparrotcentre.com/forum/index.php?topic=481560.0
http://www.theparrotcentre.com/forum/index.php?topic=481568.0
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=3b5b1774a53642f6d7ea4028cb268f17&topic=704.0
https://altaylarteknoloji.com/index.php?topic=1246.0
https://altaylarteknoloji.com/index.php?topic=1251.0
https://danceplanet.se/commodore/index.php?topic=16487.0
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3347755
http://www.original-craft.net/index.php?topic=307485.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/170602
http://dpmarketingsystems.com/hd720-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://roikjer.com/forum/index.php?topic=758496.0
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1499424
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/169655
http://www.deliberarchia.org/forum/index.php?topic=930680.0
http://www.ekemoon.com/140523/050720191005/
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4727202
http://www.arunagreen.com/index.php/component/k2/itemlist/user/436745
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=784262
http://www.m1avio.com/?option=com_k2&view=itemlist&task=user&id=3613778
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=764812
http://www.siirtorganik.com/index.php/component/k2/itemlist/user/764848
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/292689
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3303512
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=14168
http://153.120.114.241/eso/index.php/16869728-edinoe-serdce-tek-yurek-14-seria-wljr-edinoe-serdce-tek-yurek-1
http://www.vivelabmanizales.com/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v9-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3/
http://www.ekemoon.com/148013/052220192706/
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2509390
http://www.vivelabmanizales.com/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-live-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/67664
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3732421
https://khuyenmaikk13.info/index.php?topic=178623.0
https://members.fbhaters.com/index.php?topic=76171.0
http://withinfp.sakura.ne.jp/eso/index.php/16882325-rannaa-ptaska-erkenci-kus-39-seria-wnpe-rannaa-ptaska-erkenci-k
http://www.atab.com.sa/?option=com_k2&view=itemlist&task=user&id=1563555
http://www.emrabq8.com/index.php/component/k2/itemlist/user/1778949
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=289423
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2563815
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1128470
http://svgrossburgwedel.de/component/k2/itemlist/user/5346
https://members.fbhaters.com/index.php?topic=75839.0
http://matrixpharm.ru/forum/index.php?PHPSESSID=7o47khcntiud72ltd6aggc6250&action=profile;u=173072
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3322356
http://www.emrabq8.com/index.php/component/k2/itemlist/user/1768610
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kw4%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f05-05-2019/
http://poselokgribovo.ru/forum/index.php?topic=716948.0
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4826938
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1567049
http://www.ekemoon.com/159857/051720191908/
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=187913
http://www.critico-expository.com/forum/index.php?topic=2671.0
http://www.deliberarchia.org/forum/index.php?topic=963790.0
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1543160
https://szenarist.ru/forum/index.php?topic=205014.0
https://l2thalassic.org/Forum/index.php?topic=774.0
http://menulisilmiah.net/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jp3%d0%bd/
http://153.120.114.241/eso/index.php/16864837-holostak-9-sezon-vypusk-8-cast-1-svholostak-9-sezon-vypusk-8-ca
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/478126
http://bitpark.co.kr/board_IzjM66/3750054
http://www.siirtorganik.com/index.php/component/k2/itemlist/user/762229
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2519822
http://vsalda.edinros66.ru/component/k2/itemlist/user/44104
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=15981
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=500985
http://withinfp.sakura.ne.jp/eso/index.php/16872218-po-zakonam-voennogo-vremeni-3-sezon-7-seria-05052019-g5-po-zako
http://mediaville.me/index.php/component/k2/itemlist/user/206599
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/214079
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2564350
http://www.vivelabmanizales.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n3-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1/
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=501125
http://www.ekemoon.com/164071/051020191209/
http://menulisilmiah.net/%d0%bc%d0%b5%d1%80%d1%82%d0%b2%d0%be%d0%b5-%d0%be%d0%b7%d0%b5%d1%80%d0%be-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kw5%d0%bc%d0%b5%d1%80%d1%82%d0%b2%d0%be%d0%b5-%d0%be%d0%b7%d0%b5%d1%80%d0%be-9-%d1%81/
http://guiadetudo.com/index.php/component/k2/itemlist/user/11063
http://withinfp.sakura.ne.jp/eso/index.php/16865446-post-sou-holostak-10-05-19-whpost-sou-holostak-10-05-1972-post-/0
http://menulisilmiah.net/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e8-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be/
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=43687
http://153.120.114.241/eso/index.php/16881970-nasa-istoria-64-seria-zfvu-nasa-istoria-64-seria
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=13665
http://poselokgribovo.ru/forum/index.php?topic=738974.0
https://lucky28003.nl/forum/index.php?topic=10268.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/569205
http://www.vivelabmanizales.com/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8d%d1%84%d0%b8%d1%80-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-5/
http://batubersurat.com/index.php/component/k2/itemlist/user/43891
http://married.dike.gr/index.php/component/k2/itemlist/user/49314
http://arunagreen.com/index.php/component/k2/itemlist/user/420979
http://dcasociados.eu/component/k2/itemlist/user/87446
http://www.spazioad.com/component/k2/itemlist/user/7238397
http://withinfp.sakura.ne.jp/eso/index.php/16889309-smotret-tolarobot-1-sezon-5-seria-h8-tolarobot-1-sezon-5-seria/0
http://www.phan-aen.go.th/forum/index.php?topic=628486.0
http://dev.aabn.org.gh/component/k2/itemlist/user/537502
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=1014895
http://thermoplast.envolgroupe.com/component/k2/author/74056
http://proxima.co.rw/index.php/component/k2/itemlist/user/564324
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2391007
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1003320
http://bitpark.co.kr/board_IzjM66/3789266
http://www.nienkevanrijn.nl/component/k2/itemlist/user/432033
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=66833
http://sfah.ch/de/component/k2/itemlist/user/14950
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=79560
http://arunagreen.com/index.php/component/k2/itemlist/user/434888
http://proxima.co.rw/index.php/component/k2/itemlist/user/570215
http://proxima.co.rw/index.php/component/k2/itemlist/user/573772
http://windowshopgoa.com/index.php/component/k2/itemlist/user/189051
http://associationsila.org/index.php/component/k2/itemlist/user/290401
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1114001
https://www.mutlualisverisler.com/?p=1005041
https://khuyenmaikk13.info/index.php?topic=182699.0
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=198970
https://l2thalassic.org/Forum/index.php?topic=1706.0
http://thermoplast.envolgroupe.com/component/k2/author/71265
http://haniel.ir/index.php/component/k2/itemlist/user/77040
http://batubersurat.com/index.php/component/k2/itemlist/user/42377
http://ovotecegg.com/component/k2/itemlist/user/121188
http://k2.akademitelkom.ac.id/component/k2/itemlist/user/289438
http://dohairbiz.com/en/component/k2/itemlist/user/2705499.html
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=208260
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1357775
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-16-%d1%81%d0%b5%d1%80-3/
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/471263
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=50773
http://adsudoeste.com.br/?option=com_k2&view=itemlist&task=user&id=21554
https://alvarogarciatorero.com/index.php/component/k2/itemlist/user/47633
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=47996
http://menulisilmiah.net/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q8-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6/
https://members.fbhaters.com/index.php?topic=80008.0
http://seoksoononly.dothome.co.kr/?document_srl=765909
https://tg.vl-mp.com/index.php?topic=1331843.0
http://dpordering.cetco.com/User-Profile/userId/567263
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/228037
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1126749
http://febrescordero.gob.ec/?option=com_k2&view=itemlist&task=user&id=85358
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=756986
http://thanosakademi.com/index.php?topic=65340.0
http://poselokgribovo.ru/forum/index.php?topic=715793.0
https://danceplanet.se/commodore/index.php?topic=13615.0
http://multikopterforum.hu/index.php?topic=12011.0
http://www.tessabannampad.go.th/webboard/index.php?topic=185574.0
https://danceplanet.se/commodore/index.php?topic=13814.0
http://otitismediasociety.org/forum/index.php?topic=148450.0
http://forum.kopkargobel.com/index.php?topic=3332.0
http://153.120.114.241/eso/index.php/16848158-igra-prestolov-2019-8-sezon-3-seria-aa4-igra-prestolov-2019-8-s
http://www.maquinasdecoserjroman.es/component/k2/itemlist/user/3770
http://danielmillsap.com/forum/index.php?topic=963679.0
http://poselokgribovo.ru/forum/index.php?topic=708455.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/'a-etoo-2019-8-eo-5-e'-a-etoo-2019-8-eo-5-e-m7p1/?PHPSESSID=0sqiu4lf9rkhkj2k0qqsp2uo70
https://adsensebih.com/index.php?topic=8912.0
http://multikopterforum.hu/index.php?topic=12977.0
http://roikjer.com/forum/index.php?PHPSESSID=p0fq50canhu9ju34k775ogfpk3&topic=790483.0
http://otitismediasociety.org/forum/index.php?topic=143339.0
http://www.ekemoon.com/147598/052120194806/
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=25390.0
http://kurnaz.1to.us/index.php?topic=1.480
http://seoksoononly.dothome.co.kr/?document_srl=801014
http://ru-realty.com/forum/index.php?PHPSESSID=k83kole75tcfslrefbjqtanss6&topic=444636.0
http://www.popolsku.fr.pl/forum/index.php?topic=20407.55050
http://blog.ptpintcast.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-w8-v7-%d0%b8%d0%b3/
http://poselokgribovo.ru/forum/index.php?topic=690664.0
http://otitismediasociety.org/forum/index.php?topic=147880.0
http://HyUa.1fps.icu/l/szIaeDC
http://danielmillsap.com/forum/index.php?topic=837675.0
http://www.phan-aen.go.th/forum/index.php?topic=610857.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=893225
http://muratliziraatodasi.org/forum/index.php?topic=340451.0
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1554537
https://tg.vl-mp.com/index.php?topic=1283369.0
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=197620
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/199089
http://tradebest.org/board_MdUI61/1570070
http://c3isecurity.com.br/?option=com_k2&view=itemlist&task=user&id=392834
https://mcsetup.tk/bbs/index.php?topic=227622.0
http://avengerro.top/forum/index.php?topic=18702.0
http://danielmillsap.com/forum/index.php?topic=808919.0
https://tg.vl-mp.com/index.php?topic=1338321.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/290498
http://dessa.com.br/component/k2/itemlist/user/269756
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1226683
http://teambuildingpremium.com/forum/index.php?topic=663175.0
http://pptforum.dothome.co.kr/board_APMk06/685834
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=408002
http://withinfp.sakura.ne.jp/eso/index.php/16838191-igra-prestolov-game-of-thrones-8-sezon-4-seria-igra-prestolov-g/0
http://freebeer.me/index.php?topic=302691.0
http://codeerror.in/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-4/
http://sextomariotienda.com/blog/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gt5-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://bobr.site/index.php?topic=84864.0
http://ru-realty.com/forum/index.php?PHPSESSID=0o6ggrisrjcr6qa5j4rfuio8u7&topic=460495.0
http://1vh.info/index.php?topic=13751.0
http://forum.kopkargobel.com/index.php?topic=3324.0
http://ptu.imoove.kr/ko/content/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-5-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90rd8%E3%80%91-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-5
http://dpmarketingsystems.com/%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-06-05-2019/
https://www.shaiyax.com/index.php?topic=326319.0
http://bobr.site/index.php?topic=84691.0
http://metropolis.ga/index.php?topic=1994.0
http://www.tekparcahdfilm.com/forum/index.php?topic=45546.0
http://www.critico-expository.com/forum/index.php?topic=3893.0
http://roikjer.com/forum/index.php?topic=798774.0
http://kurnaz.1to.us/index.php?topic=1.930
http://bobr.site/index.php?topic=89988.0
http://www.theocraticamerica.org/forum/index.php/topic,22539.0.html
http://www.ekemoon.com/149679/050120193607/
https://reficulcoin.com/index.php?topic=10359.0
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v0-u2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
http://8.droror.co.il/uncategorized/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hg9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/60992
https://luckychancerescue.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90gf4%e3%80%91-%d0%b8%d0%b3%d1%80/
http://153.120.114.241/eso/index.php/16853119-drugaa-insa-18-seria-f8-drugaa-insa-18-seria
http://www.ekemoon.com/142835/051920191405/
http://kurnaz.1to.us/index.php?topic=1.900
http://metropolis.ga/index.php?topic=5219.0
http://www.remify.app/foro/index.php?topic=202059.0
http://yuptalk.ru/other_food_household_cosmetics_etc/-t12724.0.html;msg114874
http://multikopterforum.hu/index.php?topic=10782.0
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-3/
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=27932.0
https://khuyenmaikk13.info/index.php?topic=174601.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.nienkevanrijn.nl/component/k2/itemlist/user/426298
http://webp.online/index.php?topic=42594.0
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/656480
http://macdistri.com/index.php/component/k2/itemlist/user/311029
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/471693
http://www.vivelabmanizales.com/%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5%d0%bd%d0%b8%d0%b5-vuslat-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mgtw-%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd/
https://grajalesabogados.com.mx/?option=com_k2&view=itemlist&task=user&id=61455
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/660759
http://www.vivelabmanizales.com/%d0%b2%d0%be%d1%80%d0%be%d0%bd-kuzgun-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cmso-%d0%b2%d0%be%d1%80%d0%be%d0%bd-kuzgun-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=66761
http://withinfp.sakura.ne.jp/eso/index.php/16864218-edinoe-serdce-tek-yurek-19-seria-exxj-edinoe-serdce-tek-yurek-1
http://mahdi.ehosseini.com/index.php/component/k2/itemlist/user/24768
http://153.120.114.241/eso/index.php/16866025-holostak-9-sezon-10-vypusk-uteta-yaholostak-9-sezon-10-vypusk-u
http://forum.byehaj.hu/index.php?topic=81680.0
http://www.deliberarchia.org/forum/index.php?topic=980789.0
http://www.vivelabmanizales.com/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tiln-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-5-%d1%81%d0%b5%d1%80%d0%b8/
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4828037
http://153.120.114.241/eso/index.php/16865361-rannaa-ptaska-erkenci-kus-43-seria-ubyv-rannaa-ptaska-erkenci-k
http://www.phan-aen.go.th/forum/index.php?topic=627884.0
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=50505
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3296846
http://condolencias.servisa.es/17-06-05-2019-e3-17
http://proandpro.it/?option=com_k2&view=itemlist&task=user&id=4531917
http://77.93.38.205/index.php/component/k2/itemlist/user/497784
https://tg.vl-mp.com/index.php?topic=1350826.0
http://forum.digamahost.com/index.php?topic=111209.0
http://withinfp.sakura.ne.jp/eso/index.php/16908023-ne-otpuskaj-mou-ruku-elimi-birakma-36-seria-w6ch-ne-otpuskaj-mo
http://proxima.co.rw/index.php/component/k2/itemlist/user/497212
http://poselokgribovo.ru/forum/index.php?topic=618172.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-iiv-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=38856
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/53163
https://www.youngbiker.de/wbboard/index.php?page=User&userID=782078
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=708514
http://wcwpr.com/UserProfile/tabid/85/userId/9281570/Default.aspx
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=779632
http://www.deliberarchia.org/forum/index.php?topic=964260.0
http://forum.thaibetrank.com/index.php?topic=1073218.0
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1697468
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=376861
http://healthyteethpa.org/component/k2/itemlist/user/5329943
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1470296
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7194898
http://married.dike.gr/index.php/component/k2/itemlist/user/40463
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=42892
http://www.phan-aen.go.th/forum/index.php?topic=612791.0
https://members.fbhaters.com/index.php?topic=64354.0
http://muratliziraatodasi.org/forum/index.php?topic=338545.0
http://www.tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1525056
http://teambuildingpremium.com/forum/index.php?topic=653813.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3193991
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1956597
http://dessa.com.br/index.php/component/k2/itemlist/user/294028
http://web2interactive.com/index.php/component/k2/itemlist/user/3566914
https://mcsetup.tk/bbs/index.php?topic=225551.0
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1858929
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4578033
https://tg.vl-mp.com/index.php?topic=1309790.0
http://wcwpr.com/UserProfile/tabid/85/userId/9280535/Default.aspx
http://www.sopcich.com/UserProfile/tabid/42/UserID/1561050/Default.aspx
http://teambuildingpremium.com/forum/index.php?topic=674297.0
http://seoksoononly.dothome.co.kr/qna/444685
http://teambuildingpremium.com/forum/index.php?topic=638497.0
http://sdsn.develop.cinfores.com/?option=com_k2&view=itemlist&task=user&id=139822
http://teambuildingpremium.com/forum/index.php?topic=660908.0
https://www.resproxy.com/forum/index.php/749676-cernoe-zerkalo-5-sezon-2-seria-dfs-cernoe-zerkalo-5-sezon-2-ser/0
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4830927
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ckc-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://menulisilmiah.net/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-qe5-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://www.deliberarchia.org/forum/index.php?topic=963731.0
http://www.deliberarchia.org/forum/index.php?topic=803374.0
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1132470
https://prosocyr.com/?option=com_k2&view=itemlist&task=user&id=604924
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kzs-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://www.deliberarchia.org/forum/index.php?topic=983170.0
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3541558
http://avengerro.top/forum/index.php?topic=18614.0
http://forumworldbestmt2.altervista.org/index.php?page=User&userID=124389
http://mobility-corp.com/index.php/component/k2/itemlist/user/2509750
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=648949
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=201523
http://danielmillsap.com/forum/index.php?topic=788639.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/435067
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=12308
http://danielmillsap.com/forum/index.php?topic=943132.0
http://www.phan-aen.go.th/forum/index.php?topic=609219.0
http://www.glasshouseproject.com.ng/index.php/component/k2/itemlist/user/39311
http://www.deliberarchia.org/forum/index.php?topic=908572.0
http://withinfp.sakura.ne.jp/eso/index.php/16794016-nasa-istoria-70-seria-w0bb-nasa-istoria-70-seria/0
http://www.deliberarchia.org/forum/index.php?topic=788129.0
http://tradebest.org/board_MdUI61/1564912
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=33845
http://danielmillsap.com/forum/index.php?topic=872049.0
http://muratliziraatodasi.org/forum/index.php?topic=344825.0
https://www.blog.quora.healthcare/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g7pu-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-14-%d1%81%d0%b5%d1%80%d0%b8
http://menulisilmiah.net/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u9zr-%d0%b2%d0%be%d1%81%d0%ba%d1%80/
http://seoksoononly.dothome.co.kr/qna/606679
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=288872
http://seoksoononly.dothome.co.kr/qna/451196
https://mcsetup.tk/bbs/index.php?topic=223993.0
http://www.deliberarchia.org/forum/index.php?topic=899188.0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=296187
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=535721
http://withinfp.sakura.ne.jp/eso/index.php/16777848-voskressij-ertugrul-148-seria-i6pe-voskressij-ertugrul-148-seri/0
http://muratliziraatodasi.org/forum/index.php?topic=345091.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-aoa-3-eo-20-e-vaa-aoa-3-eo-20-e/msg496427/
http://www.sopcich.com/UserProfile/tabid/42/UserID/1520982/Default.aspx
http://dscardip.com/board/index.php?page=User&userID=655326
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1308468
http://withinfp.sakura.ne.jp/eso/index.php/16793407-voron-kuzgun-20-seria-y2ta-voron-kuzgun-20-seria
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/535364
http://www.crnmedia.es/component/k2/itemlist/user/83243
http://153.120.114.241/eso/index.php/16869272-nasledie-17-seria-knw-nasledie-17-seria
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4710752
http://teambuildingpremium.com/forum/index.php?topic=600141.0
http://www.deliberarchia.org/forum/index.php?topic=973683.0
https://tg.vl-mp.com/index.php?topic=1303766.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=259523
https://tg.vl-mp.com/index.php?topic=1335250.0
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=19530
https://www.blog.quora.healthcare/%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80%d0%b4%d1%86%d0%b5-tek-yurek-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v7qs-%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80
http://tradebest.org/board_MdUI61/1561084
http://forum.thaibetrank.com/index.php?topic=1093597.0
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3576389
http://rudraautomation.com/index.php/component/k2/author/118237
http://www.phan-aen.go.th/forum/index.php?topic=628453.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/186757
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=43951
https://woodland.org.ua/groups/ru-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d1-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
https://www.burraco2.com/forum/index.php?topic=293441.0
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=520506
http://77.93.38.205/index.php/component/k2/itemlist/user/520887
http://77.93.38.205/index.php/component/k2/itemlist/user/520955
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=111099
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/493205
http://danielmillsap.com/forum/index.php?topic=991407.0
http://forum.politeknikgihon.ac.id/index.php?topic=26910.0
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=281055
http://healthyteethpa.org/component/k2/itemlist/user/5375024
http://healthyteethpa.org/component/k2/itemlist/user/5375449
http://dev.aabn.org.gh/component/k2/itemlist/user/524698
http://dev.aabn.org.gh/component/k2/itemlist/user/524708
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1865817
http://healthyteethpa.org/component/k2/itemlist/user/5340484
http://healthyteethpa.org/component/k2/itemlist/user/5340496
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1119922
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1119931
http://macdistri.com/index.php/component/k2/itemlist/user/306892
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c1-k8-%d0%b8%d0%b3/
http://www.hoonthaitoday.com/forum/index.php?topic=166405.0
http://otitismediasociety.org/forum/index.php?topic=142887.0
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4816540
https://nextezone.com/index.php?topic=32525.0
https://www.amazingworldtop.com/entretenimiento/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-r1-y3-%d1%80/
http://e-educ.net/Forum/index.php?topic=3492.0
http://otitismediasociety.org/forum/index.php?topic=143800.0
http://forum.politeknikgihon.ac.id/index.php?topic=18068.0
http://otitismediasociety.org/forum/index.php?topic=142320.0
https://danceplanet.se/commodore/index.php?topic=12700.0
http://dpmarketingsystems.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p2-%d1%81/
https://adsensebih.com/index.php?topic=9612.0
https://reficulcoin.com/index.php?topic=6627.0
http://www.nomaher.com/forum/index.php?topic=11114.0
http://www.tessabannampad.go.th/webboard/index.php?topic=192381.0
http://153.120.114.241/eso/index.php/16851756-igra-prestolov-8-sezon-3-seria-mt4-igra-prestolov-8-sezon-3-ser
http://www.gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1833218
http://dpmarketingsystems.com/%d0%b3%d1%80%d0%b0%d0%bd%d0%b4-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-23-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-05-05-2019-2/
http://poselokgribovo.ru/forum/index.php?topic=700531.0
http://ru-realty.com/forum/index.php?PHPSESSID=bgd6ln7sd0oemt2rp97k0epc20&topic=451557.0
http://www.deliberarchia.org/forum/index.php?topic=978497.0
http://e-educ.net/Forum/index.php?topic=3986.0
http://otitismediasociety.org/forum/index.php?topic=143391.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90dy3%e3%80%91-%d0%b8%d0%b3/
http://thanosakademi.com/index.php?topic=62257.0
http://www.vivelabmanizales.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-x3-y3-%d1%80/
https://chromehearts.in.th/index.php?topic=43395.0
http://help.stv.ru/index.php?PHPSESSID=fd95d8ca47790612df5f521eddef665a&topic=137463.0
https://reficulcoin.com/index.php?topic=8603.0
http://help.stv.ru/index.php?PHPSESSID=206c49880a67694b6c14fa8e1fa99924&topic=135354.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1091325
http://healthyteethpa.org/component/k2/itemlist/user/5313100
http://fbpharm.net/index.php/component/k2/itemlist/user/11984
http://www.cispace.com/us/?option=com_k2&view=itemlist&task=user&id=305382
http://www.spazioad.com/component/k2/itemlist/user/7105935
http://danielmillsap.com/forum/index.php?topic=828060.0
http://www.crnmedia.es/?option=com_k2&view=itemlist&task=user&id=83070
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/396164
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1301233
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1775951
http://metropolis.ga/index.php?topic=5292.0
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2386649
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1106524
http://tradebest.org/board_MdUI61/1557147
http://avengerro.top/forum/index.php?topic=16931.0
http://myrechockey.com/forums/index.php?topic=86094.0
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1110309
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yyk-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.popolsku.fr.pl/forum/index.php?topic=338893.0
http://muratliziraatodasi.org/forum/index.php?topic=325793.0
http://tekagrafica.com.br/index.php/component/k2/itemlist/user/1522457
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=458602
http://withinfp.sakura.ne.jp/eso/index.php/16935765-vossoedinenie-vuslat-13-seria-d4xj-vossoedinenie-vuslat-13-seri/0
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1551781
https://prosocyr.com/?option=com_k2&view=itemlist&task=user&id=607214
http://danielmillsap.com/forum/index.php?topic=788773.0
https://www.resproxy.com/forum/index.php/754662-milliardy-4-sezon-6-seria-hls-milliardy-4-sezon-6-seria-0405201/0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=296662
http://seoksoononly.dothome.co.kr/qna/452148
http://healthyteethpa.org/component/k2/itemlist/user/5278084
http://teambuildingpremium.com/forum/index.php?topic=636247.0
http://www.deliberarchia.org/forum/index.php?topic=965301.0
http://sdsn.rsu.edu.ng/?option=com_k2&view=itemlist&task=user&id=2128076
http://matinbank.ir/component/k2/itemlist/user/4458420.html
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1110472
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/175813
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kbb-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-12-%d1%81%d0%b5%d1%80/
http://pptforum.dothome.co.kr/board_APMk06/638072
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2386945
https://members.fbhaters.com/index.php?topic=71167.0
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=193112
https://tg.vl-mp.com/index.php?topic=1290867.0
http://danielmillsap.com/forum/index.php?topic=989750.0
https://www.blog.quora.healthcare/%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0%d1%8f-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b0-%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be%d0%b1%d0%be%d1%82%d0%b0-14-%d1%81%d0%b5%d1%80
https://tg.vl-mp.com/index.php?topic=1297167.0
http://www.deliberarchia.org/forum/index.php?topic=958082.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1090446
http://www.deliberarchia.org/forum/index.php?topic=978528.0
http://teambuildingpremium.com/forum/index.php?topic=622677.0
https://mcsetup.tk/bbs/index.php?topic=227208.0
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1556933
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/247104
http://www.quattroandpartners.it/component/k2/itemlist/user/1010143
http://www.deliberarchia.org/forum/index.php?topic=950757.0
http://danielmillsap.com/forum/index.php?topic=881245.0
http://danielmillsap.com/forum/index.php?topic=819523.0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/404435
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=584743.0
http://www.deliberarchia.org/forum/index.php?topic=984321.0
http://www.deliberarchia.org/forum/index.php?topic=968510.0
http://sdsn.develop.cinfores.com/?option=com_k2&view=itemlist&task=user&id=176662
http://seoksoononly.dothome.co.kr/qna/448482
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/170143
http://metropolis.ga/index.php?topic=2992.0
http://www.glasshouseproject.com.ng/index.php/component/k2/itemlist/user/32232
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=712958
http://webp.online/index.php?topic=48342.0
http://teambuildingpremium.com/forum/index.php?topic=682119.0
http://www.crowdfundingchile.cl/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kj6-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1106513
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=670636
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1108837
http://withinfp.sakura.ne.jp/eso/index.php/16773481-ne-otpuskaj-mou-ruku-elimi-birakma-40-seria-n0ng-ne-otpuskaj-mo/0
http://seoksoononly.dothome.co.kr/qna/596087
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/936142
http://dev.aabn.org.gh/component/k2/itemlist/user/530424
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l3-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
https://www.shaiyax.com/index.php?topic=330013.0
http://married.dike.gr/index.php/component/k2/itemlist/user/52305
http://rudraautomation.com/index.php/component/k2/author/122750
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1014232
http://www.spazioad.com/component/k2/itemlist/user/7240248
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3722429
http://macdistri.com/?option=com_k2&view=itemlist&task=user&id=307917
https://www.gizmoarticle.com/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81-8/
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=5707
http://roikjer.com/forum/index.php?PHPSESSID=eeqasubgqg1mlq03inv26oca63&topic=785369.0
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=1592
https://khuyenmaikk13.info/index.php?topic=151261.0
http://danielmillsap.com/forum/index.php?topic=887461.0
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/178050
http://dev.aabn.org.gh/index.php/component/k2/itemlist/user/538904
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1878212
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=274855
http://healthyteethpa.org/component/k2/itemlist/user/5359960
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1132007
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1132058
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3733473
http://married.dike.gr/index.php/component/k2/itemlist/user/51139
http://www.aloeverasas.it/index.php/component/k2/itemlist/user/18861
http://www.deliberarchia.org/forum/index.php?topic=989924.0
http://www.deliberarchia.org/forum/index.php?topic=989933.0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=586779
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=784388
http://www.tekparcahdfilm.com/forum/index.php?topic=46928.0
http://www.theparrotcentre.com/forum/index.php?topic=481267.0
http://www.theparrotcentre.com/forum/index.php?topic=481285.0
http://www.theparrotcentre.com/forum/index.php?topic=481297.0
http://theolevolosproject.org/index.php/component/k2/itemlist/user/23423
http://subforumna.x10.mx/mad/index.php?topic=190871.0
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/126702
https://members.fbhaters.com/index.php?topic=72428.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3596537
http://vtservices85.fr/smf2/index.php?PHPSESSID=35ada22408e00eb3d45f4fad6a754726&topic=198811.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/554658
http://1vh.info/index.php?topic=16279.0
http://1vh.info/index.php?topic=16283.0
http://1vh.info/index.php?topic=16291.0
http://bayareawomenmag.xyz/blogs/viewstory/17988
http://bayareawomenmag.xyz/blogs/viewstory/17997
http://bayareawomenmag.xyz/blogs/viewstory/18016
http://poselokgribovo.ru/forum/index.php?topic=743479.0
http://poselokgribovo.ru/forum/index.php?topic=743489.0
http://poselokgribovo.ru/forum/index.php?topic=743506.0
http://roikjer.com/forum/index.php?PHPSESSID=cqh8tblk25ke3dasfv8os8pg80&topic=835111.0
http://siliconvalleytalk.xyz/blogs/viewstory/14522
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1081542
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=402685
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4699547
http://teambuildingpremium.com/forum/index.php?topic=634269.0
http://webp.online/index.php?topic=41813.msg69467
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=200676
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1109729
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qw4-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
https://lucky28003.nl/forum/index.php?topic=9574.0
http://webp.online/index.php?topic=46126.0
http://aitour.kz/index.php/component/k2/itemlist/user/325793
http://afinandoemociones.com.ar/index.php/component/k2/itemlist/user/387056
https://www.resproxy.com/forum/index.php/732423-rasskaz-sluzanki-3-sezon-3-seria-ywn-rasskaz-sluzanki-3-sezon-3/0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/46105
http://malbeot.iptime.org:10009/xe/board/3735188
http://153.120.114.241/eso/index.php/16864744-lubov-smert-i-roboty-love-death-and-robots-16-seria-csj-lubov-s
http://forums.abs-cbn.com/welcome-back-kapamilya%21/aka-ak-3-eo-5-e-byl-aka-ak-3-eo-5-e-25-04-2019/?PHPSESSID=aqk0lv3tkl3m27f5rudcnfhhr6
http://www.phan-aen.go.th/forum/index.php?topic=608759.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=589044.0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=260297
http://boutique.in.th/?option=com_k2&view=itemlist&task=user&id=146022
https://www.resproxy.com/forum/index.php/744644-nasledie-14-seria-kls-nasledie-14-seria/0
http://danielmillsap.com/forum/index.php?topic=793171.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3249963
http://www.arunagreen.com/index.php/component/k2/itemlist/user/285139
http://forums.abs-cbn.com/welcome-back-kapamilya%21/aka-ak-3-eo-5-e-svt-aka-ak-3-eo-5-e-25-04-2019/?PHPSESSID=7p71ta7mc566pa7lquk95ipui1
http://tekagrafica.com.br/index.php/component/k2/itemlist/user/1506397
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/246986
http://www.deliberarchia.org/forum/index.php?topic=909468.0
https://sto54.ru/index.php/component/k2/itemlist/user/3175348
http://www.deliberarchia.org/forum/index.php?topic=979172.0
https://members.fbhaters.com/index.php?topic=71092.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/367759
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/395150
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ng0-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17/
http://www.cosl.com.sg/UserProfile/tabid/61/userId/26159006/Default.aspx
http://pptforum.dothome.co.kr/board_APMk06/628403
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rz9-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cs5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://dessa.com.br/component/k2/itemlist/user/293696
http://menulisilmiah.net/%d0%bd%d0%b5-%d0%be%d1%82%d0%bf%d1%83%d1%81%d0%ba%d0%b0%d0%b9-%d0%bc%d0%be%d1%8e-%d1%80%d1%83%d0%ba%d1%83-elimi-birakma-38-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b4ri-%d0%bd%d0%b5-%d0%be/
http://webp.online/index.php?topic=39186.0
http://www.deliberarchia.org/forum/index.php?topic=961138.0
http://teambuildingpremium.com/forum/index.php?topic=676230.0
http://metropolis.ga/index.php?topic=2141.0
https://tg.vl-mp.com/index.php?topic=1326735.0
https://www.resproxy.com/forum/index.php/771301-edinoe-serdce-tek-yurek-14-seria-s2ue-edinoe-serdce-tek-yurek-1/0
http://withinfp.sakura.ne.jp/eso/index.php/16789850-riverdejl-riverdale-3-sezon-21-seria-cmy-riverdejl-riverdale-3-/0
http://www.tessabannampad.go.th/webboard/index.php?topic=193980.0
http://seoksoononly.dothome.co.kr/qna/458477
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/141624
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/151874
http://avengerro.top/forum/index.php?topic=11614.0
http://teambuildingpremium.com/forum/index.php?topic=671562.0
http://mediaville.me/index.php/component/k2/itemlist/user/210060
http://www.glasshouseproject.com.ng/index.php/component/k2/itemlist/user/38178
http://menulisilmiah.net/%d0%b3%d1%80%d0%b0%d0%bd%d0%b4-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ab9-%d0%b3%d1%80%d0%b0%d0%bd%d0%b4-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81/
http://discussadeal.com/forum/index.php?topic=4041.0
http://www.deliberarchia.org/forum/index.php?topic=898507.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1319996
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1005071
http://jpacschoolclubs.co.uk/?option=com_k2&view=itemlist&task=user&id=3256030
http://www.deliberarchia.org/forum/index.php?topic=784596.0
http://muratliziraatodasi.org/forum/index.php?topic=327321.0
http://www.deliberarchia.org/forum/index.php?topic=952374.0
http://www.phan-aen.go.th/forum/index.php?topic=613607.0
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1654984
http://thermoplast.envolgroupe.com/component/k2/author/82910
https://members.fbhaters.com/index.php?topic=82029.0
https://www.resproxy.com/forum/index.php/808848-rasskaz-sluzanki-3-sezon-2-seria-ifz-rasskaz-sluzanki-3-sezon-2/0
https://www.resproxy.com/forum/index.php/808858-milliardy-4-sezon-9-seria-iwl-milliardy-4-sezon-9-seria-0905201/0
https://www.resproxy.com/forum/index.php/808866-cernoe-zerkalo-5-sezon-5-seria-drs-cernoe-zerkalo-5-sezon-5-ser/0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=303989
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=235083
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/9940
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=143576
http://rudraautomation.com/index.php/component/k2/author/143558
http://teambuildingpremium.com/forum/index.php?topic=790303.0
http://teambuildingpremium.com/forum/index.php?topic=790316.0
http://healthyteethpa.org/?option=com_k2&view=itemlist&task=user&id=5275633
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=298830
http://www.phan-aen.go.th/forum/index.php?topic=610583.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hzg-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://web2interactive.com/index.php/component/k2/itemlist/user/3478424
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=892001
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1469125
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=382094
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=236605
https://www.resproxy.com/forum/index.php/789441-igra-prestolov-8-sezon-7-seria-our-igra-prestolov-8-sezon-7-ser/0
https://www.resproxy.com/forum/index.php/741624-milliardy-4-sezon-5-seria-gin-milliardy-4-sezon-5-seria-0305201/0
http://www.glasshouseproject.com.ng/index.php/component/k2/itemlist/user/39091
https://tg.vl-mp.com/index.php?topic=1257421.0
http://teambuildingpremium.com/forum/index.php?topic=622740.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xoz-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
https://forum.ac-jete.it/index.php?topic=287060.0
http://teambuildingpremium.com/forum/index.php?topic=639115.0
http://flyinghonda.de/wbb/index.php?page=User&userID=804584
http://forums.abs-cbn.com/welcome-back-kapamilya%21/et-e-12-e-qget-e-12-e/?PHPSESSID=rhe92nk68on3l6nmiag9gault7
https://tg.vl-mp.com/index.php?topic=1305596.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lpp-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://mcsetup.tk/bbs/index.php?topic=224871.0
https://www.blog.quora.healthcare/%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b5-%d0%b7%d0%b5%d1%80%d0%ba%d0%b0%d0%bb%d0%be-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pwt-%d1%87%d0%b5%d1%80%d0%bd
http://www.sopcich.com/UserProfile/tabid/42/UserID/1667604/Default.aspx
http://macdistri.com/index.php/component/k2/itemlist/user/227820
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1521476
http://danielmillsap.com/forum/index.php?topic=793874.0
http://danielmillsap.com/forum/index.php?topic=816854.0
http://www.sopcich.com/UserProfile/tabid/42/UserID/1563793/Default.aspx
http://teambuildingpremium.com/forum/index.php?topic=630737.0
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cm8-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2/
http://www.ekemoon.com/159413/051520190008/
http://macdistri.com/index.php/component/k2/itemlist/user/316953
http://www.gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1864813
http://withinfp.sakura.ne.jp/eso/index.php/16888215-voskressij-ertugrul-5-sezon-29-seria-a8-voskressij-ertugrul-5-s/0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=42368
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3320377
http://www.gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1856525
http://www.vivelabmanizales.com/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-29-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-v0/
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=679115.0
https://nextezone.com/index.php?topic=34679.0
http://www.critico-expository.com/forum/index.php?topic=4425.0
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3591250
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=625104.0
http://dpmarketingsystems.com/%d0%bc%d0%b5%d1%80%d1%82%d0%b2%d0%be%d0%b5-%d0%be%d0%b7%d0%b5%d1%80%d0%be-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sqo-%d0%bc%d0%b5%d1%80%d1%82%d0%b2%d0%be%d0%b5-%d0%be%d0%b7%d0%b5%d1%80/
http://www.quattroandpartners.it/component/k2/itemlist/user/1028804
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=146172
http://dpmarketingsystems.com/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81-6/
http://thefreebitcoin.com/index.php?topic=27681.0
http://www.hoonthaitoday.com/forum/index.php?topic=94657.0
https://members.fbhaters.com/index.php?topic=57082.0
https://sanp.pro/%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0%d1%88%d0%ba%d0%b0-erkenci-kus-42-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t4-%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0%d1%88/
http://www.deliberarchia.org/forum/index.php?topic=888960.0
http://healthyteethpa.org/component/k2/itemlist/user/5326999
http://dohairbiz.com/?option=com_k2&view=itemlist&task=user&id=2695352
http://thanosakademi.com/index.php?topic=60169.0
http://www.original-craft.net/index.php?topic=294883.0
http://freebeer.me/index.php?topic=246926.0
http://universaldrive-s.cba.pl/index.php?PHPSESSID=ae7b278650dabb43b4ad4503ffbf0096&topic=17378.0
https://sanp.pro/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-81-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m8-%d0%bd%d0%b5%d0%b2%d0%b5%d1%81/
http://forums.abs-cbn.com/welcome-back-kapamilya%21/ootk-9-eo-11-k-ejootk-9-eo-11-k/?PHPSESSID=tf1ln87basj40ns7tlqej0pi30
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1832381
http://married.dike.gr/index.php/component/k2/itemlist/user/26340
https://tg.vl-mp.com/index.php?topic=1316806.0
https://mcsetup.tk/bbs/index.php?topic=232117.0
http://boutique.in.th/?option=com_k2&view=itemlist&task=user&id=145610
http://www.x2145-productions.technology/index.php?title=%C2%AB%D0%90%D0%B2%D0%B0%D1%82%D0%B0%D1%80_2_2020_%C2%BB_06-05-2019_%C2%AB%D0%90%D0%B2%D0%B0%D1%82%D0%B0%D1%80_2_2020_Watch%C2%BB_%C2%AB%D0%90%D0%B2%D0%B0%D1%82%D0%B0%D1%80_2_2020_%C2%BB
http://forum.thaibetrank.com/index.php?topic=1090943.0
http://withinfp.sakura.ne.jp/eso/index.php/16774142-milliardy-4-sezon-8-seria-nrl-milliardy-4-sezon-8-seria-0105201/0
http://healthyteethpa.org/?option=com_k2&view=itemlist&task=user&id=5290908
http://www.deliberarchia.org/forum/index.php?topic=975795.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/264410
https://www.resproxy.com/forum/index.php/741567-sverh-estestvennoe-14-sezon-15-seria-exl-sverh-estestvennoe-14-/0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=871196
http://mediaville.me/index.php/component/k2/itemlist/user/204427
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=383009
http://tradebest.org/board_MdUI61/1577357
https://www.resproxy.com/forum/index.php/797165-milliardy-4-sezon-4-seria-xbv-milliardy-4-sezon-4-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/16865582-vetrenyj-hercai-12-seria-g8aa-vetrenyj-hercai-12-seria
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1668623
https://tg.vl-mp.com/index.php?topic=1339372.0
http://www.sopcich.com/UserProfile/tabid/42/UserID/1517875/Default.aspx
http://danielmillsap.com/forum/index.php?topic=878374.0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=269203
https://mcsetup.tk/bbs/index.php?topic=229900.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3253228
http://yuptalk.ru/other_food_household_cosmetics_etc/-t12448.0.html
https://reficulcoin.com/index.php?topic=8375.0
http://8.droror.co.il/uncategorized/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-h2-w1-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://forum.elexlabs.com/index.php?topic=12286.0
http://xplorefitness.com/blog/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-2019-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-3-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90wf3%E3%80%91-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-2019-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-3-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-watch
http://haniel.ir/?option=com_k2&view=itemlist&task=user&id=74897
http://danielmillsap.com/forum/index.php?topic=923184.0
http://www.theparrotcentre.com/forum/index.php?topic=449704.0
https://nextezone.com/index.php?topic=31048.0
http://roikjer.com/forum/index.php?PHPSESSID=hb0btpe0a9bg96b3mbvui8ism0&topic=796172.0
http://podwodnyswiat.eu/forum/index.php?topic=130.0
http://danielmillsap.com/forum/index.php?topic=985322.0
https://danceplanet.se/commodore/index.php?topic=10787.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e3-r0-%d0%b8%d0%b3%d1%80/
http://www.popolsku.fr.pl/forum/index.php?topic=20407.44550
http://e-educ.net/Forum/index.php?topic=3682.0
http://www.deliberarchia.org/forum/index.php?topic=948493.0
http://taklongclub.com/forum/index.php?topic=96109.0
http://www.ekemoon.com/163839/050920191709/
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5-4/
http://8.droror.co.il/uncategorized/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-s1-l9-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=680941.0
http://golyboe.ru/forum/index.php?topic=25407.0
http://codeerror.in/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-k5-t5-%d1%80/
http://freebeer.me/index.php?topic=282617.0
https://forum.clubeicaro.pt/index.php?topic=320.0
https://sanp.pro/live-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g2-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://multikopterforum.hu/index.php?topic=10214.0
https://nextezone.com/index.php?topic=33760.0
https://sanp.pro/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-u0-k1-%d1%80/
http://roikjer.com/forum/index.php?PHPSESSID=pfh1nd918bdga1mtb9lg0av5c5&topic=791026.0
http://withinfp.sakura.ne.jp/eso/index.php/16839479-ertugrul-148-seria-kv4-ertugrul-148-seria
http://www.vivelabmanizales.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w3-v4-%d1%80%d0%b0%d1%81%d1%81/
http://forum.politeknikgihon.ac.id/index.php?topic=18088.0
http://poselokgribovo.ru/forum/index.php?topic=719002.0
http://www.deliberarchia.org/forum/index.php?topic=979904.0
http://HyUa.1fps.icu/l/szIaeDC
http://salescoach.ro/content/%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-10-%D0%B2%D1%8B%D0%BF%D1%83%D1%81%D0%BA-windows%C2%BB-af%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-10-%D0%B2%D1%8B%D0%BF%D1%83%D1%81%D0%BA-windows%C2%BB63-%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9
http://proxima.co.rw/index.php/component/k2/itemlist/user/578882
http://highlanderonline.cmshelplive.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-21-%d1%81%d0%b5%d1%80%d0%b8-8/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3293670
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3376048
http://www.ekemoon.com/157029/050620190308/
http://www.die-design-manufaktur.de/?option=com_k2&view=itemlist&task=user&id=5177319
http://smartacity.com/component/k2/itemlist/user/13632
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=287820
http://bitpark.co.kr/board_IzjM66/3737751
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2588613
https://forum.yoguely.com/welcome-and-general-discussion/live-1-8-(f8-1-8/
http://macdistri.com/index.php/component/k2/itemlist/user/299010
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/216598
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1003611
https://www.swiss-focus.ch/index.php/component/k2/itemlist/user/15812
http://febrescordero.gob.ec/index.php/component/k2/itemlist/user/83834
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=5253
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=211010
http://ru-realty.com/forum/index.php?PHPSESSID=hsbtekqdc8maourekhfqag8ai0&topic=468207.0
http://necinsurance.co.zw/component/k2/itemlist/user/19593.html
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=16581
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1337298
http://married.dike.gr/index.php/component/k2/itemlist/user/51587
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5-8/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1334668
http://ovotecegg.com/component/k2/itemlist/user/118388
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=500018
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4850040
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=7733
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=5058
http://www.artifact.website/80901-voskressij-ertugrul-150-seria-k5-voskressij-ertugrul-150-seria
http://www.artifact.website/80935-ertugrul-5-sezon-148-seria-online-o5-ertugrul-5-sezon-148-seria
http://www.artifact.website/80992-ertugrul-150-seria-watch-b7-ertugrul-150-seria
http://www.artifact.website/81092-voskressij-ertugrul-148-seria-watch-j8-voskressij-ertugrul-148-
http://www.artifact.website/81124-voskressij-ertugrul-5-sezon-150-seria-q2-voskressij-ertugrul-5-
http://www.artifact.website/81133-voskressij-ertugrul-5-sezon-28-seria-u9-voskressij-ertugrul-5-s
http://www.artifact.website/81139-voskressij-ertugrul-5-sezon-149-seria-v1-voskressij-ertugrul-5-
http://www.artifact.website/81155-voskressij-ertugrul-5-sezon-27-seria-watch-m2-voskressij-ertugr
http://www.artifact.website/81161-voskressij-ertugrul-5-sezon-26-seria-online-g5-voskressij-ertug
http://www.artifact.website/81166-voskressij-ertugrul-150-seria-j4-voskressij-ertugrul-150-seria
http://www.arunagreen.com/index.php/component/k2/itemlist/user/462904
http://www.arunagreen.com/index.php/component/k2/itemlist/user/463127
http://www.critico-expository.com/forum/index.php?topic=6259.0
http://www.critico-expository.com/forum/index.php?topic=6260.0
https://www.c-alice.org/forum/index.php?topic=69110.0
https://www.gizmoarticle.com/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-k8-%d0%b2%d0%be%d1%81/
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4701439
http://dev.fivestarpainting.com/?option=com_k2&view=itemlist&task=user&id=1855618
http://married.dike.gr/index.php/component/k2/itemlist/user/32910
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=6297.0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/44857
http://www.tessabannampad.go.th/webboard/index.php?topic=177704.0
https://khuyenmaikk13.info/index.php?topic=176372.0
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-d1-%e3%80%90-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80/
http://www.gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1833876
https://tg.vl-mp.com/index.php?topic=1251010.0
http://rudraautomation.com/index.php/component/k2/author/119451
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/187885
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/187888
http://sfah.ch/de/component/k2/itemlist/user/15058
http://smartacity.com/component/k2/itemlist/user/19126
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1638159
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1638126
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/53680
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/53690
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=187772
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=187773
http://www.afikgan.co.il/index.php/component/k2/itemlist/user/26182
http://www.afikgan.co.il/index.php/component/k2/itemlist/user/26214
http://www.afikgan.co.il/index.php/component/k2/itemlist/user/26217
http://www.aloeverasas.it/index.php/component/k2/itemlist/user/18179
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=481889
http://www.deliberarchia.org/forum/index.php?topic=795867.0
http://seoksoononly.dothome.co.kr/qna/399866
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81-27/
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=260831
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81-39/
http://avengerro.top/forum/index.php?topic=14870.0
http://teambuildingpremium.com/forum/index.php?topic=623126.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/246869
http://seoksoononly.dothome.co.kr/qna/412277
https://www.resproxy.com/forum/index.php/771078-amerikanskie-bogi-2-sezon-8-seria-duw-amerikanskie-bogi-2-sezon
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1522944
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=261718
https://members.fbhaters.com/index.php?topic=78173.0
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=21340
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=871183
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3197742
http://discussadeal.com/forum/index.php?topic=5020.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190815.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1021673
http://married.dike.gr/index.php/component/k2/itemlist/user/35370
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/279491
http://danielmillsap.com/forum/index.php?topic=880872.0
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=36335
https://lucky28003.nl/forum/index.php?topic=10367.0
http://macdistri.com/index.php/component/k2/itemlist/user/223789
http://proandpro.it/?option=com_k2&view=itemlist&task=user&id=4429706
http://sam-sanat.ir/?option=com_k2&view=itemlist&task=user&id=136571
http://minostech.co.kr/news/3355874
http://teambuildingpremium.com/forum/index.php?topic=617431.0
https://tg.vl-mp.com/index.php?topic=1319988.0
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4727590
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=276296
http://metropolis.ga/index.php?topic=784.0
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1838414
https://www.resproxy.com/forum/index.php/778170-milliardy-4-sezon-6-seria-ooj-milliardy-4-sezon-6-seria/0
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3480487
https://www.youngbiker.de/wbboard/index.php?page=User&userID=785084
http://healthyteethpa.org/component/k2/itemlist/user/5294598
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1321332
http://www.deliberarchia.org/forum/index.php?topic=963057.0
http://muratliziraatodasi.org/forum/index.php?topic=345535.0
http://seoksoononly.dothome.co.kr/qna/476768
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=191917
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/172520
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xxt-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=593281.0
https://www.youngbiker.de/wbboard/index.php?page=User&userID=782233
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/175159
http://153.120.114.241/eso/index.php/16857625-igra-prestolov-8-sezon-8-seria-dbo-igra-prestolov-8-sezon-8-ser
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4682124
http://withinfp.sakura.ne.jp/eso/index.php/16769270-amerikanskie-bogi-2-sezon-7-seria-bem-amerikanskie-bogi-2-sezon
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/204203
http://married.dike.gr/index.php/component/k2/itemlist/user/47321
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=497609
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4734844
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1107041
http://healthyteethpa.org/component/k2/itemlist/user/5291152
http://www.popolsku.fr.pl/forum/index.php?topic=339616.0
http://batubersurat.com/index.php/component/k2/itemlist/user/42110
http://danielmillsap.com/forum/index.php?topic=972891.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2540995
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7255658
http://teambuildingpremium.com/forum/index.php?topic=685892.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2487422
http://muratliziraatodasi.org/forum/index.php?topic=345144.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-2-eo-22-e-esa-2-eo-22-e/?PHPSESSID=pabjdmlemgkohj7c3tkbdbtr40
https://www.resproxy.com/forum/index.php/780927-rasskaz-sluzanki-3-sezon-2-seria-naz-rasskaz-sluzanki-3-sezon-2/0
https://tg.vl-mp.com/index.php?topic=1322947.0
http://seoksoononly.dothome.co.kr/qna/426582
http://teambuildingpremium.com/forum/index.php?topic=592181.0
https://www.resproxy.com/forum/index.php/744177-rasskaz-sluzanki-3-sezon-1-seria-pwo-rasskaz-sluzanki-3-sezon-1/0
http://tekagrafica.com.br/index.php/component/k2/itemlist/user/1508895
http://teambuildingpremium.com/forum/index.php?topic=638383.0
http://www.cosl.com.sg/UserProfile/tabid/61/userId/25926620/Default.aspx
http://mobility-corp.com/index.php/component/k2/itemlist/user/2386837
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2570830
http://www.cosl.com.sg/UserProfile/tabid/61/userId/26117127/Default.aspx
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=47135
http://puppystoreatdoral.com/?option=com_k2&view=itemlist&task=user&id=369582
http://metropolis.ga/index.php?topic=2691.0
http://married.dike.gr/index.php/component/k2/itemlist/user/37139
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1829934
http://www.glasshouseproject.com.ng/index.php/component/k2/itemlist/user/37951
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3277950
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/941102
http://soc-human.kz/index.php/component/k2/itemlist/user/1552375
http://dessa.com.br/component/k2/itemlist/user/291318
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1120416
http://danielmillsap.com/forum/index.php?topic=803662.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2497126
http://arunagreen.com/index.php/component/k2/itemlist/user/430193
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/452752
http://mobility-corp.com/index.php/component/k2/itemlist/user/2501807
http://www.deliberarchia.org/forum/index.php?topic=786031.0
https://www.resproxy.com/forum/index.php/749792-cernoe-zerkalo-5-sezon-3-seria-hsf-cernoe-zerkalo-5-sezon-3-ser/0
http://sdsn.develop.cinfores.com/?option=com_k2&view=itemlist&task=user&id=176605
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/170870
http://www.phan-aen.go.th/forum/index.php?topic=606825.0
http://teambuildingpremium.com/forum/index.php?topic=668079.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1247298
http://seoksoononly.dothome.co.kr/qna/472818
http://withinfp.sakura.ne.jp/eso/index.php/16787142-milliardy-4-sezon-9-seria-hvv-milliardy-4-sezon-9-seria-0205201/0
http://www.tessabannampad.go.th/webboard/index.php?topic=190919.0
https://tg.vl-mp.com/index.php?topic=1284532.0
http://danielmillsap.com/forum/index.php?topic=889740.0
https://www.resproxy.com/forum/index.php/766241-milliardy-4-sezon-6-seria-wtp-milliardy-4-sezon-6-seria/0
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4701146
https://lucky28003.nl/forum/index.php?topic=9474.0
http://healthyteethpa.org/component/k2/itemlist/user/5278397
http://seoksoononly.dothome.co.kr/?document_srl=641559
https://tg.vl-mp.com/index.php?topic=1260165.0
http://teambuildingpremium.com/forum/index.php?topic=618010.0
http://macdistri.com/index.php/component/k2/itemlist/user/258800
http://danielmillsap.com/forum/index.php?topic=823271.0
http://teambuildingpremium.com/forum/index.php?topic=638018.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3569768
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tnu-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-15-%d1%81%d0%b5%d1%80/
http://muratliziraatodasi.org/forum/index.php?topic=345186.0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4714733
http://jesusandmarypatna.com/index.php/component/k2/itemlist/user/3393939
http://www.m1avio.com/index.php/component/k2/itemlist/user/3598399
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=14128
http://www.vivelabmanizales.com/hd-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-y2-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://poselokgribovo.ru/forum/index.php?topic=727071.0
http://xn----7sbbahtl1ajlp0a.xn--p1ai/index.php/component/k2/itemlist/user/1249047
http://153.120.114.241/eso/index.php/16859134-voron-kuzgun-10-seria-jxjb-voron-kuzgun-10-seria
http://www.vivelabmanizales.com/%d0%b6%d0%b5%d0%bd%d1%89%d0%b8%d0%bd%d0%b0-58-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jvfh-%d0%b6%d0%b5%d0%bd%d1%89%d0%b8%d0%bd%d0%b0-58-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://rudraautomation.com/index.php/component/k2/author/135141
http://www.phan-aen.go.th/forum/index.php?topic=625812.0
https://l2thalassic.org/Forum/index.php?topic=2135.0
http://seoksoononly.dothome.co.kr/qna/794948
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3377587
http://www.babvallejo.com/index.php/component/k2/itemlist/user/606246
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1564542
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/55887
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=27244.0
https://l2thalassic.org/Forum/index.php?topic=1269.0
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/215276
http://teambuildingpremium.com/forum/index.php?topic=783225.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3293325
http://xplorefitness.com/blog/hd-%D1%82%D0%B0%D1%94%D0%BC%D0%BD%D0%B8%D1%86i-87-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-b3-%D1%82%D0%B0%D1%94%D0%BC%D0%BD%D0%B8%D1%86i-87-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/189575
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=36414
http://poselokgribovo.ru/forum/index.php?topic=735656.0
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=45526
http://poselokgribovo.ru/forum/index.php?topic=739485.0
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1560529
http://teambuildingpremium.com/forum/index.php?topic=781833.0
http://mjbosch.com/component/k2/itemlist/user/82596
http://mediaville.me/index.php/component/k2/itemlist/user/211519
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-05-05-2019-y5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=773381
http://withinfp.sakura.ne.jp/eso/index.php/16877701-smotret-tola-robot-5-seria-u5-tola-robot-5-seria/0
http://proandpro.it/?option=com_k2&view=itemlist&task=user&id=4529940
http://withinfp.sakura.ne.jp/eso/index.php/16866388-hdvideo-po-zakonam-voennogo-vremeni-3-sezon-7-seria-l4-po-zakon/0
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=12453
http://community.viajar.tur.br/index.php?p=/profile/darinwojci
http://webp.online/index.php?topic=47608.0
http://smartacity.com/component/k2/itemlist/user/24292
http://smartacity.com/component/k2/itemlist/user/24598
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/472535
http://forum.byehaj.hu/index.php?topic=78336.0
http://adsudoeste.com.br/index.php/component/k2/itemlist/user/21179
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3716592
http://koushatarabar.com/index.php/component/k2/itemlist/user/1342671
http://macdistri.com/index.php/component/k2/itemlist/user/303228
http://www.vivelabmanizales.com/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-3/
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1866171
http://withinfp.sakura.ne.jp/eso/index.php/16861216-holostak-9-sezon-10-vypusk-fil-m-ryholostak-9-sezon-10-vypusk-f/0
http://www.ekemoon.com/147783/052220190906/
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-06-05-2019-l7-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
http://rudraautomation.com/index.php/component/k2/author/108212
http://withinfp.sakura.ne.jp/eso/index.php/16868918-tajny-97-seria-05052019-r2-tajny-97-seria
http://dev.aabn.org.gh/component/k2/itemlist/user/536990
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1848348
http://soc-human.kz/index.php/component/k2/itemlist/user/1631797
http://dev.aabn.org.gh/?option=com_k2&view=itemlist&task=user&id=517237
http://zsmr.com.ua/index.php/component/k2/itemlist/user/492886
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2563054
http://seoksoononly.dothome.co.kr/qna/751417
http://menulisilmiah.net/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vt6%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://www.studioaparo.it/?option=com_k2&view=itemlist&task=user&id=545303
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1353543
http://webp.online/index.php?topic=42746.0
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/652846
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3589665
http://jesusandmarypatna.com/index.php/component/k2/itemlist/user/3373984
http://www.vivelabmanizales.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vn1d-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
https://chromehearts.in.th/index.php?topic=46417.0
http://sdsn.develop.cinfores.com/?option=com_k2&view=itemlist&task=user&id=185322
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1550965
http://www.nienkevanrijn.nl/?option=com_k2&view=itemlist&task=user&id=426523
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/68219
http://ovotecegg.com/component/k2/itemlist/user/114194
http://153.120.114.241/eso/index.php/16915260-zensina-58-seria-legp-zensina-58-seria
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1867393
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3304610
http://israengineering.com/index.php/component/k2/itemlist/user/1120459
http://forum.politeknikgihon.ac.id/index.php?topic=22897.0
http://euromouleusinage.com/index.php/component/k2/itemlist/user/113678
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3730406
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=605248
https://members.fbhaters.com/index.php/topic,77137.0.html
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/74131
http://mvisage.sk/index.php/component/k2/itemlist/user/117518
https://tg.vl-mp.com/index.php?topic=1346190.0
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=298118
http://menulisilmiah.net/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b9-%d1%82%d0%be%d0%bb%d1%8f/
http://engeena.com/component/k2/itemlist/user/8239
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-s7-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1335888
http://smartacity.com/component/k2/itemlist/user/14834
http://c3isecurity.com.br/?option=com_k2&view=itemlist&task=user&id=491690
http://fbpharm.net/index.php/component/k2/itemlist/user/22549
http://www.ekemoon.com/156647/050420195708/
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=778283
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2588409
http://www.arunagreen.com/index.php/component/k2/itemlist/user/457075
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=273115
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7346155
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4740816
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/479131
http://www.arunagreen.com/index.php/component/k2/itemlist/user/459276
https://forums.letstalkbeats.com/index.php?topic=58947.0
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3339993
http://freebeer.me/index.php?topic=246921.0
http://danielmillsap.com/forum/index.php?topic=870088.0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4654378
http://thefreebitcoin.com/index.php?topic=30107.0
https://nextezone.com/index.php?action=profile;u=2061
http://forum.politeknikgihon.ac.id/index.php?topic=12424.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=25455.0
https://forums.letstalkbeats.com/index.php?topic=61195.0
http://danielmillsap.com/forum/index.php?topic=930359.0
https://forum.ac-jete.it/index.php?topic=316544.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3254380
http://www2.yasothon.go.th/smf/index.php?topic=159.150135
http://www.critico-expository.com/forum/index.php?topic=448.0
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1866129
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/280393
http://healthyteethpa.org/component/k2/itemlist/user/5356730
http://healthyteethpa.org/component/k2/itemlist/user/5374522
http://healthyteethpa.org/component/k2/itemlist/user/5374533
http://married.dike.gr/index.php/component/k2/itemlist/user/53404
http://married.dike.gr/index.php/component/k2/itemlist/user/53476
http://married.dike.gr/index.php/component/k2/itemlist/user/53490
http://mobility-corp.com/index.php/component/k2/itemlist/user/2542897
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/218212
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=9775
http://proxima.co.rw/index.php/component/k2/itemlist/user/586175
http://rudraautomation.com/index.php/component/k2/author/143121
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1228970
http://boutique.in.th/?option=com_k2&view=itemlist&task=user&id=143430
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=38720
http://webp.online/index.php?topic=41240.0
http://www.glasshouseproject.com.ng/index.php/component/k2/itemlist/user/38662
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3197211
http://healthyteethpa.org/index.php/component/k2/itemlist/user/5335800
https://members.fbhaters.com/index.php?topic=72014.0
http://smartacity.com/component/k2/itemlist/user/14318
http://danielmillsap.com/forum/index.php?topic=833001.0
http://danielmillsap.com/forum/index.php?topic=811462.0
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3566193
http://www.deliberarchia.org/forum/index.php?topic=793796.0
http://www.telcon.gr/index.php/component/k2/itemlist/user/30023
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4610895
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kf6-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://discussadeal.com/forum/index.php?topic=2377.0
http://danielmillsap.com/forum/index.php?topic=801528.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=268640
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=301364
http://www.deliberarchia.org/forum/index.php?topic=972358.0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/53044
http://forums.abs-cbn.com/welcome-back-kapamilya%21/et-e-9-e-oqet-e-9-e/msg500446/
http://teambuildingpremium.com/forum/index.php?topic=624854.0
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1552004
http://teambuildingpremium.com/forum/index.php?topic=610959.0
http://www.spazioad.com/component/k2/itemlist/user/7231677
http://webp.online/index.php?topic=45894.0
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1110387
http://www.phan-aen.go.th/forum/index.php?topic=609632.0
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=605857
http://withinfp.sakura.ne.jp/eso/index.php/16824320-edinoe-serdce-tek-yurek-20-seria-t4qg-edinoe-serdce-tek-yurek-2/0
https://prosocyr.com/?option=com_k2&view=itemlist&task=user&id=610195
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=1204
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1316286
https://tg.vl-mp.com/index.php?topic=1307229.0
http://danielmillsap.com/forum/index.php?topic=796023.0
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/142329
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=410700
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/902725
http://pptforum.dothome.co.kr/board_APMk06/617954
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1106219
http://danielmillsap.com/forum/index.php?topic=843708.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=890111
http://mobility-corp.com/index.php/component/k2/itemlist/user/2477510
http://teambuildingpremium.com/forum/index.php?topic=622676.0
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81-49/
http://www.popolsku.fr.pl/forum/index.php?topic=340794.0
https://prosocyr.com/?option=com_k2&view=itemlist&task=user&id=609554
http://healthyteethpa.org/component/k2/itemlist/user/5320017
http://www.popolsku.fr.pl/forum/index.php?topic=339127.0
http://thermoplast.envolgroupe.com/component/k2/author/69745
http://www.deliberarchia.org/forum/index.php?topic=900577.0
http://withinfp.sakura.ne.jp/eso/index.php/16779306-ne-otpuskaj-mou-ruku-elimi-birakma-37-seria-i3dh-ne-otpuskaj-mo/0
http://e-educ.net/Forum/index.php?topic=4370.0
https://reficulcoin.com/index.php?topic=12227.0
http://forum.kopkargobel.com/index.php?topic=3876.0
http://wituclub.ru/forum/index.php?PHPSESSID=b9cd29jq6c6pakrlr9b5jsajd6&topic=25780.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90js4%e3%80%91-%d0%b8%d0%b3/
http://8.droror.co.il/uncategorized/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90gg7%e3%80%91-%d0%b8/
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=712222
http://www.hoonthaitoday.com/forum/index.php?topic=130134.0
http://www.theocraticamerica.org/forum/index.php?topic=25968.0
https://members.fbhaters.com/index.php?topic=73372.0
https://www.thedezlab.com/lab/community/index.php?topic=30.0
http://sextomariotienda.com/blog/%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-23-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.deliberarchia.org/forum/index.php?topic=940824.0
http://socialfbwidgets.com/component/k2/itemlist/user/12719.html
http://mahdi.ehosseini.com/?option=com_k2&view=itemlist&task=user&id=24611
http://danielmillsap.com/forum/index.php?topic=920685.0
http://help.stv.ru/index.php?PHPSESSID=ac9dfc5d668203e794b200d727545937&topic=138359.0
http://dpmarketingsystems.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o0-%d1%81/
http://www.deliberarchia.org/forum/index.php?topic=951632.0
https://reficulcoin.com/index.php?topic=10730.0
http://e-educ.net/Forum/index.php?topic=6436.0
https://platforma-nonstop.ro/forum/index.php?topic=258941.0
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile;u=29732
http://www.alase.net/index.php/component/k2/itemlist/user/11198
https://www.c-alice.org/forum/index.php?topic=73979.0
http://gtupuw.org/index.php/component/k2/itemlist/user/1833424
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=28394.0
http://HyUa.1fps.icu/l/szIaeDC
http://ovotecegg.com/component/k2/itemlist/user/121684
http://www.die-design-manufaktur.de/?option=com_k2&view=itemlist&task=user&id=5174545
http://www.deliberarchia.org/forum/index.php?topic=987475.0
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=51439
http://www.ekemoon.com/157191/050620192608/
http://www.ekemoon.com/145813/051720195106/
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/198343
http://www.vivelabmanizales.com/live-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f6-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81/
http://minostech.co.kr/news/3387792
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=16557
http://soc-human.kz/index.php/component/k2/itemlist/user/1642084
http://www.ekemoon.com/156329/050320195508/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1362920
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1008726
http://withinfp.sakura.ne.jp/eso/index.php/16875910-vetrenyj-hercai-24-seria-jagt-vetrenyj-hercai-24-seria
http://community.viajar.tur.br/index.php?p=/discussion/57479/vetrenyy-hercai-20-seriya-yapo-vetrenyy-hercai-20-seriya
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4838074
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2563289
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4846412
http://dohairbiz.com/en/component/k2/itemlist/user/2711765.html
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=13652
http://salescoach.ro/content/%C2%AB%D0%BD%D0%B0%D1%88%D0%B0-%D0%B8%D1%81%D1%82%D0%BE%D1%80%D0%B8%D1%8F-66-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-tvui-%C2%AB%D0%BD%D0%B0%D1%88%D0%B0-%D0%B8%D1%81%D1%82%D0%BE%D1%80%D0%B8%D1%8F-66-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=1003991
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2541856
http://webp.online/index.php?topic=40103.msg67063
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1549547
http://teambuildingpremium.com/forum/index.php?topic=612085.0
http://danielmillsap.com/forum/index.php?topic=800992.0
http://married.dike.gr/index.php/component/k2/itemlist/user/36396
https://www.resproxy.com/forum/index.php/736764-rasskaz-sluzanki-3-sezon-1-seria-cak-rasskaz-sluzanki-3-sezon-1/0
https://www.resproxy.com/forum/index.php/803540-voron-kuzgun-18-seria-s2xp-voron-kuzgun-18-seria/0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2414785
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nc2-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://jesusandmarypatna.com/index.php/component/k2/itemlist/user/3404870
http://withinfp.sakura.ne.jp/eso/index.php/16795609-vetrenyj-hercai-19-seria-w3ra-vetrenyj-hercai-19-seria
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3556063
http://www.deliberarchia.org/forum/index.php?topic=956170.0
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/584327
http://www.arunagreen.com/index.php/component/k2/itemlist/user/320150
http://proandpro.it/?option=com_k2&view=itemlist&task=user&id=4529550
http://menulisilmiah.net/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-143-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p9ed-%d0%b2%d0%be%d1%81%d0%ba%d1%80/
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=407487
http://seoksoononly.dothome.co.kr/?document_srl=642447
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7291985
https://tg.vl-mp.com/index.php?topic=1308002.0
http://discussadeal.com/forum/index.php?topic=3111.0
http://withinfp.sakura.ne.jp/eso/index.php/16789640-nevesta-iz-stambula-istanbullu-gelin-81-seria-u0wl-nevesta-iz-s/0
http://muratliziraatodasi.org/forum/index.php?topic=340031.0
http://www.x2145-productions.technology/index.php?title=%C2%AB%D0%90%D0%B2%D0%B0%D1%82%D0%B0%D1%80_2_2020_%C2%BB_05-05-2019_%22%D0%90%D0%B2%D0%B0%D1%82%D0%B0%D1%80_2_2020_Watch%22_%C2%AB%D0%90%D0%B2%D0%B0%D1%82%D0%B0%D1%80_2_2020_%C2%BB
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1748658
http://danielmillsap.com/forum/index.php?topic=840490.0
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1685622
http://foa.egerton.ac.ke/index.php/component/k2/itemlist/user/1749636
http://foa.egerton.ac.ke/index.php/component/k2/itemlist/user/1749643
http://forum.politeknikgihon.ac.id/index.php?topic=26807.0
http://healthyteethpa.org/?option=com_k2&view=itemlist&task=user&id=5375250
https://sanp.pro/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-auc-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8/
http://dev.aabn.org.gh/component/k2/itemlist/user/479874
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=557335
https://www.c-alice.org/forum/index.php?topic=66665.0
http://www.nomaher.com/forum/index.php?topic=10603.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=629534.0
http://www.deliberarchia.org/forum/index.php?topic=893479.0
https://lucky28003.nl/forum/index.php?topic=8715.0
https://members.fbhaters.com/index.php?topic=54989.0
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3359331
https://members.fbhaters.com/index.php?topic=54721.0
http://www.remify.app/foro/index.php?topic=165415.0
http://thanosakademi.com/index.php?topic=52462.msg65075
http://vtservices85.fr/smf2/index.php?PHPSESSID=dade66c2eac077e7fb5d2aa0fc4f7def&topic=201446.0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/383155
http://www.deliberarchia.org/forum/index.php?topic=946083.0
http://married.dike.gr/index.php/component/k2/itemlist/user/42909
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/451773
http://withinfp.sakura.ne.jp/eso/index.php/16863850-vetrenyj-hercai-16-seria-z8mz-vetrenyj-hercai-16-seria
http://www.spazioad.com/component/k2/itemlist/user/7104671
http://teambuildingpremium.com/forum/index.php?topic=604365.0
http://www.deliberarchia.org/forum/index.php?topic=804504.0
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3311954
http://www.phan-aen.go.th/forum/index.php?topic=607855.0
http://teambuildingpremium.com/forum/index.php?topic=664137.0
http://danielmillsap.com/forum/index.php?topic=804766.0
https://www.blog.quora.healthcare/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o0mu-%d0%b2%d0%be%d1%81%d0%ba%d1%80
http://myrechockey.com/forums/index.php?topic=90432.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1039089
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/154943
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ug7-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.sopcich.com/UserProfile/tabid/42/UserID/1666579/Default.aspx
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1090235
http://teambuildingpremium.com/forum/index.php?topic=676557.0
http://danielmillsap.com/forum/index.php?topic=835453.0
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=698317
https://tg.vl-mp.com/index.php?topic=1326322.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/276726
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile;u=30572
http://forum.drahthaar-club.com.ua/index.php?topic=689.0
http://seoksoononly.dothome.co.kr/qna/710102
http://metropolis.ga/index.php?topic=4802.0
http://www.tekparcahdfilm.com/forum/index.php?topic=45637.0
http://www.deliberarchia.org/forum/index.php?topic=966995.0
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f1-n3-%d1%80%d0%b0%d1%81%d1%81/
http://golyboe.ru/forum/index.php?topic=24881.0
http://freebeer.me/index.php?topic=283277.0
http://metropolis.ga/index.php?topic=5506.0
https://sanp.pro/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o3-%d1%81/
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n4-p7-%d1%80%d0%b0/
http://eugeniocolazzo.it/forum/index.php?topic=85590.0
http://multikopterforum.hu/index.php?topic=8447.0
http://multikopterforum.hu/index.php?topic=13233.0
https://www.amazingworldtop.com/entretenimiento/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n1-n6-%d1%80%d0%b0/
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90ex9%e3%80%91-%d0%b8%d0%b3%d1%80/
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d0-h5-%d1%80%d0%b0%d1%81%d1%81/
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1560108
http://matrixpharm.ru/forum/index.php?PHPSESSID=k302qvqcj1daqb4rgtdoojtcd1&action=profile;u=160072
http://www.popolsku.fr.pl/forum/index.php?topic=372334.0
http://withinfp.sakura.ne.jp/eso/index.php/16901322-igra-prestolov-game-of-thrones-8-sezon-7-seria-ux0-igra-prestol/0
http://www.tessabannampad.go.th/webboard/index.php?topic=188238.0
http://www.hoonthaitoday.com/forum/index.php?topic=136912.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=678510.0
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-21/
http://otitismediasociety.org/forum/index.php?topic=144182.0
http://uberdrivers.net/forum/index.php?topic=207782.0
http://metropolis.ga/index.php?topic=1978.0
http://dpmarketingsystems.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l3-%d1%81%d0%bb/
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile;u=30071
http://healthyteethpa.org/component/k2/itemlist/user/5324599
http://menulisilmiah.net/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z1-n3-%d1%80%d0%b0/
http://blog.ptpintcast.com/%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b6-%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5/
http://help.stv.ru/index.php?PHPSESSID=99229d86dbaf57950ad6d2e9c07f0a0b&topic=136003.0
http://myrechockey.com/forums/index.php?topic=82328.0
http://myrechockey.com/forums/index.php?topic=82241.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/04-05-2019-om-7-e-415832/?PHPSESSID=ca359kvc3rhp9s45gkdpk1lah4
http://forum.drahthaar-club.com.ua/index.php?topic=577.0
http://roikjer.com/forum/index.php?PHPSESSID=3t1i18p7anr7erhm4kicoi4826&topic=794198.0
http://teambuildingpremium.com/forum/index.php?topic=763805.0
http://HyUa.1fps.icu/l/szIaeDC
http://blog.ptpintcast.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vrl-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://www.popolsku.fr.pl/forum/index.php?topic=20407.msg629366
https://www.c-alice.org/forum/index.php?topic=69276.0
http://forum.politeknikgihon.ac.id/index.php?topic=15444.0
https://www.resproxy.com/forum/index.php/740418-sluga-naroda-3-sezon-5-seria-live-sluga-naroda-3-sezon-5-seria-/0
https://sanp.pro/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z7-05-05-2019-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://lucky28003.nl/forum/index.php?topic=8899.0
http://otitismediasociety.org/forum/index.php?topic=144583.0
http://www.alase.net/?option=com_k2&view=itemlist&task=user&id=11319
https://www.resproxy.com/forum/index.php/778568-vetrenyj-7-8-seria-kyb0-vetrenyj-7-8-seria/0
http://multikopterforum.hu/index.php?topic=9988.0
https://members.fbhaters.com/index.php?topic=69947.0
https://sanp.pro/%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-05-05-2019-2/
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p7-t9-%d0%b8%d0%b3%d1%80/
http://menulisilmiah.net/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90kq0%e3%80%91-%d0%b8/
http://www.vivelabmanizales.com/%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5%d0%bd%d0%b8%d0%b5-vuslat-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ilqh-%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd/
https://nextezone.com/index.php?action=profile;u=2131
http://poselokgribovo.ru/forum/index.php?topic=692743.0
http://smartacity.com/component/k2/itemlist/user/14387
http://www.telcon.gr/index.php/component/k2/itemlist/user/38455
http://bitly.com/2VsphZv
http://erhu.eu/viewtopic.php?t=228899
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1097153
http://married.dike.gr/index.php/component/k2/itemlist/user/36317
http://1vh.info/index.php?topic=3059.0
http://erhu.eu/viewtopic.php?t=241085
http://web2interactive.com/index.php/component/k2/itemlist/user/3533656
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/988988
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=26435.0
http://withinfp.sakura.ne.jp/eso/index.php/16802060-posmotret-fil-m-tola-robot-6-seria-co-posmotret-fil-m-tola-robo/0
http://bitly.com/2Vcbila
http://bitly.com/2HaF6Ly
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1567192
http://77.93.38.205/index.php/component/k2/itemlist/user/497693
http://topitop.kz/index.php/component/k2/itemlist/user/76396
http://seoksoononly.dothome.co.kr/?document_srl=782300
http://withinfp.sakura.ne.jp/eso/index.php/16902279-live-uristy-17-seria-x9-uristy-17-seria/0
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=217266
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3747117
http://teambuildingpremium.com/forum/index.php?topic=786379.0
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1007573
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2562442
http://rudraautomation.com/index.php/component/k2/author/124526
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=578234
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=7412
http://rudraautomation.com/index.php/component/k2/author/109238
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1334349
http://tekagrafica.com.br/index.php/component/k2/itemlist/user/1630804
http://healthyteethpa.org/component/k2/itemlist/user/5329461
http://salescoach.ro/content/%C2%AB%D0%BD%D0%B5-%D0%BE%D1%82%D0%BF%D1%83%D1%81%D0%BA%D0%B0%D0%B9-%D0%BC%D0%BE%D1%8E-%D1%80%D1%83%D0%BA%D1%83-elimi-birakma-41-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-nroo-%C2%AB%D0%BD%D0%B5-%D0%BE%D1%82%D0%BF%D1%83%D1%81%D0%BA%D0%B0%D0%B9-%D0%BC%D0%BE%D1%8E-%D1%80%D1%83%D0%BA%D1%83-elimi-birakma-41
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2570879
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=5135
http://www.vivelabmanizales.com/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-live-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-3/
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2580738
http://kurnaz.1to.us/index.php?topic=1.450
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3296341
http://forum.digamahost.com/index.php?topic=109081.0
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=82463
http://haniel.ir/index.php/component/k2/itemlist/user/79682
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=298643
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1127156
http://www.deliberarchia.org/forum/index.php?topic=986597.0
https://www.blog.quora.healthcare/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ajb-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/169810
https://www.blog.1mg.healthcare/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xne-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81-39/
http://thermoplast.envolgroupe.com/component/k2/author/66223
http://danielmillsap.com/forum/index.php?topic=807627.0
http://dscardip.com/board/index.php?page=User&userID=660093
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1107813
http://teambuildingpremium.com/forum/index.php?topic=617186.0
http://mediaville.me/index.php/component/k2/itemlist/user/216474
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=376297
https://www.shaiyax.com/index.php?topic=312857.0
http://danielmillsap.com/forum/index.php?topic=846467.0
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1095332
http://forum.thaibetrank.com/index.php?topic=1092506.0
http://www.popolsku.fr.pl/forum/index.php?topic=343752.0
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2418820
http://forums.abs-cbn.com/welcome-back-kapamilya%21/om-3-e-ykom-3-e/?PHPSESSID=vh9maf4nkh4dnna43oghr9el33
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3578474
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/71801
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/519419
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2469308
https://www.blog.quora.healthcare/%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0%d1%88%d0%ba%d0%b0-erkenci-kus-42-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a7aq-%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0
https://www.blog.quora.healthcare/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x6fx-%d0%b2%d0%be%d1%81%d0%ba%d1%80
http://webp.online/index.php?topic=47028.0
http://www.deliberarchia.org/forum/index.php?topic=766426.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/445817
https://instaldec.com/?option=com_k2&view=itemlist&task=user&id=609246
http://www.deliberarchia.org/forum/index.php?topic=946918.0
http://aitour.kz/?option=com_k2&view=itemlist&task=user&id=310439
https://www.shaiyax.com/index.php?topic=296840.0
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1127690
https://lucky28003.nl/forum/index.php?topic=5833.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/263305
http://married.dike.gr/index.php/component/k2/itemlist/user/29478
http://danielmillsap.com/forum/index.php?topic=812115.0
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jb7-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
https://tg.vl-mp.com/index.php?topic=1347353.0
https://tg.vl-mp.com/index.php?topic=1331075.0
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1125274
http://mediaville.me/index.php/component/k2/itemlist/user/191071
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3566138
http://smartacity.com/component/k2/itemlist/user/18992
http://danielmillsap.com/forum/index.php?topic=938729.0
http://sam-sanat.ir/?option=com_k2&view=itemlist&task=user&id=117718
https://members.fbhaters.com/index.php?topic=69112.0
http://rudraautomation.com/index.php/component/k2/author/114183
https://tg.vl-mp.com/index.php?topic=1336422.0
http://muratliziraatodasi.org/forum/index.php?topic=338854.0
http://153.120.114.241/eso/index.php/16874483-sverh-estestvennoe-14-sezon-20-seria-eix-sverh-estestvennoe-14-
http://withinfp.sakura.ne.jp/eso/index.php/16810537-voskressij-ertugrul-148-seria-x8wp-voskressij-ertugrul-148-seri/0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/392556
https://members.fbhaters.com/index.php?topic=67660.0
http://forum.thaibetrank.com/index.php?topic=1086272.0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=518618
http://withinfp.sakura.ne.jp/eso/index.php/16769258-milliardy-4-sezon-13-seria-ipg-milliardy-4-sezon-13-seria-01052/0
http://healthyteethpa.org/component/k2/itemlist/user/5291757
http://webp.online/index.php?topic=50424.0
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1453856
http://danielmillsap.com/forum/index.php?topic=792826.0
http://soc-human.kz/index.php/component/k2/itemlist/user/1605631
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=588145.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/510512
https://www.resproxy.com/forum/index.php/743906-rasskaz-sluzanki-3-sezon-2-seria-yhi-rasskaz-sluzanki-3-sezon-2/0
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=13912
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/472379
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1107207
http://www.deliberarchia.org/forum/index.php?topic=788202.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2524904
http://www.deliberarchia.org/forum/index.php?topic=839582.0
http://danielmillsap.com/forum/index.php?topic=838634.0
https://www.blog.quora.healthcare/%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0%d1%88%d0%ba%d0%b0-erkenci-kus-40-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f3sa-%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0
http://myrechockey.com/forums/index.php?topic=87769.0
http://menulisilmiah.net/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lds-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
https://www.resproxy.com/forum/index.php/755727-zvonar-24-seria-hdvideo-zvonar-24-seria-04052019/0
http://dpmarketingsystems.com/%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0%d1%8f-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b0-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xdx-%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0/
http://poselokgribovo.ru/forum/index.php?topic=671076.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=656527.0
https://www.resproxy.com/forum/index.php/757980-serial-igra-prestolov-8-sezon-6-seria-alexfilm-w2-igra-prestolo/0
http://matrixpharm.ru/forum/index.php?PHPSESSID=2nt43pb5osralmcutijc202731&action=profile;u=152205
http://www.remify.app/foro/index.php?topic=171534.0
https://lideta.workethio.com/2019/05/02/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uvd-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.deliberarchia.org/forum/index.php?topic=898934.0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=306825
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=24802
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2470691
https://forum.ac-jete.it/index.php?topic=331733.0
http://www.spazioad.com/component/k2/itemlist/user/7214121
https://www.c-alice.org/forum/index.php?topic=69880.0
http://withinfp.sakura.ne.jp/eso/index.php/16842959-igra-prestolov-8-sezon-5-seria-igra-prestolov-8-sezon-5-seria-c
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=282338
http://bobr.site/index.php?topic=88788.0
https://nextezone.com/index.php?action=profile;u=1533
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=25212.0
http://forum.bmw-e60.eu/index.php?topic=2520.0
http://multikopterforum.hu/index.php?topic=7267.0
http://sextomariotienda.com/blog/%d0%bc%d0%b5%d1%80%d1%82%d0%b2%d0%be%d0%b5-%d0%be%d0%b7%d0%b5%d1%80%d0%be-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f2-04-05-2019-%d0%bc%d0%b5%d1%80%d1%82%d0%b2%d0%be%d0%b5-%d0%be%d0%b7/
https://www.resproxy.com/forum/index.php/732005-uristy-4-seria-l2cu-uristy-4-seria/0
http://bobr.site/index.php?topic=83488.0
http://bitly.com/2VsphZv
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3546634
http://www.deliberarchia.org/forum/index.php?topic=954504.0
http://jensenbyggteam.no/index.php/component/k2/itemlist/user/11611
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jp2-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://help.stv.ru/index.php?topic=135729.0
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=40810
https://www.resproxy.com/forum/index.php/777531-hdvideo-tolarobot-7-seria-u8-tolarobot-7-seria/0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-crj-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3275005
http://bitly.com/2Vcbila
http://bitly.com/2HaF6Ly
http://www.theparrotcentre.com/forum/index.php?topic=449846.0
http://xplorefitness.com/blog/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-6-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90av0%E3%80%91-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-6-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://myrechockey.com/forums/index.php?topic=82163.0
http://otitismediasociety.org/forum/index.php?topic=143497.0
https://adsensebih.com/index.php?topic=10217.0
http://roikjer.com/forum/index.php?PHPSESSID=rp37jcn4ihgf6o3p8gce17n292&topic=806183.0
http://www.theocraticamerica.org/forum/index.php?topic=24659.0
http://sextomariotienda.com/blog/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kg1-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://lucky28003.nl/forum/index.php?topic=8085.0
http://www.deliberarchia.org/forum/index.php?topic=970300.0
http://flashboot.ru/forum/index.php?topic=94302.0
http://roikjer.com/forum/index.php?PHPSESSID=h4c4c887590tq6qpnpeg7ta1b3&topic=797769.0
http://metropolis.ga/index.php?topic=4567.0
http://www.deliberarchia.org/forum/index.php?topic=959469.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2516768
http://thanosakademi.com/index.php?topic=61700.0
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=19532
http://forum.digamahost.com/index.php?topic=108858.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-8-eo-4-e-uh2-a-etoo-8-eo-4-e/?PHPSESSID=1d75lauqvb4u8f4a3dskrt1q62
http://www.popolsku.fr.pl/forum/index.php?topic=20407.49170
http://forum.politeknikgihon.ac.id/index.php?topic=26529.0
http://HyUa.1fps.icu/l/szIaeDC
http://ovotecegg.com/component/k2/itemlist/user/121936
http://www.vivelabmanizales.com/%d1%8d%d1%84%d0%b8%d1%80-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v8-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be/
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=79735
http://married.dike.gr/index.php/component/k2/itemlist/user/47201
http://withinfp.sakura.ne.jp/eso/index.php/16886189-rannaa-ptaska-erkenci-kus-45-seria-lgek-rannaa-ptaska-erkenci-k/0
https://forums.letstalkbeats.com/index.php?topic=64600.0
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=500286
http://forum.politeknikgihon.ac.id/index.php?topic=21827.0
https://members.fbhaters.com/index.php?topic=75556.0
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=51140
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=501893
http://ptu.imoove.kr/ko/content/%C2%AB%D1%8E%D1%80%D0%B8%D1%81%D1%82%D1%8B-12-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-hd-video-%C2%AB%D1%8E%D1%80%D0%B8%D1%81%D1%82%D1%8B-12-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB332739
http://www2.yasothon.go.th/smf/index.php?topic=159.157500
http://macdistri.com/index.php/component/k2/itemlist/user/297368
http://ovotecegg.com/component/k2/itemlist/user/119678
http://healthyteethpa.org/?option=com_k2&view=itemlist&task=user&id=5329421
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=96573
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/681917
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=12793
http://dpordering.cetco.com/User-Profile/userId/567054
http://seoksoononly.dothome.co.kr/qna/787321
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vs8%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f07-05-2019/
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4832389
http://trunk.www.volkalize.com/members/noelcorby68033/
http://www.die-design-manufaktur.de/?option=com_k2&view=itemlist&task=user&id=5178815
https://khuyenmaikk13.info/index.php?topic=183745.0
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=76499
http://withinfp.sakura.ne.jp/eso/index.php/16866014-smotret-uristy-15-seria-b0-uristy-15-seria
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=572741
https://l2thalassic.org/Forum/index.php?topic=2079.0
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=517458
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/71205
https://prosocyr.com/?option=com_k2&view=itemlist&task=user&id=574589
http://www.atab.com.sa/?option=com_k2&view=itemlist&task=user&id=1518595
http://www.deliberarchia.org/forum/index.php?topic=778645.0
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3571048
http://aitour.kz/?option=com_k2&view=itemlist&task=user&id=325068
http://teambuildingpremium.com/forum/index.php?topic=646587.0
https://tg.vl-mp.com/index.php?topic=1289908.0
http://flyinghonda.de/wbb/index.php?page=User&userID=808017
http://teambuildingpremium.com/forum/index.php?topic=644120.0
http://withinfp.sakura.ne.jp/eso/index.php/16794957-igra-prestolov-8-sezon-2-seria-wbp-igra-prestolov-8-sezon-2-ser/0
https://prosocyr.com/?option=com_k2&view=itemlist&task=user&id=582428
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3605582
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kbt-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-14-%d1%81%d0%b5%d1%80/
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/458598
http://www.deliberarchia.org/forum/index.php?topic=943014.0
http://seoksoononly.dothome.co.kr/qna/431644
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=95257
http://teambuildingpremium.com/forum/index.php?topic=653856.0
http://healthyteethpa.org/component/k2/itemlist/user/5319064
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/266984
http://www.atab.com.sa/index.php/en/?option=com_k2&view=itemlist&task=user&id=1455412
http://avengerro.top/forum/index.php?topic=16257.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=587002.0
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1668355
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ms0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://www.arunagreen.com/index.php/component/k2/itemlist/user/404974
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4738289
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xjm-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-10-%d1%81%d0%b5%d1%80/
http://77.93.38.205/index.php/component/k2/itemlist/user/378651
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1100823
http://mediaville.me/index.php/component/k2/itemlist/user/218643
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/174128
http://forum.thaibetrank.com/index.php?topic=1091657.0
http://wcwpr.com/UserProfile/tabid/85/userId/9223052/Default.aspx
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4737589
http://myrechockey.com/forums/index.php?topic=54921.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/246567
http://macdistri.com/index.php/component/k2/itemlist/user/222461
https://www.resproxy.com/forum/index.php/799810-nasledie-12-seria-rog-nasledie-12-seria
http://dohairbiz.com/en/component/k2/itemlist/user/2707988.html
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=244512
http://seoksoononly.dothome.co.kr/qna/592774
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=172973
http://www.deliberarchia.org/forum/index.php?topic=785033.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2470365
http://www.m1avio.com/index.php/component/k2/itemlist/user/3598966
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=891653
http://withinfp.sakura.ne.jp/eso/index.php/16784101-milliardy-4-sezon-8-seria-rsi-milliardy-4-sezon-8-seria-0105201/0
http://metropolis.ga/index.php?topic=1336.0
http://metropolis.ga/index.php?topic=1349.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wry-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=14282
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=42338
http://danielmillsap.com/forum/index.php?topic=807942.0
http://danielmillsap.com/forum/index.php?topic=809374.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-omg-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2130986
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/597695
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1314795
https://www.youngbiker.de/wbboard/index.php?page=User&userID=784703
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=39314
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=4472
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xus-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.tessabannampad.go.th/webboard/index.php?topic=192961.0
http://withinfp.sakura.ne.jp/eso/index.php/16834470-rannaa-ptaska-erkenci-kus-39-seria-o0iz-rannaa-ptaska-erkenci-k/0
http://teambuildingpremium.com/forum/index.php?topic=613302.0
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3680753
http://poselokgribovo.ru/forum/index.php?topic=616751.0
http://withinfp.sakura.ne.jp/eso/index.php/16887486-vetrenyj-hercai-8-seria-c0zp-vetrenyj-hercai-8-seria
http://muratliziraatodasi.org/forum/index.php?topic=328398.0
http://teambuildingpremium.com/forum/index.php?topic=633918.0
http://teambuildingpremium.com/forum/index.php?topic=689832.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/284746
http://teambuildingpremium.com/forum/index.php?topic=685351.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1035943
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/188157
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/440920
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/911255
http://seoksoononly.dothome.co.kr/qna/464775
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-viv-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/469947
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/177745
http://sam-sanat.ir/?option=com_k2&view=itemlist&task=user&id=115531
http://sos.victoryaltar.org/tiki-index.php?page=UserPageallanbischofuidg
http://withinfp.sakura.ne.jp/eso/index.php/16852099-voskressij-ertugrul-144-seria-l9bb-voskressij-ertugrul-144-seri
http://dessa.com.br/component/k2/itemlist/user/261594
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3528143
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/947071
http://www.popolsku.fr.pl/forum/index.php?topic=340558.0
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7266286
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4733507
http://www.popolsku.fr.pl/forum/index.php?topic=340562.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1354476
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1084606
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=261803
http://www.deliberarchia.org/forum/index.php?topic=938600.0
http://menulisilmiah.net/%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80%d0%b4%d1%86%d0%b5-tek-yurek-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r3qd-%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80/
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1036506
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cu6-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://yogakiddoswithgaileee.com/index.php?title=%C2%AB%D0%98%D1%81%D1%82%D0%BE%D1%80%D0%B8%D1%8F_%D0%98%D0%B3%D1%80%D1%83%D1%88%D0%B5%D0%BA_4_2019_%C2%BB_08-05-2019_%22%D0%98%D1%81%D1%82%D0%BE%D1%80%D0%B8%D1%8F_%D0%98%D0%B3%D1%80%D1%83%D1%88%D0%B5%D0%BA_4_2019_Watch%22_%C2%AB%D0%98%D1%81%D1%82%D0%BE%D1%80%D0%B8%D1%8F_%D0%98%D0%B3%D1%80%D1%83%D1%88%D0%B5%D0%BA_4_2019_%C2%BB
http://danielmillsap.com/forum/index.php?topic=878614.0
http://www.deliberarchia.org/forum/index.php?topic=908002.0
http://mvisage.sk/index.php/component/k2/itemlist/user/116307
http://withinfp.sakura.ne.jp/eso/index.php/16786124-rasskaz-sluzanki-3-sezon-1-seria-uxi-rasskaz-sluzanki-3-sezon-1/0
http://forum.thaibetrank.com/index.php?topic=1091559.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/eoe-ekao-5-eo-2-e-shm-eoe-ekao-5-eo-2-e-25-04-2019/?PHPSESSID=r85dechdih745hvnjqhobfu0k4
https://tg.vl-mp.com/index.php?topic=1313976.0
http://www.phan-aen.go.th/forum/index.php?topic=607630.0
http://pptforum.dothome.co.kr/board_APMk06/643853
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1366650
http://healthyteethpa.org/component/k2/itemlist/user/5352014
http://www.spazioad.com/component/k2/itemlist/user/7235456
http://theolevolosproject.org/index.php/component/k2/itemlist/user/24556
http://www.spazioad.com/?option=com_k2&view=itemlist&task=user&id=7245698
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1874337
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=8078.0
http://www.spazioad.com/component/k2/itemlist/user/7250488
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/269432
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/68101
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=202984
http://mobility-corp.com/index.php/component/k2/itemlist/user/2528938
http://withinfp.sakura.ne.jp/eso/index.php/16946820-smotret-sluga-naroda-3-sezon-8-seria-f5-sluga-naroda-3-sezon-8-
http://withinfp.sakura.ne.jp/eso/index.php/16946829-hd-sluga-naroda-3-sezon-22-seria-n8-sluga-naroda-3-sezon-22-ser/0
http://withinfp.sakura.ne.jp/eso/index.php/16946834-smotret-sluga-naroda-3-sezon-12-seria-n1-sluga-naroda-3-sezon-1/0
http://withinfp.sakura.ne.jp/eso/index.php/16946842-hd-sluga-naroda-3-sezon-15-seria-n6-sluga-naroda-3-sezon-15-ser
http://withinfp.sakura.ne.jp/eso/index.php/16946912-hd-sluga-naroda-3-sezon-19-seria-t4-sluga-naroda-3-sezon-19-ser/0
http://wituclub.ru/forum/index.php?PHPSESSID=o2p0hehctumgftblpeq47llk11&topic=26136.0
http://www.artifact.website/89510-1tv-sluga-naroda-3-sezon-22-seria-t8-sluga-naroda-3-sezon-22-se
http://www.artifact.website/89516-tv-sluga-naroda-3-sezon-19-seria-b8-sluga-naroda-3-sezon-19-ser
http://www.artifact.website/89519-ru-sluga-naroda-3-sezon-23-seria-f9-sluga-naroda-3-sezon-23-ser
http://www.artifact.website/89527-new-sluga-naroda-3-sezon-12-seria-x4-sluga-naroda-3-sezon-12-se
http://dev.fivestarpainting.com/?option=com_k2&view=itemlist&task=user&id=1885171
http://married.dike.gr/index.php/component/k2/itemlist/user/52784
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/75833
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=9425
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/9427
http://proxima.co.rw/index.php/component/k2/itemlist/user/584143
http://proxima.co.rw/index.php/component/k2/itemlist/user/584165
http://rudraautomation.com/index.php/component/k2/author/141742
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4748519
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4748769
http://teambuildingpremium.com/forum/index.php?topic=655010.0
http://discussadeal.com/forum/index.php?topic=5331.0
https://www.blog.quora.healthcare/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c4rp-%d0%b2%d0%be%d1%81%d0%ba%d1%80
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=676199
http://grupotir.com/?option=com_k2&view=itemlist&task=user&id=42247
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1318551
http://www.m1avio.com/index.php/component/k2/itemlist/user/3501919
http://smartacity.com/component/k2/itemlist/user/14513
http://poselokgribovo.ru/forum/index.php?topic=616139.0
http://metropolis.ga/index.php?topic=1168.0
http://www.phan-aen.go.th/forum/index.php?topic=608957.0
http://danielmillsap.com/forum/index.php?topic=891380.0
http://153.120.114.241/eso/index.php/16861978-riverdejl-riverdale-3-sezon-18-seria-udk-riverdejl-riverdale-3-
http://fbpharm.net/index.php/component/k2/itemlist/user/14390
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xow-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://withinfp.sakura.ne.jp/eso/index.php/16775405-rasskaz-sluzanki-3-sezon-3-seria-pit-rasskaz-sluzanki-3-sezon-3/0
http://teambuildingpremium.com/forum/index.php?topic=681512.0
http://avengerro.top/forum/index.php?topic=19194.0
http://seoksoononly.dothome.co.kr/qna/603214
http://wcwpr.com/UserProfile/tabid/85/userId/9170441/Default.aspx
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3553942
http://www.crnmedia.es/?option=com_k2&view=itemlist&task=user&id=83043
https://www.resproxy.com/forum/index.php/730128-rasskaz-sluzanki-3-sezon-5-seria-wbc-rasskaz-sluzanki-3-sezon-5/0
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=12087
http://seoksoononly.dothome.co.kr/qna/426718
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2531904
https://mcsetup.tk/bbs/index.php?topic=224467.0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4578643
https://mcsetup.tk/bbs/index.php?topic=224514.0
http://married.dike.gr/index.php/component/k2/itemlist/user/23787
http://www.phan-aen.go.th/forum/index.php?topic=607724.0
https://www.resproxy.com/forum/index.php/732486-milliardy-4-sezon-5-seria-rbc-milliardy-4-sezon-5-seria-0305201/0
http://danielmillsap.com/forum/index.php?topic=820845.0
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3553842
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1077404
http://proxima.co.rw/index.php/component/k2/itemlist/user/542236
https://tg.vl-mp.com/index.php?topic=1297108.0
http://withinfp.sakura.ne.jp/eso/index.php/16814115-voskressij-ertugrul-149-seria-u4nt-voskressij-ertugrul-149-seri/0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=580771.0
http://muratliziraatodasi.org/forum/index.php?topic=345071.0
https://tg.vl-mp.com/index.php?topic=1297489.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3178551
http://c3isecurity.com.br/?option=com_k2&view=itemlist&task=user&id=369820
http://danielmillsap.com/forum/index.php?topic=808766.0
http://forum.thaibetrank.com/index.php?topic=1080699.0
https://mcsetup.tk/bbs/index.php?topic=230955.0
http://dessa.com.br/component/k2/itemlist/user/291628
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1226974
http://www.deliberarchia.org/forum/index.php?topic=915392.0
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/176040
http://boutique.in.th/?option=com_k2&view=itemlist&task=user&id=142442
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7172110
http://muratliziraatodasi.org/forum/index.php?topic=343377.0
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1468774
http://www.deliberarchia.org/forum/index.php?topic=974521.0
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1631112
http://avengerro.top/forum/index.php?topic=13065.0
http://macdistri.com/index.php/component/k2/itemlist/user/280106
http://teambuildingpremium.com/forum/index.php?topic=630849.0
http://teambuildingpremium.com/forum/index.php?topic=638386.0
http://www.deliberarchia.org/forum/index.php?topic=893706.0
https://mcsetup.tk/bbs/index.php?topic=231472.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/568734
http://danielmillsap.com/forum/index.php?topic=812606.0
http://webp.online/index.php?topic=38678.30
http://withinfp.sakura.ne.jp/eso/index.php/16881779-edinoe-serdce-tek-yurek-11-seria-m7fm-edinoe-serdce-tek-yurek-1/0
http://married.dike.gr/index.php/component/k2/itemlist/user/40499
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1612324
http://153.120.114.241/eso/index.php/16857143-cernoe-zerkalo-5-sezon-5-seria-iap-cernoe-zerkalo-5-sezon-5-ser
http://withinfp.sakura.ne.jp/eso/index.php/16770233-milliardy-4-sezon-7-seria-dnp-milliardy-4-sezon-7-seria-0105201/0
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/272724
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=32108
http://withinfp.sakura.ne.jp/eso/index.php/16767647-milliardy-4-sezon-8-seria-phi-milliardy-4-sezon-8-seria-0105201/0
http://seoksoononly.dothome.co.kr/qna/447292
http://rotary-laeliana.org/component/k2/itemlist/user/50953
http://153.120.114.241/eso/index.php/16876046-igra-prestolov-8-sezon-1-seria-zfp-igra-prestolov-8-sezon-1-ser
http://withinfp.sakura.ne.jp/eso/index.php/16904040-voron-kuzgun-14-seria-y7pv-voron-kuzgun-14-seria/0
http://www.spazioad.com/component/k2/itemlist/user/7165254
https://forum.ac-jete.it/index.php?topic=285434.0
http://macdistri.com/index.php/component/k2/itemlist/user/223051
http://www.deliberarchia.org/forum/index.php?topic=915707.0
http://seoksoononly.dothome.co.kr/qna/465460
http://danielmillsap.com/forum/index.php?topic=846070.0
http://www.glasshouseproject.com.ng/index.php/component/k2/itemlist/user/37927
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1245120
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=77641
http://avengerro.top/forum/index.php?topic=16484.0
http://teambuildingpremium.com/forum/index.php?topic=626071.0
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=38983
https://www.blog.quora.healthcare/%d0%bd%d0%b5-%d0%be%d1%82%d0%bf%d1%83%d1%81%d0%ba%d0%b0%d0%b9-%d0%bc%d0%be%d1%8e-%d1%80%d1%83%d0%ba%d1%83-elimi-birakma-38-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v0wq-%d0%bd%d0%b5-%d0%be
http://forumworldbestmt2.altervista.org/index.php?page=User&userID=124635
http://macdistri.com/index.php/component/k2/itemlist/user/259303
http://91.231.123.194/index.php/component/k2/itemlist/user/852732
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/483041
http://dessa.com.br/component/k2/itemlist/user/271992
http://www.ekemoon.com/143763/050220195906/
http://healthyteethpa.org/component/k2/itemlist/user/5331100
http://trunk.www.volkalize.com/members/williamsb69234/
http://seoksoononly.dothome.co.kr/qna/787392
http://www.vivelabmanizales.com/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81-19/
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/66828
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1627522
http://www.comfortcenter.es/index.php/component/k2/itemlist/user/104926
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/56970
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=48376
http://bitpark.co.kr/board_IzjM66/3800062
http://bitpark.co.kr/board_IzjM66/3800349
http://bitpark.co.kr/board_IzjM66/3800384
http://bitpark.co.kr/board_IzjM66/3800428
http://danielmillsap.com/forum/index.php?topic=994730.0
http://xplorefitness.com/blog/%C2%AB%D0%BD%D0%B0%D1%88%D0%B0-%D0%B8%D1%81%D1%82%D0%BE%D1%80%D0%B8%D1%8F-67-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-aric-%C2%AB%D0%BD%D0%B0%D1%88%D0%B0-%D0%B8%D1%81%D1%82%D0%BE%D1%80%D0%B8%D1%8F-67-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/285745
http://mobility-corp.com/index.php/component/k2/itemlist/user/2542966
http://teambuildingpremium.com/forum/index.php?topic=786297.0
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=9638
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=501783
http://withinfp.sakura.ne.jp/eso/index.php/16863046-holostak-9-sezon-10-vypusk-canon-guholostak-9-sezon-10-vypusk-c/0
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=212911
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-12-%d1%81%d0%b5%d1%80%d0%b8-3/
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=198209
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=28077.0
http://arunagreen.com/index.php/component/k2/itemlist/user/444102
http://community.viajar.tur.br/index.php?p=/profile/gilbertola
http://mobility-corp.com/index.php/component/k2/itemlist/user/2531533
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1337367
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1025650
http://www.vivelabmanizales.com/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-video-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://tg.vl-mp.com/index.php?topic=1338647.0
http://menulisilmiah.net/live-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l2-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/52835
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=19375
http://www.ekemoon.com/147741/052220190506/
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=606607
https://szenarist.ru/forum/index.php?topic=205472.0
http://www.telcon.gr/index.php/component/k2/itemlist/user/42442
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3569817
http://www.telcon.gr/index.php/component/k2/itemlist/user/40031
http://menulisilmiah.net/hd-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u0-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.deliberarchia.org/forum/index.php?topic=993005.0
http://xplorefitness.com/blog/%C2%AB%D0%B2%D0%BE%D1%81%D1%81%D0%BE%D0%B5%D0%B4%D0%B8%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5-vuslat-15-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-pgus-%C2%AB%D0%B2%D0%BE%D1%81%D1%81%D0%BE%D0%B5%D0%B4%D0%B8%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5-vuslat-15-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
https://khuyenmaikk13.info/index.php?topic=185999.0
http://laspoltrina.it/?option=com_k2&view=itemlist&task=user&id=1400250
http://robocit.com/index.php/component/k2/itemlist/user/449388
http://withinfp.sakura.ne.jp/eso/index.php/16947096-smotret-smers-6-seria-y0-smers-6-seria/0
http://www.comfybigsize.com/index.php/component/k2/itemlist/user/22588
http://bitpark.co.kr/board_IzjM66/3802769
http://bitpark.co.kr/board_IzjM66/3802844
http://withinfp.sakura.ne.jp/eso/index.php/16894095-taemnici-89-seria-06052019-r7-taemnici-89-seria
http://menulisilmiah.net/live-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z2-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://seoksoononly.dothome.co.kr/qna/739357
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2387521
https://tg.vl-mp.com/index.php?topic=1352649.0
http://www.siirtorganik.com/index.php/component/k2/itemlist/user/756699
http://salescoach.ro/content/%C2%AB%D0%BD%D0%B0%D1%88%D0%B0-%D0%B8%D1%81%D1%82%D0%BE%D1%80%D0%B8%D1%8F-68-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-dzfe-%C2%AB%D0%BD%D0%B0%D1%88%D0%B0-%D0%B8%D1%81%D1%82%D0%BE%D1%80%D0%B8%D1%8F-68-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=47639
http://dev.aabn.org.gh/component/k2/itemlist/user/515136
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1747913
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3589830
http://c3isecurity.com.br/?option=com_k2&view=itemlist&task=user&id=469446
http://mobility-corp.com/index.php/component/k2/itemlist/user/2518252
http://dev.aabn.org.gh/component/k2/itemlist/user/513728
http://seoksoononly.dothome.co.kr/qna/745380
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=8936
http://seoksoononly.dothome.co.kr/qna/796678
http://www.vivelabmanizales.com/%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80%d0%b4%d1%86%d0%b5-tek-yurek-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fbet-%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80/
http://thermoplast.envolgroupe.com/component/k2/author/67543
http://marjorieaperry.com/?option=com_k2&view=itemlist&task=user&id=479485
http://www.ekemoon.com/144307/050820190706/
http://forum.digamahost.com/index.php?topic=110116.0
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=11865
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=27901.0
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1563493
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=217887
http://poselokgribovo.ru/forum/index.php?topic=715193.0
http://grupotir.com/component/k2/itemlist/user/42447
http://xplorefitness.com/blog/hd-video-%D1%87%D1%83%D0%B6%D0%B0%D1%8F-%D0%B6%D0%B8%D0%B7%D0%BD%D1%8C-%D1%87%D1%83%D0%B6%D0%B5-%D0%B6%D0%B8%D1%82%D1%82%D1%8F-8-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-j8-%D1%87%D1%83%D0%B6%D0%B0%D1%8F-%D0%B6%D0%B8%D0%B7%D0%BD%D1%8C-%D1%87%D1%83%D0%B6%D0%B5-%D0%B6%D0%B8%D1%82%D1%82%D1%8F-8-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/62228
http://bitpark.co.kr/board_IzjM66/3811831
http://bitpark.co.kr/board_IzjM66/3811940
http://forum.digamahost.com/index.php?topic=112401.0
http://teambuildingpremium.com/forum/index.php?topic=796296.0
http://xplorefitness.com/blog/%C2%AB%D0%B5%D0%B4%D0%B8%D0%BD%D0%BE%D0%B5-%D1%81%D0%B5%D1%80%D0%B4%D1%86%D0%B5-tek-y%C3%BCrek-10-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-injm-%C2%AB%D0%B5%D0%B4%D0%B8%D0%BD%D0%BE%D0%B5-%D1%81%D0%B5%D1%80%D0%B4%D1%86%D0%B5-tek-y%C3%BCrek-10-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://withinfp.sakura.ne.jp/eso/index.php/16951742-live-tola-robot-4-seria-r6-tola-robot-4-seria/0
http://www.crnmedia.es/?option=com_k2&view=itemlist&task=user&id=84984
http://www.sollazzorefrigerazione.it/?option=com_k2&view=itemlist&task=user&id=2431561
https://alvarogarciatorero.com/component/k2/itemlist/user/48428
http://www.ekemoon.com/168313/050120191010/
http://www.ekemoon.com/168323/050120191310/
http://www.ekemoon.com/168331/050120191510/
http://ovotecegg.com/component/k2/itemlist/user/122049
http://ovotecegg.com/component/k2/itemlist/user/115366
http://married.dike.gr/index.php/component/k2/itemlist/user/53593
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=39707
http://teambuildingpremium.com/forum/index.php?topic=786582.0
http://smartacity.com/component/k2/itemlist/user/13467
http://xplorefitness.com/blog/%C2%AB%D1%80%D0%B0%D0%BD%D0%BD%D1%8F%D1%8F-%D0%BF%D1%82%D0%B0%D1%88%D0%BA%D0%B0-erkenci-kus-42-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-nwpf-%C2%AB%D1%80%D0%B0%D0%BD%D0%BD%D1%8F%D1%8F-%D0%BF%D1%82%D0%B0%D1%88%D0%BA%D0%B0-erkenci-kus-42-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://condolencias.servisa.es/84-06-05-2019-s0-84
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1841847
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1736129
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1350207
http://danielmillsap.com/forum/index.php?topic=809541.0
http://www.deliberarchia.org/forum/index.php?topic=980868.0
http://www.deliberarchia.org/forum/index.php?topic=773329.0
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=37798
http://www.spazioad.com/component/k2/itemlist/user/7105444
http://metropolis.ga/index.php?topic=875.0
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1629650
https://mcsetup.tk/bbs/index.php?topic=225967.0
http://withinfp.sakura.ne.jp/eso/index.php/16782537-lubov-smert-i-roboty-love-death-and-robots-16-seria-oeg-lubov-s
http://forum.thaibetrank.com/index.php?topic=1085991.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3609791
http://webp.online/index.php?topic=50527.30
http://www.popolsku.fr.pl/forum/index.php?topic=342630.0
http://healthyteethpa.org/component/k2/itemlist/user/5275686
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=379120
https://instaldec.com/?option=com_k2&view=itemlist&task=user&id=602319
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=304003
https://tg.vl-mp.com/index.php?topic=1337249.0
https://mcsetup.tk/bbs/index.php?topic=227751.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bjp-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-15-%d1%81%d0%b5%d1%80/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1278107
https://mcsetup.tk/bbs/index.php?topic=233667.0
https://members.fbhaters.com/index.php?topic=64625.0
http://mediaville.me/index.php/component/k2/itemlist/user/198428
https://www.shaiyax.com/index.php?topic=311095.0
http://www.spazioad.com/component/k2/itemlist/user/7107654
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1094615
http://danielmillsap.com/forum/index.php?topic=827962.0
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1746004
http://rudraautomation.com/index.php/component/k2/author/114811
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/185477
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=43062
http://www.ekemoon.com/138947/051620191904/
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/968546
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3273949
https://nextezone.com/index.php?topic=32394.0
http://www.deliberarchia.org/forum/index.php?topic=934064.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3255614
http://danielmillsap.com/forum/index.php?topic=911759.0
https://tg.vl-mp.com/index.php?topic=1293406.0
http://marjorieaperry.com/?option=com_k2&view=itemlist&task=user&id=475346
http://mobility-corp.com/index.php/component/k2/itemlist/user/2504495
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f9-a8-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
https://www.shaiyax.com/index.php?topic=327897.0
http://menulisilmiah.net/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-m9w7-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5/
http://travelsolution.info/index.php/component/k2/itemlist/user/711921
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1549421
https://lucky28003.nl/forum/index.php?topic=8085.0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=39433
http://153.120.114.241/eso/index.php/16866693-zensina-56-seria-pivk-zensina-56-seria
https://www.resproxy.com/forum/index.php/773271-efir-holostak-9-sezon-12-vypusk-h8-holostak-9-sezon-12-vypusk/0
http://bitly.com/2VsphZv
http://forum.politeknikgihon.ac.id/index.php?topic=13063.0
http://forum.bmw-e60.eu/index.php?topic=317.0
http://www.deliberarchia.org/forum/index.php?topic=901333.0
http://www.deliberarchia.org/forum/index.php?topic=939867.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=259993
https://khuyenmaikk13.info/index.php?topic=174237.0
http://www.remify.app/foro/index.php?topic=212323.0
http://bitly.com/2Vcbila
http://bitly.com/2HaF6Ly
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1564584
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7309696
http://www.camaracoyhaique.cl/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-83-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-as0%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-83/
http://webp.online/index.php?topic=49749.0
http://menulisilmiah.net/%d1%8d%d1%84%d0%b8%d1%80-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v2-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5/
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/286007
http://seoksoononly.dothome.co.kr/qna/786734
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1357791
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1631149
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3302673
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=289693
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4829166
http://www.die-design-manufaktur.de/?option=com_k2&view=itemlist&task=user&id=5179202
http://www.ekemoon.com/157845/050820192508/
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=2001276
http://www.camaracoyhaique.cl/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o6-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be/
http://necinsurance.co.zw/component/k2/itemlist/user/19579.html
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=297720
https://members.fbhaters.com/index.php?topic=79667.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3597671
http://withinfp.sakura.ne.jp/eso/index.php/16865326-efir-sluga-naroda-3-sezon-7-seria-k1-sluga-naroda-3-sezon-7-ser/0
https://forums.letstalkbeats.com/index.php?topic=65443.0
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4828253
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/184577
http://153.120.114.241/eso/index.php/16862227-holostak-ukraina-9-sezon-10-vypusk-postsou-eiholostak-ukraina-9
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=188051
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=43046
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/53231
http://danielmillsap.com/forum/index.php?topic=830273.0
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/60986
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3641443
http://webp.online/index.php?topic=50334.0
http://www.deliberarchia.org/forum/index.php?topic=772083.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1341570
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-8-eo-1-e-vvy-a-etoo-8-eo-1-e-25-04-2019/?PHPSESSID=06eldegpurcvpjqc4vv292cr91
https://instaldec.com/?option=com_k2&view=itemlist&task=user&id=573519
http://www.sopcich.com/UserProfile/tabid/42/UserID/1569498/Default.aspx
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1709670
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=379063
http://www.deliberarchia.org/forum/index.php?topic=953223.0
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1793878
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/268272
http://withinfp.sakura.ne.jp/eso/index.php/16859830-igra-prestolov-8-sezon-4-seria-onb-igra-prestolov-8-sezon-4-ser
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1473109
http://www.deliberarchia.org/forum/index.php?topic=931187.0
http://withinfp.sakura.ne.jp/eso/index.php/16768787-igra-prestolov-8-sezon-2-seria-jtg-igra-prestolov-8-sezon-2-ser
http://www.phan-aen.go.th/forum/index.php?topic=606454.0
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=930063
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=45037
http://thermoplast.envolgroupe.com/component/k2/author/67603
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-evi-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/160666
https://www.resproxy.com/forum/index.php/742517-cernoe-zerkalo-5-sezon-2-seria-ckt-cernoe-zerkalo-5-sezon-2-ser/0
https://tg.vl-mp.com/index.php?topic=1303408.0
http://www.popolsku.fr.pl/forum/index.php?topic=334539.0
http://www.popolsku.fr.pl/forum/index.php?topic=20407.35955
http://forum.thaibetrank.com/index.php?topic=1088427.0
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=407907
http://withinfp.sakura.ne.jp/eso/index.php/16909495-vetrenyj-hercai-21-seria-v8zo-vetrenyj-hercai-21-seria
https://members.fbhaters.com/index.php?topic=65913.0
https://tg.vl-mp.com/index.php?topic=1267020.0
http://dcasociados.eu/component/k2/itemlist/user/82097
http://seoksoononly.dothome.co.kr/qna/426821
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1125306
http://danielmillsap.com/forum/index.php?topic=918348.0
http://myrechockey.com/forums/index.php?topic=86470.0
http://www.deliberarchia.org/forum/index.php?topic=923049.0
http://comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=102485
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1567797
http://forum.thaibetrank.com/index.php?topic=1077409.0
http://pptforum.dothome.co.kr/board_APMk06/664473
http://www.popolsku.fr.pl/forum/index.php?topic=339041.0
http://jpacschoolclubs.co.uk/?option=com_k2&view=itemlist&task=user&id=3267838
http://matinbank.ir/component/k2/itemlist/user/4482499.html
http://poselokgribovo.ru/forum/index.php?topic=617384.0
http://danielmillsap.com/forum/index.php?topic=881430.0
https://sto54.ru/index.php/component/k2/itemlist/user/3268659
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=304376
http://seoksoononly.dothome.co.kr/qna/467103
https://tg.vl-mp.com/index.php?topic=1267161.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1328493
http://danielmillsap.com/forum/index.php?topic=871054.0
http://fbpharm.net/index.php/component/k2/itemlist/user/14485
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=43133
http://teambuildingpremium.com/forum/index.php?topic=661652.0
http://www.deliberarchia.org/forum/index.php?topic=952446.0
http://www.popolsku.fr.pl/forum/index.php?topic=352141.0
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3577313
http://www.deliberarchia.org/forum/index.php?topic=769935.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=891423
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2554017
http://israengineering.com/index.php/component/k2/itemlist/user/1114546
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=39614
https://www.resproxy.com/forum/index.php/765834-igra-prestolov-8-sezon-8-seria-frs-igra-prestolov-8-sezon-8-ser/0
https://tg.vl-mp.com/index.php?topic=1269765.0
https://www.blog.quora.healthcare/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cof-%d0%b8%d0%b3%d1%80%d0%b0
http://webp.online/index.php?topic=42132.0
http://macdistri.com/index.php/component/k2/itemlist/user/222186
https://www.blog.quora.healthcare/%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5%d0%bd%d0%b8%d0%b5-vuslat-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h2vo-%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd
http://webp.online/index.php?topic=48376.0
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2387796
http://www.deliberarchia.org/forum/index.php?topic=963286.0
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=510887
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=260431
http://arquitectosenreformas.es/component/k2/itemlist/user/78275
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1669898
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2559330
https://members.fbhaters.com/index.php?topic=76366.0
http://webp.online/index.php?topic=41335.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=873696
http://153.120.114.241/eso/index.php/16865781-cernoe-zerkalo-5-sezon-5-seria-hnr-cernoe-zerkalo-5-sezon-5-ser
http://teambuildingpremium.com/forum/index.php?topic=614926.0
http://www.crnmedia.es/?option=com_k2&view=itemlist&task=user&id=84465
http://batubersurat.com/index.php/component/k2/itemlist/user/43885
http://dev.aabn.org.gh/component/k2/itemlist/user/513060
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1334912
http://dev.aabn.org.gh/component/k2/itemlist/user/513866
http://bitpark.co.kr/board_IzjM66/3732164
http://www.spazioad.com/?option=com_k2&view=itemlist&task=user&id=7213320
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1551741
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/199602
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=269037
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1340585
http://www.vivelabmanizales.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-08-05-2019-m2-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1353961
http://www.dezhiran.com/en/component/k2/itemlist/user/16255
http://www.camaracoyhaique.cl/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ry4q-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.ekemoon.com/158601/051120190508/
https://reficulcoin.com/index.php?topic=16198.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3323811
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=17596
http://77.93.38.205/index.php/component/k2/itemlist/user/521147
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=304231
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=304446
http://associationsila.org/component/k2/itemlist/user/304414
http://breakrow.com/ijwdeangelo/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-vgq-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/493527
http://dev.aabn.org.gh/component/k2/itemlist/user/548659
http://dpmarketingsystems.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fsk-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8/
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=281397
http://healthyteethpa.org/component/k2/itemlist/user/5375622
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1143120
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3325777
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3325783
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=17972
http://153.120.114.241/eso/index.php/16949153-nasa-istoria-66-seria-f0-nasa-istoria-66-seria-watch
http://153.120.114.241/eso/index.php/16949159-nasa-istoria-74-seria-s2-nasa-istoria-74-seria
http://153.120.114.241/eso/index.php/16949185-vossoedinenie-vuslat-13-seria-j4-vossoedinenie-vuslat-13-seria-
http://212.96.116.6/index.php?topic=139618.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/273476
http://www.emrabq8.com/index.php/component/k2/itemlist/user/1758907
http://soc-human.kz/index.php/component/k2/itemlist/user/1601778
http://poselokgribovo.ru/forum/index.php?topic=651932.0
http://teambuildingpremium.com/forum/index.php?topic=745118.0
http://ru-realty.com/forum/index.php?topic=427792.0
http://danielmillsap.com/forum/index.php?topic=911392.0
http://teambuildingpremium.com/forum/index.php?topic=711931.0
https://tg.vl-mp.com/index.php?topic=1258529.0
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7296779
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=38230
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2514826
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=24916
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1669868
http://www.phan-aen.go.th/forum/index.php?topic=606807.0
http://forum.thaibetrank.com/index.php?topic=1085095.0
http://withinfp.sakura.ne.jp/eso/index.php/16791885-lubov-smert-i-roboty-love-death-and-robots-12-seria-csl-lubov-s/0
https://www.blog.quora.healthcare/%d0%b4%d1%80%d1%83%d0%b3%d0%b0%d1%8f-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90pg%e3%80%91%d0%b4%d1%80%d1%83%d0%b3%d0%b0%d1%8f-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f
http://sam-sanat.ir/?option=com_k2&view=itemlist&task=user&id=131404
https://members.fbhaters.com/index.php?topic=65340.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1084100
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4836286
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2534880
https://www.resproxy.com/forum/index.php/807955-edinoe-serdce-tek-yurek-12-seria-m6fw-edinoe-serdce-tek-yurek-1/0
http://avengerro.top/forum/index.php?topic=14158.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/445898
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3278439
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=306408
http://sos.victoryaltar.org/tiki-index.php?page=UserPagedonnyfullartonjuwd
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3545538
http://seoksoononly.dothome.co.kr/qna/453873
http://seoksoononly.dothome.co.kr/qna/587304
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1313462
http://www.deliberarchia.org/forum/index.php?topic=970450.0
http://teambuildingpremium.com/forum/index.php?topic=686443.0
https://www.shaiyax.com/index.php?topic=310851.0
http://www.spazioad.com/component/k2/itemlist/user/7108090
http://myrechockey.com/forums/index.php?topic=89953.0
http://menulisilmiah.net/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-80-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-y4wt-%d0%bd%d0%b5%d0%b2/
http://proxima.co.rw/index.php/component/k2/itemlist/user/542402
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=894761
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3195316
https://www.youngbiker.de/wbboard/index.php?page=User&userID=781309
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1108839
http://www.deliberarchia.org/forum/index.php?topic=892920.0
http://www.tessabannampad.go.th/webboard/index.php?topic=189204.0
http://macdistri.com/index.php/component/k2/itemlist/user/205198
http://www.x2145-productions.technology/index.php?title=%C2%AB%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%C2%BB_08-05-2019_%22%D0%9F%D0%BE%D1%81%D0%BB%D0%B5_Watch%22_%C2%AB%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%C2%BB
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/52674
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=276288
http://webp.online/index.php?topic=38030.0
https://tg.vl-mp.com/index.php?topic=1312876.0
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1956348
https://tg.vl-mp.com/index.php?topic=1299506.0
http://proandpro.it/?option=com_k2&view=itemlist&task=user&id=4531178
http://www.deliberarchia.org/forum/index.php?topic=987510.0
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=224964
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/190806
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=44389
http://teambuildingpremium.com/forum/index.php?topic=611958.0
https://sto54.ru/index.php/component/k2/itemlist/user/3248751
http://menulisilmiah.net/%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0%d1%88%d0%ba%d0%b0-erkenci-kus-41-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d5me-%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0/
http://teambuildingpremium.com/forum/index.php?topic=615486.0
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1126130
http://www.deliberarchia.org/forum/index.php?topic=791551.0
http://153.120.114.241/eso/index.php/16857297-milliardy-4-sezon-7-seria-chl-milliardy-4-sezon-7-seria
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3194495
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=523769
http://danielmillsap.com/forum/index.php?topic=835179.0
http://www.deliberarchia.org/forum/index.php?topic=899690.0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=466404
http://soc-human.kz/index.php/component/k2/itemlist/user/1606430
http://teambuildingpremium.com/forum/index.php?topic=682817.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1230423
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/44576
http://seoksoononly.dothome.co.kr/qna/469204
http://forum.thaibetrank.com/index.php?topic=1070947.0
http://withinfp.sakura.ne.jp/eso/index.php/16768682-cernoe-zerkalo-5-sezon-4-seria-zdw-cernoe-zerkalo-5-sezon-4-ser/0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4576305
https://www.resproxy.com/forum/index.php/786112-riverdejl-riverdale-3-sezon-19-seria-qom-riverdejl-riverdale-3-/0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/266835
http://mvisage.sk/index.php/component/k2/itemlist/user/114378
http://macdistri.com/index.php/component/k2/itemlist/user/223118
http://danielmillsap.com/forum/index.php?topic=958967.0
http://aitour.kz/?option=com_k2&view=itemlist&task=user&id=312548
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1853365
http://www.deliberarchia.org/forum/index.php?topic=957058.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889129
http://muratliziraatodasi.org/forum/index.php?topic=330442.0
http://teambuildingpremium.com/forum/index.php?topic=645049.0
http://www.popolsku.fr.pl/forum/index.php?topic=338758.0
http://macdistri.com/index.php/component/k2/itemlist/user/263487
http://www.tvmechanic.co.in/forum/index.php?topic=8443.0
http://danielmillsap.com/forum/index.php?topic=870545.0
https://www.resproxy.com/forum/index.php/762011-tola-robot-serial-aktery-4-1-seria-tola-robot-serial-aktery-4-1/0
https://members.fbhaters.com/index.php?topic=54502.0
http://seoksoononly.dothome.co.kr/qna/727749
http://roikjer.com/forum/index.php?topic=794066.0
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=195133
http://dcasociados.eu/?option=com_k2&view=itemlist&task=user&id=86729
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81-23/
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q3-j2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://sextomariotienda.com/blog/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81-32/
http://bitly.com/2VsphZv
https://tg.vl-mp.com/index.php?topic=1262026.0
http://www.quattroandpartners.it/component/k2/itemlist/user/993721
http://www2.yasothon.go.th/smf/index.php?topic=159.153210
http://associationsila.org/component/k2/itemlist/user/272599
http://forum.politeknikgihon.ac.id/index.php?topic=8213.0
http://danielmillsap.com/forum/index.php?topic=866543.0
https://sanp.pro/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%be%d1%82%d0%b8%d1%80%d0%b0%d1%82%d1%8c%d1%81%d1%8f-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be/
http://minostech.co.kr/news/3371846
http://computerscience.egerton.ac.ke/index.php/component/k2/itemlist/user/1981321
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=34407
http://teambuildingpremium.com/forum/index.php?topic=741592.0
http://www.deliberarchia.org/forum/index.php?topic=935756.0
http://bitly.com/2Vcbila
http://bitly.com/2HaF6Ly
https://members.fbhaters.com/index.php?topic=78629.0
http://bobr.site/index.php?topic=88195.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1109114
http://www.hoonthaitoday.com/forum/index.php?topic=145539.0
http://taklongclub.com/forum/index.php?topic=92181.0
http://roikjer.com/forum/index.php?PHPSESSID=c4lrc10bjjgu05gefi3bv72l86&topic=792868.0
https://reficulcoin.com/index.php?topic=7980.0
http://roikjer.com/forum/index.php?topic=806704.0
http://gtupuw.org/index.php/component/k2/itemlist/user/1831579
http://danielmillsap.com/forum/index.php?topic=942203.0
http://1vh.info/index.php?topic=7565.0
https://reficulcoin.com/index.php?topic=4467.0
http://153.120.114.241/eso/index.php/16875650-05052019-podsudimyj-13-seria
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-t3-w4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://www.popolsku.fr.pl/forum/index.php?topic=371675.0
http://www.ekemoon.com/148955/050020190107/
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=186434
http://myrechockey.com/forums/index.php?topic=81899.0
http://forum.politeknikgihon.ac.id/index.php?topic=22633.0
http://codeerror.in/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d0-g3-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://freebeer.me/index.php?topic=283321.0
http://dpmarketingsystems.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g3-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be-2/
http://help.stv.ru/index.php?topic=136925.0
http://otitismediasociety.org/forum/index.php?topic=148677.0
https://forum.ac-jete.it/index.php?topic=336701.0
http://mir3sea.com/forum/index.php?topic=985.0
http://forum.elexlabs.com/index.php?topic=12096.0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-m8-t0-%d0%b8/
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p9-z9-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://bobr.site/index.php?topic=81121.0
http://danielmillsap.com/forum/index.php?topic=930841.0
http://associationsila.org/component/k2/itemlist/user/275472
http://otitismediasociety.org/forum/index.php?topic=146010.0
http://help.stv.ru/index.php?PHPSESSID=46751ef2b3425c3e29c24709af3cbf6c&topic=136777.0
https://khuyenmaikk13.info/index.php?topic=178863.0
http://mir3sea.com/forum/index.php?topic=1097.0
http://menulisilmiah.net/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90as4%e3%80%91/
http://roikjer.com/forum/index.php?PHPSESSID=clecqgi1citca009prf0h45n63&topic=820912.0
http://www.ekemoon.com/149505/050120191407/
http://forum.politeknikgihon.ac.id/index.php?topic=17566.0
http://forum.politeknikgihon.ac.id/index.php?topic=19467.0
http://HyUa.1fps.icu/l/szIaeDC
http://forum.byehaj.hu/index.php?topic=78327.0
http://seoksoononly.dothome.co.kr/qna/723768
http://arunagreen.com/index.php/component/k2/itemlist/user/460184
http://macdistri.com/index.php/component/k2/itemlist/user/309149
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7308873
http://macdistri.com/index.php/component/k2/itemlist/user/309587
http://afinandoemociones.com.ar/index.php/component/k2/itemlist/user/387985
http://mobility-corp.com/index.php/component/k2/itemlist/user/2522070
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=490654
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1729028
http://8.droror.co.il/uncategorized/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-92-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zn9z-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-92-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1334372
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=6913
http://married.dike.gr/index.php/component/k2/itemlist/user/50462
http://www.vivelabmanizales.com/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-06-05-2019-m3-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/186954
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3575126
http://www.vivelabmanizales.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e5-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/185844
http://danielmillsap.com/forum/index.php?topic=960720.0
http://webp.online/index.php?topic=49682.30
http://www.ekemoon.com/159219/051420190608/
http://israengineering.com/index.php/component/k2/itemlist/user/1116964
http://ahudseafood.com/?option=com_k2&view=itemlist&task=user&id=7834
http://www.ekemoon.com/149353/050020195507/
http://www.deliberarchia.org/forum/index.php?topic=968787.0
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=296524
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=6065
http://www.camaracoyhaique.cl/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d0%be%d0%bd%d0%bb/
http://poselokgribovo.ru/forum/index.php?topic=728987.0
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4838475
http://batubersurat.com/index.php/component/k2/itemlist/user/43716
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1334348
http://turkeya.life/index.php?action=profile&u=440252
http://k2.akademitelkom.ac.id/component/k2/itemlist/user/296785
http://ptu.imoove.kr/ko/content/%C2%AB%D1%8E%D1%80%D0%B8%D1%81%D1%82%D1%8B-14-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%D1%81%D0%B5%D1%80%D0%B8%D0%B0%D0%BB-%C2%AB%D1%8E%D1%80%D0%B8%D1%81%D1%82%D1%8B-14-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB332348
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3392682
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/475653
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=9748
http://www.camaracoyhaique.cl/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qy9d-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1356038
http://withinfp.sakura.ne.jp/eso/index.php/16884776-po-zakonam-voennogo-vremeni-3-sezon-5-seria-06052019-i0-po-zako
http://fbpharm.net/index.php/component/k2/itemlist/user/16239
http://socialfbwidgets.com/component/k2/itemlist/user/13385.html
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=45324
http://israengineering.com/index.php/component/k2/itemlist/user/1121934
http://dessa.com.br/component/k2/itemlist/user/318528
https://l2thalassic.org/Forum/index.php?topic=1357.0
http://www.vivelabmanizales.com/hd-video-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d4-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1/
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=15786
http://proxima.co.rw/index.php/component/k2/itemlist/user/569167
http://sfah.ch/de/component/k2/itemlist/user/14908
http://forum.byehaj.hu/index.php?topic=82670.0
http://batubersurat.com/index.php/component/k2/itemlist/user/44099
http://community.viajar.tur.br/index.php?p=/discussion/57334/vossoedinenie-vuslat-15-seriya-pjar-vossoedinenie-vuslat-15-seriya
https://verdadesbiblicas.org.ec/index.php/component/k2/itemlist/user/3713411
http://www.ekemoon.com/146903/052020190806/
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4851162
http://condolencias.servisa.es/3-2-06-05-2019-w3-3-2
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=493498
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=314314
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/641841
http://rudraautomation.com/index.php/component/k2/author/118424
http://smartacity.com/component/k2/itemlist/user/16494
http://www.comfybigsize.com/?option=com_k2&view=itemlist&task=user&id=17121
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=14338
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4838931
http://healthyteethpa.org/component/k2/itemlist/user/5330926
http://menulisilmiah.net/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yx5%d0%bd/
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/682610
http://israengineering.com/index.php/component/k2/itemlist/user/1112978
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=67575
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7315899
http://ru-realty.com/forum/index.php?PHPSESSID=t3c76nr5uuc7gqo5mj38m57s33&topic=472585.0
http://withinfp.sakura.ne.jp/eso/index.php/16895874-tolarobot-1-sezon-3-seria-y3-tolarobot-1-sezon-3-seria/0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/477274
http://xplorefitness.com/blog/%D1%81%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C-%D0%BF%D0%BE-%D0%B7%D0%B0%D0%BA%D0%BE%D0%BD%D0%B0%D0%BC-%D0%B2%D0%BE%D0%B5%D0%BD%D0%BD%D0%BE%D0%B3%D0%BE-%D0%B2%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-7-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-g1-%D0%BF%D0%BE-%D0%B7%D0%B0%D0%BA%D0%BE%D0%BD%D0%B0%D0%BC-%D0%B2%D0%BE%D0%B5%D0%BD%D0%BD%D0%BE%D0%B3%D0%BE-%D0%B2%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-7
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/287516
http://www.nienkevanrijn.nl/component/k2/itemlist/user/432821
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=602808
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1633878
http://febrescordero.gob.ec/index.php/component/k2/itemlist/user/84877
https://lucky28003.nl/forum/index.php?topic=10622.0
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1640485
http://condolencias.servisa.es/3-9-06-05-2019-p0-3-9
http://sdsn.develop.cinfores.com/?option=com_k2&view=itemlist&task=user&id=189781
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1121641
http://forum.digamahost.com/index.php?topic=111366.0
http://israengineering.com/index.php/component/k2/itemlist/user/1119789
http://seoksoononly.dothome.co.kr/qna/727631
http://8.droror.co.il/uncategorized/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-11-%d1%81%d0%b5-3/
https://forums.letstalkbeats.com/index.php?topic=64822.0
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=66752
http://www.vivelabmanizales.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yc8j-%d0%b8%d0%b3%d1%80%d0%b0/
http://arquitectosenreformas.es/index.php/component/k2/itemlist/user/79512
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=497922
http://www.phan-aen.go.th/forum/index.php?topic=626577.0
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=303893
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1633032
http://www.afikgan.co.il/index.php/component/k2/itemlist/user/26335
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1116525
http://www.remify.app/foro/index.php?topic=240691.0
http://www.camaracoyhaique.cl/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fj5%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f07-05/
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/642125
http://bankmitraniaga.co.id/?option=com_k2&view=itemlist&task=user&id=4146645
http://macdistri.com/component/k2/itemlist/user/297509
http://forum.politeknikgihon.ac.id/index.php?topic=25709.0
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=762245
http://www.spazioad.com/component/k2/itemlist/user/7215934
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=781505
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=44147
http://macdistri.com/index.php/component/k2/itemlist/user/303628
http://macdistri.com/index.php/component/k2/itemlist/user/297464
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=1007933
http://storykingdom.forumside.com/index.php?topic=5569.0
http://www.siirtorganik.com/index.php/component/k2/itemlist/user/771534
http://withinfp.sakura.ne.jp/eso/index.php/16910786-uristy-16-seria-novinka-uristy-16-seria/0
http://www.ekemoon.com/148593/052320192206/
https://khuyenmaikk13.info/index.php?topic=183835.0
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-06-05-2019-o7-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
http://dev.aabn.org.gh/component/k2/itemlist/user/531209
http://153.120.114.241/eso/index.php/16888565-holostak-9-sezon-10-vypusk-5-ot-10052016-oyholostak-9-sezon-10-
http://topitop.kz/index.php/component/k2/itemlist/user/76596
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://arunagreen.com/?option=com_k2&view=itemlist&task=user&id=444246
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/156691
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2528926
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=5535
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/286060
http://withinfp.sakura.ne.jp/eso/index.php/16863923-holostak-9-sezon-10-vypusk-youtube-crholostak-9-sezon-10-vypusk/0
http://teambuildingpremium.com/forum/index.php?topic=781282.0
http://seoksoononly.dothome.co.kr/qna/805818
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=7887
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=42764
https://l2thalassic.org/Forum/index.php?topic=1128.0
http://www.camaracoyhaique.cl/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-88-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-op6j-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-88-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://smartacity.com/component/k2/itemlist/user/21845
http://seoksoononly.dothome.co.kr/qna/786693
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=202944
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=7228
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3580564
https://l2thalassic.org/Forum/index.php?topic=2171.0
http://77.93.38.205/index.php/component/k2/itemlist/user/503001
https://l2thalassic.org/Forum/index.php?topic=942.0
https://lucky28003.nl/forum/index.php?topic=11358.0
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=501344
http://ru-realty.com/forum/index.php?PHPSESSID=18dpgvvian38cjiuk8h24nscs3&topic=476162.0
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=42715
http://withinfp.sakura.ne.jp/eso/index.php/16859818-holostak-9-sezon-vypusk-10-anons-vvholostak-9-sezon-vypusk-10-a/0
http://smartacity.com/component/k2/itemlist/user/15203
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=36220
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=6028
http://dev.aabn.org.gh/component/k2/itemlist/user/527015
http://www.babvallejo.com/index.php/component/k2/itemlist/user/606975
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1837592
http://smartacity.com/component/k2/itemlist/user/14065
http://matinbank.ir/component/k2/itemlist/user/4487542.html
http://withinfp.sakura.ne.jp/eso/index.php/16868900-vossoedinenie-vuslat-13-seria-vuya-vossoedinenie-vuslat-13-seri/0
http://fbpharm.net/index.php/component/k2/itemlist/user/13042
http://condolencias.servisa.es/16-05-05-2019-s2-16
http://www.vivelabmanizales.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d2-%d1%82%d0%be%d0%bb/
http://poselokgribovo.ru/forum/index.php?topic=740310.0
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=80165
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3565384
http://haniel.ir/index.php/component/k2/itemlist/user/73539
https://khuyenmaikk13.info/index.php?topic=184046.0
http://soc-human.kz/index.php/component/k2/itemlist/user/1636781
http://www.ekemoon.com/146747/051920194906/
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/61680
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/3935
https://l2thalassic.org/Forum/index.php?topic=762.0
http://withinfp.sakura.ne.jp/eso/index.php/16888879-hd-tolarobot-1-sezon-7-seria-r1-tolarobot-1-sezon-7-seria
http://poselokgribovo.ru/forum/index.php?topic=723301.0
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=46196
http://www.spazioad.com/component/k2/itemlist/user/7098326
http://seoksoononly.dothome.co.kr/qna/431076
https://prosocyr.com/?option=com_k2&view=itemlist&task=user&id=602284
http://healthyteethpa.org/component/k2/itemlist/user/5276562
https://tg.vl-mp.com/index.php?topic=1269337.0
http://pptforum.dothome.co.kr/board_APMk06/622884
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/13629
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=32399
http://myrechockey.com/forums/index.php?topic=86365.0
https://mcsetup.tk/bbs/index.php?topic=221405.0
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=11957
http://danielmillsap.com/forum/index.php?topic=795442.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/171484
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/249183
http://mobility-corp.com/index.php/component/k2/itemlist/user/2512100
http://seoksoononly.dothome.co.kr/qna/472376
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ud6-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1250259
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=42731
https://tg.vl-mp.com/index.php?topic=1351027.0
http://sam-sanat.ir/?option=com_k2&view=itemlist&task=user&id=139896
http://married.dike.gr/index.php/component/k2/itemlist/user/51873
http://www.popolsku.fr.pl/forum/index.php?topic=337990.0
http://www.popolsku.fr.pl/forum/index.php?topic=340542.0
http://www.deliberarchia.org/forum/index.php?topic=796532.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m6pa-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-20-%d1%81%d0%b5%d1%80%d0%b8/
http://poselokgribovo.ru/forum/index.php?topic=621910.0
http://uberdrivers.net/forum/index.php?topic=224476.0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=51893
http://www.telcon.gr/index.php/component/k2/itemlist/user/48674
http://www.dap.com.py/index.php/es/?option=com_k2&view=itemlist&task=user&id=793734
https://khuyenmaikk13.info/index.php?topic=178576.0
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/52924
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=45489
http://married.dike.gr/index.php/component/k2/itemlist/user/49556
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/151146
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=77944
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1850251
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=259606
https://woodland.org.ua/members/nicolaspiesse9/
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1822707
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=37349
http://bayareawomenmag.xyz/blogs/viewstory/17907
http://dota2.host/82879-taemnici-98-seria-w4-taemnici-98-seria-taemnici-98-seria-r4
http://dota2.host/83148-grand-2-sezon-21-seria-j0-grand-2-sezon-21-seria-grand-2-sezon-
http://dota2.host/83165-holostak-9-sezon-10-vypusk-e9-holostak-9-sezon-10-vypusk-holost
http://dota2.host/83307-holostak-9-sezon-12-vypusk-p7-holostak-9-sezon-12-vypusk-holost
http://dpmarketingsystems.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j2-%e3%80%90-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://dpmarketingsystems.com/%d1%81%d0%bc%d0%b5%d1%80%d1%88-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-i7-%e3%80%90-%d1%81%d0%bc%d0%b5%d1%80%d1%88-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f%e3%80%91-%d1%81%d0%bc%d0%b5%d1%80/
http://smartacity.com/component/k2/itemlist/user/11812
http://muratliziraatodasi.org/forum/index.php?topic=345611.0
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/55594
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1079826
https://tg.vl-mp.com/index.php?topic=1282777.0
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/140956
http://www.deliberarchia.org/forum/index.php?topic=775757.0
http://married.dike.gr/index.php/component/k2/itemlist/user/38690
http://seoksoononly.dothome.co.kr/qna/421832
http://withinfp.sakura.ne.jp/eso/index.php/16844306-vetrenyj-hercai-14-seria-v2xx-vetrenyj-hercai-14-seria/0
http://mvisage.sk/?option=com_k2&view=itemlist&task=user&id=116287
http://menulisilmiah.net/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-23-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kj4-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-23-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=700169
http://abadvert.lv/index.php/component/k2/itemlist/user/3096
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=37092
http://poselokgribovo.ru/forum/index.php?topic=617361.0
http://discussadeal.com/forum/index.php?topic=2001.0
http://metropolis.ga/index.php?topic=33.0
http://danielmillsap.com/forum/index.php?topic=834146.0
http://danielmillsap.com/forum/index.php?topic=904766.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=871740
http://webp.online/index.php?topic=38203.15
http://www.popolsku.fr.pl/forum/index.php?topic=339478.0
http://avengerro.top/forum/index.php?topic=9849.0
http://www.deliberarchia.org/forum/index.php?topic=773119.0
http://danielmillsap.com/forum/index.php?topic=835395.0
http://www.spazioad.com/component/k2/itemlist/user/7196090
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1469821
http://discussadeal.com/forum/index.php?topic=3464.0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=294188
http://danielmillsap.com/forum/index.php?topic=883070.0
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=77424
http://dev.fivestarpainting.com/?option=com_k2&view=itemlist&task=user&id=1773728
http://mediaville.me/index.php/component/k2/itemlist/user/210333
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1995936
http://www.camaracoyhaique.cl/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-oc8%d0%bd/
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nu6x-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://withinfp.sakura.ne.jp/eso/index.php/16877303-sluga-naroda-3-sezon-9-seria-06052019-g1-sluga-naroda-3-sezon-9
http://mediaville.me/index.php/component/k2/itemlist/user/208724
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3312259
http://153.120.114.241/eso/index.php/16861934-holostak-9-sezon-10-vypusk-andeks-bsholostak-9-sezon-10-vypusk-
http://dpordering.cetco.com/User-Profile/userId/573371
http://bitpark.co.kr/board_IzjM66/3752854
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/288097
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=50988
http://www.elpinatarense.com/?option=com_k2&view=itemlist&task=user&id=154380
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/186880
http://153.120.114.241/eso/index.php/16883644-vetrenyj-hercai-8-seria-twsl-vetrenyj-hercai-8-seria
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/220829
http://mobility-corp.com/index.php/component/k2/itemlist/user/2519193
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3312620
https://l2thalassic.org/Forum/index.php?topic=1495.0
http://fbpharm.net/index.php/component/k2/itemlist/user/14638
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4711870
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=11400
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/60869
http://hotelnomadpalace.com/index.php/component/k2/itemlist/user/19280
http://danielmillsap.com/forum/index.php?topic=903658.0
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3682424
http://muratliziraatodasi.org/forum/index.php?topic=325580.0
https://www.blog.quora.healthcare/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r5wh-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-6-%d1%81%d0%b5%d1%80%d0%b8
https://tg.vl-mp.com/index.php?topic=1269901.0
http://teambuildingpremium.com/forum/index.php?topic=679622.0
http://danielmillsap.com/forum/index.php?topic=841405.0
http://menulisilmiah.net/%d0%bc%d0%b5%d1%80%d1%82%d0%b2%d0%be%d0%b5-%d0%be%d0%b7%d0%b5%d1%80%d0%be-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yb3-%d0%bc%d0%b5%d1%80%d1%82%d0%b2%d0%be%d0%b5-%d0%be%d0%b7%d0%b5%d1%80/
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2470932
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=583640.0
http://mediaville.me/index.php/component/k2/itemlist/user/233508
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=31018
http://flyinghonda.de/wbb/index.php?page=User&userID=804841
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1594929
https://tg.vl-mp.com/index.php?topic=1268129.0
https://tg.vl-mp.com/index.php?topic=1339920.0
http://seoksoononly.dothome.co.kr/qna/612474
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3683570
http://teambuildingpremium.com/forum/index.php?topic=648325.0
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2497651
http://teambuildingpremium.com/forum/index.php?topic=649754.0
http://teambuildingpremium.com/forum/index.php?topic=692967.0
http://www.crnmedia.es/component/k2/itemlist/user/83021
http://teambuildingpremium.com/forum/index.php?topic=684902.0
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-de5-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8/
https://mcsetup.tk/bbs/index.php?topic=230899.0
https://tg.vl-mp.com/index.php?topic=1304235.0
https://forum.ac-jete.it/index.php?topic=268213.0
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=376739
http://sdsn.develop.cinfores.com/?option=com_k2&view=itemlist&task=user&id=169284
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/442942
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/169613
http://153.120.114.241/eso/index.php/16841783-nasledie-12-seria-mff-nasledie-12-seria
http://proxima.co.rw/index.php/component/k2/itemlist/user/510718
http://poselokgribovo.ru/forum/index.php?topic=620657.0
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=408527
http://teambuildingpremium.com/forum/index.php?topic=611543.0
http://muratliziraatodasi.org/forum/index.php?topic=343850.0
http://danielmillsap.com/forum/index.php?topic=838664.0
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1095823
http://married.dike.gr/index.php/component/k2/itemlist/user/25558
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=9918
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3197873
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/45489
http://metropolis.ga/index.php?topic=2315.0
http://teambuildingpremium.com/forum/index.php?topic=679002.0
https://mcsetup.tk/bbs/index.php?topic=229362.0
https://www.resproxy.com/forum/index.php/763144-rasskaz-sluzanki-3-sezon-5-seria-bpp-rasskaz-sluzanki-3-sezon-5/0
http://sam-sanat.ir/component/k2/itemlist/user/134414
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=890978
http://teambuildingpremium.com/forum/index.php?topic=629481.0
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/144129
http://www.quattroandpartners.it/component/k2/itemlist/user/1018335
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=15148
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=676096
https://tg.vl-mp.com/index.php?topic=1273166.0
http://menulisilmiah.net/video-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r8-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://ruschinaforum.ru/index.php?topic=122373.0
http://www.jobref.de/node/2120311
http://teambuildingpremium.com/forum/index.php?topic=714298.0
http://www.spazioad.com/component/k2/itemlist/user/7222551
http://www.aloeverasas.it/index.php/component/k2/itemlist/user/17475
https://members.fbhaters.com/index.php?topic=58225.0
http://dpmarketingsystems.com/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-143-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-m7-%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81/
http://teambuildingpremium.com/forum/index.php?topic=741078.0
http://www.shturmovka.ru/blog/170441.html
http://teambuildingpremium.com/forum/index.php?topic=715059.0
https://nextezone.com/index.php?action=profile;u=1870
http://www.hoonthaitoday.com/forum/index.php?topic=155403.0
http://forum.politeknikgihon.ac.id/index.php?topic=16308.0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81-24/
http://yuptalk.ru/other_food_household_cosmetics_etc/-t13018.0.html
http://bitly.com/2VsphZv
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=546823
https://members.fbhaters.com/index.php/topic,69870.0.html
http://forum.politeknikgihon.ac.id/index.php?topic=12032.0
http://teambuildingpremium.com/forum/index.php?topic=756948.0
http://www.deliberarchia.org/forum/index.php?topic=940200.0
https://tg.vl-mp.com/index.php?topic=1283535.0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/55426
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/436691
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=278115
http://bitly.com/2Vcbila
http://bitly.com/2HaF6Ly
http://www.deliberarchia.org/forum/index.php?topic=936757.0
http://forum.digamahost.com/index.php?topic=108488.0
http://teambuildingpremium.com/forum/index.php?topic=754885.0
http://153.120.114.241/eso/index.php/16855705-05052019-podsudimyj-9-seria
http://www.hoonthaitoday.com/forum/index.php?topic=128096.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-2019-8-eo-7-e-uu4-'a-etoo-2019-8-eo-7-e-watch'/?PHPSESSID=v8e9s7d7sc9vvcjhabn72p6tf0
http://ru-realty.com/forum/index.php?PHPSESSID=vi3fbsmdraf0n0lfgc0dpurig4&topic=445212.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/08-05-2019-to-oot-8-e/?PHPSESSID=421kc27210jooeqmqf8o6cucu7
http://1vh.info/index.php?topic=13958.0
http://poselokgribovo.ru/forum/index.php?topic=695010.0
http://thermoplast.envolgroupe.com/component/k2/author/65300
http://otitismediasociety.org/forum/index.php?topic=148456.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=b746be58996fa5e2163be69e2ddd96bf&topic=204897.0
https://danceplanet.se/commodore/index.php?topic=14786.0
http://multikopterforum.hu/index.php?topic=11138.0
http://myrechockey.com/forums/index.php?topic=87391.0
http://forum.santrope-rp.ru/index.php?topic=2350.0
http://www.deliberarchia.org/forum/index.php?topic=945378.0
http://www.theocraticamerica.org/forum/index.php?topic=25509.0
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-py9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://ru-realty.com/forum/index.php?topic=445177.0
http://www.critico-expository.com/forum/index.php?topic=2357.0
https://hackersuniversity.net/index.php/topic,8524.0.html
http://www.hoonthaitoday.com/forum/index.php?topic=140079.0
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-y5-t7-%d1%80/
http://otitismediasociety.org/forum/index.php?topic=142145.0
http://poselokgribovo.ru/forum/index.php?topic=703274.0
http://dpmarketingsystems.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ff5-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://flashboot.ru/forum/index.php?topic=94348.0
http://eugeniocolazzo.it/forum/index.php?topic=81698.0
https://sanp.pro/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a2-m3-%d1%80%d0%b0%d1%81%d1%81/
http://HyUa.1fps.icu/l/szIaeDC
https://www.resproxy.com/forum/index.php/732088-igra-prestolov-8-sezon-7-seria-lgz-igra-prestolov-8-sezon-7-ser/0
http://danielmillsap.com/forum/index.php?topic=838097.0
http://seoksoononly.dothome.co.kr/qna/460451
http://withinfp.sakura.ne.jp/eso/index.php/16788644-lubov-smert-i-roboty-love-death-and-robots-9-seria-wsn-lubov-sm/0
https://tg.vl-mp.com/index.php?topic=1258489.0
http://www.phan-aen.go.th/forum/index.php?topic=607768.0
http://153.120.114.241/eso/index.php/16864804-riverdejl-riverdale-3-sezon-18-seria-bsr-riverdejl-riverdale-3-
https://tg.vl-mp.com/index.php?topic=1345327.0
https://mcsetup.tk/bbs/index.php?topic=224012.0
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=46988
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-8-eo-5-e-qul-a-etoo-8-eo-5-e-24-04-2019/?PHPSESSID=j938prf7taf1eork2kv4uls2v4
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=41830
https://www.shaiyax.com/index.php?topic=312640.0
http://withinfp.sakura.ne.jp/eso/index.php/16786473-igra-prestolov-8-sezon-3-seria-jfu-igra-prestolov-8-sezon-3-ser/0
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=688286
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=10216
https://instaldec.com/?option=com_k2&view=itemlist&task=user&id=602241
http://withinfp.sakura.ne.jp/eso/index.php/16857367-zensina-59-seria-a1ae-zensina-59-seria
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1251976
http://muratliziraatodasi.org/forum/index.php?topic=345982.0
http://danielmillsap.com/forum/index.php?topic=837862.0
http://www.arunagreen.com/?option=com_k2&view=itemlist&task=user&id=394469
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nx1-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2/
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1956140
http://seoksoononly.dothome.co.kr/qna/419970
https://www.youngbiker.de/wbboard/index.php?page=User&userID=783034
http://proxima.co.rw/index.php/component/k2/itemlist/user/506685
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=77429
http://danielmillsap.com/forum/index.php?topic=910083.0
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1667747
https://www.resproxy.com/forum/index.php/776021-sverh-estestvennoe-14-sezon-20-seria-exc-sverh-estestvennoe-14-/0
http://flyinghonda.de/wbb/index.php?page=User&userID=807894
http://danielmillsap.com/forum/index.php?topic=894199.0
http://www.cosl.com.sg/UserProfile/tabid/61/userId/26097349/Default.aspx
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=12478
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7272052
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81-28/
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=251078
http://www.tessabannampad.go.th/webboard/index.php?topic=192593.0
http://danielmillsap.com/forum/index.php?topic=801670.0
http://healthyteethpa.org/index.php/component/k2/itemlist/user/5352779
http://danielmillsap.com/forum/index.php?topic=839976.0
http://afinandoemociones.com.ar/index.php/component/k2/itemlist/user/385834
http://teambuildingpremium.com/forum/index.php?topic=621054.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ssj-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1611368
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=696725
http://withinfp.sakura.ne.jp/eso/index.php/16776015-nevesta-iz-stambula-istanbullu-gelin-80-seria-h9kn-nevesta-iz-s/0
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wj3-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8/
http://153.120.114.241/eso/index.php/16867568-lubov-smert-i-roboty-love-death-and-robots-2-seria-pnd-lubov-sm
http://danielmillsap.com/forum/index.php?topic=828656.0
https://forum.ac-jete.it/index.php?topic=283540.0
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1103639
http://www.popolsku.fr.pl/forum/index.php?topic=346161.0
http://menulisilmiah.net/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-80-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a9lc-%d0%bd%d0%b5%d0%b2/
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=292903
https://www.blog.quora.healthcare/%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90cd%e3%80%91%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bqz-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://poselokgribovo.ru/forum/index.php?topic=619818.0
https://lucky28003.nl/forum/index.php?topic=11970.0
https://www.youngbiker.de/wbboard/index.php?page=User&userID=784577
https://www.resproxy.com/forum/index.php/734032-milliardy-4-sezon-10-seria-zar-milliardy-4-sezon-10-seria-03052/0
http://seoksoononly.dothome.co.kr/qna/464855
http://mobility-corp.com/index.php/component/k2/itemlist/user/2467611
http://withinfp.sakura.ne.jp/eso/index.php/16776703-riverdejl-riverdale-3-sezon-21-seria-qbf-riverdejl-riverdale-3-/0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/246749
http://teambuildingpremium.com/forum/index.php?topic=627117.0
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/105929
http://www.deliberarchia.org/forum/index.php?topic=928862.0
http://www.deliberarchia.org/forum/index.php?topic=977631.0
http://mediaville.me/index.php/component/k2/itemlist/user/203685
http://forums.abs-cbn.com/welcome-back-kapamilya%21/ma-4-eo-7-e-rff-ma-4-eo-7-e-25-04-2019/
http://macdistri.com/index.php/component/k2/itemlist/user/300276
https://tg.vl-mp.com/index.php?topic=1323800.0
https://www.shaiyax.com/index.php?topic=314906.0
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1984766
http://travelsolution.info/index.php/component/k2/itemlist/user/705823
http://danielmillsap.com/forum/index.php?topic=836621.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/473771
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=299590
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tak-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://webp.online/index.php?topic=41239.0
https://www.youngbiker.de/wbboard/index.php?page=User&userID=785617
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/367465
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/175296
http://danielmillsap.com/forum/index.php?topic=831368.0
http://healthyteethpa.org/component/k2/itemlist/user/5310963
http://danielmillsap.com/forum/index.php?topic=881072.0
http://danielmillsap.com/forum/index.php?topic=824490.0
https://forum.ac-jete.it/index.php?topic=282196.0
http://www.phan-aen.go.th/forum/index.php?topic=608122.0
http://poselokgribovo.ru/forum/index.php?topic=620502.0
http://www.moyakmermer.com/?option=com_k2&view=itemlist&task=user&id=595526
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=12638
http://www.phan-aen.go.th/forum/index.php?topic=606991.0
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3677520
https://www.shaiyax.com/index.php?topic=313671.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1080321
http://www.deliberarchia.org/forum/index.php?topic=800036.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3499722
http://danielmillsap.com/forum/index.php?topic=944626.0
http://discussadeal.com/forum/index.php?topic=2812.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=873033
http://married.dike.gr/index.php/component/k2/itemlist/user/34098
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1673044
https://tg.vl-mp.com/index.php?topic=1258784.0
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=45877
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1128110
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3277146
http://withinfp.sakura.ne.jp/eso/index.php/16935528-edinoe-serdce-tek-yurek-12-seria-r8zu-edinoe-serdce-tek-yurek-1/0
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1709766
https://mcsetup.tk/bbs/index.php?topic=231246.0
http://teambuildingpremium.com/forum/index.php?topic=640175.0
https://www.resproxy.com/forum/index.php/807915-vetrenyj-hercai-17-seria-e7bf-vetrenyj-hercai-17-seria/0
http://www.arredoufficiomarca.com/index.php/component/k2/itemlist/user/1551105
https://tg.vl-mp.com/index.php?topic=1259305.0
http://danielmillsap.com/forum/index.php?topic=807745.0
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1454012
https://mcsetup.tk/bbs/index.php?topic=232973.0
http://teambuildingpremium.com/forum/index.php?topic=653963.0
http://otitismediasociety.org/forum/index.php?topic=142857.0
http://poselokgribovo.ru/forum/index.php?topic=714017.0
http://www.deliberarchia.org/forum/index.php?topic=932561.0
https://members.fbhaters.com/index.php?topic=80104.0
http://macdistri.com/index.php/component/k2/itemlist/user/288609
http://otitismediasociety.org/forum/index.php?topic=147334.0
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m1-k4-%d1%80%d0%b0%d1%81%d1%81/
http://www.popolsku.fr.pl/forum/index.php?topic=374173.0
https://nextezone.com/index.php?action=profile&u=2422
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3369593
http://golyboe.ru/forum/index.php?topic=24940.0
http://8.droror.co.il/uncategorized/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90ra7%e3%80%91/
http://multikopterforum.hu/index.php?topic=12006.0
http://codeerror.in/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j8-o8-%d0%b8%d0%b3%d1%80%d0%b0/
http://uberdrivers.net/forum/index.php?topic=210708.0
http://codeerror.in/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90js9%e3%80%91-%d0%b8%d0%b3/
http://blog.ptpintcast.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k7-a1-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-q6-q0-%d1%80/
http://forum.digamahost.com/index.php?topic=107789.0
http://help.stv.ru/index.php?PHPSESSID=69c3b5e175ecfe7352a45f1e0db2ffe1&topic=138457.0
http://forum.kopkargobel.com/index.php?topic=5818.0
http://forum.kopkargobel.com/index.php?topic=5440.0
http://freebeer.me/index.php?topic=287330.0
http://blog.ptpintcast.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-z8-t8-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://poselokgribovo.ru/forum/index.php?topic=708615.0
http://153.120.114.241/eso/index.php/16875064-05052019-devat-ziznej-16-seria
http://dpmarketingsystems.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-f8-f9-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://danielmillsap.com/forum/index.php?topic=924776.0
https://adsensebih.com/index.php?topic=9471.0
http://e-educ.net/Forum/index.php?topic=6682.0
https://danceplanet.se/commodore/index.php?topic=8367.0
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3558863
http://HyUa.1fps.icu/l/szIaeDC
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3261462
http://pptforum.dothome.co.kr/board_APMk06/661163
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=890717
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1470287
http://withinfp.sakura.ne.jp/eso/index.php/16777976-milliardy-4-sezon-6-seria-rmw-milliardy-4-sezon-6-seria-0105201/0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=874439
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/139048
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=235714
http://webp.online/index.php?topic=42698.0
https://www.youngbiker.de/wbboard/index.php?page=User&userID=776566
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3289089
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/236033
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1266124
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1846710
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=409132
http://teambuildingpremium.com/forum/index.php?topic=601218.0
http://jpacschoolclubs.co.uk/?option=com_k2&view=itemlist&task=user&id=3270861
http://153.120.114.241/eso/index.php/16817532-riverdejl-riverdale-3-sezon-21-seria-jdt-riverdejl-riverdale-3-
http://teambuildingpremium.com/forum/index.php?topic=682802.0
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=12137
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1278008
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1105069
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1131609
http://www.deliberarchia.org/forum/index.php?topic=956688.0
http://danielmillsap.com/forum/index.php?topic=820701.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/368633
https://www.blog.quora.healthcare/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90io%e3%80%91%d1%81%d0%bb%d1%83%d0%b3%d0%b0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=893886
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3282358
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1083339
https://lucky28003.nl/forum/index.php?topic=4970.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3293723
http://metropolis.ga/index.php?topic=4282.0
http://www.popolsku.fr.pl/forum/index.php?topic=341018.0
http://danielmillsap.com/forum/index.php?topic=897056.0
http://metropolis.ga/index.php?topic=964.0
http://danielmillsap.com/forum/index.php?topic=803956.0
http://webp.online/index.php?topic=38433.0
http://danielmillsap.com/forum/index.php?topic=829265.0
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=703277
http://muratliziraatodasi.org/forum/index.php?topic=340321.0
http://withinfp.sakura.ne.jp/eso/index.php/16771222-sverh-estestvennoe-14-sezon-14-seria-ioq-sverh-estestvennoe-14-/0
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3470103
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=892484
http://withinfp.sakura.ne.jp/eso/index.php/16825913-vetrenyj-hercai-21-seria-h4rx-vetrenyj-hercai-21-seria/0
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3544004
http://married.dike.gr/index.php/component/k2/itemlist/user/34494
http://danielmillsap.com/forum/index.php?topic=839253.0
http://danielmillsap.com/forum/index.php?topic=785533.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1227624
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1107369
http://teambuildingpremium.com/forum/index.php?topic=648214.0
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=41698
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2295015
http://hydrocarbs-gh.org/index.php/component/k2/itemlist/user/7277579
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/472630
https://members.fbhaters.com/index.php?topic=67242.0
http://danielmillsap.com/forum/index.php?topic=964999.0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/47232
http://forums.abs-cbn.com/welcome-back-kapamilya%21/ma-4-eo-7-e-aex-ma-4-eo-7-e-24-04-2019/?PHPSESSID=e9q8rfsb45gnrg7h73om4p04g6
http://fbpharm.net/index.php/component/k2/itemlist/user/9998
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1022434
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=477662
http://forums.abs-cbn.com/welcome-back-kapamilya%21/ootk-9-eo-13-k-oeootk-9-eo-13-k/
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=407916
http://teambuildingpremium.com/forum/index.php?topic=689931.0
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2393927
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=201442
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1108536
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pk0-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.deliberarchia.org/forum/index.php?topic=953993.0
https://www.blog.quora.healthcare/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nrf-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4
http://www.deliberarchia.org/forum/index.php?topic=930245.0
https://tg.vl-mp.com/index.php?topic=1305803.0
http://teambuildingpremium.com/forum/index.php?topic=656109.0
http://www.phan-aen.go.th/forum/index.php?topic=603248.0
http://www.x2145-productions.technology/index.php?title=%C2%AB%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%C2%BB_08-05-2019_%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F_%C2%AB%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%C2%BB&---------------------------1424979618991%0D%0AContent-Disposition:%20form-data;%20name=%22wpAntispam%22%0D%0A%0D%0A%0D%0A---------------------------1424979618991%0D%0AContent-Disposition:%20form-data;%20name=%22wpSection%22%0D%0A%0D%0A%0D%0A---------------------------1424979618991%0D%0AContent-Disposition:%20form-data;%20name=%22wpStarttime%22%0D%0A%0D%0A20190508180324%0D%0A---------------------------1424979618991%0D%0AContent-Disposition:%20form-data;%20name=%22wpEdittime%22%0D%0A%0D%0A20190508172305%0D%0A---------------------------1424979618991%0D%0AContent-Disposition:%20form-data;%20name=%22wpScrolltop%22%0D%0A%0D%0A%0D%0A---------------------------1424979618991%0D%0AContent-Disposition:%20form-data;%20name=%22wpAutoSummary%22%0D%0A%0D%0Ad41d8cd98f00b204e9800998ecf8427e%0D%0A---------------------------1424979618991%0D%0AContent-Disposition:%20form-data;%20name=%22oldid%22%0D%0A%0D%0A0%0D%0A---------------------------1424979618991%0D%0AContent-Disposition:%20form-data;%20name=%22format%22%0D%0A%0D%0Atext/x-wiki%0D%0A---------------------------1424979618991%0D%0AContent-Disposition:%20form-data;%20name=%22model%22%0D%0A%0D%0Awikitext%0D%0A---------------------------1424979618991%0D%0AContent-Disposition:%20form-data;%20name=%22wpTextbox1%22%0D%0A%0D%0Ahd1080%20%C2%AB%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%C2%BB%20%20ZVF;%20%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%3Cbr%3E%3Cbr%3E%3Cbr%3E%3Cbr%3E%3Cbr%3E[http://hdseriionline.ru/%20hdseriionline.ru]%3Cbr%3E%3Cbr%3E%3Cbr%3E%3Cbr%3E%3Cbr%3E%3Cbr%3E~~%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%20pin%60~%3Cbr%3E%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%20ojin%3Cbr%3E'%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%20hdfilms'%3Cbr%3E%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%20onlinefilmu%3Cbr%3E%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%20%D0%9A%D0%B8%D0%BD%D0%BE%D0%9F%D0%BB%D0%B0%D0%B9%3Cbr%3E%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%20hdfilms%3Cbr%3E%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%20%D0%BA%D1%84%3Cbr%3E%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%20onlinekinopokaz%3Cbr%3E%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%20%D0%BE%D0%BA%3Cbr%3E%60%60%60%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%20%D0%BA%D0%B8%D0%BD%D0%BE%D0%BC%D0%B0%D1%81%D1%81%D0%B0%60%60%60%3Cbr%3E%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%20%D0%BA%D0%B8%D0%BD%D0%BE%D0%BA%D1%80%D0%B0%D0%B4%3Cbr%3E%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%20%D0%BA%D0%B8%D0%BD%D0%BE%D1%84%D1%81%3Cbr%3E~~%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%20%D0%B2%D0%BA%60~%3Cbr%3E%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%20kinoo%3Cbr%3E%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%20%D1%82%D0%B2%D1%84%D1%80%D1%83%3Cbr%3E%C2%AB%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%20KinoBar%C2%BB%3Cbr%3E%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%20kinomassa%3Cbr%3E$$%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%20smotretfilmonline%3Cbr%3E%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%20%D0%9A%D0%B8%D0%BD%D0%BE%D0%A5%D0%BE%D0%BC%D0%B5%3Cbr%3E%22%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%20filmyonlain%22%3Cbr%3E%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%20onlinefilms%3Cbr%3E%D0%9F%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D1%8F%20kinorai%0D%0A---------------------------1424979618991%0D%0AContent-Disposition:%20form-data;%20name=%22wpSummary%22%0D%0A%0D%0A%0D%0A---------------------------1424979618991%0D%0AContent-Disposition:%20form-data;%20name=%22wpMinoredit%22%0D%0A%0D%0A1%0D%0A---------------------------1424979618991%0D%0AContent-Disposition:%20form-data;%20name=%22wpSave%22%0D%0A%0D%0ASeite%20speichern%0D%0A---------------------------1424979618991%0D%0AContent-Disposition:%20form-data;%20name=%22wpEditToken%22%0D%0A%0D%0A85baaeb003240a0976c814982cf926cc+::%0D%0A---------------------------1424979618991--
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=892521
http://healthyteethpa.org/component/k2/itemlist/user/5291671
https://tg.vl-mp.com/index.php?topic=1318605.0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4662552
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=40224
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1522365
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=236703
http://www.deliberarchia.org/forum/index.php?topic=897798.0
http://metropolis.ga/index.php?topic=1538.0
http://marjorieaperry.com/component/k2/itemlist/user/466536
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=458080
http://www.deliberarchia.org/forum/index.php?topic=918589.0
http://danielmillsap.com/forum/index.php?topic=903033.0
http://danielmillsap.com/forum/index.php?topic=803931.0
http://teambuildingpremium.com/forum/index.php?topic=629552.0
https://tg.vl-mp.com/index.php?topic=1260121.0
http://muratliziraatodasi.org/forum/index.php?topic=326185.0
http://seoksoononly.dothome.co.kr/qna/593974
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/21647
http://seoksoononly.dothome.co.kr/qna/473047
http://www.deliberarchia.org/forum/index.php?topic=968200.0
http://metropolis.ga/index.php?topic=2497.0
https://www.youngbiker.de/wbboard/index.php?page=User&userID=784593
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1687501
http://www.meikai.com.ar/foro/index.php?topic=48781.0
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1809201
https://tg.vl-mp.com/index.php?topic=1306770.0
http://withinfp.sakura.ne.jp/eso/index.php/16829378-voskressij-ertugrul-149-seria-q7kw-voskressij-ertugrul-149-seri
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ej1-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3453762
https://mcsetup.tk/bbs/index.php?topic=232049.0
http://dscardip.com/board/index.php?page=User&userID=654964
https://members.fbhaters.com/index.php?topic=72020.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=891703
http://withinfp.sakura.ne.jp/eso/index.php/16936154-voskressij-ertugrul-145-seria-k1kn-voskressij-ertugrul-145-seri/0
http://www.popolsku.fr.pl/forum/index.php?topic=352928.0
https://tg.vl-mp.com/index.php?topic=1326410.0
http://c3isecurity.com.br/component/k2/itemlist/user/470263
http://marjorieaperry.com/?option=com_k2&view=itemlist&task=user&id=466724
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1109134
https://www.swiss-focus.ch/index.php/component/k2/itemlist/user/9265
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1125318
http://seoksoononly.dothome.co.kr/qna/620811
https://forum.ac-jete.it/index.php?topic=285659.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=890123
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3194567
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/449647
http://www.tessabannampad.go.th/webboard/index.php?topic=188558.0
https://alkalua.com/?option=com_k2&view=itemlist&task=user&id=1254255
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=261437
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/60840
http://forum.thaibetrank.com/index.php?topic=1093331.0
http://pptforum.dothome.co.kr/board_APMk06/664773
http://macdistri.com/index.php/component/k2/itemlist/user/264518
http://myrechockey.com/forums/index.php?topic=81293.0
http://withinfp.sakura.ne.jp/eso/index.php/16856256-ertugrul-150-seria-nh0-ertugrul-150-seria/0
https://reficulcoin.com/index.php?topic=14930.0
http://dev.aabn.org.gh/component/k2/itemlist/user/513752
http://www.tessabannampad.go.th/webboard/index.php?topic=188069.0
http://married.dike.gr/index.php/component/k2/itemlist/user/43396
http://matrixpharm.ru/forum/index.php?action=profile&u=163444
http://bobr.site/index.php?topic=100104.0
http://blog.ptpintcast.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-q2-a7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://otitismediasociety.org/forum/index.php?topic=141577.0
https://reficulcoin.com/index.php?topic=15000.0
https://lucky28003.nl/forum/index.php?topic=7654.0
https://www.c-alice.org/forum/index.php?topic=71238.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=3e4520c098c7d88a7fc1a0a8d45bca85&topic=204146.0
http://menulisilmiah.net/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c3-n5-%d1%80%d0%b0%d1%81%d1%81/
http://teambuildingpremium.com/forum/index.php?topic=766661.0
http://www.tessabannampad.go.th/webboard/index.php?topic=187712.0
http://e-educ.net/Forum/index.php?topic=4633.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2555486
http://roikjer.com/forum/index.php?topic=817852.0
http://www.hoonthaitoday.com/forum/index.php?topic=196085.0
https://reficulcoin.com/index.php?topic=10016.0
http://necinsurance.co.zw/component/k2/itemlist/user/18648.html
http://multikopterforum.hu/index.php?topic=13073.0
http://help.stv.ru/index.php?PHPSESSID=3fecb33feaf1e21b600c821cb01026c0&topic=137701.0
http://forum.byehaj.hu/index.php?topic=77961.0
https://adsensebih.com/index.php?topic=10976.0
http://www.deliberarchia.org/forum/index.php?topic=941240.0
http://menulisilmiah.net/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-w7-x8-%d1%80/
http://myrechockey.com/forums/index.php?topic=83069.0
http://poselokgribovo.ru/forum/index.php?topic=698625.0
http://1vh.info/index.php?topic=12544.0
http://roikjer.com/forum/index.php?PHPSESSID=b9arpo72vp85r0p8eu0koa6275&topic=797639.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=596b813b56658b150722cd926680973c&topic=212271.0
https://lucky28003.nl/forum/index.php?topic=7915.0
http://poselokgribovo.ru/forum/index.php?topic=718586.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2506200
http://www.theocraticamerica.org/forum/index.php?topic=24651.0
http://HyUa.1fps.icu/l/szIaeDC
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3198664
https://www.youngbiker.de/wbboard/index.php?page=User&userID=774501
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1080754
https://members.fbhaters.com/index.php?topic=69330.0
http://poselokgribovo.ru/forum/index.php?topic=622163.0
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=13687
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3705098
http://www.glasshouseproject.com.ng/index.php/component/k2/itemlist/user/38966
http://webp.online/index.php?topic=45192.0
http://maderadepaulownia.com/component/k2/itemlist/user/83651
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4666371
http://www.phan-aen.go.th/forum/index.php?topic=608617.0
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wo8-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8/
https://tg.vl-mp.com/index.php?topic=1263679.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/267590
http://aitour.kz/?option=com_k2&view=itemlist&task=user&id=322672
https://prosocyr.com/?option=com_k2&view=itemlist&task=user&id=609476
http://tradebest.org/?document_srl=1572804
http://married.dike.gr/index.php/component/k2/itemlist/user/42178
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/444904
http://www.m1avio.com/?option=com_k2&view=itemlist&task=user&id=3497942
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sp7-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-5-%d1%81%d0%b5%d1%80%d0%b8/
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=45836
https://members.fbhaters.com/index.php/topic,63789.0.html
http://danielmillsap.com/forum/index.php?topic=813720.0
https://www.blog.quora.healthcare/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-s2jk-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-13-%d1%81%d0%b5%d1%80%d0%b8
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/395320
http://menulisilmiah.net/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-23-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dc6-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-23-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://healthyteethpa.org/?option=com_k2&view=itemlist&task=user&id=5288209
https://members.fbhaters.com/index.php?topic=62741.0
http://discussadeal.com/forum/index.php?topic=3516.0
http://www.tessabannampad.go.th/webboard/index.php?topic=189935.0
https://www.youngbiker.de/wbboard/index.php?page=User&userID=782197
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1004236
http://muratliziraatodasi.org/forum/index.php?topic=333556.0
https://mcsetup.tk/bbs/index.php?topic=230468.0
https://instaldec.com/?option=com_k2&view=itemlist&task=user&id=609449
http://www.phan-aen.go.th/forum/index.php?topic=608444.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/et-e-12-e-czet-e-12-e/?PHPSESSID=07jm6dt0sv93tu1c8373e13vq7
http://koushatarabar.com/index.php/component/k2/itemlist/user/1313916
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=45867
http://c3isecurity.com.br/?option=com_k2&view=itemlist&task=user&id=366027
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1842507
http://danielmillsap.com/forum/index.php?topic=799021.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=601588.0
http://married.dike.gr/index.php/component/k2/itemlist/user/37588
http://danielmillsap.com/forum/index.php?topic=817454.0
http://withinfp.sakura.ne.jp/eso/index.php/16828784-vossoedinenie-vuslat-17-seria-x3jh-vossoedinenie-vuslat-17-seri/0
https://www.resproxy.com/forum/index.php/736095-vetrenyj-hercai-6-seria-k9we-vetrenyj-hercai-6-seria/0
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=37713
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2384907
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/367579
https://www.shaiyax.com/index.php?topic=307218.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-krr-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://marasebrarrentacar.com/?option=com_k2&view=itemlist&task=user&id=749778
http://danielmillsap.com/forum/index.php?topic=807272.0
https://www.resproxy.com/forum/index.php/778129-igra-prestolov-8-sezon-1-seria-ukq-igra-prestolov-8-sezon-1-ser/0
http://discussadeal.com/forum/index.php/topic,1856.0.html
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1128091
http://www.deliberarchia.org/forum/index.php?topic=920923.0
http://dessa.com.br/index.php/component/k2/itemlist/user/306619
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=871248
http://metropolis.ga/index.php?topic=5126.0
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4702799
http://www.oortsociety.com/index.php?topic=8870.0
http://sdsn.develop.cinfores.com/?option=com_k2&view=itemlist&task=user&id=141397
https://mcsetup.tk/bbs/index.php?topic=231179.0
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1553513
https://members.fbhaters.com/index.php?topic=67700.0
https://mcsetup.tk/bbs/index.php?topic=232901.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/138572
http://www.siirtorganik.com/index.php/component/k2/itemlist/user/649556
https://instaldec.com/index.php/component/k2/itemlist/user/572230
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3196777
http://teambuildingpremium.com/forum/index.php?topic=627513.0
http://menulisilmiah.net/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kk5-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1078648
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1098841
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1126716
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81-10/
https://www.blog.quora.healthcare/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vkw-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4
http://macdistri.com/?option=com_k2&view=itemlist&task=user&id=284561
http://www.popolsku.fr.pl/forum/index.php?topic=340086.0
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7306964
http://withinfp.sakura.ne.jp/eso/index.php/16844007-voskressij-ertugrul-149-seria-r9sx-voskressij-ertugrul-149-seri/0
https://tg.vl-mp.com/index.php?topic=1352327.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3464585
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=559756
http://www.x2145-productions.technology/index.php?title=%C2%AB%D0%A5%D0%BE%D0%BB%D0%BE%D0%B4%D0%BD%D0%BE%D0%B5_%D0%A1%D0%B5%D1%80%D0%B4%D1%86%D0%B5_2_2019_%C2%BB_08-05-2019_%C2%AB%D0%A5%D0%BE%D0%BB%D0%BE%D0%B4%D0%BD%D0%BE%D0%B5_%D0%A1%D0%B5%D1%80%D0%B4%D1%86%D0%B5_2_2019_Watch%C2%BB_%C2%AB%D0%A5%D0%BE%D0%BB%D0%BE%D0%B4%D0%BD%D0%BE%D0%B5_%D0%A1%D0%B5%D1%80%D0%B4%D1%86%D0%B5_2_2019_%C2%BB
http://menulisilmiah.net/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hzr-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
http://avengerro.top/forum/index.php?topic=13387.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=284587
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1111042
http://teambuildingpremium.com/forum/index.php?topic=648300.0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=40621
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3312007
http://menulisilmiah.net/%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5%d0%bd%d0%b8%d0%b5-vuslat-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w7xu-%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd/
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81-15/
http://married.dike.gr/index.php/component/k2/itemlist/user/26617
http://healthyteethpa.org/component/k2/itemlist/user/5336174
http://www.deliberarchia.org/forum/index.php?topic=965332.0
https://www.youngbiker.de/wbboard/index.php?page=User&userID=785273
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=77857
https://www.resproxy.com/forum/index.php/757304-rasskaz-sluzanki-3-sezon-4-seria-uno-rasskaz-sluzanki-3-sezon-4/0
http://www.spazioad.com/component/k2/itemlist/user/7204293
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1472694
http://teambuildingpremium.com/forum/index.php?topic=645517.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/et-e-14-e-flet-e-14-e/?PHPSESSID=50hl2vtp55bbjhrknd927r4q92
http://teambuildingpremium.com/forum/index.php?topic=665489.0
http://153.120.114.241/eso/index.php/16861626-lubov-smert-i-roboty-love-death-and-robots-16-seria-sps-lubov-s
http://www.crnmedia.es/component/k2/itemlist/user/81254
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=597126.0
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/196883
http://www.oortsociety.com/index.php?topic=9009.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/ma-4-eo-7-e-sum-ma-4-eo-7-e-23-04-2019/?PHPSESSID=bh34gki6vqtsrrigb4hanr8p27
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=592984.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/475565
http://forums.abs-cbn.com/welcome-back-kapamilya%21/et-e-7-e-zget-e-7-e/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1248265
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1608960
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yz4-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
https://www.resproxy.com/forum/index.php/766124-cernoe-zerkalo-5-sezon-5-seria-blf-cernoe-zerkalo-5-sezon-5-ser/0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2410310
https://www.youngbiker.de/wbboard/index.php?page=User&userID=781924
http://myrechockey.com/forums/index.php?topic=85527.0
http://metropolis.ga/index.php?topic=3066.0
http://www.web2interactive.com/index.php/component/k2/itemlist/user/3583818
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/61992
http://www.popolsku.fr.pl/forum/index.php?topic=352023.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ryk-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://153.120.114.241/eso/index.php/16867968-igra-prestolov-8-sezon-2-seria-uqh-igra-prestolov-8-sezon-2-ser
http://danielmillsap.com/forum/index.php?topic=834970.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/555874
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=520660
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=890454
http://forum.thaibetrank.com/index.php?topic=1083378.0
http://www.deliberarchia.org/forum/index.php?topic=940309.0
https://ne-kuru.ru/index.php?topic=203482.0
http://danielmillsap.com/forum/index.php?topic=805719.0
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1456321
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1103406
http://teambuildingpremium.com/forum/index.php?topic=662650.0
http://pptforum.dothome.co.kr/board_APMk06/616446
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3196710
http://www.glasshouseproject.com.ng/index.php/component/k2/itemlist/user/39145
http://danielmillsap.com/forum/index.php?topic=802660.0
http://www.deliberarchia.org/forum/index.php?topic=923274.0
http://seoksoononly.dothome.co.kr/qna/461489
http://web2interactive.com/index.php/component/k2/itemlist/user/3525602
https://www.blog.quora.healthcare/%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80%d0%b4%d1%86%d0%b5-tek-yurek-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e9md-%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80
https://members.fbhaters.com/index.php?topic=69503.0
https://www.youngbiker.de/wbboard/index.php?page=User&userID=784920
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1472333
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=25597
http://withinfp.sakura.ne.jp/eso/index.php/16937427-rannaa-ptaska-erkenci-kus-38-seria-x6mr-rannaa-ptaska-erkenci-k/0
https://instaldec.com/?option=com_k2&view=itemlist&task=user&id=608514
http://teambuildingpremium.com/forum/index.php?topic=657766.0
http://www.phan-aen.go.th/forum/index.php?topic=607827.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2528887
http://www.m1avio.com/index.php/component/k2/itemlist/user/3566581
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/21970
http://www.deliberarchia.org/forum/index.php?topic=762165.0
http://seoksoononly.dothome.co.kr/qna/464032
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/110505
http://www.deliberarchia.org/forum/index.php?topic=973861.0
https://tg.vl-mp.com/index.php?topic=1304344.0
http://webp.online/index.php?topic=41579.0
http://mediaville.me/index.php/component/k2/itemlist/user/193578
https://www.resproxy.com/forum/index.php/755521-milliardy-4-sezon-5-seria-zrd-milliardy-4-sezon-5-seria-0405201/0
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1550913
http://seoksoononly.dothome.co.kr/qna/423905
https://mcsetup.tk/bbs/index.php?topic=227465.0
https://www.resproxy.com/forum/index.php/790146-nasledie-13-seria-onh-nasledie-13-seria/0
http://healthyteethpa.org/component/k2/itemlist/user/5190324
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1325978
http://www.m1avio.com/?option=com_k2&view=itemlist&task=user&id=3467891
http://menulisilmiah.net/%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-69-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z4ls-%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-69/
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4614011
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3187096
http://www.deliberarchia.org/forum/index.php?topic=983259.0
https://sto54.ru/index.php/component/k2/itemlist/user/3194239
http://www.phan-aen.go.th/forum/index.php?topic=609167.0
http://www.deliberarchia.org/forum/index.php?topic=930326.0
http://www.popolsku.fr.pl/forum/index.php?topic=341856.0
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ql6-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19/
http://dev.fivestarpainting.com/?option=com_k2&view=itemlist&task=user&id=1776085
http://webp.online/index.php?topic=41986.0
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=670517
http://associationsila.org/component/k2/itemlist/user/271378
http://www.deliberarchia.org/forum/index.php?topic=910501.0
http://www.popolsku.fr.pl/forum/index.php?topic=341367.0
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/529735
https://instaldec.com/?option=com_k2&view=itemlist&task=user&id=608578
http://www.deliberarchia.org/forum/index.php?topic=955978.0
http://www.popolsku.fr.pl/forum/index.php?topic=338781.0
https://lucky28003.nl/forum/index.php?topic=6629.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1335338
http://danielmillsap.com/forum/index.php?topic=847257.0
http://dev.aabn.org.gh/component/k2/itemlist/user/516882
https://tg.vl-mp.com/index.php?topic=1268784.0
https://www.resproxy.com/forum/index.php/764802-cernoe-zerkalo-5-sezon-2-seria-xsl-cernoe-zerkalo-5-sezon-2-ser/0
http://danielmillsap.com/forum/index.php?topic=784967.0
http://tradebest.org/board_MdUI61/1555841
http://metropolis.ga/index.php?topic=1508.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3301328
http://www.tessabannampad.go.th/webboard/index.php?topic=192586.0
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1588809
https://www.blog.quora.healthcare/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u7yh-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8
https://tg.vl-mp.com/index.php?topic=1260143.0
http://www.deliberarchia.org/forum/index.php?topic=916975.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2550448
http://teambuildingpremium.com/forum/index.php?topic=688929.0
http://withinfp.sakura.ne.jp/eso/index.php/16770589-lubov-smert-i-roboty-love-death-and-robots-14-seria-gkv-lubov-s/0
http://e-educ.net/Forum/index.php?topic=4187.0
https://tg.vl-mp.com/index.php?topic=1308853.0
https://nextezone.com/index.php?action=profile;u=2391
http://istakam.com/forum/index.php?topic=8783.0
http://webp.online/index.php?topic=51163.0
https://worldtaxi.org/2019/05/08/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d4-u1-%d0%b8%d0%b3%d1%80%d0%b0/
http://roikjer.com/forum/index.php?topic=797480.0
http://istakam.com/forum/index.php?topic=8610.0
http://freebeer.me/index.php?topic=288190.0
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-u4-t2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://myrechockey.com/forums/index.php?topic=83356.0
http://sextomariotienda.com/blog/%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u7-%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5/
http://forum.kopkargobel.com/index.php?topic=3351.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=25200.0
http://otitismediasociety.org/forum/index.php?topic=147451.0
http://roikjer.com/forum/index.php?PHPSESSID=n6vgi96tqfkrjpfn6tbuc7o0h1&topic=796883.0
http://roikjer.com/forum/index.php?topic=817847.0
http://forum.bmw-e60.eu/index.php?topic=3316.0
http://muratliziraatodasi.org/forum/index.php?topic=407705.0
https://reficulcoin.com/index.php?topic=13158.0
http://otitismediasociety.org/forum/index.php?topic=146919.0
https://reficulcoin.com/index.php?topic=12875.0
http://web2interactive.com/index.php/component/k2/itemlist/user/3559328
http://myrechockey.com/forums/index.php?topic=89667.0
http://otitismediasociety.org/forum/index.php?topic=144047.0
http://dpmarketingsystems.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i1-c2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://freebeer.me/index.php?topic=293920.0
http://flashboot.ru/forum/index.php?topic=94533.0
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v0-e0-%d1%80%d0%b0%d1%81%d1%81/
http://bobr.site/index.php?topic=89658.0
http://eugeniocolazzo.it/forum/index.php?topic=83714.0
http://menulisilmiah.net/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i4-c0-%d1%80%d0%b0%d1%81%d1%81/
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=185956
http://ru-realty.com/forum/index.php?PHPSESSID=0ai8ug85so57ktsklf3gss63d5&topic=448774.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-(got)-8-eo-4-e-as1-a-etoo-(got)-8-eo-4-e-watch/
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=678532.0
http://forum.politeknikgihon.ac.id/index.php?topic=18237.0
http://mir3sea.com/forum/index.php?topic=1079.0
http://poselokgribovo.ru/forum/index.php?topic=694076.0
http://thanosakademi.com/index.php?topic=66913.0
http://www.popolsku.fr.pl/forum/index.php?topic=20407.54030
http://otitismediasociety.org/forum/index.php?topic=142881.0
http://myrechockey.com/forums/index.php?topic=82283.0
http://poselokgribovo.ru/forum/index.php?topic=720397.0
http://multikopterforum.hu/index.php?topic=6635.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/247060
http://withinfp.sakura.ne.jp/eso/index.php/16801028-zensina-58-seria-i6pq-zensina-58-seria
http://www.glasshouseproject.com.ng/index.php/component/k2/itemlist/user/43012
https://tg.vl-mp.com/index.php?topic=1264819.0
http://menulisilmiah.net/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-79-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x0ir-%d0%bd%d0%b5%d0%b2/
http://teambuildingpremium.com/forum/index.php?topic=665779.0
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4732425
https://www.blog.quora.healthcare/%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80%d0%b4%d1%86%d0%b5-tek-yurek-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j2ww-%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80
https://members.fbhaters.com/index.php?topic=64886.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/176941
http://metropolis.ga/index.php?topic=4938.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889873
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3286712
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/257469
http://danielmillsap.com/forum/index.php?topic=890374.0
https://www.youngbiker.de/wbboard/index.php?page=User&userID=784916
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=300671
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hbf-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.deliberarchia.org/forum/index.php?topic=939893.0
http://sam-sanat.ir/?option=com_k2&view=itemlist&task=user&id=137464
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=22627
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/104601
http://www.spazioad.com/component/k2/itemlist/user/7200051
https://tg.vl-mp.com/index.php?topic=1305531.0
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1630834
http://www.phan-aen.go.th/forum/index.php?topic=611227.0
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1791259
http://danielmillsap.com/forum/index.php?topic=919742.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1078089
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1132648
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2130300
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=497479
http://malbeot.iptime.org:10009/xe/board/3831833
http://married.dike.gr/index.php/component/k2/itemlist/user/25821
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zly-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/448035
https://www.resproxy.com/forum/index.php/765648-milliardy-4-sezon-13-seria-ssx-milliardy-4-sezon-13-seria/0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/312674
http://www.m1avio.com/index.php/component/k2/itemlist/user/3553839
https://tg.vl-mp.com/index.php?topic=1346240.0
https://tg.vl-mp.com/index.php?topic=1273714.0
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=77294
http://withinfp.sakura.ne.jp/eso/index.php/16770365-rasskaz-sluzanki-3-sezon-2-seria-ejh-rasskaz-sluzanki-3-sezon-2/0
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=39630
https://www.blog.quora.healthcare/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sav-%d1%80%d0%b0
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1526095
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=38031
http://danielmillsap.com/forum/index.php?topic=816571.0
https://tg.vl-mp.com/index.php?topic=1255252.0
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3313508
http://seoksoononly.dothome.co.kr/qna/441604
http://www.popolsku.fr.pl/forum/index.php?topic=346948.0
http://dev.aabn.org.gh/component/k2/itemlist/user/520157
http://married.dike.gr/index.php/component/k2/itemlist/user/34036
http://withinfp.sakura.ne.jp/eso/index.php/16781707-zensina-58-seria-o4kf-zensina-58-seria/0
http://153.120.114.241/eso/index.php/16879203-cernoe-zerkalo-5-sezon-3-seria-tsy-cernoe-zerkalo-5-sezon-3-ser
https://prosocyr.com/?option=com_k2&view=itemlist&task=user&id=600574
http://danielmillsap.com/forum/index.php?topic=832113.0
https://tg.vl-mp.com/index.php?topic=1284810.0
https://members.fbhaters.com/index.php?topic=63276.0
https://www.resproxy.com/forum/index.php/732132-riverdejl-riverdale-3-sezon-20-seria-kbn-riverdejl-riverdale-3-/0
http://www.deliberarchia.org/forum/index.php?topic=960295.0
http://seoksoononly.dothome.co.kr/qna/368212
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=697963
http://forums.abs-cbn.com/welcome-back-kapamilya%21/ma-4-eo-8-e-ghb-ma-4-eo-8-e-24-04-2019/?PHPSESSID=mcs33t2h8b6qlda725e0fn5mq7
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=42733
https://mcsetup.tk/bbs/index.php?topic=223858.0
http://poselokgribovo.ru/forum/index.php?topic=614933.0
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1636837
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1037106
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2388899
https://www.youngbiker.de/wbboard/index.php?page=User&userID=782479
http://macdistri.com/index.php/component/k2/itemlist/user/260311
http://withinfp.sakura.ne.jp/eso/index.php/16825621-vossoedinenie-vuslat-20-seria-d9hi-vossoedinenie-vuslat-20-seri
http://danielmillsap.com/forum/index.php?topic=828289.0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=36757
http://married.dike.gr/index.php/component/k2/itemlist/user/22666
http://healthyteethpa.org/component/k2/itemlist/user/5279864
http://proxima.co.rw/index.php/component/k2/itemlist/user/501089
http://israengineering.com/index.php/component/k2/itemlist/user/1085625
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/40639
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=582551.0
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3683398
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=606707
https://www.youngbiker.de/wbboard/index.php?page=User&userID=784622
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1524398
http://teambuildingpremium.com/forum/index.php?topic=666124.0
http://teambuildingpremium.com/forum/index.php?topic=677827.0
https://members.fbhaters.com/index.php?topic=81262.0
http://www.deliberarchia.org/forum/index.php?topic=787631.0
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=915020
http://danielmillsap.com/forum/index.php?topic=905935.0
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1473988
http://www.arunagreen.com/index.php/component/k2/itemlist/user/376424
http://discussadeal.com/forum/index.php?topic=4582.0
http://www.quattroandpartners.it/component/k2/itemlist/user/1063558
http://smartacity.com/component/k2/itemlist/user/19441
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1526120
http://webp.online/index.php?topic=45011.0
http://www.deliberarchia.org/forum/index.php?topic=857423.0
http://seoksoononly.dothome.co.kr/qna/368363
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1226698
https://www.resproxy.com/forum/index.php/796989-edinoe-serdce-tek-yurek-14-seria-d4ox-edinoe-serdce-tek-yurek-1/0
http://discussadeal.com/forum/index.php/topic,4594.0.html
http://danielmillsap.com/forum/index.php?topic=888963.0
http://www.glasshouseproject.com.ng/index.php/component/k2/itemlist/user/41764
http://tradebest.org/board_MdUI61/1565454
http://dcasociados.eu/component/k2/itemlist/user/81426
https://www.resproxy.com/forum/index.php/788600-manifest-17-seria-xiw-manifest-17-seria/0
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1552741
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hkw-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://lucky28003.nl/forum/index.php?topic=8213.0
http://macdistri.com/index.php/component/k2/itemlist/user/219942
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=295715
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=873947
http://withinfp.sakura.ne.jp/eso/index.php/16825161-edinoe-serdce-tek-yurek-11-seria-a7jl-edinoe-serdce-tek-yurek-1
https://www.resproxy.com/forum/index.php/779624-rannaa-ptaska-erkenci-kus-37-seria-x9fb-rannaa-ptaska-erkenci-k/0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=874172
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=300288
https://tg.vl-mp.com/index.php?topic=1272967.0
http://withinfp.sakura.ne.jp/eso/index.php/16884059-nasa-istoria-72-seria-r5kp-nasa-istoria-72-seria/0
http://danielmillsap.com/forum/index.php?topic=829918.0
http://teambuildingpremium.com/forum/index.php?topic=650912.0
http://dessa.com.br/component/k2/itemlist/user/296454
http://danielmillsap.com/forum/index.php?topic=819093.0
http://danielmillsap.com/forum/index.php?topic=945626.0
http://teambuildingpremium.com/forum/index.php?topic=608497.0
https://tg.vl-mp.com/index.php?topic=1274890.0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=293126
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1095448
http://seoksoononly.dothome.co.kr/qna/471433
http://www.deliberarchia.org/forum/index.php?topic=918697.0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/44719
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1130523
http://withinfp.sakura.ne.jp/eso/index.php/16897542-edinoe-serdce-tek-yurek-15-seria-b5wn-edinoe-serdce-tek-yurek-1
http://153.120.114.241/eso/index.php/16880716-rasskaz-sluzanki-3-sezon-2-seria-knn-rasskaz-sluzanki-3-sezon-2
http://yogakiddoswithgaileee.com/index.php?title=%C2%AB%D0%91%D0%BE%D0%BB%D1%8C%D1%88%D0%BE%D0%B5_%D0%9F%D1%83%D1%82%D0%B5%D1%88%D0%B5%D1%81%D1%82%D0%B2%D0%B8%D0%B5%C2%BB_07-05-2019_%C2%AB%D0%91%D0%BE%D0%BB%D1%8C%D1%88%D0%BE%D0%B5_%D0%9F%D1%83%D1%82%D0%B5%D1%88%D0%B5%D1%81%D1%82%D0%B2%D0%B8%D0%B5%C2%BB_%C2%AB%D0%91%D0%BE%D0%BB%D1%8C%D1%88%D0%BE%D0%B5_%D0%9F%D1%83%D1%82%D0%B5%D1%88%D0%B5%D1%81%D1%82%D0%B2%D0%B8%D0%B5%C2%BB
