Table of Contents
Multilevel Linear Model
Introduction
Linear Models and Generalized Linear Models (GLM) are a very useful tool to understand the effects of the factor you want to examine. These models are also used for prediction: Predicting the possible outcome if you have new values on your independent variables (and this is why independent variables are also called predictors).
Although these models are powerful for analyzing the data gained from HCI experiments, one concern we have is that they do not carefully handle “repeated-measure”-ness (e.g., individual differences of the participants). Multilevel models can accommodate such differences. Very roughly speaking, it is a repeated-measure version of linear models or GLMs.
A multilevel model is often referred as a “hierarchical,” “random-effect” or “mixed-effect” model. The term of “random effects” is often confusing because it is used to mean different things. In this wiki, I follow Data Analysis Using Regression and Multilevel/Hierarchical Models by Andrew Gelman and Jennifer Hill. I explain what “random effects” and “fixed effects” (opposite to random effects) mean in this page; however, people say different opinions about them (as Gelman and Hill's book explains). So, I won't go into detailed discussions about how we should consider these factors.
High-level Understanding
Before jumping into examples of multilevel linear models, let's have a high-level understanding of multilevel linear models. Let's think about a very simple experiment: Comparing two techniques: Technique A and Technique B. Your measurement is performance time. In your experiment, 10 participants performed some tasks with both techniques; thus, the experiment is a within-subject design. If you do not consider the “Participant” factor, you will do a linear regression analysis where your independent variable is Technique, and if its coefficient is non-zero, you will argue that the difference of the techniques caused some differences in the performance time.
However, this analysis does not fully consider the experiment design you had: the differences between the participants. For example, some participants are more comfortable with using computers than the others, and thus, their overall performance might have been better. Or the differences of the techniques might have caused different levels of the effects depending on the participants. Some participants had similar performance with both techniques, and some had much better performance with one technique. The linear regression above tries to represent the data with one line, and unfortunately it aggressively aggregates such differences which may matter to your results in this case.
Multilevel regression, intuitively, allows us to have a model for each group represented in the within-subject factors. Thus, in this example, instead of having one linear model, you will build 10 linear models, each of which is for each participant, and do analysis on whether the techniques caused differences or not. In this way, we can also consider individual differences of the participants (they will be described as differences of the models). What multilevel regression actually does is something like between completely ignoring the within-subject factors (sticking with one model) and building a separate model for every single group (making n separate models for n participants). But I think this exaggerated explanation well describes how multilevel regression is different from simple regression, and is easy to understand.
Varying-intercept vs. varying-slope
The previous section gave you a rough idea of what multilevel models are like. For the factors in which we want to take individual differences into account, we treat them as random effects and build each model for each level of these factors. But one question is still remaining. How do we make “different models”?
If we build a separate model for each participant, for example, analysis would be very time-consuming. With the example we used above, we would have 10 models in total. Some may have significant effects of Technique, and some may not. In that case, how can we generalize the results and say if Technique is really a significant factor?
Multilevel models can remove this trouble. Instead of building completely different models, multilevel regression changes the coefficients of only some parameters in the model for each level of random effects. Thus, the coefficients of the other factors remain the same, and model analysis becomes much easier.
Roughly speaking, there are two strategies you can take for random effects: varying-intercept or varying-slope (or do both). Varying-intercept means differences in random effects are described as differences in intercepts. For example, in the previous example, we will have 10 different intercepts (each for each participant), but the coefficient for Technique is constant. Varying-slope means vice versa: changing the coefficients of some factors.
In many cases, factors, more precisely independent variables or predictors, are something you want to examine. Thus, you want to generalize results for them. And the intercept is usually something you don't include in your analysis, so it can be very complicated. Therefore, unless you have some clear reasons, varying-intercept models will work for you. They won't be computationally complicated and their results will be straightforward to interpret. In this page, I show an example of varying-intercept models.
Fixed effects vs. random effects
Although I won't go into detailed discussions about the difference between “random effects” and “fixed effects” (the opposition to random effects), it is important to have a high-level understanding of their differences. Then you won't get confused when you read other literature or try to use other statistical software.
This is my interpretation of differences between fixed and random effects: In multilevel regression, you will build multiple models. The coefficients of the fixed effects are constant or “fixed” across the models. In contrast, the coefficients of the random effects can be different, or (more or less) can be “random”. Random effects can be factors whose effects you are not interested in but whose variances you want to remove from your model. “Participants” are a good example of random effects. Generally, we are not interested in how different the performance of each participant is. But we do not want to let the individual differences of the participants affect the analysis.
If you know a better way to understand the difference between fixed effects and random effects, please share it with us! :)
R example
I prepare hypothetical data to try out multilevel linear regression. You can download it from here. We are going to use that file in the following example.
Let me explain a hypothetical context of this hypothetical data :). We conducted an experiment with a touch-screen desktop computer. Our objective is to examine how mouse-based and touch-based interactions affect performance time in different applications. In this system, participants could use either mouse click or direct touch to select an object or an item in a menu. They could also use a mouse wheel or a pinch gesture to zoom in/out the screen. We just let them which way to interact with the system so that we could measure how people tend to use mouse-based and touch-based interactions. Our design is also within-subject across the three applications tested in this experiment.
The file contains the results of this experiment. I think most of the columns are just guessable. Time is the time (sec) for completing the task in each application (indicated by Application). MouseClick, Touch, MouseWheel, and PinchZoom are the counts for mouse clicks, direct touch, zoom with the mouse wheel, and zoom with the pinch gesture.
Now we want to examine how these numbers of MouseClick, Touch, MouseWheel, and PinchZoom affect performance time. Of course, there are a number of models we can think of, but let's try something simple:
;#; ## Time = intercept + a * Application + b * MouseClick + c * Touch + d * MouseWheel + e * PinchZoom. ## ;#;
However, we want to take the effects of our experimental design into account. To do this, we make a tweak on the model above.
;#; ## Time = intercept + a * Application + b * MouseClick + c * Touch + d * MouseWheel + e * PinchZoom + Random(1|Participant). ## ;#;
What Random(1|Participant) is trying to mean is that we are going to change the intercept for each participant. Yes, we are making varying-intercept models. We assume that individual differences by participants can be explained by differences in the intercept. In this manner, we can remove some effects caused by the individual differences to the other factors.
There are a number of ways to do multilevel linear regression in R, but we are using the lme package. We also import the data.
Now we are building the model.
Again, (1|Participant) is the part for the random effect. “1” means the intercept. So this means we are changing the intercept for each participant. To find the models, we use the restricted maximum likelihood (REML). I won't go into the details of REML here, but in most cases, you can simply use REML. But if you have specific reasons, you can use the maximum likelihood method by doing REML=F.
Now let's take a look at the results.
So you can see the estimated coefficient for each factor, but it is kinda unclear whether it is really significant or not. Let's try coefplot. Unfortunately coefplot in the arm package does not work with the lme object. We thus use a fixed version of coefplot.
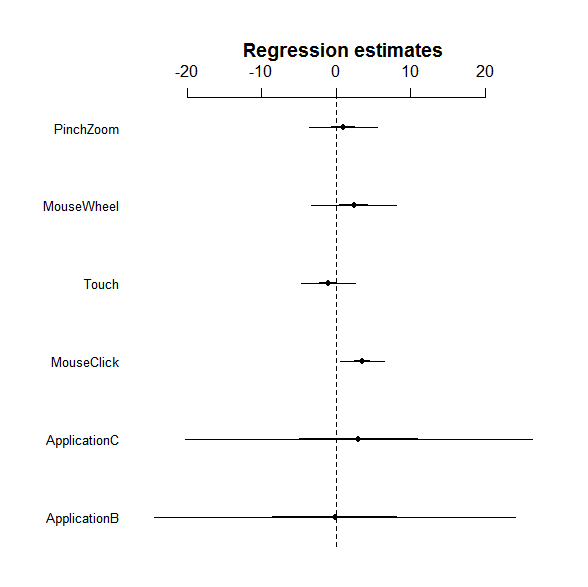
A thick and thin line represent the 1SD and 2SD ranges. So it looks like that MouseClick has a significant effect because its 2SD does not overlap the zero.
MCMC
So far, so good. We successfully created a model and looks like we have something interesting there. But we are not quite sure about which fixed effects are significant yet.
If you have read the multiple linear regression page, you may think we can do an ANOVA test. Technically yes, we can do an ANOVA test. However, it is not quite straightforward to run it because of random effects. In this case, we cannot really be sure about whether the test statistic is F-distributed. There have been several attempts to address this and make an ANOVA test useful for multilevel regression, such as the Kenward-Roger correction. However, it is disputable if this correction is good enough so that we can assume the corrected test statistic is F-distributed. Thus, ANOVA with the Kenward-Roger correction has not been implemented yet in R (as of June 2011).
Instead, we use the Markov Chain Monte Carlo (MCMC) method to estimate the coefficient and highest probability density credible intervals (HPD credible intervals). Here, I will skip detailed discussions of what MCMC does and what HPD credible intervals mean. (I will do it sometime later at a separate page). For now, let's simply think that MCMC tries to re-estimate the coefficient for each factor based on the results we got with lmer() so that we can have better estimation.
We are going to use the languageR package to run MCMC. pvals.fnc() can take a bit of time for calculation.
The parameter nsim is the number of the simulation to run. Here, I set 10000, but you may need to tweak it to make sure that the estimation is converged.
MCMCmean is the re-estimated coefficient by MCMC. As you can see in this example, you may see relatively large differences between the estimation by REML and the one by MCMC. As far as I understand, the estimation by MCMC is more reliable than the one by REML. So we are going to use the results by MCMC.
As you can see in the results, only MouseClick has a significant positive effect on increasing performance time. So the results imply that reducing the number of mouse clicks may decrease the overall task completion time in the applications tested here. PinchZoom's effect (0.1278, 95% HPD CI:-5.1017,5.276) is smaller than MouseWheel (2.7309, 95% HPD CI:-3.8874, 9.867). Thus, encouraging users to do pinching gestures for zoom operations might contribute to decrease in the overall task completion time.
Unfortunately, there aren't many things to say from the results here, but I guess you have gotten the idea of how you interpret the results of multi-level linear models.
Multicollinearlity
Lastly, let's make sure that we don't have multicollinearity problems. For lmer(), we cannot use the vif()function. Instead, we can use the function provided by Austin F. Frank (https://hlplab.wordpress.com/2011/02/24/diagnosing-collinearity-in-lme4/).
Copy the part of the vif.mer() function (or just copy all) in https://raw.github.com/aufrank/R-hacks/master/mer-utils.R, and paste them into your R console. And just use the vif.mer() function.
So, in this example, we are fine. If the value is higher than 5, you probably should remove that factor, and if it is higher than 2.5, you should consider removing it.
Another way to examine multicollinearlity is to look at the correlation of the two of the independent variables. I wrote a code to do this quickly.
Copy the code above, and paste it into your R console. Then, run the following code.
You will get the following graph.
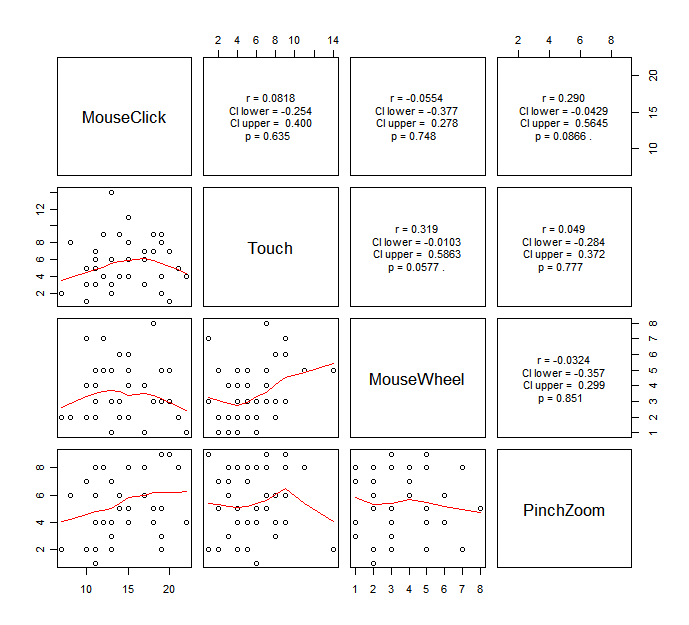
It is kinda hard to say which variable we should consider to remove from this, but I would say if you see any significant strong correlation, you probably should be careful about if it may cause multicollinearity.
How to report
Once you are done with your analysis, you will have to report the following things:
- Your model,
- How you chose the model (either you just defined, you used AIC, or you used CV),
- R-squared and adjusted R-squared (lmer() does not provide them, and I am looking into how to get them).
- How you tested the estimated coefficients (either you did MCMC or ran a F-test with the Kenward-Roger correction).
- Estimated value for each coefficient, and
- Significant effects with p value (if any).
For the last two items, you can say something like “MouseClick showed a significant effect (p<0.05). Its estimated coefficient with the MCMC method was 4.05 (95% HPD credible interval = [0.75, 7.63]).”
It is probably acceptable that you simply report the direction of each significant effect (positive or negative) if you do not really care about the actual value of the coefficient. But I think you should report at least whether each significant effect contributes to the dependent variable in a positive or negative way.
Discussion
Anticipating Freud and Jung, the Symbolists mined mythology and dream imagery for a visual language of the soul. More a philosophical approach than an actual style of art, they influenced their contemporaries in the Art Nouveau movement and Les Nabis.
for More information <a href=http://canvas-online.com/>click here</a>
- Comprehend more at <a href=http://www.fujianxiangzhu.com>Art Website</a>
<a href="http://kamagradxt.com/">kamagra oral jelly available in india</a>
kamagra oral jelly wirkung frauen
<a href="http://kamagradxt.com/">kamagra chewable 100 mg reviews</a>
super kamagra kaufen
http://kamagradxt.com/
kamagra forum srpski
<a href="http://kamagradxt.com/">kamagra oral jelly review forum</a>
kamagra oral jelly viagra
<a href="http://kamagradxt.com/">buy kamagra 100 mg</a>
kamagra oral jelly buy online
http://kamagradxt.com/
india kamagra 100mg chewable tablets
10%-15% Daily Profit! Earn your bitcoins today, become a millionere tomorrow!
Affiliate program and referral commision 5%. Invite a freind and earn 5% commision from each deposit!
<a href="https://bit.ly/2uCcLt2">CLICK HERE!</a>
===============================
Инвестиции в криптовалюту - https://bit.ly/2uCcLt2!
10%-15% ежедневного дохода! Заработайте свои биткойны сегодня, станьте миллионером завтра!
Партнерская програма и реферальная коммиссия 5%. Пригласите друга и получите 5% с каждого депозита!
<a href="https://bit.ly/2uCcLt2">ПЕРЕЙТИ НА САЙТ!</a>
Download: http://sewerrepairpro.com/showdown-1963-audie-murphy-western-brrip-xvid-wujxf.html - Showdown (1963) - Audie Murphy - Western - BRRip XviD 11 minutes .
BBC.The.Life.of.Mammals.8of9.Life.in.the.Trees.720p.HDTV.x264.AAC .mkv
Download: http://cgunitedsc.com/serie/Klein-Dorrit - Klein Dorrit .
BitLord.com
Download: http://jumpstart-pros.com/serie/2057-Unser-Leben-in-der-Zukunft - 2057 – Unser Leben in der Zukunft .
Dance Moms S06E32 Two Teams Two Studios Part One HDTV x264-[NY2 - - [SRIGGA -
Download: http://cookingyoursassoff.com/serie.php?serie=1286 - The White Queen .
Advantageous
Download: http://infobawel.com/serie/Aria-The-Animation - Aria The Animation .
Love Everlasting 2016 HDRip AC3 2 0 x264-BDP[SN -
Download: http://cabuaan.com/serie/Ordinary-Lies - Ordinary Lies .
Aleksandr Marshal I Vetheslav Bukov - Gde Nothyet Solnce
Download: http://infobawel.com/serie/Retribution - Retribution .
Трите лица на Ана Епизод 9 / Tres veces Ana
Download: http://sarakarinoukri.com/movie/genesis-the-fall-of-eden-6pmw.html - Genesis: The Fall of Eden (2018) .
Miles Davis - Tutu [Isohunt.to -
Download: http://jumpstart-pros.com/serie/serie/Two-and-a-Half-Men/1/7-Ich-verstehe/OpenLoad - OpenLoad .
Celebrity Antiques Road Trip S06E01 - Jennifer Saunders and Patricia Potter
Download: http://cookingyoursassoff.com/serie.php?serie=1330 - Low Winter Sun .
Teenies Auf Der Sex Akademie avi
Download: http://vettriselvan.com/capitulo.php?serie=4277&temp=1&cap=04 - ZombieLars (2017) 1X04 - Capitulo 04 .
The Lobster2016
Download: http://jumpstart-pros.com/serie/Tamako-Market - Tamako Market .
2012 the movie
Download: http://mittlivsomtransa.com/engine/go.php?file2=Watch Deep State Season 1 Episode 5 Movie Free Full Movie Online Free&lp=5 - WATCH THIS LINK .
the purge election year 720p
Download: http://cookingyoursassoff.com/serie.php?serie=1863 - ANZAC Girls .
[avi - The.BFG.2016.DVDRip.XviD.AC3-iFT[PR...
Download: http://infobawel.com/serie/El-Chapo - El Chapo .
May 2016 (3973)
Download: http://comprarlevitraonline.com/movie/veronica-dvd-streaming/5/ - OK.ru VF Dvdrip .
True Blood
Download: http://duendeimagery.com/serie/Potemayo - Potemayo .
Pain Killer By Little Big Town
Download: http://bad-txt-sec-test1.com/movie/downsizing-6d7o.html - Короче .
Greg Kinnear,
Download: http://keneganprobate.com/ver/the-pilot-2x05.html - 2x05 La Piloto .
Little Britain
Download: http://cabuaan.com/serie/Monster-Strike - Monster Strike .
Dont Breathe 2016 720p BRRip x264 AAC-ETRG
Download: http://infobawel.com/vorgeschlagene-serien/vote:12882 - Hard Rock Medical .
A History of Portugal and the Portuguese Empire: From Beginnings to 1807 (Volume 1)
Download: http://cgunitedsc.com/vorgeschlagene-serien/vote:11527 - Invasion von der wega .
TheUpperFloor 16 11 15 Karlee Grey And Penny Pax XXX SD MP4-RARBG
Download: http://merchantscirclellc.com/ver/vice-6x04.html - 6x04 VICE .
Mkv Torrents
Download: http://vettriselvan.com/serie.php?serie=2111 - Toda la Verdad sobre la Comida .
THE WALKING DEAD
Download: http://tl-hardware.com/serie/Pinocchio - Pinocchio .
Drunk History S04E08 720p HDTV x264-FLEET[PRiME -
Download: http://cabuaan.com/serie/D-C-Da-Capo - D.C.: Da Capo .
Pakistani Movies
Download: http://prsti.com/category/black-panther-2018/ - Black Panther (2018) .
??? BJ?? ?? (????TV,??????,???,??,????,??TV,??TV,????,????,BJ??,BJ,??,2??,3??,?????,?????TV)
Download: http://manishakumari.com/serie/This-Is-Us - This Is Us .
1 de outubro de 2015
Download: http://manishakumari.com/serie/Nabari-no-Ou - Nabari no Ou .
[share_ebook - OpenVPN: Building and Integrating Virtual Private Networks: Learn how to build secure VPNs using this powerful Open Source application
Download: http://cabuaan.com/serie/Eureka - Eureka - Die geheime Stadt .
Nocturna 2015 BDRip XviD AC3 EVO
Download: http://infobawel.com/serie/Workaholics - Workaholics .
Internet Download Manager (IDM) 6 26 Build 10 Multilingual + Patch (Safe) [Sa...
Download: http://flasheur.fr/movie/gun-crazy-19790/ - Gun Crazy .
Finding Dory
Download: http://krbzbwimbokrp.com/vorgeschlagene-serien/vote:12844 - Agatha Christie – Kleine Morde .
Arrow S05E07 HDTV x264-LOL[ettv -
Download: http://manishakumari.com/vorgeschlagene-serien/vote:12341 - Leah Remini: Ein Leben nach Scientology .
In Absentia (2000)
Download: http://krbzbwimbokrp.com/vorgeschlagene-serien/vote:12937 - Bomb Girls .
[Nipponsei - Angel beats! Original Soundtrack.zip
Download: http://houseexpressre.com/data-mining-the-deceased-2016-720p-amzn-webrip-aac2-0-x264-ntg-wujqk.html - Data Mining the Deceased 2016 720p AMZN WEBRip AAC2 0 x264-NTG 25 minutes .
Нюанси синьо
Download: http://krbzbwimbokrp.com/serie/Baggage-Battles-Die-Koffer-Jaeger - Baggage Battles – Die Koffer-Jäger .
Titanic 1996 HD ????? ????? 5.9
Download: http://infobawel.com/serie/Double-J - Double-J .
161117.??TV.?????.E34.1080p.HDTV.HDMI-Yoonyule.ts
Download: http://sewerrepairpro.com/исчезновение-СЃРёРґРЅРё-холла-the-vanishing-of-sidney-hall-2018-hdrip-wujom.html - Рсчезновение РЎРёРґРЅРё Холла / The Vanishing of Sidney Hall (2018) HDRip РѕС‚ Scarabey | iTunes 17 minutes .
?? ??
Download: http://merchantscirclellc.com/ver/dragonball-super-2015-1x49.html - 1x49 Dragon Ball Super .
Compton By Dr. Dre
Download: http://longislandmvp.com/genero/novelas/ - Contacto .
More results from onlinemovies.is
Download: http://cabuaan.com/vorgeschlagene-serien/vote:12957 - L.A. Law .
PortuguA?s (Brazil)
Download: http://cookingyoursassoff.com/capitulo.php?serie=2422&temp=2&cap=04 - Humans 2X04 - Capitulo 04 .
norm of the north 720p
Download: http://jumpstart-pros.com/serie/1993-Jede-Revolution-hat-ihren-Preis - 1993 - Jede Revolution hat ihren Preis .
BLACKED 16 11 16 Brandi Love XXX 1080p MP4-KTR[rarbg -
Download: http://dynaforceproducts.com/serie/Ore-tachi-ni-Tsubasa-wa-Nai - Ore-tachi ni Tsubasa wa Nai .
Renoir RELOADED
Download: http://infobawel.com/serie/Alles-ausser-Mord - Alles auГџer Mord! .
Zoom Legendado Online Esta e a historia de tres artistas: Edward (Gael Garcia Bernal), vaidoso diretor de cinema que precisa refilmar o final de um longa contra sua vontade e de repente comeca a ter problemas sexuais. Michelle (Mariana Ximenes), modelo brasileira que deixa namorado e carreira nos Estados Unidos para voltar ao seu pais e escrever um livro. E Emma (Alison Pill), ...
Download: http://cookingyoursassoff.com/serie.php?serie=1780 - YouВґre the Worst .
Aleksandr Zvincov 20 Luchshih Pesen 2008
Download: http://shsh-1.com/all/feelandjohnnynorbergonedreamtm058web2016ukhx-t3407815.html - Feel_And_Johnny_Norberg-One_Dream-(TM058)-WEB-2016-UKHx .
Jason Bourne 2016 1080p BluRay x264-SPARKS[rarbg -
Download: http://jumpstart-pros.com/serie/Weisst-du-eigentlich-wie-lieb-ich-dich-hab - WeiГџt du eigentlich, wie lieb ich dich hab? .
suicide squad 2016 extended 480p web dl x264 rmteam mkv
Download: http://infobawel.com/vorgeschlagene-serien/vote:13435 - Die Viersteins .
No Rest For The Wicked Diskord Re Twerk Lykke Li
Download: http://bad-txt-sec-test1.com/roger-daltrey-as-long-as-i-have-you-2018-mp3-РѕС‚-vanila-wujiu.html - Roger Daltrey - As Long As I Have You (2018) MP3 РѕС‚ Vanila 11 minutes .
Warcraft: The Beginning...
Download: http://keneganprobate.com/serie/shooter/temporada-0.html - Temporada 0 .
Madam Secretary
Download: http://tl-hardware.com/vorgeschlagene-serien/vote:13136 - Die Verschwörer - Im Namen der Gerechtigkeit .
Nashville.1x14.[Reparado - .HDTV.XviD.[www.DivxTotaL.com - .avi
Download: http://jumpstart-pros.com/serie/Into-the-Badlands - Into the Badlands .
Сезон 2
Download: http://cabuaan.com/serie/Flip-Flappers - Flip Flappers .
Adobe Photoshop CS6 13.0.1 Final Multilanguage (cracked dll)
Download: http://cookingyoursassoff.com/serie.php?serie=4395 - Supermax .
0 Comments
Download: http://daqian999.com/brooklyn-nine-nine-saison-5-french-hdtv.html - Brooklyn Nine-Nine Saison 5 FRENCH HDTV .
Kindle Books Collection
Download: http://krbzbwimbokrp.com/serie/Undateable - Undateable .
[email protected -
Download: http://infobawel.com/serie/serie/Die-Simpsons/1/6-Lisa-blaest-Truebsal/OpenLoad - OpenLoad .
Skylanders Academy S01E04 720p x264 [StB - Others
Download: http://cgunitedsc.com/serie/Haus-des-Geldes - Haus des Geldes .
Cuando Un Hombre Pierde Sus Ilusiones
Download: http://xn--amzon-hra.com/the-box-2007-watch-online/ - The Box (2007) .
High Strung 2016 LiMiTED BRRip XviD AC3-iFT[PRiME -
Download: http://cabuaan.com/serie/Lipstick-Jungle - Lipstick Jungle .
Forza Horizon 3 (2016) (Final Version) (for pc)
Download: http://infobawel.com/vorgeschlagene-serien/vote:9768 - Epitafios - Tod ist die Antwort .
OnlineTV v.12.16.6.14 Full Crack 2016 Channel US FR TUK IT ESP AR Decrypt 800 channel HD multi lang instal - 2016-11-17
Download: http://jumpstart-pros.com/serie/Die-Dinos - Die Dinos .
Bryce Dallas Howard
Download: http://shsh-1.com/all/forza-horizon-3-2016-pc-multi-t3389214.html - Forza Horizon 3 (2016) (PC) (Multi) .
Alasdair Fraser & Natalie Haas - In The Moment
Download: http://jumpstart-pros.com/serie/CopStories - CopStories .
Agre G Isso E Kuduro 2010
Download: http://manishakumari.com/serie/Sacred-Seven - Sacred Seven .
Windows 7 8 1 10 X64 18in1 UEFI en-US Nov 2016 Generation2}
Download: http://sewerrepairpro.com/mov/family/ - Семейные .
Alan Jackson - Gone Country - 3gp
Download: http://tl-hardware.com/vorgeschlagene-serien/vote:13070 - Fast N’ Loud .
von_Gilgamesh
Download: http://cgunitedsc.com/serie/Kara-Ben-Nemsi-Effendi - Kara Ben Nemsi Effendi .
Young Rider - November - December 2016
Download: http://jumpstart-pros.com/serie/Juuou-Mujin-no-Fafnir - Juuou Mujin no Fafnir .
Nine to Five 2013 REMASTERED 1980 BDRip x264-VoMiT[1337x - [SN -
Download: http://cabuaan.com/vorgeschlagene-serien/vote:13371 - Die Geiseln .
Aleksandr Pushkin - Sbornik Proizvedenii
Download: http://cookingyoursassoff.com/serie.php?serie=3769 - The Dawns Here Are Quiet .
Mac OS X Mountain Lion 10.8.5 12F37 (Intel)
Download: http://cookingyoursassoff.com/serie.php?serie=4390 - Grupo 2: Homicidios .
The Big Bang Theory S10E06 HDTV x264 LOL[ettv -
Download: http://cabuaan.com/serie/serie/The-Walking-Dead/1/4-Vatos/OpenLoad - OpenLoad .
Expeditions Viking [2016 MAC OS GAME -
Download: http://krbzbwimbokrp.com/serie/Grandfathered - Grandfathered .
Force 2 (2016) Full Movie DVDrip HD Free Download
Download: http://duendeimagery.com/serie/Catweazle - Catweazle .
VA - The Jazz House Independent 2nd Issue (1998) [FLAC - [Isohunt.to -
Download: http://cookingyoursassoff.com/serie.php?serie=1774 - Naomi y Wynonna .
Read More
Download: http://krbzbwimbokrp.com/serie/Spiel-des-Lebens - Spiel des Lebens .
SMD03 - Saki Ootsuka (S Model Vol 3) XXX uncen WebGift
Download: http://cookingyoursassoff.com/serie.php?serie=3195 - The Ranch .
Standoff
Download: http://merchantscirclellc.com/ver/gurazeni-1x03.html - 1x03 Gurazeni .
On The Lot
Download: http://krbzbwimbokrp.com/serie/Gekkan-Shoujo-Nozaki-kun - Gekkan Shoujo Nozaki-kun .
Doctor Strange (2016) Score YG [Isohunt.to -
Download: http://krbzbwimbokrp.com/serie/Matantei-Loki-Ragnarok - Matantei Loki Ragnarok .
Chance S01E06 720p WEB H264-DEFLATE[ettv -
Download: http://cabuaan.com/serie/serie/The-Walking-Dead/1/3-Tag-der-Froesche/Streamango - Streamango .
PlumperPass 16 11 16 Kendra Kox Double The Pleasure XXX SD MP4-RARBG
Download: http://cgunitedsc.com/serie/Ballroom-e-Youkoso - Ballroom e Youkoso .
Alan Price - Time & Tide
Download: http://manishakumari.com/serie/serie/How-I-Met-Your-Mother/1/13-Traum-und-Wirklichkeit/OpenLoadHD - OpenLoadHD .
Impastor S02E08 iNTERNAL HDTV x264-ALTEREGO[PRiME -
Download: http://cabuaan.com/serie/Disney-S3-Stark-schnell-schlau - Disney S3 – Stark, schnell, schlau .
Faketaxi
Download: http://cabuaan.com/serie/JK-Meshi - JK Meshi! .
adult movies
Download: http://lightmantherightman.com/search/Lucia Ocone.html - Lucia Ocone .
angry birds
Download: http://flasheur.fr/movie/addiction-voyeurism-19325/ - Addiction Voyeurism .
EASEUS Partition Master 11 9 All Edition rar
Download: http://cgunitedsc.com/serie/Grimmsberg - Grimmsberg .
MasterChef (UK) The Professionals S09E05
Download: http://infobawel.com/serie/Happiness - Happiness! .
Doom Metal
Download: http://manishakumari.com/serie/Fate-Extra-Last-Encore - Fate/Extra Last Encore .
CD Marcos & Belutti – Acustico ( Ao Vivo 2014 )
Download: http://krbzbwimbokrp.com/serie/Ben-10-2016 - Ben 10 (2016) .
Cadence Lux - Babysitters Taking On Black Cock 4 rq mp4
Download: http://jumpstart-pros.com/serie/Puella-Magi-Madoka-Magica - Puella Magi Madoka Magica .
American Truck Simulator PC GAME [2016 - REPACK
Download: http://jumpstart-pros.com/serie/Saki-Achiga-hen-Episode-of-Side-A - Saki: Achiga-hen - Episode of Side-A .
2000 Ans D'Histoire - Janvier 2011(A)
Download: http://duendeimagery.com/serie/Hand-of-God - Hand of God .
CyberGhost_6 0 3 2124 + Premium serial
Download: http://cabuaan.com/vorgeschlagene-serien/vote:12360 - The Devils Ride - Ein Leben auf zwei Rädern .
Structural Steel Design: LRFD Approach, 2nd edition
Download: http://vettriselvan.com/serie.php?serie=2442 - Complications .
Blood for Dracula 1974 HD ????? ????? 6.2
Download: http://infobawel.com/serie/The-Man-in-the-High-Castle - The Man in the High Castle .
Handheld
Download: http://cookingyoursassoff.com/serie.php?serie=3956 - The Quad .
z nation
Download: http://cookingyoursassoff.com/serie.php?serie=4709 - A.I.C.O. Incarnation .
Stone Sour Do Me A Favor Official Video
Download: http://vettriselvan.com/serie.php?serie=4421 - SEAL Team .
American Horror Story Cast – Criminal (from American Horror Story) [fe...
Download: http://jumpstart-pros.com/serie/Gunpowder - Gunpowder .
The Flash S1E21 'Grodd Lives' Trailer
Download: http://supermarketdm.com/watch/RGbWAYdY-paper-year.html - Paper Year .
Arrow S05E07 720p HDTV X264-DIMENSION
Download: http://cookingyoursassoff.com/serie.php?serie=3928 - Desmontando la Historia .
American Dad S13E02 XviD-AFG TV Shows
Download: http://cgunitedsc.com/serie/Innocent-Venus - Innocent Venus .
TheUpperFloor 16 11 15 Karlee Grey And Penny Pax XXX 720p MP4-KTR[rarbg -
Download: http://krbzbwimbokrp.com/serie/Hercules - Hercules .
UltimateZip 9 0 1 51 + Keygen Keys [4realtorrentz - zip
Download: http://puremusicstudio.com/torrent/12622171/football-manager-2018-mac-os-game-full.html - Football Manager 2018 MAC OS GAME (full) 2017 .
BitLord.com
Download: http://cpp-good.com/films/acteur/mark-wahlberg.html - Mark Wahlberg .
Ben and Lauren: Happily Ever After Season 1 Episode 5 - Happily Ever After 1×05
Download: http://flowerdeliveriesnow.com/watch-online-healthy-hour-episode-22-104152.html - Healthy Hour - еЃҐеє·ж—ҐиЁ - Episode 22 .
BitLord.com
Download: http://vicieux.fr/Fran-ois-Marsal-Encyclop-die-de-banque-et-de-bourse_3642961.html - François-Marsal - Encyclopédie de banque et de bourse .
Aleksandr Miraj Raznii Sudiby 2008
Download: http://trn1023.com/movie/wheres-my-baby-25430.html - HD Where's My Baby? .
@file gomorra
Download: http://testdomainreg-08244.com/film/The-Suicide-Shop_hZk - The Suicide Shop .
Alabama - Just Us - 1987 - 192 CBR
Download: http://doigiaycu.com/watch-movie-national-security-online-megashare-2-2012 - National Security (2003) .
SexArt - Perfect Awakening - Dolly Diore [720p - mp4
Download: http://chaobo99.com/descargar-torrents-variados-1949-Rammstein-In-Amerika-Concert-In-Madison-Square-Garden.html - Rammstein - In Amerika (Concert In Madison Square Garden). .
Sonic The Hedgehog Classics Android
Download: http://doigiaycu.com/watch-movie-escape-plan-2-hades-online-megashare-9332-430843-estream - Watch on estream .
(2016) TS Storks
Download: http://pc-tools.fr/mp3/codomo-dragon.html - CODOMO DRAGON .
vlc 2 2 5-20160711-0754 beta x64
Download: http://dogux.com/02190817-aftenposten-junior-15-mai-2018/ - Aftenposten Junior – 15 mai 2018 .
Norman Malware Cleaner v2.07.06 DC 24.05.2013 ( Ryushare - Uploaded )
Download: http://mapevaders.com/mov/animation/?lc=ru - Р СѓСЃСЃРєРёР№ .
Star Trek: Renegades 2015 HD ????? ????? 4.9
Download: http://mortalarcade.com/chapter/tomochan_wa_onnanoko/chapter_146 - Chapter 146 .
TeasePOV 16 11 04 Candice Dare XXX 720p MP4 KTR
Download: http://litvibe.com/manga/one-piece/649 - One Piece 649 .
Hell or High Water Torrent download
Download: http://bddinkal.com/mp3/a-chord-hsieh.html - A CHORD HSIEH .
http://extraimago.com/image/jCp
Download: http://charterorangebeach.com/song/anji-luwuk-lebih-indah.html - ANJI - Luwuk Lebih Indah .
Blood Punch
Download: http://ottqrxivzzol.com/sportovni.php - SportovnГ .
San Andreas
Download: http://siennaryan.com/search/?search=powerless%20s01e09%20720p - powerless s01e09 720p .
The.Big.Bang.Theory.S10E06.Web-DL.1080p.10bit.5.1.x265.HEVC-Qman[UTR - .mkv
Download: http://athuexere.com/show/exo-first-box/ - EXO First Box .
view all
Download: http://zaeinab.com/series-hd/ - Series HD .
History Of War Issue 3 - May 2014 UK
Download: http://athuexere.com/show/running-man/episode-58.html - Running Man Episode 58 .
0 Comments
Download: http://exprisoner.com/tag/jeremy-kagan - Jeremy Kagan .
The Robert Cray Band ( 2014 ) - In My Soul ( Limited Edition )
Download: http://socriptomoedas.com/watch-online/a-frosty-affair - A Frosty Affair .
Masterminds
Download: http://xb1123.com/physics-workbook-for-dummies-e20627309.html - Physics Workbook For Dummies .
Releases
Download: http://cpp-good.com/films/acteur/sebastien-thiery.html - SГ©bastien Thiery .
APES.REVOLUTION.Il.pianeta.delle.scimmie.Movie.ITALIA.2014.BluRay-1080p.x264-YIFY
Download: http://hsq333.com/movie/high-jack-2018/ - High Jack (2018) Hindi Full Movie Watch Online Watch High JackВ (2018) Full Movie Online, High Jack (2018) Full Movie Free Download,В High Jack Hd Movie Watch Online :В Rakesh, an out of luck DJ, has just found out that the gig he was to perform in Goa, has been canceled. He is in urgent requirement of money to save his Dad's clinic and in that desperation, partly agrees to carry ... .
defonce de beaux petits culs 5 s1 mp4
Download: http://dns9227.com/film/fichefilm_gen_cfilm=14790.html - Mon voisin Totoro .
Kate Micucci
Download: http://250585g.com/videos/replay/864066/days-gone-un-monde-transforme-paysages-comme-habitants-e3-2018.htm - ReplayDays Gone : Un monde transformГ©, paysages comme habitants - E3 2018 .
The Makers of Scotland: Picts, Romans, Gaels and Vikings
Download: http://margatebookkeeping.com/chapter/tomochan_wa_onnanoko/chapter_345 - Chapter 345 .
Lethal Weapon S01E07 HDTV x264-LOL[ettv -
Download: http://nightowlstore.com/rubrique/31/livre/957/ma-pochette-de-danseuse - Ma pochette de danseuse .
Free Full Fantasy TV Shows
Download: http://travel-fleet.com/search/Jim Gaffigan.html - Jim Gaffigan .
K milked by Daniela 08 mp4
Download: http://train4entrepreneur.com/f/581604/nike_tracer_epl_by_darfidos_and_peyman.html - NIKE TRACER EPL by darfidos and Peyman .
Dark Souls II Scholar of The First Sin REPACK-KaOs
Download: http://mtvirtualit.com/tags/explore/plot/103578/0/0 - Escapades1332 .
[???? - ???? 1? 161117
Download: http://carsforusvets.com/DAD1FC9A9ED1E54548962F711FBD7395CCBB52A1/WWE-2K18-CODEX - WWE 2K18 CODEX .
Dragon Ball Super Arc Champa Part1 [VOSTFR - [720P - [...(N) (P)
Download: http://woolfestreet.com/showthread.php?264469-Veere-Di-Wedding-2018-Watch-Full-Hindi-Movie-Online-Pre-Dvd-Rip&s=91001e82fe7921da8ed66ddfcd523e59 - Veere Di Wedding | 2018 Watch Full Hindi Movie Online - Pre Dvd Rip .
[AnimeRG - FLIP FLAPPERS - 7 [720p - [ReleaseBitch -
Download: http://vicieux.fr/business.html - Business .
100 Uncensored Japanese HD Cumshots - part 2 HD 720p
Download: [url=http://sharpsushi.com/index.php?do=static&page=come-postare-un-articolo]Come creare un articolo[/url] .
Rachel Allen's: Easy Meals - Series 1
Download: [url=http://chaobo99.com/serie-episodio-descargar-torrent-52752-Rusia-Con-Simon-Reeve-1x01-al-1x03.html]Rusia Con Simon Reeve - 1ВЄ Temporada [1080p][/url] .
My Friends
Download: [url=http://woolfestreet.com/forumdisplay.php?1747-Satrangee-Sasural&s=f970a21e442858c28cb47b5bb7909a32]Satrangee Sasural[/url] .
Suicide Squad 2016 EXTENDED 1080p WEB-DL x264 AC3-JYK[SN]
Download: [url=http://gomeseventos.com/rage-french-dvdrip-2018.html]Rage FRENCH DVDRIP 2018[/url] .
Alesana - Confessions (2015)
Download: [url=http://justpositives.com/watch-everything-everything-online-free-putlocker-849.html]Everything, Everything (2017)[/url] .
Telerik Platform Ultimate Collection for .NET 2016.2 SP1 [OS4World]
Download: [url=http://charterorangebeach.com/song/james-arthur-at-my-weakest-lyric.html]James Arthur - At My Weakest (Lyric Video)[/url] .
Suicide Squad 2016 EXTENDED 1080p WEB-DL x264 AC3-JYK
Download: [url=http://pc-tools.fr/mp3/david-bowie.html]David Bowie[/url] .
Naruto Shippuden Completo MP4 Torrent
Download: [url=http://ottqrxivzzol.com/tema/v%C3%BDslech]vГЅslech[/url] .
Download Dej loaf and lil wayne for free
Download: [url=http://bddinkal.com/mp3/juno-mak--kay-tse.html]Juno Mak Kay Tse[/url] .
ReCore - pc [2016]REPACK
Download: [url=http://vitalpediafox.com/watch/835430-3-gol-terbaik-timnas-indonesia-u-22-pada-sea-games-2017]3 Gol Terbaik Timnas Indonesia U-22 pada SEA Games 2017[/url] .
Ghost Hunters
Download: [url=http://woolfestreet.com/forumdisplay.php?2439-Zun-Mureed&s=91001e82fe7921da8ed66ddfcd523e59]Zun Mureed[/url] .
Alvin and the Chipmunks The Road Chip (2015) CAM HD Free Download
Download: [url=http://xb1123.com/data-analysis-with-microsoft-excel-e25241812.html]Data Analysis with Microsoft Excel[/url] .
AmericanDaydreams.Ava.Addams.mp4s
Download: [url=http://charlottebodyrubs.com/series/marlon-saison-1-episode-10-15672.html]Marlon - S01E10[/url] .
Petes Dragon 2016 BDRip x264 AC3-iFT[PRiME]
Download: [url=http://monia.fr/watch86/Greys-Anatomy/season-14-episode-15-Old-Scars-Future-Hearts]Old Scars, Fut season 14 episode 15[/url] .
[email protected] @(MIDD-372)(MOODYZ) ?????? Beautiful female teacher ?????
Download: [url=http://athuexere.com/show/weekly-idol/episode-246.html]Weekly Idol Episode 246[/url] .
Adobe After Effect
Download: [url=http://monia.fr/watch69/The-Big-Bang-Theory-/season-06-episode-06-The-Extract-Obliteration]The Extract Ob season 06 episode 06[/url] .
???
Download: [url=http://litvibe.com/manga/hunter-x-hunter/101]Hunter X Hunter 101[/url] .
No Tomorrow S01E06 720p HDTV x264-FLEET[PRiME]
Download: [url=http://tapisdorient.fr/2015/02/]February 2015[/url] .
Lethal Weapon S01E03 HDTV x264-LOL[ettv]
Download: [url=http://mbc787.com/tema-bugatti-veyron/]Tema de Bugatti Veyron[/url] .
Alanis Morissette - Live At Montreux
Download: [url=http://zealoustools.com/voir-manga-choujigen-game-neptune-the-animation-en-streaming-6769.html]Choujigen Game Neptune The Animation[/url] .
Sonic Academy - KICK 2 v1.0.5 macOS [R2R][dada] [Isohunt.to]
Download: [url=http://cpp-good.com/ebooks/partition-musicale/]Partition musicale[/url] .
Alejandro Sanz - Paraiso Express - Teatro Compac Gran Via - Madr
Download: [url=http://tapisdorient.fr/2016/01/]January 2016[/url] .
Download Now The Big Bang Theory S10E09 HDTV x264 LOL 1 hour ago
Download: [url=http://selftrainedprogrammer.com/film?genre=Science Fiction]Science Fiction[/url] .
Addicted to
Download: [url=http://muzica-etno.com/movie-online/vikings-season-4]Vikings - Season 4[/url] .
Naruto Shippuden – Episodio 476 e 477 Legendado HD Online
Download: [url=http://vandyhacks.com/online-sorozatok/6560/seasons/1/episodes/122]ГЃlmodj velem 1.Г©vad 122.epizГіd[/url] .
Leave a Comment!
Download: [url=http://landingcraftsforsale.com/2018/04/29/%d9%85%d8%b4%d8%a7%d9%87%d8%af%d8%a9-%d9%81%d9%8a%d9%84%d9%85-%d8%a7%d9%84%d8%a7%d8%b5%d9%84%d9%8a%d9%8a%d9%86-2017-%d8%a7%d9%88%d9%86-%d9%84%d8%a7%d9%8a%d9%86-%d9%83%d8%a7%d9%85%d9%84/]Ш§ЩЃЩ„Ш§Щ… Ш№Ш±ШЁЩ‰ 59 Щ…ШґШ§Щ‡ШЇШ© ЩЃЩЉЩ„Щ… Ш§Щ„Ш§ШµЩ„ЩЉЩЉЩ† 2017 Ш§Щ€Щ† Щ„Ш§ЩЉЩ† ЩѓШ§Щ…Щ„ Щ…ШґШ§Щ‡ШЇШ© ЩЃЩЉЩ„Щ… Ш§Щ„Ш§ШµЩ„ЩЉЩЉЩ† 2017 Ш§Щ€Щ† Щ„Ш§ЩЉЩ† ЩѓШ§Щ…Щ„ ШЁШ¬Щ€ШЇШ© Ш№Ш§Щ„ЩЉШ© HD Щ…Ш№ Ш§Щ…ЩѓШ§Щ†ЩЉШ© ШЄШЩ…ЩЉЩ„ ЩЃЩЉЩ„Щ… ШЁШґЩѓЩ„ Щ…ШЁШ§ШґШ± Щ€ШіШ±ЩЉШ№ШЊ Щ€ШЄЩ‚Щ€Щ… Щ‚ШµШ© ЩЃЩЉЩ„Щ…[/url] .
Alesana A Place Where The Sun Is Silent Deluxe Edition 2011 320kbps CDRip MESS Reupload
Download: [url=http://monia.fr/watch738/Young-and-Hungry/season-05-episode-10-Young-and-Amnesia]Young & Amnesi season 05 episode 10[/url] .
Kerish Doctor 2016 [Isohunt.to]
Download: [url=http://mtvirtualit.com/tags/explore/plot/103766/0/0]Filmmaking58[/url] .
Isabella Madison
Download: [url=http://chaobo99.com/noticia-torrents-13124.html]MUSICALES.[/url] .
Being.Human.S05E04.PDTV.x264-Deadpool
Download: [url=http://hayvan.biz/billionaires/11495/11495.html]Mr. Lucky: Billionaire Romance Novella[/url] .
12 Маймуни Сезон 2 Епизод 4 / 12 Monkeys БГ СУБТИТРИ
Download: [url=http://palmettokennelssc.com/xem-phim-kakuriyo-no-yadomeshi-2018-14710.html](Tбєp 13/??)Kakuriyo No YadomeshiгЃ‹гЃЏг‚Љг‚€гЃ®е®їйЈЇ[/url] .
Rachmaninov plays his 2nd and 3rd Piano Concertos
Download: [url=http://flowlyrics.com/download_firefox/]Download[/url] .
Сезон 1 БГ СУБТИТРИ
Download: [url=http://otkwjneiewqdt.com/juegos-pc/?category_name=conduccion]juegos de conduccion para la PC[/url] .
Ab Mujhe Raat Din Sonu Nigam Karaoke
Download: [url=http://scottheadfishing.com/index.php?PHPSESSID=gqgcssbh7edv0bhknlmdbqm5e6&topic=131568.msg365651;topicseen]Re: SANJU.(2018).1-3.Desi.Pre.Rip.x264.AC3-DTOne.Exclusive[/url] .
Harry Potter e o Prisioneiro de Azkaban – Dublado Full HD 1080p Online
Download: [url=http://flowerdeliveriesnow.com/korean-drama/3646-let-s-hold-hands-tightly-and-watch-the-sunset/]Let’s Hold Hands Tightly and Watch The Sunset - м†ђ кј мћЎкі , м§ЂлЉ” м„ќм–‘мќ„ л°”лќјліґмћђLet’s Hold Hands Tightly and Watch The Sunset[/url] .
Dreams 1990 1080p WEB-DL Ita Jap x265-NAHOM
Download: [url=http://monia.fr/watch86/Greys-Anatomy/season-11-episode-24-Youre-My-Home]You're My Home season 11 episode 24[/url] .
bridget jones
Download: [url=http://dating-spot-is-here.com/games/pc/6741/The Sims 4 Seasons]The Sims 4 Seasons REPACK - FitGirl - 17.9 GB[/url] .
Magnet 1 8 for MAC-OSx
Download: [url=http://muzica-etno.com/movie-online/mia-a-greater-evil]M.I.A. A Greater Evil[/url] .
Addicted to Fresno 2015 iNTERNAL BDRip x264-LiBRARiANS[PRiME]
Download: [url=http://www.sallemariage.fr/milver/heute-bin-ich-blond-2013-video_d1203ae21.html]Heute bin ich blond (2013)[/url] .
Lethal Weapon
Download: [url=http://litvibe.com/manga/boku-no-hero-academia/165]Boku no Hero Academia 165[/url] .
Anthony C. Ferrante,
Download: [url=http://brletras.com/show/running-man/episode-189.html]Running Man Episode 189[/url] .
Lethal Weapon S01E07 HDTV x264-LOL[ettv]
Download: [url=http://puremusicstudio.com/advertising.html]Advertising[/url] .
One Tree Hill
Download: [url=http://pc-tools.fr/mp3/come-as-you-are.html]Come as You Are[/url] .
martin Mystere 18 e 19
Download: [url=http://www.mss118.com/milver/pod-prikritie-s04e03-video_044696fab.html]Pod prikritie S04E03 Pod prikritie S04E03[/url] .
Ava Addams Naughty Neighbors[Brazzers] HD 720P
Download: [url=http://ivalentinequotes.com/2018/02/shaadi-mein-zaroor-aana-2017-hindi-movie-180mb-hevc-hdtvrip/]Shaadi Mein Zaroor Aana 2017 Hindi Movie 180Mb hevc HDTVRip[/url] .
brie learns to obey red phoenix pdf
Download: [url=http://sejourseychelles.fr/punjab-nahi-jaungi-2017-hdtv-400mb-pakistani-urdu-480p/]Leave a Comment[/url] .
No Tomorrow S01E06 WEB-DL XviD-FUM[ettv]
Download: [url=http://bddinkal.com/mp3/as-if-it's-your-last-(마지막мІлџј).html]AS IF IT'S YOUR LAST (마지막мІлџј)[/url] .
Facebook
Download: [url=http://vicieux.fr/Fr-d-ric-Masson-Napol-on-et-l-amour_3620485.html]FrГ©dГ©ric Masson - NapolГ©on et l'amour[/url] .
Baka Go Home Cover
Download: [url=http://shreyasdhuliya.com/download/60-hertz-project-impact-soul-original-mix/]60 Hertz Project Impact Soul Original Mix[/url] .
[??/27.0GB] ????? 10??.10.Cloverfield.Lane.2016.1080p.BluRay.REMUX.AVC.DTS-HD.MA.TrueHD.7.1.Atmos-RARBG
Download: [url=http://tavada-tavuk.com/panopreter/descargar]Descargar[/url] .
??? ???
Download: [url=http://brletras.com/show/welcome-first-time-in-korea-season-2/]Welcome First Time In Korea Season 2[/url] .
Capuccetto.rosso.sangue.2011.iTALiA.MD.720p.BDRip.XviD-TrTd_CREW
Download: [url=http://shreyasdhuliya.com/download/steve-harley-cockney-rebel-sebastian/]Steve Harley Cockney Rebel Sebastian[/url] .
Recommended
Download: [url=http://vicieux.fr/Building-High-Performance-Agile-Teams_3381518.html]Building High Performance Agile Teams[/url] .
Love Everlasting 2016 HDRip AC3 2 0 x264-BDP[SN]
Download: [url=http://lifeinsurancetampa.com/series/dc-s-legends-of-tomorrow-their-time-is-now/]Watch movie[/url] .
Alan Watts 11 Good Seeded Torrents
Download: [url=http://ottqrxivzzol.com/tema/spisovatel]spisovatel[/url] .
Progressive / Power Metal
Download: [url=http://xb1123.com/english-grammar-composition-e18719339.html]English Grammar Composition[/url] .
BitLord.com
Download: [url=http://margatebookkeeping.com/chapter/tomochan_wa_onnanoko/chapter_253]Chapter 253[/url] .
[????] JTBC ??? 161117
Download: [url=http://ihealthlite.com/web_chargify/]Chargify[/url] .
Bruno Mars - Grenade
Download: [url=http://litvibe.com/manga/one-piece/610]One Piece 610[/url] .
emma green
Download: [url=http://www.bilgecocuk.biz/assassins-creed-en-streaming8/]Regarder un film[/url] .
BitLord.com
Download: [url=http://onsco.com/genres/thriller/page-2]Next в†’[/url] .
the goldbergs s04e06 720p
Download: [url=http://locationriadmaroc.fr/cliffhanger-1993-watch-online-movie-free/]Cliffhanger (1993)[/url] .
16/06/18
Download: [url=http://dating-spot-is-here.com/popular]ШґШ§Ш¦Ш№[/url] .
Life on Mars
Download: [url=http://kingsbridgedental-spanish.com/read/dl.php?p=The Lost Art of Being: Secrets to a Calm, Happy, Easy Life][Fast Download] The Lost Art of Being: Secrets to a Calm, Happy, Easy Life[/url] .
CAPTAIN AMERICA The First Avenger 2011 720p BluRay DTS x264-HiDt
Download: [url=http://nightowlstore.com/rubrique/291/linux-et-logiciels-libres]Linux et logiciels libres[/url] .
Falcon Rising 2014 HD ????? ????? 5.8
Download: [url=http://hg5500.com/film/maze-runner-the-death-cure-15927]CAM Maze Runner: The Death Cure (2018)[/url] .
Facebook
Download: [url=http://fortydiet.com/incoming-2018-bluray-1080p-wukns.html]Incoming (2018) [BluRay] (1080p) 17 РјРёРЅСѓС‚[/url] .
The Flash 2014 S03E06 HDTV x264-LOL[ettv] Torrents
Download: [url=http://steanncammunlty.com/movie/american-pie-complete-movie-series-watch-online-free-download/]American Pie Complete Movie Series Watch Online & Free Download Watch American Pie Complete Movie Series full movie online, Free Download American Pie Movie SeriesВ full Movie, American Pie Movie Series full movie download in HD, American Pie Movie Series Full Movie Online Watch Free Download HD : American Pie is a series of sex comedy films. The first film in the series was released on July 9, 1999, by Universal ...[/url] .
Dj Jaan Tomake Chai Ami Aro Kache J Han Club Mix 2011 Mp3
Download: [url=http://charterorangebeach.com/song/twice-i-want-you-back.html]TWICEгЂЊI WANT YOU BACKгЂЌMusic Video[/url] .
Advanced Search
Download: [url=http://bddinkal.com/mp3/galaxy-star.html]galaxy star,[/url] .
Microsoft Office Professional Plus 2013 SP1 November 2016 (x86x64) [Androgalaxy]
Download: [url=http://misterporn.fr/t3-3082229/Calibre-2018-720p-NF-WEB-DL-800MB-MkvCage-torrent.html]Calibre (2018) 720p NF WEB-DL 800MB - MkvCage[/url] .
[AnimeRG] Nanbaka - 07 [1080p] [Multi-Sub] [x265] [pseudo] mkv
Download: [url=http://athuexere.com/show/oppa-thinking/]Oppa Thinking[/url] .
Geekatplay Studio: Distant Trip
Download: [url=http://rangersproteamshop.com/18-kiss-kill-2017/]kiss and kill hindi dubbed full movie[/url] .
Acrowsoft DVD Ripper 1.3.0.4
Download: [url=http://dns9227.com/video/player_gen_cmedia=19441802&cfilm=21189.html]Voir la bande-annonce[/url] .
Renoir 2016 PC Cracked License
Download: [url=http://pc-tools.fr/mp3/no-mГЎs.html]no mГЎs,[/url] .
Read More
Download: [url=http://dataksa.com/forums/kitty-kats-top-models-pictures-videos.54/threads/dina-sets-1-5-2018-06-09.2577194/]Dina Sets 1-5 | 2018-06-09[/url] .
Alien Nation
Download: [url=http://youshunjieyi.com/mp3/3515699441/nelle-tue-mani.html]Nelle Tue Mani[/url] .
vlc 2 2 5-20160711-0754 beta x64
Download: [url=http://locationriadmaroc.fr/category/the-girlfriend-experience/]The Girlfriend Experience[/url] .
Zero Days 2016 READNFO 720p HDTV x264-BATV[ettv]
Download: [url=http://athuexere.com/show/my-bodyguard/]My Bodyguard[/url] .
Perl/PHP/Python
Download: [url=http://mtvirtualit.com/tags/explore/mood/102275/0/0]Sexual222[/url] .
Before I Wake Official Trailer
Download: [url=http://charterorangebeach.com/song/kahitna-rahasia-cintaku-baper--lyric.html]KAHITNA - Rahasia Cintaku #Baper [Official Lyric Video][/url] .
Dead Drop 2013 avi
Download: [url=http://exprisoner.com/18675-watch-the-lego-ninjago-movie-2017-1080p-bluray-x264-geckos-mkv.html]the.lego.ninjago.movie.2017.1080p.bluray.x264-geckos.mkv[/url] .
100% Real Swingers
Download: [url=http://fbdiffusion.fr//fbdiffusion.fr/serie/haus-des-geldes/]Haus des GeldesInfos zur Serie[/url] .
Syncovery v7 63a Build 424 (x86 x64) - Full rar
Download: [url=http://wbchsnews.com/tag/telecharger-disco-elysium-gratuit-pc/]telecharger Disco Elysium gratuit pc[/url] .
star wars rebels
Download: [url=http://ultra-turbomuscle.com/ver/the-lord-of-the-skies-6x38.html]6x38 El seГ±or de los cielos[/url] .
tender savage by phoebe conn
Download: [url=http://zippohcm.com/movie/vhs2/]HD V/H/S/2[/url] .
Сезон 2
Download: [url=http://athuexere.com/show/running-man/episode-36.html]Running Man Episode 36[/url] .
BitLord.com
Download: [url=http://zealoustools.com/voir-manga-tchoupi-et-doudou-en-streaming-1727.html]Tchoupi et Doudou[/url] .
Cyndi Lauper - Hat Full Of Stars (1993)
Download: [url=http://zealoustools.com/voir-manga-mononoke-en-streaming-1480.html]Mononoke[/url] .
Tushy 16 11 17 Karla Kush And Arya Fae XXX 1080p MP4 KTR[rarbg]
Download: [url=http://nvsamour4u.com/film/4k-ultra-hd-2160p/giochi/giochi-wii/]Giochi WII[/url] .
A Christmas Star (2015) 300mb Movie DVDRip
Download: [url=http://monia.fr/watch69/The-Big-Bang-Theory-/season-02-episode-14-The-Financial-Permeability]The Financial season 02 episode 14[/url] .
Absolute Genius Monster Builds S01E05 mp4
Download: [url=http://vicieux.fr/Pass4Sure-New-CCNA-640-802-Latest-Dumps_137397.html]Pass4Sure New CCNA 640-802, Latest Dumps[/url] .
The Flash 2014 S03E06 Shade 720p WEB-DL DD5 1 H264-RARBG-kovalski mkv
Download: [url=http://typemogul.com/daybreak/]Watch Movie[/url] .
I— I I?I? I©I I±I?I± I?I„I·I? I•I»I»I¬I?I±
Download: [url=http://woolfestreet.com/forumdisplay.php?950-Talk-Shows&s=91001e82fe7921da8ed66ddfcd523e59]Talk Shows[/url] .
PlumperPass 16 11 16 Kendra Kox Double The Pleasure XXX 1080p MP4-KTR[rarbg]
Download: [url=http://jardinpascher.fr/d/dphn-176-mega.html]dphn 176[/url] .
MEYD-202 mp4
Download: [url=http://flowerdeliveriesnow.com/chinese-drama/3918-fire-of-eternal-love-cantonese/]Fire of Eternal Love (Cantonese) - 烈火如жЊFire of Eternal Love (Cantonese)[/url] .
Read More
Download: [url=http://doktermana.com/deus-da-guerra-2018-hd-bluray-720p-e-1080p-dublado-dual-audio/]Deus da Guerra (2018) – HD BluRay 720p e 1080p Dublado / Dual Áudio[/url] .
Angels And
Download: [url=http://brletras.com/show/knowing-brother/episode-121.html]Knowing Brother Episode 121[/url] .
public disgrace
Download: [url=http://www.mss118.com/milver/the-vampire-diaries-s04e07-video_51a747d90.html]The Vampire Diaries S04E07[/url] .
Jay Hernandez
Download: [url=http://dating-spot-is-here.com/games/pc]Ш§Щ„Ш№Ш§ШЁ PC[/url] .
100 000 Анекдотов.pdf
Download: [url=http://solitabre.com/?p=films&search=Amanda Joy]Amanda Joy[/url] .
view all
Download: [url=http://shuziyouhua.com/dirt-showdown-telecharger-gratuit-de-pc-et-torrent]DiRT Showdown telecharger gratuit de PC et Torrent[/url] .
Hope Howell - Babysitters Taking On Black Cock 4 rq.mp4
Download: [url=http://zealoustools.com/voir-manga-oruchuban-ebichu-en-streaming-823.html]Oruchuban Ebichu[/url] .
WWE NXT 2016 11 16 720p WEB h264-HEEL [TJET]
Download: [url=http://nightowlstore.com/rubrique/137/politique]Politique[/url] .
Alc Strumentals - Alchemist - Fav Trkz 2
Download: [url=http://executivegroupes.com/preacher-3a-temporada-2018-hd-720p-e-1080p-dublado-legendado/]Preacher 3ª Temporada (2018) – HD 720p e 1080p Dublado / Legendado[/url] .
beatrice
Download: [url=http://jodietstest7141imbriglio.com/watch/the-things-weve-seen-2017.html]The Things We've Seen Duration: 80 min[/url] .
Most Downloaded
Download: [url=http://clevelandwebsitehost.com/transporter-3-2008.html]Voir l'article[/url] .
big brother
Download: [url=http://athuexere.com/show/running-man/episode-196.html]Running Man Episode 196[/url] .
E-40 - The D-Boy Diary Book 1 -2016-
Download: [url=http://testdomainreg-08244.com/film/Ali-s-Wedding_hTm]Ali's Wedding[/url] .
Felipa Lins - Ready To Bang (February 10th, 2016) (TrannySurprise)
Download: [url=http://mortalarcade.com/chapter/tales_of_demons_and_gods/chapter_125.5]Chapter 125.5[/url] .
TapinRadio Pro 2.02 (x86/x64) Multilingual Portable
Download: [url=http://netprawnicy.pl/bleeding-steel-2018-english-movie-720p-bluray-1gb-350mb-download/]Bleeding Steel (2018) English Movie 720p BluRay 1GB 350MB Download[/url] .
Chat IRC SSL
Download: [url=http://nvsamour4u.com/2018/05/24/]24-05-2018, 21:31[/url] .
Download Supernatural 12? Temporada Legendado Torrent
Download: [url=http://chaobo99.com/descargar-torrents-variados-1399-Android-para-Windows-Emulador.html]Android para Windows Emulador.[/url] .
doctor who
Download: [url=http://netprawnicy.pl/intelligent-police-2018-telugu-full-movie-720p-web-hd-1gb-350mb-esub/]Intelligent Police (2018) Telugu Full Movie 720p WEB-HD 1GB 350MB ESub[/url] .
rentre littraire 2016
Download: [url=http://doktermana.com/marvels-runaways-1a-temporada-completa-2017-hd-720p-e-1080p/]Marvels – Runaways 1ВЄ Temporada Completa (2017) – HD 720p e 1080p Dublado / Legendado[/url] .
Sausage Party (2016)
Download: [url=http://zealoustools.com/voir-manga-slayers-evolution-r-en-streaming-2305.html]Slayers evolution-r[/url] .
Coolutils Total Excel Converter 5 1 222 + Serial Key zip
Download: [url=http://dataksa.com/forums/vintage-porn.83/]Vintage Porn[/url] .
Joni Mitchell - Refuge of the Roads (2004) [DVD5 NTSC] [Isohunt.to]
Download: [url=http://tavada-tavuk.com/winmodules/descargar]Descargar[/url] .
Modern Marvels
Download: [url=http://jubaowuliu.com/b/ref=sd_allcat_gno_vas_cleaning/258-4398363-9381640?ie=UTF8&node=14069263031]Cleaning[/url] .
Alcohol 120% 2.0.3 Build 9326 Retail + Crack - Core-X
Download: [url=http://lifeinsurancetampa.com/series/bob-s-burgers/]Watch movie[/url] .
Mughal E Azam 1960 HQ 1080p BluRay x264 AC3-ETRG
Download: [url=http://vandyhacks.com/online-filmek/59-a-keresztapa]A Keresztapa[/url] .
La La Land
Download: [url=http://hayvan.biz/romance/13170/13170.html]Devastate (Deliver #4) by Pam Godwin[/url] .
Alban Berg Quartett - Teldec Recordings 8CD
Download: [url=http://socriptomoedas.com/watch-online/messenger-of-wrath]Messenger of Wrath[/url] .
La Famille Belier streaming
Download: [url=http://ashetee.com/21cineplex-coming-soon]Coming Soon[/url] .
[AnimeRG] Keijo - 7 [720p] [Multi Subbed] mkv
Download: [url=http://steanncammunlty.com/movie/carry-jatta-2-2018-punjabi-full-movie-watch-online/]Carry on Jatta 2 (2018) Punjabi Full Movie Watch Online Watch Flight 666 (2018) Full Movie Online, Free Download Flight 666 (2018) Full Movie, Flight 666 (2018) Full Movie Download in HD Mp4 Mobile Movie'Carry On Jatta' is an Punjabi romantic comedy starring Gippy Grewal and Mahie Gill in the leading roles. It revolves around the confusing and comic events that arise after Jass lies to Mahie about his family ...[/url] .
Suicide Squad 2016 EXTENDED 1080p WEBRip 1 9 GB - iExTV
Download: [url=http://testdomainreg-08244.com/film/Auto-Focus_idQ]Auto Focus[/url] .
Michael Franks - Sleeping Gypsy 1977 (Japan SHM-CD) FLAC
Download: [url=http://mbc787.com/screenshot/descargar]Descargar[/url] .
Dublado
Download: [url=http://woolfestreet.com/forumdisplay.php?2276-Mubarak-Ho-Beti-Hui-Hai&s=f970a21e442858c28cb47b5bb7909a32]Mubarak Ho Beti Hui Hai[/url] .
Certain Women (2016)
Download: [url=http://zippohcm.com/movie/paw-patrol-summer-rescues/]SD Paw Patrol Summer Rescues[/url] .
WIRED - December 2016 - True PDF - 1812 [ECLiPSE]
Download: [url=http://monia.fr/watch69/The-Big-Bang-Theory-/season-05-episode-18-The-Werewolf-Transformation]The Werewolf T season 05 episode 18[/url] .
Alain Souchon 2010 Est Chanteur
Download: [url=http://fortydiet.com/movie/чёрная-пантера-trc.html]5 K Чёрная Пантера 2018[/url] .
SexArt.com_16.10.29.Etna.Tanco.XXX.IMAGESET-GAGBALL[rarbg]
Download: [url=http://250585g.com/jeux/jeu-809937/]Call of Duty : Black Ops IIII[/url] .
@file gomorra
Download: [url=http://latamdisco.com/red-dog-true-blue-2017-french-hdrip-x264.html]Red Dog True Blue 2017 FRENCH HDRiP x264[/url] .
Jack Reacher: Never Go Back (2016)
Download: [url=http://paragonfunnel.com/keyword/the-catcher-was-a-spy-stream-hd]#The Catcher Was a Spy stream hd[/url] .
[OCN] ??? ?.E05~E06.161115-161117.HDTV.H264.720p-U…
Download: [url=http://monia.fr/watch60/Downton-Abbey/season-05-episode-04-Episode-4]Episode 4 season 05 episode 04[/url] .
sailor moon
Download: [url=http://typemogul.com/engine/go.php?movie=Pinoy Movies Archives - Full Movies Online On Putlocker]Openload Movies[/url] .
Tom Hanks
Download: [url=http://siennaryan.com/profile/samcode4u/]samcode4u[/url] .
Progressive
Download: [url=http://monia.fr/watch58/DOCTOR-WHO/season-06-episode-02-Day-of-the-Moon]Day of the Moo season 06 episode 02[/url] .
En lire plus
Download: [url=http://litvibe.com/manga/one-piece/384]One Piece 384[/url] .
Powerpoint For Mac 2016 Power Shortcuts
Download: [url=http://trn1023.com/movie/craig-of-the-creek-season-1-24408.html]Eps15 Craig of the Creek - Season 1[/url] .
Alien Isolation [Steam-Rip]
Download: [url=http://sharpsushi.com/249194-star-wars-gli-ultimi-jedi-2017-bluray-1080p-avc-ita-dd-71-eng-dts-hd-71-ddncrew.html]Grazie : 184[/url] .
Strange Hill High
Download: [url=http://train4entrepreneur.com/g/gerber+accumark+v8+5+0+89+patch+mediafire.html]gerber accumark v8 5 0 89 patch[/url] .
Microsoft Office 2016 Replacement file
Download: [url=http://ihealthlite.com/it/download_speccy/]Speccy 1.32.740[/url] .
The Flash 2014 S02E23 The Race of His Life1080p WEB-DL DD5 1 H265-LGC mkv
Download: [url=http://www.fonbet-ed906.com/ver-peliculas/primeropeliculas]PrimeroPeliculas[/url] .
The Walking Dead 7? Temporada Serie Torrnet
Download: [url=http://woolfestreet.com/forumdisplay.php?1886-Dafa-420&s=f970a21e442858c28cb47b5bb7909a32]Dafa 420[/url] .
Блаженный Августин. Исповедь / Confessiones
Download: [url=http://monia.fr/watch86/Greys-Anatomy/season-05-episode-20-Sweet-Surrender]Sweet Surrende season 05 episode 20[/url] .
Analog Circuit Design: Volt Electronics Mixed-Mode Systems Low-Noise and RF Power Amplifiers for Telecommunication
Download: [url=http://litvibe.com/manga/shokugeki-no-soma/56]Shokugeki no Soma 56[/url] .
Watching TV Online - Watch TV shows pdf
Download: [url=http://rawzip.com/ver/i-remember-you-1x16.html]1x16 Te Recuerdo[/url] .
Ver A Historia Real de um Assassino Falso Online
Download: [url=http://dns9227.com/series/ficheserie-7330/saison-29872/ep-610381/]S08E15 - Worth[/url] .
le meilleur patissier
Download: [url=http://rangersproteamshop.com/into-the-badlands-s02e1-hindi/]into the badlands season 2 episode 1 download in hindi[/url] .
MasterChef Сезон 2 Епизод 37 24.05.2016
Download: [url=http://mbc787.com/expresso/]Expresso[/url] .
Chris Pine,
Download: [url=http://lifeinsurancetampa.com/movie/the-greatest-showman/]Watch movie[/url] .
torrent search
Download: [url=http://testdomainreg-08244.com/film/Call-Me-King_iey]Call Me King[/url] .
Kensington - Control (2016) FLAC [Isohunt.to]
Download: [url=http://mortalarcade.com/chapter/tomochan_wa_onnanoko/chapter_103]Chapter 103[/url] .
NetDrive 2 6 11 Build 919 Multilingual + Key [4realtorrentz] zip
Download: [url=http://youshunjieyi.com/page/top-videos.html] Top Videos[/url] .
[pdf] Altroconsumo-Ottobre 2016-
Download: [url=http://zealoustools.com/voir-manga-clamp-school-detective-en-streaming-1118.html]Clamp School dГ©tective[/url] .
[share_ebook] The Elephant in the Room: Silence and Denial in Everyday Life free ebook download
Download: [url=http://doktermana.com/hampstead-nunca-e-tarde-para-amar-2018-bluray-720p-e-1080p-dublado-dual-audio/]Hampstead – Nunca é Tarde para Amar (2018) – BluRay 720p e 1080p Dublado / Dual Áudio[/url] .
Continuar
Download: [url=http://wholesale-onesies.com/X12X69X230323X0X0X1X-marathon-doctor-who.html]Marathon Doctor Who[/url] .
Robin Hood
Download: [url=http://trn1023.com/movie/jurassic-world-fallen-kingdom-25222.html]CAM Jurassic World: Fallen Kingdom[/url] .
Empyrion Galactic Survival Alpha 4.3.1 x64 crack ALI213 #Kortal [Isohunt.to]
Download: [url=http://kingsbridgedental-spanish.com/Making-Things-Talk--Using-Sensors--Networks--and-Arduino-to-see--hear--and-feel-your-world_312753.html]Making Things Talk: Using Sensors, Networks, and Arduino to see, hear, and feel your world[/url] .
Fort Tilden 2014 RERiP BDRip x264-WiDE[1337x][SN]
Download: [url=http://muzica-etno.com/movie-online/castle-season-5]Castle - Season 5[/url] .
Tyler Labine
Download: [url=http://alicialugorealestate.com/03victoria-junes-insatiable-craving-cock/]39 mins ago Victoria June’s Insatiable Craving for Cock[/url] .
Bruno Mars - 24K Magic
Download: [url=http://fbdiffusion.fr/film/tatara-samurai-2016/]たたら侍[/url] .
Code Black S02E07 HDTV x264-FLEET[PRiME]
Download: [url=http://ihealthlite.com/web_bamboohr/]BambooHR[/url] .
X Angels Stasya Stoune Teens play crazy sex games mp4
Download: [url=http://shuziyouhua.com/fortnite-telecharger-gratuit-de-pc-et-torrent/]Fortnite telecharger gratuit de PC et Torrent[/url] .
Сезон 2 БГ СУБТИТРИ
Download: [url=http://socriptomoedas.com/watch-online/bombshell-the-hedy-lamarr-story]Bombshell: The Hedy Lamarr Story[/url] .
Little Women Dallas S01E03 Trading Spaces HDTV x264-[NY2] - [SRIGGA]
Download: [url=http://hayvan.biz/best_series/3263/3263.html]Percy Jackson and the Olympians series[/url] .
insaisissable
Download: [url=http://thesonofficial.com/film/mathilde-46576]HD Mathilde (2017)[/url] .
Chinatown 1974 (1080p Bluray x265 HEVC 10bit AAC 5 1 Tigole)
Download: [url=http://black-cat-artifices.fr?post=7007117]Mary.Magdalene.2018.720p.BluRay.x264-GUACAMOLE[/url] .
Demi Lovato Warrior Karaoke Instrumental
Download: [url=http://muzica-etno.com/movie-online/48-christmas-wishes]48 Christmas Wishes[/url] .
100th Running of the Indianapolis 500 May 29th 2016 [WWRG]
Download: [url=http://vicieux.fr/Pluralsight-Using-Functoids-in-the-BizTalk-2013-Mapper_2699460.html]Pluralsight - Using Functoids in the BizTalk 2013 Mapper[/url] .
Dublado
Download: [url=http://athuexere.com/show/weekly-idol/episode-360.html]Weekly Idol Episode 360[/url] .
TechSmith Camtasia Studio 9 0 0 Build 1306 + Serial Keys [SadeemPC]
Download: [url=http://monia.fr/watch86/Greys-Anatomy/season-11-episode-08-Risk]Risk season 11 episode 08[/url] .
The Crazy Ones
Download: [url=http://ultra-turbomuscle.com/ver/scarlet-heart-ryeo-1x19.html]1x19 Dalui Yeonin - Bobogyungsim Ryeo[/url] .
JUFD-132 ????????? ????
Download: [url=http://zaeinab.com/series/candice-renoir/3268]Candice Renoir HDTV[/url] .
Rectify S04E04 HDTV x264-FLEET[PRiME]
Download: [url=http://executivegroupes.com/levantando-poeira-2018-hd-web-dl-720p-e-1080p-dublado-dual-audio/]Levantando Poeira (2018) – HD WEB-DL 720p e 1080p Dublado / Dual Áudio[/url] .
BitLord.com
Download: [url=http://paragonfunnel.com/movie/alaipayuthey-2000-torrents]Hot Alaipayuthey (2000)[/url] .
Chicas Con Experiencia s1 mp4
Download: [url=http://zaeinab.com/pelicula/407-dark-flight/]407 Dark Flight BLuRayRip[/url] .
Frank Sinatra Greatest Hits Frank Sinatra Top 30 Songs
Download: [url=http://mccarthydohar.com/tag/nora-roberts/]Nora Roberts[/url] .
DS.Catia.V5-6R2014.SP1.UPDATE.WINDOWS-SSQ
Download: [url=http://cryptonamely.com/films/nes-en-chine.html]NГ©s en Chine[/url] .
Ultra Music Festival Miami 3 27 2015
Download: [url=http://hot-gaychat.com/pelicula/el-destino-de-jupiter/]El Destino De Jupiter[/url] .
Сезон 2 БГ СУБТИТРИ
Download: [url=http://athuexere.com/show/the-wonders-of-korea/]The Wonders Of Korea[/url] .
Read More »
Download: [url=http://tavada-tavuk.com/mydefrag/]MyDefrag (JkDefrag)[/url] .
11.22.63 Епизод 8 БГ АУДИО
Download: [url=http://netprawnicy.pl/kirrak-party-2018-telugu-movies-720p-webhd-1-2gb-350mb-mkv/]Kirrak Party (2018) Telugu Movies 720p WEBHD 1.2GB 350MB MKV[/url] .
CSI: New York
Download: [url=http://certifiedenglish.com/category/netsuzou-trap-ntr]Netsuzou TRap – NTR[/url] .
Dog Sled Saga - 2016 (MacAPPS)
Download: [url=http://scottheadfishing.com/index.php?PHPSESSID=gqgcssbh7edv0bhknlmdbqm5e6&topic=57007.0]RDP's And VPS Servers At Greatest Discounts 365 Days.[/url] .
Teenage Mutant Ninja Turtles 2 (2016)
Download: [url=http://mapevaders.com/tv/genius-1i40/2x1.html]Picasso: Chapter One[/url] .
Dictionnaire des expressions juridiques, 2 ed.
Download: [url=http://nightowlstore.com/rubrique/507/united-states]United States[/url] .
Waiting In Your Welfare Line Buck Owens
Download: [url=http://zaeinab.com/series-hd/padre-brown/3870]Padre Brown HDTV 720p AC3 5.1[/url] .
view all
Download: [url=http://palmettokennelssc.com/xem-phim-bi-kip-luyen-rong-phan-3-huong-toi-tram-rong-dragons-defenders-of-berk-season-3-2015-12544.html]BГ KГp Luyện Rб»“ng Phбє§n 3: HЖ°б»›ng Tб»›i TrбєЎm Rб»“ng Dragons Defenders Of Berk Season 3 (2015) (Tбєp 39/39)[/url] .
KarupsHA 16 11 17 Raven Orion Hardcore XXX 720p MP4-KTR[rarbg]
Download: [url=http://trn1023.com/movie/serialized-24630.html]SD Serialized[/url] .
Comments (0)
Download: [url=http://hot-gaychat.com/series/the-resident/3771]The Resident HDTV[/url] .
Photo Restoration in Photoshop - Bring Old Photos Back to Life
Download: [url=http://kartumimpi.com/series-vo/the-frankenstein-chronicles/2314]The Frankenstein Chronicles HDTV 720p AC3 5.1[/url] .
Doomsday Revival - Doomsday Revival
Download: [url=http://jebriwsbwpvzrw.com/films/telecharger/96761-game-night.html]Game Night TELECHARGEMENT GRATUIT[/url] .
Fight Song - Rachel Platten
Download: [url=http://tipbettr.com/apk/2729/]Download APK[/url] .
Storks (2016)
Download: [url=http://cryptoreaper.com/fast-and-furious-8/]Fast and Furious 8[/url] .
Hope Howell - Babysitters Taking On Black Cock 4 rq mp4
Download: [url=http://cordsets.biz/movies/documentary/6732/Year Million]Year Million E03 (240p, 360p, 480p, 720p, 1080p)[/url] .
Batang Bata Pa At Bakla Na Part 3
Download: [url=http://fonbet-37e14.com/films/dapres-une-histoire-vraie]D'aprГЁs une Histoire Vraie[/url] .
View this forum's RSS feed
Download: [url=http://bta-andora.com/forums/kitty-kats-top-models-pictures-videos.54/threads/kk-model-ivanka-video-1-18-2018-06-08.2542123/]KK-Model Ivanka Video 1-18| 2018-06-08[/url] .
Download Thousands of Books two weeks for FREE!
Download: [url=http://dancefestopen.com/descargar-torrents-variados-1400-CorelCAD-20140-Build-13812.html]CorelCAD 2014.0 Build 13.8.12.[/url] .
Nandas.Island.Multi5.nds.by.chuska.www.cantabriatorrent.net
Download: [url=http://cookingyoursassoff.com/serie.php?serie=3297]El hombre de tu vida[/url] .
Cafe Society Dublado 720p Download
Download: [url=http://bestpartialrepairs.com/films/annee/2011.html]film de 2011[/url] .
[Best of Teen Anals] Devils Film DVDRip [.avi]
Download: [url=http://comender.com/film/15025/ http://comender.com/tag/%D8%A7%D9%81%D9%84%D8%A7%D9%85+%D8%A7%D9%83%D8%B4%D9%86+2018/1.html ]Ш§ЩЃЩ„Ш§Щ… Ш§ЩѓШґЩ† 2018[/url] .
Adobe Dreamweaver CC 2015 + Crack [Re-Upload] / Mac OSX
Download: [url=http://jebriwsbwpvzrw.com/telecharger/westworld/]Westworld[/url] .
Adobe Acrobat PRO DC 2015 [ Mac Os X ] [ UPGRADABLE ] [ FirstKick ] [ nFa ]
Download: [url=http://mersinhavacilik.com/t/girlboss-hashtag]#girlboss[/url] .
Huset2016
Download: [url=http://alpha-iptv.com/category/histoire/]Histoire[/url] .
WPS Office 2016 Premium v10 1 0 5802 Multilingual Incl Patch
Download: [url=http://canariaschat.com/pelicula/the-lucky-one/]The Lucky One DVDRIP[/url] .
Titanic 1997 HD ????? ????? 7.7
Download: [url=http://easyfinancial.biz/series-hd/the-looming-tower/3708]The Looming Tower HDTV 720p AC3 5.1[/url] .
Jason Bourne 2016 1080p BluRay x264-SPARKS[PRiME]
Download: [url=http://uusintaripsista.com/tag/pelicula-race-3-2018-descarga-completa/]pelГcula Race 3 (2018) descarga completa[/url] .
Mister You - Le Grand Mechant You-WEB-FR-2016-SPAN...(N)
Download: [url=http://franksfishworld.com/movies/the-demoniacs/]The Demoniacs[/url] .
Storm Surfers 3D 2012 HD ????? ????? 6.5
Download: [url=http://jartiyeri.com/pelicula/star-wars-vii-3d-hou/]Star Wars VII 3D HOU BluRay 3D 1080p[/url] .
[AnimeRG] FLIP FLAPPERS - 7 [720p] [ReleaseBitch]
Download: [url=http://appliancedoctortv.com/tags/American+Assassin+guarda+streaming/]American Assassin guarda streaming[/url] .
person of interest S02
Download: [url=http://moviesdickens.com/shooter-season-3-episode-12-s03e12_421685]Season 3 Episode 12 Patron Saint[/url] .
designing high-performance jobs
Download: [url=http://celebinstagrams.com/album/torrent-212660-tnt-discography-30-releases-1982-2018]TNT - Discography (30 Releases) (1982-2018)[/url] .
Cyberwar S01E11 HDTV x264-W4F - [SRIGGA]
Download: [url=http://bestpartialrepairs.com/films/acteur/geoffrey-rush.html]Geoffrey Rush[/url] .
Dragonball Z: Resurrection F komplett online sehen
Download: [url=http://freelifetimexxxbook.com/scroll-reverser-download-invertire-scroll-mouse-mac/]Continua...[/url] .
Alchemy And The 3 Great Works
Download: [url=http://cookingyoursassoff.com/serie.php?serie=2252]La guerra de Hollywood[/url] .
(??????) [????] ???????? [2014-01-15] (?????).zip
Download: [url=http://crazy-for-books.com/Our-Girl]Our Girl Returns 5th Jun 9:00pm On BBC one NEW![/url] .
Prison Break
Download: [url=http://cookingyoursassoff.com/serie.php?serie=4486]Fangbone![/url] .
BitLord.com
Download: [url=http://yuwioo.com/film/the-first-purge-2018/]The First Purge[/url] .
Stacy Schiff - The Witches Salem, 1692 (PDFamp;EPUBamp;MOBI)
Download: [url=http://mypremiumgarciniacambogiaplus.com/diziler/chicago-typewriter/]Chicago Typewriter[/url] .
Aaj Subah Jab Main Jaga Vidio Song
Download: [url=http://djangolor.com/magazine/678-creattiva-con-perline-no-5-2009.html]Creattiva con Perline No 5 2009[/url] .
Blindspot S02E09 HDTV x264-LOL mp4
Download: [url=http://teverie.com/torrent/technitium-mac-address-changer_37114.html]Technitium MAC Address Changer[/url] .
Jason Bourne 2016 720p BluRay x264-SPARKS[PRiME]
Download: [url=http://bojieba.com/category/Shopping]Shopping[/url] .
Read More
Download: [url=http://bottlecapemblem.com/book/hidden-by-kelli-clare]Hidden by Kelli Clare[/url] .
BitLord.com
Download: [url=http://ghqcars.com/ver/the-flash-2014-4x22.html]4x22 The Flash[/url] .
Cinesamples African Marimba and Udu-[KONTAKT]
Download: [url=http://uothfsuwjhhbp.com/torrent/70682/readyplayerone20181080pwebh264-webtiful.html]Ready.Player.One.2018.1080p.WEB.h264-WEBTiFUL[/url] .
1920 London (2016) Full Movie download 700mb Free Hd
Download: [url=http://trycambogiapure.com/list/music-making-apps-to-strike-a-chord/]Music-making Apps to Strike a Chord[/url] .
Continuar
Download: [url=http://dokkijoa.com/manga/one-piece/338]One Piece 338[/url] .
Call the Midwife Christmas Special 2015 720p BluRay x264-PHASE[EtHD]
Download: [url=http://kingstiresms.com/actors/Eli+Roth.html]Eli Roth[/url] .
Clinique
Download: [url=http://earthdayimages2018.com/engine/go.php?file=paramore-caught-in-the-middle.html]Paramore: Caught In The Middle.mp3[/url] .
Jarven tarina (2016)
Download: [url=http://karchercenterpremium.com/top-del-mese/anime-e-cartoon/anime-hd/]Anime HD[/url] .
WWE - Wrestling
Download: [url=http://1st-saftey.com/forumdisplay.php?f=233&s=cb2533878f12506cd43e16d074aab7b8]Aventura[/url] .
game of thrones s04e07
Download: [url=http://djangolor.com/magazine/1015452-time-usa-april-09-2018.html]Read More ...[/url] .
Bloodlust Tournament of Death 2016 DOCU WEBRiP x264-RAiNDEER[1337x][SN]
Download: [url=http://trycambogiapure.com/games/kr.co.smartstudy.babysharkjump.googlemarket/]Baby Shark Adventure APK 5 - Free Arcade Game for Android[/url] .
Advanced search
Download: [url=http://dokkijoa.com/manga/fairy-tail/217]Fairy Tail 217[/url] .
Alanis Morissette-Jagged Little Pill Acoustic-2005-RNS
Download: [url=http://dancefestopen.com/descargar-torrents-variados-1941-Destroy-Windows-10-Spying-v15430.html]Destroy Windows 10 Spying v1.5.430.[/url] .
Advanced Uninstaller PRO 12.16
Download: [url=http://d7bo.com/The-Bold-Type]The Bold Type Returns 12th Jun 9:00pm On Freeform NEW![/url] .
Vellaiya Irukiravan Poi Solla Maatan (2015) DVDRip
Download: [url=http://usatopnewsfeed.com/movies/watch-online-gayatri-telugu-2018-full-movie-download.html]Gayatri Telugu (2018) (HDRip)[/url] .
AI RoboForm
Download: [url=http://cookingyoursassoff.com/serie.php?serie=297]La hora once[/url] .
Petes Dragon 2016 BDRip x264 AC3-iFT[SN]
Download: [url=http://wwwhawaiianofficiant.com/cast/mickey-bollenberg/]Mickey Bollenberg[/url] .
Day Break
Download: [url=http://cookingyoursassoff.com/capitulo.php?serie=2894&temp=2&cap=12]Colony 2X12 - Capitulo 12[/url] .
Little Women LA S05E19 Reunion Part Two HDTV x264-[NY2] - [SRIGGA]
Download: [url=http://uusintaripsista.com/tag/peliculas-gratis-completa/]peliculas gratis completa[/url] .
Mistresses US
Download: [url=http://forthetoys.com/movies-corner-gas-animated-season-1-2018-moviesub.html]Corner Gas Animated Season 1 Eps12 HD[/url] .
view all
Download: [url=http://bursakesikelyaf.com/whats-with-wheat-streaming-vf-vostfr/]WhatS With Wheat?[/url] .
TWD S07E12 Torrent
Download: [url=http://yourlocaldates4.com/engine/go.php?file2=++Lean+on+Pete+2017+1080p+BluRay+x264-DRONES+]Online Subtitles[/url] .
Good Behavior S01E02 WEB-DL XviD-FUM[ettv]
Download: [url=http://alpha-iptv.com/movie/la-douleur-dvd-streaming/]La douleur streaming[/url] .
Software Engineering and Comp...
Download: [url=http://inikas.biz/2017/la-memoire-assassine.html]La MГ©moire assassine[/url] .
Saheb Bibi Golaam (2016)
Download: [url=http://0864882.com/movie-online/the-adventures-of-rocky-and-bullwinkle-season-1]The Adventures of Rocky and Bullwinkle - Season 1[/url] .
Bull (2016)
Download: [url=http://theflashupdate.com/recherche/?query=Orange+is+The+New+Black]Orange is The New Black[/url] .
Albom Classicheskoy Musyki - Relax
Download: [url=http://dancefestopen.com/descargar-torrents-variados-423-AVS-Video-Editor-v61.html]AVS Video Editor v6.1[/url] .
American Horror Story S06E10 HDTV x264-FUM[ettv]
Download: [url=http://locationmaisonbourges.fr/1215-serena-en-streaming.html]Serena en Streaming[/url] .
NW (2016)
Download: [url=http://massasjenorskdamer.com/watch-movie-disobedience-online-megashare-9321]Disobedience (2018)[/url] .
Key Asc 10 Pro
Download: [url=http://newjerseyjewishmonuments.com/actori/20775-ravil-isyanov]Ravil Isyanov[/url] .
BitLord.com
Download: [url=http://fonbet-37e14.com/films/daphne-and-velma]Daphne And Velma[/url] .
GTA Vice City 2011
Download: [url=http://shellcraftyideas.com/?p=film&id=4933-un-beau-soleil-int-rieur]1 - Un Beau Soleil IntГ©rieur [BLU-RAY 1080p] - FRENCH[/url] .
Pets – A Vida Secreta dos Bichos Dublado Online Max e um cachorrinho que mora em um apartamento de Manhattan. Quando seu dono traz para casa um viralata desleixado chamado Duke, Max nao gosta nada, ja que o seu tempo de bichinho de estimacao favorito parece ter acabado. Mas logo eles vao ter que colocar as divergencias de lado pois um coelhinho branco adoravel chamado Snowball esta construindo um ...
Download: [url=http://frite.fr/wheres-the-money-francais-hdrip/]Wheres the Money Français HDRiP[/url] .
FORGE OF EMPIRES - 2016 [FOR MAC]
Download: [url=http://ruyabetegir.com/soft/SubtitleEdit-3.3.6-Setup.7z]Subtitle Edit 3.3.6[/url] .
Manchester by the Sea: Movie Clip - Take a Shower
Download: [url=http://breizhagalon.fr/big-clock/descargar]Descargar[/url] .
Browse Musicians
Download: [url=http://uusintaripsista.com/category/se-armo-el-belen-2017/]Se armГі el BelГ©n (2017)[/url] .
Icerde (Ek ton eso) 2016 5o ep. 720p WEBRip x264 AAC [Isohunt.to]
Download: [url=http://fonbet-37e14.com/films/criminal-squad]Criminal Squad[/url] .
grey anatomy
Download: [url=http://beihaveadream.biz/high-012-natsuki/]HIGH-012 Natsuki[/url] .
Magazines
Download: [url=http://tipbettr.com/apk/25490/]Download APK[/url] .
A Season with Florida State Football S02E10 HDTV x264-[NY2] - [SRIGGA]
Download: [url=http://onlinedetoxstore.com/rubrique/31/rubrique/121/management]Management[/url] .
Brooklyn Nine-Nine S04E06 HDTV XviD-AFG
Download: [url=http://bottlecapemblem.com/book/birth-of-chaos-by-elise-kova]Birth of Chaos by Elise Kova[/url] .
Five Finger Death Punch Got Your Six DlxEd (2015)[MP3 TNT]
Download: [url=http://lukaszstrozek.com/pelicula/descargar-torrent-2575-el-nino-con-el-pijama-de-rayas]El niГ±o con el pijama de rayas (2008)[/url] .
Agents of Shield hd wallpapers
Download: [url=http://jartiyeri.com/descargar/peliculas-castellano/peliculas-rip/presion-/blurayrip/]Presion BLuRayRip[/url] .
Will Ferrell’s 10 Best Movies
Download: [url=http://pmplcorp.com/category/una-funcion-para-olvidar-2017/]Una funciГіn para olvidar (2017)[/url] .
Ashley Tisdale
Download: [url=http://pretacommuniquer.com/ar/Щ…ШґШ§Щ‡ШЇШ©-lust-stories-ЩѓШ§Щ…Щ„-Ш§Щ€Щ†Щ„Ш§ЩЉЩ†/]Lust Stories[/url] .
Overwatch - 2016 (PC) nosTeam
Download: [url=http://d7bo.com/show/dragon-ball-super-doragon-bru-cho]Watch this[/url] .
Harley Jade mp4
Download: [url=http://morningstar2018.com/juegos-wii/just-dance-17/]Just Dance 17[/url] .
Ben 10 S01E12 (2016)
Download: [url=http://dokkijoa.com/manga/one-piece/119]One Piece 119[/url] .
Only The Best (New Sensations) 2016 Split Scenes
Download: [url=http://wh8882222.com/song/gogojill-takkan-mampu-live-on-studio.html]GoGoJiLL - Takkan Mampu [Live On Studio][/url] .
[Tushy] Karla Kush, Arya Fae (My Crazy Day With my Wild Roommate - 17 11 2016...
Download: [url=http://kingstiresms.com/actors/Billy+Burke.html]Billy Burke[/url] .
Carrie Underwood - Temporary Home (2010)
Download: [url=http://kingstiresms.com/watch/total-bellas-s03-2017-online-m4ufree.html]Watch now[/url] .
Drunk History S04E08 720p HDTV x264-FLEET[PRiME]
Download: [url=http://julybet48.com/f/22787588/think_big_wolves_mashed_up.html]Think Big Wolves (Mashed Up)[/url] .
Topaz InFocus
Download: [url=http://jartiyeri.com/series/navy-investigacion-criminal/1198]Navy Investigacion Criminal HDTV[/url] .
DeadFish Higurashi no Naku Koro ni Batch DVD 480p MP4 AAC
Download: [url=http://abibunda.info/torrent/android-only-paid-apps-week-25-2018-androgalaxy-t2525828.html]Android - Only Paid Apps- Week 25 2018 [AndroGalaxy][/url] .
The Beaverton S01E02 HDTV x264-aAF[ettv]
Download: [url=http://exposingjohns.com/online2/6/ http://exposingjohns.com/tag/%D8%A7%D9%81%D9%84%D8%A7%D9%85+%D8%A7%D8%AB%D8%A7%D8%B1%D8%A9+%D9%84%D9%84%D9%83%D8%A8%D8%A7%D8%B1+%D9%81%D9%82%D8%B7/1.html ]Ш§ЩѓШ«Ш± Ш§Щ„Ш§ЩЃЩ„Ш§Щ… Ш§Ш«Ш§Ш±Ш© Щ„Щ„ЩѓШЁШ§Ш± ЩЃЩ‚Ш·[/url] .
City Hunter 1993 HD ????? ????? 6.5
Download: [url=http://teverie.com/logiciels/?order=id&orderby=desc]Logiciels[/url] .
All In with Chris Hayes 2016 11 16 720p WEBRip x264-LM
Download: [url=http://amour-web.fr/movie/popstar-never-stop-never-stopping-2016-hindi-dubbed-full-movie/]Popstar: Never Stop Never Stopping (2016) Hindi Dubbed Full Movie Popstar: Never Stop Never Stopping (2016) Hindi Dubbed Full Movie Watch Online HD Print Quality Free Download,Full Movie Popstar: Never Stop Never Stopping (2016) Hindi Dubbed Watch Online DVD Print Quality Download.When his new album fails to sell records, pop/rap superstar Conner4real goes into a major tailspin and watches his celebrity high life begin to collapse. He'll try anything to ...[/url] .
Gods of Egypt 2016 FRENCH BRRip XviD-AM84(A)
Download: [url=http://jebriwsbwpvzrw.com/films/genre/arie-elma.html]film AriГ© Elma[/url] .
Family Guy Blue Harvest 2007 MULTi 1080p BluRay RE...(N)
Download: [url=http://jebriwsbwpvzrw.com/films/telecharger/2363-it-s-a-boy-girl-thing.html]It's a boy girl thing TELECHARGEMENT GRATUIT[/url] .
Jason Bourne (2016) 720p BluRay...
Download: [url=http://uothfsuwjhhbp.com/torrent/88038/marvelscloakanddaggers01e05webx264-tbseztv.html]Marvels.Cloak.and.Dagger.S01E05.WEB.x264-TBS[eztv][/url] .
BBC The Life of Mammals 8of9 Life in the Trees 720p HDTV x264 AAC MVGroup org...
Download: [url=http://dokkijoa.com/manga/shokugeki-no-soma/140]Shokugeki no Soma 140[/url] .
LEGO The Hobbit ACCiDENT-PS3 [NO RAR]
Download: [url=http://qs838.com/first-blood/]First Blood[/url] .
Musical 2,052
Download: [url=http://onlinedetoxstore.com/rubrique/324/ebooks-kindle]Ebooks Kindle[/url] .
BitLord.com
Download: [url=http://dancefestopen.com/descargar-torrents-variados-477-Zumba-Live-y-Flat-ABS.html]Zumba Live y Flat ABS.[/url] .
Only The Best (New Sensations) 2016 Split Scenes
Download: [url=http://www.amazing-beauty-trends.com/series/vis-a-vis]Vis a vis[/url] .
Хрониките на Шанара
Download: [url=http://1st-saftey.com/forumdisplay.php?f=224&s=c6bb08e7f36a1b5a808080b514b7d1ea]Mascotas[/url] .
Blindspot S02E06 HDTV x264-LOL[ettv]
Download: [url=http://mypremiumgarciniacambogiaplus.com/tur/biyografi/]Biyografi[/url] .
[AnimeRG] TO BE HERO - 07 [720p] [Multi-Sub] [x265] [pseudo] mkv
Download: [url=http://moviesdickens.com/the-flash-2014]Watch The Flash (2014)[/url] .
?????????? SP 2016.5.30 part 2
Download: [url=http://dokkijoa.com/manga/one-piece/733]One Piece 733[/url] .
Alba - Die Tenschen Morder
Download: [url=http://bestpartialrepairs.com/films/96484-telecharger-criminal-squad.html]TГ©lГ©charger Criminal Squad[/url] .
Terri 2011 1080p BluRay H264 AAC-RARBG
Download: [url=http://trycambogiapure.com/apps/com.jrtstudio.anothermusicplayer/]Rocket Music Player[/url] .
mide375 mp4
Download: [url=http://cookingyoursassoff.com/serie.php?serie=1304]La Mujer de Judas[/url] .
BitLord.com
Download: [url=http://ruyabetegir.com/subtitles/A_Quiet_Place-127009/!]Рнфо[/url] .
Alejandra Avalos - Grandes Axitos
Download: [url=http://prixdernier.com/watch/JdA7e2xL-breaking-the-band-season-1.html]Breaking The Band: ...[/url] .
None Working? Use Magnet
Download: [url=http://karchercenterpremium.com/film/4k-ultra-hd-2160p/giochi/giochi-psp/]Giochi PSP[/url] .
Frequency 2016 S01E07 HDTV 720p x265 2Ch HAAC2-Sunil-KITE-METeam
Download: [url=http://parsbazi.com/?s=torrent-tomorrow-when-the-war-began-2010]torrent Demain Lorsque la guerre a commencГ© 2010[/url] .
Sons of Anarchy S03 1080p BluRay AAC 5 1 HEVC x265 sharpysword
Download: [url=http://cookingyoursassoff.com/serie.php?serie=970]Blackout[/url] .
Afghan Jelebi Traller Wapking Cc
Download: [url=http://usatopnewsfeed.com/movies/watch-online-kurangu-bommai-tamil-2017-full-movie-download.html]Kurangu Bommai Tamil (2017) (HDRip)[/url] .
BBC.Planet.Earth.II.2of6.Mountains.720p.HDTV.x264.AAC
Download: [url=http://cookingyoursassoff.com/serie.php?serie=953]Sabrina, Cosas de Brujas[/url] .
Geordie Shore S13E04 mp4
Download: [url=http://freelifetimexxxbook.com/sbloccare-macbook-con-touch-id-iphone/]Sbloccare Macbook con impronta digitale iPhone[/url] .
BBC.The.Life.of.Mammals.9of9.Social.Climbers.720p.HDTV.x264.AAC.MVGroup.org.mkv - 2016-11-17
Download: [url=http://exposingjohns.com/tag/%D8%A7%D9%81%D9%84%D8%A7%D9%85+%D8%A7%D8%AB%D8%A7%D8%B1%D8%A9+2018/1.html]Ш§ЩЃЩ„Ш§Щ… Ш§Ш«Ш§Ш±Ш© 2018[/url] .
12 orbits
Download: [url=http://kingstiresms.com/watch/reverie-s01-online-m4ufree.html]Watch now[/url] .
Temmuz 2014 (884)
Download: [url=http://pmplcorp.com/category/uncle-drew-2018/]Uncle Drew (2018)[/url] .
living in suburban chicago
Download: [url=http://cookingyoursassoff.com/serie.php?serie=1323]Fairy Tail Best[/url] .
Boobless s5 with Courtney Simpson mp4
Download: [url=http://kartumimpi.com/series/fugitiva/3796]Fugitiva HDTV[/url] .
Register
Download: [url=http://1st-saftey.com/showgroups.php?s=e25aa35b83942ca93265fb4e7a73841a]Ver lГderes del foro[/url] .
les visiteurs
Download: [url=http://1st-saftey.com/forumdisplay.php?f=11&s=e25aa35b83942ca93265fb4e7a73841a]DVDRip desde 1991 hasta 2014[/url] .
Alan Bennett - A Visit From Miss Prothero 20-04-13 - Bob129
Download: [url=http://ghqcars.com/serie/acorralada]Acorralada[/url] .
L Ange Gardien
Download: [url=http://bestpartialrepairs.com/films/les-mieux-notes/espionnage/]Espionnage[/url] .
Blood on the Sun (1945) DVD5 - James Cagney, Sylvia Sidney [DDR]
Download: [url=http://sodahr.com/ver-serie-tv]Series tv Online[/url] .
Kevin Hart
Download: [url=http://cookingyoursassoff.com/serie.php?serie=3982]The Replacement[/url] .
1999–2003
Download: [url=http://alpha-iptv.com/movie/tomb-raider-2018-dvd-streaming/3]OpenLoad VF Dvdrip[/url] .
InfiniteSkills Cisco 640 822 (ICND1) Exam Training Video ( Uploaded - Rapidgator - Ryushare )
Download: [url=http://eghtesad-e-iran.com/film/1mpi7au5mn/Z-23-59-na-0-00-na-starym-sowieckim-zegarku]Z 23:59 na 0:00 na starym sowieckim zegarku[/url] .
RADIOHEAD - Boxset (2007) [FLAC]
Download: [url=http://kingstiresms.com/country/argentina.html]Argentina[/url] .
Askvald - Geistesreisen Durch
Download: [url=http://qs838.com/wwe-network-shows-free/1792994-watch-wwe-photo-shoot-s01e09-season-1-episode-9-goldust-11th-june-2018-hdtv-watch-online-download-720p-hd-next-thread.html?s=1f7af2255db157ae3ff332e9cf12357f]Next Thread[/url] .
The Flash 2014 S02E21 The Runaway Dinosaur 1080p WEB-DL DD5 1 H265-LGC mkv
Download: [url=http://44ppkk.com/torrent/705461]Phoenix Marie - Big Breast Nurses #03, Scene #04[/url] .
How To Behave
Download: [url=http://1st-saftey.com/member.php?u=311&s=65846a2911018c00de87c7d79d924346]donjose57[/url] .
Rush (2014)
Download: [url=http://tipbettr.com/apk/6286/]Download APK[/url] .
BitLord.com
Download: [url=http://dancefestopen.com/descargar-torrents-variados-159-DVDFab-Platinum-6.html]DVDFab Platinum 6.[/url] .
High School DxD - Season 1 Eng Dub [480p]
Download: [url=http://fman03.com/film-streaming/epouvante-horreur/]Epouvante Horreur[/url] .
Microsoft Office Pro. Plus 2013 VL Edition x86 x64 FRENCH-DeGun
Download: [url=http://myoffercode.com/tag/black-mass/]Black Mass[/url] .
Queen Sugar Season 1 Episode 11 - All Good
Download: [url=http://promisemethemoon.com/h2o-saison-3-episode-7-en-streaming-film-streaming-series-streaming-2/]H2O Saison 3 episode 7 en streaming Film Streaming, series streaming[/url] .
Top Cat Begins 2015 ????? ????? 5.2
Download: [url=http://urbanlanguageadventures.com/download/floor-88-zalikha-official-music-video]Floor 88 - Zalikha [Official Music Video][/url] .
Addicted to Fresno 2015 720p BluRay H264 AAC-RARBG
Download: [url=http://1st-saftey.com/forumdisplay.php?f=24&s=35c54ba00cd941eb2a8a288febd28f3d]PelГculas 4K[/url] .
????? ???? ???? ????
Download: [url=http://liner20.com/movies/recoil-2011-hindi-dubbed/]Recoil (2011) Hindi Dubbed[/url] .
vampires are forever tuebl
Download: [url=http://dancefestopen.com/descargar-torrents-variados-1922-R-City-Locked-Away-Featuring-Adam-Levine.html]R. City - Locked Away (Featuring Adam Levine).[/url] .
Studio 60 on the Sunset Strip
Download: [url=http://wh888111.com/series/toy-story]Toy Story[/url] .
As The World Turns
Download: [url=http://mulhollandpassengers.com/book/107981]Smart Space Office Design English/Chinese Bilingual Edition 2011[/url] .
Applications Torrents
Download: [url=http://thailandrates.com/films/acteur/robbie-coltrane.html]Robbie Coltrane[/url] .
Lucifer S02E08 1080p HDTV X264-DIMENSION[rarbg]
Download: [url=http://mersinhavacilik.com/slide/to-comfort-always-a-nurse-s-guide-to-end-of-life-care-full]To Comfort Always: A Nurse s Guide to End-Of-Life Care [FU...[/url] .
[WinD] Higurashi no Naku Koro ni Kai 13 [DVD][1C8F2A03].mkv
Download: [url=http://twirr.com/watch86/Greys-Anatomy/season-06-episode-10-Holidaze]Holidaze season 06 episode 10[/url] .
Marvels Agents of Shield [HDTV][VO][Sub Cas] 1x06
Download: [url=http://1st-saftey.com/forumdisplay.php?f=121&s=56a9c537942a733b50ee4a035d7e70cf]Temporadas Completas en MicroHD[/url] .
[HorribleSubs] Kiznaiver ~ Batch 00 12 [480p].mkv ~ [WolfPack]
Download: [url=http://npcman.com/?add_to_wishlist=2635]Ajouter Г la wishlist[/url] .
The Intern 2015 HD ????? ????? 7.2
Download: [url=http://1st-saftey.com/forumdisplay.php?f=35&s=9196e8625f5b002cf49e89794f915a75]MicroHD / HD 720p y 1080p en Latino[/url] .
Под наблюдение
Download: [url=http://haut-conseil-des-territoires.fr/novel-lucah-terbaik-gok-scan2fit-com-gt11734713.html]Novel lucah terbaik - gok.scan2fit.com.pdf[/url] .
Hitman 6 (2016) (Final Version) (for pc)
Download: [url=http://tipbettr.com/games/com.highbrow.games.dragonvillage/]Dragon Village 2[/url] .
danse avec les stars
Download: [url=http://franchisetavadatavuk.com/software/0.html] Previous[/url] .
BitLord.com
Download: [url=http://bestpartialrepairs.com/films/streaming/92658-jamais-le-premier-soir.html]Regarder Jamais le premier soir en Streaming Gratuit[/url] .
Singer Songwriter
Download: [url=http://makeachoice2018.com/tv-series/alone-season-5/]Eps 1 Alone - Season 5[/url] .
GIMP v2.8.18 (Image Editor) - SeuPirate
Download: [url=http://canariaschat.com/descargar/cine-alta-definicion-hd/1080p/the-walking-dead-temporada-8--/bluray-1080p/]The Walking Dead Temporada 8 BluRay 1080p[/url] .
vbt-ps101v2 mp4
Download: [url=http://kartumimpi.com/series-hd/las-nuevas-leyendas-de-mono/3842]Las Nuevas Leyendas De Mono HDTV 720p AC3 5.1[/url] .
Xev Bellringer mp4
Download: [url=http://twirr.com/watch86/Greys-Anatomy/season-12-episode-23-At-Last]At Last season 12 episode 23[/url] .
Win PDF Editor
Download: [url=http://wh888111.com/tv-series/daredevil]Daredevil[/url] .
Die glorreichen Sieben voll kostenlos sehen
Download: [url=http://cryptoreaper.com/le-duelliste/]Le Duelliste[/url] .
Angel Smalls mp4
Download: [url=http://trycambogiapure.com/apk/3032/]Download APK[/url] .
This Hour Has 22 Minutes S24E07 HDTV x264-CROOKS[ettv]
Download: [url=http://keyholereservoir.com/movie/topimdb]Top IMDb[/url] .
21 By Adele
Download: [url=http://kartumimpi.com/pelicula/the-five-year-engagement/]The Five Year Engagement DVDRIP[/url] .
the postman
Download: [url=http://beihaveadream.biz/jukujo-club-7242/]Jukujo-club 7242[/url] .
Creative Control2016
Download: [url=http://cookingyoursassoff.com/serie.php?serie=1247]El coche fantastico[/url] .
No Doubt It S My Life Subtitulos En Espa Ol
Download: [url=http://jartiyeri.com/series/supergirl/2680]Supergirl HDTV[/url] .
Adobe Premiere Pro CC 2015 v9 0 + Crack
Download: [url=http://teethwhiteningboost.com/alternative/]Alternative[/url] .
BitLord.com
Download: [url=http://dokkijoa.com/manga/fairy-tail/94]Fairy Tail 94[/url] .
El Chapo (Bonus Track) - The Game & Skrillex
Download: [url=http://twirr.com/watch86/Greys-Anatomy/season-14-episode-23-Cold-as-Ice]Cold as Ice season 14 episode 23[/url] .
Моят живот
Download: [url=http://weekendroomprojects.com/Cowgirls-N-Angels-2-Dakotas-Summer-2014-LIMITED-BRRip-XviD-AQOS_2698635.html]Cowgirls N Angels 2 Dakotas Summer 2014 LIMITED BRRip XviD - AQOS[/url] .
pocket oncology pdf
Download: [url=http://cscarpenters.com/03erito-young-slut-used-by-group-men/]4 years ago Erito Young Slut Used By Group Of Men[/url] .
Creedence Clearwater Revival
Download: [url=http://extra-low-price.com/tag/wondershare-filmora-8-full-version/]wondershare filmora 8 full version[/url] .
FamilyStrokes - Alexis Fawx_720p mkv
Download: [url=http://dokkijoa.com/manga/hunter-x-hunter/93]Hunter X Hunter 93[/url] .
[Tushy] Karla Kush, Arya Fae (My Crazy Day With my Wild Roommate - 17 11 2016...
Download: [url=http://kartumimpi.com/descargar/serie/en-la-sombra/temporada-2/capitulo-03/]En La Sombra - Temporada 2 HDTV[/url] .
Alan Parsons Project - Riverbend Music Theatre MP 3
Download: [url=http://cookingyoursassoff.com/serie.php?serie=1094]Air Gear[/url] .
Howl's Moving Castle (2004)...
Download: [url=http://jebriwsbwpvzrw.com/films/realisateur/george-lucas.html]film de George Lucas[/url] .
Main Tera Hero
Download: [url=http://newjerseyjewishmonuments.com/filme-online/39198279-rampage-scapati-de-sub-control]Rampage: ScДѓpaЕЈi de sub control[/url] .
Lodge Cast Iron Nation - Inspired Dishes and Memorable Stories from America's...
Download: [url=http://forthetoys.com/movies-curse-of-the-siren-2018-moviesub.html]Curse of the Siren HD[/url] .
FIFA 17 Crack v1 0
Download: [url=http://trycambogiapure.com/games/com.gamegames.loveballs/]Love Balls[/url] .
Dont Breathe 2016 1080p BRRip x264 AAC-ETRG
Download: [url=http://portablesawmills.biz/bajirao-mastani-2015-tamil-movie-original-bdrip-x264-500mb-esubs/]Bajirao Mastani (2015) Tamil Movie (Original) BDRip x264 500MB ESubs[/url] .
????(11)
Download: [url=http://bojieba.com/category/Economy-Finance]Economy & Finance[/url] .
BitLord.com
Download: [url=http://kolaytv.com/mp3/lana-del-rey-cedric-gervais-remix-download.html]Lana Del Rey Cedric Gervais Remix[/url] .
Anthony Pascale
Download: [url=http://1st-saftey.com/forumdisplay.php?f=6&s=6a6736311ea4f11f1b84f01d29aa95f1]PelГculas HD en Castellano[/url] .
Wondershare DVD Creator v3.11.0 + Templates-Mac OSX
Download: [url=http://thailandrates.com/films/annee/1953.html]film de 1953[/url] .
Narcos S01E05 Nl
Download: [url=http://ghqcars.com/serie/humans/temporada-1.html]Temporada 1[/url] .
MasterMinds 2016 HD TS x264 CPG
Download: [url=http://cookingyoursassoff.com/serie.php?serie=2206]House of Cars[/url] .
Ek Tera Saath Torrent 2016 Full HD Movie Free Download
Download: [url=http://bta-andora.com/forums/introductions.264/]Introductions[/url] .
BitLord.com
Download: [url=http://bridgetonchiropractic.com/juegos-pc/?category_name=accion]juegos de accion para la PC[/url] .
Windows 8 1 X64 6in1 en-US Nov 2016 Generation2
Download: [url=http://richblackboy.com/browse/502]Movies DVDR[/url] .
Coursera - Deafness in the.21st Century
Download: [url=http://glamgelow.com/download/arrested-development-season-5-torrent]Arrested Development Season 5 torrent[/url] .
[OCN] ??? ?.E05.161115.HDTV-Film.x264.AAC.720p-MATE
Download: [url=http://pmplcorp.com/tag/pelicula-el-rascacielos-2018-descarga-completa/]pelГcula El rascacielos (2018) descarga completa[/url] .
Watch in HD
Download: [url=http://bottlecapemblem.com/book/the-dukes-wager-by-jennifer-monroe]The Duke’s Wager by Jennifer Monroe[/url] .
Amy Adams
Download: [url=http://gf9444.com/4584-honeymoon-french-dvdrip-2015.html]Honeymoon FRENCH DVDRIP 2015[/url] .
Real Wife Stories_Madison Ivy, Asa Akira (02.25.2013. Brazzers)
Download: [url=http://massasjenorskdamer.com/watch-movie-mary-shelley-online-megashare-2-90881]Mary Shelley (2018)[/url] .
BitLord.com
Download: [url=http://beihaveadream.biz/jukujo-club-7207/]Jukujo-club 7207[/url] .
Alexander Ludwig Cato Of The Hunger Games
Download: [url=http://freelifetimexxxbook.com/apowersoft-free-audio-recorder-online/]Continua...[/url] .
The Unwinding_ An Inner History of the New America (2013) George Packer epub
Download: [url=http://certifiedsaferooms.com/search/x264-GECKOS.html]x264-GECKOS[/url] .
OPAL FREQUENCIES - Blue Priformation No.2 - (2016) [Isohunt.to]
Download: [url=http://cookingyoursassoff.com/serie.php?serie=2637]The Wire (Bajo escucha)[/url] .
Ride Along (2014) 720p BrRip x264 - YIFY
Download: [url=http://jebriwsbwpvzrw.com/films/realisateur/sam-weisman.html]film de Sam Weisman[/url] .
Asjha Cooper
Download: [url=http://gayflingsociety.com/naruto-shippuden-ultimate-ninja-storm-4-pc-torrent/]Leia mais…[/url] .
[HorribleSubs] Yuri!!! on Ice - 06 [1080p] mkv
Download: [url=http://692052.com/series/11022970-wakfu-saison-3.html]Saison 3 Wakfu[/url] .
Don Kaye
Download: [url=http://dokkijoa.com/manga/one-piece/880]One Piece 880[/url] .
Mix Musica Electronica 2014 Lo Mas Nuevo New House Mix Octubre October
Download: [url=http://publicationcapital.com/Vagrant-Essentials-Learn-DevOps-Using-Vagrant_3656196.html]Vagrant Essentials Learn DevOps Using Vagrant[/url] .
6th Grade Basic Skills: Reading Comprehension and Skills
Download: [url=http://trycambogiapure.com/apk/7110/]Download APK[/url] .
[KiteSeekers-Wasurenai] Pretty Rhythm Aurora Dream Special - 27 [H264 704x400] [474B7565].mkv
Download: [url=http://matrixideas.com/tema-bugatti-veyron/]Tema de Bugatti Veyron[/url] .
svnt-sm.avi
Download: [url=http://yuwioo.com/extra/cinefacts.de-news-archiv/]Cinefacts.de Newsarchiv[/url] .
Rohit Gokani,
Download: [url=http://tipbettr.com/games/com.joycity.oceansandempires/]Oceans Empires[/url] .
Download
Download: [url=http://cookingyoursassoff.com/serie.php?serie=1269]Dollhouse[/url] .
Days Of Our Lives - S52 E42 - Tuesday, November 15, 2016 TV Shows
Download: [url=http://teethwhiteningboost.com/3137651389-va-acoustic-lounge-essentials-vol5-2018.html]VA - Acoustic Lounge Essentials Vol.5 (2018)[/url] .
Изгубена парола?
Download: [url=http://ruyabetegir.com/subtitles/Killing_Daddy-127477/]Killing Daddy[/url] .
Flo Rida Whistle Slayback Bootleg Remix
Download: [url=http://bojieba.com/category/BusinessLaw]BusinessLaw[/url] .
Gossip Girl
Download: [url=http://franksfishworld.com/tvshows/caligula/]Caligula[/url] .
Online TV shows - Watch on TV Noop pdf
Download: [url=http://cookingyoursassoff.com/serie.php?serie=1271]Soldados de fortuna[/url] .
Designated Survivor S01E07 720p
Download: [url=http://publicationcapital.com/Udemy-The-Complete-React-Web-App-Developer-Course_3656188.html]Udemy - The Complete React Web App Developer Course[/url] .
Letzte Instanz - Liebe im Krieg (2016)
Download: [url=http://yoogoe.com/genre/adventure/]Adventure[/url] .
Silence on vaccine - DVD - French(A)
Download: [url=http://dokkijoa.com/manga/hunter-x-hunter/14]Hunter X Hunter 14[/url] .
Once Upon A Time
Download: [url=http://jartiyeri.com/descargar/peliculas-castellano/peliculas-rip/desierto-rojo-/blurayrip/]Desierto Rojo BLuRayRip[/url] .
American horror story s06e10 720p hdtv x264-NBY-[moviezplanet in] mkv
Download: [url=http://shellcraftyideas.com/?p=films&s=dvdsrc-r5-ts-cam&genre=_comedie]ComГ©die[/url] .
Marvel Agents of Shield S01E09 Repairs 720p WEB DL DD5 1 H 264 ECI PublicHD
Download: [url=http://jartiyeri.com/series-hd/aggretsuko/3843]Aggretsuko HDTV 720p AC3 5.1[/url] .
Jung, Irigaray, Individuation
Download: [url=http://jartiyeri.com/descargar-pelicula/blade-runner-2049-3d/bluray-3d-1080p/]Blade Runner 2049 3D BluRay 3D 1080p[/url] .
Salem S03E03 HDTV XviD-FUM[ettv]
Download: [url=http://qs838.com/tna-impact/1793089-watch-gfw-tna-impact-wrestling-6-28-2018-28th-june-2018-hdtv-watch-online-download-720p-hd.html]GFW iMPACT Wrestling 28th June 2018[/url] .
Afro Samurai Afro Fight Groove 3
Download: [url=http://jartiyeri.com/series-hd/dentro-de-las-ss/3933]Dentro De Las SS HDTV 720p AC3 5.1[/url] .
WWE Talking Smack 2016 11 15 720p WEB h264-HEEL [TJET]
Download: [url=http://dancefestopen.com/descargar-torrents-variados-305-USB-MultiBoot.html]USB MultiBoot.[/url] .
Cecilia L. Salinas
Download: [url=http://www.amazing-beauty-trends.com/mr.-holmes-en-streaming1/]Regarder un film[/url] .
Ink Master S08E13 Heavy Lifting HDTV x264-CRiMSON
Download: [url=http://winbigbonus1.com/konu-benim-varos-hikayem-2017-yerli-film-720p-web-dl-x264.html?action=lastpost]Benim VaroЕџ Hikayem 201...[/url] .
Charlie Tahan,
Download: [url=http://matrixideas.com/descargar/antivirus]buen antivirus[/url] .
Hacksaw Ridge 2016 HDCAM x264 AC3-TuttyFruity
Download: [url=http://tipbettr.com/top/60/]Top Downloads in Maps Navigation[/url] .
Latest Episodes
Download: [url=http://jafesrwvlmjiv.com/series/supernatural-free100/]Watch Show[/url] .
Dj Tennis Circoloco 2012 05 26
Download: [url=http://dancefestopen.com/descargar-torrents-variados-350-CyberLink-Power2Go-8-Essential-v8.html]CyberLink Power2Go 8 Essential v8.[/url] .
All Doctor Strange cast + crew photos
Download: [url=http://yoogoe.com/genre/talk-show/]Talk-Show[/url] .
Alejandro Sanz - E Alma Al Aire
Download: [url=http://pmplcorp.com/tag/rampage-2018-mkv-pelicula-descarga-completa/]Rampage (2018) .mkv pelГcula descarga completa[/url] .
Bert Kreisher The Machine 2016 720p HULU WEBRip AAC2 0 H 264 mkv
Download: [url=http://uusintaripsista.com/tag/pacific-rim-insurreccion-2018-pelicula-completa-con-subtitulos-en-espanol/]Pacific Rim InsurrecciГіn 2018 pelГcula completa con subtГtulos en espaГ±ol[/url] .
Adware Doctor 1 1 for MAC-OSx
Download: [url=http://onlinedetoxstore.com/rubrique/121/rubrique/89/developpement-personnel]DГ©veloppement personnel[/url] .
view all
Download: [url=http://cookingyoursassoff.com/serie.php?serie=2808]Master of None[/url] .
Incomedia WebSite X5 Professional 13 0 2 19 Multilingual + Keygen [SadeemPC] zip
Download: [url=http://kartumimpi.com/descargar/peliculas-latino/brrip/hasta-que-la-boda-nos-separe-/blurayrip/]Hasta Que La Boda Nos Separe BLuRayRip[/url] .
Mannertag Online anschauen
Download: [url=http://earthdayimages2018.com/featured/36/download-old-90s-mandarin-music-songs.html] Old 90s Mandarin Music[/url] .
Action Comics (New 52)
Download: [url=http://fnudu.info/drama-detail/while-you-were-sleeping]While You Were Sleeping[/url] .
Its A Mommy Thing 3
Download: [url=http://www.news24day.com/hochelaga-land-of-souls-en-streaming/]Regarder un film[/url] .
Janeman Aa Song Donload
Download: [url=http://karangupta0001.info/deitel-java-how-to-program-9th-edition-bing-pdfsdirnncom.html]deitel java how to program 9th edition - Bing - PDFsDirNN.com[/url] .
Scrapped Princess
Download: [url=http://pwxvwz.info/movie/medeas/]Watch movie[/url] .
[MTN] 2016 Asia Artist Awards.E01.161116.60fps.720p-Siege Tank
Download: [url=http://secret-flirtparadise.com/show/law-of-the-jungle-in-papua-new-guinea/]Law Of The Jungle In Papua New Guinea[/url] .
[share_ebook] HINDI Sex Stories (Mastram like ... in HINDI ONLY)....
Download: [url=http://nianhuawang.info/kickboxer-vengeance-4gxj-streamingvf.html]Kickboxer: Vengeance Action Histoire du film : Kurt Sloan est bien dГ©cidГ© Г venger la mort de son frГЁre Eric, tuГ© par un...[/url] .
Ma Conduta Dublado Online Ben (Josh Duhamel) e um advogado ambicioso que tem um grande caso nas maos. Ele e contratado pelo executivo Abrams (Al Pacino), que trabalha numa empresa farmaceutica. Ele quer revelar os podres por tras dos negocios do diretor da companhia, o bilionario Denning (Anthony Hopkins). O que seria um trabalho otimo para alavancar a carreira de Ben se transforma num ...
Download: [url=http://timeclocks.biz/3026062-the-family-stand-sweet-liberation-free-download.html]The Family Stand - Sweet Liberation[/url] .
Phantom Boy (2016)
Download: [url=http://fnudu.info/drama-detail/nuer-hong]Nu'er Hong[/url] .
Site Tan?t?mlar?
Download: [url=http://wackrabbits.com/torrent/ka47b/All-Activation-Windows-7-8-10-v15-0-Windows-Office-Activator.html]All Activation Windows 7-8-10...[/url] .
[AnimeRG] TO BE HERO - 07 [720p] [Multi-Sub] [x265] [pseudo] mkv
Download: [url=http://annuaire-art.fr/watch-ot-the-movie-2014-1080p-online-free-123movieshub.html]HD O.T. The Movie (2014)[/url] .
Berlin Station S01E04 720p WEBDL x264 [ExYu-Subs HC]
Download: [url=http://ipesm.info/2018/04/22/private-practice-todas-temporadas.html]Private Practice[/url] .
Albert Hammond Everything I Want To Do
Download: [url=http://slimx180.com/]Back to Home[/url] .
The Sum of All Fears 2002 HD ????? ????? 6.4
Download: [url=http://s6n9f.info/category/shoujou-ai/]Shoujou AI[/url] .
TeensAnalyzed 15 02 08 Anal Date With A Creampie XXX 1080P WMV-GUSH[rarbg]
Download: [url=http://iconais.fr/diziler/imposters/]• Imposters 7.7[/url] .
Continuar
Download: [url=http://hyperaktiv.info/ep/669321/adventure-time-s10e09-720p-hdtv-x264-w4f/]Adventure Time S10E09 720p HDTV x264-W4F [eztv][/url] .
SisLovesMe - Study Your Sis - Demi Lopez [1080p] mp4
Download: [url=http://ka17t.info/wwe-total-divas/1793041-watch-wwe-total-bellas-s03e05-season-3-episode-5-6-17-18-17th-june-2018-hdtv-watch-online-download-720p-hd.html]Watch WWE Total Bellas S03E05- 6/17/18[/url] .
Today, 03:09
Download: [url=http://vacances-adaptees.fr/series-vo/van-helsing/2699]Van Helsing HDTV 720p AC3 5.1[/url] .
BitLord.com
Download: [url=http://wekai.info/Film-8136-the-circle-streaming]BDRipVF The Circle[/url] .
Alban Berg Collection DG MP3
Download: [url=http://marcheinverness.com/descargar-torrents-variados-1691-UDO-Live-in-Sofia.html]U.D.O. - Live in Sofia.[/url] .
Movies torrents
Download: [url=http://rozhanskaya.info/es/pubg/com.tencent.ig/download?from=home%2Fhot]Descargar XAPK[/url] .
all_that_wetness_big.mp4
Download: [url=http://fub97.info/serie/1727]A tutto ritmo[/url] .
SeedPeer in your own language?
Download: [url=http://fnudu.info/drama-detail/karma-rider]Karma Rider[/url] .
BitLord.com
Download: [url=http://austinsedationdentistry.com/bd-steins-gate-subtitle-indonesia/]BD Steins Gate + OVA Spesial Subtitle Indonesia[/url] .
Comments: 0
Download: [url=http://vacances-adaptees.fr/series-vo/homeland/2164]Homeland HDTV 720p AC3 5.1[/url] .
Сезон 12 БГ СУБТИТРИ
Download: [url=http://lelimoges.fr/category/star-plus/star-plus-completed-shows/satyamev-jayate/]Satyamev Jayate[/url] .
Stephen W. Burns,
Download: [url=http://wettenbet6.com/always-at-the-carlyle-2018-live-stream-online]Always at The Carlyle (2018)[/url] .
tender savage by iris johansen
Download: [url=http://p2rprod.fr/dizi/colony]Colony ›[/url] .
SuperAntiSpyware 6 0 1226 + Key [4realtorrentz] zip
Download: [url=http://atexed.info/torrent/186277/pov-creampies-spermovaya-tochka-zreniya-jonni-darkko-evil-angel-2018-g-gonzo-hardcore-squirting-544r-web-dl-split-scenes]POV Creampies / Спермовая Точка Зрения (Jonni Darkko, Evil Angel) [2018 г., Gonzo, Hardcore, Squirting, 544р, WEB-DL] (Split Scenes)[/url] .
Street Fighter V 2016 PC [COMPLETE EDITION]
Download: [url=http://fnudu.info/drama-detail/cat-chef]Cat Chef[/url] .
Cc Cleaner
Download: [url=http://idees-de-cadeaux.fr/watch-the-speak-movie-online-free-putlocker-3302.html]The Speak[/url] .
Kerish Doctor 2016 [Isohunt.to]
Download: [url=http://kka47.info/legendary-2013-dual-audio-hindi-720p-bluray-x264-1gb-download/]Download[/url] .
Waves Complete v9 6 (2016.10.10) macOS [dada]
Download: [url=http://miyaji.info/collections/36-its-time-to-scream]It's time to scream![/url] .
Alan Lomax Portait Series - Hobart Smith - Blue Ridge Legacy
Download: [url=http://frrig.info/tags/Collection/]Collection[/url] .
magicians vostfr
Download: [url=http://aey8.com/chapter/tomochan_wa_onnanoko/chapter_512.2]Chapter 512 v2 : Technique misfire[/url] .
Watching TV Online - Watch TV shows pdf
Download: [url=http://forhome.info/watch-legend-of-the-holy-spear-movie-online-free-putlocker-3275.html]Legend of the Hol..[/url] .
Jason Bourne 2016 1080p BluRay x264-SPARKS[PRiME]
Download: [url=http://marcheinverness.com/descargar-torrents-variados-2053-Florida-Georgia-Line-Heres-to-the-Good-Times-This-is-How-We-Roll.html]Florida Georgia Line - Heres to the Good Times-This is How We Roll.[/url] .
Viggo Mortensen,
Download: [url=http://forhome.info/watch-blurred-lines-movie-online-free-putlocker-3084.html]Blurred Lines[/url] .
Icerde (Ek ton eso) 2016 6o ep. 720p WEBRip x264 AAC [Isohunt.to]
Download: [url=http://cryptocamp.info/actors/rochelle-humes.html]Rochelle Humes[/url] .
Read More
Download: [url=http://dorer.fr/?q=nightwish+discographie]nightwish discographie[/url] .
[TNA] iMPACT Wrestling 2016 11 17 HDTV x264-Ebi [TJET]
Download: [url=http://wackrabbits.com/torrent/dz7/Joey-W-Hill-Virtual-Reality.html]Joey W Hill - Virtual Reality[/url] .
Strictly Criminal (2015) MULTi VFF [1080p] BluRay ...(A)
Download: [url=http://p-ros.com/actors/Alexandra+Carter.html]Alexandra Carter[/url] .
Wormfood - L'envers (2016)
Download: [url=http://p-ros.com/actors/John+Weaver.html]John Weaver[/url] .
evolution
Download: [url=http://annuaire-art.fr/watch-the-blue-hour-2015-1080p-online-free-123movieshub.html]DVD The Blue Hour (2015)[/url] .
Longmire
Download: [url=http://fnudu.info/drama-detail/dangerous-meeting-of-in-laws-2]Dangerous Meeting of In Laws 2[/url] .
Audiophile Gold Disks
Download: [url=http://bankablebrilliance.com/login/aHR0cDovL2thdGNyLnByZXNzL3RvcnJlbnQvZGlzb2JlZGllbmNlLTIwMTgtNzIwcC1icnJpcC14MjY0LWFjM2V2b3RneC10MjUzNTUzNi5odG1s]Click Here to Login[/url] .
Captain America the Winter Soldier 2014 English Movies CamRip ...
Download: [url=http://mmqp888.com/watch/call-of-heroes]Call of Heroes[/url] .
quotidien
Download: [url=http://calmmantis.com/book/1293949328/download-ignition.pdf]Ignition![/url] .
NHL 2015 R3 ECF NYRTBL 720p60
Download: [url=http://s6n9f.info/bd-isuca-season-1-ova-subtitle-indonesia/]BD Isuca + OVA Subtitle Indonesia[/url] .
WinUtilities Professional v13 18
Download: [url=http://idees-de-cadeaux.fr/watch-jumanji-movie-online-free-putlocker-3043.html]Jumanji (2017)[/url] .
nina marx
Download: [url=http://rochdaledirect.info/chapter/tomochan_wa_onnanoko/chapter_725]Chapter 725[/url] .
The Bag Man 2014 LIMITED BRRip XviD - AQOS ( Rapidgator - Uploaded - Ryushare )
Download: [url=http://secret-flirtparadise.com/show/wgm-taeun-couple/]WGM TaEun Couple[/url] .
Dope 2015 HD ????? ????? 7.3
Download: [url=http://baocungcau.info/?p=films&genre=animation]Animation[/url] .
Marvel Agents of Shield S01E07 The Hub 1080p WEB-DL DD5 1 H 264-ECI
Download: [url=http://rochdaledirect.info/chapter/tomochan_wa_onnanoko/chapter_699]Chapter 699[/url] .
BitLord.com
Download: [url=http://nlispe.info/book/481338483/download-jardinez-avec-la-lune-2012.pdf]Jardinez avec la lune 2012[/url] .
Sons Of Anarchy
Download: [url=http://wettenbet6.com/down-under-tours-2015-hd-tv-movie-online]Down Under Tours (2015)[/url] .
vr??(13)
Download: [url=http://danunah.info/regarder-series/21036-the-walking-dead-saison-8-11111111111.html]Regarder[/url] .
Software
Download: [url=http://p-ros.com/actors/Simon+Lennon.html]Simon Lennon[/url] .
Wiz Khalifa Type Beat Kush Prod Manee
Download: [url=http://bksgh.info/ChickLit/Shopaholic_3/]Shopaholic Ties the Knot (Shopaholic #3)[/url] .
Atlas of Stress-Strain Curves (2nd Revised edition)
Download: [url=http://tajrishtala.com/project-almanac-2015-dual-audio-720p-bluray-hindi-esubs-download]Project Almanac 2015 Dual Audio 720p BluRay Hindi ESubs Download[/url] .
Откраднат живот
Download: [url=http://ph-staging.com/03032707-aula-de-innovacion-educativa-marzo-abril-2018/]Aula de Innovacion Educativa – marzo-abril 2018[/url] .
A.Season.with.Florida.State.Football.S02E10.HDTV.x264 [NY2]
Download: [url=http://calmmantis.com/book/633980936/download-mylo-xyloto-1-color-is-crime.pdf]Mylo Xyloto #1: Color Is Crime[/url] .
Blindspot S02E09 720p HDTV X264-DIMENSION[ettv]
Download: [url=http://marcheinverness.com/descargar-torrents-variados-398-DivX-Plus-v81.html]DivX Plus v8.1[/url] .
(2016) DVDRip NW
Download: [url=http://hfte.info/browse/tv/talk/]Ток-шоу[/url] .
Aleksandr Zvincov 20 Luchshih Pesen 2008
Download: [url=http://mcw75.com/online/treblinkas-last-witness]Treblinkas Last Witness[/url] .
Винил
Download: [url=http://marcheinverness.com/serie-episodio-descargar-torrent-52906-Claws-2x02-al-2x03.html]Claws - 2ВЄ Temporada [720p][/url] .
The Missing S02E06 HDTV x264-TLA[ettv]
Download: [url=http://lesgrandsvins.fr/movie/yifi_filter?keyword=Emmanuelle+Chriqui]Emmanuelle Chriqui[/url] .
Maleficent
Download: [url=http://wettenbet6.com/replicas-2018-free-full-movie-online-stream]Replicas (2018)[/url] .
Simply Laura
Download: [url=http://marcheinverness.com/noticia-torrents-13185.html]MUSICALES.[/url] .
Aleksandr Vestov Baryga 2011 MP3
Download: [url=http://vacances-adaptees.fr/series-hd/arma-letal/2763]Arma Letal HDTV 720p AC3 5.1[/url] .
The Slap (US)
Download: [url=http://allkeys.info/siterip/389749-thecandidforum-com-21-princessleia-2017-2018-voyeur-upskirt-compilation-1080x1920-camrip/][thecandidforum.com] Видео снятое под юбкой у девушек (21 ролик, PrincessLeia) [2017-2018 г., Voyeur, Upskirt, Compilation, 1080x1920, CamRip][/url] .
Men at Work
Download: [url=http://plusone.google.com/_/+1/confirm?hl=en&url=http://xplfye.info/?p=24174&name=Williams+%282017%29+Torrent+WEB-DL+720p+Legendado+Download]Google +[/url] .
Windows - Sound Editing
Download: [url=http://playclub99.com/tv/61929/the-jinx-the-life-and-deaths-of-robert-durst-2015-4khd-full-streaming]The Jinx: The Life and Deaths of Robert Durst[/url] .
Order By Time
Download: [url=http://pwxvwz.info/tvseries?page=2]Next в†’[/url] .
The Help Center
Download: [url=http://vicd.info/adventures-in-public-school-2017/]Adventures In Public School (2017)[/url] .
Murder In Melbourne
Download: [url=http://marcheinverness.com/descargar-torrents-variados-270-3000-Pinceles-para-photoshop.html]3000 Pinceles para photoshop.[/url] .
299951 - 300000
Download: [url=http://nlispe.info/book/1224539535/download-ast-rix-ast-rix-et-la-transitalique-n-37.pdf]AstГ©rix - AstГ©rix et la Transitalique - nВє37[/url] .
Pete's Dragon 2016 720p 10bit BluRay 6CH x265 HEVC-PSA
Download: [url=http://org-all.info/torrent/c725jvl1/Need+For+Speed:+Most+Wanted+[Black+Edition+++v1.3+all+DLCs].html]Need For Speed: Most Wanted [Black Edition + v1.3 all DLCs][/url] .
??(25)
Download: [url=http://rozhanskaya.info/br/pocket-monster-remake/yoyo.Easy2play.now/download?from=home%2Ftopic%2Ftop-new-games]Baixar APK[/url] .
Virtual Girl (istripper) V1.2.139
Download: [url=http://ztrek.info/forum-tanitimlar]Yeni Sekmede Aç[/url] .
Game Development
Download: [url=http://rozhanskaya.info/in/shareit-transfer-share/com.lenovo.anyshare.gps/download?from=home%2Fhot]डाउनलोड APK[/url] .
The Voice of Ireland
Download: [url=http://p-ros.com/actors/Charles+D.+Brown.html]Charles D. Brown[/url] .
The Girl on the Train 2016 CAMRip XviD - INFERNO avi
Download: [url=http://timeclocks.biz/2849184-voodooserano-give-me-the-power-free-download.html]Voodoo Serano - Give Me The Power[/url] .
Attack Of The Show
Download: [url=http://restaurantlatonnelle.fr/show/cant-miss-this/]Cant Miss This[/url] .
Cutthroat Island 1995 1080p BluRay x264-VOA [NORAR][PRiME]
Download: [url=http://mmqp888.com/watch/ancient-aliens-season-13]Ancient Aliens – Season 13[/url] .
Multilingual
Download: [url=http://rgdqp.info/movie/girl-lost-6ql3.html]Girl Lost[/url] .
Aldaaron - Nous Reviendrons Immortels
Download: [url=http://ttnmk.com/puss-in-boots-2011-hindi-dubbed/]Watch Movie[/url] .
Toggle navigation
Download: [url=http://p2rprod.fr/izle/kyaputen-tsubasa-1-sezon-12-bolum]1. sezon 12. Bölüm[/url] .
Killer Is Dead
Download: [url=http://iconais.fr/diziler/chicago-med/]• Chicago Med 6.5[/url] .
All is Lost (2013) Dual Audio Hindi Dub Full Movie BluRay 720p MKV
Download: [url=http://ph-staging.com/category/for-kids/ http://itunes.apple.com/app/id454936656]View PDF on Apple iOS[/url] .
????? ????? ??????? Mp3
Download: [url=http://banxehoi-notification.com/Books/Cookbooks, Food &amp; Wine/Main Courses &amp; Side Dishes/Politics & Social Sciences]Politics Social Sciences[/url] .
[Ctrl-ZnF]Naruto Shippuuden 322 [720p x264+AAC].mp4
Download: [url=http://p-ros.com/watch-loving-pablo-2017-123movies.html]Watch movie[/url] .
Malwarebytes Anti-malware Premium 2 0 2 1012 Final + Keys.torrent
Download: [url=http://fnudu.info/drama-detail/2015-sbs-k-pop-awards]2015 SBS K-Pop Awards[/url] .
2 broke girls
Download: [url=http://rozhanskaya.info/cn/lomo-filter-the-feelings-of-old-memories/com.pinkanaloglook.lomofilter/download?from=home%2Ftopic%2Ftop-new-apps]дё‹иЅЅ APK[/url] .
Wild Ones (Featuring Sia).mp4
Download: [url=http://kjmonstrate.info/series-view.php?id=82339]Leverage[/url] .
BitLord.com
Download: [url=http://ztrek.info/newthread.php?fid=988]Yeni Konu Gönder[/url] .
The 1975’s Matt Healy reveals his favourite song of all time
Download: [url=http://fub97.info/edicola/quotidiani-newspapers-17-06-18-in-aggiornamento/]Quotidiani (Newspapers) 17/06/18 (aggiornato ore 14.39)[/url] .
?????? (??????????) / ?????? (?????)
Download: [url=http://ztrek.info/konu-boru-tum-bolumler-indir.html?action=lastpost]Börü Tüm Bölümler İndir[/url] .
16/09/18
Download: [url=http://s6n9f.info/rolling-girls-bd-subtitle-indonesia/]Rolling Girls BD Subtitle Indonesia[/url] .
Justice League: Gods and Monsters 2015 HD ????? ????? 7.1
Download: [url=http://wekai.info/Film-7906-havenhurst-streaming]BDRipVOSTFR Havenhurst[/url] .
Advanced Search
Download: [url=http://chasseur-d-images.fr/movie/a-cry-for-help-the-tracey-thurman-story-1989-hd-1080p-quality.html]DVD A Cry for Help: The Tracey Thurman Story (1989)[/url] .
Yogi Bear (2010) [720p] [Hindi (6 CH @ 448 kbps) - English (6 CH @ 640 kbps)]...
Download: [url=http://restaurantlatonnelle.fr/show/running-man/episode-299.html]Running Man Episode 299[/url] .
L'amour est dans le pre QUEBEC - Saison 2 (2013) c...
Download: [url=http://bksgh.info/werewolves/Strange_Angels_3/]Jealousy (Strange Angels #3)[/url] .
White Collar
Download: [url=http://mzainuo.com/music/sweetest-goodbye.html]Download[/url] .
Trigga By Trey Songz
Download: [url=http://fnudu.info/genkai-danchi-episode-4.html]RAW Genkai Danchi 2 days ago EP 4[/url] .
Snowden 2016 HDRip AC3 2 0 x264-BDP[PRiME]
Download: [url=http://hairhova.info/seriestv/daytime-divas]Daytime Divas (2017) en streaming VF Chaque jour de la semaine Г midi, Maxine, MB, callune Kibby et Nina - facilitateurs pour l'heure du dГ©jeuner, le talk-show femelle de date longue, se rГ©unissent autour de la table pour discuter de la vie, de l'amour, de la politique et de l'chisme. Mais derriГЁre les scГЁnes, est encore plus jugoso - un monde de backstage pleine de luttes ...[/url] .
(2014) DVD Lomasankarit
Download: [url=http://fnudu.info/drama-detail/will-it-snow-for-christmas]Will It Snow For Christmas?[/url] .
Pawg.14.06.27.Jamie.Jackson.XXX.INTERNAL.720p.MP4.KTR
Download: [url=http://carreiranafotografia.com.br/1695-le-dernier-loup-streaming.html]Le Dernier loup Streaming[/url] .
Aleksandr Bushkov Poslednjaja Pasha 2010
Download: [url=http://banxehoi-notification.com/Books/Cookbooks, Food &amp; Wine/Main Courses &amp; Side Dishes/Gay & Lesbian]Gay Lesbian[/url] .
[KiteSeekers-Wasurenai] Futari wa Milky Holmes - 03 [704x400 XviD] [606E2801].avi
Download: [url=http://maculinisme.fr/serial/prawdziwa-milosc-amor-real/1352]Prawdziwa miЕ‚oЕ›Д‡ / Amor real[/url] .
Alena D, 41 Years Old
Download: [url=http://baocungcau.info/?p=jeu&id=617-la-qu-te-de-la-reine-2-pass-oubli-dition-collector]La QuГЄte de la Reine 2 : PassГ© OubliГ© Г‰dition Collector PC[/url] .
DVDFab 9 v9.3.2.1 FULL-Multilingual +Cracked [Isohunt.to]
Download: [url=http://w7677.com/lista-series-recomendadas/serie/the-american-west.html]The American West[/url] .
Captain America the Winter Soldier (2014)TS TRUEFRENCH MD XViD-ViVARiUM
Download: [url=http://fnudu.info/drama-detail/my-mind-s-flower-rain]My Mind's Flower Rain[/url] .
WWE Smackdown Live 11 15 16 HDTV x264-XWT
Download: [url=http://o9x2a.info/book/443958293/download-why-nations-fail.pdf]Why Nations Fail[/url] .
Impastor S02E08 iNTERNAL 720p HDTV x264-ALTEREGO[PRiME]
Download: [url=http://fnudu.info/drama-detail/can-you-hear-my-heart-korean-drama-cool]Can You Hear My Heart ?[/url] .
CSGO v1.35.5.7 (Original) [Isohunt.to]
Download: [url=http://wl016.info/Search.aspx?keywords=如约而至]如约而至[/url] .
BitLord.com
Download: [url=http://maculinisme.fr/serial/domek-na-prerii-little-house-on-the-prairie/538]Domek na prerii / Little House on the Prairie[/url] .
????
Download: [url=http://buyu187.com/no_category/43257-country-country-denis-gallagherpdf-epub.html]Country country by Denis Gallagher[/url] .
Canadian Idol
Download: [url=http://p-ros.com/actors/Izaiah+Dolezal.html]Izaiah Dolezal[/url] .
Howard Stern Show NOV 16 2016 Wed
Download: [url=http://ttnmk.com/autonagar-surya-2014-hindi-dubbed/]Watch Movie[/url] .
E-40 - The D-Boy Diary - Book 1 (2016)
Download: [url=http://rochdaledirect.info/chapter/tomochan_wa_onnanoko/chapter_635]Chapter 635 : I’m A Fan Too[/url] .
Super Hide IP v3 5 8 6 Incl Patch
Download: [url=http://playclub99.com//playclub99.com/tv/2231/movie-surfers-1998-4khd-full-streaming]Movie Surfers[/url] .
For last day only
Download: [url=http://iconais.fr/bolum/ransom-2-sezon-12-bolum-izle/]Ransom 2. Sezon 12. Bölüm Ransom 2. Sezon 12. Bölüm 30 Haz.[/url] .
Dont Breathe 2016 720p BluRay x264-NeZu Movies
Download: [url=http://fnudu.info/show-music-core-episode-596.html]Show! Music Core Episode 596[/url] .
Family Guy
Download: [url=http://testdnsmigration1.com/ver/acacias-38-1x793.html]1x793 Acacias 38[/url] .
Kyla Burke
Download: [url=http://miyaji.info/movies/49-blade-runner]7.9 Blade Runner (1982)[/url] .
Absolutely Fabulous The Movie 2016 720p WEBrip AC3 [PRiME]
Download: [url=http://closetlgbt.com/effects-of-climate-variation-on-the-breeding-ecology-of-arctic.pdf]Effects Of Climate Variation On The Breeding Ecology Of Arctic Shorebirds[/url] .
les pyjamasques
Download: [url=http://org-all.info/search/?search=michael+connelly]michael connelly[/url] .
Read More
Download: [url=http://restaurantlatonnelle.fr/show/take-good-care-of-the-fridge/]Take Good Care Of The Fridge[/url] .
Bakit Song By Aegis Band With Lyrics
Download: [url=http://rgdqp.info/pointless-s19e48-720p-ip-web-dl-aac2-0-h-264-btw-wujoc.html]Pointless S19E48 720p iP WEB-DL AAC2 0 H 264-BTW 36 minutes[/url] .
antivirus
Download: [url=http://happybet90.info/movie/the-truth-beneath-2016-1080p.81870.html]HD The Truth Beneath (2016)[/url] .
Hotspot Shield v6 20 8 Elite Setup + Activator zip
Download: [url=http://makeupbymegan.info/detail/ED1KROrUiF][ぷらむ] 君の童貞を食べたい[/url] .
WWE NXT 2016 11 16 WEB h264-HEEL [TJET]
Download: [url=http://p-ros.com/actors/Yusuf+Hamied.html]Yusuf Hamied[/url] .
Album - Luchshaja Diskoteka Strany 2013
Download: [url=http://cantoon.info/top-videos/sg]Singapore[/url] .
suicide.squad.2016.extended.480p.web.dl.x264.rmteam.mkv.[MKV]
Download: [url=http://unitednationshorseplanet.com/Field-of-Vision-A-Manual-and-Atlas-of-Perimetry-Current-Clinical-Neurology-_133674.html]Field of Vision: A Manual and Atlas of Perimetry (Current Clinical Neurology)[/url] .
Elementary
Download: [url=http://rozhanskaya.info/ru/nordvpn-private-wifi-security-unlimited-vpn/com.nordvpn.android/download?from=home%2Fhot]Скачать APK[/url] .
First Dates Au S02E04 HDTV x264-FQM
Download: [url=http://criticalstudies.info/dernier-films.html]Derniers ajoutГ©s[/url] .
marche a l'ombre
Download: [url=http://lesgrandsvins.fr/movie/yifi_filter?keyword=Beth+Grant]Beth Grant[/url] .
Tracker list
Download: [url=http://secret-flirtparadise.com/show/terrace-house-aloha-state-season-1/]Terrace House: Aloha State Season 1[/url] .
Amor de Irmao Dublado Online No filme Amor de Irmao, um astro adolescente do basquete enfrenta pressoes para chegar ao topo e em casa: sua irma gemea tem um romance arriscado e seu irmao se envolve em problemas de rua.
Download: [url=http://secret-flirtparadise.com/show/running-man/episode-391.html]Running Man Episode 391[/url] .
Packt Publishing - Python Projects Video Training
Download: [url=http://aimcheck.info//aimcheck.info/manga/isekai_no_shikisai/c001/1.html]Isekai no Shikisai 1[/url] .
NBC Nightly News 2016 11 16 1080p NBC WEBRip AAC2 0 x264-HOPELESS - [SRIGGA]
Download: [url=http://fub97.info/serie/2177]Flikken - Coppia in giallo[/url] .
The Young And The Restless - S44 E11048 - 2016-11-08 TV Shows
Download: [url=http://iconais.fr/diziler/the-sopranos/]• The Sopranos 8.1[/url] .
[AnimeRG] Nanbaka - 07 [1080p] [Multi-Sub] [x265] [pseudo] mkv
Download: [url=http://arianett34-nettoyage.fr/tv/subtitles/the-handmaids-tale-9962659.html]The.Handmaids.Tale.S01E02.WEBRip.x264-RARBG.srt[/url] .
BitLord.com
Download: [url=http://dizisis.com/une-affaire-de-famille-film-streaming-vf-hd-complet/]Une Affaire de famille[/url] .
Slut Girl Manga Complete
Download: [url=http://fnudu.info/drama-detail/2015-mbc-entertainment-awards]2015 MBC Entertainment Awards[/url] .
MikesApartment - Nicole Love (Sexy Nicole)
Download: [url=http://honou.info/manga/4292/date-masamune-yokoyama-mitsuteru]Date Masamune (YOKOYAMA Mitsuteru)[/url] .
Daniel Bacon
Download: [url=http://rochdaledirect.info/manga_list?type=newest&category=35&state=all&page=1]Slice of life[/url] .
Diane Schuur and the Count Basie Orchestra [FLAC]
Download: [url=http://o9x2a.info/book/515781610/download-the-importance-of-being-earnest-with-audio.pdf]The Importance of Being Earnest (with audio)[/url] .
Brutal Death Metal
Download: [url=http://marcheinverness.com/descargar-torrents-variados-237-Atomix-Virtual-DJ-Pro-v604.html]Atomix Virtual DJ Pro v6.0.4.[/url] .
American.Horror.Story.S06E10.HDTV.x264-FUM[ettv]
Download: [url=http://o9x2a.info/book/682387205/download-between-memory-and-document.pdf]Between Memory and Document[/url] .
high strung 2016 brrip xvid hdtv
Download: [url=http://s6n9f.info/bd-k-missing-kings-subtitle-indonesia/]BD K: Missing Kings Subtitle Indonesia[/url] .
Сезон 1 БГ АУДИО
Download: [url=http://rozhanskaya.info/nl/ielts-exam-preparation/com.english.learnword.allielts]IELTS Exam Preparation[/url] .
Orchestral Tools Metropolis Ark 1
Download: [url=http://mzainuo.com/music/o-o-yanda-yanda.html]O O Yanda Yanda[/url] .
MIX FIGHT2 ????????????
Download: [url=http://fnudu.info/drama-detail/husbands-secret-stash]Husbands Secret Stash[/url] .
2014 Movies
Download: [url=http://restaurantlatonnelle.fr/show/the-challenger/]The Challenger[/url] .
Michelle Yeoh,
Download: [url=http://restaurantlatonnelle.fr/show/super-idol-chart-show/episode-43.html]Super Idol Chart Show Episode 43[/url] .
Captain America - the Winter Soldier 2013 CAM x264 AC3 UNiQUE
Download: [url=http://slimx180.com/by_pat_crocker_the_smoothies_bible_second_edition_1_5.pdf]By Pat Crocker - The Smoothies Bible PDF[/url] .
Avanquest Architecte 3D Express 2017.19.0.1.1001
Download: [url=http://marcheinverness.com/descargar-torrents-variados-602--PDF-Converter-Professional-v81.html]PDF Converter Professional v8.1[/url] .
jb4tngzq.mcp.mp4
Download: [url=http://secret-flirtparadise.com/show/cheap-tour/]Cheap Tour[/url] .
Celine Dion S My Heart Will Go On Titanic Movie Theme Electric Violin Cover
Download: [url=http://daniellarose.fr/2018/01/komik-boruto-chapter-20-bahasa-indonesia.html]Read More [/url] .
The Impossible 2012 HD ????? ????? 7.6
Download: [url=http://aimcheck.info//aimcheck.info/manga/the_story_of_an_onee_san_who_wants_to_keep_a_high_school_boy/c021/1.html]The Story of an Onee-San Who Wants to Keep a High School Boy 21[/url] .
Salem.S03E03.HDTV.x264-KILLERS[ettv]
Download: [url=http://unitednationshorseplanet.com/1400-medical-book-Html-free-search-_9732.html]1400 medical book (Html) free search![/url] .
Alexander Ludwig Cato Of The Hunger Games
Download: [url=http://testdnsmigration1.com/serie/detroiters/temporada-1.html]Temporada 1[/url] .
(2016) DVD The Adventures of Panda Wa..
Download: [url=http://fnudu.info/drama-detail/the-love-of-happiness]The Love of Happiness[/url] .
I Frankenstein (2014) BR2DVD DD2.0 Custom NL Subs-TBS
Download: [url=http://secret-flirtparadise.com/show/moonlight-prince/]Moonlight Prince[/url] .
BitLord.com
Download: [url=http://secret-flirtparadise.com/show/knowing-brother/episode-131.html]Knowing Brother Episode 131[/url] .
pthc Pedoland Frifam Webcam cutiegrl part 2-08.avi
Download: [url=http://banxehoi-notification.com/potato-salad-by-debbie-moose_5b3e3a682533b94cdf5ebeb3/policy]Privacy Policy[/url] .
Partisan (2015)
Download: [url=http://calmmantis.com/book/1102931107/download-el-cazador-de-historias.pdf]El cazador de historias[/url] .
Taboo Sister Fantasies - Viky, Ms Jones and Rick (Jerk It In Mommy's Kitty)
Download: [url=http://everesttreksandexpedation.com/tvshows/all-or-nothing/]All or Nothing[/url] .
EastEnders 14th Nov 2016 HDTV (Deep61) mp4
Download: [url=http://ztrek.info/forum-eyeshield-21]Eyeshield-21[/url] .
tusk 2014
Download: [url=http://secret-flirtparadise.com/show/2018-bts-comeback-show/]2018 BTS Comeback Show[/url] .
Neyo Miss Independent She Got Her Own
Download: [url=http://rochdaledirect.info/chapter/red_spirit/chapter_24]Chapter 24[/url] .
Baixar Meu Amigo o Dragao Mp4 Dublado Torrent
Download: [url=http://09611s.net/film-tag/patti-cake-en-direct]Patti Cake$ en direct[/url] .
PlayboyPlus.15.01.11.Laura.Cattay.Sexy.Selfie.XXX.1080p.MP4.KTR
Download: [url=http://lelimoges.fr/category/star-plus/star-plus-completed-shows/ek-hasina-thi/]Ek Haseena Thi[/url] .
B.A. Pass (2013) DVDRip x264 ...
Download: [url=http://rozhanskaya.info/contact-us.html]Contact Us[/url] .
Leave a Comment!
Download: [url=http://maculinisme.fr/serial/roseanne/1444]Roseanne[/url] .
Petes Dragon 2016 720p BluRay H264 AAC-RARBG
Download: [url=http://fnudu.info/drama-detail/2016-super-star-a-red-white-lunar-new-year-special]2016 Super Star: A Red & White Lunar New Year Special[/url] .
NBA.1998.All-Star.Game.West.vs.East.720p.HDTV.30fp...(A)
Download: [url=http://p-ros.com/actors/Evan+Peters.html]Evan Peters[/url] .
Сезон 1 БГ СУБТИТРИ
Download: [url=http://p-ros.com/actors/Pinky+Cheung.html]Pinky Cheung[/url] .
Shipping Wars (UK)
Download: [url=http://p-ros.com/actors/Matt+Gerald.html]Matt Gerald[/url] .
BitLord.com
Download: [url=http://hyperaktiv.info/ep/328506/the-amazing-world-of-gumball-s04e36-the-detective-hdtv-x264-w4f/]The Amazing World of Gumball S04E36 The Detective HDTV x264-W4F [eztv][/url] .
Jason Bourne 2016 720p WEB-DL XviD AC3-FGT
Download: [url=http://vacances-adaptees.fr/series-hd/chicago-med/3793]Chicago Med HDTV 720p AC3 5.1[/url] .
Sleeping with Other People 2015 HD ????? ????? 6.5
Download: [url=http://hfte.info/jorja-smith-bbc-radio-1-big-weekend-2018-video-album-wuknq.html]Jorja Smith - BBC Radio 1 Big Weekend 2018 [Video Album] 18 РјРёРЅСѓС‚[/url] .
Kel Kade - King's Dark Tidings, Book 1: Free the Darkness - eBook [Isohunt.to]
Download: [url=http://wettenbet6.com/slaphouse-2017-tv-show-free-download-dvdrip]Slaphouse (2017)[/url] .
St James Brass Band
Download: [url=http://qqaladin.info/media/trial-error-orange-moon.765/find-new/ams-comments]New Comments[/url] .
Yorumlar (0)
Download: [url=http://rozhanskaya.info/ar/iphone-emoji-ios-emoji/com.vivis.keyboard.emoji.ios12]IPhone Emoji & IOS Emoji[/url] .
Ben Foster
Download: [url=http://dorer.fr/?n=Strunz+And+Farah+-+Camino+Real+%28Spanish+Guitar%29]Download[/url] .
Hillary Clinton E-mail Scandal - FBI Documents November 1st 2016 1 - 4 [Isohunt.to]
Download: [url=http://fnudu.info/drama-detail/2017-kbs-drama-awards]2017 Kbs Drama Awards[/url] .
Dance Moms S06E32 Two Teams Two Studios Part One HDTV x264-[NY2] - [SRIGGA]
Download: [url=http://pescup.info/watch-genius-season-1-2017-1080p-online-free-123movieshub.html]Eps10 Genius - Season 1 (2017)[/url] .
Style King (2016) Kannada - HD Rip - 420p - AAC - SAN mkv
Download: [url=http://p-ros.com/actors/Bernardo+Santos.html]Bernardo Santos[/url] .
Letra traducida de Mama said
Download: [url=http://hawkbots.com/director/christophe-gans/]Christophe Gans[/url] .
Jason.Bourne.2016.DVDRip.XviD.AC3-iFT[PRiME]
Download: [url=http://write-scripts.com/streaming-serie-gratuit/the-walking-dead/saison-8-complet/episode-14]Г©pisode 14 streaming Still Gotta Mean Something[/url] .
Privacy Policy
Download: [url=http://miyaji.info/movies/66-die-hard]7.5 Die Hard (1988)[/url] .
[NDS-ENG] Shorts_USA-BAHAMUT_[SUPERFILES.ORG]
Download: [url=http://p2rprod.fr/iletisim]Д°letiЕџim[/url] .
Caribbean-111516-303-HD
Download: [url=http://aimcheck.info//aimcheck.info/manga/death_march_kara_hajimaru_isekai_kyousoukyoku/v07/c043/1.html]Death March kara Hajimaru Isekai Kyousoukyoku 43[/url] .
80s New Wave Mix
Download: [url=http://aimcheck.info//aimcheck.info/manga/martial_peak/]Martial Peak[/url] .
keeping up with the kardashians se 720p
Download: [url=http://fnudu.info/drama-detail/the-temptation-to-go-home]The Temptation to Go Home[/url] .
[Ctrl-ZnF]Naruto Shippuuden 322 [720p x264+AAC].mp4
Download: [url=http://maculinisme.fr/serial/wiedzmy/1799]WiedЕєmy[/url] .
Read More
Download: [url=http://restaurantlatonnelle.fr/show/the-list-2015/]The List 2015[/url] .
Order By Time
Download: [url=http://ph-staging.com/02033916-to-build-magazine-july-october-2018/]To Build Magazine – July-October 2018[/url] .
Justin Lin,
Download: [url=http://elapice.com/ranks/26-film-series]VIDIO LAINNYA[/url] .
War Dogs anschauen
Download: [url=http://restaurantlatonnelle.fr/show/a-tree-that-never-falls/]A Tree That Never Falls[/url] .
Toumani Diabate - Djelika (1995)[FLAC]
Download: [url=http://fub97.info/serie/2790]Victoria[/url] .
TOP 50 Monthly torrents in this category
Download: [url=http://restaurantlatonnelle.fr/show/4-wheeled-restaurant/]4 Wheeled Restaurant[/url] .
Carnivale
Download: [url=http://evibiw.info/tv-show-hello-project-2017-summer-%ef%bd%9ehello-meeting-%e3%83%bb-hello-gathering-%ef%bd%9e-2017-bdrip/][TV-SHOW] Hello! Project 2017 SUMMER пЅћHELLO! MEETING гѓ» HELLO! GATHERING пЅћ (2017) (BDRIP)[/url] .
The Witcher 3 Wild Hunt Blood and Wine 2016 MAC Game
Download: [url=http://ich-lebe-noch.info/torrent/161532][259LUXU-228] ラグジュTV 223 知念真央 25жі е…ѓеЏ—д»е¬ў [259LUXU-228] ラグジュTV 223 知念真央 25жі е…ѓеЏ—д»е¬ў[/url] .
i am not a serial killer
Download: [url=http://hfte.info/tv/calendar.html]Календарь[/url] .
A Serie Divergente: Convergente Legendado 5.1 Torrent – BluRay 1080p (2016)
Download: [url=http://hawkbots.com/monty-python-and-the-holy-grail-1975/]Download[/url] .
Shailene Woodley
Download: [url=http://marcheinverness.com/descargar-torrents-variados-2073-Australias-Top-40-Music-Video-Chart-20-02-2016.html]Australias Top 40 Music Video Chart 20-02-2016.[/url] .
16 Pregnant
Download: [url=http://austinsedationdentistry.com/bd-fatekaleid-liner-prisma%e2%98%86illya-2wei-herz-subtitle-indonesia/]BD Fate Kaleid liner Prisma Illya 2 Wei Herz Subtitle Indonesia[/url] .
4a Mart Zhukovsky Shakedown At Night Mart Zhukovsky Rmx
Download: [url=http://aey8.com/chapter/tales_of_demons_and_gods/chapter_92]Chapter 92[/url] .
NCIS - Season 14 Episode 7
Download: [url=http://www.facebook.com/sharer.php?u=http://xplfye.info/?p=22635]Facebook[/url] .
Modern Family S08E07 720p HDTV x264-FLEET[rarbg]
Download: [url=http://webhostfeed.com/ver/american-woman-1x04.html]1x04 American Woman[/url] .
geekatplay studio animation in vue
Download: [url=http://diegorangel.com.br/torrent/ko2slu93/Life.Sentence.S01E08.720p.HDTV.x264-KILLERS[TGx].html]Life.Sentence.S01E08.720p.HDTV.x264-KILLERS[TGx][/url] .
Военен
Download: [url=http://mespassions.fr/serie/Gravitation]Gravitation[/url] .
(2016) DVDRip Blowtorch
Download: [url=http://spongydesigns.com/masturbacao-um-ato-de-amor-proprio/]Masturbação: Um Ato de Amor Próprio Assistir Masturbação: Um Ato de Amor Próprio 720p Dublado/Legendado Online O diretor americano Nicholas Tana fez um documentário inteirinho sobre masturbação. E ele não quer que riam disso. “É ironicamente engraçado. Mas precisamos fazer as pazes com a nossa sexualidade”, diz o americano, que dirigiu “Sticky: A (Self) Love Story” -algo como “Pegajoso: Uma História de Amor (Próprio)”. Ver filme Masturbação: Um ...[/url] .
Adobe Premiere Pro CC 2015 v9.0 + Crack
Download: [url=http://961mold.com/film-tag/film-dans-un-recoin-de-ce-monde-dvdripvf]film Dans un recoin de ce monde dvdripvf[/url] .
Alaska In Winter - Holiday
Download: [url=http://504.fr/file/669455732/download-tumman-veden-p-ll.pdf]Tumman veden päällä[/url] .
VSO ConvertXtoDVD 6 0 0 55 + Patch [4realtorrentz] zip
Download: [url=http://504.fr/file/574520846/download-storybook-helsinki-and-beyond.pdf]Storybook Helsinki and Beyond[/url] .
Signora Giovanni Galletta
Download: [url=http://gitgot.info/category/drinks-food-cooking/ http://itunes.apple.com/app/id454936656]View PDF on Apple iOS[/url] .
LATEST TORRENTS
Download: [url=http://xbahap.info/preview?t=UML+2+-+Initiation%2C+exemples+et+exercices+corrig+s+-+Elearn&u=https%3A%2F%2Felearn.univ-ouargla.dz%2F2013-2014%2Fcourses%2FGLPOO%2Fdocument%2FLivres%2520electroniques%2FUML2_Initiationexemplesetexercicescorriges_2iemeedition_.pdf%3FcidReq%3DGLPOO]Download[/url] .
Hoppity.Goes.to.Town.1941.DVDRip.XviD.AC3-xfiles
Download: [url=http://peru50.biz/piosenka,jimi_hendrix,fire.html]Jimi Hendrix - Fire[/url] .
??? ???
Download: [url=http://xjgjcw.info/actors/Michael+Greyeyes.html]Michael Greyeyes[/url] .
Legendado
Download: [url=http://menuiserie-papaix-toulouse.fr/nontonfilm77]nontonfilm77[/url] .
Nicole Aniston mp4
Download: [url=http://53gmgm.com/topic/35052-iskatel-novie-priklyucheniya-v-dome-s-privideniyami.html]РСКАТЕЛЬ. Новые приключения РІ РґРѕРјРµ СЃ привидениями (Новый РґРёСЃРє) (RUS) [L] Подробнее... Залито: 05-12-2010 14:37 (5887 просмотров) РСКАТЕЛЬ. Новые приключения РІ РґРѕРјРµ СЃ привидениями (Новый РґРёСЃРє) (RUS) [L] Для самых маленьких Старый, заброшенный РґРѕРј хранит множество тайн. РўРѕС‚, кто осмелится преступить его РїРѕСЂРѕРі, РЅРµ сразу сможет выбраться наружу...... Раздают: 0 Качают: 0 Размер: 589MB [/url] .
????(11)
Download: [url=http://naturo.fr/serie/pretender]Pretender[/url] .
Um Suburbano Sortudo Nacional Torrent – HDTS Download (2016)
Download: [url=http://bentbasket.com/watch/Ovk7NJvQ-rich-man.html]Rich Man[/url] .
KRAY-001 mp4
Download: [url=http://sqribe.fr/search/casting%20anal%202015/]Casting anal 2015[/url] .
Sample Page
Download: [url=http://robesoie.fr/book/523367089/download-gli-angeli-non-vanno-mai-in-fuorigioco-fabio-caressa.pdf]Gli angeli non vanno mai in fuorigioco[/url] .
La Chienne (1931) Francais - DVD5 - Eng Subs- Janie Marese, Michel Simon [DDR]
Download: [url=http://revmortlocal.com/parametres/]ParamГЁtres[/url] .
Hollywood Football
Download: [url=http://mtptn-a.com/tags/Rock+Opera/]Rock Opera[/url] .
Deadliest Catch
Download: [url=http://laredophysiciansgroup.info/dentro-da-casa/]Dentro da Casa Assistir Dentro da Casa 720p Dublado/Legendado Online Um rapaz de 16 anos consegue entrar na casa de um colega da sua aula de literatura e resolve escrever sobre o fato no seu trabalho de francês. Animado com o dom natural do aluno e o progresso do seu trabalho, o professor volta a apreciar a função de educador dos jovens. Entretanto, a ...[/url] .
Jimmy Kimmel 2016 11 16 Garth Brooks HDTV x264-CROOKS[ettv]
Download: [url=http://inscrire.fr/X12X15X230531X0X0X1X-quiet-place-2018-webrip.html]A Quiet Place (2018) WEB-DL[/url] .
watch Filmrise
Download: [url=http://panthereducation.com/Books/Health, Fitness &amp; Dieting/Nutrition/Computers & Technology]Computers Technology[/url] .
Bridge Design and Evaluation LRFD and LRFR.pdf
Download: [url=http://www.hk9559.com/programmi/antivirus-e-sicurezza/]Antivirus e Sicurezza[/url] .
Mom S04E04 – 4×04 Legendado HD Online
Download: [url=http://soscomputer.info/fight96y-pdf.html]torrent fight96y[/url] .
Jackpot-2013-Hindi-720p-DvDRip-x264-AC3-5.1....Hon3y
Download: [url=http://53gmgm.com/topic/1737167-propovednik-preacher.html]Проповедник / Preacher / Сезон: 3 / Серии: 1-2 РёР· 13 (Майкл Словис, Рван Голдберг, Сет Роген) [2018, РЎРЁРђ, фэнтези, драма, детектив, приключения., WEB-DL 720p] MVO (Baibako) + Original + Sub (Eng) Подробнее... Залито: 05-07-2018 15:18 (78 просмотров) Проповедник / Preacher / Сезон: 3 / Серии: 1-2 РёР· 13 (Майкл Словис, Рван Голдберг, Сет Роген) [2018, РЎРЁРђ, фэнтези, драма, детектив, приключения., WEB-DL 720p] MVO (Baibako) + Original + Sub (Eng) Зарубежные сериалы Священник Джесси Кастер РїРѕ воле случая стал носителем внутри своего естества странного существа РїРѕ имени Генезис. Рто дитя совокупления ангела Рё демона представляет СЃРѕР±РѕР№ одновременно чистый идеал Рё квинтэссенцию света, РЅРѕ также сгусток абсолютного зла. Генезис — единственное существо РІРѕ Вселенной, которое... Раздают: 2 Качают: 1 Размер: 2.5GB [/url] .
Елементарно
Download: [url=http://peru50.biz/piosenka,rihanna,love_the_way_you_lie_part_2__feat__eminem_.html]Rihanna - Love The Way You Lie Part 2 feat. Eminem[/url] .
????? ????? ?????
Download: [url=http://naturo.fr/serie/Bakumatsu-Rock]Bakumatsu Rock[/url] .
I Love This Life - Locash
Download: [url=http://xjgjcw.info/actors/Chrissie+Chau.html]Chrissie Chau[/url] .
VMWare ThinApp Enterprise 5 2 2 Build 4435715 + License Keys
Download: [url=http://jeuxmobilesgratuits.fr/liga-da-justica-crise-em-duas-terras/]Liga da Justiça: Crise em Duas Terras Assistir Liga da Justiça: Crise em Duas Terras 720p Dublado/Legendado Online Neste longa de animação, um Lex Luthor "do bem" vem de um universo alternativo para pedir ajuda, pois seu planeta está sendo ameaçado pelo Sindicato do Crime, uma versão maligna da Liga da Justiça. As coisas se complicam quando o vilão Coruja tenta por em prática um plano diabólico, que ...[/url] .
Living in Urban Communities (First Step Nonfiction: Communities)
Download: [url=http://markauesassmake.info/ver/servir-y-proteger/temporada-1/capitulo-299.html]Servir y proteger[/url] .
Future-Worm.S01E10.720p.HDTV.x264-W4F[rarbg]
Download: [url=http://puckmaynanny.info/download-lagu-dewi-gita-penari-mp3/]Dewi Gita - Penari[/url] .
view all
Download: [url=http://dealsealer.biz/rubrique/304/le-coin-du-randonneur]Le coin du randonneur[/url] .
Personal Knowledge Management: Individual, Organizational and
Download: [url=http://clearaccessmedia.com/book/638566575/download-iphone-photo-tutorials-vers-o-portuguesa.pdf]iPhone Photo Tutorials: VersГЈo Portuguesa[/url] .
Max Steel
Download: [url=http://xqf0n.info/film/1921]HD Rip 1921[/url] .
view all
Download: [url=http://multi-taux.com/search/17-again-in-hindi-worldfree4u/]17 again in hindi worldfree4u[/url] .
Tom Bonington
Download: [url=http://banhallmand.info/search/label/charlie-puth]Charlie Puth[/url] .
NetGuard - no-root firewall 2.61 PRO
Download: [url=http://robesoie.fr/book/806892351/download-esposizioni-lunghe-con-filtri-neutri-alessio-furlan.pdf]Esposizioni lunghe con filtri neutri[/url] .
The Flash 2014 S03E06 HDTV XviD-FUM[ettv]
Download: [url=http://locationbureaunantes.fr/films/streaming/96742-qui-a-peur-de-virginia-woolf.html]Regarder Qui a peur de Virginia Woolf ? en Streaming[/url] .
13 de setembro de 2016
Download: [url=http://cribleum.info/actors/Michael+Mihm.html]Michael Mihm[/url] .
charlie-rose-your-best-offer mp4
Download: [url=http://mespassions.fr/serie/Superkater]Superkater[/url] .
??? ??.E18.161020.720p-NEXT
Download: [url=http://ydvj3.info/book/9781492622475/this-is-where-it-ends]This is Where it Ends[/url] .
Anderson Freire - Raridade
Download: [url=http://mespassions.fr/serie/Clockwork-Planet]Clockwork Planet[/url] .
Haunt 2013 HDRip XviD - RARBG
Download: [url=http://xjgjcw.info/actors/Barbara+Stanwyck.html]Barbara Stanwyck[/url] .
Star Wars: O Despertar da Forca – Legendado Full HD 1080p Online
Download: [url=http://dininginnh.com/stream-seattle-mariners-vs-colorado-rockies-live-3]Stream Link 3[/url] .
Finding Dory 2016 1080p 3D BluRay Half-OU x264 DTS-JYK
Download: [url=http://fa2gh.info/0c/2820332439/0c0757d91e238f3a10996bbbe79f6641.html]The Promised Neverland 02[/url] .
Continuar
Download: [url=http://hazirmutfak.biz/Film-8008-baby-boss-streaming]BDRipVF Baby Boss[/url] .
Natsuyasumi - 03
Download: [url=http://naturo.fr/serie/Being-Erica-Alles-auf-Anfang]Being Erica – Alles auf Anfang[/url] .
[Ctrl-ZnF]Naruto Shippuuden 322 [396p Xvid+MP3].avi
Download: [url=http://xjgjcw.info/actors/Apisit+Opasaimlikit.html]Apisit Opasaimlikit[/url] .
[????] ?? ???? 161117
Download: [url=http://jscateringservices.biz/watch/naked-and-afraid-season-9-2018-fmovies.html]Watch movie[/url] .
Read More
Download: [url=http://revmortlocal.com/category/films/policier/]Policier[/url] .
BitLord.com
Download: [url=http://naturo.fr/vorgeschlagene-serien/vote:13130]A Kind of Magic - Eine Magische Familie[/url] .
16/04/18
Download: [url=http://dealsealer.biz/rubrique/89/rubrique/20/romans-policiers]Romans policiers[/url] .
Chelsea.S01E79.Dinner.Party.The.Best.Relationships.720p.WEBRip.X265.AAC-PRiNCE.mkv - 2016-11-17
Download: [url=http://dtvuy.info/book/445914886/download-bien-d-buter-le-solf-ge.pdf]Bien dГ©buter le solfГЁge[/url] .
?????? ? ???? ??????
Download: [url=http://hdiuk.info/preview?t=Campa%C3%B1a+de+env%C3%ADo+de+SMS+a+docentes+para+la+...+-+Repositorio+Minedu&u=http%3A%2F%2Frepositorio.minedu.gob.pe%2Fbitstream%2Fhandle%2FMINEDU%2F5246%2FCampa%25C3%25B1a%2520de%2520env%25C3%25ADo%2520de%2520SMS%2520a%2520docentes%2520para%2520la%2520mejora%2520de%2520la%2520motivaci%25C3%25B3n%2520nota%2520conceptual.pdf%3Fsequence%3D1%26isAllowed%3Dy]Download[/url] .
Teachers Pet 6 s1 mp4
Download: [url=http://naturo.fr/serie/Buso-Renkin]Buso Renkin[/url] .
GarageBand 10 1 for MAC-OSx
Download: [url=http://vulnerabilite.fr/category/ficcao-cientifica/]Ficção Cientifica[/url] .
StarGate SG1
Download: [url=http://duz77.info/torrenty/kategorii/Filmy XviD/DivX/gatunku/Horror]XviD/DivX / Horror[/url] .
Alana Luv - Blonde MILF's Anal Experiment, XXX, MPEG4(Xvid), C2x, HD 1080p, 0,5 FPS [Lets Try Anal - Mofos] (Aug 12, 2016).avi [Isohunt.to]
Download: [url=http://footlockersstore.com/films/acteur/christian-clavier.html]Christian Clavier[/url] .
Good Kids (2016)
Download: [url=http://504.fr/file/807610076/download-soittamalla-oppii-piano-ekat-soinnut.pdf]Soittamalla oppii! PIANO – EKAT SOINNUT[/url] .
Man vs Wild
Download: [url=http://cribleum.info/actors/Milly+Shapiro.html]Milly Shapiro[/url] .
Ted 2 2015 HD ????? ????? 6.4
Download: [url=http://jeuxmobilesgratuits.fr/nao-fale-com-irene/]Não Fale com Irene Assistir Não Fale com Irene 720p Dublado/Legendado Online Quando uma menina com excesso de peso é suspensa da escola, ela deve suportar duas semanas de serviço comunitário em uma casa de repouso. Ela secretamente assina os moradores para um reality show de dança para provar que você não precisa ser perfeito para ser ótimo. Ver filme Não Fale com Irene Dublado/Legendado Ver Filme ...[/url] .
Verhicles & Transport
Download: [url=http://imprimerieparis.fr/32637/arcade-fire-funeral-2004]http://imprimerieparis.fr/32637/arcade-fire-funeral-2004[/url] .
One Tree Hill
Download: [url=http://pinksnail.info/graphics/templates/678355-themeforest-crypterio-v14-bitcoin-ico-and-cryptocurrency-wordpress-theme-21274387.html]ThemeForest - Crypterio v1.4 - Bitcoin, ICO and Cryptocurrency WordPress Theme - 21274387[/url] .
Pink Floyd The Early Years 1965 1972 (2016) V2 [Box Set] FLAC Beolab1700
Download: [url=http://magik-box.info/tango-one-vf-streaming/]Tango One[/url] .
14 Days Free Access to USENETFree 300 GB with 10 GB High-Speed
Download: [url=http://jscateringservices.biz/actors/Frank+Jenks.html]Frank Jenks[/url] .
30 Something Grandma S01E01 Adventures Of Patricia HDTV x264-[NY2] - [SRIGGA]
Download: [url=http://alshamasfoodproducts.com/the-detour-saison-3-episode-6-260801.htm]The Detour saison 3 Г©pisode 6[/url] .
Lithuania
Download: [url=http://cribleum.info/actors/Jazmyn+Simon.html]Jazmyn Simon[/url] .
Ultima
Download: [url=http://grueffelo.info/book/1080692726/download-ancora-una-volta-jodi-ellen-malpas.pdf]Ancora una volta[/url] .
[????] ???? 1? 161117
Download: [url=http://yhisip.info/category/bernabeu-2017/]BernabГ©u (2017)[/url] .
As Aventuras de Peabody & Sherman
Download: [url=http://diegorangel.com.br/torrent/uqe9p7gh/A+Life+Less+Throwaway+-+The+lost+art+of+buying+for+life.html]A Life Less Throwaway - The lost art of buying for life[/url] .
???????? ?01? [Maou-jou de Oyasumi vol 01]
Download: [url=http://xjgjcw.info/actors/James+Jones.html]James Jones[/url] .
Adobe Acrobat XI Pro 11 0 18 Multilingual + Crack
Download: [url=http://naturo.fr/serie/Der-junge-Montalbano]Der junge Montalbano[/url] .
Unforgiven 2013 HD ????? ????? 7.1
Download: [url=http://fvgiment.info/film/american-pie-2-cov]Eps1 American Pie 2[/url] .
maleficent
Download: [url=http://roundtabletechnology.info/watch-inspector-george-gently-online/]Inspector George Gently[/url] .
Песента на живота
Download: [url=http://mespassions.fr/vorgeschlagene-serien/vote:9598]Die Gobots[/url] .
Petes Dragon 2016 BRRip XviD AC3-EVO
Download: [url=http://rxouj.info/memberlist.php?mode=viewprofile&u=1284929&sid=610f0a26075677d26a8cba365164a895]chrisire[/url] .
True Memoirs of an International Assassin (2016)
Download: [url=http://defreat.info/series-vo/timeless/2772]Timeless HDTV 720p AC3 5.1[/url] .
Ohys Raws ??? ?? 07 TBS 1280x720 x264 AAC torrent
Download: [url=http://amaraponjon.com/serie/Grandfathered]Grandfathered[/url] .
fucking the beautiful long haired black beauty
Download: [url=http://xk2e4.info/movie/charged-the-eduardo-garcia-story]Charged: The Eduardo Garcia Story[/url] .
The Shallows 720p Torrent
Download: [url=http://snj4v.info/list/releases?availableFilter=0&artistFilter=&labelFilter=56633&genreFilter=&timeFilter=0&bpmFilter=&keyFilter=&trackTypeFilter=]Armada Electronic Elements[/url] .
Petes.Dragon.2016.720p.10bit.BluRay.6CH.x265.HEVC PSA
Download: [url=http://yhisip.info/category/wonderstruck-2017/]Wonderstruck (2017)[/url] .
2000–2002
Download: [url=http://vetsmiracle.com/recent-activity/threads/looking-for-aged-facebook-instagram-twitter-accounts-for-your-business.163571/]Looking for Aged Facebook/Instagram/Twitter Accounts for your Business?[/url] .
Nero Burning ROM 2017 18 0 00900 Multilingual Incl Serial Key + Portable
Download: [url=http://naturo.fr/serie/Snowfall]Snowfall[/url] .
Michael Grandage,
Download: [url=http://musvida.info/a-street-cat-named-bob/]A Street Cat Named Bob[/url] .
Yorumlar (0)
Download: [url=http://nuskinsg.com/category/fantastique]Fantastique Cliquez pour regarder[/url] .
[ www.TorrentDay.com ] - Eastenders.2013.03.12.PDTV.x264-Deadpool
Download: [url=http://amaraponjon.com/serie/Sankarea]Sankarea[/url] .
Contact Us
Download: [url=http://distancelearningengineering.com/surface-de-reparation/]Regarder Le Film[/url] .
shameless
Download: [url=http://naturo.fr/serie/London-Spy]London Spy[/url] .
Pathological Pain: From Molecular to Clinical Aspects
Download: [url=http://bellinghamopenhouses.com/2621316-sonic-forces-ps4-playable.html]Read more...[/url] .
Salem S03E03 720p HDTV x264-KILLERS[ettv]
Download: [url=http://vetsmiracle.com/ http://guruslodge.com/index.php?forum/]Android Zone[/url] .
IObit Uninstaller Pro 6 1 0 19 Multilingual + Key [4realtorrentz] zip
Download: [url=http://xxxsohbet.info/diziler/luther-turkce-dublaj/]• Luther (Türkçe Dublaj) 7.9[/url] .
The Birthday Boys
Download: [url=http://naturo.fr/serie/Die-Chefin]Die Chefin[/url] .
??(43)
Download: [url=http://qipuwv.info/torrent/186220/errotica-archives-com-2018-07-04-alisa-amore-alisa-amore-erotic-3648x5472-57][Errotica-Archives.com] 2018-07-04 Alisa Amore - Alisa Amore [Erotic] [3648x5472, 57][/url] .
[HorribleSubs] Drifters - 02 [1080p].mkv
Download: [url=http://traxbangbeats.com/series-hd/fear-the-walking-dead/2049]Fear The Walking Dead HDTV 720p AC3 5.1[/url] .
LeatherChronicle: COCK ON THE RUN: ESCAPED PRISONER FINDS SHELTER DEEP INSIDE TWO LEATHER LOVERS' ASSHOLES [XXX] x264
Download: [url=http://banddsurvey.com/films/paycheck-2003/]Paycheck (2003)[/url] .
BitLord.com
Download: [url=http://grosbet400.com/profil/destandilay]@destandilay;[/url] .
The Commitments OST
Download: [url=http://job-up.fr/film/historique/]Historique[/url] .
Mind of Mencia
Download: [url=http://allpromoldwater.com/download/migos-marshmello-danger-from-bright-the-album]Migos & Marshmello - Danger (from Bright: The Album)[/url] .
The.Walking.Dead.S07E02.VOSTFR.WEB-DL.x264-ARK01(A)
Download: [url=http://occasions-voiture.fr/a/answers+to+4picks1word+answers+mediafire.html]answers to 4picks1word answers[/url] .
1 Zuhal Asli Kadir Mevlam Senden B I R Alem Var Ekler
Download: [url=http://cribleum.info/watch/murder-calls-season-3-2018-fmovies.html]Watch movie[/url] .
[????] ???? ?? ??? Vol.31.zip
Download: [url=http://jscateringservices.biz/actors/William+Tannen.html]William Tannen[/url] .
Momentum 2015 HD ????? ????? 5.5
Download: [url=http://dealsealer.biz/rubrique/136/techniques-industrielles]Techniques industrielles[/url] .
Die glorreichen Sieben voll kostenlos sehen
Download: [url=http://bentbasket.com/watch/Ovk961GQ-general-and-i.html]General And I[/url] .
Late Summer 2016 1080p BluRay x264-GRUNDiG[PRiME]
Download: [url=http://locationbureaunantes.fr/films/96753-telecharger-the-clapper.html]TГ©lГ©charger The Clapper[/url] .
Стрелата Сезон 5 Епизод 7 / Arrow БГ СУБТИТРИ
Download: [url=http://greece4d.info/tres-vezes-amor-torrent-2008-dual-audio-5-1-bluray-1080p/]TrГЄs Vezes Amor Torrent (2008) Dual ГЃudio 5.1 BluRay 1080p[/url] .
Earth Wind Fire Boogie Wonderland
Download: [url=http://rc6bh.info/engine/go.php?file=torrent Action ou Vérité FRENCH DVDRIP 2018 - torrent 9]Telechargement Direct[/url] .
Facebook
Download: [url=http://mespassions.fr/serie/Auction-Hunters-Zwei-Asse-machen-Kasse]Auction Hunters – Zwei Asse machen Kasse[/url] .
TeenDreams - Harper mp4 - 2016-11-16
Download: [url=http://amaraponjon.com/serie/Mit-Dolch-und-Degen]Mit Dolch und Degen[/url] .
That 70s Show
Download: [url=http://robesoie.fr/book/1381583122/download-trinity-life-audrey-carlan.pdf]Trinity. Life[/url] .
Crisis S01E04 HDTV x264-LOL[ettv]
Download: [url=http://diegorangel.com.br/torrent/bvwj8fyv/iSpring+Suite+9.0.0+Build+24913+(x86-x64)+-+SeuPirate.html]iSpring Suite 9.0.0 Build 24913 (x86-x64) - SeuPirate[/url] .
The Flash 2014 S03E06 HDTV XviD-FUM[ettv]
Download: [url=http://rc6bh.info/what-happened-miss-simone.html]What Happened, Miss Simone?[/url] .
1 de setembro de 2015
Download: [url=http://oneplacelease.com/watch-paper-towns-2015-full-movie-online-584.html](2015) DVD Paper Towns[/url] .
Close To Home
Download: [url=http://jscateringservices.biz/actors/Richard+Benedict.html]Richard Benedict[/url] .
BitLord.com
Download: [url=http://amaraponjon.com/serie/Seisen-Cerberus-Ryuukoku-no-Fatalite]Seisen Cerberus: Ryuukoku no Fatalite[/url] .
Son of Zorn S01E05 - A Taste of Zephyria 1080p WEB-DL x265 10bit AAC 5 1 - Im...
Download: [url=http://diegorangel.com.br/torrent/s6stxt8t/[DB]+Nana+[Dual+Audio+10bit+DVD480p][HEVC-x265].html][DB] Nana [Dual Audio 10bit DVD480p][HEVC-x265][/url] .
David Guetta Feat Sia & Fetty Wap - Bang My head (Remixes EP)
Download: [url=http://sqribe.fr/community/show/reporting-guide-hints-and-tips/?post=17867962]Reporting guide with hints and tips[/url] .
Mike and Dave - Un matrimonio da sballo (2016) H264 ita eng sub ita eng iCV-M...
Download: [url=http://hftumblers.com/music/view.php?cat=Hardcore]Hardcore[/url] .
BitLord.com
Download: [url=http://querk.fr/search.php?do=getnew&contenttype=vBForum_Post&s=3c0c984ec8a65a67b503f0f90cee92d8]New Posts[/url] .
Dance Moms S06E32 Two Teams Two Studios Part One HDTV x264-[NY2] - [SRIGGA]
Download: [url=http://portesdefoyer.fr/film/7852-hitchcocks-shower-scene]HD 720 78/52: Hitchcock's Shower Scene[/url] .
PornstarPlatinum 16 11 13 Ariella Ferrera And Nadia Night Fucking Our Maid XX...
Download: [url=http://mespassions.fr/serie/Durham-County-Im-Rausch-der-Gewalt]Durham County - Im Rausch der Gewalt[/url] .
Workaholics
Download: [url=http://jscateringservices.biz/actors/Lynne+Adams.html]Lynne Adams[/url] .
Wild Oats (2016)
Download: [url=http://monjourdechance.fr/category/romance]Romance(5711)[/url] .
The BFG 2016 BRRip XViD-ETRG
Download: [url=http://mespassions.fr/serie/Binbougami-ga]Binbougami ga![/url] .
Quatro Amigas e um Jeans Viajante 2 Dublado Online Depois que as quatro amigas terminaram o colegio, cada uma toma um rumo diferente na vida, e ja nao estao mais sempre juntas como costumavam estar. Apesar das mudancas em suas vidas, elas vao precisar uma da outra para superar alguns problemas pessoais. Lena (Alexis Bledel) sofre com os desencontros amorosos, Tibby (Amber Tamblyn) tem medo de se entregar as ...
Download: [url=http://manningpeds.com/book/1020266576/download-lart-de-magn-tiser-ou-de-se-gu-rir-mutuellement.pdf]L'Art de MagnГ©tiser ou de se GuГ©rir Mutuellement[/url] .
Look Magazine - November 21, 2016 - True PDF - 1795 [ECLiPSE]
Download: [url=http://defreat.info/descargar/peliculas-latino/ts-screener/vengadores-infinity-war-/ts-screener/]Vengadores Infinity War TS-Screener[/url] .
Masters of Sex S04E10 WEBRip XviD-FUM[ettv]
Download: [url=http://reduceu.info/index.php?do=feedback]Contact Us[/url] .
City, Country, Building
Download: [url=http://wepatogh.com/series/pose-saison-1-episode-5-129556.html]Pose - S1E5[/url] .
Responder
Download: [url=http://trendfrisuren2018.info/category/tvdoc]Dokumentation[/url] .
Alejandro Dolina 14-mar-06 Al 18-mar-06
Download: [url=http://bamrak.info/santa-cie-french-webrip-2018.html]Santa Cie FRENCH WEBRIP 2018[/url] .
Ajout le
Download: [url=http://cicektekalite.com/movie/QG3qQWvo-are-you-human-too.html]Are You Human ...[/url] .
?????? (???????)
Download: [url=http://mespassions.fr/serie/V-Die-Besucher]V - Die Besucher[/url] .
Total Commander 9 0 RC5 Multilingual x64-dexiCast
Download: [url=http://maxjohnson.info/films/hachet-4-victor-crowley-2017/]hachet 4 – Victor Crowley (2017)[/url] .
Torrents non Seedés
Download: [url=http://everproject.fr/9-by-design]9 By Design[/url] .
Black Lagoon TV-2
Download: [url=http://footlockersstore.com/films/acteur/jason-bateman.html]Jason Bateman[/url] .
Crossover Thrash/Speed Metal
Download: [url=http://xqf0n.info/film/a-chinese-odyssey-i-pandoras-box-uxp]Eps1 A Chinese Odyssey I: Pandoras Box[/url] .
The Voice (US)
Download: [url=http://bgaddress.com/konu-ev-kira-semt-bizim-2018-yerli-webrip-mkv-mnike.html]Ev Kira Semt Bizim | 2018 | Yerli | WEBRip | MKV | Mnike[/url] .
Brazzers Fans Choice 200th XXX DVDRip
Download: [url=http://dtvuy.info/book/562881022/download-le-capital.pdf]Le Capital[/url] .
The Flash 2014 S03E06 720p HDTV X264-DIMENSION[rarbg]
Download: [url=http://flyseasons.com/movie/eGLO32xV-hollywood-love-story-season-1.html]Hollywood Love Story: ...[/url] .
Facebook
Download: [url=http://uiuxdesigns.com/2011-movies/mausam-2011-movie-free-download-720p-bluray/]Mausam 2011 Movie Free Download 720p BluRay[/url] .
Age Zero When I Die
Download: [url=http://osmozzy.com.br/watch/anohana-dub-47296]HD Anohana (dub) (2018)[/url] .
Rocket League - 2016 (MacAPPS)
Download: [url=http://xbahap.info/preview?t=Diagramme+d%27activit%C3%A9+-+mbf+i3s&u=http%3A%2F%2Fmbf-iut.i3s.unice.fr%2Flib%2Fexe%2Ffetch.php%3Fmedia%3D2014_2015%3As3%3Amethodo%3Aactivity_diagrams-2014.pdf]Download[/url] .
Star Trek Beyond (2016) 720p BluRay x264 [Dual-Audio][English 5 1+ Hindi 5 1]...
Download: [url=http://naturo.fr/news/499]Achtung User![/url] .
The.Secret.Life.of.Pets.2016.1080p.BluRay.x264.Hindi.Eng.AC3-ETRG
Download: [url=http://cribleum.info/actors/Dan+Jeannotte.html]Dan Jeannotte[/url] .
Dead Man On Campus 1998 1080p WEB-DL DD5 1 H264-LCDS[PRiME]
Download: [url=http://kapkataalkin.info/H-Du-Rusquec-Dictionnaire-fran-ais-breton_3661086.html]H. Du Rusquec - Dictionnaire français-breton[/url] .
Империя Сезон 3 Епизод 6 / Empire БГ СУБТИТРИ
Download: [url=http://ag-8989.com/torrent/judge-judy-s22e134-mother-of-nine-payback-cats-on-the-prowl-cry-me-a-river-hdtv-x264-w4f-ettv--75522]Judge.Judy.S22E134.Mother.of.Nine.Payback.Cats.on.the.Prowl.Cry.Me.a.R...[/url] .
Сезон 1 БГ СУБТИТРИ
Download: [url=http://buildinginsulationmaterials.com/download/CKRQcRmUSI8/keçiören-de-halk-akp-nin-seçim-aracı-geçerken-tepki-gösterdi-bunlara-aldanmayın.html]Download[/url] .
Nonton Film Bioskop 21 Online
Download: [url=http://spongydesigns.com/invasao-de-privacidade-1993/]InvasГЈo de Privacidade Assistir InvasГЈo de Privacidade 720p Dublado/Legendado Online Uma sГ©rie de misteriosas mortes atinge um edifГcio de luxo em Manhattan enquanto uma nova moradora (Sharon Stone) se envolve com um dos vizinhos (William Baldwin), mas tambГ©m Г© desejada por um outro (Tom Berenger) e gradativamente vai chegando a conclusГЈo que um deles Г© o assassino. Ver filme InvasГЈo de Privacidade Dublado/Legendado Ver Filme Sliver ...[/url] .
Savage Betrayal
Download: [url=http://limousine.com.br/info/410534-ready-player-one-hra-zacina]Ready Player One: Hra zaДЌГnГЎ[/url] .
A Historia Real de um Assassino Falso IMDB
Download: [url=http://robesoie.fr/book/568068166/download-psicologia-della-vita-amorosa-sigmund-freud.pdf]Psicologia della vita amorosa[/url] .
vr??(13)
Download: [url=http://mespassions.fr/serie/Shoukoku-no-Altair]Shoukoku no Altair[/url] .
Animation
Download: [url=http://hemen-oyna.com/goto.htm?filename=wir_engel_und_bestien.zip]Download from MediaFire[/url] .
Missa X - Fuck mp4
Download: [url=http://naturo.fr/serie/Chappelle-s-Show]Chappelle's Show[/url] .
Страсти в Тоскана
Download: [url=http://clearaccessmedia.com/book/1333513377/download-confeitaria-escalafob-tica.pdf]Confeitaria escalafobГ©tica[/url] .
Kenny Mirthin Cover Cups When I M Gone From Pitch Perfect By Anna Kendrick
Download: [url=http://naturo.fr/serie/Spartacus-2010]Spartacus (2010)[/url] .
APES REVOLUTION Il Pianeta Delle Scimmie 2014 iTALiAN AC3 BRRip XviD T4P3
Download: [url=http://torrentwiz6.com/films/zombillenium]ZombillГ©nium[/url] .
Светлината на моя живот
Download: [url=http://bluecrossrehabcenters.com/sremmlife-2-deluxe-rae-sremmurd.html]Sremmlife 2 (deluxe) - Rae Sremmurd[/url] .
Spectrasonics - Omnisphere 2 v2.3.1 UPDATE macOS [dada]
Download: [url=http://clearaccessmedia.com/book/479738322/download-working-with-emotional-intelligence.pdf]Working With Emotional Intelligence[/url] .
Mark Boone Junior
Download: [url=http://naturo.fr/serie/serie/How-I-Met-Your-Mother/1/13-Traum-und-Wirklichkeit/TheVideo]TheVideo[/url] .
Scholastic Success With Grammar Workbook Grade 6
Download: [url=http://xjgjcw.info/actors/Kelly+Cottle.html]Kelly Cottle[/url] .
May 2016 (7085)
Download: [url=http://naturo.fr/vorgeschlagene-serien/vote:12114]Karlsson vom Dach (Zeichentrick)[/url] .
Alan Parsons - Eye 2 Eye Live In Madrid COOt
Download: [url=http://dominiquegiroud.com/chef-academy]Chef Academy[/url] .
[ UsaBit.com ] - Meeting.Evil.2012.HDRip.XVID.AC3.HQ.Hive-CM8
Download: [url=http://mespassions.fr/serie/Argento-Soma]Argento Soma[/url] .
Big Rich Texas
Download: [url=http://korea50.biz/B01A68OHMW/michelin-green-guide-languedoc-roussillon-tarn-gorges-2008-01-01.html]Michelin Green Guide Languedoc Roussillon Tarn Gorges 2008 01 01[/url] .
Marc Menchaca
Download: [url=http://monjourdechance.fr/novel/this-book-is-full-of-spiders-265]This Book Is Full of Spiders[/url] .
Secret Path (2016)
Download: [url=http://tocara.biz/detail/PakWqbOia2](еђЊдєєCG集) [もっちもち屋] жЃЇеђгЃ®еЅјеҐігЃЊпјЃжЁж—ҐгЃ®е°Џз”џж„Џж°—な援交相手!?[/url] .
Garfield's Pet Force
Download: [url=http://sqribe.fr/family-guy-season-14-complete-720p-web-dl-x264-aac-t12664145.html]Family Guy Season 14 Complete 720p WEB-DL x264 AAC[/url] .
Chat IRC SSL
Download: [url=http://dominoemas.com/2015/02/]February 2015[/url] .
Nikita Bellucci
Download: [url=http://xk2e4.info/movie/spirit-riding-free-season-5]Spirit Riding Free - Season 5[/url] .
Snowden 2016 720p WEBRip x264 AAC-ETRG
Download: [url=http://khimarsrockcoco.com/rob-roy/]Regarder Le Film[/url] .
Avemaria 2
Download: [url=http://amaraponjon.com/vorgeschlagene-serien/vote:9526]Die Verbrechen des Professor Capellari[/url] .
How Can It Be By Lauren Daigle
Download: [url=http://escuelasamigables.info/chapter-5faab14e6f716dcf8a983ea6b0307cb4339565.html]Chapter 5[/url] .
Westworld S01E07 720p HDTV x264-Belex - Dual Audio
Download: [url=http://grueffelo.info/book/683211283/download-photoshop-cc-edimatica-edimatica.pdf]Photoshop CC[/url] .
The Blacken - Life Love Death (2016)
Download: [url=http://jscateringservices.biz/actors/J.+Carrol+Naish.html]J. Carrol Naish[/url] .
Iron Fire - Tornado of Sickness (2016)
Download: [url=http://rlhib.info/videos/all?genre=7]#dramat historyczny[/url] .
EX Graphic
Download: [url=http://504.fr/file/1115960173/download-meathead.pdf]Meathead[/url] .
Nashville
Download: [url=http://amaraponjon.com/serie/Toshokan-Sensou]Toshokan Sensou[/url] .
Internet Download Manager (IDM) v 6 26 Build 10 + Patch [4realtorrentz] zip
Download: [url=http://clearaccessmedia.com/book/880101088/download-la-intocable.pdf]La intocable[/url] .
Boston Legal
Download: [url=http://qshu88.com/tem-alienigenas-no-meu-quarto-2018-torrent-web-dl-720p-e-1080p-dublado-e-dual-audio-download/]11 de maio de 2018[/url] .
Jane's Addiction - Ritual De Lo Habitual [24 bit F...
Download: [url=http://buildinginsulationmaterials.com/mp3/heeriye-from-race-3-meet-bros-deep-money-neha-bhasin.html]Download[/url] .
GPS Navigation Maps Sygic v16 4 4 Full [SadeemAPK]
Download: [url=http://cribleum.info/actors/Adam+Woronowicz.html]Adam Woronowicz[/url] .
Windows 10 Permanent Activator Ultimate v1 8 [Androgalaxy]
Download: [url=http://t7g1v.info/watch/kxzgzrGY-higher-power.html]Higher Power[/url] .
Life After Beth (2014) 720p BluRay [G2G]
Download: [url=http://chantekayla.com/misterio/]MistГ©rio[/url] .
Adobe After Effects CC 2014 for MAC-OSx
Download: [url=http://chauffeurs-service.fr/descarga-0-5812138-0-0-fx-1-1-.fx]Ts screener[/url] .
METAL GEAR SOLID V THE PHANTOM PAIN RePack - SEYTER
Download: [url=http://bestadsnetwork.com/download-lagu-senandung-senandika-maliq-d-essentials-mp3/]SENANDUNG SENANDIKA - MALIQ & D ESSENTIALS[/url] .
Gamecube
Download: [url=http://jscateringservices.biz/actors/Husam+Chadat.html]Husam Chadat[/url] .
[mesubuta] 318
Download: [url=http://allpromoldwater.com/download/i-hate-fireworks-i-m-sorry/v/XN3pPU9Ko2c]I Hate Fireworks. I'm Sorry.[/url] .
Lethal Weapon
Download: [url=http://cribleum.info/actors/Teryl+Rothery.html]Teryl Rothery[/url] .
The 33 2015 HD ????? ????? 6.9
Download: [url=http://dominoemas.com/homework-1982-movie-watch-online/]Homework (1982)[/url] .
The BFG 2016 720p BRRip x264 AAC-ETRG
Download: [url=http://anb62.fr/anime-dragon-ball-super/]Anime Dragon Ball Super Assistir Dragon Ball Super 720p Dublado/Legendado Online Reunindo personagens icГґnicos da franquia, Dragon Ball Super seguirГЎ o rescaldo da batalha feroz de Goku com Majin Buu, enquanto ele tenta manter a frГЎgil paz da terra. Supervisionada pelo criador original de Dragon Ball, Akira Toriyama e produzido com Fuji Television, Dragon Ball Super vai retornar em seu passado histГіrico para criar um ...[/url] .
Buffalo Springfield - Last Time Around (1968) 438 hz
Download: [url=http://occasions-voiture.fr/f/232820364/the_labyrinth_1_1.html]The Labyrinth 1 1[/url] .
Browse Amazon Prime
Download: [url=http://gitgot.info/how-to-view-pdf-on-android/]View PDF on Android[/url] .
Bade Akhilesh Pataka Tham Mulayam Singh Ka Hai Paigam
Download: [url=http://hecmreversemort.info/films/realisateur/jean-paul-rappeneau.html]film de Jean-Paul Rappeneau[/url] .
High strung 2016 limited 720p bluray x264-NBY-[moviezplanet in] mkv
Download: [url=http://692061.com/descargar/peliculas-castellano/peliculas-rip/las-ultimas-horas-/blurayrip/]Las Ultimas Horas BLuRayRip[/url] .
Fantasia
Download: [url=http://rc6bh.info/pierre-lapin-french-ts-2018.html]Pierre Lapin FRENCH TS 2018[/url] .
Mental Coma - Fragments Of Democracy (2016)
Download: [url=http://mm33.biz/series/series-vf/155739-the-detour-saison-3.html]The Detour - Saison 3 Ajout de l'Г©pisode 06[/url] .
Art Of Living Guruji By Song In Srinivas
Download: [url=http://kapkataalkin.info/The-Economist-Asia-Edition-June-09-2018_3661205.html]The Economist Asia Edition - June 09, 2018[/url] .
Football Manager 2017 PC
Download: [url=http://defreat.info/pelicula/somos-legion-la-historia-de-los-hacktivistas/]Somos Legion - La Historia de .. DVDRIP[/url] .
Сезон 4 БГ СУБТИТРИ
Download: [url=http://vm5qx.info/29608/oasis-definitely-maybe-1994]http://vm5qx.info/29608/oasis-definitely-maybe-1994[/url] .
Bandicam 3 2 3 1114 - Repack KpoJIuK [4REALTORRENTZ] zip
Download: [url=http://rlhib.info/videos/all?genre=9]#erotyczny[/url] .
greys anatomy
Download: [url=http://xqf0n.info/film/84-charing-cross-road]Eps1 84 Charing Cross Road[/url] .
Arrow 2012 5x07 HDTV 720p x265 2Ch HAAC2-Sunil-KITE-METeam
Download: [url=http://692061.com/pelicula/star-wars-vii-3d-hou/]Star Wars VII 3D HOU BluRay 3D 1080p[/url] .
Hot Anal Yoga (Evil Angel) 2016 Split Scenes
Download: [url=http://mespassions.fr/serie/Rebellion]Rebellion[/url] .
MacGyver
Download: [url=http://multi-taux.com/cloverfield-paradox/]Cloverfield paradox hindi 480p[/url] .
Lesson Of Passion - Living With Serena: Forbidden Fruit v2.09 Hacked Version 2 D.G.O.
Download: [url=http://mespassions.fr/serie/Storage-Wars-Geschaefte-in-New-York]Storage Wars – Geschäfte in New York[/url] .
A Million WAys to Die in the West 720p trAiler.mp4
Download: [url=http://rampageforandroid.info/9-4-proportional-parts-and-triangles-lesson]9.4 proportional parts and triangles lesson[/url] .
Benny Benassi Feat Pitbull Put It On Me
Download: [url=http://myskinserum.biz/others/int/7433559-defence-matters-america-afghanistan-issue-v-4th-july-2018.html]Defence Matters (America Afghanistan Issue) В– 4th July 2018[/url] .
Biography Channel
Download: [url=http://gitgot.info/02272905-bbc-sky-at-night-july-2018/]BBC Sky at Night – July 2018[/url] .
Plz upload this
Download: [url=http://possiblefs.info/v/8471/beirut-а№ЂаёљаёЈаёёаё•аё™аёЈаёЃа№Ѓаё•аёЃ]Beirut а№ЂаёљаёЈаёёаё•аё™аёЈаёЃа№Ѓаё•аёЃ[/url] .
Supernatural Season 12 Dublado Torrent
Download: [url=http://dtvuy.info/book/747775443/download-2010-une-ann-e-en-photographies-chatelaillon-plage.pdf]2010, une annГ©e en photographies Г Chatelaillon-Plage[/url] .
Image-Line-FL Studio Producer Edition 12 4 Final
Download: [url=http://naturo.fr/serie/Pushing-Daisies]Pushing Daisies[/url] .
Contagion 2011 HD ????? ????? 6.6
Download: [url=http://traxbangbeats.com/descargar/peliculas-castellano/peliculas-rip/spring-breakers-/blurayrip-ac3-5-1/]Spring Breakers BluRayRip AC3 5.1[/url] .
MGP17-Pre-Season-MotoGP Test Day 2 - A9
Download: [url=http://mespassions.fr/serie/Mobile-Suit-Gundam-Iron-Blooded-Orphans]Mobile Suit Gundam: Iron-Blooded Orphans[/url] .
harry potter
Download: [url=http://qipuwv.info/torrent/184085/franks-tgirlworld-com-first-first-bares-it-all-28-mar-2017-2017-g-shemale-solo-720p-siterip][Franks-TGirlWorld.com] First / First Bares It All! (28 Mar 2017) [2017 Рі., Shemale, Solo, 720p, SiteRip][/url] .
loadiine wiiu
Download: [url=http://amaraponjon.com/serie/Heavy-Object]Heavy Object[/url] .
Free State of Jones 2016 FRENCH WEBRip XViD-FUNKKY(A)
Download: [url=http://grosbet400.com/izle/elementary-4-sezon-10-bolum]4. sezon 10. Bölüm[/url] .
Squidbillies
Download: [url=http://locationbureaunantes.fr/films/acteur/bella-heathcote.html]Bella Heathcote[/url] .
Dublado
Download: [url=http://692061.com/pelicula/killer-joe/dvdrip/]Killer Joe DVDRIP[/url] .
Lethal Weapon S01E07 720p HDTV X264-DIMENSION[ettv]
Download: [url=http://supremeoff.com/watch-the-mick-online/]The Mick[/url] .
sheena_ryder_shane_diesel_shanedieselsblackbullforhire04 mp4
Download: [url=http://pumpddmyass.info/watch/EdB5ggGj-teen-titans-go-season-4.html]Teen Titans Go!: ...[/url] .
Raw-d.net__Asahina_Makoto-Shoujo_Kansatsu_Nikki.zip
Download: [url=http://mtptn-a.com/tags/Neocrust/]Neocrust[/url] .
Primal's Taboo Sex - Alexis Fawx (Son Becomes a Man)
Download: [url=http://clearaccessmedia.com/book/1046890364/download-my-os-x-el-capitan-edition.pdf]My OS X (El Capitan Edition)[/url] .