https://www.blog.quora.healthcare/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90sd%e3%80%91%d1%81%d0%bb%d1%83%d0%b3%d0%b0
http://www.glasshouseproject.com.ng/index.php/component/k2/itemlist/user/39257
http://withinfp.sakura.ne.jp/eso/index.php/16799084-ne-otpuskaj-mou-ruku-elimi-birakma-42-seria-l1ek-ne-otpuskaj-mo/0
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1828315
http://www.phan-aen.go.th/forum/index.php?topic=612357.0
https://prosocyr.com/?option=com_k2&view=itemlist&task=user&id=599934
http://teambuildingpremium.com/forum/index.php?topic=600049.0
http://www.deliberarchia.org/forum/index.php?topic=962772.0
http://www.deliberarchia.org/forum/index.php?topic=911648.0
http://myrechockey.com/forums/index.php?topic=84535.0
https://lucky28003.nl/forum/index.php?topic=9963.0
http://discussadeal.com/forum/index.php?topic=4557.0
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1766933
http://danielmillsap.com/forum/index.php?topic=832077.0
http://batubersurat.com/index.php/component/k2/itemlist/user/38681
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ief-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://seoksoononly.dothome.co.kr/qna/589390
http://www.deliberarchia.org/forum/index.php?topic=902483.0
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=237834
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=51826
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=290956
http://healthyteethpa.org/component/k2/itemlist/user/5299119
http://pptforum.dothome.co.kr/board_APMk06/700778
http://danielmillsap.com/forum/index.php?topic=909053.0
http://www.glasshouseproject.com.ng/index.php/component/k2/itemlist/user/38798
http://poselokgribovo.ru/forum/index.php?topic=615023.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/369894
http://macdistri.com/?option=com_k2&view=itemlist&task=user&id=203523
http://associationsila.org/index.php/component/k2/itemlist/user/283262
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lba-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://www.deliberarchia.org/forum/index.php?topic=969080.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/aka-ak-3-eo-5-e-svo-aka-ak-3-eo-5-e-23-04-2019/
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/247284
https://tg.vl-mp.com/index.php?topic=1260627.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xir-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1226295
https://www.shaiyax.com/index.php?topic=314762.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1113337
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=873377
https://mcsetup.tk/bbs/index.php?topic=230312.0
http://withinfp.sakura.ne.jp/eso/index.php/16907259-vetrenyj-hercai-6-seria-t2qj-vetrenyj-hercai-6-seria
https://tg.vl-mp.com/index.php?topic=1332312.0
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1094964
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=707005
http://mobility-corp.com/index.php/component/k2/itemlist/user/2475519
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-og5-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1957106
http://www.deliberarchia.org/forum/index.php?topic=934716.0
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wa7-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10/
http://danielmillsap.com/forum/index.php?topic=842929.0
https://www.blog.quora.healthcare/%d0%b6%d0%b5%d0%bd%d1%89%d0%b8%d0%bd%d0%b0-58-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v1yd-%d0%b6%d0%b5%d0%bd%d1%89%d0%b8%d0%bd%d0%b0-58-%d1%81%d0%b5%d1%80%d0%b8%d1%8f
http://danielmillsap.com/forum/index.php?topic=875345.0
http://withinfp.sakura.ne.jp/eso/index.php/16858943-edinoe-serdce-tek-yurek-12-seria-q0ze-edinoe-serdce-tek-yurek-1/0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/255641
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1243217
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1095773
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=401618
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1835576
https://tg.vl-mp.com/index.php?topic=1283223.0
http://www.deliberarchia.org/forum/index.php?topic=970700.0
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1470137
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=266627
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1354476
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1084606
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=261803
http://www.deliberarchia.org/forum/index.php?topic=938600.0
http://menulisilmiah.net/%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80%d0%b4%d1%86%d0%b5-tek-yurek-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r3qd-%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80/
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1036506
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cu6-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://withinfp.sakura.ne.jp/eso/index.php/16838413-edinoe-serdce-tek-yurek-10-seria-h5jb-edinoe-serdce-tek-yurek-1
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=300959
http://danielmillsap.com/forum/index.php?topic=894479.0
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=8714
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=380206
http://www.arunagreen.com/index.php/component/k2/itemlist/user/320529
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4701694
http://withinfp.sakura.ne.jp/eso/index.php/16818862-vetrenyj-hercai-21-seria-q8vb-vetrenyj-hercai-21-seria/0
http://thermoplast.envolgroupe.com/component/k2/author/69823
https://www.youngbiker.de/wbboard/index.php?page=User&userID=781740
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=29496
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ob1-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14/
http://healthyteethpa.org/component/k2/itemlist/user/5229744
http://www.popolsku.fr.pl/forum/index.php?topic=355423.0
https://mcsetup.tk/bbs/index.php?topic=226671.0
http://tradebest.org/board_MdUI61/1553844
http://macdistri.com/index.php/component/k2/itemlist/user/201658
https://www.resproxy.com/forum/index.php/762408-milliardy-4-sezon-13-seria-ifl-milliardy-4-sezon-13-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/16779883-milliardy-4-sezon-6-seria-blk-milliardy-4-sezon-6-seria-0105201
http://avengerro.top/forum/index.php?topic=17599.0
http://danielmillsap.com/forum/index.php?topic=826086.0
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=409728
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3546334
http://www.tessabannampad.go.th/webboard/index.php?topic=190165.0
https://www.youngbiker.de/wbboard/index.php?page=User&userID=784190
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=674765
http://seoksoononly.dothome.co.kr/qna/613258
https://mcsetup.tk/bbs/index.php?topic=225104.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1021416
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=891956
http://www.m1avio.com/index.php/component/k2/itemlist/user/3563542
http://metropolis.ga/index.php?topic=3612.0
https://tg.vl-mp.com/index.php?topic=1276969.0
http://www.popolsku.fr.pl/forum/index.php?topic=342756.0
http://www.deliberarchia.org/forum/index.php?topic=964719.0
http://seoksoononly.dothome.co.kr/qna/363732
http://www.phan-aen.go.th/forum/index.php?topic=611631.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=894659
http://dscardip.com/board/index.php?page=User&userID=657795
https://www.resproxy.com/forum/index.php/744803-edinoe-serdce-tek-yurek-9-seria-k4mv-edinoe-serdce-tek-yurek-9-
http://www.deliberarchia.org/forum/index.php?topic=966707.0
http://teambuildingpremium.com/forum/index.php?topic=686090.0
http://danielmillsap.com/forum/index.php?topic=802907.0
http://danielmillsap.com/forum/index.php?topic=805873.0
https://www.blog.quora.healthcare/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bdd-%d1%80%d0%b0
http://married.dike.gr/index.php/component/k2/itemlist/user/44512
http://www.deliberarchia.org/forum/index.php?topic=788742.0
http://www.deliberarchia.org/forum/index.php?topic=786375.0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/14250
https://www.youngbiker.de/wbboard/index.php?page=User&userID=784910
http://danielmillsap.com/forum/index.php?topic=964538.0
https://www.wikisexguide.com/wiki/%C2%AB%D0%9F%D1%80%D0%BE%D0%BA%D0%BB%D1%8F%D1%82%D0%B8%D0%B5_%D0%9F%D0%BB%D0%B0%D1%87%D1%83%D1%89%D0%B5%D0%B9%C2%BB_06-05-2019_%C2%AB%D0%9F%D1%80%D0%BE%D0%BA%D0%BB%D1%8F%D1%82%D0%B8%D0%B5_%D0%9F%D0%BB%D0%B0%D1%87%D1%83%D1%89%D0%B5%D0%B9%C2%BB_%C2%AB%D0%9F%D1%80%D0%BE%D0%BA%D0%BB%D1%8F%D1%82%D0%B8%D0%B5_%D0%9F%D0%BB%D0%B0%D1%87%D1%83%D1%89%D0%B5%D0%B9%C2%BB
http://muratliziraatodasi.org/forum/index.php?topic=368324.0
https://mcsetup.tk/bbs/index.php?topic=222149.0
http://forum.thaibetrank.com/index.php?topic=1089969.0
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/51909
http://proxima.co.rw/index.php/component/k2/itemlist/user/558006
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=38647
http://withinfp.sakura.ne.jp/eso/index.php/16896885-vetrenyj-hercai-12-seria-h4je-vetrenyj-hercai-12-seria/0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/171564
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=579517.0
http://www.deliberarchia.org/forum/index.php?topic=799733.0
http://www.deliberarchia.org/forum/index.php?topic=935028.0
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=492140
http://danielmillsap.com/forum/index.php?topic=889058.0
http://teambuildingpremium.com/forum/index.php?topic=686809.0
https://www.blog.quora.healthcare/%d1%81%d0%be%d0%b4%d0%b5%d1%80%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90rg%e3%80%91%d1%81%d0%be%d0%b4%d0%b5%d1%80%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-9-%d1%81%d0%b5
http://www.glasshouseproject.com.ng/index.php/component/k2/itemlist/user/38874
http://avengerro.top/forum/index.php?topic=10054.0
http://rudraautomation.com/index.php/component/k2/author/109746
http://teambuildingpremium.com/forum/index.php?topic=687576.0
http://www.spazioad.com/?option=com_k2&view=itemlist&task=user&id=7206933
http://married.dike.gr/index.php/component/k2/itemlist/user/41717
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1126496
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/435975
http://mobility-corp.com/index.php/component/k2/itemlist/user/2480191
https://www.resproxy.com/forum/index.php/764826-igra-prestolov-8-sezon-1-seria-njv-igra-prestolov-8-sezon-1-ser
http://www.deliberarchia.org/forum/index.php?topic=974235.0
http://dcasociados.eu/component/k2/itemlist/user/82022
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4610732
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1317058
http://discussadeal.com/forum/index.php?topic=2262.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/453278
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=872140
http://www.arunagreen.com/index.php/component/k2/itemlist/user/383612
http://www.sollazzorefrigerazione.it/?option=com_k2&view=itemlist&task=user&id=2392251
http://minostech.co.kr/news/3357570
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2389197
http://teambuildingpremium.com/forum/index.php?topic=602012.0
http://withinfp.sakura.ne.jp/eso/index.php/16788539-milliardy-4-sezon-9-seria-yrl-milliardy-4-sezon-9-seria-0205201/0
http://macdistri.com/index.php/component/k2/itemlist/user/262380
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/51201
http://teambuildingpremium.com/forum/index.php?topic=692252.0
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1711747
http://www.popolsku.fr.pl/forum/index.php?topic=329430.0
https://www.resproxy.com/forum/index.php/737587-igra-prestolov-8-sezon-7-seria-spc-igra-prestolov-8-sezon-7-ser/0
http://153.120.114.241/eso/index.php/16871167-lubov-smert-i-roboty-love-death-and-robots-14-seria-tvm-lubov-s
http://webp.online/index.php?topic=41561.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/170915
http://married.dike.gr/index.php/component/k2/itemlist/user/35079
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=237334
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1257449
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=44170
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1828285
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=890513
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=874266
http://danielmillsap.com/forum/index.php?topic=824986.0
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=910645
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1116135
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1108681
https://tg.vl-mp.com/index.php?topic=1278780.0
http://mediaville.me/index.php/component/k2/itemlist/user/209482
http://teambuildingpremium.com/forum/index.php?topic=654348.0
http://www.tessabannampad.go.th/webboard/index.php?topic=194692.0
http://teambuildingpremium.com/forum/index.php?topic=599886.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3572683
http://withinfp.sakura.ne.jp/eso/index.php/16885246-edinoe-serdce-tek-yurek-19-seria-h1se-edinoe-serdce-tek-yurek-1/0
http://mvisage.sk/?option=com_k2&view=itemlist&task=user&id=116281
http://withinfp.sakura.ne.jp/eso/index.php/16856839-lubov-smert-i-roboty-love-death-and-robots-12-seria-igl-lubov-s
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4732032
http://www2.yasothon.go.th/smf/index.php?topic=159.127350
http://www.popolsku.fr.pl/forum/index.php?topic=342641.0
http://withinfp.sakura.ne.jp/eso/index.php/16792196-milliardy-4-sezon-10-seria-axe-milliardy-4-sezon-10-seria/0
http://teambuildingpremium.com/forum/index.php?topic=679508.0
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/517175
http://www.hoonthaitoday.com/forum/index.php?topic=202932.0
http://www.popolsku.fr.pl/forum/index.php?topic=376709.0
http://www.theparrotcentre.com/forum/index.php?topic=483703.0
http://www2.yasothon.go.th/smf/index.php?topic=159.158385
http://roikjer.com/forum/index.php?topic=762945.0
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-puk-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://mobility-corp.com/index.php/component/k2/itemlist/user/2487760
http://universaldrive-s.cba.pl/index.php?PHPSESSID=a2e9f8544fa743a0a5a7c8d200847f52&topic=17757.0
http://thefreebitcoin.com/index.php?topic=29127.0
http://taklongclub.com/forum/index.php?topic=114445.0
http://taklongclub.com/forum/index.php?topic=114469.0
http://taklongclub.com/forum/index.php?topic=114470.0
http://thanosakademi.com/index.php?topic=75695.0
http://thanosakademi.com/index.php?topic=75704.0
http://thanosakademi.com/index.php?topic=75710.0
http://thanosakademi.com/index.php?topic=75714.0
http://www.critico-expository.com/forum/index.php?topic=10008.0
http://www.critico-expository.com/forum/index.php?topic=9976.0
http://www.nomaher.com/forum/index.php?topic=13755.0
http://www.nomaher.com/forum/index.php?topic=13765.0
http://smartacity.com/component/k2/itemlist/user/21813
http://www.m1avio.com/index.php/component/k2/itemlist/user/3608448
http://rudraautomation.com/index.php/component/k2/author/142999
http://universalcommunity.se/Forum/index.php?topic=1010.0
http://socintegra.lv/ru/component/k2/itemlist/user/43901
http://mediaville.me/index.php/component/k2/itemlist/user/217794
http://www.nomaher.com/forum/index.php?topic=11222.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/297943
http://danielmillsap.com/forum/index.php?topic=977598.0
https://www.resproxy.com/forum/index.php/785024-voskressij-ertugrul-150-seria-f2-voskressij-ertugrul-150-seria/0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/186874
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=681719.0
http://mediaville.me/index.php/component/k2/itemlist/user/234397
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=d3a2d0d4c495a8477837bfbe6181d72c&topic=726.0
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://www.vivelabmanizales.com/%d1%84%d1%83%d0%bb%d0%bbhd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c0-%d1%81%d0%bb%d1%83%d0%b3/
http://www.vivelabmanizales.com/hd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-s4-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://www.vivelabmanizales.com/hd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k9-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://www.vivelabmanizales.com/hd-video-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c7-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://www.vivelabmanizales.com/new-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-s5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://healthyteethpa.org/component/k2/itemlist/user/5284298
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=249534
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/978407
http://teambuildingpremium.com/forum/index.php?topic=712259.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2470399
http://roikjer.com/forum/index.php?PHPSESSID=plrb6p18he6kbccsteehhh54j7&topic=784983.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/(e-eka-aota-16-e)-gt-(e-eka-aota-16-e)-oo-m-oa/?PHPSESSID=bt9j4ros8lg96ppgvtr6jepp81
http://153.120.114.241/eso/index.php/16872292-igra-prestolov-8-sezon-8-seria-dal-igra-prestolov-8-sezon-8-ser
https://www.youngbiker.de/wbboard/index.php?page=User&userID=777268
http://forums.abs-cbn.com/welcome-back-kapamilya%21/om-5-e-fqom-5-e/?PHPSESSID=u6rp9poagpvq0utgimgd1spla2
http://webp.online/index.php?topic=48923.0
http://www.popolsku.fr.pl/forum/index.php?topic=357844.0
http://menulisilmiah.net/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m0dl-%d0%b2%d0%be%d1%81%d0%ba%d1%80/
http://proxima.co.rw/index.php/component/k2/itemlist/user/539994
https://forum.ac-jete.it/index.php?topic=287389.0
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=73057
https://tg.vl-mp.com/index.php?topic=1318790.0
https://prosocyr.com/?option=com_k2&view=itemlist&task=user&id=611288
https://tg.vl-mp.com/index.php?topic=1307935.0
http://myrechockey.com/forums/index.php?topic=86626.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1342570
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/536418
http://www.cosl.com.sg/UserProfile/tabid/61/userId/25923790/Default.aspx
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3559474
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=890280
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/957688
http://avengerro.top/forum/index.php?topic=17713.0
http://rudraautomation.com/index.php/component/k2/author/110178
http://withinfp.sakura.ne.jp/eso/index.php/16785666-igra-prestolov-8-sezon-7-seria-uqn-igra-prestolov-8-sezon-7-ser/0
http://www.spazioad.com/component/k2/itemlist/user/7239307
http://muratliziraatodasi.org/forum/index.php?topic=328446.0
http://dscardip.com/board/index.php?page=User&userID=648670
http://www.phan-aen.go.th/forum/index.php?topic=623303.0
http://muratliziraatodasi.org/forum/index.php?topic=338119.0
http://withinfp.sakura.ne.jp/eso/index.php/16787729-riverdejl-riverdale-3-sezon-23-seria-irf-riverdejl-riverdale-3-
http://forum.thaibetrank.com/index.php?topic=1088231.0
https://prosocyr.com/?option=com_k2&view=itemlist&task=user&id=608938
http://seoksoononly.dothome.co.kr/?document_srl=594000
http://danielmillsap.com/forum/index.php?topic=872090.0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/44201
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1313630
http://www.spazioad.com/component/k2/itemlist/user/7163233
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=757247
http://teambuildingpremium.com/forum/index.php?topic=684091.0
http://married.dike.gr/index.php/component/k2/itemlist/user/39393
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1849621
https://tg.vl-mp.com/index.php?topic=1259469.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=588420.0
https://tg.vl-mp.com/index.php?topic=1275154.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/495315
http://withinfp.sakura.ne.jp/eso/index.php/16771956-milliardy-4-sezon-9-seria-san-milliardy-4-sezon-9-seria-0105201
https://tg.vl-mp.com/index.php?topic=1309489.0
http://poselokgribovo.ru/forum/index.php?topic=623983.0
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2126842
http://teambuildingpremium.com/forum/index.php?topic=686338.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/173733
http://teambuildingpremium.com/forum/index.php?topic=692106.0
http://c3isecurity.com.br/component/k2/itemlist/user/434925
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/20099
https://www.blog.quora.healthcare/%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-65-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e4ob-%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-65
https://www.shaiyax.com/index.php?topic=300471.0
http://danielmillsap.com/forum/index.php?topic=788777.0
http://webp.online/index.php?topic=44935.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/543861
http://danielmillsap.com/forum/index.php?topic=984040.0
https://www.resproxy.com/forum/index.php/781466-amerikanskie-bogi-2-sezon-8-seria-ofe-amerikanskie-bogi-2-sezon/0
http://israengineering.com/index.php/component/k2/itemlist/user/1081279
https://tg.vl-mp.com/index.php?topic=1335206.0
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1109218
http://withinfp.sakura.ne.jp/eso/index.php/16867265-edinoe-serdce-tek-yurek-19-seria-r5sj-edinoe-serdce-tek-yurek-1/0
http://myrechockey.com/forums/index.php?topic=86176.0
https://tg.vl-mp.com/index.php?topic=1282793.0
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=410384
http://www.glasshouseproject.com.ng/index.php/component/k2/itemlist/user/40650
http://www.deliberarchia.org/forum/index.php?topic=917464.0
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1834826
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3198205
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=241426
http://www.oortsociety.com/index.php?topic=9398.0
http://seoksoononly.dothome.co.kr/qna/450166
https://tg.vl-mp.com/index.php?topic=1255443.0
http://healthyteethpa.org/component/k2/itemlist/user/5282522
http://metropolis.ga/index.php?topic=2752.0
http://www.teedinubon.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h6-u2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://www.teedinubon.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t0-m2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://www.teedinubon.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-z4-q5-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
http://www.teedinubon.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-z4-s1-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://www.teedinubon.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-h5-e6-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
http://www.theocraticamerica.org/forum/index.php?topic=29579.0
http://www.theocraticamerica.org/forum/index.php?topic=29586.0
http://www.theparrotcentre.com/forum/index.php?topic=490787.0
https://hackersuniversity.net/index.php?topic=10138.0
https://hackersuniversity.net/index.php?topic=10140.0
https://luckychancerescue.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q9-b2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
https://members.fbhaters.com/index.php?topic=87936.0
https://members.fbhaters.com/index.php?topic=87953.0
https://nextezone.com/index.php?topic=41961.0
http://www.deliberarchia.org/forum/index.php?topic=983690.0
http://forum.bmw-e60.eu/index.php?topic=1958.0
http://1vh.info/index.php?topic=9043.0
http://married.dike.gr/index.php/component/k2/itemlist/user/44064
https://members.fbhaters.com/index.php?topic=70481.0
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/999153
http://withinfp.sakura.ne.jp/eso/index.php/16851206-04052019-ne-zenskaa-rabota-ne-zinoca-robota-21-seria
http://www.hoonthaitoday.com/forum/index.php?topic=140630.0
http://www.hoonthaitoday.com/forum/index.php?topic=140056.0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-14/
http://help.stv.ru/index.php?PHPSESSID=95653152cc37a385196e8709ee57a0d5&topic=135285.0
https://reficulcoin.com/index.php?topic=8800.0
http://www.moyakmermer.com/index.php/component/k2/itemlist/user/627472
http://wituclub.ru/forum/index.php?PHPSESSID=2eh63o14dso5vafngqq369v3v6&topic=25450.0
http://www.hoonthaitoday.com/forum/index.php?topic=195575.0
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-23/
https://adsensebih.com/index.php?topic=8705.0
http://www.deliberarchia.org/forum/index.php?topic=970772.0
http://subforumna.x10.mx/mad/index.php?topic=187703.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-(got)-8-eo-5-e-hj6-a-etoo-(got)-8-eo-5-e/?PHPSESSID=gi4318jpg3paiqtjjai43666v4
http://e-educ.net/Forum/index.php?topic=6032.0
http://mir3sea.com/forum/index.php?topic=554.0
https://sanp.pro/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-y8-z6-%d1%80%d0%b0%d1%81%d1%81/
http://HyUa.1fps.icu/l/szIaeDC
https://woodland.org.ua/members/melvinawaters1/
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=769399
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=566270
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2588235
https://www.gizmoarticle.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-27-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l8-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7/
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=6052
http://taklongclub.com/forum/index.php?topic=113941.0
http://taklongclub.com/forum/index.php?topic=113946.0
http://taklongclub.com/forum/index.php?topic=113953.0
http://www.ekemoon.com/171141/050920192510/
http://www.theparrotcentre.com/forum/index.php?topic=491255.0
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=f3f33c218b68a0b17227d5b91646cf51&topic=1706.0
http://www.vivelabmanizales.com/hd720-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f4-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=684631.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=684634.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=684643.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=684645.0
https://nextezone.com/index.php?topic=42093.0
https://nextezone.com/index.php?topic=42099.0
https://sanp.pro/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k1-%d1%81%d0%bb/
https://sanp.pro/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-3/
http://thefreebitcoin.com/index.php?topic=27668.0
http://freebeer.me/index.php?topic=283862.0
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/48899
http://web2interactive.com/index.php/component/k2/itemlist/user/3555821
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/183021
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/47082
http://marjorieaperry.com/?option=com_k2&view=itemlist&task=user&id=473486
http://www2.yasothon.go.th/smf/index.php?topic=159.149895
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-taka-(erkenci-kus)-42-e-o9-a-taka-(erkenci-kus)-42-e/?PHPSESSID=7oo4m8prqei34lvikgsg7obsl6
http://healthyteethpa.org/component/k2/itemlist/user/5269131
https://khuyenmaikk13.info/index.php?topic=159873.0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4663154
http://freebeer.me/index.php?topic=252841.0
http://withinfp.sakura.ne.jp/eso/index.php/16760588-ne-otpuskaj-mou-ruku-elimi-birakma-38-seria-online-w7-ne-otpusk/0
http://matrixpharm.ru/forum/index.php?PHPSESSID=ios3v5pu5ctev1j1g7sm8i8265&action=profile;u=162684
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/184979
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/529278
http://www.deliberarchia.org/forum/index.php?topic=915253.0
http://mjbosch.com/component/k2/itemlist/user/80644
https://tg.vl-mp.com/index.php?topic=1258539.0
http://teambuildingpremium.com/forum/index.php?topic=594979.0
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1746904
http://www.arunagreen.com/index.php/component/k2/itemlist/user/403441
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=252745
http://www.deliberarchia.org/forum/index.php?topic=950709.0
http://seoksoononly.dothome.co.kr/qna/428965
https://www.resproxy.com/forum/index.php/795046-rannaa-ptaska-erkenci-kus-43-seria-j2rm-rannaa-ptaska-erkenci-k/0
http://teambuildingpremium.com/forum/index.php?topic=607253.0
http://danielmillsap.com/forum/index.php?topic=820454.0
http://menulisilmiah.net/%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5%d0%bd%d0%b8%d0%b5-vuslat-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v0un-%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd/
http://seoksoononly.dothome.co.kr/qna/643918
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1574543
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/246798
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889382
http://webp.online/index.php?topic=45782.0
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81-31/
https://members.fbhaters.com/index.php?topic=63864.0
http://www.quattroandpartners.it/component/k2/itemlist/user/1065026
http://www.phan-aen.go.th/forum/index.php?topic=612170.0
http://153.120.114.241/eso/index.php/16879939-igra-prestolov-8-sezon-8-seria-xsd-igra-prestolov-8-sezon-8-ser
https://www.resproxy.com/forum/index.php/767452-milliardy-4-sezon-10-seria-ant-milliardy-4-sezon-10-seria-05052/0
http://macdistri.com/index.php/component/k2/itemlist/user/221910
https://instaldec.com/?option=com_k2&view=itemlist&task=user&id=606484
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2531878
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7263529
http://dessa.com.br/index.php/component/k2/itemlist/user/303847
http://webp.online/index.php?topic=42255.0
http://www.deliberarchia.org/forum/index.php?topic=957811.0
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3302037
http://www.cosl.com.sg/UserProfile/tabid/61/UserID/25882242/Default.aspx
http://withinfp.sakura.ne.jp/eso/index.php/16767232-rasskaz-sluzanki-3-sezon-3-seria-sdg-rasskaz-sluzanki-3-sezon-3/0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/171380
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/4548
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1118429
http://danielmillsap.com/forum/index.php?topic=805675.0
http://menulisilmiah.net/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-80-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g8ce-%d0%bd%d0%b5%d0%b2/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mjg-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2523306
https://tg.vl-mp.com/index.php?topic=1284735.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/247284
https://tg.vl-mp.com/index.php?topic=1260627.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xir-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1226295
https://www.shaiyax.com/index.php?topic=314762.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1113337
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=873377
https://mcsetup.tk/bbs/index.php?topic=230312.0
http://withinfp.sakura.ne.jp/eso/index.php/16907259-vetrenyj-hercai-6-seria-t2qj-vetrenyj-hercai-6-seria
https://tg.vl-mp.com/index.php?topic=1332312.0
https://www.blog.quora.healthcare/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90oq%e3%80%91%d1%81%d0%bb%d1%83%d0%b3%d0%b0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/21114
https://tg.vl-mp.com/index.php?topic=1302779.0
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=929973
http://www.deliberarchia.org/forum/index.php?topic=977566.0
https://www.resproxy.com/forum/index.php/738307-milliardy-4-sezon-11-seria-buh-milliardy-4-sezon-11-seria-03052/0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/247009
http://macdistri.com/index.php/component/k2/itemlist/user/223154
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=103519
http://teambuildingpremium.com/forum/index.php?topic=597536.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/et-e-7-e-eoet-e-7-e/?PHPSESSID=i2lrq05deq3n7cd9b2t3g4tdj6
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/51539
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1603635
http://danielmillsap.com/forum/index.php?topic=803349.0
http://withinfp.sakura.ne.jp/eso/index.php/16785254-milliardy-4-sezon-9-seria-sxu-milliardy-4-sezon-9-seria-0105201/0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=594560.0
http://healthyteethpa.org/component/k2/itemlist/user/5310022
http://metropolis.ga/index.php?topic=5818.0
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1108476
http://withinfp.sakura.ne.jp/eso/index.php/16784576-voskressij-ertugrul-146-seria-w3hw-voskressij-ertugrul-146-seri/0
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=34177
http://77.93.38.205/index.php/component/k2/itemlist/user/495793
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dze-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3586328
http://married.dike.gr/index.php/component/k2/itemlist/user/26367
https://www.youngbiker.de/wbboard/index.php?page=User&userID=785595
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1795199
http://dohairbiz.com/en/component/k2/itemlist/user/2657921.html
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1106388
http://zsmr.com.ua/index.php/component/k2/itemlist/user/405080
http://forums.abs-cbn.com/welcome-back-kapamilya%21/om-1-e-wlom-1-e/
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=402195
http://mobility-corp.com/index.php/component/k2/itemlist/user/2409591
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/144011
https://members.fbhaters.com/index.php/topic,64714.0.html
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3195641
http://proandpro.it/?option=com_k2&view=itemlist&task=user&id=4529014
http://withinfp.sakura.ne.jp/eso/index.php/16775340-milliardy-4-sezon-11-seria-aio-milliardy-4-sezon-11-seria-01052/0
https://www.wikisexguide.com/index.php?title=%C3%82%C2%AB%C3%90%C5%B8%C3%90%C2%BE_%C3%90%C3%A2%E2%82%AC%E2%84%A2%C3%90%C2%BE%C3%90%C2%BB%C3%90%C2%B5_%C3%90%E2%80%98%C3%90%C2%BE%C3%90%C2%B6%C3%91%C5%92%C3%90%C2%B5%C3%90%C2%B9%C3%82%C2%BB_06-05-2019_%C3%90%C5%B8%C3%90%C2%BE_%C3%90%C3%A2%E2%82%AC%E2%84%A2%C3%90%C2%BE%C3%90%C2%BB%C3%90%C2%B5_%C3%90%E2%80%98%C3%90%C2%BE%C3%90%C2%B6%C3%91%C5%92%C3%90%C2%B5%C3%90%C2%B9_%C3%82%C2%AB%C3%90%C5%B8%C3%90%C2%BE_%C3%90%C3%A2%E2%82%AC%E2%84%A2%C3%90%C2%BE%C3%90%C2%BB%C3%90%C2%B5_%C3%90%E2%80%98%C3%90%C2%BE%C3%90%C2%B6%C3%91%C5%92%C3%90%C2%B5%C3%90%C2%B9%C3%82%C2%BB&wpName=LeslieStanfill1&wpPassword=Izoff4EP8&wploginattempt=Log+in&wpEditToken=%2B%5C&authAction=login&force=&wpLoginToken=6fd8efc10ade1cbdc3b00f6561fd272a5ccf9598%2B%5C
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1650044
http://www.arunagreen.com/index.php/component/k2/itemlist/user/322304
http://metropolis.ga/index.php?topic=4536.0
http://www.glasshouseproject.com.ng/index.php/component/k2/itemlist/user/39798
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2138580
http://pptforum.dothome.co.kr/board_APMk06/660844
http://webp.online/index.php?topic=50994.0
http://married.dike.gr/index.php/component/k2/itemlist/user/38174
http://withinfp.sakura.ne.jp/eso/index.php/16825039-voron-kuzgun-9-seria-x8nh-voron-kuzgun-9-seria
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-8-eo-6-e-qpo-a-etoo-8-eo-6-e-25-04-2019/?PHPSESSID=d479k3qm19lgr0cnmvo8rjgbe1
http://tradebest.org/board_MdUI61/1546350
https://members.fbhaters.com/index.php?topic=71619.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/435031
http://seoksoononly.dothome.co.kr/qna/373935
http://withinfp.sakura.ne.jp/eso/index.php/16915150-voskressij-ertugrul-147-seria-b1ff-voskressij-ertugrul-147-seri
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=407570
https://lucky28003.nl/forum/index.php?topic=7069.0
http://seoksoononly.dothome.co.kr/qna/470205
http://www.deliberarchia.org/forum/index.php?topic=946841.0
http://www.deliberarchia.org/forum/index.php?topic=790165.0
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=77989
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yn3-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6/
http://muratliziraatodasi.org/forum/index.php?topic=340275.0
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1125854
http://muratliziraatodasi.org/forum/index.php?topic=333427.0
http://avengerro.top/forum/index.php?topic=10830.0
http://seoksoononly.dothome.co.kr/qna/446504
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2470113
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3605221
https://www.resproxy.com/forum/index.php/801169-riverdejl-riverdale-3-sezon-18-seria-zhx-riverdejl-riverdale-3-/0
http://withinfp.sakura.ne.jp/eso/index.php/16803211-ne-otpuskaj-mou-ruku-elimi-birakma-36-seria-p5nz-ne-otpuskaj-mo/0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/394247
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=259628
http://teambuildingpremium.com/forum/index.php?topic=619039.0
http://www.tessabannampad.go.th/webboard/index.php?topic=195034.0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/66147
http://webp.online/index.php?topic=40217.0
http://danielmillsap.com/forum/index.php?topic=825364.0
http://teambuildingpremium.com/forum/index.php?topic=638687.0
http://withinfp.sakura.ne.jp/eso/index.php/16836578-voron-kuzgun-15-seria-o5gr-voron-kuzgun-15-seria/0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/56853
http://soc-human.kz/index.php/component/k2/itemlist/user/1608805
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=236967
http://www.m1avio.com/index.php/component/k2/itemlist/user/3598395
http://www.arunagreen.com/index.php/component/k2/itemlist/user/289554
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/41828
http://k2.akademitelkom.ac.id/index.php/component/k2/itemlist/user/293463
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1127877
https://tg.vl-mp.com/index.php?topic=1327896.0
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/202332
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=172864
http://danielmillsap.com/forum/index.php?topic=903304.0
http://www.popolsku.fr.pl/forum/index.php?topic=341305.0
http://danielmillsap.com/forum/index.php?topic=835774.0
http://danielmillsap.com/forum/index.php?topic=875639.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=891437
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1956326
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=711562
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jk2-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11/
http://www.deliberarchia.org/forum/index.php?topic=943230.0
http://danielmillsap.com/forum/index.php?topic=798579.0
http://macdistri.com/index.php/component/k2/itemlist/user/222460
https://www.youngbiker.de/wbboard/index.php?page=User&userID=785028
http://www.glasshouseproject.com.ng/index.php/component/k2/itemlist/user/38593
http://www.phan-aen.go.th/forum/index.php?topic=609811.0
http://flyinghonda.de/wbb/index.php?page=User&userID=804761
https://tg.vl-mp.com/index.php?topic=1351810.0
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vl0-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3/
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2495915
http://webp.online/index.php?topic=44126.0
http://sdsn.develop.cinfores.com/?option=com_k2&view=itemlist&task=user&id=170762
http://www.deliberarchia.org/forum/index.php?topic=906785.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2512027
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3475717
http://withinfp.sakura.ne.jp/eso/index.php/16882526-voskressij-ertugrul-143-seria-i3xl-voskressij-ertugrul-143-seri/0
https://members.fbhaters.com/index.php?topic=66872.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a0im-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-17-%d1%81%d0%b5%d1%80%d0%b8/
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=701616
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-typ-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/144071
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1463019
http://dessa.com.br/component/k2/itemlist/user/298807
http://www.popolsku.fr.pl/forum/index.php?topic=350483.0
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=80505
http://dev.aabn.org.gh/component/k2/itemlist/user/516807
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=260656
http://withinfp.sakura.ne.jp/eso/index.php/16876742-rannaa-ptaska-erkenci-kus-43-seria-n5qa-rannaa-ptaska-erkenci-k/0
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81-45/
https://mcsetup.tk/bbs/index.php?topic=232704.0
http://married.dike.gr/index.php/component/k2/itemlist/user/34450
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/448061
http://www.spazioad.com/component/k2/itemlist/user/7059117
http://www.popolsku.fr.pl/forum/index.php?topic=332292.0
https://www.youngbiker.de/wbboard/index.php?page=User&userID=784465
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=279273
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1615017
http://danielmillsap.com/forum/index.php?topic=896877.0
http://153.120.114.241/eso/index.php/16862939-lubov-smert-i-roboty-love-death-and-robots-5-seria-qwc-lubov-sm
http://proxima.co.rw/index.php/component/k2/itemlist/user/544732
http://www.popolsku.fr.pl/forum/index.php?topic=355066.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2537892
http://danielmillsap.com/forum/index.php?topic=887407.0
http://macdistri.com/?option=com_k2&view=itemlist&task=user&id=258941
http://withinfp.sakura.ne.jp/eso/index.php/16782564-igra-prestolov-8-sezon-3-seria-nwx-igra-prestolov-8-sezon-3-ser
http://macdistri.com/index.php/component/k2/itemlist/user/227820
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1521476
http://mobility-corp.com/index.php/component/k2/itemlist/user/2419130
http://withinfp.sakura.ne.jp/eso/index.php/16786711-milliardy-4-sezon-11-seria-vfa-milliardy-4-sezon-11-seria-02052/0
http://webp.online/index.php?topic=38262.0
http://married.dike.gr/index.php/component/k2/itemlist/user/34093
https://www.blog.quora.healthcare/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p0mk-%d0%b2%d0%be%d1%81%d0%ba%d1%80
http://153.120.114.241/eso/index.php/16874465-nasledie-15-seria-vbh-nasledie-15-seria
http://danielmillsap.com/forum/index.php?topic=831793.0
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1124920
http://mjbosch.com/index.php/component/k2/itemlist/user/81735
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=201072
http://teambuildingpremium.com/forum/index.php?topic=630893.0
https://www.blog.quora.healthcare/%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90yv%e3%80%91%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd
http://www.spazioad.com/component/k2/itemlist/user/7166481
http://danielmillsap.com/forum/index.php?topic=847337.0
http://danielmillsap.com/forum/index.php?topic=811922.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/eoe-ekao-5-eo-4-e-iqv-eoe-ekao-5-eo-4-e-23-04-2019/msg494178/
http://withinfp.sakura.ne.jp/eso/index.php/16931728-voron-kuzgun-16-seria-p8fq-voron-kuzgun-16-seria
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2488084
http://www.svedmyr.nu/install/UserProfile/tabid/61/userId/368869/Default.aspx
https://www.blog.quora.healthcare/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%e3%80%90vv%e3%80%91%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9
http://www.sopcich.com/UserProfile/tabid/42/UserID/1784743/Default.aspx
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1550041
http://boutique.in.th/index.php/component/k2/itemlist/user/142472
http://153.120.114.241/eso/index.php/16778547-riverdejl-riverdale-3-sezon-22-seria-dtk-riverdejl-riverdale-3-
http://www.deliberarchia.org/forum/index.php?topic=952315.0
https://tg.vl-mp.com/index.php?topic=1331246.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/170373
https://www.blog.quora.healthcare/%d0%bd%d0%b5-%d0%be%d1%82%d0%bf%d1%83%d1%81%d0%ba%d0%b0%d0%b9-%d0%bc%d0%be%d1%8e-%d1%80%d1%83%d0%ba%d1%83-elimi-birakma-40-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d3eu-%d0%bd%d0%b5-%d0%be
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1793616
https://members.fbhaters.com/index.php?topic=71108.0
http://danielmillsap.com/forum/index.php?topic=831421.0
http://www.arredoufficiomarca.com/index.php/component/k2/itemlist/user/1552176
http://seoksoononly.dothome.co.kr/qna/610894
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1094702
http://www.arunagreen.com/index.php/component/k2/itemlist/user/321934
http://danielmillsap.com/forum/index.php?topic=944381.0
https://tg.vl-mp.com/index.php?topic=1324019.0
http://soc-human.kz/index.php/component/k2/itemlist/user/1551305
http://dscardip.com/board/index.php?page=User&userID=657049
http://avengerro.top/forum/index.php?topic=12908.0
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/42367
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1642844
http://www.oortsociety.com/index.php?topic=11025.0
http://tekagrafica.com.br/index.php/component/k2/itemlist/user/1523074
http://www.deliberarchia.org/forum/index.php?topic=786703.0
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1104132
https://tg.vl-mp.com/index.php?topic=1275739.0
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=410799
http://foa.egerton.ac.ke/index.php/component/k2/itemlist/user/1679835
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1030619
http://www.deliberarchia.org/forum/index.php?topic=762856.0
http://www.deliberarchia.org/forum/index.php?topic=986752.0
http://www.popolsku.fr.pl/forum/index.php?topic=340199.0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=259822
http://withinfp.sakura.ne.jp/eso/index.php/16803237-edinoe-serdce-tek-yurek-18-seria-p4ms-edinoe-serdce-tek-yurek-1
http://rudraautomation.com/index.php/component/k2/author/109981
https://tg.vl-mp.com/index.php?topic=1256214.0
https://www.blog.quora.healthcare/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90uw%e3%80%91%d1%81%d0%bb%d1%83%d0%b3%d0%b0
http://withinfp.sakura.ne.jp/eso/index.php/16771251-milliardy-4-sezon-5-seria-dux-milliardy-4-sezon-5-seria-0105201/0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2386367
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1126169
https://lucky28003.nl/forum/index.php?topic=5012.0
http://metropolis.ga/index.php?topic=405.0
http://www.cosl.com.sg/UserProfile/tabid/61/userId/26242338/Default.aspx
https://forum.ac-jete.it/index.php?topic=269328.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2386348
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/172411
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=7389
http://danielmillsap.com/forum/index.php?topic=786492.0
http://teambuildingpremium.com/forum/index.php?topic=652134.0
http://www.popolsku.fr.pl/forum/index.php?topic=340582.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=280918
http://www.popolsku.fr.pl/forum/index.php?topic=340045.0
http://www.tessabannampad.go.th/webboard/index.php?topic=192524.0
http://pptforum.dothome.co.kr/?document_srl=667277
https://forum.ac-jete.it/index.php?topic=280555.0
http://www.spazioad.com/component/k2/itemlist/user/7098149
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1248024
https://instaldec.com/?option=com_k2&view=itemlist&task=user&id=609578
https://tg.vl-mp.com/index.php?topic=1338881.0
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=1082
http://153.120.114.241/eso/index.php/16883349-amerikanskie-bogi-2-sezon-6-seria-bai-amerikanskie-bogi-2-sezon
https://www.blog.quora.healthcare/%d0%b2%d0%be%d1%80%d0%be%d0%bd-kuzgun-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r2qn-%d0%b2%d0%be%d1%80%d0%be%d0%bd-kuzgun-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f
http://danielmillsap.com/forum/index.php?topic=819802.0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=269969
http://batubersurat.com/index.php/component/k2/itemlist/user/43285
http://proandpro.it/?option=com_k2&view=itemlist&task=user&id=4455130
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889971
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kvd-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.deliberarchia.org/forum/index.php?topic=798739.0
https://tg.vl-mp.com/index.php?topic=1254970.0
http://www.tessabannampad.go.th/webboard/index.php?topic=188237.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=583284.0
http://married.dike.gr/index.php/component/k2/itemlist/user/35306
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zqr-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://tradebest.org/board_MdUI61/1559726
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=269422
http://teambuildingpremium.com/forum/index.php?topic=690344.0
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1108430
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1110593
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=265388
http://www.spazioad.com/component/k2/itemlist/user/7178361
http://hydrocarbs-gh.org/index.php/component/k2/itemlist/user/7173701
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4675417
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=77897
http://www.tessabannampad.go.th/webboard/index.php?topic=192946.0
http://danielmillsap.com/forum/index.php?topic=810771.0
http://www.deliberarchia.org/forum/index.php?topic=965318.0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4674887
http://dev.aabn.org.gh/component/k2/itemlist/user/484864
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=200698
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=915020
http://danielmillsap.com/forum/index.php?topic=905935.0
http://danielmillsap.com/forum/index.php?topic=962732.0
http://www.ekemoon.com/162283/050320192309/
http://soc-human.kz/index.php/component/k2/itemlist/user/1648096
http://mobility-corp.com/index.php/component/k2/itemlist/user/2519397
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/70748
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/68071
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=9877.0
http://danielmillsap.com/forum/index.php?topic=974562.0
http://www.nomaher.com/forum/index.php?topic=11323.0
http://www2.yasothon.go.th/smf/index.php?topic=159.msg180360
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1576613
http://roikjer.com/forum/index.php?PHPSESSID=edn3bomfkgqq1v0k97oe7t5ug7&topic=833056.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/193784
http://teambuildingpremium.com/forum/index.php?topic=790037.0
http://teambuildingpremium.com/forum/index.php?topic=790052.0
http://uberdrivers.net/forum/index.php?topic=241780.0
http://www.afikgan.co.il/index.php/component/k2/itemlist/user/26471
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4753544
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1367574
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=1038632
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1038612
http://www.gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1866526
http://www.m1avio.com/index.php/component/k2/itemlist/user/3637394
http://www.pdctransport.co.th/index.php/component/k2/itemlist/user/14413
http://www.sopcich.com/UserProfile/tabid/42/UserID/1841798/Default.aspx
http://www.telcon.gr/index.php/component/k2/itemlist/user/52030
https://danceplanet.se/commodore/index.php?topic=17729.0
https://danceplanet.se/commodore/index.php?topic=17743.0
https://members.fbhaters.com/index.php?topic=84440.0
https://reficulcoin.com/index.php?topic=17687.0
http://1vh.info/index.php?topic=17063.0
http://eugeniocolazzo.it/forum/index.php?topic=107017.0
http://forum.politeknikgihon.ac.id/index.php?topic=28944.0
http://forum.politeknikgihon.ac.id/index.php?topic=28963.0
http://hi-mar.com/forum/index.php?PHPSESSID=34c464f1db6f7aaca34acf1c2c31e752&topic=32356.0
http://menulisilmiah.net/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p4-z8-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://forums.abs-cbn.com/welcome-back-kapamilya%21/ootk-9-eo-12-k-koootk-9-eo-12-k/?PHPSESSID=52qi5sif897tsgnorh75131nt5
http://pptforum.dothome.co.kr/board_APMk06/665355
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3542289
http://mobility-corp.com/index.php/component/k2/itemlist/user/2478920
https://tg.vl-mp.com/index.php?topic=1256481.0
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1540446
https://www.resproxy.com/forum/index.php/781923-nasa-istoria-67-seria-q2xf-nasa-istoria-67-seria/0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/267397
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3273234
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1573303
http://seoksoononly.dothome.co.kr/qna/467641
http://mediaville.me/index.php/component/k2/itemlist/user/203097
http://dcasociados.eu/component/k2/itemlist/user/84951
http://www.phan-aen.go.th/forum/index.php?topic=611813.0
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1549324
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dak-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=238381
http://www.m1avio.com/index.php/component/k2/itemlist/user/3596949
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=40218
http://webp.online/index.php?topic=38678.msg64278
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=263231
http://www.deliberarchia.org/forum/index.php?topic=803323.0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/374029
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1867044
http://withinfp.sakura.ne.jp/eso/index.php/16776770-riverdejl-riverdale-3-sezon-21-seria-gci-riverdejl-riverdale-3-/0
http://danielmillsap.com/forum/index.php?topic=879630.0
https://instaldec.com/?option=com_k2&view=itemlist&task=user&id=573069
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/43857
http://www.deliberarchia.org/forum/index.php?topic=974448.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3495002
http://sam-sanat.ir/?option=com_k2&view=itemlist&task=user&id=137617
http://married.dike.gr/index.php/component/k2/itemlist/user/25931
http://www.m1avio.com/index.php/component/k2/itemlist/user/3568372
http://poselokgribovo.ru/forum/index.php?topic=616180.0
https://mcsetup.tk/bbs/index.php?topic=232133.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=584420.0
https://mcsetup.tk/bbs/index.php?topic=226103.0
http://153.120.114.241/eso/index.php/16872158-cernoe-zerkalo-5-sezon-5-seria-gjw-cernoe-zerkalo-5-sezon-5-ser
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=32658
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=44710
http://matinbank.ir/component/k2/itemlist/user/4483364.html
http://xn--22cmah2caecpucll2cycdoj4d0knajrq3e5pbj9w0c.americanwolfthailand.com/DJPetjah/index.php?topic=1461825.0
http://married.dike.gr/index.php/component/k2/itemlist/user/37365
http://married.dike.gr/index.php/component/k2/itemlist/user/29595
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4691587
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=262877
http://www.sopcich.com/UserProfile/tabid/42/UserID/1519612/Default.aspx
http://tradebest.org/board_MdUI61/1586996
http://www.deliberarchia.org/forum/index.php?topic=952893.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3502566
http://www.popolsku.fr.pl/forum/index.php?topic=337675.0
http://zsmr.com.ua/index.php/component/k2/itemlist/user/382702
http://teambuildingpremium.com/forum/index.php?topic=633737.0
http://macdistri.com/?option=com_k2&view=itemlist&task=user&id=217873
https://members.fbhaters.com/index.php?topic=67770.0
https://mcsetup.tk/bbs/index.php?topic=231327.0
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=8551
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1603537
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-upm-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/406177
http://withinfp.sakura.ne.jp/eso/index.php/16780061-lubov-smert-i-roboty-love-death-and-robots-17-seria-tkg-lubov-s/0
https://www.youngbiker.de/wbboard/index.php?page=User&userID=781063
http://withinfp.sakura.ne.jp/eso/index.php/16798973-vetrenyj-hercai-12-seria-i5uv-vetrenyj-hercai-12-seria/0
http://avengerro.top/forum/index.php?topic=19006.0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/395940
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1472556
http://mobility-corp.com/index.php/component/k2/itemlist/user/2513807
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1305044
http://forum.thaibetrank.com/index.php?topic=1076075.0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=30081
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3314266
http://myrechockey.com/forums/index.php?topic=54801.0
http://www.deliberarchia.org/forum/index.php?topic=900506.0
http://www.deliberarchia.org/forum/index.php?topic=790038.0
https://www.resproxy.com/forum/index.php/766027-manifest-17-seria-wfy-manifest-17-seria
http://www.quattroandpartners.it/component/k2/itemlist/user/1038700
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=243663
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3193030
https://tg.vl-mp.com/index.php?topic=1294195.0
http://withinfp.sakura.ne.jp/eso/index.php/16794260-sverh-estestvennoe-14-sezon-15-seria-quh-sverh-estestvennoe-14-/0
http://withinfp.sakura.ne.jp/eso/index.php/16849241-rannaa-ptaska-erkenci-kus-44-seria-y0yz-rannaa-ptaska-erkenci-k
http://healthyteethpa.org/component/k2/itemlist/user/5310579
http://danielmillsap.com/forum/index.php?topic=905764.0
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=5684
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=180529
http://teambuildingpremium.com/forum/index.php?topic=693336.0
http://redgatetech.co/?option=com_k2&view=itemlist&task=user&id=713645
http://www.phan-aen.go.th/forum/index.php?topic=609291.0
http://metropolis.ga/index.php?topic=5903.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/172879
http://webp.online/index.php?topic=46307.msg75857
http://seoksoononly.dothome.co.kr/qna/633083
http://webp.online/index.php?topic=41124.msg68599
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/589155
http://forums.abs-cbn.com/welcome-back-kapamilya%21/et-e-3-e-jset-e-3-e/
https://www.blog.quora.healthcare/%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90ac%e3%80%91%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd
http://web2interactive.com/index.php/component/k2/itemlist/user/3475412
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1091538
http://withinfp.sakura.ne.jp/eso/index.php/16791174-manifest-19-seria-dtv-manifest-19-seria/0
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3555890
http://withinfp.sakura.ne.jp/eso/index.php/16767399-lubov-smert-i-roboty-love-death-and-robots-4-seria-wau-lubov-sm
http://teambuildingpremium.com/forum/index.php?topic=655686.0
https://tg.vl-mp.com/index.php?topic=1279735.0
http://danielmillsap.com/forum/index.php?topic=971479.0
http://seoksoononly.dothome.co.kr/qna/476309
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/444747
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rdx-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://withinfp.sakura.ne.jp/eso/index.php/16800269-ne-otpuskaj-mou-ruku-elimi-birakma-38-seria-o3ao-ne-otpuskaj-mo/0
http://flyinghonda.de/wbb/index.php?page=User&userID=808068
http://webp.online/index.php?topic=45814.0
https://mcsetup.tk/bbs/index.php?topic=224556.0
http://www.phan-aen.go.th/forum/index.php?topic=609606.0
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1128314
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/60749
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1125406
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3455562
https://tg.vl-mp.com/index.php?topic=1303241.0
http://153.120.114.241/eso/index.php/16864054-rasskaz-sluzanki-3-sezon-1-seria-xgp-rasskaz-sluzanki-3-sezon-1
http://pptforum.dothome.co.kr/board_APMk06/647407
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1129496
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1315095
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ik8-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://www.youngbiker.de/wbboard/index.php?page=User&userID=781733
http://withinfp.sakura.ne.jp/eso/index.php/16769636-riverdejl-riverdale-3-sezon-20-seria-uma-riverdejl-riverdale-3-/0
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/194086
http://www.deliberarchia.org/forum/index.php?topic=961412.0
http://webp.online/index.php?topic=41746.0
http://danielmillsap.com/forum/index.php?topic=844221.0
http://flyinghonda.de/wbb/index.php?page=User&userID=806607
http://www.phan-aen.go.th/forum/index.php?topic=607978.0
http://freebeer.me/index.php?topic=294132.0
https://sanp.pro/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o1-t6-%d1%80%d0%b0%d1%81%d1%81/
http://multikopterforum.hu/index.php?topic=8236.0
http://mir3sea.com/forum/index.php?topic=844.0
http://dpmarketingsystems.com/%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-04-05-2019-3/
https://polyframetrade.co.uk/%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-watch-f0-g3-%D1%80%D0%B0/
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-25/
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d6-i1-%d0%b8%d0%b3%d1%80/
http://thanosakademi.com/index.php?topic=69478.0
http://www.tekparcahdfilm.com/forum/index.php?topic=45789.0
https://www.amazingworldtop.com/entretenimiento/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-s2-z4-%d1%80%d0%b0/
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=679443.0
http://danielmillsap.com/forum/index.php?topic=949150.0
http://forum.kopkargobel.com/index.php?topic=4918.0
https://sto54.ru/index.php/component/k2/itemlist/user/3289509
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=679096.0
https://luckychancerescue.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90es3%e3%80%91-%d0%b8/
http://www.hoonthaitoday.com/forum/index.php?topic=175983.0
http://myrechockey.com/forums/index.php?topic=85520.0
http://sextomariotienda.com/blog/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ft8-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.popolsku.fr.pl/forum/index.php?topic=20407.43380
http://forum.bmw-e60.eu/index.php?topic=3428.0
http://codeerror.in/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c2-i1-%d0%b8%d0%b3%d1%80/
http://forums.abs-cbn.com/welcome-back-kapamilya%21/(a-etoo-(got)-8-eo-3-e)-a-etoo-(got)-8-eo-3-e-t0g3/?PHPSESSID=n4p2eattgevtll980196gi3tq4
http://roikjer.com/forum/index.php?PHPSESSID=9h4rfdfn81tvtp7i7m5mfua0r3&topic=791097.0
http://HyUa.1fps.icu/l/szIaeDC
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=289910
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=40606
http://married.dike.gr/index.php/component/k2/itemlist/user/42047
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-8-eo-7-e-ojo-a-etoo-8-eo-7-e-23-04-2019/
http://www.cosl.com.sg/UserProfile/tabid/61/userId/25899302/Default.aspx
http://www.deliberarchia.org/forum/index.php?topic=962901.0
https://www.resproxy.com/forum/index.php/808402-voron-kuzgun-10-seria-h1bg-voron-kuzgun-10-seria
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=204248
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bbz-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1037640
http://web2interactive.com/index.php/component/k2/itemlist/user/3534641
https://mcsetup.tk/bbs/index.php?topic=226596.0
https://prosocyr.com/?option=com_k2&view=itemlist&task=user&id=606495
https://www.shaiyax.com/index.php?topic=285122.0
http://avengerro.top/forum/index.php?topic=17424.0
http://married.dike.gr/index.php/component/k2/itemlist/user/22245
https://members.fbhaters.com/index.php?topic=70379.0
http://www.telcon.gr/index.php/component/k2/itemlist/user/32493
http://withinfp.sakura.ne.jp/eso/index.php/16915305-vossoedinenie-vuslat-19-seria-b8dv-vossoedinenie-vuslat-19-seri/0
https://lucky28003.nl/forum/index.php?topic=6086.0
https://www.shaiyax.com/index.php?topic=301590.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i8gg-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-22-%d1%81%d0%b5%d1%80%d0%b8/
http://www.deliberarchia.org/forum/index.php?topic=936763.0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/20481
https://www.youngbiker.de/wbboard/index.php?page=User&userID=784484
https://tg.vl-mp.com/index.php?topic=1304428.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=891214
http://pptforum.dothome.co.kr/board_APMk06/637040
http://www.popolsku.fr.pl/forum/index.php?topic=355213.0
http://withinfp.sakura.ne.jp/eso/index.php/16794409-lubov-smert-i-roboty-love-death-and-robots-16-seria-jts-lubov-s/0
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3597416
http://tradebest.org/board_MdUI61/1573387
https://tg.vl-mp.com/index.php?topic=1308658.0
https://www.blog.quora.healthcare/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90tt%e3%80%91%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1850641
https://www.blog.quora.healthcare/%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80%d0%b4%d1%86%d0%b5-tek-yurek-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e0zu-%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=542262
http://tradebest.org/board_MdUI61/1577655
http://muratliziraatodasi.org/forum/index.php?topic=327817.0
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1525009
https://www.blog.quora.healthcare/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-144-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n9ny-%d0%b2%d0%be%d1%81%d0%ba%d1%80
http://menulisilmiah.net/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zr2-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.deliberarchia.org/forum/index.php?topic=899459.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=889441
http://dcasociados.eu/component/k2/itemlist/user/82275
http://tradebest.org/board_MdUI61/1550851
http://www.deliberarchia.org/forum/index.php?topic=956336.0
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pa9-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://tg.vl-mp.com/index.php?topic=1308646.0
http://teambuildingpremium.com/forum/index.php?topic=666480.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/476526
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2478956
http://www.deliberarchia.org/forum/index.php?topic=956017.0
http://www.deliberarchia.org/forum/index.php?topic=763714.0
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1004370
http://mobility-corp.com/index.php/component/k2/itemlist/user/2513351
https://www.resproxy.com/forum/index.php/782360-sverh-estestvennoe-14-sezon-16-seria-blz-sverh-estestvennoe-14-/0
http://www.aroshan.com/?option=com_k2&view=itemlist&task=user&id=928190
http://forums.abs-cbn.com/welcome-back-kapamilya%21/ma-4-eo-9-e-hpc-ma-4-eo-9-e-23-04-2019/msg491663/
http://www.popolsku.fr.pl/forum/index.php?topic=342423.0
http://metropolis.ga/index.php?topic=3879.0
http://www.crnmedia.es/?option=com_k2&view=itemlist&task=user&id=83212
http://menulisilmiah.net/%d0%bd%d0%b5-%d0%be%d1%82%d0%bf%d1%83%d1%81%d0%ba%d0%b0%d0%b9-%d0%bc%d0%be%d1%8e-%d1%80%d1%83%d0%ba%d1%83-elimi-birakma-35-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b9ot-%d0%bd%d0%b5-%d0%be/
http://married.dike.gr/index.php/component/k2/itemlist/user/21511
http://seoksoononly.dothome.co.kr/qna/598223
http://arquitectosenreformas.es/index.php/component/k2/itemlist/user/76834
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4704207
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/55287
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=294749
http://www.pcosmetic.ir/?option=com_k2&view=itemlist&task=user&id=10020
https://lucky28003.nl/forum/index.php?topic=7389.0
http://www.deliberarchia.org/forum/index.php?topic=959662.0
http://myrechockey.com/forums/index.php?topic=85347.0
http://healthyteethpa.org/component/k2/itemlist/user/5208188
https://members.fbhaters.com/index.php?topic=69651.0
http://c3isecurity.com.br/?option=com_k2&view=itemlist&task=user&id=468170
http://danielmillsap.com/forum/index.php?topic=870327.0
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=38087
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1745235
https://lucky28003.nl/forum/index.php?topic=11227.0
http://forum.thaibetrank.com/index.php?topic=1061998.0
http://avengerro.top/forum/index.php?topic=17320.0
http://jpacschoolclubs.co.uk/?option=com_k2&view=itemlist&task=user&id=3268089
https://instaldec.com/?option=com_k2&view=itemlist&task=user&id=575760
https://tg.vl-mp.com/index.php?topic=1275202.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190526.0
http://teambuildingpremium.com/forum/index.php?topic=638733.0
http://153.120.114.241/eso/index.php/16861845-igra-prestolov-8-sezon-7-seria-klm-igra-prestolov-8-sezon-7-ser
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=576627
http://macdistri.com/index.php/component/k2/itemlist/user/299003
https://www.youngbiker.de/wbboard/index.php?page=User&userID=785094
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=406951
http://metropolis.ga/index.php?topic=5774.0
http://www.deliberarchia.org/forum/index.php?topic=902534.0
http://www.quattroandpartners.it/component/k2/itemlist/user/990842
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=701380
http://otitismediasociety.org/forum/index.php?topic=149588.0
http://otitismediasociety.org/forum/index.php?topic=149589.0
http://roikjer.com/forum/index.php?PHPSESSID=8vf5q6svqr7sf0umoj5oaempd2&topic=839130.0
http://roikjer.com/forum/index.php?PHPSESSID=smppav22u3ca4pplk76ghje2p2&topic=839144.0
http://roikjer.com/forum/index.php?topic=839096.0
http://www.deliberarchia.org/forum/index.php?topic=995636.0
http://www.deliberarchia.org/forum/index.php?topic=995642.0
https://members.fbhaters.com/index.php/topic,85747.0.html
https://members.fbhaters.com/index.php?topic=85739.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190627.0
http://www.critico-expository.com/forum/index.php?topic=2148.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=49ce159a03cd884d6d211348391d8077&topic=210918.0
http://forum.bmw-e60.eu/index.php?topic=2986.0
http://www2.yasothon.go.th/smf/index.php?topic=159.154590
https://forum.clubeicaro.pt/index.php?topic=197.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=679973.0
https://reficulcoin.com/index.php?topic=6403.0
http://forum.politeknikgihon.ac.id/index.php?topic=17877.0
http://storykingdom.forumside.com/index.php?topic=4073.0
http://bobr.site/index.php?topic=84512.0
http://www.hoonthaitoday.com/forum/index.php?topic=178554.0
http://metropolis.ga/index.php?topic=3558.0
http://e-educ.net/Forum/index.php?topic=5646.0
http://www.hoonthaitoday.com/forum/index.php?topic=147944.0
http://forum.politeknikgihon.ac.id/index.php?topic=19189.0
https://reficulcoin.com/index.php?topic=14601.0
http://www.tessabannampad.go.th/webboard/index.php?topic=192128.0
http://withinfp.sakura.ne.jp/eso/index.php/16849884-igra-prestolov-got-8-sezon-7-seria-ow6-igra-prestolov-got-8-sez/0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-u2-v5-%d0%b8%d0%b3%d1%80/
http://multikopterforum.hu/index.php?topic=12550.0
http://ru-realty.com/forum/index.php?topic=450658.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=677726.0
http://help.stv.ru/index.php?topic=136177.0
http://HyUa.1fps.icu/l/szIaeDC
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nk0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=43274
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3268298
http://webp.online/index.php?topic=44603.0
http://www.pcosmetic.ir/?option=com_k2&view=itemlist&task=user&id=9990
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=215841
http://danielmillsap.com/forum/index.php?topic=843505.0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/377881
http://www.deliberarchia.org/forum/index.php?topic=802685.0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=272023
https://mcsetup.tk/bbs/index.php?topic=226299.0
https://www.blog.quora.healthcare/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t1qx-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-20-%d1%81%d0%b5%d1%80%d0%b8
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1098430
https://www.resproxy.com/forum/index.php/783094-sverh-estestvennoe-14-sezon-20-seria-eox-sverh-estestvennoe-14-/0
http://withinfp.sakura.ne.jp/eso/index.php/16777361-cernoe-zerkalo-5-sezon-2-seria-pyb-cernoe-zerkalo-5-sezon-2-ser/0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4577276
http://danielmillsap.com/forum/index.php?topic=835950.0
http://macdistri.com/index.php/component/k2/itemlist/user/222341
https://www.resproxy.com/forum/index.php/750689-cernoe-zerkalo-5-sezon-3-seria-dny-cernoe-zerkalo-5-sezon-3-ser/0
http://www.sopcich.com/UserProfile/tabid/42/UserID/1770305/Default.aspx
http://www.deliberarchia.org/forum/index.php?topic=948379.0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/20724
http://www.spazioad.com/component/k2/itemlist/user/7108376
http://fbpharm.net/index.php/component/k2/itemlist/user/15366
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1256191
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1007640
https://tg.vl-mp.com/index.php?topic=1338179.0
https://lucky28003.nl/forum/index.php?topic=5745.0
http://www.popolsku.fr.pl/forum/index.php?topic=341994.0
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=406251
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=890161
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2510455
https://tg.vl-mp.com/index.php?topic=1262585.0
http://danielmillsap.com/forum/index.php?topic=796879.0
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3588315
http://dessa.com.br/component/k2/itemlist/user/304164
http://teambuildingpremium.com/forum/index.php?topic=601107.0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/388801
http://menulisilmiah.net/%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-74-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h1wk-%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-74/
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/177424
http://www.quattroandpartners.it/component/k2/itemlist/user/1037794
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2543553
http://www.deliberarchia.org/forum/index.php?topic=965703.0
http://danielmillsap.com/forum/index.php?topic=844571.0
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1956555
http://danielmillsap.com/forum/index.php?topic=941315.0
http://www.phan-aen.go.th/forum/index.php?topic=612521.0
http://matinbank.ir/component/k2/itemlist/user/4459914.html
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/387805
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tra-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-12-%d1%81%d0%b5%d1%80/
http://withinfp.sakura.ne.jp/eso/index.php/16769129-lubov-smert-i-roboty-love-death-and-robots-10-seria-lar-lubov-s
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1552372
http://forums.abs-cbn.com/welcome-back-kapamilya%21/om-9-e-juom-9-e/msg498791/
http://sam-sanat.ir/?option=com_k2&view=itemlist&task=user&id=128735
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jof-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-14-%d1%81%d0%b5%d1%80/
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1632662
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2415111
http://danielmillsap.com/forum/index.php?topic=830835.0
http://www.deliberarchia.org/forum/index.php?topic=954509.0
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/530019
http://noktayazilim.com.tr/component/k2/itemlist/user/136130
http://webp.online/index.php?topic=41124.msg68592
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1223574
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=272606
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3562242
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/522258
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=674574
http://muratliziraatodasi.org/forum/index.php?topic=330413.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/393229
http://poselokgribovo.ru/forum/index.php?topic=621896.0
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2486284
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81-14/
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4611480
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1572458
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-8-eo-4-e-paj-a-etoo-8-eo-4-e-25-04-2019/
http://www.popolsku.fr.pl/forum/index.php?topic=20407.34305
http://healthyteethpa.org/component/k2/itemlist/user/5283985
http://www.arunagreen.com/index.php/component/k2/itemlist/user/394798
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1954915
http://www.quattroandpartners.it/component/k2/itemlist/user/1051741
https://tg.vl-mp.com/index.php?topic=1289349.0
http://dohairbiz.com/en/component/k2/itemlist/user/2638724.html
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1128192
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-upe-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://withinfp.sakura.ne.jp/eso/index.php/16780431-vetrenyj-hercai-21-seria-n5ux-vetrenyj-hercai-21-seria/0
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2131305
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pl1-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://teambuildingpremium.com/forum/index.php?topic=676083.0
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3564202
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/369085
http://seoksoononly.dothome.co.kr/qna/587100
http://www.deliberarchia.org/forum/index.php?topic=796741.0
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1109100
http://aitour.kz/index.php/component/k2/itemlist/user/325423
http://withinfp.sakura.ne.jp/eso/index.php/16785664-nasa-istoria-66-seria-c0ww-nasa-istoria-66-seria
http://www.atab.com.sa/index.php/en/?option=com_k2&view=itemlist&task=user&id=1454136
http://www.deliberarchia.org/forum/index.php?topic=968458.0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=484826
https://www.blog.quora.healthcare/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n3jl-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-5-%d1%81%d0%b5%d1%80%d0%b8
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1978072
https://www.blog.quora.healthcare/%d0%b2%d0%be%d1%80%d0%be%d0%bd-kuzgun-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a0yu-%d0%b2%d0%be%d1%80%d0%be%d0%bd-kuzgun-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f
http://www.arunagreen.com/index.php/component/k2/itemlist/user/314403
http://forum.thaibetrank.com/index.php?topic=1087447.0
http://aitour.kz/?option=com_k2&view=itemlist&task=user&id=312133
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3644252
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/369538
https://www.youngbiker.de/wbboard/index.php?page=User&userID=783368
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=34270
http://www.deliberarchia.org/forum/index.php?topic=780491.0
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=758726
http://metropolis.ga/index.php?topic=2680.0
http://withinfp.sakura.ne.jp/eso/index.php/16769448-rasskaz-sluzanki-3-sezon-4-seria-qrv-rasskaz-sluzanki-3-sezon-4/0
http://macdistri.com/index.php/component/k2/itemlist/user/258597
https://tg.vl-mp.com/index.php?topic=1278178.0
http://web2interactive.com/index.php/component/k2/itemlist/user/3535231
http://robocit.com/index.php/component/k2/itemlist/user/447599
http://www.glasshouseproject.com.ng/?option=com_k2&view=itemlist&task=user&id=33308
http://avengerro.top/forum/index.php?topic=13126.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1037735
http://seoksoononly.dothome.co.kr/qna/426928
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qo9-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8/
https://tg.vl-mp.com/index.php?topic=1349216.0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=517755
https://www.swiss-focus.ch/index.php/component/k2/itemlist/user/13006
http://seoksoononly.dothome.co.kr/qna/457417
http://danielmillsap.com/forum/index.php?topic=827764.0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=306227
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vlc-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dgb-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=16590
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/471772
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-df5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://danielmillsap.com/forum/index.php?topic=801065.0
http://healthyteethpa.org/component/k2/itemlist/user/5305994
http://seoksoononly.dothome.co.kr/qna/639869
https://instaldec.com/?option=com_k2&view=itemlist&task=user&id=609350
http://www.deliberarchia.org/forum/index.php?topic=926760.0
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=91929
http://www.x2145-productions.technology/index.php?title=%C2%AB%D0%98%D1%81%D1%82%D0%BE%D1%80%D0%B8%D1%8F_%D0%98%D0%B3%D1%80%D1%83%D1%88%D0%B5%D0%BA_4_2019_%C2%BB_06-05-2019_%22%D0%98%D1%81%D1%82%D0%BE%D1%80%D0%B8%D1%8F_%D0%98%D0%B3%D1%80%D1%83%D1%88%D0%B5%D0%BA_4_2019_Watch%22_%C2%AB%D0%98%D1%81%D1%82%D0%BE%D1%80%D0%B8%D1%8F_%D0%98%D0%B3%D1%80%D1%83%D1%88%D0%B5%D0%BA_4_2019_%C2%BB
http://withinfp.sakura.ne.jp/eso/index.php/16841185-vossoedinenie-vuslat-14-seria-m4jt-vossoedinenie-vuslat-14-seri/0
http://www.x2145-productions.technology/index.php?title=%C2%AB%D0%91%D0%BE%D0%BD%D0%B4_25_2020_%C2%BB_07-05-2019_%D0%91%D0%BE%D0%BD%D0%B4_25_2020_%C2%AB%D0%91%D0%BE%D0%BD%D0%B4_25_2020_%C2%BB
http://www.popolsku.fr.pl/forum/index.php?topic=356511.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2519968
http://metropolis.ga/index.php?topic=3344.0
http://danielmillsap.com/forum/index.php?topic=909313.0
http://mediaville.me/index.php/component/k2/itemlist/user/191186
http://www.popolsku.fr.pl/forum/index.php?topic=343110.0
http://danielmillsap.com/forum/index.php?topic=802126.0
http://healthyteethpa.org/?option=com_k2&view=itemlist&task=user&id=5202452
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2471766
http://healthyteethpa.org/component/k2/itemlist/user/5276184
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3195658
https://tg.vl-mp.com/index.php?topic=1281531.0
http://www.popolsku.fr.pl/forum/index.php?topic=347743.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=677190.0
http://poselokgribovo.ru/forum/index.php?topic=708767.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1111666
http://forum.kopkargobel.com/index.php?topic=4600.0
https://members.fbhaters.com/index.php?topic=73530.0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4707085
http://poselokgribovo.ru/forum/index.php?topic=712515.0
http://www.theocraticamerica.org/forum/index.php?topic=27148.0
http://menulisilmiah.net/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g3-n8-%d1%80%d0%b0%d1%81%d1%81/
https://members.fbhaters.com/index.php?topic=69074.0
https://doe.go.th/prd/forum_nongkhai/1535026-148-rt0-148
http://withinfp.sakura.ne.jp/eso/index.php/16854874-podsudimyj-16-seria-05052019
http://forum.kopkargobel.com/index.php?topic=3066.0
http://myrechockey.com/forums/index.php?topic=89833.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=1d0d14e3fc192af71f703a86497cc3ea&topic=210335.0
http://menulisilmiah.net/08-05-2019-%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://istakam.com/forum/index.php?topic=9779.0
http://www.hoonthaitoday.com/forum/index.php?topic=160716.0
https://members.fbhaters.com/index.php?topic=71031.0
http://multikopterforum.hu/index.php?topic=12227.0
http://myrechockey.com/forums/index.php?topic=83076.0
http://1vh.info/index.php?topic=13415.0
http://www.remify.app/foro/index.php?topic=235568.0
https://reficulcoin.com/index.php?topic=12930.0
http://ru-realty.com/forum/index.php?topic=448555.0
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=291287
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1834219
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v3-v8-%d1%80%d0%b0/
http://mobility-corp.com/index.php/component/k2/itemlist/user/2504811
http://8.droror.co.il/uncategorized/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-st6-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.critico-expository.com/forum/index.php?topic=2123.0
http://ru-realty.com/forum/index.php?PHPSESSID=dd5apaqv93mi7kn4e1u2o30k14&topic=454044.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1327393
http://myrechockey.com/forums/index.php?topic=85548.0
http://www.hoonthaitoday.com/forum/index.php?topic=127502.0
http://www.tessabannampad.go.th/webboard/index.php?topic=184393.0
http://poselokgribovo.ru/forum/index.php?topic=707162.0
http://teambuildingpremium.com/forum/index.php?topic=761526.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=095a3d0aae979a18d2c91dca5d0850d0&topic=205283.0
https://hackersuniversity.net/index.php?topic=6394.0
http://216.104.186.20/index.php?topic=303604.0
http://www.theparrotcentre.com/forum/index.php?topic=476258.0
http://forum.politeknikgihon.ac.id/index.php?topic=16342.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.theparrotcentre.com/forum/index.php?topic=476018.0
http://www.vivelabmanizales.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ubf-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2-%d1%81%d0%b5%d1%80%d0%b8/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3318125
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/296922
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2581092
http://www.spazioad.com/component/k2/itemlist/user/7252658
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=6651
http://mediaville.me/index.php/component/k2/itemlist/user/217986
http://healthyteethpa.org/?option=com_k2&view=itemlist&task=user&id=5355609
http://www.tessabannampad.go.th/webboard/index.php?topic=199079.0
http://www.theparrotcentre.com/forum/index.php?topic=494272.0
https://nextezone.com/index.php?topic=42848.0
https://sanp.pro/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u4-%d1%81/
https://sanp.pro/%d1%8d%d1%84%d0%b8%d1%80-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f9-%d1%81%d0%bb%d1%83/
https://sanp.pro/new-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
https://sanp.pro/video-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g7-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
https://www.shaiyax.com/index.php?topic=337179.0
http://153.120.114.241/eso/index.php/16966059-nasa-istoria-68-seria-r4-nasa-istoria-68-seria
http://forum.politeknikgihon.ac.id/index.php?topic=33548.0
http://poselokgribovo.ru/forum/index.php?topic=754142.0
http://poselokgribovo.ru/forum/index.php?topic=754145.0
http://roikjer.com/forum/index.php?PHPSESSID=aqsjqaa34n98cvh12on56i8tu2&topic=845845.0
http://roikjer.com/forum/index.php?PHPSESSID=m1metgkngg1d4v8qi82cdok5t6&topic=845865.0
http://www.siirtorganik.com/index.php/component/k2/itemlist/user/784501
http://www.spazioad.com/component/k2/itemlist/user/7256646
http://www.spazioad.com/component/k2/itemlist/user/7256669
http://xekhachduyetthuy.com.vn/index.php/component/k2/itemlist/user/183824
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=521799
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=521806
http://zsmr.com.ua/index.php/component/k2/itemlist/user/521836
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3324027
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3324046
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=17590
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=17640
https://www.swiss-focus.ch/index.php/component/k2/itemlist/user/17628
https://www.swiss-focus.ch/index.php/component/k2/itemlist/user/17631
http://healthyteethpa.org/component/k2/itemlist/user/5279709
https://www.shaiyax.com/index.php?topic=298351.0
http://danielmillsap.com/forum/index.php?topic=889748.0
http://www.deliberarchia.org/forum/index.php?topic=761501.0
http://danielmillsap.com/forum/index.php?topic=826207.0
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gz1-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
https://mcsetup.tk/bbs/index.php?topic=227729.0
http://danielmillsap.com/forum/index.php?topic=870241.0
http://metropolis.ga/index.php?topic=2646.0
http://www.deliberarchia.org/forum/index.php?topic=797243.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/177962
http://www.arunagreen.com/index.php/component/k2/itemlist/user/422335
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/51742
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-23-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uy5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://withinfp.sakura.ne.jp/eso/index.php/16800992-voskressij-ertugrul-143-seria-o0lq-voskressij-ertugrul-143-seri
https://www.resproxy.com/forum/index.php/766521-cernoe-zerkalo-5-sezon-4-seria-wql-cernoe-zerkalo-5-sezon-4-ser/0
https://tg.vl-mp.com/index.php?topic=1266368.0
https://www.youngbiker.de/wbboard/index.php?page=User&userID=783357
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=37700
http://withinfp.sakura.ne.jp/eso/index.php/16904740-zensina-60-seria-s0wf-zensina-60-seria/0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/177232
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4672375
http://danielmillsap.com/forum/index.php?topic=868651.0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=43680
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-njn-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://muratliziraatodasi.org/forum/index.php?topic=329177.0
http://poselokgribovo.ru/forum/index.php?topic=744380.0
http://poselokgribovo.ru/forum/index.php?topic=744385.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/588794
http://roikjer.com/forum/index.php?PHPSESSID=2kq107nvrehhl9s1eoeprhtmg2&topic=835947.0
http://roikjer.com/forum/index.php?PHPSESSID=ilogi4b3128122k1qk2ru4fik3&topic=835938.0
http://ru-realty.com/forum/index.php?topic=478700.0
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=145308
http://sdsn.develop.cinfores.com/?option=com_k2&view=itemlist&task=user&id=194918
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1656793
https://www.mutlualisverisler.com/?p=978018
http://www.ekemoon.com/139511/052220192604/
https://www.gizmoarticle.com/online-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-y3-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://danielmillsap.com/forum/index.php?topic=861136.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1071199
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=622251.0
http://forum.byehaj.hu/index.php?topic=70716.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=c35f57289e9c959485ae52a10055362b&topic=199772.0
http://teambuildingpremium.com/forum/index.php?topic=797464.0
http://thanosakademi.com/index.php?topic=74150.0
http://uberdrivers.net/forum/index.php?topic=249037.0
http://www.critico-expository.com/forum/index.php?topic=7875.0
http://www.critico-expository.com/forum/index.php?topic=7896.0
http://www.aloeverasas.it/index.php/component/k2/itemlist/user/18048
http://www.hoonthaitoday.com/forum/index.php?topic=172747.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/189681
http://www.m1avio.com/index.php/component/k2/itemlist/user/3611764
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=c969c9e75e49a118705f51d7496d7fbc&topic=306.0
http://rudraautomation.com/index.php/component/k2/author/142159
http://mvisage.sk/?option=com_k2&view=itemlist&task=user&id=117965
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=27166.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/490857
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2518723
http://theolevolosproject.org/index.php/component/k2/itemlist/user/24390
http://theolevolosproject.org/index.php/component/k2/itemlist/user/24392
http://www.nomaher.com/forum/index.php?topic=11167.0
http://www.nomaher.com/forum/index.php?topic=11171.0
http://www.nomaher.com/forum/index.php?topic=11177.0
https://forums.letstalkbeats.com/index.php?topic=63227.0
https://forums.letstalkbeats.com/index.php?topic=63251.0
https://tg.vl-mp.com/index.php?topic=1260787.0
http://forum.bmw-e60.eu/index.php?topic=1230.0
http://macdistri.com/index.php/component/k2/itemlist/user/272042
https://npi.org.es/smf/index.php?topic=107559.0
http://1vh.info/index.php?topic=5948.0
http://sextomariotienda.com/blog/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81-3/
https://www.c-alice.org/forum/index.php?topic=63880.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1335596
http://c3isecurity.com.br/component/k2/itemlist/user/462240
http://married.dike.gr/index.php/component/k2/itemlist/user/43946
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90yj5%e3%80%91/
http://flashboot.ru/forum/index.php?topic=94321.0
http://help.stv.ru/index.php?PHPSESSID=eab1276c5caf0fe5047211b045fd48a1&topic=138559.0
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-q0-s2-%d1%80/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90jn5%e3%80%91-%d0%b8%d0%b3/
http://roikjer.com/forum/index.php?PHPSESSID=fvi140i7tfr31qbqu1r4798cf5&topic=806133.0
https://www.thedezlab.com/lab/community/index.php?topic=232.0
http://www.popolsku.fr.pl/forum/index.php?topic=372315.0
http://multikopterforum.hu/index.php?topic=5659.0
http://8.droror.co.il/uncategorized/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90ud1%e3%80%91/
http://help.stv.ru/index.php?topic=137435.0
http://help.stv.ru/index.php?PHPSESSID=6abd23bda48f1b9243f857d651c5f2cf&topic=136724.0
http://podwodnyswiat.eu/forum/index.php?topic=306.0
http://forum.kopkargobel.com/index.php?topic=4776.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w1-a4-%d0%b8%d0%b3%d1%80/
http://dpmarketingsystems.com/06-05-2019-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.hoonthaitoday.com/forum/index.php?topic=146141.0
http://e-educ.net/Forum/index.php?topic=4954.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=ccac6ba69d64897af1799cb1f4b97f2d&topic=211476.0
http://HyUa.1fps.icu/l/szIaeDC
https://www.blog.quora.healthcare/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hut-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b
http://teambuildingpremium.com/forum/index.php?topic=594196.0
http://macdistri.com/index.php/component/k2/itemlist/user/258205
https://www.youngbiker.de/wbboard/index.php?page=User&userID=776363
http://macdistri.com/index.php/component/k2/itemlist/user/308175
http://webp.online/index.php?topic=47887.0
http://withinfp.sakura.ne.jp/eso/index.php/16874051-zensina-59-seria-p5ul-zensina-59-seria
http://teambuildingpremium.com/forum/index.php?topic=674203.0
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=405905
http://menulisilmiah.net/%d0%bc%d0%b5%d1%80%d1%82%d0%b2%d0%be%d0%b5-%d0%be%d0%b7%d0%b5%d1%80%d0%be-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fh5-%d0%bc%d0%b5%d1%80%d1%82%d0%b2%d0%be%d0%b5-%d0%be%d0%b7%d0%b5%d1%80/
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1106584
http://married.dike.gr/index.php/component/k2/itemlist/user/53185
https://tg.vl-mp.com/index.php?topic=1266882.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3602572
http://www.popolsku.fr.pl/forum/index.php?topic=339708.0
https://forum.ac-jete.it/index.php?topic=289239.0
http://webp.online/index.php?topic=48846.15
http://www.popolsku.fr.pl/forum/index.php?topic=343508.0
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=4477
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/172800
http://mobility-corp.com/index.php/component/k2/itemlist/user/2479841
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1956890
http://foa.egerton.ac.ke/index.php/component/k2/itemlist/user/1677613
http://danielmillsap.com/forum/index.php?topic=843579.0
http://danielmillsap.com/forum/index.php?topic=869176.0
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gl6-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7/
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=318770
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=259894
https://www.blog.quora.healthcare/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rdn-%d0%b8%d0%b3%d1%80%d0%b0
https://www.shaiyax.com/index.php?topic=307684.0
http://www.deliberarchia.org/forum/index.php?topic=956074.0
http://withinfp.sakura.ne.jp/eso/index.php/16785462-riverdejl-riverdale-3-sezon-22-seria-sgu-riverdejl-riverdale-3-
https://www.youngbiker.de/wbboard/index.php?page=User&userID=785258
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/388922
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1614539
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=261717
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/367910
https://tg.vl-mp.com/index.php?topic=1309018.0
https://members.fbhaters.com/index.php/topic,71396.0.html
https://www.resproxy.com/forum/index.php/744218-milliardy-4-sezon-6-seria-fxt-milliardy-4-sezon-6-seria-0405201/0
http://puppystoreatdoral.com/?option=com_k2&view=itemlist&task=user&id=344070
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/135165
http://webp.online/index.php?topic=48411.0
http://www.web2interactive.com/index.php/component/k2/itemlist/user/3473313
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2128665
http://www.popolsku.fr.pl/forum/index.php?topic=339462.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=892150
http://menulisilmiah.net/%d0%bd%d0%b5-%d0%be%d1%82%d0%bf%d1%83%d1%81%d0%ba%d0%b0%d0%b9-%d0%bc%d0%be%d1%8e-%d1%80%d1%83%d0%ba%d1%83-elimi-birakma-36-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r5eu-%d0%bd%d0%b5-%d0%be/
http://jpacschoolclubs.co.uk/?option=com_k2&view=itemlist&task=user&id=3268322
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1084448
http://danielmillsap.com/forum/index.php?topic=816518.0
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=143393
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1471607
http://forum.thaibetrank.com/index.php?topic=1070740.0
http://seoksoononly.dothome.co.kr/qna/460927
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/483249
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jo3-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3278439
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=306408
http://sos.victoryaltar.org/tiki-index.php?page=UserPagedonnyfullartonjuwd
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3545538
http://seoksoononly.dothome.co.kr/qna/453873
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=875256
http://healthyteethpa.org/component/k2/itemlist/user/5333655
https://mcsetup.tk/bbs/index.php?topic=227365.0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=533692
http://www2.yasothon.go.th/smf/index.php?topic=159.msg145878
http://muratliziraatodasi.org/forum/index.php?topic=331631.0
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1825254
http://www.deliberarchia.org/forum/index.php?topic=949673.0
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4730110
http://withinfp.sakura.ne.jp/eso/index.php/16835123-edinoe-serdce-tek-yurek-10-seria-d0vs-edinoe-serdce-tek-yurek-1
http://www.popolsku.fr.pl/forum/index.php?topic=329126.0
http://healthyteethpa.org/component/k2/itemlist/user/5189542
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/484943
http://metropolis.ga/index.php?topic=2724.0
http://webp.online/index.php?topic=48708.15
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=593006.0
http://menulisilmiah.net/%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mq5-%d1%81%d0%be%d1%81%d0%b5%d0%b4%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15/
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=41206
http://teambuildingpremium.com/forum/index.php?topic=660908.0
https://www.resproxy.com/forum/index.php/749676-cernoe-zerkalo-5-sezon-2-seria-dfs-cernoe-zerkalo-5-sezon-2-ser/0
http://www.popolsku.fr.pl/forum/index.php?topic=342443.0
http://withinfp.sakura.ne.jp/eso/index.php/16777067-voron-kuzgun-17-seria-g0uq-voron-kuzgun-17-seria/0
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=188443
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=874930
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1035467
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/297296
http://webp.online/index.php?topic=41393.0
http://danielmillsap.com/forum/index.php?topic=843537.0
http://www.spazioad.com/component/k2/itemlist/user/7166546
http://metropolis.ga/index.php?topic=1339.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/247479
http://danielmillsap.com/forum/index.php?topic=841420.0
http://avengerro.top/forum/index.php?topic=18020.0
http://macdistri.com/index.php/component/k2/itemlist/user/297215
http://aitour.kz/index.php/component/k2/itemlist/user/312632
http://www.deliberarchia.org/forum/index.php?topic=898432.0
http://danielmillsap.com/forum/index.php?topic=888121.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=873944
https://www.youngbiker.de/wbboard/index.php?page=User&userID=785485
http://www.deliberarchia.org/forum/index.php?topic=919846.0
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7257191
http://withinfp.sakura.ne.jp/eso/index.php/16825200-edinoe-serdce-tek-yurek-8-seria-m4yw-edinoe-serdce-tek-yurek-8-
http://www.deliberarchia.org/forum/index.php?topic=788032.0
http://pptforum.dothome.co.kr/board_APMk06/791316
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/234286
http://web2interactive.com/index.php/component/k2/itemlist/user/3586901
http://macdistri.com/index.php/component/k2/itemlist/user/311633
http://www.aloeverasas.it/index.php/component/k2/itemlist/user/18031
http://lavaggio.com.vn/index.php/component/k2/itemlist/user/3746405
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hlm-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://www.quattroandpartners.it/component/k2/itemlist/user/1049616
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=762605
http://www.siirtorganik.com/index.php/component/k2/itemlist/user/762623
http://www.spazioad.com/component/k2/itemlist/user/7225482
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=202989
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=220800
http://forum.politeknikgihon.ac.id/index.php?topic=21008.0
http://poselokgribovo.ru/forum/index.php?topic=745376.0
http://poselokgribovo.ru/forum/index.php?topic=745411.0
http://ruschinaforum.ru/index.php/topic,131876.0.html
http://siliconvalleytalk.xyz/blogs/viewstory/16457
http://siliconvalleytalk.xyz/blogs/viewstory/16526
http://siliconvalleytalk.xyz/blogs/viewstory/16541
http://siliconvalleytalk.xyz/blogs/viewstory/16554
http://siliconvalleytalk.xyz/blogs/viewstory/16589
http://teambuildingpremium.com/forum/index.php?topic=794361.0
http://teambuildingpremium.com/forum/index.php?topic=794385.0
http://thanosakademi.com/index.php?topic=72752.0
http://uberdrivers.net/forum/index.php?topic=245847.0
http://websites.start-a-idea.online/blogs/viewstory/161221
http://websites.start-a-idea.online/blogs/viewstory/161245
http://websites.start-a-idea.online/blogs/viewstory/161273
http://www.deliberarchia.org/forum/index.php?topic=950718.0
http://muratliziraatodasi.org/forum/index.php?topic=402465.0
http://driversed.tv/blog/archives/35725
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-42/
http://www.tessabannampad.go.th/webboard/index.php?topic=188116.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-(got)-8-eo-3-e-a-etoo-(got)-8-eo-3-e-h8k3/?PHPSESSID=55lnf6qk834i875k0ib5qrs611
http://www.ekemoon.com/160211/051920191308/
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=110741
http://www.theparrotcentre.com/forum/index.php?topic=470827.0
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3558676
http://roikjer.com/forum/index.php?PHPSESSID=2im00pkemmqd3km9cn9k1f32s5&topic=801778.0
https://verdadesbiblicas.org.ec/index.php/component/k2/itemlist/user/3712879
https://danceplanet.se/commodore/index.php?topic=8759.0
http://www.critico-expository.com/forum/index.php?topic=5153.0
https://members.fbhaters.com/index.php?topic=73400.0
http://help.stv.ru/index.php?PHPSESSID=1052c5f1c50d15c8641b8be0c49b3d59&topic=138572.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/e-eka-aota-(e-ioa-oota)-16-e-07-05-2019/?PHPSESSID=eg5gv4tsbo6jb8qo4vcdmmqqi5
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=678623.0
http://married.dike.gr/index.php/component/k2/itemlist/user/43602
http://www.deliberarchia.org/forum/index.php?topic=934485.0
http://forum.politeknikgihon.ac.id/index.php?topic=19218.0
http://otitismediasociety.org/forum/index.php?topic=146647.0
http://bobr.site/index.php?topic=84167.0
http://eugeniocolazzo.it/forum/index.php?topic=87598.0
http://help.stv.ru/index.php?topic=137939.0
http://www.deliberarchia.org/forum/index.php?topic=954538.0
http://ptu.imoove.kr/ko/content/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-got-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-7-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90ho6%E3%80%91-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-got-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-7-%D1%81%D0%B5%D1%80%D0%B8%D1%8F330326
http://forum.digamahost.com/index.php?topic=108220.0
http://blog.ptpintcast.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90ej4%e3%80%91-%d0%b8%d0%b3/
http://roikjer.com/forum/index.php?topic=792472.0
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=996314
http://danielmillsap.com/forum/index.php?topic=948827.0
http://www.deliberarchia.org/forum/index.php?topic=977106.0
http://metropolis.ga/index.php?topic=5273.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=678523.0
https://forums.letstalkbeats.com/index.php?topic=65368.0
http://danielmillsap.com/forum/index.php?topic=981064.0
http://multikopterforum.hu/index.php?topic=14165.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.deliberarchia.org/forum/index.php?topic=959295.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=679170.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3627033
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/8016
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1025709
http://dev.aabn.org.gh/component/k2/itemlist/user/534943
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-njt-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://healthyteethpa.org/component/k2/itemlist/user/5341495
http://www.vivelabmanizales.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cbt-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-5-%d1%81%d0%b5%d1%80%d0%b8/
http://danielmillsap.com/forum/index.php?topic=989966.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1146485
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=36815
http://marjorieaperry.com/?option=com_k2&view=itemlist&task=user&id=484420
http://matinbank.ir/component/k2/itemlist/user/4502013.html
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=238440
http://mediaville.me/index.php/component/k2/itemlist/user/238700
http://mediaville.me/index.php/component/k2/itemlist/user/238833
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=78981
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/78971
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=10806
http://proxima.co.rw/index.php/component/k2/itemlist/user/590621
http://robocit.com/index.php/component/k2/itemlist/user/449410
https://mcsetup.tk/bbs/index.php?topic=247779.0
https://mcsetup.tk/bbs/index.php?topic=247785.0
https://npi.org.es/smf/index.php?topic=114048.0
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i3-%e3%80%90-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f3-%e3%80%90-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80-2/
https://sanp.pro/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l2-%e3%80%90-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://www.c-alice.org/forum/index.php?topic=78402.0
https://www.c-alice.org/forum/index.php?topic=78407.0
http://healthyteethpa.org/?option=com_k2&view=itemlist&task=user&id=5294936
https://instaldec.com/?option=com_k2&view=itemlist&task=user&id=600454
http://discussadeal.com/forum/index.php?topic=2748.0
http://macdistri.com/index.php/component/k2/itemlist/user/220593
https://www.resproxy.com/forum/index.php/742200-milliardy-4-sezon-7-seria-ofp-milliardy-4-sezon-7-seria-0405201/0
http://seoksoononly.dothome.co.kr/qna/656968
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4706452
https://www.youngbiker.de/wbboard/index.php?page=User&userID=784112
http://teambuildingpremium.com/forum/index.php?topic=660415.0
http://www.popolsku.fr.pl/forum/index.php?topic=332075.0
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2386945
https://members.fbhaters.com/index.php?topic=71167.0
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=193112
https://tg.vl-mp.com/index.php?topic=1290867.0
http://danielmillsap.com/forum/index.php?topic=989750.0
https://www.blog.quora.healthcare/%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0%d1%8f-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b0-%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be%d0%b1%d0%be%d1%82%d0%b0-14-%d1%81%d0%b5%d1%80
https://tg.vl-mp.com/index.php?topic=1297167.0
http://www.deliberarchia.org/forum/index.php?topic=958082.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1090446
http://www.deliberarchia.org/forum/index.php?topic=978528.0
http://c3isecurity.com.br/component/k2/itemlist/user/478773
http://teambuildingpremium.com/forum/index.php?topic=601414.0
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/182057
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hwu-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
http://teambuildingpremium.com/forum/index.php?topic=647839.0
https://www.youngbiker.de/wbboard/index.php?page=User&userID=785527
http://myrechockey.com/forums/index.php?topic=54718.0
http://married.dike.gr/index.php/component/k2/itemlist/user/39890
http://www.deliberarchia.org/forum/index.php?topic=943619.0
http://pptforum.dothome.co.kr/board_APMk06/842716
http://thermoplast.envolgroupe.com/component/k2/author/66066
http://menulisilmiah.net/%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0%d1%88%d0%ba%d0%b0-erkenci-kus-41-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g3bi-%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1314540
http://www.m1avio.com/index.php/component/k2/itemlist/user/3606621
http://dessa.com.br/component/k2/itemlist/user/294052
http://myrechockey.com/forums/index.php?topic=55252.0
http://withinfp.sakura.ne.jp/eso/index.php/16789340-milliardy-4-sezon-8-seria-apd-milliardy-4-sezon-8-seria-0205201/0
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/4284
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4829246
http://www.merrygoroundtoronto.com/boutique/?option=com_k2&view=itemlist&task=user&id=483304
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4681028
http://danielmillsap.com/forum/index.php?topic=819693.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1094918
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4614974
http://danielmillsap.com/forum/index.php?topic=833173.0
http://www.popolsku.fr.pl/forum/index.php?topic=339016.0
http://menulisilmiah.net/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-pr0-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1822402
https://www.youngbiker.de/wbboard/index.php?page=User&userID=781304
http://withinfp.sakura.ne.jp/eso/index.php/16777831-lubov-smert-i-roboty-love-death-and-robots-14-seria-etq-lubov-s/0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/268612
http://danielmillsap.com/forum/index.php?topic=812612.0
http://www.deliberarchia.org/forum/index.php?topic=905993.0
http://webp.online/index.php?topic=42215.0
http://www.spazioad.com/component/k2/itemlist/user/7161696
http://married.dike.gr/index.php/component/k2/itemlist/user/31752
http://withinfp.sakura.ne.jp/eso/index.php/16780591-nasa-istoria-64-seria-f9ur-nasa-istoria-64-seria/0
http://metropolis.ga/index.php?topic=5934.0
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1127696
http://danielmillsap.com/forum/index.php?topic=792976.0
http://www.deliberarchia.org/forum/index.php?topic=765503.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1298703
https://tg.vl-mp.com/index.php?topic=1265573.0
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yp7-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8/
http://mobility-corp.com/index.php/component/k2/itemlist/user/2473375
http://withinfp.sakura.ne.jp/eso/index.php/16915150-voskressij-ertugrul-147-seria-b1ff-voskressij-ertugrul-147-seri
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=407570
https://lucky28003.nl/forum/index.php?topic=7069.0
http://seoksoononly.dothome.co.kr/qna/470205
http://www.deliberarchia.org/forum/index.php?topic=946841.0
http://www.deliberarchia.org/forum/index.php?topic=790165.0
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=77989
http://www.quattroandpartners.it/component/k2/itemlist/user/1051566
https://tg.vl-mp.com/index.php?topic=1259553.0
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/589099
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3246219
http://danielmillsap.com/forum/index.php?topic=874224.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1324397
http://webp.online/index.php?topic=42082.0
https://ne-kuru.ru/index.php?topic=202382.0
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1795181
http://webp.online/index.php?topic=43713.0
http://macdistri.com/index.php/component/k2/itemlist/user/281580
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=77960
https://tg.vl-mp.com/index.php?topic=1260638.0
http://seoksoononly.dothome.co.kr/qna/467668
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81-41/
http://danielmillsap.com/forum/index.php?topic=824702.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3604076
http://www.dap.com.py/index.php/es/?option=com_k2&view=itemlist&task=user&id=787986
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1552103
http://married.dike.gr/index.php/component/k2/itemlist/user/39014
http://dev.aabn.org.gh/component/k2/itemlist/user/500748
http://roikjer.com/forum/index.php?PHPSESSID=dnqnmq481vlib6dr2odibpkct6&topic=849178.0
http://roikjer.com/forum/index.php?PHPSESSID=v6nhm9p17ifkr5qoi2rojp9ui2&topic=849181.0
http://roikjer.com/forum/index.php?topic=849142.0
http://sexfork.com/uncategorized/igra-prestolov-8-sezon-6-seriya-c8%f4igra-prestolov-8-sezon-6-seriya-igra-prestolov-8-sezon-6-seriya/
http://www.deliberarchia.org/forum/index.php?topic=1005948.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-l3-f6-%d0%b8%d0%b3/
http://danielmillsap.com/forum/index.php?topic=1007080.0
http://forum.elexlabs.com/index.php/topic,19069.0.html
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-(got)-8-eo-2-e-a-etoo-(got)-8-eo-2-e-c8t2/?PHPSESSID=93fkaen5dqhvdmaqev64cqe010
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=31290.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=31292.0
http://www.hoonthaitoday.com/forum/index.php?topic=220477.0
http://www.tessabannampad.go.th/webboard/index.php?topic=199551.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-9/
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pc2-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x5-l7-%d0%b8%d0%b3%d1%80/
https://reficulcoin.com/index.php?topic=5941.0
https://nextezone.com/index.php?topic=31964.0
http://roikjer.com/forum/index.php?PHPSESSID=3337mujss4ljr4mpqn7ortsjh7&topic=804492.0
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-l6-k4-%d0%b8%d0%b3%d1%80/
https://sanp.pro/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q7-k8-%d1%80%d0%b0%d1%81%d1%81/
http://matrixpharm.ru/forum/index.php?PHPSESSID=le82a09kunahcf6id833nu52k0&action=profile;u=164914
http://poselokgribovo.ru/forum/index.php?topic=688784.0
http://multikopterforum.hu/index.php?topic=9438.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2557288
http://blog.ptpintcast.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-s2-g4-%d0%b8%d0%b3/
http://teambuildingpremium.com/forum/index.php?topic=766760.0
https://danceplanet.se/commodore/index.php?topic=11278.0
http://otitismediasociety.org/forum/index.php?topic=144307.0
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2558229
http://wituclub.ru/forum/index.php?PHPSESSID=1ou1ri9j036jh0ehqc98nt6u00&topic=25900.0
https://danceplanet.se/commodore/index.php?topic=12173.0
http://wb.hvekorat.com/index.php?topic=40583.0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-b0-z2-%d0%b8%d0%b3%d1%80%d0%b0/
http://HyUa.1fps.icu/l/szIaeDC
http://www.deliberarchia.org/forum/index.php?topic=981115.0
https://alquilervideobeam.com.co/?option=com_k2&view=itemlist&task=user&id=54940
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vwa-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://webp.online/index.php?topic=48397.0
http://webp.online/index.php?topic=44422.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3178779
https://www.youngbiker.de/wbboard/index.php?page=User&userID=784666
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/626754
http://dcasociados.eu/component/k2/itemlist/user/82107
https://instaldec.com/index.php/component/k2/itemlist/user/601533
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=203353
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/174859
http://menulisilmiah.net/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xp4-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.x2145-productions.technology/index.php?title=%C2%AB%D0%9F%D0%BB%D0%BE%D1%85%D0%B8%D0%B5_%D0%9F%D0%B0%D1%80%D0%BD%D0%B8_3_2020_%C2%BB_08-05-2019_%C2%AB%D0%9F%D0%BB%D0%BE%D1%85%D0%B8%D0%B5_%D0%9F%D0%B0%D1%80%D0%BD%D0%B8_3_2020_%C2%BB_%C2%AB%D0%9F%D0%BB%D0%BE%D1%85%D0%B8%D0%B5_%D0%9F%D0%B0%D1%80%D0%BD%D0%B8_3_2020_%C2%BB
http://teambuildingpremium.com/forum/index.php?topic=685397.0
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/46571
http://danielmillsap.com/forum/index.php?topic=952305.0
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bd8-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
https://members.fbhaters.com/index.php?topic=76948.0
https://www.youngbiker.de/wbboard/index.php?page=User&userID=782539
http://www.x2145-productions.technology/index.php?title=%C3%82%C2%AB%C3%90%C3%A2%E2%82%AC%E2%84%A2%C3%91%E2%82%AC%C3%90%C2%B5%C3%90%C2%BC%C3%91_%C3%90%C5%93%C3%90%C2%BE%C3%90%C2%BD%C3%91%C3%91%E2%80%9A%C3%91%E2%82%AC%C3%90%C2%BE%C3%90%C2%B2%C3%82%C2%BB_06-05-2019_%C3%90%C3%A2%E2%82%AC%E2%84%A2%C3%91%E2%82%AC%C3%90%C2%B5%C3%90%C2%BC%C3%91_%C3%90%C5%93%C3%90%C2%BE%C3%90%C2%BD%C3%91%C3%91%E2%80%9A%C3%91%E2%82%AC%C3%90%C2%BE%C3%90%C2%B2_%C3%82%C2%AB%C3%90%C3%A2%E2%82%AC%E2%84%A2%C3%91%E2%82%AC%C3%90%C2%B5%C3%90%C2%BC%C3%91_%C3%90%C5%93%C3%90%C2%BE%C3%90%C2%BD%C3%91%C3%91%E2%80%9A%C3%91%E2%82%AC%C3%90%C2%BE%C3%90%C2%B2%C3%82%C2%BB
http://www.m1avio.com/?option=com_k2&view=itemlist&task=user&id=3598545
http://teambuildingpremium.com/forum/index.php?topic=669545.0
http://www.deliberarchia.org/forum/index.php?topic=955233.0
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=292788
http://dev.aabn.org.gh/component/k2/itemlist/user/492127
http://discussadeal.com/forum/index.php/topic,2593.0.html
http://associationsila.org/component/k2/itemlist/user/263654
http://sos.victoryaltar.org/tiki-index.php?page=UserPagestephanyuygydkntvwg
http://webp.online/index.php?topic=49348.0
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3302981
http://www.deliberarchia.org/forum/index.php?topic=907737.0
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=557278
http://webp.online/index.php?topic=48064.0
https://sto54.ru/index.php/component/k2/itemlist/user/3248902
http://www.popolsku.fr.pl/forum/index.php?topic=340505.0
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1109753
http://myrechockey.com/forums/index.php?topic=56196.0
http://teambuildingpremium.com/forum/index.php?topic=653790.0
http://www.deliberarchia.org/forum/index.php?topic=781102.0
http://teambuildingpremium.com/forum/index.php?topic=662031.0
http://withinfp.sakura.ne.jp/eso/index.php/16819286-nasa-istoria-69-seria-o6go-nasa-istoria-69-seria
https://www.shaiyax.com/index.php?topic=314490.0
https://members.fbhaters.com/index.php?topic=65240.0
http://avengerro.top/forum/index.php?topic=18628.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/447925
http://withinfp.sakura.ne.jp/eso/index.php/16770653-riverdejl-riverdale-3-sezon-18-seria-sgs-riverdejl-riverdale-3-/0
http://www.popolsku.fr.pl/forum/index.php?topic=341364.0
http://israengineering.com/index.php/component/k2/itemlist/user/1092267
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=50718
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1082006
http://menulisilmiah.net/%d0%b6%d0%b5%d0%bd%d1%89%d0%b8%d0%bd%d0%b0-59-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i7pe-%d0%b6%d0%b5%d0%bd%d1%89%d0%b8%d0%bd%d0%b0-59-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://danielmillsap.com/forum/index.php?topic=984824.0
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kj4-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=668797
https://www.shaiyax.com/index.php?topic=299581.0
http://myrechockey.com/forums/index.php?topic=85640.0
http://teambuildingpremium.com/forum/index.php?topic=628931.0
http://withinfp.sakura.ne.jp/eso/index.php/16794537-cernoe-zerkalo-5-sezon-5-seria-iku-cernoe-zerkalo-5-sezon-5-ser
http://www.popolsku.fr.pl/forum/index.php?topic=336483.0
http://webp.online/index.php?topic=47482.msg77784
http://danielmillsap.com/forum/index.php?topic=841014.0
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/915070
http://withinfp.sakura.ne.jp/eso/index.php/16823474-rannaa-ptaska-erkenci-kus-40-seria-f0jp-rannaa-ptaska-erkenci-k
http://webp.online/index.php?topic=38364.0
http://danielmillsap.com/forum/index.php?topic=905343.0
https://forum.ac-jete.it/index.php?topic=285623.0
http://web47.luke.servertools24.de/gw2/wbb/upload/index.php?page=User&userID=873518
http://menulisilmiah.net/%d0%b2%d0%be%d1%80%d0%be%d0%bd-kuzgun-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m5bl-%d0%b2%d0%be%d1%80%d0%be%d0%bd-kuzgun-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rk4-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://healthyteethpa.org/component/k2/itemlist/user/5288121
https://tg.vl-mp.com/index.php?topic=1268805.0
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1709986
http://www.deliberarchia.org/forum/index.php?topic=919338.0
http://teambuildingpremium.com/forum/index.php?topic=630843.0
http://metropolis.ga/index.php?topic=3034.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3252819
http://www.popolsku.fr.pl/forum/index.php?topic=347459.0
http://seoksoononly.dothome.co.kr/qna/415891
http://soc-human.kz/index.php/component/k2/itemlist/user/1551896
http://metropolis.ga/index.php?topic=885.0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=36790
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1296901
http://webp.online/index.php?topic=50261.0
https://www.blog.quora.healthcare/%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5%d0%bd%d0%b8%d0%b5-vuslat-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v3yu-%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd
http://mahdi.ehosseini.com/?option=com_k2&view=itemlist&task=user&id=15324
http://danielmillsap.com/forum/index.php?topic=906821.0
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2303663
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=30741
http://danielmillsap.com/forum/index.php?topic=982696.0
http://fbpharm.net/index.php/component/k2/itemlist/user/14137
https://prosocyr.com/?option=com_k2&view=itemlist&task=user&id=608769
https://www.shaiyax.com/index.php?topic=297799.0
http://www.deliberarchia.org/forum/index.php?topic=793736.0
http://153.120.114.241/eso/index.php/16872641-sverh-estestvennoe-14-sezon-19-seria-ggd-sverh-estestvennoe-14-
http://dscardip.com/board/index.php?page=User&userID=659981
http://pptforum.dothome.co.kr/board_APMk06/614530
https://reficulcoin.com/index.php?topic=8161.0
https://khuyenmaikk13.info/index.php?topic=177209.0
http://danielmillsap.com/forum/index.php?topic=986422.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=274985
https://forum.clubeicaro.pt/index.php?topic=830.0
http://www.deliberarchia.org/forum/index.php?topic=958837.0
http://153.120.114.241/eso/index.php/16852581-igra-prestolov-2019-8-sezon-7-seria-igra-prestolov-2019-8-sezon
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m7-f6-%d1%80%d0%b0%d1%81%d1%81/
http://withinfp.sakura.ne.jp/eso/index.php/16860961-tolarobot-8-seria-p2-tolarobot-8-seria/0
http://roikjer.com/forum/index.php?topic=827717.0
http://menulisilmiah.net/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90rv2%e3%80%91-%d0%b8%d0%b3/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l8-g7-%d0%b8%d0%b3%d1%80/
https://danceplanet.se/commodore/index.php?topic=13521.0
https://www.shaiyax.com/index.php?topic=334006.0
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-m0-d3-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
https://reficulcoin.com/index.php?topic=5492.0
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=603359
http://www.deliberarchia.org/forum/index.php?topic=942303.0
http://danielmillsap.com/forum/index.php?topic=921563.0
https://khuyenmaikk13.info/index.php?topic=175066.0
http://www.remify.app/foro/index.php?topic=241719.0
http://thanosakademi.com/index.php?topic=62350.0
http://www.deliberarchia.org/forum/index.php?topic=932835.0
http://help.stv.ru/index.php?PHPSESSID=1c8149f6a357e45bd72715e12baee364&topic=136502.0
http://multikopterforum.hu/index.php?topic=4665.0
https://reficulcoin.com/index.php?topic=8855.0
http://roikjer.com/forum/index.php?PHPSESSID=5tqpnfqcidc0qebfmll0grcv05&topic=792903.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=671528.0
http://www.ekemoon.com/150643/050520193207/
http://yuptalk.ru/other_food_household_cosmetics_etc/-t12829.0.html;msg114979
https://khuyenmaikk13.info/index.php?topic=177742.0
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i5-u0-%d0%b8%d0%b3%d1%80%d0%b0/
http://HyUa.1fps.icu/l/szIaeDC
http://macdistri.com/index.php/component/k2/itemlist/user/223325
http://discussadeal.com/forum/index.php?topic=2234.0
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2542063
http://withinfp.sakura.ne.jp/eso/index.php/16821170-zensina-57-seria-f7cw-zensina-57-seria/0
http://metropolis.ga/index.php?topic=1698.0
http://menulisilmiah.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sge-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=916375
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1713448
http://teambuildingpremium.com/forum/index.php?topic=617773.0
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1829220
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4669345
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1551828
http://seoksoononly.dothome.co.kr/qna/469060
https://members.fbhaters.com/index.php?topic=69848.0
http://seoksoononly.dothome.co.kr/?document_srl=628143
https://prosocyr.com/index.php/component/k2/itemlist/user/578153
http://danielmillsap.com/forum/index.php?topic=834089.0
http://dessa.com.br/index.php/component/k2/itemlist/user/320408
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1960689
http://travelsolution.info/index.php/component/k2/itemlist/user/699251
http://mobility-corp.com/index.php/component/k2/itemlist/user/2417381
http://1vh.info/index.php?topic=16386.0
http://dpmarketingsystems.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-w0-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5/
http://forum.bmw-e60.eu/index.php?topic=4925.0
http://forum.bmw-e60.eu/index.php?topic=4926.0
http://forum.bmw-e60.eu/index.php?topic=4927.0
http://forum.bmw-e60.eu/index.php?topic=4929.0
http://forum.politeknikgihon.ac.id/index.php?topic=27903.0
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=282303
http://healthyteethpa.org/?option=com_k2&view=itemlist&task=user&id=5377741
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1144272
http://poselokgribovo.ru/forum/index.php?topic=743693.0
http://poselokgribovo.ru/forum/index.php?topic=743787.0
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3412496
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3412518
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3412727
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=36975
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=36976
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=36977
https://nextezone.com/index.php?action=profile;u=3594
https://nextezone.com/index.php?topic=39598.0
https://reficulcoin.com/index.php?topic=17214.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-s8-u7-%d0%b8%d0%b3/
https://tg.vl-mp.com/index.php?topic=1360780.0
https://tg.vl-mp.com/index.php?topic=1360788.0
http://poselokgribovo.ru/forum/index.php?topic=718804.0
http://multikopterforum.hu/index.php?topic=6250.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=d88024ab562d42ec8b6e3d9eb462826f&topic=211775.0
http://teambuildingpremium.com/forum/index.php?topic=757478.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-z7-j2-%d0%b8%d0%b3%d1%80%d0%b0/
http://153.120.114.241/eso/index.php/16854756-05052019-drugaa-insa-19-seria
http://poselokgribovo.ru/forum/index.php?topic=693820.0
http://seoksoononly.dothome.co.kr/qna/737128
http://forum.politeknikgihon.ac.id/index.php?topic=17907.0
http://multikopterforum.hu/index.php?topic=8544.0
http://blog.ptpintcast.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-l0-d1-%d0%b8%d0%b3%d1%80%d0%b0/
http://codeerror.in/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0/
http://menulisilmiah.net/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90uv3%e3%80%91/
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-21/
http://www.spazioad.com/component/k2/itemlist/user/7232893
http://multikopterforum.hu/index.php?topic=5417.0
http://www.tessabannampad.go.th/webboard/index.php?topic=189127.0
http://codeerror.in/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-s1-h3-%d1%80%d0%b0%d1%81%d1%81/
http://forum.kopkargobel.com/index.php?topic=5802.0
https://worldtaxi.org/2019/05/08/%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0%d1%8f-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b0-%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be%d0%b1%d0%be%d1%82%d0%b0-19-%d1%81%d0%b5/
http://freebeer.me/index.php?topic=307290.0
http://storykingdom.forumside.com/index.php?topic=4060.0
http://www.critico-expository.com/forum/index.php?topic=2959.0
http://www.tekparcahdfilm.com/forum/index.php?topic=46341.0
http://www.tessabannampad.go.th/webboard/index.php?topic=185417.0
http://www.deliberarchia.org/forum/index.php?topic=956528.0
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c8-u9-%d1%80%d0%b0%d1%81%d1%81/
http://HyUa.1fps.icu/l/szIaeDC
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2544284
http://mobility-corp.com/index.php/component/k2/itemlist/user/2544271
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/218908
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=10130
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=10133
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=143978
http://rudraautomation.com/index.php/component/k2/author/143969
http://rudraautomation.com/index.php/component/k2/itemlist/user/143980
http://sextomariotienda.com/blog/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kyp-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://sextomariotienda.com/blog/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dvi-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://sextomariotienda.com/blog/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-ydk-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://theolevolosproject.org/index.php/component/k2/itemlist/user/25390
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/62668
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=189710
https://nextezone.com/index.php?topic=40170.0
https://reficulcoin.com/index.php?topic=17989.0
http://1vh.info/index.php?topic=17213.0
http://1vh.info/index.php?topic=17216.0
http://dota2.host/91446-smotret-sluga-naroda-3-sezon-8-seria-s3-sluga-naroda-3-sezon-8-
http://dota2.host/91489-smotret-sluga-naroda-3-sezon-14-seria-j6-sluga-naroda-3-sezon-1
http://dota2.host/91695-new-sluga-naroda-3-sezon-4-seria-h1-sluga-naroda-3-sezon-4-seri
http://dota2.host/92038-online-sluga-naroda-3-sezon-9-seria-c9-sluga-naroda-3-sezon-9-s
http://dota2.host/92322-smotret-sluga-naroda-3-sezon-8-seria-t6-sluga-naroda-3-sezon-8-
http://dota2.host/92395-online-sluga-naroda-3-sezon-20-seria-x5-sluga-naroda-3-sezon-20
http://dota2.host/92435-hd-sluga-naroda-3-sezon-16-seria-h4-sluga-naroda-3-sezon-16-ser
http://dota2.host/92599-tv-sluga-naroda-3-sezon-14-seria
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3277287
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=6531.0
https://chromehearts.in.th/index.php?topic=39577.0
https://sto54.ru/index.php/component/k2/itemlist/user/3239285
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=261660
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=755365
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1815213
http://uberdrivers.net/forum/index.php?topic=185907.0
http://poselokgribovo.ru/forum/index.php?topic=650410.0
http://israengineering.com/index.php/component/k2/itemlist/user/1075684
http://uberdrivers.net/forum/index.php?topic=186476.0
http://web2interactive.com/index.php/component/k2/itemlist/user/3527681
http://www.ekemoon.com/152281/051220192607/
https://reficulcoin.com/index.php?topic=14347.0
http://www.hoonthaitoday.com/forum/index.php?topic=127758.0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/74619
http://euromouleusinage.com/index.php/component/k2/itemlist/user/102965
http://multikopterforum.hu/index.php?topic=6999.0
https://forum.clubeicaro.pt/index.php?topic=172.0
http://teambuildingpremium.com/forum/index.php?topic=759933.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=25511.0
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t5-s4-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
https://sanp.pro/hd-video-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t3-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://menulisilmiah.net/%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l9-%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-13-%d1%81%d0%b5%d1%80/
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l8-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/09-05-2019-%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://menulisilmiah.net/09-05-2019-%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0%d1%8f-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b0-%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be%d0%b1%d0%be%d1%82%d0%b0-20/
http://menulisilmiah.net/09-05-2019-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/09-05-2019-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/09-05-2019-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
https://danceplanet.se/commodore/index.php?topic=17148.0
https://danceplanet.se/commodore/index.php?topic=17151.0
https://khuyenmaikk13.info/index.php?topic=185282.0
https://khuyenmaikk13.info/index.php?topic=185291.0
https://members.fbhaters.com/index.php/topic,83652.0.html
http://HyUa.1fps.icu/l/szIaeDC
http://rudraautomation.com/index.php/component/k2/author/120491
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=6890
https://sanp.pro/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-s9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/585466
http://www.m1avio.com/index.php/component/k2/itemlist/user/3631006
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/255093
http://forums.abs-cbn.com/welcome-back-kapamilya%21/(ta-93-e)-oyi'-ta-93-e-29-04-2019/?PHPSESSID=92h7r6q9plsp9r3k5e1c6soro3
http://www.critico-expository.com/forum/index.php?topic=581.0
http://dessa.com.br/index.php/component/k2/itemlist/user/292949
http://uberdrivers.net/forum/index.php?topic=176444.0
http://www.remify.app/foro/index.php?topic=195869.0
http://israengineering.com/index.php/component/k2/itemlist/user/1071930
http://marjorieaperry.com/component/k2/itemlist/user/473227
http://www.spazioad.com/component/k2/itemlist/user/7152788
https://sanp.pro/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-i3-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.m1avio.com/index.php/component/k2/itemlist/user/3587310
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/63863
http://websites.start-a-idea.online/blogs/viewstory/161107
http://websites.start-a-idea.online/blogs/viewstory/161144
http://www.critico-expository.com/forum/index.php?topic=6824.0
http://www.deliberarchia.org/forum/index.php?topic=993008.0
http://multikopterforum.hu/index.php?topic=8639.0
http://www.popolsku.fr.pl/forum/index.php?topic=20407.46110
http://www.tessabannampad.go.th/webboard/index.php?topic=192155.0
http://multikopterforum.hu/index.php?topic=9234.0
https://reficulcoin.com/index.php?topic=5733.0
http://thanosakademi.com/index.php?topic=68216.0
http://withinfp.sakura.ne.jp/eso/index.php/16859984-05052019-devat-ziznej-9-seria
http://withinfp.sakura.ne.jp/eso/index.php/16861439-ertugrul-146-seria-fk2-ertugrul-146-seria/0
http://dpmarketingsystems.com/06-05-2019-%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x8-n9-%d1%80%d0%b0%d1%81%d1%81/
http://myrechockey.com/forums/index.php?topic=85179.0
http://www.remify.app/foro/index.php?topic=212727.0
https://forums.letstalkbeats.com/index.php?topic=61206.0
http://otitismediasociety.org/forum/index.php?topic=142836.0
http://8.droror.co.il/uncategorized/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ds1-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://www.shaiyax.com/index.php?topic=332657.0
http://roikjer.com/forum/index.php?PHPSESSID=0uatf39ndid426basf7i1g8qi6&topic=800415.0
http://flashboot.ru/forum/index.php?topic=94537.0
http://www.hoonthaitoday.com/forum/index.php?topic=155645.0
http://teambuildingpremium.com/forum/index.php?topic=752273.0
http://www.critico-expository.com/forum/index.php?topic=1806.0
http://withinfp.sakura.ne.jp/eso/index.php/16837995-igra-prestolov-2019-8-sezon-7-seria-nq3-igra-prestolov-2019-8-s/0
https://sanp.pro/%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-05-05-2019-2/
http://taklongclub.com/forum/index.php?topic=97781.0
http://www.arunagreen.com/?option=com_k2&view=itemlist&task=user&id=412019
http://www.deliberarchia.org/forum/index.php?topic=933318.0
http://withinfp.sakura.ne.jp/eso/index.php/16875796-igra-prestolov-game-of-thrones-8-sezon-4-seria-qm9-igra-prestol/0
http://bobr.site/index.php?topic=84552.0
http://danielmillsap.com/forum/index.php?topic=918382.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.arredoufficiomarca.com/index.php/component/k2/itemlist/user/1567742
http://www.autospa.lv/index.php/lv/component/k2/itemlist/user/9531
http://www.deliberarchia.org/forum/index.php?topic=990703.0
http://www.hoonthaitoday.com/forum/index.php?topic=201211.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3638870
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/689955
http://www.nomaher.com/forum/index.php?topic=12170.0
http://www.popolsku.fr.pl/forum/index.php?topic=376460.0
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1075879
http://www.tekparcahdfilm.com/forum/index.php?topic=46974.0
https://members.fbhaters.com/index.php?topic=83746.0
https://nextezone.com/index.php?action=profile&u=3516
https://nextezone.com/index.php?action=profile;u=3626
https://nextezone.com/index.php?topic=39410.0
https://npi.org.es/smf/index.php?topic=113488.0
https://reficulcoin.com/index.php?topic=17010.0
https://www.gizmoarticle.com/%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0%d1%88%d0%ba%d0%b0-erkenci-kus-40-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-w4-%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82/
https://www.resproxy.com/forum/index.php/811926-rannaa-ptaska-erkenci-kus-45-seria-o7-rannaa-ptaska-erkenci-kus/0
https://www.resproxy.com/forum/index.php/811988-voskressij-ertugrul-148-seria-m5-voskressij-ertugrul-148-seria/0
https://www.resproxy.com/forum/index.php/812007-nasa-istoria-72-seria-l4-nasa-istoria-72-seria-online/0
https://www.resproxy.com/forum/index.php/812027-voskressij-ertugrul-150-seria-r9-voskressij-ertugrul-150-seria/0
http://153.120.114.241/eso/index.php/16945626-smotret-sluga-naroda-3-sezon-6-seria-z8-sluga-naroda-3-sezon-6-
http://1vh.info/index.php?topic=16589.0
http://websites.start-a-idea.online/blogs/viewstory/167691
http://websites.start-a-idea.online/blogs/viewstory/167698
http://websites.start-a-idea.online/blogs/viewstory/167699
http://www.artifact.website/136445-igra-prestolov-2019-8-sezon-7-seria-w2-m6-igra-prestolov-2019-8
http://www.deliberarchia.org/forum/index.php?topic=1004932.0
http://www.ekemoon.com/149379/050020195707/
http://danielmillsap.com/forum/index.php?topic=931731.0
http://cats.uuu3.ru/index.php?topic=10781.0
http://sextomariotienda.com/blog/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sg5-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://forum.elexlabs.com/index.php?topic=12741.0
http://otitismediasociety.org/forum/index.php?topic=142771.0
http://otitismediasociety.org/forum/index.php?topic=147272.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=681282.0
http://thanosakademi.com/index.php?topic=69076.0
http://www.hoonthaitoday.com/forum/index.php?topic=139371.0
http://codeerror.in/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90oq5%e3%80%91/
http://www.tessabannampad.go.th/webboard/index.php?topic=191924.0
https://tg.vl-mp.com/index.php?topic=1322708.0
http://matrixpharm.ru/forum/index.php?PHPSESSID=1hsno51ufmech207d8fq9c89s5&action=profile;u=164004
https://forum.shaiyaslayer.tk/index.php?topic=92567.0
http://flashboot.ru/forum/index.php?topic=94019.0
http://poselokgribovo.ru/forum/index.php?topic=698504.0
https://szenarist.ru/forum/index.php?topic=204398.0
http://danielmillsap.com/forum/index.php?topic=976028.0
http://help.stv.ru/index.php?PHPSESSID=90a13171870da2d7de15ce73bf1c26e1&topic=138473.0
http://withinfp.sakura.ne.jp/eso/index.php/16851458-ertugrul-146-seria-ip6-ertugrul-146-seria/0
http://codeerror.in/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n9-e0-%d0%b8%d0%b3/
http://jensenbyggteam.no/index.php/component/k2/itemlist/user/12027
http://help.stv.ru/index.php?PHPSESSID=bd2c50aab54858853cf868168aa44fd4&topic=136752.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/e-eka-aota-(e-ioa-oota)-15-e-06-05-2019-418639/?PHPSESSID=6pspdfi33uopfnc7rkn5dah2c2
http://bobr.site/index.php?topic=80701.0
http://multikopterforum.hu/index.php?topic=9622.0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90ls6%e3%80%91-2/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3287177
http://dpmarketingsystems.com/%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p6-%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5/
http://roikjer.com/forum/index.php?PHPSESSID=3r1051s6hvuha74he0h7mqmil0&topic=831563.0
http://otitismediasociety.org/forum/index.php?topic=144266.0
http://roikjer.com/forum/index.php?PHPSESSID=hqdp2bdf8lb5h6lkfcdnp4t7u2&topic=791282.0
http://HyUa.1fps.icu/l/szIaeDC
http://www2.yasothon.go.th/smf/index.php?topic=159.159255
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=11425.0
https://chromehearts.in.th/index.php?topic=47375.0
https://chromehearts.in.th/index.php?topic=47377.0
https://forum.ac-jete.it/index.php?topic=359449.0
https://reficulcoin.com/index.php?topic=20989.0
https://sanp.pro/%d1%81%d0%bb%d0%b5%d0%b4%d0%be%d0%b2%d0%b0%d1%82%d0%b5%d0%bb%d1%8c-%d0%b3%d0%be%d1%80%d1%87%d0%b0%d0%ba%d0%be%d0%b2%d0%b0-%d1%81%d0%bbi%d0%b4%d1%87%d0%b8%d0%b9-%d0%b3%d0%be%d1%80%d1%87%d0%b0%d0%ba-25/
http://www.m1avio.com/index.php/component/k2/itemlist/user/3646045
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/593096
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=54377
http://xekhachduyetthuy.com.vn/index.php/component/k2/itemlist/user/187026
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=528276
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=528351
http://zsmr.com.ua/index.php/component/k2/itemlist/user/527848
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3328619
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3328655
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=18383
https://www.swiss-focus.ch/index.php/component/k2/itemlist/user/18351
http://153.120.114.241/eso/index.php/16958713-full-hd-sluga-naroda-3-sezon-9-seria-z5-sluga-naroda-3-sezon-9-
http://153.120.114.241/eso/index.php/16958758-smotret-sluga-naroda-3-sezon-21-seria-s3-sluga-naroda-3-sezon-2
http://healthyteethpa.org/component/k2/itemlist/user/5279794
http://forum.byehaj.hu/index.php?topic=71227.0
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1534124
http://vtservices85.fr/smf2/index.php?PHPSESSID=7ba1a05bdd40f86f9531b19ddc8d2347&topic=201557.0
http://compultras.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=187704
http://golyboe.ru/forum/index.php?topic=25244.0
https://www.shaiyax.com/index.php?topic=326382.0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-19/
http://forum.politeknikgihon.ac.id/index.php?topic=11218.0
http://www.hoonthaitoday.com/forum/index.php?topic=152595.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3288304
http://ru-realty.com/forum/index.php?PHPSESSID=ggt988trh00tpad6im6i64hhc1&topic=455599.0
http://www.critico-expository.com/forum/index.php?topic=3931.0
http://ru-realty.com/forum/index.php?topic=471517.0
http://roikjer.com/forum/index.php?PHPSESSID=53ldjk8lk2m2oojj2jng0sotf5&topic=811163.0
http://forum.kopkargobel.com/index.php?topic=5188.0
https://reficulcoin.com/index.php?topic=13843.0
http://storykingdom.forumside.com/index.php?topic=4987.0
http://taklongclub.com/forum/index.php?topic=104573.0
https://nextezone.com/index.php?topic=32964.0
http://highlanderonline.cmshelplive.net/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ff9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1553956
http://dpmarketingsystems.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ks5-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=110857
http://danielmillsap.com/forum/index.php?topic=941307.0
http://myrechockey.com/forums/index.php?topic=84648.0
http://metropolis.ga/index.php?topic=5797.0
http://blog.ptpintcast.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-w4-k7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
https://khuyenmaikk13.info/index.php?topic=181379.0
http://driversed.tv/blog/
https://forums.letstalkbeats.com/index.php?topic=63183.0
https://cybergsm.es/index.php?topic=7666.0
http://myrechockey.com/forums/index.php?topic=84497.0
http://forum.politeknikgihon.ac.id/index.php?topic=18017.0
http://help.stv.ru/index.php?PHPSESSID=f58c9659cc07809a7ded2003d4d3de8e&topic=135749.0
http://www.tessabannampad.go.th/webboard/index.php?topic=186617.0
http://macdistri.com/index.php/component/k2/itemlist/user/292920
http://multikopterforum.hu/index.php?topic=12949.0
http://menulisilmiah.net/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90jh7%e3%80%91/
http://www.theocraticamerica.org/forum/index.php?topic=27494.0
http://danielmillsap.com/forum/index.php?topic=949711.0
http://e-educ.net/Forum/index.php?topic=4587.0
http://HyUa.1fps.icu/l/szIaeDC
http://danielmillsap.com/forum/index.php?topic=958227.0
http://forum.digamahost.com/index.php?topic=107688.0
https://reficulcoin.com/index.php?topic=6153.0
http://taklongclub.com/forum/index.php?topic=93759.0
http://web2interactive.com/index.php/component/k2/itemlist/user/3557216
https://reficulcoin.com/index.php?topic=11622.0
http://www.remify.app/foro/index.php?topic=202950.0
http://www.hoonthaitoday.com/forum/index.php?topic=155723.0
http://otitismediasociety.org/forum/index.php?topic=142358.0
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i9-o9-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://otitismediasociety.org/forum/index.php?topic=142986.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=275166
http://teambuildingpremium.com/forum/index.php?topic=766628.0
http://ptu.imoove.kr/ko/content/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-7-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90da7%E3%80%91-%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-7
http://ru-realty.com/forum/index.php?PHPSESSID=vjkg733okkvraj1f9mm3bum6d0&topic=459788.0
http://salescoach.ro/content/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-2019-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-3-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90ie6%E3%80%91-%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-2019-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-3-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://www.deliberarchia.org/forum/index.php?topic=960172.0
http://forum.stollen24.com/index.php?topic=3701.0
http://www.theparrotcentre.com/forum/index.php?topic=449817.0
http://withinfp.sakura.ne.jp/eso/index.php/16838957-igra-prestolov-game-of-thrones-8-sezon-4-seria-igra-prestolov-g/0
http://poselokgribovo.ru/forum/index.php?topic=710856.0
http://e-educ.net/Forum/index.php?topic=6461.0
https://sanp.pro/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t5-o4-%d1%80%d0%b0%d1%81%d1%81/
http://taklongclub.com/forum/index.php?topic=93313.0
http://e-educ.net/Forum/index.php?topic=5091.0
https://www.thedezlab.com/lab/community/index.php?topic=272.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e4-o7-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=754475
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=317454
http://istakam.com/forum/index.php?topic=10112.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/'a-etoo-(got)-8-eo-5-e'-a-etoo-(got)-8-eo-5-e-b3e9/?PHPSESSID=3t3snpc6856ub0gp7spj63cgl5
http://thanosakademi.com/index.php?topic=58287.0
http://multikopterforum.hu/index.php?topic=8557.0
http://withinfp.sakura.ne.jp/eso/index.php/16838841-04052019-drugaa-insa-19-seria
https://adsensebih.com/index.php?topic=10415.0
http://poselokgribovo.ru/forum/index.php?topic=719958.0
http://forum.bmw-e60.eu/index.php?topic=1867.0
http://www.deliberarchia.org/forum/index.php?topic=977447.0
http://teambuildingpremium.com/forum/index.php?topic=764311.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1329091
https://sanp.pro/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-e1-p6-%d1%80/
http://HyUa.1fps.icu/l/szIaeDC
http://matrixpharm.ru/forum/index.php?PHPSESSID=fenlh6tj2b08jo3vthdomm6a46&action=profile;u=151766
https://nextezone.com/index.php?action=profile;u=2548
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1883286
https://forums.letstalkbeats.com/index.php?topic=69614.0
https://www.shaiyax.com/index.php?topic=329864.0
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=789495
http://danielmillsap.com/forum/index.php?topic=870975.0
http://dpmarketingsystems.com/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-144-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-i1-%d0%b2%d0%be%d1%81%d0%ba/
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=263857
http://poselokgribovo.ru/forum/index.php?topic=650575.0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/61315
http://danielmillsap.com/forum/index.php?topic=881874.0
http://menulisilmiah.net/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-81-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-jyt-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc/
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-czh-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8/
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=36929
http://roikjer.com/forum/index.php?PHPSESSID=aa92bff9lknh03fisqh577n0m4&topic=763087.0
https://tg.vl-mp.com/index.php?topic=1246631.0
http://www.critico-expository.com/forum/index.php?topic=432.0
http://danielmillsap.com/forum/index.php?topic=868462.0
https://tg.vl-mp.com/index.php?topic=1247822.0
http://macdistri.com/?option=com_k2&view=itemlist&task=user&id=255635
http://poselokgribovo.ru/forum/index.php?topic=647612.0
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1105009
http://roikjer.com/forum/index.php?PHPSESSID=hnphunpqb6ne2kln7vmrg5hs73&topic=783734.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/166708
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=250338
http://wb.hvekorat.com/index.php?topic=39910.0
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1106495
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/129887
http://forum.kopkargobel.com/index.php?topic=6587.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=cd9e2d350599c604686645142b4355d9&topic=216560.0
http://www.critico-expository.com/forum/index.php?topic=9174.0
http://www.critico-expository.com/forum/index.php?topic=9181.0
http://www.critico-expository.com/forum/index.php?topic=9186.0
http://www.hoonthaitoday.com/forum/index.php?topic=210701.msg225557
https://reficulcoin.com/index.php?topic=20869.0
https://reficulcoin.com/index.php?topic=20878.0
http://uberdrivers.net/forum/index.php?topic=250664.0
http://www.hoonthaitoday.com/forum/index.php?topic=210733.0
http://www.popolsku.fr.pl/forum/index.php?topic=377823.0
http://www.tessabannampad.go.th/webboard/index.php?topic=197273.0
https://members.fbhaters.com/index.php?topic=87898.0
https://nextezone.com/index.php?topic=41920.0
http://otitismediasociety.org/forum/index.php?topic=150006.0
http://otitismediasociety.org/forum/index.php?topic=150008.0
http://www.remify.app/foro/index.php?topic=230401.0
http://www.deliberarchia.org/forum/index.php?topic=949788.0
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81-6/
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=186361
http://forum.stollen24.com/index.php?topic=2785.0
http://wituclub.ru/forum/index.php?PHPSESSID=65968l9notpl6ihbhodnunfs20&topic=25697.0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90we2%e3%80%91-%d0%b8%d0%b3/
http://metropolis.ga/index.php?topic=2659.0
https://tg.vl-mp.com/index.php?topic=1319486.0
http://multikopterforum.hu/index.php?topic=5006.0
http://HyUa.1fps.icu/l/szIaeDC
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=520624
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/493036
http://danielmillsap.com/forum/index.php?topic=991564.0
http://married.dike.gr/index.php/component/k2/itemlist/user/53899
http://minostech.co.kr/news/3411706
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2544121
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/40809
http://www.ekemoon.com/140109/050320194405/
http://www.atab.com.sa/?option=com_k2&view=itemlist&task=user&id=1497948
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=520695
http://thefreebitcoin.com/index.php?topic=36197.0
https://npi.org.es/smf/index.php?topic=109815.0
http://forum.politeknikgihon.ac.id/index.php?topic=31676.0
http://menulisilmiah.net/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p4-c0-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://poselokgribovo.ru/forum/index.php?topic=750374.0
http://roikjer.com/forum/index.php?PHPSESSID=3f6679fgcnpmg1b5fdkr2vvc74&topic=841953.0
http://roikjer.com/forum/index.php?PHPSESSID=88nmt9c1hqo04c0i3avr4nadg7&topic=841990.0
http://roikjer.com/forum/index.php?topic=841865.0
http://vhost12299.cpsite.ru/107467-igra-prestolov-got-8-sezon-5-seria-l7-g5-igra-prestolov-got-8-s
http://vhost12299.cpsite.ru/107477-igra-prestolov-2019-8-sezon-7-seria-y7-m0-igra-prestolov-2019-8
https://npi.org.es/smf/index.php?topic=113549.0
https://polyframetrade.co.uk/%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-11-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-q8-t4-%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4/
https://polyframetrade.co.uk/%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-9-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-t4-x7-%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81/
https://reficulcoin.com/index.php?topic=17669.0
https://reficulcoin.com/index.php?topic=17683.0
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n4-p7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-m5-k0-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
https://woodland.org.ua/groups/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z3-e4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
https://woodland.org.ua/groups/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-z3-p4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
https://www.limscave.com/forum/viewtopic.php?f=6&t=31711&view=print
http://roikjer.com/forum/index.php?PHPSESSID=f8e5j5hgrir6c7g6gct1f5upn0&topic=811173.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/'a-etoogame-of-thrones-8-eo-1-e'-a-etoogame-of-thrones-8-eo-1-e-x6s1/?PHPSESSID=2uitpe2dm8esuigof2n5ap42d0
http://poselokgribovo.ru/forum/index.php?topic=700163.0
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-s2-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
https://reficulcoin.com/index.php?topic=9849.0
http://webp.online/index.php?topic=45434.0
http://danielmillsap.com/forum/index.php?topic=953902.0
http://roikjer.com/forum/index.php?PHPSESSID=dlim1n54cvo9mbq2jtglhaboi0&topic=797893.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=26821.0
http://uberdrivers.net/forum/index.php?topic=225692.0
http://withinfp.sakura.ne.jp/eso/index.php/16842585-igra-prestolov-8-sezon-4-seria-ka7-igra-prestolov-8-sezon-4-ser/0
https://www.c-alice.org/forum/index.php?topic=74045.0
http://1vh.info/index.php?topic=9060.0
http://storykingdom.forumside.com/index.php?topic=5577.0
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n4-v6-%d1%80%d0%b0/
http://miklja.net/forum/index.php?topic=26627.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u3-b7-%d0%b8%d0%b3%d1%80/
http://multikopterforum.hu/index.php?topic=6743.0
https://khuyenmaikk13.info/index.php?topic=177898.0
http://eugeniocolazzo.it/forum/index.php?topic=84058.0
https://danceplanet.se/commodore/index.php?topic=8204.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/669434
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2578573
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=29077.0
https://www.gizmoarticle.com/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81-8/
https://www.gizmoarticle.com/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-143-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t7-%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88/
http://www.critico-expository.com/forum/index.php?topic=4775.0
http://rudraautomation.com/index.php/component/k2/author/120318
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1849107
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4723131
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/190119
http://necinsurance.co.zw/component/k2/itemlist/user/19413.html
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/61308
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7333070
https://lucky28003.nl/forum/index.php?topic=9954.0
http://forum.politeknikgihon.ac.id/index.php?topic=31823.0
http://forum.politeknikgihon.ac.id/index.php?topic=31851.0
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile;u=33945
http://poselokgribovo.ru/forum/index.php?topic=750594.0
http://poselokgribovo.ru/forum/index.php?topic=750649.0
http://roikjer.com/forum/index.php?PHPSESSID=2ot7fskfmoegukl5s09tuvnfg0&topic=842296.0
http://roikjer.com/forum/index.php?PHPSESSID=g7uggf4e9ek8fpjdmmi26o4587&topic=842291.0
http://wikiwires.com/2019/05/09/%d0%bd%d0%b5-%d0%be%d1%82%d0%bf%d1%83%d1%81%d0%ba%d0%b0%d0%b9-%d0%bc%d0%be%d1%8e-%d1%80%d1%83%d0%ba%d1%83-elimi-birakma-41-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q3-%d0%bd%d0%b5-%d0%be%d1%82%d0%bf%d1%83/
http://wikiwires.com/2019/05/09/%d0%bd%d0%b5-%d0%be%d1%82%d0%bf%d1%83%d1%81%d0%ba%d0%b0%d0%b9-%d0%bc%d0%be%d1%8e-%d1%80%d1%83%d0%ba%d1%83-elimi-birakma-41-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-v0-%d0%bd%d0%b5-%d0%be/
http://www.deliberarchia.org/forum/index.php?topic=999101.0
http://www.ekemoon.com/170501/050720192910/
http://www.ekemoon.com/170573/050720193910/
http://www.hoonthaitoday.com/forum/index.php?topic=210322.0
http://www.hoonthaitoday.com/forum/index.php?topic=210410.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3645406
https://khuyenmaikk13.info/index.php?topic=176081.0
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=262192
https://www.c-alice.org/forum/index.php?topic=69346.0
https://mcsetup.tk/bbs/index.php?topic=237799.0
http://dpmarketingsystems.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-oao-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/997564
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/969655
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=641818.0
https://forum.ac-jete.it/index.php?topic=326322.0
http://www.deliberarchia.org/forum/index.php?topic=956008.0
http://forum.kopkargobel.com/index.php?topic=2714.0
http://blog.ptpintcast.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-e5-q9-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://dpmarketingsystems.com/hd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b1-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://freebeer.me/index.php?topic=290291.0
http://poselokgribovo.ru/forum/index.php?topic=701768.0
http://8.droror.co.il/uncategorized/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-k3-s8-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://taklongclub.com/forum/index.php?topic=97668.0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=556899
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=25092.0
http://www.obal-shop.sk/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-s0-x0-%d1%80/
http://ruschinaforum.ru/index.php?topic=125794.0
http://www.hoonthaitoday.com/forum/index.php?topic=174282.0
http://216.104.186.20/index.php?topic=296867.0
http://otitismediasociety.org/forum/index.php?topic=143558.0
http://www.deliberarchia.org/forum/index.php?topic=955541.0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90cu7%e3%80%91-%d0%b8%d0%b3%d1%80/
https://danceplanet.se/commodore/index.php?topic=13513.0
http://www.hoonthaitoday.com/forum/index.php?topic=161225.0
http://forum.drahthaar-club.com.ua/index.php?topic=531.0
http://www.deliberarchia.org/forum/index.php?topic=964800.0
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=996781
http://www.quattroandpartners.it/component/k2/itemlist/user/1038392
http://www.critico-expository.com/forum/index.php?topic=5837.0
http://HyUa.1fps.icu/l/szIaeDC
http://blog.ptpintcast.com/%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0%d1%8f-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b0-%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be%d0%b1%d0%be%d1%82%d0%b0-17-%d1%81%d0%b5-5/
https://reficulcoin.com/index.php?topic=11333.0
http://roikjer.com/forum/index.php?PHPSESSID=sos6ito14lersmt7e6f7ijq9u6&topic=832491.0
https://sanp.pro/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-t2-k7-%d1%80%d0%b0%d1%81/
http://roikjer.com/forum/index.php?PHPSESSID=etr8utine5v6ptvrk3rm4ka670&topic=789839.0
http://forum.drahthaar-club.com.ua/index.php?topic=512.0
http://122.154.49.125/Forum/index.php?topic=46.0
http://multikopterforum.hu/index.php?topic=11672.0
http://www.hoonthaitoday.com/forum/index.php?topic=187979.0
http://poselokgribovo.ru/forum/index.php?topic=697120.0
http://roikjer.com/forum/index.php?PHPSESSID=34bpmsddsi8hmn9att233l1bf3&topic=813036.0
http://forum.kopkargobel.com/index.php?topic=3393.0
http://roikjer.com/forum/index.php?topic=828785.0
http://www.deliberarchia.org/forum/index.php?topic=953111.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=415289afb42ea63dd2ef43a4dc6a4ff7&topic=211428.0
https://sanp.pro/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z5-p1-%d1%80%d0%b0/
http://istakam.com/forum/index.php?topic=9369.0
http://153.120.114.241/eso/index.php/16852008-igra-prestolov-8-sezon-6-seria-igra-prestolov-8-sezon-6-seria-o
https://forums.letstalkbeats.com/index.php?topic=58933.0
http://www.hoonthaitoday.com/forum/index.php?topic=170528.0
http://myrechockey.com/forums/index.php?topic=82521.0
http://rnspl.com/component/k2/itemlist/user/2195
https://platforma-nonstop.ro/forum/index.php?topic=261556.0
https://reficulcoin.com/index.php?topic=7598.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=4e13a9c26cd75933fe3e8854d07f1d9d&topic=210549.0
http://www.remify.app/foro/index.php?topic=232581.0
https://danceplanet.se/commodore/index.php?topic=12122.0
http://thanosakademi.com/index.php?topic=61895.0
http://muonlineint.com/forum/index.php?topic=552.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=274470
http://www.popolsku.fr.pl/forum/index.php?topic=20407.54570
http://www.critico-expository.com/forum/index.php?topic=1799.0
http://myrechockey.com/forums/index.php?topic=90253.0
https://lucky28003.nl/forum/index.php?topic=7229.0
http://HyUa.1fps.icu/l/szIaeDC
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1901767
http://tripviet.com/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-29-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-t7/
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=599574
http://www.sopprabhospital.go.th/webboard/index.php?PHPSESSID=5muhih406f3rqfin416mu9uqh7&topic=13861.0
http://www.sopprabhospital.go.th/webboard/index.php?PHPSESSID=ticmb7te5uuk498t59mga9muq1&topic=13860.0
https://reficulcoin.com/index.php?topic=24872.0
https://tg.vl-mp.com/index.php?topic=1383440.0
https://www.shaiyax.com/index.php?topic=338095.0
http://1vh.info/index.php?topic=21737.0
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1902038
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4753808
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1578176
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1578635
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1369160
http://www.autospa.lv/index.php/lv/component/k2/itemlist/user/9522
http://www.boutique.in.th/?option=com_k2&view=itemlist&task=user&id=150018
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1040133
http://www.dap.com.py/index.php/es/?option=com_k2&view=itemlist&task=user&id=795009
http://www.m1avio.com/?option=com_k2&view=itemlist&task=user&id=3637790
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/688810
http://www.quattroandpartners.it/component/k2/itemlist/user/1075156
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=52519
http://dota2.host/89248-igra-prestolov-game-of-thrones-8-sezon-5-seria-o0-g6-igra-prest
http://dota2.host/89272-igra-prestolov-got-8-sezon-5-seria-b9-g4-igra-prestolov-got-8-s
http://dota2.host/89312-igra-prestolov-got-8-sezon-5-seria-online-d6-s9-igra-prestolov-
http://dota2.host/89326-igra-prestolov-got-8-sezon-6-seria-i5-w5-igra-prestolov-got-8-s
http://eugeniocolazzo.it/forum/index.php?topic=106758.0
http://eugeniocolazzo.it/forum/index.php?topic=106766.0
http://eugeniocolazzo.it/forum/index.php?topic=106792.0
http://forum.bmw-e60.eu/index.php?topic=5169.0
http://forum.digamahost.com/index.php?topic=112000.0
http://forum.politeknikgihon.ac.id/index.php?topic=28659.0
http://forum.politeknikgihon.ac.id/index.php?topic=28677.0
http://forum.politeknikgihon.ac.id/index.php?topic=28686.0
http://taklongclub.com/forum/index.php?topic=112533.0
http://uberdrivers.net/forum/index.php?topic=249327.0
http://uberdrivers.net/forum/index.php?topic=249352.0
http://www.critico-expository.com/forum/index.php?topic=8054.0
http://www.deliberarchia.org/forum/index.php?topic=997224.0
http://www.deliberarchia.org/forum/index.php?topic=997238.0
http://www.deliberarchia.org/forum/index.php?topic=997244.0
http://www.deliberarchia.org/forum/index.php?topic=997257.0
http://www.deliberarchia.org/forum/index.php?topic=997271.0
https://nextezone.com/index.php?topic=40590.0
https://www.gizmoarticle.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z9-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://help.stv.ru/index.php?PHPSESSID=5eb1b6c391c1b124264db880339d0aff&topic=139678.0
http://help.stv.ru/index.php?PHPSESSID=d28e7d6633d4353d2070d20eebd82407&topic=139679.0
http://roikjer.com/forum/index.php?PHPSESSID=sr1g0thkqj30kd8m33c9n23mv4&topic=838597.0
http://ru-realty.com/forum/index.php?PHPSESSID=5l7ser6v01s0pdaara3su44680&topic=480655.0
http://ru-realty.com/forum/index.php?PHPSESSID=v214a7thl8cmv86ao5v1ufp5t6&topic=480643.0
https://danceplanet.se/commodore/index.php?topic=18511.0
https://sanp.pro/live-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n7-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
https://danceplanet.se/commodore/index.php?topic=18519.0
https://khuyenmaikk13.info/index.php?topic=187182.0
https://khuyenmaikk13.info/index.php?topic=187196.0
https://members.fbhaters.com/index.php?topic=85414.0
https://sanp.pro/%d0%b4%d1%80%d1%83%d0%b3%d0%b0%d1%8f-i%d0%bd%d1%88%d0%b0-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c3-%d0%b4%d1%80%d1%83%d0%b3%d0%b0%d1%8f-i%d0%bd%d1%88%d0%b0-19-%d1%81%d0%b5%d1%80/
https://sanp.pro/09-05-2019-%d0%b4%d1%80%d1%83%d0%b3%d0%b0%d1%8f-i%d0%bd%d1%88%d0%b0-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://www.gizmoarticle.com/%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-09-05-2019/
https://www.gizmoarticle.com/09-05-2019-%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
https://www.gizmoarticle.com/09-05-2019-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://dpmarketingsystems.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p0-%d1%81/
http://HyUa.1fps.icu/l/szIaeDC
http://wituclub.ru/forum/index.php?PHPSESSID=jgulrtq6q1e7453emtd7ahlm21&topic=25264.0
http://teambuildingpremium.com/forum/index.php?topic=753970.0
http://freebeer.me/index.php?topic=300598.0
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-d5-f5-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=291371
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t9-l7-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://153.120.114.241/eso/index.php/16883971-06052019-podsudimyj-10-seria
http://vtservices85.fr/smf2/index.php?topic=205302.0
http://xplorefitness.com/blog/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-got-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90vs9%E3%80%91-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-got-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
https://www.gizmoarticle.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qu8-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.tekparcahdfilm.com/forum/index.php?topic=46284.0
http://www.hoonthaitoday.com/forum/index.php?topic=155275.0
http://otitismediasociety.org/forum/index.php?topic=141803.0
http://photogrotto.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90oc6%e3%80%91-%d0%b8%d0%b3%d1%80/
http://e-educ.net/Forum/index.php?topic=5930.0
https://reficulcoin.com/index.php?topic=10485.0
http://myrechockey.com/forums/index.php?topic=85379.0
http://poselokgribovo.ru/forum/index.php?topic=697099.0
http://1vh.info/index.php?topic=9748.0
http://danielmillsap.com/forum/index.php?topic=989384.0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=550074
http://poselokgribovo.ru/forum/index.php?topic=687822.0
http://eugeniocolazzo.it/forum/index.php?topic=82655.0
http://roikjer.com/forum/index.php?PHPSESSID=bav5q8ri66dpla1lle7cu1qo60&topic=824679.0
http://thanosakademi.com/index.php?topic=62179.0
https://forum.ac-jete.it/index.php?topic=329902.0
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x4-b9-%d1%80%d0%b0%d1%81%d1%81/
http://e-educ.net/Forum/index.php?topic=6300.0
http://taklongclub.com/forum/index.php?topic=92099.0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-b0-g7-%d0%b8%d0%b3%d1%80%d0%b0/
http://roikjer.com/forum/index.php?topic=800360.0
http://roikjer.com/forum/index.php?PHPSESSID=m7dfvhg7sda6ccmdfpqkokobf5&topic=805842.0
http://ruschinaforum.ru/index.php?topic=125973.0
https://www.thedezlab.com/lab/community/index.php?topic=238.0
http://www.ekemoon.com/154419/052120192307/
http://HyUa.1fps.icu/l/szIaeDC
http://vervetama.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a6-r5-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://vervetama.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-q6-c7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://www.critico-expository.com/forum/index.php?topic=7363.0
http://www.deliberarchia.org/forum/index.php?topic=995893.0
http://www.deliberarchia.org/forum/index.php?topic=995929.0
http://www.ekemoon.com/168559/050120194910/
http://www.ekemoon.com/168561/050120195010/
http://www.nomaher.com/forum/index.php?topic=12956.0
http://www.nomaher.com/forum/index.php?topic=12961.0
http://www.ofqj.org/hebergementfrance/4-11-h6-q4-4-11-4-11
http://roikjer.com/forum/index.php?PHPSESSID=3dunu57d6r8hn7ujen5t49ih46&topic=805286.0
http://wb.hvekorat.com/index.php?topic=40562.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90wn6%e3%80%91/
https://reficulcoin.com/index.php?topic=7895.0
http://ru-realty.com/forum/index.php?PHPSESSID=bgd6ln7sd0oemt2rp97k0epc20&topic=451557.0
http://www.deliberarchia.org/forum/index.php?topic=978497.0
http://e-educ.net/Forum/index.php?topic=3986.0
http://otitismediasociety.org/forum/index.php?topic=143391.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90dy3%e3%80%91-%d0%b8%d0%b3/
http://thanosakademi.com/index.php?topic=62257.0
http://www.vivelabmanizales.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-x3-y3-%d1%80/
https://chromehearts.in.th/index.php?topic=43395.0
http://help.stv.ru/index.php?PHPSESSID=fd95d8ca47790612df5f521eddef665a&topic=137463.0
https://reficulcoin.com/index.php?topic=8603.0
http://HyUa.1fps.icu/l/szIaeDC
http://roikjer.com/forum/index.php?PHPSESSID=lkfsor9nnn9jrs58qpjsbrjtg2&topic=804971.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190180.0
https://szenarist.ru/forum/index.php?topic=204503.0
http://www.theparrotcentre.com/forum/index.php?topic=476110.0
http://withinfp.sakura.ne.jp/eso/index.php/16845036-igra-prestolov-game-of-thrones-8-sezon-2-seria-igra-prestolov-g
http://poselokgribovo.ru/forum/index.php?topic=701612.0
http://www.vivelabmanizales.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-n7-y0-%d1%80%d0%b0%d1%81/
https://sanp.pro/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b6-f7-%d1%80%d0%b0/
http://myrechockey.com/forums/index.php?topic=82081.0
http://yuptalk.ru/other_food_household_cosmetics_etc/-t13057.0.html
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=274812
http://freebeer.me/index.php?topic=294085.0
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-28/
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=59401
http://forum.digamahost.com/index.php?topic=108850.0
https://www.shoppidlok.com/smf/index.php?topic=303.0
http://forum.bmw-e60.eu/index.php?topic=1760.0
https://www.c-alice.org/forum/index.php?topic=75563.0
http://miklja.net/forum/index.php?topic=27141.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/e-eka-aota-(e-ioa-oota)-21-e-04-05-2019-415139/
http://216.104.186.20/index.php?topic=304930.0
http://otitismediasociety.org/forum/index.php?topic=141265.0
http://multikopterforum.hu/index.php?topic=4718.0
http://www.theparrotcentre.com/forum/index.php?topic=478343.0
http://flashboot.ru/forum/index.php?topic=94527.0
http://forum.politeknikgihon.ac.id/index.php?topic=17406.0
http://muonlineint.com/forum/index.php?topic=330.0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-29/
https://sanp.pro/%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-05-05-2019-3/
http://dpmarketingsystems.com/%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-05-05-2019/
http://forum.drahthaar-club.com.ua/index.php?topic=1262.0
http://teambuildingpremium.com/forum/index.php?topic=764965.0
http://withinfp.sakura.ne.jp/eso/index.php/16862107-tolarobot-5-seria-05052019
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=28899.0
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j9-m3-%d1%80%d0%b0%d1%81%d1%81/
http://HyUa.1fps.icu/l/szIaeDC
http://sextomariotienda.com/blog/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mdc-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-10-05-2019/
http://taklongclub.com/forum/index.php?topic=117372.0
http://taklongclub.com/forum/index.php?topic=117404.0
http://teambuildingpremium.com/forum/index.php?topic=803908.0
http://wituclub.ru/forum/index.php?PHPSESSID=fri3csn1rag4ggfm4podntuee3&topic=26422.0
http://wituclub.ru/forum/index.php?PHPSESSID=r4ali2pla9v9ubplg92lhliba5&topic=26423.0
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1575865
http://www.hoonthaitoday.com/forum/index.php?topic=164282.0
http://dohairbiz.com/en/component/k2/itemlist/user/2712305.html
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7320974
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3382726
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3720795
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=6293
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=120865
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1015554
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1015572
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1769522
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/568757
http://www.original-craft.net/index.php?topic=295146.0
http://roikjer.com/forum/index.php?PHPSESSID=tp85er0ri0aqr50c2bsap88qm3&topic=758503.0
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1522888
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1522148
http://www.popolsku.fr.pl/forum/index.php?topic=365104.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=903307d2e2dd4f3d84170e125ec7ef4b&topic=201663.0
https://tg.vl-mp.com/index.php?topic=1262919.0
https://www.gizmoarticle.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qzc-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://www.deliberarchia.org/forum/index.php?topic=886033.0
http://www.edelweis.com/UserProfile/tabid/42/UserID/1575591/Default.aspx
http://www.tessabannampad.go.th/webboard/index.php?topic=176200.0
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/514368
https://www.limscave.com/forum/viewtopic.php?t=31718
https://www.limscave.com/forum/viewtopic.php?t=31720
http://otitismediasociety.org/forum/index.php?topic=149345.0
http://otitismediasociety.org/forum/index.php?topic=149346.0
http://otitismediasociety.org/forum/index.php?topic=149347.0
http://otitismediasociety.org/forum/index.php?topic=149349.0
http://roikjer.com/forum/index.php?PHPSESSID=95bo9023e02l5rtu181mionao4&topic=837291.0
http://www.deliberarchia.org/forum/index.php?topic=993498.0
http://www.deliberarchia.org/forum/index.php?topic=993501.0
http://www.deliberarchia.org/forum/index.php?topic=993517.0
https://members.fbhaters.com/index.php?topic=84593.0
https://members.fbhaters.com/index.php?topic=84596.0
https://worldtaxi.org/2019/05/09/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k0-o7-%d0%b8%d0%b3%d1%80/
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i4-p2-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z3-p4-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h6-m2-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t7-c8-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://www.remify.app/foro/index.php?topic=247099.0
http://www.remify.app/foro/index.php?topic=247117.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=683440.0
http://otitismediasociety.org/forum/index.php?topic=148564.0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-6/
http://www.theparrotcentre.com/forum/index.php?topic=447636.0
http://www.deliberarchia.org/forum/index.php?topic=941933.0
http://uberdrivers.net/forum/index.php?topic=208427.0
http://forum.elexlabs.com/index.php?topic=12847.0
http://www.deliberarchia.org/forum/index.php?topic=967132.0
http://danielmillsap.com/forum/index.php?topic=985284.0
https://reficulcoin.com/index.php?topic=15202.0
https://reficulcoin.com/index.php?topic=5309.0
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-y5-n4-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://vtservices85.fr/smf2/index.php?PHPSESSID=83f86ae09a9d5de43899df7ad31f74eb&topic=203297.0
http://withinfp.sakura.ne.jp/eso/index.php/16851354-igra-prestolovgame-of-thrones-8-sezon-6-seria-igra-prestolovgam
http://8.droror.co.il/uncategorized/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b8-u2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
https://forum.ac-jete.it/index.php?topic=341879.0
http://HyUa.1fps.icu/l/szIaeDC
https://www.resproxy.com/forum/index.php/782101-ertugrul-5-sezon-26-seria-online-l9-ertugrul-5-sezon-26-seria/0
https://www.netprofessional.gr/component/k2/itemlist/user/3291.html
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1551590
http://www.ekemoon.com/163357/050720192009/
http://dohairbiz.com/en/component/k2/itemlist/user/2723006.html
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-m1-%d0%b8%d0%b3%d1%80%d0%b0/
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=28039.0
http://rudraautomation.com/index.php/component/k2/itemlist/user/127667
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=142315
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1752879
http://foa.egerton.ac.ke/index.php/component/k2/itemlist/user/1753307
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1869817
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=283539
http://healthyteethpa.org/component/k2/itemlist/user/5380855
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7350977
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1145549
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1145569
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=36786
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=36787
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3752947
http://marjorieaperry.com/?option=com_k2&view=itemlist&task=user&id=484310
http://marjorieaperry.com/?option=com_k2&view=itemlist&task=user&id=484311
http://necinsurance.co.zw/component/k2/itemlist/user/19331.html
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/66971
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/66994
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=5369
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/5340
http://rudraautomation.com/index.php/component/k2/author/116167
http://smartacity.com/component/k2/itemlist/user/18400
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1636851
http://forum.bmw-e60.eu/index.php?topic=4581.0
http://menulisilmiah.net/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90nl8%e3%80%91-%d0%b8%d0%b3/
http://poselokgribovo.ru/forum/index.php?topic=705313.0
http://thanosakademi.com/index.php?topic=61251.0
http://www.critico-expository.com/forum/index.php?topic=5570.0
http://bobr.site/index.php?topic=101960.0
http://withinfp.sakura.ne.jp/eso/index.php/16905759-ertugrul-147-seria-zp7-ertugrul-147-seria/0
http://www.theparrotcentre.com/forum/index.php?topic=445313.0
http://miklja.net/forum/index.php?topic=26428.0
https://reficulcoin.com/index.php?topic=10952.0
http://sextomariotienda.com/blog/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ew7-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://roikjer.com/forum/index.php?topic=796796.0
http://www.tessabannampad.go.th/webboard/index.php?topic=194853.0
https://worldtaxi.org/2019/05/09/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81-4/
http://freebeer.me/index.php?topic=289186.0
https://npi.org.es/smf/index.php?topic=111652.0
https://danceplanet.se/commodore/index.php?topic=13722.0
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/997125
http://menulisilmiah.net/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x5-x3-%d1%80%d0%b0%d1%81%d1%81/
http://153.120.114.241/eso/index.php/16865170-05052019-ne-zenskaa-rabota-ne-zinoca-robota-13-seria
https://nextezone.com/index.php?action=profile;u=2973
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o6-c8-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
https://forum.shaiyaslayer.tk/index.php?topic=97142.0
https://reficulcoin.com/index.php?topic=14355.0
http://roikjer.com/forum/index.php?PHPSESSID=elim4lnt92g8bl2ug097o4q2j2&topic=808728.0
http://codeerror.in/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90ty1%e3%80%91-%d0%b8%d0%b3/
http://HyUa.1fps.icu/l/szIaeDC
https://reficulcoin.com/index.php?topic=25767.0
https://sanp.pro/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online/
https://sanp.pro/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b8/
https://tg.vl-mp.com/index.php?topic=1385780.0
http://dota2.host/158866-holostak-9-sezon-11-vypusk-qsl-holostak-9-sezon-11-vypusk-11052
http://menulisilmiah.net/%d1%81%d0%bb%d0%b5%d0%b4%d0%be%d0%b2%d0%b0%d1%82%d0%b5%d0%bb%d1%8c-%d0%b3%d0%be%d1%80%d1%87%d0%b0%d0%ba%d0%be%d0%b2%d0%b0-%d1%81%d0%bbi%d0%b4%d1%87%d0%b8%d0%b9-%d0%b3%d0%be%d1%80%d1%87%d0%b0%d0%ba-131/
http://vhost12299.cpsite.ru/158860-zvonar-21-seria-xmh-zvonar-21-seria-11052019
http://vtservices85.fr/smf2/index.php?topic=220989.0
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1094450
http://www.vivelabmanizales.com/%d1%81%d0%bb%d0%b5%d0%b4%d0%be%d0%b2%d0%b0%d1%82%d0%b5%d0%bb%d1%8c-%d0%b3%d0%be%d1%80%d1%87%d0%b0%d0%ba%d0%be%d0%b2%d0%b0-%d1%81%d0%bbi%d0%b4%d1%87%d0%b8%d0%b9-%d0%b3%d0%be%d1%80%d1%87%d0%b0%d0%ba-141/
http://www.ekemoon.com/149361/050020195507/
http://www.hoonthaitoday.com/forum/index.php?topic=162750.0
http://www.phan-aen.go.th/forum/index.php?topic=625697.0
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3719667
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=5980
http://www.svedmyr.nu/install/UserProfile/tabid/61/userId/473260/Default.aspx
http://www.tekparcahdfilm.com/forum/index.php?topic=48372.0
http://www.tessabannampad.go.th/webboard/index.php?topic=199724.0
http://www.theparrotcentre.com/forum/index.php?topic=499841.0
http://www.theparrotcentre.com/forum/index.php?topic=499871.0
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f8-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-q6-%d0%b8%d0%b3/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3333113
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3333114
https://www.c-alice.org/forum/index.php?topic=79251.0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v3-p6-%d0%b8%d0%b3%d1%80/
http://www.tessabannampad.go.th/webboard/index.php?topic=188743.0
http://www.deliberarchia.org/forum/index.php?topic=984460.0
http://bobr.site/index.php?topic=97767.0
http://153.120.114.241/eso/index.php/16876641-igra-prestolov-8-sezon-7-seria-hh1-igra-prestolov-8-sezon-7-ser
http://golyboe.ru/forum/index.php?topic=25151.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=27743.0
http://www.tessabannampad.go.th/webboard/index.php?topic=190909.0
http://blog.ptpintcast.com/%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m8-%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-14-%d1%81%d0%b5/
https://forum.clubeicaro.pt/index.php?topic=202.0
http://forum.politeknikgihon.ac.id/index.php?topic=23393.0
http://www.critico-expository.com/forum/index.php?topic=1972.0
http://roikjer.com/forum/index.php?PHPSESSID=tkgq9iumbol6acb6b15v71jr21&topic=797662.0
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p7-j2-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://withinfp.sakura.ne.jp/eso/index.php/16839816-igra-prestolovgame-of-thrones-8-sezon-1-seria-igra-prestolovgam/0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=676685.0
http://www.hoonthaitoday.com/forum/index.php?topic=139846.0
https://forum.clubeicaro.pt/index.php?topic=336.0
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n0-h3-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
http://jensenbyggteam.no/index.php/component/k2/itemlist/user/12131
http://poselokgribovo.ru/forum/index.php?topic=714546.0
http://www.tessabannampad.go.th/webboard/index.php?topic=187360.0
http://vtservices85.fr/smf2/index.php?topic=203653.0
http://eugeniocolazzo.it/forum/index.php?topic=86357.0
https://polyframetrade.co.uk/%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-i1-u5-%D1%80%D0%B0%D1%81%D1%81/
http://bobr.site/index.php?topic=87435.0
http://1vh.info/index.php?topic=10190.0
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rz4-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://help.stv.ru/index.php?PHPSESSID=dccf4684361aa8aaa8d67cf28d3ed85e&topic=137710.0
https://www.regalepadova.it/index.php/component/k2/itemlist/user/6170
http://www.critico-expository.com/forum/index.php?topic=5639.0
http://matrixpharm.ru/forum/index.php?PHPSESSID=kvgm9dipuq6rl74o6il0no23n0&action=profile;u=159239
http://poselokgribovo.ru/forum/index.php?topic=734038.0
http://otitismediasociety.org/forum/index.php?topic=141625.0
http://thermoplast.envolgroupe.com/component/k2/author/66900
http://216.104.186.20/index.php?topic=302142.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=678483.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/998342
https://www.amazingworldtop.com/entretenimiento/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d0-t7-%d1%80%d0%b0%d1%81%d1%81/
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile;u=30980
http://www.hoonthaitoday.com/forum/index.php?topic=129292.0
http://1vh.info/index.php?topic=9236.0
http://eugeniocolazzo.it/forum/index.php?topic=85274.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=978c7930770a7e431d899e00cc8d234f&topic=205288.0
http://www.theparrotcentre.com/forum/index.php?topic=462028.0
https://members.fbhaters.com/index.php?topic=69157.0
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1534545
http://guiadetudo.com/?option=com_k2&view=itemlist&task=user&id=10605
http://miklja.net/forum/index.php?topic=26915.0
http://istakam.com/forum/index.php?topic=10297.0
https://www.shaiyax.com/index.php?topic=327239.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=676287.0
http://www.ekemoon.com/155529/050020195908/
https://forum.shaiyaslayer.tk/index.php?topic=89466.0
https://reficulcoin.com/index.php?topic=13862.0
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-q5-m2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://blog.ptpintcast.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-s4-k5-%d0%b8%d0%b3%d1%80%d0%b0/
http://codeerror.in/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90bt0%e3%80%91/
http://thanosakademi.com/index.php?topic=67070.0
http://blog.ptpintcast.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t5-s6-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://menulisilmiah.net/10-05-2019-%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/10-05-2019-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://menulisilmiah.net/10-05-2019-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/10-05-2019-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://danceplanet.se/commodore/index.php?topic=20685.0
https://khuyenmaikk13.info/index.php?topic=190018.0
https://khuyenmaikk13.info/index.php?topic=190067.0
https://khuyenmaikk13.info/index.php?topic=190068.0
https://nextezone.com/index.php?action=profile;u=5355
https://nextezone.com/index.php?topic=42142.0
http://help.stv.ru/index.php?topic=139964.0
http://myrechockey.com/forums/index.php?topic=92817.0
http://otitismediasociety.org/forum/index.php?topic=150111.0
http://otitismediasociety.org/forum/index.php?topic=150113.0
http://roikjer.com/forum/index.php?topic=843293.0
http://teambuildingpremium.com/forum/index.php?topic=799995.0
http://HyUa.1fps.icu/l/szIaeDC
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-57/
http://demo.caribe.vps-private.net/blog/milliardy-4-sezon-10-seriya-j0-m8-milliardy-4-sezon-10-seriya-milliardy-4-sezon-10-seriya
http://demo.caribe.vps-private.net/blog/milliardy-4-sezon-10-seriya-j6-k6-milliardy-4-sezon-10-seriya-milliardy-4-sezon-10-seriya
http://demo.caribe.vps-private.net/blog/milliardy-4-sezon-10-seriya-z2-y8-milliardy-4-sezon-10-seriya-milliardy-4-sezon-10-seriya-onlin
http://demo.caribe.vps-private.net/blog/milliardy-4-sezon-11-seriya-e6-r9-milliardy-4-sezon-11-seriya-milliardy-4-sezon-11-seriya
http://demo.caribe.vps-private.net/blog/milliardy-4-sezon-11-seriya-watch-r1-b3-milliardy-4-sezon-11-seriya-milliardy-4-sezon-11-seriya
http://demo.caribe.vps-private.net/blog/milliardy-4-sezon-12-seriya-m3-f4-milliardy-4-sezon-12-seriya-milliardy-4-sezon-12-seriya
http://demo.caribe.vps-private.net/blog/milliardy-4-sezon-8-seriya-online-i2-s2-milliardy-4-sezon-8-seriya-milliardy-4-sezon-8-seriya
http://forum.elexlabs.com/index.php?topic=17011.0
http://myrechockey.com/forums/index.php?topic=92070.0
http://muonlineint.com/forum/index.php?topic=369.0
http://e-educ.net/Forum/index.php?topic=3946.0
http://forum.elexlabs.com/index.php?topic=13357.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=24876.0
http://forum.politeknikgihon.ac.id/index.php?topic=16430.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3288040
http://www.hoonthaitoday.com/forum/index.php?topic=140504.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=86fd6de3a3100063fd969ffebcae4626&topic=206840.0
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n1-u0-%d1%80%d0%b0%d1%81%d1%81/
http://roikjer.com/forum/index.php?topic=801579.0
http://podwodnyswiat.eu/forum/index.php?topic=323.0
https://reficulcoin.com/index.php?topic=9185.0
http://153.120.114.241/eso/index.php/16869211-igra-prestolov-2019-8-sezon-1-seria-igra-prestolov-2019-8-sezon
http://roikjer.com/forum/index.php?PHPSESSID=iscp7453teuh61g0bj4habm6m2&topic=798520.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=26243.0
http://muonlineint.com/forum/index.php?topic=439.0
https://forum.shaiyaslayer.tk/index.php?topic=87809.0
http://roikjer.com/forum/index.php?PHPSESSID=8d21lhpr6gc252q494ai9p2lc1&topic=798556.0
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1985740
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90fa8%e3%80%91/
http://blog.ptpintcast.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v1-n7-%d0%b8%d0%b3%d1%80/
http://otitismediasociety.org/forum/index.php?topic=141834.0
http://menulisilmiah.net/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m6-i7-%d1%80%d0%b0%d1%81%d1%81/
http://forum.drahthaar-club.com.ua/index.php?topic=1277.0
http://danielmillsap.com/forum/index.php?topic=942809.0
http://HyUa.1fps.icu/l/szIaeDC
http://roikjer.com/forum/index.php?topic=811097.0
http://ru-realty.com/forum/index.php?PHPSESSID=6pgq5ais5klnl9ouihkbb0ngq1&topic=456341.0
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z3-k5-%d1%80%d0%b0/
https://nextezone.com/index.php?topic=35753.0
http://married.dike.gr/index.php/component/k2/itemlist/user/43563
http://bobr.site/index.php?topic=100427.0
http://roikjer.com/forum/index.php?topic=805076.0
http://sextomariotienda.com/blog/%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0%d1%8f-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b0-%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be%d0%b1%d0%be%d1%82%d0%b0-18-%d1%81%d0%b5-14/
https://danceplanet.se/commodore/index.php?topic=11628.0
http://bobr.site/index.php?topic=96541.0
http://ruschinaforum.ru/index.php?topic=128309.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=26973.0
http://freebeer.me/index.php?topic=306836.0
http://e-educ.net/Forum/index.php?topic=4443.0
http://www.deliberarchia.org/forum/index.php?topic=937035.0
http://poselokgribovo.ru/forum/index.php?topic=709721.0
http://e-educ.net/Forum/index.php?topic=5714.0
http://forum.bmw-e60.eu/index.php?topic=3700.0
http://ru-realty.com/forum/index.php?PHPSESSID=5t2n9m1k8cuptii66dctro1696&topic=447958.0
http://myrechockey.com/forums/index.php?topic=84342.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=675829.0
http://taklongclub.com/forum/index.php?topic=84514.0
http://poselokgribovo.ru/forum/index.php?topic=699419.0
http://help.stv.ru/index.php?PHPSESSID=8d318427c5611e813cb3a0d2bcd67a1a&topic=137793.0
http://teambuildingpremium.com/forum/index.php?topic=796430.0
http://teambuildingpremium.com/forum/index.php?topic=796461.0
https://members.fbhaters.com/index.php?topic=85824.0
https://danceplanet.se/commodore/index.php?topic=18816.0
https://nextezone.com/index.php?action=profile&u=4381
https://nextezone.com/index.php?topic=40805.0
https://sanp.pro/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e4-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://otitismediasociety.org/forum/index.php?topic=149605.0
http://otitismediasociety.org/forum/index.php?topic=149610.0
http://roikjer.com/forum/index.php?PHPSESSID=p5meetm2o3n5otiglqbu98nof3&topic=839270.0
http://teambuildingpremium.com/forum/index.php?topic=796524.0
https://danceplanet.se/commodore/index.php?topic=18838.0
https://danceplanet.se/commodore/index.php?topic=18842.0
https://members.fbhaters.com/index.php?topic=85845.0
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t7-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
https://sanp.pro/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p4-%d1%81/
http://HyUa.1fps.icu/l/szIaeDC
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-37/
http://www.proandpro.it/?option=com_k2&view=itemlist&task=user&id=4533098
http://multikopterforum.hu/index.php?topic=6987.0
http://otitismediasociety.org/forum/index.php?topic=144405.0
http://multikopterforum.hu/index.php?topic=10193.0
http://153.120.114.241/eso/index.php/16874117-ne-zenskaa-rabota-ne-zinoca-robota-13-seria-05052019
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90nl3%e3%80%91-%d0%b8%d0%b3/
http://withinfp.sakura.ne.jp/eso/index.php/16862684-igra-prestolov-2019-8-sezon-6-seria-igra-prestolov-2019-8-sezon/0
https://chromehearts.in.th/index.php?topic=43939.0
http://e-educ.net/Forum/index.php?topic=3206.0
http://teambuildingpremium.com/forum/index.php?topic=767328.0
http://www.deliberarchia.org/forum/index.php?topic=942990.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=675591.0
http://poselokgribovo.ru/forum/index.php?topic=727441.0
http://multikopterforum.hu/index.php?topic=7279.0
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z1-t1-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://e-educ.net/Forum/index.php?topic=4689.0
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1989378
http://www.deliberarchia.org/forum/index.php?topic=965527.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=669909.0
http://www.theocraticamerica.org/forum/index.php?topic=26881.0
http://153.120.114.241/eso/index.php/16849041-igra-prestolov-got-8-sezon-2-seria-igra-prestolov-got-8-sezon-2
https://danceplanet.se/commodore/index.php?topic=12720.0
http://ru-realty.com/forum/index.php?topic=454454.0
https://reficulcoin.com/index.php?topic=8584.0
http://storykingdom.forumside.com/index.php?topic=3722.0
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=59461
http://forum.kopkargobel.com/index.php?topic=5556.0
http://poselokgribovo.ru/forum/index.php?topic=730171.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1327508
http://help.stv.ru/index.php?PHPSESSID=572beaf73f17c967125bd049195f431c&topic=137254.0
http://forum.politeknikgihon.ac.id/index.php?topic=20209.0
http://poselokgribovo.ru/forum/index.php?topic=703325.0
http://muonlineint.com/forum/index.php?topic=1623.0
https://www.c-alice.org/forum/index.php?topic=70136.0
http://miklja.net/forum/index.php?topic=25802.0
http://storykingdom.forumside.com/index.php?topic=5638.0
http://ru-realty.com/forum/index.php?PHPSESSID=gvlki9fnsd3cqh2403p0j1aq82&topic=459241.0
http://vtservices85.fr/smf2/index.php?topic=207866.0
http://ru-realty.com/forum/index.php?PHPSESSID=c69r8uateht1c0se4jh5pnkik7&topic=459232.0
http://www.deliberarchia.org/forum/index.php?topic=943275.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.deliberarchia.org/forum/index.php?topic=989879.0
http://www.ekemoon.com/164729/051420195209/
http://www.ekemoon.com/164739/051420195309/
http://www.ekemoon.com/164753/051420195509/
http://www.ekemoon.com/164777/051520190209/
http://www.moyakmermer.com/?option=com_k2&view=itemlist&task=user&id=689081
http://www.nomaher.com/forum/index.php?topic=12102.0
http://www.popolsku.fr.pl/forum/index.php?topic=376313.0
http://www.spazioad.com/component/k2/itemlist/user/7256425
http://www.tekparcahdfilm.com/forum/index.php?topic=46923.0
http://www.tekparcahdfilm.com/forum/index.php?topic=46926.0
http://www.theparrotcentre.com/forum/index.php?topic=481094.0
http://www.theparrotcentre.com/forum/index.php?topic=481240.0
http://withinfp.sakura.ne.jp/eso/index.php/17001524-vossoedinenie-vuslat-15-seria-n8-vossoedinenie-vuslat-15-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/17001675-rannaa-ptaska-erkenci-kus-45-seria-f7-rannaa-ptaska-erkenci-kus
http://withinfp.sakura.ne.jp/eso/index.php/17002071-voskressij-ertugrul-148-seria-l8-voskressij-ertugrul-148-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/17002142-nasa-istoria-70-seria-online-k7-nasa-istoria-70-seria
http://www.deliberarchia.org/forum/index.php?topic=1010532.0
http://www.deliberarchia.org/forum/index.php?topic=1010547.0
http://www.deliberarchia.org/forum/index.php?topic=1010557.0
http://www.theparrotcentre.com/forum/index.php?topic=505918.0
http://www.theparrotcentre.com/forum/index.php?topic=505933.0
http://www.theparrotcentre.com/forum/index.php?topic=505954.0
https://reficulcoin.com/index.php?topic=27101.0
http://eugeniocolazzo.it/forum/index.php?topic=118440.0
http://eugeniocolazzo.it/forum/index.php?topic=118447.0
http://www.theparrotcentre.com/forum/index.php?topic=480731.0
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=0af8fe6b4b1e244024451456f59f58ff&topic=607.0
http://www.vivelabmanizales.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c3-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://www.vivelabmanizales.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o9-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://www.vivelabmanizales.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-y4-%d0%b8%d0%b3%d1%80/
http://www.vivelabmanizales.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j3-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5/
http://www.vivelabmanizales.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-h8-%d0%b8%d0%b3%d1%80%d0%b0/
http://www.vivelabmanizales.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-z3-%d0%b8%d0%b3%d1%80%d0%b0/
http://www.vivelabmanizales.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a1-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://www.vivelabmanizales.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v0-%d0%b8%d0%b3%d1%80/
http://www.vivelabmanizales.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-u4-%d0%b8%d0%b3%d1%80/
http://www.vivelabmanizales.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-c3-%d0%b8%d0%b3/
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=682549.0
http://vervetama.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90rf2%e3%80%91-%d0%b8%d0%b3/
http://otitismediasociety.org/forum/index.php?topic=141718.0
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=187008
http://roikjer.com/forum/index.php?PHPSESSID=6jmpvn81j2rk9j522qnad8usr7&topic=804705.0
http://danielmillsap.com/forum/index.php?topic=945459.0
http://multikopterforum.hu/index.php?topic=7332.0
http://metropolis.ga/index.php?topic=3822.0
https://szenarist.ru/forum/index.php?topic=201749.0
http://forum.byehaj.hu/index.php?topic=77887.0
https://khuyenmaikk13.info/index.php?topic=177382.0
http://roikjer.com/forum/index.php?PHPSESSID=vf3mujnt9ii8og9qr34mhsfl17&topic=796272.0
http://otitismediasociety.org/forum/index.php?topic=145853.0
http://www.hoonthaitoday.com/forum/index.php?topic=153218.0
http://www.ekemoon.com/149505/050120191407/
http://forum.politeknikgihon.ac.id/index.php?topic=17566.0
http://forum.politeknikgihon.ac.id/index.php?topic=19467.0
http://macdistri.com/index.php/component/k2/itemlist/user/290285
http://multikopterforum.hu/index.php?topic=12755.0
http://www.hoonthaitoday.com/forum/index.php?topic=150764.0
https://reficulcoin.com/index.php?topic=8948.0
https://www.gizmoarticle.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-04-05-2019-2/
http://poselokgribovo.ru/forum/index.php?topic=693463.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/07-05-2019-om-10-e-420038/msg557626/
http://www.deliberarchia.org/forum/index.php?topic=958940.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1329157
http://www.hoonthaitoday.com/forum/index.php?topic=140064.0
http://dohairbiz.com/en/component/k2/itemlist/user/2700806.html
https://szenarist.ru/forum/index.php?topic=205289.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.ekemoon.com/145779/051720194706/
http://forum.politeknikgihon.ac.id/index.php?topic=24910.0
http://www.theparrotcentre.com/forum/index.php?topic=456447.0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4740559
http://smartacity.com/component/k2/itemlist/user/17731
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=6134
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=9071
http://danielmillsap.com/forum/index.php?topic=955819.0
http://smartacity.com/component/k2/itemlist/user/23681
http://www.ekemoon.com/163375/050720192809/
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1565896
https://tg.vl-mp.com/index.php?topic=1333742.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/292714
http://www.m1avio.com/index.php/component/k2/itemlist/user/3637406
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/586119
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=52037
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/235814
http://zsmr.com.ua/index.php/component/k2/itemlist/user/520494
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=17368
http://153.120.114.241/eso/index.php/16938141-hd1080-sluga-naroda-3-sezon-19-seria-x3-sluga-naroda-3-sezon-19
http://1vh.info/index.php?topic=15475.0
http://dota2.host/75052-hd720-sluga-naroda-3-sezon-14-seria-q1-sluga-naroda-3-sezon-14-
http://dota2.host/75114-smotret-sluga-naroda-3-sezon-18-seria-o1-sluga-naroda-3-sezon-1
http://dota2.host/75275-hd1080-sluga-naroda-3-sezon-23-seria-d2-sluga-naroda-3-sezon-23
http://dpmarketingsystems.com/%d0%be%d0%bd%d0%bb%d0%b0%d0%b9%d0%bd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c4-%d1%81%d0%bb%d1%83/
http://dpmarketingsystems.com/new-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://dpmarketingsystems.com/video-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p2-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=751367a90dde339c5788636e7b81b9d4&topic=3354.0
https://forum.ac-jete.it/index.php?topic=370577.0
https://npi.org.es/smf/index.php?topic=114953.0
https://reficulcoin.com/index.php?topic=27765.0
https://reficulcoin.com/index.php?topic=27768.0
https://www.c-alice.org/forum/index.php?topic=79959.0
https://www.c-alice.org/forum/index.php?topic=79961.0
http://bayareawomenmag.xyz/blogs/viewstory/39941
http://bayareawomenmag.xyz/blogs/viewstory/39955
http://eugeniocolazzo.it/forum/index.php?topic=119292.0
http://forum.bmw-e60.eu/index.php?topic=6728.0
http://forum.bmw-e60.eu/index.php?topic=6731.0
http://poselokgribovo.ru/forum/index.php?topic=744832.0
http://roikjer.com/forum/index.php?PHPSESSID=0u5i124novrobone9a7j18v5e7&topic=836383.0
http://roikjer.com/forum/index.php?PHPSESSID=e32dmmbvnp59advt6h94gkthh4&topic=836374.0
http://roikjer.com/forum/index.php?PHPSESSID=o66n4vf0e15fnelcqrtvkuko32&topic=836364.0
http://roikjer.com/forum/index.php?PHPSESSID=ruqbn97q9vg239k9a7qoh1g363&topic=836397.0
http://ru-realty.com/forum/index.php?PHPSESSID=81gffkkglvaa2jpeq9febd6pr4&topic=479010.0
http://seoksoononly.dothome.co.kr/qna/826485
http://seoksoononly.dothome.co.kr/qna/826520
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1657085
http://taklongclub.com/forum/index.php?topic=110243.0
http://teambuildingpremium.com/forum/index.php?topic=793665.0
http://eugeniocolazzo.it/forum/index.php?topic=118239.0
http://forum.politeknikgihon.ac.id/index.php?topic=36393.0
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile;u=34840
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://metropolis.ga/index.php?topic=7753.0
http://sextomariotienda.com/blog/on-line-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c1-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://vtservices85.fr/smf2/index.php?PHPSESSID=1262b6ec6cdd0a27667c99112e9b70c0&topic=222183.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=43975808ac905d20e079d6423e09cba6&topic=222189.0
http://www.artifact.website/168271-hd-sluga-naroda-3-sezon-10-seria-d6-sluga-naroda-3-sezon-10-ser?---------------------------8648668141043%0D%0AContent-Disposition:%20form-data;%20name=%22token%22%0D%0A%0D%0A9eae57514d212%0D%0A---------------------------8648668141043%0D%0AContent-Disposition:%20form-data;%20name=%22title%22%0D%0A%0D%0A[~%D0%A5%D0%94~]%20%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%9D%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D0%A1%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D0%A1%D0%B5%D1%80%D0%B8%D1%8F%20$D6%20%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%9D%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D0%A1%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D0%A1%D0%B5%D1%80%D0%B8%D1%8F%0D%0A---------------------------8648668141043%0D%0AContent-Disposition:%20form-data;%20name=%22content%22%0D%0A%0D%0A11-05-2019%20%C2%AB%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB%20%0D%0A%0D%0A[url=http://zfilm4.ru/watch/4sm0KsYP/][img]https://i.imgur.com/Wy1bUcF.jpg[/img][/url]%0D%0A%0D%0A[url=http://zfilm4.ru/watch/4sm0KsYP/]%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F[/url]%0D%0A[url=http://zfilm4.ru/watch/4sm0KsYP/]%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F[/url]%0D%0A[url=http://zfilm4.ru/watch/4sm0KsYP/]%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F[/url]%0D%0A%0D%0A%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20kz%0D%0A%3E%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%B2%D0%BA%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D1%8E%D1%82%D1%83%D0%B1%0D%0A---------------------------8648668141043%0D%0AContent-Disposition:%20form-data;%20name=%22postReply%22%0D%0A%0D%0A%D0%9D%D0%B0%D1%87%D0%B0%D1%82%D1%8C%20%D0%BE%D0%B1%D1%81%D1%83%D0%B6%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5%0D%0A---------------------------8648668141043--%0D%0A&---------------------------8648668141043%0D%0AContent-Disposition:%20form-data;%20name=%22token%22%0D%0A%0D%0A9eae57514d212%0D%0A---------------------------8648668141043%0D%0AContent-Disposition:%20form-data;%20name=%22title%22%0D%0A%0D%0A[~%D0%A5%D0%94~]%20%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%9D%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D0%A1%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D0%A1%D0%B5%D1%80%D0%B8%D1%8F%20$D6%20%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%9D%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D0%A1%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D0%A1%D0%B5%D1%80%D0%B8%D1%8F%0D%0A---------------------------8648668141043%0D%0AContent-Disposition:%20form-data;%20name=%22content%22%0D%0A%0D%0A11-05-2019%20%C2%AB%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB%20%0D%0A%0D%0A[url=http://zfilm4.ru/watch/4sm0KsYP/][img]https://i.imgur.com/Wy1bUcF.jpg[/img][/url]%0D%0A%0D%0A[url=http://zfilm4.ru/watch/4sm0KsYP/]%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F[/url]%0D%0A[url=http://zfilm4.ru/watch/4sm0KsYP/]%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F[/url]%0D%0A[url=http://zfilm4.ru/watch/4sm0KsYP/]%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F[/url]%0D%0A%0D%0A%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20kz%0D%0A%3E%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%B2%D0%BA%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D1%8E%D1%82%D1%83%D0%B1%0D%0A---------------------------8648668141043%0D%0AContent-Disposition:%20form-data;%20name=%22postReply%22%0D%0A%0D%0A%D0%9D%D0%B0%D1%87%D0%B0%D1%82%D1%8C%20%D0%BE%D0%B1%D1%81%D1%83%D0%B6%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5%0D%0A---------------------------8648668141043--%0D%0A&---------------------------8648668141043%0D%0AContent-Disposition:%20form-data;%20name=%22token%22%0D%0A%0D%0A9eae57514d212%0D%0A---------------------------8648668141043%0D%0AContent-Disposition:%20form-data;%20name=%22title%22%0D%0A%0D%0A[~%D0%A5%D0%94~]%20%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%9D%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D0%A1%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D0%A1%D0%B5%D1%80%D0%B8%D1%8F%20$D6%20%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%9D%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D0%A1%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D0%A1%D0%B5%D1%80%D0%B8%D1%8F%0D%0A---------------------------8648668141043%0D%0AContent-Disposition:%20form-data;%20name=%22content%22%0D%0A%0D%0A11-05-2019%20%C2%AB%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB%20%0D%0A%0D%0A[url=http://zfilm4.ru/watch/4sm0KsYP/][img]https://i.imgur.com/Wy1bUcF.jpg[/img][/url]%0D%0A%0D%0A[url=http://zfilm4.ru/watch/4sm0KsYP/]%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F[/url]%0D%0A[url=http://zfilm4.ru/watch/4sm0KsYP/]%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F[/url]%0D%0A[url=http://zfilm4.ru/watch/4sm0KsYP/]%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F[/url]%0D%0A%0D%0A%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20kz%0D%0A%3E%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%B2%D0%BA%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%2010%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D1%8E%D1%82%D1%83%D0%B1%0D%0A---------------------------8648668141043%0D%0AContent-Disposition:%20form-data;%20name=%22postReply%22%0D%0A%0D%0A%D0%9D%D0%B0%D1%87%D0%B0%D1%82%D1%8C%20%D0%BE%D0%B1%D1%81%D1%83%D0%B6%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5%0D%0A---------------------------8648668141043--
http://www.remify.app/foro/index.php?topic=266507.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=24269.0
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xxu-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/437318
http://thefreebitcoin.com/index.php?topic=32198.0
https://khuyenmaikk13.info/index.php?topic=167832.0
https://sanp.pro/%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0%d1%88%d0%ba%d0%b0-erkenci-kus-42-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-y7-%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0/
http://dev.aabn.org.gh/component/k2/itemlist/user/475585
http://1vh.info/index.php?topic=14835.0
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile;u=29783
http://thanosakademi.com/index.php?topic=71280.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81-20/
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=41377
http://dpmarketingsystems.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mp1-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://danceplanet.se/commodore/index.php?topic=8956.0
http://www.tessabannampad.go.th/webboard/index.php?topic=184657.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=29405.0
http://mir3sea.com/forum/index.php?topic=135.0
https://reficulcoin.com/index.php?topic=5681.0
http://myrechockey.com/forums/index.php?topic=89938.0
http://menulisilmiah.net/%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l8-%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-7-%d1%81%d0%b5%d1%80/
https://www.c-alice.org/forum/index.php?topic=69441.0
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1012897
https://members.fbhaters.com/index.php?topic=74222.0
http://roikjer.com/forum/index.php?PHPSESSID=bua3gav0b43mtdqst05ko4r3f1&topic=831558.0
http://216.104.186.20/index.php?topic=302184.0
http://roikjer.com/forum/index.php?topic=819595.0
https://reficulcoin.com/index.php?topic=8478.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5-10/
http://blog.ptpintcast.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-t1-i7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90hn7%e3%80%91/
http://forums.abs-cbn.com/welcome-back-kapamilya%21/(a-etoo-2019-8-eo-7-e)-a-etoo-2019-8-eo-7-e-g2p5/?PHPSESSID=n84dqjjqi88kv8dcmn6r6o1ui6
http://thanosakademi.com/index.php?topic=60917.0
http://1vh.info/index.php?topic=5977.0
http://myrechockey.com/forums/index.php?topic=89651.0
http://poselokgribovo.ru/forum/index.php?topic=689619.0
http://sextomariotienda.com/blog/05-05-2019-%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0%d1%8f-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b0-%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be%d0%b1%d0%be%d1%82%d0%b0-17-5/
http://forum.byehaj.hu/index.php?topic=79125.0
http://roikjer.com/forum/index.php?PHPSESSID=iseqth4jvdsruch0tso6a042s1&topic=830096.0
http://www.hoonthaitoday.com/forum/index.php?topic=140348.0
http://8.droror.co.il/uncategorized/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5-5/
http://poselokgribovo.ru/forum/index.php?topic=708293.0
http://www.theparrotcentre.com/forum/index.php?topic=469976.0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-39/
http://universaldrive-s.cba.pl/index.php?PHPSESSID=f54448cb6213f47ed6970673f6e9bb34&topic=19872.0
http://help.stv.ru/index.php?PHPSESSID=e847599d0af81785d254b6fc13aec3cd&topic=135358.0
http://otitismediasociety.org/forum/index.php?topic=144512.0
http://forum.stollen24.com/index.php?topic=2933.0
http://sextomariotienda.com/blog/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k5-i3-%d1%80%d0%b0%d1%81%d1%81/
http://freebeer.me/index.php?topic=283474.0
https://reficulcoin.com/index.php?topic=14998.0
http://withinfp.sakura.ne.jp/eso/index.php/16861326-ertugrul-145-seria-tj6-ertugrul-145-seria/0
http://www.hoonthaitoday.com/forum/index.php?topic=142776.0
http://dpmarketingsystems.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fl1-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://HyUa.1fps.icu/l/szIaeDC
http://www.siirtorganik.com/index.php/component/k2/itemlist/user/763982
http://forum.politeknikgihon.ac.id/index.php?topic=26653.0
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7321442
http://matrixpharm.ru/forum/index.php?PHPSESSID=9vujjd9cmha5ij63mnim8jm0n6&action=profile;u=167273
http://www.ekemoon.com/152013/051120193907/
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=51432
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/9158
http://universalcommunity.se/Forum/index.php?topic=847.0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=24642
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=992800
http://www.m1avio.com/index.php/component/k2/itemlist/user/3585168
http://travelsolution.info/?option=com_k2&view=itemlist&task=user&id=713069
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-r8-%d0%b8%d0%b3/
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4672199
http://thefreebitcoin.com/index.php?topic=30169.0
http://servicioswts.com/component/k2/itemlist/user/3607919
http://jesusandmarypatna.com/index.php/component/k2/itemlist/user/3367132
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/441938
http://danielmillsap.com/forum/index.php?topic=906841.0
https://www.gizmoarticle.com/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-y4-%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81/
http://uberdrivers.net/forum/index.php?topic=210230.0
http://www2.yasothon.go.th/smf/index.php?topic=159.msg173663
http://xn--22cmah2caecpucll2cycdoj4d0knajrq3e5pbj9w0c.americanwolfthailand.com/DJPetjah/index.php?topic=1479377.0
http://danielmillsap.com/forum/index.php?topic=975450.0
https://nextezone.com/index.php?topic=37180.0
http://forum.digamahost.com/index.php?topic=110252.0
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=9294.0
https://forum.ac-jete.it/index.php?topic=348819.0
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1018246
http://www.ekemoon.com/152743/051320194807/
https://forums.letstalkbeats.com/index.php?topic=67497.0
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=96621
http://macdistri.com/index.php/component/k2/itemlist/user/310404
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/187326
https://nextezone.com/index.php?topic=38517.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/187049
http://smartacity.com/component/k2/itemlist/user/25865
http://dev.aabn.org.gh/component/k2/itemlist/user/524708
http://universalcommunity.se/Forum/index.php?topic=963.0
http://mediaville.me/index.php/component/k2/itemlist/user/217680
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/54253
http://www.spazioad.com/?option=com_k2&view=itemlist&task=user&id=7239542
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3734995
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=8768
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1028123
http://www.spazioad.com/component/k2/itemlist/user/7243721
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=28827.0
https://lucky28003.nl/forum/index.php?topic=11580.0
http://www.critico-expository.com/forum/index.php?topic=4793.0
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/8765
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1028171
http://www.emrabq8.com/index.php/component/k2/itemlist/user/1776806
http://www.m1avio.com/index.php/component/k2/itemlist/user/3628109
http://myrechockey.com/forums/index.php?topic=91222.0
http://poselokgribovo.ru/forum/index.php?topic=744342.0
http://ru-realty.com/forum/index.php?PHPSESSID=fpp9tr350dl6n9g9rd5nu6aqu0&topic=478612.0
http://seoksoononly.dothome.co.kr/qna/824107
http://seoksoononly.dothome.co.kr/qna/824215
http://seoksoononly.dothome.co.kr/qna/824353
http://seoksoononly.dothome.co.kr/qna/824403
http://seoksoononly.dothome.co.kr/qna/824451
http://seoksoononly.dothome.co.kr/qna/824475
http://siliconvalleytalk.xyz/blogs/viewstory/15222
http://siliconvalleytalk.xyz/blogs/viewstory/15307
http://siliconvalleytalk.xyz/blogs/viewstory/15314
http://www.deliberarchia.org/forum/index.php?topic=934668.0
https://lucky28003.nl/forum/index.php?topic=12014.0
http://ruschinaforum.ru/index.php?topic=126275.0
http://roikjer.com/forum/index.php?PHPSESSID=n07ba0gitg7kkmim7vgk740904&topic=801962.0
http://1vh.info/index.php?topic=7048.0
http://blog.ptpintcast.com/%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p2-%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5/
http://uberdrivers.net/forum/index.php?topic=224937.0
http://wituclub.ru/forum/index.php?PHPSESSID=2m02kvkveosse2jju0g6lr4mh7&topic=26035.0
http://www.popolsku.fr.pl/forum/index.php?topic=370562.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=677484.0
http://roikjer.com/forum/index.php?PHPSESSID=6gkfg2flhm4k3df3ijdsk1v930&topic=822867.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2556111
https://cybergsm.es/index.php?topic=8151.0
http://roikjer.com/forum/index.php?topic=795429.0
https://danceplanet.se/commodore/index.php?topic=10523.0
http://metropolis.ga/index.php?topic=3484.0
https://worldtaxi.org/2019/05/08/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-4/
http://multikopterforum.hu/index.php?topic=13997.0
https://adsensebih.com/index.php?topic=7514.0
https://adsensebih.com/index.php?topic=7928.0
http://muonlineint.com/forum/index.php?topic=888.0
http://www.deliberarchia.org/forum/index.php?topic=947270.0
http://otitismediasociety.org/forum/index.php?topic=142277.0
http://forum.bmw-e60.eu/index.php?topic=3041.0
http://eugeniocolazzo.it/forum/index.php?topic=97539.0
https://danceplanet.se/commodore/index.php?topic=9782.0
http://forum.bmw-e60.eu/index.php?topic=3802.0
http://www.theparrotcentre.com/forum/index.php?topic=463019.0
http://dpmarketingsystems.com/%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-06-05-2019-4/
http://miklja.net/forum/index.php?topic=27581.0
http://blog.ptpintcast.com/%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d3-%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-10-%d1%81%d0%b5%d1%80/
http://HyUa.1fps.icu/l/szIaeDC
http://uberdrivers.net/forum/index.php?topic=254345.0
http://universalcommunity.se/Forum/index.php?topic=2951.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=ddd25d50f1aeb83c6fe0a6063e6faad3&topic=219897.0
http://www.ekemoon.com/176115/050820192711/
http://www.ekemoon.com/176183/050820194111/
http://www.ekemoon.com/176207/050820194711/
http://www.quattroandpartners.it/component/k2/itemlist/user/1091532
http://www.tekparcahdfilm.com/forum/index.php?topic=48423.0
http://www.theparrotcentre.com/forum/index.php?topic=501119.0
https://sanp.pro/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-i5-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5/
http://uberdrivers.net/forum/index.php?topic=175505.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/533070
http://www.xn--q3cx6g8a.net/board/index.php?topic=187106.0
http://macdistri.com/index.php/component/k2/itemlist/user/297346
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=253223
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3518327
http://menulisilmiah.net/tv-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c4-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
https://reficulcoin.com/index.php?topic=29620.0
http://myrechockey.com/forums/index.php?topic=96136.0
http://poselokgribovo.ru/forum/index.php?topic=765976.0
http://poselokgribovo.ru/forum/index.php?topic=766002.0
http://teambuildingpremium.com/forum/index.php?topic=813118.0
http://www.tessabannampad.go.th/webboard/index.php?topic=202279.0
http://www.theparrotcentre.com/forum/index.php?topic=511403.0
https://khuyenmaikk13.info/index.php?topic=194969.0
https://reficulcoin.com/index.php?topic=29622.0
http://istakam.com/forum/index.php?topic=15142.0
http://multikopterforum.hu/index.php?topic=12169.0
http://myrechockey.com/forums/index.php?topic=87156.0
http://www.hoonthaitoday.com/forum/index.php?topic=139057.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=40fefca03d40de18258f63cbfdc3bd72&topic=210045.0
http://www.deliberarchia.org/forum/index.php?topic=972510.0
http://danielmillsap.com/forum/index.php?topic=977982.0
https://szenarist.ru/forum/index.php?topic=201873.0
http://multikopterforum.hu/index.php?topic=11930.0
http://guiadetudo.com/index.php/component/k2/itemlist/user/10908
http://otitismediasociety.org/forum/index.php?topic=142960.0
http://danielmillsap.com/forum/index.php?topic=971017.0
http://webp.online/index.php?topic=48612.0
https://www.gizmoarticle.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-id7-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://216.104.186.20/index.php?topic=293210.0
http://153.120.114.241/eso/index.php/16862173-igra-prestolov-got-8-sezon-1-seria-igra-prestolov-got-8-sezon-1
http://wituclub.ru/forum/index.php?PHPSESSID=s9l9glv1ccp17icrrtse9sijs7&topic=25911.0
https://danceplanet.se/commodore/index.php?topic=13743.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/184107
http://sextomariotienda.com/blog/hd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f8-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
https://danceplanet.se/commodore/index.php?topic=8236.0
http://muonlineint.com/forum/index.php?topic=1525.0
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-l6-a8-%d1%80/
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5-18/
http://highlanderonline.cmshelplive.net/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81/
http://codeerror.in/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0/
http://poselokgribovo.ru/forum/index.php?topic=694173.0
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2393096
http://roikjer.com/forum/index.php?topic=790690.0
https://tg.vl-mp.com/index.php?topic=1306272.0
http://multikopterforum.hu/index.php?topic=13718.0
http://freebeer.me/index.php?topic=313957.0
http://forum.digamahost.com/index.php?topic=107059.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=74b44e41b8711dc9f2a6fbae57665ab2&topic=205080.0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=557486
https://www.gizmoarticle.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-y5-o5-%d1%80%d0%b0%d1%81%d1%81/
http://www.tessabannampad.go.th/webboard/index.php?topic=186309.0
http://HyUa.1fps.icu/l/szIaeDC
http://smartacity.com/component/k2/itemlist/user/17841
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=776426
http://www.dap.com.py/index.php/es/?option=com_k2&view=itemlist&task=user&id=790505
http://menulisilmiah.net/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-96-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-bug-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94/
http://dohairbiz.com/en/component/k2/itemlist/user/2716154.html
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1552006
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3596565
http://www.nomaher.com/forum/index.php?topic=11377.0
http://smartacity.com/component/k2/itemlist/user/17847
http://www.phan-aen.go.th/forum/index.php?topic=626619.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=679801.0
https://forums.letstalkbeats.com/index.php?topic=66046.0
http://www.critico-expository.com/forum/index.php?topic=4021.0
http://www.ekemoon.com/153435/051620194907/
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=282924
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=552695
https://forums.letstalkbeats.com/index.php?topic=49096.0
http://www.tessabannampad.go.th/webboard/index.php?topic=174734.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/434691
http://c3isecurity.com.br/?option=com_k2&view=itemlist&task=user&id=442467
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/167803
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1599978
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=665799.0
http://8.droror.co.il/uncategorized/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l2-m8-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://8.droror.co.il/uncategorized/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t8-l0-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://d2bchannel.co.in/blog/2019/05/10/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g7-o3-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
http://demo.caribe.vps-private.net/blog/milliardy-4-sezon-11-seriya-watch-i9-b4-milliardy-4-sezon-11-seriya-milliardy-4-sezon-11-seriya
http://demo.caribe.vps-private.net/blog/milliardy-4-sezon-12-seriya-l6-n6-milliardy-4-sezon-12-seriya-milliardy-4-sezon-12-seriya
http://forum.elexlabs.com/index.php/topic,17701.0.html
http://forum.elexlabs.com/index.php?topic=17705.0
http://forum.elexlabs.com/index.php?topic=17707.0
http://forum.politeknikgihon.ac.id/index.php?topic=31855.0
http://forum.politeknikgihon.ac.id/index.php?topic=31863.0
http://forum.politeknikgihon.ac.id/index.php?topic=31865.0
http://metropolis.ga/index.php?topic=6800.0
http://metropolis.ga/index.php?topic=6802.0
http://metropolis.ga/index.php?topic=6803.0
http://metropolis.ga/index.php?topic=6804.0
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b7-c2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-c8-g8-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c7-o2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-o7-s8-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://roikjer.com/forum/index.php?PHPSESSID=0jdnv46f6827c22l3v6768r6b0&topic=842304.0
http://roikjer.com/forum/index.php?PHPSESSID=tf8ilevae8s9h7lv96920nnej5&topic=842309.0
http://roikjer.com/forum/index.php?PHPSESSID=u1ot395a12844anssg46am7g00&topic=842297.0
https://danceplanet.se/commodore/index.php?topic=25465.0
https://prelease.club/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x9-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://otitismediasociety.org/forum/index.php?topic=153371.0
http://otitismediasociety.org/forum/index.php?topic=153387.0
http://otitismediasociety.org/forum/index.php?topic=153392.0
http://roikjer.com/forum/index.php?PHPSESSID=dik7snauonclgacndlaqvrfgf3&topic=856255.0
http://roikjer.com/forum/index.php?PHPSESSID=l439mbmpceifavvio0rlr5mhq6&topic=856234.0
https://danceplanet.se/commodore/index.php?topic=25484.0
https://prelease.club/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
https://prelease.club/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u5-%d1%81%d0%bb/
https://prelease.club/hd-video-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i7-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://help.stv.ru/index.php?PHPSESSID=24ff3d8ae41e7360f30a3508c1585ea4&topic=140568.0
http://help.stv.ru/index.php?PHPSESSID=ba6b32d87cf5875978b629f6dd27a3a3&topic=140569.0
http://myrechockey.com/forums/index.php?topic=95439.0
http://roikjer.com/forum/index.php?PHPSESSID=5m9milhgfti4at0bcgs9jat6f2&topic=856284.0
http://help.stv.ru/index.php?PHPSESSID=80c1b516394844595c36dc4738e3824e&topic=140570.0
http://otitismediasociety.org/forum/index.php?topic=153415.0
https://prelease.club/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-s2-%d1%81/
http://help.stv.ru/index.php?PHPSESSID=62ff4b7a7d439729e7a8ed853117804b&topic=140571.0
https://danceplanet.se/commodore/index.php?topic=25522.0
https://prelease.club/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-y9-%d1%81%d0%bb/
https://prelease.club/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c6-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
https://prelease.club/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
https://prelease.club/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e7-%d1%81/
https://prelease.club/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i3-%d1%81/
http://HyUa.1fps.icu/l/szIaeDC
https://www.gizmoarticle.com/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-23-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nrt-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-23-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-10-05-2019/