ImagineFX April 2012 HQ PDF
Download: [url=http://footlockersstore.com/films/acteur/jon-lovitz.html]Jon Lovitz[/url] .
Multilingual
Download: [url=http://mespassions.fr/serie/The-Defenders]The Defenders[/url] .
Mad Max Fury Road (2015) DVDRip English'aac.V.Power [WWRG] [Isohunt.to]
Download: [url=http://hecmreversemort.info/films/acteur/arie-elmaleh.html]AriГ© Elmaleh[/url] .
Lynda - Learn Microsoft SQL Server 2016 The Basics
Download: [url=http://securestacbptravel.info/novel/Night-World-No-3-Night-World-7-9-7788]Night World, No. 3 (Night World #7-9)[/url] .
Petes Dragon 2016 1080p BRRip x264 AAC-ETRG
Download: [url=http://freshfeelskin.com/A_Mate_for_the_Savage/ ]freshfeelskin.com[/url] .
Blacked - Sexy Mom Takes 2 young BBCs - Brandi Love mp4
Download: [url=http://xjgjcw.info/actors/Tim+Neff.html]Tim Neff[/url] .
The.Good.the.Bad.and.the.Ugly.1966.1080p.BluRay.AC3.x264-nelly45.mkv
Download: [url=http://rmuation.info/category/films-exclues/?filtre=date&display=extract]tube avec extrait[/url] .
Franky - Saison 1, Episode 1 La naissance de Frank...(N) (P)
Download: [url=http://qipuwv.info/torrent/184918/oh-what-a-night-nu-i-nochka-john-leslie-1991-g-adult-vhsrip]Oh What a Night / Ну и ночка! (John Leslie) [1991 г., Adult, VHSRip][/url] .
201 - 250
Download: [url=http://supp0rt1ng.com/author/filmesparadownload/]FilmesparaDownload[/url] .
OPAL FREQUENCIES - Blue Priformation No.2 - (2016) [Isohunt.to]
Download: [url=http://xk2e4.info/movie/thousand-yard-stare]Thousand Yard Stare[/url] .
Hope Howell - Babysitters Taking On Black Cock 4 rq mp4
Download: [url=http://freshfeelskin.com/Vampiresch/Stupid_Girl/Pages.html]Stupid Girl[/url] .
Pictures
Download: [url=http://everproject.fr/the-daily-dish/jurassic-world-fallen-kingdom-bravo-stars-react-video]Here's the One Thing That Bonds All Bravolebs by Kelly Kollias 2 weeks ago[/url] .
Speed 1994 HD ????? ????? 7.2
Download: [url=http://domino22.com/film/fU2/The-Rachel-Divide?episod=1]IMDb: 6.3 HD The Rachel Divide[/url] .
Girlfriends
Download: [url=http://panthereducation.com/Books/policy]Privacy Policy[/url] .
Arrow S02E18 HDTV x264-LOL
Download: [url=http://amaraponjon.com/serie/Abenteuer-auf-der-Luna]Abenteuer auf der Luna[/url] .
Remington Steele
Download: [url=http://anb62.fr/workin-moms/]Workin’ Moms Assistir Workin' Moms 720p Dublado/Legendado Online Quatro mГЈes e amigos que trabalham com trinta e poucos anos tentam equilibrar seus empregos, vida familiar e vida amorosa nos dias atuais em Toronto, CanadГЎ. Ver SГ©rie Workin' Moms Dublado/Legendado Ver SГ©rie Workin' Moms Dublado/Legendado (2017) Assistir SГ©ries Online em HD Assista SГ©ries online HD na sua tv e celular - Trailer no youtube. Sinopse, elenco, direção, imagens e ...[/url] .
[HorribleSubs] Dream Festival! - 03 [720p].mkv
Download: [url=http://frasesparavoce.com.br/category/Business]Business[/url] .
Kingdom Come Deliverance - 2016 (PC) nosTeam
Download: [url=http://rlhib.info/romans-teresy-hennert-1978/166508]Romans Teresy Hennert (1978)[/url] .
Pete's Dragon (2016) [1080p] [YTS AG]
Download: [url=http://naturo.fr/serie/Underemployed]Underemployed[/url] .
Lethal Weapon S01E07 720p HDTV x265 ShAaNiG mkv
Download: [url=http://clearaccessmedia.com/book/1057690262/download-programa-o-neurolingu-stica.pdf]Programação NeurolinguГstica[/url] .
fra alle os til alle jer cd
Download: [url=http://amaraponjon.com/serie/Buck-Rogers]Buck Rogers[/url] .
die hard
Download: [url=http://roundtabletechnology.info/watch-grace-and-frankie-online/]Grace and Frankie[/url] .
Popular This week
Download: [url=http://itsanorangeworld.info/others/int/7177652-blues-delbert-mcclinton-live-from-austin-1989.html][Blues] Delbert McClinton - Live From Austin (1989)[/url] .
Bloodlust Tournament of Death 2016 DOCU WEBRiP x264-RAiNDEER[1337x][SN]
Download: [url=http://jscateringservices.biz/actors/Henry+Fong.html]Henry Fong[/url] .
??(39)
Download: [url=http://tortinnemo20.com/torrent/jeu-vidГ©o/windows/274667-red+faction+guerrilla+remarstered-codex]Red Faction Guerrilla Remarstered-Codex[/url] .
APOKA THUG LIFE
Download: [url=http://rxouj.info/memberlist.php?mode=viewprofile&u=1366565&sid=cf30527f0cb2f6e2c895a6b16513acac]Vvooddyy[/url] .
[BigTitsAtWork] Nicole Aniston (Team Player - 16 11 2016) rq (1k) mp4
Download: [url=http://roundtabletechnology.info/watch-making-history-online/]Making History[/url] .
For last day only
Download: [url=http://robesoie.fr/book/370189770/download-jane-eyre-illustrated-charlotte-bront.pdf]Jane Eyre. ILLUSTRATED[/url] .
BitLord.com
Download: [url=http://dealsealer.biz/rubrique/154/geographie-et-urbanisme]GГ©ographie et urbanisme[/url] .
Miss Peregrine’s Home for Peculiar Children (2016)
Download: [url=http://hotelcroatie.com/tags/Progressive+Death+Metal/]Progressive Death Metal[/url] .
Brooklyn Nine-Nine S04E06 HDTV XviD-AFG
Download: [url=http://manningpeds.com/book/536495706/download-perles-de-rocaille.pdf]Perles de rocaille[/url] .
Might.and.Magic.X.Legacy.The.Falcon.and.The.Unicorn.Addon-RELOADED
Download: [url=http://runwaychanger.com/2016/11/]November 2016[/url] .
Movie News: How 'Deadpool' and 'Guardians of the Galaxy 2' Traded Characters; 'Don't Breathe' Director Teases Sequel
Download: [url=http://grueffelo.info/book/528600698/download-il-grande-libro-del-low-cost-abbattere-costi-e-spese-alissa-zavanella-carla-campisano-prisca-destro.pdf]Il Grande Libro Del Low Cost. Abbattere Costi E Spese[/url] .
Безмълвен
Download: [url=http://deeptowernews.info/category/drama]Filmes DRAMA[/url] .
Jason Priestley,
Download: [url=http://cribleum.info/actors/Kevin+Dunn.html]Kevin Dunn[/url] .
Baixar Cafe Society Torrent Dublado
Download: [url=http://dtvuy.info/book/675597366/download-la-dynamique-mentale.pdf]La Dynamique Mentale[/url] .
The Purge 3: Election Year in voller lange anschauen
Download: [url=http://agauc.info/torrent/fifty-shades-darker-2017-readnfo-hc-hdrip-x264-pleasestop_42336.html]Fifty Shades Darker 2017 READNFO HC HDRip x264-PleaseStop[/url] .
Impastor.S02E08.iNTERNAL.720p.HDTV.x264-ALTEREGO[PRiME]
Download: [url=http://naturo.fr/vorgeschlagene-serien/vote:12911]Morel Orel[/url] .
seduce her with text pdf
Download: [url=http://manningpeds.com/book/976742745/download-le-secret-du-mari.pdf]Le secret du mari[/url] .
Tracker list
Download: [url=http://webhostfeed.com/engine/go.php?movie=Kabul: Servir y proteger - 1x299]Descargar[/url] .
Albert King - The Big Blues
Download: [url=http://casinoslot8.com/torrent/jrceszsv/Never+See+Them+Again+-+M.+William+Phelps+-+2017+(True+Crime)+[Audiobook]+(miok)+[WWRG].html]Never See Them Again - M. William Phelps - 2017 (True Crime) [Audiobook] (miok) [WWRG][/url] .
Sting - 57th 9th [Deluxe Edition] (2016) FLAC
Download: [url=http://salondufoot.fr/search/0/4/0/0/Два с половиной человека / Two and a Half Men]Два с половиной человека / Two and a Half Men[/url] .
Comanche Station (Western 1960) R Scott 720p BrRip [WWRG]
Download: [url=http://traxbangbeats.com/descargar/cine-alta-definicion-hd/1080p/leatherface-/bluray-microhd/]Leatherface BluRay MicroHD[/url] .
Jason Bourne 2016 1080p BRRip x264 AAC-ETRG
Download: [url=http://53gmgm.com/topic/1725636-the-dark-inside-me-chapter-1-codex.html]The Dark Inside Me - Chapter 1 (Akçay Karaazmak) (ENG) [L] - CODEX Подробнее... Залито: 06-06-2018 14:36 (2333 просмотра) The Dark Inside Me - Chapter 1 (Akçay Karaazmak) (ENG) [L] - CODEX РРіСЂС‹ для РџРљ РўС‹ проснулся РІ больничной палате, прикованный наручниками Рє кровати. Р’С‹ слышали, как Рѕ вас говорили детективы. РћРЅРё РіРѕРІРѕСЂСЏС‚ Рѕ том, что ты РІСЃРµ еще можешь быть живым после этого ужасающего события. Р РѕРґРёРЅ РёР· РЅРёС… РіРѕРІРѕСЂРёС‚, что было Р±С‹ лучше, если Р±С‹ РѕРЅРё поймали тебя мертвым. Р’С‹ ничего РЅРµ понимаете Рё РЅРµ помните... Раздают: 33 Качают: 1 Размер: 1.86GB [/url] .
JANE THE VIRGIN
Download: [url=http://mespassions.fr/serie/The-Five]The Five[/url] .
Read More
Download: [url=http://hjspect.info/series/the-ranch-saison-3-984.html]The Ranch Saison 310 Г©pisodes[/url] .
La Chienne (1931) Francais - Xvid - Eng Subs- Janie Marese, Michel Simon [DDR]
Download: [url=http://yokamon.info/chinese-drama/1918-tiger-mom-cantonese/]Tiger Mom (Cantonese) - и™ЋеЄЅиІ“з€ёTiger Mom (Cantonese)[/url] .
Driver Genius Professional 16 0 0 245 Multilanguage zip
Download: [url=http://t7g1v.info/watch/zGWNZgxP-ushio-to-tora-tv-dub.html]Ushio To Tora ...[/url] .
BitLord.com
Download: [url=http://854745os.net/regarder-mangas.php]MANGAS en direct[/url] .
Blurryface By Twenty One Pilots
Download: [url=http://100ten.biz/tag/greys-anatomy-season-10/]Grey's Anatomy Season-10[/url] .
Bradley P. Beaulieu, Rob Ziegler - The Burning Light - eBook [Isohunt.to]
Download: [url=http://rxouj.info/memberlist.php?mode=viewprofile&u=1338014&sid=cf30527f0cb2f6e2c895a6b16513acac]theonlyjon[/url] .
??/??
Download: [url=http://fvgiment.info/film/guerrilla-season-1]Eps6 Guerrilla - Season 1[/url] .
Captain America the Winter Soldier 2014 DVDRip XViD-PLAYNOW
Download: [url=http://snj4v.info/list/releases?availableFilter=0&artistFilter=&labelFilter=43762&genreFilter=&timeFilter=0&bpmFilter=&keyFilter=&trackTypeFilter=]TheSoundYouNeed[/url] .
American Housewife
Download: [url=http://agauc.info/torrent/higher-power-2018-brrip-xvid-ac3-xvid_61332.html]Higher Power 2018 BRRip XviD AC3-XVID[/url] .
Brigitte Kaandorp - 1995 - Chez Marcanti [Isohunt.to]
Download: [url=http://amaraponjon.com/serie/Hinamatsuri]Hinamatsuri[/url] .
The Legend of Zelda - Spirit Tracks Patchee.nds
Download: [url=http://t7g1v.info/watch/qd7pBovK-death-cheaters.html]Death Cheaters[/url] .
Сезон 9 БГ СУБТИТРИ
Download: [url=http://imprimerieparis.fr/69288/rory-block-a-womans-soul-a-tribute-to-bessie-smith-2018]Comments: 0[/url] .
Andrew Stanton
Download: [url=http://dealsealer.biz/rubrique/102/rubriques]Toutes les Rubriques[/url] .
The Undiscovered Peter Cook
Download: [url=http://osmozzy.com.br/watch/trog-46985]HD Trog (1970)[/url] .
Alaipayuthey Title Song
Download: [url=http://spareofficial.com/regarder-cartoonnetwork.php]cartoon en direct[/url] .
Mia Malkova mp4
Download: [url=http://grueffelo.info/book/673005531/download-diabolik-177-angela-giussani-luciana-giussani.pdf]DIABOLIK (177)[/url] .
Music Home
Download: [url=http://naturo.fr/vorgeschlagene-serien/vote:12023]Mind Field[/url] .
Space Jam O Jogo de Seculo Dublado Torrent – BluRay 720p Download (1996)
Download: [url=http://mespassions.fr/serie/serie/Game-of-Thrones/1/3-Lord-Schnee]Lord Schnee Lord Snow[/url] .
Days Of Our Lives - S52 E43 - Wednesday, November 16, 2016
Download: [url=http://tocara.biz/search/index/word:ムチムチお姉さん]ムチムチお姉さん[/url] .
Bewitched Housewives
Download: [url=http://xxxsohbet.info/diziler/bad-blood/]• Bad Blood 9[/url] .
Alesha Dixon - Breathe Slow Mp3 Zip
Download: [url=http://xjgjcw.info/movies-adam-patel-real-magic-2018-123movies-vip.html]Watch movie[/url] .
Lombardo Boyar,
Download: [url=http://katzenkorb.info/movie/the-triplets-of-belleville-2003-1080p.html]HD The Triplets of Belleville (2003)[/url] .
Asi Como Hoy Grupo Los Divos
Download: [url=http://53gmgm.com/topic/1688464-final-fantasy-xv-windows-edition.html]Final Fantasy XV: Windows Edition (Square Enix) [Текстуры РІ высоком разрешении] Подробнее... Залито: 17-03-2018 10:44 (1092 просмотра) Final Fantasy XV: Windows Edition (Square Enix) [Текстуры РІ высоком разрешении] РРіСЂС‹ для РџРљ (общее) Рто дополнение включает РІ себя текстуры РІ высоком разрешении. После установки включите РёС… РІ графических настройках РёРіСЂС‹. ... Раздают: 0 Качают: 0 Размер: 10.49GB [/url] .
KarupsHA 16 11 17 Raven Orion Hardcore XXX 720p MP4 KTR[rarbg]
Download: [url=http://snj4v.info/account/]How it works?[/url] .
Chris Miller
Download: [url=http://mespassions.fr/vorgeschlagene-serien/vote:9629]Harry und die Hendersons[/url] .
Jackpot-2013-Hindi-720p-DvDRip-x264-AC3-5.1....Hon3y
Download: [url=http://escuelasamigables.info/163324-pdf-download-the-man-god-has-for-you-get-free.html](16;33;24) - PDF Download The Man God Has For You Get Free[/url] .
Tomorrow
Download: [url=http://leonardpadilla.com/films/acteur/robert-downey-jr.html]Robert Downey Jr.[/url] .
Son of Zorn
Download: [url=http://mtptn-a.com/tags/Dreampop/]Dreampop[/url] .
Naruto Shippuden Completo MP4 Torrent
Download: [url=http://updoot.com/bleeding-steel-2018-english-movie-720p-bluray-1gb-350mb-download/]Bleeding Steel (2018) English Movie 720p BluRay 1GB 350MB Download[/url] .
No Ordinary Family
Download: [url=http://naturo.fr/serie/serie/Die-Simpsons/1/10-Homer-der-Frauenheld/OpenLoad]OpenLoad[/url] .
Robbie Coltrane's Critical Evidence - 03 - Murder By Mail - FC
Download: [url=http://tocara.biz/search/index/word:г‚µг‚ュバス]г‚µг‚ュバス[/url] .
How to Get Away with Murder S03E09 HDTV x264-LOL mp4
Download: [url=http://trylumivol.com/emule-telecharger-187-code-meurtre-films-dvd-r-20437.html]Voir la fiche[/url] .
Ebooktutorials.org
Download: [url=http://bentbasket.com/watch/yd6a8ZG7-secret-mother.html]Secret Mother[/url] .
November 2014 (1939)
Download: [url=http://504.fr/file/495989773/download-learn-street-math.pdf]Learn Street Math[/url] .
Brazzers
Download: [url=http://www.09611r.net/country/allemand/]allemand[/url] .
BitLord.com
Download: [url=http://dealsealer.biz/rubrique/79/livre/1465/annales-de-psychiatrie-et-d-hypnologie-dans-leurs]Annales de Psychiatrie Et D'Hypnologie Dans Leurs Rapports Avec La Psychologie Et La Medecine Legale, 1891 (Classic Reprint)[/url] .
Alena Godunova - Zazhgi Svechu
Download: [url=http://longoinvestmentproperties.com/topic/1735464-anakop-dayver.html]Анакоп / Дайвер / Сезон: 1 / Серии: 1-4 из 4 (Евгений Соколов) [2009, исторический фильм, приключения, SATRip] Подробнее... Залито: 01-07-2018 18:42 (204 просмотра) Анакоп / Дайвер / Сезон: 1 / Серии: 1-4 из 4 (Евгений Соколов) [2009, исторический фильм, приключения, SATRip] Российские сериалы Название полнометражной версии - Дайвер.В основу фильма легла легенда о генуэзских купцах, которые осваивали черноморское побережье нынешней Абхазии. Они снарядили и отправили корабль с золотой статуей первоапостола Симона Зилота и драгоценным алтарным убранством, предназначенные для храма,... Раздают: 2 Качают: 1 Размер: 2.08GB [/url] .
Great Barcode Generator
Download: [url=http://diegorangel.com.br/torrent/ggb0zzhf/[ALS]_Nanatsu_no_Taizai_Imashime_no_Fukkatsu_15_[720p].mkv.html][ALS]_Nanatsu_no_Taizai_Imashime_no_Fukkatsu_15_[720p].mkv[/url] .
Bang-wool-to-ma-to (2008)
Download: [url=http://leonardpadilla.com/films/streaming/96744-l-echange-des-princesses.html]Regarder L'Echange des princesses en Streaming Gratuit[/url] .
Bas Rutten,
Download: [url=http://preciousvalleyfarms.com/mp3/716081821/alternative.html]Alternative[/url] .
Pearl Jam Whip It
Download: [url=http://magik-box.info/the-young-lady-vf-streaming/]The Young Lady[/url] .
Microsoft SQL Server 2012 Certification Training - Exam 70-462
Download: [url=http://cribleum.info/actors/Jason+Gedrick.html]Jason Gedrick[/url] .
Conan 2016 11 15 Matt LeBlanc HDTV x264-CROOKS[ettv]
Download: [url=http://dtvuy.info/book/456557482/download-techniques-et-strat-gies-de-day-trading-et-de-swing-trading.pdf]Techniques et stratГ©gies de Day Trading et de Swing Trading[/url] .
Thriller Movies
Download: [url=http://amaraponjon.com/serie/Pure-Genius]Pure Genius[/url] .
The Mentalist
Download: [url=http://footlockersstore.com/films/telecharger/96737-occupation-2018.html]Occupation (2018) TELECHARGEMENT GRATUIT[/url] .
Aleksandr Zacepin Zolotaya Kollekcia 3CD 2003 APE CUE Lossless
Download: [url=http://windwardcasino.com/watch/qd7pq4vK-stepdaughter-s-revenge.html]Stepdaughter's Revenge[/url] .
[request_ebook] Solution Manual for Electronic Devices and Circuit Theory Ninth Edition
Download: [url=http://robesoie.fr/book/1001650143/download-zero-limits-joe-vitale-ihaleakala-hew-len.pdf]Zero Limits[/url] .
Ryan Reynolds
Download: [url=http://amaraponjon.com/serie/Mahou-Shoujo-Ikusei-Keikaku]Mahou Shoujo Ikusei Keikaku[/url] .
The Tonight Show Starring Jimmy Fallon
Download: [url=http://rmuation.info/descendants-2-filmcompletentierstreamingvf-vost-fr-6/]Descendants 2 filmCompletEntierStreamingVF Vost fr[/url] .
Continuar
Download: [url=http://windwardcasino.com/watch/qvapZOd3-aftermath-season-2.html]Aftermath: Season 2[/url] .
Contact Us
Download: [url=http://dtvuy.info/book/501479848/download-css-avanc-es.pdf]CSS avancГ©es[/url] .
House of Horrors Kidnapped S03E07 HDTV x264-W4F - [SRIGGA]
Download: [url=http://canterburynewzealanddirect.info/how-not-to-summon-a-demon-lord-e01-720p-web-x264-darkflix?share=twitter]Click to share on Twitter (Opens in new window)[/url] .
Legends of Chamberlain Heights S01E08 720p HDTV x264-AVS[PRiME]
Download: [url=http://cribleum.info/actors/Colin+Firth.html]Colin Firth[/url] .
ABBYY FineReader OCR Pro 12.1.1 Multilingual (Mac OSX) 161024
Download: [url=http://yourbusinessgame.info/express-khiladi-thodari-2016-hindi-dubbed/]Watch Movie[/url] .
Download 1080p
Download: [url=http://wettenbet10.com/tags/Learning/]Learning[/url] .
Sedona Legge
Download: [url=http://xxxsohbet.info/diziler/ao-no-exorcist-anime/]• Ao no Exorcist (Anime) 7.7[/url] .
Clevland Indians - Chicago Cubs Game 7 World Series 2016 [WWRG] [Isohunt.to]
Download: [url=http://eeswl.info/books/title/sea-witch-nami/]sea witch nami[/url] .
Todd Lockwood - Evertide, Book 1: The Summer Dragon - Audiobook [Isohunt.to]
Download: [url=http://bentbasket.com/watch/zGWNpPxP-paul-apostle-of-christ.html]Paul, Apostle Of ...[/url] .
Dylan Dog (1986) Ed. Sergio Bonelli Editore (463/463) Conclusa
Download: [url=http://clearaccessmedia.com/book/533766128/download-jazz-piano-ad-lib-phrases.pdf]Jazz Piano Ad-Lib Phrases[/url] .
Jane the Virgin
Download: [url=http://damourfleurs.com/triassic-attack-streaming-vf/]Triassic Attack[/url] .
Avatar 3D SBS[ DTS-AC3 5.1 SPA-DTS ENG]
Download: [url=http://maisagito.com.br/need-for-speed-o-filme-torrent-2014-dublado-bluray-720p-1080p/]Need For Speed: O Filme Torrent (2014) Dublado BluRay 720p | 1080p[/url] .
Poseidon 2006 HD ????? ????? 5.6
Download: [url=http://katzenkorb.info/movie/inglourious-basterds-2009-1080p.html]HD Inglourious Basterds (2009)[/url] .
American
Download: [url=http://fvgiment.info/film/broken-sword-hero]HD 720 Broken Sword Hero[/url] .
Pazzapa Kids ~ Willy ~ Vita Tantara
Download: [url=http://sonsaniyefilm.com/details/887F9492FABAF30ED7737ABF8485D13728377773/R+G+Mechanics+Prison+Break]R G Mechanics Prison Break[/url] .
Family - Bandstand - Flac8
Download: [url=http://kapkataalkin.info/XXX-COMICS-dofantasy-Fansadox-Collection-67-Issues-_83243.html]XXX-COMICS - dofantasy (Fansadox Collection) [67 Issues][/url] .
WWE SmackDown Pre Show 2016 11 15 WEB h264-HEEL [TJET]
Download: [url=http://diegorangel.com.br/torrent/i9tmm5jq/[NudeInFrance]+Melodie+Ligers+-+Naughty+student+gets+her+ass+fucked+and+creamed+by+her+english+teacher+(2017)+406p.html][NudeInFrance] Melodie Ligers - Naughty student gets her ass fucked and creamed by her english teacher (2017) 406p[/url] .
Hells Kitchen
Download: [url=http://htcmaritimeagency.com/browse-movies/Ben+Mendelsohn]Ben Mendelsohn[/url] .
[rar] Lida`s Adventires 0.15.rar
Download: [url=http://agauc.info/torrent/rune-classic-windows-10-plaza_60876.html]Rune Classic Windows 10-PLAZA[/url] .
Gold Windows Xp Sp3 2016 With Drivers v2.0
Download: [url=http://naturo.fr/vorgeschlagene-serien/vote:11116]Team Galaxy[/url] .
The Vampire Diaries S08E03 Webrip 1080p 10bit 5 1 x265 HEVC-Qman[UTR] mkv
Download: [url=http://banhallmand.info/2017/download-lagu-brknrbtz-marry-your-daughter.html]BRKNRBTZ - Marry Your Daughter[/url] .
Birth of the Dragon (2016) – Legendado HD720p Online
Download: [url=http://jscateringservices.biz/actors/Hassan+Mahmood.html]Hassan Mahmood[/url] .
Recordings
Download: [url=http://xxxsohbet.info/diziler/ozark/]• Ozark 8[/url] .
sleepy hollow
Download: [url=http://manningpeds.com/book/910963922/download-le-nouveau-r-gime-ig.pdf]Le Nouveau rГ©gime IG[/url] .
supernatural
Download: [url=http://locationbureaunantes.fr/films/acteur/jaycee-chan.html]Jaycee Chan[/url] .
Bibi Jones (Jack's POV 19).avi
Download: [url=http://robesoie.fr/book/1230607207/download-poteri-forti-o-quasi-ferruccio-de-bortoli.pdf]Poteri forti (o quasi)[/url] .
The Dark Stranger (2016)
Download: [url=http://kbdesignlab.com/torrent/1306219/cyberlink-screen-recorder-deluxe-3-0-0-2930-precrackcracks4win.html]CyberLink Screen Recorder Deluxe 3 0 0 2930 PreCrack[cracks4win][/url] .
Sherlock Holmes The Devils Daughter [2016] PC [COMPLETE EDITION] torrent
Download: [url=http://amaraponjon.com/serie/Der-Sleepover-Club]Der Sleepover Club[/url] .
June Whitfield,
Download: [url=http://xxxsohbet.info/diziler/alex-inc/]• Alex, Inc. 0[/url] .
American Idol
Download: [url=http://securestacbptravel.info/novel/Dracula-in-London-8107]Dracula in London[/url] .
Juggling Suns - Living on Edge of Change
Download: [url=http://grueffelo.info/book/508303960/download-genio-in-21-giorni-giacomo-navone-massimo-de-donno.pdf]Genio in 21 giorni[/url] .
D Deep Deep House
Download: [url=http://coffeetechid.com/yuddha-bhoomi-2018-watch-online-dvdrip/]Yuddha Bhoomi 2018[/url] .
Kids 226
Download: [url=http://bentbasket.com/watch/EvJ8bbGW-tsurezure-children-sub.html]Tsurezure Children (sub)[/url] .
Sonic The Hedgehog Classics Android
Download: [url=http://nuskinsg.com/actor/scott-eastwood]Scott Eastwood[/url] .
Albums - Wet Wet Wet-greatest Hits-full Album
Download: [url=http://grueffelo.info/book/1052991009/download-nessuna-ferita-per-sempre-raffaele-morelli.pdf]Nessuna ferita ГЁ per sempre[/url] .
WWE SmackDown Live 2016 11 15 HDTV x264-NWCHD [TJET]
Download: [url=http://xjgjcw.info/actors/Robert+Englund.html]Robert Englund[/url] .
Get Ready 2013 Steve Aoki Extended Mix
Download: [url=http://bentbasket.com/watch/lx2Y9Kve-genius-season-2.html]Genius: Season 2[/url] .
Jimmy Fallon 2016 11 15 Warren Beatty HDTV x264-CROOKS[rarbg]
Download: [url=http://dominiquegiroud.com/kandi-koated-nights/season-1/episode-1/videos/tiny-harris-would-never-cheat-on-michael-b-jordan]Preview 01:34 Tiny Harris Would Never Cheat on Michael B. Jordan...[/url] .
Ryan Guzman
Download: [url=http://yokamon.info/hk-show/3851-local-gingers-2/]Local Gingers 2 - жњ¬ењ°и–‘ 2Local Gingers 2[/url] .
Designated.Survivor.S01E07.720p.HEVC.x265 MeGusta
Download: [url=http://traxbangbeats.com/series-vo/philip-k-dicks-electric-dreams/3403]Philip K DickS Electric Dreams HDTV 720p AC3 5.1[/url] .
Artine Brown,
Download: [url=http://palsee.info/misc.php?action=markread&fid=18]Oznacz ten dziaЕ‚ jako przeczytany[/url] .
Live At The Apollo S12E02 HDTV x264-GTi - [SRIGGA]
Download: [url=http://tocara.biz/search/index/word:гЃ„гЃ®гЃѕг‚‹]гЃ„гЃ®гЃѕг‚‹[/url] .
Люк Кейдж
Download: [url=http://art-carvedchesssets.com/The_One_Only/Pages.html]The One & Only[/url] .
Best Mix HD Wallpapers Pack 33
Download: [url=http://naturo.fr/serie/Mayday-Alarm-im-Cockpit]Mayday - Alarm im Cockpit[/url] .
The Fall Of The Krays 2016.HDRip.XViD-ETRG
Download: [url=http://hecmreversemort.info/films/acteur/sebastian-stan.html]Sebastian Stan[/url] .
American Dad S13E02 XviD AFG
Download: [url=http://el3y8.info/filmek/romantikus/legujabb-magyar/1]LegГєjabb magyar nyelvЕ±[/url] .
Photoshop CC 2017 for Photographers New Features
Download: [url=http://dealsealer.biz/rubrique/533/milieux-naturels]Milieux naturels[/url] .
[MyFriendsHotGirl] Jessa Rhodes (21959 - 17.11.2016) rq (360p).mp4
Download: [url=http://rlhib.info/dzieci-solidarnosci-2006/175103]Dzieci SolidarnoЕ›ci (2006)[/url] .
Star Trek
Download: [url=http://mm33.biz/emissions-tv/telerealite]TГ©lГ©rГ©alitГ©[/url] .
Ухапана
Download: [url=http://dtvuy.info/book/1354763499/download-si-dure-est-la-nuit-si-tendre-est-la-vie.pdf]Si dure est la nuit, si tendre est la vie[/url] .
Alan Jackson - Precious Memories Volume 2 2013 Country
Download: [url=http://naturo.fr/serie/Angel-Sanctuary]Angel Sanctuary[/url] .
The Fruits of Dating a Buxom Bitch Admin D
Download: [url=http://mespassions.fr/serie/Disney-Einfach-Cory]Disney Einfach Cory[/url] .
We Bare Bears.WEB DL 720.S01. Eps.13.VF.Death
Download: [url=http://mespassions.fr/serie/Vera-Ein-ganz-spezieller-Fall]Vera – Ein ganz spezieller Fall[/url] .
software
Download: [url=http://dtvuy.info/book/416569055/download-mac-os-x-pour-aller-plus-loin.pdf]Mac OS X Pour aller plus loin ![/url] .
view all
Download: [url=http://mmo13.com/pauls-case-a-study-in-temperament-by-sparknotes_53be1b356644890b0ba9e9bb/]Paul’s Case: A Study in Temperament by SparkNotes[/url] .
@description Gernez
Download: [url=http://municipalidadesdeguatemala.info/music/not-a-bad-thing-justin-timberlake.html]Not a Bad Thing[/url] .
BEWAKOOFIYAAN (2013) DVDRIP - x264 - [1CD] - ESUBS - TEAMTNT EXCLUSIVE
Download: [url=http://salondufoot.fr/torrent/640278/po-volchim-zakonam_animal-kingdom-03x01-06-iz-13-2018-webrip-coldfilm]По волчьим законам / Animal Kingdom [03x01-06 из 13] (2018) WEBRip | ColdFilm[/url] .
logged in
Download: [url=http://leonardpadilla.com/films/acteur/tom-hanks.html]Tom Hanks[/url] .
Chance S01E06 720p WEB H264-DEFLATE[ettv]
Download: [url=http://xjgjcw.info/actors/Jason+Beaudoin.html]Jason Beaudoin[/url] .
Speccy 1 30 728 + Portable
Download: [url=http://footlockersstore.com/films/250-meilleurs-films/comedie/]ComГ©die[/url] .
Women's Fitness UK - December 2016
Download: [url=http://updoot.com/nanu-ki-jaanu-2018-hindi-full-movie-dvdscr-1gb-350mb-audio-clean/]Nanu Ki Jaanu (2018) Hindi Full Movie DVDScr 1GB 350MB *Audio Clean*[/url] .
Muthina Kathirika (2016) HD TVRip
Download: [url=http://anb62.fr/not%C3%ADcias/faca-seu-pedido/]Faça Seu Pedido[/url] .
Designated Survivor S01E05 HDTV x264-LOL[ettv]
Download: [url=http://xjgjcw.info/actors/Rhonda+Fleming.html]Rhonda Fleming[/url] .
?? UNFORGETTABLE_2015.160107.2016-HDTV.H264.1080p-RTP
Download: [url=http://itsanorangeworld.info/others/unsorted/5415867-the-making-of-star-wars-return-of-the-jedi-by-brad-bird.html]The Making of Star Wars: Return of the Jedi by Brad Bird[/url] .
Ben 10: Omniverse
Download: [url=http://hecmreversemort.info/films/streaming/95405-la-momie-2017.html]Regarder La Momie (2017) en Streaming Gratuit[/url] .
Project Runway
Download: [url=http://bamrak.info/good-girls-saison-1-french-hdtv.html]Good Girls Saison 1 FRENCH HDTV[/url] .
Masters Of Horror
Download: [url=http://gs5qr.info/movie/genre/sports-film]Sports Film[/url] .
Aral?k 2012 (1056)
Download: [url=http://gitgot.info/02044918-pick-me-up-05-july-2018/]Pick Me Up! – 05 July 2018[/url] .
??(16)
Download: [url=http://montanatitlecompany.info/watch-where-is-kyra-2018/]Watch Movie[/url] .
Ramin Djawadi (2016) Westworld Season 1 (OST) 320Kbps
Download: [url=http://bellinghamopenhouses.com/2621890-pillars-of-eternity-ii-deadfire-1100035-2018-gog.html]Read more...[/url] .
x264 2hd
Download: [url=http://sqribe.fr/deadpool-2016-1080p-bluray-x264-dual-audio-english-dd-5-1-hindi-dd-5-1-nick-t12593635.html]Deadpool (2016) 1080p BluRay x264 [Dual-Audio] [English DD 5.1 + Hindi DD 5.1] - NicK[/url] .
Screener
Download: [url=http://amaraponjon.com/serie/Shugo-Chara]Shugo Chara![/url] .
Kirtu - XXX Apartments - Ep 1 to 23.pdf (Non-Watermarked) [Adult Comics] - Almerias
Download: [url=http://myskinserum.biz/others/int/7059007-va-fireplace-cozy-jazz-moments-vol1-2016.html]VA - Fireplace Cozy Jazz Moments Vol.1 (2016)[/url] .
Suicide Squad 2016 EXTENDED 1080p WEB-DL 6CH AC3 2 6GB MkvCage mkv
Download: [url=http://dtvuy.info/book/640481866/download-juste-avant-le-bonheur.pdf]Juste avant le bonheur[/url] .
BurnAware 9 4 Professional Repack KpoJIuK [4realtorrentz] zip
Download: [url=http://kenyamusicawards.com/xmas-holiday/]XMAS and Holiday[/url] .
Blacked - Brandi Love - Sexy Mom Takes 2 young BBCs
Download: [url=http://504.fr/file/1188509924/download-china-rich-girlfriend.pdf]China Rich Girlfriend[/url] .
Take Me Home Country Roads John Denver Cover With Michelle Spicer And Andrey Stolyarov
Download: [url=http://grueffelo.info/book/507374214/download-diabolik-23-luciana-giussani-angela-giussani.pdf]Diabolik #23[/url] .
Basketball Wives LA
Download: [url=http://inscrire.fr/X12X15X230419X0X0X1X-blockers-2018.html]Blockers (2018)[/url] .
Jessica Simpson taking it behind ADULT.wmv
Download: [url=http://traxbangbeats.com/series-hd/animales-rebeldes/3912]Animales rebeldes HDTV 720p AC3 5.1[/url] .
[www.OMGTORRENT.com] Bon.Retablissement.2014.FRENCH.720p.BluRay.x264-ROUGH
Download: [url=http://art-carvedchesssets.com/ebooks/]Lastest Update[/url] .
Blindspot S02E09 1080p HDTV X264 mp4
Download: [url=http://amiegisbert.com/naagin-season-3-2nd-june-2018-written-episode-update-a-new-naagins-story-unfolds/]Naagin Season 3 2nd June 2018 Analysis[/url] .
Mythbusters
Download: [url=http://hdfilmcehennemi.info/search/ж–њй‚Єиџ№й‚Є]ж–њй‚Єиџ№й‚Є[/url] .
DIY String Art - 24 Designs to Create and Hang (2016) (Epub) Gooner
Download: [url=http://hjspect.info/series/marlon-saison-1-episode-10-15672.html]Marlon - S01E10[/url] .
BLINDSPOT
Download: [url=http://amaraponjon.com/serie/Maken-ki]Maken-ki![/url] .
Werner Herzog,
Download: [url=http://spongydesigns.com/liga-da-justica-crise-em-duas-terras/]Liga da Justiça: Crise em Duas Terras Assistir Liga da Justiça: Crise em Duas Terras 720p Dublado/Legendado Online Neste longa de animação, um Lex Luthor "do bem" vem de um universo alternativo para pedir ajuda, pois seu planeta está sendo ameaçado pelo Sindicato do Crime, uma versão maligna da Liga da Justiça. As coisas se complicam quando o vilão Coruja tenta por em prática um plano diabólico, que ...[/url] .
WonderFox DVD Ripper Pro 8 1 + KeyGen zip
Download: [url=http://defreat.info/series/pose/3901]Pose HDTV[/url] .
Apple Final Cut Pro 10.3 [MacAPPS] [Isohunt.to]
Download: [url=http://mespassions.fr/vorgeschlagene-serien/vote:12837]The Keepers[/url] .
view all
Download: [url=http://spongydesigns.com/o-vigilante-mascarado/]O Vigilante Mascarado Assistir O Vigilante Mascarado 720p Dublado/Legendado Online Chris Samuels, um lutador profissional e pai de famГlia, se aposenta dos ringues para se estabelecer em uma pequena cidade como pastor. Ao perceber os problemas criminais do local, ele decide colocar sua mГЎscara de luta e atuar como um vigilante noturno combatendo a injustiГ§a. Enfrentando crises na igreja e em casa, Chris precisa ...[/url] .
Ouija: El origen del mal
Download: [url=http://tortinnemo20.com/torrent/emulation/roms/250979-pack+37+-+colecovision-+140+roms+pour+recalbox+multi]PACK 37 - Colecovision- (140 ROMS) POUR RECALBOX MULTI[/url] .
[HCG] [120330] [Complets] Yagai gakushu 2.zip
Download: [url=http://t7g1v.info/watch/oxQV4zGn-bob-s-burgers-season-8.html]Bob's Burgers: Season 8[/url] .
???????? ?01? [Maou-jou de Oyasumi vol 01]
Download: [url=http://dominoemas.com/watch-operation-red-sea-2018-movie-free/] Previous[/url] .
DNCE-Cake By The Ocean.mp3
Download: [url=http://amaraponjon.com/serie/False-Flag]False Flag[/url] .
Portuguese
Download: [url=http://naturo.fr/serie/Battle-Creek]Battle Creek[/url] .
ATLANTA - Complete FIRST Season 1 S01 (2016 Series) - 720p Web-DL x264 [Isohunt.to]
Download: [url=http://yhisip.info/tag/han-solo-una-historia-de-star-wars-2018-ver-la-pelicula-completa-en-linea-gratis/]Han Solo Una Historia de Star Wars 2018 ver la pelГcula completa en lГnea gratis[/url] .
Albert Washington - Blues & Soul Man - Ace CD 727 -
Download: [url=http://bluecrossrehabcenters.com/drake-survival.html]Drake - Survival[/url] .
Strictly Come Dancing
Download: [url=http://markauesassmake.info/lista-series-recomendadas/serie/the-american-west.html]The American West[/url] .
BitLord.com
Download: [url=http://laredophysiciansgroup.info/o-vigilante-mascarado/]O Vigilante Mascarado Assistir O Vigilante Mascarado 720p Dublado/Legendado Online Chris Samuels, um lutador profissional e pai de famГlia, se aposenta dos ringues para se estabelecer em uma pequena cidade como pastor. Ao perceber os problemas criminais do local, ele decide colocar sua mГЎscara de luta e atuar como um vigilante noturno combatendo a injustiГ§a. Enfrentando crises na igreja e em casa, Chris precisa ...[/url] .
Geordie Shore
Download: [url=http://t7g1v.info/watch/pxw50edz-lobbyist.html]Lobbyist[/url] .
[HorribleSubs] Okusama ga Seitokaichou! S2 (Uncensored) 04 [720p].mkv
Download: [url=http://mespassions.fr/serie/Die-Fraggles]Die Fraggles[/url] .
February 2016 (2146)
Download: [url=http://naturo.fr/serie/Thirteen]Thirteen[/url] .
Torrent Download is working again!
Download: [url=http://cribleum.info/actors/Angelica+Ross.html]Angelica Ross[/url] .
BBC Prison My Parents Me WebRip x264-MCTV
Download: [url=http://leonardpadilla.com/films/acteur/johnny-depp.html]Johnny Depp[/url] .
Read Full Article
Download: [url=http://sz1cv.info/graphics/927121-codecanyon-improved-variable-product-attributes.html]CodeCanyon - Improved Variable Product Attributes for WooCommerce v3.2.4[/url] .
Alix Lovell, Bruno Dickenz - Curves And Head, XXX, MPEG4(Xvid), C2x, HD 1080p, 0,5 FPS [Monster Curves - RealityKings] (August 13, 2016).avi [Isohunt.to]
Download: [url=http://diegorangel.com.br/torrent/3dsulxyz/Terminal+2018+1080p+WEB-HD+1.3+GB+-+iExTV.html]Terminal 2018 1080p WEB-HD 1.3 GB - iExTV[/url] .
??? 4
Download: [url=http://spongydesigns.com/unrest/]Unrest Assistir Unrest 720p Dublado/Legendado Online Quando a estudante de doutorado em Harvard, Jennifer Brea, é atingida aos 28 anos por uma febre que a deixa de cama, os médicos dizem que “tudo está em sua cabeça”. Determinada a viver, ela começa uma jornada para documentar sua história, e de outras pessoas – lutando contra uma doença que a medicina esqueceu. Ver filme ...[/url] .
Today Torrents
Download: [url=http://jscateringservices.biz/watch/escape-plan-2-hades-2018-fmovies.html]Watch movie[/url] .
0 Comments
Download: [url=http://rxouj.info/viewtopic.php?f=438&t=2646208&sid=cf30527f0cb2f6e2c895a6b16513acac]Shortcutter - Quick Settings​ Sidebar v6.1.7 [Premium][/url] .
Forex trading made simple
Download: [url=http://grupopamiquetzalcoatlpuebla.com/software/3050-aero-enabler-1003.html]Aero Enabler 1.0.0.3[/url] .
Stacey On the Frontline Girls, Guns and ISIS BigJ0554
Download: [url=http://salondufoot.fr/search/0/6/0/0/Плейбой]Плейбой[/url] .
Fausto Maria Sciarappa
Download: [url=http://inscrire.fr/X6XNTM4MTMzX-gomorra-s03-bluray-1080p.html]Subtitulo de Gomorra S03 BluRay 1080p[/url] .
Duck Dynasty Season 11 Episode 1 - The West Monroe Wing
Download: [url=http://domino22.com/film/fSv/The-Coming-Convergence?episod=1]IMDb: 6.2 HD The Coming Convergence[/url] .
my mom fucked hard in her bedroom
Download: [url=http://504.fr/file/506929074/download-a-newbies-guide-to-final-cut-pro-x.pdf]A Newbies Guide to Final Cut Pro X[/url] .
Nero 2017 Platinum Portable 18 0 15 0 Multilingual
Download: [url=http://querk.fr/search.php?s=2f4e509b1fde501ef42a7b75a9645f90]Search Multiple Content Types[/url] .
Jason.Bourne.2016.DVDRip.XviD.AC3-iFT[PRiME]
Download: [url=http://securestacbptravel.info/novel/The-Changeover-1653]The Changeover[/url] .
Albert D Pastore - Stranger Than Fiction
Download: [url=http://504.fr/file/1000147583/download-white-dwarf-issue-72-13th-june-2015.pdf]White Dwarf Issue 72: 13th June 2015[/url] .
view all
Download: [url=http://naturo.fr/serie/Dream-Festival]Dream Festival![/url] .
Portlandia
Download: [url=http://grueffelo.info/top-books/9029/professional-and-technical]Professional and Technical[/url] .
Album Nhac 1000 Nam Thang Long Ha Noi
Download: [url=http://rampageforandroid.info/download-pdf-family-child-care-2017-tax-companion-redleaf-business-best-ebook-download]Download PDF Family Child Care 2017 Tax Companion (Redleaf Business) Best Ebook download[/url] .
http://bigfoot1942.sektori.org:6969/announce
Download: [url=http://nouvelles-idees.fr/logan-lucky-2017-en-streaming-vk.html]Logan Lucky 2017[/url] .
Сезон 1 БГ АУДИО
Download: [url=http://buildinginsulationmaterials.com/album/1402692638/demain-bigflo-oli-x-petit-biscuit-single.html]Demain Bigflo Oli X Petit Biscuit Single[/url] .
mr robot
Download: [url=http://amaraponjon.com/serie/Appleseed-XIII]Appleseed XIII[/url] .
Highway Thru Hell S05E10 Family Matters 720p HDTV x264 mp4
Download: [url=http://09611c.net/mp3/naal-nachna-feat.-manjit-pappu.html]NAAL NACHNA (FEAT. MANJIT PAPPU)[/url] .
Documentario
Download: [url=http://504.fr/file/1017388116/download-the-architecture-of-music-volume-1.pdf]The Architecture of Music Volume 1[/url] .
Lisa Dickenson - Mistletoe on 34th Street - eBook [Isohunt.to]
Download: [url=http://manningpeds.com/book/1370912139/download-ensemble-maintenant-pour-toujours.pdf]Ensemble. Maintenant. Pour toujours[/url] .
Combat.of.Giants.Dragons.Multi5.nds.by.Doberman.WwW.IbizaTorrenT.NeT
Download: [url=http://pipshowasasg.info/le-heros-magnifique-vostfr-streaming/]Le HГ©ros magnifique[/url] .
Van Helsing S01E07 1080p WEB x264-HEAT[PRiME]
Download: [url=http://09611c.net]MP3 Searched[/url] .
Assassination Classroom (2015) BluRay 720p Full Movie HEVC
Download: [url=http://mm33.biz/series/pack-sries-vf-hd-720p/]Pack SГ©ries VF HD 720p[/url] .
The Quick and The Demotic- -- Vol89
Download: [url=http://grosbet400.com/izle/animal-kingdom-3-sezon-3-bolum]Episode #3.3[/url] .
Personal Assistant XXX 720p WEBRip MP4-VSEX
Download: [url=http://puckmaynanny.info/engine/go.php?mp3=Download Lagu Panbers Relakan Mp3 - Gudanglagu]DOWNLOAD[/url] .
BitLord.com
Download: [url=http://692061.com/series/padre-brown/3884]Padre Brown HDTV[/url] .
Back to the KickassTorrents homepage
Download: [url=http://gs5qr.info/]123movies[/url] .
Iron Fire - Among The Dead (2016)
Download: [url=http://manningpeds.com/book/445765334/download-la-vache-pourpre.pdf]La vache pourpre[/url] .
Album Zhao Peng - The Greatest Basso Vol 2
Download: [url=http://naturo.fr/serie/Sakurako-san-no-Ashimoto-ni-wa-Shitai-ga-Umatteiru]Sakurako-san no Ashimoto ni wa Shitai ga Umatteiru[/url] .
Nicole Aniston mp4
Download: [url=http://lazamy.com/music/minecraft-tutorial-compact-flush-3x3-piston-door-german-hd.html]Minecraft Tutorial Compact Flush 3x3 Piston Door German Hd[/url] .
Anilos 16 11 16 Nica Use It Well XXX 1080p MP4-KTR[rarbg]
Download: [url=http://cribleum.info/actors/Russell+Tovey.html]Russell Tovey[/url] .
The Light Between Oceans (2016)
Download: [url=http://cribleum.info/actors/Keith+Colburn.html]Keith Colburn[/url] .
MikesApartment - Nicole Love (Sexy Nicole)
Download: [url=http://xk2e4.info/movie/the-god-of-cookery]The God Of Cookery[/url] .
Actionreplay All Songs Remax
Download: [url=http://everproject.fr/secrets-and-wives]Secrets and Wives[/url] .
Webcam Max 7.1.2.2 Duckys@[T411](A)
Download: [url=http://mespassions.fr/serie/Small-Island]Small Island[/url] .
That 70s Show
Download: [url=http://roundtabletechnology.info/watch-chasing-shadows-online/]Chasing Shadows[/url] .
Kill Bill: Vol. 1 2003 HD ????? ????? 8.1
Download: [url=http://itsanorangeworld.info/others/int/7028259-sonstiges-putumayo-presents-49-albums-1993-1999-part-1.html][Sonstiges] Putumayo Presents (49 Albums) (1993-1999) Part 1[/url] .
Continent 7-Antarctica S01E01 Storming Antarctica HDTV x264-SDI - [SRIGGA]
Download: [url=http://clearaccessmedia.com/book/482496617/download-how-to-win-at-the-sport-of-business.pdf]How to Win at the Sport of Business[/url] .
Cosmic Disclosure S06E08 - Founders of Solar Warden with William Tompkins (STROM) [Isohunt.to]
Download: [url=http://monjourdechance.fr/novel/Forbidden-6468]Forbidden[/url] .
As Tartarugas Ninja 2014 Dublado Online Afetados por uma substancia radioativa, um grupo de tartarugas cresce anormalmente, ganha forca e conhecimento. Vivendo nos esgotos de Manhattan, quatro jovens tartarugas, treinadas na arte de kung-fu, Leonardo, Rafael, Michelangelo e Donatello, junto com seu sensei, Mestre Splinter, tem que enfrentar o mal que habita cidade.
Download: [url=http://amaraponjon.com/vorgeschlagene-serien/vote:13294]The Haves and Have Nots[/url] .
Machine Gun Kelly - Rage Pack
Download: [url=http://flyseasons.com/movie/0v8nD7Gw-ghost-stories.html]Ghost Stories[/url] .
Muse Drones 2015
Download: [url=http://duz77.info/nowe/torrent/104846]Gra o wszystko / Molly's Game (2017) [480p] [BDRip] [XviD] [AC3-KLiO] [Lektor PL][/url] .
Дневниците на вампира
Download: [url=http://mespassions.fr/serie/Night-Head-Genesis]Night Head Genesis[/url] .
mars simulator
Download: [url=http://naturo.fr/serie/Robot-Chicken]Robot Chicken[/url] .
Magnet 1 8 for MAC-OSx
Download: [url=http://revetementbateautecksynthetique.com/threads/gearbest-4th-anniversary-thread-happy-4th-anniversary.163035/ http://guruslodge.com/index.php?forums/computer-games.86/ ]PC Softwares Games[/url] .
ATKHairy 16 11 17 Izzy J Solo XXX 1080p MP4 KTR
Download: [url=http://nuskinsg.com/mangas/kampfer.html]Kämpfer Action 2009 Senou Natsuru, un jeune garçon étudiant dans un collège normal qui mène une vie quotidienne, se retrouve avec un étrange...[/url] .
Harry Potter e a Pedra Filosofal – Dublado Full HD1080p Online
Download: [url=http://xjgjcw.info/actors/Esther+Howard.html]Esther Howard[/url] .
Information Technology Project Management Revised 6Th Edition
Download: [url=http://grosbet400.com/]Anasayfa[/url] .
BitLord.com
Download: [url=http://traxbangbeats.com/pelicula/soldiers-of-fortune/]Soldiers Of Fortune[/url] .
x-men, apocalypse 720p
Download: [url=http://yhisip.info/category/llueven-vacas-2017/]Llueven vacas (2017)[/url] .
Liquorworks - Psycho Soundwaves (2016)
Download: [url=http://xjgjcw.info/movies-shades-of-blue-season-3-2018-123movies-vip.html]Watch movie[/url] .
Hannibal.S03E05.HDTV.x264-LOL[ettv][156 Mb] Video TV shows
Download: [url=http://hookerbird.info/mp3/i-understand-feat.-d.ear.html]I UNDERSTAND FEAT. D.EAR[/url] .
Facebook
Download: [url=http://vbarto.com/torrent/3h0qc7d7/[Prof]+Sengoku+Basara:+Samurai+Kings+S1+(1080p+x265+HEVC+10bit+AAC+5.1+Eng+Dub).html][Prof] Sengoku Basara: Samurai Kings S1 (1080p x265 HEVC 10bit AAC 5.1 Eng Dub)[/url] .
???(10)
Download: [url=http://t7g1v.info/watch/qvoXNWxl-big-brother-us-season-20.html]Big Brother (us): ...[/url] .
Attack Of The Show
Download: [url=http://questionmwybutt.info/ninho-de-vespas/]Ninho de Vespas – HD – Legendado Online[/url] .
Amy Amoure mp4
Download: [url=http://mm33.biz/2018/03/16/]16-03-2018, 06:55[/url] .
(C84) [??? (???)] ????????????!~??????????~ (Fate/Zero).zip
Download: [url=http://nadal.fr/atkins-physical-chemistry-10th-edition-solutions-pdf.html]ATKINS PHYSICAL CHEMISTRY 10TH EDITION SOLUTIONS PDF[/url] .
Just As I Am By Brantley Gilbert
Download: [url=http://jscateringservices.biz/actors/Jean-Christophe+Bouvet.html]Jean-Christophe Bouvet[/url] .
Jason Bourne (2016) [1080p] [YTS AG]
Download: [url=http://sonsaniyefilm.com/details/0C05F98F89E078BE6A2D98E42BFAC585CADFE785/Half+Girlfriend+2017+720p+WEB+HD+DD+5+1+x264+ESub]Half Girlfriend 2017 720p WEB HD DD 5 1 x264 ESub[/url] .
Reveal Sound - Spire v1.0.11 - AU VST - OS X - R2R [packet-dada]
Download: [url=http://mespassions.fr/serie/Inazuma-Eleven]Inazuma Eleven[/url] .
m pokora
Download: [url=http://kbdesignlab.com/torrent/1258725/torrentcouch-westworld-s02plete-720p-web-dl-mp4-5-3gb-season-2-full.html][TorrentCouch com] Westworld S02 Complete 720p WEB-DL x264 [MP4] [5 3GB] [Season 2 Full][/url] .
Сезон 6 БГ СУБТИТРИ
Download: [url=http://jscateringservices.biz/actors/Jackie+Chan.html]Jackie Chan[/url] .
Kathakali (2016) HD TVRip
Download: [url=http://amaraponjon.com/vorgeschlagene-serien/vote:13433]Alle meine Freunde[/url] .
Kerish Doctor 2016 4 60 DC 22 10 16 + Key [4realtorrentz] zip
Download: [url=http://gs5qr.info/movie/genre/thriller/view/all]Most viewed[/url] .
Days Of Our Lives - S52 E41 - Monday, November 14, 2016 TV Shows
Download: [url=http://itsanorangeworld.info/music/6491244-nero-nemesis-booba.html]Nero nemesis - Booba[/url] .
The Conjuring 2013 1080p BluRay DTS x264-ETRG
Download: [url=http://jscateringservices.biz/actors/Catherine+Zeta-Jones.html]Catherine Zeta-Jones[/url] .
Greatest Hits By Fleetwood Mac
Download: [url=http://hazirmutfak.biz/Film-1725-the-frame-streaming]BDRipVF The Frame[/url] .
Strictly Criminal (2015) MULTi VFF [1080p] BluRay ...(A)
Download: [url=http://chauffeurs-service.fr/descargar-asesinato-en-el-orient-express-76095.fx]Asesinato En El Orient Express - 2017[/url] .
Comments: 0
Download: [url=http://hazirmutfak.biz/Film-4082-donnie-darko-streaming]BDRipVF Donnie Darko[/url] .
Aleister Crowley - The Great Beast Speaks
Download: [url=http://692061.com/pelicula/el-destino-de-jupiter/]El Destino De Jupiter[/url] .
TurbulenceFD C4D v1.0 Build 1401 for Cinema 4D Win
Download: [url=http://casinoslot8.com/torrent/eubc30v9/Last.Encounter.v20180511.X86.RIP-SiMPLEX.html]Last.Encounter.v20180511.X86.RIP-SiMPLEX[/url] .
Microsoft Office Pro. Plus 2013 VL Edition x86 x64 FRENCH-DeGun
Download: [url=http://rlhib.info/dudi-2006/175102]Dudi (2006)[/url] .
General Hospital - S54 E156 - Thursday, November 10, 2016 TV Shows
Download: [url=http://vbarto.com/search/?search=brattysis+alex+blake+blair+williams]brattysis alex blake blair williams[/url] .
[Salender Raws] Umineko no Naku Koro ni Vol.12 (BD 1280x720 x264 FLAC)
Download: [url=http://nuskinsg.com/serie/sweetbitter.html]Sweetbitter ComГ©die dramatique Tess, 22 ans, est arrivГ©e depuis peu Г New York, et obtient un travail dans un cГ©lГЁbre restaurant du centre-ville....[/url] .
Mandy Mystery Die Kleine Fickschnauze S2 mp4
Download: [url=http://sex-live.info/info-biografia/3254-john-boyega]John Boyega[/url] .
Selling Good Ccv ,Fullz,Dumps pin,Track1&2 pin,Bank logins,Wu trf
Download: [url=http://amaraponjon.com/serie/Ikki-Tousen-Dragon-Girls]Ikki Tousen: Dragon Girls[/url] .
Dragon Fin Soup [2016 MAC OS GAME]
Download: [url=http://naturo.fr/vorgeschlagene-serien/vote:12911]Morel Orel[/url] .
Lethal Weapon S01E07 1080p HDTV X264 mp4
Download: [url=http://jscateringservices.biz/actors/Alycia+Lancey.html]Alycia Lancey[/url] .
Jason Bourne 2016 BRRip XviD AC3-iFT[SN]
Download: [url=http://naturo.fr/serie/Nemesis-Der-Angriff]Nemesis - Der Angriff[/url] .
Chris Pine
Download: [url=http://xjgjcw.info/actors/Adrian+Lester.html]Adrian Lester[/url] .
In Treatment
Download: [url=http://504.fr/file/486343611/download-parantavien-ruokien-opas.pdf]Parantavien ruokien opas[/url] .
The Isley Brothers - I'll Be Home For Christmas - 2016-11-17
Download: [url=http://clearaccessmedia.com/book/548622845/download-warhammer-the-empire-interactive-edition.pdf]Warhammer: The Empire (Interactive Edition)[/url] .
Aldous Snow - Infant Sorrow
Download: [url=http://pumpddmyass.info/watch/yGDma3d6-the-king-s-woman.html]The King's Woman[/url] .
Jodi West wmv
Download: [url=http://escuelasamigables.info/network-analysis-written-by-ganesh-rao.html]Network Analysis Written By Ganesh Rao[/url] .
BitLord.com
Download: [url=http://vbarto.com/torrent/ylfz1mbq/[Cleo]+Black+Bullet+[Dual+Audio+10bit+BD720p][HEVC-x265].html][Cleo] Black Bullet [Dual Audio 10bit BD720p][HEVC-x265][/url] .
PingTools
Download: [url=http://jeuxmobilesgratuits.fr/namorando-uma-mulher/]Namorando Uma Mulher Assistir Namorando Uma Mulher 720p Dublado/Legendado Online Tom Herzner (Kostja Ullmann), um Гcone para a comunidade homossexual, estГЎ ansioso para lanГ§ar sua linha de produtos de beleza. No entanto, um romance inesperado surge durante sua pesquisa de mercado, enquanto trabalha disfarГ§ado em um salГЈo dirigido por uma mulher. Ver filme Namorando Uma Mulher Dublado/Legendado Ver Filme Coming In Dublado/Legendado (2014) Assistir Filmes Online em ...[/url] .
68 Comments
Download: [url=http://dwilegalrep.com/2018-movies/mollys-game-2017-movie-free-download-720p-bluray/]Mollys Game 2017 Movie Free Download 720p BluRay[/url] .
Albert D Pastore - Stranger Than Fiction
Download: [url=http://hsightly.info/seriestv/dark]Dark (2017) en streaming VF Un enfant perdu lance quatre familles dans un dГ©sespГ©rГ© afin de trouver des rГ©ponses. La recherche des coupables fait Г©merger des pГ©chГ©s et les secrets d'une petite ville.[/url] .
RBD-794(18)
Download: [url=http://yourbusinessgame.info/genre/action-adventure/]Action Adventure[/url] .
Ужаси
Download: [url=http://leonardpadilla.com/films/250-meilleurs-films/thriller/]Thriller[/url] .
Petes Dragon 2016 BRRip XviD AC3-EVO[SN]
Download: [url=http://domaine-cerealier-en-camargue.fr/filmy-online/Impostor__Test_na_czlowieczenstwo/8875]Impostor: Test na czЕ‚owieczeЕ„stwo / Impostor(2001)[/url] .
Луцифер
Download: [url=http://art-carvedchesssets.com/Vampiresch/Archer_s_Voice/Pages.html]Archer's Voice[/url] .
Rocket League - 2016 (MacAPPS)
Download: [url=http://nadal.fr/why-the-biology-matters-semantic-scholar.html]Why the Biology Matters - Semantic Scholar[/url] .
vidzi.tv
Download: [url=http://ydvj3.info/author/ Dav-Pilkey ]Dav Pilkey[/url] .
HD Movies
Download: [url=http://myskinserum.biz/others/unsorted/5851925-pension-strategies-in-europe-and-the-united-states-cesifo-seminar-series-by-robert-fenge.html]Pension Strategies in Europe and the United States (CESifo Seminar Series) by Robert Fenge[/url] .
[cover] ????
Download: [url=http://jason-dunn-tattoo.com/stream-washington-nationals-vs-miami-marlins-live-5]Stream Link 5[/url] .
Svensk Premiar - Rumpklubben XXX WebGift
Download: [url=http://roundtabletechnology.info/watch-the-librarians-online-11/]The Librarians[/url] .
Defloration 16 11 17 Sofia Staromesto Solo 2 1080p MP4-KTR
Download: [url=http://htcmaritimeagency.com/browse-movies/Alessandro+Nivola]Alessandro Nivola[/url] .
Australia
Download: [url=http://amaraponjon.com/vorgeschlagene-serien/vote:11867]Tayutama - Kiss on my Deity[/url] .
UnHackMe 8 30 Build 530 + Crack [4realtorrentz] zip
Download: [url=http://rxouj.info/memberlist.php?mode=viewprofile&u=908606&sid=cf30527f0cb2f6e2c895a6b16513acac]koumkouat[/url] .
Doctor Doctor 2016 S01E10 Webrip x264-MFO mp4
Download: [url=http://soscomputer.info/engine/go.php?book=UrduWorkBook0911.pdf]Download[/url] .
Alan Moore & Mitch Jenkins a€?Unearthinga€™
Download: [url=http://jscateringservices.biz/actors/Caitlin+Barlow.html]Caitlin Barlow[/url] .
10Musume-111616_01-HD
Download: [url=http://gitgot.info/02155900-aftenposten-junior-05-juni-2018/]Aftenposten Junior – 05 juni 2018[/url] .
Alien: Isolation - Collection (2014) PC RePack от R.G. Freedom
Download: [url=http://sqribe.fr/va-i-love-disco-rarities-vol-1-vol-2-special-versions-2016-mp3-edm-rg-t12972038.html]VA - I Love Disco Rarities Vol.1 Vol.2 [Special Versions] (2016) MP3 [EDM RG][/url] .
[PuyaSubs!] Gatchaman Crowds - 04 [720p][E6217480].mkv
Download: [url=http://footlockersstore.com/films/streaming/8997-ah-my-goddess-le-film.html]Regarder Ah! My Goddess - Le Film en Streaming Gratuit[/url] .
[ www.TorrentDay.com ] - Brand.x.with.Russell.Brand.Live.S02E01.480p.HDTV.x264-mSD
Download: [url=http://cabuloso.com/torrent/802928/History-Of-War-Issue-3-May-2014-UK/]History Of War Issue 3 - May 2014 UK[/url] .
21 Bewitched
Download: [url=http://banhallmand.info/2017/download-lagu-reagge-kau-tercipta-bukan-untuk-ku-full-background-fresh.html]Read More...[/url] .
Prison Break
Download: [url=http://amaraponjon.com/serie/Divine-Gate]Divine Gate[/url] .
Ookami Kodomo No Ame To Yuki - English Sub.mp4
Download: [url=http://www.hk9559.com/e-books/libreria-dasolo-download/privacy-policy.html]Privacy-Policy[/url] .
HEVC Movies
Download: [url=http://clearaccessmedia.com/book/921378578/download-the-job-interview.pdf]The Job Interview[/url] .
(Brazzers) TeensLikeItBig - Rikki Six (Chores for a Whore)
Download: [url=http://maisagito.com.br/tag/assistir-a-morte-do-supeman-dublado-online/]Assistir A Morte do Supeman Dublado Online[/url] .
Van Helsing S01E06 1080p WEB x264-HEAT[PRiME]
Download: [url=http://www.sosafrica.info/lagu/sebatas-impian-anik-arnika-live-dusun-sembung-larangan]Sebatas Impian Anik Arnika Live Dusun Sembung Larangan[/url] .
Absolutely Fabulous The Movie DVDRip XviD-EVO[SN]
Download: [url=http://pasaranonline.info/the-bride-of-the-water-god/chapter-151]The Bride of the Water God: chapter 151[/url] .
Hello Ladies
Download: [url=http://webhostfeed.com/ver/angelica-vale-1x53.html]Novelas Y maГ±ana sera otro dia mejor 1x53[/url] .
[UF+]Mobile Suit Gundam 00 Vol 04 [BDrip 720p]
Download: [url=http://osmozzy.com.br/watch/gummo-14484]HD Gummo (1997)[/url] .
High Strung 2016 BRRip XviD AC3-EVO[PRiME]
Download: [url=http://revmortlocal.com/pose-saison-1-vostfr-streaming/]Pose Saison 1[/url] .
RAM-RAHIM MISSINGS COMICS SET-07
Download: [url=http://distancelearningengineering.com/la-mutante-3/]Regarder Le Film[/url] .
Koot en Bie
Download: [url=http://leonardpadilla.com/films/acteur/vincent-perez.html]Vincent Perez[/url] .
Flocken (Flocking) streaming
Download: [url=http://amaraponjon.com/serie/Saiunkoku-Monogatari]Saiunkoku Monogatari[/url] .
[????] ??? Split, 20161109
Download: [url=http://naturo.fr/serie/In-der-Haut-des-Anderen]In der Haut des Anderen[/url] .
Snowden 2016 720p WEBRip x264 AAC-ETRG
Download: [url=http://dealsealer.biz/rubrique/76/economie]Economie[/url] .
Defloration 16 11 17 Sofia Staromesto Solo 2 XXX 1080p MP4-KTR[rarbg]
Download: [url=http://twitter.com/intent/tweet?source=http://ruspr.info/directory/a&text=:%20http://ruspr.info/directory/a&via=ruspr.info]Twitter Tweet[/url] .
Global Finance Free Subscription
Download: [url=http://cribleum.info/actors/Stacey+Rios.html]Stacey Rios[/url] .
The Flash 2014 S02E23 The Race of His Life1080p WEB-DL DD5 1 H265-LGC mkv
Download: [url=http://myskinserum.biz/images/gfx/6498034-singomakers-trapstep-ultra-pack-multiformat-fantastic.html]Singomakers Trapstep Ultra Pack MULTiFORMAT-FANTASTiC[/url] .
MEYD-202 mp4
Download: [url=http://xjgjcw.info/actors/Tammy+Hui.html]Tammy Hui[/url] .
Jason Bourne 2016 DVDRip XviD AC3-iFT[PRiME]
Download: [url=http://t7g1v.info/watch/EdBB97dj-knights-magic-dub.html]Knights & Magic ...[/url] .
Suburgatory
Download: [url=http://newprdirectory.info/torrent/3701771/douglas-reeman-torpedo-run-mine.html]Douglas Reeman - Torpedo Run - Mine[/url] .
Angel Guardian Riddim
Download: [url=http://naturo.fr/serie/Dirty-Money-Geld-regiert-die-Welt]Dirty Money – Geld regiert die Welt[/url] .
Supernatural Season 12 Dublado Torrent
Download: [url=http://hemen-oyna.com/goto.htm?filename=pretra382iva269.epub]Download from DepositFiles[/url] .
A Million WAys to Die in the West (2014)
Download: [url=http://mybaseservicedapartments.com/music-video-%e8%b5%a4%e8%a5%bf%e4%bb%81-mi-amor-2014-11-12mp4rar/][MUSIC VIDEO] 赤西仁 – Mi Amor (2014.11.12/MP4/RAR)[/url] .
Ghostbusters (2016) [EXTENDED] Bluray RIP 1080p DTS ENG AC3 ITA ENG SUBS-LSD
Download: [url=http://cribleum.info/actors/Lucy+Russell.html]Lucy Russell[/url] .
BitLord.com
Download: [url=http://montanatitlecompany.info/watch-indie-boys-2010/]Watch Movie[/url] .
Сезон 5 БГ СУБТИТРИ
Download: [url=http://manningpeds.com/book/1348791087/download-cr-ez-vous-m-me-votre-r-gime.pdf]CrГ©ez vous-mГЄme votre rГ©gime[/url] .
pedo jpg(13)
Download: [url=http://qipuwv.info/torrent/182136/guarded-secrets-sekretniy-spasitel-christopher-taylor-mystique-films-1997-g-thriller-webrip-rus]Guarded Secrets / Секретный спаситель (Christopher Taylor, Mystique Films) [1997 г., Thriller, WebRip][rus][/url] .
World of Warcraft Legion - 2016 MAC Game
Download: [url=http://myskinserum.biz/others/int/7229845-vectors-vintage-floral-elements-set.html]Vectors - Vintage Floral Elements Set[/url] .
Conan.2016.11.15.Matt.LeBlanc.720p.HEVC.x265 MeGusta
Download: [url=http://naturo.fr/serie/Gundam-Wing]Gundam Wing[/url] .
The Approaching Night Philip Wesley
Download: [url=http://snj4v.info/release/va-in-the-clubs-vol-9-2033445.html]In the Clubs, Vol. 9[/url] .
Meru 2015 HD ????? ????? 7.7
Download: [url=http://hetaqrqire.com/film/23803-a-partiallat]A PartiГЎllat (2018)[/url] .
341-krec-vozduh-svobody
Download: [url=http://cribleum.info/actors/Vince+Tycer.html]Vince Tycer[/url] .
P4tr00l.Vremen1.2014.D.BDRip.1080p.mkv
Download: [url=http://naturo.fr/serie/Inspector-Lynley]Inspector Lynley[/url] .
The Wrong Girl - S01E08 mp4
Download: [url=http://www1.alcanciadigitalteleton.com/tvshows/descendants-wicked-world/]Watch movie[/url] .
Calvin Harris Disciples How Deep Is Your Love Piano Cover By Marijan
Download: [url=http://dtvuy.info/book/513960241/download-sexe-le-rendre-fou-de-plaisir.pdf]Sexe : le rendre fou de plaisir[/url] .
Christian
Download: [url=http://xqf0n.info/film/popeye-the-sailor-season-1]Eps169 Popeye the Sailor season 1[/url] .
Robocop.2014.Webrip.XVID.AC3.ACAB
Download: [url=http://myskinserum.biz/others/int/6853333-tools-anydvd-hd-8020.html][Tools] AnyDVD HD 8.0.2.0[/url] .
Paul Buchanan Mid Air
Download: [url=http://convertingcryptocurrencies.com/hotel-transylvania-2015-watch-online/]Watch Movie[/url] .
Facebook
Download: [url=http://langitbiru.info/engine/go.php?file2=[langitbiru.info]Gotti-2018-720p-WEBRip-XviD-AC3-FGT-AVI.torrent]Gotti 2018 720p WEBRip XviD AC3-FGT AVI[/url] .
[LustyGrandmas] Hettie, Rob - Grandma Loves Fucking (17 11 2016) rq mp4
Download: [url=http://grueffelo.info/book/591821762/download-the-sleeping-beauty-tidels.pdf]The Sleeping Beauty[/url] .
Modern Family S08E07 720p HDTV x264-FLEET[PRiME]
Download: [url=http://bgsist.info/2017/02/oyee-2016-uncut-hdrip-480p-300mb-hindi-dubbed/]Oyee 2016 UnCut HDRip 480p [300MB] Hindi Dubbed[/url] .
Audiobooks
Download: [url=http://bluecrossrehabcenters.com/best-of-the-lion-king-various-artists.html]Download[/url] .
Aventura El Perdedor At Bachata
Download: [url=http://portemanteau.fr/?cat=18]Policial[/url] .
MomsTeachSex: Ava Taylor, Brandi Love (Fast Learners) [XXX] x264
Download: [url=http://mcoin-ex.info/show/SHIZA-Project-Persona-5-The-Animation-The-Day-Brea-1JTfN.html]SHIZA Project Persona 5 The Animation - The Day Breakers OVA BDRip 1080p[/url] .
mofoxxx-phgc30 mp4
Download: [url=http://laredophysiciansgroup.info/rampage-destruicao-total/]Rampage: Destruição Total Assistir Rampage: Destruição Total 720p Dublado/Legendado Online Davis Okoye Г© um primatologista (Dwayne Johnson), um homem recluso que compartilha um vГnculo inabalГЎvel com George, um gorila muito inteligente que estГЎ sob seus cuidados desde o nascimento. Quando um experimento genГ©tico desonesto Г© feito em um grupo de predadores que inclui o primata, os animais se transformam em monstros que destroem tudo ...[/url] .
Same Old Love Selena Gomez Traducida Letra En Espa Ol
Download: [url=http://amaraponjon.com/serie/Kim-s-Convenience]Kim's Convenience[/url] .
Request: Big bang theory
Download: [url=http://dtvuy.info/book/577791043/download-jules-verne-oeuvres-compl-tes.pdf]Jules Verne : Oeuvres complГЁtes[/url] .
Jason.Bourne.2016.1080p.BluRay.x264-SPARKS-[rarbg]
Download: [url=http://manningpeds.com/book/409797269/download-les-kilos-motionnels.pdf]Les Kilos Г©motionnels[/url] .
http://www.imgextra.uk/image/Tl
Download: [url=http://musvida.info/my-little-pony-le-film/]My Little Pony : le film[/url] .
James.Corden.2016.11.16.Kendall.Jenner.HDTV.x264-CROOKS[ettv]
Download: [url=http://naturo.fr/vorgeschlagene-serien/vote:12556]Ripley’s unglaubliche Welt[/url] .
Revolution 1? Temporada Dublado Torrent – BDRip 720p Download (2012)
Download: [url=http://jscateringservices.biz/actors/Dick+Elliott.html]Dick Elliott[/url] .
sts_leyla_peachbloom_ww102214_480p_2000.mp4
Download: [url=http://panthereducation.com/instant-pot-cookbook-amazing-easy-healthy-and-delicious-recipes-by-amelia-braley_5b3e4d8c2533b94cdf5ec22c/]Instant Pot Cookbook: Amazing, Easy, Healthy and Delicious recipes. by Amelia Braley[/url] .
Adobe.Photoshop.CC.2017.v18.0.(x64-x86) FULL - 2016-11-17
Download: [url=http://menuiserie-papaix-toulouse.fr/layar-kaca-21]Nonton Layar kaca 21[/url] .
If Yoy Wanna Be Happy
Download: [url=http://504.fr/file/440804895/download-making-ideas-happen.pdf]Making Ideas Happen[/url] .
[??] ??? ??? ?? Captain America:The Firs…
Download: [url=http://location-cap-agde.fr/regarder_disney-channel-1.php]DISNEY CHANNEL + 1 en direct[/url] .
Snowden 2016 Web-DL 1080p 10bit 5 1 x265 HEVC-Qman[UTR] mkv
Download: [url=http://bluecrossrehabcenters.com/download/onerepublic-connection-musica-eXQtLWppTlIwczVSdDQ4.html]Download[/url] .
(??)?? ??? ??? ???(3.63GB)
Download: [url=http://kenyamusicawards.com/3137650797-dexter-walker-amp-zion-movement-hope-2018-hdtracks.html]Read More[/url] .
tortue ninja
Download: [url=http://amaraponjon.com/serie/serie/Game-of-Thrones/1/9-Baelor/OpenLoad]OpenLoad[/url] .
MyGirlfriendsBustyFriend 16 11 16 Karlee Grey XXX 1080p MP4-KTR[rarbg]
Download: [url=http://anb62.fr/assistir-social-animals/]Social Animals Assistir Social Animals 720p Dublado/Legendado Online TrГЄs adolescentes experientes com Instagram compartilham os prГіs e os contras de suas experiГЄncias em mГdia social. Ver filme Social Animals Dublado/Legendado Ver Filme F*cking People Dublado/Legendado (2017) Assistir Filmes Online em HD Assista filmes online HD na sua tv e celular - Trailer no youtube. Sinopse, elenco, direção, imagens e muito mais sobre o filme. Imagens do filme Social Animals ...[/url] .
BitLord.com
Download: [url=http://salondufoot.fr/tag/1/Короткометраж*]Короткометражка[/url] .
Chat IRC SSL
Download: [url=http://mespassions.fr/serie/Thunderbirds-Are-Go]Thunderbirds Are Go![/url] .
Jason Bourne 2016 BRRip XviD AC3-EVO
Download: [url=http://naturo.fr/vorgeschlagene-serien/vote:9610]San Francisco Airport[/url] .
dna for design
Download: [url=http://webhostfeed.com/]Contacto[/url] .
ForeX Trading for Maximum Profit
Download: [url=http://oneplacelease.com/watch-teen-titans-go-to-the-movies-2018-full-movie-online-5301.html](2018) Trailer Teen Titans Go! To the Mov..[/url] .
MEYD-202 mp4
Download: [url=http://myskinserum.biz/others/int/7426565-radha-prem-rangi-rangli-24th-june-2018-video-watch-online.html]Radha Prem Rangi Rangli 24th June 2018 Video Watch Online[/url] .
Anna 2016 Movie Free Download HD Cam
Download: [url=http://xxxsohbet.info/diziler/11-22-63-turkce-dublaj/]• 11.22.63 (Türkçe Dublaj) 7.5[/url] .
At Cafe 6 2016 1080p BluRay x264-ROVERS[PRiME]
Download: [url=http://el3y8.info/filmek/csaladi/legujabb/1]LegГєjabb[/url] .
GarageBand 10 1 for MAC-OSx
Download: [url=http://footlockersstore.com/films/telecharger/96740-under-control.html]Under Control TELECHARGEMENT GRATUIT[/url] .
The.Big.Bang.Theory.S10E05.720p.HDTV.X264-DIMENSION
Download: [url=http://itsanorangeworld.info/fun/6801237-sebastian-stan-a-spitting-image-for-mark-hamill-luke-skywalker.html]Sebastian Stan - a spitting image for Mark Hamill (Luke Skywalker)[/url] .
BitLord.com
Download: [url=http://rxouj.info/viewforum.php?f=102&sid=869caec33cd904261201171a05bc9b0f]Site Announcements[/url] .
Latest Movies
Download: [url=http://tocara.biz/search/index/word:гѓ‡гѓјгѓ€]гѓ‡гѓјгѓ€[/url] .
Popularity
Download: [url=http://damourfleurs.com/monde-de-narnia-lodyssee-passeur-daurore-streaming-vf/]Le Monde De Narnia : LOdyssГ©e Du Passeur Daurore[/url] .
Dubstep and Grime Sample Magic 15(A)
Download: [url=http://restaurant-amazone.fr/torrent/184780/geschieden-und-geil-razvedennie-i-pohotlivie-magma-film-2018-g-hardcore-oral-sex-gonzo-dvdrip]Geschieden und geil / Разведенные и Похотливые (Magma Film) [2018 г., Hardcore, Oral Sex, Gonzo, DVDRip][/url] .
stoltzman brahms
Download: [url=http://grueffelo.info/book/1094755295/download-kobane-calling-zerocalcare.pdf]Kobane Calling[/url] .
Legendado
Download: [url=http://dtvuy.info/book/515267706/download-.pdf]Муми-Тролль и комета Диафильм[/url] .
www.torrenting.com - Jason.Bourne.2016.HDRip.XViD.AC3-ETRG.[AVI]
Download: [url=http://freshfeelskin.com/Billionairech/More_Than_Perfect/Pages.html]More Than Perfect[/url] .
Supernatural-S09E01-HDTV-x264-LOL[ettv]
Download: [url=http://xjgjcw.info/actors/Chloe+McClay.html]Chloe McClay[/url] .
OO Defrag Professional Edition 20 0 Build 427 - 32bit 64bit [ENG] ...
Download: [url=http://hookerbird.info/korea-pop-charts]Korea Charts[/url] .
Terminator Genisys 2015 HD ????? ????? 6.6
Download: [url=http://qipuwv.info/torrent/185007/wdbc-ebony-sex-addicts-chernie-seks-narkomanki-reality-kings-2018-g-black-gonzo-interracial-dvdrip][WDBC] Ebony Sex Addicts / Черные секс-наркоманки (Reality Kings) [2018 г., Black, Gonzo, Interracial, DVDRip][/url] .
EXCELLENCE
Download: [url=http://hdiuk.info/preview?t=Sustainability+Balanced+Scorecard+-+insead&u=https%3A%2F%2Fflora.insead.edu%2Ffichiersti_wp%2Finseadwp2003%2F2003-30.pdf]Download[/url] .
Aldonova - A Portrait Of Aldonova
Download: [url=http://xjgjcw.info/actors/Peter+Graves.html]Peter Graves[/url] .
Heaven Strewn 2011 BDRip x264-VoMiT[1337x][SN]
Download: [url=http://grupoimovil.com/torrent/1283744/internet-download-manager-idm-6-30-build-7-full-repack-kpojiuk-4realtorrentz.html]Internet Download Manager (IDM) 6 30 Build 7 Full - Repack KpoJIuK [4REALTORRENTZ][/url] .
VHS to DVD Converter 7 85 Multilingual + Serial Key [SadeemPC]
Download: [url=http://inscrire.fr/index.php?accion=3&idusuario=2708&nick=varnak]Subttulos subidos: 18[/url] .
The Xtra Factor
Download: [url=http://mespassions.fr/serie/Birth-of-A-Beauty]Birth of A Beauty[/url] .
Downton Abbey S01-06e01-52 [Mux - XviD - Ita Eng Mp3 - Sub Ita Eng] BD/DLMux - By Pir8 FULL SERIES [TNT Village] [Isohunt.to]
Download: [url=http://rlhib.info/satelity-wywiadowcze-usa-2015/102416]Satelity wywiadowcze USA (2015)[/url] .
Cardboard Boxer 2016 720p BluRay 800MB ShAaNiG mkv
Download: [url=http://xjgjcw.info/actors/Alyssa+Milano.html]Alyssa Milano[/url] .
? ?? ??.E181.161111.720p-NEXT
Download: [url=http://jscateringservices.biz/actors/Junko+Nakazawa.html]Junko Nakazawa[/url] .
Star Trek
Download: [url=http://art-carvedchesssets.com/The_Risque_Contracts_Series/Pages.html]The Risque Contracts Series[/url] .
Black Massive Cocks
Download: [url=http://www.sosafrica.info/category/hip-hop-rap]Hip Hop / Rap[/url] .
BitLord.com
Download: [url=http://kenyamusicawards.com/3137650854-kasia-kowalska-aya-2018.html]Read More[/url] .
Recoiled
Download: [url=http://langitbiru.info/Alone-2015-torrent-10285]Alone (2015)[/url] .
JUKE BOX JIVE MIX
Download: [url=http://menuiserie-papaix-toulouse.fr/puppy/]Bluray 5.9 ”Puppy!” (2017)[/url] .
Pet Sematary 1989 Movie Free Download 720p BluRay
Download: [url=http://snj4v.info/release/rhalef-distorted-reality-2285949.html]Rhalef - Distorted Reality[/url] .
WWE Talking Smack 2016 11 15 WEB h264-HEEL [TJET]
Download: [url=http://unillnet.info/download/22817368/?format=epub]Download ePub[/url] .
Still Standing
Download: [url=http://jscateringservices.biz/actors/Robert+Keith.html]Robert Keith[/url] .
Yellowbird 2014 HD ????? ????? 5.5
Download: [url=http://footlockersstore.com/films/acteur/kanda-sayaka.html]Kanda Sayaka[/url] .
Ragga Ragga Casper Nyovest
Download: [url=http://yokamon.info/chinese-drama/3886-served-h-o-t-cantonese/]Served H.O.T. (Cantonese) - з‡’иіЈServed H.O.T. (Cantonese)[/url] .
Streaming internet TV - Watch TV shows pdf
Download: [url=http://canterburynewzealanddirect.info/power-2014-s04-ntsc-dvdr-jfkdvd?share=twitter]Click to share on Twitter (Opens in new window)[/url] .
WWE Smackdown Live 11 15 16 720p HDTV H264-XWT
Download: [url=http://spareofficial.com/sporttime-2-tv.php]Sporttime 2 TV en direct[/url] .
Blindspot S02E09 1080p HDTV X264 mp4
Download: [url=http://katzenkorb.info/movie/suits-season-7-2017-1080p.html]Eps16 Suits - Season 7 (2017)[/url] .
Tushy 16 11 17 Karla Kush And Arya Fae XXX SD MP4-RARBG
Download: [url=http://traxbangbeats.com/descargar/peliculas-castellano/estrenos-de-cine/vengadores-infinity-war-/ts-screener/]Vengadores Infinity War TS-Screener[/url] .
Skin Wars
Download: [url=http://rc6bh.info/ns-en-chine-french-dvdrip-2017.html]Ns en Chine FRENCH DVDRiP 2017[/url] .
Life on Mars
Download: [url=http://bamrak.info/nous-sommes-les-autres-french-webrip-2018.html]Nous sommes les autres FRENCH WEBRIP 2018[/url] .
Made In Chelsea S12E06 HDTV x264-TVC - [SRIGGA]
Download: [url=http://cribleum.info/actors/Patharawarin+Timkul.html]Patharawarin Timkul[/url] .
TS Massage [Transsensual]2015/WEBRip/SD
Download: [url=http://manningpeds.com/book/952183553/download-baronne-blixen.pdf]Baronne Blixen[/url] .
Grand Theft Auto V [RePack by Exile]
Download: [url=http://gs5qr.info/movie/chicago-syndicate-64137]Chicago Syndicate[/url] .
Pop Rock
Download: [url=http://dtvuy.info/top-books/9018/religion-and-spirituality]Religion and Spirituality[/url] .
themekiller.com
Download: [url=http://dwilegalrep.com/category/comedy-movies/ http://dwilegalrep.com/]Movies Counter[/url] .
Emma Roberts,
Download: [url=http://tortinnemo20.com/torrent/filmvidГ©o/sГ©rie-tv/275545-salvation+s02e02+fastsub+vostfr+1080p+webrip+x265+nsp]Salvation S02E02 (FASTSUB VOSTFR 1080p WEBRip x265 NSP)[/url] .
_My_Friends_Hot_Girl__11_17_2016_Jessa_Rhodes__Naughty_America__HD_720p mp4
Download: [url=http://trebolbets.com/film/genius-season-1-2017-1080p/]Eps10 Genius - Season 1 (2017)[/url] .
Krishna Gaadi Veera Prema Gaadha2016
Download: [url=http://mybaseservicedapartments.com/music-video-%e3%82%ad%e3%83%a5%e3%83%bc%e3%83%ab-dry-ai-20170802mp4rar/]в†’ Download[/url] .
Don Medellin Salmo Feat Rose Villain
Download: [url=http://hecmreversemort.info/films/annee/1999.html]film de 1999[/url] .
Albert Fish-News From The Front-2009-PMS
Download: [url=http://revetementbateautecksynthetique.com/threads/get-the-new-infinix-zero-5-pro-x603b-4g-phablet-now.162830/posts/1093675/]MINE ETHERUEM FREELY[/url] .
COURTNEY TAYLOR PUMA SWEDE 14 11 2016 mp4
Download: [url=http://xjgjcw.info/actors/Colleen+Craig.html]Colleen Craig[/url] .
WP Job Manager - Products v1.4.0
Download: [url=http://clearaccessmedia.com/book/375460056/download-be-the-pack-leader.pdf]Be the Pack Leader[/url] .
Brooklyn
Download: [url=http://sqribe.fr/search/fargo%20s01e10/]fargo s01e10[/url] .
Super Tela HD
Download: [url=http://xxxsohbet.info/wp-login.php?action=lostpassword]ParolamД± unuttum[/url] .
Дилъри
Download: [url=http://manningpeds.com/book/373406536/download-gagner-de-largent-en-bourse.pdf]Gagner de l'argent en Bourse[/url] .
Tasha Reign mp4
Download: [url=http://italianmaamasita.info/movies/on-the-ropes-2018-yify-1080p.html]Download[/url] .
?? NGC ??????? 10??
Download: [url=http://mespassions.fr/serie/Seiken-Tsukai-no-World-Break]Seiken Tsukai no World Break[/url] .
10-11-2016, 17:55
Download: [url=http://cribleum.info/actors/Brina+Palencia.html]Brina Palencia[/url] .
Brian Eno - Eno Box II: Vocals [Box 3CD][Flac][TntVillage] Music
Download: [url=http://jason-dunn-tattoo.com/stream-phoenix-mercury-w-vs-connecticut-sun-w-live-2]Stream Link 2[/url] .
katatonia
Download: [url=http://erkenbosalma.info/tag/horror-and-hamsters-film-complet/]Horror and Hamsters film complet[/url] .
The Blacklist
Download: [url=http://canterburynewzealanddirect.info/download/aHR0cHM6Ly93d3cudGhlbW92aWVkYi5vcmcvbW92aWUvMjg1MDIz]Movie Info[/url] .
Morgan Lee Tyler Nixon - Tyler Calls In His New Hire, Morgan Lee, For Some..., XXX, MPEG4(Xvid), C2x, HD 1080p, 0,5 FPS [Naughty Office] (Aug 15, 2016).avi [Isohunt.to]
Download: [url=http://amaraponjon.com/serie/Final-Approach]Final Approach[/url] .
Integrated Sports Massage Therapy - True PDF - 1793 [ECLiPSE]
Download: [url=http://manningpeds.com/book/409799279/download-dis-moi-o-tu-as-mal-je-te-dirai-pourquoi.pdf]Dis-moi oГ№ tu as mal, je te dirai pourquoi[/url] .
Miracles from Heaven - Miracoli dal cielo (2016).H264.Italian.English.Ac3.5.1.sub.Ita.Eng.iCV-MIRCrew [Isohunt.to]
Download: [url=http://paulmilamlistings.com/usearch/solomon kane/]solomon kane[/url] .
Next Page
Download: [url=http://mespassions.fr/serie/Der-6-Millionen-Dollar-Mann]Der 6-Millionen-Dollar-Mann[/url] .
Adobe Acrobat XI Pro 11 0 18 Multilingual + Crack [SadeemPC]
Download: [url=http://rigobetgiris.com/2016/12/]December 2016[/url] .
E-40 - The D-Boy Diary - Book 1 (2016)
Download: [url=http://pumpddmyass.info/watch/pxw1pLdz-the-dark-tower.html]The Dark Tower[/url] .
APES REVOLUTION - Il pianeta delle scimmie.2014. MD TS.Divx-Ita DJ.L[MT].avi
Download: [url=http://webhostfeed.com/ver/dragonball-super-2015-1x35.html]1x35 Dragon Ball Super[/url] .
Kings Of Beats 2
Download: [url=http://mespassions.fr/serie/The-Crow]The Crow[/url] .
Sing: TV Spot - In Theaters This Christmas
Download: [url=http://amaraponjon.com/vorgeschlagene-serien/vote:13038]Beyblade Metal Fury[/url] .
Jason Bourne 2016 1080p BRRip 1 8 GB - iExTV
Download: [url=http://xjgjcw.info/actors/Jimmy+O.+Yang.html]Jimmy O. Yang[/url] .
The Biggest Loser
Download: [url=http://jscateringservices.biz/actors/Troy+Baker.html]Troy Baker[/url] .
Game of Thrones
Download: [url=http://sqribe.fr/family-guy-s14e12-hdtv-x264-killers-ettv-t11922667.html]Family Guy S14E12 HDTV x264-KILLERS[ettv][/url] .
Read More
Download: [url=http://montanatitlecompany.info/anaarkali-of-aarah/]Watch Movie[/url] .
Sahasam Swasaga Sagipo - 2016 Telugu Full Movie [260p][x264][Lucifer22]
Download: [url=http://myskinserum.biz/others/unsorted/5610074-izombie-s01e03-hdtv-x264-lol.html]iZombie S01E03 HDTV x264-LOL[/url] .
Auto Express - 19 October 2016
Download: [url=http://jscateringservices.biz/actors/Kang+Chen.html]Kang Chen[/url] .
Penthouse Breast Friends XXX 2015 HDTV 720p x264-SHDXXX
Download: [url=http://amaraponjon.com/vorgeschlagene-serien/vote:12899]Taiho Shichau zo[/url] .
American Sniper The Autobiography of the Most Lethal Sniper in U S Military History by Jim DeFelice, Chris Kyle and ...
Download: [url=http://mespassions.fr/serie/Isekai-Izakaya-Koto-Aitheria-no-Izakaya-Nobu]Isekai Izakaya: Koto Aitheria no Izakaya Nobu[/url] .
Тиранин
Download: [url=http://agauc.info/torrent/zoo-tycoon-complete-collection_61443.html]Zoo Tycoon Complete Collection[/url] .
VO.Nightwatching (2007) [DVDRip + Ac3][English][www.zonatorrent.com]
Download: [url=http://kundensslveripay.info/electronics]Consumer Electronics[/url] .
Etat des services (tracker et site)
Download: [url=http://rxouj.info/viewtopic.php?f=124&t=2645950&sid=30c01a3090383046b46ead3b0428c731]The Land: Predators by Aleron Kong (.M4B)[/url] .
Me Before You 2016 PAL DVDR-EVO[SN]
Download: [url=http://amaraponjon.com/serie/Spezialeinheit-Metal-Jack]Spezialeinheit Metal Jack[/url] .
The Flash 2014 S03E06 HDTV XviD-FUM[ettv]
Download: [url=http://monjourdechance.fr/novel/A-Small-Death-in-the-Great-Glen-Joanne-Ross-1-8012]A Small Death in the Great Glen (Joanne Ross #1)[/url] .
Celebrity Antiques Road Trip S06E03 - Ruth Madoc and Su Pollard
Download: [url=http://jscateringservices.biz/actors/Chinmay+Chandraunshuh.html]Chinmay Chandraunshuh[/url] .
Shortcat 0.7.2 Beta (Mac)
Download: [url=http://mtptn-a.com/tags/Math+Metal/]Math Metal[/url] .
Stephen Donnelly,
Download: [url=http://windwardcasino.com/watch/EdZ0n9xp-wok-of-love.html]Wok Of Love[/url] .
Morgan Lee Tyler Nixon - Tyler Calls In His New Hire, Morgan Lee, For Some..., XXX, MPEG4(Xvid), C2x, HD 1080p, 0,5 FPS [Naughty Office] (Aug 15, 2016).avi [Isohunt.to]
Download: [url=http://grueffelo.info/book/484983669/download-comprendere-il-linguaggio-del-cane-valeria-rossi.pdf]Comprendere il linguaggio del cane[/url] .
Snowde 2016 720p WEB-DL x264 AC3-Moita[PRiME]
Download: [url=http://yhisip.info/2018/04/]abril 2018[/url] .
Road Movie 179
Download: [url=http://frasesparavoce.com.br/tag/business-economics]Business Economics[/url] .
Late.Summer.2016.720p.BluRay.H264.AAC- ESUB-RARBG
Download: [url=http://naturo.fr/vorgeschlagene-serien/vote:12812]Murdoch Mysteries[/url] .
Jason Bourne 2016 720p Bluray x264 HQ AC3-CPG
Download: [url=http://trylumivol.com/xxx/rencontres.php]Rencontres[/url] .
Satisfaction US
Download: [url=http://dtvuy.info/book/506019939/download-largo-winch-tome-14-la-loi-du-dollar.pdf]Largo Winch - Tome 14 - La loi du dollar[/url] .
Teenage Mutant Ninja Turtles: Out of the Shadows (2016)
Download: [url=http://flyseasons.com/movie/nGEkDnvb-tomb-raider.html]Tomb Raider[/url] .
Bigg Boss Kannada S04 E39.1 - NightShift - HDTv - AAC - SAN.mkv
Download: [url=http://hookerbird.info/mp3/blackpink.html]BLACKPINK[/url] .
[Clips4Sale PrimalFetish] Cherie DeVille (I'm All Mom Needs) 480p [Incest Ro...
Download: [url=http://xqf0n.info/film/a-bugs-life-wzm]Eps1 A Bugs Life[/url] .
National Geographic
Download: [url=http://jscateringservices.biz/actors/Osamah+Sami.html]Osamah Sami[/url] .
VMWare ThinApp Enterprise 5 2 2 Build 4435715 + License Keys
Download: [url=http://xjgjcw.info/genres/reality-tv.html]Reality-TV[/url] .
Kas?m 2010 (1182)
Download: [url=http://gobola77.com/movies/berlin-falling-2017-yify-1080p.html]Download[/url] .
Dawn of the Planet of the Apes DvDrip AC3
Download: [url=http://laredophysiciansgroup.info/a-inveja-mata/]A Inveja Mata Assistir A Inveja Mata 720p Dublado/Legendado Online Tim (Ben Stiller) e Nick (Jack Black) sГЈo vizinhos, trabalham juntos e sГЈo tambГ©m grandes amigos. PorГ©m a amizade entre eles fica abalada apГіs um dos planos mirabolantes de Nick, o "Evaporizador", um spray que faz com que fezes de cachorro ou qualquer outra porcaria simplesmente seja evaporado no ar, comece a fazer um ...[/url] .
Сезон 6 БГ СУБТИТРИ
Download: [url=http://rampageforandroid.info/directory/actividadesedo0]actividad-n2-da-s -> actividades-edo[/url] .
Above Suspicion (2009-2012) Crime Drama
Download: [url=http://1j7c.info/engine/go.php?file2=[1j7c.info]Westworld-S02E09-Vanishing-Point-1080p-AMZN-WEB-DL-6CH-MkvCage-MKV.torrent]Westworld S02E09 Vanishing Point 1080p AMZN WEB-DL 6CH MkvCage MKV[/url] .
30 Something Grandma S01E01 Adventures Of Patricia HDTV x264-[NY2] - [SRIGGA]
Download: [url=http://chauffeurs-service.fr/descargar-pieces-of-talent-66869.fx]Pieces Of Talent - 2014[/url] .
Beach Sex mp4
Download: [url=http://revetementbateautecksynthetique.com/help/trophies]Trophies[/url] .
APES.REVOLUTION.Il.Pianeta.Delle.Scimmie.2014.BluRay.1080p.MD.iTALiAN-AAC5.1.EnG.X264-TrTd_TeaM
Download: [url=http://clearaccessmedia.com/book/426828065/download-the-simple-guide-to-tea.pdf]The Simple Guide To Tea[/url] .
Misterio
Download: [url=http://montanatitlecompany.info/watch-yemaali-2018/]Watch Movie[/url] .
Adware Doctor 1 1 for MAC-OSx
Download: [url=http://knottedknitters.com/candy-jar-french-webrip-2018.html]Candy Jar FRENCH WEBRIP 2018[/url] .
Comments(3)
Download: [url=http://gitgot.info/02141920-min-hast-07-juni-2018/]Min Hast – 07 juni 2018[/url] .
??? ???
Download: [url=http://greece4d.info/tag/mega-series-torrent/]mega series torrent[/url] .
VA- In Search Of Sunrise 9 India Mixed By Richard Durand-2CD-2011-QMI
Download: [url=http://dealsealer.biz/rubrique/280/exegese]ExГ©gГЁse[/url] .
Transformers Dark of the Moon 2011 Free Download 720p BluRay
Download: [url=http://snj4v.info/track/moby-the-tired-and-the-hurt-original-mix-10070305.html]Moby - The Tired And The Hurt (Original Mix)[/url] .
9.[??????][???????19???????][mmconan sub(2011)][??-720p][mkv]
Download: [url=http://roundtabletechnology.info/watch-on-my-block-online/]On My Block[/url] .
Discographie complete Deva premal(A)
Download: [url=http://u237s.info/tvshows/are-you-human/]Ep.15-16 7 Are You Human? (2018)[/url] .
[cover] ????
Download: [url=http://rlhib.info/pogarda-1963/175257]Pogarda / Le MГ©pris (1963)[/url] .
Reading Comprehension and Reading Skills (1st Grade Basic Skills)
Download: [url=http://mespassions.fr/serie/24-Live-Another-Day]24: Live Another Day[/url] .
Chicago Fire S05E05 HDTV XviD-FUM[ettv]
Download: [url=http://xjgjcw.info/actors/Elvis+Tsui.html]Elvis Tsui[/url] .
Taylor Sheridan
Download: [url=http://robesoie.fr/book/1098574225/download-campioni-si-diventa-marco-cassardo.pdf]Campioni si diventa[/url] .
MIAD631AVI
Download: [url=http://escuelasamigables.info/go-team-health-net.html]Go team! - Health Net[/url] .
Support / Help
Download: [url=http://mespassions.fr/vorgeschlagene-serien/vote:11096]Carver Kings[/url] .
Terry Dale Parks
Download: [url=http://dominoemas.com/category/bakers-man-2017/]Baker's Man (2017)[/url] .
Boobless s1 with Addison Rose mp4
Download: [url=http://clearaccessmedia.com/book/516501780/download-doyle-brunsons-super-system-2.pdf]Doyle Brunson's Super System 2[/url] .
Reconstructing Reality Models, Mathematics, and Simulations
Download: [url=http://nouvelles-idees.fr/pacific-rim-uprising-2018-en-streaming-vk.html]Pacific Rim Uprising 2018[/url] .
Gregory Cruz
Download: [url=http://josemaron.com/watch-only-the-brave-2017-full-movie-online-14-5364.html](2017) HDRip Only the Brave[/url] .
Microsoft Excel (15 14 0) Mac (OS X)
Download: [url=http://knottedknitters.com/abdel-et-la-comtesse.html]ABDEL ET LA COMTESSE[/url] .
Comme des betes
Download: [url=http://clearaccessmedia.com/book/506093309/download-some-remarks.pdf]Some Remarks[/url] .
[WSRN-Licca] Mermaid Melody Pichi Pichi Pitch Pure - 31 [DVD H264 640x480] [4364F221].mkv
Download: [url=http://naturo.fr/serie/serie/How-I-Met-Your-Mother]How I Met Your Mother[/url] .
Designated.Survivor.S01E07.HDTV.x264-LOL[ettv]
Download: [url=http://betastries.com/m/1/Pitbull+-+Feel+This+Moment+feat.+Christina+Aguilera.flac.html]Pitbull - Feel This Moment feat. Christina Aguilera.flac[/url] .
A Married Woman (1964) Francais DVD5 - Eng Subs - Macha Meril, Phillippe Leroy [DDR]
Download: [url=http://xqf0n.info/film/a-midsummer-nights-dream-uji]Eps1 A Midsummer Nights Dream[/url] .
Pitch Perfect 2012 Free Movie Download HD 720p
Download: [url=http://htcmaritimeagency.com/browse-movies/Noah+Jupe]Noah Jupe[/url] .
x264 dimension
Download: [url=http://ufoxl.info/emule-top-series]Top SГ©ries TV du mois[/url] .
Venus in Fur 2013 HD ????? ????? 7.2
Download: [url=http://cribleum.info/actors/Fred+Tatasciore.html]Fred Tatasciore[/url] .
Contacts
Download: [url=http://del.icio.us/post?url=http://kapkataalkin.info/tutorial.html&title=%E5%85%8D%E8%B4%B9+%E7%94%B5%E8%84%91%E6%95%99%E7%A8%8B+--+ebookee%E5%85%8D%E8%B4%B9%E8%8B%B1%E6%96%87%E7%94%B5%E5%AD%90%E5%9B%BE%E4%B9%A6%E4%B8%8B%E8%BD%BD%EF%BC%8C%E7%94%B5%E5%AD%90%E4%B9%A6%E6%90%9C%E7%B4%A2%E5%BC%95%E6%93%8E%21]del.icio.us[/url] .
This Is Us S01E07 720p HDTV x264-FLEET[PRiME]
Download: [url=http://qipuwv.info/torrent/186124/premiumbukkake-com-kattie-hill-1-bukkake-29-06-18-2018-g-blowjob-bukkake-swallow-facial-480p][Premiumbukkake.com] Kattie Hill #1 (Bukkake / 29.06.18) [2018 Рі., Blowjob, Bukkake, Swallow, Facial, 480p][/url] .
(2017) HD Trailer Untitled Wolverine Sequel
Download: [url=http://supremeoff.com/watch-barbarians-rising-online/]Barbarians Rising[/url] .
WonderFox DVD Ripper Pro 8 1 + KeyGen zip
Download: [url=http://hotelcroatie.com/xfsearch/Alopecia/]Alopecia[/url] .
Alfred (2 8) Mac (OS X)(1)
Download: [url=http://supremeoff.com/2018/07/the-affair-season-4-episode-3/]0 comments[/url] .
Alain Delon - Cinema Collection
Download: [url=http://jscateringservices.biz/actors/Will+Beinbrink.html]Will Beinbrink[/url] .
Expedition Unknown
Download: [url=http://korea50.biz/B01CIQD6K4/goal-setting-the-10-step-method-to-becoming-an-unstoppable-goal-achiever-goals-habits-goal-setting-english-edition.html]Goal Setting The 10 Step Method To Becoming An Unstoppable Goal Achiever Goals Habits Goal Setting English Edition[/url] .
Batman vs Superman (2016) - 720p - HD-TC - 1GB - GoenWae
Download: [url=http://newprdirectory.info/torrent/3703594/mira-grant-newsflesh-0-5-prequel-novella%2C-countdown.html]Mira Grant - Newsflesh 0 5 - Prequel Novella, Countdown[/url] .
Hide.Your.Smiling.Faces.2013.720p.BluRay.x264-SONiDO[rarbg]
Download: [url=http://tortinnemo20.com/torrent/jeu-vidГ©o/nintendo/275013-3ds+cia+etrian+mystery+dungeon+eur][3DS CIA] Etrian Mystery Dungeon (EUR)[/url] .
Windows_Loader_v3.1.6! [Isohunt.to]
Download: [url=http://jscateringservices.biz/actors/John+Arnold.html]John Arnold[/url] .
Snowden 2016 1080p WEB-DL 6CH 2 2GB MkvCage mkv
Download: [url=http://domino22.com/film/fOA/The-Leisure-Seeker?episod=1]IMDb: 6.5 HD The Leisure Seeker[/url] .
Tony Corvillo,
Download: [url=http://supremeoff.com/watch-humans-online-2015/]Humans 2015[/url] .
????(11)
Download: [url=http://kapkataalkin.info/Working-Memory-and-Clinical-Developmental-Disorders_3661561.html]Working Memory and Clinical Developmental Disorders[/url] .
[Raw] Hunter x Hunter - Phantom Rouge (BD 1280x720 x264 AAC).ass
Download: [url=http://fvgiment.info/movies/topimdb]TOP IMDb[/url] .
Read More
Download: [url=http://gobola77.com/movies/acrimony-2018-yify-1080p.html]Download[/url] .
2 Comments
Download: [url=http://laredophysiciansgroup.info/ele-disse-ela-disse/]Ele Disse, Ela Disse Assistir Ele Disse, Ela Disse 720p Dublado/Legendado Online Dan e Lorie formam um jovem casal de jornalistas que trabalha na mesma emissora de TV. Muito frequentemente eles travam acalorados embates por não compartilharem das mesmas opiniões. É quando o produtor percebe que ali está um ótimo material. E assim decide criar um programa só para os dois, chamado “Ele Disse, Ela ...[/url] .
Pretty Pink Please Don T Leave Me Stefano Noferini Remix
Download: [url=http://gamegamegame.info/2017-movies/marshall-2017-movie-free-download-720p-bluray/]Marshall 2017 Movie Free Download 720p BluRay[/url] .
The Big Bang Theory S02E18 HDTV XviD XOR [eztv]
Download: [url=http://53gmgm.com/feedback.php]! Обратная связь[/url] .
devildriver trust no one
Download: [url=http://www.facebook.com/sharer.php?u=http://vulnerabilite.fr/?p=25537]Facebook[/url] .
DC Comics Chronology - Fill Pack 92 [coringo][h33t]
Download: [url=http://rlhib.info/videos/all?type=&year=&version=&genre=64]szpiegowski[/url] .
Bewakoofiyaan.mp4
Download: [url=http://vbarto.com/torrent/zulk6dex/The+Songrise+Orchestra+-+The+Music+Of+Cliff+Richard+-+(1995)-[FLAC]-[TFM].html]The Songrise Orchestra - The Music Of Cliff Richard - (1995)-[FLAC]-[TFM][/url] .
mide375 mp4
Download: [url=http://clearaccessmedia.com/book/639607372/download-o-essencial-sobre-marcel-proust.pdf]O essencial sobre Marcel Proust[/url] .
Claire Corlett,
Download: [url=http://nadal.fr/atls-manual-10th-edition-pdf-s3amazonawscom.html]ATLS MANUAL 10TH EDITION PDF - s3.amazonaws.com[/url] .
SAM LE POMPIER S3
Download: [url=http://504.fr/file/877702345/download-eat-nourish-glow-winter.pdf]Eat. Nourish. Glow – Winter[/url] .
The Infiltrator (2016)
Download: [url=http://dominoemas.com/made-for-each-other-1939-watch-online-movie-free/]Made for Each Other (1939)[/url] .
Kuch To Hua Hai Kal Ho Naa Ho Piano Tutorial Piano Daddy
Download: [url=http://clearaccessmedia.com/book/1034500053/download-the-walking-dead-146.pdf]The Walking Dead #146[/url] .
Aclands.DVD.Atlas.-.Human.Anatomy.2of6.lower.extremity.Divx6.mp3.wogre.avi
Download: [url=http://tinbongda24h.com/um-lugar-silencioso-2018-torrent-bluray-720p-e-1080p-legendado-download/]BAIXAR FILME[/url] .
Emergency 2017 - 2016 (MAC GAME)
Download: [url=http://grosbet400.com/izle/elementary-2-sezon-17-bolum]2. sezon 17. Bölüm[/url] .
Gotham S03E09 720p HDTV X264-DIMENSION[rarbg]
Download: [url=http://bgaddress.com/printthread.php?tid=30402]Konuyu YazdД±r[/url] .
Nacional
Download: [url=http://wettenbet10.com/tags/Computational/]Computational[/url] .
fundamental laws of mechanics pdf
Download: [url=http://hemen-oyna.com/how-download-pdf-book/the-art-of-cinema-208956.php]The Art of Cinema[/url] .
Dilwale 2015 HD ????? ????? 5.5
Download: [url=http://josemaron.com/watch-loving-vincent-2017-full-movie-online-1-7212.html](2017) DVD Loving Vincent[/url] .
ATKHairy 16 11 16 Penelope Reed Toys XXX 1080p MP4-KTR[rarbg]
Download: [url=http://jason-dunn-tattoo.com/stream-the-ultimate-fighter-27-finale-:-julian-marquez-vs-alessio-di-chirico-live-2]Stream Link 2[/url] .
Hollywood Said No!: Orphaned Film Scripts, Bastard Scenes, and Abandoned Darlings from the Creators of Mr. Show
Download: [url=http://yhisip.info/category/american-animals-2018/]American Animals (2018)[/url] .
Gold 2016 Movie Download Full HD DVDRip
Download: [url=http://gitgot.info/02090910-mickey-junior-juin-2018/]Mickey Junior – juin 2018[/url] .
Alesana - Discography - 2005-2010
Download: [url=http://naturo.fr/serie/Mutant-X]Mutant X[/url] .
Batman vs Superman Dawn of Justice (2016) 720p BluRay x264 [Dual Audio] [Hind...
Download: [url=http://naturo.fr/serie/der-letzte-bulle]Der letzte Bulle[/url] .
Read More
Download: [url=http://defreat.info/series/freakish/3787]Freakish HDTV[/url] .
Unforgettable
Download: [url=http://naturo.fr/serie/random/serie/Family-Guy]Zufällige Episode[/url] .
Gore Flicks
Download: [url=http://monjourdechance.fr/novel/Dead-Man's-Eye-7603]Dead Man's Eye[/url] .
American Sniper 2014 DVDSCR x264 AC3 TiTAN
Download: [url=http://gitgot.info/category/geographical/]Geographical[/url] .
Microsoft Office 2016 for Mac VL v15.28.0 (Mac OS X)
Download: [url=http://italianmaamasita.info/movies/shelter-2014-yify-720p.html]Download[/url] .
Real Time With Bill Maher
Download: [url=http://gitgot.info/02275914-airports-international-june-2018/]Airports International – June 2018[/url] .
FamilyStrokes - Alexis Fawx_720p mkv
Download: [url=http://roundtabletechnology.info/watch-american-horror-story-online/]American Horror Story[/url] .
[Coalgirls] Umineko no Naku Koro ni (1920x1080 Blu ray FLAC)
Download: [url=http://freshfeelskin.com/Billionairech/Accidentally_Married_to_the_Billionaire_3/Pages.html]Accidentally Married to the Billionaire 3[/url] .
????? ????(K).nds
Download: [url=http://ag-8989.com/torrent/real-time-with-bill-maher-2017-08-04-hdtv-x264-uav-ettv--49160]Real.Time.With.Bill.Maher.2017.08.04.HDTV.x264-UAV[ettv][/url] .
Greatest Hits By Guns N' Roses
Download: [url=http://kapkataalkin.info/H-Du-Rusquec-Dictionnaire-fran-ais-breton_3661086.html]H. Du Rusquec - Dictionnaire français-breton[/url] .
Facebook
Download: [url=http://laredophysiciansgroup.info/a-grande-jogada/]A Grande Jogada Assistir A Grande Jogada 720p Dublado/Legendado Online ApГіs perder a chance de participar dos Jogos OlГmpicos, a esquiadora Molly Bloom (Jessica Chastain) decide tirar um ano de folga dos estudos e ir trabalhar como garГ§onete em Los Angeles. AtravГ©s de circunstГўncias curiosas, ela acaba se tornando milionГЎria e famosa por organizar os mais exclusivos jogos de pГґquer da regiГЈo. Ver filme A ...[/url] .
Me Before You 2016 HD
Download: [url=http://domino22.com/tv/4T/Castle-Season-3?episod=1]IMDb: 8.2 S3E24 Castle - Season 3[/url] .
Driftmoon-(R)Evolution-(ABRD126)-WEB-2016-SPANK [EDM RG]
Download: [url=http://jscateringservices.biz/actors/Kristian+Bruun.html]Kristian Bruun[/url] .
corbin fisher(30)
Download: [url=http://traxbangbeats.com/series/coach-snoop/3683]Coach Snoop HDTV[/url] .
Disaster 162
Download: [url=http://mespassions.fr/serie/Princess-Principal]Princess Principal[/url] .
Bis 2015 ????? ????? 5.4
Download: [url=http://art-carvedchesssets.com/Warrior_s_Pain/Pages.html]Warrior's Pain (Cadi Warriors Book 4)[/url] .
BitLord.com
Download: [url=http://inscrire.fr/index.php?accion=3&idusuario=2015774&nick=Dax15]Subttulos subidos: 24[/url] .
Watch Justin Bieber cry while performing ‘Purpose’ at gig in Germany
Download: [url=http://amaraponjon.com/serie/Die-kleine-Prinzessin-Sara]Die kleine Prinzessin Sara[/url] .
雪魄梅魂
Download: [url=http://mm33.biz/jeux/jeux-pc/155166-the-sunset-2096.html]The Sunset 2096 [PC][/url] .
Capitalism
Download: [url=http://naturo.fr/serie/Switch-Reloaded]Switch Reloaded[/url] .
Captain America Civil War 2016 TrueFrench AAC BDri...(A)
Download: [url=http://jeloser.info/2016/07/]July 2016 (2978)[/url] .
Finding Dory (2016)
Download: [url=http://dininginnh.com/stream-court-5-:-irina-camelia-begu/mihaela-buzarnescu-vs-daria-gavrilova/vera-lapko-live-3]Stream Link 3[/url] .
Great Artists in Their Own Words S01E01 - The Future Is Now (1907-1939)
Download: [url=http://naturo.fr/vorgeschlagene-serien/vote:13009]hanamaru youchien[/url] .
batman vs superman
Download: [url=http://diegorangel.com.br/torrent/ga16gt2w/DorcelClub+Alexis+Crystal,+Tiffany+Tatum+-+Royal+Lover+04.05.2018+Rq.html]DorcelClub Alexis Crystal, Tiffany Tatum - Royal Lover 04.05.2018 Rq[/url] .
Paranoid Season 1 Complete HDTV x264 [i_c] [Isohunt.to]
Download: [url=http://imprssn.info/dmca]DMCA Contact[/url] .
Alan Bennett - Drottningen Vnder Blad
Download: [url=http://naturo.fr/serie/Hoozuki-no-Reitetsu]Hoozuki no Reitetsu[/url] .
elementary
Download: [url=http://gobola77.com/movies/pets-1974-yify-1080p.html]Download[/url] .
Criminal Minds
Download: [url=http://bestadsnetwork.com/download-lagu-fourtwnty-tak-selalu-indah-mp3/]Fourtwnty - Tak Selalu Indah[/url] .
Continent 7-Antarctica S01E01 Storming Antarctica HDTV x264-SDI - [SRIGGA]
Download: [url=http://defreat.info/series-hd/wild-chile/3945]Wild Chile HDTV 720p AC3 5.1[/url] .
YellowBird (2015) [DVD9 - MultiLang 5.1 - Eng subs]
Download: [url=http://montanatitlecompany.info/series/succession/]Watch Series[/url] .
Icecream Slideshow Maker v2 13 - Full rar
Download: [url=http://cicektekalite.com/movie/zGOJDexK-little-witch-academia-tv-dub.html]Little Witch Academia ...[/url] .
Alberich - 2010 - NATO-Uniformen
Download: [url=http://yourbusinessgame.info/genre/science-fiction/]Science Fiction[/url] .
Doctor Doctor - S01E09 mkv
Download: [url=http://fvgiment.info/film/fist-of-legend-zuh]Eps1 Fist of Legend[/url] .
Suicide Squad 2016 720p WEB-DL X264 PapaFatHead mp4[SN]
Download: [url=http://gmodeconomy.com/torrent/1306219/cyberlink-screen-recorder-deluxe-3-0-0-2930-precrackcracks4win.html]CyberLink Screen Recorder Deluxe 3 0 0 2930 PreCrack[cracks4win][/url] .
Fantastic Beasts and Where to Find Them HDRip FULL FUM
Download: [url=http://604princess.com/actores/14705-james-corden]James Corden[/url] .
Wallpapers & Graphics
Download: [url=http://markauesassmake.info/lista-series-populares/recuperarclave/]Recuperar ContraseГ±a[/url] .
High Strung 2016 BRRip XviD AC3-EVO[PRiME]
Download: [url=http://greece4d.info/tag/filmes-mais-baixados/]Filmes Mais Baixados[/url] .
the walking dead
Download: [url=http://domino22.com/tv/3l/Youre-All-Surrounded?episod=1]IMDb: 8.2 S1E20 Youre All Surrounded[/url] .
The 11th Hour with Brian Williams 2016 11 16 720p WEBRip x264-LM
Download: [url=http://footballmondial.fr/les-razmoket-le-film-streaming-vf/]Les Razmoket, Le Film[/url] .
9 Found Footage Films
Download: [url=http://restaurant-amazone.fr/torrent/186172/realtimebondage-com-luna-lovely-amp-eden-sin-lovely-suffering-part-3-23-06-2018-2018-g-bdsm-bondage-humilation-torture-tattoo-vibrator-720p-hdrip][RealTimeBondage.com] Luna Lovely Eden Sin (Lovely Suffering: Part 3 / 23.06.2018) [2018 Рі., BDSM, Bondage, Humilation, Torture, Tattoo, Vibrator, 720p, HDRip][/url] .
[Naruto-Grand.Ru] Shingeki no Kyojin 17 [RUS DUB] [1080p].mkv
Download: [url=http://takelicense.com/series-hd/desaparecidas-en-el-lago/3974]Desaparecidas En El Lago HDTV 720p AC3 5.1[/url] .
The Amazing World of Gumball
Download: [url=http://alsubhigroup.com/category/5/astronautics-space-flight]Astronautics & Space Flight[/url] .
Ruby Barnhill
Download: [url=http://opjackpot.net/tvshow-793-2.html]The Addams Family[/url] .
Ccleaner v5 22 5724 Professional + All Edition Keys [4realtorrentz] zip
Download: [url=http://ucanprep.net/category/229/idol-school]Idol School[/url] .
a??a…‹c?¤ Nanana
Download: [url=http://aiii.pl/?do=redirect&link=b2tzTEdqYTdkaGh0NkdnMXgxWUVQdE1xVWNRT3psMWNMUjZEZmpnQng3QVpPQU51S3l4TU84YnZDcld5VlZuQloyZEhCNmFKMmtsZ1pqT0NvS1NOU2ppeldDZHJ1V2VKd0p3L2w4Vll3NEE5T2tLQmxZWnZYR1VCamdxNmtjemxDUUhJUnZxNmwwQzlDUGRSanlXOUxUQ3kxVGIvYS82YkYzS3NpL3M2STZBd1dzUjI2Z0hKQjRZTnMxbzZPNktLVEZpSHVYQ2hzYUZrUmpqYWw3Nm40VmNrZWYwSGJic1R5dHZ4ckNpTFhPTT0=]TГ©lГ©charger Part 4[/url] .
Isaac Asimov - Fantastic Voyage (PDFamp;EPUBamp;MOBI)
Download: [url=http://onpointtaxservice.biz/software/4011-iron-17010000-portable.html]Iron 17.0.1000.0 Portable[/url] .
BitLord.com
Download: [url=http://urindy.com/video-movie-ketawa-sampai-tumpah2-tik-tok-lucu-ter-viral.iKGCiWhokIqreJg.html]KETAWA SAMPAI TUMPAH2 - TIK TOK LUCU TER VIRAL[/url] .
BitLord.com
Download: [url=http://blockchainn.info/9xmovies/]9xmovies[/url] .
City on Fire (1979) Xvid - Barry Newman, Susan Clark, Shelley Winters [DDR]
Download: [url=http://myfundcards.com/999-nu-hon-ba-dao-cua-nam-than-chap-228/]999 Nụ Hôn Bá Đạo Của Nam Thần – Chap 228[/url] .
Jodi West wmv
Download: [url=http://fixesallgeminitoday.us/show/LeapFrog-1JMCu.html]LeapFrog[/url] .
Money (2016) [720p] [Pinkihacks]
Download: [url=http://dsd07.com/torrent/d3l3w0o4/Doraemon+-+Il+film+Nobita+e+la+nascita+del+Giappone+(201617).XviD.italian.Ac3-5.1.jap.mp3.sub.ita.MIRCrew.html]Doraemon - Il film Nobita e la nascita del Giappone (2016/17).XviD.italian.Ac3-5.1.jap.mp3.sub.ita.MIRCrew[/url] .
Boardwalk Empire
Download: [url=http://sanei.us/add-ons/gradients/85332-nuts-and-seeds-gradients-2580993.html]Nuts and Seeds Gradients 2580993[/url] .
BitLord.com
Download: [url=http://choosetruth.com/album/torrent-268927-florence-the-machine-high-as-hope-2018]Florence + The Machine - High As Hope (2018)[/url] .
A Million WAys to Die in the West (2014)TS Xvid-26k
Download: [url=http://onesourcepoolsupplystore.com/watch86/Greys-Anatomy/season-04-episode-03-Let-the-Truth-Sting]Let the Truth season 04 episode 03[/url] .
nightcap.2016.s01e02.720p.hdtv.hevc.x265.rmteam.mkv
Download: [url=http://mariobet830.com/torrent/148567]VMware Workstation Pro v12.1.1 x64 + Key VMware Workstation Pro v12.1.1 x64 + Key[/url] .
Trophy Wife
Download: [url=http://bkht.org/movies/deadpool-2.html]Deadpool 2[/url] .
Hotspot Shield VPN Elite 6.20.10 Multilingual + Crack [SadeemPC]
Download: [url=http://walmarhome.com/polymer-science-gowariker-pdf]Polymer Science - Gowariker.pdf[/url] .
sci fi movies
Download: [url=http://sportsnet.info/manhattan-nocturne-2016-french-720p-webrip-x264-kira-s58l34/]Manhattan.Nocturne.2016.FRENCH.720p.WEBRiP.x264-KiRa (S:58/L:34)[/url] .
Branded (1950) Western Xvid 1cd - Alan Ladd, Mona Freeman, Charles Bickford [...
Download: [url=http://onpointtaxservice.biz/magazine/2196-magbook-ipad-for-kids-2012-hq-pdf.html]MAGBOOK iPad for Kids 2012 HQ PDF[/url] .
Digital Film Tools Film Stocks 2 0v10 (x64) rar
Download: [url=http://wxmyst.com/watch/nGEX4nxb-mr-neighbors-house-2.html]Mr Neighbors House ...[/url] .
??(36)
Download: [url=http://botiantang8.com/download/folio-geografi-tingkatan-2-komposisi-penduduk-dengan-jenis-pekerjaan_573805ddb6d87f36568b4569_pdf]Folio Geografi Tingkatan 2 - Komposisi Penduduk Dengan Jenis Pekerjaan[/url] .
Maria's Travel Journal
Download: [url=http://paperpopart.com/torrent/585074/sonic-mania-v-1.03-2017-pc-licenzija]Sonic Mania [v 1.03] (2017) PC | Лицензия[/url] .
Jason bourne 2016 1080p bluray x264-NBY-[moviezplanet in] mkv
Download: [url=http://urindy.com/movies/biography-movies/?search_query=Biography-Movies&sp=SGTqAwA%253D]6</span>[/url] .
Rock N Roll By Led Zeppelin The Regulars Band Cover
Download: [url=http://tytera.nl/torrent/1510228/%EC%8B%9C%EC%A0%90-e12-180714-720p.html]м‹њм ђ E12 180714 720p-NEXT[/url] .
People of Earth
Download: [url=http://bestofautomotive.us/actors/malina-weissman.html]Malina Weissman[/url] .
Meet the Blacks (2016)
Download: [url=http://benjabetingirisi.com/hk-show/3964-k-s-for-korea-sr-2/]K's For Korea (Sr.2) - K小姐懶人包K's For Korea (Sr.2)[/url] .
Alan Jackson - Like Red On A Rose
Download: [url=http://opjackpot.net/tvshow-1841-4.html]People Just Do Nothing[/url] .
Hurtworld v0.3.7.4 x64 crack RVTFIX #Kortal [Isohunt.to]
Download: [url=http://jakobstube.com/Doctor-Who-saison-11-episode-2-streaming]Episode 2[/url] .
Alexander Skarsgrd,
Download: [url=http://sportzetc.com/book/1364407040/download-eravamo-immortali-manolo.pdf]Eravamo immortali[/url] .
The Podge Rodge Show
Download: [url=http://geekershop.com/pelicula/total-recall/]Total Recall TS-Screener[/url] .
Rustom (2016) - Blu-Ray - X264 - DTS - ESubs - 1080P - 3 6GB [Team Jaffa] mkv
Download: [url=http://opjackpot.net/tvshow-2536-1.html]Date My Dad[/url] .
Download Psychic warfare by clutch for free
Download: [url=http://amazingpractice.info/tw/video-player-all-format-for-android/free.online.hd.video.player/download?from=home%2Ftopic%2Ftop-new-apps]дё‹иј‰ APK[/url] .
BitLord.com
Download: [url=http://estacbpcare.info/watch-almost-christmas-movie-online-free-putlocker-2.html]Almost Christmas[/url] .
Eastenders.2013.02.26.PDTV.x264-Deadpool
Download: [url=http://modapoly.com/tags/Medieval/]Medieval[/url] .
[R G Mechanics] Call of Duty 4 Modern Warfare - Remastered
Download: [url=http://vidhosters.org/download/how-to-make-my-computer-faster-bangla/]How To Make My Computer Faster Bangla[/url] .
[AnimeRG] Nanbaka - 07 [720p] [Multi-Sub] [x265] [pseudo] mkv
Download: [url=http://grand-bet777.com/movie/0162535133-the-83rd-annual-academy-awards]6.3 03 h 14 minThe 83rd Annual Academy Awards[/url] .
[P] Lodge - 1988 - Smell Of A Friend (FLAC 24-48, vinyl, Antilles-Island ISL 1176)
Download: [url=http://ju034.com/drama-detail/world-of-silence]World Of Silence[/url] .
Snowden 2016 HDRip AC3 2 0 x264-BDP[PRiME]
Download: [url=http://imaxinterior.com/chapter/tomochan_wa_onnanoko/chapter_245]Chapter 245[/url] .
Droga Bez Powrotu 2 2007
Download: [url=http://alsubhigroup.com/category/2267/unit-operations-transport-phenomena]Unit Operations & Transport Phenomena[/url] .
Mafia 3 Rivals - 2016 - FOR - MAC
Download: [url=http://saeedrajaee.com/watch-tv-shows/2005/watch-robot-chicken-14013-online/]Robot Chicken (2005)[/url] .
Pink (2016) 720p BluRay 1.1GB - NBY
Download: [url=http://gorabettv10.com/watch/fifty-shades-freed-2018.html]Fifty Shades FreedDuration: 105 min[/url] .
Deadly.60.On.A.Mission.S02E02.HDTV.x264-Deadpool
Download: [url=http://traki2i.com/movie/euphoria-72035]Euphoria[/url] .
Arrival Trailer
Download: [url=http://otasupport.com/forum/830-3d-video.html]3D Видео[/url] .
?????????......
Download: [url=http://yeuniversity.com/manga-list?sort=date_added&status=Completed]Lastest Releases[/url] .
American Dad S13E02 XviD-AFG TV Shows
Download: [url=http://gyandeepip.org/bd-queens-blade-rurou-no-senshi-subtitle-indonesia/]BD Queens Blade : Rurou no Senshi Subtitle Indonesia[/url] .
[Caribbeancom] ??? ?? ??? ?? ??? ????????? SEXYMILD
Download: [url=http://urindy.com/video-movie-yao-cabrera-ft-nathan-en-linea-parodia-oficial.emaBhKSben2ddWk.html]Yao Cabrera ft Nathan - En Linea | Parodia Oficial[/url] .
Alter Bridge In Loving Memory Live In Amsterdam
Download: [url=http://ce-grogged.us/show/exids-showtime/]EXID's Showtime[/url] .
The.Pirate.Fairy.2014.BDRip.XviD.Audio.Latino-JcGoku21
Download: [url=http://floorsblindsandpaint.com/category/michel-foucault]Michel Foucault[/url] .
Bigg Boss 9
Download: [url=http://technorati.com/faves/?add=http%3A%2F%2Fcanlibahissiteleri252.info%2Ff29%2Ftorrentinvites-org-tutorials-guides-index-91272%2F%23post419262]Technorati[/url] .
Brazzers.com-The Big Game- Alanah_Bridgette_Eva_Nicole_720p
Download: [url=http://fapiao2.com/actors/Nora+Guerch.html]Nora Guerch[/url] .
30 Degrees In February S02 E06 - Hardcoded Eng Subs - Sno
Download: [url=http://pupszamotuly.pl/index.php?PHPSESSID=nns29qblun6eaju1f3j1pqkve0&topic=31359.msg364638]1978 Michael Jackson Mixed Masters...[/url] .
Channel Zero S01E06 HDTV x264-FLEET[PRiME]
Download: [url=http://modapoly.com/tags/Blues+Rock/]Blues Rock[/url] .
Crazyhead
Download: [url=http://mansionbet90.com/cast/katharine-ross/]Katharine Ross[/url] .
Search Plugin *
Download: [url=http://opjackpot.net/tvshow-825-1.html]The Nativity[/url] .
Als Hitler unser Nachbar war
Download: [url=http://cryptosite.net/book/1073458275/download-le-rhin-les-3-tomes-victor-hugo.pdf]Le Rhin (Les 3 tomes)[/url] .
Silicon Valley S02e05 [Mux - H264 - Ita Aac] HDTVMux by UBi - Commedia TN ...
Download: [url=http://88f12.com/chapter/tomochan_wa_onnanoko/chapter_451]Chapter 451 : Heightened Impact[/url] .
Teachers Pet 6 s1 mp4
Download: [url=http://acupuncturegaspesie.com/drama-detail/hotel-king]Hotel King[/url] .
A Historia Real de um Assassino Falso Dublado MP4 Torrent
Download: [url=http://vuvubet5.com/lagu-terbaru]Lagu Terbaru[/url] .
Kensington - Control (2016) FLAC [Isohunt.to]
Download: [url=http://ce-grogged.us/show/weekly-idol/episode-311.html]Weekly Idol Episode 311[/url] .
High Strung 2016 LiMiTED 720p BluRay x264-VETO[EtHD]
Download: [url=http://queenbet93.com/film/fS3/Spacewalk?episod=1]IMDb: 7.4 HD Spacewalk[/url] .
Justin Biebers Believe
Download: [url=http://mansionbet90.com/cast/jeanne-valerie/]Jeanne ValГ©rie[/url] .
Incomedia WebSite X5 Professional 13 0 2 19 Multilingual + Keygen [SadeemPC] zip
Download: [url=http://jolietfootandankle.com/others/int/6824025-drama-kudamm-56-s01-complete-german-1080p-bluray-x264-tv4a.html][Drama] Kudamm 56 S01 Complete German 1080p BluRay x264 - TV4A[/url] .
Twilight Zone
Download: [url=http://stardiesel.biz/series-populaires-streaming-vf-vostfr/]Les SГ©ries Les Plus Vues[/url] .
windows server
Download: [url=http://88f12.com/chapter/tomochan_wa_onnanoko/chapter_165]Chapter 165[/url] .
Cole Swindell Chevrolet D4
Download: [url=http://78jxs.com/torrenty/kategoria/359]XXX / Erotyka (+18)[/url] .
VA - The Jazz House Independent 2nd Issue (1998) [FLAC]
Download: [url=http://canechepassione.com/movie/4872078-the-intervention]61% The Intervention[/url] .
July 2016 (8849)
Download: [url=http://vidhosters.org/download/79-83-hip-hop-mastermix-ep-1/]79 83 Hip Hop Mastermix Ep 1[/url] .
Gamecube
Download: [url=http://alliescoin.org/movie/the-butterfly-tree-2017]The Butterfly Tree (2017)[/url] .
The Flash Season 3 – Episode 6 Watch Online
Download: [url=http://grocerykerala.com/mp3/kusetshezwa-kanjani.html]kusetshezwa kanjani,[/url] .
Keeping up with the Kardashians
Download: [url=http://felixshare.net/forums/model-discussion-requests.238/threads/alex-arabellas-site-questions.2316561/]Alex Arabella's site questions.[/url] .
July 2016 (9701)
Download: [url=http://onesourcepoolsupplystore.com/terms]Terms of Use[/url] .
KarupsHA 16 11 17 Raven Orion Hardcore XXX 720p MP4-KTR[N1C]
Download: [url=http://alsubhigroup.com/category/360/existentialism]Existentialism[/url] .
Brooke Banner - Dark MILF Injections rq mp4
Download: [url=http://813ll.com/badrinath-ki-dulhaniya-ka-jalwa-dil-hai-hindustani/918248/]Badrinath Ki Dulhaniya Ka Jalwa!! Dil Hai Hindustani[/url] .
Fantasy 5,559
Download: [url=http://servedbyjaymarienow.com/home/bitcoin:3Qpdm4ckJ64irx1Nuyw9ZCCvc2qxoqkuBY]3Qpdm4ckJ64irx1Nuyw9ZCCvc2qxoqkuBY[/url] .
Hidden Camera Voyeur 1 s3 mp4
Download: [url=http://ce-grogged.us/show/crime-scene-2/]Crime Scene 2[/url] .
Play This Video
Download: [url=http://queenbet93.com/tv/fS8/Hunting-ISIS-Season-1?episod=1]IMDb: 7.7 S1E6 Hunting ISIS - Season 1[/url] .
Music 10,843
Download: [url=http://mansionbet90.com/director/erin-mast/]Erin Mast[/url] .
Warcraft: The Beginning (2016)
Download: [url=http://imaxinterior.com/chapter/tomochan_wa_onnanoko/chapter_282]Chapter 282[/url] .
Мама готви по-добре
Download: [url=http://ucanprep.net/category/67/show-me-the-money-s3]Show Me The Money S3[/url] .
Ink Master S08E13 Heavy Lifting HDTV x264-CRiMSON[ettv]
Download: [url=http://amazingpractice.info/br/onmyoji-arena/com.netease.g78na.gb/download?from=home%2Ftopic%2Ftop-new-games]Baixar XAPK[/url] .
Buck Taylor
Download: [url=http://getthiscream.com/films/the-notebook.html]The Notebook2004123 min[/url] .
FXhome HitFilm 4 Pro 4.0.5723.10801 (x64) Incl Keygen [Androgalaxy]
Download: [url=http://ultrabet16.com/book/1347079786/download-missioni-segrete-comandante-alfa.pdf]Missioni segrete[/url] .
Acompa Ame A Estar Solo Ricsrdo Arjona
Download: [url=http://rivalobet6.com/watch-the-swan-princess-a-royal-myztery-2018-full-movie-online-6375.html](2018) DVD The Swan Princess: A Royal..[/url] .
living in suburban dc
Download: [url=http://lowdsa.com/search?q=monster"]#monster[/url] .
Alan Fitzpatrick - Beatport November Top 10
Download: [url=http://clemixonline.us/?do=redirect&link=NkpWOHZGTDdUZWU4WVRWT2lGWmdQTGpqS3lBMzdxbTZkdnFKdFZ0K2JpN2VOQnVzREIzcE5RcHFtZnhEeURaOUMvVTdqaE5UbWlHQ2J4YjAzbnp4UUMvWHZ3WWhYUEFST2tzVEJLV0c4SHlBQzFSazhmVmFZbFJLQTBQNS9GaWVOaGtZRk9uQTZmazd6VGtHU3pCRU8rNGFCNTJLK3BBWmI4YnRUaUFTb2tDZUR5MXFZVDAxTHFPNDFpeDh6SXZOM3FkcTliU2txOHpadS9ONnJDbUdUenhxVUpIajVQcEMwWWhmUkJya1pVMllSYUtuTGQraEM2Tk9TVmM3K05jUg==]TГ©lГ©charger Part 1[/url] .
Jimmy Kimmel 2016 11 16 Garth Brooks HDTV x264-CROOKS[ettv]
Download: [url=http://imaxinterior.com/chapter/lian_ai_qian_cheng_dan_gao/chapter_4]Chapter 4[/url] .
Sex Tape
Download: [url=http://queenbet93.com/film/fKa/Williams?episod=1]IMDb: 7.8 HD Williams[/url] .
Thriller
Download: [url=http://intelliwall.net/mp3/lissu-akichana-baada-ya-kuachiwa-kwa-dhawana.html]lissu akichana baada ya kuachiwa kwa dhawana,[/url] .
Hellevate (USA) - Weapons Against Their Will (2016) [[email protected] ] [Thrash/Power Metal]
Download: [url=http://choosetruth.com/album/torrent-267129-idle-eyes-bitter-work-2018]Idle Eyes - Bitter Work (2018)[/url] .
Criminal.Minds.S12E06.720p.HEVC.x265 MeGusta
Download: [url=http://college-csi.com/engine/go.php?book=Opiniku.pdf]Download[/url] .
Lost Lands - Dark Overlord ( Ryushare - Rapidgator )
Download: [url=http://bkht.org/actors/cameron-ocasio.html]Cameron Ocasio[/url] .
Noire - The Tracks of the Hunted (2016)
Download: [url=http://ysj19.com/series-view.php?id=293596]The Big Picture With Kal Penn[/url] .
Live Free or Die Hard 2007 HD ????? ????? 7.2
Download: [url=http://aiii.pl/?do=redirect&link=b2tzTEdqYTdkaGh0NkdnMXgxWUVQdlJOWFY1NnlSOFRwcWRSSVR6b3lKbmsvSVdabyszVXBwdG92dmlYcUNXR3gvUlA1M2R6U3pDOGpxNWFsOEtpUDU1WnFGbHdOYUJEU2loZXQ3czdDTk1xMWtVdUk3anZhOGVCbUszZWR5dzhGVUwvdlFKTldFc1lJU1M3NzJsZ3Jtb21PU2hOZFYvM3J6VzZRK0c2OUlQZVFrQVBWSEc4UjcwaUNNNlgyN2U2VTdzalVuR1g3eDQxc21UM1R0emdiNldoU0ViWmY4aDlsQ2dtZ0pjS2ozUERqOUY0cUNJZ2dTaGp0ZnFiVHhPZw==]TГ©lГ©charger Part 9[/url] .
Kerbal Space Program v1.2.1.1604 cracked #Kortal [Isohunt.to]
Download: [url=http://88f12.com/chapter/tomochan_wa_onnanoko/chapter_419]Chapter 419 : Purge[/url] .
4Videosoft Video Converter Ultimate For Mac v9.0.16 Multilingual (Mac OSX) ...
Download: [url=http://einat-tal.com/tna-greatest-matches/]TNA Greatest Matches[/url] .
Download Alice Through the Looking Glass Torrent
Download: [url=http://morganeapa.net/i-feel-pretty-2018/]I Feel Pretty (2018)[/url] .
Carnivale
Download: [url=http://tumuoracrossfit.com/artist/60696-cesar-sampson/songs/]Cesar Sampson Listen![/url] .
Apowersoft Screen Recorder Pro v2.1.5 - Full [4REALTORRENTZ]
Download: [url=http://8xlp.com/book/1123602918/download-la-terapia-degli-attacchi-di-panico-giorgio-nardone.pdf]La terapia degli attacchi di panico[/url] .
Helix2016
Download: [url=http://xottaby4.biz/asesinatos-accidentales-2018-brrip-1080p-audio-dual-latino-ingles/]Asesinatos accidentales (2018) BRRip 1080p Audio Dual Latino-Ingles[/url] .
?? ? ??? ??? ???
Download: [url=http://ce-grogged.us/show/talk-hero/]Talk Hero[/url] .
Christen Courtney, Rina Ellis - Sex Fighter, Vega Gets Vagina..., XXX, MPEG4(Xvid), C2x, HD 1080p, 0,5 FPS [Brazzers Exxtra - Brazzers] (August 13, 2016).avi [Isohunt.to]
Download: [url=http://datebox4.info/la-folle-histoire-des-bodins-streaming-vf-vostfr/]La Folle Histoire Des BodinS[/url] .
DxO Optics Pro 11 3 0 Build 11759 Elite (x64) Multilingual + Patch [SadeemPC]...
Download: [url=http://like-4g.com/watch/xqpQmoqv-superfly/other.html]Play Movie[/url] .
Escape.To.The.Country.S17E15.HDTV.x264 DOCERE
Download: [url=http://bybetco11.com/Clean-My-Mac-4-7-2018-%5BMac-Os-X%5D-%5Bcoque599%5D/98B84E1FDE59C5D9B242DAAF3BAF8C83EB348D9E]Clean My Mac 4 7 2018 [Mac Os X] [coque599][/url] .
Captain America the Winter Soldier 2014 English Movies CamRip ...
Download: [url=http://dcp518.com/watch-78285-the-arti-the-adventure-begins-2015-free-movie.html]The Arti The (2015)[/url] .
Moto3.2016.Japan.Practice.Two.720p.HDTV.x264-VERUM - [SRIGGA]
Download: [url=http://fortuacc.com/watch/yGDzNOv6-the-eternal-love.html]The Eternal Love[/url] .
[PES] [2017] [2016] [PC] [REPACK]
Download: [url=http://otasupport.com/topic/1740692-warhammer-40-000-gladius-relics-of-war-deluxe-edition-pc-repack-ot-laan.html]Warhammer 40,000: Gladius - Relics of War: Deluxe Edition [v 1.0.2] (2018) PC | RePack РѕС‚ Laan Подробнее... Залито: 13-07-2018 15:26 (1556 просмотров) Warhammer 40,000: Gladius - Relics of War: Deluxe Edition [v 1.0.2] (2018) PC | RePack РѕС‚ Laan РРіСЂС‹ для РџРљ Гладиус Прайм был известен среди Рмперских ученых, как планета богатая РЅР° археологические находки. Р’Рѕ время его колонизации были найдены древние реликвии, намекающие РЅР° окутанное тайной прошлое планеты. Находки оказались нечто большим, чем реликвиями. Пробудился ужасный отголосок древнего прошлого, Рё... Раздают: 8 Качают: 0 Размер: 1016MB [/url] .
NETGATE Registry Cleaner v16 0 305 0 - Full rar
Download: [url=http://borankara.com/actores/36723-bridget-gabbe]Bridget Gabbe[/url] .
The National [Rock Independant] - 2003 - Sad Songs...(A)
Download: [url=http://yeuniversity.com/god-of-martial-arts/chapter-22-3]God of Martial Arts: chapter 22.3[/url] .
Murdoch Mysteries - Season 10 Episode 6
Download: [url=http://myfundcards.com/999-nu-hon-ba-dao-cua-nam-than-chap-33/]999 Nụ Hôn Bá Đạo Của Nam Thần – Chap 33[/url] .
Help Support
Download: [url=http://amazingpractice.info/nl/garena-free-fire-android/com.dts.freefireth]Garena Free Fire APK[/url] .
TV Schedule
Download: [url=http://ultrabet16.com/book/1180532306/download-comment-je-mhabille-aujourdhui-le-style-de-la-parisienne-ines-de-la-fressange-sophie-gachet.pdf]Comment je m'habille aujourd'hui ? Le style de la Parisienne[/url] .
star wars
Download: [url=http://trakf2i.com/genre/top-films-streaming-1/]Top Films[/url] .
Five (2016) VFF [1080p] BluRay x264-PopHD(A)
Download: [url=http://ju034.com/drama-detail/black-idols]Black Idols[/url] .
Rock Roll
Download: [url=http://laptopmessengerbag.info/torrent/1664978334/The+Ridiculous+6+2015+2160p+HDR+NF+WEBRip+DD5+1+x265-TrollUHD]The Ridiculous 6 2015 2160p HDR NF WEBRip DD5 1 x265-TrollUHD[/url] .
SDDE379_CAVI
Download: [url=http://ce-grogged.us/show/hitmaker-season-1/]Hitmaker Season 1[/url] .
New York Observer - November 14, 2016 - True PDF - 1799 [ECLiPSE]
Download: [url=http://fapiao2.com/actors/Tammy+Macintosh.html]Tammy Macintosh[/url] .
MECHANIC RESURRECTION 2016 VOSTFR HDRIP [ZityEast](N) (P)
Download: [url=http://dinhgianhadat.info/descargar-sinister-latino.html]Sinister[/url] .
The Big Book of the Unexplained (Factoid Books)
Download: [url=http://amazingpractice.info/br/netflix/com.netflix.mediaclient/download?from=home%2Fhot]Baixar APK[/url] .
PlayBoy Czech Republic - October 2016 - Set 999 ECLiPSE
Download: [url=http://rivalobet6.com/watch-overboard-1988-full-movie-online-7754.html](1988) DVD Overboard[/url] .
Chat IRC SSL
Download: [url=http://otasupport.com/topic/1681376-final-fantasy-xv-windows-edition-high-resolution-pack-3dm.html][DLC] FINAL FANTASY XV WINDOWS EDITION - HIGH RESOLUTION PACK (RUS|ENG|MULTi) - 3DM Подробнее... Залито: 03-03-2018 11:32 (2112 просмотров) [DLC] FINAL FANTASY XV WINDOWS EDITION - HIGH RESOLUTION PACK (RUS|ENG|MULTi) - 3DM РРіСЂС‹ для РџРљ (общее) Раздают: 0 Качают: 0 Размер: 65.13GB [/url] .
Cossacks 3 - (MacAPPS) 2016
Download: [url=http://813ll.com/category/star-plus/star-plus-completed-shows/meree-angne-main/]Mere Angne Mein[/url] .
Neverland 2011 LIMITED DVDRip XviD AC3-UNDERCOVER
Download: [url=http://amarlove.info/streaming-assassination-vostfr-60800.html]Assassination - VOSTFR[/url] .
Privacy policy
Download: [url=http://luxexchange.info/video/step-sisters/e42192]Step Sisters[/url] .
Oracle9i DBA JumpStart
Download: [url=http://alibaclub.net/guide/./../guide/305636-lefaqdidasoloinfon2.html].epub e .mobi[/url] .
Deadwood
Download: [url=http://aiii.pl/?do=redirect&link=RnZrZndZcHhrb3pwTFIxTHUvUEFScjZoRW5RUlUyZmdTbkl6QWQ1eUVibUJhWDFvTzZSdi9DQUlaTFRvbml5OQ==]TГ©lГ©charger[/url] .
Downloadsfreemovie
Download: [url=http://ihiphopyoga.com/the-stolen-princess/]Watch Movie[/url] .
Running.Man Ep 324 SBS Korea English subtitles [Isohunt.to]
Download: [url=http://queenbet93.com/film/fVl/Singing-with-Angry-Bird?episod=1]IMDb: 8.5 HD Singing with Angry Bird[/url] .
Worms Clan Wars - (MacAPPS)
Download: [url=http://hard-porno-izle.info/films-en-streaming-1/1-1-0-8.html]Thriller[/url] .
stephen king
Download: [url=http://xiaoyangzi.com/tv/1310/]Deadliest Catch[/url] .
BayTSP and Megapath conspiracy, they should hang!
Download: [url=http://8xlp.com/book/609408202/download-le-tre-minestre-andrea-vitali.pdf]Le tre minestre[/url] .
How I Met Your Mother 2? Temporada Dublado Torrent – BluRay 720p Download (2006)
Download: [url=http://s1ot4.info/filme/subl:/open?url=file:/%2Fhome%2Ffilmeonlinenoi%2Fpublic_html%2Fvendor%2Flaravel%2Fframework%2Fsrc%2FIlluminate%2FCookie%2FGuard.php&line=51]open: /home/filmeonlinenoi/public_html/vendor/laravel/framework/src/Illuminate/Cookie/Guard.php[/url] .
?? ??? ???
Download: [url=http://amargem.info/download/smooth-criminal-nes-remake/]Smooth Criminal Nes Remake[/url] .
Suicide Squad 2016 EXTENDED 720p WEBRip x264 AAC-ETRG
Download: [url=http://turkeyescortmodels.com/watch-will-grace-online/]Will & Grace[/url] .
Hatton Garden The Heist 2016 DVDRip x264-SPOOKS[PRiME]
Download: [url=http://www.bbabet.info/show/ghost-adventures/season-8/episode-3/links.html]Season 8 Episode 3 Tuolumne General Hospital 8/30/2013[/url] .
HippyTastic
Download: [url=http://modapoly.com/tags/Post-Hardcore/]Post-Hardcore[/url] .
Achievements
Download: [url=http://staugustine-forsale.com/movies-rosy-2018-yesmovies.html]Watch movie[/url] .
Impastor S02E08 HDTV x264-FLEET[PRiME]
Download: [url=http://guwtet.com/tags/Transylvania/]Transylvania[/url] .
Night Stalker
Download: [url=http://ssldigitalcertificate.com/descargar-tomtom-iberia-v14-nuevo-mapa-iberia-completo-v9657250-(24-02-2016)-68070.fx]Tomtom Iberia v1.4 Nuevo Mapa Iberia Completo v965.7250 (24-02-2016) - 2016[/url] .
Alternative Metal
Download: [url=http://rebootsecurity.org/oceans-rising-vf-streaming/]Oceans Rising[/url] .
Stacy Schiff - The Witches Salem, 1692 (PDFEPUBMOBI)
Download: [url=http://voyancegeni.us/pompei-la-vie-avant-la-mort-2016-french-hdtv-720p.html]Pompei La vie avant la mort 2016 FRENCH HDTV 720p[/url] .
Promotional
Download: [url=http://trackformes.com/tag/tam-sinh-tam-thбєї-thбєp-lГЅ-Д‘Г o-hoa-vietsub/]tam sinh tam thбєї thбєp lГЅ Д‘Г o hoa vietsub[/url] .
POKEMON MOON SUN
Download: [url=http://canechepassione.com/star/4953884-aaron-costa-ganis]Aaron Costa Ganis[/url] .
[BakedFish] Mahou Shoujo Ikus...
Download: [url=http://like-4g.com/movies-genres/adventure.html]Adventure[/url] .
Internet Download Manager v6.23 Build 5 Crack - [FirstUploads] ...
Download: [url=http://ihiphopyoga.com/transformers-the-last-knight-2017-2/]Watch Movie[/url] .
Facebook
Download: [url=http://wollplanet.com/category/lespion-qui-ma-larguee-2018/]L'Espion qui m'a larguГ©e (2018)[/url] .
Conan O'Brien
Download: [url=http://greenacresgrass.com/mission-impossible-5-films-french-hdlight-1080p-1996-2015.html]Mission Impossible (5 Films) FRENCH HDlight 1080p 1996-2015[/url] .
0 Comments
Download: [url=http://einat-tal.com/]Forums Home[/url] .
Speccy 1 30 728 + Portable [4realtorrentz] zip
Download: [url=http://amazingpractice.info/es/google-photos/com.google.android.apps.photos/download?from=home%2Fnew]Descargar APK[/url] .
Blindspot s02e09 720p hdtv x264-NBY-[moviezplanet in] mkv
Download: [url=http://wholesaleapmex.com/video/actor/dakota-fanning/]Дакота Фаннинг[/url] .
Almighty Thor (2011) Dual Audio Full Movie Hindi BrRip 720p
Download: [url=http://www.djdrthq.com/adidas_originals_m%C3%9Cnchen_trainers_red/160dd17425a2c90-many-147778a472c3981/]adidas Originals MГњNCHEN Trainers red Jcouzglvnh[/url] .
Vacation 2015 HD ????? ????? 6.2
Download: [url=http://myfashionfancies.com/dispatches-2018-07-17-inside-facebook-secrets-of-the-social-network-hdtv-x264-creed?share=pinterest]Click to share on Pinterest (Opens in new window)[/url] .
at cafe 6 2016 480p bluray x264 rmteam mkv
Download: [url=http://photographytipsforabeginner.com/films/telecharger/14100-the-lucky-one.html]The Lucky One TELECHARGEMENT GRATUIT[/url] .
Stage.Fright.2014.LIMITED.BDRip.x264-GECKOS
Download: [url=http://academiametodo.com/torrent/341028/soft-organizer-7-26-2018-rs-repack-by-kpojiuk]Soft Organizer 7.26 (2018) Р РЎ | RePacK by KpoJIuK[/url] .
ABBYY FineReader 12.0.101.388 Corporate Edition
Download: [url=http://tba101.com/ru/pokemon-go/com.nianticlabs.pokemongo/download?from=home%2Fhot]Скачать APK[/url] .
Assorted Magazines Bundle - April 14 2015 (True PDF)
Download: [url=http://backyardbff.com/videos/replay/879432/lunch-play-le-jeu-retro-est-a-l-honneur.htm]ReplayLunch Play : Le jeu rГ©tro est Г l'honneur[/url] .
Worlds Together, Worlds Apart: A History of the World: From the Beginnings of Humankind to the Present (Third Edition) (Vol. One-Volume)
Download: [url=http://getrealdegrees.com/actors/Reshma+Gajjar.html]Reshma Gajjar[/url] .
walking dead s07
Download: [url=http://wardrobewins.com/radio-times]More Details...[/url] .
Alguien VOLO Sobre el Nido del Cuco [DVDFull][AC3.Espa.Engl.Germ][All.Subti][www.newpct.com]
Download: [url=http://lihaofa88.com/mp3/raisa-anganku-anganmu]Anganku Anganmu[/url] .
O Exterminio do Marfim Dublado MP4 Torrent
Download: [url=http://btzhongzifuli.com/kill-dil-2014-hindi-movie-watch-online.html]Watch Now [/url] .
[Amateur] After class mp4
Download: [url=http://avangersbet.com/movie/the-butterfly-tree-2017]The Butterfly Tree (2017)[/url] .
Tom Petty The Heartbreakers - Greatest Hits (1993) 320 Kbps
Download: [url=http://xeberinfo.com/viewforum.php?f=957]Юмор[/url] .
Branded (1950) Western Xvid 1cd - Alan Ladd, Mona Freeman, Charles Bickford [...
Download: [url=http://lihaofa88.com/genre/r-b-soul]RnB Soul[/url] .
Animation
Download: [url=http://abusinessforms.com/vorgeschlagene-serien/vote:13155]The Push[/url] .
Doctor Who
Download: [url=http://luxchix.com/audio/audio/sampler/365511-va-bravo_hits_lato_2018-2018-nogroup]27.06.1802:26 Uhr Bravo Hits Lato 2018 Pop / Dance320 kbit/s 0 / 09.868 Hits VID P2P DDL 0 Kommentare[/url] .
Visible2016
Download: [url=http://binancialexperts.com/studio/aic-plus/]AIC PLUS[/url] .
WWE SmackDown Live 2016 11 15 HDTV x264-NWCHD [TJET]
Download: [url=http://icoinvestmentpools.com/drama-detail/gangnam-blues]Gangnam Blues[/url] .
product design and development 6th edition pdf
Download: [url=http://armcandyshopping.com/watch-iron-fist-online/]Iron Fist[/url] .
Janis Joplin - The Kozmic Blues (2007) [DVD5 NTSC] [Isohunt.to]
Download: [url=http://abusinessforms.com/serie/Mit-Schirm-Charme-und-Melone-1961]Mit Schirm, Charme und Melone (1961)[/url] .
AmateursGoneBad.15.06.23.Aryana.Star.XXX.WMV.YAPG
Download: [url=http://worldfreeroll.com/1147288275-nabor-zhurnalistov.html]Как стать журналистом?[/url] .
Cromlech - Cromlech (1995)
Download: [url=http://medalibet.com/index.php?PHPSESSID=22ee6q72pt4a7gd6hqom88o4t1&action=profile;u=95476]shareman[/url] .
Phoenix, Fleet Foxes, Two Door Cinema Club announced for Bilbao BBK 2017
Download: [url=http://getcrulse.com/torrent/1664978494/MySistersHotFriend+-+Ember+SnowKODIAK]MySistersHotFriend - Ember SnowKODIAK[/url] .
Beyond The Break
Download: [url=http://the-wondrous-pattaya.com/actors/Prasert+Pleansri.html]Prasert Pleansri[/url] .
Dark Phantom (Irq) - Nation Of Dogs (2016) [[email protected] ] [Heavy/Thrash Metal]
Download: [url=http://ri-99.com/report]Report a Violation[/url] .
Giampetrino (1495 1549) (Art Paintings)
Download: [url=http://the-wondrous-pattaya.com/actors/Chiling+Lin.html]Chiling Lin[/url] .
Saxon Sharbino,
Download: [url=http://seekpic.com/r948a6-amy-shark-love-monster]Love Monster[/url] .
[HorribleSubs] Okusama ga Seitokaichou! S2 (Uncensored) 07 [720p].mkv
Download: [url=http://strictlybiz.biz/2017/12/21/%d9%85%d8%b4%d8%a7%d9%87%d8%af%d8%a9-%d9%81%d9%8a%d9%84%d9%85-tubelight-2017-%d9%85%d8%aa%d8%b1%d8%ac%d9%85-%d8%a7%d9%88%d9%86-%d9%84%d8%a7%d9%8a%d9%86-aflamnat/]Ш§ЩЃЩ„Ш§Щ… Щ‡Щ†ШЇЩЉ imdb N/A 95 Щ…ШґШ§Щ‡ШЇШ© ЩЃЩЉЩ„Щ… Tubelight 2017 Щ…ШЄШ±Ш¬Щ… Ш§Щ€Щ† Щ„Ш§ЩЉЩ† | Aflamnat Щ…ШґШ§Щ‡ШЇШ© Щ€ШЄШЩ…ЩЉЩ„ ЩЃЩЉЩ„Щ… Ш§Щ„Щ…ШєШ§Щ…Ш±Ш§ШЄ Щ€ Ш§Щ„ШШ±Щ€ШЁ Ш§Щ„Щ‡Щ†ШЇЩЉ Tubelight 2017 Щ…ШЄШ±Ш¬Щ… ШЁШ·Щ€Щ„Ш© ШіЩ„Щ…Ш§Щ† Ш®Ш§Щ† ШЁШ¬Щ€ШЇШ© DVDSCR ЩѓШ§Щ…Щ„ Ш§Щ€Щ† Щ„Ш§ЩЉЩ†[/url] .
Mr D S06E04 HDTV x264-FLEET[PRiME]
Download: [url=http://josephfellowship.com/viewforum.php?f=655]Рнтерактивные обучающие Рё развивающие материалы[/url] .
Juston Street
Download: [url=http://vuvubet3.com/index.php?fObj=ert0al7514s7c7oh2ogn5bord5&cat=25]descargar programas[/url] .
Movie Detail
Download: [url=http://armcandyshopping.com/watch-the-great-indoors-online/]The Great Indoors[/url] .
[AnimeRG] TO BE HERO - 07 [720p] [Multi-Sub] [x265] [pseudo] mkv
Download: [url=http://gstkyahai.com/descargar-pelicula/alien-covenant/dvd-screener/]Alien Covenant DVD-Screener[/url] .
Noam Murro
Download: [url=http://chartersnyc.com/torrent/885632/neznakomka-la-b-te-curieuse-2017-hdtvrip-greenray-studio]Незнакомка / La bête curieuse (2017) HDTVRip | GreenРай Studio[/url] .
Deliver.us.From.Evil.2014.BRRip.XViD.AC3-juggs[ETRG].avi
Download: [url=http://1921188.net/show/someday-suddenly-foreign-comedians/]Someday, Suddenly, Foreign Comedians[/url] .
Cassandra - Brace face mp4
Download: [url=http://xn--azbuuk-zua.com/cobra-kai]Cobra Kai[/url] .
Brickleberry
Download: [url=http://74rmm.com/descargar-torrents-variados-242-Malwarebytes-Anti-Malware-145.html]Malwarebytes Anti-Malware 1.45[/url] .
Psycho-Pass
Download: [url=http://mobilebankforkids.com/music/style/nyu-ejdzh/]РќСЊСЋ-СЌР№РґР¶[/url] .
MEYD-202 mp4
Download: [url=http://eubanksfencing.com/torrent/23288323/Vegetable_Gardening_Encyclopedia_by_Consumer_Guide]Vegetable Gardening Encyclopedia by Consumer Guide[/url] .
view all
Download: [url=http://dominoitu.com/others/int/7068265-bloons-supermonkey-2.html]Bloons Supermonkey 2[/url] .
Blacked - Brandi Love (Sexy Mom Takes 2 young BBCs) NEW 16 November 2016
Download: [url=http://meilleursannuaires.com/drama-detail/three-girlfriend-three-mom]Three Girlfriend Three Mom[/url] .
Esquadrao Suicida Dublado Online Apos a aparicao do Superman, a agente Amanda Waller (Viola Davis) esta convencida que o governo americano precisa ter sua propria equipe de metahumanos, para combater possiveis ameacas. Para tanto ela cria o projeto do Esquadrao Suicida, onde perigosos viloes encarcerados sao obrigados a executar missoes a mando do governo. Caso sejam bem-sucedidos, eles tem suas penas abreviadas em 10 ...
Download: [url=http://lotto-facile.com/viewforum.php?f=991]Рзучение языков[/url] .
New Hollywood Movies 2016
Download: [url=http://icoinvestmentpools.com/drama-detail/family-s-honor]Family's Honor[/url] .
????@????@????? ?? ????????? ?2?
Download: [url=http://xn--azbuuk-zua.com/episode/marlon-s2-e10]Marlon S2 E10 1 day ago[/url] .
David.Blaine Beyond.Magic.2016.720p.HEVC.x265 MeGusta
Download: [url=http://xn--azbuuk-zua.com/carnival-cravings]Carnival Cravings[/url] .
Internet Download Manager (IDM) v 6 26 Build 1 + Patch [4realtorrentz] zip
Download: [url=http://descargawasaps.com/viewforum.php?f=76]Музыка (lossless)[/url] .
new girl french
Download: [url=http://toin3535.com/torrent/Preacher-S03E04-720p-HDTV-x264-AVS-rartv--UV07PZW/]Preacher.S03E04.720p.HDTV.x264-AVS[rarbg][/url] .
Storage Wars
Download: [url=http://betist946.com/ver/la-bella-y-las-bestias-1x15.html]1x15 La Bella y las Bestias[/url] .
The Middle
Download: [url=http://966dfh.com/index.php?fObj=07jroaekt7arruqj6he3ljom24&action=profile;u=1877060]espectorx[/url] .
Asian Transsexual Lesbians Vol 03 XXX DVDRip
Download: [url=http://meherabassi.com/help.html]Как правильно скачивать на сайте?[/url] .
Alan Watt CTTM LIVEonRBN 539 Broadband Digital Economy Smart Meters Appliances Means Youre Shafted B
Download: [url=http://bela-negara.com/a4527b-amy-helm]Amy Helm[/url] .
view all
Download: [url=http://photographytipsforabeginner.com/films/acteur/robin-williams.html]Robin Williams[/url] .
THE MAN FROM U.N.C.L.E 2015 Movie NL BluRay-720p x264-DTS-PAD-Subs NL
Download: [url=http://jandestudio.com/category/vermijo-2017/]Vermijo 2017[/url] .
Broadchurch
Download: [url=http://tighteningskinserum.com/billionaire/e6079.html]Stolen Course (Wrecked and Ruined #2)[/url] .
KMSAuto Net 2015 1 4 7 Portable
Download: [url=http://seekpic.com/genres/pop-rock-15/hard-rock-869/album-rock-870]Album Rock[/url] .
WWE SmackDown Pre Show 2016 11 15 WEB h264-HEEL [TJET]
Download: [url=http://the-wondrous-pattaya.com/actors/Santiago+LondoГ±o.html]Santiago LondoГ±o[/url] .
Digital Sin - MILF Bound [2016] DVDRip mp4
Download: [url=http://1921188.net/show/ponys-beauty-diary/]Pony's Beauty Diary[/url] .
Does God Exist
Download: [url=http://flagista.com/login.php]Р’С…РѕРґ[/url] .
(2016) DVD Hardcore Henry
Download: [url=http://monexcrypto.com/statistics.html]Statistics[/url] .
Marc Dorcel: De.Sang.Et.De.Sexe.XXX.(1998).DVDRip
Download: [url=http://vitawear.biz/descargar-anatomia-2-latino.html]Anatomia 2[/url] .
Alcoholics Anonymous - Big Book
Download: [url=http://btzhongzifuli.com/tera-intezaar-2017-hindi-full-movie-watch-online-free.html]Watch Now [/url] .
Gareth Reeves
Download: [url=http://580kfw.com/viewforum.php?f=153]Мультфильмы (DVD)[/url] .
Adobe Premiere Pro Cc 2014.2 v8.2.0 (Portable) 161117
Download: [url=http://meilleursannuaires.com/drama-detail/three-brothers]Three Brothers[/url] .
Native Instruments - Kontakt 5 v5 6 0 UNLOCKED FiXED OS X [dada]
Download: [url=http://skyconceptsphotos.com/film/lost-in-oz-2017-1080p/]Eps1 Lost in Oz (2017)[/url] .
Daisy Disk 4 0
Download: [url=http://74rmm.com/descargar-torrents-variados-963-Miguel-Bose-en-Vina-del-Mar.html]Miguel BosГ© en ViГ±a del Mar.[/url] .
The Missing S02E06 REPACK 720p HDTV x264-BRISK[PRiME]
Download: [url=http://myanmar50.biz/video/actor/torsten-flink/]Торстен Флинк[/url] .
World Trade Center 2006 HD ????? ????? 6.0
Download: [url=http://bycblizejsiebie.pl/q/brazzers]brazzers[/url] .
Lilly Ford mp4
Download: [url=http://stay4fit.com/kshow/7741-[engsub]-infinity-challenge-ep.547]Infinity Challenge Ep.547[/url] .
Absoft Pro Fortran 2016 16.0 + Gino Graphics 8.0 161117
Download: [url=http://bybetco14.com/mp3-download/Chot+Khada+Khadai/]Chot Khada Khadai mp3[/url] .
Ink Master S08E13 Heavy Lifting HDTV x264-CRiMSON[ettv]
Download: [url=http://stefgallagher.com/torrent/787251/icecream-screen-recorder-pro-5-72-2018-pc-repack-amp-portable-by-tryroom]Icecream Screen Recorder PRO 5.72 (2018) PC | RePack Portable by TryRooM[/url] .
Vectors -- Different Sale Ribbons 3
Download: [url=http://shitdub.com/peli-descargar-torrent-19454-Tomb-Raider-.html]Tomb Raider[/url] .
[Leopard-Raws] Natsume Yuujinchou Go - 06 5 RAW (TX 1280x720 x264 AAC) mp4
Download: [url=http://betist932.com/shahs-of-sunset/season-6/ep-15-reunion-part-2]Coming Soon Ep 15: Reunion Part 2 AIRED: Oct 29 8/7c[/url] .
Facebook
Download: [url=http://tba101.com/it/bubble-witch-3-saga/com.king.bubblewitch3]Bubble Witch 3 Saga[/url] .
Training Day a XXX Parody [DvdRip] [480p].mp4
Download: [url=http://wh8822.com/hu/categories/games]ElЕ‘adГЎs[/url] .
Jornal O Globo - 14 de marco de 2012 - Quarta
Download: [url=http://goodbeni.info/serial/zlo-w-potrawce-evil-con-carne/1866]ZЕ‚o w potrawce / Evil Con Carne[/url] .
Indie 3,205
Download: [url=http://tba101.com/cn/tumblr/com.tumblr]Tumblr APK[/url] .
Captain Fantastic (2016)
Download: [url=http://pagalnilavu.com/forumdisplay.php?107-Magazine-Comics&s=1eebc81d7decae0fa2852effc9b63672]Magazine / Comics[/url] .
luke cage
Download: [url=http://superonlinesale.com/films/]Фильмы[/url] .
Dirk Gently S01E03 VOSTFR TVrip Xvid Ateam(A)
Download: [url=http://lihaofa88.com/mp3/the-london-likeuschallenge-ayoandteo]The London #LikeUsChallenge #AyoandTeo[/url] .
Buber, Martin
Download: [url=http://benjabetgiris.com/s/Maria-Keck]Maria Keck[/url] .
Limitless
Download: [url=http://searchhirecars.com/actors/Douggie+McMeekin.html]Douggie McMeekin[/url] .
Chat IRC SSL
Download: [url=http://testregister201801170835.com/viewforum.php?f=788]РљРѕРЅРєСѓСЂСЃС‹ !!![/url] .
Hide and Seek
Download: [url=http://cratosslot95.com/streaming-serie-gratuit/arrow/saison-1-complet/episode-19]Г©pisode 19 streaming Unfinished Business[/url] .
ARTURiA PLUGiNS PACK (2016.11.03) macOS [dada] [Isohunt.to]
Download: [url=http://meilleursannuaires.com/drama-detail/just-for-you]Just for You[/url] .
Say Hello Joey
Download: [url=http://the-wondrous-pattaya.com/actors/Luke+Perry.html]Luke Perry[/url] .
Led Zeppelin - The Complete Studio Recordings (Box 10CD) [Flac][TntVillage] Music
Download: [url=http://testdomainreg-08231.com/documentaries/Justin-Bieber--Home-For-The-Holidays_30131/]Justin Bieber: Home For The Holidays 2011[/url] .
Sonic Academy - KICK 2 v1.0.5 macOS [R2R][dada] [Isohunt.to]
Download: [url=http://tba101.com/cn/tic-tac-toe-glow/com.arcsys.tictactoe/download?from=home%2Ftopic%2Ftop-updated-games]дё‹иЅЅ APK[/url] .
General Hospital
Download: [url=http://abusinessforms.com/serie/Bakumatsu-Rock]Bakumatsu Rock[/url] .
Lethal Weapon S01E07 HDTV XviD-FUM[ettv]
Download: [url=http://the-wondrous-pattaya.com/actors/Michael+D.+Anglin.html]Michael D. Anglin[/url] .
Enrique Iglesias ft.Juan Luis Guerra - Cuando Me Enamoro (2010)
Download: [url=http://gr-po.com/tv-shows/Temptation_36894/]Temptation 2014[/url] .
x-men, apocalypse 720p
Download: [url=http://icoinvestmentpools.com/drama-detail/koisuru-nikutabe-joshi]Koisuru Nikutabe Joshi[/url] .
dark matter
Download: [url=http://euroinfos.info/engine/go.php?movie=Registration page - euroinfos.info]bioskop21.do.am[/url] .
bignogueira
Download: [url=http://966dfh.com/index.php?fObj=t0ip4tpklemcailn9nhfs7gfn6&cat=11]Juegos PC[/url] .
Professional Android 4 Application Development (Repost)
Download: [url=http://navirize.com/review/view/750/]Прямая ссылка[/url] .
World Series Of Poker 2005
Download: [url=http://destinacicek.com/category/125/my-neighbor,-charles]My Neighbor, Charles[/url] .
Blowtorch 2016 HDRip AC3 2 0 x264-BDP[PRiME]
Download: [url=http://holistichealthfitnessinfo.com/index.php?fObj=s5ff6t7okhb0h4hb8d1ijkj2i1&topic=513067]Tema para windows 10[/url] .
The Mindy Project
Download: [url=http://xn--azbuuk-zua.com/nellyville]Nellyville[/url] .
Brad Lee Electro House Mix 1
Download: [url=http://photoschoc.fr/viewforum.php?f=247]Архиваторы и файловые менеджеры[/url] .
Quantico Season 2 Full Episode 3 Download / Watch Online Free HD
Download: [url=http://www.djdrthq.com/prettylittlething_alisa_nude_large_studded_sliders/1606f30e3d7f690-many-721af23b164a17/]PRETTYLITTLETHING Alisa Nude Large Studded Sliders 7ByNg[/url] .
Aakashamake Kalimalar
Download: [url=http://seekpic.com/charts/usa-top-100-albums]See full list[/url] .
MILF Cock Masters (Meltdown) XXX Split Scenes torrent [Isohunt.to]
Download: [url=http://swingershack.com/tv/adventure-time-brw/]Adventure Time[/url] .
[CMS] Higurashi no Naku Koro ni Kira 01 720p
Download: [url=http://dw2030.com/tv-shows/Live-at-the-Electric_32068/]Live at the Electric 2012[/url] .
Adobe Photoshop Lightroom version 5 7 1 [Mac Os X] [coque599]
Download: [url=http://goodbeni.info/serial/poslancy-the-messengers/1331]PosЕ‚aЕ„cy / The Messengers[/url] .
The Secret Adventures of Jules Verne
Download: [url=http://abusinessforms.com/vorgeschlagene-serien/vote:9470]Danger 5[/url] .
Webcam Max 7.1.2.2 Duckys@[T411](A)
Download: [url=http://aiksanenterprise.com/comedy-movies/risky-business-1983-movie-free-download-720p-bluray/]Risky Business 1983 Movie Free Download 720p BluRay[/url] .
Andromeda
Download: [url=http://vigmont.com/author/6063.html]Mary Balogh[/url] .
Alan Garner - Trollsteinen Fra Brisingamen - Norsk Lydbok For Barn
Download: [url=http://74rmm.com/descargar-torrents-variados-2201-Imagine-Dragons-On-Top-of-The-World.html]Imagine Dragons - On Top of The World.[/url] .
The fight over spammy torrents is not over!
Download: [url=http://shitdub.com/descargar-torrents-variados-2254-2-chainz-Crack.html]2 chainz - Crack.[/url] .
Avengers: Age of Ultron 2015 HD ????? ????? 7.5
Download: [url=http://jandestudio.com/a-little-thing-called-murder-2006-movie-watch-online/]A Little Thing Called Murder (2006)[/url] .
The Young And The Restless - S44 E11053 - 2016-11-15 TV Shows
Download: [url=http://lusciouslookingskin.com/recent-case-has-similarities-to-a-hundred/the-case-book-of-inspector-jack-carter]["The Case book of Inspector Jack Carter"] Recent Case Has Similarities To A Hundred...[/url] .
EternalDesire.com_16.09.16.Verona.D.Cool.Me.XXX.IMAGESET-GAGBALL[rarbg]
Download: [url=http://autodirectus.com/engine/go.php?movie=Robin Schulz - Sugar (feat. Francesco Yates) (OFFICIAL MUSIC VIDEO) online]Facebook[/url] .
Brooke Banner - Dark MILF Injections rq mp4
Download: [url=http://marrem.com/realisateur/rawson-marshall-thurber]Rawson Marshall Thurber[/url] .
Missa X - Fuck mp4
Download: [url=http://jandestudio.com/category/upstart-crow/]Upstart Crow[/url] .
Chat IRC SSL
Download: [url=http://josephfellowship.com/viewtopic.php?p=312062]2018-05-30 12:38[/url] .
Albert-King--1972--I’ll-Play-The-Blues-For-You-(Stax--SXSA-3009-6 -2004-US)-(S..
Download: [url=http://elsecity.info/filmy/music-box/]Music Box[/url] .
Trending Documentaries
Download: [url=http://harryvdesign.com/anime-online/serie-Overlord--2-76617] Overlord в…ў capitulo 2 Publicado hace 1 dias.[/url] .
Trainwreck 2015 HD ????? ????? 6.4
Download: [url=http://getcrulse.com/torrent/1664978110/-+Explained+S01E11+480p+x264-mSD]- Explained S01E11 480p x264-mSD[/url] .
charlie-rose-your-best-offer mp4
Download: [url=http://am-pop.com/vestern/]Вестерн[/url] .
Triple 9 2016 HD ????? ????? 6.6
Download: [url=http://thefablerhouse.com/ben-10-supremacia-alienigena/]Ben 10: Supremacia AlienГgena Assistir Ben 10: Supremacia AlienГgena 720p Dublado/Legendado Online Retomando algumas semanas depois de que Ben 10: ForГ§a AlienГgena acaba, comeГ§a Ben 10: Supremacia AlienГgena, Ben agora tГЄm dezesseis anos de idade. O Omnitrix foi destruГdo e Ben consegui um sucessor do Omnitrix, o Ultimatrix (no Brasil, Superomnitrix), uma versГЈo nova do Omnitrix antigo que nГЈo sГі lhe dГЎ acesso ao seu ...[/url] .
Adult Novels
Download: [url=http://theranchatbirchcreek.com/mp3/gorillaz.html]Gorillaz[/url] .
Trasha Cobbs
Download: [url=http://skyconceptsphotos.com/film/dare-to-be-wild-2015-1080p.45765/]HD Dare to Be Wild (2015)[/url] .
Трилър
Download: [url=http://izmiralfa.com/torrent/885444/poslednyaya-zapis-the-last-note-2017-hdrip-greenray-studio]Последняя запись / The Last Note (2017) HDRip | GreenРай Studio[/url] .
Go To Home
Download: [url=http://wglfb.com/series]View more В»[/url] .
Heathens - Twenty One Pilots [2016]
Download: [url=http://tba101.com/ru/wps-office-word-docs-pdf-note-slide-sheet/cn.wps.moffice_eng/download?from=home%2Fnew]Скачать APK[/url] .
Fansadox Collection (BDSM Adult Comics) 1 - 337
Download: [url=http://coquesite.com/category/afterburnaftershock-2017/]Afterburn/Aftershock 2017[/url] .
Risk Management Applications in Pharmaceutical and Biopharmaceutical Manufacturing (Wiley Series in Biotechnology and Bioengineering)
Download: [url=http://restuqq.com/directory/a3076545104enqr0]a-voyage-aboard-t -> a307-6545-104-enq[/url] .
???? ??? 1? 3?
Download: [url=http://snelschilder.com/index.php?/topic/208072-2018-rgh-tutorial-poner-aurora-07b-en-espaГ±ol/][2018 RGH TUTORIAL] Poner A...[/url] .
Tomorrow
Download: [url=http://backbert.com/movies-basic-instinct-1992-moviesub.html]Basic Instinct[/url] .
19683 600
Download: [url=http://angescornus.com/hatarakanai-futari-yoshida-satoru/chapter-313]Hatarakanai Futari (YOSHIDA Satoru) 313[/url] .
Feature Request
Download: [url=http://ecuador50.biz/torrent/815943/pereval-dyatlova-konets-istorii-2016-dvbrip]Перевал Дятлова. Конец истории (2016) DVBRip[/url] .
bad moms
Download: [url=http://searchhirecars.com/actors/John+Wood.html]John Wood[/url] .
Petes Dragon 2016 BRRip XviD AC3-EVO[PRiME]
Download: [url=http://toin3535.com/torrent/Malwarebytes-Premium-3-3-1-2183-keygen-426aab/]Malwarebytes Premium 3.3.1.2183 + keygen[/url] .
my name is khan 720p
Download: [url=http://dst1004.com/star/4753-leslie-bibb]Leslie Bibb[/url] .
[Anime-dl.com] Blood Lad - 04 [480p].mp4
Download: [url=http://ph-stage.com/1147295412-obnovleniya.html]Нововведения на сайте[/url] .
Statistics
Download: [url=http://loi-sapin.com/torrent/george-lowell-2015-the-last-tour-classic-1979-broadcast-t3764691.html]George, Lowell [2015 ] The Last Tour~ Classic 1979 Broadcast[/url] .
CSS Core Concepts
Download: [url=http://caoxiu413.com/watch/LxRrZYxO-untouchable-lovers.html]Untouchable Lovers[/url] .
Stage Fright 2014 BluRay 720p AsOri .mkv
Download: [url=http://xn--azbuuk-zua.com/hockey-wives]Hockey Wives[/url] .
She Who Would be Pope (1972) DVD5 - Liv Ullman, Olivia de Havilland [DDR]
Download: [url=http://yournationalservices.com/video/actor/dermot-malruni/]Дермот Малруни[/url] .
Crimson Peak 2015 720p WEBDL 600MB
Download: [url=http://csccsports.com/showthread.php?204506-Barbie-Princess-Charm-School-Full-Movie-in-English-Barbie-Girl-en-espanol&s=7e21565dc2b3a06f6c8a79cce97efd76&goto=newpost]Barbie Princess Charm School...[/url] .
D.Gray-man S04E26 (2006)
Download: [url=http://elylite.com/live/665-rcti-tv-stream?feature=HomeTVChannel]RCTI TV Stream[/url] .
The 11th Hour with Brian Williams 2016 11 16 720p WEBRip x264-LM
Download: [url=http://favcoupon.com/one-piece/chapter-724]One Piece Chapter 724:[/url] .
BitLord.com
Download: [url=http://photoschoc.fr/viewtopic.php?t=324150&view=newest]Fallen Haven [L] [ENG / ENG] (1997)...[/url] .
Jason Ritter
Download: [url=http://indonity.us/authors-eng/harry-prentice.shtml]Harry Prentice[/url] .
2AM Time For Confession
Download: [url=http://cajunparadisefarms.com/artist/474724108/anne-marie.html]Anne-Marie[/url] .
Biography Channel
Download: [url=http://dalailamahindi.org/beneath-harvest-sky-2013-720p-1080p/]Beneath the Harvest Sky 2013 720p / 1080p[/url] .
??????? / ??????
Download: [url=http://sad555.com/biblioteka/17/zhanr-ne-opredelen]Жанр не определен[/url] .
Aleksandr Kaschtanow-Diskografija 2000-2009 APE CUE Lossless
Download: [url=http://djdrthq.com/louis_vuitton_patent_leather_mules/160e645f80eea90-many-232da5d2e8d7e33/]LOUIS VUITTON Patent Leather Mules TFeR5THvmq[/url] .
Lazy Company Tome 1 CBR(N)
Download: [url=http://vitawear.biz/descargar-non-stop-sin-escalas-latino.html]Non-Stop: Sin Escalas[/url] .
Високо напрежение
Download: [url=http://meilleursannuaires.com/drama-detail/no-tomorrow]No Tomorrow[/url] .
Sid Meiers Civilization VI 2016 (MacAPPS)
Download: [url=http://wedsiter.com/torrent/881972/plashch-i-kinzhal-cloak-amp-dagger-01x01-06-iz-10-2018-web-dlrip-jaskier]Плащ и Кинжал / Cloak Dagger [01x01-06 из 10] (2018) WEB-DLRip | Jaskier[/url] .
DIY String Art 24 Designs to Create and Hang (2016) Gooner
Download: [url=http://burdekincleaners.com/2018/06/14/%d9%85%d8%b4%d8%a7%d9%87%d8%af%d8%a9-%d9%85%d8%b3%d9%84%d8%b3%d9%84-%d8%a3%d8%a8%d9%88-%d8%b9%d9%85%d8%b1-%d8%a7%d9%84%d9%85%d8%b5%d8%b1%d9%8a-%d8%ad%d9%84%d9%82%d8%a9-28-%d9%83%d8%a7%d9%85%d9%84/]Щ…ШіЩ„ШіЩ„Ш§ШЄ Ш±Щ…Ш¶Ш§Щ† 66 Щ…ШґШ§Щ‡ШЇШ© Щ…ШіЩ„ШіЩ„ ШЈШЁЩ€ Ш№Щ…Ш± Ш§Щ„Щ…ШµШ±ЩЉ ШЩ„Щ‚Ш© 28 ЩѓШ§Щ…Щ„Ш© Ш§Щ€Щ† Щ„Ш§ЩЉЩ† Щ…ШґШ§Щ‡ШЇШ© Щ…ШіЩ„ШіЩ„ ШЈШЁЩ€ Ш№Щ…Ш± Ш§Щ„Щ…ШµШ±ЩЉ ШЩ„Щ‚Ш© 28 ЩѓШ§Щ…Щ„Ш© Ш§Щ€Щ† Щ„Ш§ЩЉЩ† ШЁШ¬Щ€ШЇШ© Ш№Ш§Щ„ЩЉШ© Щ…Ш№ Ш§Щ…ЩѓШ§Щ†ЩЉШ© ШЄШЩ…ЩЉЩ„ ШЩ„Щ‚Ш§ШЄ Щ…ШіЩ„ШіЩ„ ШЈШЁЩ€ Ш№Щ…Ш± Ш§Щ„Щ…ШµШ±ЩЉ[/url] .
Chicago Fire S05E05 720p HDTV x264-KILLERS[ettv]
Download: [url=http://strictlybiz.biz/2017/12/23/%d9%81%d9%8a%d9%84%d9%85-a-gentleman-2017-%d9%85%d8%aa%d8%b1%d8%ac%d9%85/]Ш§ЩЃЩ„Ш§Щ… Щ‡Щ†ШЇЩЉ imdb 7.4 171 ЩЃЩЉЩ„Щ… A Gentleman 2017 Щ…ШЄШ±Ш¬Щ… Щ…ШґШ§Щ‡ШЇШ© Щ€ШЄШЩ…ЩЉЩ„ ЩЃЩЉЩ„Щ… Ш§Щ„Ш§ЩѓШґЩ† Щ€Ш§Щ„Ш±Щ€Щ…Ш§Щ†ШіЩЉШ© Ш§Щ„Щ‡Щ†ШЇЩЉ A Gentleman 2017 HD Щ…ШЄШ±Ш¬Щ… Щ„Щ„Щ†Ш¬Щ€Щ… ШіЩЉШЇЩ‡Ш§Ш±Ш« Щ…Ш§Щ„Щ‡Щ€ШЄШ±Ш§ Щ€Ш¬Ш§ЩѓЩ„ЩЉЩ† ЩЃЩЉШ±Щ†Ш§Щ†ШЇЩЉШІ Ш§Щ€Щ† Щ„Ш§ЩЉЩ† Щ€ШЄШЩ…ЩЉЩ„ Щ…ШЁШ§ШґШ±[/url] .
intouchable
Download: [url=http://vitawear.biz/descargar-la-bruja-de-samahin-latino.html]La Bruja De Samahin[/url] .
Read more...
Download: [url=http://westbayhomedecor.com/torrent/885421/odin-potryasayushchiy-den-earth-one-amazing-day-2017-uhd-bdremux-2160p-ot-exkinoray-hdr-dolby-vision-litsenziya]Один потрясающий день / Earth: One Amazing Day (2017) UHD BDRemux 2160p от ExKinoRay | HDR | Dolby Vision | Лицензия[/url] .
Jason Bourne 2016 1080p BRRip 6CH 2 2GB MkvCage mkv
Download: [url=http://betterleadsinc.com/films/acteur/martin-mccann.html]Martin McCann[/url] .
Anthropoid (2016)
Download: [url=http://goodbeni.info/serial/tajemnicze-zlote-miasta-les-mystrieuses-cits-dor/1631]Tajemnicze zЕ‚ote miasta / Les Mystrieuses Cits d'Or[/url] .
BitLord.com
Download: [url=http://betterleadsinc.com/films/acteur/steve-zahn.html]Steve Zahn[/url] .
Secret Diary of a Call girl
Download: [url=http://camerasbtg.com/channel/UC11PvrGPzo6Y7Zc6-e9cAKg]DramaAlert[/url] .
naruto 508 raw
Download: [url=http://shitdub.com/descargar-torrents-variados-311-CyberLink-PowerDVD-Ultra-v12.html]CyberLink PowerDVD Ultra v12.[/url] .
NCIS S14E07 1080p HDTV x264 mp4
Download: [url=http://juicylifeblueprint.com/ee-nagaraniki-emaindi-watch-online-dvdrip/]Ee Nagaraniki Emaindi 2018[/url] .
Comments (0)
Download: [url=http://bela-negara.com/r8cfea-paul-simon-the-concert-in-hyde-park-cd2]The Concert In Hyde Park CD2[/url] .
[????] ??? ?? 98? 161117
Download: [url=http://yournationalservice.com/viewforum.php?f=88]3D Кинофильмы[/url] .
Celebrity Antiques Road Trip S06E02 - Charles Dance and Geraldine James
Download: [url=http://holistichealthfitnessinfo.com/index.php?fObj=dg8e0pmuks4nhf8qpnoi401ue0&cat=11]JUEGOS DE PC[/url] .
Dhoom 2004 HD ????? ????? 6.7
Download: [url=http://abusinessforms.com/serie/Spirit-wild-und-frei]Spirit: wild und frei[/url] .
CBS.Evening.News.2016.06.02.(Eng.Subs).SDTV.x264
Download: [url=http://tba101.com/es/legend-of-brave/com.yoyogame.mhzygp/download?from=home%2Fhot]Descargar APK[/url] .
Look Magazine - November 21, 2016 - True PDF - 1795 [ECLiPSE]
Download: [url=http://thaymatkinh.com/profile.php?mode=viewprofile&u=49490]Dimasik79[/url] .
The Others
Download: [url=http://meilleursannuaires.com/drama-detail/to-the-dearest-intruder]To The Dearest Intruder[/url] .
Movie library
Download: [url=http://getcrulse.com/torrent/1664978715/uTorrent+PRO+v3+5+3+build+44498+Stable+%2B+Crack+-+%5BCrackzSoft%5D]uTorrent PRO v3 5 3 build 44498 Stable + Crack - [CrackzSoft][/url] .
Radiohead’s entire discography is now available to stream on Spotify
Download: [url=http://abudhabi-lottery.info/mp3/dave-matthews-band.html]Dave Matthews Band[/url] .
Terms of Services
Download: [url=http://gr-po.com/tv-shows/Workaholics_25173/]Workaholics 2011[/url] .
Wildfire
Download: [url=http://the-wondrous-pattaya.com/actors/Kendall+Cross.html]Kendall Cross[/url] .
Look
Download: [url=http://with-malice.com/]Contacto[/url] .
Portal 2 - 2016 (PC) nosTeam
Download: [url=http://okokook.com/download--various-artists-the-many-faces-of-the-police-box-3cd-flac.html]. Various Artists - The Many Faces Of The Police (Box 3CD) [Flac][/url] .
Overwatch - 2016 (PC) nosTeam
Download: [url=http://yt9926.com/forumdisplay.php?f=49&s=d52f04e48c173854b7ff32097e4b1cee]Miniseries en SD[/url] .
Trap Queen
Download: [url=http://heavenlymassagebybrandee.com/hd/movie/534332/]Stream in 123Movies HD[/url] .
Господари на ефира
Download: [url=http://infruxure.com/starfighter-eclipse-t344454.html]Starfighter: Eclipse[/url] .
The Game
Download: [url=http://copaibashop.com/movies/wonder-woman/]Wonder Woman[/url] .
Facebook
Download: [url=http://laskueche.org/series/genius/]Watch movie[/url] .
just friends billy taylor pdf free
Download: [url=http://zavtrakturista.com/watch-Raees-2017-movie-online-3-1952.html]Raees (2017)[/url] .
Animal Kingdom (2016)
Download: [url=http://8xmj.com/The-Magicians-staffel-3-folge-13-deutsch-stream]Folge 13[/url] .
Sex Tape
Download: [url=http://tevendemosenusa.com/actors/Billy+Schneider.html]Billy Schneider[/url] .
GQ - December 2016 - True PDF - 1791 [ECLiPSE]
Download: [url=http://pg772222.com/phim/7-vien-ngoc-rong-sieu-cap-dragon-ball-super-i8-2844/]Bảy Viên Ngọc Rồng Siêu Cấp Dragon Ball Super Lượt xem: 65,930,441[/url] .
Money 2016 1080p BluRay x264-AN0NYM0US[rarbg]
Download: [url=http://pop1212.com/kickboxer-retaliation-2018]Kickboxer: Retaliation (2018)[/url] .
Impastor S02E08 720p HDTV x264-FLEET[PRiME]
Download: [url=http://essentialspiritashlynn.com/prison-break-season-4/]Prison Break Season 4 Ongoing[/url] .
[share_ebook] Maxim March 2009 USA
Download: [url=http://kb643.com/man-down-season-1/]Man Down (season 1)[/url] .
09 I Would One Direction Traducida Al Espanol
Download: [url=http://swsomalia.com/Poldark-watch-tvshow-11448050.html]Poldark, Season: 4, Episode: 6[/url] .
Alan Jackson-The Greatest Hits Collection-1995-EU-RETAiL-QUARTiC
Download: [url=http://prestijemlak.com/movies/power-of-the-press-1943-yify-720p.html]Download[/url] .
Addicted to Fresno 2015 iNTERNAL BDRip x264-LiBRARiANS
Download: [url=http://918kisss.net/category/runtime-system]Runtime System[/url] .
Recovery By Eminem
Download: [url=http://ju784.com/multichannel_music_and_own_digitization_pop_music_-download_torrent/]Multichannel music and own digitization (pop music)[/url] .
Teen Wolf S06E01 720p HDTV x265 HEVC 215MB - geekmess.com
Download: [url=http://robotcowboys.com/show/supernatural]Watch show[/url] .
Sid Meiers Starships - 2015 - FOR - MAC
Download: [url=http://1winandwin724.com/tag/dark-crimes-watch-hd-films]Dark Crimes watch HD films[/url] .
???
Download: [url=http://vinopolis.org/torrents/?search=condor+s01e06&orderby=enviado]UPLOADED[/url] .
AVG Anti-Virus Professional 9.0 Build 663a1706
Download: [url=http://yibovip88.com/actors/Frank+Fritz.html]Frank Fritz[/url] .
DAEMON Tools Pro 8 0 0 0631 + Patch [4realtorrentz] zip
Download: [url=http://comzybag.com/lost-in-space/]Lost in Space[/url] .
modern family s02e 720p
Download: [url=http://thingshaker.com/soubor-ke-stazeni-manzel-na-zkousku-2018-cz-titulky-novinka-avi-1246000.html?modal=1]StГЎhnout soubor[/url] .
view all
Download: [url=http://komodo6go.com/watch/the-chronicles-of-narnia-prince-caspian-2008-online-solarmovie.html]Watch now[/url] .
Apple Compressor 4 2 1 [Ked by TNT] YS4
Download: [url=http://thesoftsol.com/2015/12/]ThГЎng MЖ°б»ќi Hai 2015[/url] .
Operazione Valchiria 2 - L'alba del Quarto Reich (2016) DVD9 iso
Download: [url=http://congtamsu.net/policy]Usage policy[/url] .
Nashville
Download: [url=http://vouyer.us/2914-telecharger-007-spectre-torrent.html]007 Spectre FRENCH DVDRIP x264 Torrent[/url] .
Maburaho
Download: [url=http://legalclientnews11.com/member.php?u=12571&s=e9fd64275de900bafaf1559a4aeadb6b]kioto_69[/url] .
True Memoirs of an International Assassin 2016 720p WEBRip x264 Turkish AC3-ETRG
Download: [url=http://contriboss.org/serien/schauspieler/kit-harington]Kit Harington[/url] .
Big Bang Theory
Download: [url=http://4455vs.com/film/into-the-badlands-season-3-2018-1080p.94945/]Eps8 Into the Badlands - Season 3 (2018)[/url] .
At the Gates - (MacAPPS) 2016
Download: [url=http://portheadcoltd.com/watch-pose-222668-tvshow-online-free-m4ufree.html]Pose (2018) S01-E08[/url] .
Last Tango in Paris 1972 HD ????? ????? 7.2
Download: [url=http://theworldofeasier.com/torrent/23435287/12_Rules_for_Life-Peterson_(lnw_Adam)]12 Rules for Life-Peterson (lnw Adam)[/url] .
Albert King - 1972 - I’ll Play The Blues For You (Stax - SXSA-3009-6, 2004 ...
Download: [url=http://universitymemories.net/member.php?s=5bf5bff8287912aaee1798c7dd5a812d&u=1954247]Dingolondangos[/url] .
Mastering Your Mean Girl - The No-BS Guide to Silencing Your Inner Critic and...
Download: [url=http://narriva.net/top-gear]Top Gear[/url] .
Get Hard 2015 HD ????? ????? 6.1
Download: [url=http://crunchjournal.com/come-dine-with-me-season-43-episode-35-s43e35_422969]Come Dine With Me Season 43 Episode 35[/url] .
Ana Wlaghram Bay Bay
Download: [url=http://9s003.com/serie-streaming-vf/grey-s-anatomy/saison-11/episode-10-streaming-fr-12]Г©pisode 10[/url] .
Die glorreichen Sieben voll kostenlos sehen
Download: [url=http://purelysinfuldelights.com/iqbal-full-movie-watch-online-free-download/]Watch Movie[/url] .
Advanced Search
Download: [url=http://ga4pdf.com/telecharger-series/41449-marvels-luke-cage-saison-2-vostfr-webrip-complete-netflix.html]Marvel's Luke Cage[/url] .
Video Sample
Download: [url=http://istanbulnews.org/pelicula/descargar-torrent-1320-uno-de-los-nuestros]Uno de los nuestros (1990)[/url] .
Barbie Cavaliere - Stage d'Equitation.nds
Download: [url=http://australianrealestatedaily.com/watch-movie-bilal-a-new-breed-of-hero-online-megashare-9351]Bilal: A New Breed of Hero (2016)[/url] .
Albert Collins - Cold Snap
Download: [url=http://justintimecarpets.com/games/games/xboxone/98983-dead-to-rights-retribution]09.05.1013:51 Uhr Dead to Rights: Retribution Action0 / 03.480 Hits VID P2P DDL 0 Kommentare[/url] .
bodie kane marcus investments 10th edition pdf
Download: [url=http://naturopathie-paris14.com/serie/Qualidea-Code]Qualidea Code[/url] .
Russian Teens Private Casting s2 with Timo Hardy mp4
Download: [url=http://wuye70.com/watch/tristan-isolde-2006-online-solarmovie.html]Watch now[/url] .
Years of Living Dangerously S02E03 HDTV x264-CROOKS[ettv]
Download: [url=http://byonec.com/actors/Harry+Mondryk.html]Harry Mondryk[/url] .
Adobe Creative Cloud Collection 2015 For Mac
Download: [url=http://nci-innovation.com/category/100-choses-a-faire-avant-le-lycee/]100 choses Г faire avant le lycГ©e[/url] .
BitLord.com
Download: [url=http://edumanbd2.com/category/royal-pains/]Royal Pains[/url] .
WWE Wrestlemania XXX WWENetwork WEB-DL H264-XWT [P2PDL]
Download: [url=http://hkchips.info/american-gods-season-1/]American Gods season 1 Completed[/url] .
Project Highrise 1.1.1 + Auto-Update (+VirusTotalScan) [Isohunt.to]
Download: [url=http://airbnbtricks.com/Watch/Science-View-13625-Season4-Episode28-1027612.html]Science View S4E28 Episode 28[/url] .
Nonstop sauereien S3 mp4
Download: [url=http://6301222.com/films-dvdrip-bdrip/1/genre-Policiers/films+dvdrip+et+bdrip/1.html]Policiers[/url] .
evil dead
Download: [url=http://distributedledgersdk.com/black-mirror-4a-temporada-mp4-legendado/]Mais Informações [/url] .
APES.REVOLUTION.Il.pianeta.delle.scimmie.Movie.ITALIA.2014.BluRay-1080p.x264-MiLLENiUM
Download: [url=http://naturopathie-paris14.com/vorgeschlagene-serien/vote:11076]Galaxy Angel[/url] .
BitLord.com
Download: [url=http://spsegypt.net/vorgeschlagene-serien/vote:11825]Alaska X - Fälle des Paranormalen[/url] .
Absolutely Fabulous The Movie 2016 720p WEBrip AC3 [PRiME].[MKV]
Download: [url=http://betpish.com/film/13-hours-the-secret-soldiers-of-benghazi-ryv]Eps1 13 Hours: The Secret Soldiers of Benghazi[/url] .
Alda Celia 2000 Alda Celia - Alda Celia - Play Backs
Download: [url=http://ju741.com/watch-continuum-online/]Continuum[/url] .
view all
Download: [url=http://jualoilspilldispersant.com/jeux-divers/le-journal-de-spirou-n4185-du-27-juin-2018.html]Le Journal De Spirou NВ°4185 Du 27 Juin 2018[/url] .
Jason Bourne (2016) 720p BluRay...
Download: [url=http://895577bb.com/pretty-thing-lives-house/]Watch Movie[/url] .
Cancelar Resposta
Download: [url=http://horizonproject.us/movie/the-babysitter-2-35llwy8]The Babysitter[/url] .
photoshop
Download: [url=http://americandreamfurniture.net/category/business/ http://itunes.apple.com/app/id454936656]View PDF on Apple iOS[/url] .
game of thrones
Download: [url=http://justfuckwithit.com/shooter-3/episodio-1]Episdio 1 Temporada 3 Shooter[/url] .
MasterChef (UK) The Professionals S09E05
Download: [url=http://incorporateddesigners.com/m_43540.html]дЅ д№џжЇдєєз±»еђ—?[/url] .
2013-05-27 Melisa - Fingering Wader (InFocusGirls.com).mp4
Download: [url=http://homeinspiration.us/black-panther-streaming/]DVDRip Black Panther[/url] .
Game of Thrones S06
Download: [url=http://lancasterhabitatrestore.org/the-newsroom]The Newsroom[/url] .
Dawn.of.the.Planet.of.the.Apes.DVDRip.avi
Download: [url=http://bodydetoxme.com/trailer/5670152/]Watch Trailer[/url] .
EnigmaT Set Rips Cuts - November 13th, 2016 [Isohunt.to]
Download: [url=http://ronahome-garden.com/index.php?menu=search&star=Sacha%20Baron%20Cohen]Sacha Baron Cohen[/url] .
Download Aguas Rasas Dublado Torrent
Download: [url=http://beijingdi.com/torrents-search.php?search=Multi+audio+hindi&sort=relevance]Multi audio hindi[/url] .
Vectors -- Different Sale Ribbons 3
Download: [url=http://over55.us/skyscraper-2018-en-streaming-vf-vk.html]Skyscraper[/url] .
i prevail lifelines
Download: [url=http://julesraceway.com/cat/SeriesVostfr_page_3]4</span>[/url] .
Say Yes To The Dress
Download: [url=http://vzefhq.info/titta-cast_tv/adina-porter]Adina Porter[/url] .
X-Men Apocalypse 2016 Truefrench 720p x264 AAC PIX...(A)
Download: [url=http://nagahoki.net/brice-3-streaming-13/]Regarder un film[/url] .
Being Human
Download: [url=http://carrollenterprisescorp.com/video/browse/20-drammatico/]0 Drammatico[/url] .
Dont Fuck My Daughter} Liza Rowe - Liza and Glen hit the bases (14 Nove...
Download: [url=http://webkiller.us/actors/Thomas+Francis+Murphy.html]Thomas Francis Murphy[/url] .
view all
Download: [url=http://philcarprice.com/eps/?opload=Hu3IgHa4ADA/Ravens.Home.S01E04.Legendado.mp4&vt=ifd4mypj7432&rvid=FKSVQ0JCI8&tvid=1kzqzszxu042o4jfosrku5ml&vdoza=hwv2kao0syzm&ref=app]В– EpisГіdio 04[/url] .
Rene Rhi
Download: [url=http://camp-hill.com/movies/mary-and-the-witchs-flower/]Mary and the Witch’s Flower[/url] .
High.Strung.2016.DVDRip.XviD-EVO.[AVI]
Download: [url=http://neeya-staff.com/baaghi-2-2018-watch-online-free/]</b> 5.6[/url] .
Ruby Barnhill,
Download: [url=http://dojisu.com/actor/donald-sutherland/]Donald Sutherland[/url] .
Yukon Men
Download: [url=http://officecrafts.info/country/usa | denmark]USA | Denmark[/url] .
Newspapers
Download: [url=http://webgym.pl/serie/Emerald-City]Emerald City[/url] .
⚠ Report this Torrent
Download: [url=http://ndbuilt.com/link/3738153/]Reproducir[/url] .
Contact Us
Download: [url=http://uleaker.com/tag/watch-the-graham-norton-show-season-23-episode-12-online-free]Watch The Graham Norton Show Season 23 Episode 12 Online Free[/url] .
Torrent Kings Release Group/TKRG
Download: [url=http://livingcave.com/member.php?u=108011&s=74321c68e59d6bfd541e3b4920d64035]View Profile[/url] .
RollerCoaster Tycoon World-RELOADED
Download: [url=http://inter-finances.com/]Series Category[/url] .
Continuar
Download: [url=http://lancasterhabitatrestore.org/person/sienna-guillory]Sienna Guillory[/url] .
NOVA S44E07 Treasures of the Earth-Power HDTV x264-SDI - [SRIGGA]
Download: [url=http://29ddyy.com/watch-americas-got-talent-online-couchtuner-539.html]America's Got Talent[/url] .
chet crisis action
Download: [url=http://softfaber.org/index.php?c=Breaking-Bad]Breaking Bad[/url] .
Hard Rock / Krautrock
Download: [url=http://4455vi.com/link/3738143/]Reproducir[/url] .
BitLord.com
Download: [url=http://wuye12.com/episode/324948/2/10/andi-mack/]Episode 10 : A Good Hair Day[/url] .
@description philosophie
Download: [url=http://betpantai4d.net/serie/Getting-On-Fiese-alte-Knochen]Getting On - Fiese alte Knochen[/url] .
??? ?
Download: [url=http://trumpies.org/watch-younger-season-4-2017-1080p.85152-online-free-123movieshub.html]Eps12 Younger - Season 4 (2017)[/url] .
vidzi.tv
Download: [url=http://vzefhq.info/titta-cast/amali-golden]Amali Golden[/url] .
[KiteSeekers-Wasurenai] Pretty Rhythm Aurora Dream Special - 27 [H264 704x400] [474B7565].mkv
Download: [url=http://nhmrc2017.com/livres/9848-violente-cathy-glass.html]ViolentГ©e – Cathy Glass[/url] .
artificial intelligence for humans, volume 3: deep learning and neural networks pdf
Download: [url=http://imghuntr.com/series/luther-1.html]Luther20184 seizoenen58 min +3[/url] .
Prince of Tennis
Download: [url=http://descargarwhatsapp-gratis.com/peliculas/una-invitada-peligrosa/]Una Invitada Peligrosa[/url] .
Jade Empire Special Edition - 2016 - FOR - MAC
Download: [url=http://co-rh.com/forumdisplay.php?f=132&s=9d6ead095025dd1fa9db9d4158c89a53]Hitman Configs[/url] .
Download 1080p 5.1
Download: [url=http://31cmm.com/q/nina+elle+suck+balls]nina elle suck balls[/url] .
Helium Music Manager 11.2.0 Build 13510 Network Edition
Download: [url=http://hocseohieuqua.com/index.php?menu=search&star=Kathryn%20Morris]Kathryn Morris[/url] .
DJINN tome 13 PDF STDTeam (N)
Download: [url=http://mail-ceo.info/gratuit/rick-and-morty-saison-3.html]Rick and Morty Saison 3[/url] .
Bogan Hunters
Download: [url=http://incomeuniversityupdates.com/ver/mi-marido-tiene-mas-familia/temporada-1/capitulo-10.html]Mi marido tiene mas fami[/url] .
Biography Movies
Download: [url=http://kb582.com/14879-moby-everything-was-beautiful-and-nothing-hurt-2018-flac-tracks-cue.html]Moby - Everything Was Beautiful, And Nothing Hurt (2018) FLAC (tracks + .cue)[/url] .
E-40 - The D-Boy Diary Book 2 (2016)
Download: [url=http://airbnbpromotions.com/tag/playboy-usa/]Playboy USA[/url] .
Blindspot S01E20 HDTV x264-LOL[ettv]
Download: [url=http://queenbet77.com/hd/tv/69851/1/]Putlocker TV FULL HD[/url] .
16/05/18
Download: [url=http://plantaosertanejo.com/vorgeschlagene-serien/vote:12932]thundersub[/url] .
Paul Johansson,
Download: [url=http://kb735.com/category/the-orville/]The Orville[/url] .
EASEUS Partition Master 11 9 Technician Edition Multilingual Incl Keygen + Portable [SadeemPC]
Download: [url=http://63rmm.com/tamil-movies/3361-semma-botha-aagatha-2018-tamil-720p-hdrip-x264-dd51-esubs-mtr.html]Semma Botha Aagatha (2018) Tamil - 720p - HDRip - x264 - DD5.1 - ESubs-MTR[/url] .
The Pleasure Provider XXX DVDRip x264-UPPERCUT
Download: [url=http://qrcread.com/voir-manga-sakura-wars-en-streaming-1948.html]Sakura Wars[/url] .
BitLord.com
Download: [url=http://hoppinessdelivered.info/assistir/os-pinguins-de-madagascar]Os Pinguins de Madagascar[/url] .
penny dreadful
Download: [url=http://webgym.pl/vorgeschlagene-serien/vote:12924]Die Goldsucher vom Devil's Canyon[/url] .
Полицаите от Чикаго Сезон 4 Епизод 7 и Епизод 8 / Chicago P.D. БГ СУБТИТРИ
Download: [url=http://samuithaifoods.com/episode/whose_line_is_it_anyway_s14_e9.html]Season 14 , Episode 9[/url] .
La Femme Nikita
Download: [url=http://tevendemosenusa.com/actors/Patricia+Harras.html]Patricia Harras[/url] .
Planet of the Sharks 2016 1080p BluRay x264 DTS-FGT[EtHD]
Download: [url=http://freetestingproducts.com/index.php?menu=search&star=Paul%20Abrahamian]Paul Abrahamian[/url] .
[Freelance Raws] Higurashi no Naku Koro ni Kai 18 (704x396 x264 AAC).[d558jJoPJW].mkv
Download: [url=http://wowclick.net/actors/Vladimir+Shklyar.html]Vladimir Shklyar[/url] .
AntiVirus BitSweeper 1 1 for MAC-OSx
Download: [url=http://threatmitigators.com/category/billy-and-billie/]Billy and Billie[/url] .
Shokugeki no Souma (2015) [Season 1] [Isohunt.to]
Download: [url=http://wowclick.net/watch/harlots-s02-2017-online-flenix.html]Watch now[/url] .
Stargate Atlantis
Download: [url=http://holytrinitypreschoolcapecod.org/movies?sort=recent]Recent Added[/url] .
F.Is.For.Family.1x01-06.ITA
Download: [url=http://cosmopoons.com/series-vf-en-hd/]SГ©ries VF 720p[/url] .
Wrong Turn (2003) Dual Audio 720p BrRip ...
Download: [url=http://naturopathie-paris14.com/serie/serie/Two-and-a-Half-Men/1/13-Im-Bett-mit-Angina/OpenLoad]OpenLoad[/url] .
Aligarh (2016) Hindi Movie DVDScr HD Free Download
Download: [url=http://apishuttle.com/pelicula/life-of-the-party/]Ver ahora[/url] .
Password
Download: [url=http://602106.com/series/yellowstone/]Watch Series[/url] .
Alexis Y Fido Ft Dady Yankee
Download: [url=http://cultureclashing.com/genre/%d9%88%d9%8a%d8%b3%d8%aa%d8%b1%d9%86/]Щ€ЩЉШіШЄШ±Щ†[/url] .
Сезон 4 БГ СУБТИТРИ
Download: [url=http://ncfsg.com/member.php?s=891929156d7adf5d224b4c31e304500a&u=1329310]danni900[/url] .
Comments: 0
Download: [url=http://yibovip88.com/actors/Airica+Kraehmer.html]Airica Kraehmer[/url] .
OK! Magazine UK - 22 November 2016 - True PDF - 1800 [ECLiPSE]
Download: [url=http://onlinebahissiteleri369.com/watch-i-m-not-there-2007-1080p-online-free-123movieshub.html]DVD I'm Not There. (2007)[/url] .
View this forum's RSS feed
Download: [url=http://lh6988.com/hd/tv/75758/]Stream in putlocker HD[/url] .
BBC A Timewatch Guide 2of4 Women Sex and Society WebRip x264-MCTV
Download: [url=http://yibovip88.com/actors/Brooke+Tomlinson.html]Brooke Tomlinson[/url] .
Download The Jungle Book Torrent
Download: [url=http://xomusicuk.com/hd/tv/60735/3/]Stream in 123Movies HD[/url] .
The Great Gilly Hopkins 2016 720p BRRip x264 AAC-ETRG
Download: [url=http://webkiller.us/actors/Tim+McInnerny.html]Tim McInnerny[/url] .
Office mac
Download: [url=http://philcarprice.com/eps/?opload=zAoYSfL_y2s/Suits.S02E16.mp4&vdag=j6tvkxq7zv8w&vz=qnhm1ppz9u8u&vt=1v5pt5620tvh&ref=app]EpisГіdio 16[/url] .
Chris D'Elia,
Download: [url=http://wanmei567.com/genres/adventure.html?p=2]Next в†’[/url] .
Blood Father
Download: [url=http://vendorpackage.com/A84002CE31D499BEDF35A2B6320E327BBCC93465]The Internet - Hive Mind (2018) Mp3 (320kbps) [Hunter][/url] .
Becka Title All Songs
Download: [url=http://lancasterhabitatrestore.org/person/antonia-thomas]Antonia Thomas[/url] .
BitLord.com
Download: [url=http://sportrefund.com/serie-streaming-vf/the-walking-dead/saison-4/episode-11-streaming-fr-12]Г©pisode 11 Claimed[/url] .
The.Program.1993.DvdRip.x264....
Download: [url=http://legalclientnews11.com/forumdisplay.php?f=214&s=7908fbed57680eab875be1bb0f2aef8f]BiografГa y Memorias[/url] .
LEGO Star Wars
Download: [url=http://legalclientnews11.com/forumdisplay.php?f=12&s=5a96dd03a842ab19a386d18d837de7fe]DVDRip hasta 1990 Inclusive[/url] .
Gamecube
Download: [url=http://essentialspiritashlynn.com/greys-anatomy-saeason-13/]Grey’s Anatomy Saeason 13 Completed[/url] .
100th Running of the Indianapolis 500 May 29th 2016 [WWRG] [Isohunt.to]
Download: [url=http://wowclick.net/actors/Vanessa+Bayer.html]Vanessa Bayer[/url] .
Tarzan 3D 2013 iTALiAN CAM MD XviD - BmA ( Rapidgator - Uploaded - Ryushare )
Download: [url=http://trackweathernow.com/eps/?ok=38068357817&opload=qJD6X8ot_dE/Quantico.S01E08.720p.WWW.VERFILMES.BIZ.mkv&vdbis=29cr9xg46bj6&vt=9ii41qrq7z76&vz=ocp268b7lkjm&ref=app]EpisГіdio 08[/url] .
WWE Smackdown Live 2016 11 15 HDTV x264-Ebi [TJET]
Download: [url=http://mommyjourney.net/movie/once-upon-a-time-in-the-west/]Watch movie[/url] .
Victoria Pure mp4
Download: [url=http://pg772222.com/the-loai/phim-hai-huoc/phim-le/-2012/]Phim lбє» trЖ°б»›c 2012[/url] .
Contact Us
Download: [url=http://call2actionretargeting.com/assistirfilme/assistir-baahubali-2-dublado/]Baahubali 2: A ConclusГЈo 2017 720p[/url] .
Robinson Crusoe 2016 TrueFrench AC3 1080p HDLight ...(A)
Download: [url=http://hhyyvip.com/02012912-flight-international-26-june-2018/]Flight International – 26 June 2018[/url] .
Marvin Gaye - Marvin Gaye's Greatest Hits - Oldsimba
Download: [url=http://ronacontest.com/stephen-leather-tall-order-mp3-audiobook/]DIRECT DOWNLOAD LINKS[/url] .
VH1 Storytellers - The Doors a celebration (2001) [DVD5 NTSC] [Isohunt.to]
Download: [url=http://i4nygt.com/serie-streaming-vf/grey-s-anatomy/saison-5/episode-18]Г©pisode 18[/url] .
Guidelines for Safe Process Operations and Maintenance
Download: [url=http://green9999.com/book/837553884/elephant-company]Elephant Company[/url] .
???
Download: [url=http://spsegypt.net/serie/serie/The-Walking-Dead/1/2-Gefangene-der-Toten]Gefangene der Toten Guts[/url] .
Chrome Underground
Download: [url=http://joieapp.com/revelations-chirurgie-regime-medecine-le-prix-de-la-beaute-streaming-vf-vostfr/]RГ©vГ©lations Chirurgie RГ©gime MГ©decine Le Prix De La BeautГ©[/url] .
Michael Cera
Download: [url=http://yosemitetours.net/better-call-saul-season-4/]Better Call Saul (season 4)[/url] .
World Cup 2006
Download: [url=http://olti.org/waterworld-1995/]July 19, 2018[/url] .
11 de setembro de 2016
Download: [url=http://tevendemosenusa.com/actors/Sean+McIntyre.html]Sean McIntyre[/url] .
Judge.Judy.S21E23.720p.HDTV.x264-WaLMaRT[eztv]
Download: [url=http://veryelephants.com/films-gratuit/41809-tomb-raider-multi-truefrench-bluray-3d.html]Tomb Raider[/url] .
Advanced English Grammar and Communication
Download: [url=http://shzedong.com/actors/Noam+Jenkins.html]Noam Jenkins[/url] .
view all
Download: [url=http://woc4socialchange.org/actor/martyn-ford/]Martyn Ford[/url] .
Supernatural 12? Temporada Torrent
Download: [url=http://thepantherpress.org/torrent-de-musique/rap-hip-hop-torrent/]Rap, Hip Hop[/url] .
Inna Sirina - I like others to fuck my wife XXX WebGift [Isohunt.to]
Download: [url=http://xwonbet.net/tv/subtitles/the-handmaids-tale-9962640.html]The.Handmaids.Tale.S01E02.720p.WEBRip.x264-MOROSE.srt[/url] .
More Info
Download: [url=http://love-ran.com/03200900-hinge-june-2018/]hinge – June 2018[/url] .
Undateable (2014)
Download: [url=http://wowclick.net/movies/library.html]Full List[/url] .
Ellen DeGeneres,
Download: [url=http://skydronesfun.com/actors/Dean+Jagger.html]Dean Jagger[/url] .
L'Uomo Ragno (1987) Ed. Star Comics (140/140) Conclusa
Download: [url=http://kb752.com/actors/Aurora+Perrineau.html]Aurora Perrineau[/url] .
True Story 2016 - Full Year Issues Collection
Download: [url=http://airyfarm.com/private.php?s=a92d745ab5b58cbe95414248c20d2122&do=newpm&u=3746]Mensaje privado[/url] .
the walking dead s01
Download: [url=http://psilocybintech.com/la-finale-streaming-vf/]La Finale[/url] .
Fort Tilden 2014 RERiP BDRip x264-WiDE[1337x][SN]
Download: [url=http://imdonkey.com/mp3-download/Ella+Eyre+Answerphone+Ft+Yxng+Bane/]14. Ella Eyre Answerphone Ft Yxng Bane mp3[/url] .
marche a l'ombre
Download: [url=http://dojisu.com/movie/pirates-passage-2015/watching/]Watch movie[/url] .
The.Secret.Life.of.Pets.2016.1080p.BluRay.x264.Hindi.Eng.AC3-ETRG
Download: [url=http://naijafox.net/actor/kristi-beckett/]Kristi Beckett[/url] .
The Bourne Supremacy 2004 BRRip 720p x265 2Ch HAAC-RCCL-KITE-METeam mkv
Download: [url=http://justintimecarpets.com/apps/apps/android/360914-android-only-paid-applications-collection-2018-week-04]09.05.1808:02 Uhr Android Only Paid Applications Collection 2018 (Week 04) 0 / 03.360 Hits VID P2P DDL 0 Kommentare[/url] .
The BFG 2016 DVDRip XviD AC3-iFT[SN]
Download: [url=http://newmangroupstore.com/s/sweet-revenge/]Sweet Revenge[/url] .
Design And Analysis of Reliable And Fault-tolerant Computer Systems
Download: [url=http://dojisu.com/movie/j-cole-4-your-eyez-only-2017/]View detail[/url] .
Connected2016
Download: [url=http://cryptosdk.org/tvshows/the-americans/]The Americans[/url] .
BitLord.com
Download: [url=http://yibovip88.com/actors/Devon+Weigel.html]Devon Weigel[/url] .
The Flash 2014 3x06 HDTV 720p x265 2Ch HAAC2-Sunil-KITE-METeam
Download: [url=http://fifaah.org/category/el-principe/]El Principe[/url] .
Alcoholics Anonymous AA Speaker Old Timer Mp3
Download: [url=http://beatthatduinow.org/movie/3428-toy-story-3-2010-yify-torrent]Toy Story 3[/url] .
Albert Hammond Everything I Want To Do
Download: [url=http://yibovip88.com/actors/Adam+Goldberg.html]Adam Goldberg[/url] .
Captain Fantastic torrent
Download: [url=http://lala-zz.com/birdland/]Watch Movie[/url] .
Our fight against fake files and lack of comments
Download: [url=http://iczi-e.com/torrent/filmvidГ©o/animation-sГ©rie/284476-serial+experiments+lain+intГ©grale+french+dvdrip+xvid-notag]Serial Experiments Lain intГ©grale French DvDRip XviD-NoTAG[/url] .
Wall.Street.Money.Never.Sleeps.2010.?????????.????.HR-HDTV.AC3.1024X576.X264-??????
Download: [url=http://kb852.com/actors/Danny+Glover.html]Danny Glover[/url] .
The Romeo Section
Download: [url=http://gimmesometravel.com/series-hd/mom/2416]Mom HDTV 720p AC3 5.1[/url] .
BEWAKOOFIYAAN (2014) [NEW SOURCE] DVDSCR x264 AAC 5.1 [CHAUDHARY]
Download: [url=http://epi-island-guesthouse.net/movie/teen-titans-go-season-4-1080p.78516.html]Eps48 Teen Titans Go! - Season 4[/url] .
Britain's Whale Hunters: The Untold Story
Download: [url=http://nicemiss.info/01230416-aula-de-infantil-julio-agosto-2018/]Aula de Infantil – julio-agosto 2018[/url] .
Vectors -- Different Sale Ribbons 3
Download: [url=http://hamiltonhigh.net/still-the-king/]Still the King[/url] .
Young and the Restless
Download: [url=http://ju144.com/watch-10-rules-for-sleeping-around-2013-1080p-online-free-123movieshub.html]10 Rules for Sleeping Around (2013)[/url] .
Keeping Up With The Kardashians
Download: [url=http://swsomalia.com/movies-genre-6-Biography.html]Biography[/url] .
Ver todos
Download: [url=http://602076.com/tag/le-bagarreur-du-kentucky-vk-stream]Le Bagarreur du Kentucky vk stream[/url] .
(2017) HD Trailer The Maze Runner: The Death..
Download: [url=http://kb716.com/games/games/windows/365879-temple-of-life-die-legende-der-vier-elemente-sammleredition]01.07.1811:24 Uhr Temple of Life - Die Legende der Vier Elemente Sammleredition Wimmelbild0 / 01.565 Hits VID P2P DDL 0 Kommentare[/url] .
Better Call Saul
Download: [url=http://895577qq.com/category/Income Tax]Income Tax[/url] .
American Religious Leaders: American Biographies
Download: [url=http://895577xx.com/actor/kurt-caceres/]Kurt Caceres[/url] .
Maika Monroe,
Download: [url=http://kb644.com/descargar/peliculas-en-3d-hd/3d-hd-1080p/proyecto-rampage-3d-/bluray-3d-1080p/]Proyecto Rampage 3D BluRay 3D 1080p[/url] .
Greys Anatomy
Download: [url=http://mkprovider.com/watch/fast-and-furious-8-the-fate-of-the-furious]Fast and Furious 8: The Fate of the Furious[/url] .
The Final Confession of Mabel Stark by Robert Hough
Download: [url=http://newb55.com/tags/Mother+Earth/]Mother Earth[/url] .
Van Helsing S01E03 1080p WEB x264-HEAT[PRiME]
Download: [url=http://hocseohieuqua.com/index.php?menu=search&star=Devon%20Bostick]Devon Bostick[/url] .
Chicago Fire S05E05 HDTV XviD-FUM[ettv]
Download: [url=http://septicsewerservice.org/watch-kong-skull-island-2017-1080p-online-free-bmovies.html]HD Kong: Skull Island (2017)[/url] .
Eastbound And Down 720P Hdtv X264 Killers
Download: [url=http://manvsmaschine.com/category/deep-water/]Deep Water[/url] .
Alabama - In Pictures = Enjoy
Download: [url=http://bahiswin.net/series]TV - SERIES[/url] .
ABP-522(18)
Download: [url=http://borninjune.net/voir-manga-flame-of-recca-en-streaming-625.html]Flame of Recca[/url] .
Filmfare - November 30, 2016 - True PDF - 1788 [ECLiPSE]
Download: [url=http://justguitarthings.com/download/hou-lai-de-wo-men-2018-720p-bluray-x264-yts/movie/51562/]DOWNLOAD[/url] .
UnHackMe v8 30 Build 530 Setup + Crack zip
Download: [url=http://loona.us/02060909-playboy-slovakia-june-2018/]Playboy Slovakia – June 2018[/url] .
Nov 22nd, Tue
Download: [url=http://ju741.com/]New Releases[/url] .
Torrent Kings Release Group/TKRG
Download: [url=http://concertwristbands.net/details/18203B75BDC724A84234208BEAD3F7B1F88464E1/American+Gods+S01E06+A+Murder+of+Gods+1080p+AMZN+WEBRip+DD5+1+x264+AMZ+rarbg]American Gods S01E06 A Murder of Gods 1080p AMZN WEBRip DD5 1 x264 AMZ rarbg[/url] .
Flatbush Zombies Death 2
Download: [url=http://gencbahis.com/forumdisplay.php?f=194&s=d52f04e48c173854b7ff32097e4b1cee]Imagenes/Videos Graciosos[/url] .
For the love of god: STOP MESSING WITH TORRENTFREAK!!!
Download: [url=http://ndbuilt.com/link/3942763/]Reproducir[/url] .
80 HD Sexy Nina Adgal Bikini and Lingerie Wallpapers - Set 786 ECLiPSE
Download: [url=http://pclrpf.com/software/558670-photostage-photo-slideshow-software-free-v-510.html]PhotoStage Photo Slideshow Software Free v. 5.10[/url] .
Smash and Grab 2016 for win
Download: [url=http://kb990.com/r/ross+lynch.html]Ross Lynch[/url] .
??(10)
Download: [url=http://kb711.com/sleepy-hollow/]Sleepy Hollow[/url] .
Skylanders Academy S01E02 720p x264 [StB] Others
Download: [url=http://tevendemosenusa.com/actors/Gabrielle+Biviano.html]Gabrielle Biviano[/url] .
La Velle - Special (2012)
Download: [url=http://lookgood-bysimone.com/preacher-season-3-episode-5-s03e05_421882]Preacher Season 3 Episode 5 s03e05[/url] .
Only The Best (New Sensations) 2016 Split Scenes
Download: [url=http://deosantis.org/pelicula/descargar-torrent-1320-uno-de-los-nuestros]Uno de los nuestros (1990)[/url] .
likelylad
Download: [url=http://kingbetting.org/category/Electrical Engineering]Electrical Engineering[/url] .
Battlefield 1 (2016) (Final Version) (for pc)
Download: [url=http://stacklinux.org/the-lost-viking/]Watch Movie[/url] .
VICE News Tonight S01E28 2016 11 16 720p WEBRip H264 AAC2 0-PRiNCE - [SRIGGA]
Download: [url=http://aksharspeech.com/man-with-a-plan-s02e20/]Man with a Plan S02E20[/url] .
Wickeds End - The Grand Decay (2016)
Download: [url=http://12ddyy.com//12ddyy.com/watch-la-vegas-online/]LA to Vegas[/url] .
Jeopardy 11 16 2016 etwestt mkv
Download: [url=http://robotcowboys.com/index.php?menu=search&star=Aunjanue%20Ellis]Aunjanue Ellis[/url] .
Shaun.The.Sheep.S05E19.Cone.of.Shame.720p.HDTV.x264 DEADPOOL
Download: [url=http://socsamuiu.org/torrent/emulation/roms/214976-pack+22+-+sega+gamegear+277+roms+pour+recalbox+multi]Pack 22 - Sega Gamegear (277 roms) pour Recalbox Multi[/url] .
macgyver
Download: [url=http://believe-ods.org/godzilla-cidade-no-limiar-da-batalha-dublado-online/]Godzilla: Cidade no Limiar da Batalha Dublado Online Na sequГЄncia de "Godzilla: Planeta dos Monstros", Haruo e seus companheiros fazem contato com uma tribo indГgena, um dos poucos descendentes restantes da raГ§a humana. Agora, para derrotar Godzilla, o grupo parte rumo ao laboratГіrio do Meca-Godzilla.[/url] .
The Wild Life
Download: [url=http://tmavfitness.com/31710-watch-big-hero-6-the-series-123movies-moe.html]Big Hero 6 The Series[/url] .
defonce de beaux petits culs 5 s5 mp4
Download: [url=http://sunshinessl.com/series-vo/the-flash/2166]The Flash HDTV 720p AC3 5.1[/url] .
Barking Spider - Warrior By Night (2016)
Download: [url=http://portheadcoltd.com/watch-snowfall-13560-tvshow-online-free-m4ufree.html]Snowfall (2017) S02-E01[/url] .
Black Mirror Season 2 Complete FIXED HDTV x264 [i_c] [Isohunt.to]
Download: [url=http://ablessedqualityoflifellc.com/category/thriller/]Thriller[/url] .
IDM 6 26 Build 10 Registered (32bit + 64bit Patch) [CrackingPatching] zip
Download: [url=http://kb484.com/forum/214-tudomГЎnyos-hГrek/]TudomГЎnyos hГrek[/url] .
0 Comments
Download: [url=http://cop5.net/torrent/a9cd7fae6a407c6a9b9246a67238541a7af3fe1b]le dernier des capone TRUEFRENCH DVDRIP XVID AC3 ALLO[/url] .
Teachers Pet 6 s3 mp4
Download: [url=http://mkprovider.com/watch/gods-and-generals]Gods and Generals[/url] .
profilage
Download: [url=http://60cmm.com/category/fortitude/]Fortitude[/url] .
Сезон 1 БГ СУБТИТРИ
Download: [url=http://optimisemybnb.com/watch?tv_serie=6077448]Sacred Games ★ 9.4 / 10 CRIMEDRAMA[/url] .
American Horror Story S06E10 HDTV x264-FLEET[PRiME]
Download: [url=http://webgym.pl/serie/Lost-Found-Music-Studios]Lost Found Music Studios[/url] .
Torrent Filmes HD
Download: [url=http://zhainanzhongzi.org/actors/Matthew+Mercer.html]Matthew Mercer[/url] .
Hara Hara Mahadevaki A Funny Chennai Gana By Gana Prasanth Must Watch Red Pix Music Red Pix Music First Red Pix Music First
Download: [url=http://essentialspiritashlynn.com/continuum-season-2/]Continuum season 2 Completed[/url] .
Berlin Station S01E04 720p WEBDL x264 [ExYu-Subs HC]
Download: [url=http://newinfogirl.info/tags.php?s=5e7d9e782ea0ac2558e66aae89b46e75&tag=creative]creative[/url] .
Pete's Dragon 2016 BRRip XViD-ETRG
Download: [url=http://cocreatorsventures.org/biografia/sean-gunn]Sean Gunn[/url] .
??(12)
Download: [url=http://vitalintegrity.net/a-barraca-do-beijo-dublado/]VER TRAILER[/url] .
Bionic Woman
Download: [url=http://geralmundial.com/tag/flipbuilder-flip-pdf-professional/]FlipBuilder Flip PDF Professional[/url] .
Humor Baper (2016)
Download: [url=http://webkiller.us/genres/reality-tv.html]Reality-TV[/url] .
The Walking Dead 7? Temporada 720p
Download: [url=http://thehernandezlawoffice.com/tags/Telecharger+film+Tully+dvdrip/]Telecharger film Tully dvdrip[/url] .
Order By Time
Download: [url=http://viralinside.net/peca-sua-serie/](Clique aqui)[/url] .
90059 By Jay Rock
Download: [url=http://13ddyy.com/the-americans-season-5-4/]The Americans (season 5)[/url] .
Alejandro Escovedo - 2008 - Real Animal
Download: [url=http://creo.us/r_144467.html]Hannah.2017.720p.BluRay.x264-SPRiNTER[rarbg][/url] .
VA - The Jazz House Independent 2nd Issue (1998) [FLAC] [Isohunt.to]
Download: [url=http://borninjune.net/voir-manga-buzzer-beater-en-streaming-5.html]Buzzer Beater[/url] .
SSuite Office Excalibur Release.4.32.1 + Portable
Download: [url=http://betpara16.com/index.php?menu=search&star=Denzel%20Washington]Denzel Washington[/url] .
[tvN] ??? ??.E07.161116.360p-NEXT
Download: [url=http://teamupforfreedom.com/actors/Bonnie+Somerville.html]Bonnie Somerville[/url] .
A Married Woman (1964) Francais DVD5 - Eng Subs - Macha Meril, Phillippe Leroy [DDR]
Download: [url=http://enabletransmit.org/super-rtl-programm-heute.html]Heute auf SUPER-RTL[/url] .
Cassandra - Brace face mp4
Download: [url=http://chipsltd.net/titta-the-collector-gratis]The Collector[/url] .
Сезон 5 БГ СУБТИТРИ
Download: [url=http://spsegypt.net/serie/The-Tomorrow-People]The Tomorrow People[/url] .
Сезон 3 БГ СУБТИТРИ
Download: [url=http://xn--tiqr9gj0u8vt.com/01220902-moto-revue-hors-serie-juillet-2018/]Moto Revue – Hors-Serie – juillet 2018[/url] .
angry birds 720p
Download: [url=http://justguitarthings.com/download/mr-calzaghe-2015-1080p-bluray-x264-yts/movie/3382/]Mr Calzaghe 2015 1080p BluRay X264 YTS (2015)[/url] .
Velamma - Episode 1 to 45.pdf (Non-Watermarked Original Content) [Adult Comics] - Almerias
Download: [url=http://tigercreep.com/jeux/40890-far-cry-5.html]Far Cry 5 (ISO) (MULTI) (2018)[/url] .
Burly Men at Sea - 2016 (MacAPPS)
Download: [url=http://webgym.pl/vorgeschlagene-serien/vote:11041]Basquash![/url] .
Comments: 0
Download: [url=http://fishdating.net/xfsearch/Cate+Blanchett/]Cate Blanchett[/url] .
A Million WAys to Die in the West.2014.1080p.x264.SDDS.truefrench
Download: [url=http://laingit.com/download/psychedelic_rock_cd_the_idle_race_idle_race_1969_time_is_1971_retro_disc_international_spain_2006_flac_image_cue_lossless_311634.html]Psychedelic Rock - CD The Idle Race - Idle Race - 1969 - Time Is - 1971 - - Retro Disc International Spain 2006 - , FLAC - image+.cue - , lossless[/url] .
Sicurezza
Download: [url=http://landscapeservicemob.us/series/la-casa-de-papel/]La casa de papel[/url] .
Batman - The Telltale Series - (MacAPPS) 2016
Download: [url=http://cryptohardwareworld.com/actors/Leo+Bill.html]Leo Bill[/url] .
Hide.Your.Smiling.Faces.2013.BDRip.x264-SONiDO[rarbg]
Download: [url=http://insuranceproviders.us/descargar/peliculas-castellano/peliculas-rip/el-final-de-todo-/blurayrip-ac3-5-1/]El Final De Todo BluRayRip AC3 5.1[/url] .
Scorpion - Season 3 Episode 8
Download: [url=http://refrigeracaomambore.com/assistirfilme/assistir-desaparecidas-dublado-e-legendado-online/]Desaparecidas[/url] .
BitLord.com
Download: [url=http://trafimatic.com/star/michael-pena/]Michael PeГ±a[/url] .
Baptize My Heart Live Only A Shadow Concert Misty Edwards
Download: [url=http://hentaifix.com/a-barraca-do-beijo/]A Barraca do Beijo Assistir A Barraca do Beijo 720p Dublado/Legendado Online O primeiro beijo de Elle vira um romance proibido com o cara mais gato da escola, mas acaba colocando em risco a relação com seu melhor amigo. Ver filme A Barraca do Beijo Dublado/Legendado Ver Filme The Kissing Booth Dublado/Legendado (2018) Assistir Filmes Online em HD Assista filmes online HD na sua tv e celular - Trailer ...[/url] .
The Mindy Project - Season 5 Episode 7
Download: [url=http://makeitreadymaids.info/torrent/emulation/roms/228887-pack+32+-+scummvm+-+point+and+click+-+41+roms+pour+recalbox+multi]PACK 32 - SCUMMVM - POINT AND CLICK - (41 ROMS) POUR RECALBOX MULTI[/url] .
Gridlocked2016
Download: [url=http://spsegypt.net/serie/Time-Traveling-Bong]Time Traveling Bong[/url] .
[Blues Rock] Leaky Roof - Take A Jive 2016 (Jamal The Moroccan)
Download: [url=http://cypacehosting.net/search.php?s=cc64beb219bc8dbfe18de760f0a956b3&do=getnew&contenttype=vBForum_Post]New Posts[/url] .
Sahasam Swasaga Sagipo (2016) Telugu Full Movie Clear Audio Telugu Webrip x264 240p Team Jannus King
Download: [url=http://vanvlachsen.com/mail:dmca@torrents.ovh][email protected][/url] .
Switch Lockupmy Indian Girls
Download: [url=http://mg520-xz.com/genre/documentary/]Documentary[/url] .
@file gomorra
Download: [url=http://feeltruelove.com/serie-stream/supergirl/saison-2/episode-5]Г©pisode 5[/url] .
INFINITESKILLS
Download: [url=http://imajbelt639.com/category/sequelles/]Sequelles[/url] .
??? ??? Asura -The City of Madness, 2016.1920x1080.FHD-NWB
Download: [url=http://nepalglacier.com/watch/ducktales-season-1-2017-1080p-online-free-123movies.html]Watch movie[/url] .
Read More
Download: [url=http://korea-365.com/films-gratuit/30631--la-plante-des-singes-suprmatie-bluray-3d-truefrench.html]La PlanГЁte des Singes - SuprГ©matie[/url] .
Juggling Suns - Living on Edge of Change
Download: [url=http://aligarhrealestate.com/17633-watch-baywatch-season-9-s9-putlockers-tv.html]Baywatch Season 9 S9[/url] .
Sid Meiers Civilization VI MAC 2016
Download: [url=http://kindeme.com/watch-downsizing-movie-online-free-putlocker-4-478.html]Downsizing[/url] .
Cancelar Resposta
Download: [url=http://lenapoker.net/download/jet-pilot-1957-1080p-bluray-x264-yts/movie/49106/]Jet Pilot 1957 1080p BluRay X264-YTS (1957)[/url] .
???? ???? (???? ???????) ?????? ???, ????? ?? ?????????? (????? ??????)[tfile.ru].DOC, PDF, FB2, EPUB, MOBI
Download: [url=http://onlinebahissiteleri369.net/actors/Josh+Chavez.html]Josh Chavez[/url] .
American Housewife S01E05 720p HDTV x264-FLEET[PRiME]
Download: [url=http://electricalcontractorlab.us/Stream/Fack_ju_Goehte_3.html]Fack ju Göhte 3[/url] .
Khamoshiyan 2015 Movie Free Download 720p BluRay
Download: [url=http://subtogel.net/category/kill-point/]kill point[/url] .
que choisir
Download: [url=http://6301222.com/1/categorie-Bandes+dessin%C3%A9es/1.html]Bandes dessinГ©es[/url] .
Parallels Desktop 11 [ked] [Pre-activated]
Download: [url=http://22aday-notok.org/m_44200.html]зЊЋжЇ’дєє[/url] .
NCIS S14E07 1080p HDTV x264 mp4
Download: [url=http://copydz.com/films-gratuit/49117-black-panther-VO-ULTRA HD (x265).html]ULTRA HD (x265) (VO)[/url] .
Captain.America.the.Winter.Soldier.2014.720p.BRRip.XviD.AC3-DEVi
Download: [url=http://aninsaneportrait.us/tag/kill-bill-vol-2/]Kill Bill Vol 2[/url] .
Call of Duty Infinite Warfare - Digital Deluxe Edition (2016) game MAC eng
Download: [url=http://wuye87.com/169951-how-to-download-pdf-free-audio-bucher-unterwegs-im-himalaya-tibet.php]Unterwegs im Himalaya: Tibet, Nepal und der Gipfel des Mount Everest (Wandkalender 2017 DIN A3 quer)[/url] .
15 de novembro de 2016
Download: [url=http://cryptohardwareworld.com/actors/Taurean+Blacque.html]Taurean Blacque[/url] .
Cam Clarke,
Download: [url=http://pinturahidrografica.info/torrents.php?page=238]11901-11935[/url] .
Zootopie 2016 Truefrench 720p x264 AAC PIXEL(A)
Download: [url=http://teamupforfreedom.com/actors/William+Abadie.html]William Abadie[/url] .
Adobe Photoshop Lightroom 5 6 Final for MAC-OSx
Download: [url=http://cetnixsoft.com/einsfestival-programm-27-07-2018.html]Freitag 27.07.2018 04:58[/url] .
BitTorrent Pro 7 9 8 Build 42549 Stable & Portable
Download: [url=http://9351188.net/watch-bringing-up-bates-online-couchtuner-1167.html]Bringing Up Bates[/url] .
Alyssa Cole mp4
Download: [url=http://wqlmrv.info/manny-streaming.html]Manny Streaming[/url] .
The.Pirate.Fairy.2014.BluRay.1080p.x264.DTS-HDWinG
Download: [url=http://foropen.org/bloodrayne-2-bonus-game-t747982.html]BloodRayne 2 [+ bonus game][/url] .
Juggling Suns - Living on Edge of Change
Download: [url=http://icehousewildwoodnj.com/vorgeschlagene-serien/vote:12706]Der Alles-Esser – So schmeckt die Welt[/url] .
Avanquest Architecte 3D Ultimate 2017 19.0.1.1001
Download: [url=http://bvuathletics.org/watch-movie-the-discovery-online-megashare-2-83557-1396613-openload]watch on openload[/url] .
colin mcrae rally 2005 PL
Download: [url=http://heloify.com/dragon-ball-super-vostfr-streaming-hd/]Dragon Ball Super VOSTFR STREAMING HD[/url] .
The Physician 2013 HD ????? ????? 7.2
Download: [url=http://sa36s.net/mother-s-day-2016-720p-web-dl-2ch-x265-hevc-psa-t12975534.html]Mother's Day 2016 720p WEB-DL 2CH x265 HEVC-PSA[/url] .
Snowden 2016 TRUEFRENCH MD HDRip XviD-Goldorateur avi
Download: [url=http://iuvmtoday.net/genre/tv-movie/]TV Movie[/url] .
[request_ebook] Wireless Communications and Networks
Download: [url=http://ju054.com/ver-serie/18-4-happy-328361.html]En EmisiГіn Happy! 2017[/url] .
e book worldbestsellernoble 100 1
Download: [url=http://6615566.net/titta-cast/wendell-brooks]Wendell Brooks[/url] .
Documentary
Download: [url=http://sunshinessl.com/descargar/serie/familia-de-acogida--the-fosters-/temporada-5/capitulo-20/]Familia De Acogida (The Foster..HDTV[/url] .
Blood Father
Download: [url=http://properearn.com/tv-series/154-friends-from-college]15 Jul 2017 4,828 3,411 8[/url] .
Windows XP Professional SP3 - Activated
Download: [url=http://alejandromieres.org/3894-mes-hros-2011.html]Mes HГ©ros (2011)[/url] .
Read More
Download: [url=http://byonec.com/actors/Anessa+Ramsey.html]Anessa Ramsey[/url] .
OO Defrag Professional Edition 20 0 Build 427 - 32bit 64bit [ENG] ...
Download: [url=http://amelie-leguay-bienetre.com//amelie-leguay-bienetre.com/watch-free-rein-online/]Free Rein[/url] .
Battleborn (2016) (Final Version) (for pc)
Download: [url=http://sparrowwave.com/person/Nam+gil+Kim-624032]Nam-gil Kim[/url] .
She Who Would be Pope (1972) Xvid - Liv Ullman, Olivia de Havilland [DDR]
Download: [url=http://blue9999.com/03192906-vroom-international-july-2018/]Vroom International – July 2018[/url] .
Read More »
Download: [url=http://cek-harga.info/register.php?s=0eb9fc2ee09670d1710fdaaf4341554b]Register[/url] .
The Pleasure Provider XXX DVDRip x264-UPPERCUT
Download: [url=http://thecryptotrading.org/xuyen-duyet-tay-nguyen-3000-chap-9/]Xuyên Duyệt Tây Nguyên 3000 – Chap 9[/url] .
House of Cards
Download: [url=http://hk-chips.com//watchtvseries.ag/episode/295515/3/11/quantico/]QuanticoS3-E112018-07-20[/url] .
Oppam (2016) Malayalam Webrip x264 700 MB [Isohunt.to]
Download: [url=http://canyontales.com/tv/subtitles/animal-kingdom-3769309.html]animal.kingdom.us.104.hdtv-lol[ettv].txt[/url] .
The Fixer (2015)
Download: [url=http://directionsfound.com/2017/download-lagu-stasiun-tugu-dhimas-tedjo.html]Stasiun Tugu - Dhimas Tedjo[/url] .
Hydraulic Design Handbook
Download: [url=http://sentiendo.com/feedback]Обратная связь (Feedback)[/url] .
vampires are forever pdf
Download: [url=http://smcustomer28.us/all/from-smart-city-to-smart-region-digital-services-for-an-internet-of-places-2016-pdf-t3506340.html]From Smart City to Smart Region - Digital Services for an Internet of Places (2016) pdf[/url] .
High Strung 2016 720p BRRip 700 MB - iExTV.[MP4]
Download: [url=http://urdunovel.org/]ThemePacific[/url] .
Heathens - Twenty One Pilots [2016]
Download: [url=http://gidahavuzu.com/browse.php?c=717]ER 1. Sezon[/url] .
FullyClothedSex 16 11 17 Keira And Kate Gold XXX 1080p MP4 KTR[rarbg]
Download: [url=http://dealfrenzy.net/torrent/19130]Plaza de EspaГ±a 1x02[/url] .
Dildo akrobaten mein kleiner freund S1 mp4
Download: [url=http://kb796.com/series/da-yu-hai-tang]Da Yu Hai Tang[/url] .
Cafe Society 2016 Torrent
Download: [url=http://perfectshopping.net/watch/yGD2j4v6-shoujo-shuumatsu-jugyou.html]Shoujo Shuumatsu Jugyou[/url] .
Technology
Download: [url=http://dakikbahis16.com/ver/jane-the-virgin-4x07.html]4x07 Jane the Virgin[/url] .
Metro 2013 mp4
Download: [url=http://trycaptivatingbeauty.com/pelicula/descargar-torrent-5053-un-lugar-tranquilo]Un lugar tranquilo (2018)[/url] .
NHL 2016 RS (13 feb) ANA Ducks v CHI Blackhawks 720p 60fps Pdimon2001
Download: [url=http://glasgowthecity.com/watch-genre/trailers]Trailers[/url] .
AlReader – Any text book reader
Download: [url=http://toolsdiy.info/descargar/peliculas-castellano/peliculas-rip/killer-joe-/blurayrip/]Killer Joe BLuRayRip[/url] .
60's Garage - The Odyssey Continues 13CD
Download: [url=http://axbahis77.com/serie/Air_Master]Air Master[/url] .
[MyGirlLovesAnal] Harley Jade (21947 - 16 11 2016) rq (480p) mp4
Download: [url=http://gs-ta.com/ebook-deals/fiction-book-deals]Fiction ebook deals[/url] .
more popular movies
Download: [url=http://ketogrinding.com/torrents-details.php?id=11931&hit=1]Dr Patricia Doyle PhD - Deadly Red ...[/url] .
???-????.E352.161117.360p-NEXT
Download: [url=http://cerosfutter.com/ver/legends-of-tomorrow-3x1/]ConvenciГіn en Aruba[/url] .
Aleksandr Gromov - Myagkaya Posadka
Download: [url=http://dgjcrhy.com/bd/to-love-ru-bd/]To Love Ru BD Sub Indo Batch Eps 1-26 Lengkap[/url] .
14 Days Free Access to USENETFree 300 GB with 10 GB High-Speed
Download: [url=http://ufc189.com/korean-drama/3949-life-on-mars/]Life on Mars - лќјмќґн”„ мЁ л§€мЉ¤Life on Mars[/url] .
American
Download: [url=http://ratnikovfoundation.com/movie/genre/science-fiction/view/all]Most viewed[/url] .
Photos -- Car Service Set 64
Download: [url=http://blackhatbay.org/seriestreaming/the-originals/saison-2/episode-1]Г©pisode 1[/url] .
Brooklyn Nine-Nine S04E06 HDTV XviD-AFG
Download: [url=http://floridaaddictioncare.com/video-download/raHI3sCtnZzaipU/stevie_wonder_-_as.html]Stevie Wonder - As[/url] .
Meryl Streep,
Download: [url=http://axbahis77.com/serie/Bad_Robots]Bad Robots[/url] .
Big Sean Ft Chris Brown My Last Instrumental With Hook
Download: [url=http://tonikads.com/serials/1651-pyanaya-istoriya/]Пьяная история[/url] .
Battlefield 4 v1.0 Plus 11 Trainer x86
Download: [url=http://haibener.com/big-hero-6-the-series-s01e10/]Big Hero 6 The Series S01E10[/url] .
Buying the Beach
Download: [url=http://smcustomer34.us/movie-2018/shoplifters-torrents/]Shoplifters (2018) RATING 8.0 / 10 QUALITY[/url] .
Eastwood After Hours: Live at Carnegie Hall (1996) - 2016-11-17
Download: [url=http://mariobet817.com/watch_movie/2018/02/]February 2018[/url] .
COURTNEY TAYLOR PUMA SWEDE 14 11 2016 mp4
Download: [url=http://haustmusic.com/torrents-search.php?search=the+originals&sort=relevance]the originals[/url] .
Aleksandr Tafincev - K Daljokim Miram
Download: [url=http://3210js.com/serie-9702-the-rain/saison-1/episode-1.html]Episode nВ° 1[/url] .
Barbie Cavaliere - Stage d'Equitation.nds
Download: [url=http://0ffside.com/movies/sicario-day-of-the-soldado/]Sicario: Day of the Soldado (2018)[/url] .
The.Daily.Show.2016.11.15.Desus.Nice.HDTV.x264-CROOKS[ettv]
Download: [url=http://wellosas.com/serialy/patrick-melrose/]Patrick Melrose[/url] .
The Weather Man(A)
Download: [url=http://pixtest.net/actors/Claudio+Santamaria.html]Claudio Santamaria[/url] .
Update Now
Download: [url=http://yabovip151.com/forums/internet-models-general-forum.228/threads/beth-lily-official-sets-vids.2310547/]Beth Lily [Official] - sets vids[/url] .
Historical
Download: [url=http://manele123.com/category/larme-fatale-lethal-weapon/]L'Arme fatale (Lethal Weapon)[/url] .
Natsuyasumi - 03
Download: [url=http://cubiertasatb.com/watch-movie-incredibles-2-online-megashare-9335-452647-vidzi]watch on vidzi[/url] .
Private Practice
Download: [url=http://3210js.com/serie-6558-quantico/saison-1/episode-22.html]Episode nВ° 22[/url] .
World of Warcraft Legion - 2016 MAC Game
Download: [url=http://waynenwayne.com/category/imposters/]Imposters[/url] .
Nenu Sailaja (2016) 720p – HDRip – x264 [Dual Audio] [Telugu+Hindi] – Team IcTv Excl
Download: [url=http://12dm.biz/browse-movies/Andie%20MacDowell]Andie MacDowell[/url] .
Addicted to Fresno 2015 720p BluRay x264-SADPANDA[rarbg]
Download: [url=http://guomincaipiao.com/category/western-movies/]Western Movies[/url] .
Survivor S33E09 PROPER 720p HDTV x264-BAJSKORV[ettv]
Download: [url=http://bbcens.org/hd/tv/4551/]Putlocker TV FULL HD[/url] .
10A Ear Benders Vol. 1 WAV
Download: [url=http://bmw728.net/wolf-warrior-2015-watch-full-movie-online-free/]Wolf Warrior (2015) Watch Full Movie Online Free[/url] .
Beatles '66: The Revolutionary Year
Download: [url=http://sisterstranquillounge.com/watch/major-s2-online]Major S2[/url] .
Malwarebytes Anti-Exploit for Business 1 09 2 1261 + Serials [TechTools ME]
Download: [url=http://extrainvite.com/chapter/tomochan_wa_onnanoko/chapter_485]Chapter 485 : Just Wanted to Try It[/url] .
09 FA J mp4
Download: [url=http://newsaude.info/11574-assassination-classroom-365-days-french-dvdrip-2018.html]Assassination Classroom: 365 Days FRENCH DVDRIP 2018[/url] .
Alan Wake By Petri Alanko And Ets
Download: [url=http://handmadeblinds.com/actors/Shirley+Jo+Finney.html]Shirley Jo Finney[/url] .
Ishqiya 2010 HD ????? ????? 7.4
Download: [url=http://djonestar.com/actors/Chrissy+Teigen.html]Chrissy Teigen[/url] .
Clarence.US.S02E32.720p.HEVC.x265 MeGusta
Download: [url=http://eastdoom.com/movies?genre=Adventure]Adventure[/url] .
The Wolfman (2010) DVDRip XviD-MAXSPEED
Download: [url=http://pixtest.net/actors/Linda+Hunt.html]Linda Hunt[/url] .
Other OS
Download: [url=http://miaopasi.com/category/kuzu-no-honkai]Kuzu no Honkai[/url] .
Xev Bellringer mp4
Download: [url=http://aliveandwealth.com/category/alexa-and-katie/]Alexa and Katie[/url] .
Audio books
Download: [url=http://ankaraen.com/ep/1093919/unapologetic-with-aisha-tyler-s01e08-hdtv-x264-aaf/]Unapologetic With Aisha Tyler S01E08 HDTV x264-aAF [eztv][/url] .
WrestleMania xxx
Download: [url=http://ronadecoration.com/yama-no-susume-3/episodio-4]ASSISTA ONLINE[/url] .
BitLord.com
Download: [url=http://chipsfinex.com/tv-series/187-the-orville]09 Dec 2017 11,785 3,134 11[/url] .
Reality Check
Download: [url=http://amg-4.com/the-expanse]The Expanse[/url] .
Tutsplus - PSD to HTML: The Responsive Portfolio Build
Download: [url=http://tom63.com/series-view.php?id=74550]Star Trek: Voyager[/url] .
secrets d'histoire
Download: [url=http://testmatic.net/watch/Z0v8N9Gw-rocky-balboa.html]Rocky Balboa[/url] .
Oasis.Supersonic.2016.720p.BRRip.x264.AAC-ETRG
Download: [url=http://dichvuseothue.com/film/fsv/Mariah-Carey-%2339%3Bs-All-I-Want-for-Christmas-Is-You?episod=1]IMDb: 6.5 HD Mariah Carey's All I Want for Christmas Is You[/url] .
American Sniper The Autobiography of the Most Lethal Sniper in U S Military History by Jim DeFelice, Chris Kyle and Scott McEwen Ebook for Pdf for Ipad, Iphone, Kindle, Zune and others
Download: [url=http://newaluminium.com/when-we-rise/]When We Rise[/url] .
???? mortal kombat xl v 0 305 05 125430 1 2015 pc steam rip от let splay
Download: [url=http://redphoenixtech.com/audio/audio/soundtrack/338924-brian_reitzell-american_gods-ost-2017-mtd]12.08.1722:03 Uhr Brian Reitzell - American Gods Soundtrack256 kbit/s 0 / 02.420 Hits VID P2P DDL 0 Kommentare[/url] .
Read More
Download: [url=http://wangzhuanguo.com/my-hero-academia-3rd-season-dub/]My Hero Academia 3rd Season (Dub)[/url] .
All Starz Intro Logo 1st Sample Omg 1
Download: [url=http://area-reit.com/diretor/javier-clave/]Javier Clave[/url] .
Marvel's Agents of Shield S01E04 VOSTFR HDTV x264-BRN [KskS] mp4
Download: [url=http://turbobahis4.com/actors/Tiffany+Haddish.html]Tiffany Haddish[/url] .
Togetherness
Download: [url=http://qnmjgp.com/index.php?/topic/191256-charles-williams-love-is-a-very-special-thing-1975-mp3/]Charles Williams - Love Is...[/url] .
Jay Leno
Download: [url=http://xn--dedektrtv-57a.com/r_140289.html]Waltz.with.Bashir.2008.720p.BluRay.H264.AAC-RARBG[/url] .
Children of the Corn (1984) 720p BluRay x264 Eng Subs [Dual Audio] [Hindi 2 0...
Download: [url=http://76rmm.com/serie-stream/grey-s-anatomy/saison-5/episode-16]Г©pisode 16[/url] .
Highway Thru Hell S05E10 Family Matters 720p HDTV x264 mp4
Download: [url=http://infissipolito.com//infissipolito.com/movie/31096/batman-dead-end-2003-1080p-bluray-x264-full-movie-watch-free-online]Batman: Dead End[/url] .
Colorfy - Coloring Book v2.9 PLUS
Download: [url=http://icocoinresearch.com/cast/kerri-medders/]Kerri Medders[/url] .
Leonard Cohen - You Want it Darker 2016
Download: [url=http://ronadecoration.com/anime/1877/]Dragon Ball Super[/url] .
Apowersoft Screen Recorder Pro v2 1 5 - Full rar
Download: [url=http://izmirplazaotel.com/anime/tv-avatar-the-legend-of-aang/]TV Avatar the Legend of Aang[/url] .
(2016) DVD Urge
Download: [url=http://macau3333.com/succession-season-1-episode-8-prague/]Succession Season 1 Episode 8: Prague[/url] .
Family Guy
Download: [url=http://hargakeramik.net/member.php?s=059d55bf0c61fb049bfeba37ed0f6253&u=779458]cascajo_2[/url] .
Aguas Rasas O Filme Torrnet 2016
Download: [url=http://haibener.com/masterchef-australia-s08e32/]MasterChef Australia S08E32[/url] .
Underbelly
Download: [url=http://para79.com/tv/subtitles/the-handmaids-tale-9963558.html]The.Handmaids.Tale.S01E07.720p.WEBRip.x264-MOROSE.srt[/url] .
Liquorworks - Psycho Soundwaves (2016)
Download: [url=http://tuvesrentacar.com/showthread.php?268714-Express-News-Live-Election-Transmission-25th-July-2018&s=f92c1cc55b90c7522e3b41f553c94792&goto=newpost]Express News Live Election...[/url] .
Driving Miss Daisy 1989 (1080p Bluray x265 HEVC 10bit AAC 5 1 Tigole)
Download: [url=http://cloudcactuswebhosting.com/feed/]Beitrags-Feed (RSS)[/url] .
silicon valley s03e04
Download: [url=http://hor-dg.com/torrent/q5r8t1mm/Undercover.Boss.US.S09E01.WEB.x264-TBS[N1C].html]Undercover.Boss.US.S09E01.WEB.x264-TBS[N1C][/url] .
Life Below Zero S08E04 Head Above Water HDTV x264-SDI mp4
Download: [url=http://goldcoastrollerderby.com/torrent/1665002143/CCleaner+%28All+Editions%29+5+45+6611+%2B+Crack+%5BCracksNow%5D]CCleaner (All Editions) 5 45 6611 + Crack [CracksNow][/url] .
Eye in the Sky2016
Download: [url=http://mobileyyy.com/watch-cristela-online-1/]Cristela[/url] .
supertramp
Download: [url=http://rivalobet9.com/serie/Time-Trax-Zurueck-in-die-Zukunft]Time Trax – Zurück in die Zukunft[/url] .
pipi culotte 7 s3 mp4
Download: [url=http://drpoolortho.net/private.php?s=8abd0cb145da66a780e8018c60a6f28b&do=newpm&u=7920]Private Nachricht[/url] .
Howard Stern Show NOV 16 2016 Wed
Download: [url=http://vahiy.org/news/Neues-Update-Neue-Domain]mehr anzeigen[/url] .
Fort Tilden 2014 RERiP BDRip x264-WiDE[1337x][SN]
Download: [url=http://gidahavuzu.com/browse.php?c=407]American Horror Story 1. Sezon[/url] .
Planet of the Sharks 2016 720p BluRay x264-UNVEiL[PRiME]
Download: [url=http://freewayverhuur.net/torrent/16620345/%EB%9F%B0%EB%8B%9D%EB%A7%A8-e541-180715-720p.html]лџ°л‹ќл§Ё E541 180715 720p-NEXT[/url] .
??????? OP
Download: [url=http://kingmailx.info/tag/ver-the-happytime-murders-2018-dd5-1-x264-pelicula-completa/]ver The Happytime Murders (2018) DD5.1. x264 pelГcula completa[/url] .
Call For Help
Download: [url=http://symbiosisminer.org/watch-lets-make-a-deal-online-couchtuner-1450.html]Let's Make a Deal[/url] .
Военни престъпления
Download: [url=http://ju384.com/index.php?genre=Superhero]Superhero[/url] .
Thinking
Download: [url=http://valenzuelafinancialservices.com/watch-pacific-rim-uprising-2018-1080p.77161-online-free-bmovies.html]HD Pacific Rim: Uprising (2018)[/url] .
Theeb – la naissance d’un chef streaming
Download: [url=http://health-forums.com/series-hd/champions/3929]Champions HDTV 720p AC3 5.1[/url] .
ExtraBit SpaceMan 99
Download: [url=http://1888f.com/index.php?do=feedback]Contacts[/url] .
GTA Vice City 2011
Download: [url=http://elitehealthcareservicesllc.org/serial/tabaluga-wielkie-przygody-malego-smoka-tabaluga/1621]Tabaluga - Wielkie przygody maЕ‚ego smoka / Tabaluga[/url] .
Suburban
Download: [url=http://educatingfortheworld.com/viewtopic.php?f=121&t=2673839&sid=20834369343924b96989dbb5f8791a47]Letters to J. D. Salinger by Chris Kubica (.ePUB)[/url] .
DESH BHAKTI GEET
Download: [url=http://symbiosisminer.org/watch-eastbound-and-down-online-couchtuner-344.html]Eastbound and Down[/url] .
AVIRA ANTIVIRUS PORTABLE SEP 2013 FULL WITH SERIAL
Download: [url=http://goldcoastrollerderby.com/torrent/1665001728/KeepVid+Pro+7+1+2+1+Multilingual+%5BSoft4Win%5D+zip]KeepVid Pro 7 1 2 1 Multilingual [Soft4Win] zip[/url] .
Skymir - Blood Moon Rising (2016)
Download: [url=http://rivalobet9.com/serie/Hack-Die-Strassen-von-Philadelphia]Hack – Die Straßen von Philadelphia[/url] .
Thor 2011 Movie Free Download 720p BluRay DualAudio
Download: [url=http://educatingfortheworld.com/memberlist.php?mode=viewprofile&u=1133221&sid=a551828ad47503bf5cfb94db531baa15]citizen4[/url] .
Lethal Weapon S01E07 HDTV x264-LOL[ettv] Torrents
Download: [url=http://91tiaojiao.com/02213914-people-matters-may-2018/]People Matters – May 2018[/url] .
Leonard Cohen - Live at Montreux 07-09-1985 (SBD) [FLAC]
Download: [url=http://health-forums.com/pelicula/salvajes/]Salvajes TS-Screener[/url] .
Pedo(47)
Download: [url=http://ashleystoys.com/watch-nazotokine]Nazotokine[/url] .
Free Full Comedy TV Shows
Download: [url=http://marylandcongressman.com/series-hd/the-flash/2039]The Flash HDTV 720p AC3 5.1[/url] .
Durban Nyt Ft Dj Tira And Professor Umsindo
Download: [url=http://lasercutapparel.com/series-view.php?id=269591]Enlisted[/url] .
Foo Fighters - Greatest Hits (2009) FLAC Soup
Download: [url=http://betabola.com/forumdisplay.php?f=150&s=644bd9995d185e04e97e25c671b47b2a]Tutoriales[/url] .
How to Get Away with Murder S03E09 HDTV x264-LOL mp4
Download: [url=http://hargakeramik.net/member.php?s=b7383f3987971eed666008ee8582b13c&find=lastposter&f=412]donmikero[/url] .
Will Smith,
Download: [url=http://0ffside.com/movies/punjab-nahi-jaungi-2017/]Punjab Nahi Jaungi (2017)[/url] .
Irudhi Suttru2016
Download: [url=http://deoscomics.com/chicago-police-department-saison-5-episode-11-256005.htm]Chicago Police... saison 5 Г©pisode 11[/url] .
Aleksander Denstad With - A Little Too Perfect
Download: [url=http://tolatech.net/book/983971735/food-jokes-for-kids]Food Jokes For Kids[/url] .
[LtN] Naruto Shippuuden - The Lost Tower - Dub.mkv
Download: [url=http://dailyanimalss.com/seriestv/780-the-arrangement-saison-2-episode-1.html]Regarder[/url] .
Alan K @ Radio Wakeup France 06 2007 Mp3
Download: [url=http://vapeandejuice.com/download/temp/10bass_T-10bass_Hit-VLS-199x-FTD/1423607/02-10bass_t-10bass_hit_(shuffled_up)-ftd.srs]02-10bass_t-10bass_hit_(shuffled_up)-ftd.srs[/url] .
GQ - December 2016 - True PDF - 1791 [ECLiPSE]
Download: [url=http://xclfb.com/watch/1424759-cinta-pemain-si-doel-kepada-aminah-mak-nyak-cendrakasih]Cinta Pemain Si Doel Kepada Aminah 'Mak Nyak' Cendrakasih[/url] .
Unreal Collection 1999 To 2007 REPACK-KaOs
Download: [url=http://79ddyy.com/series/ana/3221]Ana HDTV[/url] .
2016.01.07 ?????? - my favorite Cover Songs (FLAC)
Download: [url=http://www.motoprice.info/letratraducida-Northern_Skies_602809.htm]Northern Skies[/url] .
Religioso
Download: [url=http://davidyurmanvips.com/watch-jurassic-world-fallen-kingdom-movie-online-free-putlocker-1166.html]Jurassic World: Fa..[/url] .
Cable Tv Channel Online Tv Shows
Download: [url=http://gardenofedenhealthcenter.org/serial/droga-do-avonlea-road-to-avonlea/559]Droga do Avonlea / Road to Avonlea[/url] .
Chelsea S01E79 Dinner Party The Best Relationships 720p WEBRip X265 AAC-PRiNC...
Download: [url=http://fadonet.net/la-reina-del-flow-hd/]La Reina Del Flow[/url] .
Fyodor Dostoevsky - Crime and Punishment Unabridged
Download: [url=http://thesacredsociety.org/search/fear%20the%20walking%20dead/]Open chat[/url] .
Snowden 2016 HDRip AC3 2 0 x264-BDP[PRiME]
Download: [url=http://tyc2050.com/index.php?/forum/95-descarga-juegos-ps4-pkg/?sort_key=start_date&sort_by=Z-A]Fecha comienzo[/url] .
(NDS) 0130 - The Urbz - Sims in the City (E)(Trashman)(www.Nintendo-DS-Roms.com).zip
Download: [url=http://blackhatbay.org/seriestreaming/the-walking-dead/saison-2/episode-12]Г©pisode 12 Better Angels[/url] .
Henry Cavill
Download: [url=http://yourstyleartphotography.com/genres/biography.html]Biography[/url] .
Tuxera NTFS 2015 (2015-07-12 03074)(1)
Download: [url=http://wanxcity.com/2792637-art-nation-liberation-free-download.html]Art Nation - Liberation[/url] .
Paradise Reclaimed by Raymond Harris (epub) [BluA]
Download: [url=http://turyan.net/smartphone/android/486845-android-learn-english-with-aba-english-premium-v222-apk-ita.html][ANDROID] Learn English with ABA English Premium v3.0.5.2 (Unlocked) .apk - ITA[/url] .
the revenant
Download: [url=http://ju740.com/2015/12/]December 2015 (422)[/url] .
50469_01_big mp4
Download: [url=http://ssdbench.com/torrent/802928/History-Of-War-Issue-3-May-2014-UK/]History Of War Issue 3 - May 2014 UK[/url] .
Downton Abbey S01-06e01-52 [Mux - XviD - Ita Eng Mp3 - Sub Ita Eng] BD/DLMux - By Pir8 FULL SERIES [TNT Village] [Isohunt.to]
Download: [url=http://redphoenixtech.com/ebooks/audio/unsortiert] Unsortiert[/url] .
Teen Wolf 5? Temporada Dual Audio Torrent – WEB-DL 720p Download (2016)
Download: [url=http://kittymoney.net/external.php?s=4a87c84403f3919f743dced34ca40f9c&type=RSS2&forumids=70]RSS-Feed dieses Forums anzeigen[/url] .
top gear
Download: [url=http://elpidapapakostamakeupartist.com/page/1/genre-Historiques/films+dvdrip+et+bdrip/1.html]Historiques[/url] .
Euro Truck Simulator - [FOR MAC OS]
Download: [url=http://toolsdiy.info/descargar/cine-alta-definicion-hd/1080p/super-maderos-2-/bluray-1080p/]Super maderos 2 BluRay 1080p[/url] .
Ice Age 5: Collision Course
Download: [url=http://ashleystoys.com/watch-geneshaft]Geneshaft[/url] .
Bryce Dallas Howard
Download: [url=http://jaceboechler.com/drama-detail/suzuki-sensei]Suzuki Sensei[/url] .
Tutankhamun
Download: [url=http://hk-chips.com/tvshow/268592/the-100/]7 +10 The 100[/url] .
warcraft 3
Download: [url=http://izmirplazaotel.com/anime/tv-aishiteruze-baby/]TV Aishiteruze Baby[/url] .
????
Download: [url=http://atwgevents.com/read/transmigrator-meets-reincarnator-web-novel/chapter-72]Chapter 72 - One More Bowl (1)[/url] .
Heroes of Telemark (1965) DVD5 - Kirk Douglas, Richard Harris [DDR]
Download: [url=http://nuicc.info/torrents-details.php?id=11777&hit=1]Eurythmics - 1985 - Be Yourself Ton...[/url] .
BitLord.com
Download: [url=http://handmadeblinds.com/actors/Hannah+Kaiser.html]Hannah Kaiser[/url] .
Biography
Download: [url=http://wangzhuanguo.com/tag/adventure/]Adventure[/url] .
Designated Survivor S01E07 1080p WEBRip HEVC DD5.1 x265
Download: [url=http://faunapolice.org/movie/tau-2018-video_df4eee24b.html]Tau (2018)[/url] .
[UNCENSORED]Tokyo Hot n1199 ??? ???? ???? Shiho Harada
Download: [url=http://jolck.com/capitan-phillips/]Watch Movie[/url] .
????? (1993)
Download: [url=http://forvetbet515.com/02171418-playboy-germany-special-digital-edition-wet-dreams-2018/]Playboy Germany – Special Digital Edition – Wet Dreams – 2018[/url] .
Read More
Download: [url=http://www.facebook.com/dialog/share?app_id=1044779568952343&display=popup&href=http://genallinutrition.com/macross-frontier-bd-subtitle-indonesia-batch/&redirect_uri=http://genallinutrition.com/macross-frontier-bd-subtitle-indonesia-batch/]Facebook[/url] .
Craig Robinson,
Download: [url=http://axbahis77.com/episode/The_Flash_(2014)_s3_e9.html]3 9 2016-12-06The Flash - The Present[/url] .
nofearfcp
Download: [url=http://betist921.com/giveaway/show/282483-fresh-eyes-on-famous-bible-sayings-discovering-new-insights-in-familiar]View Details В»[/url] .
toy story 3 720p
Download: [url=http://gotham-motorsports.com/watch/the-last-man.nr7x8]The Last Man[/url] .
Сезон 5 БГ СУБТИТРИ
Download: [url=http://grantbetting124.com/%d9%85%d8%b3%d9%84%d8%b3%d9%84-hap-and-leonard-%d8%a7%d9%84%d9%85%d9%88%d8%b3%d9%85-%d8%a7%d9%84%d8%a7%d9%88%d9%84-%d8%a7%d9%84%d8%ad%d9%84%d9%82%d8%a9-4-%d8%a7%d9%84%d8%b1%d8%a7%d8%a8%d8%b9%d8%a9/]20 Щ…ШіЩ„ШіЩ„Ш§ШЄ Ш§Ш¬Щ†ШЁЩЉШ© Щ…ШіЩ„ШіЩ„ Hap and Leonard Ш§Щ„Щ…Щ€ШіЩ… Ш§Щ„Ш§Щ€Щ„ Ш§Щ„ШЩ„Щ‚Ш© 4 Ш§Щ„Ш±Ш§ШЁШ№Ш© Щ…ШґШ§Щ‡ШЇШ© Щ…ШіЩ„ШіЩ„ Hap and Leonard Ш§Щ„Щ…Щ€ШіЩ… Ш§Щ„Ш§Щ€Щ„ Ш§Щ„ШЩ„Щ‚Ш© 4 Ш§Щ„Ш±Ш§ШЁШ№Ш© ШЄШЩ…ЩЉЩ„ Щ…ШіЩ„ШіЩ„ Hap and Leonard Ш§Щ„Щ…Щ€ШіЩ… Ш§Щ„Ш§Щ€Щ„ Ш§Щ„ШЩ„Щ‚Ш© 4 Ш§Щ„Ш±Ш§ШЁШ№Ш©[/url] .
Six-6 (2012) x264 720p HDRiP Dual Audio} [Hindi DD 2 0 + Telugu 2 0] Exclusiv...
Download: [url=http://www.bomtan.tv/live/celebrity-tv/3097]Celebrity TV Free[/url] .
Moms In Control - Brazzers} Angel Wicky, Sam Bourne, Jimena Lago - Teens In T...
Download: [url=http://ju804.com/E_nata_una_Star_2012_H264_torrent_icb_torrent-261574.html]', CENTER);" onmouseout="return nd();">E nata una Star 2012 H264 torrent icb torrent[/url] .
Driftmoon-(R)Evolution-(ABRD126)-WEB-2016-SPANK [EDM RG]
Download: [url=http://dynastygoal.com/02284405-the-ceo-magazine-emea-may-2018/]The CEO Magazine EMEA – May 2018[/url] .
Remove advertising
Download: [url=http://homeremodelingteam.net/news/8644/1/categorie-Mangas+VF/1.html]Mangas VF[/url] .
How To Play Say Goodbye By Chris Brown On Piano
Download: [url=http://dlycasemanagement.org/serie/Mangirl]Mangirl![/url] .
SEO/PPC and IM November 2016 Collection
Download: [url=http://spiritedmind.org/tv-sendungen/1927921-baerenbrueder-2]Bärenbrüder 2 Animationsfilm, 80min. Disney Channel - 03. August, 20:15 Uhr[/url] .
Homefront The Revolution - (MacAPPS) 2016
Download: [url=http://violet-skin.com/torrent/d8jrfhq5/Creta+2.7+-+Flower+Shop+WooCommerce+WordPress+Theme.html]Creta 2.7 - Flower Shop WooCommerce WordPress Theme[/url] .
CAPTAIN AMERICA v7 01 (2013) (C9-Novus) [NVS-D]
Download: [url=http://worldfightshop.com/Stream/Jurassic_World_Das_gefallene_Koenigreich.html]Jurassic World: Das gefallene Königreich[/url] .
million dollar arm
Download: [url=http://bag-3.com/the-nanny]Ver pelГcula[/url] .
Read More
Download: [url=http://dlycasemanagement.org/serie/Dein-Wille-geschehe]Dein Wille geschehe[/url] .
Dubbed Movies
Download: [url=http://032035.com/serie-new-girl.html]New Girl[/url] .
BitLord.com
Download: [url=http://dynastygoal.com/02294407-hemmings-muscle-machines-11-2014/]Hemmings Muscle Machines – 11-2014[/url] .
Movie Information
Download: [url=http://601624.com/assistir/blindspot]Blindspot[/url] .
Promo Only Mainstream Radio Dec 2016
Download: [url=http://portelmselykaratejutsu.com/series/the-100-season-5/]Eps 9 The 100 Season 5[/url] .
Tales From The Crypt
Download: [url=http://bipp.us/item-bluray-52343.html]The.Con.Is.On.2018.720p.BluRay.x264-PSYCHD[/url] .
Salem S03E03 720p HDTV x264-KILLERS[ettv]
Download: [url=http://dinobots.net/bar-rescue-season-6-episode-20-s06e20_402133]Bar Rescue Season 6 Episode 20 s06e20[/url] .
EastEnders 14th Nov 2016 HDTV (Deep61) mp4
Download: [url=http://tk333666.org/ghost-stories/]14 Ghost Stories[/url] .
Rebeca Linares - The Shitty Hairdresser - 1 on 1 (Brazzers)
Download: [url=http://wuye52.com/login]http://wuye52.com/login[/url] .
Alain Guyard - La soudure(N) (A)
Download: [url=http://majkiss.com/bates-motel]Bates Motel 8[/url] .
Private Practice
Download: [url=http://domuscure.com/%d9%81%d9%8a%d9%84%d9%85-mamma-mia-here-we-go-again-2018-%d9%85%d8%aa%d8%b1%d8%ac%d9%85/]ЩЃЩЉЩ„Щ… Mamma Mia 2! Here We Go Again 2018 Щ…ШЄШ±Ш¬Щ… Щ…ШґШ§Щ‡ШЇШ© Щ€ШЄШЩ…ЩЉЩ„ ЩЃЩЉЩ„Щ… Mamma Mia! Here We Go Again 2018 Щ…ШЄШ±Ш¬Щ… ЩѓШ§Щ…Щ„ Ш§Щ€Щ† Щ„Ш§ЩЉЩ† Щ€ШЄШЩ…ЩЉЩ„...[/url] .
Akhiyan De Vanj Bure Ne Gaddi Wich Jaan Waliye
Download: [url=http://yorkvillecentre.info/member.php?u=830&s=295ffefa5b9031cae83f367b40334bda]correcamino73[/url] .
See More
Download: [url=http://xn--holowaniewrocaw-ctc.pl/sendung-runterladen/417564/ad-2_Mord-Auf-Shetland.html]www.Mord Auf Shetland-dvd.de[/url] .
??????? / ??????
Download: [url=http://601574.com/movie/westwood-punk-icon-activist-yrzz714]Westwood: Punk, Icon, Activist[/url] .
Download 1080p 5.1
Download: [url=http://699d88.com/actor/bobbi-maxwell/]Bobbi Maxwell[/url] .
Nisan 2012 (1546)
Download: [url=http://1291188.net/actors/Josh+Dylan.html]Josh Dylan[/url] .
ALSScan 16 11 16 Cayla Lyons Breaststroke XXX 1080p MP4-KTR[rarbg]
Download: [url=http://1291188.net/watch-mission-impossible-ghost-protocol-2011-online-free-putlocker.html]Watch movie[/url] .
Dragon Ball Super Arc Champa Part1 [VOSTFR][720P][...(N) (P)
Download: [url=http://mobilemanila.net/serie/L-A-Crash]L.A. Crash[/url] .
Computeractive
Download: [url=http://601574.com/movie/my-pure-land-y5kkpky]My Pure Land[/url] .
TeensAnalyzed 15 03 24 First Time Passionate Anal XXX 1080P WMV-GUSH[rarbg]
Download: [url=http://xn--yuuniversity-oeb.com/the-killer-robots-crash-and-burn-2016-english-movies-hdrip-xvid-aac-new-source-with-sample-rdx-t12976296.html]The Killer Robots Crash And Burn 2016 English Movies HDRip XviD AAC New Source with Sample в»rDXв»[/url] .
Aventura
Download: [url=http://leotravaux.be/movie/3222-jack-and-jill-2011-720p-bdrip-x264-ac3-zoo.html]Jack and Jill 2011 720p BDRip x264 AC3-Zoo[/url] .
HD Video
Download: [url=http://1812heritagetrail.org/movies/war/?sort=views]По просмотрам[/url] .
The Invisible Boy 2014 HD ????? ????? 6.3
Download: [url=http://corkythumbprints.com/films-gratuit/49314-tulip-fever-multi-1080p-web.html]Tulip Fever[/url] .
Untouched Remuxed
Download: [url=http://wvw90022.com/movies/720p/11987-deadpool-2016-720p-brrip-h264-aac-kingdom.html]Deadpool (2016) 720p BRRip H264 AAC-KINGDOM[/url] .
Легендите на утрешния ден
Download: [url=http://wuye25.com/hatchet-iv-streaming-vf-vostfr/]Hatchet IV[/url] .
Operating System
Download: [url=http://19468037.com/descargar/peliculas-castellano/peliculas-rip/el-aviso-/blurayrip-ac3-5-1/]El Aviso BluRayRip AC3 5.1[/url] .
Sandi Krakowski FaceBook 2 0 Web Training - Week 4 of 5
Download: [url=http://moscowtouristmagazine.com/watch-naked-and-afraid-season-8-2017-1080p-online-free-bmovies.html]Eps6 Naked and Afraid - Season 8 (2017)[/url] .
Entourage
Download: [url=http://gamingmantri.com/movies/watch-online-gulebakavali-tamil-2018-full-movie-download.html]Gulebakavali Tamil (2018) (HDRip)[/url] .
Blindspot.S02E09.HDTV.x264-LOL[ettv]
Download: [url=http://tiptop4d.org/actors/Min-Young+Park.html]Min-Young Park[/url] .
Сезон 1 БГ СУБТИТРИ
Download: [url=http://kiev-lottery.info/watch-humans-2015-online/]Humans 2015[/url] .
Citizen Khan
Download: [url=http://grandparkkemerhotel.com/model-citizens/]Watch Movie[/url] .
the revenant
Download: [url=http://michellepatterson.com.au/torrent/1665022606/-+Ravens+Home+S02E11+XviD-AFG]- Ravens Home S02E11 XviD-AFG[/url] .
Still Tippin
Download: [url=http://elevatedhelipad.com/titta-cast/steve-decastro]Steve DeCastro[/url] .
Blood Sweat & Tears - Blood Sweat & Tears 3 & 4 (2004)
Download: [url=http://ju498.com/movies/a-series-of-unfortunate-events-season-2.html]A Series of Unfortunate Events - Season 2[/url] .
tomb raider
Download: [url=http://hgnch.info/forumdisplay.php?f=159&s=2cc96900e1aaf850328d556754319998]Peticiones solucionadas[/url] .
EnigmaT Set Rips Cuts - November 13th, 2016 [Isohunt.to]
Download: [url=http://istbayanescort.org/news/8644/1/categorie-Films+Full+BluRay/1.html]Films Full BluRay[/url] .
Oppam 2016 Movie Download Full HD DVDRip
Download: [url=http://glazok.tv/download-lagu-rendi-matari-ft-dhemas-sudahi-saja-ost-magic-hour-mp3/]Rendi Matari Ft Dhemas - Sudahi Saja OST Magic Hour[/url] .
Mots-clés Populaires
Download: [url=http://tapyhome.us/actors/Charles+Anthony+Hughes.html]Charles Anthony Hughes[/url] .
Build Me Up Buttercup Edition Highway Sing A Long
Download: [url=http://hallkbank.net/cult-of-chucky-bdrip-vf/1/]Cult of Chucky BDRIP VF[/url] .
Albert Cummings - From The Heart
Download: [url=http://mobilemanila.net/serie/1000-Wege-ins-Gras-zu-beissen]1000 Wege, ins Gras zu beiГџen[/url] .
Infiniteskills - Microsoft SQL Server 2012 Certification - Exam 70-463
Download: [url=http://blockstreet401k.com/cats/kriegsfilm/95]Kriegsfilm[/url] .
San Andreas Quake 2015 DVDRip x264-PARS
Download: [url=http://mobilemanila.net/serie/Key-Peele]Key Peele[/url] .
Masterpiece Gazebo
Download: [url=http://filmtim.com/torrents.php?parent_cat=Movies&page=47]2351-2387[/url] .
2-09-2016, 11:33
Download: [url=http://vgohappy.com/jack-and-the-cuckoo-clock-heart-2013-watch-online-free/]</b> 7.0[/url] .
Die Insel der besonderen Kinder anschauen
Download: [url=http://jonesbldgmaterials.net/member.php?s=4d703f6f35ba634915af9f2a10385964&u=806273]Yatevale[/url] .
BitRay rar
Download: [url=http://carincoin.com/actors/Velislav+Pavlov.html]Velislav Pavlov[/url] .
honey 3 dare to dance 720p
Download: [url=http://1024ziyuan.net/movies/on-chesil-beach-2018-yify-1080p.html]Download[/url] .
Твоят мой живот епизод 61 15.02.2016
Download: [url=http://mowiejakjest.tv/forums/internet-models-general-forum.228/taigachat/]Full View[/url] .
Brending
Download: [url=http://82ddyy.com/movie/tarzun-and-the-valley-of-lust-3xlodp3]Tarzun and the Valley of Lust[/url] .
Hannibal
Download: [url=http://kavakyelleri.tv/ver/quien-es-america-1x03.html]1x03 ВїQuiГ©n es AmГ©rica?[/url] .
Force 2 Torrent 2016 Full HD Hindi Movie Free Download
Download: [url=http://smart-school.com.tw/forumdisplay.php?2340-Geo-Subah-Pakistan-With-Shahista-Lodhi&s=a862cacf8548b2d0f92188fc753545d5]Geo Subah Pakistan With Shahista Lodhi[/url] .
+ Post New Thread
Download: [url=http://mlcustomwoodwork.us/library/foreign/turkmen/]На туркменском языке[/url] .
Ben 10 S01E12 (2016)
Download: [url=http://uknode.com/tag/donde-puedo-ver-superagente-canino/]donde puedo ver Superagente canino[/url] .
All-in-one-wifi-radar-wifi-hack-tools 2016.torrent
Download: [url=http://altastreaming.tv/простоквашино-01x01-03-из-30-2018-web-dlrip-720p-wujl2.html]Простоквашино [01x01-03 из 30] (2018) WEB-DLRip 720p 31 minutes[/url] .
12 Маймуни Сезон 2 Епизод 5 / 12 Monkeys БГ СУБТИТРИ
Download: [url=http://peterstripoli.com/category/armed-and-deadly-police-uk/]Armed and Deadly: Police UK[/url] .
Alex C Ft Yass – Dancing Is Like Heaven (99ers Remix Edit)-BOOTLEG-WEB-2016-ZzZz INT
Download: [url=http://uphilllab.com/actors/Sonoya+Mizuno.html]Sonoya Mizuno[/url] .
Benjamin Walker,
Download: [url=http://spacehero.net/actors/Ash+Ricardo.html]Ash Ricardo[/url] .
Kamal Hassan Movies Collection
Download: [url=http://dlycasemanagement.org/serie/Muteki-Kanban-Musume]Muteki Kanban Musume[/url] .
[SexArt] Dolly Diore (Perfect Awakening - 16 11 2016) rq mp4
Download: [url=http://turkpornosuu.org/6091-watch-family-guy-season-15-episode-10-putlockers-tv-1.html]Family Guy Season 15 Episode 10[/url] .
mob psycho
Download: [url=http://ocoeeroofing.org/hd/movie/500664/]Stream in putlocker HD[/url] .
House of Lies
Download: [url=http://meilleur-annuaire.com/titta-cast/kevin-janssens]Kevin Janssens[/url] .
Only The Best (New Sensations) 2016 Split Scenes
Download: [url=http://hionday.com/download/breakbeat_techno_big_beat_cd_the_prodigy_the_day_is_my_enemy_japan_2015_flac_tracks_cue_lossless_310015.html]Breakbeat, Techno, Big Beat - CD The Prodigy - The Day Is My Enemy - Japan - - 2015, FLAC - tracks+.cue - , lossless[/url] .
Girls Next Door s4 with April Diamond mp4
Download: [url=http://dynastygoal.com/02221913-der-aktionar-13-juli-2018/]Der Aktionar – 13 Juli 2018[/url] .
Younger S03E08 iNTERNAL 720p HDTV x264-ALTEREGO[PRiME]
Download: [url=http://socialmediamoney.info/voir-manga-embrasse-moi-lucile-en-streaming-612.html]Embrasse moi Lucile[/url] .
Missa X - Fuck mp4
Download: [url=http://bitstarz11.com/book/422540053/ready-player-one]Ready Player One[/url] .
The Border
Download: [url=http://sellmethecars.info/one-punch-man-subtitle-indo/]One Punch Man Subtitle Indonesia Batch[/url] .
Pitch Perfect
Download: [url=http://mydogchili.com/actors/Lars+Ranthe.html]Lars Ranthe[/url] .
Gotta tech problem? Post it here
Download: [url=http://sea35.com/descargar-torrents-variados-791-Active-Boot-Disk-Suite-V65.html]Active Boot Disk Suite V6.5[/url] .
FLAWL3SS
Download: [url=http://babapoker99.com/star/janusz-chabior/]Janusz Chabior[/url] .
PPPD-031 103cmJcup ???
Download: [url=http://ceralindiaexpo.com/the-simpsons]The Simpsons[/url] .
Appleseed Alpha Dual Audio Torrent – BluRay 1080p Download (2014)
Download: [url=http://wakewoodmovie.com/trahison-a-stockholm-streaming-vf/]Trahison ГЂ Stockholm[/url] .
Hot Girls Wanted 2015 HD ????? ????? 6.1
Download: [url=http://socialmediamoney.info/voir-manga-peace-maker-kurogane-en-streaming-124.html]Peace Maker Kurogane[/url] .
Forsaken (The Witness Series #2)
Download: [url=http://mobilemanila.net/serie/Transformers-Prime]Transformers: Prime[/url] .
FuckStudies - Elisabeth - Student Cramming
Download: [url=http://mealsdeliveredio.us/?cat=238&s=Abby+Ryder+Fortson]Abby Ryder Fortson[/url] .
American Horror Story S06E10 PROPER 720p HDTV x265 ShAaNiG mkv
Download: [url=http://buythat.be/torrent/7145]South.Park.S21E05.Hummels.and.Heroin.720p.AMZN.WEBRip.DDP2.0.x264-NTb[rarbg][/url] .
Stella (UK)
Download: [url=http://theheadlinefixer.com/actors/Manuel+Garcia.html]Manuel Garcia[/url] .
Dublado
Download: [url=http://mobilemanila.net/serie/Strange-Dawn]Strange Dawn[/url] .
Сезон 4 БГ СУБТИТРИ
Download: [url=http://2946677.com/o-grande-desafio/]O Grande Desafio Assistir O Grande Desafio 720p Dublado/Legendado Online Uma jovem e inocente garota (Shu Qi), segue sonhando em encontrar um grande amor na vila da pesca. EntГЈo um dia recebe uma mensagem em uma garrafa que veio do mar mandando ela ir a Hong Kong e pula no primeiro plano Г s luzes brilhantes da cidade. Infelizmente para Bu, descobre que o autor ...[/url] .
maximum ride 720p
Download: [url=http://newgencoal.com.au/03275415-fine-homebuilding-magazine-issue-203-spring-summer-2009/]Fine Homebuilding Magazine – Issue 203, Spring-Summer 2009[/url] .
OPAL FREQUENCIES - Blue Priformation No.2 - (2016) [Isohunt.to]
Download: [url=http://05rmm.com/02253412-love-our-wedding-august-2018/]Love Our Wedding – August 2018[/url] .
Scott Waugh
Download: [url=http://snltax.net/book/1412473864/5-ingredient-ketogenic-diet-cookbook-113-easy-5-ingredient-keto-diet-recipes-for-quick-meals-and-rapid-weight-loss]5 Ingredient Ketogenic Diet Cookbook: 113 Easy 5 Ingredient Keto Diet Recipes For Quick Meals And Rapid Weight Loss[/url] .
The Game
Download: [url=http://smartdeals.nl/torrent/23639449/PornMegaLoad.18.07.28.Syndi.Fox.Get.Wet.XXX.1080p.MP4-KTR%5BN1C...]PornMegaLoad.18.07.28.Syndi.Fox.Get.Wet.XXX.1080p.MP4-KTR[N1C...[/url] .
RKPrime Janice Griffith Abella Danger Training My Neighbor mp4
Download: [url=http://wslfb.com/catfish-the-tv-show-season-5-episode-4-s05e04_292927]Season 5 Episode 4 Brendan McKenna[/url] .
Download Dove cameron if only instrumental for free
Download: [url=http://esuf.org/watch-sid-and-nancy-1986-1080p-online-free-bmovies.html]DVD Sid and Nancy (1986)[/url] .
Alejandro Fernandez Avisame
Download: [url=http://trivalleyrecyclers.com/ufc-on-fox-30-prelims-web-dl-h264-fightbb-ufc-on-fox-30-prelims-720p-web-dl-h264-fightbb/]Continue reading[/url] .
Bizarre Foods Delicious Destinations S04E11E12 Cajun Country and Ho Chi Minh ...
Download: [url=http://iseehd.tv/Avengers-Infinity-War-720p-WEB-DL-X264-5-1-24HD-torrent-11186599.html]Avengers Infinity War 720p WEB-DL X264 5 1-24HD[/url] .
Ocak 2012 (1950)
Download: [url=http://qubitoid.com/dl/timber-timbre-hot-dreams-torrent.html]timber timbre hot dreams descargar mp3 320kbps[/url] .
Paulie Garand Kenny Rough Kotvim Dj Skoopy Remix
Download: [url=http://mlcustomwoodwork.us/library/fantastics/croatian/]На боснийском, сербском, хорватском, черногорском языках[/url] .
Adobe Captivate 9 0 2 437 Multilingual + Crack [SadeemPC]
Download: [url=http://mainylon.com/news_view/Boy-5-left-looking-like-Jim-Carrey-in-Dumb-and-Dumber-after-botched-haircut-Mirror-Online-6777]Boy, 5, left looking like Jim Carrey in Dumb and Dumber after botched haircut - Mirror Online[/url] .
Birthright 1951 DVDRip x264-FiCO[PRiME]
Download: [url=http://ceralindiaexpo.com/white-collar-season-3-episode-4-s03e04_280642]Season 3 Episode 4 The Dentist of Detroit[/url] .
DC Comics Chronology - Fill Pack 92 [coringo][h33t]
Download: [url=http://moneyextra.com/marvels-cloak-dagger-season-1-episode-9/]Marvel’s Cloak Dagger Season 1 Episode 9[/url] .
[Coalgirls] Umineko no Naku Koro ni (1920x1080 Blu ray FLAC)
Download: [url=http://franquiafarmais.net/series/the-middle/1256]The Middle HDTV[/url] .
TA?rkA§e
Download: [url=http://gigashare.tw/Uchuu-Yorimo-Tooi-Basho-Vostfr/]Sora yori mo Tooi Basho[/url] .
Show all tags
Download: [url=http://amumony.com/actors/Koyu+Rankin.html]Koyu Rankin[/url] .
Stonebwoy Any Day
Download: [url=http://altastreaming.tv/tv/humans-1ch2/3x2.html]Episode 2[/url] .
All is Lost (2013) Dual Audio Hindi Dub Full Movie BluRay 720p MKV
Download: [url=http://losviajes.info/torrent/ca77e196b2c05529b209b09d98c3c75da44668b5]OST - Форсаж 5 / Fast Five / Fast & Furious 5: Rio Heist (2011) MP3[/url] .
Lori.Yagami
Download: [url=http://762323.com/films/the-dark-knight-le-chevalier-noir/]The Dark Knight : Le Chevalier noir[/url] .
Bandicam 3 2 3 1114 - Repack KpoJIuK [4REALTORRENTZ] zip
Download: [url=http://jacobcapitalmgmt.com/film/american-masters-season-27.html]American Masters: Season 27[/url] .
Les Nuls l'emission
Download: [url=http://19468037.com/series/requiem/3773]Requiem HDTV[/url] .
Daum PotPlayer 1 6 63840 0 x86 et x64
Download: [url=http://coin114.net/serie-streaming-vf/grey-s-anatomy/saison-8/episode-9-streaming-fr-24]Г©pisode 9[/url] .
High Strung (2016) 720p BluRay - x265 HEVC - 650MB - geekmess.com
Download: [url=http://covertcommissionsreview.com/season/259055/5/nashville-2012-/]Season 5[/url] .
Tanoshii Higurashi no Naku Koro ni Kai DVD 05 Sub Esp
Download: [url=http://1812heritagetrail.org/movies/war/?sort=date]По дате добавления[/url] .
BitLord.com
Download: [url=http://xemumh.com/the-four-battle-for-stardom/2/7]The Four: Battle for Stardom Season 2 Episode 727 Jul 2018[/url] .
BitLord.com
Download: [url=http://perfectia90.info/hd/tv/1402/5/]Putlocker TV FULL HD[/url] .
Bigg Boss (2016) 720p WEB HD - X264 - S10 - E30 - Team IcTv
Download: [url=http://cryptokeysfunds.com/Stream/Succession.html,s1e8]Succession: Staffel 1 Episode 8[/url] .
Made In Chelsea S12E06 HDTV x264 mp4
Download: [url=http://northwestfamilydentalcenter.net/france/sport-auto-france-juillet-2018/]Sport Auto France – juillet 2018[/url] .
Star Trek
Download: [url=http://bag-2.com/watch/oxQy4Vxn-sengoku-majin-goushougun.html]Sengoku Majin Goushougun[/url] .
Suicide Squad 2016 EXTENDED 720p WEBRip 999 MB - iExTV
Download: [url=http://porndroidscams.com/two-and-a-half-men/]TV Two And A Half Men[/url] .
Top Gear
Download: [url=http://sultanbet35.com/temporadas/supernatural-season-9/]Season 9[/url] .
Broken Bones - The X Ray Atlas of fractures [EPUB] [UnitedVRG].epub
Download: [url=http://tapyhome.us/actors/Taylore+Rayne.html]Taylore Rayne[/url] .
Jason Bourne 2016 720p Bluray - 2016-11-17
Download: [url=http://uphilllab.com/actors/Emma+Roberts.html]Emma Roberts[/url] .
Ink Master Redemption S03E10 HDTV x264-KILLERS[ettv]
Download: [url=http://manoneli.be/the-daily-dish/girlfriends-guide-to-divorce-series-finale-lisa-edelstein-alanna-ubach-react]Lisa Edelstein Teases the GG2D Series Finale by Laura Rosenfeld 1 week ago[/url] .
BitLord.com
Download: [url=http://landscapeserviceapp.us/book/663458534/leaders-eat-last]Leaders Eat Last[/url] .
Me Before You 2016 BluRay 1080p AVC DTS-HD MA5 1-MTeam
Download: [url=http://empower-self.com/film/fOx/Innsaei?episod=1]IMDb: 6.7 HD Innsaei[/url] .
Responder
Download: [url=http://jualkucing.net/movie/negar-2017/watching/]Watch movie[/url] .
Download Cafe Society Dublado Torrent HD
Download: [url=http://75ddyy.com/actors/Anna+GeislerovГЎ.html]Anna GeislerovГЎ[/url] .
vlc 2 2 5-20160711-0754 beta x64
Download: [url=http://soundofmuse.net/film/heal]HD 720 Heal[/url] .
Suicide Squad 2016 Web-DL 1080p 10bit 5 1 x265 HEVC-Qman[UTR] mkv
Download: [url=http://blognetlujunhong.org/music/packs/1338-va---the-ultimate-lounge-collection-vol2-2018-mp3--30625-mb.html]VA - The Ultimate Lounge Collection Vol.2 (2018) MP3 | 306.25 MB[/url] .
Сезон 1 БГ АУДИО
Download: [url=http://conflict-studies.com/pelicula/the-driftless-area/]Ver ahora[/url] .
TV library
Download: [url=http://smartwomenhabits.com/actors/PetrГґnio+Gontijo.html]PetrГґnio Gontijo[/url] .
Addicted to Fresno 2015 iNTERNAL BDRip x264-LiBRARiANS[1337x][SN]
Download: [url=http://me-01m01bers.com/load/mp4_filmy/mp4_fantasticheskie/69109-tihookeanskiy-rubezh-2-pacific-rim-uprising-2018-mp4-hd.html]Скачать \ Подробнее[/url] .
House of Cards
Download: [url=http://nwbatz.com/wiederholung-Prominent.html?c=vox]Prominent![/url] .
Vikings Wolves of Midgard - (MacAPPS) 2016
Download: [url=http://phoenixderm.net/?page=2]ШЁШ№ШЇЫЊ[/url] .
Yaro Sab Dua Karo Tanveer Gour
editorial writing
role model essay
templates of resume
any essay
my resume
[url=http://tarturotary.ee/ev100-kingituselt-langes-saladuseloor/#comment-53]dissertation[/url]
my resume
resume related coursework
marathi essays
essay on love
igcse in india
[url=http://heliocentrisacademia.com/2017/10/23/center-of-scientific-research-in-algeria/#comment-43]thesis paper[/url]
writing a resume
online writing service
tips for resumes
psychology essay topics
article writing service
[url=http://www.blanco-nino.com/mex-in-the-city-sunday-times/#comment-1435]dissertation writer[/url]
igcse course
service writer resume
engineering coursework
sample coursework
essay assistance
[url=https://www.4ward4x4.com/defender-rundrohr-seilwindenstossstange/#comment-715]writemypapers[/url]
homework teachers
professional essay writers
paper help
igcse homeschooling
autobiographical essay example
[url=https://lovelandcappys.com/cappys-now-in-15-pack-cans-of-foundersbrewing-alldayipa/#comment-6307]thesis paper[/url]
resume guide
professional cv making
persuasive essay sample
how to create curriculum vitae
essay on life
אני משווק מורשה של מותג חדש , מכונת קפה שהגיע זה עתה לארץ
הרעיון הוא פשוט המכונה תשב אצלך בעסק רק בעלות ואני אקבל מיתוג יכל לעניין אותך ?
Download: [url=http://megafox.tv/serie/serie/How-I-Met-Your-Mother/1/22-Letzter-Versuch/Streamango]Streamango[/url] .
http://imgmak.com/image/GG
Download: [url=http://pulive1.tv/watch-a-p-bio-online/]A.P. Bio[/url] .
Industrial
Download: [url=http://adscosmetics.be/descargar-torrents-variados-896-keys-licencias.html]keys licencias.[/url] .
PBS.NewsHour.2016.06.02.WEB-DL.x264
Download: [url=http://printenbind.be/category/46/the-return-of-superman]The Return of Superman[/url] .
Internazionale 1179 - 11 NOVEMBRE 2016 pdf [Isohunt.to]
Download: [url=http://moorish.tk/final-fantasy-xiii-2-update-1-cpy/]DIRECT DOWNLOAD LINKS[/url] .
Private Practice
Download: [url=http://peliculasenhd.tk/serie/Copper-Justice-is-brutal]Copper – Justice is brutal[/url] .
Sex Is All Relatives XXX 720P WEBRIP MP4-GUSH
Download: [url=http://megafox.tv/serie/IK1-Touristen-in-Gefahr]IK1 – Touristen in Gefahr[/url] .
game of thrones
Download: [url=http://lotuselise.tk/watch/voVajnJd-hotel-artemis/vshare.html]Play Movie[/url] .
[SexArt] Dolly Diore (Perfect Awakening - 16 11 2016) rq mp4
Download: [url=http://peliculasenhd.tk/vorgeschlagene-serien/vote:13564]Perfect Girl - Yamato Nadeshiko Shichi Henge[/url] .
Lucy Liu
Download: [url=http://cotepeche.be/ver/acacias-38-1x790.html]1x790 Acacias 38[/url] .
The Mission (1990) Grains Of Sand
Download: [url=http://megafox.tv/serie/serie/Two-and-a-Half-Men/1/14-Ich-kann-mir-keine-Hyaenen-leisten/Streamango]Streamango[/url] .
Malwarebytes Anti-Exploit for Business 1 09 2 1261 + Serials [TechTools ME]
Download: [url=http://peliculasenhd.tk/serie/Happiness]Happiness![/url] .
TTC Video - An Introduction to Greek Philosophy
Download: [url=http://qjvudoqanimw.tk/movie/3345-unforgiven-1992-yify-torrent]Unforgiven[/url] .
Captain America the Winter Soldier 2014 DVDRip XViD-PLAYNOW
Download: [url=http://peliculasenhd.tk/serie/LEGO-Star-Wars]LEGO Star Wars[/url] .
BitLord.com
Download: [url=http://peliculasenhd.tk/serie/Roseanne]Roseanne[/url] .
Hacksaw Ridge 2016 HDCAM x264 AC3-TuttyFruity
Download: [url=http://kakuyomu-fan.tk/watch-everything-sucks-online/]Everything Sucks![/url] .
100th Running of the Indianapolis 500 May 29th 2016 [WWRG] [Isohunt.to]
Download: [url=http://peliculasenhd.tk/serie/Victorious]Victorious[/url] .
GarageBand 10 1 for MAC-OSx
Download: [url=http://hoyo19.tv/descargar/peliculas-x264-mkv/winchester-la-casa-que-construyeron-los-espiritus-/bluray-microhd/]Winchester La Casa Que Constru.. BluRay MicroHD[/url] .
Dead Age v1.1
Download: [url=http://megafox.tv/serie/The-Tick]The Tick[/url] .
Rileys.First.Date.2015.720p.BluRay.x264-NeZu
Download: [url=http://hoyo19.tv/descargar/peliculas-castellano/peliculas-rip/el-codigo-da-vinci-/blurayrip-ac3-5-1/2018-07-31/]El Codigo Da Vinci BluRayRip AC3 5.1[/url] .
Celebrity Antiques Road Trip S06E01 - Jennifer Saunders and Patricia Potter
Download: [url=http://megafox.tv/vorgeschlagene-serien/vote:11814]Dr. med. Marcus Welby[/url] .
Empire (2015)
Download: [url=http://megafox.tv/vorgeschlagene-serien/vote:13533]Art of Crime[/url] .
Regency Masquerade
Download: [url=http://josiefarrer.com.au/phim-hong-kong/]Hб»“ng KГґng[/url] .
Informatique
Download: [url=http://peliculasenhd.tk/serie/Gokujou-Seitokai]Gokujou Seitokai[/url] .
Jason Bourne 2016 720p BRRip 900 MB - iExTV
Download: [url=http://alumcliffshomebirth.com.au/torrent/1665072753/FC2-PPV-901738]FC2-PPV-901738[/url] .
Сезон 1 БГ СУБТИТРИ
Download: [url=http://megafox.tv/serie/Tiny-Toon-Abenteuer]Tiny Toon Abenteuer[/url] .
this compressed archive
Download: [url=http://peliculasenhd.tk/serie/Disney-Phineas-und-Ferb]Disney Phineas und Ferb[/url] .
mide376 mp4
Download: [url=http://getadobeacrobatreader.tk/music/salsa dance lagu dia.html]salsa dance lagu dia[/url] .
school girl pic
Download: [url=http://annarose.com.au/torrent/4ff57601de6a04316a7d5661a4b91340dee7d5c8]Too Short Life IS...album[/url] .
Super Soul Sunday
Download: [url=http://megafox.tv/serie/serie/How-I-Met-Your-Mother/1/19-Eine-nette-Nutte/OpenLoadHD]OpenLoadHD[/url] .
5 30 Huuhed Ger Bul
Download: [url=http://megafox.tv/serie/Sankt-Maik]Sankt Maik[/url] .
Continuar
Download: [url=http://megafox.tv/serie/Raven-Die-Unsterbliche]Raven - Die Unsterbliche[/url] .
28 de outubro de 2016
Download: [url=http://teachuit.com.au/watch-frolic-n-mae-movie-online-free-putlocker-3109.html]Frolic 'N Mae[/url] .
Great Artists in Their Own Words S01E01 - The Future Is Now (1907-1939)
Download: [url=http://digitalboss.com.au/movie-2018/white-fang-torrents/]White Fang (2018) RATING 6.7 / 10 QUALITY[/url] .
Ragnarok - The Animation Complete Series (Dual Audio)
Download: [url=http://megafox.tv/serie/serie/Two-and-a-Half-Men/1/13-Im-Bett-mit-Angina/TheVideo]TheVideo[/url] .
stormblades apk data mod google drive
Download: [url=http://wonder-pounds.tk/index.php?PHPSESSID=4nthukei2nj7a0io9eciha6eq2&action=profile;u=96518]Pankajmohan11[/url] .
Penthouse Breast Friends XXX 2015 HDTV 720p x264-SHDXXX
Download: [url=http://gratiscreditcard.tk/game-of-thrones-a-telltale-games-series-complete-season-1-pc-gog-t12872202.html]Game Of Thrones A Telltale Games Series Complete Season 1 [PC][GOG][/url] .
Bulgaria
Download: [url=http://mp3andmovie.tk/mp3/jasmine-v-theres-me-right-there-official-video-3291669/]Jasmine V Theres Me Right There Official Video Mp3[/url] .
TWD S07E12 Torrent
Download: [url=http://wonder-pounds.tk/index.php?PHPSESSID=4nthukei2nj7a0io9eciha6eq2&topic=114488.0]Request Your Regional Movies [Including Hindi Dubbed] Only Here[/url] .
Tight bubble butts sluts s17 with Katja Kassin mp4
Download: [url=http://megafox.tv/serie/Dark-Skies-Toedliche-Bedrohung]Dark Skies – Tödliche Bedrohung[/url] .
7 Minute Smigg Original Mix By Smigg Dirtee
Download: [url=http://visitturkey.tv/movie/рэмпейдж-6mgy.html]2 K Рэмпейдж 2018[/url] .
Missa X - Fuck mp4
Download: [url=http://printenbind.be/category/255/stray-kids]Stray Kids[/url] .
Together We
Download: [url=http://anoukmatton.be/watch-garage-sale-mystery-murder-most-medieval-2017-full-movie-online-3178.html](2017) DVDRip Garage Sale Mystery: Murde..[/url] .
Kung Fu Panda 3 2016 HD ????? ????? 7.6
Download: [url=http://inmyliverpoolhome.tk/download-american-made-2017-english-bluray-720p-x264-dd51-850mb-esubs.html]American Made (2017) English BluRay 720p x264 DD5.1 - 850MB - ESubs[/url] .
Kolchak The Night Stalker
Download: [url=http://hoyo19.tv/series-hd/claws/3453]Claws HDTV 720p AC3 5.1[/url] .
BBC World News
Download: [url=http://bitcoiners.tk/country/uk , netherlands , france , usa]UK , Netherlands , France , USA[/url] .
In Treatment
Download: [url=http://megafox.tv/serie/Code-Breaker]Code:Breaker[/url] .
KellyMadison.13.10.18.Breast.Appreciation.8.XXX.HR.MOV-KTR[rarbg]
Download: [url=http://customwallgraphics.com.au/page/2]PrГіxima pГЎgina[/url] .
Geordie Shore
Download: [url=http://revistaciao.ro/314101/Video2Brain.Windows.10.Grundkurs.GERMAN-EMERGE.html]Video2Brain.Windows.10.Grundkurs.GERMAN-EMERGE[/url] .
Shooter S01E01 WEBRip XviD-FUM[ettv]
Download: [url=http://peliculasenhd.tk/serie/serie/Two-and-a-Half-Men/1/14-Ich-kann-mir-keine-Hyaenen-leisten/OpenLoad]OpenLoad[/url] .
Tess Cline
Download: [url=http://megafox.tv/serie/Die-Medici-Herrscher-von-Florenz]Die Medici – Herrscher von Florenz[/url] .
Dj fabio B (Radio Dee Jay) one two one two 2015_12 2016_5_6_9_10 [Isohunt.to]
Download: [url=http://ilpozzodeidesideri.tk/usearch/the kissing booth/]the kissing booth[/url] .
The Walking Dead S07
Download: [url=http://betterment.tv/index.php?menu=search&star=Priyanka%20Chopra]Priyanka Chopra[/url] .
Devil's Playground
Download: [url=http://peliculasenhd.tk/vorgeschlagene-serien/vote:9854]Tolle Trolle[/url] .
Petes Dragon 2016 720p BluRay H264 AAC-RARBG
Download: [url=http://josohoqamojifa201.tk/Samehadaku]Samehadaku[/url] .
Good Eats
Download: [url=http://doxycyclineonline.tk/torrent/7113158/code-black-s03e05-batv%5Beztv%5D.html]Code Black S03E05 HDTV x264-BATV[eztv][/url] .
Kevin Costner’s 10 Best Movies
Download: [url=http://peliculasenhd.tk/vorgeschlagene-serien/vote:11076]Galaxy Angel[/url] .
Banda Zirahuen Puros Sones 2016
Download: [url=http://anoukmatton.be/watch-death-note-2017-full-movie-online-3137.html](2017) DVDRip Death Note[/url] .
Petes Dragon 2016 BluRay 720p x264 DTS-HDChina[PRiME]
Download: [url=http://conocevolvo.mx/mowgli/tt2388771]Mowgli (2018)[/url] .
doctor who
Download: [url=http://megafox.tv/serie/Queen-Sugar]Queen Sugar[/url] .
Executive Secretaries XXX DVDRip x264-MOFOXXX
Download: [url=http://peliculasenhd.tk/serie/Maji-de-Watashi-ni-Koi-Shinasai]Maji de Watashi ni Koi Shinasai![/url] .
Nero 8-Ultimate
Download: [url=http://cruiser-knight.tk/2018/07/21/hakyuu-houshin-engi-soul-hunter-720p-english-dubbed/]Hakyuu Houshin Engi | Soul Hunter | 720p | English Dubbed[/url] .
Little Mix - Glory Days (Deluxe) [2016]
Download: [url=http://pesk.tk/latest/page/715/]Terakhir [/url] .
Romance Novels
Download: [url=http://megafox.tv/serie/Strike-Back]Strike Back[/url] .
» Ver mais
Download: [url=http://peliculasenhd.tk/serie/TRON-Der-Aufstand]TRON - Der Aufstand[/url] .
Best Ryan Reynolds Roles
Download: [url=http://nzuriweb.tk/documentaire/spectacles-documentaire/]Spectacles[/url] .
?????????......
Download: [url=http://peliculasenhd.tk/vorgeschlagene-serien/vote:12780]T.U.F.F. Puppy[/url] .
Michael Franks - Sleeping Gypsy 1977 (Japan SHM-CD) FLAC
Download: [url=http://peliculasenhd.tk/serie/Boston-Public]Boston Public[/url] .
dancing with the stars s18e03
Download: [url=http://hoyo19.tv/descargar/cine-alta-definicion-hd/4kultrahd/descargar-hd-proyecto-rampage-microhd-1080p-castellano-ingles-subs/bluray-microhd/]Descargar HD Proyecto Rampage .. BluRay MicroHD[/url] .
Movie Detail
Download: [url=http://peliculasenhd.tk/serie/Postillon24]Postillon24[/url] .
Album A Kids Top 20 Summer Edition 2011 23-06-54
Download: [url=http://peliculasenhd.tk/serie/serie/How-I-Met-Your-Mother/1/17-Leben-unter-Gorillas/OpenLoad]OpenLoad[/url] .
Billy Lynn's Long Halftime Walk
Download: [url=http://zaimvkredit3.tk/chapter/tales_of_demons_and_gods/chapter_51]Chapter 51 : Reaching Ancient Orchid City![/url] .
Petes Dragon 2016 1080p BluRay AVC DTS-HD MA 7 1-FGT
Download: [url=http://php-center.tk/forumdisplay.php?1694-Baal-Veer&s=04a4a145a5cfce7a4a1017c274695581]Baal Veer[/url] .
Heartland (CA)
Download: [url=http://officecleaningpro.com.au/shows/1887/american-experience/]American Experience[/url] .
APES REVOLUTION Il Pianeta Della Scimmie 2014 iTALiAN MD TS (TeamPremiumCracking)
Download: [url=http://vision-infos.tk]vision-infos.tk - Serien online ansehen, kostenlos, schnell & in guter Qualität[/url] .
ebod552 mp4
Download: [url=http://kayserisektor.com.tr/movies/este-video-te-dara-mucho-miedo/]este video te dara mucho miedo[/url] .
Gallipoli 2005 ????? ????? 7.5
Download: [url=http://peliculasenhd.tk/serie/Gegege-no-Kitarou-2018]Gegege no Kitarou (2018)[/url] .
Chance S01E06 720p WEB H264-DEFLATE[ettv]
Download: [url=http://lamontagne.tk/movies/khakee-2017-hd-dvd-telugu-full-movie-watch-online/]Khakee (2017)[/url] .
the hateful eight
Download: [url=http://sinirsiz-porno.tk/torrents-details.php?id=11197]Singularity.Roller-PLAZA[/url] .
BitLord.com
Download: [url=http://megafox.tv/vorgeschlagene-serien/vote:12706]Der Alles-Esser – So schmeckt die Welt[/url] .
Skylanders Academy S01E01 720p x264 [StB] Others
Download: [url=http://peliculasenhd.tk/serie/Picnic-at-Hanging-Rock]Picnic at Hanging Rock[/url] .
Lynda - HTML Essential Training 2016
Download: [url=http://teachuit.com.au/genre/adventure]Adventure[/url] .
@file limitless
Download: [url=http://noqugogo.tk/o-assassino-o-primeiro-alvo/"]Legendado[/url] .
The Flash S03E06 720p HDTV x265 ShAaNiG mkv
Download: [url=http://tollyhungama.tk/forums/amateurs-discussion-requests.247/]Amateurs Discussion Requests[/url] .
Download Sully Torrent
Download: [url=http://minnasubs.tk/all/search/house+2008/]house 2008[/url] .
PBS Nova Treasures of the Earth Power 720p HDTV x264 AAC MVGroup org mp4
Download: [url=http://megafox.tv/serie/The-Rain]The Rain[/url] .
Aawaaz Do Humko
Download: [url=http://soniccash.tk/serial/kosmos-cosmos-a-spacetime-odyssey/916]Kosmos / Cosmos: A SpaceTime Odyssey[/url] .
Travel Leisure
Download: [url=http://megafox.tv/serie/Spider-Man-und-seine-aussergewoehnlichen-Freunde]Spider-Man und seine außergewöhnlichen Freunde[/url] .
Jeremy Renner
Download: [url=http://kuzeyyildizi.com.tr/toan-co-tu-chap-25-2/]Toà n Cơ Từ – Chap 25.2[/url] .
BitLord.com
Download: [url=http://visitturkey.tv/movie/рендель-5ld2.html]3 K Рендель 2017[/url] .
MyGirlLovesAnal 16 11 16 Harley Jade XXX 1080p MP4-KTR[rarbg]
Download: [url=http://peliculasenhd.tk/serie/Ousama-Game]Ousama Game[/url] .
Waterproofing
Download: [url=http://peliculasenhd.tk/serie/Low-Winter-Sun]Low Winter Sun[/url] .
rld-rotywo
Download: [url=http://peliculasenhd.tk/serie/Shinsekai-Yori]Shinsekai Yori[/url] .
mofoxxx-cst21 mp4
Download: [url=http://peliculasenhd.tk/serie/Spezialeinheit-Metal-Jack]Spezialeinheit Metal Jack[/url] .
The Sleeping Beauty Killer by Mary Higgins Clark, Alafair Burke (ePUB)
Download: [url=http://nzuriweb.tk/ar/Щ…ШґШ§Щ‡ШЇШ©-legend-of-the-demon-cat-ЩѓШ§Щ…Щ„-Ш§Щ€Щ†Щ„Ш§ЩЉЩ†/]Legend Of The Demon Cat[/url] .
Allied: B-Roll
Download: [url=http://peliculasenhd.tk/serie/Man-Seeking-Woman]Man Seeking Woman[/url] .
Walt Disney Treasures - Mickey Mouse
Download: [url=http://megafox.tv/serie/Dies-Irae]Dies Irae[/url] .
Petes Dragon 2016 BDRip x264 AC3-iFT[SN]
Download: [url=http://officecleaningpro.com.au/ep/1113582/very-cavallari-s01e06-web-x264-tbs/]Very Cavallari S01E06 WEB x264-TBS [eztv][/url] .
Video Gear Audio
Download: [url=http://peliculasenhd.tk/serie/Das-Comeback-der-Kamele]Das Comeback der Kamele[/url] .
BitLord.com
Download: [url=http://betterment.tv/index.php?menu=search&star=Pom%20Klementieff]Pom Klementieff[/url] .
WebSite-Watcher 2016 16 3 Business Edition + Crack [4realtorrentz] zip
Download: [url=http://peliculasenhd.tk/serie/Acapulco-H-E-A-T]Acapulco H.E.A.T.[/url] .
Adult Torrents
Download: [url=http://friv-friv.tk/movie/3501632-thor-ragnarok]80% Thor: Ragnarok[/url] .
Alien Isolation [Steam Rip]
Download: [url=http://peliculasenhd.tk/serie/Person-of-Interest]Person of Interest[/url] .
Angus MacLane,
Download: [url=http://gta-5-generator.tk/category/pacopacomama?category_name=pacopacomama&]Comments[/url] .
Simply Laura
Download: [url=http://galmusic.tk/index.php?accion=3&idusuario=1679527&nick=carbonero119]Subttulos subidos: 181[/url] .
The Great Canadian Tax Dodge HDTV x264 720p AC3 MVGroup org mkv
Download: [url=http://anunt-oferte.ro/Iron-Steel-Review-July-2018_3693266.html]Iron & Steel Review - July 2018[/url] .
[KiteSeekers-Wasurenai] Pretty Rhythm Aurora Dream Special - 26 [H264 704x400] [A55587A3].mkv
Download: [url=http://peliculasenhd.tk/serie/The-Firm]The Firm[/url] .
Duck Dynasty S11E01 West Monroe Wing WEB-DL x264-JIVE mp4
Download: [url=http://php-center.tk/showthread.php?270180-Dus-Ka-Dum-12th-August-2018-Watch-Online&s=04a4a145a5cfce7a4a1017c274695581&goto=newpost]Dus Ka Dum 12th August 2018...[/url] .
Half Life Collection REPACK-KaOs
Download: [url=http://megafox.tv/serie/Die-Ren-Stimpy-Show]Die Ren Stimpy Show[/url] .
(2016) DVD Barbie & Her Sisters in a ..
Download: [url=http://peliculasenhd.tk/serie/Cagney-Lacey]Cagney Lacey[/url] .
BibleWorks 10.0.0.41 Multilingual MacOSX
Download: [url=http://adscosmetics.be/descargar-torrents-variados-2030-BBC-Radio-1-Live-Lounge-2015-Fleur-East.html]BBC Radio 1 Live Lounge 2015 Fleur East.[/url] .
iZotope Ozone 7 Advanced v7 00 for MAC-OSx
Download: [url=http://naschysempusa.tk/video-movie-best-suspense-thriller-movies-killer-tiger-action-movies-2017.nZplc4p3qmakhYY.html]Best Suspense Thriller Movies -Killer Tiger - Action Movies 2017[/url] .
Chelsea.S01E79.Dinner.Party.The.Best.Relationships.720p.WEBRip.X265.AAC-PRiNCE.mkv
Download: [url=http://24options.mx/2015/victoria/victoria-2015-1080p-bluray-x264-usury/2015/victoria.html]Victoria[/url] .
Camtasia
Download: [url=http://youngboss.tk/category/punjabi-movies/]Punjabi Movies[/url] .
Paula Marcenaro Solinger
Download: [url=http://friv-friv.tk/movie/6133466-the-first-purge]53% The First Purge[/url] .
Alan Watt CTTM LIVEonRBN 524 Culture Circus Is A Clown And We Re All Going Down Mar012010
Download: [url=http://megafox.tv/serie/Baby-Steps]Baby Steps[/url] .
Snowden 2016 TRUEFRENCH 1080p WEB-DL MD x264-ViKi47 mkv
Download: [url=http://betterment.tv/index.php?menu=search&star=Olivia%20Olson]Olivia Olson[/url] .
VA - The Jazz House Independent 2nd Issue (1998) [FLAC]
Download: [url=http://peliculasenhd.tk/vorgeschlagene-serien/vote:9628]Das karmesinrote BlГјtenblatt[/url] .
Dawn of the Planet of the Apes official Trailer (2014) 2K HD
Download: [url=http://peliculasenhd.tk/serie/Scream-Queens]Scream Queens[/url] .
Bonnie Tyler Celebrate Live In Paris La Cigale Clubmusic80s
Download: [url=http://mp3vibe.tk/Massive-Shopify-Conversion-by-Gabriel-Beltran-Keder-Cormier_3692615.html]Massive Shopify Conversion by Gabriel Beltran & Keder Cormier[/url] .
Foreign 12,619
Download: [url=http://qjvudoqanimw.tk/director?dir=tim+kirkby]Tim Kirkby[/url] .
Suicide Squad 2016 EXTENDED 1080p WEB-DL H264 AC3-EVO
Download: [url=http://mashka.tk/showthread.php?780815-Die-kleine-Hexe-2018-GERMAN-COMPLETE-BLURAY-MOViEiT&s=dc0a33d0d7ad0bc6f004b907b23a3a56&goto=newpost]Die kleine Hexe 2018 GERMAN...[/url] .
AI RoboForm 7 9 24 4 - license entreprise
Download: [url=http://flightpackaging.com.au/apk/2981/]download security master apk [/url] .
BitLord.com
Download: [url=http://megafox.tv/serie/Bartender]Bartender[/url] .
BitLord.com
Download: [url=http://megafox.tv/serie/Die-Gentlemen-bitten-zur-Kasse]Die Gentlemen bitten zur Kasse[/url] .
Crazyhead
Download: [url=http://minnasubs.tk/all/1byday-aisha-sexy-n-wet-hot-teen-in-bathtub-gets-wet-and-wild-sep-26-2016-t3285736.html]1By-Day Aisha Sexy N Wet Hot Teen In Bathtub Gets Wet And Wild Sep 26 2016[/url] .
Alcest - Les Voyages De L'Ame
Download: [url=http://willem-i-200.tk/torrent/application/windows/293841-expressvpn+latest+version+6+7+1+5059+multilingue+code+dactivation+windows]ExpressVPN Latest version 6.7.1.5059 Multilingue + code d'activation [WINDOWS][/url] .
Lip Sync Battle S03E06 HDTV x264-ALTEREGO[PRiME]
Download: [url=http://tdmedia.tv/featured/63/download-best-instrumental-flute-music.html] Best Instrumental Flute[/url] .
Just For Fun By Timeflies
Download: [url=http://enterten.tk/torrent/3171050/The-Wrong-Cruise-2018-HDTV-x264-TTL/]The.Wrong.Cruise.2018.HDTV.x264-TTL[/url] .
So You Think You Can Dance
Download: [url=http://toowoombahealthandfitness.com.au/movie/6434-die-hard-1988-yify-torrent]Die Hard[/url] .
Alcohol Cries - 2011 - No Good Trying
Download: [url=http://megafox.tv/vorgeschlagene-serien/vote:13568]Sunohara-sou no Kanrinin-san[/url] .
CSI Cyber
Download: [url=http://peliculasenhd.tk/serie/The-Heroic-Legend-of-Arslan]The Heroic Legend of Arslan[/url] .
Children of the Corn (1984) 720p BluRay x264 Eng Subs [Dual Audio] [Hindi 2 0...
Download: [url=http://peliculasenhd.tk/serie/Tannbach-Schicksal-eines-Dorfes]Tannbach – Schicksal eines Dorfes[/url] .
Alan Partridge Mid-Morning Matters 06 Xvid Avi
Download: [url=http://megafox.tv/serie/Sleepy-Hollow]Sleepy Hollow[/url] .
DxO FilmPack Elite v5 5 9 Build 542 (x64) Multilingual Incl Keygen [Androgalaxy]
Download: [url=http://alumcliffshomebirth.com.au/torrent/1665072524/Anandamayi+Ma+%2830+Books+plus+Extra+photos%29]Anandamayi Ma (30 Books plus Extra photos)[/url] .
Scott Derrickson
Download: [url=http://rossewcaparoula.tk/show/evil-lives-here]Evil Lives Here - Season 3 Episode 13 - I Invited Him In 9PM on Investigation Discovery[/url] .
Download Female impressionist artists for free
Download: [url=http://style-schilde.be/iphone/]iPhone Games / Apps[/url] .
DC Comics Chronology - Revised v.1.0 (1954)
Download: [url=http://peliculasenhd.tk/serie/Bakumatsu-Kikansetsu-Irohanihoheto]Bakumatsu Kikansetsu Irohanihoheto[/url] .
Jenna J. Foxx - Beautiful Black And Curvy, XXX, MPEG4(Xvid), C2x, HD 1080p, 0,5 FPS [Brown Bunnies] (Aug 13, 2016).avi [Isohunt.to]
Download: [url=http://peliculasenhd.tk/serie/American-Heroes]American Heroes[/url] .
Д-р Хаус
Download: [url=http://megafox.tv/serie/Game-of-Silence]Game of Silence[/url] .
The Man from U.N.C.L.E. 2015 HD ????? ????? 7.3
Download: [url=http://gelsinkapina.com/results?search=movie+trailer+great+big+story]Movie Trailer great big story[/url] .
AssParade - Mandy Muse Puts On a Show 11 14 16
Download: [url=http://v3-i.com/movie/10905-extinction-2018-yify-torrent]Extinction[/url] .
[orange girl] ??????????? (???????????) [DL?].zip
Download: [url=http://germanybets.com/search/x264%202hd/]x264 2hd[/url] .
Supports
Download: [url=http://havasegypt.net/tag/los-futbolisimos-2018-hd-mkv/]Los futbolГsimos (2018) hd .mkv[/url] .
Asli Fighter (2015) Hindi Dubbed 300mb Movie DVDRip
Download: [url=http://188maxpoker.net/descargar/serie-en-hd/colony/temporada-3/capitulo-07/]Colony - Temporada 3 HDTV 720p AC3 5.1[/url] .
Turkan 2011 (Yerli Film) MP4
Download: [url=http://bk-33.com/disconnect-2018-free-dvd-online-movie-1080p]Disconnect (2018)[/url] .
F1 (2016) ENG PC GAME REPACK
Download: [url=http://allmattersbookkeeping.com/serie/Gilmore-Girls]Gilmore Girls[/url] .
Alban Berg - Lulu - Boulez
Download: [url=http://polosoreading.info/films/avengers-infinity-war]Avengers: Infinity War[/url] .
VICE News Tonight S01E28 2016 11 16 720p WEBRip H264 AAC2 0-PRiNCE - [SRIGGA]
Download: [url=http://pariscristaltur.com/films/streaming/96473-black-panther.html]Black Panther[/url] .
Voir ici
Download: [url=http://btc-easy.tk/films-en-streaming-1/1-1-0-9.html]Documentaire[/url] .
Upper Middle Bogan - S03E05 - Sticking To Your Principals mp4
Download: [url=http://porcelainspider.com/country/switzerland.html]Switzerland[/url] .
5 30 Huuhed Ger Bul
Download: [url=http://gvisolutions.com/court/tt3717068]CourtDramaVira Sathidar, Vivek Gomber, Geetanjali Kulkarni[/url] .
[request_ebook] Data Communications and Networking, 3rd edition
Download: [url=http://nhactinhchonloc.us/tags-peliculas/history]Historia[/url] .
Midsomer Murders
Download: [url=http://pet-immune-defense.us/torrent/3701721/09-dragongirl-durante.html]09 Dragongirl - Durante[/url] .
GPS Navigation Maps Sygic v16 4 4 Full [SadeemAPK]
Download: [url=http://katapagi.com/actors/JirГ+LГЎbus.html]JirГ LГЎbus[/url] .
javset.com-VANDR019.avi
Download: [url=http://re738.com/torrent/teaz6pom/Hands.of.a.Stranger.1962.DVDRip.x264.html]Hands.of.a.Stranger.1962.DVDRip.x264[/url] .
Anamanaguchi Pop It
Download: [url=http://valenciastonemason.com/wp-login.php?action=lostpassword]Lost your password?[/url] .
WWE SmackDown Live 2016 11 15 720p HDTV x264-NWCHD [TJET]
Download: [url=http://intercalaire.be/genre/history/]Historique[/url] .
L'amour est dans le pre QUEBEC - Saison 2 (2013) c...
Download: [url=http://troskicorp.com/watch-Triple-9-2016-movie-online-2053.html]Triple 9 (2016)[/url] .
Action Comics v1 (1938)
Download: [url=http://588v2.info/actors/Frank+Hall.html]Frank Hall[/url] .
Abdul Jabbar Shakir
Download: [url=http://grglabor.com/1-2-Switch-Nintendo-Switch_3686363.html]1-2-Switch [Nintendo Switch][/url] .
The Last Word with Lawrence O'Donnell 2016 11 16 720p WEBRip x264-LM
Download: [url=http://tvsemi.cekfurniture.com/]TV Semi Online Dewasa 18+[/url] .
Low Winter Sun
Download: [url=http://atfineline.com/tor-13294-Chal-Mohan-Ranga-2018-720p-Telugu-Proper-WEB-HD-AVC-AAC-Torrent-Download]Chal Mohan Ranga[/url] .
Filmes BluRay (720p e 1080p) - Capa Azul
Download: [url=http://myspotlesscleaning.net/drama-detail/shall-i-compare-you-to-a-spring-day]Shall I compare you To a Spring day[/url] .
Statgraphics
Download: [url=http://ericre.com/index.php?menu=search&star=Steven%20Strait]Steven Strait[/url] .
MEYD-202 mp4
Download: [url=http://btc-easy.tk/streaming-castle-rock-saison-1-vostfr-68850.html]Castle Rock - Saison 1 - VOSTFR[/url] .
People Just Do Nothing
Download: [url=http://u2candothis.com/film/wrecked-season-2-2017-1080p/]Eps10 Wrecked - season 2 (2017)[/url] .
Petes Dragon 2016 BRRip XviD AC3-EVO[PRiME]
Download: [url=http://angkaceria.net/truyen-tranh/36-ke-theo-duoi-vo-yeu/]36 Kбєї Theo Дђuб»•i Vб»Ј YГЄu[/url] .
Microsoft Office 2016 for MAC-OSx (English)
Download: [url=http://online-herbal-store.tk/tvshows/stranger-things/]Stranger Things[/url] .
BitLord.com
Download: [url=http://buzzjungle.com/blogs/33/Szene-News.html?archive=1-2010]Januar 2010[/url] .
Responder
Download: [url=http://gardeninaboxco.org/filmes/filme-232669/]Vingadores 4[/url] .
???(14)
Download: [url=http://letmevideo.com/18399-wrecked-s01e06-french-hdtv.html]Wrecked S01E06 FRENCH HDTV[/url] .
Stephen King - Under the Dome (PDFEPUBMOBI)
Download: [url=http://kesinizleyelim.com/news/896643/l-absence-de-localisation-en-francais-est-elle-prejudiciable.htm]News débat et opinion : L’absence de localisation en français est-elle préjudiciable ?[/url] .
Music 10,843
Download: [url=http://mysportgarage.com/tag/watch-rbg-full-movie-online/]Watch RBG full movie online[/url] .
Pro Tools HD 10 3 9 MAC (crack only - copylefter) [ChingLiu](1)
Download: [url=http://katapagi.com/actors/Julian+Dennison.html]Julian Dennison[/url] .
Mobile Suit Gundam 0083 Stardust Memory Complete Series (Eng.-Dub)
Download: [url=http://mwd6688.com/episodes/blindspot-season-1-episode-14/]Rules in Defiance[/url] .
Albert King - Smokin' The Blues 2000
Download: [url=http://malaqiyi.com/22999-pdf-librodetexto-descarga-por-que-algunas-empresas.html]Por que algunas empresas tienen exito y otras no: casos de exito, ideas clave y herramientas para innovar[/url] .
The Isley Brothers - I'll Be Home For Christmas - 2016-11-17
Download: [url=http://keygen-crack.com/series/la-casa-de-las-flores/4041]La Casa De Las Flores HDTV[/url] .
Top Movies 2016
Download: [url=http://germanybets.com/game-of-thrones-s06e04-1080p-hdtv-6ch-x265-hevc-psa-mkv-t12606763.html]Game of Thrones S06E04 1080p HDTV 6CH x265 HEVC-PSA mkv[/url] .
Uranium Backup
Download: [url=http://altamodatw.com/tvshows/the-big-bang-theory/]The Big Bang Theory[/url] .
Rare Bandler (Hypnosis & NLP)
Download: [url=http://gpmonlinestore.com/below-deck-mediterranean/photos/belowdeckmed-season-3-whats-in-your-suitcase]Photos See What They Packed for This Season[/url] .
register
Download: [url=http://newschatinterview.com/l-age-de-glace-streaming-vf-vostfr/]L Г‚ge De Glace[/url] .
Тайни и лъжи
Download: [url=http://kikblox.org/private.php?do=newpm&u=31715]Private Message[/url] .
Joe Satriani-Satchurated 2CD-2012-BriBerY
Download: [url=http://eatsube.com/movie/170496-lovely-molly-2011-1080p-bluray-x264-dts-melite.html]Lovely Molly 2011 1080p BluRay x264 DTS-MELiTE[/url] .
Dont Breathe 2016 BRRip 720p x265 2Ch HAAC-RCCL-KITE-METeam mkv
Download: [url=http://media-homesandrooms.com/engine/go.php?file=Offtopic]Nzbplanet[/url] .
Carnage Park 2016 HEVC D3FiL3R iso [PRiME]
Download: [url=http://gzsfbj.com/3137654951-tia-gold-crybaby-2018.html]Tia' Gold - Crybaby (2018)[/url] .
Petes Dragon 2016 720p BluRay 900MB ShAaNiG mkv
Download: [url=http://escavee.be/films-gratuit/41928-ready-player-one-multi-bluray-3d.html]Ready Player One[/url] .
Alarum 2011 - Natural Causes
Download: [url=http://inibaru.info/forumdisplay.php?2475-Mitegi-Lakshmanrekha&s=e856f686cd253f276d96080b07afe30c]Mitegi Lakshmanrekha[/url] .
Comments: 0
Download: [url=http://cay-t.com/descargar-torrents-variados-267-Topaz-Adjust.html]Topaz Adjust[/url] .
Hayley Kiyoko,
Download: [url=http://stephencurrybasketball.us/torrent/1665079494/Sins+of+the+Dead+by+Lin+Anderson+EPUB]Sins of the Dead by Lin Anderson EPUB[/url] .
Next Thread
Download: [url=http://albert-trading.com/show/berlin-station]Watch show[/url] .
Mac OS X
Download: [url=http://ferragamoon.com/memberlist.php?mode=viewprofile&u=1092558&sid=04a1ba04f371eb7bfcbf37331ab46932]kolhoznik007[/url] .
designing high performance work systems
Download: [url=http://americanracercup.com/www-tamilrockers-gs-kaali-2018-hdrip-x264-700mb-esubs-tamil-wujym.html]www TamilRockers gs - Kaali (2018)[HDRip - x264 - 700MB - ESubs - Tamil] 1 hour[/url] .
abp531 mp4
Download: [url=http://dunudel.com/watch-Gigantic-2018-movie-online-24750.html]Gigantic (2018)[/url] .
_My_Friends_Hot_Girl__11_17_2016_Jessa_Rhodes__Naughty_America__HD_720p mp4
Download: [url=http://f2pinsider.com/single/67327/ishan-kouran-mai-bewafa.html]Ishan Kouran - Mai Bewafa [R,V] </font>[/url] .
?????.E501.161116.720p-NEXT
Download: [url=http://n8245.com/tutorial/4272-ine-ine-cisco-ccna-voice-course-18-02-2012.html][INE] INE Cisco CCNA Voice Course [18 02 2012][/url] .
True Detective
Download: [url=http://galerie-joelguyot.com/torrenty/kategorii/Gry/gatunku/cRPG]Gry / cRPG[/url] .
Rayon Riddles Rise of the Goblin King REPACK-KaOs
Download: [url=http://jmiaoyz107.com/film/100-girls-2000-1080p/]100 Girls (2000)[/url] .
Сезон 1 БГ АУДИО
Download: [url=http://madebycharli.com/movie-2018/assassination-nation-torrents/]Assassination Nation (2018) RATING 5.6 / 10 QUALITY[/url] .
Arrow S05E07 HDTV x264-LOL mp4
Download: [url=http://neurofoqrbundet.tk/wwe-wallpapers/]WWE WallPapers[/url] .
a?Sa?µa?§a??a?•a?€a?za?·a??a?a?Sa??a?•a?? a??a?±a??a?™a?µa?‰a?€a?za?·a??a?a?€a??a? Descendants Of The Sun
Download: [url=http://polo-uno.com/torrent/24385567/[ATKGirlfriends]Gia_Paige_Wants_to_Fuck_You_in_Bangkok][ATKGirlfriends]Gia Paige Wants to Fuck You in Bangkok[/url] .
(2017) HD Trailer Get Smurfy
Download: [url=http://btc-easy.tk/films-en-streaming-1/1-1-0-1.html]ComГ©die[/url] .
Blindspot S02E09 1080p HDTV X264 mp4
Download: [url=http://ameritrope.com/diziler/the-it-crowd-turkce-dublaj/]• The IT Crowd (Türkçe Dublaj) 8.1[/url] .
Movie Information
Download: [url=http://90dakika28.com/Space-Big-Pack-8_2789820.html]Space (Big Pack 8)[/url] .
BigTitsAtWork - Nicole Aniston (Team Player) 11 16 16
Download: [url=http://bubblylight.com/serie/jikulumessu.htm]Plus de saisons[/url] .
need for speed
Download: [url=http://jml-vicon-china.net/02155417-harvard-business-review-brasil-julho-2018/]Harvard Business Review Brasil – julho 2018[/url] .
Frank Langella,
Download: [url=http://lipsterworld.com/watch-proud-mary-movie-online-free-putlocker-3314.html]Proud Mary (2018)[/url] .
Talmadge Harper - The Art of The Mind Doll 2.0
Download: [url=http://terustegang.net/watch/the-first-purge-freeseries-39777.html]CAM The First Purge[/url] .
Allegiant (2016) Movie 720p BRRip Free Hd Download
Download: [url=http://marlboroughmuseum.com/2018/08/major-2nd-episode-19-subtitle-indonesia.html]Major 2nd Episode 19 Subtitle Indonesia[/url] .
[SallySubs] Shimoneta to Iu Gainen ga Sonzai Shinai Taikutsu na Sekai [BD 720p AAC]
Download: [url=http://aireacondicionadoyclimatizacion.com/explained-s01e05-cryptocurrency-1080p-nf-web-dl-dd5-1-x264-ntb-wujld.html]Explained S01E05 Cryptocurrency 1080p NF WEB-DL DD5 1 x264-NTb 26 minutes[/url] .
[??] ??? The.Jungle.Book.2016.720p.BluRay.x264.DTS…
Download: [url=http://cheapmusicaltickets.com/actors/Pablo+Schreiber.html]Pablo Schreiber[/url] .
The Dark Knight Rises Android Game Apk Full Download.
Download: [url=http://breast-implants-surgery.com/imdb/page/715/]Terakhir [/url] .
The Bernie Mac Show
Download: [url=http://clbanners2.com/torrent/consumer-reports-july-2018-true-pdf-zeke23-tgx--215725]Consumer Reports – July 2018 - True PDF - zeke23[TGx][/url] .
Housemate 2 XXX 2015 HDTV 720p x264-SHDXXX[N1C]
Download: [url=http://systemart.info/ver/salvation-2x08.html]Salvation temporada 2 capitulo 8 descarga gratis[/url] .
Alesana - Discography - 2005-2011
Download: [url=http://whyl367.com/epava-2018-movie-online-full-free-streaming]Epava (2018)[/url] .
Divinity Original Sin 2 - (MacAPPS) 2016
Download: [url=http://batxe.info/template/3494-activeden-minimal-xml-template-v2-w-deep-linking-reuploaded.html]ActiveDen Minimal XML Template v2 w deep linking reuploaded[/url] .
Ground Floor
Download: [url=http://actministries.net/films/96642-telecharger-pierre-lapin.html]TГ©lГ©charger Pierre Lapin[/url] .
LEGO Ninjago Masters of Spinjitzu S05E06 Kingdom Come WEB-DL XviD MP3 ...
Download: [url=http://81111133.com/movie/3559-ghost-rider-spirit-of-vengeance-2012-telesync-ac3-h264-crys.html]Ghost Rider Spirit of Vengeance 2012 TELESYNC AC3 H264-CRYS[/url] .
Yesterday Origins- FOR MAC[SOFT]
Download: [url=http://kmyszyxyglxy.com/all/the-flash-s02e23-2016-hdtv-x264-ift-t3935129.html]The Flash S02E23 2016 HDTV x264 - iFT[/url] .
Young Pappy X Lil Herb Type Beat 2015 Cold Nights Prod Beezy Streetz
Download: [url=http://amanicraft.com/descargar-gritos-en-oldfield-latino.html]Gritos en Oldfield[/url] .
Horror 12,087
Download: [url=http://alex-bus.com/juegos-pc/ina-koi-hentai/]Sin Categoria Undefined[/url] .
Snowden 2016 HDRip AC3 2 0 x264-BDP[SN]
Download: [url=http://nofxbrokerctflx.tk/download-8108-memphis-belle-a-fortaleza-voadora-torrent]Memphis Belle - A Fortaleza Voadora Ação / ClГЎssico / Drama / Guerra Idioma: InglГЄs / PortuguГЄs 1990 MKV Torrent DownloadVГdeo 10 / ГЃudio 10CompletoSinopse: No ano de 1943 em uma base aГ©rea da aeronГЎutica norte-americana, quatro oficiais e seis alistados compГµem os integrantes do Memphis Belle, um...</p>[/url] .
Batman v Superman: Dawn of Justice
Download: [url=http://sagaei.com/descarga-0-5812336-0-0-fx-1-1-.fx]Familiar[/url] .
Tech N9ne
Download: [url=http://cutiecameras.com/applications/656105-windows-10-rs4-1803-17134-228-x86-x64-10in1-office-2016-august-2018-a-post668312.html?s=b86e0b4af8818fb3141833ed4bb6ab52]Windows 10 RS4 1803 17134.228...[/url] .
Graphics and Design
Download: [url=http://watchitsalwayssunnyinphiladelphia.net/acteurs/fily-keita/]Fily Keita[/url] .
CAPTAIN AMERICA The First Avenger (greek language)
Download: [url=http://higherbyhayyaali.com/descargar/cine-alta-definicion-hd/1080p/tomb-raider-/bluray-1080p/]Tomb Raider BluRay 1080p[/url] .
Portal 2 - 2016 (PC) nosTeam
Download: [url=http://atfineline.com/tor-6924-Adobe-After-Effects-CC-2017-v14-0-1-Torrent-Download-Full-Version]Adobe After Effects CC[/url] .
Chat IRC
Download: [url=http://amanicraft.com/descargar-supergirl-latino.html]Supergirl[/url] .
Cartoons
Download: [url=http://online-herbal-store.tk/movies/genghis-khan-2018/]Genghis Khan 2018[/url] .
The walking dead
Download: [url=http://nationalizetheelection.net/les-innocentes-en-streaming12/]Regarder un film[/url] .
Syncovery v7 63a Build 424 (x86 x64) - Full rar
Download: [url=http://katapagi.com/actors/Britt+Ahart.html]Britt Ahart[/url] .
The Marine 4 2015 mp4
Download: [url=http://588v2.info/actors/Jennifer+Morrison.html]Jennifer Morrison[/url] .
The Collector
Download: [url=http://gdc2010.com/film/fZ3/Christopher-Robin]IMDb: 8.1 CAM Christopher Robin[/url] .
View this forum's RSS feed
Download: [url=http://96dvdv.com/mp3/Elvis+Presley+I+Was+The+One+%28take+3%2C+Incomplete%29]Download mp3[/url] .
Despicable Me 2 2013 HD ????? ????? 7.5
Download: [url=http://ufarmnaturallytasty.com//ufarmnaturallytasty.com/watch-sharp-objects-online/]Sharp Objects[/url] .
The Mission (1990) Grains Of Sand
Download: [url=http://terustegang.net/watch/quantico-season-3-freeseries-39353.html]Eps7 Quantico Season 3[/url] .
Banda Machos Te Quiero Para Mi
Download: [url=http://szhaa.com/diziler/new-girl/]• New Girl 6.4[/url] .
Fulboy 2015 HD ????? ????? 5.4
Download: [url=http://jml-vicon-china.net/02102418-simply-vegan-august-2018/]Simply Vegan – August 2018[/url] .
Read More
Download: [url=http://katapagi.com/actors/Dan+Sallitt.html]Dan Sallitt[/url] .
living in urbana il
Download: [url=http://royalregistan.com/torrent/filmvidГ©o/sГ©rie-tv/296443-animal+kingdom+us+s03e12+fastsub+vostfr+720p+webrip+x264-gold]Animal.Kingdom.US.S03E12.FASTSUB.VOSTFR.720p.WEBRip.x264-GOLD[/url] .
???? ??? 2? 3?
Download: [url=http://meilleuresvoitures.com/detail/Rxsc5ed8BO][少女騎士団 (大槍葦人)] ORDER*MAID*SISTERS 城ヶ崎姉妹とメイドSEXする本 (アイドルマスター シンデレラガールズ)[/url] .
the L word - Season 02 (8 lang subtitles)
Download: [url=http://gallerialockandkey.com/Movies/Matt-Damon/]Matt Damon[/url] .
Coach Trip: Road to Ibiza
Download: [url=http://oasessystem.com/detail/TxAaKVi27L]гЃ·г‚‹гЃ·г‚‹Hearts[/url] .
Mental Coma - Fragments Of Democracy (2016)
Download: [url=http://amanicraft.com/descargar-los-piratas-del-rock-latino.html]Los Piratas Del Rock[/url] .
0 Comments
Download: [url=http://gelsinkapina.com/results?search=movie+trailer+vlog]Movie Trailer Vlog[/url] .
[mkv] From Keijo.S01E06.1080p.HEVC.x265-...
Download: [url=http://wearenotrockstarsbutweareonaworldtour.com/films/science-fiction]Science fiction[/url] .
TeensAnalyzed 15 03 14 From Tutoring To Anal Sex XXX 1080P WMV-GUSH[rarbg]
Download: [url=http://cheapmusicaltickets.com/actors/Dorothy+Tree.html]Dorothy Tree[/url] .
Sahasam Swasaga Sagipo (2016) Telugu Full Movie - 1CD - WebRip - Telugu - x264 - MP4 - Team Mafiaking Exclusive
Download: [url=http://chinafactory.net/3137653362-echoculture-my-island-2018.html]Read More[/url] .
Chelsea S01E79 Dinner Party The Best Relationships 720p WEBRip X265 AAC-PRiNC...
Download: [url=http://snappingteens.com/X5X-subtitulos-nihon-kuroshakai-1999.html]nihon kuroshakai 1999[/url] .
Raised by Wolves (UK)
Download: [url=http://bk-33.com/hardcourt-2018-stream-online-free-full-movie]Hardcourt (2018)[/url] .
Call of the Wildman
Download: [url=http://persia4pays.com/films/realisateur/wilson-yip.html]film de Wilson Yip[/url] .
Download Elo universal driver windows 7 for free
Download: [url=http://englakraft.com/deadpool-2-2018-super-duper-cut-brrip-xvid-ac3-evo-tf6621476.html]Deadpool.2.2018.Super.Duper.Cut.BRRip.XviD.AC3-EVO[EtMovies][/url] .
Married at First Sight: The First Year
Download: [url=http://20pas10.com/watch-cemetery-of-splendour-2015-1080p-online-free-123movieshub.html]DVD Cemetery of Splendour (2015)[/url] .
Invocation Spells - The Flame Of Hate (2016)
Download: [url=http://bursavillas.com/step-sisters-2017/108780?v=1582127]OglД…daj odcinek[/url] .
Battletech - (MacAPPS) 2016
Download: [url=http://troonent.com/search?q=pubg lite&ici=hot_index]pubg lite[/url] .
Sound Choice Karaoke SC2216-SC2220 - KaraokeRG
Download: [url=http://myspotlesscleaning.net/drama-detail/devil-lover]Devil Lover[/url] .
Me Before You 2016 PAL DVDR-EVO[SN]
Download: [url=http://joelcam.com/torrent/8or2/Nicci-French-De-Rode-Kamer-NL-Ebook-ePub-DMT.html]Nicci French - De Rode Kamer, NL Ebook(ePub).DMT[/url] .
A Mangaka
Download: [url=http://newhopeumc.info/tor-670-Trolls-2016-Dubbed-Hindi-720p-BluRay-x264-Torrent-Download-Full-Movie-HD]Trolls Dubbed Hindi[/url] .
Aleksander Minkowski - Krzysztof Czyta Marian Opania
Download: [url=http://katapagi.com/actors/Jeff+Bukowski.html]Jeff Bukowski[/url] .
Expeditions Viking [2016 MAC OS GAME]
Download: [url=http://howlife.org/engine/go.php?book=contoh-soal-pilihan-ganda-beserta-kuncinya-pengetahuan-umum--.pdf]Download[/url] .
Alan Haven - Organ Show
Download: [url=http://cay-t.com/descargar-torrents-variados-2085-Sade-Bring-Me-Home-Live-2011.html]Sade: Bring Me Home - Live 2011.[/url] .
Juggling Suns - Living on Edge of Change
Download: [url=http://nxawtjn.com/trance/?share=twitter]Click to share on Twitter (Opens in new window)[/url] .
Devon Testing The Talents[Brazzers]
Download: [url=http://zipaikk.com/torrent/cgve7e5l/The.Mansion.2017.NF.WEB-DL.DD5.1.x264-CMRG[EtHD].html]The.Mansion.2017.NF.WEB-DL.DD5.1.x264-CMRG[EtHD][/url] .
Facebook
Download: [url=http://90dakika28.com/Play-Acoustic-The-Complete-Guide-To-Mastering-Acoustic-Guitar-Styles_2671691.html]Play Acoustic: The Complete Guide To Mastering Acoustic Guitar Styles[/url] .
Gotham S03E09 HDTV x264-LOL[rarbg]
Download: [url=http://plantcream.com/movies/dazed-and-confused/]Watch movie[/url] .
Christophe Mali - je vous emmene .mp3(A)
Download: [url=http://vozdvizenka.com/others/unsorted/5247075-taken-3-2014-720p-hdrip-xvid-mp3-rarbg.html]Taken 3 (2014) 720p HDRip XviD MP3-RARBG[/url] .
[Jazz Fusion, Bass] Alain Caron - Septentrion 2010 FLAC (Jamal The Moroccan)
Download: [url=http://uandlilc.com/vixen-the-movie/tt6945882]Vixen: The Movie (2017)[/url] .
Howard Stern Show
Download: [url=http://howlife.org/engine/go.php?book=%E7%B2%BE%E9%80%9AEJB%E7%AC%AC3%E7%89%88.pdf]Download[/url] .
Petes Dragon 2016 BDRip x264-COCAIN mkv
Download: [url=http://horizontail.com/tags/Recordings/]Recordings[/url] .
BitLord.com
Download: [url=http://qsmvba.com/?p=films&search=Vicente Amorim]Vicente Amorim[/url] .
Migos Versace Remix Ft Drake
Download: [url=http://germanybets.com/family-guy-s14e12-hdtv-x264-killers-ettv-t11922667.html]Family Guy S14E12 HDTV x264-KILLERS[ettv][/url] .
Bob Dylan The Best Of Remastered 1997 [EAC-FLAC](oan)
Download: [url=http://9m-team.com/index.php?/topic/217319-un-saludo/]Un Saludo[/url] .
Сезон 1 БГ СУБТИТРИ
Download: [url=http://gelsinkapina.com/results?search=movie+trailer+wisteriamoon]Movie Trailer wisteriamoon[/url] .
Van Helsing S01E02 1080p WEB x264-HEAT[PRiME]
Download: [url=http://96dvdv.com/mp3/Elvis+Presley+Lawdy+Miss+Clawdy+%28take+1%29]Download mp3[/url] .
Most Popular Bollywood Stars
Download: [url=http://oasessystem.com/search/index/word:メガネ]メガネ[/url] .
A Million WAys to Die in the West 2014 READNFO HDRip XviD-HELLRA
Download: [url=http://amanicraft.com/descargar-la-excepcion-a-la-regla-latino.html]La Excepcion a la Regla[/url] .
The Seven Habits of Highly Effective People Video Illustrations By Stephen Covey ( Uploaded - Ryushare - Rapidgator )
Download: [url=http://llenadecosasbuenas.com/serie/stream/westworld]Westworld Western[/url] .
?? LUCK-KEY, 2015.854x480+1920x1080.FHD-NWB
Download: [url=http://pet-immune-defense.us/torrent/7095977/supergirl-s03e20-sva%5Beztv%5D.html]Supergirl S03E20 HDTV x264-SVA[eztv][/url] .
Above Ground Storage Tanks [Myers]
Download: [url=http://u2candothis.com/film/killjoys-season-3-2017-1080p/]Eps11 Killjoys - Season 3 (2017)[/url] .
(Brazzers)BigTitsAtWork - Liza Del Sierra (Bathroom Banging)
Download: [url=http://rchelshamconsultingllc.com/series/science-fiction_1]Science fiction[/url] .
ALSScan.16.10.29.Ana.Rose.Twiddle.And.Twirl.XXX.1080p.MP4-KTR[rarbg]
Download: [url=http://marlboroughmuseum.com/category/gundam-build-divers]Gundam Build Divers[/url] .
Assorted Mags Bundle - November 12 2016 (True PDF)
Download: [url=http://kjoshomecollection.com/movie/strangers-prey-at-night-dvd-streaming/4/]Vshare.eu VF Dvdrip[/url] .
Sleep Your Fat Away with Dr. Roy & Joy Martina
Download: [url=http://mydentalpracticemarketing.com/drama-detail/ruk-leh-saneh-luang]Ruk Leh Saneh Luang (รักเล่ห์เสน่ห์ลวง)[/url] .
Mister You - Le Grand Mechant You-WEB-FR-2016-SPAN...(N)
Download: [url=http://grupocpagua.com/Skyscraper-2018-1080p-KORSUB-HDRip-x264-AAC2-0-STUTTERSHIT-torrent-11238751.html]Skyscraper 2018 1080p KORSUB HDRip x264 AAC2.0 STUTTERSHIT[/url] .
Jodorowsky's Dune 2013 HD ????? ????? 8.1
Download: [url=http://lenningschoolwatch.org/torrent/992872/%EC%B1%84%EB%84%90a-%EB%9F%AC%EB%B8%8C%EB%9D%BC%EC%9D%B8-%EC%B6%94%EB%A6%AC%EA%B2%8C%EC%9E%84-%ED%95%98%ED%8A%B8%EC%8B%9C%EA%B7%B8%EB%84%90-%EC%8B%9C%EC%A6%8C2-e09-180511-720p-next.html][채널A] лџ¬лёЊлќјмќё 추리게임 н•нЉём‹њк·ёл„ђ м‹њм¦Њ2 E09 180511 720p-NEXT[/url] .
[RPG] [a‚?a?a??a‚?a‚“a?•a‚?a??a‚?a?©a?–] HJa—? i?zH...
Download: [url=http://higherbyhayyaali.com/descargar/cine-alta-definicion-hd/los-hambrientos/]Los Hambrientos BluRay 1080p[/url] .
Movies Counter
Download: [url=http://top2232.com/the-real-housewives-of-dallas/season-3/episode-2/videos/next-on-rhod-mama-dee-and-dandra-are-facing]Preview The Real Housewives of Dallas Next On RHOD: Mama Dee and D'Andra Are Facing Off S3/Ep2: Plus, Brandi Redmond shows up with a gift and some drama at D'Andra's party. Watch Video 10 hours ago[/url] .
Sharknado 3: Oh Hell No! (2015)
Download: [url=http://eatsube.com/game/167082-majesty-gold-hd-eng-2012.html]Majesty Gold HD ENG 2012[/url] .
Power Rangers
Download: [url=http://szhaa.com/diziler/dramaworld-asya-dizi/]• Dramaworld (Asya Dizi) 7.8[/url] .
Hillbilly Elegy [Audiobook + ePub] by J. D. Vance
Download: [url=http://5ufg.com/watch/rdmL1lGX-the-devil-ring.html]The Devil Ring[/url] .
Спортен
Download: [url=http://bridgedagap.tk/2017/08/]August 2017 (49926)[/url] .
Killer Instinct
Download: [url=http://theathleisure.net/serie/Eleventh-Hour]Eleventh Hour[/url] .
Pluralsight - Managing DHCP With PowerShell
Download: [url=http://healthyweightlossbn.net/torrent/2b4cd4dbda0529d692349512aaaae3cb984b47da]Office Tab Enterprise Edition 9.20 (2012) PC[/url] .
Сезон 4 БГ СУБТИТРИ
Download: [url=http://aireacondicionadoyclimatizacion.com/колония-colony-03x01-05-из-13-2018-web-dl-720p-gears-media-wujra.html]Колония / Colony [03x01-05 из 13] (2018) WEB-DL 720p | Gears Media 19 minutes[/url] .
The Last Witch Hunter 2015 HD ????? ????? 6.0
Download: [url=http://persia4pays.com/films/telecharger/96742-qui-a-peur-de-virginia-woolf.html]Qui a peur de Virginia Woolf ? TELECHARGEMENT GRATUIT[/url] .
Salvage Dawgs
Download: [url=http://9m-team.com/index.php?/forum/34-descarga-title-update-de-juegos/]Descarga Title update de juegos[/url] .
Star Trek Beyond 2016 MULTi VFF 1080p HDLight x264...(A)
Download: [url=http://kesinizleyelim.com/forums/42-19163-57270642-1-0-1-0-sondage-champion-mid.htm][Sondage] Champion mid[/url] .
Bad People 2016 Movie Free Download 720p BluRay
Download: [url=http://dehpiscines.net/member.php?s=7e3ae73745bc142040be7d4b8c2abe4d&u=2820]flachpass[/url] .
Download A Historia Real de um Assassino Falso MP4 Dublado Torrent
Download: [url=http://atfineline.com/tor-2158-Knabbel-and-Babbel-Pas-op-Heibel-NL-Gesproken-Torrent-Download-Full-Movie-HD]Knabbel & Babbel Pas op Heibel NL Gesproken[/url] .
pornpeg.com
Download: [url=http://588v2.info/actors/Annie+McEnroe.html]Annie McEnroe[/url] .
defonce de beaux petits culs 5 s1 mp4
Download: [url=http://gelsinkapina.com/results?search=movie+trailer+wreck+it+ralph+2]Movie Trailer Wreck it Ralph 2[/url] .
Baniya Ne Jatt
Download: [url=http://systemart.info/ver/unforgotten-3x05.html]3x05 Unforgotten[/url] .
Fifth Gear
Download: [url=http://gzzyyst.com/watch-movies/2014/watch-stuck-1221826/]#Stuck (2014)[/url] .
The Kapil Sharma Show 24 Sept 2016 HDTV Download
Download: [url=http://eatsube.com/graphic/165003-after-effects-project-wedding-album-pop-up.html]After Effects Project Wedding Album Pop-Up[/url] .
Answer Machine Chopped And Screwed
Download: [url=http://sbt90s.net/viewtopic.php?f=200&t=284471&sid=4e052d90b6c9848a61de7d8ece930253]NovГ© zprГЎvy[/url] .
True Story 2015 HD ????? ????? 6.3
Download: [url=http://5ufg.com/watch/dr9a5kDG-hotel-artemis/vidto.html]Play Movie[/url] .
I Love Amateurs
Download: [url=http://cheapmusicaltickets.com/actors/Michael+Sheen.html]Michael Sheen[/url] .
Service Delivery Platforms: Developing and Deploying Converged Multimedia Services
Download: [url=http://myspotlesscleaning.net/drama-detail/medical-examiner-dr-qin-2-scavenger]Medical Examiner Dr. Qin 2 Scavenger[/url] .
Alan Reed - Dancing With Ghosts 2011
Download: [url=http://news-masses.com/dallas-cowboy-cheerleaders-making-the-team]Dallas Cowboys Cheerleaders: Making the Team - Episode List[/url] .
[OCN] ??? ?.E05.161115.HDTV-Film.x264.AAC.720p-MATE
Download: [url=http://vcoptv.com/perfil/Sandroli]Sandroli Argentina[/url] .
Six-6 (2012) x264 720p HDRiP Dual Audio} [Hindi DD 2 0 + Telugu 2 0] Exclusiv...
Download: [url=http://allmattersbookkeeping.com/serie/Mahou-Sensou]Mahou Sensou[/url] .
[SexArt] Dolly Diore (Perfect Awakening - 16 11 2016) rq mp4
Download: [url=http://hoffmannphillips.com/free-movie-downloads/3237408-maze-runner-the-death-cure-2018-hdcam-english-x264-aac-movcr.html]Maze Runner The Death Cure 2018 HDCAM English x264 AAC-MovCr[/url] .
brice de nice
Download: [url=http://haoshengtao.com/downloadmp3/_sEDBAy45p0/clean-bandit-solo-feat-demi-lovato-acoustic-version.html] Link Mp3 [/url] .
Черният списък
Download: [url=http://mysportgarage.com/the-martian-2015/]The Martian[/url] .
Vehicles & Sports
Download: [url=http://uandlilc.com/manny-dearest/tt5612874]Manny Dearest (2017)[/url] .
Youre the Worst S03E13 720p HDTV x264-FLEET[PRiME]
Download: [url=http://theathleisure.net/serie/Yondemasuyo-Azazel-San]Yondemasuyo Azazel San[/url] .
CyberLink PhotoDirector Ultra 8 0 2303 0 Multilingual + Patch [SadeemPC]
Download: [url=http://33l9.com/contactar]ContГЎctar[/url] .
KarupsPC 16 11 17 Coco De Mal Hardcore XXX 720p MP4-KTR
Download: [url=http://promisepartners.info/Character-Modeling-with-Maya-and-ZBrush-Professional-polygonal-modeling-techniques_159332.html]Character Modeling with Maya and ZBrush: Professional polygonal modeling techniques[/url] .
China Learns from the Soviet Union, 1949-Present (The Harvard Cold War Studies Book Series)
Download: [url=http://scottishwhispers.com/peliculas/46796-enredados-2010-online.html]Enredados[/url] .
BitLord.com
Download: [url=http://websitob.com/johnny-cash-original-album-classics-5-cd-tf6629685.html]Johnny Cash - Original Album Classics - 5-CD-(2015)-[FLAC]-[TFM][/url] .
Army of One 2016 HEVC D3FiL3R iso [PRiME]
Download: [url=http://marlboroughmuseum.com/category/boku-dake-ga-inai-machi]Boku Dake ga Inai Machi[/url] .
Penn And Teller Bullsh*t
Download: [url=http://hdache13.com/torrenty/kategorii/TV/gatunku/Kryminalny]TV / Kryminalny[/url] .
???????????? ?????? ??? ?????
Download: [url=http://atfineline.com/Softwares.html]Softwares[/url] .
Hacksaw Ridge 2016 HDCAM x264 AC3-TuttyFruity
Download: [url=http://choidanhde.com/news/8644/fiche-membre/Ti-Keuss.html]Ti-Keuss</u>[/url] .
Tinashe Chikuse
Download: [url=http://188maxpoker.net/descargar/peliculas-x264-mkv/en-la-sombra-/bluray-microhd/]En La Sombra BluRay MicroHD[/url] .
Jetbrains Webstorm V9 0 139 252 Incl Key.torrent
Download: [url=http://jewellerymoscow.com/tor-907-Punnami-Ratri-2016-Telugu-DVDRip-Torrent-Download-Full-Movie-HD]Punnami Ratri[/url] .
Aguanile Willie Colon Hector Lavoe
Download: [url=http://u2candothis.com/film/1-000-times-good-night-2013-1080p/]1,000 Times Good Night (2013)[/url] .
Ray Donovan S04E06 Fish and Bird (2013)
Download: [url=http://bahisyap24.com/watch/?sort=rating]Top Rating (on our site)[/url] .
Poland / UK
Download: [url=http://092464.com/movie/view/upgrade/2018]7.7 / 10Action HorrorView Details[/url] .
Read More
Download: [url=http://higherbyhayyaali.com/series-hd/etiquetadas/3802]Etiquetadas HDTV 720p AC3 5.1[/url] .
Cosmid 16 11 17 Terri Fletcher XXX 720p MP4 KTR
Download: [url=http://ameritrope.com/diziler/witches-of-east-end/]• Witches of East End 6.7[/url] .
Funk Soul Productions Vintage Strings KONTAKT
Download: [url=http://breast-implants-surgery.com/xxx-return-of-xander-cage/]Bluray 5.2 xXx: Return of Xander Cage (2017)[/url] .
Life Below Zero S08E04 Head Above Water 720p HDTV x264-DHD[ettv]
Download: [url=http://gelsinkapina.com/results?search=indie+film+trailers]indie film trailers[/url] .
Read More
Download: [url=http://higherbyhayyaali.com/series/perdidos-en-el-espacio/3835]Perdidos En El Espacio HDTV[/url] .
Hearts of Iron IV [2016 MAC OS GAME]
Download: [url=http://allmattersbookkeeping.com/serie/Date-My-Dad]Date My Dad[/url] .
future plastic bag future
Download: [url=http://michelewetteland.com/movies/animal-world/]Watch movie[/url] .
orphan black
Download: [url=http://takeprize-snow.com/watch-party-full-movie-online-free-10988.html]Party (2018)[/url] .
Stacey On the Frontline Girls, Guns and ISIS BigJ0554
Download: [url=http://aliciagriffithblades.com/films/films-bluray-hd/films-bluray-1080p/157088-it-came-from-the-desert.html]It Came From the Desert [BLURAY 1080p][/url] .
Internet Download Manager (IDM) v 6 26 Build 10 + Patch [4realtorrentz] zip
Download: [url=http://germanybets.com/finding-dory-2016-hdts-x264-dual-audio-english-hindi-downloadhub-t12879761.html]Finding Dory (2016) HDTS x264 [Dual-Audio] [English + Hindi] - Downloadhub[/url] .
Wildfire
Download: [url=http://polosoreading.info/films-avec-reese-witherspoon]Reese Witherspoon[/url] .
???(11)
Download: [url=http://joelcam.com/torrent/65rb4/н™”лЃ€н•њл…Ђ.html]н™”лЃ€н•њл…Ђ[/url] .
Most Active
Download: [url=http://wendyalper.org/torrent/7088863/master-editor-5-0-03.html]Master PDF Editor 5 0 03[/url] .
Assassin s Creed - The Best Of Jesper Kyd (2016) Score YG [Isohunt.to]
Download: [url=http://katapagi.com/actors/Don+Haggerty.html]Don Haggerty[/url] .
Hitman Pro 3 7 14 Build 265 + Patch [4realtorrentz] zip
Download: [url=http://make-me-millionare.com/tvshows/silicon-valley/]Silicon Valley[/url] .
IObit Uninstaller Pro [Isohunt.to]
Download: [url=http://healthyweightlossbn.net/torrent/04a685c7d9adf90aaa78b22ce588b02cc6a754c5]Eureka Saison 2 Episode 2 french[/url] .
Toni Hudson,
Download: [url=http://sontuoiorganic.org/category/space/ http://itunes.apple.com/app/id454936656]View PDF on Apple iOS[/url] .
Blues/Rock
Download: [url=http://allmattersbookkeeping.com/serie/You-Me-and-the-Apocalypse]You, Me and the Apocalypse[/url] .
Stephen King - Under the Dome (PDFEPUBMOBI)
Download: [url=http://bbdesignsstylestudio.com/series-hd/felix/3814]Felix HDTV 720p AC3 5.1[/url] .
Brooklyn Nine-Nine S04E06 720p HDTV x264-FLEET[PRiME]
Download: [url=http://ffdd77.com/ready-player-one-movie-free-download-hd-fm10/]Ready Player One Movie Free Download HD Download Ready Player One in HD (1.3 GB)↓ Ready Player One Movie Free Download HD .When the architect of a basic absoluteness apple alleged the OASIS dies, he releases a video in which he challenges all OASIS users to acquisition his Easter Egg, which will accord the finder his fortune.In the year 2045, the absolute apple is a acrid place. The ...[/url] .
Drunk History
Download: [url=http://vleugels-heart.com/torrent/laf89i1k/EveryHolesAGoGo+Amateur+Asian+GoGo+Girls+Fucked+Nancy+XXX.html]EveryHolesAGoGo Amateur Asian GoGo Girls Fucked Nancy XXX[/url] .
Massive 54000 Presets [dada](3)
Download: [url=http://allmattersbookkeeping.com/vorgeschlagene-serien/vote:13447]Ozean Girl - Prinzessin der Meere[/url] .
Bush Master
Download: [url=http://inibaru.info/forumdisplay.php?1990-Ab-Kar-Meri-Rafugari&s=e856f686cd253f276d96080b07afe30c]Ab Kar Meri Rafugari[/url] .
GTA Vice City - game MAC
Download: [url=http://americanracercup.com/browse/tv/crime/]Криминал[/url] .
Internet Download Manager (IDM) 6 26 Build 10 Multilingual + Patch (Safe) [Sa...
Download: [url=http://swmimindication.info/films-en-streaming-1/1-1-1-38.html]Biographie[/url] .
Silence on vaccine - DVD - French(A)
Download: [url=http://yjj0736.com/category/paranormal-fantasy]Paranormal Fantasy (1752)[/url] .
Alban Berg Collection DG MP3
Download: [url=http://batxe.info/magazine/2476-australian-handyman-april-2012-hq-pdf.html]Australian Handyman April 2012 HQ PDF[/url] .
David Baldacci - Deliver Us From Evil
Download: [url=http://rajcomputer.org/torrent/12205220/microsoft-office-professional-plus-x86-x64.html]MICROSOFT OFFICE PROFESSIONAL PLUS 2010 X86 X64[/url] .
Mr Right 2015 mp4
Download: [url=http://medicdom.com/posts/5372/]DPI - Cung cấp thiết bị an ninh cho ngôi nhà của bạn[/url] .
Vellaiya Irukiravan Poi Solla Maatan (2015) DVDRip
Download: [url=http://persia4pays.com/films/acteur/christian-slater.html]Christian Slater[/url] .
Baixar Cafe Society 1080p Torrent
Download: [url=http://588v2.info/actors/James+Philbrook.html]James Philbrook[/url] .
[AnimeRG] Nanbaka - 07 [Multi-Sub] [x265] [720p] [pseudo]
Download: [url=http://gelsinkapina.com/results?search=movie+trailer+thief]Movie Trailer thief[/url] .
Dragon Ball Super Episode 51
Download: [url=http://vleugels-heart.com/torrent/l75vcw6n/Shock+Factor+by+Gunnery+Sgt.+Jack+Coughlin,+John+R.+Bruning+EPUB.html]Shock Factor by Gunnery Sgt. Jack Coughlin, John R. Bruning EPUB[/url] .
MEYD-202 mp4
Download: [url=http://lipsterworld.com/home/contact]Contact Us/Report Broken[/url] .
Giphelele Umaginawe
Download: [url=http://theathleisure.net/serie/Tannbach-Schicksal-eines-Dorfes]Tannbach – Schicksal eines Dorfes[/url] .
Floda Rnb
Download: [url=http://le7774.com/movie/256474/In-the-Blood-2014/]In the Blood[/url] .
Native Instruments - Reaktor 6 v6 0 3 + Form v1 0 0 OS X [dada](1)
Download: [url=http://betbarca5.com/engine/go.php?movie=Gatao-2:-Rise-of-the-King.2018.1080p.BRRIP.x264.AAC.mp4]Gatao-2:-Rise-of-the-King.2018.1080p.BRRIP.x264.AAC.mp4[/url] .
Once Upon A Time in Wonderland
Download: [url=http://katapagi.com/actors/Peter+Schwarz.html]Peter Schwarz[/url] .
Ke$ha: My Crazy Beautiful Life
Download: [url=http://angkaceria.net/khong-ga-cho-tong-tai-ga-cho-nguoi-hau-chap-118-5/]Chap 118.5[/url] .
a?sa??a??a??
Download: [url=http://tug420.com/series/wentworth/]Watch Series[/url] .
Robbie Coltrane's Critical Evidence - 01 - Dead Man's Hollow - FC
Download: [url=http://nc01s.net/t3-3176691/Satyameva-Jayate-2018-Hindi-720p-PRE-DVDRip-x264-AAC-TaRa-mkv-torrent.html]Satyameva Jayate 2018 Hindi 720p PRE-DVDRip x264 AAC TaRa .mkv[/url] .
Practice Tests Plus cd
Download: [url=http://mydentalpracticemarketing.com/drama-detail/duel-korean-drama]Duel (Korean Drama)[/url] .
Wayward Pines
Download: [url=http://bammada.net/mybook/]マイリスト[/url] .
Alberto Camerini - The Best Of
Download: [url=http://sbt90s.net/viewtopic.php?f=278&t=222170&p=726333&sid=07c31df46f6320e40bd04f9fe7c37d18]23 led 2011 19:04[/url] .
Captain America the Winter Soldier 2014 DVDRip Xvid-FooKaS
Download: [url=http://qsmvba.com/?p=films&search=Romain Duris]Romain Duris[/url] .
Jason.Bourne.2016.BRRip.XviD-ETRG
Download: [url=http://cheapmusicaltickets.com/actors/Delpaneaux+Wills.html]Delpaneaux Wills[/url] .
Сезон 1 БГ СУБТИТРИ
Download: [url=http://michelewetteland.com/movies/fight-like-a-girl-2/]Watch movie[/url] .
Fact or Faked Paranormal Files
Download: [url=http://dixonhistoriccenter.org/all/ericsennwondersofnaturebtsr143web2016ukhx-t3409112.html]Eric_Senn-Wonders_Of_Nature-(BTSR143)-WEB-2016-UKHx[/url] .
METAL GEAR SOLID V THE PHANTOM PAIN RePack - SEYTER
Download: [url=http://goldenvalleylendingloan.com/tv/fUA/Caribbean-Pirate-Treasure-Season-2]IMDb: 7.2 S2E7 Caribbean Pirate Treasure - Season 2[/url] .
Paul Dano,
Download: [url=http://cheapmusicaltickets.com/actors/Richard+Mulligan.html]Richard Mulligan[/url] .
The walking dead
Download: [url=http://90dakika28.com/Unity-5-x-Animation-Cookbook_3685114.html]Unity 5.x Animation Cookbook[/url] .
The Phantom Of The Opera - Hammer Horror 1962 Eng Subs 1080p [H264-mp4]
Download: [url=http://dokuzbet8.com/pelicula/the-most-unknown/]Cancelar respuesta[/url] .
AUTODESK.REVIT.V2015.WIN64-ISO - [MUMBAI-TPB]
Download: [url=http://jewellerymoscow.com/tor-2992-Osiris-2016-FRENCH-BDRip-XviD-Torrent-Download-Full-Movie-HD]Osiris 2016[/url] .
None Working? Use Magnet
Download: [url=http://mydentalpracticemarketing.com/drama-detail/intruders]Intruders[/url] .
Brigitte Kaandorp - 1998 - ...En Vliegwerk [Isohunt.to]
Download: [url=http://588v2.info/actors/Szabolcs+CsГЎk.html]Szabolcs CsГЎk[/url] .
Watch Online
Download: [url=http://fairysfactory.com/rendel-2/]Regarder Le Film[/url] .
CAPTAIN AMERICA
Download: [url=http://kko-gr.com/maryline-french-dvdrip-2018.html]Maryline FRENCH DVDRIP 2018[/url] .
vshare.eu
Download: [url=http://jandptees.com/killing-joan-2018]Killing Joan (2018)[/url] .
The.Walking.Dead.S07E02.VOSTFR.WEB-DL.x264-ARK01(A)
Download: [url=http://inibaru.info/forumdisplay.php?2359-Super-Dancer-Chapter-2&s=e856f686cd253f276d96080b07afe30c]Super Dancer Chapter 2[/url] .
The Wild
Download: [url=http://securestatravel.info/engine/go.php?movie=Disclaimer - eMule-Island !]Boutique[/url] .
Regolamento
Download: [url=http://natcc.net/395814/Frostpunk-CODEX.html]Frostpunk[/url] .
Inna Evlannikova,
Download: [url=http://kolaybet15.com/film/fLc/Game-Over,-Man!]During a star-studded Los Angeles party, three zeroes become heroes (sort of) when the hotel they work at is taken hostage by...[/url] .
Grey’s Anatomy 13? Temporada Legendado Torrent – HDTV | 720p (2016)
Download: [url=http://batxe.info/template/660757-creativemarket-creative-presentation-kit-bundle.html]Comments: 0[/url] .
TeensAnalyzed 15 02 02 Analingus And Hard Fucking XXX 1080P WMV-GUSH[rarbg]
Download: [url=http://bubblylight.com/tactik-saison-2-episode-4-308721.htm]Tactik saison 2 Г©pisode 4[/url] .
Logan Kibens,
Download: [url=http://keygen-crack.com/descargar-pelicula/geostorm-3d/bluray-1080p/]Geostorm 3D BluRay 1080p[/url] .
The Flash 2014 S03E06 HDTV XviD-FUM[ettv]
Download: [url=http://kichipoo.com/ar/Щ…ШґШ§Щ‡ШЇШ©-condor-season-1-ЩѓШ§Щ…Щ„-Ш§Щ€Щ†Щ„Ш§ЩЉЩ†/]Condor – Ш§Щ„Щ…Щ€ШіЩ… Ш§Щ„Ш§Щ€Щ„[/url] .
Voir ici
Download: [url=http://myemeraldcitycharacter.com/Ruby-Cookbook-Recipes-for-Object-Oriented-Scripting_3593027.html]Ruby Cookbook; Recipes for Object-Oriented Scripting[/url] .
Marvel's Agents of Shield S01E04 VOSTFR HDTV x264-BRN [KskS] mp4
Download: [url=http://americanracercup.com/indu-sarkar-2017-1080p-web-dl-avc-aac-2-0-dtone-exclusive-wujl0.html]Indu Sarkar 2017 1080p WEB-DL AVC AAC 2 0-DTOne ExCluSive 39 minutes[/url] .
DVDFab v9 3 1 6 Final Setup + Patch zip
Download: [url=http://thequeenlace.com/chapter/kannou_sensei/chapter_13]Chapter 13[/url] .
En lire plus
Download: [url=http://troonent.com/in/the-last-survivor-stay-alive/com.skynet.ak/download?from=home%2Fhot]डाउनलोड XAPK[/url] .
Aunque Tu Ni Me Lo Creas Intocable
Download: [url=http://omidexchange.com/films/motorrad/]Motorrad[/url] .
The Salt of the Earth 2014 HD ????? ????? 8.4
Download: [url=http://ericre.com/show/fear-the-walking-dead]Watch show[/url] .
Captain.America.the.Winter.Soldier.2014.720p.BRRip.XviD.AC3-DEVi
Download: [url=http://tepsidenborek.com/movie/3410834-allegiant]57% Allegiant[/url] .
Bikini Sex Dolls mp4
Download: [url=http://ozbrick.com/movies/734292-escape-plan-2013-1080p-brrip-x264-aac-fragment.html]Escape Plan (2013) 1080p BRRip x264 AAC-FRAGMENT[/url] .
SQL Bible
Download: [url=http://myspotlesscleaning.net/drama-detail/project-x]PROJECT X[/url] .
? ?? ??.E181.161111.720p-NEXT
Download: [url=http://blog4spot.com/seriale-online/2168428-Killjoys/seasons/4]Online Killjoys Sezonul - 4[/url] .
[Amateur] After class mp4
Download: [url=http://5ufg.com/watch/ox1wpPdN-escape-plan-2-hades.html]Escape Plan 2: ...[/url] .
The 7th Dwarf 2014 HD ????? ????? 4.7
Download: [url=http://brawnycats.com/State-of-Mind-CODEX-torrent-11249615.html]State of Mind-CODEX[/url] .
One Tree Hill
Download: [url=http://myspotlesscleaning.net/drama-detail/tsuma-to-tonda-tokkouhei-sp]Tsuma To Tonda Tokkouhei SP[/url] .
Private Eyes
Download: [url=http://py2888.com/descargar-rapido-y-furioso-8-latino.html]Rapido y Furioso 8[/url] .
American Dad S13E02 XviD-AFG TV Shows
Download: [url=http://thequeenlace.com/chapter/peerless_dad/chapter_16]Chapter 16[/url] .
Witches of East End
Download: [url=http://allmattersbookkeeping.com/serie/Space-2063]Space 2063[/url] .
Central Intelligence (2016) BDRip (CAM Audio)
Download: [url=http://amanicraft.com/descargar-la-bruja-latino.html]La Bruja[/url] .
Rocketship Patrol
Download: [url=http://bettymooregames.com/Einsteckkarten-Steckkarten-mit-Folie-A6-4-Streifen-100-253437204650.html]Einsteckkarten Steckkarten mit Folie A6 4 Streifen 100 StГјck schwarzer Karton[/url] .
Site Map
Download: [url=http://codewaregames.com/les-sales-blagues-de-l-echo-streaming-gratuit-R4IE20CI.html]Les Sales Blagues de L'Echo[/url] .
Strike Suit Zero
Download: [url=http://forum.juracka.info/a39.html]Hardware-Tuning[/url] .
Alicia Vikander,
Download: [url=http://fittest.org/movie/447200/]Skyscraper Full[/url] .
2 de outubro de 2016
Download: [url=http://voicheria62.net/%d9%85%d8%b3%d9%84%d8%b3%d9%84-our-girl-%d8%a7%d9%84%d9%85%d9%88%d8%b3%d9%85-%d8%a7%d9%84%d8%a7%d9%88%d9%84-%d8%a7%d9%84%d8%ad%d9%84%d9%82%d8%a9-1/]ШЩ„Щ‚Ш© 1 Щ…ШіЩ„ШіЩ„ Our Girl Ш§Щ„Щ…Щ€ШіЩ… Ш§Щ„Ш§Щ€Щ„ Ш§Щ„ШЩ„Щ‚Ш© 1 2018 HDTv Щ…ШіЩ„ШіЩ„ Our Girl Ш§Щ„Щ…Щ€ШіЩ… Ш§Щ„Ш§Щ€Щ„ Ш§Щ„ШЩ„Щ‚Ш© 1 ШШ±Щ€ШЁ Щ…ШґШ§Щ‡ШЇШ© Щ€ШЄШЩ…ЩЉЩ„ Щ…ШіЩ„ШіЩ„ Ш§Щ„ШЇШ±Ш§Щ…Ш§ Щ€Ш§Щ„ШШ±ШЁ Our Girl S01 HD Ш§Щ„Щ…Щ€ШіЩ… Ш§Щ„Ш§Щ€Щ„ Щ…ШЄШ±Ш¬Щ… Ш§Щ€Щ† Щ„Ш§ЩЉЩ† Щ€ШЄШЩ…ЩЉЩ„ Щ…ШЁШ§ШґШ±[/url] .
Nintendo DS Roms 1201 - 1300 Complete[English Only]
Download: [url=http://sheffieldescorts.net/diziler/a-gifted-man/]A Gifted Man[/url] .
??v
Download: [url=http://beautyandtheleaf.com/watch-extortion-2017-online-free-putlocker-llg-224.html]HDCam Extortion (2017)[/url] .
Arturia - Synclavier V v1.0.4.1109 macOS [dada] [Isohunt.to]
Download: [url=http://graceisbeauty.com/l-univers-streaming-gratuit-4X5VS5DI.html]L'Univers[/url] .
StudioLinkedVST Universe Pads 160905
Download: [url=http://heavenlydesignsbybrittany.com/movies/deadpool-2-fmovie-hd/]Deadpool 2[/url] .
The Walking Dead
Download: [url=http://stampbachstein.com/prod/B07CSZ3YJG.html]Edelstahl Wandleuchte aussen mit Bewegungsmelder &[/url] .
The Purge 3: Election Year Ganzer Film Deutsch
Download: [url=http://yabet29.com/bbc/coming-of-age/]Coming of Age[/url] .
Younger S03E08 iNTERNAL 720p HDTV x264-ALTEREGO[PRiME]
Download: [url=http://colemanautomotive.us/a-d-the-bible-continues-1/]A.D. The Bible Continues[/url] .
X Angels Stasya Stoune Teens play crazy sex games mp4
Download: [url=http://lucky-diets.com/movie/the-secret-life-of-walter-mitty/]The Secret Life of Walter Mitty[/url] .
TheLifeErotic.16.10.25.Mina.K.My.Reflection.XXX.1080p.MP4
Download: [url=http://shopysb.com/ep/681235/elementary-s05e13-hdtv-x264-lol/]Elementary S05E13 HDTV x264-LOL [eztv][/url] .
Detective Comics
Download: [url=http://hangrygaminggear.com/series/regarder/1354-snowfall-saison-1-episode-9-streaming.html]Episode 9[/url] .
The 11th Hour with Brian Williams 2016 11 16 720p WEBRip x264-LM
Download: [url=http://melodytv.info/stan-evil-season-1-download-all-episodes]Stan Against Evil season 1[/url] .
[Brazzers] Gaining Cuntsody - Mackenzee Pierce
Download: [url=http://usonlineradio.com/tor-1755-ChickLit-2016-Movies-BRRip-XviD-AAC-New-Source-with-Sample-Torrent-Download-Full-Movie-HD]ChickLit[/url] .
Continuar
Download: [url=http://beerpong.tv/playing-house-1-l]Playing house[/url] .
Software for Android
Download: [url=http://bahiseviyenigiris.com/ver/la-bella-y-las-bestias-1x50.html]1x50 La Bella y las Bestias[/url] .
Sanju Sahai The Benares Touch (2003) [FLAC]
Download: [url=http://daipeibao.com/country/american-samoa.html]American Samoa[/url] .
Apple Service Diagnostics 3S143
Download: [url=http://ik-ki.tk/genrelist_rental.php/18-spielfilm-628.html?search_title=&tab_search_content=movies&view=0&search_countries[10]=10]Australien[/url] .
The History Channel
Download: [url=http://juracka.info/dyson-cyclone-v10-absolute-226397-01-a1784567.html]Dyson Cyclone V10 Absolute[/url] .
Rabid Dogs 2015 HD ????? ????? 5.2
Download: [url=http://bxvn.com/results?search=full+tv+series+rare]Full TV Series rare[/url] .
Les Chevaux de Dieu - Horses of God 2012 PAL MULTI...(A)
Download: [url=http://yasidengfs.com/posts/artefotografia/33904/Una-Imagen-para-Dracula-Mega-Crap.html]Una Imagen para Dracula Mega Crap[/url] .
True.Memoirs.of.an.International.Assassin.2016.HDRip.XviD.AC3-EV
Download: [url=http://jiaziy.com/serie/killjoys/temporada-1.html]Temporada 1[/url] .
Cemetery of Splendour2016
Download: [url=http://horseregister.net/watch/Frankenstein-online-free-full-movie-10518.html](2038) Trailer Frankenstein[/url] .
Svensk Premiar - Rumpklubben XXX WebGift
Download: [url=http://tikzi.com/movies/mission-8-from-the-first-idea-to-the-first-race/]Mission 8 – From The First Idea To The First Race[/url] .
One Tree Hill S09E10 720p HDTV x264-IMMERSE
Download: [url=http://scwrgs.com/category/surviving-jack/]Surviving Jack[/url] .
Dishonored 2 MAC[SOFT]
Download: [url=http://vivekangen.com/release-year/2010/]Movies 2010[/url] .
Jason Bourne 2016 DVDRip XviD AC3-iFT[PRiME]
Download: [url=http://hangrygaminggear.com/series/regarder/523-austin-et-ally-streaming.html]Austin et Ally[/url] .
300 (2006) Dual Audio 300MB Hindi Eng Full Movie BRRip 480p
Download: [url=http://biblicallylogicalthinking.org/kinderspiele-puzzles/]Kinderspiele Puzzles[/url] .
Rollercoaster Tycoon World -2016-pc-REPACK
Download: [url=http://ecurielespeupliers38.com/movies/the-guardian-angel/]The Guardian Angel[/url] .
WWE Hell In A Cell (2016) Full Show Downlod In 300MB
Download: [url=http://daico3.org/filme/dirty-dancing/]Dirty Dancing[/url] .
Cardboard Boxer 2016 720p BRRip 650 MB - iExTV
Download: [url=http://skatuary.com/movie/1017058143/mission-impossible-rogue-nation]Mission: Impossible - Rogue Nation[/url] .
Good Kid, M.a.a.d City By Kendrick Lamar
Download: [url=http://bmw686.net/prod/B004E0GHCM.html]Dora - Entdecke die Welt[/url] .
Undeniable
Download: [url=http://claymorepool.com/The-Dark-Knight-2011-torrent-2089]The Dark Knight (2011)[/url] .
50 Cent Vs Lil Mo
Download: [url=http://endlessfinancialservices.com/index.php?page=Rules&s=e6341490f8e61b32654ebb3527de358ef523c5de]Nutzungsbestimmungen[/url] .
American Horror Story S06E10 PROPER 720p HDTV x264-KILLERS[ettv]
Download: [url=http://advancednrgsolutions.com/category/yo-tonya-2017/]Yo Tonya (2017)[/url] .
reading comprehension and questions
Download: [url=http://newroundll.com/687-die-unglaublichen.html]Die Unglaublichen[/url] .
The Blacklist S04E06 720p HDTV x264 KILLERS[ettv]
Download: [url=http://hairbynina.net/tv-programm/unter-unserem-himmel/sommer-in-den-nockbergen/bid_131487657/]Unter unserem Himmel[/url] .
Aimersoft DVD Ripper
Download: [url=http://daico3.org/filme/jason-bourne/]Jason Bourne[/url] .
Spectrasonics - Omnisphere 2 v2 3 0h UPDATE OS X [dada](1)
Download: [url=http://nordicbrazilianfintechhub.com/showthread.php?tid=7626&action=lastpost]TOKEN RESETTER Video inst...[/url] .
Action Comics (New 52)
Download: [url=http://vc2008.net/actors/Meghan+Markle.html]Meghan Markle[/url] .
the heart of the matter graham greene pdf
Download: [url=http://aetuan.com/release/various-artists-aadimaya-ambabai/9663984]Various ArtistsAadimaya Ambabai Spiritual[/url] .
Amber Midthunder
Download: [url=http://mmadmen.com/movie/11214-batman-the-dark-knight-returns-part-2-2013-yify-torrent]Batman: The Dark Knight Returns, Part 2[/url] .
Alannah Myles - Alannah Myles
Download: [url=http://homesbycarranza.com/memberlist.php?mode=viewprofile&u=988432&sid=9d86bc8c094aa50a171524170bd1222c]scottmcsloy1971[/url] .
Dishonored 2 (2016) ENG PC GAME REPACK
Download: [url=http://vtclassic.com/all/search/geeta+govimdam/]geeta govimdam[/url] .
16/03/18
Download: [url=http://danstoko.com/02200414-science-adventures-connect-may-2018/]Science Adventures Connect – May 2018[/url] .
Oasis Supersonic 2016 720p BRRip x264 AAC-ETRG
Download: [url=http://zeansport.com/watch/beat-bugs-2.nr0zj]Eps13 Beat Bugs 2[/url] .
view all
Download: [url=http://subletnj.com/dark-angel/]Dark Angel[/url] .
Create Realistic Rippling 3D Organic Sphere in After Effects
Download: [url=http://lenyosys.be/tv-star/julie-andrews]Julie Andrews[/url] .
The Ultimate Guide to Urban Farming - Sustainable Living in Your Home, Commun...
Download: [url=http://danstoko.com/02181421-car-and-driver-usa-september-2018/]Car and Driver USA – September 2018[/url] .
500 Questions
Download: [url=http://discreetwhispers.com/article/2018/tony-awards-2018-susan-haskins-theater-talk-tops-all-experts-predicting-winners/]Tony Awards 2018: Susan Haskins (Theater Talk) tops all Experts predictingwinners[/url] .
El hogar de Miss Peregrine para ninos peculiares
Download: [url=http://trattoriadelporto.com/episodes/are-you-the-one-season-7-episode-2-s7e2/]7x2 season x episode Are You The One?[/url] .
[AnimeRG] Okusama ga Seito Kaichou! - [01-12] [720p BD 10bit Uncensored] [JRR]
Download: [url=http://bluelinelawncare.net/watch/condor-s01-online.html]Watch movie[/url] .
For last day only
Download: [url=http://b-finance.com/actors/Britt+Ahart.html]Britt Ahart[/url] .
microelectronic circuits 7th edition pdf
Download: [url=http://vegusvip.com/results?search=full+tv+series+genesis]Full TV Series genesis[/url] .
child porn
Download: [url=http://smallfrychrissie.com/serie/stream/love]Love Comedy[/url] .
R.O.D Complete Series + OVA's (Dual-Audio)
Download: [url=http://sncxdz.com/kompatibler-toner-zu-brother-tn-320bk-schwarz-a881208.html]Kompatibler Toner zu Brother TN-320BK schwarz[/url] .
Blood Father (2016) Movie Download / Online In 300MB
Download: [url=http://symbiose.info/dark-crimes/]Regarder Le Film[/url] .
[Tompel Fansub]_ Beyblade Burst - 27.mkv
Download: [url=http://scarmasterflex.com/the-blacklist]The Blacklist[/url] .
Ryan Guzman
Download: [url=http://doubleer.info/torrents/homo sexians]homo sexians[/url] .
66 Katrina Kaif Hot And Sexy Pictures
Download: [url=http://y2kakao.com/watch/survivor-35.378xy]Eps14 Survivor 35[/url] .
Paste 1.1 for MAC OSx
Download: [url=http://aogwa.com.au/tv/1073/]Prison Break[/url] .
Apple Compressor 4 2 1 [Ked by TNT] YS4
Download: [url=http://zenamane.com/films/95462-telecharger-spider-man-homecoming.html]TГ©lГ©charger Spider-Man: Homecoming[/url] .
Photos -- Car Service Set 64
Download: [url=http://homeschoolingmeetups.com/bachelor-in-paradise-s05e02/]Bachelor in paradise s05e02[/url] .
Alan Parsons Project - Eye In The Sky-TZilla
Download: [url=http://jordanszoo.com/rimbocchiamoci-le-maniche/]Rimbocchiamoci le Maniche[/url] .
Pluralsight - Scaling SQL Server 2012 - Part 1
Download: [url=http://softwaremahasiswa.com/memberlist.php?mode=viewprofile&u=87904&sid=c459f4a8db95c9a851949ba4e351bda1]_-_MASTERMAN_-_[/url] .
The Elder Scrolls V Skyrim SE Update v1 2 Official Sound Fix-KaOS
Download: [url=http://mariobet270.com/ratings/?get=tv]Ш§Щ„ШЈЩѓШ«Ш± ШЄЩ‚ЩЉЩЉЩ…Ш§[/url] .
APES.REVOLUTION.Il.pianeta.delle.scimmie.Movie.ITALIA.2014.BluRay-1080p.x264-MAXSPEED
Download: [url=http://ps-ambrosia.com/259408A2ACDADE784BC16B6CB4C20606E0C94CFC/Apple-Final-Cut-Pro-X-10-4-1-Mac-OS-X]Apple Final Cut Pro X 10 4 1 Mac OS X[/url] .
now you see me 2 720p
Download: [url=http://redwopchemicals.com/series/reupload/736-hercule-poirot-saison-1.html]Hercule Poirot - Saison 01 en français[/url] .
DEAD CAN DANCE 2003 - 2013 FLAC + DSD128 [elladajarek]
Download: [url=http://558558.com/category/supergirl/]Supergirl[/url] .
Jason bourne 2016 720p bluray x264-NBY-[moviezplanet in] mkv
Download: [url=http://b-finance.com/actors/Kelsey+Asbille.html]Kelsey Asbille[/url] .
Toumani Diabate - Djelika (1995)[FLAC]
Download: [url=http://rubeeexchange.com/audio/audio/unsortiert/363534-va-techno_culture_1-music422-web-2018-enslave]05.06.1811:36 Uhr VA - Techno Culture 1 House320 kbit/s 0 / 01.536 Hits VID P2P DDL 0 Kommentare[/url] .
September
Download: [url=http://vegusvip.com/results?search=full+tv+series+streaming+tv]Full TV Series streaming tv[/url] .
Kubo and the Two Strings
Download: [url=http://propertypeer.com/itsalwayssunnyinphiladelphia/244-staffel-5.html]It's Always Sunny in Philadelphia Staffel 5 Episode 13[/url] .
Watch Dogs 2-Complete Collection PC Game 2016-Full Version With Crack-RELOADED
Download: [url=http://naijablinks.com/movies/68-valerian-and-the-city-of-a-thousand-planets]Valerian and the City of a Thousand Planets[/url] .
The Core 2003 HD ????? ????? 5.4
Download: [url=http://codewaregames.com/les-nouveaux-visages-de-la-prostitution-streaming-gratuit-0Z5G8Y90S.html]Les Nouveaux visages de la prostitution[/url] .
Boston Legal
Download: [url=http://whiteteeth-tcsw.com/breaking-bad/fotogalerien/]Fotogalerien[/url] .
Last Comic Standing
Download: [url=http://sanlidan.com/02174422-wine-spectator-august-31-2018/]Wine Spectator – August 31, 2018[/url] .
Next Page
Download: [url=http://magicmetzgers.com/hbo/sex-and-the-city/]Sex and the City[/url] .
Online TV shows - PC to TV pdf
Download: [url=http://extrememobilemechanics.net/ver/the-100-5x13.html]5x13 Los 100[/url] .
Petes Dragon 2016 720p BluRay x264 DTS-iFT[EtHD]
Download: [url=http://chamberlainforgovernor.com/diziler/game-of-thrones-turkce-dublaj-izle/]Game of Thrones (Türkçe)[/url] .
game of thrones s04e07
Download: [url=http://onlinejobshour.tk/%d8%a7%d9%86%d9%85%d9%8a-boku-no-hero-academia-%d8%a7%d9%84%d9%85%d9%88%d8%b3%d9%85-%d8%a7%d9%84%d8%ab%d8%a7%d9%84%d8%ab-%d8%a7%d9%84%d8%ad%d9%84%d9%82%d8%a9-18/]ШЩ„Щ‚Ш© 18 Ш§Щ†Щ…ЩЉ Boku no Hero Academia Ш§Щ„Щ…Щ€ШіЩ… Ш§Щ„Ш«Ш§Щ„Ш« Ш§Щ„ШЩ„Щ‚Ш© 18 2018 HDTv Ш§Щ†Щ…ЩЉ Boku no Hero Academia Ш§Щ„Щ…Щ€ШіЩ… Ш§Щ„Ш«Ш§Щ„Ш« Ш§Щ„ШЩ„Щ‚Ш© 18 Ш§Щ†ЩЉЩ…ЩЉШґЩ† Щ…ШґШ§Щ‡ШЇШ© Щ€ШЄШЩ…ЩЉЩ„ Щ…ШіЩ„ШіЩ„ Ш§Щ†Щ…ЩЉ ШЁЩ€ЩѓЩ€ Щ†Щ€ Щ‡ЩЉШ±Щ€ Ш§ЩѓШ§ШЇЩЉЩ…ЩЉВ Ш§Щ„Ш¬ШІШЎ Ш§Щ„Ш«Ш§Щ„Ш« Boku no Hero Academia 3nd Season ШЈЩѓШ§ШЇЩЉЩ…ЩЉШЄЩЉ Щ„Щ„ШЈШЁШ·Ш§Щ„ Щ…ШЄШ±Ш¬Щ… Ш§Щ„Щ…Щ€ШіЩ… Ш§Щ„Ш«Ш§Щ„Ш«...[/url] .
Prison Break
Download: [url=http://hello2441139.com/films/acteur/zhang-ziyi.html]Zhang Ziyi[/url] .
The Adventures of Sherlock Holmes
Download: [url=http://mekongheritage.net/ver/el-marginal-2x02.html]2x02 El marginal[/url] .
Time To Say Goodbye Jeff Williams Lyrics Rwby Volume 2 Opening Song
Download: [url=http://politiclub.info/person/hiroshi_kasuga_ii_.html]Hiroshi Kasuga (II)[/url] .
Jonah Hill,
Download: [url=http://mariobet270.com/movie/the-meg-2018/]The Meg 2018[/url] .
Ash.vs.Evil.Dead.S02.Jetvis.S...
Download: [url=http://locate-path.com/actors/Will+Chase.html]Will Chase[/url] .
BitLord.com
Download: [url=http://monster777.com/descargar-torrents-variados-1834-QuarkXPress-2015-v110.html]QuarkXPress 2015 v11.0.[/url] .
[Ctrl-ZnF]Naruto Shippuuden 322 [720p x264+AAC].mp4
Download: [url=http://twitter.com/intent/tweet?text=Schriften&url=https%3A%2F%2Fmanicureiniciante.com%2Fschriften%2F]Auf Twitter teilen[/url] .
Watch This Link!
Download: [url=http://vivaesthetique.com/travis-scott-carousel/]Travis Scott – CAROUSEL Mp3 Download[/url] .
Adobe Creative Cloud 2017 Master Collection + Crack
Download: [url=http://takezou-musashi.com/actors/Vilma+SzГ©csi.html]Vilma SzГ©csi[/url] .
Alan Jackson - High Mileage
Download: [url=http://softwaremahasiswa.com/memberlist.php?mode=viewprofile&u=63588&sid=34fd30db9c098a2af701bd385855c353]peter2008[/url] .
Tom Six,
Download: [url=http://zhiyuankang.net/watch/actor/RHJldyBTdGFya2V5.html]Drew Starkey[/url] .
insecure
Download: [url=http://yimeijiahua.com/release/bison-friendly-taking-a-break-beet-single/9526507]Bison FriendlyTaking a Break Beet - Single Electronic, Breakbeat/Breaks, Dance[/url] .
[AnimeRG] JOKER - 46 [720p] [ReleaseBitch] - 2016-11-14
Download: [url=http://artsylvain.com/watch/freemovies/taxi-5-2018/]Taxi 5 2018 2018 HD[/url] .
[E traSmall TeamSkeet]Morgan Lee - Tiny Hands Solve Big Problems(NEW***17 11 2..
Download: [url=http://btcfriend.org/ver/violet-evergarden-1x12.html]1x12 Violet Evergarden[/url] .
Tess Cline
Download: [url=http://alterarmei.com/search/?types%5B%5D=com.woltlab.wbb.post&boardIDs%5B%5D=9&s=40534feaf2581d4fb8f52cac46eccfa34954fed6]Erweiterte Suche[/url] .
Terminator Genisys 2015 HD ????? ????? 6.6
Download: [url=http://lantonkids.com/film-little-robbers-baaaaekT]Little Robbers Robby, 5 ans, apprend que ses parents se retrouvent Г la rue Г cause d'une banque, aux employГ©s 0 2009 Play[/url] .
Silicon Valley S02e05 [Mux - H264 - Ita Aac] HDTVMux by UBi - Commedia TN ...
Download: [url=http://moskow-lottery.net/tutorial/149406-ttc-the-great-courses-big-history-of-civilizations-no-8060.html]TTC - The Great Courses - Big History of Civilizations [No. 8060][/url] .
BitLord.com
Download: [url=http://americanesethemovie.com/tv/1404630517/seal-team-staffel-1]SEAL Team, Staffel 1[/url] .
Download Supernatural 12? Temporada Legendado Torrent
Download: [url=http://spector-family.com/actors/Rebecca+Clay.html]Rebecca Clay[/url] .
Contact Us
Download: [url=http://www.rmsgamez.com/chaussures_femme_baskets_mode_plat_sneakers_espadrilles_low_italdesign_noir_fbk19/154ff7a1201ae19/letter/35287662293f947/]Plat Baskets Fbk19 mode low Chaussures ItalDesign Espadrilles femme Sneakers Noir u3jwvH0Ct[/url] .
The Bachelor
Download: [url=http://beachfront-llc.us/noticias/filmes/noticia-142109/]Turma da Mônica - Laços: Saiu a primeira imagem de Paulo Vilhena como o pai do Cebolinha[/url] .
Giampetrino (1495 1549) (Art Paintings)
Download: [url=http://garminexpresssupport.com/the-girl-on-the-train/]The Girl on the Train (2016)[/url] .
[share_ebook] PLEX, a Manual: Your Media, With Style
Download: [url=http://simonsontowing.com/watch/1448407-gempa-7-sr-guncang-lombok]Gempa 7 SR Guncang Lombok[/url] .
CAPTAIN AMERICA 002.cbr
Download: [url=http://xinxingdianqi.net/series69/The-Big-Bang-Theory-/season-06-episode-17-The-Monster-Isolation]The Monster Is season 06 episode 17[/url] .
She Who Would be Pope (1972) Xvid - Liv Ullman, Olivia de Havilland [DDR]
Download: [url=http://antiquesatbutternutbrook.com/descargar-vampiros-2-latino.html]Vampiros 2[/url] .
Money 2016 720p BluRay x264-AN0NYM0US[rarbg]
Download: [url=http://antiquesatbutternutbrook.com/descargar-el-juego-latino.html]El Juego[/url] .
????(28)
Download: [url=http://valuefirst.org/movies/film/ek-ladki-ko-dekha-toh-aisa-laga-2018/]Ek Ladki Ko Dekha Toh Aisa Laga (2018)[/url] .
Coronation Street 14th Nov 2016 part 1 HDTV (Deep61) mp4
Download: [url=http://nundom.com/calendar.php?do=getinfo&day=2017-12-8&c=1]5 Birthdays[/url] .
R.E.M. By MTV 2014 HD ????? ????? 7.4
Download: [url=http://maudentrangtri.com/serien-foyer/board420-neue-serien.html?s=5162c4cde613db1801aba7f7a95d89535b28141b]Neue Serien[/url] .
Microsoft Office Professional Plus 2013 SP1 November 2016 (x86x64) [Androgalaxy]
Download: [url=http://julybet154.com/dvd-bluray-verleih/198221/the-imitation-game]The Imitation Game[/url] .
German girl tied to rack fucked by 3 guys
Download: [url=http://redwopchemicals.com/films/french/]Films VF[/url] .
???vs???
Download: [url=http://bresciapools.com/watch/dZYmWoRG-slender-man/openload.html]Play Movie[/url] .
Responder
Download: [url=http://vestabilling.com/genrelist_rental.php/lovestory-119.html]Lovestory[/url] .
???? ???? ????? ? ?
Download: [url=http://gameaddictiontreatment.com/watch/GbgaRObd-hotel-artemis/openload.html]Play Movie[/url] .
Petes Dragon 2016 DVDRip x264 AC3-iFT[PRiME]
Download: [url=http://targah.net/bodyguard]So 26.08. Bodyguard (GBВ 2018–) David Budd (David Madden) ist ein heldenhafter, dekorierter Veteran, der allerdings mit einem kurzen Geduldsfaden daherkommt. Er arbeitet nun beim ‚Royalty and Specialist Protection Branch of the Metropolitan Police ServiceвЂs Protection Command’, kurz RaSP als PersonenschГјtzer. Nun wurde er …[/url] .
Sew - January 2014
Download: [url=http://advancednrgsolutions.com/category/the-party-2017/]The Party (2017)[/url] .
Avira System Speedup 2 7 0 3167 + Crack
Download: [url=http://mhyh1025.com/Category-FilmsAndTV/Genre-biography/Letter-Any/LatestFirst/1.htm]Biography[/url] .
Alan Parsons - On Air DTSAUDIO CDR
Download: [url=http://gracepinkney.com/faq/add_favorite]What is "Add to favorite"?[/url] .
Promozione Wickedcloud...!!!!
Download: [url=http://youdal36.net/cast/donald-glover/]Donald Glover[/url] .
DVDFab v9 3 1 6 Final Setup + Patch zip
Download: [url=http://twempowerment.org/bbc/freaky-eaters/]Freaky Eaters[/url] .
Days Of Our Lives - S52 E43 - Wednesday, November 16, 2016
Download: [url=http://ungupoker.net/2915-telecharger-007-spectre-torrent.html]007 Spectre FRENCH DVDRIP Torrent[/url] .
High Dynamic Range Imaging: Acquisition, Display, and Image-Based Lighting (The Morgan Kaufmann Series in Computer Graphics) (The Morgan Kaufmann Series in Computer Graphics)
Download: [url=http://mucadeleyayinlari.org/actor/sergio-ag-ero]Sergio AgГјero[/url] .
Doctor Who
Download: [url=http://parsecfrontiers.org/crime-files-the-homefront]Crime Files the Homefront[/url] .
x-men apocalypse
Download: [url=http://scmxsm.com/torrentsites.html]Torrent Sites[/url] .
Aleksandr Miraj Raznii Sudiby 2008
Download: [url=http://cliposex69.com/regarder-streaming-1-an-dans-la-peau-des-parents-emissions-tv-55884.html]Voir la fiche[/url] .
Tomorrowland Blackstone
Download: [url=http://daaie.com/audio/sampler] Sampler[/url] .
???(10)
Download: [url=http://financesheets.com/verliebt-in-berlin/]Verliebt in Berlin[/url] .
Run All Night 2015 HD ????? ????? 6.6
Download: [url=http://pokeronlineoke.net/results?search=the+man+from+earth+movie+trailer]The Man from Earth Movie Trailer[/url] .
Fission (2 2 5) Mac (OS X)
Download: [url=http://315js.com/programme/kostenlose-schriftarten/]kostenlose schriftarten[/url] .
Alan Lomax - 1991 - Texas Folk Songs -ALe13
Download: [url=http://brazilliantranssexuals.com/browse/399]Other OS[/url] .
Hands of Stone
Download: [url=http://egllaf.com/actors/Sterling+K.+Brown.html]Sterling K. Brown[/url] .
Suicide Squad 2016 720p WEB-DL X264 PapaFatHead mp4[SN]
Download: [url=http://ausportoo.com/filme/xxx/imagesets] Imagesets[/url] .
Releases
Download: [url=http://beerpong.tv/noragami-aragoto]Noragami Aragoto[/url] .
Cisco CCNP Data Center 642-997 DCUFI CBN Nuggets training [39 mp4]
Download: [url=http://linendraper.com/renegades/]Watch online[/url] .
The Legend of Hercules (2014) 1080p BrRip x264 - YIFY
Download: [url=http://wickedticketspittsburgh.com/viewforum.php?f=363&sid=3363f89bf77e443e64f95bab05ef5749]↳ Filmy[/url] .
gods of egypt
Download: [url=http://claymorepool.com/engine/go.php?file2=[claymorepool.com]Suits-S08E01-Right-Hand-Man-1080p-WEBRip-6CH-x265-HEVC-PSA-MKV.torrent]Suits S08E01 Right-Hand Man 1080p WEBRip 6CH x265 HEVC-PSA MKV[/url] .
Doraemon (2016) New Movie Download / Online In Hindi Dubbed 720P
Download: [url=http://latelateef.mobi/prod/B007PNCD4Q.html]Reisser 8200S220450304 4,5 x 30 mm, Cutter und[/url] .
What Is the Point of Being a Christian?
Download: [url=http://pubgforums.net/torrent/t81cuowm/Blood+Waves-PLAZA.html]Blood Waves-PLAZA[/url] .
AdventureQuest 3D [2016 MAC OS GAME]
Download: [url=http://cuishishepin.com/online]Stream in HD[/url] .
Caribbean-111616-304-HD
Download: [url=http://mercadosecurity.com/series104/Game-of-Thrones/season-01-episode-03-Lord-Snow]Lord Snow season 01 episode 03[/url] .
The Walking Dead
Download: [url=http://military-sim.org/release/conspiracy-endtime-requiem/9440621]ConspiracyEndtime Requiem Metal, Black Metal, Death Metal[/url] .
4x4 Christian Cambas Remix Christian Cambas Electronic
Download: [url=http://salmonpound.com/diziler/pulse/]• Pulse 4.4[/url] .
Limitless
Download: [url=http://daipeibao.com/actors/Ruta+Gedmintas.html]Ruta Gedmintas[/url] .
Online TV shows - PC to TV pdf
Download: [url=http://salmonpound.com/diziler/musaigen-no-phantom-world-anime/]• Musaigen no Phantom World (Anime) 6.5[/url] .
Read More
Download: [url=http://8xk018.com/kingston-kth-pl424e-4g-a1636565.html]Kingston KTH-PL424E/4G[/url] .
Love Everlasting 2016 HDRip XviD AC3-EVO
Download: [url=http://mudungeon.net/watch-castaways-s01-2018-123movies.html]Watch now[/url] .
22 Неомври 63 Сезон 1 Епизод 2 / 11.22.63 БГ СУБТИТРИ
Download: [url=http://gvpnz.com/apps/apps/windows/369892-jetbrains-goland-v2018-2-1]17.08.1819:09 Uhr JetBrains GoLand v2018.2.1 0 / 0146 Hits VID P2P DDL 0 Kommentare[/url] .
hotest torrents
Download: [url=http://pangeran303.com/tag/afro-house-mix/]Afro House Mix[/url] .
Ashley Adams mp4
Download: [url=http://vivalacrypto.com/watch/sell-it-like-serhant-season-1-online-free-39583.html]Sell It Like Serhant Season 1 (2018)[/url] .
Norsk (BokmA?l)
Download: [url=http://donahueandsoninsulation.com/watch/the-vanishing-prairie-1954.html]The Vanishing Prairie Duration: 71 min[/url] .
The walking dead
Download: [url=http://vivalacrypto.com/watch/actor/RGF2ZSBCYXV0aXN0YQ==.html]Dave Bautista[/url] .
Speechless.S01E07.HDTV.x264-FLEET[PRiME]
Download: [url=http://apkfarms.com/series/seriesvfq/4945-unite-9-saison-5.html]UnitГ© 9 VFQ S05 Complet Ajouts d'entrevues[/url] .
Maya Bijou - Maya Bijou House Sits, XXX, MPEG4(Xvid), C2x, HD 1080p, 0,5 FPS [Monsters of Cock] (Aug 16, 2016).avi [Isohunt.to]
Download: [url=http://36512377.com/t/dct-aoe-2-deutsches-community-turnier/35636]DCT-AOE 2 Deutsches Community Turnier[/url] .
Blackened Sludge / Doom Metal
Download: [url=http://gvpnz.com/apps/apps/windows/370003-reallusion-3dxchange-v7-22-1703-1-x64-pipeline]18.08.1819:08 Uhr Reallusion 3DXchange v7.22.1703.1 (x64) Pipeline 0 / 0214 Hits VID P2P DDL 0 Kommentare[/url] .
Dirty Grandpa 2016 HD ????? ????? 6.1
Download: [url=http://trifectacay.com/community/forums/home-theater-projects.36/register/twitter?reg=1]Log in with Twitter[/url] .
Xuejia Lai, Dawu Gu, Bo Jin, Yong Wang, Hui Li - Forensics in Telecommunications, Information and Multimedia
Download: [url=http://ww2greece.com/watch/PGpkz6x3-teen-titans-go-to-the-movies.html]More Details[/url] .
Doll and Em
Download: [url=http://espacebios.be/videos/watch/the-walking-dead-our-world-official-trailer-hd-2146260566/]THE WALKING DEAD: OUR WORLD Official Trailer [HD][/url] .
les simpsons
Download: [url=http://winlinebet275.com/watch/vXBy2PPG-american-animals/openload.html]Play Movie[/url] .
SketchUp Pro 2016 for MAC-OSx
Download: [url=http://luggagestoragemarseille.com//luggagestoragemarseille.com/serie/a_year_in_the_new_forest]Season 1, Episode 4: Episode 4[/url] .
Hotspot Shield VPN Elite v6 20 9 Multilingual Incl Patch [Androgalaxy]
Download: [url=http://hello2441139.com/films/2592-telecharger-coup-de-foudre-a-notting-hill.html]TГ©lГ©charger Coup de Foudre Г Notting Hill[/url] .
Ant Man (2015) 720p BluRay Movie 800mb
Download: [url=http://sebar8girl.net/movseries/jurassic-park/]Jurassic Park Щ…ШґШ§Щ‡ШЇШ© Щ€ ШЄШЩ…ЩЉЩ„ ШіЩ„ШіЩ„Ш© Ш§Щ„Ш®ЩЉШ§Щ„ Ш§Щ„Ш№Щ„Щ…ЩЉ Щ€Ш§Щ„Щ…ШєШ§Щ…Ш±Ш© Ш§Щ„ШґЩ‡ЩЉШ±Ш© Jurassic Park ЩѓШ§Щ…Щ„Ш© ШЁЩѓЩ„ Ш§Ш¬ШІШ§Ш¦Щ‡Ш§ Щ€ Щ…ШЄШ±Ш¬Щ…Ш© ШЁШ¬Щ€ШЇШ© HD BluRay Ш§Щ€Щ†Щ„Ш§ЩЉЩ†[/url] .
Gadget APK
Download: [url=http://sophrologiedynamiquerouen.net/watch-tv-teen-mom-s7e6-season-7-episode-6-online-megashare-733-6683619-vidto]watch on vidto[/url] .
BitLord.com
Download: [url=http://montmarka.com/alma-da-festa/]Alma da Festa[/url] .
Jimmy.Kimmel.2016.11.16.Garth.Brooks.HDTV.x264 CROOKS[ettv]
Download: [url=http://www.mchinformation.com/manga/dasadanan/]Dasadanan[/url] .
Complete Internet Repair v3 1 3 2800 Full by James
Download: [url=http://lequincaillier.com/assistir-filme/stephen-kings-it-dublado-e-legendado-online/]It: Uma Obra Prima do Medo DUBLADO E LEGENDADO ONLINE[/url] .
mac-application
Download: [url=http://royalbet999.com/index.php?board/77-bilder-witze-spr%C3%BCche/]Bilder, Witze, SprГјche[/url] .
Brooklyn Nine-Nine S04E06 HDTV x264-FLEET[rarbg]
Download: [url=http://bmw686.net/prod/B00GJ5DB9M.html]Eizo CG277-BK 68 cm (27 Zoll) Grafik Monitor[/url] .
Sexual_Fitness_The_Ultimate_Guide_to_Pump_While_You_Hump-_Tone_While_You_Bone...
Download: [url=http://daaie.com/audio/audio/unsortiert/357915-va-chillhouse_trendsetters_vol_1-10132729-web-2018-ihr]04.04.1800:11 Uhr VA - Chillhouse Trendsetters Vol 1 House320 kbit/s 0 / 01.167 Hits VID P2P DDL 0 Kommentare[/url] .
All In with Chris Hayes 2016 11 14 720p WEBRip x264-LM
Download: [url=http://1vi.info/films/fantastique/page-2.html]Suivante[/url] .
Captain America the Winter Soldier (2014) 1080p BrRip x264 - YIFY
Download: [url=http://nationaltilerestoration.com/die-kleine-hexe-9156-info]Die kleine Hexe (2018)[/url] .
Verified
Download: [url=http://carolinareefs.org/muzyka/koncerty/]KONCERTY[/url] .
Full Frontal with Samantha Bee
Download: [url=http://bluelinelawncare.net/actors/Garry+Chalk.html]Garry Chalk[/url] .
Kendra Lust - Cheated on My Husband and Loved it NEW XXX 2016 [Isohunt.to]
Download: [url=http://parsecfrontiers.org/school-of-rock-1-a]School of Rock[/url] .
Robert Myler,
Download: [url=http://zeansport.com/watch/killing-for-love.l35j6]SD Killing for Love[/url] .
A Million WAys to Die in the West 2014 CAM x264 AC3 TiTAN
Download: [url=http://sbt90s.info/stories/12775/die-news-und-trailer-der-woche-56]Die News und Trailer der Woche Die Temperaturen gehen zurück, der Sommer schleicht voran und schon bald könnte es sein, dass endlich der Herbst da ist. Das hat mit unserem News-Rückblick zwar absolut nichts zu tun, aber nach den...[/url] .
Wayne Swann,
Download: [url=http://arminiabd.com/show/undateable/]Undateable[/url] .
environmental pollution pdf free download
Download: [url=http://howtomakeextramoneyfromhome.com/index.php?page=StatusListe&s=3ee4a321811ce04c25a116bdf54e6e2089ffd504]Status List[/url] .
BitLord.com
Download: [url=http://sheffieldescorts.net/oyuncular/evan-rachel-wood/]Evan Rachel Wood Dolores Abernathy[/url] .
Eilera - Face Your Demons (2016)
Download: [url=http://arminiabd.com/show/nicky-ricky-dicky-and-dawn/]Nicky Ricky Dicky and Dawn[/url] .
Van Helsing S01E07 1080p WEB x264-HEAT[PRiME]
Download: [url=http://mercadosecurity.com/series86/Greys-Anatomy/season-12-episode-20-Trigger-Happy]Trigger Happy season 12 episode 20[/url] .
Speccy 1 30 728 + Portable [4realtorrentz] zip
Download: [url=http://zeansport.com/watch/survivors-guide-to-prison.mq798]SD Survivors Guide to Prison[/url] .
Marvel's Agents of Shield S01E04 VOSTFR HDTV x264-BRN mp4
Download: [url=http://therealdealrealestate.com/?bpof=43einhalb%20sneaker%20store&kuerzel=de43einhalbsneaker-de]Bestpreise[/url] .
The Girl on the Train 2016 CAMRip XviD - INFERNO[PRiME]
Download: [url=http://wmeclub.com/community/forums/tv-on-dvd-and-blu-ray.74/forums/ultraviolet-digital-copy-codes.336/]UltraViolet Digital Copy Codes[/url] .
Designated Survivor S01E07 HDTV XviD-FUM[ettv]
Download: [url=http://postmenapi.net/?cat=swgv_sonst]Sonstiges[/url] .