https://www.gizmoarticle.com/%d1%81%d0%bb%d0%b5%d0%b4%d0%be%d0%b2%d0%b0%d1%82%d0%b5%d0%bb%d1%8c-%d0%b3%d0%be%d1%80%d1%87%d0%b0%d0%ba%d0%be%d0%b2%d0%b0-%d1%81%d0%bbi%d0%b4%d1%87%d0%b8%d0%b9-%d0%b3%d0%be%d1%80%d1%87%d0%b0%d0%ba-23/
http://153.120.114.241/eso/index.php/16959649-ertugrul-148-seria-f8-ertugrul-148-seria
http://8.droror.co.il/uncategorized/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-29-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a9/
http://8.droror.co.il/uncategorized/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l8-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2596606
http://dota2.host/112418-voskressij-ertugrul-149-seria-f7-voskressij-ertugrul-149-seria
http://forum.politeknikgihon.ac.id/index.php?topic=32388.0
http://married.dike.gr/index.php/component/k2/itemlist/user/55285
http://muratliziraatodasi.org/forum/index.php?topic=423611.0
http://muratliziraatodasi.org/forum/index.php?topic=423619.0
http://www.remify.app/foro/index.php?topic=266152.0
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=e604a7930a87a52b0e24ee12fdbf98d2&topic=3127.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=687566.0
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=14877.0
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=14894.0
https://nextezone.com/index.php?topic=44487.0
https://prelease.club/hd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
https://prelease.club/hd1080-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
https://prelease.club/online-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x7-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
https://prelease.club/tv-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u1-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
https://reficulcoin.com/index.php?topic=26764.0
https://reficulcoin.com/index.php?topic=26772.0
https://reficulcoin.com/index.php?topic=26774.0
https://reficulcoin.com/index.php?topic=26778.0
https://sanp.pro/new-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3747474
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3747480
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3747481
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2542476
http://rudraautomation.com/index.php/component/k2/author/142893
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3599479
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4752378
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1037477
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1037835
http://roikjer.com/forum/index.php?PHPSESSID=377vfbggklgkqk9f050hrqrvb4&topic=838813.0
http://roikjer.com/forum/index.php?topic=838796.0
http://www.deliberarchia.org/forum/index.php?topic=995273.0
http://www.deliberarchia.org/forum/index.php?topic=995287.0
http://www.deliberarchia.org/forum/index.php?topic=995292.0
https://members.fbhaters.com/index.php/topic,85530.0.html
https://members.fbhaters.com/index.php?topic=85553.0
https://members.fbhaters.com/index.php?topic=85557.0
https://reficulcoin.com/index.php?topic=18754.0
https://reficulcoin.com/index.php?topic=18795.0
https://worldtaxi.org/2019/05/09/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l4-s4-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
https://worldtaxi.org/2019/05/09/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-e4-i8-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
https://worldtaxi.org/2019/05/09/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e4-o3-%d0%b8%d0%b3%d1%80/
http://blog.ptpintcast.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m1-w4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://blog.ptpintcast.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-o9-a1-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://blog.ptpintcast.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a7-v7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://blog.ptpintcast.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j0-c5-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://blog.ptpintcast.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w9-t4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://d2bchannel.co.in/blog/2019/05/10/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k0-t0-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://dailypatriot.net/phpbb/viewtopic.php?t=412606
http://jdcalc.com/forum/viewtopic.php?t=167803
http://metropolis.ga/index.php?topic=6508.0
http://216.104.186.20/index.php?topic=302240.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=669090.0
http://multikopterforum.hu/index.php?topic=11409.0
https://danceplanet.se/commodore/index.php?topic=15554.0
http://flashboot.ru/forum/index.php?topic=94210.0
http://danielmillsap.com/forum/index.php?topic=989161.0
http://withinfp.sakura.ne.jp/eso/index.php/16849946-ertugrul-149-seria-yn2-ertugrul-149-seria
http://dpmarketingsystems.com/live-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k2-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
https://reficulcoin.com/index.php?topic=5863.0
http://www.tessabannampad.go.th/webboard/index.php?topic=185929.0
https://npi.org.es/smf/index.php?topic=111616.0
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=161971
https://members.fbhaters.com/index.php?topic=73250.0
http://www.aloeverasas.it/index.php/component/k2/itemlist/user/17116
http://HyUa.1fps.icu/l/szIaeDC
https://reficulcoin.com/index.php?topic=11568.0
http://sextomariotienda.com/blog/05-05-2019-%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://golyboe.ru/forum/index.php?topic=25335.0
http://dev.aabn.org.gh/component/k2/itemlist/user/516344
http://freebeer.me/index.php?topic=283064.0
http://istakam.com/forum/index.php?topic=8866.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-11/
https://forum.ac-jete.it/index.php?topic=340550.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90uc2%e3%80%91-%d0%b8%d0%b3/
http://forum.elexlabs.com/index.php?topic=14205.0
http://vtservices85.fr/smf2/index.php?topic=203867.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=678447.0
http://www.critico-expository.com/forum/index.php?topic=3562.0
http://multikopterforum.hu/index.php?topic=9296.0
http://www.newb.northstarchiangrai.com/index.php?topic=23573.0
https://khuyenmaikk13.info/index.php?topic=180194.0
http://menulisilmiah.net/%d0%b4%d1%80%d1%83%d0%b3%d0%b0%d1%8f-i%d0%bd%d1%88%d0%b0-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-06-05-2019/
http://otitismediasociety.org/forum/index.php?topic=145916.0
http://ru-realty.com/forum/index.php?PHPSESSID=n16upcj1v6pfc6vv1021rjlr52&topic=474816.0
http://roikjer.com/forum/index.php?PHPSESSID=l4smg14n091hl2umgbq2ei8gb7&topic=811937.0
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=185924
http://metropolis.ga/index.php?topic=5182.0
http://www.killerknuts.com/groups/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-s6-j7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
http://macdistri.com/index.php/component/k2/itemlist/user/294573
http://thanosakademi.com/index.php?topic=65447.0
http://ru-realty.com/forum/index.php?PHPSESSID=p03agbekcne3l73uj3i4kdusc4&topic=455915.0
http://otitismediasociety.org/forum/index.php?topic=145628.0
http://flashboot.ru/forum/index.php?topic=94264.0
http://poselokgribovo.ru/forum/index.php?topic=692290.0
http://freebeer.me/index.php?topic=307725.0
http://sextomariotienda.com/blog/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u9-%d1%81/
http://haniel.ir/index.php/component/k2/itemlist/user/71712
http://metropolis.ga/index.php?topic=5100.0
http://ru-realty.com/forum/index.php?PHPSESSID=os71qfdv9d0m9dpes390vapp92&topic=466472.0
http://dpmarketingsystems.com/hd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k4-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
https://adsensebih.com/index.php?topic=8540.0
http://freebeer.me/index.php?topic=288232.0
http://eugeniocolazzo.it/forum/index.php?topic=102766.0
http://www.deliberarchia.org/forum/index.php?topic=947460.0
http://roikjer.com/forum/index.php?PHPSESSID=p2kdmq7oqj37c6drid5lrdt1u7&topic=803458.0
http://www.deliberarchia.org/forum/index.php?topic=967173.0
http://HyUa.1fps.icu/l/szIaeDC
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/487218
http://www.tessabannampad.go.th/webboard/index.php?topic=193316.0
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=762678
http://married.dike.gr/index.php/component/k2/itemlist/user/53370
http://smartacity.com/component/k2/itemlist/user/23493
http://www.spazioad.com/?option=com_k2&view=itemlist&task=user&id=7242512
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2588350
https://forums.letstalkbeats.com/index.php?topic=68315.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/189637
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3586166
http://dohairbiz.com/?option=com_k2&view=itemlist&task=user&id=2720019
http://www.nomaher.com/forum/index.php?topic=11182.0
http://www.theparrotcentre.com/forum/index.php?topic=434035.0
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lek-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://www.deliberarchia.org/forum/index.php?topic=935300.0
https://npi.org.es/smf/index.php?topic=108163.0
http://www.tessabannampad.go.th/webboard/index.php?topic=176386.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/536180
http://thanosakademi.com/index.php?topic=59219.0
http://teambuildingpremium.com/forum/index.php?topic=747068.0
http://www.theparrotcentre.com/forum/index.php?topic=441921.0
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=260235
http://teambuildingpremium.com/forum/index.php?topic=800430.0
http://teambuildingpremium.com/forum/index.php?topic=800444.0
http://thanosakademi.com/index.php?topic=75674.0
http://www.critico-expository.com/forum/index.php?topic=9957.0
http://www.critico-expository.com/forum/index.php?topic=9962.0
http://www.critico-expository.com/forum/index.php?topic=9970.0
http://www.remify.app/foro/index.php?topic=253014.0
http://www.theparrotcentre.com/forum/index.php?topic=492041.0
http://myrechockey.com/forums/index.php?topic=84322.0
http://216.104.186.20/index.php?topic=302100.0
https://khuyenmaikk13.info/index.php?topic=175190.0
http://podwodnyswiat.eu/forum/index.php?topic=203.0
http://roikjer.com/forum/index.php?topic=818655.0
http://www.tessabannampad.go.th/webboard/index.php?topic=188839.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-(got)-8-eo-4-e-kz2-'a-etoo-(got)-8-eo-4-e-watch'/?PHPSESSID=u6u5qdrr3eb9jgeul111i3g3s4
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=675775.0
http://poselokgribovo.ru/forum/index.php?topic=714040.0
http://ru-realty.com/forum/index.php?PHPSESSID=bfs4851138lpiuafknlomf5590&topic=445073.0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5-22/
https://reficulcoin.com/index.php?topic=7477.0
http://menulisilmiah.net/08-05-2019-%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://flashboot.ru/forum/index.php?topic=94037.0
http://www.theocraticamerica.org/forum/index.php?topic=26972.0
http://otitismediasociety.org/forum/index.php?topic=143297.0
http://forum.politeknikgihon.ac.id/index.php?topic=11314.0
http://153.120.114.241/eso/index.php/16842083-igra-prestolovgame-of-thrones-8-sezon-6-seria-igra-prestolovgam
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=492921
http://roikjer.com/forum/index.php?PHPSESSID=0f6h3e9nu7tk6hm942inhsie81&topic=832718.0
http://www.deliberarchia.org/forum/index.php?topic=941051.0
http://www.deliberarchia.org/forum/index.php?topic=937924.0
http://withinfp.sakura.ne.jp/eso/index.php/16841346-igra-prestolovgame-of-thrones-8-sezon-3-seria-igra-prestolovgam/0
https://polyframetrade.co.uk/%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-3-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-e1-w9-%D1%80%D0%B0%D1%81%D1%81/
http://forum.stollen24.com/index.php?topic=3286.0
http://forum.drahthaar-club.com.ua/index.php?topic=798.0
http://wituclub.ru/forum/index.php?PHPSESSID=9n6tf1coitvgqnq951t9gmcle5&topic=25137.0
https://adsensebih.com/index.php?topic=7514.0
https://adsensebih.com/index.php?topic=7928.0
http://muonlineint.com/forum/index.php?topic=888.0
http://www.deliberarchia.org/forum/index.php?topic=947270.0
http://otitismediasociety.org/forum/index.php?topic=142277.0
http://forum.bmw-e60.eu/index.php?topic=3041.0
http://eugeniocolazzo.it/forum/index.php?topic=97539.0
https://danceplanet.se/commodore/index.php?topic=9782.0
http://forum.bmw-e60.eu/index.php?topic=3802.0
http://www.theparrotcentre.com/forum/index.php?topic=463019.0
http://dpmarketingsystems.com/%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-06-05-2019-4/
http://HyUa.1fps.icu/l/szIaeDC
https://nextezone.com/index.php?topic=42350.0
https://reficulcoin.com/index.php?topic=21485.0
https://sanp.pro/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p6-%d0%b2/
https://tg.vl-mp.com/index.php?topic=1370326.0
http://dev.aabn.org.gh/component/k2/itemlist/user/555589
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/80711
http://www2.yasothon.go.th/smf/index.php?topic=159.msg184456
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3762610
http://matinbank.ir/component/k2/itemlist/user/4506893.html
http://matinbank.ir/component/k2/itemlist/user/4506988.html
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/83760
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=12224
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/12235
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/199251
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/199253
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1663775
http://withinfp.sakura.ne.jp/eso/index.php/16756907-nasa-istoria-65-seria-watch-h5-nasa-istoria-65-seria-watch/0
http://uberdrivers.net/forum/index.php?topic=173946.0
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=990314
http://ru-realty.com/forum/index.php?PHPSESSID=2h9s0052ecjreud1njb89htkh3&topic=428783.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1088483
http://uberdrivers.net/forum/index.php?topic=178082.0
http://sfah.ch/de/component/k2/itemlist/user/14733
http://dohairbiz.com/?option=com_k2&view=itemlist&task=user&id=2685651
http://ru-realty.com/forum/index.php?topic=419125.0
http://matrixpharm.ru/forum/index.php?PHPSESSID=nebtc75d470nqr50log9laglq6&action=profile;u=148630
http://poselokgribovo.ru/forum/index.php?topic=648793.0
http://metropolis.ga/index.php?topic=6657.0
http://myrechockey.com/forums/index.php?topic=92326.0
http://partemp.com/en/groups/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f7-r6-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j3-i5-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://roikjer.com/forum/index.php?PHPSESSID=k5tsci4fatdtib44b981i2s1h5&topic=840652.0
http://roikjer.com/forum/index.php?topic=840607.0
http://roikjer.com/forum/index.php?topic=840630.0
http://taklongclub.com/forum/index.php?topic=112570.0
http://vervetama.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b2-d1-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://poselokgribovo.ru/forum/index.php?topic=698662.0
http://e-educ.net/Forum/index.php?topic=3247.0
http://8.droror.co.il/uncategorized/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p2-u6-%d1%80%d0%b0%d1%81%d1%81/
http://forum.politeknikgihon.ac.id/index.php?topic=19369.0
http://teambuildingpremium.com/forum/index.php?topic=786259.0
https://members.fbhaters.com/index.php?topic=72476.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1327512
http://www.deliberarchia.org/forum/index.php?topic=977528.0
http://vtservices85.fr/smf2/index.php?topic=210146.0
http://immobilia.gr/index.php/component/k2/itemlist/user/15820
http://HyUa.1fps.icu/l/szIaeDC
http://www.critico-expository.com/forum/index.php?topic=8266.0
http://www.remify.app/foro/index.php?topic=250260.0
http://www.remify.app/foro/index.php?topic=250263.0
http://www.tessabannampad.go.th/webboard/index.php?topic=197040.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=684122.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=684125.0
https://members.fbhaters.com/index.php?topic=87000.0
https://nextezone.com/index.php?action=profile;u=4938
https://nextezone.com/index.php?topic=41422.0
http://roikjer.com/forum/index.php?PHPSESSID=ljti38svpj20lta7jf2h45lbo1&topic=840981.0
http://www.deliberarchia.org/forum/index.php?topic=997716.0
https://reficulcoin.com/index.php?topic=20067.0
http://8.droror.co.il/uncategorized/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t9-h1-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://d2bchannel.co.in/blog/2019/05/10/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c9-d3-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://d2bchannel.co.in/blog/2019/05/10/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g1-v7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://d2bchannel.co.in/blog/2019/05/10/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r2-o7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://forum.elexlabs.com/index.php?topic=17335.0
http://forum.politeknikgihon.ac.id/index.php?topic=31183.0
http://partemp.com/en/groups/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u7-h6-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h1-a2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-e3-a7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://poselokgribovo.ru/forum/index.php?topic=749470.0
http://poselokgribovo.ru/forum/index.php?topic=749499.0
http://roikjer.com/forum/index.php?PHPSESSID=9md5s81agf8pvv2ccm8bhsjho7&topic=840975.0
http://roikjer.com/forum/index.php?PHPSESSID=vkbd5qu3clnrlu2jmkr10dfeq7&topic=812089.0
http://help.stv.ru/index.php?PHPSESSID=dff1dc73b04df0f440f85bed68b5de09&topic=138819.0
http://www.remify.app/foro/index.php?topic=214792.0
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-n8-a3-%d1%80/
http://roikjer.com/forum/index.php?PHPSESSID=ai838k36nciua4t5vucsrtgar2&topic=822741.0
http://sextomariotienda.com/blog/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h4/
https://reficulcoin.com/index.php?topic=12219.0
http://sfah.ch/component/k2/itemlist/user/14587
http://dpmarketingsystems.com/05-05-2019-%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0%d1%8f-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b0-%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be%d0%b1%d0%be%d1%82%d0%b0-19-2/
https://reficulcoin.com/index.php?topic=6971.0
http://216.104.186.20/index.php?topic=298630.0
http://thanosakademi.com/index.php?topic=67291.0
https://nextezone.com/index.php?topic=35767.0
http://otitismediasociety.org/forum/index.php?topic=148166.0
http://ru-realty.com/forum/index.php?topic=454602.msg565464
http://withinfp.sakura.ne.jp/eso/index.php/16841994-ertugrul-148-seria-rm5-ertugrul-148-seria/0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=676419.0
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1727527
http://www.critico-expository.com/forum/index.php?topic=3592.0
http://www.remify.app/foro/index.php?topic=201322.0
http://HyUa.1fps.icu/l/szIaeDC
http://otitismediasociety.org/forum/index.php?topic=149844.0
http://roikjer.com/forum/index.php?PHPSESSID=sn0703meumol9lm4bgg43o8hi2&topic=841219.0
http://www.deliberarchia.org/forum/index.php?topic=997994.0
https://members.fbhaters.com/index.php?topic=87114.0
https://members.fbhaters.com/index.php?topic=87125.0
https://reficulcoin.com/index.php?topic=20167.0
https://reficulcoin.com/index.php?topic=20173.0
http://forum.digamahost.com/index.php?topic=112795.0
http://forum.elexlabs.com/index.php?topic=17403.0
http://forum.elexlabs.com/index.php?topic=17412.0
http://forum.elexlabs.com/index.php?topic=17413.0
http://forum.elexlabs.com/index.php?topic=17416.0
http://forum.politeknikgihon.ac.id/index.php?topic=31300.0
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-j0-u1-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://freebeer.me/index.php?topic=283557.0
https://danceplanet.se/commodore/index.php?topic=15197.0
http://www.tekparcahdfilm.com/forum/index.php?topic=45356.0
http://forum.politeknikgihon.ac.id/index.php?topic=19776.0
http://roikjer.com/forum/index.php?PHPSESSID=evgagg22me20upjelupb13l3k7&topic=797851.0
https://members.fbhaters.com/index.php?topic=70915.0
http://eugeniocolazzo.it/forum/index.php?topic=82561.0
http://sextomariotienda.com/blog/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-um1-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://wituclub.ru/forum/index.php?PHPSESSID=dbjehpign2goee1v2cfp1g1re4&topic=25997.0
http://www.theparrotcentre.com/forum/index.php?topic=453144.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.ofqj.org/hebergementfrance/4-10-h1-r3-4-10-4-10
http://www.popolsku.fr.pl/forum/index.php?topic=377927.0
http://www.remify.app/foro/index.php?topic=252071.0
http://www.teedinubon.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-l7-w6-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://www.teedinubon.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u0-n3-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://www.theocraticamerica.org/forum/index.php?topic=29680.0
http://www.theocraticamerica.org/forum/index.php?topic=29681.0
http://www.theparrotcentre.com/forum/index.php?topic=491143.0
http://www.theparrotcentre.com/forum/index.php?topic=491154.0
http://www.theparrotcentre.com/forum/index.php?topic=491160.0
https://members.fbhaters.com/index.php/topic,88158.0.html
https://members.fbhaters.com/index.php/topic,88168.0.html
https://members.fbhaters.com/index.php?topic=88155.0
https://members.fbhaters.com/index.php?topic=88177.0
https://nextezone.com/index.php?topic=42049.0
https://reficulcoin.com/index.php?topic=21087.0
http://otitismediasociety.org/forum/index.php?topic=150058.0
http://otitismediasociety.org/forum/index.php?topic=150061.0
http://roikjer.com/forum/index.php?PHPSESSID=0rbmj3io97pu144an5nskce217&topic=842927.0
http://roikjer.com/forum/index.php?PHPSESSID=lk04nmgjjpcdf7mkudsu839ri5&topic=842944.0
http://otitismediasociety.org/forum/index.php?topic=147008.0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-13/
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=41832
http://danielmillsap.com/forum/index.php?topic=924796.0
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w5-j3-%d1%80%d0%b0%d1%81%d1%81/
http://dpmarketingsystems.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-t3-l9-%d1%80/
https://members.fbhaters.com/index.php?topic=73903.0
http://taklongclub.com/forum/index.php?topic=83616.0
https://polyframetrade.co.uk/%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-z0-g5-%D1%80%D0%B0/
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90am6%e3%80%91/
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a3-h7-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://vtservices85.fr/smf2/index.php?PHPSESSID=4c2a768d6de8002f608a18f1909d466f&topic=204035.0
http://salescoach.ro/content/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90nf9%E3%80%91-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4
http://multikopterforum.hu/index.php?topic=6231.0
http://xplorefitness.com/blog/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-got-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-6-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%E3%80%90tk3%E3%80%91-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-got-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-6-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://www.theparrotcentre.com/forum/index.php?topic=474743.0
http://forum.politeknikgihon.ac.id/index.php?topic=19509.0
https://reficulcoin.com/index.php?topic=14438.0
http://matrixpharm.ru/forum/index.php?PHPSESSID=6lnk74jiqs2uc51jfrklaj3f95&action=profile;u=159201
http://danielmillsap.com/forum/index.php?topic=941030.0
http://dpmarketingsystems.com/06-05-2019-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://poselokgribovo.ru/forum/index.php?topic=690457.0
http://www.ekemoon.com/154931/052320190507/
http://ru-realty.com/forum/index.php?PHPSESSID=s8ffs4bbmtvu5f1ocrm5kmadn1&topic=449608.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1355811
http://www.aloeverasas.it/index.php/component/k2/itemlist/user/18168
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=782958
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/476140
http://universalcommunity.se/Forum/index.php?topic=626.0
http://sfah.ch/?option=com_k2&view=itemlist&task=user&id=14862
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/634708
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=755536
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=755603
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=755790
http://www.spazioad.com/component/k2/itemlist/user/7223862
https://www.netprofessional.gr/component/k2/itemlist/user/2840.html
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile;u=27183
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=26852.0
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=9631
http://rudraautomation.com/index.php/component/k2/author/142627
http://smartacity.com/component/k2/itemlist/user/28457
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/61583
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4751043
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4751515
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4751594
http://www.arunagreen.com/index.php/component/k2/itemlist/user/459722
http://www.arunagreen.com/index.php/component/k2/itemlist/user/459729
http://www.arunagreen.com/index.php/component/k2/itemlist/user/459816
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1366199
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1037228
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=793435
http://istakam.com/forum/index.php?topic=8816.0
http://thanosakademi.com/index.php?topic=62448.0
http://danielmillsap.com/forum/index.php?topic=943488.0
http://withinfp.sakura.ne.jp/eso/index.php/16866215-ertugrul-146-seria-jl3-ertugrul-146-seria/0
http://www.ekemoon.com/144629/051120191306/
https://khuyenmaikk13.info/index.php?topic=180053.0
http://freebeer.me/index.php?topic=306871.0
http://istakam.com/forum/index.php?topic=9811.0
http://wb.hvekorat.com/index.php?topic=40878.0
http://forum.byehaj.hu/index.php?topic=76924.0
http://www.tessabannampad.go.th/webboard/index.php?topic=192795.0
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v4-j1-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=162033
https://lucky28003.nl/forum/index.php?topic=7419.0
http://matrixpharm.ru/forum/index.php?PHPSESSID=huhd4smc3q8vm1p3mtcvamoq33&action=profile;u=161437
http://forum.digamahost.com/index.php?topic=108337.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=1b9590dea0f101915fce4f15d89b39a3&topic=207442.0
http://roikjer.com/forum/index.php?PHPSESSID=l9g6b04a06lemcj5tk2i0052n2&topic=811945.0
http://forum.politeknikgihon.ac.id/index.php?topic=21128.0
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-b6-c6-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
http://poselokgribovo.ru/forum/index.php?topic=703819.0
http://metropolis.ga/index.php?topic=2225.0
http://roikjer.com/forum/index.php?PHPSESSID=bs7ed14pnu3d1c3hspd9tqjgp7&topic=825659.0
http://www.hoonthaitoday.com/forum/index.php?topic=173764.0
http://forum.politeknikgihon.ac.id/index.php?topic=20386.0
http://poselokgribovo.ru/forum/index.php?topic=710635.0
http://golyboe.ru/forum/index.php?topic=25133.0
https://members.fbhaters.com/index.php?topic=79711.0
http://sextomariotienda.com/blog/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mp0-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://golyboe.ru/forum/index.php?topic=25360.0
http://lavaggio.com.vn/index.php/component/k2/itemlist/user/3697066
http://www.vivelabmanizales.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q6-i3-%d1%80%d0%b0%d1%81%d1%81/
http://otitismediasociety.org/forum/index.php?topic=148185.0
http://menulisilmiah.net/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h2-u0-%d1%80%d0%b0%d1%81%d1%81/
https://danceplanet.se/commodore/index.php?topic=10983.0
http://blog.ptpintcast.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o5-b2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-44/
http://poselokgribovo.ru/forum/index.php?topic=690548.0
http://metropolis.ga/index.php?topic=2200.0
http://taklongclub.com/forum/index.php?topic=98009.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-29/
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=24237.0
http://www.critico-expository.com/forum/index.php?topic=2761.0
http://ru-realty.com/forum/index.php?PHPSESSID=om1l8re5bbrl6sf00n0l631tc1&topic=446577.0
http://HyUa.1fps.icu/l/szIaeDC
http://freebeer.me/index.php?topic=309543.0
http://www.tessabannampad.go.th/webboard/index.php?topic=187745.0
http://wb.hvekorat.com/index.php?topic=40340.0
http://multikopterforum.hu/index.php?topic=5912.0
http://www.remify.app/foro/index.php?topic=229740.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81-16/
http://forum.stollen24.com/index.php?topic=3057.0
http://blog.ptpintcast.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v3-e9-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://golyboe.ru/forum/index.php?topic=25367.0
http://dpmarketingsystems.com/05-05-2019-%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://poselokgribovo.ru/forum/index.php?topic=695081.0
http://myrechockey.com/forums/index.php?topic=95753.0
http://ru-realty.com/forum/index.php?PHPSESSID=e2g5f6ian1h717aqs50i44has3&topic=497613.0
http://ru-realty.com/forum/index.php?topic=497571.0
https://danceplanet.se/commodore/index.php?topic=26105.0
https://danceplanet.se/commodore/index.php?topic=26109.0
https://prelease.club/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c6-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
https://prelease.club/%d1%8d%d1%84%d0%b8%d1%80-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o0-%d1%81%d0%bb%d1%83%d0%b3/
http://myrechockey.com/forums/index.php?topic=95763.0
http://roikjer.com/forum/index.php?PHPSESSID=vh031mt7mn8vugf1a8dfnp6e13&topic=858068.0
http://ru-realty.com/forum/index.php?PHPSESSID=aj6t1tu62077apmmr034bbg5j2&topic=497667.0
http://otitismediasociety.org/forum/index.php?topic=153998.0
http://otitismediasociety.org/forum/index.php?topic=153987.0
https://danceplanet.se/commodore/index.php?topic=26150.0
https://prelease.club/live-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://myrechockey.com/forums/index.php?topic=95775.0
http://myrechockey.com/forums/index.php?topic=95785.0
http://roikjer.com/forum/index.php?PHPSESSID=8llhg52o32eja8ic4tv2fjhf20&topic=858148.0
https://danceplanet.se/commodore/index.php?topic=26164.0
http://myrechockey.com/forums/index.php?topic=95794.0
http://otitismediasociety.org/forum/index.php?topic=154031.0
http://ru-realty.com/forum/index.php?PHPSESSID=9titkubogselbacjaj383351f7&topic=497799.0
https://prelease.club/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://prelease.club/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-23-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p4-%d1%81/
https://prelease.club/%d1%8d%d1%84%d0%b8%d1%80-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-23-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z5-%d1%81%d0%bb%d1%83%d0%b3/
https://prelease.club/hd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b9-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://HyUa.1fps.icu/l/szIaeDC
http://forum.elexlabs.com/index.php?topic=23643.0
http://forum.elexlabs.com/index.php?topic=23645.0
http://forum.kopkargobel.com/index.php?topic=8212.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=32712.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=32714.0
http://www.tessabannampad.go.th/webboard/index.php?topic=204105.0
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5-8/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81-11/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-8/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-20/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-15/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-14/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5-11/
https://reficulcoin.com/index.php?topic=32540.0
https://reficulcoin.com/index.php?topic=32548.0
https://reficulcoin.com/index.php?topic=32553.0
https://reficulcoin.com/index.php?topic=32557.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81-38/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-41/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5-48/
http://bobr.site/index.php?topic=125247.0
http://www.deliberarchia.org/forum/index.php?topic=977220.0
http://forum.bmw-e60.eu/index.php?topic=1588.0
http://multikopterforum.hu/index.php?topic=10977.0
http://sextomariotienda.com/blog/hd-video-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r6-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
https://nextezone.com/index.php?action=profile;u=1729
http://forum.drahthaar-club.com.ua/index.php?topic=1157.0
http://roikjer.com/forum/index.php?topic=829521.0
http://myrechockey.com/forums/index.php?topic=82453.0
http://www.obal-shop.sk/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n0-f5-%d1%80%d0%b0%d1%81%d1%81/
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i7-c0-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://bobr.site/index.php?topic=92614.0
http://www.hoonthaitoday.com/forum/index.php?topic=153725.0
http://roikjer.com/forum/index.php?PHPSESSID=r0j7kma4osh7u7jhemobh5q0l4&topic=803785.0
http://www.tessabannampad.go.th/webboard/index.php?topic=188927.0
http://danielmillsap.com/forum/index.php?topic=940287.0
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j2-g7-%d1%80%d0%b0%d1%81%d1%81-2/
http://myrechockey.com/forums/index.php?topic=89289.0
http://forum.politeknikgihon.ac.id/index.php?topic=17643.0
http://www.alase.net/index.php/component/k2/itemlist/user/11311
http://HyUa.1fps.icu/l/szIaeDC
http://vhost12299.cpsite.ru/81500-voskressij-ertugrul-5-sezon-147-seria-k0-voskressij-ertugrul-5-
http://vhost12299.cpsite.ru/81528-voskressij-ertugrul-5-sezon-27-seria-watch-t7-voskressij-ertugr
http://vhost12299.cpsite.ru/81533-voskressij-ertugrul-5-sezon-29-seria-t8-voskressij-ertugrul-5-s
http://www.artifact.website/80716-voskressij-ertugrul-5-sezon-26-seria-a3-voskressij-ertugrul-5-s
http://www.artifact.website/80723-ertugrul-5-sezon-150-seria-j1-ertugrul-5-sezon-150-seria
http://www.artifact.website/80786-ertugrul-5-sezon-27-seria-k0-ertugrul-5-sezon-27-seria
http://www.artifact.website/80901-voskressij-ertugrul-150-seria-k5-voskressij-ertugrul-150-seria
http://www.artifact.website/80935-ertugrul-5-sezon-148-seria-online-o5-ertugrul-5-sezon-148-seria
http://www.artifact.website/80992-ertugrul-150-seria-watch-b7-ertugrul-150-seria
http://www.artifact.website/81092-voskressij-ertugrul-148-seria-watch-j8-voskressij-ertugrul-148-
http://www.artifact.website/81124-voskressij-ertugrul-5-sezon-150-seria-q2-voskressij-ertugrul-5-
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=131994
http://rudraautomation.com/index.php/component/k2/author/131510
http://rudraautomation.com/index.php/component/k2/author/131741
http://www.hoonthaitoday.com/forum/index.php?topic=177836.0
http://www.phan-aen.go.th/forum/index.php?topic=627085.0
http://www.phan-aen.go.th/forum/index.php?topic=627090.0
https://forum.ac-jete.it/index.php?topic=348103.0
http://dohairbiz.com/en/component/k2/itemlist/user/2717144.html
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/8233
http://www.critico-expository.com/forum/index.php?topic=1008.0
http://roikjer.com/forum/index.php?PHPSESSID=l4nnmm472lgeh3fmjqpe9c8pu5&topic=779742.0
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3517794
http://teambuildingpremium.com/forum/index.php?topic=744772.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/533418
http://withinfp.sakura.ne.jp/eso/index.php/16786582-smotret-sluga-naroda-3-sezon-21-seria-d7-sluga-naroda-3-sezon-2/0
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1548193
http://www.quattroandpartners.it/component/k2/itemlist/user/1024240
http://matrixpharm.ru/forum/index.php?PHPSESSID=47k8jqk3do4o9ebb4r1ohgo347&action=profile;u=149652
http://danielmillsap.com/forum/index.php?topic=867157.0
http://danielmillsap.com/forum/index.php?topic=884054.0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=536948
https://wwwelibga.000webhostapp.com/%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0%d1%88%d0%ba%d0%b0-erkenci-kus-42-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g0-%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0%d1%88/lisette70c/86245/
http://www.lustralesdevallehermoso.com/index.php/component/k2/itemlist/user/48207
http://mobility-corp.com/index.php/component/k2/itemlist/user/2534380
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4727017
https://www.c-alice.org/forum/index.php?topic=71754.0
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=273665
https://ne-kuru.ru/index.php?topic=211985.0
https://lucky28003.nl/forum/index.php?topic=6582.0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=301012
https://sanp.pro/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-auc-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8/
http://dev.aabn.org.gh/component/k2/itemlist/user/479874
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=557335
https://www.c-alice.org/forum/index.php?topic=66665.0
https://reficulcoin.com/index.php?topic=17102.0
https://reficulcoin.com/index.php?topic=17114.0
https://tg.vl-mp.com/index.php?topic=1360582.0
https://www.c-alice.org/forum/index.php?topic=77201.0
http://1vh.info/index.php?topic=16633.0
http://bayareawomenmag.xyz/blogs/viewstory/19211
http://bayareawomenmag.xyz/blogs/viewstory/19242
http://dota2.host/86972-igra-prestolov-2019-8-sezon-5-seria-g7-m0-igra-prestolov-2019-8
http://dota2.host/86998-igra-prestolov-2019-8-sezon-6-seria-u1-r4-igra-prestolov-2019-8
http://dota2.host/87146-igra-prestolov-got-8-sezon-6-seria-o6-u6-igra-prestolov-got-8-s
http://dota2.host/87190-igra-prestolov-game-of-thrones-8-sezon-5-seria-online-z6-z8-igr
http://dota2.host/87237-igra-prestolov-8-sezon-7-seria-r9-r9-igra-prestolov-8-sezon-7-s
http://dota2.host/87242-igra-prestolov-got-8-sezon-5-seria-w1-n5-igra-prestolov-got-8-s
http://dota2.host/87282-igra-prestolov-8-sezon-7-seria-h1-i2-igra-prestolov-8-sezon-7-s
http://dota2.host/87318-igra-prestolov-2019-8-sezon-7-seria-q3-d6-igra-prestolov-2019-8
http://www.studioaparo.it/?option=com_k2&view=itemlist&task=user&id=543762
http://forum.politeknikgihon.ac.id/index.php?topic=18046.0
https://nextezone.com/index.php?action=profile;u=1967
http://forums.abs-cbn.com/welcome-back-kapamilya%21/e-eka-aota-(e-ioa-oota)-14-e-~-f8-e-eka-aota-(e-ioa-oota)-14-e/msg555739/
http://teambuildingpremium.com/forum/index.php?topic=763655.0
http://freebeer.me/index.php?topic=294634.0
http://danielmillsap.com/forum/index.php?topic=981929.0
https://reficulcoin.com/index.php?topic=13001.0
http://forum.stollen24.com/index.php?topic=3385.0
https://forum.shaiyaslayer.tk/index.php?topic=94819.0
http://menulisilmiah.net/09-05-2019-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://worldtaxi.org/2019/05/08/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80-2/
http://codeerror.in/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a4-b3-%d1%80%d0%b0%d1%81/
http://www.ekemoon.com/159745/051620193908/
http://sextomariotienda.com/blog/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rh3-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://otitismediasociety.org/forum/index.php?topic=144737.0
http://1vh.info/index.php?topic=8138.0
https://nextezone.com/index.php?topic=37815.0
http://vtservices85.fr/smf2/index.php?topic=208879.0
http://www.critico-expository.com/forum/index.php?topic=2130.0
https://forums.letstalkbeats.com/index.php?topic=67834.0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/61848
http://myrechockey.com/forums/index.php?topic=88478.0
https://www.amazingworldtop.com/entretenimiento/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r8-n5-%d1%80%d0%b0%d1%81%d1%81/
http://blog.ptpintcast.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z8-n5-%d0%b8%d0%b3%d1%80/
http://multikopterforum.hu/index.php?topic=7030.0
https://worldtaxi.org/2019/05/08/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5/
https://sanp.pro/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://danceplanet.se/commodore/index.php?topic=10378.0
http://danielmillsap.com/forum/index.php?topic=955672.0
http://menulisilmiah.net/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90ay1%e3%80%91/
http://www.critico-expository.com/forum/index.php?topic=5651.0
http://www.tessabannampad.go.th/webboard/index.php?topic=194313.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=276366
http://multikopterforum.hu/index.php?topic=4706.0
http://HyUa.1fps.icu/l/szIaeDC
http://codeerror.in/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0/
https://reficulcoin.com/index.php?topic=6526.0
http://uberdrivers.net/forum/index.php?topic=237923.0
http://help.stv.ru/index.php?topic=138546.0
http://thanosakademi.com/index.php?topic=69021.0
http://www.remify.app/foro/index.php?topic=201697.0
http://guiadetudo.com/index.php/component/k2/itemlist/user/10648
http://forum.kopkargobel.com/index.php?topic=4953.0
https://reficulcoin.com/index.php?topic=5991.0
http://www.tessabannampad.go.th/webboard/index.php?topic=186509.0
http://blog.ptpintcast.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p9-d4-%d0%b8%d0%b3%d1%80/
http://www.spazioad.com/component/k2/itemlist/user/7203238
http://www.remify.app/foro/index.php?topic=231962.0
http://roikjer.com/forum/index.php?PHPSESSID=mbbksehsjftjaqt0je98bmupc5&topic=790167.0
http://otitismediasociety.org/forum/index.php?topic=145163.0
http://freebeer.me/index.php?topic=302262.0
http://sextomariotienda.com/blog/%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v0-%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5/
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z4-r2-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://teambuildingpremium.com/forum/index.php?topic=765900.0
http://dpmarketingsystems.com/hd-video-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k1-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://forums.abs-cbn.com/welcome-back-kapamilya%21/06-05-2019-to-oot-2-e/?PHPSESSID=uq8e3reve7bpuvlb9lvnf3llr5
https://khuyenmaikk13.info/index.php?topic=180068.0
http://www.remify.app/foro/index.php?topic=221507.0
https://danceplanet.se/commodore/index.php?topic=11643.0
http://sextomariotienda.com/blog/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hm0-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://153.120.114.241/eso/index.php/16862876-igra-prestolov-game-of-thrones-8-sezon-7-seria-igra-prestolov-g
http://www.theparrotcentre.com/forum/index.php?topic=449931.0
https://members.fbhaters.com/index.php?topic=81250.0
http://labmaster.top/smf2/index.php?topic=13702.0
http://e-educ.net/Forum/index.php?topic=6792.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.ekemoon.com/152343/051220193907/
http://mediaville.me/index.php/component/k2/itemlist/user/229454
http://www.theparrotcentre.com/forum/index.php?topic=479058.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3617139
http://forum.digamahost.com/index.php?topic=109664.0
http://www.elpinatarense.com/?option=com_k2&view=itemlist&task=user&id=152910
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3337823
http://www.quattroandpartners.it/component/k2/itemlist/user/1032252
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=44998
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1330582
http://www.meikai.com.ar/foro/index.php?topic=48769.0
http://sextomariotienda.com/blog/%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be%d0%b1%d0%be%d1%82%d0%b0-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cre-%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be/
http://poselokgribovo.ru/forum/index.php?topic=651495.0
https://tg.vl-mp.com/index.php?topic=1255229.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3569477
http://healthyteethpa.org/component/k2/itemlist/user/5293851
http://www.spazioad.com/component/k2/itemlist/user/7174725
http://macdistri.com/?option=com_k2&view=itemlist&task=user&id=286503
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1613441
http://poselokgribovo.ru/forum/index.php?topic=649367.0
http://www.hoonthaitoday.com/forum/index.php?topic=173726.0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4723766
http://mvisage.sk/?option=com_k2&view=itemlist&task=user&id=118060
http://teambuildingpremium.com/forum/index.php?topic=770116.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/575055
http://www.ekemoon.com/164001/050920195409/
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile;u=29370
http://www.spazioad.com/component/k2/itemlist/user/7227980
http://www.vivelabmanizales.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xyz-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2-%d1%81%d0%b5%d1%80%d0%b8/
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/220778
https://npi.org.es/smf/index.php?topic=108275.0
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1597065
http://married.dike.gr/index.php/component/k2/itemlist/user/33714
https://members.fbhaters.com/index.php?topic=54069.0
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2476708
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=306109
http://www.arunagreen.com/index.php/component/k2/itemlist/user/409646
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/271250
http://mahdi.ehosseini.com/?option=com_k2&view=itemlist&task=user&id=18844
http://roikjer.com/forum/index.php?PHPSESSID=n75qc0fqoeklrracp5b6f7g6n2&topic=763244.0
https://sanp.pro/%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0%d1%8f-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b0-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rst-%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0/
http://www.nomaher.com/forum/index.php?topic=10891.0
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=169306
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1331393
http://withinfp.sakura.ne.jp/eso/index.php/16757100-nasa-istoria-69-seria-g2-nasa-istoria-69-seria/0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=278375
http://www.vivelabmanizales.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-83-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ljy-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-83-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-04-05-2019/
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=275634
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3274175
http://www.boutique.in.th/index.php/component/k2/itemlist/user/145332
http://proxima.co.rw/index.php/component/k2/itemlist/user/558432
http://www2.yasothon.go.th/smf/index.php?topic=159.153495
http://forum.digamahost.com/index.php?topic=106557.0
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1516212
http://eugeniocolazzo.it/forum/index.php?topic=82036.0
http://dpmarketingsystems.com/%d1%81%d0%be%d0%b4%d0%b5%d1%80%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-oaa-%d1%81%d0%be%d0%b4%d0%b5%d1%80%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-9-%d1%81%d0%b5%d1%80/
http://dpmarketingsystems.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jxg-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8/
http://dpmarketingsystems.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-ciq-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://dpmarketingsystems.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-yez-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://dpmarketingsystems.com/%d1%87%d1%83%d0%b6%d0%b0%d1%8f-%d0%b6%d0%b8%d0%b7%d0%bd%d1%8c-%d1%87%d1%83%d0%b6%d0%b5-%d0%b6%d0%b8%d1%82%d1%82%d1%8f-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uxg-%d1%87%d1%83%d0%b6/
http://menulisilmiah.net/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-oeb-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
http://web2interactive.com/index.php/component/k2/itemlist/user/3526265
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=30728
https://lucky28003.nl/forum/index.php?topic=4259.0
https://tg.vl-mp.com/index.php?topic=1247394.0
http://danielmillsap.com/forum/index.php?topic=891796.0
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=187531
http://www.tvmechanic.co.in/forum/index.php?topic=8292.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1288079
http://www.spazioad.com/component/k2/itemlist/user/7163947
http://soc-human.kz/index.php/component/k2/itemlist/user/1644533
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4735750
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1562510
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1354543
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1354822
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1022401
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1022437
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/75950
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4748310
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=14077
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=1023300
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1893800
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1893897
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1755577
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1755849
http://healthyteethpa.org/component/k2/itemlist/user/5384958
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=36889
http://marjorieaperry.com/?option=com_k2&view=itemlist&task=user&id=484651
http://marjorieaperry.com/component/k2/itemlist/user/484601
http://mediaville.me/index.php/component/k2/itemlist/user/240830
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/79670
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=11102
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-g7-a8-%d0%b8%d0%b3%d1%80/
http://forum.bmw-e60.eu/index.php?topic=5658.0
http://hi-mar.com/forum/index.php?PHPSESSID=2c8582b3e6531addaeed9693eb555e2b&topic=32417.0
http://hi-mar.com/forum/index.php?PHPSESSID=33d145ae08c7d3829fcfd13041ee0c76&topic=32419.0
http://hi-mar.com/forum/index.php?PHPSESSID=6fbe65031c7d08c5739efded7ceea5bf&topic=32416.0
http://hi-mar.com/forum/index.php?PHPSESSID=d6a1635fbe8cc91bc860a67bf764e352&topic=32418.0
http://myrechockey.com/forums/index.php?topic=91927.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/291939
http://www.spazioad.com/component/k2/itemlist/user/7230363
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=16936
http://soc-human.kz/index.php/component/k2/itemlist/user/1649730
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1136576
http://www.ekemoon.com/145837/051720195406/
http://www.deliberarchia.org/forum/index.php?topic=965131.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1359438
http://1vh.info/index.php?topic=11613.0
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-szs-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=76126
http://www.ekemoon.com/158179/050920193208/
http://8.droror.co.il/uncategorized/%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-68-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t6-%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-68-%d1%81%d0%b5%d1%80/
http://roikjer.com/forum/index.php?PHPSESSID=3intcbq8k88gafavnf4qsg4k14&topic=856500.0
http://roikjer.com/forum/index.php?topic=856463.0
http://roikjer.com/forum/index.php?topic=856508.0
http://sextomariotienda.com/blog/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a8-%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5/
http://www.gtupuw.org/index.php/component/k2/itemlist/user/1874827
http://www.nsc-radio.eu/ngs/index.php?page=User&userID=1131110
http://www.popolsku.fr.pl/forum/index.php?topic=378510.0
http://www.remify.app/foro/index.php?topic=254409.0
http://www.remify.app/foro/index.php?topic=254416.0
http://www.tekparcahdfilm.com/forum/index.php?topic=47942.0
http://www.tekparcahdfilm.com/forum/index.php?topic=47943.0
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=cf16042fb49af036e0240c1c5c73c78b&topic=1995.0
https://altaylarteknoloji.com/index.php?topic=2463.0
https://altaylarteknoloji.com/index.php?topic=2464.0
https://mcsetup.tk/bbs/index.php?topic=247897.0
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x8-%e3%80%90-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
https://www.cosmologyathome.org/view_profile.php?userid=1529023
https://reficulcoin.com/index.php?topic=32063.0
https://worldtaxi.org/2019/05/09/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g0-a1-%d0%b8%d0%b3%d1%80%d0%b0/
http://otitismediasociety.org/forum/index.php?topic=158306.0
http://forum.byehaj.hu/index.php?topic=83723.0
http://www.critico-expository.com/forum/index.php?topic=7874.0
http://otitismediasociety.org/forum/index.php?topic=149437.0
https://worldtaxi.org/2019/05/09/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v2-s5-%d0%b8%d0%b3%d1%80/
http://forum.elexlabs.com/index.php?topic=16992.0
http://forum.elexlabs.com/index.php?topic=23205.0
http://forum.elexlabs.com/index.php?topic=18750.0
http://www.teedinubon.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m2-s8-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://vervetama.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r4-k3-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://www.tessabannampad.go.th/webboard/index.php?topic=199595.0
https://members.fbhaters.com/index.php?topic=87046.0
http://forum.elexlabs.com/index.php?topic=17163.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-8-eo-1-e'-a-etoo-8-eo-1-e-z4z5/?PHPSESSID=jq3diqgolc6ub1hcuso11tns51
http://roikjer.com/forum/index.php?PHPSESSID=mtgn6l3sd8077q23rgkbhli8u5&topic=842996.0
http://www.hoonthaitoday.com/forum/index.php?topic=201247.0
https://luckychancerescue.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
https://nextezone.com/index.php?topic=41877.0
http://roikjer.com/forum/index.php?PHPSESSID=hi9lvn8lti8dj43l7r1h200v83&topic=842040.0
https://khuyenmaikk13.info/index.php?topic=189041.0
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-t7-o0-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=6405f8696051410ee919c27b33a34ff3&topic=1025.0
https://luckychancerescue.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o1-k1-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
https://reficulcoin.com/index.php?topic=17409.0
http://www.deliberarchia.org/forum/index.php?topic=1018610.0
http://ru-realty.com/forum/index.php?PHPSESSID=f8pja9q3480gmbkild4gpetgt2&topic=481088.0
http://uberdrivers.net/forum/index.php?topic=248229.0
https://khuyenmaikk13.info/index.php?topic=185764.0
https://cybergsm.es/index.php?topic=8653.0
http://www.tessabannampad.go.th/webboard/index.php?topic=200198.0
http://otitismediasociety.org/forum/index.php?topic=154253.0
https://khuyenmaikk13.info/index.php?topic=190452.0
http://otitismediasociety.org/forum/index.php?topic=154703.0
https://sanp.pro/%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b0-%d1%81%d0%bb%d1%83-2/
https://members.fbhaters.com/index.php/topic,89399.0.html
https://members.fbhaters.com/index.php?topic=86117.0
http://menulisilmiah.net/%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-10-05-2019-3/
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile;u=34434
https://akutthjelper.no/members/sophiemosley7/
http://ru-realty.com/forum/index.php?topic=480557.0
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fp1-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8/
http://otitismediasociety.org/forum/index.php?topic=149100.0
http://forum.digamahost.com/index.php?topic=113079.0
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-7/
http://HyUa.1fps.icu/l/szIaeDC
https://members.fbhaters.com/index.php?topic=85230.0
http://www.ofqj.org/hebergementquebec/4-11-s2-j4-4-11-4-11-online
http://ptu.imoove.kr/ko/content/%E2%80%9E%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-online-s1-b6-%C2%AB%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-13
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=32442.0
https://members.fbhaters.com/index.php?topic=83143.0
http://www.critico-expository.com/forum/index.php?topic=9685.0
http://8.droror.co.il/uncategorized/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e1-h9-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g9-p5-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
http://vtservices85.fr/smf2/index.php?PHPSESSID=0ac5e06f743774d60297fa5ad257a7f6&topic=215444.0
http://poselokgribovo.ru/forum/index.php?topic=745101.0
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-w2-k5-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=685893.0
https://members.fbhaters.com/index.php?topic=84675.0
https://members.fbhaters.com/index.php?topic=84989.0
https://danceplanet.se/commodore/index.php?topic=18708.0
https://worldtaxi.org/2019/05/09/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a8-q1-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://help.stv.ru/index.php?PHPSESSID=ff27a870c263c931eca96d41e7e2be76&topic=139575.0
https://prelease.club/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jl6-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-29/
https://prelease.club/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wl7-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://nextezone.com/index.php?action=profile;u=4997
http://roikjer.com/forum/index.php?topic=840995.0
http://www.theparrotcentre.com/forum/index.php?topic=488919.0
https://www.limscave.com/forum/viewtopic.php?t=31808
http://www.deliberarchia.org/forum/index.php?topic=1020523.0
http://danielmillsap.com/forum/index.php?topic=1006255.0
https://forum.clubeicaro.pt/index.php?topic=943.0
http://otitismediasociety.org/forum/index.php?topic=157032.0
http://ru-realty.com/forum/index.php?PHPSESSID=d65bfejhf9pljnip4nr04kofc6&topic=489888.0
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v6-u3-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://www.deliberarchia.org/forum/index.php?topic=992765.0
http://demo.caribe.vps-private.net/blog/milliardy-4-sezon-12-seriya-s8-d5-milliardy-4-sezon-12-seriya-milliardy-4-sezon-12-seriya
http://otitismediasociety.org/forum/index.php?topic=157848.0
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yt6-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://forum.byehaj.hu/index.php?topic=83546.0
https://prelease.club/hd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p9-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://forum.byehaj.hu/index.php?topic=86148.0
https://altaylarteknoloji.com/index.php?topic=2160.0
http://otitismediasociety.org/forum/index.php?topic=149663.0
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q5-j3-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n0-w1-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://forum.elexlabs.com/index.php?topic=19283.0
https://danceplanet.se/commodore/index.php?topic=25009.0
http://HyUa.1fps.icu/l/szIaeDC
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2572613
http://withinfp.sakura.ne.jp/eso/index.php/16882933-uristy-14-seria-smotret-uristy-14-seria
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=78825
http://www.ekemoon.com/158247/050920194808/
http://teambuildingpremium.com/forum/index.php?topic=783367.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/579542
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1116351
http://proandpro.it/?option=com_k2&view=itemlist&task=user&id=4537640
https://l2thalassic.org/Forum/index.php?topic=1775.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1346034
http://haniel.ir/index.php/component/k2/itemlist/user/83821
http://bitpark.co.kr/board_IzjM66/3740014
http://www.camaracoyhaique.cl/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uv3%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://forum.politeknikgihon.ac.id/index.php?topic=24964.0
http://lavaggio.com.vn/index.php/component/k2/itemlist/user/3710173
https://reficulcoin.com/index.php?topic=35300.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t6-q3-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i0-b7-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://roikjer.com/forum/index.php?PHPSESSID=krv81rbko8hi2mkvejdru96ie0&topic=844423.0
http://forum.byehaj.hu/index.php?topic=86779.0
https://hackersuniversity.net/index.php?topic=10486.0
http://www.theparrotcentre.com/forum/index.php?topic=492341.0
http://www.deliberarchia.org/forum/index.php?topic=999617.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=005873a1edc7b5fb86bd6f7281b15c7e&topic=216592.0
http://roikjer.com/forum/index.php?topic=835886.0
http://eugeniocolazzo.it/forum/index.php?topic=124774.0
http://forum.elexlabs.com/index.php?topic=18776.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=685008.0
http://d2bchannel.co.in/blog/2019/05/10/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k0-t0-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://miklja.net/forum/index.php?topic=29120.0
http://forum.elexlabs.com/index.php?topic=20344.0
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-7/
https://members.fbhaters.com/index.php?topic=85722.0
http://ru-realty.com/forum/index.php?PHPSESSID=9j9f8v8u114a6ogsdk9n5fblg7&topic=479556.0
https://sanp.pro/10-05-2019-%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0%d1%8f-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b0-%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be%d0%b1%d0%be%d1%82%d0%b0-15/
http://roikjer.com/forum/index.php?PHPSESSID=0d9atb562jvlht01kt2mj66m27&topic=838001.0
https://reficulcoin.com/index.php?topic=20283.0
https://reficulcoin.com/index.php?topic=30749.0
http://ru-realty.com/forum/index.php?PHPSESSID=epalpgmbvqkufsi8s41v8btg67&topic=478539.0
http://danielmillsap.com/forum/index.php?topic=1015766.0
http://8.droror.co.il/uncategorized/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sf0-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://nextezone.com/index.php?topic=42363.0
http://www.ofqj.org/hebergementquebec/4-11-v6-p8-4-11-4-11
https://reficulcoin.com/index.php?topic=29913.0
http://www.hoonthaitoday.com/forum/index.php?topic=207246.0
https://www.limscave.com/forum/viewtopic.php?f=6&t=31943&bookmark=1&hash=d535714b
http://www.critico-expository.com/forum/index.php?topic=12205.0
https://nextezone.com/index.php?topic=42446.0
http://help.stv.ru/index.php?PHPSESSID=eab86e293a0f006778a2a2bdf4946eef&topic=140131.0
http://forum.elexlabs.com/index.php?topic=16508.0
http://HyUa.1fps.icu/l/szIaeDC
http://dev.aabn.org.gh/component/k2/itemlist/user/527504
http://svgrossburgwedel.de/component/k2/itemlist/user/5325
http://rudraautomation.com/index.php/component/k2/author/104269
http://zsmr.com.ua/index.php/component/k2/itemlist/user/504147
http://seoksoononly.dothome.co.kr/qna/742904
http://www.deliberarchia.org/forum/index.php?topic=976837.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/569941
http://bitpark.co.kr/board_IzjM66/3759831
http://servicioswts.com/component/k2/itemlist/user/3624535
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3376869
http://www.vivelabmanizales.com/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-21-%d1%81%d0%b5-4/
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=764607
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/248984
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/249097
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3341013
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3341014
http://xplorefitness.com/blog/%C2%AB%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-9-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-11-05-2019-p2-%C2%AB%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-9-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://arunagreen.com/index.php/component/k2/itemlist/user/486878
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/511630
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/297154
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=318386
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=318404
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=318466
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=318473
http://married.dike.gr/index.php/component/k2/itemlist/user/57521
http://married.dike.gr/index.php/component/k2/itemlist/user/57523
http://cccpvideo.forumside.com/index.php?topic=849.0
http://menulisilmiah.net/hd-video-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.m1avio.com/index.php/component/k2/itemlist/user/3608344
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=64929
http://gtupuw.org/index.php/component/k2/itemlist/user/1855477
http://fbpharm.net/index.php/component/k2/itemlist/user/21685
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=76141
http://hotelnomadpalace.com/component/k2/itemlist/user/19537
https://members.fbhaters.com/index.php?topic=76239.0
http://condolencias.servisa.es/i-81-06-05-2019-h7-i-81
http://www.vivelabmanizales.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p2-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5/
http://mediaville.me/index.php/component/k2/itemlist/user/216253
http://rockndata.net/UserProfile/tabid/61/userId/18161800/Default.aspx
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=38968
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1859410
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/61452
http://socialfbwidgets.com/?option=com_k2&view=itemlist&task=user&id=12849
http://www.emrabq8.com/index.php/component/k2/itemlist/user/1763163
http://www.arredoufficiomarca.com/index.php/component/k2/itemlist/user/1555650
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4723568
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3734799
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=566188
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1544204
http://rudraautomation.com/index.php/component/k2/author/131035
https://khuyenmaikk13.info/index.php?topic=183142.0
http://moyakmermer.com/?option=com_k2&view=itemlist&task=user&id=687252
http://dev.aabn.org.gh/component/k2/itemlist/user/529465
http://seoksoononly.dothome.co.kr/qna/794325
http://ptu.imoove.kr/ko/content/%C2%AB%D1%8E%D1%80%D0%B8%D1%81%D1%82%D1%8B-18-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%C2%AB%D1%8E%D1%80%D0%B8%D1%81%D1%82%D1%8B-18-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB331698
http://www.afikgan.co.il/index.php/component/k2/itemlist/user/26054
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1555201
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2387729
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1861948
http://ptu.imoove.kr/ko/content/%C2%AB%D1%8E%D1%80%D0%B8%D1%81%D1%82%D1%8B-10-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-hd-video-%C2%AB%D1%8E%D1%80%D0%B8%D1%81%D1%82%D1%8B-10-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB332563
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=47765
http://seoksoononly.dothome.co.kr/qna/731750
http://seoksoononly.dothome.co.kr/qna/740478
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1340355
https://khuyenmaikk13.info/index.php?topic=182745.0
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=757349
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-om5%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f05-05-2019/
http://smartacity.com/component/k2/itemlist/user/14520
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1576011
http://poselokgribovo.ru/forum/index.php?topic=714721.0
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1624796
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=269792
http://xn----7sbbahtl1ajlp0a.xn--p1ai/index.php/component/k2/itemlist/user/1248756
http://www.spazioad.com/component/k2/itemlist/user/7238488
http://teambuildingpremium.com/forum/index.php?topic=772457.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/184272
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=285786
https://khuyenmaikk13.info/index.php?topic=183572.0
http://withinfp.sakura.ne.jp/eso/index.php/16883130-nikogda-ne-govori-nikogda-2-seria-06052019-v4-nikogda-ne-govori
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1838070
https://khuyenmaikk13.info/index.php?topic=179379.0
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=36525
http://dohairbiz.com/?option=com_k2&view=itemlist&task=user&id=2707978
http://condolencias.servisa.es/3-2-05-05-2019-i3-3-2
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=502863
http://hydrocarbs-gh.org/index.php/component/k2/itemlist/user/7308026
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ku2%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://webp.online/index.php?topic=45997.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2562349
https://khuyenmaikk13.info/index.php?topic=181990.0
http://poselokgribovo.ru/forum/index.php?topic=714938.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2563568
http://153.120.114.241/eso/index.php/16876102-edinoe-serdce-tek-yurek-10-seria-ihjv-edinoe-serdce-tek-yurek-1
http://seoksoononly.dothome.co.kr/qna/752075
http://mediaville.me/index.php/component/k2/itemlist/user/211560
http://153.120.114.241/eso/index.php/16862528-rannaa-ptaska-erkenci-kus-45-seria-tkoh-rannaa-ptaska-erkenci-k
http://dessa.com.br/component/k2/itemlist/user/315039
http://dohairbiz.com/en/component/k2/itemlist/user/2709836.html
http://www.phan-aen.go.th/forum/index.php?topic=628713.0
http://www.die-design-manufaktur.de/index.php/component/k2/itemlist/user/5183665
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=296003
http://www.atab.com.sa/?option=com_k2&view=itemlist&task=user&id=1545083
http://seoksoononly.dothome.co.kr/qna/729325
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=214045
http://hotelnomadpalace.com/component/k2/itemlist/user/19793
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2561958
http://condolencias.servisa.es/1-05-05-2019-m9-1
http://www.ekemoon.com/161089/052220195208/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1334491
http://bitpark.co.kr/board_IzjM66/3732179
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3296152
https://l2thalassic.org/Forum/index.php?topic=1187.0
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=271210
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2574233
http://bitpark.co.kr/board_IzjM66/3786687
http://condolencias.servisa.es/i-84-06-05-2019-x3-i-84
http://www.critico-expository.com/forum/index.php?topic=2912.0
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1542507
http://www.vivelabmanizales.com/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-25-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cejl-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-25-%d1%81%d0%b5%d1%80%d0%b8/
http://condolencias.servisa.es/3-1-06-05-2019-v3-3-1
http://www.critico-expository.com/forum/index.php?topic=2598.0
https://www.shaiyax.com/index.php?topic=329181.0
https://l2thalassic.org/Forum/index.php?topic=2000.0
http://febrescordero.gob.ec/index.php/component/k2/itemlist/user/82650
http://thermoplast.envolgroupe.com/component/k2/author/70762
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=789973
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1018073
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=203353
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=17061
http://withinfp.sakura.ne.jp/eso/index.php/16903769-novinka-tola-robot-3-seria-f5-tola-robot-3-seria/0
http://www.ekemoon.com/144161/050620195306/
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/4083
http://withinfp.sakura.ne.jp/eso/index.php/16862196-voron-kuzgun-18-seria-alpo-voron-kuzgun-18-seria/0
https://www.swiss-focus.ch/index.php/component/k2/itemlist/user/14894
http://forum.politeknikgihon.ac.id/index.php?topic=23591.0
http://www.m1avio.com/?option=com_k2&view=itemlist&task=user&id=3603411
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2415022
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/280321
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ns5%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f06-05-2019/
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/673941
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/222495
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=4588
http://thermoplast.envolgroupe.com/component/k2/author/77418
http://salescoach.ro/content/%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-10-%D0%B2%D1%8B%D0%BF%D1%83%D1%81%D0%BA-%D1%86%D0%B5%D1%80%D0%B5%D0%BC%D0%BE%D0%BD%D0%B8%D1%8F-%D1%80%D0%BE%D0%B7%C2%BB-cc%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-10-%D0%B2%D1%8B%D0%BF%D1%83%D1%81%D0%BA-%D1%86%D0%B5%D1%80%D0%B5%D0%BC%D0%BE%D0%BD%D0%B8%D1%8F-%D1%80%D0%BE%D0%B7%C2%BB76
http://www.vivelabmanizales.com/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sizx-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-11-%d1%81%d0%b5%d1%80%d0%b8/
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/50620
http://forum.politeknikgihon.ac.id/index.php?topic=24557.0
http://rudraautomation.com/index.php/component/k2/author/125055
http://mediaville.me/index.php/component/k2/itemlist/user/207355
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=268831
http://ovotecegg.com/component/k2/itemlist/user/123393
http://mobility-corp.com/index.php/component/k2/itemlist/user/2513312
http://smartacity.com/component/k2/itemlist/user/22984
http://www.ekemoon.com/156179/050320191308/
http://153.120.114.241/eso/index.php/16877819-nasa-istoria-72-seria-nwnr-nasa-istoria-72-seria
http://rudraautomation.com/index.php/component/k2/author/116578
http://seoksoononly.dothome.co.kr/qna/711194
http://salescoach.ro/content/%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-10-%D0%B2%D1%8B%D0%BF%D1%83%D1%81%D0%BA-2-%D1%87%D0%B0%D1%81%D1%82%D1%8C-%D1%81%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C-%D0%BE%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD%C2%BB-dx%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-10-%D0%B2%D1%8B%D0%BF%D1%83%D1%81%D0%BA-2-%D1%87%D0%B0%D1%81%D1%82%D1%8C
https://www.gizmoarticle.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-27-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-y3-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5/
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=17817
http://dpmarketingsystems.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xxl-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nyk-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wux-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8/
http://menulisilmiah.net/%d1%87%d1%83%d0%b6%d0%b0%d1%8f-%d0%b6%d0%b8%d0%b7%d0%bd%d1%8c-%d1%87%d1%83%d0%b6%d0%b5-%d0%b6%d0%b8%d1%82%d1%82%d1%8f-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-acx-%d1%87%d1%83%d0%b6/
http://menulisilmiah.net/%d1%87%d1%83%d0%b6%d0%b0%d1%8f-%d0%b6%d0%b8%d0%b7%d0%bd%d1%8c-%d1%87%d1%83%d0%b6%d0%b5-%d0%b6%d0%b8%d1%82%d1%82%d1%8f-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nrd-%d1%87%d1%83%d0%b6/
http://sextomariotienda.com/blog/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mlt-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://sextomariotienda.com/blog/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-96-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-trk-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd/
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=304400
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=304421
http://associationsila.org/component/k2/itemlist/user/304431
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/493503
http://dev.aabn.org.gh/component/k2/itemlist/user/548636
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=281352
http://healthyteethpa.org/component/k2/itemlist/user/5375997
http://healthyteethpa.org/component/k2/itemlist/user/5376009
http://israengineering.com/index.php/component/k2/itemlist/user/1142933
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=36592
http://www.m1avio.com/index.php/component/k2/itemlist/user/3617753
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=767470
http://www.spazioad.com/component/k2/itemlist/user/7233720
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=45543
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=45545
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=294711
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3305757
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-y4-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g6-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-k4-%d0%b8%d0%b3%d1%80%d0%b0/
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-q1-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://forum.kopkargobel.com/index.php?topic=8264.0
http://forum.politeknikgihon.ac.id/index.php?topic=28288.0
http://forum.kopkargobel.com/index.php?topic=8162.0
http://myrechockey.com/forums/index.php?topic=93183.0
http://forum.elexlabs.com/index.php?topic=23231.0
https://prelease.club/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q5/
http://otitismediasociety.org/forum/index.php?topic=150129.0
https://nextezone.com/index.php?action=profile;u=6477
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dy9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://eugeniocolazzo.it/forum/index.php?topic=106874.0
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w1-x3-%d0%b8%d0%b3%d1%80/
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-i2-g7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
https://reficulcoin.com/index.php?topic=21165.0
http://vervetama.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x3-g1-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
http://www.ofqj.org/hebergementfrance/4-13-watch-d0-c9-4-13-4-13
https://reficulcoin.com/index.php?topic=19314.0
https://prelease.club/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u0-%d1%81%d0%bb/
http://forum.byehaj.hu/index.php?topic=84596.0
http://122.154.49.125/Forum/index.php?topic=84.0
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-q4-l8-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
https://polyframetrade.co.uk/%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-k5-c9-%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4/
http://roikjer.com/forum/index.php?PHPSESSID=a5au8c25rmdj3nov66narhubi6&topic=864923.0
http://otitismediasociety.org/forum/index.php?topic=149004.0
https://danceplanet.se/commodore/index.php?topic=21131.0
http://forum.kopkargobel.com/index.php?topic=6561.0
https://akutthjelper.no/members/brittneymclend/
http://www.ofqj.org/hebergementfrance/4-11-c7-r5-4-11-4-11
https://lucky28003.nl/forum/index.php?topic=13193.0
http://forum.elexlabs.com/index.php?topic=20128.0
http://blog.ptpintcast.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-x6-o2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
http://forums.abs-cbn.com/welcome-back-kapamilya%21/(a-etoogame-of-thrones-8-eo-5-e)-a-etoogame-of-thrones-8-eo-5-e-n0g4/?PHPSESSID=12r36n32kam3577uidnsp6gt53
http://www.ofqj.org/hebergementfrance/4-12-i0-p5-4-12-4-12
http://HyUa.1fps.icu/l/szIaeDC
http://www.theocraticamerica.org/forum/index.php?topic=29112.0
http://arunagreen.com/?option=com_k2&view=itemlist&task=user&id=468746
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1893565
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1872026
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/11029
http://vehibook.com/members/antoinetteguth/
http://webp.online/index.php?topic=51697.msg86730
http://www.critico-expository.com/forum/index.php?topic=7889.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/476308
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1021264
http://highlanderonline.cmshelplive.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://menulisilmiah.net/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r4-%d1%82%d0%be%d0%bb%d1%8f/
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=65759
http://rudraautomation.com/index.php/component/k2/author/117451
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1339211
http://mediaville.me/index.php/component/k2/itemlist/user/210004
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/61543
http://webp.online/index.php?topic=47466.0
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/61691
http://xplorefitness.com/blog/%C2%AB%D0%BD%D0%B8%D0%BA%D0%BE%D0%B3%D0%B4%D0%B0-%D0%BD%D0%B5-%D0%B3%D0%BE%D0%B2%D0%BE%D1%80%D0%B8-%C2%AB%D0%BD%D0%B8%D0%BA%D0%BE%D0%B3%D0%B4%D0%B0%C2%BB-1-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-07-05-2019-v5-%C2%AB%D0%BD%D0%B8%D0%BA%D0%BE%D0%B3%D0%B4%D0%B0-%D0%BD%D0%B5-%D0%B3%D0%BE%D0%B2%D0%BE%D1%80%D0%B8-%C2%AB%D0%BD%D0%B8%D0%BA%D0%BE%D0%B3%D0%B4%D0%B0%C2%BB-1-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://www.deliberarchia.org/forum/index.php?topic=970136.0
http://seoksoononly.dothome.co.kr/qna/746274
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=13192
http://patagroupofcompanies.com/component/k2/itemlist/user/200239
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=492522
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/476059
http://cccpvideo.forumside.com/index.php?topic=781.0
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=289142
http://hiyou.com.vn/?option=com_k2&view=itemlist&task=user&id=1311542
http://poselokgribovo.ru/forum/index.php?topic=720491.0
http://fbpharm.net/index.php/component/k2/itemlist/user/14006
http://www.dap.com.py/index.php/component/k2/itemlist/user/782886
http://highlanderonline.cmshelplive.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-07-05-2019-c1-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/597340
http://www.spazioad.com/component/k2/itemlist/user/7274264
http://www.tekparcahdfilm.com/forum/index.php?topic=48235.0
http://www.theparrotcentre.com/forum/index.php?topic=497555.0
http://www.theparrotcentre.com/forum/index.php?topic=497585.0
http://www.vivelabmanizales.com/%d1%81%d0%bb%d0%b5%d0%b4%d0%be%d0%b2%d0%b0%d1%82%d0%b5%d0%bb%d1%8c-%d0%b3%d0%be%d1%80%d1%87%d0%b0%d0%ba%d0%be%d0%b2%d0%b0-%d1%81%d0%bbi%d0%b4%d1%87%d0%b8%d0%b9-%d0%b3%d0%be%d1%80%d1%87%d0%b0%d0%ba-113/
http://www.vivelabmanizales.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-92-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tye-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8/
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=243546
http://mvisage.sk/index.php/component/k2/itemlist/user/118333
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=11229
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=11236
http://robocit.com/index.php/component/k2/itemlist/user/449440
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/196733
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/196762
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2268899
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2268908
http://soc-human.kz/index.php/component/k2/itemlist/user/1660838
http://wikiwires.com/2019/05/09/%d1%81%d0%bc%d0%b5%d1%80%d1%88-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-y2-%e3%80%90-%d1%81%d0%bc%d0%b5%d1%80%d1%88-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f%e3%80%91-%d1%81%d0%bc%d0%b5%d1%80/
http://wikiwires.com/2019/05/09/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j8-%e3%80%90-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=189696
http://www.artifact.website/77140-taemnici-94-seria-j0-taemnici-94-seria-taemnici-94-seria-watch-
http://www.artifact.website/77276-cuzaa-zizn-cuze-zitta-8-seria-online-a4-cuzaa-zizn-cuze-zitta-8
http://www.artifact.website/77497-cuzaa-zizn-cuze-zitta-3-seria-a3-cuzaa-zizn-cuze-zitta-3-seria-
http://www.artifact.website/77558-sluga-naroda-3-sezon-21-seria-watch-o3-sluga-naroda-3-sezon-21-
http://www.artifact.website/77566-smers-8-seria-t1-smers-8-seria-smers-8-seria-z6
http://www.artifact.website/77573-igra-prestolov-game-of-thrones-8-sezon-7-seria-a2-igra-prestolo
http://www.artifact.website/77579-dockimateri-dockimateri-17-seria-watch-d8-dockimateri-dockimate
http://www.artifact.website/77633-tajny-101-seria-l4-tajny-101-seria-tajny-101-seria-f8
http://www.artifact.website/77648-taemnici-98-seria-t4-taemnici-98-seria-taemnici-98-seria-e0
http://www.artifact.website/77730-holostak-9-sezon-13-vypusk-watch-v6-holostak-9-sezon-13-vypusk-
http://forum.elexlabs.com/index.php?topic=25311.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=33433.0
http://ovotecegg.com/component/k2/itemlist/user/140978
http://ru-realty.com/forum/index.php?topic=506796.0
http://teambuildingpremium.com/forum/index.php?topic=822345.0
http://teambuildingpremium.com/forum/index.php?topic=822353.0
http://thermoplast.envolgroupe.com/component/k2/author/101202
http://universalcommunity.se/Forum/index.php?topic=7164.0
http://vervetama.com/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-s2/
http://vhost12299.cpsite.ru/270642-voskressij-ertugrul-5-sezon-27-seria-g1-voskressij-ertugrul-5-s
http://vtservices85.fr/smf2/index.php?PHPSESSID=53a94cb5051d11b43ae60b56a1f38efe&topic=234531.0
http://www.newb.northstarchiangrai.com/index.php?PHPSESSID=lhchidsj38drf00vnbl32u45t4&topic=23983.0
http://www.remify.app/foro/index.php?topic=285100.0
http://www.sopprabhospital.go.th/webboard/index.php?PHPSESSID=74pbp89hesm08q06v175kc3947&topic=13984.0
https://reficulcoin.com/index.php?topic=28669.0
https://www.c-alice.org/forum/index.php?topic=80197.0
http://forum.bmw-e60.eu/index.php?topic=6938.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=31979.0
http://taklongclub.com/forum/index.php?topic=126471.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=687985.0
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=16430.0
https://khuyenmaikk13.info/index.php?topic=194463.0
http://bayareawomenmag.xyz/blogs/viewstory/23632
http://bayareawomenmag.xyz/blogs/viewstory/23636
http://bayareawomenmag.xyz/blogs/viewstory/23639
http://dota2.host/96876-igra-prestolovgame-of-thrones-8-sezon-5-seria-w1-q0-igra-presto
http://dota2.host/96992-igra-prestolov-8-sezon-6-seria-online-k7-p0-igra-prestolov-8-se
http://dota2.host/96996-igra-prestolovgame-of-thrones-8-sezon-7-seria-t2-k7-igra-presto
http://dota2.host/97020-igra-prestolov-game-of-thrones-8-sezon-7-seria-n3-y4-igra-prest
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e6-k6-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c6-u2-%d0%b8%d0%b3%d1%80/
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k9-m8-%d0%b8%d0%b3%d1%80/
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-p8-i0-%d0%b8%d0%b3/
http://eugeniocolazzo.it/forum/index.php?topic=107641.0
http://sexfork.com/uncategorized/igra-prestolov-2019-8-sezon-4-seriya-igra-prestolov-2019-8-sezon-4-seriya-a3l3/
http://demo.caribe.vps-private.net/blog/milliardy-4-sezon-12-seriya-k2-n4-milliardy-4-sezon-12-seriya-milliardy-4-sezon-12-seriya-watch
https://khuyenmaikk13.info/index.php?topic=188911.0
https://danceplanet.se/commodore/index.php?topic=19221.0
http://roikjer.com/forum/index.php?PHPSESSID=jrdgv9r2hm19fd75sgntcbbip2&topic=843396.0
http://ru-realty.com/forum/index.php?PHPSESSID=fdair0ec7qnqrcisg3nbohbqb3&topic=485758.0
http://www.deliberarchia.org/forum/index.php?topic=997857.0
http://www.newb.northstarchiangrai.com/index.php?PHPSESSID=37pvc426v47ktfd168pjc598q5&topic=23921.0
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b0-x6-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v0-k0-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
http://www.tekparcahdfilm.com/forum/index.php?topic=47246.0
http://www.critico-expository.com/forum/index.php?topic=7111.0
http://teambuildingpremium.com/forum/index.php?topic=797881.0
http://www.critico-expository.com/forum/index.php?topic=10101.0
http://www.popolsku.fr.pl/forum/index.php?topic=376871.0
http://jdcalc.com/forum/viewtopic.php?t=169955
https://www.gizmoarticle.com/%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-09-05-2019/
http://www.nomaher.com/forum/index.php?topic=12428.0
https://sanp.pro/09-05-2019-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-4/
http://forum.elexlabs.com/index.php?topic=22618.0
http://forum.politeknikgihon.ac.id/index.php?topic=30198.0
https://nextezone.com/index.php?action=profile;u=5468
https://members.fbhaters.com/index.php?topic=86055.0
http://forum.elexlabs.com/index.php?topic=22809.0
https://members.fbhaters.com/index.php?topic=83725.0
http://poselokgribovo.ru/forum/index.php?topic=746233.0
http://danielmillsap.com/forum/index.php?topic=999440.0
http://poselokgribovo.ru/forum/index.php?topic=745503.0
http://www.deliberarchia.org/forum/index.php?topic=1016542.0
https://www.limscave.com/forum/viewtopic.php?t=31866
http://www.remify.app/foro/index.php?topic=245929.0
http://poselokgribovo.ru/forum/index.php?topic=753424.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/'a-etoo-(got)-8-eo-1-e'-a-etoo-(got)-8-eo-1-e-r8z5/?PHPSESSID=q966mfu2mddcqsd28520gsvpu5
https://nextezone.com/index.php?action=profile;u=3413
http://bobr.site/index.php?topic=108908.0
http://teambuildingpremium.com/forum/index.php?topic=816822.0
http://roikjer.com/forum/index.php?PHPSESSID=9llgqr0bghv0o20c36q5iib740&topic=864205.0
http://forum.kopkargobel.com/index.php?topic=7667.0
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ho6-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.deliberarchia.org/forum/index.php?topic=994793.0
https://nextezone.com/index.php?action=profile;u=3697
http://roikjer.com/forum/index.php?PHPSESSID=tha1n9qpf3rdafddmsna1l8jt7&topic=836936.0
http://www.teedinubon.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f4-k8-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://HyUa.1fps.icu/l/szIaeDC
http://forum.digamahost.com/index.php?topic=109033.0
http://highlanderonline.cmshelplive.net/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-08-05-2019-l3-%d0%b8%d0%b3%d1%80/
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1004314
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=289679
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7309146
http://menulisilmiah.net/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a8-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be/
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=211737
http://withinfp.sakura.ne.jp/eso/index.php/16995619-efir-holostak-9-sezon-12-vypusk-d2-holostak-9-sezon-12-vypusk/0
http://withinfp.sakura.ne.jp/eso/index.php/16996042-smotret-igra-prestolov-8-sezon-5-seria-u7-igra-prestolov-8-sezo/0
http://withinfp.sakura.ne.jp/eso/index.php/16996101-smotret-sluga-naroda-3-sezon-19-seria-e6-sluga-naroda-3-sezon-1/0
http://xplorefitness.com/blog/%D1%81%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C-%D1%81%D0%BB%D1%83%D0%B3%D0%B0-%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-8-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-e6-%D1%81%D0%BB%D1%83%D0%B3%D0%B0-%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-8-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://xplorefitness.com/blog/%D1%82%D0%BE%D0%BB%D1%8F-%D1%80%D0%BE%D0%B1%D0%BE%D1%82-4-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-h0-%D1%82%D0%BE%D0%BB%D1%8F-%D1%80%D0%BE%D0%B1%D0%BE%D1%82-4-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=20561
http://withinfp.sakura.ne.jp/eso/index.php/16996190-efir-dockimateri-dockimateri-15-seria-m2-dockimateri-dockimater/0
http://www.crnmedia.es/component/k2/itemlist/user/85277
http://www.emrabq8.com/index.php/component/k2/itemlist/user/1795659
http://www.sollazzorefrigerazione.it/component/k2/itemlist/user/2450414
http://xplorefitness.com/blog/%D1%81%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C-%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-11-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-v1-%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-11-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://xplorefitness.com/blog/%D1%8D%D1%84%D0%B8%D1%80-%D1%81%D0%BB%D1%83%D0%B3%D0%B0-%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-14-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-f5-%D1%81%D0%BB%D1%83%D0%B3%D0%B0-%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-14-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=81173
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=97577
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4839314
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/52891
http://dev.aabn.org.gh/component/k2/itemlist/user/519851
https://forums.letstalkbeats.com/index.php?topic=64775.0
http://www.ekemoon.com/147375/052120191306/
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=294911
http://withinfp.sakura.ne.jp/eso/index.php/16867068-smotret-sluga-naroda-3-sezon-5-seria-d5-sluga-naroda-3-sezon-5-/0
http://www.ekemoon.com/143715/050220193706/
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=288716
http://gtupuw.org/index.php/component/k2/itemlist/user/1841991
http://www.m1avio.com/index.php/component/k2/itemlist/user/3625638
http://www.ekemoon.com/156181/050320191408/
http://married.dike.gr/index.php/component/k2/itemlist/user/47530
http://dev.aabn.org.gh/?option=com_k2&view=itemlist&task=user&id=546617
http://topitop.kz/index.php/component/k2/itemlist/user/76333
https://forums.letstalkbeats.com/index.php?topic=47844.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=b359ec71d205bc2d3f92c804182a8aa1&topic=197757.0
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/190987
http://sextomariotienda.com/blog/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bgg-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://smartacity.com/component/k2/itemlist/user/12499
https://tg.vl-mp.com/index.php?topic=1295289.0
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1850515
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=262090
http://uberdrivers.net/forum/index.php?topic=177150.0
http://www.ekemoon.com/138959/051620192504/
http://marjorieaperry.com/?option=com_k2&view=itemlist&task=user&id=473996
https://forum.ac-jete.it/index.php?topic=312875.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/177023
http://forum.politeknikgihon.ac.id/index.php?topic=33100.0
http://poselokgribovo.ru/forum/index.php?topic=753184.0
http://roikjer.com/forum/index.php?PHPSESSID=1jv8chjboll3quu4sqrupuir66&topic=844909.0
http://roikjer.com/forum/index.php?PHPSESSID=ph0ds2gl7qvv2jktd15q097s22&topic=844944.0
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-q4-l7-%d0%b8%d0%b3/
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c7-d5-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b5-x0-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://www.tekparcahdfilm.com/forum/index.php?topic=47402.0
https://luckychancerescue.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m6-m4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
https://reficulcoin.com/index.php?topic=17118.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k4-v2-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://www.vivelabmanizales.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x6-g4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
https://nextezone.com/index.php?action=profile&u=5433
http://forums.abs-cbn.com/welcome-back-kapamilya%21/'a-etoogame-of-thrones-8-eo-5-e'-a-etoogame-of-thrones-8-eo-5-e-r5r2/?PHPSESSID=b6mri0et567g4sg6ivpo985mv3
http://roikjer.com/forum/index.php?PHPSESSID=1rtkbb8skm3hvf4mj6jo7j2dg6&topic=840927.0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j4-y3-%d0%b8%d0%b3%d1%80/
https://nextezone.com/index.php?topic=43394.0
http://www.critico-expository.com/forum/index.php?topic=8988.0
http://menulisilmiah.net/%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0%d1%8f-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b0-%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be%d0%b1%d0%be%d1%82%d0%b0-13-%d1%81%d0%b5-20/
http://www.deliberarchia.org/forum/index.php?topic=1001990.0
http://www.deliberarchia.org/forum/index.php?topic=999989.0
http://help.stv.ru/index.php?PHPSESSID=9a59f98fdfe256c7b50d95bfc301fa11&topic=140333.0
http://otitismediasociety.org/forum/index.php?topic=152116.0
https://worldtaxi.org/2019/05/10/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5-2/
http://forum.elexlabs.com/index.php?topic=19334.0
http://www.popolsku.fr.pl/forum/index.php?topic=377581.0
http://www.hoonthaitoday.com/forum/index.php?topic=209533.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=7de7b6372e8fe18706f5d7b0ca9dc7fb&topic=224365.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=31999.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-b1-z6-%d0%b8%d0%b3/
http://demo.caribe.vps-private.net/blog/milliardy-4-sezon-10-seriya-q2-j1-milliardy-4-sezon-10-seriya-milliardy-4-sezon-10-seriya-watch
http://forum.politeknikgihon.ac.id/index.php?topic=30660.0
http://roikjer.com/forum/index.php?PHPSESSID=p2ju6b5hcoj990f9fab8rlfka7&topic=848450.0
https://worldtaxi.org/2019/05/09/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l1-u9-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
https://khuyenmaikk13.info/index.php?topic=187150.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-28/
http://uberdrivers.net/forum/index.php?topic=263881.0
http://www.critico-expository.com/forum/index.php?topic=10823.0
http://HyUa.1fps.icu/l/szIaeDC
http://menulisilmiah.net/10-05-2019-%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://roikjer.com/forum/index.php?topic=836543.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-(got)-8-eo-1-e'-a-etoo-(got)-8-eo-1-e-r8h2/msg560616/
https://members.fbhaters.com/index.php?topic=84894.0
https://reficulcoin.com/index.php?topic=22156.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/(a-etoo-8-eo-6-e)-a-etoo-8-eo-6-e-s4g3/?PHPSESSID=9erjmh3gedrtme84a8obiu91b0
https://nextezone.com/index.php?action=profile;u=3912
https://prelease.club/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q5-%d1%81%d0%bb/
https://nextezone.com/index.php?action=profile&u=5332
http://help.stv.ru/index.php?PHPSESSID=82d2b4709a036416f421c2bc36df95aa&topic=139905.0
http://roikjer.com/forum/index.php?topic=860305.0
http://help.stv.ru/index.php?PHPSESSID=2b90981c48e67f8df85cf8bccfd20921&topic=139601.0
http://otitismediasociety.org/forum/index.php?topic=150340.0
http://ru-realty.com/forum/index.php?topic=491666.0
http://help.stv.ru/index.php?PHPSESSID=50619e0fd69f13b57237f4fbf570e3d0&topic=140614.0
http://forum.elexlabs.com/index.php?topic=20693.0
https://prelease.club/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wy8-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://sextomariotienda.com/blog/live-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%82%d1%80%d0%b5%d0%b9%d0%bb%d0%b5/
http://sextomariotienda.com/blog/live-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b4%d0%b0%d1%82%d0%b0-%d0%b2%d1%8b/
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1680349
http://svgrossburgwedel.de/component/k2/itemlist/user/5533
http://taklongclub.com/forum/index.php?topic=134383.0
http://thermoplast.envolgroupe.com/component/k2/author/100647
http://twitchdevs.com/c/other/(~smotret~)-rasskaz-sluzhanki-3-sezon-3-seriya-smotret/
http://twitchdevs.com/c/other/live-rasskaz-sluzhanki-3-sezon-data-vyhoda-1-serii/
http://vervetama.com/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://vervetama.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80-2/
http://vervetama.com/hd-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80/
http://vervetama.com/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%be%d0%bd%d0%bb%d0%b0%d0%b9/
http://vervetama.com/live-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bd%d0%b0-%d1%81%d0%b5%d1%80%d0%b8/
http://vtservices85.fr/smf2/index.php?PHPSESSID=8d4d316b91bd933ab291c2b383b3bb4f&topic=233930.0
http://www.autospa.lv/index.php/lv/component/k2/itemlist/user/9947
http://www.deliberarchia.org/forum/index.php?topic=1026725.0
http://www.deliberarchia.org/forum/index.php?topic=1026739.0
http://www.deliberarchia.org/forum/index.php?topic=1026744.0
http://www.deliberarchia.org/forum/index.php?topic=1026756.0
http://www.deliberarchia.org/forum/index.php?topic=1026762.0
http://www.deliberarchia.org/forum/index.php?topic=1026770.0
http://www.deliberarchia.org/forum/index.php?topic=1026775.0
http://www.ekemoon.com/184557/052320190313/
http://www.mmc24.ru/forum/index.php?PHPSESSID=i91ildlj20vlhg3tdf0ratqf74&topic=804.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/155365
http://www.critico-expository.com/forum/index.php?topic=2562.0
http://salescoach.ro/content/%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-10-05%C2%BB-ot%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-10-05%C2%BB39-%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-10-05
http://dev.aabn.org.gh/component/k2/itemlist/user/514575
http://www.ekemoon.com/146445/051920190906/
https://forum.ac-jete.it/index.php?topic=351801.0
http://roikjer.com/forum/index.php?PHPSESSID=spi8pnfqeg1o0q9urv3grsm4q7&topic=824662.0
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1630079
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/212783
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=211217
http://www.ekemoon.com/147603/052120194806/
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1112981
http://www.vivelabmanizales.com/%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5%d0%bd%d0%b8%d0%b5-vuslat-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-aflt-%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd/
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2578015
http://www.ekemoon.com/148709/052320193106/
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3708285
http://www.ekemoon.com/149461/050120190607/
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2562278
http://highlanderonline.cmshelplive.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-08-05-2019-x3-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80/
http://community.viajar.tur.br/index.php?p=/profile/rondasavoy
http://smartacity.com/component/k2/itemlist/user/15102
http://www.ekemoon.com/143397/052320195305/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3293902
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=272770
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=52331
http://www.sakitoandrichifantasy.gr/index.php/component/k2/itemlist/user/156108
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/184819
http://web2interactive.com/index.php/component/k2/itemlist/user/3566344
http://matrixpharm.ru/forum/index.php?PHPSESSID=13ufej74lh7ogf6u0bvadi3o56&action=profile;u=167848
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=46567
http://seoksoononly.dothome.co.kr/qna/717784
http://proxima.co.rw/index.php/component/k2/itemlist/user/566329
http://dcasociados.eu/component/k2/itemlist/user/86765
http://seoksoononly.dothome.co.kr/?document_srl=770508
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1542570
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/206395
http://poselokgribovo.ru/forum/index.php?topic=739649.0
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/56177
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/299660
http://withinfp.sakura.ne.jp/eso/index.php/16878075-tajny-taemnici-91-seria-06052019-d2-tajny-taemnici-91-seria
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3304309
http://www.ekemoon.com/162565/050420192609/
https://www.swiss-focus.ch/index.php/component/k2/itemlist/user/12437
http://mvisage.sk/?option=com_k2&view=itemlist&task=user&id=118122
http://poselokgribovo.ru/forum/index.php?topic=718344.0
http://dev.aabn.org.gh/component/k2/itemlist/user/541688
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3306852
http://bitpark.co.kr/board_IzjM66/3744922
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3598251
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3325792
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=17974
http://seoksoononly.dothome.co.kr/qna/832883
http://seoksoononly.dothome.co.kr/qna/832947
http://seoksoononly.dothome.co.kr/qna/833020
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2593231
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2593127
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=306900
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=306912
http://rudraautomation.com/index.php/component/k2/author/142837
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/190700
http://www.m1avio.com/index.php/component/k2/itemlist/user/3632430
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=8676
http://married.dike.gr/index.php/component/k2/itemlist/user/49859
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2576617
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=210978
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=220847
https://sanp.pro/%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5%d0%bd%d0%b8%d0%b5-vuslat-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l6-%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5%d0%bd/
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=36466
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1622361
http://www.gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1830011
https://members.fbhaters.com/index.php?topic=55383.0
http://www.remify.app/foro/index.php?topic=169936.0
http://necinsurance.co.zw/component/k2/itemlist/user/18295.html
http://www2.yasothon.go.th/smf/index.php?topic=159.153555
http://thefreebitcoin.com/index.php?topic=35898.0
http://www.deliberarchia.org/forum/index.php?topic=933380.0
http://married.dike.gr/index.php/component/k2/itemlist/user/49004
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=82142
http://mobility-corp.com/index.php/component/k2/itemlist/user/2523135
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=69605
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=6723
http://proxima.co.rw/index.php/component/k2/itemlist/user/572148
http://storykingdom.forumside.com/index.php?topic=4772.0
http://dev.aabn.org.gh/component/k2/itemlist/user/514242
http://www.arredoufficiomarca.com/index.php/component/k2/itemlist/user/1560976
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1553552
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1643755
http://www.m1avio.com/?option=com_k2&view=itemlist&task=user&id=3599714
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1644778
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3381569
http://seoksoononly.dothome.co.kr/?document_srl=761485
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/185740
http://forum.digamahost.com/index.php?topic=110194.0
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=781244
http://soc-human.kz/index.php/component/k2/itemlist/user/1643169
http://rudraautomation.com/index.php/component/k2/author/107853
https://tg.vl-mp.com/index.php?topic=1334721.0
http://macdistri.com/index.php/component/k2/itemlist/user/308419
http://necinsurance.co.zw/component/k2/itemlist/user/19490.html
http://mobility-corp.com/index.php/component/k2/itemlist/user/2528365
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1013974
http://lavaggio.com.vn/index.php/component/k2/itemlist/user/3734636
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=8700
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1120196
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1544768
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=1005528
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1867121
http://cccpvideo.forumside.com/index.php?topic=689.0
http://svgrossburgwedel.de/component/k2/itemlist/user/5323
http://xplorefitness.com/blog/%C2%AB%D0%BF%D0%BE-%D0%B7%D0%B0%D0%BA%D0%BE%D0%BD%D0%B0%D0%BC-%D0%B2%D0%BE%D0%B5%D0%BD%D0%BD%D0%BE%D0%B3%D0%BE-%D0%B2%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-9-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-08-05-2019-o5-%C2%AB%D0%BF%D0%BE-%D0%B7%D0%B0%D0%BA%D0%BE%D0%BD%D0%B0%D0%BC-%D0%B2%D0%BE%D0%B5%D0%BD%D0%BD%D0%BE%D0%B3%D0%BE-%D0%B2%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%B8-3
http://married.dike.gr/index.php/component/k2/itemlist/user/53577
http://islamiccall.info/index.php/component/k2/itemlist/user/857113
https://tg.vl-mp.com/index.php?topic=1353633.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3301090
http://condolencias.servisa.es/i-93-06-05-2019-c8-i-93
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=189186
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=305131
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=305151
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3748120
http://mvisage.sk/index.php/component/k2/itemlist/user/118140
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=78061
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/78053
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/78092
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/78115
http://ovotecegg.com/?option=com_k2&view=itemlist&task=user&id=125923
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/10341
http://proxima.co.rw/index.php/component/k2/itemlist/user/588051
http://servicioswts.com/?option=com_k2&view=itemlist&task=user&id=3636757
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1642487
https://forum.ac-jete.it/index.php?topic=370461.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p9-r5-%d0%b8%d0%b3%d1%80%d0%b0/
https://khuyenmaikk13.info/index.php?topic=187884.0
http://metropolis.ga/index.php?topic=6604.0
http://www.remify.app/foro/index.php?topic=245854.0
http://help.stv.ru/index.php?PHPSESSID=44f6375857af930db7155806d2fe78f8&topic=139693.0
http://roikjer.com/forum/index.php?PHPSESSID=5bl53a63k8po08btuhs6bmeo41&topic=848486.0
http://myrechockey.com/forums/index.php?topic=91063.0
https://sanp.pro/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q9-%d1%81%d0%bb/
https://members.fbhaters.com/index.php?topic=85674.0
http://myrechockey.com/forums/index.php?topic=96510.0
http://roikjer.com/forum/index.php?PHPSESSID=176igg5e20u01dgmsdl2vb7p17&topic=863637.0
https://worldtaxi.org/2019/05/09/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l3-w4-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
https://reficulcoin.com/index.php?topic=16772.0
https://khuyenmaikk13.info/index.php?topic=186078.0
http://poselokgribovo.ru/forum/index.php?topic=747416.0
http://www.teedinubon.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c6-b7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-g8-v1-%d0%b8%d0%b3%d1%80/
http://www.ofqj.org/hebergementfrance/4-10-u0-j8-4-10-4-10
https://worldtaxi.org/2019/05/09/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k1-l6-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://forum.elexlabs.com/index.php?topic=22899.0
http://www.ofqj.org/hebergementfrance/4-10-a5-w1-4-10-4-10
https://members.fbhaters.com/index.php/topic,88484.0.html
https://reficulcoin.com/index.php?topic=27742.0
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fk6-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://roikjer.com/forum/index.php?PHPSESSID=bunv4o9msn8fnjvfp7d1mj94h6&topic=842159.0
http://udrpsucks.com/blog/?p=338
https://prelease.club/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tq4-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://members.fbhaters.com/index.php?topic=88505.0
https://reficulcoin.com/index.php?topic=30398.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.remify.app/foro/index.php?topic=251776.0
http://www.remify.app/foro/index.php?topic=251794.0
http://www.tekparcahdfilm.com/forum/index.php?topic=47602.0
http://www.theparrotcentre.com/forum/index.php?topic=490894.0
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=11406.0
https://danceplanet.se/commodore/index.php?topic=20456.0
http://freebeer.me/index.php?topic=304696.0
http://www.critico-expository.com/forum/index.php?topic=3735.0
http://www.popolsku.fr.pl/forum/index.php?topic=374122.0
http://www.popolsku.fr.pl/forum/index.php?topic=374125.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=679632.0
https://forums.letstalkbeats.com/index.php?topic=65529.0
https://lucky28003.nl/forum/index.php?topic=10867.0
http://dohairbiz.com/?option=com_k2&view=itemlist&task=user&id=2713859
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3724600
http://mahdi.ehosseini.com/?option=com_k2&view=itemlist&task=user&id=25668
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=6973
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1018157
http://www.m1avio.com/index.php/component/k2/itemlist/user/3618501
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/662793
http://www.siirtorganik.com/index.php/component/k2/itemlist/user/767966
http://www.artifact.website/94613-igra-prestolov-game-of-thrones-8-sezon-7-seria-watch-a1-c5-igra
http://www.artifact.website/94649-igra-prestolov-got-8-sezon-5-seria-watch-j9-s5-igra-prestolov-g
http://www.artifact.website/94731-igra-prestolov-8-sezon-7-seria-b9-t8-igra-prestolov-8-sezon-7-s
http://www.artifact.website/94772-igra-prestolov-2019-8-sezon-7-seria-m1-q1-igra-prestolov-2019-8
http://www.deliberarchia.org/forum/index.php?topic=994383.0
http://www.deliberarchia.org/forum/index.php?topic=994391.0
http://www.deliberarchia.org/forum/index.php?topic=994394.0
http://help.stv.ru/index.php?PHPSESSID=6b13c30c76634ac43c8e81665848453a&topic=139784.0
http://forum.elexlabs.com/index.php/topic,18902.0.html
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-i9-s8-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://www.deliberarchia.org/forum/index.php?topic=997063.0
http://forum.elexlabs.com/index.php/topic,16998.0.html
http://www.theocraticamerica.org/forum/index.php?topic=28557.0
https://hackersuniversity.net/index.php?topic=9408.0
http://sexfork.com/uncategorized/ertugrul-150-seriya-ft4-ertugrul-150-seriya/
https://danceplanet.se/commodore/index.php?topic=20798.0
http://forum.elexlabs.com/index.php?topic=18553.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/(a-etoo-2019-8-eo-1-e)-a-etoo-2019-8-eo-1-e-y1q8/?PHPSESSID=tsfi05slu3nipmhhehok6ssff6
http://myrechockey.com/forums/index.php?topic=91383.0
http://www.sharmaraco.com/blog/%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-c8-f0-%C2%AB%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-watch
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d6-q1-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://www.deliberarchia.org/forum/index.php?topic=1001145.0
http://teambuildingpremium.com/forum/index.php?topic=816753.0
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-x2-f8-%d0%b8%d0%b3/
http://forum.elexlabs.com/index.php?topic=20429.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-79/
https://danceplanet.se/commodore/index.php?topic=18102.0
http://teambuildingpremium.com/forum/index.php?topic=794996.0
https://reficulcoin.com/index.php?topic=19391.0
http://www.deliberarchia.org/forum/index.php?topic=991896.0
http://sextomariotienda.com/blog/hd-video-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://forum.elexlabs.com/index.php?topic=17986.0
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vs6-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://polyframetrade.co.uk/%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-10-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-g9-s1-%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4/
https://nextezone.com/index.php?topic=42250.0
http://www.tessabannampad.go.th/webboard/index.php?topic=197165.0
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ya5-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://khuyenmaikk13.info/index.php?topic=185273.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.m1avio.com/index.php/component/k2/itemlist/user/3627529
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1014534
http://www.afikgan.co.il/index.php/component/k2/itemlist/user/26123
http://www.ekemoon.com/151935/051120192007/
https://www.shaiyax.com/index.php?topic=330599.0
http://married.dike.gr/index.php/component/k2/itemlist/user/47436
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2520383
http://www.digitalbul.com/%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0%d1%88%d0%ba%d0%b0-erkenci-kus-43-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k8-%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0%d1%88%d0%ba/
http://www.digitalbul.com/%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0%d1%88%d0%ba%d0%b0-erkenci-kus-43-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-f5-%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0%d1%88/
http://www.gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1895146
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=615922
https://altaylarteknoloji.com/index.php?topic=3748.0
https://altaylarteknoloji.com/index.php?topic=3749.0
https://altaylarteknoloji.com/index.php?topic=3750.0
http://danielmillsap.com/forum/index.php?topic=1036049.0
http://thanosakademi.com/index.php?topic=86637.0
http://www.hoonthaitoday.com/forum/index.php?topic=252363.0
http://www.digitalbul.com/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h5-%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81/
http://www.digitalbul.com/%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5%d0%bd%d0%b8%d0%b5-vuslat-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-u4-%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd/
http://www.hoonthaitoday.com/forum/index.php?topic=252380.0
http://www.phperos.net/foro/index.php?topic=134349.0
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=814014
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l3-h2-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m0-f0-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l7-s2-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-s3-e2-%d0%b8%d0%b3%d1%80%d0%b0/
https://www.shaiyax.com/index.php?topic=340512.0
http://8.droror.co.il/uncategorized/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-88-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-o6-%e3%80%90-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-88-%d1%81%d0%b5%d1%80%d0%b8%d1%8f%e3%80%91-%d1%82%d0%b0%d0%b9%d0%bd/
http://8.droror.co.il/uncategorized/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l6-%e3%80%90-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://8.droror.co.il/uncategorized/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-watch-n9-%e3%80%90-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
http://demo.woltlab.fr/lite1/wbb/index.php?page=User&userID=1164788
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=1046
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=989
http://yoriyorifood.com/xxxx/spacial/3075
http://yoriyorifood.com/xxxx/spacial/3080
https://dolcoin.net/free_talk/1728
https://dolcoin.net/free_talk/1733
https://dolcoin.net/free_talk/1747
https://mencoin.net/talk_fm/1665
https://mencoin.net/talk_fm/1670
https://nextezone.com/index.php?topic=48745.0
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j7-p6-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://otitismediasociety.org/forum/index.php?topic=149458.0
https://khuyenmaikk13.info/index.php?topic=186952.0
https://woodland.org.ua/groups/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m9-f7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://forum.elexlabs.com/index.php?topic=18454.0
http://roikjer.com/forum/index.php?PHPSESSID=ebo5pb86br2ob5nh9c7a8kboa5&topic=856048.0
http://www.critico-expository.com/forum/index.php?topic=8573.0
http://forum.elexlabs.com/index.php?topic=17260.0
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p4-b8-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-7/
http://www.teedinubon.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i5-d4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://HyUa.1fps.icu/l/szIaeDC
http://153.120.114.241/eso/index.php/16864532-holostak-9-sezon-10-vypusk-quattroporte-dcholostak-9-sezon-10-v
http://8.droror.co.il/uncategorized/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5-8/
http://dev.aabn.org.gh/component/k2/itemlist/user/518901
http://www.vivelabmanizales.com/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-11/
http://bitpark.co.kr/?document_srl=3790591
http://mjbosch.com/index.php/component/k2/itemlist/user/82426
http://www.deliberarchia.org/forum/index.php?topic=968982.0
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2398490
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/271225
https://grajalesabogados.com.mx/?option=com_k2&view=itemlist&task=user&id=61455
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/660759
http://www.vivelabmanizales.com/%d0%b2%d0%be%d1%80%d0%be%d0%bd-kuzgun-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cmso-%d0%b2%d0%be%d1%80%d0%be%d0%bd-kuzgun-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=66761
http://withinfp.sakura.ne.jp/eso/index.php/16864218-edinoe-serdce-tek-yurek-19-seria-exxj-edinoe-serdce-tek-yurek-1
http://mahdi.ehosseini.com/index.php/component/k2/itemlist/user/24768
http://153.120.114.241/eso/index.php/16866025-holostak-9-sezon-10-vypusk-uteta-yaholostak-9-sezon-10-vypusk-u
http://forum.byehaj.hu/index.php?topic=81680.0
https://tg.vl-mp.com/index.php?topic=1341122.0
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=270302
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=297768
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=20660
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3430708
http://k2.akademitelkom.ac.id/component/k2/itemlist/user/319674
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3774810
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3775073
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/713012
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/88345
http://ovotecegg.com/component/k2/itemlist/user/134805
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/232967
https://khuyenmaikk13.info/index.php?topic=184227.0
https://lucky28003.nl/forum/index.php?topic=12776.0
https://members.fbhaters.com/index.php?topic=82062.0
https://nextezone.com/index.php?action=profile;u=3143
https://reficulcoin.com/index.php?topic=15762.0
https://reficulcoin.com/index.php?topic=15767.0
https://www.gizmoarticle.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-27-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7/
https://www.resproxy.com/forum/index.php/808885-ertugrul-149-seria-online-t7-ertugrul-149-seria/0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=668757.0
http://www.tvmechanic.co.in/forum/index.php?topic=7517.0
https://ne-kuru.ru/index.php?topic=211005.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=276513
http://www.ekemoon.com/139951/050220192605/
http://associationsila.org/index.php/component/k2/itemlist/user/252348
http://matrixpharm.ru/forum/index.php?PHPSESSID=si6qv9m5vi4ktjil9rnp1ekm23&action=profile;u=152174
http://uberdrivers.net/forum/index.php?topic=183512.0
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=142402
http://dohairbiz.com/en/component/k2/itemlist/user/2705003.html
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=715043
http://roikjer.com/forum/index.php?topic=776822.0
http://www.critico-expository.com/forum/index.php?topic=179.0
http://www.spazioad.com/component/k2/itemlist/user/7165083
http://www.oortsociety.com/index.php?topic=10924.0
https://danceplanet.se/commodore/index.php?topic=26353.0
https://nextezone.com/index.php?topic=45253.0
https://npi.org.es/smf/index.php?topic=115089.0
https://tg.vl-mp.com/index.php?topic=1394363.0
http://sexfork.com/uncategorized/sluga-naroda-3-sezon-23-seriya-jkb-sluga-naroda-3-sezon-23-seriya/
https://prelease.club/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-87-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pye-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-87-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://prelease.club/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-89-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-psm-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-89-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://prelease.club/%d1%87%d1%83%d0%b6%d0%b0%d1%8f-%d0%b6%d0%b8%d0%b7%d0%bd%d1%8c-%d1%87%d1%83%d0%b6%d0%b5-%d0%b6%d0%b8%d1%82%d1%82%d1%8f-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nve-%d1%87%d1%83%d0%b6/
https://sanp.pro/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zwm-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-5-%d1%81%d0%b5%d1%80%d0%b8/
http://www.autospa.lv/index.php/lv/component/k2/itemlist/user/9498
http://www.m1avio.com/?option=com_k2&view=itemlist&task=user&id=3637931
http://www.m1avio.com/index.php/component/k2/itemlist/user/3637970
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=586452
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=52228
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1850448
http://foa.egerton.ac.ke/index.php/component/k2/itemlist/user/1676203
http://uberdrivers.net/forum/index.php?topic=188084.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/166620
http://dev.aabn.org.gh/component/k2/itemlist/user/472935
http://www.gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1803036
http://proxima.co.rw/index.php/component/k2/itemlist/user/556243
http://www.gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1817818
http://forum.stollen24.com/index.php?topic=1629.0
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=231204
http://dpmarketingsystems.com/%d0%b2%d0%b8%d0%b4%d0%b5%d0%be-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c9-%d1%81%d0%bb%d1%83/
http://uberdrivers.net/forum/index.php?topic=184860.0
http://www.nomaher.com/forum/index.php?topic=11403.0
http://rudraautomation.com/index.php/component/k2/author/119923
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3735435
http://www.spazioad.com/component/k2/itemlist/user/7252394
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=764812
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1014022
http://forum.politeknikgihon.ac.id/index.php?topic=21097.0
http://www.nomaher.com/forum/index.php?topic=13439.0
http://www.nomaher.com/forum/index.php?topic=13447.0
http://www.theparrotcentre.com/forum/index.php?topic=490295.0
https://altaylarteknoloji.com/index.php?topic=2178.0
https://forum.ac-jete.it/index.php?topic=359144.0
https://members.fbhaters.com/index.php?topic=87663.0
https://members.fbhaters.com/index.php?topic=87684.0
https://nextezone.com/index.php?action=profile;u=5166
https://nextezone.com/index.php?action=profile;u=5209
https://nextezone.com/index.php?topic=41794.0
https://nextezone.com/index.php?topic=41799.0
http://77.93.38.205/index.php/component/k2/itemlist/user/527651
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=309495
http://smartacity.com/component/k2/itemlist/user/22040
http://smartacity.com/component/k2/itemlist/user/22060
http://www.arunagreen.com/?option=com_k2&view=itemlist&task=user&id=442929
http://www.arunagreen.com/index.php/component/k2/itemlist/user/442878
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1353575
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=1020864
http://www.dap.com.py/index.php/es/?option=com_k2&view=itemlist&task=user&id=786690
http://www.m1avio.com/index.php/component/k2/itemlist/user/3620383
http://www.m1avio.com/index.php/component/k2/itemlist/user/3620772
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=573316
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=769406
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1562510
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=71038
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4737182
http://married.dike.gr/index.php/component/k2/itemlist/user/48947
http://www.ekemoon.com/159925/051720194108/
http://wituclub.ru/forum/index.php?PHPSESSID=9er0tt0vc43bmjv0il44fhdhv2&topic=25532.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/580223
https://reficulcoin.com/index.php?topic=29052.0
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=297136
http://healthyteethpa.org/component/k2/itemlist/user/5408045
http://help.stv.ru/index.php?PHPSESSID=2bea748ce3ae65b59e6496902ff61726&topic=140654.0
http://roikjer.com/forum/index.php?PHPSESSID=a9hj9qs6k6ai1vi0p51v71iif6&topic=859166.0
http://www.deliberarchia.org/forum/index.php?topic=1014377.0
http://www.deliberarchia.org/forum/index.php?topic=1014407.0
http://www.deliberarchia.org/forum/index.php?topic=1014426.0
http://www.theparrotcentre.com/forum/index.php?topic=510336.0
https://danceplanet.se/commodore/index.php?topic=26536.0
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=8a8d02aff1986c6bf1edeb6186f816c4&topic=658.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=682651.0
http://zsmr.com.ua/index.php/component/k2/itemlist/user/521458
https://khuyenmaikk13.info/index.php?topic=184486.0
https://members.fbhaters.com/index.php/topic,82579.0.html
https://members.fbhaters.com/index.php?topic=82574.0
https://members.fbhaters.com/index.php?topic=82587.0
https://members.fbhaters.com/index.php?topic=82590.0
https://ne-kuru.ru/index.php?topic=215305.0
https://reficulcoin.com/index.php?topic=16183.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3323792
https://www.c-alice.org/forum/index.php?topic=76971.0
https://www.c-alice.org/forum/index.php?topic=76974.0
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=17587
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/187674
http://www.spazioad.com/component/k2/itemlist/user/7241156
http://withinfp.sakura.ne.jp/eso/index.php/16862918-hdvideo-sluga-naroda-3-sezon-12-seria-z9-sluga-naroda-3-sezon-1/0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3311923
http://153.120.114.241/eso/index.php/16869787-vossoedinenie-vuslat-13-seria-rude-vossoedinenie-vuslat-13-seri
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=681664.0
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2390363
http://rudraautomation.com/index.php/component/k2/author/118247
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3746409
http://withinfp.sakura.ne.jp/eso/index.php/16860724-novinka-tolarobot-1-sezon-7-seria-k1-tolarobot-1-sezon-7-seria/0
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=492611
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/53563
https://forums.letstalkbeats.com/index.php?topic=64072.0
http://married.dike.gr/index.php/component/k2/itemlist/user/47440
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=10959
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3335851
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=19123
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2606509
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2606562
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2606563
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=81113
http://batubersurat.com/index.php/component/k2/itemlist/user/50734
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/506982
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/507174
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/507178
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=2013627
https://lucky28003.nl/forum/index.php?topic=12981.0
https://members.fbhaters.com/index.php?topic=82704.0
https://members.fbhaters.com/index.php?topic=82712.0
https://nextezone.com/index.php?action=profile;u=3306
https://reficulcoin.com/index.php?topic=16241.0
https://www.resproxy.com/forum/index.php/810254-voskressij-ertugrul-148-seria-v7-voskressij-ertugrul-148-seria/0
http://www.deliberarchia.org/forum/index.php?topic=932799.0
http://macdistri.com/index.php/component/k2/itemlist/user/292909
http://marjorieaperry.com/?option=com_k2&view=itemlist&task=user&id=475443
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/167644
http://wb.hvekorat.com/index.php?topic=40174.0
http://ru-realty.com/forum/index.php?PHPSESSID=9uqvracm4hr6ouf1s4lepss5v0&topic=481582.0
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-r9-%d0%b8/
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e0-%d0%b8%d0%b3%d1%80%d0%b0-2/
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f0-%d0%b8%d0%b3%d1%80/
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z3-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/223029
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/197121
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/197315
http://www.afikgan.co.il/index.php/component/k2/itemlist/user/27133
http://www.arunagreen.com/index.php/component/k2/itemlist/user/471164
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1375400
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/512645
http://mobility-corp.com/index.php/component/k2/itemlist/user/2478284
http://danielmillsap.com/forum/index.php?topic=875820.0
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/185626
https://www.shaiyax.com/index.php?topic=319628.0
http://1vh.info/index.php?topic=20389.0
http://bayareawomenmag.xyz/blogs/viewstory/35692
http://bayareawomenmag.xyz/blogs/viewstory/35699
http://dota2.host/123353-igra-prestolov-8-sezon-5-seria-online-j2-c6-igra-prestolov-8-se
http://dota2.host/123439-igra-prestolov-2019-8-sezon-7-seria-watch-b3-t3-igra-prestolov-
http://withinfp.sakura.ne.jp/eso/index.php/16869660-holostak-9-sezon-10-vypusk-post-sou-hzholostak-9-sezon-10-vypus/0
https://www.swiss-focus.ch/index.php/component/k2/itemlist/user/15104
http://rudraautomation.com/index.php/component/k2/author/103485
http://ovotecegg.com/component/k2/itemlist/user/114209
http://rudraautomation.com/index.php/component/k2/author/104303
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2581745
http://seoksoononly.dothome.co.kr/qna/745428
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/185546
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=282118
http://forum.politeknikgihon.ac.id/index.php?topic=22132.0
http://arunagreen.com/index.php/component/k2/itemlist/user/422676
http://www.vivelabmanizales.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d6-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1/
http://www.arunagreen.com/index.php/component/k2/itemlist/user/505422
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/257129
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/257160
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=554435
http://zsmr.com.ua/index.php/component/k2/itemlist/user/554459
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3354265
http://forum.digamahost.com/index.php?topic=120928.0
http://zanoza.h1n.ru/2019/05/14/%d0%bd%d0%b5-%d0%be%d1%82%d0%bf%d1%83%d1%81%d0%ba%d0%b0%d0%b9-%d0%bc%d0%be%d1%8e-%d1%80%d1%83%d0%ba%d1%83-elimi-birakma-42-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-piwz-%d0%bd%d0%b5-%d0%be/
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=16184
http://www.arunagreen.com/index.php/component/k2/itemlist/user/505488
http://www.m1avio.com/?option=com_k2&view=itemlist&task=user&id=3684520
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fw4l-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://zanoza.h1n.ru/2019/05/14/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bn8o-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://thermoplast.envolgroupe.com/component/k2/author/101498
http://w9builders.co.uk/index.php/component/k2/itemlist/user/71326
http://www.arredoufficiomarca.com/index.php/component/k2/itemlist/user/1590034
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1616032
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=816733
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=20489
http://thermoplast.envolgroupe.com/component/k2/author/66839
http://islamiccall.info/?option=com_k2&view=itemlist&task=user&id=856905
http://www.remify.app/foro/index.php?topic=238131.0
http://77.93.38.205/index.php/component/k2/itemlist/user/492924
http://www.vivelabmanizales.com/%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5%d0%bd%d0%b8%d0%b5-vuslat-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xsyt-%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd/
http://www.vivelabmanizales.com/hd-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3709894
http://mobility-corp.com/index.php/component/k2/itemlist/user/2527166
http://socialfbwidgets.com/component/k2/itemlist/user/13622.html
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3709322
https://khuyenmaikk13.info/index.php?topic=181949.0
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1650014
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=103931
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/49834
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2578238
http://ptu.imoove.kr/ko/content/%C2%AB%D1%8E%D1%80%D0%B8%D1%81%D1%82%D1%8B-15-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-hd-%C2%AB%D1%8E%D1%80%D0%B8%D1%81%D1%82%D1%8B-15-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB332590
http://thermoplast.envolgroupe.com/component/k2/author/66421
http://zsmr.com.ua/index.php/component/k2/itemlist/user/490975
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1546655
http://www.sollazzorefrigerazione.it/?option=com_k2&view=itemlist&task=user&id=2420732
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=28559.0
https://polyframetrade.co.uk/%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-12-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-v9-o3-%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81/
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=684168.0
http://tripviet.com/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a7-%d1%81%d0%bb/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80-19/
http://poselokgribovo.ru/forum/index.php?topic=743577.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/'a-etoo-2019-8-eo-1-e'-a-etoo-2019-8-eo-1-e-n3n5/?PHPSESSID=bgkh8o7471bq0a68j9jtkuvtu1
http://forum.drahthaar-club.com.ua/index.php?topic=1417.0
http://dpmarketingsystems.com/hd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k1-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://forum.elexlabs.com/index.php?topic=22025.0
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u7-v1-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
https://reficulcoin.com/index.php?topic=25601.0
https://www.gizmoarticle.com/09-05-2019-%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-3/
http://forums.abs-cbn.com/welcome-back-kapamilya%21/ma-4-eo-12-e-watch-x1-~-f1-ma-4-eo-12-e-'-ma-4-eo-12-e/?PHPSESSID=r0t2t2bt5o794j3flpmfg0qko4
http://otitismediasociety.org/forum/index.php?topic=151074.0
http://www.theparrotcentre.com/forum/index.php?topic=491415.0
http://www.hoonthaitoday.com/forum/index.php?topic=209717.0
http://sexfork.com/en/uncategorized/ertugrul-147-seriya-yf9-ertugrul-147-seriya/
https://polyframetrade.co.uk/%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-9-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-online-a3-b5-%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80/
https://www.gizmoarticle.com/%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-09-05-2019-3/
https://sanp.pro/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d1-%d1%81%d0%bb/
http://ru-realty.com/forum/index.php?topic=486520.0
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i8-f8-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://roikjer.com/forum/index.php?PHPSESSID=tahrclnp21nj0e3c1oclg0a2p0&topic=835848.0
http://forum.elexlabs.com/index.php?topic=21920.0
https://reficulcoin.com/index.php?topic=32035.0
http://www.theparrotcentre.com/forum/index.php?topic=483481.0
http://istakam.com/forum/index.php?topic=15357.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=8f8f0bbf3c40049eb764205f5aec3113&topic=226896.0
http://www.deliberarchia.org/forum/index.php?topic=1001934.0
https://prelease.club/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e4-%d1%81%d0%bb/
http://ru-realty.com/forum/index.php?PHPSESSID=5l7ser6v01s0pdaara3su44680&topic=480655.0
http://demo.caribe.vps-private.net/blog/milliardy-4-sezon-12-seriya-t4-h1-milliardy-4-sezon-12-seriya-milliardy-4-sezon-12-seriya
http://myrechockey.com/forums/index.php?topic=96222.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=684174.0
https://members.fbhaters.com/index.php?topic=83334.0
http://roikjer.com/forum/index.php?PHPSESSID=r27rjoij3jukcm1jd08aj0m4p3&topic=842132.0
http://HyUa.1fps.icu/l/szIaeDC
http://rudraautomation.com/index.php/component/k2/author/142276
http://thermoplast.envolgroupe.com/component/k2/author/70425
http://seoksoononly.dothome.co.kr/qna/786055
http://menulisilmiah.net/hd-video-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q1-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://seoksoononly.dothome.co.kr/qna/736681
http://www.siirtorganik.com/index.php/component/k2/itemlist/user/755737
http://www.critico-expository.com/forum/index.php?topic=2608.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1340664
http://mvisage.sk/?option=com_k2&view=itemlist&task=user&id=117714
http://www.siirtorganik.com/index.php/component/k2/itemlist/user/762529
http://forum.politeknikgihon.ac.id/index.php?topic=21736.0
http://www.vivelabmanizales.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-dailymotion-vk%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
http://www.ekemoon.com/149365/050020195607/
http://healthyteethpa.org/component/k2/itemlist/user/5343682
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=13003
http://seoksoononly.dothome.co.kr/qna/748820
http://jstech.kr/index.php?mid=board_lqyj42&document_srl=1285
http://moavalve.co.kr/faq/430
http://proxima.co.rw/index.php/component/k2/itemlist/user/616799
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=639
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/207004
http://menulisilmiah.net/%d1%81%d0%bc%d0%b5%d1%80%d1%88-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hdx-%d1%81%d0%bc%d0%b5%d1%80%d1%88-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-pgp-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://menulisilmiah.net/%d1%87%d1%83%d0%b6%d0%b0%d1%8f-%d0%b6%d0%b8%d0%b7%d0%bd%d1%8c-%d1%87%d1%83%d0%b6%d0%b5-%d0%b6%d0%b8%d1%82%d1%82%d1%8f-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-reo-%d1%87%d1%83%d0%b6/
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/219232
http://sextomariotienda.com/blog/%d0%b4%d0%be%d1%87%d0%ba%d0%b8-%d0%bc%d0%b0%d1%82%d0%b5%d1%80%d0%b8-%d0%b4%d0%be%d1%87%d0%ba%d0%b8-%d0%bc%d0%b0%d1%82%d0%b5%d1%80i-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dim-%d0%b4/
http://sextomariotienda.com/blog/%d0%b4%d0%be%d1%87%d0%ba%d0%b8-%d0%bc%d0%b0%d1%82%d0%b5%d1%80%d0%b8-%d0%b4%d0%be%d1%87%d0%ba%d0%b8-%d0%bc%d0%b0%d1%82%d0%b5%d1%80i-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ext-%d0%b4/
http://sextomariotienda.com/blog/%d1%87%d1%83%d0%b6%d0%b0%d1%8f-%d0%b6%d0%b8%d0%b7%d0%bd%d1%8c-%d1%87%d1%83%d0%b6%d0%b5-%d0%b6%d0%b8%d1%82%d1%82%d1%8f-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-biq-%d1%87%d1%83%d0%b6/
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1039771
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=14508
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mxr-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=521412
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gsn-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://www.hicleaning.kr/board_wash/15326
http://www.hicleaning.kr/board_wash/15389
http://www.hicleaning.kr/board_wash/15427
http://www.hsaura.com/?document_srl=9096
http://www.hsaura.com/noty/9047
http://www.hsaura.com/noty/9052
http://www.hsaura.com/noty/9066
https://tg.vl-mp.com/index.php?topic=1278729.0
http://roikjer.com/forum/index.php?topic=793845.0
http://teambuildingpremium.com/forum/index.php?topic=714077.0
http://servicioswts.com/?option=com_k2&view=itemlist&task=user&id=3607195
http://healthyteethpa.org/component/k2/itemlist/user/5322606
http://www.moyakmermer.com/index.php/en/component/k2/itemlist/user/626417
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vcs-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd-2/
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uvr-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://www.vivelabmanizales.com/%d1%81%d0%bc%d0%b5%d1%80%d1%88-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xud-%d1%81%d0%bc%d0%b5%d1%80%d1%88-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.vivelabmanizales.com/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-100-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ype-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-100-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://tg.vl-mp.com/index.php?topic=1280775.0
http://poselokgribovo.ru/forum/index.php?topic=650525.0
https://lucky28003.nl/forum/index.php?topic=5554.0
http://xekhachduyetthuy.com.vn/component/k2/itemlist/user/143380
http://www.nomaher.com/forum/index.php?topic=10279.0
https://npi.org.es/smf/index.php?topic=110966.0
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vlv-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://forum.byehaj.hu/index.php?topic=70586.0
https://lucky28003.nl/forum/index.php?topic=3676.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/568585
http://rudraautomation.com/index.php/component/k2/author/115311
http://sdsn.develop.cinfores.com/?option=com_k2&view=itemlist&task=user&id=186750
http://www.critico-expository.com/forum/index.php?topic=2257.0
http://www.critico-expository.com/forum/index.php?topic=2260.0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=565437
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=565444
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=42100
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=7939.0
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=7946.0
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=7948.0
http://smartengbiz.com/s1/6855
http://vn7.vn/customizing/42094
http://vn7.vn/qna/42071
http://vn7.vn/qna/42127
http://warmfund.net/p/index.php?mid=financing&document_srl=43623
http://warmfund.net/p/index.php?mid=financing&document_srl=43729
http://warmfund.net/p/index.php?mid=financing&document_srl=43760
http://warmfund.net/p/index.php?mid=financing&document_srl=43785
http://www.datascientist.co.kr/index.php?mid=blog&document_srl=37800
http://www.datascientist.co.kr/index.php?mid=blog&document_srl=37836
http://www.deliberarchia.org/forum/index.php?topic=1030858.0
http://www.deliberarchia.org/forum/index.php?topic=1030861.0
http://www.gforgirl.com/xe/poster/5536
http://forum.elexlabs.com/index.php?topic=16963.0
http://forum.elexlabs.com/index.php?topic=19023.0
http://menulisilmiah.net/%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-10-05-2019/
https://worldtaxi.org/2019/05/09/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j6-i6-%d0%b8/
http://www.hoonthaitoday.com/forum/index.php?topic=236110.0
http://demo.caribe.vps-private.net/blog/milliardy-4-sezon-12-seriya-s5-d0-milliardy-4-sezon-12-seriya-milliardy-4-sezon-12-seriya-watch
http://sexfork.com/uncategorized/ertugrul-146-seriya-xo6-ertugrul-146-seriya/
http://menulisilmiah.net/%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e0-%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-16-%d1%81%d0%b5%d1%80/
http://forum.elexlabs.com/index.php/topic,22336.0.html
https://danceplanet.se/commodore/index.php?topic=17304.0
http://www.deliberarchia.org/forum/index.php?topic=1006589.0
https://www.limscave.com/forum/viewtopic.php?t=31873
http://forum.politeknikgihon.ac.id/index.php?topic=29930.0
https://worldtaxi.org/2019/05/10/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x5-j0-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://www.theparrotcentre.com/forum/index.php?topic=490105.0
http://www.nomaher.com/forum/index.php?topic=12695.0
https://members.fbhaters.com/index.php?topic=86036.0
https://prelease.club/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nr6-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-09-05-2019-3/
https://members.fbhaters.com/index.php?topic=85992.0
http://forum.elexlabs.com/index.php?topic=16339.0
http://www.critico-expository.com/forum/index.php?topic=11680.0
http://poselokgribovo.ru/forum/index.php?topic=746864.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.tessabannampad.go.th/webboard/index.php?topic=205322.0
https://worldtaxi.org/2019/05/10/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-d6-g4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://menulisilmiah.net/%d0%b4%d1%80%d1%83%d0%b3%d0%b0%d1%8f-i%d0%bd%d1%88%d0%b0-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-y5-%d0%b4%d1%80%d1%83%d0%b3%d0%b0%d1%8f-i%d0%bd%d1%88%d0%b0-18-%d1%81%d0%b5%d1%80/
https://prelease.club/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x9-%d1%81/
https://prelease.club/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qj0-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://forum.elexlabs.com/index.php?topic=22097.0
https://danceplanet.se/commodore/index.php?topic=19892.0
http://www.tessabannampad.go.th/webboard/index.php?topic=205004.0
https://nextezone.com/index.php?topic=42123.0
http://www.deliberarchia.org/forum/index.php?topic=997244.0
http://www.tessabannampad.go.th/webboard/index.php?topic=196455.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=b7a9900c9c723c2fa7765a70e488833d&topic=220869.0
http://danielmillsap.com/forum/index.php?topic=1025929.0
http://www.hoonthaitoday.com/forum/index.php?topic=202678.0
http://www.deliberarchia.org/forum/index.php?topic=1015420.0
https://danceplanet.se/commodore/index.php?topic=29205.0
http://sexfork.com/uncategorized/ertugrul-149-seriya-fq2-ertugrul-149-seriya/
http://otitismediasociety.org/forum/index.php?topic=149713.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c2-e7-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
https://nextezone.com/index.php?action=profile&u=4852
https://akutthjelper.no/members/renategilson32/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mb9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.ofqj.org/hebergementfrance/4-8-u7-b4-4-8-4-8-online
http://forum.elexlabs.com/index.php/topic,22550.0.html
http://poselokgribovo.ru/forum/index.php?topic=751655.0
https://prelease.club/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t6-%d1%81/
https://polyframetrade.co.uk/%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-w7-e8-%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4/
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://otitismediasociety.org/forum/index.php?topic=156844.0
https://sanp.pro/%d0%b3%d1%80%d0%b0%d0%bd%d0%b4-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-23-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-10-05-2019/
http://www.hoonthaitoday.com/forum/index.php?topic=233981.0
http://www.hoonthaitoday.com/forum/index.php?topic=207069.0
https://lucky28003.nl/forum/index.php?topic=13051.0
http://HyUa.1fps.icu/l/szIaeDC
http://uberdrivers.net/forum/index.php?topic=221780.0
http://www.aloeverasas.it/index.php/component/k2/itemlist/user/17940
http://necinsurance.co.zw/component/k2/itemlist/user/19217.html
http://www.nomaher.com/forum/index.php?topic=11430.0
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=54566
http://married.dike.gr/index.php/component/k2/itemlist/user/52011
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/476487
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=8072.0
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=270832
http://mediaville.me/index.php/component/k2/itemlist/user/225395
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=794933
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=795136
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1784199
http://www.m1avio.com/index.php/component/k2/itemlist/user/3638611
http://www.m1avio.com/index.php/component/k2/itemlist/user/3638631
http://www.proandpro.it/?option=com_k2&view=itemlist&task=user&id=4562070
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=522350
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3324278
https://www.netprofessional.gr/component/k2/itemlist/user/3352.html
https://www.netprofessional.gr/component/k2/itemlist/user/3371.html
https://www.regalepadova.it/?option=com_k2&view=itemlist&task=user&id=7097
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=17655
https://www.swiss-focus.ch/index.php/component/k2/itemlist/user/17686
http://forum.politeknikgihon.ac.id/index.php?topic=29321.0
http://hi-mar.com/forum/index.php?PHPSESSID=a349d2f2b65c5f88422058967ebb26d9&topic=32375.0
http://hi-mar.com/forum/index.php?PHPSESSID=dadb6671886d446f265f6ddc7a7f3255&topic=32373.0
http://hi-mar.com/forum/index.php?PHPSESSID=e3398ed18850303195e74bea6d1f195f&topic=32371.0
http://hi-mar.com/forum/index.php?PHPSESSID=e6341f9f65dc63bd34064f14dc34f59e&topic=32374.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=30403.0
http://poselokgribovo.ru/forum/index.php?topic=745940.0
http://poselokgribovo.ru/forum/index.php?topic=745987.0
http://roikjer.com/forum/index.php?PHPSESSID=vrahgoquvgspkg4hoihs742pl0&topic=837599.0
http://ru-realty.com/forum/index.php?topic=480035.0
http://ruschinaforum.ru/index.php/topic,132010.0.html
http://ruschinaforum.ru/index.php?topic=132008.0
http://forum.byehaj.hu/index.php?topic=88423.0
https://luckychancerescue.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g4-e2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://www.ofqj.org/hebergementfrance/4-8-p2-l3-4-8-4-8-watch
http://www.critico-expository.com/forum/index.php?topic=7663.0
https://forum.clubeicaro.pt/index.php?topic=978.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/(a-etoo-2019-8-eo-5-e)-a-etoo-2019-8-eo-5-e-d0v9/?PHPSESSID=vb4hf2e0dg42kllku7ojp72627
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5-14/
http://help.stv.ru/index.php?PHPSESSID=6fdb01a6af4c2951b52aef730a051f86&topic=140687.0
http://www.theparrotcentre.com/forum/index.php?topic=485494.0
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=6aa06d1ad7c959a4a322531f93cec792&topic=794.0
http://forum.kopkargobel.com/index.php?topic=6797.0
https://sanp.pro/hd-video-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m7-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://forum.kopkargobel.com/index.php?topic=6529.0
http://forum.byehaj.hu/index.php?topic=85268.0
http://www.verenas-unterwasserwelt.de/forum/index.php?topic=850.0
http://help.stv.ru/index.php?PHPSESSID=0ec7208327de7de2ed4fc3527496eac5&topic=139902.0
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-23/
http://otitismediasociety.org/forum/index.php?topic=153590.0
http://forum.elexlabs.com/index.php/topic,17180.0.html
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=10918.0
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b5-l7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://help.stv.ru/index.php?PHPSESSID=a3157c0ba391df25c71c44f773d6eb1d&topic=139725.0
http://uberdrivers.net/forum/index.php?topic=244266.0
https://danceplanet.se/commodore/index.php?topic=21836.0
https://reficulcoin.com/index.php?topic=30836.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=685645.0
http://forum.byehaj.hu/index.php?topic=89060.0
https://members.fbhaters.com/index.php?topic=87158.0
http://otitismediasociety.org/forum/index.php?topic=149687.0
https://reficulcoin.com/index.php?topic=20228.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c2-t7-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://www.deliberarchia.org/forum/index.php?topic=1020482.0
http://122.154.49.125/Forum/index.php?topic=119.0
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-24/
http://roikjer.com/forum/index.php?PHPSESSID=7ualb9hfvj9niqr621gj7l6uk6&topic=842792.0
http://help.stv.ru/index.php?PHPSESSID=98253abf43af2de341b81d9ba29327f2&topic=139870.0
http://roikjer.com/forum/index.php?PHPSESSID=fv4nmbf18eq7dulap6f8mutjo2&topic=838000.0
https://forum.clubeicaro.pt/index.php?topic=1006.0
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lp8-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8/
http://HyUa.1fps.icu/l/szIaeDC
http://hyeonjun.co.kr/menu3/938
http://hyeonjun.co.kr/menu3/943
http://hyeonjun.co.kr/menu3/948
http://hyeonjun.co.kr/menu3/953
http://indiefilm.kr/xe/?document_srl=3144
http://indiefilm.kr/xe/board/3098
http://indiefilm.kr/xe/board/3129
http://indiefilm.kr/xe/board/3139
http://indiefilm.kr/xe/board/3148
http://indiefilm.kr/xe/board/3158
http://indiefilm.kr/xe/board/3163
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p8-n0-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://www.deliberarchia.org/forum/index.php?topic=990724.0
http://www.tessabannampad.go.th/webboard/index.php?topic=196292.0
http://www.remify.app/foro/index.php?topic=269954.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=f0cbcf27871d9cabeab8ad848d1db7ad&topic=219287.0
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uo9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://forum.elexlabs.com/index.php?topic=17089.0
http://forum.byehaj.hu/index.php?topic=86581.0
http://myrechockey.com/forums/index.php?topic=91951.0
http://www.tessabannampad.go.th/webboard/index.php?topic=199251.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=32001.0
https://prelease.club/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ew2-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8/
http://www.ekemoon.com/167513/052320190309/
https://forum.clubeicaro.pt/index.php?topic=940.0
http://roikjer.com/forum/index.php?topic=848733.0
http://www.remify.app/foro/index.php?topic=246582.0
http://www.deliberarchia.org/forum/index.php?topic=995273.0
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rb6-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://8.droror.co.il/uncategorized/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kt3-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://www.gizmoarticle.com/09-05-2019-%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://otitismediasociety.org/forum/index.php?topic=156430.0
https://akutthjelper.no/members/wesleygertrude/
http://www.critico-expository.com/forum/index.php?topic=7470.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.vivelabmanizales.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-%d0%b7%d0%b0-10-05-19-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-wb%d1%85%d0%be%d0%bb/
http://153.120.114.241/eso/index.php/16878339-vetrenyj-hercai-15-seria-ydcp-vetrenyj-hercai-15-seria
http://dev.aabn.org.gh/component/k2/itemlist/user/513041
http://bitpark.co.kr/board_IzjM66/3788814
http://www.vivelabmanizales.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-07-05-2019-j2-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1546618
http://www.deliberarchia.org/forum/index.php?topic=962564.0
https://l2thalassic.org/Forum/index.php?topic=579.0
http://xplorefitness.com/blog/%D0%BD%D0%BE%D0%B2%D0%B8%D0%BD%D0%BA%D0%B0-%D1%81%D0%BB%D1%83%D0%B3%D0%B0-%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://dev.aabn.org.gh/component/k2/itemlist/user/528486
http://proxima.co.rw/index.php/component/k2/itemlist/user/576208
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=41442
http://mahdi.ehosseini.com/index.php/component/k2/itemlist/user/31995
http://mvisage.sk/index.php/component/k2/itemlist/user/118697
http://www.ekemoon.com/181091/050420194013/
http://www.ekemoon.com/181093/050420194113/
http://www.ekemoon.com/181105/050420194713/
http://www.vivelabmanizales.com/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zf9a/
http://www.vivelabmanizales.com/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81-41/
http://www.vivelabmanizales.com/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81-45/
http://www.vivelabmanizales.com/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81-28/
http://www.vivelabmanizales.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-mj4h-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vd6u-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://euromouleusinage.com/index.php/component/k2/itemlist/user/135395
http://www.ekemoon.com/181087/050420193813/
http://www.ekemoon.com/181101/050420194413/
http://www.ekemoon.com/181113/050420194913/
http://haniel.ir/index.php/component/k2/itemlist/user/81629
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1003401
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=47346
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=48904
http://arunagreen.com/index.php/component/k2/itemlist/user/448775
http://forum.byehaj.hu/index.php?topic=81721.0
http://seoksoononly.dothome.co.kr/?document_srl=793311
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1994978
http://www.pdctransport.co.th/index.php/component/k2/itemlist/user/14186
http://danielmillsap.com/forum/index.php?topic=1028472.0
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ye4-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://metropolis.ga/index.php?topic=6830.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80-12/
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wb5-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d9-y4-%d0%b8%d0%b3%d1%80/
https://reficulcoin.com/index.php?topic=26257.0
https://sanp.pro/%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0%d1%8f-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b0-%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be%d0%b1%d0%be%d1%82%d0%b0-19-%d1%81%d0%b5-48/
http://ru-realty.com/forum/index.php?PHPSESSID=d7mhvcns67upsnkr701ltor2s5&topic=483194.0
http://help.stv.ru/index.php?PHPSESSID=86d04fcd9b582f70ba12c24431c90b88&topic=139880.0
https://prelease.club/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zw7-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q1-d9-%d1%80%d0%b0%d1%81%d1%81/
http://poselokgribovo.ru/forum/index.php?topic=743346.0
https://reficulcoin.com/index.php?topic=20437.0
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81-2/
http://vervetama.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w4-y8-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://www.tessabannampad.go.th/webboard/index.php?topic=201200.0
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r0-e9-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j9-b6-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=31057.0
http://danielmillsap.com/forum/index.php?topic=1023092.0
https://members.fbhaters.com/index.php/topic,86004.0.html
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-q6-o6-%d0%b8%d0%b3/
http://www.ekemoon.com/169137/050320193210/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80-5/
http://danielmillsap.com/forum/index.php?topic=1022698.0
http://roikjer.com/forum/index.php?PHPSESSID=5tpklvapmrld6lqqbck99h3nh5&topic=843502.0
https://prelease.club/hd-video-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b2-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-y4-i9-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://poselokgribovo.ru/forum/index.php?topic=752128.0
http://dpmarketingsystems.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k9-%d1%81%d0%bb/
http://forum.elexlabs.com/index.php?topic=18301.0
http://menulisilmiah.net/%d0%bd%d0%b5-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b0%d1%8f-%d1%80%d0%b0%d0%b1%d0%be%d1%82%d0%b0-%d0%bd%d0%b5-%d0%b6i%d0%bd%d0%be%d1%87%d0%b0-%d1%80%d0%be%d0%b1%d0%be%d1%82%d0%b0-17-%d1%81%d0%b5-23/
https://members.fbhaters.com/index.php?topic=85085.0
http://otitismediasociety.org/forum/index.php?topic=158641.0
http://roikjer.com/forum/index.php?PHPSESSID=ba7ln1l6d2jq67ocg17s5samo1&topic=860640.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=142972eb5afda183f2a6166a20acb376&topic=228838.0
http://HyUa.1fps.icu/l/szIaeDC
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/479309
https://www.swiss-focus.ch/index.php/component/k2/itemlist/user/16772
http://www.ekemoon.com/145257/051620192706/
http://mvisage.sk/index.php/component/k2/itemlist/user/117882
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3382171
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4728938
http://proxima.co.rw/index.php/component/k2/itemlist/user/574396
http://healthyteethpa.org/component/k2/itemlist/user/5371457
http://www.quattroandpartners.it/component/k2/itemlist/user/994211
https://sanp.pro/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t9-%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5/
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/178738
http://freebeer.me/index.php?topic=257551.0
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/232418
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1595479
http://www.m1avio.com/?option=com_k2&view=itemlist&task=user&id=3569659
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/973482
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=295439
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=146131
http://www.popolsku.fr.pl/forum/index.php?topic=370227.0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/394402
http://8.droror.co.il/uncategorized/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://withinfp.sakura.ne.jp/eso/index.php/16893463-smotret-tola-robot-6-seria-d7-tola-robot-6-seria/0
http://jensenbyggteam.no/?option=com_k2&view=itemlist&task=user&id=12242
http://dohairbiz.com/en/component/k2/itemlist/user/2723584.html
http://thermoplast.envolgroupe.com/component/k2/author/76294
http://www.ekemoon.com/143365/052320193005/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3312279
http://seoksoononly.dothome.co.kr/qna/723105
http://koushatarabar.com/index.php/component/k2/itemlist/user/1325712
http://zsmr.com.ua/index.php/component/k2/itemlist/user/552667
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=1003
http://forum.digamahost.com/index.php?topic=119640.0
http://teambuildingpremium.com/forum/index.php?topic=822127.0
http://teambuildingpremium.com/forum/index.php?topic=822135.0
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=2117
http://www.hsaura.com/noty/2137
http://www.jesusonly.life/calendar/1630
http://www.jesusonly.life/calendar/1641
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=446174
http://www.sp1.football/index.php?mid=faq&document_srl=1468
http://xn--9m1b83j39hz6exwonmf.com/board_IYPe43/473346
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2623540
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3644103
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1591602
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1620351
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4908179
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4908253
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=556485
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=556493
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3356155
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=20855
http://xplorefitness.com/blog/%C2%AB%D1%81%D0%BE%D0%B4%D0%B5%D1%80%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-9-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-14-05-2019-i5-%C2%AB%D1%81%D0%BE%D0%B4%D0%B5%D1%80%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-9-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/525096
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=326492
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=308454
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=20947
http://jiquilisco.org/component/k2/itemlist/user/4849
https://hackersuniversity.net/index.php?topic=9217.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80-21/
http://forum.elexlabs.com/index.php?topic=22820.0
http://uberdrivers.net/forum/index.php?topic=246103.0
http://d2bchannel.co.in/blog/2019/05/10/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g2-b7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://otitismediasociety.org/forum/index.php?topic=150247.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=682997.0
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-eh3-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.deliberarchia.org/forum/index.php?topic=1019972.0
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-r2-d4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90fz2%e3%80%91-%d0%b8%d0%b3/
http://forum.byehaj.hu/index.php?topic=89015.0
http://122.154.49.125/Forum/index.php?topic=189.0
https://members.fbhaters.com/index.php?topic=84778.0
https://worldtaxi.org/2019/05/10/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z1-a9-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
https://reficulcoin.com/index.php?topic=30501.0
https://nextezone.com/index.php?action=profile;u=6918
https://nextezone.com/index.php?topic=48306.0
https://nextezone.com/index.php?topic=48307.0
https://nextezone.com/index.php?topic=48309.0
https://theprodigy.info/forum/index.php?topic=28924.0
https://theprodigy.info/forum/index.php?topic=28925.0
https://theprodigy.info/forum/index.php?topic=28926.0
https://turimex.mx.solemti.net/index.php/component/k2/itemlist/user/910
https://www.gizmoarticle.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80-33/
https://www.gizmoarticle.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80-30/
https://www.gizmoarticle.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80-31/
http://HyUa.1fps.icu/l/szIaeDC
https://reficulcoin.com/index.php?topic=17918.0
https://reficulcoin.com/index.php?topic=20312.0
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u8-t8-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
https://members.fbhaters.com/index.php?topic=84762.0
http://d2bchannel.co.in/blog/2019/05/10/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g7-o3-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
http://www.teedinubon.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j7-k3-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://roikjer.com/forum/index.php?topic=837272.0
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yu6-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://vtservices85.fr/smf2/index.php?PHPSESSID=42d2cde8ac76d26a4ee5c2235dc04cd3&topic=216884.0
https://reficulcoin.com/index.php?topic=30383.0
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile;u=33192
http://teambuildingpremium.com/forum/index.php?topic=794946.0
https://khuyenmaikk13.info/index.php?topic=190437.0
http://www.remify.app/foro/index.php?topic=251370.0
https://sanp.pro/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-23-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d0-%d1%81%d0%bb/
http://poselokgribovo.ru/forum/index.php?topic=752172.0
http://otitismediasociety.org/forum/index.php?topic=149752.0
http://poselokgribovo.ru/forum/index.php?topic=750914.0
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-27/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80-19/
https://reficulcoin.com/index.php?topic=17159.0
https://khuyenmaikk13.info/index.php?topic=190280.0
https://forum.shaiyaslayer.tk/index.php?topic=115988.0
http://www.tessabannampad.go.th/webboard/index.php?topic=201723.0
http://www.ofqj.org/hebergementquebec/4-8-r1-e5-4-8-4-8
http://forum.byehaj.hu/index.php?topic=84195.0
http://www.critico-expository.com/forum/index.php?topic=6797.0
https://danceplanet.se/commodore/index.php?topic=27468.0
http://www.ofqj.org/hebergementquebec/4-8-k2-f7-4-8-4-8
http://uberdrivers.net/forum/index.php?topic=262151.0
https://nextezone.com/index.php?topic=41229.0
http://roikjer.com/forum/index.php?PHPSESSID=oen9li2l61lam2ib76mbhc1eo2&topic=841262.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-(got)-8-eo-6-e-a-etoo-(got)-8-eo-6-e-n4z5/msg561624/
https://lucky28003.nl/forum/index.php?topic=13076.0
http://www.ofqj.org/hebergementquebec/4-8-p7-g2-4-8-4-8
http://HyUa.1fps.icu/l/szIaeDC
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=3553
http://www.generalwalker.org/board_Zyyd91/994
http://www.gforgirl.com/xe/poster/1944
http://www.gforgirl.com/xe/poster/1972
http://www.gforgirl.com/xe/poster/2008
http://www.golden-nail.co.kr/press/1650
http://www.golden-nail.co.kr/press/1655
http://www.golden-nail.co.kr/press/1682
http://www.golden-nail.co.kr/press/1728
http://www.golden-nail.co.kr/press/1733
http://www.golden-nail.co.kr/press/1741
http://www.jesusonly.life/calendar/2694
http://www.jesusonly.life/calendar/2698
https://prelease.club/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wx6-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.deliberarchia.org/forum/index.php?topic=992108.0
http://forum.elexlabs.com/index.php?topic=17469.0
http://poselokgribovo.ru/forum/index.php?topic=751128.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m7-e4-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
https://reficulcoin.com/index.php?topic=19057.0
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l2-f6-%d0%b8%d0%b3%d1%80%d0%b0/
http://roikjer.com/forum/index.php?PHPSESSID=ol2tkg0vlbn1r0mmtum5odf196&topic=839383.0
http://metropolis.ga/index.php?topic=6692.0
http://www.deliberarchia.org/forum/index.php?topic=993301.0
http://taklongclub.com/forum/index.php?topic=113777.0
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-r1-c6-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://HyUa.1fps.icu/l/szIaeDC
http://forum.politeknikgihon.ac.id/index.php?topic=24939.0
http://rudraautomation.com/index.php/component/k2/author/140790
http://subforumna.x10.mx/mad/index.php?topic=205221.0
http://married.dike.gr/index.php/component/k2/itemlist/user/49665
http://forum.politeknikgihon.ac.id/index.php?topic=24794.0
http://robocit.com/index.php/component/k2/itemlist/user/448420
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1550673
https://forums.letstalkbeats.com/index.php?topic=59195.0
http://matrixpharm.ru/forum/index.php?PHPSESSID=vld75gitj6ct18q56npolabin6&action=profile;u=141871
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3346141
http://freebeer.me/index.php?topic=245763.0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=36564
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1542463
http://poselokgribovo.ru/forum/index.php?topic=647460.0
https://sanp.pro/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tln-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8/
http://www.deliberarchia.org/forum/index.php?topic=882739.0
http://matrixpharm.ru/forum/index.php?PHPSESSID=hu1thiuchp9o0soldq2pmthuk1&action=profile;u=142340
http://macdistri.com/index.php/component/k2/itemlist/user/292444
http://married.dike.gr/index.php/component/k2/itemlist/user/40478
http://forum.politeknikgihon.ac.id/index.php?topic=30313.0
http://hi-mar.com/forum/index.php?PHPSESSID=a3ba5da39449cf514dd74818150b1b41&topic=32434.0
http://myrechockey.com/forums/index.php?topic=92038.0
http://roikjer.com/forum/index.php?PHPSESSID=ea34294a7q2cgrfeflvgk1ghr5&topic=839354.0
http://roikjer.com/forum/index.php?PHPSESSID=lpkqo0mjvjstmuouur7bgbftu4&topic=839316.0
http://ru-realty.com/forum/index.php?PHPSESSID=039eade01e12f8ma5tr7qh4sj2&topic=481149.0
http://www.ekemoon.com/162541/050420192209/
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7311197
http://www.m1avio.com/index.php/component/k2/itemlist/user/3634288
https://l2thalassic.org/Forum/index.php?topic=620.0
https://chromehearts.in.th/index.php?topic=45096.0
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=79606
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1112874
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4829318
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=28556.0
http://www.nienkevanrijn.nl/component/k2/itemlist/user/428303
http://matrixpharm.ru/forum/index.php?PHPSESSID=vjeij1lcgjsdcplbpccohsgv32&action=profile;u=167611
http://webp.online/index.php?topic=44230.0
http://ru-realty.com/forum/index.php?PHPSESSID=thkr4qmc7u8bnq27vgnfmb2hg3&topic=462470.0
http://thermoplast.envolgroupe.com/component/k2/author/73516
http://danielmillsap.com/forum/index.php?topic=974536.0
http://seoksoononly.dothome.co.kr/qna/795087
http://forum.politeknikgihon.ac.id/index.php?topic=25763.0
http://storykingdom.forumside.com/index.php?topic=4707.0
http://www.ekemoon.com/144683/051120194506/
http://bitpark.co.kr/board_IzjM66/3751988
http://menulisilmiah.net/%d1%8d%d1%84%d0%b8%d1%80-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j0-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5/
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1646841
http://grupotir.com/?option=com_k2&view=itemlist&task=user&id=42367
http://www.ekemoon.com/153699/051720195507/
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/185697
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=292918
https://tg.vl-mp.com/index.php?topic=1344278.0
http://seoksoononly.dothome.co.kr/qna/798889
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1648092
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=492275
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1036344
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=18572
http://www.camaracoyhaique.cl/%d0%be%d1%82%d0%b5%d0%bb%d1%8c-%d1%82%d0%be%d0%bb%d0%b5%d0%b4%d0%be-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sr1%d0%be%d1%82%d0%b5%d0%bb%d1%8c-%d1%82%d0%be%d0%bb%d0%b5%d0%b4%d0%be/
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2574515
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=80212
http://withinfp.sakura.ne.jp/eso/index.php/16882807-nasa-istoria-64-seria-iwyv-nasa-istoria-64-seria/0
http://rudraautomation.com/index.php/component/k2/author/119467
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1335421
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=14361
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=492394
http://www.ekemoon.com/148943/050020190007/
http://fbpharm.net/index.php/component/k2/itemlist/user/19704
http://seoksoononly.dothome.co.kr/qna/796984
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-16/
https://forum.clubeicaro.pt/index.php?topic=878.0
http://forum.kopkargobel.com/index.php?topic=6087.0
http://forum.byehaj.hu/index.php?topic=84109.0
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nd0-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://forum.kopkargobel.com/index.php?topic=8067.0
http://www.remify.app/foro/index.php?topic=275027.0
http://www.critico-expository.com/forum/index.php?topic=6857.0
http://www.teedinubon.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q7-d3-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://myrechockey.com/forums/index.php?topic=94221.0
http://www.deliberarchia.org/forum/index.php?topic=993431.0
https://sanp.pro/hd-video-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e4-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://myrechockey.com/forums/index.php?topic=98198.0
http://www.deliberarchia.org/forum/index.php?topic=1011733.0
http://www.ekemoon.com/169863/050520193110/
http://help.stv.ru/index.php?topic=139640.0
http://forum.elexlabs.com/index.php?topic=20820.0
https://worldtaxi.org/2019/05/10/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-z5-w7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
https://khuyenmaikk13.info/index.php?topic=191363.0
http://forum.elexlabs.com/index.php?topic=16941.0
http://www.ekemoon.com/168099/050020192510/
http://help.stv.ru/index.php?PHPSESSID=6b13c30c76634ac43c8e81665848453a&topic=139784.0
https://reficulcoin.com/index.php?topic=20922.0
https://sanp.pro/09-05-2019-%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.ekemoon.com/168117/050020192910/
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z8-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
https://reficulcoin.com/index.php?topic=20180.0
https://khuyenmaikk13.info/index.php?topic=190764.0
https://worldtaxi.org/2019/05/10/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-q3-l5-%d0%b8%d0%b3/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l2-j8-%d0%b8%d0%b3%d1%80/
http://www.tessabannampad.go.th/webboard/index.php?topic=201444.0
http://partemp.com/en/groups/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n6-l9-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
http://forum.elexlabs.com/index.php/topic,22566.0.html
http://help.stv.ru/index.php?PHPSESSID=dd85d6232e98e79a2419979553bc9034&topic=140907.0
https://prelease.club/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w6-%d1%81%d0%bb%d1%83/
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=32140.0
http://www.deliberarchia.org/forum/index.php?topic=1008225.0
http://forum.byehaj.hu/index.php?topic=86576.0
http://poselokgribovo.ru/forum/index.php?topic=752514.0
http://myrechockey.com/forums/index.php?topic=95536.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-m6-k4/
http://myrechockey.com/forums/index.php?topic=91229.0
http://www.critico-expository.com/forum/index.php?topic=7509.0
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://HyUa.1fps.icu/l/szIaeDC
http://www.vivelabmanizales.com/%d1%81%d0%bb%d0%b5%d0%b4%d0%be%d0%b2%d0%b0%d1%82%d0%b5%d0%bb%d1%8c-%d0%b3%d0%be%d1%80%d1%87%d0%b0%d0%ba%d0%be%d0%b2%d0%b0-%d1%81%d0%bbi%d0%b4%d1%87%d0%b8%d0%b9-%d0%b3%d0%be%d1%80%d1%87%d0%b0%d0%ba-67/
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=763490
http://matrixpharm.ru/forum/index.php?PHPSESSID=n4huco91r9bdsde31kd3k7kpv5&action=profile;u=168370
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=8966
http://www.m1avio.com/index.php/component/k2/itemlist/user/3634935
http://www.ekemoon.com/148773/052320194006/
http://www.gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1852645
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=20291
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1020696
http://www.aloeverasas.it/index.php/component/k2/itemlist/user/18150
https://reficulcoin.com/index.php?topic=10126.0
http://teambuildingpremium.com/forum/index.php?topic=769696.0
http://thanosakademi.com/index.php?topic=66094.0
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=269074
http://associationsila.org/component/k2/itemlist/user/272519
http://freebeer.me/index.php?topic=257836.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/442692
http://www.sakitoandrichifantasy.gr/?option=com_k2&view=itemlist&task=user&id=151011
http://freebeer.me/index.php?topic=246662.0
http://dpmarketingsystems.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n2-%d1%81%d0%bb/
http://www.popolsku.fr.pl/forum/index.php?topic=365838.0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=298235
http://www.quattroandpartners.it/component/k2/itemlist/user/982903
http://dpmarketingsystems.com/hd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o6-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://www.tekparcahdfilm.com/forum/index.php?topic=44254.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=e4e208245682f1d687998dbe57a6752f&topic=195614.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=262164
http://thefreebitcoin.com/index.php?topic=30611.0
http://myrechockey.com/forums/index.php?topic=81649.0
http://ruschinaforum.ru/index.php?topic=135284.0
http://siliconvalleytalk.xyz/blogs/viewstory/31249
http://siliconvalleytalk.xyz/blogs/viewstory/31252
http://siliconvalleytalk.xyz/blogs/viewstory/31255
http://siliconvalleytalk.xyz/blogs/viewstory/31256
http://siliconvalleytalk.xyz/blogs/viewstory/31261
http://siliconvalleytalk.xyz/blogs/viewstory/31262
http://teambuildingpremium.com/forum/index.php?topic=810024.0
http://websites.start-a-idea.online/blogs/viewstory/172889
http://websites.start-a-idea.online/blogs/viewstory/172923
http://www.theparrotcentre.com/forum/index.php?topic=489459.0
http://www.sharmaraco.com/blog/%C2%AB%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-9-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-watch%C2%BB-t2-u6-%C2%AB%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-9-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-9-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://www.theocraticamerica.org/forum/index.php?topic=28484.0
http://www.hoonthaitoday.com/forum/index.php?topic=250248.0
http://www.hoonthaitoday.com/forum/index.php?topic=240711.0
https://prelease.club/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-im8-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://forum.byehaj.hu/index.php?topic=85290.0
http://www.teedinubon.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g5-z6-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
https://prelease.club/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rs7-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://vervetama.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b5-t6-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
https://reficulcoin.com/index.php?topic=31062.0
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-y9-t6-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
https://worldtaxi.org/2019/05/09/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i1-p8-%d0%b8/
https://prelease.club/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b0-%d1%81%d0%bb/
http://www.critico-expository.com/forum/index.php?topic=8619.0
http://roikjer.com/forum/index.php?PHPSESSID=a41jqdq29e0hfc23gier4ferg0&topic=835082.0
http://www.hoonthaitoday.com/forum/index.php?topic=206992.0
http://metropolis.ga/index.php?topic=6398.0
http://www.popolsku.fr.pl/forum/index.php?topic=385296.0
http://eugeniocolazzo.it/forum/index.php?topic=109434.0
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o5-t9-%d0%b8%d0%b3%d1%80/
http://teambuildingpremium.com/forum/index.php?topic=807382.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w9-x6-%d0%b8/
http://photogrotto.com/%d1%8d%d1%84%d0%b8%d1%80-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81/
http://photogrotto.com/hd-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%be%d0%bd%d0%bb%d0%b0%d0%b9/
http://photogrotto.com/hd-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lostfilm/
http://photogrotto.com/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b5%d1%85/
http://photogrotto.com/live-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-%d0%b4%d0%b0%d1%82%d0%b0-%d0%b2%d1%8b%d1%85%d0%be%d0%b4%d0%b0-1-%d1%81/
http://poselokgribovo.ru/forum/index.php?topic=777245.0
http://poselokgribovo.ru/forum/index.php?topic=777248.0
http://poselokgribovo.ru/forum/index.php?topic=777250.0
http://poselokgribovo.ru/forum/index.php?topic=777259.0
http://roikjer.com/forum/index.php?PHPSESSID=0irhvdlij9c9afdbl0gvm4ih65&topic=868968.0
http://roikjer.com/forum/index.php?PHPSESSID=5pnqj4ktjf7bh9bcmg9ql1ga71&topic=868963.0
http://roikjer.com/forum/index.php?PHPSESSID=csn049rrsvs700pd46bimcges3&topic=868958.0
http://roikjer.com/forum/index.php?PHPSESSID=mi9mukjslvo3dvi2n8b5a63rr6&topic=868919.0
http://sexfork.com/uncategorized/hd-video-rasskaz-sluzhanki-3-sezon-2-seriya-04/
http://sexfork.com/uncategorized/smotret-rasskaz-sluzhanki-serial-3-sezon-data-vyihoda/
http://sextomariotienda.com/blog/%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://sextomariotienda.com/blog/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8/
http://sextomariotienda.com/blog/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80-2/
http://sextomariotienda.com/blog/%d1%8d%d1%84%d0%b8%d1%80-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2/
http://sextomariotienda.com/blog/hd-video-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80/
http://sextomariotienda.com/blog/live-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2017/
http://sextomariotienda.com/blog/live-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2018/
http://taklongclub.com/forum/index.php?topic=134294.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.theparrotcentre.com/forum/index.php?topic=456308.0
http://rudraautomation.com/index.php/component/k2/author/130237
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=46815
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4723554
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b7-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1305095
http://www.nomaher.com/forum/index.php?topic=10824.0
http://thefreebitcoin.com/index.php?topic=34496.0
http://www.remify.app/foro/index.php?topic=177101.0
http://healthyteethpa.org/component/k2/itemlist/user/5268011
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-swh-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://mobility-corp.com/index.php/component/k2/itemlist/user/2510098
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/438713
http://freebeer.me/index.php?topic=290312.0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=26193
http://www.ekemoon.com/139097/051820191804/
http://married.dike.gr/index.php/component/k2/itemlist/user/42743
http://www.vivelabmanizales.com/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-k9/
http://married.dike.gr/index.php/component/k2/itemlist/user/50585
http://mediaville.me/index.php/component/k2/itemlist/user/225731
http://mediaville.me/index.php/component/k2/itemlist/user/225777
http://mediaville.me/index.php/component/k2/itemlist/user/225780
http://mobility-corp.com/index.php/component/k2/itemlist/user/2530537
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/72110
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/190776
http://smartacity.com/index.php/component/k2/itemlist/user/23450
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1645929
http://tekagrafica.com.br/index.php/component/k2/itemlist/user/1628302
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3586396
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4737746
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=970
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=975
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=980
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=985
https://dolcoin.net/?document_srl=1715
https://dolcoin.net/?document_srl=1724
https://dolcoin.net/?document_srl=1737
https://dolcoin.net/free_talk/1720
https://esel.gist.ac.kr/esel2/board_hmgj23/4387
https://esel.gist.ac.kr/esel2/board_hmgj23/4392
https://esel.gist.ac.kr/esel2/board_hmgj23/4397
http://teambuildingpremium.com/forum/index.php?topic=818255.0
http://otitismediasociety.org/forum/index.php?topic=150790.0
http://www.theocraticamerica.org/forum/index.php?topic=30323.0
https://nextezone.com/index.php?action=profile;u=6583
https://polyframetrade.co.uk/%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-c1-t7-%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4/
https://cybergsm.es/index.php?topic=8654.0
http://vervetama.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l5-z2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
https://prelease.club/hd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v4-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://myrechockey.com/forums/index.php?topic=92823.0
http://www.remify.app/foro/index.php?topic=278611.0
http://www.ofqj.org/hebergementfrance/4-10-watch-m9-c0-4-10-4-10
https://reficulcoin.com/index.php?topic=17307.0
http://vervetama.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kj9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://danceplanet.se/commodore/index.php?topic=29225.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81-46/
https://luckychancerescue.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h1-c2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
https://forum.ac-jete.it/index.php?topic=363988.0
https://forum.clubeicaro.pt/index.php?topic=957.0
http://uberdrivers.net/forum/index.php?topic=262427.0
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ae1-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://vervetama.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l5-h3-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
https://worldtaxi.org/2019/05/09/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w4-k8-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://partemp.com/en/groups/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k9-j7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://HyUa.1fps.icu/l/szIaeDC
https://mencoin.net/talk_fm/1779
https://nextezone.com/index.php?topic=48880.0
https://nextezone.com/index.php?topic=48884.0
https://reficulcoin.com/index.php?topic=36105.0
https://reficulcoin.com/index.php?topic=36111.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q0-m7-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u0-l1-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=1371
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=1392
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=2087
http://photogrotto.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80-5/
http://photogrotto.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80/
http://poselokgribovo.ru/forum/index.php?topic=781998.0
http://poselokgribovo.ru/forum/index.php?topic=782010.0
http://sextomariotienda.com/blog/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-%d0%b4%d0%b0%d1%82%d0%b0/
http://twitchdevs.com/c/other/(hd-video)-rasskaz-sluzhanki-3-sezon-8-seriya/
http://uberdrivers.net/forum/index.php?topic=270303.0
http://uberdrivers.net/forum/index.php?topic=270312.0
http://vintage.codns.com/Board/9271
http://vintage.codns.com/Board/9276
http://vintage.codns.com/Board/9281
http://vn7.vn/qna/44551
http://vn7.vn/qna/44568
http://www.afikgan.co.il/index.php/component/k2/itemlist/user/27795
http://www.deliberarchia.org/forum/index.php?topic=1032302.0
http://www.deliberarchia.org/forum/index.php?topic=1032314.0
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uakino/
http://www.teedinubon.com/hd-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%be-%d1%87%d0%b5%d0%bc/
http://www.theocraticamerica.org/forum/index.php?topic=38333.0
http://www.theocraticamerica.org/forum/index.php?topic=38337.0
http://www.theocraticamerica.org/forum/index.php?topic=38340.0
http://HyUa.1fps.icu/l/szIaeDC
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1646541
http://webp.online/index.php?topic=51725.msg86819
http://www.camaracoyhaique.cl/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d0%bf%d1%80%d0%be%d0%bc%d0%be-cw%d1%85%d0%be%d0%bb%d0%be/
http://www.camaracoyhaique.cl/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d1%87%d0%b0%d1%81%d1%82%d1%8c-1-rt%d1%85%d0%be%d0%bb%d0%be/
http://www.camaracoyhaique.cl/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-gi%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81/
http://www.ekemoon.com/169503/050420193110/
http://dcasociados.eu/component/k2/itemlist/user/87882
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=14761
http://8.droror.co.il/uncategorized/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nb5%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://8.droror.co.il/uncategorized/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jt9%d0%bd/
http://8.droror.co.il/uncategorized/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pm0%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f08-05/
http://www.camaracoyhaique.cl/%d1%81%d0%bc%d0%b5%d1%80%d1%88-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ky7%d1%81%d0%bc%d0%b5%d1%80%d1%88-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f09-05-2019/
http://www.critico-expository.com/forum/index.php?topic=8169.0
http://www.critico-expository.com/forum/index.php?topic=8172.0
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=14046
http://mediaville.me/index.php/component/k2/itemlist/user/211725
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/187206
http://8.droror.co.il/uncategorized/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-21-%d1%81%d0%b5-3/
http://ptu.imoove.kr/ko/content/%C2%AB%D1%8E%D1%80%D0%B8%D1%81%D1%82%D1%8B-20-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%D0%BD%D0%BE%D0%B2%D0%B8%D0%BD%D0%BA%D0%B0-%C2%AB%D1%8E%D1%80%D0%B8%D1%81%D1%82%D1%8B-20-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB331578
http://highlanderonline.cmshelplive.net/%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5%d0%bd%d0%b8%d0%b5-vuslat-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dxov-%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd/
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=46494
http://seoksoononly.dothome.co.kr/?document_srl=736123
http://forum.politeknikgihon.ac.id/index.php?topic=25296.0
http://www.ekemoon.com/158668/051120192108/
http://seoksoononly.dothome.co.kr/qna/752191
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=9740
http://dev.aabn.org.gh/?option=com_k2&view=itemlist&task=user&id=517299
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=97137
http://fbpharm.net/index.php/component/k2/itemlist/user/25989
http://fbpharm.net/index.php/component/k2/itemlist/user/26110
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=282448
http://hotelnomadpalace.com/index.php/component/k2/itemlist/user/20359
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1144448
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=307067
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=307114
http://married.dike.gr/index.php/component/k2/itemlist/user/54310
http://mediaville.me/index.php/component/k2/itemlist/user/236460
http://mobility-corp.com/index.php/component/k2/itemlist/user/2545733
http://forum.digamahost.com/index.php?topic=109220.0
http://ovotecegg.com/component/k2/itemlist/user/122331
https://members.fbhaters.com/index.php?topic=75902.0
http://sextomariotienda.com/blog/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-3/
http://ovotecegg.com/component/k2/itemlist/user/121480
https://marketengine.enginethemes.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-91-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-au1%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-91-%d1%81%d0%b5%d1%80%d0%b8%d1%8f07-05-2019/
http://arunagreen.com/?option=com_k2&view=itemlist&task=user&id=432617
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/285492
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=500694
http://haniel.ir/?option=com_k2&view=itemlist&task=user&id=74333
http://svgrossburgwedel.de/component/k2/itemlist/user/5363
http://roikjer.com/forum/index.php?PHPSESSID=s8c0tq80r4h7n9918590pkr854&topic=825031.0
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1626184
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1025401
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1552239
http://withinfp.sakura.ne.jp/eso/index.php/16916683-uristy-20-seria-serial-uristy-20-seria/0
http://servicioswts.com/?option=com_k2&view=itemlist&task=user&id=3624927
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/475777
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1591663
http://www.arunagreen.com/index.php/component/k2/itemlist/user/507943
http://www.comfortcenter.es/index.php/component/k2/itemlist/user/106072
http://www.emrabq8.com/index.php/component/k2/itemlist/user/1807705
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4908332
http://www.spazioad.com/component/k2/itemlist/user/7212769
http://laspoltrina.it/component/k2/itemlist/user/1387445
http://myrechockey.com/forums/index.php?topic=90211.0
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=81569
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2580053
http://married.dike.gr/index.php/component/k2/itemlist/user/46770
http://www.ekemoon.com/164253/051120190709/
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2512415
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=220306
http://www.camaracoyhaique.cl/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-eq8b-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://xplorefitness.com/blog/%C2%AB%D1%82%D0%BE%D0%BB%D1%8F-%D1%80%D0%BE%D0%B1%D0%BE%D1%82-1-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-07-05-2019-a9-%C2%AB%D1%82%D0%BE%D0%BB%D1%8F-%D1%80%D0%BE%D0%B1%D0%BE%D1%82-1-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1554301
http://withinfp.sakura.ne.jp/eso/index.php/16903843-hd-tola-robot-9-seria-q8-tola-robot-9-seria/0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=283918
http://storykingdom.forumside.com/index.php?topic=5580.0
http://www.ekemoon.com/144997/051420193806/
http://www.ekemoon.com/158877/051220191108/
http://www.vivelabmanizales.com/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-aagp-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-8-%d1%81%d0%b5%d1%80%d0%b8/
https://lucky28003.nl/forum/index.php?topic=11368.0
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=15925
http://seoksoononly.dothome.co.kr/qna/749128
http://poselokgribovo.ru/forum/index.php?topic=733329.0
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=289724
http://menulisilmiah.net/hd-video-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v0-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://dev.aabn.org.gh/component/k2/itemlist/user/516459
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2562249
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=96272
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/222108
http://married.dike.gr/index.php/component/k2/itemlist/user/48637
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/216924
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1124628
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=773564
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/52793
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3392764
http://forum.politeknikgihon.ac.id/index.php?topic=23123.0
https://www.resproxy.com/forum/index.php/779893-voskressij-ertugrul-5-sezon-27-seria-watch-g4-voskressij-ertugr
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3731860
http://www.golden-nail.co.kr/press/5821
http://www.golden-nail.co.kr/press/5845
http://www.golden-nail.co.kr/press/5850
http://www.golden-nail.co.kr/press/5855
http://www.golden-nail.co.kr/press/5860
http://www.golden-nail.co.kr/press/5883
http://www.golden-nail.co.kr/press/5887
http://www.hsaura.com/noty/19465
http://www.hsaura.com/noty/19703
http://www.jesusonly.life/?document_srl=19249
http://www.jesusonly.life/?document_srl=19256
http://www.jesusonly.life/calendar/19277
http://www.jesusonly.life/calendar/19282
http://www.josephmaul.org/menu41/29115
http://www.josephmaul.org/menu41/29125
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-c7-o0-%d0%b8%d0%b3/
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=552120
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2622862
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/521010
http://corumotoanahtar.com/component/k2/itemlist/user/1115.html
http://eugeniocolazzo.it/forum/index.php?topic=127222.0
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1797476
http://forum.elexlabs.com/index.php?topic=24973.0
http://forum.elexlabs.com/index.php?topic=24974.0
http://forum.elexlabs.com/index.php?topic=24977.0
http://money.bitcoinsstockpicks.com/blogs/viewstory/35205
http://help.stv.ru/index.php?PHPSESSID=eb5025eb0f58c0115a90209207e815f8&topic=140910.0
http://teambuildingpremium.com/forum/index.php?topic=792860.0
http://roikjer.com/forum/index.php?PHPSESSID=04j9kl17c4dshmta41oiii2ce5&topic=861659.0
http://forum.elexlabs.com/index.php?topic=18000.0
https://prelease.club/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bz7-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.deliberarchia.org/forum/index.php?topic=1017578.0
http://www.tekparcahdfilm.com/forum/index.php?topic=47385.0
http://www.theparrotcentre.com/forum/index.php?topic=489620.0
http://www.ofqj.org/hebergementfrance/4-12-a6-k5-4-12-4-12-watch
https://members.fbhaters.com/index.php?topic=86407.0
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=111670
http://bobr.site/index.php?topic=128191.0
http://bobr.site/index.php?topic=128203.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/520744
http://compultras.com/?option=com_k2&view=itemlist&task=user&id=216945
http://corumotoanahtar.com/component/k2/itemlist/user/1109.html
http://dcasociados.eu/component/k2/itemlist/user/88729
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1918409
http://engeena.com/component/k2/itemlist/user/8414
http://engeena.com/component/k2/itemlist/user/8415
http://eugeniocolazzo.it/forum/index.php?topic=127103.0
http://eugeniocolazzo.it/forum/index.php?topic=127106.0
http://eugeniocolazzo.it/forum/index.php?topic=127109.0
http://eugeniocolazzo.it/forum/index.php?topic=127118.0
http://flashboot.ru/forum/index.php?topic=94679.0
http://flashboot.ru/forum/index.php?topic=94680.0
http://flashboot.ru/forum/index.php?topic=94681.0
http://forum.byehaj.hu/index.php?topic=89614.0
http://forum.byehaj.hu/index.php?topic=89615.0
http://forum.byehaj.hu/index.php?topic=89616.0
http://forum.byehaj.hu/index.php?topic=89617.0
http://forum.elexlabs.com/index.php?topic=24824.0
http://forum.elexlabs.com/index.php?topic=24830.0
http://forum.elexlabs.com/index.php?topic=24831.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=558099
http://seoksoononly.dothome.co.kr/qna/806559
http://www.vivelabmanizales.com/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-13-%d1%81%d0%b5%d1%80%d0%b8-2/
http://fbpharm.net/index.php/component/k2/itemlist/user/13635
http://www.emrabq8.com/index.php/component/k2/itemlist/user/1764397
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=16216
http://www.vivelabmanizales.com/%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0%d1%88%d0%ba%d0%b0-erkenci-kus-43-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fmly-%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0/
http://condolencias.servisa.es/3-22-06-05-2019-j4-3-22
http://rudraautomation.com/index.php/component/k2/author/130460
http://xplorefitness.com/blog/%C2%AB%D1%8E%D1%80%D0%B8%D1%81%D1%82%D1%8B-12-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-06-05-2019-c8-%C2%AB%D1%8E%D1%80%D0%B8%D1%81%D1%82%D1%8B-12-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=514249
http://www.ekemoon.com/143491/050020193606/
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-live-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-3/
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/560014
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=9814
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=755473
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/184471
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2580485
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/484395
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1373483
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=14763
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/240096
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3327784
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=18256
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2594768
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=308598
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=308628
http://c3isecurity.com.br/component/k2/itemlist/user/498126
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/498121
http://computerscience.egerton.ac.ke/index.php/component/k2/itemlist/user/2007017
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/190077
http://bitpark.co.kr/board_IzjM66/3744089
http://www.ekemoon.com/148433/052320190506/
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=272166
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1645849
http://macdistri.com/index.php/component/k2/itemlist/user/298134
http://israengineering.com/index.php/component/k2/itemlist/user/1112932
http://menulisilmiah.net/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-89-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zx2%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-89-%d1%81%d0%b5%d1%80%d0%b8%d1%8f08-05-2019/
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/184144
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1337866
http://fbpharm.net/index.php/component/k2/itemlist/user/15988
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/190202
http://mediaville.me/index.php/component/k2/itemlist/user/209976
http://withinfp.sakura.ne.jp/eso/index.php/16882847-live-tolarobot-1-sezon-7-seria-q3-tolarobot-1-sezon-7-seria/0
http://highlanderonline.cmshelplive.net/%d0%b6%d0%b5%d0%bd%d1%89%d0%b8%d0%bd%d0%b0-60-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lgbg-%d0%b6%d0%b5%d0%bd%d1%89%d0%b8%d0%bd%d0%b0-60-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4726621
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3381910
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/481339
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4838004
http://www.ekemoon.com/145579/051720192206/
http://married.dike.gr/index.php/component/k2/itemlist/user/58315
http://married.dike.gr/index.php/component/k2/itemlist/user/58318
http://mediaville.me/index.php/component/k2/itemlist/user/255883
http://mjbosch.com/index.php/component/k2/itemlist/user/83130
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/90185
http://patagroupofcompanies.com/component/k2/itemlist/user/234931
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=14693
http://rudraautomation.com/index.php/component/k2/author/171103
http://smartacity.com/component/k2/itemlist/user/40459
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1675622
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1675646
http://thermoplast.envolgroupe.com/component/k2/author/96461
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1585086
http://www.spazioad.com/component/k2/itemlist/user/7294434
https://www.gizmoarticle.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-28-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-c4-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5/
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=6138
https://www.resproxy.com/forum/index.php/781670-voskressij-ertugrul-150-seria-s3-voskressij-ertugrul-150-seria/0
http://www.ekemoon.com/161781/050120194009/
http://forum.politeknikgihon.ac.id/index.php?topic=26547.0
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pqj-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://www.afikgan.co.il/index.php/component/k2/itemlist/user/26970
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4760342
http://www.arunagreen.com/index.php/component/k2/itemlist/user/469063
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1583514
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1583790
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1373819
http://www.theparrotcentre.com/forum/index.php?topic=480205.0
http://www.theparrotcentre.com/forum/index.php?topic=480211.0
http://www.theparrotcentre.com/forum/index.php?topic=480221.0
http://www.theparrotcentre.com/forum/index.php?topic=480225.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=682442.0
https://aljazeeratechnology.net/groups/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-99-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-b1-%e3%80%90-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-99-%d1%81%d0%b5%d1%80%d0%b8%d1%8f%e3%80%91-%d1%82%d0%b0%d0%b9%d0%bd/
https://climateathome.info/climateathome/view_profile.php?userid=21576
https://danceplanet.se/commodore/index.php?topic=15970.0
https://khuyenmaikk13.info/index.php?topic=184244.0
https://khuyenmaikk13.info/index.php?topic=184248.0
https://lucky28003.nl/forum/index.php?topic=12794.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3323373
http://withinfp.sakura.ne.jp/eso/index.php/16877187-po-zakonam-voennogo-vremeni-3-sezon-4-seria-06052019-c2-po-zako
http://www.ekemoon.com/144599/051020194706/
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=14338
http://associationsila.org/component/k2/itemlist/user/289242
http://febrescordero.gob.ec/index.php/component/k2/itemlist/user/85151
http://highlanderonline.cmshelplive.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-05-05-2019-e4-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/580787
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3747848
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=314431
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/195013
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1369994
http://www.deliberarchia.org/forum/index.php?topic=992356.0
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=204455
https://sanp.pro/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yyte-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-13-%d1%81%d0%b5%d1%80%d0%b8/
http://www.ekemoon.com/166135/051920193409/
http://www.vivelabmanizales.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-92-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xa5f-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-92-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://withinfp.sakura.ne.jp/eso/index.php/16945951-smotret-sluga-naroda-3-sezon-6-seria-w0-sluga-naroda-3-sezon-6-
http://withinfp.sakura.ne.jp/eso/index.php/16946019-cuzaa-zizn-cuze-zitta-13-seria-r2-cuzaa-zizn-cuze-zitta-13-seri/0
http://withinfp.sakura.ne.jp/eso/index.php/16946201-smotret-dockimateri-dockimateri-12-seria-l9-dockimateri-dockima/0
http://153.120.114.241/eso/index.php/16865549-holostak-9-sezon-10-vypusk-smotret-onlajn-1-cast-zoholostak-9-s
http://condolencias.servisa.es/21-05-05-2019-k8-21
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=287164
http://poselokgribovo.ru/forum/index.php?topic=732761.0
http://mediaville.me/index.php/component/k2/itemlist/user/226327
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1644065
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=276702
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3720457
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/293146
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1552544
http://salescoach.ro/content/%C2%AB%D0%B6%D0%B5%D0%BD%D1%89%D0%B8%D0%BD%D0%B0-57-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-htmw-%C2%AB%D0%B6%D0%B5%D0%BD%D1%89%D0%B8%D0%BD%D0%B0-57-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
https://khuyenmaikk13.info/index.php?topic=190138.0
https://members.fbhaters.com/index.php/topic,88426.0.html
https://members.fbhaters.com/index.php?topic=88417.0
https://npi.org.es/smf/index.php?topic=113938.0
http://ye-dream.com/qa/5787
https://dolcoin.net/free_talk/3300
https://esel.gist.ac.kr/esel2/board_hmgj23/5960
https://esel.gist.ac.kr/esel2/board_hmgj23/5970
https://esel.gist.ac.kr/esel2/board_hmgj23/5975
https://esel.gist.ac.kr/esel2/board_hmgj23/5990
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=3772
http://bath-family.com/photo_zone/5491
http://bath-family.com/photo_zone/5500
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=685202.0
https://nextezone.com/index.php?topic=42842.0
https://nextezone.com/index.php?topic=42843.0
https://npi.org.es/smf/index.php?topic=114164.0
http://forum.politeknikgihon.ac.id/index.php?topic=33525.0
http://myrechockey.com/forums/index.php?topic=93361.0
http://poselokgribovo.ru/forum/index.php?topic=754066.0
http://poselokgribovo.ru/forum/index.php?topic=754094.0
http://poselokgribovo.ru/forum/index.php?topic=754105.0
http://poselokgribovo.ru/forum/index.php?topic=754116.0
http://poselokgribovo.ru/forum/index.php?topic=754121.0
http://roikjer.com/forum/index.php?PHPSESSID=20n4a9oc97k3s9a1cdmofkjdt6&topic=845813.0
http://roikjer.com/forum/index.php?PHPSESSID=3ovl5omt8vsmbotb4tekj9vio3&topic=845788.0
http://roikjer.com/forum/index.php?PHPSESSID=q9c6cc8upqj9lfe3ad9mhjk4s4&topic=845835.0
https://luckychancerescue.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a4-r4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
http://otitismediasociety.org/forum/index.php?topic=152777.0
https://members.fbhaters.com/index.php?topic=88433.0
http://8.droror.co.il/uncategorized/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sn4-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mk3-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://otitismediasociety.org/forum/index.php?topic=149092.0
http://www.ofqj.org/hebergementquebec/4-12-w8-x9-4-12-4-12
http://danielmillsap.com/forum/index.php?topic=1015905.0
https://reficulcoin.com/index.php?topic=28858.0
http://e-educ.net/Forum/index.php?topic=10310.0
http://eugeniocolazzo.it/forum/index.php?topic=131324.0
http://eugeniocolazzo.it/forum/index.php?topic=131342.0
http://flashboot.ru/forum/index.php?topic=95015.0
http://myrechockey.com/forums/index.php?topic=101807.0
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-eng-2/
http://photogrotto.com/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80-2/
http://photogrotto.com/live-%d1%84%d0%b8%d0%bb%d1%8c%d0%bc-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://roikjer.com/forum/index.php?PHPSESSID=bhvtdtbukq8inkahvlmmtdu3f5&topic=875438.0
http://roikjer.com/forum/index.php?PHPSESSID=lip6g8ci50i2rffd0vq4n1jbp5&topic=875442.0
http://roikjer.com/forum/index.php?PHPSESSID=n41im7r9dgh442vavnhrme42o2&topic=875466.0
http://roikjer.com/forum/index.php?PHPSESSID=r2f6lr3srapbhr54mp4vnvqjh2&topic=875454.0
http://twitchdevs.com/c/other/((hd))-rasskaz-sluzhanki-3-sezon-7-seriya-vo-production/
http://HyUa.1fps.icu/l/szIaeDC
http://www.vivelabmanizales.com/%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yib-%d0%b7%d0%b2%d0%be%d0%bd%d0%b0%d1%80%d1%8c-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-09-05-2019-2/
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4729064
http://www.vivelabmanizales.com/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-98-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yce-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-98-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-06-05-2019/
http://freebeer.me/index.php?topic=298856.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/577606
https://nextezone.com/index.php?topic=34987.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3310835
http://forum.digamahost.com/index.php?topic=110256.0
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=129008
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/215210
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1354990
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=264333
http://www.deliberarchia.org/forum/index.php?topic=903611.0
https://khuyenmaikk13.info/index.php?topic=156004.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/171574
http://danielmillsap.com/forum/index.php?topic=864245.0
http://sextomariotienda.com/blog/%d1%81%d0%bc%d0%b5%d1%80%d1%88-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-f2-%e3%80%90-%d1%81%d0%bc%d0%b5%d1%80%d1%88-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f%e3%80%91-%d1%81%d0%bc%d0%b5%d1%80/
http://sextomariotienda.com/blog/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-94-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-r4-%e3%80%90-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd/
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1678092
http://teambuildingpremium.com/forum/index.php?topic=818978.0
http://theolevolosproject.org/index.php/component/k2/itemlist/user/26116
http://websites.start-a-idea.online/blogs/viewstory/181774?---------------------------60645845688%0D%0AContent-Disposition:%20form-data;%20name=%22title%22%0D%0A%0D%0A[%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F]%20t9%20%E3%80%90%20%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%E3%80%91.%20%60%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%60%20'%20u0%0D%0A---------------------------60645845688%0D%0AContent-Disposition:%20form-data;%20name=%22form_content%22%0D%0A%0D%0A%C2%AB%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB%20%%20d8%20%C2%AB%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB%2013-05-2019%0D%0A%0D%0A%0D%0A%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%0D%0A%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%0D%0A%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%0D%0A%0D%0A%C2%AB%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB%60%60%C2%AB%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB,%60%D0%B2,%60%D1%85%D0%BE%D1%80%D0%BE%D1%88%D0%B5%D0%BC%20%D0%BA%D0%B0%D1%87%D0%B5%D1%81%D1%82%D0%B2%D0%B5.%20%C2%AB%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB%0D%0A%D0%A1%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C%20%C2%AB%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB%0D%0A%0D%0A%0D%0A%0D%0A%0D%0A%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%BA%D1%84%0D%0A..%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D1%80%D1%83..%0D%0A%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20fb%0D%0A'%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D1%80%D1%83%D1%81'%0D%0A%60%60%60%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D1%82%D0%B2%60%60%60%0D%0A%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20tv%0D%0A%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%BE%D0%BA%0D%0A%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D1%83%D0%BA%D1%80%0D%0A..%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%BE%D0%BA..%0D%0A%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D1%82%D0%B2%0D%0A%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20pin%0D%0A%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D1%80%D1%83%0D%0A%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D1%8E%D1%82%D1%83%D0%B1%0D%0A%C2%AB%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D1%84%D0%B1%C2%BB%0D%0A%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%BA%D1%84%0D%0A%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D1%8E%D1%82%D1%83%D0%B1%0D%0A%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%B2%D0%BA%0D%0A%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%B2%D0%BA%0D%0A%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%B2%D0%BA%0D%0A%60%60%60%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D1%82%D0%B2%60%60%60%0D%0A..%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%BF%D0%B4..%0D%0A'%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D1%82%D0%B2'%0D%0A%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%0D%0A%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%0D%0A%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%0D%0A%D0%A2%D0%B0%D0%B9%D0%BD%D1%8B%2092%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%0D%0A---------------------------60645845688%0D%0AContent-Disposition:%20form-data;%20name=%22tags%22%0D%0A%0D%0A%D0%A1%D0%BB%D1%83%D0%B3%D0%B0%20%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0%203%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F,%20%D0%A7%D1%83%D0%B6%D0%B0%D1%8F%20%D0%B6%D0%B8%D0%B7%D0%BD%D1%8C%20(%D0%A7%D1%83%D0%B6%D0%B5%20%D0%B6%D0%B8%D1%82%D1%82%D1%8F)%209%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F,%20%D0%A7%D1%83%D0%B6%D0%B0%D1%8F%20%D0%B6%D0%B8%D0%B7%D0%BD%D1%8C%20(%D0%A7%D1%83%D0%B6%D0%B5%20%D0%B6%D0%B8%D1%82%D1%82%D1%8F)%207%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%0D%0A---------------------------60645845688%0D%0AContent-Disposition:%20form-data;%20name=%22page_id%22%0D%0A%0D%0A157802%0D%0A---------------------------60645845688--
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=192082
http://www.arunagreen.com/index.php/component/k2/itemlist/user/497636
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1400828
http://www.digitalbul.com/%d1%81%d0%bc%d0%b5%d1%80%d1%88-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h8-%e3%80%90-%d1%81%d0%bc%d0%b5%d1%80%d1%88-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f%e3%80%91-%d1%81%d0%bc%d0%b5%d1%80%d1%88-12/
http://www.digitalbul.com/%d1%81%d0%be%d0%b4%d0%b5%d1%80%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t2-%e3%80%90-%d1%81%d0%be%d0%b4%d0%b5%d1%80%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-9-%d1%81%d0%b5%d1%80%d0%b8/
http://www.digitalbul.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e6-%e3%80%90-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.digitalbul.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-c3-%e3%80%90-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5/
http://www.teedinubon.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t5-%e3%80%90-%d0%b8/
http://forum.digamahost.com/index.php?topic=109913.0
http://bitpark.co.kr/board_IzjM66/3752089
http://withinfp.sakura.ne.jp/eso/index.php/16860380-uristy-19-seria-efir-uristy-19-seria/0
http://www.babvallejo.com/index.php/component/k2/itemlist/user/602263
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=268306
http://salescoach.ro/content/%C2%AB%D0%B2%D0%BE%D1%81%D0%BA%D1%80%D0%B5%D1%81%D1%88%D0%B8%D0%B9-%D1%8D%D1%80%D1%82%D1%83%D0%B3%D1%80%D1%83%D0%BB-145-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-udjb-%C2%AB%D0%B2%D0%BE%D1%81%D0%BA%D1%80%D0%B5%D1%81%D1%88%D0%B8%D0%B9-%D1%8D%D1%80%D1%82%D1%83%D0%B3%D1%80%D1%83%D0%BB-145-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2588825
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/470187
http://www.crnmedia.es/component/k2/itemlist/user/85027
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1082063
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=204690
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=48460
http://forum.digamahost.com/index.php?topic=112984.0
http://www.ekemoon.com/170679/050720195710/
http://www.spazioad.com/component/k2/itemlist/user/7264195
http://teambuildingpremium.com/forum/index.php?topic=799179.0
http://teambuildingpremium.com/forum/index.php?topic=799196.0
http://www.deliberarchia.org/forum/index.php?topic=999246.0
http://www.deliberarchia.org/forum/index.php?topic=999255.0
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/696586
http://withinfp.sakura.ne.jp/eso/index.php/16957607-efir-sluga-naroda-3-sezon-9-seria-l5-sluga-naroda-3-sezon-9-ser/0
http://withinfp.sakura.ne.jp/eso/index.php/16957714-hdvideo-taemnici-96-seria-k4-taemnici-96-seria/0
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=802386
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=802672
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=802699
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2445638
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/247718
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2609004
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=51043
http://dcasociados.eu/component/k2/itemlist/user/88293
http://dev.aabn.org.gh/component/k2/itemlist/user/566446
http://ye-dream.com/?document_srl=5915
http://www.golden-nail.co.kr/press/4446
http://www.studyxray.com/Sangdam/17066
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=7231
http://zanoza.h1n.ru/2019/05/15/video-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m1-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://sexfork.com/uncategorized/smotret-sluga-naroda-3-sezon-14-seriya-f5-sluga-naroda-3-sezon-14-seriya/
http://forum.elexlabs.com/index.php?topic=26810.0
http://www.ekemoon.com/190535/052320192614/
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=3983
http://moavalve.co.kr/?document_srl=10205
https://danceplanet.se/commodore/index.php?topic=33502.0
http://www.josephmaul.org/menu41/27566
http://divespace.co.kr/board/1924
http://sextomariotienda.com/blog/%d0%be%d0%bd%d0%bb%d0%b0%d0%b9%d0%bd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x5-%d1%81%d0%bb%d1%83/
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=6612
http://atemshow.com/atemfair_domestic/2872
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=723543
http://www.josephmaul.org/menu41/31170
http://ye-dream.com/qa/3688
http://www.sp1.football/index.php?mid=faq&document_srl=14936
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=6146
http://divespace.co.kr/board/1621
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=12329
https://dolcoin.net/free_talk/2589
http://www.jesusonly.life/calendar/20508
http://www.studyxray.com/Sangdam/13121
http://www.xn--xy1b45gp4h0qgb9g.com/?document_srl=6232
http://ye-dream.com/qa/3494
http://bath-family.com/photo_zone/7926
http://vn7.vn/qna/50645
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=17642
http://www.jesusonly.life/calendar/19052
https://woodland.org.ua/groups/tv-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-23-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://shinilspring.com/board_qsfb01/12420
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=6009
http://azone.synology.me/xe/?document_srl=10623
http://skangseo.org/xe/board_UoEl68/6639
http://www.golden-nail.co.kr/press/5148
https://reficulcoin.com/index.php?topic=38352.0
http://ye-dream.com/qa/4768
http://shinilspring.com/board_qsfb01/14381
http://bebopindia.com/notcie/10259
http://bath-family.com/photo_zone/3963
http://erhu.eu/viewtopic.php?t=324400
http://www.josephmaul.org/menu41/29960
http://smartengbiz.com/s1/26324
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=7643
http://bebopindia.com/notcie/7010
http://sextomariotienda.com/blog/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-y8-%d1%81%d0%bb/
http://yoriyorifood.com/xxxx/spacial/5559
http://hyeonjun.co.kr/?document_srl=1871
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=2041
http://divespace.co.kr/?document_srl=5008
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=6436
http://www.ekemoon.com/190617/052320195414/
http://jstech.kr/index.php?mid=board_lqyj42&document_srl=10039
https://esel.gist.ac.kr/esel2/board_hmgj23/7537
http://www.hicleaning.kr/board_wash/15427
http://www.theocraticamerica.org/forum/index.php?topic=39770.0
http://www.hsaura.com/noty/20758
http://sexfork.com/uncategorized/novinka-sluga-naroda-3-sezon-15-seriya-o3-sluga-naroda-3-sezon-15-seriya/
http://shinilspring.com/?document_srl=17248
http://www.rationalkorea.com/xe/index.php?mid=asboard&document_srl=448733
http://www.studyxray.com/Sangdam/14525
http://forum.elexlabs.com/index.php?topic=27065.0
http://masarapphil.com/board_tmXx76/21633
http://shinilspring.com/board_qsfb01/17273
http://photogrotto.com/tnt-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q3-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://photogrotto.com/hd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.golden-nail.co.kr/press/4064
http://www.theparrotcentre.com/forum/index.php?topic=530124.0
http://www.studyxray.com/Sangdam/6711
http://universalcommunity.se/Forum/index.php?topic=8133.0
http://atemshow.com/atemfair_domestic/2448
http://yoriyorifood.com/xxxx/spacial/5486
http://proxima.co.rw/index.php/component/k2/itemlist/user/576688
http://haniel.ir/index.php/component/k2/itemlist/user/81957
http://withinfp.sakura.ne.jp/eso/index.php/16897581-live-tolarobot-1-sezon-9-seria-w4-tolarobot-1-sezon-9-seria
http://www.ekemoon.com/148785/052320194206/
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=771406
https://www.gizmoarticle.com/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81/
http://forum.byehaj.hu/index.php?topic=82356.0
https://prelease.club/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bx4h/
https://prelease.club/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qi0x-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
https://prelease.club/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-99-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yi9m-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd/
https://prelease.club/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kj8f-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://prelease.club/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ok7m-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://prelease.club/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tv9g-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.vivelabmanizales.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-ih8r-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=97907
http://mvisage.sk/index.php/component/k2/itemlist/user/118689
http://www.vivelabmanizales.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-98-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fd6g-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd/
http://mahdi.ehosseini.com/?option=com_k2&view=itemlist&task=user&id=31871
https://prelease.club/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81-13/
http://www.vivelabmanizales.com/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81-39/
http://www.vivelabmanizales.com/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sh0c-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1370721
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1370726
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1042531
http://www.lustralesdevallehermoso.com/index.php/component/k2/itemlist/user/48418
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4867397
http://www.pcosmetic.ir/?option=com_k2&view=itemlist&task=user&id=10767
http://www.pcosmetic.ir/?option=com_k2&view=itemlist&task=user&id=10768
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=786697
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2429625
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/237992
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3325706
http://seoksoononly.dothome.co.kr/qna/832146
http://seoksoononly.dothome.co.kr/qna/832331
http://seoksoononly.dothome.co.kr/qna/832394
http://menulisilmiah.net/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pk5%d0%bd/
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4751068
http://fbpharm.net/index.php/component/k2/itemlist/user/13756
http://www.vivelabmanizales.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-08-05-2019-s2-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=43692
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=1035509
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1630310
https://alquilervideobeam.com.co/?option=com_k2&view=itemlist&task=user&id=56385
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=500172
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/470858
http://roikjer.com/forum/index.php?PHPSESSID=n91q9u5gq02kvdig84itkmnc10&topic=824231.0
http://married.dike.gr/index.php/component/k2/itemlist/user/47940
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=573303
http://menulisilmiah.net/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xh3%d0%bd/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3298549
https://l2thalassic.org/Forum/index.php?topic=1683.0
http://batubersurat.com/index.php/component/k2/itemlist/user/45867
http://engeena.com/component/k2/itemlist/user/7882
http://www.vivelabmanizales.com/hd-video-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w5-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=501392
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/473674
https://forums.letstalkbeats.com/index.php?topic=67418.0
http://dev.aabn.org.gh/?option=com_k2&view=itemlist&task=user&id=585311
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1923123
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=309317
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1183210
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3796020
http://married.dike.gr/index.php/component/k2/itemlist/user/60621
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=83407
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2589749
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/729478
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/729529
http://sdsn.develop.cinfores.com/?option=com_k2&view=itemlist&task=user&id=209014
http://smartacity.com/component/k2/itemlist/user/44651
http://soc-human.kz/index.php/component/k2/itemlist/user/1683773
http://ovotecegg.com/?option=com_k2&view=itemlist&task=user&id=121797
http://www.ekemoon.com/148465/052320190906/
http://www.vivelabmanizales.com/hd-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u2-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81/
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=51233
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1112591
http://arunagreen.com/index.php/component/k2/itemlist/user/423602
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3586139
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1345139
http://www.vivelabmanizales.com/%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80%d0%b4%d1%86%d0%b5-tek-yurek-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fqho-%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80/
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=44565
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1552611
http://ovotecegg.com/component/k2/itemlist/user/122024
http://marjorieaperry.com/?option=com_k2&view=itemlist&task=user&id=483179
http://highlanderonline.cmshelplive.net/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-05-05-2019-p0-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=681116.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/565860
http://thermoplast.envolgroupe.com/component/k2/itemlist/user/65677
https://l2thalassic.org/Forum/index.php?topic=994.0
http://married.dike.gr/index.php/component/k2/itemlist/user/50125
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3296521
https://members.fbhaters.com/index.php?topic=79553.0
http://bitpark.co.kr/board_IzjM66/3740043
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1062573
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1062590
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=58880
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=19533
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=19534
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1887177
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=37919
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=38027
http://www.gforgirl.com/xe/poster/24515
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=475159
http://www.studyxray.com/?document_srl=25134
http://www.studyxray.com/?document_srl=25208
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3266880
http://xn----3x5er9r48j7wemud0a387h.com/?document_srl=4335
http://xn----3x5er9r48j7wemud0a387h.com/?document_srl=4357
http://ye-dream.com/qa/16412
http://ye-dream.com/qa/16431
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=10364
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=10374
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=10388
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=10221
http://ye-dream.com/qa/10369
http://www.golden-nail.co.kr/press/6871
http://yoriyorifood.com/xxxx/spacial/11492
http://www.studyxray.com/Sangdam/10320
http://www.lozic.co.kr/gallery/6703
http://lucky.kidspann.net/index.php?mid=qna&document_srl=5871
http://skylinecam.co.kr/photo/10614
https://saltriverbg.com/2019/05/14/tv-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
https://www.ex-ttcommunity.com/forum/viewtopic.php?f=2&t=205685&view=print
http://www.artifact.website/315144-smotret-sluga-naroda-3-sezon-8-seria-o3-sluga-naroda-3-sezon-8-
http://vervetama.com/video-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h8-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://poselokgribovo.ru/forum/index.php?topic=783009.0
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=713312
http://smartengbiz.com/s1/19949
http://roikjer.com/forum/index.php?PHPSESSID=nb8949jq0f1o08v6c1mbe32mc6&topic=837673.0
http://myrechockey.com/forums/index.php?topic=97435.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=6ddc394271a41ac853f195857ac02247&topic=218273.0
http://help.stv.ru/index.php?topic=139438.0
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a1-i9-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://forums.abs-cbn.com/welcome-back-kapamilya%21/et-e-9-e-k2-et-e-9-e/?PHPSESSID=5oa20eo939di5ifm2ctu9gqhq3
http://www.theparrotcentre.com/forum/index.php?topic=488046.0
http://ru-realty.com/forum/index.php?PHPSESSID=mh374gfn59fl6omeebadn7u637&topic=481649.0
http://help.stv.ru/index.php?topic=139791.0
https://worldtaxi.org/2019/05/10/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z0-f2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://forum.elexlabs.com/index.php?topic=17816.0
https://www.limscave.com/forum/viewtopic.php?t=31875
http://forum.elexlabs.com/index.php?topic=23004.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80-17/
https://reficulcoin.com/index.php?topic=18379.0
https://polyframetrade.co.uk/%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-j3-r2-%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81/
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-w3-z4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
https://sanp.pro/hd-video-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a4-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://www.remify.app/foro/index.php?topic=276514.0
http://myrechockey.com/forums/index.php?topic=91125.0
https://reficulcoin.com/index.php?topic=18761.0
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=aea7c0cb4b2bfda67ca49e3a69b3e770&topic=763.0
http://forum.elexlabs.com/index.php?topic=19881.0
http://forum.elexlabs.com/index.php?topic=16771.0
http://www.hoonthaitoday.com/forum/index.php?topic=244149.0
http://uberdrivers.net/forum/index.php?topic=244305.0
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81-5/
http://roikjer.com/forum/index.php?PHPSESSID=5627drp22vvn2e22dhj996pbi5&topic=852303.0
http://www.remify.app/foro/index.php?topic=251649.0
http://www.remify.app/foro/index.php?topic=273678.0
https://prelease.club/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o2-%d1%81/
http://www.critico-expository.com/forum/index.php?topic=6343.0
http://forum.elexlabs.com/index.php?topic=16409.0
https://prelease.club/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zy7-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://forum.elexlabs.com/index.php?topic=22177.0
http://forum.politeknikgihon.ac.id/index.php?topic=31083.0
http://HyUa.1fps.icu/l/szIaeDC
http://foxy-tv.com/index.php?mid=board_arik22&document_srl=6073
http://vn7.vn/qna/70120
http://www.hsaura.com/noty/34710
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=39810
https://esel.gist.ac.kr/esel2/board_hmgj23/11574
http://websites.start-a-idea.online/blogs/viewstory/173127
http://k-cea.org/board_Hnyj62/18876
http://www.rationalkorea.com/xe/index.php?mid=asboard&document_srl=455744
http://1vh.info/index.php?topic=28764.0
http://azone.synology.me/xe/index.php?document_srl=18394&mid=board_SDnQ73
http://www.golden-nail.co.kr/press/6088
http://www.ekemoon.com/165537/051820190709/
http://xn--ok1bpqi43ahtb.net/board_eASW07/22454
http://jjimdak.callbank.kr/?document_srl=732740
http://xn--9m1b83j39hz6exwonmf.com/board_IYPe43/480722
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q0-w7-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/gumdanapt/6176
http://www.vivelabmanizales.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g4-s7-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
https://esel.gist.ac.kr/esel2/board_hmgj23/10139
http://www.studyxray.com/Sangdam/26674
http://indiefilm.kr/xe/board/23628
http://erhu.eu/viewtopic.php?f=9&t=323224
http://www.studyxray.com/Sangdam/25636
http://smartengbiz.com/slider_m/29883
http://hyeonjun.co.kr/menu3/10445
http://www.theparrotcentre.com/forum/index.php?topic=515818.0
http://jstech.kr/index.php?mid=board_lqyj42&document_srl=5104
http://daesestudy.co.kr/ipsi_docu/6926
https://dolcoin.net/free_talk/3524
http://www.gforgirl.com/xe/poster/23010
http://indiefilm.kr/xe/board/28977
http://cafe.dokseosil.co.kr/community/49967
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=627231
http://roikjer.com/forum/index.php?PHPSESSID=muptrbh2i5hhg3rf9067at7ek5&topic=843466.0
http://atemshow.com/atemfair_domestic/5603
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=11355
http://ye-dream.com/?document_srl=4086
http://www.jesusonly.life/calendar/40558
http://skylinecam.co.kr/photo/7208
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2766198
http://dota2.host/103603-igra-prestolov-2019-8-sezon-7-seria-o5-l7-igra-prestolov-2019-8
http://cafe.dokseosil.co.kr/?document_srl=51870
http://forum.politeknikgihon.ac.id/index.php?topic=33100.0
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=12456
http://www.artifact.website/310309-online-sluga-naroda-3-sezon-20-seria-k0-sluga-naroda-3-sezon-20
https://reficulcoin.com/index.php?topic=19015.0
http://carrierworld.co.kr/index.php?document_srl=6922&mid=board_UlGv44
http://haeple.com/index.php?document_srl=18629&mid=etc
http://shinilspring.com/board_qsfb01/21316
http://hyeonjun.co.kr/menu3/2685
http://forum.bmw-e60.eu/index.php?topic=7626.0
http://shinilspring.com/board_qsfb01/19178
http://www.rationalkorea.com/xe/index.php?mid=asboard&document_srl=451926
http://poselokgribovo.ru/forum/index.php?topic=743659.0
http://www.studyxray.com/Sangdam/10725
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=3320
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=3348
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=3362
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=3371
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=3380
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=3384
http://www.gforgirl.com/xe/poster/1870
http://www.gforgirl.com/xe/poster/1880
http://www.gforgirl.com/xe/poster/1891
http://www.gforgirl.com/xe/poster/1896
http://www.golden-nail.co.kr/press/1596
http://www.golden-nail.co.kr/press/1646
http://twitchdevs.com/c/other/(-(smotret)-)-rasskaz-sluzhanki-3-sezon-3-seriya-yutub-2507/
http://uberdrivers.net/forum/index.php?topic=271004.0
http://vervetama.com/%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-4/
http://vervetama.com/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-3-%d1%81%d0%b5%d0%b7%d0%be/
http://vervetama.com/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8-2/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-%d0%b4%d0%b0%d1%82%d0%b0-%d0%b2%d1%8b%d1%85%d0%be%d0%b4%d0%b0-1-%d1%81-2/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%88%d0%b0%d0%b4%d0%b8%d0%bd%d1%81/
http://vervetama.com/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8-2/
http://vervetama.com/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8/
http://vervetama.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80-5/
http://vervetama.com/%d1%8d%d1%84%d0%b8%d1%80-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8f/
http://HyUa.1fps.icu/l/szIaeDC
http://menulisilmiah.net/10-05-2019-%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-5/
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90dv4%e3%80%91/
http://www.theocraticamerica.org/forum/index.php?topic=28423.0
http://forum.elexlabs.com/index.php?topic=22576.0
http://myrechockey.com/forums/index.php?topic=93282.0
http://forum.byehaj.hu/index.php?topic=88166.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=30703.0
http://roikjer.com/forum/index.php?PHPSESSID=k64a1gcaqp8mmd1i09v1th1183&topic=860107.0
http://poselokgribovo.ru/forum/index.php?topic=751490.0
https://nextezone.com/index.php?action=profile;u=5371
http://danielmillsap.com/forum/index.php?topic=1000594.0
http://menulisilmiah.net/%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z1-%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-7-%d1%81%d0%b5%d1%80/
http://help.stv.ru/index.php?PHPSESSID=ad7587d6467a698ee8735b44afaafe72&topic=139610.0
http://forum.elexlabs.com/index.php?topic=18410.0
http://www.popolsku.fr.pl/forum/index.php?topic=20407.56190
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-z2-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://forum.byehaj.hu/index.php?topic=88511.0
https://sanp.pro/%d1%8d%d1%84%d0%b8%d1%80-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b0-%d1%81%d0%bb%d1%83%d0%b3/
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-q9-e8-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
http://www.remify.app/foro/index.php?topic=246800.0
http://help.stv.ru/index.php?PHPSESSID=3b590beac6c39158861c871d7bafc193&topic=139901.0
http://www.deliberarchia.org/forum/index.php?topic=991981.0
http://poselokgribovo.ru/forum/index.php?topic=791881.0
http://poselokgribovo.ru/forum/index.php?topic=791886.0
http://roikjer.com/forum/index.php?PHPSESSID=t9t4sbk6vid4cssdif50575im2&topic=878980.0
http://roikjer.com/forum/index.php?topic=878989.0
http://sextomariotienda.com/blog/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80-5/
http://sextomariotienda.com/blog/%d1%8d%d1%84%d0%b8%d1%80-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bigcinem/
http://twitchdevs.com/c/other/(((efir)))-()-rasskaz-sluzhanki-3-sezon-4-seriya-igra-prestolov/
http://twitchdevs.com/c/other/((hd-video))-rasskaz-sluzhanki-3-sezon-7-seriya/
http://www.deliberarchia.org/forum/index.php?topic=1042634.0
http://www.deliberarchia.org/forum/index.php?topic=1042645.0
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=47283
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=47298
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=47353
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=47373
http://www.ekemoon.com/195649/050020191516/
https://chromehearts.in.th/index.php?topic=51749.0
https://nextezone.com/index.php?topic=51792.0
https://sanp.pro/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80/
https://sanp.pro/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80/
https://sanp.pro/%d1%8d%d1%84%d0%b8%d1%80-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-3-%d1%81/
https://sanp.pro/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82/
http://1vh.info/index.php?topic=29342.0
http://bobr.site/index.php?topic=136461.0
http://HyUa.1fps.icu/l/szIaeDC
https://mencoin.net/talk_fm/9098
https://mencoin.net/talk_fm/9128
https://prelease.club/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-szh-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%82%d0%be/
https://prelease.club/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zhz-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5/
https://prelease.club/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2019-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-eay-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2019-6-%d1%81%d0%b5/
https://test.baseyou21.kr/index.php?document_srl=16376&mid=main_slider
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=16495
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=131836
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=22636
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=22893
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=22919
http://hyeonjun.co.kr/menu3/14781
http://hyeonjun.co.kr/menu3/14785
http://hyeonjun.co.kr/menu3/14790
http://indiefilm.kr/xe/?document_srl=31193
http://indiefilm.kr/xe/board/31059
http://indiefilm.kr/xe/board/31263
http://indiefilm.kr/xe/board/31283
http://indiefilm.kr/xe/board/31327
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3265485
http://bebopindia.com/notcie/17114
http://dota2.host/109287-igra-prestolov-2019-8-sezon-5-seria-w7-e2-igra-prestolov-2019-8
http://haeple.com/index.php?mid=etc&document_srl=19654
http://bayareawomenmag.xyz/blogs/viewstory/38888
http://www.deliberarchia.org/forum/index.php?topic=1024375.0
http://www.sp1.football/index.php?mid=faq&document_srl=14553
http://www.vivelabmanizales.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-s4-j0-%d0%b8%d0%b3%d1%80%d0%b0/
http://www.sp1.football/?document_srl=32993
http://divespace.co.kr/board/2800
http://bebopindia.com/notcie/21598
http://lucky.kidspann.net/index.php?mid=qna&document_srl=5507
http://zanoza.h1n.ru/2019/05/15/hd720-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g3-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://www.vivelabmanizales.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-o6-n2-%d0%b8%d0%b3/
http://www.studyxray.com/Sangdam/15335
http://www.theparrotcentre.com/forum/index.php?topic=485861.0
http://www.xn--xy1b45gp4h0qgb9g.com/?document_srl=11585
http://www.rationalkorea.com/xe/index.php?mid=asboard&document_srl=454558
http://lucky.kidspann.net/index.php?mid=qna&document_srl=3170
http://www.golden-nail.co.kr/press/11764
https://reficulcoin.com/index.php?topic=37585.0
http://hyeonjun.co.kr/menu3/6646
http://vhost12299.cpsite.ru/97111-igra-prestolovgame-of-thrones-8-sezon-5-seria-h0-r3-igra-presto
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=42166
http://www.sp1.football/index.php?mid=faq&document_srl=34293
http://skylinecam.co.kr/photo/9720
http://skylinecam.co.kr/photo/6261
http://atemshow.com/atemfair_domestic/7703
http://roikjer.com/forum/index.php?topic=871770.0
http://www.gforgirl.com/xe/?document_srl=21898
http://foxy-tv.com/index.php?mid=board_arik22&document_srl=4615
http://smartengbiz.com/s1/28043
http://www.josephmaul.org/menu41/34135
https://mencoin.net/talk_fm/4328
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/531463
http://www.studyxray.com/?document_srl=25481
http://forum.digamahost.com/index.php?topic=120213.0
https://nextezone.com/index.php?topic=50829.0
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=20429
https://www.tedyun.com/xe/?document_srl=126075
http://www.jesusonly.life/calendar/9900
http://bayareawomenmag.xyz/blogs/viewstory/19211
https://mencoin.net/talk_fm/5600
http://poselokgribovo.ru/forum/index.php?topic=761360.0
http://vn7.vn/qna/71116
http://xn--ok1bpqi43ahtb.net/board_eASW07/19810
http://bayareawomenmag.xyz/blogs/viewstory/40580
http://www.jesusonly.life/calendar/31311
http://jjimdak.callbank.kr/index.php?document_srl=735836&mid=board_OGFN30
https://mencoin.net/talk_fm/4695
http://maka-222.com/?document_srl=11064
http://roikjer.com/forum/index.php?PHPSESSID=07l3pnm2u3rckjhcpb2gca7t44&topic=837426.0
http://www.josephmaul.org/menu41/28413
https://reficulcoin.com/index.php?topic=17055.0
http://8.droror.co.il/uncategorized/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-so8-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-je3-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-oq7-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://eugeniocolazzo.it/forum/index.php?topic=133890.0
http://uberdrivers.net/forum/index.php?topic=278357.0
http://uberdrivers.net/forum/index.php?topic=278365.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=48d615e3c10b18e296297bb126e76f2a&topic=244213.0
http://www.popolsku.fr.pl/forum/index.php?topic=393876.0
http://www.remify.app/foro/index.php?topic=299153.0
https://nextezone.com/index.php?topic=51659.0
https://forum.ac-jete.it/index.php?topic=388561.0
http://duopos.net/xe/board_CofP84/672
http://joinbohum.kr/board/381
http://shinilspring.com/board_qsfb01/28698
http://shinilspring.com/board_qsfb01/28712
http://shinilspring.com/board_qsfb01/28727
http://www.ds712.net/guest/?document_srl=45349
http://forum.elexlabs.com/index.php?topic=16391.0
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-o1-y5-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w8-f2-%d0%b8%d0%b3%d1%80/
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-us3-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://forum.elexlabs.com/index.php?topic=18948.0
https://nextezone.com/index.php?topic=40472.0
http://sexfork.com/uncategorized/igra-prestolov-8-sezon-3-seriya-watch-v1-l2-igra-prestolov-8-sezon-3-seriya-igra-prestolov-8-sezon-3-seriya-online/
http://otitismediasociety.org/forum/index.php?topic=156856.0
http://forum.elexlabs.com/index.php?topic=23173.0
https://luckychancerescue.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n9-a6-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
https://www.limscave.com/forum/viewtopic.php?t=31768
http://poselokgribovo.ru/forum/index.php?topic=751292.0
https://danceplanet.se/commodore/index.php?topic=18816.0
http://myrechockey.com/forums/index.php?topic=93295.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=30054.0
http://menulisilmiah.net/09-05-2019-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
https://members.fbhaters.com/index.php?topic=84227.0
https://nextezone.com/index.php?action=profile;u=4215
http://HyUa.1fps.icu/l/szIaeDC
http://indiefilm.kr/xe/board/5664
http://indiefilm.kr/xe/board/5679
http://indiefilm.kr/xe/board/5693
http://isch.kr/board_PowH60/1627
http://isch.kr/board_PowH60/1638
http://isch.kr/board_PowH60/1643
http://isch.kr/board_PowH60/1647
http://jnk-ent.jp/index.php?mid=gallery&document_srl=4219
http://jnk-ent.jp/index.php?mid=gallery&document_srl=4228
http://otitismediasociety.org/forum/index.php?topic=150201.0
http://www.hoonthaitoday.com/forum/index.php?topic=237607.0
https://prelease.club/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kx8-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://forum.kopkargobel.com/index.php?topic=8381.0
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-21/
http://www.popolsku.fr.pl/forum/index.php?topic=20407.57045
http://www.tessabannampad.go.th/webboard/index.php?topic=197456.0
https://worldtaxi.org/2019/05/09/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l3-d5-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://www.tessabannampad.go.th/webboard/index.php?topic=202428.0
https://prelease.club/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g5-%d1%81%d0%bb/
https://www.limscave.com/forum/viewtopic.php?t=31686
http://www.hoonthaitoday.com/forum/index.php?topic=209161.0
http://danielmillsap.com/forum/index.php?topic=1025693.0
https://reficulcoin.com/index.php?topic=18025.0
https://prelease.club/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g5-%d1%81%d0%bb/
http://otitismediasociety.org/forum/index.php?topic=158533.0
http://demo.caribe.vps-private.net/blog/milliardy-4-sezon-10-seriya-h3-k3-milliardy-4-sezon-10-seriya-milliardy-4-sezon-10-seriya
https://khuyenmaikk13.info/index.php?topic=185894.0
https://members.fbhaters.com/index.php?topic=88301.0
https://prelease.club/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w3-%d1%81/
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=684260.0
https://khuyenmaikk13.info/index.php?topic=189548.0
http://HyUa.1fps.icu/l/szIaeDC
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=19906
http://www.gforgirl.com/xe/poster/22137
http://myrechockey.com/forums/index.php?topic=99082.0
http://yoriyorifood.com/xxxx/spacial/9977
http://www.studyxray.com/?document_srl=20835
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=16182
http://moavalve.co.kr/?document_srl=5481
http://indiefilm.kr/xe/board/20167
http://www.theocraticamerica.org/forum/index.php?topic=40679.0
http://www.golden-nail.co.kr/press/13381
http://cafe.dokseosil.co.kr/community/47389
http://www.deliberarchia.org/forum/index.php?topic=996903.0
http://www.ekemoon.com/173449/052320192210/
http://forum.digamahost.com/index.php?topic=112178.0
http://vervetama.com/tv-hd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=4146
http://yoriyorifood.com/xxxx/spacial/15249
http://www.datascientist.co.kr/?document_srl=57590
http://www.jesusonly.life/calendar/35937
http://www.sp1.football/index.php?mid=faq&document_srl=27383
http://shinhwaair2017.cafe24.com/?document_srl=103889
http://www.ekemoon.com/177623/051720195811/
http://www.ekemoon.com/169957/050520194610/
https://nextezone.com/index.php?action=profile;u=7140
http://haeple.com/index.php?mid=etc&document_srl=36397
http://haeple.com/index.php?mid=etc&document_srl=36414
http://haeple.com/index.php?mid=gameit&document_srl=36482
http://hyeonjun.co.kr/menu3/21808
http://hyeonjun.co.kr/menu3/21836
http://hyeonjun.co.kr/menu3/21922
http://hyeonjun.co.kr/menu3/21932
http://moavalve.co.kr/faq/33835
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=57794
http://roikjer.com/forum/index.php?PHPSESSID=a5qipl3esa1mv1d116cohr4651&topic=880112.0
http://roikjer.com/forum/index.php?PHPSESSID=tsiomodc0uqhikl8bkjjjfuk60&topic=880100.0
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=198962
http://shinhwaair2017.cafe24.com/?document_srl=123942
http://shinilspring.com/?document_srl=37503
http://www.datascientist.co.kr/index.php?mid=blog&document_srl=66288
http://dailypatriot.net/phpbb/viewtopic.php?t=460103
http://www.jesusonly.life/calendar/36873
http://www.lozic.co.kr/?document_srl=16922
https://nextezone.com/index.php?action=profile;u=7427
http://haeple.com/index.php?mid=etc&document_srl=21254
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=17902
http://websites.start-a-idea.online/blogs/viewstory/163988
http://teambuildingpremium.com/forum/index.php?topic=797036.0
http://www.josephmaul.org/menu41/27522
http://divespace.co.kr/board/3508
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1188695
http://yoriyorifood.com/xxxx/spacial/19458
http://poselokgribovo.ru/forum/index.php?topic=753542.0
http://siliconvalleytalk.xyz/blogs/viewstory/31752
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=24921
https://saltriverbg.com/2019/05/14/tv-hd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.lozic.co.kr/?document_srl=23469
http://www.lozic.co.kr/gallery/23513
http://www.lozic.co.kr/gallery/23532
http://www.studyxray.com/?document_srl=29463
http://www.studyxray.com/Sangdam/29172
http://www.studyxray.com/Sangdam/29265
http://www.studyxray.com/Sangdam/29502
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3267796
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3267839
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3267883
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3267902
http://www.theparrotcentre.com/forum/index.php?topic=533687.0
http://xn--9m1b83j39hz6exwonmf.com/board_IYPe43/482236
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=9667
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=9708
http://menulisilmiah.net/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n1-e1-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://ru-realty.com/forum/index.php?topic=478325.0
http://skylinecam.co.kr/photo/3798
http://skylinecam.co.kr/photo/21237
http://www.studyxray.com/Sangdam/21764
http://ye-dream.com/qa/3703
http://www.golden-nail.co.kr/press/10856
http://skangseo.org/xe/?document_srl=11763
http://smartengbiz.com/s1/35103
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=10053
http://www.golden-nail.co.kr/press/13216
http://www.golden-nail.co.kr/press/13281
http://www.golden-nail.co.kr/press/13339
http://www.golden-nail.co.kr/press/13368
http://www.golden-nail.co.kr/press/13476
http://www.golden-nail.co.kr/press/13517
http://www.golden-nail.co.kr/press/13602
http://www.golden-nail.co.kr/press/13621
http://www.golden-nail.co.kr/press/13678
http://www.golden-nail.co.kr/press/13812
http://www.golden-nail.co.kr/press/13894
http://www.golden-nail.co.kr/press/13914
https://www.tedyun.com/xe/index.php?mid=recycle_bin&document_srl=132376
http://0433.net/?document_srl=8611
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=45924
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=45966
http://bebopindia.com/?document_srl=28078
http://carrierworld.co.kr/?document_srl=13107
http://foxy-tv.com/?document_srl=16299
http://foxy-tv.com/index.php?mid=board_arik22&document_srl=16303
http://foxy-tv.com/index.php?mid=board_arik22&document_srl=16310
http://goldenpowerball2.com/?document_srl=24021
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=24016
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=24027
http://haeple.com/index.php?mid=etc&document_srl=24605
http://haeple.com/index.php?mid=etc&document_srl=24679
http://hyeonjun.co.kr/menu3/12420
http://indiefilm.kr/xe/board/27864
http://indiefilm.kr/xe/board/27869
http://indiefilm.kr/xe/board/27892
http://isch.kr/board_PowH60/7421
http://isch.kr/board_PowH60/7431
http://jiquilisco.org/index.php/component/k2/itemlist/user/6022
http://jjikduk.net/DATA/19036
http://jjimdak.callbank.kr/?document_srl=737035
http://jjimdak.callbank.kr/?document_srl=737066
http://jjimdak.callbank.kr/?document_srl=737096
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=737026
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=737120
http://jnk-ent.jp/index.php?mid=gallery&document_srl=16509
http://jnk-ent.jp/index.php?mid=gallery&document_srl=16514
http://lahch.co.kr/index.php?mid=board_jHAP41&document_srl=10625
http://www.teedinubon.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-y7-g7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
http://forum.byehaj.hu/index.php?topic=88468.0
https://luckychancerescue.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-d9-g0-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
https://luckychancerescue.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-t7-v8-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nz1-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://8.droror.co.il/uncategorized/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o9-d7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
https://reficulcoin.com/index.php?topic=28848.0
http://122.154.49.125/Forum/index.php?topic=128.0
http://myrechockey.com/forums/index.php?topic=98019.0
http://poselokgribovo.ru/forum/index.php?topic=744813.0
https://prelease.club/%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-s4-%d1%81%d0%bb%d1%83/
http://www.theparrotcentre.com/forum/index.php?topic=489891.0
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=10514.0
https://altaylarteknoloji.com/index.php?topic=1861.0
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rj4-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://uberdrivers.net/forum/index.php?topic=257750.0
https://khuyenmaikk13.info/index.php?topic=185626.0
http://forum.bmw-e60.eu/index.php?topic=4884.0
http://vervetama.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-b8-z2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://forum.elexlabs.com/index.php?topic=22815.0
https://prelease.club/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pd2-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://HyUa.1fps.icu/l/szIaeDC
https://reficulcoin.com/index.php?topic=35429.0
https://reficulcoin.com/index.php?topic=35434.0
https://reficulcoin.com/index.php?topic=35438.0
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=818
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=926
http://davichville.com/notice/board/25766
http://indiefilm.kr/xe/board/1732
http://jnk-ent.jp/index.php?document_srl=883&mid=gallery
http://jnk-ent.jp/index.php?mid=gallery&document_srl=878
http://nnkumw.org/xe/index.php?mid=board_yNQm00&document_srl=1929
http://nnkumw.org/xe/index.php?mid=board_yNQm00&document_srl=1934
http://otitismediasociety.org/forum/index.php?topic=160749.0
http://otitismediasociety.org/forum/index.php?topic=160780.0
http://stockpan.net/board_HNpV06/1195
http://sum-songdobeach.kr/qna/701
http://twks.dothome.co.kr/?document_srl=710
http://www.datascientist.co.kr/index.php?mid=blog&document_srl=31893
http://www.deliberarchia.org/forum/index.php?topic=1027643.0
http://www.deliberarchia.org/forum/index.php?topic=1027744.0
http://www.deliberarchia.org/forum/index.php?topic=1027760.0
http://partemp.com/en/groups/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h0-m9-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
http://www.ofqj.org/hebergementquebec/4-12-t6-v4-4-12-4-12
http://forum.elexlabs.com/index.php?topic=21553.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=c6c99aad2fd2aab5a34fcbc204450b30&topic=215416.0
http://forum.elexlabs.com/index.php?topic=20814.0
https://prelease.club/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qv7-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://roikjer.com/forum/index.php?PHPSESSID=se960u2pl3ri8qs8inq30v9h03&topic=848664.0
http://jdcalc.com/forum/viewtopic.php?t=167896
https://members.fbhaters.com/index.php?topic=83153.0
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gl4-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fm3-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://reficulcoin.com/index.php?topic=29360.0
https://luckychancerescue.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m8-m2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
http://vtservices85.fr/smf2/index.php?topic=217085.0
http://ru-realty.com/forum/index.php?topic=479899.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-81/
http://universalcommunity.se/Forum/index.php?topic=1457.0
http://HyUa.1fps.icu/l/szIaeDC
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yv0-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://roikjer.com/forum/index.php?topic=848075.0
http://www.ekemoon.com/170513/050720193110/
https://reficulcoin.com/index.php?topic=25248.0
http://www.teedinubon.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d3-b2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://otitismediasociety.org/forum/index.php?topic=155461.0
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ky5-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://danielmillsap.com/forum/index.php?topic=1029651.0
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k2-d1-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://eugeniocolazzo.it/forum/index.php?topic=124559.0
http://roikjer.com/forum/index.php?PHPSESSID=k26atpnkj2a2ema76kic5rkrj0&topic=861403.0
https://www.gizmoarticle.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l9-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://otitismediasociety.org/forum/index.php?topic=149457.0
https://prelease.club/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dp3-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://roikjer.com/forum/index.php?PHPSESSID=48p4d9fj8gb8agr3qnb0d98cg4&topic=843410.0
http://forum.elexlabs.com/index.php?topic=16748.0
https://www.shaiyax.com/index.php?topic=342894.0
http://1vh.info/index.php?topic=25224.0
http://41.89.96.92/?option=com_k2&view=itemlist&task=user&id=2021979
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2622036
http://arnikabolt.ro/component/k2/itemlist/user/111648
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=54302
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=54309
http://bobr.site/index.php?topic=127943.0
http://corumotoanahtar.com/component/k2/itemlist/user/1075
http://engeena.com/component/k2/itemlist/user/8390
http://eugeniocolazzo.it/forum/index.php?topic=126875.0
http://eugeniocolazzo.it/forum/index.php?topic=126876.0
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1796184
http://forum.byehaj.hu/index.php?topic=89533.0
http://forum.elexlabs.com/index.php?topic=24629.0
http://forum.elexlabs.com/index.php?topic=24630.0
http://forum.elexlabs.com/index.php?topic=24632.0
http://forum.multicommander.com/forum/index.php?topic=3263.0
http://forum.multicommander.com/forum/index.php?topic=3264.0
http://HyUa.1fps.icu/l/szIaeDC
https://saltriverbg.com/2019/05/16/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-c8-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3365271
https://www.chirorg.com/?document_srl=5905
https://www.chirorg.com/video/5828
https://www.chirorg.com/video/5838
https://www.shaiyax.com/index.php?topic=347957.0
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=22094
http://8.droror.co.il/uncategorized/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e5-%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5/
http://8.droror.co.il/uncategorized/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-27-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g8-%d0%b2/
http://agiteshop.com/xe/qa/3048
http://agiteshop.com/xe/qa/3053
http://agiteshop.com/xe/qa/3096
http://ye-dream.com/qa/17307
http://siliconvalleytalk.xyz/blogs/viewstory/39437
http://lucky.kidspann.net/?document_srl=9241
http://www.ds712.net/guest/?document_srl=37556
http://erhu.eu/viewtopic.php?t=323610
http://sextomariotienda.com/blog/new-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n8-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://vn7.vn/qna/45353
http://bebopindia.com/?document_srl=17049
http://www.ds712.net/guest/?document_srl=39199
http://siliconvalleytalk.xyz/blogs/viewstory/28137
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=32229.0
http://ariji.kr/?document_srl=777059
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=5924
http://www.nomaher.com/forum/index.php?topic=12778.0
https://tg.vl-mp.com/index.php?topic=1370210.0
http://hyeonjun.co.kr/menu3/15510
http://iamking.net/board/573
http://jejucctv.co.kr/A5/464
http://poselokgribovo.ru/forum/index.php?topic=791703.0
http://poselokgribovo.ru/forum/index.php?topic=791757.0
https://nextezone.com/index.php?topic=48744.0
https://nextezone.com/index.php?topic=48746.0
https://pacock.com/rec/3457
https://pacock.com/tip/3505
https://pacock.com/tip/3525
https://test.baseyou21.kr/?document_srl=1051
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=1042
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=1048
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-u0-c9-%d0%b8%d0%b3%d1%80/
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-n2-d1-%d0%b8%d0%b3%d1%80%d0%b0/
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-l9-l1-%d0%b8%d0%b3%d1%80/
http://0433.net/budongsan/2333
http://0433.net/budongsan/2338
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=27655
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=27632
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=27641
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=27646
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=27651
http://2872870.com/est/2349
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81-35/
http://www.theparrotcentre.com/forum/index.php?topic=487247.0
http://ru-realty.com/forum/index.php?PHPSESSID=1em1r5kmt3pl91kg40ta76b3h5&topic=491570.0
http://forum.elexlabs.com/index.php?topic=21542.0
http://www.hoonthaitoday.com/forum/index.php?topic=247854.0
http://www.ofqj.org/hebergementfrance/4-8-watch-b7-v3-4-8-4-8
https://members.fbhaters.com/index.php?topic=85015.0
http://vervetama.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-g3-s4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://ru-realty.com/forum/index.php?PHPSESSID=nqnd4b8bvau8ljfj4574c0dlh0&topic=482836.0
http://www.hoonthaitoday.com/forum/index.php?topic=245725.0
https://nextezone.com/index.php?topic=42142.0
http://metropolis.ga/index.php?topic=6606.0
https://reficulcoin.com/index.php?topic=32672.0
http://forum.elexlabs.com/index.php?topic=22868.0
http://roikjer.com/forum/index.php?PHPSESSID=6j2au117jjsnece1nhe7j290l4&topic=845151.0
http://forum.elexlabs.com/index.php?topic=23169.0
https://prelease.club/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bj9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.nomaher.com/forum/index.php?topic=13228.0
http://eugeniocolazzo.it/forum/index.php?topic=107254.0
http://HyUa.1fps.icu/l/szIaeDC
http://cwon.kr/xe/board_bnSr36/25651
http://jjimdak.callbank.kr/?document_srl=760897
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=760838
http://roikjer.com/forum/index.php?PHPSESSID=dfi9kntc8ea8cebbur63f06bs0&topic=882283.0
http://www.datascientist.co.kr/?document_srl=86633
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=76322
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=76335
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=76406
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=76416
http://www.gforgirl.com/xe/?document_srl=56911
http://www.gforgirl.com/xe/?document_srl=56985
http://www.gforgirl.com/xe/poster/56939
http://www.gforgirl.com/xe/poster/57017
http://www.golden-nail.co.kr/?document_srl=37279
http://asin.itts.co.kr/board_rtXs84/1587
http://haeple.com/index.php?mid=etc&document_srl=25164
http://forum.elexlabs.com/index.php/topic,27039.0.html
http://www.lozic.co.kr/gallery/10883
https://www.tedyun.com/xe/?document_srl=128056
http://1vh.info/index.php?topic=24004.0
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=9726
http://photogrotto.com/new-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p8-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://www.theparrotcentre.com/forum/index.php?topic=520563.0
http://teambuildingpremium.com/forum/index.php?topic=792701.0
http://themasters.pro/file_01/8787
http://www.flixian.com/main/?document_srl=5273
http://www.flixian.com/main/QnA/5234
http://www.flixian.com/main/QnA/5253
http://www.flixian.com/main/QnA/5263
http://www.flixian.com/main/QnA/5268
http://www.flixian.com/main/QnA/5288
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=21169
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=21182
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/gumdanapt/21049
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/gumdanapt/21063
http://bebopindia.com/notcie/51742
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=8123
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=38239
http://hyeonjun.co.kr/menu3/29615
http://jnk-ent.jp/index.php?mid=gallery&document_srl=21148
http://lucky.kidspann.net/index.php?mid=qna&document_srl=23472
http://otitismediasociety.org/forum/index.php?topic=168961.0
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-o5-q6-%d0%b8%d0%b3%d1%80/
https://danceplanet.se/commodore/index.php?topic=19851.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5-16/
http://8.droror.co.il/uncategorized/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ua2-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://sanp.pro/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m7-%d1%81/
http://forum.elexlabs.com/index.php?topic=18031.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=d24fa6d7409c2a2804ccdf89e7144758&topic=227329.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/ma-4-eo-9-e-b0-n9-ma-4-eo-9-e-'ma-4-eo-9-e-watch'/?PHPSESSID=8hvkg6jg28j6ie7qmqoo5ff186
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-41/
http://myrechockey.com/forums/index.php?topic=97496.0
http://www.theparrotcentre.com/forum/index.php?topic=489579.0
http://www.deliberarchia.org/forum/index.php?topic=993830.0
http://www.sharmaraco.com/blog/%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-w2-l5-%C2%AB%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
https://members.fbhaters.com/index.php?topic=87333.0
http://HyUa.1fps.icu/l/szIaeDC
http://help.stv.ru/index.php?PHPSESSID=8d10d9786cdcb83c7e6a1d9260368d18&topic=140243.0
http://www.hoonthaitoday.com/forum/index.php?topic=210807.0
http://forum.byehaj.hu/index.php?topic=88497.0
http://www.teedinubon.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o6-y1-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
https://reficulcoin.com/index.php?topic=28540.0
http://www.critico-expository.com/forum/index.php?topic=6666.0
https://prelease.club/%d1%8d%d1%84%d0%b8%d1%80-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-y2-%d1%81%d0%bb%d1%83%d0%b3/
http://www.hoonthaitoday.com/forum/index.php?topic=206471.0
http://roikjer.com/forum/index.php?topic=841880.0
https://reficulcoin.com/index.php?topic=30653.0
https://reficulcoin.com/index.php?topic=22143.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/'a-etoogame-of-thrones-8-eo-2-e'-a-etoogame-of-thrones-8-eo-2-e-q2f3/?PHPSESSID=m108fs3jq7utea7vbttvlb6rd0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=31330.0
https://sanp.pro/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r3-%d1%81/
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gl0-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://vtservices85.fr/smf2/index.php?PHPSESSID=9aae0ba561625cd57e7ca9b3935d6621&topic=221247.0
http://www.popolsku.fr.pl/forum/index.php?topic=386914.0
http://8.droror.co.il/uncategorized/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q3-y6-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
http://teambuildingpremium.com/forum/index.php?topic=800859.0
http://8.droror.co.il/uncategorized/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-h7-j8-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
https://worldtaxi.org/2019/05/10/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5-3/
http://www.critico-expository.com/forum/index.php?topic=8548.0
https://luckychancerescue.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u4-c2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
https://prelease.club/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r2-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://www.deliberarchia.org/forum/index.php?topic=1021128.0
http://www.popolsku.fr.pl/forum/index.php?topic=376647.0
http://HyUa.1fps.icu/l/szIaeDC
http://indiefilm.kr/xe/board/44246
http://indiefilm.kr/xe/board/44343
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=752024
http://moavalve.co.kr/?document_srl=36570
http://moavalve.co.kr/faq/36349
https://cybergsm.es/index.php?topic=14782.0
http://forum.digamahost.com/index.php?topic=118269.0
http://zanoza.h1n.ru/2019/05/15/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-h1-v5-%d0%b8%d0%b3%d1%80/
http://shinilspring.com/board_qsfb01/17305
http://bayareawomenmag.xyz/blogs/viewstory/38387
http://www.xn--xy1b45gp4h0qgb9g.com/sub_09_05/7566
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=32179.0
http://www.critico-expository.com/forum/index.php?topic=12873.0
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=12685
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=684921.0
http://0433.net/junggo/6280
https://mencoin.net/talk_fm/6221
http://k-cea.org/board_Hnyj62/16180
http://cwon.kr/xe/board_bnSr36/6213
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=2911
http://vn7.vn/?document_srl=83769
http://vn7.vn/qna/83444
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=57940
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=58248
http://www.flixian.com/main/QnA/1876
http://www.flixian.com/main/QnA/1915
http://smartengbiz.com/s1/31713
http://hyeonjun.co.kr/menu3/7104
http://taklongclub.com/forum/index.php?topic=131743.0
http://vhost12299.cpsite.ru/141410-igra-prestolov-game-of-thrones-8-sezon-7-seria-p9-j8-igra-prest
http://forum.politeknikgihon.ac.id/index.php?topic=29051.0
http://www.vivelabmanizales.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o5-u6-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://indiefilm.kr/xe/board/25289
http://roikjer.com/forum/index.php?PHPSESSID=9vjg54kq9nga1t8jfm6bhah171&topic=873168.0
http://websites.start-a-idea.online/blogs/viewstory/168883
http://websites.start-a-idea.online/blogs/viewstory/165674?---------------------------442624820004%0D%0AContent-Disposition:%20form-data;%20name=%22title%22%0D%0A%0D%0A%60%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%60%20K7%20[%20b8%20%C2%AB%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB%20@%20%C2%AB%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20watch%C2%BB%0D%0A---------------------------442624820004%0D%0AContent-Disposition:%20form-data;%20name=%22form_content%22%0D%0A%0D%0A%C2%AB%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB%2010-05-2019%0D%0A%0D%0A%0D%0A%0D%0A%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%0D%0A%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%0D%0A%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%0D%0A%0D%0A(%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F)%20%E2%80%94%20%C2%AB%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB%20%D0%A5%D0%BE%D1%80%D0%BE%D1%88%D0%B8%D0%B9%20%D0%A4%D0%B8%D0%BB%D1%8C%D0%BC%20%D0%9E%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD%20345%0D%0A[%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F]%20-%20%C2%AB%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB%20%D0%9A%D0%B8%D0%BD%D0%BE%202018%20572%205%0D%0A%22%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%22%20%3E%C2%AB%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB%20%D0%A1%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C%20%D0%A4%D0%B8%D0%BB%D1%8C%D0%BC%D1%8B%20861%201%0D%0A%22%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%22%20%3E%3E%E2%80%9E%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%22%20%D0%9A%D0%98%D0%9D%20202%204%0D%0A%22%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%22%20%E2%80%94%20(%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F)%20%D0%A1%D0%9C%D0%9E%D0%A2%D0%A0%D0%95%D0%A2%D0%AC%20%D0%9D%D0%9E%D0%E2%80%99%D0%98%D0%9D%D0%9A%D0%98%20+%D0%9A%D0%9E%D0%A2%D0%9E%D0%A0%D0%AB%D0%95%20+%D0%A3%D0%96%D0%95%20%D0%E2%80%99%D0%AB%D0%A8%D0%9B%D0%98%20609%207%0D%0A%C2%AB%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB%20%3E(%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F)%20%D0%9D%D0%9E%D0%E2%80%99%D0%AB%D0%95%20%D0%E2%80%99%D0%98%D0%94%D0%95%D0%9E%20146%207%0D%0A(%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F)%20-%20(%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F)%20%D0%A1%D0%9C%D0%9E%D0%A2%D0%A0%D0%95%D0%A2%D0%AC%20%D0%A4%D0%98%D0%9B%D0%AC%D0%9C%20%D0%9F%D0%9E%D0%9B%D0%9D%D0%9E%D0%A1%D0%A2%D0%AC%D0%AE%20433%200%0D%0A%E2%80%9E%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%22%20%3E[%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F]%20%D0%A1%D0%9C%D0%9E%D0%A2%D0%A0%D0%95%D0%A2%D0%AC%20%D0%9B%D0%A3%D0%A7%D0%A8%D0%98%D0%95%20%D0%A4%D0%98%D0%9B%D0%AC%D0%9C%D0%AB%20321%205%0D%0A%22%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%22%20[%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F]%20%D0%A4%D0%98%D0%9B%D0%AC%D0%9C%D0%AB%20%D0%9D%D0%9E%D0%E2%80%99%D0%98%D0%9D%D0%9A%D0%98%20+%D0%9A%D0%9E%D0%A2%D0%9E%D0%A0%D0%AB%D0%95%20+%D0%A3%D0%96%D0%95%20%D0%E2%80%99%D0%AB%D0%A8%D0%9B%D0%98%20150%200%0D%0A%E2%80%9E%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%22%20%22%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%22%20%D0%A4%D0%98%D0%9B%D0%AC%D0%9C%D0%AB%202%20940%205%0D%0A%0D%0A..%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%B7%D1%8D%D0%B4%D1%84%D0%B8%D0%BB%D1%8C%D0%BC..%0D%0A%3E%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%20%D0%B2%D1%8B%D1%81%D0%BE%D0%BA%D0%BE%D0%B5%20%D1%80%D0%B0%D0%B7%D1%80%D0%B5%D1%88%D0%B5%D0%BD%D0%B8%D0%B5%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%0D%0A%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%0D%0A%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%0D%0A---------------------------442624820004%0D%0AContent-Disposition:%20form-data;%20name=%22tags%22%0D%0A%0D%0A%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%20(GoT)%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F,%20%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%207%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F,%20%D0%98%D0%B3%D1%80%D0%B0%20%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2%202019%208%20%D1%81%D0%B5%D0%B7%D0%BE%D0%BD%205%20%D1%81%D0%B5%D1%80%D0%B8%D1%8F%0D%0A---------------------------442624820004%0D%0AContent-Disposition:%20form-data;%20name=%22page_id%22%0D%0A%0D%0A158655%0D%0A---------------------------442624820004--
http://moavalve.co.kr/faq/43582
http://moavalve.co.kr/faq/43592
http://photogrotto.com/%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5%d0%bd%d0%b8%d0%b5-vuslat-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-s6-%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5/
http://ru-realty.com/forum/index.php?PHPSESSID=5g5s1p4924a2k02tfsrqnl4ha1&topic=518310.0
http://ru-realty.com/forum/index.php?PHPSESSID=5t4smckp7sei329tmsnr75i1q1&topic=518392.0
http://ru-realty.com/forum/index.php?PHPSESSID=a055tqt1i972oos7h6cddedgc2&topic=518353.0
http://ru-realty.com/forum/index.php?PHPSESSID=l95avbmaols80pkpmgltm92dp7&topic=518346.0
http://ru-realty.com/forum/index.php?PHPSESSID=m2ddd1cfe5npmu8a3lmhasdrt2&topic=518386.0
http://ru-realty.com/forum/index.php?PHPSESSID=oqknl564m2ugj7d960knhkqmh1&topic=518373.0
http://shinhwaair2017.cafe24.com/issue/141089
http://shinilspring.com/board_qsfb01/12791
http://smartengbiz.com/slider_m/32237
http://dota2.host/145986-igra-prestolov-8-sezon-5-seria-watch-u5-k5-igra-prestolov-8-sez
http://indiefilm.kr/xe/board/23106
http://vn7.vn/qna/55882
http://indiefilm.kr/xe/board/20226
http://toeden.co.kr/Product_new/2004
http://toeden.co.kr/Product_new/2009
http://toeden.co.kr/Product_new/2019
http://vervetama.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90qz8%e3%80%91-%d0%b8%d0%b3%d1%80/
http://vervetama.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90ey5%e3%80%91/
http://vervetama.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90tk6%e3%80%91/
http://vervetama.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90dv9%e3%80%91-%d0%b8%d0%b3/
http://vervetama.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90fh7%e3%80%91/
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=1251
http://www.siheunglove.com/chulip/4561
http://www.sp1.football/index.php?mid=tr_video&document_srl=54244
http://www.studyxray.com/Sangdam/38099
http://www.studyxray.com/Sangdam/38158
http://moavalve.co.kr/faq/22767
http://moavalve.co.kr/faq/22805
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/100502
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=5110
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=5127
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=5131
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=5137
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=5142
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=5148
http://oss.obigo.com/oss/index.php?mid=board_ksaA03&document_srl=3521
http://HyUa.1fps.icu/l/szIaeDC
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3708336
http://ptu.imoove.kr/ko/content/%C2%AB%D1%8E%D1%80%D0%B8%D1%81%D1%82%D1%8B-14-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%D0%B2-%D1%8D%D1%84%D0%B8%D1%80%D0%B5-%C2%AB%D1%8E%D1%80%D0%B8%D1%81%D1%82%D1%8B-14-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB331750
http://topitop.kz/index.php/component/k2/itemlist/user/76756
http://www.ekemoon.com/155369/050020193008/
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tg1p-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://zanoza.h1n.ru/2019/05/15/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nc1g/
http://zanoza.h1n.ru/2019/05/15/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ou0e-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://zanoza.h1n.ru/2019/05/15/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ec0i-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://prelease.club/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tl6y-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
https://prelease.club/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uj3t-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
https://prelease.club/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-85-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ee0t-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-85-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://cafe.dokseosil.co.kr/community/43980
http://cafe.dokseosil.co.kr/community/43986
http://cafe.dokseosil.co.kr/community/43991
http://cafe.dokseosil.co.kr/community/44012
http://arunagreen.com/?option=com_k2&view=itemlist&task=user&id=507779
http://c3isecurity.com.br/?option=com_k2&view=itemlist&task=user&id=525031
http://corumotoanahtar.com/component/k2/itemlist/user/1776
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=326502
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=326503
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=326540
http://fbpharm.net/index.php/component/k2/itemlist/user/39368
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1803820
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=308431
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1181736
http://mediaville.me/index.php/component/k2/itemlist/user/263239
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/727912
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/96001
http://ovotecegg.com/component/k2/itemlist/user/143176
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=16483
http://divespace.co.kr/board/1572
http://jjikduk.net/DATA/18432
http://1vh.info/index.php?topic=17115.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-m0-z8-%d0%b8%d0%b3/
http://daesestudy.co.kr/ipsi_docu/4343
http://menulisilmiah.net/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d3-z7-%d0%b8%d0%b3%d1%80/
http://cwon.kr/xe/board_bnSr36/7036
http://jstech.kr/index.php?document_srl=6316&mid=board_lqyj42
http://forum.digamahost.com/index.php?topic=119843.0
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=40479
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=40509
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=40529
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=40583
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=40612
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=40672
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=40720
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=40760
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=40784
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=40799
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=40953
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=41004
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=41676
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=41715
http://www.lozic.co.kr/gallery/21402
http://www.studyxray.com/Sangdam/19635
http://xn--ok1bpqi43ahtb.net/board_eASW07/15949
http://pcksummit.bscs.org/node/3437
http://www.gforgirl.com/xe/?document_srl=24200
http://www.die-design-manufaktur.de/?option=com_k2&view=itemlist&task=user&id=5174885
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/184911
http://associationsila.org/component/k2/itemlist/user/282823
http://webp.online/index.php?topic=48238.0
http://www.deliberarchia.org/forum/index.php?topic=978830.0
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/49880
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=7079
http://seoksoononly.dothome.co.kr/qna/770289
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/473938
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1344754
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=10283
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/189830
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=12312
http://fbpharm.net/index.php/component/k2/itemlist/user/24591
https://forums.letstalkbeats.com/index.php?topic=64729.0
http://www.ekemoon.com/149099/050020191907/
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1858491
https://lucky28003.nl/forum/index.php?topic=12209.0
http://seoksoononly.dothome.co.kr/?document_srl=727335
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1346950
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/639597
http://condolencias.servisa.es/i-99-05-05-2019-s2-i-99
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8d%d1%84%d0%b8%d1%80-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://xplorefitness.com/blog/%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2/game-thrones-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-08-05-2019-k1-%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2/game-thrones-8
http://poselokgribovo.ru/forum/index.php?topic=714915.0
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=47924
http://vtservices85.fr/smf2/index.php?PHPSESSID=ac61af7de5558fc8677f93a62f186ed9&topic=213274.0
http://www.quattroandpartners.it/component/k2/itemlist/user/1050444
https://lucky28003.nl/forum/index.php?topic=12135.0
http://www.elpinatarense.es/index.php/component/k2/itemlist/user/154486
http://rudraautomation.com/index.php/component/k2/author/121517
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2566761
http://sextomariotienda.com/blog/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ja8b-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=6514
http://withinfp.sakura.ne.jp/eso/index.php/17038729-live-sluga-naroda-3-sezon-9-seria-p9-sluga-naroda-3-sezon-9-ser/0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4798772
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1616493
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/3742
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=553741
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=553991
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=20525
http://corumotoanahtar.com/component/k2/itemlist/user/1419.html
http://jjikduk.net/DATA/3178
http://www.deliberarchia.org/forum/index.php?topic=1029086.0
http://www.deliberarchia.org/forum/index.php?topic=1029105.0
http://xplorefitness.com/blog/%C2%AB%D0%BD%D0%B5-%D0%BE%D1%82%D0%BF%D1%83%D1%81%D0%BA%D0%B0%D0%B9-%D0%BC%D0%BE%D1%8E-%D1%80%D1%83%D0%BA%D1%83-elimi-birakma-40-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-vhfc-%C2%AB%D0%BD%D0%B5-%D0%BE%D1%82%D0%BF%D1%83%D1%81%D0%BA%D0%B0%D0%B9-%D0%BC%D0%BE%D1%8E-%D1%80%D1%83%D0%BA%D1%83-elimi-birakma-40-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
https://prelease.club/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nijq-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-9-%d1%81%d0%b5%d1%80%d0%b8/
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1583230
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1373569
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1045364
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=591724
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=789023
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=789041
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/239781
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/239951
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3327691
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=18220
https://danceplanet.se/commodore/index.php?topic=37916.0
https://hackersuniversity.net/index.php/topic,16454.0.html
https://hackersuniversity.net/index.php/topic,16460.0.html
https://hackersuniversity.net/index.php?topic=16456.0
https://reficulcoin.com/index.php?topic=42976.0
https://saltriverbg.com/2019/05/16/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7/
https://saltriverbg.com/2019/05/16/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-29-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-u3-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-5-%d1%81/
https://www.amazingworldtop.com/entretenimiento/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m9-%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5/
http://hyeonjun.co.kr/menu3/6811
https://mencoin.net/?document_srl=5944
http://seoksoononly.dothome.co.kr/qna/821847
http://www.ds712.net/guest/?document_srl=25060
http://shinilspring.com/?document_srl=21001
http://www.ekemoon.com/194799/052020190015/
http://dota2.host/322692-igra-prestolov-8-sezon-6-seria-a5-n6-igra-prestolov-8-sezon-6-s
http://foxy-tv.com/?document_srl=4980
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-q0-k4/
http://eugeniocolazzo.it/forum/index.php?topic=119793.0
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=16639
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2641354
http://bebopindia.com/notcie/45948
http://bebopindia.com/notcie/46002
http://bebopindia.com/notcie/46062
http://bebopindia.com/notcie/46090
http://cwon.kr/xe/board_bnSr36/22156
http://d-tube.info/?document_srl=218865
http://d-tube.info/?document_srl=218875
http://d-tube.info/board_jvyO69/218860
http://d-tube.info/board_jvyO69/218869
http://d-tube.info/board_jvyO69/218880
http://d-tube.info/board_jvyO69/218886
http://d-tube.info/board_jvyO69/218892
http://daesestudy.co.kr/?document_srl=16082
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=2648
http://cwon.kr/xe/board_bnSr36/2662
http://emjun.com/index.php?mid=hangtotal&document_srl=5983
http://emjun.com/index.php?mid=hangtotal&document_srl=6016
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=9947
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=9993
http://gxpfactory.net/index.php?mid=Guide&document_srl=1483
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2763628
http://haeple.com/index.php?mid=etc&document_srl=8351
http://haeple.com/index.php?mid=etc&document_srl=8371
http://hyeonjun.co.kr/menu3/2770
http://forum.elexlabs.com/index.php?topic=23968.0
http://www.ofqj.org/hebergementfrance/4-10-online-k9-w2-4-10-4-10
http://roikjer.com/forum/index.php?PHPSESSID=fj0bhcs37laavo6rbiqrps64c7&topic=850169.0
http://forum.elexlabs.com/index.php?topic=18084.0
https://worldtaxi.org/2019/05/10/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k9-y1-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
https://members.fbhaters.com/index.php?topic=83743.0
http://otitismediasociety.org/forum/index.php?topic=157593.0
https://reficulcoin.com/index.php?topic=18984.0
http://metropolis.ga/index.php?topic=6642.0
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xb1-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://vtservices85.fr/smf2/index.php?topic=215369.0
https://khuyenmaikk13.info/index.php?topic=184773.0
http://menulisilmiah.net/%d0%b4%d0%b5%d0%b2%d1%8f%d1%82%d1%8c-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b5%d0%b9-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-10-05-2019-2/
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=30104.0
http://HyUa.1fps.icu/l/szIaeDC
http://smartengbiz.com/s1/34396
http://smartengbiz.com/s1/34429
http://smartengbiz.com/s1/34451
http://smartengbiz.com/s1/34497
http://smartengbiz.com/s1/34512
http://vn7.vn/qna/69346
http://vn7.vn/qna/69381
http://vn7.vn/qna/69497
http://www.artangel.co.kr/index.php?mid=Activities&document_srl=3192
http://eugeniocolazzo.it/forum/index.php?topic=109459.0
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v1-g3-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://dpmarketingsystems.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w1-i7-%d0%b8%d0%b3%d1%80%d0%b0/
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=32940.0
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-6/
http://www.nomaher.com/forum/index.php?topic=13423.0
http://www.critico-expository.com/forum/index.php?topic=13219.0
http://forum.byehaj.hu/index.php?topic=88032.0
https://khuyenmaikk13.info/index.php?topic=190155.0
https://sanp.pro/%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i2-%d1%81%d0%bb%d1%83/
http://demo.caribe.vps-private.net/blog/milliardy-4-sezon-13-seriya-f9-s2-milliardy-4-sezon-13-seriya-milliardy-4-sezon-13-seriya
http://vervetama.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-c3-y7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
http://HyUa.1fps.icu/l/szIaeDC
http://www.critico-expository.com/forum/index.php?topic=9248.0
http://www.critico-expository.com/forum/index.php?topic=9258.0
http://www.critico-expository.com/forum/index.php?topic=9260.0
http://www.critico-expository.com/forum/index.php?topic=9263.0
http://www.critico-expository.com/forum/index.php?topic=9266.0
http://www.critico-expository.com/forum/index.php?topic=9268.0
http://www.ekemoon.com/170837/050820192810/
http://www.ekemoon.com/170857/050820193110/
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/291615
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=21043
http://webp.online/index.php?topic=43834.msg72027
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/184123
https://forums.letstalkbeats.com/index.php?topic=65715.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2522843
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=495990
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=46809
http://community.viajar.tur.br/index.php?p=/profile/landonsher
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-px1w-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://www.arredoufficiomarca.com/index.php/component/k2/itemlist/user/1562390
http://www.deliberarchia.org/forum/index.php?topic=961838.0
http://www.m1avio.com/?option=com_k2&view=itemlist&task=user&id=3597900
http://www.afikgan.co.il/index.php/component/k2/itemlist/user/26458
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/190961
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1335317
http://www.vivelabmanizales.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-06-05-2019-c8-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-5-%d1%81%d0%b5%d1%80/
http://ovotecegg.com/component/k2/itemlist/user/115546
https://lucky28003.nl/forum/index.php?topic=10575.0
http://highlanderonline.cmshelplive.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8-3/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3297951
http://ovotecegg.com/component/k2/itemlist/user/117734
http://socialfbwidgets.com/component/k2/itemlist/user/12954.html
http://menulisilmiah.net/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-93-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ee9%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-93/
https://www.shaiyax.com/index.php?topic=334270.0
http://condolencias.servisa.es/3-9-06-05-2019-z2-3-9
http://dev.aabn.org.gh/component/k2/itemlist/user/516842
http://sextomariotienda.com/blog/hd-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b9-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81/
http://www.vivelabmanizales.com/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-100-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-df7m-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-100-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://forum.byehaj.hu/index.php?topic=81869.0
http://macdistri.com/index.php/component/k2/itemlist/user/302743
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/195616
http://teambuildingpremium.com/forum/index.php?topic=795523.0
http://febrescordero.gob.ec/index.php/component/k2/itemlist/user/86667
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1643759
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=104970
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/62169
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1394430
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1394445
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=806543
http://www.spazioad.com/component/k2/itemlist/user/7292187
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=59578
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/316754
http://forum.elexlabs.com/index.php?topic=22398.0
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ke5-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://roikjer.com/forum/index.php?PHPSESSID=hnlbmaqg1h7necvjilmupc3o10&topic=843373.0
https://www.limscave.com/forum/viewtopic.php?t=31754
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m8-r0-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://roikjer.com/forum/index.php?PHPSESSID=fii1tuk1sl2p6tvmf08ebq19s3&topic=841056.0
http://dpmarketingsystems.com/hd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d8-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://forums.abs-cbn.com/welcome-back-kapamilya%21/10-05-2019-om-16-e/?PHPSESSID=0vm7pa6ju0q7a46etgda0b60v1
http://www.teedinubon.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g8-r1-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://forum.elexlabs.com/index.php?topic=18212.0
http://8.droror.co.il/uncategorized/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fc5-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://reficulcoin.com/index.php?topic=26652.0
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tc8-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://reficulcoin.com/index.php?topic=33104.0
http://forum.elexlabs.com/index.php?topic=16356.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=31823.0
https://worldtaxi.org/2019/05/09/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-online-s2-z4-%d0%b8/
https://khuyenmaikk13.info/index.php?topic=184919.0
http://www.taeshinmedia.com/index.php?mid=genealogy_free_board&document_srl=3270724
http://www.theocraticamerica.org/forum/index.php/topic,41691.0.html
http://xn----3x5er9r48j7wemud0a387h.com/news/8542
https://www.shaiyax.com/index.php?topic=347740.0
http://8.droror.co.il/uncategorized/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bd%d0%b0-%d1%80%d1%83%d1%81/
http://eugeniocolazzo.it/forum/index.php?topic=134673.0
http://eugeniocolazzo.it/forum/index.php?topic=134680.0
http://forum.bmw-e60.eu/index.php?topic=8173.0
http://forum.elexlabs.com/index.php/topic,30889.0.html
http://foxy-tv.com/index.php?mid=board_arik22&document_srl=19345
http://gallerychoi.com/Exhibition/26550
http://hyeonjun.co.kr/menu3/20715
http://hyeonjun.co.kr/menu3/20841
http://hyeonjun.co.kr/menu3/21040
http://jjikduk.net/DATA/24598
http://jjikduk.net/STUFFED/24567
http://jjimdak.callbank.kr/index.php?document_srl=748304&mid=board_OGFN30
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=748498
http://poselokgribovo.ru/forum/index.php?topic=793231.0
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=20786
http://roikjer.com/forum/index.php?PHPSESSID=c338a9abd3uj69127mp2b0qba1&topic=879945.0
http://roikjer.com/forum/index.php?PHPSESSID=hfie9g3sl7ci65v8o3m4d7ipq4&topic=879939.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.rocktheboat.cc/groups/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d0%be%d0%bd%d0%bb%d0%b0%d0%b9%d0%bd-qy%d1%85%d0%be%d0%bb/
http://menulisilmiah.net/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-ki2%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5/
http://robocit.com/index.php/component/k2/itemlist/user/449493
http://www.spazioad.com/component/k2/itemlist/user/7275306
http://menulisilmiah.net/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zk4%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://menulisilmiah.net/%d1%81%d0%bc%d0%b5%d1%80%d1%88-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pw5%d1%81%d0%bc%d0%b5%d1%80%d1%88-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f10-05-2019/
http://hydrocarbs-gh.org/index.php/component/k2/itemlist/user/7361334
http://www.digitalbul.com/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sn8o/
http://www.digitalbul.com/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ds2y-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
https://prelease.club/%d1%81%d0%be%d0%b4%d0%b5%d1%80%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zw7s-%d1%81%d0%be%d0%b4%d0%b5%d1%80%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-9-%d1%81%d0%b5%d1%80/
http://cafe.dokseosil.co.kr/community/38907
http://cafe.dokseosil.co.kr/community/38912
http://cafe.dokseosil.co.kr/community/38928
http://forum.digamahost.com/index.php?topic=121990.0
http://forum.digamahost.com/index.php?topic=121993.0
http://teambuildingpremium.com/forum/index.php?topic=828047.0
http://www.deliberarchia.org/forum/index.php?topic=1036583.0
http://xplorefitness.com/blog/%C2%AB%D0%BD%D0%B5-%D0%BE%D1%82%D0%BF%D1%83%D1%81%D0%BA%D0%B0%D0%B9-%D0%BC%D0%BE%D1%8E-%D1%80%D1%83%D0%BA%D1%83-elimi-birakma-40-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-mqvp-%C2%AB%D0%BD%D0%B5-%D0%BE%D1%82%D0%BF%D1%83%D1%81%D0%BA%D0%B0%D0%B9-%D0%BC%D0%BE%D1%8E-%D1%80%D1%83%D0%BA%D1%83-elimi-birakma-40-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://www.ekemoon.com/192097/050520195115/
https://prelease.club/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qu9q-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://prelease.club/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nz0z-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4914842
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=825277
http://www.urbantutorial.com/?option=com_k2&view=itemlist&task=user&id=110590
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/20857
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=21231
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=21232
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2633084
http://www.crnmedia.es/?option=com_k2&view=itemlist&task=user&id=85250
http://www.ekemoon.com/177387/051520190611/
http://www.ekemoon.com/177391/051520190711/
http://www.emrabq8.com/index.php/component/k2/itemlist/user/1795278
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=602510
http://www.rocktheboat.cc/groups/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d1%8d%d0%ba%d1%81%d1%82%d1%80%d0%b0%d1%81%d0%b5%d0%bd%d1%81%d0%be%d0%b2/
http://www.theocraticamerica.org/forum/index.php?topic=31835.0
http://www.deliberarchia.org/forum/index.php?topic=1037569.0
http://xplorefitness.com/blog/%C2%AB%D1%80%D0%B0%D0%BD%D0%BD%D1%8F%D1%8F-%D0%BF%D1%82%D0%B0%D1%88%D0%BA%D0%B0-erkenci-kus-40-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-aykz-%C2%AB%D1%80%D0%B0%D0%BD%D0%BD%D1%8F%D1%8F-%D0%BF%D1%82%D0%B0%D1%88%D0%BA%D0%B0-erkenci-kus-40-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
https://prelease.club/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nbqu-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-20-%d1%81%d0%b5%d1%80%d0%b8/
https://prelease.club/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tsjr-%d0%b2%d0%be%d1%81%d0%ba%d1%80/
https://prelease.club/%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-69-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mukr-%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-69/
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7392025
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3451769
http://jiquilisco.org/index.php/component/k2/itemlist/user/5484
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=329000
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=329018
http://mediaville.me/index.php/component/k2/itemlist/user/267766
http://mobility-corp.com/index.php/component/k2/itemlist/user/2594047
http://ovotecegg.com/index.php/component/k2/itemlist/user/146118
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=17315
http://soc-human.kz/index.php/component/k2/itemlist/user/1686744
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2563688
http://www.ekemoon.com/163495/050720195109/
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=5603
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=773132
http://www.ekemoon.com/144581/051020193806/
http://seoksoononly.dothome.co.kr/?document_srl=734530
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4837075
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1860884
http://www.m1avio.com/?option=com_k2&view=itemlist&task=user&id=3613506
http://koushatarabar.com/index.php/component/k2/itemlist/user/1330584
http://www.m1avio.com/index.php/component/k2/itemlist/user/3604177
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=774417
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=298106
http://www.deliberarchia.org/forum/index.php?topic=1046719.0
http://www.deliberarchia.org/forum/index.php?topic=1046734.0
http://www.deliberarchia.org/forum/index.php?topic=1046741.0
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=72763
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=72882
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=72897
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=72921
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/5463
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/5465
http://www.spazioad.com/component/k2/itemlist/user/7324725
http://www.urbantutorial.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=111701
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=264315
http://euromouleusinage.com/?option=com_k2&view=itemlist&task=user&id=113502
http://highlanderonline.cmshelplive.net/%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5%d0%bd%d0%b8%d0%b5-vuslat-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-npmc-%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd/
http://menulisilmiah.net/hd-video-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p0-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1/
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=43986
https://l2thalassic.org/Forum/index.php?topic=1967.0
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=229731
http://dcasociados.eu/component/k2/itemlist/user/86689
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=13494
http://bitpark.co.kr/board_IzjM66/3782712
http://arunagreen.com/index.php/component/k2/itemlist/user/426568
http://www.spazioad.com/?option=com_k2&view=itemlist&task=user&id=7212989
http://k2.akademitelkom.ac.id/component/k2/itemlist/user/296573
http://forum.politeknikgihon.ac.id/index.php?topic=21240.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/189943
http://sextomariotienda.com/blog/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-video-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/472187
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1636246
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1007310
https://szenarist.ru/forum/index.php?topic=205307.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2562039
http://salescoach.ro/content/%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-9-%D0%B2%D0%B8%D0%BF%D1%83%D1%81%D0%BA%C2%BB-ex%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-9-%D0%B2%D0%B8%D0%BF%D1%83%D1%81%D0%BA%C2%BB91-%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-9-%D0%B2%D0%B8%D0%BF%D1%83%D1%81%D0%BA
https://tg.vl-mp.com/index.php?topic=1344074.0
http://danielmillsap.com/forum/index.php?topic=981694.0
http://c3isecurity.com.br/?option=com_k2&view=itemlist&task=user&id=486296
http://c3isecurity.com.br/?option=com_k2&view=itemlist&task=user&id=492819
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/188182
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1550779
http://153.120.114.241/eso/index.php/16865836-ne-otpuskaj-mou-ruku-elimi-birakma-41-seria-pbiv-ne-otpuskaj-mo
http://www.ekemoon.com/147389/052120191406/
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=3327
http://cafe.dokseosil.co.kr/community/32681
http://cafe.dokseosil.co.kr/community/32706
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=3375
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=3380
http://emjun.com/?document_srl=8103
http://emjun.com/index.php?mid=hangtotal&document_srl=8108
http://foxy-tv.com/index.php?mid=board_arik22&document_srl=7390
http://indiefilm.kr/xe/board/11079
http://indiefilm.kr/xe/board/11083
http://indiefilm.kr/xe/board/11088
http://indiefilm.kr/xe/board/11092
http://isch.kr/board_PowH60/4089
http://isch.kr/board_PowH60/4094
http://jjikduk.net/DATA/9658
http://jnk-ent.jp/index.php?mid=gallery&document_srl=8439
http://jnk-ent.jp/index.php?mid=gallery&document_srl=8458
http://k-cea.org/board_Hnyj62/8756
http://k-cea.org/board_Hnyj62/8793
http://lahch.co.kr/index.php?mid=board_jHAP41&document_srl=8414
https://prelease.club/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80-9/
https://prelease.club/%d1%8d%d1%84%d0%b8%d1%80-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%be/
https://prelease.club/%d1%8d%d1%84%d0%b8%d1%80-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%89/
https://prelease.club/live-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lostfilm/
https://saltriverbg.com/2019/05/15/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3362188
https://tg.vl-mp.com/index.php?topic=1438560.0
https://tg.vl-mp.com/index.php?topic=1438562.0
https://theprodigy.info/forum/index.php?topic=29203.0
https://www.amazingworldtop.com/entretenimiento/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80/
https://www.amazingworldtop.com/entretenimiento/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uakino/
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=129212
http://HyUa.1fps.icu/l/szIaeDC
http://shinilspring.com/board_qsfb01/66795
http://skylinecam.co.kr/photo/62657
http://skylinecam.co.kr/photo/62675
http://skylinecam.co.kr/photo/62730
http://skylinecam.co.kr/photo/62735
http://www.youngfile.com/?document_srl=5183
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o1-z9-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c9-y5-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=89349
http://ariji.kr/?document_srl=796053
http://ariji.kr/?document_srl=796056
http://ariji.kr/?document_srl=796073
http://ariji.kr/?document_srl=796082
http://atemshow.com/atemfair_domestic/25513
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=51418
https://prelease.club/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80-11/
https://prelease.club/%d1%84%d0%b8%d0%bb%d1%8c%d0%bc-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
https://prelease.club/%d1%8d%d1%84%d0%b8%d1%80-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ivi/
https://prelease.club/%d1%8d%d1%84%d0%b8%d1%80-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ivi/
http://asiagroup.co.kr/index.php?mid=board_5&document_srl=131331
http://atemshow.com/atemfair_domestic/7457
http://bethanychurch.kr/board_vpkl62/4105
http://bethanychurch.kr/board_vpkl62/4111
http://forum.elexlabs.com/index.php?topic=28987.0
http://poselokgribovo.ru/forum/index.php?topic=789851.0
http://poselokgribovo.ru/forum/index.php?topic=789855.0
http://roikjer.com/forum/index.php?PHPSESSID=p3ejkmoki6c2ss3hq575005ei6&topic=877714.0
http://twitchdevs.com/c/other/()-rasskaz-sluzhanki-3-sezon-7-seriya-na-russkom-yazyke/
http://uberdrivers.net/forum/index.php?topic=276864.0
http://www.datascientist.co.kr/index.php?mid=blog&document_srl=62116
http://www.datascientist.co.kr/index.php?mid=blog&document_srl=62125
http://www.deliberarchia.org/forum/index.php?topic=1040630.0
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=35811
http://HyUa.1fps.icu/l/szIaeDC
http://koushatarabar.com/index.php/component/k2/itemlist/user/1343204
http://seoksoononly.dothome.co.kr/qna/754928
https://nextezone.com/index.php?action=profile;u=2636
http://withinfp.sakura.ne.jp/eso/index.php/16880514-otel-toledo-2-seria-06052019-a0-otel-toledo-2-seria
http://socintegra.lv/component/k2/itemlist/user/43886
http://dev.aabn.org.gh/component/k2/itemlist/user/528388
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4719296
http://married.dike.gr/index.php/component/k2/itemlist/user/49199
http://withinfp.sakura.ne.jp/eso/index.php/16927608-uristy-16-seria-v-efire-uristy-16-seria/0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2579467
http://socialfbwidgets.com/component/k2/itemlist/user/13678.html
http://withinfp.sakura.ne.jp/eso/index.php/16905621-serial-sluga-naroda-3-sezon-11-seria-y8-sluga-naroda-3-sezon-11/0
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=81394
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=296756
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=10848
http://www.deliberarchia.org/forum/index.php?topic=960216.0
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3709885
http://seoksoononly.dothome.co.kr/qna/747068
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=51530
http://www.web2interactive.com/index.php/component/k2/itemlist/user/3593211
http://menulisilmiah.net/%d0%be%d1%82%d0%b5%d0%bb%d1%8c-%d1%82%d0%be%d0%bb%d0%b5%d0%b4%d0%be-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nw8%d0%be%d1%82%d0%b5%d0%bb%d1%8c-%d1%82%d0%be%d0%bb%d0%b5%d0%b4%d0%be/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3294616
http://seoksoononly.dothome.co.kr/qna/738078
http://thermoplast.envolgroupe.com/component/k2/author/65840
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1335247
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=578589
https://khuyenmaikk13.info/index.php?topic=179230.0
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=11773
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1344697
http://withinfp.sakura.ne.jp/eso/index.php/16886045-novinka-uristy-21-seria-i8-uristy-21-seria
http://batubersurat.com/index.php/component/k2/itemlist/user/42271
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=3738
http://xn--ok1bpqi43ahtb.net/board_EkDG82/51747
http://ye-dream.com/qa/41394
https://2002.shyoon.com/board_2002/9689
https://khuyenmaikk13.info/index.php?topic=204138.0
https://khuyenmaikk13.info/index.php?topic=204141.0
https://www.chirorg.com/?document_srl=7502
http://0433.net/?document_srl=17388
http://2872870.com/est/4949
http://ariji.kr/?document_srl=787586
http://bethanychurch.kr/board_vpkl62/7295
http://ekitchen.co.kr/intro/1019662
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=39053
https://saltriverbg.com/2019/05/15/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8/
https://saltriverbg.com/2019/05/15/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-3-%d1%81%d0%b5/
https://saltriverbg.com/2019/05/15/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80-4/
https://saltriverbg.com/2019/05/15/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b4%d0%b0%d1%82%d0%b0/
http://forum.elexlabs.com/index.php?topic=28459.0
http://poselokgribovo.ru/forum/index.php?topic=788669.0
http://roikjer.com/forum/index.php?PHPSESSID=f9q6pt19stqvfbthfmv4sb0m93&topic=876954.0
http://twitchdevs.com/c/other/(-(serial)-)-rasskaz-sluzhanki-3-sezon-5-seriya-gde/
http://uberdrivers.net/forum/index.php?topic=275895.0
http://uberdrivers.net/forum/index.php?topic=275916.0
http://uberdrivers.net/forum/index.php?topic=275922.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.jesusonly.life/calendar/67110
http://www.jesusonly.life/calendar/67153
http://www.jesusonly.life/calendar/67198
http://www.jesusonly.life/calendar/67307
https://saltriverbg.com/2019/05/16/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e9-h0-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
https://saltriverbg.com/2019/05/16/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o2-k4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=41188
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=41261
http://xn--9m1b83j39hz6exwonmf.com/board_IYPe43/490328
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h7-n6-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://roikjer.com/forum/index.php?topic=877388.0
http://taklongclub.com/forum/index.php?topic=140826.0
http://twitchdevs.com/c/other/()-rasskaz-sluzhanki-3-sezon-11-seriya-3-sezon/
http://twitchdevs.com/c/other/(hd-video)-rasskaz-sluzhanki-3-sezon-13-seriya-smotret-onlajn-lostfilm-iyun-2019/
http://www.ds712.net/guest/?document_srl=32866
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=32680
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=32704
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=32745
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=32764
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=32856
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=32885
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=32895
http://www.ekemoon.com/194175/051620192415/
http://www.hoonthaitoday.com/forum/index.php?topic=270785.0
http://www.teedinubon.com/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8-4/
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2018/
http://www.teedinubon.com/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8-4/
http://www.teedinubon.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80-6/
http://www.teedinubon.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80-15/
http://www.teedinubon.com/live-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2017/
http://www.teedinubon.com/live-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bigcinema/
http://www.web2interactive.com/index.php/component/k2/itemlist/user/3651612
http://ye-dream.com/qa/13635
http://yoriyorifood.com/xxxx/spacial/15424
http://yoriyorifood.com/xxxx/spacial/15431
http://HyUa.1fps.icu/l/szIaeDC
http://cwon.kr/xe/board_bnSr36/26168
http://d-tube.info/?document_srl=220918
http://daltso.com/index.php?mid=board_cUYy21&document_srl=4081
http://dnienertec.com/qna/14322
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=7006
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=7038
http://duopos.net/xe/board_CofP84/6867
http://esiapolisthesharp2.co.kr/g1/8290
http://esiapolisthesharp2.co.kr/g1/8305
http://f-tube.info/board/66929
http://f-tube.info/board/66934
http://gochon-iusell.co.kr/g1/7385
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=6286
http://hanalove.kidspann.net/index.php?mid=qna&document_srl=43135
http://herdental.co.kr/index.php?mid=online&document_srl=6803
http://hk-metal.co.kr/hkweb/?document_srl=3646
http://hk-metal.co.kr/hkweb/QnA/3656
http://hkmtv.co.kr/contentset/4714
http://hkmtv.co.kr/contentset/4721
http://hkmtv.co.kr/contentset/4726
http://hyundeok.iptime.org/zbxe/?document_srl=28825
http://iamking.net/?document_srl=5768
http://jejucctv.co.kr/A5/4237
http://jejucctv.co.kr/A5/4242
http://atemshow.com/atemfair_domestic/6954
http://atemshow.com/atemfair_domestic/7010
http://atemshow.com/atemfair_domestic/7017
http://atemshow.com/atemfair_domestic/7038
http://atemshow.com/atemfair_domestic/7057
http://bethanychurch.kr/board_vpkl62/4018
http://bethanychurch.kr/board_vpkl62/4024
http://eugeniocolazzo.it/forum/index.php?topic=133099.0
http://forum.kopkargobel.com/index.php?topic=9950.0
http://poselokgribovo.ru/forum/index.php?topic=789615.0
http://twitchdevs.com/c/other/(((efir)))-()-rasskaz-sluzhanki-3-sezon-6-seriya-igra-prestolov/
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=34457
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=34594
http://HyUa.1fps.icu/l/szIaeDC
http://skylinecam.co.kr/photo/64907
http://skylinecam.co.kr/photo/64927
http://skylinecam.co.kr/photo/64940
http://skylinecam.co.kr/photo/64945
http://toeden.co.kr/Product_new/12755
http://toeden.co.kr/Product_new/12769
http://www.gforgirl.com/xe/?document_srl=85329
http://www.gforgirl.com/xe/poster/85193
http://www.gforgirl.com/xe/poster/85207
http://www.gforgirl.com/xe/poster/85291
http://www.gforgirl.com/xe/poster/85304
http://uberdrivers.net/forum/index.php?topic=247033.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=689013.0
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pg7-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://forum.clubeicaro.pt/index.php?topic=938.0
https://members.fbhaters.com/index.php?topic=84788.0
http://www.teedinubon.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h6-u2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://vervetama.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d7-f8-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80-11/
http://demo.caribe.vps-private.net/blog/milliardy-4-sezon-8-seriya-d3-l1-milliardy-4-sezon-8-seriya-milliardy-4-sezon-8-seriya
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81-26/
http://vervetama.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-s2-q8-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
https://sanp.pro/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k6/
https://danceplanet.se/commodore/index.php?topic=18445.0
https://members.fbhaters.com/index.php?topic=89302.0
http://forum.elexlabs.com/index.php?topic=16542.0
http://otitismediasociety.org/forum/index.php?topic=150159.0
https://khuyenmaikk13.info/index.php?topic=188943.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/(a-etoo-(got)-8-eo-7-e)-a-etoo-(got)-8-eo-7-e-c4s7/?PHPSESSID=6abq6ms85ovisokhgi9o5rbn63
http://www.popolsku.fr.pl/forum/index.php?topic=377542.0
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p8-u5-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://www.deliberarchia.org/forum/index.php?topic=1005666.0
http://HyUa.1fps.icu/l/szIaeDC
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=5407
http://oneandonly1127.com/guest/476
http://oss.obigo.com/oss/index.php?mid=board_mxLS91&document_srl=3920
http://peskorea.co.kr/board_yPso06/6437
http://peskorea.co.kr/board_yPso06/6442
http://readingbible.org/board_xxpp62/687169
http://readingbible.org/board_xxpp62/687259
http://sd-xi.co.kr/g1/790
http://sd-xi.co.kr/g1/817
http://sd-xi.co.kr/g1/821
http://sd-xi.co.kr/g1/825
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90mg6%e3%80%91/
http://shinhwaair2017.cafe24.com/issue/112925
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=218
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=229
http://skinda.co.kr/laser/2330
http://skinda.co.kr/laser/2357
http://sofficer.net/xe/teach/202330
http://sunele.co.kr/board_ReBD97/31771
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-14/
http://myrechockey.com/forums/index.php?topic=93280.0
http://www.sharmaraco.com/blog/%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-k6-p2-%C2%AB%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%C2%AB%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=31831.0
https://fasttrack.education/groups/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-q3-u1-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lz0-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://8.droror.co.il/uncategorized/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wc3-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-148-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.critico-expository.com/forum/index.php?topic=8008.0
http://www.teedinubon.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b2-c4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://www.hoonthaitoday.com/forum/index.php?topic=212593.0
https://nextezone.com/index.php?topic=39088.0
http://ru-realty.com/forum/index.php?PHPSESSID=60fuhh418ccaiqrignl4q11qn0&topic=480789.0
https://nextezone.com/index.php?action=profile;u=6760
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vd3-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.hoonthaitoday.com/forum/index.php?topic=237992.0
http://HyUa.1fps.icu/l/szIaeDC
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=296588
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1023071
https://khuyenmaikk13.info/index.php?topic=178713.0
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1839137
http://seoksoononly.dothome.co.kr/qna/738676
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4828680
http://seoksoononly.dothome.co.kr/qna/758001
http://webp.online/index.php?topic=46205.15
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2628882
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/524982
http://healthyteethpa.org/component/k2/itemlist/user/5428354
http://www.ekemoon.com/188609/051420192214/
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2476429
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=257903
http://zanoza.h1n.ru/2019/05/14/%d0%be%d1%82%d0%b5%d0%bb%d1%8c-%d1%82%d0%be%d0%bb%d0%b5%d0%b4%d0%be-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hu8x-%d0%be%d1%82%d0%b5%d0%bb%d1%8c-%d1%82%d0%be%d0%bb%d0%b5/
http://zanoza.h1n.ru/2019/05/14/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81-3/
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=21660
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=21695
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=45097
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=45156
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2637377
http://bath-family.com/photo_zone/9633
http://bath-family.com/photo_zone/9651
http://bath-family.com/photo_zone/9674
http://bebopindia.com/notcie/26288
http://bebopindia.com/notcie/26322
http://bebopindia.com/notcie/26412
http://bebopindia.com/notcie/26432
http://bebopindia.com/notcie/76421
http://shinilspring.com/board_qsfb01/68846
http://shinilspring.com/board_qsfb01/68942
http://skylinecam.co.kr/photo/63899
http://skylinecam.co.kr/photo/63903
http://www.jesusonly.life/calendar/91523
http://www.jesusonly.life/calendar/91586
http://www.lovestory.or.kr/topic/1380
http://zanoza.h1n.ru/2019/05/17/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t1-s7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
http://zanoza.h1n.ru/2019/05/17/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-y9-s4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://zanoza.h1n.ru/2019/05/17/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k1-b6-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://zanoza.h1n.ru/2019/05/17/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n9-z1-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d9-l9-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
http://shinilspring.com/board_qsfb01/62244
http://shinilspring.com/board_qsfb01/62297
http://shinilspring.com/board_qsfb01/62323
http://shinilspring.com/board_qsfb01/62329
http://skangseo.org/xe/?document_srl=28532
http://skangseo.org/xe/board_Atnj46/28488
http://sy.korean.net/?document_srl=36243
http://sy.korean.net/qna/17461
http://sy.korean.net/qna/36200
http://sy.korean.net/qna/36226
http://sy.korean.net/qna/36280
http://www.artangel.co.kr/index.php?document_srl=7441&mid=Activities
http://HyUa.1fps.icu/l/szIaeDC
http://dohairbiz.com/en/component/k2/itemlist/user/2716503.html
http://teambuildingpremium.com/forum/index.php?topic=784967.0
http://withinfp.sakura.ne.jp/eso/index.php/16869178-holostak-9-sezon-10-vypusk-post-sou-rkholostak-9-sezon-10-vypus/0
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/204257
http://www.m1avio.com/index.php/component/k2/itemlist/user/3625527
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=274760
http://married.dike.gr/index.php/component/k2/itemlist/user/46440
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=210510
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=209751
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-06-05-2019-n2-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
http://webp.online/index.php?topic=47145.0
http://engeena.com/component/k2/itemlist/user/7945
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2572558
http://www.vivelabmanizales.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-05-05-2019-p7-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80/
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=272500
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=63842
http://www.telcon.gr/index.php/component/k2/itemlist/user/49774
http://www.camaracoyhaique.cl/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81-2/
http://macdistri.com/index.php/component/k2/itemlist/user/309115
http://mediaville.me/index.php/component/k2/itemlist/user/210137
http://trunk.www.volkalize.com/members/garfieldqueen7/
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4712586
https://forums.letstalkbeats.com/index.php?topic=64595.0
https://forums.letstalkbeats.com/index.php?topic=63441.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2513334
http://smartacity.com/component/k2/itemlist/user/28772
http://www.ekemoon.com/142879/051920192705/
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/51606
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/53268
http://www.jesusonly.life/calendar/33454
http://www.jesusonly.life/calendar/33474
http://www.jesusonly.life/calendar/33489
http://www.josephmaul.org/menu41/34000
http://www.sp1.football/index.php?mid=faq&document_srl=27628
http://www.svteck.co.kr/customer_gratitude/16426
http://www.theocraticamerica.org/forum/index.php/topic,40438.0.html
http://www.xn--xy1b45gp4h0qgb9g.com/?document_srl=9003
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=5859
http://yoriyorifood.com/xxxx/spacial/34682
https://saltriverbg.com/2019/05/16/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5-6/
http://bath-family.com/photo_zone/22900
http://bath-family.com/photo_zone/22940
http://bethanychurch.kr/board_vpkl62/6770
http://bethanychurch.kr/board_vpkl62/6781
http://flashboot.ru/forum/index.php?topic=95339.0
http://hyeonjun.co.kr/menu3/28484
http://hyeonjun.co.kr/menu3/28527
http://hyeonjun.co.kr/menu3/28574
http://lucky.kidspann.net/index.php?mid=qna&document_srl=22731
http://lucky.kidspann.net/index.php?mid=qna&document_srl=22756
http://lucky.kidspann.net/index.php?mid=qna&document_srl=22816
http://myrechockey.com/forums/index.php?topic=104051.0
http://myrechockey.com/forums/index.php?topic=104065.0
http://preach.kr/?document_srl=3414
http://preach.kr/Amharic_Music/3399
http://HyUa.1fps.icu/l/szIaeDC
http://webp.online/index.php?action=profile;u=167562
http://sindicatodechoferespichincha.com.ec/index.php/component/k2/itemlist/user/6679442
http://withinfp.sakura.ne.jp/eso/index.php/16862742-nasa-istoria-74-seria-vqvn-nasa-istoria-74-seria/0
http://dev.aabn.org.gh/component/k2/itemlist/user/515887
http://webp.online/index.php?topic=45397.0
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1607763
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=566455
http://ovotecegg.com/component/k2/itemlist/user/125699
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=754620
http://www.ekemoon.com/143453/050020191806/
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/232218
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/3512
http://xplorefitness.com/blog/%D0%B2-%D1%8D%D1%84%D0%B8%D1%80%D0%B5-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-2019-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-6-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-d6-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-2019-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-6-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=256377
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/256382
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=552918
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=552922
http://zsmr.com.ua/index.php/component/k2/itemlist/user/552925
https://grajalesabogados.com.mx/?option=com_k2&view=itemlist&task=user&id=62964
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=20444
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2623519
http://fbpharm.net/index.php/component/k2/itemlist/user/37702
http://healthyteethpa.org/component/k2/itemlist/user/5422813
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=6306
http://www.digitalbul.com/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bj2q/
http://www.digitalbul.com/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ks3y/
http://soc-human.kz/index.php/component/k2/itemlist/user/1672667
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3626516
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=805364
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/316037
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/249639
http://xplorefitness.com/blog/%C2%AB%D0%B4%D0%BE%D1%87%D0%BA%D0%B8-%D0%BC%D0%B0%D1%82%D0%B5%D1%80%D0%B8-%D0%B4%D0%BE%D1%87%D0%BA%D0%B8-%D0%BC%D0%B0%D1%82%D0%B5%D1%80i-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-11-05-2019-h2-%C2%AB%D0%B4%D0%BE%D1%87%D0%BA%D0%B8-%D0%BC%D0%B0%D1%82%D0%B5%D1%80%D0%B8-%D0%B4%D0%BE%D1%87%D0%BA%D0%B8-%D0%BC%D0%B0%D1%82%D0%B5%D1%80i-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/4669
http://xn--2e0bk61btjo.com/notice/6005
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=7117
http://ye-dream.com/qa/60398
https://betshin.com/Story/13440
https://betshin.com/Story/13461
https://betshin.com/Story/13471
https://esel.gist.ac.kr/esel2/board_hmgj23/35837
https://forum.clubeicaro.pt/index.php?topic=1285.0
https://prelease.club/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5-2/
https://prelease.club/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80-3/
https://prelease.club/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80-6/
https://prelease.club/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80-10/
https://prelease.club/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80-5/
https://prelease.club/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80-6/
https://prelease.club/%d1%8d%d1%84%d0%b8%d1%80-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%82/
https://prelease.club/hd-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d0%b4%d0%b0%d1%82%d0%b0-%d0%b2/
https://prelease.club/hd-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-8-03-2016/
https://prelease.club/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-%d0%b4%d0%b0%d1%82%d0%b0-%d0%b2%d1%8b%d1%85%d0%be%d0%b4%d0%b0-2/
https://www.shaiyax.com/index.php?topic=346507.0
https://www.thedezlab.com/lab/community/index.php?topic=2786.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=46f79f32205fe29e24b78ad1a61dc3f9&topic=242684.0
http://www.deliberarchia.org/forum/index.php?topic=1039866.0
http://xn----3x5er9r48j7wemud0a387h.com/news/2606
http://xn----3x5er9r48j7wemud0a387h.com/news/2623
http://ye-dream.com/qa/12970
http://1vh.info/index.php?topic=28508.0
http://forum.elexlabs.com/index.php?topic=28686.0
http://poselokgribovo.ru/forum/index.php?topic=789071.0
http://poselokgribovo.ru/forum/index.php?topic=789137.0
http://roikjer.com/forum/index.php?topic=877268.0
http://twitchdevs.com/c/other/((hd))-rasskaz-sluzhanki-3-sezon-4-seriya-lostfilm/
http://vn7.vn/qna/65298
http://HyUa.1fps.icu/l/szIaeDC
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7333469
http://highlanderonline.cmshelplive.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-5/
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1648364
http://www.deliberarchia.org/forum/index.php?topic=976712.0
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r8-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://batubersurat.com/index.php/component/k2/itemlist/user/43963
https://szenarist.ru/forum/index.php?topic=205688.0
http://sindicatodechoferespichincha.com.ec/index.php/component/k2/itemlist/user/6688478
http://ovotecegg.com/component/k2/itemlist/user/117107
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1026530
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/217967
http://www.ekemoon.com/143549/050020195506/
http://guiadetudo.com/index.php/component/k2/itemlist/user/11122
http://www.dezhiran.com/en/component/k2/itemlist/user/15553
http://www.vivelabmanizales.com/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-05-05-2019-w6-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://febrescordero.gob.ec/index.php/component/k2/itemlist/user/83871
http://seoksoononly.dothome.co.kr/?document_srl=720662
http://ovotecegg.com/index.php/component/k2/itemlist/user/117770
http://mobility-corp.com/index.php/component/k2/itemlist/user/2541657
http://c3isecurity.com.br/?option=com_k2&view=itemlist&task=user&id=470408
http://poselokgribovo.ru/forum/index.php?topic=739397.0
http://ovotecegg.com/component/k2/itemlist/user/118059
https://l2thalassic.org/Forum/index.php?topic=2327.0
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=81404
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1861349
http://salescoach.ro/content/%C2%AB%D0%B2%D0%BE%D1%81%D1%81%D0%BE%D0%B5%D0%B4%D0%B8%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5-vuslat-15-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-mdal-%C2%AB%D0%B2%D0%BE%D1%81%D1%81%D0%BE%D0%B5%D0%B4%D0%B8%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5-vuslat-15-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://withinfp.sakura.ne.jp/eso/index.php/16893864-efir-sluga-naroda-3-sezon-16-seria-d1-sluga-naroda-3-sezon-16-s/0
https://l2thalassic.org/Forum/index.php?topic=2201.0
http://www.emrabq8.com/index.php/component/k2/itemlist/user/1775451
http://haniel.ir/index.php/component/k2/itemlist/user/77332
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=603854
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1654595
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1645633
http://www.lustralesdevallehermoso.com/index.php/component/k2/itemlist/user/48425
http://www.supergondolas.com.br/index.php/component/k2/itemlist/user/204575
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3743908
http://bitpark.co.kr/board_IzjM66/3812332
http://bitpark.co.kr/board_IzjM66/3812454
http://fbpharm.net/index.php/component/k2/itemlist/user/24922
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=755832
http://www.telcon.gr/index.php/component/k2/itemlist/user/48455
http://dpordering.cetco.com/User-Profile/userId/567677
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/207056
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-6/
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4721790
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/219755
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=41364
http://yooseok.com/board_BkvT46/323420
http://yooseok.com/board_BkvT46/323467
http://yoriyorifood.com/xxxx/spacial/54942
http://ye-dream.com/?document_srl=14324
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f9-e3-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://shinilspring.com/board_qsfb01/20073
http://azone.synology.me/xe/index.php?document_srl=17424&mid=board_SDnQ73
http://taklongclub.com/forum/index.php?topic=140757.0
http://cafe.dokseosil.co.kr/community/50642
http://www.sp1.football/index.php?mid=faq&document_srl=33859
http://www.golden-nail.co.kr/press/7230
http://seoksoononly.dothome.co.kr/qna/835156
http://www.hoonthaitoday.com/forum/index.php?topic=250438.0
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=8105
http://haeple.com/index.php?mid=etc&document_srl=25728
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=17821
http://bebopindia.com/?document_srl=19231
http://herdental.co.kr/index.php?mid=online&document_srl=8657
http://kitekorea.co.kr/?document_srl=10872
http://kitekorea.co.kr/board_Chea81/10890
http://kitekorea.co.kr/board_Chea81/10914
http://kyj1225.godohosting.com/board_mebR72/5976
http://mglpcm.org/?document_srl=9532
http://mglpcm.org/board_ETkS12/9496
http://mglpcm.org/board_ETkS12/9520
http://skangseo.org/xe/?document_srl=26174
http://77.93.38.205/index.php/component/k2/itemlist/user/496296
http://teambuildingpremium.com/forum/index.php?topic=773257.0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=38912
http://withinfp.sakura.ne.jp/eso/index.php/16860121-ne-otpuskaj-mou-ruku-elimi-birakma-42-seria-axna-ne-otpuskaj-mo/0
http://webp.online/index.php?topic=44138.msg72402
http://servicioswts.com/?option=com_k2&view=itemlist&task=user&id=3625590
http://kurnaz.1to.us/index.php?topic=1.1260
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2562810
https://l2thalassic.org/Forum/index.php?topic=1881.0
http://arunagreen.com/index.php/component/k2/itemlist/user/425095
https://forums.letstalkbeats.com/index.php?topic=67960.0
http://salescoach.ro/content/%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-10-%D0%B2%D1%8B%D0%BF%D1%83%D1%81%D0%BA-%D1%82%D0%B5%D0%BB%D0%B5%D0%BF%D0%BE%D1%80%D1%82%D0%B0%D0%BB%C2%BB-jw%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-10-%D0%B2%D1%8B%D0%BF%D1%83%D1%81%D0%BA-%D1%82%D0%B5%D0%BB%D0%B5%D0%BF%D0%BE%D1%80%D1%82%D0%B0%D0%BB%C2%BB99-%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=607332
http://koushatarabar.com/index.php/component/k2/itemlist/user/1313353
http://cccpvideo.forumside.com/index.php?topic=722.0
https://alvarogarciatorero.com/index.php/component/k2/itemlist/user/47530
http://www.ekemoon.com/147739/052220190506/
http://www.vivelabmanizales.com/%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80%d0%b4%d1%86%d0%b5-tek-yurek-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-moks-%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80/
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/291413
http://www.phan-aen.go.th/forum/index.php?topic=625714.0
https://members.fbhaters.com/index.php?topic=80584.0
http://fbpharm.net/index.php/component/k2/itemlist/user/45140
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1825058
http://jiquilisco.org/index.php/component/k2/itemlist/user/6917
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3813010
http://mediaville.me/index.php/component/k2/itemlist/user/274914
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=83632
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/742962
http://mvisage.sk/index.php/component/k2/itemlist/user/118922
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/103088
http://ovotecegg.com/component/k2/itemlist/user/151394
http://www.sp1.football/index.php?mid=faq&document_srl=21539
http://atemshow.com/atemfair_domestic/6033
http://divespace.co.kr/?document_srl=9058
http://erhu.eu/viewtopic.php?t=323977
http://www.critico-expository.com/forum/index.php?topic=7860.0
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3265818
http://skangseo.org/xe/board_UoEl68/11770
https://nextezone.com/index.php?topic=39294.0
http://forum.elexlabs.com/index.php?topic=28567.0
http://erhu.eu/viewtopic.php?f=8&t=326000
http://eugeniocolazzo.it/forum/index.php?topic=117369.0
https://esel.gist.ac.kr/esel2/board_uNln70/6740
http://roikjer.com/forum/index.php?PHPSESSID=3ki2fscqvoa2u73cnh498dhto5&topic=852808.0
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=53788
http://www.gforgirl.com/xe/poster/37630
http://www.gforgirl.com/xe/poster/37759
http://www.golden-nail.co.kr/press/23689
http://www.golden-nail.co.kr/press/23771
http://www.josephmaul.org/menu41/43464
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=24899
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=24915
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=24932
http://www.livetank.cn/market1/1410
http://www.xn--xy1b45gp4h0qgb9g.com/?document_srl=15714
http://xn--ok1bpqi43ahtb.net/board_eASW07/33507
http://xn--ok1bpqi43ahtb.net/board_eASW07/33587
http://xn--ok1bpqi43ahtb.net/board_eASW07/33607
http://0433.net/junggo/29950
http://0433.net/junggo/30015
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=97015
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=97023
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=97028
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=97049
http://azone.synology.me/xe/?document_srl=59554
http://zanoza.h1n.ru/2019/05/16/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-l3-g3-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n2-w5-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m0-j5-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=42088
http://vtservices85.fr/smf2/index.php?PHPSESSID=c0a3677acd22c0a61f933f98bece8407&topic=247652.0
http://www.tessabannampad.go.th/webboard/index.php?topic=210211.0
http://49.247.3.43/index.php?mid=board_PiDQ29&document_srl=4778
http://5starcoffee.co.kr/board_EBXY17/2456
http://apt2you2.cafe24.com/?document_srl=1173
http://apt2you2.cafe24.com/g1/1153
http://arte.dgau.ac.kr/board_qna/7360
http://aso-cn.com/index.php?mid=board_KRpb39&document_srl=5961
http://beautypouch.net/index.php?mid=board_09&document_srl=3315
http://callman.co.kr/index.php?mid=qa&document_srl=12868
http://constellation.kro.kr/board_kbku73/1044
http://esiapolisthesharp2.co.kr/g1/8935
http://f-tube.info/board/67140
http://gochon-iusell.co.kr/g1/8034
http://hanalove.kidspann.net/index.php?mid=qna&document_srl=43188
http://herdental.co.kr/index.php?document_srl=7013&mid=online
http://hk-metal.co.kr/hkweb/QnA/3921
http://hyundeok.iptime.org/zbxe/index.php?mid=family&document_srl=29094
http://indiefilm.kr/xe/board/57651
http://vervetama.com/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-%d0%b4%d0%b0%d1%82%d0%b0-3/
http://vervetama.com/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bb%d0%be%d1%81%d1%82%d1%84/
http://vervetama.com/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bb%d0%be%d1%81%d1%82-2/
http://www.ekemoon.com/200553/052120192716/
http://www.ekemoon.com/200727/052220190816/
http://www.ekemoon.com/200845/052220194016/
http://www.ekemoon.com/201017/052320191016/
http://yoriyorifood.com/xxxx/?document_srl=44890
http://yoriyorifood.com/xxxx/spacial/44807
http://yoriyorifood.com/xxxx/spacial/44882
https://nextezone.com/index.php?action=profile;u=8384
http://HyUa.1fps.icu/l/szIaeDC
https://nextezone.com/index.php?topic=41144.0
http://otitismediasociety.org/forum/index.php?topic=149104.0
http://forum.kopkargobel.com/index.php?topic=7009.0
http://forum.elexlabs.com/index.php?topic=22673.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d7-v4-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n6-q2-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://forum.elexlabs.com/index.php/topic,22248.0.html
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-m0-z7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://forum.byehaj.hu/index.php?topic=84207.0
https://sanp.pro/%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r6-%d0%bf%d0%be%d0%b4%d1%81%d1%83%d0%b4%d0%b8%d0%bc%d1%8b%d0%b9-15-%d1%81%d0%b5%d1%80/
https://danceplanet.se/commodore/index.php?topic=21219.0
http://atemshow.com/atemfair_domestic/9509
http://bobr.site/index.php?topic=135958.0
http://cwon.kr/xe/board_bnSr36/10132
http://eugeniocolazzo.it/forum/index.php?topic=133758.0
http://forum.bmw-e60.eu/index.php?topic=8110.0
http://forum.byehaj.hu/index.php?topic=90665.0
http://forum.elexlabs.com/index.php/topic,29421.0.html
http://forum.elexlabs.com/index.php?topic=29409.0
http://forum.elexlabs.com/index.php?topic=29426.0
http://forum.elexlabs.com/index.php?topic=29433.0
http://forum.kopkargobel.com/index.php?topic=10074.0
http://hyeonjun.co.kr/menu3/13459
http://indiefilm.kr/xe/board/29566
http://poselokgribovo.ru/forum/index.php?topic=791010.0
http://poselokgribovo.ru/forum/index.php?topic=791025.0
http://roikjer.com/forum/index.php?PHPSESSID=m5glq6og0i40v7iiqfh67bv6b7&topic=878379.0
http://ru-realty.com/forum/index.php?PHPSESSID=bt6flssfqhtf8m5uvldbj67on4&topic=514994.0
http://ru-realty.com/forum/index.php?PHPSESSID=mkn2dgglpvqilc1jjl43lnjja7&topic=514999.0
http://twitchdevs.com/c/other/(((efir)))-()-rasskaz-sluzhanki-3-sezon-9-seriya-smotret-onlajn-v-horoshem-kache/
http://vervetama.com/hd-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lostfilm/
http://vn7.vn/qna/72296
http://www.datascientist.co.kr/index.php?mid=blog&document_srl=66776
http://www.datascientist.co.kr/index.php?mid=blog&document_srl=66873
http://www.datascientist.co.kr/index.php?mid=blog&document_srl=67021
http://HyUa.1fps.icu/l/szIaeDC
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/702874
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1654498
http://www.ekemoon.com/173197/051720190510/
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1085785
http://smartacity.com/component/k2/itemlist/user/18388
http://menulisilmiah.net/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vg2%d0%bd/
http://salescoach.ro/content/%C2%AB%D0%BD%D0%B0%D1%88%D0%B0-%D0%B8%D1%81%D1%82%D0%BE%D1%80%D0%B8%D1%8F-64-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-gnwc-%C2%AB%D0%BD%D0%B0%D1%88%D0%B0-%D0%B8%D1%81%D1%82%D0%BE%D1%80%D0%B8%D1%8F-64-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://www.ekemoon.com/144045/050520194306/
http://www.atab.com.sa/index.php/en/?option=com_k2&view=itemlist&task=user&id=1559616
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=501381
http://febrescordero.gob.ec/index.php/component/k2/itemlist/user/82994
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1122851
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2565967
http://webp.online/index.php?action=profile;u=174073
http://dcasociados.eu/component/k2/itemlist/user/86944
http://www.vivelabmanizales.com/hd-video-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x5-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1/
http://seoksoononly.dothome.co.kr/qna/718524
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/714302
http://ovotecegg.com/component/k2/itemlist/user/135305
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=14139
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/14081
http://proxima.co.rw/index.php/component/k2/itemlist/user/607703
http://proxima.co.rw/index.php/component/k2/itemlist/user/607718
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1668029
http://thermoplast.envolgroupe.com/component/k2/author/94955
http://thermoplast.envolgroupe.com/component/k2/itemlist/user/94935
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1583501
http://www.atab.com.sa/index.php/en/?option=com_k2&view=itemlist&task=user&id=1603146
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1063640
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1063668
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=44077
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=44101
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=44262
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=44531
http://www.fassen.co.kr/xe/board_VCum96/5856
http://www.gforgirl.com/xe/poster/29487
http://www.gforgirl.com/xe/poster/29545
http://www.gforgirl.com/xe/poster/29743
http://www.jesusonly.life/calendar/43382
http://www.jesusonly.life/calendar/43556
http://www.jesusonly.life/calendar/43576
http://www.jesusonly.life/calendar/43622
http://www.jesusonly.life/calendar/43632
http://www.lozic.co.kr/?document_srl=24158
http://www.lozic.co.kr/gallery/24181
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=460036
http://www.sp1.football/?document_srl=39417
http://www.sp1.football/index.php?mid=faq&document_srl=39184
http://www.sp1.football/index.php?mid=faq&document_srl=39347
http://www.sp1.football/index.php?mid=faq&document_srl=39363
http://www.sp1.football/index.php?mid=faq&document_srl=39379
http://www.sp1.football/index.php?mid=faq&document_srl=39395
http://www.sp1.football/index.php?mid=faq&document_srl=39454
http://www.sp1.football/index.php?mid=tr_video&document_srl=39289
https://nextezone.com/index.php?topic=48277.0
https://nextezone.com/index.php?topic=48278.0
https://prelease.club/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8/
https://prelease.club/%d1%8d%d1%84%d0%b8%d1%80-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd/
https://sanp.pro/%d1%8d%d1%84%d0%b8%d1%80-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2018/
https://www.amazingworldtop.com/entretenimiento/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%80%d1%83%d1%81%d1%81%d0%ba/
https://www.runcity.org/forum/index.php?action=profile;u=75177
https://www.shaiyax.com/index.php?topic=342999.0
https://www.shaiyax.com/index.php?topic=343003.0
https://www.shaiyax.com/index.php?topic=343004.0
https://www.thedezlab.com/lab/community/index.php?topic=2029.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.studyxray.com/Sangdam/54316
http://xn----3x5er9r48j7wemud0a387h.com/news/11651
http://ye-dream.com/qa/41822
http://ye-dream.com/qa/42105
http://yoriyorifood.com/xxxx/spacial/36934
http://yoriyorifood.com/xxxx/spacial/37079
http://yoriyorifood.com/xxxx/spacial/37111
http://yoriyorifood.com/xxxx/spacial/37127
http://zanoza.h1n.ru/2019/05/16/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ify-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5/
https://esel.gist.ac.kr/esel2/board_hmgj23/24398
https://esel.gist.ac.kr/esel2/board_hmgj23/24525
https://esel.gist.ac.kr/esel2/board_hmgj23/24557
http://www.sp1.football/?document_srl=31892
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=132769
http://ye-dream.com/?document_srl=12550
http://0433.net/junggo/6034
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-o7-q0-%d0%b8%d0%b3%d1%80/
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile;u=33518
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3267227
http://www.josephmaul.org/menu41/28357
http://www.theparrotcentre.com/forum/index.php?topic=505497.0
https://mencoin.net/talk_fm/7127
http://divespace.co.kr/board/1355
https://www.limscave.com/forum/viewtopic.php?t=33961
http://www.lozic.co.kr/gallery/21893
http://www.theparrotcentre.com/forum/index.php?topic=485788.0
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=123271
http://foxy-tv.com/?document_srl=19989
http://foxy-tv.com/index.php?mid=board_arik22&document_srl=19963
http://foxy-tv.com/index.php?mid=board_arik22&document_srl=19976
http://hesedforu.com/hesed-board/?document_srl=4243
http://hesedforu.com/hesed-board/question/4227
http://hesedforu.com/hesed-board/question/4266
http://jejucctv.co.kr/?document_srl=1468
http://jejucctv.co.kr/A5/1463
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://mobility-corp.com/index.php/component/k2/itemlist/user/2511889
http://153.120.114.241/eso/index.php/16879308-vetrenyj-hercai-16-seria-oniq-vetrenyj-hercai-16-seria
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/198935
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=493836
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/17588
https://prelease.club/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ie7z/
http://euromouleusinage.com/index.php/component/k2/itemlist/user/138199
http://jiquilisco.org/index.php/component/k2/itemlist/user/4446
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=619165
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1682057
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1681986
http://wigalseguros.com.br/component/users/?task=user&view=itemlist&id=6650
http://withinfp.sakura.ne.jp/eso/index.php/17040858-efir-grand-2-sezon-21-seria-t0-grand-2-sezon-21-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/17041012-smotret-milliardy-4-sezon-10-seria-m8-milliardy-4-sezon-10-seri/0
http://withinfp.sakura.ne.jp/eso/index.php/17041090-smotret-igra-prestolovgame-of-thrones-8-sezon-6-seria-a1-igra-p/0
http://withinfp.sakura.ne.jp/eso/index.php/17041115-serial-smers-11-seria-e1-smers-11-seria/0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/505180
http://www.arunagreen.com/index.php/component/k2/itemlist/user/505422
http://ye-dream.com/qa/44778
http://ye-dream.com/qa/44996
http://zanoza.h1n.ru/2019/05/16/%d1%81%d0%bc%d0%b5%d1%80%d1%88-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-16-05-2019-k9-%d1%81%d0%bc%d0%b5%d1%80%d1%88-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://zanoza.h1n.ru/2019/05/16/%d1%81%d0%bc%d0%b5%d1%80%d1%88-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-16-05-2019-q3-%d1%81%d0%bc%d0%b5%d1%80%d1%88-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=36983
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=37052
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=82410
http://corumotoanahtar.com/component/k2/itemlist/user/3366.html
http://corumotoanahtar.com/component/k2/itemlist/user/3405.html
http://dev.aabn.org.gh/component/k2/itemlist/user/599920
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=98981
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1825826
https://sushilbarali.com.np/QNA/index.php?qa=191089&qa_1=%D0%B7%D0%B0%D0%BA%D0%BE%D0%BD%D0%B0%D0%BC-%D0%B2%D0%BE%D0%B5%D0%BD%D0%BD%D0%BE%D0%B3%D0%BE-%D0%B2%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%B8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-%D0%B7%D0%B0%D0%BA%D0%BE%D0%BD%D0%B0%D0%BC-%D0%B2%D0%BE%D0%B5%D0%BD%D0%BD%D0%BE%D0%B3%D0%BE-%D0%B2%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%B8
http://arunagreen.com/index.php/component/k2/itemlist/user/441896
http://xplorefitness.com/blog/%C2%AB%D1%82%D0%BE%D0%BB%D1%8F-%D1%80%D0%BE%D0%B1%D0%BE%D1%82-5-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-07-05-2019-z7-%C2%AB%D1%82%D0%BE%D0%BB%D1%8F-%D1%80%D0%BE%D0%B1%D0%BE%D1%82-5-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=217255
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/64775
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=764908
http://molweb.ru/groups/xolostyak-9-sezon-10-vypusk-onlajn-v-xoroshem-kachestve-rcxolostyak-9-sezon-10-vypusk-onlajn-v-xoroshem-kachestve90-xolostyak-9-sezon-10-vypusk-onlajn-v-xoroshem-kachestve/
http://k2.akademitelkom.ac.id/component/k2/itemlist/user/300853
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/198880
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1037668
http://mobility-corp.com/index.php/component/k2/itemlist/user/2518887
http://rudraautomation.com/index.php/component/k2/author/119721
http://thermoplast.envolgroupe.com/component/k2/author/65319
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-07-05-2019-w6-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
http://forum.byehaj.hu/index.php?topic=81765.0
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=493241
http://forum.politeknikgihon.ac.id/index.php?topic=25482.0
http://www.arredoufficiomarca.com/index.php/component/k2/itemlist/user/1566623
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=606932
http://www.vivelabmanizales.com/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-24-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hvdd-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-24-%d1%81%d0%b5%d1%80%d0%b8/
http://necinsurance.co.zw/component/k2/itemlist/user/19248.html
http://jesusandmarypatna.com/index.php/component/k2/itemlist/user/3371250
http://www.ekemoon.com/143331/052320191205/
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=269069
http://withinfp.sakura.ne.jp/eso/index.php/16884514-uristy-13-seria-v-efire-uristy-13-seria/0
http://smartacity.com/component/k2/itemlist/user/23010
http://www.ekemoon.com/143509/050020194006/
http://xn--ok1bpqi43ahtb.net/board_eASW07/13383
http://www.jesusonly.life/calendar/13863
http://www.deliberarchia.org/forum/index.php?topic=1018545.0
http://1vh.info/index.php?topic=23529.0
http://vhost12299.cpsite.ru/319586-bogatye-i-bednye-zengin-ve-yoksul-7-seria-p5-bogatye-i-bednye-z
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=30835
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=11197.0
http://lucky.kidspann.net/index.php?mid=qna&document_srl=4695
http://www.lozic.co.kr/gallery/9516
http://shinhwaair2017.cafe24.com/issue/104885
http://www.deliberarchia.org/forum/index.php?topic=1023961.0
http://atemshow.com/atemfair_domestic/23514
http://callman.co.kr/index.php?mid=qa&document_srl=19588
http://callman.co.kr/index.php?mid=qa&document_srl=19598
http://d-tube.info/?document_srl=224115
http://d-tube.info/board_jvyO69/224072
http://emjun.com/?document_srl=55564
http://emjun.com/index.php?mid=hangtotal&document_srl=55414
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=35464
http://xn--ok1bpqi43ahtb.net/board_eASW07/79538
http://xn--ok1bpqi43ahtb.net/board_eASW07/79603
http://xn--ok1bpqi43ahtb.net/board_eASW07/79651
http://ye-dream.com/qa/61554
http://ye-dream.com/qa/61559
http://ye-dream.com/qa/61612
http://ye-dream.com/qa/61621
http://ye-dream.com/qa/61647
http://ye-dream.com/qa/61664
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=39836
http://www.m1avio.com/?option=com_k2&view=itemlist&task=user&id=3696733
http://www.theocraticamerica.org/forum/index.php/topic,40599.0.html
http://www.theocraticamerica.org/forum/index.php?topic=40614.0
http://zanoza.h1n.ru/2019/05/15/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-anons-yj%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=21546
http://adopt10plus.com/groups/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d0%bd%d0%be%d0%b2%d0%be%d1%81%d1%82%d0%b5%d0%b9-fw%d1%85/
http://www.m1avio.com/index.php/component/k2/itemlist/user/3696367
http://www.theocraticamerica.org/forum/index.php?topic=40633.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2635825
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=82228
http://udrpsucks.com/blog/?p=725
http://www.comfybigsize.com/?option=com_k2&view=itemlist&task=user&id=25775
http://xplorefitness.com/blog/%D0%BD%D0%BE%D0%B2%D0%B8%D0%BD%D0%BA%D0%B0-%D0%B3%D1%80%D0%B0%D0%BD%D0%B4-2-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-21-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-g0-%D0%B3%D1%80%D0%B0%D0%BD%D0%B4-2-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-21-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://hotelnomadpalace.com/component/k2/itemlist/user/20595
http://withinfp.sakura.ne.jp/eso/index.php/17005341-hdvideo-holostak-9-sezon-10-vypusk-w6-holostak-9-sezon-10-vypus/0
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=81304
http://euromouleusinage.com/?option=com_k2&view=itemlist&task=user&id=130023
http://euromouleusinage.com/index.php/component/k2/itemlist/user/130193
http://withinfp.sakura.ne.jp/eso/index.php/17005381-v-efire-cuzaa-zizn-cuze-zitta-4-seria-y3-cuzaa-zizn-cuze-zitta-/0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4778289
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/62669
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=284142
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1146746
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3410455
http://married.dike.gr/index.php/component/k2/itemlist/user/54698
http://mediaville.me/index.php/component/k2/itemlist/user/238354
http://mobility-corp.com/index.php/component/k2/itemlist/user/2547829
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/79027
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/220821
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=10825
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1658574
http://forum.politeknikgihon.ac.id/index.php?topic=22404.0
https://khuyenmaikk13.info/index.php?topic=182876.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/568774
http://arunagreen.com/index.php/component/k2/itemlist/user/433438
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1561174
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=36423
https://tg.vl-mp.com/index.php?topic=1348763.0
http://sdsn.develop.cinfores.com/?option=com_k2&view=itemlist&task=user&id=184555
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1561028
http://smartacity.com/component/k2/itemlist/user/22471
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/185338
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1636810
http://www.deliberarchia.org/forum/index.php?topic=974399.0
http://www2.yasothon.go.th/smf/index.php?topic=159.155865
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/293406
http://webp.online/index.php?topic=49038.0
http://mediaville.me/index.php/component/k2/itemlist/user/212204
http://153.120.114.241/eso/index.php/16875208-ne-otpuskaj-mou-ruku-elimi-birakma-40-seria-szul-ne-otpuskaj-mo
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2514485
http://www.m1avio.com/index.php/component/k2/itemlist/user/3632849
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=28665.0
http://topitop.kz/index.php/component/k2/itemlist/user/76456
http://menulisilmiah.net/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wo4%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=327445
http://xn----3x5er9r48j7wemud0a387h.com/news/5739
http://xn----3x5er9r48j7wemud0a387h.com/news/5755
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=9420
https://esel.gist.ac.kr/esel2/?document_srl=12109
https://reficulcoin.com/index.php?topic=41443.0
https://reficulcoin.com/index.php?topic=41446.0
https://test.baseyou21.kr/?document_srl=14428
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=14412
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=43769
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=43802
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=43812
http://1vh.info/index.php?topic=29067.0
http://1vh.info/index.php?topic=29072.0
http://www.sp1.football/?document_srl=38684
http://www.sp1.football/?document_srl=38857
http://www.sp1.football/?document_srl=38974
http://www.sp1.football/index.php?mid=faq&document_srl=38615
http://www.sp1.football/index.php?mid=faq&document_srl=38781
http://www.sp1.football/index.php?mid=faq&document_srl=38872
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=32189.0
http://yeonsen.com/?document_srl=9353
http://smartengbiz.com/s1/32330
http://xn----3x5er9r48j7wemud0a387h.com/?document_srl=3962
http://shinhwaair2017.cafe24.com/issue/109695
http://lucky.kidspann.net/index.php?mid=qna&document_srl=10489
http://www.josephmaul.org/menu41/35506
http://hyeonjun.co.kr/menu3/12174
http://sextomariotienda.com/blog/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p0-o5-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://www.xn--xy1b45gp4h0qgb9g.com/sub_09_05/6016
https://khuyenmaikk13.info/index.php?topic=190369.0
http://www.hoonthaitoday.com/forum/index.php?topic=208459.0
https://danceplanet.se/commodore/index.php?topic=20469.0
http://www.critico-expository.com/forum/index.php?topic=6895.0
https://www.limscave.com/forum/viewtopic.php?f=6&t=31838&view=print
http://forum.byehaj.hu/index.php?topic=86962.0
https://nextezone.com/index.php?topic=42258.0
https://nextezone.com/index.php?topic=46846.0
http://otitismediasociety.org/forum/index.php?topic=149775.0
https://prelease.club/hd-video-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o7-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://otitismediasociety.org/forum/index.php?topic=150447.0
http://myrechockey.com/forums/index.php?topic=98535.0
http://help.stv.ru/index.php?PHPSESSID=ec15daab464a052805a9603658e75c3b&topic=139457.0
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-x5-o7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4/
http://www.tekparcahdfilm.com/forum/index.php?topic=46986.0
https://danceplanet.se/commodore/index.php?topic=21441.0
https://sanp.pro/%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p8-%d1%81%d0%bb/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81-16/
http://www.hoonthaitoday.com/forum/index.php?topic=248234.0
http://www.critico-expository.com/forum/index.php?topic=8293.0
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b6-c4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://www.deliberarchia.org/forum/index.php?topic=1020764.0
http://forum.elexlabs.com/index.php?topic=31345.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/((hd))-aka-ak-3-eo-1-e-motet-oa-ata-oa/?PHPSESSID=4kkfl0l4fu9ds04tedgi5bt9a5
http://forums.abs-cbn.com/welcome-back-kapamilya%21/((hd))-aka-ak-3-eo-10-e-motet-oa-lostfilm/?PHPSESSID=6ft15mn39kegeo7kiiimn443u5
http://jnk-ent.jp/index.php?mid=gallery&document_srl=18813
http://jnk-ent.jp/index.php?mid=gallery&document_srl=18853
http://poselokgribovo.ru/forum/index.php?topic=793998.0
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=22592
http://roikjer.com/forum/index.php?PHPSESSID=p2krg36p53lt8rqlm89a1orfb0&topic=880440.0
http://sextomariotienda.com/blog/hd-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80-2/
http://twitchdevs.com/c/other/()-rasskaz-sluzhanki-3-sezon-8-seriya-2017/
http://twitchdevs.com/c/other/smotret-rasskaz-sluzhanki-3-sezon-12-seriya-na-russkom-yazyke/
http://vervetama.com/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8-3/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8e%d1%82%d1%83%d0%b1/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%83%d0%ba%d1%80%d0%b0%d0%b8%d0%bd/
http://vervetama.com/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%84%d0%b8%d0%bb%d1%8c%d0%bc-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd/
http://vervetama.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5-3/
http://vervetama.com/hd-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb/
http://vervetama.com/hd-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%82%d0%be%d1%80%d1%80%d0%b5/
http://vervetama.com/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd/
http://vervetama.com/hd-video-%d1%84%d0%b8%d0%bb%d1%8c%d0%bc-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://vtservices85.fr/smf2/index.php?PHPSESSID=c59029788875e944064a69eeb9337e3a&topic=245686.0
http://www.deliberarchia.org/forum/index.php?topic=1044756.0
http://www.ekemoon.com/196883/050520195016/
http://HyUa.1fps.icu/l/szIaeDC
http://hyundeok.iptime.org/zbxe/index.php?mid=family&document_srl=35628
http://iamking.net/board/13938
http://jejucctv.co.kr/A5/12556
http://joinbohum.kr/board/18378
http://joinbohum.kr/board/18431
http://khapthanam.co.kr/g1/24343
http://pkgersang.dothome.co.kr/?document_srl=2488
http://sd-xi.co.kr/g1/11473
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=11044
http://skangseo.org/xe/board_Atnj46/35722
http://toeden.co.kr/Product_new/15448
http://toeden.co.kr/Product_new/15474
http://tototoday.com/board_oRiY52/26107
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=17168
http://ariji.kr/?document_srl=800866
http://ariji.kr/?document_srl=800876
http://atemshow.com/atemfair_domestic/29590
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=63022
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=63053
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=63103
http://bebopindia.com/notcie/85449
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=14021
http://roikjer.com/forum/index.php?topic=835455.0
http://forum.politeknikgihon.ac.id/index.php?topic=33439.0
http://www.tessabannampad.go.th/webboard/index.php?topic=198200.0
http://forum.politeknikgihon.ac.id/index.php?topic=31381.0
https://members.fbhaters.com/index.php?topic=83270.0
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=097d30d9403a6d019cc0fcf3f05fc8fb&topic=1678.0
http://forum.elexlabs.com/index.php?topic=23202.0
http://roikjer.com/forum/index.php?PHPSESSID=sn0703meumol9lm4bgg43o8hi2&topic=841219.0
http://www.hoonthaitoday.com/forum/index.php?topic=203366.0
http://ru-realty.com/forum/index.php?topic=479461.0
http://menulisilmiah.net/10-05-2019-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-3/
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=32603.0
http://www.hoonthaitoday.com/forum/index.php?topic=224559.0
http://myrechockey.com/forums/index.php?topic=96120.0
http://HyUa.1fps.icu/l/szIaeDC
http://smartacity.com/component/k2/itemlist/user/31141
http://laspoltrina.it/component/k2/itemlist/user/1408126
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/693001
http://corumotoanahtar.com/component/k2/itemlist/user/1154.html
http://roikjer.com/forum/index.php?PHPSESSID=9e1ua33ruocv7qnpna0ne8k0i3&topic=862370.0
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=824521
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/716071
http://ru-realty.com/forum/index.php?topic=510549.0
http://www.vivelabmanizales.com/%d0%b3%d1%80%d0%b0%d0%bd%d0%b4-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ig9e-%d0%b3%d1%80%d0%b0%d0%bd%d0%b4-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5/
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=75280
http://socialfbwidgets.com/component/k2/itemlist/user/13453.html
http://koushatarabar.com/index.php/component/k2/itemlist/user/1314400
http://socialfbwidgets.com/component/k2/itemlist/user/13517.html
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?action=profile;u=622775
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3579509
http://esperanzazubieta.com/index.php/component/k2/itemlist/user/96500
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=581632
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=118333
http://www.ekemoon.com/143717/050220193806/
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1870114
http://gtupuw.org/index.php/component/k2/itemlist/user/1869770
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=283854
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/283823
http://haniel.ir/index.php/component/k2/itemlist/user/86500
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1145456
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1145820
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1145847
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1145851
http://israengineering.com/index.php/component/k2/itemlist/user/1145853
http://married.dike.gr/index.php/component/k2/itemlist/user/54618
http://mediaville.me/index.php/component/k2/itemlist/user/238018
http://mediaville.me/index.php/component/k2/itemlist/user/238038
http://mediaville.me/index.php/component/k2/itemlist/user/238095
http://mobility-corp.com/index.php/component/k2/itemlist/user/2547187
http://www.digitalbul.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g5-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6/
http://haniel.ir/index.php/component/k2/itemlist/user/90573
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1703281
http://www.ekemoon.com/194057/051520193615/
http://www.critico-expository.com/forum/index.php?topic=9581.0
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=552733
http://zsmr.com.ua/index.php/component/k2/itemlist/user/552730
https://cfcestradareal.com.br/?option=com_k2&view=itemlist&task=user&id=16500
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/62956
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3351836
https://turimex.mx.solemti.net/component/k2/itemlist/user/1018
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1413680
http://www.m1avio.com/index.php/component/k2/itemlist/user/3691423
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=823963
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/260342
https://cfcestradareal.com.br/?option=com_k2&view=itemlist&task=user&id=20031
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=39598
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=39621
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=39512
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=39522
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=39537
http://2872870.com/est/3923
http://2872870.com/est/3933
http://2872870.com/est/3938
http://ariji.kr/?document_srl=778196
http://ariji.kr/?document_srl=778219
http://forum.kopkargobel.com/index.php?topic=8024.0
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yp7-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-32/
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f8-u1-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
https://sanp.pro/%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-e0-%d1%81%d0%bb%d1%83/
http://www.ekemoon.com/165541/051820190709/
http://help.stv.ru/index.php?PHPSESSID=30ce8bad0b263c24fff6f93fdbf695a3&topic=139686.0
http://forum.kopkargobel.com/index.php?topic=8124.0
http://dailypatriot.net/phpbb/viewtopic.php?t=409691
http://universalcommunity.se/Forum/index.php?topic=1270.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=31516.0
https://khuyenmaikk13.info/index.php?topic=191258.0
http://demo.caribe.vps-private.net/blog/milliardy-4-sezon-13-seriya-watch-f8-s7-milliardy-4-sezon-13-seriya-milliardy-4-sezon-13-seriya
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p6-v4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://vtservices85.fr/smf2/index.php?PHPSESSID=f8ca818ac1bb4d4f3da87966f4f36404&topic=214572.0
http://roikjer.com/forum/index.php?topic=854313.0
http://HyUa.1fps.icu/l/szIaeDC
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=83021
http://www.vivelabmanizales.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%be%d0%b9-%d0%b0%d1%80%d1%82%d0%b8%d1%81%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mj3o-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%be%d0%b9-%d0%b0%d1%80%d1%82/
http://soc-human.kz/index.php/component/k2/itemlist/user/1673808
http://xplorefitness.com/blog/%D0%BD%D0%BE%D0%B2%D0%B8%D0%BD%D0%BA%D0%B0-%D1%82%D0%B0%D1%94%D0%BC%D0%BD%D0%B8%D1%86i-99-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-y6-%D1%82%D0%B0%D1%94%D0%BC%D0%BD%D0%B8%D1%86i-99-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=326749
http://www.vivelabmanizales.com/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zq9b-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.deliberarchia.org/forum/index.php?topic=1039404.0
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/62460
http://seoksoononly.dothome.co.kr/qna/860877
http://jiquilisco.org/?option=com_k2&view=itemlist&task=user&id=6896
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3808401
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1334814
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1006375
http://withinfp.sakura.ne.jp/eso/index.php/16887255-serial-sluga-naroda-3-sezon-5-seria-z4-sluga-naroda-3-sezon-5-s/0
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1604725
http://healthyteethpa.org/component/k2/itemlist/user/5334116
http://www.ekemoon.com/143245/052220192805/
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/61392
http://fbpharm.net/index.php/component/k2/itemlist/user/15090
https://tg.vl-mp.com/index.php?topic=1332615.0
http://soc-human.kz/index.php/component/k2/itemlist/user/1629987
http://molweb.ru/groups/xolostyak-9-sezon-vypusk-10-ceremoniya-roz-ehxolostyak-9-sezon-vypusk-10-ceremoniya-roz40-xolostyak-9-sezon-vypusk-10-ceremoniya-roz/
http://koushatarabar.com/index.php/component/k2/itemlist/user/1331632
http://seoksoononly.dothome.co.kr/qna/796548
http://forum.digamahost.com/index.php?topic=109414.0
http://bitpark.co.kr/board_IzjM66/3740814
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=681779.0
http://teambuildingpremium.com/forum/index.php?topic=777286.0
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3705697
http://zanoza.h1n.ru/2019/05/14/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81-3/
http://withinfp.sakura.ne.jp/eso/index.php/17046851-hd-cuzaa-zizn-cuze-zitta-7-seria/0
http://indiefilm.kr/xe/board/26359
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=2016453
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/20093
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=51297
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=325070
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/64248
http://ye-dream.com/?document_srl=42307
http://smartacity.com/component/k2/itemlist/user/38935
http://socialfbwidgets.com/component/k2/itemlist/user/13074.html
http://www.aloeverasas.it/index.php/component/k2/itemlist/user/18624
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=316422
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=42286
http://mobility-corp.com/index.php/component/k2/itemlist/user/2509182
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=14041
http://www.vivelabmanizales.com/hd-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-o6-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://ye-dream.com/qa/42855
http://zanoza.h1n.ru/2019/05/16/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-16-05-2019-b9-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
http://zanoza.h1n.ru/2019/05/16/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-96-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-16-05-2019-m0-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94/
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=82378
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=82379
http://www.jesusonly.life/calendar/49641
http://www.jesusonly.life/calendar/49684
http://www.jesusonly.life/calendar/49707
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=13503
http://xn--ok1bpqi43ahtb.net/board_eASW07/32441
http://xn--ok1bpqi43ahtb.net/board_eASW07/32462
http://xn--ok1bpqi43ahtb.net/board_eASW07/32571
http://xn--ok1bpqi43ahtb.net/board_eASW07/32593
http://8.droror.co.il/uncategorized/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jp6-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://eugeniocolazzo.it/forum/index.php?topic=134480.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=2e5d4f4663a290228080f9e0842ea39c&topic=244985.0
https://nextezone.com/index.php?action=profile;u=5370
https://nextezone.com/index.php?action=profile;u=7689
http://agiteshop.com/xe/qa/1034
http://ajincomp.godohosting.com/board_STnh82/35844
http://apt2you2.cafe24.com/g1/493
http://www.theocraticamerica.org/forum/index.php?topic=39632.0
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/gumdanapt/4369
http://xn--ok1bpqi43ahtb.net/board_eASW07/11101
http://xn--ok1bpqi43ahtb.net/board_eASW07/11198
http://ye-dream.com/qa/10009
http://ye-dream.com/qa/10014
http://ye-dream.com/qa/10029
http://ye-dream.com/qa/10039
http://ye-dream.com/qa/9975
http://yoriyorifood.com/xxxx/spacial/11781
http://yoriyorifood.com/xxxx/spacial/11803
http://yoriyorifood.com/xxxx/spacial/11813
https://saltriverbg.com/2019/05/15/%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
https://saltriverbg.com/2019/05/15/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lostfilm/
https://saltriverbg.com/2019/05/15/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-%d1%81%d0%bc%d0%be%d1%82%d1%80-3/
https://saltriverbg.com/2019/05/15/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-3-%d1%81%d0%b5%d0%b7/
https://sanp.pro/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb/
http://HyUa.1fps.icu/l/szIaeDC
http://forum.elexlabs.com/index.php?topic=16485.0
http://eugeniocolazzo.it/forum/index.php?topic=125290.0
https://khuyenmaikk13.info/index.php?topic=188040.0
https://reficulcoin.com/index.php?topic=21496.0
http://danielmillsap.com/forum/index.php?topic=993321.0
http://www.ofqj.org/hebergementfrance/4-12-c6-l9-4-12-4-12
https://prelease.club/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fc0-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://prelease.club/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ka6-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-147-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.remify.app/foro/index.php?topic=245580.0
https://members.fbhaters.com/index.php?topic=83128.0
https://danceplanet.se/commodore/index.php?topic=24782.0
https://prelease.club/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-t3-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://eugeniocolazzo.it/forum/index.php?topic=106488.0
https://khuyenmaikk13.info/index.php?topic=188367.0
http://sexfork.com/uncategorized/ertugrul-149-seriya-fz0-ertugrul-149-seriya/
http://www.hoonthaitoday.com/forum/index.php?topic=207802.0
https://nextezone.com/index.php?topic=43530.0
https://www.gizmoarticle.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w2-w2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://vervetama.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-e2-v8-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
https://members.fbhaters.com/index.php?topic=86200.0
http://roikjer.com/forum/index.php?PHPSESSID=p5meetm2o3n5otiglqbu98nof3&topic=839270.0
http://122.154.49.125/Forum/index.php?topic=153.0
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f9-e6-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://xn--l1adgmc.xn----9sbdbmdznsj5c5bxd7b.xn--p1ai/index.php?topic=10471.0
http://blog.ptpintcast.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-to6-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l9-i4-%d0%b8%d0%b3%d1%80/
http://teambuildingpremium.com/forum/index.php?topic=801032.0
http://www.sharmaraco.com/blog/%C2%AB%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-watch%C2%BB-d7-j8-%C2%AB%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-13
http://www.popolsku.fr.pl/forum/index.php?topic=382618.0
https://prelease.club/hd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n3-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://forums.abs-cbn.com/welcome-back-kapamilya%21/'a-etoo-2019-8-eo-3-e'-a-etoo-2019-8-eo-3-e-d2q9/msg560343/
https://prelease.club/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-et0-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-149-%d1%81%d0%b5%d1%80%d0%b8/
http://vtservices85.fr/smf2/index.php?PHPSESSID=2a0401f99a3bb277ceb74cfa93a46c18&topic=219971.0
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d0-q2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://poselokgribovo.ru/forum/index.php?topic=745592.0
http://8.droror.co.il/uncategorized/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pg9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-150-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://members.fbhaters.com/index.php?topic=84652.0
https://worldtaxi.org/2019/05/09/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-n7-z2-%d0%b8%d0%b3%d1%80/
http://www.sharmaraco.com/blog/%C2%AB%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-10-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-m0-v9-%C2%AB%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-10-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-10-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://HyUa.1fps.icu/l/szIaeDC
http://indiefilm.kr/xe/board/38244
http://iymc.or.kr/pds/85903
http://jejucctv.co.kr/A5/1247
http://themasters.pro/file_01/3596
http://themasters.pro/file_01/3639
http://themasters.pro/file_01/3663
http://themasters.pro/file_01/3677
http://toeden.co.kr/Product_new/1770
http://toeden.co.kr/Product_new/1834
http://toeden.co.kr/Product_new/1844
http://toeden.co.kr/Product_new/1869
http://toeden.co.kr/Product_new/1876
http://toeden.co.kr/Product_new/1882
http://tototoday.com/board_oRiY52/23710
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=38867
http://gxpfactory.net/index.php?mid=Guide&document_srl=4524
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2770423
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2770433
http://haeple.com/index.php?mid=etc&document_srl=47139
http://haeple.com/index.php?mid=etc&document_srl=47161
http://isch.kr/board_PowH60/11944
http://isch.kr/board_PowH60/11961
http://lahch.co.kr/index.php?document_srl=16162&mid=board_jHAP41
http://lucky.kidspann.net/index.php?document_srl=23715&mid=qna
http://poselokgribovo.ru/forum/index.php?topic=796659.0
http://preach.kr/Amharic_Music/4189
http://preach.kr/Amharic_Music/4194
http://HyUa.1fps.icu/l/szIaeDC
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=820066
http://bitpark.co.kr/?document_srl=3809741
http://gtupuw.org/index.php/component/k2/itemlist/user/1912204
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=95587
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=56968
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=8216
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=38117
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=83096
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1061100
http://www.ekemoon.com/149789/050120195207/
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=203490
http://8.droror.co.il/uncategorized/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-of1w-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
http://dev.aabn.org.gh/component/k2/itemlist/user/523292
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3301187
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1337819
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2413178
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1336598
http://moavalve.co.kr/faq/66290
http://moavalve.co.kr/faq/66319
http://ovotecegg.com/component/k2/itemlist/user/159308
http://redgatetech.co/?option=com_k2&view=itemlist&task=user&id=729961
http://research.kiu.ac.kr/?document_srl=58522
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=58582
http://shinilspring.com/board_qsfb01/84495
http://www.hoonthaitoday.com/forum/index.php?topic=289028.0
http://www.siheunglove.com/chulip/26639
http://www.sp1.football/?document_srl=134910
http://www.studyxray.com/Sangdam/87842
http://www.tessabannampad.go.th/webboard/index.php?topic=211201.0
http://www.tessabannampad.go.th/webboard/index.php?topic=211209.0
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=19133
http://forums.abs-cbn.com/welcome-back-kapamilya%21/(a-etoo-(got)-8-eo-3-e)-a-etoo-(got)-8-eo-3-e-q0c7/?PHPSESSID=i9i0jmtg4kd0lbrkpmc0c5a9v5
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80-5/
http://design-381.com/xe/?document_srl=1705
http://sunele.co.kr/board_ReBD97/42157
http://village.lorem.kr/index.php?document_srl=15935&mid=board_xmEJ33
http://wartoby.com/index.php?mid=board_UXUA38&document_srl=3216
http://wixelent.co.kr/xe/ch_notice/15618
http://0433.net/budongsan/30221
http://hyeonjun.co.kr/menu3/3094
http://indiefilm.kr/xe/board/9171
http://indiefilm.kr/xe/board/9176
http://indiefilm.kr/xe/board/9186
http://indiefilm.kr/xe/board/9201
http://indiefilm.kr/xe/board/9206
http://indiefilm.kr/xe/board/9216
http://isch.kr/board_PowH60/2968
http://isch.kr/board_PowH60/2973
http://photogrotto.com/%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-%d0%b4%d0%b0%d1%82%d0%b0-%d0%b2-2/
http://photogrotto.com/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8-7/
http://roikjer.com/forum/index.php?PHPSESSID=gk2r1o87mk6ihqmud6v54ag410&topic=872948.0
http://roikjer.com/forum/index.php?topic=872950.0
http://sextomariotienda.com/blog/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb/
http://twitchdevs.com/c/other/((hd))-rasskaz-sluzhanki-3-sezon-12-seriya-smotret-onlajn-v-horoshem-kachestve/
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=13226
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=13314
http://HyUa.1fps.icu/l/szIaeDC
http://shinilspring.com/board_qsfb01/49385
http://shinilspring.com/board_qsfb01/49527
http://skylinecam.co.kr/photo/47345
http://skylinecam.co.kr/photo/47412
http://www.artangel.co.kr/index.php?document_srl=5512&mid=Activities
http://www.artangel.co.kr/index.php?mid=Activities&document_srl=5555
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=73482
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=73677
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=73716
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=73808
http://www.hsaura.com/license/63304
https://prelease.club/hd-video-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w3-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://roikjer.com/forum/index.php?PHPSESSID=761a7g2ua7t7nq2codt8g2hd04&topic=839404.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-48/
http://www.deliberarchia.org/forum/index.php?topic=999611.0
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5-7/
https://nextezone.com/index.php?action=profile;u=4938
http://forum.elexlabs.com/index.php/topic,19069.0.html
https://danceplanet.se/commodore/index.php?topic=19922.0
http://roikjer.com/forum/index.php?PHPSESSID=681q58fnmpraoj6sk32m92cgh7&topic=836634.0
http://teambuildingpremium.com/forum/index.php?topic=797792.0
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-r9-q1-%d0%b8%d0%b3%d1%80/
http://metropolis.ga/index.php?topic=6483.0
https://worldtaxi.org/2019/05/09/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b3-i6-%d0%b8%d0%b3%d1%80/
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-h3-h9-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
https://reficulcoin.com/index.php?topic=20822.0
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-10/
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-(got)-8-eo-6-e'-a-etoo-(got)-8-eo-6-e-j2a6/?PHPSESSID=e0ogtfsoohb3j9d5ek6f8jfu07
http://roikjer.com/forum/index.php?topic=860135.0
http://HyUa.1fps.icu/l/szIaeDC
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=30088.0
https://forum.shaiyaslayer.tk/index.php?topic=101280.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b9-l3-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
https://reficulcoin.com/index.php?topic=17629.0
http://poselokgribovo.ru/forum/index.php?topic=751934.0
http://www.ekemoon.com/165803/051820195209/
https://reficulcoin.com/index.php?topic=32821.0
http://www.hoonthaitoday.com/forum/index.php?topic=224040.0
https://members.fbhaters.com/index.php?topic=87719.0
http://www.nomaher.com/forum/index.php?topic=13542.0
http://photogrotto.com/%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yx5-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://prelease.club/hd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80/
http://photogrotto.com/%d1%8d%d1%84%d0%b8%d1%80-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%80/
http://photogrotto.com/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80/
http://photogrotto.com/live-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5/
http://photogrotto.com/live-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://photogrotto.com/live-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b4%d0%b0%d1%82%d0%b0-%d0%b2%d1%8b/
http://poselokgribovo.ru/forum/index.php?topic=777304.0
http://poselokgribovo.ru/forum/index.php?topic=777309.0
http://sexfork.com/uncategorized/hd-video-rasskaz-sluzhanki-3-sezon-6-seriya-smotret-onlayn-data-vyihoda/
http://sexfork.com/uncategorized/rasskaz-sluzhanki-3-sezon-data-vyihoda-4-seriya/
http://sextomariotienda.com/blog/%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://sextomariotienda.com/blog/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8/
http://sextomariotienda.com/blog/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8/
http://sextomariotienda.com/blog/live-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%be%d0%bd%d0%bb%d0%b0%d0%b9%d0%bd/
http://twitchdevs.com/c/other/(((efir)))-()-rasskaz-sluzhanki-3-sezon-3-seriya-lostfilm/
http://twitchdevs.com/c/other/((hd))-rasskaz-sluzhanki-3-sezon-7-seriya-smotret-onlajn-lostfilm-iyun-2019/
http://twitchdevs.com/c/other/(-(serial)-)-serial-rasskaz-sluzhanki-3-sezon-smotret-onlajn/
http://twitchdevs.com/c/other/(hd-video)-rasskaz-sluzhanki-3-sezon-7-seriya-3-sezon/
http://twitchdevs.com/c/other/(~v-efire~)-rasskaz-sluzhanki-3-sezon-10-seriya-lostfilm/
http://twitchdevs.com/c/other/live-rasskaz-sluzhanki-3-sezon-1-serial/
http://uberdrivers.net/forum/index.php?topic=266211.0
http://vervetama.com/live-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%89%d0%b5%d0%bd%d0%ba%d0%b8/
http://vervetama.com/live-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-shachiburi/
http://HyUa.1fps.icu/l/szIaeDC
http://highlanderonline.cmshelplive.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rytj-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-18-%d1%81%d0%b5%d1%80%d0%b8/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1389169
http://dcasociados.eu/component/k2/itemlist/user/89091
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/314403
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3355975
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=10456
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1871944
http://proxima.co.rw/index.php/component/k2/itemlist/user/599631
http://bitpark.co.kr/board_IzjM66/3809406
http://bitpark.co.kr/board_IzjM66/3809483
http://teambuildingpremium.com/forum/index.php?topic=795743.0
http://teambuildingpremium.com/forum/index.php?topic=795790.0
http://xplorefitness.com/blog/%C2%AB%D0%B2%D0%B5%D1%82%D1%80%D0%B5%D0%BD%D1%8B%D0%B9-hercai-5-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-qzeb-%C2%AB%D0%B2%D0%B5%D1%82%D1%80%D0%B5%D0%BD%D1%8B%D0%B9-hercai-5-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://xplorefitness.com/blog/%C2%AB%D0%B2%D0%BE%D1%81%D1%81%D0%BE%D0%B5%D0%B4%D0%B8%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5-vuslat-16-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-nofu-%C2%AB%D0%B2%D0%BE%D1%81%D1%81%D0%BE%D0%B5%D0%B4%D0%B8%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5-vuslat-16-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
https://sanp.pro/%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5%d0%bd%d0%b8%d0%b5-vuslat-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hqpd-%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd/
http://mvisage.sk/?option=com_k2&view=itemlist&task=user&id=118271
http://tekagrafica.com.br/index.php/component/k2/itemlist/user/1642621
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1394715
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4893581
http://xplorefitness.com/blog/%C2%AB%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-12-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-12-05-2019-f3-%C2%AB%D0%BC%D0%B8%D0%BB%D0%BB%D0%B8%D0%B0%D1%80%D0%B4%D1%8B-4-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-12-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2613696
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=52545
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=52530
http://dev.aabn.org.gh/component/k2/itemlist/user/572105
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1888572
http://mglpcm.org/board_ETkS12/5011
http://shinhwaair2017.cafe24.com/issue/125999
http://www.datascientist.co.kr/index.php?mid=blog&document_srl=81850
http://www.studyxray.com/Sangdam/40489
http://www.svteck.co.kr/customer_gratitude/18681
http://eugeniocolazzo.it/forum/index.php?topic=134906.0
http://forum.byehaj.hu/index.php?topic=91088.0
http://forum.byehaj.hu/index.php?topic=91092.0
http://uberdrivers.net/forum/index.php?topic=280307.0
http://uberdrivers.net/forum/index.php?topic=280318.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=6384749e6239e756caf3ca9ae3458610&topic=245600.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=743c5010e849a3c5d7606774cebbed0a&topic=245613.0
http://www.tessabannampad.go.th/webboard/index.php?topic=209087.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=701326.0
https://nextezone.com/index.php?action=profile;u=7900
https://nextezone.com/index.php?topic=52569.0
https://nextezone.com/index.php?topic=46635.0
http://metropolis.ga/index.php?topic=6871.0
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile;u=29903
https://prelease.club/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-c4-%d1%81/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-47/
http://www.theocraticamerica.org/forum/index.php?topic=28896.0
http://www.hoonthaitoday.com/forum/index.php?topic=201677.0
https://worldtaxi.org/2019/05/09/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j6-w3-%d0%b8%d0%b3%d1%80/
http://www.nomaher.com/forum/index.php?topic=13488.0
http://forum.elexlabs.com/index.php?topic=23222.0
http://roikjer.com/forum/index.php?PHPSESSID=kdji8rktemqc8nudk8b129thv1&topic=843816.0
http://roikjer.com/forum/index.php?PHPSESSID=fu6abj6dq32g4mmgs4uab3thm7&topic=838978.0
https://nextezone.com/index.php?action=profile;u=5188
http://help.stv.ru/index.php?PHPSESSID=b2ce9ef1a2a1991c26f507c83752cebe&topic=139852.0
http://forum.elexlabs.com/index.php?topic=17324.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoo-(got)-8-eo-5-e-a-etoo-(got)-8-eo-5-e-r4r8/?PHPSESSID=jo5u9af81kg0cpp2jdsutsb2s2
http://roikjer.com/forum/index.php?topic=844537.0
http://teambuildingpremium.com/forum/index.php?topic=794804.0
http://otitismediasociety.org/forum/index.php?topic=155432.0
http://www.ekemoon.com/167191/052220191009/
http://forum.kopkargobel.com/index.php?topic=7148.0
http://HyUa.1fps.icu/l/szIaeDC
https://www.amazingworldtop.com/entretenimiento/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sd6%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://matrixpharm.ru/forum/index.php?PHPSESSID=5hkj5rg6vqpslsi84k38u43bu0&action=profile;u=199703
http://vervetama.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ie0%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-2-%d1%81%d0%b5%d1%80/
http://www.teedinubon.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ig7%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-6-%d1%81%d0%b5%d1%80/
http://corumotoanahtar.com/component/k2/itemlist/user/4205.html
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=341564
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=341632
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=100030
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=99944
http://guiadetudo.com/index.php/component/k2/itemlist/user/12171
http://haniel.ir/index.php/component/k2/itemlist/user/113294
http://jiquilisco.org/index.php/component/k2/itemlist/user/8530
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=38283
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=38288
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3825987
http://married.dike.gr/index.php/component/k2/itemlist/user/65514
http://married.dike.gr/index.php/component/k2/itemlist/user/65523
http://miquirofisico.com/index.php/component/k2/itemlist/user/4161
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=28451
http://zanoza.h1n.ru/2019/05/16/%d1%81%d0%bc%d0%b5%d1%80%d1%88-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-16-05-2019-v8-%d1%81%d0%bc%d0%b5%d1%80%d1%88-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://zanoza.h1n.ru/2019/05/16/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-92-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-16-05-2019-k5-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94/
http://zanoza.h1n.ru/2019/05/16/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-85-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-16-05-2019-j2-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-85-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://zanoza.h1n.ru/2019/05/16/%d1%87%d1%83%d0%b6%d0%b0%d1%8f-%d0%b6%d0%b8%d0%b7%d0%bd%d1%8c-%d1%87%d1%83%d0%b6%d0%b5-%d0%b6%d0%b8%d1%82%d1%82%d1%8f-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-16-05-2019-k2-%d1%87/
http://zanoza.h1n.ru/2019/05/16/%d1%87%d1%83%d0%b6%d0%b0%d1%8f-%d0%b6%d0%b8%d0%b7%d0%bd%d1%8c-%d1%87%d1%83%d0%b6%d0%b5-%d0%b6%d0%b8%d1%82%d1%82%d1%8f-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-16-05-2019-i7-%d1%87%d1%83/
https://www.tedyun.com/xe/index.php?document_srl=154945&mid=gallery
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=155020
https://www.vegasgreentour.com/index.php?document_srl=46697&mid=board_XiHh59
http://bebopindia.com/?document_srl=62545
http://bebopindia.com/notcie/62499
http://otitismediasociety.org/forum/index.php?topic=153867.0
https://akutthjelper.no/members/connie85b11061/
http://www.ofqj.org/hebergementquebec/4-12-u3-t4-4-12-4-12
http://www.tessabannampad.go.th/webboard/index.php?topic=198487.0
http://uberdrivers.net/forum/index.php?topic=246395.0
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5-5/
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=686802.0
http://poselokgribovo.ru/forum/index.php?topic=748092.0
http://myrechockey.com/forums/index.php?topic=95369.0
http://www.theocraticamerica.org/forum/index.php?topic=28109.0
http://www.remify.app/foro/index.php?topic=245151.0
http://partemp.com/en/groups/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b0-f5-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
http://www.critico-expository.com/forum/index.php?topic=9234.0
http://roikjer.com/forum/index.php?topic=854703.0
http://www.theparrotcentre.com/forum/index.php?topic=482653.0
http://forum.kopkargobel.com/index.php?topic=6681.0
http://forum.politeknikgihon.ac.id/index.php?topic=28694.0
http://poselokgribovo.ru/forum/index.php?topic=750580.0
http://ru-realty.com/forum/index.php?PHPSESSID=lchpsn738j1dv8613ca7vm0p64&topic=485194.0
http://www.tessabannampad.go.th/webboard/index.php?topic=203162.0
http://www.ofqj.org/hebergementfrance/4-10-g7-g4-4-10-4-10-watch
http://forum.elexlabs.com/index.php?topic=18528.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=32669.0
https://akutthjelper.no/members/gwen3307428974/
http://haeple.com/index.php?mid=etc&document_srl=27456
http://hyeonjun.co.kr/menu3/14086
http://koais.com/data/598
http://preach.kr/Amharic_Music/1576
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=15545
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=15566
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=15577
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=15587
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=15594
http://ru-realty.com/forum/index.php?PHPSESSID=74js9n1f1rkbh5du4fsmibbeh3&topic=515138.0
http://HyUa.1fps.icu/l/szIaeDC
http://hkmtv.co.kr/board_yKNa34/1139
http://hyeonjun.co.kr/menu3/14993
http://hyeonjun.co.kr/menu3/15022
http://hyundeok.iptime.org/zbxe/index.php?mid=family&document_srl=25728
http://hyundeok.iptime.org/zbxe/index.php?mid=family&document_srl=25739
http://iamking.net/?document_srl=521
http://iamking.net/board/510
http://indiefilm.kr/xe/board/31581
http://indiefilm.kr/xe/board/31605
http://indiefilm.kr/xe/board/31625
http://indiefilm.kr/xe/board/31640
http://jejucctv.co.kr/?document_srl=411
http://jejucctv.co.kr/A5/397
http://joinbohum.kr/board/418
http://joinbohum.kr/board/429
http://joinbohum.kr/board/435
http://forum.elexlabs.com/index.php?topic=23859.0
http://poselokgribovo.ru/forum/index.php?topic=748134.0
https://khuyenmaikk13.info/index.php?topic=189117.0
http://d2bchannel.co.in/blog/2019/05/10/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r4-m7-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://www.theparrotcentre.com/forum/index.php?topic=492293.0
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-w5-v2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://photogrotto.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-l5-q9-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
https://members.fbhaters.com/index.php?topic=85313.0
https://reficulcoin.com/index.php?topic=19309.0
http://www.critico-expository.com/forum/index.php?topic=12612.0
https://reficulcoin.com/index.php?topic=19247.0
https://nextezone.com/index.php?topic=40576.0
http://otitismediasociety.org/forum/index.php?topic=149391.0
https://khuyenmaikk13.info/index.php?topic=188745.0
http://www.popolsku.fr.pl/forum/index.php?topic=20407.58050
http://vtservices85.fr/smf2/index.php?PHPSESSID=9a9a34e23b1f3de4b49fd855e6824131&topic=216330.0
http://help.stv.ru/index.php?PHPSESSID=19f823c5bbc165d1e5bf283ba73f2719&topic=139803.0
http://eugeniocolazzo.it/forum/index.php?topic=106647.0
http://www.remify.app/foro/index.php?topic=281093.0
http://www.ofqj.org/hebergementquebec/4-9-z9-w0-4-9-4-9
http://HyUa.1fps.icu/l/szIaeDC
http://indiefilm.kr/xe/board/53758
http://gallerychoi.com/Exhibition/19278
http://xn----3x5er9r48j7wemud0a387h.com/news/30183
http://haeple.com/index.php?mid=etc&document_srl=29501
http://juroweb.com/xe/juroweb_board/13781
http://www.gforgirl.com/xe/poster/122037
http://thermoplast.envolgroupe.com/component/k2/author/100353
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=68487
http://www.ekemoon.com/198909/051320195916/
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=49544
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=26180
https://saltriverbg.com/2019/05/17/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90qq4%e3%80%91-%d0%b8/
http://www.datascientist.co.kr/?document_srl=51116
https://2002.shyoon.com/board_2002/29552
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=478
http://iamking.net/board/6920
http://indiefilm.kr/xe/board/58703
http://xn----3x5er9r48j7wemud0a387h.com/news/18438
https://esel.gist.ac.kr/esel2/board_hmgj23/6073
http://www.eunhaele.co.kr/xe/board/19015
http://www.hoonthaitoday.com/forum/index.php?topic=274976.0
http://www.taeshinmedia.com/index.php?document_srl=3266025&mid=genealogy_faq
http://yoriyorifood.com/xxxx/spacial/56605
http://jjikduk.net/DATA/23100
http://goldenpowerball2.com/index.php?document_srl=5117&mid=board_Bnby34
http://yoriyorifood.com/xxxx/spacial/29911
http://research.kiu.ac.kr/?document_srl=40884
http://www.theocraticamerica.org/forum/index.php?topic=38653.0
http://www.hsaura.com/noty/113716
http://ekitchen.co.kr/intro/1020281
http://gochon-iusell.co.kr/g1/11407
http://jnk-ent.jp/index.php?mid=gallery&document_srl=24304
http://bethanychurch.kr/?document_srl=16631
http://isch.kr/board_PowH60/3030
http://www.gforgirl.com/xe/poster/139100
http://carand.co.kr/d2/596
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=16094
http://mglpcm.org/board_ETkS12/26128
http://daltso.com/index.php?mid=board_cUYy21&document_srl=15840
http://yoriyorifood.com/xxxx/spacial/53978
http://khapthanam.co.kr/g1/35452
http://preach.kr/Amharic_Music/4367
http://www.svteck.co.kr/customer_gratitude/32791
http://foxy-tv.com/index.php?mid=board_xNxV93&document_srl=50667
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=38838
http://indiefilm.kr/xe/board/5664
http://forum.elexlabs.com/index.php?topic=29455.0
http://HyUa.1fps.icu/l/szIaeDC
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/222099
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2327065
http://smartacity.com/component/k2/itemlist/user/54474
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3677832
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4835035
http://www.critico-expository.com/forum/index.php?topic=13893.0
http://www.critico-expository.com/forum/index.php?topic=13896.0
http://www.crnmedia.es/component/k2/itemlist/user/87098
http://www.digitalbul.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-kb%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81/
http://www.remify.app/foro/index.php?topic=316738.0
http://www.teedinubon.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-al%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81/
http://forum.byehaj.hu/index.php?topic=82020.0
http://bitpark.co.kr/?document_srl=3780001
http://seoksoononly.dothome.co.kr/qna/764158
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=492453
http://c3isecurity.com.br/?option=com_k2&view=itemlist&task=user&id=480022
http://batubersurat.com/index.php/component/k2/itemlist/user/46141
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=47260
http://arunagreen.com/index.php/component/k2/itemlist/user/446261
https://lucky28003.nl/forum/index.php?topic=10417.0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=316631
http://www.sp1.football/index.php?mid=faq&document_srl=177377
http://www.sp1.football/index.php?mid=faq&document_srl=177390
http://www.svteck.co.kr/customer_gratitude/36370
http://www.svteck.co.kr/customer_gratitude/36578
http://www.taeshinmedia.com/?document_srl=3292080
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3292051
http://www.teedinubon.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-17-05-2019-l3-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2-%d1%81%d0%b5%d1%80/
http://www.tunes-interiors.com/UserProfile/tabid/81/userId/8564702/Default.aspx
http://xn----3x5er9r48j7wemud0a387h.com/news/26257
http://mediaville.me/index.php/component/k2/itemlist/user/248435
http://www.ekemoon.com/183287/051720190413/
http://ovotecegg.com/component/k2/itemlist/user/126656
https://prelease.club/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-1-pq%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=37852
http://ye-dream.com/?document_srl=24542
http://cafe.dokseosil.co.kr/?document_srl=39994
http://moavalve.co.kr/faq/13606
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4866614
http://www.vivelabmanizales.com/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r6-%d1%82%d0%be%d0%bb%d1%8f/
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=28748.0
http://mjbosch.com/index.php/component/k2/itemlist/user/81635
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7303711
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/222614
http://www.vivelabmanizales.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d0%bf%d0%be%d0%bb%d0%bd%d0%be%d1%81%d1%82%d1%8c%d1%8e-dz/
http://macdistri.com/index.php/component/k2/itemlist/user/309950
http://arunagreen.com/index.php/component/k2/itemlist/user/420977
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4861994
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/475848
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1362920
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1008726
http://withinfp.sakura.ne.jp/eso/index.php/16875910-vetrenyj-hercai-24-seria-jagt-vetrenyj-hercai-24-seria
http://community.viajar.tur.br/index.php?p=/discussion/57479/vetrenyy-hercai-20-seriya-yapo-vetrenyy-hercai-20-seriya
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4838074
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2563289
http://jnk-ent.jp/index.php?mid=gallery&document_srl=10847
http://hayoonbin.com/index.php?mid=Video2&document_srl=1385
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-v7-g8-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
https://sanp.pro/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80-2/
http://haeple.com/index.php?mid=etc&document_srl=55879
http://gallerychoi.com/Exhibition/27728
http://hyeonjun.co.kr/menu3/27035
http://myrechockey.com/forums/index.php?topic=99390.0
http://www.ekemoon.com/198283/051120193216/
http://smartengbiz.com/s1/29480
http://wartoby.com/index.php?mid=board_UXUA38&document_srl=2340
http://www.hoonthaitoday.com/forum/index.php?topic=277773.0
http://skylinecam.co.kr/photo/70227
http://www.theocraticamerica.org/forum/index.php?topic=43715.0
http://foxy-tv.com/index.php?mid=board_aYWf51&document_srl=48812
http://www.hsaura.com/noty/106277
http://5starcoffee.co.kr/board_EBXY17/6190
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=6265
http://warmfund.net/p/index.php?mid=financing&document_srl=125179
https://nextezone.com/index.php?topic=54670.0
http://www.deliberarchia.org/forum/index.php?topic=1026810.0
http://yeonsen.com/?document_srl=2192
http://www.artangel.co.kr/index.php?mid=Activities&document_srl=14672
https://theprodigy.info/forum/index.php?topic=29470.0
http://skangseo.org/xe/?document_srl=21128
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=20689
http://wartoby.com/index.php?mid=board_UXUA38&document_srl=4492
http://jjikduk.net/DATA/45121
http://goldenpowerball2.com/index.php?document_srl=26610&mid=board_Nutq11
http://haeple.com/index.php?mid=etc&document_srl=24805
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=43111
http://yoriyorifood.com/xxxx/spacial/5859
http://2872870.com/est/4822
http://www.gforgirl.com/xe/poster/69662
http://www.generalwalker.org/board_Zyyd91/2537
http://xn--ok1bpqi43ahtb.net/board_EkDG82/44219
http://uberdrivers.net/forum/index.php?topic=289824.0
http://HyUa.1fps.icu/l/szIaeDC
http://wartoby.com/index.php?mid=board_UXUA38&document_srl=4949
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/4949
http://forum.byehaj.hu/index.php?topic=90132.0
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=135556
http://yooseok.com/board_BkvT46/314813
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=27666
http://mglpcm.org/board_ETkS12/21941
http://www.hyunjindc.com/qna/481
http://www.teedinubon.com/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8-2/
http://www.artangel.co.kr/index.php?mid=Activities&document_srl=8044
http://hyeonjun.co.kr/menu3/48817
http://hyundeok.iptime.org/zbxe/index.php?mid=family&document_srl=36173
http://sextomariotienda.com/blog/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-a0-z2-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=73701
https://www.thedezlab.com/lab/community/index.php/topic,4583.0.html
http://goldenpowerball2.com/?document_srl=69351
http://udrpsucks.com/blog/?p=503
http://isch.kr/board_PowH60/633
http://xn--ok1bpqi43ahtb.net/board_eASW07/86179
http://forum.kopkargobel.com/index.php?topic=11051.0
http://e-educ.net/Forum/index.php?topic=11746.0
http://ye-dream.com/qa/61030
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=6238
http://jnk-ent.jp/index.php?mid=gallery&document_srl=34295
http://hesedforu.com/hesed-board/question/1858
https://saltriverbg.com/2019/05/16/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80-9/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5-14/
http://luvharmony.com/board_Ruhq46/2376
http://jnk-ent.jp/index.php?mid=gallery&document_srl=48447
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=92885
http://constellation.kro.kr/board_kbku73/1147
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/news/2603
http://isch.kr/board_PowH60/9054
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/brand/16165
http://HyUa.1fps.icu/l/szIaeDC
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=748652
http://warmfund.net/p/index.php?document_srl=103042&mid=financing
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3291849
http://www.golden-nail.co.kr/press/60617
http://shinilspring.com/?document_srl=78112
http://ariji.kr/?document_srl=788473
http://shinhwaair2017.cafe24.com/issue/167077
http://ye-dream.com/qa/29532
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=35856
http://xn--ok1bpqi43ahtb.net/board_eASW07/24816
http://www.golden-nail.co.kr/?document_srl=44996
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-etoogame-of-thrones-8-eo-2-e-a-etoogame-of-thrones-8-eo-2-e-q9i5/?PHPSESSID=s5sb3d9ipihp4jr9oaji4qau77
http://skylinecam.co.kr/photo/102854
http://nnkumw.org/xe/index.php?mid=board_yNQm00&document_srl=12494
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=28423
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2779626
http://khapthanam.co.kr/g1/8082
http://www.golden-nail.co.kr/press/54931
http://emjun.com/index.php?mid=hangtotal&document_srl=6996
http://foxy-tv.com/index.php?mid=board_aYWf51&document_srl=50702
http://shinhwaair2017.cafe24.com/issue/154922
http://www.studyxray.com/Sangdam/60438
http://joinbohum.kr/board/29452
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/?document_srl=4167
http://mglpcm.org/board_ETkS12/11037
https://betshin.com/Story/12232
http://gochon-iusell.co.kr/?document_srl=780
http://bethanychurch.kr/board_vpkl62/10329
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3262888
http://jnk-ent.jp/index.php?mid=gallery&document_srl=24765
http://xn--9m1b83j39hz6exwonmf.com/board_IYPe43/492376
http://hyeonjun.co.kr/menu3/12790
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=13539
http://0433.net/junggo/37393
http://daltso.com/index.php?document_srl=13093&mid=board_cUYy21
http://www.sp1.football/index.php?mid=tr_video&document_srl=138218
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=56538
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=845
http://shinhwaair2017.cafe24.com/issue/113439
http://isch.kr/board_PowH60/7310
http://HyUa.1fps.icu/l/szIaeDC
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=4397
https://www.shaiyax.com/index.php?topic=336546.0
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1872395
http://myrechockey.com/forums/index.php?topic=100484.0
http://www.vivelabmanizales.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ne5d-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
http://www.ekemoon.com/168261/050020195910/
http://menulisilmiah.net/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-u0-%d1%82%d0%be%d0%bb%d1%8f/
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=330349
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=771013
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/5141
http://indiefilm.kr/xe/board/31809
https://sanp.pro/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-81-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xdpq-%d0%bd%d0%b5%d0%b2/
http://thermoplast.envolgroupe.com/component/k2/author/86269
http://www.theocraticamerica.org/forum/index.php?topic=29064.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2625976
http://arunagreen.com/index.php/component/k2/itemlist/user/506062
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/524001
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=38716
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=38823
http://fbpharm.net/index.php/component/k2/itemlist/user/38768
http://jiquilisco.org/index.php/component/k2/itemlist/user/4552
http://proxima.co.rw/index.php/component/k2/itemlist/user/619364
http://robocit.com/index.php/component/k2/itemlist/user/449616
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=6731
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=32058
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/338700
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/277579
http://zsmr.com.ua/index.php/component/k2/itemlist/user/590276
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3381976
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=766353
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=239882
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4866681
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=15888
http://seoksoononly.dothome.co.kr/qna/823775
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1880441
http://thermoplast.envolgroupe.com/component/k2/itemlist/user/94528
http://soc-human.kz/index.php/component/k2/itemlist/user/1657316
http://www.m1avio.com/index.php/component/k2/itemlist/user/3703414
http://fbpharm.net/index.php/component/k2/itemlist/user/38354
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=617292
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=683807.0
http://cwon.kr/xe/board_bnSr36/7984
http://www.vivelabmanizales.com/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81-29/
http://www.deliberarchia.org/forum/index.php?topic=1030323.0
https://sanp.pro/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fbys-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-9-%d1%81%d0%b5%d1%80%d0%b8/
http://ovotecegg.com/component/k2/itemlist/user/142310
http://www.arunagreen.com/index.php/component/k2/itemlist/user/505498
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1617986
http://www.urbantutorial.com/?option=com_k2&view=itemlist&task=user&id=109627
http://xplorefitness.com/blog/hd-video-%D1%87%D1%83%D0%B6%D0%B0%D1%8F-%D0%B6%D0%B8%D0%B7%D0%BD%D1%8C-%D1%87%D1%83%D0%B6%D0%B5-%D0%B6%D0%B8%D1%82%D1%82%D1%8F-10-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-j4-%D1%87%D1%83%D0%B6%D0%B0%D1%8F-%D0%B6%D0%B8%D0%B7%D0%BD%D1%8C-%D1%87%D1%83%D0%B6%D0%B5-%D0%B6%D0%B8%D1%82%D1%82%D1%8F-10-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=194678
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=194698
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=194713
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=194722
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=194766
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=194771
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=194791
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=194821
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=194826
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=194831
http://xn--ok1bpqi43ahtb.net/board_eASW07/56712
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1753298
http://ovotecegg.com/component/k2/itemlist/user/136115
http://www.ekemoon.com/169977/050520195110/
http://fbpharm.net/index.php/component/k2/itemlist/user/40705
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=1179
http://www.critico-expository.com/forum/index.php?topic=11115.0
http://www.ekemoon.com/172507/051420194610/
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/17267
http://www.vivelabmanizales.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-bd2m-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1598928
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pl7%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f10-05/
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=22686
https://khuyenmaikk13.info/index.php?topic=188247.0
http://cafe.dokseosil.co.kr/community/39870
http://cafe.dokseosil.co.kr/community/39900
http://cafe.dokseosil.co.kr/community/39906
http://cafe.dokseosil.co.kr/community/39921
http://cafe.dokseosil.co.kr/community/39931
http://cafe.dokseosil.co.kr/community/39947
http://cafe.dokseosil.co.kr/community/39954
http://jjikduk.net/DATA/11989
http://www.deliberarchia.org/forum/index.php?topic=1036981.0
http://xplorefitness.com/blog/%C2%AB%D0%B2%D0%BE%D1%81%D0%BA%D1%80%D0%B5%D1%81%D1%88%D0%B8%D0%B9-%D1%8D%D1%80%D1%82%D1%83%D0%B3%D1%80%D1%83%D0%BB-144-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-hfhw-%C2%AB%D0%B2%D0%BE%D1%81%D0%BA%D1%80%D0%B5%D1%81%D1%88%D0%B8%D0%B9-%D1%8D%D1%80%D1%82%D1%83%D0%B3%D1%80%D1%83%D0%BB-144-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
https://sanp.pro/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-146-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mzwp-%d0%b2%d0%be%d1%81%d0%ba%d1%80/
http://www.vivelabmanizales.com/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jg9k/
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=278346
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=4538
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=24878
http://0433.net/junggo/51241
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=142601
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=142646
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=142652
http://asin.itts.co.kr/board_rtXs84/9913
http://atemshow.com/?document_srl=48878
http://atemshow.com/atemfair_domestic/48957
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=100000
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=100031
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=100041
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=99916
https://khuyenmaikk13.info/index.php?topic=200880.0
http://cafe.dokseosil.co.kr/community/39153
http://soc-human.kz/index.php/component/k2/itemlist/user/1673515
http://www.ekemoon.com/194071/051520194215/
https://prelease.club/%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-74-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-binh-%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-74/
http://xplorefitness.com/blog/hd-video-%D1%82%D0%BE%D0%BB%D1%8F-%D1%80%D0%BE%D0%B1%D0%BE%D1%82-6-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-p0-%D1%82%D0%BE%D0%BB%D1%8F-%D1%80%D0%BE%D0%B1%D0%BE%D1%82-6-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://www.digitalbul.com/live-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=318903
http://married.dike.gr/index.php/component/k2/itemlist/user/54285
http://asin.itts.co.kr/board_rtXs84/6225
http://asin.itts.co.kr/board_rtXs84/6232
http://asin.itts.co.kr/board_rtXs84/6248
http://asin.itts.co.kr/board_rtXs84/6253
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=76751
http://bebopindia.com/notcie/103093
http://bebopindia.com/notcie/103654
http://emjun.com/index.php?mid=hangtotal&document_srl=77878
http://emjun.com/index.php?mid=hangtotal&document_srl=77906
http://emjun.com/index.php?mid=hangtotal&document_srl=77930
http://haeple.com/index.php?document_srl=86344&mid=etc
http://hyeonjun.co.kr/menu3/65237
http://soc-human.kz/index.php/component/k2/itemlist/user/1632178
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1859206
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=269310
http://rudraautomation.com/index.php/component/k2/author/117713
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=756265
http://poselokgribovo.ru/forum/index.php?topic=724343.0
http://seoksoononly.dothome.co.kr/qna/750491
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=490627
http://www.ekemoon.com/148395/052320190106/
http://www.vivelabmanizales.com/%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0%d1%88%d0%ba%d0%b0-erkenci-kus-38-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fjfs-%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3318161
http://www.web2interactive.com/index.php/component/k2/itemlist/user/3577442
http://www.ekemoon.com/198095/051020194516/
http://indiefilm.kr/xe/board/17223
http://www.ekemoon.com/184933/052320195513/
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=71570
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=731770
http://danielmillsap.com/forum/index.php?topic=1030988.0
http://arquitectosenreformas.es/component/k2/itemlist/user/80994
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3446332
http://smartacity.com/component/k2/itemlist/user/39067
http://vtservices85.fr/smf2/index.php?topic=241734.0
http://ye-dream.com/?document_srl=53117
http://thermoplast.envolgroupe.com/component/k2/author/93234
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/239684
http://www.vivelabmanizales.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bm0j-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.vivelabmanizales.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-ds1k-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://www.ekemoon.com/181883/050920190513/
http://www.ekemoon.com/181891/050920190713/
http://www.ekemoon.com/181897/050920190813/
http://www.ekemoon.com/181901/050920190913/
http://www.vivelabmanizales.com/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-83-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-el2m-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-83-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.vivelabmanizales.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ll8w-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.vivelabmanizales.com/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kl4g-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=69801
http://www.ekemoon.com/197977/051020192016/
http://www.ekemoon.com/198095/051020194516/
http://www.ekemoon.com/198099/051020194616/
http://www.ekemoon.com/198109/051020194916/
http://www.ekemoon.com/198129/051020195416/
http://www.ekemoon.com/198135/051020195616/
http://www.hsaura.com/noty/60998
http://www.hsaura.com/noty/61031
http://vervetama.com/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8-2/
http://www.sp1.football/index.php?document_srl=145771&mid=faq
http://hyeonjun.co.kr/menu3/5509
http://www.studyxray.com/Sangdam/61137
http://2872870.com/est/10881
http://lahch.co.kr/index.php?mid=board_jHAP41&document_srl=7126
http://www.lozic.co.kr/gallery/23402
https://theprodigy.info/forum/index.php?topic=29280.0
http://hayoonbin.com/index.php?mid=Video2&document_srl=2212
http://pkgersang.dothome.co.kr/board_jiKY24/1246
https://nextezone.com/index.php?topic=52358.0
https://dolcoin.net/?document_srl=3170
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2776047
http://bebopindia.com/notcie/108343
http://xn--ok1bpqi43ahtb.net/board_eASW07/22146
http://emjun.com/index.php?mid=hangtotal&document_srl=75921
http://k-cea.org/board_Hnyj62/54251
http://www.golden-nail.co.kr/press/40275
http://forum.elexlabs.com/index.php?topic=29411.0
http://xn--2e0bk61btjo.com/notice/7885
http://www.teedinubon.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80-4/
http://gochon-iusell.co.kr/g1/12295
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/937
http://callman.co.kr/index.php?mid=qa&document_srl=42173
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=22193
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=22198
http://dreamplusart.com/mn03_01/17677
http://f-tube.info/board/79319
http://f-tube.info/board/79339
http://foxy-tv.com/?document_srl=55350
http://foxy-tv.com/index.php?mid=board_xNxV93&document_srl=55278
http://foxy-tv.com/index.php?mid=board_xNxV93&document_srl=55377
http://foxy-tv.com/index.php?mid=board_xNxV93&document_srl=55383
http://foxy-tv.com/index.php?mid=board_xNxV93&document_srl=55392
http://foxy-tv.com/index.php?mid=board_xNxV93&document_srl=55466
http://foxy-tv.com/index.php?mid=board_xNxV93&document_srl=55492
http://foxy-tv.com/index.php?mid=board_xNxV93&document_srl=55522
http://foxy-tv.com/index.php?mid=board_xNxV93&document_srl=55526
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=98147
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=98204
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=98266
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=98360
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=98378
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=98386
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=98415
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=98434
http://herdental.co.kr/index.php?mid=online&document_srl=22070
http://hk-metal.co.kr/hkweb/?document_srl=19901
http://HyUa.1fps.icu/l/szIaeDC
http://jnk-ent.jp/index.php?mid=gallery&document_srl=31980
http://www.golden-nail.co.kr/press/1567
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=109238
http://www.jesusonly.life/calendar/137801
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-z6-t2-%d0%b8%d0%b3%d1%80/
http://mglpcm.org/board_ETkS12/17069
http://skylinecam.co.kr/photo/91194
http://indiefilm.kr/xe/board/57722
http://goldenpowerball2.com/index.php?mid=board_Bnby34&document_srl=53348
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=35246
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=770047
http://xn--ok1bpqi43ahtb.net/board_EkDG82/54109
http://matrixpharm.ru/forum/index.php?PHPSESSID=32ioq5mjnsjmq1cdbuqihpj141&action=profile;u=200572
http://k-cea.org/board_Hnyj62/17424
http://49.247.3.43/index.php?mid=board_PiDQ29&document_srl=893
http://www.josephmaul.org/menu41/57336
http://emjun.com/index.php?mid=hangtotal&document_srl=90444
http://flashboot.ru/forum/index.php?topic=94695.0
http://gallerychoi.com/Exhibition/58809
http://wartoby.com/index.php?mid=board_UXUA38&document_srl=2711
http://bebopindia.com/notcie/95477
http://gallerychoi.com/Exhibition/51061
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=103269
http://www.xn--xy1b45gp4h0qgb9g.com/?document_srl=10943
http://HyUa.1fps.icu/l/szIaeDC
http://bitpark.co.kr/board_IzjM66/3924602
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1874637
http://soc-human.kz/index.php/component/k2/itemlist/user/1660050
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1896821
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=20947
http://forum.digamahost.com/index.php?topic=124422.0
http://8.droror.co.il/uncategorized/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-90-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fo6h-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd/
http://fbpharm.net/index.php/component/k2/itemlist/user/39458
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3604535
http://arunagreen.com/index.php/component/k2/itemlist/user/513101
http://www.remify.app/foro/index.php?topic=259681.0
http://cafe.dokseosil.co.kr/community/49761
http://zanoza.h1n.ru/2019/05/16/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-25-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ifyz-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-25-%d1%81%d0%b5%d1%80%d0%b8/
http://soc-human.kz/index.php/component/k2/itemlist/user/1656956
http://www.ekemoon.com/179795/051520190912/
http://www.ekemoon.com/179801/051520191812/
http://www.ekemoon.com/179807/051520192212/
http://www.ekemoon.com/179811/051520193212/
http://www.vivelabmanizales.com/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81-26/
http://www.ekemoon.com/179813/051520193512/
http://www.ekemoon.com/179815/051520193712/
http://www.ekemoon.com/179819/051520193812/
http://www.ekemoon.com/179825/051520194112/
http://www.vivelabmanizales.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xj7p-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://mahdi.ehosseini.com/index.php/component/k2/itemlist/user/31491
http://www.ekemoon.com/179827/051520194312/
https://prelease.club/%d0%bc%d0%b5%d1%80%d1%82%d0%b2%d0%be%d0%b5-%d0%be%d0%b7%d0%b5%d1%80%d0%be-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zb2n-%d0%bc%d0%b5%d1%80%d1%82%d0%b2%d0%be%d0%b5-%d0%be%d0%b7%d0%b5%d1%80/
https://prelease.club/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ke3q/
https://prelease.club/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81-9/
http://dev.aabn.org.gh/component/k2/itemlist/user/570894
http://dev.fivestarpainting.com/?option=com_k2&view=itemlist&task=user&id=1909910
http://fbpharm.net/index.php/component/k2/itemlist/user/33214
http://fbpharm.net/index.php/component/k2/itemlist/user/33313
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3431401
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3344078
http://dohairbiz.com/en/?option=com_k2&view=itemlist&task=user&id=2743844
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2602875
http://thermoplast.envolgroupe.com/component/k2/author/106332
http://cwon.kr/xe/board_bnSr36/19094
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=13872
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=62290
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=218725
http://rudraautomation.com/index.php/component/k2/author/218722
http://shinilspring.com/?document_srl=88877
http://shinilspring.com/board_qsfb01/88924
http://shinilspring.com/board_qsfb01/89075
http://sixangles.co.kr/qna/602035
http://sixangles.co.kr/qna/602062
http://www.digitalbul.com/%d0%b1%d0%be%d0%b3%d0%b0%d1%82%d1%8b%d0%b5-%d0%b8-%d0%b1%d0%b5%d0%b4%d0%bd%d1%8b%d0%b5-zengin-ve-yoksul-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-keas-%d0%b1%d0%be%d0%b3%d0%b0%d1%82%d1%8b/
http://www.ds712.net/guest/index.php?document_srl=137064&mid=guest07
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=136834
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=136869
http://zanoza.h1n.ru/2019/05/16/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-16-05-2019-w9-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
http://zanoza.h1n.ru/2019/05/16/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-85-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-16-05-2019-a8-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-85-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://zanoza.h1n.ru/2019/05/16/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-93-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-16-05-2019-n9-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-93-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://zanoza.h1n.ru/2019/05/16/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-16-05-2019-u4-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82/
http://zanoza.h1n.ru/2019/05/16/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-16-05-2019-t5-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
https://test.baseyou21.kr/index.php?document_srl=41879&mid=main_slider
http://haeple.com/index.php?mid=etc&document_srl=81217
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=2766
http://www.jesusonly.life/calendar/37995
http://viamania.net/index.php?mid=board_raYV15&document_srl=483
http://gallerychoi.com/Exhibition/33477
http://hyeonjun.co.kr/menu3/71981
http://www.sp1.football/index.php?mid=faq&document_srl=145745
http://oneandonly1127.com/guest/3573
http://www.gforgirl.com/xe/poster/2894
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=13940
http://skylinecam.co.kr/photo/70659
http://skylinecam.co.kr/photo/61804
http://forum.bmw-e60.eu/index.php?topic=7915.0
http://lucky.kidspann.net/index.php?mid=qna&document_srl=64068
http://2872870.com/?document_srl=2677
http://www.hsaura.com/noty/119279
http://www.ekemoon.com/205391/051120192217/
http://hk-metal.co.kr/hkweb/QnA/6766
http://flashboot.ru/forum/index.php?topic=94810.0
https://www.chirorg.com/?document_srl=13738
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=1862
http://xn----3x5er9r48j7wemud0a387h.com/news/20475
http://duopos.net/xe/board_CofP84/12769
http://xn--ok1bpqi43ahtb.net/board_eASW07/97407
http://www.lgue.co.kr/?document_srl=13738
http://bath-family.com/?document_srl=36100
http://www.tessabannampad.go.th/webboard/index.php?topic=211453.0
http://gallerychoi.com/Exhibition/70707
http://xn--ok1bpqi43ahtb.net/board_eASW07/86140
http://bath-family.com/photo_zone/23080
http://otitismediasociety.org/forum/index.php?topic=173151.0
http://photogrotto.com/%d1%8d%d1%84%d0%b8%d1%80-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%82/
http://www.teedinubon.com/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%83%d0%ba%d1%80%d0%b0%d0%b8/
http://vtservices85.fr/smf2/index.php?PHPSESSID=ca642b672029b4fffb978e9ea0a42bcd&topic=248171.0
http://lahch.co.kr/index.php?mid=board_jHAP41&document_srl=8032
http://www.jshwanghoan.com/?document_srl=71473
http://ye-dream.com/qa/81719
http://xn----3x5er9r48j7wemud0a387h.com/news/928
http://ariji.kr/?document_srl=807376
http://bebopindia.com/notcie/75012
http://emjun.com/index.php?mid=hangtotal&document_srl=85216
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=57918
http://HyUa.1fps.icu/l/szIaeDC
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1752571
http://ovotecegg.com/component/k2/itemlist/user/142728
http://emjun.com/index.php?mid=hangtotal&document_srl=15381
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=15332
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=307589
http://rudraautomation.com/index.php/component/k2/author/168617
http://xplorefitness.com/blog/%C2%AB%D0%B2%D0%B5%D1%82%D1%80%D0%B5%D0%BD%D1%8B%D0%B9-hercai-21-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-fjzk-%C2%AB%D0%B2%D0%B5%D1%82%D1%80%D0%B5%D0%BD%D1%8B%D0%B9-hercai-21-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://www.m1avio.com/index.php/component/k2/itemlist/user/3647973
http://www.spazioad.com/component/k2/itemlist/user/7267111
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=204744
http://xplorefitness.com/blog/%D1%82%D0%B0%D0%B9%D0%BD%D1%8B-%D1%82%D0%B0%D1%94%D0%BC%D0%BD%D0%B8%D1%86i-95-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-z5-%D1%82%D0%B0%D0%B9%D0%BD%D1%8B-%D1%82%D0%B0%D1%94%D0%BC%D0%BD%D0%B8%D1%86i-95-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/62339
http://www.ekemoon.com/172009/051320190310/
http://teambuildingpremium.com/forum/index.php?topic=801055.0
http://teambuildingpremium.com/forum/index.php?topic=801074.0
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4839872
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1544520
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=577580
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=51506
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3569432
http://withinfp.sakura.ne.jp/eso/index.php/16864714-ne-otpuskaj-mou-ruku-elimi-birakma-38-seria-nfup-ne-otpuskaj-mo/0
https://szenarist.ru/forum/index.php?topic=206247.0
http://dev.aabn.org.gh/component/k2/itemlist/user/525767
http://seoksoononly.dothome.co.kr/qna/806806
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3570413
http://www.vivelabmanizales.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tl8f-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://web2interactive.com/index.php/component/k2/itemlist/user/3565438
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/185102
http://arunagreen.com/index.php/component/k2/itemlist/user/432711
http://withinfp.sakura.ne.jp/eso/index.php/16892698-tola-robot-7-seria-06052019-v0-tola-robot-7-seria
http://moavalve.co.kr/faq/12329
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/494193
http://hydrocarbs-gh.org/index.php/component/k2/itemlist/user/7391388
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/702837
http://proxima.co.rw/index.php/component/k2/itemlist/user/633243
http://indiefilm.kr/xe/board/32534
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1594987
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=157008
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=169562
http://www.digitalbul.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-torrent-iw%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://tekagrafica.com.br/index.php/component/k2/itemlist/user/1647563
http://jiquilisco.org/index.php/component/k2/itemlist/user/6628
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/207633
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/17404
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=62290
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=218725
http://rudraautomation.com/index.php/component/k2/author/218722
http://shinilspring.com/?document_srl=88877
http://shinilspring.com/board_qsfb01/88924
http://shinilspring.com/board_qsfb01/89075
http://sixangles.co.kr/qna/602035
http://sixangles.co.kr/qna/602062
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3343853
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3343937
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=19938
http://xplorefitness.com/blog/%C2%AB%D1%82%D0%B0%D1%94%D0%BC%D0%BD%D0%B8%D1%86i-85-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-12-05-2019-k9-%C2%AB%D1%82%D0%B0%D1%94%D0%BC%D0%BD%D0%B8%D1%86i-85-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=53026
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=53110
http://gounface.com/?document_srl=572518
http://gspara01.dothome.co.kr/?document_srl=2584
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=1665
http://hanalove.kidspann.net/index.php?mid=qna&document_srl=45615
http://hanalove.kidspann.net/index.php?mid=qna&document_srl=45620
http://iymc.or.kr/pds/88473
http://iymc.or.kr/pds/88478
http://jejucctv.co.kr/?document_srl=18967
http://jejucctv.co.kr/A5/18885
http://jejucctv.co.kr/A5/18997
http://jejucctv.co.kr/A5/19010
http://jejucctv.co.kr/A5/19034
http://jejucctv.co.kr/A5/19053
http://jejucctv.co.kr/A5/19058
http://f-tube.info/board/79335
http://foxy-tv.com/?document_srl=55295
http://foxy-tv.com/index.php?mid=board_xNxV93&document_srl=55273
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=24993
http://goldenpowerball2.com/?document_srl=98113
http://goldenpowerball2.com/?document_srl=98181
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=1240
http://herdental.co.kr/?document_srl=22020
http://herdental.co.kr/index.php?mid=online&document_srl=21970
http://herdental.co.kr/index.php?mid=online&document_srl=22000
http://herdental.co.kr/index.php?mid=online&document_srl=22005
http://hk-metal.co.kr/hkweb/?document_srl=19772
http://hk-metal.co.kr/hkweb/QnA/19715
http://hk-metal.co.kr/hkweb/QnA/19724
http://hk-metal.co.kr/hkweb/QnA/19762
http://hk-metal.co.kr/hkweb/QnA/19767
http://iymc.or.kr/pds/88135
http://HyUa.1fps.icu/l/szIaeDC
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=88938
http://xn--ok1bpqi43ahtb.net/board_eASW07/119303
http://praisesound.co.kr/sub04_01/3582
http://twitchdevs.com/c/other/()-rasskaz-sluzhanki-3-sezon-2-seriya-smotret-onlajn-2717/
http://www.sweetparis41.com/xe/board/528
http://1vh.info/index.php?topic=27511.0
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n5-x1-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=134945
http://ucckorea.kr/index.php?document_srl=10036&mid=board_AuHE49
http://jnk-ent.jp/index.php?mid=gallery&document_srl=45038
http://www.lozic.co.kr/gallery/10642
http://themasters.pro/file_01/44726
http://lahch.co.kr/index.php?mid=board_jHAP41&document_srl=14947
http://guiadetudo.com/index.php/component/k2/itemlist/user/11407
https://www.gizmoarticle.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80-27/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf-27/
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2779947
http://foxy-tv.com/index.php?mid=board_lgTk68&document_srl=35166
https://prelease.club/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%82%d0%be%d1%80%d1%80%d0%b5%d0%bd/
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=13451
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=34934.0
http://bebopindia.com/notcie/15886
http://49.247.3.43/index.php?mid=board_PiDQ29&document_srl=17294
http://zanoza.h1n.ru/2019/05/18/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%e3%80%90jq5%e3%80%91/
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile;u=37085
http://haeple.com/index.php?mid=etc&document_srl=22019
http://HyUa.1fps.icu/l/szIaeDC
http://teambuildingpremium.com/forum/index.php?topic=844194.0
http://teambuildingpremium.com/forum/index.php?topic=844207.0
http://teambuildingpremium.com/forum/index.php?topic=844214.0
http://teambuildingpremium.com/forum/index.php?topic=844223.0
http://teambuildingpremium.com/forum/index.php?topic=844229.0
http://teambuildingpremium.com/forum/index.php?topic=844232.0
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3827279
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2617116
http://mvisage.sk/index.php/component/k2/itemlist/user/119037
http://netsconsults.com/index.php/component/k2/itemlist/user/793273
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/220862
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2324144
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1703295
http://rudraautomation.com/index.php/component/k2/author/107892
http://batubersurat.com/index.php/component/k2/itemlist/user/42277
http://forum.politeknikgihon.ac.id/index.php?topic=25495.0
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=42980
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/285704
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=79115
http://soc-human.kz/index.php/component/k2/itemlist/user/1631575
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4863722
http://febrescordero.gob.ec/index.php/component/k2/itemlist/user/81362
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3582421
http://moyakmermer.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=677647
http://soc-human.kz/index.php/component/k2/itemlist/user/1638938
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=501986
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=303297
http://forum.byehaj.hu/index.php?topic=92973.0
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-r2-f0-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
http://lahch.co.kr/index.php?mid=board_jHAP41&document_srl=8258
http://bebopindia.com/notcie/31826
http://www.svteck.co.kr/customer_gratitude/22096
http://isch.kr/board_PowH60/28643
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/63104
http://k-cea.org/?document_srl=52513
http://constellation.kro.kr/board_kbku73/1247
http://9mantv.com/index.php?mid=board_BwRi12&document_srl=12390
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2772978
http://kyj1225.godohosting.com/board_mebR72/2339
http://askpharm.net/board_NQiz06/13128
http://www.jesusonly.life/calendar/104197
http://indiefilm.kr/xe/board/70576
http://www.studyxray.com/Sangdam/18940
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=35294
https://betshin.com/Story/39867
https://betshin.com/Story/39879
https://celekt.com/%d0%91%d0%be%d0%bb%d1%8c%d1%88%d0%b0%d1%8f-%d0%bc%d0%b0%d0%bb%d0%b5%d0%bd%d1%8c%d0%ba%d0%b0%d1%8f-%d0%bb%d0%be%d0%b6%d1%8c-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qf5i/
https://celekt.com/%d0%91%d0%be%d0%bb%d1%8c%d1%88%d0%b0%d1%8f-%d0%bc%d0%b0%d0%bb%d0%b5%d0%bd%d1%8c%d0%ba%d0%b0%d1%8f-%d0%bb%d0%be%d0%b6%d1%8c-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zy3x/
https://esel.gist.ac.kr/esel2/?document_srl=70660
https://esel.gist.ac.kr/esel2/board_hmgj23/70637
https://esel.gist.ac.kr/esel2/board_hmgj23/70650
https://esel.gist.ac.kr/esel2/board_hmgj23/70741
https://esel.gist.ac.kr/esel2/board_hmgj23/70770
http://2872870.com/est/18028
http://2872870.com/est/18367
http://HyUa.1fps.icu/l/szIaeDC
http://bebopindia.com/notcie/134715
http://bebopindia.com/notcie/134803
http://bebopindia.com/notcie/134831
http://bebopindia.com/notcie/134846
http://bethelpray.com/counsel/9238
http://bethelpray.com/counsel/9243
http://bitpark.co.kr/board_IzjM66/4025251
http://bitpark.co.kr/board_IzjM66/4025316
http://bitpark.co.kr/board_IzjM66/4025368
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=853513
http://joinbohum.kr/board/38619
http://joocafe.com/board_HWSm10/64824
http://joocafe.com/board_HWSm10/64830
http://kyj1225.godohosting.com/board_mebR72/13678
http://majorcebu.com/board_OhfH50/1125346
http://metropolis.ga/index.php?topic=12791.0
http://neosky.net/xe/space_station/2445
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=46187
http://hanalove.kidspann.net/?document_srl=43620
http://poselokgribovo.ru/forum/index.php?topic=789851.0
http://praisesound.co.kr/sub04_01/9080
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=111773
http://photogrotto.com/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d0%b4%d0%b0%d1%82%d0%b0/
http://mglpcm.org/?document_srl=11187
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=16956
http://apt2you2.cafe24.com/?document_srl=1540
http://shinilspring.com/board_qsfb01/81608
http://www.ekemoon.com/199137/051520190716/
http://skylinecam.co.kr/photo/91166
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=9065
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2769783
http://oceangray.i234.me/index.php?document_srl=1898&mid=board_vsVi16
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=49433
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=42000
http://daltso.com/index.php?mid=board_cUYy21&document_srl=11338
https://forum.clubeicaro.pt/index.php?topic=1150.0
http://www.josephmaul.org/menu41/39017
http://HyUa.1fps.icu/l/szIaeDC
http://mahdi.ehosseini.com/?option=com_k2&view=itemlist&task=user&id=33702
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=474130
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/298863
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3351590
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=18143
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/84438
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=16624
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=457054
http://ovotecegg.com/component/k2/itemlist/user/132108
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/244604
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=18023
http://www.ekemoon.com/182893/051420191913/
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=571429
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/218165
http://www.babvallejo.com/index.php/component/k2/itemlist/user/605420
http://smartacity.com/component/k2/itemlist/user/14877
http://www.elpinatarense.com/?option=com_k2&view=itemlist&task=user&id=155505
http://web2interactive.com/index.php/component/k2/itemlist/user/3567674
http://proxima.co.rw/index.php/component/k2/itemlist/user/584340
http://mediaville.me/index.php/component/k2/itemlist/user/208288
http://teambuildingpremium.com/forum/index.php?topic=786676.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/189560
https://khuyenmaikk13.info/index.php?topic=181305.0
http://www.ekemoon.com/146969/052020191806/
https://lucky28003.nl/forum/index.php?topic=10643.0
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=5714
http://withinfp.sakura.ne.jp/eso/index.php/16890823-smotret-tolarobot-1-sezon-2-seria-p5-tolarobot-1-sezon-2-seria
http://webp.online/index.php?topic=44080.0
http://engeena.com/component/k2/itemlist/user/8778
http://engeena.com/component/k2/itemlist/user/8788
http://engeena.com/component/k2/itemlist/user/8789
http://jensenbyggteam.no/index.php/component/k2/itemlist/user/13380
http://jiquilisco.org/?option=com_k2&view=itemlist&task=user&id=8559
http://mobility-corp.com/index.php/component/k2/itemlist/user/2616053
http://mobility-corp.com/index.php/component/k2/itemlist/user/2616108
http://necinsurance.co.zw/component/k2/itemlist/user/21120.html
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/110324
http://ovotecegg.com/component/k2/itemlist/user/159890
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/260610
http://sdsn.develop.cinfores.com/?option=com_k2&view=itemlist&task=user&id=220155
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2322870
http://www.gforgirl.com/xe/poster/104468
https://khuyenmaikk13.info/index.php?topic=200561.0
http://bebopindia.com/notcie/24872
http://wipln.com/music/21035
http://haeple.com/index.php?mid=etc&document_srl=80210
http://eugeniocolazzo.it/forum/index.php?topic=135709.0
http://indiefilm.kr/xe/board/103212
http://xn----c28ewjj6ubwku6frtcuzec29ae5b.com/?document_srl=7760
http://haeple.com/index.php?mid=etc&document_srl=35472
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=165770
http://ye-dream.com/qa/64072
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/9518
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/4759
http://xn--9m1b83j39hz6exwonmf.com/?document_srl=519328
http://xn--9m1b83j39hz6exwonmf.com/board_IYPe43/519356
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=69276
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=69304
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=69332
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=69382
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=515
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/4166
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/4177
http://HyUa.1fps.icu/l/szIaeDC
http://www.ekemoon.com/177575/051720191511/
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=73673
https://www.shaiyax.com/index.php?topic=337493.0
http://bitpark.co.kr/board_IzjM66/3817697
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1374497
http://tekagrafica.com.br/index.php/component/k2/itemlist/user/1693690
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1656246
http://proxima.co.rw/index.php/component/k2/itemlist/user/608463
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=317052
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/315049
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/207315
http://www.deliberarchia.org/forum/index.php?topic=1019670.0
https://khuyenmaikk13.info/index.php?topic=201631.0
http://matrixpharm.ru/forum/index.php?PHPSESSID=kpvh1dg42bo68gond0obab00n2&action=profile;u=199298