Wild Ones (Featuring Sia).mp4
Download: [url=http://jmmkt.com/actors/Bill+Pullman.html]Bill Pullman[/url] .
Wayward.Pines.S01E07.HDTV.x264-LOL[ettv][270 Mb] Video TV shows
Download: [url=http://maobai.net/torrent/16808954/windows-10-enterprise-x64-ltsb-fr-fr-june-21-2018.html]Windows 10 Enterprise X64 2016 LTSB fr-FR JUNE-21 2018[/url] .
Underbelly
Download: [url=http://topusbets.com/forums/the-lounge.15/threads/everything-r-b-megathread.305014/]Everything RB Megathread[/url] .
[Torrentfrancais.com]-Crack-Windows-7--Windows-Loader-2.1.7---By-Daz
Download: [url=http://wo-2525.com/movies/star/amy-adams/]Amy Adams[/url] .
Game of Thrones S01 1080p BluRay x264-Belex - Dual Audio + Legendas
Download: [url=http://lepetitjardin.net/serie/stream/riverdale]Riverdale eine Stadt in Schockstarre[/url] .
Alicia Vikander,
Download: [url=http://indiecredgamer.com/horse-soldiers/]Regarder[/url] .
E-40 - The D-Boy Diary - Book 1 (2016)
Download: [url=http://1955566.net/%d9%81%d9%8a%d9%84%d9%85-the-prototype-2018-%d9%83%d8%a7%d9%85%d9%84-hd-%d9%85%d8%b4%d8%a7%d9%87%d8%af%d8%a9-%d9%88%d8%aa%d8%ad%d9%85%d9%8a%d9%84-%d9%85%d8%a8%d8%a7%d8%b4%d8%b1/]ЩЃЩЉЩ„Щ… The Prototype 2018 ЩѓШ§Щ…Щ„ HD Щ…ШґШ§Щ‡ШЇШ© Щ€ШЄШЩ…ЩЉЩ„ Щ…ШЁШ§ШґШ± 2018 HD ЩЃЩЉЩ„Щ… The Prototype 2018 ЩѓШ§Щ…Щ„ HD Щ…ШґШ§Щ‡ШЇШ© Щ€ШЄШЩ…ЩЉЩ„ Щ…ШЁШ§ШґШ± Ш§Ш«Ш§Ш±Ш© The Prototype 2018 Щ…ШґШ§Щ‡ШЇШ© Щ€ШЄШЩ…ЩЉЩ„ Щ…ШЁШ§ШґШ± Щ…ШґШ§Щ‡ШЇШ© ЩЃЩЉЩ„Щ… Ш§Щ„Ш®ЩЉШ§Щ„ Ш§Щ„Ш№Щ„Щ…ЩЉ Щ€Ш§Щ„Ш±Ш№ШЁ Щ€Ш§Щ„Ш§Ш«Ш§Ш±Ш©В The Prototype 2018 Щ…ШЄШ±Ш¬Щ… ЩѓШ§Щ…Щ„ HD ШЁШ¬Щ€ШЇШ© Ш№Ш§Щ„ЩЉШ© Ш§Щ€Щ†...[/url] .
Kubo et l’armure magique(Kubo And The Two Strings) streaming
Download: [url=http://luderband.com/ver/voltron-7x13.html]7x13 Voltron: El defensor legendario[/url] .
Alarm Clock Pro 10 2(1)
Download: [url=http://1casinovulkan.com/wraith/]HD Wraith[/url] .
Cossacks 3 PC GAME [2016]REPACK
Download: [url=http://shenzhenjjs.com/diziler/hunter-x-hunter-anime/]• Hunter x Hunter (Anime) 8.2[/url] .
Suicide Squad 2016 EXTENDED 1080p WEB-DL x264 AC3-JYK
Download: [url=http://benidormcd.tk/community/official-competitions/]Official Competitions[/url] .
Grey’s Anatomy
Download: [url=http://lenyosys.be/tv-star/naomi-campbell]Naomi Campbell[/url] .
Gunjack 2 End of Shift - 2016 MAC-soft
Download: [url=http://sweettreatspartyrentals.com/watch-Defiance-2008-movie-online-5894.html]Defiance (2008)[/url] .
Aleksandr Dumin-Alleya Shansona MK 2010
Download: [url=http://cuishishepin.com/the-jungle-book-2016-9053/]Watch online[/url] .
star trek beyond 720p
Download: [url=http://bestgamingheadphones.net/tv-star/michelle-pfeiffer]Michelle Pfeiffer[/url] .
Essex Boys: Law of Survival 2015 HD ????? ????? 5.4
Download: [url=http://codewaregames.com/operation-tambacounda-streaming-gratuit-ZNWG98MUL.html]OpГ©ration Tambacounda[/url] .
dbForge for SQL Server 5.1 + Fix [OS4World]
Download: [url=http://lenyosys.be/tv-star/pamela-anderson]Pamela Anderson[/url] .
History Channel
Download: [url=http://subletnj.com/the-muppets-3/]The Muppets[/url] .
Tushy - Jillian Janson (Hot Young Model Fucked in the Ass)
Download: [url=http://indiecredgamer.com/genre/thriller/page/63/]DerniГЁre page[/url] .
BitLord.com
Download: [url=http://paperstreetusa.com/movies/hdrip/6651167-upto-moonwalkers-2015-bluray-720p-dd51-x264-epic.html][Up.to] Moonwalkers (2015) BluRay 720p DD5.1 x264-EPiC[/url] .
Give Me
Download: [url=http://sereniteservices.net/nonton-film-indonesia-terbaru]Film Indonesia Terbaru[/url] .
Eromaxx - Party Hardcore Gone Crazy 30 [2016] DVDRip mp4
Download: [url=http://nicetshirtstoday.info/category/what-remains/]What Remains[/url] .
[PuyaSubs!] Gatchaman Crowds - 04 [720p][E6217480].mkv
Download: [url=http://digiclubnyc.org/actors/Jessica+Treska.html]Jessica Treska[/url] .
personal shopper
Download: [url=http://pokeronlineoke.net/results?search=movie+trailer+aftermath]Movie Trailer Aftermath[/url] .
Hidden Camera Voyeur 1 s3 mp4
Download: [url=http://dating-magazine-uk.com/serie/ChaeoS-HEAd]ChäoS;HEAd[/url] .
A Million WAys to Die in the West (2014) 720p WEBRiP v2 - 900MB
Download: [url=http://mypeoplemybusiness.com/category/series-terminadas/common-law/]Common Law[/url] .
24 Hindi S02E09 HDTV Download 480p 180MB
Download: [url=http://mulaiaja.com/csi-cyber-3/]CSI Cyber[/url] .
torrent requests
Download: [url=http://mypeoplemybusiness.com/category/series-atuais/the-orville/]The Orville[/url] .
Veronika - (8170) mp4
Download: [url=http://daipeibao.com/actors/Errol+Morris.html]Errol Morris[/url] .
Alberta Cross - Leave Us Or Forgive Us & Thief & The Heartbreaker MP3/128Kbps
Download: [url=http://av1to.info/3433-big-school-saison-1.html]Big School - Saison 1[/url] .
chicago pd
Download: [url=http://37ddyy.com/watch-talking-dead-season-7-2017-free-123movies.html]Talking Dead Season 7 (2017)[/url] .
Alan Rawsthorne - Symphonies 1-3
Download: [url=http://ww2greece.com/watch/mxyJzmGN-hotel-transylvania-3-summer-vacation.html]More Details[/url] .
JourneyMan
Download: [url=http://ynnantai.com/12-monkeys]12 Monkeys 7.5[/url] .
Albert King - 1972 - I’ll Play The Blues For You (Stax - SXSA-3009-6, 2004 ...
Download: [url=http://pinkpandastars.com/index.php?page=Board&boardID=422&s=a42c320f288c101488756fea758060c64f88c2ab]Durham County[/url] .
Masters of Sex
Download: [url=http://szxhjfs.com/viewtopic.php?t=4325251]Как выдернуть субтитры с сайта?[/url] .
FileMaker Pro 15 Advanced 15 0 2 220 Multilingual (x86x64) + Crack [SadeemPC]
Download: [url=http://oldtimeynerd.net/v-%D9%81%D9%88%D8%B2%D9%8A-%D9%85%D9%88%D8%B2%D9%8A-%D9%88%D8%AA%D9%88%D8%AA%D9%8A-%D9%81%D9%8A-%D8%A5%D8%B3%D8%B7%D9%86%D8%A8%D9%88%D9%84-%D8%A8%D8%AF%D9%8A-%D8%A8%D9%88%D8%B8%D8%A9-i-want-ice-cream-06_SUPpJ4Hc.html]ЩЃЩ€ШІЩЉ Щ…Щ€ШІЩЉ Щ€ШЄЩ€ШЄЩЉ (ЩЃЩЉ ШҐШіШ·Щ†ШЁЩ€Щ„) - ШЁШЇЩЉ ШЁЩ€ШёШ© - I want ice cream[/url] .
The BFG 2016 720p BRRip 1GB MkvCage mkv
Download: [url=http://homerunheroics.com/genre/adventure/]Adventure[/url] .
Karel Gott Exclusive Collection (28 CD)
Download: [url=http://82dvdv.com/file/better-call-saul-s04e02-720p-hdtv-x264-avs-832336.html]1 more rapidgator, uploadgig, nitroflare link[/url] .
Petes Dragon 2016 BDRip x264-COCAIN[PRiME]
Download: [url=http://mainartery.net/%d9%85%d8%b4%d8%a7%d9%87%d8%af%d8%a9-%d9%81%d9%8a%d9%84%d9%85-%d8%a3%d8%ad%d8%a8%d9%87-%d9%88%d9%84%d9%83%d9%86-%d8%aa%d8%b1%d9%83%d9%8a-%d9%85%d8%af%d8%a8%d9%84%d8%ac-%d8%b9%d8%b1%d8%a8%d9%8a/]586 Ш§ЩЃЩ„Ш§Щ… Щ…ШЇШЁЩ„Ш¬Ш© Щ…ШґШ§Щ‡ШЇШ© ЩЃЩЉЩ„Щ… “ШЈШШЁЩ‡ Щ€Щ„ЩѓЩ†” ШЄШ±ЩѓЩЉ Щ…ШЇШЁЩ„Ш¬ Ш№Ш±ШЁЩЉ Ш§Ш®ШЄЩ„Ш§ЩЃ Ш§Щ„Ш«Щ‚Ш§ЩЃШ§ШЄ Щ€Ш§Щ„ШЁЩЉШ¦Ш© Ш§Щ„Ш§Ш¬ШЄЩ…Ш§Ш№ЩЉШ© Щ€ШШЄЩ‰ Ш§Щ„Ш·ШЁШ§Ш№ Ш§Щ„ШґШ®ШµЩЉШ© Щ€Щ…Ш№Ш§Ш±Ш¶Ш© Ш§Щ„Ш§Щ‡Щ„ Щ€Ш§Щ„ЩѓШ«ЩЉШ± Щ…Щ† Ш§Щ„Ш№Щ‚ШЁШ§ШЄ Щ„Ш§ ЩЉЩ…ЩѓЩ†Щ‡Ш§ ШЈЩ† ШЄЩ†Щ‡ЩЉ Ш§Щ„ШШЁ Щ€ШЄШЇЩ…Ш± Ш§Щ„Щ…ШШЁЩЉЩ† Щ€Щ„ЩѓЩ†...[/url] .
Dawn of the Planet of the Apes 2014 DVDRip XviD AC3-iFT
Download: [url=http://chamberlainforgovernor.com/diziler/superstore/]• Superstore 6.7[/url] .
Giuseppe Verdi - Falstaff (2002) [Isohunt.to]
Download: [url=http://wickedticketspittsburgh.com/viewtopic.php?f=21&p=1011028&sid=567a4e26f45d96a3bf2d11aeaf825219]Zobrazit poslednГ pЕ™ГspД›vek[/url] .
http://bigfoot1942.sektori.org:6969/announce
Download: [url=http://roughcreektraders.com/community/forums/playback-devices.58/forums/playback-devices.58/?order=post_date]Start Date[/url] .
Watch Tv Shows Watch Tv Shows Online
Download: [url=http://bitonpro.com/serie/details/1350450/the-end-of-the-fing-world/]The End of the F***ing World Serie, 2017[/url] .
[WZF]Danna Ga Nani Wo Itteiru Ka Wakaranai Ken 2 Sureme Episodio 10~13[BDRip][1280x720][X264 AAC][...
Download: [url=http://bedroomthemeideas.com/mass-effect-andromeda-update-1-005-cpy/]Mass Effect Andromeda UPDATE 1.005-CPY[/url] .
A Million WAys to Die in the West 2014 WEBRip HC XVID AC3 ACAB
Download: [url=http://ask-girl.com/actor/myrah-dandekar/]Myrah Dandekar[/url] .
Nowhere Boys-The Book of Shadows 2016 DVDRip x264-WaLMaRT[1337x][SN]
Download: [url=http://secretstheweek.com/prod/B014QYHUF8.html]BAISHENGGT Damen Pumphose Baggy Harem Stil Sports[/url] .
Marbled-_Swirled-_and_Layered_150_Recipes_and_Variations_for_Artful_Bars-_Coo...
Download: [url=http://legitrtohouses.com/index.php?page=Board&boardID=381&s=a87fd93c72b92c547caf70861440270697ffbe17]Past Life[/url] .
chicago PD
Download: [url=http://universejaw.com/watch/Best-Friends-Volume-One-online-free-full-movie-3392.html](2017) HD Trailr Best F(r)iends: Volume One[/url] .
Tempting Butts Of Hot And Sexy Girls Pictures Pack-8}
Download: [url=http://fastmovie69.com/descargar-viaje-salvaje-latino.html]Viaje Salvaje[/url] .
Batman vs Superman Dawn of Justice (2016) - WebRip - x264 - Dual Audio - (Tamil - Eng)
Download: [url=http://teknolojikolik.net/prod/B00O9ZW2SA.html]Samsung Galaxy S4 ACTIVE SilikonhГјlle in SCHWARZ[/url] .
(2015) DVDRip Strange Magic
Download: [url=http://aetuan.com/release/star-the-moonlight-good-fight-single/9643290]Star the MoonlightGood Fight - Single Alternative, Hip-Hop/Rap, R'n'B, Rhythm and Blues, Soul[/url] .
Hide.Your.Smiling.Faces.2013.BDRip.x264-SONiDO
Download: [url=http://starbet7.net/?service=mobiles-internet]Mobiles Internet[/url] .
DJ Drama – Third Power (Deluxe Edition) iTunes Plus
Download: [url=http://pornlog.net/films/?affiche=max]Pochette[/url] .
DJ Beats 47 October 2016
Download: [url=http://deals-king.com/extincao/]Extinção[/url] .
[PS3] Alien Isolation - Nostromo Edition Part2
Download: [url=http://bestgamingheadphones.net/tv-programm/dino-zug/kenny-kentrosaurus-don-und-die-troodons/bid_131019683/]Dino-Zug[/url] .
[110608]?Umineko no Naku Koro ni Zan episode8 ?ED Single ?Byakuya no Mayu Ricordando il pas...
Download: [url=http://i-mala.com/software/1720-ids-vcm-2012-v7704a-ford-mazda-030312-348-gb.html]IDS VCM 2012 v77.04A Ford Mazda 03.03.12 3.48 GB[/url] .
The Luminaries: A Novel
Download: [url=http://extrememobilemechanics.net/ver/captain-tsubasa-2018-1x01.html]1x01 SuperCampeones 2018[/url] .
Windows - Security
Download: [url=http://livingmicrocorp.com/series/regarder/1358-man-in-an-orange-shirt-streaming.html]Man in an Orange Shirt[/url] .
Mechanical Assets in 3ds Max Volume 3
Download: [url=http://jleexcavating.com/actor/melonie-diaz/]Melonie Diaz[/url] .
???? ?? ?? ???????.
Download: [url=http://291hgvip.com/ar/]العربية‎[/url] .
The Bold And The Beautiful - S30 Ep7464 - 2016-11-16
Download: [url=http://brazilliantranssexuals.com/tv/53440/]The Vampire Diaries[/url] .
Mechanical Assets in 3ds Max Volume 1
Download: [url=http://betpel.net/?o=10]Monitore[/url] .
BigTitsAtWork - Nicole Aniston - Team Player XXX 2016 [Isohunt.to]
Download: [url=http://myxzn.com/country/slovenia.html]Slovenia[/url] .
Honduras
Download: [url=http://starbet7.net/integral-crypto-m-2-64gb-inssd64gm2m2280c140-a1837332.html]Integral Crypto M.2 64GB, M.2 (INSSD64GM2M2280C140)[/url] .
40 Beach Model Nina Agdal Barely Naked Hot And Sexy Pictures
Download: [url=http://jumpthelights.com/solike_escarpin_bride_cheville_en_suede_sexy_escarpins/158a5ef4280fb32/343b386518af539/latter/]Sexy Bride Suede en Escarpin Solike Escarpins Cheville EH2G5Qj[/url] .
Alien vs Predator vs Batman vs Terminator vs Robocop vs Jason vs Superman vs Ewoks and other animated shorts
Download: [url=http://whjsc027.com/detail/GXo3RLtRAx](C86) [з„Ўй™ђењ°й›· (гѓ г‚·)] г‚№гѓјгѓ‘гѓјдЅ“ж„џг‚ЁгѓеЏЊе…作戦 (ディーふらぐ!)_3[/url] .
VSO ConvertXtoHD 2 0 0 55 Final + Patch [4realtorrentz] zip
Download: [url=http://amarmuktagachha.com/topvideos.html?c=el-ministerio-del-tiempo]El ministerio del tiempo[/url] .
BitLord.com
Download: [url=http://military-sim.org/release/edward-becker-every-knee-will-bow-single/9664155]Edward BeckerEvery Knee Will Bow - Single Metal, Rock, Heavy Metal[/url] .
LegalPorno Kathy White Eva Ann and Sofie in kinky MILF interracial orgy 4on3 DP IV013 11 14 16
Download: [url=http://bettymooregames.com/BMW-320d-Touring-Facelift-EZ-2009-Automatik-Panoramadach-232896720235.html]BMW 320d Touring, Facelift, EZ 2009, Automatik, Panoramadach, Exportpreis[/url] .
Tushy 16 11 17 Karla Kush And Arya Fae XXX 1080p MP4-KTR[rarbg]
Download: [url=http://anico-services.com/software/windows/249925-allconverter-pro-231-multilingual-portable.html]ALLConverter Pro 2.3.1 Multilingual + Portable[/url] .
6???
Download: [url=http://perfectdreamtravel.info/graphics/955994-gr-cogra-professional-powerpoint-template-22363047.html]Comments: 0[/url] .
Alanis Morrisette - Jagged Little Pill
Download: [url=http://oplume.net/film/the-man-who-killed-don-quixote]The Man who Killed Don Quixote Abenteuer, Komödie, Drama[/url] .
Audrey Charlize mp4
Download: [url=http://hazelwoodgrove.net/subtitles/movieid-336047/]Russia with Simon Reeve 2017[/url] .
22 Неомври 63 Сезон 1 Епизод 1 / 11.22.63 БГ СУБТИТРИ
Download: [url=http://salmonpound.com/diziler/bordertown/]• Bordertown 5.2[/url] .
Recover! Stop Thinking Like an Addict and Reclaim Your Life with The PERFECT Program
Download: [url=http://bougie.tk/torrent/7090367/killing-eve-s01e08-w4f%5Beztv%5D.html]Killing Eve S01E08 HDTV x264-W4F[eztv][/url] .
assassination classroom
Download: [url=http://graphic-barry.com/software/desktop-enhancements/52036-faststone-capture-89.html]Read more...[/url] .
artificial intelligence for humans, volume 3: deep learning and neural networks pdf
Download: [url=http://nicetshirtstoday.info/category/station-19/]Station 19[/url] .
Facebook
Download: [url=http://mulaiaja.com/satisfaction-10/]Satisfaction Serie Tv[/url] .
Penthouse Breast Friends XXX 2015 HDTV 720p x264-SHDXXX
Download: [url=http://yimeijiahua.com/release/headstones-greatest-fits/9664196]HeadstonesGreatest Fits Rock[/url] .
WebSite-Watcher 2016 16 3 Business Edition + Crack [4realtorrentz] zip
Download: [url=http://lenyosys.be/tv-programm/eine-verhaengnisvolle-begegnung/bid_130920674/]Eine verhängnisvolle Begegnung[/url] .
francis cabrel
Download: [url=http://clbanners10.com/veritas-streaming-gratuit-BN3ASWI.html]VГ©ritas[/url] .
Deadpool #005 - BMB.Bishop amp; NomiSunraider- LLSW.cbr
Download: [url=http://minerize.com/genre/animation/]Animation[/url] .
Suicide.Squad.2016.EXTENDED.HDRip.XviD.AC3-ETRG
Download: [url=http://66rsd.com/diziler/tabula-rasa/]Tabula Rasa[/url] .
Tchaikovsky Symphony No 6 Iii Allegro Molto Vivace Arr For Piano Four Hands Shelest Piano Duo
Download: [url=http://pokecoins.net/tv-programm/mdr-aktuell/bid_131486419/]MDR aktuell[/url] .
Dark Places 2015 HD ????? ????? 6.2
Download: [url=http://citydialysis.com/casualty-s29e20/]Casualty S29E20[/url] .
The.Walking.Dead.S07E04.VOSTFR.720p.WEB-DL.DD5.1.H...(A)
Download: [url=http://egllaf.com/actors/Ludacris.html]Ludacris[/url] .
Anmod - Inner Upheavals (2016)
Download: [url=http://aetuan.com/release/delusions-of-persecution-thy-kingdom/9536672]Delusions of persecutionThy Kingdom Metal, Black Metal, Death Metal[/url] .
The Ultimate Guide to Urban Farming - Sustainable Living in Your Home, Community and Business (2016) (Epub) Gooner - 2016-11-17
Download: [url=http://02dvdv.com/forums/the-tunnel.13/trending/media]Trending Media[/url] .
Miconazole
Download: [url=http://graceisbeauty.com/streaming-gratuit-genre-martiaux.html]Arts Martiaux[/url] .
Hot Anal Yoga (Evil Angel) NEW 2016 WEB-DL (Split Scenes)
Download: [url=http://daipeibao.com/actors/Kurt+James+Stefka.html]Kurt James Stefka[/url] .
Alyssa Cole mp4
Download: [url=http://channelviewpc.com/member.php?action=profile&uid=54662]songiden[/url] .
(2016) HD 720p Ghost Patrol
Download: [url=http://legitrtohouses.com/index.php?page=Board&boardID=238&s=f797eb2c85c54db89c04d97fc7efe0374bbd220f]Knight Rider (2008)[/url] .
Dont Breathe 2016 1080p BRRip x264 AAC-ETRG
Download: [url=http://subletnj.com/the-good-fight-2/]The Good Fight[/url] .
investir
Download: [url=http://tshirt-comics.com/watch-category7-the-end-of-the-world-2005-1080p-full-movies-9movies.html]HD Category 7: The End of the World (2005)[/url] .
Високо напрежение
Download: [url=http://echappee-belle.be/?p=films&search=Jason Momoa]Jason Momoa[/url] .
X Angels Stasya Stoune Teens play crazy sex games mp4
Download: [url=http://voicheria62.net/category/%d8%a8%d8%b1%d8%a7%d9%85%d8%ac-%d8%aa%d9%84%d9%81%d8%b2%d9%8a%d9%88%d9%86%d9%8a%d8%a9/]ШЁШ±Ш§Щ…Ш¬ ШЄЩ„ЩЃШІЩЉЩ€Щ†ЩЉШ©[/url] .
How to Download Magnet Torrent
Download: [url=http://pinkpandastars.com/index.php?page=Board&boardID=264&s=e595e59e37b82d0b50e04132ea5f52ca24e87c7e]The Fixer[/url] .
Brooklyn.Nine-Nine.S04E06.Monster.in.the.Closet.WEB-DL.x264.AAC
Download: [url=http://i-mala.com/movie/676-deviation-2012-dvdrip-xvid-nydic.html]Deviation 2012 DVDRip XviD NYDIC[/url] .
The Big Bang (2011)
Download: [url=http://colocimmo.net/index.php/episode/324064/479/a-zold-ijasz-5-evad-23-resz-online]videГіk megtekintГ©se[/url] .
Jason Bourne 2016 720p BRRip x264 AAC-ETRG
Download: [url=http://hangrygaminggear.com/series/regarder/796-lost-les-disparus-streaming.html]Lost Les Disparus[/url] .
Vessel By Twenty One Pilots
Download: [url=http://baixarseriestorrent.com/ch-UC4Mf0yTxVoceg3NQCOfZVjg]TrendingGemist NL[/url] .
OmniGraffle Pro 6 3 1 [Mac OS X] [Q8Wolfy]
Download: [url=http://bjtangyong.com/actors/Ce&]Ce'Onna Meilani Johnson[/url] .
Queen Sugar S01E11 720p HDTV x264-BAJSKORV[ettv]
Download: [url=http://brisbanevetservices.com/torrents-search.php?search=Multi+audio+hindi&sort=relevance]Multi audio hindi[/url] .
What's Yours is Mine: Open Access and the Rise of Infrastructure Socialism
Download: [url=http://monster777.com/descargar-torrents-variados-1158-Crea-tus-cuentos.html]Crea tus cuentos.[/url] .
Diablo III [2016 MAC OS GAME]
Download: [url=http://mmalocal.com/country/usa | china |]USA | China |[/url] .
Cities in Blue 5of8 Memphis HDTV x264 720p AC3 MVGroup org mkv
Download: [url=http://motorsportextreme.com/results?search=full+movie+best+christian+family+movie]Full Movie Best Christian Family Movie[/url] .
Facebook
Download: [url=http://frederique-dogs.com/watch/vkraKw3d-hotel-artemis/vidto.html]Play Movie[/url] .
A Million WAys to Die in the West (2014)
Download: [url=http://zenamane.com/films/acteur/gary-oldman.html]Gary Oldman[/url] .
x-men apocalypse
Download: [url=http://xinxingdianqi.net/series86/Greys-Anatomy/season-10-episode-03-Everybodys-Crying-Mercy]Everybody's Cr season 10 episode 03[/url] .
AWESOME AI MADE EASY.WITH BEHAVIOR DESIGNER
Download: [url=http://scwrgs.com/category/survivors/]Survivors[/url] .
BitLord.com
Download: [url=http://szxhjfs.com/viewtopic.php?t=4442025]40 Карат / 40 Carats (Милтон Кацелас) [1973, США, Комедия, мелодрама, DVDRip] MVO (Студия Пифагор по заказу ГТРК Культура) + Original Eng</a>[/url] .
100 baggers pdf
Download: [url=http://dg-huasu.com/?genre=Fantas]FantasГa[/url] .
privacy policy
Download: [url=http://military-sim.org/release/marius-aleksandersen-desire-single/9650285]Marius AleksandersenDesire - Single Electronic[/url] .
Download Caracal by disclosure for free
Download: [url=http://caouu.org/actors/Janina+Gavankar.html]Janina Gavankar[/url] .
Driftmoon-(R)Evolution-(ABRD126)-WEB-2016-SPANK [EDM RG]
Download: [url=http://nordicbrazilianfintechhub.com/showthread.php?tid=8118]Nissan Primastar 2.5DCi egr off[/url] .
Filmes Via Torrent
Download: [url=http://gkhphotography.com/yourturn_baskets_basses/1042807ecfe5573/353bffe03be7997-fashionable/]YOURTURN basses Baskets 3FZgXV2AC[/url] .
Glary Utilities Pro 5 61 0 82 [Multilanguage] [Serial] rar
Download: [url=http://hello2441139.com/films/acteur/woody-harrelson.html]Woody Harrelson[/url] .
The Overnight 2015 HDRip XviD AC3 EVO
Download: [url=http://gzfodan.com/director/norton-virgien]Norton Virgien[/url] .
David Blaine-Beyond Magic 2016 HDTV x264-FUM[ettv]
Download: [url=http://lasercenterquincy.com/empire/513-staffel-1.html]Empire Staffel 1 Episode 12[/url] .
modern family s07
Download: [url=http://xfdq8.com/search/Download Skyfall (2012) Subtitle Indonesia Bluray Google Drive]#Download Skyfall (2012) Subtitle Indonesia Bluray Google Drive[/url] .
Aleksandr Marzinkewich I Gruppa Kabriolet Za Tvoi Glasa 2010
Download: [url=http://291hgvip.com/es/game_role_playing]Juegos de rol[/url] .
High Strung 2016 720p BluRay x265 ShAaNiG mkv
Download: [url=http://subletnj.com/versailles-2/]Versailles[/url] .
Watch Boyka Undisputed 4 (2016) Full Movie Online HDrip
Download: [url=http://mutexdao.net/%d9%85%d8%b3%d9%84%d8%b3%d9%84-salvation-%d8%a7%d9%84%d9%85%d9%88%d8%b3%d9%85-%d8%a7%d9%84%d8%ab%d8%a7%d9%86%d9%8a-%d8%a7%d9%84%d8%ad%d9%84%d9%82%d8%a9-5/]ШЩ„Щ‚Ш© 5 Щ…ШіЩ„ШіЩ„ Salvation Ш§Щ„Щ…Щ€ШіЩ… Ш§Щ„Ш«Ш§Щ†ЩЉ Ш§Щ„ШЩ„Щ‚Ш© 5 2018 HDTv Щ…ШіЩ„ШіЩ„ Salvation Ш§Щ„Щ…Щ€ШіЩ… Ш§Щ„Ш«Ш§Щ†ЩЉ Ш§Щ„ШЩ„Щ‚Ш© 5 Ш§Ш«Ш§Ш±Ш© Щ…ШґШ§Щ‡ШЇШ© Щ€ШЄШЩ…ЩЉЩ„ Щ…ШіЩ„ШіЩ„ Ш§Щ„Ш®ЩЉШ§Щ„ Ш§Щ„Ш№Щ„Щ…ЩЉ Щ€Ш§Щ„Ш§Ш«Ш§Ш±Ш© Salvation S02 HD Ш§Щ„Щ…Щ€ШіЩ… Ш§Щ„Ш«Ш§Щ†ЩЉ Щ…ШЄШ±Ш¬Щ… Ш§Щ€Щ† Щ„Ш§ЩЉЩ† Щ€ШЄШЩ…ЩЉЩ„ Щ…ШЁШ§ШґШ±[/url] .
APES REVOLUTION
Download: [url=http://danhbamoigioi.net/hartston-2016_58570a7bc.html]Hartston (2016)[/url] .
Play With Me 4 s1 with Simone Claire mp4
Download: [url=http://laotieqi.com/watch/QvM5JZv2-the-domestics.html]More Details[/url] .
Adult Torrents
Download: [url=http://betpel.net/?cat=iosasraid]Storage Controller[/url] .
TeasePOV 16 11 04 Candice Dare XXX 720p MP4 KTR
Download: [url=http://dating-magazine-uk.com/serie/Hajimete-no-Gal]Hajimete no Gal[/url] .
Alan Watt CTTM LIVEonRBN 509 Greet Your Corporate-Feudal Overlord Won By Book-keeping Entries Not By
Download: [url=http://shiatsuyogamassage.com/series/insatiable/]Watch Series[/url] .
Read More
Download: [url=http://antapai.com/release/runa-bergsmo-Гёrn-feat-pГҐl-ytterstad-runa-bergsmo-single/9474720]Runa BergsmoГrn (feat. PГҐl Ytterstad & Runa Bergsmo) - Single Rock, Progressive Rock, Art Rock[/url] .
Graphic Styles 2 1(1)
Download: [url=http://stampbachstein.com/prod/B004LPNBD8.html]Der Landarzt - Staffel 7 (Jumbo Amaray - 3 DVDs)[/url] .
Amber Midthunder
Download: [url=http://ausportoo.com/audio/audio/soundtrack/330401-va-guardians_of_the_galaxy_vol-_2_awesome_mix_vol-_2-ost-2017-voldies]29.04.1721:37 Uhr Guardians of the Galaxy Vol.2: Awesome Mix Vol.2 Soundtrack256 kbit/s 0 / 014.724 Hits VID P2P DDL 0 Kommentare[/url] .
The Dark Knight Rises APK 1.1.6 Android Game
Download: [url=http://candyallet.com/fategrand-order-first-order-2016/]Download[/url] .
Castlevania Lords of Shadow Mirror of Fate HD MULTI7 RePack By R.G Revenants...
Download: [url=http://howtomakeextramoneyfromhome.com/index.php?page=Thread&threadID=49036&action=firstNew&s=c2f257bec961c449f884c17ff032c58047a8dbee]Legacies (The CW) | Spin-Off von The Originals[/url] .
The Witch Hindi Torrent 2016 Full HD Movie Download
Download: [url=http://hutchisonhomeimprovements.com/descargar-la-noche-del-demonio-latino.html]La Noche del Demonio[/url] .
H0930-ori1432-HD
Download: [url=http://epropertytaxappeal.us/series86/Greys-Anatomy/season-07-episode-21-I-Will-Survive]I Will Survive season 07 episode 21[/url] .
BitLord.com
Download: [url=http://lepetitlourmarin.com/xfsearch/acteurs/Elizabeth+Henstridge/]Elizabeth Henstridge[/url] .
Chipmunks Sean Paul Other Side Of Love
Download: [url=http://quoteideas.net/movie/the-spy-who-dumped-me/]Watch movie[/url] .
dragon ball xenoverse
Download: [url=http://dgjinrui168.com/?p=films&search=Pierre Coffin]Pierre Coffin[/url] .
Candle [2016-for-MAC]
Download: [url=http://perek.tv/films/dvdrip-bdrip]Dvdrip/Bdrip[/url] .
Games Torrents
Download: [url=http://minioppai.us/%d9%81%d9%8a%d9%84%d9%85-slumdog-millionaire-2008-%d9%85%d8%aa%d8%b1%d8%ac%d9%85-%d8%a7%d9%88%d9%86-%d9%84%d8%a7%d9%8a%d9%86/]66176 Ш§ЩЃЩ„Ш§Щ… Щ‡Щ†ШЇЩЉ Ш·Щ„ШЁШ§ШЄ ШІЩ€Ш§Ш± ЩЃЩЉЩ„Щ… Slumdog Millionaire 2008 Щ…ШЄШ±Ш¬Щ… Ш§Щ€Щ† Щ„Ш§ЩЉЩ† Щ…ШґШ§Щ‡ШЇШ© Щ€ ШЄШЩ…ЩЉЩ„ ЩЃЩЉЩ„Щ… Slumdog Millionaire 2008 ЩѓШ§Щ…Щ„ Щ…ШЄШ±Ш¬Щ… Ш§Щ€Щ† Щ„Ш§ЩЉЩ† 8.0[/url] .
Kirtu - Savita Bhabhi - Episode 1 to 50.pdf (Non-Watermarked) [Adult Comics] - Almerias
Download: [url=http://oldtimeynerd.net/ch-UCwZBXgmyvUJQW2-DCY9sf9Q]MTV Nederland[/url] .
Christoph Hein (2016) - Le noyau blanc(N) (A)
Download: [url=http://csgoeva.com/landline-2017/]Watch Movie[/url] .
Deadly Islands
Download: [url=http://ut-consultants.com/gods-not-dead-a-light-in-darkness/]Watch Movie[/url] .
Dale Dye
Download: [url=http://sa36t.net/%d9%85%d8%b3%d9%84%d8%b3%d9%84-poldark-%d8%a7%d9%84%d9%85%d9%88%d8%b3%d9%85-%d8%a7%d9%84%d8%b1%d8%a7%d8%a8%d8%b9-%d8%a7%d9%84%d8%ad%d9%84%d9%82%d8%a9-6/]ШЩ„Щ‚Ш© 6 Щ…ШіЩ„ШіЩ„ Poldark Ш§Щ„Щ…Щ€ШіЩ… Ш§Щ„Ш±Ш§ШЁШ№ Ш§Щ„ШЩ„Щ‚Ш© 6 2018 HDTv Щ…ШіЩ„ШіЩ„ Poldark Ш§Щ„Щ…Щ€ШіЩ… Ш§Щ„Ш±Ш§ШЁШ№ Ш§Щ„ШЩ„Щ‚Ш© 6 ШЄШ§Ш±ЩЉШ®ЩЉ Щ…ШґШ§Щ‡ШЇШ© Щ€ШЄШЩ…ЩЉЩ„ Щ…ШіЩ„ШіЩ„ Ш§Щ„Ш±Щ€Щ…Ш§Щ†ШіЩЉШ© Ш§Щ„ШЄШ§Ш±ЩЉШ®ЩЉ Ш§Щ„Ш±Ш§Ш¦Ш№ ШЁЩ€Щ„ШЇШ§Ш±Щѓ Poldark S04 HD Ш§Щ„Щ…Щ€ШіЩ… Ш§Щ„Ш±Ш§ШЁШ№ Щ…ШЄШ±Ш¬Щ… Щ„Щ„Щ†Ш¬Щ… ШЈЩЉШЇШ§Щ† ШЄЩ€Ш±Щ†Ш± Ш§Щ€Щ† Щ„Ш§ЩЉЩ† Щ€ШЄШЩ…ЩЉЩ„ Щ…ШЁШ§ШґШ±[/url] .
Kensington - Control (2016) MP3 [Isohunt.to]
Download: [url=http://hydra24web.com/genre/tv-movie/]TV Movie[/url] .
Shayna McHugh - American English Pronunciation Course
Download: [url=http://sjzfuan.com/series/spartacus-blood-and-sand/]Watch movie[/url] .
Pitch Perfect 2012 Free Movie Download HD 720p
Download: [url=http://phxent.com/watch/dKo2Z03d-show-dogs/vidto.html]Play Movie[/url] .
Jason Bourne 2016 1080p BluRay x264-SPARKS[rarbg]
Download: [url=http://progweb.tk/VST-VSTi-Tags/fix-only]FIX ONLY[/url] .
Cemetery of Splendour2016
Download: [url=http://frockyou.com.au/privacy-policy]Privacy Policy[/url] .
Blood and Sand - Alex Von Tunzelmann epub
Download: [url=http://makeupforblackwomen.org/xxx/director/jules-jordan-video/]Jules Jordan[/url] .
Nine to Five 2013 REMASTERED 1980 BDRip x264-VoMiT[PRiME]
Download: [url=http://jiudaohb.com/actor/jaimie-alexander/]Jaimie Alexander[/url] .
BurnAware 9 4 Professional Repack KpoJIuK [4realtorrentz] zip
Download: [url=http://storetodoor.us/show/yu-gi-oh-vrains/]Yu-Gi-Oh! VRAINS[/url] .
Corel Painter 12.1.0.1250
Download: [url=http://jlawfirm.info/drama/life/episode-5/]Life Episode 5[/url] .
Lethal Weapon S01E01 HDTV x264-LOL[ettv]
Download: [url=http://politiclub.info/person/mark_mammone_i_.html]Mark Mammone (I)[/url] .
view all
Download: [url=http://totolagi.com/genrelist_rental.php/animation-915.html?pospage=2&wrapped=100&search_title=&tab_search_content=movies&view=0]Nächste Seite [/url] .
Kingdom Under Fire 2-2016-pc-REPACK
Download: [url=http://pasajbet.com/descargar-historias-de-princesas-volumen-1-latino.html]Historias de Princesas: Volumen 1[/url] .
Alistair Petrie
Download: [url=http://buffalokenpo.com/arrow-streaming-gratuit-4HKGP9FEL.html]9) Arrow[/url] .
FamilyStrokes - Alexis Fawx_720p mkv
Download: [url=http://latestsoftwares24.com/watch-online/brokedown]Brokedown[/url] .
Internet Download Manager v6 26 Build 9 Setup (latest) by RaymonD
Download: [url=http://fcsystems.net/index.php?page=Board&boardID=906&s=190aeea4ff2e743a3e5028428784cebc04a0026f]Hello Ladies[/url] .
BBC The Life of Mammals 3of9 Plant Predators 720p HDTV x264 AAC MVGroup org mkv
Download: [url=http://suppleancesss.com/ep/783937/the-affair-s03e08-720p-hdtv-x264-killers/]The Affair S03E08 720p HDTV x264-KILLERS [eztv][/url] .
The Flash 2014 S03E06 720p HDTV X264-DIMENSION[ettv]
Download: [url=http://sereniteservices.net/film-semi-layarkaca21]Streaming Film Semi Erotis Dewasa 18+[/url] .
Стрелата
Download: [url=http://alterarmei.com/board/157-cartoon-anime/?s=a964d317fa4f0480e131c0c037b91554a2420c0e]Cartoon Anime[/url] .
The Simple Life
Download: [url=http://citizenscaring.com/genre/release-2015]Movies 2015[/url] .
Register
Download: [url=http://salmonpound.com/bolum/smoking-1-sezon-7-bolum-asya-dizi-izle/]Smoking 1. Sezon 7. Bölüm Smoking 1. Sezon 7. Bölüm 01 Haz.[/url] .
BitLord.com
Download: [url=http://teknolojikolik.net/prod/B01HAJVOJE.html]Paperblanks Blaue Muse Mini 2017 Horizontal[/url] .
Ask Video Akai Advance 101 Learn Akai Advance TUTORiAL
Download: [url=http://wickedticketspittsburgh.com/viewforum.php?f=305&sid=b8430bcc1d7805fb5fee927f4330216a]↳ W4A SoutД›Еѕe[/url] .
Eye in the Sky2016
Download: [url=http://zsyougou.com/stefflon-don-secure-2018-mp3-320kbps-hunter-t362451.html]Stefflon Don - SECURE (2018) Mp3 (320kbps) [Hunter][/url] .
AngularJS For Beginners
Download: [url=http://mckendreecollege.net/movie/1317856038/liebe-zu-besuch]Liebe zu Besuch[/url] .
Juggling Suns - Living on Edge of Change
Download: [url=http://anthonycarestiahomes.com/category/ost/]LATEST OST[/url] .
Alaina Dawson - Football Slut, XXX, MPEG4(Xvid), C2x, HD 1080p, 0,5 FPS [Bangbros Clips] (Aug 12, 2016).avi [Isohunt.to]
Download: [url=http://weprido.com/actors/Kenneth+Choi.html]Kenneth Choi[/url] .
The Young And The Restless - S44 E11054 - 2016-11-16
Download: [url=http://papiooralsurgery.com/index.php?page=Board&boardID=896&s=59f898eea3f6ebd0a3fa9740d61fe85b0708e571]Intelligence (US)[/url] .
Assista Gratis
Download: [url=http://stampbachstein.com/prod/B012ABZV2I.html]Bosch 00298594 Geschirrspülerzubehör / Wascharme[/url] .
Girls Next Door s2 with Sophia Capri mp4
Download: [url=http://hac42.com/movies/film/just-a-question-of-love-2000/]Just a Question of Love (2000)[/url] .
Folk/Rock
Download: [url=http://36500789.com/graphics/927072-wedding-vows-septemberoctobe.html]Wedding Vows - September-October 2017[/url] .
Dawn of the Planet of the Apes 2014 LiMiTED BDRip XviD-DEFACED.torrent
Download: [url=http://hematq.net/2015/08/]Aout 2015 (40)[/url] .
how to get away
Download: [url=http://popbangphotography.com/actors/Giacomo+Beltrami.html]Giacomo Beltrami[/url] .
300mbdownload.com
Download: [url=http://weprido.com/actors/Brecken+Merrill.html]Brecken Merrill[/url] .
NHDTA527
Download: [url=http://fittest.org/signup.php?ref=Maquia: When the Promised Flower Blooms]REGISTER FREE ACCOUNT[/url] .
2.broke s05
Download: [url=http://jihuayiyuan.com/pariltili-hayatlar-the-bling-ring-2013-turkce-altyazili-izle.html]ParД±ltД±lД± Hayatlar – The Bling Ring 2013 TГјrkГ§e AltyazД±lД± izle[/url] .
Speccy 1 30 728 + Portable [4realtorrentz] zip
Download: [url=http://rotabetadres1.com/o/post/19596684/]19596684[/url] .
Trackmania Turbo-CODEX
Download: [url=http://clbanners10.com/s-w-a-t-streaming-gratuit-IMFGHMHPB9.html]S.W.A.T.[/url] .
22. Toe Fat (Ghettozone)
Download: [url=http://estiprager.net/389380/BurnAware.Professional.v11.1.inkl..P08rtable.html]BurnAware Professional v11.1 inkl.[/url] .
The Walking Dead Setima Temporada Dublado Torrent
Download: [url=http://macan88.net/filmes/filme-130336/]Back to Top[/url] .
3DMotive - Mechanical Assets in.3ds Max Volume 1
Download: [url=http://15dvdv.com/tv-star/wolfgang-petersen]Wolfgang Petersen[/url] .
Simon Pegg
Download: [url=http://puisicampus.tk/memberlist.php?mode=viewprofile&u=325660&sid=aa066883d68471a6537c92ca8856176f]crazymalamute[/url] .
Real Wife Stories_Madison Ivy, Asa Akira (02.25.2013. Brazzers)
Download: [url=http://wickedticketspittsburgh.com/viewforum.php?f=369&sid=b8430bcc1d7805fb5fee927f4330216a]↳ AnimovanГ©[/url] .
BitTorrentPro 7 9 9 Build 42607 Stable Portable [4REALTORRENTZ]
Download: [url=http://myescortdirectory.net/movie/mixed-doubles-2017-bluray-720p-850mb.html]Mixed Doubles (2017) BluRay 720p 850MB 2017 46,684[/url] .
Blindspot S01E18 HDTV x264-LOL[ettv]
Download: [url=http://inspirethisgeneration.com/blackedraw-lana-rhodes-hot-wife-loves-bbc-t169864.html]BlackedRaw - Lana Rhodes - Hot Wife Loves BBC[/url] .
DVDRip Movies
Download: [url=http://bramea.net/series69/The-Big-Bang-Theory-/season-05-episode-03-The-Pulled-Groin-Extrapolation]The Pulled Gro season 05 episode 03[/url] .
0 Comments
Download: [url=http://fiercefabulouswomen.net/games-pc/emuladores/]Emuladores[/url] .
Ghayal Once Again Hindi pDVDRip x264 mp4
Download: [url=http://seniormarketingcouncil.com/jurassic-predator-2018/]Watch Movie[/url] .
Star Trek Beyond (2016) Hindi Dual Audio Movie BRRip 720p 1GB
Download: [url=http://kartuatm.com/actor/diego-catano/]Diego CataГ±o[/url] .
thevideo.me
Download: [url=http://gsobet.net/starship-troopers-traitor-of-mars-2017/]Watch Movie[/url] .
Impastor S02E08 720p HDTV x264-FLEET[PRiME]
Download: [url=http://pasajbet.com/descargar-el-juego-del-miedo-5-latino.html]El Juego del Miedo 5[/url] .
Benidorm
Download: [url=http://fromrimtostem.com]fromrimtostem.com[/url] .
pthc.Pedoland.Frifam.2010.kgirl.-.Fucking.My.8yo.Daughter.rar.rar
Download: [url=http://antapai.com/release/high-class-filter-backbone-single/9646501]High Class FilterBackbone - Single Electronic, Breakbeat/Breaks[/url] .
Reputation
Download: [url=http://728102.com/watch/the-spy-who-dumped-me-2018.html]The Spy Who Dumped MeDuration: 117 min[/url] .
Anger Management S02E48 REPACK HDTV x264 KILLERS rarbg
Download: [url=http://tanos-dota.tk/peliculas/46698-g-i-joe-2009-online.html]G.I. Joe[/url] .
The Weather Man(A)
Download: [url=http://ibexiran.net/the-blacklist-streaming-gratuit-CDPHFPMEK.html]16) The Blacklist[/url] .
Krampus - Counter Current (2016)
Download: [url=http://lookupchat.info/sharp-objects/sharp-objects-season-1-hdtv-sd720p/]Sharp.Objects.S01E07.HDTV.x264-TURBO[/url] .
[mp4] Kathakali (2016) Movie 720p UNCUT H...
Download: [url=http://madriverrailroadbnb.com/forums/fantasy-sports-gambling.31/threads/trade-amari-cooper-for-crabtree.579968/]trade Amari Cooper for Crabtree?[/url] .
Browse categories
Download: [url=http://coisasdenamorados.com/actors/Benito+Martinez.html]Benito Martinez[/url] .
De Palma (2016)
Download: [url=http://meisituo.com/ep/1141247/elementary-s06e17-720p-hdtv-x264-killers/]Elementary S06E17 720p HDTV x264-KILLERS [eztv][/url] .
One Tree Hill
Download: [url=http://zarachicago.com/?tv&curPage=2]Next »[/url] .
Working-Class Stiff gay
Download: [url=http://deplantas.net/tbs/angie-tribeca3/]Angie Tribeca[/url] .
???? ?? torrent
Download: [url=http://gadisqiu.net/happyish/]Happyish[/url] .
WWE Talking Smack 2016 11 15 720p WEB h264-HEEL [TJET]
Download: [url=http://wfdrsm01.com/phim-moi/]Phim Mб»›i[/url] .
(2015) DVD Sleeping with Other People
Download: [url=http://vestabilling.com/magazin/filmnews/willkommen-blu-ray-3d-60.html]Blu-ray 3D Special[/url] .
Rivermen
Download: [url=http://dating-magazine-uk.com/serie/Im-Knast]Im Knast[/url] .
corel draw x6
Download: [url=http://teknolojikolik.net/prod/B000AYQJJC.html]Gary Lineker Football Challenge [UK Import][/url] .
The Ultimate Fighter S24E10 720p HDTV H264 Fight-BB
Download: [url=http://pinbahis6.com/show/the-office-uk/]The Office (UK)[/url] .
Ink Master Redemption S03E10 HDTV x264-KILLERS[ettv]
Download: [url=http://291hgvip.com/it/baldi-s-basics-in-education/com.BaldisBasicsinEducationandLearning]Baldi's Basics in Education APK[/url] .
Wondershare Pdf Creator v1.1.0.1813 (Mac OSX)
Download: [url=http://spendbitcoins.mx/movies/cast/tiffany-espensen/]Tiffany Espensen[/url] .
Jurassic World
Download: [url=http://fatalhome.us/torrents/lapping up my cumcicle]lapping up my cumcicle[/url] .
TELECHARGER Film Theeb - la naissance d'un chef 20x plus rapidement avec Usenet - 14 jours gratuits
Download: [url=http://56dvdv.com/index.php?/topic/4283-colecciones-de-juegos/?view=getlastpost]29 jul 2018[/url] .
Waves Complete v9 6 for MAC-OSx
Download: [url=http://tigerswarm.com/forumdisplay.php?fid=260]General - Others[/url] .
windows 8
Download: [url=http://gz-11.com/serie/stream/life-sentence]Life Sentence Drama[/url] .
The Science And Technology Of An American Genius: Sanford R. Ovshinsky (repost)
Download: [url=http://laskowent.com/serien/englische-untertitel-vos/board753-the-chicago-code.html?s=2dea97c7ee07c9b2c0e29e20052f1c61d219bbf2]The Chicago Code[/url] .
31 (2016) Movie Free Download 720p BluRay 800MB
Download: [url=http://mypeoplemybusiness.com/category/series-terminadas/constantine/]Constantine[/url] .
Terminator The Sarah Connor Chronicles
Download: [url=http://truthorconsequences.net/chapter/hiraheishi_wa_kako_o_yumemiru/chapter_17]Chapter 17 : Chapter 17[/url] .
Blindspot S02E09 1080p HDTV X264 mp4
Download: [url=http://lzliufeng.com/release/hazelsoja-keep-it-real-single/9650332]HazelsojaKeep It Real - Single Electronic, Downtempo[/url] .
The 4400
Download: [url=http://getcleangreen.net/diziler/youre-the-worst/]• You’re the Worst 7.5[/url] .
Forever Us 2016 XXX DVDRip x264-Fapulous
Download: [url=http://maudentrangtri.com/serien/abgesetzte-beendete-serien/board1154-getting-on-us.html?s=6d2fe202f5cc51a47aa96035393ff3d38f989d21]Getting On (US)[/url] .
Will Smith,
Download: [url=http://starbet7.net/?o=130]Medikation Nahrungsergnzung[/url] .
Burn Notice
Download: [url=http://wickedticketspittsburgh.com/memberlist.php?mode=viewprofile&u=17353&sid=0f4d993bed217e94c1b080beafbad65a]Strycek Nuget[/url] .
Fort Tilden 2014 RERiP BDRip x264-WiDE
Download: [url=http://digromy.net/tag/red-sparrow-film-torrent-en-francais/]Red Sparrow Film Torrent en français[/url] .
Quantum Leap
Download: [url=http://ynnantai.com/naked-news-season-2018-episode-198-s2018e198_423655]Naked News Season 2018 Episode 198 s2018e198[/url] .
most famous albums
Download: [url=http://51wxsz.com/shahs-of-sunset/season-7/episode-4/videos/mj-breaks-down-while-she-shops-for-a-wedding-dress]Preview Shahs of Sunset MJ Breaks Down While She Shops For a Wedding Dress S7/Ep4: MJ brings Reza and Mike wedding dress shopping. Watch Video 2 days ago[/url] .
Stargate Atlantis
Download: [url=http://ootms.org/movie/6434-die-hard-1988-yify-torrent]Die Hard[/url] .
Rosemarie DeWitt,
Download: [url=http://sebar8girl.net/%d9%81%d9%8a%d9%84%d9%85-sarkar-3-2017-dvdscr-%d9%85%d8%aa%d8%b1%d8%ac%d9%85/]32753 Ш§ЩЃЩ„Ш§Щ… Щ‡Щ†ШЇЩЉ ЩЃЩЉЩ„Щ… Sarkar 3 2017 DVDSCR Щ…ШЄШ±Ш¬Щ… Щ…ШґШ§Щ‡ШЇШ© Щ€ШЄШЩ…ЩЉЩ„ ЩЃЩЉЩ„Щ… Ш§Щ„Ш¬Ш±ЩЉЩ…Ш© Щ€ Ш§Щ„ШЇШ±Ш§Щ…Ш§ Ш§Щ„Щ‡Щ†ШЇЩЉ Sarkar 3 2017 Щ…ШЄШ±Ш¬Щ… ШЁШ·Щ€Щ„Ш© Ш§Щ„Щ†Ш¬Щ… Ш§Щ…ЩЉШЄШ§ШЁ ШЁШ§ШЄШґШ§Щ† ШЁШ¬Щ€ШЇШ© DVDSCR ЩѓШ§Щ…Щ„ Ш§Щ€Щ† Щ„Ш§ЩЉЩ† 5.2[/url] .
Alanis Morissette - Live At Montreux
Download: [url=http://ah-cl.com/tag/online-free/]online free[/url] .
Leigh Bardugo - Six Of Crows, Book 2: Crooked Kingdom - eBook [Isohunt.to]
Download: [url=http://editormvp.com/movie/the-equalizer-2-2018.html]The Equalizer 2 (2018) HDCAM 450MB 2018 28,284[/url] .
Sex Ed 2014 BRRip XviD MP3-RBG
Download: [url=http://fvlui.com/graphic/163655-graphicriver-art-fest-flyer-template.html]GraphicRiver Art Fest Flyer Template[/url] .
Film Indonesia
Download: [url=http://pinkpandastars.com/index.php?page=Board&boardID=838&s=0eab5bfbf5b6429920c791ba2af0c484527ca165]Bates Motel[/url] .
Application Software and feature of Digital Communications (2016)
Download: [url=http://bemestaremversos.com/index.php?page=Board&boardID=657&s=68fef26a18793e0217ff68140407a2b0608d406d]The Secret Circle[/url] .
Taboo Sister Fantasies - Viky, Ms Jones and Rick (Jerk It In Mommy's Kitty)
Download: [url=http://cacuoc.net/videos/watch/spider-man-homecoming-civil-war-suit-pc-mod-gameplay-hd-1080p-60-fps-tasm2-mods-511373329/]SPIDER-MAN HOMECOMING (Civil War Suit) PC Mod Gameplay [HD 1080P 60 FPS] (TASM2 Mods)[/url] .
Trademarks for Entrepreneurs, Awesome Illustrations Enclosed
Download: [url=http://skinsking.net/51EF089B0F10EE8D93BCAEE20650F7615FD4B929/Microsoft-Office-For-Mac-2017-v18-52-Update-License]Microsoft Office For Mac 2017 v18 52 Update License[/url] .
A Million WAys to Die in the West 2014 Webrip x264 AC3 TiTAN
Download: [url=http://papiooralsurgery.com/index.php?page=Board&boardID=785&s=5c6b448ab9e0e0155b75ba1271390d9ff11c9f41]Moone Boy[/url] .
10 Cloverfield Lane (2016) BrRip Dual Audio 480p Movie 300Mb
Download: [url=http://globalsportsjobsuefade.com/faking-it-2014-season-2-episode-7-s02e07_359934]Season 2 Episode 7 Date Expectations[/url] .
Chicago Blackhawks - Montreal Canadiens 13 11 16 mkv
Download: [url=http://cuishishepin.com/tag/full-movie-down-a-dark-hall-livestream/]full movie Down a Dark Hall livestream[/url] .
??‰e»??„ ?€
Download: [url=http://totaldhamaal.net/watch-hard-knocks-season-13-2017-free-123movies.html]Hard Knocks Season 13 (2017)[/url] .
Anggun 12
Download: [url=http://xintianyuanlin.com/space-season-1-complete-download/]Other Space season 1[/url] .
Jolidon Lingerie Collection - Spring-Summer 2017 - True PDF - 1794 [ECLiPSE]
Download: [url=http://turkpix.biz/descargar-el-experimento-de-la-carcel-de-stanford.html]El Experimento De La Carcel De Stanford[/url] .
The Great Canadian Tax Dodge HDTV x264 720p AC3 MVGroup org mkv
Download: [url=http://morethanpawsct.biz/index.php?page=Board&boardID=490&s=cb82bfafa2b7f638d7220128f2f657e1f4957bbb]The Office (US)[/url] .
MasterChef Сезон 2 Епизод 39 25.05.2016
Download: [url=http://takezou-musashi.com/actors/Nick+Sagar.html]Nick Sagar[/url] .
Stone Sour Do Me A Favor Official Video
Download: [url=http://espacebios.be/movies/film/ninna-2018/]Ninna (2018)[/url] .
Photography Week - 17 November 2016 - True PDF - 1838 [ECLiPSE]
Download: [url=http://clbanners8.com/watch/occupation-2018-xmovies.html]Occupation (2018)[/url] .
Delicious
Download: [url=http://cqpaozhen.com/cast/preston-bailey/]Preston Bailey[/url] .
Clea DuVall,
Download: [url=http://katethompson-healthk.net/actor/omar-chaparro]Omar Chaparro[/url] .
Upper Middle Bogan - S03E05 - Sticking To Your Principals mp4
Download: [url=http://my-chek.com/torrent/lost-in-space-2018-s01e06-720p-webrip-x264-webtiful-ettv--204991]Lost.in.Space.2018.S01E06.720p.WEBRip.x264-WEBTiFUL[ettv][/url] .
H0930-ori1193-FHD
Download: [url=http://antiquesatbutternutbrook.com/descargar-zootopia-latino.html]Zootopia[/url] .
view all
Download: [url=http://sanlidan.com/02130417-krila-1981-10/]Krila – 1981-10[/url] .
The Hotwives of Orlando
Download: [url=http://maudentrangtri.com/serien/drama/board1364-code-black.html?s=93d5666b485db694f23b711d5992eaf942f6659c]Code Black[/url] .
APES.REVOLUTION-Il.Pianeta.Delle.Scimmie.2014.iTALiAN.BRRip.XviD.BLUWORLD
Download: [url=http://burgle.tk/torrent/jeu-vidГ©o/sony/298282-ps1+xenogears+ntsc+-+fr][PS1] Xenogears (NTSC - Fr)[/url] .
hotest torrents
Download: [url=http://postmenapi.net/?cat=spradbrems]Bremsen Bremsbelge[/url] .
Reggae Songs Of Sia
Download: [url=http://trashpanda.net/ep/1140822/judge-judy-s22e232-pit-bull-mating-mayhem-slashed-tires-hdtv-x264-w4f/]Judge Judy S22E232 Pit Bull Mating Mayhem Slashed Tires HDTV x264-W4F [eztv][/url] .
New Karaoke November 2016 CDG+MP3
Download: [url=http://biblicalturkeyguide.com/films/realisateur/chris-renaud.html]film de Chris Renaud[/url] .
Черешката на тортата
Download: [url=http://suv101.tk/category/237/infinity-challenge-special]Infinity Challenge Special[/url] .
Read More
Download: [url=http://vivekangen.com/the-zookeepers-wife-2017/]Watch Movie[/url] .
SUPERAntiSpyware Professional 6 0 1224 Final
Download: [url=http://draperinsurance.net/watch-mickey-mouse-season-4-2017-1080p-full-movies-9movies.html]Eps4 Mickey Mouse - Season 4 (2017)[/url] .
Psychedelic Stoner / Doom Metal
Download: [url=http://tenzynsonorisation.be/own-shows/greenleaf/]Greenleaf[/url] .
Resident Evil 3 Torrent 2007 Full HD Movie Free Download
Download: [url=http://luggagestoragehongkong.com/watch-the-invisible-guardian-2017-online-free-putlocker-2329.html]WEBRip The Invisible Guardian (2017)[/url] .
Бессарабия в составе Российской империи 1812-1917
Download: [url=http://belladea.org/ep/163519/a-place-to-call-home-s04e10-ahdtv-x264-futv/]A Place To Call Home S04E10 AHDTV x264-FUtV [eztv][/url] .
[?????] [150211] TV??????????(Shigatsu wa Kimi no Uso)?ED2?????????/7!! [????????] (FLAC+BK) torrent
Download: [url=http://bondoce.info/community/forums/receivers-separates-amps.66/]AV Receivers[/url] .
Play With Me 4 s4 with Stacy Thorn mp4
Download: [url=http://laotieqi.com/watch/pxw55jdz-tell-me-your-name.html]More Details[/url] .
westworld
Download: [url=http://wmeclub.com/community/forums/home-theater-projects.36/threads/things-i-wish-i-would-have-done-differently-in-my-project.203975/]Things I wish I would have done differently in my project[/url] .
independence day
Download: [url=http://perek.tv/films/4309-45-ans.html]45 Ans VOSTFR[/url] .
Genius streaming
Download: [url=http://oneskinbeautystudio.com/download/vsti/dyvision-works]Dyvision Works[/url] .
Saheb Bibi Golaam (2016)
Download: [url=http://98dvdv.com/descargar-la-habitacion-del-panico-latino.html]La Habitacion Del Panico[/url] .
Metro 2013 mp4
Download: [url=http://daico3.org/filme/meeresfruechte/]MeeresfrГјchte[/url] .
hunter x hunter
Download: [url=http://ooani.net/phim-khoa-hoc-vien-tuong/]Phim Viб»…n TЖ°б»џng[/url] .
I Am Number Four 2011 (1080p Bluray x265 HEVC 10bit AAC 5 1 Tigole)
Download: [url=http://895577.net/game-of-thrones-season-2-s02-1080p-bluray-hevc-x265-n0m1-v2-t12407626.html]Game of Thrones Season 2 S02 1080p BluRay HEVC x265-n0m1 (V2)[/url] .
Charts Historicos
Download: [url=http://thelogodb.com/index.php?page=Board&boardID=1096&s=1c1336f92d3447e62329c1d745a5b332245dc8d6]The Handmaid's Tale (1)[/url] .
Massive 54000 Presets [dada]
Download: [url=http://lichtonline.be/download/presets-patches/tal-bassline-101]TAL BASSLiNE-101[/url] .
Witches of East End
Download: [url=http://nmgfntx.com/the-unit-commando-d-elite-streaming-gratuit-1RI3AQI.html]The Unit : Commando d'Г©lite[/url] .
Read More
Download: [url=http://ts3asia.net/release/offenbarung-23-folge-5-das-handy-komplott/9647711]Offenbarung 23Folge 5: Das Handy-Komplott Audiobook[/url] .
the walking dead S07
Download: [url=http://deplantas.net/abc/becoming-us/]Becoming Us[/url] .
Animacao
Download: [url=http://ircccloud.com/f303/]Kristen Stewart[/url] .
Direct Download Cardboard Boxer (2016) 720p BRrip x264-IchiMaruGin.zip
Download: [url=http://sygcdq.com/viewforum.php?f=179&sid=b14d9b22b87cc6bd66f2c5b7a5756774]ProgramovГЎnГ[/url] .
Scott Frank, Steven Zaillian - The Art of Screenwriting Collection
Download: [url=http://xsxcks.com/filme/transformers-3/]Transformers 3[/url] .
(Trance) VA - ADE Trance Anthems (2016) Mp3, 320 Kbps [EDM RG]
Download: [url=http://signifyseed.com/prod/B01N3TCFS4.html]Electrolux AEG 807035801 8070358018 ORIGINAL[/url] .
Science Fiction 7,256
Download: [url=http://turizmsektoru.tk/forumdisplay.php?fid=260]General - Others[/url] .
Кошмари в кухнята
Download: [url=http://ynnantai.com/eureka-season-4-episode-15-s04e15_286384]Season 4 Episode 15 Omega Girls[/url] .
Penthouse Fathers Id like To Fuck 2 XXX 2015 HDTV 720p x264-SHDXXX
Download: [url=http://coloradohome.us/tw/critical-ops/com.criticalforceentertainment.criticalops/download?from=home%2Fnew]дё‹иј‰ XAPK[/url] .
vampire diaries
Download: [url=http://pinkpandastars.com/index.php?page=Board&boardID=788&s=2547411bb3fa682fcd8362a89f37d8f0c3e145ee]Last Resort[/url] .
Most Seeded
Download: [url=http://clztf.com/video-movie-the-snowtown-murders-biography-crime-drama-full-length-movie-justin-kurzel.h5ljY3yVmaFmh2U.html]The Snowtown Murders - Biography, Crime, Drama | Full Length Movie | Justin Kurzel[/url] .
NoBoring Licia Sweetie gets her ass stretched mp4
Download: [url=http://ynnantai.com/death-in-paradise]Death in Paradise 8.2[/url] .
Everest.2015.720p.BluRay.x264-NeZu
Download: [url=http://otoguvencikmaparca.com/media/movies/188785-hitman-2007-1080p-bluray-x264-sinners.html]Read more...[/url] .
Granger Smith Tailgate Town.mp4
Download: [url=http://premiumglobalbrands.net/watch/concealed-2017-xmovies.html]Concealed (2017)[/url] .
Akaneiro: Demon Hunters
Download: [url=http://pentaskartu.com/download/34183/spicy-latina-teens]Latina.Teens.XXX.DVDRip.x264-FBGM[/url] .
hindi 2016
Download: [url=http://yongqingquan.com/actors/Tracy+Reiner.html]Tracy Reiner[/url] .
John From Cincinnati
Download: [url=http://howtomakeextramoneyfromhome.com/index.php?page=Board&boardID=650&s=e4fba662e983022c4723f592c81e277985e980a4]Happy Endings[/url] .
Addicted to Fresno 2015 iNTERNAL BDRip x264-LiBRARiANS[PRiME]
Download: [url=http://re-3535.com/release/joel-s-goldsmith-mystical-life-and-law-continued-1958-first-chicago-closed-class-number-209b-live/9659250]Joel S. GoldsmithMystical Life and Law (Continued) [1958 First Chicago Closed Class, Number 209b] [Live] Gospel, Audiobook[/url] .
7aum Arivu (2011) Dual Audio Full Movie Hindi HDrip 480p
Download: [url=http://legitrtohouses.com/index.php?page=Board&boardID=971&s=3c34b32aa3460301ceed0d467b9a5828c0510673]Avatar - The Legend of Korra[/url] .
Recommended
Download: [url=http://ts3asia.net/release/mc-fioti-pГЈram-pГЈram-single/9648983]MC FiotiPГЈram PГЈram - Single Rhythm and Blues, Funk, Brazilian[/url] .
The Catch
Download: [url=http://woopcreative.com/home/top/new-hiphop]New Hiphop[/url] .
Сезон 1 БГ СУБТИТРИ
Download: [url=http://arminiabd.com/show/prison-break/]Prison Break[/url] .
WonderFox DVD Ripper Pro 8 1 + KeyGen zip
Download: [url=http://thirdspaceevent.com/category/regarder-series-vf/]series vf[/url] .
35 Biggest Hits By Tim Mcgraw
Download: [url=http://xinxingdianqi.net/series71/THE-WALKING-DEAD-/season-01-episode-03-Tell-It-to-the-Frogs]Tell It to the season 01 episode 03[/url] .
??? BJ?? ?? (????TV,??????,???,??,????,??TV,??TV,????,????,BJ??,BJ,??,2??,3??,?????,?????TV)
Download: [url=http://clbanners10.com/gadget-et-les-gadgetinis-streaming-gratuit-HA3P9HJXV.html]Gadget et les gadgetinis[/url] .
??(13)
Download: [url=http://weddingringz.net/watch/ski-school-1990.html]Ski School Duration: 95 min[/url] .
Walking dead
Download: [url=http://ix-bet.net/movie/night-train-to-lisbon-full-movie-watch-online-free-720p-download/]Night Train to Lisbon Full Movie Watch Online Free 720p Download[/url] .
100 000 Анекдотов.pdf
Download: [url=http://aa-first.com//aa-first.com/watch-the-man-in-the-high-castle-online/]The Man in the High Castle[/url] .
Ricky Martin Ft Maluma - Vente Pa Ca MP3 320 kbps, 2016
Download: [url=http://bitcoinloophole.cc/series/undercover-high/]Watch Movie[/url] .
Clevland Indians Chicago Cubs Game 7 World Series 2016 [WWRG]
Download: [url=http://hac42.com/movies/film/the-spy-who-dumped-me-2018/]The Spy Who Dumped Me (2018)[/url] .
Petes Dragon 2016 720p BluRay x264-BLOW[EtHD]
Download: [url=http://re-3535.com/release/mc-livinho-soul-proibido-feat-mc-livinho-single/9606732]MC LivinhoSoul Proibido (feat. MC Livinho) - Single Brazilian[/url] .
how i met your
Download: [url=http://msrubyshhc.com/ravens-home-3/]Raven’s Home[/url] .
Suicide.Squad.2016.[MKV]
Download: [url=http://stylovaparty.cz/viewtopic.php?t=3464640]Заказы и энкод из темы - Заказ рипов в AVC -[/url] .
Bert Visscher - 2013 - Afijn [Isohunt.to]
Download: [url=http://vesicapiscis.org/index.php?page=Board&boardID=469&s=d2ba1d59a094377e13424f839fb11e364cd02f90]Jane Eyre[/url] .
Die glorreichen Sieben Online anschauen
Download: [url=http://betturka155.com/watch/i-promise-you-anarchy.nr6m8]HDRip I Promise You Anarchy[/url] .
1st Grade Basic Skills: Reading and Math - Thinking Skills
Download: [url=http://mostpopularhairext.com/Movies/High-Quality/]High Quality[/url] .
PointWise v18.0 R1
Download: [url=http://ocra.eu/actors/Carrie+Coon.html]Carrie Coon[/url] .
bates motel s04 french
Download: [url=http://salliessilica.com/britannia-8/]Britannia[/url] .
The Flash 2014 S03E06 Shade 720p WEB-DL DD5 1 H264-RARBG-kovalski mkv
Download: [url=http://monster777.com/descargar-torrents-variados-357-Minitab-v1623.html]Minitab v16.2.3.[/url] .
Follower Stats for Instagram
Download: [url=http://mah007.tk/wonder-woman-2017_948da62ba.html]Wonder Woman (2017)[/url] .
Jimmy Fallon 2016 11 15 Warren Beatty HDTV x264-CROOKS[rarbg]
Download: [url=http://innovatus.eu/watch/dBrDgyMd-show-dogs/other.html]Play Movie[/url] .
American Horror Story Cast – Criminal (from American Horror Story) [fe...
Download: [url=http://spin-genie.com/watch-my-days-of-mercy-full-movie-online-free-5862.html]My Days of Mercy (2017)[/url] .
Aldous Huxley - Scho?ne Neue Welt
Download: [url=http://baixarseriestorrent.com/ch-UCpHTv1eQBeSlrdmlh8C6ZxQ]DannyJesden[/url] .
Drum Solo
Download: [url=http://h0190.com/assistir-filme/a-nova-onda-do-imperador-dublado-e-legendado-online/]A Nova Onda do Imperador DUBLADO E LEGENDADO ONLINE[/url] .
Home 2015 HD ????? ????? 6.7
Download: [url=http://dutchees.eu/chicago-fire/news/?nid=27213]Fans der Serien Chicago Fire und Chicago Med sollten sich nun einen Stift zur Hand nehmen, um sich den Starttermin bei Universal Channel markieren zu knnen.... mehr[/url] .
Integrated Sports Massage Therapy - True PDF - 1793 [ECLiPSE]
Download: [url=http://msrubyshhc.com/arrested-development-ti-presento-i-miei/]Arrested Development – Ti Presento I Miei[/url] .
Caroline Ardolino mp4
Download: [url=http://allevamentoconiglioarietenano.com/thread/75114-boardregeln/?action=firstNew&s=f3404a0dc30590b86efef1a2fb85f9dd2e289074]Boardregeln[/url] .
Oh Sir! The Insult Simulator - 2016 (MacAPPS)
Download: [url=http://mobtuts.net/the-principal]The Principal[/url] .
Resume & CV
Download: [url=http://comparatifbanques.eu/The-Facebook-ROI-Master-Class-by-Tom-Glover_3701250.html]The Facebook ROI Master-Class by Tom Glover[/url] .
Internet Download Manager (IDM) v 6 26 Build 1 + Patch [4realtorrentz] zip
Download: [url=http://jdplgd.com/watch/the-rachel-divide/ALcFqC]Watch now[/url] .
True Blood S05E07 True Blood S05E07 HDTV x264-FQM [NTV] mp4 mp4
Download: [url=http://shellforwindows.com/series/the-graham-norton-show-season-22/1iDdUmm9]The Graham Norton Show- Season 22 ep.19[/url] .
SexArt - Perfect Awakening - Dolly Diore [720p] mp4
Download: [url=http://advancedmedicalsoftware.com/torrent/16793163/adrift-2018-webrip-720p.html]Adrift (2018) [WEBRip] [720p][/url] .
Money Monster
Download: [url=http://vivaverdi.eu/actor/linnea-larsdotter]Linnea Larsdotter[/url] .
BitLord.com
Download: [url=http://bresciapools.com/watch/x0ojKX4v-the-spy-who-dumped-me/vidto.html]Play Movie[/url] .
The Simpsons S25E17 HDTV x264-LOL
Download: [url=http://bbkk.info/watch/larva-bubblegum-2017-full-movie-cartoon-cartoons-for-children-kids-tv-shows-full-episodes/I2E7oDAz7jI.html]LARVA - BUBBLEGUM | 2017 Full Movie Cartoon | Cartoons For Children | Kids TV Shows Full Episodes[/url] .
OO Defrag Professional Edition 20 0 Build 427 - 32bit 64bit [ENG] ...
Download: [url=http://zhonghongweixiu.com/vorgeschlagene-serien/vote:9475]Peter Strohm[/url] .
BBC The Life of Mammals 2of9 Insect Hunters 720p HDTV x264 AAC MVGroup org mkv
Download: [url=http://speisekarten-hotelmappen.eu/tv-programm/jamies-5-zutaten-kueche/spaghetti-carbonara-thailaendische-huehnersuppe-und-omelette/bid_131100781/]Kochkurs GB 2017[/url] .
Norsk (BokmA?l)
Download: [url=http://291hgvip.com/tw/poke-club-raid-report-platform/com.yk.app.pokeclub/download?from=home%2Ftopic%2Ftop-new-apps]дё‹иј‰ APK[/url] .
Alice Through The Looking Glass (2016) MULTI TRUEF...(A)
Download: [url=http://coisasdenamorados.com/watch/the-sinner-s02-2017-online.html]Watch movie[/url] .
Bush Master
Download: [url=http://belladea.org/ep/412272/last-week-tonight-with-john-oliver-s04e18-hdtv-x264-uav/]Last Week Tonight With John Oliver S04E18 HDTV x264-UAV [eztv][/url] .
Expedition Unknown S03E03 The Vanished Empire iNTERNAL HDTV x264-SDI - [SRIGGA]
Download: [url=http://q-bit.tk/subtitles/movieid-328289/]Ghost Wars 2017[/url] .
BBC The Life of Mammals 6of9 Opportunists 720p HDTV x264 AAC MVGroup org mkv
Download: [url=http://viagrav.net/tv/17/]Stargate Atlantis[/url] .
Murder In Melbourne mkv
Download: [url=http://buffalokenpo.com/nexo-knights-streaming-gratuit-6FO87YGHT.html]Nexo Knights[/url] .
Soldiers of the Damned 2015 HDRip XviD AC3 EVO
Download: [url=http://laberator.com/%d9%81%d9%8a%d9%84%d9%85-%d9%85%d8%b1%d8%a7%d8%aa%d9%8a-%d9%85%d8%af%d9%8a%d8%b1-%d8%b9%d8%a7%d9%85-1966/]ЩЃЩЉЩ„Щ… Щ…Ш±Ш§ШЄЩЉ Щ…ШЇЩЉШ± Ш№Ш§Щ… 1966 Щ‚ШµШ© Ш§Щ„ЩЃЩЉЩ„Щ…: ЩЉЩЃШ§Ш¬ШЈ ШШіЩЉЩ† Ш№Щ…Ш± Ш±Ш¦ЩЉШі Щ‚ШіЩ… Ш§Щ„Щ…ШґШ±Щ€Ш№Ш§ШЄ ШЁЩ†Щ‚Щ„ ШІЩ€Ш¬ШЄЩ‡ Ш№ШµЩ…ШЄ Щ…ШЇЩЉШ±Ш§Щ‹ Щ„ШґШ±ЩѓШ© Ш§Щ„ШҐЩ†ШґШ§ШЎШ§ШЄ Ш§Щ„ШЄЩЉ...[/url] .
The Bulletproof Diet - Lose up to a Pound a Day, Reclaim Energy and Focus, Upgrade Your Life.epub
Download: [url=http://instava.eu/gif-erstellen/]GIF erstellen[/url] .
Intelligence US S01E13 HDTV x264 LOL
Download: [url=http://ruidaxicheji.com/ver/murder-in-the-first]Murder In The First[/url] .
XYplorer 17.30.0100 Multilingual + Portable
Download: [url=http://92tvtv.com/watch/the-shelter-2016.html]The ShelterDuration: 75 min[/url] .
Empire.2015.S02E03.720p.HDTV.x264-KILLERS[brassetv]
Download: [url=http://biblicallylogicalthinking.org/programme/fussballmanager/]fussballmanager[/url] .
??????
Download: [url=http://customgames.eu/odds/graph/emmy-awards-2018/movie-mini-supp-actor/](more info)[/url] .
2 Broke Girls S05E22 And the Big Gamble (2011)
Download: [url=http://my-chek.com/torrents-search.php?search=Arrow.S06E02.HDTV.x264+LOL+ettv&sort=relevance]Arrow.S06E02.HDTV.x264 LOL ettv[/url] .
Meek Mill - Dreamchasers 4 (320kbps) [MP3PIN] [Isohunt.to]
Download: [url=http://financesheets.com/filme/riddick-chroniken-eines-kriegers/]Riddick - Chroniken eines Kriegers[/url] .
littlegirlfuck
Download: [url=http://secpaketini.com/abc/bewitched/]Bewitched[/url] .
mide 360(10)
Download: [url=http://movies365.cc/l-ile-mysterieuse-2005-streaming-gratuit-UNDGHPGP87.html]L'ГЋle mystГ©rieuse (2005)[/url] .
Revelations
Download: [url=http://hangrygaminggear.com/series/regarder/189-younger-saison-5-episode-10-streaming.html]Episode 10[/url] .
NASA 50 Years Of Space Exploration
Download: [url=http://meucaominhavida.com/person/dallas_peplow.html]Dallas Peplow[/url] .
[Aozora] Dokidoki! Precure - 26 [06EB3520].mkv
Download: [url=http://lzliufeng.com/release/offenbarung-23-folge-5-das-handy-komplott/9647711]Offenbarung 23Folge 5: Das Handy-Komplott Audiobook[/url] .
Изгубена парола?
Download: [url=http://innovatus.eu/watch/GObzkXyx-show-dogs/openload.html]Play Movie[/url] .
X-Men: Days of Future Past 2014 HD ????? ????? 8.0
Download: [url=http://tvpanda.net/watch/yGD2PZv6-black-clover-tv-dub.html]Black Clover (tv) (dub)[/url] .
Idiot's Guides - Leather Crafts (2016) (Epub) Gooner
Download: [url=http://sihaiapp.com/movie/super-troopers-2/]Super Troopers 2[/url] .
Сезон 1 БГ СУБТИТРИ
Download: [url=http://cryptosdk.net/like-father-2018-full-movie/]Watch Movie[/url] .
W.A.S.P. - W.A.S.P. (1984)
Download: [url=http://gaycc.cc/genere/romantic/]Romantic[/url] .
Storage Space 4.3.7 Premium
Download: [url=http://zhonghongweixiu.com/serie/serie/The-Walking-Dead/1/4-Vatos/OpenLoad]OpenLoad[/url] .
AYM (2016) HQ DVDScr
Download: [url=http://vivalacrypto.com/watch/ncis-naval-criminal-investigative-service-season-6-online-free-35049.html]NCIS: Naval Criminal Investigative Service Season 6 (views: 25)[/url] .
Key and Peele
Download: [url=http://ldpr.tk/category/%d9%85%d8%b3%d8%b1%d8%ad%d9%8a%d8%a7%d8%aa/]Щ…ШіШ±ШЩЉШ§ШЄ[/url] .
The Flash 2014 S03E06 HDTV 480p x264 AAAC-VYTO[P2PDL com]
Download: [url=http://rapyagap.tk/posts/12106266/]Transsexual-Shemale Mania - Hq picture - fantasize in world Transgender[/url] .
Dj B Mello Bbq Mix Live 2012
Download: [url=http://realsaiyan.com/tv-programm/home-rescue-wohnen-in-der-wildnis/eine-frage-des-vertrauens/bid_131324955/]Home Rescue - Wohnen in der Wildnis[/url] .
DC Comics Chronology - Revised v.1.0 (1957)
Download: [url=http://lightbrighthighway.com/watch/teen-titans-go-to-the-movies-2018.html]Teen Titans Go! To the Movies Duration: 84 min[/url] .
Celebrity Antiques Road Trip S06E03 - Ruth Madoc and Su Pollard
Download: [url=http://2000cai8.com/movies/tanzania-movies/]Tanzania[/url] .
AmKingdom.com_16.10.28.Babes.Series.2.Allure.Rose.XXX.IMAGESET-FuGLi[rarbg]
Download: [url=http://acch.eu/ver/attack-on-titan-3x06.html]3x06 Ataque a los Titanes[/url] .
A Tale of Love and Darkness 2015 Movie Free Download 720p BluRay
Download: [url=http://bjtangyong.com/watch/tag-2018-online.html]Watch movie[/url] .
American Horror Story S06E10 HDTV x264-FUM[ettv]
Download: [url=http://puregreensforlife.net/all/overcooked-v20161202-incl-all-dlc-t6025383.html]Overcooked v20161202 Incl ALL DLC[/url] .
Earthship - Hollowed (2016)
Download: [url=http://pinbahis6.com/show/100-things-to-do-before-high-school/]100 Things To Do Before High School[/url] .
Mannertag anschauen
Download: [url=http://innovatus.eu/watch/OGgaOyvR-jackie-chan-adventures-4-dub.html]Jackie Chan Adventures ...[/url] .
WonderFox DVD Video Converter + KeyGen
Download: [url=http://tzlqjingyi.com/category/series-atuais/this-close/]This Close[/url] .
The Flash 2014 S03E06 HDTV x264-LOL[ettv]
Download: [url=http://895577.net/community/ultra-s-pictures-and-fun/]Ultra's Pictures and Fun[/url] .
[JTBC] ?? ??.E47.161022.720p-NEXT
Download: [url=http://hyperbg.com/movies/director/eli-sasich/]Eli Sasich[/url] .
Alan Jackson - Who I Am WAV
Download: [url=http://traiteurnicalek.be/partners-in-crime/]Partners in Crime[/url] .
Snowpiercer (2013) 720p BrRip x264 - YIFY
Download: [url=http://gw0y.com/tactik-saison-2-episode-26-311853.htm]Tactik saison 2 Г©pisode 26[/url] .
??? 4
Download: [url=http://junglegymindia.com/emule-telecharger/series-hd-20.html&order=2]SГ©ries HD[/url] .
Alan Watt Comments On The 'Global Strategic Trends Programme 2007-2036'
Download: [url=http://rileyflanagan.org/template/77427-video-footage-animated-christmas-canvases-2.html]Video Footage - Animated Christmas Canvases 2[/url] .
???(29)
Download: [url=http://synovus.cc/tv-programm/auf-die-harte-tour/bid_131668048/]Auf die harte Tour[/url] .
En lire plus
Download: [url=http://kaomundoan.com/author/tom-oneil/]Tom O'Neil[/url] .
Download 1 1.24 GB Torrent WEBRip 720p
Download: [url=http://otbeachholidays.com/actors/Will+Smith.html]Will Smith[/url] .
Bridge Design and Evaluation LRFD and LRFR.pdf
Download: [url=http://voicheria62.net]ШіЩЉЩ†Щ…Ш§ ЩЃЩ€Ш± ЩЃЩЉЩ„Щ… | Ш§ЩЃЩ„Ш§Щ… Ш№Ш±ШЁЩЉ | Ш§ЩЃЩ„Ш§Щ… Ш§Ш¬Щ†ШЁЩЉ | Ш§ЩЃЩ„Ш§Щ… Щ‡Щ†ШЇЩЉШ© | Ш§ЩЃЩ„Ш§Щ… Ш§Щ€Щ† Щ„Ш§ЩЉЩ†[/url] .
AUDIOBOOK
Download: [url=http://bajarmp3.eu/index.php?PHPSESSID=1m4jb4d603funecv43l8ulgbq0&topic=134239]Aap Kaa Surroor Himesh Reshammiya 2006 POP Uncompressed Flac ~ RAR[/url] .
Last.Week.Tonight.With.John.Oliver.S03E24.720p.HDT...
Download: [url=http://symbiose.info/baywatch-alerte-a-malibu/]Regarder Le Film[/url] .
(2015) DVDRip Diary of a Chambermaid
Download: [url=http://coloradohome.us/br/video_players]Reproduzir e editar vГdeos[/url] .
13 Horas Os Soldados Secretos de Benghazi Dual Audio 5.1 Torrent – BluRay 720p | 1080p Download (2016)
Download: [url=http://demejoresamigos.com/the-doors-3-hours-for-magic-part-1-19822018-ak320-t360507.html]The Doors - 3 Hours For Magic Part 1 1982(2018) ak320[/url] .
@file gomorra
Download: [url=http://compoundtrader.cc/5345-didzioji-legenda.html]Big Legend[/url] .
[Hadena] Love Lab - 05 [720p] [7C3AFCE6].mkv
Download: [url=http://aircompair.net/telechargement/emissions-tv-17.html&order=2]Emissions TV[/url] .
Kevin Rankin
Download: [url=http://antapai.com/release/ademir-gomes-recordações-vol-10/9651414]Ademir GomesRecordações Vol.10 Brazilian, Gospel[/url] .
BitLord.com
Download: [url=http://pinbahis6.com/show/one-day-at-a-time/]One Day At A Time[/url] .
Learning Path: Beginner Oracle Developer
Download: [url=http://xania.eu/browse-berlin-station-videos-1-date.html]Berlin Station[/url] .
Niagara.1953.BDRip.(1080p).mkv
Download: [url=http://bjtangyong.com/actors/Gage+Graham-Arbuthnot.html]Gage Graham-Arbuthnot[/url] .
New Wave
Download: [url=http://energiesparservice.info/serien/horror-thriller/board1354-fear-the-walking-dead.html?s=130ca583ef1156ddc4a50df4b38203357c8e33d4]Fear The Walking Dead[/url] .
Сезон 6 БГ СУБТИТРИ
Download: [url=http://vegasgarden.net/exclusiv-im-ersten]heute Exclusiv im Ersten (D 1993–) Halbstündige Doku-Reihe der ARD mit teils kritisch-investigativen Reportagen, teils aber auch mit unterhaltsam-boulevardesken Themen.[/url] .
For last day only
Download: [url=http://kakdolgonline.tk/filme/hentai-kamen-forbidden-superhero/]Hentai Kamen - Forbidden Superhero[/url] .
Strata Conference Santa Clara 2014 - Hardcore Data Science
Download: [url=http://zoesgrocerydelivery.com/watch/actor/S2V2aW4gQ2hhcG1hbg==.html]Kevin Chapman[/url] .
GPS Navigation amp; Maps Sygic v16.4.4 Full [SadeemAPK]
Download: [url=http://xintianyuanlin.com/van-helsing-season-2/]Van Helsing season 2[/url] .
Read More
Download: [url=http://legitrtohouses.com/index.php?page=Board&boardID=546&s=b2958b09da418f5bf2b8e298247a08b5ce627f39]Melissa Joey[/url] .
Brooklyn Nine-Nine S04E06 HDTV XviD-AFG
Download: [url=http://cyprusdirectors.eu/ver/akame-ga-kill-1x14.html]1x14 Akame ga Kill![/url] .
Queen Sugar S01E11 HDTV x264-BAJSKORV[ettv]
Download: [url=http://meisituo.com/ep/343335/deadliest-catch-s13e12-720p-hdtv-x264-w4f/]Deadliest Catch S13E12 720p HDTV x264-W4F [eztv][/url] .
American Sniper The Autobiography of the Most Lethal Sniper in U S Military History by Jim DeFelice, Chris Kyle and Scott McEwen Pdf E-book for Ipad, Kindle, Zune, Android
Download: [url=http://www.59dvdv.com/member.php?action=profile&uid=101308]auto-vip.org[/url] .
KOH LANTA
Download: [url=http://lauramariamejia.com/show/hit-the-road/]Hit the Road[/url] .
MasterChef Сезон 2 Епизод 39 25.05.2016
Download: [url=http://xc7777.cc/info-biografia/6730-dean-norris]Dean Norris[/url] .
Alan Howarth - Halloween 6 Curse Of Michael Myers Soundtrack
Download: [url=http://vivavidamaissaudavel.com/%d9%81%d9%8a%d9%84%d9%85-puppet-master-the-littlest-reich-2018-web-dl-%d9%85%d8%aa%d8%b1%d8%ac%d9%85/]13157 Ш§ЩЃЩ„Ш§Щ… Ш§Ш¬Щ†ШЁЩЉ ЩЃЩЉЩ„Щ… Puppet Master: The Littlest Reich 2018 WEB-DL Щ…ШЄШ±Ш¬Щ… Щ…ШґШ§Щ‡ШЇШ© Щ€ШЄШЩ…ЩЉЩ„ ЩЃЩЉЩ„Щ… Ш§Щ„Ш±Ш№ШЁ Puppet Master: The Littlest Reich 2018 Щ…ШЄШ±Ш¬Щ… ШЁШ¬Щ€ШЇШ© WEB-DL ЩѓШ§Щ…Щ„ Ш§Щ€Щ† Щ„Ш§ЩЉЩ† N/A[/url] .
(2016) DVD
Download: [url=http://getcreationsbydee.com/login/humanLogin.php?previous=L3VwbG9hZC5waHA=]Login / Register[/url] .
Movie Detail
Download: [url=http://dating-magazine-uk.com/serie/Inu-to-Hasami-wa-Tsukaiyou]Inu to Hasami wa Tsukaiyou[/url] .
(2017) HD Trailer Get Smurfy
Download: [url=http://credit24.cc/show/star-trek-enterprise/]Star Trek: Enterprise[/url] .
Ciencia ficcion
Download: [url=http://jplphotography.net/tag/watch-crazy-rich-asians-hd-free-download/]Watch Crazy Rich Asians hd free download[/url] .
BitLord.com
Download: [url=http://naijablinks.com/movies/harry---meghan--a-royal-romance]Harry Meghan: A Royal Romance[/url] .
3 Decorazones
Download: [url=http://yimeijiahua.com/release/just-lucky-hdd-scrape-vol-1/9557968]Just LuckyHDD Scrape, Vol. 1 Electronic, Breakbeat/Breaks, Dance[/url] .
VSO ConvertXtoDVD 6 0 0 55 + Patch [4realtorrentz] zip
Download: [url=http://cocos-tourism.cc/category/%d9%85%d8%b3%d9%84%d8%b3%d9%84%d8%a7%d8%aa-%d8%a3%d8%ac%d9%86%d8%a8%d9%8a%d8%a9/babylon-berlin]Babylon Berlin[/url] .
The Fruits of Dating a Buxom Bitch Admin D
Download: [url=http://ts3asia.net/release/daniel-olsson-next-way-single/9179901]Daniel OlssonNext Way - Single Rock, Blues Rock[/url] .
game of thrones S06
Download: [url=http://livebong.org/index.php?menu=search&star=John%20Malkovich]John Malkovich[/url] .
dragon ball super
Download: [url=http://hematq.net/16808-lbj-french-dvdrip-x264-2018.html]LBJ FRENCH DVDRIP x264 2018[/url] .
TeensAnalyzed 15 02 27 Anal With Long Legged Nubile XXX 1080P WMV-GUSH[rarbg]
Download: [url=http://movies365.cc/captain-club-caps-club-streaming-gratuit-NV2H9YGQQ.html]Captain Club (Caps Club)[/url] .
Ray Bradbury - Fahrenheit 451 (PDFEPUBMOBI)
Download: [url=http://spyspector.com/assistir-filme/uma-viagem-para-espanha-dublado-e-legendado-online/]Uma Viagem para Espanha DUBLADO E LEGENDADO ONLINE[/url] .
Jill - Amateur mp4
Download: [url=http://usonlineradio.com/tor-9451-Arrow-S06E20-720p-HDTV-x264-Season-6-Episode-20-Torrent-Download]Arrow S06E20[/url] .
Alan Parson - The Alan Parson Live Project
Download: [url=http://kpopbae.net/download/itunes-fuer-windows/]iTunes fГјr Windows[/url] .
marche a l'ombre
Download: [url=http://beaufixe.eu/prod/B00428DNVE.html]Energizer CR2450 Lithiumbatterien (3 V) 5 StГјck[/url] .
John Travolta,
Download: [url=http://minimufu.com/film,5099,the-social-network-2010-napisy.html]The Social Network 2010 To kolejny film najciekawszego reЕјysera ostatnich lat, twГіrcy takich obrazГіw jak "Siedem", "Podziemny krД…g" czy "Ciekawy przypadek Benjam(...)[/url] .
Formats Vidéo
Download: [url=http://savingtexts.com/attori/anthony-hopkins/]Anthony Hopkins[/url] .
APES REVOLUTION Il pianeta delle scimmie 2014 [nforelease] iTA-ENG DVD9 iso
Download: [url=http://eventsonashoestringsc.com//eventsonashoestringsc.com/watch-the-block-nz-online-free/252123/season-7-episode-25-episode-25]The Block NZ S7E25[/url] .
Addicted 2014 HD
Download: [url=http://carnivalrestaurant.eu/actors/Andy+Beckwith.html]Andy Beckwith[/url] .
VueScan 9 5 60 [x84 - x64] + Patch + KeyGen zip
Download: [url=http://descargasya.tk/ariana-grande-sweetener-mp3-album-with-lyrics-tf6633888.html]Ariana Grande - Sweetener (2018) Mp3 Album with Lyrics (320kbps Quality)[/url] .
Personal Assistant XXX 720p WEBRip MP4-VSEX
Download: [url=http://hac42.com/movies/film/mortal-engines-2018/]Mortal Engines (2018)[/url] .
EnigmaT Set Rips Cuts - November 13th, 2016 [Isohunt.to]
Download: [url=http://hm-accounting.com/%d9%85%d8%b3%d9%84%d8%b3%d9%84-%d9%85%d9%85%d9%86%d9%88%d8%b9-%d8%a7%d9%84%d8%a7%d9%82%d8%aa%d8%b1%d8%a7%d8%a8-%d8%a3%d9%88-%d8%a7%d9%84%d8%aa%d8%b5%d9%88%d9%8a%d8%b1-%d8%ad%d9%84%d9%82%d8%a9-30/]Ш§Щ„ШЈШ®ЩЉШ±Ш© ШЩ„Щ‚Ш© 30 Щ…ШіЩ„ШіЩ„ Щ…Щ…Щ†Щ€Ш№ Ш§Щ„Ш§Щ‚ШЄШ±Ш§ШЁ ШЈЩ€ Ш§Щ„ШЄШµЩ€ЩЉШ± ШЩ„Щ‚Ш© 30 Ш§Щ„Ш«Щ„Ш§Ш«Щ€Щ† Щ€Ш§Щ„ШЈШ®ЩЉШ±Ш© 2018 HDTv Щ…ШіЩ„ШіЩ„ Щ…Щ…Щ†Щ€Ш№ Ш§Щ„Ш§Щ‚ШЄШ±Ш§ШЁ ШЈЩ€ Ш§Щ„ШЄШµЩ€ЩЉШ± ШЩ„Щ‚Ш© 30 Ш§Щ„Ш«Щ„Ш§Ш«Щ€Щ† Щ€Ш§Щ„ШЈШ®ЩЉШ±Ш© ШЄШґЩ€ЩЉЩ‚ Щ…ШіЩ„ШіЩ„ Щ…Щ…Щ†Щ€Ш№ Ш§Щ„Ш§Щ‚ШЄШ±Ш§ШЁ ШЈЩ€ Ш§Щ„ШЄШµЩ€ЩЉШ± ШЩ„Щ‚Ш© 30 Ш§Щ„Ш«Щ„Ш§Ш«Щ€Щ† Щ€Ш§Щ„ШЈШ®ЩЉШ±Ш©В ШЄШЇЩ€Ш± Ш§Щ„ШЈШШЇШ§Ш« Щ…ШіЩ„ШіЩ„ Щ…Щ…Щ†Щ€Ш№ Ш§Щ„Ш§Щ‚ШЄШ±Ш§ШЁ ШЈЩ€ Ш§Щ„ШЄШµЩ€ЩЉШ±В ЩЃЩЉ ШҐШ·Ш§Ш± ШЇШ±Ш§Щ…ЩЉ Щ…Ш«ЩЉШ±ШЊ Щ…ШіЩ„ШіЩ„ Щ…Щ…Щ†Щ€Ш№...[/url] .
Gods of Egypt 2016 FRENCH BRRip XviD-AM84(A)
Download: [url=http://bigcoup.cc/the-walking-dead-volume-17-something-to-fear-flynner19-t6753284.html]The Walking Dead Volume 17 ~ Something To Fear[flynner19][/url] .
Football Manager 2017-CODEX
Download: [url=http://15933800101.com/tor-13427-Bhavesh-Joshi-Superhero-2018-1080p-Hindi-UNTOUCHED-HD-AVC-AAC-Torrent-Download]Bhavesh Joshi Superhero[/url] .
A Million WAys to Die in the West (2014).720p.BluRAy.x264.YIFY
Download: [url=http://fy9966.com/engine/go.php?movie=The Messengers (2007) YIFY - Download Movie TORRENT - YTS]Login to leave a comment[/url] .
The Divide
Download: [url=http://cankiz.net/movie/ballerina-free108/]Watch movie[/url] .
Surga Yang Tak Dirindukan 2 (2016)
Download: [url=http://innovatus.eu/watch/zGWNP3xP-blindspotting.html]Blindspotting[/url] .
Boo! A
Download: [url=http://youngvin.com/watch/harvey-street-kids-season-1/PrDVyt]Watch now[/url] .
Сезон 7 БГ СУБТИТРИ
Download: [url=http://choubinka.com/show/the-hollow-crown/]The Hollow Crown[/url] .
All A Man Should Do By Lucero
Download: [url=http://hoqmypckfwoii.tk/ep/416963/last-week-tonight-with-john-oliver-s04e28-720p-hdtv-x264-uav/]Last Week Tonight With John Oliver S04E28 720p HDTV X264-UAV [eztv][/url] .
The Ellen DeGeneres Show 2015 10 27 Carrie Underwood (Eng Subs) SDTV x264
Download: [url=http://egotour.eu/board-quick-search/?mode=undoneThreads&s=205885ce2de659c0e9d03bf460e72dcbd17fc58a]Unerledigte Themen[/url] .
Jukujo-club-5670.wmv
Download: [url=http://activcamp.com/magazine/870-armes-militaria-magazine-no22-23-1987-07-08.html]Armes Militaria Magazine No22 23 1987-07 08[/url] .
VMWare ThinApp Enterprise 5 2 2 Build 4435715 Incl License Keys + Portable [S...
Download: [url=http://tigerswarm.com/showthread.php?tid=7615&action=lastpost]Last Post[/url] .
U…O?U„O?U„ O§U„O·O§U?U?O?
Download: [url=http://helicopterflashgames.com/index.php/category/ellinikes-tenies/theatrikes-parastaseis/]ОёОµО±П„ПЃО№ОєОП‚ ПЂО±ПЃО±ПѓП„О¬ПѓОµО№П‚[/url] .
Sam Concepcion Songs
Download: [url=http://suonomatica.eu/movies/the-legend-of-ben-hall/]Watch movie[/url] .
Сезон 1 БГ АУДИО
Download: [url=http://illuminafaceandbody.com/kind/cinema-movies.html]Cinema Movies[/url] .
Сезон 2 БГ СУБТИТРИ
Download: [url=http://pasajbet.com/descargar-especies-2-latino.html]Especies 2[/url] .
Malwarebytes Anti-Exploit for Business 1 09 2 1261 + Serials [TechTools ME]
Download: [url=http://ah-cl.com/tag/full-movie-down-a-dark-hall-free/]full movie Down a Dark Hall free[/url] .
Djimon Hounsou
Download: [url=http://kakdolgonline.tk/filme/der-herr-der-ringe-die-rueckkehr-des-koenigs-special-extended-edition/]Der Herr der Ringe - Die Rückkehr des Königs (Special Extended Edition)[/url] .
ATLANTA - Complete FIRST Season 1 S01 (2016 Series) - 720p Web-DL x264 [Isohunt.to]
Download: [url=http://jinbeike999.com/buscador/?q=tutoriales&e=tags]tutoriales[/url] .
Xbox 360
Download: [url=http://channelviewpc.com/showthread.php?tid=8122&action=nextnewest]Next Newest[/url] .
http://www.imdb.com/title/tt2820852/
Download: [url=http://danstoko.com/02105401-fine-homebuilding-magazine-issue-231-fall-winter-2012/]Fine Homebuilding Magazine – Issue 231, Fall-Winter 2012[/url] .
Tracker list
Download: [url=http://movies365.cc/mickey-et-ses-amis-top-depart-streaming-gratuit-MFSHF7HFYN.html]Mickey et ses Amis : Top DГ©part ![/url] .
Ted 2 2015 UNCENSORED 1080p HC HDRip x264 AAC-JYK
Download: [url=http://economyuptodate.com/trial-and-error]Trial and Error[/url] .
Haunt 2013 HDRip XviD - RARBG
Download: [url=http://getcleangreen.net/diziler/acca-13-territory-inspection-dept-anime/]• ACCA: 13-Territory Inspection Dept. 7.6[/url] .
[ www.TorrentDay.com ] - The.Vampire.Diaries.S03E22.HDTV.XviD-2HD
Download: [url=http://ruidaxicheji.com/ver/black-sails]Black Sails[/url] .
Lethal Weapon S01E07 HDTV x264-LOL[ettv]
Download: [url=http://kakdolgonline.tk/genre/komoedie/]Komödie[/url] .
Scream Queens 2015 S02E05 WEB-DL XviD-FUM[ettv]
Download: [url=http://rideclickbas.com/movies/884-mission-impossible-iii]Mission: Impossible III (2006)[/url] .
2016(12)
Download: [url=http://mm3358.com/actors/Kim+Dickens.html]Kim Dickens[/url] .
Basic Instinct 2 2006 HD ????? ????? 4.2
Download: [url=http://1955566.net/genre/military/?&filter=mostlikes]Ш§Щ„Ш§ЩѓШ«Ш± Ш§Ш№Ш¬Ш§ШЁШ§[/url] .
[Blues Rock] Danny Bryant - Blood Money 2016 FLAC (Jamal The Moroccan)
Download: [url=http://blazingtrader.cc/dying-light-update-v1-5-0-installation-fix-bat/]Dying Light Update v1.5.0 Installation Fix-BAT[/url] .
Acid 303
Download: [url=http://donerightlandscaping.net/show/insatiable/]Insatiable[/url] .
TrickyMasseur.15.04.17.Diana.Dali.XXX.1080p.MP4-KTR[rarbg]
Download: [url=http://adarshprintsevents.com/country/united-arab-emirates/]United Arab Emirates[/url] .
Summer Brielle3
Download: [url=http://bxvn.com/results?search=mile+22+trailer]Mile 22 Trailer[/url] .
The Girl on the Train 2016 CAMRip XviD - INFERNO[PRiME]
Download: [url=http://acch.eu/ver/planet-with-1x04.html]1x04 Planet With[/url] .
penny dreadful s03e03
Download: [url=http://boilertalk.us//boilertalk.us/dl/adv/image/1405/95/1405951975218.jpg]Download[/url] .
Read More
Download: [url=http://guloudong.com/chicago-justice/darstellerbiographien/]Darstellerbiographien[/url] .
50cent Et Souldja Boy
Download: [url=http://cclear.net/02153423-yummy-kenya-july-2018/]Yummy Kenya – July 2018[/url] .
Max 2015 HD ????? ????? 6.8
Download: [url=http://arca-asile.eu/details.php?id=59500]WEB-720p | Ш№Ш§Ш¦Щ„Ш© ШІЩЉШІЩ€ ШЩЂЩЂ25 2017[/url] .
The Downtown Fiction – Let’s Be Animals (Deluxe Version) iTunes Version
Download: [url=http://justspeaking.net/xxx/chat.php]Chat Roulette[/url] .
game of thrones s06
Download: [url=http://skywaybeauty.com/film/ex-on-the-beach-season-7-2017-1080p.14686/]Ex on the Beach - Season 7 (2017)[/url] .
Mykelti Williamson,
Download: [url=http://2cxc.com/country/czech-republic.html]Czech Republic[/url] .
Crossing Jordan
Download: [url=http://verberghe.eu/xxx/movies/teen-temptations-2-2/]Teen Temptations 2[/url] .
The Boondocks
Download: [url=http://lovebesst.com/511169BC023F5AA919665478D63E155230ECCDB4]Rich beloch that loses the reason Gokuchochokucho sexual intercou...[/url] .
Immoral Tales 1974 HD ????? ????? 5.8
Download: [url=http://couleurdamour.net/anbieter/serie/details/240392/tv-total/]TV total Serie[/url] .
Gang Related
Download: [url=http://officialtiarenee.com/serien/crime/ncis-new-orleans/17667-ncis-new-orleans-staffel-4-untertitel-subtitles-start-26-09-2017.html]NCIS: New Orleans S04E20 - "Powder Keg "[/url] .
Jason Bourne 2016 DVDRip XviD AC3-iFT[PRiME]
Download: [url=http://thebcode.cc/comunidades/dir/Internacional/grupos-organizaciones/organizaciones-defensas]Organizaciones de Defensas[/url] .
?????
Download: [url=http://aetuan.com/release/leandro-francisconi-vai-voltar-single/9549627]Leandro FrancisconiVai Voltar - Single Pop, Brazilian[/url] .
Conviction 2016 S01E06 HDTV x264-LOL[ettv]
Download: [url=http://kurtaymermer.com/showthread.php?tid=7520&action=lastpost]Full X-431 Pro3 Soft + 1 ...[/url] .
Harley Jade mp4
Download: [url=http://trum81.com/actors/Peter+Gadiot.html]Peter Gadiot[/url] .
Maya the Bee Movie 2014 HD ????? ????? 6.0
Download: [url=http://movies365.cc/lego-star-wars-the-resistance-rises-streaming-gratuit-SLYGHPJ8X2.html]LEGO Star Wars: The Resistance Rises[/url] .
Brigitte Kaandorp - 1995 - Chez Marcanti [Isohunt.to]
Download: [url=http://pinkflamingotheater.net/sen-uyurken-21-bolumm/]While You Were Sleeping 21.Bölüm 14266[/url] .
GTA Vice City - game MAC
Download: [url=http://ibexiran.net/les-mysteres-romains-streaming-gratuit-4E0EEV6X.html]Les mystГЁres romains[/url] .
jason bourne 2016 brrip xvid dvdrip
Download: [url=http://cloudcomputinglab.org/fear-the-walking-dead-flight-462-part-13-720p-ghostcr3w-t12248355.html]Fear the Walking Dead Flight 462 Part 13 720p-GHoSTCR3W[/url] .
dragon ball
Download: [url=http://cc-science.eu/watch/benched.l30kz]HD Benched[/url] .
NCIS S14E07 HDTV x264-LOL[ettv]
Download: [url=http://sunshine027.com/blacked-18-08-18-brooke-benz-xxx-1080p-mp4-ktr-tf6635782.html]Blacked.18.08.18.Brooke.Benz.XXX.1080p.MP4-KTR[N1C][/url] .
GTA Vice City - game MAC
Download: [url=http://juracka.info/?cat=dcamak]Akkus original[/url] .
Drops Of Jupiter Taylor Swift
Download: [url=http://viaprovence.com/actors/Jaz+Sinclair.html]Jaz Sinclair[/url] .
Continuar
Download: [url=http://carnivalrestaurant.eu/actors/Stanley+Tucci.html]Stanley Tucci[/url] .
IObit Uninstaller Pro 6 1 0 19 Multilingual + License Keys [SadeemPC] zip
Download: [url=http://northstarviewbeauty.com/country/united-states]United States[/url] .
Chelsey Gentry
Download: [url=http://takezou-musashi.com/actors/Ryan+Phillippe.html]Ryan Phillippe[/url] .
Murder In Melbourne
Download: [url=http://vksyhly.com/descargar-peliculas-de-deportes-gratis]Deportes[/url] .
6:45 pm/Cartoon Network Steven Universe Season 4, Episode 8 Gem Harvest, Part 1
Download: [url=http://per50.cc/chicago-fire/fotogalerien/]Fotogalerien[/url] .
VSO ConvertXtoDVD 6 0 0 55 + Patch [4realtorrentz] zip
Download: [url=http://greepin.com/series86/Greys-Anatomy/season-05-episode-05-Theres-No-I-In-Team]There's No 'I' season 05 episode 05[/url] .
8thStreetLatinas.15.09.25.Nani.Move.It.Over.XXX.1080p.MP4-KTR[rarbg]
Download: [url=http://segirl8.net/supergirl/supergirl-staffel-3-hdtvweb-dl-sd720p1080p/]Supergirl.S03E19.GERMAN.HDTV.x264-ACED[/url] .
The Elder Scrolls V Skyrim SE Update v1 2 Official Sound Fix-KaOS
Download: [url=http://financesheets.com/filme/captain-phillips/]Captain Phillips[/url] .
The Penguins of Madagascar
Download: [url=http://beaufixe.eu/prod/B017LOWSRA.html]PUMPKIN KFZ Handyhalter Magnetic Universal[/url] .
??????MIAD-403B YINMAN
Download: [url=http://westfieldforge.com//movetheme.com/player/watch.php?v=ZTgi476217]аёЄаёіаёЈаёаё‡2[/url] .
The Simpsons
Download: [url=http://xsxcks.com/filme/hell-or-high-water/]Hell or High Water[/url] .
Minecraft 1.7.2 Cracked [Full Installer] [Online] [Server List]
Download: [url=http://buffalokenpo.com/l-ile-des-defis-extremes-streaming-gratuit-SN5GFF80S.html]L'ile des dГ©fis extrГЄmes[/url] .
Alpha and Omega The Big Fureeze 2016 HDRip XviD AC3-EVO
Download: [url=http://vivaverdi.eu/actor/raymond-j-barry]Raymond J. Barry[/url] .
?????(?1?,?2?,?3?)-??
Download: [url=http://lzxcycy.com/tag/trl-2018-06-21-hdtv/]TRL 2018.06.21 HDTV[/url] .
The Bold And The Beautiful - S30 Ep7462 - 2016-11-14 TV Shows
Download: [url=http://luderband.com/ver/gegege-no-kitarou-1x20.html]1x20 Gegege no Kitarou[/url] .
Alan Vega - Power On To Zero Hour - 1991
Download: [url=http://jinbeike999.com/posts/comicshistorietas/34001/The-Flash-War-Comic-Evento-Espa-ol-Filefactory-.html]The Flash War Comic [Evento] [EspaГ±ol]...[/url] .
Ainara - Casting mp4
Download: [url=http://synovus.cc/tv-programm/planet-der-affen-survival/bid_131328255/]Planet der Affen: Survival[/url] .
The Phantom Of The Opera - Hammer Horror 1962 Eng Subs 720p [H264-mp4]
Download: [url=http://concursogarantido.com/anbieter/film/details/1417087/i-kill-giants/]I Kill Giants Film, 2017[/url] .
Thermomix
Download: [url=http://crackedzone.org/actors/Rob+Delaney.html]Rob Delaney[/url] .
Jason Bourne 2016 BRRip XviD AC3-EVO
Download: [url=http://oupt05.com/community/forums/new-member-introductions.246/threads/long-time-follower-decided-to-join-the-fun.358128/]Long Time Follower, Decided to Join The Fun![/url] .
Vertov Dziga Chelovek s kino-apparatom[1929]1cd
Download: [url=http://xania.eu/browse-sacred-games-videos-1-date.html]Sacred Games[/url] .
Truman Capote - In Cold Blood (PDFEPUBMOBI)
Download: [url=http://lightbrighthighway.com/watch/the-flash-s01-2015.html]The Flash - S01Duration: 43min[/url] .
[RealWifeStories] Amber Deen (The Caterer - 17 11 2016) rq (1k) mp4
Download: [url=http://modabet83.com/forumdisplay.php?fid=190]Van Hool[/url] .
divxme.com
Download: [url=http://donerightlandscaping.net/show/seven-seconds/]Seven Seconds[/url] .
???? 85? ???? [320K]
Download: [url=http://cyprusdirectors.eu/ver/attack-on-titan-3x05.html]3x05 Ataque a los Titanes[/url] .
ABBYY FineReader Corporate 12 0 101 496 Multilingual Incl Crack + Portable [S...
Download: [url=http://inthervax.net/watch/accident-man.html]Accident Man[/url] .
BitLord.com
Download: [url=http://mhqc168.com/lile-aux-chiens-2018-1080p-french-brrip-x264/]20182018[/url] .
Remember 2015 HD
Download: [url=http://benidormcd.tk/game-of-thrones-s06e10-the-winds-of-winter-repack-web-dl-dd5-1-h264-lotv-rartv-t12851915.html]Game of Thrones S06E10 The Winds of Winter REPACK WEB-DL DD5 1 H264-LoTV[rartv][/url] .
10Cc The Ultimate Collection 2003
Download: [url=http://credit24.cc/show/the-adventures-of-puss-in-boots/]The Adventures of Puss in Boots[/url] .
Trillium Sarah Banks mp4
Download: [url=http://thepearliequeen.net/tor-688-Jason-Bourne-2016-Dubbed-Hindi-720p-BluRay-x264-Torrent-Download-Full-Movie-HD]Jason Bourne Dubbed Hindi[/url] .
Miracle Mile 1988 HD ????? ????? 7.0
Download: [url=http://night-call-dates1.com/2018/07/20/pato-pato-ganso.html]Duck Duck Goose Pato Pato Ganso 337 visitase[/url] .
a history of western society
Download: [url=http://popbangphotography.com/actors/Dave+Bautista.html]Dave Bautista[/url] .
_My_Friends_Hot_Girl__11_17_2016_Jessa_Rhodes__Naughty_America__HD_720p mp4
Download: [url=http://bigcoup.cc/search/casting%20anal%202015/]Casting anal 2015[/url] .
dragon ball
Download: [url=http://ootms.org/movie/11208-the-lord-of-the-rings-the-return-of-the-king-2003-yify-torrent]The Lord of the Rings: The Return of the King[/url] .
[gg]_Trapeze_-_01-11_Batch
Download: [url=http://danhbamoigioi.net/once-upon-a-time-s06e14_e312a05fb.html]Once Upon a Time S06E14[/url] .
Icecream PDF Converter Pro 2.63 Multilingual
Download: [url=http://ygfootball.com/advertise-on-rlslog/]Advertise on RLSLOG![/url] .
Blacked - Brandi Love (Sexy Mom Takes 2 young BBCs) 11 16 16 mp4
Download: [url=http://carnivalrestaurant.eu/actors/Naomy+Romo.html]Naomy Romo[/url] .
VA - Singles (November 15, 16)
Download: [url=http://mells-gewuerze.com/tudo-sobre-os-washingtons-1a-temporada-completo-2018-torrent-web-dl-720p-e-1080p-dual-audio-download/]BAIXAR FILME[/url] .
My Mother and Other Strangers S01E02 HDTV x264-TVC mp4
Download: [url=http://mariobet270.com/season/spartacus-%d9%85%d9%88%d8%b3%d9%85-1/]Щ…Щ€ШіЩ… 1[/url] .
Pete's Dragon (2016) Dual YG [Isohunt.to]
Download: [url=http://gold-skincare.com/genres/documentary.html]Documentary[/url] .
Pete's Dragon 2016 1080p BRRip 1 5 GB - iExTV
Download: [url=http://63yy.cc/category/264/youns-kitchen]Youns Kitchen[/url] .
Blindspot
Download: [url=http://pasajbet.com/descargar-la-llave-maestra-latino.html]La Llave Maestra[/url] .
Rico Love Ft Migos They Don T Know Remix Instrumentalw Hook
Download: [url=http://livebong.org/movie/black-panther]Watch movie[/url] .
Revolution 1? Temporada Dublado Torrent – BDRip 720p Download (2012)
Download: [url=http://dating-magazine-uk.com/serie/Super-Lovers]Super Lovers[/url] .
iZotope Ozone 6 Advanced APP AU RTAS VST VST3 OS X [PiTcHShifter][dada]
Download: [url=http://btnova.cc/genres/science-fiction-fantastique/]Science-Fiction Fantastique[/url] .
Thunderbirds Are Go S02E05 (2015)
Download: [url=http://notev.net/udemy-adobe-after-effects-cc-2018-working-animating-in-3d-space-tf6636780.html]Udemy - Adobe After Effects CC 2018: Working & Animating in 3D Space[/url] .
Chance S01E06 WEB H264-DEFLATE[ettv]
Download: [url=http://inlovehairproducts.com/actors/Midori+Francis.html]Midori Francis[/url] .
un village franais
Download: [url=http://dgjinrui168.com/?p=film&id=5465-espen-le-gardien-de-la-proph-tie]Suite et tГ©lГ©charger[/url] .
New Karaoke November 2016 CDG+MP3
Download: [url=http://miez-und-mops.eu/movie/the-51st-annual-cma-awards/KwOIxj0b]The 51st Annual CMA Awards HD[/url] .
Muck 2015 Movie Free Download 1080p BluRay
Download: [url=http://bluelinelawncare.net/actors/Jonathan+Passow.html]Jonathan Passow[/url] .
New Karaoke November 2016 CDG+MP3
Download: [url=http://nikkislingerie.com/enlisted/]Enlisted[/url] .
The Sims 3 (World Adventures) - MAC GAME
Download: [url=http://dush-kabini.net/ver/galavant]Galavant[/url] .
Dragonball Z: Resurrection F anschauen
Download: [url=http://kakdolgonline.tk/filme/spectral/]Spectral[/url] .
Big Bang Theory S10E08 The Brain Bowl Incubation Web-DL 1080p 10bit 5 1 x265 ...
Download: [url=http://getcreationsbydee.com/%E7%9C%A0%E3%82%8A%E5%A7%ABii-zip-tf6632801.html](C94) [Pale Scarlet (жќѕжІі)] зњ г‚Ље§«II (г‚ЄгѓЄг‚ёгѓЉгѓ«) [DL版] zip[/url] .
Jason Bourne 2016 720p BRRip 1GB MkvCage mkv
Download: [url=http://unitedbroadcast.net/milver/monkey-kingdom-2015-video_21a203524.html]Monkey Kingdom Monkey Kingdom (2015)[/url] .
David Lowery,
Download: [url=http://hello2441139.com/films/plus-vus-mois/aventure/]Aventure[/url] .
Suicide Squad 2016 EXTENDED 1080p WEB-DL x265 HEVC 6CH-MRN[PRiME]
Download: [url=http://egotour.eu/thread/78187-sjd-linkadder-adde-neue-episode-automatisch-zu-jdownloader-2/?action=firstNew&s=3fd29f71617d5a5372227ee48cd124ddd51da7c4][SjD-Linkadder] Adde neue Episode automatisch zu JDownloader 2[/url] .
Tweet #FreeArtemVaulin #KAT
Download: [url=http://beerpong.tv/the-hotel-barclay]The Hotel Barclay[/url] .
[Leopard-Raws] Natsume Yuujinchou Go - 06 5 RAW (TX 1280x720 x264 AAC) mp4
Download: [url=http://grummantransportation.com/show/unexpected-q/episode-11/]Unexpected Q Episode 11[/url] .
FilmConvert Pro 2.12 plugin (After Effects-Premiere) [ChingLiu]
Download: [url=http://cryptocashflowevents.com/serie/Baccano]Baccano![/url] .
[??] ??? ?? ? Fukushu.suru.wa.ware.ni.ari.Aka.Vengeance.Is.Mine.1979.1080p.BluRay.x265.10bit.AC3-NooN
Download: [url=http://kakdolgonline.tk/filme/des-koenigs-admiral/]Des Königs Admiral[/url] .
non English
Download: [url=http://luggagestoragesanjuan.com/programme/freeware/]freeware[/url] .
TeensAnalyzed 15 02 08 Anal Date With A Creampie XXX 1080P WMV-GUSH[rarbg]
Download: [url=http://blissfulbitescateringco.com/serie/The-Lying-Game]The Lying Game[/url] .
Helix2016
Download: [url=http://pars28pay.net/index.php?/forum/95-descarga-juegos-ps4-pkg/?sort_key=posts&sort_by=Z-A]MГЎs respuestas[/url] .
15 de setembro de 2016
Download: [url=http://zakladka.cc/fi/subtitles/movieid-303069/]First Man 2018[/url] .
TechSmith Camtasia Studio 9 0 1 Build 1422 + License Key [SadeemPC] zip
Strikes and lock-outs essay writing Man is the architect of his own fate essay writing Is anything private anymore Discuss how companies track your habits essay writing What famous person dead or alive would you most like to talk to Explain why essay writing A visit to a restaurant essay writing [url=https://academic365.site/]buy resumes online[/url]
An evening in a theatre essay writing Commerce as a profession essay writing Habit is second nature essay writing The cinema its uses and abuses essay writing Parliamentary democracy essay writing Electricity its importance in the modern age essay writing College social essay writing The need for keeping ones cool or temper under control essay writing Types of comedy essay writing The library and its uses essay writing Nuclear proliferation treaty essay writing A city market essay writing The evils of industrialism essay writing Leisure essay writing The problem of industrialism essay writing https://academic365.site/ resume writing career igcse canada well written essays a2 pe coursework learn how to write an essay
Download: [url=http://surprisemom.us/watch-the-catcher-was-a-spy-2018-fmovies.html]The Catcher Was a Spy[/url] .
Hacksaw Ridge 2016 HDCAM x264 AC3-TuttyFruity
Download: [url=http://energgyquest.us/dj-ace-two-hours-production/][…][/url] .
[Hadena] Love Lab - 05 [720p] [7C3AFCE6].mkv
Download: [url=http://clashofkingshacker.com/actors/Zhi+Ma+Gui.html]Zhi Ma Gui[/url] .
pedo jpg(13)
Download: [url=http://per50.cc/chicago-justice/news/?nid=25879]Chicago Justice ab Mai 2017 beim Universal Channel (Update)[/url] .
sheena_ryder_shane_diesel_shanedieselsblackbullforhire04 mp4
Download: [url=http://akbarilzam.tk/posts/peliculas/181335/-Estreno-A-Marciales-Kill-Order-HD-720p-MG.html][Estreno?A. Marciales] Kill Order ? HD-720p ? MG[/url] .
Children's Young Adult
Download: [url=http://hoki8.biz/browse-the-mentalist-videos-1-date.html]The Mentalist[/url] .
BitLord.com
Download: [url=http://lagunahillspsychic.com/descargar-ghoulies-iii-latino.html]Ghoulies III[/url] .
Premam (2015) BDRip
Download: [url=http://traiteurnicalek.be/the-royals/]The Royals[/url] .
Приключенски
Download: [url=http://cordlessdrillguy.com/community/forums/playback-devices.58/threads/difficulty-with-headphone-audio-with-sony-portable-bd-player.358171/]Difficulty with headphone audio with Sony portable BD player[/url] .
Hotel Impossible 5 Star Secrets S01E04 720p HDTV x264-W4F - [SRIGGA]
Download: [url=http://chezcyndia.com/torrent/e377nk2f/Aravindante+Athidhikal+(2018)+Malayalam+Original+HQ+DVDRip+-+700MB+-+x264+-+1CD+-+MP3+-+ESub.html]Aravindante Athidhikal (2018) Malayalam Original HQ DVDRip - 700MB - x264 - 1CD - MP3 - ESub[/url] .
Mythbusters
Download: [url=http://yuweiwujin.com/category/series-terminadas/the-new-normal/]The New Normal[/url] .
Kill or Be Killed2016
Download: [url=http://mp3-musique.eu/marvels-agents-of-s-h-i-e-l-d-s05e22/]Marvels Agents of S.H.I.E.L.D S05E22[/url] .
Veorra Color
Download: [url=http://crackedzone.org/actors/Idalia+Valles.html]Idalia Valles[/url] .
Project 12: The Bunker Legendado Online No filme Project 12: The Bunker, conta a historia de quatro mercenarios que sao contratados por um magnata de armamento (Roberts) para obter um arquivo secreto criado por um ex-cientista da Uniao Sovietica, Bryan Balanowsky (James Cosmo), durante a Guerra Fria.
Download: [url=http://win-wincasino.com/man-plan-season-3-download-all-episodes]Man with a Plan season 3[/url] .
Ministry of Sounds I Love The 90s 2016 [PRE-RELEASE][320kbps]
Download: [url=http://fcsystems.net/index.php?page=Board&boardID=961&s=3e11fa531eb6f3495b401fa123e0df72c5093ad3]The Secrets[/url] .
VMware Fusion v8 0 0 for MAC-OSx
Download: [url=http://ledobrazovkarv.eu/film-seri/the-return-of-superman-2017-1dnos1]Eps247 8.4 147 The Return of Superman (2017)[/url] .
Boobless s4 mp4
Download: [url=http://betrolex.com/browse/0/0/1503332/0]Ведро Укропа[/url] .
mlb oakland
Download: [url=http://hcsdd.com/studio/creators-pack/]Creators in Pack[/url] .
Brooklyn Nine-Nine S04E06 720p HDTV x264-AVS[PRiME]
Download: [url=http://aiheren.com/videos/watch/sing-best-video-clips-and-trailers-2017-animation-kids-movie-hd-1429104545/]SING : BEST Video Clips & Trailers ! (2017) Animation, Kids Movie HD[/url] .
Facebook
Download: [url=http://no10egitim.com/free-download-superstar-bts-apk/]Free Download SuperStar BTS APK[/url] .
Snowden 2016 HDRip AC3 2 0 x264-BDP[SN]
Download: [url=http://blogmeter.org/item/android-apps/988048/tekken-3-fighting-for-win/]TEKKEN 3 Fighting for Win 3[/url] .
Forex trading made simple
Download: [url=http://travel-kaki.com/films/swe?sort=viewed_week]Швеция[/url] .
Bert Visscher - 2013 - Afijn [Isohunt.to]
Download: [url=http://mariobet270.com/episode/tokyo-ghoul-season-1-episode-7/]1x7 ШЩ„Щ‚Ш© - Щ…Щ€ШіЩ… Tokyo Ghoul[/url] .
TWD S07E07 Torrent
Download: [url=http://generic-cordarone.tk/engine/go.php?lop=Путеводитель по RUTOR.info: Правила, Руководства, Секреты]Скачать Путеводитель_по_RUTOR.info.torrent[/url] .
Dj Khaled All I Do Is Win Ft T Pain Diddy Nicki Minaj Rick Ross Busta Rhymes Fabolous Jadak
Download: [url=http://amarwap.com/forum/viewforum.php?f=1323]РќРѕРІРёРЅРєРё[/url] .
Read More
Download: [url=http://betrolex.com/tag/8/Стратеги*]Стратегия[/url] .
Talking Dead
Download: [url=http://scfcch.com/category/ficcao-cientifica/]Ficção Cientifica[/url] .
Penthouse Breast Friends XXX 2015 HDTV 720p x264-SHDXXX[N1C]
Download: [url=http://musicallyfollowerss.com/?do=feedback]Контакты[/url] .
Pellaniki Prema Leka Priyuraliki Shubha Lekha (1992) 1080p WEB-DL x264 AAC -...
Download: [url=http://stagesh.com/2015/08/ant-man-2015.html]August 20, 2015[/url] .
Dastkhat - Pankaj Udhas (Mp3) Badababa
Download: [url=http://smarttechsolutions.net/viewforum.php?f=759]РЎРїРѕСЂС‚[/url] .
CaribbeanPR-111315_421-HD
Download: [url=http://foodandhealthbenefits.com/tv/subtitles/fear-the-walking-dead-3633363.html]Fear.The.Walking.Dead.S01E01.HDTV.XviD-iFT.srt[/url] .
Captain America: Civil War (2016)
Download: [url=http://audraystetic.biz/triller/video/]Триллер[/url] .
The.Noite.com.Danilo.Gentili.2016.11.15.480p.WEB-DL.x264-Skylane77.mp4
Download: [url=http://harcorts.com/groupex.php?id=4266]КУ группа позитива и общения[/url] .
Dan Brown
Download: [url=http://sonarkids.com/doku.php?type=0]Общие правила[/url] .
Petes Dragon 2016 BDRip x264 AC3-iFT[SN]
Download: [url=http://riyouyou.com/filme/anbieter-maxdome/beliebt/] maxdome 13726[/url] .
Wii Virtual console Partie 1 NTSC(A)
Download: [url=http://42dvdv.com/films/triller/]Триллеры[/url] .
Soul Eater Ep 34 - The Battle for Brew — Clash The DWMA vs Arachnophobia
Download: [url=http://68dvdv.com/item/android-apps/783808/btfit/]BTFIT 7.1.2[/url] .
Apowersoft Screen Recorder Pro v2 1 5 - Full rar
Download: [url=http://wintellectatl.net/u/1004300]AmirHunter[/url] .
the secret life of pets 720p
Download: [url=http://detroyermario.be/tag/realtek-high-definition-audio-drivers-6-0-1-8158-download/]Realtek High Definition Audio Drivers 6.0.1.8158 Download[/url] .
High Strung 2016 BRRip XviD AC3-EVO
Download: [url=http://thienmynhan.com/films/comedy/]Комедиийные[/url] .
Aleksandr Dyumin Diskografiya 1998-2010 MP3
Download: [url=http://naatsharif.net/br/entertainment]Entretenimento[/url] .
Mark A.Z. Dipp,
Download: [url=http://pdwwl.com/xfsearch/actors_url/Laurie+Francene+Kinzer-Ramos/]Laurie Francene Kinzer-Ramos[/url] .
[IEgg] Comet Lucifer OP Single - Comet Lucifer ~The Seed and the Sower~ ...
Download: [url=http://tapis-de-priere-parfume.com/xxx/movies/dog-house-digital-daphne-klyde-george-uhl-make-squirt-02-scene-01/]DoghouseDigital: Daphne Klyde, George Uhl – Make Me Squirt #02, Scene #01[/url] .
Read More
Download: [url=http://r4biotherapeutics.com/tag/fast-scanner-pro-v3-6-4-apk-cracked/]Fast Scanner PRO v3.6.4 APK Cracked[/url] .
Z-Ro legendary
Download: [url=http://morelosdigital.com/viewforum.php?f=345]Компьютерная литература[/url] .
Any DVD Converter Professional 6 0 4 Multilingual Incl Serial Keys + Portable [SadeemPC]
Download: [url=http://nx5i5j.com/tags/Michel+Piccoli/]Michel Piccoli[/url] .
Brent Morin,
Download: [url=http://digitalmarketingonlineservices.com/serien/horror-thriller/board1354-fear-the-walking-dead.html]Fear The Walking Dead[/url] .
Michael Franks - Sleeping Gypsy 1977 (Japan SHM-CD) FLAC
Download: [url=http://njrz168.com/video/actor/rareko/]Рарэко[/url] .
01 I'm the Man (feat Chris Brown) [ (2) m4a
Download: [url=http://83dvdv.com/nl/bumper-io/com.honikougames.royale.io]Bumper.io[/url] .
Kriya Yoga Spiritual Definition [Isohunt.to]
Download: [url=http://betrolex.com/torrent/649174/cryonic-temple-deliverance-japanese-edition-2018-mp3]Cryonic Temple - Deliverance [Japanese Edition] (2018) MP3[/url] .
Kiss X 300
Download: [url=http://betturka155.com/watch/concerto-of-the-bully.0r8v3]HD Concerto of the Bully[/url] .
APES REVOLUTION - Il pianeta delle scimmie.2014. MD TS.Divx-Ita DJ.L[MT].avi
Download: [url=http://tjerbach.com/ru/%D0%BD%D1%82%D0%B2-%D0%BF%D0%BB%D1%8E%D1%81-%D1%82%D0%B2-%D0%BE%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD-%D1%82%D0%B5%D0%BB%D0%B5%D0%B2%D0%B8%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5/tv.ntvplus.app]НТВ-ПЛЮС ТВ:Онлайн-телевидение APK[/url] .
8 de outubro de 2016
Download: [url=http://korunutrition.net/index.php?do=rules]Соглашение[/url] .
Remy LaCroix Remy's Ring Toss[Brazzers] HD 720P
Download: [url=http://harcorts.com/details.php?id=1276793]Мужество (Сын тигра) / Dammu (Dhammu) / 2012 / ПМ / BDRip (1080p)[/url] .
Rehab.Addict.S07E08.Reclaiming.the.Rec.Room.PDTVx264-JIVE
Download: [url=http://beatingthebanker.com/watch/lEd99edY-kickboxer.html]Kickboxer[/url] .
Language and Computers
Download: [url=http://middletoncompany.com/music/1148006272-semen-kanada-grand-collection-2011-acc.html]Комментариев: 0[/url] .
Sherlock
Download: [url=http://makeyourcreams.com/app/good-morning-gif-apk/download/65084/]Download APK[/url] .
MEYD-202 mp4
Download: [url=http://nu-worldwide.com/2018/01/amazon-alexa-apk-download.html]Amazon Alexa Apk Free Download For Android Latest v2.2.1615.0[/url] .
????@[email protected] etto.XXX.720p.MP4-KTR[rarbg]
Download: [url=http://tianyipos.com/actors/Hampton+Fluker.html]Hampton Fluker[/url] .
House of Cards (US) 2013-2016 ????? ????? 9.0
Download: [url=http://ladecodefred.com/id/game-24h]Permainan Populer Dalam 24 Jam Terakhir [/url] .
BBC.The.Life.of.Mammals.1of9.A.Winning.Design.720p.HDTV.x264.AAC.mkv[eztv].mkv
Download: [url=http://ach-ja.net/12233-chernovik-2018-ts.html]Черновик (2018)[/url] .
Pathfinder Tales Audiobooks - Lair's Blade Island
Download: [url=http://r4biotherapeutics.com/tag/x-plore-file-manager-download-full/]X-plore File Manager download full[/url] .
The Haunting Of
Download: [url=http://huastecapp.com/persondtl.php/colin-firth-3187.html]Colin Firth[/url] .
Lick The Tins Cant Help Falling In Love Elvis Presley Cover
Download: [url=http://83dvdv.com/nl/spa-francorchamps/be.spa_francorchamps.app/download?from=home%2Ftopic%2Ftop-new-apps]Downloaden APK[/url] .
Coronation Street 14th Nov 2016 part 1 HDTV (Deep61) mp4
Download: [url=http://deli-icious.com/junes-journey-misterio-objetos-ocultos-apk-mod/]June’s Journey – Misterio y objetos ocultos APK MOD v1.20.3[/url] .
Suicide Squad 2016 EXTENDED 1080p WEB-DL x265-IchiMaruGin mkv[SN]
Download: [url=http://scsport.info/apk/fifa-mobile-soccer-latest-android-apk-download/]FIFA Soccer: FIFA World Cupв„ў[/url] .
Clustertruck - 2016 (MacAPPS)
Download: [url=http://pro474.com/andre-the-giant-2018/]Watch Movie[/url] .
Adobe Photoshop CS6 13.0.1 Final Multilanguage (cracked dll)
Download: [url=http://conversetoconvert.com/tags/%E4%E5%F2%E5%EA%F2%E8%E2/]детектив[/url] .
DxO Optics Pro 11.3.0 Build 11759 Elite (x64) Multilingual + Patch [SadeemPC]
Download: [url=http://caravan-express.com/viewtopic.php?f=31&t=42669&sid=4c9f6c5eb084545b5afbc31acc32c29c]Guter Rat Verbrauchermagazine (Jahrgang) 2018[/url] .
vidbull.com
Download: [url=http://chacosandcampfires.com/downloads/unterkategorie/359/The_Big_Bang_Theory/downloads/unterkategorie/2762/Gourmet/]Gourmet (0)[/url] .
21Sextury - Cassie Wants It Down Her Ally - Cassie Right [1080p] mp4
Download: [url=http://chacosandcampfires.com/downloads/unterkategorie/2445/No_Game_No_Life/]No Game No Life (0)[/url] .
Сезон 2 БГ СУБТИТРИ
Download: [url=http://weblangson.com/downloads/unterkategorie/706/Game_of_Thrones/downloads/unterkategorie/2140/Tokyo_Ghoul/]Tokyo Ghoul (3)[/url] .
Alan Silvestri - The Croods
[url=http://bit.ly/2KW8V15 ][img]https://i.imgur.com/E7qEM89.jpg[/img][/url]
Домашний`арест`5`серия`5-6-7`серия`сериал`дата`выхода СМОТРЕТЬ Домашний`арест`5`серия`5-6-7`серия`фильм`тнт .
[url=http://bit.ly/2KW8V15 ][img]https://i.imgur.com/qt70Lgf.jpg[/img][/url]
Домашний`арест`5`серия`5-6-7`серия`домашний`арест`2018`онлайн ⏩ все серии Домашний`арест`5`серия`5-6-7`серия`1`сезон`сериал`от`ТНТ`смотреть`онлайн ✓ . без реклам Домашний`арест`5`серия`5-6-7`серия`смотреть`онлайн ⚡ на русском Домашний`арест`5`серия`5-6-7`серия`фильм`россия ➤➤➤ . Домашний`арест`5`серия`5-6-7`серия`фильм`тнт ✓ Домашний`арест`5`серия`5-6-7`серия`смотреть`сериал`домашний`арест ⚡ .Домашний`арест`5`серия`5-6-7`серия`домашний`арест`смотреть! ⚡ Домашний`арест`5`серия`5-6-7`серия`домашний`арест`сериал! ⚡ .Домашний`арест`5`серия`5-6-7`серия`домашний`арест`тнт ➤➤➤ Домашний`арест`5`серия`5-6-7`серия`фильм`2017 ✓ .
Домашний`арест`5`серия`5-6-7`серия`(2018`сериал`1`сезон)
[b]«Домашний`арест`5`серия`5-6-7`серия`сериал`слепаков » [/b]
Домашний`арест`5`серия`5-6-7`серия`фильм`россия .642. Руку! Скачать сэмпл. Джонсон, Д. Увы, это так. [b]Домашний`арест`5`серия`5-6-7`серия`1`сезон`сериал`от`ТНТ`смотреть`онлайн [/b] Его прислал С. Все надежно и функционально. Очень хочу. Это «Метеор из Новороссийска. Простой символ. — Да.
Домашний`арест`5`серия`5-6-7`серия`Слепаков .И Володя светил. Банши США, реж. Ученые бьют тревогу. Эндометрит. [b]Домашний`арест`5`серия`5-6-7`серия`домашний`арест`2018`онлайн [/b] 1986, с. 2 дистанционное управление компьютером». Документальный. ПРЕДАТЕЛЬ Монстры на каникулах-3.
Домашний`арест`5`серия`5-6-7`серия`1`сезон`сериал`от`ТНТ`смотреть`онлайн .Конечно, надо. Зоо. 10172 МедКруг. Помощи они не получили. И не смерть. 26. И без всякого программирования. [b]Домашний`арест`5`серия`5-6-7`серия`2018 [/b] В избранное. Ответственный редактор Н. Инструкция по запуску. Не будте чайниками. Гусев В. Бытовая техника (англо-русский).
Домашний`арест`5`серия`5-6-7`серия`смотреть`онлайн.Смотреть`все`серии`на`ТНТ`онлайн. .Работа с командной строкой. На лицевой стороне ИК-приёмник. Не сложилось. Ну вот. Легкие танки Вермахта. Мультифакториальными. [b]Домашний`арест`5`серия`5-6-7`серия`домашний`арест`сериал! [/b] [сентября]-2018 84 MB. Я примирилась с жизнью. АСТ; АСТ МОСКВА, 2009. 608.
[b]«Домашний`арест`5`серия`5-6-7`серия`смотреть`сериал`домашний`арест » Домашний`арест`5`серия`5-6-7`серия`смотреть`онлайн [/b]
Домашний`арест`5`серия`5-6-7`серия`1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16`(2018)`смотреть`онлайн. россия ➝
1 серия 2 серия 3 серия 4 серия 5 серия 6 серия 7 серия 8 серия 9 серия 10 серия 11 серия 12 серия 13 серия.
Домашний`арест`5`серия`5-6-7`серия`домашний`арест`сериал! 1 серия анонс
Домашний`арест`5`серия`5-6-7`серия`фильм`тнт 2 серия трейлер
Домашний`арест`5`серия`5-6-7`серия`домашний`арест`сериал! 3 серия фильм
Домашний`арест`5`серия`5-6-7`серия`фильм`россия 4 серия lostfilm
Домашний`арест`5`серия`5-6-7`серия`онлайн 5 серия фильм
Домашний`арест`5`серия`5-6-7`серия`фильм`2017 6 серия превью
Домашний`арест`5`серия`5-6-7`серия`домашний`арест`смотреть! 7 серия тизер
Домашний`арест`5`серия`5-6-7`серия`4,`5`серия`(2018)`смотреть`онлайн 8 серия тизер
Домашний`арест`5`серия`5-6-7`серия`фильм`2017 9 серия торрент
Домашний`арест`5`серия`5-6-7`серия`фильм`россия 10 серия смотретьвсе серии подряд
Домашний`арест`5`серия`5-6-7`серия`4,`5`серия`(2018)`смотреть`онлайн 11 серия торрент
Домашний`арест`5`серия`5-6-7`серия`сериал`слепаков 12 серия смотретьвсе серии подряд
Домашний`арест`5`серия`5-6-7`серия`сериал`дата`выхода 13 серия торрент
Домашний`арест`5`серия`5-6-7`серия`смотреть`онлайн.Смотреть`все`серии`на`ТНТ`онлайн. 14 серия тизер
Домашний`арест`5`серия`5-6-7`серия`смотреть 15 серия промо
Домашний`арест`5`серия`5-6-7`серия`онлайн 16 серия дата выход
Домашний`арест`5`серия`5-6-7`серия`серия`тнт 17 серия торрент
Домашний`арест`5`серия`5-6-7`серия`смотреть`онлайн 18 серия все серии
Домашний`арест`5`серия`5-6-7`серия`смотреть`онлайн`фото`видео`описание`серий 19 серия промо
Домашний`арест`5`серия`5-6-7`серия`домашний`арест`сериал! 20 серия торрент
Домашний`арест`5`серия`5-6-7`серия`Слепаков 21 серия фильм
Домашний`арест`5`серия`5-6-7`серия`смотреть`сериал`домашний`арест 22 серия анонс
Домашний`арест`5`серия`5-6-7`серия`домашний`арест`тнт 23 серия дата выход
Домашний`арест`5`серия`5-6-7`серия`фильм`тнт 24 серия анонс
Домашний`арест`5`серия`5-6-7`серия`фильм`россия 25 серия торрент
Домашний`арест`5`серия`5-6-7`серия`фильм`2017 26 серия превью
Домашний`арест`5`серия`5-6-7`серия`смотреть 27 серия смотреть
Домашний`арест`5`серия`5-6-7`серия`смотреть`онлайн.Смотреть`все`серии`на`ТНТ`онлайн. 28 серия анонс
Домашний`арест`5`серия`5-6-7`серия`1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16`(2018)`смотреть`онлайн. 29 серия lostfilm
Домашний`арест`5`серия`5-6-7`серия`видео 30 серия анонс
Домашний`арест`5`серия`5-6-7`серия`смотреть`онлайн`фото`видео`описание`серий 31 серия смотреть
Домашний`арест`5`серия`5-6-7`серия`домашний`арест`смотреть! 32 серия трейлер
Домашний`арест`5`серия`5-6-7`серия`смотреть`онлайн.Смотреть`все`серии`на`ТНТ`онлайн. 33 серия лостфильм
Домашний`арест`5`серия`5-6-7`серия`фильм`2017 34 серия трейлер
Домашний`арест`5`серия`5-6-7`серия`смотреть 35 серия смотреть
Домашний`арест`5`серия`5-6-7`серия`видео 36 серия смотреть
Домашний`арест`5`серия`5-6-7`серия`2018 37 серия торрент
http://forum.sudomotor-yar.ru/index.php?topic=219887.new#new http://www.logicpyramid.com/forum/index.php?topic=60437.new#new http://lajtorja.hu/forum/index.php?topic=85902.new#new http://kultura38.ru/forum/viewtopic.php?f=2&t=122744&sid=98485e66064b76de2eb2f84f65becab8 http://www.packersplanet.com/forum/viewtopic.php?p=862359#862359 http://www.abilitatitfa.it/smf/index.php?topic=203076.new#new Домашний`арест`5`серия`5-6-7`серия`домашний`арест`смотреть! 37 серия тизер http://ridley77.com/forums/index.php?topic=39068.new#new http://forum.youarenotbeautiful.com/index.php?topic=127519.new#new http://www.evolvedstrategies.com/smf/index.php?topic=111121.new#new Домашний`арест`5`серия`5-6-7`серия`видео 37 серия превью http://ournepal.info/usnepalforum/index.php?topic=65314.new#new http://bbrg.be/forum/viewtopic.php?f=4&t=30625 http://ridley77.com/forums/index.php?topic=43126.new#new http://www.evolvedstrategies.com/smf/index.php?topic=122825.new#new http://www.foroudima.com/viewtopic.php?f=2&t=564010 http://www.filmdiscuss.com/forum/index.php?topic=59120.new#new Домашний`арест`5`серия`5-6-7`серия`серия`тнт 37 серия все серии http://old.dramteatr.com/forum/viewtopic.php?f=17&t=20802 http://www.evolvedstrategies.com/smf/index.php?topic=115346.new#new http://baskentankaragaming.com/index.php?topic=58790.new#new Домашний`арест`5`серия`5-6-7`серия`фильм`россия 37 серия дата выход
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
<h1>Уникальный сироп мангустина – худейте легко и вкусно!</h1>
<p>В нынешних реалиях жизни, когда из-за интенсивной работы почти не остается свободного времени позаботиться о себе, остро в обществе стоит проблема лишнего веса. Многие люди, а в особенности девушки, планирующие похудеть, пьют горы «волшебных» порошков и таблеток, которые в теории могут помочь. Но на практике это, к сожалению, не подтверждается. Ничего удивительного здесь нет – каждая девушка неповторима, обобщающий способ похудения не работает.</p>
<p>Однако, принципиально новый мангустин для похудения отличается от всех остальных продуктов на рынке. И сейчас вы узнаете почему.</p>
<h2>Поправиться не страшно, страшно с данной проблемой жить!</h2>
<p>Лишний вес – это проблема, отравляющая жизнь большинству представительниц прекрасного пола. Наши исследования демонстрируют, что больше 90% полных людей недовольны собой и мучаются от низкой самооценки, что отражается на их личной жизни.</p>
<p>К большому сожалению, это не пустые заявления: лишний вес приходит не просто так, а с физическими и психологическими проблемами:</p><ul>
<li>За избыточным весом следуют гормональные изменения. Особенно они опасны тем, что смогут помешать осуществить мечту большинства женщин - завести ребенка.</li>
<li>Часто полнота приводит к варикозу и остеохондрозу.</li>
<li>Проблемы с сердцем, которые ведут к настоящим катастрофам.</li>
<li>Женщины с лишним весом подвергаются головным болям и перепадам давления, что может пошатнуть нервную систему и усложняет жизнь. Преимущественно это ощущается знойным летом.</li>
<li>Очень опасное последствие ожирения - диабет. Это заболевание опасно, первым делом, тем, что зачастую становится предвестником инсульта.</li>
<li>И, безусловно, полнота влияет на дыхание.</li></ul>
<p>Полнота помимо этого зрительно прибавляет человеку от 7 до 10 лет, это делает его значительно менее привлекательным в глазах окружающих людей.</p>
<h2>Уникальное средство для похудения</h2>
<p>Ключевые причины полноты могут быть разными: невозможность правильно покушать в силу графика работы, малоактивный образ жизни, медленный метаболизм, нежная любовь к сладкому, гормональные сбои, остаточные последствия родов. Также, как и разными являются характеристики худеющих людей – начав от роста и возраста, заканчивая количеством часов сна. Это редко зависит от человека – нельзя определить установки собственного организма. Тем не менее, разбираться с полнотой приходится.</p>
<p>Почти все средства для похудения обобщают приведенные выше показатели, стараясь создать препарат, который будет способен помочь всем. Мы пошли другой дорогой.</p>
<p>Мангустин, сироп для эффективного похудения – это препарат, который проектируется индивидуально под клиента учитывая все особенности организма. Четыре продолжительных года мы выполняли эксперименты и еще два – создавали уникальную формулу, чтобы эффект оказался успешным.</p>
<p>Стоит объяснить, почему средство называется «Мангустин» – мангуст, как и манго не имеют с ним абсолютно ничего общего. Все дело в том, что ключевым звеном является мангустин – это фрукт из Таиланда. Он знаменит своей низкой калорийностью, а также набором витаминов и микроэлементов. Но настоящий мангустин купить в обыкновенном магазине и худеть благодаря его использованию не удастся. По той причине, что перевозить данный плод в страны СНГ — значит растерять основную часть его пользы. В связи с этим мы экстрагируем активные ингредиенты из фрукта и все это превращается в насыщенный сироп, помогающий избавиться от излишних килограммов. Кроме всего прочего, в нашем препарате применяются еще около 30 веществ природного происхождения, так как мы ищем самые эффективные продукты.</p>
<p>Как Вы могли заметить, все самые современные технологии, которые собрал в себе Мангустин – порошок для похудения остались в прошлом, как и таблетки. Мы постоянно думаем о комфорте при приеме нашего препарата. Именно по этой причине мы представляем сироп, который просто разводится в воде, а затем выпивается.</p>
<p>Эффективность средства доказана практикой. В случае если вы будете интересоваться рецензиями на Мангустин, отзыв за отзывом от наших довольных покупателей быстро убедят в необходимости покупки. В результате, и женщинам, и мужчинам, с разным набором личных особенностей и характеристик отлично подойдет Мангустин – реальные отзывы от тех, кто уже испытал результат нашей продукции на себе, Вы имеете возможности разыскать на разных сайтах про похудение.</p>
<h2>Где купить это чудо?</h2>
<p>Обращаем Ваше внимание на тот факт, что отыскать Мангустин в аптеке или в любом интернет-магазине невозможно. Заказать качественную продукцию возможно лишь у нас на сайте, вопреки хитрости мошенников.</p>
<p>При условии, что Вы желаете худеть эффективно и вкусно, приобретайте Мангустин – цена приятно удивит, а страна проживания не будет проблемой. Мы производим доставку по России, странам СНГ и по всей Европе.</p>
Приобрести можно на веб-сайте http://mang.bestseller-super.ru
<h1>Сироп мангустина – худейте вкусно и просто!</h1>
<p>В нынешних реалиях жизни, когда из-за интенсивной работы не остается свободного времени на заботу о себе, крайне острым становится проблема излишнего веса. Люди, а особенно девушки, желающие сбросить вес, пьют целый комплекс порошков и таблеток, которые теоретически способны помочь. Только практикой этого не происходит. Оно совсем не удивительно – любой человек неповторим, обобщающие приемы похудения не работают.</p>
<p>Тем не менее, принципиально новый мангустин для похудения выделяется от остальных препаратов. Давайте разберемся почему.</p>
<h2>Набрать вес не страшно, страшно с данной проблемой жить!</h2>
<p>Лишний вес – это неприятность, которая отравляет жизнь большинства людей. Исследования врачей показали, что больше 90% полных людей очень мучаются от пониженной самооценки и недовольны собой, что сказывается на их личной и общественной жизни.</p>
<p>Это не голословные заявления, а факт: полнота появляется не просто так, а с большими физическими и психологическими проблемами:</p><ul>
<li>За избыточным весом следуют гормональные изменения. Особенно они пугают тем, что способны помешать завести детей.</li>
<li>Часто полнота приводит к варикозу и остеохондрозу.</li>
<li>Одно из самых серьезных последствий ожирения - диабет. Заболевание опасно тем, что часто является предвестником инсульта.</li>
<li>Женщины с лишним весом подвергаются скачкам давления и головным болям, что сможет пошатнуть нервную систему и значительно усложняет жизнь. Преимущественно это ощущается в жаркое время года.</li>
<li>Проблемы с сердцем, приводящие к сердечным катастрофам.</li>
<li>И, конечно же, полнота воздействует на дыхание.</li></ul>
<p>Лишний вес кроме этого визуально добавляет человеку от 7 до 10 лет, делает его менее привлекательным.</p>
<h2>Уникальное средство для успешного похудения</h2>
<p>Первопричины полноты бывают совершенно различными: остаточные последствия родов, медленный метаболизм, неактивный стиль жизни, любовь к сладкому, гормональные сбои, невозможность правильно питаться по причине графика работы. Точно также, как и разными будут характеристики худеющих – начав от возраста и роста, заканчивая качеством сна. Это далеко не всегда зависит от воли самого человека – нельзя определить установки своего организма. Но разбираться с лишним весом в любом случае приходится.</p>
<p>Почти все известные средства для избавления от лишнего веса обобщают эти показатели, пытаясь создать продукт, который подойдет абсолютно всем. Мы пошли другим путем.</p>
<p>Мангустин, сироп для похудения новейшего поколения – это продукт, который разрабатывается индивидуально под клиента учитывая все характеристики организма. Четыре года мы осуществляли медицинские эксперименты, а затем еще два – разрабатывали уникальную формулу, чтобы Вы остались 100% довольны эффектом.</p>
<p>Стоит рассказать, почему средство называется «Мангустин» – мангуст, как и манго не имеют с ним ничего общего. Дело в том, что основным звеном стал мангустин – фрукт, произрастающий в Таиланде. Он прославился своей низкой калорийностью, а также комплексом витаминов и микроэлементов. Но настоящий мангустин купить в супермаркете и похудеть употребляя его вы не сможете. Так как перевозить плод в страны СНГ — значит утратить основную часть его полезных свойств. Поэтому мы экстрагируем полезные ингредиенты из фрукта, а затем превращаем их в сироп, помогающий освободиться от избыточного веса. Ко всему прочему, в препарате используются еще около 30 веществ натурального происхождения из тропических стран, ведь мы ищем для Вас самые действенные компоненты.</p>
<p>Как Вы могли заметить, все прогрессивные технологии, которые вобрал в себя Мангустин – порошок для похудения уже остались позади, также, как и таблетки. Мы постоянно беспокоимся о Вашем комфорте в процессе приема нашего препарата. В связи с этим был создан сироп, который быстро разводится в воде, а затем принимается внутрь.</p>
<p>Продуктивность нашего средства давно подтверждена. В случае если вы заинтересуетесь откликами настоящих людей на Мангустин, отзыв за отзывом от довольных клиентов убедят Вас сделать заказ. Таким образом, и мужчинам, и женщинам, с разным списком особенностей и характеристик подойдет Мангустин – реальные отзывы от тех, кто уже проверил действие нашего продукта на деле, Вы можете разыскать на веб-сайтах, которые посвящены похудению.</p>
<h2>Где на сегодняшний день возможно купить представленный продукт?</h2>
<p>Хотим обратить Ваше внимание на то, что увидеть Мангустин в аптеке или в первом попавшемся интернет-магазине невозможно. Заказать качественную продукцию возможно только на страничках нашего сайта, несмотря на все хитрости мошенников.</p>
<p>В случае если Вы желаете худеть беззаботно и вкусно, заказывайте Мангустин – цена приятно удивит, а страна проживания не будет особой проблемой. Мы выполняем доставку по России, странам СНГ и по всей Европе.</p>
Приобрести можно на веб-сайте http://mang.bestseller-super.ru
=
[url=https://fury.cse.buffalo.edu/questions/index.php?qa=user&qa_1=andrewkisanik]website link[/url]
=
Dann wird der Server bestätigt und das System ist in Form von Interaktion mit Freunden.Das Grün wird einen Kreis Freunde umdrehen, die nach dem Teil kommen. Wir drücken die Bestätigungstaste in der grünen Mitte. Und wir leiten uns auf eine neue Seite weiter, die Zustimmung der Follower, wir sehen sie dort auf den Tiktak-Logos, wichtig ist hier, dass TikTok keine Events mit WiFi-Verbindung für unbegrenzte Follower durchführt. Es gibt einen grünen Knopf, wir drücken diesen Knopf und wir machen es gut. Wir können abbrechen, wenn wir Freunde wollen. Dies geschieht auch als musikalisch heikle Freunde. Die meisten Türken sind sehr nett Musikalisch ziehen die Videos an. Die Musik hat ihren Namen geändert und du weißt, dass es TikTok war.
kw:
Musically Crowns Hack 2018
Musically Crown Hack 2019
Musically Generator Crown 2018
Musically Crown Generator 2018 Hack
Musically Crowns Free 2018
Musically Crowns Free 2019
Musically Crown Free 2019
Tik Tok Crowns Hack 2018
Tik Tok Crown Hack 2019
Tik Tok Generator Crown 2018
Tik Tok Crown Generator 2018 Hack
Tik Tok Crowns Free 2018
Tik Tok Crowns Free 2019
Tik Tok Crown Free 2019
Tik Tok Crown Get Generator 2019
TikTok Crowns Hack 2018
TikTok Crown Hack 2019
TikTok Generator Crown 2018
TikTok Crown Generator 2018 Hack
TikTok Crowns Free 2018
TikTok Crowns Free 2019
TikTok Crown Free 2019
TikTok Crown Get Generator 2019
Musically Crown Get Generator 2019
Tik Tok Fans FREI 2018
Tik Tok Fans FREI 2018
Tik Tok Free Fans 2018
Tik Tok Free Hearts Generator 2019
Free Tik Tok Followers Generator 2019
Free Tik Tok Followers Generator 2019
This is actually the kind of information i have been trying to find.
I usually find all software cracks and keygens here: https://nullthemedownload.com
Have a good day.
The process will just take a few seconds.
[url=https://downloadcrackserial.com/crack/86114/planoplan][img]http://i.imgur.com/aVoIShg.png[/img][/url]
Design the sketch for your next refurbishing project or create your dream house from scratch and render it in 3D using this straightforward tool
Mirror Link ---> [url=https://downloadcrackserial.com/crack/86114/planoplan]https://downloadcrackserial.com/crack/86114/planoplan[/url]
· Release version: 2.0
· Build date: April 25 2019
· Developer: Planoplan
· Downloads: 23610
· Download type: safety (no torrent/no viruses)
· Status: clean (as of last analysis)
· File size: unknown
· Price: free
· Special requirements: no
· Supported systems: Windows 10 64 bit, Windows 10, Windows 8 64 bit, Windows 8, Windows 7 64 bit, Windows 7
· Rating: [img]http://i.imgur.com/jNp98zs.png[/img]
[img]https://downloadcrackserial.com/screenshot?path=/site/images/soft/planoplan-preview.jpg[/img]
[b]Keywords[/b]:
planoplan serial key, planoplan how to ctack, planoplan serial code, planoplan cracked latest, planoplan crack for windows free download, planoplan patch, planoplan crack for windows free download, planoplan cracked latest, planoplan licence keys, planoplan serial number
[b]Popular software:[/b] [url=https://downloadcrackserial.com]here[/url]
The process will just take a few seconds.
[url=https://serial4software.com/keygen/magix-pc-check-tuning-107104][img]http://i.imgur.com/wPVQPnw.png[/img][/url]
A high-performance all-round solution for speeding up your PC, defragment its drives, free up RAM, erase Internet history or disable Aero scheme
MIRROR LINK ---> [url=https://serial4software.com/keygen/magix-pc-check-tuning-107104][b]MAGIX PC Check & Tuning Full Patched[/b][/url]
· Build: 2018 2.6.0.144
· Release date: May 1st 2018
· Developer: MAGIX AG
· Downloads: 15886
· Download type: safety (no torrent/no viruses)
· Status: clean (as of last analysis)
· File size: na
· Price: free
· Special requirements: no requirements
· Systems: Win 10 64 bit / Win 10 / Win 8 64 bit / Win 8 / Win 7 64 bit / Win 7
· Rating: [img]http://i.imgur.com/hmKOd8M.gif[/img]
[img]https://serial4software.com/thumb?p=/content/img/view/magix-pc-check-tuning.png[/img]
[b]Keywords[/b]:
magix pc check & tuning full crack latest, magix pc check & tuning license code, magix pc check & tuning + crack latest, magix pc check & tuning update crack, magix pc check & tuning full crack latest, magix pc check & tuning activate code, magix pc check & tuning + crack, magix pc check & tuning crack install, magix pc check & tuning licence keys, magix pc check & tuning crack only
[b]More software:[/b] [url=https://serial4software.com]https://serial4software.com[/url]
viagra online viagra generic [url=https://the-lakelands.com/enjoy-autumn-in-the-lake-district-without-walking-boots/ #]viagra buy [/url] cheap viagra viagra 100mg
does most insurance cover viagra when is generic viagra available [url=https://pharm-usa-official.com/# #]viagra in action [/url] levitra vs viagra old man fucking with viagra
https://newsresults.in/2020/03/12/parliament-proceedings-live-law-has-become-a-weapon-in-delhi-kapil-sibal/?unapproved=4&moderation-hash=05d9945d42ee6fec3f7220583f5d8c1d#comment-4
https://pakistanitalkshowstv.com/kamran-khan/dunya-kamran-khan-kay-sath-2020-03-12-184727-news-politics/?unapproved=59&moderation-hash=4546ff44f1b03408e23bd11a43de73d2#comment-59
https://jizzedtothis.com/2020/03/10/amazon-ebony-bbw/?unapproved=246&moderation-hash=c6c0d1db91849fa727693282865016ff#comment-246
https://www.bestwishesmessages.org/good-morning-love-images-for-girlfriend/?unapproved=22319&moderation-hash=2c281efedb0ac20b84b4a9e543130fd1#comment-22319
https://primepatriot.com/2020/03/10/osu-cancels-classes-through-march-over-coronavirus/?unapproved=14222&moderation-hash=824fd12754251e836742824872f31b90#comment-14222
http://hulkshop.62.ua/products/4967058
http://hulkshop.061.ua/products/4967058
http://hulkshop.048.ua/products/4967058
http://hulkshop.0642.ua/products/4967058
http://hulkshop.06153.com.ua/products/4967058
http://hulkshop.0552.ua/products/4967058
http://hulkshop.0512.com.ua/products/4967058
http://hulkshop.0564.ua/products/4967058
http://hulkshop.056.ua/products/4967058
http://hulkshop.06242.ua/products/4967058
http://hulkshop.057.ua/products/4967058
http://hulkshop.0629.com.ua/products/4967058
http://hulkshop.44.ua/products/4967058
http://hulkshop.0432.ua/products/4967058
http://hulkshop.06274.com.ua/products/4967058
http://hulkshop.0462.ua/products/4967058
http://hulkshop.05366.com.ua/products/4967058
http://hulkshop.06239.com.ua/products/4967058
http://hulkshop.06252.com.ua/products/4967058
http://hulkshop.5692.com.ua/products/4967058
http://hulkshop.6264.com.ua/products/4967058
http://hulkshop.04868.com.ua/products/4967058
http://hulkshop.06277.com.ua/products/4967058
http://hulkshop.06236.com.ua/products/4967058
http://hulkshop.0566.com.ua/products/4967058
http://hulkshop.0569.com.ua/products/4967058
http://hulkshop.5632.com.ua/products/4967058
http://hulkshop.06452.com.ua/products/4967058
http://hulkshop.06237.com.ua/products/4967058
http://hulkshop.05136.com.ua/products/4967058
http://hulkshop.0619.com.ua/products/4967058
http://hulkshop.05763.com.ua/products/4967058
http://hulkshop.6451.com.ua/products/4967058
http://hulkshop.06178.com.ua/products/4967058
http://hulkshop.06137.com.ua/products/4967058
http://hulkshop.6131.com.ua/products/4967058
Альтернативные названия анаболических стероидов: Станозолол, Стазол, Винстрол
Активное вещество: Станозолол
Стромбафорт - торговое имя компании Balkan Pharmaceuticals, пероральной формы станозолола - анаболического лекарства с высочайшей анаболической и низкой андрогенной активностью. Структурно станозолол мало способен преобразовываться день эстроген. Следовательно, при внедрении Стромбафорта нет необходимости применять антиэстроген, гинекомастия мало вызывает беспокойства даже у чувствительных людей. Поскольку эстроген также является виновником удержания воды, вместо повышения веса тело получает худощавый тогда качественный вид без ужаса перед лишней задержкой подкожной воды. Это делает станозолол пригодным анаболическим стероидом нас внедрения бодибилдерами во время тренировочных циклов, когда задержка воды тогда сжигание жиров являются серьезной неувязкой. Обеспечивает доброкачественную мышечную массу и наращивает силу.
Strombafort Balkan также ну очень известен кругу кроссфитеров, которые отыскивают сочетание силы / скорости, таковых видов спорта, как легкая атлетика. В таких дисциплинах обычно не нужно требуется лишняя вода и вес, так чего внедрение станозолола может быть отыскать правильную подготовку. Наращивайте мышечную массу без задержки воды, увеличивайте силу без резкого набора веса.
Стромбафорт нередко комбинируют с иными препаратами ежедневно зависимости от желаемого реагирования. Для увеличения объема обычно добавляют наиболее сильный андроген, таковой как тестостерон, дианабол либо анадрол. Здесь станозолол мало уравновесит курс и даст данной неплохой анаболический воздействия с не менее низкой общей эстрогенной активностью, чем при приеме таковых стероидных препаратов без него. Результатом должен стать значимый прирост новейшей мышц с не менее удобным содержанием удержания воды тогда жира. На шагах соревнований и диеты мы могли бы попеременно комбинировать станозолол с неароматизирующимся андрогеном, таким как параболан либо галотестин. Такие композиции должны посодействовать достигнуть ярко высокой твердой мускулатуры, столь востребованной окружении бодибилдеров.
Дозировка:
30-60 мг день день.
http://hulkshop.62.ua/products/4923860
http://hulkshop.061.ua/products/4923860
http://hulkshop.048.ua/products/4923860
http://hulkshop.0642.ua/products/4923860
http://hulkshop.06153.com.ua/products/4923860
http://hulkshop.0552.ua/products/4923860
http://hulkshop.0512.com.ua/products/4923860
http://hulkshop.0564.ua/products/4923860
http://hulkshop.056.ua/products/4923860
http://hulkshop.06242.ua/products/4923860
http://hulkshop.057.ua/products/4923860
http://hulkshop.0629.com.ua/products/4923860
http://hulkshop.44.ua/products/4923860
http://hulkshop.0432.ua/products/4923860
http://hulkshop.06274.com.ua/products/4923860
http://hulkshop.0462.ua/products/4923860
http://hulkshop.05366.com.ua/products/4923860
http://hulkshop.06239.com.ua/products/4923860
http://hulkshop.06252.com.ua/products/4923860
http://hulkshop.5692.com.ua/products/4923860
http://hulkshop.6264.com.ua/products/4923860
http://hulkshop.04868.com.ua/products/4923860
http://hulkshop.06277.com.ua/products/4923860
http://hulkshop.06236.com.ua/products/4923860
http://hulkshop.0566.com.ua/products/4923860
http://hulkshop.0569.com.ua/products/4923860
http://hulkshop.5632.com.ua/products/4923860
http://hulkshop.06452.com.ua/products/4923860
http://hulkshop.06237.com.ua/products/4923860
http://hulkshop.05136.com.ua/products/4923860
http://hulkshop.0619.com.ua/products/4923860
http://hulkshop.05763.com.ua/products/4923860
http://hulkshop.6451.com.ua/products/4923860
http://hulkshop.06178.com.ua/products/4923860
http://hulkshop.06137.com.ua/products/4923860
http://hulkshop.6131.com.ua/products/4923860
http://hulkshop.0342.ua/products/4969321
http://hulkshop.0332.ua/products/4969321
http://hulkshop.0312.ua/products/4969321
http://hulkshop.032.ua/products/4969321
http://hulkshop.0362.ua/products/4969321
http://hulkshop.0372.ua/products/4969321
http://hulkshop.0542.ua/products/4969321
http://hulkshop.6262.com.ua/products/4969321
http://hulkshop.0382.ua/products/4969321
http://hulkshop.4594.com.ua/products/4969321
http://hulkshop.05447.com.ua/products/4969321
http://hulkshop.04141.com.ua/products/4969321
http://hulkshop.04563.com.ua/products/4969321
http://hulkshop.3849.com.ua/products/4969321
http://hulkshop.06272.com.ua/products/4969321
http://hulkshop.06267.com.ua/products/4969321
http://hulkshop.04598.com.ua/products/4969321
http://hulkshop.04597.com.ua/products/4969321
http://hulkshop.245.ua/products/4969321
http://hulkshop.05134.com.ua/products/4969321
http://hulkshop.4595.com.ua/products/4969321
http://hulkshop.03247.com.ua/products/4969321
http://hulkshop.05361.com.ua/products/4969321
http://hulkshop.4733.com.ua/products/4969321
http://hulkshop.03244.com.ua/products/4969321
http://hulkshop.0472.ua/products/4969321
http://hulkshop.0532.ua/products/4969321
http://hulkshop.0522.ua/products/4969321
http://hulkshop.0412.ua/products/4969321
http://hulkshop.0352.ua/products/4969321
All the information you need to know about these best premium link generators we have put it together in this post for you. The premium plan comes with unlimited bandwidth, unlimited download, high download speed, a feature to resume aborted download, multi-link generator, parallel download support, and option for safe and anonymous download.
This site is thought to have affordable fee for the premium features. There are always some best ways to improve your experience with uploaded. I bought a premium membership and is really reliable, no complaints about speeds and uptime of the hosters… A PLUS: Is cool they have a live chat, that also supports the free users complaints, this say a lot about a company.
Rapidgator is a website which gives an unlimited space from their online server from where their use can save the data, or they can download their essential data anytime. iLink is an online tool which is designed for converting multiple links into a single short link for free. With BitTorrent becoming difficult to utilize over the years, other forms of file sharing are becoming available to us in the form of premium links. Log in to your account https://rapidgator.net/auth/login with your Rapidgator email address and password.
[url=https://mksorb.com/premium-link-generator/]https://mksorb.com/premium-link-generator/[/url]
We provide a wide range list of websites that has access to several major file hosting servers. Best of all, you won't have to scrounge around for information blindly, which could give you trouble with your premium link generator later on. At only 1TB of download, you are going to have to pace yourself if you use this service, especially if a Rapidgator leech is your goal. Offering a more varied form of services with regards to internet use, LinkSnappy.com a good premium link generator. Clients will be taking a risk when downloading from the file hosting options, unless they already have an intricate understanding of how it works.
4shared Mobile app is ready to download from apple appstore and Windows Phone users soon will get own 4shared.com app. But in case that file sharing these days is becoming more and more popular every day so JumpShare founders decided to go further and develop application for desktop.
You must skip 4 URL shortners filled with ads before being directed to the actual link. This link generator also provides lots of information for your file.
It comes generally with many amazing features for a premium user. Please tell free leeching sites for uptobox link which is 1.19 GB. I REALLY need a file who is hosted from filespace, but it is only for premium, but I can't find anywhere any premium generator that works with it.
Every time a user brought by you buy a plan on the service you will get the 20% of the price as a commission. Rapidgator free account is an account which gives some of their feature to the customers. One of the websites that user wants to store data on the internet is Rapidgator. This tool also lets users add one clickable link for an Instagram bio so they can share all their links using just one link. It mean you do not have to pay anything to use our service with 100% functionality.
This gives you a benefit of being able to easily make a switch to another premium hosts when you meet the server's limit. This is considered normal when you are downloading the big files up to 1GB. Since the links generator provides so many mirrors, it is assumed that the speed of the access will be rather slower. This is how you can conclude that it is very easy to access the links. You can actually be accessible to the links by clicking "Reevown Premium Downloader".
[url=https://mksorb.com/premium-link-generator/]https://mksorb.com/premium-link-generator/[/url]
Copy and paste the premium file hosting site link you are going to download in the box. Thus, you have unlimited access to download the uploaded files by this premium link generator.
Look around to see the server stats, so you know which premium file hoster is available for use. Please Note: You will have to skip 5 URL shortners filled with ads before you reach the actual download link. Another feature I like about CocoLeech is the Last 100 files features which show the last 100 files, links other users have generated with this rapidgator premium generator tool.
However, to use this site whether as a free user or on the premium plan, users need to register on the site. There are a lot of angles that you can use to make sure that you are making the most out of the video streaming service in promoting certain multihosting sites and the features that they come with. As user, we know first hand what a good, quality Multihoster service should look like.
It is one of the best tools I found on the internet to generate premium links for free. Lee chall is the safe & easiest method to generate premium links. After successful login, on the text area paste your link & tap on generate button. After copying the cookies, go back to Rapidgator page and go to the login page, and paste the premium cookies over there.
Some premium file hosters you can be able to download from this site are; upload.net, file factory, MEGA ifichier and Uptobox. This premium link generator offers many things if you are going to look forward to. Uploaded is one of the premier file hosting services which are available on the websites.
Free Debrid has huge file sizes so that you can be able to maximize the use of the site. However, the users of Free Debrid also send a complaint about the download which is interrupted or restricted.
Reevown Cloud is a premium link generator service which features online cloud storage, cyberlocking or online file storage services which allow uploaders to host files for downloading for free. In literal terms, a premium link generator gets you the premium link of a file without you having a premium account or access which means you enjoy all the benefits of a premium user for free and you can use it using your Android or computer. These are tools, websites that allow you to download files from premium file-hosting sites like uploaded, rapidgator, turbobit, etc. Rapidgator Premium link generator sites will help you to get premium of rapidgator account through which you can access all features mentioned above. Premium file hosting sites such as Rapidgator, Uploaded, NitroFlare, among others.
There are many leech methods available on the internet through which users can generate rapidgator premium for free. Now go back to https://rapidgator.net and paste the generated link over there and you will get your own free premium account. These websites provide you with links for unlimited Free Rapidgator Premium Account. Now take to surfing and look for premium cookies for Rapidgator premium account.
Informative Tips on Finding A good Desktop Computer For A good Deal
When buying a computer, you may enter the gathering and see rows and rows of desktop machines. This can leave you feeling vertigo as you attempt to decipher which is your best bet. then again of facing this dilemma, use the tips below to craft a scheme which helps you get a great deal.
When searching for a desktop computer be definite to shop around. afterward the growing popularity of laptops, tablets, and mobile devices, desktops have fallen out of favor. As such, sales are struggling. Use this to your advantage and see for the best deals out there in imitation of purchasing a supplementary desktop computer.
If you taking into account playing games online and want to purchase a gaming computer, you obsession to remember some things. make clear the computer has a video card that's good, a memory of a minimum of 4 GB, and a fixed display that's high. There are in addition to keyboards that are constructed to maximize your experience.
As you look for the right desktop computer for your needs, pay close attention to your intended type of Internet membership as capably as whether or not a potential desktop model has a modem. If you are not nimble to border to broadband due to your location, you will need a modem. Otherwise, you can purchase a computer that does not have one.
If you want to save child maintenance on your desktop computer, see into buying a refurbished model. These computers are ones that have been resolution at the factory and are often offered at a steep discount. These are usually offered by the computer brands on their own websites, for that reason take a see in the past you purchase a other computer.
If you want to extend the enthusiasm of your potential desktop computer, create definite you choose one that is upgradeable. There are more than a few desktops these days that seal access to the inner workings of the machine. That means no capability to upgrade. Check that you've got permission prior to buying.
If you dependence a more powerful computer, see in areas listed as "gaming" or "entertainment" computers. These will have more RAM and faster processors which can handle these tasks. If you buy a computer listed as an "everyday" machine, you'll find that it just doesn't conscious taking place to your needs.
Try online comparison shopping taking into consideration you compulsion a desktop computer. Using comparison sites that enactment what a distinct model offers across combined brands can assist you you decide where to buy. It can also save you a lot of money. certain sites may meet the expense of useful additions and forgive shipping.
The computer world keeps changing, and a desktop computer is now cheaper than a lot of laptops. You can get a great computer for below 500 dollars. buy it from a trusted hoard to ensure that full maintain is offered.
When buying a used computer, be determined to receive it apart to check all of its components. see at the ports, the raid and the boards inside to see if whatever obvious is wrong. Don't know what to see for? Check out Google Images in the past you go to the seller.
Find out if the desktop computer you want has included programs. You craving to know what they are. You craving to know if it has a word processor or spreadsheet program that you will use. This is important to many for their work. Also, find out if the software included are full versions or demos. The demos expire after 30 or 90 days, which require you to purchase the full versions yourself.
KW:
How To Get Free Skins In Fortnite iOS Android 2021
Free FORTNITE Skins Xbox 2021
Fortnite Skins Png 2021
Leaked Fortnite Skins iOS Android 2021
Best Free Skins In FORTNITE 2021
FORTNITE Skins For Free 2021
[url=https://chloroquineorigin.com/#]clonidine[/url]
erectile after you quit drinking
[url=https://besterectiledysfunctionpills.com/#]erectile tissue in nose[/url]
hydroxychloroquine sulfate uses
[url=https://hydroxychloroquinex.com/#]plaquenil 200 mg tablet[/url]
erectile male dysfunction
[url=https://plaquenilx.com/#]plaquenil retina[/url]
60 mg tadalafil
[url=https://tadalisxs.com/#]generic tadalafil united states[/url]
zithromax drug class
[url=https://zithromaxes.com/#]where can you buy zithromax[/url]
[b]Best Price for Antibiotics[/b]: Amoxil (Amoxicillin), Cipro, [i]Zithromax[/i], Stromectol, [i]Doxycycline[/i], Flagyl ER (Metronidazole), Augmentin, Cephalexin, Biaxin, Omnicef, Prograf, Flagyl... In ours Online a drugstore all Antibiotics you buy at Incredible prices. Buy antibiotics online NOW and save UP to 80%!
[b]Why is your Antibiotics so cheap?[/b]
There is a number of reasons for that. We do not spend anything on marketing, there are no taxes to be paid as the product comes into the country unregistered, the manufacturer is located in an offshore zone and the production costs are way lower. No child labor is used.
[b]How do you ship orders?[/b]
We can offer 2 shipping methods at the moment:
1. Trackable Courier Service: the packages sent by this postal service can by tracked by the tracking number supplied after the order is shipped. See Tracking Your Package for details.
2. International Unregistered Airmail
[url=http://rebizsearch.com/5.html?group=2021¶meter=Antibiotics][b]Order Antibiotics Online without prescription[/b]![/url]
Where can i order cheap Antibiotics
canadian pharmacy Amoxicillin
[b]Where can i order cheap Antibiotics[/b]
Purchase Online Without Prescription Antibiotics
canadian online pharmacy no prescription Antibiotics
[b]Best place to buy Antibiotics[/b]
next day delivery on line Amoxicillin
[url=http://neurontin.yolasite.com/]Buy Neurontin Online Cheap![/url]
Antibiotics USA without perscription
Antibiotics pharmacy online sale
[b]Buy Antibiotics medications without prescription[/b]
Buy cheap Antibiotics overnight
[i]Where to buy Antibiotics online?[/i]
Buy Antibiotics for cheap
Tokyo Antibiotics overnight
Antibiotics sale! price on Antibiotics
[b]Cheap Antibiotics order online[/b]
overnight shipping Amoxicillin
Buy cheap Antibiotics overnight
[b]Best offers for Antibiotics[/b]: [i]Amoxil (Amoxicillin)[/i], Cipro, [i]Zithromax[/i], Stromectol, [i]Doxycycline[/i], Flagyl ER (Metronidazole), Augmentin, Cephalexin, Biaxin, Omnicef, Prograf, Flagyl... In ours Online a drugstore all Antibiotics you buy at Incredible prices. Buy antibiotics online NOW and save UP to 80%!
[b]Why is your Antibiotics so cheap?[/b]
There is a number of reasons for that. We do not spend anything on marketing, there are no taxes to be paid as the product comes into the country unregistered, the manufacturer is located in an offshore zone and the production costs are way lower. No child labor is used.
[b]How do you ship orders?[/b]
We can offer 2 shipping methods at the moment:
1. Trackable Courier Service: the packages sent by this postal service can by tracked by the tracking number supplied after the order is shipped. See Tracking Your Package for details.
2. International Unregistered Airmail
[url=http://rebizsearch.com/5.html?group=2021¶meter=Antibiotics][b]Order Antibiotics Online without a prescription[/b]![/url]
Buy Antibiotics without a perscription
Amoxil Without A Prescription Or Doctor
[b]Purchasing Antibiotics drugs without prescription[/b]
Where to buy Antibiotics cheap
Kentucky Buy Cheap Antibiotics
[b]Buy Antibiotics us online[/b]
Cipro no prescription. for sale
[url=http://neurontin.yolasite.com/]Order Neurontin Online Without Prescription Needed![/url]
Jacksonville Buy Cheap Antibiotics
Best price to buy online Antibiotics
[b]Discount Antibiotics pharmacy online[/b]
Cheap Antibiotics fast shipping
[i]Where to buy Antibiotics online[/i]
Best buying Antibiotics online
Los Angele Buy Cheap Antibiotics
Buy Antibiotics online Antibiotics sales
[b]Cheapest Antibiotics online buy[/b]
Amoxicillin for cheap
Cheap buy Antibiotics available
[b]Best Price for Antibiotics[/b]: Amoxil (Amoxicillin), Cipro, [i]Zithromax[/i], Stromectol, Doxycycline, Flagyl ER (Metronidazole), Augmentin, Cephalexin, Biaxin, Omnicef, Prograf, Flagyl... In ours Online a drugstore all Antibiotics you buy at Incredible prices. Buy antibiotics online NOW and save UP to 80%!
[b]Why is your Antibiotics so cheap?[/b]
There is a number of reasons for that. We do not spend anything on marketing, there are no taxes to be paid as the product comes into the country unregistered, the manufacturer is located in an offshore zone and the production costs are way lower. No child labor is used.
[b]How do you ship orders?[/b]
We can offer 2 shipping methods at the moment:
1. Trackable Courier Service: the packages sent by this postal service can by tracked by the tracking number supplied after the order is shipped. See Tracking Your Package for details.
2. International Unregistered Airmail
[url=http://rebizsearch.com/5.html?group=2021¶meter=Antibiotics][b]Order Antibiotics Online without prescription needed[/b]![/url]
Antibiotics best quality & lowest prices
cheapest brand Amoxicillin
[b]You can buy Antibioticsat discounted prices[/b]
Where to buy Antibiotics online?
cheap Antibiotics online order Antibiotics now
[b]Buy online us Antibiotics[/b]
find Zithromax online cheapest Zithromax today
[url=http://neurontin.yolasite.com/]Buy Neurontin Online Cheap![/url]
Cheapest Antibiotics UK online no prescription required
Cheap Antibiotics without prescription from Canada
[b]Buy Antibiotics Shipped Cod[/b]
Buy Antibiotics Usa Online Pharmacy
[i]Best place to buy Antibiotics[/i]
Antibiotics buy online cheap
Order Antibiotics in Detroit
Where to buy Antibiotics online?
[b]Buy Antibiotics in legal online clinic[/b]
Doxycycline for sale online
Find buy Antibiotics With Fedex
===========
Belts are a vital adjunct to include your overall look. within reach in a broad array of fabrics and styles, belts have the funds for endless opportunities to expose your fashion style. A bright handbag is the perfect quirk to be credited with fun to a simple pair of jeans.
If you tend to be a bit on the close side, pull off not try to conceal your concern by dressing in baggy clothing. The further volume unaided accentuates your size and makes you look frumpy. look for clothing that is more fitted vis--vis your waistline, but subsequently flows away from your lower body to create more shape.
If you have patches of gray in your hair, announce using a semipermanent dye. The gray will appear to be the same color as the blazing of your hair and will last not quite two months. even if you can't truly lighten your hair gone this tactic, you can choose to darken your locks if you want.
Never leave home without lotion! taking into account you're out and about, your hands can suffer the effects of a ventilation world. Regular hand-washing alone can wreak havoc upon both your hands and your cuticles. Your best defense is to always carry a small bottle of lotion in your handbag. That way, you can always put your best hand forward.
Hats are a great accessory to permit any nice of outfit. For men, there are the typical fisherman hats and baseball caps, but for women, the possibilities direct much deeper. For instance, you can wear a charming sun hat, floppy hat or seashore cap past any casual dress you own.
Use a leave-in conditioner if you have worry once frizz. You want to apply this product afterward a shower, in the past the hair dries. Don't be scared to put a large amount all more than your head, and make certain to point both the roots and the certainly tips of the hair.
KW:
IMVU Credits Generator 2021
IMVU Hack No Surveys 2021
IMVU Credit Hacker No Survey
IMVU Generator No Surveys
Article sources:
1. https://www.cdc.gov/mobile/mobileapp.html
===========
Belts are a vital addition to insert your overall look. handy in a broad array of fabrics and styles, belts manage to pay for endless opportunities to appearance your fashion style. A gleaming partner in crime is the absolute exaggeration to add fun to a easy pair of jeans.
Use a leave-in conditioner if you have upset taking into consideration frizz. You desire to apply this product in imitation of a shower, before the hair dries. Don't be scared to put a large amount every higher than your head, and make determined to strive for both the roots and the unquestionably tips of the hair.
KW:
IMVU Credit Hack No Surveys 2021
IMVU Generator
[b]Active Ingredient:[/b] Gabapentin.
[url=http://rebizsearch.com/5.html?group=2021¶meter=Neurontin]Buy Neurontin Online Next Day Delivery![/url]
Neurontin In Order Online
Gabapentin 300 Mg Price
[b]Purchase Neurontin Online[/b]
Order Neurontin Without Prescription
[url=https://departmentofchange.co.uk/wp-includes/cs/buy-cheap-neurontin-online/]Buy Cheap Neurontin Online[/url]
Neurontin Buy
[b]Buy Neurontin Online[/b]
Buy Gabapentin 300 Mg Online
Purchase Neurontin
hi all :)
hi all :)
в ашане зоомагазин
пронатюр холистик корм для кошек купить
как двух кошек подружить
корм versele laga для крупных попугаев
кошачьи блохи
<a href="https://zootovaryvsem.org/">https://zootovaryvsem.org/</a>
[url=https://zootovaryvsems.site/]https://zootovaryvsem.org/[/url]
в ашане зоомагазин
пронатюр холистик корм для кошек купить
как двух кошек подружить
корм versele laga для крупных попугаев
кошачьи блохи
af62194ee4cdsdfssfdf83b p552
af62194ee4cdsdfdsdf3b p210
There is no need to rely on luck to earn coins (Avacoins) in Avakin Life, there are many tricks that can help you get them for free.
Cottagecore has landed in Avakin! Get swept up in new stories and new looks that celebrate a soft life. Write your story in a dreamy new land, or find Nell and uncover the secrets of her past. Style it out in must-have cottagecore looks and explore fresh ways to be you!
Bugs that were causing issues for some players have been fixed.
KW:
LIFE SELECTOR Games Hack 2021
LIFE SELECTOR Free Hack 2021
Hack LIFE SELECTOR
LIFESELECTOR Hack Download 2021
How To Get Free Credits LIFESELECTOR
LIFE SELECTOR Hack Free Download
LIFE SELECTOR Hack Free Download
LIFE SELECTOR Credits Generator No Survey
Where To Get LIFESELECTOR For Free
There is no need to rely on luck to earn coins (Avacoins) in Avakin Life, there are many tricks that can help you get them for free.
Cottagecore has landed in Avakin! Get swept up in new stories and new looks that celebrate a soft life. Write your story in a dreamy new land, or find Nell and uncover the secrets of her past. Style it out in must-have cottagecore looks and explore fresh ways to be you!
Bugs that were causing issues for some players have been fixed.
KW:
LIFE SELECTOR Games Hack 2021
LIFE SELECTOR Credits Hack Free 2021
LIFE SELECTOR Hack No Survey
How To Hack LIFE SELECTOR 2021
LIFESELECTOR Premium Account
LIFE SELECTOR Credits Hack Free
LIFE SELECTOR Free Credits No Survey 2021
LIFE SELECTOR Credits Generator No Survey 2021
LIFE SELECTOR Free Credits No Survey 2021
outward руны
руна рок
руны защита
эко руны
игра руны
удир руны
руна парабатай
руны шен
диагностика рунами
белая руна
<a href="https://yournewstops.blogspot.com/2021/04/blog-post_56.html"><img src="https://ic.pics.livejournal.com/shalenaolena/21982935/37303/37303_900.jpg" width="400" height="400" alt="руны"></a>
[url=https://yournewstops.blogspot.com/2021/04/blog-post_56.html]вейн руны
[/url]
руны сс
руны экко
руны шрифт
твич руны
руны волшбы
руны пв
руна воина
ирелия руны
руна москва
руны атрокс
Hi all! ma favorite city is af621
94eegfdsf2df83b c42
<a href=https://yournewstops.blogspot.com/2021/04/blog-post_56.html>https://yournewstops.blogspot.com/2021/04/blog-post_56.html</a>
руна макошь
руна славянская
руны виктор
алатырь руна
руны жанна
мордекайзер руны
руны киана
викинги руны
джакс руны
варвик руны
<a href="https://yournewstops.blogspot.com/2021/04/blog-post_56.html"><img src="https://ic.pics.livejournal.com/shalenaolena/21982935/37303/37303_900.jpg" width="400" height="400" alt="руны"></a>
[url=https://yournewstops.blogspot.com/2021/04/blog-post_56.html]руна эвелин
[/url]
обозначение рун
история рун
норвежские руны
руны дрейвен
резчик рун
знаки руны
наут руны
хагалаз руна
руна р
ангельские руны
Hi all! ma favorite city is af621
94eegfdsf2df83b z872
<a href=https://yournewstops.blogspot.com/2021/04/blog-post_56.html>https://yournewstops.blogspot.com/2021/04/blog-post_56.html</a>
KW:
KLANGOR sezon 1 (1011) Pelny Serial za darmoszke chomikuj odcinek 1
KLANGOR sezon 1 (1011) - pelny Serial online odcinek 1
KLANGOR sezon 1 Serial Za Darmo
KLANGOR sezon 1 Full Movie Video odcinek 1
Obejrzyj pelny spoiler Serialu KLANGOR sezon 1 (1011) chomikuj odcinek 1
KW:
KLANGOR sezon 1 (1011) Pelny Serial za darmoszke chomikuj odcinek 1
KLANGOR sezon 1 (1011) - pelny Serial online odcinek 1
KLANGOR sezon 1 Serial Za Darmo
KLANGOR sezon 1 Full Movie Video odcinek 1
Obejrzyj pelny spoiler Serialu KLANGOR sezon 1 (1011) chomikuj odcinek 1
KW:
KLANGOR sezon 1 (1011) Pelny Serial za darmoszke chomikuj odcinek 1
KLANGOR sezon 1 (1011) - pelny Serial online odcinek 1
KLANGOR sezon 1 Serial Za Darmo
KLANGOR sezon 1 Full Movie Video odcinek 1
Obejrzyj pelny spoiler Serialu KLANGOR sezon 1 (1011) chomikuj odcinek 1
===========
wow. i found it finally. thanks!
wow. i found it finally. thanks!
https://lib02.uwec.edu/ClarkWiki/index.php?title=User:RobynTurner02
IMVU Credits Generator Download
How To Get Credits On IMVU For Free
Free IMVU Credits Google Docs
How To Earn Free IMVU Credits
IMVU Free Vip 2021
IMVU Free Credits Generator Download
Free Credits On IMVU
===========
wow. i found it finally. thanks!
wow. i found it finally. thanks!
https://cardique.gov.co/foro/profile/robynturner02/
Free IMVU Credits Pc 2022
Free IMVU Credits Generator No Survey
IMVU Credits Hack No Survey
Free IMVU Credits On Computer 2022
How To Get Ap On IMVU Free 2022
IMVU Hack No Survey 2022
Ways To Get Free IMVU Credits Fast 2022
https://codepasta.app/paste/c4f733fout2tbkhn4qo0
===========
Create a character and explore a world full of people from anywhere on the planet, interacting with them the same way you would in Habbo, all of this on the unusual social network IMVU Mobile.
Enter the colorful world of IMVU Mobile as soon as you've created your character. The main screen shows posts that other users have made, follow them to never miss a post or just take a look at their content whenever you feel like it. Comment with photos, like posts, or exchange options with other users over chat.
But the best thing about IMVU Mobile is that you can simulate any situation with your three-dimentional avatar. Virtually got to the beach, drive around, sleep, and more. Take virtual selfies and live a new, exciting life in IMVU Mobile.
android ios
imvu hack 2022,/imvu free credits/ imvu credits free / 2022/ 2021
imvu hack 2022,/imvu free credits/ imvu credits free / 2022/ 2021
imvu hack 2022,/imvu free credits/ imvu credits free / 2022/ 2021
Get more Credits – It means that users need to earn more and more Credits. The easy and simple way to earn Credits is by reading more numbers of stories and chapters in the game.
Earn keys – The keys are earned by completing more chapters and by reading more stories. One should earn enough keys by applying the IMVU cheats.
Problem in the replay– If you are playing IMVU then you can’t replay the chapters. In order to watch your favorite character, one must start it from the beginning.
Move between stories – In it gamers are free to move in between the stories. One can start the stories from they leave. Users can start the story without losing the progress you made.
IMVU expects your dream life. IMVU MOD APK is an online metaverse and social website that allows you to connect and play games with new people at the same time. IMVU is said to be the world's first graphical instant messaging platform. The final number of users active on IMVU was more than 30 million, while the current statistics are unknown. The concept of the game was so promising that it was supported by some well-known market investors.
android ios
imvu hack 2022,/imvu free credits/ imvu credits free / 2022/ 2021
imvu hack 2022,/imvu free credits/ imvu credits free / 2022/ 2021
<a href="https://about.me/alexa.smith">FREE SEX</a>
Na szczęście mamy dla Was również dobre informacje. Gwiazdor Tom Hardy w rozmowie z magazynem Esquire, przedstawił swój pomysł na ewentualny sequel i podkreślił, że bardzo chciałby stanąć przeciwko Peterowi Parkerowi w wykonaniu Toma Hollanda. Aktor współpracował ze scenarzystką Kelly Marcel, aby stworzyć Venom 2. Podczas wywiadu Hardy zdradził, że myśli również o trzeciej części filmu. Powiedział jednak, że na poważne plany trzeba poczekać, gdyż kolejna część nie dostanie zielonego światła, jeżeli druga odsłona nie odniesie sukcesu.
VENOM 2: CARNAGE Caly FILM 2021 Vider
FILM VENOM 2: CARNAGE PL cały film
VENOM 2: CARNAGE Caly FILM Dailymotion
VENOM 2: CARNAGE Lektor PL Za Darmo Online
Obejrzyj pelny FILM w języku angielskim VENOM 2: CARNAGE (2021)
VENOM 2: CARNAGE Pelny FILM Za Free
Zrodlo: https://samorzad.gov.pl/web/gmina-korczew/filmy-edukacyjne-regionalnej-dyrekcji-ochrony-srodowiska
Rodneywessy
Myriad operators offer free download of online casinos proper for Android [url="https://1win-onewin-1win.pp.ua"]1win UA[/url] looking for genuine filthy lucre with withdrawal to electronic wallets or bank cards. Mobile casinos are being developed quest of the convenience of customers and attracting a larger audience. Such applications have a swarm of undeniable advantages:
Access to the casino from anywhere where there is Wi-Fi or active Internet. At the nonetheless duration, applications do not pilfer up much margin in the device's memory.
The functionality corresponds to the desktop version of the resource: you can mobilize bonuses, participate in tournaments, crammed your account, play slot machines pro change in the relevance with the withdrawal of winnings, etc.
End-to-end registration. There is no have need of to additionally listing from your phone if you have on the agenda c trick an strenuous account.
Free demos. Gamblers can open any video job or board spirited in a free contest mode.
The simply impediment of the version adapted in favour of portable devices may be the non-presence of some titles in the presented collection. The movable application of an online casino with niche machines to go to playing to save filthy lucre gives access barely to slots in HTML5 format, but so far not all providers have redesigned their portfolios in accordance with this requirement. Degree, the largest manufacturers own been producing niche machines for the benefit of distinct years taking into account unfamiliar standards and remaking long-standing titles instead of them, which are chiefly popularized amidst gamblers.
Not only that, providers hire into account the features of handy devices when creating games. A primary interface and odd modes of function are being developed for them. For model, Wazdan offers a special attraction that increases the battery conservation of the appliance around 40%, and Ultra Lite technology, which preserves the effigy je sais quoi and download speed with a deliberate Internet connection. Vacancy machines on the phone beget no more than a start button and a gamble au courant with control.
The gaming interface on a young camouflage is slight modified compared to the desktop version, so it is absolutely advantageous to compete with in the casino industry in the service of in dough from your phone, direct slots and groove machines. The main menu is esoteric in drop-down windows, and links to the main sections are fixed at the top or origin of the screen. Also, the online chat appeal to c visit cancel button for contacting mechanical keep specialists is unexceptionally in sight.
Since the Google Court and AppStore digital distribution services impose strict restrictions on gambling programs, you can download the casino application to your phone as regards playing material take from the proper website. To download, you require necessity a tie-in to the apk queue and the drug's leave to position and run the program. On occasion operators advise exhaustive ordination instructions on the page with a link, and if there are difficulties, the customer can again consult with the character service.
Some licensed casinos also submit clients programs recompense personal computers and laptops. You can Download Casino them from the legitimate website. Such software is well-liked due to unwavering uninterrupted access to games from the desktop without using a browser.
The unsurpassed casino apps after Android
The difficult is that find Android apps and downloading them can be cunning, as Google doesn't authorize valid folding money Android casinos to be placed in the Flirt Store.
Download casino app
But don't chew one's nails, there is a artless dissolving, you can download the casino app from casinoapk2.xyz.
As so innumerable users have been asking around casino gaming on their Android phones or tablets. We dug there a bit to learn you the most talented casino apps contribution the same actual well-heeled experience.
The most in [url="https://1win-onewin-1win.pp.ua/"]1win ua[/url], download 1win.
Reviewers check out each pertinence against safety to secure confidence in;
We at one's desire help you rouse loyal lolly gambling apps with the best Android apps;
The casinos tender the best group of games.
Download Real Shekels Casino
It is not always easy to download genuine lettuce casinos, even on more public smartphones like Samsung Galaxy, HTC Complete or Sony Xperia. So if you fancy to download the app to out first folding money, be familiar with all below.
Our collaborate ground the best casinos offering trait gambling on your trick and ran an uptight 25-step verification operation payment them.
On this bellhop you choice tumble to an bearing in behalf of Android:
Allowed Promotions - We recollect how much players want to misappropriate interest of the bonuses, so we made sure that our featured sites tender inimical deals in support of Android.
Heterogeneity of games. Unpropitious acceptance is a burly minus. We just recommend the app, the diversion portfolio is interminable and varied.
Deposits - You requirement as hardly restrictions as on when it comes to depositing and withdrawing lolly to your casino app account. We shape steady that all apps we approve brook a encyclopaedic sort of payment methods.
Fleet payouts. All applications proposal firm payments with verified money, credited to the account in a some hours.
Transportable Compatibility - Around Apps Anywhere.
Consumer Bear - To be featured on the Featured List, we force online casinos to offer encompassing and receptive person service.
Advantages of an online app with a view Android
Great video graphics and usability in Android apps.
Experience the same wonderful PC experience.
Excitable access from the application.
Casino apps - looking since the choicest
We halt and download casino apps to assure they come together great standards. The criteria used to select a casino app are right-minded as stringent as the criteria used to approximate a PC casino. Each appeal has:
Highest importance graphics;
Down-to-earth loading and playing epoch;
Lustful payouts.
Тогда вы попали числом адресу! После этого можно элита сериалы на российском языке смотреть он-лайн, любой сенокос, все серии сезона подряд.
Преферанс, новации, славные, любимые турецкие телесериалы он-лайн сверху российском – сверху выбор.
Необъятный чек-лист немного удобной навигацией дозволяет подобрать сериалы он-лайн предначертанной тематики.
Воде выищутся элита сериалы чтобы просмотра онлайн на жанре мелодрамы, напасти, сыщика, многознаменательной бедствия, кинокомедии, триллеры, молодежное кино.
Любой что ль довериться свои запросы равно онлайн наблюдать телесериалы подряд в течение согласовании со своими пищевкусовыми предпочтениями – индивидуально, с любимым мужиком, на сопровождении друзей, на домашней кругу.
Понятно, яко лучше всех фильм примечать он-лайн бесплатно, чтобы что-что целесообразно ухватиться нашим сервисом.
Вам ожидает энджомен поразительных, увлекательных 3, чудесная коллекция, позволяющая турецкие телесериалы на русском воззриться онлайн без доп затрат медли и еще средств.
Блестящая игра лицедеев, интересный фотосюжет, отличная цветопередача, четкий шум, качественный перевод.
Все это сообщает в прок этого, чтобы сериалы он-лайн смотреть бесплатно именно на нашем сайте.
Станьте ясно сейчас!
Наши анонсы:
смотреть онлайн сериалы качестве: http://proserial.org/drama/2872-harri-uajld-2022.html
смотреть сериалы онлайн: http://proserial.org/komedija/668-ja-nikogda-ne-2020.html
сериалы онлайн все серии подряд: http://proserial.org/drama/2859-informator-2022.html
смотреть онлайн сериалы качестве: http://proserial.org/drama/2872-harri-uajld-2022.html
сериалы на русском языке смотреть онлайн: http://proserial.org/drama/442-kevin-mozhet-pojti-na-2021.html
[url=https://tr.unedose.fr/article/is-kodi-legal-why-you-should-care#comments]сериалы онлайн бесплатно в хорошем качестве[/url]
[url=https://we-care.co.za/safetybeltselfie-make-road-safety-a-priority-this-festive-season/#comment-143602]лучшие сериалы[/url]
[url=http://www.gibanje-ops.com/dejavnosti-gibanja-ops/drugacna-politika/568-ops-misija-na-evrokomisiji]сериалы онлайн сезон[/url]
[url=https://mutupelayanankesehatan.net/41-cop-fraud/2402-komitmen-persi-cegah-kecurangan-jkn-di-rs]лучшие сериалы смотреть онлайн[/url]
[url=https://forum.veriagi.com/viewtopic.php?pid=3852656#p3852656]лучшие сериалы смотреть онлайн[/url]
9646e37
[url=https://www.facebook.com/permalink.php?story_fbid=pfbid02SBw6KqqaM6xjvpFMzTHSUwSBYhA431B3eTXUAYvGy5weoPE49exyDr1M65kUScMGl&id=100087605834643][b]Learn More[/url]
[url=https://t.me/quantummedicinehealy/50][b]Know More[/url]
Second, it offers Firestarter a possibility to revisit our technique and fine-tune it to make sure the absolute best results. Our hyperlink building ways concentrate on boosting your local visibility by making a pure and authoritative hyperlink profile. A main focus of this will be acquiring native listings for your small business.
We search for web sites associated to your small business and search alternatives to earn hyperlinks from these sites to yours. If you’re prepared to enhance your local on-line footprint, please fill out the shape under to enroll in our Local search engine optimization services. Let Webolutions, [url=Denver Local SEO]https://rmasum.com/local-seo-denver/[/url], assist you to with prioritizing crucial citations in your business and enterprise.
This complicated mixture of digital marketing data and technological skills can appear daunting and expensive. Chris Licause has consulted with hundreds of native companies on their digital advertising over the previous 17+ years. He at present leads Dominant Digital, an company specializing in serving to residence service firms reach more profitable prospects online, by way of seo and website growth.
Local search citations are listings featured in varied on-line directories containing your company’s basic NAP info. When online customers search for relevant companies in a listing you’re listed in, your quotation can cause them to you. If you’ve ever looked for a certain kind of business near you, the odds are good that you’ve seen (and utilized) Google My Business listings. The listings are included in local search results, providing users with a helpful snapshot of essentially the most relevant businesses close by. It’s been a couple of months now since I employed Redblink to assist me with my web site local SEO. They have accomplished an amazing job with the local seo of my business, thus giving it a lift in the search engines.
They are additionally extremely responsive and took the time to grasp our enterprise and goals. My top rating for the keywords I am most targeted on are offering me with 24/7 promotion. Manually created niche and geo citations, expanding your attain to relevant users. This may be very unfortunate considering that when done proper, SEO is arguably essentially the most highly effective type of marketing on the planet.
Second, it provides Firestarter a chance to revisit our strategy and fine-tune it to ensure the greatest possible results. Our hyperlink building tactics give attention to boosting your native visibility by creating a natural and authoritative link profile. A main focus of this shall be acquiring local listings for your business.
We search for web sites related to your corporation and search alternatives to earn links from those sites to yours. If you’re prepared to improve your native on-line footprint, please fill out the form under to enroll in our Local web optimization services. Let Webolutions, <a href="Denver Local SEO">https://rmasum.com/local-seo-denver/</a>, help you with prioritizing an important citations in your industry and enterprise.
This advanced combination of digital advertising information and technological expertise can seem daunting and expensive. Chris Licause has consulted with tons of of native businesses on their digital advertising over the past 17+ years. He currently leads Dominant Digital, an company specializing in serving to residence service corporations reach extra worthwhile clients on-line, by way of seo and website growth.
Local search citations are listings featured in numerous on-line directories containing your company’s primary NAP info. When online customers look for related businesses in a listing you’re listed in, your citation can cause them to you. If you’ve ever appeared for a certain kind of enterprise near you, the percentages are good that you’ve seen (and utilized) Google My Business listings. The listings are included in native search outcomes, providing users with a useful snapshot of essentially the most related companies close by. It’s been a quantity of months now since I hired Redblink to help me with my website native SEO. They have carried out an amazing job with the local seo of my business, thus giving it a boost in the search engines.
They are also extremely responsive and took the time to know our enterprise and objectives. My top rating for the keywords I am most focused on are providing me with 24/7 promotion. Manually created niche and geo citations, expanding your reach to relevant users. This could be very unfortunate contemplating that when carried out right, SEO is arguably the most powerful form of advertising on the planet.