http://mediaville.me/index.php/component/k2/itemlist/user/283767
http://mediaville.me/index.php/component/k2/itemlist/user/283772
http://netsconsults.com/?option=com_k2&view=itemlist&task=user&id=792890
http://ovotecegg.com/?option=com_k2&view=itemlist&task=user&id=159592
http://ovotecegg.com/component/k2/itemlist/user/159761
http://ovotecegg.com/component/k2/itemlist/user/159852
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/260591
http://photogrotto.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-100-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-iy7u-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd/
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=169041
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=169118
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=169128
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=169276
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=169301
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=169504
http://www.golden-nail.co.kr/?document_srl=104326
http://www.golden-nail.co.kr/?document_srl=104392
http://www.golden-nail.co.kr/press/104073
http://www.golden-nail.co.kr/press/104260
http://www.golden-nail.co.kr/press/104270
http://jiquilisco.org/index.php/component/k2/itemlist/user/6155
http://www.ekemoon.com/166043/051920192209/
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/708631
http://rudraautomation.com/index.php/component/k2/author/170504
http://skylinecam.co.kr/photo/47402
http://cafe.dokseosil.co.kr/community/26908
https://khuyenmaikk13.info/index.php?topic=178555.0
http://xplorefitness.com/blog/%C2%AB%D0%B2%D0%B5%D1%82%D1%80%D0%B5%D0%BD%D1%8B%D0%B9-hercai-17-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-zvzn-%C2%AB%D0%B2%D0%B5%D1%82%D1%80%D0%B5%D0%BD%D1%8B%D0%B9-hercai-17-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
https://www.shaiyax.com/index.php?topic=334073.0
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=199335
http://ptu.imoove.kr/ko/content/%C2%AB%D1%8E%D1%80%D0%B8%D1%81%D1%82%D1%8B-12-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%D1%81%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C-%C2%AB%D1%8E%D1%80%D0%B8%D1%81%D1%82%D1%8B-12-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB332733
http://seoksoononly.dothome.co.kr/?document_srl=722370
http://married.dike.gr/index.php/component/k2/itemlist/user/48351
http://salescoach.ro/content/%C2%AB%D0%B2%D0%B5%D1%82%D1%80%D0%B5%D0%BD%D1%8B%D0%B9-hercai-5-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-vomk-%C2%AB%D0%B2%D0%B5%D1%82%D1%80%D0%B5%D0%BD%D1%8B%D0%B9-hercai-5-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://highlanderonline.cmshelplive.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-12-%d1%81%d0%b5%d1%80%d0%b8/
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=1016378
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=20476
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7360660
http://hydrocarbs-gh.org/index.php/component/k2/itemlist/user/7360279
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=313074
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=56177
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=82870
http://ovotecegg.com/component/k2/itemlist/user/130837
http://ovotecegg.com/component/k2/itemlist/user/130848
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=257903
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1570876
https://turimex.mx.solemti.net/en/?option=com_k2&view=itemlist&task=user&id=1560
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1094015
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=555405
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3624183
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1685945
http://www.ekemoon.com/181691/050820191113/
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=50175
http://menulisilmiah.net/live-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g7-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81/
http://www.ekemoon.com/143555/050120190106/
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=198588
http://c3isecurity.com.br/component/k2/itemlist/user/482852
http://smartacity.com/component/k2/itemlist/user/21387
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=494372
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3332397
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3753125
http://xplorefitness.com/blog/%C2%AB%D1%81%D0%BB%D1%83%D0%B3%D0%B0-%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-23-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-10-05-2019-i7-%C2%AB%D1%81%D0%BB%D1%83%D0%B3%D0%B0-%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-23-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://xplorefitness.com/blog/%C2%AB%D1%82%D0%B0%D0%B9%D0%BD%D1%8B-86-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-10-05-2019-v8-%C2%AB%D1%82%D0%B0%D0%B9%D0%BD%D1%8B-86-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://arunagreen.com/index.php/component/k2/itemlist/user/476710
http://arunagreen.com/index.php/component/k2/itemlist/user/476922
http://dev.aabn.org.gh/component/k2/itemlist/user/560041
http://fbpharm.net/index.php/component/k2/itemlist/user/29695
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=290705
http://ovotecegg.com/component/k2/itemlist/user/127090
http://myrechockey.com/forums/index.php?topic=98250.0
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-du5m-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=10814
http://xplorefitness.com/blog/%C2%AB%D1%82%D0%B0%D0%B9%D0%BD%D1%8B-90-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-15-05-2019-x1-%C2%AB%D1%82%D0%B0%D0%B9%D0%BD%D1%8B-90-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
https://tg.vl-mp.com/index.php?topic=1344566.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3293516
http://webp.online/index.php?topic=46549.0
http://dev.aabn.org.gh/component/k2/itemlist/user/517757
https://members.fbhaters.com/index.php?topic=80154.0
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7309122
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1640459
http://withinfp.sakura.ne.jp/eso/index.php/16862263-sluga-naroda-3-sezon-19-seria-05052019-t4-sluga-naroda-3-sezon-
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/243636
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3332455
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3332461
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=18698
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=18766
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=18769
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2602756
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=73201
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1418778
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=83404
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=327649
http://thermoplast.envolgroupe.com/component/k2/author/84249
http://myrechockey.com/forums/index.php?topic=100641.0
http://gtupuw.org/index.php/component/k2/itemlist/user/1903820
http://seoksoononly.dothome.co.kr/qna/832103
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/17193
http://www.ds712.net/guest/?document_srl=41465
http://myrechockey.com/forums/index.php?topic=95633.0
http://arunagreen.com/index.php/component/k2/itemlist/user/485503
http://www.sp1.football/index.php?mid=faq&document_srl=89248
http://www.vivelabmanizales.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-ep6a-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://danielmillsap.com/forum/index.php?topic=997158.0
http://forum.digamahost.com/index.php?topic=112362.0
http://forum.digamahost.com/index.php?topic=112364.0
http://highlanderonline.cmshelplive.net/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-145-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-davr-%d0%b2%d0%be%d1%81%d0%ba%d1%80/
http://highlanderonline.cmshelplive.net/%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-74-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-muxc-%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-74/
http://teambuildingpremium.com/forum/index.php?topic=796115.0
http://www.deliberarchia.org/forum/index.php?topic=995230.0
http://xplorefitness.com/blog/%C2%AB%D0%B2%D0%B5%D1%82%D1%80%D0%B5%D0%BD%D1%8B%D0%B9-hercai-10-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-gujy-%C2%AB%D0%B2%D0%B5%D1%82%D1%80%D0%B5%D0%BD%D1%8B%D0%B9-hercai-10-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://xplorefitness.com/blog/%C2%AB%D0%B2%D0%B5%D1%82%D1%80%D0%B5%D0%BD%D1%8B%D0%B9-hercai-25-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-wzpo-%C2%AB%D0%B2%D0%B5%D1%82%D1%80%D0%B5%D0%BD%D1%8B%D0%B9-hercai-25-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
https://sto54.ru/index.php/component/k2/itemlist/user/3326686
http://withinfp.sakura.ne.jp/eso/index.php/16951493-v-efire-taemnici-90-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/16951495-hd-milliardy-4-sezon-10-seria-c6-milliardy-4-sezon-10-seria/0
http://www.comfybigsize.com/?option=com_k2&view=itemlist&task=user&id=22752
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=204539
http://8.droror.co.il/uncategorized/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-89-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gt4m-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-89-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=553781
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=553805
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=1179
https://turimex.mx.solemti.net/en/?option=com_k2&view=itemlist&task=user&id=1137
http://xplorefitness.com/blog/%C2%AB%D1%81%D0%BB%D1%83%D0%B3%D0%B0-%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-20-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-13-05-2019-b4-%C2%AB%D1%81%D0%BB%D1%83%D0%B3%D0%B0-%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-20-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2625210
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/522909
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/522942
http://corumotoanahtar.com/index.php/component/k2/itemlist/user/1339
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=325542
http://wgamez.net/index.php?mid=board_KGzu43&document_srl=2676
http://www.teedinubon.com/hd-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b0%d0%bd%d0%be%d0%bd%d1%81/
http://skylinecam.co.kr/photo/47412
http://xn----3x5er9r48j7wemud0a387h.com/news/1607
http://gallerychoi.com/Exhibition/36985
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=3801
http://skylinecam.co.kr/photo/44641
http://holysweat.dothome.co.kr/data/1330
http://www.golden-nail.co.kr/press/32023
http://aso-cn.com/index.php?mid=board_KRpb39&document_srl=2515
http://bethanychurch.kr/board_vpkl62/13441
http://indiefilm.kr/xe/board/97932
http://www.gforgirl.com/xe/?document_srl=137748
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/news/1974
http://xn--ok1bpqi43ahtb.net/board_EkDG82/108477
http://otitismediasociety.org/forum/index.php?topic=176223.0
http://holysweat.dothome.co.kr/data/1091
http://jnk-ent.jp/index.php?mid=gallery&document_srl=40868
http://mglpcm.org/board_ETkS12/3192
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=93815
http://www.lozic.co.kr/gallery/5518
http://www.josephmaul.org/menu41/132451
http://www.lgue.co.kr/?document_srl=27272
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=5901
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=5906
http://www.siheunglove.com/chulip/66036
https://2002.shyoon.com/board_2002/45101
https://2002.shyoon.com/board_2002/45118
https://betshin.com/Story/44857
https://betshin.com/Story/44869
https://esel.gist.ac.kr/esel2/board_hmgj23/77817
https://esel.gist.ac.kr/esel2/board_hmgj23/77827
https://ttmt.net/crypto_lab_2F/461319
https://ttmt.net/crypto_lab_2F/461361
http://8.droror.co.il/uncategorized/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://agiteshop.com/xe/?document_srl=51357
http://agiteshop.com/xe/qa/51300
http://agiteshop.com/xe/qa/51327
http://agiteshop.com/xe/qa/51387
http://alastair030.dothome.co.kr/index.php?mid=board_MMiF30&document_srl=6038
http://HyUa.1fps.icu/l/szIaeDC
http://vtservices85.fr/smf2/index.php?PHPSESSID=ddba2c9be48d814908e20884367e4b72&topic=215242.0
http://forum.digamahost.com/index.php?topic=120269.0
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=73583
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=52673
http://thermoplast.envolgroupe.com/component/k2/author/92430
http://soc-human.kz/index.php/component/k2/itemlist/user/1681116
http://menulisilmiah.net/%d1%81%d0%bc%d0%b5%d1%80%d1%88-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ju1%d1%81%d0%bc%d0%b5%d1%80%d1%88-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f10-05-2019/
https://www.shaiyax.com/index.php?topic=349304.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=702744.0
http://www.die-design-manufaktur.de/?option=com_k2&view=itemlist&task=user&id=5237812
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1186417
http://www.remify.app/foro/index.php?topic=289034.0
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=80524
http://dcasociados.eu/component/k2/itemlist/user/87760
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=204401
http://xplorefitness.com/blog/hd-video-%D1%87%D1%83%D0%B6%D0%B0%D1%8F-%D0%B6%D0%B8%D0%B7%D0%BD%D1%8C-%D1%87%D1%83%D0%B6%D0%B5-%D0%B6%D0%B8%D1%82%D1%82%D1%8F-5-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-k1-%D1%87%D1%83%D0%B6%D0%B0%D1%8F-%D0%B6%D0%B8%D0%B7%D0%BD%D1%8C-%D1%87%D1%83%D0%B6%D0%B5-%D0%B6%D0%B8%D1%82%D1%82%D1%8F-5-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/56957
http://mvisage.sk/index.php/component/k2/itemlist/user/118215
http://www.ekemoon.com/165865/051820195909/
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=9710
http://married.dike.gr/index.php/component/k2/itemlist/user/49394
http://www.phan-aen.go.th/forum/index.php?topic=625737.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1365056
http://withinfp.sakura.ne.jp/eso/index.php/16896636-tola-robot-4-seria-j0-tola-robot-4-seria/0
http://married.dike.gr/index.php/component/k2/itemlist/user/53421
http://married.dike.gr/index.php/component/k2/itemlist/user/48173
http://withinfp.sakura.ne.jp/eso/index.php/16890361-uristy-12-seria-06052019-l3-uristy-12-seria
http://vn7.vn/qna/70687
http://www.gforgirl.com/xe/poster/96725
http://xn--9m1b83j39hz6exwonmf.com/board_IYPe43/499682
http://www.artangel.co.kr/index.php?mid=Activities&document_srl=9194
http://ru-realty.com/forum/index.php?PHPSESSID=dcm4sgrdesben1eesuur0b1mo2&topic=526646.0
http://sixangles.co.kr/qna/512997
http://www.artangel.co.kr/index.php?mid=Activities&document_srl=5373
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/brand/2363
http://sunele.co.kr/board_ReBD97/46169
https://reficulcoin.com/index.php?topic=51302.0
http://www.remify.app/foro/index.php?topic=311683.0
http://ye-dream.com/qa/56048
http://d-tube.info/board_jvyO69/216051
http://gallerychoi.com/Exhibition/14337
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=38468
https://nextezone.com/index.php?topic=50303.0
http://8.droror.co.il/uncategorized/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5/
http://www.sp1.football/index.php?mid=faq&document_srl=146723
https://pacock.com/tip/3525
http://arte.dgau.ac.kr/board_qna/37881
http://arte.dgau.ac.kr/board_qna/37886
http://arte.dgau.ac.kr/board_qna/37901
http://arte.dgau.ac.kr/board_qna/37921
http://arte.dgau.ac.kr/board_qna/37926
http://arte.dgau.ac.kr/board_qna/37951
http://arte.dgau.ac.kr/board_qna/37966
http://bebopindia.com/notcie/127990
http://bebopindia.com/notcie/128005
http://bebopindia.com/notcie/128064
http://bethelpray.com/counsel/8881
http://bethelpray.com/counsel/8887
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=21012
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=21027
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=21048
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=21062
http://cwon.kr/xe/?document_srl=72969
http://cwon.kr/xe/board_bnSr36/72925
http://cwon.kr/xe/board_bnSr36/72930
http://HyUa.1fps.icu/l/szIaeDC
http://www.xn--xy1b45gp4h0qgb9g.com/?document_srl=2973
http://wipln.com/?document_srl=42663
http://atemshow.com/atemfair_domestic/23994
http://www.ds712.net/guest/?document_srl=42959
http://haeple.com/index.php?mid=etc&document_srl=50136
http://hyundeok.iptime.org/zbxe/index.php?mid=family&document_srl=34841
http://xn--ok1bpqi43ahtb.net/board_eASW07/69987
http://isch.kr/?document_srl=28896
http://lucky.kidspann.net/index.php?mid=qna&document_srl=29263
http://ye-dream.com/qa/8000
http://shinilspring.com/?document_srl=96487
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=768645
http://yeonsen.com/?document_srl=61791
http://gallerychoi.com/Exhibition/23540
http://jnk-ent.jp/index.php?mid=gallery&document_srl=5715
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=758
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p0-s0-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-s5-e5-%d0%b8%d0%b3%d1%80/
http://sixangles.co.kr/qna/565495
http://xn----3x5er9r48j7wemud0a387h.com/news/42751
http://xn----3x5er9r48j7wemud0a387h.com/news/42757
http://xn----3x5er9r48j7wemud0a387h.com/news/42763
http://xn----3x5er9r48j7wemud0a387h.com/news/42784
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/8186
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/8191
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/news/10846
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/news/10851
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/news/10862
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/11789
http://HyUa.1fps.icu/l/szIaeDC
http://preach.kr/Amharic_Music/3874
https://gonggamlaw.com/lawcase/1498
http://bewasia.com/?document_srl=1245
http://www.xn--xy1b45gp4h0qgb9g.com/sub_09_05/13812
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=1657
http://f-tube.info/board/75303
http://vintage.codns.com/Board/8750
http://vintage.codns.com/Board/8987
http://daltso.com/index.php?mid=board_cUYy21&document_srl=642
http://skylinecam.co.kr/photo/97464
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=2608
http://forum.byehaj.hu/index.php?topic=90195.0
http://sheepofani.dothome.co.kr/index.php?mid=board_Zxan02&document_srl=2828
http://www.hsaura.com/license/81813
http://www.fassen.co.kr/xe/board_VCum96/8150
http://atemshow.com/atemfair_domestic/41364
http://sy.korean.net/qna/71788
http://sy.korean.net/qna/71824
http://sy.korean.net/qna/71829
http://www.flixian.com/main/QnA/36425
http://www.flixian.com/main/QnA/36435
http://www.flixian.com/main/QnA/36454
http://www.golden-nail.co.kr/press/106635
http://www.golden-nail.co.kr/press/106677
http://www.grupojover.com/index.php/es/component/k2/itemlist/user/4311
http://www.haetsaldun-clinic.co.kr/Question/3873
http://www.haetsaldun-clinic.co.kr/Question/3879
http://www.hicleaning.kr/board_wash/100507
http://www.hsaura.com/noty/160474
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=99690
http://HyUa.1fps.icu/l/szIaeDC
http://viamania.net/index.php?mid=board_raYV15&document_srl=1082
http://www.artangel.co.kr/index.php?mid=Activities&document_srl=8620
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=813613
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=62915
http://toeden.co.kr/Product_new/24466
http://cafe.dokseosil.co.kr/community/25919
http://indiefilm.kr/xe/board/67403
http://hyeonjun.co.kr/menu3/5879
http://praisesound.co.kr/sub04_01/6950
http://isch.kr/board_PowH60/21139
http://isch.kr/board_PowH60/25440
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=46418
http://koais.com/data/21999
http://ye-dream.com/qa/50256
http://www.studyxray.com/Sangdam/55003
http://iymc.or.kr/pds/86035
http://emjun.com/index.php?mid=hangtotal&document_srl=80041
http://www.theocraticamerica.org/forum/index.php/topic,37988.0.html
http://gallerychoi.com/Exhibition/48263
https://prelease.club/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80-3/
http://sy.korean.net/qna/72020
http://www.flixian.com/main/QnA/36560
http://www.flixian.com/main/QnA/36565
http://www.flixian.com/main/QnA/36585
http://www.golden-nail.co.kr/press/106784
http://www.golden-nail.co.kr/press/106794
http://www.golden-nail.co.kr/press/106833
http://www.golden-nail.co.kr/press/106838
http://www.golden-nail.co.kr/press/106848
http://www.golden-nail.co.kr/press/106858
http://www.haetsaldun-clinic.co.kr/Question/3893
http://www.josephmaul.org/?document_srl=123882
http://www.josephmaul.org/menu41/123814
http://www.josephmaul.org/menu41/123850
http://www.lovestory.or.kr/topic/3633
http://www.lovestory.or.kr/topic/3665
http://HyUa.1fps.icu/l/szIaeDC
https://gonggamlaw.com/lawcase/1532
http://1vh.info/index.php?topic=26622.0
http://0433.net/budongsan/36175
http://isch.kr/board_PowH60/4853
http://www.siheunglove.com/chulip/42618
http://www.hicleaning.kr/board_wash/73745
http://shinilspring.com/board_qsfb01/51669
http://www.jesusonly.life/calendar/104627
http://isch.kr/board_PowH60/15119
http://preach.kr/Amharic_Music/1298
http://isch.kr/board_PowH60/19304
https://www.shaiyax.com/index.php?topic=345490.0
http://lahch.co.kr/index.php?mid=board_jHAP41&document_srl=8757
http://yoriyorifood.com/xxxx/spacial/15785
http://gochon-iusell.co.kr/g1/16933
http://hyeonjun.co.kr/menu3/32535
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=7421
https://nextezone.com/index.php?topic=57518.0
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=824846
https://www.chirorg.com/?document_srl=6588
http://indiefilm.kr/xe/board/76290
http://hk-metal.co.kr/hkweb/QnA/23237
http://hk-metal.co.kr/hkweb/QnA/23242
http://hyundeok.iptime.org/zbxe/index.php?mid=family&document_srl=45535
http://hyundeok.iptime.org/zbxe/index.php?mid=family&document_srl=45540
http://hyundeok.iptime.org/zbxe/index.php?mid=family&document_srl=45551
http://iamking.net/board/29701
http://iymc.or.kr/pds/88546
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=865354
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=865379
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=865413
http://joinbohum.kr/board/42141
http://laokorea.com/orange_menu1/30168
http://laokorea.com/orange_menu1/30173
http://laokorea.com/orange_menu1/30178
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=50075
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=50087
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=82113
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=82127
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=82137
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=82142
http://rudraautomation.com/index.php/component/k2/author/224077
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=24090
http://skylinecam.co.kr/photo/124804
http://skylinecam.co.kr/photo/124844
http://HyUa.1fps.icu/l/szIaeDC
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1808373
http://soc-human.kz/index.php/component/k2/itemlist/user/1681997
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2611114
http://ru-realty.com/forum/index.php?PHPSESSID=oo1oaj8mf1afamsdt4t6j8vf77&topic=508898.0
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7383430
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=835120
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1395726
http://arquitectosenreformas.es/component/k2/itemlist/user/80514
http://fbpharm.net/index.php/component/k2/itemlist/user/26980
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=8726
http://menulisilmiah.net/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-l3-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9/
http://forum.politeknikgihon.ac.id/index.php?topic=24790.0
http://withinfp.sakura.ne.jp/eso/index.php/16889575-efir-tola-robot-1-seria-r4-tola-robot-1-seria
http://dev.aabn.org.gh/component/k2/itemlist/user/516244
http://www.afikgan.co.il/index.php/component/k2/itemlist/user/26360
http://bitpark.co.kr/?document_srl=3763018
http://poselokgribovo.ru/forum/index.php?topic=734482.0
http://condolencias.servisa.es/3-10-06-05-2019-y4-3-10
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4863674
http://www.deliberarchia.org/forum/index.php?topic=963251.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=27187.0
http://skylinecam.co.kr/photo/110202
http://skylinecam.co.kr/photo/110346
http://www.hicleaning.kr/?document_srl=91833
http://www.hicleaning.kr/?document_srl=91891
http://www.hicleaning.kr/board_wash/91778
http://www.hsaura.com/?document_srl=146012
http://www.hsaura.com/?document_srl=146085
http://www.hsaura.com/noty/145812
http://www.hsaura.com/noty/145871
http://ovotecegg.com/component/k2/itemlist/user/131022
http://zanoza.h1n.ru/2019/05/15/%d1%81%d0%bc%d0%b5%d1%80%d1%88-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ah2%d1%81%d0%bc%d0%b5%d1%80%d1%88-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f15-05-2019/
http://www.m1avio.com/index.php/component/k2/itemlist/user/3694751
http://www.deliberarchia.org/forum/index.php?topic=1023797.0
http://jjikduk.net/DATA/18426
http://www.hsaura.com/noty/68600
http://www.digitalbul.com/%d0%bc%d0%b5%d1%80%d1%82%d0%b2%d0%be%d0%b5-%d0%be%d0%b7%d0%b5%d1%80%d0%be-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qz4i-%d0%bc%d0%b5%d1%80%d1%82%d0%b2%d0%be%d0%b5-%d0%be%d0%b7%d0%b5%d1%80/
http://www.ekemoon.com/199593/051720192116/
http://cwon.kr/xe/board_bnSr36/27610
http://www.hsaura.com/license/68653
http://www.hsaura.com/noty/68648
http://zanoza.h1n.ru/2019/05/16/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wxvn-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-11-%d1%81%d0%b5%d1%80%d0%b8/
http://zanoza.h1n.ru/2019/05/16/%d0%b6%d0%b5%d0%bd%d1%89%d0%b8%d0%bd%d0%b0-56-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-iiee-%d0%b6%d0%b5%d0%bd%d1%89%d0%b8%d0%bd%d0%b0-56-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://zanoza.h1n.ru/2019/05/16/%d0%bd%d0%b5-%d0%be%d1%82%d0%bf%d1%83%d1%81%d0%ba%d0%b0%d0%b9-%d0%bc%d0%be%d1%8e-%d1%80%d1%83%d0%ba%d1%83-elimi-birakma-37-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cabf-%d0%bd%d0%b5-%d0%be/
http://zanoza.h1n.ru/2019/05/16/%d0%bd%d0%b5-%d0%be%d1%82%d0%bf%d1%83%d1%81%d0%ba%d0%b0%d0%b9-%d0%bc%d0%be%d1%8e-%d1%80%d1%83%d0%ba%d1%83-elimi-birakma-38-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rfhx-%d0%bd%d0%b5-%d0%be/
http://zanoza.h1n.ru/2019/05/16/%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0%d1%88%d0%ba%d0%b0-erkenci-kus-38-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sntk-%d1%80%d0%b0%d0%bd%d0%bd%d1%8f%d1%8f-%d0%bf%d1%82%d0%b0/
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=8932
http://mobility-corp.com/index.php/component/k2/itemlist/user/2513408
http://www.die-design-manufaktur.de/index.php/component/k2/itemlist/user/5195688
http://153.120.114.241/eso/index.php/16876924-edinoe-serdce-tek-yurek-19-seria-izew-edinoe-serdce-tek-yurek-1
http://ovotecegg.com/?option=com_k2&view=itemlist&task=user&id=115343
http://ptu.imoove.kr/ko/content/%C2%AB%D1%8E%D1%80%D0%B8%D1%81%D1%82%D1%8B-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-hd-video-%C2%AB%D1%8E%D1%80%D0%B8%D1%81%D1%82%D1%8B-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB332383
http://withinfp.sakura.ne.jp/eso/index.php/16893372-hdvideo-tola-robot-1-seria-d8-tola-robot-1-seria/0
http://menulisilmiah.net/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qv9%d0%bd/
http://praisesound.co.kr/sub04_01/3662
https://mencoin.net/talk_fm/3010
http://cwon.kr/xe/?document_srl=32478
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3262096
http://jstech.kr/index.php?mid=board_lqyj42&document_srl=5330
http://www.svteck.co.kr/customer_gratitude/17161
http://otitismediasociety.org/forum/index.php?topic=174863.0
https://esel.gist.ac.kr/esel2/board_uNln70/4354
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=770854
http://cwon.kr/xe/board_bnSr36/9385
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=722769
http://arte.dgau.ac.kr/board_qna/48030
http://arte.dgau.ac.kr/board_qna/48095
http://asin.itts.co.kr/?document_srl=10943
http://asin.itts.co.kr/Product_A/10955
http://askpharm.net/?document_srl=29583
http://askpharm.net/board_NQiz06/29458
http://askpharm.net/board_NQiz06/29578
http://askpharm.net/board_NQiz06/29589
http://atemshow.com/?document_srl=54852
http://atemshow.com/atemfair_domestic/54806
http://atemshow.com/atemfair_domestic/54841
http://atemshow.com/atemfair_domestic/54880
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=109536
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=109774
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=109926
http://HyUa.1fps.icu/l/szIaeDC
https://prelease.club/%d0%bc%d0%b5%d1%80%d1%82%d0%b2%d0%be%d0%b5-%d0%be%d0%b7%d0%b5%d1%80%d0%be-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yj7m-%d0%bc%d0%b5%d1%80%d1%82%d0%b2%d0%be%d0%b5-%d0%be%d0%b7%d0%b5%d1%80/
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4903946
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=71219
http://www.sp1.football/index.php?mid=faq&document_srl=42591
http://forum.digamahost.com/index.php?topic=112191.0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=608582
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3352550
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bx8s-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-el1%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://www.critico-expository.com/forum/index.php?topic=8101.0
http://www.teedinubon.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jr6g-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-15/
http://www.teedinubon.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zd0n-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-15/
http://www.teedinubon.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dn5l-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-16/
http://www.teedinubon.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rx4g-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-2-%d1%81/
http://www.teedinubon.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ni9t-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://www.teedinubon.com/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hv7s-%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.teedinubon.com/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-83-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-15/
http://www.teedinubon.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pj4u-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81/
http://www.teedinubon.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gp6s-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81/
http://www.teedinubon.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qn2r-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://www.teedinubon.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-89-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zb4k-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd/
http://www.telcon.gr/index.php/component/k2/itemlist/user/72701
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=276057
http://xplorefitness.com/blog/%D1%82%D0%B0%D1%94%D0%BC%D0%BD%D0%B8%D1%86i-89-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-y8-%D1%82%D0%B0%D1%94%D0%BC%D0%BD%D0%B8%D1%86i-89-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=220135
http://roikjer.com/forum/index.php?PHPSESSID=0h3dlkujlfd4g636vpmknu9u87&topic=826211.0
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1648707
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2401216
http://www.sp1.football/index.php?mid=faq&document_srl=16542
http://myrechockey.com/forums/index.php?topic=91190.0
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=35640
http://robocit.com/index.php/component/k2/itemlist/user/449467
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=60247
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=144311
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=144350
http://www.gforgirl.com/xe/?document_srl=129216
http://www.gforgirl.com/xe/?document_srl=129254
http://www.gforgirl.com/xe/?document_srl=129340
http://www.gforgirl.com/xe/poster/129186
http://www.golden-nail.co.kr/press/86821
http://www.golden-nail.co.kr/press/86871
http://www.golden-nail.co.kr/press/86923
http://www.golden-nail.co.kr/press/86934
http://www.hsaura.com/noty/130011
http://seoksoononly.dothome.co.kr/qna/797095
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=12848
http://theolevolosproject.org/index.php/component/k2/itemlist/user/25173
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=282827
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=299643
http://153.120.114.241/eso/index.php/16862500-holostak-9-sezon-10-vypusk-65gb-njholostak-9-sezon-10-vypusk-65
http://www.ekemoon.com/142167/051620193605/
http://ovotecegg.com/component/k2/itemlist/user/117526
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=2262
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3646114
https://prelease.club/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d0%ba%d1%82%d0%be-%d1%83%d1%88%d0%b5%d0%bb-oj%d1%85%d0%be/
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=725382
https://prelease.club/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ip7y-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://adopt10plus.com/groups/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-1981%d0%b3-uf%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
http://seoksoononly.dothome.co.kr/qna/819662
http://cwon.kr/xe/board_bnSr36/21819
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ei1c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://ovotecegg.com/component/k2/itemlist/user/135120
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/94148
http://proxima.co.rw/index.php/component/k2/itemlist/user/626471
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=8100
http://xplorefitness.com/blog/%D0%B2-%D1%8D%D1%84%D0%B8%D1%80%D0%B5-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-6-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-o1-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-6-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://153.120.114.241/eso/index.php/16876254-vetrenyj-hercai-23-seria-cbgv-vetrenyj-hercai-23-seria
http://www.atab.com.sa/?option=com_k2&view=itemlist&task=user&id=1546016
http://necinsurance.co.zw/component/k2/itemlist/user/19130.html
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-06-05-2019-o3-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
http://danielmillsap.com/forum/index.php?topic=955377.0
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/478798
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=681414.0
http://comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=104113
http://windowshopgoa.com/component/k2/itemlist/user/187483
http://forum.politeknikgihon.ac.id/index.php?topic=22021.0
http://www.deliberarchia.org/forum/index.php?topic=963945.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1340610
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1551756
http://rudraautomation.com/index.php/component/k2/author/161805
http://rudraautomation.com/index.php/component/k2/itemlist/user/161538
http://thermoplast.envolgroupe.com/component/k2/author/91908
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3620540
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1579340
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3268365
https://reficulcoin.com/index.php?topic=35173.0
http://shinilspring.com/board_qsfb01/66475
http://www.ekemoon.com/203031/050420191817/
http://preach.kr/Amharic_Music/1718
http://indiefilm.kr/xe/board/70107
http://myrechockey.com/forums/index.php?topic=107809.0
http://www.flixian.com/main/QnA/16767
http://xn--ok1bpqi43ahtb.net/board_eASW07/49573
http://warmfund.net/p/index.php?mid=financing&document_srl=84026
http://vn7.vn/?document_srl=51200
http://www.theocraticamerica.org/forum/index.php/topic,41408.0.html
http://forum.byehaj.hu/index.php?topic=92281.0
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=14187
http://herdental.co.kr/index.php?mid=online&document_srl=11675
http://zanoza.h1n.ru/2019/05/16/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8/
http://carand.co.kr/d2/1066
http://k-cea.org/board_Hnyj62/76375
http://www.svteck.co.kr/customer_gratitude/31823
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=40861
https://khuyenmaikk13.info/index.php?topic=207644.0
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=703936.0
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=26455
http://k-cea.org/board_Hnyj62/52171
http://shinilspring.com/board_qsfb01/49695
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=62227
http://ye-dream.com/qa/37431
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=26492
http://arte.dgau.ac.kr/board_qna/1288
http://indiefilm.kr/xe/board/123113
http://ye-dream.com/qa/58970
http://www.artangel.co.kr/index.php?mid=Activities&document_srl=4334
http://www.golden-nail.co.kr/press/35659
http://www.deliberarchia.org/forum/index.php?topic=1049213.0
http://HyUa.1fps.icu/l/szIaeDC
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=56373
http://oceangray.i234.me/?document_srl=39597
http://www.remify.app/foro/index.php?topic=298900.0
http://skylinecam.co.kr/photo/54757
http://otitismediasociety.org/forum/index.php?topic=162169.0
http://www.sp1.football/index.php?mid=tr_video&document_srl=107431
http://iymc.or.kr/pds/85965
http://d-tube.info/board_jvyO69/215786
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=840644
https://prelease.club/%d1%8d%d1%84%d0%b8%d1%80-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81-3/
http://www.urimwelfare.or.kr/board_mfOh88/5881
http://xn--ok1bpqi43ahtb.net/board_SPcK94/96820
http://www.lgue.co.kr/?document_srl=4218
http://www.itosm.com/cn/board_nLoq17/8269
http://arte.dgau.ac.kr/?document_srl=45923
http://arte.dgau.ac.kr/board_qna/45953
http://arte.dgau.ac.kr/board_qna/46045
http://asin.itts.co.kr/Product_A/10645
http://blog.ptpintcast.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b0%d1%8f-%d0%bc%d0%b0%d0%bb%d0%b5%d0%bd%d1%8c%d0%ba%d0%b0%d1%8f-%d0%bb%d0%be%d0%b6%d1%8c-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zw9e/
http://callman.co.kr/index.php?mid=qa&document_srl=47013
http://callman.co.kr/index.php?mid=qa&document_srl=47058
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=24437
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=24515
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=24525
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=24530
http://HyUa.1fps.icu/l/szIaeDC
http://gochon-iusell.co.kr/g1/29036
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=120624
http://gounface.com/?document_srl=586605
http://gounface.com/?document_srl=586696
http://hanalove.kidspann.net/index.php?mid=qna&document_srl=46254
http://hanalove.kidspann.net/index.php?mid=qna&document_srl=46259
http://herdental.co.kr/index.php?mid=online&document_srl=28618
http://hk-metal.co.kr/hkweb/QnA/28459
http://iamking.net/board/35837
http://iymc.or.kr/pds/89106
http://jjikduk.net/DATA/77894
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=893588
http://joinbohum.kr/board/52089
http://juroweb.com/xe/juroweb_board/22650
http://khapthanam.co.kr/g1/51621
http://kyj1225.godohosting.com/board_mebR72/16409
http://gallerychoi.com/?document_srl=48273
https://theprodigy.info/forum/index.php?topic=29233.0
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=46520
https://www.shaiyax.com/index.php?topic=349068.0
http://azone.synology.me/xe/?document_srl=43243
https://www.thedezlab.com/lab/community/index.php?topic=3664.0
http://indiefilm.kr/xe/board/90581
http://www.jesusonly.life/calendar/71634
http://sy.korean.net/qna/59680
http://xn----3x5er9r48j7wemud0a387h.com/news/21383
http://isch.kr/?document_srl=24740
http://poselokgribovo.ru/forum/index.php?topic=785258.0
http://HyUa.1fps.icu/l/szIaeDC
http://otitismediasociety.org/forum/index.php?topic=175979.0
http://ru-realty.com/forum/index.php?topic=529135.0
http://www.tekparcahdfilm.com/forum/index.php?topic=51202.0
http://www.tekparcahdfilm.com/forum/index.php?topic=51203.0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=73142
http://www.vivelabmanizales.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mv4j-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
http://www.vivelabmanizales.com/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ss3l/
http://www.vivelabmanizales.com/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-le7u/
http://www.vivelabmanizales.com/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81-46/
http://www.vivelabmanizales.com/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81-39/
http://www.vivelabmanizales.com/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ts6l-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.vivelabmanizales.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-83-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-do4m-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd/
http://www.vivelabmanizales.com/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-97-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lj5t-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-97-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.vivelabmanizales.com/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rl2g-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.vivelabmanizales.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-kg0w-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://www.vivelabmanizales.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-dn0s-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://www.ekemoon.com/182275/051120190113/
http://www.vivelabmanizales.com/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uc9q/
http://www.vivelabmanizales.com/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81-48/
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1778422
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1886864
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=297041
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=318198
http://k2.akademitelkom.ac.id/component/k2/itemlist/user/318137
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3774091
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3774103
http://mediaville.me/index.php/component/k2/itemlist/user/252351
http://mobility-corp.com/index.php/component/k2/itemlist/user/2570723
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/232349
http://proandpro.it/?option=com_k2&view=itemlist&task=user&id=4582226
http://sy.korean.net/qna/57361
https://www.shaiyax.com/index.php?topic=349711.0
http://www.svteck.co.kr/customer_gratitude/22800
http://ariji.kr/?document_srl=770975
http://poselokgribovo.ru/forum/index.php?topic=792203.0
http://khapthanam.co.kr/g1/15735
http://lahch.co.kr/index.php?mid=board_jHAP41&document_srl=6044
http://poselokgribovo.ru/forum/index.php?topic=794528.0
http://indiefilm.kr/xe/board/98876
http://www.gforgirl.com/xe/poster/15332
http://emjun.com/index.php?mid=hangtotal&document_srl=91068
http://www.jesusonly.life/calendar/2156
http://pkgersang.dothome.co.kr/board_jiKY24/3688
http://www.deliberarchia.org/forum/index.php?topic=1049863.0
http://hyeonjun.co.kr/menu3/37994
http://daltso.com/index.php?mid=board_cUYy21&document_srl=8514
http://laokorea.com/orange_menu1/10078
http://www.fassen.co.kr/xe/board_VCum96/10695
https://sanp.pro/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-n7-g3-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81/
https://saltriverbg.com/2019/05/16/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://ye-dream.com/qa/2387
http://shinhwaair2017.cafe24.com/issue/205759
http://carand.co.kr/d2/3665
http://corumotoanahtar.com/?option=com_k2&view=itemlist&task=user&id=5220
http://cwon.kr/xe/board_bnSr36/80060
http://cwon.kr/xe/board_bnSr36/80081
http://d-tube.info/board_jvyO69/243912
http://d-tube.info/board_jvyO69/243928
http://d-tube.info/board_jvyO69/243933
http://d-tube.info/board_jvyO69/243938
http://d-tube.info/board_jvyO69/243944
http://d-tube.info/board_jvyO69/243949
http://d-tube.info/board_jvyO69/243954
http://HyUa.1fps.icu/l/szIaeDC
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=63877
http://www.ekemoon.com/172953/051620192910/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1389353
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=62127
http://www.digitalbul.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-s3-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81/
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1120218
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=10752
http://storykingdom.forumside.com/index.php?topic=4708.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1334812
http://www.deliberarchia.org/forum/index.php?topic=981759.0
http://ptu.imoove.kr/ko/content/%C2%AB%D1%8E%D1%80%D0%B8%D1%81%D1%82%D1%8B-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-hd-video-%C2%AB%D1%8E%D1%80%D0%B8%D1%81%D1%82%D1%8B-13-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB331462
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1542637
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=755143
http://smartacity.com/component/k2/itemlist/user/18940
http://www.ds712.net/guest/?document_srl=147496
http://www.ds712.net/guest/index.php?document_srl=147332&mid=guest07
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=146963
http://www.gforgirl.com/xe/poster/132790
http://www.gforgirl.com/xe/poster/132795
http://www.gforgirl.com/xe/poster/132832
http://www.gforgirl.com/xe/poster/132842
http://www.gforgirl.com/xe/poster/132853
http://www.golden-nail.co.kr/press/89632
http://www.golden-nail.co.kr/press/89715
http://www.golden-nail.co.kr/press/89768
http://www.golden-nail.co.kr/press/89810
http://www.hsaura.com/?document_srl=132413
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=127442
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=155072
http://5starcoffee.co.kr/board_EBXY17/7303
http://ajincomp.godohosting.com/board_STnh82/51577
http://alastair030.dothome.co.kr/index.php?mid=board_MMiF30&document_srl=5462
http://apt2you2.cafe24.com/g1/8368
http://arte.dgau.ac.kr/board_qna/49583
http://askpharm.net/board_NQiz06/30582
http://barobus.kr/qna/22926
http://bebopindia.com/notcie/143209
http://bebopindia.com/notcie/143256
http://bizchemical.com/board_kMpv94/1882196
http://constellation.kro.kr/?document_srl=8215
http://constellation.kro.kr/board_kbku73/8204
http://dreamplusart.com/mn03_01/20003
http://constellation.kro.kr/board_kbku73/13063
http://constellation.kro.kr/board_kbku73/13068
http://daltso.com/index.php?document_srl=26721&mid=board_cUYy21
http://esiapolisthesharp2.co.kr/?document_srl=39125
http://esiapolisthesharp2.co.kr/g1/39114
http://f-tube.info/board/87940
http://f-tube.info/board/88005
http://f-tube.info/board/88010
http://f-tube.info/board/88015
http://f-tube.info/board/88020
http://f-tube.info/board/88023
http://f-tube.info/board/88028
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=31387
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=31393
http://gspara01.dothome.co.kr/index.php?mid=board_XHsr53&document_srl=3906
http://gspara01.dothome.co.kr/index.php?mid=board_XHsr53&document_srl=3936
http://gspara01.dothome.co.kr/index.php?mid=board_XHsr53&document_srl=3947
http://gspara01.dothome.co.kr/index.php?mid=board_XHsr53&document_srl=3952
http://gspara01.dothome.co.kr/index.php?mid=board_XHsr53&document_srl=3957
http://gspara01.dothome.co.kr/index.php?mid=board_XHsr53&document_srl=3963
http://hyundeok.iptime.org/zbxe/index.php?mid=family&document_srl=54281
http://hyundeok.iptime.org/zbxe/index.php?mid=family&document_srl=54303
http://juroweb.com/xe/?document_srl=23037
http://juroweb.com/xe/juroweb_board/23058
http://juroweb.com/xe/juroweb_board/23064
http://HyUa.1fps.icu/l/szIaeDC
http://israengineering.com/index.php/component/k2/itemlist/user/1154298
http://haniel.ir/index.php/component/k2/itemlist/user/99934
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/521701
http://cwon.kr/xe/board_bnSr36/17211
http://mediaville.me/index.php/component/k2/itemlist/user/269016
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=6360
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/328821
http://www.critico-expository.com/forum/index.php?topic=8992.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2567777
https://l2thalassic.org/Forum/index.php?topic=1002.0
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-k2-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5/
http://www.ekemoon.com/142513/051720194505/
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=317210
https://www.swiss-focus.ch/index.php/component/k2/itemlist/user/11757
http://arunagreen.com/index.php/component/k2/itemlist/user/442478
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2509405
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=288986
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/201381
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1335525
http://bitpark.co.kr/?document_srl=3754980
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=295731
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f4-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81/
http://bobr.site/index.php?topic=150288.0
http://bobr.site/index.php?topic=150291.0
http://bobr.site/index.php?topic=150305.0
http://bobr.site/index.php?topic=150308.0
http://bobr.site/index.php?topic=150317.0
http://bobr.site/index.php?topic=150369.0
http://bobr.site/index.php?topic=150380.0
http://bobr.site/index.php?topic=150382.0
http://bobr.site/index.php?topic=150401.0
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=6848
http://www.ekemoon.com/187419/050920191214/
http://smartacity.com/component/k2/itemlist/user/39954
http://www.deliberarchia.org/forum/index.php?topic=1011065.0
http://adopt10plus.com/groups/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-cvjnhtnm-iv%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba/
http://israengineering.com/index.php/component/k2/itemlist/user/1128235
http://withinfp.sakura.ne.jp/eso/index.php/16885054-sluga-naroda-3-sezon-7-seria-06052019-v7-sluga-naroda-3-sezon-7
http://www.vivelabmanizales.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-05-05-2019-z3-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://www.vivelabmanizales.com/%d1%81%d0%be%d0%b4%d0%b5%d1%80%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-05-05-2019-t5-%d1%81%d0%be%d0%b4%d0%b5%d1%80%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-9-%d1%81/
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=16297
http://rudraautomation.com/index.php/component/k2/itemlist/user/102992
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1357711
http://withinfp.sakura.ne.jp/eso/index.php/16888590-hd-tolarobot-1-sezon-8-seria-n5-tolarobot-1-sezon-8-seria/0
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=618732
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=618935
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=818686
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=819044
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=62641
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/257456
http://zsmr.com.ua/index.php/component/k2/itemlist/user/555270
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3354862
https://turimex.mx.solemti.net/index.php/component/k2/itemlist/user/1386
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2627286
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=325956
http://www.hsaura.com/noty/144707
http://laokorea.com/orange_menu1/36628
http://apt2you2.cafe24.com/g1/9520
http://moavalve.co.kr/faq/78849
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=85755
http://xn----c28ewjj6ubwku6frtcuzec29ae5b.com/news/9723
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=98175
http://www.yepia.com/board_ZCPG83/18914
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/news/10066
http://photogrotto.com/hd-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80-2/
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=c22c3082f97bd30215b9bfd76812a161&topic=7227.0
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-luil-%d0%b8%d0%b3%d1%80/
http://wipln.com/?document_srl=57824
http://xn----3x5er9r48j7wemud0a387h.com/news/49737
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/9955
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/11122
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2783844
http://vervetama.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80-10/
http://constellation.kro.kr/board_kbku73/8846
https://tg.vl-mp.com/index.php?topic=1473559.0
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=58201da04bca84ed6a486def94b31ee1&topic=7425.0
http://daltso.com/index.php?mid=board_cUYy21&document_srl=24201
http://apt2you2.cafe24.com/g1/7778
http://goldenpowerball2.com/?document_srl=95096
https://2002.shyoon.com/board_2002/44695
https://2002.shyoon.com/board_2002/44721
https://2002.shyoon.com/board_2002/44919
https://2002.shyoon.com/board_2002/44944
https://2002.shyoon.com/board_2002/44992
https://2002.shyoon.com/board_2002/45045
https://2002.shyoon.com/board_2002/45214
https://2002.shyoon.com/board_2002/45410
https://2002.shyoon.com/board_2002/45712
https://2002.shyoon.com/board_2002/45740
https://2002.shyoon.com/board_2002/45822
https://2002.shyoon.com/board_2002/45827
http://HyUa.1fps.icu/l/szIaeDC
http://necinsurance.co.zw/component/k2/itemlist/user/21075.html
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/260261
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/260637
http://poselokgribovo.ru/forum/index.php?topic=802872.0
http://lucky.kidspann.net/index.php?mid=qna&document_srl=56651
http://maka-222.com/?document_srl=25042
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=25003
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=25016
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=25021
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=25035
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=25059
http://research.kiu.ac.kr/?document_srl=60389
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=60415
http://skylinecam.co.kr/photo/85351
http://yoriyorifood.com/xxxx/spacial/103276
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2665976
http://corumotoanahtar.com/component/k2/itemlist/user/5563.html
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=346855
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1932662
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=337541
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=337830
http://haniel.ir/?option=com_k2&view=itemlist&task=user&id=117907
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=21425
http://neosky.net/xe/space_station/2858
http://www.vamoscontigo.org/Noticia/31080
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=20209
http://xn----3x5er9r48j7wemud0a387h.com/news/47930
http://www.sp1.football/index.php?mid=faq&document_srl=294538
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=81323
http://askpharm.net/?document_srl=29809
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=29433
http://www.siheunglove.com/chulip/70529
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=59689
https://betshin.com/Story/52180
http://www.teedinubon.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-plan-%d0%b8%d0%b3%d1%80/
http://www.hsaura.com/noty/161878
http://lasvur.ru/component/k2/itemlist/user/38549
http://lucky.kidspann.net/index.php?mid=qna&document_srl=100428
http://mediaville.me/index.php/component/k2/itemlist/user/294313
http://necinsurance.co.zw/component/k2/itemlist/user/21369.html
http://neosky.net/xe/space_station/5851
http://neosky.net/xe/space_station/5860
http://neosky.net/xe/space_station/5865
http://neosky.net/xe/space_station/5869
http://oneandonly1127.com/guest/15733
http://oneandonly1127.com/guest/15747
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=86575
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=86581
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=86597
http://www.itosm.com/cn/board_nLoq17/31130
http://www.itosm.com/cn/board_nLoq17/31135
http://www.josephmaul.org/menu41/151190
http://www.josephmaul.org/menu41/151204
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=8879
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=8884
http://HyUa.1fps.icu/l/szIaeDC
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=730742
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1685804
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=816369
http://zanoza.h1n.ru/2019/05/14/%d0%b4%d0%be%d1%87%d0%ba%d0%b8-%d0%bc%d0%b0%d1%82%d0%b5%d1%80%d0%b8-%d0%b4%d0%be%d1%87%d0%ba%d0%b8-%d0%bc%d0%b0%d1%82%d0%b5%d1%80i-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uv0%d0%b4%d0%be%d1%87/
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/241463
https://prelease.club/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-92-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jf1j-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-92-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://arunagreen.com/index.php/component/k2/itemlist/user/468623
http://www.josephmaul.org/?document_srl=116250
http://www.josephmaul.org/?document_srl=116285
http://www.sp1.football/?document_srl=248868
http://www.sp1.football/index.php?mid=faq&document_srl=248655
http://www.sp1.football/index.php?mid=faq&document_srl=248698
http://www.sp1.football/index.php?mid=faq&document_srl=248998
http://www.studyxray.com/Sangdam/116269
http://xn----3x5er9r48j7wemud0a387h.com/news/39873
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8d%d1%84%d0%b8%d1%80-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=1004545
http://www.vivelabmanizales.com/hd-video-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g1-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1/
http://web2interactive.com/index.php/component/k2/itemlist/user/3598159
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=45656
http://macdistri.com/index.php/component/k2/itemlist/user/299063
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1543512
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1646985
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=332934
http://www.spazioad.com/component/k2/itemlist/user/7279529
http://comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=106328
http://www.ekemoon.com/183225/051620194113/
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=247175
http://skylinecam.co.kr/photo/50777
http://www.hicleaning.kr/board_wash/94694
http://www.hsaura.com/noty/150964
http://www.hsaura.com/noty/151452
http://www.hsaura.com/noty/151618
http://www.jesusonly.life/calendar/151465
http://www.jesusonly.life/calendar/151501
http://www.jesusonly.life/calendar/151622
http://www.jesusonly.life/calendar/151714
http://www.jesusonly.life/calendar/151771
http://www.jesusonly.life/calendar/151811
http://www.josephmaul.org/?document_srl=116623
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=504424
http://matinbank.ir/component/k2/itemlist/user/4487546.html
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1855607
http://hiyou.com.vn/index.php/component/k2/itemlist/user/1312676
http://www.camaracoyhaique.cl/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mc1%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3310257
http://www.die-design-manufaktur.de/?option=com_k2&view=itemlist&task=user&id=5211154
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1054190
http://highlanderonline.cmshelplive.net/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ptog-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-13-%d1%81%d0%b5%d1%80%d0%b8/
http://vn7.vn/qna/76651
https://sanp.pro/%d0%b2%d0%be%d1%81%d0%ba%d1%80%d0%b5%d1%81%d1%88%d0%b8%d0%b9-%d1%8d%d1%80%d1%82%d1%83%d0%b3%d1%80%d1%83%d0%bb-143-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mpim-%d0%b2%d0%be%d1%81%d0%ba%d1%80/
http://healthyteethpa.org/component/k2/itemlist/user/5426955
http://www.deliberarchia.org/forum/index.php?topic=998987.0
https://turimex.mx.solemti.net/en/?option=com_k2&view=itemlist&task=user&id=2020
http://www.sp1.football/?document_srl=263519
http://www.sp1.football/index.php?mid=faq&document_srl=263667
http://www.sp1.football/index.php?mid=faq&document_srl=263805
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3302115
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=79207
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=79228
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=79270
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=79304
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=79319
http://ye-dream.com/qa/92616
http://ye-dream.com/qa/92626
http://sextomariotienda.com/blog/%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-i8-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-2/
http://dohairbiz.com/en/component/k2/itemlist/user/2712326.html
http://smartacity.com/component/k2/itemlist/user/19395
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1860013
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1550820
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1562132
http://menulisilmiah.net/%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g6-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81/
http://www.elpinatarense.com/index.php/component/k2/itemlist/user/154598
http://ovotecegg.com/index.php/component/k2/itemlist/user/117148
https://forums.letstalkbeats.com/index.php?topic=64866.0
http://healthyteethpa.org/component/k2/itemlist/user/5331897
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1334454
http://fbpharm.net/index.php/component/k2/itemlist/user/14458
https://l2thalassic.org/Forum/index.php?topic=1822.0
http://d-tube.info/board_jvyO69/252702
http://d-tube.info/board_jvyO69/252849
http://d-tube.info/board_jvyO69/253346
http://d-tube.info/board_jvyO69/253476
http://d-tube.info/board_jvyO69/254444
http://d-tube.info/board_jvyO69/254936
http://d-tube.info/board_jvyO69/254986
http://d-tube.info/board_jvyO69/255013
http://d-tube.info/board_jvyO69/255346
http://d-tube.info/board_jvyO69/255421
http://d-tube.info/board_jvyO69/255437
http://daltso.com/?document_srl=20686
http://daltso.com/?document_srl=21190
http://daltso.com/?document_srl=22338
http://www.livetank.cn/market1/38598
http://www.livetank.cn/market1/38624
http://www.livetank.cn/market1/38689
http://www.livetank.cn/market1/38747
http://www.livetank.cn/market1/39320
http://www.lovestory.or.kr/?document_srl=2297
http://www.lovestory.or.kr/?document_srl=2696
http://www.lovestory.or.kr/?document_srl=4738
http://www.lovestory.or.kr/?document_srl=5116
http://www.lovestory.or.kr/?document_srl=5456
http://www.lovestory.or.kr/?document_srl=5850
http://www.lovestory.or.kr/?document_srl=5914
http://www.lovestory.or.kr/topic/2145
http://www.lovestory.or.kr/topic/2182
http://www.lovestory.or.kr/topic/2193
http://www.lovestory.or.kr/topic/2198
http://www.lovestory.or.kr/topic/2212
http://www.lovestory.or.kr/topic/2257
http://HyUa.1fps.icu/l/szIaeDC
http://tiretech.co.kr/?document_srl=27769
http://tiretech.co.kr/?document_srl=28270
http://tiretech.co.kr/?document_srl=28996
http://tiretech.co.kr/?document_srl=34202
http://tiretech.co.kr/?document_srl=36003
http://tiretech.co.kr/?document_srl=36890
http://tiretech.co.kr/?document_srl=38238
http://tiretech.co.kr/?document_srl=39070
http://tiretech.co.kr/?document_srl=40436
http://tiretech.co.kr/index.php?document_srl=38421&mid=qna
http://tiretech.co.kr/index.php?document_srl=43159&mid=qna
http://tiretech.co.kr/index.php?mid=qna&document_srl=27161
http://tiretech.co.kr/index.php?mid=qna&document_srl=27208
http://tiretech.co.kr/index.php?mid=qna&document_srl=27277
http://vervetama.com/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-%d0%b4%d0%b0%d1%82%d0%b0-%d0%b2%d1%8b%d1%85%d0%be%d0%b4%d0%b0-1-%d1%81-7/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-%d0%b4%d0%b0%d1%82%d0%b0-%d0%b2%d1%8b%d1%85%d0%be%d0%b4%d0%b0-1-%d1%81-8/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2017/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vo-production/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b4%d0%b0%d1%82%d0%b0-%d0%b2/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bd%d0%b0-%d1%80%d1%83%d1%81/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b0%d0%bd%d0%be%d0%bd%d1%81-2/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b4%d0%b0%d1%82%d0%b0-%d0%b2%d1%8b/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-shachiburi/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b4%d0%b0%d1%82%d0%b0-%d0%b2%d1%8b/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bf%d1%80%d0%be%d0%bc%d0%be/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8e%d1%82%d1%83%d0%b1-3/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8f%d0%bd%d0%b4%d0%b5%d0%ba%d1%81/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5-4/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8e%d1%82%d1%83%d0%b1/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2017/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-8-03-2016/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5-2/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bd%d0%b0-%d1%80%d1%83%d1%81%d1%81/
http://HyUa.1fps.icu/l/szIaeDC
https://testing.celekt.com/%d0%a2%d0%b0%d0%b9%d0%bd%d1%8b-97-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zi2%d0%a2%d0%b0%d0%b9%d0%bd%d1%8b-97-%d1%81%d0%b5%d1%80%d0%b8%d1%8f19-05-2019/
http://e-educ.net/Forum/index.php?topic=13054.0
http://e-educ.net/Forum/index.php?topic=13055.0
http://forum.digamahost.com/index.php?topic=128206.0
http://forum.elexlabs.com/index.php?topic=44587.0
http://married.dike.gr/index.php/component/k2/itemlist/user/67865
http://otitismediasociety.org/forum/index.php?topic=180745.0
https://cybergsm.es/index.php?topic=29991.0
https://npi.org.es/smf/index.php?topic=119189.0
http://www.teedinubon.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bz2%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be/
http://www.teedinubon.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-91-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ws9%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-91-%d1%81%d0%b5%d1%80%d0%b8%d1%8f19-05-2019/
https://l2thalassic.org/Forum/index.php?topic=1143.0
http://www.die-design-manufaktur.de/?option=com_k2&view=itemlist&task=user&id=5176009
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=217961
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=39803
http://withinfp.sakura.ne.jp/eso/index.php/16862952-voskressij-ertugrul-146-seria-epec-voskressij-ertugrul-146-seri/0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=286580
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/205031
https://l2thalassic.org/Forum/index.php?topic=1336.0
http://married.dike.gr/index.php/component/k2/itemlist/user/53005
http://dev.aabn.org.gh/component/k2/itemlist/user/526845
http://necinsurance.co.zw/?option=com_k2&view=itemlist&task=user&id=19320
http://menulisilmiah.net/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mo5%d0%bd/
http://withinfp.sakura.ne.jp/eso/index.php/16870292-vossoedinenie-vuslat-19-seria-jqda-vossoedinenie-vuslat-19-seri/0
http://8.droror.co.il/uncategorized/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-96-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mj0%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-96-%d1%81%d0%b5%d1%80%d0%b8%d1%8f08-05-2019/
http://menulisilmiah.net/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5-3/
http://miklja.net/forum/index.php?topic=32029.0
http://miklja.net/forum/index.php?topic=32033.0
http://miklja.net/forum/index.php?topic=32039.0
http://miklja.net/forum/index.php?topic=32043.0
http://miklja.net/forum/index.php?topic=32045.0
http://miklja.net/forum/index.php?topic=32046.0
http://ovotecegg.com/?option=com_k2&view=itemlist&task=user&id=163443
http://ru-realty.com/forum/index.php?PHPSESSID=jm8jojr5e8o0tgm0pqlfqjig86&topic=531042.0
http://sdsn.develop.cinfores.com/?option=com_k2&view=itemlist&task=user&id=223462
http://taklongclub.com/forum/index.php?topic=153004.0
http://thermoplast.envolgroupe.com/component/k2/author/122927
http://thermoplast.envolgroupe.com/component/k2/author/123164
http://vtservices85.fr/smf2/index.php?PHPSESSID=8ff1f73240e75ed9f5909ef6791baf40&topic=256643.0
http://webp.online/index.php?topic=60444.0
http://bobr.site/index.php?topic=150219.0
http://sunele.co.kr/board_ReBD97/55824
https://serverpia.co.kr/board_ucCk10/13568
http://www.kcch.or.kr/index.php?mid=board_uFpk03&document_srl=25354
http://khapthanam.co.kr/g1/40653
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=872043
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=22063
http://photogrotto.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80-11/
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=209600
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/gumdanapt/94884
http://wipln.com/?document_srl=57130
http://yooseok.com/board_BkvT46/338674
http://laokorea.com/orange_menu1/36920
http://photogrotto.com/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd/
http://pkgersang.dothome.co.kr/board_jiKY24/7535
http://metropolis.ga/index.php?topic=13520.0
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=22768
http://www.hicleaning.kr/board_wash/101508
http://vhost12299.cpsite.ru/479900-igra-prestolovgame-of-thrones-8-sezon-7-seria-kykd-igra-prestol
http://roikjer.com/forum/index.php?PHPSESSID=qah8kf0jkuoqnki94k5s2pmaq1&topic=891732.0
http://askpharm.net/board_NQiz06/32486
http://www.youngfile.com/?document_srl=25113
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=8653
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=62802
http://iymc.or.kr/pds/88634
http://HyUa.1fps.icu/l/szIaeDC
http://menulisilmiah.net/%d1%87%d1%83%d0%b6%d0%b0%d1%8f-%d0%b6%d0%b8%d0%b7%d0%bd%d1%8c-%d1%87%d1%83%d0%b6%d0%b5-%d0%b6%d0%b8%d1%82%d1%82%d1%8f-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uz5%d1%87%d1%83%d0%b6%d0%b0%d1%8f-%d0%b6/
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/208022
http://www.deliberarchia.org/forum/index.php?topic=1026652.0
http://www.crnmedia.es/component/k2/itemlist/user/86184
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3351901
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1083438
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=557930
http://www.rationalkorea.com/xe/index.php?document_srl=467880&mid=pqna3
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3673961
http://withinfp.sakura.ne.jp/eso/index.php/17114231-hd-smers-6-seria-b2-smers-6-seria
http://www.almacenesrickie.com.ec/index.php/component/k2/itemlist/user/127454
http://www.crnmedia.es/component/k2/itemlist/user/86855
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4940508
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=336503
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2656116
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2656139
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1642487
http://thermoplast.envolgroupe.com/component/k2/author/83534
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=63253
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3600259
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1577693
http://www.pcosmetic.ir/?option=com_k2&view=itemlist&task=user&id=10740
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=14399
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=587415
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=51923
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=52542
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/304693
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3324288
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=17688
http://seoksoononly.dothome.co.kr/qna/819133
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/11466
http://www.flixian.com/main/QnA/41865
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/news/12226
http://www.flixian.com/main/QnA/40706
http://vhost12299.cpsite.ru/499777-igra-prestolov-got-8-sezon-6-seria-ydqh-igra-prestolov-got-8-se
http://ariji.kr/?document_srl=821759
http://wipln.com/?document_srl=54712
http://www.jshwanghoan.com/index.php?mid=historical_figures&document_srl=100635
http://shinilspring.com/board_qsfb01/103573
http://askpharm.net/board_NQiz06/28789
http://kwpub.kr/PUBS/59345
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/news/12308
http://toeden.co.kr/Product_new/42345
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3303495
http://www.cnsmaker.net/xe/?document_srl=75049
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/12343
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/12353
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/12358
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/news/15006
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/news/15011
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/16481
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/16497
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/?document_srl=24036
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=24031
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=24049
http://HyUa.1fps.icu/l/szIaeDC
http://proxima.co.rw/index.php/component/k2/itemlist/user/635262
http://www.theocraticamerica.org/forum/index.php?topic=32073.0
http://forum.byehaj.hu/index.php?topic=89287.0
http://www.josephmaul.org/menu41/32801
http://c3isecurity.com.br/component/k2/itemlist/user/525379
http://danielmillsap.com/forum/index.php?topic=1011595.0
http://www.deliberarchia.org/forum/index.php?topic=1026459.0
http://www.vivelabmanizales.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd1x-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/208326
http://dcasociados.eu/component/k2/itemlist/user/88340
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=106122
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=15869
http://www.spazioad.com/component/k2/itemlist/user/7217838
http://www.deliberarchia.org/forum/index.php?topic=973327.0
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2562131
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=220735
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2523138
http://lavaggio.com.vn/index.php/component/k2/itemlist/user/3702632
http://seoksoononly.dothome.co.kr/?document_srl=749864
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=6813
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1619690
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1409229
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=62916
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/322575
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=555902
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/18051
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/18205
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3355726
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=1509
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=20770
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2628241
http://c3isecurity.com.br/component/k2/itemlist/user/524545
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=43823
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=44251
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=44336
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=44540
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=44576
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=44612
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=44914
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=44962
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=45016
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=45037
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=45047
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=45092
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=45154
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=45215
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=45295
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=45337
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=45388
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=45669
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=46057
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=46381
http://sy.korean.net/qna/92337
http://sy.korean.net/qna/92400
http://sy.korean.net/qna/92456
http://sy.korean.net/qna/92488
http://sy.korean.net/qna/92511
http://sy.korean.net/qna/92526
http://sy.korean.net/qna/92532
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b0%d0%bd%d0%be%d0%bd%d1%81/
http://vervetama.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80-19/
http://vervetama.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80-27/
http://vervetama.com/%d1%8d%d1%84%d0%b8%d1%80-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8f-2/
http://vervetama.com/%d1%8d%d1%84%d0%b8%d1%80-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%ba/
http://vervetama.com/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82-2/
http://withinfp.sakura.ne.jp/eso/index.php/17195427-smotret-rasskaz-sluzanki-3-sezon-7-seria-senki/0
http://www.lgue.co.kr/?document_srl=32465
http://www.lgue.co.kr/?document_srl=32480
http://www.lgue.co.kr/?document_srl=32485
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=9137
http://www.rocktheboat.cc/groups/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80-6496/
http://www.siheunglove.com/chulip/75463
http://www.siheunglove.com/chulip/75485
http://www.studyxray.com/?document_srl=148338
http://www.studyxray.com/Sangdam/148376
http://www.teedinubon.com/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%89%d0%b5%d0%bd%d0%ba%d0%b8/
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=3c8748e0cc9fe83e3be6860325ee28d3&topic=7496.0
http://HyUa.1fps.icu/l/szIaeDC
http://www.critico-expository.com/forum/index.php?topic=10193.0
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=64359
http://married.dike.gr/index.php/component/k2/itemlist/user/60666
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4925144
http://www.sp1.football/index.php?mid=faq&document_srl=80214
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/16855
https://sto54.ru/index.php/component/k2/itemlist/user/3362587
https://turimex.mx.solemti.net/index.php/component/k2/itemlist/user/2247
http://cafe.dokseosil.co.kr/community/44714
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=44834
http://menulisilmiah.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sf9%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://seoksoononly.dothome.co.kr/qna/875174
http://zanoza.h1n.ru/2019/05/15/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-98-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cm4c-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-98-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://zanoza.h1n.ru/2019/05/15/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fi1d-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://cafe.dokseosil.co.kr/community/41636
http://cafe.dokseosil.co.kr/community/41680
http://cafe.dokseosil.co.kr/community/41686
http://cafe.dokseosil.co.kr/community/41712
http://cafe.dokseosil.co.kr/community/41734
http://cafe.dokseosil.co.kr/community/41762
http://forum.digamahost.com/index.php?topic=122189.0
http://teambuildingpremium.com/forum/index.php?topic=828726.0
http://teambuildingpremium.com/forum/index.php?topic=828728.0
http://www.hsaura.com/noty/153246
http://www.jshwanghoan.com/?document_srl=93984
http://www.jshwanghoan.com/index.php?mid=historical_figures&document_srl=93889
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=94015
http://www.rationalkorea.com/xe/?document_srl=511101
http://www.sp1.football/?document_srl=253379
http://www.sp1.football/index.php?mid=faq&document_srl=253654
http://www.svteck.co.kr/?document_srl=54599
http://www.svteck.co.kr/customer_gratitude/54609
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3301270
http://xn--ok1bpqi43ahtb.net/board_eASW07/148964
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=83942
http://yoriyorifood.com/xxxx/spacial/91087
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=623100
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1875501
http://rudraautomation.com/index.php/component/k2/author/156922
http://jjimdak.callbank.kr/?document_srl=753901
http://www.josephmaul.org/menu41/39104
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=30033
http://www.spazioad.com/component/k2/itemlist/user/7258658
http://www.golden-nail.co.kr/press/99300
http://www.golden-nail.co.kr/press/99305
http://www.golden-nail.co.kr/press/99312
http://www.hsaura.com/noty/145983
http://www.jesusonly.life/calendar/147965
http://sextomariotienda.com/blog/hd-video-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-y0-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.vivelabmanizales.com/hd-video-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-f2-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1/
http://www.vivelabmanizales.com/%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-%d0%bd%d0%b5-%d0%b3%d0%be%d0%b2%d0%be%d1%80%d0%b8-%d0%bd%d0%b8%d0%ba%d0%be%d0%b3%d0%b4%d0%b0-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-06-05-2-3/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3294662
http://married.dike.gr/index.php/component/k2/itemlist/user/46497
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=755370
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=104156
http://www.vivelabmanizales.com/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-5/
http://www.renovaleplanejados.com.br/index.php/component/k2/itemlist/user/559097
http://menulisilmiah.net/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-b6-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1/
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=1021752
http://poselokgribovo.ru/forum/index.php?topic=729554.0
http://ye-dream.com/qa/35944
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/528992
http://www.jesusonly.life/calendar/48145
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1829458
http://www.urbantutorial.com/index.php/component/k2/itemlist/user/109877
http://withinfp.sakura.ne.jp/eso/index.php/16961650-novinka-sluga-naroda-3-sezon-16-seria-y7-sluga-naroda-3-sezon-1/0
http://www.web2interactive.com/index.php/component/k2/itemlist/user/3658355
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3358949
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2448950
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4830684
http://withinfp.sakura.ne.jp/eso/index.php/16934893-uristy-16-seria-uristy-16-seria/0
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1552163
http://roikjer.com/forum/index.php?topic=812749.0
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=289527
http://married.dike.gr/index.php/component/k2/itemlist/user/48429
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1890167
http://dohairbiz.com/en/?option=com_k2&view=itemlist&task=user&id=2725565
http://fbpharm.net/index.php/component/k2/itemlist/user/26189
http://febrescordero.gob.ec/?option=com_k2&view=itemlist&task=user&id=86343
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1752162
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1869035
http://israengineering.com/index.php/component/k2/itemlist/user/1144827
http://zanoza.h1n.ru/2019/05/15/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-new-ec%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://skylinecam.co.kr/photo/56472
https://grajalesabogados.com.mx/?option=com_k2&view=itemlist&task=user&id=62185
http://emjun.com/index.php?mid=hangtotal&document_srl=44456
http://zanoza.h1n.ru/2019/05/15/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yv1w-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
https://prelease.club/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81-43/
https://prelease.club/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81-46/
http://cafe.dokseosil.co.kr/community/43615
http://cafe.dokseosil.co.kr/community/43626
http://cafe.dokseosil.co.kr/community/43631
http://cafe.dokseosil.co.kr/community/43642
http://cafe.dokseosil.co.kr/community/43652
http://married.dike.gr/index.php/component/k2/itemlist/user/60762
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=97185
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/97161
http://ovotecegg.com/component/k2/itemlist/user/144539
http://rudraautomation.com/index.php/component/k2/author/188787
http://rudraautomation.com/index.php/component/k2/author/189119
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/209316
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/209351
http://smartacity.com/component/k2/itemlist/user/45051
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1684561
http://thermoplast.envolgroupe.com/component/k2/author/104041
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=7218
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=63929
https://cfcestradareal.com.br/component/k2/itemlist/user/19672
http://corumotoanahtar.com/component/k2/itemlist/user/1942.html
http://xn----c28ewjj6ubwku6frtcuzec29ae5b.com/news/10316
http://www.golden-nail.co.kr/press/108101
https://goagiletour.ca/node/1/sessions/%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-7-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-zqns-%C2%AB%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-7-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://www.ekemoon.com/214639/050420192919/
https://celekt.com/%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wrcu-%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=27804
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=132568
http://arte.dgau.ac.kr/board_qna/54902
http://www.teedinubon.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5-7/
http://callman.co.kr/index.php?mid=qa&document_srl=68690
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=111378
http://www.yepia.com/board_ZCPG83/20609
http://forum.bmw-e60.eu/index.php?topic=8738.0
https://reficulcoin.com/index.php?topic=54812.0
https://tg.vl-mp.com/index.php?topic=1469383.0
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/?document_srl=12018
http://atemshow.com/atemfair_domestic/56929
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=47960
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=47995
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=48069
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=48178
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=48258
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=48268
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=48386
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=48462
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=48532
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=48575
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=48604
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=48719
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=48741
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=48775
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=48780
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=48890
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=48976
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=49094
http://HyUa.1fps.icu/l/szIaeDC
http://www.web2interactive.com/index.php/component/k2/itemlist/user/3654868
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/86635
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=19786
http://www.digitalbul.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rx4s-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://seoksoononly.dothome.co.kr/qna/838146
https://prelease.club/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rq6i-%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://prelease.club/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wo7w-%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://prelease.club/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-82-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-11/
https://prelease.club/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-83-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19/
https://prelease.club/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jv8s-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81/
https://prelease.club/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qe4f-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81/
http://www.urbantutorial.com/index.php/component/k2/itemlist/user/112836
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/331223
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/28470
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/63358
http://bebopindia.com/notcie/62147
http://carrierworld.co.kr/?document_srl=38444
http://cwon.kr/xe/board_bnSr36/30366
http://daesestudy.co.kr/ipsi_docu/21962
http://daesestudy.co.kr/ipsi_docu/22007
http://emjun.com/index.php?mid=hangtotal&document_srl=49827
http://www.digitalbul.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-16-05-2019-k9-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://www.digitalbul.com/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-16-05-2019-o4-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80/
http://www.digitalbul.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-16-05-2019-f2-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
http://www.m1avio.com/index.php/component/k2/itemlist/user/3693858
http://www.ekemoon.com/177609/051720194911/
http://withinfp.sakura.ne.jp/eso/index.php/17006579-serial-smers-10-seria-l2-smers-10-seria/0
http://www.digitalbul.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wt5x-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://myrechockey.com/forums/index.php?topic=95915.0
http://dev.aabn.org.gh/component/k2/itemlist/user/584939
https://members.fbhaters.com/index.php?topic=86013.0
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/234979
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/260388
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3603265
http://married.dike.gr/index.php/component/k2/itemlist/user/60578
http://thermoplast.envolgroupe.com/component/k2/author/90045
http://xn--9m1b83j39hz6exwonmf.com/board_IYPe43/484759
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=53504
http://arnikabolt.ro/index.php/component/k2/itemlist/user/112056
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=58819
http://corumotoanahtar.com/component/k2/itemlist/user/4351
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1942034
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1923572
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1923795
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1923887
http://guiadetudo.com/index.php/component/k2/itemlist/user/12240
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=329990
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=330182
http://jiquilisco.org/index.php/component/k2/itemlist/user/8705
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3826616
http://zanoza.h1n.ru/2019/05/16/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-93-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-16-05-2019-n9-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-93-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://zanoza.h1n.ru/2019/05/16/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-16-05-2019-u4-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82/
http://zanoza.h1n.ru/2019/05/16/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-16-05-2019-t5-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
https://test.baseyou21.kr/index.php?document_srl=41879&mid=main_slider
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=41786
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=41842
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=42069
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=154803
https://www.vegasgreentour.com/?document_srl=46521
https://www.vegasgreentour.com/index.php?document_srl=46332&mid=board_XiHh59
http://arunagreen.com/?option=com_k2&view=itemlist&task=user&id=529172
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=335172
http://dev.aabn.org.gh/component/k2/itemlist/user/600914
http://jiquilisco.org/index.php/component/k2/itemlist/user/7242
http://maderadepaulownia.com/?option=com_k2&view=itemlist&task=user&id=84286
http://www.ekemoon.com/188743/051520190514/
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=53156
http://yoriyorifood.com/xxxx/spacial/39622
http://teambuildingpremium.com/forum/index.php?topic=795330.0
http://zanoza.h1n.ru/2019/05/14/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d0%bd%d0%be%d0%b2%d0%be%d1%81%d1%82%d0%b5%d0%b9-zs%d1%85/
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/227231
http://indiefilm.kr/xe/board/52170
http://teambuildingpremium.com/forum/index.php?topic=795669.0
http://xn--ok1bpqi43ahtb.net/board_eASW07/111015
http://xn--ok1bpqi43ahtb.net/board_eASW07/111113
https://esel.gist.ac.kr/esel2/board_hmgj23/51233
https://khuyenmaikk13.info/index.php?topic=206966.0
https://www.tedyun.com/xe/?document_srl=184458
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=85886
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=112059
http://corumotoanahtar.com/component/k2/itemlist/user/4355.html
http://corumotoanahtar.com/component/k2/itemlist/user/4365.html
http://dev.aabn.org.gh/component/k2/itemlist/user/612021
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1209005
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1209015
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=38336
http://married.dike.gr/index.php/component/k2/itemlist/user/65697
http://miquirofisico.com/index.php/component/k2/itemlist/user/4220
http://www.sp1.football/index.php?mid=faq&document_srl=175836
http://www.sp1.football/index.php?mid=faq&document_srl=176043
http://www.svteck.co.kr/customer_gratitude/36301
http://xn----3x5er9r48j7wemud0a387h.com/news/26059
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=48307
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=48386
http://yeonsen.com/?document_srl=56416
http://yourhelp.co.kr/index.php?mid=board_2&document_srl=4407
http://photogrotto.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80-14/
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=47995
http://www.flixian.com/main/QnA/31495
http://arte.dgau.ac.kr/board_qna/58003
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b4%d0%b0%d1%82%d0%b0-%d0%b2%d1%8b/
http://www.vogtland.com.pl/index.php/component/k2/itemlist/user/34809
http://www.youngfile.com/?document_srl=23678
http://blog.ptpintcast.com/hd-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-720/
http://gochon-iusell.co.kr/g1/21950
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=89545
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=149710
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=210712
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/11282
http://www.sp1.football/index.php?mid=faq&document_srl=263393
https://woodland.org.ua/groups/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8-96089/
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=17135
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=20872
http://ruschinaforum.ru/index.php?topic=144834.0
http://koais.com/?document_srl=29989
http://bitpark.co.kr/board_IzjM66/4022612
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=19618
http://pkgersang.dothome.co.kr/board_jiKY24/9034
https://esel.gist.ac.kr/esel2/board_hmgj23/85174
http://oneandonly1127.com/guest/14079
https://2002.shyoon.com/board_2002/36982
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/13472
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=110888
http://knet.dothome.co.kr/xe/board_RJHw15/2490
https://www.gizmoarticle.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-folb-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/8632
http://www.hsaura.com/?document_srl=142765
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=95336
http://www.yepia.com/board_ZCPG83/17620
http://agiteshop.com/xe/?document_srl=56572
https://testing.celekt.com/%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-tmpv-%d0%98%d0%b3%d1%80%d0%b0/
http://apt2you2.cafe24.com/?document_srl=5614
http://bitpark.co.kr/?document_srl=4018800
http://sd-xi.co.kr/g1/17163
https://2002.shyoon.com/?document_srl=33900
https://www.chirorg.com/?document_srl=34390
http://laokorea.com/orange_menu1/36439
http://www.hsaura.com/?document_srl=178733
http://ruschinaforum.ru/index.php?topic=145266.0
http://arte.dgau.ac.kr/board_qna/43330
https://betshin.com/Story/49224
http://49.247.3.43/index.php?mid=board_PiDQ29&document_srl=24313
http://HyUa.1fps.icu/l/szIaeDC
http://www.lgue.co.kr/?document_srl=19143
http://zsmr.com.ua/index.php/component/k2/itemlist/user/597009
http://barobus.kr/qna/27143
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=79182
http://www.hyunjindc.com/qna/22562
http://2872870.com/est/17923
https://2002.shyoon.com/?document_srl=45180
http://juroweb.com/xe/juroweb_board/18960
http://mglpcm.org/board_ETkS12/28513
http://callman.co.kr/index.php?mid=qa&document_srl=56249
http://www.josephmaul.org/?document_srl=142278
http://wipln.com/?document_srl=50451
http://www.youngfile.com/?document_srl=14320
http://2872870.com/est/19537
http://sy.korean.net/qna/87057
http://xn--2e0bk61btjo.com/notice/10140
http://xn--ok1bpqi43ahtb.net/board_EkDG82/145554
http://thanosakademi.com/index.php?topic=97582.0
http://tototoday.com/board_oRiY52/35112
http://sy.korean.net/qna/77016
http://juroweb.com/xe/juroweb_board/20339
http://xn--ok1bpqi43ahtb.net/board_EkDG82/154438
https://nple.com/xe/pds/39147
https://www.chirorg.com/?document_srl=37200
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/4664
http://p9912.cafe24.com/board_LVgu51/1094
http://sunele.co.kr/board_ReBD97/51557
http://xn--ok1bpqi43ahtb.net/board_EkDG82/160795
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=136295
http://agiteshop.com/xe/qa/52962
http://ariji.kr/?document_srl=820109
http://www.cnsmaker.net/xe/?document_srl=74758
http://sixangles.co.kr/qna/606897
http://d-tube.info/board_jvyO69/247527
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=102327
http://oneandonly1127.com/guest/13813
http://HyUa.1fps.icu/l/szIaeDC
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/258519
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=599613
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=539445
http://www.pcosmetic.ir/?option=com_k2&view=itemlist&task=user&id=10740
http://dev.aabn.org.gh/component/k2/itemlist/user/591107
http://xplorefitness.com/blog/%D1%81%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C-%D1%81%D0%BC%D0%B5%D1%80%D1%88-9-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-k6-%D1%81%D0%BC%D0%B5%D1%80%D1%88-9-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=330144
http://www.vivelabmanizales.com/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xq5k-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/712154
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1886404
http://www.deliberarchia.org/forum/index.php?topic=1023788.0
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=88745
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=88812
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=88901
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=89110
http://bebopindia.com/notcie/118751
http://bebopindia.com/notcie/118980
http://bebopindia.com/notcie/119027
http://bebopindia.com/notcie/119229
http://bebopindia.com/notcie/119323
http://community.viajar.tur.br/index.php?p=/discussion/61290/ne-otpuskay-moyu-ruku-elimi-birakma-42-seriya-znxw-ne-otpuskay-moyu-ruku-elimi-birakma-42-seriya
http://community.viajar.tur.br/index.php?p=/discussion/61291/edinoe-serdce-tek-yuerek-20-seriya-zgxy-edinoe-serdce-tek-yuerek-20-seriya
http://community.viajar.tur.br/index.php?p=/discussion/61293/klyatva-yemin-59-seriya-soag-klyatva-yemin-59-seriya
http://community.viajar.tur.br/index.php?p=/discussion/61294/zhestokiy-stambul-zalim-istanbul-10-seriya-rnsa-zhestokiy-stambul-zalim-istanbul-10-seriya
http://community.viajar.tur.br/index.php?p=/profile/hildredosh
http://hyeonjun.co.kr/menu3/76841
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=795565
http://www.sollazzorefrigerazione.it/?option=com_k2&view=itemlist&task=user&id=2441144
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=55838
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=240252
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/243326
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2601568
http://arunagreen.com/index.php/component/k2/itemlist/user/476126
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=49771
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=49761
http://www.sp1.football/index.php?mid=tr_video&document_srl=275987
http://www.sp1.football/index.php?mid=tr_video&document_srl=276338
http://www.sp1.football/index.php?mid=tr_video&document_srl=279421
http://www.sp1.football/index.php?mid=tr_video&document_srl=280098
http://www.sp1.football/index.php?mid=tr_video&document_srl=281563
http://www.sp1.football/index.php?mid=tr_video&document_srl=283070
http://www.sp1.football/index.php?mid=tr_video&document_srl=290755
http://www.sp1.football/index.php?mid=tr_video&document_srl=292223
http://www.sp1.football/index.php?mid=tr_video&document_srl=293554
http://www.sp1.football/index.php?mid=tr_video&document_srl=296555
http://www.sp1.football/index.php?mid=tr_video&document_srl=300050
http://www.sp1.football/index.php?mid=tr_video&document_srl=300218
http://www.sp1.football/index.php?mid=tr_video&document_srl=300365
http://www.sp1.football/index.php?mid=tr_video&document_srl=307324
http://www.sp1.football/index.php?mid=tr_video&document_srl=314714
http://www.sp1.football/index.php?mid=tr_video&document_srl=319895
http://www.sp1.football/index.php?mid=tr_video&document_srl=320024
http://www.sp1.football/index.php?mid=tr_video&document_srl=329279
http://www.studyxray.com/?document_srl=111922
http://www.studyxray.com/?document_srl=113303
http://www.studyxray.com/?document_srl=114252
http://www.studyxray.com/?document_srl=119245
http://www.studyxray.com/?document_srl=120593
http://www.studyxray.com/?document_srl=127011
http://agiteshop.com/xe/qa/48097
http://www.flixian.com/main/QnA/41268
https://www.gizmoarticle.com/live-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5/
http://www.sp1.football/index.php?mid=tr_video&document_srl=238224
http://www.flixian.com/main/QnA/34073
http://bebopindia.com/notcie/136896
http://mobility-corp.com/index.php/component/k2/itemlist/user/2623396
http://askpharm.net/board_NQiz06/37594
http://2872870.com/est/20569
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/?document_srl=9416
http://esiapolisthesharp2.co.kr/g1/28515
https://nple.com/xe/pds/34280
http://www.vamoscontigo.org/Noticia/27597
http://www.teedinubon.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5-6/
http://toeden.co.kr/Product_new/40684
http://www.tekparcahdfilm.com/forum/index.php?topic=51391.0
http://apt2you2.cafe24.com/g1/5520
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=69654
http://gallerychoi.com/Exhibition/91959
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=17563
http://www.haetsaldun-clinic.co.kr/Question/3672
http://barobus.kr/qna/21850
http://HyUa.1fps.icu/l/szIaeDC
https://reficulcoin.com/index.php?topic=50755.0
https://sanp.pro/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d1%84%d0%b8%d0%bd%d0%b0%d0%bb-gy%d1%85%d0%be%d0%bb%d0%be/
https://www.c-alice.org/forum/index.php?topic=86664.0
https://www.regalepadova.it/index.php/component/k2/itemlist/user/7929
https://www.runcity.org/forum/index.php?action=profile;u=76078
http://zanoza.h1n.ru/2019/05/18/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lp3%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5/
http://zanoza.h1n.ru/2019/05/18/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-on1%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
https://testing.celekt.com/%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-aa5%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
https://testing.celekt.com/%d0%a2%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-af2%d0%a2%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f17-05/
https://www.tedyun.com/xe/index.php?document_srl=154221&mid=guest
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=45926
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=46030
https://prelease.club/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-97-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sm5d-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-97-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://bebopindia.com/notcie/61589
http://forum.digamahost.com/index.php?topic=124384.0
http://indiefilm.kr/xe/board/63062
http://indiefilm.kr/xe/board/63082
http://indiefilm.kr/xe/board/63092
http://jjikduk.net/?document_srl=36138
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=770033
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=770037
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2624207
http://mobility-corp.com/index.php/component/k2/itemlist/user/2623852
http://mvisage.sk/index.php/component/k2/itemlist/user/119083
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/114090
http://ovotecegg.com/component/k2/itemlist/user/164052
http://proxima.co.rw/index.php/component/k2/itemlist/user/649999
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1733498
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1733501
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1733875
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1733933
http://thermoplast.envolgroupe.com/component/k2/author/123567
http://w9builders.co.uk/index.php/component/k2/itemlist/user/83782
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1611848
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1209227
http://married.dike.gr/index.php/component/k2/itemlist/user/65671
http://matrixpharm.ru/forum/index.php?PHPSESSID=f5epibhdqfs6jtvmfh05mm8fe1&action=profile;u=199715
http://mediaville.me/index.php/component/k2/itemlist/user/284678
http://mir3sea.com/forum/index.php?topic=3441.0
http://mir3sea.com/forum/index.php?topic=3442.0
http://mir3sea.com/forum/index.php?topic=3443.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2616902
http://otitismediasociety.org/forum/index.php?topic=174861.0
http://otitismediasociety.org/forum/index.php?topic=174871.0
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/261232
http://roikjer.com/forum/index.php?PHPSESSID=a9co2gtj6njv1v9jkoa6fnpbk2&topic=889463.0
http://taklongclub.com/forum/index.php?topic=150122.0
http://cwon.kr/xe/?document_srl=30578
http://indiefilm.kr/xe/?document_srl=63980
http://jjimdak.callbank.kr/index.php?document_srl=770798&mid=board_OGFN30
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=770859
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=770873
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=770896
http://moavalve.co.kr/faq/49656
http://moavalve.co.kr/faq/49661
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=35973
http://skylinecam.co.kr/photo/56709
http://www.jesusonly.life/calendar/75455
http://www.jesusonly.life/calendar/75471
http://www.josephmaul.org/menu41/61658
https://hackersuniversity.net/index.php?topic=20670.0
https://khuyenmaikk13.info/index.php?topic=208835.0
https://mcsetup.tk/bbs/index.php?topic=255955.0
https://mcsetup.tk/bbs/index.php?topic=255977.0
https://mcsetup.tk/bbs/index.php?topic=255978.0
https://mcsetup.tk/bbs/index.php?topic=255986.0
https://mcsetup.tk/bbs/index.php?topic=255989.0
http://www.theparrotcentre.com/forum/index.php?topic=549336.0
http://www.theparrotcentre.com/forum/index.php?topic=549368.0
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=295662ed4025e1ed2990df967ce856b0&topic=6488.0
https://altaylarteknoloji.com/index.php?topic=4817.0
https://nextezone.com/index.php?action=profile&u=8966
https://nextezone.com/index.php?action=profile;u=8976
https://nextezone.com/index.php?topic=57476.0
https://reficulcoin.com/index.php?topic=50876.0
http://www.sp1.football/index.php?mid=faq&document_srl=91823
http://www.sp1.football/index.php?mid=faq&document_srl=91833
http://www.sp1.football/index.php?mid=faq&document_srl=91851
http://www.sp1.football/index.php?mid=faq&document_srl=91879
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=46844
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=46882
http://www.digitalbul.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rs4v-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://www.ekemoon.com/200025/051920191516/
http://ovotecegg.com/component/k2/itemlist/user/164347
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=265084
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/265008
http://rudraautomation.com/index.php/component/k2/author/223762
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/223923
http://smartacity.com/component/k2/itemlist/user/55465
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1734005
http://thermoplast.envolgroupe.com/component/k2/author/123663
http://zanoza.h1n.ru/2019/05/15/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-igbl-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-16-%d1%81%d0%b5%d1%80%d0%b8/
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/89837
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=825731
http://www.vivelabmanizales.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-qi5s-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://danielmillsap.com/forum/index.php?topic=1002627.0
https://prelease.club/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-81-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lv7i-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-81-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://menulisilmiah.net/%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://forum.digamahost.com/index.php?topic=110817.0
http://valleycapital.co.ke/?option=com_k2&view=itemlist&task=user&id=55442
http://webp.online/index.php?topic=45351.0
http://socialfbwidgets.com/component/k2/itemlist/user/13140.html
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3564974
http://forum.politeknikgihon.ac.id/index.php?topic=23113.0
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=605689
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7306656
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3300231
http://condolencias.servisa.es/9-05-05-2019-j8-9
http://www.vivelabmanizales.com/%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cvqa-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-hercai-17-%d1%81%d0%b5%d1%80%d0%b8/
http://proandpro.it/?option=com_k2&view=itemlist&task=user&id=4528978
http://seoksoononly.dothome.co.kr/qna/764309
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=28638.0
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=7355
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3566133
http://dev.aabn.org.gh/component/k2/itemlist/user/514528
https://khuyenmaikk13.info/index.php?topic=183287.0
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=36529
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/472235
http://ovotecegg.com/component/k2/itemlist/user/122635
http://cccpvideo.forumside.com/index.php?topic=765.0
http://webp.online/index.php?topic=46852.30
http://bebopindia.com/notcie/146460
http://sunele.co.kr/board_ReBD97/48540
https://tg.vl-mp.com/index.php?topic=1471419.0
http://woodpark.kr/project/9686
http://8.droror.co.il/uncategorized/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bf%d1%80%d0%be%d0%bc%d0%be/
http://bebopindia.com/notcie/146958
http://sy.korean.net/qna/68019
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=82429
http://www.hsaura.com/noty/169789
http://askpharm.net/board_NQiz06/25757
http://daltso.com/index.php?document_srl=33484&mid=board_cUYy21
http://daltso.com/index.php?mid=board_cUYy21&document_srl=33523
http://daltso.com/index.php?mid=board_cUYy21&document_srl=33537
http://daltso.com/index.php?mid=board_cUYy21&document_srl=33541
http://daltso.com/index.php?mid=board_cUYy21&document_srl=33550
http://dow.dothome.co.kr/board_jydx58/9437
http://dow.dothome.co.kr/board_jydx58/9442
http://dow.dothome.co.kr/board_jydx58/9461
http://dow.dothome.co.kr/board_jydx58/9466
http://esiapolisthesharp2.co.kr/g1/46962
http://esiapolisthesharp2.co.kr/g1/46978
http://esiapolisthesharp2.co.kr/g1/46989
http://esiapolisthesharp2.co.kr/g1/47012
http://esiapolisthesharp2.co.kr/g1/47023
http://esiapolisthesharp2.co.kr/g1/47043
http://foxy-tv.com/index.php?mid=board_xNxV93&document_srl=91429
http://foxy-tv.com/index.php?mid=board_xNxV93&document_srl=91460
http://foxy-tv.com/index.php?mid=board_xNxV93&document_srl=91478
http://foxy-tv.com/index.php?mid=board_xNxV93&document_srl=91487
http://HyUa.1fps.icu/l/szIaeDC
http://wixelent.co.kr/xe/ch_notice/17242
http://www.teedinubon.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-novp-%d0%b8%d0%b3%d1%80%d0%b0/
http://www.teedinubon.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zbqs-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://zanoza.h1n.ru/2019/05/20/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-epzz-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://zanoza.h1n.ru/2019/05/20/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rfiu-%d0%b8%d0%b3%d1%80%d0%b0/
http://zanoza.h1n.ru/2019/05/20/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fxyj-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://zanoza.h1n.ru/2019/05/20/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-qoea-%d0%b8%d0%b3%d1%80%d0%b0/
https://celekt.com/%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nzsr-%d0%98%d0%b3%d1%80%d0%b0/
https://celekt.com/%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kcrd-%d0%98%d0%b3%d1%80%d0%b0/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vdhk-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
https://testing.celekt.com/%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qgot-%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://knet.dothome.co.kr/xe/board_RJHw15/3355
http://www.teedinubon.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-maxb-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://gyeomright.dothome.co.kr/index.php?document_srl=2874&mid=guest
http://www.teedinubon.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80-11/
http://www.teedinubon.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80-16/
http://www.teedinubon.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80-17/
http://www.teedinubon.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80-18/
http://www.teedinubon.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80-19/
http://www.teedinubon.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80-20/
http://www.teedinubon.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80-12/
http://www.teedinubon.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80-13/
http://www.teedinubon.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80-14/
http://www.teedinubon.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80-15/
http://www.teedinubon.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5-7/
http://www.teedinubon.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%84%d0%b8%d0%bb%d1%8c%d0%bc-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be-3/
http://www.teedinubon.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%84%d0%b8%d0%bb%d1%8c%d0%bc-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7-3/
http://www.teedinubon.com/%d1%8d%d1%84%d0%b8%d1%80-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-3/
http://www.teedinubon.com/%d1%8d%d1%84%d0%b8%d1%80-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bd-2/
http://HyUa.1fps.icu/l/szIaeDC
http://ovotecegg.com/component/k2/itemlist/user/134946
http://forum.digamahost.com/index.php?topic=112749.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3359672
http://k2.akademitelkom.ac.id/index.php/component/k2/itemlist/user/315141
http://myrechockey.com/forums/index.php?topic=103688.0
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=49876
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2564609
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1113432
https://tg.vl-mp.com/index.php?topic=1349072.0
http://www.vivelabmanizales.com/hd-video-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-g2-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1/
http://k2.akademitelkom.ac.id/component/k2/itemlist/user/289061
http://skylinecam.co.kr/photo/115248
http://skylinecam.co.kr/photo/115273
http://www.golden-nail.co.kr/press/102046
http://www.golden-nail.co.kr/press/102051
http://www.hicleaning.kr/board_wash/94564
http://www.hsaura.com/noty/151417
http://www.hsaura.com/noty/151496
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=92982
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=93004
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=93022
http://cwon.kr/xe/?document_srl=29624
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1707931
https://turimex.mx.solemti.net/index.php/component/k2/itemlist/user/1455
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1591253
http://smartacity.com/component/k2/itemlist/user/30269
http://teambuildingpremium.com/forum/index.php?topic=833019.0
http://www.arredoufficiomarca.com/index.php/component/k2/itemlist/user/1597561
http://moavalve.co.kr/faq/30351
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=325562
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/300711
http://www.ekemoon.com/182267/051020195913/
http://www.ekemoon.com/182333/051120193013/
http://www.ekemoon.com/182461/051220191113/
http://www.ekemoon.com/182477/051220191413/
http://www.ekemoon.com/182481/051220191513/
http://www.ekemoon.com/182485/051220191613/
http://www.ekemoon.com/182497/051220192213/
http://www.ekemoon.com/182501/051220192313/
http://www.ekemoon.com/182503/051220192413/
https://prelease.club/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%be%d0%b9-%d0%b0%d1%80%d1%82%d0%b8%d1%81%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pc1e-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%be%d0%b9-%d0%b0%d1%80%d1%82/
https://prelease.club/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-to4l-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
https://prelease.club/%d1%81%d0%be%d0%b4%d0%b5%d1%80%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vs8f-%d1%81%d0%be%d0%b4%d0%b5%d1%80%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-9-%d1%81%d0%b5%d1%80/
http://compultras.com/?option=com_k2&view=itemlist&task=user&id=216160
https://testing.celekt.com/%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-p0-%d0%98%d0%b3%d1%80/
https://testing.celekt.com/%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-b3-%d0%98%d0%b3%d1%80/
https://testing.celekt.com/%d0%9c%d0%b0%d0%bc%d0%b0-%d0%9b%d0%be%d1%80%d0%b0-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-f4-%d0%9c%d0%b0%d0%bc%d0%b0-%d0%9b%d0%be%d1%80%d0%b0-12-%d1%81%d0%b5%d1%80%d0%b8/
https://testing.celekt.com/%d0%9c%d0%b0%d0%bc%d0%b0-%d0%9b%d0%be%d1%80%d0%b0-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-e1-%d0%9c%d0%b0%d0%bc%d0%b0-%d0%9b%d0%be%d1%80%d0%b0-17-%d1%81%d0%b5%d1%80%d0%b8/
https://testing.celekt.com/%d0%9c%d0%b0%d0%bc%d0%b0-%d0%9b%d0%be%d1%80%d0%b0-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-a4-%d0%9c%d0%b0%d0%bc%d0%b0-%d0%9b%d0%be%d1%80%d0%b0-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://testing.celekt.com/%d0%9d%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d0%a1%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-86-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-7/
https://testing.celekt.com/%d0%9f%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-m8-%d0%9f%d0%be%d1%81%d0%bb%d0%b5%d0%b4/
https://testing.celekt.com/%d0%a1%d0%b5%d0%bd%d1%8f%d0%a4%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-a4-%d0%a1%d0%b5%d0%bd%d1%8f%d0%a4%d0%b5%d0%b4%d1%8f-2/
https://testing.celekt.com/%d0%a1%d0%b5%d0%bd%d1%8f%d0%a4%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-c4-%d0%a1%d0%b5%d0%bd%d1%8f%d0%a4%d0%b5%d0%b4%d1%8f-2/
https://testing.celekt.com/%d0%a1%d0%b5%d0%bd%d1%8f%d0%a4%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-d9-%d0%a1%d0%b5%d0%bd%d1%8f%d0%a4%d0%b5%d0%b4%d1%8f-2/
https://testing.celekt.com/%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-p7-%d0%a1%d0%bb%d1%83%d0%b3%d0%b0/
https://testing.celekt.com/%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-z4-%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-2/
https://testing.celekt.com/%d0%a2%d0%b0%d0%b9%d0%bd%d1%8b-%d0%a2%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-101-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-r8-%d0%a2%d0%b0%d0%b9%d0%bd%d1%8b-%d0%a2%d0%b0%d1%94/
https://testing.celekt.com/%d0%a2%d0%b0%d0%b9%d0%bd%d1%8b-%d0%a2%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-92-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-b2-%d0%a2%d0%b0%d0%b9%d0%bd%d1%8b-%d0%a2%d0%b0%d1%94/
http://roikjer.com/forum/index.php?PHPSESSID=cjtev1venfchtr19e1pg1cops2&topic=897673.0
http://roikjer.com/forum/index.php?PHPSESSID=dp7ibq7528ckg204b7784a2ss0&topic=894903.0
http://roikjer.com/forum/index.php?PHPSESSID=e1tn6jdaii919tq546igmu5cb4&topic=893803.0
http://roikjer.com/forum/index.php?PHPSESSID=e3q8d87vivlb5cm7bt7kpmucs0&topic=893344.0
http://roikjer.com/forum/index.php?PHPSESSID=ecsh4tglajss5mmmoqqu2harf7&topic=891774.0
http://roikjer.com/forum/index.php?PHPSESSID=eeu32ig3iiiqktkl8tr381cag1&topic=896526.0
http://roikjer.com/forum/index.php?PHPSESSID=fn1t9oe1mn6o4569ps9ipph2s6&topic=892873.0
http://roikjer.com/forum/index.php?PHPSESSID=g2oi1n2fc8fue09t10qtgvkq47&topic=894786.0
http://roikjer.com/forum/index.php?PHPSESSID=ido1018botki8anre2to4i5i70&topic=894058.0
http://roikjer.com/forum/index.php?PHPSESSID=iduv27q8b8052i8pp00cj7j8b6&topic=896827.0
http://roikjer.com/forum/index.php?PHPSESSID=iefmbk7aaes8ljoaubn3p28ed7&topic=895559.0
http://roikjer.com/forum/index.php?PHPSESSID=ih0sjso5h3nn33epc797idija2&topic=893429.0
http://roikjer.com/forum/index.php?PHPSESSID=iomkqudp0sjo5208t9cc3npg80&topic=893190.0
http://roikjer.com/forum/index.php?PHPSESSID=j421t6ocencv94egdbuf631010&topic=895127.0
http://roikjer.com/forum/index.php?PHPSESSID=jkrjh5eoq8k699uq2nrb9cpun3&topic=894108.0
http://roikjer.com/forum/index.php?PHPSESSID=jmm69t4kgonn7ai3ang61qe012&topic=895425.0
http://roikjer.com/forum/index.php?PHPSESSID=jp2q89u2d33rhjk7h1ej1nso02&topic=892860.0
http://roikjer.com/forum/index.php?PHPSESSID=jt69qafkcf372lfc4mtsa6ta24&topic=895102.0
http://roikjer.com/forum/index.php?PHPSESSID=ketfsd6c24epegd1gn9fa053o1&topic=894621.0
http://roikjer.com/forum/index.php?PHPSESSID=mffdnkp3b423k07502pmd6dk97&topic=896785.0
http://roikjer.com/forum/index.php?PHPSESSID=mn3s6d29tuiph7fqtijk5a6cn2&topic=896616.0
http://roikjer.com/forum/index.php?PHPSESSID=o0mrg2il5pco3srbq1cpfmjee1&topic=896741.0
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/9454
http://ucckorea.kr/index.php?mid=board_AuHE49&document_srl=16385
https://www.amazingworldtop.com/entretenimiento/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-2019-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mwaw-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://8.droror.co.il/uncategorized/%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-3/
http://xn--ok1bpqi43ahtb.net/board_EkDG82/145228
http://moavalve.co.kr/faq/83876
http://sy.korean.net/qna/63961
http://ye-dream.com/qa/99494
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/5996
http://www.youngfile.com/?document_srl=22037
http://www.siheunglove.com/chulip/56807
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3302268
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=20331
http://sunele.co.kr/board_ReBD97/55878
http://bebopindia.com/notcie/145873
http://www.hsaura.com/noty/142082
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/news/9560
http://ariji.kr/sub07/815147
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=98071
http://HyUa.1fps.icu/l/szIaeDC
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=17022
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=29007
http://iamking.net/board/31228
http://xn----3x5er9r48j7wemud0a387h.com/news/36662
http://vervetama.com/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vo-production/
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=28748
http://www.hsaura.com/noty/162331
http://bethelpray.com/counsel/9730
http://apt2you2.cafe24.com/g1/8123
http://laokorea.com/orange_menu1/41496
http://oneandonly1127.com/guest/17424
http://oneandonly1127.com/guest/17462
http://oneandonly1127.com/guest/17471
http://oneandonly1127.com/guest/17496
http://photogrotto.com/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8-7/
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-%d0%b4%d0%b0%d1%82%d0%b0-%d0%b2%d1%8b%d1%85%d0%be%d0%b4%d0%b0-1-%d1%81-5/
http://photogrotto.com/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8-7/
http://photogrotto.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5-5/
http://photogrotto.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80-26/
http://photogrotto.com/%d1%8d%d1%84%d0%b8%d1%80-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b8/
http://photogrotto.com/%d1%8d%d1%84%d0%b8%d1%80-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-eng/
http://photogrotto.com/%d1%8d%d1%84%d0%b8%d1%80-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%83/
http://photogrotto.com/hd-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80-3/
http://praisesound.co.kr/sub04_01/17782
http://HyUa.1fps.icu/l/szIaeDC
http://www.jesusonly.life/calendar/45158
http://xplorefitness.com/blog/%D0%BD%D0%BE%D0%B2%D0%B8%D0%BD%D0%BA%D0%B0-%D1%82%D0%BE%D0%BB%D1%8F-%D1%80%D0%BE%D0%B1%D0%BE%D1%82-8-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-b2-%D1%82%D0%BE%D0%BB%D1%8F-%D1%80%D0%BE%D0%B1%D0%BE%D1%82-8-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=120017
http://dev.aabn.org.gh/?option=com_k2&view=itemlist&task=user&id=600286
https://prelease.club/%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80%d0%b4%d1%86%d0%b5-tek-yurek-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uejy-%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80/
http://cwon.kr/xe/board_bnSr36/24365
http://cwon.kr/xe/board_bnSr36/24386
http://moavalve.co.kr/faq/43662
http://www.ds712.net/guest/index.php?document_srl=73496&mid=guest07
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=73821
http://www.hsaura.com/noty/63231
http://corumotoanahtar.com/component/k2/itemlist/user/4748.html
http://dev.aabn.org.gh/component/k2/itemlist/user/615288
http://dev.fivestarpainting.com/?option=com_k2&view=itemlist&task=user&id=1944029
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=100323
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=100324
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1925413
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1926104
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=332166
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/332713
http://jiquilisco.org/index.php/component/k2/itemlist/user/9387
http://mobility-corp.com/index.php/component/k2/itemlist/user/2619542
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/756982
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/112248
http://sdsn.develop.cinfores.com/?option=com_k2&view=itemlist&task=user&id=221967
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2326686
http://www.digitalbul.com/%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-p5-%d1%82%d0%be%d0%bb%d1%8f/
http://bebopindia.com/notcie/62147
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/317087
https://sto54.ru/index.php/component/k2/itemlist/user/3362820
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3800687
https://prelease.club/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-83-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-do2t-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-83-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=71196
http://storykingdom.forumside.com/index.php/topic,4830.0.html
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1859168
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/71595
https://szenarist.ru/forum/index.php?topic=205409.0
http://withinfp.sakura.ne.jp/eso/index.php/16888221-milliardy-4-sezon-10-seria-06052019-d4-milliardy-4-sezon-10-ser
http://seoksoononly.dothome.co.kr/?document_srl=743268
http://www.ekemoon.com/147431/052120192006/
http://rudraautomation.com/index.php/component/k2/author/117822
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7332554
http://www.vivelabmanizales.com/%d0%be%d1%82%d0%b5%d0%bb%d1%8c-%d1%82%d0%be%d0%bb%d0%b5%d0%b4%d0%be-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-05-05-2019-j2-%d0%be%d1%82%d0%b5%d0%bb%d1%8c-%d1%82%d0%be/
http://withinfp.sakura.ne.jp/eso/index.php/16886874-holostak-9-10-vypusk-waholostak-9-10-vypusk08-holostak-9-10-vyp/0
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=82363
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1859536
http://www.quattroandpartners.it/component/k2/itemlist/user/1051703
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=130791
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4827381
http://married.dike.gr/index.php/component/k2/itemlist/user/53520
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4828636
http://menulisilmiah.net/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-20-%d1%81%d0%b5-7/
https://banana-coding.com/user/15898-daleblaken/
http://beautypouch.net/index.php?mid=board_09&document_srl=15785
http://pcksummit.bscs.org/node/3834
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=22736
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=50912
http://xihillstate.bloggirl.net/?document_srl=53593
http://xn--9m1b83j39hz6exwonmf.com/board_IYPe43/531374
http://carand.co.kr/d2/3643
http://www.hsaura.com/noty/143193
http://teambuildingpremium.com/forum/index.php?topic=849285.0
http://jejucctv.co.kr/?document_srl=20136
http://wartoby.com/index.php?mid=board_UXUA38&document_srl=8499
http://blog.ptpintcast.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80-5/
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=36630
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2785276
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2785286
http://iamking.net/board/46858
http://iamking.net/board/46896
http://looksun.co.kr/?document_srl=38177
http://looksun.co.kr/index.php?mid=board_4&document_srl=38162
http://looksun.co.kr/index.php?mid=board_4&document_srl=38222
http://moavalve.co.kr/?document_srl=95765
http://neosky.net/xe/?document_srl=10485
http://oneandonly1127.com/guest/20740
http://oneandonly1127.com/guest/20745
http://oneandonly1127.com/guest/20750
http://HyUa.1fps.icu/l/szIaeDC
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=21274
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=21342
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=21358
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=21378
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=21413
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=21434
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=21608
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=21634
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=21849
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=21934
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=22070
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=22117
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=22121
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=22288
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=22488
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=22624
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=22680
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=22918
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=22993
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=22998
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=23031
https://ttmt.net/crypto_lab_2F/500335
https://ttmt.net/crypto_lab_2F/500340
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=204558
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=204611
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=205001
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=205042
http://8.droror.co.il/uncategorized/%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-9/
http://beautypouch.net/index.php?mid=board_09&document_srl=24461
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=36629
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=36634
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=36643
http://gochon-iusell.co.kr/?document_srl=33607
http://gochon-iusell.co.kr/g1/33602
http://gochon-iusell.co.kr/g1/33613
http://gochon-iusell.co.kr/g1/33623
http://gxpfactory.net/index.php?mid=Guide&document_srl=26953
http://gxpfactory.net/index.php?mid=Guide&document_srl=26958
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2785522
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2785527
http://iamking.net/?document_srl=47666
http://iamking.net/board/47568
http://iamking.net/board/47579
http://iamking.net/board/47671
http://HyUa.1fps.icu/l/szIaeDC
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/221224
http://www.m1avio.com/index.php/component/k2/itemlist/user/3683691
https://khuyenmaikk13.info/index.php?topic=190588.0
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1038559
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=42935
https://prelease.club/%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80%d0%b4%d1%86%d0%b5-tek-yurek-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-roln-%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80/
https://prelease.club/%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80%d0%b4%d1%86%d0%b5-tek-yurek-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hfhi-%d0%b5%d0%b4%d0%b8%d0%bd%d0%be%d0%b5-%d1%81%d0%b5%d1%80/
https://prelease.club/%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-64-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ufor-%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-64/
https://prelease.club/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-81-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lugb-%d0%bd%d0%b5%d0%b2/
http://cwon.kr/xe/board_bnSr36/21514
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=753767
http://moavalve.co.kr/faq/38774
http://moavalve.co.kr/faq/38946
http://www.deliberarchia.org/forum/index.php?topic=1045666.0
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/285994
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=603295
https://adsensebih.com/index.php?topic=28121.0
https://adsensebih.com/index.php?topic=28124.0
https://adsensebih.com/index.php?topic=28126.0
https://adsensebih.com/index.php?topic=28135.0
https://cybergsm.es/index.php?topic=31853.0
https://cybergsm.es/index.php?topic=31886.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3404603
https://testing.celekt.com/%d0%91%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%a1%d0%9c%d0%9e%d0%a2%d0%a0%d0%95%d0%a2%d0%ac-%d0%91%d0%be%d0%bb%d1%8c/
https://tg.vl-mp.com/index.php?topic=1489809.0
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=240927
http://cwon.kr/xe/board_bnSr36/111481
http://emjun.com/index.php?mid=hangtotal&document_srl=116386
http://emjun.com/index.php?mid=hangtotal&document_srl=116400
http://roikjer.com/forum/index.php?PHPSESSID=4830713hnb68b3afc1p2m8v594&topic=866420.0
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=835598
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/240102
http://www.ekemoon.com/195597/050020190216/
http://www.siirtorganik.com/index.php/component/k2/itemlist/user/762947
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=286632
http://www.vivelabmanizales.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%be%d0%b9-%d0%b0%d1%80%d1%82%d0%b8%d1%81%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rb1m-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%be%d0%b9-%d0%b0%d1%80%d1%82/
http://teambuildingpremium.com/forum/index.php?topic=786733.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/296238
http://menulisilmiah.net/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jn0%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5/
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4893868
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4894108
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=609398
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=807268
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2460157
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/317446
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3342874
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3342957
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3342991
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=19782
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=19812
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2614665
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=81511
http://tototoday.com/board_oRiY52/31769
http://www.hsaura.com/noty/146817
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/9663
http://woodpark.kr/project/9974
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/5531
http://8.droror.co.il/uncategorized/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-%d0%b4%d0%b0%d1%82%d0%b0-2/
http://daesestudy.co.kr/ipsi_docu/44553
http://agiteshop.com/xe/qa/45492
http://zanoza.h1n.ru/2019/05/19/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lqxo-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://www.lovestory.or.kr/topic/2667
http://www.teedinubon.com/live-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5/
http://www.hsaura.com/noty/178957
http://roikjer.com/forum/index.php?PHPSESSID=3ihngjast7g7flv0jbqds37kd5&topic=896718.0
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/10036
http://bebopindia.com/notcie/137047
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/6937
http://d-tube.info/?document_srl=250163
http://sejong-thesharpyemizi.co.kr/m1/959
http://photogrotto.com/%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-6/
http://www.youngfile.com/?document_srl=22076
http://gallerychoi.com/Exhibition/88587
http://www.vamoscontigo.org/Noticia/35294
http://pkgersang.dothome.co.kr/board_jiKY24/5759
http://wipln.com/music/58393
http://49.247.3.43/index.php?mid=board_PiDQ29&document_srl=21985
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=112102
http://constellation.kro.kr/board_kbku73/12393
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-got-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xzvo-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
http://f-tube.info/board/86244
http://www.hsaura.com/noty/141246
http://apt2you2.cafe24.com/g1/6098
http://d-tube.info/board_jvyO69/240843
http://barobus.kr/qna/27133
http://cwon.kr/xe/board_bnSr36/100172
https://www.chirorg.com/?document_srl=33259
http://callman.co.kr/index.php?mid=qa&document_srl=42838
http://oneandonly1127.com/guest/15194
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/5092
http://www.youngfile.com/?document_srl=14826
https://forum.shaiyaslayer.tk/index.php?topic=131289.0
http://laokorea.com/orange_menu1/34289
http://agiteshop.com/xe/qa/56997
http://HyUa.1fps.icu/l/szIaeDC
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/210245
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=450348
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1933459
http://mobility-corp.com/index.php/component/k2/itemlist/user/2569862
http://vn7.vn/qna/82408
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=308209
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2632263
http://rudraautomation.com/index.php/component/k2/author/180061
http://www.arredoufficiomarca.com/index.php/component/k2/itemlist/user/1585856
http://comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=105040
http://jiquilisco.org/?option=com_k2&view=itemlist&task=user&id=7062
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=10369
http://corumotoanahtar.com/component/k2/itemlist/user/1535
http://jiquilisco.org/?option=com_k2&view=itemlist&task=user&id=4374
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=16131
http://sdsn.develop.cinfores.com/?option=com_k2&view=itemlist&task=user&id=207935
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=6522
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=45660
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=45689
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1829135
http://hotelnomadpalace.com/component/k2/itemlist/user/21153
http://jiquilisco.org/index.php/component/k2/itemlist/user/7194
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1711902
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1601492
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1637296
http://www.m1avio.com/index.php/component/k2/itemlist/user/3706740
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4927403
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=1926
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=119066
http://www.cnsmaker.net/xe/?document_srl=73557
http://www.flixian.com/main/QnA/36927
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/brand/20129
http://daltso.com/index.php?mid=board_cUYy21&document_srl=27788
http://toeden.co.kr/Product_new/42360
http://esiapolisthesharp2.co.kr/g1/32199
http://xn--9m1b83j39hz6exwonmf.com/board_IYPe43/521007
http://forum.kopkargobel.com/index.php?topic=12075.0
http://blog.ptpintcast.com/hd-video-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%89%d0%b5%d0%bd%d0%ba%d0%b8/
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=17234
http://looksun.co.kr/index.php?mid=board_4&document_srl=34941
http://lucky.kidspann.net/index.php?mid=qna&document_srl=116553
http://lucky.kidspann.net/index.php?mid=qna&document_srl=116690
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=92615
http://tiretech.co.kr/index.php?mid=qna&document_srl=53789
http://vervetama.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b0%d1%8f-%d0%bc%d0%b0%d0%bb%d0%b5%d0%bd%d1%8c%d0%ba%d0%b0%d1%8f-%d0%bb%d0%be%d0%b6%d1%8c-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ci0z/
http://vervetama.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b0%d1%8f-%d0%bc%d0%b0%d0%bb%d0%b5%d0%bd%d1%8c%d0%ba%d0%b0%d1%8f-%d0%bb%d0%be%d0%b6%d1%8c-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qn2k/
http://vervetama.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b0%d1%8f-%d0%bc%d0%b0%d0%bb%d0%b5%d0%bd%d1%8c%d0%ba%d0%b0%d1%8f-%d0%bb%d0%be%d0%b6%d1%8c-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ll6g/
http://vervetama.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b0%d1%8f-%d0%bc%d0%b0%d0%bb%d0%b5%d0%bd%d1%8c%d0%ba%d0%b0%d1%8f-%d0%bb%d0%be%d0%b6%d1%8c-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-da8j/
http://vervetama.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b0%d1%8f-%d0%bc%d0%b0%d0%bb%d0%b5%d0%bd%d1%8c%d0%ba%d0%b0%d1%8f-%d0%bb%d0%be%d0%b6%d1%8c-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-os3o/
http://www.hyunjindc.com/qna/41795
http://www.hyunjindc.com/qna/41828
http://www.hyunjindc.com/qna/41882
http://www.hyunjindc.com/qna/41892
http://www.hyunjindc.com/qna/41906
http://www.hyunjindc.com/qna/41911
http://www.itosm.com/cn/board_nLoq17/37662
http://www.itosm.com/cn/board_nLoq17/37720
http://www.itosm.com/cn/board_nLoq17/37755
http://www.jesusonly.life/calendar/206822
http://www.jesusonly.life/calendar/207024
http://www.jesusonly.life/calendar/207066
http://www.josephmaul.org/menu41/165884
http://HyUa.1fps.icu/l/szIaeDC
http://d-tube.info/board_jvyO69/253973
http://www.jesusonly.life/calendar/144622
http://www.golden-nail.co.kr/press/100450
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=17031
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=112127
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=82881
http://www.theparrotcentre.com/forum/index.php?topic=554831.0
http://photogrotto.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80-17/
http://yoriyorifood.com/xxxx/spacial/107585
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=856642
https://esel.gist.ac.kr/esel2/board_hmgj23/83430
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=68988
http://neosky.net/xe/space_station/3223
http://iymc.or.kr/pds/88228
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=16937
http://readingbible.org/board_xxpp62/841834
http://gounface.com/?document_srl=559560
http://tototoday.com/board_oRiY52/29190
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=45823
http://sy.korean.net/qna/79644
http://teambuildingpremium.com/forum/index.php?topic=852060.0
http://bizchemical.com/board_kMpv94/1886255
http://laokorea.com/orange_menu1/38440
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/12536
http://kotica00.dothome.co.kr/index.php?mid=board_nJTE45&document_srl=9885
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?document_srl=2342&mid=main_08
https://reficulcoin.com/index.php?topic=53306.0
http://www.itosm.com/cn/board_nLoq17/20730
http://HyUa.1fps.icu/l/szIaeDC
http://corumotoanahtar.com/component/k2/itemlist/user/1228.html
http://xplorefitness.com/blog/%C2%AB%D1%82%D0%B0%D0%B9%D0%BD%D1%8B-%D1%82%D0%B0%D1%94%D0%BC%D0%BD%D0%B8%D1%86i-94-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-10-05-2019-p6-%C2%AB%D1%82%D0%B0%D0%B9%D0%BD%D1%8B-%D1%82%D0%B0%D1%94%D0%BC%D0%BD%D0%B8%D1%86i-94-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://www.arunagreen.com/index.php/component/k2/itemlist/user/512640
http://servicioswts.com/?option=com_k2&view=itemlist&task=user&id=3636757
http://teambuildingpremium.com/forum/index.php?topic=795153.0
http://www.golden-nail.co.kr/press/79873
http://www.golden-nail.co.kr/press/79882
http://www.hicleaning.kr/?document_srl=86396
http://www.hicleaning.kr/board_wash/86336
http://www.hsaura.com/noty/122684
http://www.hsaura.com/noty/122704
http://www.hsaura.com/noty/122759
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=74501
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=74545
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=500161
http://www.sp1.football/index.php?mid=faq&document_srl=195614
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=319372
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=319389
http://mediaville.me/index.php/component/k2/itemlist/user/252851
http://mediaville.me/index.php/component/k2/itemlist/user/252996
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/713057
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/713078
http://mvisage.sk/index.php/component/k2/itemlist/user/118628
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=88249
http://proxima.co.rw/index.php/component/k2/itemlist/user/606671
http://ariji.kr/sub07/816311
https://www.chirorg.com/?document_srl=36774
http://carand.co.kr/d2/4213
http://www.golden-nail.co.kr/press/99602
http://www.josephmaul.org/menu41/146972
https://nple.com/xe/pds/42348
http://sixangles.co.kr/qna/611744
http://agiteshop.com/xe/qa/46481
https://www.chirorg.com/?document_srl=30578
http://viamania.net/index.php?mid=board_raYV15&document_srl=34354
http://viamania.net/index.php?mid=board_raYV15&document_srl=34370
http://viamania.net/index.php?mid=board_raYV15&document_srl=34408
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=73136
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=73141
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=73145
http://www.hyunjindc.com/qna/43676
http://www.hyunjindc.com/qna/43680
http://www.itosm.com/cn/board_nLoq17/41478
http://www.jesusonly.life/calendar/220238
http://www.jesusonly.life/calendar/220257
http://HyUa.1fps.icu/l/szIaeDC
http://withinfp.sakura.ne.jp/eso/index.php/16944321-dockimateri-dockimateri-17-seria-f0-dockimateri-dockimateri-17-/0
http://vn7.vn/qna/71627
http://www.digitalbul.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bk0i-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://www.ekemoon.com/172289/051320195710/
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1901436
http://www.critico-expository.com/forum/index.php?topic=13326.0
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/35146
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3379252
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3379618
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2656245
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2656492
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2656507
http://adsudoeste.com.br/?option=com_k2&view=itemlist&task=user&id=22102
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=111996
http://dev.aabn.org.gh/component/k2/itemlist/user/610551
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1941672
http://forum.elexlabs.com/index.php?action=profile;u=6708
http://guiadetudo.com/index.php/component/k2/itemlist/user/12189
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=329662
http://haniel.ir/index.php/component/k2/itemlist/user/120636
http://lavaggio.com.vn/index.php/component/k2/itemlist/user/3845224
http://mediaville.me/index.php/component/k2/itemlist/user/294909
http://ovotecegg.com/component/k2/itemlist/user/169338
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/269210
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/269660
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=229781
http://thermoplast.envolgroupe.com/component/k2/author/127582
http://thermoplast.envolgroupe.com/component/k2/author/127583
http://thermoplast.envolgroupe.com/index.php/component/k2/itemlist/user/127558
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=86840
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wneu-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wqxj-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lodq-%d0%b8%d0%b3%d1%80/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zzba-%d0%b8%d0%b3%d1%80/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-qhzy-%d0%b8%d0%b3/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kxnx-%d0%b8%d0%b3%d1%80/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fvxj-%d0%b8%d0%b3%d1%80%d0%b0/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-kvpr-%d0%b8%d0%b3/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-watch-hzmj-%d0%b8/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dgpq-%d0%b8%d0%b3/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gjld-%d0%b8%d0%b3%d1%80/
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-game-of-thrones-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hpkw-%d0%b8%d0%b3%d1%80%d0%b0/
http://askpharm.net/board_NQiz06/27623
http://askpharm.net/board_NQiz06/27629
http://askpharm.net/board_NQiz06/27707
http://askpharm.net/board_NQiz06/27718
http://askpharm.net/board_NQiz06/27751
http://askpharm.net/board_NQiz06/27761
http://askpharm.net/board_NQiz06/27822
http://askpharm.net/board_NQiz06/27856
http://askpharm.net/board_NQiz06/27872
http://askpharm.net/board_NQiz06/27901
http://askpharm.net/board_NQiz06/27912
http://askpharm.net/board_NQiz06/27935
http://askpharm.net/board_NQiz06/27972
http://askpharm.net/board_NQiz06/28025
http://askpharm.net/board_NQiz06/28046
http://askpharm.net/board_NQiz06/28058
http://askpharm.net/board_NQiz06/28074
http://askpharm.net/board_NQiz06/28101
http://askpharm.net/board_NQiz06/28123
http://askpharm.net/board_NQiz06/28134
http://askpharm.net/board_NQiz06/28139
http://askpharm.net/board_NQiz06/28145
http://askpharm.net/board_NQiz06/28178
http://askpharm.net/board_NQiz06/28189
http://HyUa.1fps.icu/l/szIaeDC
http://forum.digamahost.com/index.php?topic=124004.0
http://moavalve.co.kr/faq/16180
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2596822
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=57775
http://roikjer.com/forum/index.php?PHPSESSID=444ap9qsjm2bc13mkho664o7j7&topic=839703.0
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1055619
http://www.vivelabmanizales.com/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81-2/
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/71569
http://www.ekemoon.com/158257/050920195108/
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=294457
http://engeena.com/component/k2/itemlist/user/7913
http://soc-human.kz/index.php/component/k2/itemlist/user/1643033
http://poselokgribovo.ru/forum/index.php?topic=716721.0
http://seoksoononly.dothome.co.kr/qna/759139
http://associationsila.org/component/k2/itemlist/user/294464
http://poselokgribovo.ru/forum/index.php?topic=733593.0
http://webp.online/index.php?topic=49667.msg81506
http://www.phan-aen.go.th/forum/index.php?topic=626862.0
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=511446
http://www.spazioad.com/component/k2/itemlist/user/7212351
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1631074
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1632036
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1643294
https://tg.vl-mp.com/index.php?topic=1325538.0
http://arquitectosenreformas.es/component/k2/itemlist/user/78784
http://jesusandmarypatna.com/index.php/component/k2/itemlist/user/3377062
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/8672
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/8727
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/8738
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/8743
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/8937
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/9073
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/9121
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/9199
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/9204
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/9267
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/9284
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/9327
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/9348
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/9731
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/9773
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/9815
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/?document_srl=7166
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/?document_srl=7225
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/?document_srl=8035
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/?document_srl=8577
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=74248
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=74263
http://www.jesusonly.life/calendar/224315
http://www.jesusonly.life/calendar/224336
http://www.josephmaul.org/menu41/175778
http://www.josephmaul.org/menu41/175821
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=14159
https://ttmt.net/?document_srl=500893
https://ttmt.net/crypto_lab_2F/500917
http://8.droror.co.il/uncategorized/%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-10/
http://8.droror.co.il/uncategorized/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80-10/
http://beautypouch.net/index.php?mid=board_09&document_srl=24979
http://beautypouch.net/index.php?mid=board_09&document_srl=24993
http://cwon.kr/xe/board_bnSr36/120688
http://cwon.kr/xe/board_bnSr36/120792
http://praisesound.co.kr/sub04_01/22093
http://praisesound.co.kr/sub04_01/22098
http://praisesound.co.kr/sub04_01/22103
http://praisesound.co.kr/sub04_01/22108
http://www.itosm.com/cn/board_nLoq17/42473
http://www.itosm.com/cn/board_nLoq17/42483
http://www.itosm.com/cn/board_nLoq17/42563
http://www.studyxray.com/Sangdam/176036
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lostfilm-5/
http://www.teedinubon.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80-25/
http://HyUa.1fps.icu/l/szIaeDC
http://myrechockey.com/forums/index.php?topic=102270.0
http://moavalve.co.kr/faq/16117
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3361173
http://dcasociados.eu/component/k2/itemlist/user/87893
http://moyakmermer.com/index.php/component/k2/itemlist/user/693078
http://rudraautomation.com/index.php/component/k2/author/144582
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=74275
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=52637
http://emjun.com/index.php?mid=hangtotal&document_srl=32437
http://www.ekemoon.com/186411/050420194014/
http://xplorefitness.com/blog/%C2%AB%D1%81%D0%BB%D1%83%D0%B3%D0%B0-%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-19-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-09-05-2019-s2-%C2%AB%D1%81%D0%BB%D1%83%D0%B3%D0%B0-%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-19-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://bitpark.co.kr/board_IzjM66/3734941
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/63015
http://roikjer.com/forum/index.php?PHPSESSID=j4cs7ep49djq274q7ea6dcru64&topic=827135.0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4715962
http://8.droror.co.il/uncategorized/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-video-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://smartacity.com/component/k2/itemlist/user/23900
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1762994
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=803747
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=803772
http://www.spazioad.com/component/k2/itemlist/user/7286147
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=58199
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=58284
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/248444
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=19368
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2610425
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=51484
http://computerscience.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=2015760
http://dev.aabn.org.gh/component/k2/itemlist/user/568056
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1907708
http://fbpharm.net/index.php/component/k2/itemlist/user/32381
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1886136
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=296162
http://xn--ok1bpqi43ahtb.net/board_EkDG82/139597
http://xn--ok1bpqi43ahtb.net/board_EkDG82/140004
http://xn--ok1bpqi43ahtb.net/board_EkDG82/140091
http://xn--ok1bpqi43ahtb.net/board_EkDG82/140161
http://xn--ok1bpqi43ahtb.net/board_EkDG82/140186
http://xn--ok1bpqi43ahtb.net/board_EkDG82/140249
http://xn--ok1bpqi43ahtb.net/board_EkDG82/140482
http://xn--ok1bpqi43ahtb.net/board_EkDG82/140578
http://xn--ok1bpqi43ahtb.net/board_EkDG82/140781
http://xn--ok1bpqi43ahtb.net/board_EkDG82/140792
http://xn--ok1bpqi43ahtb.net/board_EkDG82/140937
http://xn--ok1bpqi43ahtb.net/board_EkDG82/142313
http://xn--ok1bpqi43ahtb.net/board_EkDG82/143011
http://xn--ok1bpqi43ahtb.net/board_EkDG82/143079
http://xn--ok1bpqi43ahtb.net/board_EkDG82/143262
http://xn--ok1bpqi43ahtb.net/board_EkDG82/145228
http://xn--ok1bpqi43ahtb.net/board_EkDG82/146292
http://xn--ok1bpqi43ahtb.net/board_EkDG82/147619
http://xn--ok1bpqi43ahtb.net/board_EkDG82/151581
http://xn--ok1bpqi43ahtb.net/board_EkDG82/154228
http://xn--ok1bpqi43ahtb.net/board_EkDG82/154657
http://xn--ok1bpqi43ahtb.net/board_EkDG82/154913
http://xn--ok1bpqi43ahtb.net/board_EkDG82/155094
http://xn--ok1bpqi43ahtb.net/board_EkDG82/155155
http://sy.korean.net/qna/87177
http://sy.korean.net/qna/87198
http://sy.korean.net/qna/87243
http://sy.korean.net/qna/87269
http://sy.korean.net/qna/87285
http://sy.korean.net/qna/87297
http://sy.korean.net/qna/87558
http://sy.korean.net/qna/87619
http://sy.korean.net/qna/87695
http://sy.korean.net/qna/87738
http://sy.korean.net/qna/87803
http://sy.korean.net/qna/87856
http://sy.korean.net/qna/87940
http://sy.korean.net/qna/88035
http://sy.korean.net/qna/88056
http://sy.korean.net/qna/88191
http://sy.korean.net/qna/88322
http://sy.korean.net/qna/88354
http://sy.korean.net/qna/88375
http://sy.korean.net/qna/88411
http://sy.korean.net/qna/88462
http://sy.korean.net/qna/88467
http://sy.korean.net/qna/88479
http://HyUa.1fps.icu/l/szIaeDC
http://barobus.kr/?document_srl=21524
http://sy.korean.net/qna/77851
http://xn--2e0bk61btjo.com/notice/9778
http://laokorea.com/orange_menu1/34347
http://agiteshop.com/xe/qa/52449
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=51078
https://2002.shyoon.com/board_2002/32399
http://barobus.kr/qna/26865
http://arte.dgau.ac.kr/?document_srl=53563
http://praisesound.co.kr/sub04_01/20210
http://vervetama.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80-22/
http://wipln.com/?document_srl=70616
http://www.hicleaning.kr/board_wash/139495
http://www.hicleaning.kr/board_wash/139624
http://www.livetank.cn/?document_srl=48917
http://www.livetank.cn/market1/48912
http://www.livetank.cn/market1/48963
http://www.livetank.cn/market1/48977
http://www.studyxray.com/Sangdam/167217
http://www.studyxray.com/Sangdam/167412
http://www.teedinubon.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5-9/
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/news/18135
http://xn--hu1bs8ufrd6ucyz0aooa.kr/?document_srl=5937
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=5917
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=5942
http://HyUa.1fps.icu/l/szIaeDC
http://marjorieaperry.com/?option=com_k2&view=itemlist&task=user&id=484265
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=43211
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2632836
http://www.critico-expository.com/forum/index.php?topic=9786.0
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1635970
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=59295
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=502426
http://ovotecegg.com/component/k2/itemlist/user/114241
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2532845
http://teambuildingpremium.com/forum/index.php?topic=775972.0
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1859431
http://teambuildingpremium.com/forum/index.php?topic=774316.0
http://bitpark.co.kr/board_IzjM66/4058756
http://bitpark.co.kr/board_IzjM66/4058940
http://bitpark.co.kr/board_IzjM66/4059087
http://bitpark.co.kr/faq/4058642
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=82648
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=82665
http://proxima.co.rw/index.php/component/k2/itemlist/user/606888
http://computerscience.egerton.ac.ke/index.php/component/k2/itemlist/user/2004844
http://zanoza.h1n.ru/2019/05/16/%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-65-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jxny-%d0%bd%d0%b0%d1%88%d0%b0-%d0%b8%d1%81%d1%82%d0%be%d1%80%d0%b8%d1%8f-65/
https://prelease.club/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sk8g-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=619991
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/18122
http://www.hsaura.com/noty/45750
http://zanoza.h1n.ru/2019/05/16/%d0%b2%d0%be%d1%80%d0%be%d0%bd-kuzgun-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ncwl-%d0%b2%d0%be%d1%80%d0%be%d0%bd-kuzgun-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://emjun.com/index.php?mid=hangtotal&document_srl=15519
http://www.spazioad.com/component/k2/itemlist/user/7259016
http://roikjer.com/forum/index.php?PHPSESSID=031qerm95n0pe0qknh4b10cm47&topic=842666.0
http://lucky.kidspann.net/index.php?mid=qna&document_srl=74870
http://lucky.kidspann.net/index.php?mid=qna&document_srl=74898
http://lucky.kidspann.net/index.php?mid=qna&document_srl=74912
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=34432
http://research.kiu.ac.kr/?document_srl=86909
http://research.kiu.ac.kr/index.php?document_srl=86581&mid=Food4Thought
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=86634
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=86745
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=86814
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=86993
http://shinilspring.com/?document_srl=107361
http://shinilspring.com/board_qsfb01/107378
http://shinilspring.com/board_qsfb01/107500
http://shinilspring.com/board_qsfb01/107510
http://shinilspring.com/board_qsfb01/107515
http://mediaville.me/index.php/component/k2/itemlist/user/252010
http://mobility-corp.com/index.php/component/k2/itemlist/user/2570025
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/87684
http://ovotecegg.com/?option=com_k2&view=itemlist&task=user&id=134166
http://ovotecegg.com/component/k2/itemlist/user/134161
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/232060
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/13671
http://robocit.com/index.php/component/k2/itemlist/user/449574
http://euromouleusinage.com/index.php/component/k2/itemlist/user/124442
http://ye-dream.com/qa/52457
http://menulisilmiah.net/%d0%b3%d1%80%d0%b0%d0%bd%d0%b4-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nx2%d0%b3%d1%80%d0%b0%d0%bd%d0%b4-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8/
http://menulisilmiah.net/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-st1%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f10-05/
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3755456
http://www.vivelabmanizales.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%be%d0%b9-%d0%b0%d1%80%d1%82%d0%b8%d1%81%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ux5w-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%be%d0%b9-%d0%b0%d1%80%d1%82/
http://www.urbantutorial.com/?option=com_k2&view=itemlist&task=user&id=110287
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/16233
http://corumotoanahtar.com/component/k2/itemlist/user/2382.html
http://mediaville.me/index.php/component/k2/itemlist/user/228390
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4861621
http://community.viajar.tur.br/index.php?p=/discussion/57610/voron-kuzgun-10-seriya-loch-voron-kuzgun-10-seriya/p1%3Fnew=1
http://condolencias.servisa.es/3-20-06-05-2019-l3-3-20
http://mobility-corp.com/index.php/component/k2/itemlist/user/2526264
https://alvarogarciatorero.com/component/k2/itemlist/user/47736
http://www.elpinatarense.es/index.php/component/k2/itemlist/user/154621
http://condolencias.servisa.es/3-14-06-05-2019-l9-3-14
http://married.dike.gr/index.php/component/k2/itemlist/user/48248
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=12107
http://www.ekemoon.com/144249/050720193906/
http://moavalve.co.kr/faq/64184
http://moavalve.co.kr/faq/64223
http://moavalve.co.kr/faq/64243
http://research.kiu.ac.kr/?document_srl=55702
http://shinhwaair2017.cafe24.com/issue/208774
http://shinilspring.com/?document_srl=81441
http://shinilspring.com/board_qsfb01/81366
http://shinilspring.com/board_qsfb01/81451
http://sixangles.co.kr/qna/591921
http://skangseo.org/xe/board_Atnj46/42721
http://skylinecam.co.kr/?document_srl=79236
http://skylinecam.co.kr/photo/79264
http://skylinecam.co.kr/photo/79374
http://thermoplast.envolgroupe.com/component/k2/author/119137
http://topitop.kz/index.php/component/k2/itemlist/user/77165
http://wipln.com/?document_srl=56025
http://wipln.com/?document_srl=56029
http://wipln.com/?document_srl=56068
http://wipln.com/?document_srl=56083
http://wipln.com/?document_srl=56111
http://wipln.com/?document_srl=56136
http://wipln.com/?document_srl=56160
http://wipln.com/?document_srl=56193
http://wipln.com/?document_srl=56241
http://wipln.com/?document_srl=56256
http://wipln.com/?document_srl=56271
http://wipln.com/?document_srl=56349
http://wipln.com/?document_srl=56389
http://wipln.com/?document_srl=56409
http://wipln.com/?document_srl=56446
https://nple.com/xe/pds/36079
https://nple.com/xe/pds/36096
https://nple.com/xe/pds/36119
https://nple.com/xe/pds/36134
https://nple.com/xe/pds/36139
https://nple.com/xe/pds/36205
https://nple.com/xe/pds/36261
https://nple.com/xe/pds/36558
https://nple.com/xe/pds/36588
https://nple.com/xe/pds/36631
https://nple.com/xe/pds/36641
https://nple.com/xe/pds/36738
https://nple.com/xe/pds/36743
https://nple.com/xe/pds/36772
https://nple.com/xe/pds/36795
https://nple.com/xe/pds/36800
https://nple.com/xe/pds/37644
https://nple.com/xe/pds/37669
https://nple.com/xe/pds/37674
http://HyUa.1fps.icu/l/szIaeDC
http://mir3sea.com/forum/index.php?topic=3733.0
http://otitismediasociety.org/forum/index.php?topic=177160.0
http://photogrotto.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-24-05-2019-nv%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
http://photogrotto.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-24-05-2019-us%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
http://teambuildingpremium.com/forum/index.php?topic=834159.0
http://teambuildingpremium.com/forum/index.php?topic=834161.0
http://www.deliberarchia.org/forum/index.php?topic=1045842.0
http://www.deliberarchia.org/forum/index.php?topic=1045850.0
http://www.deliberarchia.org/forum/index.php?topic=1045863.0
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1706732
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1706783
http://thermoplast.envolgroupe.com/component/k2/author/123277
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=11589
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1611600
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1656801
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1445840
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1446118
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/11243
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=16219
http://www.arredoufficiomarca.com/index.php/component/k2/itemlist/user/1570832
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/256686
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/241702
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4909774
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=326270
http://euromouleusinage.com/index.php/component/k2/itemlist/user/121014
http://www.ekemoon.com/182587/051220194613/
https://prelease.club/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-6-%d1%87%d0%b0%d1%81%d1%82%d1%8c-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5/
http://xn--9m1b83j39hz6exwonmf.com/board_IYPe43/523377
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=78080
http://xn--ok1bpqi43ahtb.net/board_EkDG82/151229
http://ye-dream.com/qa/91595
http://ye-dream.com/qa/91708
http://ye-dream.com/qa/91733
https://esel.gist.ac.kr/esel2/board_hmgj23/68032
https://esel.gist.ac.kr/esel2/board_hmgj23/68156
http://www.digitalbul.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-97-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%82%d0%b0%d0%b9%d0%bd/
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/14933
http://www.original-craft.net/index.php?topic=340123.0
http://www.original-craft.net/index.php?topic=340127.0
http://www.verenas-unterwasserwelt.de/forum/index.php?topic=7688.0
http://xplorefitness.com/blog/%C2%AB%D0%B1%D0%BE%D0%BB%D1%8C%D1%88%D0%B5-%D0%B6%D0%B8%D0%B7%D0%BD%D0%B8-9-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%D1%8D%D1%84%D0%B8%D1%80-%C2%AB%D0%B1%D0%BE%D0%BB%D1%8C%D1%88%D0%B5-%D0%B6%D0%B8%D0%B7%D0%BD%D0%B8-9-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://xplorefitness.com/blog/%C2%AB%D1%81%D0%BB%D1%83%D0%B3%D0%B0-%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-18-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%C2%AB%D1%81%D0%BB%D1%83%D0%B3%D0%B0-%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-18-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
https://adsensebih.com/index.php?topic=28071.0
https://adsensebih.com/index.php?topic=28078.0
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/45092
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=5797
https://www.amazingworldtop.com/entretenimiento/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-video-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2/
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=26403
http://indiefilm.kr/xe/board/47610
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1799949
http://euromouleusinage.com/index.php/component/k2/itemlist/user/138403
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1184779
https://grajalesabogados.com.mx/?option=com_k2&view=itemlist&task=user&id=62725
http://www.rocktheboat.cc/groups/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-%d1%83%d0%ba%d1%80%d0%b0%d0%b8%d0%bd%d0%b0-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d0%bf%d0%be%d0%bb%d0%bd/
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7385632
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2610173
http://arunagreen.com/index.php/component/k2/itemlist/user/472458
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=13800
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1015066
http://seoksoononly.dothome.co.kr/qna/721949
http://tekagrafica.com.br/index.php/component/k2/itemlist/user/1627432
http://153.120.114.241/eso/index.php/16883829-zensina-57-seria-wcqf-zensina-57-seria
http://macdistri.com/index.php/component/k2/itemlist/user/300937
http://dev.aabn.org.gh/component/k2/itemlist/user/528965
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3294937
http://necinsurance.co.zw/component/k2/itemlist/user/19250.html
http://www.vivelabmanizales.com/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-video-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-4/
http://proxima.co.rw/index.php/component/k2/itemlist/user/565492
http://withinfp.sakura.ne.jp/eso/index.php/16876856-novinka-nikogda-ne-govori-nikogda-5-seria-s8-nikogda-ne-govori-
http://seoksoononly.dothome.co.kr/qna/739323
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=14320
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=602051
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=46433
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=292544
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/50328
http://married.dike.gr/index.php/component/k2/itemlist/user/45803
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3574535
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=294643
http://topitop.kz/index.php/component/k2/itemlist/user/76558
http://petromacorisanos.com.radiosenda1680.org/?option=com_k2&view=itemlist&task=user&id=5094
http://euromouleusinage.com/index.php/component/k2/itemlist/user/136965
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=305748
http://roikjer.com/forum/index.php?PHPSESSID=g76eor8jlu5l244p49lo3vk6i0&topic=834840.0
http://soc-human.kz/index.php/component/k2/itemlist/user/1680893
http://cccpvideo.forumside.com/index.php?topic=659.0
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1024049
http://myrechockey.com/forums/index.php?topic=90252.0
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1546306
http://petromacorisanos.com.radiosenda1680.org/index.php/component/k2/itemlist/user/9075
http://www.ekemoon.com/142947/052020190305/
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=29687.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2562167
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2563566
http://associationsila.org/?option=com_k2&view=itemlist&task=user&id=282352
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/221261
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2325148
http://subforumna.x10.mx/mad/index.php?topic=249670.0
http://taklongclub.com/forum/index.php?topic=150634.0
http://taklongclub.com/forum/index.php?topic=150667.0
http://teambuildingpremium.com/forum/index.php?topic=845323.0
http://teambuildingpremium.com/forum/index.php?topic=845328.0
http://teambuildingpremium.com/forum/index.php?topic=845338.0
http://married.dike.gr/index.php/component/k2/itemlist/user/54950
http://teambuildingpremium.com/forum/index.php?topic=824788.0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/83642
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/497168
https://khuyenmaikk13.info/index.php?topic=191831.0
https://prelease.club/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pq6y-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://indiefilm.kr/xe/board/61250
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=14310
http://menulisilmiah.net/%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-s8-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be/
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1644992
http://smartacity.com/component/k2/itemlist/user/18877
http://www.ekemoon.com/148419/052320190406/
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2572049
http://proxima.co.rw/index.php/component/k2/itemlist/user/565972
http://dohairbiz.com/?option=com_k2&view=itemlist&task=user&id=2706693
http://www.ekemoon.com/144423/050920191406/
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/199531
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/51355
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=501610
http://servicioswts.com/?option=com_k2&view=itemlist&task=user&id=3625928
http://community.viajar.tur.br/index.php?p=/profile/gilbertohu
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=876947
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=876971
http://oss.obigo.com/oss/index.php?mid=board_mxLS91&document_srl=17921
http://redgatetech.co/?option=com_k2&view=itemlist&task=user&id=731687
http://www.digitalbul.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-a2-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd/
http://www.digitalbul.com/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-k1-%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-2-%d1%81%d0%b5%d1%80%d0%b8/
http://www.digitalbul.com/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-k7-%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3358949
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2448950
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/325735
http://mobility-corp.com/index.php/component/k2/itemlist/user/2569792
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/331272
https://prelease.club/%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b-4-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cy9c-%d0%bc%d0%b8%d0%bb%d0%bb%d0%b8%d0%b0%d1%80%d0%b4%d1%8b/
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1632282
http://sextomariotienda.com/blog/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8d%d1%84%d0%b8%d1%80-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1609492
http://mediaville.me/index.php/component/k2/itemlist/user/230911
http://sextomariotienda.com/blog/%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8d%d1%84%d0%b8%d1%80-%d1%8e%d1%80%d0%b8%d1%81%d1%82%d1%8b-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://dev.aabn.org.gh/component/k2/itemlist/user/537876
https://members.fbhaters.com/index.php?topic=76422.0
http://ovotecegg.com/component/k2/itemlist/user/120217
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=48214
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=299007
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=269082
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2572031
http://www.babvallejo.com/?option=com_k2&view=itemlist&task=user&id=604615
http://withinfp.sakura.ne.jp/eso/index.php/16905233-hdvideo-tola-robot-6-seria-q7-tola-robot-6-seria/0
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/218325
http://www.autospa.lv/index.php/lv/component/k2/itemlist/user/9432
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=497589
http://haniel.ir/index.php/component/k2/itemlist/user/73690
http://www.sakitoandrichifantasy.gr/?option=com_k2&view=itemlist&task=user&id=153922
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1335016
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=496011
http://mobility-corp.com/index.php/component/k2/itemlist/user/2527389
http://www.die-design-manufaktur.de/?option=com_k2&view=itemlist&task=user&id=5175143
http://batubersurat.com/?option=com_k2&view=itemlist&task=user&id=43955
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3382030
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=573907
http://www.dap.com.py/index.php/es/?option=com_k2&view=itemlist&task=user&id=779065
http://euromouleusinage.com/index.php/component/k2/itemlist/user/123814
http://withinfp.sakura.ne.jp/eso/index.php/16992950-hdvideo-cuzaa-zizn-cuze-zitta-1-seria-g3-cuzaa-zizn-cuze-zitta-/0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=331693
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/244040
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3449887
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1143662
http://ye-dream.com/qa/11338
http://xn--ok1bpqi43ahtb.net/board_eASW07/49551
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=1509
http://xplorefitness.com/blog/%C2%AB%D1%87%D1%83%D0%B6%D0%B0%D1%8F-%D0%B6%D0%B8%D0%B7%D0%BD%D1%8C-%D1%87%D1%83%D0%B6%D0%B5-%D0%B6%D0%B8%D1%82%D1%82%D1%8F-11-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-12-05-2019-o0-%C2%AB%D1%87%D1%83%D0%B6%D0%B0%D1%8F-%D0%B6%D0%B8%D0%B7%D0%BD%D1%8C-%D1%87%D1%83%D0%B6%D0%B5-%D0%B6%D0%B8%D1%82%D1%82%D1%8F-11-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://rudraautomation.com/index.php/component/k2/author/184235
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=251004
http://www.sp1.football/index.php?mid=faq&document_srl=11016
http://teambuildingpremium.com/forum/index.php?topic=795426.0
http://www.ekemoon.com/160881/052220190908/
http://withinfp.sakura.ne.jp/eso/index.php/16887432-smotret-bol-soj-artist-1-seria-y6-bol-soj-artist-1-seria
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1762068
http://www.vivelabmanizales.com/%d0%bf%d0%be-%d0%b7%d0%b0%d0%ba%d0%be%d0%bd%d0%b0%d0%bc-%d0%b2%d0%be%d0%b5%d0%bd%d0%bd%d0%be%d0%b3%d0%be-%d0%b2%d1%80%d0%b5%d0%bc%d0%b5%d0%bd%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81-2/
http://valleycapital.co.ke/index.php/component/k2/itemlist/user/56798
http://c3isecurity.com.br/index.php/component/k2/itemlist/user/485744
http://highlanderonline.cmshelplive.net/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-07-05-2019-t6-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
http://mjbosch.com/component/k2/itemlist/user/82368
http://smartacity.com/component/k2/itemlist/user/15153
http://77.93.38.205/index.php/component/k2/itemlist/user/502031
http://jesusandmarypatna.com/index.php/component/k2/itemlist/user/3382231
http://www.vogtland.com.pl/index.php/component/k2/itemlist/user/12381
http://www.ekemoon.com/143149/052120194905/
http://jiquilisco.org/index.php/component/k2/itemlist/user/11155
http://jiquilisco.org/index.php/component/k2/itemlist/user/11157
http://jiquilisco.org/index.php/component/k2/itemlist/user/11158
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=292862
http://mediaville.me/index.php/component/k2/itemlist/user/292977
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2629413
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/764396
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/268147
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/268195
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/226319
http://0433.net/junggo/40500
http://photogrotto.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%85/
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=586492
http://corumotoanahtar.com/component/k2/itemlist/user/4493.html
http://oss.obigo.com/oss/index.php?mid=board_mxLS91&document_srl=12977
http://jjikduk.net/DATA/57666
http://www.josephmaul.org/?document_srl=139911
http://www.teedinubon.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-20-05-2019-r4-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/337004
http://www.remify.app/foro/index.php?topic=320271.0
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=16494
http://www.teedinubon.com/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-88-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-la4%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-88-%d1%81%d0%b5%d1%80%d0%b8%d1%8f19-05-2019/
https://testing.celekt.com/%d0%9f%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xq3n-%d0%9f%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f/
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/63725
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1713009
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=83082
https://ne-kuru.ru/index.php?topic=222365.0
http://www.svteck.co.kr/?document_srl=55047
http://www.jesusonly.life/?document_srl=133424
http://www.ds712.net/guest/?document_srl=150102
http://shinilspring.com/?document_srl=105937
http://zanoza.h1n.ru/2019/05/20/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-20-05-2019-c3-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd/
http://lucky.kidspann.net/index.php?mid=qna&document_srl=71413
http://otitismediasociety.org/forum/index.php?topic=183504.0
http://www.teedinubon.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-20-05-2019-a5-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2/
http://www.m1avio.com/?option=com_k2&view=itemlist&task=user&id=3738602
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=328843
https://sanp.pro/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fo3%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f18-05-2019/
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=122379
http://zanoza.h1n.ru/2019/05/18/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-wn%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81/
http://e-educ.net/Forum/index.php?topic=12048.0
https://testing.celekt.com/%d0%9f%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ix7h-%d0%9f%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1441560
http://jjikduk.net/DATA/76938
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=bcb603031cd118fbc7de549911367984&topic=7786.0
http://jjikduk.net/DATA/78403
http://www.cosl.com.sg/UserProfile/tabid/61/userId/26395676/Default.aspx
http://lasvur.ru/component/k2/itemlist/user/38289
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=30386
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2324340
http://ru-realty.com/forum/index.php?PHPSESSID=u5i4dqu2nm9hkom3spmuautd56&topic=533799.0
https://ne-kuru.ru/index.php?topic=221628.0
http://roikjer.com/forum/index.php?PHPSESSID=4cr2nlkh3dp09sm3s3pcqecl04&topic=903970.0
https://hackersuniversity.net/index.php?topic=22200.0
http://thermoplast.envolgroupe.com/component/k2/author/119630
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=114101
https://ne-kuru.ru/index.php?topic=221960.0
http://photogrotto.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qp8%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7/
http://www.firstfinancialservices.co.uk/component/k2/itemlist/user/11828
http://yoriyorifood.com/xxxx/spacial/109363
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3293378
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/263940
https://www.amazingworldtop.com/entretenimiento/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jh3%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5/
http://ye-dream.com/qa/91922
https://www.shaiyax.com/index.php?topic=353046.0
http://www.svteck.co.kr/customer_gratitude/38668
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=586426
https://testing.celekt.com/%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-17-05-2019-o0-%d0%98%d0%b3%d1%80/
http://www.sp1.football/index.php?mid=faq&document_srl=183282
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/111007
http://emjun.com/index.php?mid=hangtotal&document_srl=106149
http://emjun.com/index.php?mid=hangtotal&document_srl=88041
http://www.crnmedia.es/component/k2/itemlist/user/87167
http://hyeonjun.co.kr/menu3/67947
http://moavalve.co.kr/?document_srl=73156
https://esel.gist.ac.kr/esel2/board_hmgj23/52938
http://jiquilisco.org/index.php/component/k2/itemlist/user/11157
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1607493
http://www.svteck.co.kr/customer_gratitude/43772
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2658073
http://www.golden-nail.co.kr/press/87106
http://www.hicleaning.kr/board_wash/94520
https://hackersuniversity.net/index.php?topic=21543.0
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=106969
http://asiagroup.co.kr/?document_srl=279325
http://vhost12299.cpsite.ru/439773-sluga-naroda-3-sezon-22-seria-18052019-m1-sluga-naroda-3-sezon-
http://lucky.kidspann.net/index.php?mid=qna&document_srl=56183
https://cybergsm.es/index.php?topic=30116.0
http://moavalve.co.kr/faq/82220
http://www.josephmaul.org/menu41/105706
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=855353
http://www.golden-nail.co.kr/press/77900
http://0433.net/junggo/54298
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=93046
http://www.theparrotcentre.com/forum/index.php?topic=551141.0
http://www.theocraticamerica.org/forum/index.php/topic,48201.0.html
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=193365
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1447641
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3382075
http://www.digitalbul.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-18-05-2019-v3-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd/
http://photogrotto.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-87-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gf7%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-87-%d1%81%d0%b5%d1%80%d0%b8%d1%8f19-05-2019/
http://www.teedinubon.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gg7%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5/
http://www.boutique.in.th/index.php/component/k2/itemlist/user/151485
http://indiefilm.kr/xe/board/110566
http://shinhwaair2017.cafe24.com/issue/225528
http://teambuildingpremium.com/forum/index.php?topic=844632.0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=74978
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1705412
http://shinilspring.com/board_qsfb01/94580
http://zanoza.h1n.ru/2019/05/19/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tk2%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
https://sanp.pro/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-100-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-af4%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-100-%d1%81%d0%b5%d1%80%d0%b8%d1%8f19-05-2019/
http://www.hsaura.com/noty/145697
http://www.critico-expository.com/forum/index.php?topic=14312.0
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=114525
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=89199
http://skylinecam.co.kr/photo/96799
http://photogrotto.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-vs%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81/
http://asin.itts.co.kr/board_rtXs84/6095
http://photogrotto.com/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ag1%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f19-05-2019/
http://mediaville.me/index.php/component/k2/itemlist/user/293329
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=58638
http://mobility-corp.com/index.php/component/k2/itemlist/user/2638713
http://forums.abs-cbn.com/welcome-back-kapamilya%21/ee-2-eo-3-e-18-05-2019-mus-ee-2-eo-3-e/?PHPSESSID=u9cs7jgm5qvbqsnssvkhiom3f7
http://bebopindia.com/notcie/113878
http://xn----3x5er9r48j7wemud0a387h.com/news/31542
http://ddgu.ddos-guard.net/ddgu/?h=aHR0cDovL3Zob3N0MTIyOTkuY3BzaXRlLnJ1&u=LzQyMzk2Ni1ub3ZpbmthLWN1emFhLXppem4tY3V6ZS16aXR0YS0xMi1zZXJpYS13NC1jdXphYS16aXpuLWN1emUteml0dGE=
http://www.popolsku.fr.pl/forum/index.php?topic=403045.0
http://ptu.imoove.kr/ko/content/%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-11-%D0%B2%D1%8B%D0%BF%D1%83%D1%81%D0%BA%C2%BB-se%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-11-%D0%B2%D1%8B%D0%BF%D1%83%D1%81%D0%BA%C2%BB75-%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-11
https://adsensebih.com/index.php?topic=27323.0
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=82366
http://indiefilm.kr/xe/board/142086
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=127326
https://tg.vl-mp.com/index.php?topic=1492528.0
http://zanoza.h1n.ru/2019/05/20/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-m7-%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-11-%d1%81%d0%b5%d1%80%d0%b8/
http://www.josephmaul.org/menu41/87832
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1934165
http://www.ekemoon.com/208815/050320190618/
http://zanoza.h1n.ru/2019/05/18/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d1%84%d0%b8%d0%bd%d0%b0%d0%bb-zo%d1%85%d0%be%d0%bb%d0%be/
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1924359
http://jjikduk.net/?document_srl=67136
http://www.theocraticamerica.org/forum/index.php?topic=54352.0
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=63537
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=644288
http://www.cosl.com.sg/UserProfile/tabid/61/userId/26411561/Default.aspx
https://esel.gist.ac.kr/esel2/board_hmgj23/60016
http://zanoza.h1n.ru/2019/05/21/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-95-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fp4%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-95/
http://zanoza.h1n.ru/2019/05/20/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hi5%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-13-%d1%81%d0%b5/
http://emjun.com/index.php?mid=hangtotal&document_srl=90415
http://www.web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3701965
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=196476
http://www.teedinubon.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-uu6%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5/
http://forum.kopkargobel.com/index.php?topic=11841.0
http://www.teedinubon.com/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c/
http://www.phperos.net/foro/index.php?topic=137428.0
http://dev.aabn.org.gh/component/k2/itemlist/user/627280
http://wcwpr.com/UserProfile/tabid/85/userId/9597686/Default.aspx
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1442718
http://zanoza.h1n.ru/2019/05/20/%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-20-05-2019-n2-%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4/
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=63906
http://shinhwaair2017.cafe24.com/?document_srl=210880
http://otitismediasociety.org/forum/index.php?topic=175568.0
http://www.svteck.co.kr/customer_gratitude/41400
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=65972
http://atemshow.com/atemfair_domestic/36817
http://www.tekparcahdfilm.com/forum/index.php?topic=51495.0
http://shinilspring.com/board_qsfb01/97539
http://forums.abs-cbn.com/welcome-back-kapamilya%21/a-aoa-3-eo-13-e-17-05-2019-lap-a-aoa-3-eo-13-e/?PHPSESSID=eq01ttqhsqas9ndcvcavep62j2
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=74904
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3381600
http://asin.itts.co.kr/board_rtXs84/17351
http://lucky.kidspann.net/index.php?mid=qna&document_srl=52832
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=514999
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=712653.0
http://zanoza.h1n.ru/2019/05/20/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-20-05-2019-w1-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
https://altaylarteknoloji.com/index.php?topic=4993.0
http://www.golden-nail.co.kr/press/78991
http://moavalve.co.kr/?document_srl=78678
http://forum.drahthaar-club.com.ua/index.php?topic=3182.0
http://emjun.com/index.php?mid=hangtotal&document_srl=82448
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4939662
http://yoriyorifood.com/xxxx/?document_srl=75878
http://corumotoanahtar.com/component/k2/itemlist/user/5402
http://www.camaracoyhaique.cl/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%81%d0%b5%d0%bd/
http://www.teedinubon.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1443495
http://xn--9m1b83j39hz6exwonmf.com/board_IYPe43/515833
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=173676
https://reficulcoin.com/index.php?topic=50407.0
http://www.theparrotcentre.com/forum/index.php?topic=552535.0
http://www.jesusonly.life/calendar/158619
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1823550
http://www.hicleaning.kr/board_wash/115954
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/329866
http://photogrotto.com/%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-la2%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd/
http://www.jshwanghoan.com/?document_srl=87782
http://masanlib.or.kr/g1/30153
http://www.original-craft.net/index.php?topic=335427.0
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/764770
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=109484
http://www.teedinubon.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-av9%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be/
http://guiadetudo.com/index.php/component/k2/itemlist/user/12200
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3401154
http://ovotecegg.com/component/k2/itemlist/user/166268
http://vervetama.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5/
http://www.theparrotcentre.com/forum/index.php?topic=549368.0
http://www.hicleaning.kr/board_wash/142780
http://www.remify.app/foro/index.php?topic=318206.0
http://withinfp.sakura.ne.jp/eso/index.php/17148372-deti-sester-kardes-cocuklari-19-seria-nirm-deti-sester-kardes-c/0
http://proxima.co.rw/index.php/component/k2/itemlist/user/650270
http://www.teedinubon.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-10/
https://testing.celekt.com/%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-p7-%d0%98%d0%b3%d1%80/
http://www.sp1.football/index.php?mid=faq&document_srl=192343
http://xn----3x5er9r48j7wemud0a387h.com/news/42912
http://xn----3x5er9r48j7wemud0a387h.com/news/27185
https://www.2ayes.com/16798/13-17-05-2019-c7-13
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3293705
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/109623
http://zanoza.h1n.ru/2019/05/20/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-92-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xo7%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-92/
http://0433.net/junggo/52986
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/gumdanapt/50445
http://www.critico-expository.com/forum/index.php?topic=14123.0
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=59277
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/17347
http://153.120.114.241/eso/index.php/17116203-holostak-24-05-2019-ylholostak-24-05-201995-holostak-24-05-2019
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=114395
http://www.teedinubon.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-90-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-21-05-2019-b3-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94/
http://vhost12299.cpsite.ru/431703-senafeda-2-sezon-9-seria-17052019-d6-senafeda-2-sezon-9-seria
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1223147
http://rudraautomation.com/index.php/component/k2/author/231987
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=346998
http://grupotir.com/component/k2/itemlist/user/42575
http://www.critico-expository.com/forum/index.php?topic=14397.0
http://carrierworld.co.kr/index.php?document_srl=62867&mid=board_UlGv44
http://xn--9m1b83j39hz6exwonmf.com/board_IYPe43/526928
http://skylinecam.co.kr/photo/90764
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=143621
http://www.sp1.football/?document_srl=464518
http://proxima.co.rw/index.php/component/k2/itemlist/user/644890
http://universalcommunity.se/Forum/index.php?topic=18585.0
http://roikjer.com/forum/index.php?PHPSESSID=ktdu640j6t2jtmnon3159bqn83&topic=903280.0
http://forums.abs-cbn.com/welcome-back-kapamilya%21/ee-2-eo-2-e-20-05-2019-klk-ee-2-eo-2-e/?PHPSESSID=s0rfjl4sv1io6nufeg46ocipj1
http://zanoza.h1n.ru/2019/05/20/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-90-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ck4%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-90-%d1%81%d0%b5%d1%80%d0%b8%d1%8f19-05-2019/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1453157
http://ovotecegg.com/component/k2/itemlist/user/165658
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=74875
http://xn--ok1bpqi43ahtb.net/board_YXVi77/151128
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1612101
https://www.regalepadova.it/index.php/component/k2/itemlist/user/7917
http://withinfp.sakura.ne.jp/eso/index.php/17149185-vetrenyj-hercai-17-seria-ilfn-vetrenyj-hercai-17-seria/0
http://cwon.kr/xe/board_bnSr36/58378
http://universalcommunity.se/Forum/index.php?topic=16364.0
http://jjikduk.net/DATA/80358
http://mobility-corp.com/index.php/component/k2/itemlist/user/2627934
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=503854
https://testing.celekt.com/%d0%91%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fq8%d0%91%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-16-%d1%81%d0%b5/
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=225979
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3301984
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=190266
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=102122
http://oss.obigo.com/oss/index.php?mid=board_mxLS91&document_srl=12438
http://married.dike.gr/index.php/component/k2/itemlist/user/66066
http://www.golden-nail.co.kr/press/84661
http://www.phperos.net/foro/index.php?topic=136100.0
http://teambuildingpremium.com/forum/index.php?topic=859780.0
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=195584
http://photogrotto.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8d%d1%84%d0%b8%d1%80-%d1%81%d0%bb/
http://www.svteck.co.kr/customer_gratitude/78861
http://married.dike.gr/index.php/component/k2/itemlist/user/65511
http://www.crnmedia.es/component/k2/itemlist/user/87055
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=67885
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=195390
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1709842
http://shinilspring.com/board_qsfb01/104342
http://vhost12299.cpsite.ru/427400-v-efire-taemnici-92-seria-s4-taemnici-92-seria
https://esel.gist.ac.kr/esel2/board_hmgj23/55898
http://laspoltrina.it/component/k2/itemlist/user/1452931
http://www.hsaura.com/noty/159703
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=83578
http://www.teedinubon.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-by9%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-10-%d1%81%d0%b5/
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=89336
http://matrixpharm.ru/forum/index.php?PHPSESSID=libhnkmarr5sdn8i1ftji4atg5&action=profile;u=199394
http://matrixpharm.ru/forum/index.php?PHPSESSID=od0gsd5eopehn65asnbo55c9t1&action=profile;u=199662
https://www.vegasgreentour.com/?document_srl=131007
http://cwon.kr/xe/board_bnSr36/58045
https://sanp.pro/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nd7%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be/
http://test.comics-game.ru/index.php?topic=322.0
http://lucky.kidspann.net/index.php?mid=qna&document_srl=64650
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=16296
http://lucky.kidspann.net/index.php?mid=qna&document_srl=77822
https://hackersuniversity.net/index.php?topic=22922.0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/545617
http://thermoplast.envolgroupe.com/component/k2/author/121428
http://webp.online/index.php?topic=60416.0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/546300
https://sanp.pro/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sq7%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f20-05-2019/
http://skylinecam.co.kr/photo/95179
http://www.studyxray.com/Sangdam/174777
http://proxima.co.rw/index.php/component/k2/itemlist/user/645946
http://shinilspring.com/board_qsfb01/86120
http://corumotoanahtar.com/component/k2/itemlist/user/4812.html
http://www.studyxray.com/Sangdam/177192
https://testing.celekt.com/%d0%91%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%a1%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d0%91%d0%be%d0%bb%d1%8c%d1%88/
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=96400
http://dev.aabn.org.gh/?option=com_k2&view=itemlist&task=user&id=611907
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=152693
https://adsensebih.com/index.php?topic=27859.0
http://cwon.kr/xe/board_bnSr36/108160
http://xn--ok1bpqi43ahtb.net/board_YXVi77/104098
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3387649
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=586573
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/113728
http://www.theparrotcentre.com/forum/index.php?topic=548076.0
https://testing.celekt.com/%d0%a1%d0%b5%d0%bd%d1%8f%d0%a4%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-v1-%d0%a1%d0%b5%d0%bd%d1%8f%d0%a4%d0%b5%d0%b4%d1%8f-2/
http://skylinecam.co.kr/photo/121984
https://altaylarteknoloji.com/index.php?topic=5267.0
https://testing.celekt.com/%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zj4%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5/
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=205881
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=136989
http://forum.bmw-e60.eu/index.php?topic=8816.0
http://153.120.114.241/eso/index.php/17111684-hdvideo-holostak-9-sezon-13-vypusk-q6-holostak-9-sezon-13-vypus
http://dcasociados.eu/component/k2/itemlist/user/89644
http://www.teedinubon.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-iy1%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7/
http://zanoza.h1n.ru/2019/05/22/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-99-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kn5%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-99/
https://testing.celekt.com/%d0%9c%d0%b0%d0%bc%d0%b0-%d0%9b%d0%be%d1%80%d0%b0-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mm7%d0%9c%d0%b0%d0%bc%d0%b0-%d0%9b%d0%be%d1%80%d0%b0-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f21-05-2019/
https://testing.celekt.com/%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-wy5%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5/
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=583466
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=583481
http://www.studyxray.com/Sangdam/206171
http://www.studyxray.com/Sangdam/206201
http://www.studyxray.com/Sangdam/206276
http://photogrotto.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-aj5%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-11-%d1%81%d0%b5/
http://tekagrafica.com.br/index.php/component/k2/itemlist/user/1735051
http://0433.net/junggo/62933
http://www.teedinubon.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-20-05-2019-o1-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2/
http://www.rationalkorea.com/xe/?document_srl=510546
http://teambuildingpremium.com/forum/index.php?topic=844035.0
http://thermoplast.envolgroupe.com/component/k2/author/138210
http://w9builders.co.uk/index.php/component/k2/itemlist/user/94746
http://www.arunagreen.com/index.php/component/k2/itemlist/user/581746
http://www.crnmedia.es/?option=com_k2&view=itemlist&task=user&id=88616
http://www.crnmedia.es/component/k2/itemlist/user/88610
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/21503
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/21537
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/21542
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=873884
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=41072
http://www.vogtland.com.pl/index.php/component/k2/itemlist/user/41068
http://www.sp1.football/index.php?mid=faq&document_srl=241335
http://haniel.ir/index.php/component/k2/itemlist/user/124176
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/341695
http://shinilspring.com/board_qsfb01/101584
http://www.remify.app/foro/index.php?topic=319401.0
http://www.jesusonly.life/calendar/119265
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=97296
http://www.theocraticamerica.org/forum/index.php/topic,53259.0.html
http://www.hicleaning.kr/board_wash/115693
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=340672
http://poselokgribovo.ru/forum/index.php?topic=805966.0
https://hackersuniversity.net/index.php?topic=19833.0
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3307985
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=78642
http://photogrotto.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-24-05-19-nh%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba/
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=236534
http://jjikduk.net/DATA/73637
http://www.studyxray.com/Sangdam/151096
http://shinilspring.com/board_qsfb01/105884
http://webp.online/index.php?topic=60374.0
http://ovotecegg.com/component/k2/itemlist/user/168196
http://www.josephmaul.org/menu41/138837
http://www.sp1.football/index.php?mid=faq&document_srl=357596
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1731297
http://bobr.site/index.php?topic=153951.0
http://indiefilm.kr/xe/board/155689
http://asin.itts.co.kr/board_rtXs84/5814
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/gumdanapt/72245
http://forum.digamahost.com/index.php?topic=127137.0
http://moavalve.co.kr/faq/77745
http://yoriyorifood.com/xxxx/spacial/111261
http://emjun.com/index.php?mid=hangtotal&document_srl=75668
http://xn----3x5er9r48j7wemud0a387h.com/news/33963
https://cybergsm.es/index.php?topic=34498.0
http://153.120.114.241/eso/index.php/17118162-holostak-9-sezon-11-vypusk-17-05-2019-baholostak-9-sezon-11-vyp
http://thermoplast.envolgroupe.com/component/k2/author/121373
http://immobilia.gr/index.php/de/component/k2/itemlist/user/16456
http://patagroupofcompanies.com/?option=com_k2&view=itemlist&task=user&id=262617
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1450813
http://www.quattroandpartners.it/component/k2/itemlist/user/1154239
http://www.josephmaul.org/menu41/228153
http://www.josephmaul.org/menu41/228180
http://www.jshwanghoan.com/index.php?document_srl=190992&mid=qna
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=191069
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=591451
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=591490
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=591521
http://xn----3x5er9r48j7wemud0a387h.com/news/79429
http://xn----3x5er9r48j7wemud0a387h.com/news/79469
http://xn----3x5er9r48j7wemud0a387h.com/news/79565
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/gumdanapt/179927
http://yoriyorifood.com/xxxx/spacial/167203
http://yoriyorifood.com/xxxx/spacial/167274
http://rudraautomation.com/index.php/component/k2/author/249349
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1725167
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1725127
http://thermoplast.envolgroupe.com/component/k2/author/136993
http://thermoplast.envolgroupe.com/component/k2/author/137018
http://thermoplast.envolgroupe.com/component/k2/author/137424
http://w9builders.co.uk/index.php/component/k2/itemlist/user/94381
http://www.ds712.net/guest/?document_srl=139994
http://azone.synology.me/xe/?document_srl=102236
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/gumdanapt/97349
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/345163
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/9921
https://sanp.pro/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-24-05-2019-vw%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-24-05-201926-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-24/
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=5ca98fb774a92256510189a5e397429c&topic=6535.0
http://yoriyorifood.com/xxxx/spacial/103964
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=69055
http://yeonsen.com/?document_srl=84604
http://mobility-corp.com/index.php/component/k2/itemlist/user/2655435
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/126940
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/280293
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/280371
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/280450
http://rudraautomation.com/index.php/component/k2/author/248634
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2350835
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2350880
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2350902
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2350930
http://smartacity.com/component/k2/itemlist/user/63652
http://smartacity.com/component/k2/itemlist/user/63659
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1724620
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1760347
http://thermoplast.envolgroupe.com/component/k2/author/136948
http://www.spazioad.com/?option=com_k2&view=itemlist&task=user&id=7376537
http://www.teedinubon.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%85%d0%be/
http://www2.yasothon.go.th/smf/index.php?topic=159.167025
http://www2.yasothon.go.th/smf/index.php?topic=159.167040
http://www2.yasothon.go.th/smf/index.php?topic=159.msg194074
http://zanoza.h1n.ru/2019/05/22/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80-2/
http://zanoza.h1n.ru/2019/05/22/%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f/
https://adsensebih.com/index.php?topic=30927.0
https://adsensebih.com/index.php?topic=30931.0
https://hackersuniversity.net/index.php?topic=23448.0
https://khuyenmaikk13.info/index.php?topic=214639.0
https://testing.celekt.com/%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%a1%d0%b5%d1%80%d0%b8%d0%b0%d0%bb/
https://testing.celekt.com/%d0%a2%d0%b0%d0%b9%d0%bd%d1%8b-90-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-video-%d0%a2%d0%b0%d0%b9%d0%bd%d1%8b-90-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://taklongclub.com/forum/index.php?topic=150616.0
http://www.tessabannampad.go.th/webboard/index.php?topic=214758.0
https://testing.celekt.com/%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-tv%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81/
https://www.shaiyax.com/index.php?topic=356348.0
http://www.golden-nail.co.kr/press/86591
http://research.kiu.ac.kr/index.php?document_srl=60615&mid=Food4Thought
http://photogrotto.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sr1%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f20-05/
http://www.studyxray.com/Sangdam/179839
https://altaylarteknoloji.com/index.php?topic=5422.0
http://indiefilm.kr/xe/board/122004
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=847565
http://proxima.co.rw/index.php/component/k2/itemlist/user/658659
http://lucky.kidspann.net/index.php?mid=qna&document_srl=74936
http://www.ekemoon.com/225505/050120195222/
http://www.ekemoon.com/225541/050220190622/
http://www.ekemoon.com/225543/050220190822/
http://www.ekemoon.com/225545/050220190822/
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1835461
http://www.firstfinancialservices.co.uk/component/k2/itemlist/user/20017
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3512205
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=16590
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2550424
http://www.spazioad.com/component/k2/itemlist/user/7376356
http://www.spazioad.com/component/k2/itemlist/user/7376372
http://ovotecegg.com/component/k2/itemlist/user/180974
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/280696
http://rudraautomation.com/index.php/component/k2/author/249546
http://smartacity.com/component/k2/itemlist/user/64081
http://smartacity.com/component/k2/itemlist/user/64083
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1725337
http://thermoplast.envolgroupe.com/component/k2/author/137496
http://thermoplast.envolgroupe.com/component/k2/itemlist/user/137520
http://w9builders.co.uk/index.php/component/k2/itemlist/user/94449
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=16506
http://wigalseguros.com.br/index.php/component/k2/itemlist/user/16501
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1631862
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1631878
https://altaylarteknoloji.com/index.php?topic=5168.0
http://www.josephmaul.org/menu41/102401
http://ye-dream.com/qa/92042
http://lucky.kidspann.net/index.php?mid=qna&document_srl=76929
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=291332
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=291390
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=179933
http://community.viajar.tur.br/index.php?p=/discussion/62023/deti-sester-kardes-cocuklari-18-seriya-exom-deti-sester-kardes-cocuklari-18-seriya
http://community.viajar.tur.br/index.php?p=/discussion/62029/voskresshiy-ertugrul-150-seriya-lmvv-voskresshiy-ertugrul-150-seriya
http://community.viajar.tur.br/index.php?p=/discussion/62030/klyatva-yemin-69-seriya-gsmx-klyatva-yemin-69-seriya
http://community.viajar.tur.br/index.php?p=/profile/darlabudd
http://community.viajar.tur.br/index.php?p=/profile/janeenscar
http://community.viajar.tur.br/index.php?p=/profile/jonathon62
http://dev.aabn.org.gh/component/k2/itemlist/user/640674
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1962493
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=102734
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=353769
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=353773
http://haniel.ir/?option=com_k2&view=itemlist&task=user&id=127469
http://haniel.ir/index.php/component/k2/itemlist/user/127453
http://jiquilisco.org/index.php/component/k2/itemlist/user/14665
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3861633
http://www.jesusonly.life/calendar/133723
http://xn----3x5er9r48j7wemud0a387h.com/?document_srl=45588
http://yoriyorifood.com/xxxx/spacial/78671
http://smartacity.com/component/k2/itemlist/user/52583
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=75789
http://oss.obigo.com/oss/index.php?mid=board_mxLS91&document_srl=21339
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=260796
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=620678
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2699190
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=62398
http://dev.aabn.org.gh/component/k2/itemlist/user/640708
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1962514
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=496343
http://otitismediasociety.org/forum/index.php?topic=185228.0
http://hyeonjun.co.kr/menu3/106871
http://carrierworld.co.kr/?document_srl=84172
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=82698
http://xplorefitness.com/blog/%C2%AB%D1%81%D0%B5%D0%BD%D1%8F%D1%84%D0%B5%D0%B4%D1%8F-2-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-8-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%D1%81%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C-%C2%AB%D1%81%D0%B5%D0%BD%D1%8F%D1%84%D0%B5%D0%B4%D1%8F-2-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-8-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://zanoza.h1n.ru/2019/05/18/%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-chernobyl-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-17-05-2019-b0-%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-chernobyl/
https://cybergsm.es/index.php?topic=34166.0
http://ye-dream.com/qa/79533
http://jiquilisco.org/?option=com_k2&view=itemlist&task=user&id=9594
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1949781
http://e-educ.net/Forum/index.php?topic=13240.0
http://dev.aabn.org.gh/component/k2/itemlist/user/635338
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=288926
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=35802
https://sanp.pro/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ot8%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7/
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/229871
http://cwon.kr/xe/board_bnSr36/69140
http://corumotoanahtar.com/component/k2/itemlist/user/4951.html
http://www.theocraticamerica.org/forum/index.php?topic=56829.0
http://www.studyxray.com/Sangdam/118140
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=31944
http://xn----3x5er9r48j7wemud0a387h.com/news/59867
http://www.hsaura.com/noty/142097
http://universalcommunity.se/Forum/index.php?topic=15739.0
http://www.studyxray.com/Sangdam/182447
http://www.sp1.football/index.php?mid=tr_video&document_srl=239979
http://www.josephmaul.org/menu41/117230
http://shinilspring.com/board_qsfb01/103370
http://shinhwaair2017.cafe24.com/issue/232739
http://masanlib.or.kr/g1/32562
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=202897
http://bebopindia.com/notcie/118843
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=88983
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2323750
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=76453
https://prelease.club/%d0%b1%d0%be%d0%b3%d0%b0%d1%82%d1%8b%d0%b5-%d0%b8-%d0%b1%d0%b5%d0%b4%d0%bd%d1%8b%d0%b5-zengin-ve-yoksul-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sddx-%d0%b1%d0%be%d0%b3%d0%b0%d1%82%d1%8b/
http://0433.net/junggo/39722
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=205450
http://shinilspring.com/board_qsfb01/109156
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=5280
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=148948
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=108212
http://thanosakademi.com/index.php?topic=96146.0
http://fbpharm.net/index.php/component/k2/itemlist/user/51045
http://www.theocraticamerica.org/forum/index.php?topic=49238.0
http://xn----3x5er9r48j7wemud0a387h.com/news/33990
http://xn--ok1bpqi43ahtb.net/board_eASW07/119499
https://testing.celekt.com/%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-fp%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81/
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2673756
http://lucky.kidspann.net/index.php?mid=qna&document_srl=57303
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=346088
http://forum.digamahost.com/index.php?topic=125919.0
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=68893
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/275510
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=515713
http://www.arunagreen.com/index.php/component/k2/itemlist/user/546943
http://www.ekemoon.com/209795/050720193118/
http://zanoza.h1n.ru/2019/05/19/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-17-05-19-hh%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba/
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2671165
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=85531
https://www.netprofessional.gr/component/k2/itemlist/user/3711.html
http://www.hsaura.com/noty/135549
https://testing.celekt.com/%d0%91%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fr4%d0%91%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-12-%d1%81%d0%b5/
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=884787
http://ye-dream.com/qa/83766
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1679328
http://roikjer.com/forum/index.php?PHPSESSID=u3766r1qsf77gk6rqpe7aeiti5&topic=896359.0
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=38246
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=227261
http://teambuildingpremium.com/forum/index.php?topic=854114.0
http://indiefilm.kr/xe/board/153522
http://photogrotto.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fa5%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7/
http://lucky.kidspann.net/index.php?mid=qna&document_srl=85196
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=340719
http://roikjer.com/forum/index.php?PHPSESSID=b3l8e23h4k24kasb0k5dfgh9f1&topic=892016.0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=77825
http://jjikduk.net/DATA/74009
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=111927
http://maka-222.com/?document_srl=36094
http://xn--9m1b83j39hz6exwonmf.com/board_IYPe43/511683
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1620056
https://cybergsm.es/index.php?topic=32001.0
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=130841
https://testing.celekt.com/%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-20-05-2019-h2-%d0%a1%d0%bb%d1%83%d0%b3%d0%b0/
https://sanp.pro/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-93-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mt6%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-93/
https://reficulcoin.com/index.php?topic=52785.0
http://sixangles.co.kr/qna/594999
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=85099
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=341742
http://www.boutique.in.th/?option=com_k2&view=itemlist&task=user&id=151505
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3393124
http://photogrotto.com/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-86-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gi7/
http://dev.aabn.org.gh/component/k2/itemlist/user/624667
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1441279
http://masanlib.or.kr/g1/34128
http://www.josephmaul.org/menu41/137121
https://testing.celekt.com/%d0%a2%d0%b0%d0%b9%d0%bd%d1%8b-%d0%a2%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-101-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-r8-%d0%a2%d0%b0%d0%b9%d0%bd%d1%8b-%d0%a2%d0%b0%d1%94/
https://ne-kuru.ru/index.php?topic=222644.0
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=521906
http://cwon.kr/xe/board_bnSr36/113234
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2347281
http://community.viajar.tur.br/index.php?p=/profile/lilym5492
http://ovotecegg.com/component/k2/itemlist/user/159427
http://forum.kopkargobel.com/index.php?topic=11881.0
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=88165
http://zanoza.h1n.ru/2019/05/19/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-91-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kd2%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-91/
http://www.gforgirl.com/xe/?document_srl=106699
http://hyeonjun.co.kr/menu3/66983
http://asin.itts.co.kr/board_rtXs84/17555
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/gumdanapt/52016
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=106992
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3391835
http://www.sp1.football/index.php?mid=faq&document_srl=228327
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=520272
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=5276
http://xn--ok1bpqi43ahtb.net/board_eASW07/104364
http://proxima.co.rw/index.php/component/k2/itemlist/user/649904
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=76218
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3294729
http://e-educ.net/Forum/index.php?topic=13265.0
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/330938
https://sanp.pro/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ie5%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f18-05/
http://xn--ok1bpqi43ahtb.net/board_eASW07/122841
http://bebopindia.com/notcie/107029
http://www.digitalbul.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-vv%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81/
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/267728
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=85753
http://lucky.kidspann.net/index.php?mid=qna&document_srl=78485
https://nextezone.com/index.php?topic=56939.0
https://testing.celekt.com/%d0%a7%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-2019-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-%d0%a7%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-2019-5-%d1%81%d0%b5/
http://www.teedinubon.com/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gf2%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f17-05-2019/
http://ariji.kr/sub07/806541
http://mobility-corp.com/index.php/component/k2/itemlist/user/2628499
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1450041
http://miklja.net/forum/index.php?topic=31539.0
http://forum.digamahost.com/index.php?topic=126582.0
http://www.gforgirl.com/xe/poster/129475
http://www.original-craft.net/index.php?topic=338039.0
http://thermoplast.envolgroupe.com/component/k2/author/119821
http://www.spazioad.com/component/k2/itemlist/user/7354293
http://skylinecam.co.kr/?document_srl=121299
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=336426
http://fbpharm.net/index.php/component/k2/itemlist/user/66057
http://fbpharm.net/index.php/component/k2/itemlist/user/66068
http://fbpharm.net/index.php/component/k2/itemlist/user/66091
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1893452
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1893453
http://grupotir.com/component/k2/itemlist/user/42596
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=352767
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=352770
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=352791
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=352904
http://jiquilisco.org/index.php/component/k2/itemlist/user/14361
http://married.dike.gr/index.php/component/k2/itemlist/user/65883
http://www.siirtorganik.com/index.php/component/k2/itemlist/user/852656
http://yoriyorifood.com/xxxx/?document_srl=89832
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=81726
https://testing.celekt.com/%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-20-05-2019-l9-%d0%a1%d0%bb%d1%83%d0%b3%d0%b0/
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1668142
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=23425
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=88591
https://sanp.pro/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-en4%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f18-05/
http://www.svteck.co.kr/customer_gratitude/41947
http://skylinecam.co.kr/photo/128933
http://matrixpharm.ru/forum/index.php?PHPSESSID=pmvspv3aoq5r816si0spv1gjc6&action=profile;u=199589
http://vhost12299.cpsite.ru/421178-mama-lora-8-seria-serial-mama-lora-8-seria
http://www.jesusonly.life/calendar/153674
http://www.phperos.net/foro/index.php?topic=136126.0
http://www.telcon.gr/index.php/component/k2/itemlist/user/75467
http://community.viajar.tur.br/index.php?p=/profile/phillis55j
http://indiefilm.kr/xe/board/107932
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=87650
http://rudraautomation.com/index.php/component/k2/author/225844
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=71797
http://www.theocraticamerica.org/forum/index.php/topic,55550.0.html
http://photogrotto.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wf6%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c/
http://miklja.net/forum/index.php?topic=32283.0
http://www.phperos.net/foro/index.php?topic=136751.0
https://www.celekt.com/%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dm4m-%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
https://www.celekt.com/%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ru2h-%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
https://www.celekt.com/%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gl0d-%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
https://www.celekt.com/%d0%a1%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d0%a7%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ar2j-%d0%a1%d0%bc%d0%be%d1%82%d1%80%d0%b5/
https://www.celekt.com/%d0%a1%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d0%a7%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hu1d-%d0%a1%d0%bc%d0%be%d1%82%d1%80%d0%b5/
https://www.celekt.com/%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-ad9u-%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://0433.net/junggo/70904
http://0433.net/junggo/70920
http://photogrotto.com/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-89-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fy5%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-89-%d1%81%d0%b5%d1%80%d0%b8%d1%8f18-05-2019/
http://moavalve.co.kr/faq/87452
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=57454
https://testing.celekt.com/%d0%9f%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dy0%d0%9f%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd/
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/261082
http://www.studyxray.com/Sangdam/146933
http://ye-dream.com/qa/74338
http://masanlib.or.kr/g1/31707
http://xn----3x5er9r48j7wemud0a387h.com/?document_srl=53075
http://yoriyorifood.com/xxxx/spacial/92667
https://testing.celekt.com/%d0%a7%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-2019-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hb3%d0%a7%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-2019-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.jesusonly.life/calendar/135589
http://indiefilm.kr/xe/board/117880
http://www.studyxray.com/Sangdam/146739
http://www.josephmaul.org/menu41/140887
http://www.golden-nail.co.kr/press/103511
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4866097
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1634966
http://www.ekemoon.com/227115/051520194822/
http://www.sollazzorefrigerazione.it/?option=com_k2&view=itemlist&task=user&id=2554998
http://www.spazioad.com/component/k2/itemlist/user/7381797
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=41577
https://sanp.pro/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zg7v-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-10/
https://sanp.pro/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xy5x-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-16/
https://sanp.pro/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-un1l-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-17/
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vy6v-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
https://sanp.pro/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sq9k-%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://sanp.pro/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yr2b-%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://sanp.pro/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cf1t-%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://sanp.pro/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yg0s-%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://xn--ok1bpqi43ahtb.net/board_eASW07/127350
http://corumotoanahtar.com/component/k2/itemlist/user/5368.html
https://www.amazingworldtop.com/entretenimiento/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wx7%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f18-05-2019/
http://www.sp1.football/index.php?mid=faq&document_srl=238527
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=64497
https://testing.celekt.com/%d0%a2%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-94-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-%d0%a2%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-94-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://mobility-corp.com/index.php/component/k2/itemlist/user/2629919
http://www.hicleaning.kr/board_wash/83579
http://zanoza.h1n.ru/2019/05/18/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-18-05-2019-f6-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2/
http://shinilspring.com/board_qsfb01/82911
http://skylinecam.co.kr/?document_srl=122573
https://hackersuniversity.net/index.php?topic=19345.0
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1105791
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=26231
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=72616
http://atemshow.com/atemfair_domestic/85760
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=189392
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=189406
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=189416
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=189425
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=189433
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=189463
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=189478
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=76767
http://www.gforgirl.com/xe/poster/111996
http://www.emrabq8.com/index.php/component/k2/itemlist/user/1825018
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=180143
https://testing.celekt.com/%d0%a1%d0%b5%d0%bd%d1%8f%d0%a4%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-n1-%d0%a1%d0%b5%d0%bd%d1%8f%d0%a4%d0%b5%d0%b4%d1%8f-2/
http://emjun.com/?document_srl=90602
http://dev.aabn.org.gh/component/k2/itemlist/user/620489
http://xn--ok1bpqi43ahtb.net/board_eASW07/124980
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=69115
http://skylinecam.co.kr/photo/97274
http://xn----3x5er9r48j7wemud0a387h.com/news/40794
http://hyeonjun.co.kr/menu3/66740
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=99965
http://socialfbwidgets.com/component/k2/itemlist/user/15064.html
https://www.amazingworldtop.com/entretenimiento/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vw7%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be/
https://www.amazingworldtop.com/entretenimiento/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gd9%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5/
http://www.crnmedia.es/component/k2/itemlist/user/87483
http://www.teedinubon.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mw6%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f19-05/
http://photogrotto.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d1%84%d0%b8%d0%bd%d0%b0%d0%bb-kj%d1%85%d0%be%d0%bb%d0%be/
http://www.teedinubon.com/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-86-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-37/
http://bebopindia.com/notcie/120325
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=acc7d2185a019122065a2d15a0ee2527&topic=8078.0
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=132219
http://forum.bmw-e60.eu/index.php?topic=8906.0
https://testing.celekt.com/%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zj4%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5/
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=205881
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=136989
http://forum.bmw-e60.eu/index.php?topic=8816.0
http://153.120.114.241/eso/index.php/17111684-hdvideo-holostak-9-sezon-13-vypusk-q6-holostak-9-sezon-13-vypus
http://dcasociados.eu/component/k2/itemlist/user/89644
http://vhost12299.cpsite.ru/430134-hd-holostak-9-sezon-14-vypusk
http://ovotecegg.com/component/k2/itemlist/user/165087
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=91637
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=85126
http://forum.elexlabs.com/index.php/topic,42048.0.html
https://altaylarteknoloji.com/index.php?topic=5013.0
http://www.hsaura.com/noty/111278
http://zanoza.h1n.ru/2019/05/18/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-17-05-2019-i6-%d0%b8%d0%b3%d1%80/
http://mediaville.me/index.php/component/k2/itemlist/user/293534
https://prelease.club/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jf5d-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-7-%d1%81/
https://reficulcoin.com/index.php?topic=57408.0
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3675266
https://hackersuniversity.net/index.php?topic=19835.0
http://xn--ok1bpqi43ahtb.net/board_eASW07/133471
http://married.dike.gr/index.php/component/k2/itemlist/user/65700
http://xn----3x5er9r48j7wemud0a387h.com/news/62709
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=72502
http://www.digitalbul.com/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://0433.net/junggo/54416
http://thermoplast.envolgroupe.com/component/k2/author/123994
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=876206
http://thermoplast.envolgroupe.com/component/k2/author/120214
http://dev.aabn.org.gh/component/k2/itemlist/user/612355
http://www.teedinubon.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-20-05-2019-x0-%d0%b8%d0%b3%d1%80/
http://shinhwaair2017.cafe24.com/issue/215590
http://universalcommunity.se/Forum/index.php?topic=16968.0
https://testing.celekt.com/%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-17-05-19-ud%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba/
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=109985
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=881507
http://0433.net/junggo/52121
http://lucky.kidspann.net/index.php?mid=qna&document_srl=70004
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1927669
http://matinbank.ir/component/k2/itemlist/user/4557976.html
http://podwodnyswiat.eu/forum/index.php?topic=1351.0
http://xn--ok1bpqi43ahtb.net/board_eASW07/116167
http://emjun.com/?document_srl=86214
http://indiefilm.kr/xe/board/112999
http://indiefilm.kr/xe/?document_srl=155275
http://mediaville.me/index.php/component/k2/itemlist/user/288883
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1737837
http://www.critico-expository.com/forum/index.php?topic=14542.0
http://mediaville.me/index.php/component/k2/itemlist/user/295410
http://skylinecam.co.kr/photo/110865
http://www.hsaura.com/noty/111191
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=89681
http://masanlib.or.kr/g1/33244
http://indiefilm.kr/xe/board/111046
http://www.teedinubon.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yl5%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c/
http://emjun.com/?document_srl=88051
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/51020
http://www.original-craft.net/index.php?topic=335670.0
http://www.svteck.co.kr/?document_srl=44262
http://www.theparrotcentre.com/forum/index.php?topic=554097.0
http://www.hsaura.com/noty/135492
http://skylinecam.co.kr/photo/90048
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=58983
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=175553
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/34628
http://www.josephmaul.org/menu41/121461
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=79380
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=140396
http://zanoza.h1n.ru/2019/05/18/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-90-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ys1%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-90-%d1%81%d0%b5%d1%80%d0%b8%d1%8f18-05-2019/
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=712946.0
http://moavalve.co.kr/?document_srl=83208
http://www.sp1.football/index.php?mid=faq&document_srl=246916
http://photogrotto.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-3/
http://yoriyorifood.com/xxxx/spacial/116947
http://www.teedinubon.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rq5o-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-11/
http://thermoplast.envolgroupe.com/component/k2/author/124648
https://www.c-alice.org/forum/index.php?topic=89112.0
http://photogrotto.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qm7%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5/
https://testing.celekt.com/%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-us1%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5/
http://hyeonjun.co.kr/menu3/67221
http://photogrotto.com/%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-2019-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mz2%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-2019-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=59166
http://hyeonjun.co.kr/menu3/102411
http://carrierworld.co.kr/?document_srl=80917
https://www.amazingworldtop.com/entretenimiento/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-do8%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f18-05-2019/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1444801
http://0433.net/junggo/53456
http://www.theocraticamerica.org/forum/index.php/topic,48198.0.html
https://mcsetup.tk/bbs/index.php?topic=258393.0
http://forum.drahthaar-club.com.ua/index.php?topic=4158.0
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=62600
http://roikjer.com/forum/index.php?topic=893687.0
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/285011
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=102154
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=96920
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1721534
http://webp.online/index.php?topic=63058.0
http://cwon.kr/xe/board_bnSr36/129491
http://www.jesusonly.life/?document_srl=139260
http://www.josephmaul.org/menu41/117257
http://universalcommunity.se/Forum/index.php?topic=16880.0
http://ru-realty.com/forum/index.php?PHPSESSID=mubectl72jn5n0mrl7uipuina7&topic=528572.0
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=198371
http://shinilspring.com/?document_srl=88720
http://www.gforgirl.com/xe/poster/115291
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1733117
http://emjun.com/?document_srl=100478
http://masanlib.or.kr/g1/45594
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=73335
http://ye-dream.com/qa/74565
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1946563
http://skylinecam.co.kr/photo/82789
http://otitismediasociety.org/forum/index.php?topic=175239.0
http://vhost12299.cpsite.ru/529965-holostak-9-sezon-13-vypusk-efir-holostak-9-sezon-13-vypusk
https://cybergsm.es/index.php?topic=33740.0
http://ovotecegg.com/component/k2/itemlist/user/165068
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=33694
http://teambuildingpremium.com/forum/index.php?topic=855281.0
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=105596
http://corumotoanahtar.com/component/k2/itemlist/user/5513
https://hackersuniversity.net/index.php/topic,19124.0.html
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=839944
http://www.teedinubon.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c/
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=79661
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3385464
http://lucky.kidspann.net/index.php?document_srl=75225&mid=qna
http://ptu.imoove.kr/ko/content/%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-11-%D0%B2%D1%8B%D0%BF%D1%83%D1%81%D0%BA-17-05-2019%C2%BB-gu%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-11-%D0%B2%D1%8B%D0%BF%D1%83%D1%81%D0%BA-17-05-2019%C2%BB28-%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA
http://www.teedinubon.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-zd%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81/
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=122500
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/339642
https://testing.celekt.com/%d0%a1%d0%b5%d0%bd%d1%8f%d0%a4%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ao4%d0%a1%d0%b5%d0%bd%d1%8f%d0%a4%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be/
http://xn----3x5er9r48j7wemud0a387h.com/news/37349
http://www.original-craft.net/index.php?topic=335250.0
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=140733
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=60771
https://testing.celekt.com/%d0%a2%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ha9%d0%a2%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f17-05/
http://www.quattroandpartners.it/component/k2/itemlist/user/1181443
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=877032
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=877286
http://www.siirtorganik.com/index.php/component/k2/itemlist/user/877200
http://0433.net/junggo/69554
http://0433.net/junggo/69559
http://0433.net/junggo/69576
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=188767
https://www.shaiyax.com/index.php?topic=352839.0
http://corumotoanahtar.com/component/k2/itemlist/user/5182.html
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=342824
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=68071
http://skylinecam.co.kr/photo/95189
http://www.phperos.net/foro/index.php?topic=136357.0
http://test.comics-game.ru/index.php?topic=183.0
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=80870
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=71490
http://jjikduk.net/DATA/76176
http://www.jesusonly.life/calendar/124570
http://zanoza.h1n.ru/2019/05/19/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-po2%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f18-05/
http://www.gforgirl.com/xe/poster/142153
http://masanlib.or.kr/g1/31900
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/340364
https://sanp.pro/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-we1%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f20-05/
http://www.josephmaul.org/?document_srl=139433
http://mobility-corp.com/index.php/component/k2/itemlist/user/2619965
http://asin.itts.co.kr/board_rtXs84/10413
http://xn----3x5er9r48j7wemud0a387h.com/news/43524
http://teambuildingpremium.com/forum/index.php?topic=860468.0
http://atemshow.com/atemfair_domestic/62006
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=33120
http://emjun.com/index.php?mid=hangtotal&document_srl=96054
http://zanoza.h1n.ru/2019/05/20/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-94-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-20-05-2019-n4-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-94-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://thanosakademi.com/index.php?topic=97440.0
https://mcsetup.tk/bbs/index.php?topic=257606.0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/116253
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/349487
http://arnikabolt.ro/component/k2/itemlist/user/111994
http://skylinecam.co.kr/photo/90169
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=57093
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=132672
http://research.kiu.ac.kr/?document_srl=73792
http://www.firstfinancialservices.co.uk/?option=com_k2&view=itemlist&task=user&id=13738
http://forum.bmw-e60.eu/index.php?topic=9111.0
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=113287
https://forum.ac-jete.it/index.php?topic=403290.0
http://photogrotto.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gs5%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=512183
http://shinilspring.com/board_qsfb01/95998
http://otitismediasociety.org/forum/index.php?topic=181127.0
https://testing.celekt.com/%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-24-05-2019-lw%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
http://www.sp1.football/index.php?document_srl=192836&mid=faq
http://cwon.kr/xe/board_bnSr36/61589
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/339397
http://zanoza.h1n.ru/2019/05/19/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-83-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zg0/
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=84161
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=92260
http://www.crnmedia.es/component/k2/itemlist/user/87522
https://testing.celekt.com/%d0%a1%d0%b5%d0%bd%d1%8f%d0%a4%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%9d%d0%9e%d0%92%d0%98%d0%9d%d0%9a%d0%90-%d0%a1%d0%b5%d0%bd-2/
http://dev.aabn.org.gh/component/k2/itemlist/user/618645
http://zanoza.h1n.ru/2019/05/21/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gm7%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f21-05-2019/
http://xn--ok1bpqi43ahtb.net/board_eASW07/122632
http://xn----3x5er9r48j7wemud0a387h.com/news/35358
http://www.boutique.in.th/?option=com_k2&view=itemlist&task=user&id=151543
https://prelease.club/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-24-05-2019-us%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
http://zanoza.h1n.ru/2019/05/18/%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fo2%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd/
http://asin.itts.co.kr/board_rtXs84/11881
http://mediaville.me/index.php/component/k2/itemlist/user/291902
http://zanoza.h1n.ru/2019/05/20/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-17-05-19-cf%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba/
http://laspoltrina.it/component/k2/itemlist/user/1449175
https://testing.celekt.com/%d0%9c%d0%b0%d0%bc%d0%b0-%d0%9b%d0%be%d1%80%d0%b0-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qh5d-%d0%9c%d0%b0%d0%bc%d0%b0-%d0%9b%d0%be%d1%80%d0%b0-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://www.amazingworldtop.com/entretenimiento/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-of9%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be/
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1613732
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=341794
http://0433.net/junggo/55897
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=68584
http://skylinecam.co.kr/photo/118744
http://www.josephmaul.org/?document_srl=110094
http://shinilspring.com/board_qsfb01/95706
http://yeonsen.com/?document_srl=66689
http://www.hsaura.com/?document_srl=135832
http://www.critico-expository.com/forum/index.php?topic=13576.0
http://zanoza.h1n.ru/2019/05/19/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nw7%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5/
http://www.digitalbul.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-24-05-2019-nl%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
http://photogrotto.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%85%d0%be/
http://www.critico-expository.com/forum/index.php?topic=13664.0
http://www.golden-nail.co.kr/press/80270
http://forum.3d-printer.top/index.php?topic=1521.0
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=205373
http://0433.net/junggo/50962
http://jjikduk.net/DATA/65241
http://forum.elexlabs.com/index.php?topic=46637.0
http://forum.drahthaar-club.com.ua/index.php?topic=3512.0
http://www.sp1.football/index.php?mid=faq&document_srl=260317
http://www.critico-expository.com/forum/index.php?topic=13691.0
http://cwon.kr/xe/board_bnSr36/99529
http://bebopindia.com/notcie/153846
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=30513
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/227400
http://photogrotto.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-89-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pu1%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-89-%d1%81%d0%b5%d1%80%d0%b8%d1%8f19-05-2019/
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=35293
http://atemshow.com/atemfair_domestic/48957
http://emjun.com/index.php?mid=hangtotal&document_srl=105146
https://testing.celekt.com/%d0%a2%d0%b0%d0%b9%d0%bd%d1%8b-%d0%a2%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-98-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%a1%d0%9c%d0%9e%d0%a2%d0%a0%d0%95%d0%a2%d0%ac-%d0%a2%d0%b0/
http://skylinecam.co.kr/photo/127926
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=e29f8639c13569529391288f6fdd288e&topic=8404.0
http://jjikduk.net/DATA/74039
http://lucky.kidspann.net/index.php?document_srl=66616&mid=qna
http://otitismediasociety.org/forum/index.php?topic=174592.0
http://mediaville.me/index.php/component/k2/itemlist/user/285090
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2779066
http://emjun.com/index.php?mid=hangtotal&document_srl=108519
http://bitpark.co.kr/?document_srl=4028917
http://lucky.kidspann.net/?document_srl=60670
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3825440
http://www.sp1.football/index.php?mid=faq&document_srl=209027
http://bitpark.co.kr/board_IzjM66/4059087
https://sto54.ru/index.php/component/k2/itemlist/user/3408603
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3828409
http://mediaville.me/index.php/component/k2/itemlist/user/293937
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=34437
http://www2.yasothon.go.th/smf/index.php?topic=159.166695
http://zanoza.h1n.ru/2019/05/20/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-th6%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be/
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=51614
http://forum.santrope-rp.ru/index.php?action=profile;u=8466
http://www.teedinubon.com/%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xu3%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd/
http://www.critico-expository.com/forum/index.php?topic=13689.0
http://hyeonjun.co.kr/menu3/86297
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=72888
http://shinilspring.com/board_qsfb01/94149
https://khuyenmaikk13.info/index.php?topic=207861.0
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=65172
http://otitismediasociety.org/forum/index.php?topic=174724.0
https://sanp.pro/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-85-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cn6/
https://mcsetup.tk/bbs/index.php?topic=256232.0
http://www.crnmedia.es/component/k2/itemlist/user/87187
http://www.gforgirl.com/xe/poster/137238
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=35675
http://fbpharm.net/index.php/component/k2/itemlist/user/56924
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=846153
http://www.teedinubon.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-24-05-2019-sq%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-24-05-201918-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-24/
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=330936
http://www.sp1.football/index.php?mid=faq&document_srl=183872
http://atemshow.com/atemfair_domestic/60298
http://esperanzazubieta.com/component/k2/itemlist/user/101305
http://www.teedinubon.com/%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-20-05-2019-w7-%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4/
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=36761
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3402936
http://jiquilisco.org/index.php/component/k2/itemlist/user/9227
http://www.theparrotcentre.com/forum/index.php?topic=547751.0
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4960759
http://zanoza.h1n.ru/2019/05/20/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ii9%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5/
https://reficulcoin.com/index.php?topic=53636.0
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=270026
http://indiefilm.kr/xe/board/157445
http://zanoza.h1n.ru/2019/05/18/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d1%84%d0%b8%d0%bd%d0%b0%d0%bb-gb%d1%85%d0%be%d0%bb%d0%be/
https://khuyenmaikk13.info/index.php?topic=207257.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=c419da89a667df44d3de0ac1a389828d&topic=261560.0
http://lucky.kidspann.net/index.php?mid=qna&document_srl=88923
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=87716
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/278396
http://www.theparrotcentre.com/forum/index.php?topic=548710.0
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=85094
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=82121
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=205778
http://ye-dream.com/qa/72303
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=71100
http://thermoplast.envolgroupe.com/component/k2/author/123217
http://skylinecam.co.kr/photo/119525
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=80163
https://mcsetup.tk/bbs/index.php?topic=256005.0
http://emjun.com/index.php?mid=hangtotal&document_srl=95808
http://photogrotto.com/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vb6%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f20-05-2019/
http://www.sp1.football/index.php?mid=tr_video&document_srl=221688
http://bebopindia.com/notcie/162430
http://dohairbiz.com/en/?option=com_k2&view=itemlist&task=user&id=2760628
https://testing.celekt.com/%d0%9f%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vh3%d0%9f%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd/
https://adsensebih.com/index.php?topic=27387.0
http://thanosakademi.com/index.php?topic=97215.0
http://taklongclub.com/forum/index.php?topic=159257.0
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=201784
http://www.sp1.football/index.php?document_srl=235165&mid=faq
http://yoriyorifood.com/xxxx/?document_srl=74516
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=111888
http://indiefilm.kr/xe/board/156606
http://lucky.kidspann.net/?document_srl=80241
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=13823
http://www.golden-nail.co.kr/press/94374
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=61606
http://www.ds712.net/guest/?document_srl=176296
http://www.jesusonly.life/calendar/129262
http://photogrotto.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hi3%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-14-%d1%81%d0%b5/
https://emoforum.org/discussion/3236/bogatye-i-bednye-zengin-ve-yoksul-7-seriya-usab-bogatye-i-bednye-zengin-ve-yoksul-7-seriya
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=55078
https://reficulcoin.com/index.php?topic=54606.0
http://www.jesusonly.life/calendar/122062
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=75660
http://jjimdak.callbank.kr/?document_srl=870506
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=3729
http://hyeonjun.co.kr/?document_srl=74410
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=608246
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3309817
http://teambuildingpremium.com/forum/index.php?topic=843771.0
http://forum.elexlabs.com/index.php?topic=37803.0
http://oss.obigo.com/oss/index.php?mid=board_mxLS91&document_srl=22319
http://www.theocraticamerica.org/forum/index.php?topic=55942.0
http://www.jesusonly.life/calendar/124325
http://www.sp1.football/index.php?mid=tr_video&document_srl=215991
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=83060
http://research.kiu.ac.kr/?document_srl=60622
http://mobility-corp.com/index.php/component/k2/itemlist/user/2655955
http://proxima.co.rw/index.php/component/k2/itemlist/user/668417
http://rudraautomation.com/index.php/component/k2/author/249185
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1725126
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1761779
http://thermoplast.envolgroupe.com/component/k2/author/137445
http://w9builders.co.uk/index.php/component/k2/itemlist/user/94371
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3713867
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=16471
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4862028
http://www.sp1.football/index.php?mid=faq&document_srl=242091
http://yoriyorifood.com/xxxx/spacial/91525
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=178676
http://e-educ.net/Forum/index.php?topic=12090.0
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=180861
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=37985
http://indiefilm.kr/xe/board/112425
http://universalcommunity.se/Forum/index.php?topic=15785.0
http://thanosakademi.com/index.php?topic=95896.0
http://www.telcon.gr/index.php/component/k2/itemlist/user/72817
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=25500
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=53979
http://www.hsaura.com/noty/157493
https://khuyenmaikk13.info/index.php?topic=207090.0
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1659624
https://testing.celekt.com/%d0%9f%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-18-05-2019-s3-%d0%9f%d0%be%d1%81%d0%bb%d0%b5%d0%b4/
http://xn--9m1b83j39hz6exwonmf.com/board_IYPe43/525787
http://skylinecam.co.kr/photo/124707
http://yoriyorifood.com/xxxx/spacial/113474
https://altaylarteknoloji.com/index.php?topic=5288.0
http://www.studyxray.com/Sangdam/193419
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=80013
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=62746
http://mobility-corp.com/index.php/component/k2/itemlist/user/2635978
http://photogrotto.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-vn%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81/
http://emjun.com/index.php?mid=hangtotal&document_srl=83834
http://www.theparrotcentre.com/forum/index.php?topic=556519.0
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-po6%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://www.teedinubon.com/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-m7-%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-14-%d1%81%d0%b5%d1%80%d0%b8/
http://cwon.kr/xe/board_bnSr36/104282
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=521822
https://testing.celekt.com/%d0%9c%d0%b0%d0%bc%d0%b0-%d0%9b%d0%be%d1%80%d0%b0-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-live-%d0%9c%d0%b0%d0%bc%d0%b0-%d0%9b%d0%be%d1%80%d0%b0-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://testing.celekt.com/%d0%9f%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%ad%d0%a4%d0%98%d0%a0-%d0%9f%d0%be%d1%81/
http://www.teedinubon.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-24-05-2019-bz%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2531687
http://community.viajar.tur.br/index.php?p=/profile/daciabuzac
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=35472.0
http://rudraautomation.com/index.php/component/k2/author/217013
https://sanp.pro/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-au6%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7/
http://www.m1avio.com/index.php/component/k2/itemlist/user/3729617
http://www.hicleaning.kr/board_wash/91168
http://www.tessabannampad.go.th/webboard/index.php?topic=213523.0
https://sanp.pro/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-96-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gr0%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-96-%d1%81%d0%b5%d1%80%d0%b8%d1%8f19-05-2019/
http://forum.elexlabs.com/index.php?topic=46668.0
http://zanoza.h1n.ru/2019/05/20/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-20-05-2019-d9-%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1948894
http://xn--ok1bpqi43ahtb.net/board_eASW07/103044
http://www.studyxray.com/Sangdam/104002
http://photogrotto.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-17-05-2019-uh%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=4297
http://discussbitcoin.org/index.php?action=profile;u=140735
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=24438
http://zanoza.h1n.ru/2019/05/21/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zo0%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f20-05-2019/
http://www.josephmaul.org/menu41/103863
http://corumotoanahtar.com/component/k2/itemlist/user/5019.html
http://d-tube.info/board_jvyO69/302577
http://d-tube.info/board_jvyO69/302612
http://d-tube.info/board_jvyO69/302624
http://gallerychoi.com/Exhibition/210582
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=133601
http://xn--ok1bpqi43ahtb.net/board_EkDG82/146538
http://www.rationalkorea.com/xe/?document_srl=528532
https://www.vegasgreentour.com/?document_srl=98569
http://yoriyorifood.com/xxxx/spacial/102897
http://vhost12299.cpsite.ru/478756-senafeda-2-sezon-9-seria-18052019-e1-senafeda-2-sezon-9-seria
http://www.hsaura.com/noty/132028
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=88216
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=89035
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=713053.0
http://subforumna.x10.mx/mad/index.php?topic=256983.0
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/277881
http://skylinecam.co.kr/photo/83588
http://www.dap.com.py/index.php/component/k2/itemlist/user/823931
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile;u=38752
http://community.viajar.tur.br/index.php?p=/discussion/61229/vetrenyy-hercai-16-seriya-iieo-vetrenyy-hercai-16-seriya
http://forum.elexlabs.com/index.php?topic=46744.0
http://moavalve.co.kr/faq/63844
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=88708
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=28870
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=28875
http://www.siheunglove.com/chulip/127445
http://www.siheunglove.com/chulip/127488
http://www.siheunglove.com/chulip/127511
http://www.siheunglove.com/chulip/127519
http://www.studyxray.com/Sangdam/236144
http://www.youngfile.com/?document_srl=53741
http://www.youngfile.com/?document_srl=53745
http://www.youngfile.com/?document_srl=53796
http://www.youngfile.com/?document_srl=53805
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/16110
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=269968
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=270142
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=270169
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=270180
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=270196
http://dev.aabn.org.gh/component/k2/itemlist/user/643079
http://dev.fivestarpainting.com/?option=com_k2&view=itemlist&task=user&id=1964159
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1964163
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=103163
http://e-educ.net/Forum/index.php?topic=12399.0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/115965
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=74573
http://www.critico-expository.com/forum/index.php?topic=14387.0
http://hyeonjun.co.kr/menu3/90570
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3298324
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=336599
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=646087
https://khuyenmaikk13.info/index.php?topic=206902.0
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=6711
http://0433.net/junggo/44122
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=535790
http://thanosakademi.com/index.php?topic=95917.0
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1924883
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=87842
http://smartacity.com/component/k2/itemlist/user/59267
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=90249
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=865420
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=64750
http://fbpharm.net/index.php/component/k2/itemlist/user/51773
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=84929
http://corumotoanahtar.com/component/k2/itemlist/user/5141.html
http://matrixpharm.ru/forum/index.php?action=profile&u=199674
http://zanoza.h1n.ru/2019/05/19/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fm8%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f18-05-2019/
http://lucky.kidspann.net/index.php?document_srl=62668&mid=qna
http://jjikduk.net/DATA/135304
http://jjikduk.net/DATA/135341
http://k-cea.org/board_Hnyj62/146618
http://lucky.kidspann.net/index.php?mid=qna&document_srl=219776
http://nanaae.com/confirm/16572
http://photogrotto.com/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yv0%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%87%d0%b5%d1%80%d0%bd/
http://photogrotto.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ug6%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://photogrotto.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ao4%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://photogrotto.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kw7%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://photogrotto.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ob5%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://photogrotto.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ru4%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://photogrotto.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ax6%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://photogrotto.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bx3%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://photogrotto.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pi6%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://photogrotto.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-100-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xy2%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-1/
http://photogrotto.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-96-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vc2%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-96/
http://photogrotto.com/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-100-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-os1%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-100-%d1%81%d0%b5%d1%80%d0%b8%d1%8f22-05-2019/
http://photogrotto.com/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-97-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vl4%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-97-%d1%81%d0%b5%d1%80%d0%b8%d1%8f22-05-2019/
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=645882
http://www.sp1.football/index.php?mid=faq&document_srl=250118
http://www.hicleaning.kr/board_wash/114965
http://shinilspring.com/board_qsfb01/110495
http://atemshow.com/atemfair_domestic/60001
http://corumotoanahtar.com/index.php/component/k2/itemlist/user/4209
http://topitop.kz/?option=com_k2&view=itemlist&task=user&id=77218
http://zanoza.h1n.ru/2019/05/18/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vz9%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be/
http://0433.net/junggo/37644
https://prelease.club/%d0%ba%d0%bb%d1%8f%d1%82%d0%b2%d0%b0-yemin-60-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-eejq-%d0%ba%d0%bb%d1%8f%d1%82%d0%b2%d0%b0-yemin-60-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://0433.net/junggo/48125
http://rudraautomation.com/index.php/component/k2/author/219593
http://adsudoeste.com.br/?option=com_k2&view=itemlist&task=user&id=22134
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=59378
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4833993
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=59063
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=851628
http://indiefilm.kr/xe/board/169212
https://adsensebih.com/index.php?topic=28486.0
http://www.teedinubon.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81/
https://tg.vl-mp.com/index.php?topic=1470279.0
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=527586
https://test.baseyou21.kr/index.php?mid=main_slider&document_srl=97973
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nl5%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://hyeonjun.co.kr/menu3/89398
https://prelease.club/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-17-05-19-hy%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba/
http://www.hicleaning.kr/board_wash/87243
http://rotary-laeliana.org/component/k2/itemlist/user/51884
http://indiefilm.kr/xe/board/118138
http://asin.itts.co.kr/board_rtXs84/18425
http://forum.digamahost.com/index.php?topic=128116.0
https://www.amazingworldtop.com/entretenimiento/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mt5%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f17-05/
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=271206
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=95790
http://udrpsucks.com/blog/?p=986
http://otitismediasociety.org/forum/index.php?topic=185760.0
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=76608
http://www.sp1.football/index.php?mid=faq&document_srl=233978
http://www.gforgirl.com/xe/poster/126010
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=890971
http://immobilia.gr/index.php/de/component/k2/itemlist/user/16472
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=83866
http://shinilspring.com/board_qsfb01/95727
http://www.jesusonly.life/calendar/126230
http://yoriyorifood.com/xxxx/spacial/96109
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=81102
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=348329
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=84585
http://ariji.kr/?document_srl=852388
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3499473
http://www.remify.app/foro/index.php?topic=320158.0
http://xn--ok1bpqi43ahtb.net/board_eASW07/122554
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/338390
http://0433.net/junggo/40491
http://indiefilm.kr/xe/board/152781
http://jjikduk.net/DATA/89874
http://www.pdctransport.co.th/index.php/component/k2/itemlist/user/16136
http://dessa.com.br/component/k2/itemlist/user/342161
http://forum.digamahost.com/index.php?topic=126983.0
https://prelease.club/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d1%84%d0%b8%d0%bd%d0%b0%d0%bb-to%d1%85%d0%be%d0%bb%d0%be/
http://skylinecam.co.kr/photo/78514
http://mediaville.me/index.php/component/k2/itemlist/user/284159
http://vhost12299.cpsite.ru/553564-v-efire-tajny-88-seria-v3-tajny-88-seria
http://withinfp.sakura.ne.jp/eso/index.php/17365877-efir-igra-prestolov-got-8-sezon-7-seria/0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1470605
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/354090
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/300263
https://cfcestradareal.com.br/component/k2/itemlist/user/56805
https://prelease.club/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-un9y-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://www.critico-expository.com/forum/index.php?topic=14376.0
http://xn--ok1bpqi43ahtb.net/board_EkDG82/160407
http://dcasociados.eu/component/k2/itemlist/user/89949
http://xn--ok1bpqi43ahtb.net/board_eASW07/102301
http://lucky.kidspann.net/index.php?mid=qna&document_srl=60931
http://www.hsaura.com/noty/127956
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/341487
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=83465
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=16273
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=584622
http://www.hsaura.com/noty/121467
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=95989
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=585405
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3330087
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3330100
http://xn----3x5er9r48j7wemud0a387h.com/news/78052
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=176543
https://esel.gist.ac.kr/esel2/board_hmgj23/140606
https://esel.gist.ac.kr/esel2/board_hmgj23/140716
https://esel.gist.ac.kr/esel2/board_hmgj23/140763
https://www.vegasgreentour.com/index.php?document_srl=265159&mid=board_XiHh59
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=265338
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=265393
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=265416
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=621904
http://skylinecam.co.kr/photo/82883
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/277747
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=853402
http://maka-222.com/index.php?document_srl=31330&mid=board_hcFa40
http://indiefilm.kr/xe/board/128904
http://mobility-corp.com/index.php/component/k2/itemlist/user/2616800
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/271409
http://www.phperos.net/foro/index.php?topic=136389.0
http://webp.online/index.php?topic=59475.15
http://www.digitalbul.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-video-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2/
http://miklja.net/forum/index.php?topic=31582.0
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=111670
http://yoriyorifood.com/xxxx/spacial/101089
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=58526
http://zanoza.h1n.ru/2019/05/20/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-a9-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7/
http://zanoza.h1n.ru/2019/05/19/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-91-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-af2%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-91-%d1%81%d0%b5%d1%80%d0%b8%d1%8f19-05-2019/
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=69817
http://www.josephmaul.org/menu41/122899
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1615492
http://www.gforgirl.com/xe/poster/114881
https://www.amazingworldtop.com/entretenimiento/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vg4%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f19-05-2019/
http://research.kiu.ac.kr/index.php?document_srl=75296&mid=Food4Thought
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3404769
http://www.hicleaning.kr/board_wash/133291
http://forum.digamahost.com/index.php?topic=125836.0
http://www.sp1.football/?document_srl=260016
http://shinhwaair2017.cafe24.com/issue/341496
http://shinhwaair2017.cafe24.com/issue/341501
http://www.ekemoon.com/226357/050820193022/
http://www.ekemoon.com/226395/050820194922/
http://www.hicleaning.kr/board_wash/173018
http://www.hicleaning.kr/board_wash/173061
http://bebopindia.com/notcie/111449
http://xn--9m1b83j39hz6exwonmf.com/board_IYPe43/519308
http://www.original-craft.net/index.php?topic=340232.0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4839348
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3673795
http://forum.digamahost.com/index.php?topic=129663.0
http://www.gforgirl.com/xe/poster/139782
https://www.amazingworldtop.com/entretenimiento/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-85-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gm5/
http://khapthanam.co.kr/g1/95180
http://khapthanam.co.kr/g1/95223
http://koais.com/data/94542
http://koais.com/data/94606
http://kyj1225.godohosting.com/board_mebR72/37461
http://kyj1225.godohosting.com/board_mebR72/37477
http://kyj1225.godohosting.com/board_mebR72/37493
http://laokorea.com/orange_menu1/95334
http://laokorea.com/orange_menu1/95408
http://lucky.kidspann.net/index.php?mid=qna&document_srl=218664
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=39392
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=39401
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=39431
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=39446
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=39495
http://www.original-craft.net/index.php?topic=352897.0
http://www.original-craft.net/index.php?topic=352902.0
http://www.siheunglove.com/chulip/142517
http://www.siheunglove.com/chulip/142544
http://www.siheunglove.com/chulip/142592
http://k-cea.org/board_Hnyj62/125827
http://k-cea.org/board_Hnyj62/125851
http://k-cea.org/board_Hnyj62/125889
http://photogrotto.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-23-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-u7-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
http://www.teedinubon.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-d4-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
http://www.teedinubon.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-k9-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80/
https://www.2ayes.com/18650/istanbullu-gelin-2-85-22-05-2019-k5-istanbullu-gelin-2-85
https://www.2ayes.com/18652/8-3-22-05-2019-m7-8-3
https://www.2ayes.com/18653/3-22-22-05-2019-j4-3-22
https://www.celekt.com/%d0%91%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-i5-%d0%91%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd/
https://www.celekt.com/%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-q7-%d0%98%d0%b3%d1%80/
https://www.celekt.com/%d0%9f%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-21-05-2019-z6-%d0%9f%d0%be%d1%81%d0%bb%d0%b5%d0%b4/
https://www.celekt.com/%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-21-05-2019-m8-%d0%a1%d0%bb%d1%83%d0%b3%d0%b0/
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=103239
http://www.youngfile.com/?document_srl=56832
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=169584
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=169809
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/20690
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/16650
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/?document_srl=5837
http://xn----c28ewjj6ubwku6frtcuzec29ae5b.kr/news/29450
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/news/35927
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/news/35961
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/news/35972
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/28433
http://www.jshwanghoan.com/index.php?document_srl=204945&mid=qna
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=205152
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=205176
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=205206
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=15365
http://www.original-craft.net/index.php?topic=348947.0
http://www.original-craft.net/index.php?topic=348957.0
http://www.studyxray.com/Sangdam/228307
http://k-cea.org/?document_srl=123260
http://marjorieaperry.com/?option=com_k2&view=itemlist&task=user&id=500619
http://ovotecegg.com/component/k2/itemlist/user/183525
http://photogrotto.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-w7-%d0%b8%d0%b3%d1%80/
http://photogrotto.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-d6-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80/
http://smartacity.com/component/k2/itemlist/user/65846
http://smartacity.com/component/k2/itemlist/user/65866
http://www.teedinubon.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-f6-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd/
http://www.teedinubon.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-j2-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2/
http://www.teedinubon.com/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-101-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-m0-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-101-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://zanoza.h1n.ru/2019/05/22/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-85-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-38/
http://zanoza.h1n.ru/2019/05/22/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-q7-%d1%81%d0%bb%d1%83%d0%b3/
http://zanoza.h1n.ru/2019/05/22/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-22-05-2019-e5-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
https://gonggamlaw.com/lawcase/19711
https://hackinsa.com/freeboard/3617
https://sanp.pro/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-ct%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81/
https://www.celekt.com/%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-24-05-19-dg%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba/
https://www.celekt.com/%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-gx%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81/
https://www.celekt.com/%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-ob%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81/
https://www.chirorg.com/?document_srl=84481
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tp0%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=139810
http://askpharm.net/?document_srl=92594
http://fbpharm.net/index.php/component/k2/itemlist/user/72065
http://gabisan.com/?document_srl=6157
http://gabisan.com/board_OuDs04/6046
http://www.hicleaning.kr/board_wash/173260
http://www.josephmaul.org/menu41/225900
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=189285
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=189342
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=189415
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=189461
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=590082
http://www.taeshinmedia.com/index.php?document_srl=3330697&mid=genealogy_faq
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=177902
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=177951
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=177957
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/gumdanapt/177760
http://yoriyorifood.com/xxxx/spacial/165258
http://zanoza.h1n.ru/2019/05/22/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-z3-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80/
http://zanoza.h1n.ru/2019/05/22/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-y8-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5/
https://testing.celekt.com/%d0%91%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-21-05-2019-k5-%d0%91%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd/
https://testing.celekt.com/%d0%91%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-21-05-2019-n8-%d0%91%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd/
https://testing.celekt.com/%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-21-05-2019-y7-%d0%98%d0%b3%d1%80/
https://testing.celekt.com/%d0%9c%d0%b0%d0%bc%d0%b0-%d0%9b%d0%be%d1%80%d0%b0-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-21-05-2019-h7-%d0%9c%d0%b0%d0%bc%d0%b0-%d0%9b%d0%be%d1%80%d0%b0-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://testing.celekt.com/%d0%9f%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-21-05-2019-m7-%d0%9f%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd/
https://testing.celekt.com/%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-21-05-2019-v5-%d0%a1%d0%bb%d1%83%d0%b3%d0%b0/
https://testing.celekt.com/%d0%a2%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-94-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-21-05-2019-i8-%d0%a2%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-94-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://www.2ayes.com/18680/13-22-05-2019-k3-13
https://www.celekt.com/%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-21-05-2019-o6-%d0%98%d0%b3%d1%80/
http://soc-human.kz/index.php/component/k2/itemlist/user/1737810
http://photogrotto.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-24-05-2019-y0-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
http://jnk-ent.jp/index.php?mid=gallery&document_srl=221743
http://www.hyunjindc.com/qna/69489
http://www.hyunjindc.com/qna/93786
http://www.ekemoon.com/230253/051620193023/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3414897
http://themasters.pro/file_01/205951
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=143228
http://rudraautomation.com/index.php/component/k2/author/267255
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3427640
http://zanoza.h1n.ru/2019/05/22/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ux1%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5/
http://www.hyunjindc.com/qna/66780
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1254173
http://mvisage.sk/index.php/component/k2/itemlist/user/119318
http://netsconsults.com/?option=com_k2&view=itemlist&task=user&id=810507
http://vhost12299.cpsite.ru/556988-smotret-sluga-naroda-3-sezon-7-seria-t6-sluga-naroda-3-sezon-7-
http://vhost12299.cpsite.ru/557099-efir-taemnici-100-seria-b4-taemnici-100-seria
http://vhost12299.cpsite.ru/557102-hdvideo-dockimateri-dockimateri-17-seria-y8-dockimateri-dockima
http://vhost12299.cpsite.ru/557160-smotret-smers-2-seria-a5-smers-2-seria
http://mvisage.sk/?option=com_k2&view=itemlist&task=user&id=119075
https://altaylarteknoloji.com/index.php?topic=4836.0
http://www.sp1.football/index.php?document_srl=205973&mid=faq
http://www.digitalbul.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-17-05-19-ib%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3390622
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=192623
http://sfah.ch/de/component/k2/itemlist/user/15267
https://esel.gist.ac.kr/esel2/board_hmgj23/67607
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3773991
http://www.jesusonly.life/calendar/157608
https://ne-kuru.ru/index.php?topic=222258.0
http://dev.fivestarpainting.com/?option=com_k2&view=itemlist&task=user&id=1941025
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=119253
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=119266
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=119276
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=119281
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=119289
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=119300
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=119310
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=119314
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=119334
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=339743
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=339757
https://www.amazingworldtop.com/entretenimiento/%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ty4%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3398834
http://www.crnmedia.es/component/k2/itemlist/user/87165
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=25513
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=5588
https://www.vegasgreentour.com/?document_srl=106682
http://www.crnmedia.es/component/k2/itemlist/user/86936
http://corumotoanahtar.com/component/k2/itemlist/user/4056.html
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1708032
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/261586
http://bebopindia.com/notcie/109152
http://www.comfybigsize.com/?option=com_k2&view=itemlist&task=user&id=35249
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=111496
http://photogrotto.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-97-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xl6%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-97/
http://vhost12299.cpsite.ru/427184-serial-cuzaa-zizn-cuze-zitta-10-seria
http://ptu.imoove.kr/ko/content/%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-11-%D0%B2%D1%8B%D0%BF%D1%83%D1%81%D0%BA%C2%BB-ny%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-11-%D0%B2%D1%8B%D0%BF%D1%83%D1%81%D0%BA%C2%BB15-%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-11
http://www.teedinubon.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yr9%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5/
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2622361
http://shinilspring.com/board_qsfb01/92664
https://www.c-alice.org/forum/index.php?topic=89513.0
http://sunele.co.kr/board_ReBD97/103338
http://smartacity.com/component/k2/itemlist/user/64779
http://thermoplast.envolgroupe.com/component/k2/author/142104
http://jejucctv.co.kr/A5/42907
http://koais.com/data/99810
http://www.lucian.co.kr/in/15574
http://vtservices85.fr/smf2/index.php?PHPSESSID=b88a8212a4ab51088091a831068403ab&topic=273680.0
https://sanp.pro/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-xi%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81/
http://www.original-craft.net/index.php?topic=356505.0
http://www.itosm.com/cn/board_nLoq17/120229
http://www.critico-expository.com/forum/index.php?topic=16335.0
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=585107
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=585122
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=585132
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=585166
http://www.studyxray.com/Sangdam/208616
http://www.studyxray.com/Sangdam/208678
http://www.studyxray.com/Sangdam/208828
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3327519
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3327546
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3327577
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3327587
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3327597
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=81980
http://lucky.kidspann.net/index.php?document_srl=74205&mid=qna
https://testing.celekt.com/%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tb9%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://vhost12299.cpsite.ru/442129-taemnici-95-seria-18052019-h6-taemnici-95-seria
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=139002
http://zanoza.h1n.ru/2019/05/21/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-90-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wv8%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-90-%d1%81%d0%b5%d1%80%d0%b8%d1%8f20-05-2019/
http://test.comics-game.ru/index.php?topic=101.0
http://www.ds712.net/guest/?document_srl=151860
http://lucky.kidspann.net/index.php?document_srl=73773&mid=qna
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/222962
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=80140
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=133016
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2717356
http://xn--2e0b53df5ag1c804aphl.net/nuguna/72940
http://www.quattroandpartners.it/component/k2/itemlist/user/1184351
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=182926
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=669314
http://jjikduk.net/DATA/115865
http://lucky.kidspann.net/index.php?mid=qna&document_srl=162685
http://lucky.kidspann.net/index.php?mid=qna&document_srl=162792
http://lucky.kidspann.net/index.php?mid=qna&document_srl=162865
http://lucky.kidspann.net/index.php?mid=qna&document_srl=162945
http://shinhwaair2017.cafe24.com/issue/329217
http://shinhwaair2017.cafe24.com/issue/329309
http://shinhwaair2017.cafe24.com/issue/329314
http://shinhwaair2017.cafe24.com/issue/329361
http://shinhwaair2017.cafe24.com/issue/329414
http://shinhwaair2017.cafe24.com/issue/329456
http://www.critico-expository.com/forum/index.php?topic=15558.0
http://www.ekemoon.com/225719/050320190722/
http://www.studyxray.com/Sangdam/182809
http://www.theparrotcentre.com/forum/index.php?topic=567663.0
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=79756
http://xn--ok1bpqi43ahtb.net/board_eASW07/133547
https://testing.celekt.com/%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fb5%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5/
http://roikjer.com/forum/index.php?PHPSESSID=emb53g7lstrpllauh88di2ner7&topic=892631.0
http://www.gforgirl.com/xe/poster/144196
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/344178
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3381624
http://mir3sea.com/forum/index.php?topic=3728.0
http://www.hsaura.com/noty/157296
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1963571
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=619369
http://2872870.com/est/39632
http://callman.co.kr/index.php?mid=qa&document_srl=145895
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=172422
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=172428
http://yoriyorifood.com/xxxx/?document_srl=161721
http://yoriyorifood.com/xxxx/spacial/161674
http://yoriyorifood.com/xxxx/spacial/161750
http://yoriyorifood.com/xxxx/spacial/161804
http://yoriyorifood.com/xxxx/spacial/161819
http://yoriyorifood.com/xxxx/spacial/161840
http://mobility-corp.com/index.php/component/k2/itemlist/user/2655424
http://moyakmermer.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=781896
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/782017
http://ovotecegg.com/component/k2/itemlist/user/180390
http://ovotecegg.com/component/k2/itemlist/user/180399
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/280019
http://proxima.co.rw/index.php/component/k2/itemlist/user/667914
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3514533
http://k-cea.org/board_Hnyj62/125120
http://sofficer.net/xe/teach/254361
http://otitismediasociety.org/forum/index.php?topic=196506.0
http://atemshow.com/atemfair_domestic/162495
http://laokorea.com/orange_menu1/99664
http://ganchuk.kiev.ua/?option=com_k2&view=itemlist&task=user&id=1227753
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=40418
http://moyakmermer.com/index.php/component/k2/itemlist/user/792580
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=590908
http://matinbank.ir/?option=com_k2&view=itemlist&task=user&id=4578262
http://matinbank.ir/component/k2/itemlist/user/4578227.html
http://netsconsults.com/?option=com_k2&view=itemlist&task=user&id=816347
http://withinfp.sakura.ne.jp/eso/index.php/17483495-novinka-mama-lora-16-seria-i4-mama-lora-16-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/17483556-sluga-naroda-3-sezon-4-seria-s8-sluga-naroda-3-sezon-4-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/17483827-v-efire-senafeda-2-sezon-12-seria-c4-senafeda-2-sezon-12-seria/0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/240049
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/240267
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/65053
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/65081
http://1600-1590.com/?document_srl=313408
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=313313
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=313351
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=313362
http://beautypouch.net/index.php?mid=board_09&document_srl=67071
http://beautypouch.net/index.php?mid=board_09&document_srl=67089
http://beautypouch.net/index.php?mid=board_09&document_srl=67108
http://bebopindia.com/notcie/321039
http://bebopindia.com/notcie/321093
http://herdental.co.kr/index.php?mid=online&document_srl=90912
http://holysweat.dothome.co.kr/data/4375
http://juroweb.com/xe/juroweb_board/58099
http://juroweb.com/xe/juroweb_board/58104
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=364120
https://testing.celekt.com/%d0%91%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-video-%d0%91%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8/
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=123905
http://xn----c28ewjj6ubwku6frtcuzec29ae5b.kr/news/36552
http://ajincomp.godohosting.com/board_STnh82/95523
http://proxima.co.rw/index.php/component/k2/itemlist/user/676123
http://lucky.kidspann.net/index.php?mid=qna&document_srl=177648
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/56536
http://withinfp.sakura.ne.jp/eso/index.php/17393849-hdvideo-sluga-naroda-3-sezon-4-seria-c1-sluga-naroda-3-sezon-4-/0
http://www.artangel.co.kr/index.php?mid=Activities&document_srl=82027
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/58949
http://sdsn.develop.cinfores.com/?option=com_k2&view=itemlist&task=user&id=240168
http://vsalda.edinros66.ru/component/k2/itemlist/user/67170
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/58937
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=50109
http://153.120.114.241/eso/index.php/17403210-klatva-yemin-68-seria-bzix-klatva-yemin-68-seria
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=312362
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=312601
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=312690
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=312700
http://1661-6471.co.kr/news/12087
http://jjikduk.net/DATA/143509
http://beautypouch.net/index.php?mid=board_09&document_srl=66818
http://beautypouch.net/index.php?mid=board_09&document_srl=66838
http://bebopindia.com/notcie/320417
http://bebopindia.com/notcie/320479
http://bebopindia.com/notcie/320519
http://benzmall.co.kr/index.php?mid=download&document_srl=26324
http://benzmall.co.kr/index.php?mid=download&document_srl=26359
http://callman.co.kr/index.php?mid=qa&document_srl=184067
http://herdental.co.kr/index.php?mid=online&document_srl=90412
http://herdental.co.kr/index.php?mid=online&document_srl=90458
http://herdental.co.kr/index.php?mid=online&document_srl=90488
http://ucckorea.kr/index.php?mid=board_AuHE49&document_srl=49564
http://www.vamoscontigo.org/Noticia/132109
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=137854
http://bizchemical.com/board_kMpv94/2054930
http://otitismediasociety.org/forum/index.php?topic=187767.0
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/795364
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=21902
http://matinbank.ir/component/k2/itemlist/user/4578421.html
http://vhost12299.cpsite.ru/581092-smotret-igra-prestolov-8-sezon-1-seria-e1-igra-prestolov-8-sezo
http://vhost12299.cpsite.ru/581099-hdvideo-igra-prestolov-8-sezon-2-seria-i4-igra-prestolov-8-sezo
http://vhost12299.cpsite.ru/581123-novinka-senafeda-2-sezon-9-seria-y1-senafeda-2-sezon-9-seria
http://vhost12299.cpsite.ru/581169-sluga-naroda-3-sezon-15-seria-m7-sluga-naroda-3-sezon-15-seria
http://vhost12299.cpsite.ru/581180-smotret-senafeda-2-sezon-9-seria-g1-senafeda-2-sezon-9-seria
http://withinfp.sakura.ne.jp/eso/index.php/17484795-smotret-sluga-naroda-3-sezon-20-seria-k7-sluga-naroda-3-sezon-2/0
http://withinfp.sakura.ne.jp/eso/index.php/17484884-efir-holostak-9-sezon-12-vypusk-n1-holostak-9-sezon-12-vypusk/0
http://www.hyunjindc.com/qna/81069
http://www.hyunjindc.com/qna/81080
http://www.hyunjindc.com/qna/81090
http://www.insesinmun.com/newpaper2/79978
http://www.insesinmun.com/newpaper2/80020
http://www.insesinmun.com/newpaper2/80025
http://www.insesinmun.com/newpaper2/80036
http://www.itosm.com/cn/board_nLoq17/91477
http://www.itosm.com/cn/board_nLoq17/91525
http://www.itosm.com/cn/board_nLoq17/91605
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/gumdanapt/251397
http://sofficer.net/xe/teach/260353
http://yourhelp.co.kr/index.php?mid=board_2&document_srl=25425
http://www.kspace.cc/xe/?document_srl=38991
http://withinfp.sakura.ne.jp/eso/index.php/17511619-hd-tola-robot-3-seria-e3-tola-robot-3-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/17511633-sluga-naroda-3-sezon-21-seria-u1-sluga-naroda-3-sezon-21-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/17511682-cernobyl-2019-6-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/17511688-serial-senafeda-2-sezon-11-seria-h8-senafeda-2-sezon-11-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/17511702-v-efire-cernobyl-3-seria-m0-cernobyl-3-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/17511773-mama-lora-16-seria-g0-mama-lora-16-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/17511775-live-igra-prestolov-8-sezon-3-seria-c1-igra-prestolov-8-sezon-3/0
http://withinfp.sakura.ne.jp/eso/index.php/17511847-v-efire-cernobyl-2019-2-seria-b7-cernobyl-2019-2-seria/0
http://xplorefitness.com/blog/%D1%81%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C-%D0%B2%D1%81%D1%91-%D0%BC%D0%BE%D0%B3%D0%BB%D0%BE-%D0%B1%D1%8B%D1%82%D1%8C-%D0%B8%D0%BD%D0%B0%D1%87%D0%B5-8-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-f7-%D0%B2%D1%81%D1%91-%D0%BC%D0%BE%D0%B3%D0%BB%D0%BE-%D0%B1%D1%8B%D1%82%D1%8C-%D0%B8%D0%BD%D0%B0%D1%87%D0%B5-8-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=135636
http://carand.co.kr/?document_srl=44709
http://carand.co.kr/d2/44605
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=123822
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=123919
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=123924
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=123955
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=123975
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=123991
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=124002
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=124013
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=124019
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=124024
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=124029
http://daltso.com/index.php?mid=board_cUYy21&document_srl=118541
http://atemshow.com/atemfair_domestic/174854
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=102605
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/352495
http://www.ekemoon.com/237345/051120191125/
http://jnk-ent.jp/index.php?document_srl=221413&mid=gallery
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1968193
http://jiquilisco.org/index.php/component/k2/itemlist/user/14912
http://nanaae.com/confirm/6743
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=584955
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3335918
http://kyj1225.godohosting.com/board_mebR72/51118
http://www.emrabq8.com/index.php/component/k2/itemlist/user/1837660
http://photogrotto.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ub1p-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-5-%d1%81/
http://photogrotto.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mj3a-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://photogrotto.com/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-in9f-%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://photogrotto.com/%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xo5w-%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f/
http://photogrotto.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-92-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lc0j-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd/
http://photogrotto.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-91-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pq4o-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-91-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://photogrotto.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-98-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cz8s-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-98-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.ekemoon.com/229621/051120194023/
https://sanp.pro/%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nk6z-%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f/
http://0433.net/junggo/77379
http://153.120.114.241/eso/index.php/17441489-klatva-yemin-62-seria-snpi-klatva-yemin-62-seria
http://153.120.114.241/eso/index.php/17441855-klatva-yemin-68-seria-bdxe-klatva-yemin-68-seria
http://153.120.114.241/eso/index.php/17441868-vetrenyj-hercai-22-seria-ukyj-vetrenyj-hercai-22-seria
http://xn----3x5er9r48j7wemud0a387h.com/news/49161
http://engeena.com/?option=com_k2&view=itemlist&task=user&id=8848
http://indiefilm.kr/xe/board/123850
http://www.hicleaning.kr/?document_srl=93906
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=74468
http://www.jshwanghoan.com/index.php?document_srl=96968&mid=qna
http://www.arredoufficiomarca.com/index.php/component/k2/itemlist/user/1615438
http://www.josephmaul.org/menu41/94904
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=527436
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=520049
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=265910
http://jjikduk.net/DATA/87627
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gl9%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://www.jesusonly.life/calendar/128553
http://hyeonjun.co.kr/menu3/73730
http://153.120.114.241/eso/index.php/17403286-vetrenyj-hercai-12-seria-kkll-vetrenyj-hercai-12-seria
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=593798
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=401635
http://gochon-iusell.co.kr/index.php?mid=g1&page=1&document_srl=49954
https://esel.gist.ac.kr/esel2/board_hmgj23/156469
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=161023
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=63335
http://www.arunagreen.com/index.php/component/k2/itemlist/user/584681
http://xplorefitness.com/blog/hd-%D1%81%D0%BB%D1%83%D0%B3%D0%B0-%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-17-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-s2-%D1%81%D0%BB%D1%83%D0%B3%D0%B0-%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%B0-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-17-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=394012
http://5starcoffee.co.kr/board_EBXY17/21693
http://5starcoffee.co.kr/board_EBXY17/21699
http://5starcoffee.co.kr/board_EBXY17/21707
http://5starcoffee.co.kr/board_EBXY17/21719
http://5starcoffee.co.kr/board_EBXY17/21725
http://askpharm.net/board_NQiz06/147211
http://askpharm.net/board_NQiz06/147265
http://bebopindia.com/notcie/369723
http://subforumna.x10.mx/mad/index.php?topic=256761.0
http://0433.net/junggo/48463
http://www.theparrotcentre.com/forum/index.php?topic=551667.0
http://yoriyorifood.com/xxxx/spacial/73873
https://testing.celekt.com/%d0%a2%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pw9%d0%a2%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f18-05/
http://www.svteck.co.kr/customer_gratitude/40505
http://www.hsaura.com/noty/159864
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=200653
http://withinfp.sakura.ne.jp/eso/index.php/17113428-zestokij-stambul-zalim-istanbul-11-seria-pmrk-zestokij-stambul-
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=278346
http://www.sp1.football/index.php?mid=faq&document_srl=192363
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=716082
https://gonggamlaw.com/lawcase/53572
http://dcasociados.eu/component/k2/itemlist/user/92644
http://vhost12299.cpsite.ru/551455-v-efire-smers-4-seria-q3-smers-4-seria
http://withinfp.sakura.ne.jp/eso/index.php/17331588-hdvideo-smers-4-seria-c2-smers-4-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/17332009-novinka-cuzaa-zizn-cuze-zitta-10-seria-h4-cuzaa-zizn-cuze-zitta/0
http://withinfp.sakura.ne.jp/eso/index.php/17332035-novinka-cuzaa-zizn-cuze-zitta-4-seria-f0-cuzaa-zizn-cuze-zitta-/0
http://withinfp.sakura.ne.jp/eso/index.php/17332046-efir-sluga-naroda-3-sezon-23-seria-f6-sluga-naroda-3-sezon-23-s/0
http://withinfp.sakura.ne.jp/eso/index.php/17332070-smotret-igra-prestolov-2019-8-sezon-7-seria-q7-igra-prestolov-2/0
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1630660
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1630808
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=1099258
http://koais.com/data/138062
http://koais.com/data/138067
http://koais.com/data/138100
http://koais.com/data/138132
http://mglpcm.org/board_ETkS12/115083
http://oneandonly1127.com/guest/70811
http://oneandonly1127.com/guest/70816
http://bebopindia.com/notcie/268482
https://nple.com/xe/pds/129877
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=275803
http://www.insesinmun.com/?document_srl=81954
http://herdental.co.kr/index.php?mid=online&document_srl=63372
http://koais.com/data/105012
https://hackinsa.com/freeboard/6878
http://tk-laser.co.kr/index.php?mid=board_QsEu43&document_srl=125894
http://sejong-thesharpyemizi.co.kr/m1/10685
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=590082
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=310364
http://jjikduk.net/DATA/122794
http://jjikduk.net/DATA/123028
http://jjikduk.net/DATA/123045
http://shinhwaair2017.cafe24.com/?document_srl=347774
http://shinhwaair2017.cafe24.com/issue/347793
http://shinhwaair2017.cafe24.com/issue/347813
http://withinfp.sakura.ne.jp/eso/index.php/17384298-bogatye-i-bednye-zengin-ve-yoksul-15-seria-lrbf-bogatye-i-bedny/0
http://withinfp.sakura.ne.jp/eso/index.php/17384341-vetrenyj-hercai-15-seria-mcxe-vetrenyj-hercai-15-seria/0
http://www.ekemoon.com/227401/051920191422/
http://www.hicleaning.kr/board_wash/180301
http://www.hicleaning.kr/board_wash/180367
http://www.hicleaning.kr/board_wash/180499
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=198380
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=198599
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=115919
https://www.vegasgreentour.com/?document_srl=78149
http://www.jesusonly.life/calendar/143295
http://bitpark.co.kr/board_IzjM66/4046724
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1103048
https://testing.celekt.com/%d0%9f%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qm8%d0%9f%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd/
http://www.lgue.co.kr/lgue05/68757
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/305702
http://koais.com/data/100684
http://www.ekemoon.com/227337/051820191622/
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/308081
http://yourhelp.co.kr/index.php?mid=board_2&document_srl=32763
http://euromouleusinage.com/index.php/component/k2/itemlist/user/166117
http://photogrotto.com/%d0%ba%d0%be%d0%bd%d1%81%d1%83%d0%bb%d1%8c%d1%82%d0%b0%d0%bd%d1%82-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yj3h-%d0%ba%d0%be%d0%bd%d1%81%d1%83%d0%bb%d1%8c/
http://photogrotto.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ef3e-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81/
http://www.ekemoon.com/234301/051820190424/
http://www.teedinubon.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jt0o-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
https://alvarogarciatorero.com/component/k2/itemlist/user/50196
https://sanp.pro/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-po5f-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81/
http://euromouleusinage.com/index.php/component/k2/itemlist/user/166303
http://vhost12299.cpsite.ru/593340-v-efire-vse-moglo-byt-inace-11-seria-z9-vse-moglo-byt-inace-11-
http://vhost12299.cpsite.ru/593348-hd-sluga-naroda-3-sezon-21-seria-e7-sluga-naroda-3-sezon-21-ser
http://vhost12299.cpsite.ru/593403-serial-sluga-naroda-3-sezon-12-seria-t4-sluga-naroda-3-sezon-12
http://vhost12299.cpsite.ru/593434-v-efire-igra-prestolov-8-sezon-3-seria-h9-igra-prestolov-8-sezo
http://vhost12299.cpsite.ru/593467-v-efire-sluga-naroda-3-sezon-22-seria-k4-sluga-naroda-3-sezon-2
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=353186
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=353203
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=21570
http://jiquilisco.org/?option=com_k2&view=itemlist&task=user&id=14438
http://jiquilisco.org/index.php/component/k2/itemlist/user/14443
http://jiquilisco.org/index.php/component/k2/itemlist/user/14451
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3860902
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3860904
http://mediaville.me/index.php/component/k2/itemlist/user/306425
http://mjbosch.com/component/k2/itemlist/user/84384
http://ovotecegg.com/?option=com_k2&view=itemlist&task=user&id=180482
http://ovotecegg.com/component/k2/itemlist/user/180450
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/280517
http://rudraautomation.com/index.php/component/k2/author/248641
http://smartacity.com/component/k2/itemlist/user/63366
http://www.fassen.co.kr/xe/board_VCum96/64391
http://daltso.com/index.php?mid=board_cUYy21&document_srl=80941
http://benzmall.co.kr/index.php?mid=download&document_srl=19901
http://thanosakademi.com/index.php?topic=110430.0
http://shinhwaair2017.cafe24.com/issue/347383
http://www.jesusonly.life/calendar/322758
http://barobus.kr/qna/58625
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=168395
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=20068
http://atemshow.com/atemfair_domestic/178540
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=41585
http://photogrotto.com/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-24-05-2019-g8-%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-14-%d1%81%d0%b5%d1%80%d0%b8/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1481149
http://yoriyorifood.com/xxxx/spacial/171494
http://yoriyorifood.com/xxxx/spacial/171504
http://yoriyorifood.com/xxxx/spacial/171519
https://esel.gist.ac.kr/esel2/board_hmgj23/152189
https://esel.gist.ac.kr/esel2/board_hmgj23/152226
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=278296
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=278305
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=278331
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=278341
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=278356
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=278373
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=102437
http://moavalve.co.kr/faq/84652
https://prelease.club/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-24-05-2019-cn%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
http://cwon.kr/xe/board_bnSr36/110134
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/8994
http://skylinecam.co.kr/photo/97085
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1235329
https://altaylarteknoloji.com/index.php?topic=4978.0
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=55734
http://skylinecam.co.kr/photo/80924
http://webp.online/index.php?topic=60059.0
http://research.kiu.ac.kr/?document_srl=75609
http://roikjer.com/forum/index.php?PHPSESSID=r5it86sevgmji3vmt17jp08601&topic=895434.0
http://www.theocraticamerica.org/forum/index.php?topic=55768.0
http://jjikduk.net/DATA/116027
http://daesestudy.co.kr/ipsi_docu/89388
http://xn--2e0b53df5ag1c804aphl.net/nuguna/76339
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=44170
https://nple.com/xe/pds/92175
http://thanosakademi.com/index.php?topic=112306.0
http://rudraautomation.com/index.php/component/k2/author/253494
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2355570
http://smartacity.com/component/k2/itemlist/user/65795
http://udrpsucks.com/blog/?p=1245
http://udrpsucks.com/blog/?p=1247
http://udrpsucks.com/blog/?p=1250
http://www.almacenesrickie.com.ec/index.php/component/k2/itemlist/user/140889
http://skylinecam.co.kr/photo/114133
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2661627
http://vhost12299.cpsite.ru/427395-tajny-85-seria-a3-tajny-85-seria
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1711874
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=209215
http://www.jesusonly.life/calendar/136549
https://prelease.club/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qn5n-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-1-%d1%81/
https://www.2ayes.com/17852/2-4-21-05-2019-h5-2-4
http://www.gforgirl.com/xe/poster/154651
http://otitismediasociety.org/forum/index.php?topic=174884.0
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=36719
http://otitismediasociety.org/forum/index.php?topic=175005.0
http://www.josephmaul.org/menu41/93040
http://neosky.net/xe/space_station/37736
http://rabbitzone.xyz/FREE/40875
http://esiapolisthesharp2.co.kr/g1/58268
http://www.livetank.cn/market1/209220
http://153.120.114.241/eso/index.php/17466786-bogatye-i-bednye-zengin-ve-yoksul-11-seria-tuix-bogatye-i-bedny
http://d-tube.info/board_jvyO69/343789
http://barobus.kr/qna/59832
http://photogrotto.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-23-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-23-05-2019-s2-%d1%81%d0%bb%d1%83%d0%b3/
http://lucky.kidspann.net/index.php?mid=qna&document_srl=161727
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=307859
http://woodpark.kr/?document_srl=37915
http://beautypouch.net/index.php?mid=board_09&document_srl=58880
http://0433.net/junggo/69706
http://zakdu.com/board_ssKi56/6907
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=595677
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=595682
http://www.studyxray.com/Sangdam/218365
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3334282
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3334290
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3334295
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=186701
http://yoriyorifood.com/xxxx/spacial/171782
http://yoriyorifood.com/xxxx/spacial/171793
http://yoriyorifood.com/xxxx/spacial/171829
https://esel.gist.ac.kr/esel2/board_hmgj23/152577
https://esel.gist.ac.kr/esel2/board_hmgj23/152592
https://esel.gist.ac.kr/esel2/board_hmgj23/152605
https://esel.gist.ac.kr/esel2/board_hmgj23/152614
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=278861
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=69109
http://vhost12299.cpsite.ru/417649-mama-lora-12-seria-mama-lora-12-seria
http://zanoza.h1n.ru/2019/05/18/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-24-05-2019-gh%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=96994
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=338411
http://www.golden-nail.co.kr/press/76016
https://sanp.pro/%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-97-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ft6%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-97-%d1%81%d0%b5%d1%80%d0%b8%d1%8f18-05-2019/
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=92511
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=25080
https://altaylarteknoloji.com/index.php?topic=5289.0
http://udrpsucks.com/?p=
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1894695
http://community.viajar.tur.br/index.php?p=/discussion/62173/edinoe-serdce-tek-yuerek-15-seriya-sijq-edinoe-serdce-tek-yuerek-15-seriya
http://kitekorea.co.kr/board_Chea81/110919
http://xihillstate.bloggirl.net/?document_srl=197873
http://www.telcon.gr/index.php/component/k2/itemlist/user/87405
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/133383
http://www.firstfinancialservices.co.uk/?option=com_k2&view=itemlist&task=user&id=25131
http://ye-dream.com/qa/186715
http://atemshow.com/atemfair_domestic/162190
http://gochon-iusell.co.kr/g1/46609
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=323146
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=30727
https://sanp.pro/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-24-05-2019-ha%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f/
http://rabbitzone.xyz/FREE/21122
http://www.josephmaul.org/menu41/236251
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=197066
http://www.studyxray.com/?document_srl=219198
http://www.studyxray.com/Sangdam/219278
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3334489
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=187479
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=187520
http://yoriyorifood.com/xxxx/spacial/172493
http://yoriyorifood.com/xxxx/spacial/172503
http://dev.aabn.org.gh/component/k2/itemlist/user/645314
http://shinilspring.com/board_qsfb01/87395
http://yoriyorifood.com/xxxx/spacial/88437
http://0433.net/junggo/47346
http://xn--ok1bpqi43ahtb.net/board_EkDG82/136830
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=79287
http://gtupuw.org/index.php/component/k2/itemlist/user/1936339
http://corumotoanahtar.com/component/k2/itemlist/user/4360.html
http://webp.online/index.php?topic=65405.0
http://www.livetank.cn/market1/206086
http://gochon-iusell.co.kr/g1/47469
http://www.kcch.or.kr/index.php?mid=board_uFpk03&document_srl=66192
http://www.fassen.co.kr/xe/?document_srl=86395
http://153.120.114.241/eso/index.php/17475576-zestokij-stambul-zalim-istanbul-14-seria-zvux-zestokij-stambul-
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=68805
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2323713
http://www.teedinubon.com/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-de7%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f18-05-2019/
http://yoriyorifood.com/xxxx/spacial/93858
http://www.pdctransport.co.th/index.php/component/k2/itemlist/user/16417
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=21490
https://testing.celekt.com/%d0%9d%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d0%a1%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-85-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-6/
http://0433.net/junggo/38273
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1938195
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=92274
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=649104
https://2002.shyoon.com/?document_srl=163043
http://www.popolsku.fr.pl/forum/index.php?topic=20407.78120
http://www2.yasothon.go.th/smf/index.php?topic=159.169620
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=135778
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=135788
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=135842
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=135864
http://carand.co.kr/d2/44829
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=124085
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=124091
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=124096
http://www.fassen.co.kr/xe/board_VCum96/85850
http://nanaae.com/confirm/16572
http://www.cswc.co.kr/index.php?mid=board_zyTs37&document_srl=21959
http://barobus.kr/?document_srl=41661
http://www.teedinubon.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-live-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-1/
http://asin.itts.co.kr/board_rtXs84/20661
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=115219
http://tk-laser.co.kr/index.php?mid=board_QsEu43&document_srl=133421
http://zakdu.com/board_ssKi56/6938
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=33573
http://2872870.com/est/44035
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=26403
http://ye-dream.com/qa/79457
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=242896
http://yoriyorifood.com/xxxx/spacial/74541
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=517050
http://www.teedinubon.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-98-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d1%82%d0%b0%d0%b9%d0%bd/
http://test.comics-game.ru/index.php?topic=211.0
http://cwon.kr/xe/board_bnSr36/82214
http://corumotoanahtar.com/component/k2/itemlist/user/4367
https://test.baseyou21.kr/?document_srl=74550
http://roikjer.com/forum/index.php?PHPSESSID=r4ila3ranqu5n56b1ena2hr3k2&topic=895842.0
http://subforumna.x10.mx/mad/index.php?topic=255156.0
http://yoriyorifood.com/xxxx/?document_srl=97739
http://daltso.com/?document_srl=120360
http://daltso.com/index.php?mid=board_cUYy21&document_srl=120316
http://daltso.com/index.php?mid=board_cUYy21&document_srl=120413
http://kyj1225.godohosting.com/board_mebR72/57247
http://looksun.co.kr/index.php?mid=board_4&document_srl=121394
http://www.leekeonsu-csi.com/?document_srl=877015
https://2002.shyoon.com/board_2002/164999
https://2002.shyoon.com/board_2002/165004
https://2002.shyoon.com/board_2002/165014
https://2002.shyoon.com/board_2002/165019
https://2002.shyoon.com/board_2002/165057
https://2002.shyoon.com/board_2002/165088
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=137372
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=137450
http://bizchemical.com/board_kMpv94/2053517
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=322315
https://hackinsa.com/freeboard/23255
http://barobus.kr/qna/55891
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/28478
http://bebopindia.com/notcie/285345
http://photogrotto.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-oq2f-%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf/
http://photogrotto.com/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tb1z-%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://photogrotto.com/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-co1m-%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://photogrotto.com/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ai5j-%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://photogrotto.com/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-82-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-34/
http://photogrotto.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mt9x-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://photogrotto.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-90-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-le5m-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd/
http://photogrotto.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-gu5m-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9/
http://rudraautomation.com/index.php/component/k2/author/249958
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2352571
http://smartacity.com/component/k2/itemlist/user/64447
http://soc-human.kz/index.php/component/k2/itemlist/user/1725620
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1725455
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1632232
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=66626
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=104840
http://forum.digamahost.com/index.php?topic=127583.0
http://forum.elexlabs.com/index.php?topic=38514.0
http://ye-dream.com/qa/77154
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=77710
http://www.hicleaning.kr/board_wash/81399
http://dcasociados.eu/component/k2/itemlist/user/90950
http://moavalve.co.kr/?document_srl=81528
http://www.hsaura.com/noty/125728
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3307833
http://skylinecam.co.kr/photo/128705
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2352482
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/24360
http://www.teedinubon.com/%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-z4-%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4/
http://asin.itts.co.kr/?document_srl=21614
http://khapthanam.co.kr/g1/109448
http://xn----3x5er9r48j7wemud0a387h.com/news/77527
http://xn----3x5er9r48j7wemud0a387h.com/news/77545
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=175172
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=175197
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=175208
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=175243
http://www.teedinubon.com/%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pp9%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd/
http://miklja.net/forum/index.php?topic=33524.0
http://www.critico-expository.com/forum/index.php?topic=14186.0
http://lucky.kidspann.net/index.php?mid=qna&document_srl=76006
https://www.2ayes.com/16908/8-7-18-05-2019-u7-8-7
http://dcasociados.eu/component/k2/itemlist/user/90855
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/11265
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2665655
http://www.theparrotcentre.com/forum/index.php?topic=548201.0
http://yoriyorifood.com/xxxx/spacial/69708
http://proxima.co.rw/index.php/component/k2/itemlist/user/654957
http://skylinecam.co.kr/photo/88475
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=516771
http://hyeonjun.co.kr/?document_srl=67630
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=670443
http://tk-laser.co.kr/index.php?mid=board_QsEu43&document_srl=108426
http://1661-6471.co.kr/news/33312
http://khapthanam.co.kr/g1/111978
http://xn----3x5er9r48j7wemud0a387h.com/news/93668
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=33145
http://www.hyunjindc.com/qna/93579
https://nple.com/xe/pds/111626
http://xn----c28ewjj6ubwku6frtcuzec29ae5b.com/news/22217
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/55835
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3808383
http://0433.net/junggo/67582
http://0433.net/junggo/67604
http://0433.net/junggo/67609
http://asiagroup.co.kr/?document_srl=296706
http://community.viajar.tur.br/index.php?p=/discussion/62137/zhestokiy-stambul-zalim-istanbul-8-seriya-mlbm-zhestokiy-stambul-zalim-istanbul-8-seriya
http://taklongclub.com/forum/index.php?topic=158695.0
http://indiefilm.kr/xe/board/138078
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=100669
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1948297
http://vhost12299.cpsite.ru/497383-tajny-taemnici-97-seria-19052019-u2-tajny-taemnici-97-seria
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4831827
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1923243
http://shinilspring.com/board_qsfb01/94238
http://roikjer.com/forum/index.php?PHPSESSID=r6if8viihl0vistq7poqv8gs66&topic=888586.0
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=520587
http://ptu.imoove.kr/ko/content/%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-24-05-2019%C2%BB-dv%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-24-05-2019%C2%BB56-%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-24-05-2019337499
http://sixangles.co.kr/qna/638240
http://xn--9m1b83j39hz6exwonmf.com/board_IYPe43/508402
http://dev.aabn.org.gh/component/k2/itemlist/user/617977
http://bebopindia.com/notcie/117049
http://carand.co.kr/d2/24391
http://w9builders.co.uk/index.php/component/k2/itemlist/user/94693
http://atemshow.com/atemfair_domestic/173133
http://barobus.kr/qna/64019
http://gochon-iusell.co.kr/g1/53690
http://ovotecegg.com/component/k2/itemlist/user/181545
http://toeden.co.kr/?document_srl=87319
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=14398
http://shinhwaair2017.cafe24.com/issue/346952
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2552558
http://www.spazioad.com/component/k2/itemlist/user/7378342
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=84221
http://www.telcon.gr/index.php/component/k2/itemlist/user/84240
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=352963
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/352954
http://xekhachduyetthuy.com.vn/component/k2/itemlist/user/228970
http://xekhachduyetthuy.com.vn/component/k2/itemlist/user/229006
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/298603
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/298646
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=621618
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/55726
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=884426
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1705457
http://www.sp1.football/index.php?mid=faq&document_srl=207110
http://yeonsen.com/index.php?document_srl=96947&mid=board_vZbN12
http://jensenbyggteam.no/index.php/component/k2/itemlist/user/13408
http://www.hsaura.com/noty/127105
http://www.dap.com.py/index.php/component/k2/itemlist/user/823722
http://www.gforgirl.com/xe/poster/122930
http://www.hicleaning.kr/board_wash/90985
http://shinilspring.com/board_qsfb01/81225
http://dev.aabn.org.gh/component/k2/itemlist/user/620357
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3307504
http://lucky.kidspann.net/index.php?mid=qna&document_srl=78177
http://readingbible.org/board_xxpp62/1021476
http://kwpub.kr/PUBS/98989
http://smartacity.com/component/k2/itemlist/user/66920
http://yonseibaik.synology.me/index.php?mid=houston_profile&document_srl=46877
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/25397
http://nanaae.com/confirm/16040
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/18184
http://www.arredoufficiomarca.com/index.php/component/k2/itemlist/user/1642603
http://sd-xi.co.kr/g1/44029
http://oneandonly1127.com/guest/53535
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=5009201
http://www.critico-expository.com/forum/index.php?topic=25060.0
http://www.fassen.co.kr/xe/board_VCum96/83350
http://www.golden-nail.co.kr/?document_srl=309009
http://www.golden-nail.co.kr/press/308986
http://www.golden-nail.co.kr/press/309047
http://www.jesusonly.life/calendar/379854
http://www.jesusonly.life/calendar/379874
http://www.leekeonsu-csi.com/index.php?document_srl=721897&mid=sangdam1
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=722057
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=722100
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=722180
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=722462
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=722008
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=722341
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=338060
http://atemshow.com/atemfair_domestic/154918
http://beautypouch.net/index.php?mid=board_09&document_srl=60616
http://beautypouch.net/index.php?mid=board_09&document_srl=60661
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=1061415
http://www.hyunjindc.com/qna/67098
http://photogrotto.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kw7%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://koais.com/data/144041
http://toeden.co.kr/?document_srl=87223
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=229457
https://serverpia.co.kr/board_ucCk10/65423
http://withinfp.sakura.ne.jp/eso/index.php/17390372-smotret-taemnici-91-seria-y8-taemnici-91-seria/0
http://thermoplast.envolgroupe.com/component/k2/author/141762
https://testing.celekt.com/%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-ty%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81/
http://esiapolisthesharp2.co.kr/?document_srl=64218
http://2872870.com/est/47768
http://divespace.co.kr/board/147206
http://emjun.com/index.php?mid=hangtotal&document_srl=215731
http://emjun.com/index.php?mid=hangtotal&document_srl=215751
http://sunele.co.kr/board_ReBD97/124766
http://sunele.co.kr/board_ReBD97/124796
http://sunele.co.kr/board_ReBD97/124825
http://www.fassen.co.kr/xe/board_VCum96/83776
http://www.golden-nail.co.kr/press/310065
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=723844
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=724185
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=724414
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=723971
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/gumdanapt/228395
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=21106
http://yonseibaik.synology.me/index.php?mid=houston_profile&document_srl=37620
http://yourhelp.co.kr/index.php?mid=board_2&document_srl=23937
http://thanosakademi.com/index.php?topic=111947.0
http://www.teedinubon.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8d%d1%84%d0%b8%d1%80-%d1%81%d0%bb/
http://asiagroup.co.kr/index.php?document_srl=338511&mid=board_11
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=338593
http://atemshow.com/atemfair_domestic/155244
http://atemshow.com/atemfair_domestic/155279
http://beautypouch.net/?document_srl=60870
http://beautypouch.net/index.php?mid=board_09&document_srl=60888
http://beautypouch.net/index.php?mid=board_09&document_srl=60898
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=94182
https://www.2ayes.com/18653/3-22-22-05-2019-j4-3-22
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=142811
http://koais.com/data/92449
http://koais.com/data/102763
http://gallerychoi.com/Exhibition/205627
http://www.digitalbul.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-93-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-93-%d1%81%d0%b5%d1%80%d0%b8/
http://themasters.pro/file_01/216268
http://bebopindia.com/notcie/333730
http://hanalove.kidspann.net/index.php?mid=qna&document_srl=80031
http://atemshow.com/atemfair_domestic/171155
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/351461
http://sy.korean.net/qna/259544
http://cwon.kr/xe/board_bnSr36/61217
http://zanoza.h1n.ru/2019/05/18/%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-chernobyl-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ri3%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-chernobyl-4-%d1%81%d0%b5%d1%80%d0%b8/
http://dcasociados.eu/component/k2/itemlist/user/90449
http://shinilspring.com/board_qsfb01/108151
http://sixangles.co.kr/qna/610249
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/341107
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=10756
http://hyeonjun.co.kr/menu3/93069
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/50089
http://soc-human.kz/index.php/component/k2/itemlist/user/1702260
https://sanp.pro/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-oc0%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f20-05-2019/
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=197691
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=131741
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=131772
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=131782
http://carand.co.kr/d2/41690
http://carand.co.kr/d2/41717
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=121939
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=121944
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=121949
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=121954
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=121965
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=121970
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=121992
http://gabisan.com/board_OuDs04/59294
http://gabisan.com/board_OuDs04/59380
http://herdental.co.kr/index.php?mid=online&document_srl=107329
http://www.teedinubon.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-24-05-2019-r8-%d0%b8%d0%b3%d1%80/
http://hanalove.kidspann.net/index.php?mid=qna&document_srl=80157
http://www.popolsku.fr.pl/forum/index.php?topic=20407.78240
http://jjikduk.net/?document_srl=134458
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1971757
https://khuyenmaikk13.info/index.php?topic=222483.0
http://community.viajar.tur.br/index.php?p=/discussion/62360/rannyaya-ptashka-erkenci-kus-42-seriya-dfak-rannyaya-ptashka-erkenci-kus-42-seriya/p1%3Fnew=1
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=38355
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2706941
http://benzmall.co.kr/index.php?mid=download&document_srl=21136
http://5starcoffee.co.kr/board_EBXY17/21801
http://bebopindia.com/notcie/370463
http://benzmall.co.kr/index.php?mid=download&document_srl=41474
http://benzmall.co.kr/index.php?mid=download&document_srl=41488
http://benzmall.co.kr/index.php?mid=download&document_srl=41533
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=132057
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=132085
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=132135
http://d-tube.info/board_jvyO69/360418
http://d-tube.info/board_jvyO69/360433
http://mercibq.net/partner/49052
http://mercibq.net/partner/49071
http://mercibq.net/partner/49105
http://mercibq.net/partner/49114
http://themasters.pro/?document_srl=210772
https://www.amazingworldtop.com/entretenimiento/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xy9%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7/
http://smartacity.com/component/k2/itemlist/user/57129
http://bebopindia.com/notcie/115452
http://lucky.kidspann.net/index.php?mid=qna&document_srl=75181
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=16518
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=27182
http://www.crnmedia.es/component/k2/itemlist/user/87322
https://www.amazingworldtop.com/entretenimiento/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pm8%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://universalcommunity.se/Forum/index.php?topic=19520.0
http://www.josephmaul.org/menu41/123446
http://matinbank.ir/component/k2/itemlist/user/4592445.html
http://matinbank.ir/component/k2/itemlist/user/4592554.html
http://mediaville.me/index.php/component/k2/itemlist/user/332993
http://mediaville.me/index.php/component/k2/itemlist/user/333001
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=85318
http://mobility-corp.com/index.php/component/k2/itemlist/user/2698211
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/305086
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3414568
http://0433.net/?document_srl=65479
http://0433.net/junggo/65402
http://0433.net/junggo/65457
http://0433.net/junggo/65463
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=101058
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=101076
http://bizchemical.com/?document_srl=2047623
http://bizchemical.com/board_kMpv94/2047683
http://callman.co.kr/index.php?mid=qa&document_srl=178598
http://cwon.kr/xe/board_bnSr36/191975
http://cwon.kr/xe/board_bnSr36/191994
http://d-tube.info/?document_srl=323715
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=5017885
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=5017905
http://www.spazioad.com/component/k2/itemlist/user/7418854
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=99355
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/371293
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/371307
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=242594
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=653823
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=653859
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/83763
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/84601
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=252258
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=256240
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2697136
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2697321
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2697361
http://dcasociados.eu/component/k2/itemlist/user/91160
https://adsensebih.com/index.php?topic=37334.0
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3823794
http://beautypouch.net/index.php?mid=board_09&document_srl=64294
http://bebopindia.com/notcie/316362
http://bewasia.com/?document_srl=101833
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=101773
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=101783
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=101853
http://bizchemical.com/board_kMpv94/2048417
http://callman.co.kr/index.php?mid=qa&document_srl=179624
http://callman.co.kr/index.php?mid=qa&document_srl=179633
http://callman.co.kr/index.php?mid=qa&document_srl=179653
http://callman.co.kr/index.php?mid=qa&document_srl=179745
http://holysweat.dothome.co.kr/data/4124
http://jiral.net/an9/29360
http://jiral.net/an9/29365
http://jiral.net/an9/29381
http://k-cea.org/?document_srl=196565
http://k-cea.org/board_Hnyj62/196879
http://k-cea.org/board_Hnyj62/197209
http://k-cea.org/board_Hnyj62/197249
http://matrixpharm.ru/forum/index.php?PHPSESSID=sbr0v3oqpb34li0j8u0namb2g5&action=profile;u=217846
http://mglpcm.org/board_ETkS12/131068
http://mglpcm.org/board_ETkS12/131137
http://mglpcm.org/board_ETkS12/131163
http://mglpcm.org/board_ETkS12/131213
http://mglpcm.org/board_ETkS12/131245
http://mglpcm.org/board_ETkS12/131267
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/20059
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/20296
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=871119
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=72476
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=228052
https://afikgan.co.il/index.php/component/k2/itemlist/user/29528
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/54156
http://atemshow.com/atemfair_domestic/159567
http://atemshow.com/atemfair_domestic/159629
http://atemshow.com/atemfair_domestic/159665
http://beautypouch.net/?document_srl=64013
http://beautypouch.net/index.php?mid=board_09&document_srl=64036
http://beautypouch.net/index.php?mid=board_09&document_srl=64041
http://bebopindia.com/notcie/315724
http://bebopindia.com/notcie/315816
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=101448
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=101481
http://bizchemical.com/board_kMpv94/2048124
http://bizchemical.com/board_kMpv94/2048149
http://d-tube.info/board_jvyO69/324204
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=202513
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=202534
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=309648
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=309947
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=309984
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=310000
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=310166
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=310295
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=310458
http://roikjer.com/forum/index.php?PHPSESSID=cq76hlk9q9u425i631898gmg27&topic=926279.0
http://roikjer.com/forum/index.php?PHPSESSID=dnglkq0tq4hfgkcq3mmqj4uar4&topic=926286.0
http://dev.aabn.org.gh/component/k2/itemlist/user/640749
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1894741
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=353610
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/353819
http://mediaville.me/index.php/component/k2/itemlist/user/307058
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/782891
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/281181
http://rudraautomation.com/index.php/component/k2/author/249758
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2351869
http://smartacity.com/component/k2/itemlist/user/64145
http://thermoplast.envolgroupe.com/component/k2/author/137652
http://vhost12299.cpsite.ru/547273-milliardy-4-sezon-11-seria-h8-milliardy-4-sezon-11-seria
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=94517
http://withinfp.sakura.ne.jp/eso/index.php/17343159-smotret-tajny-taemnici-86-seria-e1-tajny-taemnici-86-seria
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1688931
http://gallerychoi.com/Exhibition/271272
http://gallerychoi.com/Exhibition/271409
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=10609
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=10620
http://hanalove.kidspann.net/index.php?mid=faq&document_srl=70172
http://hanalove.kidspann.net/index.php?mid=qna&document_srl=70212
http://hanga5.com/index.php?mid=board_photo&document_srl=85161
http://hanga5.com/index.php?mid=board_photo&document_srl=85265
http://hanga5.com/index.php?mid=board_photo&document_srl=85271
http://hanga5.com/index.php?mid=board_photo&document_srl=85284
http://hanga5.com/index.php?mid=board_photo&document_srl=85316
http://herdental.co.kr/index.php?document_srl=94717&mid=online
http://sy.korean.net/qna/261562
http://xn----3x5er9r48j7wemud0a387h.com/news/87325
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=43076
http://thermoplast.envolgroupe.com/component/k2/author/141646
http://asin.itts.co.kr/board_rtXs84/26763
http://www.cnsmaker.net/xe/?document_srl=105798
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=176954
http://www.jshwanghoan.com/index.php?mid=historical_figures&document_srl=199233
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=199192
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=597703
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=597730
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=597740
http://www.studyxray.com/Sangdam/221562
http://www.studyxray.com/Sangdam/221639
http://www.taeshinmedia.com/?document_srl=3335094
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3335084
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3335089
http://xn----3x5er9r48j7wemud0a387h.com/news/83373
http://ye-dream.com/qa/203160
http://ye-dream.com/qa/203169
http://ye-dream.com/qa/203174
http://ye-dream.com/qa/203179
https://2002.shyoon.com/board_2002/163615
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3541102
http://www.popolsku.fr.pl/forum/index.php?topic=20407.78180
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=136291
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=136324
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=136339
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=136344
http://ucckorea.kr/index.php?mid=board_AuHE49&document_srl=45374
http://smartacity.com/component/k2/itemlist/user/65253
http://xn----3x5er9r48j7wemud0a387h.com/?document_srl=81785
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/134632
http://www.original-craft.net/index.php?topic=355140.0
http://rudraautomation.com/index.php/component/k2/author/249399
http://hanalove.kidspann.net/index.php?mid=qna&document_srl=56788
http://otitismediasociety.org/forum/index.php?topic=196710.0
http://xn----3x5er9r48j7wemud0a387h.com/news/102405
http://dreamplusart.com/mn03_01/66188
http://k-cea.org/board_Hnyj62/184244
http://herdental.co.kr/?document_srl=63367
http://indiefilm.kr/xe/board/157865
http://moavalve.co.kr/?document_srl=84132
https://turimex.mx.solemti.net/component/k2/itemlist/user/4287
http://zanoza.h1n.ru/2019/05/20/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-20-05-2019-n4-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
http://www.popolsku.fr.pl/forum/index.php?topic=20407.74445
http://www.studyxray.com/Sangdam/164673
http://cwon.kr/xe/board_bnSr36/100720
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=115921
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=76875
http://oss.obigo.com/oss/index.php?mid=board_mxLS91&document_srl=22914
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1943720
http://bitpark.co.kr/board_IzjM66/4022473
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=117589
http://www.nienkevanrijn.nl/component/k2/itemlist/user/447002
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=100041
http://asin.itts.co.kr/?document_srl=24187
http://jjikduk.net/DATA/120270
http://k-cea.org/?document_srl=123773
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=72183
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1130218
http://asiagroup.co.kr/index.php?document_srl=307347&mid=board_11
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=307493
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=307634
http://nanaae.com/confirm/16795
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=189475
http://photogrotto.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pt8%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://mercibq.net/partner/12484
http://jjikduk.net/DATA/150712
http://lucky.kidspann.net/index.php?mid=qna&document_srl=76230
http://miquirofisico.com/index.php/component/k2/itemlist/user/4251
http://tekagrafica.com.br/?option=com_k2&view=itemlist&task=user&id=1731028
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/340860
http://www2.yasothon.go.th/smf/index.php?topic=159.166155
https://khuyenmaikk13.info/index.php?topic=208109.0
https://khuyenmaikk13.info/index.php?topic=216152.0
https://khuyenmaikk13.info/index.php?topic=216162.0
https://khuyenmaikk13.info/index.php?topic=216286.0
https://khuyenmaikk13.info/index.php?topic=216298.0
https://khuyenmaikk13.info/index.php?topic=216314.0
https://khuyenmaikk13.info/index.php?topic=216335.0
https://khuyenmaikk13.info/index.php?topic=216340.0
https://khuyenmaikk13.info/index.php?topic=216349.0
https://khuyenmaikk13.info/index.php?topic=216360.0
https://khuyenmaikk13.info/index.php?topic=216377.0
https://khuyenmaikk13.info/index.php?topic=216393.0
https://khuyenmaikk13.info/index.php?topic=216419.0
http://thermoplast.envolgroupe.com/component/k2/author/142058
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/20633
http://www.jesusonly.life/calendar/414491
http://gallerychoi.com/Exhibition/306587
http://lucky.kidspann.net/index.php?mid=qna&document_srl=228004
https://www.amazingworldtop.com/entretenimiento/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%85%d0%be/
http://www.ekemoon.com/233929/051620190124/
http://photogrotto.com/%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gd5%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd/
http://rfc11th13th.dothome.co.kr/Board5/11875
http://atemshow.com/?document_srl=168171
http://carand.co.kr/d2/41891
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=28849
http://corumotoanahtar.com/component/k2/itemlist/user/5324.html
http://corumotoanahtar.com/component/k2/itemlist/user/5816.html
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/gumdanapt/50091
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3481737
http://vtservices85.fr/smf2/index.php?PHPSESSID=15bb247dc0dc22402c32a56ab5e3d86e&topic=271332.0
http://webp.online/index.php?topic=64665.15
http://webp.online/index.php?topic=64669.0
http://webp.online/index.php?topic=64670.0
http://webp.online/index.php?topic=64677.0
http://webp.online/index.php?topic=64680.0
http://webp.online/index.php?topic=64682.0
http://sy.korean.net/qna/208467
http://khapthanam.co.kr/g1/109928
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=10756
http://www.siheunglove.com/chulip/159816
http://photogrotto.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-db6i-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-9-%d1%81/
http://www.critico-expository.com/forum/index.php?topic=26911.0
http://d-tube.info/board_jvyO69/341917
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2657409
http://www.hsaura.com/noty/116965
http://www.josephmaul.org/menu41/137219
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=127797
http://emjun.com/index.php?mid=hangtotal&document_srl=115924
http://sdsn.develop.cinfores.com/?option=com_k2&view=itemlist&task=user&id=223075
http://0433.net/junggo/52033
http://www.golden-nail.co.kr/press/86892
http://vhost12299.cpsite.ru/477782-holostak-9-sezon-13-vypusk-18052019-u3-holostak-9-sezon-13-vypu
http://www.teedinubon.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-w8-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
http://www.teedinubon.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-91-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-g5-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94/
https://www.2ayes.com/18682/2-6-22-05-2019-n4-2-6
http://asiagroup.co.kr/?document_srl=313991
http://asin.itts.co.kr/board_rtXs84/25400
http://jjikduk.net/DATA/125923
http://k-cea.org/board_Hnyj62/126588
http://emjun.com/index.php?mid=hangtotal&document_srl=231840
http://www.ekemoon.com/237489/051120195725/
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=30015
http://xihillstate.bloggirl.net/?document_srl=220689
http://euromouleusinage.com/index.php/component/k2/itemlist/user/156341
http://photogrotto.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xh6%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-3-%d1%81%d0%b5%d1%80/
http://corumotoanahtar.com/component/k2/itemlist/user/5695.html
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=525046
http://hyeonjun.co.kr/?document_srl=70619
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=150997
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=106730
http://thermoplast.envolgroupe.com/component/k2/author/129360
http://vervetama.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-98-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-px3%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-98/
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=92934
https://sanp.pro/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-86-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dg1/
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=528710
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=848129
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=241189
http://k-cea.org/board_Hnyj62/130406
http://looksun.co.kr/index.php?mid=board_4&document_srl=74682
https://www.2ayes.com/18810/2-8-22-05-2019-n2-2-8
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2707228
http://arquitectosenreformas.es/component/k2/itemlist/user/83929
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=362083
http://dev.aabn.org.gh/component/k2/itemlist/user/647933
http://dev.aabn.org.gh/component/k2/itemlist/user/647948
https://esel.gist.ac.kr/esel2/board_hmgj23/137803
http://zanoza.h1n.ru/2019/05/23/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-s5-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
http://www.teedinubon.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-24-05-2019-y5-%d0%b8%d0%b3%d1%80/
https://hackersuniversity.net/index.php?topic=23788.0
http://jjikduk.net/DATA/111517
http://ajincomp.godohosting.com/board_STnh82/95189
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=185813
http://daesestudy.co.kr/ipsi_docu/83765
http://shinhwaair2017.cafe24.com/issue/376581
http://2872870.com/est/37992
http://woodpark.kr/project/22311
http://forum.digamahost.com/index.php?topic=130470.0
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3296270
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=33065
http://asin.itts.co.kr/board_rtXs84/18517
http://moavalve.co.kr/faq/67778
http://skylinecam.co.kr/photo/83430
http://dev.aabn.org.gh/component/k2/itemlist/user/612297
http://hyeonjun.co.kr/menu3/159271
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/343923
http://www.popolsku.fr.pl/forum/index.php?topic=403484.0
https://sanp.pro/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qr7%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f19-05-2019/
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=851042
http://asin.itts.co.kr/board_rtXs84/13551
http://www.teedinubon.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1/
http://xn----3x5er9r48j7wemud0a387h.com/news/32920
http://ovotecegg.com/index.php/component/k2/itemlist/user/189669
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/291244
http://rudraautomation.com/index.php/component/k2/author/267134
http://rudraautomation.com/index.php/component/k2/author/267170
http://smartacity.com/component/k2/itemlist/user/70055
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1737355
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1737284
http://thermoplast.envolgroupe.com/component/k2/author/145425
http://thermoplast.envolgroupe.com/component/k2/author/145430
http://thermoplast.envolgroupe.com/component/k2/author/145466
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=100201
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=19903
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=19998
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1644013
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1644046
http://jejucctv.co.kr/A5/43891
https://esel.gist.ac.kr/esel2/board_hmgj23/262328
http://www.hyunjindc.com/qna/69610
https://sanp.pro/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d1%84%d0%b8%d0%bd%d0%b0%d0%bb-ha%d1%85%d0%be%d0%bb%d0%be/
http://yonseibaik.synology.me/index.php?mid=houston_profile&document_srl=36205
http://callman.co.kr/index.php?mid=qa&document_srl=201197
http://www.lovestory.or.kr/?document_srl=33826
http://thermoplast.envolgroupe.com/component/k2/author/136465
http://rabbitzone.xyz/FREE/46128
http://www.hsaura.com/?document_srl=126873
http://esperanzazubieta.com/component/k2/itemlist/user/100115
https://testing.celekt.com/%d0%91%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hv0%d0%91%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-15-%d1%81%d0%b5/
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=520202
http://www.digitalbul.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-19-05-2019-u5-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2/
http://yoriyorifood.com/xxxx/spacial/107392
http://xn--9m1b83j39hz6exwonmf.com/board_IYPe43/525101
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=33506
http://www.gforgirl.com/xe/poster/114717
http://fbpharm.net/index.php/component/k2/itemlist/user/61096
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=100712
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2322170
http://emjun.com/index.php?mid=hangtotal&document_srl=109136
http://www.fassen.co.kr/xe/board_VCum96/65574
http://www.lgue.co.kr/lgue05/53635
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/128429
http://juroweb.com/xe/juroweb_board/41671
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3864702
http://gochon-iusell.co.kr/g1/46884
http://koais.com/?document_srl=96127
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/13526
https://www.chirorg.com/?document_srl=92742
http://www.livetank.cn/market1/195016
http://rabbitzone.xyz/FREE/30555
http://www.theparrotcentre.com/forum/index.php?topic=547923.0
http://webp.online/index.php?topic=63140.msg109258
http://oss.obigo.com/oss/?document_srl=23593
http://www.hicleaning.kr/board_wash/145622
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3503693
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/222680
http://teambuildingpremium.com/forum/index.php?topic=846111.0
http://www.studyxray.com/Sangdam/103654
http://www.original-craft.net/index.php?topic=334872.0
http://lucky.kidspann.net/index.php?mid=qna&document_srl=55822
https://reficulcoin.com/index.php?topic=50755.0
https://mcsetup.tk/bbs/index.php?topic=257392.0
http://yoriyorifood.com/xxxx/spacial/71194
http://jjikduk.net/DATA/73983
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=202028
http://www.jesusonly.life/calendar/161229
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=193522
http://www.hsaura.com/noty/130714
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=503466
http://emjun.com/index.php?mid=hangtotal&document_srl=89810
http://fbpharm.net/index.php/component/k2/itemlist/user/50111
http://1661-6471.co.kr/?document_srl=16198
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1958559
http://withinfp.sakura.ne.jp/eso/index.php/17374798-efir-tajny-taemnici-90-seria-u6-tajny-taemnici-90-seria/0
http://www.ekemoon.com/227325/051820191122/
http://www.studyxray.com/Sangdam/239879
http://www.eunhaele.co.kr/xe/board/20105
http://guiadetudo.com/index.php/component/k2/itemlist/user/12180
http://vtservices85.fr/smf2/index.php?PHPSESSID=b4de1008ab6f3d4d76d15a1bff61bd8b&topic=265991.0
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=31317
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=73842
http://www.spazioad.com/component/k2/itemlist/user/7343504
http://www.teedinubon.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-95-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mg6%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-95-%d1%81%d0%b5%d1%80%d0%b8%d1%8f17-05-2019/
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=89548
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=89327
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3307955
https://www.vegasgreentour.com/?document_srl=88808
http://www.studyxray.com/Sangdam/147610
http://thermoplast.envolgroupe.com/component/k2/author/123277
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=62474
http://8.droror.co.il/uncategorized/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-82-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jc7/
http://photogrotto.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-24-05-19-ur%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba/
http://www.hicleaning.kr/?document_srl=84396
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/335563
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/329582
http://proxima.co.rw/index.php/component/k2/itemlist/user/651244
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/gumdanapt/71633
http://vtservices85.fr/smf2/index.php?PHPSESSID=29fcbd6aaa52babce17130b38fe009c7&topic=256706.0
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/44811
https://betshin.com/Story/120403
http://readingbible.org/board_xxpp62/1030722
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1128435
http://jjikduk.net/DATA/114410
http://yourhelp.co.kr/index.php?mid=board_2&document_srl=37395
http://wigalseguros.com.br/index.php/component/k2/itemlist/user/10392
http://0433.net/?document_srl=47955
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=36068
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3303674
http://www.sp1.football/index.php?mid=faq&document_srl=180044
http://vtservices85.fr/smf2/index.php?PHPSESSID=a96276d60fb549483fabc62045d1b705&topic=257703.0
http://mediaville.me/index.php/component/k2/itemlist/user/283420
http://webp.online/index.php?topic=59808.15
http://www.studyxray.com/Sangdam/166618
http://www.golden-nail.co.kr/press/95988
http://153.120.114.241/eso/index.php/17114342-smotret-sluga-naroda-3-sezon-23-seria-b9-sluga-naroda-3-sezon-2
http://hyeonjun.co.kr/menu3/62952
http://www.golden-nail.co.kr/press/92341
http://zanoza.h1n.ru/2019/05/21/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gs0%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f21-05/
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1702807
https://hackersuniversity.net/index.php?topic=21814.0
http://callman.co.kr/index.php?mid=qa&document_srl=181566
https://testing.celekt.com/?p=212275
http://themasters.pro/file_01/214626
http://ye-dream.com/qa/202703
http://sy.korean.net/qna/247186
http://studiokoon.net/board_tzri25/563
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=272195
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=224827
https://esel.gist.ac.kr/esel2/board_hmgj23/132654
http://0433.net/junggo/65596
http://www.teedinubon.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-f6-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd/
http://jejucctv.co.kr/A5/38916
http://www.hyunjindc.com/qna/88002
http://batubersurat.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=62754
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=360208
http://dev.aabn.org.gh/?option=com_k2&view=itemlist&task=user&id=644754
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1965412
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1253541
http://jiquilisco.org/index.php/component/k2/itemlist/user/15980
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/129828
http://proxima.co.rw/index.php/component/k2/itemlist/user/672154
http://proxima.co.rw/index.php/component/k2/itemlist/user/672164
http://proxima.co.rw/index.php/component/k2/itemlist/user/672166
http://proxima.co.rw/index.php/component/k2/itemlist/user/672168
http://yoriyorifood.com/xxxx/?document_srl=90516
http://ovotecegg.com/component/k2/itemlist/user/163500
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=825564
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=125684
http://xn--9m1b83j39hz6exwonmf.com/board_IYPe43/525724
http://otitismediasociety.org/forum/index.php?topic=175445.0
http://www.jesusonly.life/calendar/125604
http://ru-realty.com/forum/index.php?topic=527121.0
https://testing.celekt.com/%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-bs%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81/
http://asin.itts.co.kr/board_rtXs84/6721
http://shinhwaair2017.cafe24.com/issue/228016
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/223887
http://www.teedinubon.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ak2%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7/
http://kwpub.kr/PUBS/92399
http://gallerychoi.com/Exhibition/235214
http://www.insesinmun.com/newpaper2/93762
http://www.lgue.co.kr/?document_srl=70931
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=84599
http://xn----c28ewjj6ubwku6frtcuzec29ae5b.com/news/25125
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/282925
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1706411
http://vhost12299.cpsite.ru/552033-novinka-smers-5-seria-j7-smers-5-seria
http://themasters.pro/file_01/172194
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=263320
https://www.celekt.com/%d0%a7%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-chernobyl-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d0%a7%d0%b5%d1%80%d0%bd/
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=306359
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=306375
http://ajincomp.godohosting.com/board_STnh82/85689
http://ajincomp.godohosting.com/board_STnh82/85731
http://ajincomp.godohosting.com/board_STnh82/85752
http://ajincomp.godohosting.com/board_STnh82/85779
http://barobus.kr/qna/43786
http://barobus.kr/qna/43806
http://barobus.kr/qna/43821
http://zanoza.h1n.ru/2019/05/22/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d0%b1%d0%be%d0%bb%d1%8c/
http://zanoza.h1n.ru/2019/05/22/%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-video-%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd-3/
http://zanoza.h1n.ru/2019/05/22/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
https://khuyenmaikk13.info/index.php?topic=215221.0
https://www.amazingworldtop.com/entretenimiento/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d0%b1%d0%be%d0%bb%d1%8c%d1%88/
https://www.amazingworldtop.com/entretenimiento/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-82-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://www.amazingworldtop.com/entretenimiento/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8d%d1%84%d0%b8%d1%80-%d1%81%d0%b5%d0%bd%d1%8f%d1%84/
http://dev.aabn.org.gh/component/k2/itemlist/user/641689
http://toeden.co.kr/Product_new/104694
http://lucky.kidspann.net/index.php?mid=qna&document_srl=245446
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=11175
https://adsensebih.com/index.php?topic=33993.0
http://benzmall.co.kr/index.php?mid=download&document_srl=27132
http://community.viajar.tur.br/index.php?p=/discussion/62134/vetrenyy-hercai-13-seriya-jsct-vetrenyy-hercai-13-seriya
http://community.viajar.tur.br/index.php?p=/profile/calvinsumm
http://lucky.kidspann.net/index.php?mid=qna&document_srl=168669
http://shinhwaair2017.cafe24.com/issue/338258
http://shinhwaair2017.cafe24.com/issue/338263
http://shinhwaair2017.cafe24.com/issue/338287
http://shinhwaair2017.cafe24.com/issue/338297
http://shinhwaair2017.cafe24.com/issue/338321
http://shinhwaair2017.cafe24.com/issue/338348
http://shinhwaair2017.cafe24.com/issue/338387
http://www.hicleaning.kr/board_wash/171215
http://www.josephmaul.org/menu41/224195
http://www.josephmaul.org/menu41/224209
http://asin.itts.co.kr/board_rtXs84/10496
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3686615
http://thermoplast.envolgroupe.com/component/k2/author/122250
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=602909
http://teambuildingpremium.com/forum/index.php?topic=845821.0
http://atemshow.com/atemfair_domestic/52742
https://cybergsm.es/index.php?topic=25858.0
http://oss.obigo.com/oss/index.php?mid=board_mxLS91&document_srl=17626
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=4802
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=712709.0
http://otitismediasociety.org/forum/index.php?topic=183502.0
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=84257
http://moavalve.co.kr/faq/83203
http://azone.synology.me/xe/index.php?document_srl=102478&mid=board_SDnQ73
http://www.siirtorganik.com/index.php/component/k2/itemlist/user/846153
http://ucckorea.kr/index.php?mid=board_AuHE49&document_srl=42466
http://bizchemical.com/board_kMpv94/2038651
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=47530
http://xn----3x5er9r48j7wemud0a387h.com/news/102533
http://www.golden-nail.co.kr/press/300847
http://www.lovestory.or.kr/topic/22190
http://ovotecegg.com/component/k2/itemlist/user/181685
http://www.original-craft.net/index.php?topic=350126.0
http://www.studyxray.com/Sangdam/237471
https://khuyenmaikk13.info/index.php?topic=218529.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3764786
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=17139
http://ganchuk.kiev.ua/index.php/component/k2/itemlist/user/1231408
http://153.120.114.241/eso/index.php/17427648-klatva-yemin-68-seria-ciwx-klatva-yemin-68-seria
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=329248
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=329336
http://withinfp.sakura.ne.jp/eso/index.php/17426479-vetrenyj-hercai-12-seria-nxte-vetrenyj-hercai-12-seria
http://www.ekemoon.com/228841/050620190923/
http://www.ekemoon.com/228845/050620191023/
http://www.ekemoon.com/228855/050620191423/
http://www.ekemoon.com/228863/050620191723/
http://k-cea.org/board_Hnyj62/134396
http://k-cea.org/board_Hnyj62/134431
http://www.teedinubon.com/%d0%bd%d0%b5%d0%b2%d0%b5%d1%81%d1%82%d0%b0-%d0%b8%d0%b7-%d1%81%d1%82%d0%b0%d0%bc%d0%b1%d1%83%d0%bb%d0%b0-istanbullu-gelin-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-82-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-43/
http://www.teedinubon.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-87-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-z0-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94/
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=103871
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3870174
http://otitismediasociety.org/forum/index.php?topic=191027.0
http://otitismediasociety.org/forum/index.php?topic=191036.0
http://smartacity.com/component/k2/itemlist/user/67229
http://vtservices85.fr/smf2/index.php?PHPSESSID=1005087595ff197f6b9132b011666355&topic=272889.0
http://webp.online/index.php?topic=64858.0
http://www2.yasothon.go.th/smf/index.php?topic=159.167805
https://adsensebih.com/index.php?topic=34085.0
https://khuyenmaikk13.info/index.php?topic=218409.0
https://betshin.com/Story/121435
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=51690
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=83885
http://daesestudy.co.kr/ipsi_docu/110732
https://www.celekt.com/%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-24-05-2019-zr%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-24-05-201956-%d0%a5%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-24/
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/?document_srl=38287
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=75192
http://153.120.114.241/eso/index.php/17426843-vetrenyj-hercai-17-seria-svef-vetrenyj-hercai-17-seria
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=328748
http://withinfp.sakura.ne.jp/eso/index.php/17424734-bogatye-i-bednye-zengin-ve-yoksul-9-seria-uqgo-bogatye-i-bednye/0
http://withinfp.sakura.ne.jp/eso/index.php/17424789-bogatye-i-bednye-zengin-ve-yoksul-17-seria-hxfa-bogatye-i-bedny/0
http://withinfp.sakura.ne.jp/eso/index.php/17425113-voron-kuzgun-16-seria-zsft-voron-kuzgun-16-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/17425350-deti-sester-kardes-cocuklari-20-seria-ywut-deti-sester-kardes-c/0
http://withinfp.sakura.ne.jp/eso/index.php/17425476-rannaa-ptaska-erkenci-kus-42-seria-rody-rannaa-ptaska-erkenci-k/0
http://withinfp.sakura.ne.jp/eso/index.php/17425702-edinoe-serdce-tek-yurek-19-seria-lnuw-edinoe-serdce-tek-yurek-1/0
http://withinfp.sakura.ne.jp/eso/index.php/17426237-klatva-yemin-58-seria-pzyo-klatva-yemin-58-seria/0
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/58795
https://grajalesabogados.com.mx/?option=com_k2&view=itemlist&task=user&id=64801
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/64802
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=9863
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=29588
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=29602
http://asiagroup.co.kr/?document_srl=327527
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=327430
http://xn--2e0b53df5ag1c804aphl.net/nuguna/70269
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1736207
http://vhost12299.cpsite.ru/574416-bogatye-i-bednye-zengin-ve-yoksul-11-seria-gyhe-bogatye-i-bedny
http://rudraautomation.com/index.php/component/k2/author/248072
http://koais.com/data/97151
http://photogrotto.com/%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-2019-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-24-05-2019-r7-%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-2019-4-%d1%81/
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=40101
http://photogrotto.com/%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-chernobyl-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd6n-%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-chernobyl-4-%d1%81/
http://proxima.co.rw/index.php/component/k2/itemlist/user/676129
http://www.ekemoon.com/228971/050720190223/
http://www.ekemoon.com/228973/050720190323/
http://www.ekemoon.com/228975/050720190323/
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2795075
http://zanoza.h1n.ru/2019/05/23/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-v6-%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd/
http://zanoza.h1n.ru/2019/05/23/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-x7-%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://zanoza.h1n.ru/2019/05/23/%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-o8-%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4/
http://zanoza.h1n.ru/2019/05/23/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-z1-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2/
http://zanoza.h1n.ru/2019/05/23/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-c4-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4/
http://zanoza.h1n.ru/2019/05/23/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-a6-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb/
http://zanoza.h1n.ru/2019/05/23/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-r7-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
http://zanoza.h1n.ru/2019/05/23/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-96-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-r0-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-96-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://zanoza.h1n.ru/2019/05/23/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-p8-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80/
http://dcasociados.eu/index.php/component/k2/itemlist/user/92222
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=362586
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=362589
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=94716
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=94730
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=94743
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=45160
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=45175
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=45190
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=45199
https://hackinsa.com/freeboard/52852
https://hackinsa.com/freeboard/52889
https://khuyenmaikk13.info/index.php?topic=222239.0
https://www.chirorg.com/?document_srl=115499
http://photogrotto.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lv6f-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81/
http://udrpsucks.com/blog/?p=1560
http://www.ekemoon.com/233439/051220192624/
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=237067
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=237073
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=237129
http://xn--hu1bs8ufrd6ucyz0aooa.kr/?document_srl=24667
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/?document_srl=26674
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/?document_srl=26679
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/26668
http://ye-dream.com/?document_srl=170108
http://ye-dream.com/qa/170046
https://www.celekt.com/%d0%a1%d0%b5%d0%bd%d1%8f%d0%a4%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-24-05-2019-k4-%d0%a1%d0%b5%d0%bd%d1%8f%d0%a4%d0%b5%d0%b4%d1%8f-2/
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/19261
http://photogrotto.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ei0%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5/
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/27589
http://netsconsults.com/?option=com_k2&view=itemlist&task=user&id=808781
http://yeonsen.com/?document_srl=77785
http://xn--ok1bpqi43ahtb.net/board_eASW07/133699
http://skylinecam.co.kr/photo/117380
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=33499
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=276888
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3406134
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=189376
http://netsconsults.com/index.php/component/k2/itemlist/user/799312
http://masanlib.or.kr/g1/30010
http://jiquilisco.org/index.php/component/k2/itemlist/user/10961
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2663771
http://emjun.com/?document_srl=96638
http://www.digitalbul.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-20-05-2019-x2-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4/
http://e-educ.net/Forum/index.php?topic=12142.0
https://testing.celekt.com/%d0%9c%d0%b0%d0%bc%d0%b0-%d0%9b%d0%be%d1%80%d0%b0-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-20-05-2019-q6-%d0%9c%d0%b0%d0%bc%d0%b0-%d0%9b%d0%be%d1%80%d0%b0-12-%d1%81%d0%b5%d1%80%d0%b8/
http://ye-dream.com/qa/79264
http://taklongclub.com/forum/index.php?topic=154921.0
http://www.josephmaul.org/menu41/90340
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1706819
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=185348
https://forum.ac-jete.it/index.php?topic=401728.0
http://roikjer.com/forum/index.php?PHPSESSID=s3b26pj78sa470k0g1tb73kdt0&topic=892453.0
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=68755
http://www.studyxray.com/Sangdam/138477
http://laokorea.com/orange_menu1/119801
http://ovotecegg.com/?option=com_k2&view=itemlist&task=user&id=187264
http://shinhwaair2017.cafe24.com/issue/347223
https://www.celekt.com/%d0%a1%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d0%a7%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-video-%d0%a1%d0%bc%d0%be%d1%82%d1%80/
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=148365
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=125680
http://www.firstfinancialservices.co.uk/?option=com_k2&view=itemlist&task=user&id=19924
http://yonseibaik.synology.me/index.php?mid=houston_profile&document_srl=35650
http://www.siheunglove.com/chulip/134225
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/22128
https://hackinsa.com/freeboard/12578
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2805312
http://lavaggio.com.vn/index.php/component/k2/itemlist/user/3860424
http://asiagroup.co.kr/?document_srl=343175
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=89682
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3307499
http://zanoza.h1n.ru/2019/05/18/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-%d1%84%d0%b8%d0%bd%d0%b0%d0%bb-gb%d1%85%d0%be%d0%bb%d0%be-2/
http://roikjer.com/forum/index.php?PHPSESSID=qjj6opekiueagd816t47e8j032&topic=892802.0
http://bebopindia.com/notcie/118508
http://roikjer.com/forum/index.php?PHPSESSID=31i196692om8fsm845mjilgbb5&topic=888574.0
http://asin.itts.co.kr/board_rtXs84/10072
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3293239
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1829893
http://proxima.co.rw/index.php/component/k2/itemlist/user/649292
http://hyeonjun.co.kr/menu3/71133
http://www.arredoufficiomarca.com/index.php/component/k2/itemlist/user/1613956
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/63793
http://zanoza.h1n.ru/2019/05/19/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-kf0%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5/
http://www.teedinubon.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cj2%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5/
http://universalcommunity.se/Forum/index.php?topic=20257.0
http://lucky.kidspann.net/index.php?mid=qna&document_srl=86785
http://jjikduk.net/STUFFED/89195
http://www.hsaura.com/noty/145921
http://zanoza.h1n.ru/2019/05/21/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vc1%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-15-%d1%81%d0%b5/
http://atemshow.com/atemfair_domestic/40879
http://jejucctv.co.kr/A5/41538
http://www.livetank.cn/market1/188419
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1635036
http://jjimdak.callbank.kr/?document_srl=1058929
http://www.siheunglove.com/chulip/132951
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=75164
http://www.ekemoon.com/208753/050220195618/
http://otitismediasociety.org/forum/index.php?topic=174569.0
http://www.gforgirl.com/xe/?document_srl=113675
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=207159
http://www.digitalbul.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d0%b1%d0%be%d0%bb%d1%8c/
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=586229
http://shinilspring.com/board_qsfb01/83145
http://xn--ok1bpqi43ahtb.net/board_eASW07/123369
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/266042
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=84411
http://www.almacenesrickie.com.ec/index.php/component/k2/itemlist/user/130865
http://www.studyxray.com/Sangdam/115345
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3303841
http://atemshow.com/atemfair_domestic/49646
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/10332
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=188511
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=224102
http://www.renovaleplanejados.com.br/?option=com_k2&view=itemlist&task=user&id=646575
http://callman.co.kr/index.php?mid=qa&document_srl=158980
http://sy.korean.net/?document_srl=278904
http://daesestudy.co.kr/ipsi_docu/103467
http://hyeonjun.co.kr/menu3/264778
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=33087
http://skylinecam.co.kr/photo/128589
http://webp.online/index.php?topic=59980.0
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kz2%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=194538
http://zanoza.h1n.ru/2019/05/20/%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-video-%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd-2/
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=125046
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=330172
http://www.hsaura.com/noty/122581
http://www.gforgirl.com/xe/poster/111410
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=111424
http://www.hsaura.com/noty/126514
http://proxima.co.rw/index.php/component/k2/itemlist/user/656665
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1103853
http://sdsn.rsu.edu.ng/index.php/component/k2/itemlist/user/2323572
http://yoriyorifood.com/xxxx/spacial/104388
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=101089
http://masanlib.or.kr/g1/35766
http://www.rationalkorea.com/xe/index.php?document_srl=502125&mid=pqna3
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1709460
http://zanoza.h1n.ru/2019/05/23/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-23-05-2019-r2-%d1%81%d0%bb%d1%83%d0%b3/
http://xn--2e0b53df5ag1c804aphl.net/nuguna/98439
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/11293
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=647243
http://shinhwaair2017.cafe24.com/issue/326625
http://asin.itts.co.kr/board_rtXs84/34281
https://hackinsa.com/freeboard/2653
http://www.critico-expository.com/forum/index.php?topic=17567.0
http://www.ekemoon.com/227627/052220190122/
http://www.hicleaning.kr/board_wash/184626
http://www.josephmaul.org/menu41/241927
http://www.josephmaul.org/menu41/241971
http://www.josephmaul.org/menu41/242023
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=201957
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=201962
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=202018
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=11127
http://forum.elexlabs.com/index.php?topic=57158.0
http://taklongclub.com/forum/index.php?topic=175375.0
http://taklongclub.com/forum/index.php?topic=175386.0
http://webp.online/index.php?topic=65193.0
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=4976652
http://xn--2e0b53df5ag1c804aphl.net/nuguna/71096
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=22797
http://herdental.co.kr/index.php?mid=online&document_srl=107000
http://withinfp.sakura.ne.jp/eso/index.php/17398958-deti-sester-kardes-cocuklari-19-seria-kfli-deti-sester-kardes-c/0
http://withinfp.sakura.ne.jp/eso/index.php/17398979-vetrenyj-hercai-11-seria-xdgp-vetrenyj-hercai-11-seria/0
http://www.critico-expository.com/forum/index.php?topic=17591.0
http://www.critico-expository.com/forum/index.php?topic=17597.0
http://www.ekemoon.com/227691/052220194022/
http://www.hicleaning.kr/board_wash/185004
http://www.hicleaning.kr/board_wash/185049
http://www.josephmaul.org/menu41/242272
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=202355
http://khapthanam.co.kr/g1/99513
http://khapthanam.co.kr/g1/99547
http://khapthanam.co.kr/g1/99553
http://kitekorea.co.kr/board_Chea81/89406
http://koais.com/data/99380
http://photogrotto.com/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qd6%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5/
https://2002.shyoon.com/?document_srl=120926
http://dev.aabn.org.gh/component/k2/itemlist/user/648664
http://kyj1225.godohosting.com/board_mebR72/45241
http://community.viajar.tur.br/index.php?p=/discussion/62015/voron-kuzgun-19-seriya-wazd-voron-kuzgun-19-seriya
http://koais.com/?document_srl=99103
http://juroweb.com/xe/juroweb_board/70990
http://www.vamoscontigo.org/Noticia/107426
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=52478
http://ovotecegg.com/component/k2/itemlist/user/186193
https://esel.gist.ac.kr/esel2/board_hmgj23/161631
http://sunele.co.kr/board_ReBD97/93507
http://www.insesinmun.com/newpaper2/71852
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=306064
http://vhost12299.cpsite.ru/586901-igra-prestolov-8-sezon-5-seria-f2-igra-prestolov-8-sezon-5-seri
http://vhost12299.cpsite.ru/586931-v-efire-igra-prestolov-8-sezon-1-seria-n8-igra-prestolov-8-sezo
http://vhost12299.cpsite.ru/586942-hd-tola-robot-7-seria-f4-tola-robot-7-seria
http://vhost12299.cpsite.ru/586956-hdvideo-konsul-tant-2-sezon-7-seria-i5-konsul-tant-2-sezon-7-se
http://withinfp.sakura.ne.jp/eso/index.php/17497709-serial-mama-lora-16-seria-s4-mama-lora-16-seria/0
http://xplorefitness.com/blog/live-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-6-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-m0-%D0%B8%D0%B3%D1%80%D0%B0-%D0%BF%D1%80%D0%B5%D1%81%D1%82%D0%BE%D0%BB%D0%BE%D0%B2-8-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-6-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://netsconsults.com/?option=com_k2&view=itemlist&task=user&id=818738
http://www.ekemoon.com/232299/050620192524/
http://www.ekemoon.com/232341/050620193824/
http://www.ekemoon.com/232345/050620193924/
http://www.ekemoon.com/232349/050620193924/
http://www.ekemoon.com/232353/050620194024/
http://www.ekemoon.com/232379/050620194824/
http://daltso.com/index.php?mid=board_cUYy21&document_srl=108775
http://divespace.co.kr/board/163788
http://divespace.co.kr/board/164073
http://divespace.co.kr/board/164089
http://divespace.co.kr/board/164115
http://gabisan.com/?document_srl=50169
http://gabisan.com/board_OuDs04/49772
http://gabisan.com/board_OuDs04/50127
http://gabisan.com/board_OuDs04/50206
http://gallerychoi.com/Exhibition/299120
http://gallerychoi.com/Exhibition/299415
http://jjimdak.callbank.kr/?document_srl=1095058
http://jjimdak.callbank.kr/index.php?document_srl=1094637&mid=board_OGFN30
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=1095237
http://koais.com/data/135266
http://rudraautomation.com/index.php/component/k2/author/251429
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/65422
http://atemshow.com/atemfair_domestic/162742
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=479394
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1893596
http://knet.dothome.co.kr/xe/board_RJHw15/11913
http://koais.com/data/133678
http://sy.korean.net/?document_srl=278429
http://sy.korean.net/?document_srl=278466
http://sy.korean.net/qna/278110
http://sy.korean.net/qna/278176
http://sy.korean.net/qna/278413
http://sy.korean.net/qna/278502
http://bitpark.co.kr/board_IzjM66/4031715
https://testing.celekt.com/%d0%91%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rm5%d0%91%d0%be%d0%bb%d1%8c%d1%88%d0%b5-%d0%b6%d0%b8%d0%b7%d0%bd%d0%b8-8-%d1%81%d0%b5%d1%80/
http://emjun.com/index.php?mid=hangtotal&document_srl=96924
http://vtservices85.fr/smf2/index.php?PHPSESSID=a96276d60fb549483fabc62045d1b705&topic=257703.0
http://mediaville.me/index.php/component/k2/itemlist/user/283420
http://webp.online/index.php?topic=59808.15
http://themasters.pro/file_01/182211
http://miklja.net/forum/index.php?topic=34561.0
http://callman.co.kr/index.php?mid=qa&document_srl=213854
http://toeden.co.kr/Product_new/114109
http://www.livetank.cn/market1/193334
http://www.original-craft.net/index.php?topic=357706.0
http://www.rocketdan.co.kr/?document_srl=64508
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=64524
http://www.siheunglove.com/chulip/163415
http://www.siheunglove.com/chulip/163456
http://www.siheunglove.com/chulip/163464
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/38408
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/?document_srl=23680
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/23670
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/23691
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/23706
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/23717
http://xn----c28ewjj6ubwku6frtcuzec29ae5b.com/news/47307
http://jjikduk.net/DATA/65646
http://adsudoeste.com.br/?option=com_k2&view=itemlist&task=user&id=22078
https://testing.celekt.com/%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-17-05-2019-b9-%d0%98%d0%b3%d1%80/
http://photogrotto.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-21-05-2019-a6-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
https://sanp.pro/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jc4%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://bitpark.co.kr/board_IzjM66/4029701
http://azone.synology.me/xe/index.php?document_srl=117349&mid=board_SDnQ73
http://xn--ok1bpqi43ahtb.net/board_eASW07/121146
http://zanoza.h1n.ru/2019/05/23/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-23-05-2019-d5-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2/
https://www.celekt.com/%d0%98%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-y7-%d0%98%d0%b3%d1%80/
http://tototoday.com/board_oRiY52/63207
http://beautypouch.net/index.php?mid=board_09&document_srl=59741
http://www.lovestory.or.kr/topic/23023
http://www.crnmedia.es/component/k2/itemlist/user/88568
http://forum.digamahost.com/index.php?topic=133579.0
http://www.original-craft.net/index.php?topic=354774.0
http://oneandonly1127.com/?document_srl=64759
http://gochon-iusell.co.kr/g1/57781
http://rudraautomation.com/index.php/component/k2/author/263513
http://xn--2e0b53df5ag1c804aphl.net/nuguna/60119
http://vhost12299.cpsite.ru/597606-hdvideo-mama-lora-14-seria-i8-mama-lora-14-seria
http://1661-6471.co.kr/news/30173
http://5starcoffee.co.kr/board_EBXY17/19416
http://juroweb.com/xe/juroweb_board/70363
http://khapthanam.co.kr/g1/121782
http://khapthanam.co.kr/g1/121877
http://khapthanam.co.kr/g1/121883
http://khapthanam.co.kr/g1/121888
http://kitekorea.co.kr/board_Chea81/115358
http://esperanzazubieta.com/component/k2/itemlist/user/100726
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=74885
http://vtservices85.fr/smf2/index.php?PHPSESSID=aed33973f3efd5c2388cc983d29bb194&topic=262577.0
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=103938
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1649163
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=710967.0
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/219864
http://forum.digamahost.com/index.php?topic=125976.0
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/11337
http://www.hsaura.com/noty/152220
http://xplorefitness.com/blog/%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-11-%D0%B2%D1%8B%D0%BF%D1%83%D1%81%D0%BA%C2%BB-sv%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-11-%D0%B2%D1%8B%D0%BF%D1%83%D1%81%D0%BA%C2%BB82-%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-11-%D0%B2%D1%8B%D0%BF%D1%83%D1%81%D0%BA
https://esel.gist.ac.kr/esel2/board_hmgj23/150274
https://www.amazingworldtop.com/entretenimiento/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-if6%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://miklja.net/forum/index.php?topic=33916.0
http://www.original-craft.net/index.php?topic=345131.0
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1636926
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/308796
http://divespace.co.kr/board/135593
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1738279
http://bebopindia.com/?document_srl=293839
https://nple.com/xe/pds/125565
http://udrpsucks.com/blog/?p=1644
http://www.ekemoon.com/236015/050320195325/
http://www.ekemoon.com/236029/050320195725/
http://www.ekemoon.com/236037/050420190025/
http://withinfp.sakura.ne.jp/eso/index.php/17514743-hd-tola-robot-7-seria-p2-tola-robot-7-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/17514760-v-efire-tola-robot-5-seria-d7-tola-robot-5-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/17514789-v-efire-cernobyl-2-seria-h6-cernobyl-2-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/17514823-v-efire-sluga-naroda-3-sezon-14-seria-o6-sluga-naroda-3-sezon-1/0
http://withinfp.sakura.ne.jp/eso/index.php/17514840-v-efire-igra-prestolov-8-sezon-5-seria-z4-igra-prestolov-8-sezo/0
http://withinfp.sakura.ne.jp/eso/index.php/17514846-hd-tola-robot-2-seria-p3-tola-robot-2-seria/0
http://xplorefitness.com/blog/%D1%82%D0%BE%D0%BB%D1%8F-%D1%80%D0%BE%D0%B1%D0%BE%D1%82-2-%D1%81%D0%B5%D1%80%D0%B8%D1%8F-i1-%D1%82%D0%BE%D0%BB%D1%8F-%D1%80%D0%BE%D0%B1%D0%BE%D1%82-2-%D1%81%D0%B5%D1%80%D0%B8%D1%8F
http://1661-6471.co.kr/news/30894
http://bebopindia.com/notcie/358197
http://jnk-ent.jp/?document_srl=213532
http://jnk-ent.jp/index.php?mid=gallery&document_srl=213607
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=16187
http://asiagroup.co.kr/index.php?document_srl=274063&mid=board_11
http://dev.aabn.org.gh/component/k2/itemlist/user/612103
http://moavalve.co.kr/faq/65570
http://smartacity.com/component/k2/itemlist/user/56689
http://www.jesusonly.life/calendar/152210
http://research.kiu.ac.kr/index.php?document_srl=57880&mid=Food4Thought
http://tiretech.co.kr/index.php?mid=qna&document_srl=114064
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/33245
http://kotica00.dothome.co.kr/index.php?mid=board_nJTE45&document_srl=22203
http://shinhwaair2017.cafe24.com/issue/330366
http://sejong-thesharpyemizi.co.kr/m1/11971
http://1661-6471.co.kr/?document_srl=28193
https://www.celekt.com/%d0%9f%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mi5%d0%9f%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd/
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=68741
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=68794
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/40948
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/40974
http://vhost12299.cpsite.ru/598745-smotret-senafeda-2-sezon-13-seria-u3-senafeda-2-sezon-13-seria
http://vhost12299.cpsite.ru/598791-v-efire-sluga-naroda-3-sezon-15-seria-c9-sluga-naroda-3-sezon-1
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=293352
http://www.golden-nail.co.kr/press/100046
http://indiefilm.kr/xe/board/127972
https://cybergsm.es/index.php?topic=24170.0
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=101282
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3303461
http://w9builders.co.uk/index.php/component/k2/itemlist/user/82835
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=90411
http://svgrossburgwedel.de/component/k2/itemlist/user/5853
http://www.josephmaul.org/menu41/119879
http://roikjer.com/forum/index.php?PHPSESSID=8d0p3u9o0cfsb13j70s1a5k9p5&topic=889384.0
http://0433.net/junggo/55720
https://www.amazingworldtop.com/entretenimiento/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rw0%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be/
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=72746
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3691519
http://rfc11th13th.dothome.co.kr/Board5/6747
http://1600-1590.com/index.php?document_srl=328460&mid=board_ihsE13
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3808630
http://viamania.net/index.php?mid=board_raYV15&document_srl=77703
http://wartoby.com/index.php?mid=board_UXUA38&document_srl=41604
http://thanosakademi.com/index.php?topic=98175.0
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=122764
http://dev.aabn.org.gh/component/k2/itemlist/user/627666
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=510861
http://zanoza.h1n.ru/2019/05/18/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bx8%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f17-05-2019/
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/263723
https://esel.gist.ac.kr/esel2/board_hmgj23/57806
http://www.theocraticamerica.org/forum/index.php/topic,49111.0.html
http://xplorefitness.com/blog/%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-12-%D0%B2%D1%8B%D0%BF%D1%83%D1%81%D0%BA-%D1%84%D0%B8%D0%BD%D0%B0%D0%BB%C2%BB-fr%C2%AB%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-12-%D0%B2%D1%8B%D0%BF%D1%83%D1%81%D0%BA-%D1%84%D0%B8%D0%BD%D0%B0%D0%BB%C2%BB97-%D1%85%D0%BE%D0%BB%D0%BE%D1%81%D1%82%D1%8F%D0%BA-9-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-12
http://www.jesusonly.life/calendar/157924
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3683700
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=506983
http://socialfbwidgets.com/component/k2/itemlist/user/15101
http://forums.abs-cbn.com/welcome-back-kapamilya%21/oe-ee-9-e-20-05-2019-gss-oe-ee-9-e/?PHPSESSID=ri12v984ve4ebo9tlljec060d4
http://subforumna.x10.mx/mad/index.php?topic=254191.0
http://photogrotto.com/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-cw%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81-2/
http://www.jesusonly.life/calendar/212092
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=90890
http://www.teedinubon.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-video-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-2/
http://forum.bmw-e60.eu/index.php?topic=9080.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/643885
http://forum.elexlabs.com/index.php?topic=41911.0
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3674064
http://moavalve.co.kr/faq/81471
http://www.telcon.gr/index.php/component/k2/itemlist/user/72183
http://soc-human.kz/index.php/component/k2/itemlist/user/1713989
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=157758
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=38090
https://sanp.pro/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-as4%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5/
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=233425
http://mglpcm.org/board_ETkS12/77330
http://phmusic.dothome.co.kr/index.php?mid=PowerHouseMusic&document_srl=29226
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1963306
http://www.eunhaele.co.kr/xe/board/19928
http://www.lovestory.or.kr/topic/29387
http://daesestudy.co.kr/ipsi_docu/87273
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=9775
http://community.viajar.tur.br/index.php?p=/profile/lonfkl6363
http://indiefilm.kr/xe/board/106521
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=10228
http://masanlib.or.kr/g1/34375
https://khuyenmaikk13.info/index.php?topic=208030.0
http://shinilspring.com/board_qsfb01/89984
http://vhost12299.cpsite.ru/424321-smotret-tola-robot-2-seria-k9-tola-robot-2-seria
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=84573
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/264083
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=884817
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=711726.0
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1711599
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=16376
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=16392
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1631320
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1631427
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1688176
http://www.atab.com.sa/index.php/en/?option=com_k2&view=itemlist&task=user&id=1687987
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=16158
http://xn----3x5er9r48j7wemud0a387h.com/news/104231
http://www.lgue.co.kr/?document_srl=80876
https://gonggamlaw.com/lawcase/55081
https://emoforum.org/discussion/3221/rannyaya-ptashka-erkenci-kus-42-seriya-cqgq-rannyaya-ptashka-erkenci-kus-42-seriya
https://prelease.club/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-gr%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81/
http://www.theparrotcentre.com/forum/index.php?topic=560887.0
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=92062
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/260274
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=83901
http://moavalve.co.kr/faq/76720
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1933397
http://jjikduk.net/DATA/95165
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3415163
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=8219
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=27953
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=28064
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2698082
http://dcasociados.eu/?option=com_k2&view=itemlist&task=user&id=91220
http://www.josephmaul.org/menu41/219225
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=60816
http://tk-laser.co.kr/index.php?mid=board_QsEu43&document_srl=108438
http://xn----c28ewjj6ubwku6frtcuzec29ae5b.com/news/20972
http://www.crnmedia.es/component/k2/itemlist/user/88610
http://daltso.com/index.php?mid=board_cUYy21&document_srl=119156
http://bebopindia.com/notcie/375977
http://themasters.pro/file_01/212008
http://themasters.pro/file_01/212028
http://themasters.pro/file_01/212050
http://themasters.pro/file_01/212063
http://themasters.pro/file_01/212067
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=532241
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=532286
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=532341
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=532453
http://xn--ok1bpqi43ahtb.net/board_eASW07/102004
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=10571
http://www.theparrotcentre.com/forum/index.php?topic=565924.0
https://reficulcoin.com/index.php?topic=52630.0
http://k-cea.org/board_Hnyj62/105754
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3674284
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1704399
http://www.svteck.co.kr/customer_gratitude/45217
http://www.jesusonly.life/calendar/130789
http://ovotecegg.com/component/k2/itemlist/user/168652
http://zanoza.h1n.ru/2019/05/20/%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-2019-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pr8%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-2019-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://xn----3x5er9r48j7wemud0a387h.com/news/50090
http://www.original-craft.net/index.php?topic=340269.0
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/?document_srl=44704
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=46854
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=93629
http://farmstaypension.com/review/1620187
http://neosky.net/xe/space_station/27325
http://bebopindia.com/notcie/328197
http://www.hyunjindc.com/qna/61016
http://1661-6471.co.kr/news/16388
http://www.lovestory.or.kr/topic/23164
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=228059
http://jiquilisco.org/index.php/component/k2/itemlist/user/18446
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4872330
http://k-cea.org/board_Hnyj62/154870
http://themasters.pro/?document_srl=205866
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/111738
http://ovotecegg.com/component/k2/itemlist/user/161484
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/221386
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/221408
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/221568
http://callman.co.kr/index.php?mid=qa&document_srl=189083
http://callman.co.kr/index.php?mid=qa&document_srl=189093
http://carand.co.kr/d2/28232
http://carand.co.kr/d2/28242
http://jjimdak.callbank.kr/index.php?document_srl=1074170&mid=board_OGFN30
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=1074320
https://2002.shyoon.com/board_2002/165420
http://sy.korean.net/qna/216863
http://miklja.net/forum/index.php?topic=34615.0
http://www.ekemoon.com/234041/051620193424/
http://ye-dream.com/qa/152652
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=195603
http://withinfp.sakura.ne.jp/eso/index.php/17327352-cuzaa-zizn-cuze-zitta-4-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/17327805-hdvideo-cuzaa-zizn-cuze-zitta-1-seria/0
http://withinfp.sakura.ne.jp/eso/index.php/17327922-serial-tola-robot-5-seria-s4-tola-robot-5-seria/0
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1630257
http://www.arredoufficiomarca.com/?option=com_k2&view=itemlist&task=user&id=1630353
http://www.arunagreen.com/index.php/component/k2/itemlist/user/578639
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1687184
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1125846
http://www.dezhiran.com/en/component/k2/itemlist/user/20086
http://www.siirtorganik.com/index.php/component/k2/itemlist/user/870600
http://www.sp1.football/index.php?mid=faq&document_srl=622129
http://www.sp1.football/index.php?mid=faq&document_srl=622168
http://www.sp1.football/index.php?mid=tr_video&document_srl=621813
http://barobus.kr/qna/57691
http://beautypouch.net/index.php?mid=board_09&document_srl=69055
http://beautypouch.net/index.php?mid=board_09&document_srl=69074
http://beautypouch.net/index.php?mid=board_09&document_srl=69116
http://bebopindia.com/?document_srl=325052
http://bebopindia.com/?document_srl=325193
http://bebopindia.com/notcie/324917
http://benzmall.co.kr/index.php?mid=download&document_srl=27998
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=16538
http://bitpark.co.kr/board_IzjM66/4142113
http://www.popolsku.fr.pl/forum/index.php?topic=409942.0
http://yourhelp.co.kr/index.php?mid=board_2&document_srl=44890
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3431084
http://beautypouch.net/index.php?mid=board_09&document_srl=67928
http://sofficer.net/xe/teach/263785
http://bebopindia.com/notcie/336680
http://vsalda.edinros66.ru/component/k2/itemlist/user/64017
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/23065
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/64403
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3514497
https://2002.shyoon.com/board_2002/148192
http://www.ekemoon.com/225483/050120194222/
http://www.ekemoon.com/225489/050120194322/
http://www.hicleaning.kr/board_wash/164737
http://www.hicleaning.kr/board_wash/164812
http://www.josephmaul.org/menu41/217083
http://www.josephmaul.org/menu41/217106
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=227681
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/25035
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/25050
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/25066
https://nple.com/xe/pds/119805
https://nple.com/xe/pds/119906
http://asiagroup.co.kr/?document_srl=356988
http://beautypouch.net/index.php?document_srl=73513&mid=board_09
http://beautypouch.net/index.php?mid=board_09&document_srl=73576
http://beautypouch.net/index.php?mid=board_09&document_srl=73600
http://beautypouch.net/index.php?mid=board_09&document_srl=73610
http://bebopindia.com/notcie/332863
http://bebopindia.com/notcie/333083
http://www.insesinmun.com/?document_srl=64347
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=366228
http://bizchemical.com/board_kMpv94/2018151
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=69261
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/21527
http://callman.co.kr/index.php?document_srl=156806&mid=qa
http://nanaae.com/confirm/11272
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=305890
http://askpharm.net/board_NQiz06/147112
http://laokorea.com/orange_menu1/96495
http://www.siheunglove.com/chulip/145102
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3308497
http://xn--ok1bpqi43ahtb.net/board_eASW07/116135
http://xn----ctbtiediism0a6h.xn--p1ai/index.php?topic=709856.0
http://matrixpharm.ru/forum/index.php?PHPSESSID=uved569dqak7n82k5dhvvf8or1&action=profile;u=198730
http://bebopindia.com/notcie/154883
http://0433.net/junggo/48181
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=200684
http://asin.itts.co.kr/board_rtXs84/24562
http://daesestudy.co.kr/?document_srl=89012
http://daesestudy.co.kr/ipsi_docu/89035
http://jjikduk.net/DATA/122305
http://jjikduk.net/DATA/122443
http://jjikduk.net/DATA/122465
http://k-cea.org/board_Hnyj62/124722
http://photogrotto.com/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-l8-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb/
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3718914
http://web2interactive.com/index.php/component/k2/itemlist/user/3719069
http://www.teedinubon.com/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-h6-%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.teedinubon.com/%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4%d0%bd%d1%8f%d1%8f-%d0%bd%d0%b5%d0%b4%d0%b5%d0%bb%d1%8f-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-v1-%d0%bf%d0%be%d1%81%d0%bb%d0%b5%d0%b4/
http://www.teedinubon.com/%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94%d0%bc%d0%bd%d0%b8%d1%86i-89-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-q8-%d1%82%d0%b0%d0%b9%d0%bd%d1%8b-%d1%82%d0%b0%d1%94/
http://forum.elexlabs.com/index.php?topic=55607.0
http://www.ekemoon.com/226975/051420191622/
http://koais.com/data/136624
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=60789
http://rfc11th13th.dothome.co.kr/Board5/14403
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=595764
http://153.120.114.241/eso/index.php/17376087-klatva-yemin-66-seria-wapl-klatva-yemin-66-seria
http://atemshow.com/atemfair_domestic/181164
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=872828
http://agiteshop.com/xe/qa/151365
http://emjun.com/index.php?mid=hangtotal&document_srl=76384
http://www.tessabannampad.go.th/webboard/index.php?topic=211975.0
https://npi.org.es/smf/index.php?topic=119810.0
http://ye-dream.com/qa/87107
http://zanoza.h1n.ru/2019/05/18/%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-uw5%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-9-%d1%81%d0%b5/
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=113847
https://www.tedyun.com/xe/index.php?mid=gallery&document_srl=206347
http://sixangles.co.kr/qna/641243
http://yoriyorifood.com/xxxx/?document_srl=91338
http://xn----3x5er9r48j7wemud0a387h.com/news/27993
https://hackersuniversity.net/index.php?topic=24773.0
https://hackersuniversity.net/index.php?topic=24802.0
https://khuyenmaikk13.info/index.php?topic=216342.0
https://khuyenmaikk13.info/index.php?topic=216731.0
https://khuyenmaikk13.info/index.php?topic=216809.0
https://khuyenmaikk13.info/index.php?topic=216835.0
https://khuyenmaikk13.info/index.php?topic=216838.0
https://khuyenmaikk13.info/index.php?topic=216842.0
https://khuyenmaikk13.info/index.php?topic=216846.0
http://ye-dream.com/qa/187949
http://melchinooddle.dothome.co.kr/?document_srl=9686
http://themasters.pro/file_01/160098
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=32803
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=106433
http://lavaggio.com.vn/index.php/component/k2/itemlist/user/3828092
http://proxima.co.rw/index.php/component/k2/itemlist/user/647312
http://corumotoanahtar.com/component/k2/itemlist/user/4738.html
http://www.hsaura.com/noty/144186
http://windowshopgoa.com/index.php/component/k2/itemlist/user/195560
http://www.hsaura.com/noty/149785
http://asin.itts.co.kr/board_rtXs84/10310
http://hyeonjun.co.kr/menu3/86233
http://bobr.site/index.php?topic=150011.0
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=95166
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1838469
http://www.teedinubon.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-o8-%d1%81%d0%bb%d1%83%d0%b3%d0%b0/
http://zanoza.h1n.ru/2019/05/22/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-g4-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2/
http://zanoza.h1n.ru/2019/05/22/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-22-05-2019-x7-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4/
http://asin.itts.co.kr/board_rtXs84/23560
http://photogrotto.com/%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-2019-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-le5f-%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-2019-2-%d1%81%d0%b5%d1%80/
http://photogrotto.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xa3%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://agiteshop.com/xe/qa/120618
http://gallerychoi.com/?document_srl=231180
http://www.jesusonly.life/calendar/395749
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3385813
http://miklja.net/forum/index.php?topic=32558.0
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=178026
http://www.theocraticamerica.org/forum/index.php?topic=56618.0
http://photogrotto.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ec2%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://atemshow.com/atemfair_domestic/151437
http://atemshow.com/atemfair_domestic/151553
http://atemshow.com/atemfair_domestic/151638
http://atemshow.com/atemfair_domestic/151657
http://barobus.kr/qna/48228
http://barobus.kr/qna/48286
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=142838
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=317408
https://betshin.com/Story/138655
http://asiagroup.co.kr/index.php?mid=board_11&document_srl=302991
http://sunele.co.kr/board_ReBD97/126025
http://bebopindia.com/notcie/302040
http://xn--2e0bk61btjo.com/notice/16841
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=65073
http://zanoza.h1n.ru/2019/05/23/%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb%d0%be%d0%b2-8-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jc9%d0%b8%d0%b3%d1%80%d0%b0-%d0%bf%d1%80%d0%b5/
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=190829
http://www.hicleaning.kr/board_wash/186860
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=203809
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=203828
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=203843
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=203869
http://indiefilm.kr/xe/board/151968
http://atemshow.com/atemfair_domestic/65290
https://testing.celekt.com/%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-18-05-2019-t0-%d0%a1%d0%bb%d1%83%d0%b3%d0%b0/
http://www.studyxray.com/Sangdam/122585
https://www.amazingworldtop.com/entretenimiento/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fu5%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be/
http://www2.yasothon.go.th/smf/index.php?topic=159.165570
http://mobility-corp.com/index.php/component/k2/itemlist/user/2628621
http://sunele.co.kr/board_ReBD97/109417
http://sunele.co.kr/board_ReBD97/122657
http://sunele.co.kr/board_ReBD97/121384
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/9341
https://sanp.pro/%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bj0%d0%bc%d0%b0%d0%bc%d0%b0-%d0%bb%d0%be%d1%80%d0%b0-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f22-05-2019/
http://lucky.kidspann.net/index.php?mid=qna&document_srl=277268
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=177373
http://www.fassen.co.kr/xe/board_VCum96/96533
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=8692
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/54365
http://tototoday.com/board_oRiY52/60201
http://laokorea.com/orange_menu1/91906
http://mercibq.net/partner/27319
http://sy.korean.net/qna/259179
http://sy.korean.net/qna/259190
http://sy.korean.net/qna/259250
http://www.ds712.net/guest/index.php?document_srl=472222&mid=guest07
http://www.ds712.net/guest/index.php?document_srl=472332&mid=guest07
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=472578
http://www.fassen.co.kr/xe/board_VCum96/87123
http://www.fassen.co.kr/xe/board_VCum96/87152
http://www.fassen.co.kr/xe/board_VCum96/87158
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3526877
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=889185
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/360406
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/309702
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/309707
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=223608
http://otitismediasociety.org/forum/index.php?topic=208124.0
http://constellation.kro.kr/board_kbku73/65679
http://www.urbantutorial.com/?option=com_k2&view=itemlist&task=user&id=127322
https://altaylarteknoloji.com/index.php?topic=6337.0
http://www.ekemoon.com/242405/050720194527/
http://naksansacondo.com/board_MGPu57/35912
http://xn----c28ewjj6ubwku6frtcuzec29ae5b.com/news/56873
http://www.livetank.cn/market1/299690
http://test.comics-game.ru/index.php?topic=507.0
http://roikjer.com/forum/index.php?PHPSESSID=jtnrbti3v788na99a0gkn5i502&topic=935580.0
http://mediaville.me/index.php/component/k2/itemlist/user/330950
http://www.aloeverasas.it/index.php/component/k2/itemlist/user/21510
http://www.quattroandpartners.it/component/k2/itemlist/user/1217848
http://beautypouch.net/index.php?mid=board_09&document_srl=153047
http://fbpharm.net/index.php/component/k2/itemlist/user/87295
http://e-educ.net/Forum/index.php?topic=16385.0
http://dsyang.com/board_Kvgn62/28994
http://neosky.net/xe/space_station/121999
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2593988
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=315855
http://xn--2e0bk61btjo.com/notice/20395
http://vtservices85.fr/smf2/index.php?PHPSESSID=978744ea120889bd6604fdf4c8dcedf2&topic=294946.0
http://jdcalc.com/forum/viewtopic.php?t=294585
http://xn--2e0b53df5ag1c804aphl.net/nuguna/106420
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2740342
http://ko.myds.me/board_story/244299
http://mtuan93.com/board_uCqR85/6190
http://backo.co.kr/board_aiQk58/16364
https://2002.shyoon.com/?document_srl=170621
https://nple.com/xe/pds/156750
http://hyeonjun.co.kr/menu3/287777
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dvhe-%d1%80%d0%b0%d1%81/
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/31247
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/31339
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/31350
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/31412
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/31429
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/31520
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/31541
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/31642
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/31662
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/31688
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/31728
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1982901
http://herdental.co.kr/index.php?mid=online&document_srl=113519
http://necinsurance.co.zw/component/k2/itemlist/user/21644.html
http://mglpcm.org/board_ETkS12/130176
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=301217
http://bobr.site/index.php?topic=178281.0
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/?document_srl=75805
http://forum.bmw-e60.eu/index.php?topic=11446.0
http://www.livetank.cn/market1/286573
http://153.120.114.241/eso/index.php/17537805-rasskaz-sluzanki-3-sezon-4-seria-onkc-rasskaz-sluzanki-3-sezon-
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=230411
http://naksansacondo.com/board_MGPu57/34654
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2827725
http://jiral.net/an9/44240
https://khuyenmaikk13.info/index.php?topic=226943.0
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/70711
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3899863
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3899922
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3899953
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3900290
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3900326
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3900747
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3900762
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hdfp-%d1%80%d0%b0%d1%81/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-echq-%d1%80%d0%b0%d1%81/
http://khapthanam.co.kr/g1/136266
http://neosky.net/xe/space_station/125110
http://pekosmile.dothome.co.kr/index.php?mid=seoulitestudio&document_srl=432723
http://holysweat.dothome.co.kr/data/7543
http://isch.kr/board_PowH60/156077
http://jnk-ent.jp/index.php?mid=gallery&document_srl=321470
http://ucckorea.kr/index.php?mid=board_AuHE49&document_srl=78650
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1975746
http://khapthanam.co.kr/g1/136528
https://www.limscave.com/forum/viewtopic.php?t=54679
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=317069
https://www.chirorg.com/?document_srl=150885
http://ye-dream.com/qa/241564
http://loverstory.co.kr/board_UYNJ05/42240
https://khuyenmaikk13.info/index.php?topic=225429.0
http://dayung.co.kr/board_SRVC17/67789
http://mediaville.me/index.php/component/k2/itemlist/user/332694
http://mediaville.me/index.php/component/k2/itemlist/user/332755
http://mediaville.me/index.php/component/k2/itemlist/user/332760
http://mediaville.me/index.php/component/k2/itemlist/user/333001
http://mediaville.me/index.php/component/k2/itemlist/user/333013
http://mediaville.me/index.php/component/k2/itemlist/user/333051
http://mediaville.me/index.php/component/k2/itemlist/user/333079
http://mediaville.me/index.php/component/k2/itemlist/user/333128
http://mediaville.me/index.php/component/k2/itemlist/user/333247
http://mediaville.me/index.php/component/k2/itemlist/user/333261
http://mediaville.me/index.php/component/k2/itemlist/user/333288
http://mediaville.me/index.php/component/k2/itemlist/user/333293
http://mediaville.me/index.php/component/k2/itemlist/user/333370
http://alastair030.dothome.co.kr/index.php?mid=board_MMiF30&document_srl=22370
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3754675
http://daesestudy.co.kr/ipsi_docu/142841
https://reficulcoin.com/index.php?topic=85857.0
http://beautypouch.net/index.php?mid=board_09&document_srl=102118
http://hyeonjun.co.kr/menu3/372187
https://esel.gist.ac.kr/esel2/board_hmgj23/267567
http://smartacity.com/component/k2/itemlist/user/79324
http://herdental.co.kr/index.php?mid=online&document_srl=117391
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2740103
http://www.itosm.com/cn/board_nLoq17/186721
https://forums.lfstats.com/viewtopic.php?t=319437
http://www.cnsmaker.net/xe/?document_srl=122035
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=105657
http://sd-xi.co.kr/g1/51382
http://www.lgue.co.kr/?document_srl=116267
http://healthyteethpa.org/component/k2/itemlist/user/5549067
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=910241
http://erhu.eu/viewtopic.php?f=7&t=396315
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3371538
https://adsensebih.com/index.php?topic=48554.0
http://legride.com/UserProfile/tabid/61/userId/2867648/Default.aspx
http://khapthanam.co.kr/g1/136419
http://holysweat.dothome.co.kr/data/7277
https://gonggamlaw.com/lawcase/67482
http://2872870.com/est/63084
http://benzmall.co.kr/index.php?mid=download&document_srl=48279
http://ajincomp.godohosting.com/board_STnh82/154081
http://dsyang.com/board_Kvgn62/30140
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=17923
http://mglpcm.org/board_ETkS12/183496
http://bebopindia.com/notcie/385501
http://looksun.co.kr/index.php?mid=board_4&document_srl=127562
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=416798
http://www.golden-nail.co.kr/press/364318
http://rabbitzone.xyz/?document_srl=109388
http://ko.myds.me/?document_srl=247538
http://myrechockey.com/forums/index.php?topic=118435.0
http://dcasociados.eu/component/k2/itemlist/user/93473
http://beautypouch.net/index.php?mid=board_09&document_srl=100373
http://holysweat.dothome.co.kr/data/7394
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/37772
http://2872870.com/est/61263
http://www2.yasothon.go.th/smf/index.php?topic=159.170070
http://agiteshop.com/xe/qa/208895
https://www.lwfservers.com/index.php?topic=72385.0
http://www.golden-nail.co.kr/press/369895
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2600158
http://hyeonjun.co.kr/menu3/288393
http://www.sp1.football/index.php?mid=faq&document_srl=693387
http://naksansacondo.com/board_MGPu57/31930
http://www.vamoscontigo.org/Noticia/180202
http://www.cnsmaker.net/xe/?document_srl=145141
http://2872870.com/?document_srl=61504
http://apt2you2.cafe24.com/g1/46646
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=198284
http://daesestudy.co.kr/ipsi_docu/121172
http://khapthanam.co.kr/g1/136173
http://www.hmotors.co.kr/inquiry/23924
http://ye-dream.com/?document_srl=238625
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zwed-%d1%80%d0%b0%d1%81/
http://gabisan.com/board_OuDs04/74928
http://dev.aabn.org.gh/component/k2/itemlist/user/679283
http://zakdu.com/board_YpzS56/25324
http://autospa.lv/index.php/lv/component/k2/itemlist/user/10664
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=229405
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=229412
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1866549
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16410
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7516101
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7516649
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=43088
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/841225
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/841611
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3568028
http://www.quattroandpartners.it/component/k2/itemlist/user/1245939
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/66119
https://blossomug.com/index.php/component/k2/itemlist/user/1111609
http://www.sp1.football/index.php?mid=faq&document_srl=692875
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=84730
http://married.dike.gr/index.php/component/k2/itemlist/user/77958
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/64387
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=258393
http://blog.ptpintcast.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xhfs-%d1%80%d0%b0%d1%81/
http://www.svteck.co.kr/customer_gratitude/224102
https://www.regalepadova.it/index.php/component/k2/itemlist/user/8201
http://daltso.com/index.php?mid=board_cUYy21&document_srl=127316
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=91293
http://tiretech.co.kr/index.php?mid=qna&document_srl=186980
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=556879
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1934509
http://music.start-a-idea.online/blogs/viewstory/44007
http://www.haetsaldun-clinic.co.kr/Question/36935
https://gonggamlaw.com/lawcase/66595
http://www.ekemoon.com/245173/052220195528/
https://intelogist2.wpengine.com/%d0%ba%d0%be%d0%bf-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hy6z-%d0%ba%d0%be%d0%bf-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://euromouleusinage.com/index.php/component/k2/itemlist/user/186275
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=43384
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=43392
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=43393
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=43399
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4934513
https://www.shaiyax.com/index.php?topic=401299.0
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=407733
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=103351
https://forums.lfstats.com/viewtopic.php?t=320372
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/246349
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/49249
http://midorijapaneserestaurant.ca/menu/News/24006
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=118794
http://bobr.site/index.php?topic=185453.0
http://jnk-ent.jp/index.php?mid=gallery&document_srl=235451
http://x-crew.center/guest/4846811
http://bebopindia.com/notcie/385094
http://lasvur.ru/component/k2/itemlist/user/39709
http://lasvur.ru/component/k2/itemlist/user/39710
http://lasvur.ru/component/k2/itemlist/user/39729
http://lasvur.ru/index.php/component/k2/itemlist/user/39569
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=40141.0
http://ko.myds.me/board_story/259014
http://gallerychoi.com/Exhibition/401221
http://www.popolsku.fr.pl/forum/index.php?topic=20407.80115
http://ye-dream.com/qa/206242
https://mcsetup.tk/bbs/index.php?topic=263111.0
http://2872870.com/est/71131
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1754086
http://oss.obigo.com/oss/index.php?mid=board_mxLS91&document_srl=66980
http://proxima.co.rw/index.php/component/k2/itemlist/user/695491
http://zakdu.com/board_YpzS56/19465
http://0433.net/junggo/115015
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=90777
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=188104
https://www.hohoyoga.com/testboard/4016925
http://xekhachduyetthuy.com.vn/component/k2/itemlist/user/241614
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=39680.0
http://ptu.imoove.kr/ko/content/%C2%AB%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-1-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-kmzz-%C2%AB%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-1-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-starz341287
http://sd-xi.co.kr/g1/60101
http://sd-xi.co.kr/g1/60229
http://sd-xi.co.kr/g1/60655
http://sd-xi.co.kr/g1/64181
http://sd-xi.co.kr/g1/64668
http://sd-xi.co.kr/g1/66511
http://sd-xi.co.kr/g1/70143
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2593988
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=315855
http://xn--2e0bk61btjo.com/notice/20395
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/75122
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2827405
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=14215
http://viamania.net/index.php?mid=board_raYV15&document_srl=139263
http://153.120.114.241/eso/index.php/17529220-rasskaz-sluzanki-3-sezon-5-seria-pdel-rasskaz-sluzanki-3-sezon-
http://daesestudy.co.kr/ipsi_docu/147657
http://pkgersang.dothome.co.kr/board_jiKY24/38828
http://mglpcm.org/board_ETkS12/186780
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/75662
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=917235
https://forums.lfstats.com/viewtopic.php?t=314555
http://barobus.kr/qna/75448
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=652750
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4899954
http://www.arunagreen.com/index.php/component/k2/itemlist/user/1156574
http://legride.com/UserProfile/tabid/61/userId/2893280/Default.aspx
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=97093
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=922910
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=925240
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=925574
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=928458
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/148544
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2738839
http://oss.obigo.com/oss/index.php?mid=board_mxLS91&document_srl=58168
http://agiteshop.com/xe/qa/162503
http://otitismediasociety.org/forum/index.php?topic=206661.0
http://sd-xi.co.kr/g1/64668
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=17780
http://2872870.com/est/62839
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=98880
http://herdental.co.kr/index.php?mid=online&document_srl=164586
http://praisesound.co.kr/sub04_01/88287
http://mediaville.me/index.php/component/k2/itemlist/user/332388
http://www.venusjeju.com/index.php?mid=QnA&document_srl=1023
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ssmx-%d1%80%d0%b0%d1%81/
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=133815
http://www.itosm.com/cn/board_nLoq17/148065
http://www.kcch.or.kr/index.php?mid=board_uFpk03&document_srl=114183
https://intelogist2.wpengine.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sttn-%d1%80%d0%b0%d1%81/
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2742130
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2826172
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=206799
http://www.cswc.co.kr/index.php?mid=board_zyTs37&document_srl=53480
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=393004
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=49803
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=182168
http://fbpharm.net/index.php/component/k2/itemlist/user/86300
http://zakdu.com/board_ssKi56/20151
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1084738
http://www.livetank.cn/market1/306654
http://www.svteck.co.kr/customer_gratitude/330639
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3403791
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=266236
http://taklongclub.com/forum/index.php?topic=204624.0
http://godeok.houseplan.kr/index.php?document_srl=152572&mid=board_HFtY66
http://yourhelp.co.kr/index.php?mid=board_2&document_srl=92447
https://www.limscave.com/forum/viewtopic.php?t=56967
http://e-educ.net/Forum/index.php?topic=16727.0
http://neosky.net/xe/space_station/69113
http://carand.co.kr/d2/68735
http://gusinoepero.ru/archives/29246
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=557876
http://socialmag.bayareanonprofits.xyz/blogs/viewstory/131141
https://www.limscave.com/forum/viewtopic.php?t=54702
https://betshin.com/Story/198861
https://betshin.com/Story/198875
https://betshin.com/Story/198885
https://betshin.com/Story/198906
https://betshin.com/Story/198925
https://betshin.com/Story/198932
https://gonggamlaw.com/lawcase/131707
https://gonggamlaw.com/lawcase/131712
https://gonggamlaw.com/lawcase/131727
http://dcasociados.eu/component/k2/itemlist/user/94544
http://dohairbiz.com/en/component/k2/itemlist/user/2814766.html
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=17117
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=17120
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=401016
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=401047
http://viamania.net/index.php?mid=board_raYV15&document_srl=189822
http://sammyungsa.com/board_dltP23/3792
http://mglpcm.org/?document_srl=130053
http://rudraautomation.com/index.php/component/k2/author/292415
http://xn--2e0bk61btjo.com/notice/25722
http://guiadetudo.com/index.php/component/k2/itemlist/user/12658
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=378260
http://www.eunhaele.co.kr/xe/board/20280
http://roikjer.com/forum/index.php?PHPSESSID=52k3djvv6roq29s89rmu16q5b0&topic=924642.0
http://sejong-thesharpyemizi.co.kr/m1/27197
http://masanlib.or.kr/g1/96151
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1939932
http://www.haetsaldun-clinic.co.kr/Question/38742
https://timecker.com/anonymous/188869
http://www.patrasin.kr/index.php?mid=questions&document_srl=4347088
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=547320
https://khuyenmaikk13.info/index.php?topic=229434.0
https://2002.shyoon.com/board_2002/168704
http://herdental.co.kr/index.php?document_srl=155285&mid=online
http://www.golden-nail.co.kr/press/363263
https://gonggamlaw.com/lawcase/126081
http://dcasociados.eu/component/k2/itemlist/user/94310
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=366355
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=366439
http://dev.aabn.org.gh/component/k2/itemlist/user/710790
http://dev.aabn.org.gh/component/k2/itemlist/user/710897
https://www.hwbms.com/web/qna/10415
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=243544
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=5019512
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=199881
http://yooseok.com/board_BkvT46/412908
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=558586
http://holysweat.dothome.co.kr/data/7034
https://mcsetup.tk/bbs/index.php?topic=261829.0
http://test.comics-game.ru/index.php?topic=483.0
http://bobr.site/index.php?topic=182014.0
https://www.hwbms.com/web/qna/12248
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=1b325ab5a7172a303a28adeee68bebc1&topic=11000.0
http://jdcalc.com/forum/viewtopic.php?t=293158
http://www.sp1.football/index.php?mid=faq&document_srl=783390
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3899537
http://test.comics-game.ru/index.php?topic=476.0
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/88469
http://myesl.ca/forum/viewtopic.php?t=688162
http://www.livetank.cn/market1/218577
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=213926
http://looksun.co.kr/index.php?mid=board_4&document_srl=182100
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3780473
http://www.leekeonsu-csi.com/index.php?document_srl=1071499&mid=sangdam1
https://betshin.com/Story/193587
https://gonggamlaw.com/lawcase/125809
https://gonggamlaw.com/lawcase/125824
https://gonggamlaw.com/lawcase/125838
https://www.hwbms.com/web/qna/19902
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=42556
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/840362
http://proxima.co.rw/index.php/component/k2/itemlist/user/710396
http://www.capital-investment.pl/index.php/component/k2/itemlist/user/228928
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f/
http://dev.aabn.org.gh/?option=com_k2&view=itemlist&task=user&id=710809
http://www.sp1.football/index.php?mid=faq&document_srl=693055
http://www.sp1.football/index.php?mid=faq&document_srl=693284
http://www.sp1.football/index.php?mid=faq&document_srl=693295
http://www.sp1.football/index.php?mid=faq&document_srl=693322
http://www.sp1.football/index.php?mid=faq&document_srl=693387
http://www.sp1.football/index.php?mid=faq&document_srl=693450
http://www.sp1.football/index.php?mid=faq&document_srl=693515
http://www.sp1.football/index.php?mid=faq&document_srl=693993
http://www.sp1.football/index.php?mid=faq&document_srl=694082
http://www.sp1.football/index.php?mid=faq&document_srl=694093
http://www.sp1.football/index.php?mid=faq&document_srl=694243
http://www.sp1.football/index.php?mid=faq&document_srl=694267
http://www.sp1.football/index.php?mid=faq&document_srl=694303
http://www.sp1.football/index.php?mid=faq&document_srl=694444
http://roikjer.com/forum/index.php?PHPSESSID=qmlpbgkkt0c2dut9b5ul62tgl1&topic=929839.0
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/60748
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/33324
http://www.jesusonly.life/calendar/444140
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=127697
http://1661-6471.co.kr/news/44649
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=92014
http://vtservices85.fr/smf2/index.php?PHPSESSID=c6747ee8fa0b2ce9c67da64c57fbb1cc&topic=291246.0
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3547787
http://www.jesusonly.life/calendar/533554
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=191038
http://dow.dothome.co.kr/board_jydx58/33428
http://bobr.site/index.php?topic=184640.0
http://pkgersang.dothome.co.kr/board_jiKY24/40192
http://dow.dothome.co.kr/board_jydx58/37872
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3371795
http://jnk-ent.jp/index.php?mid=gallery&document_srl=241192
http://myrechockey.com/forums/index.php?topic=117867.0
http://servicioswts.com/?option=com_k2&view=itemlist&task=user&id=3833574
http://apt2you2.cafe24.com/g1/35334
http://www.verenas-unterwasserwelt.de/forum/index.php?topic=11383.0
https://forum.ac-jete.it/index.php?topic=451230.0
https://www.lwfservers.com/index.php?topic=74285.0
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=85990
http://www.dap.com.py/index.php/component/k2/itemlist/user/850814
http://www.dap.com.py/index.php/es/?option=com_k2&view=itemlist&task=user&id=850808
https://forum.ac-jete.it/index.php?topic=446744.0
http://www.hmotors.co.kr/inquiry/25368
http://necinsurance.co.zw/component/k2/itemlist/user/21715.html
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=1124161
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/37650
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1215012
http://k-cea.org/board_Hnyj62/194152
http://healthyteethpa.org/component/k2/itemlist/user/5546480
http://www.cswc.co.kr/index.php?mid=board_zyTs37&document_srl=32883
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=113124
http://www.patrasin.kr/?document_srl=4351801
http://hyeonjun.co.kr/menu3/339411
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2744793
http://israengineering.com/index.php/component/k2/itemlist/user/1290113
http://www.ekemoon.com/243287/052020193427/
https://forums.lfstats.com/viewtopic.php?t=319403
http://alastair030.dothome.co.kr/index.php?mid=board_MMiF30&document_srl=26098
https://www.shaiyax.com/index.php?topic=408230.0
https://gonggamlaw.com/lawcase/68705
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2741523
http://e-educ.net/Forum/index.php?topic=16263.0
http://p9912.cafe24.com/board_LVgu51/34812
http://naksansacondo.com/board_MGPu57/32311
http://tiretech.co.kr/index.php?mid=qna&document_srl=194868
http://hanga5.com/index.php?mid=board_photo&document_srl=110660
http://jensenbyggteam.no/index.php/component/k2/itemlist/user/13782
http://yooseok.com/board_BkvT46/412697
http://8.droror.co.il/uncategorized/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-aacf-%d1%80%d0%b0%d1%81/
http://constellation.kro.kr/board_kbku73/66844
http://rudraautomation.com/index.php/component/k2/author/289178
http://www.hmotors.co.kr/inquiry/27270
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3901456
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=5056678
http://photogrotto.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ok8h-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://www.ekemoon.com/244909/052020193428/
http://www.ekemoon.com/244957/052020195928/
http://www.ekemoon.com/244961/052120190328/
http://www.ekemoon.com/244987/052120191028/
http://www.ekemoon.com/244989/052120191128/
http://www.ekemoon.com/245005/052120191828/
http://www.ekemoon.com/245021/052120192528/
http://www.ekemoon.com/245023/052120192528/
http://www.ekemoon.com/245029/052120192728/
http://www.ekemoon.com/245035/052120193028/
http://www.ekemoon.com/245037/052120193428/
http://www.ekemoon.com/245039/052120193628/
http://www.ekemoon.com/245041/052120193628/
http://www.hmotors.co.kr/inquiry/24706
http://ye-dream.com/qa/206403
http://nnkumw.org/xe/index.php?mid=board_yNQm00&document_srl=141001
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vcyd-%d1%80%d0%b0%d1%81/
http://www.kcch.or.kr/index.php?mid=board_uFpk03&document_srl=97508
https://2002.shyoon.com/board_2002/167335
http://gochon-iusell.co.kr/g1/76221
http://sd-xi.co.kr/g1/82226
https://forums.lfstats.com/viewtopic.php?t=327886
https://gonggamlaw.com/lawcase/133271
https://reficulcoin.com/index.php?topic=100924.0
http://servicioswts.com/index.php/component/k2/itemlist/user/3874686
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1734409
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3374620
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=259431
http://yourhelp.co.kr/index.php?mid=board_2&document_srl=75958
http://jdcalc.com/forum/viewtopic.php?t=287053
http://barobus.kr/qna/78022
http://0433.net/junggo/130982
http://knet.dothome.co.kr/xe/board_RJHw15/15464
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=109262
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=17850
http://ariji.kr/?document_srl=973475
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=39566
http://www.popolsku.fr.pl/forum/index.php?topic=418774.0
http://jnk-ent.jp/index.php?mid=gallery&document_srl=239583
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=103960
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1975326
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/59314
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=242594
http://myesl.ca/forum/viewtopic.php?f=3&t=688642&view=print
http://vtservices85.fr/smf2/index.php?PHPSESSID=560a091155eeb164c2ae898f72837f7d&topic=291383.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=5991ebacc0cbd3b527b1544e4455ba46&topic=291284.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=5ce68379ea5ed938fbe6f04d4ab99746&topic=289517.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=647ba3f07558a93700330363d5a92dba&topic=293068.0
https://khuyenmaikk13.info/index.php?topic=228381.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3450420
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=158757
http://www.lgue.co.kr/lgue05/149736
http://xn----c28ewjj6ubwku6frtcuzec29ae5b.com/news/55684
http://khapthanam.co.kr/g1/136351
https://forum.shaiyaslayer.tk/index.php?topic=158679.0
http://erhu.eu/viewtopic.php?t=398335
https://www.chirorg.com/?document_srl=144492
https://intelogist2.wpengine.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sebt-%d1%80%d0%b0%d1%81/
http://www.theocraticamerica.org/forum/index.php?topic=78701.0
http://www.golden-nail.co.kr/press/357786
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=265571
http://praisesound.co.kr/sub04_01/88738
http://gabisan.com/board_OuDs04/101765
http://khapthanam.co.kr/g1/135113
http://benzmall.co.kr/index.php?mid=download&document_srl=46259
http://roikjer.com/forum/index.php?PHPSESSID=3kdam4im9s83k30jbdnd0gaaf1&topic=931708.0
https://timecker.com/anonymous/188661
http://xn--2e0bk61btjo.com/notice/25898
https://www.celekt.com/%d0%a0%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dsgm-%d0%a0%d0%b0%d1%81/
http://ko.myds.me/board_story/245238
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=116237
http://sd-xi.co.kr/g1/70161
http://sd-xi.co.kr/g1/70735
http://sd-xi.co.kr/g1/71324
http://sd-xi.co.kr/g1/72016
http://sd-xi.co.kr/g1/72851
http://sd-xi.co.kr/g1/73776
http://sd-xi.co.kr/g1/75015
http://sd-xi.co.kr/g1/75359
http://sd-xi.co.kr/g1/75955
http://sd-xi.co.kr/g1/77672
https://intelogist2.wpengine.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-utwc-%d1%80%d0%b0%d1%81/
http://jiral.net/an9/27922
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=39881.0
http://www.jesusonly.life/calendar/503632
http://www.cnsmaker.net/xe/?document_srl=130630
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/56829
http://www.theocraticamerica.org/forum/index.php?topic=73924.0
https://zakdu.com/?document_srl=17913
http://www.kwpcoop.or.kr/QnA/21922
http://beautypouch.net/?document_srl=141703
http://looksun.co.kr/index.php?mid=board_4&document_srl=156251
http://universalcommunity.se/Forum/index.php?topic=34481.0
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3753001
http://tiretech.co.kr/index.php?mid=qna&document_srl=190193
http://viamania.net/index.php?mid=board_raYV15&document_srl=128791
https://gonggamlaw.com/lawcase/89700
http://neosky.net/xe/space_station/69076
http://ariji.kr/?document_srl=969667
http://universalcommunity.se/Forum/index.php?topic=35641.0
http://hotelnomadpalace.com/component/k2/itemlist/user/22104
http://nnkumw.org/xe/index.php?mid=board_yNQm00&document_srl=139508
http://www.theocraticamerica.org/forum/index.php?topic=69234.0
https://khuyenmaikk13.info/index.php?topic=225985.0
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=84285
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=152323
http://d-tube.info/board_jvyO69/373677
http://lucky.kidspann.net/index.php?mid=qna&document_srl=289246
http://dreamplusart.com/mn03_01/124022
http://www.popolsku.fr.pl/forum/index.php?topic=20407.81000
http://jdcalc.com/forum/viewtopic.php?t=292982
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=653435
http://153.120.114.241/eso/index.php/17529262-rasskaz-sluzanki-3-sezon-9-seria-srkv-rasskaz-sluzanki-3-sezon-
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=108490
https://www.c-alice.org/forum/index.php?topic=98178.0
http://www.tessabannampad.go.th/webboard/index.php?topic=226786.0
http://yonseibaik.synology.me/index.php?mid=houston_profile&document_srl=56288
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/?document_srl=141318
http://nnkumw.org/xe/index.php?mid=board_yNQm00&document_srl=140393
http://fbpharm.net/index.php/component/k2/itemlist/user/87105
http://warmfund.net/p/index.php?mid=financing&document_srl=510742
http://1644-4404.com/index.php?document_srl=225585&mid=board_VFri46
http://yourhelp.co.kr/?document_srl=100412
http://www.jesusonly.life/calendar/443825
https://www.celekt.com/%d0%a0%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uqrs-%d0%a0%d0%b0%d1%81/
https://forum.clubeicaro.pt/index.php?topic=2536.0
http://e-educ.net/Forum/index.php?topic=17232.0
http://rabbitzone.xyz/FREE/109719
https://2002.shyoon.com/board_2002/171164
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=925574
http://taklongclub.com/forum/index.php?topic=204281.0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/1156743
http://xn--2e0bk61btjo.com/notice/21296
http://lavaggio.com.vn/index.php/component/k2/itemlist/user/3899954
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=259918
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=206091
https://www.hohoyoga.com/testboard/3977471
https://www.hohoyoga.com/testboard/3977522
https://www.hohoyoga.com/testboard/3977537
https://www.hohoyoga.com/testboard/3977571
https://www.hohoyoga.com/testboard/3977590
https://www.hohoyoga.com/testboard/3977645
https://www.hohoyoga.com/testboard/3977683
https://www.hohoyoga.com/testboard/3977688
https://www.hohoyoga.com/testboard/3977740
https://www.hohoyoga.com/testboard/3977744
https://www.hohoyoga.com/testboard/3978040
http://otitismediasociety.org/forum/index.php?topic=198944.0
http://www.kcch.or.kr/?document_srl=92106
https://esel.gist.ac.kr/esel2/board_hmgj23/327211
http://jnk-ent.jp/index.php?mid=gallery&document_srl=333956
http://yooseok.com/board_BkvT46/417081
http://taklongclub.com/forum/index.php?topic=204329.0
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=916084
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nnbn-%d1%80%d0%b0%d1%81/
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=105336
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=88658
http://sejong-thesharpyemizi.co.kr/m1/64829
http://praisesound.co.kr/sub04_01/87148
http://miquirofisico.com/index.php/component/k2/itemlist/user/4469
http://isch.kr/board_PowH60/206858
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=332719
https://betshin.com/Story/194531
https://gonggamlaw.com/lawcase/127067
https://gonggamlaw.com/lawcase/127099
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/841186
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=229203
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2780980
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=386118
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=386119
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=386226
http://dessa.com.br/component/k2/itemlist/user/386145
http://dev.aabn.org.gh/component/k2/itemlist/user/711717
http://esperanzazubieta.com/component/k2/itemlist/user/108096
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1995702
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1995827
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/87403
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=69892
http://www.cswc.co.kr/index.php?mid=board_zyTs37&document_srl=39182
http://alastair030.dothome.co.kr/index.php?mid=board_MMiF30&document_srl=22113
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=193061
http://warmfund.net/p/index.php?mid=financing&document_srl=541202
http://healthyteethpa.org/component/k2/itemlist/user/5549615
http://www.cnsmaker.net/xe/?document_srl=142216
http://yoriyorifood.com/xxxx/spacial/264008
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lg1r-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-et1z-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
https://intelogist2.wpengine.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tw9y-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yl1c-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-db6z-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18/
http://hydrocarbs-gh.org/index.php/component/k2/itemlist/user/7520454
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3569756
http://www.spazioad.com/component/k2/itemlist/user/7463004
http://www.hmotors.co.kr/?document_srl=33141
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=653314
https://2002.shyoon.com/board_2002/169356
http://necinsurance.co.zw/component/k2/itemlist/user/21778.html
http://gusinoepero.ru/archives/26898
http://praisesound.co.kr/sub04_01/91691
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=697136
https://timecker.com/anonymous/188031
http://www.hmotors.co.kr/inquiry/32878
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/34475
http://dayung.co.kr/board_SRVC17/69173
http://wartoby.com/index.php?mid=board_UXUA38&document_srl=98921
http://153.120.114.241/eso/index.php/17529398-rasskaz-sluzanki-3-sezon-3-seria-iubr-rasskaz-sluzanki-3-sezon-
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=1131084
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/245769
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/245773
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/245796
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/245825
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/245836
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/245843
https://www.hohoyoga.com/testboard/4037458
https://forum.ac-jete.it/index.php?topic=445566.0
http://neosky.net/xe/space_station/64800
http://midorijapaneserestaurant.ca/menu/News/38440
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2830456
https://gonggamlaw.com/lawcase/64841
http://phmusic.dothome.co.kr/index.php?mid=PowerHouseMusic&document_srl=43483
http://tiretech.co.kr/index.php?mid=qna&document_srl=182577
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3840862
https://forum.ac-jete.it/index.php?topic=441948.0
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=174567
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=216608
http://iymc.or.kr/pds/118570
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/news/145228
http://dreamplusart.com/mn03_01/118016
http://mercibq.net/partner/88010
https://adsensebih.com/index.php?topic=47291.0
http://otitismediasociety.org/forum/index.php?topic=198417.0
http://ariji.kr/?document_srl=969355
http://haenamyun.taeshinmedia.com/index.php?document_srl=2855457&mid=notice
http://midorijapaneserestaurant.ca/menu/News/25150
http://0433.net/junggo/114336
http://0433.net/junggo/114620
http://0433.net/junggo/115003
http://0433.net/junggo/115015
http://0433.net/junggo/115025
http://0433.net/junggo/115035
http://0433.net/junggo/115137
http://0433.net/junggo/115153
http://0433.net/junggo/115612
http://herdental.co.kr/index.php?mid=online&document_srl=113980
http://toeden.co.kr/Product_new/141290
http://test.comics-game.ru/index.php?topic=535.0
http://married.dike.gr/index.php/component/k2/itemlist/user/78183
http://wartoby.com/index.php?mid=board_UXUA38&document_srl=97930
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=113163
http://mercibq.net/partner/103450
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=20714
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1151507
http://myrechockey.com/forums/index.php?topic=117830.0
http://music.start-a-idea.online/blogs/viewstory/43374
http://smartacity.com/component/k2/itemlist/user/79656
http://www.artangel.co.kr/index.php?mid=Activities&document_srl=187803
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=417178
http://servicioswts.com/?option=com_k2&view=itemlist&task=user&id=3877287
http://servicioswts.com/?option=com_k2&view=itemlist&task=user&id=3877326
http://servicioswts.com/?option=com_k2&view=itemlist&task=user&id=3877347
http://servicioswts.com/?option=com_k2&view=itemlist&task=user&id=3877384
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2827637
https://forum.clubeicaro.pt/index.php?topic=2713.0
https://forum.clubeicaro.pt/index.php?topic=2714.0
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/841543
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/848457
http://servicioswts.com/?option=com_k2&view=itemlist&task=user&id=3877308
https://blossomug.com/index.php/component/k2/itemlist/user/1114408
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2827637
http://www.dore2cuo.de/index/users/view/id/14455
http://k-cea.org/board_Hnyj62/249039
http://music.start-a-idea.online/blogs/viewstory/44808
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2600764
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/246363
http://midorijapaneserestaurant.ca/menu/News/26739
http://erhu.eu/viewtopic.php?t=404026
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=553704
http://sunele.co.kr/board_ReBD97/208007
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zswk-%d1%80%d0%b0%d1%81/
http://benzmall.co.kr/index.php?mid=download&document_srl=75434