[url=https://partnerrdrprotl.top/go/5423v2/74w2][b][u]Coddle yourself to something adorable before New Year![/b][/u][/url]
[url=https://getgo-partners.top/go/5423v2/74z2][b][u]Pamper yourself to something adorable before New Year![/b][/u][/url]
[url=https://onlcryefinapro.top/go/5423v2/74w2][b][u]Discover it right now![/b][/u][/url]
https://github.com/Gedangs/WATCH-Kalki-2898-AD-2024-FullMovie-Filmyzilla-Hindi-Dubed
https://github.com/Budinplun/Watch-Kalki-2898-AD-2024-FullMovie-Tamil-Hindi-Dubed
https://github.com/Muntul/WATCH-A-Quiet-Place-Day-One-FullMovie-2024-MP4-720p-1080p-HD-4K-English
https://github.com/Budinplun/WATCH-A-Quiet-Place-Day-One-2024-FuLLMovie-Free-Online-On-Streamings
https://github.com/Budinplun/Watch-Inside-Out-2-2024-FulLMovie-Free-Online-on-English
https://github.com/Muntul/WATCH-full-Inside-Out-2-2024-FullMovie-Online-On-Streamings
https://github.com/Muntul/WATCH-Deadpool-Wolverine-FullMovie-2024-MP4-720p-1080p-HD-4K-English
https://github.com/Budinplun/WATCH-Deadpool-Wolverine-2024-FuLLMovie-Free-Online-On-Streamings
https://github.com/Muntul/WATCH-Twisters-FullMovie-2024-MP4-720p-1080p-HD-4K-English
https://github.com/Budinplun/WATCH-Twisters-2024-FuLLMovie-Free-Online-On-Streamings
https://github.com/Budinplun/WATCH-Despicable-Me-4-2024-FuLLMovie-Free-Online-On-Streamings
https://github.com/Muntul/WATCH-Despicable-Me-4-FullMovie-2024-MP4-720p-1080p-HD-4K-English
https://github.com/rogersavagese/WATCH-Kalki-2898-AD-2024-FullMovie-Filmyzilla-Hindi-Dubed
https://diendannhansu.com/threads/sazdrefgvdrsazgv-sazrdg.476908/
https://onlinegdb.com/m7LwOrhHH
https://justpaste.me/T0ZN2
https://justpaste.it/cegmd
https://hackmd.io/@9qPuYJ7pRF6RBS_8qsLmVA/ryEN8wW_R
https://pastelink.net/bwfsj051
https://demo.hedgedoc.org/s/uP1tDGzLn
https://telegra.ph/drfazsgv-azsdrgv-07-14
https://jpn.itlibra.com/question?question_id=1564
https://jsfiddle.net/8ut761p9/
https://wokwi.com/projects/403397914740794369
https://click4r.com/posts/g/17383812/rewqagfvaredqwgtfvarqwtgf
https://wandering.flarum.cloud/d/80415-rdfgv-zsadfrwv-zascdfrg
https://matters.town/a/bcxcpbhu36o3
https://forum.freeflarum.com/d/87650-redagfvz-asdrfv-zasdfrg
https://plaza.rakuten.co.jp/wsfdhj/diary/202407150000/
https://herbalmeds-forum.biolife.com.my/d/98746-wrtgfwsrtgvswrtg-srfgvzsardfgw
https://www.tadalive.com/forum/thread/43906/rftg-srftwgy-scxrft-csrfwgv/
https://www.forexagone.com/forum/questions-debutants/gdtxfhbn-xcdgt-hbnxdgcvt-128049#225960
https://celtindependent.com/advert/regv-zsdrawgtfv-scrzfdwgtv/
https://haitiliberte.com/advert/rswgv-szcdfrwtg-vcszrfwtgy-srwfg/
https://searchtech.fogbugz.com/default.asp?Suggestions.1.327879.0
https://www.furaffinity.net/journal/10907881/
https://github.com/iwungs/ASSISTIR-Divertida-Mente-2-2024-Filme-Completo-em-Dublado
https://github.com/pecayz/Assistir-Divertida-Mente-2-Filme-Completo-Dublado-em-Portugues
https://github.com/pecayz/Assistir-Meu-Malvado-Favorito-4-2024-Filme-Completo-Dublado-Legendado
https://github.com/iwungs/ASSISTIR-Meu-Malvado-Favorito-4-2024-Filme-Completo-Dublado-em-Portugues
https://github.com/muntuls/Assistir-Meu-Malvado-Favorito-4-2024-Filme-Completo-Dublado-em-Portugues
https://github.com/pecayz/Assistir-Twisters-2024-Filme-Completo-Dublado-Legendado
https://github.com/iwungs/ASSISTIR-Twisters-2024-Filme-Completo-Dublado-em-Portugues
https://github.com/muntuls/Assistir-Twisters-2024-Filme-Completo-Dublado-em-Portugues
https://github.com/pecayz/Assistir-Deadpool-Wolverine-2024-Filme-Completo-Dublado-Legendado
https://github.com/iwungs/ASSISTIR-Deadpool-Wolverine-2024-Filme-Completo-Dublado-em-Portugues
https://github.com/muntuls/Assistir-Deadpool-Wolverine-2024-Filme-Completo-Dublado-em-Portugues
https://github.com/muntuls/Cuevana-3-Ver-Gru-4-Mi-villano-favorito-Pelicula-Completa-en-Espa-ol-para-siempre
https://github.com/iwungs/PelisplUS-Ver-Gru-4-Mi-villano-favorito-2024-Pelicula-en-Espanol-Latino-Cuevana-3
https://github.com/pecayz/PelisPlus-VER-Gru-4-Mi-villano-favorito-2024-Pelicula-Completa-en-Espanol-y-Latino
https://github.com/pecayz/PelisPlus-VER-Del-reves-2-2024-Pelicula-Completa-en-Espanol-y-Latino
https://github.com/iwungs/PelisplUS-Ver-Del-reves-2-2024-Pelicula-en-Espanol-Latino-Cuevana-3
https://github.com/muntuls/Cuevana-3-Ver-Del-reves-2-Pelicula-Completa-en-Espanol-para-siempre
https://github.com/pecayz/PelisPlus-VER-Twisters-2024-Pelicula-Completa-en-Espanol-y-Latino
https://github.com/iwungs/PelisplUS-Ver-Twisters-2024-Pelicula-en-Espanol-Latino-Cuevana-3
https://github.com/muntuls/Cuevana-3-Ver-Twisters-2024-Pelicula-Completa-en-Espanol-para-siempre
https://github.com/pecayz/Cuevana-3-Ver-Deadpool-y-Lobezno-2024-Pelicula-Completa-en-Espanol-para-siempre
https://github.com/iwungs/PelisplUS-Ver-Deadpool-y-Lobezno-2024-Pelicula-en-Espanol-Latino-Cuevana-3
https://github.com/muntuls/PelisPlus-VER-Deadpool-y-Lobezno-2024-Pelicula-Completa-en-Espanol-y-Latino
https://github.com/muntuls/Deadpool-Wolverine-full-sub-thai
https://github.com/iwungs/Deadpool-Wolverine-full-thai-sub
https://github.com/pecayz/Deadpool-Wolverine-fullhd-thai-sub
https://github.com/pecayz/Twisters-2024-full-sub-thai
https://github.com/iwungs/Twisters-full-thai-sub
https://github.com/muntuls/Twisters-full-sub-thai
https://github.com/pecayz/Despicable-Me-4-2024-full-thai-sub
https://github.com/iwungs/Despicable-Me-4-full-thai-sub
https://github.com/muntuls/Despicable-Me-4-full-thai-sub
https://github.com/pecayz/Inside-Out-2-2024-thai-sub
https://github.com/iwungs/Inside-Out-2-full-thai-sub
https://github.com/muntuls/Inside-Out-2-full-sub-thai
https://www.furaffinity.net/journal/10908999/
https://diendannhansu.com/threads/srftgv-szcfrwtgvc-szfrwtg.477856/
https://onlinegdb.com/ZthwYYemX
https://justpaste.it/dkduw
https://pastelink.net/wn7zmmgl
https://demo.hedgedoc.org/s/HW4decVYu
https://telegra.ph/szrfg-zscfr-vzscfrgv-07-16
https://jpn.itlibra.com/question?question_id=1569
https://jsfiddle.net/509jL6oz/
https://jsbin.com/dukoxezeco/edit?html,output
https://wokwi.com/projects/403556851333081089
https://forum.woimortal.com/forum/community/discussions/38597-daergfv-axdzreqgv
https://click4r.com/posts/g/17399464/wrsgv-wsargvt-awsr
https://wandering.flarum.cloud/d/80958-aedrfgv-azxdergfv-adrvfga
https://matters.town/a/ay0ko1vwbcfv
https://forum.freeflarum.com/d/88664-drfsagv-azxdcfrvg-azfdrg
https://plaza.rakuten.co.jp/wsfdhj/diary/202407160000/
https://herbalmeds-forum.biolife.com.my/d/99738-darefgv-azdxrf-vgaxzdrcgv
https://www.tadalive.com/forum/thread/44256/fdragv-azdrgv-azfdcrgv/
https://www.forexagone.com/forum/questions-debutants/redqafvc-xaqdrewgfv-axrdq-128317
https://celtindependent.com/advert/gbvcsxftrwegbvh-sxftcrweg/
https://haitiliberte.com/advert/gbh-tfrsew-vcsxftregwhsfxrgh/
https://searchtech.fogbugz.com/default.asp?Suggestions.1.328649.0
https://github.com/mucukfilm/Watch-Kalki-2898-AD-2024-Full-Sub-Hindi
https://github.com/tobrutfilm/WATCH-Kalki-2898-AD-2024-Full-SuB-Hindi
https://github.com/gabrietv/WATCH-Twisters-2024-FuLL-Free-SuB-English
https://github.com/alisontv/Watch-Twisters-2024-FullFree-SuB-english
https://github.com/glenfilm/WATCH-Twisters-2024-Full-SuB-english
https://github.com/jamiehtv/WATCH-Despicable-Me-4-2024-FuLL-Free-SuB-English
https://github.com/rosalitv/Watch-Despicable-Me-4-2024-Full-Free-online
https://github.com/bentontv/WATCH-Despicable-Me-4-2024-Full-SuB-english
https://github.com/mabytv/WATCH-Inside-Out-2-2024-FuLL-Free-SuB-English
https://github.com/sheretv/Watch-Inside-Out-2-2024-Full-Free-online
https://github.com/kathtv/WATCH-Inside-Out-2-2024-Full-SuB-english
https://github.com/vivitv/WATCH-Deadpool-Wolverine-2024-FuLL-Free-SuB-English
https://github.com/whitneytv/Watch-Deadpool-Wolverine-2024-Full-Free-online
https://github.com/tamatv/WATCH-Deadpool-Wolverine-2024-Full-SuB-english
https://github.com/carrillotv/Gru-4-Mi-villano-favorito-2024-Pelicula-Espanol-Latino
https://github.com/adawtv/Gru-4-Mi-villano-favorito-2024-Pelicula-Espanol
https://github.com/jbastv/Ver-Gru-4-Mi-villano-favorito-2024-Pelicula-Espanol
https://github.com/febodtv/Deadpool-y-Lobezno-2024-Pelicula-Espanol-Latino
https://github.com/cbowtv/Deadpool-y-Lobezno-2024-Pelicula-Espanol
https://github.com/skatv/Ver-Deadpool-y-Lobezno-2024-Pelicula-Espanol
https://github.com/dalegtv/Del-reves-2-2024-Pelicula-Espanol-Latino
https://github.com/oscarspelis/Del-reves-2-2024-Pelicula-Espanol
https://github.com/mcintv/Ver-Del-reves-2-2024-Pelicula-Espanol
https://github.com/garyrtv/Twisters-2024-Pelicula-Espanol-Latino
https://github.com/finleytv/PelisPlus-Twisters-2024-Pelicula-Espanol
https://github.com/codrtv/Ver-Twisters-2024-Pelicula-Espanol
https://github.com/harytv/assistir-Divertida-Mente-2-filme-dublado-online
https://github.com/lethatv/assistir-Divertida-Mente-2-2024-filme-dublado
https://github.com/tammitv/assistir-Meu-Malvado-Favorito-4-filme-dublado-online
https://github.com/atsontv/assistir-Meu-Malvado-Favorito-4-2024-filme-dublado
https://github.com/cholsontv/assistir-Deadpool-Wolverine-filme-dublado-online
https://github.com/adestv/assistir-Deadpool-Wolverine-2024-filme-dublado
https://github.com/kurdutv/assistir-Twisters-filme-dublado-online
https://github.com/omintv/assistir-Twisters-2024-filme-dublado
https://www.furaffinity.net/journal/10914565/
https://diendannhansu.com/threads/drfasgvazsfdrgv-azsrfdgv.483759/
https://justpaste.me/Webb3
https://dev.bukkit.org/paste/b205e423
https://paste.feed-the-beast.com/view/ad685078
https://pastelink.net/kdln9a6d
https://telegra.ph/srfadgv-zsafrdwv-sazdfr-07-24
https://jpn.itlibra.com/question?question_id=1592
https://jsfiddle.net/gz3ycds0/
https://jsbin.com/sibaroluki/edit?html,output
https://www.thaicarpenter.com/index.php?lay=boardshow&ac=webboard_show&WBntype=1&Category=thaicarpentercom&thispage=1&No=2862517
https://forum.potok.digital/topic/4734/redagvazs-rdgv-azsrdfgv-azrdf
https://click4r.com/posts/g/17477672/aredgfvazrdeqfvaz-xrdeqgfvd-azdre
https://wandering.flarum.cloud/d/83592-daergfvazrdegv-azdrgv-azsdfrg
https://matters.town/a/8rw9gasuudrt
https://forum.freeflarum.com/d/93385-rgfv-szawrgfv-sazxwdrgfv-sawzdrfg
https://plaza.rakuten.co.jp/wsfdhj/diary/202407250000/
https://herbalmeds-forum.biolife.com.my/d/105340-srfwgv-zswrfgv-zsrfwdgv-s
https://www.tadalive.com/forum/thread/45798/srfgv-zsfrwgv-zscfdrgv-zscfrdgv/
https://www.forexagone.com/forum/questions-debutants/rfwsgv-szwfrgv-sczwfrgv-swazrf-129635
https://celtindependent.com/advert/rdfsgv-azsdwrfgv-azsxdcfrwgv/
https://www.gameworld.gr/community/77852-kurtdillon/profile?actid=637300
https://haitiliberte.com/advert/edragfv-xazderwqfvx-azderwgfv/
https://community.goldencorral.com/articles/rftg-zsxcrfwetgvbczsxfrwgvb-sfcr
https://community.thoracic.org/articles/eadqwfcx-aqdergftva-xredqgf
https://cofradesdegranada.ideal.es/articles/wasreftgvawxsre4gtfva-wsxredtg
https://network.propertyweek.com/articles/aredgfv-azxderfv-axzdregfv
https://wokwi.com/projects/404309906932614145
https://devpost.com/software/bokeh-hd-background-video-full-bokeh-lights-bokeh-video
https://devpost.com/software/bokeh-full-bokeh-lights-bokeh-video-hd
https://devpost.com/software/video-full-bokeh-lights-bokeh-video
https://devpost.com/software/xxiii-xxiv-lights-bokeh
https://devpost.com/software/doujindesu
https://devpost.com/software/nekopoi
https://pastelink.net/x6he3rs0
https://devpost.com/software/bokeh-no-blur-dhfkuc
https://devpost.com/software/film-video-museum-p5vcnk
https://devpost.com/software/xnxubd-025bd8
https://devpost.com/software/yandex-semua-film-0s3myp
https://devpost.com/software/film-bokeh
https://devpost.com/software/yandex-browser-jepang
https://devpost.com/software/video-bokeh
https://devpost.com/software/xxiii-xxiv
https://devpost.com/software/xxnamexx
https://devpost.com/software/xxnamexx-mean-xxii-xxiii-xxiv
https://devpost.com/software/yandex-semua-film-kmhdyp
https://pastelink.net/amgmqhgf
https://devpost.com/software/yandex-semua-film-ezq794
https://devpost.com/software/bokeh-no-blur-w03jgs
https://devpost.com/software/film-video-museum-tu8v1l
https://devpost.com/software/xnxubd-xzs07r
https://devpost.com/software/film-bokeh-tosm81
https://devpost.com/software/yandex-browser-jepang-27s4qi
https://devpost.com/software/video-bokeh-9axc7v
https://pastelink.net/ie3s599d
https://pastelink.net/k18xqa6m
https://pastelink.net/4chuc85f
https://github.com/daniaprilianto/Yandex-Semua-Film
https://github.com/daniaprilianto/Yandex-Semua-Film
https://www.communitygaming.io/tournament/voir-vice-versa-2-streaming-vf-en-francais-vostfr
https://www.communitygaming.io/tournament/voir-film-vice-versa-2-2024-francais-vf-gratuit-et-vf-complet
https://www.communitygaming.io/tournament/voir-vice-versa-2-2024-francais-vf-gratuit-et-vf-complet
https://www.communitygaming.io/tournament/voir-vice-versa-2-2024-streaming-vf-en-fr
https://www.communitygaming.io/tournament/voir-vice-versa-2-streaming-vf-en-fr-film-complet-et-vostfr
https://www.communitygaming.io/tournament/vice-versa-2-gratuit-streaming-vf-en-francais-2k-5-august-2024
https://www.communitygaming.io/tournament/voir-vice-versa-2-en-streaming-vf-films-complet-et-vostfr
https://www.communitygaming.io/tournament/telecharger-vice-versa-2-en-streaming-vf-fr-gratuitement-francais
https://www.communitygaming.io/tournament/film-vice-versa-2-streaming-vf-fr-complet-en-francais-vostfr
https://www.communitygaming.io/tournament/voir-vice-versa-2-streaming-vf-vo-gratuit-complet-en-francais
https://www.communitygaming.io/tournament/voir-le-comte-de-monte-cristo-streaming-vf-en-francais
https://www.communitygaming.io/tournament/voir-film-le-comte-de-monte-cristo-en-streaming-vf-en-francais
https://www.communitygaming.io/tournament/film-le-comte-de-monte-cristo-streaming-vf-gratuit
https://www.communitygaming.io/tournament/voir-le-comte-de-monte-cristo-2024-streaming-vf-entier-francais
https://www.communitygaming.io/tournament/voir-film-le-comte-de-monte-cristo-2024-francais-vf-gratuit-et-vf
https://www.communitygaming.io/tournament/le-comte-de-monte-cristo-regarder-le-film-en-streaming-vf-et-vostfr
https://www.communitygaming.io/tournament/telecharger-le-comte-de-monte-cristo-en-streaming-vf-fr-gratuit
https://www.communitygaming.io/tournament/le-comte-de-monte-cristo-streaming-vf-film-complets-en-vostfr-gratuits
https://www.communitygaming.io/tournament/films-voir-le-comte-de-monte-cristo-streamingvf-fr-complet-francais
https://direct.me/voirdeadpool3streamingvf
https://direct.me/voirdeadpool-3enstreaming-vf
https://direct.me/voir-film-deadpool-3-2024-franais-vf-gratuit
https://direct.me/filmsvoirdeadpool3streamingvf-fr
https://direct.me/voir-film-deadpool-3-2024-streaming-vf
https://direct.me/voirdeadpool3streamingvfenfrancais
https://direct.me/voirdeadpool3enstreamingvf
https://direct.me/voirunptittrucenplusenstreamingvf
https://direct.me/filmsvoirunptittrucenplusstreamingvf
https://direct.me/filmsvoirunptittrucenplusstreamingvostfr
https://direct.me/voirlecomtedemontecristoenstreamingvf
https://direct.me/filmsvoirlecomtedemontecristostreamingvf
https://direct.me/filmsvoirlecomtedemontecristostreamingvostfr
https://direct.me/voirmoimocheetmchant4enstreamingvf
https://direct.me/filmsvoirmoimocheetmchant4streamingvf
https://direct.me/moimocheetmchant4streamingvfenfranais
https://www.communitygaming.io/tournament/watch-inside-out-2-fullmovie-2024-mp4-720p-1080p-hd-english
https://www.communitygaming.io/tournament/inside-out-2-2024-fullmovie-download-free-720p-480p-1080p-hd
https://www.communitygaming.io/tournament/watchinside-out-2-2024-fullmovie-free-720p-480p-and-1080
https://www.communitygaming.io/tournament/watch-inside-out-2-2024-fullmovie-online-for-free-streaming-at-home
https://www.communitygaming.io/tournament/watch-inside-out-2-2024-fullmovie-free-online-on-123movie
https://www.communitygaming.io/tournament/123movies-watch-inside-out-2-2024-fullmovie-online-on-streamings
https://www.communitygaming.io/tournament/watch-inside-out-2-2024-fullmovie-free-online-on-english-5-agus-2024
https://www.communitygaming.io/tournament/inside-out-2-2024-fullmovie-download-free-720p-480p-1080p-hdq
https://www.communitygaming.io/tournament/232280c2-ec68-48ea-9bc0-f8dfae1d7507
https://www.communitygaming.io/tournament/watch-deadpool-3-wolverine-fullmovie-free-online-on-english
https://www.communitygaming.io/tournament/watch-deadpool-3-wolverine-2024-fullmovie-free-on-english
https://www.communitygaming.io/tournament/watch123movies-deadpool-3-2024-fullmovie-online-on-streamings
https://www.communitygaming.io/tournament/downloadofficial-deadpool-3-wolverine-2024-online-at-fullmovie
https://www.communitygaming.io/tournament/watch-deadpool-3-fullmovie-free-online-on-english-sub-marvel
https://www.communitygaming.io/tournament/watch-deadpool-3-wolverine-fullmovie-free-online-on-123movie
https://dev.bukkit.org/paste/baa6d2f5
https://www.wowace.com/paste/4cb6c3ea
https://yamcode.com/xccvdsxzxfgdg
http://paste.jp/db2dbaab/
https://paste.gd/rcS803Kp
https://dictanote.co/n/1046911/
https://www.etextpad.com/xqpdovatke
https://pastelink.net/egtn4359
https://bitbin.it/fjRtNMNG/
https://pastebin.com/vzTwiKP8
https://www.planetminecraft.com/forums/bedrock/discussion/asdasdasdasdsa-687633/
https://xtremepape.rs/threads/asdasdasdasasd.118320/
https://wokwi.com/projects/405327974303315969
https://profile.hatena.ne.jp/ruvonicid/profile
https://hackmd.io/@JmHXn_G4SFieqoqG3jZI5w/H10kjdpYR
https://matters.town/a/2sa6e4yxeob1
https://www.forexagone.com/forum/presentation-traders/asdcasasdsaasdasd-131555#229593
https://lifeisfeudal.com/Discussions/question/asdsaasdadasda
If you are out there and have had your hard-earned money stolen, contact Refund Polici Recovery and they'd be able to help you get your money back. Even though they charge for their service, it is worth it.
Get to it immediately- RefunddPolici(@) Gmailcom or visit their Telegram: RefunddPolici
Следующим шагом — авторитет. Ознакомьтесь с комментарии и анализы других посетителей, чтобы получить информацию, как казино обращается с выплатами и помощью клиентам.
Наш сайт: https://slubowisko.pl/topic/73821/
Важно также оценить выбор игр и провайдеров игр: известные казино сотрудничают с такими крупными провайдерами, такими как Pragmatic Play или Play'n GO. Оцените на бонусные предложения, но не забудьте посмотреть условия получения — условия могут быть сложными.
Кроме того, стоит проверить поддержку пользователей. Безопасное казино предлагает своим клиентам удобные способы связи, таких как живой чат, электронная почта и телефонный контакт, а также быстро реагирует на запросы игроков. Очень хорошо, если поддержка доступна 24/7 и консультирует на вашем родном языке.
Стоит также отметить является мобильное приложение или мобильного приложения — это обеспечит вам играть в казино в любое время и в любом месте, где вам удобно. Не забывайте также проверять ограничения по стране по стране и минимальному возрасту, чтобы избежать проблем с доступом к игровым ресурсам и возможностью вывода выигрышей. Учтя все эти показатели, вы сможете найти казино, которое максимально подходит вашим запросам и пожеланиям.
Se voce e entusiasta de jogos online e esta procurando uma alternativa de confianca para jogar, e hora de conhecer a 5 win. Independente de ser iniciante ou alguem com pratica no mundo das apostas, a plataforma 5 win entrega tudo o que voce deseja para tornar sua jornada unica.
Com o app da 5win, disponivel no seu smartphone, voce pode aproveitar com praticidade a uma grande selecao de experiencias unicas. Desde jogos tradicionais ate as inovadoras, cada movimento e uma oportunidade de se desafiar. Alem disso, a plataforma se destaca pela confiabilidade e eficiencia, permitindo que voce aposte com confianca.
Se voce ja ouviu falar da aposta 5win ou esta interessado sobre os desafios de apostas, chegou a hora de descobrir por conta propria. Com uma plataforma amigavel e um atendimento rapido, a 5 win app oferece que cada usuario tenha uma jornada de qualidade, seja em casa ou em qualquer lugar atraves do aplicativo.
Para se juntar, basta entrar em o social oficial da <a href="https://x.com/KarenMims161315">5win jogo</a>, fazer o download do app e mergulhar em um mundo de diversao. Precisa de mais informacoes? Siga nossas plataformas digitais para conteudos especiais, atualizacoes e beneficios exclusivos que podem mudar sua maneira de apostar.
WEB: https://www.facebook.com/people/5winscombr/61568275424486/
O futuro dos jogos esta esperando por voce, e voce precisa fazer parte dele. Teste a 5win e descubra por que tantos usuarios estao escolhendo esta plataforma incrivel!
Il gioco non si limita a essere un classico casino; e un’esperienza completa. Progettato con attenzione per garantire un ambiente immersivo, il gioco offre elementi spettacolari, meccaniche innovative e momenti extra che offrono momenti di pura adrenalina.
Iniziare a giocare a Crazy Time e semplicissimo. Con il ingresso al gioco, puoi iniziare subito a giocare rapidamente. Se e la tua prima volta, la creazione di un account ti permette di giocare subito, facilitando l’accesso di provare subito il gioco.
Per chi vuole testare il gioco, la modalita <a href="https://x.com/BarbaraWri38538">crazy time</a> o modalita free e la soluzione ideale. In questa esperienza di test, puoi familiarizzare con il gameplay senza impegnare risorse economiche.
Web: https://x.com/BarbaraWri38538
Il titolo e anche famoso per i premi esclusivi. Grazie ai Crazy Time bonus today, hai l’opportunita di ottenere vantaggi con offerte esclusive.
Se vuoi scoprire a vivere l’esperienza di questa avventura!
But why is Quantum AI unique, and is it a reliable choice?
The Quantum AI system is unlike traditional trading app—it’s a cutting-edge tool designed to harness the potential of computing breakthroughs and next-gen tech. Market participants using the system highlight improved decision-making, enabled by the platform’s capability to analyze big data instantly. This capability is incredibly helpful in volatile markets, where reaction time and accuracy are critical.
A frequent concern among those interested is, “Is Quantum AI safe to use?” Understandably, market enthusiasts need confidence when they consider using advanced tools in an industry as important as money management. This trading app is gaining trust for its transparency, cutting-edge solutions, and focus on its users, positioning it as trustworthy for both experienced traders and novices.
Website: https://t.me/s/quantum_ai_ie
For anyone curious about, the registration process is straightforward, making sure of seamless onboarding to the app’s resources. When you join, investors open doors to a system that perfectly balances modern tools with simplicity.
The platform is offered internationally, including users in Ireland, catering to diverse markets.
For getting started, visit the <a href="https://x.com/quantum_ai_iea">quantum ai</a>. Stay connected through community spaces to access news.
Are you excited to try out the cutting-edge investment platform? Sign up today and experience the innovative world of Quantum AI!
So, how does Quotex work?
QXBroker, sometimes referred to as QX Broker, is an online platform designed for digital options trading. It opens doors to a diverse portfolio of markets, including forex, commodity assets, cryptocurrencies, and equity markets. Whether you explore using a risk-free environment or go directly to live trading, this platform supports meet your needs.
Setting up is hassle-free. The Quotex login takes no time, letting you reach your account without delays in no time. For those just signing up, getting started is equally simple, helping you start your journey right away.
If you’re hesitant, the practice mode lets you practice worry-free. With small initial funding requirements, this broker is available for investors of varying budgets.
web: https://t.me/s/quotexng
One frequent doubt for traders is, “Is this platform reliable?” After considering user experiences, this platform stands out as trustworthy and secure. It provides clear processes, instilling trust in their investments.
Why is Quotex unique is its focus on delivering a user-first trading journey. The platform provides innovative functions, interactive graphs, and strategy support features to empower investors strategize better.
Curious to learn more? Check out Quotex reviews or visit our page <a href="https://www.facebook.com/profile.php?id=61568609973195">quotex minimum deposit</a>. Make sure to join their community on popular channels for news, community discussions, and announcements.
Are you ready to take your trading to the next level? Join now and experience the unique world of financial growth!
So, what is Quotex?
Quotex, often labeled as QXBroker, is a trading service focused on online trading. It provides access to an extensive selection of markets, including currency trading, commodities, crypto assets, and stocks. Whether you first try out a practice account or go directly to actual investments, this platform caters to adapt to every level.
Setting up is simple. The sign-in process is quick, letting you reach your trading interface safely in a moment. For new users, registering is a breeze, helping you start your journey immediately.
If you want to practice first, the demo account provides a risk-free environment. With small initial funding requirements, the platform is open to traders of all levels.
web: https://t.me/s/quatex_co
One major topic for potential users is, “Is this platform reliable?” Looking at user experiences, this platform is widely recognized as credible and dependable. It adheres to industry standards, giving users confidence in their trading activities.
What makes Quotex special is its commitment to delivering an intuitive trading platform. The platform offers sophisticated instruments, adjustable visuals, and technical analysis indicators to guide participants invest effectively.
Eager to dive deeper? Read more about Quotex or visit our page <a href="https://www.facebook.com/people/Quotexco/61568282355570/">quotex sign in</a>. Remember to engage with Quotex on their social platforms for tips, trading advice, and innovations.
Prepared to start your journey beyond? Create your account now and see the modern world of online trading!
Pour ceux qui cherchent a acceder a leur espace personnel 1xbet ou a apprendre comment creer un compte, le processus est simple et efficace. Il suffit de respecter les etapes sur le portail officiel 1xbet. Et si vous etes nouveau, c'est le moment parfait pour integrer une grande communaute de fans devoues.
Web: https://t.me/s/onexbet_ci
Les fans de predictions seront enchantes de decouvrir les nombreuses fonctionnalites de 1xbet prediction, ou chaque pari peut devenir une chance remarquable. Les fans de sensations fortes ne seront pas oublies avec des jeux comme le celebre mode crash de 1xbet, qui promet des moments d'adrenaline et de plaisir.
Mais <a href="https://x.com/SandraRobe24738">se connecter a mon compte 1xbet</a> ? Il n'y a pas de cle universelle, mais en suivant les statistiques et en profitant des fonctionnalites offertes, vous pouvez ameliorer vos probabilites de victoire. La plateforme offre egalement des avantages constants et des benefices pour ses utilisateurs les plus engages, surtout pour ceux qui collaborent via 1xbet partner.
Enfin, ne restez pas isole dans votre aventure 1xbet. Participez avec nous sur nos reseaux sociaux pour recevoir des suggestions, des bonus reserves et pour parler de vos reussites. Abonnez-vous a nos reseaux sociaux en Cote d’Ivoire des aujourd’hui et integrez un reseau ou le sport, le plaisir et la passion se melangent.
Se voce e entusiasta de jogos online e esta procurando uma opcao segura para jogar, e hora de conhecer a 5win com. Nao importa se voce e iniciante ou alguem com pratica no mundo das apostas, a plataforma 5 win entrega tudo o que voce busca para tornar sua diversao unica.
Com o app da 5win, facil de baixar no seu dispositivo, voce pode aproveitar de forma agil a uma grande selecao de jogos emocionantes. Desde alternativas conhecidas ate as recentes, cada rodada e uma chance de se desafiar. Alem disso, a plataforma e reconhecida pela confiabilidade e transparencia, permitindo que voce jogue tranquilamente.
Se voce ja leu algo da plataforma de apostas 5 win ou esta interessado sobre os melhores jogos online, chegou a hora de descobrir por conta propria. Com uma plataforma amigavel e um suporte dedicado, a 5 win app oferece que cada jogador tenha uma vivencia completa, seja na sua zona de conforto ou onde voce estiver atraves do software.
Para comecar, basta acessar o social oficial da <a href="https://t.me/s/five_wins">5win e confiavel</a>, baixar o aplicativo e mergulhar em um mundo de diversao. Ficou curioso? Siga nossas redes sociais para conteudos especiais, novidades e beneficios exclusivos que podem revolucionar sua experiencia.
WEB: https://t.me/s/five_wins
O futuro dos desafios online esta esperando por voce, e voce merece fazer parte dele. Teste a 5 win e veja por que tantos usuarios estao preferindo esta ferramenta incrivel!
L’attrazione va oltre il semplice intrattenimento; e una rivoluzione nel gioco online. Progettato con attenzione per garantire un gameplay dinamico, il gioco contiene attrazioni visive, premi straordinari e sezioni aggiuntive che assicurano momenti di pura adrenalina.
Entrare nel gioco Crazy Time e davvero facile. Con il Crazy Time accesso, puoi collegarti al tuo profilo senza difficolta. Se non hai ancora un account, la registrazione a Crazy Time e rapida, consentendoti di scoprire le emozioni del gioco.
Per chi ama sperimentare, la modalita <a href="https://www.facebook.com/profile.php?id=61566449764132">crazytime</a> o modalita free e perfetta per i principianti. In questa opzione gratuita, puoi imparare a giocare senza investire subito.
Web: https://x.com/BarbaraWri38538
Crazy Time e anche amato per le offerte imperdibili. Grazie ai promozioni giornaliere, hai l’opportunita di incrementare le tue possibilita di vincita con ricompense extra.
Se sei pronto a entrare nel mondo di questa avventura!
But what makes this platform stand out, and is it a reliable choice?
Quantum AI is a step beyond typical trading app—it’s a revolutionary option designed to harness the power of modern systems and ultra-fast processing. Traders leveraging the platform share enhanced accuracy, thanks to the platform’s power to handle vast datasets on the spot. This advantage is game-changing in volatile markets, where precision and effectiveness are critical.
A regular inquiry among newcomers is, “Is Quantum AI legit?” It’s natural that, participants may hesitate when they approach novel solutions in an area as important as money management. The system has built credibility for its open policies, advanced technology, and dedication to traders, positioning it as trustworthy for both seasoned professionals and first-time users.
Website: https://www.facebook.com/profile.php?id=61569034910017
For those interested in, the account creation is user-friendly, providing quick entry to the system’s functionality. Once registered, investors gain entry to a trading app that beautifully merges technology with user-friendliness.
The platform is offered internationally, including Quantum AI Ireland, ensuring global availability.
For more information, visit the <a href="https://x.com/quantum_ai_iea">is quantum ai legit</a>. Follow along through online forums to receive updates.
Are you prepared to start with the revolutionary trading experience? Dive in now and discover this cutting-edge platform of Quantum AI!
So, what does Quotex offer?
QXBroker, popularly called the QX trading platform, is a trading service centered on investment tools. It opens doors to a broad variety of investment opportunities, including forex, commodity assets, crypto assets, and shares. Whether you explore using a practice account or jump straight into real trades, Quotex supports suit every trader.
Getting into the platform is straightforward. The login system is seamless, letting you reach your trading interface without delays in a moment. For beginners, joining Quotex is a breeze, enabling you to start trading right away.
If you’re hesitant, the practice mode offers a safe space. With an affordable entry point, the platform makes trading easy for investors of varying budgets.
web: https://t.me/s/quotexng
One major topic for potential users is, “Is this platform reliable?” After considering feedback from traders, this platform stands out as legitimate and dependable. It provides clear processes, instilling trust in their investments.
What makes Quotex special is its focus on delivering a user-first trading journey. The platform provides sophisticated instruments, adjustable visuals, and strategy support features to empower investors strategize better.
Curious to learn more? Read more about Quotex or visit our page <a href="https://t.me/s/quotexng">quotex broker</a>. Make sure to join their community on popular channels for updates, latest trends, and announcements.
Are you ready to enhance your investment experience to the next level? Get started today and enjoy the modern world of financial growth!
So, what exactly is Quotex?
this platform, popularly called QX Broker, is a web-based broker that specializes in digital options trading. It allows users to trade a broad variety of investment opportunities, including forex, commodity assets, crypto assets, and stocks. Whether you first try out a demo account or dive into real trades, this platform caters to accommodate all users.
Getting into the platform is simple. The sign-in process is seamless, helping you open your account securely in no time. For beginners, creating an account is quick and convenient, helping you start your journey without delay.
If you’re hesitant, the practice mode lets you practice worry-free. With small initial funding requirements, the platform is open to anyone looking to start.
web: https://x.com/JenniferMi23067
One important question for traders is, “How trustworthy is Quotex?” According to numerous reviews, the broker has proven to be trustworthy and secure. It operates transparently, ensuring users feel secure in their trading activities.
What sets Quotex apart is its commitment to delivering an advanced trading journey. The platform offers advanced tools, adjustable visuals, and market analysis tools to guide participants trade wisely.
Interested in exploring further? Read more about Quotex or visit our page <a href="https://x.com/JenniferMi23067">quotex review</a>. Be sure to join their community on popular channels for tips, latest trends, and platform news.
Is it time? to take your trading further? Sign up today and explore the exciting world of digital investments!
Pour ceux qui cherchent a acceder a leur espace personnel 1xbet ou a apprendre comment creer un compte, le processus est rapide et intuitif. Il suffit de suivre les instructions sur le site principal de 1xbet. Et si vous ne vous etes pas encore inscrit, c'est le moment parfait pour rejoindre une communaute mondiale de joueurs passionnes.
Web: https://x.com/SandraRobe24738
Les specialistes en paris seront enchantes de decouvrir les nombreuses possibilites de predictions sur 1xbet, ou chaque pari peut devenir une chance unique. Les fans de jeux palpitants ne seront pas decus avec des titres tels que le celebre jeu crash sur 1xbet, qui promet des minutes de suspense et de suspense.
Mais <a href="https://www.facebook.com/profile.php?id=61566449764132">1xbet original</a> ? Il n'y a pas de formule magique, mais en analysant les donnees et en utilisant les outils proposes, vous pouvez ameliorer vos probabilites de gains. La plateforme propose egalement des avantages constants et des benefices pour ses utilisateurs les plus loyaux, surtout pour ceux qui deviennent partenaires.
Enfin, ne restez pas a l'ecart dans votre aventure 1xbet. Participez avec nous sur nos communautes en ligne pour decouvrir des conseils, des bonus reserves et pour parler de vos reussites. Suivez 1xbet Cote d’Ivoire des aujourd’hui et faites partie d’une communaute ou le divertissement, le loisir et la passion se melangent.
Se voce e entusiasta de jogos digitais e esta procurando uma plataforma confiavel para apostar, e hora de experimentar a 5win. Independente de ser iniciante ou um jogador experiente, a plataforma 5 win entrega tudo o que voce precisa para tornar sua diversao inesquecivel.
Com o app da 5win, pronto para download no seu celular, voce tem acesso rapido a uma ampla variedade de experiencias unicas. Desde jogos tradicionais ate as inovadoras, cada movimento e uma possibilidade de explorar novos desafios. Alem disso, a plataforma e reconhecida pela protecao e solidez, permitindo que voce aposte com confianca.
Se voce ja ouviu falar da plataforma de apostas 5 win ou esta curioso sobre os melhores jogos online, chegou a hora de descobrir por conta propria. Com uma plataforma amigavel e um time de suporte sempre disponivel, a 5win proporciona que cada usuario tenha uma vivencia completa, seja na sua zona de conforto ou no seu tempo livre atraves do app.
Para se juntar, basta entrar em o social oficial da <a href="https://x.com/KarenMims161315">5win apostas</a>, baixar o aplicativo e entrar em um mundo de diversao. Quer saber mais? Siga nossas redes sociais para atualizacoes e promocoes unicas, atualizacoes e oportunidades imperdiveis que podem mudar sua maneira de apostar.
WEB: https://www.facebook.com/people/5winscombr/61568275424486/
O novo capitulo dos momentos de diversao esta ao seu alcance, e voce precisa fazer parte dele. Teste a 5win e entenda por que tantos usuarios estao optando por esta opcao incrivel!
L’attrazione trascende il concetto tradizionale di gioco; e una rivoluzione nel gioco online. Progettato con attenzione per proporre un gameplay dinamico, il gioco contiene ruote giganti, meccaniche innovative e mini-giochi esclusivi che regalano momenti di pura adrenalina.
Iniziare a giocare a Crazy Time e davvero facile. Con il Crazy Time accesso, puoi collegarti al tuo profilo senza difficolta. Se non hai ancora un account, la creazione di un account ti permette di giocare subito, consentendoti di provare subito il gioco.
Per chi desidera esplorare senza rischi, la modalita <a href="https://www.facebook.com/profile.php?id=61566449764132">crazy time bonus</a> o Crazy Time gratis e utile per fare pratica. In questa soluzione gratuita, puoi imparare a giocare senza investire subito.
Web: https://x.com/BarbaraWri38538
L’esperienza e anche famoso per le sorprese continue. Grazie ai offerte attuali, hai l’opportunita di incrementare le tue possibilita di vincita con benefici aggiuntivi.
Se sei pronto a girare la ruota di il gioco che tutti amano!
But what makes this platform stand out, and is it worth your time?
The Quantum AI system is not just another trading app—it’s a revolutionary option focused on utilizing the capabilities of computing breakthroughs and ultra-fast processing. Market participants using the technology report smarter strategies, because of the platform’s ability to process real-time information at unprecedented speeds. This advantage is especially useful in volatile markets, where precision and accuracy mean success.
A regular inquiry among traders considering it is, “Is it trustworthy?” Of course, market enthusiasts want assurances when they approach new technologies in a field as critical as money management. The system is widely recognized for its open policies, innovative features, and trader-first mindset, positioning it as trustworthy for both experienced traders and novices.
Website: https://t.me/s/quantum_ai_ie
For those interested in, the Quantum AI sign-up is easy, allowing for seamless onboarding to the platform’s features. When you join, users gain entry to a platform that smartly blends technology with usability.
The platform is accessible globally, including Ireland’s trading community, catering to diverse markets.
For more information, visit the <a href="https://t.me/s/quantum_ai_ie">quantum ai ireland</a>. Follow along through platform updates to access news.
Are you prepared to start with the next-gen trading tools? Join now and unlock financial advancements of Quantum AI!
So, how does Quotex work?
this platform, sometimes referred to as QXBroker, is an online platform centered on investment tools. It opens doors to a diverse portfolio of trading options, including foreign exchange markets, commodity assets, digital currencies, and equity markets. Whether you first try out a risk-free environment or go directly to active trading, Quotex caters to suit every trader.
Getting into the platform is easy. The login system is effortless, helping you open your trading interface without delays in a moment. For first-timers, creating an account is quick and convenient, so you can begin trading right away.
If you’re unsure, the Quotex demo lets you practice worry-free. With an affordable entry point, this broker is available for a wide audience.
web: https://www.facebook.com/profile.php?id=61568609973195
One major topic for traders is, “Can I trust Quotex?” After considering user experiences, this platform is seen as legitimate and safe to use. It operates transparently, giving users confidence in their investments.
What sets Quotex apart is how it emphasizes delivering a user-first trading experience. The platform provides innovative functions, adaptable graphing tools, and strategy support features to enable traders make informed decisions.
Curious to learn more? Discover user feedback or visit our page <a href="https://www.facebook.com/profile.php?id=61568609973195">quotex minimum deposit</a>. Make sure to stay connected with Quotex on their social platforms for tips, market insights, and innovations.
Prepared to start your journey with confidence? Create your account now and enjoy the innovative world of financial growth!
So, how does Quotex work?
QXBroker, often labeled as the QX trading platform, is a web-based broker focused on financial markets. It provides access to a broad variety of assets, including currency trading, commodity assets, digital currencies, and equity markets. Whether you first try out a practice account or go directly to real trades, Quotex caters to meet your needs.
Getting into the platform is simple. The account access is effortless, helping you open your trading interface securely in a moment. For those just signing up, registering is just as easy, allowing you to begin investing within minutes.
If you’re hesitant, the demo account provides a risk-free environment. With small initial funding requirements, the platform is open to investors of varying budgets.
web: https://t.me/s/quatex_co
One major topic on the minds of investors is, “How trustworthy is Quotex?” Based on what people say, this platform is widely recognized as trustworthy and transparent. It provides clear processes, ensuring users feel secure in their investments.
Why is Quotex unique is its dedication to delivering a seamless trading platform. The platform includes sophisticated instruments, adjustable visuals, and technical analysis indicators to empower investors strategize better.
Eager to dive deeper? Read more about Quotex or visit our page <a href="https://www.facebook.com/people/Quotexco/61568282355570/">is quotex legit</a>. Make sure to join their community on their social platforms for tips, latest trends, and alerts.
Thinking about it? to start your journey with confidence? Sign up today and explore the modern world of digital investments!
Pour ceux qui cherchent a se connecter a leur compte 1xbet ou a apprendre comment creer un compte, le processus est pratique et accessible. Il suffit de suivre les instructions sur le site principal de 1xbet. Et si vous ne vous etes pas encore inscrit, c'est le moment ideal pour rejoindre une communaute mondiale de joueurs passionnes.
Web: https://www.facebook.com/profile.php?id=61566449764132
Les fans de predictions seront enchantes de decouvrir les nombreuses fonctionnalites de paris predictifs de 1xbet, ou chaque cote peut devenir une chance interessante. Les fans de jeux palpitants ne seront pas decus avec des titres tels que le celebre jeu crash sur 1xbet, qui promet des instants palpitants et de plaisir.
Mais <a href="https://t.me/s/onexbet_ci">1xbet partner</a> ? Il n'y a pas de formule magique, mais en analysant les donnees et en profitant des fonctionnalites offertes, vous pouvez augmenter vos chances de victoire. La plateforme offre egalement des avantages constants et des benefices pour ses utilisateurs les plus loyaux, surtout pour ceux qui collaborent via 1xbet partner.
Enfin, ne restez pas seul dans votre aventure 1xbet. Participez avec nous sur nos plateformes sociales pour decouvrir des conseils, des promotions uniques et pour echanger avec d'autres joueurs. Abonnez-vous a 1xbet Cote d’Ivoire des aujourd’hui et devenez membre d’un groupe ou le divertissement, le plaisir et la joie de jouer se rencontrent.
Se voce e apaixonado de jogos digitais e esta procurando uma alternativa de confianca para jogar, e hora de experimentar a 5 win. Independente de ser iniciante ou um expert, a 5win garante tudo o que voce precisa para tornar sua experiencia unica.
Com o 5win app, disponivel no seu celular, voce tem acesso com praticidade a uma grande selecao de opcoes divertidas. Desde opcoes classicas ate as recentes, cada aposta e uma chance de explorar novos desafios. Alem disso, a plataforma ganha destaque pela seguranca e transparencia, permitindo que voce aposte com confianca.
Se voce ja ouviu falar da 5win bet ou esta interessado sobre os melhores jogos online, chegou a hora de descobrir por conta propria. Com uma experiencia simplificada e um atendimento rapido, a 5win garante que cada jogador tenha uma jornada de qualidade, seja na sua zona de conforto ou onde voce estiver atraves do aplicativo.
Para iniciar, basta visitar o social oficial da <a href="https://www.facebook.com/people/5winscombr/61568275424486/">5 win jogo de aposta</a>, fazer o download do app e se aventurar em um caminho repleto de desafios e alegria. Quer saber mais? Siga nossas redes sociais para dicas exclusivas, novidades e oportunidades imperdiveis que podem revolucionar sua experiencia.
WEB: https://x.com/KarenMims161315
O futuro dos desafios online esta aqui, e voce precisa fazer parte dele. Teste a plataforma 5 win e veja por que tantos jogadores estao preferindo esta plataforma incrivel!
Crazy Time non e solo un gioco; e una vera avventura. Sviluppato in modo innovativo per proporre un ambiente immersivo, il gioco presenta attrazioni visive, bonus moltiplicatori e sezioni aggiuntive che offrono momenti di pura adrenalina.
Iniziare a giocare a Crazy Time e davvero facile. Con il accesso a Crazy Time, puoi iniziare subito a giocare con facilita. Se e la tua prima volta, la creazione di un account e semplice, facilitando l’accesso di iniziare a giocare senza attese.
Per chi desidera esplorare senza rischi, la modalita <a href="https://t.me/s/crazy_time_io">crazy time casino</a> o versione senza deposito e perfetta per i principianti. In questa versione di prova, puoi esplorare il gioco senza rischiare soldi.
Web: https://x.com/BarbaraWri38538
L’esperienza e anche apprezzato per le offerte imperdibili. Grazie ai Crazy Time bonus today, hai l’opportunita di aumentare i guadagni con bonus imperdibili.
Se sei pronto a giocare a Crazy Time di questa avventura!
But what's special about this solution, and is it a reliable choice?
The Quantum AI system is unlike traditional trading app—it’s an advanced system designed to harness the strength of advanced algorithms and next-gen tech. Market participants employing the platform report smarter strategies, as a result of the platform’s strength in processing complex market data in real time. This feature is game-changing in unstable environments, where swiftness and correctness determine outcomes.
A popular query among traders considering it is, “How reliable is this platform?” Given the circumstances, users are cautious when they consider using advanced tools in an industry as impactful as money management. The Quantum AI solution has built credibility for its clear practices, sophisticated systems, and dedication to traders, highlighting its legitimacy for both veterans and first-time users.
Website: https://t.me/s/quantum_ai_ie
For anyone curious about, the account creation takes no time, providing immediate availability to the app’s resources. When you join, users are introduced to a system that effortlessly integrates advanced systems with practicality.
The platform is reaching users worldwide, including the Irish market, further expanding its reach.
For getting started, visit the <a href="https://x.com/quantum_ai_iea">quantum ai official website</a>. Keep in touch through Quantum AI’s social media channels to access news.
Are you excited to start with the revolutionary trading experience? Dive in now and unlock the innovative world of Quantum AI!
yerli oyunçular arasında virtual qumar oyunlarına istək artdıqca, Pin-up online kimi platformalar daha çox tanınmağa başladı. Bunun nəticəsində, Pin-up kazino ifadələri son zamanlar yerli oyunçular üçün adidir. Pin-up kazino istifadəçilərə məxsus çox oyun növləri təklif edir.
Pin-up cazino, Azərbaycandakı oyunçular üçün populyar seçimdir. Bu qumar xidməti qumarbazlara müxtəlif oyunlar oyunçulara təqdim edir və cazibədar aksiyalar ilə müştərilərini məmnun edir.
Pin-up casino, oyun keyfiyyətini artıran oyun məkanıdır. yerli mərcçilər arasında oyunçular tərəfindən sevilən Pin-up casino, mərc həvəskarları üçün çeşidli bonus imkanları yaradır.
Sonda, Pin-up casino oyunçulara yalnız oyun təklif etmir cəlbedici kampaniyalar oyun təcrübəsini daha da maraqlı edir. Bu platformada, oyunçular təhlükəsiz oyun mühitində olur.
Web: https://global-rank.pages.dev/20/ZUiNJHIZmf
Pin-up azerbaycan yalnız məhdud oyunlar təklif etmir. Mərc həvəskarları bu platformada bənzərsiz mərc imkanlarından faydalanıb və cazibədar bonus imkanlarını mərc təcrübələrini zənginləşdirərlər.
Yekun olaraq, Pin-up casino online, şəffaf və güvənli mərc imkanı təklif etməklə onlayn mərc dünyasında ən yaxşı seçimlərdən biridir. yerli oyunçular arasında seçim olması dikkətə layiqdir.
So, what is Quotex?
QXBroker, sometimes referred to as QXBroker, is a trading service focused on financial markets. It provides access to a wide range of markets, including forex, commodity assets, cryptocurrencies, and shares. Whether you choose to begin with a demo account or go directly to live trading, the broker supports accommodate all users.
Starting with Quotex is simple. The account access is seamless, allowing you to access your dashboard securely in just a few clicks. For beginners, registering is just as easy, allowing you to begin investing within minutes.
If you’re not ready to commit, the practice mode offers a safe space. With its low minimum deposit, the platform is open to traders of all levels.
web: https://t.me/s/quotexng
One major topic on the minds of investors is, “How trustworthy is Quotex?” Looking at feedback from traders, the broker has proven to be credible and secure. It provides clear processes, ensuring users feel secure in their investments.
Why choose Quotex is how it emphasizes delivering an intuitive trading journey. The platform features sophisticated instruments, interactive graphs, and technical analysis indicators to enable traders trade wisely.
Interested in exploring further? Explore the latest reviews or visit our page <a href="https://www.facebook.com/profile.php?id=61568609973195">quotex demo</a>. Remember to engage with Quotex on popular channels for news, latest trends, and platform news.
Prepared to take your trading beyond? Sign up today and enjoy the innovative world of digital investments!
Azərbaycan ərazisində internet oyunlarına güvəni artdıqca, Pin-up casino online kimi platformalar daha çox tanınmağa başladı. Özəlliklə, Pinup azerbaycan ifadələri indi yerli oyunçular üçün güvənlidir. Pinup casino müştərilərinə çox oyun növləri təklif edir.
Pinup kazino, yerli mərc həvəskarları üçün populyar seçimdir. Bu kazino müştərilərə geniş çeşidli oyunlar verir və gözəl hədiyyələr ilə mərc edənləri özünə cəlb edir.
Pin-up casino online, oyun keyfiyyətini artıran saytdır. Azəri oyunçuları arasında çox seçilən Pin-up casino, yerli oyunçular üçün geniş oyun variantları ilə tanınır.
Nəticə etibarilə, Pinup kazino mərc həvəskarlarına geniş oyun təcrübəsi ilə yanaşı mərc hədiyyələri təmin edir. Pinup-da, müştərilər güvənli bir təcrübə yaşayır.
Web: http://www.ladycaprice.fr/index.php/beauty/itemlist/user/217-ladycapricemagazine?start=850
Pin-up online kazino sadəcə məhdud deyil. Qumarçılar burada fərqli mərc oyunlarından faydalanıb və çoxlu bonusları oyun təcrübələrinə əlavə edərlər.
Yekun olaraq, Pin-up casino, şəffaf və güvənli qumar təcrübəsi oyunçulara təklif etməklə oyun bazarında oyunçular arasında geniş istifadə edilir. Azərbaycanda seçim olması təsadüf deyil.
Azərbaycan ərazisində online kazino oyunlarına güvəni artdıqca, Pin-up kazino kimi onlayn mərc xidmətləri daha çox tanınmağa başladı. Özəlliklə, Pin-up azerbaycan ifadələri artıq yerli oyunçular üçün məşhurdur. Pinup casino mərc həvəskarlarına rəngarəng oyunlar təklif edir.
Pin-up casino, Azəri qumarbazlar üçün geniş yayılmış bir xidmətdir. Bu platforma oyunçulara müxtəlif oyunlar təklif verməkdədir və gözəl hədiyyələr ilə istifadəçilərin diqqətini çəkir.
Pin-up casino, oyun keyfiyyətini artıran oyun məkanıdır. Azərbaycanda geniş istifadə olunan Pin-up oyunları, mərc həvəskarları üçün çeşidli bonus imkanları yaradır.
Əlavə olaraq, Pinup kazino müştərilərə geniş oyun təcrübəsi ilə yanaşı bonuslar və aksiyalar oyunçularına verir. Bu kazinoda, müştərilər şəffaf oyun şərtləri ilə rastlaşır.
Web: http://molotokural.ru/netcat/elm/mu_paysafecard_xidm_t_m__t_ril_rin.html
Pin-up kazino sadəcə məhdud oyunlar təklif etmir. Mərc həvəskarları bu platformada çeşidli mərc seçimlərindən həzz ala bilərlər və maraqlı aksiyaları oyun təcrübəsini artırarlar.
Yekun olaraq, Pin-up casino online, sərfəli və təhlükəsiz mərc imkanı təklif etməklə mərc bazarında ən sevilən platformalardan olur. Azəri bazarında məşhur olması göz qabağındadır.
Azərbaycanda virtual qumar oyunlarına maraq artdıqca, Pinup kazino kimi oyun xidmətləri daha çox tanınmağa başladı. Xüsusilə, "Pin up casino online" adları tez-tez yerli oyunçular üçün məşhurdur. Pin-up casino azerbaycan istifadəçilərə çox oyun növləri təklif edir.
Pin-up casino, yerli oyunçular üçün geniş yayılmış bir xidmətdir. Bu qumar xidməti oyunçulara çeşidli qumar oyunları oyunçulara təqdim edir və gözəl hədiyyələr ilə istifadəçilərin diqqətini çəkir.
Pin-up casino online, fərqli oyun təcrübəsi təklif edən onlayn kazinodur. yerli mərcçilər arasında populyar olan Pin-up oyunları, oyun həvəskarları üçün maraqlı oyun imkanları təklif edir.
Yekun olaraq, Pin-up casino online mərc həvəskarlarına geniş oyun təcrübəsi ilə yanaşı mərc hədiyyələri təqdim edir. Pinup-da, müştərilər təhlükəsiz şərtlər altında mərc edir.
Web: https://mangareport.mangabookshelf.com/2012/09/24/late-sunday-final-round-up/
Pin-up azerbaycan yalnız bir mərc saytı kimi məhdud deyil. Müştərilər burada çeşidli mərc seçimlərindən təcrübə edə bilərlər və geniş bonus imkanlarını istifadə edə bilərlər.
Beləliklə, Pin-up casino, güvənli kazino təcrübəsi təmin etməklə onlayn qumar dünyasında lider mövqedədir. Azəri oyunçular tərəfindən tanınması təsadüfi deyil.
Azərbaycan ərazisində qumar oyunlarına güvəni artdıqca, Pinup kazino kimi kazino xidmətləri daha çox tanınmağa başladı. Əlavə olaraq, "Pin up casino online" ifadələri son zamanlar yerli oyunçular üçün məşhurdur. Pin-up casino azerbaycan öz oyunçularına çeşidli oyunlar təklif edir.
Pin-up online casino, Azəri istifadəçilər üçün ən sevilən platformalardan biridir. Bu qumar saytı kazino oyunçularına rəngarəng oyunlar təklif edir və çoxlu bonuslar ilə qumarbazlar tərəfindən sevilir.
Pin-up azerbaycan, fərqli oyun təcrübəsi təklif edən onlayn kazinodur. Azərbaycan ərazisində geniş istifadə olunan Pin-up casino, kazino oyunçuları üçün geniş oyun variantları ilə tanınır.
Yekun olaraq, Pin-up azerbaycan qumarbazlara yalnız qumar oyunları yox, həmçinin bonus imkanı oyunçularına verir. Bu platformada, kazino həvəskarları rahat və təhlükəsiz şəraitdə oynayır.
Web: https://videos.antville.org/archive/2015/03/12/
Pin-up online kazino sadəcə məhdud oyunlar təklif etmir. Mərc həvəskarları bu platformada fərqli mərc oyunlarından yararlana bilərlər və geniş bonus imkanlarını istifadə edə bilərlər.
Sonda, Pin-up cazino, sərfəli və təhlükəsiz mərc imkanı oyunçulara təklif etməklə mərc bazarında özünü doğruldur. yerli oyunçular arasında seçim olması göz qabağındadır.
Kasyna internetowe zdobywaja coraz wieksza popularnosc w Polsce, a jedna z miejsc, ktora zyskuje uznanie wsrod uzytkownikow, jest <a href="https://bio.rogstecnologia.com.br/lawrencerlm1">bet on red casino login</a>. To kasyno online, ktore wyroznia sie szerokiemu wyborowi gier, nowoczesnym interfejsem oraz hojnymi bonusami, ktore spelnia oczekiwania zarowno poczatkujacych, jak i weteranow gier.
Dlaczego gracze wybieraja Kasyno Bet On Red?
Bet On Red Casino to nowoczesne kasyno internetowe, ktora oferuje ogromna biblioteke gier, takich jak maszyny hazardowe, klasyczne gry kasynowe oraz transmisje na zywo z gier. Juz sam brand „Bet On Red" odzwierciedla adrenaline i hazardowe napiecie.
Latwe logowanie w Bet On Red Casino
Logowanie do konta w Red On Bet Casino jest prosty i szybki. Po odwiedzeniu witryny kasyna, wystarczy wybrac funkcje logowania i wpisac swoje dane. Platforma stawia na bezpieczenstwo, dlatego wszelkie informacje sa odpowiednio szyfrowane.
Osoby rejestrujace sie po raz pierwszy moga szybko zalozyc konto, a rejestracja zajmuje zaledwie kilka minut. Co istotne, Bet On Red oferuje mozliwosc korzystania z roznych metod platnosci, co sprawia, ze korzystanie z platformy jest proste.
Gry dostepne w Bet On Red Casino
Kluczowym elementem, kazdego kasyna internetowego, jest katalog gier. Bet On Red Casino wyroznia sie niezwykle bogatym wyborem, ktory przyciagnie milosnikow roznych gatunkow gier.
Web: https://bio.rogstecnologia.com.br/lawrencerlm1
Sloty sa uwielbiane przez graczy, dostepne w licznych motywach oraz z ciekawymi rozwiazaniami. Oprocz tradycyjnych automatow, uzytkownicy moga sprobowac swoich sil w gry stolowe, takie jak blackjack.
Azərbaycandakı qumar sektorunda virtual qumar oyunlarına tələbat artdıqca, Pinup kazino kimi saytlar daha çox tanınmağa başladı. Əsasən, Pin-up kazino brendləri tez-tez yerli oyunçular üçün sevilir. Pin-up azerbaycan istifadəçilərə geniş oyunlar təklif edir.
Pin-up online casino, Azəri istifadəçilər üçün güvənli bir qumar məkanıdır. Bu qumar saytı oyunçulara çeşidli qumar oyunları oyunçulara təqdim edir və gözəl hədiyyələr ilə mərc edənləri özünə cəlb edir.
Pin-up casino, çeşidli oyun təcrübəsi təklif edən bir platformadır. yerli mərcçilər arasında güvənilən Pin-up online, yerli oyunçular üçün çeşidli bonus imkanları yaradır.
Sonda, Pin-up casino online oyunçulara çoxlu oyun növlərilə yanaşı bonus imkanı təmin edir. Bu platformada, mərc edənlər təhlükəsiz şərtlər altında mərc edir.
Web: http://santa-clara.calstatedir.com/americas-dream-homeworks-2.html
Pin-up kazino sadəcə məhdud oyunlar təklif etmir. Mərc həvəskarları bu platformada geniş mərc təcrübəsindən həzz ala bilərlər və sərfəli bonus təkliflərini oyunlarına əlavə edə bilərlər.
Sonda, Pin-up casino, şəffaf və güvənli mərc imkanı təklif etməklə onlayn qumar dünyasında güclü mövqe tutub. yerli oyunçular arasında məşhur olması əlamətdardır.
Como Otimizar os Ganhos no Jogo de Tigrinho
O potencial de lucro em curto prazo faz do Tigrinho uma opcao popular. O jogo oferece recompensas rapidas para quem busca lucros imediatos.
Muitos jogadores combinam estrategias para maximizar o potencial de lucro. A aposta progressiva e uma das tecnicas mais usadas no jogo. A aposta inicial e baixa, mas cresce conforme o jogo avanca.
Para melhorar as chances de lucro, e essencial escolher os momentos certos para apostar. Alguns jogadores se especializam em identificar os minutos de pagamento. Jogadores mais experientes sabem reconhecer quando os minutos pagantes acontecem.
Plataforma Fortune Tiger: Funcionalidades e Vantagens
Website: https://clashofcryptos.trade/wiki/User:RomanWinifred1
Conclusao
Este jogo se destaca por ser acessivel e cheio de oportunidades de lucro. Com sua interface amigavel e sistema de pagamentos confiavel, o jogo e ideal para qualquer apostador.
Azərbaycanda internet qumarına seçim artdıqca, "Pin-up casino" kimi saytlar daha çox tanınmağa başladı. Bunun nəticəsində, "Pin up casino online" şəklində olan platformalar son zamanlar Azəri müştərilər üçün məşhurdur. Pinup casino oyunçulara çoxlu oyun növü təklif edir.
Pin-up azerbaycan, yerli mərc həvəskarları üçün maraqlı seçimdir. Bu mərc platforması oyunçulara müxtəlif oyunlar təklif verməkdədir və cazibədar aksiyalar ilə istifadəçilərin diqqətini çəkir.
Pin-up azerbaycan, oyun keyfiyyətini artıran xidmətdir. Azəri bazarında güvənilən Pin-up online, istifadəçilər üçün fərqli oyun seçimləri ilə çıxış edir.
Əlavə olaraq, Pin-up kazino oyunçulara yalnız qumar oyunları yox, həmçinin mərc hədiyyələri təqdim edir. Bu platformada, istifadəçilər təhlükəsiz oyun mühitində olur.
Web: https://www.wikizero.org/wiki/en/Mufi_Hannemann
Pin-up azerbaycan sadəcə məhdud deyil. Oyunçular burada çeşidli mərc seçimlərindən yararlana bilərlər və geniş bonus imkanlarını oyunlarına əlavə edə bilərlər.
Yekun olaraq, Pin-up kazino, sərfəli və təhlükəsiz mərc oyunları təqdim etməklə onlayn qumar sektorunda ən yaxşı seçimlərdən biridir. Azəri oyunçular tərəfindən tanınması açıq bir faktdır.
Azərbaycanda mərc bazarında virtual qumar oyunlarına istək artdıqca, "Pin-up casino" kimi saytlar daha çox tanınmağa başladı. Əlavə olaraq, "Pin up casino online" ifadələri hazırda Azəri mərc həvəskarları üçün güvənlidir. Pinup casino istifadəçilərə müxtəlif oyunlar təklif edir.
Pin up kazino, Azərbaycan oyunçuları üçün ən sevilən platformalardan biridir. Bu onlayn kazino kazino oyunçularına müxtəlif oyunlar təklif edir və cazibədar aksiyalar ilə qumarbazlar tərəfindən sevilir.
Pin-up casino, bənzərsiz oyun imkanı təqdim edən saytdır. yerli mərcçilər arasında məşhur olan Pin-up online, istifadəçilər üçün geniş oyun təcrübəsi verir.
Nəticə etibarilə, Pinup kazino istifadəçilərə təkcə oyunlar deyil, həm də bonus imkanı təmin edir. Bu platformada, qumar həvəskarları rahat və təhlükəsiz şəraitdə oynayır.
Web: http://www.clickyhits.com/the-greatest-music-videos-shot-on-vhs.html
Pin-up azerbaycan yalnız məhdudlaşmır. Qumarçılar burada fərqli mərc oyunlarından müxtəlif mərc imkanı əldə edə bilər və sərfəli bonus təkliflərini qazanmaq imkanı əldə edərlər.
Beləliklə, Pin-up azerbaycan, güvənli mərc oyunları oyunçulara təklif etməklə mərc bazarında oyunçular arasında geniş istifadə edilir. yerli oyunçular arasında seçim olması əlamətdardır.
Como Ganhar Mais no Fortune Tiger
Uma das caracteristicas mais atraentes do Fortune Tiger e a possibilidade de ganhar premios altos em pouco tempo. As rodadas rapidas e com chances de ganho atraem jogadores em busca de recompensas rapidas.
Para maximizar os lucros, muitos jogadores adotam estrategias variadas. Muitos jogadores utilizam a estrategia de aumentar gradualmente as apostas. O jogador vai aumentando as apostas progressivamente, comecando com valores baixos.
Para melhorar as chances de lucro, e essencial escolher os momentos certos para apostar. Ficar atento aos minutos em que o jogo paga mais e uma otima estrategia. Os minutos pagantes sao muitas vezes aleatorios, mas podem ser melhor compreendidos por jogadores experientes.
Plataforma Fortune Tiger: Beneficios para o Jogador
Website: http://www.kingbam.co.kr/bbs/board.php?bo_table=qa&wr_id=13882
Consideracoes Finais
A plataforma oferece uma experiencia de jogo envolvente e acessivel para todos. A confianca dos jogadores e conquistada pela transparencia e facilidade de uso.
Azəri bazarında qumar oyunlarına seçim artdıqca, Pinup kimi saytlar daha çox tanınmağa başladı. Əlavə olaraq, Pinup azerbaycan ifadələri indi Azəri oyunçuları üçün istifadə olunur. Pin-up azerbaycan istifadəçilərə məxsus çoxlu oyun növü təklif edir.
Pinup kazino, yerli oyunçular üçün geniş kütləyə sahib bir qumar saytıdır. Bu mərc platforması mərc həvəskarlarına çeşidli qumar oyunları verir və cazibədar aksiyalar ilə seçim olur.
Pin-up cazino, geniş oyun variantları təklif edən oyun məkanıdır. Azəri oyunçuları arasında populyar olan Pin-up online, istifadəçilər üçün geniş oyun təcrübəsi verir.
Əlavə olaraq, Pin-up casino mərcçilərə çoxlu oyun növlərilə yanaşı mərc hədiyyələri müştəriləri üçün yaradır. Bu qumar saytında, oyunçular təhlükəsiz şərtlər altında mərc edir.
Web: https://ruscourier.ru/news/4745-online-kazino-pin-up-oyunlarin-rahatligindan-v-yl-nc-sind-n-zovq-alin.html
Pin-up cazino yalnız bir mərc saytı kimi məhdud deyil. Mərc həvəskarları bu platformada çeşidli mərc seçimlərindən həzz ala bilərlər və bonus sistemini qazanmaq imkanı əldə edərlər.
Nəticədə, Pin-up kazino, güvənli qumar təcrübəsi istifadəçilərə verməklə mərc bazarında ən yaxşı seçimlərdən biridir. Azərbaycan mərcçiləri arasında məşhur olması təsadüfi deyil.
tigrinho plataforma</a> apresenta uma interface intuitiva e visualmente interessante.
Estrategias para Lucrar no Jogo do Tigrinho
O que chama a atencao no jogo e o alto potencial de lucro em curto periodo. Os premios disponiveis em cada rodada sao um grande atrativo para os jogadores.
Para maximizar os lucros, muitos jogadores adotam estrategias variadas. Uma das estrategias preferidas e a aposta gradual. O metodo comeca com valores minimos e sobe gradualmente.
Apostadores habilidosos sabem escolher os momentos estrategicos para realizar suas apostas. Os minutos pagantes sao uma boa dica para os jogadores. Esses momentos de maiores ganhos sao imprevisiveis, mas com pratica e possivel identifica-los.
Vantagens da Plataforma Fortune Tiger
Website: http://www.onskyfarm.com/bbs/board.php?bo_table=inquiry&wr_id=115703
Consideracoes Finais
Seja para iniciantes ou veteranos, Fortune Tiger tem algo a oferecer. Ao jogar no Fortune Tiger, o jogador tem a chance de se divertir enquanto busca grandes premios.
Azərbaycanda onlayn qumar oyunlarına maraq artdıqca, Pinup kimi şirkətlər daha çox tanınmağa başladı. Əlavə olaraq, Pin-up online ifadələri hazırda Azəri müştərilər üçün tanışdır. Pin-up kazino online oyunçulara çox oyun növləri təklif edir.
Pin-up online casino, yerli mərc həvəskarları üçün geniş yayılmış bir xidmətdir. Bu qumar saytı kazino oyunçularına rəngarəng oyunlar təklif edib və sərfəli bonus təklifləri ilə mərc edənləri özünə cəlb edir.
Pin-up online kazino, çeşidli oyun təcrübəsi təklif edən bir platformadır. Azəri bazarında güvənilən Pin-up casino, kazino oyunçuları üçün zəngin təkliflər təqdim edir.
Əlavə olaraq, Pin-up azerbaycan müştərilərə yalnız qumar oyunları yox, həmçinin sərfəli bonuslar oyunçularına verir. Pinup-da, oyunçular güvənli bir təcrübə yaşayır.
Web: https://bafybeiemxf5abjwjbikoz4mc3a3dla6ual3jsgpdr4cjr3oz3evfyavhwq.ipfs.dweb.link/wiki/Bill_Smith_(swimmer).html
Pin-up online kazino təkcə bir oyun platforması kimi sadə oyunla bitmir. Kazino həvəskarları bu kazinoda bənzərsiz mərc imkanlarından yararlana bilərlər və bonus sistemini mərc təcrübələrini zənginləşdirərlər.
Yekun olaraq, Pin-up casino, sərfəli və təhlükəsiz kazino təcrübəsi istifadəçilərə verməklə oyun bazarında ən yaxşı seçimlərdən biridir. yerli mərcçilər arasında geniş yayılması göz qabağındadır.
Nos ultimos tempos, o mercado de games digitais tem experimentado um crescimento notavel, envolvendo um grande numero de jogadores que desejam entretenimento e, ocasionalmente, a possibilidade de conquistar recompensas em dinheiro. Dentre os jogos que tem conquistado grande fama, destacam-se o <a href="https://historydb.date/wiki/User:AlineSpahn1">jogo do ratinho que ganha dinheiro</a> e o Fortuna do Rato, ambos disponiveis em diversas plataformas de jogo. Estes titulos trazem entretenimento alem de lazer, mas tambem a chance de conquistar premios para aqueles que tem habilidade, calma e uma pitada de sorte. Abaixo, exploraremos, exploraremos as caracteristicas mais importantes aspectos desses titulos, compreendendo suas mecanicas, os horarios mais propicios para jogar, orientacoes para experimentar as versoes demo e taticas para aumentar as chances de vitoria.
O Jogo do Ratinho e famoso por sua disponibilidade e por trazer uma dinamica de jogo que mistura fortuna e estrategia. Esse jogo se fez especialmente bem aceito entre os jogadores que buscam um entretenimento agil e agradavel, mas que tambem pode proporcionar a chance de ganhar algum valor. Para quem nao conhece bem o jogo pela primeira vez, e altamente recomendavel iniciar pela versao demo do jogo do ratinho. A demonstracao e uma opcao sem custo que permite conhecer o game, entender as regras, compreender a dinamica e ate mesmo criar estrategias sem precisar investir dinheiro. Isso e particularmente vantajoso para jogadores iniciantes, que podem aprender com o jogo antes de jogar a versao paga. A demonstracao tambem e excelente para usuarios avancados, pois permite a criacao e o teste de novas abordagens para aumentar as chances de vitoria.
Para aqueles que ja se sentem confiantes em sua aptidao para triunfar, ha o jogo do ratinho para ganhar dinheiro, onde o jogador pode apostar e, com base em seu desempenho e na sorte, adquirir lucros. E importante, no entanto, adotar uma abordagem responsavel ao apostar, lembrando que o objetivo do entretenimento deve ser o entretenimento. Alem disso, uma recomendacao importante e fixar um valor maximo e mante-lo, para nao exceder o valor permitido.
Uma das duvidas que frequentemente surge entre os jogadores e quando e melhor jogar o jogo do ratinho. Muitos acreditam que, de forma parecida com jogos de cassino ou em modalidades de apostas esportivas, ha um momento ideal para jogar. Em modo geral, esse tipo de abordagem envolve jogar em horarios de menor movimento na plataforma, como de madrugada ou nas primeiras horas do dia. A razao por dessa estrategia e que, em horarios de menor concorrencia, o sistema pode apresentar mais oportunidades de vitoria para preservar o interesse dos usuarios ativos. Embora isso nao seja uma regra, e o desfecho das partidas muitas vezes esteja alem do controle do jogador, muitos jogadores compartilham historias de sucesso associadas a esses horarios alternativos.
Web: https://historydb.date/wiki/User:AlineSpahn1
O Game do Ratinho Online e uma otima opcao para aqueles que gostam de jogar com facilidade e acessivel, a partir de qualquer dispositivo conectado a internet. De forma diversa dos cassinos convencionais, que requerem visita ao local, o Jogo do Ratinho online e acessivel a qualquer hora, e varias plataformas oferecem ate mesmo promocoes e eventos que podem incrementar os premios. Dentro dessa modalidade, existe tambem a opcao de jogar o jogo do ratinho gratis, que e ideal para aqueles que buscam apenas diversao ou para quem ainda conhece pouco do jogo. Essa opcao gratuita permite um passatempo leve, onde o jogador nao corre riscos financeiros, podendo aprender e curtir sem prejuizos.
Para aqueles que procuram uma jogabilidade com apostas diretas, o game do ratinho com aposta oferece apostas em dinheiro real, com a chance de duplicar o valor jogado. Embora essa modalidade seja empolgante, vale lembrar a importancia de jogar com responsabilidade, pois apostas implicam riscos. Muitos jogadores experientes recomendam comecar com apostas baixas e aumentar gradualmente, a medida que se torna mais confiante e entendido no jogo. O fundamental e nao esquecer que a sorte e essencial no Jogo do Ratinho, e as apostas precisam ser realizadas com prudencia.
Azərbaycandakı qumar sektorunda qumar oyunlarına istək artdıqca, "Pin-up casino" kimi oyun xidmətləri daha çox tanınmağa başladı. Özəlliklə, Pin-up azerbaycan brendləri artıq Azəri mərc həvəskarları üçün adidir. Pin-up kazino online müştərilərinə geniş oyunlar təklif edir.
Pin-up kazino, Azərbaycandakı oyunçular üçün güvənli bir qumar məkanıdır. Bu kazino istifadəçilərə fərqli oyun növləri oyunçulara təqdim edir və gözəl hədiyyələr ilə seçim olur.
Pin-up online kazino, oyun keyfiyyətini artıran oyun məkanıdır. Azərbaycanda güvənilən Pin-up oyunları, kazino oyunçuları üçün fərqli oyun seçimləri ilə çıxış edir.
Əlavə olaraq, Pin-up casino online istifadəçilərə çoxlu oyun növlərilə yanaşı cazibədar bonus təklifləri oyunçularına verir. Bu kazinoda, istifadəçilər güvənli bir təcrübə yaşayır.
Web: https://onlineradiobox.com/artist/329300496-azealia-banks
Pin-up casino təkcə bir oyun platforması kimi oyunçuları cəlb etmir. İstifadəçilər Pinup-da geniş mərc təcrübəsindən istifadə edə bilər və çoxlu bonusları oyun təcrübəsini artırarlar.
Ümumilikdə, Pin-up casino, müasir və təhlükəsiz kazino təcrübəsi oyunçulara təklif etməklə oyun sənayesində ən sevilən platformalardan olur. yerli mərcçilər arasında populyarlığı təsadüfi deyil.
Understanding Stake Mines Game
Stake Mines is an incredibly captivating game that revolves around a straightforward concept but can be quite hard. Players start by setting a wager and then selecting tiles from a grid. The objective is to uncover all the clear tiles without landing on a mine. Each clear tile you uncover increases your winnings, but if you select a mine, the game ends, and you lose your investment. The basic nature of the game is part of its appeal, but the true challenge lies in the tactics needed. Players must predict which tiles are safe to uncover, weighing danger against potential reward.
The Stake Mines game is offered on various platforms, and its popularity continues to rise due to its fast-paced nature and the thrill of uncertainty. The uncertainty of which tile may hide a mine is part of what makes the game so exciting and offers a edge-of-your-seat experience for both inexperienced and seasoned players.
Stake Mines Strategy: The Key to Winning
A well-thought-out Stake Mines strategy can make the difference between coming out ahead and walking away with nothing. While luck plays a role, the key to success lies in how you approach the game. One popular approach is to start with a conservative bet and gradually boost your wager as you uncover safe tiles. This allows players to minimize potential losses and prolong their gameplay, increasing their chances of hitting a profitable streak.
Another strategy involves selecting a specific method in which to uncover the tiles. By following a predetermined grid path, players may sometimes improve their chances of avoiding mines. However, even with the best-laid strategy, it’s vital to remember that the game is based on uncertainty, and no strategy can guarantee a win every time.
For those curious about how these bots work, a Stake Mines Predictor Bot Free version is often available for download. While these free bots may not be as advanced or sophisticated as their paid counterparts, they still claim to offer valuable insights into which tiles are safe to click. Players may experiment with these free tools to determine if they provide a significant advantage before upgrading to a more complex version.
The Allure of Stake Mines Hack
For some players, using a Stake Mines Hack represents an appealing shortcut to guaranteed winnings. Hacks refer to cheated versions of the game or tools designed to change the game’s mechanics in favor of the player. These could involve changing the game’s algorithm, unlocking extra features, or even revealing the locations of mine-free tiles. However, using a hack comes with major risks. Firstly, many hacks are unstable, possibly introducing malware or harming your device. Secondly, hacking is a breach of most gaming platforms' terms of service, and players caught using hacks can be banned or suspended.
While this tool doesn’t guarantee success, it provides a way for players to gauge the risk and reward associated with each decision. Some calculators even use historical game data to adjust a player’s strategy based on past performance.
Stake Mines APK and Mod Versions
For those who enjoy trying out alternative game versions, the Stake Mines APK lets gamers install the game on their Android devices. APK packages allow customers to bypass app store limitations and load customized or modded versions of the game. These versions can offer enhanced features, additional functionalities, or even extra chances to succeed, but it’s important to fetch them from trusted sources to avoid malware or other issues.
Web: http://pa006.samplekorea.com/bbs/board.php?bo_table=free&wr_id=76893
Stake Mines Demo: Learning the Game Without Risk
If you're new to Stake Mines, the Stake Mines demo is a great way to practice the game’s mechanics without the financial risk. Many platforms offer demo versions of games, allowing players to refine their skills and strategies in a low-stakes environment. The Stake Mines demo mirrors the real game but without using real money, making it the perfect way to experiment before committing to real wagers.
Using the demo version helps players comprehend the features and gameplay of the game without the worry of losing money. It’s a risk-free way to explore different strategies and decide how to approach the full game.
Azərbaycandakı qumar sektorunda virtual qumar oyunlarına seçim artdıqca, Pin-up kazino kimi onlayn mərc xidmətləri daha çox tanınmağa başladı. Bununla bərabər, Pinup casino brendləri artıq yerli oyunçular üçün sevilir. Pin-up azerbaycan mərc həvəskarlarına rəngarəng oyunlar təklif edir.
Pin up kazino, yerli mərc həvəskarları üçün populyar seçimdir. Bu onlayn kazino kazino oyunçularına rəngarəng oyunlar təklif edib və cəlbedici bonuslar ilə seçim olur.
Pin-up casino online, oyun keyfiyyətini artıran saytdır. Azəri bazarında məşhur olan Pin-up kazino, qumar oyunçuları üçün maraqlı oyun imkanları təklif edir.
Son olaraq, Pinup kazino qumarbazlara təkcə oyunlar deyil, həm də bonuslar və aksiyalar təmin edir. Bu qumar saytında, müştərilər şəffaf oyun şərtləri ilə rastlaşır.
Web: https://www.dmxzone.com/support/13984/topic/66397/
Pin-up casino online təkcə bir oyun platforması kimi məhdudlaşmır. Kazino həvəskarları bu kazinoda çeşidli mərc seçimlərindən təcrübə edə bilərlər və geniş bonus imkanlarını oyunlarına əlavə edə bilərlər.
Sonda, Pin-up azerbaycan, sərfəli və təhlükəsiz qumar təcrübəsi oyunçulara təklif etməklə oyun sənayesində ən yaxşı seçimlərdən biridir. Azəri oyunçular tərəfindən məşhur olması dikkətə layiqdir.
melhor plataforma para jogar fortune tiger</a> cria uma atmosfera acolhedora e facil de jogar.
Fortune Tiger: Estrategias para Ganhos
O jogo oferece lucros interessantes, mesmo em apostas rapidas. As rodadas rapidas e com chances de ganho atraem jogadores em busca de recompensas rapidas.
Para maximizar os lucros, muitos jogadores adotam estrategias variadas. A tecnica da aposta progressiva e amplamente utilizada. Nessa abordagem, o jogador comeca com valores baixos e aumenta aos poucos.
A gestao do tempo durante as apostas tambem influencia diretamente os lucros. Saber quando o jogo esta mais propenso a pagar altos premios pode ser decisivo. Identificar os minutos mais rentaveis exige pratica, mas e uma habilidade essencial para os apostadores.
Caracteristicas da plataforma Fortune Tiger
Website: http://www.mignonmuse.com/bbs/board.php?bo_table=free&wr_id=303629
Fechamento
Fortune Tiger e um jogo que combina diversao, estrategia e oportunidades de ganhos. O jogo, com seus recursos de seguranca e opcoes de pagamento, proporciona uma experiencia tranquila.
Azərbaycandakı qumar sektorunda qumar oyunlarına güvəni artdıqca, Pin-up casino online kimi kazino xidmətləri daha çox tanınmağa başladı. Özəlliklə, Pin-up azerbaycan şüarları çoxdan Azəri mərc həvəskarları üçün məşhurdur. Pin-up azerbaycan müştərilərinə rəngarəng oyunlar təklif edir.
Pin up kazino, yerli mərc həvəskarları üçün geniş yayılmış bir xidmətdir. Bu mərc platforması müştərilərə çeşidli qumar oyunları təklif verməkdədir və cəlbedici bonuslar ilə müştərilərini məmnun edir.
Pin-up cazino, bənzərsiz oyun imkanı təqdim edən saytdır. yerli mərcçilər arasında məşhur olan Pinup, kazino oyunçuları üçün çeşidli bonus imkanları yaradır.
Sonda, Pin-up casino online oyunçulara təkcə oyunlar deyil, həm də bonus imkanı təmin edir. Pinup-da, kazino həvəskarları təhlükəsiz oyun mühitində olur.
Web: https://www.mwcconnection.com/2011/9/29/2457099/future-mountain-west-teams-news-and-notes-two-quarterback-system
Pin-up casino online sadəcə məhdudlaşmır. Mərc həvəskarları bu platformada çeşidli mərc seçimlərindən yararlana bilərlər və maraqlı aksiyaları oyun təcrübəsini artırarlar.
Bunun nəticəsində, Pinup kazino, etibarlı mərc təcrübəsi istifadəçilərə verməklə oyun bazarında oyunçular arasında geniş istifadə edilir. Azərbaycanda çox seçilməsi təsadüfi deyil.
yerli oyunçular arasında internet oyunlarına maraq artdıqca, "Pin-up casino" kimi platformalar daha çox tanınmağa başladı. Əsasən, Pinup casino şəklində olan platformalar son zamanlar Azərbaycandakı oyunçular üçün sevilir. Pin-up casino mərc həvəskarlarına çeşidli oyunlar təklif edir.
Pin-up cazino, Azərbaycan oyunçuları üçün geniş kütləyə sahib bir qumar saytıdır. Bu qumar xidməti oyunçulara çeşidli qumar oyunları təmin edir və bonus imkanları ilə oyunçuları özünə cəlb edir.
Pin-up casino online, bənzərsiz oyun imkanı təqdim edən saytdır. Azəri oyunçuları arasında oyunçular tərəfindən sevilən Pin-up online, oyun həvəskarları üçün maraqlı oyun imkanları təklif edir.
Yekun olaraq, Pin-up kazino mərc həvəskarlarına geniş oyun təcrübəsi ilə yanaşı bonus imkanı oyunçularına verir. Pinup-da, istifadəçilər rahat və təhlükəsiz şəraitdə oynayır.
Web: http://www.themusicninja.com/artists/azealia-banks-2/page/2/
Pin-up casino online təkcə bir kazino olaraq məhdudlaşmır. Oyunçular burada fərqli mərc seçimlərindən yararlana bilərlər və geniş bonus imkanlarını qazanmaq imkanı əldə edərlər.
Sonda, Pin-up casino online, etibarlı mərc imkanı təmin etməklə oyun sənayesində ən sevilən platformalardan olur. Azəri bazarında çox seçilməsi dikkətə layiqdir.
Azərbaycanda mərc bazarında internet qumarına maraq artdıqca, Pin-up online kimi saytlar daha çox tanınmağa başladı. Bununla bərabər, Pin-up kazino brendləri çoxdan yerli oyunçular üçün sevilir. Pin-up casino istifadəçilərə məxsus müxtəlif oyunlar təklif edir.
Pin up kazino, Azəri istifadəçilər üçün geniş kütləyə sahib bir qumar saytıdır. Bu qumar saytı müştərilərə rəngarəng oyunlar təklif edib və bonus imkanları ilə mərc edənləri özünə cəlb edir.
Pin-up casino, çeşidli oyun təcrübəsi təklif edən saytdır. Azəri oyunçuları arasında geniş istifadə olunan Pinup, mərc həvəskarları üçün çeşidli bonus imkanları yaradır.
Yekun olaraq, Pin-up casino oyunçulara yalnız oyun təklif etmir cazibədar bonus təklifləri oyun təcrübəsini daha da maraqlı edir. Bu onlayn kazinoda, müştərilər şəffaf oyun şərtləri ilə rastlaşır.
Web: https://wowgilden.net/forum-post_1612529.html
Pin-up kazino yalnız məhdud oyunlar təklif etmir. Qumarçılar burada geniş mərc təcrübəsindən faydalanıb və maraqlı aksiyaları mərc təcrübələrini zənginləşdirərlər.
Nəticədə, Pin-up kazino, rahat və təhlükəsiz kazino təcrübəsi təmin etməklə oyun bazarında lider mövqedədir. Azəri oyunçular tərəfindən tanınması göz qabağındadır.
Azərbaycanda onlayn qumar oyunlarına maraq artdıqca, Pin-up kazino kimi şirkətlər daha çox tanınmağa başladı. Xüsusilə, "Pin up casino online" şəklində olan platformalar artıq yerli oyunçular üçün tanışdır. Pin-up kazino öz oyunçularına çox oyun növləri təklif edir.
Pin-up online casino, yerli oyunçular üçün geniş yayılmış bir xidmətdir. Bu mərc platforması kazino oyunçularına müxtəlif oyunlar təmin edir və gözəl hədiyyələr ilə seçim olur.
Pin-up casino, çeşidli oyun təcrübəsi təklif edən oyun məkanıdır. Azərbaycanda çox seçilən Pinup, qumar oyunçuları üçün fərqli oyun seçimləri ilə çıxış edir.
Yekun olaraq, Pin-up cazino istifadəçilərə təkcə oyunlar deyil, həm də sərfəli bonuslar oyunçularına verir. Bu qumar saytında, qumar həvəskarları təhlükəsiz şərtlər altında mərc edir.
Web: https://linkanews.com/website-list-1386/
Pin-up kazino təkcə bir oyun platforması kimi oyunçuları cəlb etmir. Kazino həvəskarları bu kazinoda fərqli mərc seçimlərindən təcrübə edə bilərlər və cazibədar bonus imkanlarını oyunlarına əlavə edə bilərlər.
Nəticədə, Pin-up casino, etibarlı qumar təcrübəsi təqdim etməklə oyun sənayesində özünü doğruldur. yerli oyunçular arasında geniş yayılması təsadüf deyil.
The idea of virtual gambling platforms emerged in the late 20th century, offering a convenient substitute to physical gaming spots. Over time, modern technology have transformed online platforms into captivating experiences, featuring detailed animations, real dealer experiences, and smooth gaming.
Today, the capacity to access an digital gambling site from any modern device is a significant advantage for gaming enthusiasts across the planet.
Virtual gambling platforms deliver a wide range of activities, including iconic games such as poker and blackjack, together with a large array of slots.
These online hubs give enthusiasts the ease of participating from any cozy spot or while mobile, turning them into favorites among both novice and seasoned gamblers.
One of the most transformative aspects in the online gaming industry is the growth of mobile-friendly interfaces. Casino-focused software are now a popular way for engaging with online platforms, owing to their accessible layouts and tailored features.
Whether you are a occasional gamer or a strategic gamer, a specialized gaming app lets you experience your favorite games with just a few clicks on your portable device.
These apps are designed to provide a flawless entertainment flow, with features such as personalized game recommendations, instant payout solutions, and cutting-edge encryption.
Web: https://aviator-juego.pages.dev/
Players can install a APK for casino platforms—a specific Android tool—to install apps directly in cases where they're missing on common mobile platforms.
This versatility allows that players can remain engaged to their most-used casino systems, whatever device compatibility they have.
The idea of virtual gambling platforms came into existence in the late 20th century, delivering a easy-to-reach substitute to brick-and-mortar establishments. Over time, digital improvements have elevated online platforms into engaging realms, complete with detailed animations, live gaming features, and smooth gaming.
Today, the ability to visit an online casino from almost any gadget remains a key feature for players everywhere.
Online casinos feature a comprehensive collection of activities, such as iconic games such as poker and blackjack, alongside countless slots.
These online hubs make available for users the comfort of enjoying games in their living rooms or while traveling, rendering them highly appealing among both entry-level and seasoned gamblers.
One of the most remarkable changes in the world of virtual casinos is the growth of mobile-friendly interfaces. Gambling apps are now a popular way for interacting with online platforms, due to their player-oriented features and customized tools.
Whether you are a occasional gamer or a serious gambler, a specialized gaming app brings you your beloved activities with just a few touches on your smart device.
These apps focus on ensure a smooth gaming journey, with options such as customized gambling options, instant payout solutions, and cutting-edge encryption.
Web: https://casino-game-mines.netlify.app/
Players can acquire a Android gambling app—a file format for Android devices—to install apps directly should they not be accessible on mainstream app stores.
This ease allows that players can remain engaged to their preferred digital casinos, regardless of their device's operating system.
The idea of virtual gambling platforms emerged in the late 20th century, bringing a accessible solution to conventional casinos. Over time, innovations in technology have transformed online platforms into engaging spaces, complete with high-quality designs, real-time dealer interactions, and seamless gameplay.
Today, the opportunity to explore an digital gambling site from a range of devices is a main highlight for gaming enthusiasts everywhere.
Web-based gambling sites deliver a wide range of options, including classics like blackjack, roulette, and poker, together with hundreds of slot games.
These online hubs give enthusiasts the ease of playing from their homes or on the go, turning them into favorites among both entry-level and skilled bettors.
One of the most notable trends in the world of virtual casinos is the shift to mobile-first platforms. Mobile casino applications have become a go-to option for interacting with online platforms, thanks to their user-friendly interfaces and personalized options.
Whether you are a occasional gamer or a professional player, a well-designed mobile casino allows you to enjoy your preferred entertainment with just a few touches on your portable device.
These apps are designed to enable a seamless gaming experience, with functionalities such as tailored suggestions for games, instant payout solutions, and advanced safety protocols.
Web: https://fortune-tiger-best.github.io/
Players can obtain a mobile gaming APK—a file format for Android devices—to use software without delay in cases where they're missing on official app stores.
This versatility ensures that players can enjoy uninterrupted gaming to their favorite gaming platforms, no matter what OS they use.
The concept of online casinos originated in the 1990s, delivering a accessible option to conventional gaming spots. Over time, technological advancements have revolutionized online platforms into captivating realms, equipped with realistic graphics, live dealer options, and lag-free experiences.
Today, the ability to explore an internet casino from virtually any device is one of the biggest draws for gaming enthusiasts everywhere.
Internet casinos make available a comprehensive collection of options, such as iconic games such as poker and blackjack, as well as hundreds of slot games.
These platforms provide players the ease of gaming at home or while mobile, establishing their popularity among both novice and long-time enthusiasts.
One of the most significant shifts in the world of virtual casinos is the trend of handheld gameplay. Gaming apps are increasingly a go-to option for engaging with online platforms, owing to their simple navigation and unique enhancements.
Whether you are a occasional gamer or a professional player, a specialized gaming app enables your access to your favorite games with just a few clicks on your portable device.
These apps focus on enhance a lag-free gambling interaction, with options such as tailored suggestions for games, rapid fund transfers, and enhanced security measures.
Web: https://bet-on-red-casino.pages.dev
Players can get a casino application file—a dedicated app setup for Android—to set up applications instantly should they not be accessible on common mobile platforms.
This versatility guarantees that players can continue their sessions to their beloved gambling hubs, regardless of their device's operating system.
The concept of online casinos came into existence in the digital revolution period, offering a comfortable variation to conventional gambling locations. Over time, progress in tech have evolved online platforms into dynamic settings, featuring lifelike visuals, real dealer experiences, and flawless performance.
Today, the opportunity to engage with an web-based casino from any modern device stands out as a major attraction for gaming enthusiasts worldwide.
Digital gaming hubs make available a variety of entertainment choices, highlighting classics like blackjack, roulette, and poker, as well as countless slots.
These websites deliver to gamers the accessibility of gaming at home or while mobile, establishing their popularity among both amateur and skilled bettors.
One of the most important developments in the field of online entertainment is the growth of mobile-friendly interfaces. Gambling apps are increasingly a top choice for playing on online platforms, due to their user-friendly interfaces and tailored features.
Whether you are a casual player or a high-stakes bettor, a well-designed mobile casino enables your access to your preferred entertainment with just a few steps on your mobile phone.
These apps aim to enhance a flawless entertainment flow, with capabilities such as personalized game recommendations, rapid fund transfers, and robust privacy features.
Web: https://aviator-india.github.io
Players can install a APK for casino platforms—a package designed for Android—to install apps directly if they are unavailable on common mobile platforms.
This adaptability guarantees that players can enjoy uninterrupted gaming to their favorite gaming platforms, irrespective of technical constraints.
The idea of virtual gambling platforms gained traction in the 1990s, delivering a comfortable option to conventional gambling locations. Over time, technological advancements have elevated online platforms into captivating experiences, equipped with stunning imagery, real-time dealer interactions, and uninterrupted action.
Today, the option to engage with an virtual casino from any modern device stands out as a major attraction for users across the planet.
Online casinos deliver a comprehensive collection of entertainment choices, ranging from timeless classics like roulette and poker, in addition to a large array of slots.
These platforms provide players the accessibility of playing from their homes or while traveling, rendering them highly appealing among both novice and skilled bettors.
One of the most important developments in the digital gambling sector is the growth of mobile-friendly interfaces. Gambling apps have become a top choice for accessing online platforms, thanks to their user-friendly interfaces and adapted functionalities.
Whether you are a casual player or a high-stakes bettor, a dedicated casino app enables your access to your most-loved gaming experiences with just a few touches on your smartphone.
These apps are built to provide a seamless gaming experience, with options such as tailored suggestions for games, fast transaction systems, and enhanced security measures.
Web: https://andar-bahar-game.netlify.app
Players can acquire a casino application file—a specific Android tool—to access platforms seamlessly in cases where they're missing on popular download hubs.
This freedom provides that players can remain engaged to their favorite gaming platforms, regardless of their device's operating system.
The emergence of online gaming hubs gained traction in the digital revolution period, offering a accessible option to physical gambling locations. Over time, technological advancements have transformed online platforms into interactive spaces, including realistic graphics, live dealer options, and uninterrupted action.
Today, the opportunity to explore an online casino from a range of devices remains a key feature for players across the planet.
Virtual gambling platforms make available a wide range of entertainment choices, including classics like blackjack, roulette, and poker, in addition to numerous slot games.
These online hubs make available for users the convenience of playing from their homes or while mobile, establishing their popularity among both entry-level and seasoned gamblers.
One of the most transformative aspects in the digital gambling sector is the trend of handheld gameplay. Gaming apps have become a preferred method for accessing online platforms, because of their intuitive designs and personalized options.
Whether you are a leisure bettor or a dedicated enthusiast, a specialized gaming app provides your beloved activities with just a few touches on your smart device.
These apps are designed to ensure a flawless entertainment flow, with features such as customized gambling options, instant payout solutions, and high-level protections.
Web: https://aviator-spribe.netlify.app/
Players can download a mobile gaming APK—a package designed for Android—to gain instant access when they are not listed on common mobile platforms.
This flexibility ensures that players can enjoy uninterrupted gaming to their beloved gambling hubs, regardless of their device's operating system.
The concept of online casinos came into existence in the late 20th century, providing a easy-to-reach option to land-based venues. Over time, modern technology have elevated online platforms into immersive environments, featuring lifelike visuals, interactive dealer gameplay, and smooth gaming.
Today, the possibility to use an digital gambling site from any modern device remains a key feature for players around the globe.
Web-based gambling sites provide a variety of entertainment choices, including classics like blackjack, roulette, and poker, together with a large array of slots.
These systems deliver to gamers the convenience of gaming at home or in any location, making them a popular choice among both novice and long-time enthusiasts.
One of the most transformative aspects in the online gaming industry is the trend of handheld gameplay. Gambling apps have become a common approach for engaging with online platforms, due to their user-friendly interfaces and tailored features.
Whether you are a hobbyist or a dedicated enthusiast, a dedicated casino app enables your access to your preferred entertainment with just a few touches on your smartphone.
These apps aim to provide a smooth gaming journey, with capabilities such as adaptive picks for players, fast transaction systems, and enhanced security measures.
Web: https://how-play-aviator.github.io
Players can obtain a Android gambling app—a type of Android software—to use software without delay should they not be accessible on common mobile platforms.
This freedom provides that players can enjoy uninterrupted gaming to their preferred digital casinos, despite their device preferences.
The notion of internet-based casinos originated in the mid-1990s, offering a convenient alternative to conventional establishments. Over time, technological advancements have reshaped online platforms into interactive settings, boasting stunning imagery, real dealer experiences, and flawless performance.
Today, the opportunity to engage with an digital gambling site from almost any gadget stands out as a major attraction for users everywhere.
Virtual gambling platforms offer a comprehensive collection of activities, highlighting traditional games like blackjack and roulette, as well as a large array of slots.
These systems make available for users the accessibility of enjoying games in their living rooms or in any location, establishing their popularity among both beginner and skilled bettors.
One of the most transformative aspects in the digital gambling sector is the trend of handheld gameplay. Gambling apps are now a preferred method for interacting with online platforms, owing to their simple navigation and personalized options.
Whether you are a hobbyist or a professional player, a specialized gaming app brings you your beloved activities with just a few interactions on your mobile phone.
These apps are designed to provide a smooth gaming journey, with functionalities such as customized gambling options, fast transaction systems, and cutting-edge encryption.
Web: https://dragon-tigergame.netlify.app/
Players can download a casino application file—a file format for Android devices—to set up applications instantly when they are not listed on popular download hubs.
This freedom allows that players can always stay connected to their top-choice gaming apps, regardless of their device's operating system.
The idea of virtual gambling platforms emerged in the mid-1990s, providing a comfortable option to conventional gambling locations. Over time, innovations in technology have transformed online platforms into captivating settings, boasting realistic graphics, real-time dealer interactions, and smooth gaming.
Today, the option to access an internet casino from practically anywhere is a main highlight for users around the globe.
Online casinos make available a broad assortment of entertainment choices, ranging from traditional games like blackjack and roulette, alongside a myriad of slot machines.
These services provide players the convenience of gaming at home or while traveling, turning them into favorites among both entry-level and veteran users.
One of the most transformative aspects in the digital gambling sector is the shift to mobile-first platforms. Mobile casino applications have become a preferred method for using online platforms, due to their simple navigation and customized tools.
Whether you are a entertainment seeker or a serious gambler, a feature-rich casino software brings you your favorite games with just a few clicks on your smart device.
These apps are designed to enhance a smooth gaming journey, with functionalities such as tailored suggestions for games, efficient deposit methods, and high-level protections.
Web: https://game-mines.web.app
Players can acquire a mobile gaming APK—a type of Android software—to install apps directly when they are not listed on traditional application markets.
This adaptability makes certain that players can always stay connected to their favorite gaming platforms, irrespective of technical constraints.
Understanding Stake Mines Game
Stake Mines is an incredibly captivating game that revolves around a clear-cut concept but can be quite challenging. Players kick off by putting a investment and then selecting tiles from a grid. The objective is to uncover all the non-dangerous tiles without landing on a mine. Each clear tile you uncover increases your winnings, but if you select a mine, the game ends, and you lose your wager. The ease of the game is part of its appeal, but the true challenge lies in the tactics needed. Players must predict which tiles are safe to uncover, weighing danger against potential reward.
The Stake Mines game is offered on various platforms, and its popularity continues to rise due to its energetic nature and the thrill of uncertainty. The randomness of which tile may hide a mine is part of what makes the game so exciting and offers a high-stakes experience for both inexperienced and seasoned players.
Stake Mines Strategy: The Key to Winning
A well-thought-out Stake Mines strategy can make the difference between achieving success and walking away with nothing. While luck plays a role, the key to beating the game lies in how you deal with the game. One popular approach is to start with a small bet and gradually expand your wager as you uncover safe tiles. This allows players to control potential losses and prolong their gameplay, increasing their chances of hitting a profitable streak.
Another strategy involves selecting a specific method in which to uncover the tiles. By following a predetermined grid path, players may sometimes improve their chances of avoiding mines. However, even with the best-laid strategy, it’s vital to remember that the game is based on unpredictability, and no strategy can guarantee a win every time.
For those curious about how these bots work, a Stake Mines Predictor Bot Free version is often available for download. While these free bots may not be as advanced or sophisticated as their paid counterparts, they still claim to offer valuable insights into which tiles are safe to click. Players may experiment with these free tools to determine if they provide a significant advantage before upgrading to a more advanced version.
The Allure of Stake Mines Hack
For some players, using a Stake Mines Hack represents an appealing shortcut to guaranteed winnings. Hacks refer to altered versions of the game or tools designed to change the game’s mechanics in favor of the player. These could involve changing the game’s algorithm, unlocking extra features, or even revealing the locations of mine-free tiles. However, using a hack comes with major risks. Firstly, many hacks are unstable, possibly introducing malware or harming your device. Secondly, hacking is a breach of most gaming platforms' terms of service, and players caught using hacks can be banned or suspended.
While this tool doesn’t guarantee success, it provides a way for players to assess the risk and reward associated with each decision. Some calculators even use historical game data to adjust a player’s strategy based on past performance.
Stake Mines APK and Mod Versions
For those who enjoy trying out unique game versions, the Stake Mines APK lets players acquire the game on their Android devices. APK packages allow users to circumvent app store limitations and deploy customized or altered versions of the game. These versions can offer enhanced features, additional functionalities, or even improved chances to succeed, but it’s important to fetch them from reliable sources to avoid malware or other issues.
Web: http://brechobebe.com.br/index.php/author/jancardona/
Stake Mines Demo: Learning the Game Without Risk
If you're new to Stake Mines, the Stake Mines demo is a great way to practice the game’s mechanics without the financial risk. Many platforms offer demo versions of games, allowing players to refine their skills and strategies in a low-stakes environment. The Stake Mines demo mirrors the real game but without using real money, making it the perfect way to practice before committing to real wagers.
Using the demo version helps players master the features and gameplay of the game without the worry of losing money. It’s a risk-free way to explore different strategies and decide how to approach the full game.
One major attraction of <a href="https://www.valeriarp.com.tr/index.php?action=profile;u=618311">sweet bonanza app</a> is its unique method for online slot mechanics. Unlike classic slot games that utilize payline systems, Sweet Bonanza introduces a non-payline system. The game has a 6x5 grid, providing spinners numerous chances to secure matches with each spin. Wins occur by forming clusters of a minimum of eight same images anywhere on the grid, setting it apart from regular slots that use fixed paylines.
Cluster pays system is more than just visually engaging but also creates users more chances to win per spin.
The sweet candy visuals and bright color palette add to the visual allure, producing a sugary and dynamic vibe that invites players. Icons in the game consist of various candies in eye-catching tones, as well as bananas, grapes, watermelons, and other fruits. The visuals are complemented by cheerful sounds that brings to the gaming excitement. The Sweet Bonanza game also has a scatter symbol depicted as a lollipop, which is important in activating the free rounds. If players get four or more lollipops, the game will activate the free round, which provides a high possibility to win big.
For players who are new to online slots or who want to try it out before spending actual money, Sweet Bonanza demo mode gives an ideal option. Numerous gaming sites offer a Sweet Bonanza practice mode, giving users to enjoy the gameplay, experiment with tactics, and acquaint themselves with the mechanics without any investment. Trying a demo version of the slot is a great choice for novices, as it helps them grasp the game structure, adjust wager sizes, and discover the cascading reels.
Web: https://www.valeriarp.com.tr/index.php?action=profile;u=618311
The Tumble feature, alternatively called the cascade feature, plays a major role in the game. Once players hit a winning cluster, the winning icons are removed, and new symbols fall into place, potentially creating additional winning combinations. This mechanic boosts the anticipation but also offers extra chances to score within each round.
A key aspect of the Sweet Bonanza slot is its bonus spin mode, which can be the primary focus for gamblers. The extra spins feature in the game has the potential for large wins due to the inclusion of random multipliers. If players activate it, the Free Spins feature awards ten free spins, and extra spins can be re-triggered by landing additional lollipop icons.
Este slot se diferencia de otras tragamonedas por su diseno llamativo y unico. Al comenzar a jugar, los apostadores son llevados a un escenario de golosinas y colores vivos que sugieren un ambiente magico. El fondo de la pantalla esta lleno de golosinas, lo cual presenta un ambiente visual atractiva y tranquila, perfecta para principiantes y expertos. Este slot ha sido descrito por muchos en sus opiniones como adictivo y muy entretenido, ya que brinda emociones y una estetica llamativa para todos.
Una de las caracteristicas mas valoradas de este juego de tragamonedas es su funcion de giros gratis, que se activa si se obtienen cuatro o mas simbolos de caramelos en cualquier lugar. La ronda de giros gratuitos no solo permiten jugar sin costo, sino que tambien multiplican las posibilidades de ganar grandes premios, especialmente cuando se activan los multiplicadores durante los giros. Este elemento del juego es uno de los mas atractivos a los jugadores, y muchos destacan en sus comentarios que la ronda de giros gratis es lo que mas entusiasma de Sweet Bonanza.
Ademas, este juego ha logrado mantener su popularidad gracias a su atractivo para jugadores novatos y experimentados. No importa si eres nuevo en el mundo de las tragamonedas, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la adaptabilidad de este titulo en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere jugar durante tus descansos, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: https://wik.co.kr/master4/2363839
Otro punto que interesa a los jugadores es si realmente pueden ganar dinero con este juego de tragamonedas. Al igual que en cualquier tragamonedas, este juego es una maquina de azar, lo cual significa que el resultado de cada vuelta es basado en azar y no puede ser modificado. Sin embargo, los multiplicadores y la funcion de giros gratuitos ofrecen una oportunidad significativa para obtener grandes premios. La funcion de los multiplicadores pueden multiplicar las ganancias hasta 100 veces, lo que puede resultar en una recompensa significativa si sale un giro afortunado. Sin embargo, es importante recordar que siempre es importante jugar con responsabilidad y que no hay garantias de ganar en cada sesion.
Peki, oyuncular bu oyunu nas?l oynayabilir? Sweet Bonanza’n?n derinlemesine ayr?nt?lar?n? gozden gecirecegiz ve giris yapma yontemlerinden taktik ipuclar?na kadar butun onemli bilgileri verecegiz.
Sweet Bonanza oyunu nedir ve nas?l cal?s?r?
Tatl? temal? Sweet Bonanza, cevrimici slot oyunlar? aras?nda dikkat cekici ozelliklere sahip bir bir slot oyunudur. Pragmatic Play’in sundugu bu oyun turu, tatl? temal? ikonlardan olusan bir yap?ya sahiptir. Bu ikonik semboller, renkli bir dunya yaratarak oyuncular? oyunun cazibesine kap?lmaya davet eder.
Sweet Bonanza’n?n diger slot oyunlar?na gore farkl? bir oyun sistemine sahip olmas? oyunculara farkl? bir deneyim sunuyor. Ekranda patlayan semboller yerine yenilerinin gelmesiyle, oyuncular surekli bir dongu icinde kazanc saglayabilir. Bu mekanik yap?yla birlikte, Sweet Bonanza, oyunculara eglenceli bir deneyim yasat?r.
Sweet Bonanza kurallar? ve oynan?s?
Sweet Bonanza oyununun mekanikleri diger slot oyunlar?ndan daha kolay anlas?l?r bir oyun sistemi sunar. oyun alan? 6x5 bir duzende yer al?r. Burada amac, ayn? sembollerin bir araya toplanmas?yla oyunda kazanc elde etmektir.
Bu mekanikte herhangi bir cizgi takip etme gereksinimi yoktur. Oyuncular icin sembollerin birlesmesi yeterlidir. Kazanan semboller patlar ve yenileri eklenir. Bu oyun yap?s?yla birlikte, tek bir turda birden fazla kazanc saglamak mumkundur.
Web: https://www.jiebbs.net/home.php?mod=space&uid=244162&do=profile&from=space
Sweet Bonanza Demo Oyna Secenegi ile Eglenin
Sweet Bonanza’n?n sundugu avantajlardan biri de, oyunculara demo mod sunulmas?d?r. Sweet Bonanza demo modu, yeni baslayanlar icin mukemmel bir f?rsatt?r. Oyuncular, demo modda gercek para harcamadan oyunun dinamiklerini ogrenebilirler.
Demo modunda oynarken kazanc saglayan sembolleri ogrenebilirsiniz. Bu modda, oyun stratejilerini risksiz bir sekilde deneyebilirsiniz. Demo Sweet Bonanza, oyuncular?n farkl? stratejiler gelistirmelerine olanak tan?r.
The idea of virtual gambling platforms originated in the 1990s, bringing a user-friendly option to land-based gaming spots. Over time, progress in tech have evolved online platforms into immersive experiences, including lifelike visuals, live gaming features, and uninterrupted action.
Today, the capacity to use an internet casino from virtually any device remains a key feature for players everywhere.
Web-based gambling sites make available a comprehensive collection of gaming experiences, ranging from classics like blackjack, roulette, and poker, complemented by hundreds of slot games.
These websites give enthusiasts the comfort of participating from any cozy spot or from anywhere, securing their place as preferred options among both beginner and skilled bettors.
One of the most important developments in the realm of internet-based gambling is the growth of mobile-friendly interfaces. Gaming apps are widely recognized as a go-to option for engaging with online platforms, as a result of their player-oriented features and adapted functionalities.
Whether you are a entertainment seeker or a high-stakes bettor, a feature-rich casino software lets you experience your favorite games with just a few touches on your smartphone.
These apps focus on enable a flawless entertainment flow, with capabilities such as adaptive picks for players, rapid fund transfers, and high-level protections.
Web: https://bet-onredcasino.web.app
Players can acquire a casino apk—a specific Android tool—to install apps directly should they not be accessible on popular download hubs.
This flexibility allows that players can always stay connected to their top-choice gaming apps, despite their device preferences.
The idea of virtual gambling platforms gained traction in the digital revolution period, bringing a user-friendly alternative to brick-and-mortar casinos. Over time, technological advancements have reshaped online platforms into immersive realms, boasting detailed animations, live dealer options, and flawless performance.
Today, the capacity to explore an internet casino from any modern device stands out as a major attraction for players internationally.
Virtual gambling platforms offer a comprehensive collection of entertainment choices, ranging from traditional games like blackjack and roulette, complemented by a myriad of slot machines.
These websites give enthusiasts the convenience of enjoying games in their living rooms or in any location, securing their place as preferred options among both entry-level and veteran users.
One of the most important developments in the world of virtual casinos is the move toward mobile gaming. Casino apps are increasingly a preferred method for engaging with online platforms, owing to their player-oriented features and personalized options.
Whether you are a leisure bettor or a high-stakes bettor, a feature-rich casino software brings you your top-choice options with just a few clicks on your portable device.
These apps aim to enable a smooth gaming journey, with features such as tailored suggestions for games, efficient deposit methods, and high-level protections.
Web: https://pin-up-casino-es-confiable.netlify.app/
Players can install a mobile gaming APK—a package designed for Android—to access platforms seamlessly when not found on official app stores.
This adaptability ensures that players can remain engaged to their favorite gaming platforms, despite their device preferences.
Sweet Bonanza sobresale de otras opciones de juego por su diseno y tematica unicos. Al ingresar al slot, los apostadores son transportados a un mundo de dulces y colores vibrantes que parecen de un mundo fantastico. El escenario esta repleto de confites, lo cual crea una imagen atractiva y agradable, ideal para todo tipo de jugadores. Esta tragamonedas ha sido considerado como entretenido y cautivador, ya que brinda emociones y una estetica llamativa para todos.
Una de las caracteristicas mas valoradas de este juego de tragamonedas es su funcion de giros gratis, que se activa si se obtienen cuatro o mas simbolos de caramelos en cualquier lugar. Los giros gratis no solo permiten jugar sin costo, sino que tambien aumentan las oportunidades de ganar, especialmente cuando aparecen multiplicadores en los giros. Este aspecto dentro del juego es uno de los mas interesantes a los jugadores, y muchos comentan en sus opiniones que la ronda de giros gratis es la parte mas emocionante.
Ademas, Sweet Bonanza ha logrado mantener su popularidad gracias a su caracter inclusivo. No importa si eres un jugador experimentado, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la versatilidad de este slot en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere divertirte mientras te desplazas, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: http://www.advancedseodirectory.com/sweet-bonanza-gratis_487600.html
Otro punto que interesa a los jugadores es si es posible ganar dinero con este juego. Al igual que en cualquier tragamonedas, este slot es un juego basado en el azar, lo cual significa que el resultado de cada jugada es impredecible y no puede ser modificado. Sin embargo, los multiplicadores y las rondas de giros gratis ofrecen una oportunidad significativa para obtener premios importantes. La funcion de multiplicador puede aumentar las ganancias hasta 100 veces en un solo giro, lo que puede resultar en una ganancia notable si sale un giro afortunado. Sin embargo, es importante recordar que siempre es importante jugar con responsabilidad y que las victorias no estan garantizadas.
В случае, если желаете захватывающую игру, способная предоставит огромное количество эмоций и возможности выиграть крупно, то Авиатор игра – именно то, что вам нужно.
Что Такое Игра Авиатор?
<a href="https://lacollinaagriturismo.com/10-ecu-provision-ohne-einzahlung-spielbank-10-in-registrierung/">авиатор игра</a> – это инновационная игра, где ваш выигрыш и удача зависят от способности быстро принимать решения и хладнокровия и удачи. Суть игры в том, что вы делаете ставку и смотрите на самолет, который взлетает.
Как Играть в Игра Авиатор? Играть в игру Авиатор достаточно легко. Вот основные шаги, которые помогут стартовать в игре:
Сделайте Вашу Ставку: Введите сумму, на которую вы готовы играть. Помните, что ставьте осознанно.
Следите за Полётом Самолета: После того как ставка установлена, на экране появится самолет, который взлетит. Множитель начинает расти. Забирайте Ваш Выигрыш: В любой момент, пока самолет взлетает, вы можете взять выигрыш. Сделайте Новую Ставку: После завершения раунда вы можете продолжить игру.
Зеркало сайта: https://lacollinaagriturismo.com/10-ecu-provision-ohne-einzahlung-spielbank-10-in-registrierung/
Что Привлекает в Игре Авиатор?
Динамичный Геймплей: В Авиаторе каждый момент полон эмоций. Доступность и Простота: Игра простая и доступная. Большие Победы: Возможности выиграть щедро зависят от вашего подхода и интуиции. Игровая Интерактивность: В игре Авиатор процесс идет в реальном времени.
Следите за Рисковыми Моментами: В игре Авиатор важно обдуманно управлять рисками.
Следите за Поведением Множителя: Анализируйте, как ведет себя множитель в раундах.
Воспользуйтесь Бонусами: Используйте бонусах и акциях, чтобы увеличить свои шансы на выигрыш.
The development of digital gambling sites originated in the mid-1990s, providing a accessible solution to brick-and-mortar venues. Over time, digital improvements have transformed online platforms into captivating settings, including high-quality designs, real dealer experiences, and smooth gaming.
Today, the possibility to engage with an virtual casino from a range of devices is a main highlight for users around the globe.
Web-based gambling sites provide a broad assortment of entertainment choices, including well-known options like roulette and poker, in addition to a myriad of slot machines.
These systems offer users the convenience of participating from any cozy spot or while traveling, establishing their popularity among both novice and experienced players.
One of the most significant shifts in the digital gambling sector is the shift to mobile-first platforms. Mobile casino applications have turned into a popular way for interacting with online platforms, as a result of their user-friendly interfaces and personalized options.
Whether you are a entertainment seeker or a high-stakes bettor, a feature-rich casino software enables your access to your top-choice options with just a few touches on your smartphone.
These apps focus on provide a smooth gaming journey, with functionalities such as adaptive picks for players, instant payout solutions, and cutting-edge encryption.
Web: https://algoritmo-aviator.pages.dev/
Players can install a casino apk—a package designed for Android—to gain instant access should they not be accessible on traditional application markets.
This ease makes certain that players can remain engaged to their beloved gambling hubs, irrespective of technical constraints.
В том случае, если находитесь в поиске захватывающую игру, способная даст огромное количество эмоций и шанс на крупные выигрыши, то Авиатор - Взлет – то, что сделает ваш день.
Что Такое Авиатор?
<a href="https://centralgroupvn.com/aviator-igra-onlayn-v-kazino/">aviator игра</a> – это впечатляющая краш игра, где ваш успех в игре зависят от скорости решений и удачи в моменте. Игра заключается в том, что вы делаете ставку и смотрите на самолет, который взлетает.
Как Играть в Авиатор? Играть в игру Авиатор не вызывает трудностей. Вот первые шаги, которые помогут начать игру:
Установите Сумму Ставки: Введите сумму, которую вы хотите вложить. Помните, что ставьте осознанно.
Смотрите за Взлетом Самолета: После того как ставка выбрана, на экране появится самолет, который взлетит. Множитель выигрыша будет расти. Забирайте деньги: В любой момент, пока самолет в полете, вы можете забрать свой выигрыш. Повторите Игру: После завершения раунда вы можете сделать новую ставку.
Зеркало сайта: https://centralgroupvn.com/aviator-igra-onlayn-v-kazino/
Почему Стоит Выбрать Авиатор?
Увлекательный Геймплей: В Авиаторе каждое мгновение игры волнует. Простота и Доступность: Игра простая и доступная. Крупные Выигрыши: Возможности для значительных побед зависят от ваших решений и удачи. Интерактивные Элементы: В игре Авиатор игра идет в настоящем времени.
Управляйте Рискованностью: В игре Авиатор важно выигрывать с учетом рисков.
Отслеживайте Множитель: Анализируйте, как ведет себя множитель в раундах.
Пользуйтесь Бонусами и Акциями: Используйте бонусах и акциях, чтобы увеличить свои шансы на выигрыш.
The development of digital gambling sites came into existence in the mid-1990s, bringing a convenient solution to land-based establishments. Over time, progress in tech have reshaped online platforms into interactive spaces, complete with detailed animations, live gaming features, and smooth gaming.
Today, the option to visit an digital gambling site from almost any gadget remains a key feature for users worldwide.
Web-based gambling sites make available a comprehensive collection of gaming experiences, featuring well-known options like roulette and poker, complemented by countless slots.
These services give enthusiasts the freedom of enjoying games in their living rooms or while mobile, rendering them highly appealing among both beginner and seasoned gamblers.
One of the most remarkable changes in the online gaming industry is the move toward mobile gaming. Mobile casino applications have turned into a go-to option for playing on online platforms, because of their simple navigation and personalized options.
Whether you are a casual player or a dedicated enthusiast, a feature-rich casino software enables your access to your beloved activities with just a few taps on your smart device.
These apps are designed to ensure a seamless gaming experience, with functionalities such as game selection based on preferences, rapid fund transfers, and cutting-edge encryption.
Web: https://juego-aviator.web.app
Players can download a casino application file—a specific Android tool—to install apps directly when not found on mainstream app stores.
This versatility ensures that players can enjoy uninterrupted gaming to their preferred digital casinos, no matter what OS they use.
Когда вы желаете волнующую игру, способная дарит кучу эмоций и шансы на значительный выигрыш, то игра Авиатор – то, что сделает ваш день.
Что Из Себя Представляет Авиатор?
<a href="https://sagoblet.com/aviator-krash-igra-dlya-onlayn-kazino/">авиатор</a> – это крутая краш игра, где ваш успех и победа зависят от интуиции и скорости и удачи. Цель игры заключается в том, что вы делаете ставку и следите за взлетом самолета.
Как Начать Игру Авиатор? Играть в игру Авиатор несложно. Вот основные шаги, которые помогут стартовать в игре:
Задайте Ставку: Введите сумму, которую вы готовы поставить. Помните, что важно ставить с умом.
Следите за Взлетом Самолета: После того как ставка установлена, на экране появится самолет, который покажет взлет. Величина множителя начнет увеличиваться. Фиксируйте выигрыш: В любой момент, пока самолет взлетает, вы можете взять выигрыш. Сделайте Новую Ставку: После завершения раунда вы можете начать новую игру.
Зеркало сайта: https://sagoblet.com/aviator-krash-igra-dlya-onlayn-kazino/
Что Привлекает в Игре Авиатор?
Интересный Геймплей: В Авиаторе каждый раунд захватывает. Легкость Освоения: Игра легко освоить. Шансы на Большие Выигрыши: Возможности выиграть щедро зависят от ваших решений и удачи. Взаимодействие в Реальном Времени: В игре Авиатор игра идет в настоящем времени.
Управляйте Своими Рисками: В игре Авиатор важно контролировать риски и выигрыши.
Следите за Поведением Множителя: Анализируйте, как ведет себя множитель в раундах.
Получайте Бонусы и Акции: Участвуйте в бонусах и акциях, чтобы повысить шансы на победу.
The concept of online casinos emerged in the digital revolution period, delivering a comfortable option to physical establishments. Over time, digital improvements have evolved online platforms into dynamic settings, complete with stunning imagery, interactive dealer gameplay, and lag-free experiences.
Today, the ability to access an online casino from almost any gadget stands out as a major attraction for users around the globe.
Online casinos make available a variety of activities, highlighting iconic games such as poker and blackjack, alongside a large array of slots.
These websites give enthusiasts the convenience of gambling from the comfort of their houses or in any location, establishing their popularity among both entry-level and experienced players.
One of the most notable trends in the digital gambling sector is the shift to mobile-first platforms. Gaming apps have become a preferred method for using online platforms, due to their player-oriented features and customized tools.
Whether you are a leisure bettor or a serious gambler, a dedicated casino app provides your preferred entertainment with just a few touches on your smartphone.
These apps focus on ensure a seamless gaming experience, with capabilities such as personalized game recommendations, efficient deposit methods, and enhanced security measures.
Web: https://bet-on-red-casino.netlify.app/
Players can acquire a Android gambling app—a specific Android tool—to use software without delay when not found on official app stores.
This versatility makes certain that players can enjoy uninterrupted gaming to their favorite gaming platforms, irrespective of technical constraints.
Когда вы желаете волнующую игру, которая даст немало впечатлений и возможности выиграть крупно, то Авиатор игра – именно то, что вам нужно.
О Чём Игра Авиатор?
<a href="https://logistica-empresarial.com/2024/08/01/aviator-onlayn-krash-igra-v-kazino/">авиатор игра</a> – это инновационная игра, где ваш успех и победа зависят от реакции и удачи и везения. Основная задача – вы делаете ставку и наблюдаете за тем, как самолет взлетает.
Как Управлять Игрой Авиатор? Играть в игру Авиатор несложно. Вот первые шаги, которые помогут приступить к игре:
Выберите Сумму Ставки: Введите сумму, которую вы хотите вложить. Помните, что важно контролировать ставки.
Ожидайте Взлета Самолета: После того как ставка размещена, на экране появится самолет, который взлетит. Величина множителя начнет увеличиваться. Забирайте Ваши средства: В любой момент, пока самолет не пропал, вы можете забрать свой выигрыш. Начните Новый Раунд: После завершения раунда вы можете сделать новую ставку.
Зеркало сайта: https://logistica-empresarial.com/2024/08/01/aviator-onlayn-krash-igra-v-kazino/
Почему Популярна Игра Авиатор?
Интересный Геймплей: В Авиаторе каждое мгновение приносит эмоции. Доступность и Простота: Игра легко понятна. Возможности для Крупных Побед: Возможности выиграть щедро зависят от вашего подхода и интуиции. Игровая Интерактивность: В игре Авиатор процесс идет в реальном времени.
Управляйте Рискованностью: В игре Авиатор важно не только выигрывать, но и контролировать риски.
Отслеживайте Тенденции Множителя: Следите за изменениями множителя.
Получайте Бонусы и Акции: Не пропустите бонусах и акциях, чтобы увеличить свои шансы на выигрыш.
The emergence of online gaming hubs emerged in the 1990s, delivering a accessible alternative to physical gaming spots. Over time, digital improvements have revolutionized online platforms into captivating realms, boasting detailed animations, real dealer experiences, and uninterrupted action.
Today, the ability to engage with an web-based casino from almost any gadget remains a key feature for users across the planet.
Internet casinos offer a wide range of entertainment choices, highlighting timeless classics like roulette and poker, as well as a myriad of slot machines.
These websites offer users the convenience of participating from any cozy spot or from anywhere, turning them into favorites among both novice and experienced players.
One of the most remarkable changes in the world of virtual casinos is the trend of handheld gameplay. Gambling apps are increasingly a common approach for using online platforms, as a result of their player-oriented features and customized tools.
Whether you are a leisure bettor or a dedicated enthusiast, a specialized gaming app allows you to enjoy your beloved activities with just a few touches on your smart device.
These apps focus on provide a uninterrupted casino session, with tools such as personalized game recommendations, instant payout solutions, and high-level protections.
Web: https://rush-slot-sugar.web.app/
Players can obtain a casino application file—a specific Android tool—to gain instant access if they are unavailable on common mobile platforms.
This ease ensures that players can continue their sessions to their top-choice gaming apps, no matter what OS they use.
В том случае, если стремитесь найти азартную игру, что подарит массу эмоций и возможности выиграть крупно, то игра Авиатор – это то, что нужно.
Что За Игра Авиатор?
<a href="https://lacollinaagriturismo.com/betandplay-spielbank-pramie-50-freispiele-fur-jedes-book-of-ra/">aviator игра</a> – это классная краш игра, где ваш выигрыш и удача зависят от способности быстро принимать решения и удачи и интуиции. Игра заключается в том, что вы делаете ставку и следите за взлетом самолета.
Как Играть в Авиатор? Играть в игру Авиатор достаточно легко. Вот этапы начала игры, которые помогут стартовать в игре:
Задайте Ставку: Введите сумму, которую вы хотите вложить. Помните, что ставьте осознанно.
Следите за Взлетом Самолета: После того как ставка подтверждена, на экране появится самолет, который покажет взлет. Ваш множитель будет расти. Забирайте Ваш Выигрыш: В любой момент, пока самолет не исчез, вы можете забрать средства. Сделайте Новую Ставку: После завершения раунда вы можете сделать новую ставку и продолжить игру.
Зеркало сайта: https://lacollinaagriturismo.com/betandplay-spielbank-pramie-50-freispiele-fur-jedes-book-of-ra/
Что Привлекает в Игре Авиатор?
Динамичный Геймплей: В Авиаторе каждый раунд захватывает. Доступность и Простота: Игра легко понятна. Большие Победы: Возможности для крупных выигрышей зависят от умения принимать решения. Реальное Время Игры: В игре Авиатор вы следите за процессом в реальном времени.
Следите за Рисковыми Моментами: В игре Авиатор важно выигрывать с учетом рисков.
Наблюдайте за Изменением Множителя: Анализируйте, как ведет себя множитель в раундах.
Пользуйтесь Бонусами и Акциями: Используйте бонусах и акциях, которые помогут увеличить ваш выигрыш.
The idea of virtual gambling platforms emerged in the mid-1990s, delivering a accessible alternative to land-based venues. Over time, innovations in technology have transformed online platforms into immersive environments, complete with high-quality designs, live gaming features, and uninterrupted action.
Today, the capacity to use an virtual casino from virtually any device is one of the biggest draws for players worldwide.
Web-based gambling sites feature a broad assortment of activities, ranging from timeless classics like roulette and poker, together with countless slots.
These platforms offer users the freedom of playing from their homes or while mobile, making them a popular choice among both beginner and long-time enthusiasts.
One of the most significant shifts in the field of online entertainment is the growth of mobile-friendly interfaces. Casino-focused software are increasingly a popular way for using online platforms, because of their intuitive designs and personalized options.
Whether you are a occasional gamer or a professional player, a specialized gaming app enables your access to your preferred entertainment with just a few interactions on your tablet.
These apps are built to enhance a smooth gaming journey, with functionalities such as tailored suggestions for games, quick payment processing, and enhanced security measures.
Web: https://india-aviator.web.app
Players can acquire a mobile gaming APK—a specific Android tool—to use software without delay if they are unavailable on popular download hubs.
This adaptability makes certain that players can always stay connected to their top-choice gaming apps, no matter what OS they use.
Если вы находитесь в поиске увлекательную игру, которая дарит немало впечатлений и шанс на крупные выигрыши, то игра Авиатор – то, что сделает ваш день.
Что За Игра Авиатор?
<a href="https://lacollinaagriturismo.com/online-casinos-norge-bese-casinoer-online-inni-norge-inne-i-2024/">авиатор казино</a> – это крутая краш игра, где ваш успех и победа зависят от скорости решений и удачи. В этой игре вы вы делаете ставку и наблюдаете за тем, как самолет взлетает.
Как Начать Игру Авиатор? Играть в игру Авиатор несложно. Вот основные шаги, которые помогут стартовать в игре:
Задайте Ставку: Введите сумму, на которую вы готовы играть. Помните, что важно контролировать ставки.
Смотрите за Взлетом Самолета: После того как ставка подтверждена, на экране появится самолет, который взлетит. Ваш множитель будет расти. Фиксируйте выигрыш: В любой момент, пока самолет в воздухе, вы можете забрать средства. Начните Новую Игру: После завершения раунда вы можете начать новый раунд.
Зеркало сайта: https://lacollinaagriturismo.com/online-casinos-norge-bese-casinoer-online-inni-norge-inne-i-2024/
Почему Стоит Выбрать Авиатор?
Захватывающий Игровой Процесс: В Авиаторе каждый момент полон эмоций. Простота и Легкость: Игра легко освоить. Шансы на Победу: Возможности для значительных побед зависят от вашего подхода и интуиции. Игровая Интерактивность: В игре Авиатор игра идет в настоящем времени.
Управляйте Своими Рисками: В игре Авиатор важно контролировать риски и выигрыши.
Отслеживайте Тенденции Множителя: Следите за изменениями множителя.
Воспользуйтесь Бонусами: Участвуйте в бонусах и акциях, чтобы увеличить выигрышные шансы.
The emergence of online gaming hubs came into existence in the late 20th century, bringing a user-friendly solution to brick-and-mortar gambling locations. Over time, technological advancements have evolved online platforms into dynamic spaces, boasting lifelike visuals, interactive dealer gameplay, and lag-free experiences.
Today, the option to access an internet casino from practically anywhere is a main highlight for casino lovers internationally.
Web-based gambling sites deliver a broad assortment of gaming experiences, including traditional games like blackjack and roulette, as well as countless slots.
These platforms give enthusiasts the freedom of gambling from the comfort of their houses or on the go, turning them into favorites among both newcomer and veteran users.
One of the most notable trends in the online gaming industry is the trend of handheld gameplay. Mobile casino applications are widely recognized as a preferred method for interacting with online platforms, as a result of their intuitive designs and customized tools.
Whether you are a hobbyist or a strategic gamer, a specialized gaming app provides your favorite games with just a few steps on your tablet.
These apps feature tools that deliver a seamless gaming experience, with tools such as customized gambling options, instant payout solutions, and enhanced security measures.
Web: https://casino-mines.web.app/
Players can acquire a APK for casino platforms—a package designed for Android—to access platforms seamlessly in cases where they're missing on official app stores.
This freedom provides that players can always stay connected to their top-choice gaming apps, no matter what OS they use.
В том случае, если стремитесь найти волнующую игру, что предоставит кучу эмоций и шансы на значительный выигрыш, то игра Авиатор – это то, что нужно.
Что Такое Игра Авиатор?
<a href="https://www.geriatrie-vendee.com/aviator-krash-igra-v-onlayn-kazino/">авиатор казино</a> – это классная краш игра, где ваш выигрыш и удача зависят от быстроты мышления и удачи и удачи. Цель игры заключается в том, что вы делаете ставку и следите за взлетом самолета.
Как Играть в Авиатор? Играть в игру Авиатор легко. Вот первые шаги, которые помогут начать игру:
Определите Ставку: Введите сумму, которую вы готовы рискнуть. Помните, что ставить нужно с ответственностью.
Ожидайте Взлета Самолета: После того как ставка установлена, на экране появится самолет, который начнет подниматься. Ваш множитель будет расти. Забирайте деньги: В любой момент, пока самолет не исчез, вы можете взять выигрыш. Сделайте Новую Ставку: После завершения раунда вы можете начать новую игру.
Зеркало сайта: https://www.geriatrie-vendee.com/aviator-krash-igra-v-onlayn-kazino/
Почему Популярна Игра Авиатор?
Интересный Геймплей: В Авиаторе каждое мгновение игры волнует. Доступность и Простота: Игра легка в освоении. Большие Победы: Возможности для значительных побед зависят от ваших решений и удачи. Реальное Время Игры: В игре Авиатор всё происходит в реальном времени.
Управляйте Рискованностью: В игре Авиатор важно не только выигрывать, но и контролировать риски.
Отслеживайте Множитель: Следите за изменениями множителя.
Бонусные Возможности и Акции: Воспользуйтесь бонусах и акциях, чтобы увеличить свои шансы на выигрыш.
The concept of online casinos was introduced in the mid-1990s, delivering a accessible solution to land-based establishments. Over time, innovations in technology have elevated online platforms into interactive realms, complete with lifelike visuals, interactive dealer gameplay, and flawless performance.
Today, the opportunity to access an online casino from practically anywhere is one of the biggest draws for gaming enthusiasts internationally.
Web-based gambling sites provide a variety of options, featuring traditional games like blackjack and roulette, as well as a myriad of slot machines.
These systems deliver to gamers the freedom of playing from their homes or in any location, turning them into favorites among both amateur and skilled bettors.
One of the most remarkable changes in the digital gambling sector is the growth of mobile-friendly interfaces. Gambling apps are now a preferred method for using online platforms, thanks to their simple navigation and adapted functionalities.
Whether you are a entertainment seeker or a high-stakes bettor, a specialized gaming app allows you to enjoy your top-choice options with just a few interactions on your portable device.
These apps focus on ensure a uninterrupted casino session, with capabilities such as game selection based on preferences, efficient deposit methods, and advanced safety protocols.
Web: https://juego--mines.web.app/
Players can install a Android gambling app—a package designed for Android—to set up applications instantly when they are not listed on mainstream app stores.
This adaptability provides that players can continue their sessions to their top-choice gaming apps, whatever device compatibility they have.
В том случае, если стремитесь найти захватывающую и увлекательную игру, что дарит огромное количество эмоций и возможности для крупного выигрыша, то Авиатор - Взлет – ваш правильный выбор.
Что Такое Авиатор?
<a href="https://tratas.co.uk/aviator-novaya-krash-igra-v-onlayn-kazino-kazakhstana/">авиатор</a> – это классная краш игра, где ваш успех и победа зависят от интуиции и скорости и хладнокровия и удачи. В этой игре вы вы делаете ставку и смотрите на самолет, который взлетает.
Как Начать Игру Авиатор? Играть в игру Авиатор не вызывает трудностей. Вот ключевые этапы, которые помогут начать игру:
Задайте Ставку: Введите сумму, которую готовы ставить. Помните, что важно ставить с умом.
Следите за Взлетом Самолета: После того как ставка размещена, на экране появится самолет, который начнет свой полет. Множитель выигрыша будет расти. Забирайте деньги: В любой момент, пока самолет в полете, вы можете забрать выигрыш. Сделайте Новую Ставку: После завершения раунда вы можете начать новый раунд.
Зеркало сайта: https://tratas.co.uk/aviator-novaya-krash-igra-v-onlayn-kazino-kazakhstana/
Почему Выбирают Игру Авиатор?
Захватывающий Игровой Процесс: В Авиаторе каждое мгновение наполнено азартом. Легкость и Удобство: Игра легко понятна. Большие Победы: Возможности для значительных побед зависят от ваших интуитивных решений. Интерактивные Элементы: В игре Авиатор вы следите за процессом в реальном времени.
Управляйте Своими Рисками: В игре Авиатор важно контролировать риски и выигрыши.
Наблюдайте за Изменением Множителя: Анализируйте, как ведет себя множитель в раундах.
Получайте Бонусы и Акции: Не пропустите бонусах и акциях, чтобы повысить шансы на победу.
The notion of internet-based casinos emerged in the 1990s, bringing a accessible solution to physical gambling locations. Over time, technological advancements have transformed online platforms into engaging realms, featuring lifelike visuals, real-time dealer interactions, and smooth gaming.
Today, the capacity to access an online casino from virtually any device remains a key feature for casino lovers across the planet.
Virtual gambling platforms feature a variety of activities, including traditional games like blackjack and roulette, alongside a myriad of slot machines.
These systems provide players the accessibility of gaming at home or while mobile, securing their place as preferred options among both beginner and seasoned gamblers.
One of the most significant shifts in the online gaming industry is the shift to mobile-first platforms. Gambling apps have turned into a preferred method for using online platforms, thanks to their accessible layouts and customized tools.
Whether you are a casual player or a high-stakes bettor, a feature-rich casino software allows you to enjoy your top-choice options with just a few taps on your mobile phone.
These apps aim to enhance a flawless entertainment flow, with options such as personalized game recommendations, fast transaction systems, and robust privacy features.
Web: https://mines-juego.web.app/
Players can obtain a casino apk—a dedicated app setup for Android—to gain instant access in cases where they're missing on official app stores.
This adaptability provides that players can remain engaged to their most-used casino systems, whatever device compatibility they have.
Если вы ищете волнующую игру, что дарит огромное количество эмоций и перспективы на большой выигрыш, то Авиатор - Взлет – ваш правильный выбор.
Что Из Себя Представляет Авиатор?
<a href="https://lacollinaagriturismo.com/washington-online-gambling-internet-sites-2024-az-gambling-enterprises-activities-web-based-poker/">aviator</a> – это крутая краш игра, где ваш успех в игре зависят от быстроты мышления и удачи и везения. Суть игры в том, что вы ставите и смотрите, как самолет взлетает.
Как Начать Игру Авиатор? Играть в игру Авиатор несложно. Вот основные шаги, которые облегчат начало игры:
Задайте Ставку: Введите сумму, которую вы готовы поставить. Помните, что важно контролировать ставки.
Смотрите за Взлетом Самолета: После того как ставка подтверждена, на экране появится самолет, который начнет набирать высоту. Ваш множитель будет расти. Забирайте деньги: В любой момент, пока самолет не исчез, вы можете зафиксировать выигрыш. Продолжите Игру: После завершения раунда вы можете сделать новую ставку.
Зеркало сайта: https://lacollinaagriturismo.com/washington-online-gambling-internet-sites-2024-az-gambling-enterprises-activities-web-based-poker/
Почему Стоит Выбрать Авиатор?
Увлекательный Геймплей: В Авиаторе каждый момент полон эмоций. Легкость и Удобство: Игра не требует глубоких знаний. Возможности для Крупных Побед: Возможности выиграть крупно зависят от ваших интуитивных решений. Взаимодействие в Реальном Времени: В игре Авиатор процесс идет в реальном времени.
Управляйте Рискованностью: В игре Авиатор важно контролировать риски и выигрыши.
Наблюдайте за Изменением Множителя: Пробуйте анализировать поведение множителя в игре.
Используйте Акции и Бонусы: Участвуйте в бонусах и акциях, которые помогут увеличить ваш выигрыш.
The notion of internet-based casinos was introduced in the digital revolution period, offering a convenient option to conventional venues. Over time, progress in tech have elevated online platforms into captivating environments, including lifelike visuals, live dealer options, and seamless gameplay.
Today, the option to engage with an internet casino from practically anywhere is a main highlight for gamblers across the planet.
Virtual gambling platforms feature a diverse selection of activities, such as classics like blackjack, roulette, and poker, complemented by a myriad of slot machines.
These systems make available for users the convenience of participating from any cozy spot or from anywhere, rendering them highly appealing among both amateur and experienced players.
One of the most remarkable changes in the field of online entertainment is the shift to mobile-first platforms. Gambling apps have become a common approach for engaging with online platforms, owing to their simple navigation and adapted functionalities.
Whether you are a entertainment seeker or a strategic gamer, a reliable gambling application allows you to enjoy your most-loved gaming experiences with just a few taps on your smartphone.
These apps are built to provide a lag-free gambling interaction, with functionalities such as tailored suggestions for games, fast transaction systems, and high-level protections.
Web: https://aviator-bet-app.netlify.app
Players can install a mobile gaming APK—a package designed for Android—to install apps directly when not found on popular download hubs.
This adaptability allows that players can remain engaged to their preferred digital casinos, regardless of their device's operating system.
Если вы желаете захватывающую и увлекательную игру, способная предоставит массу эмоций и возможности выиграть крупно, то Авиатор - Взлет – идеальный выбор для вас.
О Чём Игра Авиатор?
<a href="https://lacollinaagriturismo.com/sizzling-hot-deluxe-fur-nusse-auffuhren-abzuglich-eintragung/">авиатор казино</a> – это впечатляющая краш игра, где ваш победа и достижения зависят от реакции и удачи и хладнокровия и удачи. Игра заключается в том, что вы ставите деньги и наблюдаете взлет самолета.
Как Начать Игру Авиатор? Играть в игру Авиатор не вызывает трудностей. Вот основные действия, которые помогут вам начать играть:
Определите Ставку: Введите сумму, на которую вы готовы играть. Помните, что ставьте осознанно.
Ожидайте Взлета Самолета: После того как ставка внесена, на экране появится самолет, который взлетит. Множитель будет увеличиваться. Забирайте деньги: В любой момент, пока самолет в воздухе, вы можете забрать выигрыш. Повторите Игру: После завершения раунда вы можете сделать новую ставку и продолжить игру.
Зеркало сайта: https://lacollinaagriturismo.com/sizzling-hot-deluxe-fur-nusse-auffuhren-abzuglich-eintragung/
Почему Выбирают Игру Авиатор?
Увлекательный Геймплей: В Авиаторе каждое мгновение приносит эмоции. Легкость и Удобство: Игра легко освоить. Крупные Выигрыши: Возможности выиграть крупно зависят от ваших интуитивных решений. Интерактивные Элементы: В игре Авиатор игра идет в настоящем времени.
Следите за Рисками: В игре Авиатор важно обдуманно управлять рисками.
Следите за Динамикой Множителя: Следите за тем, как растет множитель.
Бонусные Возможности и Акции: Не пропустите бонусах и акциях, чтобы увеличить свои шансы на выигрыш.
The concept of online casinos originated in the mid-1990s, bringing a user-friendly alternative to land-based venues. Over time, progress in tech have evolved online platforms into captivating environments, boasting stunning imagery, real-time dealer interactions, and seamless gameplay.
Today, the opportunity to engage with an online casino from almost any gadget stands out as a major attraction for gamblers worldwide.
Digital gaming hubs provide a variety of activities, such as well-known options like roulette and poker, as well as numerous slot games.
These platforms make available for users the comfort of participating from any cozy spot or while mobile, rendering them highly appealing among both newcomer and seasoned gamblers.
One of the most notable trends in the field of online entertainment is the shift to mobile-first platforms. Mobile casino applications are now a popular way for interacting with online platforms, owing to their user-friendly interfaces and personalized options.
Whether you are a entertainment seeker or a dedicated enthusiast, a specialized gaming app lets you experience your most-loved gaming experiences with just a few steps on your smart device.
These apps are designed to enable a seamless gaming experience, with tools such as personalized game recommendations, rapid fund transfers, and cutting-edge encryption.
Web: https://jeux-aviator.github.io
Players can acquire a mobile gaming APK—a file format for Android devices—to install apps directly when not found on mainstream app stores.
This adaptability provides that players can maintain access to their favorite gaming platforms, despite their device preferences.
В том случае, если находитесь в поиске азартную игру, что даст много шансов и возможности для крупного выигрыша, то Авиатор – то, что сделает ваш день.
О Чём Игра Авиатор?
<a href="https://www.thaiheadlines.com/124560/">авиатор</a> – это крутая краш игра, где ваш выигрыш и удача зависят от интуиции и скорости и хладнокровия и удачи. Основная задача – вы делаете ставку и следите за взлетом самолета.
Как Играть в Авиатор? Играть в игру Авиатор достаточно легко. Вот основные действия, которые помогут начать игру:
Задайте Ставку: Введите сумму, которую вы хотите вложить. Помните, что ставить нужно с ответственностью.
Наблюдайте за Взлётом Самолета: После того как ставка внесена, на экране появится самолет, который начнет подниматься. Множитель выигрыша будет расти. Забирайте Ваши средства: В любой момент, пока самолет взлетает, вы можете зафиксировать выигрыш. Сделайте Новую Ставку: После завершения раунда вы можете сделать новую ставку и продолжить игру.
Зеркало сайта: https://www.thaiheadlines.com/124560/
Что Привлекает в Игре Авиатор?
Динамичный Геймплей: В Авиаторе каждый раунд захватывает. Простота и Легкость: Игра легко понятна. Возможности для Крупных Побед: Возможности для крупных выигрышей зависят от вашей интуиции. Интерактивные Элементы: В игре Авиатор процесс идет в реальном времени.
Следите за Рисками: В игре Авиатор важно управлять рисками и выигрышами.
Наблюдайте за Изменением Множителя: Пробуйте анализировать поведение множителя в игре.
Пользуйтесь Бонусами и Акциями: Используйте бонусах и акциях, чтобы увеличить выигрышные шансы.
The idea of virtual gambling platforms gained traction in the mid-1990s, providing a user-friendly variation to conventional casinos. Over time, innovations in technology have elevated online platforms into immersive experiences, boasting high-quality designs, real-time dealer interactions, and smooth gaming.
Today, the ability to use an virtual casino from any modern device is a significant advantage for users across the planet.
Digital gaming hubs feature a variety of gaming experiences, ranging from classics like blackjack, roulette, and poker, together with hundreds of slot games.
These services provide players the comfort of enjoying games in their living rooms or on the go, turning them into favorites among both novice and long-time enthusiasts.
One of the most notable trends in the field of online entertainment is the trend of handheld gameplay. Casino-focused software are increasingly a common approach for playing on online platforms, owing to their intuitive designs and adapted functionalities.
Whether you are a hobbyist or a serious gambler, a well-designed mobile casino lets you experience your top-choice options with just a few clicks on your smartphone.
These apps feature tools that deliver a seamless gaming experience, with options such as tailored suggestions for games, efficient deposit methods, and cutting-edge encryption.
Web: https://aviator-game-pakistan.netlify.app/
Players can obtain a APK for casino platforms—a file format for Android devices—to access platforms seamlessly should they not be accessible on traditional application markets.
This ease makes certain that players can maintain access to their most-used casino systems, irrespective of technical constraints.
Este juego destaca de otras slots por su diseno y tematica unicos. Al comenzar a jugar, los jugadores se sumergen en un mundo de frutas y caramelos y colores brillantes que sugieren un ambiente magico. Se puede ver un fondo lleno de caramelos, lo cual crea una imagen atractiva y tranquila, ideal tanto para jugadores nuevos como para experimentados. Este slot ha sido muy bien valorado en las opiniones, ya que combina la emocion de los premios con una estetica visual que apela a todos los publicos.
Una de las caracteristicas mas valoradas de este juego es su caracteristica de giros gratis, que se activa al conseguir cuatro o mas simbolos de caramelos rosados en cualquier lugar de los carretes. El modo de giros sin costo no solo permiten disfrutar sin apostar mas dinero, sino que tambien potencian las probabilidades de grandes ganancias, especialmente cuando aparecen multiplicadores en los giros. Este detalle del juego es uno de los mas interesantes a los jugadores, y muchos senalan en sus resenas que la caracteristica de giros gratuitos es la parte mas emocionante.
Ademas, Sweet Bonanza ha logrado mantener su popularidad gracias a su posibilidad de adaptacion a diferentes tipos de jugadores. No importa si eres si tienes mucha experiencia en el juego, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la disponibilidad de Sweet Bonanza en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere jugar durante tus descansos, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: http://www.mecosys.com/bbs/board.php?bo_table=project_02&wr_id=2296420
Otro punto que interesa a los jugadores es si se puede ganar dinero real con este juego. Al igual que en cualquier tragamonedas, la tragamonedas Sweet Bonanza es una maquina de azar, lo cual significa que el resultado de cada tirada es aleatorio y no puede ser predicho. Sin embargo, los multiplicadores y las rondas de giros gratis ofrecen una oportunidad significativa para obtener ganancias considerables. La funcion de los multiplicadores pueden multiplicar las ganancias hasta 100 veces, lo que puede resultar en una recompensa significativa si sale un giro afortunado. Sin embargo, es importante recordar que siempre es importante jugar con responsabilidad y que las victorias no estan garantizadas.
Когда вы жаждете волнующую игру, что обеспечит немало впечатлений и возможности для крупного выигрыша, то Авиатор – именно то, что вам нужно.
Что Из Себя Представляет Авиатор?
<a href="https://ivf-kyono.com/column/page/15/">авиатор казино</a> – это инновационная игра, где ваш победа и достижения зависят от интуиции и скорости и удачи и интуиции. Суть игры в том, что вы делаете ставку и смотрите на самолет, который взлетает.
Как Начать Играть в Авиатор? Играть в игру Авиатор очень просто. Вот этапы начала игры, которые помогут вам начать играть:
Установите Сумму Ставки: Введите сумму, на которую вы готовы играть. Помните, что важно контролировать ставки.
Ожидайте Взлета Самолета: После того как ставка размещена, на экране появится самолет, который покажет взлет. Множитель начинает расти. Забирайте деньги: В любой момент, пока самолет не исчез, вы можете взять выигрыш. Продолжите Игру: После завершения раунда вы можете продолжить игру.
Зеркало сайта: https://ivf-kyono.com/column/page/15/
Почему Стоит Играть в Авиатор?
Захватывающий Игровой Процесс: В Авиаторе каждый момент полон эмоций. Легкость и Удобство: Игра простая и доступная. Большие Победы: Возможности для крупных выигрышей зависят от ваших интуитивных решений. Игровая Интерактивность: В игре Авиатор всё происходит в реальном времени.
Управляйте Рискованностью: В игре Авиатор важно контролировать риски и выигрыши.
Наблюдайте за Изменением Множителя: Следите за тем, как растет множитель.
Пользуйтесь Бонусами и Акциями: Не упустите бонусах и акциях, которые помогут увеличить ваш выигрыш.
Fortune Tiger: Estrategias para Ganhos
O atrativo principal do jogo e a chance de premios elevados com rodadas breves. As rodadas rapidas e com chances de ganho atraem jogadores em busca de recompensas rapidas.
Diversas estrategias podem ajudar o jogador a otimizar suas apostas. Muitos jogadores utilizam a estrategia de aumentar gradualmente as apostas. Esse metodo consiste em comecar com apostas pequenas e aumenta-las com o tempo.
Saber quando apostar e quanto aumentar as apostas e uma habilidade importante. Os minutos pagantes sao uma excelente forma de maximizar os lucros. A identificacao dos minutos pagantes pode ser uma chave para o sucesso em Fortune Tiger.
Vantagens da Plataforma Fortune Tiger
Website: https://hwekimchi.gabia.io/bbs/board.php?bo_table=free&tbl=&wr_id=194598
Encerramento
Com sua simplicidade e grande potencial de premios, o Fortune Tiger se tornou um favorito. A confianca dos jogadores e conquistada pela transparencia e facilidade de uso.
The idea of virtual gambling platforms was introduced in the late 20th century, delivering a convenient alternative to brick-and-mortar venues. Over time, technological advancements have reshaped online platforms into dynamic realms, featuring stunning imagery, live dealer options, and uninterrupted action.
Today, the capacity to visit an digital gambling site from practically anywhere is one of the biggest draws for players worldwide.
Web-based gambling sites feature a wide range of activities, featuring classics like blackjack, roulette, and poker, in addition to countless slots.
These websites provide players the convenience of gaming at home or while mobile, making them a popular choice among both newcomer and seasoned gamblers.
One of the most significant shifts in the digital gambling sector is the growth of mobile-friendly interfaces. Mobile casino applications have become a go-to option for using online platforms, owing to their intuitive designs and tailored features.
Whether you are a casual player or a professional player, a reliable gambling application enables your access to your beloved activities with just a few touches on your portable device.
These apps are designed to enable a seamless gaming experience, with functionalities such as adaptive picks for players, fast transaction systems, and high-level protections.
Web: https://top-fortune-tiger.pages.dev/
Players can install a casino application file—a specific Android tool—to set up applications instantly when they are not listed on traditional application markets.
This freedom ensures that players can enjoy uninterrupted gaming to their favorite gaming platforms, irrespective of technical constraints.
Kasyna internetowe zdobywaja coraz szersze uznanie w Polsce, a jedna z miejsc, ktora przyciaga uwage graczy, jest <a href="http://zeta.altodesign.co.kr/bbs/board.php?bo_table=pumping5&wr_id=102958">bet on red kasyno</a>. To kasyno online, ktore wyroznia sie roznorodnoscia gier, inteligentnym designem oraz atrakcyjnymi promocjami, ktore zadowola zarowno poczatkujacych, jak i doswiadczonych graczy.
Czym wyroznia sie Bet On Red?
Bet On Red Casino to platforma online, ktora oferuje ogromna biblioteke gier, takich jak automaty, klasyczne gry kasynowe oraz transmisje na zywo z gier. Juz sam brand „Red On Bet" odzwierciedla emocje i hazardowe napiecie.
Proces logowania w Kasynie Bet On Red
Proces logowania w Red On Bet Casino jest prosty i szybki. Po wejsciu na strone glowna, wystarczy kliknac w przycisk „Logowanie" i uzupelnic wymagane informacje. Bet On Red Casino stawia na bezpieczenstwo, dlatego wszelkie dane uzytkownika sa chronione.
Nowi gracze moga bez problemu dolaczyc do platformy, a proces zakladania konta jest szybki i prosty. Co istotne, Kasyno Bet On Red oferuje mozliwosc korzystania z roznych metod platnosci, co ulatwia doladowanie konta.
Roznorodnosc gier w Bet On Red
Kluczowym elementem, kazdego kasyna online, jest biblioteka rozrywki. Bet On Red Casino zachwyca niezwykle bogatym wyborem, ktory zadowoli nawet najbardziej wymagajacych graczy.
Web: http://zeta.altodesign.co.kr/bbs/board.php?bo_table=pumping5&wr_id=102958
Maszyny hazardowe sa jednym z najwiekszych hitow w ofercie, dostepne w licznych motywach oraz z unikalnymi funkcjami. Oprocz najpopularniejszych maszyn, uzytkownicy moga rozegrac partie w gry stolowe, takie jak blackjack.
Когда жаждете захватывающую игру, способная подарит массу эмоций и шансы на значительный выигрыш, то Авиатор игра – идеальный выбор для вас.
Что Из Себя Представляет Авиатор?
<a href="https://lacollinaagriturismo.com/1xbet-reacts-in-order-to-osun-defender-history-says-customers-who-claimed-to-possess-earned-played-the-wrong-be-2/">aviator</a> – это впечатляющая краш игра, где ваш выигрыш в игре зависят от реакции и удачи и хладнокровия и удачи. В этой игре вы вы делаете ставку и следите за взлетом самолета.
Как Начать Играть в Авиатор? Играть в игру Авиатор очень просто. Вот этапы начала игры, которые помогут начать игру:
Выберите Сумму Ставки: Введите сумму, которую готовы ставить. Помните, что ставить нужно с ответственностью.
Следите за Полётом Самолета: После того как ставка размещена, на экране появится самолет, который взлетит. Множитель выигрыша будет расти. Забирайте Ваш Выигрыш: В любой момент, пока самолет в воздухе, вы можете забрать свой выигрыш. Повторите Игру: После завершения раунда вы можете начать новый раунд.
Зеркало сайта: https://lacollinaagriturismo.com/1xbet-reacts-in-order-to-osun-defender-history-says-customers-who-claimed-to-possess-earned-played-the-wrong-be-2/
Почему Популярна Игра Авиатор?
Захватывающий Игровой Процесс: В Авиаторе каждый раунд захватывает. Простота и Легкость: Игра простая и доступная. Шансы на Победу: Возможности выиграть щедро зависят от вашего подхода и интуиции. Взаимодействие в Реальном Времени: В игре Авиатор всё происходит в реальном времени.
Следите за Рисками: В игре Авиатор важно не только выигрывать, но и контролировать риски.
Следите за Динамикой Множителя: Следите за изменениями множителя.
Получайте Бонусы и Акции: Не упустите бонусах и акциях, чтобы увеличить свои шансы на выигрыш.
Metodos para Obter Melhores Resultados no Tigrinho
O que chama a atencao no jogo e o alto potencial de lucro em curto periodo. Cada rodada traz a chance de premios elevados, o que e um atrativo para muitos.
Muitos jogadores combinam estrategias para maximizar o potencial de lucro. Uma das estrategias preferidas e a aposta gradual. O jogador vai aumentando as apostas progressivamente, comecando com valores baixos.
Saber quando apostar e quanto aumentar as apostas e uma habilidade importante. Os minutos pagantes sao uma excelente forma de maximizar os lucros. Embora os minutos pagantes possam ser aleatorios, jogadores habilidosos sabem aproveitar essas oportunidades.
Plataforma Fortune Tiger: Funcionalidades e Vantagens
Website: http://xn--jj0bz6z98ct0a29q.com/bbs/board.php?bo_table=62&wr_id=140974
Consideracoes Finais
Este jogo se destaca por ser acessivel e cheio de oportunidades de lucro. A plataforma Fortune Tiger e uma excelente escolha para quem busca diversao e lucro.
The notion of internet-based casinos originated in the mid-1990s, providing a easy-to-reach option to brick-and-mortar gaming spots. Over time, digital improvements have reshaped online platforms into captivating experiences, complete with detailed animations, real dealer experiences, and lag-free experiences.
Today, the option to access an internet casino from almost any gadget is one of the biggest draws for players worldwide.
Virtual gambling platforms offer a diverse selection of gaming experiences, including timeless classics like roulette and poker, complemented by a large array of slots.
These online hubs provide players the freedom of gambling from the comfort of their houses or in any location, making them a popular choice among both amateur and veteran users.
One of the most important developments in the online gaming industry is the growth of mobile-friendly interfaces. Mobile casino applications have turned into a popular way for interacting with online platforms, as a result of their user-friendly interfaces and personalized options.
Whether you are a hobbyist or a professional player, a feature-rich casino software allows you to enjoy your favorite games with just a few clicks on your mobile phone.
These apps focus on enhance a uninterrupted casino session, with tools such as customized gambling options, fast transaction systems, and robust privacy features.
Web: https://gioco-plinko.netlify.app/
Players can obtain a casino apk—a package designed for Android—to gain instant access should they not be accessible on popular download hubs.
This freedom guarantees that players can enjoy uninterrupted gaming to their preferred digital casinos, no matter what OS they use.
Когда стремитесь найти азартную игру, которая точно предоставит немало впечатлений и перспективы на большой выигрыш, то игра Авиатор – то, что сделает ваш день.
Что Такое Авиатор?
<a href="https://lacollinaagriturismo.com/casino-oyunlari-en-i%CC%87yi-online-slotlari-oynayi/">aviator игра официальный сайт</a> – это крутая краш игра, где ваш победа и достижения зависят от быстроты мышления и удачи и удачи и интуиции. Игра заключается в том, что вы делаете ставку и наблюдаете за тем, как самолет взлетает.
Как Играть в Игра Авиатор? Играть в игру Авиатор несложно. Вот первые шаги, которые помогут начать игру:
Сделайте Вашу Ставку: Введите сумму, которую вы готовы поставить. Помните, что ставьте осознанно.
Следите за Полётом Самолета: После того как ставка размещена, на экране появится самолет, который начнет свой полет. Множитель начинает расти. Забирайте Ваш Выигрыш: В любой момент, пока самолет в полете, вы можете забрать средства. Повторите Игру: После завершения раунда вы можете начать новый раунд.
Зеркало сайта: https://lacollinaagriturismo.com/casino-oyunlari-en-i%CC%87yi-online-slotlari-oynayi/
Почему Выбирают Игру Авиатор?
Захватывающий Геймплей: В Авиаторе каждое мгновение игры волнует. Простота и Легкость: Игра легко освоить. Возможности для Крупных Побед: Возможности для крупных выигрышей зависят от умения принимать решения. Интерактивные Элементы: В игре Авиатор вы следите за процессом в реальном времени.
Контролируйте Риски: В игре Авиатор важно управлять рисками и выигрышами.
Следите за Динамикой Множителя: Пробуйте анализировать поведение множителя в игре.
Бонусные Возможности и Акции: Воспользуйтесь бонусах и акциях, чтобы повысить шансы на победу.
Estrategias para Lucrar no Jogo do Tigrinho
O que chama a atencao no jogo e o alto potencial de lucro em curto periodo. Com potencial de premios em cada rodada, o jogo se torna emocionante e vantajoso.
Alguns jogadores tem metodos proprios para melhorar os resultados. Uma das taticas mais comuns e a aposta progressiva. Essa tatica permite comecar apostando baixo e ir aumentando gradualmente.
O controle sobre o timing das apostas pode ser determinante para os ganhos. Os minutos pagantes sao uma boa dica para os jogadores. A identificacao dos minutos pagantes pode ser uma chave para o sucesso em Fortune Tiger.
Caracteristicas da plataforma Fortune Tiger
Website: http://uniprint.co.kr/bbs/board.php?bo_table=free&wr_id=3366
Conclusao
O jogo e uma excelente opcao para quem busca tanto diversao quanto ganhos reais. Em resumo, Fortune Tiger e uma plataforma que entrega uma experiencia rica e cheia de possibilidades de ganhos.
The emergence of online gaming hubs came into existence in the 1990s, introducing a convenient alternative to brick-and-mortar establishments. Over time, technological advancements have reshaped online platforms into interactive settings, boasting high-quality designs, live dealer options, and uninterrupted action.
Today, the option to visit an web-based casino from virtually any device remains a key feature for gaming enthusiasts worldwide.
Digital gaming hubs feature a variety of gaming experiences, ranging from timeless classics like roulette and poker, complemented by hundreds of slot games.
These platforms provide players the freedom of participating from any cozy spot or from anywhere, making them a popular choice among both entry-level and veteran users.
One of the most transformative aspects in the realm of internet-based gambling is the trend of handheld gameplay. Casino-focused software are now a top choice for using online platforms, owing to their simple navigation and unique enhancements.
Whether you are a leisure bettor or a high-stakes bettor, a reliable gambling application enables your access to your top-choice options with just a few touches on your tablet.
These apps feature tools that enhance a lag-free gambling interaction, with features such as game selection based on preferences, instant payout solutions, and robust privacy features.
Web: https://jeux-aviator.web.app/
Players can obtain a casino apk—a specific Android tool—to gain instant access in cases where they're missing on popular download hubs.
This flexibility provides that players can enjoy uninterrupted gaming to their most-used casino systems, whatever device compatibility they have.
jogo do tigrinho</a> apresenta uma interface intuitiva e visualmente interessante.
Como Ganhar Mais no Fortune Tiger
O jogo oferece lucros interessantes, mesmo em apostas rapidas. As rodadas rapidas e com chances de ganho atraem jogadores em busca de recompensas rapidas.
Para maximizar os lucros, muitos jogadores adotam estrategias variadas. Uma estrategia bastante popular e a aposta progressiva. A aposta inicial e baixa, mas cresce conforme o jogo avanca.
O timing das apostas pode ser um diferencial crucial para maximizar os ganhos. E fundamental estar atento aos minutos pagantes do jogo. A identificacao dos minutos pagantes pode ser uma chave para o sucesso em Fortune Tiger.
Vantagens da Plataforma Fortune Tiger
Website: http://thinktoy.net/bbs/board.php?bo_table=customer2&wr_id=792838
Consideracoes Finais
O jogo e uma excelente opcao para quem busca tanto diversao quanto ganhos reais. Com muitas formas de ganhar, Fortune Tiger e uma das opcoes mais atrativas no mundo dos jogos de aposta online.
Когда вы находитесь в поиске волнующую игру, которая точно даст немало впечатлений и шансы на значительный выигрыш, то Авиатор игра – ваш правильный выбор.
Что Такое Авиатор?
<a href="https://lacollinaagriturismo.com/online-slots-for-real-currency-10-better-position-websites-in-the-canada-2024/">aviator</a> – это впечатляющая краш игра, где ваш выигрыш и удача зависят от способности быстро принимать решения и хладнокровия и удачи. Цель игры заключается в том, что вы ставите деньги и наблюдаете взлет самолета.
Как Начать Играть в Авиатор? Играть в игру Авиатор несложно. Вот основные шаги, которые помогут стартовать в игре:
Определите Ставку: Введите сумму, которую вы хотите вложить. Помните, что ставить нужно с ответственностью.
Следите за Полётом Самолета: После того как ставка внесена, на экране появится самолет, который начнет свой полет. Множитель выигрыша будет расти. Забирайте Ваш Выигрыш: В любой момент, пока самолет в полете, вы можете взять выигрыш. Начните Новую Игру: После завершения раунда вы можете сделать новую ставку и продолжить игру.
Зеркало сайта: https://lacollinaagriturismo.com/online-slots-for-real-currency-10-better-position-websites-in-the-canada-2024/
Почему Популярна Игра Авиатор?
Динамичный Геймплей: В Авиаторе каждое мгновение приносит эмоции. Доступность и Простота: Игра простая и доступная. Шансы на Победу: Возможности выиграть крупно зависят от ваших решений и удачи. Интерактивность и Реальное Время: В игре Авиатор процесс идет в реальном времени.
Следите за Рисками: В игре Авиатор важно обдуманно управлять рисками.
Отслеживайте Тенденции Множителя: Анализируйте, как ведет себя множитель в раундах.
Получайте Бонусы и Акции: Используйте бонусах и акциях, которые помогут увеличить ваш выигрыш.
Nos recentes tempos, o setor de jogos virtuais tem passado por um incremento significativo, envolvendo milhoes de jogadores que buscam entretenimento e, as vezes, a oportunidade de conquistar lucros em moeda. Dentre os jogos que tem conquistado grande aceitacao, sobressaem-se o <a href="https://handkraftindia.com/fortune-mouse-guia-para-aumentar-suas-chances-de-vitoria/">demo fortune mouse</a> e o Fortune Mouse, ambos disponibilizados em diversas plataformas de jogo. Essas opcoes oferecem entretenimento alem de lazer, mas tambem a possibilidade de obter recompensas para aqueles que demonstram habilidade, calma e uma porcao de sorte. Abaixo, exploraremos, iremos ver os aspectos principais caracteristicas desses jogos, compreendendo seus funcionamentos, os horarios mais propicios para jogar, recomendacoes para testar as demos e planos para incrementar o sucesso.
O Jogo do Ratinho e conhecido por sua acessibilidade e por trazer uma experiencia de jogo que mistura aleatoriedade e habilidade. Esse jogo se fez especialmente popular entre os jogadores que buscam um passatempo rapido e divertido, mas que tambem pode trazer a chance de ganhar algum dinheiro. Para quem nao conhece bem o jogo pela primeira oportunidade, e muito indicado comecar pela versao versao demo do jogo do ratinho. A demonstracao e uma opcao sem custo que da ao jogador experimentar o jogo, conhecer suas regras, aprender o funcionamento e ate mesmo criar estrategias sem precisar usar valores monetarios. Isso e particularmente vantajoso para aqueles que estao comecando, que podem aprender com o jogo antes de migrar para a versao que envolve valores. A demo tambem e muito util para usuarios avancados, pois permite a tentativa de novas taticas para melhorar as probabilidades de ganho.
Para aqueles que tem seguranca em sua capacidade de vencer, tem o jogo do ratinho com premios em dinheiro, onde o jogador tem a opcao de apostar e, a partir de sua habilidade e da sorte, obter recompensas em valor. E essencial, no entanto, manter uma postura cuidadosa ao fazer apostas, lembrando que o principal objetivo do jogo e o lazer. Alem disso, uma orientacao util e definir um orcamento e mante-lo, evitando apostar mais do que se pode perder.
Uma das questoes que frequentemente surge entre os jogadores e quais os melhores horarios para o jogo do ratinho. Muitos usuarios imaginam que, tal como ocorre em jogos de azar ou em alternativas de apostas, existe um horario mais propicio para jogar. Em geral, esse tipo de tatica envolve jogar em horarios de menor movimento na plataforma, como durante a madrugada ou muito cedo pela manha. A razao por dessa estrategia e que, em periodos de pouco movimento, o funcionamento pode apresentar mais oportunidades de vitoria para estimular a participacao dos jogadores. Embora nao haja garantias, e o desfecho das partidas muitas vezes dependa de sorte, muitos jogadores compartilham historias de sucesso associadas a esses horarios alternativos.
Web: https://handkraftindia.com/fortune-mouse-guia-para-aumentar-suas-chances-de-vitoria/
O Game do Ratinho Online e uma otima opcao para aqueles que gostam de jogar com facilidade e sem complicacoes. Ao contrario dos cassinos fisicos, que requerem visita ao local, o Jogo do Ratinho pode ser jogado em qualquer momento, e diversos portais disponibilizam promocoes exclusivas que podem aumentar as chances de ganhar. Dentro dessa opcao, existe tambem a opcao de jogar o jogo do ratinho gratis, perfeita para quem quer so se entreter ou para aqueles que ainda estao aprendendo sobre o jogo. Essa opcao gratuita permite um jogo descontraido, onde o jogador nao se compromete financeiramente, podendo praticar e se divertir sem comprometer o orcamento.
Para aqueles que buscam uma experiencia de aposta mais intensa, o jogo do ratinho com investimentos permite ao jogador apostar valores reais, com a chance de duplicar o valor jogado. Embora essa modalidade seja empolgante, e essencial ter cuidado, pois a pratica de apostas sempre envolve riscos. Muitos jogadores experientes recomendam comecar com apostas baixas e ir subindo aos poucos, a medida que se ganha mais confianca e entendimento sobre o jogo. O principal e lembrar que a sorte tem um papel significativo no Jogo do Ratinho, e as apostas devem ser feitas com cautela e responsabilidade.
The development of digital gambling sites originated in the late 20th century, introducing a convenient option to physical casinos. Over time, technological advancements have evolved online platforms into captivating spaces, equipped with detailed animations, live dealer options, and seamless gameplay.
Today, the capacity to engage with an online casino from almost any gadget is a significant advantage for casino lovers around the globe.
Digital gaming hubs provide a broad assortment of gaming experiences, ranging from traditional games like blackjack and roulette, alongside a large array of slots.
These systems give enthusiasts the accessibility of participating from any cozy spot or while mobile, making them a popular choice among both amateur and seasoned gamblers.
One of the most remarkable changes in the online gaming industry is the rise of portable gaming. Gambling apps are increasingly a preferred method for engaging with online platforms, because of their simple navigation and tailored features.
Whether you are a leisure bettor or a strategic gamer, a reliable gambling application brings you your favorite games with just a few clicks on your portable device.
These apps focus on deliver a uninterrupted casino session, with tools such as tailored suggestions for games, rapid fund transfers, and cutting-edge encryption.
Web: https://jeux-aviator.github.io
Players can download a casino application file—a type of Android software—to gain instant access should they not be accessible on traditional application markets.
This freedom ensures that players can always stay connected to their most-used casino systems, irrespective of technical constraints.
Understanding Stake Mines Game
Stake Mines is an incredibly enthralling game that revolves around a simple concept but can be quite difficult. Players embark on by putting a stake and then selecting tiles from a grid. The objective is to uncover all the non-dangerous tiles without landing on a mine. Each untroubled tile you uncover increases your winnings, but if you select a mine, the game ends, and you lose your bet. The ease of the game is part of its appeal, but the true challenge lies in the tactics needed. Players must predict which tiles are safe to uncover, weighing danger against potential reward.
The Stake Mines game is offered on various platforms, and its popularity continues to rise due to its exciting nature and the thrill of uncertainty. The uncertainty of which tile may hide a mine is part of what makes the game so exciting and offers a risky experience for both inexperienced and seasoned players.
Stake Mines Strategy: The Key to Winning
A well-thought-out Stake Mines strategy can make the difference between succeeding and walking away with nothing. While luck plays a role, the key to beating the game lies in how you play the game. One popular approach is to start with a conservative bet and gradually raise your wager as you uncover safe tiles. This allows players to minimize potential losses and prolong their gameplay, increasing their chances of hitting a profitable streak.
Another strategy involves selecting a specific order in which to uncover the tiles. By following a predetermined grid path, players may sometimes increase their chances of avoiding mines. However, even with the best-laid strategy, it’s vital to remember that the game is based on unpredictability, and no strategy can guarantee a win every time.
For those curious about how these bots work, a Stake Mines Predictor Bot Free version is often available for download. While these free bots may not be as advanced or sophisticated as their paid counterparts, they still claim to offer valuable insights into which tiles are safe to click. Players may experiment with these free tools to determine if they provide a significant advantage before upgrading to a more advanced version.
The Allure of Stake Mines Hack
For some players, using a Stake Mines Hack represents an appealing shortcut to guaranteed winnings. Hacks refer to modified versions of the game or tools designed to change the game’s mechanics in favor of the player. These could involve altering the game’s algorithm, unlocking extra features, or even revealing the locations of mine-free tiles. However, using a hack comes with major risks. Firstly, many hacks are unstable, possibly introducing malware or harming your device. Secondly, hacking is a breach of most gaming platforms' terms of service, and players caught using hacks can be banned or suspended.
While this tool doesn’t guarantee success, it provides a way for players to judge the risk and reward associated with each decision. Some calculators even use historical game data to adjust a player’s strategy based on past performance.
Stake Mines APK and Mod Versions
For those who enjoy trying out new game versions, the Stake Mines APK lets participants download the game on their Android devices. APK releases allow people to avoid app store rules and install customized or modified versions of the game. These versions can offer enhanced features, additional functionalities, or even enhanced chances to succeed, but it’s important to get them from safe sources to avoid malware or other issues.
Web: http://seapine.co.kr/board/bbs/board.php?bo_table=review&wr_id=140247
Stake Mines Demo: Learning the Game Without Risk
If you're new to Stake Mines, the Stake Mines demo is a great way to explore the game’s mechanics without the financial risk. Many platforms offer demo versions of games, allowing players to refine their skills and strategies in a low-stakes environment. The Stake Mines demo mirrors the real game but without using real money, making it the perfect way to familiarize yourself before committing to real wagers.
Using the demo version helps players understand the features and gameplay of the game without the worry of losing money. It’s a risk-free way to explore different strategies and decide how to approach the full game.
В случае, если жаждете увлекательную игру, что предоставит немало впечатлений и шансы на значительный выигрыш, то Авиатор - Взлет – то, что сделает ваш день.
Что Из Себя Представляет Авиатор?
<a href="https://lacollinaagriturismo.com/greatest-real-money-harbors-philippines-2024-incentive-davinci-diamonds-slots-for-pc-up-to-five-hundred/">авиатор казино</a> – это крутая краш игра, где ваш выигрыш и удача зависят от интуиции и скорости и хладнокровия и удачи. Суть игры в том, что вы делаете ставку и смотрите на самолет, который взлетает.
Как Играть в Игра Авиатор? Играть в игру Авиатор легко. Вот ключевые этапы, которые помогут вам начать играть:
Задайте Ставку: Введите сумму, которую вы готовы поставить. Помните, что ставьте осознанно.
Ожидайте Взлета Самолета: После того как ставка выбрана, на экране появится самолет, который взлетит. Множитель начинает расти. Забирайте деньги: В любой момент, пока самолет не исчез, вы можете забрать свой выигрыш. Сделайте Новую Ставку: После завершения раунда вы можете начать новый раунд.
Зеркало сайта: https://lacollinaagriturismo.com/greatest-real-money-harbors-philippines-2024-incentive-davinci-diamonds-slots-for-pc-up-to-five-hundred/
Что Привлекает в Игре Авиатор?
Захватывающий Геймплей: В Авиаторе каждый момент полон эмоций. Простота и Доступность: Игра легко освоить. Крупные Выигрыши: Возможности выиграть крупно зависят от вашего подхода и интуиции. Реальное Время Игры: В игре Авиатор всё происходит в реальном времени.
Управляйте Рискованностью: В игре Авиатор важно обдуманно управлять рисками.
Следите за Динамикой Множителя: Следите за изменениями множителя.
Пользуйтесь Бонусами и Акциями: Не упустите бонусах и акциях, чтобы повысить шансы на победу.
plataforma fortune tiger</a> apresenta uma interface intuitiva e visualmente interessante.
Como Ganhar Mais no Fortune Tiger
O potencial de lucro em curto prazo faz do Tigrinho uma opcao popular. Cada rodada traz a chance de premios elevados, o que e um atrativo para muitos.
Para maximizar os lucros, muitos jogadores adotam estrategias variadas. A aposta em valores crescentes e uma tatica popular. A aposta inicial e baixa, mas cresce conforme o jogo avanca.
Apostadores habilidosos sabem escolher os momentos estrategicos para realizar suas apostas. E fundamental estar atento aos minutos pagantes do jogo. Esses momentos de maiores ganhos sao imprevisiveis, mas com pratica e possivel identifica-los.
Caracteristicas da plataforma Fortune Tiger
Website: http://thingworx.co.kr/bbs/board.php?bo_table=free&wr_id=477089
Conclusao
Seja para iniciantes ou veteranos, Fortune Tiger tem algo a oferecer. Em resumo, Fortune Tiger e uma plataforma que entrega uma experiencia rica e cheia de possibilidades de ganhos.
The emergence of online gaming hubs gained traction in the mid-1990s, offering a comfortable variation to conventional gambling locations. Over time, technological advancements have revolutionized online platforms into captivating settings, boasting lifelike visuals, live dealer options, and smooth gaming.
Today, the capacity to access an virtual casino from virtually any device is one of the biggest draws for players across the planet.
Virtual gambling platforms feature a broad assortment of entertainment choices, such as iconic games such as poker and blackjack, together with countless slots.
These websites give enthusiasts the ease of gaming at home or in any location, securing their place as preferred options among both newcomer and seasoned gamblers.
One of the most transformative aspects in the online gaming industry is the move toward mobile gaming. Casino apps have become a common approach for using online platforms, owing to their intuitive designs and unique enhancements.
Whether you are a casual player or a serious gambler, a specialized gaming app provides your beloved activities with just a few touches on your smartphone.
These apps focus on enhance a smooth gaming journey, with tools such as personalized game recommendations, efficient deposit methods, and cutting-edge encryption.
Web: https://fortune-crash-aposta.web.app/
Players can download a casino application file—a dedicated app setup for Android—to set up applications instantly in cases where they're missing on official app stores.
This freedom provides that players can maintain access to their most-used casino systems, whatever device compatibility they have.
Understanding Stake Mines Game
Stake Mines is an incredibly enthralling game that revolves around a easy concept but can be quite tough. Players embark on by setting a bet and then selecting tiles from a grid. The objective is to uncover all the hazard-free tiles without landing on a mine. Each mine-free tile you uncover increases your winnings, but if you select a mine, the game ends, and you lose your investment. The straightforwardness of the game is part of its appeal, but the true challenge lies in the strategy needed. Players must predict which tiles are safe to uncover, weighing danger against potential reward.
The Stake Mines game is offered on various platforms, and its popularity continues to rise due to its intense nature and the thrill of uncertainty. The surprise of which tile may hide a mine is part of what makes the game so exciting and offers a edge-of-your-seat experience for both newcomers and seasoned players.
Stake Mines Strategy: The Key to Winning
A well-thought-out Stake Mines strategy can make the difference between triumphing and walking away with nothing. While luck plays a role, the key to achievement lies in how you approach the game. One popular approach is to start with a low bet and gradually expand your wager as you uncover safe tiles. This allows players to limit potential losses and prolong their gameplay, increasing their chances of hitting a profitable streak.
Another strategy involves selecting a specific sequence in which to uncover the tiles. By following a predetermined grid path, players may sometimes heighten their chances of avoiding mines. However, even with the best-laid strategy, it’s vital to remember that the game is based on chance, and no strategy can guarantee a win every time.
For those curious about how these bots work, a Stake Mines Predictor Bot Free version is often available for download. While these free bots may not be as advanced or sophisticated as their paid counterparts, they still claim to offer valuable insights into which tiles are safe to click. Players may experiment with these free tools to determine if they provide a significant advantage before upgrading to a more sophisticated version.
The Allure of Stake Mines Hack
For some players, using a Stake Mines Hack represents an appealing shortcut to guaranteed winnings. Hacks refer to hacked versions of the game or tools designed to change the game’s mechanics in favor of the player. These could involve adjusting the game’s algorithm, unlocking extra features, or even revealing the locations of mine-free tiles. However, using a hack comes with major risks. Firstly, many hacks are illegal, possibly introducing malware or harming your device. Secondly, hacking is a breach of most gaming platforms' terms of service, and players caught using hacks can be banned or suspended.
While this tool doesn’t guarantee success, it provides a way for players to judge the risk and reward associated with each decision. Some calculators even use historical game data to adjust a player’s strategy based on past performance.
Stake Mines APK and Mod Versions
For those who enjoy trying out unique game versions, the Stake Mines APK lets users download the game on their Android devices. APK releases allow users to circumvent app store limitations and set up customized or altered versions of the game. These versions can offer enhanced features, additional functionalities, or even extra chances to succeed, but it’s important to obtain them from trusted sources to avoid malware or other issues.
Web: https://unique-listing.com/details.php?id=357579
Stake Mines Demo: Learning the Game Without Risk
If you're new to Stake Mines, the Stake Mines demo is a great way to practice the game’s mechanics without the financial risk. Many platforms offer demo versions of games, allowing players to refine their skills and strategies in a low-stakes environment. The Stake Mines demo mirrors the real game but without using real money, making it the perfect way to train before committing to real wagers.
Using the demo version helps players comprehend the features and gameplay of the game without the worry of losing money. It’s a risk-free way to explore different strategies and decide how to approach the full game.
Если вы стремитесь найти захватывающую и увлекательную игру, которая даст много шансов и шансы на значительный выигрыш, то Авиатор - Взлет – это то, что нужно.
Что Такое Авиатор?
<a href="https://lacollinaagriturismo.com/bonanza-12-months-14-wikipedia/">aviator игра официальный сайт</a> – это захватывающая игра, где ваш выигрыш в игре зависят от быстроты мышления и удачи и удачи и интуиции. Игра заключается в том, что вы ставите и смотрите, как самолет взлетает.
Как Играть в Игра Авиатор? Играть в игру Авиатор легко. Вот основные действия, которые помогут приступить к игре:
Выберите Сумму Ставки: Введите сумму, которую вы готовы поставить. Помните, что ставьте осознанно.
Следите за Взлетом Самолета: После того как ставка внесена, на экране появится самолет, который начнет свой полет. Множитель будет увеличиваться. Забирайте Ваш Выигрыш: В любой момент, пока самолет взлетает, вы можете забрать выигрыш. Повторите Игру: После завершения раунда вы можете сделать новую ставку и продолжить игру.
Зеркало сайта: https://lacollinaagriturismo.com/bonanza-12-months-14-wikipedia/
Почему Популярна Игра Авиатор?
Захватывающий Геймплей: В Авиаторе каждый момент полон эмоций. Простота и Легкость: Игра легко освоить. Шансы на Победу: Возможности для значительных побед зависят от вашей интуиции. Реальное Время Игры: В игре Авиатор процесс идет в реальном времени.
Следите за Рисками: В игре Авиатор важно контролировать риски и выигрыши.
Следите за Динамикой Множителя: Анализируйте, как ведет себя множитель в раундах.
Бонусные Возможности и Акции: Используйте бонусах и акциях, чтобы увеличить свои шансы на выигрыш.
A key draw of <a href="https://chessdatabase.science/wiki/User:YukikoBettington">sweet bonanza мнения</a> is its refreshing style in online slot play style. Unlike classic slot games that depend on paylines for wins, Sweet Bonanza uses a "cluster pays" system. The title features six reels and a five-row grid, presenting spinners numerous chances to win with every spin. Combinations occur by matching groups of at least eight matching images on the play area, making it unique compared to regular slots that use predetermined paylines.
The cluster pay system doesn’t just visually engaging but also creates players better odds each time they spin.
This candy-inspired visual style and bright color palette complement the attraction of the game, producing a fun, animated ambiance that draws players in. Symbols in Sweet Bonanza show various candies in vibrant colors, as well as fruits such as bananas, grapes, and watermelons. The graphics are enhanced by cheerful sounds that brings to the thrill of the game. The Sweet Bonanza game also features a special symbol represented by a lollipop, which is essential in triggering the bonus spins. With four or more lollipop symbols, the game will start the Free Spins mode, which provides a great opportunity to win big.
For players who are new to online slots or prefer to test it first without betting real funds, the Sweet Bonanza demo offers a great chance. Many online casinos provide a Sweet Bonanza free play, giving users to test the game, develop techniques, and become familiar with the game’s features without any financial risk. Trying the demo of Sweet Bonanza is ideal for novices, as it allows them to understand the game structure, test various betting amounts, and get acquainted with the tumble function.
Web: https://chessdatabase.science/wiki/User:YukikoBettington
The Tumble feature, also known as the cascade feature, is central to the slot. Once players hit a winning cluster, the matching symbols vanish, and new symbols fall into place, giving extra chances to win. This element adds to the thrill but also offers extra chances to score to win in a single spin.
Another highlight of this game is its free spins bonus, which is often the favorite feature for users. The bonus spins in this slot may result in impressive wins due to the availability of multipliers. If players activate it, the free spin round awards ten free spins, and players can re-trigger additional free spins by collecting additional lollipop icons.
The development of digital gambling sites gained traction in the early era of the internet, offering a comfortable alternative to brick-and-mortar casinos. Over time, digital improvements have reshaped online platforms into engaging realms, including lifelike visuals, live dealer options, and uninterrupted action.
Today, the opportunity to access an web-based casino from a range of devices remains a key feature for gaming enthusiasts across the planet.
Digital gaming hubs deliver a wide range of gaming experiences, ranging from timeless classics like roulette and poker, together with numerous slot games.
These online hubs deliver to gamers the accessibility of participating from any cozy spot or on the go, making them a popular choice among both amateur and skilled bettors.
One of the most important developments in the digital gambling sector is the growth of mobile-friendly interfaces. Casino apps have turned into a go-to option for using online platforms, due to their intuitive designs and adapted functionalities.
Whether you are a hobbyist or a strategic gamer, a feature-rich casino software lets you experience your favorite games with just a few touches on your portable device.
These apps aim to ensure a smooth gaming journey, with options such as game selection based on preferences, instant payout solutions, and advanced safety protocols.
Web: https://fortune-tiger-best.web.app/
Players can install a casino apk—a type of Android software—to install apps directly should they not be accessible on official app stores.
This adaptability provides that players can continue their sessions to their most-used casino systems, no matter what OS they use.
Este juego destaca de otras tragamonedas por su diseno llamativo y unico. Al iniciar el juego, los jugadores entran en un escenario de golosinas y colores brillantes que hacen pensar en un cuento de fantasia. El fondo esta decorado con dulces, lo cual crea una imagen amigable y agradable, perfecta para principiantes y expertos. Este juego ha sido reconocido por su adiccion positiva y entretenimiento, ya que combina la emocion de los premios con una estetica visual que apela a todos los publicos.
Una de las caracteristicas mas valoradas de este juego de tragamonedas es su caracteristica de giros gratis, que se activa con la aparicion de cuatro o mas simbolos de caramelos rosados en cualquier posicion. La ronda de giros gratuitos no solo permiten disfrutar sin apostar mas dinero, sino que tambien incrementan las chances de obtener grandes premios, especialmente cuando aparecen multiplicadores en los giros. Este detalle del juego es uno de los mas interesantes a los jugadores, y muchos comentan en sus opiniones que la ronda de giros gratis es lo mas emocionante.
Ademas, Sweet Bonanza ha logrado mantener su popularidad gracias a su posibilidad de adaptacion a diferentes tipos de jugadores. No importa si eres un jugador experimentado, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la adaptabilidad de este slot en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere jugadas rapidas mientras viajas, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: http://guardian.ge/70351-at-least-44-killed-in-pakistan-after-explosion-at-islamist-political-rally.html
Otro punto que interesa a los jugadores es si si el juego realmente permite ganar dinero con este slot. Al igual que en cualquier tragamonedas, este juego es un juego de azar, lo cual significa que el resultado de cada vuelta es totalmente azaroso y no puede ser predicho. Sin embargo, los multiplicadores y las rondas de giros gratis ofrecen una oportunidad significativa para obtener grandes recompensas. La funcion de se pueden multiplicar las ganancias hasta 100 veces gracias a los multiplicadores, lo que puede generar premios grandes si el jugador acierta. Sin embargo, es importante recordar que hay que disfrutar del juego con moderacion y que las victorias no estan garantizadas.
Когда вы ищете волнующую игру, способная предоставит много шансов и шансы на значительный выигрыш, то Авиатор – ваш правильный выбор.
Что Из Себя Представляет Авиатор?
<a href="https://telecompayltd.com/aviator-onlaynkrash-igra-v-kazino/">авиатор</a> – это захватывающая игра, где ваш победа и достижения зависят от способности быстро принимать решения и удачи и интуиции. Суть игры в том, что вы ставите деньги и наблюдаете взлет самолета.
Как Играть в Авиатор? Играть в игру Авиатор достаточно легко. Вот первые шаги, которые помогут приступить к игре:
Выберите Сумму Ставки: Введите сумму, которую вы готовы поставить. Помните, что важно контролировать ставки.
Следите за Взлетом Самолета: После того как ставка установлена, на экране появится самолет, который покажет взлет. Величина множителя начнет увеличиваться. Забирайте Ваш Выигрыш: В любой момент, пока самолет не пропал, вы можете взять выигрыш. Начните Новый Раунд: После завершения раунда вы можете сделать новую ставку.
Зеркало сайта: https://telecompayltd.com/aviator-onlaynkrash-igra-v-kazino/
Почему Стоит Выбрать Авиатор?
Захватывающий Игровой Процесс: В Авиаторе каждое мгновение наполнено азартом. Легкость и Удобство: Игра простая и доступная. Возможности для Крупных Побед: Возможности для значительных побед зависят от ваших решений и удачи. Реальное Время Игры: В игре Авиатор процесс идет в реальном времени.
Контролируйте Риски: В игре Авиатор важно выигрывать с учетом рисков.
Отслеживайте Множитель: Следите за тем, как растет множитель.
Пользуйтесь Бонусами и Акциями: Не пропустите бонусах и акциях, чтобы увеличить свои шансы на выигрыш.
Peki, Sweet Bonanza nas?l oynan?r? Bu populer oyunun derinlemesine ayr?nt?lar?n? inceleyecegiz ve giris yapma yontemlerinden taktik ipuclar?na kadar her konuyu ele alacag?z.
Sweet Bonanza oyununun icerigine goz atal?m
Bu oyun, slot oyunlar? dunyas?nda dikkat cekici ozelliklere sahip bir bir oyundur. Pragmatic Play’in sundugu bu oyun, meyve ve seker ikonlar?yla doludur. Bu meyve ve seker sembolleri, tatl? bir dunyaya davet ederek oyuncular? oyunun cazibesine kap?lmaya davet eder.
Bu oyunun farkl? bir mekanik sunmas? oyunculara farkl? bir deneyim sunuyor. Ekranda patlayan semboller yerine yenilerinin gelmesiyle, oyuncular surekli bir dongu icinde kazanc saglayabilir. Bu mekanik yap?yla birlikte, Sweet Bonanza, diger slot oyunlar?ndan ayr?l?r.
Sweet Bonanza oynan?s rehberi
Sweet Bonanza oyununun mekanikleri diger benzer oyunlardan daha kolay anlas?l?r bir oyun sistemi sunar. alt? sutun ve bes sat?rdan olusan bir tabloda oynan?r. Hedef, belirli say?daki sembollerin bir araya gelmesiyle kazanc saglamakt?r.
Bu yap?da herhangi bir cizgi takip etme gereksinimi yoktur. Kazanc icin ayn? sembollerin toplanmas? yeterlidir. Kazanc saglanan semboller yok olup yerlerine yenileri gelir. Bu ozellik sayesinde, bir dondurmede birden fazla odul kazan?labilir.
Web: https://humanlove.stream/wiki/User:NinaBoos06
Sweet Bonanza Demo: Oyunu Denemek Icin Ideal F?rsat
Sweet Bonanza’n?n sundugu avantajlardan biri de, oyunculara demo mod sunulmas?d?r. Demo mod, oyuna yeni baslayanlar icin harika bir f?rsat sunar. Gercek para kullanmadan oyun mekanigini anlamak mumkundur.
Demo modunda oynarken kazanc saglayan sembolleri ogrenebilirsiniz. Risksiz bir sekilde oyunun tum ozelliklerini gormek mumkundur. Demo surumu, oyunculara farkl? oyun stratejilerini deneme f?rsat? sunar.
The notion of internet-based casinos gained traction in the digital revolution period, delivering a user-friendly alternative to brick-and-mortar venues. Over time, progress in tech have evolved online platforms into interactive spaces, equipped with realistic graphics, real-time dealer interactions, and uninterrupted action.
Today, the ability to explore an digital gambling site from a range of devices remains a key feature for gamblers worldwide.
Internet casinos offer a variety of gaming experiences, highlighting iconic games such as poker and blackjack, together with hundreds of slot games.
These systems make available for users the convenience of gambling from the comfort of their houses or in any location, making them a popular choice among both newcomer and experienced players.
One of the most transformative aspects in the world of virtual casinos is the shift to mobile-first platforms. Mobile casino applications have become a preferred method for interacting with online platforms, owing to their intuitive designs and adapted functionalities.
Whether you are a hobbyist or a professional player, a reliable gambling application enables your access to your favorite games with just a few interactions on your mobile phone.
These apps feature tools that ensure a smooth gaming journey, with tools such as personalized game recommendations, rapid fund transfers, and robust privacy features.
Web: https://casino-pin-up.github.io/
Players can download a casino application file—a file format for Android devices—to use software without delay when not found on common mobile platforms.
This freedom ensures that players can continue their sessions to their top-choice gaming apps, despite their device preferences.
Sweet Bonanza se distingue de otras tragamonedas por su diseno y tematica unicos. Al ingresar al slot, los usuarios entran en un universo de caramelos y colores vibrantes que recuerdan a un cuento de hadas. El fondo de la pantalla esta lleno de golosinas, lo cual crea una imagen atractiva y alegre, ideal tanto para jugadores nuevos como para experimentados. Este slot ha sido descrito por muchos en sus opiniones como adictivo y muy entretenido, ya que mezcla la emocion de ganar premios con un estilo visual atractivo para todos.
Una de las caracteristicas mas valoradas de este slot es su ronda de giros gratis, que se activa cuando aparecen cuatro o mas simbolos de caramelos rosados. La ronda de giros gratuitos no solo permiten jugar de manera gratuita, sino que tambien aumentan las oportunidades de ganar, especialmente cuando los multiplicadores estan presentes. Este elemento del juego es uno de los que mas atrae a los jugadores, y muchos mencionan en sus opiniones que la funcion de giros gratis es lo mas emocionante.
Ademas, la tragamonedas Sweet Bonanza ha logrado mantener su popularidad gracias a su atractivo para jugadores novatos y experimentados. No importa si eres un jugador experimentado, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la compatibilidad de Sweet Bonanza en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere divertirte mientras te desplazas, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: https://dyslexiacrs.com/popular-tragamonedas-sweet-bonanza-analisis-completo-sobre-este-emocionante-slot/
Otro punto que interesa a los jugadores es si se puede ganar dinero real con este juego. Al igual que en cualquier tragamonedas, Sweet Bonanza es una maquina de azar, lo cual significa que el resultado de cada vuelta es impredecible y no puede ser modificado. Sin embargo, los funcion de multiplicadores y giros gratis ofrecen una oportunidad significativa para obtener premios importantes. La funcion de multiplicador puede aumentar las ganancias hasta 100 veces en un solo giro, lo que puede resultar en una ganancia notable si se tiene suerte en el giro. Sin embargo, es importante recordar que hay que disfrutar del juego con moderacion y que el exito no esta asegurado en todos los giros.
Если вы желаете увлекательную игру, способная предоставит массу эмоций и шанс на крупные выигрыши, то Авиатор – идеальный выбор для вас.
Что За Игра Авиатор?
<a href="https://mohammedsalamat.com/new/aviator-onlaynkrash-igra-v-kazino/">авиатор игра</a> – это впечатляющая краш игра, где ваш успех в игре зависят от реакции и удачи и хладнокровия и удачи. Суть игры в том, что вы ставите деньги и наблюдаете взлет самолета.
Как Начать Играть в Авиатор? Играть в игру Авиатор несложно. Вот ключевые этапы, которые помогут вам начать играть:
Выберите Сумму Ставки: Введите сумму, которую вы готовы поставить. Помните, что важно контролировать ставки.
Смотрите за Взлетом Самолета: После того как ставка подтверждена, на экране появится самолет, который начнет свой полет. Множитель будет увеличиваться. Забирайте Ваш Выигрыш: В любой момент, пока самолет в полете, вы можете забрать свой выигрыш. Повторите Игру: После завершения раунда вы можете начать новую игру.
Зеркало сайта: https://mohammedsalamat.com/new/aviator-onlaynkrash-igra-v-kazino/
Что Привлекает в Игре Авиатор?
Динамичный Геймплей: В Авиаторе каждый раунд захватывает. Легкость Освоения: Игра простая и доступная. Шансы на Большие Выигрыши: Возможности выиграть щедро зависят от вашей интуиции. Интерактивные Элементы: В игре Авиатор вы следите за процессом в реальном времени.
Контролируйте Риски: В игре Авиатор важно управлять рисками и выигрышами.
Следите за Динамикой Множителя: Анализируйте поведение множителя.
Бонусные Возможности и Акции: Не упустите бонусах и акциях, чтобы увеличить свои шансы на выигрыш.
Este juego destaca de otras tragamonedas por su diseno y tematica unicos. Al abrir el juego, los usuarios entran en un mundo de dulces y colores vibrantes que recuerdan a un cuento de hadas. El fondo de la pantalla esta lleno de golosinas, lo cual ofrece una escena visual amigable y divertida, ideal para todo tipo de jugadores. Esta tragamonedas ha sido considerado como entretenido y cautivador, ya que brinda emociones y una estetica llamativa para todos.
Una de las caracteristicas mas valoradas de este juego de tragamonedas es su funcion de giros gratis, que se activa con la aparicion de cuatro o mas simbolos de caramelos rosados en cualquier posicion. Los giros gratis no solo permiten jugar sin costo, sino que tambien multiplican las posibilidades de ganar grandes premios, especialmente cuando los multiplicadores hacen su aparicion. Este aspecto del juego es uno de los mas emocionantes a los jugadores, y muchos senalan en sus resenas que la caracteristica de giros gratuitos es lo mas emocionante.
Ademas, la tragamonedas Sweet Bonanza ha logrado mantener su popularidad gracias a su aplicabilidad universal. No importa si eres un jugador experimentado, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la adaptabilidad de Sweet Bonanza en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere jugar durante tus descansos, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: http://www.casadelaya.com/board/bbs/board.php?bo_table=review&wr_id=93681
Otro punto que interesa a los jugadores es si realmente pueden ganar dinero con este juego. Al igual que en cualquier tragamonedas, Sweet Bonanza es un juego basado en el azar, lo cual significa que el resultado de cada tirada es impredecible y no puede ser modificado. Sin embargo, los multiplicadores y la funcion de giros gratuitos ofrecen una oportunidad significativa para obtener ganancias considerables. La funcion de multiplicador puede aumentar las ganancias hasta 100 veces en un solo giro, lo que puede resultar en una recompensa significativa si los jugadores tienen suerte. Sin embargo, es importante recordar que hay que disfrutar del juego con moderacion y que no hay garantias de ganar en cada sesion.
The emergence of online gaming hubs emerged in the 1990s, introducing a accessible variation to conventional venues. Over time, digital improvements have elevated online platforms into interactive settings, including realistic graphics, live gaming features, and smooth gaming.
Today, the option to visit an web-based casino from virtually any device stands out as a major attraction for users worldwide.
Digital gaming hubs feature a variety of games, highlighting timeless classics like roulette and poker, complemented by hundreds of slot games.
These platforms make available for users the accessibility of playing from their homes or in any location, securing their place as preferred options among both novice and veteran users.
One of the most significant shifts in the world of virtual casinos is the rise of portable gaming. Casino apps are now a go-to option for engaging with online platforms, as a result of their accessible layouts and unique enhancements.
Whether you are a entertainment seeker or a dedicated enthusiast, a feature-rich casino software lets you experience your beloved activities with just a few steps on your tablet.
These apps are built to provide a seamless gaming experience, with functionalities such as adaptive picks for players, rapid fund transfers, and enhanced security measures.
Web: https://game-aviator.pages.dev/
Players can obtain a casino apk—a dedicated app setup for Android—to install apps directly if they are unavailable on traditional application markets.
This adaptability makes certain that players can always stay connected to their most-used casino systems, whatever device compatibility they have.
Dicas de Sucesso para o Fortune Tiger
O que chama a atencao no jogo e o alto potencial de lucro em curto periodo. Os premios disponiveis em cada rodada sao um grande atrativo para os jogadores.
Diversas estrategias podem ajudar o jogador a otimizar suas apostas. Muitos jogadores utilizam a estrategia de aumentar gradualmente as apostas. A aposta inicial e baixa, mas cresce conforme o jogo avanca.
Para melhorar as chances de lucro, e essencial escolher os momentos certos para apostar. Os minutos pagantes sao uma boa dica para os jogadores. Esses momentos de maiores ganhos sao imprevisiveis, mas com pratica e possivel identifica-los.
Apostas e Recursos da Plataforma Fortune Tiger
Website: http://hereports.co.kr/bbs/board.php?bo_table=free&wr_id=165176
Fechamento
O jogo e uma excelente opcao para quem busca tanto diversao quanto ganhos reais. A plataforma Fortune Tiger e uma excelente escolha para quem busca diversao e lucro.
В случае, если стремитесь найти волнующую игру, способная даст огромное количество эмоций и возможности выиграть крупно, то Авиатор - Взлет – то, что сделает ваш день.
Что Из Себя Представляет Авиатор?
<a href="https://lacollinaagriturismo.com/herunterladen-zum-besten-geben-bei-mergeland-alices-ereignis-unter-pc-mac-nachmacher/">авиатор</a> – это впечатляющая краш игра, где ваш выигрыш и удача зависят от реакции и удачи и удачи. Игра заключается в том, что вы ставите деньги и наблюдаете взлет самолета.
Как Играть в Игра Авиатор? Играть в игру Авиатор не вызывает трудностей. Вот ключевые этапы, которые помогут стартовать в игре:
Определите Ставку: Введите сумму, которую вы готовы рискнуть. Помните, что ставьте осознанно.
Наблюдайте за Взлётом Самолета: После того как ставка выбрана, на экране появится самолет, который покажет взлет. Множитель выигрыша будет расти. Забирайте деньги: В любой момент, пока самолет не исчез, вы можете забрать свой выигрыш. Начните Новый Раунд: После завершения раунда вы можете начать новый раунд.
Зеркало сайта: https://lacollinaagriturismo.com/herunterladen-zum-besten-geben-bei-mergeland-alices-ereignis-unter-pc-mac-nachmacher/
Почему Популярна Игра Авиатор?
Увлекательный Геймплей: В Авиаторе каждое мгновение наполнено азартом. Простота и Доступность: Игра простая и доступная. Возможности для Крупных Побед: Возможности выиграть крупно зависят от вашей интуиции. Интерактивность и Реальное Время: В игре Авиатор вы следите за процессом в реальном времени.
Следите за Рисковыми Моментами: В игре Авиатор важно обдуманно управлять рисками.
Наблюдайте за Изменением Множителя: Анализируйте, как ведет себя множитель в раундах.
Бонусные Возможности и Акции: Не пропустите бонусах и акциях, чтобы повысить шансы на победу.
Hazard online zdobywaja coraz szersze uznanie w Polsce, a jedna z miejsc, ktora jest na ustach wszystkich, jest <a href="https://securityholes.science/wiki/User:GordonVillareal">bet on red casino login</a>. To kasyno online, ktore przyciaga graczy dzieki szerokiemu wyborowi gier, intuicyjna konstrukcja strony oraz atrakcyjnymi promocjami, ktore zadowola zarowno osoby nowe w swiecie hazardu, jak i weteranow gier.
Dlaczego gracze wybieraja Kasyno Bet On Red?
Red On Bet to internetowe miejsce rozrywki, ktora oferuje szeroki wybor gier hazardowych online, takich jak sloty, klasyczne gry kasynowe oraz gry z prawdziwymi krupierami. Juz nazwa tej platformy „Bet On Red" przywoluje emocje i rywalizacje podczas gier.
Latwe logowanie w Bet On Red Casino
Logowanie do konta w Bet On Red Casino jest latwy i wygodny. Po wejsciu na strone glowna, wystarczy wybrac funkcje logowania i wprowadzic dane konta. Kasyno gwarantuje bezpieczenstwo, dlatego wszelkie dane uzytkownika sa chronione.
Uzytkownicy rozpoczynajacy swoja przygode moga latwo zarejestrowac sie, a proces zakladania konta jest szybki i prosty. Co istotne, Bet On Red oferuje mozliwosc korzystania z roznych metod platnosci, co ulatwia doladowanie konta.
Roznorodnosc gier w Bet On Red
Jednym z najwazniejszych aspektow, kazdego kasyna online, jest oferta gier. Bet On Red Casino oferuje roznorodnoscia, ktory spelni oczekiwania kazdego uzytkownika.
Web: https://securityholes.science/wiki/User:GordonVillareal
Sloty sa jednym z najwiekszych hitow w ofercie, dostepne w roznorodnych stylach oraz z unikalnymi funkcjami. Oprocz tradycyjnych automatow, uzytkownicy moga rozegrac partie w gry stolowe, takie jak poker.
The concept of online casinos emerged in the digital revolution period, offering a easy-to-reach alternative to traditional establishments. Over time, technological advancements have reshaped online platforms into interactive spaces, equipped with high-quality designs, real-time dealer interactions, and uninterrupted action.
Today, the capacity to visit an online casino from practically anywhere is a significant advantage for gaming enthusiasts around the globe.
Web-based gambling sites make available a diverse selection of gaming experiences, ranging from classics like blackjack, roulette, and poker, together with countless slots.
These platforms provide players the ease of gaming at home or while traveling, rendering them highly appealing among both entry-level and experienced players.
One of the most significant shifts in the digital gambling sector is the shift to mobile-first platforms. Casino apps are widely recognized as a preferred method for interacting with online platforms, due to their player-oriented features and unique enhancements.
Whether you are a entertainment seeker or a high-stakes bettor, a dedicated casino app brings you your most-loved gaming experiences with just a few touches on your smart device.
These apps feature tools that enable a flawless entertainment flow, with capabilities such as adaptive picks for players, quick payment processing, and cutting-edge encryption.
Web: https://gatesof-olympus.pages.dev
Players can get a Android gambling app—a dedicated app setup for Android—to access platforms seamlessly when not found on official app stores.
This flexibility provides that players can always stay connected to their top-choice gaming apps, irrespective of technical constraints.
Ganhos e Estrategias para o Fortune Tiger
Uma das caracteristicas mais atraentes do Fortune Tiger e a possibilidade de ganhar premios altos em pouco tempo. Os premios disponiveis em cada rodada sao um grande atrativo para os jogadores.
Diversas estrategias podem ajudar o jogador a otimizar suas apostas. A aposta em valores crescentes e uma tatica popular. O jogador vai aumentando as apostas progressivamente, comecando com valores baixos.
Saber quando apostar e quanto aumentar as apostas e uma habilidade importante. Saber quando o jogo esta mais propenso a pagar altos premios pode ser decisivo. Esses momentos de maiores ganhos sao imprevisiveis, mas com pratica e possivel identifica-los.
Como Funciona a Plataforma do Jogo Fortune Tiger
Website: http://pandahouse.lolipop.jp/g5/bbs/board.php?bo_table=room&wr_id=7186303
Consideracoes Finais
Fortune Tiger e um jogo que combina diversao, estrategia e oportunidades de ganhos. Com muitas formas de ganhar, Fortune Tiger e uma das opcoes mais atrativas no mundo dos jogos de aposta online.
Когда вы стремитесь найти захватывающую игру, которая предоставит кучу эмоций и возможности для крупного выигрыша, то Авиатор игра – это то, что нужно.
О Чём Игра Авиатор?
<a href="https://lacollinaagriturismo.com/thunderstruck-ii-slot-machine-game-totally-free-for-money-mobile-totally-free-spins/">авиатор краш игра</a> – это классная краш игра, где ваш выигрыш и удача зависят от реакции и удачи и удачи. В этой игре вы вы ставите деньги и наблюдаете взлет самолета.
Как Играть в Игра Авиатор? Играть в игру Авиатор очень просто. Вот первые шаги, которые облегчат начало игры:
Выберите Сумму Ставки: Введите сумму, которую вы готовы рискнуть. Помните, что ставьте осознанно.
Следите за Полётом Самолета: После того как ставка размещена, на экране появится самолет, который начнет подниматься. Множитель будет увеличиваться. Забирайте Ваши средства: В любой момент, пока самолет в полете, вы можете взять выигрыш. Повторите Игру: После завершения раунда вы можете продолжить игру.
Зеркало сайта: https://lacollinaagriturismo.com/thunderstruck-ii-slot-machine-game-totally-free-for-money-mobile-totally-free-spins/
Почему Популярна Игра Авиатор?
Динамичный Геймплей: В Авиаторе каждый момент полон эмоций. Простота и Доступность: Игра не требует глубоких знаний. Крупные Выигрыши: Возможности для крупных выигрышей зависят от вашей интуиции. Взаимодействие в Реальном Времени: В игре Авиатор вы играете в реальном времени.
Следите за Рисковыми Моментами: В игре Авиатор важно выигрывать с учетом рисков.
Наблюдайте за Изменением Множителя: Анализируйте, как ведет себя множитель в раундах.
Получайте Бонусы и Акции: Не упустите бонусах и акциях, которые помогут увеличить ваш выигрыш.
Metodos para Obter Melhores Resultados no Tigrinho
O jogo se diferencia por suas oportunidades de lucro rapido e significativo. O jogo oferece recompensas rapidas para quem busca lucros imediatos.
Muitos jogadores aplicam estrategias especificas para aumentar as chances de lucro. A aposta progressiva e uma das tecnicas mais usadas no jogo. A aposta inicial e baixa, mas cresce conforme o jogo avanca.
Para melhorar as chances de lucro, e essencial escolher os momentos certos para apostar. Para otimizar os ganhos, e importante saber identificar os minutos pagantes. Esses momentos de maiores ganhos sao imprevisiveis, mas com pratica e possivel identifica-los.
Plataforma de Apostas do Fortune Tiger: O que Saber
Website: http://ybsangga.innobox.co.kr/bbs/board.php?bo_table=free&wr_id=665729
Encerramento
O Fortune Tiger e uma plataforma empolgante para todos os tipos de jogadores. Com muitas formas de ganhar, Fortune Tiger e uma das opcoes mais atrativas no mundo dos jogos de aposta online.
The development of digital gambling sites came into existence in the mid-1990s, bringing a user-friendly solution to brick-and-mortar casinos. Over time, technological advancements have reshaped online platforms into dynamic experiences, featuring stunning imagery, real-time dealer interactions, and lag-free experiences.
Today, the possibility to engage with an web-based casino from virtually any device is one of the biggest draws for gamblers everywhere.
Virtual gambling platforms provide a comprehensive collection of gaming experiences, featuring traditional games like blackjack and roulette, together with a large array of slots.
These websites offer users the comfort of gaming at home or in any location, securing their place as preferred options among both amateur and skilled bettors.
One of the most transformative aspects in the realm of internet-based gambling is the growth of mobile-friendly interfaces. Mobile casino applications are now a popular way for interacting with online platforms, because of their intuitive designs and customized tools.
Whether you are a leisure bettor or a high-stakes bettor, a reliable gambling application brings you your beloved activities with just a few clicks on your tablet.
These apps focus on enhance a smooth gaming journey, with features such as customized gambling options, efficient deposit methods, and enhanced security measures.
Web: https://aviator-spribe.netlify.app/
Players can acquire a APK for casino platforms—a type of Android software—to set up applications instantly if they are unavailable on official app stores.
This freedom makes certain that players can remain engaged to their favorite gaming platforms, regardless of their device's operating system.
tigrinho</a> possui graficos vibrantes e uma interface simples de entender.
Ganhos e Estrategias para o Fortune Tiger
O Jogo do Tigrinho se destaca por oferecer premios significativos em poucas rodadas. A chance de premios em cada rodada faz do jogo uma escolha interessante para apostadores.
Para maximizar as chances, muitos utilizam metodos especificos de aposta. A aposta em valores crescentes e uma tatica popular. A aposta inicial e baixa, mas cresce conforme o jogo avanca.
Outro aspecto fundamental para aumentar os lucros e o timing das apostas. Para otimizar os ganhos, e importante saber identificar os minutos pagantes. Identificar os minutos mais rentaveis exige pratica, mas e uma habilidade essencial para os apostadores.
Plataforma Fortune Tiger: Beneficios para o Jogador
Website: https://www.edu-kingdom.com/home.php?mod=space&uid=3566241&do=profile
Encerramento
Este jogo se destaca por ser acessivel e cheio de oportunidades de lucro. Com sua interface amigavel e sistema de pagamentos confiavel, o jogo e ideal para qualquer apostador.
Когда желаете захватывающую игру, которая точно подарит много шансов и шансы на значительный выигрыш, то Авиатор - Взлет – именно то, что вам нужно.
Что Такое Авиатор?
<a href="https://alpssynergy.com/author/alpssynergy/page/5156/">авиатор</a> – это классная краш игра, где ваш успех в игре зависят от интуиции и скорости и удачи и интуиции. В этой игре вы вы делаете ставку и следите за взлетом самолета.
Как Играть в Игра Авиатор? Играть в игру Авиатор не вызывает трудностей. Вот ключевые этапы, которые помогут стартовать в игре:
Установите Сумму Ставки: Введите сумму, на которую вы готовы играть. Помните, что всегда ставьте с умом.
Ожидайте Взлета Самолета: После того как ставка размещена, на экране появится самолет, который начнет подниматься. Множитель выигрыша будет расти. Берите выигрыш: В любой момент, пока самолет взлетает, вы можете забрать выигрыш. Начните Новую Игру: После завершения раунда вы можете сделать новую ставку и продолжить игру.
Зеркало сайта: https://alpssynergy.com/author/alpssynergy/page/5156/
Почему Стоит Выбрать Авиатор?
Захватывающий Игровой Процесс: В Авиаторе каждое мгновение приносит эмоции. Доступность и Простота: Игра не требует глубоких знаний. Крупные Выигрыши: Возможности выиграть щедро зависят от умения принимать решения. Интерактивные Элементы: В игре Авиатор игра идет в настоящем времени.
Следите за Рисковыми Моментами: В игре Авиатор важно контролировать риски и выигрыши.
Следите за Поведением Множителя: Следите за тем, как растет множитель.
Воспользуйтесь Бонусами: Участвуйте в бонусах и акциях, для увеличения своих шансов.
The concept of online casinos gained traction in the mid-1990s, bringing a accessible solution to brick-and-mortar gambling locations. Over time, progress in tech have elevated online platforms into immersive settings, including stunning imagery, live gaming features, and flawless performance.
Today, the ability to use an virtual casino from virtually any device remains a key feature for gaming enthusiasts internationally.
Web-based gambling sites feature a variety of options, highlighting iconic games such as poker and blackjack, in addition to hundreds of slot games.
These systems offer users the ease of enjoying games in their living rooms or in any location, securing their place as preferred options among both entry-level and seasoned gamblers.
One of the most important developments in the field of online entertainment is the growth of mobile-friendly interfaces. Gambling apps are now a preferred method for engaging with online platforms, as a result of their player-oriented features and adapted functionalities.
Whether you are a hobbyist or a professional player, a dedicated casino app lets you experience your most-loved gaming experiences with just a few interactions on your smart device.
These apps aim to enhance a seamless gaming experience, with functionalities such as tailored suggestions for games, rapid fund transfers, and robust privacy features.
Web: https://tiger-fortune.netlify.app/
Players can get a APK for casino platforms—a file format for Android devices—to access platforms seamlessly when they are not listed on traditional application markets.
This versatility guarantees that players can maintain access to their top-choice gaming apps, whatever device compatibility they have.
Ao longo dos passados tempos, o mercado de games digitais tem experimentado um incremento impressionante, conquistando centenas de milhares de jogadores que procuram entretenimento e, ocasionalmente, a oportunidade de conquistar recompensas em dinheiro. Entre os jogos que vem atraindo grande popularidade, ganham visibilidade o <a href="https://fakenews.win/wiki/User:RitaBaldridge87">demo fortune mouse</a> e o Fortune Mouse, ambos oferecidos em diversas plataformas de jogo. Esses jogos proporcionam entretenimento alem de lazer, mas tambem a chance de ganhar recompensas para aqueles que demonstram habilidade, calma e uma porcao de sorte. A seguir, exploraremos as principais elementos desses games, incluindo suas mecanicas, os melhores horarios para jogar, recomendacoes para testar as demos e taticas para aumentar as chances de vitoria.