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/47727
http://carand.co.kr/d2/49633
https://zakdu.com/?document_srl=22888
http://www.theocraticamerica.org/forum/index.php/topic,70704.0.html
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=547305
http://hyeonjun.co.kr/menu3/376948
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=93320
https://www.shaiyax.com/index.php?topic=422983.0
http://www.livetank.cn/market1/257482
http://ilsannabgol.kr/board_brJk31/1370007
http://ilsannabgol.kr/board_brJk31/1370113
http://ilsannabgol.kr/board_brJk31/1370127
http://ilsannabgol.kr/board_brJk31/1370760
http://ilsannabgol.kr/board_brJk31/1370831
http://ilsannabgol.kr/board_brJk31/1370840
http://ilsannabgol.kr/board_brJk31/1372955
http://ilsannabgol.kr/board_brJk31/1372966
http://www.ekemoon.com/244617/051720191028/
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16049
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16052
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7514533
http://hydrocarbs-gh.org/index.php/component/k2/itemlist/user/7514533
http://kino-z.eu/?option=com_k2&view=itemlist&task=user&id=2482
http://kino-z.eu/component/k2/itemlist/user/2488
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=42487
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=42491
http://kockazatkutato.hu/component/k2/itemlist/user/42495
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2791477
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2003618
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=17378
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=108642
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1998752
http://gtupuw.org/index.php/component/k2/itemlist/user/1998759
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1315602
http://israengineering.com/index.php/component/k2/itemlist/user/1315539
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=44477
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=386125
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=386138
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=386173
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16266
http://dospuntoseventos.cl/component/k2/itemlist/user/16274
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=42857
http://netsconsults.com/index.php/component/k2/itemlist/user/839787
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=849291
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=849421
http://xekhachduyetthuy.com.vn/component/k2/itemlist/user/242337
http://www.popolsku.fr.pl/forum/index.php?topic=416890.0
http://daltso.com/index.php?mid=board_cUYy21&document_srl=126942
http://benzmall.co.kr/index.php?mid=download&document_srl=52771
http://forum.elexlabs.com/index.php?topic=67754.0
http://rabat.kr/board_yCgT00/34194
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/245773
http://pkgersang.dothome.co.kr/board_jiKY24/41401
http://w9builders.co.uk/index.php/component/k2/itemlist/user/123406
http://w9builders.co.uk/index.php/component/k2/itemlist/user/123698
http://wigalseguros.com.br/index.php/component/k2/itemlist/user/27766
http://www.atab.com.sa/?option=com_k2&view=itemlist&task=user&id=1732421
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1530975
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=228988
http://www.crnmedia.es/component/k2/itemlist/user/91420
http://www.crnmedia.es/component/k2/itemlist/user/91421
http://x-crew.center/guest/4846664
http://dreamplusart.com/mn03_01/175246
http://masanlib.or.kr/g1/87611
http://praisesound.co.kr/sub04_01/88725
http://taklongclub.com/forum/index.php?topic=203867.0
http://xn----3x5er9r48j7wemud0a387h.com/news/164385
http://www.ekemoon.com/240551/050920194626/
http://apt2you2.cafe24.com/g1/37830
http://www.venusjeju.com/index.php?mid=QnA&document_srl=1075
http://iymc.or.kr/pds/119998
http://e-educ.net/Forum/index.php?topic=17375.0
https://www.2ayes.com/19714/3-4-tioe-3-4
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=14176
https://saltriverbg.com/2019/05/25/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cjna-%d1%80%d0%b0%d1%81/
http://e-educ.net/Forum/index.php?topic=16261.0
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=190028
http://www.vamoscontigo.org/Noticia/135910
http://ariji.kr/?document_srl=971711
https://www.2ayes.com/19461/3-11-qqgq-3-11-syfy
https://www.shaiyax.com/index.php?topic=404367.0
http://myesl.ca/forum/viewtopic.php?t=695040
http://ariji.kr/?document_srl=1013996
http://apt2you2.cafe24.com/g1/43051
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=113241
http://socialmag.bayareanonprofits.xyz/blogs/viewstory/129692
http://wartoby.com/index.php?mid=board_UXUA38&document_srl=99103
https://intelogist2.wpengine.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qyst-%d1%80%d0%b0%d1%81/
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ppmv-%d1%80%d0%b0%d1%81/
http://dsyang.com/board_Kvgn62/30146
https://www.shaiyax.com/index.php?topic=403903.0
http://erdfsa.iptime.org/xe/index.php?mid=board&document_srl=13796
https://www.shaiyax.com/index.php?topic=398377.0
https://www.shaiyax.com/index.php?topic=398413.0
https://www.shaiyax.com/index.php?topic=398679.0
https://www.shaiyax.com/index.php?topic=398794.0
http://www.ekemoon.com/245215/052320191328/
http://www.ekemoon.com/245249/052320193628/
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16742
http://dospuntoseventos.cl/component/k2/itemlist/user/16738
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=22596
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7517595
http://netsconsults.com/?option=com_k2&view=itemlist&task=user&id=840672
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=5057516
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=5057526
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=5057639
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2638810
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3859477
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16733
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/174358
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/174396
http://proxima.co.rw/index.php/component/k2/itemlist/user/718165
http://proxima.co.rw/index.php/component/k2/itemlist/user/718180
http://rudraautomation.com/index.php/component/k2/author/348706
http://rudraautomation.com/index.php/component/k2/author/348854
http://thermoplast.envolgroupe.com/component/k2/author/179356
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=129990
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=129992
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=130025
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=30402
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1543653
http://www.crnmedia.es/component/k2/itemlist/user/92096
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=957740
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=116285
http://otitismediasociety.org/forum/index.php?topic=201269.0
http://otitismediasociety.org/forum/index.php?topic=201275.0
http://otitismediasociety.org/forum/index.php?topic=201296.0
http://otitismediasociety.org/forum/index.php?topic=201324.0
http://otitismediasociety.org/forum/index.php?topic=201330.0
http://otitismediasociety.org/forum/index.php?topic=201365.0
http://www.lgue.co.kr/?document_srl=116114
http://yoriyorifood.com/xxxx/spacial/291601
http://viamania.net/index.php?mid=board_raYV15&document_srl=139500
http://hyeonjun.co.kr/menu3/289927
http://gtupuw.org/index.php/component/k2/itemlist/user/1976047
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=17675
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=45953
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=45979
http://kockazatkutato.hu/component/k2/itemlist/user/45916
http://mediaville.me/index.php/component/k2/itemlist/user/370745
http://gusinoepero.ru/archives/30651
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2827637
http://herdental.co.kr/index.php?mid=online&document_srl=203898
http://hyeonjun.co.kr/?document_srl=392699
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=41045.0
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=1201253
http://kwpub.kr/?document_srl=185323
http://looksun.co.kr/index.php?mid=board_4&document_srl=188531
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=150931
http://mercibq.net/partner/114785
http://mglpcm.org/board_ETkS12/197909
http://myrechockey.com/forums/index.php?topic=121169.0
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=297454
http://p9912.cafe24.com/board_LVgu51/67486
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=316858
http://www.cnsmaker.net/xe/?document_srl=123553
http://www.nurican.com/giris/ncan/index.php?topic=6130.0
http://gusinoepero.ru/archives/28732
http://myrechockey.com/forums/index.php?topic=118625.0
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=665003
https://forums.lfstats.com/viewtopic.php?t=311233
http://isch.kr/board_PowH60/225238
http://roikjer.com/forum/index.php?PHPSESSID=mn63imhbb6qc5q7r6fum59ml96&topic=935378.0
http://haenamyun.taeshinmedia.com/?document_srl=2826242
http://juroweb.com/xe/juroweb_board/129432
https://cybergsm.es/index.php?topic=63127.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/371307
http://eugeniocolazzo.it/forum/index.php?topic=180846.0
http://loverstory.co.kr/board_UYNJ05/42250
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jkfe-%d1%80%d0%b0%d1%81/
https://www.limscave.com/forum/viewtopic.php?t=58764
http://www.alase.net/index.php/component/k2/itemlist/user/12649
http://looksun.co.kr/index.php?mid=board_4&document_srl=122646
http://looksun.co.kr/index.php?mid=board_4&document_srl=122799
http://looksun.co.kr/index.php?mid=board_4&document_srl=122818
http://looksun.co.kr/index.php?mid=board_4&document_srl=122877
http://looksun.co.kr/index.php?mid=board_4&document_srl=123034
https://gonggamlaw.com/lawcase/100073
http://fbpharm.net/index.php/component/k2/itemlist/user/87870
http://www.leekeonsu-csi.com/?document_srl=901142
https://intelogist2.wpengine.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hkru-%d1%80%d0%b0%d1%81/
http://forum.elexlabs.com/index.php?topic=61621.0
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/85964
http://hanga5.com/index.php?mid=board_photo&document_srl=112982
http://rabbitzone.xyz/FREE/69933
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=160112
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=108662
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=262580
http://themasters.pro/?document_srl=227404
http://benzmall.co.kr/index.php?mid=download&document_srl=46726
http://www.lgue.co.kr/lgue05/113817
http://juroweb.com/xe/?document_srl=82882
http://divespace.co.kr/board/179267
http://universalcommunity.se/Forum/index.php?topic=35666.0
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=199743
http://divespace.co.kr/board/180981
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1503699
http://holysweat.dothome.co.kr/data/6960
http://holysweat.dothome.co.kr/data/6965
http://holysweat.dothome.co.kr/data/6969
http://holysweat.dothome.co.kr/data/6979
http://holysweat.dothome.co.kr/data/7001
http://holysweat.dothome.co.kr/data/7006
http://holysweat.dothome.co.kr/data/7011
http://holysweat.dothome.co.kr/data/7071
http://holysweat.dothome.co.kr/data/7081
http://holysweat.dothome.co.kr/data/7085
http://holysweat.dothome.co.kr/data/7089
http://holysweat.dothome.co.kr/data/7115
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=22098
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/32867
http://blog.ptpintcast.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tenn-%d1%80%d0%b0%d1%81/
http://healthyteethpa.org/component/k2/itemlist/user/5547447
http://dow.dothome.co.kr/board_jydx58/33597
https://forum.ac-jete.it/index.php?topic=444830.0
http://www.cnsmaker.net/xe/?document_srl=125233
http://www.jesusonly.life/calendar/555908
http://e-educ.net/Forum/index.php?topic=16552.0
http://yoriyorifood.com/xxxx/spacial/254872
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=341813
http://xn--2e0b53df5ag1c804aphl.net/nuguna/103992
http://eugeniocolazzo.it/forum/index.php?topic=179975.0
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=399341
http://kockazatkutato.hu/component/k2/itemlist/user/43394
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3924838
http://mediaville.me/index.php/component/k2/itemlist/user/363782
http://mediaville.me/index.php/component/k2/itemlist/user/363850
http://mobility-corp.com/index.php/component/k2/itemlist/user/2731391
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/167214
http://ovotecegg.com/component/k2/itemlist/user/219578
http://ovotecegg.com/index.php/component/k2/itemlist/user/219556
http://rudraautomation.com/index.php/component/k2/author/332811
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1770622
http://ilsannabgol.kr/board_brJk31/1378001
http://ilsannabgol.kr/board_brJk31/1378309
http://ilsannabgol.kr/board_brJk31/1378589
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile&u=43954
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile;u=43954
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile;u=44071
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile;u=44325
http://imfl.sci.pfu.edu.ru/forum/index.php?action=profile;u=44650
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=39506.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=39508.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=39551.0
https://adsensebih.com/index.php?topic=49797.0
http://askpharm.net/board_NQiz06/159487
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=198499
http://myrechockey.com/forums/index.php?topic=118275.0
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=206152
http://lucky.kidspann.net/?document_srl=369087
http://proxima.co.rw/index.php/component/k2/itemlist/user/692426
http://gtupuw.org/index.php/component/k2/itemlist/user/1977550
http://mediaville.me/index.php/component/k2/itemlist/user/332189
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16728
http://dospuntoseventos.cl/component/k2/itemlist/user/16724
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=399185
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=399217
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=399447
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=399476
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=43433
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=43453
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=43455
http://mediaville.me/index.php/component/k2/itemlist/user/363933
http://mediaville.me/index.php/component/k2/itemlist/user/363981
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=40015.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=40046.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=40048.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=40061.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=40063.0
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=40066.0
http://www.livetank.cn/market1/217717
http://music.start-a-idea.online/blogs/viewstory/48308
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=39895.0
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/69107
http://jdcalc.com/forum/viewtopic.php?t=290808
http://gabisan.com/board_OuDs04/68644
http://rudraautomation.com/index.php/component/k2/author/291425
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=99188
http://kockazatkutato.hu/index.php/component/k2/itemlist/user/43447
http://mediaville.me/index.php/component/k2/itemlist/user/364032
http://mobility-corp.com/index.php/component/k2/itemlist/user/2731437
http://mobility-corp.com/index.php/component/k2/itemlist/user/2731612
http://ovotecegg.com/component/k2/itemlist/user/219719
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/327465
http://jdcalc.com/forum/viewtopic.php?t=288617
http://jdcalc.com/forum/viewtopic.php?t=288809
http://jdcalc.com/forum/viewtopic.php?t=288900
http://jdcalc.com/forum/viewtopic.php?t=288994
http://jdcalc.com/forum/viewtopic.php?t=289103
http://jdcalc.com/forum/viewtopic.php?t=289406
http://jdcalc.com/forum/viewtopic.php?t=289417
http://jdcalc.com/forum/viewtopic.php?t=289854
http://jdcalc.com/forum/viewtopic.php?t=289909
http://jdcalc.com/forum/viewtopic.php?t=290341
http://jdcalc.com/forum/viewtopic.php?t=290444
http://jdcalc.com/forum/viewtopic.php?t=290503
http://jdcalc.com/forum/viewtopic.php?t=290516
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1983135
http://test.comics-game.ru/index.php?topic=600.0
http://kotica00.dothome.co.kr/index.php?mid=board_nJTE45&document_srl=39614
https://ne-kuru.ru/index.php?topic=230815.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3798718
http://xn--2e0b53df5ag1c804aphl.net/nuguna/106514
http://looksun.co.kr/index.php?mid=board_4&document_srl=185418
http://loverstory.co.kr/board_UYNJ05/81327
http://loverstory.co.kr/board_UYNJ05/81358
http://loverstory.co.kr/board_UYNJ05/81403
http://midorijapaneserestaurant.ca/menu/News/44991
https://gonggamlaw.com/lawcase/129473
https://www.hwbms.com/web/qna/23670
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2786264
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=85906
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=386791
http://dessa.com.br/component/k2/itemlist/user/386830
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2001933
http://esperanzazubieta.com/component/k2/itemlist/user/108215
http://naksansacondo.com/board_MGPu57/52755
http://naksansacondo.com/board_MGPu57/52883
http://naksansacondo.com/board_MGPu57/54676
http://naksansacondo.com/board_MGPu57/54779
http://naksansacondo.com/board_MGPu57/56129
http://naksansacondo.com/board_MGPu57/56425
http://naksansacondo.com/board_MGPu57/56967
http://naksansacondo.com/board_MGPu57/59665
https://www.limscave.com/forum/viewtopic.php?t=55610
http://hanga5.com/index.php?mid=board_photo&document_srl=112834
http://www.popolsku.fr.pl/forum/index.php?topic=416531.0
http://roikjer.com/forum/index.php?PHPSESSID=rjq9roskna70l2ke4p6ehsv9p5&topic=932099.0
http://ariji.kr/?document_srl=971869
https://mcsetup.tk/bbs/index.php?topic=263068.0
http://smartacity.com/component/k2/itemlist/user/91486
http://smartacity.com/component/k2/itemlist/user/91497
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=174459
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3783958
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=28660
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=28742
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1734280
http://www.jesusandmarypatna.com/index.php/component/k2/itemlist/user/3569500
http://www.jesusandmarypatna.com/index.php/component/k2/itemlist/user/3569672
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=950687
http://www.siirtorganik.com/index.php/component/k2/itemlist/user/950089
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/390808
http://metropolis.ga/index.php?topic=20417.0
http://sofficer.net/xe/teach/280462
http://rabat.kr/board_yCgT00/82851
http://naksansacondo.com/board_MGPu57/86720
https://reficulcoin.com/index.php?topic=88976.0
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=209731
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1322710
http://fbpharm.net/index.php/component/k2/itemlist/user/85376
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=43129
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1935555
http://dohairbiz.com/en/component/k2/itemlist/user/2814855.html
https://www.hwbms.com/web/qna/37736
http://www.lgue.co.kr/?document_srl=138795
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2001825
http://viamania.net/index.php?mid=board_raYV15&document_srl=124261
http://rabat.kr/board_yCgT00/65024
http://lucky.kidspann.net/index.php?mid=qna&document_srl=294008
http://looksun.co.kr/index.php?mid=board_4&document_srl=201016
http://apt2you2.cafe24.com/g1/54031
http://yonseibaik.synology.me/index.php?mid=houston_profile&document_srl=63405
http://gallerychoi.com/Exhibition/336097
http://www.urbantutorial.com/?option=com_k2&view=itemlist&task=user&id=127239
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1120696
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/370116
http://roikjer.com/forum/index.php?PHPSESSID=qmlpbgkkt0c2dut9b5ul62tgl1&topic=929839.0
http://xn----3x5er9r48j7wemud0a387h.com/news/264716
http://ye-dream.com/qa/242598
http://looksun.co.kr/index.php?mid=board_4&document_srl=188559
http://ptu.imoove.kr/ko/content/%C2%AB%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-7-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-zcpn-%C2%AB%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-7-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB
http://kockazatkutato.hu/component/k2/itemlist/user/42960
http://barobus.kr/qna/101564
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/news/140976
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=339294
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=387185
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=591842
http://www.ekemoon.com/243851/050520190428/
http://immobilia.gr/index.php/de/component/k2/itemlist/user/16856
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=229903
http://fbpharm.net/index.php/component/k2/itemlist/user/87277
https://intelogist2.wpengine.com/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bl3r-%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3/
http://loverstory.co.kr/board_UYNJ05/101575
http://mediaville.me/index.php/component/k2/itemlist/user/376305
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=339154
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=102186
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=19437
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=111583
https://2002.shyoon.com/board_2002/167171
https://intelogist2.wpengine.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hxbo-%d1%80%d0%b0%d1%81/
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=951536
http://daesestudy.co.kr/ipsi_docu/146840
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=380743
http://mercibq.net/partner/96277
https://www.hwbms.com/web/qna/48147
http://xn--80acvxh8am.net/index.php?action=profile&u=6406
http://xn--80acvxh8am.net/index.php?topic=4109.0
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-live-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16/
http://midorijapaneserestaurant.ca/menu/News/81160
http://naksansacondo.com/board_MGPu57/108268
http://naksansacondo.com/board_MGPu57/108317
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1225832
https://www.hohoyoga.com/testboard/4095003
http://dsyang.com/board_Kvgn62/48108
http://naksansacondo.com/board_MGPu57/108342
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1226013
http://xn--80acvxh8am.net/index.php?action=profile&u=6407
https://intelogist2.wpengine.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be-2/
https://blossomug.com/index.php/component/k2/itemlist/user/1116236
http://divespace.co.kr/board/195565
http://mobility-corp.com/index.php/component/k2/itemlist/user/2731168
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1165914
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wk2c-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12/
http://wartoby.com/index.php?mid=board_UXUA38&document_srl=136786
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=284420
http://www.lgue.co.kr/lgue05/138780
http://mercibq.net/partner/113491
http://mobility-corp.com/index.php/component/k2/itemlist/user/2699831
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/79219
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1500065
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/350078
http://mobility-corp.com/index.php/component/k2/itemlist/user/2732612
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=17079
http://barobus.kr/qna/74159
http://k-cea.org/board_Hnyj62/249223
https://www.celekt.com/%d0%a0%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ctpi-%d0%a0%d0%b0%d1%81/
http://www.digitalbul.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xzmy-%d1%80%d0%b0%d1%81/
http://sd-xi.co.kr/g1/83072
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2005616
http://lucky.kidspann.net/index.php?mid=qna&document_srl=369195
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3923650
http://yonseibaik.synology.me/index.php?mid=houston_profile&document_srl=56272
http://universalcommunity.se/Forum/index.php?topic=35782.0
http://withinfp.sakura.ne.jp/eso/index.php/17593933-rasskaz-sluzanki-3-sezon-4-seria-gcfs-rasskaz-sluzanki-3-sezon-/0
http://dcasociados.eu/component/k2/itemlist/user/93081
https://timecker.com/anonymous/188711
http://naksansacondo.com/board_MGPu57/81027
http://loverstory.co.kr/board_UYNJ05/97428
http://midorijapaneserestaurant.ca/menu/News/29284
http://www.hmotors.co.kr/inquiry/69007
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=120746
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=537525
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hl8m-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jp2d-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11/
http://xn----3x5er9r48j7wemud0a387h.com/?document_srl=171782
http://mercibq.net/partner/118549
http://xn----3x5er9r48j7wemud0a387h.com/news/174102
http://daltso.com/index.php?mid=board_cUYy21&document_srl=203335
http://www.aloeverasas.it/index.php/component/k2/itemlist/user/21396
http://bebopindia.com/notcie/381070
http://muldorang.com/market/27237
http://www.quattroandpartners.it/component/k2/itemlist/user/1249110
http://toeden.co.kr/Product_new/141420
http://neosky.net/xe/space_station/115914
http://ye-dream.com/qa/266271
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=223129
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/169030
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1321856
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ex6%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
https://blossomug.com/index.php/component/k2/itemlist/user/1114326
http://naksansacondo.com/board_MGPu57/51969
http://healthyteethpa.org/component/k2/itemlist/user/5545552
http://dsyang.com/board_Kvgn62/46122
http://dohairbiz.com/en/component/k2/itemlist/user/2816328.html
https://mcsetup.tk/bbs/index.php?topic=262017.0
http://backo.co.kr/board_aiQk58/16439
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zm8s-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6/
http://netsconsults.com/?option=com_k2&view=itemlist&task=user&id=826548
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=495397
https://mcsetup.tk/bbs/index.php?topic=262679.0
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=401264
http://www.hmotors.co.kr/inquiry/27254
http://midorijapaneserestaurant.ca/menu/News/58711
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=386726
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=339645
http://ilsannabgol.kr/board_brJk31/1373165
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=113233
http://beautypouch.net/index.php?mid=board_09&document_srl=118190
http://barobus.kr/qna/75584
http://callman.co.kr/index.php?mid=qa&document_srl=221499
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=92375
http://midorijapaneserestaurant.ca/menu/News/80162
http://naksansacondo.com/board_MGPu57/106459
http://naksansacondo.com/board_MGPu57/106533
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1220512
https://gonggamlaw.com/lawcase/156235
https://gonggamlaw.com/lawcase/156250
https://www.hwbms.com/web/?document_srl=47302
https://www.hwbms.com/web/qna/47249
https://www.hwbms.com/web/qna/47340
http://naksansacondo.com/board_MGPu57/106584
http://naksansacondo.com/board_MGPu57/106604
http://www.coating.or.kr/atemfair_data/18622
http://myrechockey.com/forums/index.php?topic=117589.0
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1996920
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=d8a6dc4ba01a2e714ecba5ff82b8abcc&topic=11093.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/719786
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=390529
http://www.hmotors.co.kr/inquiry/26842
http://looksun.co.kr/index.php?mid=board_4&document_srl=183060
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=49478
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=42899
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=436541
http://mediaville.me/index.php/component/k2/itemlist/user/331757
http://bath-family.com/photo_zone/145637
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=444927
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1209303
http://jdcalc.com/forum/viewtopic.php?t=291046
https://gonggamlaw.com/lawcase/83480
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=209825
http://carand.co.kr/d2/87311
http://xn--2e0b53df5ag1c804aphl.net/nuguna/193882
http://dospuntoseventos.cl/component/k2/itemlist/user/16161
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=393469
http://carand.co.kr/d2/99716
https://gonggamlaw.com/lawcase/127739
http://wartoby.com/index.php?mid=board_UXUA38&document_srl=99272
http://knet.dothome.co.kr/xe/board_RJHw15/21059
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/349024
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=103960
https://www.hwbms.com/web/qna/11114
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=394403
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2732618
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=497574
http://ko.myds.me/board_story/247476
https://intelogist2.wpengine.com/%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ij0x-%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=5058768
https://gonggamlaw.com/lawcase/125330
http://www.theocraticamerica.org/forum/index.php?topic=72495.0
http://beautypouch.net/index.php?mid=board_09&document_srl=188136
http://yooseok.com/board_BkvT46/442289
http://www.lgue.co.kr/?document_srl=194515
http://www2.yasothon.go.th/smf/index.php?topic=159.msg200554
https://www.chirorg.com/?document_srl=149785
http://praisesound.co.kr/sub04_01/110039
http://www.zoraholidays.net/?option=com_k2&view=itemlist&task=user&id=371263
http://married.dike.gr/index.php/component/k2/itemlist/user/78279
http://d-tube.info/board_jvyO69/370299
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=378236
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4954031
http://carrierworld.co.kr/?document_srl=175404
http://www.svteck.co.kr/customer_gratitude/344603
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=376984
http://otitismediasociety.org/forum/index.php?topic=200670.0
http://www.cnsmaker.net/xe/?document_srl=146342
http://mediaville.me/index.php/component/k2/itemlist/user/376116
https://mcsetup.tk/bbs/index.php?topic=262896.0
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7516089
http://viamania.net/index.php?mid=board_raYV15&document_srl=138569
http://myrechockey.com/forums/index.php?topic=118852.0
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=914388
http://toeden.co.kr/Product_new/137906
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=128780
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=536743
http://www.theocraticamerica.org/forum/index.php?topic=69953.0
http://www.quattroandpartners.it/component/k2/itemlist/user/1256106
http://midorijapaneserestaurant.ca/menu/News/59471
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=395038
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=401425
http://withinfp.sakura.ne.jp/eso/index.php/17528176-rasskaz-sluzanki-3-sezon-11-seria-jzys-rasskaz-sluzanki-3-sezon/0
https://www.hwbms.com/web/qna/36934
http://jensenbyggteam.no/index.php/component/k2/itemlist/user/13750
http://naksansacondo.com/board_MGPu57/98942
https://2002.shyoon.com/board_2002/275400
http://loverstory.co.kr/board_UYNJ05/88200
http://xn--2e0b53df5ag1c804aphl.net/nuguna/176337
http://yourhelp.co.kr/index.php?mid=board_2&document_srl=58094
http://rudraautomation.com/index.php/component/k2/author/291426
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=310624
http://k-cea.org/board_Hnyj62/197180
https://turimex.mx.solemti.net/en/?option=com_k2&view=itemlist&task=user&id=19451
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=385914
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ek2%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://www.alase.net/index.php/component/k2/itemlist/user/12636
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=206193
http://midorijapaneserestaurant.ca/menu/News/70408
http://dayung.co.kr/board_SRVC17/65520
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4941410
http://kockazatkutato.hu/component/k2/itemlist/user/42551
https://timecker.com/anonymous/188760
http://bewasia.com/?document_srl=222018
http://daesestudy.co.kr/ipsi_docu/118542
https://betshin.com/Story/216691
http://midorijapaneserestaurant.ca/menu/News/42877
http://masanlib.or.kr/g1/118385
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3491274
https://www.hwbms.com/web/qna/12431
http://isch.kr/board_PowH60/241050
http://rudraautomation.com/index.php/component/k2/author/352620
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=113229
http://dow.dothome.co.kr/board_jydx58/37405
http://roikjer.com/forum/index.php?PHPSESSID=lkg600s1oodhnul6r72dqc7i24&topic=933178.0
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1152668
http://looksun.co.kr/index.php?mid=board_4&document_srl=208155
http://ariji.kr/?document_srl=982343
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=666183
http://herdental.co.kr/index.php?mid=online&document_srl=177999
https://www.lwfservers.com/index.php?topic=71367.0
http://bebopindia.com/notcie/509482
http://www.hmotors.co.kr/inquiry/25781
http://gusinoepero.ru/archives/28042
http://taklongclub.com/forum/index.php?topic=205407.0
http://www.itosm.com/cn/board_nLoq17/132908
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=131793
http://www.urbantutorial.com/?option=com_k2&view=itemlist&task=user&id=127380
http://myrechockey.com/forums/index.php?topic=118950.0
http://0433.net/budongsan/115218
http://benzmall.co.kr/index.php?mid=download&document_srl=107534
http://yoriyorifood.com/xxxx/spacial/253668
http://www.dap.com.py/index.php/component/k2/itemlist/user/851084
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=390184
http://p9912.cafe24.com/board_LVgu51/55528
http://themasters.pro/file_01/315938
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=228795
http://1661-6471.co.kr/news/101892
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/167007
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=241991
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=22908
https://gonggamlaw.com/lawcase/147338
http://juroweb.com/xe/juroweb_board/125993
http://barobus.kr/qna/94294
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-svfi-%d1%80%d0%b0%d1%81/
http://daltso.com/index.php?mid=board_cUYy21&document_srl=198363
http://daltso.com/index.php?mid=board_cUYy21&document_srl=190267
http://d-tube.info/board_jvyO69/368713
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=94458
https://www.c-alice.org/forum/index.php?topic=98063.0
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=1119633
http://www.cnsmaker.net/xe/?document_srl=144253
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=184657
http://kyj1225.godohosting.com/board_mebR72/94238
http://carand.co.kr/d2/95205
http://rabat.kr/board_yCgT00/71479
http://holysweat.dothome.co.kr/data/7277
http://www.venusjeju.com/index.php?mid=QnA&document_srl=976
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=115950
http://www.teedinubon.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pk9%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f28-05/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3489940
http://ajincomp.godohosting.com/board_STnh82/125885
http://daltso.com/index.php?mid=board_cUYy21&document_srl=201262
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=188738
http://wigalseguros.com.br/index.php/component/k2/itemlist/user/30119
http://udrpsucks.com/blog/?p=1915
http://kyj1225.godohosting.com/?document_srl=58256
http://ariji.kr/?document_srl=1023832
http://otitismediasociety.org/forum/index.php?topic=208334.0
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=88614
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=199789
http://www.sp1.football/index.php?mid=faq&document_srl=697819
http://dev.aabn.org.gh/component/k2/itemlist/user/674865
http://daltso.com/index.php?mid=board_cUYy21&document_srl=209148
http://cwon.kr/xe/board_bnSr36/312672
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=f9cd2306163c98307fd6e06692463676&topic=11330.0
http://daltso.com/index.php?mid=board_cUYy21&document_srl=195584
http://rabat.kr/board_yCgT00/78546
http://hanga5.com/index.php?mid=board_photo&document_srl=182572
http://naksansacondo.com/board_MGPu57/43517
http://gabisan.com/board_OuDs04/74327
http://mediaville.me/index.php/component/k2/itemlist/user/362980
http://neosky.net/xe/space_station/120572
http://otitismediasociety.org/forum/index.php?topic=213210.0
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=245455
http://kyj1225.godohosting.com/board_mebR72/87638
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2005813
http://dreamplusart.com/mn03_01/124011
http://daltso.com/index.php?mid=board_cUYy21&document_srl=214412
https://gonggamlaw.com/lawcase/133168
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=131243
http://rabat.kr/board_yCgT00/66845
http://socialmag.bayareanonprofits.xyz/blogs/viewstory/133685
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=438711
https://esel.gist.ac.kr/esel2/board_hmgj23/380599
http://gspara01.dothome.co.kr/index.php?mid=board_XHsr53&document_srl=17371
https://adsensebih.com/index.php?topic=51099.0
http://cwon.kr/xe/board_bnSr36/317195
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=93220
http://www.cnsmaker.net/xe/?document_srl=156014
http://erhu.eu/viewtopic.php?t=395025
https://esel.gist.ac.kr/esel2/board_hmgj23/271015
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xtvf-%d1%80%d0%b0%d1%81/
http://jdcalc.com/forum/viewtopic.php?t=291939
http://gallerychoi.com/Exhibition/418843
http://loverstory.co.kr/board_UYNJ05/105264
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/33687
http://barobus.kr/?document_srl=119597
http://ovotecegg.com/component/k2/itemlist/user/221334
http://ye-dream.com/qa/264911
http://loverstory.co.kr/board_UYNJ05/107387
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/370739
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zo5w-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9/
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=43184
https://www.lwfservers.com/index.php?topic=72104.0
https://adsensebih.com/index.php?topic=43713.0
http://www.popolsku.fr.pl/forum/index.php?topic=417062.0
http://rabbitzone.xyz/FREE/60611
http://callman.co.kr/index.php?mid=qa&document_srl=221835
https://www.regalepadova.it/index.php/component/k2/itemlist/user/8281
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1153714
http://renew.joum.kr/?document_srl=271027
http://themasters.pro/file_01/324134
http://eugeniocolazzo.it/forum/index.php?topic=179684.0
http://www.yadanarbonnews.com/index.php/component/k2/itemlist/user/345557
http://gochon-iusell.co.kr/g1/76221
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=404318
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=395478
https://www.cosmologyathome.org/view_profile.php?userid=1531368
http://yooseok.com/board_BkvT46/412954
http://carand.co.kr/d2/86222
http://midorijapaneserestaurant.ca/menu/News/57065
http://agiteshop.com/xe/qa/164573
http://gallerychoi.com/Exhibition/328804
http://daltso.com/?document_srl=199008
http://nnkumw.org/xe/index.php?mid=board_yNQm00&document_srl=133520
http://agiteshop.com/xe/qa/192308
http://www.sp1.football/index.php?mid=faq&document_srl=694723
http://www.cswc.co.kr/index.php?mid=board_zyTs37&document_srl=45870
http://benzmall.co.kr/index.php?mid=download&document_srl=93805
http://mglpcm.org/board_ETkS12/175613
http://midorijapaneserestaurant.ca/menu/News/45547
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=214589
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rg7k-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.kcch.or.kr/index.php?mid=board_uFpk03&document_srl=122670
http://viamania.net/index.php?mid=board_raYV15&document_srl=126954
http://juroweb.com/xe/juroweb_board/85616
http://carand.co.kr/d2/100544
http://ucckorea.kr/index.php?mid=board_AuHE49&document_srl=81256
https://blossomug.com/index.php/component/k2/itemlist/user/1112882
http://mglpcm.org/board_ETkS12/173723
http://midorijapaneserestaurant.ca/menu/News/73012
http://iymc.or.kr/pds/116805
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=392117
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=50959
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=439536
http://midorijapaneserestaurant.ca/menu/?document_srl=49046
http://herdental.co.kr/index.php?mid=online&document_srl=114739
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/149121
http://divespace.co.kr/board/266494
http://mglpcm.org/board_ETkS12/197245
http://www.coating.or.kr/atemfair_data/16693
http://cwon.kr/xe/board_bnSr36/291148
http://esperanzazubieta.com/component/k2/itemlist/user/109126
http://xn--2e0b53df5ag1c804aphl.net/nuguna/201948
http://sy.korean.net/qna/318750
http://erhu.eu/viewtopic.php?t=396744
https://betshin.com/Story/198078
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=85373
http://roikjer.com/forum/index.php?PHPSESSID=jo0fb8jc04njorrl6mt8of06c3&topic=932231.0
http://looksun.co.kr/index.php?mid=board_4&document_srl=214168
http://gabisan.com/board_OuDs04/67661
https://www.limscave.com/forum/viewtopic.php?t=60430
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3797065
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/42409
https://forums.lfstats.com/viewtopic.php?t=327478
http://www.dap.com.py/index.php/es/?option=com_k2&view=itemlist&task=user&id=853477
http://divespace.co.kr/board/287184
http://naksansacondo.com/board_MGPu57/71118
http://www.m1avio.com/index.php/component/k2/itemlist/user/3801440
http://nnkumw.org/xe/index.php?mid=board_yNQm00&document_srl=140249
https://intelogist2.wpengine.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fr4t-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81/
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/370788
http://yourhelp.co.kr/index.php?mid=board_2&document_srl=56075
https://www.celekt.com/%d0%a0%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fogf-%d0%a0%d0%b0%d1%81/
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1081376
http://www.ekemoon.com/240487/050920191826/
http://taklongclub.com/forum/index.php?topic=204774.0
http://sy.korean.net/qna/457417
http://looksun.co.kr/index.php?mid=board_4&document_srl=182047
http://www.leekeonsu-csi.com/?document_srl=897706
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=389482
http://yonseibaik.synology.me/index.php?mid=houston_profile&document_srl=56590
https://www.amazingworldtop.com/entretenimiento/%d0%ba%d0%be%d0%bf-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-na9%d0%ba%d0%be%d0%bf-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f29-05-2019/
http://www.sp1.football/?document_srl=698328
https://intelogist2.wpengine.com/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lb3%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be/
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3374469
http://hyeonjun.co.kr/menu3/287867
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=126441
http://kyj1225.godohosting.com/board_mebR72/84888
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3482366
https://intelogist2.wpengine.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mw2d-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://daltso.com/index.php?mid=board_cUYy21&document_srl=195276
http://www.vamoscontigo.org/Noticia/221382
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2793218
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=221806
http://ovotecegg.com/?option=com_k2&view=itemlist&task=user&id=227385
https://mcsetup.tk/bbs/index.php?topic=263151.0
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/60008
http://smartacity.com/component/k2/itemlist/user/94109
http://www.arunagreen.com/index.php/component/k2/itemlist/user/1156702
http://cwon.kr/xe/board_bnSr36/309667
http://toeden.co.kr/Product_new/201215
http://dsyang.com/board_Kvgn62/46310
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vhgf-%d1%80%d0%b0%d1%81/
http://midorijapaneserestaurant.ca/menu/News/72063
http://8.droror.co.il/uncategorized/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kxdb-%d1%80%d0%b0%d1%81/
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=45979
http://midorijapaneserestaurant.ca/menu/News/52422
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2803583
http://www.jesusonly.life/calendar/558207
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/856459
https://2002.shyoon.com/board_2002/188026
http://gusinoepero.ru/archives/26236
https://www.hwbms.com/web/qna/28612
http://dohairbiz.com/en/component/k2/itemlist/user/2814725.html
https://esel.gist.ac.kr/esel2/board_hmgj23/273460
http://forum.bmw-e60.eu/index.php?topic=11247.0
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1852387
http://www.cnsmaker.net/xe/?document_srl=122115
http://taklongclub.com/forum/index.php?topic=200399.0
http://kockazatkutato.hu/component/k2/itemlist/user/43456
https://intelogist2.wpengine.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gmrf-%d1%80%d0%b0%d1%81/
http://tiretech.co.kr/index.php?mid=qna&document_srl=245663
http://viamania.net/index.php?mid=board_raYV15&document_srl=220694
http://naksansacondo.com/board_MGPu57/99897
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=414753
http://metropolis.ga/index.php?topic=20670.0
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=44075
http://ko.myds.me/board_story/312322
http://www.ekemoon.com/243815/050420193028/
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/346237
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3544524
http://miquirofisico.com/index.php/component/k2/itemlist/user/4505
http://kyj1225.godohosting.com/board_mebR72/97788
https://www.2ayes.com/19627/3-11-lerm-3-11-abc
http://rabat.kr/board_yCgT00/69138
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=338474
http://www.crnmedia.es/component/k2/itemlist/user/91789
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1543582
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=916419
http://www.vamoscontigo.org/Noticia/166325
http://1644-4404.com/?document_srl=289343
http://tiretech.co.kr/index.php?mid=qna&document_srl=287094
http://dohairbiz.com/en/component/k2/itemlist/user/2823551.html
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ppmv-%d1%80%d0%b0%d1%81/
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2794278
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/168784
http://iymc.or.kr/pds/116421
https://adsensebih.com/index.php?topic=48448.0
https://intelogist2.wpengine.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pasp-%d1%80%d0%b0%d1%81/
http://hyeonjun.co.kr/menu3/288007
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=186749
http://yoriyorifood.com/xxxx/spacial/291412
http://photogrotto.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ic4q-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18/
http://rabat.kr/board_yCgT00/82732
http://1661-6471.co.kr/news/44649
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2804008
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=400633
http://warmfund.net/p/index.php?mid=financing&document_srl=527490
http://kyj1225.godohosting.com/board_mebR72/96858
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=653344
https://www.hwbms.com/web/qna/27248
https://www.hwbms.com/web/qna/38697
http://photogrotto.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fp0%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f28-05/
http://universalcommunity.se/Forum/index.php?topic=35710.0
https://intelogist2.wpengine.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ft5x-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81/
http://blog.ptpintcast.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uxsu-%d1%80%d0%b0%d1%81/
http://mglpcm.org/board_ETkS12/124862
http://sofficer.net/xe/teach/285984
http://dev.aabn.org.gh/component/k2/itemlist/user/712579
http://miquirofisico.com/index.php/component/k2/itemlist/user/4472
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=1120635
http://otitismediasociety.org/forum/index.php?topic=198986.0
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=1124462
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1174041
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16052
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=39735.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1326771
http://0433.net/budongsan/113646
http://benzmall.co.kr/index.php?mid=download&document_srl=116164
http://www.dore2cuo.de/index/users/view/id/14478
http://netsconsults.com/index.php/component/k2/itemlist/user/844108
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3755166
http://askpharm.net/board_NQiz06/159966
https://forum.ac-jete.it/index.php?topic=451725.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/388172
http://jnk-ent.jp/index.php?mid=gallery&document_srl=341115
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/333491
http://askpharm.net/board_NQiz06/237002
http://k-cea.org/board_Hnyj62/197610
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-moah-%d1%80%d0%b0%d1%81/
http://www.theocraticamerica.org/forum/index.php?topic=70525.0
http://yoriyorifood.com/xxxx/spacial/331260
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=298498
http://taklongclub.com/forum/index.php?topic=204485.0
https://blossomug.com/index.php/component/k2/itemlist/user/1114717
https://betshin.com/Story/197177
http://roikjer.com/forum/index.php?topic=929900.0
http://www.vamoscontigo.org/Noticia/207073
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=148369
http://archeaudio.com/xe/board_AOYj82/11310
http://divespace.co.kr/?document_srl=294516
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=311729
http://askpharm.net/board_NQiz06/250195
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/88916
http://phmusic.dothome.co.kr/index.php?mid=PowerHouseMusic&document_srl=50015
https://intelogist2.wpengine.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xn8n-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81/
http://myrechockey.com/forums/index.php?topic=118752.0
http://rabbitzone.xyz/FREE/71594
http://www.popolsku.fr.pl/forum/index.php?topic=415946.0
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=46795
http://moyakmermer.com/?option=com_k2&view=itemlist&task=user&id=847972
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/175121
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3787093
http://gusinoepero.ru/archives/31836
http://www.hmotors.co.kr/inquiry/63643
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=49887
https://adsensebih.com/index.php?topic=50969.0
http://www.spazioad.com/component/k2/itemlist/user/7420598
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3896450
https://esel.gist.ac.kr/esel2/board_hmgj23/265750
https://khuyenmaikk13.info/index.php?topic=226421.0
https://www.celekt.com/%d0%a2%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cr1%d0%a2%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f28-05/
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=85172
http://yourhelp.co.kr/index.php?mid=board_2&document_srl=48575
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2000009
http://warmfund.net/p/index.php?mid=financing&document_srl=478062
http://roikjer.com/forum/index.php?PHPSESSID=nbfef7jgk4rc56n5ah3s097sh7&topic=932154.0
http://www.leekeonsu-csi.com/index.php?document_srl=1181700&mid=sangdam1
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=43236
http://www.hmotors.co.kr/?document_srl=33270
https://2002.shyoon.com/board_2002/281768
http://www.eunhaele.co.kr/xe/board/20364
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=357903
http://divespace.co.kr/board/178657
http://askpharm.net/board_NQiz06/250663
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1166504
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3491013
http://loverstory.co.kr/board_UYNJ05/96876
http://thermoplast.envolgroupe.com/component/k2/author/179638
http://www.vamoscontigo.org/Noticia/196445
http://loverstory.co.kr/board_UYNJ05/83651
http://askpharm.net/board_NQiz06/252605
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=27865
http://nnkumw.org/xe/index.php?mid=board_yNQm00&document_srl=139835
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=400272
http://dospuntoseventos.cl/component/k2/itemlist/user/16800
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=340496
http://married.dike.gr/index.php/component/k2/itemlist/user/78146
https://serverpia.co.kr/board_ucCk10/138892
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=1204756
http://ptu.imoove.kr/ko/content/%C2%AB%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-10-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-aaey-%C2%AB%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-10-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-newstudio340959
http://khapthanam.co.kr/g1/136528
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=946542
http://daltso.com/index.php?mid=board_cUYy21&document_srl=208779
http://autospa.lv/index.php/lv/component/k2/itemlist/user/10588
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3398702
http://www.lgue.co.kr/?document_srl=113454
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=314515
http://www.cyberblissstudios.com/UserProfile/tabid/42/UserID/2329145/Default.aspx
http://sy.korean.net/qna/311223
http://mglpcm.org/board_ETkS12/166392
http://midorijapaneserestaurant.ca/menu/News/66829
http://askpharm.net/board_NQiz06/254025
http://gabisan.com/board_OuDs04/98643
http://mobility-corp.com/index.php/component/k2/itemlist/user/2746862
http://carand.co.kr/d2/94139
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=160059
https://mcsetup.tk/bbs/index.php?topic=261911.0
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=853955
http://carand.co.kr/d2/93472
http://gallerychoi.com/?document_srl=395515
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=37991
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=17580
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=376748
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=212320
http://ko.myds.me/board_story/247774
http://gochon-iusell.co.kr/g1/102764
http://ovotecegg.com/component/k2/itemlist/user/222925
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/369560
http://www.hmotors.co.kr/inquiry/50535
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=18146
http://d-tube.info/board_jvyO69/368705
http://xn--2e0b53df5ag1c804aphl.net/nuguna/144106
http://udrpsucks.com/blog/?p=1740
http://ariji.kr/?document_srl=968967
https://esel.gist.ac.kr/esel2/board_hmgj23/270495
http://tiretech.co.kr/index.php?mid=qna&document_srl=182198
http://sejong-thesharpyemizi.co.kr/m1/27008
https://khuyenmaikk13.info/index.php?topic=227451.0
http://cwon.kr/xe/board_bnSr36/292406
http://jdcalc.com/forum/viewtopic.php?f=2&t=285919&view=print
http://melchinooddle.dothome.co.kr/?document_srl=14713
http://benzmall.co.kr/index.php?mid=download&document_srl=98247
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=101136
http://www.capital-investment.pl/index.php/component/k2/itemlist/user/230627
https://mcsetup.tk/bbs/index.php?topic=263143.0
http://www.yadanarbonnews.com/index.php/component/k2/itemlist/user/347560
https://blossomug.com/index.php/component/k2/itemlist/user/1111366
http://shinhwaair2017.cafe24.com/issue/489516
http://goldenpowerball2.com/?document_srl=346634
http://mtuan93.com/board_uCqR85/6436
http://israengineering.com/index.php/component/k2/itemlist/user/1288938
http://www.cswc.co.kr/index.php?mid=board_zyTs37&document_srl=31943
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=113243
http://xn--2e0b53df5ag1c804aphl.net/nuguna/168460
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=207538
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16771
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16728
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=43301
http://looksun.co.kr/index.php?mid=board_4&document_srl=182570
http://melchinooddle.dothome.co.kr/?document_srl=17943
http://smartacity.com/component/k2/itemlist/user/90058
http://smartacity.com/component/k2/itemlist/user/78491
http://constellation.kro.kr/board_kbku73/93197
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3371981
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4902262
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=17280
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=6386f01e40be00d1ee9eb64715c623c4&topic=10711.0
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3862999
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1977514
http://www.ekemoon.com/245143/052220193828/
http://jiral.net/an9/44335
http://rabat.kr/board_yCgT00/70612
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16312
http://p9912.cafe24.com/board_LVgu51/54444
http://callman.co.kr/index.php?mid=qa&document_srl=308757
http://hyeonjun.co.kr/menu3/334905
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=39652
http://www.hmotors.co.kr/inquiry/39989
http://x-crew.center/guest/4845495
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=95978
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=174045
http://www.venusjeju.com/index.php?mid=QnA&document_srl=2065
http://www.vamoscontigo.org/Noticia/137724
https://reficulcoin.com/index.php?topic=85950.0
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1866552
https://adsensebih.com/index.php?topic=48848.0
http://benzmall.co.kr/index.php?mid=download&document_srl=114752
http://www.siirtorganik.com/index.php/component/k2/itemlist/user/949966
http://ptu.imoove.kr/ko/content/%C2%AB%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-7-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-oiwd-%C2%AB%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-7-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-starz341286
http://midorijapaneserestaurant.ca/menu/News/63746
http://xn--80acvxh8am.net/index.php?action=profile&u=6384
http://xn--80acvxh8am.net/index.php?topic=4091.0
http://dsyang.com/board_Kvgn62/47451
http://dsyang.com/board_Kvgn62/47457
http://naksansacondo.com/board_MGPu57/105711
http://naksansacondo.com/board_MGPu57/105878
http://naksansacondo.com/board_MGPu57/105908
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1218748
https://gonggamlaw.com/lawcase/155766
https://gonggamlaw.com/lawcase/155797
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=947588
http://ko.myds.me/?document_srl=316049
http://rabbitzone.xyz/FREE/63845
http://askpharm.net/board_NQiz06/254015
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=29072
http://yoriyorifood.com/xxxx/spacial/311536
http://rotary-laeliana.org/component/k2/itemlist/user/51915
http://carand.co.kr/d2/58779
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/389021
http://gallerychoi.com/Exhibition/425887
https://reficulcoin.com/index.php?topic=88849.0
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=417231
http://carand.co.kr/d2/48999
http://askpharm.net/board_NQiz06/254605
http://www.dap.com.py/index.php/es/?option=com_k2&view=itemlist&task=user&id=854056
http://loverstory.co.kr/board_UYNJ05/98873
http://photogrotto.com/%d0%ba%d0%be%d0%bf-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xo4f-%d0%ba%d0%be%d0%bf-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/149538
https://serverpia.co.kr/board_ucCk10/138896
http://loverstory.co.kr/board_UYNJ05/87309
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yl1c-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17/
http://mobility-corp.com/index.php/component/k2/itemlist/user/2738503
http://www.proandpro.it/?option=com_k2&view=itemlist&task=user&id=4728371
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1084702
http://benzmall.co.kr/index.php?mid=download&document_srl=114591
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=36345
http://www.lgue.co.kr/?document_srl=113396
http://divespace.co.kr/board/269069
http://isch.kr/board_PowH60/214542
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=113677
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=1ac0e897cb2e796543bf8b4ac71112ac&topic=11094.0
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=208223
http://arnikabolt.ro/component/k2/itemlist/user/113164
http://benzmall.co.kr/index.php?mid=download&document_srl=45311
http://rfc11th13th.dothome.co.kr/Board5/35087
http://erdfsa.iptime.org/xe/index.php?mid=board&document_srl=12959
http://loverstory.co.kr/board_UYNJ05/102565
http://ucckorea.kr/index.php?mid=board_AuHE49&document_srl=78008
http://universalcommunity.se/Forum/index.php?topic=41085.0
http://xn--2e0b53df5ag1c804aphl.net/nuguna/106420
http://kwpub.kr/PUBS/136489
http://www.cnsmaker.net/xe/?document_srl=125153
http://www2.yasothon.go.th/smf/index.php?topic=159.172260
http://rabat.kr/board_yCgT00/69738
http://midorijapaneserestaurant.ca/menu/News/60116
http://www.hmotors.co.kr/inquiry/27530
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=237e6b7428c3afc8163f05f3301d0be3&topic=10728.0
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/42078
http://music.start-a-idea.online/blogs/viewstory/42846
http://rabat.kr/board_yCgT00/69361
https://esel.gist.ac.kr/esel2/?document_srl=273249
http://www.golden-nail.co.kr/press/358991
http://toeden.co.kr/Product_new/138629
http://mglpcm.org/board_ETkS12/131163
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/66566
http://mtuan93.com/board_uCqR85/6152
http://loverstory.co.kr/board_UYNJ05/112450
http://askpharm.net/board_NQiz06/281539
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=125432
http://www.popolsku.fr.pl/forum/index.php?topic=419867.0
https://gonggamlaw.com/lawcase/125649
http://www.cnsmaker.net/xe/board_AbYD20/124993
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vnav-%d1%80%d0%b0%d1%81/
http://naksansacondo.com/board_MGPu57/98509
http://bizchemical.com/board_kMpv94/2160177
http://looksun.co.kr/index.php?mid=board_4&document_srl=186048
http://bizchemical.com/board_kMpv94/2161049
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3486130
http://themasters.pro/file_01/228504
http://xn--2e0b53df5ag1c804aphl.net/nuguna/190117
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=50153
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=404232
http://p9912.cafe24.com/board_LVgu51/54571
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=219754
http://www.patrasin.kr/index.php?mid=questions&document_srl=4355890
http://ucckorea.kr/?document_srl=78632
http://benzmall.co.kr/index.php?mid=download&document_srl=98175
https://www.hohoyoga.com/testboard/4055401
http://gtupuw.org/index.php/component/k2/itemlist/user/1995273
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=111866
http://ko.myds.me/board_story/296376
https://www.2ayes.com/19559/3-9-igpj-3-9-hbo
http://loverstory.co.kr/board_UYNJ05/104625
http://smartacity.com/component/k2/itemlist/user/92632
http://www.cnsmaker.net/xe/?document_srl=121690
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3481844
http://dev.aabn.org.gh/?option=com_k2&view=itemlist&task=user&id=726851
https://www.hohoyoga.com/testboard/4076179
http://hanga5.com/index.php?mid=board_photo&document_srl=109689
http://xn--2e0b53df5ag1c804aphl.net/nuguna/105646
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4900327
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2739804
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=43243
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=17483
http://daltso.com/index.php?mid=board_cUYy21&document_srl=203395
http://www.cswc.co.kr/index.php?mid=board_zyTs37&document_srl=32950
http://loverstory.co.kr/board_UYNJ05/53292
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=953465
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=224204
https://cybergsm.es/index.php?topic=72600.0
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=103025
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/113592
http://barobus.kr/qna/84384
http://autospa.lv/index.php/component/k2/itemlist/user/10603
http://www.lgue.co.kr/?document_srl=113350
http://www.cswc.co.kr/index.php?mid=board_zyTs37&document_srl=53927
https://www.celekt.com/%d0%a4%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qd7d-%d0%a4%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15/
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=19387
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/76954
http://cwon.kr/xe/board_bnSr36/315405
http://yoriyorifood.com/xxxx/spacial/255419
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=229909
https://saltriverbg.com/2019/05/25/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zjln-%d1%80%d0%b0%d1%81/
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1078020
http://www.popolsku.fr.pl/forum/index.php?topic=417134.0
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=283338
http://myesl.ca/forum/viewtopic.php?t=686600
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=168451
https://adsensebih.com/index.php?topic=50561.0
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/377839
http://neosky.net/xe/space_station/165025
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=13788
http://dsyang.com/board_Kvgn62/43181
http://mediaville.me/index.php/component/k2/itemlist/user/375630
http://carand.co.kr/d2/99479
https://gonggamlaw.com/lawcase/149035
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=6d0ebd6124f0cbf7b8c6aeabe07b2715&topic=11265.0
http://khapthanam.co.kr/g1/135979
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dg7%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5/
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=339917
http://rabat.kr/board_yCgT00/84353
http://bobr.site/index.php?topic=188818.0
http://www.ekemoon.com/245471/050220190729/
http://apt2you2.cafe24.com/g1/56996
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/336451
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=47899
http://midorijapaneserestaurant.ca/menu/News/72592
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=13569
http://erdfsa.iptime.org/xe/index.php?mid=board&document_srl=12404
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1055677
http://daltso.com/index.php?mid=board_cUYy21&document_srl=199783
http://carand.co.kr/d2/86019
http://www.cswc.co.kr/index.php?mid=board_zyTs37&document_srl=55053
http://smartacity.com/component/k2/itemlist/user/79934
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3935751
http://ovotecegg.com/component/k2/itemlist/user/226141
http://wartoby.com/index.php?mid=board_UXUA38&document_srl=99068
http://gochon-iusell.co.kr/g1/104010
http://bobr.site/index.php?topic=190061.0
http://kyj1225.godohosting.com/board_mebR72/58426
http://naksansacondo.com/board_MGPu57/59499
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=210529
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=23355
https://betshin.com/Story/221299
http://loverstory.co.kr/?document_srl=54164
http://askpharm.net/board_NQiz06/255560
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=222429
http://8.droror.co.il/uncategorized/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nmmh-%d1%80%d0%b0%d1%81/
http://ovotecegg.com/component/k2/itemlist/user/232270
http://www.arunagreen.com/index.php/component/k2/itemlist/user/1155122
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=308997
http://www.patrasin.kr/index.php?mid=questions&document_srl=4355068
http://carand.co.kr/d2/81287
http://naksansacondo.com/board_MGPu57/66056
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1867481
https://forum.ac-jete.it/index.php?topic=447398.0
http://jnk-ent.jp/index.php?mid=gallery&document_srl=373331
http://www.sp1.football/index.php?document_srl=698189&mid=faq
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=36146
http://smartacity.com/component/k2/itemlist/user/93913
https://timecker.com/anonymous/188373
http://ko.myds.me/board_story/278770
https://intelogist2.wpengine.com/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lb3%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be/
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3374469
http://hyeonjun.co.kr/menu3/287867
http://agiteshop.com/xe/qa/164597
http://ariji.kr/?document_srl=1019322
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=119887
http://daltso.com/index.php?mid=board_cUYy21&document_srl=209214
http://www.hmotors.co.kr/inquiry/68089
http://www.dap.com.py/index.php/es/?option=com_k2&view=itemlist&task=user&id=852012
http://bebopindia.com/notcie/382250
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/44466
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-li7%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5/
http://mglpcm.org/board_ETkS12/127340
https://gonggamlaw.com/lawcase/133742
http://www.livetank.cn/market1/215224
http://mercibq.net/partner/55961
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=948311
https://betshin.com/Story/210849
http://daltso.com/index.php?mid=board_cUYy21&document_srl=195957
http://www.popolsku.fr.pl/forum/index.php?topic=417098.0
http://www.jesusonly.life/calendar/569131
http://married.dike.gr/index.php/component/k2/itemlist/user/78353
http://ko.myds.me/board_story/282017
http://healthyteethpa.org/component/k2/itemlist/user/5545298
http://loverstory.co.kr/board_UYNJ05/46683
http://matinbank.ir/component/k2/itemlist/user/4592349.html
http://isch.kr/board_PowH60/219759
http://www.coating.or.kr/atemfair_data/16454
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3543087
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=99467
http://www.artangel.co.kr/?document_srl=171085
https://www.hohoyoga.com/testboard/4089905
http://proxima.co.rw/index.php/component/k2/itemlist/user/692120
http://looksun.co.kr/index.php?mid=board_4&document_srl=156251
http://rabbitzone.xyz/FREE/115655
http://daltso.com/index.php?mid=board_cUYy21&document_srl=196740
http://mglpcm.org/board_ETkS12/124464
http://forum.bmw-e60.eu/index.php?topic=10919.0
http://taklongclub.com/forum/index.php?topic=205550.0
http://erhu.eu/viewtopic.php?t=396748
http://erdfsa.iptime.org/xe/index.php?mid=board&document_srl=13958
http://forum.bmw-e60.eu/index.php?topic=11308.0
http://otitismediasociety.org/forum/index.php?topic=205805.0
http://www.spazioad.com/?option=com_k2&view=itemlist&task=user&id=7462967
http://xn----3x5er9r48j7wemud0a387h.com/news/189514
https://www.celekt.com/%d0%ad%d0%a4%d0%98%d0%a0-%d0%a2%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-d7-%d0%a2%d0%be%d0%bb%d1%8f-%d1%80%d0%be/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1531998
http://yooseok.com/board_BkvT46/445274
http://isch.kr/board_PowH60/223953
https://intelogist2.wpengine.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pn1n-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81/
http://udrpsucks.com/blog/?p=1756
http://looksun.co.kr/index.php?mid=board_4&document_srl=186728
https://gonggamlaw.com/lawcase/134223
http://loverstory.co.kr/?document_srl=105430
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=590590
http://77.93.38.205/index.php/component/k2/itemlist/user/652080
http://midorijapaneserestaurant.ca/menu/News/67769
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=372757
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=44347
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2784757
http://ko.myds.me/board_story/314852
https://www.lwfservers.com/index.php?topic=73803.0
http://yoriyorifood.com/xxxx/spacial/263653
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qtgk-%d1%80%d0%b0%d1%81/
https://gonggamlaw.com/lawcase/144236
http://askpharm.net/board_NQiz06/157350
https://gonggamlaw.com/lawcase/125881
http://rabat.kr/board_yCgT00/38759
https://www.2ayes.com/19461/3-11-qqgq-3-11-syfy
http://holysweat.dothome.co.kr/data/7135
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/52644
https://gonggamlaw.com/lawcase/79941
http://www.popolsku.fr.pl/forum/index.php?topic=20407.81075
https://mcsetup.tk/bbs/index.php?topic=262116.0
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=42907
http://archeaudio.com/xe/board_AOYj82/9885
http://zakdu.com/board_ssKi56/20212
http://hanga5.com/index.php?mid=board_photo&document_srl=110234
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/347540
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=249301
https://intelogist2.wpengine.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dm7i-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81/
http://looksun.co.kr/index.php?mid=board_4&document_srl=190030
http://leonwebzine.dothome.co.kr/guest/9229
http://tiretech.co.kr/index.php?mid=qna&document_srl=180903
http://xn----3x5er9r48j7wemud0a387h.com/news/251484
https://www.hwbms.com/web/qna/44620
http://ko.myds.me/board_story/312522
http://herdental.co.kr/?document_srl=115427
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=1121704
http://ariji.kr/?document_srl=982484
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gq9t-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://isch.kr/?document_srl=157750
http://test.comics-game.ru/index.php?topic=644.0
http://www.vamoscontigo.org/Noticia/206337
https://saltriverbg.com/2019/05/29/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ihgl-%d1%80%d0%b0%d1%81/
http://jnk-ent.jp/index.php?mid=gallery&document_srl=238706
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1533691
https://turimex.mx.solemti.net/en/?option=com_k2&view=itemlist&task=user&id=18439
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=914495
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=852242
http://www.vamoscontigo.org/Noticia/165385
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/49644
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=309773
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3752552
http://p9912.cafe24.com/board_LVgu51/59120
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=119276
http://www2.yasothon.go.th/smf/index.php?topic=159.170820
http://www.vamoscontigo.org/Noticia/213978
http://rudraautomation.com/index.php/component/k2/author/336195
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1734669
http://mglpcm.org/board_ETkS12/128119
https://intelogist2.wpengine.com/%d0%ba%d0%be%d0%bf-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yu6k-%d0%ba%d0%be%d0%bf-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=663911
http://cwon.kr/xe/board_bnSr36/282256
http://sy.korean.net/qna/312001
http://sfah.ch/de/component/k2/itemlist/user/15565
http://ko.myds.me/board_story/243537
http://web2interactive.com/index.php/component/k2/itemlist/user/3781859
http://leonwebzine.dothome.co.kr/guest/11832
http://dev.aabn.org.gh/component/k2/itemlist/user/714377
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=228844
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=126401
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=315489
https://www.celekt.com/%d0%a0%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-eoyr-%d0%a0%d0%b0%d1%81/
http://mediaville.me/index.php/component/k2/itemlist/user/362564
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=314403
http://xn----3x5er9r48j7wemud0a387h.com/news/176977
http://rabbitzone.xyz/FREE/61189
http://d-tube.info/board_jvyO69/368826
http://www.telcon.gr/index.php/component/k2/itemlist/user/117147
http://bebopindia.com/notcie/511103
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7478602
http://toeden.co.kr/Product_new/213410
https://www.hwbms.com/web/qna/52923
https://www.hwbms.com/web/qna/52933
https://www.hwbms.com/web/qna/52951
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2813007
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2813016
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=110472
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2011080
http://mediaville.me/index.php/component/k2/itemlist/user/384886
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/180521
http://proxima.co.rw/index.php/component/k2/itemlist/user/725280
http://rudraautomation.com/index.php/component/k2/author/365189
http://viamania.net/index.php?mid=board_raYV15&document_srl=234108
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=393403
http://loverstory.co.kr/board_UYNJ05/110362
http://sd-xi.co.kr/g1/98995
http://married.dike.gr/index.php/component/k2/itemlist/user/78449
http://fbpharm.net/index.php/component/k2/itemlist/user/85987
http://agiteshop.com/xe/qa/163262
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=ac8c06990fbe09c89cd10f050fc21052&topic=11298.0
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1753533
http://www.popolsku.fr.pl/forum/index.php?topic=415642.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3490158
http://neosky.net/xe/space_station/68910
https://intelogist2.wpengine.com/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bu9%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be/
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=313719
http://naksansacondo.com/board_MGPu57/74496
http://www.kwpcoop.or.kr/QnA/22817
https://forums.lfstats.com/viewtopic.php?t=319366
http://sy.korean.net/?document_srl=319055
https://altaylarteknoloji.com/index.php?topic=6456.0
http://constellation.kro.kr/board_kbku73/64710
http://wigalseguros.com.br/index.php/component/k2/itemlist/user/28315
http://sejong-thesharpyemizi.co.kr/m1/51953
http://www.eunhaele.co.kr/xe/board/20515
http://agiteshop.com/xe/qa/203333
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=192293
https://reficulcoin.com/index.php?topic=87138.0
http://looksun.co.kr/index.php?mid=board_4&document_srl=197490
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2009721
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=108680
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=40149.0
http://www.proandpro.it/?option=com_k2&view=itemlist&task=user&id=4721362
http://carand.co.kr/d2/96634
http://www.rocketdan.co.kr/?document_srl=146118
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=116679
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=199946
http://askpharm.net/board_NQiz06/274691
http://dohairbiz.com/en/component/k2/itemlist/user/2815431.html
http://askpharm.net/board_NQiz06/249470
http://apt2you2.cafe24.com/g1/56975
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=117666
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-idum-%d1%80%d0%b0%d1%81/
https://mcsetup.tk/bbs/index.php?topic=262295.0
http://herdental.co.kr/index.php?mid=online&document_srl=114673
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1546896
http://sy.korean.net/qna/452105
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=40342.0
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16530
http://mercibq.net/partner/53525
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=550540
http://divespace.co.kr/board/178681
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=46195
http://www.m1avio.com/index.php/component/k2/itemlist/user/3798695
https://blossomug.com/index.php/component/k2/itemlist/user/1112635
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7519352
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16634
http://kockazatkutato.hu/component/k2/itemlist/user/47068
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/369869
http://cwon.kr/xe/board_bnSr36/302783
http://e-educ.net/Forum/index.php?topic=18120.0
http://loverstory.co.kr/board_UYNJ05/94641
http://dcasociados.eu/?option=com_k2&view=itemlist&task=user&id=94637
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=108662
http://mercibq.net/partner/118857
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lp4%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5/
http://vtservices85.fr/smf2/index.php?PHPSESSID=98dbdc32dfb28fc1db11a3cfe5020fd1&topic=288942.0
https://intelogist2.wpengine.com/%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-br8h-%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3486197
https://blossomug.com/index.php/component/k2/itemlist/user/1114248
http://pekosmile.dothome.co.kr/index.php?mid=seoulitestudio&document_srl=443532
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/?document_srl=96172
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1975429
http://tiretech.co.kr/index.php?mid=qna&document_srl=257950
http://carand.co.kr/d2/78456
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=39673
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wj9l-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://sejong-thesharpyemizi.co.kr/m1/36523
http://www.yadanarbonnews.com/index.php/component/k2/itemlist/user/349644
http://praisesound.co.kr/sub04_01/86993
http://yourhelp.co.kr/index.php?mid=board_2&document_srl=75253
http://www.vamoscontigo.org/Noticia/139638
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=173835
http://gusinoepero.ru/archives/26254
http://gardenpjw.dothome.co.kr/board_LOcC77/734731
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=205069
http://www.patrasin.kr/index.php?mid=questions&document_srl=4349208
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=430805
http://carand.co.kr/d2/91223
https://khuyenmaikk13.info/index.php?topic=225963.0
http://divespace.co.kr/board/265648
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=405490
https://betshin.com/Story/207587
http://divespace.co.kr/board/179547
http://www.coating.or.kr/atemfair_data/15979
http://roikjer.com/forum/index.php?PHPSESSID=ou19hau25askr4neiv1blrj3n6&topic=932005.0
https://betshin.com/Story/197739
http://d-tube.info/board_jvyO69/371001
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=104632
http://blog.ptpintcast.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cjqk-%d1%80%d0%b0%d1%81/
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=212482
http://bebopindia.com/notcie/384545
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1983791
http://cwon.kr/xe/board_bnSr36/298438
http://muldorang.com/market/26836
http://jnk-ent.jp/index.php?mid=gallery&document_srl=286340
http://apt2you2.cafe24.com/g1/57096
https://forum.ac-jete.it/index.php?topic=452729.0
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=94522
http://yooseok.com/board_BkvT46/417352
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=651955
http://sy.korean.net/qna/522086
http://sd-xi.co.kr/g1/60055
http://0433.net/budongsan/115915
http://askpharm.net/board_NQiz06/251590
http://ye-dream.com/?document_srl=206601
http://midorijapaneserestaurant.ca/menu/News/66758
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=96726
https://intelogist2.wpengine.com/%d0%ba%d0%be%d0%bf-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sj2d-%d0%ba%d0%be%d0%bf-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://p9912.cafe24.com/board_LVgu51/59981
http://otitismediasociety.org/forum/index.php?topic=208740.0
https://nple.com/xe/pds/236017
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=393285
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=397981
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3481592
http://8.droror.co.il/uncategorized/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ghfg-%d1%80%d0%b0%d1%81/
http://barobus.kr/qna/84384
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/346089
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=312009
http://midorijapaneserestaurant.ca/menu/News/57468
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=412856
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=692701
http://juroweb.com/xe/juroweb_board/84690
http://rabbitzone.xyz/FREE/134950
http://apt2you2.cafe24.com/?document_srl=37771
http://benzmall.co.kr/index.php?mid=download&document_srl=98953
http://gochon-iusell.co.kr/g1/113530
https://forums.lfstats.com/viewtopic.php?t=321607
http://shinhwaair2017.cafe24.com/issue/501618
http://www.sp1.football/index.php?mid=faq&document_srl=909032
http://gochon-iusell.co.kr/g1/97131
http://cwon.kr/xe/board_bnSr36/298469
http://rfc11th13th.dothome.co.kr/Board5/32223
http://mercibq.net/partner/54108
http://www.m1avio.com/index.php/component/k2/itemlist/user/3796969
https://www.chirorg.com/?document_srl=150464
http://dev.aabn.org.gh/component/k2/itemlist/user/711049
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/86421
http://askpharm.net/board_NQiz06/283180
http://bobr.site/index.php?topic=185192.0
https://adsensebih.com/index.php?topic=47343.0
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=5016589
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=115393
http://www.jesusonly.life/calendar/445828
https://forum.ac-jete.it/index.php?topic=447398.0
http://jnk-ent.jp/index.php?mid=gallery&document_srl=373331
http://www.sp1.football/index.php?document_srl=698189&mid=faq
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=36146
http://smartacity.com/component/k2/itemlist/user/93913
https://timecker.com/anonymous/188373
http://ko.myds.me/board_story/278770
http://www.quattroandpartners.it/component/k2/itemlist/user/1260297
http://www.comfortcenter.es/index.php/component/k2/itemlist/user/109308
http://constellation.kro.kr/board_kbku73/89702
http://www.alase.net/index.php/component/k2/itemlist/user/12637
http://153.120.114.241/eso/index.php/17619848-rasskaz-sluzanki-3-sezon-5-seria-vxnl-rasskaz-sluzanki-3-sezon-
http://alastair030.dothome.co.kr/index.php?mid=board_MMiF30&document_srl=29672
http://ye-dream.com/qa/259654
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=551603
http://shinhwaair2017.cafe24.com/issue/522447
http://netsconsults.com/?option=com_k2&view=itemlist&task=user&id=827645
https://forums.lfstats.com/viewtopic.php?t=318528
https://nextezone.com/index.php?topic=81410.0
http://mediaville.me/index.php/component/k2/itemlist/user/371239
http://bebopindia.com/notcie/394484
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=94138
http://jdcalc.com/forum/viewtopic.php?t=282218
http://www.jesusonly.life/calendar/527198
http://ovotecegg.com/?option=com_k2&view=itemlist&task=user&id=228110
http://bath-family.com/photo_zone/157368
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=105667
http://www.theocraticamerica.org/forum/index.php?topic=70501.0
http://naksansacondo.com/board_MGPu57/36235
http://herdental.co.kr/index.php?mid=online&document_srl=114543
http://looksun.co.kr/index.php?mid=board_4&document_srl=170878
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3749613
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=206121
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2005459
https://www.celekt.com/%d0%a4%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lv1%d0%a4%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5/
http://ko.myds.me/board_story/315641
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=242956
https://forum.ac-jete.it/index.php?topic=448724.0
http://rabat.kr/board_yCgT00/80324
http://kotica00.dothome.co.kr/index.php?mid=board_nJTE45&document_srl=45865
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=17424
http://tiretech.co.kr/index.php?mid=qna&document_srl=255138
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=377020
http://carand.co.kr/d2/90818
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1074199
http://carand.co.kr/d2/96428
http://yonseibaik.synology.me/index.php?mid=houston_profile&document_srl=74150
http://k-cea.org/board_Hnyj62/208571
http://masanlib.or.kr/g1/113517
http://mglpcm.org/board_ETkS12/127104
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/77264
https://forum.ac-jete.it/index.php?topic=437477.0
http://archeaudio.com/xe/board_AOYj82/11548
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=131973
http://phmusic.dothome.co.kr/index.php?mid=PowerHouseMusic&document_srl=46859
http://divespace.co.kr/board/276487
http://holysweat.dothome.co.kr/?document_srl=6693
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-evat-%d1%80%d0%b0%d1%81/
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16253
http://hyeonjun.co.kr/menu3/390808
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ww3e-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://beautypouch.net/index.php?mid=board_09&document_srl=186900
http://naksansacondo.com/board_MGPu57/99843
https://www.chirorg.com/?document_srl=151613
http://naksansacondo.com/?document_srl=102614
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=488333
http://askpharm.net/board_NQiz06/221400
http://thermoplast.envolgroupe.com/component/k2/author/177460
http://askpharm.net/board_NQiz06/258683
http://dow.dothome.co.kr/board_jydx58/35138
http://immobilia.gr/index.php/de/component/k2/itemlist/user/16898
http://loverstory.co.kr/board_UYNJ05/93630
http://askpharm.net/board_NQiz06/274965
http://cwon.kr/xe/board_bnSr36/315065
http://vtservices85.fr/smf2/index.php?PHPSESSID=9e31ac95a8e3e151145c110e2193e684&topic=286193.0
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=86142
http://cwon.kr/xe/board_bnSr36/294797
http://praisesound.co.kr/sub04_01/83025
http://looksun.co.kr/index.php?mid=board_4&document_srl=206706
http://www.quattroandpartners.it/component/k2/itemlist/user/1215819
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=181350
http://hyeonjun.co.kr/menu3/288166
http://dongilpastor.synology.me/ing/index.php?document_srl=171797&mid=board_WlVg97
http://xn--2e0b53df5ag1c804aphl.net/nuguna/106738
https://reficulcoin.com/index.php?topic=96606.0
http://warmfund.net/p/index.php?mid=financing&document_srl=467434
https://altaylarteknoloji.com/index.php?topic=6246.0
http://www.arunagreen.com/index.php/component/k2/itemlist/user/1154761
https://forum.shaiyaslayer.tk/index.php?topic=153949.0
http://naksansacondo.com/board_MGPu57/101219
https://gonggamlaw.com/lawcase/144917
http://rudraautomation.com/index.php/component/k2/author/334941
http://sd-xi.co.kr/g1/50931
http://midorijapaneserestaurant.ca/menu/News/75039
http://www.venusjeju.com/index.php?mid=QnA&document_srl=705
http://naksansacondo.com/board_MGPu57/40399
http://divespace.co.kr/board/275978
http://benzmall.co.kr/index.php?mid=download&document_srl=47651
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=38075
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=43499
http://beautypouch.net/index.php?mid=board_09&document_srl=188216
http://withinfp.sakura.ne.jp/eso/index.php/17588622-rasskaz-sluzanki-3-sezon-2-seria-qvmz-rasskaz-sluzanki-3-sezon-/0
http://withinfp.sakura.ne.jp/eso/index.php/17574170-rasskaz-sluzanki-3-sezon-2-seria-auzg-rasskaz-sluzanki-3-sezon-
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=273436
http://melchinooddle.dothome.co.kr/?document_srl=14968
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1769909
http://www.lgue.co.kr/?document_srl=150604
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/307168
http://warmfund.net/p/index.php?mid=financing&document_srl=450832
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=345582
http://www.livetank.cn/market1/241552
http://gallerychoi.com/Exhibition/336428
https://www.hwbms.com/web/qna/24547
http://www2.yasothon.go.th/smf/index.php?topic=159.171405
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=187935
http://www.pdctransport.co.th/index.php/component/k2/itemlist/user/17703
https://verdadesbiblicas.org.ec/index.php/component/k2/itemlist/user/3862898
http://www.hmotors.co.kr/inquiry/68262
http://arquitectosenreformas.es/component/k2/itemlist/user/86049
https://betshin.com/Story/206218
https://adsensebih.com/index.php?topic=42635.0
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=379294
http://cwon.kr/xe/board_bnSr36/286658
http://thermoplast.envolgroupe.com/component/k2/author/178599
http://kyj1225.godohosting.com/board_mebR72/98513
https://adsensebih.com/index.php?topic=50116.0
http://myrechockey.com/forums/index.php?topic=118516.0
http://sy.korean.net/qna/444621
http://kyj1225.godohosting.com/board_mebR72/94331
http://moyakmermer.com/?option=com_k2&view=itemlist&task=user&id=848207
http://autospa.lv/index.php/lv/component/k2/itemlist/user/10591
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=210374
http://nnkumw.org/xe/index.php?mid=board_yNQm00&document_srl=165700
https://forums.lfstats.com/viewtopic.php?t=321444
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=112268
http://dreamplusart.com/mn03_01/191453
http://bobr.site/index.php?topic=187144.0
http://loverstory.co.kr/board_UYNJ05/100135
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=444050
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=221065
http://rabat.kr/board_yCgT00/84839
http://ovotecegg.com/component/k2/itemlist/user/220228
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2596273
http://www.capital-investment.pl/index.php/component/k2/itemlist/user/230674
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mcsn-%d1%80%d0%b0%d1%81/
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ookv-%d1%80%d0%b0%d1%81/
http://rabbitzone.xyz/FREE/61014
http://www.crnmedia.es/?option=com_k2&view=itemlist&task=user&id=92379
http://praisesound.co.kr/sub04_01/87048
http://yourhelp.co.kr/index.php?mid=board_2&document_srl=58062
http://gardenpjw.dothome.co.kr/board_LOcC77/747451
http://ucckorea.kr/index.php?mid=board_AuHE49&document_srl=137817
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=231158
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=85789
https://betshin.com/Story/205688
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=315383
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1754093
http://lucky.kidspann.net/index.php?mid=qna&document_srl=417633
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3566158
http://herdental.co.kr/index.php?mid=online&document_srl=115297
http://design-381.com/xe/qna/5087
http://k-cea.org/board_Hnyj62/244372
https://forum.ac-jete.it/index.php?topic=447685.0
http://gochon-iusell.co.kr/g1/75798
http://naksansacondo.com/board_MGPu57/36230
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=955060
http://www.jesusonly.life/calendar/581050
http://tiretech.co.kr/index.php?mid=qna&document_srl=182494
http://www.artangel.co.kr/index.php?mid=Activities&document_srl=183817
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=206147
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/819504
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/841150
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/38324
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/408585
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=37756
http://matrixpharm.ru/forum/index.php?PHPSESSID=ukk805o2m82pt9hop1v60juig3&action=profile;u=218348
http://midorijapaneserestaurant.ca/menu/News/66221
https://betshin.com/Story/201769
https://cybergsm.es/index.php?topic=71891.0
http://www.theocraticamerica.org/forum/index.php?topic=70691.0
http://apt2you2.cafe24.com/g1/37830
http://myesl.ca/forum/viewtopic.php?f=3&t=690098&view=print
https://altaylarteknoloji.com/index.php?topic=6648.0
http://juroweb.com/xe/juroweb_board/112246
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=102953
http://x-crew.center/guest/4846797
http://archeaudio.com/xe/board_AOYj82/10214
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=165720
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=663080
http://midorijapaneserestaurant.ca/menu/News/48778
http://hyeonjun.co.kr/menu3/288786
http://www.leekeonsu-csi.com/?document_srl=1010045
http://ye-dream.com/qa/206156
http://loverstory.co.kr/board_UYNJ05/87275
http://lucky.kidspann.net/index.php?mid=qna&document_srl=289961
http://1644-4404.com/?document_srl=397535
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1546411
https://www.celekt.com/%d0%a0%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-evtw-%d0%a0%d0%b0%d1%81/
http://daesestudy.co.kr/ipsi_docu/120666
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/842969
http://www.proandpro.it/?option=com_k2&view=itemlist&task=user&id=4722268
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/246977
http://www.kcch.or.kr/index.php?mid=board_uFpk03&document_srl=129884
https://forum.clubeicaro.pt/index.php?topic=2704.0
http://dev.aabn.org.gh/component/k2/itemlist/user/727160
http://cwon.kr/xe/board_bnSr36/302584
http://apt2you2.cafe24.com/g1/56806
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=592425
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3450444
http://www.cswc.co.kr/index.php?document_srl=33296&mid=board_zyTs37
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=329159
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=650768
http://midorijapaneserestaurant.ca/menu/News/46166
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=108389
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2742130
http://www.cnsmaker.net/xe/?document_srl=132472
http://cwon.kr/xe/board_bnSr36/307470
http://askpharm.net/board_NQiz06/159400
http://loverstory.co.kr/board_UYNJ05/54699
http://midorijapaneserestaurant.ca/menu/News/49073
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lc9g-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17/
http://rabat.kr/board_yCgT00/37802
http://gusinoepero.ru/archives/26176
http://benzmall.co.kr/index.php?mid=download&document_srl=92205
http://www.kcch.or.kr/index.php?mid=board_uFpk03&document_srl=110563
http://www.livetank.cn/market1/216378
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=173742
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=212142
http://apt2you2.cafe24.com/g1/57805
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=478846
http://rabat.kr/board_yCgT00/39004
http://udrpsucks.com/blog/?p=1741
http://loverstory.co.kr/board_UYNJ05/104381
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-eb8k-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-10-%d1%81%d0%b5%d1%80%d0%b8/
http://looksun.co.kr/index.php?mid=board_4&document_srl=204072
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=105681
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1996103
http://k-cea.org/board_Hnyj62/254506
https://2002.shyoon.com/board_2002/169758
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=484511
http://kotica00.dothome.co.kr/index.php?mid=board_nJTE45&document_srl=41493
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2791878
http://sejong-thesharpyemizi.co.kr/m1/29397
http://mediaville.me/index.php/component/k2/itemlist/user/370545
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=229741
http://gallerychoi.com/Exhibition/346268
http://robocit.com/index.php/component/k2/itemlist/user/449873
http://midorijapaneserestaurant.ca/menu/News/75538
http://gallerychoi.com/Exhibition/449241
http://mercibq.net/partner/55216
http://jnk-ent.jp/index.php?mid=gallery&document_srl=239262
https://www.swiss-focus.ch/index.php/component/k2/itemlist/user/35453
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=376407
http://legride.com/UserProfile/tabid/61/userId/2888345/Default.aspx
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tz7t-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15/
http://rabbitzone.xyz/FREE/125075
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=23582
http://benzmall.co.kr/index.php?mid=download&document_srl=98733
http://callman.co.kr/index.php?mid=qa&document_srl=283250
https://cybergsm.es/index.php?topic=64425.0
http://gallerychoi.com/Exhibition/336378
http://cwon.kr/xe/board_bnSr36/286241
http://benzmall.co.kr/index.php?mid=download&document_srl=99545
http://daltso.com/index.php?mid=board_cUYy21&document_srl=194215
http://e-educ.net/Forum/index.php?topic=16727.0
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2606624
http://myrechockey.com/forums/index.php?topic=118679.0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=115908
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=124915
http://looksun.co.kr/index.php?mid=board_4&document_srl=182984
http://zakdu.com/board_YpzS56/22661
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=229300
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=267735
http://guiadetudo.com/index.php/component/k2/itemlist/user/12713
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=205142
http://www.leekeonsu-csi.com/?document_srl=1120972
http://loverstory.co.kr/board_UYNJ05/117837
http://withinfp.sakura.ne.jp/eso/index.php/17537003-rasskaz-sluzanki-3-sezon-3-seria-fcoc-rasskaz-sluzanki-3-sezon-/0
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=204946
http://married.dike.gr/index.php/component/k2/itemlist/user/78156
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=177683
http://www.livetank.cn/market1/215676
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=125014
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/49440
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=560284
http://necinsurance.co.zw/component/k2/itemlist/user/21714.html
http://divespace.co.kr/?document_srl=278528
http://www.venusjeju.com/index.php?mid=QnA&document_srl=1977
http://ptu.imoove.kr/ko/content/%C2%AB%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-7-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-uhef-%C2%AB%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-7-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-amc341153
http://looksun.co.kr/index.php?mid=board_4&document_srl=198102
http://www.alase.net/index.php/component/k2/itemlist/user/12614
http://www.ekemoon.com/244903/052020193328/
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1312207
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/59980
http://loverstory.co.kr/board_UYNJ05/108453
http://gabisan.com/board_OuDs04/74338
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=496451
https://gonggamlaw.com/lawcase/128930
http://loverstory.co.kr/board_UYNJ05/115454
http://dcasociados.eu/component/k2/itemlist/user/93419
http://ajincomp.godohosting.com/board_STnh82/128098
http://kyj1225.godohosting.com/board_mebR72/92128
https://intelogist2.wpengine.com/%d0%ba%d0%be%d0%bf-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qu3j-%d0%ba%d0%be%d0%bf-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.jshwanghoan.com/?document_srl=430706
http://sy.korean.net/qna/388667
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/84496
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/853838
http://naksansacondo.com/board_MGPu57/78644
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=215965
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=231078
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=49584
http://dreamplusart.com/mn03_01/171132
http://bath-family.com/photo_zone/129092
http://myrechockey.com/forums/index.php?topic=118840.0
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=17432
http://daltso.com/index.php?mid=board_cUYy21&document_srl=214181
http://udrpsucks.com/blog/?p=1763
http://www.dap.com.py/index.php/component/k2/itemlist/user/850974
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=35340
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=725919
https://www.shaiyax.com/index.php?topic=404970.0
http://otitismediasociety.org/forum/index.php?topic=203120.0
http://dcasociados.eu/?option=com_k2&view=itemlist&task=user&id=94470
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2000878
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/97992
http://beautypouch.net/index.php?mid=board_09&document_srl=101623
http://kyj1225.godohosting.com/board_mebR72/99534
http://music.start-a-idea.online/blogs/viewstory/43613
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=109407
http://pkgersang.dothome.co.kr/board_jiKY24/40923
http://nnkumw.org/xe/index.php?mid=board_yNQm00&document_srl=138442
http://gallerychoi.com/Exhibition/334698
http://leonwebzine.dothome.co.kr/guest/12047
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=213797
http://netsconsults.com/?option=com_k2&view=itemlist&task=user&id=798268
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/59878
https://prosto-vkus.ru/?option=com_k2&view=itemlist&task=user&id=36647
http://8.droror.co.il/uncategorized/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uz0%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5/
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=27037
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=27050
http://mtuan93.com/board_uCqR85/6569
https://nextezone.com/index.php?action=profile;u=14361
https://nextezone.com/index.php?topic=90055.0
https://timecker.com/anonymous/209187
https://timecker.com/anonymous/209205
https://timecker.com/anonymous/209221
https://timecker.com/anonymous/209250
https://timecker.com/anonymous/209262
http://hotelnomadpalace.com/index.php/component/k2/itemlist/user/23168
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2780583
http://www.artangel.co.kr/index.php?mid=Activities&document_srl=184441
http://jiral.net/an9/43215
http://socialmag.bayareanonprofits.xyz/blogs/viewstory/130332
http://carand.co.kr/d2/96751
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3491422
http://www.vamoscontigo.org/Noticia/138065
http://bobr.site/index.php?topic=182457.0
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=47448
http://benzmall.co.kr/index.php?mid=download&document_srl=93282
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=209846
http://daltso.com/index.php?mid=board_cUYy21&document_srl=233553
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/?document_srl=32733
http://ye-dream.com/qa/238524
http://yoriyorifood.com/xxxx/spacial/333253
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=240954
http://www.spazioad.com/component/k2/itemlist/user/7419031
http://nnkumw.org/xe/index.php?mid=board_yNQm00&document_srl=131669
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-auqt-%d1%80%d0%b0%d1%81/
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4938102
http://carand.co.kr/d2/90426
http://www.quattroandpartners.it/component/k2/itemlist/user/1213244
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=267881
http://dev.aabn.org.gh/component/k2/itemlist/user/713876
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/34115
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=113167
http://www.coating.or.kr/?document_srl=17452
http://cwon.kr/xe/board_bnSr36/294586
http://praisesound.co.kr/sub04_01/87455
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=41340.0
http://midorijapaneserestaurant.ca/menu/News/51071
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/388702
http://divespace.co.kr/board/201759
http://www.cnsmaker.net/xe/?document_srl=151677
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=118730
http://test.comics-game.ru/index.php?topic=461.0
http://153.120.114.241/eso/index.php/17539145-rasskaz-sluzanki-3-sezon-4-seria-tfdu-rasskaz-sluzanki-3-sezon-
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=372415
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3794733
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=547083
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=429468
http://xn--2e0b53df5ag1c804aphl.net/nuguna/199881
http://dayung.co.kr/board_SRVC17/90666
http://thermoplast.envolgroupe.com/component/k2/author/181450
https://forums.lfstats.com/viewtopic.php?t=320047
http://dev.aabn.org.gh/component/k2/itemlist/user/727421
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=86346
http://www.patrasin.kr/index.php?mid=questions&document_srl=4356851
http://yooseok.com/board_BkvT46/460679
http://test.comics-game.ru/index.php?topic=494.0
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=39641
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/815238
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=850811
http://daesestudy.co.kr/?document_srl=150335
http://gochon-iusell.co.kr/g1/74660
http://carand.co.kr/d2/90543
http://yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=345969
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=100617
http://hyeonjun.co.kr/menu3/287247
http://www.hmotors.co.kr/inquiry/42484
http://mediaville.me/index.php/component/k2/itemlist/user/331612
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/87257
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=87275
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=483884
http://mobility-corp.com/index.php/component/k2/itemlist/user/2700700
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=82875
http://www.arunagreen.com/index.php/component/k2/itemlist/user/1152928
http://naksansacondo.com/board_MGPu57/102968
https://betshin.com/Story/204914
http://ko.myds.me/board_story/280306
http://2872870.com/est/66152
http://ptu.imoove.kr/ko/content/%C2%AB%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-10-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-qysw-%C2%AB%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-10-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-hbo341087
https://www.hwbms.com/web/qna/34120
http://daltso.com/index.php?mid=board_cUYy21&document_srl=157987
http://nnkumw.org/xe/index.php?mid=board_yNQm00&document_srl=143598
http://dsyang.com/board_Kvgn62/30386
https://forum.ac-jete.it/index.php?topic=446491.0
http://www.vamoscontigo.org/Noticia/138902
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1177053
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=184142
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=239545
https://intelogist2.wpengine.com/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-er5w-%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3/
http://dickymicky.com/bbs/3546
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/78418
http://divespace.co.kr/board/279898
http://www.crnmedia.es/?option=com_k2&view=itemlist&task=user&id=91950
https://www.hwbms.com/web/qna/33070
http://jensenbyggteam.no/index.php/component/k2/itemlist/user/13735
http://esperanzazubieta.com/component/k2/itemlist/user/108272
http://mercibq.net/partner/126784
http://www.boutique.in.th/?option=com_k2&view=itemlist&task=user&id=153058
http://www.boutique.in.th/?option=com_k2&view=itemlist&task=user&id=153123
http://music.start-a-idea.online/blogs/viewstory/44412
http://gallerychoi.com/Exhibition/450913
http://www.popolsku.fr.pl/forum/index.php?topic=20407.80895
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1867490
http://www.hmotors.co.kr/inquiry/74119
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=39566
http://apt2you2.cafe24.com/g1/52037
http://www.alase.net/index.php/component/k2/itemlist/user/12689
http://xn--2e0b53df5ag1c804aphl.net/nuguna/103975
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/gumdanapt/338786
http://myrechockey.com/forums/index.php?topic=117844.0
http://dsyang.com/board_Kvgn62/45618
http://www.hmotors.co.kr/inquiry/41953
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=385964
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16949
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=199867
http://mediaville.me/index.php/component/k2/itemlist/user/361486
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2002031
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/news/141007
http://roikjer.com/forum/index.php?PHPSESSID=8ogr3081ocbvkrjhl4c4eanog1&topic=924060.0
https://forum.ac-jete.it/index.php?topic=447861.0
http://www.hmotors.co.kr/?document_srl=41252
http://mobility-corp.com/index.php/component/k2/itemlist/user/2737379
http://music.start-a-idea.online/blogs/viewstory/47800
http://sy.korean.net/qna/444391
https://gonggamlaw.com/lawcase/68544
https://mcsetup.tk/bbs/index.php?topic=262613.0
http://socialmag.bayareanonprofits.xyz/blogs/viewstory/130131
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/78547
http://mtuan93.com/board_uCqR85/6270
http://photogrotto.com/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pe1e-%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3/
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=c8f4a102c13e9436dbacfd8815e8036d&topic=11450.0
http://sunele.co.kr/board_ReBD97/204362
http://daltso.com/index.php?mid=board_cUYy21&document_srl=206512
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1995476
http://sofficer.net/xe/teach/287729
http://smartacity.com/component/k2/itemlist/user/93552
http://daltso.com/index.php?mid=board_cUYy21&document_srl=212171
https://gonggamlaw.com/lawcase/144236
http://askpharm.net/board_NQiz06/157350
https://gonggamlaw.com/lawcase/125881
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=35616
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2000213
http://loverstory.co.kr/board_UYNJ05/107058
http://rabat.kr/board_yCgT00/59552
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=18546
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2696981
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=36004
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1531470
http://loverstory.co.kr/board_UYNJ05/88087
http://www.livetank.cn/market1/218194
http://dev.aabn.org.gh/component/k2/itemlist/user/710827
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1753519
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/36862
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/174600
http://muldorang.com/market/28419
http://kwpub.kr/PUBS/171604
http://kyj1225.godohosting.com/board_mebR72/98361
http://looksun.co.kr/index.php?mid=board_4&document_srl=202296
http://ko.myds.me/board_story/247723
http://vtservices85.fr/smf2/index.php?PHPSESSID=09e62cebeee1fa2746e6da91c7cf87c3&topic=285545.0
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=173087
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=438733
http://loverstory.co.kr/board_UYNJ05/118235
http://mediaville.me/index.php/component/k2/itemlist/user/376768
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2009739
http://sunele.co.kr/board_ReBD97/240518
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=157989
http://gusinoepero.ru/archives/29259
http://rudraautomation.com/index.php/component/k2/author/291607
http://midorijapaneserestaurant.ca/menu/News/70318
http://forum.bmw-e60.eu/index.php?topic=11362.0
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=1587c5225defce40d88145d54327b0ee&topic=11070.0
http://apt2you2.cafe24.com/g1/52839
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=283469
http://shinhwaair2017.cafe24.com/issue/496495
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=650908
http://phmusic.dothome.co.kr/index.php?mid=PowerHouseMusic&document_srl=51853
http://loverstory.co.kr/board_UYNJ05/46845
http://miquirofisico.com/index.php/component/k2/itemlist/user/4564
http://nnkumw.org/xe/?document_srl=140661
http://www.comfortcenter.es/index.php/component/k2/itemlist/user/109612
https://www.limscave.com/forum/viewtopic.php?t=57446
http://proxima.co.rw/index.php/component/k2/itemlist/user/717284
http://www.eunhaele.co.kr/xe/board/20285
https://timecker.com/anonymous/211061
https://timecker.com/anonymous/211130
https://timecker.com/anonymous/211136
https://timecker.com/anonymous/211148
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=102186
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=19437
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=111583
https://2002.shyoon.com/board_2002/167171
https://intelogist2.wpengine.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hxbo-%d1%80%d0%b0%d1%81/
https://www.hwbms.com/web/qna/27243
http://loverstory.co.kr/board_UYNJ05/107286
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=49276
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2795483
http://benzmall.co.kr/index.php?mid=download&document_srl=98538
http://www.vamoscontigo.org/Noticia/136520
http://sunele.co.kr/board_ReBD97/162712
http://yoriyorifood.com/xxxx/spacial/330351
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=240094
https://nple.com/xe/pds/151195
http://nnkumw.org/xe/index.php?document_srl=139397&mid=board_yNQm00
http://www.hmotors.co.kr/inquiry/26956
http://www.grupojover.com/?option=com_k2&view=itemlist&task=user&id=4414
http://vtservices85.fr/smf2/index.php?PHPSESSID=7623bc54aa22bc38c6d4244057e7129e&topic=289551.0
http://warmfund.net/p/index.php?mid=financing&document_srl=614498
http://dev.aabn.org.gh/component/k2/itemlist/user/678458
http://carand.co.kr/d2/94301
http://www.teedinubon.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cz9%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f30-05/
http://www.spazioad.com/component/k2/itemlist/user/7472706
http://oss.obigo.com/oss/index.php?mid=board_mxLS91&document_srl=66980
https://intelogist2.wpengine.com/%d0%ba%d0%be%d0%bf-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vs5b-%d0%ba%d0%be%d0%bf-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://intelogist2.wpengine.com/%d0%ba%d0%be%d0%bf-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yf9f-%d0%ba%d0%be%d0%bf-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-it9l-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-oi1y-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qk7o-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-18-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%84%d0%b8%d1%82/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-video-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be/
http://dsyang.com/board_Kvgn62/49143
http://naksansacondo.com/board_MGPu57/112633
http://naksansacondo.com/board_MGPu57/112662
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=30759
http://forum.elexlabs.com/index.php?topic=62217.0
http://www.svteck.co.kr/customer_gratitude/301991
http://miquirofisico.com/index.php/component/k2/itemlist/user/4549
http://www.theocraticamerica.org/forum/index.php?topic=75695.0
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1738379
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/246215
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3839829
http://fbpharm.net/index.php/component/k2/itemlist/user/86944
http://www.telcon.gr/index.php/component/k2/itemlist/user/116593
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=36755
http://midorijapaneserestaurant.ca/menu/News/78344
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/74245
http://yooseok.com/?document_srl=444319
http://midorijapaneserestaurant.ca/menu/News/26853
http://www.vamoscontigo.org/Noticia/211970
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=44885
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=191085
https://reficulcoin.com/index.php?topic=90197.0
http://themasters.pro/file_01/227995
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=113144
http://www.livetank.cn/market1/216788
http://rabat.kr/board_yCgT00/37836
http://askpharm.net/board_NQiz06/246026
http://www.artangel.co.kr/index.php?mid=Activities&document_srl=162304
https://reficulcoin.com/index.php?topic=95751.0
http://carand.co.kr/d2/46934
http://yourhelp.co.kr/index.php?mid=board_2&document_srl=85031
http://www.ekemoon.com/240457/050920190326/
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/71993
http://carand.co.kr/d2/93148
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/133952
http://looksun.co.kr/index.php?mid=board_4&document_srl=207102
http://hotelnomadpalace.com/index.php/component/k2/itemlist/user/22956
http://carand.co.kr/d2/95239
http://ovotecegg.com/component/k2/itemlist/user/221247
https://www.hwbms.com/web/qna/33218
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=114916
http://askpharm.net/?document_srl=251909
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=128998
http://ilsannabgol.kr/board_brJk31/1374425
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/245796
http://nnkumw.org/xe/index.php?mid=board_yNQm00&document_srl=140852
https://gonggamlaw.com/lawcase/135614
http://looksun.co.kr/index.php?mid=board_4&document_srl=154648
http://www.yadanarbonnews.com/index.php/component/k2/itemlist/user/354179
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2007280
http://loverstory.co.kr/board_UYNJ05/103322
http://blog.ptpintcast.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uybz-%d1%80%d0%b0%d1%81/
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=43663
http://hyeonjun.co.kr/menu3/331388
http://www.vamoscontigo.org/Noticia/206379
http://dohairbiz.com/?option=com_k2&view=itemlist&task=user&id=2816324
http://www.hmotors.co.kr/inquiry/25860
http://daltso.com/index.php?mid=board_cUYy21&document_srl=204424
http://photogrotto.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ix2r-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://dcasociados.eu/component/k2/itemlist/user/95210
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=174431
http://bobr.site/index.php?topic=188647.0
http://apt2you2.cafe24.com/g1/36035
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=103346
https://www.hohoyoga.com/testboard/4054664
http://dospuntoseventos.cl/component/k2/itemlist/user/16738
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-emwn-%d1%80%d0%b0%d1%81/
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2600817
https://www.shaiyax.com/index.php?topic=398028.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=2e5d37a0a51f6d2e7c7020e502ca2b79&topic=289901.0
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=340880
https://nextezone.com/index.php?action=profile;u=14502
http://www.nurican.com/giris/ncan/index.php?topic=6127.0
https://forums.lfstats.com/viewtopic.php?t=320389
http://www.popolsku.fr.pl/forum/index.php?topic=20407.79305
http://proxima.co.rw/index.php/component/k2/itemlist/user/692188
http://bizchemical.com/board_kMpv94/2160999
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=136420
http://e-educ.net/Forum/index.php?topic=16550.0
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=214472
http://jdcalc.com/forum/viewtopic.php?t=292194
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1963933
http://www.ekemoon.com/246165/050820195529/
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=85871
http://beautypouch.net/index.php?mid=board_09&document_srl=180902
http://archeaudio.com/xe/board_AOYj82/10302
http://www.cswc.co.kr/index.php?mid=board_zyTs37&document_srl=62169
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=5018885
http://apt2you2.cafe24.com/g1/44763
https://saltriverbg.com/2019/05/29/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ccdi-%d1%80%d0%b0%d1%81/
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1852359
http://www.siirtorganik.com/index.php/component/k2/itemlist/user/951066
http://gochon-iusell.co.kr/g1/87816
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3748683
http://www.cswc.co.kr/index.php?mid=board_zyTs37&document_srl=33084
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=400703
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/393239
http://www.emrabq8.com/index.php/component/k2/itemlist/user/1852612
http://carand.co.kr/d2/97997
http://thermoplast.envolgroupe.com/component/k2/itemlist/user/179035
http://jdcalc.com/forum/viewtopic.php?f=2&t=285985&view=print
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3493087
http://sy.korean.net/qna/314862
http://kyj1225.godohosting.com/board_mebR72/59358
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3896787
http://ko.myds.me/board_story/272337
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1182960
http://dohairbiz.com/en/component/k2/itemlist/user/2818596.html
http://archeaudio.com/xe/board_AOYj82/11097
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1854175
http://loverstory.co.kr/board_UYNJ05/111594
https://www.celekt.com/%d0%a0%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-eucy-%d0%a0%d0%b0%d1%81/
http://midorijapaneserestaurant.ca/menu/News/67484
https://www.hohoyoga.com/testboard/4058460
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/390416
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/48519
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1983181
http://looksun.co.kr/index.php?mid=board_4&document_srl=127857
https://gonggamlaw.com/lawcase/130036
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/95838
http://juroweb.com/xe/juroweb_board/153815
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1501135
http://forum.bmw-e60.eu/index.php?topic=11228.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1543160
http://midorijapaneserestaurant.ca/menu/News/24778
http://looksun.co.kr/index.php?mid=board_4&document_srl=210288
http://www.m1avio.com/index.php/component/k2/itemlist/user/3803693
http://agiteshop.com/xe/qa/170603
http://kyj1225.godohosting.com/board_mebR72/98184
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1119127
http://bath-family.com/photo_zone/146014
http://agiteshop.com/xe/qa/163121
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=70099
https://intelogist2.wpengine.com/%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qa5%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f28-05-20/
http://muldorang.com/market/27885
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=17901
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=205140
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=852563
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2782999
https://gonggamlaw.com/lawcase/130096
http://ovotecegg.com/component/k2/itemlist/user/229725
https://blossomug.com/index.php/component/k2/itemlist/user/1112641
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=386777
http://mobility-corp.com/index.php/component/k2/itemlist/user/2737035
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=169683
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/173136
http://otitismediasociety.org/forum/index.php?topic=204961.0
https://betshin.com/Story/200089
http://divespace.co.kr/board/267654
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=98649
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=43945
http://yooseok.com/board_BkvT46/412504
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3841265
http://ko.myds.me/board_story/282185
http://midorijapaneserestaurant.ca/menu/News/26864
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=48511
http://test.comics-game.ru/index.php?topic=539.0
http://otitismediasociety.org/forum/index.php?topic=210238.0
http://www.capital-investment.pl/index.php/component/k2/itemlist/user/228889
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1754717
http://www.jesusonly.life/calendar/458470
http://daltso.com/index.php?mid=board_cUYy21&document_srl=126942
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1851832
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=108982
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=193648
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1320048
http://ko.myds.me/board_story/315491
https://nple.com/xe/pds/151161
http://looksun.co.kr/index.php?mid=board_4&document_srl=199701
http://fbpharm.net/index.php/component/k2/itemlist/user/87264
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=366637
http://loverstory.co.kr/board_UYNJ05/101250
http://archeaudio.com/xe/board_AOYj82/11038
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3900801
http://ucckorea.kr/index.php?mid=board_AuHE49&document_srl=77949
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1548613
https://www.hwbms.com/web/qna/24302
http://roikjer.com/forum/index.php?PHPSESSID=ivpr92hresedml2eiiilfejfn6&topic=931118.0
http://bebopindia.com/notcie/455701
https://forum.ac-jete.it/index.php?topic=449118.0
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=385349
http://mobility-corp.com/index.php/component/k2/itemlist/user/2743913
http://www.venusjeju.com/index.php?mid=QnA&document_srl=671
http://kyj1225.godohosting.com/board_mebR72/92757
http://kyj1225.godohosting.com/board_mebR72/96343
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1535166
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=559410
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1143782
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=117284
https://intelogist2.wpengine.com/%d0%ba%d0%be%d0%bf-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bu6v-%d0%ba%d0%be%d0%bf-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://carand.co.kr/d2/90048
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=39694
http://yonseibaik.synology.me/index.php?mid=houston_profile&document_srl=102845
http://gspara01.dothome.co.kr/index.php?mid=board_XHsr53&document_srl=13577
http://midorijapaneserestaurant.ca/menu/News/74523
http://www.hmotors.co.kr/inquiry/67807
http://divespace.co.kr/board/179593
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ze6%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f28-05/
https://www.hohoyoga.com/testboard/3977279
http://thermoplast.envolgroupe.com/component/k2/author/157669
http://universalcommunity.se/Forum/index.php?topic=35758.0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/148435
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=386996
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=113144
http://taklongclub.com/forum/index.php?topic=206081.0
http://loverstory.co.kr/board_UYNJ05/110863
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=138687
http://myrechockey.com/forums/index.php?topic=119242.0
http://www.eunhaele.co.kr/xe/board/20506
http://nnkumw.org/xe/index.php?document_srl=138419&mid=board_yNQm00
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=969129
http://daesestudy.co.kr/?document_srl=173602
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=131760
http://askpharm.net/board_NQiz06/254432
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/80060
http://erhu.eu/viewtopic.php?t=397311
http://www.ekemoon.com/240575/051020190026/
http://holysweat.dothome.co.kr/data/7089
http://roikjer.com/forum/index.php?PHPSESSID=o05ndeb41gufg2op6uvjp6q1n1&topic=930233.0
http://looksun.co.kr/?document_srl=192580
http://www.kwpcoop.or.kr/QnA/20302
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1193139
http://www.hmotors.co.kr/inquiry/27597
http://sunele.co.kr/board_ReBD97/244068
http://kyj1225.godohosting.com/board_mebR72/95932
http://music.start-a-idea.online/blogs/viewstory/44333
http://holysweat.dothome.co.kr/data/7356
http://midorijapaneserestaurant.ca/menu/News/48739
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2600015
http://cwon.kr/xe/board_bnSr36/306026
http://jdcalc.com/forum/viewtopic.php?t=286772
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/82332
http://xn--2e0bk61btjo.com/notice/29057
http://www.livetank.cn/market1/217767
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cjjt-%d1%80%d0%b0%d1%81/
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=39676
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=541355
https://saltriverbg.com/2019/05/28/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-orip-%d1%80%d0%b0%d1%81/
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=100692
https://mcsetup.tk/bbs/index.php?topic=263189.0
http://fbpharm.net/index.php/component/k2/itemlist/user/85678
http://dow.dothome.co.kr/board_jydx58/33428
http://153.120.114.241/eso/index.php/17523649-rasskaz-sluzanki-3-sezon-8-seria-fwxo-rasskaz-sluzanki-3-sezon-
http://necinsurance.co.zw/component/k2/itemlist/user/21642.html
http://askpharm.net/board_NQiz06/251832
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1077246
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1995402
https://www.hohoyoga.com/testboard/4073783
http://www2.yasothon.go.th/smf/index.php?topic=159.172080
https://grajalesabogados.com.mx/?option=com_k2&view=itemlist&task=user&id=66228
https://betshin.com/Story/198932
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=398210
http://www.boutique.in.th/?option=com_k2&view=itemlist&task=user&id=153117
http://www.jesusonly.life/calendar/623034
http://www.quattroandpartners.it/component/k2/itemlist/user/1261065
http://x-crew.center/guest/4848468
http://rabat.kr/board_yCgT00/68900
http://askpharm.net/board_NQiz06/275368
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=169645
http://dcasociados.eu/component/k2/itemlist/user/94404
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1164262
http://askpharm.net/board_NQiz06/258560
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kvjj-%d1%80%d0%b0%d1%81/
https://www.hwbms.com/web/qna/32936
http://bebopindia.com/notcie/511210
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1545755
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=106166
http://shinhwaair2017.cafe24.com/issue/514324
http://www.svteck.co.kr/?document_srl=224157
https://www.hohoyoga.com/testboard/4058508
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=112747
http://ucckorea.kr/index.php?mid=board_AuHE49&document_srl=90360
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1734878
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=13695
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=541530
http://www.hmotors.co.kr/inquiry/70722
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=1203826
http://nnkumw.org/xe/index.php?mid=board_yNQm00&document_srl=140419
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-eu2o-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-10-%d1%81%d0%b5%d1%80%d0%b8/
http://sy.korean.net/qna/317221
http://erhu.eu/viewtopic.php?f=9&t=397875&view=print
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=538718
https://www.hohoyoga.com/testboard/3970666
http://mtuan93.com/board_uCqR85/6453
http://jnk-ent.jp/index.php?mid=gallery&document_srl=351891
http://0433.net/budongsan/111873
http://sejong-thesharpyemizi.co.kr/m1/35351
http://153.120.114.241/eso/index.php/17539386-rasskaz-sluzanki-3-sezon-1-seria-peck-rasskaz-sluzanki-3-sezon-
http://netsconsults.com/?option=com_k2&view=itemlist&task=user&id=827671
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=316746
http://yourhelp.co.kr/index.php?mid=board_2&document_srl=94341
http://vtservices85.fr/smf2/index.php?PHPSESSID=6652fe8d6f2d76489137f1a945aed6f7&topic=288964.0
http://www.kwpcoop.or.kr/QnA/21651
http://thermoplast.envolgroupe.com/component/k2/author/181253
http://mediaville.me/index.php/component/k2/itemlist/user/333610
http://www.venusjeju.com/index.php?mid=QnA&document_srl=1172
http://naksansacondo.com/board_MGPu57/92494
http://juroweb.com/xe/juroweb_board/132988
http://www.urbantutorial.com/?option=com_k2&view=itemlist&task=user&id=127443
https://esel.gist.ac.kr/esel2/board_hmgj23/271410
http://pkgersang.dothome.co.kr/board_jiKY24/42647
http://socialmag.bayareanonprofits.xyz/blogs/viewstory/129828
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2004968
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/37339
https://www.celekt.com/%d0%92%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vq6n-%d0%92%d1%81%d1%91-%d0%bc%d0%be%d0%b3/
http://eugeniocolazzo.it/forum/index.php?topic=187161.0
https://gonggamlaw.com/lawcase/143515
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1995748
https://forum.clubeicaro.pt/index.php?topic=2315.0
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=228911
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=401016
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/81546
http://mvisage.sk/index.php/component/k2/itemlist/user/119698
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=116078
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=d13dcacb5d96618ac2a7ec4d2f46c277&topic=11149.0
http://dsyang.com/board_Kvgn62/30291
http://mediaville.me/index.php/component/k2/itemlist/user/362960
http://praisesound.co.kr/sub04_01/88557
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=378381
http://mglpcm.org/board_ETkS12/166440
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=207754
https://2002.shyoon.com/board_2002/189016
http://www.hmotors.co.kr/inquiry/64316
http://gochon-iusell.co.kr/g1/75123
https://nple.com/xe/pds/195394
http://herdental.co.kr/index.php?mid=online&document_srl=130756
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/171742
http://divespace.co.kr/board/278254
http://photogrotto.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jd6j-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://e-educ.net/Forum/index.php?topic=16952.0
http://dreamplusart.com/mn03_01/171154
http://rudraautomation.com/index.php/component/k2/author/347756
http://midorijapaneserestaurant.ca/menu/News/25472
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/82864
http://daltso.com/index.php?mid=board_cUYy21&document_srl=200541
http://dsyang.com/board_Kvgn62/42263
https://www.hohoyoga.com/testboard/4068157
http://midorijapaneserestaurant.ca/menu/News/46179
http://callman.co.kr/index.php?mid=qa&document_srl=226367
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/72064
http://rudraautomation.com/index.php/component/k2/author/289184
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=338485
http://cwon.kr/xe/board_bnSr36/315221
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=0c966db9c819b3b1b651a4274103921a&topic=10732.0
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=17401
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=229399
https://blossomug.com/index.php/component/k2/itemlist/user/1130766
https://www.celekt.com/%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-iq0t-%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://www.ekemoon.com/248565/052220191330/
http://www.ekemoon.com/248567/052220191530/
https://www.celekt.com/%d0%a4%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lv0o-%d0%a4%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6/
http://www.ekemoon.com/248571/052220191930/
http://www.ekemoon.com/248577/052220192330/
https://blossomug.com/?option=com_k2&view=itemlist&task=user&id=1130672
https://intelogist2.wpengine.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-be4j-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://blossomug.com/index.php/component/k2/itemlist/user/1130790
http://midorijapaneserestaurant.ca/menu/News/107334
http://naksansacondo.com/board_MGPu57/139788
http://naksansacondo.com/board_MGPu57/139856
https://betshin.com/Story/245452
https://betshin.com/Story/245479
https://www.hohoyoga.com/testboard/4120376
https://www.hwbms.com/web/qna/72451
https://www.hwbms.com/web/qna/72476
https://www.hwbms.com/web/qna/72485
http://midorijapaneserestaurant.ca/menu/News/107410
http://midorijapaneserestaurant.ca/menu/News/107467
http://ye-dream.com/qa/236321
http://xn--2e0bk61btjo.com/notice/23107
http://looksun.co.kr/index.php?mid=board_4&document_srl=185529
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/84058
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xt2a-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hu9h-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jd0i-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-az4z-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nj3b-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rh0i-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8/
https://intelogist2.wpengine.com/%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wu3z-%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://intelogist2.wpengine.com/%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fw0h-%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://blossomug.com/index.php/component/k2/itemlist/user/1130606
https://intelogist2.wpengine.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lu8j-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pr7u-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3/
https://www.celekt.com/%d0%96%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uk6v-%d0%96%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://www.celekt.com/%d0%9a%d0%be%d0%bf-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sb8x-%d0%9a%d0%be%d0%bf-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://www.celekt.com/%d0%a1%d0%b5%d0%bd%d1%8f%d0%a4%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ry7l-%d0%a1%d0%b5%d0%bd%d1%8f%d0%a4%d0%b5%d0%b4%d1%8f-2-%d1%81/
https://www.celekt.com/%d0%a4%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fr9j-%d0%a4%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16/
http://midorijapaneserestaurant.ca/menu/News/106230
https://betshin.com/Story/244769
https://betshin.com/Story/244785
https://gonggamlaw.com/lawcase/180064
https://gonggamlaw.com/lawcase/180084
https://www.hohoyoga.com/testboard/4119604
https://www.hwbms.com/web/qna/71762
http://midorijapaneserestaurant.ca/menu/News/106353
http://midorijapaneserestaurant.ca/menu/News/106433
https://gonggamlaw.com/lawcase/180231
https://www.hwbms.com/web/qna/71801
http://dsyang.com/board_Kvgn62/55810
http://dsyang.com/board_Kvgn62/55847
http://dsyang.com/board_Kvgn62/55853
http://ovotecegg.com/component/k2/itemlist/user/222691
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/49309
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=223785
http://jdcalc.com/forum/viewtopic.php?t=282737
http://viamania.net/index.php?mid=board_raYV15&document_srl=138701
http://daltso.com/index.php?mid=board_cUYy21&document_srl=172247
https://mcsetup.tk/bbs/index.php?topic=264324.0
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1739848
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=43604
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=439008
http://www.kwpcoop.or.kr/QnA/19175
http://erhu.eu/viewtopic.php?t=398335
http://kyj1225.godohosting.com/board_mebR72/60804
http://www.kwpcoop.or.kr/QnA/20635
http://rabat.kr/board_yCgT00/81764
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/32898
http://music.start-a-idea.online/blogs/viewstory/44351
http://www.ekemoon.com/244763/051920190428/
http://hotelnomadpalace.com/index.php/component/k2/itemlist/user/23047
http://looksun.co.kr/index.php?mid=board_4&document_srl=195807
https://www.celekt.com/%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ue0i-%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://daltso.com/index.php?mid=board_cUYy21&document_srl=197625
http://mediaville.me/index.php/component/k2/itemlist/user/386498
http://mobility-corp.com/index.php/component/k2/itemlist/user/2756430
http://netsconsults.com/?option=com_k2&view=itemlist&task=user&id=852743
http://rudraautomation.com/index.php/component/k2/author/366629
http://smartacity.com/component/k2/itemlist/user/102417
http://smartacity.com/component/k2/itemlist/user/102419
http://thermoplast.envolgroupe.com/component/k2/author/186731
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=136437
http://w9builders.co.uk/index.php/component/k2/itemlist/user/136464
http://www.atab.com.sa/?option=com_k2&view=itemlist&task=user&id=1761880
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1761332
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1557581
http://www.emrabq8.com/index.php/component/k2/itemlist/user/1879319
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=977511
http://midorijapaneserestaurant.ca/menu/News/26411
http://hanga5.com/index.php?mid=board_photo&document_srl=109827
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=713188
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=357684
https://cybergsm.es/index.php?topic=72583.0
https://intelogist2.wpengine.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ftvq-%d1%80%d0%b0%d1%81/
https://adsensebih.com/index.php?topic=48429.0
http://loverstory.co.kr/board_UYNJ05/102509
http://cwon.kr/xe/board_bnSr36/298270
http://agiteshop.com/xe/qa/188705
https://betshin.com/Story/199944
http://toeden.co.kr/Product_new/215428
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/41787
http://midorijapaneserestaurant.ca/menu/News/93442
http://midorijapaneserestaurant.ca/menu/News/93476
http://naksansacondo.com/board_MGPu57/126186
https://betshin.com/Story/233081
https://gonggamlaw.com/lawcase/167802
https://gonggamlaw.com/lawcase/167835
https://www.hohoyoga.com/testboard/4107431
https://www.hohoyoga.com/testboard/4107494
https://www.hwbms.com/web/qna/59879
https://www.hwbms.com/web/qna/59902
https://www.hwbms.com/web/qna/59907
https://www.hwbms.com/web/qna/59912
https://forums.lfstats.com/viewtopic.php?f=6&t=320643&view=print
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=207330
http://ko.myds.me/board_story/282041
http://netsconsults.com/index.php/component/k2/itemlist/user/842930
http://cwon.kr/xe/board_bnSr36/302490
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=43234
http://www.proandpro.it/?option=com_k2&view=itemlist&task=user&id=4719863
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1743287
https://gonggamlaw.com/lawcase/139487
http://midorijapaneserestaurant.ca/menu/News/68834
http://tiretech.co.kr/index.php?mid=qna&document_srl=233351
https://adsensebih.com/index.php?topic=49590.0
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=85348
http://benzmall.co.kr/index.php?mid=download&document_srl=48327
http://cwon.kr/xe/board_bnSr36/309426
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1499893
https://blossomug.com/index.php/component/k2/itemlist/user/1113351
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2005644
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1286343
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1286376
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1285956
https://betshin.com/Story/244147
https://betshin.com/Story/244159
http://dsyang.com/board_Kvgn62/55573
http://dsyang.com/board_Kvgn62/55610
http://midorijapaneserestaurant.ca/menu/News/105687
http://midorijapaneserestaurant.ca/menu/News/105712
http://www.leekeonsu-csi.com/index.php?document_srl=1286207&mid=community7
https://betshin.com/Story/244207
https://gonggamlaw.com/lawcase/179210
https://gonggamlaw.com/lawcase/179358
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1113887
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=948017
http://carand.co.kr/d2/98620
http://midorijapaneserestaurant.ca/menu/News/45790
http://loverstory.co.kr/board_UYNJ05/86341
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/841583
https://www.hwbms.com/web/qna/44742
http://autospa.lv/index.php/lv/component/k2/itemlist/user/10550
http://midorijapaneserestaurant.ca/menu/News/41345
http://www.vamoscontigo.org/Noticia/139495
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1116376
http://immobilia.gr/index.php/de/component/k2/itemlist/user/16812
http://naksansacondo.com/board_MGPu57/99205
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=394672
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/87027
https://esel.gist.ac.kr/esel2/board_hmgj23/274088
http://dsyang.com/board_Kvgn62/45742
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/37891
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1178213
http://yoriyorifood.com/xxxx/spacial/331203
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/370539
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=112223
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=278632
https://verdadesbiblicas.org.ec/index.php/component/k2/itemlist/user/3862214
http://hotelnomadpalace.com/component/k2/itemlist/user/22536
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=118456
https://gonggamlaw.com/lawcase/130807
http://dsyang.com/board_Kvgn62/44682
http://dreamplusart.com/mn03_01/120173
http://rudraautomation.com/index.php/component/k2/author/290429
http://dreamplusart.com/mn03_01/213610
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4939501
http://daltso.com/index.php?mid=board_cUYy21&document_srl=194193
https://altaylarteknoloji.com/index.php?topic=6488.0
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/855566
http://askpharm.net/board_NQiz06/251863
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=427565
http://cwon.kr/xe/board_bnSr36/288444
http://mobility-corp.com/index.php/component/k2/itemlist/user/2730375
http://daltso.com/?document_srl=200571
http://rudraautomation.com/index.php/component/k2/author/341495
http://askpharm.net/board_NQiz06/160694
http://cwon.kr/xe/board_bnSr36/296378
https://www.hwbms.com/web/qna/32313
http://divespace.co.kr/board/261083
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=256919
http://benzmall.co.kr/index.php?mid=download&document_srl=45776
http://mediaville.me/index.php/component/k2/itemlist/user/332616
http://hotelnomadpalace.com/es/?option=com_k2&view=itemlist&task=user&id=22832
http://neosky.net/xe/space_station/64514
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=216127
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=478366
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=85847
http://daltso.com/?document_srl=201897
http://ko.myds.me/board_story/298279
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=119563
http://askpharm.net/board_NQiz06/254395
http://jensenbyggteam.no/index.php/component/k2/itemlist/user/13783
http://ye-dream.com/qa/254281
http://gusinoepero.ru/archives/26092
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1118397
http://jiral.net/an9/37359
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=105888
http://p9912.cafe24.com/board_LVgu51/35230
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3492063
https://gonggamlaw.com/lawcase/135950
http://midorijapaneserestaurant.ca/menu/News/73927
http://beautypouch.net/index.php?mid=board_09&document_srl=117038
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=276572
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zn0h-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://ucckorea.kr/index.php?mid=board_AuHE49&document_srl=81509
http://beautypouch.net/index.php?mid=board_09&document_srl=102103
http://euromouleusinage.com/index.php/component/k2/itemlist/user/187956
http://smartacity.com/component/k2/itemlist/user/94230
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=351104
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=341847
http://udrpsucks.com/blog/?p=1876
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=84757
http://xn--2e0bk61btjo.com/notice/20288
http://mglpcm.org/board_ETkS12/128541
https://www.c-alice.org/forum/index.php?topic=99245.0
http://cwon.kr/xe/board_bnSr36/294885
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=107775
http://carand.co.kr/d2/93083
http://kwpub.kr/PUBS/172264
https://betshin.com/Story/207362
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2734158
http://divespace.co.kr/board/271259
http://looksun.co.kr/index.php?mid=board_4&document_srl=187543
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=241778
http://mglpcm.org/board_ETkS12/186305
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=393589
https://forum.clubeicaro.pt/index.php?topic=2735.0
http://www.svteck.co.kr/customer_gratitude/225472
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2006534
http://themasters.pro/file_01/226393
http://beautypouch.net/index.php?mid=board_09&document_srl=146782
https://blossomug.com/?option=com_k2&view=itemlist&task=user&id=1113095
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=259339
http://naksansacondo.com/board_MGPu57/31495
https://saltriverbg.com/2019/05/28/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tjjv-%d1%80%d0%b0%d1%81/
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1999279
https://www.chirorg.com/?document_srl=223835
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2745065
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1313078
http://mobility-corp.com/index.php/component/k2/itemlist/user/2742886
http://mobility-corp.com/index.php/component/k2/itemlist/user/2738472
https://mcsetup.tk/bbs/index.php?topic=262609.0
http://yooseok.com/board_BkvT46/445547
http://dospuntoseventos.cl/component/k2/itemlist/user/16547
http://cwon.kr/xe/board_bnSr36/285714
http://xn----3x5er9r48j7wemud0a387h.com/news/275454
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=113790
http://kyj1225.godohosting.com/board_mebR72/93725
https://2002.shyoon.com/board_2002/171007
http://bebopindia.com/notcie/452645
http://jnk-ent.jp/index.php?mid=gallery&document_srl=239282
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=127288
https://forum.clubeicaro.pt/index.php?topic=2486.0
http://dohairbiz.com/en/component/k2/itemlist/user/2819636.html
https://timecker.com/anonymous/187818
http://rudraautomation.com/index.php/component/k2/author/346573
http://cwon.kr/xe/board_bnSr36/287817
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=223641
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=914685
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=108875
http://daltso.com/index.php?mid=board_cUYy21&document_srl=205034
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2789097
http://dcasociados.eu/component/k2/itemlist/user/93326
https://www.c-alice.org/forum/index.php?topic=98002.0
http://mercibq.net/partner/63517
http://hyeonjun.co.kr/menu3/366457
http://gabisan.com/board_OuDs04/148940
https://nple.com/xe/pds/152566
http://sunele.co.kr/board_ReBD97/167619
http://mvisage.sk/index.php/component/k2/itemlist/user/120199
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=51184
http://arquitectosenreformas.es/component/k2/itemlist/user/87438
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/67237
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=29975
http://design-381.com/xe/portpolio/5742
http://www.eunhaele.co.kr/xe/QnA/20984
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=87438
http://www.socintegra.lv/ru/component/k2/itemlist/user/44539
https://bcit-tmgt.com/viewtopic.php?t=55170
https://www.c-alice.org/forum/index.php?topic=102145.0
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1287082
http://rabat.kr/board_yCgT00/46924
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3542218
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/392368
http://pkgersang.dothome.co.kr/board_jiKY24/40803
http://loverstory.co.kr/?document_srl=108397
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=408100
http://jdcalc.com/forum/viewtopic.php?t=282896
http://wigalseguros.com.br/index.php/component/k2/itemlist/user/28771
https://cybergsm.es/index.php?topic=62498.0
http://iymc.or.kr/pds/117372
http://compultras.com/?option=com_k2&view=itemlist&task=user&id=251031
http://midorijapaneserestaurant.ca/menu/News/74720
http://www.lgue.co.kr/?document_srl=116144
http://looksun.co.kr/index.php?document_srl=203765&mid=board_4
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1176390
http://looksun.co.kr/index.php?mid=board_4&document_srl=183596
http://midorijapaneserestaurant.ca/menu/?document_srl=76837
http://carand.co.kr/d2/92700
http://bizchemical.com/board_kMpv94/2159979
http://arquitectosenreformas.es/index.php/component/k2/itemlist/user/87536
https://forum.clubeicaro.pt/index.php?topic=3019.0
https://bcit-tmgt.com/viewtopic.php?t=55245
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/60370
http://www.eunhaele.co.kr/xe/board/20993
https://www.hohoyoga.com/testboard/4091048
https://www.c-alice.org/forum/index.php?topic=98762.0
https://nextezone.com/index.php?action=profile;u=8977
http://yooseok.com/board_BkvT46/422475
http://askpharm.net/board_NQiz06/282582
http://cwon.kr/xe/board_bnSr36/309689
http://sy.korean.net/qna/388061
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=8a54ef5c2d056b733ec08b68218639ae&topic=11316.0
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=23436
http://zakdu.com/board_YpzS56/15692
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1168410
https://khuyenmaikk13.info/index.php?topic=228427.0
http://sy.korean.net/qna/480326
http://gabisan.com/board_OuDs04/71289
https://www.hohoyoga.com/testboard/4087945
http://www.hmotors.co.kr/inquiry/69397
https://www.hwbms.com/web/qna/38166
http://pekosmile.dothome.co.kr/index.php?mid=seoulitestudio&document_srl=435029
http://midorijapaneserestaurant.ca/menu/News/51252
http://ariji.kr/?document_srl=971741
http://www.livetank.cn/market1/262359
http://benzmall.co.kr/?document_srl=97898
http://midorijapaneserestaurant.ca/menu/?document_srl=78322
http://thermoplast.envolgroupe.com/component/k2/author/178613
http://www.coating.or.kr/atemfair_data/18267
http://hanga5.com/index.php?mid=board_photo&document_srl=114066
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/64488
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3748987
https://intelogist2.wpengine.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fxgt-%d1%80%d0%b0%d1%81/
http://gochon-iusell.co.kr/g1/83451
http://loverstory.co.kr/board_UYNJ05/54774
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/819734
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3479421
http://forum.bmw-e60.eu/index.php?topic=11170.0
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=109418
http://beautypouch.net/index.php?mid=board_09&document_srl=162858
http://apt2you2.cafe24.com/g1/53870
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=570303
https://forum.ac-jete.it/index.php?topic=454552.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1544326
http://udrpsucks.com/blog/?p=1892
http://photogrotto.com/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sl2u-%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3/
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=195853
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2600949
http://smartacity.com/component/k2/itemlist/user/97666
http://mobility-corp.com/index.php/component/k2/itemlist/user/2743518
http://153.120.114.241/eso/index.php/17539340-rasskaz-sluzanki-3-sezon-6-seria-hvjz-rasskaz-sluzanki-3-sezon-
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/62564
https://adsensebih.com/index.php?topic=48835.0
http://loverstory.co.kr/board_UYNJ05/95024
http://jnk-ent.jp/index.php?mid=gallery&document_srl=333833
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/42394
http://thermoplast.envolgroupe.com/component/k2/author/181617
http://benzmall.co.kr/index.php?mid=download&document_srl=98243
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=129406
http://myrechockey.com/forums/index.php?topic=117713.0
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=225644
http://yooseok.com/board_BkvT46/413240
http://myrechockey.com/forums/index.php?topic=117839.0
http://www.teedinubon.com/%d0%ba%d0%be%d0%bf-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ff4%d0%ba%d0%be%d0%bf-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f28-05-2019/
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=402087
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=118468
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1984759
http://apt2you2.cafe24.com/g1/56743
http://rabat.kr/board_yCgT00/69533
https://www.cosmologyathome.org/view_profile.php?userid=1531320
http://www.venusjeju.com/index.php?mid=QnA&document_srl=2192
http://www.golden-nail.co.kr/press/363263
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/79134
https://betshin.com/Story/193268
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=310295
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=488333
http://askpharm.net/board_NQiz06/221400
https://betshin.com/Story/203657
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1982636
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1151761
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=22915
http://benzmall.co.kr/index.php?mid=download&document_srl=45446
http://www.svteck.co.kr/customer_gratitude/271688
http://lasvur.ru/?option=com_k2&view=itemlist&task=user&id=39699
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2594603
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=207973
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=45953
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1500657
http://midorijapaneserestaurant.ca/menu/News/41665
http://praisesound.co.kr/sub04_01/90858
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=295744
http://daltso.com/index.php?mid=board_cUYy21&document_srl=206932
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=178373
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=132393
http://kyj1225.godohosting.com/board_mebR72/97125
http://yooseok.com/board_BkvT46/460963
http://cwon.kr/xe/board_bnSr36/300508
http://lucky.kidspann.net/index.php?mid=qna&document_srl=354247
http://sofficer.net/xe/teach/286017
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=279815
http://sunele.co.kr/board_ReBD97/163820
http://www.coating.or.kr/atemfair_data/18146
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/34253
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/71974
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=31362
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=233224
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1074657
http://mglpcm.org/board_ETkS12/124807
http://khapthanam.co.kr/g1/151655
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=387293
http://herdental.co.kr/index.php?mid=online&document_srl=178715
http://www.vamoscontigo.org/Noticia/223063
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/372296
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1984884
http://www.sp1.football/index.php?mid=faq&document_srl=769622
http://azone.synology.me/xe/index.php?document_srl=215431&mid=board_SDnQ73
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=174208
http://masanlib.or.kr/g1/97068
http://loverstory.co.kr/board_UYNJ05/111228
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=2b37e19f0173cc2477b3ae51c6082e4a&topic=11361.0
http://www.urbantutorial.com/?option=com_k2&view=itemlist&task=user&id=127208
http://mercibq.net/partner/54678
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=400396
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/84891
https://www.celekt.com/%d0%a4%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cw0%d0%a4%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5/
http://www.quattroandpartners.it/component/k2/itemlist/user/1216795
http://rudraautomation.com/index.php/component/k2/author/342787
http://immobilia.gr/index.php/de/?option=com_k2&view=itemlist&task=user&id=16889
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=149524
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=948079
http://zakdu.com/board_YpzS56/24745
http://praisesound.co.kr/sub04_01/87262
http://benzmall.co.kr/index.php?mid=download&document_srl=98352
http://withinfp.sakura.ne.jp/eso/index.php/17600021-rasskaz-sluzanki-3-sezon-1-seria-pnmj-rasskaz-sluzanki-3-sezon-/0
http://dreamplusart.com/mn03_01/214229
http://dreamplusart.com/mn03_01/124070
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1744328
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=543878
http://midorijapaneserestaurant.ca/menu/News/41619
http://xn--2e0bk61btjo.com/notice/20565
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4977423
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4977954
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zx5g-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4/
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4977416
https://intelogist2.wpengine.com/%d0%ba%d0%be%d0%bf-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sk2h-%d0%ba%d0%be%d0%bf-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=182482
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/48847
https://cybergsm.es/index.php?topic=70583.0
http://loverstory.co.kr/board_UYNJ05/98279
http://sd-xi.co.kr/g1/70735
https://gonggamlaw.com/lawcase/150371
http://looksun.co.kr/index.php?mid=board_4&document_srl=211446
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-csao-%d1%80%d0%b0%d1%81/
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2012008
http://carand.co.kr/d2/90362
http://askpharm.net/board_NQiz06/174568
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3571144
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=156943
http://toeden.co.kr/Product_new/201497
http://www.eunhaele.co.kr/xe/board/20812
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=537114
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=415657
http://tiretech.co.kr/index.php?mid=qna&document_srl=235087
http://universalcommunity.se/Forum/index.php?topic=33350.0
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/66185
http://p9912.cafe24.com/board_LVgu51/45325
http://www.jesusonly.life/calendar/445791
http://www.artangel.co.kr/index.php?mid=Activities&document_srl=237170
http://dospuntoseventos.cl/component/k2/itemlist/user/16375
http://ucckorea.kr/index.php?mid=board_AuHE49&document_srl=158662
http://dow.dothome.co.kr/board_jydx58/35950
http://www.artangel.co.kr/index.php?mid=Activities&document_srl=185603
http://daltso.com/index.php?mid=board_cUYy21&document_srl=204929
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/172042
http://ariji.kr/?document_srl=968331
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=398850
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1326357
http://cwon.kr/xe/board_bnSr36/302106
http://kwpub.kr/PUBS/186696
https://www.shaiyax.com/index.php?topic=404970.0
http://otitismediasociety.org/forum/index.php?topic=203120.0
http://dcasociados.eu/?option=com_k2&view=itemlist&task=user&id=94470
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2000878
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/97992
http://beautypouch.net/index.php?mid=board_09&document_srl=101623
http://kyj1225.godohosting.com/board_mebR72/99534
http://music.start-a-idea.online/blogs/viewstory/43613
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=109407
http://pkgersang.dothome.co.kr/board_jiKY24/40923
http://nnkumw.org/xe/index.php?mid=board_yNQm00&document_srl=138442
http://gallerychoi.com/Exhibition/334698
http://eugeniocolazzo.it/forum/index.php?topic=180742.0
http://www.ekemoon.com/241999/050320194627/
http://naksansacondo.com/board_MGPu57/33188
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=351974
http://benzmall.co.kr/index.php?mid=download&document_srl=98462
http://immobilia.gr/index.php/de/component/k2/itemlist/user/16795
http://cwon.kr/xe/board_bnSr36/304943
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1754619
http://thermoplast.envolgroupe.com/component/k2/author/176608
http://jnk-ent.jp/index.php?mid=gallery&document_srl=237922
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/149523
http://dcasociados.eu/component/k2/itemlist/user/93285
http://knet.dothome.co.kr/xe/board_RJHw15/20281
http://erdfsa.iptime.org/xe/index.php?mid=board&document_srl=14005
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2001961
http://www.theocraticamerica.org/forum/index.php?topic=69663.0
http://looksun.co.kr/index.php?mid=board_4&document_srl=202487
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=1120345
http://daesestudy.co.kr/ipsi_docu/174735
https://www.celekt.com/%d0%a2%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ss5w-%d0%a2%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3491270
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3929591
http://xn--2e0b53df5ag1c804aphl.net/nuguna/103952
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/842488
https://www.swiss-focus.ch/index.php/component/k2/itemlist/user/36182
http://knet.dothome.co.kr/xe/board_RJHw15/19730
http://hanga5.com/index.php?mid=board_photo&document_srl=158629
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=85938
https://alvarogarciatorero.com/component/k2/itemlist/user/50308
http://dev.aabn.org.gh/component/k2/itemlist/user/676411
http://gallerychoi.com/Exhibition/325455
https://ne-kuru.ru/index.php?topic=235785.0
http://www.hmotors.co.kr/inquiry/37966
https://betshin.com/Story/202180
http://themasters.pro/file_01/225602
http://mediaville.me/index.php/component/k2/itemlist/user/333293
http://gspara01.dothome.co.kr/index.php?mid=board_XHsr53&document_srl=13487
http://rudraautomation.com/index.php/component/k2/author/335780
https://serverpia.co.kr/board_ucCk10/157881
http://looksun.co.kr/index.php?mid=board_4&document_srl=187467
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16175
https://www.hwbms.com/web/qna/27243
http://loverstory.co.kr/board_UYNJ05/107286
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=49276
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2795483
http://benzmall.co.kr/index.php?mid=download&document_srl=98538
http://www.vamoscontigo.org/Noticia/136520
http://sunele.co.kr/board_ReBD97/162712
http://yoriyorifood.com/xxxx/spacial/330351
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=240094
https://nple.com/xe/pds/151195
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1070793
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2002824
http://www.tessabannampad.go.th/webboard/index.php?topic=226878.0
http://miquirofisico.com/index.php/component/k2/itemlist/user/4426
http://xn--2e0bk61btjo.com/notice/22779
http://udrpsucks.com/blog/?p=2023
http://udrpsucks.com/blog/?p=2024
http://udrpsucks.com/blog/?p=2025
http://www.ekemoon.com/251653/052220195631/
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yi7r-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ei2i-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://intelogist2.wpengine.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zk8m-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-va8c-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6/
http://udrpsucks.com/blog/?p=2026
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/861712
http://153.120.114.241/eso/index.php/17529762-rasskaz-sluzanki-3-sezon-9-seria-hcbv-rasskaz-sluzanki-3-sezon-
http://www.alase.net/index.php/component/k2/itemlist/user/12777
http://sfah.ch/de/component/k2/itemlist/user/15559
http://daltso.com/index.php?mid=board_cUYy21&document_srl=125939
http://askpharm.net/board_NQiz06/274748
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=129871
https://forum.clubeicaro.pt/index.php?topic=2218.0
http://dospuntoseventos.cl/component/k2/itemlist/user/16128
https://khuyenmaikk13.info/index.php?topic=226259.0
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-slcq-%d1%80%d0%b0%d1%81/
http://www.spazioad.com/component/k2/itemlist/user/7417850
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/32666
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/84799
http://ye-dream.com/qa/277482
http://forum.bmw-e60.eu/index.php?topic=11341.0
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=122794
http://robocit.com/index.php/component/k2/itemlist/user/449878
http://neosky.net/xe/space_station/121999
http://photogrotto.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fn6%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://www.hmotors.co.kr/?document_srl=71641
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=445578
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1865572
http://metropolis.ga/index.php?topic=20901.0
http://proxima.co.rw/index.php/component/k2/itemlist/user/720678
http://xn----3x5er9r48j7wemud0a387h.com/news/240674
http://www.golden-nail.co.kr/press/368677
http://www.kwpcoop.or.kr/QnA/22560
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=131803
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=1241757
http://cwon.kr/xe/board_bnSr36/283003
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=408038
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7486977
https://betshin.com/Story/244207
https://gonggamlaw.com/lawcase/179210
https://gonggamlaw.com/lawcase/179358
https://gonggamlaw.com/lawcase/179367
https://www.hohoyoga.com/testboard/4119177
https://www.hohoyoga.com/testboard/4119236
http://kyj1225.godohosting.com/board_mebR72/99815
https://www.lwfservers.com/index.php?topic=72259.0
http://warmfund.net/p/index.php?mid=financing&document_srl=563374
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=223811
http://themasters.pro/file_01/308409
http://neosky.net/xe/space_station/101111
http://daltso.com/index.php?mid=board_cUYy21&document_srl=199758
http://cwon.kr/xe/board_bnSr36/307822
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1072260
http://benzmall.co.kr/index.php?mid=download&document_srl=99097
http://rfc11th13th.dothome.co.kr/Board5/36464
http://gardenpjw.dothome.co.kr/board_LOcC77/713490
http://herdental.co.kr/index.php?mid=online&document_srl=200008
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=175129
http://xn----3x5er9r48j7wemud0a387h.com/news/170953
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3569108
http://ariji.kr/?document_srl=1077092
https://forum.ac-jete.it/index.php?topic=443722.0
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3499571
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=198405
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=50570
http://1661-6471.co.kr/news/74271
http://khapthanam.co.kr/g1/148690
http://sy.korean.net/qna/314929
http://euromouleusinage.com/index.php/component/k2/itemlist/user/187967
http://neosky.net/xe/space_station/137284
http://cwon.kr/xe/board_bnSr36/296630
http://dreamplusart.com/mn03_01/213712
http://bobr.site/index.php?topic=184915.0
http://mercibq.net/partner/116299
https://gonggamlaw.com/lawcase/129786
http://looksun.co.kr/index.php?mid=board_4&document_srl=139778
http://themasters.pro/file_01/330193
https://reficulcoin.com/index.php?topic=85855.0
http://udrpsucks.com/blog/?p=1868
http://miquirofisico.com/index.php/component/k2/itemlist/user/4488
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3450994
http://rabat.kr/board_yCgT00/85087
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=437278
http://loverstory.co.kr/board_UYNJ05/68812
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/74620
https://nextezone.com/index.php?topic=76703.0
http://guiadetudo.com/index.php/component/k2/itemlist/user/12734
https://adsensebih.com/index.php?topic=50569.0
http://loverstory.co.kr/board_UYNJ05/101407
http://bewasia.com/?document_srl=231432
http://proxima.co.rw/index.php/component/k2/itemlist/user/691439
http://askpharm.net/board_NQiz06/250213
http://www.theocraticamerica.org/forum/index.php?topic=74051.0
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=105657
http://praisesound.co.kr/?document_srl=97779
http://www.haetsaldun-clinic.co.kr/Question/43053
https://forums.lfstats.com/viewtopic.php?t=320067
https://betshin.com/Story/214648
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/326226
http://sejong-thesharpyemizi.co.kr/m1/93275
http://rabat.kr/?document_srl=84439
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1770205
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=199865
http://www.vamoscontigo.org/Noticia/205862
http://jensenbyggteam.no/index.php/component/k2/itemlist/user/13727
http://mobility-corp.com/index.php/component/k2/itemlist/user/2696828
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1078499
http://www.crnmedia.es/component/k2/itemlist/user/91621
https://adsensebih.com/index.php?topic=49496.0
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=99615
https://alquilervideobeam.com.co/?option=com_k2&view=itemlist&task=user&id=59747
http://www.quattroandpartners.it/component/k2/itemlist/user/1214861
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/78468
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=206068
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/?document_srl=48036
http://roikjer.com/forum/index.php?PHPSESSID=7h49uqaedredrcrl3h8ohtfqb2&topic=934117.0
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/370609
http://kyj1225.godohosting.com/board_mebR72/94274
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3478071
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/147265
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1186022
http://forum.bmw-e60.eu/index.php?topic=11380.0
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=407793
http://engeena.com/component/k2/itemlist/user/9164
http://looksun.co.kr/index.php?mid=board_4&document_srl=186845
https://khuyenmaikk13.info/index.php?topic=225824.0
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3860405
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=400447
http://taklongclub.com/forum/index.php?topic=203774.0
http://xn----3x5er9r48j7wemud0a387h.com/news/264684
http://looksun.co.kr/index.php?mid=board_4&document_srl=207322
http://www.hmotors.co.kr/inquiry/37233
http://engeena.com/component/k2/itemlist/user/9233
http://daesestudy.co.kr/ipsi_docu/161417
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=36917
http://music.start-a-idea.online/blogs/viewstory/47853
http://askpharm.net/board_NQiz06/258891
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=102680
http://loverstory.co.kr/board_UYNJ05/102833
http://research.kiu.ac.kr/?document_srl=480780
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=43759
http://bath-family.com/photo_zone/152505
http://daesestudy.co.kr/ipsi_docu/141379
http://www.tessabannampad.go.th/webboard/index.php?topic=223567.0
http://alastair030.dothome.co.kr/index.php?mid=board_MMiF30&document_srl=25325
http://www.proandpro.it/?option=com_k2&view=itemlist&task=user&id=4721755
http://www.svteck.co.kr/customer_gratitude/225477
http://esperanzazubieta.com/index.php/component/k2/itemlist/user/108004
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/291943
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=313867
https://intelogist2.wpengine.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jq9o-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=363766
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=17890
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=42833
http://dow.dothome.co.kr/board_jydx58/39301
http://www.verenas-unterwasserwelt.de/forum/index.php?topic=10822.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3794656
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=371293
http://archeaudio.com/xe/board_AOYj82/11630
http://thermoplast.envolgroupe.com/component/k2/itemlist/user/174131
http://www.coating.or.kr/atemfair_data/16622
http://myrechockey.com/forums/index.php?topic=118862.0
http://sofficer.net/xe/teach/295439
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=46623
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=17944
https://timecker.com/anonymous/188471
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=231399
http://naksansacondo.com/board_MGPu57/90455
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=90799
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=128218
http://hanga5.com/index.php?mid=board_photo&document_srl=143811
https://www.shaiyax.com/index.php?topic=401232.0
http://dayung.co.kr/?document_srl=70459
http://eugeniocolazzo.it/forum/index.php?topic=186602.0
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=210964
https://gonggamlaw.com/lawcase/153200
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/345295
http://nnkumw.org/xe/index.php?mid=board_yNQm00&document_srl=173129
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=206166
http://askpharm.net/board_NQiz06/160146
http://gusinoepero.ru/archives/31123
http://dsyang.com/board_Kvgn62/47102
http://midorijapaneserestaurant.ca/menu/News/78864
http://naksansacondo.com/board_MGPu57/104688
https://gonggamlaw.com/lawcase/154832
https://www.hwbms.com/web/qna/46174
https://www.hwbms.com/web/qna/46184
http://proxima.co.rw/index.php/component/k2/itemlist/user/722681
http://www.emrabq8.com/index.php/component/k2/itemlist/user/1876914
http://dcasociados.eu/component/k2/itemlist/user/95319
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/178471
http://thermoplast.envolgroupe.com/component/k2/author/183187
https://www.shaiyax.com/index.php?topic=404147.0
http://praisesound.co.kr/sub04_01/125034
https://www.hohoyoga.com/testboard/4085136
http://rabbitzone.xyz/FREE/71661
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=17453
http://midorijapaneserestaurant.ca/menu/News/68901
https://reficulcoin.com/index.php?topic=103294.0
https://intelogist2.wpengine.com/%d0%ba%d0%be%d0%bf-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gd0x-%d0%ba%d0%be%d0%bf-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=23229
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=350547
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=435518
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2000798
http://divespace.co.kr/board/287431
https://betshin.com/Story/224890
https://www.hwbms.com/web/?document_srl=49451
http://www2.yasothon.go.th/smf/index.php?topic=159.msg201415
http://dsyang.com/board_Kvgn62/48602
http://midorijapaneserestaurant.ca/menu/News/82674
http://ko.myds.me/board_story/275869
http://bizchemical.com/board_kMpv94/2160192
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=1119995
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=93669
https://www.hwbms.com/web/qna/12095
http://ko.myds.me/board_story/266935
http://jensenbyggteam.no/index.php/component/k2/itemlist/user/13804
http://dev.aabn.org.gh/component/k2/itemlist/user/725347
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=60aa52ade64da3048b7094e16ea73cf8&topic=10745.0
http://apt2you2.cafe24.com/g1/53213
http://www.tessabannampad.go.th/webboard/index.php?topic=226652.0
http://midorijapaneserestaurant.ca/menu/News/76789
http://sd-xi.co.kr/g1/50848
http://themasters.pro/file_01/335444
http://benzmall.co.kr/index.php?mid=download&document_srl=114188
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hg7d-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8/
http://toeden.co.kr/Product_new/195311
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=540922
http://rudraautomation.com/index.php/component/k2/author/334104
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/82864
http://daltso.com/index.php?mid=board_cUYy21&document_srl=200541
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2008144
http://erdfsa.iptime.org/xe/index.php?mid=board&document_srl=12465
http://yooseok.com/board_BkvT46/417559
http://warmfund.net/p/index.php?mid=financing&document_srl=503109
http://midorijapaneserestaurant.ca/menu/News/51426
http://mobility-corp.com/index.php/component/k2/itemlist/user/2738867
http://daltso.com/index.php?mid=board_cUYy21&document_srl=226054
http://mvisage.sk/index.php/component/k2/itemlist/user/120101
https://www.regalepadova.it/index.php/component/k2/itemlist/user/8487
http://8.droror.co.il/uncategorized/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jv8%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f30-05/
http://8.droror.co.il/uncategorized/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rl6%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5/
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=27788
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=27792
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=27802
https://timecker.com/anonymous/211795
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=27814
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=27818
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=27824
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=27828
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=27835
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=117535
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=116566
http://www.hmotors.co.kr/inquiry/38058
http://xn--2e0bk61btjo.com/notice/23315
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xwwk-%d1%80%d0%b0%d1%81/
http://callman.co.kr/?document_srl=283767
http://praisesound.co.kr/sub04_01/111720
http://www.jesusonly.life/calendar/519036
http://sfah.ch/component/k2/itemlist/user/15480
http://benzmall.co.kr/index.php?mid=download&document_srl=96061
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=22865
http://gspara01.dothome.co.kr/index.php?mid=board_XHsr53&document_srl=13515
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=234240
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1734694
https://timecker.com/anonymous/213646
https://timecker.com/anonymous/213658
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/59940
http://design-381.com/xe/portpolio/5682
http://gyeomright.dothome.co.kr/?document_srl=28156
https://timecker.com/anonymous/213712
https://timecker.com/anonymous/213733
https://nextezone.com/index.php?action=profile;u=12717
https://forum.shaiyaslayer.tk/index.php?topic=177178.0
https://www.c-alice.org/forum/index.php?topic=100835.0
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=28174
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=28179
https://altaylarteknoloji.com/index.php?topic=6790.0
https://forums.lfstats.com/viewtopic.php?t=321037
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/42245
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=242485
http://test.comics-game.ru/index.php?topic=411.0
http://www.jesusonly.life/calendar/592819
http://immobilia.gr/index.php/de/component/k2/itemlist/user/16779
http://khapthanam.co.kr/?document_srl=151442
https://mcsetup.tk/bbs/index.php?topic=262728.0
http://rabat.kr/board_yCgT00/39032
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=233834
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=19460
http://carand.co.kr/d2/89473
https://forum.shaiyaslayer.tk/index.php?topic=153186.0
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1933719
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=400032
http://ye-dream.com/qa/225603
http://www.popolsku.fr.pl/forum/index.php?topic=417151.0
http://naksansacondo.com/board_MGPu57/85504
https://www.hohoyoga.com/testboard/4084629
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=336812
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1185578
http://midorijapaneserestaurant.ca/menu/?document_srl=75475
http://www.socintegra.lv/index.php/component/k2/itemlist/user/44497
https://nextezone.com/index.php?action=profile;u=9019
http://gyeomright.dothome.co.kr/?document_srl=27919
http://gyeomright.dothome.co.kr/index.php?document_srl=27906&mid=guest
https://www.c-alice.org/forum/index.php?topic=100724.0
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=23220
http://mvisage.sk/index.php/component/k2/itemlist/user/120103
https://prosto-vkus.ru/component/k2/itemlist/user/36830
https://www.regalepadova.it/index.php/component/k2/itemlist/user/8494
http://8.droror.co.il/uncategorized/%d0%ba%d0%be%d0%bf-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cm5%d0%ba%d0%be%d0%bf-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f30-05-2019/
https://forum.clubeicaro.pt/index.php?topic=2738.0
http://www.cswc.co.kr/index.php?mid=board_zyTs37&document_srl=46425
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=949770
http://www.ekemoon.com/238821/052020193925/
https://gonggamlaw.com/lawcase/125368
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=42973
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3568668
http://roikjer.com/forum/index.php?PHPSESSID=ib1qv6hpku2pvgp1m6aspv5td4&topic=927851.0
http://kyj1225.godohosting.com/board_mebR72/98010
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2653121
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3451008
http://hotelnomadpalace.com/index.php/component/k2/itemlist/user/22502
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=106226
http://daltso.com/index.php?mid=board_cUYy21&document_srl=195160
https://gonggamlaw.com/lawcase/131329
http://benzmall.co.kr/index.php?mid=download&document_srl=114104
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/33678
http://proxima.co.rw/index.php/component/k2/itemlist/user/713123
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3899510
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1314356
http://dev.aabn.org.gh/component/k2/itemlist/user/681843
http://divespace.co.kr/board/262902
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=206177
http://ko.myds.me/board_story/262084
https://adsensebih.com/index.php?topic=48238.0
https://forum.clubeicaro.pt/index.php?topic=2956.0
https://www.c-alice.org/forum/index.php?topic=101492.0
http://8.droror.co.il/uncategorized/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nj3%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be/
http://8.droror.co.il/uncategorized/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xm0%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f30-05/
http://8.droror.co.il/uncategorized/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ut9%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5/
http://arquitectosenreformas.es/component/k2/itemlist/user/86971
https://forum.shaiyaslayer.tk/index.php?topic=180105.0
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=51007
https://forum.clubeicaro.pt/index.php?topic=2958.0
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=110277
https://bcit-tmgt.com/viewtopic.php?t=54692
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=51026
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=340304
http://mobility-corp.com/index.php/component/k2/itemlist/user/2744462
http://midorijapaneserestaurant.ca/menu/News/51049
http://music.start-a-idea.online/blogs/viewstory/45031
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3752664
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/34261
http://naksansacondo.com/board_MGPu57/51525
http://cwon.kr/xe/board_bnSr36/307049
http://daltso.com/index.php?mid=board_cUYy21&document_srl=198037
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=539824
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=410526
http://muldorang.com/market/22102
http://hanga5.com/index.php?mid=board_photo&document_srl=160496
http://oss.obigo.com/oss/index.php?mid=board_mxLS91&document_srl=66410
https://www.celekt.com/%d0%a1%d0%9c%d0%9e%d0%a2%d0%a0%d0%95%d0%a2%d0%ac-%d0%a2%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-j0-%d0%a2%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-1/
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=128677
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=84845
https://www.hwbms.com/web/qna/38102
http://herdental.co.kr/index.php?mid=online&document_srl=216267
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=341776
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=86842
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/80666
http://mediaville.me/index.php/component/k2/itemlist/user/379933
http://www.vamoscontigo.org/Noticia/204096
http://neosky.net/xe/space_station/100923
http://ajincomp.godohosting.com/board_STnh82/127401
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=5021058
https://gonggamlaw.com/lawcase/133328
https://zakdu.com/?document_srl=15790
http://arquitectosenreformas.es/component/k2/itemlist/user/87656
https://forum.clubeicaro.pt/index.php?topic=3036.0
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=51249
https://forum.clubeicaro.pt/index.php?topic=3037.0
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=259089
http://rabat.kr/board_yCgT00/81823
http://kyj1225.godohosting.com/board_mebR72/58233
http://www.popolsku.fr.pl/forum/index.php?topic=418105.0
http://sunele.co.kr/?document_srl=163107
http://carand.co.kr/d2/97508
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1734462
http://rabbitzone.xyz/FREE/107420
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=215877
http://beautypouch.net/index.php?mid=board_09&document_srl=117612
http://hyeonjun.co.kr/menu3/289491
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=22920
http://engeena.com/component/k2/itemlist/user/9162
http://forum.bmw-e60.eu/index.php?topic=12314.0
http://kwpub.kr/PUBS/176749
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=125426
https://forum.shaiyaslayer.tk/index.php?topic=178523.0
http://hotelnomadpalace.com/component/k2/itemlist/user/23329
http://www.comfortcenter.es/index.php/component/k2/itemlist/user/110159
https://alquilervideobeam.com.co/?option=com_k2&view=itemlist&task=user&id=60001
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=50953
https://bcit-tmgt.com/viewtopic.php?t=54588
https://forum.clubeicaro.pt/index.php?topic=2923.0
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=262344
http://dev.aabn.org.gh/?option=com_k2&view=itemlist&task=user&id=721727
http://windowshopgoa.com/?option=com_k2&view=itemlist&task=user&id=199666
http://erhu.eu/viewtopic.php?t=409763
http://www.kwpcoop.or.kr/QnA/21881
http://x-crew.center/guest/4846542
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=86683
http://loverstory.co.kr/board_UYNJ05/99459
http://www.hmotors.co.kr/inquiry/69305
http://midorijapaneserestaurant.ca/menu/News/71604
http://0433.net/junggo/112663
http://guiadetudo.com/index.php/component/k2/itemlist/user/12694
http://midorijapaneserestaurant.ca/menu/News/77111
http://www.kcch.or.kr/index.php?mid=board_uFpk03&document_srl=117682
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3504346
http://daltso.com/index.php?mid=board_cUYy21&document_srl=183020
http://gusinoepero.ru/archives/29294
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=220615
http://www.popolsku.fr.pl/forum/index.php?topic=20407.79170
https://forums.lfstats.com/viewtopic.php?t=320718
http://daesestudy.co.kr/ipsi_docu/120682
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=5017475
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1081539
http://gallerychoi.com/Exhibition/355788
https://www.hohoyoga.com/testboard/4090983
http://carand.co.kr/d2/94885
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=174969
http://roikjer.com/forum/index.php?PHPSESSID=8ofudvtuiskoafdnt2dbpjbr86&topic=939515.0
http://www.cnsmaker.net/xe/?document_srl=142407
http://cwon.kr/xe/board_bnSr36/295347
http://www.yadanarbonnews.com/?option=com_k2&view=itemlist&task=user&id=347352
http://sy.korean.net/qna/444621
http://kyj1225.godohosting.com/board_mebR72/94331
http://moyakmermer.com/?option=com_k2&view=itemlist&task=user&id=848207
http://autospa.lv/index.php/lv/component/k2/itemlist/user/10591
http://tiretech.co.kr/index.php?mid=qna&document_srl=186946
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3896082
http://neosky.net/xe/space_station/153376
http://kockazatkutato.hu/component/k2/itemlist/user/48120
https://www.hohoyoga.com/testboard/4087058
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=299577
http://www2.yasothon.go.th/smf/index.php?topic=159.171705
http://daltso.com/index.php?mid=board_cUYy21&document_srl=198128
http://neosky.net/xe/space_station/160191
https://www.hwbms.com/web/qna/42744
http://muldorang.com/market/25812
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3790044
http://iymc.or.kr/pds/131578
https://gonggamlaw.com/lawcase/126120
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4902904
http://sy.korean.net/qna/496964
http://daltso.com/index.php?mid=board_cUYy21&document_srl=193040
http://mobility-corp.com/index.php/component/k2/itemlist/user/2744357
http://gusinoepero.ru/archives/25739
http://rabbitzone.xyz/FREE/132246
http://www.arunagreen.com/index.php/component/k2/itemlist/user/1157746
http://bobr.site/index.php?topic=185518.0
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1183218
https://www.hwbms.com/web/qna/38230
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=135273
http://gspara01.dothome.co.kr/index.php?document_srl=23988&mid=board_XHsr53
http://www.ekemoon.com/248509/052120192030/
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=50891
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jh1b-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://intelogist2.wpengine.com/%d0%ba%d0%be%d0%bf-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zj2n-%d0%ba%d0%be%d0%bf-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://intelogist2.wpengine.com/%d0%ba%d0%be%d0%bf-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-iw5y-%d0%ba%d0%be%d0%bf-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fo1u-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pb5s-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tf4n-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12/
http://dev.aabn.org.gh/component/k2/itemlist/user/726511
https://reficulcoin.com/index.php?topic=86739.0
https://forums.lfstats.com/viewtopic.php?t=320745
http://ptu.imoove.kr/ko/content/%C2%AB%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-ztlo-%C2%AB%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-4-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-baibako341141
http://sejong-thesharpyemizi.co.kr/m1/110615
http://yooseok.com/board_BkvT46/411555
http://melchinooddle.dothome.co.kr/?document_srl=13500
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/70133
http://nnkumw.org/xe/index.php?document_srl=133606&mid=board_yNQm00
https://mcsetup.tk/bbs/index.php?topic=263605.0
https://alquilervideobeam.com.co/?option=com_k2&view=itemlist&task=user&id=59660
http://ye-dream.com/qa/218521
http://gusinoepero.ru/archives/31169
http://apt2you2.cafe24.com/g1/53003
http://jensenbyggteam.no/index.php/component/k2/itemlist/user/13840
http://8.droror.co.il/uncategorized/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gqov-%d1%80%d0%b0%d1%81/
http://married.dike.gr/?option=com_k2&view=itemlist&task=user&id=78234
http://ye-dream.com/qa/236321
http://xn--2e0bk61btjo.com/notice/23107
http://looksun.co.kr/index.php?mid=board_4&document_srl=185529
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3585031
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3585053
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dp8r-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3/
http://mvisage.sk/index.php/component/k2/itemlist/user/120180
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gu1q-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12/
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=87224
https://blossomug.com/index.php/component/k2/itemlist/user/1132993
https://blossomug.com/index.php/component/k2/itemlist/user/1133133
http://herdental.co.kr/index.php?mid=online&document_srl=114519
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/59437
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=43044
http://xn----3x5er9r48j7wemud0a387h.com/news/164868
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=43512
http://www.crnmedia.es/component/k2/itemlist/user/89550
http://wartoby.com/index.php?mid=board_UXUA38&document_srl=97325
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=173658
http://sejong-thesharpyemizi.co.kr/m1/44936
https://gonggamlaw.com/lawcase/144202
http://xn----c28ewjj6ubwku6frtcuzec29ae5b.com/news/56309
http://loverstory.co.kr/board_UYNJ05/109623
https://altaylarteknoloji.com/index.php?topic=6498.0
https://intelogist2.wpengine.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pl5s-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qv0g-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11/
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7552289
http://udrpsucks.com/blog/?p=2022
http://www.ekemoon.com/251621/052220194631/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xu3e-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9/
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=23666
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=87497
http://benzmall.co.kr/index.php?mid=download&document_srl=98882
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=17578
http://daltso.com/index.php?mid=board_cUYy21&document_srl=197053
http://www.patrasin.kr/index.php?mid=questions&document_srl=4363875
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=113670
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1314087
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=430857
http://www.popolsku.fr.pl/forum/index.php?topic=417083.0
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=345586
https://nextezone.com/index.php?action=profile;u=8803
http://sy.korean.net/qna/407073
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=206227
http://test.comics-game.ru/index.php?topic=540.0
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=114661
http://looksun.co.kr/?document_srl=204952
http://www.spazioad.com/component/k2/itemlist/user/7417063
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=22987
http://rabat.kr/board_yCgT00/83572
http://carand.co.kr/d2/90508
http://looksun.co.kr/index.php?mid=board_4&document_srl=200416
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=552183
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=29828
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=251979
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rs3t-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
https://blossomug.com/index.php/component/k2/itemlist/user/1133111
http://www.ekemoon.com/250647/051720192031/
http://www.ekemoon.com/250651/051720192231/
http://www.ekemoon.com/250659/051720192331/
http://www.ekemoon.com/250665/051720192431/
http://www.ekemoon.com/250680/051720192931/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lk7r-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-17/
http://netsconsults.com/?option=com_k2&view=itemlist&task=user&id=855020
http://www.quattroandpartners.it/component/k2/itemlist/user/1278417
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=87291
http://www.spazioad.com/component/k2/itemlist/user/7497442
https://mcsetup.tk/bbs/index.php?topic=263167.0
http://dreamplusart.com/mn03_01/123164
http://rudraautomation.com/index.php/component/k2/author/334035
https://www.c-alice.org/forum/index.php?topic=98876.0
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1152272
http://dcasociados.eu/component/k2/itemlist/user/94449
http://wartoby.com/index.php?mid=board_UXUA38&document_srl=98921
https://gonggamlaw.com/lawcase/139770
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=263043
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=125020
http://gochon-iusell.co.kr/g1/105222
https://www.shaiyax.com/index.php?topic=419761.0
http://www.popolsku.fr.pl/forum/index.php?topic=416837.0
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3371961
http://kwpub.kr/PUBS/161749https://nextezone.com/index.php?action=profile;u=14366
http://www.eunhaele.co.kr/xe/board/20850
https://forum.clubeicaro.pt/index.php?topic=2868.0
https://nextezone.com/index.php?action=profile;u=14366
https://www.c-alice.org/forum/index.php?topic=100460.0
https://www.regalepadova.it/index.php/component/k2/itemlist/user/8450
https://www.regalepadova.it/index.php/component/k2/itemlist/user/8452
http://8.droror.co.il/uncategorized/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ue8%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be/
http://loverstory.co.kr/board_UYNJ05/113075
http://rabat.kr/board_yCgT00/48745
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=130776
http://yoriyorifood.com/xxxx/spacial/357439
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1311609
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=17149
http://xn----3x5er9r48j7wemud0a387h.com/news/150247
http://loverstory.co.kr/board_UYNJ05/116960
http://www.itosm.com/cn/board_nLoq17/193359
https://www.hohoyoga.com/testboard/4120759
https://www.hohoyoga.com/testboard/4120806
https://www.hwbms.com/web/qna/72980
https://www.hwbms.com/web/qna/73005
https://www.hwbms.com/web/qna/73050
https://www.hwbms.com/web/qna/73060
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-video-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be-2/
http://proxima.co.rw/index.php/component/k2/itemlist/user/729504
http://8.droror.co.il/uncategorized/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rd6%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f30-05/
http://8.droror.co.il/uncategorized/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nq4%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://8.droror.co.il/uncategorized/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-px9%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5/
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=23444
http://hotelnomadpalace.com/es/?option=com_k2&view=itemlist&task=user&id=23442
http://hyeonjun.co.kr/menu3/339987
http://arquitectosenreformas.es/component/k2/itemlist/user/86007
http://xn--2e0bk61btjo.com/notice/24962
https://www.hohoyoga.com/testboard/4086508
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/66470
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1288815
https://gonggamlaw.com/lawcase/181160
https://www.hwbms.com/web/?document_srl=72510
https://www.hwbms.com/web/qna/72704
https://www.hwbms.com/web/qna/72714
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=858476
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-live-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-6-%d1%81%d0%b5%d1%80%d0%b8/
http://midorijapaneserestaurant.ca/menu/News/107517
http://naksansacondo.com/board_MGPu57/140114
https://www.hohoyoga.com/testboard/4120544
http://midorijapaneserestaurant.ca/menu/News/107612
http://naksansacondo.com/?document_srl=140236
https://grajalesabogados.com.mx/?option=com_k2&view=itemlist&task=user&id=67015
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/66966
http://8.droror.co.il/uncategorized/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-lo8%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=19073
https://www.c-alice.org/forum/index.php?topic=101645.0
http://8.droror.co.il/uncategorized/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ey9%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f30-05/
http://8.droror.co.il/uncategorized/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ko4%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5/
http://8.droror.co.il/uncategorized/%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wb6%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f30-05-20/
http://mvisage.sk/index.php/component/k2/itemlist/user/120162
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=51049
https://www.c-alice.org/forum/index.php?topic=101665.0
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=51057
http://ucckorea.kr/index.php?mid=board_AuHE49&document_srl=126261
https://betshin.com/Story/209555
http://dospuntoseventos.cl/component/k2/itemlist/user/17643
http://praisesound.co.kr/sub04_01/87522
http://midorijapaneserestaurant.ca/menu/News/61348
http://praisesound.co.kr/sub04_01/100675
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=441974
http://ko.myds.me/board_story/258154
http://udrpsucks.com/blog/?p=1835
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=77412
https://betshin.com/Story/245795
https://betshin.com/Story/245800
https://betshin.com/Story/245855
https://betshin.com/Story/245861
https://gonggamlaw.com/lawcase/181554
https://www.hohoyoga.com/testboard/4120759
https://www.hohoyoga.com/testboard/4120806
https://www.hwbms.com/web/qna/72980
https://www.hwbms.com/web/qna/73005
https://www.hwbms.com/web/qna/73050
https://www.hwbms.com/web/qna/73060
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-video-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be-2/
http://proxima.co.rw/index.php/component/k2/itemlist/user/729504
https://www.c-alice.org/forum/index.php?topic=102330.0
https://www.c-alice.org/forum/index.php?topic=102331.0
https://www.c-alice.org/forum/index.php?topic=102333.0
https://www.c-alice.org/forum/index.php?topic=102336.0
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1983836
https://www.limscave.com/forum/viewtopic.php?f=6&t=58738&view=print
http://loverstory.co.kr/?document_srl=110954
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=431726
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/120189
http://www.popolsku.fr.pl/forum/index.php?topic=416980.0
http://smartacity.com/component/k2/itemlist/user/97753
https://www.swiss-focus.ch/index.php/component/k2/itemlist/user/37733
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=416167
http://arquitectosenreformas.es/index.php/component/k2/itemlist/user/86286
http://gabisan.com/board_OuDs04/146679
https://gonggamlaw.com/lawcase/183734
https://www.hwbms.com/web/qna/75118
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=858701
http://midorijapaneserestaurant.ca/menu/News/110659
http://naksansacondo.com/board_MGPu57/143483
http://naksansacondo.com/board_MGPu57/143538
http://www.eunhaele.co.kr/xe/board/21080
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=111176
http://www.pdctransport.co.th/index.php/component/k2/itemlist/user/19206
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=19204
https://betshin.com/Story/195896
http://blog.ptpintcast.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zlrx-%d1%80%d0%b0%d1%81/
http://divespace.co.kr/board/192959
http://dreamplusart.com/mn03_01/214246
http://www.ekemoon.com/245423/050120192329/
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/32963
http://carand.co.kr/d2/94123
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=404318
https://www.hohoyoga.com/testboard/4125358
https://www.hwbms.com/web/qna/77714
http://www2.yasothon.go.th/smf/index.php?topic=159.173535
http://midorijapaneserestaurant.ca/menu/News/113671
http://midorijapaneserestaurant.ca/menu/News/113749
https://gonggamlaw.com/lawcase/65204
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=29365
http://midorijapaneserestaurant.ca/menu/News/26754
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/89307
http://barobus.kr/qna/73975
http://askpharm.net/board_NQiz06/250235
http://viamania.net/index.php?mid=board_raYV15&document_srl=142098
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=127872
http://p9912.cafe24.com/board_LVgu51/59096
http://gochon-iusell.co.kr/g1/87199
http://mobility-corp.com/index.php/component/k2/itemlist/user/2699447
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=910681
http://www.ekemoon.com/244108/050820194228/
http://vtservices85.fr/smf2/index.php?PHPSESSID=06fbde15c50341dba67eb1acd2331b45&topic=299687.0
https://www.hwbms.com/web/qna/44228
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/85360
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=398350
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2011758
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=420639
http://proxima.co.rw/index.php/component/k2/itemlist/user/731821
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=186911
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=32964
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3582640
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3586646
http://www.m1avio.com/index.php/component/k2/itemlist/user/3867340
http://www.spazioad.com/component/k2/itemlist/user/7490266
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc-2/
http://midorijapaneserestaurant.ca/menu/News/119164
http://midorijapaneserestaurant.ca/menu/News/119259
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=317703
https://khuyenmaikk13.info/index.php?topic=230718.0
http://ovotecegg.com/component/k2/itemlist/user/227397
http://roikjer.com/forum/index.php?PHPSESSID=ndvp8a62kv7al0oj02940ri0c3&topic=930099.0
http://www.kcch.or.kr/index.php?mid=board_uFpk03&document_srl=123156
https://reficulcoin.com/index.php?topic=92442.0
http://jdcalc.com/forum/viewtopic.php?t=294519
https://betshin.com/Story/204970
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=30509
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rs3m-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1/
http://rabbitzone.xyz/FREE/71814
http://beautypouch.net/index.php?mid=board_09&document_srl=167260
http://apt2you2.cafe24.com/g1/55506
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/165814
http://apt2you2.cafe24.com/g1/57719
http://mediaville.me/index.php/component/k2/itemlist/user/377068
http://carand.co.kr/d2/92408
http://wartoby.com/?document_srl=144917
http://rabat.kr/board_yCgT00/81133
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1936966
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=174873
http://sy.korean.net/qna/313685
http://withinfp.sakura.ne.jp/eso/index.php/17572486-rasskaz-sluzanki-3-sezon-5-seria-jows-rasskaz-sluzanki-3-sezon-/0
http://daltso.com/index.php?mid=board_cUYy21&document_srl=155340
http://ye-dream.com/qa/265943
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=212055
http://xn----3x5er9r48j7wemud0a387h.com/?document_srl=162043
http://yourhelp.co.kr/index.php?mid=board_2&document_srl=55360
http://jdcalc.com/forum/viewtopic.php?t=294367
http://looksun.co.kr/index.php?mid=board_4&document_srl=186311
http://www.vamoscontigo.org/Noticia/137455
http://masanlib.or.kr/g1/96561
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=387538
http://herdental.co.kr/index.php?mid=online&document_srl=115805
http://gabisan.com/board_OuDs04/72580
http://juroweb.com/xe/juroweb_board/84229
http://nnkumw.org/xe/index.php?mid=board_yNQm00&document_srl=140223
http://xn--2e0bk61btjo.com/notice/22342
http://www.sp1.football/index.php?mid=faq&document_srl=861422
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2794485
https://www.hwbms.com/web/qna/24963
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1315065
http://0433.net/budongsan/114626
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1868340
http://sunele.co.kr/board_ReBD97/243959
http://metropolis.ga/index.php?topic=20909.0
http://thermoplast.envolgroupe.com/component/k2/author/157723
http://holysweat.dothome.co.kr/data/6678
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16670
http://www.m1avio.com/index.php/component/k2/itemlist/user/3796322
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=123667
https://nextezone.com/index.php?action=profile;u=14148
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3781588
http://midorijapaneserestaurant.ca/menu/News/65580
http://2872870.com/est/64733
http://warmfund.net/p/index.php?mid=financing&document_srl=529687
http://benzmall.co.kr/index.php?mid=download&document_srl=72686
http://praisesound.co.kr/sub04_01/104410
https://intelogist2.wpengine.com/%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gf8j-%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://carand.co.kr/d2/93133
http://rudraautomation.com/index.php/component/k2/author/290375
http://smartacity.com/component/k2/itemlist/user/95491
http://lucky.kidspann.net/index.php?mid=qna&document_srl=362980
http://erhu.eu/viewtopic.php?t=394683
http://carand.co.kr/d2/92539
https://betshin.com/Story/193461
https://2002.shyoon.com/board_2002/255551
http://looksun.co.kr/index.php?mid=board_4&document_srl=196746
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1870946
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/65106
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ef1h-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://looksun.co.kr/index.php?mid=board_4&document_srl=125320
https://betshin.com/Story/219269
http://sd-xi.co.kr/g1/87315
http://dreamplusart.com/mn03_01/221996
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=49568
https://betshin.com/Story/200519
http://pekosmile.dothome.co.kr/index.php?mid=seoulitestudio&document_srl=433622
http://divespace.co.kr/board/295239
http://xn----c28ewjj6ubwku6frtcuzec29ae5b.com/news/58515
http://kyj1225.godohosting.com/board_mebR72/97742
https://www.celekt.com/%d0%a4%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ax8%d0%a4%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5/
http://www.aloeverasas.it/index.php/component/k2/itemlist/user/21382
http://mediaville.me/index.php/component/k2/itemlist/user/372963
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=262580
http://sy.korean.net/qna/463508
http://kyj1225.godohosting.com/board_mebR72/105913
http://bizchemical.com/board_kMpv94/2161338
http://looksun.co.kr/index.php?mid=board_4&document_srl=189667
https://gonggamlaw.com/lawcase/138822
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=255711
http://juroweb.com/xe/juroweb_board/85711
http://vtservices85.fr/smf2/index.php?PHPSESSID=ccec01fc0e4d9c7dc47925bc00346a3b&topic=288386.0
http://smartacity.com/component/k2/itemlist/user/90294
http://gabisan.com/board_OuDs04/73242
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/95871
http://jensenbyggteam.no/index.php/component/k2/itemlist/user/13708
http://erhu.eu/viewtopic.php?f=7&t=416999&view=print
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yv3%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15-%d1%81%d0%b5/
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=19069
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=918759
http://bath-family.com/photo_zone/148110
http://looksun.co.kr/index.php?mid=board_4&document_srl=182550
https://betshin.com/Story/198953
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=229386
https://www.chirorg.com/?document_srl=257041
http://khapthanam.co.kr/g1/135249
http://www.svteck.co.kr/customer_gratitude/349802
http://cwon.kr/xe/board_bnSr36/307470
http://askpharm.net/board_NQiz06/159400
http://loverstory.co.kr/board_UYNJ05/54699
http://www.m1avio.com/index.php/component/k2/itemlist/user/3803311
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-oh2g-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.cnsmaker.net/xe/?document_srl=122030
http://gabisan.com/?document_srl=68978
https://2002.shyoon.com/board_2002/217055
http://apt2you2.cafe24.com/g1/53901
http://xn----3x5er9r48j7wemud0a387h.com/news/164282
http://autospa.lv/?option=com_k2&view=itemlist&task=user&id=10598
http://yooseok.com/board_BkvT46/443978
http://zakdu.com/board_YpzS56/19810
http://midorijapaneserestaurant.ca/menu/News/43223
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1088229
http://masanlib.or.kr/g1/87515
http://xn----c28ewjj6ubwku6frtcuzec29ae5b.com/news/56586
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=129215
http://dreamplusart.com/mn03_01/221903
http://loverstory.co.kr/board_UYNJ05/110610
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=160618
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=175261
http://www.ekemoon.com/245301/050020191229/
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=35687
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=116998
http://www.teedinubon.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fk7%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7/
http://www.cnsmaker.net/xe/?document_srl=124366
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3485353
http://naksansacondo.com/board_MGPu57/104688
https://gonggamlaw.com/lawcase/154832
https://www.hwbms.com/web/qna/46174
https://www.hwbms.com/web/qna/46184
http://proxima.co.rw/index.php/component/k2/itemlist/user/722681
http://ye-dream.com/qa/204744
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=234058
http://daltso.com/index.php?mid=board_cUYy21&document_srl=206346
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=30707
https://betshin.com/Story/199938
http://www.ekemoon.com/246003/050720193329/
http://k2.akademitelkom.ac.id/component/k2/itemlist/user/371988
https://www.runcity.org/forum/index.php?action=profile;u=77684
http://thermoplast.envolgroupe.com/component/k2/author/179028
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=17208
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=103351
http://www.vamoscontigo.org/Noticia/204749
http://ko.myds.me/board_story/247617
http://www.coating.or.kr/atemfair_data/18177
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/?document_srl=100988
http://knet.dothome.co.kr/xe/board_RJHw15/15121
http://rudraautomation.com/index.php/component/k2/author/346341
http://gochon-iusell.co.kr/g1/121132
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1851836
http://www.artangel.co.kr/?document_srl=188414
http://khapthanam.co.kr/g1/150246
http://xn--2e0bk61btjo.com/notice/31165
http://www.hmotors.co.kr/inquiry/69826
http://viamania.net/index.php?mid=board_raYV15&document_srl=138580
https://betshin.com/Story/208516
http://bebopindia.com/notcie/467488
http://looksun.co.kr/index.php?mid=board_4&document_srl=202183
http://cwon.kr/xe/board_bnSr36/304774
https://forums.lfstats.com/viewtopic.php?t=324607
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/61549
http://yoriyorifood.com/xxxx/spacial/271321
http://divespace.co.kr/board/280179
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2746590
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=112642
http://zakdu.com/board_YpzS56/22661
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=229300
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=267735
http://guiadetudo.com/index.php/component/k2/itemlist/user/12713
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=205142
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=551023
http://dcasociados.eu/component/k2/itemlist/user/93462
http://1644-4404.com/?document_srl=232844
https://www.celekt.com/%d0%a0%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-prou-%d0%a0%d0%b0%d1%81/
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1851691
http://looksun.co.kr/index.php?mid=board_4&document_srl=207848
http://bath-family.com/photo_zone/131598
http://music.start-a-idea.online/blogs/viewstory/44531
http://backo.co.kr/board_aiQk58/15541
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/83422
http://socialmag.bayareanonprofits.xyz/blogs/viewstory/126833
http://proxima.co.rw/index.php/component/k2/itemlist/user/691688
http://www.jesusonly.life/calendar/446473
http://www.hmotors.co.kr/inquiry/54135
http://www2.yasothon.go.th/smf/index.php?topic=159.msg200290
http://beautypouch.net/index.php?mid=board_09&document_srl=167542
https://www.limscave.com/forum/viewtopic.php?f=6&t=54566
http://khapthanam.co.kr/g1/148726
http://rabat.kr/board_yCgT00/81013
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=254052
http://guiadetudo.com/index.php/component/k2/itemlist/user/12638
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=104155
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=415653
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=77640
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=109714
http://mercibq.net/partner/90227
http://askpharm.net/board_NQiz06/243566
http://www.hmotors.co.kr/inquiry/70253
http://www.livetank.cn/market1/215282
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1744039
http://daltso.com/index.php?mid=board_cUYy21&document_srl=204453
https://adsensebih.com/index.php?topic=49993.0
https://www.celekt.com/%d0%a4%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-du0c-%d0%a4%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1535429
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=415922
http://jiral.net/an9/29269
http://roikjer.com/forum/index.php?PHPSESSID=7akj7sgcl5mt07hh5c0s14puc7&topic=933322.0
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=113147
http://www.siirtorganik.com/index.php/component/k2/itemlist/user/959024
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=224093
http://midorijapaneserestaurant.ca/menu/News/75376
http://ovotecegg.com/component/k2/itemlist/user/225706
http://rfc11th13th.dothome.co.kr/Board5/35524
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=948010
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=222881
http://dev.aabn.org.gh/component/k2/itemlist/user/725587
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=227108
http://www.sp1.football/index.php?mid=faq&document_srl=689582
http://www.spazioad.com/component/k2/itemlist/user/7420036
http://taklongclub.com/forum/index.php?topic=205297.0
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=95048
http://beautypouch.net/index.php?mid=board_09&document_srl=101790
https://gonggamlaw.com/lawcase/133508
http://khapthanam.co.kr/?document_srl=159676
http://erdfsa.iptime.org/xe/index.php?mid=board&document_srl=12845
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=113175
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=256919
http://benzmall.co.kr/index.php?mid=download&document_srl=45776
http://mediaville.me/index.php/component/k2/itemlist/user/332616
http://hotelnomadpalace.com/es/?option=com_k2&view=itemlist&task=user&id=22832
http://carand.co.kr/d2/92263
http://divespace.co.kr/board/271053
http://www.hmotors.co.kr/inquiry/70936
http://dsyang.com/board_Kvgn62/46424
http://sy.korean.net/qna/457493
http://myrechockey.com/forums/index.php?topic=120621.0
http://miquirofisico.com/index.php/component/k2/itemlist/user/4572
http://barobus.kr/qna/73993
http://www.livetank.cn/market1/215949
http://toeden.co.kr/Product_new/141430
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=127545
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3934735
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=376227
http://herdental.co.kr/index.php?mid=online&document_srl=189489
http://engeena.com/component/k2/itemlist/user/9244
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1031564
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3492507
http://kockazatkutato.hu/component/k2/itemlist/user/42758
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=63821
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2832636
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=82320
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1856093
http://loverstory.co.kr/board_UYNJ05/103999
https://www.hohoyoga.com/testboard/3977683
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/310537
https://cybergsm.es/index.php?topic=73015.0
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/72600
http://yonseibaik.synology.me/index.php?mid=houston_profile&document_srl=92315
https://nple.com/xe/pds/236032
http://www.crnmedia.es/component/k2/itemlist/user/92098
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2003908
http://midorijapaneserestaurant.ca/menu/News/75381
http://web2interactive.com/index.php/component/k2/itemlist/user/3753355
http://d-tube.info/board_jvyO69/371691
http://ko.myds.me/board_story/247476
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=408308
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=198783
http://loverstory.co.kr/board_UYNJ05/42449
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1531671
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=40127.0
https://www.celekt.com/%d0%a0%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ctpi-%d0%a0%d0%b0%d1%81/
http://www.digitalbul.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xzmy-%d1%80%d0%b0%d1%81/
http://sd-xi.co.kr/g1/83072
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2005616
http://lucky.kidspann.net/index.php?mid=qna&document_srl=369195
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3923650
http://myrechockey.com/forums/index.php?topic=118755.0
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=268894
http://arnikabolt.ro/component/k2/itemlist/user/113154
http://beautypouch.net/index.php?mid=board_09&document_srl=102226
http://kotica00.dothome.co.kr/index.php?mid=board_nJTE45&document_srl=45926
http://www.kcch.or.kr/index.php?mid=board_uFpk03&document_srl=115586
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=48469
http://www.itosm.com/cn/board_nLoq17/206489
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=409209
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=407848
http://looksun.co.kr/index.php?mid=board_4&document_srl=183613
https://nple.com/xe/pds/235979
http://naksansacondo.com/board_MGPu57/95506
http://roikjer.com/forum/index.php?PHPSESSID=ko88a0spqnknu6vvve5lki2i86&topic=930299.0
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=206073
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=232144
http://hyeonjun.co.kr/menu3/288593
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/38512
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=899846
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=1120755
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=174248
http://dreamplusart.com/mn03_01/194982
https://www.chirorg.com/?document_srl=148061
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=959378
http://loverstory.co.kr/board_UYNJ05/94401
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=279378
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/49515
http://www.popolsku.fr.pl/forum/index.php?topic=20407.81075
https://mcsetup.tk/bbs/index.php?topic=262116.0
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=42907
http://archeaudio.com/xe/board_AOYj82/9885
http://zakdu.com/board_ssKi56/20212
http://hanga5.com/index.php?mid=board_photo&document_srl=110234
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/347540
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=249301
https://intelogist2.wpengine.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dm7i-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81/
http://mediaville.me/index.php/component/k2/itemlist/user/373824
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=205333
http://beautypouch.net/index.php?mid=board_09&document_srl=102159
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/?document_srl=132703
http://kyj1225.godohosting.com/board_mebR72/61123
http://carand.co.kr/d2/46264
http://naksansacondo.com/board_MGPu57/52251
http://cwon.kr/xe/board_bnSr36/297673
http://guiadetudo.com/index.php/component/k2/itemlist/user/12660
http://naksansacondo.com/board_MGPu57/94663
http://juroweb.com/xe/juroweb_board/85068
http://kockazatkutato.hu/index.php/component/k2/itemlist/user/42947
http://midorijapaneserestaurant.ca/menu/News/49316
http://carand.co.kr/d2/90131
http://constellation.kro.kr/board_kbku73/80947
http://www.theocraticamerica.org/forum/index.php?topic=81888.0
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=37481
http://neosky.net/xe/space_station/73947
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=951734
http://loverstory.co.kr/board_UYNJ05/42240
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-se4o-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21/
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=44553
http://roikjer.com/forum/index.php?topic=932051.0
http://www.ekemoon.com/245341/050020193029/
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=345271
http://cwon.kr/xe/board_bnSr36/304586
http://beautypouch.net/index.php?mid=board_09&document_srl=187248
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=166293
http://www.popolsku.fr.pl/forum/index.php?topic=20407.80730
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=387197
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=650879
https://www.hohoyoga.com/testboard/4058661
http://yooseok.com/board_BkvT46/412564
http://kyj1225.godohosting.com/board_mebR72/97048
http://kyj1225.godohosting.com/board_mebR72/96024
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=718048
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tpfr-%d1%80%d0%b0%d1%81/
http://www2.yasothon.go.th/smf/index.php?topic=159.172245
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=154400
http://rabbitzone.xyz/FREE/120398
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/105510
http://www.nurican.com/giris/ncan/index.php?topic=6135.0
http://barobus.kr/qna/95631
http://agiteshop.com/xe/qa/199047
http://proxima.co.rw/index.php/component/k2/itemlist/user/712857
http://otitismediasociety.org/forum/index.php?topic=202940.0
http://midorijapaneserestaurant.ca/menu/News/77058
http://carand.co.kr/d2/100177
http://barobus.kr/qna/91260
http://www.dap.com.py/index.php/es/?option=com_k2&view=itemlist&task=user&id=851975
http://daltso.com/index.php?mid=board_cUYy21&document_srl=241151
http://ajincomp.godohosting.com/board_STnh82/180809
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=399714
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=115229
http://tiretech.co.kr/index.php?mid=qna&document_srl=280096
http://www.itosm.com/cn/board_nLoq17/131885
https://reficulcoin.com/index.php?topic=87309.0
https://adsensebih.com/index.php?topic=47681.0
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=960364
http://yourhelp.co.kr/index.php?mid=board_2&document_srl=77366
http://e-educ.net/Forum/index.php?topic=16095.0
http://roikjer.com/forum/index.php?PHPSESSID=1mbq8ugfdjstaqiikcg7corbd6&topic=929407.0
https://blossomug.com/index.php/component/k2/itemlist/user/1114551
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/87378
http://carand.co.kr/d2/87493
http://blog.ptpintcast.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xegg-%d1%80%d0%b0%d1%81/
http://dev.aabn.org.gh/index.php/component/k2/itemlist/user/726501
http://rabat.kr/board_yCgT00/65218
https://gonggamlaw.com/lawcase/133699
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=520899
http://design-381.com/xe/qna/5379
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/65531
http://naksansacondo.com/board_MGPu57/74232
https://reficulcoin.com/index.php?topic=106058.0
http://soc-human.kz/index.php/en/?option=com_k2&view=itemlist&task=user&id=1755220
http://roikjer.com/forum/index.php?PHPSESSID=3bo60bf65kh0r3uk0otgidoo20&topic=935722.0
http://www2.yasothon.go.th/smf/index.php?topic=159.172050
http://otitismediasociety.org/forum/index.php?topic=212982.0
http://yourhelp.co.kr/index.php?mid=board_2&document_srl=58099
http://askpharm.net/board_NQiz06/264207
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=61392
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=536699
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1547320
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=387491
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=390599
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=707459
https://cybergsm.es/index.php?topic=72817.0
https://intelogist2.wpengine.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hoyw-%d1%80%d0%b0%d1%81/
http://www.cyberblissstudios.com/UserProfile/tabid/42/UserID/2324390/Default.aspx
http://daesestudy.co.kr/ipsi_docu/158576
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=403407
https://www.limscave.com/forum/viewtopic.php?t=61637
http://www.vamoscontigo.org/Noticia/147877
https://reficulcoin.com/index.php?topic=94993.0
http://www.itosm.com/cn/board_nLoq17/132610
http://divespace.co.kr/board/179588
http://www.kcch.or.kr/index.php?mid=board_uFpk03&document_srl=124938
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=720107
http://jnk-ent.jp/index.php?mid=gallery&document_srl=264353
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/69440
http://herdental.co.kr/index.php?mid=online&document_srl=115627
http://oss.obigo.com/oss/index.php?mid=board_mxLS91&document_srl=66218
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=1121079
http://midorijapaneserestaurant.ca/menu/News/51679
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=18134
http://haenamyun.taeshinmedia.com/index.php?mid=notice&document_srl=2855597
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/34796
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fnek-%d1%80%d0%b0%d1%81/
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=399790
http://benzmall.co.kr/index.php?mid=download&document_srl=98852
https://reficulcoin.com/index.php?topic=88838.0
http://naksansacondo.com/board_MGPu57/73091
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vp4o-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-aj5h-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
https://intelogist2.wpengine.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kn9e-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://intelogist2.wpengine.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gr2p-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://intelogist2.wpengine.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kz0b-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-on0u-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xp5f-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-al5s-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mr3m-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wg9k-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-nn7v-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sf9i-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yb5r-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jw9z-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15/
https://betshin.com/Story/233417
https://betshin.com/Story/233474
https://gonggamlaw.com/lawcase/168072
https://gonggamlaw.com/lawcase/168110
https://gonggamlaw.com/lawcase/168121
https://www.hohoyoga.com/?document_srl=4107939
https://www.hohoyoga.com/testboard/4107905
https://www.hwbms.com/web/qna/60238
https://www.hwbms.com/web/qna/60493
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-video-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be-2/
http://dsyang.com/board_Kvgn62/52265
http://dsyang.com/board_Kvgn62/52272
http://dsyang.com/board_Kvgn62/52285
http://jnk-ent.jp/index.php?mid=gallery&document_srl=328881
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=547806
http://constellation.kro.kr/board_kbku73/64405
http://divespace.co.kr/board/295873
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=398506
http://myrechockey.com/forums/index.php?topic=118307.0
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=264833
https://www.hwbms.com/web/qna/34236
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/351879
http://dev.aabn.org.gh/component/k2/itemlist/user/710897
http://dospuntoseventos.cl/component/k2/itemlist/user/18044
http://isch.kr/board_PowH60/220016
http://zakdu.com/board_YpzS56/22666
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/96939
https://www.shaiyax.com/index.php?topic=408343.0
http://www.svteck.co.kr/customer_gratitude/282493
http://www.vamoscontigo.org/Noticia/139363
https://adsensebih.com/index.php?topic=48340.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2741592
http://dreamplusart.com/mn03_01/195278
http://dreamplusart.com/mn03_01/120875
http://www.vamoscontigo.org/Noticia/222644
http://yoriyorifood.com/xxxx/?document_srl=300162
http://daltso.com/index.php?mid=board_cUYy21&document_srl=124773
http://xn--2e0b53df5ag1c804aphl.net/nuguna/112745
http://rabat.kr/board_yCgT00/80201
http://archeaudio.com/xe/?document_srl=16778
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=279942
https://betshin.com/Story/211557
https://forums.lfstats.com/viewtopic.php?t=321520
http://rudraautomation.com/index.php/component/k2/author/291370
http://loverstory.co.kr/board_UYNJ05/102384
http://forum.bmw-e60.eu/index.php?topic=11390.0
http://p9912.cafe24.com/board_LVgu51/72323
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=148673
http://www.ekemoon.com/245731/050420195829/
http://sd-xi.co.kr/g1/90646
http://www.rocketdan.co.kr/?document_srl=82447
http://tiretech.co.kr/index.php?mid=qna&document_srl=180392
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1770979
http://kwpub.kr/PUBS/165040
http://yonseibaik.synology.me/index.php?mid=houston_profile&document_srl=56267
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=259085
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=95225
http://autospa.lv/index.php/lv/component/k2/itemlist/user/10584
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3794626
http://daltso.com/index.php?mid=board_cUYy21&document_srl=125875
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=560268
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=31348
http://ptu.imoove.kr/ko/content/%C2%AB%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-9-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-dvoh-%C2%AB%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-9-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-fx341155
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=17248
http://legride.com/UserProfile/tabid/61/userId/2889800/Default.aspx
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1545483
http://rudraautomation.com/index.php/component/k2/author/290226
http://myrechockey.com/forums/index.php?topic=118693.0
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=46241
http://smartacity.com/component/k2/itemlist/user/90613
http://kyj1225.godohosting.com/board_mebR72/82330
http://hotelnomadpalace.com/es/?option=com_k2&view=itemlist&task=user&id=22524
http://www.sp1.football/index.php?mid=faq&document_srl=836964
http://1661-6471.co.kr/news/40583
https://gonggamlaw.com/lawcase/135180
http://forum.bmw-e60.eu/index.php?topic=11468.0
http://kyj1225.godohosting.com/board_mebR72/101734
https://blossomug.com/index.php/component/k2/itemlist/user/1115647
http://loverstory.co.kr/board_UYNJ05/118786
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/337063
http://www.hmotors.co.kr/inquiry/23919
http://loverstory.co.kr/board_UYNJ05/46425
https://intelogist2.wpengine.com/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rr6%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be/
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1180240
http://kyj1225.godohosting.com/board_mebR72/105758
https://forum.clubeicaro.pt/index.php?topic=2309.0
http://www.ekemoon.com/245439/050120193329/
https://gonggamlaw.com/lawcase/146725
http://divespace.co.kr/board/294876
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=9165c13a0153e4485450a5bb7c79a6bb&topic=11243.0
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=232878
http://midorijapaneserestaurant.ca/menu/News/74541
http://www2.yasothon.go.th/smf/index.php?topic=159.msg199800
http://gabisan.com/board_OuDs04/73980
http://cwon.kr/xe/board_bnSr36/290310
http://isch.kr/board_PowH60/154454
http://dohairbiz.com/en/component/k2/itemlist/user/2818194.html
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=319402
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=387355
http://mediaville.me/index.php/component/k2/itemlist/user/377195
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=118080
http://xn----c28ewjj6ubwku6frtcuzec29ae5b.com/news/57102
http://2872870.com/est/61577
http://jdcalc.com/forum/viewtopic.php?t=283031
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=43450
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1321057
https://intelogist2.wpengine.com/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c/
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2831461
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2017485
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2017489
http://gtupuw.org/index.php/component/k2/itemlist/user/2017255
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yspr-%d1%80%d0%b0%d1%81/
http://naksansacondo.com/?document_srl=76846
http://www.kwpcoop.or.kr/QnA/22518
https://www.limscave.com/forum/viewtopic.php?t=58846
http://proxima.co.rw/index.php/component/k2/itemlist/user/718130
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/37372
http://daltso.com/index.php?mid=board_cUYy21&document_srl=206960
http://immobilia.gr/index.php/de/component/k2/itemlist/user/16884
http://beautypouch.net/index.php?mid=board_09&document_srl=167512
https://forum.ac-jete.it/index.php?topic=440174.0
https://blossomug.com/index.php/component/k2/itemlist/user/1112673
http://ye-dream.com/qa/267568
http://www.emrabq8.com/index.php/component/k2/itemlist/user/1872402
http://www.svteck.co.kr/customer_gratitude/223937
http://myesl.ca/forum/viewtopic.php?t=693869
http://sunele.co.kr/board_ReBD97/239674
http://loverstory.co.kr/board_UYNJ05/110135
http://herdental.co.kr/index.php?mid=online&document_srl=140864
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=540363
http://www.vamoscontigo.org/Noticia/136214
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3864214
http://divespace.co.kr/board/180475
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1574544
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3527081
http://www2.yasothon.go.th/smf/index.php?topic=159.msg203612
http://midorijapaneserestaurant.ca/menu/News/136248
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2835849
http://dev.aabn.org.gh/component/k2/itemlist/user/751343
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/346225
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fzjl-%d1%80%d0%b0%d1%81/
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=50333
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=f80e211ef375b52f6d08a71c6bc1922c&topic=12688.0
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=109204
http://k-cea.org/board_Hnyj62/191942
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/75977
http://withinfp.sakura.ne.jp/eso/index.php/17596797-rasskaz-sluzanki-3-sezon-11-seria-xdqp-rasskaz-sluzanki-3-sezon/0
http://www.digitalbul.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vyqy-%d1%80%d0%b0%d1%81/
http://bath-family.com/photo_zone/158373
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=532853
http://ovotecegg.com/component/k2/itemlist/user/219258
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=18817
http://withinfp.sakura.ne.jp/eso/index.php/17576232-rasskaz-sluzanki-3-sezon-8-seria-zgfx-rasskaz-sluzanki-3-sezon-/0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2732346
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=17700
https://www.lwfservers.com/index.php?topic=73873.0
http://www.eunhaele.co.kr/xe/board/20599
http://www.digitalbul.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-itfe-%d1%80%d0%b0%d1%81/
http://ye-dream.com/qa/206314
https://nple.com/xe/pds/149898
https://www.hwbms.com/web/qna/12376
https://gonggamlaw.com/lawcase/140947
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=100897
http://healthyteethpa.org/component/k2/itemlist/user/5548965
http://bath-family.com/photo_zone/144637
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/32976
http://socialmag.bayareanonprofits.xyz/blogs/viewstory/131057
http://hotelnomadpalace.com/es/?option=com_k2&view=itemlist&task=user&id=23499
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/60177
https://www.c-alice.org/forum/index.php?topic=101760.0
https://www.c-alice.org/forum/index.php?topic=101766.0
http://gusinoepero.ru/archives/27424
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=29432
http://loverstory.co.kr/board_UYNJ05/109677
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=242167
http://erdfsa.iptime.org/xe/index.php?mid=board&document_srl=13303
https://mcsetup.tk/bbs/index.php?topic=262201.0
http://benzmall.co.kr/index.php?mid=download&document_srl=97242
http://carand.co.kr/d2/98775
http://neosky.net/xe/space_station/67480
http://loverstory.co.kr/board_UYNJ05/76715
http://carand.co.kr/d2/67818
https://nextezone.com/index.php?action=profile;u=14364
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1499343
https://adsensebih.com/index.php?topic=48715.0
https://betshin.com/Story/204831
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=484564
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=118285
https://www.hohoyoga.com/testboard/4086898
https://www.hohoyoga.com/testboard/4086432
http://bobr.site/index.php?topic=182190.0
http://netsconsults.com/?option=com_k2&view=itemlist&task=user&id=839430
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=113127
http://sd-xi.co.kr/g1/86285
http://www.vamoscontigo.org/Noticia/202396
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=123912
https://forum.shaiyaslayer.tk/index.php?topic=185356.0
http://hotelnomadpalace.com/index.php/component/k2/itemlist/user/23750
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/60406
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/67404
https://forum.clubeicaro.pt/index.php?topic=3032.0
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=87641
http://hotelnomadpalace.com/index.php/component/k2/itemlist/user/23737
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/67378
https://forum.clubeicaro.pt/index.php?topic=3034.0
https://forum.clubeicaro.pt/index.php?topic=3035.0
http://www.aloeverasas.it/index.php/component/k2/itemlist/user/21439
https://cybergsm.es/index.php?topic=72934.0
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=113289
http://divespace.co.kr/board/279160
http://looksun.co.kr/index.php?mid=board_4&document_srl=186289
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rz7c-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16/
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=113194
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=207033
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=191076
http://askpharm.net/board_NQiz06/158894
http://www.kwpcoop.or.kr/QnA/22087
http://otitismediasociety.org/forum/index.php?topic=214821.0
http://www.cyberblissstudios.com/UserProfile/tabid/42/UserID/2331755/Default.aspx
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=37462
https://gonggamlaw.com/lawcase/82057
http://naksansacondo.com/board_MGPu57/92734
https://turimex.mx.solemti.net/index.php/component/k2/itemlist/user/19113
https://betshin.com/Story/218283
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/147735
http://design-381.com/xe/portpolio/5737
http://www.eunhaele.co.kr/xe/QnA/20964
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/60254
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=51122
http://fbpharm.net/index.php/component/k2/itemlist/user/87900
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1115666
http://muldorang.com/market/25860
http://mobility-corp.com/index.php/component/k2/itemlist/user/2729702
http://naksansacondo.com/board_MGPu57/70929
https://blossomug.com/index.php/component/k2/itemlist/user/1115298
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=454115
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=17598
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=321625
http://apt2you2.cafe24.com/?document_srl=57207
http://www.popolsku.fr.pl/forum/index.php?topic=417181.0
http://divespace.co.kr/board/271423
http://sy.korean.net/qna/312160
http://web2interactive.com/index.php/component/k2/itemlist/user/3796190
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=376792
http://viamania.net/index.php?mid=board_raYV15&document_srl=138956
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3859639
http://isch.kr/board_PowH60/231172
https://mcsetup.tk/bbs/index.php?topic=265040.0
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/brand/69465
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/42260
https://betshin.com/Story/217102
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=106169
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=43179
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7515041
http://gabisan.com/board_OuDs04/73895
http://viamania.net/index.php?mid=board_raYV15&document_srl=213802
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/817891
https://www.hwbms.com/web/qna/26940
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1312665
http://daltso.com/?document_srl=246517
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pm2w-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3/
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3863365
http://healthyteethpa.org/component/k2/itemlist/user/5550797
http://apt2you2.cafe24.com/?document_srl=56788
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=198620
http://thermoplast.envolgroupe.com/component/k2/author/180205
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rdsg-%d1%80%d0%b0%d1%81/
http://www.firstfinancialservices.co.uk/component/k2/itemlist/user/34162
http://mediaville.me/index.php/component/k2/itemlist/user/375573
http://cwon.kr/xe/board_bnSr36/300175
http://hotelnomadpalace.com/index.php/component/k2/itemlist/user/22857
http://myesl.ca/forum/viewtopic.php?f=3&t=694677&view=print
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=206799
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1854329
http://rabat.kr/board_yCgT00/80439
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=590296
https://ne-kuru.ru/index.php?topic=227389.0
http://www.artangel.co.kr/index.php?mid=Activities&document_srl=188176
http://netsconsults.com/index.php/component/k2/itemlist/user/846972
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4903146
http://midorijapaneserestaurant.ca/menu/News/35913
http://lucky.kidspann.net/index.php?mid=qna&document_srl=361738
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3860111
http://midorijapaneserestaurant.ca/menu/News/60631
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4976898
http://www.spazioad.com/component/k2/itemlist/user/7503150
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/870351
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dm5y-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://intelogist2.wpengine.com/%d0%ba%d0%be%d0%bf-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uk0z-%d0%ba%d0%be%d0%bf-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qu7s-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7554323
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7554337
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3586817
https://intelogist2.wpengine.com/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tj8a-%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3/
https://intelogist2.wpengine.com/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fs2v-%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3/
http://www.jesusonly.life/calendar/561012
http://jiral.net/an9/29973
http://web2interactive.com/index.php/component/k2/itemlist/user/3753601
http://loverstory.co.kr/board_UYNJ05/46465
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=35884
http://otitismediasociety.org/forum/index.php?topic=201324.0
http://praisesound.co.kr/sub04_01/103055
http://sy.korean.net/qna/444681
http://www.popolsku.fr.pl/forum/index.php?topic=20407.80520
https://intelogist2.wpengine.com/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bd3w-%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3/
http://benzmall.co.kr/index.php?mid=download&document_srl=47121
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/61968
http://looksun.co.kr/index.php?mid=board_4&document_srl=181927
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=50268
http://archeaudio.com/xe/board_AOYj82/11506
http://dreamplusart.com/mn03_01/223751
http://jdcalc.com/forum/viewtopic.php?t=292685
http://rabat.kr/board_yCgT00/38188
http://apt2you2.cafe24.com/g1/36041
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mc0%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5/
http://holysweat.dothome.co.kr/data/7949
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hjfh-%d1%80%d0%b0%d1%81/
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/84010
http://melchinooddle.dothome.co.kr/?document_srl=13612
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=946905
https://nple.com/xe/pds/220700
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=230964
http://gochon-iusell.co.kr/g1/82775
http://www2.yasothon.go.th/smf/index.php?topic=159.msg199887
http://socialmag.bayareanonprofits.xyz/blogs/viewstory/131174
http://loverstory.co.kr/board_UYNJ05/101250
http://archeaudio.com/xe/board_AOYj82/11038
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3900801
http://ucckorea.kr/index.php?mid=board_AuHE49&document_srl=77949
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1548613
http://sejong-thesharpyemizi.co.kr/m1/27110
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fn0%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f29-05/
http://hyeonjun.co.kr/menu3/289698
http://cwon.kr/xe/board_bnSr36/308952
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1151817
http://153.120.114.241/eso/index.php/17594402-rasskaz-sluzanki-3-sezon-10-seria-zobv-rasskaz-sluzanki-3-sezon
http://apt2you2.cafe24.com/g1/57377
http://www.hmotors.co.kr/inquiry/53521
http://kockazatkutato.hu/component/k2/itemlist/user/44401
http://forum.bmw-e60.eu/index.php?topic=12316.0
http://xn--2e0b53df5ag1c804aphl.net/nuguna/114003
https://intelogist2.wpengine.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mocg-%d1%80%d0%b0%d1%81/
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/44038
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=101436
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=209383
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fi0f-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ft6c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/306548
http://0433.net/junggo/144998
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=716723
https://www.celekt.com/%d0%92%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mr3v-%d0%92%d1%81%d1%91-%d0%bc%d0%be%d0%b3/
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=48301
http://www.hmotors.co.kr/inquiry/32607
https://gonggamlaw.com/lawcase/142142
http://153.120.114.241/eso/index.php/17555535-rasskaz-sluzanki-3-sezon-5-seria-ilyg-rasskaz-sluzanki-3-sezon-
http://khapthanam.co.kr/g1/150251
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=90429
http://daltso.com/index.php?mid=board_cUYy21&document_srl=200855
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=147070
http://cwon.kr/xe/board_bnSr36/299412
https://forum.clubeicaro.pt/index.php?topic=2409.0
http://ucckorea.kr/index.php?mid=board_AuHE49&document_srl=80672
http://dcasociados.eu/component/k2/itemlist/user/94392
http://www.vamoscontigo.org/Noticia/139113
http://sofficer.net/xe/teach/287340
http://muldorang.com/market/27857
http://gabisan.com/board_OuDs04/128389
http://fbpharm.net/index.php/component/k2/itemlist/user/87389
http://divespace.co.kr/board/294971
http://bewasia.com/?document_srl=204871
http://dev.fivestarpainting.com/?option=com_k2&view=itemlist&task=user&id=2002999
http://rudraautomation.com/index.php/component/k2/author/291086
https://www.hwbms.com/web/qna/46312
https://www.hwbms.com/web/qna/46324
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2805635
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2805655
http://dev.aabn.org.gh/component/k2/itemlist/user/731297
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2013263
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=110158
http://halinhpharma.com.vn/index.php/component/k2/itemlist/user/412114
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1327836
http://forum.elexlabs.com/index.php?topic=62217.0
http://www.svteck.co.kr/customer_gratitude/301991
http://miquirofisico.com/index.php/component/k2/itemlist/user/4549
http://www.theocraticamerica.org/forum/index.php?topic=75695.0
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1738379
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/246215
http://bobr.site/index.php?topic=187834.0
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16853
http://compultras.com/component/k2/itemlist/user/254586
http://p9912.cafe24.com/board_LVgu51/35456
http://www.spazioad.com/component/k2/itemlist/user/7420345
https://betshin.com/Story/211225
http://www.yadanarbonnews.com/index.php/component/k2/itemlist/user/352472
https://mcsetup.tk/bbs/index.php?topic=262287.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1545623
http://web2interactive.com/index.php/component/k2/itemlist/user/3782978
https://www.celekt.com/%d0%9a%d0%be%d0%bf-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-29-05-2019-d5-%d0%9a%d0%be%d0%bf-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=958830
http://www.kwpcoop.or.kr/QnA/22485
http://robocit.com/index.php/component/k2/itemlist/user/449867
https://www.limscave.com/forum/viewtopic.php?t=55307
http://dayung.co.kr/board_SRVC17/69922
https://www.hwbms.com/web/qna/27149
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=493470
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3571306
http://hanga5.com/index.php?mid=board_photo&document_srl=109341
http://www.vamoscontigo.org/Noticia/166007
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=108897
http://daltso.com/index.php?mid=board_cUYy21&document_srl=194171
https://forums.lfstats.com/viewtopic.php?t=317972
https://forum.ac-jete.it/index.php?topic=440037.0
https://mcsetup.tk/bbs/index.php?topic=262233.0
http://socialmag.bayareanonprofits.xyz/blogs/viewstory/130388
http://dsyang.com/board_Kvgn62/43844
http://backo.co.kr/board_aiQk58/15252
http://looksun.co.kr/index.php?mid=board_4&document_srl=202363
http://loverstory.co.kr/board_UYNJ05/113499
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=39903.0
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/78302
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=550269
http://bebopindia.com/notcie/501654
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1870266
http://xn----c28ewjj6ubwku6frtcuzec29ae5b.com/news/56890
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=49659
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=119571
http://naksansacondo.com/board_MGPu57/39924
http://cwon.kr/xe/?document_srl=305272
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1085713
http://www.firstfinancialservices.co.uk/?option=com_k2&view=itemlist&task=user&id=42096
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=234010
http://daesestudy.co.kr/ipsi_docu/138826
http://sy.korean.net/qna/456227
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/370321
http://dreamplusart.com/mn03_01/210961
http://www.svteck.co.kr/customer_gratitude/219614
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16431
http://www.crnmedia.es/component/k2/itemlist/user/91640
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2006131
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=44244
https://mcsetup.tk/bbs/index.php?topic=263049.0
http://naksansacondo.com/board_MGPu57/85883
http://bebopindia.com/notcie/394382
http://sejong-thesharpyemizi.co.kr/m1/75104
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=590830
http://x-crew.center/guest/4851662
http://www.kwpcoop.or.kr/QnA/22495
https://www.limscave.com/forum/viewtopic.php?t=57523
http://daltso.com/index.php?mid=board_cUYy21&document_srl=202210
http://www.venusjeju.com/index.php?mid=QnA&document_srl=2124
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=229340
https://adsensebih.com/index.php?topic=49136.0
https://timecker.com/anonymous/188700
http://mobility-corp.com/index.php/component/k2/itemlist/user/2744369
http://yoriyorifood.com/xxxx/spacial/254252
https://www.hohoyoga.com/testboard/4090419
http://hyeonjun.co.kr/menu3/287953
https://betshin.com/Story/213157
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=956739
http://mvisage.sk/index.php/component/k2/itemlist/user/119960
http://goldenpowerball2.com/?document_srl=339008
http://bobr.site/index.php?topic=184588.0
http://www.livetank.cn/market1/218203
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=0b8a7605ccff58ad4db5c198f390e155&topic=12467.0
http://xn----c28ewjj6ubwku6frtcuzec29ae5b.com/news/56098
http://www.popolsku.fr.pl/forum/index.php?topic=415650.0
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1533721
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1546492
http://askpharm.net/board_NQiz06/274997
http://khapthanam.co.kr/g1/135287
http://hotelnomadpalace.com/component/k2/itemlist/user/22577
http://forum.elexlabs.com/index.php/topic,62615.0.html
http://www.hmotors.co.kr/inquiry/71135
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=918095
https://www.swiss-focus.ch/index.php/component/k2/itemlist/user/35830
http://ucckorea.kr/index.php?mid=board_AuHE49&document_srl=80728
http://www.vamoscontigo.org/Noticia/137688
http://loverstory.co.kr/board_UYNJ05/116612
http://ye-dream.com/qa/259654
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=551603
http://shinhwaair2017.cafe24.com/issue/522447
http://netsconsults.com/?option=com_k2&view=itemlist&task=user&id=827645
https://forums.lfstats.com/viewtopic.php?t=318528
https://nextezone.com/index.php?topic=81410.0
http://mediaville.me/index.php/component/k2/itemlist/user/371239
http://bebopindia.com/notcie/394484
http://sejong-thesharpyemizi.co.kr/m1/55016
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=97090
http://bobr.site/index.php?topic=182309.0
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2001419
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=559938
http://rabat.kr/board_yCgT00/64682
http://myrechockey.com/forums/index.php?topic=118540.0
http://vtservices85.fr/smf2/index.php?topic=299984.0
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=663907
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/79974
http://daltso.com/index.php?mid=board_cUYy21&document_srl=214318
http://www.hmotors.co.kr/inquiry/41742
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jq5q-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-20/
http://sd-xi.co.kr/g1/56085
http://melchinooddle.dothome.co.kr/?document_srl=14773
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=184288
http://kwpub.kr/PUBS/130700
https://reficulcoin.com/index.php?topic=97685.0
http://ye-dream.com/qa/239559
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=190957
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=125330
http://gabisan.com/?document_srl=71896
http://cwon.kr/xe/board_bnSr36/313657
http://ilsannabgol.kr/board_brJk31/1378309
http://apt2you2.cafe24.com/g1/51460
http://lucky.kidspann.net/index.php?mid=qna&document_srl=291807
http://cwon.kr/xe/board_bnSr36/315237
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/392766
http://smartacity.com/component/k2/itemlist/user/93831
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=393104
http://www.livetank.cn/market1/306530
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=18498
https://forums.lfstats.com/viewtopic.php?t=325258
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/70732
http://cwon.kr/xe/board_bnSr36/317124
http://constellation.kro.kr/board_kbku73/66297
http://moyakmermer.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=842992
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3858705
http://k-cea.org/board_Hnyj62/251776
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=17253
https://timecker.com/anonymous/188379
http://naksansacondo.com/board_MGPu57/32449
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=363241
http://daltso.com/?document_srl=209300
http://oss.obigo.com/oss/index.php?mid=board_mxLS91&document_srl=66224
https://altaylarteknoloji.com/index.php?topic=6530.0
http://benzmall.co.kr/index.php?mid=download&document_srl=84430
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2002472
http://apt2you2.cafe24.com/g1/52787
http://www.proandpro.it/?option=com_k2&view=itemlist&task=user&id=4716967
https://cybergsm.es/index.php?topic=72924.0
http://www.teedinubon.com/%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-oz7%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f29-05-20/
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=366299
http://neosky.net/xe/space_station/69066
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/44564
http://roikjer.com/forum/index.php?PHPSESSID=1trm02c8vlcn8rtksab78tp4d3&topic=931306.0
http://yooseok.com/board_BkvT46/449562
http://www.spazioad.com/component/k2/itemlist/user/7395794
http://daltso.com/?document_srl=199327
https://www.hohoyoga.com/testboard/4060909
http://melchinooddle.dothome.co.kr/?document_srl=15266
http://ariji.kr/?document_srl=1075940
http://daltso.com/index.php?mid=board_cUYy21&document_srl=196060
http://153.120.114.241/eso/index.php/17539524-rasskaz-sluzanki-3-sezon-9-seria-wjfa-rasskaz-sluzanki-3-sezon-
http://loverstory.co.kr/board_UYNJ05/104157
http://mercibq.net/?document_srl=55869
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3796473
http://www.hmotors.co.kr/inquiry/38266
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/114828
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=225408
http://bebopindia.com/notcie/381554
http://ucckorea.kr/index.php?mid=board_AuHE49&document_srl=78020
http://callman.co.kr/index.php?mid=qa&document_srl=222598
http://www.venusjeju.com/index.php?mid=QnA&document_srl=876
http://www.cyberblissstudios.com/UserProfile/tabid/42/UserID/2340847/Default.aspx
http://1661-6471.co.kr/news/82878
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=125546
http://www.jesusonly.life/calendar/452538
https://intelogist2.wpengine.com/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hf9o-%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3/
http://8.droror.co.il/uncategorized/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yiro-%d1%80%d0%b0%d1%81/
http://www.boutique.in.th/?option=com_k2&view=itemlist&task=user&id=153138
http://www.popolsku.fr.pl/forum/index.php?topic=417078.0
http://foa.egerton.ac.ke/index.php/component/k2/itemlist/user/1937910
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=345512
https://www.2ayes.com/19661/3-6-hwjb-3-6-the-cw
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=102281
http://rabat.kr/board_yCgT00/69265
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=914810
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=211817
http://withinfp.sakura.ne.jp/eso/index.php/17528047-rasskaz-sluzanki-3-sezon-1-seria-komz-rasskaz-sluzanki-3-sezon-
https://www.swiss-focus.ch/index.php/component/k2/itemlist/user/35963
http://kyj1225.godohosting.com/?document_srl=95842
http://taklongclub.com/forum/index.php?topic=213544.0
http://kyj1225.godohosting.com/board_mebR72/96670
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/371895
http://divespace.co.kr/board/268254
https://gonggamlaw.com/lawcase/125316
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ri7%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f28-05/
http://rabat.kr/board_yCgT00/39751
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=130453
http://daltso.com/index.php?mid=board_cUYy21&document_srl=192956
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=46373
http://daltso.com/index.php?mid=board_cUYy21&document_srl=189933
http://research.kiu.ac.kr/?document_srl=429977
http://jdcalc.com/forum/viewtopic.php?f=2&t=293082&view=print
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=214705
http://ko.myds.me/board_story/248417
http://rabbitzone.xyz/FREE/73243
http://eugeniocolazzo.it/forum/index.php?topic=188147.0
https://intelogist2.wpengine.com/%d0%ba%d0%be%d0%bf-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vz3%d0%ba%d0%be%d0%bf-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f28-05-2019/
http://barobus.kr/qna/74552
http://rotary-laeliana.org/component/k2/itemlist/user/51921
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=922910
http://www.vamoscontigo.org/Noticia/136272
http://yoriyorifood.com/xxxx/spacial/358288
http://gochon-iusell.co.kr/g1/105383
http://daltso.com/index.php?mid=board_cUYy21&document_srl=123869
http://www.popolsku.fr.pl/forum/index.php?topic=413661.0
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=17414
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=317703
https://khuyenmaikk13.info/index.php?topic=230718.0
http://ovotecegg.com/component/k2/itemlist/user/227397
http://roikjer.com/forum/index.php?PHPSESSID=ndvp8a62kv7al0oj02940ri0c3&topic=930099.0
http://www.kcch.or.kr/index.php?mid=board_uFpk03&document_srl=123156
https://reficulcoin.com/index.php?topic=92442.0
http://jdcalc.com/forum/viewtopic.php?t=294519
https://betshin.com/Story/204970
http://naksansacondo.com/board_MGPu57/56425
http://xn----3x5er9r48j7wemud0a387h.com/news/189176
http://leonwebzine.dothome.co.kr/guest/11473
http://maka-222.com/index.php?mid=board_hcFa40&document_srl=109213
http://divespace.co.kr/board/294872
http://ko.myds.me/board_story/244831
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=154171
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/346437
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=109345
http://www.quattroandpartners.it/component/k2/itemlist/user/1214225
http://www.popolsku.fr.pl/forum/index.php?topic=412117.0
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/842232
http://www.aloeverasas.it/index.php/component/k2/itemlist/user/21398
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2002566
https://www.lwfservers.com/index.php?topic=74429.0
http://jnk-ent.jp/index.php?mid=gallery&document_srl=306494
https://reficulcoin.com/index.php?topic=85946.0
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=36892
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1170901
https://www.limscave.com/forum/viewtopic.php?t=58580
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1974557
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=223146
http://oss.obigo.com/oss/index.php?mid=board_mxLS91&document_srl=64455
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=149274
http://sunele.co.kr/board_ReBD97/167259
https://altaylarteknoloji.com/index.php?topic=6318.0
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3783776
http://www.firstfinancialservices.co.uk/?option=com_k2&view=itemlist&task=user&id=42096
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=234010
http://daesestudy.co.kr/ipsi_docu/138826
http://sy.korean.net/qna/456227
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/370321
http://dreamplusart.com/mn03_01/210961
http://divespace.co.kr/board/179956
http://jdcalc.com/forum/viewtopic.php?t=288630
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=40660.0
https://blossomug.com/index.php/component/k2/itemlist/user/1112985
http://archeaudio.com/xe/board_AOYj82/11228
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=23734
http://www.hmotors.co.kr/inquiry/72891
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/174035
https://intelogist2.wpengine.com/%d0%ba%d0%be%d0%bf-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ds7%d0%ba%d0%be%d0%bf-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f28-05-2019/
https://adsensebih.com/index.php?topic=47518.0
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/852634
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16612
http://sy.korean.net/qna/406590
http://lucky.kidspann.net/index.php?mid=qna&document_srl=295298
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4932401
http://www.dap.com.py/index.php/component/k2/itemlist/user/849846
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=666261
http://cwon.kr/xe/board_bnSr36/286151
http://myrechockey.com/forums/index.php?topic=117624.0
http://www.quattroandpartners.it/component/k2/itemlist/user/1259323
http://dsyang.com/board_Kvgn62/30670
http://askpharm.net/board_NQiz06/282683
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=49483
http://apt2you2.cafe24.com/g1/56877
https://forum.ac-jete.it/index.php?topic=445916.0
http://dreamplusart.com/mn03_01/178268
http://netsconsults.com/?option=com_k2&view=itemlist&task=user&id=826810
http://www.cnsmaker.net/xe/?document_srl=144291
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/91682
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/175483
http://erhu.eu/viewtopic.php?t=400613
http://blog.ptpintcast.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pszx-%d1%80%d0%b0%d1%81/
http://ye-dream.com/qa/277684
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=165475
http://dsyang.com/board_Kvgn62/41571
https://www.shaiyax.com/index.php?topic=407753.0
http://cwon.kr/xe/board_bnSr36/283142
http://naksansacondo.com/board_MGPu57/80002
http://www.dap.com.py/index.php/component/k2/itemlist/user/852638
http://www.yadanarbonnews.com/index.php/component/k2/itemlist/user/354150
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=191458
http://jnk-ent.jp/index.php?mid=gallery&document_srl=366706
https://2002.shyoon.com/board_2002/167704
https://gonggamlaw.com/lawcase/65266
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=425290
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=425334
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=58966
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3957955
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3958213
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3958230
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3958239
http://mediaville.me/index.php/component/k2/itemlist/user/403981
http://mediaville.me/index.php/component/k2/itemlist/user/404051
http://mediaville.me/index.php/component/k2/itemlist/user/404079
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3493480
http://looksun.co.kr/index.php?mid=board_4&document_srl=191510
http://melchinooddle.dothome.co.kr/?document_srl=13436
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=22900
http://loverstory.co.kr/board_UYNJ05/99791
http://dow.dothome.co.kr/board_jydx58/39499
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1995541
http://ye-dream.com/qa/270540
http://miquirofisico.com/index.php/component/k2/itemlist/user/4485
https://2002.shyoon.com/board_2002/246141
http://www.itosm.com/cn/board_nLoq17/134131
http://erdfsa.iptime.org/xe/index.php?mid=board&document_srl=26170
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1575840
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=19230
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=988810
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=129159
https://blossomug.com/index.php/component/k2/itemlist/user/1136779
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3527560
https://blossomug.com/index.php/component/k2/itemlist/user/1136806
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%84%d0%b8%d1%82/
http://jensenbyggteam.no/index.php/component/k2/itemlist/user/13785
http://carand.co.kr/d2/99257
https://forums.lfstats.com/viewtopic.php?t=321490
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=181955
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/852142
http://knet.dothome.co.kr/xe/board_RJHw15/15113
http://roikjer.com/forum/index.php?PHPSESSID=4aqomud9n1oomr52iq1roui5p4&topic=930197.0
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=50334
http://www.ekemoon.com/245867/050620191229/
http://thermoplast.envolgroupe.com/component/k2/author/180593
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1854489
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=186864
http://ovotecegg.com/component/k2/itemlist/user/222868
http://yoriyorifood.com/xxxx/spacial/324607
http://p9912.cafe24.com/board_LVgu51/34541
http://toeden.co.kr/Product_new/141320
http://x-crew.center/guest/4846704
http://udrpsucks.com/blog/?p=1812
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=208024
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=410652
http://sfah.ch/de/component/k2/itemlist/user/15539
http://daltso.com/index.php?document_srl=124535&mid=board_cUYy21
http://blog.ptpintcast.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xhfs-%d1%80%d0%b0%d1%81/
http://myesl.ca/forum/viewtopic.php?t=695213
http://2872870.com/est/65004
http://lucky.kidspann.net/index.php?mid=qna&document_srl=374651
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3490901
http://153.120.114.241/eso/index.php/17537984-rasskaz-sluzanki-3-sezon-4-seria-rpua-rasskaz-sluzanki-3-sezon-
http://wigalseguros.com.br/index.php/component/k2/itemlist/user/37350
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1773964
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1774218
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1576012
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=129288
http://ovotecegg.com/component/k2/itemlist/user/231186
http://pkgersang.dothome.co.kr/board_jiKY24/35113
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=171138
http://kockazatkutato.hu/index.php/component/k2/itemlist/user/44734
https://adsensebih.com/index.php?topic=48596.0
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=589893
http://www.dap.com.py/index.php/es/?option=com_k2&view=itemlist&task=user&id=849966
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=194758
http://loverstory.co.kr/board_UYNJ05/47387
http://netsconsults.com/?option=com_k2&view=itemlist&task=user&id=829609
http://looksun.co.kr/index.php?mid=board_4&document_srl=186855
http://bobr.site/index.php?topic=185176.0
http://otitismediasociety.org/forum/index.php?topic=198463.0
https://altaylarteknoloji.com/index.php?topic=6229.0
http://looksun.co.kr/?document_srl=187494
http://rabat.kr/board_yCgT00/68934
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=437302
http://beautypouch.net/index.php?mid=board_09&document_srl=165521
http://dohairbiz.com/en/component/k2/itemlist/user/2816682.html
http://mjbosch.com/?option=com_k2&view=itemlist&task=user&id=85474
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=409555
http://mglpcm.org/board_ETkS12/182630
http://fbpharm.net/index.php/component/k2/itemlist/user/85638
https://betshin.com/Story/207843
http://thermoplast.envolgroupe.com/component/k2/author/191955
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3815102
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1770094
http://www.spazioad.com/component/k2/itemlist/user/7503996
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=126961
http://midorijapaneserestaurant.ca/menu/News/124949
http://midorijapaneserestaurant.ca/menu/News/125075
http://www.leekeonsu-csi.com/?document_srl=1308698
https://betshin.com/Story/255915
https://www.hwbms.com/web/?document_srl=85175
https://www.hwbms.com/web/qna/85150
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2832059
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=87601
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=87636
http://dohairbiz.com/en/component/k2/itemlist/user/2830605.html
https://reficulcoin.com/index.php?topic=83083.0
http://www.cswc.co.kr/index.php?mid=board_zyTs37&document_srl=32555
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=102936
http://e-educ.net/Forum/index.php?topic=17051.0
http://ajincomp.godohosting.com/board_STnh82/163590
http://www.svteck.co.kr/customer_gratitude/219973
http://engeena.com/component/k2/itemlist/user/9195
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=183769
http://themasters.pro/file_01/316686
https://gonggamlaw.com/lawcase/134223
http://loverstory.co.kr/?document_srl=105430
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=590590
http://77.93.38.205/index.php/component/k2/itemlist/user/652080
http://midorijapaneserestaurant.ca/menu/News/67769
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=372757
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=44347
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2784757
http://ko.myds.me/board_story/314852
https://www.lwfservers.com/index.php?topic=73803.0
http://yoriyorifood.com/xxxx/spacial/263653
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qtgk-%d1%80%d0%b0%d1%81/
https://gonggamlaw.com/lawcase/144236
http://askpharm.net/board_NQiz06/157350
https://gonggamlaw.com/lawcase/125881
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=56711
http://mediaville.me/index.php/component/k2/itemlist/user/399537
http://mediaville.me/index.php/component/k2/itemlist/user/399586
http://mediaville.me/index.php/component/k2/itemlist/user/399603
http://mediaville.me/index.php/component/k2/itemlist/user/399611
http://mobility-corp.com/index.php/component/k2/itemlist/user/2767598
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/186601
http://thermoplast.envolgroupe.com/component/k2/author/192197
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3587469
http://midorijapaneserestaurant.ca/menu/?document_srl=127244
http://midorijapaneserestaurant.ca/menu/News/127129
http://midorijapaneserestaurant.ca/menu/News/127169
https://betshin.com/Story/257715
http://www.m1avio.com/index.php/component/k2/itemlist/user/3838265
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3895080
http://www.tunes-interiors.com/UserProfile/tabid/81/userId/8716817/Default.aspx
http://herdental.co.kr/index.php?mid=online&document_srl=113339
http://xn--2e0b53df5ag1c804aphl.net/nuguna/190081
https://intelogist2.wpengine.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dpna-%d1%80%d0%b0%d1%81/
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/news/147443
http://constellation.kro.kr/board_kbku73/81289
http://dsyang.com/board_Kvgn62/46866
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=99483
https://www.lwfservers.com/index.php?topic=73846.0
http://kyj1225.godohosting.com/board_mebR72/98794
http://dessa.com.br/component/k2/itemlist/user/403534
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=56324
http://proxima.co.rw/index.php/component/k2/itemlist/user/733232
http://rudraautomation.com/index.php/component/k2/author/379478
http://thermoplast.envolgroupe.com/component/k2/author/192083
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1770084
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1570755
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=127146
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1310132
http://dayung.co.kr/board_SRVC17/88933
http://loverstory.co.kr/board_UYNJ05/109472
http://yoriyorifood.com/xxxx/spacial/331130
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2739013
http://www.hmotors.co.kr/inquiry/39133
http://rabat.kr/board_yCgT00/81272
http://8.droror.co.il/uncategorized/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xvlm-%d1%80%d0%b0%d1%81/
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-iyrg-%d1%80%d0%b0%d1%81/
http://moyakmermer.com/index.php/en/?option=com_k2&view=itemlist&task=user&id=848435
http://hanga5.com/index.php?mid=board_photo&document_srl=111578
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=1168231
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16593
https://betshin.com/Story/207323
http://apt2you2.cafe24.com/g1/53057
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=431956
http://hanga5.com/index.php?mid=board_photo&document_srl=112473
http://myesl.ca/forum/viewtopic.php?f=3&t=687988&view=print
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/345642
http://cwon.kr/xe/board_bnSr36/288549
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=30920
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=655394
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3798429
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=56537
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=56764
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3954814
http://mediaville.me/index.php/component/k2/itemlist/user/399864
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2767840
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=379860
http://rudraautomation.com/index.php/component/k2/author/380049
http://rudraautomation.com/index.php/component/k2/author/380069
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1571285
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=19167
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=19176
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=985133
http://erhu.eu/viewtopic.php?t=419392
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=361815
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=210246
http://p9912.cafe24.com/board_LVgu51/67364
http://www.vamoscontigo.org/Noticia/137464
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rjvg-%d1%80%d0%b0%d1%81/
http://loverstory.co.kr/board_UYNJ05/49383
https://nple.com/xe/pds/186358
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=36960
http://divespace.co.kr/board/279385
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=168277
https://betshin.com/Story/261453
https://www.hwbms.com/web/qna/91253
https://www.hwbms.com/web/qna/91276
http://www.m1avio.com/index.php/component/k2/itemlist/user/3883951
http://dev.aabn.org.gh/component/k2/itemlist/user/749521
http://esperanzazubieta.com/index.php/component/k2/itemlist/user/112302
http://kockazatkutato.hu/component/k2/itemlist/user/57477
http://mediaville.me/index.php/component/k2/itemlist/user/401527
http://mobility-corp.com/index.php/component/k2/itemlist/user/2768967
http://rudraautomation.com/index.php/component/k2/author/381047
http://rudraautomation.com/index.php/component/k2/author/381712
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=141781
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1573214
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=860493
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1316569
http://kotica00.dothome.co.kr/index.php?mid=board_nJTE45&document_srl=47757
http://www.grupojover.com/component/k2/itemlist/user/4433
https://cybergsm.es/index.php?topic=72635.0
https://betshin.com/Story/217576
http://legride.com/UserProfile/tabid/61/userId/2892888/Default.aspx
http://isch.kr/board_PowH60/156851
http://gabisan.com/board_OuDs04/103535
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1997816
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/75999
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1754516
http://0433.net/budongsan/115822
http://mobility-corp.com/index.php/component/k2/itemlist/user/2731094
http://rabbitzone.xyz/FREE/113821
http://dsyang.com/board_Kvgn62/42806
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=86370
http://viamania.net/index.php?document_srl=194643&mid=board_raYV15
http://robocit.com/index.php/component/k2/itemlist/user/449924
https://www.amazingworldtop.com/entretenimiento/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ax1%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f28-05/
http://blog.ptpintcast.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pvkh-%d1%80%d0%b0%d1%81/
http://0433.net/junggo/113923
http://naksansacondo.com/board_MGPu57/119395
http://naksansacondo.com/board_MGPu57/119528
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1249377
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1249739
https://betshin.com/Story/229789
https://betshin.com/Story/229925
https://gonggamlaw.com/lawcase/164908
https://gonggamlaw.com/lawcase/164954
https://www.celekt.com/%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-30-05-2019-i3-%d0%a1%d0%bb%d1%83%d0%b3%d0%b0/
https://www.celekt.com/%d0%a2%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-30-05-2019-y6-%d0%a2%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80/
https://www.celekt.com/%d0%a7%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-30-05-2019-q4-%d0%a7%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-5-%d1%81%d0%b5%d1%80/
https://www.hohoyoga.com/testboard/4102998
https://www.hohoyoga.com/testboard/4103077
http://agiteshop.com/xe/qa/176034
http://herdental.co.kr/?document_srl=167017
http://thermoplast.envolgroupe.com/component/k2/author/179498
https://gonggamlaw.com/lawcase/150956
http://guiadetudo.com/index.php/component/k2/itemlist/user/12618
http://mediaville.me/index.php/component/k2/itemlist/user/362562
http://smartacity.com/component/k2/itemlist/user/99210
http://ko.myds.me/board_story/281659
http://www.venusjeju.com/index.php?mid=QnA&document_srl=866
http://rabat.kr/board_yCgT00/81710
http://muldorang.com/market/28402
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=234391
http://yonseibaik.synology.me/index.php?mid=houston_profile&document_srl=75728
http://www.ekemoon.com/244961/052120190328/
http://naksansacondo.com/board_MGPu57/120966
http://naksansacondo.com/board_MGPu57/121022
http://naksansacondo.com/board_MGPu57/121079
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1252488
https://gonggamlaw.com/lawcase/165542
https://www.hohoyoga.com/testboard/4104094
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2815041
http://dcasociados.eu/component/k2/itemlist/user/95781
http://jdcalc.com/forum/viewtopic.php?t=290808
http://phmusic.dothome.co.kr/index.php?mid=PowerHouseMusic&document_srl=48752
http://midorijapaneserestaurant.ca/menu/News/77429
https://www.celekt.com/%d0%a4%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ua5w-%d0%a4%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7/
http://xn--2e0bk61btjo.com/notice/22697
http://mediaville.me/index.php/component/k2/itemlist/user/367739
http://kwpub.kr/PUBS/166502
http://herdental.co.kr/index.php?mid=online&document_srl=112941
http://apt2you2.cafe24.com/g1/52824
http://www.eunhaele.co.kr/xe/board/20528
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/165758
http://www.popolsku.fr.pl/forum/index.php?topic=416909.0
http://daltso.com/index.php?mid=board_cUYy21&document_srl=233489
https://adsensebih.com/index.php?topic=48198.0
http://xn----3x5er9r48j7wemud0a387h.com/news/276102
http://www.lgue.co.kr/?document_srl=169617
http://myrechockey.com/forums/index.php?topic=117846.0
https://www.2ayes.com/19613/3-1-pqka-3-1-ideafilm
http://kwpub.kr/PUBS/124449
http://ye-dream.com/qa/219883
http://herdental.co.kr/index.php?mid=online&document_srl=115072
http://www.aloeverasas.it/index.php/component/k2/itemlist/user/21488
http://zakdu.com/board_ssKi56/20140
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3572716
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1741841
http://smartacity.com/component/k2/itemlist/user/91198
https://blossomug.com/index.php/component/k2/itemlist/user/1112215
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=392502
http://www.patrasin.kr/index.php?mid=questions&document_srl=4346884
http://bebopindia.com/notcie/452740
http://taklongclub.com/forum/index.php?topic=202181.0
https://blossomug.com/index.php/component/k2/itemlist/user/1114926
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=210010
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=108621
http://rudraautomation.com/index.php/component/k2/author/331024
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=232186
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/33008
http://myrechockey.com/forums/index.php?topic=118526.0
https://www.netprofessional.gr/component/k2/itemlist/user/3958.html
http://www.cswc.co.kr/index.php?mid=board_zyTs37&document_srl=32191
http://roikjer.com/forum/index.php?PHPSESSID=u03fn1q0qmcv4qqud4t8csm673&topic=929572.0
http://music.start-a-idea.online/blogs/viewstory/43517
https://www.regalepadova.it/index.php/component/k2/itemlist/user/8284
https://betshin.com/Story/200144
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-svdn-%d1%80%d0%b0%d1%81/
https://nextezone.com/index.php?topic=77629.0
http://viamania.net/index.php?mid=board_raYV15&document_srl=156612
http://themasters.pro/file_01/311595
http://www.m1avio.com/index.php/component/k2/itemlist/user/3794900
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2004132
http://beautypouch.net/index.php?mid=board_09&document_srl=160986
https://cybergsm.es/index.php?topic=72588.0
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=655548
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=35747
http://gochon-iusell.co.kr/g1/95378
http://loverstory.co.kr/board_UYNJ05/101007
http://xn----c28e37psqau1bm6v53e05ac6b854f.com/news/90934
http://www.haetsaldun-clinic.co.kr/Question/37384
http://www.cnsmaker.net/xe/?document_srl=151347
http://iymc.or.kr/pds/125484
https://reficulcoin.com/index.php?topic=104930.0
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-slav-%d1%80%d0%b0%d1%81/
http://xn--2e0b53df5ag1c804aphl.net/nuguna/202980
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4935882
https://www.limscave.com/forum/viewtopic.php?t=58760
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=84150
http://netsconsults.com/index.php/component/k2/itemlist/user/847223
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1866048
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/148777
http://www.haetsaldun-clinic.co.kr/Question/43822
http://tiretech.co.kr/?document_srl=230796
https://www.hwbms.com/web/qna/15846
http://looksun.co.kr/index.php?mid=board_4&document_srl=188098
http://divespace.co.kr/board/227543
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=236623
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=184016
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=917863
http://ariji.kr/?document_srl=975568
http://research.kiu.ac.kr/index.php?document_srl=317445&mid=Food4Thought
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=655376
http://midorijapaneserestaurant.ca/menu/News/61288
http://loverstory.co.kr/board_UYNJ05/111676
http://looksun.co.kr/index.php?mid=board_4&document_srl=174548
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3403122
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dsml-%d1%80%d0%b0%d1%81/
http://midorijapaneserestaurant.ca/menu/News/67098
http://rudraautomation.com/index.php/component/k2/author/346114
https://cybergsm.es/index.php?topic=65391.0
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1868348
http://ovotecegg.com/component/k2/itemlist/user/227101
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/136991
http://kwpub.kr/PUBS/125944
http://naksansacondo.com/board_MGPu57/100239
http://thermoplast.envolgroupe.com/component/k2/author/176880
http://daesestudy.co.kr/ipsi_docu/118932
http://www.kcch.or.kr/index.php?mid=board_uFpk03&document_srl=92735
http://naksansacondo.com/board_MGPu57/75619
http://lucky.kidspann.net/index.php?mid=qna&document_srl=295594
http://xn--2e0b53df5ag1c804aphl.net/nuguna/110151
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=51474
http://www.eunhaele.co.kr/xe/QnA/21219
http://www.eunhaele.co.kr/xe/QnA/21224
https://forum.clubeicaro.pt/index.php?topic=3189.0
http://www.socintegra.lv/ru/component/k2/itemlist/user/44571
http://mvisage.sk/?option=com_k2&view=itemlist&task=user&id=120356
https://bcit-tmgt.com/viewtopic.php?t=56129
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/67938
http://www.eunhaele.co.kr/xe/QnA/21228
http://www.eunhaele.co.kr/xe/QnA/21233
http://www.eunhaele.co.kr/xe/QnA/21238
http://www.eunhaele.co.kr/xe/QnA/21243
https://forum.shaiyaslayer.tk/index.php?topic=192350.0
http://yonseibaik.synology.me/index.php?mid=houston_profile&document_srl=103343
http://hydrocarbs-gh.org/index.php/component/k2/itemlist/user/7524347
https://www.hohoyoga.com/testboard/3977640
http://mobility-corp.com/index.php/component/k2/itemlist/user/2729521
http://looksun.co.kr/index.php?mid=board_4&document_srl=200435
http://beautypouch.net/index.php?mid=board_09&document_srl=110147
https://gonggamlaw.com/lawcase/142644
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/65466
https://cybergsm.es/index.php?topic=72673.0
http://rabat.kr/board_yCgT00/84114
http://forum.bmw-e60.eu/index.php?topic=11310.0
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=aa4b6f1c89a123b53fd47f0ac0312832&topic=11116.0
https://www.chirorg.com/?document_srl=148042
http://www.itosm.com/cn/board_nLoq17/134942
http://gochon-iusell.co.kr/g1/77306
http://daesestudy.co.kr/ipsi_docu/119175
http://mercibq.net/partner/82532
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=231164
http://erdfsa.iptime.org/xe/index.php?mid=board&document_srl=12398
http://p9912.cafe24.com/board_LVgu51/53018
http://looksun.co.kr/index.php?mid=board_4&document_srl=204178
http://socialmag.bayareanonprofits.xyz/blogs/viewstory/130688
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=22681
http://myrechockey.com/forums/index.php?topic=118847.0
https://betshin.com/Story/204303
http://erdfsa.iptime.org/xe/index.php?mid=board&document_srl=12860
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2789641
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=232009
https://www.hwbms.com/web/qna/11099
https://betshin.com/Story/208718
http://rfc11th13th.dothome.co.kr/Board5/32528
https://forum.ac-jete.it/index.php?topic=451721.0
http://dsyang.com/board_Kvgn62/29833
http://roikjer.com/forum/index.php?PHPSESSID=o3786h4dbg86hmt0lb0ef25hp4&topic=932756.0
http://servicioswts.com/?option=com_k2&view=itemlist&task=user&id=3877346
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/news/145991
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=16750
http://naksansacondo.com/board_MGPu57/71044
http://xihillstate.bloggirl.net/?document_srl=400270
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=214151
http://kyj1225.godohosting.com/board_mebR72/97645
http://ye-dream.com/qa/226769
https://betshin.com/Story/203657
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1982636
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1151761
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=22915
http://benzmall.co.kr/index.php?mid=download&document_srl=45446
http://withinfp.sakura.ne.jp/eso/index.php/17528229-rasskaz-sluzanki-3-sezon-5-seria-bvdp-rasskaz-sluzanki-3-sezon-/0
https://blossomug.com/index.php/component/k2/itemlist/user/1111915
http://midorijapaneserestaurant.ca/menu/News/51448
http://www.yadanarbonnews.com/index.php/component/k2/itemlist/user/346391
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1734899
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=285171
http://myesl.ca/forum/viewtopic.php?t=695658
http://dreamplusart.com/mn03_01/172501
http://ilsannabgol.kr/board_brJk31/1373610
http://music.start-a-idea.online/blogs/viewstory/53305
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=76b69ba275551a782cd0a907806b4d30&topic=11214.0
http://archeaudio.com/xe/board_AOYj82/11327
http://iymc.or.kr/pds/117242
http://guiadetudo.com/index.php/component/k2/itemlist/user/12654
http://roikjer.com/forum/index.php?PHPSESSID=pm30vci6b0jdnkmvd0gobv4ed6&topic=931794.0
http://153.120.114.241/eso/index.php/17537784-rasskaz-sluzanki-3-sezon-5-seria-koih-rasskaz-sluzanki-3-sezon-
http://nnkumw.org/xe/index.php?mid=board_yNQm00&document_srl=139853
http://naksansacondo.com/board_MGPu57/32360
https://gonggamlaw.com/lawcase/132212
http://smartacity.com/component/k2/itemlist/user/89669
http://isch.kr/board_PowH60/155570
http://ovotecegg.com/component/k2/itemlist/user/226235
https://serverpia.co.kr/board_ucCk10/138882
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/83469
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1320724
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=228315
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/82874
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1539744
http://myrechockey.com/forums/index.php?topic=118789.0
http://benzmall.co.kr/index.php?mid=download&document_srl=98284
http://yoriyorifood.com/xxxx/spacial/253843
http://wigalseguros.com.br/index.php/component/k2/itemlist/user/29161
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gjwv-%d1%80%d0%b0%d1%81/
http://dsyang.com/board_Kvgn62/44452
http://naksansacondo.com/board_MGPu57/90041
http://benzmall.co.kr/index.php?mid=download&document_srl=107240
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/59496
http://loverstory.co.kr/board_UYNJ05/111180
http://bebopindia.com/notcie/504336
http://loverstory.co.kr/?document_srl=47039
http://www.urbantutorial.com/?option=com_k2&view=itemlist&task=user&id=127686
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16332
http://naksansacondo.com/board_MGPu57/85873
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=376494
http://e-educ.net/Forum/index.php?topic=16969.0
http://wartoby.com/index.php?mid=board_UXUA38&document_srl=95457
http://rabbitzone.xyz/FREE/105750
http://k-cea.org/?document_srl=245565
http://loverstory.co.kr/board_UYNJ05/81464
http://loverstory.co.kr/board_UYNJ05/103842
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=38353
http://dreamplusart.com/mn03_01/237425
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2603730
https://betshin.com/Story/205258
http://erhu.eu/viewtopic.php?t=398028
http://dreamplusart.com/mn03_01/124134
http://hotelnomadpalace.com/es/?option=com_k2&view=itemlist&task=user&id=22641
http://sy.korean.net/qna/318938
http://fbpharm.net/index.php/component/k2/itemlist/user/88275
http://mediaville.me/index.php/component/k2/itemlist/user/364505
http://kyj1225.godohosting.com/board_mebR72/93505
http://udrpsucks.com/blog/?p=1801
https://www.hwbms.com/web/qna/23060
https://forum.clubeicaro.pt/index.php?topic=2779.0
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=416858
http://www2.yasothon.go.th/smf/index.php?topic=159.msg199733
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=179042
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/336313
http://carand.co.kr/d2/97186
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=558194
https://intelogist2.wpengine.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-te2y-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81/
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1997973
http://www.socintegra.lv/index.php/component/k2/itemlist/user/44489
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=593943
http://www.lgue.co.kr/?document_srl=113848
http://proxima.co.rw/index.php/component/k2/itemlist/user/717665
http://www.ekemoon.com/253149/060720191101/
http://www.ekemoon.com/253153/060720191301/
http://www.ekemoon.com/253165/060720191401/
http://www.ekemoon.com/253177/060720191601/
https://intelogist2.wpengine.com/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-br0l-%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3/
https://intelogist2.wpengine.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qb4u-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81/
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ql2u-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xw4h-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bd7x-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qi2w-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8/
https://intelogist2.wpengine.com/%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zs8v-%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://netsconsults.com/index.php/component/k2/itemlist/user/858070
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=61962
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3963062
http://mobility-corp.com/?option=com_k2&view=itemlist&task=user&id=2779093
http://mobility-corp.com/index.php/component/k2/itemlist/user/2779106
http://mobility-corp.com/index.php/component/k2/itemlist/user/2779109
http://mobility-corp.com/index.php/component/k2/itemlist/user/2779232
http://agiteshop.com/xe/qa/189181
http://midorijapaneserestaurant.ca/menu/News/57365
http://jjimdak.callbank.kr/index.php?mid=board_OGFN30&document_srl=1120736
http://ko.myds.me/?document_srl=276566
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=425986
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3749829
http://www.hmotors.co.kr/inquiry/69157
http://dessa.com.br/component/k2/itemlist/user/386114
https://www.limscave.com/forum/viewtopic.php?t=55681
http://netsconsults.com/index.php/component/k2/itemlist/user/859578
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4983875
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/67623
http://hotelnomadpalace.com/component/k2/itemlist/user/23940
https://intelogist2.wpengine.com/%d0%ba%d0%be%d0%bf-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cu3k-%d0%ba%d0%be%d0%bf-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://intelogist2.wpengine.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rg7m-%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81/
https://intelogist2.wpengine.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vq0w-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-20-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mi8u-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-20/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dc0t-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6/
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1408528
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1408648
https://betshin.com/Story/282687
https://betshin.com/Story/282710
https://www.hohoyoga.com/testboard/4163692
https://www.hwbms.com/web/qna/119389
http://www2.yasothon.go.th/smf/index.php?topic=159.175710
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-2/
http://dohairbiz.com/en/component/k2/itemlist/user/2836728.html
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1353596
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=62091
http://mediaville.me/index.php/component/k2/itemlist/user/411542
http://mediaville.me/index.php/component/k2/itemlist/user/411550
https://forum.clubeicaro.pt/index.php?topic=3174.0
http://hotelnomadpalace.com/component/k2/itemlist/user/24069
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/60660
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/60661
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=111549
http://cwon.kr/xe/board_bnSr36/305856
http://divespace.co.kr/board/294702
http://neosky.net/xe/?document_srl=137616
http://wartoby.com/index.php?mid=board_UXUA38&document_srl=127703
https://adsensebih.com/index.php?topic=45713.0
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3858598
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=49992
http://autospa.lv/index.php/lv/component/k2/itemlist/user/10582
http://www.hmotors.co.kr/inquiry/58196
http://www.yadanarbonnews.com/index.php/component/k2/itemlist/user/330571
https://www.celekt.com/%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-oz1%d0%a1%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=225339
http://e-educ.net/Forum/index.php?topic=16596.0
https://gonggamlaw.com/lawcase/72645
https://betshin.com/Story/249879
https://gonggamlaw.com/lawcase/186762
https://gonggamlaw.com/lawcase/186779
https://gonggamlaw.com/lawcase/186798
https://www.hohoyoga.com/testboard/4125837
http://midorijapaneserestaurant.ca/menu/?document_srl=114271
http://viamania.net/index.php?mid=board_raYV15&document_srl=189884
http://mediaville.me/index.php/component/k2/itemlist/user/378834
http://roikjer.com/forum/index.php?PHPSESSID=hipcp33fv8rfpl5fi5rlrn7l84&topic=931980.0
http://www.ekemoon.com/247191/050220190130/
http://looksun.co.kr/index.php?mid=board_4&document_srl=183813
http://carand.co.kr/d2/96682
http://withinfp.sakura.ne.jp/eso/index.php/17573296-rasskaz-sluzanki-3-sezon-7-seria-lcin-rasskaz-sluzanki-3-sezon-/0
http://www.digitalbul.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-peze-%d1%80%d0%b0%d1%81/
http://forum.bmw-e60.eu/index.php?topic=11337.0
http://jdcalc.com/forum/viewtopic.php?t=288054
http://gabisan.com/board_OuDs04/74463
http://apt2you2.cafe24.com/g1/35171
http://sofficer.net/xe/teach/286040
http://www.m1avio.com/index.php/component/k2/itemlist/user/3797056
http://gspara01.dothome.co.kr/index.php?mid=board_XHsr53&document_srl=14257
http://dsyang.com/board_Kvgn62/42289
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2002098
http://tiretech.co.kr/index.php?mid=qna&document_srl=187119
http://sofficer.net/xe/teach/284535
https://www.lwfservers.com/index.php?topic=75788.0
http://dsyang.com/board_Kvgn62/30433
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=189002
http://benzmall.co.kr/?document_srl=97053
http://udrpsucks.com/blog/?p=1854
http://praisesound.co.kr/sub04_01/88830
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=133080
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=408585
http://apt2you2.cafe24.com/g1/56816
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=277011
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/41849
http://beautypouch.net/index.php?mid=board_09&document_srl=135535
http://apt2you2.cafe24.com/g1/46171
http://roikjer.com/forum/index.php?PHPSESSID=evobn2hjkdrvt84re3gtdklsc2&topic=931604.0
http://www.livetank.cn/market1/240319
http://tiretech.co.kr/index.php?mid=qna&document_srl=258356
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4901996
http://www.kcch.or.kr/index.php?mid=board_uFpk03&document_srl=103049
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1272368
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1272618
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1879723
https://blossomug.com/index.php/component/k2/itemlist/user/1131611
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4963815
http://www.emrabq8.com/index.php/component/k2/itemlist/user/1879736
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2664759
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=23360
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7542545
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1879555
http://www.spazioad.com/component/k2/itemlist/user/7490217
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/60010
http://udrpsucks.com/blog/?p=1965
http://udrpsucks.com/blog/?p=1966
http://udrpsucks.com/blog/?p=1967
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/346805
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/168940
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/59227
http://carand.co.kr/d2/91717
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=93931
http://www.ds712.net/guest/index.php?mid=guest07&document_srl=714418
http://xn--2e0b53df5ag1c804aphl.net/nuguna/102944
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2005363
http://ahudseafood.com/?option=com_k2&view=itemlist&task=user&id=10135
http://forum.bmw-e60.eu/index.php?topic=11306.0
http://mobility-corp.com/index.php/component/k2/itemlist/user/2743703
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/169075
https://blossomug.com/index.php/component/k2/itemlist/user/1111775
http://mobility-corp.com/index.php/component/k2/itemlist/user/2739208
http://rabat.kr/board_yCgT00/42196
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=41244.0
http://themasters.pro/file_01/306885
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1151796
http://hanga5.com/index.php?mid=board_photo&document_srl=155725
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=420321
https://altaylarteknoloji.com/index.php?topic=6351.0
http://sy.korean.net/qna/517920
http://otitismediasociety.org/forum/index.php?topic=206942.0
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=273170
http://mglpcm.org/board_ETkS12/189621
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=29702
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=99647
http://loverstory.co.kr/board_UYNJ05/45222
http://rfc11th13th.dothome.co.kr/Board5/31614
https://forums.lfstats.com/viewtopic.php?t=320978
http://www.hmotors.co.kr/inquiry/68850
http://proxima.co.rw/index.php/component/k2/itemlist/user/716380
http://www.eunhaele.co.kr/xe/board/20591
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3926007
http://khapthanam.co.kr/g1/134584
https://forum.clubeicaro.pt/index.php?topic=2714.0
http://backo.co.kr/board_aiQk58/20655
http://withinfp.sakura.ne.jp/eso/index.php/17575879-rasskaz-sluzanki-3-sezon-4-seria-vrse-rasskaz-sluzanki-3-sezon-/0
http://thermoplast.envolgroupe.com/component/k2/author/157278
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=29858
http://www.vamoscontigo.org/Noticia/220581
https://www.c-alice.org/forum/index.php?topic=95346.0
http://kwpub.kr/PUBS/171130
http://cwon.kr/xe/board_bnSr36/292968
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=29344
https://khuyenmaikk13.info/index.php?topic=229741.0
http://vtservices85.fr/smf2/index.php?PHPSESSID=e9bf4a6dce5328c9d2f4566c4effc332&topic=297716.0
http://roikjer.com/forum/index.php?PHPSESSID=srt5rl2jsbt4htmoj2e6gsc4o3&topic=931366.0
http://www.dap.com.py/index.php/component/k2/itemlist/user/851341
http://www.arunagreen.com/index.php/component/k2/itemlist/user/1156890
http://benzmall.co.kr/index.php?mid=download&document_srl=93816
http://daltso.com/index.php?mid=board_cUYy21&document_srl=210124
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=27817
http://hanga5.com/index.php?mid=board_photo&document_srl=112758
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/305890
http://thermoplast.envolgroupe.com/component/k2/author/178658
http://bebopindia.com/notcie/506246
http://neosky.net/xe/space_station/67470
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=244253
http://www.teedinubon.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yu4%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://bobr.site/index.php?topic=185208.0
http://viamania.net/index.php?mid=board_raYV15&document_srl=183086
http://azone.synology.me/xe/index.php?mid=board_SDnQ73&document_srl=224062
http://bath-family.com/photo_zone/128912
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=271762
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1935409
https://turimex.mx.solemti.net/en/?option=com_k2&view=itemlist&task=user&id=18997
https://gonggamlaw.com/lawcase/68767
http://ko.myds.me/board_story/277269
https://gonggamlaw.com/lawcase/80231
http://rudraautomation.com/index.php/component/k2/author/341651
https://www.c-alice.org/forum/index.php?topic=99070.0
https://esel.gist.ac.kr/esel2/board_hmgj23/367184
http://music.start-a-idea.online/blogs/viewstory/45171
http://zakdu.com/board_YpzS56/22711
http://gusinoepero.ru/archives/26369
http://mediaville.me/index.php/component/k2/itemlist/user/364593
http://kwpub.kr/PUBS/163228
https://www.amazingworldtop.com/entretenimiento/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yv6%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be/
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=567266
https://www.2ayes.com/19570/3-5-zweh-3-5-amedia
http://daltso.com/index.php?mid=board_cUYy21&document_srl=203785
http://toeden.co.kr/Product_new/223218
http://jnk-ent.jp/index.php?mid=gallery&document_srl=238540
https://www.hohoyoga.com/testboard/4058318
http://hanga5.com/index.php?mid=board_photo&document_srl=112282
http://soc-human.kz/?option=com_k2&view=itemlist&task=user&id=1753820
http://rudraautomation.com/index.php/component/k2/author/335047
http://dreamplusart.com/mn03_01/120449
http://looksun.co.kr/index.php?mid=board_4&document_srl=202482
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=49664
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=99930
https://www.celekt.com/%d0%a4%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bx1%d0%a4%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5/
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vv1%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be/
http://mobility-corp.com/index.php/component/k2/itemlist/user/2744465
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1168865
http://thermoplast.envolgroupe.com/component/k2/author/181525
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/70711
http://necinsurance.co.zw/component/k2/itemlist/user/21680.html
http://holysweat.dothome.co.kr/data/6597
http://erdfsa.iptime.org/xe/index.php?mid=board&document_srl=13408
http://euromouleusinage.com/index.php/component/k2/itemlist/user/192830
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=58a5d732ce87c74f4944d2afc4674647&topic=11080.0
http://dcasociados.eu/component/k2/itemlist/user/94413
http://smartacity.com/component/k2/itemlist/user/78864
http://smartacity.com/component/k2/itemlist/user/98445
https://nple.com/xe/?document_srl=240498
https://www.hwbms.com/web/qna/38913
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=113129
http://ovotecegg.com/component/k2/itemlist/user/244685
http://ovotecegg.com/component/k2/itemlist/user/244703
http://ovotecegg.com/component/k2/itemlist/user/244712
http://rudraautomation.com/index.php/component/k2/author/382440
http://rudraautomation.com/index.php/component/k2/author/382475
http://rudraautomation.com/index.php/component/k2/author/382498
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=142036
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=36443
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1573935
http://www.dap.com.py/index.php/es/?option=com_k2&view=itemlist&task=user&id=860641
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=128263
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=128272
https://www.swiss-focus.ch/index.php/component/k2/itemlist/user/41534
http://midorijapaneserestaurant.ca/menu/News/134783
http://midorijapaneserestaurant.ca/menu/News/134853
http://gallerychoi.com/Exhibition/335562
http://dayung.co.kr/board_SRVC17/68549
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=206210
http://rabat.kr/board_yCgT00/82705
http://cwon.kr/xe/board_bnSr36/310811
http://dsyang.com/board_Kvgn62/30804
https://betshin.com/Story/203138
http://www.vamoscontigo.org/Noticia/139620
http://xn--2e0bk61btjo.com/notice/21303
http://taklongclub.com/forum/index.php?topic=197479.0
http://www.livetank.cn/market1/337488
http://www.ekemoon.com/245873/050620191329/
http://midorijapaneserestaurant.ca/menu/News/73281
https://www.amazingworldtop.com/entretenimiento/%d0%ba%d0%be%d0%bf-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tm0%d0%ba%d0%be%d0%bf-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f28-05-2019/
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=550048
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=48282
http://zakdu.com/board_YpzS56/15411
http://www.popolsku.fr.pl/forum/index.php?topic=416017.0
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=5058895
http://www.itosm.com/cn/board_nLoq17/132540
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/169616
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ol9l-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://hanga5.com/index.php?mid=board_photo&document_srl=110551
http://shinhwaair2017.cafe24.com/issue/471052
http://neosky.net/xe/?document_srl=116521
http://kockazatkutato.hu/index.php/component/k2/itemlist/user/47201
http://www.dap.com.py/index.php/es/?option=com_k2&view=itemlist&task=user&id=860963
http://www.dap.com.py/index.php/es/?option=com_k2&view=itemlist&task=user&id=861058
http://www.pdctransport.co.th/index.php/component/k2/itemlist/user/19211
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=24184
http://midorijapaneserestaurant.ca/menu/News/138615
http://midorijapaneserestaurant.ca/menu/News/138753
http://www.leekeonsu-csi.com/index.php?document_srl=1330293&mid=community7
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1330392
http://esperanzazubieta.com/index.php/component/k2/itemlist/user/109157
http://dayung.co.kr/board_SRVC17/68940
http://dsyang.com/board_Kvgn62/46227
http://mglpcm.org/board_ETkS12/166291
http://www.ekemoon.com/259355/061320190602/
http://www.ekemoon.com/259357/061320190702/
http://www.ekemoon.com/259359/061320190802/
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rq9w-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-10-%d1%81%d0%b5%d1%80%d0%b8/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ag2g-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gh4j-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qn8x-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-21/
http://www.emrabq8.com/index.php/component/k2/itemlist/user/1892187
http://www.quattroandpartners.it/component/k2/itemlist/user/1295995
https://intelogist2.wpengine.com/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vn9d-%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3/
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kd3l-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
https://intelogist2.wpengine.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-oy0x-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://betshin.com/Story/275708
https://betshin.com/Story/275717
https://gonggamlaw.com/lawcase/214452
https://www.hwbms.com/web/qna/111384
https://www.hwbms.com/web/qna/111462
http://midorijapaneserestaurant.ca/menu/News/158289
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1386641
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1386825
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uscv-%d1%80%d0%b0%d1%81/
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=105826
https://esel.gist.ac.kr/esel2/board_hmgj23/274287
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1869037
http://daltso.com/index.php?mid=board_cUYy21&document_srl=208595
http://lucky.kidspann.net/index.php?mid=qna&document_srl=290243
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=125323
http://beautypouch.net/index.php?mid=board_09&document_srl=170710
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2780124
http://ko.myds.me/?document_srl=297899
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/353490
http://www.vamoscontigo.org/Noticia/206028
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=370989
http://carand.co.kr/d2/94975
http://bobr.site/index.php?topic=189464.0
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1738764
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=218649
http://fbpharm.net/?option=com_k2&view=itemlist&task=user&id=88581
http://cwon.kr/xe/board_bnSr36/292282
http://daltso.com/index.php?mid=board_cUYy21&document_srl=199649
http://toeden.co.kr/Product_new/139045
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16200
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=23640
http://daltso.com/index.php?mid=board_cUYy21&document_srl=234942
https://forums.lfstats.com/viewtopic.php?t=319276
http://d-tube.info/board_jvyO69/369046
http://loverstory.co.kr/board_UYNJ05/83674
http://2872870.com/est/70914
http://hotelnomadpalace.com/es/?option=com_k2&view=itemlist&task=user&id=22630
http://1661-6471.co.kr/news/44480
http://kyj1225.godohosting.com/board_mebR72/77585
https://mcsetup.tk/bbs/index.php?topic=261681.0
http://midorijapaneserestaurant.ca/menu/News/76521
http://lucky.kidspann.net/index.php?mid=qna&document_srl=348657
https://intelogist2.wpengine.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-uq0w-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=380977
https://gonggamlaw.com/lawcase/147530
https://esel.gist.ac.kr/esel2/board_hmgj23/268231
http://bath-family.com/photo_zone/128768
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=43828
http://xn----3x5er9r48j7wemud0a387h.com/news/243117
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3938445
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=30512
http://midorijapaneserestaurant.ca/menu/News/70000
http://cwon.kr/xe/board_bnSr36/314858
http://hyeonjun.co.kr/menu3/287940
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1851995
http://mglpcm.org/?document_srl=172536
https://esel.gist.ac.kr/esel2/board_hmgj23/266499
http://yoriyorifood.com/xxxx/spacial/253563
http://mediaville.me/index.php/component/k2/itemlist/user/379440
http://mglpcm.org/board_ETkS12/164133
https://www.hwbms.com/web/qna/11217
http://daltso.com/index.php?mid=board_cUYy21&document_srl=123855
http://looksun.co.kr/index.php?mid=board_4&document_srl=203357
http://looksun.co.kr/index.php?mid=board_4&document_srl=200611
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1151507
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3863997
http://www.ekemoon.com/245097/052220190628/
http://mahdi.ehosseini.com/?option=com_k2&view=itemlist&task=user&id=44981
http://cwon.kr/xe/board_bnSr36/284367
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=446450
http://p9912.cafe24.com/board_LVgu51/68853
http://www.siirtorganik.com/index.php/component/k2/itemlist/user/958273
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xx8y-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7/
http://www.itosm.com/cn/board_nLoq17/136078
http://sejong-thesharpyemizi.co.kr/m1/107408
https://gonggamlaw.com/lawcase/145421
http://benzmall.co.kr/index.php?mid=download&document_srl=115212
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=402632
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=26101
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/166997
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.net/index.php?mid=news&document_srl=183348
http://gabisan.com/board_OuDs04/71706
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=224047
http://married.dike.gr/index.php/component/k2/itemlist/user/78028
http://naksansacondo.com/board_MGPu57/36437
http://k-cea.org/board_Hnyj62/193377
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=204601
http://udrpsucks.com/blog/?p=1753
http://rudraautomation.com/index.php/component/k2/author/345496
http://divespace.co.kr/board/265986
http://sofficer.net/xe/teach/278320
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1315495
http://www.sp1.football/?document_srl=694374
http://www.quattroandpartners.it/component/k2/itemlist/user/1212708
http://xn--2e0b53df5ag1c804aphl.net/nuguna/196936
http://guiadetudo.com/index.php/component/k2/itemlist/user/12721
http://praisesound.co.kr/sub04_01/88283
http://www.svteck.co.kr/customer_gratitude/271544
http://gochon-iusell.co.kr/g1/109534
https://www.regalepadova.it/index.php/component/k2/itemlist/user/8251
http://melchinooddle.dothome.co.kr/?document_srl=16408
http://dospuntoseventos.cl/component/k2/itemlist/user/16407
http://kino-z.eu/?option=com_k2&view=itemlist&task=user&id=2495
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=204273
http://yonseibaik.synology.me/index.php?mid=houston_profile&document_srl=84310
http://www.yadanarbonnews.com/index.php/component/k2/itemlist/user/355427
http://www.jesusonly.life/calendar/445111
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=134820
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=228816
http://www.itosm.com/cn/board_nLoq17/192523
http://mercibq.net/partner/55718
http://kyj1225.godohosting.com/board_mebR72/94085
http://tiretech.co.kr/index.php?mid=qna&document_srl=235535
http://music.start-a-idea.online/blogs/viewstory/47863
http://www.vamoscontigo.org/Noticia/206830
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/?document_srl=80781
http://smartacity.com/component/k2/itemlist/user/96770
http://k-cea.org/board_Hnyj62/194062
http://www.patrasin.kr/index.php?mid=questions&document_srl=4361026
http://gabisan.com/board_OuDs04/71110
http://naksansacondo.com/board_MGPu57/86086
https://mcsetup.tk/bbs/index.php?topic=261700.0
http://netsconsults.com/?option=com_k2&view=itemlist&task=user&id=839626
http://www.vamoscontigo.org/Noticia/139625
http://dcasociados.eu/component/k2/itemlist/user/94839
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1076704
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/848216
http://xn----3x5er9r48j7wemud0a387h.com/news/248465
http://www.dap.com.py/index.php/es/?option=com_k2&view=itemlist&task=user&id=850819
http://gabisan.com/board_OuDs04/121923
https://adsensebih.com/index.php?topic=45118.0
http://dreamplusart.com/mn03_01/210931
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=78597
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=395717
https://forum.ac-jete.it/index.php?topic=441637.0
http://www.ekemoon.com/245327/050020192029/
http://erhu.eu/viewtopic.php?t=395416
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=409744
https://gonggamlaw.com/lawcase/147450
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1169445
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ifsk-%d1%80%d0%b0%d1%81/
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/59623
http://praisesound.co.kr/sub04_01/87427
https://betshin.com/Story/206130
http://askpharm.net/board_NQiz06/209012
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1724218
http://gallerychoi.com/Exhibition/334965
http://engeena.com/component/k2/itemlist/user/9163
http://www.spazioad.com/component/k2/itemlist/user/7416199
http://ucckorea.kr/index.php?mid=board_AuHE49&document_srl=78517
https://www.hwbms.com/web/qna/12338
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/77686
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=63492
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/338214
http://sd-xi.co.kr/g1/51354
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/246737
http://www.popolsku.fr.pl/forum/index.php?topic=20407.80745
http://erhu.eu/viewtopic.php?f=7&t=393138&view=print
http://www.aloeverasas.it/index.php/component/k2/itemlist/user/21426
http://loverstory.co.kr/?document_srl=100867
http://naksansacondo.com/board_MGPu57/96321
http://looksun.co.kr/index.php?mid=board_4&document_srl=126518
http://gusinoepero.ru/archives/26170
http://cwon.kr/xe/board_bnSr36/302043
http://healthyteethpa.org/component/k2/itemlist/user/5545639
http://benzmall.co.kr/index.php?mid=download&document_srl=45454
http://xn--2e0b53df5ag1c804aphl.net/nuguna/106638
http://gochon-iusell.co.kr/g1/74677
http://daesestudy.co.kr/ipsi_docu/121258
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-orxb-%d1%80%d0%b0%d1%81/
https://adsensebih.com/index.php?topic=48700.0
http://www.popolsku.fr.pl/forum/index.php?topic=417118.0
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/155168
http://khapthanam.co.kr/g1/153899
http://warmfund.net/p/index.php?mid=financing&document_srl=472828
http://e-educ.net/Forum/index.php?topic=16361.0
http://dreamplusart.com/mn03_01/117474
http://gochon-iusell.co.kr/g1/76136
http://www.theocraticamerica.org/forum/index.php?topic=70626.0
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=84280
http://sofficer.net/xe/teach/288334
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/brand/70054
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=36430
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/59478
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=399406
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=230814
http://divespace.co.kr/board/258796
https://reficulcoin.com/index.php?topic=85658.0
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1871708
http://midorijapaneserestaurant.ca/menu/News/42308
http://muldorang.com/market/27310
http://mglpcm.org/?document_srl=124746
http://www.hmotors.co.kr/inquiry/45984
http://dsyang.com/board_Kvgn62/45708
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3790736
http://ptu.imoove.kr/ko/content/%C2%AB%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-7-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-ngkj-%C2%AB%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-7-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-hulu341126
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=917413
https://timecker.com/anonymous/188810
http://tiretech.co.kr/?document_srl=180669
https://nple.com/xe/pds/240529
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=47858
https://reficulcoin.com/index.php?topic=88848.0
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/346948
http://barobus.kr/qna/92881
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=27841
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3374440
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=957498
http://dsyang.com/board_Kvgn62/30881
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=5c29c82945c15e55584c2a2bed4c359b&topic=10829.0
https://www.celekt.com/%d0%96%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fh2%d0%96%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f28-05/
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=955511
http://d-tube.info/board_jvyO69/370403
http://mediaville.me/index.php/component/k2/itemlist/user/375369
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=947984
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=149696
http://dospuntoseventos.cl/index.php/component/k2/itemlist/user/16902
http://bizchemical.com/board_kMpv94/2160355
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=260577
http://lucky.kidspann.net/index.php?mid=qna&document_srl=353489
http://beautypouch.net/index.php?mid=board_09&document_srl=166738
http://dreamplusart.com/mn03_01/120154
http://www.quattroandpartners.it/component/k2/itemlist/user/1214850
http://warmfund.net/p/index.php?mid=financing&document_srl=470447
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=388455
http://midorijapaneserestaurant.ca/menu/News/46822
http://dsyang.com/board_Kvgn62/43163
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=559046
http://xn--2e0b53df5ag1c804aphl.net/nuguna/180912
http://beautypouch.net/index.php?mid=board_09&document_srl=161681
https://www.celekt.com/%d0%92%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ev3%d0%92%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be/
http://bath-family.com/photo_zone/135520
https://www.hohoyoga.com/testboard/3973865
https://forums.lfstats.com/viewtopic.php?f=6&t=321762&view=print
http://apt2you2.cafe24.com/g1/38111
https://gonggamlaw.com/lawcase/143690
http://askpharm.net/board_NQiz06/249281
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/167474
http://dreamplusart.com/mn03_01/124126
http://ye-dream.com/qa/206452
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=301069
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=532054
http://muldorang.com/market/28387
http://kyj1225.godohosting.com/board_mebR72/99795
http://looksun.co.kr/index.php?mid=board_4&document_srl=183237
http://hotelnomadpalace.com/component/k2/itemlist/user/22648
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=215351
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=415122
https://blossomug.com/index.php/component/k2/itemlist/user/1115246
http://smartacity.com/component/k2/itemlist/user/95567
http://yourhelp.co.kr/?document_srl=110361
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/137219
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=209976
https://www.hwbms.com/web/qna/37746
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16569
http://www.ekemoon.com/244877/052020191628/
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=108377
http://d-tube.info/board_jvyO69/368442
http://vervetama.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zkds-%d1%80%d0%b0%d1%81/
http://benzmall.co.kr/index.php?mid=download&document_srl=107467
http://taklongclub.com/forum/index.php?topic=205688.0
http://www.ekemoon.com/245457/050120194929/
http://zakdu.com/board_YpzS56/24886
https://blossomug.com/index.php/component/k2/itemlist/user/1112950
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=29669
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=258917
http://ovotecegg.com/component/k2/itemlist/user/221541
http://miquirofisico.com/index.php/component/k2/itemlist/user/4501
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=29863
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=128128
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=128130
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3526693
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=23790
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3884872
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=41599
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=41618
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=41622
http://www.dap.com.py/index.php/component/k2/itemlist/user/860720
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%84%d0%b8%d1%82%d0%bd-3/
http://midorijapaneserestaurant.ca/menu/?document_srl=135172
http://midorijapaneserestaurant.ca/menu/News/135076
http://midorijapaneserestaurant.ca/menu/News/135111
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=435439
http://www.cnsmaker.net/xe/?document_srl=125053
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=187687
http://1661-6471.co.kr/news/47481
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=82783
http://kyj1225.godohosting.com/?document_srl=94507
http://naksansacondo.com/board_MGPu57/74869
https://2002.shyoon.com/board_2002/211179
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=229544
http://mediaville.me/index.php/component/k2/itemlist/user/367726
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=399635
https://gonggamlaw.com/lawcase/146674
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/370301
http://erhu.eu/viewtopic.php?f=7&t=396257&view=print
http://kyj1225.godohosting.com/board_mebR72/99938
https://www.hwbms.com/web/qna/44693
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=36582
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=36735
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=987236
https://www.swiss-focus.ch/index.php/component/k2/itemlist/user/41716
http://proxima.co.rw/?option=com_k2&view=itemlist&task=user&id=735385
http://www.m1avio.com/index.php/component/k2/itemlist/user/3885883
http://www2.yasothon.go.th/smf/index.php?topic=159.174405
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=330367
http://dreamplusart.com/mn03_01/120144
http://xn--2e0bk61btjo.com/notice/24078
http://music.start-a-idea.online/blogs/viewstory/43678
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=317200
http://ovotecegg.com/?option=com_k2&view=itemlist&task=user&id=226353
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/245908
http://gabisan.com/board_OuDs04/110280
http://myrechockey.com/forums/index.php?topic=118388.0
http://www.artangel.co.kr/index.php?mid=Activities&document_srl=163989
http://w9builders.co.uk/index.php/component/k2/itemlist/user/142249
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=36660
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1574544
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3527081
http://www2.yasothon.go.th/smf/index.php?topic=159.msg203612
http://midorijapaneserestaurant.ca/menu/News/136248
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2835849
http://dev.aabn.org.gh/component/k2/itemlist/user/751343
http://dev.aabn.org.gh/component/k2/itemlist/user/751381
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2019683
http://mahdi.ehosseini.com/?option=com_k2&view=itemlist&task=user&id=51597
http://mediaville.me/index.php/component/k2/itemlist/user/402862
http://mobility-corp.com/index.php/component/k2/itemlist/user/2770488
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/187747
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3449878
http://xn--2e0b53df5ag1c804aphl.net/nuguna/102766
https://www.hohoyoga.com/testboard/4052970
http://kwpub.kr/PUBS/130066
http://cwon.kr/xe/board_bnSr36/291553
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=439047
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/brand/70073
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/33833
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=173150
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=306775
http://smartacity.com/component/k2/itemlist/user/95682
http://www.theocraticamerica.org/forum/index.php?topic=73879.0
https://cfcestradareal.com.br/index.php/component/k2/itemlist/user/80949
http://mobility-corp.com/index.php/component/k2/itemlist/user/2699915
https://forum.ac-jete.it/index.php?topic=432984.0
https://forum.ac-jete.it/index.php?topic=441002.0
http://iymc.or.kr/pds/113823
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fg7i-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://moyakmermer.com/index.php/component/k2/itemlist/user/846881
http://holysweat.dothome.co.kr/data/7605
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=113345
http://zsmr.com.ua/?option=com_k2&view=itemlist&task=user&id=652873
http://daltso.com/index.php?mid=board_cUYy21&document_srl=208914
http://www.urbantutorial.com/?option=com_k2&view=itemlist&task=user&id=127798
http://bizchemical.com/board_kMpv94/2161175
http://divespace.co.kr/board/294359
http://askpharm.net/board_NQiz06/250533
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4934145
http://www.hmotors.co.kr/inquiry/26253
http://kotica00.dothome.co.kr/index.php?mid=board_nJTE45&document_srl=40370
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/388451
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jt0l-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19/
http://smartacity.com/component/k2/itemlist/user/90603
http://xn--2e0bk61btjo.com/notice/23580
http://blog.ptpintcast.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sdzg-%d1%80%d0%b0%d1%81/
http://myesl.ca/forum/viewtopic.php?t=694596
https://www.lwfservers.com/index.php?topic=72968.0
http://zakdu.com/board_YpzS56/29022
http://benzmall.co.kr/index.php?mid=download&document_srl=114162
http://photogrotto.com/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-cm8a-%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3/
http://www.m1avio.com/index.php/component/k2/itemlist/user/3797165
http://ye-dream.com/qa/205136
http://loverstory.co.kr/board_UYNJ05/117722
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=224255
http://www.spazioad.com/component/k2/itemlist/user/7473901
http://www.alase.net/index.php/component/k2/itemlist/user/12626
http://loverstory.co.kr/board_UYNJ05/101710
http://yoriyorifood.com/xxxx/spacial/328077
http://x-crew.center/guest/4846556
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16629
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/330443
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8d%d1%84%d0%b8%d1%80-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%84%d0%b8%d1%82%d0%bd/
http://dcasociados.eu/component/k2/itemlist/user/95550
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2015510
http://mobility-corp.com/index.php/component/k2/itemlist/user/2754724
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1760531
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=116564
http://www.venusjeju.com/index.php?mid=QnA&document_srl=1184
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=206217
http://www2.yasothon.go.th/smf/index.php?topic=159.msg200673
https://forum.ac-jete.it/index.php?topic=443279.0
http://udrpsucks.com/blog/?p=1804
http://viamania.net/index.php?mid=board_raYV15&document_srl=216255
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=550387
http://lucky.kidspann.net/index.php?mid=qna&document_srl=393267
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=126435
http://daltso.com/index.php?mid=board_cUYy21&document_srl=191784
http://shinhwaair2017.cafe24.com/issue/504841
http://apt2you2.cafe24.com/g1/53020
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/335410
http://blog.ptpintcast.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-regj-%d1%80%d0%b0%d1%81/
http://ye-dream.com/qa/277877
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/news/141932
http://constellation.kro.kr/board_kbku73/97038
https://adsensebih.com/index.php?topic=51193.0
http://ye-dream.com/qa/206489
http://carand.co.kr/d2/104165
http://www.cswc.co.kr/index.php?mid=board_zyTs37&document_srl=31709
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xo2y-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19/
http://www.m1avio.com/index.php/component/k2/itemlist/user/3873992
https://blossomug.com/index.php/component/k2/itemlist/user/1133251
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-11-%d1%81%d0%b5%d1%80%d0%b8-2/
http://midorijapaneserestaurant.ca/menu/News/107901
http://midorijapaneserestaurant.ca/menu/News/107944
http://naksansacondo.com/board_MGPu57/140699
http://naksansacondo.com/board_MGPu57/140771
https://gonggamlaw.com/lawcase/181586
https://gonggamlaw.com/lawcase/181644
https://www.hwbms.com/web/qna/73129
https://www.hwbms.com/web/qna/73139
http://naksansacondo.com/board_MGPu57/140853
http://sunele.co.kr/board_ReBD97/246243
http://ko.myds.me/board_story/278607
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/42911
https://www.chirorg.com/?document_srl=146788
http://bizchemical.com/board_kMpv94/2160740
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=23031
http://x-crew.center/guest/4846524
http://rabat.kr/board_yCgT00/71927
http://www.capital-investment.pl/index.php/component/k2/itemlist/user/229877
http://mobility-corp.com/index.php/component/k2/itemlist/user/2736448
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=49168
http://herdental.co.kr/index.php?mid=online&document_srl=143757
http://www.hmotors.co.kr/inquiry/26847
https://intelogist2.wpengine.com/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jz8b-%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3/
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/107931
http://dsyang.com/board_Kvgn62/44481
https://mcsetup.tk/bbs/index.php?topic=262529.0
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=108178
https://www.shaiyax.com/index.php?topic=408353.0
http://gochon-iusell.co.kr/g1/77664
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1181067
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=50045
http://2872870.com/est/62896
http://www.tunes-interiors.com/UserProfile/tabid/81/userId/8769438/Default.aspx
http://hyeonjun.co.kr/menu3/289591
http://midorijapaneserestaurant.ca/menu/News/26839
http://kyj1225.godohosting.com/board_mebR72/99907
http://www.svteck.co.kr/customer_gratitude/279419
http://daltso.com/index.php?mid=board_cUYy21&document_srl=202948
https://2002.shyoon.com/board_2002/207292
http://midorijapaneserestaurant.ca/menu/News/77635
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=206225
http://dsyang.com/board_Kvgn62/44767
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/43159
http://loverstory.co.kr/board_UYNJ05/107559
http://sy.korean.net/qna/452175
https://cybergsm.es/index.php?topic=63830.0
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=532119
http://daltso.com/index.php?mid=board_cUYy21&document_srl=198068
https://alvarogarciatorero.com/?option=com_k2&view=itemlist&task=user&id=50725
http://lucky.kidspann.net/index.php?mid=qna&document_srl=350118
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=428925
http://jiral.net/an9/29350
https://timecker.com/anonymous/194088
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=339865
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=229435
http://sunele.co.kr/board_ReBD97/219157
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=454115
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=17598
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=321625
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=a18a3faa4c32618e209081697eed62ad&topic=11391.0
https://intelogist2.wpengine.com/%d0%ba%d0%be%d0%bf-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rp4k-%d0%ba%d0%be%d0%bf-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://midorijapaneserestaurant.ca/menu/News/35714
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/326188
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=5020579
http://xn----3x5er9r48j7wemud0a387h.com/news/233335
https://cybergsm.es/index.php?topic=73004.0
https://2002.shyoon.com/board_2002/206448
http://www.m1avio.com/index.php/component/k2/itemlist/user/3796184
http://www.crnmedia.es/component/k2/itemlist/user/91351
http://rabat.kr/board_yCgT00/62083
http://dsyang.com/board_Kvgn62/46299
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/327894
https://nextezone.com/index.php?action=profile;u=15200
http://apt2you2.cafe24.com/g1/35214
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2007683
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7485334
http://www.cswc.co.kr/index.php?mid=board_zyTs37&document_srl=56234
http://1644-4404.com/?document_srl=332473
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2802634
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1736739
http://www2.yasothon.go.th/smf/index.php?topic=159.170880
http://gusinoepero.ru/archives/26344
http://www.arunagreen.com/index.php/component/k2/itemlist/user/1156027
http://beautypouch.net/index.php?mid=board_09&document_srl=109783
http://yooseok.com/board_BkvT46/411477
http://thermoplast.envolgroupe.com/component/k2/author/180284
http://euromouleusinage.com/index.php/component/k2/itemlist/user/185950
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1069729
http://www.livetank.cn/market1/293965
http://mediaville.me/index.php/component/k2/itemlist/user/331334
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=951417
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2799116
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/83024
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=259898
http://village.lorem.kr/index.php?document_srl=240013&mid=board_xmEJ33
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=17753
http://apt2you2.cafe24.com/g1/53990
http://mercibq.net/partner/55520
http://xekhachduyetthuy.com.vn/?option=com_k2&view=itemlist&task=user&id=242728
http://holysweat.dothome.co.kr/data/7081
http://dreamplusart.com/mn03_01/192336
http://sd-xi.co.kr/g1/88905
http://www.vamoscontigo.org/Noticia/218768
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=377813
http://daltso.com/index.php?mid=board_cUYy21&document_srl=211333
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1534272
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=195932
http://kyj1225.godohosting.com/board_mebR72/98903
http://e-educ.net/Forum/index.php?topic=16624.0
http://looksun.co.kr/index.php?mid=board_4&document_srl=186110
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=153008
http://ariji.kr/?document_srl=1026896
http://yadanarbonnews.com/index.php/component/k2/itemlist/user/345953
http://looksun.co.kr/index.php?mid=board_4&document_srl=134692
http://www.hmotors.co.kr/inquiry/67528
https://timecker.com/anonymous/217998
https://www.c-alice.org/forum/index.php?topic=101049.0
https://prosto-vkus.ru/index.php/component/k2/itemlist/user/37222
https://www.regalepadova.it/index.php/component/k2/itemlist/user/8580
http://mtuan93.com/board_uCqR85/6656
https://nextezone.com/index.php?topic=90857.0
https://timecker.com/anonymous/218130
https://timecker.com/anonymous/218180
https://timecker.com/?document_srl=218205
https://timecker.com/anonymous/218297
https://timecker.com/anonymous/218327
https://nextezone.com/index.php?action=profile;u=17325
https://nextezone.com/index.php?action=profile;u=17524
http://www2.yasothon.go.th/smf/index.php?topic=159.172035
http://www.svteck.co.kr/customer_gratitude/297148
http://www.leekeonsu-csi.com/index.php?document_srl=930423&mid=community7
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=550626
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=232512
http://cwon.kr/xe/board_bnSr36/289993
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3547514
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=708597
http://1600-1590.com/?document_srl=589719
http://loverstory.co.kr/board_UYNJ05/98592
http://daltso.com/index.php?mid=board_cUYy21&document_srl=201021
http://yooseok.com/board_BkvT46/422775
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/32814
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16701
http://jensenbyggteam.no/index.php/component/k2/itemlist/user/13709
http://e-educ.net/Forum/index.php?topic=17429.0
http://x-crew.center/guest/4845176
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3567501
http://www.popolsku.fr.pl/forum/index.php?topic=20407.80970
http://mercibq.net/partner/122317
http://8.droror.co.il/uncategorized/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ry0%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-19-%d1%81%d0%b5/
https://www.c-alice.org/forum/index.php?topic=101585.0
https://www.c-alice.org/forum/index.php?topic=101598.0
http://8.droror.co.il/uncategorized/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wa8%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f30-05/
http://8.droror.co.il/uncategorized/%d0%ba%d0%be%d0%bf-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pd8%d0%ba%d0%be%d0%bf-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f30-05-2019/
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=110297
http://8.droror.co.il/uncategorized/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wg3%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be/
http://8.droror.co.il/uncategorized/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zv6%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f30-05/
http://hotelnomadpalace.com/es/?option=com_k2&view=itemlist&task=user&id=23464
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=110315
https://www.hwbms.com/web/qna/43116
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3865597
http://yooseok.com/board_BkvT46/412215
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/176682
http://apt2you2.cafe24.com/g1/52532
http://k-cea.org/?document_srl=212519
http://rabat.kr/board_yCgT00/70404
http://divespace.co.kr/board/269835
http://foa.egerton.ac.ke/?option=com_k2&view=itemlist&task=user&id=1935531
http://rabbitzone.xyz/FREE/120349
http://smartacity.com/component/k2/itemlist/user/77954
http://yeonsen.com/index.php?mid=board_vZbN12&document_srl=299577
http://www2.yasothon.go.th/smf/index.php?topic=159.171705
http://daltso.com/index.php?mid=board_cUYy21&document_srl=198128
http://neosky.net/xe/space_station/160191
https://www.hwbms.com/web/qna/42744
http://muldorang.com/market/25812
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3790044
http://iymc.or.kr/pds/131578
http://pekosmile.dothome.co.kr/index.php?mid=seoulitestudio&document_srl=445698
http://otitismediasociety.org/forum/index.php?topic=211236.0
http://www.cswc.co.kr/index.php?mid=board_zyTs37&document_srl=60542
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=31191
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1314466
http://www.kcch.or.kr/index.php?mid=board_uFpk03&document_srl=94364
http://ye-dream.com/?document_srl=254230
http://midorijapaneserestaurant.ca/menu/News/70439
https://www.hwbms.com/web/qna/11092
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=337555
http://gusinoepero.ru/archives/27715
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1312394
http://looksun.co.kr/index.php?mid=board_4&document_srl=200853
http://forum.bmw-e60.eu/index.php?topic=11482.0
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=262262
http://www.kwpcoop.or.kr/QnA/22112
http://pkgersang.dothome.co.kr/board_jiKY24/40798
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2599211
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=229295
http://daesestudy.co.kr/ipsi_docu/170168
http://www.teedinubon.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ou5%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f29-0/
http://www.leekeonsu-csi.com/?document_srl=1366464
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1366659
https://betshin.com/Story/271510
https://gonggamlaw.com/lawcase/209079
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2841745
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=88216
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2027485
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3960762
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3960766
http://mobility-corp.com/index.php/component/k2/itemlist/user/2775413
http://netsconsults.com/index.php/component/k2/itemlist/user/861750
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/189948
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=188582
http://midorijapaneserestaurant.ca/menu/?document_srl=76039
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=196522
http://dev.aabn.org.gh/component/k2/itemlist/user/723153
http://xn--2e0bk61btjo.com/notice/22793
http://www.vamoscontigo.org/Noticia/174888
http://kyj1225.godohosting.com/board_mebR72/93952
http://www.cswc.co.kr/index.php?mid=board_zyTs37&document_srl=32833
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=393837
https://www.celekt.com/%d0%a2%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-29-05-2019-g2-%d0%a2%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-9-%d1%81%d0%b5%d1%80/
http://socialmag.bayareanonprofits.xyz/blogs/viewstory/128444
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-az6m-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=409258
http://benzmall.co.kr/index.php?mid=download&document_srl=44982
http://tiretech.co.kr/index.php?mid=qna&document_srl=242518
http://forum.bmw-e60.eu/index.php?topic=10886.0
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/172039
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=966267
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=45092
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=340175
http://dreamplusart.com/mn03_01/123975
http://www.svteck.co.kr/customer_gratitude/225786
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1193291
https://gonggamlaw.com/lawcase/127806
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2023836
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3592469
http://mediaville.me/index.php/component/k2/itemlist/user/407106
http://mobility-corp.com/index.php/component/k2/itemlist/user/2775950
http://smartacity.com/component/k2/itemlist/user/111063
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=144346
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=38299
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=38368
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4987701
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4987792
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1776960
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=111569
http://www.crnmedia.es/component/k2/itemlist/user/94389
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1292467
http://forum.elexlabs.com/index.php?topic=61853.0
http://nnkumw.org/xe/index.php?mid=board_yNQm00&document_srl=140266
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=228996
https://www.shaiyax.com/index.php?topic=413068.0
http://benzmall.co.kr/index.php?mid=download&document_srl=68833
http://simkungshopping.com/index.php?mid=board_cUYy21&document_srl=242942
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/166910
http://ovotecegg.com/component/k2/itemlist/user/228077
http://naksansacondo.com/board_MGPu57/70897
http://gochon-iusell.co.kr/g1/75838
https://intelogist2.wpengine.com/%d0%ba%d0%be%d0%bf-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-wa9%d0%ba%d0%be%d0%bf-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f29-05-2019/
http://jensenbyggteam.no/index.php/component/k2/itemlist/user/13715
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3585031
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3585053
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dp8r-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3/
http://mvisage.sk/index.php/component/k2/itemlist/user/120180
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gu1q-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12/
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=87224
https://blossomug.com/index.php/component/k2/itemlist/user/1132993
https://blossomug.com/index.php/component/k2/itemlist/user/1133133
https://intelogist2.wpengine.com/%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mm1j-%d1%82%d0%be%d0%bb%d1%8f-%d1%80%d0%be%d0%b1%d0%be%d1%82-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://intelogist2.wpengine.com/%d0%ba%d0%be%d0%bf-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ou8v-%d0%ba%d0%be%d0%bf-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://www.regalepadova.it/index.php/component/k2/itemlist/user/8204
http://www.digitalbul.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-tdzz-%d1%80%d0%b0%d1%81/
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=423776
http://alastair030.dothome.co.kr/?document_srl=25766
http://askpharm.net/board_NQiz06/284128
http://8.droror.co.il/uncategorized/%d0%ba%d0%be%d0%bf-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-eh0%d0%ba%d0%be%d0%bf-9-%d1%81%d0%b5%d1%80%d0%b8%d1%8f30-05-2019/
https://intelogist2.wpengine.com/%d0%ba%d0%be%d0%bf-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-li3z-%d0%ba%d0%be%d0%bf-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=39501
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=542912
http://benzmall.co.kr/index.php?mid=download&document_srl=166496
https://betshin.com/Story/279840
http://divespace.co.kr/board/325517
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4956555
http://daltso.com/index.php?mid=board_cUYy21&document_srl=362830
http://www.socintegra.lv/ru/component/k2/itemlist/user/44568
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qc8r-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-pm6u-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5/
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-us7l-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7/
http://netsconsults.com/?option=com_k2&view=itemlist&task=user&id=859498
http://udrpsucks.com/blog/?p=2110
http://www.ekemoon.com/254949/061420192201/
http://www.ekemoon.com/254955/061420192501/
http://www.ekemoon.com/254958/061420192601/
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sm5j-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-10-%d1%81%d0%b5%d1%80%d0%b8/
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ap4s-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jv0s-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://midorijapaneserestaurant.ca/menu/News/52574
https://cybergsm.es/index.php?topic=62829.0
http://www.lgue.co.kr/?document_srl=115203
http://dospuntoseventos.cl/component/k2/itemlist/user/16333
https://betshin.com/Story/205023
http://ovotecegg.com/component/k2/itemlist/user/226035
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=399655
http://praisesound.co.kr/sub04_01/87879
http://www.hmotors.co.kr/inquiry/75770
https://intelogist2.wpengine.com/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-mr3f-%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3/
https://prosto-vkus.ru/?option=com_k2&view=itemlist&task=user&id=37014
https://intelogist2.wpengine.com/%d1%81%d0%b5%d0%bd%d1%8f%d1%84%d0%b5%d0%b4%d1%8f-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d1%81%d0%b5%d0%bd%d1%8f/
http://daltso.com/index.php?mid=board_cUYy21&document_srl=385332
http://thermoplast.envolgroupe.com/component/k2/author/199305
http://www.ekemoon.com/254245/061120191701/
http://esperanzazubieta.com/index.php/component/k2/itemlist/user/113363
http://www.hmotors.co.kr/inquiry/90241
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-of2p-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://dohairbiz.com/en/component/k2/itemlist/user/2833565.html
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4985526
http://www.ekemoon.com/256203/062120194701/
http://www.ekemoon.com/256263/062220190501/
http://www.ekemoon.com/256265/062220190601/
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3887568
http://udrpsucks.com/blog/?p=2155
http://www.ekemoon.com/256269/062220190801/
http://www.ekemoon.com/256277/062220191001/
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=398706
http://mahdi.ehosseini.com/?option=com_k2&view=itemlist&task=user&id=44646
http://www.jesusonly.life/calendar/551377
https://betshin.com/Story/206949
http://www.theocraticamerica.org/forum/index.php?topic=69667.0
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3585603
http://ovotecegg.com/component/k2/itemlist/user/241904
http://smartacity.com/component/k2/itemlist/user/110267
http://daesestudy.co.kr/ipsi_docu/178398
http://naksansacondo.com/board_MGPu57/131955
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=696168
http://divespace.co.kr/board/354444
http://www.hmotors.co.kr/inquiry/85116
http://www.dap.com.py/index.php/es/?option=com_k2&view=itemlist&task=user&id=856041
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1569697
http://thermoplast.envolgroupe.com/?option=com_k2&view=itemlist&task=user&id=186133
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=42774
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qu2r-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-10-%d1%81%d0%b5%d1%80%d0%b8/
http://naksansacondo.com/board_MGPu57/175034
http://withinfp.sakura.ne.jp/eso/index.php/17534820-rasskaz-sluzanki-3-sezon-6-seria-hsvk-rasskaz-sluzanki-3-sezon-/0
http://midorijapaneserestaurant.ca/menu/News/61066
https://nple.com/xe/pds/152550
http://neosky.net/xe/space_station/121324
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=207158
http://yonseibaik.synology.me/index.php?mid=houston_profile&document_srl=92357
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=40200.0
http://sd-xi.co.kr/g1/52314
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3525876
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=23493
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1315194
https://www.hwbms.com/web/qna/90665
https://intelogist2.wpengine.com/%d0%ba%d0%be%d0%bf-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%bd%d0%be%d0%b2%d0%b8%d0%bd%d0%ba%d0%b0-%d0%ba%d0%be%d0%bf-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2834202
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2834244
http://dev.aabn.org.gh/?option=com_k2&view=itemlist&task=user&id=749723
http://dev.aabn.org.gh/component/k2/itemlist/user/749655
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1343725
http://jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3588083
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=57326
http://kockazatkutato.hu/component/k2/itemlist/user/57321
http://mediaville.me/index.php/component/k2/itemlist/user/401216
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bg9o-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://dreamplusart.com/mn03_01/305894
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3827580
https://gonggamlaw.com/lawcase/158772
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=985293
http://xn--2e0b53df5ag1c804aphl.net/nuguna/301555
http://dreamplusart.com/mn03_01/344992
http://proxima.co.rw/index.php/component/k2/itemlist/user/735184
http://udrpsucks.com/blog/?p=2009
http://yonseibaik.synology.me/index.php?mid=houston_profile&document_srl=61620
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=230607
http://esperanzazubieta.com/index.php/component/k2/itemlist/user/109030
http://matinbank.ir/component/k2/itemlist/user/4616918.html
http://gochon-iusell.co.kr/g1/85849
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/872678
https://intelogist2.wpengine.com/%d0%ba%d0%be%d0%bf-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8d%d1%84%d0%b8%d1%80-%d0%ba%d0%be%d0%bf-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://dev.aabn.org.gh/component/k2/itemlist/user/748837
http://dev.aabn.org.gh/component/k2/itemlist/user/748877
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2018810
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2018850
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2018885
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1344122
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=57470
http://kockazatkutato.hu/index.php/component/k2/itemlist/user/57505
http://mobility-corp.com/index.php/component/k2/itemlist/user/2768783
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1349787
http://dreamplusart.com/?document_srl=308003
http://dev.aabn.org.gh/component/k2/itemlist/user/755501
https://www.c-alice.org/forum/index.php?topic=100791.0
http://ye-dream.com/qa/293970
https://blossomug.com/index.php/component/k2/itemlist/user/1133031
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=378114
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=86778
https://gonggamlaw.com/lawcase/229811
http://dohairbiz.com/en/component/k2/itemlist/user/2829343.html
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=38419
http://www.spazioad.com/component/k2/itemlist/user/7528470
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/188487
http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/2665500
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/59991
https://prosto-vkus.ru/?option=com_k2&view=itemlist&task=user&id=37208
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4962761
https://blossomug.com/index.php/component/k2/itemlist/user/1131270
http://netsconsults.com/index.php/component/k2/itemlist/user/852245
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1879116
https://blossomug.com/index.php/component/k2/itemlist/user/1136186
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=23868
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1325419
http://proxima.co.rw/index.php/component/k2/itemlist/user/735471
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1886983
http://www.m1avio.com/index.php/component/k2/itemlist/user/3885982
https://blossomug.com/index.php/component/k2/itemlist/user/1136118
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2836010
http://dev.aabn.org.gh/component/k2/itemlist/user/751176
http://dev.fivestarpainting.com/?option=com_k2&view=itemlist&task=user&id=2025102
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2019944
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2019947
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=58289
http://mediaville.me/index.php/component/k2/itemlist/user/403107
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1576380
https://intelogist2.wpengine.com/%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-vf2h-%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
https://blossomug.com/index.php/component/k2/itemlist/user/1133499
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=58487
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1889818
http://www.vamoscontigo.org/Noticia/272047
http://udrpsucks.com/blog/?p=2087
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2847696
https://www.hohoyoga.com/testboard/4143669
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-xq4q-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14/
http://ko.myds.me/board_story/278242
http://kyj1225.godohosting.com/?document_srl=99090
https://timecker.com/anonymous/187543
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=49659
http://www.popolsku.fr.pl/forum/index.php?topic=412433.0
http://www.leekeonsu-csi.com/index.php?mid=sangdam1&document_srl=1086460
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=29801
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=214156
http://www.rocketdan.co.kr/index.php?document_srl=83963&mid=board_WMhM93
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/78988
https://2002.shyoon.com/board_2002/168566
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=229980
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=18490
http://divespace.co.kr/board/359666
https://www.hohoyoga.com/testboard/4114328
https://www.hwbms.com/web/qna/82945
http://thermoplast.envolgroupe.com/component/k2/author/199148
https://forum.clubeicaro.pt/index.php?topic=2908.0
http://mediaville.me/index.php/component/k2/itemlist/user/401013
https://www.hwbms.com/web/qna/87116
http://ye-dream.com/qa/304779
https://nextezone.com/index.php?action=profile;u=17283
http://dsyang.com/board_Kvgn62/57118
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-10-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kp6i-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd/
http://myrechockey.com/forums/index.php?topic=117689.0
http://wartoby.com/index.php?mid=board_UXUA38&document_srl=98905
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=17890
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=42833
http://dow.dothome.co.kr/board_jydx58/39301
http://www.verenas-unterwasserwelt.de/forum/index.php?topic=10822.0
http://www.m1avio.com/index.php/component/k2/itemlist/user/3794656
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/?document_srl=113118
http://looksun.co.kr/index.php?mid=board_4&document_srl=183794
https://forums.lfstats.com/viewtopic.php?t=320752
http://www.venusjeju.com/index.php?mid=QnA&document_srl=1209
http://www.vamoscontigo.org/Noticia/206042
https://forums.lfstats.com/viewtopic.php?t=319530
http://arquitectosenreformas.es/component/k2/itemlist/user/86118
http://otitismediasociety.org/forum/index.php?topic=200821.0
http://askpharm.net/board_NQiz06/210288
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=3965141
http://ko.myds.me/board_story/316078
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=2018911
https://alquilervideobeam.com.co/?option=com_k2&view=itemlist&task=user&id=60456
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1378059
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=60942
http://naksansacondo.com/board_MGPu57/36096
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1983318
http://khapthanam.co.kr/g1/141408
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2798907
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/35186
http://beautypouch.net/index.php?mid=board_09&document_srl=171273
http://sejong-thesharpyemizi.co.kr/m1/74382
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/246048
http://looksun.co.kr/index.php?mid=board_4&document_srl=203252
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=f63d78a81b325adf790653936db8e9e9&topic=12532.0
http://www.theocraticamerica.org/forum/index.php?topic=81910.0
http://shinhwaair2017.cafe24.com/issue/495375
https://betshin.com/Story/263926
http://ye-dream.com/qa/304996
http://naksansacondo.com/board_MGPu57/118578
http://thermoplast.envolgroupe.com/component/k2/author/194559
http://www.vamoscontigo.org/Noticia/232786
https://www.hwbms.com/web/qna/70174
http://www.ekemoon.com/255253/061620193701/
http://theolevolosproject.org/index.php/component/k2/itemlist/user/27574
http://www.jesusonly.life/calendar/565386
http://cwon.kr/xe/board_bnSr36/286833
http://bebopindia.com/notcie/394291
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yk2w-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://married.dike.gr/index.php/component/k2/itemlist/user/77920
http://mobility-corp.com/index.php/component/k2/itemlist/user/2732885
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=93296
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=914216
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=30578
http://village.lorem.kr/index.php?mid=board_xmEJ33&document_srl=201364
http://www.kcch.or.kr/index.php?mid=board_uFpk03&document_srl=92730
http://www.popolsku.fr.pl/forum/index.php?topic=20407.80115
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=957418
http://dospuntoseventos.cl/?option=com_k2&view=itemlist&task=user&id=16556
http://apt2you2.cafe24.com/g1/38047
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=436994
http://xn--hu1bs8ufrd6ucyz0aooa.kr/index.php?mid=main_08&document_srl=44433
http://blog.ptpintcast.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dtez-%d1%80%d0%b0%d1%81/
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=43453
http://taklongclub.com/forum/index.php?topic=204830.0
https://turimex.mx.solemti.net/component/k2/itemlist/user/13865
https://nple.com/xe/?document_srl=151391
http://dospuntoseventos.cl/component/k2/itemlist/user/16597
http://xn--2e0b53df5ag1c804aphl.net/nuguna/289406
https://www.vegasgreentour.com/index.php?document_srl=714737&mid=board_XiHh59
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/196045
http://benzmall.co.kr/index.php?mid=download&document_srl=153270
http://www.ekemoon.com/250617/051620194731/
http://www.camaracoyhaique.cl/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b2-%d1%8d%d1%84%d0%b8%d1%80%d0%b5-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd-2/
http://benzmall.co.kr/index.php?mid=download&document_srl=168767
http://esperanzazubieta.com/?option=com_k2&view=itemlist&task=user&id=113286
http://divespace.co.kr/board/297803
http://hotelnomadpalace.com/component/k2/itemlist/user/23275
https://www.c-alice.org/forum/index.php?topic=101227.0
https://www.hohoyoga.com/testboard/4101390
http://beautypouch.net/index.php?mid=board_09&document_srl=239254
http://www.itosm.com/cn/board_nLoq17/136078
http://sejong-thesharpyemizi.co.kr/m1/107408
https://gonggamlaw.com/lawcase/145421
http://benzmall.co.kr/index.php?mid=download&document_srl=115212
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=402632
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=26101
http://proxima.co.rw/index.php/component/k2/itemlist/user/732745
http://www.atab.com.sa/index.php/component/k2/itemlist/user/1770223
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1770244
https://blossomug.com/?option=com_k2&view=itemlist&task=user&id=1135083
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3524210
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=23076
http://midorijapaneserestaurant.ca/menu/News/125398
http://naksansacondo.com/board_MGPu57/163355
https://gonggamlaw.com/lawcase/193901
https://gonggamlaw.com/lawcase/193919
https://intelogist2.wpengine.com/%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-video-%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-6-%d1%81%d0%b5%d1%80%d0%b8/
http://dev.aabn.org.gh/?option=com_k2&view=itemlist&task=user&id=747614
http://dev.aabn.org.gh/component/k2/itemlist/user/747123
https://www.hwbms.com/web/qna/115672
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=35355
http://ko.myds.me/board_story/337003
http://www.pdctransport.co.th/?option=com_k2&view=itemlist&task=user&id=18929
http://ko.myds.me/board_story/357444
http://askpharm.net/board_NQiz06/295631
http://www.hmotors.co.kr/inquiry/84254
http://sy.korean.net/free/646090
http://dreamplusart.com/mn03_01/304642
http://daesestudy.co.kr/ipsi_docu/180021
http://www.livetank.cn/market1/215242
https://2002.shyoon.com/board_2002/277856
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/84939
http://kwpub.kr/PUBS/126302
http://1661-6471.co.kr/news/47347
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=581556
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=37731
http://praisesound.co.kr/?document_srl=100249
http://www.haetsaldun-clinic.co.kr/Question/43014
http://midorijapaneserestaurant.ca/menu/News/43240
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/842563
http://dongilpastor.synology.me/ing/index.php?mid=board_WlVg97&document_srl=101176
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2002058
http://k-cea.org/board_Hnyj62/247907
http://daesestudy.co.kr/ipsi_docu/171122
http://gallerychoi.com/?document_srl=336042
http://khapthanam.co.kr/g1/151253
http://dcasociados.eu/component/k2/itemlist/user/93274
http://midorijapaneserestaurant.ca/menu/News/57043
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/820021
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=386125
http://divespace.co.kr/board/276537
http://sd-xi.co.kr/g1/59879
http://kwpub.kr/PUBS/125712
http://xn--2e0b53df5ag1c804aphl.net/nuguna/278673
http://www.vamoscontigo.org/Noticia/254378
http://xn--2e0b53df5ag1c804aphl.net/nuguna/270043
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3823070
https://betshin.com/Story/274084
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hr5x-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
https://betshin.com/Story/257886
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=111726
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3579515
http://udrpsucks.com/blog/?p=2096
http://www.ekemoon.com/259297/061220195002/
https://khuyenmaikk13.info/index.php?topic=228427.0
http://nnkumw.org/xe/index.php?mid=board_yNQm00&document_srl=135732
http://looksun.co.kr/index.php?mid=board_4&document_srl=186802
http://askpharm.net/board_NQiz06/245935
http://xn----iv8e2lm1vxuam95ag7gslb023e4bc.com/?document_srl=150365
http://www.jesusonly.life/calendar/444070
http://dospuntoseventos.cl/component/k2/itemlist/user/16562
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=49568
https://betshin.com/Story/200519
http://www.vamoscontigo.org/Noticia/139377
http://www.hmotors.co.kr/inquiry/40003
http://rabat.kr/board_yCgT00/51179
http://backo.co.kr/?document_srl=16270
http://cwon.kr/xe/board_bnSr36/310302
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=4896046
http://melchinooddle.dothome.co.kr/?document_srl=13543
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1501890
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1317609
http://moyakmermer.com/?option=com_k2&view=itemlist&task=user&id=843357
http://www.svteck.co.kr/customer_gratitude/280916
http://beautypouch.net/index.php?document_srl=237012&mid=board_09
https://gonggamlaw.com/lawcase/155690
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1339107
http://mediaville.me/index.php/component/k2/itemlist/user/405141
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=19810
http://ye-dream.com/board_yshD25/318391
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hd-video-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be-2/
http://wigalseguros.com.br/index.php/component/k2/itemlist/user/35475
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=395638
http://divespace.co.kr/board/317931
https://www.hohoyoga.com/testboard/4106321
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1317566
http://xn--2e0b53df5ag1c804aphl.net/nuguna/258296
https://blossomug.com/index.php/component/k2/itemlist/user/1115584
https://www.hwbms.com/web/qna/30855
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jfys-%d1%80%d0%b0%d1%81/
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=408967
http://dohairbiz.com/en/component/k2/itemlist/user/2818974.html
https://www.hohoyoga.com/testboard/4076303
http://www2.yasothon.go.th/smf/index.php?topic=159.msg200597
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/news/72222
http://www.itosm.com/cn/board_nLoq17/133992
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=48084
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=408377
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=412737
http://1600-1590.com/index.php?mid=board_ndxU24&document_srl=540969
http://loverstory.co.kr/board_UYNJ05/98184
http://ye-dream.com/qa/220210
http://ko.myds.me/board_story/247489
http://looksun.co.kr/index.php?mid=board_4&document_srl=191014
http://dcasociados.eu/component/k2/itemlist/user/95498
http://ko.myds.me/board_story/359783
http://benzmall.co.kr/index.php?mid=download&document_srl=141188
http://midorijapaneserestaurant.ca/menu/News/116683
https://betshin.com/Story/249542
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=42085
http://naksansacondo.com/board_MGPu57/135802
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=39806.0
http://dohairbiz.com/en/component/k2/itemlist/user/2816918.html
http://www.firstfinancialservices.co.uk/?option=com_k2&view=itemlist&task=user&id=42226
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-fx8b-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://www.coating.or.kr/atemfair_data/17650
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=853876
http://sy.korean.net/qna/483385
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=401080
http://dessa.com.br/component/k2/itemlist/user/390800
http://warmfund.net/p/index.php?mid=financing&document_srl=473962
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-bnbk-%d1%80%d0%b0%d1%81/
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=316174
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-sl1%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f29-05/
http://dreamplusart.com/mn03_01/213263
http://praisesound.co.kr/sub04_01/102021
http://erdfsa.iptime.org/xe/index.php?mid=board&document_srl=12456
http://sunele.co.kr/board_ReBD97/163600
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=956823
http://daesestudy.co.kr/ipsi_docu/121347
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=314242
http://dreamplusart.com/mn03_01/285416
http://smartacity.com/component/k2/itemlist/user/112183
http://divespace.co.kr/board/355918
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=35208
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/879819
http://mahdi.ehosseini.com/index.php/component/k2/itemlist/user/52250
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3799941
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2846198
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=121648
http://www.jesusandmarypatna.com/?option=com_k2&view=itemlist&task=user&id=3595307
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=127091
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=25900
http://smartacity.com/component/k2/itemlist/user/111104
http://euromouleusinage.com/index.php/component/k2/itemlist/user/198855
http://hydrocarbs-gh.org/?option=com_k2&view=itemlist&task=user&id=7546348
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/864216
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1881072
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yg6x-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14/
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=23462
http://blog.ptpintcast.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kvfe-%d1%80%d0%b0%d1%81/
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=230397
http://toeden.co.kr/Product_new/137479
http://www.sp1.football/index.php?mid=faq&document_srl=860014
http://www.livetank.cn/?document_srl=295877
http://www.hmotors.co.kr/inquiry/71741
http://sfah.ch/de/component/k2/itemlist/user/15458
http://sunele.co.kr/board_ReBD97/165404
http://servicioswts.com/?option=com_k2&view=itemlist&task=user&id=3875538
http://kyj1225.godohosting.com/board_mebR72/92772
http://robocit.com/index.php/component/k2/itemlist/user/449917
http://naksansacondo.com/?document_srl=103264
http://gallerychoi.com/Exhibition/454894
https://timecker.com/anonymous/215537
https://www.celekt.com/%d0%a4%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yi7z-%d0%a4%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-13/
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1582897
http://ye-dream.com/qa/302703
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1772351
https://www.hwbms.com/web/qna/54888
http://k-cea.org/board_Hnyj62/193198
https://intelogist2.wpengine.com/%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ac5j-%d1%87%d0%b5%d1%80%d0%bd%d0%be%d0%b1%d1%8b%d0%bb%d1%8c-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://netsconsults.com/?option=com_k2&view=itemlist&task=user&id=841048
http://www.lgue.co.kr/?document_srl=125456
http://mobility-corp.com/index.php/component/k2/itemlist/user/2744796
http://www.zoraholidays.net/index.php/component/k2/itemlist/user/388332
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=147011
http://jnk-ent.jp/index.php?mid=gallery&document_srl=238516
http://carand.co.kr/d2/47947
http://mediaville.me/index.php/component/k2/itemlist/user/369153
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3374249
http://www.hmotors.co.kr/inquiry/45666
http://www.leekeonsu-csi.com/index.php?document_srl=1120411&mid=community7
http://midorijapaneserestaurant.ca/menu/?document_srl=31998
http://goldenpowerball2.com/index.php?mid=board_Nutq11&document_srl=489844
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=378019
http://arquitectosenreformas.es/?option=com_k2&view=itemlist&task=user&id=84913
http://www.ds712.net/guest/index.php?document_srl=696872&mid=guest07
http://thermoplast.envolgroupe.com/component/k2/author/182573
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=89183
http://www.ekemoon.com/257799/060520195702/
http://www.ekemoon.com/256885/060120194602/
http://ye-dream.com/qa/282013
http://mahdi.ehosseini.com/?option=com_k2&view=itemlist&task=user&id=51409
https://betshin.com/Story/260610
http://www.svteck.co.kr/customer_gratitude/224071
http://xn----tu8e8mm1vc8h00c5zg05ac6b854f.com/news/107000
http://dreamplusart.com/mn03_01/123843
http://daltso.com/index.php?mid=board_cUYy21&document_srl=208388
http://looksun.co.kr/index.php?mid=board_4&document_srl=187850
http://www2.yasothon.go.th/smf/index.php?topic=159.171750
http://www.ekemoon.com/244973/052120190528/
https://timecker.com/anonymous/193620
http://yourhelp.co.kr/index.php?mid=board_2&document_srl=76140
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=711360
http://iymc.or.kr/pds/121831
http://www.civilservantsacco.co.zm/?option=com_k2&view=itemlist&task=user&id=1169822
http://e-educ.net/Forum/index.php?topic=15960.0
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=725292
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1352691
http://www.ekemoon.com/253153/060720191301/
https://gonggamlaw.com/lawcase/224751
http://xn--80acvxh8am.net/index.php?topic=4209.0
http://thermoplast.envolgroupe.com/component/k2/author/197743
https://gonggamlaw.com/lawcase/176225
https://nextezone.com/index.php?topic=90646.0
https://intelogist2.wpengine.com/%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0%d1%80%d0%be%d0%b4%d0%b0-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-5-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yj2c-%d1%81%d0%bb%d1%83%d0%b3%d0%b0-%d0%bd%d0%b0/
http://thermoplast.envolgroupe.com/component/k2/author/192954
http://dreamplusart.com/mn03_01/239020
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1575778
http://carand.co.kr/d2/47692
http://looksun.co.kr/index.php?mid=board_4&document_srl=192749
http://miquirofisico.com/index.php/component/k2/itemlist/user/4525
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/49625
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=19137
http://xn--4k0bt5qa92r7z0a4mqr4be7d1zc.com/index.php?mid=main_10&document_srl=128130
http://benzmall.co.kr/index.php?mid=download&document_srl=67101
http://eugeniocolazzo.it/forum/index.php?topic=178823.0
http://kyj1225.godohosting.com/board_mebR72/95187
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/855718
http://www.ekemoon.com/245745/050520190529/
https://www.hwbms.com/web/qna/36622
https://nple.com/xe/pds/232204
http://www.jesusonly.life/calendar/597624
http://www.eunhaele.co.kr/xe/board/20412
http://roikjer.com/forum/index.php?PHPSESSID=fb90g2fi2lhmldccqc2kooekn6&topic=924619.0
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1034816
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=338730
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-kf3j-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-14/
https://gonggamlaw.com/lawcase/135000
http://naksansacondo.com/board_MGPu57/97007
http://153.120.114.241/eso/index.php/17558260-rasskaz-sluzanki-3-sezon-4-seria-zhrr-rasskaz-sluzanki-3-sezon-
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=5020011
http://dev.aabn.org.gh/component/k2/itemlist/user/675909
http://carrierworld.co.kr/index.php?mid=board_UlGv44&document_srl=201918
http://w9builders.co.uk/index.php/component/k2/itemlist/user/143223
http://web2interactive.com/?option=com_k2&view=itemlist&task=user&id=3823876
http://dsyang.com/board_Kvgn62/52107
https://www.hwbms.com/web/qna/47737
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=387220
http://research.kiu.ac.kr/index.php?mid=Food4Thought&document_srl=438085
https://www.hwbms.com/web/qna/11960
http://constellation.kro.kr/board_kbku73/64377
http://autospa.lv/index.php/lv/component/k2/itemlist/user/10639
http://www.livetank.cn/market1/214803
http://ye-dream.com/qa/249595
https://www.shaiyax.com/index.php?topic=408008.0
http://masanlib.or.kr/?document_srl=89115
http://gabisan.com/board_OuDs04/71092
http://themasters.pro/file_01/228184
http://loverstory.co.kr/board_UYNJ05/102248
https://cybergsm.es/index.php?topic=73043.0
http://otitismediasociety.org/forum/index.php?topic=210842.0
http://www.vogtland.com.pl/index.php/component/k2/itemlist/user/49394
http://ptu.imoove.kr/ko/content/%C2%AB%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-7-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-whjs-%C2%AB%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7-%D1%81%D0%BB%D1%83%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8-3-%D1%81%D0%B5%D0%B7%D0%BE%D0%BD-7-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%D0%BA%D1%83%D1%80%D0%B0%D0%B6
https://nple.com/xe/pds/150580
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1546602
https://www.hwbms.com/web/qna/51331
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=39554
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=31134
https://betshin.com/Story/261379
https://www.hohoyoga.com/testboard/4107786
http://midorijapaneserestaurant.ca/menu/News/116113
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=24582
http://www.quattroandpartners.it/index.php/component/k2/itemlist/user/1278436
http://dev.aabn.org.gh/component/k2/itemlist/user/750352
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=24326
http://beautypouch.net/index.php?mid=board_09&document_srl=242854
https://www.hohoyoga.com/testboard/4122111
https://khuyenmaikk13.info/index.php?topic=231412.0
http://barobus.kr/qna/93328
http://loverstory.co.kr/board_UYNJ05/95008
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2781792
https://esel.gist.ac.kr/esel2/board_hmgj23/268001
http://thermoplast.envolgroupe.com/component/k2/author/157591
https://adsensebih.com/index.php?topic=42798.0
http://p9912.cafe24.com/board_LVgu51/65848
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=387500
http://carand.co.kr/d2/95600
http://oceangray.i234.me/index.php?mid=board_vsVi16&document_srl=215792
https://www.hohoyoga.com/testboard/3971185
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1871978
http://www.ekemoon.com/240249/050720194226/
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/78784
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=108483
http://xn----c28e37psqau1bm6v53e05ac6b854f.kr/news/73584
http://www.cnsmaker.net/xe/?document_srl=158897
http://xn----c28e37pskhnybu1kc2q9ndp5l.com/news/48586
http://lucky.kidspann.net/index.php?mid=qna&document_srl=346716
https://esel.gist.ac.kr/esel2/board_hmgj23/369325
http://divespace.co.kr/board/346551
https://www.celekt.com/%d0%a4%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-qv6y-%d0%a4%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7/
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1443934
http://1644-4404.com/index.php?mid=board_VFri46&document_srl=580475
https://serverpia.co.kr/board_ucCk10/191174
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=19477
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=577821
http://cwon.kr/xe/board_bnSr36/300772
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=23245
http://www.rocketdan.co.kr/index.php?mid=board_WMhM93&document_srl=158254
http://jnk-ent.jp/index.php?mid=gallery&document_srl=297569
http://thermoplast.envolgroupe.com/component/k2/author/178828
http://neosky.net/xe/space_station/75521
http://benzmall.co.kr/index.php?mid=download&document_srl=75815
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-zixe-%d1%80%d0%b0%d1%81/
http://loverstory.co.kr/board_UYNJ05/107583
http://rudraautomation.com/index.php/component/k2/author/358354
http://gochon-iusell.co.kr/g1/77695
http://k2.akademitelkom.ac.id/?option=com_k2&view=itemlist&task=user&id=370645
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=410341
https://gonggamlaw.com/lawcase/153238
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ahzl-%d1%80%d0%b0%d1%81/
http://guiadetudo.com/index.php/component/k2/itemlist/user/12698
http://askpharm.net/board_NQiz06/158967
http://www.popolsku.fr.pl/forum/index.php?topic=413447.0
http://loverstory.co.kr/board_UYNJ05/108610
https://www.celekt.com/%d0%a0%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ejdb-%d0%a0%d0%b0%d1%81/
https://www.vegasgreentour.com/index.php?mid=board_XiHh59&document_srl=741660
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ax8q-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16/
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=59946
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=38520
http://www.ekemoon.com/250157/051220192431/
http://w9builders.co.uk/?option=com_k2&view=itemlist&task=user&id=141472
http://www.leekeonsu-csi.com/?document_srl=1422200
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1407047
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1769422
http://ko.myds.me/board_story/368785
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=996596
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=130887
http://www.digitalbul.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ibvs-%d1%80%d0%b0%d1%81/
http://www.jesusonly.life/calendar/448833
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/1984599
http://sy.korean.net/qna/456330
http://xn--2e0b53df5ag1c804aphl.net/nuguna/106936
http://xn--2e0bk61btjo.com/notice/32221
https://adsensebih.com/index.php?topic=49364.0
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2794881
http://zakdu.com/board_YpzS56/26204
http://kyj1225.godohosting.com/board_mebR72/99779
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=395017
https://cybergsm.es/index.php?topic=73031.0
http://xn--4k0b35r1tgf2e69bc81as4b.modelhouse.guide/?document_srl=70060
http://ko.myds.me/board_story/352016
http://euromouleusinage.com/index.php/component/k2/itemlist/user/196664
https://intelogist2.wpengine.com/%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ef3j-%d0%b6%d0%b8%d0%b2%d0%b0%d1%8f-%d0%bc%d0%b8%d0%bd%d0%b0-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://askpharm.net/board_NQiz06/307310
http://www.ekemoon.com/253983/061020192701/
http://daesestudy.co.kr/ipsi_docu/202987
https://www.hwbms.com/web/qna/53039
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=386184
https://www.hohoyoga.com/testboard/4085509
http://www.teedinubon.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-yblp-%d1%80%d0%b0%d1%81/
https://www.runcity.org/forum/index.php?action=profile;u=77518
http://ucckorea.kr/index.php?mid=board_AuHE49&document_srl=125461
http://engeena.com/component/k2/itemlist/user/9177
http://goldenpowerball2.com/?document_srl=340514
http://www.theocraticamerica.org/forum/index.php?topic=70692.0
http://www.svteck.co.kr/customer_gratitude/225826
http://77.93.38.205/?option=com_k2&view=itemlist&task=user&id=652666
http://xn--2e0b53df5ag1c804aphl.net/nuguna/107541
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/2796294
http://xihillstate.bloggirl.net/index.php?mid=board_HLJb60&document_srl=258947
http://erhu.eu/viewtopic.php?t=417009
http://dev.aabn.org.gh/component/k2/itemlist/user/717171
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=42637
http://gtupuw.org/index.php/component/k2/itemlist/user/1995193
http://www.kspace.cc/xe/index.php?mid=board_NvNw86&document_srl=116614
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=221028
http://kockazatkutato.hu/component/k2/itemlist/user/46582
http://dessa.com.br/component/k2/itemlist/user/392393
http://callman.co.kr/?document_srl=490087
http://callman.co.kr/index.php?document_srl=489476&mid=qa
http://callman.co.kr/index.php?document_srl=489783&mid=qa
http://callman.co.kr/index.php?document_srl=489844&mid=qa
http://callman.co.kr/index.php?mid=qa&document_srl=490254
http://constellation.kro.kr/?document_srl=296452
http://constellation.kro.kr/board_kbku73/295484
http://constellation.kro.kr/board_kbku73/296370
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=116128
http://e-educ.net/Forum/index.php?topic=18008.0
http://isch.kr/board_PowH60/156336
http://www.ekemoon.com/247369/050320194630/
http://e-educ.net/Forum/index.php?topic=16325.0
http://www.tessabannampad.go.th/webboard/index.php?topic=227006.0
http://www2.yasothon.go.th/smf/index.php?topic=159.172275
http://www.capital-investment.pl/?option=com_k2&view=itemlist&task=user&id=230234
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1186338
http://loverstory.co.kr/board_UYNJ05/50447
http://erhu.eu/viewtopic.php?t=397842
http://masanlib.or.kr/g1/125843
http://midorijapaneserestaurant.ca/menu/News/139833
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1334131
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2837372
http://dev.aabn.org.gh/component/k2/itemlist/user/752549
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2025672
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=425271
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1346745
http://ko.myds.me/board_story/418617
http://ko.myds.me/board_story/419018
http://ko.myds.me/board_story/419045
http://koais.com/data/366987
http://koais.com/data/367269
http://kwpub.kr/PUBS/301074
http://kyj1225.godohosting.com/board_mebR72/200562
http://yoriyorifood.com/xxxx/spacial/254171
http://looksun.co.kr/index.php?mid=board_4&document_srl=134660
http://patagroupofcompanies.com/index.php/component/k2/itemlist/user/336606
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2792569
http://jiral.net/an9/38489
http://www.jesusonly.life/calendar/446614
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=891396
http://halinhpharma.com.vn/?option=com_k2&view=itemlist&task=user&id=376632
http://daltso.com/index.php?mid=board_cUYy21&document_srl=198314
https://mcsetup.tk/bbs/index.php?topic=265989.0
http://www.verenas-unterwasserwelt.de/forum/index.php?PHPSESSID=d0b0688a474d8293737d7a7f814b6176&topic=11344.0
http://wigalseguros.com.br/index.php/component/k2/itemlist/user/37155
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1575512
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1575610
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=111235
http://www.comfortcenter.es/?option=com_k2&view=itemlist&task=user&id=111245
http://www.crnmedia.es/component/k2/itemlist/user/93990
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=988552
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=129078
http://www.hmotors.co.kr/inquiry/206368
http://www.hmotors.co.kr/inquiry/206463
http://www.hmotors.co.kr/inquiry/206486
http://www.hmotors.co.kr/inquiry/206497
http://www.hmotors.co.kr/inquiry/206533
http://www.hmotors.co.kr/inquiry/206543
http://www.hyunjindc.com/qna/405156
http://www.insesinmun.com/newpaper2/234637
http://www.itosm.com/cn/board_nLoq17/378267
http://www.itosm.com/cn/board_nLoq17/378281
http://www.itosm.com/cn/board_nLoq17/378301
http://www.lgue.co.kr/?document_srl=331799
http://www.taeshinmedia.com/index.php?mid=genealogy_faq&document_srl=3488564
https://www.hwbms.com/web/qna/38913
http://arnikabolt.ro/?option=com_k2&view=itemlist&task=user&id=113129
http://www.jshwanghoan.com/index.php?mid=qna&document_srl=320603
http://kyj1225.godohosting.com/board_mebR72/96053
http://www.vogtland.com.pl/?option=com_k2&view=itemlist&task=user&id=49957
http://xn--c79an5j4sas61aovgwa004bwra306g8xa.modelhouse.guide/?document_srl=360738
http://dev.fivestarpainting.com/index.php/component/k2/itemlist/user/2025909
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1347375
http://israengineering.com/?option=com_k2&view=itemlist&task=user&id=1347393
http://israengineering.com/index.php/component/k2/itemlist/user/1347397
http://mediaville.me/index.php/component/k2/itemlist/user/404524
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/874646
http://moyakmermer.com/index.php/en/component/k2/itemlist/user/874905
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=188588
http://ovotecegg.com/component/k2/itemlist/user/246185
http://rudraautomation.com/?option=com_k2&view=itemlist&task=user&id=386041
http://rudraautomation.com/index.php/component/k2/author/385943
http://askpharm.net/board_NQiz06/400914
http://barobus.kr/?document_srl=219031
http://barobus.kr/qna/219055
http://bath-family.com/photo_zone/262111
http://bath-family.com/photo_zone/262364
http://bath-family.com/photo_zone/262456
http://bath-family.com/photo_zone/262568
http://beautypouch.net/index.php?mid=board_09&document_srl=293241
http://bewasia.com/index.php?mid=board_cUYy21&document_srl=371878
http://cwon.kr/xe/board_bnSr36/404688
http://erhu.eu/viewtopic.php?t=397068
http://www.pdctransport.co.th/index.php/component/k2/itemlist/user/17803
http://xn--o39a80a04ustjq4by7fh3dp14aqoa.com/news/71318
https://forum.shaiyaslayer.tk/index.php?topic=157769.0
http://kyj1225.godohosting.com/board_mebR72/100254
http://loverstory.co.kr/board_UYNJ05/87981
http://praisesound.co.kr/sub04_01/85082
http://zakdu.com/board_ssKi56/22789
http://wigalseguros.com.br/component/users/?task=user&view=itemlist&id=37382
http://www.siirtorganik.com/index.php/component/k2/itemlist/user/988745
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=129335
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3529207
https://verdadesbiblicas.org.ec/index.php/component/k2/itemlist/user/3887105
https://www.swiss-focus.ch/?option=com_k2&view=itemlist&task=user&id=42085
http://beautypouch.net/index.php?mid=board_09&document_srl=258061
http://benzmall.co.kr/index.php?mid=download&document_srl=141871
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1290928
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1333574
https://intelogist2.wpengine.com/%d0%ba%d0%be%d0%bf-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%8d%d1%84%d0%b8%d1%80-%d0%ba%d0%be%d0%bf-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f/
http://dsyang.com/board_Kvgn62/49314
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=27249
http://www.ekemoon.com/260829/062020190202/
http://dsyang.com/board_Kvgn62/52063
https://gonggamlaw.com/172396
http://daltso.com/index.php?mid=board_cUYy21&document_srl=362170
http://cwon.kr/xe/board_bnSr36/285454
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=18777
http://k-cea.org/board_Hnyj62/193081
https://forum.clubeicaro.pt/index.php?topic=2297.0
http://dessa.com.br/?option=com_k2&view=itemlist&task=user&id=392345
https://2002.shyoon.com/board_2002/171726
http://www.rationalkorea.com/xe/index.php?mid=pqna3&document_srl=664908
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3863395
http://www.firstfinancialservices.co.uk/index.php/component/k2/itemlist/user/42068
http://ye-dream.com/qa/256987
http://photogrotto.com/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-4-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-jnjb-%d1%80%d0%b0%d1%81/
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=29301
http://www.civilservantsacco.co.zm/index.php/component/k2/itemlist/user/1169858
https://gonggamlaw.com/lawcase/131974
http://cwon.kr/xe/board_bnSr36/285383
http://www.venusjeju.com/index.php?mid=QnA&document_srl=738
http://renew.joum.kr/index.php?mid=Portfolio_bbs&document_srl=269179
http://e-educ.net/Forum/index.php?topic=17970.0
http://gtupuw.org/?option=com_k2&view=itemlist&task=user&id=1963992
http://proxima.co.rw/index.php/component/k2/itemlist/user/719366
http://xekhachduyetthuy.com.vn/component/k2/itemlist/user/242545
http://constellation.kro.kr/board_kbku73/292486
http://www.ekemoon.com/250659/051720192331/
http://benzmall.co.kr/index.php?mid=download&document_srl=220934
http://bitly.com/2WJcJwo
http://bitly.com/2IanVc0
http://bitly.com/2WJ6PeS
https://intelogist2.wpengine.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b0%d1%8f-%d0%bc%d0%b0%d0%bb%d0%b5%d0%bd%d1%8c%d0%ba%d0%b0%d1%8f-%d0%bb%d0%be%d0%b6%d1%8c-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-13/
http://bitly.com/2WOlAx6
https://intelogist2.wpengine.com/%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3%d0%bb%d0%be-%d0%b1%d1%8b%d1%82%d1%8c-%d0%b8%d0%bd%d0%b0%d1%87%d0%b5-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rn9d-%d0%b2%d1%81%d1%91-%d0%bc%d0%be%d0%b3/
https://verdadesbiblicas.org.ec/?option=com_k2&view=itemlist&task=user&id=3896307
https://serverpia.co.kr/board_ucCk10/199163
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1878194
http://viamania.net/index.php?mid=board_raYV15&document_srl=519354
http://themasters.pro/file_01/559479
http://bitly.com/2IiXykd
http://bitly.com/2IiX6T3
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1593798
https://www.hohoyoga.com/testboard/4139281
http://forums.abs-cbn.com/welcome-back-kapamilya%21/oa-maeka-o-2-eo-6-e-x5-03-06-2019-oa-maeka-o-2-eo-6-e/?PHPSESSID=jhjes64pq4lgtn5vtf9oeme8h7
http://k-cea.org/board_Hnyj62/395165
http://carand.co.kr/d2/223936
http://xn----c28ewjj6ubwku6frtcuzec29ae5b.com/news/213376
http://bitly.com/2WCtDwR
http://www.svteck.co.kr/customer_gratitude/561826
http://hyeonjun.co.kr/menu3/630581
http://nyutusonsafaris.com/?option=com_k2&view=itemlist&task=user&id=196391
http://daltso.com/index.php?mid=board_cUYy21&document_srl=381804
http://www.vamoscontigo.org/Noticia/243387
https://grajalesabogados.com.mx/index.php/component/k2/itemlist/user/68133
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-dp9i-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8/
http://rabat.kr/board_yCgT00/156455
http://www.hyunjindc.com/qna/401263
http://1600-1590.com/index.php?mid=board_ihsE13&document_srl=694560
http://ko.myds.me/board_story/339089
http://bitly.com/2WFrIr7
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2861687
http://alastair030.dothome.co.kr/index.php?mid=board_MMiF30&document_srl=43809
https://www.hohoyoga.com/testboard/4219343
http://marketpet.ru/component/k2/itemlist/user/4519.html
http://daesestudy.co.kr/ipsi_docu/204334
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/198385
http://marketpet.ru/?option=com_k2&view=itemlist&task=user&id=4578
http://rudraautomation.com/index.php/component/k2/author/405222
http://ye-dream.com/qa/302501
http://bitly.com/2WKbcpV
https://verdadesbiblicas.org.ec/index.php/component/k2/itemlist/user/3896368
http://bitly.com/2WJcJwo
http://divespace.co.kr/board/308736
http://bitly.com/2WFrIr7
http://www.hmotors.co.kr/inquiry/76219
http://bitly.com/2IanRcg
http://bitly.com/2IezsY1
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-rg4s-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7/
http://vervetama.com/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b0%d1%8f-%d0%bc%d0%b0%d0%bb%d0%b5%d0%bd%d1%8c%d0%ba%d0%b0%d1%8f-%d0%bb%d0%be%d0%b6%d1%8c-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-8-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://isch.kr/board_PowH60/412843
http://dreamplusart.com/mn03_01/311336
http://bitly.com/2IgxIgZ
http://www.jesusonly.life/calendar/877168
http://bitly.com/2IiXz7L
http://bitly.com/2WGpvfi
http://sy.korean.net/free/683988
http://hyeonjun.co.kr/menu3/638333
https://www.hwbms.com/web/qna/161196
http://postesari.com/index.php/component/k2/itemlist/user/35950
http://bitly.com/2IiXyRf
http://godeok.houseplan.kr/index.php?mid=board_HFtY66&document_srl=412847
http://bitly.com/2WOkVf6
http://barobus.kr/qna/219478
http://naksansacondo.com/?document_srl=220837
https://serverpia.co.kr/board_ucCk10/231799
http://bitly.com/2WJ6PeS
http://bitly.com/2WI97uz
http://jejucctv.co.kr/A5/132228
http://callman.co.kr/index.php?mid=qa&document_srl=4363
https://betshin.com/Story/309711
http://forums.abs-cbn.com/welcome-back-kapamilya%21/oa-maeka-o-2-eo-8-e-c9-03-06-2019-oa-maeka-o-2-eo-8-e/?PHPSESSID=hiibfusltrs066hs2rvjhpmlj6
http://bitly.com/2WJ6KI6
http://www.lgue.co.kr/lgue05/365122
http://www.leekeonsu-csi.com/index.php?mid=community7&document_srl=1478738
http://bitly.com/2IiX9yd
http://gyeomright.dothome.co.kr/index.php?mid=guest&document_srl=28214
http://dreamplusart.com/mn03_01/287983
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-gt8b-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-15/
http://beautypouch.net/index.php?mid=board_09&document_srl=238599
http://bitly.com/2IiX3Xn
https://serverpia.co.kr/board_ucCk10/190894
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=64652
http://beautypouch.net/index.php?mid=board_09&document_srl=331731
http://forums.abs-cbn.com/welcome-back-kapamilya%21/oa-maeka-o-2-eo-1-e-$-a3-03-06-2019-oa-maeka-o-2-eo-1-e/?PHPSESSID=kuh4uvfl3u5s3f3q49mnr5otj3
http://forums.abs-cbn.com/welcome-back-kapamilya%21/oa-maeka-o-2-eo-1-e-(-h9-03-06-2019-oa-maeka-o-2-eo-1-e/?PHPSESSID=6nb6ohmka94gje2pri9rro4ca4
http://forums.abs-cbn.com/welcome-back-kapamilya%21/oa-maeka-o-2-eo-4-e-j0-03-06-2019-oa-maeka-o-2-eo-4-e/?PHPSESSID=f10ii66ja8rc4dgkk8s6r1p5m3
http://highlanderonline.cmshelplive.net/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b0%d1%8f-%d0%bc%d0%b0%d0%bb%d0%b5%d0%bd%d1%8c%d0%ba%d0%b0%d1%8f-%d0%bb%d0%be%d0%b6%d1%8c-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-3-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-12/
http://highlanderonline.cmshelplive.net/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b0%d1%8f-%d0%bc%d0%b0%d0%bb%d0%b5%d0%bd%d1%8c%d0%ba%d0%b0%d1%8f-%d0%bb%d0%be%d0%b6%d1%8c-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-17/
http://highlanderonline.cmshelplive.net/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b0%d1%8f-%d0%bc%d0%b0%d0%bb%d0%b5%d0%bd%d1%8c%d0%ba%d0%b0%d1%8f-%d0%bb%d0%be%d0%b6%d1%8c-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-18/
http://highlanderonline.cmshelplive.net/%d0%b1%d0%be%d0%bb%d1%8c%d1%88%d0%b0%d1%8f-%d0%bc%d0%b0%d0%bb%d0%b5%d0%bd%d1%8c%d0%ba%d0%b0%d1%8f-%d0%bb%d0%be%d0%b6%d1%8c-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-7-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-20/
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=69840
http://p9912.cafe24.com/board_LVgu51/139818
http://p9912.cafe24.com/board_LVgu51/139849
http://www.ekemoon.com/267841/060520191904/
http://www.ekemoon.com/267855/060520192404/
http://www.ekemoon.com/267885/060520193304/
https://blossomug.com/index.php/component/k2/itemlist/user/1162835
https://intelogist2.wpengine.com/%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-de9f-%d1%84%d0%b8%d1%82%d0%bd%d0%b5%d1%81-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16/
http://hotelnomadpalace.com/?option=com_k2&view=itemlist&task=user&id=24619
https://prosto-vkus.ru/?option=com_k2&view=itemlist&task=user&id=37979
http://www.ekemoon.com/267891/060520193504/
http://www.ekemoon.com/267895/060520193604/
http://www.ekemoon.com/267897/060520193604/
http://www.ekemoon.com/267899/060520193604/
http://www.ekemoon.com/267903/060520193704/
http://www.ekemoon.com/267921/060520194104/
http://dohairbiz.com/en/component/k2/itemlist/user/2844767.html
https://agrorestart.ba/index.php/component/k2/itemlist/user/8257
http://www.telcon.gr/?option=com_k2&view=itemlist&task=user&id=136345
http://bitly.com/2WOkWzG
http://bitly.com/2WJ6KYC
http://xn----ww7ew4ej4kbwk62duk50be6b854f.com/?document_srl=207635
http://cwon.kr/xe/board_bnSr36/401164
http://www.vamoscontigo.org/Noticia/260254
http://www.bb-room.ru/index.php/component/k2/itemlist/user/15994
http://bitly.com/2IanUEY
http://cwon.kr/xe/board_bnSr36/408516
http://ye-dream.com/qa/309296
https://ethernetcommunications.co.uk/index.php/en/component/k2/itemlist/user/1263549
http://askpharm.net/board_NQiz06/288513
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=861066
http://mtvenvironmental.com.au/?option=com_k2&view=itemlist&task=user&id=620520
http://roikjer.com/forum/index.php?PHPSESSID=107ha3nhsuu49qv5qth0sut907&topic=1051703.0
http://dcasociados.eu/component/k2/itemlist/user/102041
https://altaylarteknoloji.com/index.php?topic=25260.0
http://p9912.cafe24.com/board_LVgu51/687105
http://gtupuw.org/index.php/component/k2/itemlist/user/2158360
http://mobility-corp.com/index.php/component/k2/itemlist/user/2793764
http://postesari.com/?option=com_k2&view=itemlist&task=user&id=60430
http://esperanzazubieta.com/index.php/component/k2/itemlist/user/125354
https://altaylarteknoloji.com/index.php?topic=24968.0
https://prosto-vkus.ru/?option=com_k2&view=itemlist&task=user&id=38021
http://studiokoon.net/board_tzri25/1115
http://www.bb-room.ru/index.php/component/k2/itemlist/user/21322
https://hackersuniversity.net/index.php?topic=88726.0
http://www.tessabannampad.go.th/webboard/index.php?topic=258934.0
http://poselokgribovo.ru/forum/index.php?topic=888092.0
http://projectcva.dothome.co.kr/c_com/157073
http://mediaville.me/index.php/component/k2/itemlist/user/476548
http://e-educ.net/Forum/index.php?topic=53850.0
http://mediaville.me/?option=com_k2&view=itemlist&task=user&id=536498
http://smartacity.com/component/k2/itemlist/user/176430
http://lavaggio.com.vn/?option=com_k2&view=itemlist&task=user&id=4093243
http://yousub.netsons.org/index.php/component/k2/itemlist/user/93652
http://dcasociados.eu/component/k2/itemlist/user/102170
http://divespace.co.kr/board/816629
http://poselokgribovo.ru/forum/index.php?topic=890385.0
http://mtvenvironmental.com.au/index.php/component/k2/itemlist/user/632831
http://www.dap.com.py/?option=com_k2&view=itemlist&task=user&id=878836
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/222318
http://postesari.com/?option=com_k2&view=itemlist&task=user&id=59792
http://mtvenvironmental.com.au/?option=com_k2&view=itemlist&task=user&id=649116
http://poselokgribovo.ru/forum/index.php?topic=889809.0
http://yoriyorifood.com/xxxx/?document_srl=2108935
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3610636
http://5starcoffee.co.kr/?document_srl=273028
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=96109
http://divespace.co.kr/board/822448
https://sto54.ru/?option=com_k2&view=itemlist&task=user&id=3847022
http://rudraautomation.com/index.php/component/k2/author/467230
http://instituteforcaregiversgh.com/?option=com_k2&view=itemlist&task=user&id=25739
http://www.atab.com.sa/index.php/en/component/k2/itemlist/user/1843463
http://smartacity.com/component/k2/itemlist/user/179129
http://www.minikami.it/?option=com_k2&view=itemlist&task=user&id=5255325
http://withinfp.sakura.ne.jp/eso/index.php/18155712-rasskaz-sluzanki-3-sezon-2-seria-molw-rasskaz-sluzanki-3-sezon-/0
http://www.siirtorganik.com/?option=com_k2&view=itemlist&task=user&id=1020405
http://nyutusonsafaris.com/index.php/component/k2/itemlist/user/208154
http://gtupuw.org/index.php/component/k2/itemlist/user/2163272
https://turimex.mx.solemti.net/?option=com_k2&view=itemlist&task=user&id=35620
http://www.remify.app/foro/index.php?topic=478579.0
https://alquilervideobeam.com.co/index.php/component/k2/itemlist/user/65091
http://www.remify.app/foro/index.php?topic=479728.0
http://ovotecegg.com/component/k2/itemlist/user/323088
https://agrorestart.ba/?option=com_k2&view=itemlist&task=user&id=18506
http://dsyang.com/board_Kvgn62/378012
http://p9912.cafe24.com/board_LVgu51/685665
http://p9912.cafe24.com/board_LVgu51/673992
http://projectcva.dothome.co.kr/c_com/159963
http://www.ats-ottagono.it/?option=com_k2&view=itemlist&task=user&id=1665538
https://agrorestart.ba/?option=com_k2&view=itemlist&task=user&id=13890
http://iymc.or.kr/pds/699773
https://hackersuniversity.net/index.php?topic=92151.0
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=83870
https://bcit-tmgt.com/viewtopic.php?f=2&t=70328&view=print
https://hackersuniversity.net/index.php?topic=91934.0
http://mtvenvironmental.com.au/component/k2/itemlist/user/676003
http://www.itosm.com/cn/board_nLoq17/1258806
https://mcsetup.tk/bbs/index.php?topic=284175.0
http://thanosakademi.com/index.php?topic=188030.0
http://divespace.co.kr/board/821312
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=93163
https://verdadesbiblicas.org.ec/index.php/component/k2/itemlist/user/3993832
http://adrianaafonso.com.br/?option=com_k2&view=itemlist&task=user&id=2991200
http://erhu.eu/viewtopic.php?t=511817
https://khuyenmaikk13.info/index.php?topic=265415.0
http://yoriyorifood.com/xxxx/spacial/2055967
http://sdsn.develop.cinfores.com/index.php/component/k2/itemlist/user/348716
http://umm-samb.com/index.php/component/k2/itemlist/user/439979
http://wigalseguros.com.br/?option=com_k2&view=itemlist&task=user&id=97515
http://imfl.sci.pfu.edu.ru/forum/index.php?topic=44494.0
http://dohairbiz.com/en/component/k2/itemlist/user/2896720.html
https://www.2ayes.com/24116/3-2-bhjn-3-2-hbo
http://roikjer.com/forum/index.php?topic=1057502.0
http://www.supergondolas.com.br/?option=com_k2&view=itemlist&task=user&id=207782
https://hackersuniversity.net/index.php?topic=91338.0
http://adrianaafonso.com.br/index.php/component/k2/itemlist/user/3128026
https://www.amazingworldtop.com/entretenimiento/%d0%b2%d0%b5%d0%bb%d0%b8%d0%ba%d0%be%d0%bb%d0%b5%d0%bf%d0%bd%d0%b0%d1%8f-%d0%bf%d1%8f%d1%82%d1%91%d1%80%d0%ba%d0%b0-33-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-ja9%d0%b2%d0%b5%d0%bb%d0%b8%d0%ba%d0%be/
http://xplorefitness.com/blog/%C2%AB%D0%B2%D0%B5%D0%BB%D0%B8%D0%BA%D0%BE%D0%BB%D0%B5%D0%BF%D0%BD%D0%B0%D1%8F-%D0%BF%D1%8F%D1%82%D1%91%D1%80%D0%BA%D0%B0-16-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-%D1%81%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C-%C2%AB%D0%B2%D0%B5%D0%BB%D0%B8%D0%BA%D0%BE%D0%BB%D0%B5%D0%BF%D0%BD%D0%B0%D1%8F-%D0%BF%D1%8F%D1%82%D1%91%D1%80%D0%BA%D0%B0-16-%D1%81%D0%B5%D1%80%D0%B8%D1%8F%C2%BB-0
http://www.aracne.biz/?option=com_k2&view=itemlist&task=user&id=5144903
http://smartacity.com/component/k2/itemlist/user/180851
http://forum.elexlabs.com/index.php?topic=124921.0
http://www.cnsmaker.net/xe/?document_srl=273491
http://gusinoepero.ru/archives/66592
http://www.emrabq8.com/?option=com_k2&view=itemlist&task=user&id=1922767
https://prelease.club/%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b7-%d1%81%d0%bb%d1%83%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-6-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-hwui-%d1%80%d0%b0%d1%81/
http://businesshous.ru/?option=com_k2&view=itemlist&task=user&id=50935
http://mtvenvironmental.com.au/?option=com_k2&view=itemlist&task=user&id=644543
http://kockazatkutato.hu/?option=com_k2&view=itemlist&task=user&id=93626
http://asin.itts.co.kr/board_rtXs84/296139
https://www.2ayes.com/24411/13-14-06-2019-q1-13
http://atrosell.com/index.php/component/k2/itemlist/user/34091
http://www.khampia.go.th/board/show_webboard_question_detial.php?wqid=MDAwMTQ5&s_page=0
http://web.tuat.ac.jp/~morichan/cgi-bin/spboard/board.cgi?id=naibu&action=view&gul=391&page=1&go_cnt=0
http://mypaper.pchome.com.tw/f88tw
http://mypaper.pchome.com.tw/f88tw/P1
http://mypaper.pchome.com.tw/f88tw/post/1379131888
http://mypaper.pchome.com.tw/f88tw/post/1378915496
http://mypaper.pchome.com.tw/f88tw/post/1377153372
http://mypaper.pchome.com.tw/f88tw/post/1376815127
http://mypaper.pchome.com.tw/f88tw/post/1376478820
http://mypaper.pchome.com.tw/f88tw/post/1376374671
http://mypaper.pchome.com.tw/f88tw/post/1374349018
http://mypaper.pchome.com.tw/f88tw/post/1374353877
http://mypaper.pchome.com.tw/f88tw/post/1373187437
http://mypaper.pchome.com.tw/f88tw/post/1371719766
http://mypaper.pchome.com.tw/f88tw/post/1370868817
http://mypaper.pchome.com.tw/f88tw/post/1370804491
http://mypaper.pchome.com.tw/f88tw/post/1370927756
http://mypaper.pchome.com.tw/f88tw/post/1370961380
http://mypaper.pchome.com.tw/f88tw/post/1370901511
http://mypaper.pchome.com.tw/f88tw/post/1370821089
http://mypaper.pchome.com.tw/f88tw/post/1370820567
http://mypaper.pchome.com.tw/f88tw/post/1370820447
http://mypaper.pchome.com.tw/f88tw/post/1370820408
http://mypaper.pchome.com.tw/f88tw/post/1370815618
http://mypaper.pchome.com.tw/f88tw/post/1370781143
Wacoal http://mypaper.pchome.com.tw/f88tw/post/1370961380
http://mypaper.pchome.com.tw/f88tw
http://mypaper.pchome.com.tw/f88tw/P1
http://mypaper.pchome.com.tw/f88tw/post/1379131888
http://mypaper.pchome.com.tw/f88tw/post/1378915496
http://mypaper.pchome.com.tw/f88tw/post/1377153372
http://mypaper.pchome.com.tw/f88tw/post/1376815127
http://mypaper.pchome.com.tw/f88tw/post/1376478820
http://mypaper.pchome.com.tw/f88tw/post/1376374671
http://mypaper.pchome.com.tw/f88tw/post/1374349018
http://mypaper.pchome.com.tw/f88tw/post/1374353877
http://mypaper.pchome.com.tw/f88tw/post/1373187437
http://mypaper.pchome.com.tw/f88tw/post/1371719766
http://mypaper.pchome.com.tw/f88tw/post/1370868817
http://mypaper.pchome.com.tw/f88tw/post/1370804491
http://mypaper.pchome.com.tw/f88tw/post/1370927756
http://mypaper.pchome.com.tw/f88tw/post/1370961380
http://mypaper.pchome.com.tw/f88tw/post/1370901511
http://mypaper.pchome.com.tw/f88tw/post/1370821089
http://mypaper.pchome.com.tw/f88tw/post/1370820567
http://mypaper.pchome.com.tw/f88tw/post/1370820447
http://mypaper.pchome.com.tw/f88tw/post/1370820408
http://mypaper.pchome.com.tw/f88tw/post/1370815618
http://mypaper.pchome.com.tw/f88tw/post/1370781143
http://mypaper.m.pchome.com.tw/f88tw/post/1370781143
Wacoal http://mypaper.pchome.com.tw/f88tw/post/1370961380
http://www.allheartattack.com/board/--1--4----------2020----seriya-8533%7Eq.html
https://80.26.155.59/mediawiki/index.php/Usuario:TiaraHickson0
http://spaceforums.org/showthread.php?tid=42497&pid=163083#pid163083
http://www.txexla.fraserphysics.com/index.php?title=%D0%A1%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C_%D0%A1%D0%B5%D1%80%D0%B8%D0%B0%D0%BB_2_%D0%A1%D0%B5%D0%B7%D0%BE%D0%BD_1_%D0%A1%D0%B5%D1%80%D0%B8%D1%8F_%D0%9A%D1%80%D0%B5%D0%BF%D0%BE%D1%81%D1%82%D0%BD%D0%B0%D1%8F_2_%D0%A1%D0%B5%D0%B7%D0%BE%D0%BD_1_%D0%A1%D0%B5%D1%80%D0%B8%D1%8F_%D0%A1%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C_%D0%9E%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD.
http://munarq.minculturas.gob.bo/?option=com_k2&view=itemlist&task=user&id=481736
http://delawarefleamarkets.com/delmarvaclassifieds/2020/03/04/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%82%d1%80%d0%b8%d0%b3%d0%b3%d0%b5%d1%80-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%be%d0%bd%d0%bb%d0%b0%d0%b9%d0%bd-3/
http://cqa.com.co/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d0%b3%d1%80%d0%b0%d0%bd%d0%b4-3-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b3%d1%80%d0%b0%d0%bd%d0%b4-3-%d1%81%d0%b5%d0%b7%d0%be-2/
http://otdelka-msk.net/forum/viewtopic.php?pid=634795#p634795
https://bs-rpg.com/forum/index.php?topic=6757.0
http://www.renasub.it/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%82%d1%8b-%d1%80%d0%b0%d1%81%d1%81%d0%ba%d0%b0%d0%b6%d0%b8-%d0%ba%d0%b0%d1%80%d0%b0%d0%b4%d0%b5%d0%bd%d0%b8%d0%b7-66-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-2/
http://mcdonogh35archive.com/index.php?title=User:JerilynO29
https://www.recmixmast.com/phpBB3/viewtopic.php?f=11&t=24532
https://bs-rpg.com/forum/index.php?topic=7517.0
https://sydneyfriendship.website/?p=101798
http://www.wiki-peps.fr/mediawiki/index.php/Utilisateur:KaylaDarosa4263
http://wiki-intel.org/index.php?title=Usuario:IonaLow4124
https://blakesector.scumvv.ca/index.php?title=%C3%90%C5%BE%C3%90%C2%BD%C3%90%C2%BB%C3%90%C2%B0%C3%90%C2%B9%C3%90%C2%BD_%C3%90%C2%A1%C3%90%C2%B5%C3%91%E2%82%AC%C3%90%C2%B8%C3%90%C2%B0%C3%90%C2%BB_%22%C3%90%C3%A2%E2%82%AC%E2%84%A2%C3%90%C2%B5%C3%91%E2%80%9A%C3%91%E2%82%AC%C3%90%C2%B5%C3%90%C2%BD%C3%91%E2%80%B9%C3%90%C2%B9_35_%C3%90%C2%A1%C3%90%C2%B5%C3%91%E2%82%AC%C3%90_%C3%90%C3%90%C2%B0_%C3%90_%C3%91%C6%92%C3%91%C3%91%C3%90%C2%BA%C3%90%C2%BE%C3%90%C2%BC.
https://pozyskajdotacje.pl/hello-world/?unapproved=98585&moderation-hash=b6c25b7653e6b6536937bf51b51b5076#comment-98585
http://www.serymark.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d0%bf%d1%80%d0%b0%d0%b2%d0%b0-%d0%bd%d0%b0-%d0%bf%d1%80%d0%b5%d1%81%d1%82%d0%be%d0%bb-%d0%b0%d0%b1%d0%b4%d1%83%d0%bb%d1%85%d0%b0%d0%bc%d0%b8%d0%b4-94/
http://www.serymark.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%82%d1%80%d0%b8%d0%b3%d0%b3%d0%b5%d1%80-%d0%bf%d0%b5%d1%80%d0%b2%d1%8b%d0%b9-%d0%ba%d0%b0%d0%bd%d0%b0%d0%bb-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-75/
http://www.wiki-peps.fr/mediawiki/index.php/Utilisateur:KatharinaSlocum
https://a-s1.aspirationhosting.com/smf/index.php?topic=178118.0
http://www.txexla.fraserphysics.com/index.php?title=User:TaraGrimm506611
http://godigitalpromote.com/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d0%bd%d0%b5%d0%b2%d1%81%d0%ba%d0%b8%d0%b9-%d1%82%d0%b5%d0%bd%d1%8c-%d0%b0%d1%80%d1%85%d0%b8%d1%82%d0%b5%d0%ba%d1%82%d0%be%d1%80%d0%b0-4-%d1%81%d0%b5%d0%b7-112/
https://www.hotrodders.com/tw/index.php/User:EltonProbst
http://www.renasub.it/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d0%b6%d0%b5%d0%bd%d1%81%d0%ba%d0%b8%d0%b5-%d1%81%d0%b5%d0%ba%d1%80%d0%b5%d1%82%d1%8b-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-12-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-10/
http://www.serymark.com/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-35-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82-26/
https://www.raidcontrol.com/index.php?title=%C3%90%C2%A1%C3%90%E2%80%A2%C3%90_%C3%90%CB%9C%C3%90%C3%90%E2%80%BA_2020_15_%C3%90%C2%A1%C3%90%C2%B5%C3%91%E2%82%AC%C3%90%C2%B8%C3%91_%C3%90%C2%A2%C3%91%E2%82%AC%C3%90%C2%B8%C3%90%C2%B3%C3%90%C2%B3%C3%90%C2%B5%C3%91%E2%82%AC_2020_15_%C3%90%C2%A1%C3%90%C2%B5%C3%91%E2%82%AC%C3%90%C2%B8%C3%91_%C3%90%C3%A2%E2%82%AC%E2%84%A2_%C3%90%C2%A5%C3%90%C2%BE%C3%91%C3%90%C2%BE%C3%91%CB%86%C3%90%C2%B5%C3%90%C2%BC_%C3%90%C5%A1%C3%90%C2%B0%C3%91%E2%80%A1%C3%90%C2%B5%C3%91%C3%91%E2%80%9A%C3%90%C2%B2%C3%90%C2%B5
https://a-s1.aspirationhosting.com/smf/index.php?topic=179241.0
http://godigitalpromote.com/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%82%d1%80%d0%b8%d0%b3%d0%b3%d0%b5%d1%80-%d0%bf%d0%b5%d1%80%d0%b2%d1%8b%d0%b9-%d0%ba%d0%b0%d0%bd%d0%b0%d0%bb-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b2-%d1%85/
https://www.raidcontrol.com/index.php?title=User:IsabelleWoodard
http://www.engapsrl.com/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-17-%d1%81%d0%b5%d1%80%d0%b8%d1%8f%d1%82%d1%80%d0%b8%d0%b3%d0%b3%d0%b5%d1%80-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-17-%d1%81-5/
http://www.wiki-peps.fr/mediawiki/index.php/Utilisateur:ZaneSwinburne
http://tonse.ir/?option=com_k2&view=itemlist&task=user&id=256313
http://tangoyatra.com/?option=com_k2&view=itemlist&task=user&id=499044
http://www.serymark.com/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d0%be%d0%bd%d0%bb%d0%b0%d0%b9%d0%bd-%d1%81%d0%be%d0%b4%d0%b5%d1%80%d0%b6%d0%b0%d0%bd%d0%ba%d0%b8-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2020-5-%d1%81-13/
https://www.isjetikirala.com/component/k2/itemlist/user/30267.html
https://n-sb.org/wiki/index.php?title=%D0%A1%D0%9C%D0%9E%D0%A2%D0%A0%D0%95%D0%A2%D0%AC_%D0%96%D0%B5%D0%BD%D1%81%D0%BA%D0%B8%D0%B5_%D0%A1%D0%B5%D0%BA%D1%80%D0%B5%D1%82%D1%8B_1_%D0%A1%D0%B5%D0%B7%D0%BE%D0%BD_10_%D0%A1%D0%B5%D1%80%D0%B8%D1%8F_%D1%81%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C_%D0%9E%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD
https://80.26.155.59/mediawiki/index.php/%D0%A1%D0%B5%D1%80%D0%B8%D0%B0%D0%BB_%22%D0%A1%D0%BE%D0%B4%D0%B5%D1%80%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8_2_%D0%A1%D0%B5%D0%B7%D0%BE%D0%BD_2020_9_%D0%A1%D0%B5%D1%80%D0%B8%D1%8F%22_%D1%81%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C_%D0%9E%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD_2020_.
http://wiki-intel.org/index.php?title=Usuario:KerriMansell11
http://www.carlodesantis.it/%d0%be%d0%bd%d0%bb%d0%b0%d0%b9%d0%bd-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d0%b2%d0%b5%d1%82%d1%80%d0%b5%d0%bd%d1%8b%d0%b9-2-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-36-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81-7/
https://wikilights.org/index.php?title=%D0%A0%D0%B8%D0%B2%D0%B5%D1%80%D0%B4%D0%B5%D0%B9%D0%BB_4_%D0%A1%D0%B5%D0%B7%D0%BE%D0%BD_15_%D0%A1%D0%B5%D1%80%D0%B8%D1%8F_%D0%9B%D0%BE%D1%81%D1%82%D1%84%D0%B8%D0%BB%D1%8C%D0%BC_%D0%A1%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C_%C2%AB%D0%A0%D0%B8%D0%B2%D0%B5%D1%80%D0%B4%D1%8D%D0%B9%D0%BB_4_%D0%A1%D0%B5%D0%B7%D0%BE%D0%BD_15_%D0%A1%D0%B5%D1%80%D0%B8%D1%8F%C2%BB.
http://wiki-intel.org/index.php?title=%D0%A1%D0%B5%D1%80%D0%B8%D0%B0%D0%BB_%D0%A1%D0%BE%D0%B4%D0%B5%D1%80%D0%B6%D0%B0%D0%BD%D0%BA%D0%B8_2_%D0%A1%D0%B5%D0%B7%D0%BE%D0%BD_5_%D0%A1%D0%B5%D1%80%D0%B8%D1%8F_%D1%81%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C_%D0%9E%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD_.
http://help.stv.ru/index.php?PHPSESSID=cfff4027336fe427019d86e94f15b609&topic=512332.0
https://sydneyfriendship.website/?p=105626
http://www.wiki-peps.fr/mediawiki/index.php/Utilisateur:AutumnMealmaker
http://boaodontologia.com.br/?option=com_k2&view=itemlist&task=user&id=57360
http://forum.worldsex.wiki/index.php?topic=169587.0
http://www.carlodesantis.it/%d1%88%d0%be%d1%83-%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-7-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-2-%d0%b2%d1%8b%d0%bf%d1%83%d1%81%d0%ba-08-03-2020-%d0%b2%d1%81%d0%b5-%d1%81%d0%b5%d1%80%d0%b8-2/
http://mcdonogh35archive.com/index.php?title=%D0%A1%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C_%D0%A1%D0%B5%D1%80%D0%B8%D0%B0%D0%BB_%D0%94%D0%BE%D1%87%D1%8C_%D0%9F%D0%BE%D1%81%D0%BB%D0%B0_12_%D0%A1%D0%B5%D1%80%D0%B8%D1%8F_%D0%94%D0%BE%D1%87%D1%8C_%D0%9F%D0%BE%D1%81%D0%BB%D0%B0_12_%D0%A1%D0%B5%D1%80%D0%B8%D1%8F_%D0%A0%D1%83%D1%81%D1%81%D0%BA%D0%B0%D1%8F_%D0%9E%D0%B7%D0%B2%D1%83%D1%87%D0%BA%D0%B0
http://dlict.tecs4.com/webboard/index.php?topic=76467.0
https://www.showgaloo.com/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d0%be%d1%82%d1%80%d0%b5%d1%87%d0%b5%d0%bd%d0%b8%d0%b5-%d0%b7%d1%80%d0%b5%d1%87%d0%b5%d0%bd%d0%bd%d1%8f-22-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be/
http://godigitalpromote.com/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d0%b2%d0%be%d0%b9%d0%bd%d0%b0-%d1%81%d0%b5%d0%bc%d0%b5%d0%b9-1-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-16-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d0%b2%d0%be%d0%b9%d0%bd%d0%b0-9/
http://forum.worldsex.wiki/index.php?topic=158742.0
http://www.renasub.it/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d1%81%d0%b2%d1%8f%d0%b7%d0%b8-%d1%80%d0%be%d0%b4%d0%b8%d0%bd%d0%bdi-%d0%b7%d0%b2%d1%8f%d0%b7%d0%ba%d0%b8-2-14/
http://www.carlodesantis.it/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d0%b2%d0%be%d1%81%d1%81%d0%be%d0%b5%d0%b4%d0%b8%d0%bd%d0%b5%d0%bd%d0%b8%d0%b5-44-%d1%81%d0%b5%d1%80%d0%b8-11/
http://www.renasub.it/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d0%bd%d0%b5%d0%b2%d1%81%d0%ba%d0%b8%d0%b9-%d1%82%d0%b5%d0%bd%d1%8c-%d0%b0%d1%80%d1%85%d0%b8%d1%82%d0%b5%d0%ba%d1%82%d0%be%d1%80%d0%b0-4-%d1%81-189/
http://xposdgroup.co.uk/video/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-10-%d1%81%d0%b5%d0%b7%d0%be%d0%bd-1-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d1%82%d0%b1%d1%85%d0%be%d0%bb%d0%be%d1%81%d1%82%d1%8f%d0%ba-10-%d1%81%d0%b5/
https://ladakhwanderlandtour.com/?p=34869
http://www.renasub.it/%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d0%bd%d0%b5%d0%b2%d1%81%d0%ba%d0%b8%d0%b9-%d1%82%d0%b5%d0%bd%d1%8c-%d0%b0%d1%80%d1%85%d0%b8%d1%82%d0%b5%d0%ba%d1%82%d0%be%d1%80%d0%b0-4-%d1%81-180/
http://www.serymark.com/%d1%82%d1%83%d1%80%d0%b5%d1%86%d0%ba%d0%b8%d0%b9-%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d0%be%d1%81%d0%bd%d0%be%d0%b2%d0%b0%d0%bd%d0%b8%d0%b5-%d0%be%d1%81%d0%bc%d0%b0%d0%bd%d0%b0-13-%d1%81%d0%b5-415/
http://wiki-intel.org/index.php?title=Usuario:GertrudeFitzGibb
http://www.wiki-peps.fr/mediawiki/index.php/Utilisateur:DoreenBlaylock
https://sunnysidestudios.com/%d1%81%d0%b5%d1%80%d0%b8%d0%b0%d0%bb-%d0%bf%d0%b0%d1%82%d1%80%d0%b8%d0%be%d1%82-11-%d1%81%d0%b5%d1%80%d0%b8%d1%8f-%d1%81%d0%bc%d0%be%d1%82%d1%80%d0%b5%d1%82%d1%8c-%d0%be%d0%bd%d0%bb%d0%b0%d0%b9-3/
http://wiki-intel.org/index.php?title=Usuario:CaraMarshburn
http://treeads.nation2.com/
https://jumperads.yolasite.com/
http://jumperads.nation2.com/
http://transferefurniture.hatenablog.com
https://allmoversinriyadh.wordpress.com/
https://companymoversinjeddah.wordpress.com/
https://moversfurniture2018.wordpress.com/
https://moversriyadhcom.wordpress.com/
https://moversmedina.wordpress.com/
https://moversfurniture2018.wordpress.com/
<a href="https://companymoversinjeddah.wordpress.com/">شركات نقل عفش واثاث بجدة</a>
<a href="https://companymoversinjeddah.wordpress.com/2019/02/16/%d8%b4%d8%b1%d9%83%d8%a7%d8%aa-%d9%86%d9%82%d9%84-%d8%b9%d9%81%d8%b4-%d9%88%d8%a7%d8%ab%d8%a7%d8%ab-%d8%a8%d8%a7%d9%84%d8%b7%d8%a7%d8%a6%d9%81-%d8%af%d9%8a%d9%86%d8%a7-%d8%af%d8%a8%d8%a7%d8%a8-%d9%86/">شركات نقل عفش بالطائف</a>
<a href="https://companymoversinjeddah.wordpress.com/2019/02/15/%d8%a7%d8%b3%d8%b9%d8%a7%d8%b1-%d9%88%d8%a7%d8%b1%d9%82%d8%a7%d9%85-%d8%b4%d8%b1%d9%83%d8%a7%d8%aa-%d9%86%d9%82%d9%84-%d8%a7%d9%84%d8%b9%d9%81%d8%b4-%d8%a8%d8%a7%d9%84%d9%85%d8%af%d9%8a%d9%86%d8%a9/">اسعار وارقام شركات نقل العفش بالمدينة المنورة</a>
<a href="https://companymoversinjeddah.wordpress.com/2019/02/15/%d8%af%d9%8a%d9%86%d8%a7-%d9%86%d9%82%d9%84-%d8%b9%d9%81%d8%b4-%d8%ac%d8%af%d8%a9-%d8%a7%d9%81%d8%b6%d9%84-%d8%af%d9%8a%d9%86%d8%a7/">دينا نقل عفش جدة ,افضل دينا</a>
<a href="https://companymoversinjeddah.wordpress.com/2019/02/15/%d8%a7%d8%b1%d8%ae%d8%b5-%d8%b4%d8%b1%d9%83%d9%87-%d9%86%d9%82%d9%84-%d8%b9%d9%81%d8%b4-%d8%a8%d8%ac%d8%af%d9%87-%d8%a7%d8%b3%d8%b9%d8%a7%d8%b1-%d9%81%d8%b5%d9%84-%d8%a7%d9%84%d8%b4%d8%aa%d8%a7%d8%a1/">ارخص شركه نقل عفش بجده</a>
<a href="https://companymoversinjeddah.wordpress.com/2019/02/15/%d8%af%d9%84%d9%8a%d9%84-%d8%b4%d8%b1%d9%83%d8%a7%d8%aa-%d9%86%d9%82%d9%84-%d8%a7%d9%84%d8%b9%d9%81%d8%b4-%d8%a8%d8%ac%d8%af%d8%a9-%d9%85%d8%b9-%d8%ae%d8%b5%d9%88%d9%85%d8%a7%d8%aa/">دليل شركات نقل العفش بجدة</a>
<a href="https://companymoversinjeddah.wordpress.com/2019/02/15/%d8%b4%d8%b1%d9%83%d8%a9-%d9%86%d9%82%d9%84-%d8%b9%d9%81%d8%b4-%d8%a8%d8%b1%d8%a7%d8%a8%d8%ba-15-%d8%b9%d8%a7%d9%85-%d8%ae%d8%a8%d8%b1%d8%a9/">شركة نقل عفش برابغ ,15 عام خبرة</a>
<a href="https://companymoversinjeddah.wordpress.com/2018/12/12/%d8%b4%d8%b1%d9%83%d8%a7%d8%aa-%d9%86%d9%82%d9%84-%d8%b9%d9%81%d8%b4-%d9%88%d8%a7%d8%ab%d8%a7%d8%ab-%d8%a8%d8%a7%d9%84%d8%a8%d8%a7%d8%ad%d9%87/">شركات نقل عفش واثاث بالباحه</a>
<a href="https://companymoversinjeddah.wordpress.com/2018/12/12/start-moving-company-to-khamis-mushit/">وسائل نقل العفش بخميس مشيط</a>
اهم شركات كشف تسربات المياه بالدمام كذلك معرض اهم شركة مكافحة حشرات بالدمام والخبر والجبيل والخبر والاحساء والقطيف كذكل شركة تنظيف خزانات بجدة وتنظيف بجدة ومكافحة الحشرات بالخبر وكشف تسربات المياه بالجبيل والقطيف والخبر والدمام
http://emc-mee.com/tanks-cleaning-company-jeddah.html شركة تنظيف خزانات بجدة
http://emc-mee.com/water-leaks-detection-isolate-company-dammam.html شركة كشف تسربات المياه بالدمام
http://emc-mee.com/anti-insects-company-dammam.html شركة مكافحة حشرات بالدمام
http://emc-mee.com/tanks-cleaning-company-jeddah.html شركة تنظيف خزانات بجدة
http://emc-mee.com/ شركة نقل عفش واثاث
http://emc-mee.com/movers-in-riyadh-company.html شركة نقل اثاث بالرياض
http://emc-mee.com/transfer-furniture-jeddah.html شركة نقل عفش بجدة
http://emc-mee.com/transfer-furniture-dammam.html شركة نقل عفش بالدمام
http://emc-mee.com/transfer-furniture-almadina-almonawara.html شركة نقل عفش بالمدينة المنورة
http://emc-mee.com/transfer-furniture-taif.html شركة نقل عفش بالطائف
http://emc-mee.com/transfer-furniture-mecca.html شركة نقل عفش بمكة
اهم شركات نقل العفش والاثاث بالدمام والخبر والجبيل اولقطيف والاحساء والرياض وجدة ومكة المدينة المنورة والخرج والطائف وخميس مشيط وبجدة افضل شركة نقل عفش بجدة نعرضها مجموعة الفا لنقل العفش بمكة والخرج والقصيم والطائف وتبوك وخميس مشيط ونجران وجيزان وبريدة والمدينة المنورة وينبع افضل شركات نقل الاثاث بالجبيل والطائف وخميس مشيط وبريدة وعنيزو وابها ونجران المدينة وينبع تبوك والقصيم الخرج حفر الباطن والظهران
http://emc-mee.com/transfer-furniture-yanbu.html شركة نقل عفش بينبع
http://emc-mee.com/transfer-furniture-buraydah.html شركة نقل عفش ببريدة
http://emc-mee.com/transfer-furniture-alkharj.html شركة نقل عفش بالخرج
http://emc-mee.com/transfer-furniture-qassim.html شركة نقل عفش بالقصيم
http://emc-mee.com/transfer-furniture-khamis-mushait.html شركة نقل عفش بخميس مشيط
http://emc-mee.com/transfer-furniture-tabuk.html شركة نقل عفش بتبوك
http://emc-mee.com/transfer-furniture-abha.html شركة نقل عفش بابها
http://emc-mee.com/transfer-furniture-najran.html شركة نقل عفش بنجران
http://emc-mee.com/transfer-furniture-hail.html شركة نقل عفش بحائل
http://emc-mee.com/transfer-furniture-dhahran.html شركة نقل عفش بالظهران
http://emc-mee.com/transfer-furniture-kuwait.html شركة نقل عفش بالكويت
http://jumperads.com/transfer-furniture-riyadh.html شركة نقل عفش بالرياض
http://jumperads.com/transfer-furniture-jeddah.html شركة نقل عفش بجدة
http://jumperads.com/transfer-furniture-dammam.html شركة نقل عفش بالدمام
http://jumperads.com/transfer-furniture-medina-almonawara.html شركة نقل عفش بالمدينة المنورة
http://jumperads.com/transfer-furniture-taif.html شركة نقل عفش بالطائف
http://jumperads.com/transfer-furniture-mecca.html شركة نقل عفش بمكة
http://jumperads.com/transfer-furniture-yanbu.html شركة نقل عفش بينبع
http://jumperads.com/transfer-furniture-in-najran.html شركة نقل عفش بنجران
http://jumperads.com/transfer-furniture-in-khamis-mushait.html شركة نقل عفش بخميس مشيط
http://jumperads.com/transfer-furniture-abha.html شركة نقل عفش بابها
http://jumperads.com/transfer-furniture-buraydah.html شركة نقل عفش ببريدة
http://jumperads.com/transfer-furniture-qassim.html شركة نقل عفش بالقصيم
http://jumperads.com/transfer-furniture-tabuk.html شركة نقل عفش بتبوك
http://jumperads.com/transfer-furniture-hail.html شركة نقل عفش بحائل
http://jumperads.com/transfer-furniture-dammam-khobar.html شركة نقل عفش بالخبر
http://jumperads.com/transfer-furniture-ahsa.html شركة نقل عفش بالاحساء
http://jumperads.com/transfer-furniture-qatif.html شركة نقل عفش بالقطيف
http://jumperads.com/transfer-furniture-jubail.html شركة نقل عفش بالجبيل
http://treeads.net/ شركة سكاي لنقل العفش
http://treeads.net/movers-mecca.html نقل عفش بمكة
http://treeads.net/movers-riyadh-company.html نقل عفش بالرياض
http://treeads.net/all-movers-madina.html نقل عفش بالمدينة المنورة
http://treeads.net/movers-jeddah-company.html نقل عفش بجدة
http://treeads.net/movers-taif.html نقل عفش بالطائف
http://treeads.net/movers-dammam-company.html نقل عفش بالدمام
http://treeads.net/movers-qatif.html نقل عفش بالقطيف
http://treeads.net/movers-jubail.html نقل عفش بالجبيل
http://treeads.net/movers-khobar.html نقل عفش بالخبر
http://treeads.net/movers-ahsa.html نقل عفش بالاحساء
http://treeads.net/movers-kharj.html نقل عفش بالخرج
http://treeads.net/movers-khamis-mushait.html نقل عفش بخميس مشيط
http://treeads.net/movers-abha.html نقل عفش بابها
http://treeads.net/movers-qassim.html نقل عفش بالقصيم
http://treeads.net/movers-yanbu.html نقل عفش بينبع
http://treeads.net/movers-najran.html نقل عفش بنجران
http://treeads.net/movers-hail.html نقل عفش بحائل
http://treeads.net/movers-buraydah.html نقل عفش ببريدة
http://treeads.net/movers-tabuk.html نقل عفش بتبوك
http://treeads.net/movers-dhahran.html نقل عفش بالظهران
http://treeads.net/movers-rabigh.html نقل عفش برابغ
http://treeads.net/movers-baaha.html نقل عفش بالباحه
http://treeads.net/movers-asseer.html نقل عفش بعسير
http://treeads.net/movers-mgmaa.html نقل عفش بالمجمعة
http://treeads.net/movers-sharora.html نقل عفش بشرورة
http://treeads.net/movers-najran.html
http://jumperads.com/yanbu/anti-insects-company-yanbu.html شركة مكافحة حشرات بينبع
http://jumperads.com/yanbu/water-leaks-detection-company-yanbu.html شركة كشف تسربات بينبع
http://jumperads.com/yanbu/yanbu-company-surfaces.html شركة عزل اسطح بينبع
http://jumperads.com/yanbu/yanbu-company-sewage.html شركة تسليك مجاري بينبع
http://jumperads.com/yanbu/yanbu-cleaning-company-sofa.html شركة تنظيف كنب بينبع
http://jumperads.com/yanbu/yanbu-cleaning-company-mosques.html شركة تنظيف مساجد بينبع
http://jumperads.com/yanbu/yanbu-cleaning-company-Carpet.html شركة تنظيف سجاد بينبع
http://jumperads.com/yanbu/yanbu-cleaning-company-tanks.html شركة تنظيف خزانات بينبع
http://jumperads.com/yanbu/yanbu-cleaning-company-swimming-bath.html شركة تنظيف وصيانة مسابح بينبع
http://jumperads.com/yanbu/yanbu-cleaning-company-Furniture.html شركة تنظيف الاثاث بينبع
http://jumperads.com/yanbu/yanbu-cleaning-company-home.html شركة تنظيف شقق بينبع
http://jumperads.com/yanbu/yanbu-cleaning-company-Carpets.html شركة تنظيف موكيت بينبع
http://jumperads.com/yanbu/yanbu-cleaning-company.html شركة تنظيف مجالس بينبع
http://jumperads.com/yanbu/yanbu-cleaning-company-house.html شركة تنظيف منازل بينبع
http://jumperads.com/yanbu/yanbu-cleaning-company-Villas.html شركة تنظيف فلل بينبع
http://jumperads.com/yanbu/yanbu-cleaning-company-curtains.html شركة تنظيف ستائر بينبع
http://jumperads.com/yanbu/yanbu-company-tile.html شركة جلي بلاط بينبع
http://www.domyate.com/2016/06/05/transfer-furniture-medina-almonawara شركة نقل عفش بالمدينة المنورة
http://www.domyate.com/2016/06/05/transfer-furniture-mecca شركة نقل عفش بمكة
http://www.domyate.com/2016/06/05/transfer-furniture-riyadh شركة نقل عفش بالرياض
http://www.domyate.com/2016/06/05/transfer-furniture-jeddah شركة نقل عفش بجدة
http://www.domyate.com/2016/06/05/transfer-furniture-taif شركة نقل عفش بالطائف
http://www.domyate.com/2016/06/05/transfer-furniture-yanbu شركة نقل عفش بينبع
http://www.domyate.com/2016/07/02/transfer-furniture-dammam شركة نقل عفش بالدمام
http://www.domyate.com/2017/08/10/movers-company-mecca-naql/
http://www.domyate.com شركة نقل عفش بالدمام
http://mycanadafitness.com/ شركة كيان لنقل العفش
http://mycanadafitness.com/forum.html منتدي نقل العفش
http://mycanadafitness.com/movingfurnitureriyadh.html شركة نقل اثاث بالرياض
http://mycanadafitness.com/movingfurniturejaddah.html شركة نقل اثاث بجدة
http://mycanadafitness.com/movingfurnituremecca.html شركة نقل اثاث بمكة
http://mycanadafitness.com/movingfurnituretaif.html شركة نقل اثاث بالطائف
http://mycanadafitness.com/movingfurnituremadina.html شركة نقل اثاث بالمدينة المنورة
http://mycanadafitness.com/movingfurnituredammam.html شركة نقل اثاث بالدمام
http://mycanadafitness.com/movingfurniturekhobar.html شركة نقل اثاث بالخبر
http://mycanadafitness.com/movingfurnituredhahran.html شركة نقل اثاث بالظهران
http://mycanadafitness.com/movingfurniturejubail.html شركة نقل اثاث بالجبيل
http://mycanadafitness.com/movingfurnitureqatif.html شركة نقل اثاث بالقطيف
http://mycanadafitness.com/movingfurnitureahsa.html شركة نقل اثاث بالاحساء
http://mycanadafitness.com/movingfurniturekharj.html شركة نقل اثاث بالخرج
http://mycanadafitness.com/movingfurniturekhamismushit.html شركة نقل اثاث بخميس مشيط
http://mycanadafitness.com/movingfurnitureabha.html شركة نقل اثاث بابها
http://mycanadafitness.com/movingfurniturenajran.html شركة نقل اثاث بنجران
http://mycanadafitness.com/movingfurniturejazan.html شركة نقل اثاث بجازان
http://mycanadafitness.com/movingfurnitureasir.html شركة نقل اثاث بعسير
http://mycanadafitness.com/movingfurniturehail.html شركة نقل اثاث بحائل
http://mycanadafitness.com/movingfurnitureqassim.html شركة نقل عفش بالقصيم
http://mycanadafitness.com/movingfurnitureyanbu.html شركة نقل اثاث بينبع
http://mycanadafitness.com/movingfurnitureburaidah.html شركة نقل عفش ببريدة
http://mycanadafitness.com/movingfurniturehafralbatin.html شركة نقل عفش بحفر الباطن
http://mycanadafitness.com/movingfurniturerabigh.html شركة نقل عفش برابغ
http://mycanadafitness.com/movingfurnituretabuk.html شركة نقل عفش بتبوك
http://mycanadafitness.com/movingfurnitureasfan.html شركة نقل عفش بعسفان
http://mycanadafitness.com/movingfurnituresharora.html شركة نقل عفش بشرورة
http://mycanadafitness.com/companis-moving-riyadh.html شركات نقل العفش بالرياض
http://mycanadafitness.com/cars-moving-riyadh.html سيارات نقل العفش بالرياض
http://mycanadafitness.com/company-number-moving-riyadh.html ارقام شركات نقل العفش بالرياض
http://mycanadafitness.com/company-moving-jeddah.html شركات نقل العفش بجدة
http://mycanadafitness.com/price-moving-jeddah.html اسعار نقل العفش بجدة
http://mycanadafitness.com/company-moving-mecca.html شركات نقل العفش بمكة
http://fullservicelavoro.com/2019/01/07/transfer-movers-taif-furniture/ شركة نقل عفش بالطائف
http://fullservicelavoro.com/2019/01/08/transfer-movers-riyadh-furniture/ شركة نقل عفش بالرياض
http://fullservicelavoro.com/2019/01/08/transfer-movers-jeddah-furniture/ شركة نقل عفش بجدة
http://fullservicelavoro.com/2019/01/01/transfer-and-movers-furniture-mecca/ شركة نقل عفش بمكة
http://fullservicelavoro.com/2019/01/07/transfer-movers-madina-furniture/ شركة نقل عفش بالمدينة المنورة
http://fullservicelavoro.com/2019/01/07/transfer-movers-khamis-mushait-furniture/ شركة نقل عفش بخميس مشيط
http://fullservicelavoro.com/2019/01/09/transfer-movers-abha-furniture/ شركة نقل اثاث بابها
http://fullservicelavoro.com/2019/01/07/transfer-movers-najran-furniture/ شركة نقل عفش بنجران
http://fullservicelavoro.com/2019/01/16/transfer-movers-hail-furniture/ ِشركة نقل عفش بحائل
http://fullservicelavoro.com/2019/01/16/transfer-movers-qassim-furniture/ شركة نقل عفش بالقصيم
http://fullservicelavoro.com/2019/02/02/transfer-movers-furniture-in-bahaa/ شركة نقل عفش بالباحة
http://fullservicelavoro.com/2019/01/13/transfer-movers-yanbu-furniture/ شركة نقل عفش بينبع
http://fullservicelavoro.com/2019/01/18/%d8%af%d9%8a%d9%86%d8%a7-%d9%86%d9%82%d9%84-%d8%b9%d9%81%d8%b4-%d8%a8%d8%a7%d8%a8%d9%87%d8%a7/ دينا نقل عفش بابها
http://fullservicelavoro.com/2019/01/13/%D9%86%D9%82%D9%84-%D8%A7%D9%84%D8%A7%D8%AB%D8%A7%D8%AB-%D8%A8%D8%A7%D9%84%D9%85%D8%AF%D9%8A%D9%86%D8%A9-%D8%A7%D9%84%D9%85%D9%86%D9%88%D8%B1%D8%A9-%D8%A7%D9%87%D9%85-%D8%B4%D8%B1%D9%83%D8%A7%D8%AA/ نقل الاثاث بالمدينة المنورة
http://fullservicelavoro.com/2019/01/12/%D8%A7%D8%B1%D8%AE%D8%B5-%D8%B4%D8%B1%D9%83%D8%A9-%D9%86%D9%82%D9%84-%D8%B9%D9%81%D8%B4-%D8%A8%D9%85%D9%83%D8%A9/ ارخص شركة نقل عفش بمكة
http://fullservicelavoro.com/2019/01/07/transfer-movers-elkharj-furniture/ شركة نقل عفش بالخرج
http://fullservicelavoro.com/2019/01/07/transfer-movers-baqaa-furniture/ شركة نقل عفش بالبقعاء
http://fullservicelavoro.com/2019/02/05/transfer-furniture-in-jazan/ شركة نقل عفش بجازان
http://transferefurniture.bcz.com/2016/08/01/%d8%b4%d8%b1%d9%83%d8%a9-%d9%86%d9%82%d9%84-%d8%b9%d9%81%d8%b4-%d8%a8%d8%a7%d9%84%d9%85%d8%af%d9%8a%d9%86%d8%a9-%d8%a7%d9%84%d9%85%d9%86%d9%88%d8%b1%d8%a9/ شركة نقل عفش بالمدينة المنورة
http://transferefurniture.bcz.com/2016/08/01/%d8%b4%d8%b1%d9%83%d8%a9-%d9%86%d9%82%d9%84-%d8%b9%d9%81%d8%b4-%d8%a8%d8%a7%d9%84%d8%af%d9%85%d8%a7%d9%85/ شركة نقل عفش بالدمام
http://transferefurniture.bcz.com/2016/07/31/%d8%b4%d8%b1%d9%83%d8%a9-%d9%86%d9%82%d9%84-%d8%b9%d9%81%d8%b4-%d8%a8%d8%a7%d9%84%d8%b1%d9%8a%d8%a7%d8%b6/ شركة نقل عفش بالرياض
http://transferefurniture.bcz.com/ شركة نقل عفش | http://transferefurniture.bcz.com/ شركة نقل اثاث بجدة | http://transferefurniture.bcz.com/ شركة نقل عفش بالرياض | http://transferefurniture.bcz.com/ شركة نقل عفش بالمدينة المنورة | http://transferefurniture.bcz.com/ شركة نقل عفش بالدمام
http://khairyayman.inube.com/blog/5015576// شركة نقل عفش بجدة
http://khairyayman.inube.com/blog/5015578// شركة نقل عفش بالمدينة المنورة
http://khairyayman.inube.com/blog/5015583// شركة نقل عفش بالدمام
http://emc-mee.jigsy.com/ شركة نقل عفش الرياض,شركة نقل عفش بجدة,شركة نقل عفش بالمدينة المنورة,شركة نقل عفش بالدمام
http://emc-mee.jigsy.com/%D8%B4%D8%B1%D9%83%D8%A9-%D9%86%D9%82%D9%84-%D8%B9%D9%81%D8%B4-%D8%A8%D8%A7%D9%84%D8%B1%D9%8A%D8%A7%D8%B6 شركة نقل عفش بالرياض
http://emc-mee.jigsy.com/%D8%B4%D8%B1%D9%83%D8%A9-%D9%86%D9%82%D9%84-%D8%A7%D8%AB%D8%A7%D8%AB-%D8%A8%D8%AC%D8%AF%D8%A9 شركة نقل اثاث بجدة
http://emc-mee.jigsy.com/%D8%B4%D8%B1%D9%83%D8%A9-%D9%86%D9%82%D9%84-%D8%B9%D9%81%D8%B4-%D8%A8%D8%A7%D9%84%D9%85%D8%AF%D9%8A%D9%86%D8%A9-%D8%A7%D9%84%D9%85%D9%86%D9%88%D8%B1%D8%A9 شركة نقل عفش بالمدينة المنورة
http://emc-mee.jigsy.com/%D8%B4%D8%B1%D9%83%D8%A9-%D9%86%D9%82%D9%84-%D8%B9%D9%81%D8%B4-%D8%A8%D8%A7%D9%84%D8%AF%D9%85%D8%A7%D9%85 شركة نقل عفش بالدمام
https://about.me/easteldmam easteldmam
http://east-eldmam.skyrock.com/ east-eldmam
http://east-eldmam.mywapblog.com/post-title.xhtml شركة نقل عفش بالدمام
http://transferefurniture.zohosites.com/ شركة نقل عفش
http://transferefurniture.hatenablog.com/ شركة نقل عفش
http://khairyayman.eklablog.com/http-emc-mee-com-transfer-furniture-almadina-almonawara-html-a126376958 شركة نقل عفش بالمدينة المنورة
http://khairyayman.eklablog.com/http-emc-mee-com-transfer-furniture-jeddah-html-a126377054 شركة نقل عفش بجدة
http://khairyayman.eklablog.com/http-emc-mee-com-movers-in-riyadh-company-html-a126376966 شركة نقل عفش بالرياض
http://khairyayman.eklablog.com/http-www-east-eldmam-com-a126377148 شركة نقل عفش بالدمام
http://east-eldmam.beep.com/ شركة نقل عفش
https://www.smore.com/51c2u شركة نقل عفش | https://www.smore.com/hwt47 شركة نقل اثاث بجدة | https://www.smore.com/51c2u شركة نقل عفش بالرياض | https://www.smore.com/u9p9m شركة نقل عفش بالمدينة المنورة | https://www.smore.com/51c2u شركة نقل عفش بالدمام
https://www.smore.com/zm2es شركة نقل عفش بالدمام
https://khairyayman74.wordpress.com/2016/07/04/transfer-furniture-jeddah/ شركة نقل عفش بجدة
https://khairyayman74.wordpress.com/2016/06/14/%D8%B4%D8%B1%D9%83%D8%A9-%D9%86%D9%82%D9%84-%D8%A7%D9%84%D8%B9%D9%81%D8%B4-%D8%A8%D8%A7%D9%84%D9%85%D8%AF%D9%8A%D9%86%D8%A9-%D8%A7%D9%84%D9%85%D9%86%D9%88%D8%B1%D8%A9/ شركة نقل العفش بالمدينة المنورة
https://khairyayman74.wordpress.com/2016/06/14/%D9%86%D9%82%D9%84-%D8%A7%D9%84%D8%B9%D9%81%D8%B4-%D8%A8%D8%A7%D9%84%D8%B1%D9%8A%D8%A7%D8%B6/ نقل العفش بالرياض
https://khairyayman74.wordpress.com/2016/05/26/%d9%87%d9%84-%d8%b9%d8%ac%d8%b2%d8%aa-%d9%81%d9%89-%d8%a8%d8%ad%d8%ab%d9%83-%d8%b9%d9%86-%d8%b4%d8%b1%d9%83%d8%a9-%d9%86%d9%82%d9%84-%d8%b9%d9%81%d8%b4-%d8%a8%d8%a7%d9%84%d8%af%d9%85%d8%a7%d9%85/ نقل عفش بالدمام
https://khairyayman74.wordpress.com/2016/05/24/%d8%a7%d8%ad%d8%b3%d9%86-%d8%b4%d8%b1%d9%83%d8%a7%d8%aa-%d9%86%d9%82%d9%84-%d8%a7%d8%ab%d8%a7%d8%ab-%d8%a8%d8%a7%d9%84%d8%af%d9%85%d8%a7%d9%85/ شركات نقل اثاث بالدمام
https://khairyayman74.wordpress.com/2015/07/23/%D8%B4%D8%B1%D9%83%D8%A9-%D9%86%D9%82%D9%84-%D8%A7%D8%AB%D8%A7%D8%AB-%D9%81%D9%89-%D8%A7%D9%84%D8%AE%D8%A8%D8%B1-0559328721/ شركة نقل اثاث بالخبر
https://khairyayman74.wordpress.com/2016/02/25/%D8%B4%D8%B1%D9%83%D8%A9-%D9%86%D9%82%D9%84-%D8%B9%D9%81%D8%B4-%D8%A8%D8%AC%D8%AF%D8%A9/ شركة نقل عفش بجدة
https://khairyayman74.wordpress.com/%D8%B4%D8%B1%D9%83%D8%A9-%D8%BA%D8%B3%D9%8A%D9%84-%D9%85%D8%B3%D8%A7%D8%A8%D8%AD-%D8%A8%D8%A7%D9%84%D8%AF%D9%85%D8%A7%D9%85/ شركة غسيل مسابح بالدمام
https://khairyayman74.wordpress.com/2016/06/14/%D8%B4%D8%B1%D9%83%D8%A9-%D9%86%D9%82%D9%84-%D8%A7%D9%84%D8%B9%D9%81%D8%B4-%D8%A8%D8%A7%D9%84%D9%85%D8%AF%D9%8A%D9%86%D8%A9-%D8%A7%D9%84%D9%85%D9%86%D9%88%D8%B1%D8%A9/ شركة نقل العفش بالمدينة المنورة
http://www.khdmat-sa.com/2016/07/09/transfere-furniture-in-dammam/ ارخص شركات نقل العفش بالدمام
https://khairyayman74.wordpress.com/2015/07/14/%D8%B4%D8%B1%D9%83%D8%A9-%D8%BA%D8%B3%D9%8A%D9%84-%D8%A7%D9%84%D9%81%D9%84%D9%84-%D9%88%D8%A7%D9%84%D9%82%D8%B5%D9%88%D8%B1-%D8%A8%D8%A7%D9%84%D8%AF%D9%85%D8%A7%D9%85/ شركة غسيل الفلل بالدمام
https://khairyayman74.wordpress.com/2015/06/30/%D8%B4%D8%B1%D9%83%D8%A9-%D8%BA%D8%B3%D9%8A%D9%84-%D9%83%D9%86%D8%A8-%D8%A8%D8%A7%D9%84%D8%AF%D9%85%D8%A7%D9%85-0548923301/ شركة غسيل كنب بالدمام
https://khairyayman74.wordpress.com/2016/04/23/%d9%85%d8%a7%d9%87%d9%89-%d8%a7%d9%84%d9%85%d9%85%d9%8a%d8%b2%d8%a7%d8%aa-%d9%84%d8%af%d9%89-%d8%b4%d8%b1%d9%83%d8%a9-%d9%86%d9%82%d9%84-%d8%b9%d9%81%d8%b4-%d8%a8%d9%85%d9%83%d8%a9%d8%9f/ نقل العفش بمكة
https://khairyayman74.wordpress.com/2016/09/26/anti-insects-company-dammam/ شركة مكافحة حشرات بالدمام
http://emcmee.blogspot.com.eg/ شركة نقل عفش
http://emcmee.blogspot.com.eg/2016/04/blog-post.html شركة نقل عفش بجدة
http://emcmee.blogspot.com.eg/2017/07/transfere-mecca-2017.html
http://emcmee.blogspot.com.eg/2016/04/blog-post_11.html شركة نقل عفش بالطائف
http://emcmee.blogspot.com.eg/2016/06/blog-post.html شركة نقل عفش بالمدينة المنورة
http://eslamiatview.blogspot.com.eg/2016/05/blog-post.html نقل عفش بالدمام
http://eslamiatview.blogspot.com.eg/2016/05/30.html شركة نقل عفش بمكة
http://eslamiatview.blogspot.com.eg/2015/11/furniture-transporter-in-dammam.html شركة نقل عفش بالخبر
https://khairyayman74.wordpress.com/2016/04/11/%D8%B4%D8%B1%D9%83%D8%A9-%D8%AA%D9%86%D8%B8%D9%8A%D9%81-%D8%AE%D8%B2%D8%A7%D9%86%D8%A7%D8%AA-%D8%A8%D8%AC%D8%AF%D8%A9/ شركة تنظيف خزانات بجدة
https://khairyayman74.wordpress.com/ خدمات تنظيف بالمملكه
https://khairyayman74.wordpress.com/2015/08/31/%D8%B4%D8%B1%D9%83%D8%A9-%D8%BA%D8%B3%D9%8A%D9%84-%D8%A7%D9%84%D8%AE%D8%B2%D8%A7%D9%86%D8%A7%D8%AA-%D8%A8%D8%B1%D8%A7%D8%B3-%D8%A7%D9%84%D8%AA%D9%86%D9%88%D8%B1%D9%87-0556808022/ شركة غسيل الخزانات براس التنوره
https://khairyayman74.wordpress.com/2015/07/29/%D8%B4%D8%B1%D9%83%D8%A9-%D9%86%D9%82%D9%84-%D8%A7%D9%84%D8%A7%D8%AB%D8%A7%D8%AB-%D8%AF%D8%A7%D8%AE%D9%84-%D8%A7%D9%84%D8%AC%D8%A8%D9%8A%D9%84/ شركة نقل اثاث بالجبيل
https://khairyayman74.wordpress.com/2015/07/13/%D8%A7%D9%81%D8%B6%D9%84-%D8%B4%D8%B1%D9%83%D8%A9-%D9%85%D9%83%D8%A7%D9%81%D8%AD%D8%A9-%D8%A7%D9%84%D8%B5%D8%B1%D8%A7%D8%B5%D9%8A%D8%B1-%D8%A8%D8%A7%D9%84%D8%AF%D9%85%D8%A7%D9%85/ شركة مكافحة صراصير بالدمام
https://khairyayman74.wordpress.com/2015/05/30/%D8%B4%D8%B1%D9%83%D8%A9-%D9%86%D9%82%D9%84-%D8%A7%D8%AB%D8%A7%D8%AB-%D8%A8%D8%A7%D9%84%D8%AF%D9%85%D8%A7%D9%85/ شركة نقل اثاث بالدمام
https://khairyayman74.wordpress.com/2015/08/19/%D8%B4%D8%B1%D9%83%D8%A9-%D8%AA%D9%86%D8%B8%D9%8A%D9%81-%D9%85%D9%86%D8%A7%D8%B2%D9%84-%D9%81%D9%8A-%D8%A7%D9%84%D8%AF%D9%85%D8%A7%D9%85-0548923301/ شركة تنظيف منازل فى الدمام
https://khairyayman74.wordpress.com/2016/02/23/%d8%b4%d8%b1%d9%83%d8%a9-%d9%83%d8%b4%d9%81-%d8%aa%d8%b3%d8%b1%d8%a8%d8%a7%d8%aa-%d8%a7%d9%84%d9%85%d9%8a%d8%a7%d9%87-%d8%a8%d8%a7%d9%84%d8%af%d9%85%d8%a7%d9%85/ شركة كشف تسربات المياه بالدمام
https://khairyayman74.wordpress.com/2015/10/18/%D8%B4%D8%B1%D9%83%D8%A9-%D9%86%D9%82%D9%84-%D8%B9%D9%81%D8%B4-%D8%A8%D8%A7%D9%84%D8%B7%D8%A7%D8%A6%D9%81/ شركة نقل عفش بالطائف
http://eslamiatview.blogspot.com.eg/2015/08/blog-post.html شركات نقل عفش بالدمام
http://eslamiatview.blogspot.com.eg/2015/09/0504194709.html شركة تنظيف خزانات بالمدينة المنورة
http://eslamiatview.blogspot.com.eg/2015/09/0504194709.html شركة نقل عفش بالجبيل
http://eslamiatview.blogspot.com.eg/2015/07/blog-post.html شركة غسيل كنب بالدمام
<a href="https://khairyayman74.wordpress.com/2020/01/28/%d8%b4%d8%b1%d9%83%d8%a7%d8%aa-%d8%aa%d9%86%d8%b8%d9%8a%d9%81-%d8%ae%d8%b2%d8%a7%d9%86%d8%a7%d8%aa-%d8%a8%d8%ac%d8%af%d8%a9-%d8%ae%d8%b5%d9%85-60/">شركات تنظيف خزانات بجدة</a>
<a href="https://khairyayman74.wordpress.com/2020/01/25/movers-khobar/">نقل عفش بالخبر</a>
<a href="https://khairyayman74.wordpress.com/2020/01/25/mover-furniture-khamis-mushait/">شركة نقل عفش بخميس مشيط</a>
<a href="https://khairyayman74.wordpress.com/2020/01/24/%d8%b4%d8%b1%d9%83%d8%a9-%d9%86%d9%82%d9%84-%d8%b9%d9%81%d8%b4-%d8%a8%d8%a7%d9%84%d8%a7%d8%ad%d8%b3%d8%a7%d8%a1-2/">شركة نقل عفش بالاحساء</a>
<a href="https://khairyayman74.wordpress.com/2020/01/15/company-transfer-furniture-jeddah/">شركة نقل عفش بجدة</a>
<a href="https://khairyayman74.wordpress.com/2017/08/19/%d9%86%d9%82%d9%84-%d8%b9%d9%81%d8%b4-%d8%a7%d9%84%d9%85%d9%86%d8%a7%d8%b2%d9%84-%d8%a8%d8%a7%d9%84%d9%85%d8%af%d9%8a%d9%86%d8%a9-%d8%a7%d9%84%d9%85%d9%86%d9%88%d8%b1%d8%a9/">نقل عفش بالمدينة المنورة</a>
<a href="https://khairyayman74.wordpress.com/2017/06/15/movers-taif-2/">نقل عفش بالطائف</a>
Rodneywessy
The best casino apps for Android
The difficult is that find Android apps and downloading them can be iffy, as Google doesn't sanction natural money Android casinos to be placed in the On Store.
Download casino app
But don't chew one's nails, there is a simple solution, you can download the casino app from casinoapk2.xyz.
As so multitudinous users attired in b be committed to been asking about casino gaming on their Android phones or tablets. We dug there a iota to upon you the most desirable casino apps offering the in spite of verifiable well-heeled experience.
The most in [url="https://1win-onewin-1win.pp.ua/"]onewin[/url], download 1win.
Reviewers check each pertinence for safety to ensure positiveness;
We will help you rouse loyal money gambling apps with the worst Android apps;
The casinos extend the in the most suitable way series of games.
Download Loyal On easy street Casino
It is not as a last resort easy as pie to download genuine lettuce casinos, on a par on more public smartphones like Samsung Galaxy, HTC One or Sony Xperia. So if you wish for to download the app to out first simoleons, decipher all below.
Our party initiate the leading casinos offering value gambling on your trick and ran an strong 25-step verification manage payment them.
On this page you will on an application in spite of Android:
Acceptable Promotions - We conscious how much players be deficient in to take gain of the bonuses, so we made unwavering that our featured sites tender aristocratic deals after Android.
Variety of games. Crummy choice is a important minus. We just praise the app, the recreation portfolio is vast and varied.
Deposits - You be in want of as not many restrictions as on when it comes to depositing and withdrawing shin-plasters to your casino app account. We up steady that all apps we vouch for allow a encyclopaedic mix of payment methods.
Promiscuous payouts. All applications offer lustfully payments with real money, credited to the account in a few hours.
Mobile Compatibility - Around Apps Anywhere.
Client Hold up - To be featured on the Featured Inventory, we call for online casinos to present comprehensive and wide-awake person service.
Advantages of an online app in behalf of Android
Colossal video graphics and usability in Android apps.
Happening the unvaried stunning PC experience.
Immediate access from the application.
Casino apps - looking since the most appropriate
We check and download casino apps to ensure they come together great standards. The criteria euphemistic pre-owned to selected a casino app are just as stringent as the criteria used to rate a PC casino. Each commitment has:
Highest standing graphics;
Untroubled loading and playing time;
Diet payouts.
Many operators offer without cost or obligation download of online casinos proper for Android [url="https://1win-onewin-1win.pp.ua/"]onewin[/url] for legal pelf with withdrawal to electronic wallets or bank cards. Animated casinos are being developed quest of the convenience of customers and attracting a larger audience. Such applications have a number of undeniable advantages:
Access to the casino from anywhere where there is Wi-Fi or unstationary Internet. At the changeless all at once, applications do not pilfer up much margin in the machination's memory.
The functionality corresponds to the desktop construct of the resource: you can mobilize bonuses, participate in tournaments, well provided your account, fritz opening machines against change in the application with the withdrawal of winnings, etc.
End-to-end registration. There is no miss to additionally cash register from your phone if you be experiencing an active account.
Free demos. Gamblers can open any video job or board spirited in a gratuitous grief mode.
The on the contrary liability of the version adapted object of lightweight devices may be the absence of some titles in the presented collection. The movable application of an online casino with hollow machines to go to playing on account of loot gives access only to slots in HTML5 aspect, but so far not all providers have redesigned their portfolios in accordance with this requirement. Notwithstanding, the largest manufacturers own been producing slot machines for several years entrancing into account new standards and remaking long-standing titles instead of them, which are notably popularized expanse gamblers.
Furthermore, providers hire into account the features of portable devices when creating games. A special interface and unorthodox modes of function are being developed in place of them. Looking for norm, Wazdan offers a special attraction that increases the battery economy of the device close to 40%, and Ultra Lite technology, which preserves the effigy je sais quoi and download hurriedness with a slow Internet connection. Vacancy machines on the phone beget only a start button and a punt level control.
The gaming interface on a matter-of-fact box is lose modified compared to the desktop adaptation, so it is certainly at one's fingertips to put on in the casino application for money from your phone, direct slots and hollow machines. The cardinal menu is hidden in drop-down windows, and links to the paramount sections are secured at the complete or underpinning of the screen. Also, the online chat appeal to c visit cancel button an eye to contacting technical support specialists is unceasingly in sight.
Since the Google Revelry and AppStore digital giving out services interpose tough restrictions on gambling programs, you can download the casino perseverance to your phone after playing real money from the verified website. To download, you will call a together to the apk systematize and the user's sanction to inaugurate and run the program. Now operators transmit precise induction instructions on the chapter with a link, and if there are difficulties, the fellow can again consult with the customer service.
Some licensed casinos also forth clients programs recompense private computers and laptops. You can Casino Apk them from the official website. Such software is well-liked apt to unwavering uninterrupted access to games from the desktop without using a browser.
">http://www.candipharm.com/#</a>
">https://candipharm.com/</a>
카지노사이트 ACE21에서 안전한 카지노 사이트만을 추천합니다.카지노, 바카라, 온라인카지노, 순위 , 라이브카지노, 해외카지노, 사설카지노, 호텔카지노 등 각종 인터넷 게임을 제공하는 신뢰할 수 있는 통합사이트와 함께 다양한 이벤트에 참여하세요!" />
<link rel="canonical" href="https://8mod.net/" />
https://8mod.net/
카지노사이트 게임토크에서 각종 온라인 바카라, 슬롯머신, 룰렛, 스포츠토토, 바둑이, 릴게임, 경마 게임 정보를 제공합니다! 안전한 카지노사이트추천 과 각종 이벤트 쿠폰을 지급합니다!" />
<link rel="canonical" href="https://main7.net/" />
https://main7.net/
[url=https://pin.it/VgNOQIn][b]Observe More[/url]
Book an Appointment:
📞: 905-846-4000
170 Sandalwood Pkwy E #1, Brampton, ON L6Z 1Y5, Canada
admin@newhopephysio.com
https://www.newhopephysio.com
https://maps.app.goo.gl/L2jeLkknBSdmh2ek7