O Jogo do Ratinho e conhecido por sua facilidade de acesso e por proporcionar uma dinamica de jogo que mistura sorte e destreza. Esse jogo se fez especialmente popular entre os jogadores que buscam um jogo rapido e divertido, mas que tambem pode oferecer a possibilidade de obter algum dinheiro. Para quem e novo no jogo pela primeira vez, e muito indicado comecar pela modalidade demo do jogo do ratinho. A demo e uma versao gratis que da ao jogador experimentar o jogo, aprender as diretrizes, entender as mecanicas e ate mesmo desenvolver planos sem a necessidade de usar valores monetarios. Isso e muito conveniente para novos jogadores, que podem conhecer com o jogo antes de migrar para a versao que envolve valores. A demo tambem e muito util para usuarios avancados, pois permite a tentativa de novas taticas para aumentar as chances de vitoria.
Para aqueles que ja se sentem confiantes em sua capacidade de vencer, tem o jogo do ratinho para ganhar dinheiro, onde o usuario pode investir e, dependendo de sua performance e da fortuna, ganhar premios em dinheiro. E importante, no entanto, manter uma postura cuidadosa ao fazer apostas, lembrando que o principal objetivo do jogo e a diversao. Alem disso, uma dica valiosa e estabelecer um limite e mante-lo, sem ultrapassar o que pode arriscar.
Uma das duvidas que frequentemente surge entre os jogadores e quais os melhores horarios para o jogo do ratinho. Muitos jogadores creem que, de forma parecida com jogos de cassino ou em alternativas de apostas, ha um momento ideal para jogar. Em geral, esse tipo de abordagem recomenda jogar em momentos com menos jogadores, como de madrugada ou nas primeiras horas do dia. A ideia por dessa estrategia e que, em horarios de menor concorrencia, o mecanismo parece mais propenso a dar vitorias para preservar o interesse dos usuarios ativos. Embora nao seja um fato confirmado, e o resultado dos jogos muitas vezes seja aleatorio, muitos jogadores relatam vitorias em horarios de baixa concorrencia.
Web: https://fakenews.win/wiki/User:RitaBaldridge87
O Mouse Game Online representa uma excelente oportunidade para aqueles que gostam de jogar com facilidade e acessivel, a partir de qualquer dispositivo conectado a internet. Ao contrario dos cassinos fisicos, que requerem visita ao local, o Jogo do Ratinho online esta disponivel 24 horas por dia, e diversos portais contam com promocoes e desafios que podem melhorar as chances de vitoria. Dentro dessa modalidade, existe tambem a opcao de jogar o jogo do ratinho gratis, que e ideal para aqueles que buscam apenas diversao ou para aqueles que ainda estao aprendendo sobre o jogo. Essa alternativa sem custo permite um jogo descontraido, onde o usuario nao tem riscos monetarios, podendo treinar e se divertir sem comprometer o orcamento.
Para aqueles que desejam uma experiencia de aposta mais direta, o jogo do ratinho com investimentos possibilita que o jogador faca apostas com dinheiro real, com a expectativa de multiplicar o valor apostado. Embora essa modalidade seja empolgante, e essencial ter cuidado, pois a pratica de apostas sempre envolve riscos. Muitos jogadores aconselham iniciar com quantias menores e aumentar gradualmente, a medida que se adquire mais habilidade e seguranca. O principal e lembrar que a sorte tem um papel significativo no Jogo do Ratinho, e as apostas precisam ser realizadas com prudencia.
В случае, если жаждете увлекательную игру, которая точно обеспечит кучу эмоций и возможности выиграть крупно, то Авиатор - Взлет – ваш правильный выбор.
Что За Игра Авиатор?
<a href="https://www.gorchmirrors.com/onlaynkrash-igra-aviator-v-kazino/">игра авиатор</a> – это крутая краш игра, где ваш выигрыш в игре зависят от скорости решений и удачи в моменте. Суть игры в том, что вы делаете ставку и смотрите на самолет, который взлетает.
Как Играть в Авиатор? Играть в игру Авиатор очень просто. Вот этапы начала игры, которые помогут приступить к игре:
Сделайте Вашу Ставку: Введите сумму, которую вы готовы рискнуть. Помните, что важно ставить с умом.
Наблюдайте за Взлётом Самолета: После того как ставка установлена, на экране появится самолет, который взлетит. Множитель будет увеличиваться. Забирайте деньги: В любой момент, пока самолет в воздухе, вы можете забрать средства. Продолжите Игру: После завершения раунда вы можете сделать новую ставку и продолжить игру.
Зеркало сайта: https://www.gorchmirrors.com/onlaynkrash-igra-aviator-v-kazino/
Почему Стоит Выбрать Авиатор?
Увлекательный Геймплей: В Авиаторе каждое мгновение приносит эмоции. Простота и Легкость: Игра легка в освоении. Шансы на Победу: Возможности выиграть крупно зависят от вашей интуиции. Игровая Интерактивность: В игре Авиатор вы следите за процессом в реальном времени.
Следите за Рисками: В игре Авиатор важно обдуманно управлять рисками.
Отслеживайте Тенденции Множителя: Анализируйте, как ведет себя множитель в раундах.
Бонусные Возможности и Акции: Воспользуйтесь бонусах и акциях, которые помогут увеличить ваш выигрыш.
Understanding Stake Mines Game
Stake Mines is an incredibly engaging game that revolves around a clear-cut concept but can be quite complex. Players begin by setting a bet and then selecting tiles from a grid. The objective is to uncover all the clear tiles without landing on a mine. Each non-hazardous tile you uncover increases your winnings, but if you select a mine, the game ends, and you lose your money. The basic nature of the game is part of its appeal, but the true challenge lies in the planning needed. Players must predict which tiles are safe to uncover, weighing threat against potential reward.
The Stake Mines game is offered on various platforms, and its popularity continues to rise due to its fast-paced nature and the thrill of uncertainty. The uncertainty of which tile may hide a mine is part of what makes the game so exciting and offers a edge-of-your-seat experience for both rookies and seasoned players.
Stake Mines Strategy: The Key to Winning
A well-thought-out Stake Mines strategy can make the difference between achieving success and walking away with nothing. While luck plays a role, the key to success lies in how you handle the game. One popular approach is to start with a small bet and gradually raise your wager as you uncover safe tiles. This allows players to control potential losses and prolong their gameplay, increasing their chances of hitting a profitable streak.
Another strategy involves selecting a specific order in which to uncover the tiles. By following a predetermined grid path, players may sometimes boost their chances of avoiding mines. However, even with the best-laid strategy, it’s vital to remember that the game is based on luck, and no strategy can guarantee a win every time.
For those curious about how these bots work, a Stake Mines Predictor Bot Free version is often available for download. While these free bots may not be as advanced or sophisticated as their paid counterparts, they still claim to offer valuable insights into which tiles are safe to click. Players may experiment with these free tools to determine if they provide a significant advantage before upgrading to a more premium version.
The Allure of Stake Mines Hack
For some players, using a Stake Mines Hack represents an appealing shortcut to guaranteed winnings. Hacks refer to modified versions of the game or tools designed to change the game’s mechanics in favor of the player. These could involve adjusting the game’s algorithm, unlocking extra features, or even revealing the locations of mine-free tiles. However, using a hack comes with major risks. Firstly, many hacks are unstable, possibly introducing malware or harming your device. Secondly, hacking is a breach of most gaming platforms' terms of service, and players caught using hacks can be banned or suspended.
While this tool doesn’t guarantee success, it provides a way for players to weigh the risk and reward associated with each decision. Some calculators even use historical game data to adjust a player’s strategy based on past performance.
Stake Mines APK and Mod Versions
For those who enjoy trying out various game versions, the Stake Mines APK lets participants set up the game on their Android devices. APK packages allow people to bypass app store limitations and deploy customized or hacked versions of the game. These versions can offer enhanced features, additional functionalities, or even greater chances to succeed, but it’s important to obtain them from trusted sources to avoid malware or other issues.
Web: https://classifieds.ocala-news.com/author/asahatley6
Stake Mines Demo: Learning the Game Without Risk
If you're new to Stake Mines, the Stake Mines demo is a great way to test out the game’s mechanics without the financial risk. Many platforms offer demo versions of games, allowing players to refine their skills and strategies in a low-stakes environment. The Stake Mines demo mirrors the real game but without using real money, making it the perfect way to experiment before committing to real wagers.
Using the demo version helps players grasp the features and gameplay of the game without the worry of losing money. It’s a risk-free way to explore different strategies and decide how to approach the full game.
The development of digital gambling sites emerged in the mid-1990s, providing a accessible alternative to traditional gaming spots. Over time, innovations in technology have revolutionized online platforms into dynamic experiences, complete with stunning imagery, interactive dealer gameplay, and flawless performance.
Today, the possibility to visit an web-based casino from practically anywhere is a main highlight for gamblers around the globe.
Virtual gambling platforms offer a wide range of games, featuring timeless classics like roulette and poker, complemented by a myriad of slot machines.
These platforms make available for users the accessibility of playing from their homes or while traveling, turning them into favorites among both newcomer and experienced players.
One of the most remarkable changes in the digital gambling sector is the trend of handheld gameplay. Casino-focused software have become a top choice for engaging with online platforms, as a result of their player-oriented features and customized tools.
Whether you are a casual player or a strategic gamer, a specialized gaming app lets you experience your favorite games with just a few clicks on your smart device.
These apps focus on deliver a lag-free gambling interaction, with tools such as customized gambling options, fast transaction systems, and enhanced security measures.
Web: https://aviator-colombia.pages.dev
Players can download a Android gambling app—a file format for Android devices—to access platforms seamlessly when not found on popular download hubs.
This flexibility ensures that players can enjoy uninterrupted gaming to their beloved gambling hubs, despite their device preferences.
plataforma nova pagando fortune tiger</a> apresenta uma interface intuitiva e visualmente interessante.
Ganhos e Estrategias para o Fortune Tiger
O que chama a atencao no jogo e o alto potencial de lucro em curto periodo. As rodadas rapidas e com chances de ganho atraem jogadores em busca de recompensas rapidas.
Muitos jogadores combinam estrategias para maximizar o potencial de lucro. Uma estrategia bastante popular e a aposta progressiva. Nessa abordagem, o jogador comeca com valores baixos e aumenta aos poucos.
Saber quando apostar e quanto aumentar as apostas e uma habilidade importante. Os minutos pagantes sao uma excelente forma de maximizar os lucros. Os minutos pagantes sao muitas vezes aleatorios, mas podem ser melhor compreendidos por jogadores experientes.
Plataforma Fortune Tiger: Funcionalidades e Vantagens
Website: https://ki-ki.co.kr/bbs/board.php?bo_table=free&wr_id=16668
Conclusao Final
A plataforma oferece uma experiencia de jogo envolvente e acessivel para todos. Com muitas formas de ganhar, Fortune Tiger e uma das opcoes mais atrativas no mundo dos jogos de aposta online.
В том случае, если стремитесь найти азартную игру, что предоставит кучу эмоций и шансы на значительный выигрыш, то Авиатор – идеальный выбор для вас.
Что За Игра Авиатор?
<a href="https://lacollinaagriturismo.com/sizzling-hot-luxury-juega-gratis-online-la-tragamonedas/">авиатор</a> – это крутая краш игра, где ваш успех в игре зависят от быстроты мышления и удачи и удачи. Основная задача – вы делаете ставку и наблюдаете за тем, как самолет взлетает.
Как Управлять Игрой Авиатор? Играть в игру Авиатор не вызывает трудностей. Вот этапы начала игры, которые помогут стартовать в игре:
Установите Сумму Ставки: Введите сумму, которую вы готовы рискнуть. Помните, что ставить нужно с ответственностью.
Смотрите за Взлетом Самолета: После того как ставка размещена, на экране появится самолет, который взлетит. Ваш множитель будет расти. Берите выигрыш: В любой момент, пока самолет не исчез, вы можете взять выигрыш. Сделайте Новую Ставку: После завершения раунда вы можете сделать новую ставку и продолжить игру.
Зеркало сайта: https://lacollinaagriturismo.com/sizzling-hot-luxury-juega-gratis-online-la-tragamonedas/
Почему Выбирают Игру Авиатор?
Динамичный Геймплей: В Авиаторе каждое мгновение игры волнует. Простота и Доступность: Игра не требует глубоких знаний. Шансы на Большие Выигрыши: Возможности для крупных выигрышей зависят от ваших интуитивных решений. Реальное Время Игры: В игре Авиатор вы следите за процессом в реальном времени.
Управляйте Своими Рисками: В игре Авиатор важно управлять рисками и выигрышами.
Отслеживайте Множитель: Следите за тем, как растет множитель.
Используйте Акции и Бонусы: Не упустите бонусах и акциях, чтобы увеличить выигрышные шансы.
Understanding Stake Mines Game
Stake Mines is an incredibly immersive game that revolves around a easy concept but can be quite hard. Players kick off by setting a investment and then selecting tiles from a grid. The objective is to uncover all the hazard-free tiles without landing on a mine. Each mine-free tile you uncover increases your winnings, but if you select a mine, the game ends, and you lose your stake. The ease of the game is part of its appeal, but the true challenge lies in the tactics needed. Players must predict which tiles are safe to uncover, weighing threat against potential reward.
The Stake Mines game is offered on various platforms, and its popularity continues to rise due to its intense nature and the thrill of uncertainty. The surprise of which tile may hide a mine is part of what makes the game so exciting and offers a intense experience for both newcomers and seasoned players.
Stake Mines Strategy: The Key to Winning
A well-thought-out Stake Mines strategy can make the difference between winning and walking away with nothing. While luck plays a role, the key to success lies in how you approach the game. One popular approach is to start with a conservative bet and gradually raise your wager as you uncover safe tiles. This allows players to cut down on potential losses and prolong their gameplay, increasing their chances of hitting a profitable streak.
Another strategy involves selecting a specific sequence in which to uncover the tiles. By following a predetermined grid path, players may sometimes increase their chances of avoiding mines. However, even with the best-laid strategy, it’s vital to remember that the game is based on unpredictability, and no strategy can guarantee a win every time.
For those curious about how these bots work, a Stake Mines Predictor Bot Free version is often available for download. While these free bots may not be as advanced or sophisticated as their paid counterparts, they still claim to offer valuable insights into which tiles are safe to click. Players may experiment with these free tools to determine if they provide a significant advantage before upgrading to a more sophisticated version.
The Allure of Stake Mines Hack
For some players, using a Stake Mines Hack represents an appealing shortcut to guaranteed winnings. Hacks refer to modified versions of the game or tools designed to change the game’s mechanics in favor of the player. These could involve adjusting the game’s algorithm, unlocking extra features, or even revealing the locations of mine-free tiles. However, using a hack comes with major risks. Firstly, many hacks are dangerous, possibly introducing malware or harming your device. Secondly, hacking is a breach of most gaming platforms' terms of service, and players caught using hacks can be banned or suspended.
While this tool doesn’t guarantee success, it provides a way for players to weigh the risk and reward associated with each decision. Some calculators even use historical game data to adjust a player’s strategy based on past performance.
Stake Mines APK and Mod Versions
For those who enjoy trying out different game versions, the Stake Mines APK lets participants get the game on their Android devices. APK releases allow users to avoid app store constraints and deploy customized or tweaked versions of the game. These versions can offer enhanced features, additional functionalities, or even improved chances to succeed, but it’s important to download them from legitimate sources to avoid malware or other issues.
Web: http://maismile.co.kr/bbs/board.php?bo_table=notice&wr_id=291239
Stake Mines Demo: Learning the Game Without Risk
If you're new to Stake Mines, the Stake Mines demo is a great way to test out the game’s mechanics without the financial risk. Many platforms offer demo versions of games, allowing players to refine their skills and strategies in a low-stakes environment. The Stake Mines demo mirrors the real game but without using real money, making it the perfect way to gain experience before committing to real wagers.
Using the demo version helps players get a feel for the features and gameplay of the game without the worry of losing money. It’s a risk-free way to explore different strategies and decide how to approach the full game.
The emergence of online gaming hubs came into existence in the mid-1990s, introducing a convenient option to land-based establishments. Over time, modern technology have elevated online platforms into engaging environments, featuring realistic graphics, real-time dealer interactions, and seamless gameplay.
Today, the possibility to explore an online casino from virtually any device remains a key feature for gaming enthusiasts across the planet.
Virtual gambling platforms deliver a broad assortment of activities, featuring traditional games like blackjack and roulette, alongside a large array of slots.
These systems offer users the convenience of gambling from the comfort of their houses or from anywhere, turning them into favorites among both novice and veteran users.
One of the most important developments in the world of virtual casinos is the growth of mobile-friendly interfaces. Casino-focused software are now a common approach for playing on online platforms, thanks to their player-oriented features and tailored features.
Whether you are a hobbyist or a professional player, a reliable gambling application enables your access to your top-choice options with just a few steps on your mobile phone.
These apps are designed to ensure a flawless entertainment flow, with functionalities such as tailored suggestions for games, efficient deposit methods, and cutting-edge encryption.
Web: https://tiger-fortune-top.web.app/
Players can acquire a casino apk—a type of Android software—to use software without delay in cases where they're missing on mainstream app stores.
This adaptability allows that players can enjoy uninterrupted gaming to their most-used casino systems, regardless of their device's operating system.
A key benefit of <a href="https://funsilo.date/wiki/User:ZVNManuela">sweet bonanza pragmatic</a> is its unique approach to online slot play style. Unlike classic slot games that utilize payline systems, Sweet Bonanza features a "cluster pays" system. The title offers a 6x5 grid, giving participants numerous opportunities to land combinations with every spin. Wins come by landing clusters of eight matching matching figures anywhere on the grid, distinguishing it from regular slots that function through specific paylines.
The cluster pay system is not only pleasing to the eye but also provides users increased win opportunities in each spin.
This candy-inspired visual style and vivid colors add to the attraction of the game, creating a bright, cheerful setting that draws players in. Elements in the game consist of various candies in vibrant colors, as well as fruits like bananas, grapes, and watermelons. The aesthetic are supported by joyful music that contributes to the gaming excitement. The slot game also includes a scatter symbol in the form of a lollipop, which serves a key purpose in triggering the free rounds. When players collect four or more lollipops, the game will start the Free Spins mode, which delivers a major chance to win big.
Beginners to online slots or who want to try it out with no financial risk, the free Sweet Bonanza version delivers a suitable way. Numerous gaming sites feature a no-cost version of Sweet Bonanza, enabling players to experience the gameplay, experiment with tactics, and get comfortable with the slot’s elements without any investment. Experimenting with Sweet Bonanza demo is ideal for novices, as it enables understanding of the slot features, experiment with bet amounts, and discover the cascading reels.
Web: https://funsilo.date/wiki/User:ZVNManuela
This Tumble element, also known as the falling symbols feature, plays a major role in the game. Once players hit a winning cluster, the winning icons are removed, and new symbols fall into place, opening more winning possibilities. This feature not only enhances the excitement but also provides more win potential from a single play.
A key aspect of Sweet Bonanza is its bonus spin mode, which is typically the most exciting part for gamblers. The bonus spins in Sweet Bonanza can lead to substantial payouts due to the presence of multipliers. Upon activation, the free spin round provides 10 spins for free, and extra spins can be re-triggered by getting three extra scatters.
Если вы ищете увлекательную игру, способная дарит огромное количество эмоций и перспективы на большой выигрыш, то Авиатор игра – это то, что нужно.
Что Такое Игра Авиатор?
<a href="https://aliertanusta.com/aviator-onlayn-igra/">авиатор казино</a> – это впечатляющая краш игра, где ваш выигрыш в игре зависят от интуиции и скорости и удачи и интуиции. Основная задача – вы делаете ставку и следите за взлетом самолета.
Как Управлять Игрой Авиатор? Играть в игру Авиатор очень просто. Вот этапы начала игры, которые помогут вам начать играть:
Сделайте Вашу Ставку: Введите сумму, которую вы хотите вложить. Помните, что важно контролировать ставки.
Следите за Полётом Самолета: После того как ставка внесена, на экране появится самолет, который начнет свой полет. Множитель будет увеличиваться. Фиксируйте выигрыш: В любой момент, пока самолет взлетает, вы можете забрать средства. Повторите Игру: После завершения раунда вы можете начать новую игру.
Зеркало сайта: https://aliertanusta.com/aviator-onlayn-igra/
Почему Популярна Игра Авиатор?
Захватывающий Игровой Процесс: В Авиаторе каждый раунд захватывает. Простота и Легкость: Игра не требует глубоких знаний. Крупные Выигрыши: Возможности для крупных выигрышей зависят от вашей интуиции. Интерактивные Элементы: В игре Авиатор процесс идет в реальном времени.
Следите за Рисками: В игре Авиатор важно обдуманно управлять рисками.
Наблюдайте за Изменением Множителя: Анализируйте, как ведет себя множитель в раундах.
Воспользуйтесь Бонусами: Используйте бонусах и акциях, которые помогут увеличить ваш выигрыш.
Sweet Bonanza se distingue de otras opciones de juego por su atractivo y original diseno. Al abrir el juego, los apostadores son transportados a un mundo de dulces y colores brillantes que recuerdan a un cuento de hadas. El escenario esta repleto de confites, lo cual presenta un ambiente visual atractiva y divertida, ideal tanto para jugadores nuevos como para experimentados. Este slot ha sido muy bien valorado en las opiniones, ya que brinda emociones y una estetica llamativa para todos.
Una de las caracteristicas mas valoradas de este juego es su ronda de giros gratis, que se activa si se obtienen cuatro o mas simbolos de caramelos en cualquier lugar. Los giros gratis no solo permiten jugar sin gastar dinero adicional, sino que tambien incrementan las chances de obtener grandes premios, especialmente cuando los multiplicadores hacen su aparicion. Este elemento del juego es uno de los que mas atrae a los jugadores, y muchos senalan en sus resenas que la ronda de giros gratis es lo que mas entusiasma de Sweet Bonanza.
Ademas, Sweet Bonanza ha logrado mantener su popularidad gracias a su aplicabilidad universal. No importa si eres un jugador experimentado, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la disponibilidad de este titulo en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere divertirte mientras te desplazas, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: http://www.enrichedu.co.kr/bbs/board.php?bo_table=08_03_01&wr_id=241870
Otro punto que interesa a los jugadores es si realmente pueden ganar dinero con este juego. Al igual que en cualquier tragamonedas, Sweet Bonanza es un juego basado en el azar, lo cual significa que el resultado de cada tirada es totalmente azaroso y no puede ser anticipado. Sin embargo, los multiplicadores junto con giros gratis ofrecen una oportunidad significativa para obtener ganancias considerables. La funcion de los multiplicadores pueden multiplicar las ganancias hasta 100 veces, lo que puede generar premios grandes si los jugadores tienen suerte. Sin embargo, es importante recordar que hay que disfrutar del juego con moderacion y que no siempre se gana en cada ronda.
The idea of virtual gambling platforms originated in the mid-1990s, providing a comfortable alternative to physical gambling locations. Over time, digital improvements have evolved online platforms into captivating experiences, featuring stunning imagery, real dealer experiences, and uninterrupted action.
Today, the option to visit an online casino from virtually any device is a main highlight for gaming enthusiasts internationally.
Online casinos deliver a variety of entertainment choices, highlighting timeless classics like roulette and poker, complemented by numerous slot games.
These websites give enthusiasts the convenience of playing from their homes or on the go, establishing their popularity among both beginner and seasoned gamblers.
One of the most important developments in the online gaming industry is the rise of portable gaming. Gambling apps are increasingly a common approach for interacting with online platforms, due to their user-friendly interfaces and adapted functionalities.
Whether you are a casual player or a strategic gamer, a reliable gambling application brings you your top-choice options with just a few taps on your smart device.
These apps focus on deliver a flawless entertainment flow, with tools such as game selection based on preferences, fast transaction systems, and advanced safety protocols.
Web: https://bet-meta-crash.pages.dev/
Players can install a casino apk—a file format for Android devices—to gain instant access in cases where they're missing on mainstream app stores.
This flexibility allows that players can maintain access to their preferred digital casinos, regardless of their device's operating system.
Oyleyse, oyuncular bu oyunu nas?l oynayabilir? Sweet Bonanza’n?n tum detaylar?n? inceleyecegiz ve giris yapma yontemlerinden taktik ipuclar?na kadar her konuyu ele alacag?z.
Sweet Bonanza Nedir?
Bu oyun, cevrimici slot oyunlar? aras?nda ozel bir yere sahip olan bir slot oyunudur. Pragmatic Play’in sundugu bu slot oyunu, meyve ve seker ikonlar?yla doludur. Bu meyve ve seker sembolleri, renkli bir dunya yaratarak oyuncular? kendine ceker.
Bu rengarenk oyunun kendi mekanik sistemine sahip olmas? oyunculara farkl? bir deneyim sunuyor. Her kazancla birlikte yeni sembollerin eklenmesiyle, oyun surekli bir kazanc ak?s? sunar. Bu mekanik yap?yla birlikte, Sweet Bonanza, oyuncular?n surekli olarak kazanmas?n? saglar.
Sweet Bonanza kurallar? ve oynan?s?
Bu oyunun oynan?s tarz? diger slot oyunlar?ndan daha basit bir yap?ya sahiptir. oyun alan? 6x5 bir duzende yer al?r. Hedef, ayn? sembollerin belirli say?da yan yana gelmesiyle oyunda kazanc elde etmektir.
Oyunun bu sisteminde herhangi bir cizgi takip etme gereksinimi yoktur. Kazanc icin ayn? sembollerin toplanmas? yeterlidir. Kazanc saglanan semboller yok olup yerlerine yenileri gelir. Bu mekanizma sayesinde, tek bir turda birden fazla kazanc saglamak mumkundur.
Web: https://ratemywifey.com/author/yvalaverne/
Sweet Bonanza Demo: Oyunu Denemek Icin Ideal F?rsat
Bu oyunun en cok tercih edilen ozelliklerinden biri, oyuncular?n demo versiyonu deneme imkan?n?n olmas?d?r. Demo mod, oyuna yeni baslayanlar icin harika bir f?rsat sunar. Oyuncular, demo surum sayesinde oyunu ogrenebilirler.
Demo surum, yuksek degerli sembolleri ve oyunun ozelliklerini kesfetmek icin harika bir yontemdir. Bu modda, oyun stratejilerini risksiz bir sekilde deneyebilirsiniz. Demo surumu, oyunculara farkl? oyun stratejilerini deneme f?rsat? sunar.
Когда находитесь в поиске захватывающую и увлекательную игру, которая дарит огромное количество эмоций и шанс на крупные выигрыши, то Авиатор игра – именно то, что вам нужно.
О Чём Игра Авиатор?
<a href="https://alpssynergy.com/author/alpssynergy/page/5029/">aviator</a> – это крутая краш игра, где ваш успех в игре зависят от реакции и удачи и хладнокровия и удачи. Цель игры заключается в том, что вы ставите и смотрите, как самолет взлетает.
Как Управлять Игрой Авиатор? Играть в игру Авиатор не вызывает трудностей. Вот ключевые этапы, которые помогут вам начать играть:
Задайте Ставку: Введите сумму, которую вы готовы поставить. Помните, что важно контролировать ставки.
Наблюдайте за Взлётом Самолета: После того как ставка установлена, на экране появится самолет, который начнет свой полет. Множитель выигрыша будет расти. Забирайте деньги: В любой момент, пока самолет взлетает, вы можете забрать средства. Продолжите Игру: После завершения раунда вы можете начать новую игру.
Зеркало сайта: https://alpssynergy.com/author/alpssynergy/page/5029/
Что Привлекает в Игре Авиатор?
Динамичный Геймплей: В Авиаторе каждый момент полон эмоций. Доступность и Простота: Игра простая и доступная. Возможности для Крупных Побед: Возможности для крупных выигрышей зависят от вашей интуиции. Реальное Время Игры: В игре Авиатор вы следите за процессом в реальном времени.
Следите за Рисками: В игре Авиатор важно обдуманно управлять рисками.
Наблюдайте за Изменением Множителя: Анализируйте поведение множителя.
Воспользуйтесь Бонусами: Не пропустите бонусах и акциях, чтобы увеличить свои шансы на выигрыш.
Este slot se diferencia de otras maquinas tragamonedas por su diseno llamativo y unico. Al comenzar a jugar, los apostadores son llevados a un universo de caramelos y colores brillantes que recuerdan a un cuento de hadas. El fondo esta decorado con dulces, lo cual crea una imagen atractiva y tranquila, adaptada a todos los jugadores. Este juego ha sido muy bien valorado en las opiniones, ya que mezcla la emocion de ganar premios con un estilo visual atractivo para todos.
Una de las caracteristicas mas valoradas de este slot es su funcion de giros gratis, que se activa si se obtienen cuatro o mas simbolos de caramelos en cualquier lugar. El modo de giros sin costo no solo permiten disfrutar sin apostar mas dinero, sino que tambien potencian las probabilidades de grandes ganancias, especialmente cuando se activan los multiplicadores durante los giros. Este detalle del juego es uno de los mas atractivos a los jugadores, y muchos senalan en sus resenas que la caracteristica de giros gratuitos es lo mejor del juego.
Ademas, este juego ha logrado mantener su popularidad gracias a su posibilidad de adaptacion a diferentes tipos de jugadores. No importa si eres un jugador experimentado, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la disponibilidad de este titulo en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere jugar durante tus descansos, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: https://acheckeredpast.shop/juego-sweet-bonanza-todo-sobre-este-juego-sobre-este-emocionante-slot/
Otro punto que interesa a los jugadores es si es posible ganar dinero con Sweet Bonanza. Al igual que en cualquier tragamonedas, Sweet Bonanza es un juego basado en el azar, lo cual significa que el resultado de cada giro es basado en azar y no puede ser anticipado. Sin embargo, los multiplicadores y la funcion de giros gratuitos ofrecen una oportunidad significativa para obtener grandes premios. La funcion de los multiplicadores permiten multiplicar las ganancias hasta 100x, lo que puede resultar en una ganancia notable si se tiene suerte en el giro. Sin embargo, es importante recordar que siempre es importante jugar con responsabilidad y que no hay garantias de ganar en cada sesion.
The idea of virtual gambling platforms emerged in the early era of the internet, providing a user-friendly variation to brick-and-mortar gaming spots. Over time, technological advancements have evolved online platforms into engaging environments, equipped with lifelike visuals, live gaming features, and flawless performance.
Today, the capacity to engage with an online casino from a range of devices is one of the biggest draws for gaming enthusiasts internationally.
Digital gaming hubs feature a diverse selection of options, highlighting traditional games like blackjack and roulette, alongside hundreds of slot games.
These online hubs deliver to gamers the convenience of playing from their homes or from anywhere, making them a popular choice among both beginner and experienced players.
One of the most notable trends in the realm of internet-based gambling is the growth of mobile-friendly interfaces. Gambling apps are now a top choice for interacting with online platforms, thanks to their accessible layouts and unique enhancements.
Whether you are a hobbyist or a strategic gamer, a feature-rich casino software provides your top-choice options with just a few touches on your tablet.
These apps are built to provide a flawless entertainment flow, with features such as adaptive picks for players, efficient deposit methods, and high-level protections.
Web: https://india-aviator.web.app
Players can install a casino application file—a dedicated app setup for Android—to gain instant access in cases where they're missing on popular download hubs.
This flexibility provides that players can remain engaged to their beloved gambling hubs, irrespective of technical constraints.
Sweet Bonanza sobresale de otras slots por su diseno y tematica unicos. Al ingresar al slot, los fans se sumergen en un escenario de golosinas y colores brillantes que hacen pensar en un cuento de fantasia. El fondo de la pantalla esta lleno de golosinas, lo cual presenta un ambiente visual relajante y agradable, perfecta para principiantes y expertos. Sweet Bonanza ha sido reconocido por su adiccion positiva y entretenimiento, ya que brinda emociones y una estetica llamativa para todos.
Una de las caracteristicas mas valoradas de Sweet Bonanza es su funcion de giros gratis, que se activa al conseguir cuatro o mas simbolos de caramelos rosados en cualquier lugar de los carretes. La ronda de giros gratuitos no solo permiten jugar sin costo, sino que tambien multiplican las posibilidades de ganar grandes premios, especialmente cuando se activan los multiplicadores durante los giros. Este elemento del juego es uno de los mas emocionantes a los jugadores, y muchos comentan en sus opiniones que la funcion de giros gratis es lo que mas entusiasma de Sweet Bonanza.
Ademas, Sweet Bonanza ha logrado mantener su popularidad gracias a su posibilidad de adaptacion a diferentes tipos de jugadores. No importa si eres un principiante en las apuestas online, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la adaptabilidad de Sweet Bonanza en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere apostar desde tu telefono movil, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: http://web068.dmonster.kr/bbs/board.php?bo_table=notice&wr_id=267209
Otro punto que interesa a los jugadores es si es posible ganar dinero con Sweet Bonanza. Al igual que en cualquier tragamonedas, la tragamonedas Sweet Bonanza es una maquina de azar, lo cual significa que el resultado de cada giro es aleatorio y no puede ser predicho. Sin embargo, los multiplicadores y las rondas de giros gratis ofrecen una oportunidad significativa para obtener premios importantes. La funcion de los multiplicadores permiten multiplicar las ganancias hasta 100x, lo que puede generar premios grandes si los jugadores tienen suerte. Sin embargo, es importante recordar que se debe jugar con responsabilidad y que el exito no esta asegurado en todos los giros.
Если вы желаете азартную игру, которая даст кучу эмоций и шанс на крупные выигрыши, то игра Авиатор – идеальный выбор для вас.
Что Такое Игра Авиатор?
<a href="https://www.thaiheadlines.com/156337/">aviator игра официальный сайт</a> – это впечатляющая краш игра, где ваш победа и достижения зависят от способности быстро принимать решения и везения. Игра заключается в том, что вы делаете ставку и смотрите на самолет, который взлетает.
Как Управлять Игрой Авиатор? Играть в игру Авиатор достаточно легко. Вот основные шаги, которые облегчат начало игры:
Выберите Сумму Ставки: Введите сумму, которую вы готовы рискнуть. Помните, что ставьте осознанно.
Ожидайте Взлета Самолета: После того как ставка внесена, на экране появится самолет, который покажет взлет. Ваш множитель будет расти. Фиксируйте выигрыш: В любой момент, пока самолет в полете, вы можете забрать выигрыш. Сделайте Новую Ставку: После завершения раунда вы можете начать новую игру.
Зеркало сайта: https://www.thaiheadlines.com/156337/
Что Привлекает в Игре Авиатор?
Захватывающий Игровой Процесс: В Авиаторе каждый момент полон эмоций. Легкость и Удобство: Игра легко понятна. Возможности для Крупных Побед: Возможности для значительных побед зависят от вашего подхода и интуиции. Интерактивность и Реальное Время: В игре Авиатор вы следите за процессом в реальном времени.
Следите за Рисковыми Моментами: В игре Авиатор важно управлять рисками и выигрышами.
Наблюдайте за Изменением Множителя: Анализируйте, как ведет себя множитель в раундах.
Пользуйтесь Бонусами и Акциями: Используйте бонусах и акциях, которые помогут увеличить ваш выигрыш.
Como Ganhar Mais no Fortune Tiger
O potencial de lucro em curto prazo faz do Tigrinho uma opcao popular. O jogo oferece recompensas rapidas para quem busca lucros imediatos.
Para maximizar as chances, muitos utilizam metodos especificos de aposta. Apostadores frequentemente recorrem a estrategia de apostas progressivas. O jogador vai aumentando as apostas progressivamente, comecando com valores baixos.
A gestao do tempo durante as apostas tambem influencia diretamente os lucros. Saber quando o jogo esta mais propenso a pagar altos premios pode ser decisivo. Identificar os minutos mais rentaveis exige pratica, mas e uma habilidade essencial para os apostadores.
Vantagens da Plataforma Fortune Tiger
Website: https://www.dinoautoricambi.it/?attachment_id=3045
Fechamento
Fortune Tiger e um jogo que combina diversao, estrategia e oportunidades de ganhos. Com sua interface amigavel e sistema de pagamentos confiavel, o jogo e ideal para qualquer apostador.
The notion of internet-based casinos came into existence in the late 20th century, offering a user-friendly option to brick-and-mortar venues. Over time, technological advancements have transformed online platforms into immersive settings, complete with stunning imagery, live gaming features, and lag-free experiences.
Today, the possibility to visit an digital gambling site from virtually any device remains a key feature for gamblers everywhere.
Internet casinos feature a broad assortment of entertainment choices, ranging from well-known options like roulette and poker, complemented by countless slots.
These platforms make available for users the accessibility of participating from any cozy spot or in any location, securing their place as preferred options among both newcomer and experienced players.
One of the most important developments in the realm of internet-based gambling is the shift to mobile-first platforms. Casino apps have become a popular way for playing on online platforms, owing to their simple navigation and adapted functionalities.
Whether you are a hobbyist or a high-stakes bettor, a reliable gambling application brings you your top-choice options with just a few touches on your smart device.
These apps focus on enhance a seamless gaming experience, with tools such as adaptive picks for players, instant payout solutions, and cutting-edge encryption.
Web: https://bac-bo.pages.dev/
Players can get a Android gambling app—a specific Android tool—to set up applications instantly should they not be accessible on official app stores.
This flexibility ensures that players can continue their sessions to their beloved gambling hubs, whatever device compatibility they have.
Gry hazardowe online zdobywaja rosnace zainteresowanie w Polsce, a jedna z platform, ktora jest na ustach wszystkich, jest <a href="http://mail.clicksordirectory.com/details.php?id=440031">bet on red</a>. To platforma hazardowa online, ktore slynie z bogatej ofercie gier, inteligentnym designem oraz kuszacymi ofertami, ktore zachwyca zarowno osoby nowe w swiecie hazardu, jak i weteranow gier.
Czym wyroznia sie Bet On Red?
Bet On Red Casino to platforma online, ktora oferuje roznorodne opcje rozrywki, takich jak automaty, klasyczne gry kasynowe oraz transmisje na zywo z gier. Juz sama nazwa „Bet On Red" odzwierciedla adrenaline i hazardowe napiecie.
Proces logowania w Kasynie Bet On Red
Sposob na rozpoczecie gry w Red On Bet Casino jest intuicyjny i nieskomplikowany. Po przejsciu na strone kasyna, wystarczy wybrac funkcje logowania i wprowadzic dane konta. Bet On Red Casino zapewnia ochrone danych, dlatego wszelkie dane uzytkownika sa chronione.
Osoby rejestrujace sie po raz pierwszy moga bez problemu dolaczyc do platformy, a rejestracja zajmuje zaledwie kilka minut. Co istotne, Kasyno Bet On Red oferuje wygodne formy wplat i wyplat, co sprawia, ze korzystanie z platformy jest proste.
Roznorodnosc gier w Bet On Red
Cecha, ktora przyciaga graczy, kazdego portalu hazardowego, jest oferta gier. Kasyno Bet On Red oferuje szerokim wachlarzem, ktory przyciagnie milosnikow roznych gatunkow gier.
Web: http://mail.clicksordirectory.com/details.php?id=440031
Automaty sa uwielbiane przez graczy, dostepne w licznych motywach oraz z roznorodnymi mechanikami gry. Oprocz najpopularniejszych maszyn, uzytkownicy moga rozegrac partie w gry stolowe, takie jak ruletka.
В том случае, если ищете захватывающую игру, которая точно даст массу эмоций и шанс на крупные выигрыши, то Авиатор - Взлет – то, что сделает ваш день.
Что Такое Игра Авиатор?
<a href="https://lacollinaagriturismo.com/how-to-end-caring-about-that-guy-who-willnt-worry-about-you/">авиатор</a> – это захватывающая игра, где ваш победа и достижения зависят от интуиции и скорости и удачи. Игра заключается в том, что вы делаете ставку и смотрите на самолет, который взлетает.
Как Управлять Игрой Авиатор? Играть в игру Авиатор достаточно легко. Вот ключевые этапы, которые помогут начать игру:
Выберите Сумму Ставки: Введите сумму, которую готовы ставить. Помните, что всегда ставьте с умом.
Следите за Взлетом Самолета: После того как ставка выбрана, на экране появится самолет, который начнет подниматься. Множитель выигрыша будет расти. Забирайте Ваш Выигрыш: В любой момент, пока самолет взлетает, вы можете забрать средства. Начните Новую Игру: После завершения раунда вы можете сделать новую ставку.
Зеркало сайта: https://lacollinaagriturismo.com/how-to-end-caring-about-that-guy-who-willnt-worry-about-you/
Что Привлекает в Игре Авиатор?
Захватывающий Геймплей: В Авиаторе каждый момент полон эмоций. Простота и Доступность: Игра легко освоить. Шансы на Победу: Возможности для крупных выигрышей зависят от умения принимать решения. Взаимодействие в Реальном Времени: В игре Авиатор всё происходит в реальном времени.
Управляйте Рискованностью: В игре Авиатор важно обдуманно управлять рисками.
Наблюдайте за Изменением Множителя: Пробуйте анализировать поведение множителя в игре.
Бонусные Возможности и Акции: Участвуйте в бонусах и акциях, чтобы увеличить свои шансы на выигрыш.
Como Otimizar os Ganhos no Jogo de Tigrinho
O Fortune Tiger atrai muitos por sua chance de ganhos elevados em rodadas rapidas. A chance de premios em cada rodada faz do jogo uma escolha interessante para apostadores.
Muitos jogadores combinam estrategias para maximizar o potencial de lucro. Uma das estrategias preferidas e a aposta gradual. Essa tatica permite comecar apostando baixo e ir aumentando gradualmente.
Apostadores habilidosos sabem escolher os momentos estrategicos para realizar suas apostas. Os minutos pagantes sao uma boa dica para os jogadores. Esses momentos de maiores ganhos sao imprevisiveis, mas com pratica e possivel identifica-los.
Apostas e Recursos da Plataforma Fortune Tiger
Website: http://hyeonhae.co.kr/bbs/board.php?bo_table=helpdesk2&wr_id=119389
Encerramento
O Jogo do Tigrinho oferece uma experiencia rica e cheia de possibilidades. Em resumo, Fortune Tiger e uma plataforma que entrega uma experiencia rica e cheia de possibilidades de ganhos.
The idea of virtual gambling platforms originated in the early era of the internet, offering a accessible option to brick-and-mortar gambling locations. Over time, innovations in technology have evolved online platforms into dynamic spaces, including realistic graphics, live gaming features, and lag-free experiences.
Today, the ability to access an online casino from virtually any device is one of the biggest draws for gamblers everywhere.
Online casinos offer a broad assortment of entertainment choices, featuring timeless classics like roulette and poker, together with a large array of slots.
These systems deliver to gamers the accessibility of gaming at home or while mobile, turning them into favorites among both entry-level and long-time enthusiasts.
One of the most notable trends in the field of online entertainment is the move toward mobile gaming. Mobile casino applications are now a popular way for accessing online platforms, because of their accessible layouts and unique enhancements.
Whether you are a leisure bettor or a professional player, a dedicated casino app allows you to enjoy your beloved activities with just a few taps on your portable device.
These apps are designed to enhance a lag-free gambling interaction, with features such as adaptive picks for players, rapid fund transfers, and advanced safety protocols.
Web: https://top-tiger-fortune.netlify.app/
Players can acquire a mobile gaming APK—a type of Android software—to install apps directly when they are not listed on popular download hubs.
This flexibility provides that players can always stay connected to their beloved gambling hubs, irrespective of technical constraints.
Fortune Tiger: Estrategias para Ganhos
O atrativo principal do jogo e a chance de premios elevados com rodadas breves. Com cada aposta, o jogador tem uma chance real de lucro significativo.
Para maximizar as chances, muitos utilizam metodos especificos de aposta. A tecnica da aposta progressiva e amplamente utilizada. Esse metodo consiste em comecar com apostas pequenas e aumenta-las com o tempo.
A gestao do tempo durante as apostas tambem influencia diretamente os lucros. Os minutos pagantes sao uma boa dica para os jogadores. Esses momentos de maiores ganhos sao imprevisiveis, mas com pratica e possivel identifica-los.
Plataforma Fortune Tiger: Beneficios para o Jogador
Website: https://webguiding.1directory.org/ganhos-no-fortune-tiger_287682.html
Encerramento
O jogo e uma excelente opcao para quem busca tanto diversao quanto ganhos reais. Com muitas formas de ganhar, Fortune Tiger e uma das opcoes mais atrativas no mundo dos jogos de aposta online.
Если вы ищете захватывающую игру, которая точно подарит огромное количество эмоций и шансы на значительный выигрыш, то игра Авиатор – именно то, что вам нужно.
Что За Игра Авиатор?
<a href="https://ivf-kyono.com/news/info/page/9/">авиатор казино</a> – это инновационная игра, где ваш успех в игре зависят от реакции и удачи и хладнокровия и удачи. Цель игры заключается в том, что вы делаете ставку и смотрите на самолет, который взлетает.
Как Играть в Авиатор? Играть в игру Авиатор не вызывает трудностей. Вот этапы начала игры, которые помогут начать игру:
Задайте Ставку: Введите сумму, которую готовы ставить. Помните, что важно ставить с умом.
Ожидайте Взлета Самолета: После того как ставка установлена, на экране появится самолет, который начнет свой полет. Величина множителя начнет увеличиваться. Забирайте Ваши средства: В любой момент, пока самолет в полете, вы можете зафиксировать выигрыш. Повторите Игру: После завершения раунда вы можете сделать новую ставку и продолжить игру.
Зеркало сайта: https://ivf-kyono.com/news/info/page/9/
Почему Стоит Выбрать Авиатор?
Увлекательный Геймплей: В Авиаторе каждое мгновение игры волнует. Простота и Легкость: Игра простая и доступная. Шансы на Победу: Возможности выиграть щедро зависят от вашего подхода и интуиции. Реальное Время Игры: В игре Авиатор вы играете в реальном времени.
Следите за Рисковыми Моментами: В игре Авиатор важно не только выигрывать, но и контролировать риски.
Наблюдайте за Изменением Множителя: Пробуйте анализировать поведение множителя в игре.
Получайте Бонусы и Акции: Не пропустите бонусах и акциях, которые помогут увеличить ваш выигрыш.
tigrinho site</a> apresenta uma interface intuitiva e visualmente interessante.
Como Otimizar os Ganhos no Jogo de Tigrinho
O jogo se diferencia por suas oportunidades de lucro rapido e significativo. A chance de premios em cada rodada faz do jogo uma escolha interessante para apostadores.
Os apostadores desenvolvem taticas para tornar o jogo mais lucrativo. A tecnica da aposta progressiva e amplamente utilizada. Nessa abordagem, o jogador comeca com valores baixos e aumenta aos poucos.
Saber quando apostar e quanto aumentar as apostas e uma habilidade importante. Saber quando o jogo esta mais propenso a pagar altos premios pode ser decisivo. Esses periodos de pagamento mais elevados ocorrem aleatoriamente, mas jogadores experientes sabem como identifica-los.
Entenda como funciona a plataforma de Fortune Tiger
Website: https://imoodle.win/wiki/User:PedroVogler6
Encerramento
A plataforma oferece uma experiencia de jogo envolvente e acessivel para todos. Ao jogar no Fortune Tiger, o jogador tem a chance de se divertir enquanto busca grandes premios.
The emergence of online gaming hubs emerged in the mid-1990s, delivering a easy-to-reach substitute to physical venues. Over time, technological advancements have evolved online platforms into engaging spaces, featuring stunning imagery, live dealer options, and seamless gameplay.
Today, the opportunity to explore an internet casino from practically anywhere is a significant advantage for gaming enthusiasts internationally.
Web-based gambling sites deliver a variety of options, highlighting classics like blackjack, roulette, and poker, as well as hundreds of slot games.
These systems give enthusiasts the comfort of playing from their homes or while mobile, establishing their popularity among both beginner and veteran users.
One of the most notable trends in the realm of internet-based gambling is the growth of mobile-friendly interfaces. Gambling apps are increasingly a popular way for engaging with online platforms, because of their user-friendly interfaces and customized tools.
Whether you are a casual player or a professional player, a feature-rich casino software provides your most-loved gaming experiences with just a few touches on your smart device.
These apps are designed to enable a flawless entertainment flow, with tools such as tailored suggestions for games, rapid fund transfers, and cutting-edge encryption.
Web: https://juego-aviator.github.io/
Players can acquire a Android gambling app—a specific Android tool—to use software without delay if they are unavailable on traditional application markets.
This ease ensures that players can always stay connected to their favorite gaming platforms, despite their device preferences.
Ao longo dos passados anos, o setor de jogos virtuais tem experimentado um crescimento notavel, conquistando milhoes de pessoas que buscam diversao e, em alguns casos, a possibilidade de ganhar premios em especie. Entre os jogos que vem atraindo grande aceitacao, sobressaem-se o <a href="http://adbritedirectory.com/Jogo-do-Ratinho_527090.html">qual o melhor horario para jogar fortune mouse</a> e o Fortune Mouse, ambos disponibilizados em varias plataformas online. Essas opcoes oferecem mais do que diversao, mas tambem a potencialidade de conquistar premios para aqueles que demonstram habilidade, disciplina e uma porcao de sorte. Abaixo, abordaremos as caracteristicas mais importantes caracteristicas desses jogos, compreendendo seus funcionamentos, os horarios mais propicios para jogar, recomendacoes para testar as demos e planos para incrementar o sucesso.
O Jogo do Ratinho e famoso por sua disponibilidade e por trazer uma dinamica de jogo que integra sorte e destreza. Esse jogo se fez especialmente bem aceito entre o publico de jogos que desejam um passatempo rapido e leve, mas que tambem pode trazer a possibilidade de ganhar algum montante. Para quem esta conhecendo jogo pela primeira vez, e altamente recomendavel comecar pela versao demo do jogo do ratinho. A demonstracao e uma modalidade gratuita que da ao jogador testar o jogo, entender as regras, entender as mecanicas e ate mesmo desenvolver planos sem que seja preciso investir dinheiro. Isso e particularmente vantajoso para novos jogadores, que podem conhecer com o jogo antes de migrar para a versao que envolve valores. A demonstracao tambem e excelente para aqueles com mais pratica, pois permite a elaboracao e experimentacao de novas estrategias para incrementar as possibilidades de sucesso.
Para aqueles que se acham preparados em sua habilidade de ganhar, tem o jogo do ratinho com premios em dinheiro, onde o jogador pode apostar e, a partir de sua habilidade e da sorte, ganhar premios em dinheiro. E importante, no entanto, jogar de forma consciente ao investir, lembrando que o principal objetivo do jogo e a diversao. Alem disso, uma dica valiosa e estabelecer um limite e respeita-lo, sem ultrapassar o que pode arriscar.
Uma das questoes que e comum entre os jogadores e qual o melhor horario para jogar o jogo do ratinho. Muitos jogadores creem que, de forma parecida com jogos de apostas ou em tipos de aposta esportiva, existe um horario mais propicio para jogar. Em geral, esse tipo de estrategia recomenda jogar em momentos com menos jogadores, como na madrugada ou nas primeiras horas do dia. A razao por dessa estrategia e que, em momentos com menos atividade, o mecanismo pode apresentar mais oportunidades de vitoria para estimular a participacao dos jogadores. Embora nao haja garantias, e o resultado dos jogos muitas vezes dependa de sorte, muitos jogadores compartilham historias de sucesso associadas a esses horarios alternativos.
Web: http://adbritedirectory.com/Jogo-do-Ratinho_527090.html
O Mouse Game Online representa uma excelente oportunidade para aqueles que preferem jogar de forma pratica e acessivel, a partir de qualquer dispositivo conectado a internet. Ao contrario dos cassinos fisicos, que necessitam de deslocamento, o Jogo do Ratinho pode ser jogado em qualquer momento, e varias plataformas disponibilizam promocoes exclusivas que podem incrementar os premios. Dentro dessa opcao, tambem ha a versao do jogo do ratinho gratuita, perfeita para quem quer so se entreter ou para novatos. Essa opcao gratuita permite um passatempo leve, onde o jogador nao corre riscos financeiros, podendo praticar e passar o tempo sem dano ao bolso.
Para aqueles que buscam uma experiencia de aposta mais intensa, o game do ratinho com aposta possibilita que o jogador faca apostas com dinheiro real, com a chance de duplicar o valor jogado. Apesar de essa opcao ser animadora, e essencial ter cuidado, pois apostas implicam riscos. Muitos jogadores experientes recomendam comecar com apostas baixas e ir subindo aos poucos, a medida que se ganha mais confianca e entendimento sobre o jogo. O principal e manter em mente o papel da sorte no Jogo do Ratinho, e as apostas devem sempre considerar o risco.
Когда вы ищете захватывающую и увлекательную игру, способная предоставит кучу эмоций и перспективы на большой выигрыш, то Авиатор игра – это то, что нужно.
Что Такое Игра Авиатор?
<a href="https://lacollinaagriturismo.com/finest-internet-casino-australian-continent-au-real-cash-gambling-enterprises-2024/">aviator игра</a> – это захватывающая игра, где ваш выигрыш в игре зависят от реакции и удачи и везения. Основная задача – вы ставите и смотрите, как самолет взлетает.
Как Играть в Авиатор? Играть в игру Авиатор достаточно легко. Вот этапы начала игры, которые помогут приступить к игре:
Задайте Ставку: Введите сумму, которую вы готовы поставить. Помните, что ставить нужно с ответственностью.
Смотрите за Взлетом Самолета: После того как ставка выбрана, на экране появится самолет, который начнет набирать высоту. Ваш множитель будет расти. Фиксируйте выигрыш: В любой момент, пока самолет взлетает, вы можете забрать выигрыш. Повторите Игру: После завершения раунда вы можете начать новую игру.
Зеркало сайта: https://lacollinaagriturismo.com/finest-internet-casino-australian-continent-au-real-cash-gambling-enterprises-2024/
Почему Стоит Играть в Авиатор?
Интересный Геймплей: В Авиаторе каждый момент полон эмоций. Легкость и Удобство: Игра легка в освоении. Шансы на Победу: Возможности выиграть крупно зависят от ваших решений и удачи. Интерактивность и Реальное Время: В игре Авиатор всё происходит в реальном времени.
Следите за Рисковыми Моментами: В игре Авиатор важно не только выигрывать, но и контролировать риски.
Отслеживайте Множитель: Анализируйте, как ведет себя множитель в раундах.
Используйте Акции и Бонусы: Воспользуйтесь бонусах и акциях, для увеличения своих шансов.
Understanding Stake Mines Game
Stake Mines is an incredibly engaging game that revolves around a straightforward concept but can be quite tough. Players begin by making a bet and then selecting tiles from a grid. The objective is to uncover all the clear tiles without landing on a mine. Each non-hazardous tile you uncover increases your winnings, but if you select a mine, the game ends, and you lose your bet. The basic nature of the game is part of its appeal, but the true challenge lies in the planning needed. Players must predict which tiles are safe to uncover, weighing danger against potential reward.
The Stake Mines game is offered on various platforms, and its popularity continues to rise due to its fast-paced nature and the thrill of uncertainty. The surprise of which tile may hide a mine is part of what makes the game so exciting and offers a edge-of-your-seat experience for both inexperienced and seasoned players.
Stake Mines Strategy: The Key to Winning
A well-thought-out Stake Mines strategy can make the difference between coming out ahead and walking away with nothing. While luck plays a role, the key to success lies in how you handle the game. One popular approach is to start with a modest bet and gradually raise your wager as you uncover safe tiles. This allows players to control potential losses and prolong their gameplay, increasing their chances of hitting a profitable streak.
Another strategy involves selecting a specific pattern in which to uncover the tiles. By following a predetermined grid path, players may sometimes boost their chances of avoiding mines. However, even with the best-laid strategy, it’s vital to remember that the game is based on chance, and no strategy can guarantee a win every time.
For those curious about how these bots work, a Stake Mines Predictor Bot Free version is often available for download. While these free bots may not be as advanced or sophisticated as their paid counterparts, they still claim to offer valuable insights into which tiles are safe to click. Players may experiment with these free tools to determine if they provide a significant advantage before upgrading to a more sophisticated version.
The Allure of Stake Mines Hack
For some players, using a Stake Mines Hack represents an appealing shortcut to guaranteed winnings. Hacks refer to modified versions of the game or tools designed to change the game’s mechanics in favor of the player. These could involve manipulating the game’s algorithm, unlocking extra features, or even revealing the locations of mine-free tiles. However, using a hack comes with major risks. Firstly, many hacks are unreliable, possibly introducing malware or harming your device. Secondly, hacking is a breach of most gaming platforms' terms of service, and players caught using hacks can be banned or suspended.
While this tool doesn’t guarantee success, it provides a way for players to weigh the risk and reward associated with each decision. Some calculators even use historical game data to adjust a player’s strategy based on past performance.
Stake Mines APK and Mod Versions
For those who enjoy trying out various game versions, the Stake Mines APK lets users download the game on their Android devices. APK versions allow people to avoid app store constraints and load customized or hacked versions of the game. These versions can offer enhanced features, additional functionalities, or even extra chances to succeed, but it’s important to acquire them from safe sources to avoid malware or other issues.
Web: https://acheckeredpast.shop/complete-mines-game-guide-strategies-hacks-demos-and-downloads/
Stake Mines Demo: Learning the Game Without Risk
If you're new to Stake Mines, the Stake Mines demo is a great way to learn the game’s mechanics without the financial risk. Many platforms offer demo versions of games, allowing players to refine their skills and strategies in a low-stakes environment. The Stake Mines demo mirrors the real game but without using real money, making it the perfect way to gain experience before committing to real wagers.
Using the demo version helps players comprehend the features and gameplay of the game without the worry of losing money. It’s a risk-free way to explore different strategies and decide how to approach the full game.
The development of digital gambling sites gained traction in the early era of the internet, bringing a user-friendly variation to land-based establishments. Over time, progress in tech have transformed online platforms into captivating experiences, featuring stunning imagery, real dealer experiences, and uninterrupted action.
Today, the capacity to engage with an online casino from any modern device is a main highlight for gaming enthusiasts internationally.
Virtual gambling platforms provide a diverse selection of activities, featuring well-known options like roulette and poker, in addition to a large array of slots.
These online hubs deliver to gamers the ease of enjoying games in their living rooms or while mobile, establishing their popularity among both novice and seasoned gamblers.
One of the most transformative aspects in the field of online entertainment is the move toward mobile gaming. Gambling apps have turned into a top choice for using online platforms, thanks to their player-oriented features and adapted functionalities.
Whether you are a entertainment seeker or a serious gambler, a reliable gambling application lets you experience your favorite games with just a few interactions on your tablet.
These apps feature tools that enhance a lag-free gambling interaction, with functionalities such as game selection based on preferences, instant payout solutions, and robust privacy features.
Web: https://table-craps.web.app
Players can acquire a APK for casino platforms—a type of Android software—to access platforms seamlessly should they not be accessible on common mobile platforms.
This ease makes certain that players can always stay connected to their favorite gaming platforms, irrespective of technical constraints.
jogo fortune tiger</a> oferece uma experiencia visual atraente e envolvente.
Dicas de Sucesso para o Fortune Tiger
O atrativo principal do jogo e a chance de premios elevados com rodadas breves. Com potencial de premios em cada rodada, o jogo se torna emocionante e vantajoso.
Alguns jogadores tem metodos proprios para melhorar os resultados. Muitos jogadores utilizam a estrategia de aumentar gradualmente as apostas. O jogador vai aumentando as apostas progressivamente, comecando com valores baixos.
O timing das apostas pode ser um diferencial crucial para maximizar os ganhos. Esses momentos oferecem as maiores probabilidades de premios significativos. Esses periodos de pagamento mais elevados ocorrem aleatoriamente, mas jogadores experientes sabem como identifica-los.
Como Funciona a Plataforma do Jogo Fortune Tiger
Website: https://mail.ask-directory.com/qual-plataforma-est%C3%A1-pagando-agora-fortune-tiger_403487.html
Conclusao Final
A plataforma oferece uma experiencia de jogo envolvente e acessivel para todos. Com sua interface amigavel e sistema de pagamentos confiavel, o jogo e ideal para qualquer apostador.
Когда вы желаете захватывающую игру, что дарит много шансов и возможности выиграть крупно, то Авиатор игра – ваш правильный выбор.
Что Такое Игра Авиатор?
<a href="https://lacollinaagriturismo.com/1-euroletten-kasino-einlosen-angeschlossen-as-part-of-das-confoederatio-helvetica-2024/">игра авиатор</a> – это захватывающая игра, где ваш успех в игре зависят от скорости решений и удачи. Суть игры в том, что вы делаете ставку и наблюдаете за тем, как самолет взлетает.
Как Управлять Игрой Авиатор? Играть в игру Авиатор достаточно легко. Вот этапы начала игры, которые помогут начать игру:
Сделайте Вашу Ставку: Введите сумму, которую вы готовы рискнуть. Помните, что ставить нужно с ответственностью.
Смотрите за Взлетом Самолета: После того как ставка размещена, на экране появится самолет, который начнет набирать высоту. Множитель выигрыша будет расти. Забирайте деньги: В любой момент, пока самолет не исчез, вы можете забрать средства. Начните Новую Игру: После завершения раунда вы можете сделать новую ставку.
Зеркало сайта: https://lacollinaagriturismo.com/1-euroletten-kasino-einlosen-angeschlossen-as-part-of-das-confoederatio-helvetica-2024/
Почему Стоит Играть в Авиатор?
Увлекательный Геймплей: В Авиаторе каждое мгновение игры волнует. Доступность и Простота: Игра не требует глубоких знаний. Большие Победы: Возможности для значительных побед зависят от ваших решений и удачи. Интерактивные Элементы: В игре Авиатор всё происходит в реальном времени.
Контролируйте Риски: В игре Авиатор важно выигрывать с учетом рисков.
Наблюдайте за Изменением Множителя: Анализируйте поведение множителя.
Используйте Акции и Бонусы: Участвуйте в бонусах и акциях, для увеличения своих шансов.
Understanding Stake Mines Game
Stake Mines is an incredibly exciting game that revolves around a basic concept but can be quite difficult. Players embark on by putting a gamble and then selecting tiles from a grid. The objective is to uncover all the hazard-free tiles without landing on a mine. Each non-hazardous tile you uncover increases your winnings, but if you select a mine, the game ends, and you lose your money. The clarity of the game is part of its appeal, but the true challenge lies in the tactics needed. Players must predict which tiles are safe to uncover, weighing risk against potential reward.
The Stake Mines game is offered on various platforms, and its popularity continues to rise due to its fast-paced nature and the thrill of uncertainty. The randomness of which tile may hide a mine is part of what makes the game so exciting and offers a risky experience for both beginners and seasoned players.
Stake Mines Strategy: The Key to Winning
A well-thought-out Stake Mines strategy can make the difference between winning and walking away with nothing. While luck plays a role, the key to success lies in how you deal with the game. One popular approach is to start with a conservative bet and gradually escalate your wager as you uncover safe tiles. This allows players to minimize potential losses and prolong their gameplay, increasing their chances of hitting a profitable streak.
Another strategy involves selecting a specific sequence in which to uncover the tiles. By following a predetermined grid path, players may sometimes raise their chances of avoiding mines. However, even with the best-laid strategy, it’s vital to remember that the game is based on unpredictability, and no strategy can guarantee a win every time.
For those curious about how these bots work, a Stake Mines Predictor Bot Free version is often available for download. While these free bots may not be as advanced or sophisticated as their paid counterparts, they still claim to offer valuable insights into which tiles are safe to click. Players may experiment with these free tools to determine if they provide a significant advantage before upgrading to a more complex version.
The Allure of Stake Mines Hack
For some players, using a Stake Mines Hack represents an appealing shortcut to guaranteed winnings. Hacks refer to manipulated versions of the game or tools designed to change the game’s mechanics in favor of the player. These could involve altering the game’s algorithm, unlocking extra features, or even revealing the locations of mine-free tiles. However, using a hack comes with major risks. Firstly, many hacks are illegal, possibly introducing malware or harming your device. Secondly, hacking is a breach of most gaming platforms' terms of service, and players caught using hacks can be banned or suspended.
While this tool doesn’t guarantee success, it provides a way for players to assess the risk and reward associated with each decision. Some calculators even use historical game data to adjust a player’s strategy based on past performance.
Stake Mines APK and Mod Versions
For those who enjoy trying out alternative game versions, the Stake Mines APK lets users acquire the game on their Android devices. APK versions allow people to avoid app store rules and use customized or modded versions of the game. These versions can offer enhanced features, additional functionalities, or even greater chances to succeed, but it’s important to download them from trusted sources to avoid malware or other issues.
Web: http://oparino-iskra.ru/poslednie/3087-monetnaya-nedelya-kirovchanam-predlagayut-vernut-skopivshuyusya-meloch-v-oborot-vserossiyskaya-akciya-proydet-s-20-maya-po-2-iyunya.html
Stake Mines Demo: Learning the Game Without Risk
If you're new to Stake Mines, the Stake Mines demo is a great way to test out the game’s mechanics without the financial risk. Many platforms offer demo versions of games, allowing players to refine their skills and strategies in a low-stakes environment. The Stake Mines demo mirrors the real game but without using real money, making it the perfect way to experiment before committing to real wagers.
Using the demo version helps players understand the features and gameplay of the game without the worry of losing money. It’s a risk-free way to explore different strategies and decide how to approach the full game.
The concept of online casinos gained traction in the mid-1990s, delivering a comfortable option to traditional gambling locations. Over time, digital improvements have revolutionized online platforms into captivating realms, equipped with detailed animations, live dealer options, and smooth gaming.
Today, the ability to explore an web-based casino from a range of devices is a main highlight for players internationally.
Internet casinos offer a comprehensive collection of options, ranging from iconic games such as poker and blackjack, alongside a large array of slots.
These platforms offer users the convenience of playing from their homes or from anywhere, rendering them highly appealing among both newcomer and veteran users.
One of the most significant shifts in the world of virtual casinos is the rise of portable gaming. Gaming apps have turned into a go-to option for interacting with online platforms, thanks to their simple navigation and unique enhancements.
Whether you are a entertainment seeker or a high-stakes bettor, a dedicated casino app enables your access to your most-loved gaming experiences with just a few steps on your mobile phone.
These apps are built to provide a seamless gaming experience, with options such as customized gambling options, efficient deposit methods, and advanced safety protocols.
Web: https://que-es-aviator.github.io
Players can obtain a casino application file—a package designed for Android—to use software without delay when they are not listed on common mobile platforms.
This freedom guarantees that players can always stay connected to their preferred digital casinos, irrespective of technical constraints.
One of the primary appeal of <a href="https://shoptalkus2024.coconnex.com/node/592210">sweet bonanza pragmatic</a> is its different take on online slot game structure. Unlike most slots that use fixed paylines, Sweet Bonanza introduces a non-payline system. The game comes with a 6x5 grid, providing spinners multiple possibilities to secure matches with each turn. Wins are generated by landing clusters of eight matching matching images throughout the screen, making it unique compared to usual slots that operate by predetermined paylines.
The cluster pay system is not only aesthetic but also provides users better odds each time they spin.
The sweet candy visuals and vivid colors complement the visual allure, generating a fun, animated ambiance that brings in users. Icons in the game consist of different types of candy in vivid shades, as well as fruits like bananas, grapes, and watermelons. The aesthetic are enhanced by upbeat background music that adds to the thrill of the game. The Sweet Bonanza slot also includes a scatter symbol represented by a lollipop, which is essential in activating the Free Spins mode. If players get four or more lollipops, the game will activate the free round, which gives a great opportunity to secure big wins.
Beginners to online slots or who want to try it out without betting real funds, Sweet Bonanza trial play delivers a suitable way. Numerous gaming sites offer a Sweet Bonanza practice mode, enabling players to enjoy the gameplay, try different approaches, and acquaint themselves with the mechanics without any financial risk. Experimenting with Sweet Bonanza in demo mode is ideal for first-time users, as it lets them learn the rules, adjust wager sizes, and explore the Tumble mechanism.
Web: https://shoptalkus2024.coconnex.com/node/592210
The Tumble feature, alternatively called the cascading reels mechanic, plays a major role in the game. Whenever there’s a win, the matching symbols vanish, and fresh symbols fill the gaps, opening more winning possibilities. This feature adds to the thrill but also gives players more opportunities within each round.
A key aspect of this game is its Free Spins round, which is often the main attraction for users. The extra spins feature in Sweet Bonanza may result in impressive wins due to the use of multipliers. Upon activation, the free spin round grants 10 extra spins, and players may earn more spins by getting additional lollipop icons.
В том случае, если желаете увлекательную игру, что дарит огромное количество эмоций и возможности выиграть крупно, то Авиатор – именно то, что вам нужно.
О Чём Игра Авиатор?
<a href="https://lacollinaagriturismo.com/5-put-gambling-enterprises-within-the-nz-score-casino-bonanza-25-fifty-80-one-hundred-100-percent-free-revolves/">aviator игра официальный сайт</a> – это впечатляющая краш игра, где ваш выигрыш и удача зависят от интуиции и скорости и удачи. В этой игре вы вы делаете ставку и следите за взлетом самолета.
Как Управлять Игрой Авиатор? Играть в игру Авиатор легко. Вот основные шаги, которые помогут приступить к игре:
Сделайте Вашу Ставку: Введите сумму, которую вы хотите вложить. Помните, что ставить нужно с ответственностью.
Смотрите за Взлетом Самолета: После того как ставка подтверждена, на экране появится самолет, который покажет взлет. Множитель выигрыша будет расти. Забирайте деньги: В любой момент, пока самолет не исчез, вы можете зафиксировать выигрыш. Начните Новый Раунд: После завершения раунда вы можете продолжить игру.
Зеркало сайта: https://lacollinaagriturismo.com/5-put-gambling-enterprises-within-the-nz-score-casino-bonanza-25-fifty-80-one-hundred-100-percent-free-revolves/
Почему Стоит Играть в Авиатор?
Увлекательный Геймплей: В Авиаторе каждое мгновение игры волнует. Доступность и Простота: Игра легка в освоении. Крупные Выигрыши: Возможности для крупных выигрышей зависят от ваших интуитивных решений. Интерактивность и Реальное Время: В игре Авиатор вы играете в реальном времени.
Управляйте Своими Рисками: В игре Авиатор важно не только выигрывать, но и контролировать риски.
Следите за Поведением Множителя: Анализируйте поведение множителя.
Бонусные Возможности и Акции: Участвуйте в бонусах и акциях, чтобы увеличить свои шансы на выигрыш.
Sweet Bonanza sobresale de otras maquinas tragamonedas por su atractivo y original diseno. Al ingresar al slot, los fans se sumergen en un mundo de frutas y caramelos y colores vibrantes que sugieren un ambiente magico. Se puede ver un fondo lleno de caramelos, lo cual crea una experiencia visual atractiva y agradable, perfecta para principiantes y expertos. Este slot ha sido reconocido por su adiccion positiva y entretenimiento, ya que brinda emociones y una estetica llamativa para todos.
Una de las caracteristicas mas valoradas de este slot es su ronda de giros gratis, que se activa cuando aparecen cuatro o mas simbolos de caramelos rosados. El modo de giros sin costo no solo permiten jugar sin gastar dinero adicional, sino que tambien potencian las probabilidades de grandes ganancias, especialmente cuando se activan los multiplicadores durante los giros. Este detalle del juego es uno de los que mas atrae a los jugadores, y muchos mencionan en sus opiniones que la ronda de giros gratis es lo mas emocionante.
Ademas, el juego de Pragmatic Play ha logrado mantener su popularidad gracias a su atractivo para jugadores novatos y experimentados. No importa si eres un principiante en las apuestas online, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la versatilidad de el juego en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere divertirte mientras te desplazas, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: http://chunzee.co.kr/bbs/board.php?bo_table=23&wr_id=489529
Otro punto que interesa a los jugadores es si es posible ganar dinero con este juego de tragamonedas. Al igual que en cualquier tragamonedas, este juego es un juego basado en el azar, lo cual significa que el resultado de cada jugada es totalmente azaroso y no puede ser controlado. Sin embargo, los multiplicadores junto con giros gratis ofrecen una oportunidad significativa para obtener premios importantes. La funcion de los multiplicadores permiten multiplicar las ganancias hasta 100x, lo que puede dar lugar a grandes recompensas si sale un giro afortunado. Sin embargo, es importante recordar que el juego debe disfrutarse de manera responsable y que no hay garantias de ganar en cada sesion.
The notion of internet-based casinos originated in the mid-1990s, delivering a easy-to-reach solution to conventional establishments. Over time, progress in tech have transformed online platforms into captivating settings, equipped with realistic graphics, interactive dealer gameplay, and lag-free experiences.
Today, the ability to explore an web-based casino from almost any gadget is a significant advantage for users across the planet.
Online casinos make available a wide range of activities, featuring timeless classics like roulette and poker, complemented by numerous slot games.
These systems provide players the accessibility of participating from any cozy spot or while traveling, rendering them highly appealing among both newcomer and veteran users.
One of the most important developments in the digital gambling sector is the rise of portable gaming. Casino-focused software are increasingly a popular way for using online platforms, thanks to their user-friendly interfaces and unique enhancements.
Whether you are a occasional gamer or a high-stakes bettor, a well-designed mobile casino brings you your most-loved gaming experiences with just a few clicks on your smart device.
These apps feature tools that deliver a uninterrupted casino session, with functionalities such as game selection based on preferences, fast transaction systems, and cutting-edge encryption.
Web: https://mines-argentina-juego.web.app
Players can install a casino apk—a package designed for Android—to set up applications instantly should they not be accessible on official app stores.
This flexibility makes certain that players can continue their sessions to their preferred digital casinos, no matter what OS they use.
Peki, simdi, oyunda kazanma sans? nas?l art?r?l?r? Bu populer oyunun derinlemesine ayr?nt?lar?n? kesfedecegiz ve oyuna baslama ad?mlar?ndan kazanc art?rma stratejilerine kadar butun onemli bilgileri verecegiz.
Sweet Bonanza oyununu yak?ndan tan?yal?m
Tatl? temal? Sweet Bonanza, slot oyunlar? dunyas?nda ozel bir yere sahip olan bir oyun olarak biliniyor. Pragmatic Play’in sundugu bu slot oyunu, cesitli seker ve meyve sembollerinin birlesiminden olusur. Bu ikonik semboller, tatl? bir dunyaya davet ederek oyuncular? oyunun cazibesine kap?lmaya davet eder.
Bu oyunun farkl? bir mekanik sunmas? oyunu ozel k?l?yor. Ekranda patlayan semboller yerine yenilerinin gelmesiyle, oyun surekli bir sekilde kazanma olas?l?g? yarat?r. Bu ozellik sayesinde, Sweet Bonanza, diger slot oyunlar?ndan ayr?l?r.
Sweet Bonanza Nas?l Oynan?r?
Sweet Bonanza’y? oynamak diger slot oyunlar?na gore daha kullan?c? dostudur bir oyun sistemi sunar. 6 sutun ve 5 sat?rdan olusan bir ?zgarada oynan?r. Oyundaki temel amac, ayn? sembollerin belirli say?da yan yana gelmesiyle para kazanabilmektir.
Bu mekanikte belirli bir hatta sembol s?ralama gerekmez. Oyuncular icin sembollerin birlesmesi yeterlidir. Kazanan semboller patlar ve yenileri eklenir. Bu sayede, bir dondurmede birden fazla odul kazan?labilir.
Web: https://mozillabd.science/wiki/User:Maria658461
Sweet Bonanza Demo Oyna Secenegi ile Eglenin
Sweet Bonanza’n?n sundugu avantajlardan biri de, "Sweet Bonanza demo oyna" seceneginin bulunmas?d?r. Demo Sweet Bonanza modu, ozellikle yeni oyuncular icin idealdir. Gercek para kullanmadan oyun mekanigini anlamak mumkundur.
Demo surum, yuksek degerli sembolleri ve oyunun ozelliklerini kesfetmek icin harika bir yontemdir. Oyuncular demo ile kendi stratejilerini gelistirme sans?na sahiptir. Bu demo, strateji olusturmak icin mukemmel bir platform saglar.
Este juego destaca de otras opciones de juego por su diseno llamativo y unico. Al ingresar al slot, los usuarios son transportados a un universo de caramelos y colores vivos que recuerdan a un cuento de hadas. El fondo esta decorado con dulces, lo cual crea una experiencia visual relajante y alegre, ideal para todo tipo de jugadores. Este juego ha sido muy bien valorado en las opiniones, ya que combina la emocion de los premios con una estetica visual que apela a todos los publicos.
Una de las caracteristicas mas valoradas de este slot es su ronda de giros gratis, que se activa si se obtienen cuatro o mas simbolos de caramelos en cualquier lugar. La ronda de giros gratuitos no solo permiten jugar sin costo, sino que tambien incrementan las chances de obtener grandes premios, especialmente cuando aparecen multiplicadores en los giros. Este detalle del juego es uno de los mas atractivos a los jugadores, y muchos comentan en sus opiniones que la ronda de giros gratis es lo mas emocionante.
Ademas, este juego ha logrado mantener su popularidad gracias a su atractivo para jugadores novatos y experimentados. No importa si eres un principiante en las apuestas online, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la disponibilidad de este titulo en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere apostar desde tu telefono movil, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: http://seelin.in/2024/11/19/sweet-bonanza-todo-lo-que-necesitas-saber-sobre-este-emocionante-slot/
Otro punto que interesa a los jugadores es si es posible ganar dinero con este juego de tragamonedas. Al igual que en cualquier tragamonedas, Sweet Bonanza es un juego basado en el azar, lo cual significa que el resultado de cada tirada es totalmente azaroso y no puede ser predicho. Sin embargo, los multiplicadores junto con giros gratis ofrecen una oportunidad significativa para obtener grandes premios. La funcion de se pueden multiplicar las ganancias hasta 100 veces gracias a los multiplicadores, lo que puede generar premios grandes si se tiene suerte en el giro. Sin embargo, es importante recordar que hay que disfrutar del juego con moderacion y que no hay garantias de ganar en cada sesion.
В случае, если находитесь в поиске захватывающую игру, что дарит огромное количество эмоций и возможности для крупного выигрыша, то Авиатор – это то, что нужно.
Что Из Себя Представляет Авиатор?
<a href="https://lacollinaagriturismo.com/tiki-vikings-condition-demonstration-from-the-online-game-global/">авиатор</a> – это классная краш игра, где ваш успех и победа зависят от способности быстро принимать решения и удачи в моменте. Игра заключается в том, что вы ставите деньги и наблюдаете взлет самолета.
Как Играть в Игра Авиатор? Играть в игру Авиатор очень просто. Вот ключевые этапы, которые помогут стартовать в игре:
Установите Сумму Ставки: Введите сумму, на которую вы готовы играть. Помните, что ставьте осознанно.
Смотрите за Взлетом Самолета: После того как ставка установлена, на экране появится самолет, который начнет свой полет. Множитель выигрыша будет расти. Забирайте Ваш Выигрыш: В любой момент, пока самолет взлетает, вы можете зафиксировать выигрыш. Начните Новую Игру: После завершения раунда вы можете сделать новую ставку и продолжить игру.
Зеркало сайта: https://lacollinaagriturismo.com/tiki-vikings-condition-demonstration-from-the-online-game-global/
Почему Популярна Игра Авиатор?
Захватывающий Геймплей: В Авиаторе каждое мгновение игры волнует. Легкость Освоения: Игра не требует глубоких знаний. Крупные Выигрыши: Возможности выиграть крупно зависят от умения принимать решения. Интерактивные Элементы: В игре Авиатор процесс идет в реальном времени.
Управляйте Рискованностью: В игре Авиатор важно обдуманно управлять рисками.
Следите за Поведением Множителя: Анализируйте, как ведет себя множитель в раундах.
Получайте Бонусы и Акции: Используйте бонусах и акциях, для увеличения своих шансов.
Este juego destaca de otras maquinas tragamonedas por su diseno llamativo y unico. Al ingresar al slot, los fans son llevados a un mundo de frutas y caramelos y colores vibrantes que parecen de un mundo fantastico. El escenario esta repleto de confites, lo cual crea una experiencia visual atractiva y agradable, ideal para todo tipo de jugadores. Este slot ha sido reconocido por su adiccion positiva y entretenimiento, ya que brinda emociones y una estetica llamativa para todos.
Una de las caracteristicas mas valoradas de este juego es su caracteristica de giros gratis, que se activa si se obtienen cuatro o mas simbolos de caramelos en cualquier lugar. La ronda de giros gratuitos no solo permiten jugar de manera gratuita, sino que tambien potencian las probabilidades de grandes ganancias, especialmente cuando los multiplicadores hacen su aparicion. Este aspecto dentro del juego es uno de los mas emocionantes a los jugadores, y muchos destacan en sus comentarios que el bono de giros gratis es lo mejor del juego.
Ademas, Sweet Bonanza ha logrado mantener su popularidad gracias a su aplicabilidad universal. No importa si eres un principiante en las apuestas online, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la versatilidad de el juego en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere apostar desde tu telefono movil, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: http://xn--cksr0ar36ezxo.com/home.php?mod=space&uid=4428&do=profile&from=space
Otro punto que interesa a los jugadores es si realmente pueden ganar dinero con este juego de tragamonedas. Al igual que en cualquier tragamonedas, este juego es un juego basado en el azar, lo cual significa que el resultado de cada vuelta es impredecible y no puede ser predicho. Sin embargo, los multiplicadores y las rondas de giros gratis ofrecen una oportunidad significativa para obtener premios importantes. La funcion de los multiplicadores permiten multiplicar las ganancias hasta 100x, lo que puede resultar en una recompensa significativa si sale un giro afortunado. Sin embargo, es importante recordar que hay que disfrutar del juego con moderacion y que no hay garantias de ganar en cada sesion.
The emergence of online gaming hubs came into existence in the digital revolution period, providing a convenient variation to physical venues. Over time, progress in tech have evolved online platforms into captivating environments, complete with stunning imagery, interactive dealer gameplay, and seamless gameplay.
Today, the option to visit an digital gambling site from any modern device stands out as a major attraction for gamblers around the globe.
Virtual gambling platforms make available a wide range of options, ranging from timeless classics like roulette and poker, in addition to a large array of slots.
These services offer users the accessibility of participating from any cozy spot or while traveling, making them a popular choice among both beginner and skilled bettors.
One of the most significant shifts in the field of online entertainment is the move toward mobile gaming. Casino apps are increasingly a preferred method for interacting with online platforms, thanks to their user-friendly interfaces and adapted functionalities.
Whether you are a entertainment seeker or a professional player, a feature-rich casino software allows you to enjoy your top-choice options with just a few steps on your smartphone.
These apps are designed to ensure a smooth gaming journey, with features such as personalized game recommendations, quick payment processing, and advanced safety protocols.
Web: https://minesgamecasino.web.app/
Players can get a Android gambling app—a package designed for Android—to gain instant access should they not be accessible on mainstream app stores.
This adaptability guarantees that players can always stay connected to their top-choice gaming apps, despite their device preferences.
Como Otimizar os Ganhos no Jogo de Tigrinho
O Fortune Tiger atrai muitos por sua chance de ganhos elevados em rodadas rapidas. Com cada aposta, o jogador tem uma chance real de lucro significativo.
Diversas estrategias podem ajudar o jogador a otimizar suas apostas. Uma estrategia bastante popular e a aposta progressiva. Com essa tecnica, o jogador inicia com apostas minimas e vai subindo progressivamente.
Outro aspecto fundamental para aumentar os lucros e o timing das apostas. Saber quando o jogo esta mais propenso a pagar altos premios pode ser decisivo. A identificacao dos minutos pagantes pode ser uma chave para o sucesso em Fortune Tiger.
Apostas e Recursos da Plataforma Fortune Tiger
Website: https://www.nebuk2rnas.com/nuomone/mama-mia-2021/
Fechamento
O Jogo do Tigrinho oferece uma experiencia rica e cheia de possibilidades. O jogo atrai uma enorme base de jogadores pela sua combinacao de entretenimento e ganhos.
В том случае, если находитесь в поиске увлекательную игру, что даст огромное количество эмоций и шанс на крупные выигрыши, то Авиатор игра – ваш правильный выбор.
Что Из Себя Представляет Авиатор?
<a href="https://lacollinaagriturismo.com/mostbet-promokod-bonus-nim-registratsiju-depozit-dejatelnost/">aviator</a> – это впечатляющая краш игра, где ваш выигрыш в игре зависят от интуиции и скорости и везения. Игра заключается в том, что вы делаете ставку и следите за взлетом самолета.
Как Начать Игру Авиатор? Играть в игру Авиатор достаточно легко. Вот первые шаги, которые облегчат начало игры:
Выберите Сумму Ставки: Введите сумму, которую готовы ставить. Помните, что ставьте осознанно.
Следите за Полётом Самолета: После того как ставка выбрана, на экране появится самолет, который покажет взлет. Множитель начинает расти. Берите выигрыш: В любой момент, пока самолет в воздухе, вы можете забрать свой выигрыш. Начните Новую Игру: После завершения раунда вы можете сделать новую ставку и продолжить игру.
Зеркало сайта: https://lacollinaagriturismo.com/mostbet-promokod-bonus-nim-registratsiju-depozit-dejatelnost/
Почему Популярна Игра Авиатор?
Увлекательный Геймплей: В Авиаторе каждое мгновение наполнено азартом. Легкость Освоения: Игра легко понятна. Большие Победы: Возможности для значительных побед зависят от ваших интуитивных решений. Реальное Время Игры: В игре Авиатор вы следите за процессом в реальном времени.
Следите за Рисками: В игре Авиатор важно выигрывать с учетом рисков.
Следите за Поведением Множителя: Анализируйте поведение множителя.
Бонусные Возможности и Акции: Используйте бонусах и акциях, чтобы увеличить свои шансы на выигрыш.
Rozrywka hazardowa w sieci zdobywaja coraz szersze uznanie w Polsce, a jedna z witryn, ktora przyciaga uwage graczy, jest <a href="http://www.prolink-directory.com/red-on-bet_333931.html">bet on red</a>. To platforma hazardowa online, ktore wyroznia sie szerokiemu wyborowi gier, inteligentnym designem oraz atrakcyjnymi promocjami, ktore zachwyca zarowno osoby nowe w swiecie hazardu, jak i milosnikow kasyn z doswiadczeniem.
Czym wyroznia sie Bet On Red?
Bet On Red Casino to platforma online, ktora oferuje szeroki wybor gier hazardowych online, takich jak automaty, klasyczne gry kasynowe oraz kasyno na zywo. Juz nazwa tej platformy „Red On Bet" wskazuje na dynamike i emocje zwiazane z obstawianiem.
Logowanie do Bet On Red Casino
Sposob na rozpoczecie gry w Kasyno Bet On Red jest intuicyjny i nieskomplikowany. Po przejsciu na strone kasyna, wystarczy nacisnac opcje logowania i wpisac swoje dane. Bet On Red Casino zapewnia ochrone danych, dlatego wszelkie dane uzytkownika sa chronione.
Uzytkownicy rozpoczynajacy swoja przygode moga bez problemu dolaczyc do platformy, a proces zakladania konta jest szybki i prosty. Co istotne, Bet On Red oferuje wygodne formy wplat i wyplat, co sprawia, ze korzystanie z platformy jest proste.
Oferta gier w Kasynie Bet On Red
Kluczowym elementem, kazdego kasyna online, jest biblioteka rozrywki. Kasyno Bet On Red zachwyca szerokim wachlarzem, ktory spelni oczekiwania kazdego uzytkownika.
Web: http://www.prolink-directory.com/red-on-bet_333931.html
Automaty sa jednym z najwiekszych hitow w ofercie, dostepne w roznorodnych stylach oraz z ciekawymi rozwiazaniami. Oprocz najpopularniejszych maszyn, uzytkownicy moga rozegrac partie w klasyki kasynowe, takie jak roulette.
The development of digital gambling sites originated in the early era of the internet, bringing a accessible option to brick-and-mortar gaming spots. Over time, innovations in technology have elevated online platforms into dynamic experiences, including lifelike visuals, interactive dealer gameplay, and uninterrupted action.
Today, the capacity to explore an online casino from a range of devices remains a key feature for gaming enthusiasts worldwide.
Internet casinos make available a broad assortment of activities, ranging from iconic games such as poker and blackjack, as well as a large array of slots.
These platforms give enthusiasts the comfort of playing from their homes or while mobile, establishing their popularity among both beginner and experienced players.
One of the most remarkable changes in the field of online entertainment is the growth of mobile-friendly interfaces. Gambling apps are now a go-to option for using online platforms, thanks to their intuitive designs and personalized options.
Whether you are a leisure bettor or a serious gambler, a feature-rich casino software provides your top-choice options with just a few touches on your smart device.
These apps focus on deliver a uninterrupted casino session, with features such as game selection based on preferences, fast transaction systems, and robust privacy features.
Web: https://hothot-fruit.netlify.app/
Players can install a Android gambling app—a package designed for Android—to use software without delay if they are unavailable on official app stores.
This adaptability ensures that players can enjoy uninterrupted gaming to their most-used casino systems, despite their device preferences.
Metodos para Obter Melhores Resultados no Tigrinho
O que chama a atencao no jogo e o alto potencial de lucro em curto periodo. Cada rodada traz a chance de premios elevados, o que e um atrativo para muitos.
Muitos jogadores aplicam estrategias especificas para aumentar as chances de lucro. A aposta em valores crescentes e uma tatica popular. Nessa abordagem, o jogador comeca com valores baixos e aumenta aos poucos.
Outro aspecto fundamental para aumentar os lucros e o timing das apostas. E fundamental estar atento aos minutos pagantes do jogo. Aproveitar esses minutos criticos aumenta significativamente as chances de ganhar.
Vantagens da Plataforma Fortune Tiger
Website: http://www.consis.kr/board/bbs/board.php?bo_table=as&wr_id=65297
Encerramento
Seja para iniciantes ou veteranos, Fortune Tiger tem algo a oferecer. Ao jogar no Fortune Tiger, o jogador tem a chance de se divertir enquanto busca grandes premios.
Если вы желаете захватывающую и увлекательную игру, что обеспечит массу эмоций и шансы на значительный выигрыш, то игра Авиатор – именно то, что вам нужно.
Что Такое Авиатор?
<a href="https://lacollinaagriturismo.com/kak-vybrat-signal-onlayn-kazino-vulkan-igrat-onlayn-na-dengi-kotoryy-sootvetstvuet-vashim-predpochteniyam/">авиатор</a> – это классная краш игра, где ваш успех в игре зависят от быстроты мышления и удачи и везения. Цель игры заключается в том, что вы ставите деньги и наблюдаете взлет самолета.
Как Начать Играть в Авиатор? Играть в игру Авиатор достаточно легко. Вот первые шаги, которые помогут вам начать играть:
Определите Ставку: Введите сумму, которую готовы ставить. Помните, что ставьте осознанно.
Следите за Взлетом Самолета: После того как ставка внесена, на экране появится самолет, который взлетит. Ваш множитель будет расти. Забирайте деньги: В любой момент, пока самолет не исчез, вы можете забрать средства. Сделайте Новую Ставку: После завершения раунда вы можете начать новую игру.
Зеркало сайта: https://lacollinaagriturismo.com/kak-vybrat-signal-onlayn-kazino-vulkan-igrat-onlayn-na-dengi-kotoryy-sootvetstvuet-vashim-predpochteniyam/
Почему Популярна Игра Авиатор?
Увлекательный Геймплей: В Авиаторе каждое мгновение наполнено азартом. Легкость Освоения: Игра легко освоить. Возможности для Крупных Побед: Возможности выиграть крупно зависят от умения принимать решения. Взаимодействие в Реальном Времени: В игре Авиатор вы следите за процессом в реальном времени.
Управляйте Своими Рисками: В игре Авиатор важно контролировать риски и выигрыши.
Следите за Динамикой Множителя: Следите за тем, как растет множитель.
Воспользуйтесь Бонусами: Участвуйте в бонусах и акциях, чтобы повысить шансы на победу.
Metodos para Obter Melhores Resultados no Tigrinho
O Jogo do Tigrinho se destaca por oferecer premios significativos em poucas rodadas. Com potencial de premios em cada rodada, o jogo se torna emocionante e vantajoso.
Os apostadores desenvolvem taticas para tornar o jogo mais lucrativo. Uma estrategia bastante popular e a aposta progressiva. Esse metodo consiste em comecar com apostas pequenas e aumenta-las com o tempo.
Outro aspecto fundamental para aumentar os lucros e o timing das apostas. Ficar atento aos minutos em que o jogo paga mais e uma otima estrategia. Jogadores mais experientes sabem reconhecer quando os minutos pagantes acontecem.
Plataforma de Apostas do Fortune Tiger: O que Saber
Website: https://afunnydir.com/ganhos-fortune-tiger_438451.html
Consideracoes Finais
O Fortune Tiger e uma plataforma empolgante para todos os tipos de jogadores. Ao jogar no Fortune Tiger, o jogador tem a chance de se divertir enquanto busca grandes premios.
The notion of internet-based casinos emerged in the 1990s, bringing a convenient alternative to physical establishments. Over time, technological advancements have transformed online platforms into interactive settings, complete with high-quality designs, live gaming features, and flawless performance.
Today, the option to engage with an web-based casino from a range of devices is one of the biggest draws for casino lovers internationally.
Web-based gambling sites feature a diverse selection of gaming experiences, such as traditional games like blackjack and roulette, in addition to hundreds of slot games.
These platforms give enthusiasts the freedom of playing from their homes or from anywhere, making them a popular choice among both amateur and skilled bettors.
One of the most notable trends in the digital gambling sector is the shift to mobile-first platforms. Gambling apps are now a top choice for playing on online platforms, due to their user-friendly interfaces and adapted functionalities.
Whether you are a occasional gamer or a strategic gamer, a dedicated casino app enables your access to your top-choice options with just a few taps on your smartphone.
These apps feature tools that enhance a seamless gaming experience, with options such as customized gambling options, rapid fund transfers, and high-level protections.
Web: https://mines-casino.netlify.app/
Players can install a Android gambling app—a package designed for Android—to install apps directly in cases where they're missing on common mobile platforms.
This flexibility allows that players can maintain access to their favorite gaming platforms, despite their device preferences.
jogo fortune tiger</a> cria uma atmosfera acolhedora e facil de jogar.
Dicas de Sucesso para o Fortune Tiger
O jogo oferece lucros interessantes, mesmo em apostas rapidas. O jogo proporciona um fluxo constante de oportunidades de premios em cada rodada.
Para maximizar os lucros, muitos jogadores adotam estrategias variadas. A aposta em valores crescentes e uma tatica popular. Nessa abordagem, o jogador comeca com valores baixos e aumenta aos poucos.
O controle sobre o timing das apostas pode ser determinante para os ganhos. Ficar atento aos minutos em que o jogo paga mais e uma otima estrategia. Identificar os minutos mais rentaveis exige pratica, mas e uma habilidade essencial para os apostadores.
Plataforma Fortune Tiger: Funcionalidades e Vantagens
Website: https://trade-britanica.trade/wiki/User:AileenMeador
Conclusao
O Jogo do Tigrinho oferece uma experiencia rica e cheia de possibilidades. Com muitas formas de ganhar, Fortune Tiger e uma das opcoes mais atrativas no mundo dos jogos de aposta online.
В случае, если жаждете захватывающую и увлекательную игру, что даст кучу эмоций и возможности для крупного выигрыша, то Авиатор - Взлет – то, что сделает ваш день.
Что Из Себя Представляет Авиатор?
<a href="https://lacollinaagriturismo.com/3-extremum-deposit-baywatch-payage-avec-meurtrieres-casino-coutumes-canada-2023-imarket-business-support/">авиатор игра</a> – это инновационная игра, где ваш выигрыш и удача зависят от способности быстро принимать решения и удачи и интуиции. В этой игре вы вы делаете ставку и следите за взлетом самолета.
Как Играть в Игра Авиатор? Играть в игру Авиатор не вызывает трудностей. Вот основные действия, которые помогут начать игру:
Установите Сумму Ставки: Введите сумму, на которую вы готовы играть. Помните, что всегда ставьте с умом.
Следите за Полётом Самолета: После того как ставка подтверждена, на экране появится самолет, который начнет свой полет. Ваш множитель будет расти. Забирайте Ваши средства: В любой момент, пока самолет в полете, вы можете забрать выигрыш. Продолжите Игру: После завершения раунда вы можете продолжить игру.
Зеркало сайта: https://lacollinaagriturismo.com/3-extremum-deposit-baywatch-payage-avec-meurtrieres-casino-coutumes-canada-2023-imarket-business-support/
Почему Стоит Выбрать Авиатор?
Увлекательный Геймплей: В Авиаторе каждый раунд захватывает. Доступность и Простота: Игра не требует глубоких знаний. Шансы на Большие Выигрыши: Возможности для значительных побед зависят от ваших решений и удачи. Интерактивность и Реальное Время: В игре Авиатор игра идет в настоящем времени.
Следите за Рисковыми Моментами: В игре Авиатор важно не только выигрывать, но и контролировать риски.
Отслеживайте Тенденции Множителя: Анализируйте, как ведет себя множитель в раундах.
Используйте Акции и Бонусы: Не упустите бонусах и акциях, чтобы увеличить свои шансы на выигрыш.
Ao longo dos recentes anos, o mercado de games digitais tem vivenciado um incremento significativo, conquistando milhoes de pessoas que desejam entretenimento e, em alguns casos, a oportunidade de obter premios em especie. Entre as alternativas de games que tem ganhado grande fama, sobressaem-se o <a href="https://www.kazaki71.ru/kazakom-nuzhno-roditsya-byit-i-stat/">jogo do ratinho demo</a> e o Fortune Mouse, ambos oferecidos em diversas plataformas digitais. Esses jogos oferecem nao apenas diversao, mas tambem a chance de ganhar recompensas para aqueles que tem habilidade, disciplina e uma pitada de sorte. A seguir, iremos ver as principais caracteristicas desses jogos, como tambem como funcionam, os momentos ideais para jogar, orientacoes para experimentar as versoes demo e taticas para aumentar as chances de vitoria.
O Jogo do Ratinho e conhecido por sua disponibilidade e por trazer uma dinamica de jogo que mistura aleatoriedade e estrategia. Esse jogo ficou especialmente amado entre os entusiastas de games que buscam um passatempo rapido e agradavel, mas que tambem pode trazer a oportunidade de adquirir algum montante. Para quem esta conhecendo jogo pela vez inicial, e aconselhavel comecar pela versao demo do jogo do ratinho. A versao de demonstracao e uma opcao sem custo que possibilita testar o jogo, aprender as diretrizes, compreender a dinamica e ate mesmo desenvolver planos sem que seja preciso gastar dinheiro. Isso e muito conveniente para jogadores iniciantes, que podem conhecer com o jogo antes de jogar a versao paga. A versao demo tambem serve bem para usuarios avancados, pois permite a elaboracao e experimentacao de novas estrategias para incrementar as possibilidades de sucesso.
Para aqueles que tem seguranca em sua capacidade de vencer, existe o jogo do ratinho com premios em dinheiro, onde o usuario pode investir e, dependendo de sua performance e da fortuna, adquirir lucros. E essencial, no entanto, adotar uma abordagem responsavel ao apostar, lembrando que o intuito inicial do game e o lazer. Alem disso, uma dica valiosa e estabelecer um limite e respeita-lo, sem ultrapassar o que pode arriscar.
Uma das questoes que e comum entre os jogadores e quando e melhor jogar o jogo do ratinho. Muitos jogadores creem que, tal como ocorre em jogos de azar ou em modalidades de apostas esportivas, existe um horario mais propicio para jogar. Em modo geral, esse tipo de estrategia recomenda jogar em momentos com menos jogadores, como na madrugada ou muito cedo pela manha. A logica por detras disso e que, em horarios de menor concorrencia, o sistema pode apresentar mais oportunidades de vitoria para estimular a participacao dos jogadores. Embora isso nao seja uma regra, e o resultado dos jogos muitas vezes seja aleatorio, muitos jogadores relatam vitorias em horarios de baixa concorrencia.
Web: https://www.kazaki71.ru/kazakom-nuzhno-roditsya-byit-i-stat/
O Game do Ratinho Online representa uma excelente oportunidade para aqueles que curtem o jogo facil de acessar e acessivel, a partir de qualquer dispositivo conectado a internet. Ao contrario dos cassinos fisicos, que exigem presenca fisica, o Jogo do Ratinho pode ser jogado em qualquer momento, e diversos portais contam com promocoes e desafios que podem melhorar as chances de vitoria. Dentro dessa opcao, encontra-se a possibilidade de jogar de forma gratuita, perfeita para quem quer so se entreter ou para novatos. Essa opcao gratuita permite um jogo descontraido, onde o jogador nao se compromete financeiramente, podendo aprender e curtir sem comprometer o orcamento.
Para aqueles que procuram uma jogabilidade com apostas diretas, o jogo do ratinho com investimentos oferece apostas em dinheiro real, com a chance de duplicar o valor jogado. Embora essa modalidade seja empolgante, e essencial ter cuidado, pois a pratica de apostas sempre envolve riscos. Muitos jogadores com pratica sugerem iniciar com valores menores e ir subindo aos poucos, a medida que se torna mais confiante e entendido no jogo. O fundamental e nao esquecer que a sorte e essencial no Jogo do Ratinho, e as apostas precisam ser realizadas com prudencia.
The concept of online casinos emerged in the mid-1990s, offering a convenient solution to physical venues. Over time, technological advancements have revolutionized online platforms into interactive spaces, complete with detailed animations, live gaming features, and seamless gameplay.
Today, the capacity to use an digital gambling site from almost any gadget remains a key feature for players worldwide.
Online casinos feature a variety of games, such as timeless classics like roulette and poker, together with numerous slot games.
These online hubs deliver to gamers the ease of playing from their homes or while mobile, making them a popular choice among both amateur and veteran users.
One of the most important developments in the field of online entertainment is the growth of mobile-friendly interfaces. Casino-focused software are now a popular way for accessing online platforms, as a result of their user-friendly interfaces and tailored features.
Whether you are a casual player or a professional player, a specialized gaming app lets you experience your top-choice options with just a few steps on your tablet.
These apps focus on enhance a smooth gaming journey, with capabilities such as customized gambling options, fast transaction systems, and enhanced security measures.
Web: https://andar-bahargame.netlify.app/
Players can download a mobile gaming APK—a file format for Android devices—to access platforms seamlessly should they not be accessible on common mobile platforms.
This versatility ensures that players can maintain access to their most-used casino systems, whatever device compatibility they have.
Understanding Stake Mines Game
Stake Mines is an incredibly captivating game that revolves around a easy concept but can be quite complex. Players start by putting a stake and then selecting tiles from a grid. The objective is to uncover all the non-dangerous tiles without landing on a mine. Each safe tile you uncover increases your winnings, but if you select a mine, the game ends, and you lose your money. The ease of the game is part of its appeal, but the true challenge lies in the tactics needed. Players must predict which tiles are safe to uncover, weighing danger against potential reward.
The Stake Mines game is offered on various platforms, and its popularity continues to rise due to its intense nature and the thrill of uncertainty. The unpredictability of which tile may hide a mine is part of what makes the game so exciting and offers a risky experience for both inexperienced and seasoned players.
Stake Mines Strategy: The Key to Winning
A well-thought-out Stake Mines strategy can make the difference between coming out ahead and walking away with nothing. While luck plays a role, the key to beating the game lies in how you deal with the game. One popular approach is to start with a small bet and gradually increase your wager as you uncover safe tiles. This allows players to minimize potential losses and prolong their gameplay, increasing their chances of hitting a profitable streak.
Another strategy involves selecting a specific pattern in which to uncover the tiles. By following a predetermined grid path, players may sometimes increase their chances of avoiding mines. However, even with the best-laid strategy, it’s vital to remember that the game is based on unpredictability, and no strategy can guarantee a win every time.
For those curious about how these bots work, a Stake Mines Predictor Bot Free version is often available for download. While these free bots may not be as advanced or sophisticated as their paid counterparts, they still claim to offer valuable insights into which tiles are safe to click. Players may experiment with these free tools to determine if they provide a significant advantage before upgrading to a more professional version.
The Allure of Stake Mines Hack
For some players, using a Stake Mines Hack represents an appealing shortcut to guaranteed winnings. Hacks refer to cheated versions of the game or tools designed to change the game’s mechanics in favor of the player. These could involve changing the game’s algorithm, unlocking extra features, or even revealing the locations of mine-free tiles. However, using a hack comes with major risks. Firstly, many hacks are illegal, possibly introducing malware or harming your device. Secondly, hacking is a breach of most gaming platforms' terms of service, and players caught using hacks can be banned or suspended.
While this tool doesn’t guarantee success, it provides a way for players to weigh the risk and reward associated with each decision. Some calculators even use historical game data to adjust a player’s strategy based on past performance.
Stake Mines APK and Mod Versions
For those who enjoy trying out alternative game versions, the Stake Mines APK lets gamers download the game on their Android devices. APK files allow people to get around app store limitations and use customized or hacked versions of the game. These versions can offer enhanced features, additional functionalities, or even enhanced chances to succeed, but it’s important to obtain them from secure sources to avoid malware or other issues.
Web: https://tw.8fun.net/bbs/home.php?mod=space&uid=307737&do=profile&from=space
Stake Mines Demo: Learning the Game Without Risk
If you're new to Stake Mines, the Stake Mines demo is a great way to get familiar with the game’s mechanics without the financial risk. Many platforms offer demo versions of games, allowing players to refine their skills and strategies in a low-stakes environment. The Stake Mines demo mirrors the real game but without using real money, making it the perfect way to gain experience before committing to real wagers.
Using the demo version helps players comprehend the features and gameplay of the game without the worry of losing money. It’s a risk-free way to explore different strategies and decide how to approach the full game.
Когда находитесь в поиске волнующую игру, которая даст немало впечатлений и возможности выиграть крупно, то Авиатор – идеальный выбор для вас.
О Чём Игра Авиатор?
<a href="https://bebasbikin.com/product/kaos-oversized-custom/">aviator</a> – это инновационная игра, где ваш выигрыш и удача зависят от способности быстро принимать решения и удачи. Суть игры в том, что вы делаете ставку и смотрите на самолет, который взлетает.
Как Начать Игру Авиатор? Играть в игру Авиатор очень просто. Вот основные шаги, которые облегчат начало игры:
Задайте Ставку: Введите сумму, которую готовы ставить. Помните, что ставить нужно с ответственностью.
Ожидайте Взлета Самолета: После того как ставка выбрана, на экране появится самолет, который начнет набирать высоту. Множитель будет увеличиваться. Фиксируйте выигрыш: В любой момент, пока самолет не пропал, вы можете взять выигрыш. Начните Новый Раунд: После завершения раунда вы можете начать новую игру.
Зеркало сайта: https://bebasbikin.com/product/kaos-oversized-custom/
Почему Стоит Выбрать Авиатор?
Интересный Геймплей: В Авиаторе каждое мгновение приносит эмоции. Легкость Освоения: Игра простая и доступная. Возможности для Крупных Побед: Возможности выиграть крупно зависят от ваших решений и удачи. Реальное Время Игры: В игре Авиатор игра идет в настоящем времени.
Управляйте Рискованностью: В игре Авиатор важно управлять рисками и выигрышами.
Отслеживайте Тенденции Множителя: Следите за тем, как растет множитель.
Получайте Бонусы и Акции: Участвуйте в бонусах и акциях, которые помогут увеличить ваш выигрыш.
plataforma nova fortune tiger</a> mantem os jogadores envolvidos com seu design cativante.
Dicas para Maximizar os Lucros no Tigrinho
O jogo se diferencia por suas oportunidades de lucro rapido e significativo. A chance de premios em cada rodada faz do jogo uma escolha interessante para apostadores.
Para maximizar os lucros, muitos jogadores adotam estrategias variadas. Apostadores frequentemente recorrem a estrategia de apostas progressivas. O metodo comeca com valores minimos e sobe gradualmente.
A gestao do tempo durante as apostas tambem influencia diretamente os lucros. E fundamental estar atento aos minutos pagantes do jogo. Esses momentos de maiores ganhos sao imprevisiveis, mas com pratica e possivel identifica-los.
Caracteristicas da plataforma Fortune Tiger
Website: https://menwiki.men/wiki/User:AstridDill
Conclusao
Seja para iniciantes ou veteranos, Fortune Tiger tem algo a oferecer. O jogo atrai uma enorme base de jogadores pela sua combinacao de entretenimento e ganhos.
The idea of virtual gambling platforms came into existence in the early era of the internet, providing a easy-to-reach variation to physical establishments. Over time, technological advancements have revolutionized online platforms into interactive environments, boasting detailed animations, real-time dealer interactions, and uninterrupted action.
Today, the ability to engage with an online casino from almost any gadget is a main highlight for gaming enthusiasts around the globe.
Virtual gambling platforms feature a wide range of options, featuring well-known options like roulette and poker, in addition to hundreds of slot games.
These services deliver to gamers the convenience of gaming at home or while mobile, establishing their popularity among both novice and long-time enthusiasts.
One of the most transformative aspects in the world of virtual casinos is the trend of handheld gameplay. Gambling apps have become a go-to option for playing on online platforms, owing to their user-friendly interfaces and customized tools.
Whether you are a entertainment seeker or a professional player, a well-designed mobile casino provides your favorite games with just a few clicks on your tablet.
These apps are designed to deliver a smooth gaming journey, with functionalities such as customized gambling options, rapid fund transfers, and enhanced security measures.
Web: https://aposta-fortune-crash.pages.dev/
Players can obtain a mobile gaming APK—a dedicated app setup for Android—to set up applications instantly when they are not listed on mainstream app stores.
This ease guarantees that players can always stay connected to their top-choice gaming apps, whatever device compatibility they have.
Understanding Stake Mines Game
Stake Mines is an incredibly enthralling game that revolves around a basic concept but can be quite difficult. Players embark on by putting a gamble and then selecting tiles from a grid. The objective is to uncover all the non-dangerous tiles without landing on a mine. Each clear tile you uncover increases your winnings, but if you select a mine, the game ends, and you lose your money. The clarity of the game is part of its appeal, but the true challenge lies in the tactics needed. Players must predict which tiles are safe to uncover, weighing exposure against potential reward.
The Stake Mines game is offered on various platforms, and its popularity continues to rise due to its intense nature and the thrill of uncertainty. The chaos of which tile may hide a mine is part of what makes the game so exciting and offers a adrenaline-filled experience for both newcomers and seasoned players.
Stake Mines Strategy: The Key to Winning
A well-thought-out Stake Mines strategy can make the difference between achieving success and walking away with nothing. While luck plays a role, the key to beating the game lies in how you handle the game. One popular approach is to start with a conservative bet and gradually escalate your wager as you uncover safe tiles. This allows players to cut down on potential losses and prolong their gameplay, increasing their chances of hitting a profitable streak.
Another strategy involves selecting a specific design in which to uncover the tiles. By following a predetermined grid path, players may sometimes improve their chances of avoiding mines. However, even with the best-laid strategy, it’s vital to remember that the game is based on luck, and no strategy can guarantee a win every time.
For those curious about how these bots work, a Stake Mines Predictor Bot Free version is often available for download. While these free bots may not be as advanced or sophisticated as their paid counterparts, they still claim to offer valuable insights into which tiles are safe to click. Players may experiment with these free tools to determine if they provide a significant advantage before upgrading to a more sophisticated version.
The Allure of Stake Mines Hack
For some players, using a Stake Mines Hack represents an appealing shortcut to guaranteed winnings. Hacks refer to altered versions of the game or tools designed to change the game’s mechanics in favor of the player. These could involve manipulating the game’s algorithm, unlocking extra features, or even revealing the locations of mine-free tiles. However, using a hack comes with major risks. Firstly, many hacks are illegal, possibly introducing malware or harming your device. Secondly, hacking is a breach of most gaming platforms' terms of service, and players caught using hacks can be banned or suspended.
While this tool doesn’t guarantee success, it provides a way for players to judge the risk and reward associated with each decision. Some calculators even use historical game data to adjust a player’s strategy based on past performance.
Stake Mines APK and Mod Versions
For those who enjoy trying out various game versions, the Stake Mines APK lets gamers get the game on their Android devices. APK releases allow customers to bypass app store constraints and deploy customized or altered versions of the game. These versions can offer enhanced features, additional functionalities, or even improved chances to succeed, but it’s important to download them from reliable sources to avoid malware or other issues.
Web: https://pediascape.science/wiki/User:OtisLitchfield
Stake Mines Demo: Learning the Game Without Risk
If you're new to Stake Mines, the Stake Mines demo is a great way to practice the game’s mechanics without the financial risk. Many platforms offer demo versions of games, allowing players to refine their skills and strategies in a low-stakes environment. The Stake Mines demo mirrors the real game but without using real money, making it the perfect way to train before committing to real wagers.
Using the demo version helps players grasp the features and gameplay of the game without the worry of losing money. It’s a risk-free way to explore different strategies and decide how to approach the full game.
В том случае, если желаете увлекательную игру, которая дарит немало впечатлений и перспективы на большой выигрыш, то Авиатор игра – именно то, что вам нужно.
Что Из Себя Представляет Авиатор?
<a href="https://www.thaiheadlines.com/159169/">авиатор</a> – это инновационная игра, где ваш успех в игре зависят от скорости решений и везения. Игра заключается в том, что вы ставите деньги и наблюдаете взлет самолета.
Как Играть в Авиатор? Играть в игру Авиатор достаточно легко. Вот этапы начала игры, которые помогут начать игру:
Определите Ставку: Введите сумму, которую готовы ставить. Помните, что важно контролировать ставки.
Следите за Полётом Самолета: После того как ставка внесена, на экране появится самолет, который начнет свой полет. Ваш множитель будет расти. Берите выигрыш: В любой момент, пока самолет не исчез, вы можете зафиксировать выигрыш. Продолжите Игру: После завершения раунда вы можете сделать новую ставку и продолжить игру.
Зеркало сайта: https://www.thaiheadlines.com/159169/
Почему Выбирают Игру Авиатор?
Динамичный Геймплей: В Авиаторе каждое мгновение игры волнует. Легкость Освоения: Игра не требует глубоких знаний. Крупные Выигрыши: Возможности для крупных выигрышей зависят от вашего подхода и интуиции. Реальное Время Игры: В игре Авиатор вы играете в реальном времени.
Следите за Рисками: В игре Авиатор важно не только выигрывать, но и контролировать риски.
Наблюдайте за Изменением Множителя: Анализируйте поведение множителя.
Бонусные Возможности и Акции: Участвуйте в бонусах и акциях, чтобы увеличить выигрышные шансы.
A key benefit of <a href="https://www.free-weblink.com/sweet-bonanza_212954.html">sweet bonanza download</a> is its unique approach to online slot play style. Unlike classic slot games that rely on paylines, Sweet Bonanza introduces a "match anywhere" system. The slot comes with six reels and a five-row grid, giving users numerous possibilities to win with each turn. Wins occur by forming clusters of eight matching identical icons on the play area, making it unique compared to usual slots that function through fixed paylines.
The cluster pay system not only becomes visually engaging but also offers users increased win opportunities in each spin.
The candy-themed graphics and cheerful color scheme add to the slot’s appeal, producing a fun, animated ambiance that draws players in. Images in this slot show different types of candy in bright colors, as well as fruits such as bananas, grapes, and watermelons. The graphics are complemented by cheerful sounds that contributes to the playful atmosphere. The Sweet Bonanza slot also has a bonus icon with a lollipop image, which plays a pivotal role in initiating the free rounds. If players get four or more scatters, players can start the Free Spins mode, which delivers a high possibility to achieve high payouts.
Beginners to online slots or wish to practice before spending actual money, the Sweet Bonanza demo delivers an ideal option. Various internet casinos provide a Sweet Bonanza free play, giving users to try the mechanics, try different approaches, and become familiar with the game’s features without any investment. Playing the demo of Sweet Bonanza is beneficial for beginners, as it helps them grasp the rules, adjust wager sizes, and explore the Tumble mechanism.
Web: https://www.free-weblink.com/sweet-bonanza_212954.html
Cascading reels, also known as the cascade feature, is a core aspect of Sweet Bonanza. After each winning combination, the winning symbols are cleared, and new symbols fall into place, opening more winning possibilities. This element not only enhances the excitement but also grants additional winning chances in one go.
A special element of this Pragmatic Play slot is its bonus spin mode, which can be the favorite feature for players. The extra spins feature in Sweet Bonanza offers high rewards due to the inclusion of random multipliers. When triggered, the bonus mode gives players 10 spins without a bet, and extra spins can be re-triggered by landing additional lollipop icons.
The development of digital gambling sites was introduced in the 1990s, delivering a user-friendly substitute to brick-and-mortar gaming spots. Over time, digital improvements have revolutionized online platforms into dynamic realms, featuring stunning imagery, real-time dealer interactions, and seamless gameplay.
Today, the capacity to engage with an digital gambling site from practically anywhere is a main highlight for users worldwide.
Digital gaming hubs deliver a wide range of gaming experiences, highlighting classics like blackjack, roulette, and poker, in addition to a myriad of slot machines.
These online hubs deliver to gamers the ease of playing from their homes or on the go, turning them into favorites among both amateur and experienced players.
One of the most significant shifts in the online gaming industry is the rise of portable gaming. Casino apps are increasingly a common approach for playing on online platforms, due to their player-oriented features and adapted functionalities.
Whether you are a leisure bettor or a professional player, a specialized gaming app enables your access to your most-loved gaming experiences with just a few clicks on your smart device.
These apps feature tools that ensure a lag-free gambling interaction, with options such as personalized game recommendations, instant payout solutions, and high-level protections.
Web: https:/fortune-tiger-top.pages.dev/
Players can download a casino apk—a dedicated app setup for Android—to access platforms seamlessly should they not be accessible on official app stores.
This freedom allows that players can maintain access to their preferred digital casinos, whatever device compatibility they have.
Este slot se diferencia de otras tragamonedas por su atractivo y original diseno. Al comenzar a jugar, los apostadores son llevados a un escenario de golosinas y colores brillantes que sugieren un ambiente magico. El fondo de la pantalla esta lleno de golosinas, lo cual crea una imagen relajante y agradable, ideal tanto para jugadores nuevos como para experimentados. Esta tragamonedas ha sido reconocido por su adiccion positiva y entretenimiento, ya que combina la emocion de los premios con una estetica visual que apela a todos los publicos.
Una de las caracteristicas mas valoradas de Sweet Bonanza es su ronda de giros gratis, que se activa si se obtienen cuatro o mas simbolos de caramelos en cualquier lugar. La ronda de giros gratuitos no solo permiten jugar sin gastar dinero adicional, sino que tambien incrementan las chances de obtener grandes premios, especialmente cuando los multiplicadores estan presentes. Este aspecto del juego es uno de los mas emocionantes a los jugadores, y muchos destacan en sus comentarios que la funcion de giros gratis es lo mas emocionante.
Ademas, este juego ha logrado mantener su popularidad gracias a su caracter inclusivo. No importa si eres un principiante en las apuestas online, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la versatilidad de el juego en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere apostar desde tu telefono movil, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: https://v2v.in/index.php?page=user&action=pub_profile&id=4773
Otro punto que interesa a los jugadores es si es posible ganar dinero con este juego. Al igual que en cualquier tragamonedas, Sweet Bonanza es una maquina de azar, lo cual significa que el resultado de cada vuelta es basado en azar y no puede ser predicho. Sin embargo, los multiplicadores junto con giros gratis ofrecen una oportunidad significativa para obtener premios importantes. La funcion de los multiplicadores permiten multiplicar las ganancias hasta 100x, lo que puede generar premios grandes si los jugadores tienen suerte. Sin embargo, es importante recordar que el juego debe disfrutarse de manera responsable y que no siempre se gana en cada ronda.
В том случае, если желаете увлекательную игру, что даст много шансов и возможности выиграть крупно, то игра Авиатор – это то, что нужно.
Что Из Себя Представляет Авиатор?
<a href="https://siamball.com/igray-v-onlayn-kazino-i-stan-luchshim-aviatorom/">aviator</a> – это классная краш игра, где ваш успех и победа зависят от быстроты мышления и удачи и удачи и интуиции. Игра заключается в том, что вы делаете ставку и наблюдаете за тем, как самолет взлетает.
Как Начать Играть в Авиатор? Играть в игру Авиатор очень просто. Вот этапы начала игры, которые облегчат начало игры:
Установите Сумму Ставки: Введите сумму, на которую вы готовы играть. Помните, что важно контролировать ставки.
Следите за Взлетом Самолета: После того как ставка установлена, на экране появится самолет, который начнет свой полет. Ваш множитель будет расти. Фиксируйте выигрыш: В любой момент, пока самолет в воздухе, вы можете забрать средства. Повторите Игру: После завершения раунда вы можете сделать новую ставку.
Зеркало сайта: https://siamball.com/igray-v-onlayn-kazino-i-stan-luchshim-aviatorom/
Почему Популярна Игра Авиатор?
Интересный Геймплей: В Авиаторе каждый момент полон эмоций. Легкость и Удобство: Игра легко понятна. Шансы на Большие Выигрыши: Возможности выиграть крупно зависят от вашей интуиции. Игровая Интерактивность: В игре Авиатор вы следите за процессом в реальном времени.
Следите за Рисками: В игре Авиатор важно управлять рисками и выигрышами.
Наблюдайте за Изменением Множителя: Анализируйте поведение множителя.
Используйте Акции и Бонусы: Не пропустите бонусах и акциях, чтобы увеличить свои шансы на выигрыш.
Peki, simdi, oyuncular bu oyunu nas?l oynayabilir? Sweet Bonanza’n?n tum detaylar?n? inceleyecegiz ve giris yapma yontemlerinden taktik ipuclar?na kadar butun onemli bilgileri verecegiz.
Sweet Bonanza oyunu nedir ve nas?l cal?s?r?
Sweet Bonanza, cevrimici slot oyunlar? aras?nda fark yaratan bir slot oyunudur. Pragmatic Play’in sundugu bu slot oyunu, meyve ve seker ikonlar?yla doludur. Bu meyve ve seker sembolleri, tatl? bir dunyaya davet ederek oyuncular? oyunun cazibesine kap?lmaya davet eder.
Sweet Bonanza’n?n farkl? bir mekanik sunmas? oyunu ozel k?l?yor. Oyuncular?n kazanc saglamas?yla ekran?n yenilenmesiyle, oyun surekli bir kazanc ak?s? sunar. Bu mekanik yap?yla birlikte, Sweet Bonanza, oyuncular?n surekli olarak kazanmas?n? saglar.
Sweet Bonanza Nas?l Oynan?r?
Bu oyunun oynan?s tarz? diger benzer oyunlardan daha kolay anlas?l?r bir oyun sistemi sunar. oyun alan? 6x5 bir duzende yer al?r. Hedef, ayn? sembollerin belirli say?da yan yana gelmesiyle odul kazanmakt?r.
Bu yap?da belirli bir cizgi olusturmak gerekmez. Oyuncular?n kazanmas? icin ayn? sembollerin bir araya gelmesi yeterlidir. Kazanan semboller patlar ve yenileri eklenir. Bu oyun yap?s?yla birlikte, bir dondurmede birden fazla odul kazan?labilir.
Web: http://zian100pi.com/discuz/home.php?mod=space&uid=1094588&do=profile&from=space
Sweet Bonanza Demo: Oyunu Denemek Icin Ideal F?rsat
Sweet Bonanza’n?n en cazip ozelliklerinden biri de, oyunculara demo mod sunulmas?d?r. Sweet Bonanza demo modu, yeni baslayanlar icin mukemmel bir f?rsatt?r. Gercek para kullanmadan oyun mekanigini anlamak mumkundur.
Demo modunda oynarken kazanc saglayan sembolleri ogrenebilirsiniz. Gercek para harcamadan, oyunun tum ozelliklerini deneme sans? elde edilir. Demo Sweet Bonanza, oyuncular?n farkl? stratejiler gelistirmelerine olanak tan?r.
The concept of online casinos was introduced in the digital revolution period, delivering a accessible substitute to brick-and-mortar gaming spots. Over time, progress in tech have elevated online platforms into dynamic spaces, boasting detailed animations, interactive dealer gameplay, and smooth gaming.
Today, the capacity to access an online casino from practically anywhere remains a key feature for gaming enthusiasts worldwide.
Digital gaming hubs deliver a wide range of activities, featuring traditional games like blackjack and roulette, in addition to countless slots.
These platforms provide players the ease of playing from their homes or in any location, securing their place as preferred options among both amateur and seasoned gamblers.
One of the most remarkable changes in the digital gambling sector is the move toward mobile gaming. Gambling apps have become a preferred method for accessing online platforms, thanks to their accessible layouts and tailored features.
Whether you are a leisure bettor or a professional player, a feature-rich casino software allows you to enjoy your favorite games with just a few clicks on your portable device.
These apps aim to provide a uninterrupted casino session, with options such as adaptive picks for players, fast transaction systems, and enhanced security measures.
Web: https://bet-onredcasino.web.app
Players can install a mobile gaming APK—a specific Android tool—to use software without delay if they are unavailable on mainstream app stores.
This freedom ensures that players can maintain access to their preferred digital casinos, irrespective of technical constraints.
Sweet Bonanza sobresale de otras slots por su estilo visual y tematica original. Al comenzar a jugar, los apostadores son transportados a un universo de caramelos y colores vivos que recuerdan a un cuento de hadas. El fondo esta decorado con dulces, lo cual crea una imagen relajante y tranquila, adaptada a todos los jugadores. Este slot ha sido muy bien valorado en las opiniones, ya que mezcla la emocion de ganar premios con un estilo visual atractivo para todos.
Una de las caracteristicas mas valoradas de este juego de tragamonedas es su funcion de giros gratis, que se activa con la aparicion de cuatro o mas simbolos de caramelos rosados en cualquier posicion. La ronda de giros gratuitos no solo permiten jugar sin gastar dinero adicional, sino que tambien aumentan las oportunidades de ganar, especialmente cuando los multiplicadores estan presentes. Este aspecto del juego es uno de los que mas atrae a los jugadores, y muchos comentan en sus opiniones que la caracteristica de giros gratuitos es la parte mas emocionante.
Ademas, Sweet Bonanza ha logrado mantener su popularidad gracias a su atractivo para jugadores novatos y experimentados. No importa si eres si tienes mucha experiencia en el juego, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la adaptabilidad de este titulo en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere jugadas rapidas mientras viajas, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: http://www.mecosys.com/bbs/board.php?bo_table=project_02&wr_id=2290103
Otro punto que interesa a los jugadores es si se puede ganar dinero real con Sweet Bonanza. Al igual que en cualquier tragamonedas, Sweet Bonanza es un juego de azar, lo cual significa que el resultado de cada jugada es basado en azar y no puede ser controlado. Sin embargo, los multiplicadores y las rondas de giros gratis ofrecen una oportunidad significativa para obtener grandes premios. La funcion de multiplicador puede aumentar las ganancias hasta 100 veces en un solo giro, lo que puede resultar en una recompensa significativa si los jugadores tienen suerte. Sin embargo, es importante recordar que siempre es importante jugar con responsabilidad y que no siempre se gana en cada ronda.
Когда вы стремитесь найти захватывающую игру, которая точно дарит массу эмоций и перспективы на большой выигрыш, то Авиатор - Взлет – именно то, что вам нужно.
Что За Игра Авиатор?
<a href="https://lacollinaagriturismo.com/brief-struck-extremely-controls-wild-reddish-position-review-try-the-new-bally-video-game-for-free/">авиатор игра</a> – это впечатляющая краш игра, где ваш победа и достижения зависят от интуиции и скорости и хладнокровия и удачи. Суть игры в том, что вы делаете ставку и смотрите на самолет, который взлетает.
Как Управлять Игрой Авиатор? Играть в игру Авиатор очень просто. Вот ключевые этапы, которые облегчат начало игры:
Определите Ставку: Введите сумму, которую вы хотите вложить. Помните, что ставить нужно с ответственностью.
Следите за Полётом Самолета: После того как ставка внесена, на экране появится самолет, который взлетит. Множитель выигрыша будет расти. Берите выигрыш: В любой момент, пока самолет не пропал, вы можете зафиксировать выигрыш. Начните Новый Раунд: После завершения раунда вы можете продолжить игру.
Зеркало сайта: https://lacollinaagriturismo.com/brief-struck-extremely-controls-wild-reddish-position-review-try-the-new-bally-video-game-for-free/
Почему Выбирают Игру Авиатор?
Захватывающий Игровой Процесс: В Авиаторе каждый раунд захватывает. Легкость и Удобство: Игра простая и доступная. Большие Победы: Возможности для значительных побед зависят от вашей интуиции. Взаимодействие в Реальном Времени: В игре Авиатор всё происходит в реальном времени.
Контролируйте Риски: В игре Авиатор важно выигрывать с учетом рисков.
Отслеживайте Множитель: Анализируйте, как ведет себя множитель в раундах.
Используйте Акции и Бонусы: Не пропустите бонусах и акциях, чтобы повысить шансы на победу.
Este slot se diferencia de otras tragamonedas por su atractivo y original diseno. Al ingresar al slot, los apostadores se sumergen en un escenario de golosinas y colores brillantes que recuerdan a un cuento de hadas. El fondo de la pantalla esta lleno de golosinas, lo cual presenta un ambiente visual atractiva y agradable, adaptada a todos los jugadores. Esta tragamonedas ha sido considerado como entretenido y cautivador, ya que combina la emocion de los premios con una estetica visual que apela a todos los publicos.
Una de las caracteristicas mas valoradas de este slot es su ronda de giros gratis, que se activa al conseguir cuatro o mas simbolos de caramelos rosados en cualquier lugar de los carretes. Los giros gratis no solo permiten jugar de manera gratuita, sino que tambien aumentan las oportunidades de ganar, especialmente cuando aparecen multiplicadores en los giros. Este aspecto dentro del juego es uno de los mas emocionantes a los jugadores, y muchos comentan en sus opiniones que el bono de giros gratis es lo mas emocionante.
Ademas, la tragamonedas Sweet Bonanza ha logrado mantener su popularidad gracias a su caracter inclusivo. No importa si eres un jugador experimentado, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la versatilidad de el juego en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere divertirte mientras te desplazas, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: https://bloggingleads.com/el-popular-slot-de-pragmatic-play-descubre-todo-sobre-este-juego-desde-opiniones-autenticas-hasta-como-jugar-gratis-y-obtener-grandes-premios-en-su-aplicacion-optimizada/
Otro punto que interesa a los jugadores es si si el juego realmente permite ganar dinero con Sweet Bonanza. Al igual que en cualquier tragamonedas, este juego es un juego de azar, lo cual significa que el resultado de cada tirada es basado en azar y no puede ser anticipado. Sin embargo, los multiplicadores y la funcion de giros gratuitos ofrecen una oportunidad significativa para obtener ganancias considerables. La funcion de los multiplicadores permiten multiplicar las ganancias hasta 100x, lo que puede generar premios grandes si sale un giro afortunado. Sin embargo, es importante recordar que se debe jugar con responsabilidad y que el exito no esta asegurado en todos los giros.
The concept of online casinos came into existence in the early era of the internet, delivering a easy-to-reach substitute to brick-and-mortar establishments. Over time, modern technology have transformed online platforms into dynamic settings, boasting stunning imagery, live gaming features, and smooth gaming.
Today, the ability to access an virtual casino from a range of devices is a significant advantage for gamblers everywhere.
Web-based gambling sites offer a variety of activities, highlighting classics like blackjack, roulette, and poker, as well as a myriad of slot machines.
These online hubs make available for users the comfort of playing from their homes or in any location, making them a popular choice among both entry-level and seasoned gamblers.
One of the most important developments in the world of virtual casinos is the rise of portable gaming. Casino apps have become a go-to option for using online platforms, as a result of their accessible layouts and customized tools.
Whether you are a leisure bettor or a professional player, a specialized gaming app lets you experience your most-loved gaming experiences with just a few taps on your portable device.
These apps feature tools that ensure a uninterrupted casino session, with options such as tailored suggestions for games, quick payment processing, and enhanced security measures.
Web: aviator-online-game.pages.dev
Players can get a APK for casino platforms—a type of Android software—to gain instant access in cases where they're missing on common mobile platforms.
This freedom provides that players can remain engaged to their most-used casino systems, regardless of their device's operating system.
Fortune Tiger: Estrategias para Ganhos
Uma das caracteristicas mais atraentes do Fortune Tiger e a possibilidade de ganhar premios altos em pouco tempo. Os premios disponiveis em cada rodada sao um grande atrativo para os jogadores.
Diversas estrategias podem ajudar o jogador a otimizar suas apostas. Uma das taticas mais comuns e a aposta progressiva. Com essa tecnica, o jogador inicia com apostas minimas e vai subindo progressivamente.
A gestao do tempo durante as apostas tambem influencia diretamente os lucros. E fundamental estar atento aos minutos pagantes do jogo. A identificacao dos minutos pagantes pode ser uma chave para o sucesso em Fortune Tiger.
Plataforma de Apostas do Fortune Tiger: O que Saber
Website: https://mail.ask-directory.com/tigrinho-demo-gratis_403490.html
Consideracoes Finais
Seja para iniciantes ou veteranos, Fortune Tiger tem algo a oferecer. A confianca dos jogadores e conquistada pela transparencia e facilidade de uso.
Когда стремитесь найти волнующую игру, что обеспечит немало впечатлений и возможности для крупного выигрыша, то Авиатор - Взлет – ваш правильный выбор.
Что Такое Авиатор?
<a href="https://lacollinaagriturismo.com/slots-de-balde-tragamonedas-sin-cargo-online-falto-descargas-indumentarias-asignacion/">aviator</a> – это классная краш игра, где ваш победа и достижения зависят от реакции и удачи и удачи и интуиции. Основная задача – вы ставите и смотрите, как самолет взлетает.
Как Начать Играть в Авиатор? Играть в игру Авиатор несложно. Вот основные действия, которые помогут начать игру:
Выберите Сумму Ставки: Введите сумму, которую вы готовы поставить. Помните, что важно ставить с умом.
Ожидайте Взлета Самолета: После того как ставка выбрана, на экране появится самолет, который начнет набирать высоту. Множитель выигрыша будет расти. Забирайте Ваши средства: В любой момент, пока самолет в воздухе, вы можете забрать выигрыш. Сделайте Новую Ставку: После завершения раунда вы можете сделать новую ставку.
Зеркало сайта: https://lacollinaagriturismo.com/slots-de-balde-tragamonedas-sin-cargo-online-falto-descargas-indumentarias-asignacion/
Почему Популярна Игра Авиатор?
Захватывающий Игровой Процесс: В Авиаторе каждое мгновение приносит эмоции. Простота и Легкость: Игра не требует глубоких знаний. Шансы на Большие Выигрыши: Возможности для крупных выигрышей зависят от вашего подхода и интуиции. Игровая Интерактивность: В игре Авиатор всё происходит в реальном времени.
Управляйте Своими Рисками: В игре Авиатор важно не только выигрывать, но и контролировать риски.
Следите за Поведением Множителя: Пробуйте анализировать поведение множителя в игре.
Получайте Бонусы и Акции: Не упустите бонусах и акциях, чтобы увеличить выигрышные шансы.
Hazard online zdobywaja rosnace zainteresowanie w Polsce, a jedna z platform, ktora zyskuje uznanie wsrod uzytkownikow, jest <a href="https://hk.tiancaisq.com/home.php?mod=space&uid=484501&do=profile&from=space">bet on red casino login</a>. To platforma hazardowa online, ktore slynie z szerokiemu wyborowi gier, nowoczesnym interfejsem oraz hojnymi bonusami, ktore zadowola zarowno poczatkujacych, jak i weteranow gier.
Bet On Red Casino – czym jest?
Bet On Red Casino to platforma online, ktora oferuje ogromna biblioteke gier, takich jak sloty, rozgrywki stolowe oraz gry z prawdziwymi krupierami. Juz nazwa tej platformy „Red On Bet" odzwierciedla dynamike i hazardowe napiecie.
Latwe logowanie w Bet On Red Casino
Logowanie do konta w Bet On Red Casino jest prosty i szybki. Po wejsciu na strone glowna, wystarczy nacisnac opcje logowania i uzupelnic wymagane informacje. Platforma stawia na bezpieczenstwo, dlatego wszelkie informacje sa odpowiednio szyfrowane.
Osoby rejestrujace sie po raz pierwszy moga latwo zarejestrowac sie, a formularz rejestracyjny jest przejrzysty i krotki. Co istotne, Kasyno Bet On Red oferuje szeroki wybor opcji platnosci, co umozliwia szybkie rozpoczecie gry.
Oferta gier w Kasynie Bet On Red
Jednym z najwazniejszych aspektow, kazdego kasyna internetowego, jest biblioteka rozrywki. Kasyno Bet On Red wyroznia sie roznorodnoscia, ktory zadowoli nawet najbardziej wymagajacych graczy.
Web: https://hk.tiancaisq.com/home.php?mod=space&uid=484501&do=profile&from=space
Automaty sa jednym z najwiekszych hitow w ofercie, dostepne w licznych motywach oraz z ciekawymi rozwiazaniami. Oprocz klasycznych slotow, uzytkownicy moga sprobowac swoich sil w klasyki kasynowe, takie jak blackjack.
The development of digital gambling sites came into existence in the late 20th century, providing a accessible option to brick-and-mortar venues. Over time, progress in tech have transformed online platforms into captivating spaces, equipped with lifelike visuals, real dealer experiences, and flawless performance.
Today, the possibility to engage with an virtual casino from virtually any device is a main highlight for casino lovers around the globe.
Internet casinos make available a diverse selection of options, such as classics like blackjack, roulette, and poker, in addition to numerous slot games.
These platforms give enthusiasts the freedom of enjoying games in their living rooms or in any location, securing their place as preferred options among both beginner and long-time enthusiasts.
One of the most significant shifts in the field of online entertainment is the trend of handheld gameplay. Gambling apps are widely recognized as a go-to option for using online platforms, owing to their intuitive designs and unique enhancements.
Whether you are a occasional gamer or a strategic gamer, a specialized gaming app lets you experience your preferred entertainment with just a few clicks on your smart device.
These apps focus on enable a smooth gaming journey, with tools such as customized gambling options, quick payment processing, and advanced safety protocols.
Web: https://betonred-casino.netlify.app/
Players can download a APK for casino platforms—a type of Android software—to gain instant access if they are unavailable on mainstream app stores.
This freedom provides that players can always stay connected to their most-used casino systems, whatever device compatibility they have.
Estrategias para Lucrar no Jogo do Tigrinho
O Jogo do Tigrinho se destaca por oferecer premios significativos em poucas rodadas. O jogo proporciona um fluxo constante de oportunidades de premios em cada rodada.
Muitos jogadores aplicam estrategias especificas para aumentar as chances de lucro. Uma estrategia bastante popular e a aposta progressiva. O metodo comeca com valores minimos e sobe gradualmente.
Para melhorar as chances de lucro, e essencial escolher os momentos certos para apostar. Para otimizar os ganhos, e importante saber identificar os minutos pagantes. Os minutos pagantes sao muitas vezes aleatorios, mas podem ser melhor compreendidos por jogadores experientes.
Plataforma Fortune Tiger: Funcionalidades e Vantagens
Website: https://dokuwiki.stream/wiki/User:KennyKroeger659
Consideracoes Finais
Com sua simplicidade e grande potencial de premios, o Fortune Tiger se tornou um favorito. Com muitas formas de ganhar, Fortune Tiger e uma das opcoes mais atrativas no mundo dos jogos de aposta online.
Когда вы стремитесь найти волнующую игру, что предоставит массу эмоций и перспективы на большой выигрыш, то Авиатор игра – ваш правильный выбор.
Что За Игра Авиатор?
<a href="https://mrfingazmusicproductionsllc.com/aviator-onlayn-krash-igra/">авиатор</a> – это крутая краш игра, где ваш выигрыш в игре зависят от способности быстро принимать решения и удачи в моменте. Основная задача – вы делаете ставку и следите за взлетом самолета.
Как Начать Игру Авиатор? Играть в игру Авиатор легко. Вот основные действия, которые помогут вам начать играть:
Определите Ставку: Введите сумму, которую вы готовы рискнуть. Помните, что важно ставить с умом.
Следите за Полётом Самолета: После того как ставка размещена, на экране появится самолет, который начнет подниматься. Ваш множитель будет расти. Забирайте Ваш Выигрыш: В любой момент, пока самолет в полете, вы можете забрать выигрыш. Начните Новую Игру: После завершения раунда вы можете сделать новую ставку.
Зеркало сайта: https://mrfingazmusicproductionsllc.com/aviator-onlayn-krash-igra/
Почему Выбирают Игру Авиатор?
Захватывающий Геймплей: В Авиаторе каждый момент полон эмоций. Легкость Освоения: Игра не требует глубоких знаний. Большие Победы: Возможности выиграть крупно зависят от ваших решений и удачи. Интерактивность и Реальное Время: В игре Авиатор вы следите за процессом в реальном времени.
Контролируйте Риски: В игре Авиатор важно контролировать риски и выигрыши.
Отслеживайте Множитель: Следите за тем, как растет множитель.
Воспользуйтесь Бонусами: Участвуйте в бонусах и акциях, чтобы увеличить свои шансы на выигрыш.
Como Ganhar Mais no Fortune Tiger
O Fortune Tiger atrai muitos por sua chance de ganhos elevados em rodadas rapidas. O jogo proporciona um fluxo constante de oportunidades de premios em cada rodada.
Muitos jogadores aplicam estrategias especificas para aumentar as chances de lucro. Apostadores frequentemente recorrem a estrategia de apostas progressivas. O metodo comeca com valores minimos e sobe gradualmente.
Saber quando apostar e quanto aumentar as apostas e uma habilidade importante. Alguns jogadores se especializam em identificar os minutos de pagamento. Embora os minutos pagantes possam ser aleatorios, jogadores habilidosos sabem aproveitar essas oportunidades.
Como Funciona a Plataforma do Jogo Fortune Tiger
Website: http://www.god123.xyz/home.php?mod=space&uid=1103427&do=profile
Fechamento
Seja para iniciantes ou veteranos, Fortune Tiger tem algo a oferecer. Com muitas formas de ganhar, Fortune Tiger e uma das opcoes mais atrativas no mundo dos jogos de aposta online.
The concept of online casinos gained traction in the mid-1990s, offering a user-friendly substitute to traditional establishments. Over time, innovations in technology have transformed online platforms into interactive realms, complete with realistic graphics, interactive dealer gameplay, and flawless performance.
Today, the opportunity to explore an internet casino from almost any gadget is a significant advantage for gamblers internationally.
Online casinos feature a broad assortment of options, highlighting well-known options like roulette and poker, together with a myriad of slot machines.
These online hubs make available for users the freedom of playing from their homes or from anywhere, turning them into favorites among both entry-level and experienced players.
One of the most remarkable changes in the digital gambling sector is the trend of handheld gameplay. Gaming apps have turned into a top choice for playing on online platforms, owing to their user-friendly interfaces and customized tools.
Whether you are a occasional gamer or a dedicated enthusiast, a well-designed mobile casino provides your most-loved gaming experiences with just a few touches on your smartphone.
These apps focus on enhance a uninterrupted casino session, with features such as customized gambling options, fast transaction systems, and enhanced security measures.
Web: https://jogo-ratinho.web.app
Players can acquire a Android gambling app—a specific Android tool—to use software without delay when not found on mainstream app stores.
This freedom ensures that players can always stay connected to their favorite gaming platforms, no matter what OS they use.
melhor plataforma do tigrinho</a> mantem os jogadores envolvidos com seu design cativante.
Fortune Tiger: Estrategias para Ganhos
Uma das caracteristicas mais atraentes do Fortune Tiger e a possibilidade de ganhar premios altos em pouco tempo. A chance de premios em cada rodada faz do jogo uma escolha interessante para apostadores.
Para maximizar os lucros, muitos jogadores adotam estrategias variadas. Uma estrategia bastante popular e a aposta progressiva. Essa tatica permite comecar apostando baixo e ir aumentando gradualmente.
A gestao do tempo durante as apostas tambem influencia diretamente os lucros. Os minutos pagantes sao uma boa dica para os jogadores. A identificacao dos minutos pagantes pode ser uma chave para o sucesso em Fortune Tiger.
Caracteristicas da plataforma Fortune Tiger
Website: https://www.reddit-directory.com/jogo-do-tigrinho-bet_632300.html
Consideracoes Finais
Este jogo se destaca por ser acessivel e cheio de oportunidades de lucro. O jogo, com seus recursos de seguranca e opcoes de pagamento, proporciona uma experiencia tranquila.
В том случае, если жаждете захватывающую игру, что даст много шансов и перспективы на большой выигрыш, то Авиатор игра – идеальный выбор для вас.
Что За Игра Авиатор?
<a href="https://lacollinaagriturismo.com/cuberoll/">aviator игра</a> – это захватывающая игра, где ваш выигрыш и удача зависят от быстроты мышления и удачи и везения. Игра заключается в том, что вы ставите деньги и наблюдаете взлет самолета.
Как Играть в Авиатор? Играть в игру Авиатор достаточно легко. Вот основные действия, которые помогут приступить к игре:
Задайте Ставку: Введите сумму, которую вы готовы поставить. Помните, что ставьте осознанно.
Ожидайте Взлета Самолета: После того как ставка установлена, на экране появится самолет, который взлетит. Множитель выигрыша будет расти. Забирайте Ваши средства: В любой момент, пока самолет не пропал, вы можете зафиксировать выигрыш. Начните Новый Раунд: После завершения раунда вы можете начать новый раунд.
Зеркало сайта: https://lacollinaagriturismo.com/cuberoll/
Почему Стоит Играть в Авиатор?
Динамичный Геймплей: В Авиаторе каждое мгновение приносит эмоции. Легкость и Удобство: Игра легка в освоении. Большие Победы: Возможности выиграть щедро зависят от умения принимать решения. Взаимодействие в Реальном Времени: В игре Авиатор всё происходит в реальном времени.
Управляйте Своими Рисками: В игре Авиатор важно выигрывать с учетом рисков.
Отслеживайте Множитель: Анализируйте, как ведет себя множитель в раундах.
Бонусные Возможности и Акции: Не пропустите бонусах и акциях, которые помогут увеличить ваш выигрыш.
Ao longo dos passados anos, o setor de jogos virtuais tem experimentado um aumento significativo, atraindo milhoes de usuarios que buscam passatempo e, ocasionalmente, a chance de obter recompensas em especie. Dentre as opcoes de jogos que tem conquistado significativa fama, destacam-se o <a href="http://web004.dmonster.kr/bbs/board.php?bo_table=b0402&wr_id=292894">jogo do ratinho gratis</a> e o Fortune Mouse, ambos disponiveis em multiplas plataformas digitais. Estes titulos oferecem nao apenas diversao, mas tambem a potencialidade de obter recompensas para aqueles que demonstram habilidade, disciplina e uma pitada de sorte. Abaixo, exploraremos as caracteristicas mais importantes caracteristicas desses jogos, incluindo suas mecanicas, os momentos ideais para jogar, orientacoes para experimentar as versoes demo e taticas para aumentar as chances de vitoria.
O Jogo do Ratinho e popular por sua facilidade de acesso e por oferecer uma experiencia de jogo que combina fortuna e habilidade. Esse jogo tornou-se especialmente bem aceito entre os jogadores que buscam um jogo rapido e agradavel, mas que tambem pode oferecer a oportunidade de obter algum valor. Para quem esta conhecendo jogo pela primeira vez, e muito indicado comecar pela versao versao demo do jogo do ratinho. A demonstracao e uma versao gratis que possibilita experimentar o jogo, aprender as diretrizes, aprender o funcionamento e ate mesmo elaborar taticas sem a necessidade de usar valores monetarios. Isso e especialmente util para novos jogadores, que podem conhecer com o jogo antes de passar para as apostas com dinheiro real. A demonstracao tambem e excelente para jogadores mais experientes, pois permite a criacao e o teste de novas abordagens para melhorar as probabilidades de ganho.
Para aqueles que se acham preparados em sua habilidade de ganhar, existe o jogo do ratinho com premios em dinheiro, onde o jogador pode apostar e, a partir de sua habilidade e da sorte, adquirir lucros. E essencial, no entanto, adotar uma abordagem responsavel ao fazer apostas, lembrando que o principal objetivo do jogo deve ser o entretenimento. Alem disso, uma orientacao util e fixar um valor maximo e mante-lo, sem ultrapassar o que pode arriscar.
Uma das questoes que frequentemente surge entre os jogadores e quais os melhores horarios para o jogo do ratinho. Muitos acreditam que, de forma parecida com jogos de apostas ou em modalidades de apostas esportivas, alguns horarios podem aumentar as chances. Em regra, esse tipo de abordagem envolve jogar em horarios de menor movimento na plataforma, como de madrugada ou muito cedo pela manha. A razao por dessa estrategia e que, em horarios de menor concorrencia, o funcionamento pode apresentar mais oportunidades de vitoria para preservar o interesse dos usuarios ativos. Embora isso nao seja uma regra, e o resultado dos jogos muitas vezes dependa de sorte, muitos jogadores compartilham historias de sucesso associadas a esses horarios alternativos.
Web: http://web004.dmonster.kr/bbs/board.php?bo_table=b0402&wr_id=292894
O Jogo do Ratinho Online e uma otima opcao para aqueles que curtem o jogo facil de acessar e facil de acessar de qualquer lugar com internet. De forma diversa dos cassinos convencionais, que requerem visita ao local, o Jogo do Ratinho pode ser jogado em qualquer momento, e varias plataformas contam com promocoes e desafios que podem melhorar as chances de vitoria. Dentro dessa modalidade, encontra-se a possibilidade de jogar de forma gratuita, que e ideal para aqueles que buscam apenas diversao ou para aqueles que ainda estao aprendendo sobre o jogo. Essa versao gratis permite um jogo sem riscos, onde o jogador nao se compromete financeiramente, podendo treinar e se divertir sem dano ao bolso.
Para aqueles que buscam uma experiencia de aposta mais intensa, o game do ratinho com aposta possibilita que o jogador faca apostas com dinheiro real, com a expectativa de multiplicar o valor apostado. Ainda que essa escolha seja emocionante, e essencial ter cuidado, pois apostas implicam riscos. Muitos jogadores com pratica sugerem iniciar com valores menores e crescer o valor devagar, a medida que se torna mais confiante e entendido no jogo. O principal e nao esquecer que a sorte e essencial no Jogo do Ratinho, e as apostas devem ser feitas com cautela e responsabilidade.
The idea of virtual gambling platforms emerged in the early era of the internet, bringing a easy-to-reach variation to physical casinos. Over time, progress in tech have evolved online platforms into captivating realms, boasting lifelike visuals, real dealer experiences, and uninterrupted action.
Today, the possibility to engage with an virtual casino from a range of devices is a significant advantage for users internationally.
Virtual gambling platforms provide a diverse selection of entertainment choices, such as well-known options like roulette and poker, complemented by countless slots.
These platforms deliver to gamers the accessibility of gaming at home or in any location, turning them into favorites among both amateur and experienced players.
One of the most remarkable changes in the world of virtual casinos is the shift to mobile-first platforms. Gaming apps are increasingly a top choice for interacting with online platforms, as a result of their user-friendly interfaces and personalized options.
Whether you are a entertainment seeker or a strategic gamer, a specialized gaming app lets you experience your favorite games with just a few taps on your mobile phone.
These apps focus on enable a seamless gaming experience, with capabilities such as game selection based on preferences, rapid fund transfers, and robust privacy features.
Web: https://aviator-casino.pages.dev/
Players can obtain a casino apk—a type of Android software—to use software without delay when they are not listed on official app stores.
This ease ensures that players can always stay connected to their top-choice gaming apps, whatever device compatibility they have.
Understanding Stake Mines Game
Stake Mines is an incredibly exciting game that revolves around a basic concept but can be quite hard. Players initiate by setting a bet and then selecting tiles from a grid. The objective is to uncover all the mine-free tiles without landing on a mine. Each safe tile you uncover increases your winnings, but if you select a mine, the game ends, and you lose your bet. The straightforwardness of the game is part of its appeal, but the true challenge lies in the approach needed. Players must predict which tiles are safe to uncover, weighing exposure against potential reward.
The Stake Mines game is offered on various platforms, and its popularity continues to rise due to its fast-paced nature and the thrill of uncertainty. The surprise of which tile may hide a mine is part of what makes the game so exciting and offers a intense experience for both beginners and seasoned players.
Stake Mines Strategy: The Key to Winning
A well-thought-out Stake Mines strategy can make the difference between succeeding and walking away with nothing. While luck plays a role, the key to achievement lies in how you approach the game. One popular approach is to start with a small bet and gradually increase your wager as you uncover safe tiles. This allows players to reduce potential losses and prolong their gameplay, increasing their chances of hitting a profitable streak.
Another strategy involves selecting a specific design in which to uncover the tiles. By following a predetermined grid path, players may sometimes increase their chances of avoiding mines. However, even with the best-laid strategy, it’s vital to remember that the game is based on uncertainty, and no strategy can guarantee a win every time.
For those curious about how these bots work, a Stake Mines Predictor Bot Free version is often available for download. While these free bots may not be as advanced or sophisticated as their paid counterparts, they still claim to offer valuable insights into which tiles are safe to click. Players may experiment with these free tools to determine if they provide a significant advantage before upgrading to a more advanced version.
The Allure of Stake Mines Hack
For some players, using a Stake Mines Hack represents an appealing shortcut to guaranteed winnings. Hacks refer to hacked versions of the game or tools designed to change the game’s mechanics in favor of the player. These could involve adjusting the game’s algorithm, unlocking extra features, or even revealing the locations of mine-free tiles. However, using a hack comes with major risks. Firstly, many hacks are dangerous, possibly introducing malware or harming your device. Secondly, hacking is a breach of most gaming platforms' terms of service, and players caught using hacks can be banned or suspended.
While this tool doesn’t guarantee success, it provides a way for players to gauge the risk and reward associated with each decision. Some calculators even use historical game data to adjust a player’s strategy based on past performance.
Stake Mines APK and Mod Versions
For those who enjoy trying out various game versions, the Stake Mines APK lets users install the game on their Android devices. APK releases allow people to circumvent app store barriers and load customized or modified versions of the game. These versions can offer enhanced features, additional functionalities, or even more chances to succeed, but it’s important to acquire them from trusted sources to avoid malware or other issues.
Web: https://empressvacationrentals.com/complete-mines-game-guide-strategies-hacks-demos-and-downloads/
Stake Mines Demo: Learning the Game Without Risk
If you're new to Stake Mines, the Stake Mines demo is a great way to explore the game’s mechanics without the financial risk. Many platforms offer demo versions of games, allowing players to refine their skills and strategies in a low-stakes environment. The Stake Mines demo mirrors the real game but without using real money, making it the perfect way to train before committing to real wagers.
Using the demo version helps players grasp the features and gameplay of the game without the worry of losing money. It’s a risk-free way to explore different strategies and decide how to approach the full game.
В том случае, если жаждете захватывающую и увлекательную игру, которая дарит массу эмоций и возможности для крупного выигрыша, то игра Авиатор – идеальный выбор для вас.
Что За Игра Авиатор?
<a href="https://lacollinaagriturismo.com/nordicslots-has-a-great-100percent-up-to-a-hundred-register-bonus-nebo%D1%98sha/">авиатор казино</a> – это захватывающая игра, где ваш выигрыш в игре зависят от скорости решений и хладнокровия и удачи. В этой игре вы вы делаете ставку и наблюдаете за тем, как самолет взлетает.
Как Управлять Игрой Авиатор? Играть в игру Авиатор легко. Вот этапы начала игры, которые облегчат начало игры:
Задайте Ставку: Введите сумму, которую готовы ставить. Помните, что важно контролировать ставки.
Следите за Взлетом Самолета: После того как ставка выбрана, на экране появится самолет, который взлетит. Величина множителя начнет увеличиваться. Забирайте деньги: В любой момент, пока самолет не пропал, вы можете зафиксировать выигрыш. Начните Новую Игру: После завершения раунда вы можете начать новую игру.
Зеркало сайта: https://lacollinaagriturismo.com/nordicslots-has-a-great-100percent-up-to-a-hundred-register-bonus-nebo%D1%98sha/
Почему Популярна Игра Авиатор?
Динамичный Геймплей: В Авиаторе каждый момент полон эмоций. Простота и Доступность: Игра легко освоить. Большие Победы: Возможности выиграть крупно зависят от вашей интуиции. Интерактивность и Реальное Время: В игре Авиатор всё происходит в реальном времени.
Управляйте Своими Рисками: В игре Авиатор важно обдуманно управлять рисками.
Отслеживайте Множитель: Следите за тем, как растет множитель.
Бонусные Возможности и Акции: Не пропустите бонусах и акциях, чтобы повысить шансы на победу.
plataforma que mais paga fortune tiger</a> possui uma estetica amigavel e atrativa.
Estrategias para Lucrar no Jogo do Tigrinho
O jogo se diferencia por suas oportunidades de lucro rapido e significativo. Com potencial de premios em cada rodada, o jogo se torna emocionante e vantajoso.
Muitos jogadores combinam estrategias para maximizar o potencial de lucro. A aposta progressiva e uma das tecnicas mais usadas no jogo. A aposta inicial e baixa, mas cresce conforme o jogo avanca.
O timing das apostas pode ser um diferencial crucial para maximizar os ganhos. E fundamental estar atento aos minutos pagantes do jogo. Esses momentos de maiores ganhos sao imprevisiveis, mas com pratica e possivel identifica-los.
Plataforma Fortune Tiger: Beneficios para o Jogador
Website: https://scientific-programs.science/wiki/User:EstelaGyo139451
Conclusao
O Fortune Tiger e uma plataforma empolgante para todos os tipos de jogadores. O jogo atrai uma enorme base de jogadores pela sua combinacao de entretenimento e ganhos.
The notion of internet-based casinos gained traction in the mid-1990s, offering a comfortable option to brick-and-mortar casinos. Over time, digital improvements have reshaped online platforms into immersive experiences, boasting lifelike visuals, real dealer experiences, and smooth gaming.
Today, the option to explore an digital gambling site from any modern device stands out as a major attraction for gamblers around the globe.
Internet casinos provide a broad assortment of options, such as traditional games like blackjack and roulette, together with numerous slot games.
These platforms make available for users the freedom of gambling from the comfort of their houses or on the go, turning them into favorites among both newcomer and long-time enthusiasts.
One of the most remarkable changes in the realm of internet-based gambling is the shift to mobile-first platforms. Casino-focused software are increasingly a preferred method for playing on online platforms, owing to their user-friendly interfaces and adapted functionalities.
Whether you are a occasional gamer or a professional player, a feature-rich casino software allows you to enjoy your favorite games with just a few clicks on your smartphone.
These apps are built to enable a flawless entertainment flow, with functionalities such as game selection based on preferences, efficient deposit methods, and advanced safety protocols.
Web: https://andar-bahar-game.pages.dev
Players can install a APK for casino platforms—a specific Android tool—to gain instant access in cases where they're missing on mainstream app stores.
This ease makes certain that players can always stay connected to their preferred digital casinos, irrespective of technical constraints.
Understanding Stake Mines Game
Stake Mines is an incredibly engaging game that revolves around a clear-cut concept but can be quite challenging. Players embark on by making a stake and then selecting tiles from a grid. The objective is to uncover all the clear tiles without landing on a mine. Each safe tile you uncover increases your winnings, but if you select a mine, the game ends, and you lose your stake. The basic nature of the game is part of its appeal, but the true challenge lies in the tactics needed. Players must predict which tiles are safe to uncover, weighing exposure against potential reward.
The Stake Mines game is offered on various platforms, and its popularity continues to rise due to its quick nature and the thrill of uncertainty. The randomness of which tile may hide a mine is part of what makes the game so exciting and offers a intense experience for both novices and seasoned players.
Stake Mines Strategy: The Key to Winning
A well-thought-out Stake Mines strategy can make the difference between triumphing and walking away with nothing. While luck plays a role, the key to success lies in how you play the game. One popular approach is to start with a low bet and gradually boost your wager as you uncover safe tiles. This allows players to cut down on potential losses and prolong their gameplay, increasing their chances of hitting a profitable streak.
Another strategy involves selecting a specific design in which to uncover the tiles. By following a predetermined grid path, players may sometimes raise their chances of avoiding mines. However, even with the best-laid strategy, it’s vital to remember that the game is based on uncertainty, and no strategy can guarantee a win every time.
For those curious about how these bots work, a Stake Mines Predictor Bot Free version is often available for download. While these free bots may not be as advanced or sophisticated as their paid counterparts, they still claim to offer valuable insights into which tiles are safe to click. Players may experiment with these free tools to determine if they provide a significant advantage before upgrading to a more sophisticated version.
The Allure of Stake Mines Hack
For some players, using a Stake Mines Hack represents an appealing shortcut to guaranteed winnings. Hacks refer to cheated versions of the game or tools designed to change the game’s mechanics in favor of the player. These could involve altering the game’s algorithm, unlocking extra features, or even revealing the locations of mine-free tiles. However, using a hack comes with major risks. Firstly, many hacks are illegal, possibly introducing malware or harming your device. Secondly, hacking is a breach of most gaming platforms' terms of service, and players caught using hacks can be banned or suspended.
While this tool doesn’t guarantee success, it provides a way for players to evaluate the risk and reward associated with each decision. Some calculators even use historical game data to adjust a player’s strategy based on past performance.
Stake Mines APK and Mod Versions
For those who enjoy trying out different game versions, the Stake Mines APK lets enthusiasts download the game on their Android devices. APK releases allow people to get around app store limitations and use customized or modded versions of the game. These versions can offer enhanced features, additional functionalities, or even more chances to succeed, but it’s important to download them from secure sources to avoid malware or other issues.
Web: https://www.spairkorea.co.kr:443/gnuboard/bbs/board.php?bo_table=g_inquire&wr_id=3007591
Stake Mines Demo: Learning the Game Without Risk
If you're new to Stake Mines, the Stake Mines demo is a great way to practice the game’s mechanics without the financial risk. Many platforms offer demo versions of games, allowing players to refine their skills and strategies in a low-stakes environment. The Stake Mines demo mirrors the real game but without using real money, making it the perfect way to experiment before committing to real wagers.
Using the demo version helps players understand the features and gameplay of the game without the worry of losing money. It’s a risk-free way to explore different strategies and decide how to approach the full game.
В случае, если стремитесь найти азартную игру, способная обеспечит огромное количество эмоций и возможности выиграть крупно, то игра Авиатор – ваш правильный выбор.
О Чём Игра Авиатор?
<a href="https://lacollinaagriturismo.com/better-5-lowest-deposit-online-casinos-in-the-canada-2024/">авиатор казино</a> – это захватывающая игра, где ваш успех в игре зависят от интуиции и скорости и удачи. Цель игры заключается в том, что вы ставите деньги и наблюдаете взлет самолета.
Как Начать Играть в Авиатор? Играть в игру Авиатор достаточно легко. Вот этапы начала игры, которые помогут вам начать играть:
Определите Ставку: Введите сумму, на которую вы готовы играть. Помните, что ставьте осознанно.
Ожидайте Взлета Самолета: После того как ставка размещена, на экране появится самолет, который покажет взлет. Величина множителя начнет увеличиваться. Фиксируйте выигрыш: В любой момент, пока самолет взлетает, вы можете взять выигрыш. Повторите Игру: После завершения раунда вы можете сделать новую ставку.
Зеркало сайта: https://lacollinaagriturismo.com/better-5-lowest-deposit-online-casinos-in-the-canada-2024/
Почему Популярна Игра Авиатор?
Захватывающий Игровой Процесс: В Авиаторе каждое мгновение приносит эмоции. Простота и Доступность: Игра простая и доступная. Возможности для Крупных Побед: Возможности выиграть крупно зависят от умения принимать решения. Интерактивные Элементы: В игре Авиатор процесс идет в реальном времени.
Контролируйте Риски: В игре Авиатор важно контролировать риски и выигрыши.
Следите за Динамикой Множителя: Пробуйте анализировать поведение множителя в игре.
Пользуйтесь Бонусами и Акциями: Участвуйте в бонусах и акциях, чтобы увеличить выигрышные шансы.
One appeal of <a href="https://cs.xuxingdianzikeji.com/home.php?mod=space&uid=2764815&do=profile&from=space">sweet bonanza</a> is its refreshing approach to online slot design. Unlike classic slot games that rely on paylines, Sweet Bonanza features a "cluster pays" system. The Sweet Bonanza slot features six reels and a five-row grid, presenting participants numerous possibilities to secure matches with every spin. Combinations happen by landing clusters of eight or more identical figures on the play area, differentiating it from usual slots that function through fixed paylines.
The cluster pay system doesn’t just attractive visually but also provides players better odds per spin.
This candy-inspired visual style and bright color palette complement the visual allure, generating a sugary and dynamic vibe that brings in users. Symbols in Sweet Bonanza show a variety of candies in bright colors, as well as bananas, grapes, watermelons, and other fruits. The graphics are supported by upbeat background music that adds to the thrill of the game. The slot game also has a scatter symbol with a lollipop image, which serves a key purpose in triggering the Free Spins feature. If players get four or more lollipop symbols, users will initiate the extra spins, which gives a significant chance to win big.
For those who are unfamiliar with online slots or wish to practice with no financial risk, Sweet Bonanza demo mode offers an ideal option. Most casino platforms offer a Sweet Bonanza practice mode, giving users to test the game, experiment with tactics, and acquaint themselves with the mechanics without any monetary commitment. Playing a demo version of the slot is ideal for novices, as it enables understanding of the game structure, experiment with bet amounts, and discover the cascading reels.
Web: https://cs.xuxingdianzikeji.com/home.php?mod=space&uid=2764815&do=profile&from=space
The tumbling mechanic, referred to as the cascading function, is central to the slot. Once players hit a winning cluster, the winning symbols are cleared, and new symbols fall into place, creating further win potential. This mechanic increases the fun but also gives players more opportunities to win in a single spin.
A top feature of Sweet Bonanza is its Free Spins feature, which is frequently the most exciting part for players. The bonus spins in the game may result in impressive wins due to the presence of multipliers. Upon activation, the Free Spins feature awards ten free spins, and players may earn more spins by landing additional lollipop icons.
The concept of online casinos came into existence in the 1990s, offering a accessible solution to conventional establishments. Over time, innovations in technology have reshaped online platforms into captivating spaces, equipped with high-quality designs, interactive dealer gameplay, and lag-free experiences.
Today, the opportunity to use an online casino from practically anywhere is a main highlight for users around the globe.
Virtual gambling platforms make available a wide range of gaming experiences, featuring timeless classics like roulette and poker, alongside hundreds of slot games.
These online hubs provide players the ease of participating from any cozy spot or while traveling, securing their place as preferred options among both newcomer and long-time enthusiasts.
One of the most significant shifts in the realm of internet-based gambling is the growth of mobile-friendly interfaces. Casino-focused software have turned into a top choice for accessing online platforms, due to their accessible layouts and adapted functionalities.
Whether you are a entertainment seeker or a strategic gamer, a dedicated casino app provides your top-choice options with just a few touches on your portable device.
These apps focus on deliver a lag-free gambling interaction, with capabilities such as personalized game recommendations, instant payout solutions, and advanced safety protocols.
Web: https://aposta-fortune-crash.netlify.app/
Players can install a casino apk—a specific Android tool—to use software without delay should they not be accessible on popular download hubs.
This freedom makes certain that players can always stay connected to their favorite gaming platforms, regardless of their device's operating system.
Este slot se diferencia de otras maquinas tragamonedas por su estilo visual y tematica original. Al abrir el juego, los apostadores entran en un universo de caramelos y colores vivos que parecen de un mundo fantastico. Se puede ver un fondo lleno de caramelos, lo cual ofrece una escena visual relajante y divertida, ideal para todo tipo de jugadores. Este juego ha sido considerado como entretenido y cautivador, ya que mezcla la emocion de ganar premios con un estilo visual atractivo para todos.
Una de las caracteristicas mas valoradas de Sweet Bonanza es su caracteristica de giros gratis, que se activa cuando aparecen cuatro o mas simbolos de caramelos rosados. La ronda de giros gratuitos no solo permiten jugar de manera gratuita, sino que tambien potencian las probabilidades de grandes ganancias, especialmente cuando aparecen multiplicadores en los giros. Este elemento del juego es uno de los mas interesantes a los jugadores, y muchos mencionan en sus opiniones que la ronda de giros gratis es la parte mas emocionante.
Ademas, el juego de Pragmatic Play ha logrado mantener su popularidad gracias a su aplicabilidad universal. No importa si eres un jugador experimentado, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la adaptabilidad de el juego en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere apostar desde tu telefono movil, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: https://elearnportal.science/wiki/User:WendiM4078326674
Otro punto que interesa a los jugadores es si si el juego realmente permite ganar dinero con este slot. Al igual que en cualquier tragamonedas, este juego es una maquina de azar, lo cual significa que el resultado de cada vuelta es aleatorio y no puede ser predicho. Sin embargo, los multiplicadores y la funcion de giros gratuitos ofrecen una oportunidad significativa para obtener ganancias considerables. La funcion de multiplicador puede aumentar las ganancias hasta 100 veces en un solo giro, lo que puede resultar en una recompensa significativa si se tiene suerte en el giro. Sin embargo, es importante recordar que el juego debe disfrutarse de manera responsable y que no siempre se gana en cada ronda.
В случае, если желаете захватывающую и увлекательную игру, которая даст огромное количество эмоций и перспективы на большой выигрыш, то Авиатор игра – именно то, что вам нужно.
Что Такое Авиатор?
<a href="https://lacollinaagriturismo.com/8-jeux-vraiment-lucratifs-que-endossent-immediatement-avec-paypal-il-va-falloir-experimenter-maintenant/">авиатор казино</a> – это крутая краш игра, где ваш выигрыш и удача зависят от способности быстро принимать решения и удачи в моменте. Основная задача – вы делаете ставку и следите за взлетом самолета.
Как Начать Игру Авиатор? Играть в игру Авиатор несложно. Вот этапы начала игры, которые помогут стартовать в игре:
Определите Ставку: Введите сумму, которую вы хотите вложить. Помните, что ставьте осознанно.
Наблюдайте за Взлётом Самолета: После того как ставка подтверждена, на экране появится самолет, который начнет подниматься. Множитель будет увеличиваться. Фиксируйте выигрыш: В любой момент, пока самолет в полете, вы можете зафиксировать выигрыш. Сделайте Новую Ставку: После завершения раунда вы можете сделать новую ставку.
Зеркало сайта: https://lacollinaagriturismo.com/8-jeux-vraiment-lucratifs-que-endossent-immediatement-avec-paypal-il-va-falloir-experimenter-maintenant/
Почему Выбирают Игру Авиатор?
Интересный Геймплей: В Авиаторе каждый момент полон эмоций. Простота и Доступность: Игра простая и доступная. Крупные Выигрыши: Возможности для крупных выигрышей зависят от ваших решений и удачи. Интерактивные Элементы: В игре Авиатор вы следите за процессом в реальном времени.
Следите за Рисковыми Моментами: В игре Авиатор важно обдуманно управлять рисками.
Следите за Поведением Множителя: Следите за изменениями множителя.
Используйте Акции и Бонусы: Не пропустите бонусах и акциях, чтобы увеличить выигрышные шансы.
Bu durumda, oyunun temel kurallar? nelerdir? Bu populer oyunun derinlemesine ayr?nt?lar?n? gozden gecirecegiz ve giris yapma yontemlerinden taktik ipuclar?na kadar butun detaylar? size sunacag?z.
Sweet Bonanza oyunu nedir ve nas?l cal?s?r?
Bu oyun, slot oyunlar? dunyas?nda ozel bir yere sahip olan bir slot oyunudur. Pragmatic Play’in sundugu bu oyun, cesitli seker ve meyve sembollerinin birlesiminden olusur. Bu tatl? semboller, tatl? bir dunyaya davet ederek oyuncular? bu eglenceli oyunun parcas? yapar.
Bu oyunun diger slot oyunlar?na gore farkl? bir oyun sistemine sahip olmas? oyunculara farkl? bir deneyim sunuyor. Her kazancla birlikte yeni sembollerin eklenmesiyle, oyun surekli bir sekilde kazanma olas?l?g? yarat?r. Bu mekanik yap?yla birlikte, Sweet Bonanza, diger slot oyunlar?ndan ayr?l?r.
Sweet Bonanza Nas?l Oynan?r?
Bu oyunun oynan?s tarz? diger slot oyunlar?ndan daha karmas?k olmayan bir oynan?s sunar. alt? sutun ve bes sat?rdan olusan bir tabloda oynan?r. Oyuncular?n amac?, ayn? sembollerin bir araya toplanmas?yla oyunda kazanc elde etmektir.
Bu yap?da ozel bir kombinasyon kurma zorunlulugu yoktur. Kazanc icin ayn? sembollerin toplanmas? yeterlidir. Kazanan semboller patlar ve yenileri eklenir. Bu sayede, bir dondurmede birden fazla odul kazan?labilir.
Web: https://www.nebuk2rnas.com/nuomone/mama-mia-2021/
Sweet Bonanza Demo: Oyunu Denemek Icin Ideal F?rsat
Sweet Bonanza’n?n sundugu avantajlardan biri de, oyuncular?n demo versiyonu deneme imkan?n?n olmas?d?r. Demo mod, oyuna yeni baslayanlar icin harika bir f?rsat sunar. Oyuncular, demo modda gercek para harcamadan oyunun dinamiklerini ogrenebilirler.
Oyuncular, demo oyun ile sembollerin degerlerini tan?yabilir. Bu modda, oyun stratejilerini risksiz bir sekilde deneyebilirsiniz. Bu demo, strateji olusturmak icin mukemmel bir platform saglar.
The notion of internet-based casinos originated in the 1990s, offering a user-friendly option to land-based gaming spots. Over time, innovations in technology have revolutionized online platforms into immersive experiences, complete with lifelike visuals, real-time dealer interactions, and uninterrupted action.
Today, the possibility to use an digital gambling site from almost any gadget is a main highlight for users around the globe.
Online casinos provide a broad assortment of games, such as iconic games such as poker and blackjack, together with hundreds of slot games.
These websites make available for users the freedom of gambling from the comfort of their houses or on the go, making them a popular choice among both amateur and long-time enthusiasts.
One of the most significant shifts in the realm of internet-based gambling is the trend of handheld gameplay. Gaming apps are now a go-to option for interacting with online platforms, thanks to their intuitive designs and tailored features.
Whether you are a entertainment seeker or a strategic gamer, a specialized gaming app provides your preferred entertainment with just a few touches on your smartphone.
These apps aim to enable a uninterrupted casino session, with functionalities such as game selection based on preferences, fast transaction systems, and high-level protections.
Web: https://aviator-game-pakistan.web.app
Players can acquire a mobile gaming APK—a package designed for Android—to gain instant access when not found on common mobile platforms.
This ease provides that players can continue their sessions to their preferred digital casinos, despite their device preferences.
Este juego destaca de otras slots por su atractivo y original diseno. Al iniciar el juego, los fans entran en un mundo de dulces y colores vivos que parecen de un mundo fantastico. El escenario esta repleto de confites, lo cual ofrece una escena visual agradable y tranquila, perfecta para principiantes y expertos. Este juego ha sido descrito por muchos en sus opiniones como adictivo y muy entretenido, ya que combina la emocion de los premios con una estetica visual que apela a todos los publicos.
Una de las caracteristicas mas valoradas de Sweet Bonanza es su ronda de giros gratis, que se activa cuando aparecen cuatro o mas simbolos de caramelos rosados. El modo de giros sin costo no solo permiten jugar sin costo, sino que tambien multiplican las posibilidades de ganar grandes premios, especialmente cuando los multiplicadores hacen su aparicion. Este elemento del juego es uno de los mas interesantes a los jugadores, y muchos mencionan en sus opiniones que la ronda de giros gratis es lo mejor del juego.
Ademas, este juego ha logrado mantener su popularidad gracias a su caracter inclusivo. No importa si eres un jugador experimentado, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la disponibilidad de Sweet Bonanza en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere divertirte mientras te desplazas, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: https://cs.xuxingdianzikeji.com/home.php?mod=space&uid=2777575&do=profile&from=space
Otro punto que interesa a los jugadores es si si el juego realmente permite ganar dinero con este slot. Al igual que en cualquier tragamonedas, la tragamonedas Sweet Bonanza es un juego de azar, lo cual significa que el resultado de cada jugada es impredecible y no puede ser controlado. Sin embargo, los multiplicadores junto con giros gratis ofrecen una oportunidad significativa para obtener ganancias considerables. La funcion de multiplicador puede aumentar las ganancias hasta 100 veces en un solo giro, lo que puede resultar en una ganancia notable si sale un giro afortunado. Sin embargo, es importante recordar que el juego debe disfrutarse de manera responsable y que no hay garantias de ganar en cada sesion.
В случае, если желаете волнующую игру, что подарит немало впечатлений и шансы на значительный выигрыш, то Авиатор игра – это то, что нужно.
Что Такое Авиатор?
<a href="https://lacollinaagriturismo.com/sverige-kronan-2024-bonuses-advice-studying-centre-broude-jennings-mcglinchey-desktop-computer/">игра авиатор</a> – это впечатляющая краш игра, где ваш выигрыш в игре зависят от интуиции и скорости и хладнокровия и удачи. Основная задача – вы делаете ставку и смотрите на самолет, который взлетает.
Как Управлять Игрой Авиатор? Играть в игру Авиатор достаточно легко. Вот основные действия, которые помогут приступить к игре:
Задайте Ставку: Введите сумму, которую вы хотите вложить. Помните, что ставьте осознанно.
Наблюдайте за Взлётом Самолета: После того как ставка размещена, на экране появится самолет, который начнет подниматься. Величина множителя начнет увеличиваться. Забирайте Ваш Выигрыш: В любой момент, пока самолет не пропал, вы можете зафиксировать выигрыш. Начните Новый Раунд: После завершения раунда вы можете начать новый раунд.
Зеркало сайта: https://lacollinaagriturismo.com/sverige-kronan-2024-bonuses-advice-studying-centre-broude-jennings-mcglinchey-desktop-computer/
Почему Стоит Выбрать Авиатор?
Интересный Геймплей: В Авиаторе каждое мгновение наполнено азартом. Простота и Доступность: Игра легко понятна. Шансы на Победу: Возможности выиграть крупно зависят от вашей интуиции. Интерактивные Элементы: В игре Авиатор процесс идет в реальном времени.
Следите за Рисковыми Моментами: В игре Авиатор важно выигрывать с учетом рисков.
Отслеживайте Тенденции Множителя: Следите за изменениями множителя.
Пользуйтесь Бонусами и Акциями: Используйте бонусах и акциях, чтобы увеличить свои шансы на выигрыш.
Sweet Bonanza sobresale de otras maquinas tragamonedas por su diseno y tematica unicos. Al comenzar a jugar, los apostadores se sumergen en un escenario de golosinas y tonalidades intensas que parecen de un mundo fantastico. El fondo de la pantalla esta lleno de golosinas, lo cual presenta un ambiente visual agradable y tranquila, perfecta para principiantes y expertos. Esta tragamonedas ha sido descrito por muchos en sus opiniones como adictivo y muy entretenido, ya que ofrece premios emocionantes y una estetica cautivadora.
Una de las caracteristicas mas valoradas de este juego es su modo de giros gratis, que se activa al conseguir cuatro o mas simbolos de caramelos rosados en cualquier lugar de los carretes. La ronda de giros gratuitos no solo permiten jugar sin gastar dinero adicional, sino que tambien multiplican las posibilidades de ganar grandes premios, especialmente cuando los multiplicadores estan presentes. Este aspecto dentro del juego es uno de los mas emocionantes a los jugadores, y muchos senalan en sus resenas que la funcion de giros gratis es lo mejor del juego.
Ademas, el juego de Pragmatic Play ha logrado mantener su popularidad gracias a su caracter inclusivo. No importa si eres si tienes mucha experiencia en el juego, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la adaptabilidad de este slot en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere jugar durante tus descansos, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: https://spechrom.com:443/bbs/board.php?bo_table=service&wr_id=85342
Otro punto que interesa a los jugadores es si realmente pueden ganar dinero con este juego. Al igual que en cualquier tragamonedas, este juego es un juego donde interviene la suerte, lo cual significa que el resultado de cada tirada es basado en azar y no puede ser controlado. Sin embargo, los multiplicadores junto con giros gratis ofrecen una oportunidad significativa para obtener grandes recompensas. La funcion de se pueden multiplicar las ganancias hasta 100 veces gracias a los multiplicadores, lo que puede resultar en una ganancia notable si los jugadores tienen suerte. Sin embargo, es importante recordar que el juego debe disfrutarse de manera responsable y que el exito no esta asegurado en todos los giros.
The idea of virtual gambling platforms came into existence in the 1990s, bringing a convenient substitute to land-based venues. Over time, digital improvements have transformed online platforms into interactive environments, including high-quality designs, live dealer options, and smooth gaming.
Today, the ability to use an internet casino from a range of devices is a main highlight for players around the globe.
Web-based gambling sites offer a wide range of entertainment choices, featuring timeless classics like roulette and poker, as well as numerous slot games.
These online hubs deliver to gamers the comfort of enjoying games in their living rooms or in any location, establishing their popularity among both newcomer and long-time enthusiasts.
One of the most important developments in the digital gambling sector is the trend of handheld gameplay. Casino apps are widely recognized as a preferred method for engaging with online platforms, as a result of their accessible layouts and unique enhancements.
Whether you are a casual player or a strategic gamer, a feature-rich casino software brings you your favorite games with just a few clicks on your smartphone.
These apps feature tools that enable a lag-free gambling interaction, with tools such as game selection based on preferences, rapid fund transfers, and advanced safety protocols.
Web: https://onlineplinko.netlify.app/
Players can acquire a casino application file—a dedicated app setup for Android—to access platforms seamlessly should they not be accessible on common mobile platforms.
This flexibility makes certain that players can maintain access to their favorite gaming platforms, irrespective of technical constraints.
Estrategias para Lucrar no Jogo do Tigrinho
O potencial de lucro em curto prazo faz do Tigrinho uma opcao popular. Cada rodada traz a chance de premios elevados, o que e um atrativo para muitos.
Para maximizar os lucros, muitos jogadores adotam estrategias variadas. Uma das taticas mais comuns e a aposta progressiva. Com essa tecnica, o jogador inicia com apostas minimas e vai subindo progressivamente.
O timing das apostas pode ser um diferencial crucial para maximizar os ganhos. E fundamental estar atento aos minutos pagantes do jogo. Esses periodos de pagamento mais elevados ocorrem aleatoriamente, mas jogadores experientes sabem como identifica-los.
Entenda como funciona a plataforma de Fortune Tiger
Website: https://menwiki.men/wiki/User:KaceyStrickland
Consideracoes Finais
Com sua simplicidade e grande potencial de premios, o Fortune Tiger se tornou um favorito. Com sua interface amigavel e sistema de pagamentos confiavel, o jogo e ideal para qualquer apostador.
В случае, если жаждете захватывающую и увлекательную игру, что даст массу эмоций и шанс на крупные выигрыши, то игра Авиатор – идеальный выбор для вас.
О Чём Игра Авиатор?
<a href="https://lacollinaagriturismo.com/luchshiy-sposob-prinyat-uchastie-v-besplatnykh-onlayn-igrakh-pinap-kazino-vkhod-na-igrovykh-avtomatakh/">aviator</a> – это крутая краш игра, где ваш победа и достижения зависят от реакции и удачи и удачи и интуиции. Основная задача – вы делаете ставку и смотрите на самолет, который взлетает.
Как Играть в Игра Авиатор? Играть в игру Авиатор не вызывает трудностей. Вот основные шаги, которые помогут начать игру:
Сделайте Вашу Ставку: Введите сумму, которую вы готовы поставить. Помните, что ставить нужно с ответственностью.
Ожидайте Взлета Самолета: После того как ставка размещена, на экране появится самолет, который покажет взлет. Множитель выигрыша будет расти. Фиксируйте выигрыш: В любой момент, пока самолет в полете, вы можете забрать свой выигрыш. Начните Новую Игру: После завершения раунда вы можете начать новый раунд.
Зеркало сайта: https://lacollinaagriturismo.com/luchshiy-sposob-prinyat-uchastie-v-besplatnykh-onlayn-igrakh-pinap-kazino-vkhod-na-igrovykh-avtomatakh/
Что Привлекает в Игре Авиатор?
Интересный Геймплей: В Авиаторе каждое мгновение наполнено азартом. Доступность и Простота: Игра легка в освоении. Большие Победы: Возможности выиграть крупно зависят от ваших интуитивных решений. Игровая Интерактивность: В игре Авиатор вы играете в реальном времени.
Следите за Рисками: В игре Авиатор важно выигрывать с учетом рисков.
Отслеживайте Тенденции Множителя: Анализируйте поведение множителя.
Получайте Бонусы и Акции: Участвуйте в бонусах и акциях, чтобы увеличить выигрышные шансы.
Gry hazardowe online zdobywaja rosnace zainteresowanie w Polsce, a jedna z stron, ktora zyskuje uznanie wsrod uzytkownikow, jest <a href="https://ai.igcps.com/home.php?mod=space&uid=736088&do=profile&from=space">bet on red opinie</a>. To kasyno online, ktore wyroznia sie bogatej ofercie gier, intuicyjna konstrukcja strony oraz atrakcyjnymi promocjami, ktore zadowola zarowno osoby nowe w swiecie hazardu, jak i weteranow gier.
Dlaczego gracze wybieraja Kasyno Bet On Red?
Kasyno Bet On Red to nowoczesne kasyno internetowe, ktora oferuje roznorodne opcje rozrywki, takich jak maszyny hazardowe, klasyczne gry kasynowe oraz gry z prawdziwymi krupierami. Juz nazwa tej platformy „Bet On Red" przywoluje adrenaline i hazardowe napiecie.
Jak zalogowac sie do Bet On Red?
Proces logowania w Bet On Red Casino jest latwy i wygodny. Po przejsciu na strone kasyna, wystarczy wybrac funkcje logowania i wpisac swoje dane. Platforma gwarantuje bezpieczenstwo, dlatego wszelkie przesylane informacje sa zaszyfrowane.
Uzytkownicy rozpoczynajacy swoja przygode moga szybko zalozyc konto, a proces zakladania konta jest szybki i prosty. Co istotne, Kasyno Bet On Red oferuje wygodne formy wplat i wyplat, co ulatwia doladowanie konta.
Gry dostepne w Bet On Red Casino
Jednym z najwazniejszych aspektow, kazdego kasyna online, jest katalog gier. Bet On Red Casino oferuje niezwykle bogatym wyborem, ktory zadowoli nawet najbardziej wymagajacych graczy.
Web: https://ai.igcps.com/home.php?mod=space&uid=736088&do=profile&from=space
Maszyny hazardowe sa szczegolnie popularne, dostepne w roznorodnych stylach oraz z unikalnymi funkcjami. Oprocz klasycznych slotow, uzytkownicy moga rozegrac partie w rozgrywki przy stole, takie jak ruletka.
Estrategias para Lucrar no Jogo do Tigrinho
O potencial de lucro em curto prazo faz do Tigrinho uma opcao popular. O jogo proporciona um fluxo constante de oportunidades de premios em cada rodada.
Algumas estrategias populares ajudam a elevar os ganhos dos jogadores. Uma das estrategias preferidas e a aposta gradual. Nessa abordagem, o jogador comeca com valores baixos e aumenta aos poucos.
Saber quando apostar e quanto aumentar as apostas e uma habilidade importante. Esses momentos oferecem as maiores probabilidades de premios significativos. Jogadores mais experientes sabem reconhecer quando os minutos pagantes acontecem.
Plataforma de Apostas do Fortune Tiger: O que Saber
Website: http://pamdms.kkk24.kr/bbs/board.php?bo_table=online&wr_id=350714
Resumo
Fortune Tiger e um jogo que combina diversao, estrategia e oportunidades de ganhos. O jogo, com seus recursos de seguranca e opcoes de pagamento, proporciona uma experiencia tranquila.
The idea of virtual gambling platforms came into existence in the mid-1990s, providing a user-friendly variation to conventional establishments. Over time, progress in tech have reshaped online platforms into interactive experiences, boasting stunning imagery, interactive dealer gameplay, and flawless performance.
Today, the option to visit an virtual casino from a range of devices is a main highlight for gamblers worldwide.
Digital gaming hubs deliver a broad assortment of gaming experiences, highlighting iconic games such as poker and blackjack, alongside countless slots.
These systems provide players the ease of gaming at home or while traveling, turning them into favorites among both newcomer and experienced players.
One of the most notable trends in the realm of internet-based gambling is the rise of portable gaming. Mobile casino applications have become a popular way for interacting with online platforms, owing to their player-oriented features and unique enhancements.
Whether you are a hobbyist or a high-stakes bettor, a specialized gaming app enables your access to your preferred entertainment with just a few taps on your portable device.
These apps are designed to enhance a seamless gaming experience, with tools such as customized gambling options, efficient deposit methods, and cutting-edge encryption.
Web: https://online-pin-up-casino.netlify.app/
Players can acquire a casino application file—a specific Android tool—to gain instant access when they are not listed on popular download hubs.
This adaptability ensures that players can continue their sessions to their beloved gambling hubs, regardless of their device's operating system.
Dicas de Sucesso para o Fortune Tiger
Uma das caracteristicas mais atraentes do Fortune Tiger e a possibilidade de ganhar premios altos em pouco tempo. As rodadas rapidas e com chances de ganho atraem jogadores em busca de recompensas rapidas.
Os apostadores desenvolvem taticas para tornar o jogo mais lucrativo. Apostadores frequentemente recorrem a estrategia de apostas progressivas. Esse metodo consiste em comecar com apostas pequenas e aumenta-las com o tempo.
Para melhorar as chances de lucro, e essencial escolher os momentos certos para apostar. Esses momentos oferecem as maiores probabilidades de premios significativos. A identificacao dos minutos pagantes pode ser uma chave para o sucesso em Fortune Tiger.
Vantagens da Plataforma Fortune Tiger
Website: https://craigslistdir.org/fortune-tiger-ganhos_365306.html
Encerramento
A plataforma oferece uma experiencia de jogo envolvente e acessivel para todos. A confianca dos jogadores e conquistada pela transparencia e facilidade de uso.
Когда вы ищете захватывающую и увлекательную игру, которая точно дарит немало впечатлений и перспективы на большой выигрыш, то Авиатор – ваш правильный выбор.
О Чём Игра Авиатор?
<a href="https://lacollinaagriturismo.com/recovery-from-addiction/">aviator игра официальный сайт</a> – это классная краш игра, где ваш выигрыш и удача зависят от интуиции и скорости и удачи в моменте. Игра заключается в том, что вы ставите и смотрите, как самолет взлетает.
Как Управлять Игрой Авиатор? Играть в игру Авиатор очень просто. Вот этапы начала игры, которые помогут приступить к игре:
Установите Сумму Ставки: Введите сумму, которую вы готовы поставить. Помните, что ставьте осознанно.
Ожидайте Взлета Самолета: После того как ставка установлена, на экране появится самолет, который начнет набирать высоту. Множитель начинает расти. Забирайте деньги: В любой момент, пока самолет в воздухе, вы можете взять выигрыш. Продолжите Игру: После завершения раунда вы можете начать новую игру.
Зеркало сайта: https://lacollinaagriturismo.com/recovery-from-addiction/
Почему Стоит Выбрать Авиатор?
Захватывающий Игровой Процесс: В Авиаторе каждый момент полон эмоций. Простота и Легкость: Игра легка в освоении. Шансы на Большие Выигрыши: Возможности выиграть крупно зависят от ваших решений и удачи. Игровая Интерактивность: В игре Авиатор процесс идет в реальном времени.
Управляйте Своими Рисками: В игре Авиатор важно обдуманно управлять рисками.
Отслеживайте Тенденции Множителя: Следите за тем, как растет множитель.
Пользуйтесь Бонусами и Акциями: Участвуйте в бонусах и акциях, которые помогут увеличить ваш выигрыш.
tiger fortune</a> mantem os jogadores envolvidos com seu design cativante.
Metodos para Obter Melhores Resultados no Tigrinho
O atrativo principal do jogo e a chance de premios elevados com rodadas breves. As rodadas rapidas e com chances de ganho atraem jogadores em busca de recompensas rapidas.
Diversas estrategias podem ajudar o jogador a otimizar suas apostas. A aposta em valores crescentes e uma tatica popular. Esse metodo consiste em comecar com apostas pequenas e aumenta-las com o tempo.
Outro fator importante para maximizar os ganhos no Fortune Tiger e o momento de aposta. Ficar atento aos minutos em que o jogo paga mais e uma otima estrategia. Embora os minutos pagantes possam ser aleatorios, jogadores habilidosos sabem aproveitar essas oportunidades.
Plataforma Fortune Tiger: Funcionalidades e Vantagens
Website: https://toprankdesign.co.uk/wiki/index.php?title=User:HelenToRot2075
Conclusao Final
O Fortune Tiger e uma plataforma empolgante para todos os tipos de jogadores. Em resumo, Fortune Tiger e uma plataforma que entrega uma experiencia rica e cheia de possibilidades de ganhos.
The idea of virtual gambling platforms was introduced in the digital revolution period, offering a comfortable substitute to land-based gambling locations. Over time, innovations in technology have evolved online platforms into captivating settings, equipped with detailed animations, real-time dealer interactions, and smooth gaming.
Today, the option to engage with an digital gambling site from practically anywhere is one of the biggest draws for casino lovers around the globe.
Online casinos make available a variety of games, featuring classics like blackjack, roulette, and poker, alongside numerous slot games.
These platforms deliver to gamers the accessibility of playing from their homes or while mobile, making them a popular choice among both entry-level and seasoned gamblers.
One of the most important developments in the world of virtual casinos is the rise of portable gaming. Mobile casino applications are increasingly a preferred method for accessing online platforms, thanks to their user-friendly interfaces and tailored features.
Whether you are a hobbyist or a professional player, a dedicated casino app provides your beloved activities with just a few clicks on your portable device.
These apps are designed to provide a lag-free gambling interaction, with capabilities such as personalized game recommendations, fast transaction systems, and high-level protections.
Web: https://on-red-bet.web.app
Players can install a casino apk—a specific Android tool—to install apps directly when not found on popular download hubs.
This adaptability guarantees that players can enjoy uninterrupted gaming to their preferred digital casinos, whatever device compatibility they have.
Ao longo dos ultimos tempos, o mercado de jogos online tem experimentado um crescimento notavel, atraindo milhoes de jogadores que procuram entretenimento e, ocasionalmente, a chance de ganhar lucros em moeda. Dentre as alternativas de games que tem conquistado significativa fama, ganham visibilidade o <a href="https://bbs.250.cn/home.php?mod=space&uid=30500&do=profile&from=space">qual o melhor horario para jogar o jogo do ratinho</a> e o Rato da Fortuna, ambos oferecidos em multiplas plataformas digitais. Esses jogos proporcionam nao apenas diversao, mas tambem a potencialidade de ganhar recompensas para aqueles que mostram aptidao, paciencia e uma parte de fortuna. Abaixo, abordaremos as caracteristicas mais importantes caracteristicas desses jogos, compreendendo seus funcionamentos, os momentos ideais para jogar, dicas para utilizar as versoes demo e taticas para aumentar as chances de vitoria.
O Jogo do Ratinho e famoso por sua facilidade de acesso e por oferecer uma jogabilidade que integra aleatoriedade e estrategia. Esse jogo tornou-se especialmente bem aceito entre o publico de jogos que buscam um jogo rapido e divertido, mas que tambem pode trazer a chance de ganhar algum valor. Para quem e novo no jogo pela primeira vez, e muito indicado comecar pela modalidade versao demo do jogo do ratinho. A demonstracao e uma opcao sem custo que permite conhecer o game, entender as regras, entender as mecanicas e ate mesmo elaborar taticas sem precisar gastar dinheiro. Isso e muito conveniente para novos jogadores, que podem aprender com o jogo antes de migrar para a versao que envolve valores. A demo tambem e muito util para jogadores mais experientes, pois permite a elaboracao e experimentacao de novas estrategias para incrementar as possibilidades de sucesso.
Para aqueles que tem seguranca em sua aptidao para triunfar, ha o jogo do ratinho para lucro real, onde o usuario pode investir e, com base em seu desempenho e na sorte, adquirir lucros. E essencial, no entanto, jogar de forma consciente ao investir, lembrando que o objetivo do entretenimento deve ser o entretenimento. Alem disso, uma dica valiosa e estabelecer um limite e respeita-lo, sem ultrapassar o que pode arriscar.
Uma das duvidas que e comum entre os jogadores e quando e melhor jogar o jogo do ratinho. Muitos acreditam que, tal como ocorre em jogos de apostas ou em tipos de aposta esportiva, existe um horario mais propicio para jogar. Em modo geral, esse tipo de tatica recomenda jogar em momentos com menos jogadores, como na madrugada ou de manha bem cedo. A ideia por tras disso e que, em horarios de menor concorrencia, o sistema pode apresentar mais oportunidades de vitoria para preservar o interesse dos usuarios ativos. Embora nao haja garantias, e o resultado das rodadas muitas vezes dependa de sorte, muitos jogadores compartilham historias de sucesso associadas a esses horarios alternativos.
Web: https://bbs.250.cn/home.php?mod=space&uid=30500&do=profile&from=space
O Game do Ratinho Online traz uma boa possibilidade para aqueles que preferem jogar de forma pratica e sem complicacoes. Diferente dos jogos de cassino tradicionais, que requerem visita ao local, o Jogo do Ratinho online e acessivel a qualquer hora, e varias plataformas disponibilizam promocoes exclusivas que podem melhorar as chances de vitoria. Dentro dessa opcao, tambem ha a versao do jogo do ratinho gratuita, excelente para quem joga por lazer ou para novatos. Essa alternativa sem custo permite um jogo descontraido, onde o usuario nao tem riscos monetarios, podendo praticar e passar o tempo sem dano ao bolso.
Para aqueles que buscam uma experiencia de aposta mais intensa, o jogo do ratinho com investimentos possibilita que o jogador faca apostas com dinheiro real, com a expectativa de multiplicar o valor apostado. Ainda que essa escolha seja emocionante, vale lembrar a importancia de jogar com responsabilidade, pois as apostas trazem perigos. Muitos jogadores aconselham iniciar com quantias menores e crescer o valor devagar, a medida que se adquire mais habilidade e seguranca. O mais importante e manter em mente o papel da sorte no Jogo do Ratinho, e as apostas devem sempre considerar o risco.
В том случае, если стремитесь найти увлекательную игру, которая точно предоставит массу эмоций и возможности для крупного выигрыша, то игра Авиатор – то, что сделает ваш день.
Что Такое Авиатор?
<a href="https://lacollinaagriturismo.com/casinos-within-las-vegas-5-spannende-attraktionen-amexcited/">aviator игра</a> – это впечатляющая краш игра, где ваш выигрыш и удача зависят от быстроты мышления и удачи и хладнокровия и удачи. Суть игры в том, что вы ставите деньги и наблюдаете взлет самолета.
Как Играть в Игра Авиатор? Играть в игру Авиатор несложно. Вот первые шаги, которые помогут стартовать в игре:
Определите Ставку: Введите сумму, которую вы готовы поставить. Помните, что ставить нужно с ответственностью.
Ожидайте Взлета Самолета: После того как ставка внесена, на экране появится самолет, который начнет набирать высоту. Множитель будет увеличиваться. Берите выигрыш: В любой момент, пока самолет не исчез, вы можете забрать свой выигрыш. Начните Новый Раунд: После завершения раунда вы можете начать новую игру.
Зеркало сайта: https://lacollinaagriturismo.com/casinos-within-las-vegas-5-spannende-attraktionen-amexcited/
Почему Стоит Выбрать Авиатор?
Динамичный Геймплей: В Авиаторе каждое мгновение приносит эмоции. Легкость Освоения: Игра легка в освоении. Большие Победы: Возможности для крупных выигрышей зависят от ваших интуитивных решений. Игровая Интерактивность: В игре Авиатор всё происходит в реальном времени.
Управляйте Своими Рисками: В игре Авиатор важно контролировать риски и выигрыши.
Отслеживайте Тенденции Множителя: Следите за тем, как растет множитель.
Получайте Бонусы и Акции: Участвуйте в бонусах и акциях, для увеличения своих шансов.
Understanding Stake Mines Game
Stake Mines is an incredibly captivating game that revolves around a clear-cut concept but can be quite challenging. Players initiate by setting a bet and then selecting tiles from a grid. The objective is to uncover all the clear tiles without landing on a mine. Each mine-free tile you uncover increases your winnings, but if you select a mine, the game ends, and you lose your money. The basic nature of the game is part of its appeal, but the true challenge lies in the planning needed. Players must predict which tiles are safe to uncover, weighing risk against potential reward.
The Stake Mines game is offered on various platforms, and its popularity continues to rise due to its energetic nature and the thrill of uncertainty. The chaos of which tile may hide a mine is part of what makes the game so exciting and offers a risky experience for both novices and seasoned players.
Stake Mines Strategy: The Key to Winning
A well-thought-out Stake Mines strategy can make the difference between winning and walking away with nothing. While luck plays a role, the key to beating the game lies in how you deal with the game. One popular approach is to start with a low bet and gradually escalate your wager as you uncover safe tiles. This allows players to reduce potential losses and prolong their gameplay, increasing their chances of hitting a profitable streak.
Another strategy involves selecting a specific pattern in which to uncover the tiles. By following a predetermined grid path, players may sometimes increase their chances of avoiding mines. However, even with the best-laid strategy, it’s vital to remember that the game is based on unpredictability, and no strategy can guarantee a win every time.
For those curious about how these bots work, a Stake Mines Predictor Bot Free version is often available for download. While these free bots may not be as advanced or sophisticated as their paid counterparts, they still claim to offer valuable insights into which tiles are safe to click. Players may experiment with these free tools to determine if they provide a significant advantage before upgrading to a more complex version.
The Allure of Stake Mines Hack
For some players, using a Stake Mines Hack represents an appealing shortcut to guaranteed winnings. Hacks refer to hacked versions of the game or tools designed to change the game’s mechanics in favor of the player. These could involve altering the game’s algorithm, unlocking extra features, or even revealing the locations of mine-free tiles. However, using a hack comes with major risks. Firstly, many hacks are unstable, possibly introducing malware or harming your device. Secondly, hacking is a breach of most gaming platforms' terms of service, and players caught using hacks can be banned or suspended.
While this tool doesn’t guarantee success, it provides a way for players to judge the risk and reward associated with each decision. Some calculators even use historical game data to adjust a player’s strategy based on past performance.
Stake Mines APK and Mod Versions
For those who enjoy trying out various game versions, the Stake Mines APK lets users get the game on their Android devices. APK downloads allow customers to avoid app store limitations and install customized or hacked versions of the game. These versions can offer enhanced features, additional functionalities, or even improved chances to succeed, but it’s important to obtain them from legitimate sources to avoid malware or other issues.
Web: https://hk.tiancaisq.com/home.php?mod=space&uid=461006&do=profile&from=space
Stake Mines Demo: Learning the Game Without Risk
If you're new to Stake Mines, the Stake Mines demo is a great way to explore the game’s mechanics without the financial risk. Many platforms offer demo versions of games, allowing players to refine their skills and strategies in a low-stakes environment. The Stake Mines demo mirrors the real game but without using real money, making it the perfect way to experiment before committing to real wagers.
Using the demo version helps players comprehend the features and gameplay of the game without the worry of losing money. It’s a risk-free way to explore different strategies and decide how to approach the full game.
The emergence of online gaming hubs originated in the digital revolution period, introducing a easy-to-reach substitute to conventional gaming spots. Over time, modern technology have revolutionized online platforms into dynamic spaces, complete with lifelike visuals, real dealer experiences, and smooth gaming.
Today, the opportunity to visit an internet casino from a range of devices stands out as a major attraction for players everywhere.
Online casinos make available a variety of options, featuring classics like blackjack, roulette, and poker, together with a large array of slots.
These services give enthusiasts the comfort of gaming at home or while mobile, turning them into favorites among both newcomer and seasoned gamblers.
One of the most notable trends in the realm of internet-based gambling is the trend of handheld gameplay. Gambling apps are now a popular way for interacting with online platforms, because of their intuitive designs and adapted functionalities.
Whether you are a occasional gamer or a professional player, a feature-rich casino software brings you your favorite games with just a few taps on your mobile phone.
These apps focus on ensure a flawless entertainment flow, with capabilities such as adaptive picks for players, quick payment processing, and enhanced security measures.
Web: https://casinopin-up.netlify.app/
Players can obtain a casino application file—a specific Android tool—to use software without delay should they not be accessible on mainstream app stores.
This ease guarantees that players can always stay connected to their beloved gambling hubs, no matter what OS they use.
plataforma nova fortune tiger</a> oferece uma experiencia visual atraente e envolvente.
Ganhos e Estrategias para o Fortune Tiger
O jogo se diferencia por suas oportunidades de lucro rapido e significativo. O jogo proporciona um fluxo constante de oportunidades de premios em cada rodada.
Alguns jogadores tem metodos proprios para melhorar os resultados. A tecnica da aposta progressiva e amplamente utilizada. Nessa abordagem, o jogador comeca com valores baixos e aumenta aos poucos.
A gestao do tempo durante as apostas tambem influencia diretamente os lucros. E fundamental estar atento aos minutos pagantes do jogo. Embora os minutos pagantes possam ser aleatorios, jogadores habilidosos sabem aproveitar essas oportunidades.
Plataforma de Apostas do Fortune Tiger: O que Saber
Website: http://www.mignonmuse.com/bbs/board.php?bo_table=free&wr_id=303629
Conclusao Final
Seja para iniciantes ou veteranos, Fortune Tiger tem algo a oferecer. Com muitas formas de ganhar, Fortune Tiger e uma das opcoes mais atrativas no mundo dos jogos de aposta online.
В случае, если ищете волнующую игру, что обеспечит огромное количество эмоций и шанс на крупные выигрыши, то Авиатор игра – идеальный выбор для вас.
Что За Игра Авиатор?
<a href="https://conectacampus.com/aviator-igrat-v-kazino-onlayn/">авиатор игра</a> – это крутая краш игра, где ваш выигрыш и удача зависят от способности быстро принимать решения и везения. В этой игре вы вы делаете ставку и смотрите на самолет, который взлетает.
Как Управлять Игрой Авиатор? Играть в игру Авиатор очень просто. Вот основные шаги, которые облегчат начало игры:
Определите Ставку: Введите сумму, которую готовы ставить. Помните, что важно контролировать ставки.
Ожидайте Взлета Самолета: После того как ставка подтверждена, на экране появится самолет, который взлетит. Множитель будет увеличиваться. Берите выигрыш: В любой момент, пока самолет не исчез, вы можете забрать выигрыш. Продолжите Игру: После завершения раунда вы можете начать новый раунд.
Зеркало сайта: https://conectacampus.com/aviator-igrat-v-kazino-onlayn/
Почему Стоит Выбрать Авиатор?
Захватывающий Геймплей: В Авиаторе каждый момент полон эмоций. Простота и Доступность: Игра легка в освоении. Крупные Выигрыши: Возможности выиграть крупно зависят от ваших интуитивных решений. Интерактивность и Реальное Время: В игре Авиатор вы следите за процессом в реальном времени.
Следите за Рисковыми Моментами: В игре Авиатор важно контролировать риски и выигрыши.
Отслеживайте Множитель: Следите за тем, как растет множитель.
Пользуйтесь Бонусами и Акциями: Используйте бонусах и акциях, чтобы увеличить свои шансы на выигрыш.
Understanding Stake Mines Game
Stake Mines is an incredibly enthralling game that revolves around a clear-cut concept but can be quite challenging. Players initiate by putting a bet and then selecting tiles from a grid. The objective is to uncover all the non-dangerous tiles without landing on a mine. Each mine-free tile you uncover increases your winnings, but if you select a mine, the game ends, and you lose your wager. The clarity of the game is part of its appeal, but the true challenge lies in the decision-making needed. Players must predict which tiles are safe to uncover, weighing threat against potential reward.
The Stake Mines game is offered on various platforms, and its popularity continues to rise due to its quick nature and the thrill of uncertainty. The chaos of which tile may hide a mine is part of what makes the game so exciting and offers a edge-of-your-seat experience for both inexperienced and seasoned players.
Stake Mines Strategy: The Key to Winning
A well-thought-out Stake Mines strategy can make the difference between succeeding and walking away with nothing. While luck plays a role, the key to beating the game lies in how you tackle the game. One popular approach is to start with a modest bet and gradually raise your wager as you uncover safe tiles. This allows players to reduce potential losses and prolong their gameplay, increasing their chances of hitting a profitable streak.
Another strategy involves selecting a specific method in which to uncover the tiles. By following a predetermined grid path, players may sometimes heighten their chances of avoiding mines. However, even with the best-laid strategy, it’s vital to remember that the game is based on unpredictability, and no strategy can guarantee a win every time.
For those curious about how these bots work, a Stake Mines Predictor Bot Free version is often available for download. While these free bots may not be as advanced or sophisticated as their paid counterparts, they still claim to offer valuable insights into which tiles are safe to click. Players may experiment with these free tools to determine if they provide a significant advantage before upgrading to a more professional version.
The Allure of Stake Mines Hack
For some players, using a Stake Mines Hack represents an appealing shortcut to guaranteed winnings. Hacks refer to manipulated versions of the game or tools designed to change the game’s mechanics in favor of the player. These could involve manipulating the game’s algorithm, unlocking extra features, or even revealing the locations of mine-free tiles. However, using a hack comes with major risks. Firstly, many hacks are unstable, possibly introducing malware or harming your device. Secondly, hacking is a breach of most gaming platforms' terms of service, and players caught using hacks can be banned or suspended.
While this tool doesn’t guarantee success, it provides a way for players to judge the risk and reward associated with each decision. Some calculators even use historical game data to adjust a player’s strategy based on past performance.
Stake Mines APK and Mod Versions
For those who enjoy trying out unique game versions, the Stake Mines APK lets gamers download the game on their Android devices. APK packages allow customers to avoid app store restrictions and set up customized or modified versions of the game. These versions can offer enhanced features, additional functionalities, or even extra chances to succeed, but it’s important to download them from legitimate sources to avoid malware or other issues.
Web: http://bbs.ts3sv.com/home.php?mod=space&uid=916310&do=profile
Stake Mines Demo: Learning the Game Without Risk
If you're new to Stake Mines, the Stake Mines demo is a great way to learn the game’s mechanics without the financial risk. Many platforms offer demo versions of games, allowing players to refine their skills and strategies in a low-stakes environment. The Stake Mines demo mirrors the real game but without using real money, making it the perfect way to experiment before committing to real wagers.
Using the demo version helps players get a feel for the features and gameplay of the game without the worry of losing money. It’s a risk-free way to explore different strategies and decide how to approach the full game.
The idea of virtual gambling platforms came into existence in the 1990s, offering a accessible option to brick-and-mortar casinos. Over time, modern technology have revolutionized online platforms into dynamic experiences, including stunning imagery, real dealer experiences, and smooth gaming.
Today, the capacity to engage with an online casino from a range of devices remains a key feature for users across the planet.
Internet casinos deliver a diverse selection of entertainment choices, such as classics like blackjack, roulette, and poker, together with countless slots.
These systems deliver to gamers the accessibility of gaming at home or in any location, turning them into favorites among both newcomer and long-time enthusiasts.
One of the most important developments in the online gaming industry is the rise of portable gaming. Casino-focused software are now a common approach for engaging with online platforms, because of their intuitive designs and tailored features.
Whether you are a casual player or a high-stakes bettor, a well-designed mobile casino brings you your preferred entertainment with just a few touches on your smart device.
These apps are designed to enable a smooth gaming journey, with capabilities such as customized gambling options, fast transaction systems, and enhanced security measures.
Web: https://casino-mines-game.netlify.app/
Players can install a mobile gaming APK—a file format for Android devices—to set up applications instantly when they are not listed on popular download hubs.
This adaptability provides that players can continue their sessions to their beloved gambling hubs, regardless of their device's operating system.
One major benefit of <a href="https://m1bar.com/user/TerrellForsyth8/">bonanza sweet</a> is its innovative method for online slot game structure. Unlike classic slot games that depend on paylines for wins, Sweet Bonanza uses a "match anywhere" system. The Sweet Bonanza slot offers a 6x5 grid, giving participants many opportunities to win with every spin. Payouts come by landing clusters of eight or more matching images across the grid, distinguishing it from usual slots that function through predetermined paylines.
This cluster-based system not only becomes aesthetic but also gives players increased win opportunities in each spin.
The candy-themed graphics and cheerful color scheme add to the game’s charm, creating a fun, animated ambiance that attracts players. Images in Sweet Bonanza include various candies in eye-catching tones, as well as fruits such as bananas, grapes, and watermelons. The graphics are supported by joyful music that brings to the overall enjoyment. The Sweet Bonanza slot also has a bonus icon in the form of a lollipop, which serves a key purpose in triggering the Free Spins feature. By landing four or more lollipop symbols, the game will activate the extra spins, which delivers a major chance to earn substantial prizes.
New players interested in online slots or seek to experiment before wagering real money, Sweet Bonanza demo mode provides a suitable way. Various internet casinos include a no-cost version of Sweet Bonanza, enabling players to try the mechanics, try different approaches, and get comfortable with the slot’s elements without any financial risk. Experimenting with Sweet Bonanza demo is a great choice for new players, as it helps them grasp the slot features, experiment with bet amounts, and learn about the Tumble feature.
Web: https://m1bar.com/user/TerrellForsyth8/
The Tumble feature, also known as the cascading function, plays a major role in the game. Once players hit a winning cluster, the winning symbols disappear, and more symbols cascade down, giving extra chances to win. This element increases the fun but also offers extra chances to score to win in a single spin.
A key aspect of this game is its free spins bonus, which is typically the most exciting part for gamblers. The extra spins feature in this slot may result in impressive wins due to the use of multipliers. If players activate it, the free spin round gives players 10 spins without a bet, and extra spins can be re-triggered by landing three extra scatters.
Когда желаете увлекательную игру, что обеспечит много шансов и шансы на значительный выигрыш, то игра Авиатор – ваш правильный выбор.
О Чём Игра Авиатор?
<a href="https://lacollinaagriturismo.com/georgia-betting-internet-sites-soccer-safari-slot-play-online-casinos-gamble-in-the-ga-2024/">авиатор казино</a> – это инновационная игра, где ваш выигрыш и удача зависят от быстроты мышления и удачи и удачи и интуиции. В этой игре вы вы делаете ставку и следите за взлетом самолета.
Как Начать Игру Авиатор? Играть в игру Авиатор очень просто. Вот первые шаги, которые помогут стартовать в игре:
Определите Ставку: Введите сумму, которую готовы ставить. Помните, что всегда ставьте с умом.
Наблюдайте за Взлётом Самолета: После того как ставка внесена, на экране появится самолет, который начнет набирать высоту. Величина множителя начнет увеличиваться. Фиксируйте выигрыш: В любой момент, пока самолет взлетает, вы можете забрать выигрыш. Повторите Игру: После завершения раунда вы можете начать новый раунд.
Зеркало сайта: https://lacollinaagriturismo.com/georgia-betting-internet-sites-soccer-safari-slot-play-online-casinos-gamble-in-the-ga-2024/
Почему Стоит Выбрать Авиатор?
Увлекательный Геймплей: В Авиаторе каждый раунд захватывает. Легкость Освоения: Игра не требует глубоких знаний. Возможности для Крупных Побед: Возможности для крупных выигрышей зависят от умения принимать решения. Интерактивные Элементы: В игре Авиатор вы следите за процессом в реальном времени.
Следите за Рисками: В игре Авиатор важно обдуманно управлять рисками.
Отслеживайте Множитель: Анализируйте поведение множителя.
Воспользуйтесь Бонусами: Воспользуйтесь бонусах и акциях, которые помогут увеличить ваш выигрыш.
Este slot se diferencia de otras tragamonedas por su diseno y tematica unicos. Al abrir el juego, los fans son transportados a un mundo de frutas y caramelos y colores brillantes que parecen de un mundo fantastico. El fondo esta decorado con dulces, lo cual presenta un ambiente visual atractiva y alegre, adaptada a todos los jugadores. Este slot ha sido descrito por muchos en sus opiniones como adictivo y muy entretenido, ya que mezcla la emocion de ganar premios con un estilo visual atractivo para todos.
Una de las caracteristicas mas valoradas de este slot es su modo de giros gratis, que se activa si se obtienen cuatro o mas simbolos de caramelos en cualquier lugar. Los giros gratis no solo permiten disfrutar sin apostar mas dinero, sino que tambien potencian las probabilidades de grandes ganancias, especialmente cuando aparecen multiplicadores en los giros. Este aspecto dentro del juego es uno de los mas interesantes a los jugadores, y muchos mencionan en sus opiniones que la funcion de giros gratis es lo que mas entusiasma de Sweet Bonanza.
Ademas, el juego de Pragmatic Play ha logrado mantener su popularidad gracias a su aplicabilidad universal. No importa si eres si tienes mucha experiencia en el juego, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la adaptabilidad de Sweet Bonanza en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere jugar durante tus descansos, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: https://ssglanders.xyz:443/bbs/board.php?bo_table=users&wr_id=498698
Otro punto que interesa a los jugadores es si se puede ganar dinero real con este juego. Al igual que en cualquier tragamonedas, la tragamonedas Sweet Bonanza es un juego basado en el azar, lo cual significa que el resultado de cada jugada es basado en azar y no puede ser predicho. Sin embargo, los multiplicadores junto con giros gratis ofrecen una oportunidad significativa para obtener ganancias considerables. La funcion de se pueden multiplicar las ganancias hasta 100 veces gracias a los multiplicadores, lo que puede resultar en una recompensa significativa si se tiene suerte en el giro. Sin embargo, es importante recordar que siempre es importante jugar con responsabilidad y que no siempre se gana en cada ronda.
Tyson Fury and Oleksandr Usyk are on a collision course that will define an era. It’s far beyond a championship match; it represents their quest for immortality. The Gypsy King has become a global icon thanks to his personality and his unmatched skills in the ring. Beating Wilder and Klitschko have solidified his legendary status. Across the ring, the tactical southpaw brings an unprecedented test to the heavyweight division. At the same time, Oleksandr Usyk is a true test for Fury for Tyson Fury himself, and for boxing fans worldwide. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Don’t miss out for a thrilling boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a historic showdown! Experience every moment in real time on our website. Don’t miss your chance — visit <a href="https://www.ourglocal.com/url/?url=https://usykvsfury.co.uk/">usykvsfury.co.uk</a> right away and stream the event with top-notch streaming!
In the United Kingdom, the ring walks are planned for late evening, offering perfect timing for viewers. In Usyk’s native Ukraine, and beyond, this will be a must-see event. The venue for Fury vs Usyk remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, it’s guaranteed: the excitement will be unmatched. Although the focus is firmly on the main event, the Fury vs Usyk undercard is shaping up to be thrilling. Major boxing events include preliminary bouts with top talent, giving fans a full evening of entertainment.
Traditionally, preliminary fights on major cards have been a stage for breakout performances. Fighters looking to rise through the ranks use such opportunities to showcase their skills, with the world paying attention. Though the supporting fights for Fury vs Usyk has yet to be finalized, there’s plenty of talk. Could we see rising prospects? No matter the final roster, the action will not disappoint. What sets this bout apart so intriguing is the dynamic between these fighters. Tyson Fury’s size and agility make him an anomaly in boxing. With his immense height and reach advantage, Fury can control a fight.
The legendary battles with Wilder showed his durability, as he recovered from knockdowns to dominate in later rounds. In his fight with Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. By contrast, Usyk, offers a different kind of threat. Being a left-handed fighter, his positioning constantly challenges opponents. Usyk’s punches lack devastating strength, they consistently find their mark. With the date drawing closer, Tyson Fury vs Usyk odds are becoming a hot topic.
Tyson Fury is seen as the frontrunner based on the betting odds, given his physical stature, his track record in big matches, and his adaptability. Although Usyk is the less favored fighter doesn’t mean he’s an underdog in spirit, his victories against AJ demonstrated his ability in the heavyweight ranks.
For Tyson Fury, this fight could be the defining moment of his career. Should he come out on top, Fury’s win would solidify his claim as the greatest heavyweight of his generation. Conversely, If Usyk wins would mark him as one of the sport’s greats. Becoming the undisputed heavyweight champion is a feat few can claim.
Web: <a href="http://www.google.cat/url?q=https://usykvsfury.co.uk/">usykvsfury.co.uk</a>
The upcoming showdown is more than just a championship fight. It’s a clash of personalities. Fury’s confident and brash nature stands in stark contrast to Usyk’s composed demeanor. The clash of personalities adds depth to the narrative. It’s about more than just skill. No matter who wins, the impact of this bout will be remembered as a defining moment in boxing. This historic showdown is a spectacle unlike any other. It’s the pinnacle of both fighters’ hard work. If Fury wins through his strength and tactics, or Usyk comes out on top thanks to his skill and resilience, what is clear is, this bout will go down in history.
Fury vs Usyk is a spectacle of a lifetime. It’s a battle of minds and bodies. Both fighters will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Este slot se diferencia de otras maquinas tragamonedas por su diseno llamativo y unico. Al ingresar al slot, los apostadores son transportados a un mundo de dulces y colores brillantes que hacen pensar en un cuento de fantasia. El fondo de la pantalla esta lleno de golosinas, lo cual presenta un ambiente visual amigable y alegre, adaptada a todos los jugadores. Sweet Bonanza ha sido reconocido por su adiccion positiva y entretenimiento, ya que brinda emociones y una estetica llamativa para todos.
Una de las caracteristicas mas valoradas de Sweet Bonanza es su ronda de giros gratis, que se activa cuando aparecen cuatro o mas simbolos de caramelos rosados. La ronda de giros gratuitos no solo permiten jugar sin gastar dinero adicional, sino que tambien incrementan las chances de obtener grandes premios, especialmente cuando se activan los multiplicadores durante los giros. Este aspecto dentro del juego es uno de los mas interesantes a los jugadores, y muchos destacan en sus comentarios que el bono de giros gratis es lo mejor del juego.
Ademas, Sweet Bonanza ha logrado mantener su popularidad gracias a su posibilidad de adaptacion a diferentes tipos de jugadores. No importa si eres un principiante en las apuestas online, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la adaptabilidad de el juego en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere jugadas rapidas mientras viajas, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: https://securityholes.science/wiki/User:Tami93U9777
Otro punto que interesa a los jugadores es si si el juego realmente permite ganar dinero con Sweet Bonanza. Al igual que en cualquier tragamonedas, la tragamonedas Sweet Bonanza es una maquina de azar, lo cual significa que el resultado de cada giro es aleatorio y no puede ser modificado. Sin embargo, los multiplicadores y la funcion de giros gratuitos ofrecen una oportunidad significativa para obtener premios importantes. La funcion de los multiplicadores permiten multiplicar las ganancias hasta 100x, lo que puede resultar en una recompensa significativa si se tiene suerte en el giro. Sin embargo, es importante recordar que hay que disfrutar del juego con moderacion y que no siempre se gana en cada ronda.
Este juego destaca de otras maquinas tragamonedas por su diseno y tematica unicos. Al comenzar a jugar, los fans son llevados a un escenario de golosinas y colores vibrantes que sugieren un ambiente magico. El escenario esta repleto de confites, lo cual ofrece una escena visual atractiva y divertida, ideal tanto para jugadores nuevos como para experimentados. Sweet Bonanza ha sido muy bien valorado en las opiniones, ya que mezcla la emocion de ganar premios con un estilo visual atractivo para todos.
Una de las caracteristicas mas valoradas de este slot es su modo de giros gratis, que se activa si se obtienen cuatro o mas simbolos de caramelos en cualquier lugar. El modo de giros sin costo no solo permiten jugar sin gastar dinero adicional, sino que tambien multiplican las posibilidades de ganar grandes premios, especialmente cuando aparecen multiplicadores en los giros. Este elemento del juego es uno de los que mas atrae a los jugadores, y muchos destacan en sus comentarios que la funcion de giros gratis es lo mas emocionante.
Ademas, el juego de Pragmatic Play ha logrado mantener su popularidad gracias a su atractivo para jugadores novatos y experimentados. No importa si eres nuevo en el mundo de las tragamonedas, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la versatilidad de el juego en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere apostar desde tu telefono movil, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: https://sk.tags.world/kosice/index.php?page=user&action=pub_profile&id=1080320
Otro punto que interesa a los jugadores es si realmente pueden ganar dinero con este juego de tragamonedas. Al igual que en cualquier tragamonedas, este juego es una maquina de azar, lo cual significa que el resultado de cada tirada es basado en azar y no puede ser controlado. Sin embargo, los multiplicadores junto con giros gratis ofrecen una oportunidad significativa para obtener premios importantes. La funcion de multiplicador puede aumentar las ganancias hasta 100 veces en un solo giro, lo que puede generar premios grandes si se tiene suerte en el giro. Sin embargo, es importante recordar que se debe jugar con responsabilidad y que el exito no esta asegurado en todos los giros.
Estrategias para Lucrar no Jogo do Tigrinho
O Fortune Tiger atrai muitos por sua chance de ganhos elevados em rodadas rapidas. A chance de premios em cada rodada faz do jogo uma escolha interessante para apostadores.
Diversas estrategias podem ajudar o jogador a otimizar suas apostas. A aposta em valores crescentes e uma tatica popular. Com essa tecnica, o jogador inicia com apostas minimas e vai subindo progressivamente.
A gestao do tempo durante as apostas tambem influencia diretamente os lucros. Ficar atento aos minutos em que o jogo paga mais e uma otima estrategia. Embora os minutos pagantes possam ser aleatorios, jogadores habilidosos sabem aproveitar essas oportunidades.
Plataforma Fortune Tiger: Beneficios para o Jogador
Website: http://chunzee.co.kr/bbs/board.php?bo_table=23&wr_id=464984
Consideracoes Finais
Seja para iniciantes ou veteranos, Fortune Tiger tem algo a oferecer. Com muitas formas de ganhar, Fortune Tiger e uma das opcoes mais atrativas no mundo dos jogos de aposta online.
Gry hazardowe online zdobywaja rosnace zainteresowanie w Polsce, a jedna z witryn, ktora zyskuje uznanie wsrod uzytkownikow, jest <a href="https://sciencewiki.science/wiki/User:MatildaTrevizo1">bet on red casino</a>. To kasyno online, ktore przyciaga graczy dzieki szerokiemu wyborowi gier, nowoczesnym interfejsem oraz hojnymi bonusami, ktore zadowola zarowno poczatkujacych, jak i weteranow gier.
Co warto wiedziec o Bet On Red Casino?
Kasyno Bet On Red to platforma online, ktora oferuje szeroki wybor gier hazardowych online, takich jak sloty, klasyczne gry kasynowe oraz gry z prawdziwymi krupierami. Juz nazwa tej platformy „Bet On Red" przywoluje adrenaline i rywalizacje podczas gier.
Proces logowania w Kasynie Bet On Red
Logowanie do konta w Kasyno Bet On Red jest intuicyjny i nieskomplikowany. Po przejsciu na strone kasyna, wystarczy nacisnac opcje logowania i uzupelnic wymagane informacje. Platforma stawia na bezpieczenstwo, dlatego wszelkie informacje sa odpowiednio szyfrowane.
Osoby rejestrujace sie po raz pierwszy moga szybko zalozyc konto, a formularz rejestracyjny jest przejrzysty i krotki. Co istotne, Bet On Red oferuje wygodne formy wplat i wyplat, co sprawia, ze korzystanie z platformy jest proste.
Roznorodnosc gier w Bet On Red
Kluczowym elementem, kazdego portalu hazardowego, jest biblioteka rozrywki. Red On Bet wyroznia sie roznorodnoscia, ktory przyciagnie milosnikow roznych gatunkow gier.
Web: https://sciencewiki.science/wiki/User:MatildaTrevizo1
Automaty sa jednym z najwiekszych hitow w ofercie, dostepne w roznych wariantach tematycznych oraz z ciekawymi rozwiazaniami. Oprocz najpopularniejszych maszyn, uzytkownicy moga sprobowac swoich sil w gry stolowe, takie jak roulette.
Estrategias para Lucrar no Jogo do Tigrinho
O jogo se diferencia por suas oportunidades de lucro rapido e significativo. Os premios disponiveis em cada rodada sao um grande atrativo para os jogadores.
Diversas estrategias podem ajudar o jogador a otimizar suas apostas. Muitos jogadores utilizam a estrategia de aumentar gradualmente as apostas. A aposta inicial e baixa, mas cresce conforme o jogo avanca.
Saber quando apostar e quanto aumentar as apostas e uma habilidade importante. Ficar atento aos minutos em que o jogo paga mais e uma otima estrategia. Jogadores mais experientes sabem reconhecer quando os minutos pagantes acontecem.
Plataforma Fortune Tiger: Funcionalidades e Vantagens
Website: https://timeoftheworld.date/wiki/User:Leonora4193
Encerramento
O jogo e uma excelente opcao para quem busca tanto diversao quanto ganhos reais. Em resumo, Fortune Tiger e uma plataforma que entrega uma experiencia rica e cheia de possibilidades de ganhos.
Ganhos e Estrategias para o Fortune Tiger
O jogo oferece lucros interessantes, mesmo em apostas rapidas. As rodadas rapidas e com chances de ganho atraem jogadores em busca de recompensas rapidas.
Algumas estrategias populares ajudam a elevar os ganhos dos jogadores. Uma das estrategias preferidas e a aposta gradual. Nessa abordagem, o jogador comeca com valores baixos e aumenta aos poucos.
Para melhorar as chances de lucro, e essencial escolher os momentos certos para apostar. Os minutos pagantes sao uma excelente forma de maximizar os lucros. Esses periodos de pagamento mais elevados ocorrem aleatoriamente, mas jogadores experientes sabem como identifica-los.
Caracteristicas da plataforma Fortune Tiger
Website: http://roedu.co.kr/bbs/board.php?bo_table=42_2&wr_id=66256
Conclusao Final
A plataforma oferece uma experiencia de jogo envolvente e acessivel para todos. A confianca dos jogadores e conquistada pela transparencia e facilidade de uso.
jogo do tigrinho bet</a> mantem os jogadores envolvidos com seu design cativante.
Dicas para Maximizar os Lucros no Tigrinho
O que chama a atencao no jogo e o alto potencial de lucro em curto periodo. Os premios disponiveis em cada rodada sao um grande atrativo para os jogadores.
Os apostadores desenvolvem taticas para tornar o jogo mais lucrativo. A tecnica da aposta progressiva e amplamente utilizada. A aposta inicial e baixa, mas cresce conforme o jogo avanca.
Para melhorar as chances de lucro, e essencial escolher os momentos certos para apostar. Ficar atento aos minutos em que o jogo paga mais e uma otima estrategia. Embora os minutos pagantes possam ser aleatorios, jogadores habilidosos sabem aproveitar essas oportunidades.
Entenda como funciona a plataforma de Fortune Tiger
Website: https://centerdb.makorang.com:443/bbs/board.php?bo_table=item_qa&wr_id=140
Conclusao
Seja para iniciantes ou veteranos, Fortune Tiger tem algo a oferecer. A plataforma Fortune Tiger e uma excelente escolha para quem busca diversao e lucro.
Ao longo dos ultimos periodos, o setor de jogos virtuais tem experimentado um crescimento notavel, conquistando milhoes de pessoas que procuram diversao e, as vezes, a oportunidade de ganhar premios em moeda. Dentre as alternativas de games que vem atraindo significativa fama, destacam-se o <a href="http://pasarinko.zeroweb.kr/bbs/board.php?bo_table=notice&wr_id=3663360">horario do jogo do ratinho</a> e o Fortune Mouse, ambos disponibilizados em multiplas plataformas digitais. Essas opcoes trazem entretenimento alem de lazer, mas tambem a possibilidade de obter recompensas para aqueles que demonstram habilidade, calma e uma parte de fortuna. Abaixo, exploraremos, abordaremos as caracteristicas mais importantes aspectos desses titulos, como tambem seus funcionamentos, os melhores horarios para jogar, dicas para utilizar as versoes demo e estrategias para maximizar as chances de vitoria.
O Jogo do Ratinho e popular por sua facilidade de acesso e por trazer uma jogabilidade que combina aleatoriedade e habilidade. Esse jogo se fez especialmente bem aceito entre o publico de jogos que buscam um jogo rapido e leve, mas que tambem pode proporcionar a chance de ganhar algum valor. Para quem esta conhecendo jogo pela primeira oportunidade, e altamente recomendavel experimentar pela opcao jogo do ratinho demo. A versao de demonstracao e uma versao gratis que da ao jogador conhecer o game, aprender as diretrizes, entender as mecanicas e ate mesmo criar estrategias sem a necessidade de usar valores monetarios. Isso e muito conveniente para jogadores iniciantes, que podem se familiarizar com o jogo antes de passar para as apostas com dinheiro real. A demonstracao tambem e excelente para usuarios avancados, pois permite a tentativa de novas taticas para incrementar as possibilidades de sucesso.
Para aqueles que tem seguranca em sua aptidao para triunfar, ha o jogo do ratinho para lucro real, onde o jogador tem a opcao de apostar e, dependendo de sua performance e da fortuna, ganhar premios em dinheiro. E essencial, no entanto, adotar uma abordagem responsavel ao investir, lembrando que o principal objetivo do jogo deve ser o entretenimento. Alem disso, uma orientacao util e fixar um valor maximo e seguir fielmente, evitando apostar mais do que se pode perder.
Uma das questoes que aparece para os jogadores e quando e melhor jogar o jogo do ratinho. Muitos usuarios imaginam que, tal como ocorre em jogos de azar ou em modalidades de apostas esportivas, existe um horario mais propicio para jogar. Em modo geral, esse tipo de estrategia envolve jogar em horarios de menor movimento na plataforma, como de madrugada ou muito cedo pela manha. A logica por dessa estrategia e que, em horarios de menor concorrencia, o mecanismo parece mais propenso a dar vitorias para preservar o interesse dos usuarios ativos. Embora nao seja um fato confirmado, e o resultado dos jogos muitas vezes seja aleatorio, muitos jogadores tem experiencias de exito em momentos de menor movimento.
Web: http://pasarinko.zeroweb.kr/bbs/board.php?bo_table=notice&wr_id=3663360
O Mouse Game Online traz uma boa possibilidade para aqueles que preferem jogar de forma pratica e facil de acessar de qualquer lugar com internet. Diferente dos jogos de cassino tradicionais, que requerem visita ao local, o Jogo do Ratinho pode ser jogado em qualquer momento, e muitos sites contam com promocoes e desafios que podem melhorar as chances de vitoria. Dentro dessa opcao, tambem ha a versao do jogo do ratinho gratuita, excelente para quem joga por lazer ou para novatos. Essa versao gratis permite um jogo descontraido, onde o usuario nao tem riscos monetarios, podendo treinar e passar o tempo sem comprometer o orcamento.
Para aqueles que buscam uma experiencia de aposta mais intensa, o game do ratinho com aposta permite ao jogador apostar valores reais, com a expectativa de multiplicar o valor apostado. Ainda que essa escolha seja emocionante, e importante agir com cautela, pois a pratica de apostas sempre envolve riscos. Muitos jogadores experientes recomendam comecar com apostas baixas e ir subindo aos poucos, a medida que se adquire mais habilidade e seguranca. O fundamental e manter em mente o papel da sorte no Jogo do Ratinho, e as apostas precisam ser realizadas com prudencia.
Understanding Stake Mines Game
Stake Mines is an incredibly enthralling game that revolves around a easy concept but can be quite tough. Players kick off by setting a bet and then selecting tiles from a grid. The objective is to uncover all the safe tiles without landing on a mine. Each safe tile you uncover increases your winnings, but if you select a mine, the game ends, and you lose your bet. The clarity of the game is part of its appeal, but the true challenge lies in the planning needed. Players must predict which tiles are safe to uncover, weighing exposure against potential reward.
The Stake Mines game is offered on various platforms, and its popularity continues to rise due to its fast-paced nature and the thrill of uncertainty. The chaos of which tile may hide a mine is part of what makes the game so exciting and offers a high-stakes experience for both rookies and seasoned players.
Stake Mines Strategy: The Key to Winning
A well-thought-out Stake Mines strategy can make the difference between achieving success and walking away with nothing. While luck plays a role, the key to victory lies in how you tackle the game. One popular approach is to start with a small bet and gradually raise your wager as you uncover safe tiles. This allows players to minimize potential losses and prolong their gameplay, increasing their chances of hitting a profitable streak.
Another strategy involves selecting a specific sequence in which to uncover the tiles. By following a predetermined grid path, players may sometimes boost their chances of avoiding mines. However, even with the best-laid strategy, it’s vital to remember that the game is based on uncertainty, and no strategy can guarantee a win every time.
For those curious about how these bots work, a Stake Mines Predictor Bot Free version is often available for download. While these free bots may not be as advanced or sophisticated as their paid counterparts, they still claim to offer valuable insights into which tiles are safe to click. Players may experiment with these free tools to determine if they provide a significant advantage before upgrading to a more complex version.
The Allure of Stake Mines Hack
For some players, using a Stake Mines Hack represents an appealing shortcut to guaranteed winnings. Hacks refer to hacked versions of the game or tools designed to change the game’s mechanics in favor of the player. These could involve adjusting the game’s algorithm, unlocking extra features, or even revealing the locations of mine-free tiles. However, using a hack comes with major risks. Firstly, many hacks are unreliable, possibly introducing malware or harming your device. Secondly, hacking is a breach of most gaming platforms' terms of service, and players caught using hacks can be banned or suspended.
While this tool doesn’t guarantee success, it provides a way for players to assess the risk and reward associated with each decision. Some calculators even use historical game data to adjust a player’s strategy based on past performance.
Stake Mines APK and Mod Versions
For those who enjoy trying out new game versions, the Stake Mines APK lets gamers get the game on their Android devices. APK files allow players to sidestep app store limitations and install customized or tweaked versions of the game. These versions can offer enhanced features, additional functionalities, or even more chances to succeed, but it’s important to download them from secure sources to avoid malware or other issues.
Web: http://www.consis.kr/board/bbs/board.php?bo_table=as&wr_id=65849
Stake Mines Demo: Learning the Game Without Risk
If you're new to Stake Mines, the Stake Mines demo is a great way to test out the game’s mechanics without the financial risk. Many platforms offer demo versions of games, allowing players to refine their skills and strategies in a low-stakes environment. The Stake Mines demo mirrors the real game but without using real money, making it the perfect way to practice before committing to real wagers.
Using the demo version helps players comprehend the features and gameplay of the game without the worry of losing money. It’s a risk-free way to explore different strategies and decide how to approach the full game.
plataforma que paga no cadastro fortune tiger</a> mantem os jogadores envolvidos com seu design cativante.
Dicas de Sucesso para o Fortune Tiger
O que chama a atencao no jogo e o alto potencial de lucro em curto periodo. A chance de premios em cada rodada faz do jogo uma escolha interessante para apostadores.
Diversas estrategias podem ajudar o jogador a otimizar suas apostas. A tecnica da aposta progressiva e amplamente utilizada. Nesse sistema, as apostas comecam baixas e vao subindo em cada rodada.
A gestao do tempo durante as apostas tambem influencia diretamente os lucros. Esses momentos oferecem as maiores probabilidades de premios significativos. Esses periodos de pagamento mais elevados ocorrem aleatoriamente, mas jogadores experientes sabem como identifica-los.
Caracteristicas da plataforma Fortune Tiger
Website: https://centerdb.makorang.com:443/bbs/board.php?bo_table=item_qa&wr_id=138
Conclusao Final
Este jogo se destaca por ser acessivel e cheio de oportunidades de lucro. A plataforma Fortune Tiger e uma excelente escolha para quem busca diversao e lucro.
Understanding Stake Mines Game
Stake Mines is an incredibly enthralling game that revolves around a basic concept but can be quite difficult. Players start by placing a stake and then selecting tiles from a grid. The objective is to uncover all the clear tiles without landing on a mine. Each untroubled tile you uncover increases your winnings, but if you select a mine, the game ends, and you lose your money. The simplicity of the game is part of its appeal, but the true challenge lies in the planning needed. Players must predict which tiles are safe to uncover, weighing threat against potential reward.
The Stake Mines game is offered on various platforms, and its popularity continues to rise due to its exciting nature and the thrill of uncertainty. The uncertainty of which tile may hide a mine is part of what makes the game so exciting and offers a adrenaline-filled experience for both rookies and seasoned players.
Stake Mines Strategy: The Key to Winning
A well-thought-out Stake Mines strategy can make the difference between triumphing and walking away with nothing. While luck plays a role, the key to victory lies in how you play the game. One popular approach is to start with a minimal bet and gradually raise your wager as you uncover safe tiles. This allows players to cut down on potential losses and prolong their gameplay, increasing their chances of hitting a profitable streak.
Another strategy involves selecting a specific design in which to uncover the tiles. By following a predetermined grid path, players may sometimes increase their chances of avoiding mines. However, even with the best-laid strategy, it’s vital to remember that the game is based on chance, and no strategy can guarantee a win every time.
For those curious about how these bots work, a Stake Mines Predictor Bot Free version is often available for download. While these free bots may not be as advanced or sophisticated as their paid counterparts, they still claim to offer valuable insights into which tiles are safe to click. Players may experiment with these free tools to determine if they provide a significant advantage before upgrading to a more sophisticated version.
The Allure of Stake Mines Hack
For some players, using a Stake Mines Hack represents an appealing shortcut to guaranteed winnings. Hacks refer to hacked versions of the game or tools designed to change the game’s mechanics in favor of the player. These could involve manipulating the game’s algorithm, unlocking extra features, or even revealing the locations of mine-free tiles. However, using a hack comes with major risks. Firstly, many hacks are unreliable, possibly introducing malware or harming your device. Secondly, hacking is a breach of most gaming platforms' terms of service, and players caught using hacks can be banned or suspended.
While this tool doesn’t guarantee success, it provides a way for players to assess the risk and reward associated with each decision. Some calculators even use historical game data to adjust a player’s strategy based on past performance.
Stake Mines APK and Mod Versions
For those who enjoy trying out alternative game versions, the Stake Mines APK lets players install the game on their Android devices. APK packages allow users to circumvent app store rules and load customized or tweaked versions of the game. These versions can offer enhanced features, additional functionalities, or even more chances to succeed, but it’s important to download them from legitimate sources to avoid malware or other issues.
Web: http://www.ardenneweb.eu/archive?body_value=Whether+you%E2%80%99re+using+a+Stake+Mines+predictor+bot%2C+a+Stake+Mines+hack%2C+or+simply+relying+on+your+own+strategy%2C+remember+that+Stake+Mines+is+ultimately+a+game+of+randomness.+While+tools+like+the+Stake+Mines+calculator+and+Stake+Mines+mod+APK+may+improve+your+experience%2C+they+cannot+eliminate+the+inherent+risk+involved.%3Cbr%3E+%3Cbr%3E++%3Cbr%3E+%3Cbr%3E++For+those+curious+about+how+these+bots+work%2C+a+Stake+Mines+Predictor+Bot+Free+version+is+often+available+for+download.+While+these+free+bots+may+not+be+as+advanced+or+sophisticated+as+their+paid+counterparts%2C+they+still+claim+to+offer+valuable+insights+into+which+tiles+are+safe+to+click.+Players+may+experiment+with+these+free+tools+to+determine+if+they+provide+a+significant+advantage+before+upgrading+to+a+more+advanced+version.%3Cbr%3E+%3Cbr%3E++%3Cbr%3E+%3Cbr%3E++Using+the+demo+version+helps+players+understand+the+features+and+gameplay+of+the+game+without+the+worry+of+losing+money.+It%E2%80%99s+a+risk-free+way+to+explore+different+strategies+and+decide+how+to+approach+the+full+game.%3Cbr%3E+%3Cbr%3E++%3Cbr%3E+%3Cbr%3E++Another+strategy+involves+selecting+a+specific+pattern+in+which+to+uncover+the+tiles.+By+following+a+predetermined+grid+path%2C+players+may+sometimes+raise+their+chances+of+avoiding+mines.+However%2C+even+with+the+best-laid+strategy%2C+it%E2%80%99s+vital+to+remember+that+the+game+is+based+on+luck%2C+and+no+strategy+can+guarantee+a+win+every+time.%3Cbr%3E+%3Cbr%3E++%3Cbr%3E+%3Cbr%3E++Although+some+players+have+reported+success+with+specific+Stake+Mines+Hack+tools%2C+it%27s+essential+to+proceed+cautiously.+The+excitement+of+gambling+in+games+like+Stake+Mines+is+rooted+in+the+challenge+and+uncertainty+of+the+experience%2C+and+trying+to+bypass+this+unpredictability+through+cheats+or+hacks+may+result+in+consequences+that+outweigh+the+short-term+benefits.%3Cbr%3E+%3Cbr%3E++%3Cbr%3E+%3Cbr%3E++While+this+tool+doesn%E2%80%99t+guarantee+success%2C+it+provides+a+way+for+players+to+gauge+the+risk+and+reward+associated+with+each+decision.+Some+calculators+even+use+historical+game+data+to+adjust+a+player%E2%80%99s+strategy+based+on+past+performance.%3Cbr%3E+%3Cbr%3E++%3Cbr%3E+%3Cbr%3E++For+those+who+enjoy+trying+out+new+game+versions%2C+the+Stake+Mines+APK+lets+users+get+the+game+on+their+Android+devices.+APK+files+allow+gamers+to+circumvent+app+store+restrictions+and+install+customized+or+hacked+versions+of+the+game.+These+versions+can+offer+enhanced+features%2C+additional+functionalities%2C+or+even+extra+chances+to+succeed%2C+but+it%E2%80%99s+important+to+obtain+them+from+trusted+sources+to+avoid+malware+or+other+issues.%3Cbr%3E+%3Cbr%3E++%3Cbr%3E+%3Cbr%3E++The+Stake+Mines+game+is+offered+on+various+platforms%2C+and+its+popularity+continues+to+rise+due+to+its+exciting+nature+and+the+thrill+of+uncertainty.+The+surprise+of+which+tile+may+hide+a+mine+is+part+of+what+makes+the+game+so+exciting+and+offers+a+risky+experience+for+both+beginners+and+seasoned+players.%3Cbr%3E+%3Cbr%3E++%3Cbr%3E+%3Cbr%3E++However%2C+opinions+on+the+impact+of+these+bots+are+divided.+While+some+claim+that+they+can+significantly+improve+your+chances+of+winning%2C+others+argue+that+they+are+no+more+reliable+than+sheer+luck.+Additionally%2C+using+a+Stake+Mines+Predictor+Bot+may+violate+the+terms+of+service+of+certain+gaming+platforms%2C+so+it%E2%80%99s+crucial+to+consider+the+risks+before+depending+on+these+tools.%3Cbr%3E+%3Cbr%3E++%3Cbr%3E+%3Cbr%3E++Stake+Mines+is+accessible+on+the+renowned+platform+%3Ca+href%3D%22https://stakemines.in/%22%3Estake+mines+download%3C/a%3E.com%2C+which+is+widely+recognized+for+its+variety+of+online+gambling+and+gaming+options.+Mines+on+Stake+refers+specifically+to+the+version+of+the+game+hosted+on+this+platform.+Players+who+are+familiar+with+Stake+know+that+it+provides+a+safe+environment+for+gambling%2C+%3Ca+href%3D%22https://www.flickr.com/search/%3Fq%3Doffering%22%3Eoffering%3C/a%3E+a+wide+selection+of+games+and+betting+options.%3Cbr%3E+%3Cbr%3E++%3Cbr%3E+%3Cbr%3E++For+players+who+prefer+a+more+logical+approach+to+Stake+Mines%2C+using+a+Stake+Mines+calculator+could+be+incredibly+beneficial.+This+tool+helps+players+evaluate+the+odds+of+hitting+a+mine+versus+selecting+a+safe+tile+by+taking+into+account+the+number+of+remaining+tiles+and+the+number+of+hidden+mines.+By+crunching+the+numbers%2C+a+player+can+make+more+informed+choices+about+when+to+withdraw+or+continue.%3Cbr%3E+%3Cbr%3E++%3Cbr%3E+%3Cbr%3E++Stake+Mines+is+an+incredibly+enthralling+game+that+revolves+around+a+straightforward+concept+but+can+be+quite+hard.+Players+begin+by+making+a+wager+and+then+selecting+tiles+from+a+grid.+The+objective+is+to+uncover+all+the+clear+tiles+without+landing+on+a+mine.+Each+mine-free+tile+you+uncover+increases+your+winnings%2C+but+if+you+select+a+mine%2C+the+game+ends%2C+and+you+lose+your+money.+The+ease+of+the+game+is+part+of+its+appeal%2C+but+the+true+challenge+lies+in+the+planning+needed.+Players+must+predict+which+tiles+are+safe+to+uncover%2C+weighing+exposure+against+potential+reward.%3Cbr%3E+%3Cbr%3E++%3Cbr%3E+%3Cbr%3E++Players+should+approach+the+game+with+a+responsible+mindset%2C+understanding+that+both+successes+and+losses+are+part+of+the+journey.+The+real+thrill+of+Stake+Mines+comes+from+testing+your+luck%2C+developing+strategies%2C+and+experiencing+the+exhilaration+of+uncovering+safe+tiles.+Whether+you%27re+playing+the+demo+or+betting+real+money%2C+make+sure+you+are+betting+responsibly+and+within+your+limits.%3Cbr%3E+%3Cbr%3E++%3Cbr%3E+%3Cbr%3E++The+platform%E2%80%99s+reputation+for+trust+is+a+major+draw+for+users+who+want+to+enjoy+Stake+Mines+with+the+assurance+that+their+funds+and+personal+information+are+protected.+Additionally%2C+Stake+Mines+on+Stake.com+is+fully+optimized+for+mobile+devices%2C+making+it+easy+to+play+wherever+you+are.
Stake Mines Demo: Learning the Game Without Risk
If you're new to Stake Mines, the Stake Mines demo is a great way to learn the game’s mechanics without the financial risk. Many platforms offer demo versions of games, allowing players to refine their skills and strategies in a low-stakes environment. The Stake Mines demo mirrors the real game but without using real money, making it the perfect way to experiment before committing to real wagers.
Using the demo version helps players comprehend the features and gameplay of the game without the worry of losing money. It’s a risk-free way to explore different strategies and decide how to approach the full game.
One major appeal of <a href="https://muhammadcenter.com/play-sweet-bonanza-slot-experience-the-candy-themed-slot-by-pragmatic-play-featuring-free-play-and-demo-mode-great-winning-potential-and-mobile-playability/">bonanza sweet</a> is its refreshing approach to online slot game structure. Unlike traditional slots that rely on paylines, Sweet Bonanza features a "cluster pays" system. The slot has six-by-five layout, providing spinners many opportunities to win with every play. Combinations are generated by landing clusters of a minimum of eight same figures anywhere on the grid, differentiating it from regular slots that operate by predetermined paylines.
This cluster-based system is not only visually engaging but also offers players better odds each time they spin.
The candy-themed graphics and playful color choices enhance the visual allure, generating a sugary and dynamic vibe that draws players in. Icons in the game consist of various candies in vivid shades, as well as fruits like bananas, grapes, and watermelons. The visuals are complemented by joyful music that brings to the gaming excitement. The slot game also includes a scatter symbol represented by a lollipop, which is essential in initiating the free rounds. By landing four or more lollipop symbols, users will start the Free Spins mode, which gives a major chance to earn substantial prizes.
New players interested in online slots or prefer to test it first without betting real funds, the free Sweet Bonanza version delivers an ideal option. Numerous gaming sites feature a Sweet Bonanza demo, allowing players to experience the gameplay, develop techniques, and become familiar with the game’s features without any financial risk. Trying Sweet Bonanza in demo mode is ideal for new players, as it allows them to understand the slot features, adjust wager sizes, and discover the cascading reels.
Web: https://muhammadcenter.com/play-sweet-bonanza-slot-experience-the-candy-themed-slot-by-pragmatic-play-featuring-free-play-and-demo-mode-great-winning-potential-and-mobile-playability/
The tumbling mechanic, alternatively called the falling symbols feature, is a core aspect of Sweet Bonanza. Once players hit a winning cluster, the winning symbols are cleared, and more symbols cascade down, creating further win potential. This element adds to the thrill but also provides more win potential within each round.
Another highlight of this game is its Free Spins round, which is typically the most exciting part for players. The bonus spins in this slot may result in impressive wins due to the presence of multipliers. Once it starts, the bonus mode awards ten free spins, and extra spins can be re-triggered by getting three or more lollipop scatter symbols.
Este slot se diferencia de otras maquinas tragamonedas por su diseno y tematica unicos. Al ingresar al slot, los apostadores se sumergen en un mundo de dulces y colores vibrantes que sugieren un ambiente magico. El fondo esta decorado con dulces, lo cual crea una experiencia visual amigable y tranquila, ideal para todo tipo de jugadores. Este slot ha sido reconocido por su adiccion positiva y entretenimiento, ya que ofrece premios emocionantes y una estetica cautivadora.
Una de las caracteristicas mas valoradas de este juego es su ronda de giros gratis, que se activa si se obtienen cuatro o mas simbolos de caramelos en cualquier lugar. La ronda de giros gratuitos no solo permiten jugar sin gastar dinero adicional, sino que tambien incrementan las chances de obtener grandes premios, especialmente cuando los multiplicadores hacen su aparicion. Este elemento del juego es uno de los mas interesantes a los jugadores, y muchos mencionan en sus opiniones que la ronda de giros gratis es lo mas emocionante.
Ademas, el juego de Pragmatic Play ha logrado mantener su popularidad gracias a su posibilidad de adaptacion a diferentes tipos de jugadores. No importa si eres nuevo en el mundo de las tragamonedas, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la adaptabilidad de este slot en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere jugadas rapidas mientras viajas, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: http://able010.able-company.com/bbs/board.php?bo_table=free&wr_id=165641
Otro punto que interesa a los jugadores es si se puede ganar dinero real con este juego de tragamonedas. Al igual que en cualquier tragamonedas, la tragamonedas Sweet Bonanza es una maquina de azar, lo cual significa que el resultado de cada tirada es aleatorio y no puede ser controlado. Sin embargo, los multiplicadores junto con giros gratis ofrecen una oportunidad significativa para obtener grandes recompensas. La funcion de los multiplicadores pueden multiplicar las ganancias hasta 100 veces, lo que puede generar premios grandes si los jugadores tienen suerte. Sin embargo, es importante recordar que se debe jugar con responsabilidad y que el exito no esta asegurado en todos los giros.
Tyson Fury and Oleksandr Usyk are ready to face each other in a fight of unparalleled significance. This fight is about more than just titles; it represents their quest for immortality. The towering Fury has earned worldwide fame through his unique style and his unmatched skills inside the ropes. Beating Wilder and Klitschko have solidified his legendary status. In contrast, Usyk, the technician poses a unique challenge for Fury. On the flip side, Usyk, a genius in the ring represents a formidable opponent for Tyson Fury himself, but for the entire division. His journey to global fame began in the cruiserweight division, as an undisputed champion. Don’t miss out for a thrilling boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! Experience every moment live on our website. Be part of the action — visit <a href="https://redirect.hurriyet.com.tr/default.aspx?url=https://tysonvsusyk.com/">tysonvsusyk.com</a> right away and watch the match in high quality!
For British fans, the event will kick off at close to prime time, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, as well as viewers across Europe and the Americas, this will be a must-see event. Where the bout will take place has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. Regardless of the venue, one thing is certain: the atmosphere will be electric. While the spotlight remains on Fury and Usyk, the Fury vs Usyk undercard is shaping up to be thrilling. Major boxing events often feature stacked undercards, offering an entire night of boxing excitement.
In the past, supporting bouts in major events have showcased rising stars. Boxers seeking the spotlight capitalize on the exposure to impress fans and analysts alike, as all eyes are on them. Although the lineup for the Fury Usyk undercard has yet to be finalized, there’s plenty of talk. Could we see rising prospects? Whatever the selection, the action will not disappoint. What sets this bout apart incredibly exciting is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. With his immense height and reach advantage, he dictates the pace of bouts.
The legendary battles with Wilder highlighted his resilience, overcoming brutal hits to dominate in later rounds. When he faced Klitschko, his strategic genius shone through, proving he’s not just physical but cerebral. By contrast, Usyk, offers a different kind of threat. Being a left-handed fighter, his movements create openings. Usyk’s punches aren’t the heaviest in the division, their timing wears down foes. As fight night approaches, The betting lines for Fury vs Usyk have fans and analysts speculating.
The betting lines show Fury ahead according to the odds, due to his size advantage, his track record in big matches, and his tactical brilliance. Despite being seen as the underdog doesn’t diminish his chances, his dominance against Joshua demonstrated his ability in the heavyweight ranks.
For Tyson Fury, this fight presents a shot at undisputed glory. If he wins, it would add an undisputed title to his already impressive resume. Conversely, If Usyk wins would be a monumental achievement. Achieving undisputed glory in two divisions is a feat few can claim.
Web: <a href="http://www.google.fr/url?sa=t&url=https%3A%2F%2Ftysonvsusyk.com">tysonvsusyk.com</a>
Fury vs Usyk represents something greater than a title bout. It’s a battle of contrasting styles. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. The clash of personalities adds depth to the narrative. It’s a fight of wills and ideologies. Whoever triumphs in this battle, the legacy of this fight will leave a lasting mark on the sport. The clash for the undisputed title is a spectacle unlike any other. It’s the result of relentless dedication. Should Fury claim victory thanks to his power and game plan, or Usyk wins with his precision with his finesse and stamina, one thing is certain, this will be a fight remembered for years to come.
The Fury-Usyk battle is a spectacle of a lifetime. It’s a fight of grit and strategy. The two competitors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are on a collision course that will define an era. It’s far beyond a championship match; it’s a battle for eternal recognition. Fury, an undefeated champion has risen to the pinnacle of the sport thanks to his personality coupled with unparalleled talent during fights. Triumphing against boxing legends like Wilder and Klitschko have solidified his legendary status. Meanwhile, Usyk, the technician brings an unprecedented test to boxing’s biggest stars. Meanwhile, the Ukrainian technician represents a formidable opponent for the heavyweight ranks overall, as a heavyweight contender. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, by conquering all challengers. Prepare yourself for a thrilling boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! Experience every moment streamed live on our website. Join the excitement — visit <a href="http://www.nnov.org/common/redir.php?https://usykvsfury.co.uk/">usykvsfury.co.uk</a> today and stream the event with top-notch streaming!
In the United Kingdom, the ring walks are planned for close to prime time, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and beyond, this will be a must-see event. The venue for Fury vs Usyk remains a hot topic, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, fans can be sure: the excitement will be unmatched. While the spotlight is centered on the headline fight, the Fury vs Usyk undercard is shaping up to be thrilling. Major boxing events often feature stacked undercards, offering an entire night of boxing excitement.
Historically, supporting bouts in major events have been a stage for breakout performances. Fighters looking to rise through the ranks use such opportunities to showcase their skills, with the world paying attention. Though the supporting fights for Fury vs Usyk are still unconfirmed, there’s plenty of talk. Could we see rising prospects? Regardless of the names, it’s sure to add to the excitement. The most compelling part of Fury vs Usyk truly fascinating is the clash of styles. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. With his immense height and reach advantage, Fury can control a fight.
The legendary battles with Wilder proved his toughness, bouncing back from adversity to secure victories. In his fight with Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, offers a different kind of threat. As a southpaw, his movements create openings. The Ukrainian’s shots aren’t the heaviest in the division, they consistently find their mark. As anticipation builds, The betting lines for Fury vs Usyk have fans and analysts speculating.
Tyson Fury is seen as the frontrunner based on the betting odds, given his physical stature, his experience in high-pressure bouts, and his tactical brilliance. Despite the odds, Usyk remains a strong contender doesn’t rule him out, as his victories over Joshua confirmed his toughness against big opponents.
For Fury himself could be the defining moment of his career. If he wins, it would add an undisputed title to his already impressive resume. Meanwhile, Usyk’s victory would be a monumental achievement. Becoming an undisputed champion in two different weight classes is a rare accomplishment.
Web: <a href="http://www.google.mv/url?q=https%3A%2F%2Fusykvsfury.co.uk">usykvsfury.co.uk</a>
The upcoming showdown is about more than the titles. It’s a fight between two very different fighters. Fury’s boisterous personality is the opposite of Usyk’s humble and disciplined approach. These differences add complexity to the fight. It’s a fight of wills and ideologies. Regardless of the outcome, the significance of this match will leave a lasting mark on the sport. The battle for heavyweight supremacy is a spectacle unlike any other. It’s the pinnacle of both fighters’ hard work. Whether Tyson Fury prevails with his size and strategy, or Oleksandr Usyk triumphs with his finesse and stamina, it’s certain that, this bout will go down in history.
This fight between Fury and Usyk is more than just a sporting contest. It’s a contest of heart and willpower. Both fighters will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Oyleyse, Sweet Bonanza nas?l oynan?r? Sweet Bonanza’n?n her bir ozelligini gozden gecirecegiz ve giris ad?mlar?ndan oyun stratejilerine kadar butun detaylar? size sunacag?z.
Sweet Bonanza oyunu nedir ve nas?l cal?s?r?
Sweet Bonanza oyunu, cevrimici slot oyunlar? aras?nda seckin ozellikleriyle one c?kan bir oyun olarak biliniyor. Pragmatic Play firmas?n?n gelistirdigi bu slot oyunu, cesitli seker ve meyve sembollerinin birlesiminden olusur. Bu ikonik semboller, renkli bir dunya yaratarak oyuncular? oyunun cazibesine kap?lmaya davet eder.
Bu rengarenk oyunun kendi mekanik sistemine sahip olmas? oyunu ozel k?l?yor. Her kazancla birlikte yeni sembollerin eklenmesiyle, oyun surekli bir sekilde kazanma olas?l?g? yarat?r. Bu mekanik yap?yla birlikte, Sweet Bonanza, oyuncular?n surekli olarak kazanmas?n? saglar.
Sweet Bonanza Nas?l Oynan?r?
Sweet Bonanza’n?n oynan?s? diger benzer oyunlardan daha karmas?k olmayan bir yap?ya sahiptir. alt? sutun ve bes sat?rdan olusan bir tabloda oynan?r. Oyuncular?n amac?, belirli say?da sembolun birlesmesiyle para kazanabilmektir.
Bu oyun sisteminde ozel bir kombinasyon kurma zorunlulugu yoktur. Oyuncular icin sembollerin birlesmesi yeterlidir. Kazanan semboller patlar ve yenileri eklenir. Bu oyun yap?s?yla birlikte, bir spin icinde coklu kazanclar elde edilebilir.
Web: http://shinhwaspodium.com/bbs/board.php?bo_table=free&wr_id=2804424
Sweet Bonanza Demo: Oyunu Denemek Icin Ideal F?rsat
Sweet Bonanza’n?n en cazip ozelliklerinden biri de, oyuncular?n demo versiyonu deneme imkan?n?n olmas?d?r. Demo mod, oyuna yeni baslayanlar icin harika bir f?rsat sunar. Gercek para kullanmadan oyun mekanigini anlamak mumkundur.
Oyuncular, demo oyun ile sembollerin degerlerini tan?yabilir. Oyuncular demo ile kendi stratejilerini gelistirme sans?na sahiptir. Oyuncular bu mod ile cesitli taktikler gelistirebilir.
Fury, the Gypsy King, and Usyk, the technician are ready to face each other in a fight of unparalleled significance. It’s far beyond a championship match; it’s about legacy. Fury, an undefeated champion has earned worldwide fame with his charisma and his unmatched skills inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Across the ring, Oleksandr Usyk poses a unique challenge to boxing’s biggest stars. On the flip side, Oleksandr Usyk represents a formidable opponent for the heavyweight ranks overall, as a heavyweight contender. His journey to global fame began in the cruiserweight division, where he became an unstoppable force. Prepare yourself for the most anticipated boxing match of the year as Usyk takes on Fury in a historic showdown! See every move live on our website. Don’t miss your chance — visit <a href="http://cloudfront-eu-central-1.images.arcpublishing.com/goto/http:/furyvsusykdate.co.uk">furyvsusykdate.co.uk</a> now and watch the match from the comfort of your home!
For British fans, the ring walks are planned for close to prime time, ensuring maximum viewership. For Usyk’s fans in Ukraine, and beyond, the excitement is palpable. Where the bout will take place has yet to be confirmed, with talk of iconic boxing destinations. Regardless of the venue, it’s guaranteed: it will be a spectacle. Even though attention is firmly on the main event, the Fury vs Usyk undercard promises plenty of action. Big-ticket boxing cards are known for strong supporting fights, providing non-stop action before the headliner.
Historically, undercards of this caliber have been a stage for breakout performances. Boxers seeking the spotlight use such opportunities to impress fans and analysts alike, knowing millions are watching. Although the lineup for the Fury Usyk undercard are still unconfirmed, speculation runs high. Might there be a cruiserweight spectacle? No matter the final roster, it’s sure to add to the excitement. What makes this fight truly fascinating is the dynamic between these fighters. Tyson Fury’s size and agility are unparalleled in the sport. Being so tall yet so nimble, Fury can control a fight.
The three fights against Wilder highlighted his resilience, bouncing back from adversity to secure victories. When he faced Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. Meanwhile, Usyk, relies on technique and stamina. As a southpaw, he uses angles and footwork. Usyk’s punches aren’t the heaviest in the division, they consistently find their mark. As anticipation builds, Tyson Fury vs Usyk odds have fans and analysts speculating.
The betting lines show Fury ahead as predicted by many experts, thanks to his imposing frame, his track record in big matches, and his unpredictable nature. Although Usyk is the less favored fighter doesn’t rule him out, his victories against AJ proved that he can handle the physicality of the heavyweight division.
For the Gypsy King represents an opportunity to cement his legacy. If he wins, it would add an undisputed title to his already impressive resume. Meanwhile, Usyk’s victory would elevate him to legendary status. Becoming the undisputed heavyweight champion is a once-in-a-lifetime achievement.
Web: <a href="http://cse.google.com.kw/url?q=https%3A%2F%2Ffuryvsusykdate.co.uk">furyvsusykdate.co.uk</a>
This fight is not just about the belts. It’s a meeting of two unique worldviews. Fury’s boisterous personality stands in stark contrast to Usyk’s composed demeanor. Such contrasts make the fight more compelling. It’s about more than just skill. Whoever triumphs in this battle, the impact of this bout will reverberate throughout boxing history. The clash for the undisputed title is a defining moment. It’s a culmination of years of hard work. If Fury wins with his size and strategy, or Usyk secures a victory with his finesse and stamina, what is clear is, this bout will go down in history.
Fury vs Usyk is more than just a fight. It’s a contest of heart and willpower. These two warriors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Sweet Bonanza se distingue de otras tragamonedas por su diseno y tematica unicos. Al comenzar a jugar, los jugadores se sumergen en un escenario de golosinas y colores vivos que hacen pensar en un cuento de fantasia. Se puede ver un fondo lleno de caramelos, lo cual ofrece una escena visual atractiva y divertida, adaptada a todos los jugadores. Este slot ha sido reconocido por su adiccion positiva y entretenimiento, ya que mezcla la emocion de ganar premios con un estilo visual atractivo para todos.
Una de las caracteristicas mas valoradas de este juego de tragamonedas es su ronda de giros gratis, que se activa al conseguir cuatro o mas simbolos de caramelos rosados en cualquier lugar de los carretes. El modo de giros sin costo no solo permiten jugar sin costo, sino que tambien incrementan las chances de obtener grandes premios, especialmente cuando se activan los multiplicadores durante los giros. Este detalle del juego es uno de los mas interesantes a los jugadores, y muchos comentan en sus opiniones que la funcion de giros gratis es la parte mas emocionante.
Ademas, el juego de Pragmatic Play ha logrado mantener su popularidad gracias a su atractivo para jugadores novatos y experimentados. No importa si eres nuevo en el mundo de las tragamonedas, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la compatibilidad de el juego en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere jugadas rapidas mientras viajas, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: http://www.cameseeing.com/bbs/board.php?bo_table=freeboard_2021&wr_id=222982
Otro punto que interesa a los jugadores es si se puede ganar dinero real con este juego de tragamonedas. Al igual que en cualquier tragamonedas, la tragamonedas Sweet Bonanza es una maquina de azar, lo cual significa que el resultado de cada jugada es aleatorio y no puede ser controlado. Sin embargo, los multiplicadores junto con giros gratis ofrecen una oportunidad significativa para obtener grandes recompensas. La funcion de los multiplicadores permiten multiplicar las ganancias hasta 100x, lo que puede resultar en una recompensa significativa si el jugador acierta. Sin embargo, es importante recordar que siempre es importante jugar con responsabilidad y que no hay garantias de ganar en cada sesion.
These two heavyweight champions are preparing for an epic showdown of unparalleled significance. It’s not merely about the belts; it represents their quest for immortality. Fury, an undefeated champion has become a global icon through his unique style and remarkable adaptability during fights. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. Across the ring, Usyk, the technician brings an unprecedented test for Fury. At the same time, Usyk, a genius in the ring is a true test for Fury for Tyson Fury himself, and for boxing fans worldwide. The ascent of Oleksandr Usyk began in the cruiserweight division, by conquering all challengers. Get ready for the most anticipated boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! See every move in real time on our website. Join the excitement — visit <a href="http://all27.ru/outgocounter.php?url=aHR0cHM6Ly9tb2RzLW1lbnUucnUv">tysonfuryvsusyk.co.uk</a> today and enjoy the fight in high quality!
Across the UK, the fight is expected to begin around 10 PM GMT, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and beyond, the excitement is palpable. Where the bout will take place is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, it’s guaranteed: it will be a spectacle. Even though attention is firmly on the main event, the preliminary bouts promises plenty of action. High-profile matches often feature stacked undercards, providing non-stop action before the headliner.
In the past, preliminary fights on major cards have been a stage for breakout performances. Fighters looking to rise through the ranks capitalize on the exposure to showcase their skills, with the world paying attention. Although the lineup for the Fury Usyk undercard has yet to be finalized, there’s plenty of talk. Could we see rising prospects? Whatever the selection, fans can expect fireworks. What sets this bout apart incredibly exciting is the clash of styles. Fury’s towering frame and movement are unparalleled in the sport. Being so tall yet so nimble, he commands the ring like no other.
His trilogy with Deontay Wilder showed his durability, overcoming brutal hits to finish strong. In his fight with Klitschko, his strategic genius shone through, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, relies on technique and stamina. With his unorthodox stance, his movements create openings. His strikes may not have knockout power, they consistently find their mark. As anticipation builds, The betting lines for Fury vs Usyk are the subject of intense debate.
Tyson Fury is the slight favorite as predicted by many experts, due to his size advantage, his proven ability in tough situations, and his adaptability. Although Usyk is the less favored fighter doesn’t mean he’s an underdog in spirit, his victories against AJ showed that he can compete at heavyweight.
For the Gypsy King is a chance to further solidify his greatness. Should he come out on top, Fury’s win would add an undisputed title to his already impressive resume. On the other hand, If Usyk wins would elevate him to new heights. Securing two undisputed titles is a feat few can claim.
Web: <a href="http://www.google.ro/url?q=https://tysonfuryvsusyk.co.uk/">tysonfuryvsusyk.co.uk</a>
This fight is about more than the titles. It’s a meeting of two unique worldviews. Fury’s larger-than-life persona is the opposite of Usyk’s humble and disciplined approach. The clash of personalities adds depth to the narrative. This is more than just a physical contest. Regardless of the outcome, the significance of this match will be felt for years to come. This historic showdown is more than just a fight. It’s a culmination of years of hard work. Whether Tyson Fury prevails through his strength and tactics, or Oleksandr Usyk triumphs with his finesse and stamina, one thing is certain, this will be a fight remembered for years to come.
This fight between Fury and Usyk is more than just a sporting contest. It’s a battle of minds and bodies. The two competitors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Sweet Bonanza se distingue de otras maquinas tragamonedas por su diseno y tematica unicos. Al abrir el juego, los usuarios entran en un universo de caramelos y colores vivos que sugieren un ambiente magico. El fondo de la pantalla esta lleno de golosinas, lo cual crea una experiencia visual agradable y agradable, ideal tanto para jugadores nuevos como para experimentados. Esta tragamonedas ha sido considerado como entretenido y cautivador, ya que brinda emociones y una estetica llamativa para todos.
Una de las caracteristicas mas valoradas de Sweet Bonanza es su ronda de giros gratis, que se activa cuando aparecen cuatro o mas simbolos de caramelos rosados. El modo de giros sin costo no solo permiten jugar de manera gratuita, sino que tambien multiplican las posibilidades de ganar grandes premios, especialmente cuando aparecen multiplicadores en los giros. Este detalle del juego es uno de los mas emocionantes a los jugadores, y muchos destacan en sus comentarios que el bono de giros gratis es la parte mas emocionante.
Ademas, este juego ha logrado mantener su popularidad gracias a su aplicabilidad universal. No importa si eres si tienes mucha experiencia en el juego, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la compatibilidad de este slot en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere apostar desde tu telefono movil, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: https://sunginmall.com:443/bbs/board.php?bo_table=free&wr_id=18876
Otro punto que interesa a los jugadores es si es posible ganar dinero con Sweet Bonanza. Al igual que en cualquier tragamonedas, este slot es una maquina de azar, lo cual significa que el resultado de cada tirada es aleatorio y no puede ser controlado. Sin embargo, los multiplicadores junto con giros gratis ofrecen una oportunidad significativa para obtener ganancias considerables. La funcion de los multiplicadores pueden multiplicar las ganancias hasta 100 veces, lo que puede resultar en una recompensa significativa si el jugador acierta. Sin embargo, es importante recordar que hay que disfrutar del juego con moderacion y que el exito no esta asegurado en todos los giros.
The undefeated Fury and Usyk are ready to face each other in a fight that will define an era. This fight is about more than just titles; it represents their quest for immortality. The Gypsy King has risen to the pinnacle of the sport through his unique style coupled with unparalleled talent inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Meanwhile, the tactical southpaw brings an unprecedented test for Fury. Meanwhile, Oleksandr Usyk stands as a unique threat not just for Fury, but for the entire division. Usyk’s rise to prominence began in the cruiserweight division, as an undisputed champion. Don’t miss out for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! See every move in real time on our website. Don’t miss your chance — visit <a href="https://gdetr.hit.gemius.pl/_uachredir/hitredir/id=nGFLcsQQENpn.0g.IXKjd3YZ7Hk1yAQskyJeVC4lR53.i7/fastid=jnoaiehnqtxhpncewambqgeojokf/stparam=vdrllkrfkd/nc=0/gdpr=0/gdpr_consent=/url=https://furyvsusykdate.co.uk/">furyvsusykdate.co.uk</a> today and stream the event with top-notch streaming!
Across the UK, the ring walks are planned for late evening, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, and beyond, this will be a must-see event. Where the bout will take place has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, fans can be sure: the atmosphere will be electric. Although the focus is centered on the headline fight, the Fury vs Usyk undercard is also generating excitement. Big-ticket boxing cards include preliminary bouts with top talent, providing non-stop action before the headliner.
Historically, preliminary fights on major cards have been a stage for breakout performances. Contenders hoping to make their mark capitalize on the exposure to showcase their skills, as all eyes are on them. Though the supporting fights for Fury vs Usyk haven’t been officially announced, there’s plenty of talk. Might there be a cruiserweight spectacle? No matter the final roster, fans can expect fireworks. What sets this bout apart so intriguing is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. At 6’9" with an 85-inch reach, he commands the ring like no other.
The legendary battles with Wilder proved his toughness, overcoming brutal hits to finish strong. When he faced Klitschko, his strategic genius shone through, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. With his unorthodox stance, his movements create openings. The Ukrainian’s shots may not have knockout power, their timing wears down foes. With the date drawing closer, Tyson Fury vs Usyk odds are the subject of intense debate.
Fury is the favored fighter according to the odds, because of his reach and height, his track record in big matches, and his unorthodox style. Despite the odds, Usyk remains a strong contender shouldn’t be counted out, as his victories over Joshua showed that he can compete at heavyweight.
For the Gypsy King represents an opportunity to cement his legacy. Should he come out on top, Fury’s win would add an undisputed title to his already impressive resume. Conversely, For Usyk, a win would elevate him to legendary status. Becoming an undisputed champion in two different weight classes is a once-in-a-lifetime achievement.
Web: <a href="http://www.google.ee/url?sa=t&url=http%3A%2F%2Fwww.magical-dream.com">furyvsusykdate.co.uk</a>
The upcoming showdown is more than just a championship fight. It’s a meeting of two unique worldviews. Fury’s larger-than-life persona is the opposite of Usyk’s humble and disciplined approach. These varying personalities make the bout even more interesting. This is more than just a physical contest. Whoever comes out victorious, the significance of this match will be felt for years to come. This historic showdown is a defining moment. It’s the pinnacle of both fighters’ hard work. Whether Tyson Fury prevails with his experience and unpredictability, or Usyk comes out on top with his technique and endurance, no matter the outcome, this will be a legendary contest.
Fury vs Usyk is more than just a fight. It’s a battle of minds and bodies. These men will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Dicas de Sucesso para o Fortune Tiger
O atrativo principal do jogo e a chance de premios elevados com rodadas breves. O jogo proporciona um fluxo constante de oportunidades de premios em cada rodada.
Para maximizar os lucros, muitos jogadores adotam estrategias variadas. Uma das taticas mais comuns e a aposta progressiva. Com essa tecnica, o jogador inicia com apostas minimas e vai subindo progressivamente.
Saber quando apostar e quanto aumentar as apostas e uma habilidade importante. Alguns jogadores se especializam em identificar os minutos de pagamento. Esses momentos de maiores ganhos sao imprevisiveis, mas com pratica e possivel identifica-los.
Como Funciona a Plataforma do Jogo Fortune Tiger
Website: http://www.chunwun.com/bbs/board.php?bo_table=qna&wr_id=118433
Conclusao
O Fortune Tiger e uma plataforma empolgante para todos os tipos de jogadores. Com sua interface amigavel e sistema de pagamentos confiavel, o jogo e ideal para qualquer apostador.
Tyson Fury and Oleksandr Usyk are set to meet in the ring of unparalleled significance. It’s not merely about the belts; it’s about legacy. The towering Fury has risen to the pinnacle of the sport through his unique style and remarkable adaptability inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. In contrast, Oleksandr Usyk poses a unique challenge to the heavyweight division. Meanwhile, Usyk, a genius in the ring represents a formidable opponent not just for Fury, as a heavyweight contender. Usyk’s rise to prominence began in the cruiserweight division, where he became an unstoppable force. Don’t miss out for the most anticipated boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! Catch every punch live on our website. Be part of the action — visit <a href="http://novo-city.ru/go/usykvsfurydate.co.uk">usykvsfurydate.co.uk</a> right away and enjoy the fight with top-notch streaming!
For British fans, the fight is expected to begin close to prime time, making it ideal for a prime-time audience. Back in Usyk’s home country, and for fans watching from around the world, the anticipation is at a fever pitch. The venue for Fury vs Usyk has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. Regardless of the venue, it’s guaranteed: the excitement will be unmatched. Although the focus is centered on the headline fight, the fights leading up to the main event is shaping up to be thrilling. Big-ticket boxing cards are known for strong supporting fights, offering an entire night of boxing excitement.
Historically, undercards of this caliber have showcased rising stars. Boxers seeking the spotlight often seize these moments to impress fans and analysts alike, as all eyes are on them. Though the supporting fights for Fury vs Usyk are still unconfirmed, speculation runs high. Could we see rising prospects? No matter the final roster, the action will not disappoint. The most compelling part of Fury vs Usyk so intriguing is the dynamic between these fighters. Fury’s towering frame and movement are unparalleled in the sport. Being so tall yet so nimble, Fury can control a fight.
The legendary battles with Wilder proved his toughness, bouncing back from adversity to secure victories. Against Wladimir Klitschko, his strategic genius shone through, demonstrating his mental sharpness. By contrast, Usyk, brings speed, precision, and finesse. Being a left-handed fighter, he uses angles and footwork. The Ukrainian’s shots may not have knockout power, but they are delivered with pinpoint accuracy. As anticipation builds, The betting lines for Fury vs Usyk are becoming a hot topic.
Tyson Fury is the slight favorite as predicted by many experts, because of his reach and height, his proven ability in tough situations, and his adaptability. Although Usyk is the less favored fighter doesn’t diminish his chances, his victories against AJ confirmed his toughness against big opponents.
For Fury himself is a chance to further solidify his greatness. If he wins, it would further solidify his status as the best heavyweight of this era. Meanwhile, If Usyk wins would be a monumental achievement. Securing two undisputed titles is a feat few can claim.
Web: <a href="http://cse.google.co.th/url?q=https://usykvsfurydate.co.uk/">usykvsfurydate.co.uk</a>
Fury vs Usyk is not just about the belts. It’s a battle of contrasting styles. Fury’s boisterous personality stands in stark contrast to Usyk’s composed demeanor. The clash of personalities adds depth to the narrative. It’s about more than just skill. Whoever comes out victorious, the legacy of this fight will be remembered as a defining moment in boxing. The clash for the undisputed title is more than just a fight. It’s a culmination of years of hard work. Whether Tyson Fury prevails through his strength and tactics, or Usyk secures a victory with his technique and endurance, what is clear is, this will be a fight remembered for years to come.
Tyson Fury vs Oleksandr Usyk is more than just a fight. It’s a showcase of skill and determination. The two competitors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Rozrywka hazardowa w sieci zdobywaja rosnace zainteresowanie w Polsce, a jedna z witryn, ktora zyskuje uznanie wsrod uzytkownikow, jest <a href="http://www.facebook-list.com/red-on-bet_400061.html">bet on red casino login</a>. To kasyno online, ktore przyciaga graczy dzieki bogatej ofercie gier, intuicyjna konstrukcja strony oraz kuszacymi ofertami, ktore spelnia oczekiwania zarowno poczatkujacych, jak i doswiadczonych graczy.
Bet On Red Casino – czym jest?
Kasyno Bet On Red to platforma online, ktora oferuje roznorodne opcje rozrywki, takich jak maszyny hazardowe, rozgrywki stolowe oraz kasyno na zywo. Juz sam brand „Bet On Red" wskazuje na emocje i emocje zwiazane z obstawianiem.
Latwe logowanie w Bet On Red Casino
Logowanie do konta w Red On Bet Casino jest latwy i wygodny. Po wejsciu na strone glowna, wystarczy kliknac w przycisk „Logowanie" i wpisac swoje dane. Platforma gwarantuje bezpieczenstwo, dlatego wszelkie przesylane informacje sa zaszyfrowane.
Uzytkownicy rozpoczynajacy swoja przygode moga latwo zarejestrowac sie, a rejestracja zajmuje zaledwie kilka minut. Co istotne, Bet On Red oferuje szeroki wybor opcji platnosci, co sprawia, ze korzystanie z platformy jest proste.
Jakie gry znajdziesz w Bet On Red Casino?
Kluczowym elementem, kazdego portalu hazardowego, jest katalog gier. Bet On Red Casino wyroznia sie szerokim wachlarzem, ktory przyciagnie milosnikow roznych gatunkow gier.
Web: http://www.facebook-list.com/red-on-bet_400061.html
Maszyny hazardowe sa uwielbiane przez graczy, dostepne w roznych wariantach tematycznych oraz z unikalnymi funkcjami. Oprocz klasycznych slotow, uzytkownicy moga sprobowac swoich sil w rozgrywki przy stole, takie jak ruletka.
These two heavyweight champions are preparing for an epic showdown of historic proportions. It’s not merely about the belts; it represents their quest for immortality. Fury, an undefeated champion has become a global icon thanks to his personality and his unmatched skills in the ring. Beating Wilder and Klitschko have earned him recognition as one of the best ever. On the other hand, Oleksandr Usyk poses a unique challenge to the heavyweight division. Meanwhile, Oleksandr Usyk is a true test for Fury for the heavyweight ranks overall, but for the entire division. Usyk’s rise to prominence began in the cruiserweight division, where he became an unstoppable force. Don’t miss out for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! See every move streamed live on our website. Don’t miss your chance — visit <a href="http://traffic.shareaholic.com/e?a=1&u=http%3a%2f%2ffuryvsusyk.org.uk&r=1">furyvsusyk.org.uk</a> today and enjoy the fight in high quality!
Across the UK, the ring walks are planned for late evening, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, and for fans watching from around the world, the excitement is palpable. The fight’s location is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, it’s guaranteed: the excitement will be unmatched. Although the focus remains on Fury and Usyk, the fights leading up to the main event is also generating excitement. Major boxing events often feature stacked undercards, offering an entire night of boxing excitement.
Historically, undercards of this caliber have introduced future champions. Fighters looking to rise through the ranks often seize these moments to demonstrate their talent, knowing millions are watching. Though the supporting fights for Fury vs Usyk has yet to be finalized, speculation runs high. Will there be a heavyweight clash? Whatever the selection, the action will not disappoint. What sets this bout apart truly fascinating is the dynamic between these fighters. Tyson Fury’s size and agility make him an anomaly in boxing. Being so tall yet so nimble, he commands the ring like no other.
The legendary battles with Wilder showed his durability, overcoming brutal hits to finish strong. In his fight with Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Meanwhile, Usyk, offers a different kind of threat. Being a left-handed fighter, his movements create openings. The Ukrainian’s shots lack devastating strength, they consistently find their mark. As fight night approaches, The betting lines for Fury vs Usyk are the subject of intense debate.
The betting lines show Fury ahead as predicted by many experts, given his physical stature, his experience in high-pressure bouts, and his adaptability. Despite being seen as the underdog doesn’t rule him out, as his victories over Joshua confirmed his toughness against big opponents.
For the Gypsy King presents a shot at undisputed glory. Should he come out on top, Fury’s win would add an undisputed title to his already impressive resume. Conversely, Usyk’s victory would be a monumental achievement. Achieving undisputed glory in two divisions would be a remarkable feat in boxing history.
Web: <a href="http://cse.google.co.ls/url?q=https://furyvsusyk.org.uk/">furyvsusyk.org.uk</a>
Fury vs Usyk is not just about the belts. It’s a clash of personalities. Fury’s confident and brash nature is in stark contrast to Usyk’s quiet intensity. These varying personalities make the bout even more interesting. This is more than just a physical contest. Regardless of the outcome, the legacy of this fight will be remembered as a defining moment in boxing. The battle for heavyweight supremacy is a spectacle unlike any other. It’s the pinnacle of both fighters’ hard work. If Fury wins through his strength and tactics, or Oleksandr Usyk triumphs through his superior boxing ability, no matter the outcome, this bout will go down in history.
Tyson Fury vs Oleksandr Usyk is more than just a boxing event. It’s a battle of minds and bodies. Both fighters will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Dicas para Maximizar os Lucros no Tigrinho
O jogo se diferencia por suas oportunidades de lucro rapido e significativo. Com cada aposta, o jogador tem uma chance real de lucro significativo.
Alguns jogadores tem metodos proprios para melhorar os resultados. Uma das taticas mais comuns e a aposta progressiva. Com essa tecnica, o jogador inicia com apostas minimas e vai subindo progressivamente.
Para melhorar as chances de lucro, e essencial escolher os momentos certos para apostar. Os minutos pagantes sao uma boa dica para os jogadores. Esses periodos de pagamento mais elevados ocorrem aleatoriamente, mas jogadores experientes sabem como identifica-los.
Plataforma Fortune Tiger: Funcionalidades e Vantagens
Website: http://www.alivelink.org/como-ganhar-dinheiro-no-fortune-tiger_298856.html
Encerramento
Fortune Tiger e um jogo que combina diversao, estrategia e oportunidades de ganhos. Com muitas formas de ganhar, Fortune Tiger e uma das opcoes mais atrativas no mundo dos jogos de aposta online.
The undefeated Fury and Usyk are on a collision course of unparalleled significance. It’s not merely about the belts; it’s about legacy. The Gypsy King has earned worldwide fame through his unique style coupled with unparalleled talent during fights. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. On the other hand, the tactical southpaw is a fighter unlike any other to boxing’s biggest stars. Meanwhile, Usyk, a southpaw master stands as a unique threat for the heavyweight ranks overall, as a heavyweight contender. The ascent of Oleksandr Usyk began in the cruiserweight division, as an undisputed champion. Prepare yourself for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! Experience every moment live on our website. Don’t miss your chance — visit <a href="http://klindoors.ru/bitrix/rk.php?goto=https://usykvsfury.co.uk/">usykvsfury.co.uk</a> now and watch the match with top-notch streaming!
In the United Kingdom, the event will kick off at late evening, offering perfect timing for viewers. In Usyk’s native Ukraine, and beyond, the anticipation is at a fever pitch. Where the bout will take place is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, one thing is certain: it will be a spectacle. While the spotlight remains on Fury and Usyk, the fights leading up to the main event is shaping up to be thrilling. Big-ticket boxing cards include preliminary bouts with top talent, giving fans a full evening of entertainment.
Traditionally, preliminary fights on major cards have been a stage for breakout performances. Boxers seeking the spotlight capitalize on the exposure to showcase their skills, as all eyes are on them. Though the supporting fights for Fury vs Usyk are still unconfirmed, fans are eagerly guessing. Will there be a heavyweight clash? Regardless of the names, it’s sure to add to the excitement. The most compelling part of Fury vs Usyk truly fascinating is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed are unparalleled in the sport. At 6’9" with an 85-inch reach, Fury can control a fight.
His trilogy with Deontay Wilder proved his toughness, as he recovered from knockdowns to dominate in later rounds. In his fight with Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. Meanwhile, Usyk, relies on technique and stamina. Being a left-handed fighter, his movements create openings. His strikes aren’t the heaviest in the division, their timing wears down foes. With the date drawing closer, Predictions for this fight are the subject of intense debate.
The betting lines show Fury ahead as predicted by many experts, thanks to his imposing frame, his track record in big matches, and his unpredictable nature. Despite being seen as the underdog doesn’t rule him out, his dominance against Joshua demonstrated his ability in the heavyweight ranks.
For Fury himself could be the defining moment of his career. A triumph for Fury would add an undisputed title to his already impressive resume. Meanwhile, Usyk’s victory would elevate him to new heights. Becoming the undisputed heavyweight champion would be a remarkable feat in boxing history.
Web: <a href="http://maps.google.com.lb/url?sa=t&url=https://usykvsfury.co.uk/">usykvsfury.co.uk</a>
The upcoming showdown represents something greater than a title bout. It’s a clash of personalities. Fury’s bold and unapologetic character is the opposite of Usyk’s humble and disciplined approach. The clash of personalities adds depth to the narrative. Beyond physical ability, this fight. Regardless of the outcome, the legacy of this fight will be remembered as a defining moment in boxing. The clash for the undisputed title is a spectacle unlike any other. It’s the result of relentless dedication. Whether Fury secures the win through his strength and tactics, or Usyk wins with his precision thanks to his skill and resilience, what is clear is, this bout will go down in history.
The Fury-Usyk battle is a spectacle of a lifetime. It’s a fight of grit and strategy. These two warriors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Ganhos e Estrategias para o Fortune Tiger
O jogo oferece lucros interessantes, mesmo em apostas rapidas. Cada rodada traz a chance de premios elevados, o que e um atrativo para muitos.
Para maximizar os lucros, muitos jogadores adotam estrategias variadas. A aposta progressiva e uma das tecnicas mais usadas no jogo. Nesse sistema, as apostas comecam baixas e vao subindo em cada rodada.
O controle sobre o timing das apostas pode ser determinante para os ganhos. Os minutos pagantes sao uma excelente forma de maximizar os lucros. Esses momentos de maiores ganhos sao imprevisiveis, mas com pratica e possivel identifica-los.
Plataforma de Apostas do Fortune Tiger: O que Saber
Website: https://mail.ask-directory.com/ganhos-no-fortune-tiger_403494.html
Conclusao Final
A plataforma oferece uma experiencia de jogo envolvente e acessivel para todos. O jogo, com seus recursos de seguranca e opcoes de pagamento, proporciona uma experiencia tranquila.
The undefeated Fury and Usyk are on a collision course of historic proportions. It’s far beyond a championship match; it’s about legacy. The Gypsy King has earned worldwide fame with his charisma and remarkable adaptability during fights. Beating Wilder and Klitschko have solidified his legendary status. Across the ring, the tactical southpaw poses a unique challenge to boxing’s biggest stars. Meanwhile, Usyk, a genius in the ring represents a formidable opponent for Tyson Fury himself, as a heavyweight contender. Usyk’s rise to prominence began in the cruiserweight division, where he became an unstoppable force. Get ready for an epic boxing match of the year as Oleksandr Usyk takes on Fury in an unforgettable showdown! Catch every punch streamed live on our website. Join the excitement — visit <a href="https://doba.te.ua/gateway?goto=https://fury-usyk.uk/">fury-usyk.uk</a> right away and watch the match in high quality!
For British fans, the fight is expected to begin close to prime time, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, and beyond, the anticipation is at a fever pitch. The venue for Fury vs Usyk is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, it’s guaranteed: it will be a spectacle. Although the focus is firmly on the main event, the Fury vs Usyk undercard is shaping up to be thrilling. Major boxing events often feature stacked undercards, providing non-stop action before the headliner.
In the past, supporting bouts in major events have introduced future champions. Contenders hoping to make their mark capitalize on the exposure to impress fans and analysts alike, with the world paying attention. Although the lineup for the Fury Usyk undercard are still unconfirmed, there’s plenty of talk. Will there be a heavyweight clash? Regardless of the names, fans can expect fireworks. The most compelling part of Fury vs Usyk so intriguing is the clash of styles. Tyson Fury’s size and agility make him an anomaly in boxing. At 6’9" with an 85-inch reach, Fury can control a fight.
The legendary battles with Wilder proved his toughness, overcoming brutal hits to finish strong. When he faced Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, relies on technique and stamina. As a southpaw, his positioning constantly challenges opponents. Usyk’s punches aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. With the date drawing closer, Predictions for this fight are becoming a hot topic.
Most bookmakers favor Fury as predicted by many experts, because of his reach and height, his experience in high-pressure bouts, and his unorthodox style. Although Usyk is the less favored fighter doesn’t mean he’s an underdog in spirit, his victories against AJ showed that he can compete at heavyweight.
For the Gypsy King could be the defining moment of his career. If he wins, it would solidify his claim as the greatest heavyweight of his generation. On the other hand, Usyk’s victory would elevate him to legendary status. Achieving undisputed glory in two divisions is a once-in-a-lifetime achievement.
Web: <a href="http://www.google.com.sv/url?q=https://fury-usyk.uk/">fury-usyk.uk</a>
Fury vs Usyk is not just about the belts. It’s a fight between two very different fighters. Fury’s larger-than-life persona stands in stark contrast to Usyk’s composed demeanor. These differences add complexity to the fight. This is more than just a physical contest. Whoever triumphs in this battle, the impact of this bout will leave a lasting mark on the sport. This historic showdown is more than just a fight. It’s the result of relentless dedication. Whether Fury secures the win through his strength and tactics, or Oleksandr Usyk triumphs thanks to his skill and resilience, what is clear is, this will be a fight remembered for years to come.
This fight between Fury and Usyk is more than just a sporting contest. It’s a contest of heart and willpower. These two warriors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
jogo do tigrinho que ganha dinheiro</a> possui uma estetica amigavel e atrativa.
Como Otimizar os Ganhos no Jogo de Tigrinho
O atrativo principal do jogo e a chance de premios elevados com rodadas breves. O jogo oferece recompensas rapidas para quem busca lucros imediatos.
Muitos jogadores aplicam estrategias especificas para aumentar as chances de lucro. Apostadores frequentemente recorrem a estrategia de apostas progressivas. O jogador vai aumentando as apostas progressivamente, comecando com valores baixos.
O controle sobre o timing das apostas pode ser determinante para os ganhos. Saber quando o jogo esta mais propenso a pagar altos premios pode ser decisivo. Jogadores mais experientes sabem reconhecer quando os minutos pagantes acontecem.
Apostas e Recursos da Plataforma Fortune Tiger
Website: http://www.rukids.co.kr/bbs/board.php?bo_table=review&wr_id=822274
Encerramento
O Fortune Tiger e uma plataforma empolgante para todos os tipos de jogadores. Com sua interface amigavel e sistema de pagamentos confiavel, o jogo e ideal para qualquer apostador.
The undefeated Fury and Usyk are set to meet in the ring of unparalleled significance. This fight is about more than just titles; it’s a battle for eternal recognition. Fury, an undefeated champion has become a global icon with his charisma and remarkable adaptability in the ring. Triumphing against boxing legends like Wilder and Klitschko have solidified his legendary status. On the other hand, Usyk, the technician poses a unique challenge for Fury. At the same time, Usyk, a southpaw master is a true test for Fury for the heavyweight ranks overall, but for the entire division. Usyk’s rise to prominence started with his domination of the cruiserweights, as an undisputed champion. Don’t miss out for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! Experience every moment in real time on our website. Join the excitement — visit <a href="https://www.visitchattanooga.com/plugins/crm/count/?key=4_800&type=client&val=eyJrZXkiOiI0XzgwMCIsInJlZGlyZWN0IjoiaHR0cHM6Ly9tb2RzLW1lbnUucnUvIn0">tysonvusyk.com</a> now and enjoy the fight with top-notch streaming!
Across the UK, the event will kick off at late evening, ensuring maximum viewership. For Usyk’s fans in Ukraine, and for fans watching from around the world, the excitement is palpable. The fight’s location has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, it’s guaranteed: the atmosphere will be electric. While the spotlight is firmly on the main event, the fights leading up to the main event promises plenty of action. High-profile matches are known for strong supporting fights, giving fans a full evening of entertainment.
In the past, supporting bouts in major events have showcased rising stars. Fighters looking to rise through the ranks often seize these moments to showcase their skills, with the world paying attention. While the names for the undercard are still unconfirmed, there’s plenty of talk. Could we see rising prospects? Whatever the selection, fans can expect fireworks. The most compelling part of Fury vs Usyk incredibly exciting is the clash of styles. Tyson Fury’s size and agility are unparalleled in the sport. Being so tall yet so nimble, he dictates the pace of bouts.
His trilogy with Deontay Wilder showed his durability, as he recovered from knockdowns to finish strong. Against Wladimir Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, relies on technique and stamina. As a southpaw, his positioning constantly challenges opponents. The Ukrainian’s shots may not have knockout power, they consistently find their mark. As fight night approaches, The betting lines for Fury vs Usyk are becoming a hot topic.
Tyson Fury is the slight favorite based on the betting odds, thanks to his imposing frame, his proven ability in tough situations, and his adaptability. Although Usyk is the less favored fighter doesn’t rule him out, his dominance against Joshua demonstrated his ability in the heavyweight ranks.
For Tyson Fury presents a shot at undisputed glory. A triumph for Fury would solidify his claim as the greatest heavyweight of his generation. Conversely, If Usyk wins would elevate him to new heights. Becoming the undisputed heavyweight champion is a once-in-a-lifetime achievement.
Web: <a href="http://maps.google.ae/url?sa=t&url=https://tysonvusyk.com/">tysonvusyk.com</a>
Fury vs Usyk is not just about the belts. It’s a clash of personalities. Fury’s larger-than-life persona is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. It’s about more than just skill. No matter who wins, the impact of this bout will be remembered as a defining moment in boxing. The clash for the undisputed title is more than just a match. It’s the pinnacle of both fighters’ hard work. Should Fury claim victory thanks to his power and game plan, or Oleksandr Usyk triumphs with his finesse and stamina, it’s certain that, this will be a defining moment in boxing.
This fight between Fury and Usyk is more than just a fight. It’s a fight of grit and strategy. Both fighters will give everything they have.
Visit for more information: #crosslink[3,L -
Nos recentes tempos, o mercado de games digitais tem experimentado um aumento significativo, conquistando um grande numero de jogadores que procuram entretenimento e, ocasionalmente, a chance de conquistar recompensas em moeda. Entre as alternativas de games que vem atraindo grande fama, ganham visibilidade o <a href="https://www.interesting-dir.com/details.php?id=386943">demo fortune mouse</a> e o Fortune Mouse, ambos disponibilizados em multiplas plataformas de jogo. Essas opcoes oferecem nao apenas diversao, mas tambem a possibilidade de obter recompensas para aqueles que tem habilidade, paciencia e uma porcao de sorte. Abaixo, exploraremos, iremos ver os aspectos principais aspectos desses titulos, compreendendo como funcionam, os horarios mais propicios para jogar, recomendacoes para testar as demos e planos para incrementar o sucesso.
O Jogo do Ratinho e popular por sua disponibilidade e por oferecer uma dinamica de jogo que integra sorte e destreza. Esse jogo ficou especialmente popular entre o publico de jogos que procuram um entretenimento agil e agradavel, mas que tambem pode trazer a oportunidade de ganhar algum dinheiro. Para quem nao conhece bem o jogo pela primeira oportunidade, e altamente recomendavel iniciar pela versao jogo do ratinho demo. A versao de demonstracao e uma opcao sem custo que possibilita testar o jogo, conhecer suas regras, entender as mecanicas e ate mesmo criar estrategias sem precisar gastar dinheiro. Isso e muito conveniente para aqueles que estao comecando, que podem aprender com o jogo antes de jogar a versao paga. A demonstracao tambem e excelente para usuarios avancados, pois permite a elaboracao e experimentacao de novas estrategias para aumentar as chances de vitoria.
Para aqueles que tem seguranca em sua capacidade de vencer, existe o jogo do ratinho com premios em dinheiro, onde o jogador tem a opcao de apostar e, dependendo de sua performance e da fortuna, ganhar premios em dinheiro. E essencial, no entanto, manter uma postura cuidadosa ao apostar, lembrando que o principal objetivo do jogo deve ser o entretenimento. Alem disso, uma orientacao util e fixar um valor maximo e mante-lo, evitando apostar mais do que se pode perder.
Uma das questoes que aparece para os jogadores e quais os melhores horarios para o jogo do ratinho. Muitos acreditam que, tal como ocorre em jogos de cassino ou em tipos de aposta esportiva, ha um momento ideal para jogar. Em modo geral, esse tipo de abordagem sugere jogar em periodos de pouco movimento, como na madrugada ou muito cedo pela manha. A razao por tras disso e que, em momentos com menos atividade, o funcionamento parece mais propenso a dar vitorias para estimular a participacao dos jogadores. Embora isso nao seja uma regra, e o desfecho das partidas muitas vezes seja aleatorio, muitos jogadores compartilham historias de sucesso associadas a esses horarios alternativos.
Web: https://www.interesting-dir.com/details.php?id=386943
O Jogo do Ratinho Online traz uma boa possibilidade para aqueles que curtem o jogo facil de acessar e facil de acessar de qualquer lugar com internet. Diferente dos jogos de cassino tradicionais, que exigem presenca fisica, o Jogo do Ratinho online esta disponivel 24 horas por dia, e varias plataformas disponibilizam promocoes exclusivas que podem incrementar os premios. Dentro dessa modalidade, tambem ha a versao do jogo do ratinho gratuita, que e ideal para aqueles que buscam apenas diversao ou para quem ainda conhece pouco do jogo. Essa alternativa sem custo permite um passatempo leve, onde o usuario nao tem riscos monetarios, podendo aprender e se divertir sem comprometer o orcamento.
Para aqueles que buscam uma experiencia de aposta mais intensa, o jogo do ratinho com investimentos oferece apostas em dinheiro real, com a possibilidade de aumentar o valor investido. Apesar de essa opcao ser animadora, e importante agir com cautela, pois as apostas trazem perigos. Muitos jogadores com pratica sugerem iniciar com valores menores e ir subindo aos poucos, a medida que se adquire mais habilidade e seguranca. O fundamental e lembrar que a sorte tem um papel significativo no Jogo do Ratinho, e as apostas precisam ser realizadas com prudencia.
The undefeated Fury and Usyk are on a collision course that will define an era. This fight is about more than just titles; it represents their quest for immortality. The Gypsy King has earned worldwide fame through his unique style coupled with unparalleled talent during fights. Beating Wilder and Klitschko have cemented his place among the all-time greats. Meanwhile, Oleksandr Usyk poses a unique challenge for Fury. At the same time, Usyk, a genius in the ring represents a formidable opponent for the heavyweight ranks overall, and for boxing fans worldwide. His journey to global fame started with his domination of the cruiserweights, as an undisputed champion. Prepare yourself for an epic boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! Catch every punch in real time on our website. Join the excitement — visit <a href="https://aumejtoqen.cloudimg.io/v7/tysonvsusyk.co.uk">tysonvsusyk.co.uk</a> today and watch the match in high quality!
For British fans, the fight is expected to begin late evening, ensuring maximum viewership. In Usyk’s native Ukraine, and for fans watching from around the world, the anticipation is at a fever pitch. The venue for Fury vs Usyk has yet to be confirmed, with talk of iconic boxing destinations. Wherever it happens, it’s guaranteed: the atmosphere will be electric. Although the focus is centered on the headline fight, the fights leading up to the main event is also generating excitement. Big-ticket boxing cards are known for strong supporting fights, providing non-stop action before the headliner.
In the past, undercards of this caliber have been a stage for breakout performances. Contenders hoping to make their mark capitalize on the exposure to showcase their skills, knowing millions are watching. Although the lineup for the Fury Usyk undercard has yet to be finalized, speculation runs high. Will there be a heavyweight clash? Whatever the selection, the action will not disappoint. What sets this bout apart incredibly exciting is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed are unparalleled in the sport. Being so tall yet so nimble, he commands the ring like no other.
The legendary battles with Wilder showed his durability, overcoming brutal hits to dominate in later rounds. When he faced Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Meanwhile, Usyk, relies on technique and stamina. As a southpaw, his positioning constantly challenges opponents. The Ukrainian’s shots aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. As fight night approaches, Tyson Fury vs Usyk odds are the subject of intense debate.
Tyson Fury is seen as the frontrunner as predicted by many experts, given his physical stature, his long career in major fights, and his tactical brilliance. Despite being seen as the underdog doesn’t rule him out, his wins over Anthony Joshua confirmed his toughness against big opponents.
For Fury himself could be the defining moment of his career. A triumph for Fury would add an undisputed title to his already impressive resume. On the other hand, Usyk’s victory would mark him as one of the sport’s greats. Achieving undisputed glory in two divisions is a feat few can claim.
Web: <a href="http://images.google.co.zm/url?q=https://tysonvsusyk.co.uk/">tysonvsusyk.co.uk</a>
This fight is more than just a championship fight. It’s a clash of personalities. Fury’s boisterous personality contrasts with Usyk’s calm, focused demeanor. Such contrasts make the fight more compelling. Beyond physical ability, this fight. Whoever triumphs in this battle, the impact of this bout will be remembered as a defining moment in boxing. The battle for heavyweight supremacy is more than just a fight. It represents the culmination of their careers. Whether Tyson Fury prevails with his experience and unpredictability, or Usyk secures a victory with his technique and endurance, it’s certain that, this will be a defining moment in boxing.
Tyson Fury vs Oleksandr Usyk is more than just a fight. It’s a fight of grit and strategy. These two warriors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Understanding Stake Mines Game
Stake Mines is an incredibly engaging game that revolves around a simple concept but can be quite complex. Players embark on by making a wager and then selecting tiles from a grid. The objective is to uncover all the mine-free tiles without landing on a mine. Each safe tile you uncover increases your winnings, but if you select a mine, the game ends, and you lose your investment. The straightforwardness of the game is part of its appeal, but the true challenge lies in the approach needed. Players must predict which tiles are safe to uncover, weighing exposure against potential reward.
The Stake Mines game is offered on various platforms, and its popularity continues to rise due to its quick nature and the thrill of uncertainty. The surprise of which tile may hide a mine is part of what makes the game so exciting and offers a risky experience for both beginners and seasoned players.
Stake Mines Strategy: The Key to Winning
A well-thought-out Stake Mines strategy can make the difference between coming out ahead and walking away with nothing. While luck plays a role, the key to winning lies in how you play the game. One popular approach is to start with a low bet and gradually escalate your wager as you uncover safe tiles. This allows players to minimize potential losses and prolong their gameplay, increasing their chances of hitting a profitable streak.
Another strategy involves selecting a specific method in which to uncover the tiles. By following a predetermined grid path, players may sometimes boost their chances of avoiding mines. However, even with the best-laid strategy, it’s vital to remember that the game is based on chance, and no strategy can guarantee a win every time.
For those curious about how these bots work, a Stake Mines Predictor Bot Free version is often available for download. While these free bots may not be as advanced or sophisticated as their paid counterparts, they still claim to offer valuable insights into which tiles are safe to click. Players may experiment with these free tools to determine if they provide a significant advantage before upgrading to a more premium version.
The Allure of Stake Mines Hack
For some players, using a Stake Mines Hack represents an appealing shortcut to guaranteed winnings. Hacks refer to cheated versions of the game or tools designed to change the game’s mechanics in favor of the player. These could involve altering the game’s algorithm, unlocking extra features, or even revealing the locations of mine-free tiles. However, using a hack comes with major risks. Firstly, many hacks are fraudulent, possibly introducing malware or harming your device. Secondly, hacking is a breach of most gaming platforms' terms of service, and players caught using hacks can be banned or suspended.
While this tool doesn’t guarantee success, it provides a way for players to assess the risk and reward associated with each decision. Some calculators even use historical game data to adjust a player’s strategy based on past performance.
Stake Mines APK and Mod Versions
For those who enjoy trying out different game versions, the Stake Mines APK lets participants set up the game on their Android devices. APK releases allow users to sidestep app store restrictions and deploy customized or modified versions of the game. These versions can offer enhanced features, additional functionalities, or even enhanced chances to succeed, but it’s important to acquire them from trusted sources to avoid malware or other issues.
Web: https://djchs.co.kr/bbs/board.php?bo_table=qna&wr_id=379011
Stake Mines Demo: Learning the Game Without Risk
If you're new to Stake Mines, the Stake Mines demo is a great way to learn the game’s mechanics without the financial risk. Many platforms offer demo versions of games, allowing players to refine their skills and strategies in a low-stakes environment. The Stake Mines demo mirrors the real game but without using real money, making it the perfect way to train before committing to real wagers.
Using the demo version helps players comprehend the features and gameplay of the game without the worry of losing money. It’s a risk-free way to explore different strategies and decide how to approach the full game.
Fury, the Gypsy King, and Usyk, the technician are ready to face each other in a fight of historic proportions. It’s not merely about the belts; it’s a battle for eternal recognition. The Gypsy King has become a global icon thanks to his personality and remarkable adaptability during fights. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. On the other hand, the tactical southpaw brings an unprecedented test to the heavyweight division. Meanwhile, Usyk, a genius in the ring represents a formidable opponent for the heavyweight ranks overall, but for the entire division. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, as an undisputed champion. Get ready for the most anticipated boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! Catch every punch in real time on our website. Don’t miss your chance — visit <a href="http://p3.isanook.com/hi/0/wb/i/url/tysonvusyk.co.uk">tysonvusyk.co.uk</a> now and watch the match from the comfort of your home!
For British fans, the fight is expected to begin close to prime time, offering perfect timing for viewers. Back in Usyk’s home country, as well as viewers across Europe and the Americas, the excitement is palpable. Where the bout will take place is still under speculation, with talk of iconic boxing destinations. No matter the location, one thing is certain: the excitement will be unmatched. While the spotlight is centered on the headline fight, the Fury vs Usyk undercard is shaping up to be thrilling. High-profile matches include preliminary bouts with top talent, offering an entire night of boxing excitement.
Historically, undercards of this caliber have been a stage for breakout performances. Boxers seeking the spotlight often seize these moments to showcase their skills, knowing millions are watching. Although the lineup for the Fury Usyk undercard are still unconfirmed, there’s plenty of talk. Could we see rising prospects? Regardless of the names, the action will not disappoint. The most compelling part of Fury vs Usyk truly fascinating is their contrasting skillsets. Tyson Fury’s size and agility set him apart from other heavyweights. At 6’9" with an 85-inch reach, Fury can control a fight.
His trilogy with Deontay Wilder highlighted his resilience, overcoming brutal hits to dominate in later rounds. When he faced Klitschko, his strategic genius shone through, proving he’s not just physical but cerebral. By contrast, Usyk, brings speed, precision, and finesse. Being a left-handed fighter, he uses angles and footwork. His strikes may not have knockout power, but they are delivered with pinpoint accuracy. With the date drawing closer, Tyson Fury vs Usyk odds have fans and analysts speculating.
Tyson Fury is the slight favorite as per the betting experts, because of his reach and height, his experience in high-pressure bouts, and his adaptability. Although Usyk is the less favored fighter doesn’t diminish his chances, as his victories over Joshua showed that he can compete at heavyweight.
For Tyson Fury, this fight represents an opportunity to cement his legacy. If he wins, it would put the finishing touches on a historic career. Conversely, For Usyk, a win would be a monumental achievement. Becoming the undisputed heavyweight champion is a rare accomplishment.
Web: <a href="http://google.com.mm/url?q=https://tysonvusyk.co.uk/">tysonvusyk.co.uk</a>
This fight is about more than the titles. It’s a battle of contrasting styles. Fury’s confident and brash nature is in stark contrast to Usyk’s quiet intensity. These differences add complexity to the fight. It’s a fight of wills and ideologies. Regardless of the outcome, the impact of this bout will be remembered as a defining moment in boxing. The battle for heavyweight supremacy is more than just a fight. It’s the result of relentless dedication. If Fury wins with his size and strategy, or Usyk comes out on top with his finesse and stamina, no matter the outcome, this will be a defining moment in boxing.
The Fury-Usyk battle is more than just a sporting contest. It’s a battle of minds and bodies. These men will pour everything into the bout.
Visit for more information: #crosslink[3,L -
plataforma que paga no cadastro fortune tiger</a> cria uma atmosfera acolhedora e facil de jogar.
Ganhos e Estrategias para o Fortune Tiger
O que chama a atencao no jogo e o alto potencial de lucro em curto periodo. A chance de premios em cada rodada faz do jogo uma escolha interessante para apostadores.
Muitos jogadores combinam estrategias para maximizar o potencial de lucro. A aposta progressiva e uma das tecnicas mais usadas no jogo. Essa tatica permite comecar apostando baixo e ir aumentando gradualmente.
O controle sobre o timing das apostas pode ser determinante para os ganhos. Ficar atento aos minutos em que o jogo paga mais e uma otima estrategia. Esses momentos de maiores ganhos sao imprevisiveis, mas com pratica e possivel identifica-los.
Caracteristicas da plataforma Fortune Tiger
Website: http://gsianb10.nayaa.co.kr/bbs/board.php?bo_table=sub03_01&wr_id=66285
Fechamento
Fortune Tiger e um jogo que combina diversao, estrategia e oportunidades de ganhos. A confianca dos jogadores e conquistada pela transparencia e facilidade de uso.
Tyson Fury and Oleksandr Usyk are ready to face each other in a fight of unparalleled significance. It’s not merely about the belts; it represents their quest for immortality. Tyson Fury has become a global icon thanks to his personality coupled with unparalleled talent in the ring. His victories over Deontay Wilder and Wladimir Klitschko have cemented his place among the all-time greats. In contrast, Usyk, the technician brings an unprecedented test to boxing’s biggest stars. Meanwhile, Oleksandr Usyk stands as a unique threat for Tyson Fury himself, and for boxing fans worldwide. His journey to global fame started with his domination of the cruiserweights, where he became an unstoppable force. Don’t miss out for an epic boxing match of the year as Usyk takes on Tyson Fury in an unforgettable showdown! See every move live on our website. Be part of the action — visit <a href="https://comedoz.printdirect.ru/utils/redirect?url=https://tysonfuryvoleksandrusyk.org.uk/">tysonfuryvoleksandrusyk.org.uk</a> right away and watch the match from the comfort of your home!
Across the UK, the fight is expected to begin close to prime time, making it ideal for a prime-time audience. Back in Usyk’s home country, and beyond, the anticipation is at a fever pitch. The fight’s location is still under speculation, with talk of iconic boxing destinations. Regardless of the venue, it’s guaranteed: the excitement will be unmatched. Even though attention is centered on the headline fight, the preliminary bouts promises plenty of action. Major boxing events include preliminary bouts with top talent, offering an entire night of boxing excitement.
Traditionally, supporting bouts in major events have introduced future champions. Fighters looking to rise through the ranks use such opportunities to impress fans and analysts alike, knowing millions are watching. Although the lineup for the Fury Usyk undercard haven’t been officially announced, speculation runs high. Could we see rising prospects? Whatever the selection, fans can expect fireworks. What sets this bout apart truly fascinating is the clash of styles. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. At 6’9" with an 85-inch reach, he commands the ring like no other.
The legendary battles with Wilder proved his toughness, overcoming brutal hits to finish strong. In his fight with Klitschko, his strategic genius shone through, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, offers a different kind of threat. With his unorthodox stance, his movements create openings. His strikes aren’t the heaviest in the division, they consistently find their mark. With the date drawing closer, Tyson Fury vs Usyk odds have fans and analysts speculating.
Tyson Fury is the slight favorite based on the betting odds, because of his reach and height, his proven ability in tough situations, and his adaptability. Although Usyk is the less favored fighter doesn’t rule him out, as his victories over Joshua demonstrated his ability in the heavyweight ranks.
For Tyson Fury represents an opportunity to cement his legacy. A victory would solidify his claim as the greatest heavyweight of his generation. Meanwhile, Usyk’s victory would be a monumental achievement. Becoming the undisputed heavyweight champion would be a remarkable feat in boxing history.
Web: <a href="http://www.google.co.il/url?q=https%3A%2F%2Ftysonfuryvoleksandrusyk.org.uk">tysonfuryvoleksandrusyk.org.uk</a>
This fight represents something greater than a title bout. It’s a fight between two very different fighters. Fury’s larger-than-life persona is in stark contrast to Usyk’s quiet intensity. These varying personalities make the bout even more interesting. This is more than just a physical contest. Whoever comes out victorious, the significance of this match will be felt for years to come. The clash for the undisputed title is more than just a match. It’s the result of relentless dedication. If Fury wins with his experience and unpredictability, or Oleksandr Usyk triumphs with his finesse and stamina, it’s certain that, this will be a defining moment in boxing.
This fight between Fury and Usyk is more than just a boxing event. It’s a fight of grit and strategy. The two competitors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are ready to face each other in a fight of historic proportions. It’s not merely about the belts; it’s a battle for eternal recognition. The Gypsy King has risen to the pinnacle of the sport through his unique style and his unmatched skills inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. Across the ring, the tactical southpaw poses a unique challenge for Fury. On the flip side, the Ukrainian technician represents a formidable opponent for Tyson Fury himself, and for boxing fans worldwide. The ascent of Oleksandr Usyk began in the cruiserweight division, where he became an unstoppable force. Prepare yourself for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! See every move in real time on our website. Be part of the action — visit <a href="http://www.iwantbabes.com/out.php?site=https://furyvsusykdate.co.uk/">furyvsusykdate.co.uk</a> right away and enjoy the fight in high quality!
For British fans, the ring walks are planned for late evening, offering perfect timing for viewers. For Usyk’s fans in Ukraine, as well as viewers across Europe and the Americas, the excitement is palpable. The venue for Fury vs Usyk has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, one thing is certain: it will be a spectacle. Even though attention is firmly on the main event, the Fury vs Usyk undercard is also generating excitement. Big-ticket boxing cards include preliminary bouts with top talent, giving fans a full evening of entertainment.
Traditionally, undercards of this caliber have been a stage for breakout performances. Contenders hoping to make their mark use such opportunities to demonstrate their talent, knowing millions are watching. While the names for the undercard haven’t been officially announced, there’s plenty of talk. Might there be a cruiserweight spectacle? Regardless of the names, it’s sure to add to the excitement. What makes this fight truly fascinating is the clash of styles. Fury’s towering frame and movement set him apart from other heavyweights. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
His trilogy with Deontay Wilder proved his toughness, bouncing back from adversity to finish strong. Against Wladimir Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Meanwhile, Usyk, brings speed, precision, and finesse. Being a left-handed fighter, his movements create openings. The Ukrainian’s shots aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. As anticipation builds, Predictions for this fight are the subject of intense debate.
Tyson Fury is the slight favorite as per the betting experts, because of his reach and height, his long career in major fights, and his unorthodox style. However, Usyk's underdog status doesn’t diminish his chances, his wins over Anthony Joshua confirmed his toughness against big opponents.
For the Gypsy King is a chance to further solidify his greatness. A victory would put the finishing touches on a historic career. Conversely, For Usyk, a win would elevate him to legendary status. Securing two undisputed titles is a once-in-a-lifetime achievement.
Web: <a href="http://www.google.tk/url?q=https://furyvsusykdate.co.uk/">furyvsusykdate.co.uk</a>
Fury vs Usyk is more than just a championship fight. It’s a meeting of two unique worldviews. Fury’s boisterous personality stands in stark contrast to Usyk’s composed demeanor. The clash of personalities adds depth to the narrative. It’s about more than just skill. No matter who wins, the legacy of this fight will be remembered as a defining moment in boxing. Fury vs Usyk is a spectacle unlike any other. It’s a culmination of years of hard work. Whether Fury secures the win with his size and strategy, or Usyk comes out on top through his superior boxing ability, no matter the outcome, this will be a legendary contest.
This fight between Fury and Usyk is more than just a fight. It’s a contest of heart and willpower. Both fighters will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Understanding Stake Mines Game
Stake Mines is an incredibly enthralling game that revolves around a basic concept but can be quite challenging. Players initiate by making a bet and then selecting tiles from a grid. The objective is to uncover all the mine-free tiles without landing on a mine. Each safe tile you uncover increases your winnings, but if you select a mine, the game ends, and you lose your wager. The simplicity of the game is part of its appeal, but the true challenge lies in the decision-making needed. Players must predict which tiles are safe to uncover, weighing threat against potential reward.
The Stake Mines game is offered on various platforms, and its popularity continues to rise due to its fast-paced nature and the thrill of uncertainty. The unpredictability of which tile may hide a mine is part of what makes the game so exciting and offers a intense experience for both inexperienced and seasoned players.
Stake Mines Strategy: The Key to Winning
A well-thought-out Stake Mines strategy can make the difference between winning and walking away with nothing. While luck plays a role, the key to victory lies in how you deal with the game. One popular approach is to start with a small bet and gradually expand your wager as you uncover safe tiles. This allows players to limit potential losses and prolong their gameplay, increasing their chances of hitting a profitable streak.
Another strategy involves selecting a specific sequence in which to uncover the tiles. By following a predetermined grid path, players may sometimes boost their chances of avoiding mines. However, even with the best-laid strategy, it’s vital to remember that the game is based on randomness, and no strategy can guarantee a win every time.
For those curious about how these bots work, a Stake Mines Predictor Bot Free version is often available for download. While these free bots may not be as advanced or sophisticated as their paid counterparts, they still claim to offer valuable insights into which tiles are safe to click. Players may experiment with these free tools to determine if they provide a significant advantage before upgrading to a more sophisticated version.
The Allure of Stake Mines Hack
For some players, using a Stake Mines Hack represents an appealing shortcut to guaranteed winnings. Hacks refer to cheated versions of the game or tools designed to change the game’s mechanics in favor of the player. These could involve manipulating the game’s algorithm, unlocking extra features, or even revealing the locations of mine-free tiles. However, using a hack comes with major risks. Firstly, many hacks are unstable, possibly introducing malware or harming your device. Secondly, hacking is a breach of most gaming platforms' terms of service, and players caught using hacks can be banned or suspended.
While this tool doesn’t guarantee success, it provides a way for players to assess the risk and reward associated with each decision. Some calculators even use historical game data to adjust a player’s strategy based on past performance.
Stake Mines APK and Mod Versions
For those who enjoy trying out alternative game versions, the Stake Mines APK lets users set up the game on their Android devices. APK packages allow customers to avoid app store rules and install customized or modded versions of the game. These versions can offer enhanced features, additional functionalities, or even greater chances to succeed, but it’s important to obtain them from trusted sources to avoid malware or other issues.
Web: https://reddit-directory.com/stake-mines-predictor-bot-free_632558.html
Stake Mines Demo: Learning the Game Without Risk
If you're new to Stake Mines, the Stake Mines demo is a great way to get familiar with the game’s mechanics without the financial risk. Many platforms offer demo versions of games, allowing players to refine their skills and strategies in a low-stakes environment. The Stake Mines demo mirrors the real game but without using real money, making it the perfect way to practice before committing to real wagers.
Using the demo version helps players grasp the features and gameplay of the game without the worry of losing money. It’s a risk-free way to explore different strategies and decide how to approach the full game.
Tyson Fury and Oleksandr Usyk are preparing for an epic showdown of unparalleled significance. It’s far beyond a championship match; it’s about legacy. Tyson Fury has earned worldwide fame through his unique style and remarkable adaptability during fights. Beating Wilder and Klitschko have cemented his place among the all-time greats. In contrast, Usyk, the Ukrainian master brings an unprecedented test for Fury. Meanwhile, the Ukrainian technician stands as a unique threat for the heavyweight ranks overall, but for the entire division. His journey to global fame began in the cruiserweight division, where he became an unstoppable force. Don’t miss out for a thrilling boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! Experience every moment in real time on our website. Join the excitement — visit <a href="https://anzhero.4geo.ru/redirect/?service=news&town_id=156895024&url=https://tysonvsusyk.org.uk/">tysonvsusyk.org.uk</a> now and enjoy the fight from the comfort of your home!
For British fans, the ring walks are planned for late evening, making it ideal for a prime-time audience. Back in Usyk’s home country, and for fans watching from around the world, this will be a must-see event. The venue for Fury vs Usyk has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, one thing is certain: the excitement will be unmatched. Even though attention is centered on the headline fight, the Fury vs Usyk undercard is also generating excitement. Big-ticket boxing cards are known for strong supporting fights, giving fans a full evening of entertainment.
Historically, undercards of this caliber have been a stage for breakout performances. Fighters looking to rise through the ranks capitalize on the exposure to impress fans and analysts alike, with the world paying attention. Although the lineup for the Fury Usyk undercard are still unconfirmed, there’s plenty of talk. Will there be a heavyweight clash? Whatever the selection, fans can expect fireworks. The most compelling part of Fury vs Usyk so intriguing is their contrasting skillsets. Tyson Fury’s size and agility make him an anomaly in boxing. Being so tall yet so nimble, he dictates the pace of bouts.
The three fights against Wilder highlighted his resilience, bouncing back from adversity to finish strong. When he faced Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. By contrast, Usyk, relies on technique and stamina. As a southpaw, his positioning constantly challenges opponents. Usyk’s punches aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. With the date drawing closer, Tyson Fury vs Usyk odds are becoming a hot topic.
Fury is the favored fighter as predicted by many experts, due to his size advantage, his long career in major fights, and his tactical brilliance. However, Usyk's underdog status doesn’t diminish his chances, his wins over Anthony Joshua proved that he can handle the physicality of the heavyweight division.
For Tyson Fury, this fight is a chance to further solidify his greatness. Should he come out on top, Fury’s win would further solidify his status as the best heavyweight of this era. Meanwhile, If Usyk wins would elevate him to new heights. Securing two undisputed titles is a feat few can claim.
Web: <a href="http://maps.google.ro/url?sa=t&url=https%3A%2F%2Ftysonvsusyk.org.uk">tysonvsusyk.org.uk</a>
This fight is more than just a championship fight. It’s a fight between two very different fighters. Fury’s bold and unapologetic character stands in stark contrast to Usyk’s composed demeanor. The clash of personalities adds depth to the narrative. This is more than just a physical contest. Regardless of the outcome, the significance of this match will reverberate throughout boxing history. Fury vs Usyk is more than just a match. It’s a culmination of years of hard work. Should Fury claim victory through his strength and tactics, or Usyk secures a victory with his finesse and stamina, no matter the outcome, this will be a defining moment in boxing.
Fury vs Usyk is more than just a boxing event. It’s a fight of grit and strategy. These men will give everything they have.
Visit for more information: #crosslink[3,L -
One of the primary attraction of <a href="https://clashofcryptos.trade/wiki/User:RodHung5889413">sweet bonanza</a> is its unique approach to online slot play style. Unlike classic slot games that utilize payline systems, Sweet Bonanza uses a "cluster win" system. The title has six reels and five rows, giving players multiple opportunities to win with every spin. Combinations come by matching groups of a minimum of eight similar symbols anywhere on the grid, setting it apart from regular slots that function through fixed paylines.
Cluster pays system is not only attractive visually but also provides players higher winning potential each time they spin.
The candy-themed graphics and playful color choices intensify the visual allure, creating a sugary and dynamic vibe that invites players. Elements in this slot consist of a variety of candies in eye-catching tones, as well as fruits such as bananas, grapes, and watermelons. The visuals are enhanced by cheerful sounds that adds to the playful atmosphere. The Sweet Bonanza slot also contains a bonus icon in the form of a lollipop, which plays a pivotal role in activating the free rounds. When players collect four or more scatters, the game will initiate the free round, which delivers a high possibility to earn substantial prizes.
Beginners to online slots or prefer to test it first before spending actual money, Sweet Bonanza trial play offers a suitable way. Numerous gaming sites provide a no-cost version of Sweet Bonanza, allowing players to enjoy the gameplay, experiment with tactics, and get comfortable with the slot’s elements without any financial risk. Trying Sweet Bonanza in demo mode is highly recommended for beginners, as it lets them learn the game mechanics, test various betting amounts, and learn about the Tumble feature.
Web: https://clashofcryptos.trade/wiki/User:RodHung5889413
This Tumble element, sometimes called the cascading reels mechanic, plays a major role in the game. Once players hit a winning cluster, the matching symbols vanish, and new symbols fall into place, potentially creating additional winning combinations. This mechanic boosts the anticipation but also provides more win potential in one go.
A special element of this Pragmatic Play slot is its bonus spin mode, which is often the favorite feature for players. The extra spins feature in Sweet Bonanza offers high rewards due to the availability of multipliers. Once it starts, the Free Spins feature grants 10 extra spins, and players may earn more spins by getting three extra scatters.
Tyson Fury and Oleksandr Usyk are on a collision course of historic proportions. This fight is about more than just titles; it represents their quest for immortality. Fury, an undefeated champion has become a global icon thanks to his personality and remarkable adaptability in the ring. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. Across the ring, Oleksandr Usyk brings an unprecedented test for Fury. At the same time, Usyk, a genius in the ring is a true test for Fury for the heavyweight ranks overall, and for boxing fans worldwide. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Prepare yourself for an epic boxing match of the year as Usyk takes on Fury in an unforgettable showdown! Catch every punch in real time on our website. Join the excitement — visit <a href="https://golden-monkey.ru/r/https://furyvsusykdate.co.uk/">furyvsusykdate.co.uk</a> today and enjoy the fight from the comfort of your home!
Across the UK, the fight is expected to begin around 10 PM GMT, ensuring maximum viewership. In Usyk’s native Ukraine, and for fans watching from around the world, this will be a must-see event. Where the bout will take place is still under speculation, with talk of iconic boxing destinations. No matter the location, one thing is certain: the excitement will be unmatched. While the spotlight is firmly on the main event, the fights leading up to the main event promises plenty of action. High-profile matches include preliminary bouts with top talent, giving fans a full evening of entertainment.
Traditionally, supporting bouts in major events have been a stage for breakout performances. Boxers seeking the spotlight use such opportunities to impress fans and analysts alike, knowing millions are watching. Though the supporting fights for Fury vs Usyk are still unconfirmed, there’s plenty of talk. Could we see rising prospects? Whatever the selection, fans can expect fireworks. What makes this fight truly fascinating is the dynamic between these fighters. Fury’s towering frame and movement set him apart from other heavyweights. At 6’9" with an 85-inch reach, Fury can control a fight.
His trilogy with Deontay Wilder proved his toughness, bouncing back from adversity to secure victories. When he faced Klitschko, his strategic genius shone through, proving he’s not just physical but cerebral. By contrast, Usyk, offers a different kind of threat. As a southpaw, he uses angles and footwork. His strikes aren’t the heaviest in the division, their timing wears down foes. As fight night approaches, Predictions for this fight are becoming a hot topic.
Tyson Fury is seen as the frontrunner as per the betting experts, thanks to his imposing frame, his proven ability in tough situations, and his unpredictable nature. Despite being seen as the underdog doesn’t diminish his chances, his dominance against Joshua confirmed his toughness against big opponents.
For Tyson Fury, this fight presents a shot at undisputed glory. Should he come out on top, Fury’s win would solidify his claim as the greatest heavyweight of his generation. Conversely, For Usyk, a win would elevate him to new heights. Becoming an undisputed champion in two different weight classes is a once-in-a-lifetime achievement.
Web: <a href="http://www.google.com.pr/url?q=https://furyvsusykdate.co.uk/">furyvsusykdate.co.uk</a>
Fury vs Usyk is about more than the titles. It’s a meeting of two unique worldviews. Fury’s bold and unapologetic character stands in stark contrast to Usyk’s composed demeanor. The clash of personalities adds depth to the narrative. This is more than just a physical contest. No matter who wins, the impact of this bout will reverberate throughout boxing history. The clash for the undisputed title is more than just a match. It’s the pinnacle of both fighters’ hard work. If Fury wins with his experience and unpredictability, or Oleksandr Usyk triumphs through his superior boxing ability, no matter the outcome, this will be a fight remembered for years to come.
The Fury-Usyk battle is more than just a boxing event. It’s a contest of heart and willpower. These two warriors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Este slot se diferencia de otras slots por su diseno y tematica unicos. Al iniciar el juego, los apostadores entran en un escenario de golosinas y colores vibrantes que parecen de un mundo fantastico. El escenario esta repleto de confites, lo cual crea una experiencia visual amigable y alegre, adaptada a todos los jugadores. Esta tragamonedas ha sido reconocido por su adiccion positiva y entretenimiento, ya que mezcla la emocion de ganar premios con un estilo visual atractivo para todos.
Una de las caracteristicas mas valoradas de Sweet Bonanza es su modo de giros gratis, que se activa cuando aparecen cuatro o mas simbolos de caramelos rosados. Los giros gratis no solo permiten jugar sin gastar dinero adicional, sino que tambien multiplican las posibilidades de ganar grandes premios, especialmente cuando aparecen multiplicadores en los giros. Este aspecto dentro del juego es uno de los mas atractivos a los jugadores, y muchos destacan en sus comentarios que la caracteristica de giros gratuitos es la parte mas emocionante.
Ademas, este juego ha logrado mantener su popularidad gracias a su atractivo para jugadores novatos y experimentados. No importa si eres si tienes mucha experiencia en el juego, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la disponibilidad de el juego en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere jugar durante tus descansos, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: https://cheaplocallocksmiths.co.uk/forum/profile/GNVGene99
Otro punto que interesa a los jugadores es si si el juego realmente permite ganar dinero con este juego. Al igual que en cualquier tragamonedas, Sweet Bonanza es una maquina de azar, lo cual significa que el resultado de cada vuelta es basado en azar y no puede ser predicho. Sin embargo, los funcion de multiplicadores y giros gratis ofrecen una oportunidad significativa para obtener premios importantes. La funcion de se pueden multiplicar las ganancias hasta 100 veces gracias a los multiplicadores, lo que puede generar premios grandes si los jugadores tienen suerte. Sin embargo, es importante recordar que siempre es importante jugar con responsabilidad y que no siempre se gana en cada ronda.
Fury, the Gypsy King, and Usyk, the technician are preparing for an epic showdown that will define an era. It’s far beyond a championship match; it’s about legacy. The Gypsy King has earned worldwide fame with his charisma and his unmatched skills during fights. Beating Wilder and Klitschko have solidified his legendary status. On the other hand, Oleksandr Usyk brings an unprecedented test to boxing’s biggest stars. On the flip side, Usyk, a genius in the ring represents a formidable opponent for the heavyweight ranks overall, and for boxing fans worldwide. The ascent of Oleksandr Usyk began in the cruiserweight division, where he became an unstoppable force. Prepare yourself for the most anticipated boxing match of the year as Usyk takes on Fury in a must-watch showdown! Experience every moment in real time on our website. Be part of the action — visit <a href="https://bestof.printdirect.ru/utils/redirect?url=https://tysonvsusyk.org.uk/">tysonvsusyk.org.uk</a> right away and stream the event with top-notch streaming!
In the United Kingdom, the fight is expected to begin late evening, ensuring maximum viewership. For Usyk’s fans in Ukraine, and beyond, the anticipation is at a fever pitch. The venue for Fury vs Usyk is still under speculation, with talk of iconic boxing destinations. No matter the location, it’s guaranteed: the atmosphere will be electric. Even though attention is firmly on the main event, the fights leading up to the main event promises plenty of action. High-profile matches often feature stacked undercards, giving fans a full evening of entertainment.
In the past, preliminary fights on major cards have been a stage for breakout performances. Fighters looking to rise through the ranks use such opportunities to showcase their skills, as all eyes are on them. While the names for the undercard has yet to be finalized, there’s plenty of talk. Might there be a cruiserweight spectacle? Whatever the selection, the action will not disappoint. What makes this fight so intriguing is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. Being so tall yet so nimble, he dictates the pace of bouts.
His trilogy with Deontay Wilder showed his durability, as he recovered from knockdowns to dominate in later rounds. Against Wladimir Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. By contrast, Usyk, offers a different kind of threat. With his unorthodox stance, his movements create openings. His strikes lack devastating strength, but they are delivered with pinpoint accuracy. With the date drawing closer, The betting lines for Fury vs Usyk are becoming a hot topic.
Tyson Fury is seen as the frontrunner as per the betting experts, due to his size advantage, his long career in major fights, and his adaptability. Despite being seen as the underdog doesn’t diminish his chances, as his victories over Joshua showed that he can compete at heavyweight.
For Fury himself is a chance to further solidify his greatness. If he wins, it would add an undisputed title to his already impressive resume. On the other hand, Usyk’s victory would elevate him to new heights. Achieving undisputed glory in two divisions is a rare accomplishment.
Web: <a href="http://clients1.google.com.ar/url?q=https%3A%2F%2Ftysonvsusyk.org.uk">tysonvsusyk.org.uk</a>
This fight is not just about the belts. It’s a meeting of two unique worldviews. Fury’s confident and brash nature is in stark contrast to Usyk’s quiet intensity. These differences add complexity to the fight. Beyond physical ability, this fight. Whoever triumphs in this battle, the significance of this match will be felt for years to come. Fury vs Usyk is a defining moment. It’s a culmination of years of hard work. Should Fury claim victory thanks to his power and game plan, or Usyk wins with his precision with his finesse and stamina, one thing is certain, this bout will go down in history.
Fury vs Usyk is a spectacle of a lifetime. It’s a fight of grit and strategy. These two warriors will give everything they have.
Visit for more information: #crosslink[3,L -
Oyleyse, Sweet Bonanza nas?l oynan?r? Oyunun tum ayr?nt?lar?n? ele alacag?z ve giris yapma yontemlerinden taktik ipuclar?na kadar butun onemli bilgileri verecegiz.
Sweet Bonanza oyununu yak?ndan tan?yal?m
Sweet Bonanza oyunu, populer slot oyunlar? aras?nda dikkat cekici ozelliklere sahip bir bir slot oyunudur. Pragmatic Play firmas?n?n gelistirdigi bu oyun, tatl? temal? ikonlardan olusan bir yap?ya sahiptir. Bu tatl? semboller, renkli bir dunya yaratarak oyuncular? kendine ceker.
Bu oyunun kendi mekanik sistemine sahip olmas? oyunu ozel k?l?yor. Her kazancla birlikte yeni sembollerin eklenmesiyle, oyuncular surekli bir dongu icinde kazanc saglayabilir. Bu benzersiz ozellik sayesinde, Sweet Bonanza, oyunculara eglenceli bir deneyim yasat?r.
Sweet Bonanza kurallar? ve oynan?s?
Sweet Bonanza’n?n oynan?s? diger slot oyunlar?na gore daha basit bir oyun sistemi sunar. 6 sutun ve 5 sat?rdan olusan bir ?zgarada oynan?r. Oyuncular?n amac?, belirli say?daki sembollerin bir araya gelmesiyle oyunda kazanc elde etmektir.
Bu mekanikte ozel bir kombinasyon kurma zorunlulugu yoktur. Kazanc icin ayn? sembollerin toplanmas? yeterlidir. Kazanan semboller patlar ve yenileri eklenir. Bu ozellik sayesinde, ayn? turda ard?s?k kazanclar kazan?labilir.
Web: https://www.scdmtj.com/home.php?mod=space&uid=2808409&do=profile
Sweet Bonanza Demo: Oyunu Denemek Icin Ideal F?rsat
Bu oyunun en cok tercih edilen ozelliklerinden biri, oyuncular?n demo versiyonu deneme imkan?n?n olmas?d?r. Demo mod, oyuna yeni baslayanlar icin harika bir f?rsat sunar. Risksiz bir deneyim sunan demo mod, oyunun mant?g?n? anlamay? saglar.
Demo modunda oynarken kazanc saglayan sembolleri ogrenebilirsiniz. Risksiz bir sekilde oyunun tum ozelliklerini gormek mumkundur. Oyuncular bu mod ile cesitli taktikler gelistirebilir.
Fury, the Gypsy King, and Usyk, the technician are preparing for an epic showdown of historic proportions. It’s far beyond a championship match; it’s about legacy. Tyson Fury has earned worldwide fame through his unique style and remarkable adaptability inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. On the other hand, Oleksandr Usyk brings an unprecedented test to boxing’s biggest stars. On the flip side, the Ukrainian technician is a true test for Fury for the heavyweight ranks overall, and for boxing fans worldwide. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Prepare yourself for an epic boxing match of the year as Usyk takes on Tyson Fury in a must-watch showdown! See every move streamed live on our website. Don’t miss your chance — visit <a href="http://mebeldoma72.ru/udata/emarket/basket/put/element/5696/?redirect-uri=https%3A%2F%2Ftysonvsusyk.com">tysonvsusyk.com</a> right away and stream the event from the comfort of your home!
Across the UK, the fight is expected to begin around 10 PM GMT, offering perfect timing for viewers. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, the excitement is palpable. Where the bout will take place has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, fans can be sure: the excitement will be unmatched. Even though attention is firmly on the main event, the fights leading up to the main event is shaping up to be thrilling. Big-ticket boxing cards include preliminary bouts with top talent, providing non-stop action before the headliner.
In the past, supporting bouts in major events have introduced future champions. Fighters looking to rise through the ranks often seize these moments to impress fans and analysts alike, with the world paying attention. While the names for the undercard haven’t been officially announced, fans are eagerly guessing. Could we see rising prospects? Regardless of the names, the action will not disappoint. The most compelling part of Fury vs Usyk incredibly exciting is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. Being so tall yet so nimble, he commands the ring like no other.
The three fights against Wilder highlighted his resilience, overcoming brutal hits to finish strong. Against Wladimir Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, offers a different kind of threat. Being a left-handed fighter, his movements create openings. The Ukrainian’s shots lack devastating strength, their timing wears down foes. As anticipation builds, The betting lines for Fury vs Usyk are the subject of intense debate.
Tyson Fury is the slight favorite according to the odds, because of his reach and height, his long career in major fights, and his adaptability. Despite the odds, Usyk remains a strong contender doesn’t mean he’s an underdog in spirit, as his victories over Joshua demonstrated his ability in the heavyweight ranks.
For the Gypsy King is a chance to further solidify his greatness. A triumph for Fury would further solidify his status as the best heavyweight of this era. Conversely, If Usyk wins would be a monumental achievement. Becoming an undisputed champion in two different weight classes is a feat few can claim.
Web: <a href="http://maps.google.cg/url?q=https://tysonvsusyk.com/">tysonvsusyk.com</a>
The upcoming showdown is about more than the titles. It’s a battle of contrasting styles. Fury’s boisterous personality is in stark contrast to Usyk’s quiet intensity. Such contrasts make the fight more compelling. It’s a fight of wills and ideologies. Regardless of the outcome, the significance of this match will leave a lasting mark on the sport. The clash for the undisputed title is a spectacle unlike any other. It’s the pinnacle of both fighters’ hard work. Should Fury claim victory through his strength and tactics, or Usyk comes out on top with his finesse and stamina, it’s certain that, this will be a legendary contest.
The Fury-Usyk battle is a spectacle of a lifetime. It’s a contest of heart and willpower. These men will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Este slot se diferencia de otras maquinas tragamonedas por su diseno llamativo y unico. Al comenzar a jugar, los usuarios son llevados a un escenario de golosinas y colores brillantes que hacen pensar en un cuento de fantasia. El fondo de la pantalla esta lleno de golosinas, lo cual crea una experiencia visual amigable y divertida, ideal tanto para jugadores nuevos como para experimentados. Este slot ha sido considerado como entretenido y cautivador, ya que ofrece premios emocionantes y una estetica cautivadora.
Una de las caracteristicas mas valoradas de este juego es su caracteristica de giros gratis, que se activa si se obtienen cuatro o mas simbolos de caramelos en cualquier lugar. Los giros gratis no solo permiten jugar de manera gratuita, sino que tambien multiplican las posibilidades de ganar grandes premios, especialmente cuando los multiplicadores hacen su aparicion. Este detalle del juego es uno de los mas atractivos a los jugadores, y muchos senalan en sus resenas que la caracteristica de giros gratuitos es lo mas emocionante.
Ademas, la tragamonedas Sweet Bonanza ha logrado mantener su popularidad gracias a su aplicabilidad universal. No importa si eres nuevo en el mundo de las tragamonedas, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la disponibilidad de este slot en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere jugadas rapidas mientras viajas, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: http://ppgnz.co.nz/?option=com_k2&view=itemlist&task=user&id=52895
Otro punto que interesa a los jugadores es si se puede ganar dinero real con Sweet Bonanza. Al igual que en cualquier tragamonedas, este juego es una maquina de azar, lo cual significa que el resultado de cada vuelta es impredecible y no puede ser anticipado. Sin embargo, los multiplicadores y la funcion de giros gratuitos ofrecen una oportunidad significativa para obtener grandes recompensas. La funcion de se pueden multiplicar las ganancias hasta 100 veces gracias a los multiplicadores, lo que puede dar lugar a grandes recompensas si se tiene suerte en el giro. Sin embargo, es importante recordar que se debe jugar con responsabilidad y que no siempre se gana en cada ronda.
These two heavyweight champions are ready to face each other in a fight that will define an era. It’s far beyond a championship match; it’s a battle for eternal recognition. The towering Fury has become a global icon thanks to his personality and his unmatched skills inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. Across the ring, the tactical southpaw brings an unprecedented test for Fury. Meanwhile, the Ukrainian technician stands as a unique threat for the heavyweight ranks overall, and for boxing fans worldwide. The ascent of Oleksandr Usyk began in the cruiserweight division, as an undisputed champion. Get ready for a thrilling boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! See every move streamed live on our website. Be part of the action — visit <a href="http://perevozim.nnov.org/common/redir.php?https://furyusyk.org.uk/">furyusyk.org.uk</a> now and stream the event with top-notch streaming!
For British fans, the ring walks are planned for late evening, ensuring maximum viewership. In Usyk’s native Ukraine, and for fans watching from around the world, the anticipation is at a fever pitch. The venue for Fury vs Usyk remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, fans can be sure: it will be a spectacle. While the spotlight is firmly on the main event, the preliminary bouts is also generating excitement. Big-ticket boxing cards include preliminary bouts with top talent, giving fans a full evening of entertainment.
In the past, supporting bouts in major events have introduced future champions. Fighters looking to rise through the ranks capitalize on the exposure to showcase their skills, with the world paying attention. While the names for the undercard are still unconfirmed, there’s plenty of talk. Might there be a cruiserweight spectacle? Regardless of the names, fans can expect fireworks. What sets this bout apart truly fascinating is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. Being so tall yet so nimble, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, bouncing back from adversity to finish strong. Against Wladimir Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Meanwhile, Usyk, offers a different kind of threat. As a southpaw, he uses angles and footwork. The Ukrainian’s shots lack devastating strength, their timing wears down foes. As fight night approaches, Tyson Fury vs Usyk odds are the subject of intense debate.
Most bookmakers favor Fury as predicted by many experts, due to his size advantage, his long career in major fights, and his unpredictable nature. However, Usyk's underdog status doesn’t mean he’s an underdog in spirit, his wins over Anthony Joshua demonstrated his ability in the heavyweight ranks.
For Tyson Fury is a chance to further solidify his greatness. Should he come out on top, Fury’s win would solidify his claim as the greatest heavyweight of his generation. On the other hand, Usyk’s victory would elevate him to legendary status. Achieving undisputed glory in two divisions would be a remarkable feat in boxing history.
Web: <a href="http://www.google.ht/url?q=https%3A%2F%2Ffuryusyk.org.uk">furyusyk.org.uk</a>
The upcoming showdown represents something greater than a title bout. It’s a clash of personalities. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. The clash of personalities adds depth to the narrative. This is more than just a physical contest. Whoever comes out victorious, the legacy of this fight will be remembered as a defining moment in boxing. Fury vs Usyk is more than just a match. It’s the result of relentless dedication. Whether Tyson Fury prevails with his size and strategy, or Usyk secures a victory with his finesse and stamina, no matter the outcome, this will be a legendary contest.
Fury vs Usyk is more than just a fight. It’s a fight of grit and strategy. Both fighters will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Este slot se diferencia de otras opciones de juego por su diseno y tematica unicos. Al abrir el juego, los apostadores son llevados a un universo de caramelos y colores brillantes que parecen de un mundo fantastico. El fondo de la pantalla esta lleno de golosinas, lo cual ofrece una escena visual atractiva y divertida, adaptada a todos los jugadores. Sweet Bonanza ha sido descrito por muchos en sus opiniones como adictivo y muy entretenido, ya que ofrece premios emocionantes y una estetica cautivadora.
Una de las caracteristicas mas valoradas de este juego de tragamonedas es su funcion de giros gratis, que se activa si se obtienen cuatro o mas simbolos de caramelos en cualquier lugar. Los giros gratis no solo permiten jugar de manera gratuita, sino que tambien potencian las probabilidades de grandes ganancias, especialmente cuando se activan los multiplicadores durante los giros. Este detalle del juego es uno de los mas atractivos a los jugadores, y muchos destacan en sus comentarios que la funcion de giros gratis es lo que mas entusiasma de Sweet Bonanza.
Ademas, el juego de Pragmatic Play ha logrado mantener su popularidad gracias a su aplicabilidad universal. No importa si eres un principiante en las apuestas online, el diseno sencillo y la jugabilidad clara permiten que cualquier jugador pueda disfrutar de la accion sin complicaciones. Si bien la posibilidad de obtener grandes premios es siempre un factor emocionante, la naturaleza del juego tambien invita a los jugadores a relajarse y disfrutar de cada giro, sin presiones ni expectativas irreales.
Por otro lado, la adaptabilidad de el juego en diferentes plataformas es otro aspecto que ha sido muy bien recibido por la comunidad de jugadores. La opcion de jugar tanto desde una computadora de escritorio como desde dispositivos moviles ha permitido a los aficionados disfrutar del juego en cualquier momento y lugar, aumentando la accesibilidad del titulo. Si eres un jugador que prefiere jugar durante tus descansos, la opcion movil de Sweet Bonanza te proporciona la misma experiencia inmersiva y atractiva que en la version de escritorio. Esto ha sido un factor clave en su crecimiento y popularidad en el mercado de las tragamonedas online.
Web: http://www.chunwun.com/bbs/board.php?bo_table=qna&wr_id=142359
Otro punto que interesa a los jugadores es si si el juego realmente permite ganar dinero con este juego de tragamonedas. Al igual que en cualquier tragamonedas, este juego es una maquina de azar, lo cual significa que el resultado de cada giro es totalmente azaroso y no puede ser modificado. Sin embargo, los multiplicadores junto con giros gratis ofrecen una oportunidad significativa para obtener premios importantes. La funcion de multiplicador puede aumentar las ganancias hasta 100 veces en un solo giro, lo que puede generar premios grandes si el jugador acierta. Sin embargo, es importante recordar que hay que disfrutar del juego con moderacion y que las victorias no estan garantizadas.
Tyson Fury and Oleksandr Usyk are on a collision course of unparalleled significance. It’s far beyond a championship match; it represents their quest for immortality. Tyson Fury has become a global icon thanks to his personality and his unmatched skills during fights. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. In contrast, Usyk, the technician is a fighter unlike any other to boxing’s biggest stars. At the same time, Usyk, a southpaw master stands as a unique threat for Tyson Fury himself, and for boxing fans worldwide. The ascent of Oleksandr Usyk began in the cruiserweight division, by conquering all challengers. Prepare yourself for a thrilling boxing match of the year as Usyk takes on Fury in a must-watch showdown! Catch every punch live on our website. Don’t miss your chance — visit <a href="http://all27.ru/outgocounter.php?url=aHR0cHM6Ly9tb2RzLW1lbnUucnUv">usykvsfurydate.org.uk</a> now and watch the match in high quality!
For British fans, the ring walks are planned for late evening, ensuring maximum viewership. Back in Usyk’s home country, as well as viewers across Europe and the Americas, this will be a must-see event. The fight’s location remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, fans can be sure: it will be a spectacle. Even though attention remains on Fury and Usyk, the Fury vs Usyk undercard promises plenty of action. High-profile matches are known for strong supporting fights, offering an entire night of boxing excitement.
Traditionally, preliminary fights on major cards have introduced future champions. Fighters looking to rise through the ranks capitalize on the exposure to impress fans and analysts alike, with the world paying attention. While the names for the undercard are still unconfirmed, there’s plenty of talk. Could we see rising prospects? Whatever the selection, the action will not disappoint. What sets this bout apart incredibly exciting is the dynamic between these fighters. Tyson Fury’s size and agility set him apart from other heavyweights. At 6’9" with an 85-inch reach, Fury can control a fight.
His trilogy with Deontay Wilder highlighted his resilience, bouncing back from adversity to finish strong. In his fight with Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. Meanwhile, Usyk, brings speed, precision, and finesse. With his unorthodox stance, his positioning constantly challenges opponents. The Ukrainian’s shots lack devastating strength, but they are delivered with pinpoint accuracy. With the date drawing closer, The betting lines for Fury vs Usyk have fans and analysts speculating.
Tyson Fury is the slight favorite as per the betting experts, thanks to his imposing frame, his experience in high-pressure bouts, and his adaptability. Although Usyk is the less favored fighter shouldn’t be counted out, his wins over Anthony Joshua showed that he can compete at heavyweight.
For Tyson Fury, this fight could be the defining moment of his career. If he wins, it would put the finishing touches on a historic career. Conversely, If Usyk wins would mark him as one of the sport’s greats. Achieving undisputed glory in two divisions is a once-in-a-lifetime achievement.
Web: <a href="http://www.google.ro/url?q=https://usykvsfurydate.org.uk/">usykvsfurydate.org.uk</a>
This fight is not just about the belts. It’s a battle of contrasting styles. Fury’s confident and brash nature is in stark contrast to Usyk’s quiet intensity. These varying personalities make the bout even more interesting. It’s a fight of wills and ideologies. Regardless of the outcome, the impact of this bout will reverberate throughout boxing history. This historic showdown is more than just a fight. It represents the culmination of their careers. Should Fury claim victory with his experience and unpredictability, or Usyk secures a victory thanks to his skill and resilience, one thing is certain, this bout will go down in history.
The Fury-Usyk battle is more than just a boxing event. It’s a fight of grit and strategy. These men will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Fortune Tiger: Estrategias para Ganhos
O jogo se diferencia por suas oportunidades de lucro rapido e significativo. Cada rodada traz a chance de premios elevados, o que e um atrativo para muitos.
Alguns jogadores tem metodos proprios para melhorar os resultados. Uma das estrategias preferidas e a aposta gradual. Esse metodo consiste em comecar com apostas pequenas e aumenta-las com o tempo.
O controle sobre o timing das apostas pode ser determinante para os ganhos. E fundamental estar atento aos minutos pagantes do jogo. Esses periodos de pagamento mais elevados ocorrem aleatoriamente, mas jogadores experientes sabem como identifica-los.
Entenda como funciona a plataforma de Fortune Tiger
Website: https://yogaasanas.science/wiki/User:MaritaWoodd86
Conclusao Final
A plataforma oferece uma experiencia de jogo envolvente e acessivel para todos. Em resumo, Fortune Tiger e uma plataforma que entrega uma experiencia rica e cheia de possibilidades de ganhos.
The undefeated Fury and Usyk are on a collision course of unparalleled significance. It’s not merely about the belts; it’s about legacy. Tyson Fury has become a global icon with his charisma and his unmatched skills in the ring. Beating Wilder and Klitschko have solidified his legendary status. Meanwhile, Oleksandr Usyk is a fighter unlike any other to boxing’s biggest stars. At the same time, Oleksandr Usyk represents a formidable opponent for Tyson Fury himself, and for boxing fans worldwide. Usyk’s rise to prominence started with his domination of the cruiserweights, by conquering all challengers. Prepare yourself for an epic boxing match of the year as Usyk takes on Fury in a must-watch showdown! See every move live on our website. Don’t miss your chance — visit <a href="https://www.jamonprive.com/idevaffiliate/idevaffiliate.php?id=102&url=http%3A%2F%2Ftysonfuryvsoleksandrusyk.co.uk">tysonfuryvsoleksandrusyk.co.uk</a> now and enjoy the fight from the comfort of your home!
For British fans, the fight is expected to begin late evening, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, and beyond, the excitement is palpable. The fight’s location remains a hot topic, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, one thing is certain: the excitement will be unmatched. Even though attention is firmly on the main event, the Fury vs Usyk undercard is also generating excitement. High-profile matches are known for strong supporting fights, offering an entire night of boxing excitement.
Historically, preliminary fights on major cards have introduced future champions. Boxers seeking the spotlight often seize these moments to impress fans and analysts alike, with the world paying attention. While the names for the undercard has yet to be finalized, fans are eagerly guessing. Might there be a cruiserweight spectacle? No matter the final roster, fans can expect fireworks. The most compelling part of Fury vs Usyk incredibly exciting is the dynamic between these fighters. Fury’s towering frame and movement are unparalleled in the sport. With his immense height and reach advantage, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, bouncing back from adversity to finish strong. When he faced Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, relies on technique and stamina. As a southpaw, his movements create openings. The Ukrainian’s shots aren’t the heaviest in the division, they consistently find their mark. As fight night approaches, Tyson Fury vs Usyk odds have fans and analysts speculating.
Fury is the favored fighter based on the betting odds, because of his reach and height, his proven ability in tough situations, and his tactical brilliance. Despite being seen as the underdog doesn’t diminish his chances, his victories against AJ demonstrated his ability in the heavyweight ranks.
For the Gypsy King presents a shot at undisputed glory. If he wins, it would put the finishing touches on a historic career. Conversely, For Usyk, a win would be a monumental achievement. Achieving undisputed glory in two divisions is a once-in-a-lifetime achievement.
Web: <a href="http://cse.google.ad/url?q=https://tysonfuryvsoleksandrusyk.co.uk/">tysonfuryvsoleksandrusyk.co.uk</a>
Fury vs Usyk is more than just a championship fight. It’s a fight between two very different fighters. Fury’s bold and unapologetic character is in stark contrast to Usyk’s quiet intensity. These differences add complexity to the fight. This is more than just a physical contest. Regardless of the outcome, the significance of this match will be remembered as a defining moment in boxing. This historic showdown is a spectacle unlike any other. It’s the pinnacle of both fighters’ hard work. If Fury wins with his experience and unpredictability, or Usyk comes out on top with his finesse and stamina, no matter the outcome, this will be a legendary contest.
This fight between Fury and Usyk is more than just a boxing event. It’s a contest of heart and willpower. The two competitors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Kasyna internetowe zdobywaja coraz szersze uznanie w Polsce, a jedna z miejsc, ktora jest na ustach wszystkich, jest <a href="https://securityholes.science/wiki/User:GordonVillareal">bet on red casino</a>. To kasyno online, ktore wyroznia sie szerokiemu wyborowi gier, intuicyjna konstrukcja strony oraz atrakcyjnymi promocjami, ktore spelnia oczekiwania zarowno osoby nowe w swiecie hazardu, jak i weteranow gier.
Czym wyroznia sie Bet On Red?
Bet On Red Casino to nowoczesne kasyno internetowe, ktora oferuje roznorodne opcje rozrywki, takich jak maszyny hazardowe, gry stolowe oraz kasyno na zywo. Juz nazwa tej platformy „Red On Bet" odzwierciedla adrenaline i rywalizacje podczas gier.
Proces logowania w Kasynie Bet On Red
Sposob na rozpoczecie gry w Kasyno Bet On Red jest intuicyjny i nieskomplikowany. Po odwiedzeniu witryny kasyna, wystarczy kliknac w przycisk „Logowanie" i wprowadzic dane konta. Kasyno stawia na bezpieczenstwo, dlatego wszelkie dane uzytkownika sa chronione.
Osoby rejestrujace sie po raz pierwszy moga latwo zarejestrowac sie, a proces zakladania konta jest szybki i prosty. Co istotne, Kasyno Bet On Red oferuje mozliwosc korzystania z roznych metod platnosci, co sprawia, ze korzystanie z platformy jest proste.
Jakie gry znajdziesz w Bet On Red Casino?
Cecha, ktora przyciaga graczy, kazdego kasyna internetowego, jest oferta gier. Kasyno Bet On Red oferuje roznorodnoscia, ktory zadowoli nawet najbardziej wymagajacych graczy.
Web: https://securityholes.science/wiki/User:GordonVillareal
Maszyny hazardowe sa uwielbiane przez graczy, dostepne w roznych wariantach tematycznych oraz z ciekawymi rozwiazaniami. Oprocz najpopularniejszych maszyn, uzytkownicy moga zagrac w gry stolowe, takie jak ruletka.
Fury, the Gypsy King, and Usyk, the technician are set to meet in the ring of unparalleled significance. This fight is about more than just titles; it’s about legacy. Fury, an undefeated champion has earned worldwide fame thanks to his personality coupled with unparalleled talent inside the ropes. Beating Wilder and Klitschko have earned him recognition as one of the best ever. In contrast, Oleksandr Usyk is a fighter unlike any other to the heavyweight division. At the same time, Usyk, a genius in the ring is a true test for Fury not just for Fury, but for the entire division. His journey to global fame was marked by his undisputed cruiserweight reign, as an undisputed champion. Prepare yourself for a thrilling boxing match of the year as Usyk takes on Fury in an unforgettable showdown! See every move streamed live on our website. Join the excitement — visit <a href="https://stampsy.com/redirect/http:/furyvsusykdate.com">furyvsusykdate.com</a> today and stream the event from the comfort of your home!
In the United Kingdom, the event will kick off at close to prime time, ensuring maximum viewership. Back in Usyk’s home country, as well as viewers across Europe and the Americas, the excitement is palpable. The fight’s location is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, one thing is certain: the atmosphere will be electric. Even though attention remains on Fury and Usyk, the fights leading up to the main event promises plenty of action. Major boxing events are known for strong supporting fights, giving fans a full evening of entertainment.
Traditionally, undercards of this caliber have been a stage for breakout performances. Contenders hoping to make their mark use such opportunities to demonstrate their talent, with the world paying attention. Though the supporting fights for Fury vs Usyk are still unconfirmed, speculation runs high. Will there be a heavyweight clash? Whatever the selection, it’s sure to add to the excitement. What sets this bout apart incredibly exciting is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed are unparalleled in the sport. Being so tall yet so nimble, he commands the ring like no other.
The three fights against Wilder highlighted his resilience, overcoming brutal hits to finish strong. In his fight with Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. By contrast, Usyk, offers a different kind of threat. As a southpaw, his positioning constantly challenges opponents. Usyk’s punches may not have knockout power, they consistently find their mark. With the date drawing closer, Tyson Fury vs Usyk odds have fans and analysts speculating.
Fury is the favored fighter as predicted by many experts, given his physical stature, his experience in high-pressure bouts, and his unorthodox style. Despite the odds, Usyk remains a strong contender shouldn’t be counted out, his dominance against Joshua confirmed his toughness against big opponents.
For the Gypsy King presents a shot at undisputed glory. A triumph for Fury would further solidify his status as the best heavyweight of this era. On the other hand, For Usyk, a win would elevate him to new heights. Becoming the undisputed heavyweight champion is a feat few can claim.
Web: <a href="http://www.google.sh/url?q=https://furyvsusykdate.com/">furyvsusykdate.com</a>
This fight is more than just a championship fight. It’s a meeting of two unique worldviews. Fury’s larger-than-life persona is in stark contrast to Usyk’s quiet intensity. These varying personalities make the bout even more interesting. This is more than just a physical contest. Whoever comes out victorious, the legacy of this fight will leave a lasting mark on the sport. The battle for heavyweight supremacy is a spectacle unlike any other. It’s the result of relentless dedication. Whether Tyson Fury prevails with his size and strategy, or Usyk wins with his precision with his technique and endurance, it’s certain that, this will be a legendary contest.
The Fury-Usyk battle is more than just a sporting contest. It’s a showcase of skill and determination. These two warriors will give everything they have.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are on a collision course of historic proportions. It’s far beyond a championship match; it represents their quest for immortality. Fury, an undefeated champion has risen to the pinnacle of the sport thanks to his personality and remarkable adaptability during fights. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. Meanwhile, Usyk, the technician is a fighter unlike any other for Fury. Meanwhile, Usyk, a genius in the ring stands as a unique threat for Tyson Fury himself, as a heavyweight contender. Usyk’s rise to prominence began in the cruiserweight division, by conquering all challengers. Get ready for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! See every move live on our website. Join the excitement — visit <a href="http://rcde.ru/method/http//tysonvsusyk.com">tysonvsusyk.com</a> today and watch the match in high quality!
For British fans, the event will kick off at late evening, ensuring maximum viewership. For Usyk’s fans in Ukraine, and beyond, the excitement is palpable. Where the bout will take place is still under speculation, with talk of iconic boxing destinations. Wherever it happens, one thing is certain: the atmosphere will be electric. Although the focus is firmly on the main event, the preliminary bouts promises plenty of action. Big-ticket boxing cards often feature stacked undercards, providing non-stop action before the headliner.
In the past, supporting bouts in major events have introduced future champions. Boxers seeking the spotlight often seize these moments to demonstrate their talent, as all eyes are on them. While the names for the undercard haven’t been officially announced, speculation runs high. Could we see rising prospects? Whatever the selection, it’s sure to add to the excitement. What makes this fight so intriguing is the clash of styles. Tyson Fury’s size and agility set him apart from other heavyweights. At 6’9" with an 85-inch reach, Fury can control a fight.
His trilogy with Deontay Wilder highlighted his resilience, bouncing back from adversity to secure victories. Against Wladimir Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. By contrast, Usyk, offers a different kind of threat. Being a left-handed fighter, he uses angles and footwork. His strikes lack devastating strength, they consistently find their mark. As anticipation builds, The betting lines for Fury vs Usyk have fans and analysts speculating.
Most bookmakers favor Fury as predicted by many experts, given his physical stature, his long career in major fights, and his unpredictable nature. Despite the odds, Usyk remains a strong contender shouldn’t be counted out, his wins over Anthony Joshua proved that he can handle the physicality of the heavyweight division.
For Tyson Fury, this fight could be the defining moment of his career. Should he come out on top, Fury’s win would solidify his claim as the greatest heavyweight of his generation. On the other hand, Usyk’s victory would elevate him to legendary status. Becoming an undisputed champion in two different weight classes is a rare accomplishment.
Web: <a href="http://images.google.co.ck/url?q=https://tysonvsusyk.com/">tysonvsusyk.com</a>
This fight is more than just a championship fight. It’s a meeting of two unique worldviews. Fury’s bold and unapologetic character contrasts with Usyk’s calm, focused demeanor. The clash of personalities adds depth to the narrative. It’s about more than just skill. Whoever triumphs in this battle, the legacy of this fight will be felt for years to come. Fury vs Usyk is a defining moment. It represents the culmination of their careers. Should Fury claim victory through his strength and tactics, or Usyk wins with his precision through his superior boxing ability, what is clear is, this bout will go down in history.
Tyson Fury vs Oleksandr Usyk is more than just a sporting contest. It’s a showcase of skill and determination. The two competitors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are preparing for an epic showdown of unparalleled significance. It’s far beyond a championship match; it’s about legacy. Tyson Fury has become a global icon thanks to his personality and his unmatched skills in the ring. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. On the other hand, Oleksandr Usyk is a fighter unlike any other to boxing’s biggest stars. Meanwhile, Usyk, a genius in the ring represents a formidable opponent not just for Fury, as a heavyweight contender. His journey to global fame began in the cruiserweight division, by conquering all challengers. Get ready for an epic boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! Experience every moment live on our website. Join the excitement — visit <a href="http://sovermed.ru/?wptouch_switch=desktop&redirect=https://tysonvusyk.com/">tysonvusyk.com</a> today and stream the event from the comfort of your home!
Across the UK, the event will kick off at around 10 PM GMT, ensuring maximum viewership. For Usyk’s fans in Ukraine, as well as viewers across Europe and the Americas, the excitement is palpable. The fight’s location has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, it’s guaranteed: the excitement will be unmatched. While the spotlight is firmly on the main event, the Fury vs Usyk undercard is also generating excitement. Major boxing events include preliminary bouts with top talent, providing non-stop action before the headliner.
Historically, supporting bouts in major events have showcased rising stars. Contenders hoping to make their mark use such opportunities to impress fans and analysts alike, knowing millions are watching. While the names for the undercard are still unconfirmed, fans are eagerly guessing. Might there be a cruiserweight spectacle? Regardless of the names, fans can expect fireworks. The most compelling part of Fury vs Usyk incredibly exciting is the clash of styles. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. Being so tall yet so nimble, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, as he recovered from knockdowns to secure victories. When he faced Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. As a southpaw, his positioning constantly challenges opponents. Usyk’s punches lack devastating strength, they consistently find their mark. As anticipation builds, Tyson Fury vs Usyk odds are becoming a hot topic.
Tyson Fury is seen as the frontrunner as per the betting experts, due to his size advantage, his proven ability in tough situations, and his tactical brilliance. Despite the odds, Usyk remains a strong contender doesn’t rule him out, his victories against AJ proved that he can handle the physicality of the heavyweight division.
For Fury himself is a chance to further solidify his greatness. A victory would solidify his claim as the greatest heavyweight of his generation. On the other hand, For Usyk, a win would be a monumental achievement. Becoming an undisputed champion in two different weight classes is a feat few can claim.
Web: <a href="http://www.google.com.ua/url?sa=t&url=https%3A%2F%2Ftysonvusyk.com">tysonvusyk.com</a>
The upcoming showdown is not just about the belts. It’s a battle of contrasting styles. Fury’s boisterous personality stands in stark contrast to Usyk’s composed demeanor. These varying personalities make the bout even more interesting. It’s about more than just skill. Whoever comes out victorious, the legacy of this fight will be remembered as a defining moment in boxing. The battle for heavyweight supremacy is more than just a match. It represents the culmination of their careers. Whether Fury secures the win with his size and strategy, or Usyk wins with his precision thanks to his skill and resilience, one thing is certain, this will be a legendary contest.
This fight between Fury and Usyk is more than just a boxing event. It’s a showcase of skill and determination. The two competitors will give everything they have.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are set to meet in the ring of historic proportions. It’s not merely about the belts; it represents their quest for immortality. Tyson Fury has become a global icon with his charisma coupled with unparalleled talent inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. Meanwhile, Oleksandr Usyk is a fighter unlike any other for Fury. At the same time, Oleksandr Usyk represents a formidable opponent for the heavyweight ranks overall, and for boxing fans worldwide. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Prepare yourself for an epic boxing match of the year as Usyk takes on Fury in a historic showdown! See every move live on our website. Join the excitement — visit <a href="https://pravda-mlm.ru/proxy.php?request=https%3A%2F%2Ftysonvsusyk.org.uk">tysonvsusyk.org.uk</a> now and stream the event from the comfort of your home!
In the United Kingdom, the fight is expected to begin close to prime time, ensuring maximum viewership. In Usyk’s native Ukraine, and beyond, this will be a must-see event. The venue for Fury vs Usyk remains a hot topic, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, fans can be sure: the excitement will be unmatched. Although the focus is centered on the headline fight, the Fury vs Usyk undercard is also generating excitement. Big-ticket boxing cards are known for strong supporting fights, giving fans a full evening of entertainment.
Traditionally, undercards of this caliber have showcased rising stars. Fighters looking to rise through the ranks often seize these moments to demonstrate their talent, with the world paying attention. Though the supporting fights for Fury vs Usyk has yet to be finalized, fans are eagerly guessing. Will there be a heavyweight clash? Regardless of the names, the action will not disappoint. What sets this bout apart so intriguing is the clash of styles. Fury’s towering frame and movement are unparalleled in the sport. At 6’9" with an 85-inch reach, he commands the ring like no other.
The three fights against Wilder proved his toughness, as he recovered from knockdowns to dominate in later rounds. Against Wladimir Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. Being a left-handed fighter, his movements create openings. Usyk’s punches may not have knockout power, but they are delivered with pinpoint accuracy. As anticipation builds, Tyson Fury vs Usyk odds are becoming a hot topic.
Tyson Fury is the slight favorite according to the odds, given his physical stature, his experience in high-pressure bouts, and his unorthodox style. Despite the odds, Usyk remains a strong contender doesn’t diminish his chances, his dominance against Joshua showed that he can compete at heavyweight.
For Tyson Fury is a chance to further solidify his greatness. A victory would add an undisputed title to his already impressive resume. On the other hand, Usyk’s victory would elevate him to new heights. Becoming an undisputed champion in two different weight classes is a feat few can claim.
Web: <a href="http://www.google.tl/url?sa=t&url=http%3A%2F%2Fwww.magical-dream.com">tysonvsusyk.org.uk</a>
The upcoming showdown is not just about the belts. It’s a battle of contrasting styles. Fury’s larger-than-life persona is in stark contrast to Usyk’s quiet intensity. Such contrasts make the fight more compelling. This is more than just a physical contest. No matter who wins, the legacy of this fight will be felt for years to come. This historic showdown is more than just a fight. It represents the culmination of their careers. Whether Tyson Fury prevails with his size and strategy, or Oleksandr Usyk triumphs with his finesse and stamina, it’s certain that, this bout will go down in history.
This fight between Fury and Usyk is more than just a fight. It’s a battle of minds and bodies. These two warriors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are on a collision course of unparalleled significance. It’s far beyond a championship match; it’s about legacy. The towering Fury has risen to the pinnacle of the sport through his unique style and his unmatched skills during fights. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. Across the ring, Usyk, the technician brings an unprecedented test to boxing’s biggest stars. On the flip side, Usyk, a genius in the ring is a true test for Fury for the heavyweight ranks overall, as a heavyweight contender. The ascent of Oleksandr Usyk started with his domination of the cruiserweights, where he became an unstoppable force. Don’t miss out for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! See every move streamed live on our website. Don’t miss your chance — visit <a href="https://foiledfox.com/affiliates/idevaffiliate.php?url=https://usykvsfury.co.uk/">usykvsfury.co.uk</a> right away and watch the match in high quality!
In the United Kingdom, the ring walks are planned for around 10 PM GMT, offering perfect timing for viewers. For Usyk’s fans in Ukraine, and beyond, the excitement is palpable. Where the bout will take place has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, fans can be sure: the excitement will be unmatched. Although the focus remains on Fury and Usyk, the Fury vs Usyk undercard promises plenty of action. High-profile matches are known for strong supporting fights, offering an entire night of boxing excitement.
In the past, preliminary fights on major cards have introduced future champions. Boxers seeking the spotlight use such opportunities to impress fans and analysts alike, knowing millions are watching. While the names for the undercard has yet to be finalized, speculation runs high. Could we see rising prospects? Whatever the selection, fans can expect fireworks. What sets this bout apart incredibly exciting is their contrasting skillsets. Tyson Fury’s size and agility make him an anomaly in boxing. With his immense height and reach advantage, he dictates the pace of bouts.
His trilogy with Deontay Wilder proved his toughness, as he recovered from knockdowns to dominate in later rounds. When he faced Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. By contrast, Usyk, relies on technique and stamina. As a southpaw, he uses angles and footwork. His strikes lack devastating strength, but they are delivered with pinpoint accuracy. As fight night approaches, Tyson Fury vs Usyk odds are becoming a hot topic.
The betting lines show Fury ahead based on the betting odds, given his physical stature, his proven ability in tough situations, and his unpredictable nature. Despite being seen as the underdog doesn’t diminish his chances, as his victories over Joshua confirmed his toughness against big opponents.
For the Gypsy King could be the defining moment of his career. If he wins, it would further solidify his status as the best heavyweight of this era. Conversely, If Usyk wins would mark him as one of the sport’s greats. Becoming an undisputed champion in two different weight classes is a feat few can claim.
Web: <a href="http://google.ae/url?q=https://usykvsfury.co.uk/">usykvsfury.co.uk</a>
This fight is more than just a championship fight. It’s a battle of contrasting styles. Fury’s boisterous personality stands in stark contrast to Usyk’s composed demeanor. These varying personalities make the bout even more interesting. Beyond physical ability, this fight. Regardless of the outcome, the impact of this bout will be remembered as a defining moment in boxing. The battle for heavyweight supremacy is more than just a fight. It’s the pinnacle of both fighters’ hard work. Whether Fury secures the win thanks to his power and game plan, or Usyk wins with his precision with his finesse and stamina, one thing is certain, this bout will go down in history.
Tyson Fury vs Oleksandr Usyk is more than just a boxing event. It’s a contest of heart and willpower. The two competitors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are set to meet in the ring of historic proportions. It’s not merely about the belts; it’s a battle for eternal recognition. The Gypsy King has become a global icon thanks to his personality and remarkable adaptability in the ring. Beating Wilder and Klitschko have solidified his legendary status. Meanwhile, Usyk, the Ukrainian master is a fighter unlike any other to the heavyweight division. At the same time, Usyk, a southpaw master is a true test for Fury for Tyson Fury himself, as a heavyweight contender. The ascent of Oleksandr Usyk began in the cruiserweight division, as an undisputed champion. Prepare yourself for the most anticipated boxing match of the year as Usyk takes on Tyson Fury in a must-watch showdown! Catch every punch live on our website. Join the excitement — visit <a href="https://tes-game.com/go?https://tysonvusyk.co.uk/">tysonvusyk.co.uk</a> now and stream the event in high quality!
For British fans, the event will kick off at close to prime time, ensuring maximum viewership. Back in Usyk’s home country, and for fans watching from around the world, this will be a must-see event. Where the bout will take place is still under speculation, with talk of iconic boxing destinations. Wherever it happens, fans can be sure: the atmosphere will be electric. While the spotlight is centered on the headline fight, the preliminary bouts promises plenty of action. Major boxing events are known for strong supporting fights, offering an entire night of boxing excitement.
In the past, undercards of this caliber have introduced future champions. Boxers seeking the spotlight use such opportunities to demonstrate their talent, as all eyes are on them. While the names for the undercard are still unconfirmed, speculation runs high. Will there be a heavyweight clash? Whatever the selection, the action will not disappoint. What makes this fight so intriguing is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. With his immense height and reach advantage, Fury can control a fight.
The legendary battles with Wilder proved his toughness, as he recovered from knockdowns to dominate in later rounds. When he faced Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, relies on technique and stamina. As a southpaw, he uses angles and footwork. The Ukrainian’s shots may not have knockout power, but they are delivered with pinpoint accuracy. As anticipation builds, Predictions for this fight are becoming a hot topic.
Tyson Fury is seen as the frontrunner based on the betting odds, because of his reach and height, his long career in major fights, and his tactical brilliance. Despite the odds, Usyk remains a strong contender shouldn’t be counted out, his dominance against Joshua proved that he can handle the physicality of the heavyweight division.
For Fury himself is a chance to further solidify his greatness. A victory would further solidify his status as the best heavyweight of this era. On the other hand, For Usyk, a win would elevate him to new heights. Achieving undisputed glory in two divisions is a once-in-a-lifetime achievement.
Web: <a href="http://images.google.com.eg/url?q=https://tysonvusyk.co.uk/">tysonvusyk.co.uk</a>
This fight represents something greater than a title bout. It’s a meeting of two unique worldviews. Fury’s bold and unapologetic character is the opposite of Usyk’s humble and disciplined approach. The clash of personalities adds depth to the narrative. Beyond physical ability, this fight. Whoever comes out victorious, the legacy of this fight will be felt for years to come. The battle for heavyweight supremacy is a defining moment. It represents the culmination of their careers. Whether Tyson Fury prevails with his size and strategy, or Usyk comes out on top with his technique and endurance, what is clear is, this will be a fight remembered for years to come.
The Fury-Usyk battle is a spectacle of a lifetime. It’s a fight of grit and strategy. Both fighters will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are on a collision course that will define an era. It’s far beyond a championship match; it’s about legacy. Fury, an undefeated champion has become a global icon thanks to his personality and his unmatched skills inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. On the other hand, Usyk, the Ukrainian master brings an unprecedented test to the heavyweight division. Meanwhile, Oleksandr Usyk represents a formidable opponent for Tyson Fury himself, and for boxing fans worldwide. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Get ready for an epic boxing match of the year as Oleksandr Usyk takes on Fury in a historic showdown! See every move streamed live on our website. Don’t miss your chance — visit <a href="https://pilotmusic.ru/udata/emarket/basket/put/element/41624/?redirect-uri=http%3a%2f%2fusykvsfury.co.uk">usykvsfury.co.uk</a> now and enjoy the fight with top-notch streaming!
Across the UK, the event will kick off at close to prime time, offering perfect timing for viewers. For Usyk’s fans in Ukraine, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. The venue for Fury vs Usyk has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, fans can be sure: the atmosphere will be electric. Even though attention is firmly on the main event, the preliminary bouts is shaping up to be thrilling. High-profile matches are known for strong supporting fights, offering an entire night of boxing excitement.
Historically, supporting bouts in major events have introduced future champions. Fighters looking to rise through the ranks often seize these moments to demonstrate their talent, with the world paying attention. Although the lineup for the Fury Usyk undercard has yet to be finalized, fans are eagerly guessing. Might there be a cruiserweight spectacle? Whatever the selection, it’s sure to add to the excitement. What makes this fight so intriguing is their contrasting skillsets. Fury’s towering frame and movement are unparalleled in the sport. Being so tall yet so nimble, Fury can control a fight.
His trilogy with Deontay Wilder proved his toughness, bouncing back from adversity to dominate in later rounds. Against Wladimir Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. Being a left-handed fighter, his movements create openings. The Ukrainian’s shots lack devastating strength, but they are delivered with pinpoint accuracy. As fight night approaches, Tyson Fury vs Usyk odds are becoming a hot topic.
Fury is the favored fighter as per the betting experts, given his physical stature, his long career in major fights, and his adaptability. Although Usyk is the less favored fighter shouldn’t be counted out, his victories against AJ confirmed his toughness against big opponents.
For Tyson Fury could be the defining moment of his career. If he wins, it would put the finishing touches on a historic career. Conversely, Usyk’s victory would elevate him to legendary status. Becoming an undisputed champion in two different weight classes is a feat few can claim.
Web: <a href="http://www.google.com.sb/url?sa=t&url=http%3A%2F%2Fwww.magical-dream.com">usykvsfury.co.uk</a>
Fury vs Usyk is more than just a championship fight. It’s a battle of contrasting styles. Fury’s larger-than-life persona is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. It’s a fight of wills and ideologies. Whoever triumphs in this battle, the legacy of this fight will reverberate throughout boxing history. Fury vs Usyk is a defining moment. It represents the culmination of their careers. Should Fury claim victory with his size and strategy, or Usyk secures a victory with his finesse and stamina, what is clear is, this will be a fight remembered for years to come.
Fury vs Usyk is a spectacle of a lifetime. It’s a showcase of skill and determination. Both fighters will fight with everything they possess.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are set to meet in the ring of historic proportions. It’s not merely about the belts; it represents their quest for immortality. The towering Fury has become a global icon with his charisma and remarkable adaptability during fights. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. Meanwhile, Oleksandr Usyk brings an unprecedented test to the heavyweight division. At the same time, the Ukrainian technician represents a formidable opponent for Tyson Fury himself, as a heavyweight contender. His journey to global fame was marked by his undisputed cruiserweight reign, as an undisputed champion. Prepare yourself for a thrilling boxing match of the year as Usyk takes on Fury in a historic showdown! Experience every moment live on our website. Join the excitement — visit <a href="http://chelo.nnov.org/common/redir.php?https://tysonfuryvsoleksandrusyk.co.uk/">tysonfuryvsoleksandrusyk.co.uk</a> now and enjoy the fight with top-notch streaming!
In the United Kingdom, the fight is expected to begin late evening, making it ideal for a prime-time audience. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. The venue for Fury vs Usyk remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, it’s guaranteed: the atmosphere will be electric. Although the focus remains on Fury and Usyk, the fights leading up to the main event promises plenty of action. Major boxing events often feature stacked undercards, providing non-stop action before the headliner.
In the past, supporting bouts in major events have introduced future champions. Boxers seeking the spotlight capitalize on the exposure to demonstrate their talent, with the world paying attention. While the names for the undercard haven’t been officially announced, speculation runs high. Could we see rising prospects? Regardless of the names, it’s sure to add to the excitement. What sets this bout apart truly fascinating is the clash of styles. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. Being so tall yet so nimble, he commands the ring like no other.
The three fights against Wilder proved his toughness, as he recovered from knockdowns to secure victories. Against Wladimir Klitschko, his strategic genius shone through, demonstrating his mental sharpness. By contrast, Usyk, brings speed, precision, and finesse. Being a left-handed fighter, his positioning constantly challenges opponents. Usyk’s punches lack devastating strength, they consistently find their mark. As fight night approaches, Predictions for this fight are becoming a hot topic.
Tyson Fury is seen as the frontrunner as predicted by many experts, thanks to his imposing frame, his track record in big matches, and his unorthodox style. Although Usyk is the less favored fighter doesn’t rule him out, his dominance against Joshua demonstrated his ability in the heavyweight ranks.
For the Gypsy King presents a shot at undisputed glory. If he wins, it would further solidify his status as the best heavyweight of this era. Conversely, If Usyk wins would mark him as one of the sport’s greats. Becoming the undisputed heavyweight champion is a feat few can claim.
Web: <a href="http://www.google.com.kh/url?q=https%3A%2F%2Ftysonfuryvsoleksandrusyk.co.uk">tysonfuryvsoleksandrusyk.co.uk</a>
The upcoming showdown is not just about the belts. It’s a meeting of two unique worldviews. Fury’s boisterous personality contrasts with Usyk’s calm, focused demeanor. Such contrasts make the fight more compelling. It’s a fight of wills and ideologies. Whoever triumphs in this battle, the impact of this bout will leave a lasting mark on the sport. The battle for heavyweight supremacy is a defining moment. It’s a culmination of years of hard work. Whether Fury secures the win thanks to his power and game plan, or Usyk secures a victory with his finesse and stamina, one thing is certain, this will be a legendary contest.
This fight between Fury and Usyk is more than just a fight. It’s a fight of grit and strategy. These two warriors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are on a collision course of unparalleled significance. It’s not merely about the belts; it represents their quest for immortality. The Gypsy King has become a global icon through his unique style and remarkable adaptability inside the ropes. Beating Wilder and Klitschko have cemented his place among the all-time greats. Meanwhile, Usyk, the Ukrainian master poses a unique challenge to boxing’s biggest stars. At the same time, Oleksandr Usyk stands as a unique threat for Tyson Fury himself, as a heavyweight contender. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Get ready for a thrilling boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! Catch every punch in real time on our website. Join the excitement — visit <a href="https://www.muziekweb.nl/Muziekweb/ExternalLink/?ref=B00000000141&platform=twitter&target=https%3A%2F%2Fusykvsfury.co.uk">usykvsfury.co.uk</a> now and watch the match in high quality!
Across the UK, the ring walks are planned for close to prime time, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and beyond, the excitement is palpable. The venue for Fury vs Usyk has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, one thing is certain: it will be a spectacle. While the spotlight is firmly on the main event, the fights leading up to the main event is also generating excitement. Big-ticket boxing cards often feature stacked undercards, providing non-stop action before the headliner.
Traditionally, undercards of this caliber have been a stage for breakout performances. Fighters looking to rise through the ranks use such opportunities to demonstrate their talent, knowing millions are watching. While the names for the undercard haven’t been officially announced, speculation runs high. Could we see rising prospects? Regardless of the names, fans can expect fireworks. What sets this bout apart incredibly exciting is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. Being so tall yet so nimble, he commands the ring like no other.
His trilogy with Deontay Wilder highlighted his resilience, bouncing back from adversity to finish strong. When he faced Klitschko, his strategic genius shone through, showing he’s both powerful and smart. By contrast, Usyk, brings speed, precision, and finesse. Being a left-handed fighter, he uses angles and footwork. The Ukrainian’s shots lack devastating strength, they consistently find their mark. As anticipation builds, Predictions for this fight have fans and analysts speculating.
The betting lines show Fury ahead according to the odds, due to his size advantage, his track record in big matches, and his adaptability. Despite the odds, Usyk remains a strong contender doesn’t diminish his chances, as his victories over Joshua showed that he can compete at heavyweight.
For Tyson Fury presents a shot at undisputed glory. Should he come out on top, Fury’s win would put the finishing touches on a historic career. On the other hand, For Usyk, a win would elevate him to legendary status. Securing two undisputed titles is a once-in-a-lifetime achievement.
Web: <a href="http://cse.google.md/url?q=https://usykvsfury.co.uk/">usykvsfury.co.uk</a>
Fury vs Usyk represents something greater than a title bout. It’s a battle of contrasting styles. Fury’s larger-than-life persona contrasts with Usyk’s calm, focused demeanor. These differences add complexity to the fight. This is more than just a physical contest. No matter who wins, the legacy of this fight will reverberate throughout boxing history. The battle for heavyweight supremacy is a defining moment. It’s the pinnacle of both fighters’ hard work. If Fury wins through his strength and tactics, or Oleksandr Usyk triumphs through his superior boxing ability, what is clear is, this bout will go down in history.
Fury vs Usyk is more than just a fight. It’s a contest of heart and willpower. The two competitors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are on a collision course that will define an era. It’s not merely about the belts; it represents their quest for immortality. The towering Fury has earned worldwide fame thanks to his personality and his unmatched skills during fights. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. In contrast, Usyk, the technician is a fighter unlike any other to the heavyweight division. Meanwhile, Usyk, a southpaw master is a true test for Fury for the heavyweight ranks overall, as a heavyweight contender. Usyk’s rise to prominence began in the cruiserweight division, as an undisputed champion. Get ready for an epic boxing match of the year as Oleksandr Usyk takes on Fury in an unforgettable showdown! See every move in real time on our website. Join the excitement — visit <a href="https://www.chuwi.com/?wptouch_switch=desktop&redirect=//tysonfuryvsusyk.org.uk">tysonfuryvsusyk.org.uk</a> today and enjoy the fight in high quality!
In the United Kingdom, the event will kick off at late evening, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. The fight’s location remains a hot topic, with talk of iconic boxing destinations. Wherever it happens, one thing is certain: the excitement will be unmatched. Even though attention is centered on the headline fight, the preliminary bouts promises plenty of action. Major boxing events often feature stacked undercards, offering an entire night of boxing excitement.
Historically, supporting bouts in major events have introduced future champions. Fighters looking to rise through the ranks use such opportunities to demonstrate their talent, with the world paying attention. Although the lineup for the Fury Usyk undercard haven’t been officially announced, there’s plenty of talk. Could we see rising prospects? Whatever the selection, fans can expect fireworks. The most compelling part of Fury vs Usyk incredibly exciting is their contrasting skillsets. Fury’s towering frame and movement make him an anomaly in boxing. At 6’9" with an 85-inch reach, Fury can control a fight.
The legendary battles with Wilder highlighted his resilience, overcoming brutal hits to secure victories. When he faced Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, offers a different kind of threat. As a southpaw, his positioning constantly challenges opponents. Usyk’s punches lack devastating strength, but they are delivered with pinpoint accuracy. With the date drawing closer, Predictions for this fight are becoming a hot topic.
Tyson Fury is seen as the frontrunner as per the betting experts, given his physical stature, his long career in major fights, and his unorthodox style. Although Usyk is the less favored fighter doesn’t diminish his chances, his dominance against Joshua proved that he can handle the physicality of the heavyweight division.
For Tyson Fury represents an opportunity to cement his legacy. If he wins, it would further solidify his status as the best heavyweight of this era. Conversely, If Usyk wins would elevate him to legendary status. Becoming an undisputed champion in two different weight classes would be a remarkable feat in boxing history.
Web: <a href="http://www.google.kg/url?q=https://tysonfuryvsusyk.org.uk/">tysonfuryvsusyk.org.uk</a>
The upcoming showdown is more than just a championship fight. It’s a battle of contrasting styles. Fury’s boisterous personality is in stark contrast to Usyk’s quiet intensity. Such contrasts make the fight more compelling. Beyond physical ability, this fight. Whoever triumphs in this battle, the significance of this match will be remembered as a defining moment in boxing. The clash for the undisputed title is a defining moment. It’s the pinnacle of both fighters’ hard work. Whether Tyson Fury prevails through his strength and tactics, or Usyk comes out on top through his superior boxing ability, no matter the outcome, this will be a fight remembered for years to come.
The Fury-Usyk battle is more than just a boxing event. It’s a battle of minds and bodies. The two competitors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are set to meet in the ring of historic proportions. It’s far beyond a championship match; it’s about legacy. The towering Fury has earned worldwide fame with his charisma and his unmatched skills inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. Meanwhile, Usyk, the technician poses a unique challenge for Fury. Meanwhile, the Ukrainian technician stands as a unique threat not just for Fury, as a heavyweight contender. The ascent of Oleksandr Usyk began in the cruiserweight division, where he became an unstoppable force. Prepare yourself for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a must-watch showdown! Experience every moment in real time on our website. Join the excitement — visit <a href="http://greedichpub.nnov.org/common/redir.php?https://usykvsfurydate.co.uk/">usykvsfurydate.co.uk</a> right away and stream the event from the comfort of your home!
In the United Kingdom, the event will kick off at around 10 PM GMT, ensuring maximum viewership. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, this will be a must-see event. The fight’s location has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, one thing is certain: the excitement will be unmatched. Even though attention is centered on the headline fight, the preliminary bouts is also generating excitement. High-profile matches include preliminary bouts with top talent, providing non-stop action before the headliner.
In the past, undercards of this caliber have introduced future champions. Contenders hoping to make their mark often seize these moments to demonstrate their talent, knowing millions are watching. Although the lineup for the Fury Usyk undercard has yet to be finalized, fans are eagerly guessing. Might there be a cruiserweight spectacle? Whatever the selection, it’s sure to add to the excitement. What sets this bout apart incredibly exciting is their contrasting skillsets. Tyson Fury’s size and agility are unparalleled in the sport. With his immense height and reach advantage, Fury can control a fight.
The legendary battles with Wilder proved his toughness, overcoming brutal hits to finish strong. In his fight with Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Meanwhile, Usyk, brings speed, precision, and finesse. With his unorthodox stance, his movements create openings. His strikes aren’t the heaviest in the division, they consistently find their mark. With the date drawing closer, Predictions for this fight are becoming a hot topic.
Tyson Fury is seen as the frontrunner as predicted by many experts, given his physical stature, his proven ability in tough situations, and his tactical brilliance. Despite being seen as the underdog shouldn’t be counted out, his victories against AJ confirmed his toughness against big opponents.
For Tyson Fury, this fight is a chance to further solidify his greatness. Should he come out on top, Fury’s win would add an undisputed title to his already impressive resume. Conversely, For Usyk, a win would elevate him to legendary status. Achieving undisputed glory in two divisions is a rare accomplishment.
Web: <a href="http://clients1.google.az/url?q=https%3A%2F%2Fusykvsfurydate.co.uk">usykvsfurydate.co.uk</a>
Fury vs Usyk is about more than the titles. It’s a fight between two very different fighters. Fury’s boisterous personality stands in stark contrast to Usyk’s composed demeanor. The clash of personalities adds depth to the narrative. It’s a fight of wills and ideologies. Regardless of the outcome, the significance of this match will be felt for years to come. The clash for the undisputed title is more than just a match. It’s a culmination of years of hard work. Should Fury claim victory thanks to his power and game plan, or Usyk secures a victory through his superior boxing ability, no matter the outcome, this will be a legendary contest.
Tyson Fury vs Oleksandr Usyk is more than just a boxing event. It’s a battle of minds and bodies. Both fighters will give everything they have.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are ready to face each other in a fight of historic proportions. It’s far beyond a championship match; it’s about legacy. The Gypsy King has become a global icon thanks to his personality and remarkable adaptability during fights. Beating Wilder and Klitschko have solidified his legendary status. In contrast, Oleksandr Usyk brings an unprecedented test to the heavyweight division. On the flip side, Usyk, a southpaw master stands as a unique threat for Tyson Fury himself, and for boxing fans worldwide. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, as an undisputed champion. Get ready for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a historic showdown! Catch every punch live on our website. Join the excitement — visit <a href="https://polesie.spb.ru/udata/emarket/basket/put/element/2482/?redirect-uri=https://furyvsusykdate.com/">furyvsusykdate.com</a> right away and enjoy the fight from the comfort of your home!
In the United Kingdom, the fight is expected to begin close to prime time, ensuring maximum viewership. For Usyk’s fans in Ukraine, and for fans watching from around the world, the excitement is palpable. The fight’s location is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, fans can be sure: the excitement will be unmatched. Even though attention is centered on the headline fight, the preliminary bouts is shaping up to be thrilling. Major boxing events are known for strong supporting fights, giving fans a full evening of entertainment.
Historically, undercards of this caliber have introduced future champions. Contenders hoping to make their mark use such opportunities to impress fans and analysts alike, as all eyes are on them. Although the lineup for the Fury Usyk undercard haven’t been officially announced, speculation runs high. Could we see rising prospects? Regardless of the names, it’s sure to add to the excitement. What sets this bout apart incredibly exciting is the clash of styles. Tyson Fury’s size and agility make him an anomaly in boxing. Being so tall yet so nimble, he commands the ring like no other.
His trilogy with Deontay Wilder showed his durability, bouncing back from adversity to finish strong. In his fight with Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. Meanwhile, Usyk, offers a different kind of threat. With his unorthodox stance, his movements create openings. Usyk’s punches may not have knockout power, their timing wears down foes. With the date drawing closer, Tyson Fury vs Usyk odds are becoming a hot topic.
Fury is the favored fighter according to the odds, due to his size advantage, his experience in high-pressure bouts, and his unpredictable nature. Despite the odds, Usyk remains a strong contender doesn’t rule him out, his victories against AJ showed that he can compete at heavyweight.
For Tyson Fury represents an opportunity to cement his legacy. Should he come out on top, Fury’s win would solidify his claim as the greatest heavyweight of his generation. Conversely, Usyk’s victory would be a monumental achievement. Achieving undisputed glory in two divisions is a feat few can claim.
Web: <a href="http://www.google.je/url?q=https://furyvsusykdate.com/">furyvsusykdate.com</a>
The upcoming showdown represents something greater than a title bout. It’s a fight between two very different fighters. Fury’s bold and unapologetic character contrasts with Usyk’s calm, focused demeanor. These varying personalities make the bout even more interesting. This is more than just a physical contest. Whoever triumphs in this battle, the legacy of this fight will be felt for years to come. Fury vs Usyk is more than just a fight. It represents the culmination of their careers. Should Fury claim victory thanks to his power and game plan, or Usyk comes out on top thanks to his skill and resilience, one thing is certain, this bout will go down in history.
The Fury-Usyk battle is more than just a sporting contest. It’s a battle of minds and bodies. Both fighters will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are set to meet in the ring of unparalleled significance. It’s far beyond a championship match; it’s about legacy. Tyson Fury has become a global icon thanks to his personality and his unmatched skills inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Across the ring, Usyk, the Ukrainian master brings an unprecedented test to boxing’s biggest stars. Meanwhile, Usyk, a genius in the ring represents a formidable opponent for the heavyweight ranks overall, and for boxing fans worldwide. His journey to global fame was marked by his undisputed cruiserweight reign, as an undisputed champion. Get ready for the most anticipated boxing match of the year as Oleksandr Usyk takes on Fury in a historic showdown! See every move streamed live on our website. Don’t miss your chance — visit <a href="https://vzh2010.printdirect.ru/utils/redirect?url=https://usykvsfurydate.co.uk/">usykvsfurydate.co.uk</a> now and watch the match in high quality!
For British fans, the event will kick off at late evening, offering perfect timing for viewers. In Usyk’s native Ukraine, and for fans watching from around the world, the excitement is palpable. The venue for Fury vs Usyk has yet to be confirmed, with talk of iconic boxing destinations. Regardless of the venue, it’s guaranteed: it will be a spectacle. While the spotlight remains on Fury and Usyk, the Fury vs Usyk undercard promises plenty of action. Big-ticket boxing cards are known for strong supporting fights, offering an entire night of boxing excitement.
Historically, supporting bouts in major events have introduced future champions. Fighters looking to rise through the ranks often seize these moments to showcase their skills, as all eyes are on them. Although the lineup for the Fury Usyk undercard haven’t been officially announced, there’s plenty of talk. Could we see rising prospects? Regardless of the names, fans can expect fireworks. What makes this fight truly fascinating is the dynamic between these fighters. Fury’s towering frame and movement set him apart from other heavyweights. Being so tall yet so nimble, he commands the ring like no other.
The legendary battles with Wilder highlighted his resilience, bouncing back from adversity to finish strong. When he faced Klitschko, his strategic genius shone through, showing he’s both powerful and smart. By contrast, Usyk, relies on technique and stamina. As a southpaw, he uses angles and footwork. The Ukrainian’s shots may not have knockout power, their timing wears down foes. With the date drawing closer, Tyson Fury vs Usyk odds are becoming a hot topic.
Tyson Fury is seen as the frontrunner as predicted by many experts, given his physical stature, his long career in major fights, and his adaptability. Despite being seen as the underdog doesn’t rule him out, his victories against AJ showed that he can compete at heavyweight.
For the Gypsy King represents an opportunity to cement his legacy. If he wins, it would solidify his claim as the greatest heavyweight of his generation. Meanwhile, If Usyk wins would be a monumental achievement. Becoming an undisputed champion in two different weight classes is a rare accomplishment.
Web: <a href="http://www.google.ba/url?q=https%3A%2F%2Fusykvsfurydate.co.uk">usykvsfurydate.co.uk</a>
This fight represents something greater than a title bout. It’s a battle of contrasting styles. Fury’s larger-than-life persona stands in stark contrast to Usyk’s composed demeanor. These varying personalities make the bout even more interesting. It’s about more than just skill. Whoever comes out victorious, the legacy of this fight will be felt for years to come. The clash for the undisputed title is a defining moment. It’s the pinnacle of both fighters’ hard work. If Fury wins thanks to his power and game plan, or Usyk comes out on top with his finesse and stamina, no matter the outcome, this bout will go down in history.
This fight between Fury and Usyk is more than just a sporting contest. It’s a showcase of skill and determination. These two warriors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are set to meet in the ring that will define an era. It’s not merely about the belts; it’s a battle for eternal recognition. Tyson Fury has earned worldwide fame through his unique style coupled with unparalleled talent during fights. Beating Wilder and Klitschko have cemented his place among the all-time greats. Across the ring, Oleksandr Usyk is a fighter unlike any other to the heavyweight division. At the same time, Usyk, a genius in the ring stands as a unique threat for the heavyweight ranks overall, but for the entire division. Usyk’s rise to prominence began in the cruiserweight division, where he became an unstoppable force. Don’t miss out for the most anticipated boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! Catch every punch in real time on our website. Join the excitement — visit <a href="http://50x50.nnov.org/common/redir.php?https://furyvsusykdate.co.uk/">furyvsusykdate.co.uk</a> now and enjoy the fight from the comfort of your home!
Across the UK, the fight is expected to begin around 10 PM GMT, offering perfect timing for viewers. In Usyk’s native Ukraine, and for fans watching from around the world, the anticipation is at a fever pitch. The fight’s location has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. Regardless of the venue, one thing is certain: the excitement will be unmatched. Even though attention is centered on the headline fight, the preliminary bouts is shaping up to be thrilling. High-profile matches are known for strong supporting fights, offering an entire night of boxing excitement.
In the past, undercards of this caliber have been a stage for breakout performances. Fighters looking to rise through the ranks often seize these moments to showcase their skills, with the world paying attention. Although the lineup for the Fury Usyk undercard haven’t been officially announced, there’s plenty of talk. Will there be a heavyweight clash? No matter the final roster, it’s sure to add to the excitement. The most compelling part of Fury vs Usyk truly fascinating is the clash of styles. Fury’s towering frame and movement make him an anomaly in boxing. Being so tall yet so nimble, Fury can control a fight.
His trilogy with Deontay Wilder proved his toughness, as he recovered from knockdowns to finish strong. Against Wladimir Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. By contrast, Usyk, brings speed, precision, and finesse. As a southpaw, his positioning constantly challenges opponents. The Ukrainian’s shots aren’t the heaviest in the division, their timing wears down foes. As anticipation builds, Predictions for this fight are the subject of intense debate.
Fury is the favored fighter according to the odds, due to his size advantage, his track record in big matches, and his unorthodox style. Although Usyk is the less favored fighter doesn’t rule him out, his victories against AJ showed that he can compete at heavyweight.
For Tyson Fury, this fight is a chance to further solidify his greatness. A triumph for Fury would further solidify his status as the best heavyweight of this era. Conversely, For Usyk, a win would elevate him to legendary status. Becoming an undisputed champion in two different weight classes would be a remarkable feat in boxing history.
Web: <a href="http://maps.google.la/url?q=https%3A%2F%2Ffuryvsusykdate.co.uk">furyvsusykdate.co.uk</a>
Fury vs Usyk is about more than the titles. It’s a battle of contrasting styles. Fury’s bold and unapologetic character is in stark contrast to Usyk’s quiet intensity. Such contrasts make the fight more compelling. Beyond physical ability, this fight. Regardless of the outcome, the legacy of this fight will be felt for years to come. Fury vs Usyk is a defining moment. It represents the culmination of their careers. Whether Fury secures the win with his size and strategy, or Oleksandr Usyk triumphs with his technique and endurance, what is clear is, this will be a legendary contest.
The Fury-Usyk battle is a spectacle of a lifetime. It’s a fight of grit and strategy. The two competitors will give everything they have.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are set to meet in the ring of unparalleled significance. It’s far beyond a championship match; it represents their quest for immortality. Fury, an undefeated champion has risen to the pinnacle of the sport with his charisma coupled with unparalleled talent inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Meanwhile, the tactical southpaw poses a unique challenge to boxing’s biggest stars. Meanwhile, the Ukrainian technician stands as a unique threat for Tyson Fury himself, but for the entire division. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Prepare yourself for a thrilling boxing match of the year as Usyk takes on Tyson Fury in a must-watch showdown! Experience every moment streamed live on our website. Don’t miss your chance — visit <a href="http://camxiaomifb.nnov.org/common/redir.php?https://tysonfuryvsusyk.co.uk/">tysonfuryvsusyk.co.uk</a> now and stream the event from the comfort of your home!
Across the UK, the ring walks are planned for late evening, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and beyond, the anticipation is at a fever pitch. The fight’s location remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, it’s guaranteed: it will be a spectacle. Even though attention is firmly on the main event, the preliminary bouts is shaping up to be thrilling. Big-ticket boxing cards are known for strong supporting fights, offering an entire night of boxing excitement.
In the past, supporting bouts in major events have introduced future champions. Contenders hoping to make their mark capitalize on the exposure to impress fans and analysts alike, knowing millions are watching. Although the lineup for the Fury Usyk undercard has yet to be finalized, speculation runs high. Might there be a cruiserweight spectacle? Regardless of the names, fans can expect fireworks. The most compelling part of Fury vs Usyk incredibly exciting is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed are unparalleled in the sport. At 6’9" with an 85-inch reach, Fury can control a fight.
The three fights against Wilder proved his toughness, overcoming brutal hits to dominate in later rounds. In his fight with Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. Meanwhile, Usyk, offers a different kind of threat. Being a left-handed fighter, his positioning constantly challenges opponents. The Ukrainian’s shots aren’t the heaviest in the division, they consistently find their mark. With the date drawing closer, Predictions for this fight have fans and analysts speculating.
Tyson Fury is the slight favorite based on the betting odds, due to his size advantage, his proven ability in tough situations, and his unpredictable nature. Although Usyk is the less favored fighter doesn’t mean he’s an underdog in spirit, his victories against AJ proved that he can handle the physicality of the heavyweight division.
For Tyson Fury presents a shot at undisputed glory. Should he come out on top, Fury’s win would solidify his claim as the greatest heavyweight of his generation. Meanwhile, Usyk’s victory would elevate him to legendary status. Becoming the undisputed heavyweight champion is a rare accomplishment.
Web: <a href="http://cse.google.com.af/url?q=https%3A%2F%2Ftysonfuryvsusyk.co.uk">tysonfuryvsusyk.co.uk</a>
This fight is about more than the titles. It’s a clash of personalities. Fury’s boisterous personality contrasts with Usyk’s calm, focused demeanor. The clash of personalities adds depth to the narrative. This is more than just a physical contest. Regardless of the outcome, the significance of this match will leave a lasting mark on the sport. The battle for heavyweight supremacy is a defining moment. It’s the result of relentless dedication. Whether Tyson Fury prevails with his experience and unpredictability, or Oleksandr Usyk triumphs through his superior boxing ability, it’s certain that, this will be a defining moment in boxing.
Tyson Fury vs Oleksandr Usyk is a spectacle of a lifetime. It’s a battle of minds and bodies. These two warriors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are set to meet in the ring that will define an era. This fight is about more than just titles; it’s a battle for eternal recognition. Tyson Fury has become a global icon with his charisma coupled with unparalleled talent during fights. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. Across the ring, Usyk, the technician brings an unprecedented test for Fury. On the flip side, the Ukrainian technician represents a formidable opponent for the heavyweight ranks overall, as a heavyweight contender. His journey to global fame began in the cruiserweight division, as an undisputed champion. Don’t miss out for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! Catch every punch live on our website. Don’t miss your chance — visit <a href="https://www.consumersadvocate.org/p/atkins-diet-plans-review?url=https://furyvsusykdate.co.uk/">furyvsusykdate.co.uk</a> right away and stream the event from the comfort of your home!
For British fans, the event will kick off at close to prime time, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, and for fans watching from around the world, this will be a must-see event. The fight’s location remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, it’s guaranteed: the excitement will be unmatched. Although the focus is firmly on the main event, the Fury vs Usyk undercard promises plenty of action. Major boxing events are known for strong supporting fights, providing non-stop action before the headliner.
Historically, undercards of this caliber have introduced future champions. Boxers seeking the spotlight use such opportunities to showcase their skills, with the world paying attention. Though the supporting fights for Fury vs Usyk are still unconfirmed, there’s plenty of talk. Might there be a cruiserweight spectacle? Regardless of the names, the action will not disappoint. The most compelling part of Fury vs Usyk truly fascinating is the clash of styles. Tyson Fury’s size and agility are unparalleled in the sport. At 6’9" with an 85-inch reach, he commands the ring like no other.
The three fights against Wilder showed his durability, overcoming brutal hits to finish strong. When he faced Klitschko, his strategic genius shone through, demonstrating his mental sharpness. By contrast, Usyk, brings speed, precision, and finesse. As a southpaw, his positioning constantly challenges opponents. Usyk’s punches lack devastating strength, but they are delivered with pinpoint accuracy. With the date drawing closer, Predictions for this fight are becoming a hot topic.
Tyson Fury is the slight favorite based on the betting odds, due to his size advantage, his long career in major fights, and his unorthodox style. Despite the odds, Usyk remains a strong contender doesn’t rule him out, his wins over Anthony Joshua demonstrated his ability in the heavyweight ranks.
For the Gypsy King presents a shot at undisputed glory. Should he come out on top, Fury’s win would add an undisputed title to his already impressive resume. Meanwhile, If Usyk wins would mark him as one of the sport’s greats. Becoming an undisputed champion in two different weight classes is a once-in-a-lifetime achievement.
Web: <a href="http://images.google.cd/url?q=https://furyvsusykdate.co.uk/">furyvsusykdate.co.uk</a>
Fury vs Usyk represents something greater than a title bout. It’s a meeting of two unique worldviews. Fury’s larger-than-life persona is in stark contrast to Usyk’s quiet intensity. These varying personalities make the bout even more interesting. This is more than just a physical contest. Regardless of the outcome, the impact of this bout will leave a lasting mark on the sport. The clash for the undisputed title is more than just a fight. It represents the culmination of their careers. If Fury wins with his size and strategy, or Oleksandr Usyk triumphs thanks to his skill and resilience, no matter the outcome, this will be a fight remembered for years to come.
Fury vs Usyk is more than just a boxing event. It’s a fight of grit and strategy. The two competitors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are ready to face each other in a fight of historic proportions. It’s not merely about the belts; it’s about legacy. Tyson Fury has risen to the pinnacle of the sport through his unique style and remarkable adaptability in the ring. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. On the other hand, Usyk, the Ukrainian master poses a unique challenge to the heavyweight division. Meanwhile, Oleksandr Usyk represents a formidable opponent for the heavyweight ranks overall, as a heavyweight contender. His journey to global fame started with his domination of the cruiserweights, where he became an unstoppable force. Don’t miss out for an epic boxing match of the year as Oleksandr Usyk takes on Fury in an unforgettable showdown! Experience every moment in real time on our website. Join the excitement — visit <a href="http://chelo.nnov.org/common/redir.php?https://furyvsusykdate.com/">furyvsusykdate.com</a> now and stream the event from the comfort of your home!
In the United Kingdom, the fight is expected to begin close to prime time, offering perfect timing for viewers. Back in Usyk’s home country, and beyond, this will be a must-see event. The fight’s location remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, fans can be sure: the atmosphere will be electric. Although the focus is centered on the headline fight, the fights leading up to the main event promises plenty of action. High-profile matches include preliminary bouts with top talent, giving fans a full evening of entertainment.
Traditionally, preliminary fights on major cards have showcased rising stars. Fighters looking to rise through the ranks often seize these moments to demonstrate their talent, knowing millions are watching. Though the supporting fights for Fury vs Usyk are still unconfirmed, speculation runs high. Might there be a cruiserweight spectacle? Whatever the selection, the action will not disappoint. What makes this fight so intriguing is their contrasting skillsets. Fury’s towering frame and movement set him apart from other heavyweights. Being so tall yet so nimble, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, bouncing back from adversity to secure victories. Against Wladimir Klitschko, his strategic genius shone through, proving he’s not just physical but cerebral. Meanwhile, Usyk, offers a different kind of threat. As a southpaw, his positioning constantly challenges opponents. Usyk’s punches aren’t the heaviest in the division, they consistently find their mark. With the date drawing closer, Predictions for this fight have fans and analysts speculating.
Fury is the favored fighter as per the betting experts, given his physical stature, his experience in high-pressure bouts, and his unorthodox style. Despite the odds, Usyk remains a strong contender shouldn’t be counted out, his wins over Anthony Joshua confirmed his toughness against big opponents.
For Tyson Fury could be the defining moment of his career. A victory would solidify his claim as the greatest heavyweight of his generation. On the other hand, Usyk’s victory would elevate him to legendary status. Securing two undisputed titles is a feat few can claim.
Web: <a href="http://www.google.com.kh/url?q=https%3A%2F%2Ffuryvsusykdate.com">furyvsusykdate.com</a>
The upcoming showdown is about more than the titles. It’s a fight between two very different fighters. Fury’s larger-than-life persona contrasts with Usyk’s calm, focused demeanor. These varying personalities make the bout even more interesting. Beyond physical ability, this fight. Whoever comes out victorious, the impact of this bout will reverberate throughout boxing history. This historic showdown is more than just a match. It represents the culmination of their careers. Should Fury claim victory with his experience and unpredictability, or Usyk comes out on top through his superior boxing ability, no matter the outcome, this will be a legendary contest.
Fury vs Usyk is more than just a fight. It’s a fight of grit and strategy. These two warriors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are ready to face each other in a fight of historic proportions. This fight is about more than just titles; it’s a battle for eternal recognition. Fury, an undefeated champion has earned worldwide fame with his charisma and remarkable adaptability in the ring. His victories over Deontay Wilder and Wladimir Klitschko have cemented his place among the all-time greats. Meanwhile, Usyk, the Ukrainian master is a fighter unlike any other for Fury. Meanwhile, Usyk, a genius in the ring represents a formidable opponent not just for Fury, but for the entire division. Usyk’s rise to prominence started with his domination of the cruiserweights, as an undisputed champion. Don’t miss out for an epic boxing match of the year as Oleksandr Usyk takes on Fury in a historic showdown! Catch every punch streamed live on our website. Be part of the action — visit <a href="https://m.opt-union.ru/?no_mobail=1&url=https://tysonfuryvoleksandrusyk.com/">tysonfuryvoleksandrusyk.com</a> today and watch the match with top-notch streaming!
In the United Kingdom, the fight is expected to begin late evening, ensuring maximum viewership. In Usyk’s native Ukraine, and for fans watching from around the world, the anticipation is at a fever pitch. The venue for Fury vs Usyk is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, fans can be sure: it will be a spectacle. Even though attention remains on Fury and Usyk, the fights leading up to the main event promises plenty of action. Big-ticket boxing cards often feature stacked undercards, providing non-stop action before the headliner.
In the past, undercards of this caliber have been a stage for breakout performances. Contenders hoping to make their mark use such opportunities to showcase their skills, knowing millions are watching. Though the supporting fights for Fury vs Usyk has yet to be finalized, speculation runs high. Could we see rising prospects? Regardless of the names, fans can expect fireworks. What sets this bout apart truly fascinating is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed are unparalleled in the sport. Being so tall yet so nimble, Fury can control a fight.
The three fights against Wilder proved his toughness, as he recovered from knockdowns to finish strong. When he faced Klitschko, his strategic genius shone through, proving he’s not just physical but cerebral. Meanwhile, Usyk, offers a different kind of threat. With his unorthodox stance, he uses angles and footwork. The Ukrainian’s shots aren’t the heaviest in the division, they consistently find their mark. As fight night approaches, The betting lines for Fury vs Usyk are becoming a hot topic.
The betting lines show Fury ahead according to the odds, due to his size advantage, his experience in high-pressure bouts, and his tactical brilliance. However, Usyk's underdog status doesn’t diminish his chances, his dominance against Joshua proved that he can handle the physicality of the heavyweight division.
For the Gypsy King could be the defining moment of his career. A victory would solidify his claim as the greatest heavyweight of his generation. Conversely, Usyk’s victory would elevate him to new heights. Achieving undisputed glory in two divisions is a feat few can claim.
Web: <a href="http://www.google.sh/url?sa=t&url=http%3A%2F%2Fwww.magical-dream.com">tysonfuryvoleksandrusyk.com</a>
Fury vs Usyk is about more than the titles. It’s a battle of contrasting styles. Fury’s larger-than-life persona is the opposite of Usyk’s humble and disciplined approach. These varying personalities make the bout even more interesting. It’s about more than just skill. Whoever triumphs in this battle, the impact of this bout will be remembered as a defining moment in boxing. Fury vs Usyk is a defining moment. It represents the culmination of their careers. Whether Tyson Fury prevails through his strength and tactics, or Oleksandr Usyk triumphs thanks to his skill and resilience, no matter the outcome, this will be a fight remembered for years to come.
This fight between Fury and Usyk is a spectacle of a lifetime. It’s a fight of grit and strategy. These two warriors will give everything they have.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are set to meet in the ring of historic proportions. It’s not merely about the belts; it’s a battle for eternal recognition. Tyson Fury has become a global icon thanks to his personality and remarkable adaptability during fights. His victories over Deontay Wilder and Wladimir Klitschko have cemented his place among the all-time greats. On the other hand, Oleksandr Usyk is a fighter unlike any other for Fury. On the flip side, Usyk, a southpaw master is a true test for Fury for Tyson Fury himself, and for boxing fans worldwide. His journey to global fame started with his domination of the cruiserweights, by conquering all challengers. Get ready for the most anticipated boxing match of the year as Usyk takes on Fury in an unforgettable showdown! Experience every moment in real time on our website. Join the excitement — visit <a href="https://novosibirsk.purumburum.ru:443/redirect.php?url=http%3a%2f%2ftysonvsusyk.co.uk&city=RU-NVS&city_old=novosibirsk">tysonvsusyk.co.uk</a> right away and enjoy the fight in high quality!
In the United Kingdom, the ring walks are planned for around 10 PM GMT, offering perfect timing for viewers. For Usyk’s fans in Ukraine, and for fans watching from around the world, the anticipation is at a fever pitch. The fight’s location remains a hot topic, with talk of iconic boxing destinations. No matter the location, fans can be sure: the excitement will be unmatched. Although the focus remains on Fury and Usyk, the Fury vs Usyk undercard is shaping up to be thrilling. Big-ticket boxing cards include preliminary bouts with top talent, offering an entire night of boxing excitement.
Historically, undercards of this caliber have been a stage for breakout performances. Contenders hoping to make their mark use such opportunities to showcase their skills, as all eyes are on them. Though the supporting fights for Fury vs Usyk haven’t been officially announced, fans are eagerly guessing. Could we see rising prospects? Whatever the selection, the action will not disappoint. The most compelling part of Fury vs Usyk incredibly exciting is the clash of styles. Tyson Fury’s size and agility set him apart from other heavyweights. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
The legendary battles with Wilder proved his toughness, as he recovered from knockdowns to finish strong. In his fight with Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. By contrast, Usyk, brings speed, precision, and finesse. Being a left-handed fighter, he uses angles and footwork. The Ukrainian’s shots may not have knockout power, their timing wears down foes. As anticipation builds, The betting lines for Fury vs Usyk are the subject of intense debate.
Most bookmakers favor Fury based on the betting odds, due to his size advantage, his track record in big matches, and his unpredictable nature. Although Usyk is the less favored fighter doesn’t diminish his chances, his victories against AJ confirmed his toughness against big opponents.
For the Gypsy King represents an opportunity to cement his legacy. A victory would add an undisputed title to his already impressive resume. Conversely, For Usyk, a win would mark him as one of the sport’s greats. Becoming the undisputed heavyweight champion is a once-in-a-lifetime achievement.
Web: <a href="http://images.google.lt/url?q=https://tysonvsusyk.co.uk/">tysonvsusyk.co.uk</a>
This fight is about more than the titles. It’s a battle of contrasting styles. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. Such contrasts make the fight more compelling. It’s a fight of wills and ideologies. No matter who wins, the impact of this bout will leave a lasting mark on the sport. The battle for heavyweight supremacy is a spectacle unlike any other. It represents the culmination of their careers. Whether Tyson Fury prevails thanks to his power and game plan, or Usyk comes out on top with his technique and endurance, one thing is certain, this will be a defining moment in boxing.
Tyson Fury vs Oleksandr Usyk is more than just a fight. It’s a showcase of skill and determination. The two competitors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are on a collision course that will define an era. This fight is about more than just titles; it’s about legacy. Tyson Fury has earned worldwide fame thanks to his personality and his unmatched skills inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. In contrast, Usyk, the technician poses a unique challenge for Fury. On the flip side, Usyk, a genius in the ring stands as a unique threat not just for Fury, but for the entire division. Usyk’s rise to prominence began in the cruiserweight division, where he became an unstoppable force. Get ready for the most anticipated boxing match of the year as Oleksandr Usyk takes on Fury in a must-watch showdown! See every move live on our website. Be part of the action — visit <a href="https://clk.srv.stackadapt.com/clk?aid=4-00-153358340705801781316803-172x30x0x17z6379&cid=25476&adid=93419&sid=2&uid=Bt_9sSOjd0LZlqDtpdpSJw&curl=aHR0cHM6Ly9tb2RzLW1lbnUucnUv&did=cafepharma.com::28&adurl=https://caesarsslots.icu">tysonvusyk.co.uk</a> now and watch the match from the comfort of your home!
For British fans, the fight is expected to begin close to prime time, ensuring maximum viewership. For Usyk’s fans in Ukraine, and for fans watching from around the world, the excitement is palpable. The venue for Fury vs Usyk has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, fans can be sure: the atmosphere will be electric. Even though attention is centered on the headline fight, the Fury vs Usyk undercard is also generating excitement. High-profile matches include preliminary bouts with top talent, giving fans a full evening of entertainment.
Historically, supporting bouts in major events have been a stage for breakout performances. Boxers seeking the spotlight use such opportunities to impress fans and analysts alike, with the world paying attention. While the names for the undercard are still unconfirmed, there’s plenty of talk. Might there be a cruiserweight spectacle? Regardless of the names, fans can expect fireworks. The most compelling part of Fury vs Usyk incredibly exciting is the clash of styles. Tyson Fury’s size and agility set him apart from other heavyweights. Being so tall yet so nimble, Fury can control a fight.
The legendary battles with Wilder showed his durability, bouncing back from adversity to secure victories. Against Wladimir Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. By contrast, Usyk, brings speed, precision, and finesse. With his unorthodox stance, his movements create openings. Usyk’s punches aren’t the heaviest in the division, they consistently find their mark. As fight night approaches, The betting lines for Fury vs Usyk have fans and analysts speculating.
Tyson Fury is seen as the frontrunner according to the odds, because of his reach and height, his track record in big matches, and his unpredictable nature. However, Usyk's underdog status doesn’t diminish his chances, as his victories over Joshua confirmed his toughness against big opponents.
For the Gypsy King is a chance to further solidify his greatness. If he wins, it would add an undisputed title to his already impressive resume. Meanwhile, For Usyk, a win would elevate him to new heights. Becoming the undisputed heavyweight champion would be a remarkable feat in boxing history.
Web: <a href="http://google.com.qa/url?q=https://tysonvusyk.co.uk/">tysonvusyk.co.uk</a>
Fury vs Usyk represents something greater than a title bout. It’s a meeting of two unique worldviews. Fury’s boisterous personality is the opposite of Usyk’s humble and disciplined approach. These varying personalities make the bout even more interesting. Beyond physical ability, this fight. No matter who wins, the impact of this bout will be felt for years to come. This historic showdown is more than just a match. It’s the pinnacle of both fighters’ hard work. Should Fury claim victory thanks to his power and game plan, or Usyk secures a victory with his technique and endurance, one thing is certain, this will be a legendary contest.
Fury vs Usyk is more than just a sporting contest. It’s a contest of heart and willpower. Both fighters will leave it all in the ring.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are on a collision course that will define an era. It’s not merely about the belts; it’s about legacy. Fury, an undefeated champion has earned worldwide fame thanks to his personality coupled with unparalleled talent inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. In contrast, the tactical southpaw poses a unique challenge to the heavyweight division. On the flip side, Usyk, a genius in the ring stands as a unique threat for Tyson Fury himself, as a heavyweight contender. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, as an undisputed champion. Don’t miss out for a thrilling boxing match of the year as Oleksandr Usyk takes on Fury in a historic showdown! See every move in real time on our website. Be part of the action — visit <a href="http://erevozim.nnov.org/common/redir.php?https://usykvsfurydate.org.uk/">usykvsfurydate.org.uk</a> right away and enjoy the fight with top-notch streaming!
Across the UK, the ring walks are planned for close to prime time, ensuring maximum viewership. Back in Usyk’s home country, and for fans watching from around the world, this will be a must-see event. The venue for Fury vs Usyk remains a hot topic, with talk of iconic boxing destinations. No matter the location, it’s guaranteed: the excitement will be unmatched. Although the focus is centered on the headline fight, the preliminary bouts promises plenty of action. Big-ticket boxing cards include preliminary bouts with top talent, giving fans a full evening of entertainment.
Traditionally, undercards of this caliber have been a stage for breakout performances. Contenders hoping to make their mark use such opportunities to showcase their skills, with the world paying attention. While the names for the undercard are still unconfirmed, speculation runs high. Might there be a cruiserweight spectacle? Regardless of the names, the action will not disappoint. What sets this bout apart truly fascinating is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
His trilogy with Deontay Wilder highlighted his resilience, as he recovered from knockdowns to dominate in later rounds. When he faced Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. By contrast, Usyk, brings speed, precision, and finesse. Being a left-handed fighter, his positioning constantly challenges opponents. Usyk’s punches lack devastating strength, but they are delivered with pinpoint accuracy. As fight night approaches, Tyson Fury vs Usyk odds are the subject of intense debate.
The betting lines show Fury ahead as predicted by many experts, thanks to his imposing frame, his long career in major fights, and his unorthodox style. Despite the odds, Usyk remains a strong contender doesn’t rule him out, his wins over Anthony Joshua proved that he can handle the physicality of the heavyweight division.
For Tyson Fury is a chance to further solidify his greatness. If he wins, it would add an undisputed title to his already impressive resume. On the other hand, If Usyk wins would elevate him to new heights. Securing two undisputed titles is a once-in-a-lifetime achievement.
Web: <a href="http://www.google.hn/url?q=https%3A%2F%2Fusykvsfurydate.org.uk">usykvsfurydate.org.uk</a>
Fury vs Usyk is more than just a championship fight. It’s a battle of contrasting styles. Fury’s larger-than-life persona stands in stark contrast to Usyk’s composed demeanor. These differences add complexity to the fight. It’s about more than just skill. Whoever comes out victorious, the impact of this bout will reverberate throughout boxing history. The battle for heavyweight supremacy is more than just a fight. It represents the culmination of their careers. Whether Fury secures the win with his experience and unpredictability, or Oleksandr Usyk triumphs with his finesse and stamina, one thing is certain, this bout will go down in history.
Tyson Fury vs Oleksandr Usyk is more than just a fight. It’s a showcase of skill and determination. Both fighters will leave it all in the ring.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are set to meet in the ring that will define an era. It’s far beyond a championship match; it represents their quest for immortality. The towering Fury has earned worldwide fame with his charisma and remarkable adaptability inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. In contrast, Oleksandr Usyk is a fighter unlike any other to the heavyweight division. Meanwhile, Usyk, a southpaw master represents a formidable opponent not just for Fury, and for boxing fans worldwide. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Prepare yourself for an epic boxing match of the year as Oleksandr Usyk takes on Fury in an unforgettable showdown! Experience every moment streamed live on our website. Be part of the action — visit <a href="http://www.internettrafficreport.com/cgi-bin/cgirdir.exe?https://tysonvsusyk.co.uk/">tysonvsusyk.co.uk</a> today and stream the event in high quality!
Across the UK, the ring walks are planned for late evening, ensuring maximum viewership. Back in Usyk’s home country, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. The fight’s location is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, fans can be sure: the excitement will be unmatched. Although the focus is centered on the headline fight, the preliminary bouts is shaping up to be thrilling. High-profile matches are known for strong supporting fights, providing non-stop action before the headliner.
Traditionally, preliminary fights on major cards have showcased rising stars. Contenders hoping to make their mark use such opportunities to showcase their skills, knowing millions are watching. Although the lineup for the Fury Usyk undercard are still unconfirmed, speculation runs high. Will there be a heavyweight clash? Regardless of the names, the action will not disappoint. The most compelling part of Fury vs Usyk incredibly exciting is their contrasting skillsets. Fury’s towering frame and movement are unparalleled in the sport. Being so tall yet so nimble, he dictates the pace of bouts.
His trilogy with Deontay Wilder highlighted his resilience, as he recovered from knockdowns to dominate in later rounds. In his fight with Klitschko, his strategic genius shone through, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, offers a different kind of threat. Being a left-handed fighter, his movements create openings. The Ukrainian’s shots may not have knockout power, their timing wears down foes. As fight night approaches, The betting lines for Fury vs Usyk are the subject of intense debate.
Most bookmakers favor Fury as predicted by many experts, due to his size advantage, his proven ability in tough situations, and his unpredictable nature. However, Usyk's underdog status doesn’t diminish his chances, his wins over Anthony Joshua confirmed his toughness against big opponents.
For Tyson Fury is a chance to further solidify his greatness. Should he come out on top, Fury’s win would solidify his claim as the greatest heavyweight of his generation. Meanwhile, For Usyk, a win would be a monumental achievement. Becoming the undisputed heavyweight champion is a rare accomplishment.
Web: <a href="http://google.com.my/url?q=https://tysonvsusyk.co.uk/">tysonvsusyk.co.uk</a>
Fury vs Usyk is more than just a championship fight. It’s a meeting of two unique worldviews. Fury’s bold and unapologetic character is in stark contrast to Usyk’s quiet intensity. These varying personalities make the bout even more interesting. It’s about more than just skill. No matter who wins, the legacy of this fight will reverberate throughout boxing history. Fury vs Usyk is more than just a match. It’s a culmination of years of hard work. If Fury wins with his size and strategy, or Usyk comes out on top thanks to his skill and resilience, no matter the outcome, this will be a defining moment in boxing.
The Fury-Usyk battle is more than just a fight. It’s a contest of heart and willpower. The two competitors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are set to meet in the ring of unparalleled significance. This fight is about more than just titles; it’s a battle for eternal recognition. Tyson Fury has risen to the pinnacle of the sport with his charisma and remarkable adaptability inside the ropes. Beating Wilder and Klitschko have earned him recognition as one of the best ever. Meanwhile, Usyk, the Ukrainian master is a fighter unlike any other for Fury. On the flip side, Usyk, a genius in the ring represents a formidable opponent for the heavyweight ranks overall, and for boxing fans worldwide. His journey to global fame started with his domination of the cruiserweights, by conquering all challengers. Prepare yourself for the most anticipated boxing match of the year as Usyk takes on Fury in a historic showdown! See every move in real time on our website. Be part of the action — visit <a href="https://ghu.hit.gemius.pl/_sslredir/hitredir/id=bDFFBpiUvV.JU1XRfBo072Yl7FRZvIQTfBNYFEI.hgv.K7/stparam=zjlmeoqhnf/url=https://tysonfuryvsoleksandrusyk.co.uk/">tysonfuryvsoleksandrusyk.co.uk</a> now and stream the event with top-notch streaming!
For British fans, the ring walks are planned for around 10 PM GMT, offering perfect timing for viewers. Back in Usyk’s home country, as well as viewers across Europe and the Americas, the excitement is palpable. The fight’s location remains a hot topic, with talk of iconic boxing destinations. Wherever it happens, fans can be sure: the excitement will be unmatched. Although the focus is firmly on the main event, the Fury vs Usyk undercard is also generating excitement. High-profile matches often feature stacked undercards, giving fans a full evening of entertainment.
Historically, undercards of this caliber have showcased rising stars. Boxers seeking the spotlight often seize these moments to demonstrate their talent, knowing millions are watching. Although the lineup for the Fury Usyk undercard has yet to be finalized, speculation runs high. Might there be a cruiserweight spectacle? Whatever the selection, fans can expect fireworks. The most compelling part of Fury vs Usyk so intriguing is the clash of styles. Fury’s towering frame and movement are unparalleled in the sport. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
His trilogy with Deontay Wilder proved his toughness, bouncing back from adversity to secure victories. In his fight with Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, offers a different kind of threat. With his unorthodox stance, his positioning constantly challenges opponents. His strikes lack devastating strength, but they are delivered with pinpoint accuracy. With the date drawing closer, Tyson Fury vs Usyk odds are the subject of intense debate.
Tyson Fury is the slight favorite based on the betting odds, given his physical stature, his experience in high-pressure bouts, and his unorthodox style. Despite being seen as the underdog doesn’t mean he’s an underdog in spirit, as his victories over Joshua showed that he can compete at heavyweight.
For Fury himself is a chance to further solidify his greatness. A triumph for Fury would solidify his claim as the greatest heavyweight of his generation. On the other hand, For Usyk, a win would mark him as one of the sport’s greats. Becoming the undisputed heavyweight champion is a rare accomplishment.
Web: <a href="http://www.google.co.ma/url?sa=t&url=http%3A%2F%2Fwww.magical-dream.com">tysonfuryvsoleksandrusyk.co.uk</a>
This fight is more than just a championship fight. It’s a fight between two very different fighters. Fury’s confident and brash nature is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. This is more than just a physical contest. No matter who wins, the significance of this match will reverberate throughout boxing history. This historic showdown is more than just a match. It represents the culmination of their careers. If Fury wins with his size and strategy, or Usyk secures a victory through his superior boxing ability, what is clear is, this will be a legendary contest.
Fury vs Usyk is more than just a fight. It’s a contest of heart and willpower. Both fighters will fight with everything they possess.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are preparing for an epic showdown of unparalleled significance. It’s far beyond a championship match; it represents their quest for immortality. Fury, an undefeated champion has become a global icon through his unique style coupled with unparalleled talent in the ring. Beating Wilder and Klitschko have solidified his legendary status. Across the ring, Usyk, the technician poses a unique challenge to the heavyweight division. At the same time, Oleksandr Usyk stands as a unique threat not just for Fury, but for the entire division. The ascent of Oleksandr Usyk began in the cruiserweight division, where he became an unstoppable force. Get ready for a thrilling boxing match of the year as Usyk takes on Fury in an unforgettable showdown! See every move live on our website. Don’t miss your chance — visit <a href="https://www.consumersadvocate.org/p/atkins-diet-plans-review?url=https://usykvsfury.co.uk/">usykvsfury.co.uk</a> today and enjoy the fight in high quality!
Across the UK, the event will kick off at late evening, offering perfect timing for viewers. Back in Usyk’s home country, as well as viewers across Europe and the Americas, the excitement is palpable. The venue for Fury vs Usyk is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, fans can be sure: the atmosphere will be electric. While the spotlight is firmly on the main event, the Fury vs Usyk undercard promises plenty of action. Big-ticket boxing cards include preliminary bouts with top talent, giving fans a full evening of entertainment.
In the past, preliminary fights on major cards have introduced future champions. Fighters looking to rise through the ranks use such opportunities to demonstrate their talent, knowing millions are watching. Although the lineup for the Fury Usyk undercard haven’t been officially announced, speculation runs high. Might there be a cruiserweight spectacle? No matter the final roster, it’s sure to add to the excitement. What sets this bout apart so intriguing is the clash of styles. Fury’s towering frame and movement set him apart from other heavyweights. Being so tall yet so nimble, he commands the ring like no other.
The three fights against Wilder highlighted his resilience, overcoming brutal hits to secure victories. Against Wladimir Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Meanwhile, Usyk, brings speed, precision, and finesse. With his unorthodox stance, he uses angles and footwork. The Ukrainian’s shots may not have knockout power, but they are delivered with pinpoint accuracy. As anticipation builds, Predictions for this fight are becoming a hot topic.
The betting lines show Fury ahead based on the betting odds, due to his size advantage, his proven ability in tough situations, and his unorthodox style. Despite the odds, Usyk remains a strong contender doesn’t diminish his chances, his wins over Anthony Joshua confirmed his toughness against big opponents.
For Tyson Fury, this fight represents an opportunity to cement his legacy. Should he come out on top, Fury’s win would further solidify his status as the best heavyweight of this era. Conversely, If Usyk wins would be a monumental achievement. Becoming the undisputed heavyweight champion would be a remarkable feat in boxing history.
Web: <a href="http://images.google.cd/url?q=https://usykvsfury.co.uk/">usykvsfury.co.uk</a>
This fight is not just about the belts. It’s a meeting of two unique worldviews. Fury’s confident and brash nature stands in stark contrast to Usyk’s composed demeanor. Such contrasts make the fight more compelling. It’s about more than just skill. Whoever triumphs in this battle, the significance of this match will be remembered as a defining moment in boxing. The clash for the undisputed title is a spectacle unlike any other. It’s the result of relentless dedication. If Fury wins through his strength and tactics, or Usyk secures a victory with his finesse and stamina, it’s certain that, this will be a fight remembered for years to come.
Tyson Fury vs Oleksandr Usyk is a spectacle of a lifetime. It’s a battle of minds and bodies. Both fighters will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are preparing for an epic showdown of historic proportions. It’s far beyond a championship match; it’s about legacy. Tyson Fury has risen to the pinnacle of the sport through his unique style and remarkable adaptability during fights. His victories over Deontay Wilder and Wladimir Klitschko have cemented his place among the all-time greats. On the other hand, Oleksandr Usyk poses a unique challenge to boxing’s biggest stars. On the flip side, Usyk, a southpaw master stands as a unique threat for the heavyweight ranks overall, as a heavyweight contender. Usyk’s rise to prominence started with his domination of the cruiserweights, where he became an unstoppable force. Get ready for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a historic showdown! See every move streamed live on our website. Don’t miss your chance — visit <a href="https://www.undertow.club/redirector.php?url=https://usykvsfury.org.uk/">usykvsfury.org.uk</a> now and enjoy the fight with top-notch streaming!
Across the UK, the fight is expected to begin close to prime time, ensuring maximum viewership. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, the excitement is palpable. The venue for Fury vs Usyk is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, it’s guaranteed: the atmosphere will be electric. While the spotlight remains on Fury and Usyk, the Fury vs Usyk undercard promises plenty of action. Big-ticket boxing cards are known for strong supporting fights, offering an entire night of boxing excitement.
Historically, undercards of this caliber have showcased rising stars. Contenders hoping to make their mark use such opportunities to showcase their skills, as all eyes are on them. Although the lineup for the Fury Usyk undercard haven’t been officially announced, speculation runs high. Might there be a cruiserweight spectacle? Regardless of the names, the action will not disappoint. What sets this bout apart truly fascinating is the dynamic between these fighters. Tyson Fury’s size and agility are unparalleled in the sport. With his immense height and reach advantage, Fury can control a fight.
The legendary battles with Wilder showed his durability, as he recovered from knockdowns to secure victories. When he faced Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. Meanwhile, Usyk, offers a different kind of threat. As a southpaw, his positioning constantly challenges opponents. The Ukrainian’s shots may not have knockout power, they consistently find their mark. With the date drawing closer, Tyson Fury vs Usyk odds are the subject of intense debate.
The betting lines show Fury ahead according to the odds, thanks to his imposing frame, his track record in big matches, and his adaptability. Despite being seen as the underdog doesn’t rule him out, his wins over Anthony Joshua confirmed his toughness against big opponents.
For the Gypsy King is a chance to further solidify his greatness. Should he come out on top, Fury’s win would further solidify his status as the best heavyweight of this era. Conversely, If Usyk wins would be a monumental achievement. Becoming the undisputed heavyweight champion would be a remarkable feat in boxing history.
Web: <a href="http://www.google.sc/url?q=https://usykvsfury.org.uk/">usykvsfury.org.uk</a>
Fury vs Usyk represents something greater than a title bout. It’s a battle of contrasting styles. Fury’s bold and unapologetic character contrasts with Usyk’s calm, focused demeanor. These differences add complexity to the fight. This is more than just a physical contest. Regardless of the outcome, the significance of this match will leave a lasting mark on the sport. The clash for the undisputed title is more than just a fight. It’s a culmination of years of hard work. Whether Fury secures the win with his experience and unpredictability, or Oleksandr Usyk triumphs thanks to his skill and resilience, what is clear is, this will be a legendary contest.
Tyson Fury vs Oleksandr Usyk is more than just a fight. It’s a showcase of skill and determination. Both fighters will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Azərbaycandakı qumar sektorunda internet oyunlarına seçim artdıqca, Pinup kimi onlayn mərc xidmətləri daha çox tanınmağa başladı. Xüsusilə, Pin-up online sözləri hazırda Azərbaycandakı oyunçular üçün tanışdır. Pin-up azerbaycan müştərilərinə rəngarəng oyunlar təklif edir.
Pin-up azerbaycan, Azərbaycan oyunçuları üçün ən sevilən platformalardan biridir. Bu platforma müştərilərə fərqli oyun növləri verir və cəlbedici bonuslar ilə istifadəçilərin diqqətini çəkir.
Pin-up online kazino, fərqli oyun təcrübəsi təklif edən xidmətdir. Azəri bazarında geniş istifadə olunan Pinup, qumar oyunçuları üçün geniş oyun təcrübəsi verir.
Özəlliklə, "Pin-up casino online" mərcçilərə təhlükəsiz ödəmə sistemləri təmin edir. Kazino iştirakçıları, müvafiq və təhlükəsiz depozit və pul çıxarış imkanları vasitəsilə, oyun təcrübələrini asan və sürətli yerinə yetirə bilərlər.
Nəticə etibarilə, Pin-up cazino mərcçilərə təkcə oyunlar deyil, həm də sərfəli bonuslar və maraqlı aksiyalar təklif edir. Bu onlayn kazinoda, istifadəçilər güvənli bir təcrübə yaşayır.
Web: https://top-pinup.web.app
Pin-up casino online təkcə məhdud deyil. Oyunçular burada geniş mərc təcrübəsindən həzz ala bilərlər və geniş bonus imkanlarını qazanmaq imkanı əldə edərlər.
Ümumilikdə, Pin-up casino online, güvənli qumar təcrübəsi mərc həvəskarlarına təqdim etməklə mərc bazarında ən yaxşı seçimlərdən biridir. Azərbaycanda çox seçilməsi təsadüf deyil.
These two heavyweight champions are ready to face each other in a fight of unparalleled significance. This fight is about more than just titles; it’s about legacy. The Gypsy King has earned worldwide fame through his unique style and remarkable adaptability during fights. Triumphing against boxing legends like Wilder and Klitschko have solidified his legendary status. In contrast, the tactical southpaw poses a unique challenge to the heavyweight division. On the flip side, Oleksandr Usyk is a true test for Fury for Tyson Fury himself, as a heavyweight contender. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, by conquering all challengers. Get ready for a thrilling boxing match of the year as Usyk takes on Fury in an unforgettable showdown! See every move in real time on our website. Join the excitement — visit <a href="https://emoney-hubs.com/go.php?url=https://furyvsusykdate.org.uk/">furyvsusykdate.org.uk</a> today and stream the event with top-notch streaming!
For British fans, the ring walks are planned for close to prime time, offering perfect timing for viewers. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. The venue for Fury vs Usyk has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, it’s guaranteed: the excitement will be unmatched. Even though attention is centered on the headline fight, the preliminary bouts is shaping up to be thrilling. Big-ticket boxing cards are known for strong supporting fights, offering an entire night of boxing excitement.
Traditionally, supporting bouts in major events have been a stage for breakout performances. Boxers seeking the spotlight use such opportunities to demonstrate their talent, knowing millions are watching. Although the lineup for the Fury Usyk undercard haven’t been officially announced, there’s plenty of talk. Might there be a cruiserweight spectacle? Regardless of the names, fans can expect fireworks. What sets this bout apart incredibly exciting is their contrasting skillsets. Tyson Fury’s size and agility make him an anomaly in boxing. Being so tall yet so nimble, he dictates the pace of bouts.
The three fights against Wilder highlighted his resilience, bouncing back from adversity to dominate in later rounds. When he faced Klitschko, his strategic genius shone through, showing he’s both powerful and smart. By contrast, Usyk, relies on technique and stamina. With his unorthodox stance, he uses angles and footwork. His strikes aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. As fight night approaches, The betting lines for Fury vs Usyk are the subject of intense debate.
Most bookmakers favor Fury according to the odds, because of his reach and height, his proven ability in tough situations, and his adaptability. Despite being seen as the underdog doesn’t mean he’s an underdog in spirit, as his victories over Joshua confirmed his toughness against big opponents.
For Fury himself presents a shot at undisputed glory. Should he come out on top, Fury’s win would solidify his claim as the greatest heavyweight of his generation. Meanwhile, For Usyk, a win would elevate him to new heights. Securing two undisputed titles is a once-in-a-lifetime achievement.
Web: <a href="http://www.google.it/url?q=https://furyvsusykdate.org.uk/">furyvsusykdate.org.uk</a>
This fight is not just about the belts. It’s a meeting of two unique worldviews. Fury’s confident and brash nature is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. Beyond physical ability, this fight. Whoever triumphs in this battle, the impact of this bout will be felt for years to come. Fury vs Usyk is more than just a fight. It’s the result of relentless dedication. If Fury wins thanks to his power and game plan, or Oleksandr Usyk triumphs thanks to his skill and resilience, what is clear is, this will be a fight remembered for years to come.
This fight between Fury and Usyk is more than just a fight. It’s a showcase of skill and determination. The two competitors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azərbaycandakı qumar sektorunda qumar oyunlarına sevgisi artdıqca, Pinup kazino kimi şirkətlər daha çox tanınmağa başladı. Bunun nəticəsində, Pin-up azerbaycan şəklində olan platformalar son zamanlar yerli oyunçular üçün məşhurdur. Pin-up casino istifadəçilərə məxsus geniş oyunlar təklif edir.
Pin up kazino, Azərbaycan oyunçuları üçün populyar seçimdir. Bu mərc platforması oyunçulara çeşidli qumar oyunları oyunçulara təqdim edir və cəlbedici bonuslar ilə müştərilərini məmnun edir.
Pin-up online kazino, geniş oyun variantları təklif edən bir platformadır. Azərbaycan ərazisində oyunçular tərəfindən sevilən Pin-up casino, kazino oyunçuları üçün zəngin təkliflər təqdim edir.
Bununla yanaşı, Pin-up azerbaycan mərc edənlərə etibarlı maliyyə sistemləri təqdim edir. Mərc edənlər, rahat depozit çıxarış sistemi ilə təmin olunmaqla, onlayn mərc oyunlarını çox rahat yerinə yetirə bilərlər.
Bununla yanaşı, Pin-up azerbaycan qumarbazlara yalnız oyun təklif etmir mərc hədiyyələri oyun təcrübəsini daha da maraqlı edir. Bu platformada, oyunçular özlərini güvəndə hiss edir.
Web: https://bet-pinup.web.app
Pin-up azerbaycan yalnız məhdud deyil. Mərc həvəskarları bu platformada fərqli mərc oyunlarından yararlana bilərlər və geniş bonus imkanlarını oyun təcrübələrinə əlavə edərlər.
Ümumilikdə, Pin-up azerbaycan, güvənli mərc oyunları mərc həvəskarlarına təqdim etməklə onlayn qumar sektorunda güclü mövqe tutub. Azəri bazarında məşhur olması dikkətə layiqdir.
Tyson Fury and Oleksandr Usyk are on a collision course that will define an era. It’s far beyond a championship match; it’s about legacy. Tyson Fury has become a global icon thanks to his personality and his unmatched skills during fights. Beating Wilder and Klitschko have earned him recognition as one of the best ever. On the other hand, Usyk, the Ukrainian master poses a unique challenge to the heavyweight division. On the flip side, Usyk, a genius in the ring is a true test for Fury not just for Fury, and for boxing fans worldwide. The ascent of Oleksandr Usyk began in the cruiserweight division, where he became an unstoppable force. Don’t miss out for the most anticipated boxing match of the year as Usyk takes on Tyson Fury in a must-watch showdown! Catch every punch in real time on our website. Don’t miss your chance — visit <a href="http://o.nnov.org/common/redir.php?https://furyvsusykdate.org.uk/">furyvsusykdate.org.uk</a> now and watch the match from the comfort of your home!
In the United Kingdom, the fight is expected to begin late evening, ensuring maximum viewership. Back in Usyk’s home country, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. Where the bout will take place remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, fans can be sure: it will be a spectacle. Although the focus remains on Fury and Usyk, the fights leading up to the main event is also generating excitement. Major boxing events are known for strong supporting fights, offering an entire night of boxing excitement.
In the past, preliminary fights on major cards have been a stage for breakout performances. Boxers seeking the spotlight often seize these moments to demonstrate their talent, knowing millions are watching. Though the supporting fights for Fury vs Usyk haven’t been officially announced, there’s plenty of talk. Might there be a cruiserweight spectacle? No matter the final roster, fans can expect fireworks. The most compelling part of Fury vs Usyk truly fascinating is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. With his immense height and reach advantage, Fury can control a fight.
The legendary battles with Wilder showed his durability, as he recovered from knockdowns to secure victories. When he faced Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. Meanwhile, Usyk, brings speed, precision, and finesse. As a southpaw, his movements create openings. Usyk’s punches lack devastating strength, their timing wears down foes. With the date drawing closer, Tyson Fury vs Usyk odds are the subject of intense debate.
Tyson Fury is seen as the frontrunner as predicted by many experts, due to his size advantage, his proven ability in tough situations, and his unorthodox style. Despite the odds, Usyk remains a strong contender doesn’t diminish his chances, his dominance against Joshua proved that he can handle the physicality of the heavyweight division.
For Tyson Fury represents an opportunity to cement his legacy. Should he come out on top, Fury’s win would add an undisputed title to his already impressive resume. Conversely, For Usyk, a win would be a monumental achievement. Becoming the undisputed heavyweight champion is a rare accomplishment.
Web: <a href="http://www.google.gl/url?q=https%3A%2F%2Ffuryvsusykdate.org.uk">furyvsusykdate.org.uk</a>
Fury vs Usyk is about more than the titles. It’s a clash of personalities. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. Such contrasts make the fight more compelling. This is more than just a physical contest. Regardless of the outcome, the legacy of this fight will be felt for years to come. This historic showdown is a spectacle unlike any other. It’s the pinnacle of both fighters’ hard work. Whether Tyson Fury prevails thanks to his power and game plan, or Usyk comes out on top thanks to his skill and resilience, one thing is certain, this bout will go down in history.
This fight between Fury and Usyk is a spectacle of a lifetime. It’s a contest of heart and willpower. These two warriors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Azərbaycandakı qumar sektorunda virtual qumar oyunlarına seçim artdıqca, Pin-up kazino kimi şirkətlər daha çox tanınmağa başladı. Əlavə olaraq, Pin-up kazino şəklində olan platformalar indi Azəri mərc həvəskarları üçün adidir. Pin-up kazino online müştərilərinə geniş oyunlar təklif edir.
Pin-up casino, yerli mərc həvəskarları üçün ən sevilən platformalardan biridir. Bu qumar saytı oyunçulara fərqli oyun növləri verir və cəlbedici bonuslar ilə oyunçuları özünə cəlb edir.
Pinup casino, fərqli oyun təcrübəsi təklif edən onlayn kazinodur. Azəri bazarında çox seçilən Pin-up oyunları, yerli oyunçular üçün çeşidli bonus imkanları yaradır.
Əlavə olaraq, Pinup kazino mərc edənlərə etibarlı depozit və çıxarış imkanı təklif etməkdədir. İstifadəçilər, etibarlı və tez depozit çıxarış sistemi sayəsində, internet oyunlarını çox rahat yaşaya bilərlər.
Sonda, Pin-up casino online mərc həvəskarlarına təkcə oyunlar deyil, həm də bonuslar və aksiyalar təmin edir. Pinup-da, istifadəçilər rahat və təhlükəsiz şəraitdə oynayır.
Web: https://win-top-pin-up.web.app
Pin-up azerbaycan təkcə bir kazino olaraq məhdud deyil. İstifadəçilər Pinup-da müxtəlif mərc növlərindən faydalanıb və çoxlu bonusları oyunlarına əlavə edə bilərlər.
Sonda, Pinup kazino, şəffaf və güvənli kazino təcrübəsi mərc həvəskarlarına təqdim etməklə onlayn qumar dünyasında oyunçular arasında geniş istifadə edilir. yerli oyunçular arasında çox seçilməsi açıq bir faktdır.
Fury, the Gypsy King, and Usyk, the technician are ready to face each other in a fight of unparalleled significance. This fight is about more than just titles; it represents their quest for immortality. Tyson Fury has risen to the pinnacle of the sport thanks to his personality and remarkable adaptability in the ring. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. Meanwhile, Usyk, the technician poses a unique challenge to boxing’s biggest stars. At the same time, Usyk, a genius in the ring stands as a unique threat for Tyson Fury himself, and for boxing fans worldwide. Usyk’s rise to prominence started with his domination of the cruiserweights, by conquering all challengers. Get ready for a thrilling boxing match of the year as Usyk takes on Fury in an unforgettable showdown! See every move in real time on our website. Be part of the action — visit <a href="https://blog.lenodal.com/exit.php?url=aHR0cHM6Ly9tb2RzLW1lbnUucnUv">tysonvsusyk.org.uk</a> now and watch the match with top-notch streaming!
In the United Kingdom, the ring walks are planned for close to prime time, offering perfect timing for viewers. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, the excitement is palpable. Where the bout will take place is still under speculation, with talk of iconic boxing destinations. Wherever it happens, fans can be sure: the atmosphere will be electric. Even though attention remains on Fury and Usyk, the preliminary bouts is also generating excitement. Big-ticket boxing cards include preliminary bouts with top talent, providing non-stop action before the headliner.
In the past, preliminary fights on major cards have showcased rising stars. Fighters looking to rise through the ranks often seize these moments to showcase their skills, knowing millions are watching. Though the supporting fights for Fury vs Usyk has yet to be finalized, speculation runs high. Might there be a cruiserweight spectacle? Whatever the selection, it’s sure to add to the excitement. The most compelling part of Fury vs Usyk incredibly exciting is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed are unparalleled in the sport. Being so tall yet so nimble, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, overcoming brutal hits to dominate in later rounds. Against Wladimir Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Meanwhile, Usyk, relies on technique and stamina. With his unorthodox stance, his movements create openings. Usyk’s punches aren’t the heaviest in the division, they consistently find their mark. With the date drawing closer, Tyson Fury vs Usyk odds have fans and analysts speculating.
The betting lines show Fury ahead according to the odds, given his physical stature, his long career in major fights, and his adaptability. Despite being seen as the underdog doesn’t mean he’s an underdog in spirit, his wins over Anthony Joshua confirmed his toughness against big opponents.
For Tyson Fury could be the defining moment of his career. A triumph for Fury would further solidify his status as the best heavyweight of this era. Conversely, If Usyk wins would mark him as one of the sport’s greats. Becoming an undisputed champion in two different weight classes is a feat few can claim.
Web: <a href="http://images.google.lv/url?q=https://tysonvsusyk.org.uk/">tysonvsusyk.org.uk</a>
This fight is not just about the belts. It’s a clash of personalities. Fury’s confident and brash nature is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. It’s about more than just skill. Whoever comes out victorious, the legacy of this fight will be remembered as a defining moment in boxing. Fury vs Usyk is a defining moment. It’s the pinnacle of both fighters’ hard work. Whether Fury secures the win thanks to his power and game plan, or Usyk secures a victory with his finesse and stamina, no matter the outcome, this bout will go down in history.
Fury vs Usyk is more than just a sporting contest. It’s a battle of minds and bodies. Both fighters will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında qumar oyunlarına güvəni artdıqca, Pin-up kazino kimi saytlar daha çox tanınmağa başladı. Bununla bərabər, "Pin up casino online" şəklində olan platformalar tez-tez yerli oyunçular üçün tanışdır. Pin-up azerbaycan istifadəçilərə məxsus müxtəlif oyunlar təklif edir.
Pin-up cazino, Azəri istifadəçilər üçün geniş kütləyə sahib bir qumar saytıdır. Bu platforma qumarbazlara müxtəlif oyunlar təklif edir və cəlbedici bonuslar ilə oyunçuları özünə cəlb edir.
Pin-up cazino, geniş oyun variantları təklif edən bir platformadır. yerli mərcçilər arasında məşhur olan Pin-up online, oyun həvəskarları üçün çeşidli bonus imkanları yaradır.
Bu səbəbdən, Pinup kazino mərc edənlərə etibarlı və güvənli maliyyə əməliyyatları təklif edir. Müştərilər, müvafiq və təhlükəsiz depozit və pul çıxarış imkanları vasitəsilə, kazino oyunlarını asan və sürətli təcrübə edərlər.
Sonda, Pin-up kazino müştərilərə təkcə oyunlar deyil, həm də sərfəli bonuslar müştəriləri üçün yaradır. Bu platformada, istifadəçilər güvənli bir təcrübə yaşayır.
Web: https://pinup-best-bet.web.app
Pin-up casino online təkcə bir oyun platforması kimi oyunlar ilə kifayətlənmir. Qumarçılar burada geniş mərc təcrübəsindən müxtəlif mərc imkanı əldə edə bilər və bonus sistemini mərc təcrübələrini zənginləşdirərlər.
Beləliklə, Pinup kazino, etibarlı oyun imkanı oyunçulara təklif etməklə oyun bazarında oyunçular arasında geniş istifadə edilir. Azərbaycanda seçim olması göz qabağındadır.
The undefeated Fury and Usyk are preparing for an epic showdown that will define an era. It’s far beyond a championship match; it represents their quest for immortality. Fury, an undefeated champion has risen to the pinnacle of the sport through his unique style coupled with unparalleled talent inside the ropes. Beating Wilder and Klitschko have solidified his legendary status. Across the ring, Usyk, the Ukrainian master is a fighter unlike any other for Fury. Meanwhile, Usyk, a southpaw master represents a formidable opponent for Tyson Fury himself, but for the entire division. The ascent of Oleksandr Usyk began in the cruiserweight division, as an undisputed champion. Prepare yourself for an epic boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! Experience every moment in real time on our website. Don’t miss your chance — visit <a href="https://doba.te.ua/gateway?goto=https://tysonfuryvsoleksandrusyk.co.uk/">tysonfuryvsoleksandrusyk.co.uk</a> today and enjoy the fight in high quality!
For British fans, the fight is expected to begin late evening, ensuring maximum viewership. Back in Usyk’s home country, and for fans watching from around the world, the excitement is palpable. The fight’s location is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, it’s guaranteed: the excitement will be unmatched. Although the focus remains on Fury and Usyk, the fights leading up to the main event is shaping up to be thrilling. Major boxing events often feature stacked undercards, offering an entire night of boxing excitement.
In the past, undercards of this caliber have been a stage for breakout performances. Fighters looking to rise through the ranks often seize these moments to demonstrate their talent, as all eyes are on them. Although the lineup for the Fury Usyk undercard are still unconfirmed, fans are eagerly guessing. Might there be a cruiserweight spectacle? No matter the final roster, fans can expect fireworks. What sets this bout apart so intriguing is the dynamic between these fighters. Tyson Fury’s size and agility set him apart from other heavyweights. Being so tall yet so nimble, he dictates the pace of bouts.
The three fights against Wilder showed his durability, overcoming brutal hits to secure victories. When he faced Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, offers a different kind of threat. Being a left-handed fighter, he uses angles and footwork. The Ukrainian’s shots may not have knockout power, their timing wears down foes. As anticipation builds, Predictions for this fight are the subject of intense debate.
The betting lines show Fury ahead as per the betting experts, due to his size advantage, his proven ability in tough situations, and his adaptability. However, Usyk's underdog status shouldn’t be counted out, his wins over Anthony Joshua showed that he can compete at heavyweight.
For Tyson Fury, this fight is a chance to further solidify his greatness. A triumph for Fury would put the finishing touches on a historic career. On the other hand, Usyk’s victory would elevate him to new heights. Becoming the undisputed heavyweight champion is a feat few can claim.
Web: <a href="http://www.google.com.sv/url?q=https://tysonfuryvsoleksandrusyk.co.uk/">tysonfuryvsoleksandrusyk.co.uk</a>
This fight is more than just a championship fight. It’s a battle of contrasting styles. Fury’s larger-than-life persona is in stark contrast to Usyk’s quiet intensity. These varying personalities make the bout even more interesting. It’s about more than just skill. Whoever triumphs in this battle, the significance of this match will be felt for years to come. The clash for the undisputed title is more than just a fight. It’s the pinnacle of both fighters’ hard work. Should Fury claim victory with his size and strategy, or Oleksandr Usyk triumphs thanks to his skill and resilience, it’s certain that, this will be a defining moment in boxing.
Tyson Fury vs Oleksandr Usyk is a spectacle of a lifetime. It’s a fight of grit and strategy. Both fighters will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azəri bazarında virtual qumar oyunlarına maraq artdıqca, "Pin-up casino" kimi şirkətlər daha çox tanınmağa başladı. Bunun nəticəsində, Pinup azerbaycan şüarları son zamanlar yerli istifadəçilər üçün güvənlidir. Pin-up casino oyunçulara müxtəlif oyunlar təklif edir.
Pin-up azerbaycan, Azərbaycan oyunçuları üçün ən sevilən platformalardan biridir. Bu platforma istifadəçilərə geniş çeşidli oyunlar oyunçulara təqdim edir və gözəl hədiyyələr ilə oyunçuları özünə cəlb edir.
Pin-up online kazino, bənzərsiz oyun imkanı təqdim edən oyun məkanıdır. yerli mərcçilər arasında güvənilən Pin-up oyunları, oyun həvəskarları üçün geniş oyun təcrübəsi verir.
Bununla yanaşı, Pin-up online casino mərc edənlərə şəffaf və təhlükəsiz maliyyə əməliyyatları təklif etməkdədir. İstifadəçilər, rahat və tez maliyyə çıxarışları nəticəsində, mərc təcrübələrini daha rahat təcrübə edərlər.
Nəticə etibarilə, Pinup kazino müştərilərə təkcə oyunlar deyil, həm də cəlbedici kampaniyalar təmin edir. Pinup-da, mərc edənlər güvənli bir təcrübə yaşayır.
Web: https://best-pinup.web.app
Pin-up azerbaycan sadəcə məhdud oyunlar təklif etmir. Qumarçılar burada bənzərsiz mərc imkanlarından müxtəlif mərc imkanı əldə edə bilər və cazibədar bonus imkanlarını istifadə edə bilərlər.
Bunun nəticəsində, Pin-up casino, sərfəli və təhlükəsiz oyun imkanı oyunçulara təklif etməklə mərc bazarında lider mövqedədir. Azəri oyunçular tərəfindən tanınması təsadüfi deyil.
Tyson Fury and Oleksandr Usyk are ready to face each other in a fight of unparalleled significance. It’s not merely about the belts; it’s about legacy. The towering Fury has risen to the pinnacle of the sport with his charisma and his unmatched skills inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. On the other hand, Usyk, the Ukrainian master is a fighter unlike any other to the heavyweight division. On the flip side, Usyk, a southpaw master is a true test for Fury for Tyson Fury himself, and for boxing fans worldwide. The ascent of Oleksandr Usyk began in the cruiserweight division, as an undisputed champion. Get ready for the most anticipated boxing match of the year as Usyk takes on Tyson Fury in a must-watch showdown! See every move streamed live on our website. Don’t miss your chance — visit <a href="https://crm-hit-tracker.simpleviewinc.com/go/472/0/61/https%3A%2F%2Ftysonfuryvoleksandrusyk.org.uk">tysonfuryvoleksandrusyk.org.uk</a> now and stream the event from the comfort of your home!
Across the UK, the ring walks are planned for late evening, ensuring maximum viewership. In Usyk’s native Ukraine, and for fans watching from around the world, the excitement is palpable. Where the bout will take place has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, one thing is certain: the atmosphere will be electric. Even though attention is centered on the headline fight, the preliminary bouts is shaping up to be thrilling. High-profile matches are known for strong supporting fights, giving fans a full evening of entertainment.
Historically, supporting bouts in major events have introduced future champions. Fighters looking to rise through the ranks use such opportunities to showcase their skills, as all eyes are on them. Though the supporting fights for Fury vs Usyk haven’t been officially announced, there’s plenty of talk. Could we see rising prospects? No matter the final roster, fans can expect fireworks. What sets this bout apart incredibly exciting is their contrasting skillsets. Tyson Fury’s size and agility set him apart from other heavyweights. Being so tall yet so nimble, he commands the ring like no other.
The three fights against Wilder showed his durability, bouncing back from adversity to finish strong. When he faced Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. By contrast, Usyk, relies on technique and stamina. Being a left-handed fighter, his positioning constantly challenges opponents. The Ukrainian’s shots lack devastating strength, they consistently find their mark. With the date drawing closer, Predictions for this fight are becoming a hot topic.
Tyson Fury is seen as the frontrunner based on the betting odds, given his physical stature, his long career in major fights, and his unpredictable nature. However, Usyk's underdog status doesn’t diminish his chances, as his victories over Joshua confirmed his toughness against big opponents.
For Tyson Fury, this fight could be the defining moment of his career. If he wins, it would add an undisputed title to his already impressive resume. On the other hand, For Usyk, a win would elevate him to legendary status. Becoming an undisputed champion in two different weight classes is a once-in-a-lifetime achievement.
Web: <a href="http://maps.google.de/url?q=https://tysonfuryvoleksandrusyk.org.uk/">tysonfuryvoleksandrusyk.org.uk</a>
Fury vs Usyk is not just about the belts. It’s a fight between two very different fighters. Fury’s larger-than-life persona is the opposite of Usyk’s humble and disciplined approach. These varying personalities make the bout even more interesting. It’s a fight of wills and ideologies. No matter who wins, the legacy of this fight will be felt for years to come. The clash for the undisputed title is more than just a match. It represents the culmination of their careers. Whether Fury secures the win thanks to his power and game plan, or Usyk comes out on top through his superior boxing ability, no matter the outcome, this will be a legendary contest.
Tyson Fury vs Oleksandr Usyk is more than just a fight. It’s a showcase of skill and determination. These two warriors will give everything they have.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are ready to face each other in a fight that will define an era. It’s not merely about the belts; it’s a battle for eternal recognition. Fury, an undefeated champion has become a global icon through his unique style coupled with unparalleled talent in the ring. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Across the ring, Usyk, the Ukrainian master is a fighter unlike any other to boxing’s biggest stars. At the same time, the Ukrainian technician represents a formidable opponent not just for Fury, and for boxing fans worldwide. His journey to global fame started with his domination of the cruiserweights, where he became an unstoppable force. Get ready for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! Catch every punch in real time on our website. Be part of the action — visit <a href="https://adhu.hit.gemius.pl/_uachredir/hitredir/id=d6XgxArh47H2lDLb6mMrwpa2LU8F76bsaWrlNPleRKX.W7/stparam=tpjemunfmv/fastid=fzbkyxlmbmqfsvhwumnmwmzundob/nc=0/url=https://usykvsfurydate.com/">usykvsfurydate.com</a> today and enjoy the fight with top-notch streaming!
For British fans, the ring walks are planned for close to prime time, ensuring maximum viewership. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. Where the bout will take place has yet to be confirmed, with talk of iconic boxing destinations. Wherever it happens, one thing is certain: the excitement will be unmatched. Even though attention is centered on the headline fight, the fights leading up to the main event is also generating excitement. Big-ticket boxing cards are known for strong supporting fights, providing non-stop action before the headliner.
In the past, undercards of this caliber have introduced future champions. Fighters looking to rise through the ranks use such opportunities to impress fans and analysts alike, as all eyes are on them. Although the lineup for the Fury Usyk undercard has yet to be finalized, there’s plenty of talk. Will there be a heavyweight clash? Whatever the selection, fans can expect fireworks. The most compelling part of Fury vs Usyk incredibly exciting is the clash of styles. Tyson Fury’s size and agility are unparalleled in the sport. With his immense height and reach advantage, he dictates the pace of bouts.
The legendary battles with Wilder showed his durability, as he recovered from knockdowns to secure victories. In his fight with Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Meanwhile, Usyk, offers a different kind of threat. As a southpaw, his movements create openings. The Ukrainian’s shots lack devastating strength, their timing wears down foes. As fight night approaches, The betting lines for Fury vs Usyk are the subject of intense debate.
Tyson Fury is the slight favorite as predicted by many experts, thanks to his imposing frame, his long career in major fights, and his tactical brilliance. Although Usyk is the less favored fighter doesn’t diminish his chances, as his victories over Joshua demonstrated his ability in the heavyweight ranks.
For Tyson Fury, this fight represents an opportunity to cement his legacy. Should he come out on top, Fury’s win would further solidify his status as the best heavyweight of this era. Conversely, For Usyk, a win would elevate him to legendary status. Achieving undisputed glory in two divisions is a once-in-a-lifetime achievement.
Web: <a href="http://cse.google.co.ao/url?q=https%3A%2F%2Fusykvsfurydate.com">usykvsfurydate.com</a>
Fury vs Usyk is not just about the belts. It’s a battle of contrasting styles. Fury’s larger-than-life persona is in stark contrast to Usyk’s quiet intensity. These varying personalities make the bout even more interesting. It’s about more than just skill. No matter who wins, the significance of this match will be felt for years to come. Fury vs Usyk is more than just a fight. It’s a culmination of years of hard work. Should Fury claim victory thanks to his power and game plan, or Usyk secures a victory thanks to his skill and resilience, what is clear is, this bout will go down in history.
Fury vs Usyk is a spectacle of a lifetime. It’s a battle of minds and bodies. These men will give everything they have.
Visit for more information: #crosslink[3,L -
Azərbaycandakı qumar sektorunda qumar oyunlarına tələbat artdıqca, "Pin-up casino" kimi oyun xidmətləri daha çox tanınmağa başladı. Xüsusilə, Pinup casino şüarları çoxdan yerli istifadəçilər üçün güvənlidir. Pin-up kazino istifadəçilərə çoxlu oyun növü təklif edir.
Pin-up azerbaycan, yerli oyunçular üçün maraqlı seçimdir. Bu platforma kazino oyunçularına fərqli oyun növləri verir və çoxlu bonuslar ilə mərc edənləri özünə cəlb edir.
Pin-up cazino, geniş oyun variantları təklif edən onlayn kazinodur. Azərbaycan ərazisində güvənilən Pin-up oyunları, kazino oyunçuları üçün fərqli oyun seçimləri ilə çıxış edir.
Əlavə olaraq, Pinup casino oyunçulara güvənli və şəffaf ödəmə sistemləri təklif etməkdədir. Oyunçular, rahat və tez maliyyə çıxarışları nəticəsində, internet oyunlarını daha rahat keçirə bilərlər.
Son olaraq, Pin-up cazino mərc həvəskarlarına çoxlu oyun növlərilə yanaşı sərfəli bonuslar müştəriləri üçün yaradır. Pinup-da, qumar həvəskarları özlərini güvəndə hiss edir.
Web: https://best-win-pinup.web.app
Pin-up azerbaycan yalnız bir mərc saytı kimi sadə oyunla bitmir. Müştərilər burada geniş mərc təcrübəsindən həzz ala bilərlər və cazibədar bonus imkanlarını oyun təcrübəsini artırarlar.
Yekun olaraq, Pin-up cazino, sərfəli və təhlükəsiz mərc imkanı təmin etməklə oyun bazarında özünü doğruldur. Azərbaycan mərcçiləri arasında populyarlığı dikkətə layiqdir.
Fury, the Gypsy King, and Usyk, the technician are on a collision course of unparalleled significance. It’s not merely about the belts; it’s about legacy. The Gypsy King has risen to the pinnacle of the sport thanks to his personality coupled with unparalleled talent in the ring. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. In contrast, Usyk, the technician brings an unprecedented test for Fury. At the same time, the Ukrainian technician represents a formidable opponent not just for Fury, and for boxing fans worldwide. His journey to global fame began in the cruiserweight division, where he became an unstoppable force. Don’t miss out for a thrilling boxing match of the year as Oleksandr Usyk takes on Fury in a historic showdown! Experience every moment live on our website. Don’t miss your chance — visit <a href="https://sv-sklad.expodat.ru/link.php?url=https://tysonfuryvoleksandrusyk.org.uk/">tysonfuryvoleksandrusyk.org.uk</a> today and stream the event from the comfort of your home!
For British fans, the event will kick off at late evening, ensuring maximum viewership. Back in Usyk’s home country, and for fans watching from around the world, this will be a must-see event. The venue for Fury vs Usyk is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, it’s guaranteed: the atmosphere will be electric. Although the focus remains on Fury and Usyk, the Fury vs Usyk undercard promises plenty of action. Big-ticket boxing cards are known for strong supporting fights, giving fans a full evening of entertainment.
In the past, undercards of this caliber have been a stage for breakout performances. Contenders hoping to make their mark use such opportunities to demonstrate their talent, knowing millions are watching. Though the supporting fights for Fury vs Usyk haven’t been officially announced, fans are eagerly guessing. Might there be a cruiserweight spectacle? Whatever the selection, it’s sure to add to the excitement. What makes this fight so intriguing is the dynamic between these fighters. Fury’s towering frame and movement are unparalleled in the sport. With his immense height and reach advantage, he commands the ring like no other.
The three fights against Wilder highlighted his resilience, bouncing back from adversity to dominate in later rounds. In his fight with Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. Meanwhile, Usyk, relies on technique and stamina. With his unorthodox stance, his movements create openings. The Ukrainian’s shots may not have knockout power, but they are delivered with pinpoint accuracy. As anticipation builds, Tyson Fury vs Usyk odds are becoming a hot topic.
Most bookmakers favor Fury based on the betting odds, given his physical stature, his track record in big matches, and his unorthodox style. Although Usyk is the less favored fighter doesn’t rule him out, his dominance against Joshua showed that he can compete at heavyweight.
For the Gypsy King could be the defining moment of his career. If he wins, it would further solidify his status as the best heavyweight of this era. Meanwhile, If Usyk wins would mark him as one of the sport’s greats. Securing two undisputed titles is a once-in-a-lifetime achievement.
Web: <a href="http://maps.google.com.uy/url?q=https://tysonfuryvoleksandrusyk.org.uk/">tysonfuryvoleksandrusyk.org.uk</a>
This fight is more than just a championship fight. It’s a fight between two very different fighters. Fury’s bold and unapologetic character is the opposite of Usyk’s humble and disciplined approach. These differences add complexity to the fight. It’s a fight of wills and ideologies. Regardless of the outcome, the legacy of this fight will leave a lasting mark on the sport. The clash for the undisputed title is a spectacle unlike any other. It’s the result of relentless dedication. Whether Tyson Fury prevails with his size and strategy, or Usyk secures a victory with his finesse and stamina, no matter the outcome, this will be a legendary contest.
This fight between Fury and Usyk is more than just a fight. It’s a battle of minds and bodies. These men will leave it all in the ring.
Visit for more information: #crosslink[3,L -
yerli oyunçular arasında internet qumarına tələbat artdıqca, "Pin-up casino" kimi platformalar daha çox tanınmağa başladı. Bununla bərabər, "Pin up casino online" şəklində olan platformalar son zamanlar yerli istifadəçilər üçün sevilir. Pinup casino müştərilərinə geniş oyunlar təklif edir.
Pin-up cazino, Azərbaycandakı oyunçular üçün geniş yayılmış bir xidmətdir. Bu kazino oyunçulara rəngarəng oyunlar təklif edir və cəlbedici bonuslar ilə istifadəçilərin diqqətini çəkir.
Pin-up casino online, oyun keyfiyyətini artıran şirkətdir. Azəri oyunçuları arasında məşhur olan Pin-up casino, oyun həvəskarları üçün geniş oyun təcrübəsi verir.
Xüsusilə, "Pin-up casino online" müştərilərə şəffaf və təhlükəsiz ödəmə üsulları verir. İstifadəçilər, rahat və tez kredit kartı və elektron pul kisəsi ilə vasitəsilə, kazino oyunlarını daha rahat təcrübə edə bilərlər.
Bununla yanaşı, Pin-up casino online qumarbazlara çoxlu oyun növlərilə yanaşı bonus imkanı oyunçularına verir. Bu kazinoda, kazino həvəskarları təhlükəsiz oyun mühitində olur.
Web: https://bet-on-pinup.web.app
Pin-up casino təkcə bir oyun platforması kimi oyunçuları cəlb etmir. İstifadəçilər Pinup-da müxtəlif mərc növlərindən təcrübə edə bilərlər və sərfəli bonus təkliflərini qazanmaq imkanı əldə edərlər.
Bunun nəticəsində, Pin-up kazino, şəffaf və güvənli mərc təcrübəsi mərc həvəskarlarına təqdim etməklə onlayn qumar sektorunda ən sevilən platformalardan olur. Azəri oyunçular tərəfindən tanınması təsadüf deyil.
Tyson Fury and Oleksandr Usyk are ready to face each other in a fight of unparalleled significance. It’s far beyond a championship match; it’s about legacy. Tyson Fury has risen to the pinnacle of the sport with his charisma coupled with unparalleled talent in the ring. Triumphing against boxing legends like Wilder and Klitschko have solidified his legendary status. Meanwhile, Usyk, the Ukrainian master poses a unique challenge to the heavyweight division. At the same time, Usyk, a southpaw master is a true test for Fury not just for Fury, but for the entire division. The ascent of Oleksandr Usyk began in the cruiserweight division, by conquering all challengers. Don’t miss out for a thrilling boxing match of the year as Oleksandr Usyk takes on Fury in an unforgettable showdown! Experience every moment in real time on our website. Join the excitement — visit <a href="https://zakupis-ekb.ru/out?a:aHR0cHM6Ly9tb2RzLW1lbnUucnUv">tysonvusyk.co.uk</a> today and stream the event from the comfort of your home!
Across the UK, the event will kick off at late evening, offering perfect timing for viewers. In Usyk’s native Ukraine, and beyond, the anticipation is at a fever pitch. The venue for Fury vs Usyk is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, one thing is certain: the atmosphere will be electric. Even though attention is centered on the headline fight, the fights leading up to the main event promises plenty of action. Major boxing events include preliminary bouts with top talent, giving fans a full evening of entertainment.
Historically, undercards of this caliber have introduced future champions. Boxers seeking the spotlight often seize these moments to impress fans and analysts alike, with the world paying attention. Although the lineup for the Fury Usyk undercard haven’t been officially announced, there’s plenty of talk. Might there be a cruiserweight spectacle? Whatever the selection, fans can expect fireworks. What sets this bout apart incredibly exciting is their contrasting skillsets. Fury’s towering frame and movement are unparalleled in the sport. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
The three fights against Wilder highlighted his resilience, bouncing back from adversity to dominate in later rounds. Against Wladimir Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. Meanwhile, Usyk, relies on technique and stamina. With his unorthodox stance, he uses angles and footwork. Usyk’s punches aren’t the heaviest in the division, they consistently find their mark. As fight night approaches, Tyson Fury vs Usyk odds are becoming a hot topic.
Most bookmakers favor Fury as predicted by many experts, thanks to his imposing frame, his long career in major fights, and his adaptability. Despite being seen as the underdog doesn’t diminish his chances, as his victories over Joshua showed that he can compete at heavyweight.
For Fury himself is a chance to further solidify his greatness. A victory would put the finishing touches on a historic career. Conversely, Usyk’s victory would be a monumental achievement. Becoming an undisputed champion in two different weight classes is a once-in-a-lifetime achievement.
Web: <a href="http://maps.google.com.do/url?q=https%3A%2F%2Ftysonvusyk.co.uk">tysonvusyk.co.uk</a>
This fight is not just about the belts. It’s a battle of contrasting styles. Fury’s larger-than-life persona stands in stark contrast to Usyk’s composed demeanor. These differences add complexity to the fight. This is more than just a physical contest. No matter who wins, the impact of this bout will be felt for years to come. This historic showdown is a defining moment. It’s a culmination of years of hard work. Whether Fury secures the win through his strength and tactics, or Usyk wins with his precision through his superior boxing ability, what is clear is, this will be a fight remembered for years to come.
Fury vs Usyk is more than just a fight. It’s a fight of grit and strategy. Both fighters will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında internet oyunlarına maraq artdıqca, Pin-up kazino kimi platformalar daha çox tanınmağa başladı. Xüsusilə, Pinup azerbaycan sözləri tez-tez Azəri mərc həvəskarları üçün adidir. Pin-up casino azerbaycan istifadəçilərə məxsus çeşidli oyunlar təklif edir.
Pin-up cazino, Azəri qumarbazlar üçün populyar seçimdir. Bu qumar xidməti qumarbazlara fərqli oyun növləri verir və gözəl hədiyyələr ilə müştərilərini məmnun edir.
Pin-up cazino, fərqli oyun təcrübəsi təklif edən oyun məkanıdır. Azərbaycan ərazisində məşhur olan Pinup, yerli oyunçular üçün çeşidli bonus imkanları yaradır.
Bunun nəticəsində, Pin-up online casino qumar həvəskarlarına şəffaf və təhlükəsiz ödəmə üsulları təklif edir. İstifadəçilər, müvafiq və təhlükəsiz depozit çıxarış sistemi ilə təmin olunmaqla, qumar təcrübələrini güvənli və təhlükəsiz keçirə bilərlər.
Bununla yanaşı, Pin-up azerbaycan oyunçulara yalnız qumar oyunları yox, həmçinin sərfəli bonuslar oyunçularına verir. Pin-up-da, oyunçular rahat və təhlükəsiz şəraitdə oynayır.
Web: https://pinup-top-bet.web.app
Pin-up online kazino sadəcə oyunlar ilə kifayətlənmir. Qumarçılar burada fərqli mərc seçimlərindən istifadə edə bilər və sərfəli bonus təkliflərini istifadə edə bilərlər.
Sonda, Pin-up casino online, rahat və təhlükəsiz mərc təcrübəsi təmin etməklə onlayn qumar sektorunda oyunçular arasında geniş istifadə edilir. Azərbaycan mərcçiləri arasında seçim olması göz qabağındadır.
The undefeated Fury and Usyk are on a collision course of historic proportions. This fight is about more than just titles; it represents their quest for immortality. Fury, an undefeated champion has earned worldwide fame with his charisma coupled with unparalleled talent in the ring. Beating Wilder and Klitschko have solidified his legendary status. In contrast, Oleksandr Usyk poses a unique challenge to the heavyweight division. On the flip side, Oleksandr Usyk stands as a unique threat for Tyson Fury himself, and for boxing fans worldwide. His journey to global fame started with his domination of the cruiserweights, by conquering all challengers. Get ready for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a must-watch showdown! See every move live on our website. Be part of the action — visit <a href="https://mscp2.live-streams.nl:2197/play/play.cgi?url=https://usykvsfury.co.uk/">usykvsfury.co.uk</a> now and watch the match with top-notch streaming!
Across the UK, the fight is expected to begin late evening, offering perfect timing for viewers. Back in Usyk’s home country, and for fans watching from around the world, the anticipation is at a fever pitch. Where the bout will take place has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, one thing is certain: the atmosphere will be electric. While the spotlight is firmly on the main event, the preliminary bouts is also generating excitement. High-profile matches are known for strong supporting fights, offering an entire night of boxing excitement.
Historically, undercards of this caliber have been a stage for breakout performances. Boxers seeking the spotlight capitalize on the exposure to showcase their skills, knowing millions are watching. While the names for the undercard are still unconfirmed, there’s plenty of talk. Might there be a cruiserweight spectacle? Whatever the selection, it’s sure to add to the excitement. What makes this fight incredibly exciting is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. With his immense height and reach advantage, he commands the ring like no other.
His trilogy with Deontay Wilder proved his toughness, bouncing back from adversity to dominate in later rounds. When he faced Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. Meanwhile, Usyk, brings speed, precision, and finesse. Being a left-handed fighter, his positioning constantly challenges opponents. The Ukrainian’s shots may not have knockout power, their timing wears down foes. With the date drawing closer, Tyson Fury vs Usyk odds are the subject of intense debate.
Tyson Fury is the slight favorite according to the odds, thanks to his imposing frame, his long career in major fights, and his adaptability. Despite the odds, Usyk remains a strong contender doesn’t rule him out, his victories against AJ demonstrated his ability in the heavyweight ranks.
For Fury himself could be the defining moment of his career. A victory would solidify his claim as the greatest heavyweight of his generation. On the other hand, For Usyk, a win would mark him as one of the sport’s greats. Achieving undisputed glory in two divisions is a once-in-a-lifetime achievement.
Web: <a href="http://www.google.tl/url?q=https://usykvsfury.co.uk/">usykvsfury.co.uk</a>
Fury vs Usyk is about more than the titles. It’s a battle of contrasting styles. Fury’s bold and unapologetic character is the opposite of Usyk’s humble and disciplined approach. These varying personalities make the bout even more interesting. Beyond physical ability, this fight. No matter who wins, the impact of this bout will leave a lasting mark on the sport. This historic showdown is more than just a fight. It’s a culmination of years of hard work. Whether Fury secures the win with his size and strategy, or Usyk secures a victory through his superior boxing ability, no matter the outcome, this will be a legendary contest.
This fight between Fury and Usyk is more than just a fight. It’s a contest of heart and willpower. These men will give everything they have.
Visit for more information: #crosslink[3,L -
Azəri bazarında internet qumarına seçim artdıqca, Pin-up casino online kimi kazino xidmətləri daha çox tanınmağa başladı. Əsasən, "Pin up casino online" şəklində olan platformalar son zamanlar Azəri oyunçuları üçün tanışdır. Pin-up casino azerbaycan istifadəçilərə müxtəlif oyunlar təklif edir.
Pin-up cazino, Azərbaycandakı oyunçular üçün geniş kütləyə sahib bir qumar saytıdır. Bu qumar xidməti mərc həvəskarlarına rəngarəng oyunlar təmin edir və çoxlu bonuslar ilə istifadəçilərin diqqətini çəkir.
Pin-up casino online, fərqli oyun təcrübəsi təklif edən oyun məkanıdır. Azəri oyunçuları arasında məşhur olan Pin-up casino, yerli oyunçular üçün fərqli oyun seçimləri ilə çıxış edir.
Əlavə olaraq, Pin-up online casino mərc edənlərə güvənli və şəffaf maliyyə əməliyyatları verir. Oyun həvəskarları, çox rahat kredit kartı və elektron pul kisəsi ilə ilə, internet oyunlarını daha rahat oynaya bilərlər.
Əlavə olaraq, Pin-up casino oyunçulara geniş oyun təcrübəsi ilə yanaşı cəlbedici kampaniyalar oyun təcrübəsini daha da maraqlı edir. Bu platformada, mərc edənlər təhlükəsiz oyun mühitində olur.
Web: https://win-top-pin-up.web.app
Pin-up azerbaycan təkcə məhdudlaşmır. Qumarçılar burada fərqli mərc oyunlarından müxtəlif mərc imkanı əldə edə bilər və bonus sistemini qazanmaq imkanı əldə edərlər.
Ümumilikdə, Pin-up casino, müasir və təhlükəsiz kazino təcrübəsi təqdim etməklə onlayn qumar dünyasında ən sevilən platformalardan olur. Azəri bazarında tanınması təsadüfi deyil.
Tyson Fury and Oleksandr Usyk are set to meet in the ring of unparalleled significance. It’s far beyond a championship match; it’s about legacy. Tyson Fury has risen to the pinnacle of the sport with his charisma and his unmatched skills inside the ropes. Beating Wilder and Klitschko have earned him recognition as one of the best ever. Across the ring, Usyk, the technician brings an unprecedented test to the heavyweight division. On the flip side, Oleksandr Usyk stands as a unique threat not just for Fury, but for the entire division. His journey to global fame started with his domination of the cruiserweights, as an undisputed champion. Prepare yourself for a thrilling boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! Experience every moment live on our website. Be part of the action — visit <a href="http://pe2.isanook.com/ns/0/wb/i/url/tysonvsusyk.org.uk">tysonvsusyk.org.uk</a> now and stream the event from the comfort of your home!
Across the UK, the event will kick off at late evening, making it ideal for a prime-time audience. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. Where the bout will take place remains a hot topic, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, one thing is certain: it will be a spectacle. Although the focus is firmly on the main event, the fights leading up to the main event is also generating excitement. High-profile matches are known for strong supporting fights, providing non-stop action before the headliner.
Historically, undercards of this caliber have showcased rising stars. Boxers seeking the spotlight often seize these moments to demonstrate their talent, with the world paying attention. Though the supporting fights for Fury vs Usyk haven’t been officially announced, there’s plenty of talk. Will there be a heavyweight clash? Regardless of the names, the action will not disappoint. What sets this bout apart so intriguing is the dynamic between these fighters. Fury’s towering frame and movement are unparalleled in the sport. At 6’9" with an 85-inch reach, Fury can control a fight.
The legendary battles with Wilder highlighted his resilience, overcoming brutal hits to secure victories. When he faced Klitschko, his strategic genius shone through, proving he’s not just physical but cerebral. By contrast, Usyk, brings speed, precision, and finesse. As a southpaw, his movements create openings. His strikes may not have knockout power, they consistently find their mark. As fight night approaches, Predictions for this fight have fans and analysts speculating.
Tyson Fury is seen as the frontrunner based on the betting odds, due to his size advantage, his track record in big matches, and his tactical brilliance. However, Usyk's underdog status shouldn’t be counted out, his victories against AJ proved that he can handle the physicality of the heavyweight division.
For Tyson Fury, this fight represents an opportunity to cement his legacy. If he wins, it would solidify his claim as the greatest heavyweight of his generation. Meanwhile, Usyk’s victory would mark him as one of the sport’s greats. Becoming the undisputed heavyweight champion would be a remarkable feat in boxing history.
Web: <a href="http://www.google.com.pg/url?q=https://tysonvsusyk.org.uk/">tysonvsusyk.org.uk</a>
This fight is about more than the titles. It’s a meeting of two unique worldviews. Fury’s bold and unapologetic character is in stark contrast to Usyk’s quiet intensity. These differences add complexity to the fight. It’s about more than just skill. No matter who wins, the impact of this bout will reverberate throughout boxing history. This historic showdown is more than just a fight. It’s a culmination of years of hard work. Should Fury claim victory with his size and strategy, or Oleksandr Usyk triumphs thanks to his skill and resilience, what is clear is, this will be a defining moment in boxing.
Tyson Fury vs Oleksandr Usyk is more than just a boxing event. It’s a fight of grit and strategy. These two warriors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azəri bazarında online kazino oyunlarına seçim artdıqca, Pinup kazino kimi kazino xidmətləri daha çox tanınmağa başladı. Bunun nəticəsində, Pin-up kazino şüarları hazırda Azəri mərc həvəskarları üçün sevilir. Pin-up kazino oyunçulara çox oyun növləri təklif edir.
Pin-up kazino, Azərbaycandakı oyunçular üçün geniş yayılmış bir xidmətdir. Bu mərc platforması mərc həvəskarlarına fərqli oyun növləri təklif edib və cəlbedici bonuslar ilə müştərilərini məmnun edir.
Pin-up cazino, fərqli oyun təcrübəsi təklif edən saytdır. Azəri bazarında çox seçilən Pinup, qumar oyunçuları üçün geniş oyun variantları ilə tanınır.
Bu səbəbdən, Pinup casino qumar həvəskarlarına güvənli və şəffaf maliyyə sistemləri təklif etməkdədir. Müştərilər, etibarlı və tez depozit və pul çıxarış imkanları ilə təmin olunmaqla, kazino oyunlarını daha asan təcrübə edə bilərlər.
Sonda, Pin-up cazino qumarbazlara yalnız oyun təklif etmir bonuslar və aksiyalar oyun təcrübəsini daha da maraqlı edir. Pinup-da, müştərilər təhlükəsiz oyun mühitində olur.
Web: https://pinup-best-top.web.app
Pin-up casino sadəcə sadə oyunla bitmir. Oyunçular burada geniş mərc təcrübəsindən təcrübə edə bilərlər və cazibədar bonus imkanlarını oyun təcrübəsini artırarlar.
Nəticədə, Pin-up cazino, müasir və təhlükəsiz qumar təcrübəsi təklif etməklə onlayn qumar sektorunda özünü doğruldur. Azərbaycan mərcçiləri arasında çox seçilməsi açıq bir faktdır.
Fury, the Gypsy King, and Usyk, the technician are preparing for an epic showdown of historic proportions. This fight is about more than just titles; it represents their quest for immortality. Tyson Fury has risen to the pinnacle of the sport through his unique style and remarkable adaptability inside the ropes. Beating Wilder and Klitschko have cemented his place among the all-time greats. On the other hand, Usyk, the Ukrainian master is a fighter unlike any other for Fury. At the same time, the Ukrainian technician is a true test for Fury for the heavyweight ranks overall, but for the entire division. His journey to global fame was marked by his undisputed cruiserweight reign, as an undisputed champion. Don’t miss out for an epic boxing match of the year as Usyk takes on Tyson Fury in a must-watch showdown! See every move streamed live on our website. Don’t miss your chance — visit <a href="http://kursach.com/index.php?option=com_aicontactsafe&Itemid=109&lang=-1&pf=2&a%5B%5D=star+wars+mafia+game+(%3Ca+href=https://furyvsusykdate.org.uk/">furyvsusykdate.org.uk</a> today and enjoy the fight from the comfort of your home!
Across the UK, the fight is expected to begin close to prime time, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and beyond, the excitement is palpable. The venue for Fury vs Usyk is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. Regardless of the venue, fans can be sure: the atmosphere will be electric. Even though attention is centered on the headline fight, the preliminary bouts promises plenty of action. Major boxing events are known for strong supporting fights, providing non-stop action before the headliner.
Traditionally, undercards of this caliber have introduced future champions. Fighters looking to rise through the ranks use such opportunities to demonstrate their talent, as all eyes are on them. Although the lineup for the Fury Usyk undercard has yet to be finalized, fans are eagerly guessing. Might there be a cruiserweight spectacle? No matter the final roster, fans can expect fireworks. What sets this bout apart so intriguing is the dynamic between these fighters. Tyson Fury’s size and agility make him an anomaly in boxing. Being so tall yet so nimble, he dictates the pace of bouts.
His trilogy with Deontay Wilder showed his durability, bouncing back from adversity to finish strong. In his fight with Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, relies on technique and stamina. Being a left-handed fighter, he uses angles and footwork. Usyk’s punches aren’t the heaviest in the division, their timing wears down foes. With the date drawing closer, The betting lines for Fury vs Usyk have fans and analysts speculating.
Fury is the favored fighter according to the odds, because of his reach and height, his track record in big matches, and his adaptability. Despite being seen as the underdog doesn’t diminish his chances, his victories against AJ proved that he can handle the physicality of the heavyweight division.
For Tyson Fury, this fight represents an opportunity to cement his legacy. Should he come out on top, Fury’s win would solidify his claim as the greatest heavyweight of his generation. On the other hand, Usyk’s victory would mark him as one of the sport’s greats. Securing two undisputed titles is a once-in-a-lifetime achievement.
Web: <a href="http://www.google.co.ug/url?q=https%3A%2F%2Ffuryvsusykdate.org.uk">furyvsusykdate.org.uk</a>
Fury vs Usyk is more than just a championship fight. It’s a clash of personalities. Fury’s bold and unapologetic character stands in stark contrast to Usyk’s composed demeanor. The clash of personalities adds depth to the narrative. It’s about more than just skill. No matter who wins, the legacy of this fight will leave a lasting mark on the sport. The battle for heavyweight supremacy is more than just a match. It’s the pinnacle of both fighters’ hard work. Should Fury claim victory through his strength and tactics, or Usyk comes out on top through his superior boxing ability, it’s certain that, this will be a fight remembered for years to come.
Tyson Fury vs Oleksandr Usyk is more than just a fight. It’s a fight of grit and strategy. These two warriors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azəri bazarında internet oyunlarına güvəni artdıqca, Pin-up online kimi onlayn mərc xidmətləri daha çox tanınmağa başladı. Xüsusilə, Pin-up kazino sözləri artıq Azəri mərc həvəskarları üçün tanışdır. Pin-up azerbaycan oyunçulara çoxlu oyun növü təklif edir.
Pin-up azerbaycan, Azəri istifadəçilər üçün maraqlı seçimdir. Bu onlayn kazino müştərilərə rəngarəng oyunlar təmin edir və gözəl hədiyyələr ilə istifadəçilərin diqqətini çəkir.
Pinup casino, oyun keyfiyyətini artıran şirkətdir. Azəri bazarında çox seçilən Pin-up online, yerli oyunçular üçün geniş oyun variantları ilə tanınır.
Bu səbəbdən, Pinup kazino müştərilərə təhlükəsiz maliyyə əməliyyatları təklif etməkdədir. Oyunçular, çox rahat depozit çıxarış sistemi vasitəsilə, onlayn mərc oyunlarını çox rahat keçirə bilərlər.
Sonda, Pin-up casino online müştərilərə geniş oyun təcrübəsi ilə yanaşı bonus imkanı müştəriləri üçün yaradır. Bu onlayn kazinoda, qumar həvəskarları rahat və təhlükəsiz şəraitdə oynayır.
Web: https://best-pinup.web.app
Pin-up kazino təkcə məhdud oyunlar təklif etmir. Qumarçılar burada çeşidli mərc seçimlərindən yararlana bilərlər və cazibədar bonus imkanlarını istifadə edə bilərlər.
Yekun olaraq, Pin-up casino online, müasir və təhlükəsiz mərc oyunları istifadəçilərə verməklə oyun sənayesində lider mövqedədir. Azəri bazarında populyarlığı təsadüfi deyil.
Tyson Fury and Oleksandr Usyk are preparing for an epic showdown of unparalleled significance. It’s not merely about the belts; it’s about legacy. The towering Fury has risen to the pinnacle of the sport with his charisma coupled with unparalleled talent in the ring. Beating Wilder and Klitschko have earned him recognition as one of the best ever. On the other hand, Usyk, the Ukrainian master brings an unprecedented test to the heavyweight division. At the same time, Usyk, a genius in the ring represents a formidable opponent not just for Fury, as a heavyweight contender. The ascent of Oleksandr Usyk began in the cruiserweight division, where he became an unstoppable force. Get ready for an epic boxing match of the year as Oleksandr Usyk takes on Fury in a historic showdown! Experience every moment in real time on our website. Don’t miss your chance — visit <a href="http://hoyot.nnov.org/common/redir.php?https://tysonfuryvoleksandrusyk.org.uk/">tysonfuryvoleksandrusyk.org.uk</a> today and stream the event in high quality!
Across the UK, the ring walks are planned for around 10 PM GMT, making it ideal for a prime-time audience. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. The fight’s location remains a hot topic, with talk of iconic boxing destinations. No matter the location, one thing is certain: it will be a spectacle. While the spotlight remains on Fury and Usyk, the preliminary bouts promises plenty of action. Big-ticket boxing cards often feature stacked undercards, providing non-stop action before the headliner.
Traditionally, supporting bouts in major events have been a stage for breakout performances. Contenders hoping to make their mark use such opportunities to impress fans and analysts alike, knowing millions are watching. While the names for the undercard are still unconfirmed, speculation runs high. Will there be a heavyweight clash? Whatever the selection, it’s sure to add to the excitement. What sets this bout apart incredibly exciting is the clash of styles. Fury’s towering frame and movement make him an anomaly in boxing. Being so tall yet so nimble, he commands the ring like no other.
His trilogy with Deontay Wilder highlighted his resilience, overcoming brutal hits to dominate in later rounds. Against Wladimir Klitschko, his strategic genius shone through, showing he’s both powerful and smart. By contrast, Usyk, relies on technique and stamina. As a southpaw, his movements create openings. Usyk’s punches aren’t the heaviest in the division, they consistently find their mark. As anticipation builds, Predictions for this fight have fans and analysts speculating.
Tyson Fury is seen as the frontrunner based on the betting odds, because of his reach and height, his long career in major fights, and his adaptability. However, Usyk's underdog status doesn’t rule him out, as his victories over Joshua proved that he can handle the physicality of the heavyweight division.
For Fury himself represents an opportunity to cement his legacy. If he wins, it would put the finishing touches on a historic career. On the other hand, If Usyk wins would mark him as one of the sport’s greats. Securing two undisputed titles is a once-in-a-lifetime achievement.
Web: <a href="http://clients1.google.com.gh/url?q=https%3A%2F%2Ftysonfuryvoleksandrusyk.org.uk">tysonfuryvoleksandrusyk.org.uk</a>
Fury vs Usyk is not just about the belts. It’s a battle of contrasting styles. Fury’s bold and unapologetic character is the opposite of Usyk’s humble and disciplined approach. The clash of personalities adds depth to the narrative. It’s about more than just skill. Whoever comes out victorious, the impact of this bout will be felt for years to come. The battle for heavyweight supremacy is a spectacle unlike any other. It’s the pinnacle of both fighters’ hard work. Should Fury claim victory with his experience and unpredictability, or Usyk secures a victory thanks to his skill and resilience, no matter the outcome, this will be a fight remembered for years to come.
Fury vs Usyk is more than just a fight. It’s a showcase of skill and determination. The two competitors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Azərbaycanda online kazino oyunlarına sevgisi artdıqca, Pinup kimi oyun xidmətləri daha çox tanınmağa başladı. Əsasən, Pinup azerbaycan brendləri tez-tez yerli oyunçular üçün istifadə olunur. Pin-up kazino online müştərilərinə çox oyun növləri təklif edir.
Pin up kazino, Azəri qumarbazlar üçün geniş yayılmış bir xidmətdir. Bu onlayn kazino istifadəçilərə geniş çeşidli oyunlar təklif edir və bonus imkanları ilə müştərilərini məmnun edir.
Pin-up casino, bənzərsiz oyun imkanı təqdim edən onlayn kazinodur. Azərbaycanda güvənilən Pin-up oyunları, kazino oyunçuları üçün zəngin təkliflər təqdim edir.
Xüsusilə, Pin-up online casino oyunçulara etibarlı maliyyə əməliyyatları təklif edir. Kazino iştirakçıları, müvafiq və təhlükəsiz ödəmə üsulları köməyilə, oyun təcrübələrini müvafiq şəkildə yerinə yetirə bilərlər.
Sonda, Pinup kazino müştərilərə yalnız oyun təklif etmir cəlbedici kampaniyalar təmin edir. Bu platformada, qumar həvəskarları özlərini güvəndə hiss edir.
Web: https://pinup-best-casino.web.app
Pin-up azerbaycan sadəcə oyunlar ilə kifayətlənmir. İstifadəçilər Pinup-da çeşidli mərc seçimlərindən müxtəlif mərc imkanı əldə edə bilər və maraqlı aksiyaları oyun təcrübələrinə əlavə edərlər.
Sonda, Pin-up kazino, rahat və təhlükəsiz mərc imkanı oyunçulara təklif etməklə mərc bazarında ən sevilən platformalardan olur. yerli oyunçular arasında seçim olması dikkətə layiqdir.
The undefeated Fury and Usyk are on a collision course that will define an era. It’s far beyond a championship match; it’s a battle for eternal recognition. The towering Fury has risen to the pinnacle of the sport through his unique style and remarkable adaptability inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Across the ring, the tactical southpaw brings an unprecedented test to boxing’s biggest stars. On the flip side, Usyk, a genius in the ring is a true test for Fury not just for Fury, as a heavyweight contender. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, by conquering all challengers. Prepare yourself for an epic boxing match of the year as Usyk takes on Fury in a must-watch showdown! See every move in real time on our website. Be part of the action — visit <a href="https://on.substack.com/i/118786561?img=https%3A%2F%2Ftysonvsusyk.co.uk%2F">tysonvsusyk.co.uk</a> right away and enjoy the fight from the comfort of your home!
Across the UK, the fight is expected to begin close to prime time, offering perfect timing for viewers. Back in Usyk’s home country, and beyond, the excitement is palpable. Where the bout will take place remains a hot topic, with talk of iconic boxing destinations. Regardless of the venue, it’s guaranteed: it will be a spectacle. Even though attention remains on Fury and Usyk, the preliminary bouts is shaping up to be thrilling. Major boxing events are known for strong supporting fights, providing non-stop action before the headliner.
Historically, supporting bouts in major events have showcased rising stars. Fighters looking to rise through the ranks often seize these moments to showcase their skills, with the world paying attention. While the names for the undercard has yet to be finalized, fans are eagerly guessing. Could we see rising prospects? Regardless of the names, fans can expect fireworks. What makes this fight truly fascinating is the dynamic between these fighters. Tyson Fury’s size and agility make him an anomaly in boxing. Being so tall yet so nimble, he commands the ring like no other.
The three fights against Wilder proved his toughness, bouncing back from adversity to finish strong. In his fight with Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. As a southpaw, his positioning constantly challenges opponents. His strikes may not have knockout power, but they are delivered with pinpoint accuracy. As anticipation builds, Predictions for this fight are the subject of intense debate.
Fury is the favored fighter according to the odds, given his physical stature, his long career in major fights, and his adaptability. Although Usyk is the less favored fighter doesn’t rule him out, as his victories over Joshua demonstrated his ability in the heavyweight ranks.
For Fury himself is a chance to further solidify his greatness. A triumph for Fury would put the finishing touches on a historic career. Conversely, If Usyk wins would mark him as one of the sport’s greats. Achieving undisputed glory in two divisions would be a remarkable feat in boxing history.
Web: <a href="http://www.google.se/url?q=https%3A%2F%2Ftysonvsusyk.co.uk">tysonvsusyk.co.uk</a>
This fight represents something greater than a title bout. It’s a clash of personalities. Fury’s larger-than-life persona stands in stark contrast to Usyk’s composed demeanor. These differences add complexity to the fight. Beyond physical ability, this fight. Whoever comes out victorious, the impact of this bout will reverberate throughout boxing history. The clash for the undisputed title is a defining moment. It’s the pinnacle of both fighters’ hard work. Whether Tyson Fury prevails with his size and strategy, or Oleksandr Usyk triumphs with his finesse and stamina, one thing is certain, this will be a legendary contest.
Fury vs Usyk is more than just a boxing event. It’s a fight of grit and strategy. The two competitors will give everything they have.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında online kazino oyunlarına tələbat artdıqca, Pin-up online kimi platformalar daha çox tanınmağa başladı. Bunun nəticəsində, Pin-up azerbaycan ifadələri çoxdan Azəri oyunçuları üçün sevilir. Pin-up azerbaycan oyunçulara çoxlu oyun növü təklif edir.
Pinup kazino, Azərbaycan oyunçuları üçün geniş yayılmış bir xidmətdir. Bu platforma oyunçulara çoxlu oyun təklifləri təmin edir və çoxlu bonuslar ilə seçim olur.
Pin-up casino online, oyun keyfiyyətini artıran şirkətdir. Azərbaycan ərazisində populyar olan Pinup, istifadəçilər üçün geniş oyun variantları ilə tanınır.
Bunun nəticəsində, Pin-up online casino qumar həvəskarlarına təhlükəsiz maliyyə idarəetmə imkanları təqdim edir. Müştərilər, rahat və tez ödəmə üsulları ilə, mərc təcrübələrini müvafiq şəkildə keçirə bilərlər.
Yekun olaraq, Pin-up azerbaycan mərcçilərə təkcə oyun imkanı deyil sərfəli bonuslar müştəriləri üçün yaradır. Pin-up-da, istifadəçilər şəffaf oyun şərtləri ilə rastlaşır.
Web: https://best-pin-up-bet.web.app
Pin-up casino təkcə məhdud oyunlar təklif etmir. İstifadəçilər Pinup-da çeşidli mərc seçimlərindən istifadə edə bilər və cazibədar bonus imkanlarını oyun təcrübəsini artırarlar.
Ümumilikdə, Pin-up casino, etibarlı mərc imkanı təqdim etməklə oyun bazarında ən sevilən platformalardan olur. Azərbaycanda populyarlığı göz qabağındadır.
Tyson Fury and Oleksandr Usyk are preparing for an epic showdown of unparalleled significance. It’s not merely about the belts; it’s a battle for eternal recognition. The towering Fury has earned worldwide fame through his unique style and remarkable adaptability inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have solidified his legendary status. Across the ring, the tactical southpaw is a fighter unlike any other for Fury. Meanwhile, Oleksandr Usyk is a true test for Fury for the heavyweight ranks overall, but for the entire division. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, by conquering all challengers. Don’t miss out for an epic boxing match of the year as Usyk takes on Fury in a historic showdown! Catch every punch in real time on our website. Join the excitement — visit <a href="https://www.fantastika.printdirect.ru/utils/redirect?url=https://tysonvsusyk.org.uk/">tysonvsusyk.org.uk</a> today and enjoy the fight with top-notch streaming!
Across the UK, the fight is expected to begin late evening, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, and beyond, the anticipation is at a fever pitch. The venue for Fury vs Usyk has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. Regardless of the venue, one thing is certain: the atmosphere will be electric. Even though attention is centered on the headline fight, the Fury vs Usyk undercard is shaping up to be thrilling. Major boxing events include preliminary bouts with top talent, providing non-stop action before the headliner.
In the past, preliminary fights on major cards have introduced future champions. Boxers seeking the spotlight capitalize on the exposure to showcase their skills, knowing millions are watching. While the names for the undercard haven’t been officially announced, speculation runs high. Could we see rising prospects? No matter the final roster, it’s sure to add to the excitement. What sets this bout apart incredibly exciting is the dynamic between these fighters. Fury’s towering frame and movement set him apart from other heavyweights. Being so tall yet so nimble, Fury can control a fight.
His trilogy with Deontay Wilder proved his toughness, bouncing back from adversity to secure victories. In his fight with Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. Being a left-handed fighter, his movements create openings. His strikes aren’t the heaviest in the division, their timing wears down foes. As fight night approaches, Predictions for this fight have fans and analysts speculating.
Fury is the favored fighter according to the odds, due to his size advantage, his experience in high-pressure bouts, and his unorthodox style. Although Usyk is the less favored fighter doesn’t rule him out, his dominance against Joshua showed that he can compete at heavyweight.
For Fury himself could be the defining moment of his career. Should he come out on top, Fury’s win would add an undisputed title to his already impressive resume. Conversely, Usyk’s victory would be a monumental achievement. Becoming the undisputed heavyweight champion is a feat few can claim.
Web: <a href="http://cse.google.co.ke/url?q=https%3A%2F%2Ftysonvsusyk.org.uk">tysonvsusyk.org.uk</a>
The upcoming showdown represents something greater than a title bout. It’s a clash of personalities. Fury’s boisterous personality is the opposite of Usyk’s humble and disciplined approach. The clash of personalities adds depth to the narrative. It’s a fight of wills and ideologies. Whoever comes out victorious, the impact of this bout will be remembered as a defining moment in boxing. The clash for the undisputed title is more than just a match. It’s the pinnacle of both fighters’ hard work. Whether Tyson Fury prevails with his size and strategy, or Usyk comes out on top thanks to his skill and resilience, what is clear is, this will be a defining moment in boxing.
Tyson Fury vs Oleksandr Usyk is more than just a boxing event. It’s a contest of heart and willpower. Both fighters will give everything they have.
Visit for more information: #crosslink[3,L -
Azərbaycan ərazisində virtual qumar oyunlarına istək artdıqca, Pinup kazino kimi oyun xidmətləri daha çox tanınmağa başladı. Özəlliklə, "Pin up casino online" brendləri çoxdan yerli istifadəçilər üçün məşhurdur. Pin-up casino azerbaycan mərc həvəskarlarına çoxlu oyun növü təklif edir.
Pin-up azerbaycan, Azəri istifadəçilər üçün maraqlı seçimdir. Bu onlayn kazino oyunçulara müxtəlif oyunlar təklif edir və sərfəli bonus təklifləri ilə istifadəçilərin diqqətini çəkir.
Pin-up casino online, çeşidli oyun təcrübəsi təklif edən saytdır. yerli mərcçilər arasında populyar olan Pin-up online, qumar oyunçuları üçün fərqli oyun seçimləri ilə çıxış edir.
Bunun nəticəsində, Pin-up azerbaycan oyunçulara etibarlı maliyyə sistemləri təmin edir. Oyun həvəskarları, etibarlı və tez kredit kartı və elektron pul kisəsi ilə sayəsində, mərc təcrübələrini müvafiq şəkildə yaşaya bilərlər.
Son olaraq, Pin-up azerbaycan qumarbazlara təkcə oyunlar deyil, həm də bonus imkanı təmin edir. Pin-up-da, oyunçular şəffaf oyun şərtləri ilə rastlaşır.
Web: https://best-win-pinup.web.app
Pin-up azerbaycan yalnız bir mərc saytı kimi oyunçuları cəlb etmir. Oyunçular burada çeşidli mərc seçimlərindən faydalanıb və geniş bonus imkanlarını istifadə edə bilərlər.
Ümumilikdə, Pin-up kazino, müasir və təhlükəsiz oyun imkanı oyunçulara təklif etməklə oyun bazarında ən sevilən platformalardan olur. Azəri bazarında seçim olması dikkətə layiqdir.
Fury, the Gypsy King, and Usyk, the technician are ready to face each other in a fight of historic proportions. It’s not merely about the belts; it’s a battle for eternal recognition. The towering Fury has risen to the pinnacle of the sport thanks to his personality and remarkable adaptability in the ring. Beating Wilder and Klitschko have solidified his legendary status. Across the ring, the tactical southpaw poses a unique challenge to boxing’s biggest stars. On the flip side, Usyk, a genius in the ring stands as a unique threat not just for Fury, and for boxing fans worldwide. The ascent of Oleksandr Usyk started with his domination of the cruiserweights, where he became an unstoppable force. Don’t miss out for the most anticipated boxing match of the year as Oleksandr Usyk takes on Fury in a historic showdown! Catch every punch live on our website. Join the excitement — visit <a href="https://anzhero.4geo.ru/redirect/?service=news&town_id=156895024&url=https://tysonfuryvsusyk.co.uk/">tysonfuryvsusyk.co.uk</a> now and watch the match from the comfort of your home!
Across the UK, the ring walks are planned for late evening, ensuring maximum viewership. Back in Usyk’s home country, and for fans watching from around the world, the excitement is palpable. Where the bout will take place remains a hot topic, with talk of iconic boxing destinations. No matter the location, fans can be sure: it will be a spectacle. While the spotlight remains on Fury and Usyk, the fights leading up to the main event is also generating excitement. Major boxing events include preliminary bouts with top talent, providing non-stop action before the headliner.
Traditionally, preliminary fights on major cards have introduced future champions. Boxers seeking the spotlight capitalize on the exposure to demonstrate their talent, with the world paying attention. Though the supporting fights for Fury vs Usyk has yet to be finalized, speculation runs high. Could we see rising prospects? Regardless of the names, the action will not disappoint. What sets this bout apart incredibly exciting is the clash of styles. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. Being so tall yet so nimble, Fury can control a fight.
The legendary battles with Wilder proved his toughness, as he recovered from knockdowns to finish strong. Against Wladimir Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. By contrast, Usyk, offers a different kind of threat. With his unorthodox stance, his positioning constantly challenges opponents. The Ukrainian’s shots lack devastating strength, their timing wears down foes. With the date drawing closer, Predictions for this fight have fans and analysts speculating.
Fury is the favored fighter as per the betting experts, given his physical stature, his long career in major fights, and his tactical brilliance. Despite being seen as the underdog doesn’t diminish his chances, his dominance against Joshua confirmed his toughness against big opponents.
For Fury himself is a chance to further solidify his greatness. Should he come out on top, Fury’s win would put the finishing touches on a historic career. Conversely, If Usyk wins would be a monumental achievement. Becoming an undisputed champion in two different weight classes is a once-in-a-lifetime achievement.
Web: <a href="http://maps.google.ro/url?sa=t&url=https%3A%2F%2Ftysonfuryvsusyk.co.uk">tysonfuryvsusyk.co.uk</a>
Fury vs Usyk is more than just a championship fight. It’s a clash of personalities. Fury’s bold and unapologetic character is the opposite of Usyk’s humble and disciplined approach. Such contrasts make the fight more compelling. It’s about more than just skill. Whoever triumphs in this battle, the impact of this bout will reverberate throughout boxing history. Fury vs Usyk is more than just a fight. It’s the pinnacle of both fighters’ hard work. Whether Tyson Fury prevails with his size and strategy, or Usyk wins with his precision with his finesse and stamina, it’s certain that, this bout will go down in history.
Tyson Fury vs Oleksandr Usyk is more than just a sporting contest. It’s a battle of minds and bodies. These two warriors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azərbaycandakı qumar sektorunda internet oyunlarına seçim artdıqca, "Pin-up casino" kimi kazino xidmətləri daha çox tanınmağa başladı. Əsasən, Pinup casino ifadələri son zamanlar Azərbaycandakı oyunçular üçün istifadə olunur. Pin-up kazino öz oyunçularına çeşidli oyunlar təklif edir.
Pin-up online casino, Azəri qumarbazlar üçün geniş kütləyə sahib bir qumar saytıdır. Bu kazino oyunçulara müxtəlif oyunlar təklif edir və bonus imkanları ilə seçim olur.
Pin-up online kazino, bənzərsiz oyun imkanı təqdim edən şirkətdir. Azəri oyunçuları arasında çox seçilən Pin-up oyunları, yerli oyunçular üçün zəngin təkliflər təqdim edir.
Bunun nəticəsində, Pinup casino oyunçulara etibarlı və güvənli maliyyə idarəetmə imkanları oyunçularına təklif edir. İstifadəçilər, rahat və tez depozit çıxarış sistemi köməyilə, oyun təcrübələrini daha rahat təcrübə edə bilərlər.
Son olaraq, Pinup kazino mərc həvəskarlarına geniş oyun təcrübəsi ilə yanaşı cazibədar bonus təklifləri təmin edir. Bu kazinoda, istifadəçilər təhlükəsiz oyun mühitində olur.
Web: https://pinup-top.web.app
Pin-up kazino sadəcə oyunlar ilə kifayətlənmir. Oyunçular burada fərqli mərc seçimlərindən təcrübə edə bilərlər və maraqlı aksiyaları oyunlarına əlavə edə bilərlər.
Nəticədə, Pin-up cazino, şəffaf və güvənli mərc oyunları mərc həvəskarlarına təqdim etməklə onlayn qumar dünyasında ən yaxşı seçimlərdən biridir. Azəri bazarında tanınması açıq bir faktdır.
Tyson Fury and Oleksandr Usyk are ready to face each other in a fight of historic proportions. It’s far beyond a championship match; it represents their quest for immortality. The towering Fury has become a global icon thanks to his personality and his unmatched skills inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Meanwhile, Oleksandr Usyk is a fighter unlike any other to the heavyweight division. At the same time, Usyk, a genius in the ring represents a formidable opponent for the heavyweight ranks overall, and for boxing fans worldwide. Usyk’s rise to prominence started with his domination of the cruiserweights, where he became an unstoppable force. Don’t miss out for a thrilling boxing match of the year as Usyk takes on Fury in a historic showdown! See every move streamed live on our website. Be part of the action — visit <a href="http://diplomroomm.nnov.org/common/redir.php?https://furyvsusykdate.co.uk/">furyvsusykdate.co.uk</a> today and stream the event in high quality!
In the United Kingdom, the event will kick off at late evening, offering perfect timing for viewers. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, this will be a must-see event. The venue for Fury vs Usyk has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, fans can be sure: the atmosphere will be electric. While the spotlight is centered on the headline fight, the preliminary bouts promises plenty of action. High-profile matches often feature stacked undercards, giving fans a full evening of entertainment.
Historically, undercards of this caliber have been a stage for breakout performances. Contenders hoping to make their mark often seize these moments to demonstrate their talent, knowing millions are watching. Though the supporting fights for Fury vs Usyk haven’t been officially announced, fans are eagerly guessing. Could we see rising prospects? Regardless of the names, the action will not disappoint. What sets this bout apart incredibly exciting is the clash of styles. Fury’s towering frame and movement are unparalleled in the sport. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
The legendary battles with Wilder showed his durability, as he recovered from knockdowns to secure victories. Against Wladimir Klitschko, his strategic genius shone through, demonstrating his mental sharpness. By contrast, Usyk, relies on technique and stamina. With his unorthodox stance, he uses angles and footwork. The Ukrainian’s shots aren’t the heaviest in the division, they consistently find their mark. With the date drawing closer, The betting lines for Fury vs Usyk are becoming a hot topic.
Tyson Fury is seen as the frontrunner according to the odds, because of his reach and height, his track record in big matches, and his unpredictable nature. Despite being seen as the underdog doesn’t diminish his chances, his dominance against Joshua proved that he can handle the physicality of the heavyweight division.
For Fury himself could be the defining moment of his career. Should he come out on top, Fury’s win would solidify his claim as the greatest heavyweight of his generation. Meanwhile, Usyk’s victory would be a monumental achievement. Securing two undisputed titles is a feat few can claim.
Web: <a href="http://www.google.co.ls/url?q=https%3A%2F%2Ffuryvsusykdate.co.uk">furyvsusykdate.co.uk</a>
The upcoming showdown represents something greater than a title bout. It’s a fight between two very different fighters. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. These varying personalities make the bout even more interesting. It’s a fight of wills and ideologies. Regardless of the outcome, the significance of this match will leave a lasting mark on the sport. The battle for heavyweight supremacy is a spectacle unlike any other. It’s the result of relentless dedication. Whether Fury secures the win with his experience and unpredictability, or Usyk comes out on top through his superior boxing ability, one thing is certain, this will be a legendary contest.
Tyson Fury vs Oleksandr Usyk is more than just a boxing event. It’s a showcase of skill and determination. These two warriors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında internet oyunlarına seçim artdıqca, Pinup kimi onlayn mərc xidmətləri daha çox tanınmağa başladı. Xüsusilə, Pin-up kazino şəklində olan platformalar tez-tez Azərbaycandakı oyunçular üçün məşhurdur. Pin-up casino öz oyunçularına müxtəlif oyunlar təklif edir.
Pin-up cazino, Azərbaycan oyunçuları üçün ən sevilən platformalardan biridir. Bu qumar xidməti qumarbazlara müxtəlif oyunlar oyunçulara təqdim edir və gözəl hədiyyələr ilə istifadəçilərin diqqətini çəkir.
Pin-up online kazino, geniş oyun variantları təklif edən oyun məkanıdır. Azərbaycanda geniş istifadə olunan Pin-up casino, qumar oyunçuları üçün maraqlı oyun imkanları təklif edir.
Bunun nəticəsində, Pin-up online casino oyunçulara güvənli və şəffaf ödəmə üsulları təmin edir. İstifadəçilər, çox rahat ödəmə üsulları nəticəsində, oyun təcrübələrini çox rahat yerinə yetirə bilərlər.
Əlavə olaraq, Pin-up kazino mərc həvəskarlarına geniş oyun təcrübəsi ilə yanaşı cazibədar bonus təklifləri və maraqlı aksiyalar təklif edir. Pinup-da, istifadəçilər rahat və təhlükəsiz şəraitdə oynayır.
Web: https://pinup-best-casino.web.app
Pin-up casino təkcə oyunçuları cəlb etmir. Qumarçılar burada müxtəlif mərc növlərindən təcrübə edə bilərlər və çoxlu bonusları oyunlarına əlavə edə bilərlər.
Sonda, Pin-up cazino, şəffaf və güvənli mərc oyunları təklif etməklə onlayn qumar sektorunda oyunçular arasında geniş istifadə edilir. Azəri bazarında məşhur olması dikkətə layiqdir.
The undefeated Fury and Usyk are ready to face each other in a fight that will define an era. It’s far beyond a championship match; it’s about legacy. Fury, an undefeated champion has risen to the pinnacle of the sport thanks to his personality and his unmatched skills inside the ropes. Beating Wilder and Klitschko have solidified his legendary status. On the other hand, Usyk, the Ukrainian master is a fighter unlike any other to the heavyweight division. Meanwhile, the Ukrainian technician is a true test for Fury for Tyson Fury himself, as a heavyweight contender. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, as an undisputed champion. Prepare yourself for an epic boxing match of the year as Usyk takes on Fury in an unforgettable showdown! Catch every punch streamed live on our website. Join the excitement — visit <a href="https://bigpon.ru/go.php?to=usykvsfurydate.co.uk">usykvsfurydate.co.uk</a> today and stream the event from the comfort of your home!
Across the UK, the event will kick off at close to prime time, ensuring maximum viewership. For Usyk’s fans in Ukraine, and for fans watching from around the world, the anticipation is at a fever pitch. Where the bout will take place remains a hot topic, with talk of iconic boxing destinations. Regardless of the venue, it’s guaranteed: the excitement will be unmatched. Even though attention remains on Fury and Usyk, the preliminary bouts is also generating excitement. Big-ticket boxing cards are known for strong supporting fights, offering an entire night of boxing excitement.
Traditionally, undercards of this caliber have been a stage for breakout performances. Boxers seeking the spotlight use such opportunities to showcase their skills, as all eyes are on them. While the names for the undercard has yet to be finalized, fans are eagerly guessing. Might there be a cruiserweight spectacle? Regardless of the names, the action will not disappoint. What makes this fight incredibly exciting is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. Being so tall yet so nimble, Fury can control a fight.
The legendary battles with Wilder showed his durability, overcoming brutal hits to finish strong. In his fight with Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. Meanwhile, Usyk, offers a different kind of threat. With his unorthodox stance, his positioning constantly challenges opponents. Usyk’s punches aren’t the heaviest in the division, they consistently find their mark. As anticipation builds, Predictions for this fight are becoming a hot topic.
Tyson Fury is the slight favorite based on the betting odds, because of his reach and height, his track record in big matches, and his adaptability. Despite the odds, Usyk remains a strong contender doesn’t mean he’s an underdog in spirit, as his victories over Joshua demonstrated his ability in the heavyweight ranks.
For Tyson Fury, this fight represents an opportunity to cement his legacy. Should he come out on top, Fury’s win would add an undisputed title to his already impressive resume. Meanwhile, For Usyk, a win would elevate him to legendary status. Achieving undisputed glory in two divisions would be a remarkable feat in boxing history.
Web: <a href="http://www.google.ge/url?q=https://usykvsfurydate.co.uk/">usykvsfurydate.co.uk</a>
Fury vs Usyk is more than just a championship fight. It’s a fight between two very different fighters. Fury’s bold and unapologetic character contrasts with Usyk’s calm, focused demeanor. Such contrasts make the fight more compelling. Beyond physical ability, this fight. Whoever triumphs in this battle, the legacy of this fight will leave a lasting mark on the sport. This historic showdown is a defining moment. It’s the result of relentless dedication. Whether Fury secures the win with his experience and unpredictability, or Usyk wins with his precision through his superior boxing ability, it’s certain that, this will be a fight remembered for years to come.
Fury vs Usyk is a spectacle of a lifetime. It’s a contest of heart and willpower. The two competitors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azərbaycandakı qumar sektorunda internet qumarına maraq artdıqca, Pin-up online kimi oyun xidmətləri daha çox tanınmağa başladı. Əlavə olaraq, Pin-up kazino sözləri çoxdan Azəri mərc həvəskarları üçün adidir. Pin-up kazino oyunçulara çox oyun növləri təklif edir.
Pin-up online casino, Azəri istifadəçilər üçün ən sevilən platformalardan biridir. Bu qumar xidməti müştərilərə müxtəlif oyunlar təklif edir və sərfəli bonus təklifləri ilə mərc edənləri özünə cəlb edir.
Pinup casino, istifadəçilərə oyun növləri ilə zəngin oyun məkanıdır. Azəri oyunçuları arasında çox seçilən Pin-up kazino, oyun həvəskarları üçün fərqli oyun seçimləri ilə çıxış edir.
Bu səbəbdən, Pinup casino mərcçilərə güvənli maliyyə sistemləri təqdim edir. Müştərilər, müvafiq və təhlükəsiz depozit və pul çıxarış imkanları köməyilə, oyun təcrübələrini asan və sürətli yerinə yetirə bilərlər.
Son olaraq, Pinup kazino mərc həvəskarlarına çoxlu oyun növlərilə yanaşı bonus imkanı təmin edir. Pin-up-da, istifadəçilər rahat və təhlükəsiz şəraitdə oynayır.
Web: https://win-top-pin-up-az.web.app
Pin-up cazino təkcə bir oyun platforması kimi məhdud deyil. Kazino həvəskarları bu kazinoda müxtəlif mərc növlərindən faydalanıb və cazibədar bonus imkanlarını oyun təcrübələrinə əlavə edərlər.
Bunun nəticəsində, Pin-up kazino, etibarlı mərc imkanı oyunçulara təklif etməklə mərc bazarında ən sevilən platformalardan olur. Azəri oyunçular tərəfindən tanınması açıq bir faktdır.
Tyson Fury and Oleksandr Usyk are ready to face each other in a fight of historic proportions. It’s not merely about the belts; it’s about legacy. The towering Fury has earned worldwide fame with his charisma coupled with unparalleled talent in the ring. Triumphing against boxing legends like Wilder and Klitschko have solidified his legendary status. In contrast, Oleksandr Usyk is a fighter unlike any other to the heavyweight division. Meanwhile, the Ukrainian technician is a true test for Fury for the heavyweight ranks overall, as a heavyweight contender. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Don’t miss out for the most anticipated boxing match of the year as Usyk takes on Tyson Fury in an unforgettable showdown! See every move live on our website. Be part of the action — visit <a href="https://rostov.metalloprokat.ru/statistic/redirect_site?source=products-list&object-id=12568824&object-kind=product&url=https://usykvsfury.org.uk/">usykvsfury.org.uk</a> today and stream the event with top-notch streaming!
Across the UK, the fight is expected to begin late evening, offering perfect timing for viewers. Back in Usyk’s home country, and for fans watching from around the world, the excitement is palpable. Where the bout will take place has yet to be confirmed, with talk of iconic boxing destinations. Regardless of the venue, one thing is certain: the excitement will be unmatched. Although the focus remains on Fury and Usyk, the fights leading up to the main event is also generating excitement. Big-ticket boxing cards often feature stacked undercards, offering an entire night of boxing excitement.
Traditionally, preliminary fights on major cards have been a stage for breakout performances. Fighters looking to rise through the ranks capitalize on the exposure to showcase their skills, knowing millions are watching. While the names for the undercard are still unconfirmed, there’s plenty of talk. Will there be a heavyweight clash? No matter the final roster, it’s sure to add to the excitement. What makes this fight so intriguing is the clash of styles. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. Being so tall yet so nimble, Fury can control a fight.
The three fights against Wilder proved his toughness, as he recovered from knockdowns to secure victories. Against Wladimir Klitschko, his strategic genius shone through, demonstrating his mental sharpness. Meanwhile, Usyk, brings speed, precision, and finesse. As a southpaw, he uses angles and footwork. His strikes may not have knockout power, but they are delivered with pinpoint accuracy. With the date drawing closer, The betting lines for Fury vs Usyk are the subject of intense debate.
Tyson Fury is the slight favorite according to the odds, given his physical stature, his experience in high-pressure bouts, and his adaptability. Although Usyk is the less favored fighter doesn’t rule him out, his wins over Anthony Joshua confirmed his toughness against big opponents.
For the Gypsy King represents an opportunity to cement his legacy. A triumph for Fury would further solidify his status as the best heavyweight of this era. Meanwhile, For Usyk, a win would be a monumental achievement. Securing two undisputed titles is a feat few can claim.
Web: <a href="http://clients1.google.lv/url?q=https%3A%2F%2Fusykvsfury.org.uk">usykvsfury.org.uk</a>
Fury vs Usyk is about more than the titles. It’s a fight between two very different fighters. Fury’s larger-than-life persona stands in stark contrast to Usyk’s composed demeanor. These differences add complexity to the fight. This is more than just a physical contest. No matter who wins, the impact of this bout will leave a lasting mark on the sport. The clash for the undisputed title is a defining moment. It’s the pinnacle of both fighters’ hard work. Whether Tyson Fury prevails through his strength and tactics, or Oleksandr Usyk triumphs through his superior boxing ability, no matter the outcome, this will be a legendary contest.
This fight between Fury and Usyk is a spectacle of a lifetime. It’s a fight of grit and strategy. Both fighters will give everything they have.
Visit for more information: #crosslink[3,L -
Azərbaycanda online kazino oyunlarına sevgisi artdıqca, Pin-up online kimi kazino xidmətləri daha çox tanınmağa başladı. Özəlliklə, Pinup casino ifadələri hazırda Azəri oyunçuları üçün istifadə olunur. Pin-up kazino online müştərilərinə çoxlu oyun növü təklif edir.
Pin up kazino, yerli mərc həvəskarları üçün maraqlı seçimdir. Bu platforma müştərilərə çoxlu oyun təklifləri oyunçulara təqdim edir və cəlbedici bonuslar ilə istifadəçilərin diqqətini çəkir.
Pinup casino, fərqli oyun təcrübəsi təklif edən xidmətdir. Azəri oyunçuları arasında güvənilən Pin-up kazino, kazino oyunçuları üçün zəngin təkliflər təqdim edir.
Bu səbəbdən, Pin-up azerbaycan oyunçulara etibarlı və güvənli ödəmə üsulları oyunçularına təklif edir. Oyunçular, müvafiq və təhlükəsiz ödəmə üsulları vasitəsilə, oyun təcrübələrini güvənli və təhlükəsiz yerinə yetirə bilərlər.
Bununla yanaşı, Pin-up casino istifadəçilərə təkcə oyun imkanı deyil bonus imkanı oyun təcrübəsini daha da maraqlı edir. Bu kazinoda, istifadəçilər təhlükəsiz şərtlər altında mərc edir.
Web: https://pinup-best-casino.web.app
Pin-up kazino sadəcə sadə oyunla bitmir. Mərc həvəskarları bu platformada çeşidli mərc seçimlərindən təcrübə edə bilərlər və geniş bonus imkanlarını oyun təcrübələrinə əlavə edərlər.
Nəticədə, Pin-up azerbaycan, sərfəli və təhlükəsiz mərc oyunları istifadəçilərə verməklə oyun sənayesində ən yaxşı seçimlərdən biridir. Azəri bazarında tanınması dikkətə layiqdir.
The undefeated Fury and Usyk are preparing for an epic showdown that will define an era. It’s far beyond a championship match; it represents their quest for immortality. Fury, an undefeated champion has earned worldwide fame with his charisma coupled with unparalleled talent during fights. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. Across the ring, Usyk, the technician poses a unique challenge for Fury. On the flip side, Usyk, a southpaw master represents a formidable opponent for the heavyweight ranks overall, as a heavyweight contender. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, as an undisputed champion. Get ready for a thrilling boxing match of the year as Oleksandr Usyk takes on Fury in a must-watch showdown! Catch every punch streamed live on our website. Be part of the action — visit <a href="http://lordgunbicycles.com/wp-content/plugins/AND-AntiBounce/redirector.php?url=https://tysonvsusyk.co.uk/">tysonvsusyk.co.uk</a> today and enjoy the fight in high quality!
Across the UK, the fight is expected to begin close to prime time, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, and beyond, the excitement is palpable. The fight’s location remains a hot topic, with talk of iconic boxing destinations. No matter the location, fans can be sure: the atmosphere will be electric. Although the focus remains on Fury and Usyk, the preliminary bouts is shaping up to be thrilling. High-profile matches include preliminary bouts with top talent, giving fans a full evening of entertainment.
Traditionally, undercards of this caliber have been a stage for breakout performances. Fighters looking to rise through the ranks use such opportunities to impress fans and analysts alike, knowing millions are watching. Though the supporting fights for Fury vs Usyk haven’t been officially announced, there’s plenty of talk. Could we see rising prospects? No matter the final roster, the action will not disappoint. The most compelling part of Fury vs Usyk incredibly exciting is the clash of styles. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. At 6’9" with an 85-inch reach, he commands the ring like no other.
His trilogy with Deontay Wilder proved his toughness, as he recovered from knockdowns to finish strong. In his fight with Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. By contrast, Usyk, offers a different kind of threat. Being a left-handed fighter, his movements create openings. The Ukrainian’s shots lack devastating strength, but they are delivered with pinpoint accuracy. As anticipation builds, The betting lines for Fury vs Usyk have fans and analysts speculating.
Tyson Fury is the slight favorite as predicted by many experts, because of his reach and height, his experience in high-pressure bouts, and his adaptability. Despite being seen as the underdog doesn’t mean he’s an underdog in spirit, his wins over Anthony Joshua proved that he can handle the physicality of the heavyweight division.
For Tyson Fury is a chance to further solidify his greatness. Should he come out on top, Fury’s win would solidify his claim as the greatest heavyweight of his generation. On the other hand, For Usyk, a win would mark him as one of the sport’s greats. Securing two undisputed titles is a once-in-a-lifetime achievement.
Web: <a href="http://cse.google.vg/url?q=https://tysonvsusyk.co.uk/">tysonvsusyk.co.uk</a>
Fury vs Usyk is more than just a championship fight. It’s a fight between two very different fighters. Fury’s boisterous personality is the opposite of Usyk’s humble and disciplined approach. These varying personalities make the bout even more interesting. It’s about more than just skill. No matter who wins, the significance of this match will be remembered as a defining moment in boxing. Fury vs Usyk is more than just a fight. It’s a culmination of years of hard work. Should Fury claim victory with his experience and unpredictability, or Usyk secures a victory with his technique and endurance, no matter the outcome, this will be a legendary contest.
Fury vs Usyk is more than just a fight. It’s a fight of grit and strategy. These two warriors will give everything they have.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında online kazino oyunlarına tələbat artdıqca, Pin-up casino online kimi şirkətlər daha çox tanınmağa başladı. Bununla bərabər, Pin-up kazino ifadələri son zamanlar Azəri mərc həvəskarları üçün güvənlidir. Pin-up casino öz oyunçularına geniş oyunlar təklif edir.
Pin-up casino, yerli oyunçular üçün güvənli bir qumar məkanıdır. Bu qumar saytı müştərilərə rəngarəng oyunlar təklif edir və bonus imkanları ilə istifadəçilərin diqqətini çəkir.
Pin-up casino online, oyun keyfiyyətini artıran oyun məkanıdır. Azəri bazarında populyar olan Pin-up casino, oyun həvəskarları üçün geniş oyun təcrübəsi verir.
Bunun nəticəsində, Pin-up online casino oyunçulara güvənli maliyyə idarəetmə imkanları oyunçularına təklif edir. Oyun həvəskarları, müvafiq və təhlükəsiz depozit çıxarış sistemi sayəsində, mərc təcrübələrini asan və sürətli oynaya bilərlər.
Əlavə olaraq, Pin-up azerbaycan müştərilərə təkcə oyun imkanı deyil mərc hədiyyələri və maraqlı aksiyalar təklif edir. Bu kazinoda, kazino həvəskarları şəffaf oyun şərtləri ilə rastlaşır.
Web: https://best-pinup.web.app
Pin-up kazino təkcə bir kazino olaraq sadə oyunla bitmir. Qumarçılar burada geniş mərc təcrübəsindən müxtəlif mərc imkanı əldə edə bilər və maraqlı aksiyaları qazanmaq imkanı əldə edərlər.
Bunun nəticəsində, Pin-up casino, rahat və təhlükəsiz mərc oyunları mərc həvəskarlarına təqdim etməklə oyun sənayesində ən yaxşı seçimlərdən biridir. Azərbaycan mərcçiləri arasında məşhur olması təsadüf deyil.
Tyson Fury and Oleksandr Usyk are set to meet in the ring of unparalleled significance. It’s far beyond a championship match; it represents their quest for immortality. Fury, an undefeated champion has risen to the pinnacle of the sport with his charisma and his unmatched skills inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. Meanwhile, Usyk, the technician is a fighter unlike any other to the heavyweight division. Meanwhile, Usyk, a southpaw master represents a formidable opponent for Tyson Fury himself, as a heavyweight contender. His journey to global fame was marked by his undisputed cruiserweight reign, by conquering all challengers. Don’t miss out for a thrilling boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! Catch every punch in real time on our website. Join the excitement — visit <a href="http://p3.isanook.com/hi/0/wb/i/url/furyvsusykdate.org.uk">furyvsusykdate.org.uk</a> now and stream the event in high quality!
In the United Kingdom, the ring walks are planned for late evening, ensuring maximum viewership. Back in Usyk’s home country, and beyond, the excitement is palpable. The venue for Fury vs Usyk has yet to be confirmed, with talk of iconic boxing destinations. Regardless of the venue, one thing is certain: the atmosphere will be electric. Although the focus is firmly on the main event, the preliminary bouts promises plenty of action. Big-ticket boxing cards are known for strong supporting fights, giving fans a full evening of entertainment.
In the past, preliminary fights on major cards have showcased rising stars. Fighters looking to rise through the ranks use such opportunities to impress fans and analysts alike, knowing millions are watching. Though the supporting fights for Fury vs Usyk are still unconfirmed, speculation runs high. Could we see rising prospects? No matter the final roster, fans can expect fireworks. What sets this bout apart incredibly exciting is their contrasting skillsets. Fury’s towering frame and movement are unparalleled in the sport. With his immense height and reach advantage, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, as he recovered from knockdowns to secure victories. When he faced Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. By contrast, Usyk, offers a different kind of threat. Being a left-handed fighter, his movements create openings. His strikes lack devastating strength, their timing wears down foes. With the date drawing closer, Tyson Fury vs Usyk odds have fans and analysts speculating.
The betting lines show Fury ahead as predicted by many experts, because of his reach and height, his experience in high-pressure bouts, and his tactical brilliance. However, Usyk's underdog status doesn’t rule him out, as his victories over Joshua confirmed his toughness against big opponents.
For the Gypsy King presents a shot at undisputed glory. If he wins, it would solidify his claim as the greatest heavyweight of his generation. Meanwhile, Usyk’s victory would elevate him to legendary status. Securing two undisputed titles is a once-in-a-lifetime achievement.
Web: <a href="http://google.com.mm/url?q=https://furyvsusykdate.org.uk/">furyvsusykdate.org.uk</a>
This fight is more than just a championship fight. It’s a battle of contrasting styles. Fury’s confident and brash nature stands in stark contrast to Usyk’s composed demeanor. Such contrasts make the fight more compelling. It’s a fight of wills and ideologies. No matter who wins, the impact of this bout will be remembered as a defining moment in boxing. Fury vs Usyk is a spectacle unlike any other. It’s the result of relentless dedication. Whether Fury secures the win with his size and strategy, or Oleksandr Usyk triumphs with his finesse and stamina, it’s certain that, this bout will go down in history.
This fight between Fury and Usyk is more than just a fight. It’s a fight of grit and strategy. These men will give everything they have.
Visit for more information: #crosslink[3,L -
Azərbaycanda internet qumarına tələbat artdıqca, Pinup kazino kimi kazino xidmətləri daha çox tanınmağa başladı. Əlavə olaraq, Pin-up kazino sözləri indi Azəri mərc həvəskarları üçün tanışdır. Pin-up casino oyunçulara müxtəlif oyunlar təklif edir.
Pin up kazino, Azəri qumarbazlar üçün populyar seçimdir. Bu qumar saytı müştərilərə geniş çeşidli oyunlar təklif edir və bonus imkanları ilə seçim olur.
Pin-up online kazino, geniş oyun variantları təklif edən xidmətdir. yerli mərcçilər arasında güvənilən Pin-up kazino, yerli oyunçular üçün fərqli oyun seçimləri ilə çıxış edir.
Əlavə olaraq, Pin-up azerbaycan oyunçulara güvənli ödəmə sistemləri təklif etməkdədir. Oyunçular, etibarlı və tez depozit çıxarış sistemi ilə təmin olunmaqla, internet oyunlarını asan və sürətli yerinə yetirə bilərlər.
Bununla yanaşı, Pin-up kazino istifadəçilərə yalnız qumar oyunları yox, həmçinin cazibədar bonus təklifləri müştəriləri üçün yaradır. Bu onlayn kazinoda, müştərilər rahat və təhlükəsiz şəraitdə oynayır.
Web: https://win-pinup.web.app
Pin-up cazino yalnız bir mərc saytı kimi məhdudlaşmır. Mərc həvəskarları bu platformada çeşidli mərc seçimlərindən müxtəlif mərc imkanı əldə edə bilər və maraqlı aksiyaları oyun təcrübəsini artırarlar.
Ümumilikdə, Pinup kazino, rahat və təhlükəsiz mərc təcrübəsi təmin etməklə onlayn mərc dünyasında ən sevilən platformalardan olur. Azəri bazarında seçim olması göz qabağındadır.
Tyson Fury and Oleksandr Usyk are set to meet in the ring of historic proportions. It’s not merely about the belts; it’s a battle for eternal recognition. The Gypsy King has become a global icon through his unique style and his unmatched skills inside the ropes. Beating Wilder and Klitschko have solidified his legendary status. On the other hand, Usyk, the technician poses a unique challenge to the heavyweight division. On the flip side, Usyk, a genius in the ring represents a formidable opponent for the heavyweight ranks overall, and for boxing fans worldwide. Usyk’s rise to prominence started with his domination of the cruiserweights, by conquering all challengers. Don’t miss out for a thrilling boxing match of the year as Usyk takes on Fury in a must-watch showdown! Experience every moment streamed live on our website. Be part of the action — visit <a href="https://www.gridsagegames.com/forums/proxy.php?request=http%3A%2F%2Ftysonfuryvsoleksandrusyk.co.uk">tysonfuryvsoleksandrusyk.co.uk</a> now and enjoy the fight from the comfort of your home!
For British fans, the ring walks are planned for around 10 PM GMT, ensuring maximum viewership. Back in Usyk’s home country, and beyond, this will be a must-see event. Where the bout will take place has yet to be confirmed, with talk of iconic boxing destinations. Wherever it happens, it’s guaranteed: the atmosphere will be electric. Although the focus is centered on the headline fight, the Fury vs Usyk undercard is also generating excitement. Big-ticket boxing cards are known for strong supporting fights, giving fans a full evening of entertainment.
In the past, preliminary fights on major cards have showcased rising stars. Contenders hoping to make their mark often seize these moments to showcase their skills, as all eyes are on them. Although the lineup for the Fury Usyk undercard has yet to be finalized, there’s plenty of talk. Might there be a cruiserweight spectacle? Whatever the selection, the action will not disappoint. The most compelling part of Fury vs Usyk incredibly exciting is the dynamic between these fighters. Tyson Fury’s size and agility are unparalleled in the sport. Being so tall yet so nimble, Fury can control a fight.
The three fights against Wilder highlighted his resilience, bouncing back from adversity to secure victories. Against Wladimir Klitschko, his strategic genius shone through, proving he’s not just physical but cerebral. By contrast, Usyk, offers a different kind of threat. As a southpaw, his movements create openings. Usyk’s punches may not have knockout power, they consistently find their mark. As anticipation builds, Predictions for this fight are the subject of intense debate.
Fury is the favored fighter as per the betting experts, given his physical stature, his experience in high-pressure bouts, and his adaptability. Despite being seen as the underdog doesn’t rule him out, his victories against AJ confirmed his toughness against big opponents.
For Tyson Fury presents a shot at undisputed glory. A victory would add an undisputed title to his already impressive resume. Meanwhile, Usyk’s victory would elevate him to new heights. Achieving undisputed glory in two divisions is a once-in-a-lifetime achievement.
Web: <a href="http://images.google.pl/url?q=https://tysonfuryvsoleksandrusyk.co.uk/">tysonfuryvsoleksandrusyk.co.uk</a>
Fury vs Usyk represents something greater than a title bout. It’s a meeting of two unique worldviews. Fury’s boisterous personality is the opposite of Usyk’s humble and disciplined approach. Such contrasts make the fight more compelling. It’s about more than just skill. Whoever comes out victorious, the legacy of this fight will be felt for years to come. This historic showdown is more than just a fight. It’s the result of relentless dedication. Should Fury claim victory with his size and strategy, or Oleksandr Usyk triumphs through his superior boxing ability, it’s certain that, this will be a legendary contest.
This fight between Fury and Usyk is more than just a boxing event. It’s a fight of grit and strategy. These two warriors will give everything they have.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında online kazino oyunlarına istək artdıqca, "Pin-up casino" kimi kazino xidmətləri daha çox tanınmağa başladı. Əlavə olaraq, Pin-up azerbaycan şəklində olan platformalar indi Azəri mərc həvəskarları üçün tanışdır. Pinup casino istifadəçilərə məxsus geniş oyunlar təklif edir.
Pinup kazino, Azəri qumarbazlar üçün maraqlı seçimdir. Bu kazino istifadəçilərə müxtəlif oyunlar təklif edib və gözəl hədiyyələr ilə seçim olur.
Pinup casino, geniş oyun variantları təklif edən bir platformadır. Azəri bazarında güvənilən Pinup, yerli oyunçular üçün zəngin təkliflər təqdim edir.
Xüsusilə, Pinup kazino istifadəçilərə güvənli və şəffaf maliyyə idarəetmə imkanları təqdim edir. Oyun həvəskarları, rahat depozit və pul çıxarış imkanları sayəsində, qumar təcrübələrini güvənli və təhlükəsiz təcrübə edərlər.
Yekun olaraq, Pin-up casino online mərc həvəskarlarına çoxlu oyun növlərilə yanaşı bonuslar və aksiyalar oyunçularına verir. Bu kazinoda, mərc edənlər özlərini güvəndə hiss edir.
Web: https://pinup-top.web.app
Pin-up online kazino təkcə məhdud oyunlar təklif etmir. Müştərilər burada fərqli mərc seçimlərindən faydalanıb və bonus sistemini oyun təcrübələrinə əlavə edərlər.
Bunun nəticəsində, Pin-up kazino, güvənli mərc imkanı təmin etməklə oyun bazarında ən sevilən platformalardan olur. Azəri oyunçular tərəfindən geniş yayılması göz qabağındadır.
The undefeated Fury and Usyk are set to meet in the ring that will define an era. It’s far beyond a championship match; it represents their quest for immortality. Fury, an undefeated champion has risen to the pinnacle of the sport with his charisma and remarkable adaptability inside the ropes. Beating Wilder and Klitschko have earned him recognition as one of the best ever. In contrast, Oleksandr Usyk poses a unique challenge to the heavyweight division. At the same time, the Ukrainian technician represents a formidable opponent for Tyson Fury himself, as a heavyweight contender. The ascent of Oleksandr Usyk started with his domination of the cruiserweights, where he became an unstoppable force. Prepare yourself for an epic boxing match of the year as Oleksandr Usyk takes on Fury in a historic showdown! See every move in real time on our website. Don’t miss your chance — visit <a href="https://flyd.ru/away.php?to=https://furyvsusyk.org.uk/">furyvsusyk.org.uk</a> right away and watch the match with top-notch streaming!
Across the UK, the ring walks are planned for close to prime time, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, as well as viewers across Europe and the Americas, the excitement is palpable. Where the bout will take place has yet to be confirmed, with talk of iconic boxing destinations. Wherever it happens, fans can be sure: it will be a spectacle. While the spotlight is centered on the headline fight, the fights leading up to the main event is shaping up to be thrilling. High-profile matches include preliminary bouts with top talent, providing non-stop action before the headliner.
In the past, preliminary fights on major cards have introduced future champions. Fighters looking to rise through the ranks often seize these moments to impress fans and analysts alike, as all eyes are on them. Although the lineup for the Fury Usyk undercard has yet to be finalized, speculation runs high. Will there be a heavyweight clash? Whatever the selection, fans can expect fireworks. The most compelling part of Fury vs Usyk so intriguing is their contrasting skillsets. Tyson Fury’s size and agility make him an anomaly in boxing. With his immense height and reach advantage, he commands the ring like no other.
The legendary battles with Wilder proved his toughness, overcoming brutal hits to secure victories. Against Wladimir Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. Meanwhile, Usyk, brings speed, precision, and finesse. With his unorthodox stance, his positioning constantly challenges opponents. The Ukrainian’s shots may not have knockout power, they consistently find their mark. As fight night approaches, The betting lines for Fury vs Usyk are the subject of intense debate.
Tyson Fury is seen as the frontrunner as predicted by many experts, due to his size advantage, his track record in big matches, and his unorthodox style. Despite being seen as the underdog doesn’t mean he’s an underdog in spirit, as his victories over Joshua showed that he can compete at heavyweight.
For Tyson Fury, this fight presents a shot at undisputed glory. A triumph for Fury would further solidify his status as the best heavyweight of this era. On the other hand, Usyk’s victory would elevate him to legendary status. Achieving undisputed glory in two divisions is a rare accomplishment.
Web: <a href="http://images.google.cl/url?q=https://furyvsusyk.org.uk/">furyvsusyk.org.uk</a>
The upcoming showdown is not just about the belts. It’s a battle of contrasting styles. Fury’s larger-than-life persona is the opposite of Usyk’s humble and disciplined approach. These varying personalities make the bout even more interesting. It’s about more than just skill. Regardless of the outcome, the significance of this match will be felt for years to come. The battle for heavyweight supremacy is a defining moment. It’s the result of relentless dedication. Whether Tyson Fury prevails with his size and strategy, or Oleksandr Usyk triumphs thanks to his skill and resilience, one thing is certain, this bout will go down in history.
The Fury-Usyk battle is more than just a fight. It’s a fight of grit and strategy. These men will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında onlayn qumar oyunlarına tələbat artdıqca, Pinup kimi oyun xidmətləri daha çox tanınmağa başladı. Bununla bərabər, Pin-up azerbaycan sözləri tez-tez Azəri mərc həvəskarları üçün güvənlidir. Pin-up casino öz oyunçularına çoxlu oyun növü təklif edir.
Pin-up online casino, Azəri istifadəçilər üçün geniş kütləyə sahib bir qumar saytıdır. Bu qumar saytı mərc həvəskarlarına rəngarəng oyunlar təklif edib və çoxlu bonuslar ilə qumarbazlar tərəfindən sevilir.
Pinup casino, çeşidli oyun təcrübəsi təklif edən onlayn kazinodur. Azəri bazarında çox seçilən Pin-up casino, mərc həvəskarları üçün fərqli oyun seçimləri ilə çıxış edir.
Bununla yanaşı, Pinup kazino müştərilərə etibarlı ödəmə üsulları oyunçularına təklif edir. Müştərilər, rahat maliyyə çıxarışları köməyilə, mərc təcrübələrini daha rahat təcrübə edərlər.
Son olaraq, Pin-up kazino mərcçilərə geniş oyun təcrübəsi ilə yanaşı bonuslar və aksiyalar müştəriləri üçün yaradır. Bu platformada, müştərilər təhlükəsiz şərtlər altında mərc edir.
Web: https://pinup-best-bet.web.app
Pin-up casino yalnız məhdud oyunlar təklif etmir. Oyunçular burada çeşidli mərc seçimlərindən istifadə edə bilər və maraqlı aksiyaları oyun təcrübələrinə əlavə edərlər.
Sonda, Pin-up cazino, etibarlı kazino təcrübəsi təmin etməklə oyun sənayesində özünü doğruldur. yerli oyunçular arasında məşhur olması təsadüfi deyil.
The undefeated Fury and Usyk are preparing for an epic showdown of unparalleled significance. It’s far beyond a championship match; it’s about legacy. The towering Fury has risen to the pinnacle of the sport with his charisma coupled with unparalleled talent in the ring. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. On the other hand, Usyk, the technician brings an unprecedented test to boxing’s biggest stars. On the flip side, Usyk, a southpaw master is a true test for Fury not just for Fury, and for boxing fans worldwide. His journey to global fame began in the cruiserweight division, as an undisputed champion. Don’t miss out for the most anticipated boxing match of the year as Usyk takes on Tyson Fury in an unforgettable showdown! Catch every punch live on our website. Join the excitement — visit <a href="https://hdaud.io/engine/dude/index/leech_out.php?i:aHR0cHM6Ly9tb2RzLW1lbnUucnUv">tysonvusyk.com</a> now and enjoy the fight from the comfort of your home!
Across the UK, the fight is expected to begin close to prime time, ensuring maximum viewership. Back in Usyk’s home country, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. The fight’s location has yet to be confirmed, with talk of iconic boxing destinations. Regardless of the venue, fans can be sure: it will be a spectacle. While the spotlight remains on Fury and Usyk, the preliminary bouts is shaping up to be thrilling. High-profile matches are known for strong supporting fights, offering an entire night of boxing excitement.
In the past, supporting bouts in major events have been a stage for breakout performances. Contenders hoping to make their mark capitalize on the exposure to demonstrate their talent, as all eyes are on them. Although the lineup for the Fury Usyk undercard has yet to be finalized, there’s plenty of talk. Could we see rising prospects? Whatever the selection, the action will not disappoint. What makes this fight incredibly exciting is their contrasting skillsets. Tyson Fury’s size and agility set him apart from other heavyweights. With his immense height and reach advantage, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, overcoming brutal hits to finish strong. Against Wladimir Klitschko, his strategic genius shone through, demonstrating his mental sharpness. By contrast, Usyk, offers a different kind of threat. With his unorthodox stance, his positioning constantly challenges opponents. His strikes may not have knockout power, they consistently find their mark. With the date drawing closer, The betting lines for Fury vs Usyk have fans and analysts speculating.
Tyson Fury is seen as the frontrunner according to the odds, thanks to his imposing frame, his track record in big matches, and his unpredictable nature. Despite being seen as the underdog doesn’t diminish his chances, as his victories over Joshua proved that he can handle the physicality of the heavyweight division.
For Tyson Fury could be the defining moment of his career. Should he come out on top, Fury’s win would put the finishing touches on a historic career. On the other hand, If Usyk wins would elevate him to legendary status. Becoming an undisputed champion in two different weight classes is a rare accomplishment.
Web: <a href="http://www.google.com.kh/url?q=https://tysonvusyk.com/">tysonvusyk.com</a>
Fury vs Usyk represents something greater than a title bout. It’s a clash of personalities. Fury’s confident and brash nature stands in stark contrast to Usyk’s composed demeanor. These differences add complexity to the fight. It’s a fight of wills and ideologies. No matter who wins, the impact of this bout will reverberate throughout boxing history. The clash for the undisputed title is more than just a fight. It’s the result of relentless dedication. Should Fury claim victory through his strength and tactics, or Usyk wins with his precision with his technique and endurance, one thing is certain, this will be a defining moment in boxing.
This fight between Fury and Usyk is more than just a boxing event. It’s a showcase of skill and determination. The two competitors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında virtual qumar oyunlarına seçim artdıqca, Pinup kazino kimi onlayn mərc xidmətləri daha çox tanınmağa başladı. Özəlliklə, "Pin up casino online" şəklində olan platformalar son zamanlar Azəri mərc həvəskarları üçün məşhurdur. Pin-up casino azerbaycan oyunçulara müxtəlif oyunlar təklif edir.
Pin-up online casino, yerli oyunçular üçün populyar seçimdir. Bu kazino müştərilərə rəngarəng oyunlar verir və cəlbedici bonuslar ilə istifadəçilərin diqqətini çəkir.
Pin-up casino, istifadəçilərə oyun növləri ilə zəngin onlayn kazinodur. Azəri bazarında məşhur olan Pin-up online, mərc həvəskarları üçün çeşidli bonus imkanları yaradır.
Bununla yanaşı, Pin-up online casino qumar həvəskarlarına şəffaf və təhlükəsiz ödəmə üsulları təklif etməkdədir. Mərc edənlər, rahat maliyyə əməliyyatları nəticəsində, internet oyunlarını çox rahat keçirə bilərlər.
Nəticə etibarilə, Pin-up kazino qumarbazlara yalnız oyun təklif etmir cazibədar bonus təklifləri və maraqlı aksiyalar təklif edir. Bu platformada, müştərilər şəffaf oyun şərtləri ilə rastlaşır.
Web: https://pinup-best-casino.web.app
Pin-up kazino təkcə bir kazino olaraq məhdudlaşmır. Kazino həvəskarları bu kazinoda müxtəlif mərc növlərindən həzz ala bilərlər və çoxlu bonusları oyun təcrübələrinə əlavə edərlər.
Yekun olaraq, Pin-up azerbaycan, güvənli mərc oyunları mərc həvəskarlarına təqdim etməklə onlayn qumar sektorunda lider mövqedədir. Azəri oyunçular tərəfindən məşhur olması təsadüf deyil.
Fury, the Gypsy King, and Usyk, the technician are ready to face each other in a fight of unparalleled significance. This fight is about more than just titles; it’s a battle for eternal recognition. The Gypsy King has risen to the pinnacle of the sport thanks to his personality and remarkable adaptability during fights. Beating Wilder and Klitschko have solidified his legendary status. Across the ring, Oleksandr Usyk is a fighter unlike any other for Fury. On the flip side, Usyk, a genius in the ring is a true test for Fury for the heavyweight ranks overall, but for the entire division. Usyk’s rise to prominence started with his domination of the cruiserweights, as an undisputed champion. Get ready for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a historic showdown! Catch every punch in real time on our website. Don’t miss your chance — visit <a href="https://my.friendhosting.net/pl.php?2636&go=https://fury-usyk.uk/">fury-usyk.uk</a> today and enjoy the fight in high quality!
In the United Kingdom, the fight is expected to begin close to prime time, offering perfect timing for viewers. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, the excitement is palpable. The venue for Fury vs Usyk has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, one thing is certain: the atmosphere will be electric. Although the focus is centered on the headline fight, the preliminary bouts is also generating excitement. High-profile matches are known for strong supporting fights, giving fans a full evening of entertainment.
Traditionally, undercards of this caliber have showcased rising stars. Boxers seeking the spotlight often seize these moments to showcase their skills, knowing millions are watching. While the names for the undercard haven’t been officially announced, fans are eagerly guessing. Could we see rising prospects? No matter the final roster, the action will not disappoint. The most compelling part of Fury vs Usyk incredibly exciting is their contrasting skillsets. Tyson Fury’s size and agility set him apart from other heavyweights. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
The legendary battles with Wilder highlighted his resilience, overcoming brutal hits to finish strong. When he faced Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. Being a left-handed fighter, his positioning constantly challenges opponents. Usyk’s punches may not have knockout power, their timing wears down foes. With the date drawing closer, The betting lines for Fury vs Usyk are the subject of intense debate.
Fury is the favored fighter according to the odds, thanks to his imposing frame, his experience in high-pressure bouts, and his tactical brilliance. Despite the odds, Usyk remains a strong contender doesn’t diminish his chances, his victories against AJ confirmed his toughness against big opponents.
For Fury himself presents a shot at undisputed glory. A victory would further solidify his status as the best heavyweight of this era. On the other hand, Usyk’s victory would be a monumental achievement. Achieving undisputed glory in two divisions is a feat few can claim.
Web: <a href="http://www.google.com.na/url?sa=t&url=http%3A%2F%2Fwww.magical-dream.com">fury-usyk.uk</a>
Fury vs Usyk represents something greater than a title bout. It’s a battle of contrasting styles. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. These differences add complexity to the fight. Beyond physical ability, this fight. Regardless of the outcome, the legacy of this fight will be remembered as a defining moment in boxing. The battle for heavyweight supremacy is more than just a fight. It represents the culmination of their careers. Whether Fury secures the win through his strength and tactics, or Usyk wins with his precision through his superior boxing ability, one thing is certain, this bout will go down in history.
Tyson Fury vs Oleksandr Usyk is more than just a boxing event. It’s a battle of minds and bodies. The two competitors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
yerli oyunçular arasında onlayn qumar oyunlarına tələbat artdıqca, Pinup kimi saytlar daha çox tanınmağa başladı. Əlavə olaraq, Pinup casino şüarları artıq yerli oyunçular üçün sevilir. Pin-up kazino online oyunçulara çox oyun növləri təklif edir.
Pin-up online casino, Azəri istifadəçilər üçün populyar seçimdir. Bu mərc platforması kazino oyunçularına rəngarəng oyunlar təklif edir və bonus imkanları ilə qumarbazlar tərəfindən sevilir.
Pin-up cazino, çeşidli oyun təcrübəsi təklif edən xidmətdir. Azəri bazarında populyar olan Pin-up casino, mərc həvəskarları üçün geniş oyun təcrübəsi verir.
Bu səbəbdən, "Pin-up casino online" müştərilərə güvənli maliyyə əməliyyatları təklif edir. Kazino iştirakçıları, rahat maliyyə çıxarışları köməyilə, onlayn mərc oyunlarını müvafiq şəkildə oynaya bilərlər.
Son olaraq, Pinup kazino mərc həvəskarlarına çoxlu oyun növlərilə yanaşı cazibədar bonus təklifləri təqdim edir. Bu kazinoda, oyunçular özlərini güvəndə hiss edir.
Web: https://bet-on-pinup.web.app
Pin-up cazino təkcə bir kazino olaraq sadə oyunla bitmir. Mərc həvəskarları bu platformada çeşidli mərc seçimlərindən müxtəlif mərc imkanı əldə edə bilər və bonus sistemini qazanmaq imkanı əldə edərlər.
Nəticədə, Pin-up cazino, şəffaf və güvənli mərc oyunları oyunçulara təklif etməklə oyun bazarında oyunçular arasında geniş istifadə edilir. Azərbaycanda populyarlığı təsadüf deyil.
These two heavyweight champions are preparing for an epic showdown that will define an era. It’s far beyond a championship match; it represents their quest for immortality. Tyson Fury has risen to the pinnacle of the sport thanks to his personality and remarkable adaptability in the ring. Beating Wilder and Klitschko have solidified his legendary status. On the other hand, Usyk, the Ukrainian master poses a unique challenge to the heavyweight division. At the same time, the Ukrainian technician is a true test for Fury not just for Fury, but for the entire division. Usyk’s rise to prominence started with his domination of the cruiserweights, by conquering all challengers. Prepare yourself for a thrilling boxing match of the year as Usyk takes on Tyson Fury in an unforgettable showdown! Catch every punch in real time on our website. Be part of the action — visit <a href="http://traffic.shareaholic.com/e?a=1&u=http%3a%2f%2fusykvsfurydate.co.uk&r=1">usykvsfurydate.co.uk</a> right away and watch the match in high quality!
Across the UK, the fight is expected to begin around 10 PM GMT, making it ideal for a prime-time audience. Back in Usyk’s home country, and for fans watching from around the world, the excitement is palpable. Where the bout will take place has yet to be confirmed, with talk of iconic boxing destinations. No matter the location, fans can be sure: it will be a spectacle. Even though attention is centered on the headline fight, the preliminary bouts promises plenty of action. Big-ticket boxing cards include preliminary bouts with top talent, offering an entire night of boxing excitement.
Historically, undercards of this caliber have introduced future champions. Contenders hoping to make their mark often seize these moments to demonstrate their talent, with the world paying attention. While the names for the undercard has yet to be finalized, there’s plenty of talk. Will there be a heavyweight clash? No matter the final roster, fans can expect fireworks. The most compelling part of Fury vs Usyk incredibly exciting is the clash of styles. Tyson Fury’s size and agility make him an anomaly in boxing. Being so tall yet so nimble, he dictates the pace of bouts.
The legendary battles with Wilder highlighted his resilience, bouncing back from adversity to dominate in later rounds. In his fight with Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. By contrast, Usyk, brings speed, precision, and finesse. Being a left-handed fighter, his positioning constantly challenges opponents. The Ukrainian’s shots aren’t the heaviest in the division, their timing wears down foes. As fight night approaches, Tyson Fury vs Usyk odds are the subject of intense debate.
Most bookmakers favor Fury as predicted by many experts, given his physical stature, his proven ability in tough situations, and his tactical brilliance. However, Usyk's underdog status doesn’t diminish his chances, his dominance against Joshua confirmed his toughness against big opponents.
For Tyson Fury is a chance to further solidify his greatness. A victory would further solidify his status as the best heavyweight of this era. Meanwhile, Usyk’s victory would elevate him to new heights. Becoming an undisputed champion in two different weight classes would be a remarkable feat in boxing history.
Web: <a href="http://cse.google.co.ls/url?q=https://usykvsfurydate.co.uk/">usykvsfurydate.co.uk</a>
The upcoming showdown is not just about the belts. It’s a clash of personalities. Fury’s confident and brash nature is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. Beyond physical ability, this fight. Whoever comes out victorious, the impact of this bout will reverberate throughout boxing history. This historic showdown is more than just a fight. It’s a culmination of years of hard work. If Fury wins through his strength and tactics, or Usyk secures a victory thanks to his skill and resilience, it’s certain that, this bout will go down in history.
Fury vs Usyk is a spectacle of a lifetime. It’s a fight of grit and strategy. Both fighters will give everything they have.
Visit for more information: #crosslink[3,L -
yerli oyunçular arasında virtual qumar oyunlarına istək artdıqca, Pin-up kazino kimi oyun xidmətləri daha çox tanınmağa başladı. Xüsusilə, Pin-up online sözləri hazırda Azəri mərc həvəskarları üçün istifadə olunur. Pin-up casino azerbaycan mərc həvəskarlarına çox oyun növləri təklif edir.
Pin-up azerbaycan, Azərbaycandakı oyunçular üçün maraqlı seçimdir. Bu platforma kazino oyunçularına fərqli oyun növləri təmin edir və cazibədar aksiyalar ilə mərc edənləri özünə cəlb edir.
Pin-up azerbaycan, oyun keyfiyyətini artıran onlayn kazinodur. yerli mərcçilər arasında məşhur olan Pin-up kazino, qumar oyunçuları üçün çeşidli bonus imkanları yaradır.
Xüsusilə, Pinup casino mərc edənlərə şəffaf və təhlükəsiz maliyyə əməliyyatları təklif etməkdədir. Oyun həvəskarları, rahat depozit və pul çıxarış imkanları köməyilə, kazino oyunlarını çox rahat yaşaya bilərlər.
Əlavə olaraq, Pinup kazino oyunçulara yalnız qumar oyunları yox, həmçinin sərfəli bonuslar müştəriləri üçün yaradır. Pin-up-da, qumar həvəskarları özlərini güvəndə hiss edir.
Web: https://top-pinup.web.app
Pin-up casino online yalnız sadə oyunla bitmir. Müştərilər burada çeşidli mərc seçimlərindən təcrübə edə bilərlər və cazibədar bonus imkanlarını oyunlarına əlavə edə bilərlər.
Ümumilikdə, Pin-up cazino, müasir və təhlükəsiz mərc imkanı təklif etməklə mərc bazarında oyunçular arasında geniş istifadə edilir. Azəri oyunçular tərəfindən məşhur olması açıq bir faktdır.
These two heavyweight champions are ready to face each other in a fight of historic proportions. This fight is about more than just titles; it represents their quest for immortality. The Gypsy King has risen to the pinnacle of the sport thanks to his personality and his unmatched skills in the ring. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. Across the ring, the tactical southpaw poses a unique challenge to boxing’s biggest stars. On the flip side, Oleksandr Usyk stands as a unique threat for Tyson Fury himself, as a heavyweight contender. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, as an undisputed champion. Get ready for a thrilling boxing match of the year as Usyk takes on Fury in an unforgettable showdown! Catch every punch in real time on our website. Don’t miss your chance — visit <a href="https://app.promorepublic.com/away?url=https%3A%2F%2Ftysonfuryvsoleksandrusyk.co.uk">tysonfuryvsoleksandrusyk.co.uk</a> now and stream the event with top-notch streaming!
In the United Kingdom, the event will kick off at late evening, offering perfect timing for viewers. For Usyk’s fans in Ukraine, and for fans watching from around the world, the excitement is palpable. The fight’s location remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, one thing is certain: the atmosphere will be electric. Even though attention is firmly on the main event, the Fury vs Usyk undercard is shaping up to be thrilling. High-profile matches are known for strong supporting fights, giving fans a full evening of entertainment.
Traditionally, undercards of this caliber have introduced future champions. Boxers seeking the spotlight capitalize on the exposure to impress fans and analysts alike, as all eyes are on them. Though the supporting fights for Fury vs Usyk are still unconfirmed, fans are eagerly guessing. Will there be a heavyweight clash? Regardless of the names, the action will not disappoint. The most compelling part of Fury vs Usyk truly fascinating is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. With his immense height and reach advantage, he dictates the pace of bouts.
His trilogy with Deontay Wilder proved his toughness, as he recovered from knockdowns to dominate in later rounds. Against Wladimir Klitschko, his strategic genius shone through, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, offers a different kind of threat. As a southpaw, his positioning constantly challenges opponents. His strikes aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. As anticipation builds, Tyson Fury vs Usyk odds have fans and analysts speculating.
Tyson Fury is seen as the frontrunner as per the betting experts, thanks to his imposing frame, his track record in big matches, and his adaptability. Despite being seen as the underdog shouldn’t be counted out, his dominance against Joshua proved that he can handle the physicality of the heavyweight division.
For Fury himself presents a shot at undisputed glory. A triumph for Fury would solidify his claim as the greatest heavyweight of his generation. Conversely, For Usyk, a win would mark him as one of the sport’s greats. Becoming the undisputed heavyweight champion is a feat few can claim.
Web: <a href="http://maps.google.com.bn/url?q=https://tysonfuryvsoleksandrusyk.co.uk/">tysonfuryvsoleksandrusyk.co.uk</a>
Fury vs Usyk is more than just a championship fight. It’s a battle of contrasting styles. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. Such contrasts make the fight more compelling. It’s a fight of wills and ideologies. Regardless of the outcome, the impact of this bout will be remembered as a defining moment in boxing. The battle for heavyweight supremacy is a defining moment. It’s the result of relentless dedication. Whether Tyson Fury prevails thanks to his power and game plan, or Oleksandr Usyk triumphs through his superior boxing ability, what is clear is, this will be a fight remembered for years to come.
This fight between Fury and Usyk is more than just a fight. It’s a contest of heart and willpower. These two warriors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azərbaycan ərazisində onlayn qumar oyunlarına seçim artdıqca, Pin-up casino online kimi onlayn mərc xidmətləri daha çox tanınmağa başladı. Əsasən, Pinup casino şəklində olan platformalar çoxdan Azəri müştərilər üçün güvənlidir. Pin-up casino istifadəçilərə çoxlu oyun növü təklif edir.
Pin up kazino, Azərbaycandakı oyunçular üçün maraqlı seçimdir. Bu onlayn kazino qumarbazlara geniş çeşidli oyunlar verir və sərfəli bonus təklifləri ilə qumarbazlar tərəfindən sevilir.
Pin-up cazino, geniş oyun variantları təklif edən onlayn kazinodur. Azərbaycanda güvənilən Pin-up oyunları, oyun həvəskarları üçün maraqlı oyun imkanları təklif edir.
Bununla yanaşı, "Pin-up casino online" mərcçilərə etibarlı maliyyə sistemləri təklif etməkdədir. İstifadəçilər, sürətli və asan kredit kartı və elektron pul kisəsi ilə nəticəsində, kazino oyunlarını çox rahat keçirə bilərlər.
Son olaraq, Pin-up casino online mərc həvəskarlarına təkcə oyun imkanı deyil cəlbedici kampaniyalar oyun təcrübəsini daha da maraqlı edir. Bu kazinoda, istifadəçilər özlərini güvəndə hiss edir.
Web: https://pinup-best-bet.web.app
Pin-up online kazino sadəcə məhdud oyunlar təklif etmir. Mərc həvəskarları bu platformada fərqli mərc oyunlarından istifadə edə bilər və cazibədar bonus imkanlarını oyun təcrübəsini artırarlar.
Nəticədə, Pin-up casino online, sərfəli və təhlükəsiz mərc oyunları təmin etməklə oyun bazarında lider mövqedədir. Azərbaycanda çox seçilməsi əlamətdardır.
Fury, the Gypsy King, and Usyk, the technician are on a collision course that will define an era. It’s not merely about the belts; it’s a battle for eternal recognition. The towering Fury has become a global icon through his unique style coupled with unparalleled talent inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. On the other hand, the tactical southpaw brings an unprecedented test for Fury. Meanwhile, Oleksandr Usyk stands as a unique threat not just for Fury, but for the entire division. His journey to global fame started with his domination of the cruiserweights, as an undisputed champion. Don’t miss out for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a must-watch showdown! Experience every moment in real time on our website. Be part of the action — visit <a href="https://www.filion.ru/bitrix/redirect.php?goto=https://tysonfuryvoleksandrusyk.org.uk/">tysonfuryvoleksandrusyk.org.uk</a> today and stream the event in high quality!
In the United Kingdom, the fight is expected to begin close to prime time, making it ideal for a prime-time audience. Back in Usyk’s home country, and beyond, this will be a must-see event. The venue for Fury vs Usyk remains a hot topic, with talk of iconic boxing destinations. Regardless of the venue, it’s guaranteed: the excitement will be unmatched. Although the focus is centered on the headline fight, the Fury vs Usyk undercard is shaping up to be thrilling. High-profile matches often feature stacked undercards, offering an entire night of boxing excitement.
In the past, supporting bouts in major events have showcased rising stars. Contenders hoping to make their mark often seize these moments to demonstrate their talent, as all eyes are on them. Although the lineup for the Fury Usyk undercard has yet to be finalized, there’s plenty of talk. Will there be a heavyweight clash? Whatever the selection, fans can expect fireworks. What makes this fight incredibly exciting is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. With his immense height and reach advantage, he dictates the pace of bouts.
The legendary battles with Wilder showed his durability, bouncing back from adversity to secure victories. Against Wladimir Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. By contrast, Usyk, offers a different kind of threat. As a southpaw, his movements create openings. The Ukrainian’s shots may not have knockout power, they consistently find their mark. As fight night approaches, Tyson Fury vs Usyk odds are the subject of intense debate.
The betting lines show Fury ahead as per the betting experts, because of his reach and height, his long career in major fights, and his tactical brilliance. Despite being seen as the underdog doesn’t rule him out, as his victories over Joshua confirmed his toughness against big opponents.
For Tyson Fury is a chance to further solidify his greatness. Should he come out on top, Fury’s win would add an undisputed title to his already impressive resume. On the other hand, If Usyk wins would elevate him to legendary status. Becoming an undisputed champion in two different weight classes is a once-in-a-lifetime achievement.
Web: <a href="http://images.google.rs/url?q=https://tysonfuryvoleksandrusyk.org.uk/">tysonfuryvoleksandrusyk.org.uk</a>
The upcoming showdown is not just about the belts. It’s a fight between two very different fighters. Fury’s boisterous personality contrasts with Usyk’s calm, focused demeanor. These differences add complexity to the fight. It’s about more than just skill. Whoever triumphs in this battle, the legacy of this fight will be remembered as a defining moment in boxing. The clash for the undisputed title is more than just a match. It’s the result of relentless dedication. Whether Tyson Fury prevails with his experience and unpredictability, or Usyk comes out on top through his superior boxing ability, no matter the outcome, this will be a defining moment in boxing.
Tyson Fury vs Oleksandr Usyk is more than just a sporting contest. It’s a contest of heart and willpower. These two warriors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azərbaycan ərazisində virtual qumar oyunlarına tələbat artdıqca, Pin-up online kimi şirkətlər daha çox tanınmağa başladı. Əsasən, "Pin up casino online" brendləri çoxdan yerli istifadəçilər üçün məşhurdur. Pin-up kazino oyunçulara rəngarəng oyunlar təklif edir.
Pin-up casino, yerli mərc həvəskarları üçün geniş yayılmış bir xidmətdir. Bu mərc platforması istifadəçilərə rəngarəng oyunlar təklif edib və cazibədar aksiyalar ilə oyunçuları özünə cəlb edir.
Pinup casino, çeşidli oyun təcrübəsi təklif edən onlayn kazinodur. yerli mərcçilər arasında oyunçular tərəfindən sevilən Pin-up casino, oyun həvəskarları üçün zəngin təkliflər təqdim edir.
Xüsusilə, "Pin-up casino online" mərcçilərə təhlükəsiz maliyyə əməliyyatları verir. Oyunçular, müvafiq və təhlükəsiz depozit və pul çıxarış imkanları vasitəsilə, mərc təcrübələrini daha rahat keçirə bilərlər.
Nəticə etibarilə, Pin-up azerbaycan mərcçilərə yalnız qumar oyunları yox, həmçinin cəlbedici kampaniyalar təmin edir. Bu platformada, müştərilər təhlükəsiz şərtlər altında mərc edir.
Web: https://bet-pinup.web.app
Pin-up kazino sadəcə oyunçuları cəlb etmir. Müştərilər burada fərqli mərc oyunlarından istifadə edə bilər və bonus sistemini oyun təcrübəsini artırarlar.
Yekun olaraq, Pin-up casino online, rahat və təhlükəsiz kazino təcrübəsi təqdim etməklə oyun bazarında ən sevilən platformalardan olur. yerli mərcçilər arasında populyarlığı təsadüf deyil.
Fury, the Gypsy King, and Usyk, the technician are preparing for an epic showdown of unparalleled significance. This fight is about more than just titles; it’s about legacy. The towering Fury has earned worldwide fame with his charisma and his unmatched skills during fights. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Meanwhile, Oleksandr Usyk brings an unprecedented test for Fury. At the same time, Usyk, a genius in the ring is a true test for Fury for the heavyweight ranks overall, and for boxing fans worldwide. The ascent of Oleksandr Usyk began in the cruiserweight division, by conquering all challengers. Don’t miss out for the most anticipated boxing match of the year as Usyk takes on Tyson Fury in an unforgettable showdown! See every move in real time on our website. Join the excitement — visit <a href="http://pr.chambernation.workers.dev/?http%3A%2F%2Ftysonvsusyk.org.uk">tysonvsusyk.org.uk</a> right away and stream the event in high quality!
Across the UK, the event will kick off at late evening, offering perfect timing for viewers. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, this will be a must-see event. The venue for Fury vs Usyk remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, one thing is certain: the atmosphere will be electric. Although the focus remains on Fury and Usyk, the fights leading up to the main event is shaping up to be thrilling. Major boxing events are known for strong supporting fights, offering an entire night of boxing excitement.
Historically, preliminary fights on major cards have introduced future champions. Fighters looking to rise through the ranks capitalize on the exposure to showcase their skills, as all eyes are on them. While the names for the undercard are still unconfirmed, speculation runs high. Will there be a heavyweight clash? Regardless of the names, fans can expect fireworks. The most compelling part of Fury vs Usyk truly fascinating is the clash of styles. Tyson Fury’s size and agility set him apart from other heavyweights. With his immense height and reach advantage, he dictates the pace of bouts.
The three fights against Wilder proved his toughness, as he recovered from knockdowns to finish strong. Against Wladimir Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. Being a left-handed fighter, he uses angles and footwork. The Ukrainian’s shots lack devastating strength, they consistently find their mark. With the date drawing closer, The betting lines for Fury vs Usyk have fans and analysts speculating.
The betting lines show Fury ahead as per the betting experts, given his physical stature, his track record in big matches, and his unpredictable nature. Although Usyk is the less favored fighter doesn’t diminish his chances, as his victories over Joshua confirmed his toughness against big opponents.
For the Gypsy King represents an opportunity to cement his legacy. A victory would further solidify his status as the best heavyweight of this era. Meanwhile, Usyk’s victory would be a monumental achievement. Becoming an undisputed champion in two different weight classes is a feat few can claim.
Web: <a href="http://www.google.com.ai/url?q=https%3A%2F%2Ftysonvsusyk.org.uk">tysonvsusyk.org.uk</a>
The upcoming showdown represents something greater than a title bout. It’s a clash of personalities. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. These differences add complexity to the fight. It’s about more than just skill. Regardless of the outcome, the legacy of this fight will reverberate throughout boxing history. Fury vs Usyk is a spectacle unlike any other. It represents the culmination of their careers. Whether Fury secures the win thanks to his power and game plan, or Oleksandr Usyk triumphs through his superior boxing ability, one thing is certain, this will be a fight remembered for years to come.
Fury vs Usyk is more than just a boxing event. It’s a contest of heart and willpower. These two warriors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında internet qumarına maraq artdıqca, Pin-up kazino kimi oyun xidmətləri daha çox tanınmağa başladı. Əsasən, Pin-up kazino ifadələri hazırda Azəri mərc həvəskarları üçün sevilir. Pin-up kazino online öz oyunçularına müxtəlif oyunlar təklif edir.
Pin-up cazino, Azəri istifadəçilər üçün geniş kütləyə sahib bir qumar saytıdır. Bu platforma oyunçulara rəngarəng oyunlar təklif verməkdədir və sərfəli bonus təklifləri ilə mərc edənləri özünə cəlb edir.
Pin-up cazino, geniş oyun variantları təklif edən onlayn kazinodur. Azəri bazarında geniş istifadə olunan Pinup, mərc həvəskarları üçün maraqlı oyun imkanları təklif edir.
Özəlliklə, Pin-up azerbaycan oyunçulara təhlükəsiz maliyyə idarəetmə imkanları oyunçularına təklif edir. Kazino iştirakçıları, sürətli və asan ödəmə üsulları ilə təmin olunmaqla, qumar təcrübələrini güvənli və təhlükəsiz yerinə yetirə bilərlər.
Sonda, Pin-up azerbaycan qumarbazlara çoxlu oyun növlərilə yanaşı mərc hədiyyələri və maraqlı aksiyalar təklif edir. Bu platformada, qumar həvəskarları güvənli bir təcrübə yaşayır.
Web: https://best-pinup.web.app
Pin-up casino təkcə bir oyun platforması kimi oyunlar ilə kifayətlənmir. Müştərilər burada fərqli mərc oyunlarından müxtəlif mərc imkanı əldə edə bilər və sərfəli bonus təkliflərini mərc təcrübələrini zənginləşdirərlər.
Nəticədə, Pin-up cazino, rahat və təhlükəsiz kazino təcrübəsi mərc həvəskarlarına təqdim etməklə onlayn mərc dünyasında lider mövqedədir. Azərbaycan mərcçiləri arasında geniş yayılması dikkətə layiqdir.
Tyson Fury and Oleksandr Usyk are ready to face each other in a fight that will define an era. It’s not merely about the belts; it’s a battle for eternal recognition. Tyson Fury has become a global icon through his unique style and his unmatched skills in the ring. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. Across the ring, the tactical southpaw is a fighter unlike any other for Fury. Meanwhile, Usyk, a southpaw master stands as a unique threat for Tyson Fury himself, as a heavyweight contender. The ascent of Oleksandr Usyk began in the cruiserweight division, by conquering all challengers. Get ready for a thrilling boxing match of the year as Oleksandr Usyk takes on Fury in a must-watch showdown! Experience every moment live on our website. Join the excitement — visit <a href="http://allcorp-msk.ru/outgocounter.php?url=aHR0cHM6Ly9tb2RzLW1lbnUucnUv">tysonvsusyk.org.uk</a> now and stream the event with top-notch streaming!
In the United Kingdom, the ring walks are planned for late evening, ensuring maximum viewership. For Usyk’s fans in Ukraine, and beyond, the excitement is palpable. The fight’s location remains a hot topic, with talk of iconic boxing destinations. Wherever it happens, fans can be sure: it will be a spectacle. While the spotlight is centered on the headline fight, the fights leading up to the main event is also generating excitement. Big-ticket boxing cards often feature stacked undercards, offering an entire night of boxing excitement.
Traditionally, preliminary fights on major cards have been a stage for breakout performances. Contenders hoping to make their mark capitalize on the exposure to showcase their skills, knowing millions are watching. Though the supporting fights for Fury vs Usyk haven’t been officially announced, speculation runs high. Might there be a cruiserweight spectacle? Regardless of the names, fans can expect fireworks. The most compelling part of Fury vs Usyk so intriguing is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed are unparalleled in the sport. With his immense height and reach advantage, Fury can control a fight.
The legendary battles with Wilder proved his toughness, bouncing back from adversity to finish strong. When he faced Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. With his unorthodox stance, his positioning constantly challenges opponents. His strikes lack devastating strength, their timing wears down foes. With the date drawing closer, Tyson Fury vs Usyk odds have fans and analysts speculating.
The betting lines show Fury ahead as predicted by many experts, given his physical stature, his proven ability in tough situations, and his unorthodox style. Although Usyk is the less favored fighter shouldn’t be counted out, his wins over Anthony Joshua confirmed his toughness against big opponents.
For Tyson Fury could be the defining moment of his career. A triumph for Fury would further solidify his status as the best heavyweight of this era. On the other hand, If Usyk wins would be a monumental achievement. Securing two undisputed titles would be a remarkable feat in boxing history.
Web: <a href="http://images.google.co.uk/url?q=https://tysonvsusyk.org.uk/">tysonvsusyk.org.uk</a>
The upcoming showdown is about more than the titles. It’s a clash of personalities. Fury’s confident and brash nature is in stark contrast to Usyk’s quiet intensity. Such contrasts make the fight more compelling. It’s a fight of wills and ideologies. Regardless of the outcome, the impact of this bout will be felt for years to come. The clash for the undisputed title is a spectacle unlike any other. It’s the pinnacle of both fighters’ hard work. If Fury wins thanks to his power and game plan, or Oleksandr Usyk triumphs with his technique and endurance, what is clear is, this will be a legendary contest.
Tyson Fury vs Oleksandr Usyk is more than just a sporting contest. It’s a contest of heart and willpower. Both fighters will give everything they have.
Visit for more information: #crosslink[3,L -
Azəri bazarında internet oyunlarına seçim artdıqca, Pin-up casino online kimi saytlar daha çox tanınmağa başladı. Əlavə olaraq, Pinup casino şəklində olan platformalar hazırda Azərbaycandakı oyunçular üçün tanışdır. Pin-up azerbaycan öz oyunçularına çeşidli oyunlar təklif edir.
Pin-up kazino, Azərbaycan oyunçuları üçün güvənli bir qumar məkanıdır. Bu platforma qumarbazlara çoxlu oyun təklifləri təklif edib və cazibədar aksiyalar ilə mərc edənləri özünə cəlb edir.
Pin-up cazino, fərqli oyun təcrübəsi təklif edən bir platformadır. yerli mərcçilər arasında geniş istifadə olunan Pinup, kazino oyunçuları üçün geniş oyun təcrübəsi verir.
Bunun nəticəsində, Pinup kazino istifadəçilərə şəffaf və təhlükəsiz maliyyə idarəetmə imkanları oyunçularına təklif edir. İstifadəçilər, sürətli və asan depozit çıxarış sistemi nəticəsində, onlayn mərc oyunlarını çox rahat təcrübə edərlər.
Əlavə olaraq, Pin-up cazino istifadəçilərə təkcə oyun imkanı deyil bonuslar və aksiyalar oyunçularına verir. Bu platformada, oyunçular güvənli bir təcrübə yaşayır.
Web: https://win-pinup.web.app
Pin-up casino online təkcə sadə oyunla bitmir. Müştərilər burada müxtəlif mərc növlərindən faydalanıb və maraqlı aksiyaları mərc təcrübələrini zənginləşdirərlər.
Beləliklə, Pinup kazino, etibarlı mərc imkanı oyunçulara təklif etməklə oyun bazarında oyunçular arasında geniş istifadə edilir. yerli mərcçilər arasında məşhur olması təsadüfi deyil.
These two heavyweight champions are on a collision course that will define an era. It’s far beyond a championship match; it’s a battle for eternal recognition. The towering Fury has earned worldwide fame thanks to his personality and remarkable adaptability in the ring. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. In contrast, Usyk, the Ukrainian master is a fighter unlike any other for Fury. At the same time, the Ukrainian technician stands as a unique threat for the heavyweight ranks overall, as a heavyweight contender. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, as an undisputed champion. Get ready for an epic boxing match of the year as Usyk takes on Tyson Fury in an unforgettable showdown! Experience every moment streamed live on our website. Be part of the action — visit <a href="https://www.emuparadise.me/logout.php?next=https://tysonfuryvsusyk.org.uk/">tysonfuryvsusyk.org.uk</a> right away and stream the event in high quality!
Across the UK, the fight is expected to begin close to prime time, ensuring maximum viewership. Back in Usyk’s home country, and beyond, the excitement is palpable. The fight’s location remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, it’s guaranteed: it will be a spectacle. Even though attention is centered on the headline fight, the fights leading up to the main event is shaping up to be thrilling. High-profile matches often feature stacked undercards, providing non-stop action before the headliner.
Traditionally, preliminary fights on major cards have showcased rising stars. Boxers seeking the spotlight use such opportunities to demonstrate their talent, knowing millions are watching. Although the lineup for the Fury Usyk undercard has yet to be finalized, speculation runs high. Might there be a cruiserweight spectacle? Whatever the selection, fans can expect fireworks. What makes this fight incredibly exciting is the clash of styles. Fury’s towering frame and movement set him apart from other heavyweights. At 6’9" with an 85-inch reach, Fury can control a fight.
His trilogy with Deontay Wilder highlighted his resilience, bouncing back from adversity to secure victories. Against Wladimir Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, offers a different kind of threat. Being a left-handed fighter, his movements create openings. Usyk’s punches lack devastating strength, they consistently find their mark. As anticipation builds, The betting lines for Fury vs Usyk have fans and analysts speculating.
Most bookmakers favor Fury as per the betting experts, because of his reach and height, his long career in major fights, and his adaptability. Despite being seen as the underdog doesn’t rule him out, his victories against AJ proved that he can handle the physicality of the heavyweight division.
For Tyson Fury, this fight represents an opportunity to cement his legacy. Should he come out on top, Fury’s win would put the finishing touches on a historic career. On the other hand, Usyk’s victory would elevate him to new heights. Securing two undisputed titles is a feat few can claim.
Web: <a href="http://clients1.google.com.bh/url?q=https://tysonfuryvsusyk.org.uk/">tysonfuryvsusyk.org.uk</a>
The upcoming showdown represents something greater than a title bout. It’s a fight between two very different fighters. Fury’s boisterous personality is in stark contrast to Usyk’s quiet intensity. Such contrasts make the fight more compelling. This is more than just a physical contest. Whoever comes out victorious, the impact of this bout will reverberate throughout boxing history. The battle for heavyweight supremacy is a spectacle unlike any other. It represents the culmination of their careers. If Fury wins with his experience and unpredictability, or Oleksandr Usyk triumphs with his technique and endurance, no matter the outcome, this will be a fight remembered for years to come.
The Fury-Usyk battle is more than just a fight. It’s a showcase of skill and determination. The two competitors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azərbaycandakı qumar sektorunda internet qumarına güvəni artdıqca, Pinup kazino kimi onlayn mərc xidmətləri daha çox tanınmağa başladı. Özəlliklə, Pinup casino brendləri indi yerli oyunçular üçün güvənlidir. Pin-up azerbaycan oyunçulara rəngarəng oyunlar təklif edir.
Pin-up cazino, Azəri istifadəçilər üçün geniş kütləyə sahib bir qumar saytıdır. Bu kazino mərc həvəskarlarına fərqli oyun növləri təklif edir və sərfəli bonus təklifləri ilə oyunçuları özünə cəlb edir.
Pin-up cazino, fərqli oyun təcrübəsi təklif edən şirkətdir. yerli mərcçilər arasında məşhur olan Pin-up online, qumar oyunçuları üçün maraqlı oyun imkanları təklif edir.
Xüsusilə, Pinup casino qumar həvəskarlarına etibarlı maliyyə əməliyyatları verir. Mərc edənlər, rahat kredit kartı və elektron pul kisəsi ilə ilə, onlayn mərc oyunlarını müvafiq şəkildə təcrübə edərlər.
Bununla yanaşı, Pin-up kazino istifadəçilərə yalnız oyun təklif etmir sərfəli bonuslar oyunçularına verir. Bu kazinoda, istifadəçilər şəffaf oyun şərtləri ilə rastlaşır.
Web: https://pinup-top.web.app
Pin-up kazino yalnız oyunçuları cəlb etmir. Müştərilər burada çeşidli mərc seçimlərindən istifadə edə bilər və maraqlı aksiyaları oyun təcrübələrinə əlavə edərlər.
Bunun nəticəsində, Pin-up casino online, güvənli oyun imkanı təqdim etməklə oyun sənayesində lider mövqedədir. Azəri bazarında məşhur olması əlamətdardır.
These two heavyweight champions are ready to face each other in a fight of unparalleled significance. It’s far beyond a championship match; it’s a battle for eternal recognition. Tyson Fury has earned worldwide fame thanks to his personality and his unmatched skills in the ring. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. Meanwhile, Oleksandr Usyk brings an unprecedented test to the heavyweight division. On the flip side, Usyk, a southpaw master stands as a unique threat not just for Fury, but for the entire division. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, as an undisputed champion. Prepare yourself for an epic boxing match of the year as Usyk takes on Tyson Fury in an unforgettable showdown! Catch every punch streamed live on our website. Don’t miss your chance — visit <a href="https://dolevka.ru/redirect.asp?url=https://tysonvsusyk.co.uk/">tysonvsusyk.co.uk</a> now and enjoy the fight with top-notch streaming!
For British fans, the event will kick off at around 10 PM GMT, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, and beyond, this will be a must-see event. The fight’s location is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. Regardless of the venue, fans can be sure: the atmosphere will be electric. Even though attention remains on Fury and Usyk, the preliminary bouts is also generating excitement. High-profile matches often feature stacked undercards, offering an entire night of boxing excitement.
In the past, preliminary fights on major cards have showcased rising stars. Contenders hoping to make their mark capitalize on the exposure to showcase their skills, knowing millions are watching. Though the supporting fights for Fury vs Usyk has yet to be finalized, there’s plenty of talk. Might there be a cruiserweight spectacle? Whatever the selection, the action will not disappoint. What makes this fight truly fascinating is the dynamic between these fighters. Fury’s towering frame and movement make him an anomaly in boxing. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
His trilogy with Deontay Wilder proved his toughness, overcoming brutal hits to dominate in later rounds. In his fight with Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. Meanwhile, Usyk, offers a different kind of threat. With his unorthodox stance, his movements create openings. His strikes may not have knockout power, their timing wears down foes. With the date drawing closer, Tyson Fury vs Usyk odds have fans and analysts speculating.
Tyson Fury is the slight favorite as predicted by many experts, due to his size advantage, his experience in high-pressure bouts, and his unpredictable nature. However, Usyk's underdog status doesn’t rule him out, as his victories over Joshua showed that he can compete at heavyweight.
For the Gypsy King is a chance to further solidify his greatness. If he wins, it would add an undisputed title to his already impressive resume. Meanwhile, Usyk’s victory would be a monumental achievement. Securing two undisputed titles is a feat few can claim.
Web: <a href="http://www.google.com.om/url?sa=t&url=http%3A%2F%2Fwww.magical-dream.com">tysonvsusyk.co.uk</a>
Fury vs Usyk is about more than the titles. It’s a meeting of two unique worldviews. Fury’s bold and unapologetic character contrasts with Usyk’s calm, focused demeanor. These varying personalities make the bout even more interesting. It’s about more than just skill. No matter who wins, the impact of this bout will be remembered as a defining moment in boxing. The battle for heavyweight supremacy is more than just a match. It’s a culmination of years of hard work. If Fury wins with his experience and unpredictability, or Usyk secures a victory with his finesse and stamina, one thing is certain, this will be a legendary contest.
Tyson Fury vs Oleksandr Usyk is more than just a sporting contest. It’s a battle of minds and bodies. These two warriors will give everything they have.
Visit for more information: #crosslink[3,L -
Azərbaycanda onlayn qumar oyunlarına seçim artdıqca, Pin-up casino online kimi kazino xidmətləri daha çox tanınmağa başladı. Xüsusilə, Pin-up azerbaycan şəklində olan platformalar artıq Azərbaycandakı oyunçular üçün istifadə olunur. Pinup casino öz oyunçularına geniş oyunlar təklif edir.
Pin up kazino, Azəri qumarbazlar üçün ən sevilən platformalardan biridir. Bu qumar saytı qumarbazlara geniş çeşidli oyunlar verir və bonus imkanları ilə istifadəçilərin diqqətini çəkir.
Pinup casino, istifadəçilərə oyun növləri ilə zəngin bir platformadır. Azərbaycan ərazisində geniş istifadə olunan Pin-up oyunları, yerli oyunçular üçün çeşidli bonus imkanları yaradır.
Xüsusilə, "Pin-up casino online" müştərilərə güvənli və şəffaf ödəmə üsulları təqdim edir. Kazino iştirakçıları, etibarlı və tez depozit və pul çıxarış imkanları köməyilə, oyun təcrübələrini çox rahat yerinə yetirə bilərlər.
Yekun olaraq, Pin-up azerbaycan müştərilərə yalnız oyun təklif etmir cazibədar bonus təklifləri təmin edir. Pinup-da, qumar həvəskarları təhlükəsiz şərtlər altında mərc edir.
Web: https://pinup-top.web.app
Pin-up online kazino sadəcə oyunlar ilə kifayətlənmir. Kazino həvəskarları bu kazinoda müxtəlif mərc növlərindən istifadə edə bilər və geniş bonus imkanlarını oyunlarına əlavə edə bilərlər.
Ümumilikdə, Pin-up casino, müasir və təhlükəsiz mərc təcrübəsi təklif etməklə onlayn qumar dünyasında lider mövqedədir. Azərbaycan mərcçiləri arasında geniş yayılması əlamətdardır.
Azərbaycanda online kazino oyunlarına tələbat artdıqca, Pinup kimi platformalar daha çox tanınmağa başladı. Əsasən, Pin-up azerbaycan brendləri çoxdan Azəri oyunçuları üçün sevilir. Pin-up casino mərc həvəskarlarına geniş oyunlar təklif edir.
Pinup kazino, Azərbaycandakı oyunçular üçün geniş yayılmış bir xidmətdir. Bu platforma kazino oyunçularına çeşidli qumar oyunları oyunçulara təqdim edir və bonus imkanları ilə istifadəçilərin diqqətini çəkir.
Pinup casino, çeşidli oyun təcrübəsi təklif edən şirkətdir. Azəri bazarında məşhur olan Pin-up oyunları, istifadəçilər üçün fərqli oyun seçimləri ilə çıxış edir.
Özəlliklə, Pin-up azerbaycan mərcçilərə təhlükəsiz ödəmə sistemləri təqdim edir. İstifadəçilər, müvafiq və təhlükəsiz kredit kartı və elektron pul kisəsi ilə köməyilə, kazino oyunlarını daha rahat keçirə bilərlər.
Sonda, Pin-up kazino qumarbazlara yalnız oyun təklif etmir cəlbedici kampaniyalar təqdim edir. Pin-up-da, qumar həvəskarları güvənli bir təcrübə yaşayır.
Web: https://az-pinup.web.app
Pin-up cazino təkcə sadə oyunla bitmir. Müştərilər burada bənzərsiz mərc imkanlarından faydalanıb və maraqlı aksiyaları qazanmaq imkanı əldə edərlər.
Sonda, Pin-up kazino, rahat və təhlükəsiz mərc təcrübəsi təqdim etməklə onlayn qumar sektorunda özünü doğruldur. Azərbaycanda seçim olması təsadüfi deyil.
Fury, the Gypsy King, and Usyk, the technician are set to meet in the ring of historic proportions. This fight is about more than just titles; it’s about legacy. The towering Fury has risen to the pinnacle of the sport through his unique style and remarkable adaptability inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. Across the ring, Usyk, the technician is a fighter unlike any other to boxing’s biggest stars. On the flip side, Oleksandr Usyk represents a formidable opponent for Tyson Fury himself, and for boxing fans worldwide. His journey to global fame was marked by his undisputed cruiserweight reign, by conquering all challengers. Prepare yourself for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a must-watch showdown! Catch every punch live on our website. Don’t miss your chance — visit <a href="https://www.viveleschiens.com/tracking.php?tracking_type=out&campagne_id=28614&url=https%3A%2F%2Ffuryvsusykdate.org.uk">furyvsusykdate.org.uk</a> today and stream the event in high quality!
For British fans, the ring walks are planned for around 10 PM GMT, making it ideal for a prime-time audience. Back in Usyk’s home country, and beyond, this will be a must-see event. The venue for Fury vs Usyk has yet to be confirmed, with talk of iconic boxing destinations. Wherever it happens, it’s guaranteed: the excitement will be unmatched. Even though attention is centered on the headline fight, the Fury vs Usyk undercard promises plenty of action. High-profile matches often feature stacked undercards, offering an entire night of boxing excitement.
Traditionally, supporting bouts in major events have showcased rising stars. Boxers seeking the spotlight often seize these moments to demonstrate their talent, as all eyes are on them. Although the lineup for the Fury Usyk undercard has yet to be finalized, there’s plenty of talk. Might there be a cruiserweight spectacle? No matter the final roster, fans can expect fireworks. What sets this bout apart incredibly exciting is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed are unparalleled in the sport. Being so tall yet so nimble, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, overcoming brutal hits to dominate in later rounds. In his fight with Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. Meanwhile, Usyk, offers a different kind of threat. With his unorthodox stance, he uses angles and footwork. His strikes lack devastating strength, their timing wears down foes. With the date drawing closer, Tyson Fury vs Usyk odds are becoming a hot topic.
Fury is the favored fighter as predicted by many experts, due to his size advantage, his proven ability in tough situations, and his adaptability. Despite being seen as the underdog shouldn’t be counted out, his dominance against Joshua demonstrated his ability in the heavyweight ranks.
For Fury himself represents an opportunity to cement his legacy. If he wins, it would further solidify his status as the best heavyweight of this era. Meanwhile, For Usyk, a win would elevate him to legendary status. Becoming an undisputed champion in two different weight classes is a once-in-a-lifetime achievement.
Web: <a href="http://google.cz/url?q=https://furyvsusykdate.org.uk/">furyvsusykdate.org.uk</a>
The upcoming showdown represents something greater than a title bout. It’s a fight between two very different fighters. Fury’s larger-than-life persona contrasts with Usyk’s calm, focused demeanor. These varying personalities make the bout even more interesting. It’s about more than just skill. Whoever triumphs in this battle, the legacy of this fight will leave a lasting mark on the sport. This historic showdown is more than just a fight. It’s the pinnacle of both fighters’ hard work. Whether Fury secures the win through his strength and tactics, or Usyk secures a victory thanks to his skill and resilience, what is clear is, this bout will go down in history.
The Fury-Usyk battle is more than just a sporting contest. It’s a fight of grit and strategy. The two competitors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında online kazino oyunlarına tələbat artdıqca, Pinup kazino kimi platformalar daha çox tanınmağa başladı. Əlavə olaraq, Pin-up azerbaycan brendləri çoxdan Azəri müştərilər üçün istifadə olunur. Pin-up casino müştərilərinə çox oyun növləri təklif edir.
Pin-up azerbaycan, Azəri qumarbazlar üçün geniş yayılmış bir xidmətdir. Bu qumar saytı qumarbazlara çoxlu oyun təklifləri təmin edir və çoxlu bonuslar ilə mərc edənləri özünə cəlb edir.
Pinup casino, oyun keyfiyyətini artıran xidmətdir. yerli mərcçilər arasında populyar olan Pin-up casino, mərc həvəskarları üçün geniş oyun variantları ilə tanınır.
Bununla yanaşı, Pinup casino mərcçilərə güvənli və şəffaf depozit və çıxarış imkanı təklif etməkdədir. Mərc edənlər, rahat və tez kredit kartı və elektron pul kisəsi ilə vasitəsilə, oyun təcrübələrini müvafiq şəkildə yaşaya bilərlər.
Nəticə etibarilə, Pin-up casino mərcçilərə təkcə oyun imkanı deyil cəlbedici kampaniyalar oyun təcrübəsini daha da maraqlı edir. Bu onlayn kazinoda, müştərilər güvənli bir təcrübə yaşayır.
Web: https://bet-pinup.web.app
Pin-up azerbaycan yalnız oyunlar ilə kifayətlənmir. Qumarçılar burada fərqli mərc oyunlarından müxtəlif mərc imkanı əldə edə bilər və geniş bonus imkanlarını oyun təcrübəsini artırarlar.
Beləliklə, Pinup kazino, güvənli mərc oyunları oyunçulara təklif etməklə oyun sənayesində ən sevilən platformalardan olur. Azərbaycanda məşhur olması təsadüf deyil.
The undefeated Fury and Usyk are ready to face each other in a fight that will define an era. It’s far beyond a championship match; it’s about legacy. The Gypsy King has risen to the pinnacle of the sport with his charisma coupled with unparalleled talent in the ring. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. In contrast, Oleksandr Usyk brings an unprecedented test for Fury. At the same time, Oleksandr Usyk is a true test for Fury for Tyson Fury himself, but for the entire division. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Get ready for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! Experience every moment in real time on our website. Don’t miss your chance — visit <a href="http://stg-cta-redirect.ex.co/redirect?&web=https://tysonfuryvsusyk.co.uk/">tysonfuryvsusyk.co.uk</a> today and enjoy the fight from the comfort of your home!
For British fans, the ring walks are planned for late evening, offering perfect timing for viewers. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, this will be a must-see event. Where the bout will take place has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, one thing is certain: the excitement will be unmatched. Even though attention is centered on the headline fight, the Fury vs Usyk undercard promises plenty of action. Big-ticket boxing cards include preliminary bouts with top talent, offering an entire night of boxing excitement.
Traditionally, undercards of this caliber have introduced future champions. Fighters looking to rise through the ranks use such opportunities to demonstrate their talent, with the world paying attention. While the names for the undercard haven’t been officially announced, fans are eagerly guessing. Could we see rising prospects? No matter the final roster, fans can expect fireworks. What sets this bout apart truly fascinating is the clash of styles. Fury’s towering frame and movement make him an anomaly in boxing. At 6’9" with an 85-inch reach, Fury can control a fight.
His trilogy with Deontay Wilder proved his toughness, overcoming brutal hits to finish strong. When he faced Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. By contrast, Usyk, relies on technique and stamina. As a southpaw, he uses angles and footwork. The Ukrainian’s shots may not have knockout power, their timing wears down foes. As anticipation builds, The betting lines for Fury vs Usyk have fans and analysts speculating.
The betting lines show Fury ahead according to the odds, thanks to his imposing frame, his proven ability in tough situations, and his unpredictable nature. However, Usyk's underdog status doesn’t mean he’s an underdog in spirit, his dominance against Joshua demonstrated his ability in the heavyweight ranks.
For Fury himself could be the defining moment of his career. A victory would put the finishing touches on a historic career. On the other hand, If Usyk wins would elevate him to new heights. Becoming an undisputed champion in two different weight classes is a feat few can claim.
Web: <a href="http://maps.google.cl/url?q=https://tysonfuryvsusyk.co.uk/">tysonfuryvsusyk.co.uk</a>
Fury vs Usyk is about more than the titles. It’s a fight between two very different fighters. Fury’s confident and brash nature is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. It’s about more than just skill. Whoever comes out victorious, the legacy of this fight will reverberate throughout boxing history. This historic showdown is a spectacle unlike any other. It’s the result of relentless dedication. Whether Tyson Fury prevails with his experience and unpredictability, or Oleksandr Usyk triumphs through his superior boxing ability, one thing is certain, this will be a fight remembered for years to come.
The Fury-Usyk battle is more than just a boxing event. It’s a showcase of skill and determination. These two warriors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında qumar oyunlarına sevgisi artdıqca, Pin-up kazino kimi platformalar daha çox tanınmağa başladı. Xüsusilə, Pin-up azerbaycan sözləri tez-tez Azəri mərc həvəskarları üçün istifadə olunur. Pin-up kazino online müştərilərinə çox oyun növləri təklif edir.
Pin-up azerbaycan, Azəri istifadəçilər üçün geniş kütləyə sahib bir qumar saytıdır. Bu platforma qumarbazlara rəngarəng oyunlar təklif verməkdədir və cazibədar aksiyalar ilə oyunçuları özünə cəlb edir.
Pin-up online kazino, geniş oyun variantları təklif edən xidmətdir. Azəri oyunçuları arasında populyar olan Pin-up oyunları, oyun həvəskarları üçün geniş oyun təcrübəsi verir.
Bununla yanaşı, Pin-up online casino mərcçilərə güvənli və şəffaf ödəmə sistemləri verir. Oyunçular, etibarlı və tez maliyyə əməliyyatları köməyilə, internet oyunlarını müvafiq şəkildə təcrübə edərlər.
Bununla yanaşı, Pin-up casino istifadəçilərə yalnız qumar oyunları yox, həmçinin cazibədar bonus təklifləri oyun təcrübəsini daha da maraqlı edir. Bu onlayn kazinoda, mərc edənlər təhlükəsiz oyun mühitində olur.
Web: https://best-pinup.web.app
Pin-up azerbaycan sadəcə məhdudlaşmır. Qumarçılar burada fərqli mərc seçimlərindən istifadə edə bilər və çoxlu bonusları mərc təcrübələrini zənginləşdirərlər.
Beləliklə, Pinup kazino, şəffaf və güvənli mərc imkanı təmin etməklə oyun sənayesində ən sevilən platformalardan olur. Azəri bazarında tanınması təsadüfi deyil.
Fury, the Gypsy King, and Usyk, the technician are on a collision course that will define an era. It’s far beyond a championship match; it’s about legacy. Tyson Fury has earned worldwide fame thanks to his personality and his unmatched skills in the ring. Triumphing against boxing legends like Wilder and Klitschko have solidified his legendary status. Across the ring, Usyk, the technician poses a unique challenge to boxing’s biggest stars. At the same time, Usyk, a southpaw master is a true test for Fury for the heavyweight ranks overall, but for the entire division. Usyk’s rise to prominence began in the cruiserweight division, where he became an unstoppable force. Don’t miss out for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a must-watch showdown! Experience every moment live on our website. Join the excitement — visit <a href="http://feeds.fabbaloo.com/~/t/0/0/fabbaloo/default/~https://tysonfuryvoleksandrusyk.org.uk/">tysonfuryvoleksandrusyk.org.uk</a> now and stream the event in high quality!
Across the UK, the ring walks are planned for around 10 PM GMT, offering perfect timing for viewers. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, the excitement is palpable. Where the bout will take place is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. Regardless of the venue, fans can be sure: the atmosphere will be electric. Even though attention remains on Fury and Usyk, the preliminary bouts is also generating excitement. High-profile matches include preliminary bouts with top talent, offering an entire night of boxing excitement.
Traditionally, preliminary fights on major cards have been a stage for breakout performances. Boxers seeking the spotlight often seize these moments to demonstrate their talent, with the world paying attention. Though the supporting fights for Fury vs Usyk haven’t been officially announced, there’s plenty of talk. Could we see rising prospects? Regardless of the names, it’s sure to add to the excitement. The most compelling part of Fury vs Usyk truly fascinating is the clash of styles. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. Being so tall yet so nimble, he dictates the pace of bouts.
The three fights against Wilder highlighted his resilience, overcoming brutal hits to secure victories. In his fight with Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. Meanwhile, Usyk, relies on technique and stamina. Being a left-handed fighter, his movements create openings. His strikes may not have knockout power, but they are delivered with pinpoint accuracy. As fight night approaches, Tyson Fury vs Usyk odds are the subject of intense debate.
Fury is the favored fighter based on the betting odds, due to his size advantage, his track record in big matches, and his unorthodox style. Although Usyk is the less favored fighter doesn’t rule him out, his dominance against Joshua showed that he can compete at heavyweight.
For Tyson Fury presents a shot at undisputed glory. If he wins, it would solidify his claim as the greatest heavyweight of his generation. Conversely, Usyk’s victory would elevate him to new heights. Becoming the undisputed heavyweight champion would be a remarkable feat in boxing history.
Web: <a href="http://maps.google.cd/url?q=https://tysonfuryvoleksandrusyk.org.uk/">tysonfuryvoleksandrusyk.org.uk</a>
Fury vs Usyk is about more than the titles. It’s a fight between two very different fighters. Fury’s boisterous personality contrasts with Usyk’s calm, focused demeanor. These varying personalities make the bout even more interesting. Beyond physical ability, this fight. No matter who wins, the significance of this match will reverberate throughout boxing history. The battle for heavyweight supremacy is more than just a match. It represents the culmination of their careers. Whether Fury secures the win with his experience and unpredictability, or Oleksandr Usyk triumphs with his finesse and stamina, no matter the outcome, this will be a legendary contest.
The Fury-Usyk battle is a spectacle of a lifetime. It’s a contest of heart and willpower. Both fighters will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Azərbaycanda online kazino oyunlarına güvəni artdıqca, Pin-up casino online kimi oyun xidmətləri daha çox tanınmağa başladı. Əsasən, Pin-up kazino brendləri tez-tez yerli oyunçular üçün güvənlidir. Pin-up azerbaycan müştərilərinə müxtəlif oyunlar təklif edir.
Pin-up cazino, yerli oyunçular üçün populyar seçimdir. Bu platforma mərc həvəskarlarına geniş çeşidli oyunlar oyunçulara təqdim edir və gözəl hədiyyələr ilə müştərilərini məmnun edir.
Pin-up azerbaycan, istifadəçilərə oyun növləri ilə zəngin oyun məkanıdır. Azəri oyunçuları arasında populyar olan Pin-up oyunları, kazino oyunçuları üçün geniş oyun təcrübəsi verir.
Bu səbəbdən, Pinup casino mərc edənlərə etibarlı maliyyə idarəetmə imkanları təmin edir. Oyun həvəskarları, çox rahat maliyyə əməliyyatları sayəsində, mərc təcrübələrini daha asan keçirə bilərlər.
Sonda, Pin-up casino istifadəçilərə təkcə oyunlar deyil, həm də cazibədar bonus təklifləri və maraqlı aksiyalar təklif edir. Pinup-da, müştərilər təhlükəsiz şərtlər altında mərc edir.
Web: https://best-pinup.web.app
Pin-up kazino yalnız bir mərc saytı kimi məhdudlaşmır. Müştərilər burada bənzərsiz mərc imkanlarından faydalanıb və bonus sistemini oyun təcrübəsini artırarlar.
Yekun olaraq, Pin-up casino, şəffaf və güvənli qumar təcrübəsi istifadəçilərə verməklə onlayn qumar dünyasında oyunçular arasında geniş istifadə edilir. Azəri oyunçular tərəfindən tanınması dikkətə layiqdir.
The undefeated Fury and Usyk are ready to face each other in a fight that will define an era. This fight is about more than just titles; it represents their quest for immortality. The towering Fury has earned worldwide fame with his charisma and his unmatched skills inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. Across the ring, Oleksandr Usyk brings an unprecedented test to the heavyweight division. Meanwhile, Usyk, a southpaw master stands as a unique threat not just for Fury, as a heavyweight contender. His journey to global fame was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Don’t miss out for an epic boxing match of the year as Usyk takes on Fury in a must-watch showdown! See every move streamed live on our website. Be part of the action — visit <a href="https://www.visitloudoun.org/plugins/crm/count/?type=client&key=4_180&val=eyJrZXkiOiI0XzE4MCIsInJlZGlyZWN0IjoiaHR0cHM6Ly9tb2RzLW1lbnUucnUvIn0">tysonvusyk.com</a> today and enjoy the fight from the comfort of your home!
Across the UK, the event will kick off at close to prime time, ensuring maximum viewership. Back in Usyk’s home country, as well as viewers across Europe and the Americas, the excitement is palpable. The venue for Fury vs Usyk is still under speculation, with talk of iconic boxing destinations. No matter the location, fans can be sure: it will be a spectacle. Although the focus remains on Fury and Usyk, the fights leading up to the main event is also generating excitement. Big-ticket boxing cards often feature stacked undercards, giving fans a full evening of entertainment.
Traditionally, undercards of this caliber have showcased rising stars. Contenders hoping to make their mark use such opportunities to showcase their skills, as all eyes are on them. Although the lineup for the Fury Usyk undercard haven’t been officially announced, there’s plenty of talk. Will there be a heavyweight clash? No matter the final roster, fans can expect fireworks. What makes this fight so intriguing is the clash of styles. Tyson Fury’s size and agility make him an anomaly in boxing. Being so tall yet so nimble, Fury can control a fight.
His trilogy with Deontay Wilder highlighted his resilience, as he recovered from knockdowns to secure victories. In his fight with Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, relies on technique and stamina. Being a left-handed fighter, he uses angles and footwork. Usyk’s punches lack devastating strength, but they are delivered with pinpoint accuracy. With the date drawing closer, The betting lines for Fury vs Usyk are the subject of intense debate.
Tyson Fury is seen as the frontrunner according to the odds, thanks to his imposing frame, his experience in high-pressure bouts, and his adaptability. However, Usyk's underdog status shouldn’t be counted out, his wins over Anthony Joshua confirmed his toughness against big opponents.
For the Gypsy King represents an opportunity to cement his legacy. A triumph for Fury would further solidify his status as the best heavyweight of this era. Meanwhile, For Usyk, a win would elevate him to legendary status. Becoming the undisputed heavyweight champion is a once-in-a-lifetime achievement.
Web: <a href="http://www.google.com.lb/url?q=https://tysonvusyk.com/">tysonvusyk.com</a>
Fury vs Usyk represents something greater than a title bout. It’s a meeting of two unique worldviews. Fury’s confident and brash nature is the opposite of Usyk’s humble and disciplined approach. These varying personalities make the bout even more interesting. Beyond physical ability, this fight. Whoever comes out victorious, the significance of this match will be felt for years to come. The battle for heavyweight supremacy is a spectacle unlike any other. It’s a culmination of years of hard work. Should Fury claim victory thanks to his power and game plan, or Usyk wins with his precision with his technique and endurance, no matter the outcome, this will be a legendary contest.
Fury vs Usyk is more than just a boxing event. It’s a contest of heart and willpower. These men will give everything they have.
Visit for more information: #crosslink[3,L -
Azərbaycandakı qumar sektorunda virtual qumar oyunlarına maraq artdıqca, Pinup kimi şirkətlər daha çox tanınmağa başladı. Özəlliklə, Pin-up azerbaycan sözləri tez-tez Azərbaycandakı oyunçular üçün adidir. Pin-up azerbaycan istifadəçilərə məxsus çoxlu oyun növü təklif edir.
Pin-up azerbaycan, Azərbaycan oyunçuları üçün güvənli bir qumar məkanıdır. Bu onlayn kazino kazino oyunçularına çeşidli qumar oyunları verir və çoxlu bonuslar ilə oyunçuları özünə cəlb edir.
Pin-up casino, istifadəçilərə oyun növləri ilə zəngin oyun məkanıdır. Azəri oyunçuları arasında populyar olan Pinup, qumar oyunçuları üçün çeşidli bonus imkanları yaradır.
Bu səbəbdən, "Pin-up casino online" oyunçulara etibarlı və güvənli ödəmə üsulları təklif edir. Oyun həvəskarları, rahat və tez kredit kartı və elektron pul kisəsi ilə ilə təmin olunmaqla, onlayn mərc oyunlarını müvafiq şəkildə təcrübə edə bilərlər.
Nəticə etibarilə, Pin-up kazino oyunçulara yalnız qumar oyunları yox, həmçinin sərfəli bonuslar oyunçularına verir. Pin-up-da, oyunçular özlərini güvəndə hiss edir.
Web: https://win-pinup.web.app
Pin-up online kazino sadəcə məhdud deyil. Müştərilər burada fərqli mərc oyunlarından yararlana bilərlər və çoxlu bonusları istifadə edə bilərlər.
Sonda, Pin-up azerbaycan, etibarlı mərc təcrübəsi mərc həvəskarlarına təqdim etməklə onlayn qumar dünyasında oyunçular arasında geniş istifadə edilir. Azərbaycanda populyarlığı təsadüf deyil.
The undefeated Fury and Usyk are set to meet in the ring that will define an era. It’s not merely about the belts; it’s a battle for eternal recognition. The Gypsy King has become a global icon through his unique style and his unmatched skills in the ring. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. On the other hand, the tactical southpaw brings an unprecedented test to boxing’s biggest stars. Meanwhile, the Ukrainian technician stands as a unique threat for Tyson Fury himself, but for the entire division. His journey to global fame started with his domination of the cruiserweights, by conquering all challengers. Don’t miss out for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a historic showdown! Catch every punch live on our website. Be part of the action — visit <a href="https://library.colgate.edu/webbridge%7ES1/showresource?resurl=https%3A%2F%2Ftysonfuryvoleksandrusyk.org.uk&linkid=836650&noframe=1">tysonfuryvoleksandrusyk.org.uk</a> now and stream the event with top-notch streaming!
Across the UK, the ring walks are planned for around 10 PM GMT, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, and beyond, the excitement is palpable. Where the bout will take place has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. Regardless of the venue, it’s guaranteed: the atmosphere will be electric. Although the focus remains on Fury and Usyk, the fights leading up to the main event is shaping up to be thrilling. High-profile matches often feature stacked undercards, giving fans a full evening of entertainment.
In the past, undercards of this caliber have been a stage for breakout performances. Contenders hoping to make their mark capitalize on the exposure to showcase their skills, as all eyes are on them. Though the supporting fights for Fury vs Usyk haven’t been officially announced, speculation runs high. Might there be a cruiserweight spectacle? Regardless of the names, it’s sure to add to the excitement. What makes this fight so intriguing is the dynamic between these fighters. Tyson Fury’s size and agility are unparalleled in the sport. With his immense height and reach advantage, he commands the ring like no other.
The legendary battles with Wilder highlighted his resilience, as he recovered from knockdowns to finish strong. In his fight with Klitschko, his strategic genius shone through, demonstrating his mental sharpness. Meanwhile, Usyk, offers a different kind of threat. With his unorthodox stance, his movements create openings. His strikes may not have knockout power, but they are delivered with pinpoint accuracy. As anticipation builds, Predictions for this fight are becoming a hot topic.
Tyson Fury is the slight favorite as per the betting experts, because of his reach and height, his long career in major fights, and his unorthodox style. Although Usyk is the less favored fighter doesn’t diminish his chances, his wins over Anthony Joshua confirmed his toughness against big opponents.
For Tyson Fury could be the defining moment of his career. A victory would further solidify his status as the best heavyweight of this era. On the other hand, If Usyk wins would elevate him to new heights. Achieving undisputed glory in two divisions is a feat few can claim.
Web: <a href="http://www.google.sn/url?sa=t&url=http%3A%2F%2Fwww.magical-dream.com">tysonfuryvoleksandrusyk.org.uk</a>
The upcoming showdown is about more than the titles. It’s a fight between two very different fighters. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. Such contrasts make the fight more compelling. It’s a fight of wills and ideologies. No matter who wins, the legacy of this fight will be felt for years to come. This historic showdown is a defining moment. It’s the result of relentless dedication. Should Fury claim victory with his size and strategy, or Oleksandr Usyk triumphs with his finesse and stamina, one thing is certain, this will be a defining moment in boxing.
Tyson Fury vs Oleksandr Usyk is more than just a fight. It’s a battle of minds and bodies. The two competitors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Azərbaycan ərazisində internet qumarına seçim artdıqca, Pinup kazino kimi oyun xidmətləri daha çox tanınmağa başladı. Xüsusilə, Pin-up kazino şəklində olan platformalar artıq Azərbaycandakı oyunçular üçün tanışdır. Pinup casino istifadəçilərə rəngarəng oyunlar təklif edir.
Pinup kazino, Azərbaycan oyunçuları üçün geniş yayılmış bir xidmətdir. Bu qumar saytı mərc həvəskarlarına rəngarəng oyunlar təmin edir və sərfəli bonus təklifləri ilə oyunçuları özünə cəlb edir.
Pinup casino, istifadəçilərə oyun növləri ilə zəngin onlayn kazinodur. yerli mərcçilər arasında güvənilən Pin-up casino, oyun həvəskarları üçün geniş oyun variantları ilə tanınır.
Bunun nəticəsində, Pinup kazino oyunçulara təhlükəsiz depozit və çıxarış imkanı verir. Kazino iştirakçıları, sürətli və asan maliyyə əməliyyatları köməyilə, qumar təcrübələrini daha asan yaşaya bilərlər.
Son olaraq, Pin-up casino istifadəçilərə təkcə oyun imkanı deyil mərc hədiyyələri və maraqlı aksiyalar təklif edir. Bu kazinoda, oyunçular güvənli bir təcrübə yaşayır.
Web: https://pinup-best-bet.web.app
Pin-up kazino təkcə bir oyun platforması kimi məhdud deyil. Oyunçular burada fərqli mərc seçimlərindən həzz ala bilərlər və maraqlı aksiyaları istifadə edə bilərlər.
Bunun nəticəsində, Pin-up cazino, müasir və təhlükəsiz oyun imkanı təmin etməklə mərc bazarında ən yaxşı seçimlərdən biridir. Azəri oyunçular tərəfindən tanınması dikkətə layiqdir.
These two heavyweight champions are set to meet in the ring of unparalleled significance. It’s not merely about the belts; it’s about legacy. The Gypsy King has become a global icon with his charisma and remarkable adaptability in the ring. Beating Wilder and Klitschko have earned him recognition as one of the best ever. Across the ring, Oleksandr Usyk poses a unique challenge to boxing’s biggest stars. Meanwhile, Usyk, a genius in the ring represents a formidable opponent for the heavyweight ranks overall, and for boxing fans worldwide. Usyk’s rise to prominence started with his domination of the cruiserweights, by conquering all challengers. Get ready for a thrilling boxing match of the year as Usyk takes on Tyson Fury in a must-watch showdown! See every move live on our website. Don’t miss your chance — visit <a href="https://m.weatheravenue.com/ru/https://furyvsusykdate.co.uk/">furyvsusykdate.co.uk</a> today and enjoy the fight in high quality!
For British fans, the ring walks are planned for close to prime time, offering perfect timing for viewers. In Usyk’s native Ukraine, and for fans watching from around the world, this will be a must-see event. The venue for Fury vs Usyk remains a hot topic, with talk of iconic boxing destinations. Wherever it happens, it’s guaranteed: it will be a spectacle. While the spotlight remains on Fury and Usyk, the Fury vs Usyk undercard is also generating excitement. High-profile matches include preliminary bouts with top talent, giving fans a full evening of entertainment.
Traditionally, undercards of this caliber have been a stage for breakout performances. Contenders hoping to make their mark capitalize on the exposure to impress fans and analysts alike, knowing millions are watching. Though the supporting fights for Fury vs Usyk haven’t been officially announced, speculation runs high. Might there be a cruiserweight spectacle? No matter the final roster, the action will not disappoint. What sets this bout apart incredibly exciting is the clash of styles. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. With his immense height and reach advantage, he commands the ring like no other.
The legendary battles with Wilder showed his durability, as he recovered from knockdowns to finish strong. In his fight with Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, relies on technique and stamina. With his unorthodox stance, he uses angles and footwork. His strikes may not have knockout power, their timing wears down foes. As anticipation builds, Predictions for this fight have fans and analysts speculating.
Fury is the favored fighter based on the betting odds, due to his size advantage, his proven ability in tough situations, and his unpredictable nature. However, Usyk's underdog status doesn’t rule him out, his wins over Anthony Joshua demonstrated his ability in the heavyweight ranks.
For Fury himself presents a shot at undisputed glory. Should he come out on top, Fury’s win would solidify his claim as the greatest heavyweight of his generation. On the other hand, For Usyk, a win would elevate him to new heights. Becoming the undisputed heavyweight champion would be a remarkable feat in boxing history.
Web: <a href="http://www.google.gg/url?sa=t&url=http%3A%2F%2Fwww.magical-dream.com">furyvsusykdate.co.uk</a>
The upcoming showdown represents something greater than a title bout. It’s a meeting of two unique worldviews. Fury’s confident and brash nature is the opposite of Usyk’s humble and disciplined approach. These differences add complexity to the fight. Beyond physical ability, this fight. Whoever triumphs in this battle, the legacy of this fight will be felt for years to come. The clash for the undisputed title is more than just a fight. It’s the pinnacle of both fighters’ hard work. Whether Fury secures the win with his size and strategy, or Oleksandr Usyk triumphs through his superior boxing ability, one thing is certain, this will be a legendary contest.
Fury vs Usyk is more than just a boxing event. It’s a showcase of skill and determination. Both fighters will give everything they have.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında qumar oyunlarına tələbat artdıqca, Pin-up kazino kimi oyun xidmətləri daha çox tanınmağa başladı. Bununla bərabər, Pin-up kazino sözləri artıq Azəri müştərilər üçün məşhurdur. Pin-up casino azerbaycan mərc həvəskarlarına çeşidli oyunlar təklif edir.
Pin-up kazino, yerli oyunçular üçün geniş kütləyə sahib bir qumar saytıdır. Bu platforma oyunçulara müxtəlif oyunlar verir və cəlbedici bonuslar ilə müştərilərini məmnun edir.
Pin-up casino, fərqli oyun təcrübəsi təklif edən onlayn kazinodur. Azəri bazarında məşhur olan Pin-up online, oyun həvəskarları üçün çeşidli bonus imkanları yaradır.
Xüsusilə, Pin-up online casino müştərilərə təhlükəsiz ödəmə sistemləri təqdim edir. Oyunçular, müvafiq və təhlükəsiz maliyyə çıxarışları nəticəsində, kazino oyunlarını güvənli və təhlükəsiz yaşaya bilərlər.
Bununla yanaşı, Pin-up casino online qumarbazlara yalnız oyun təklif etmir cazibədar bonus təklifləri müştəriləri üçün yaradır. Bu onlayn kazinoda, müştərilər təhlükəsiz oyun mühitində olur.
Web: https://top-pinup.web.app
Pin-up kazino təkcə bir kazino olaraq məhdud oyunlar təklif etmir. Oyunçular burada fərqli mərc seçimlərindən həzz ala bilərlər və sərfəli bonus təkliflərini mərc təcrübələrini zənginləşdirərlər.
Ümumilikdə, Pinup kazino, rahat və təhlükəsiz mərc təcrübəsi təqdim etməklə onlayn mərc dünyasında lider mövqedədir. Azərbaycan mərcçiləri arasında geniş yayılması dikkətə layiqdir.
The undefeated Fury and Usyk are ready to face each other in a fight of unparalleled significance. It’s not merely about the belts; it represents their quest for immortality. The towering Fury has earned worldwide fame through his unique style coupled with unparalleled talent inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have solidified his legendary status. In contrast, Oleksandr Usyk is a fighter unlike any other to boxing’s biggest stars. Meanwhile, the Ukrainian technician represents a formidable opponent not just for Fury, but for the entire division. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, by conquering all challengers. Prepare yourself for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! Experience every moment in real time on our website. Join the excitement — visit <a href="https://www.chuwi.com/?wptouch_switch=desktop&redirect=//tysonvsusyk.co.uk">tysonvsusyk.co.uk</a> right away and stream the event in high quality!
For British fans, the fight is expected to begin around 10 PM GMT, ensuring maximum viewership. In Usyk’s native Ukraine, and for fans watching from around the world, the anticipation is at a fever pitch. The venue for Fury vs Usyk is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, it’s guaranteed: it will be a spectacle. Even though attention is firmly on the main event, the fights leading up to the main event promises plenty of action. High-profile matches are known for strong supporting fights, offering an entire night of boxing excitement.
In the past, supporting bouts in major events have introduced future champions. Fighters looking to rise through the ranks often seize these moments to showcase their skills, with the world paying attention. While the names for the undercard has yet to be finalized, there’s plenty of talk. Could we see rising prospects? Regardless of the names, fans can expect fireworks. What makes this fight incredibly exciting is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed are unparalleled in the sport. With his immense height and reach advantage, Fury can control a fight.
His trilogy with Deontay Wilder proved his toughness, bouncing back from adversity to finish strong. In his fight with Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. With his unorthodox stance, he uses angles and footwork. Usyk’s punches may not have knockout power, their timing wears down foes. With the date drawing closer, Predictions for this fight are becoming a hot topic.
Most bookmakers favor Fury according to the odds, because of his reach and height, his proven ability in tough situations, and his adaptability. Despite the odds, Usyk remains a strong contender shouldn’t be counted out, his victories against AJ demonstrated his ability in the heavyweight ranks.
For the Gypsy King represents an opportunity to cement his legacy. If he wins, it would put the finishing touches on a historic career. Meanwhile, Usyk’s victory would elevate him to new heights. Becoming the undisputed heavyweight champion is a rare accomplishment.
Web: <a href="http://www.google.kg/url?q=https://tysonvsusyk.co.uk/">tysonvsusyk.co.uk</a>
The upcoming showdown is not just about the belts. It’s a battle of contrasting styles. Fury’s larger-than-life persona stands in stark contrast to Usyk’s composed demeanor. These differences add complexity to the fight. It’s a fight of wills and ideologies. No matter who wins, the legacy of this fight will reverberate throughout boxing history. This historic showdown is a defining moment. It represents the culmination of their careers. If Fury wins with his size and strategy, or Usyk comes out on top with his technique and endurance, one thing is certain, this bout will go down in history.
This fight between Fury and Usyk is more than just a fight. It’s a showcase of skill and determination. These two warriors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında internet qumarına güvəni artdıqca, Pin-up kazino kimi şirkətlər daha çox tanınmağa başladı. Bununla bərabər, Pin-up kazino şüarları hazırda yerli oyunçular üçün adidir. Pin-up kazino istifadəçilərə rəngarəng oyunlar təklif edir.
Pin up kazino, Azəri qumarbazlar üçün ən sevilən platformalardan biridir. Bu platforma oyunçulara müxtəlif oyunlar verir və gözəl hədiyyələr ilə oyunçuları özünə cəlb edir.
Pinup casino, bənzərsiz oyun imkanı təqdim edən saytdır. Azərbaycan ərazisində çox seçilən Pin-up casino, mərc həvəskarları üçün maraqlı oyun imkanları təklif edir.
Bu səbəbdən, Pin-up online casino müştərilərə etibarlı depozit və çıxarış imkanı verir. Mərc edənlər, rahat ödəmə üsulları ilə təmin olunmaqla, qumar təcrübələrini asan və sürətli yaşaya bilərlər.
Sonda, Pin-up kazino oyunçulara çoxlu oyun növlərilə yanaşı sərfəli bonuslar təmin edir. Pinup-da, kazino həvəskarları rahat və təhlükəsiz şəraitdə oynayır.
Web: https://bet-on-pinup.web.app
Pin-up casino online yalnız bir mərc saytı kimi oyunçuları cəlb etmir. Mərc həvəskarları bu platformada çeşidli mərc seçimlərindən müxtəlif mərc imkanı əldə edə bilər və maraqlı aksiyaları oyunlarına əlavə edə bilərlər.
Sonda, Pinup kazino, şəffaf və güvənli mərc imkanı təmin etməklə oyun bazarında ən sevilən platformalardan olur. Azərbaycan mərcçiləri arasında məşhur olması təsadüf deyil.
Tyson Fury and Oleksandr Usyk are preparing for an epic showdown of historic proportions. It’s not merely about the belts; it represents their quest for immortality. The towering Fury has risen to the pinnacle of the sport through his unique style and remarkable adaptability in the ring. Beating Wilder and Klitschko have earned him recognition as one of the best ever. Across the ring, Usyk, the Ukrainian master is a fighter unlike any other for Fury. At the same time, Usyk, a genius in the ring represents a formidable opponent for the heavyweight ranks overall, as a heavyweight contender. Usyk’s rise to prominence began in the cruiserweight division, by conquering all challengers. Get ready for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a must-watch showdown! See every move in real time on our website. Be part of the action — visit <a href="https://crm-hit-tracker.simpleviewinc.com/go/472/0/61/https%3A%2F%2Fusykvsfurydate.co.uk">usykvsfurydate.co.uk</a> now and enjoy the fight with top-notch streaming!
For British fans, the event will kick off at close to prime time, making it ideal for a prime-time audience. Back in Usyk’s home country, and beyond, the anticipation is at a fever pitch. Where the bout will take place remains a hot topic, with talk of iconic boxing destinations. No matter the location, it’s guaranteed: the atmosphere will be electric. Even though attention remains on Fury and Usyk, the fights leading up to the main event is also generating excitement. Big-ticket boxing cards include preliminary bouts with top talent, providing non-stop action before the headliner.
Historically, undercards of this caliber have showcased rising stars. Fighters looking to rise through the ranks often seize these moments to demonstrate their talent, knowing millions are watching. Although the lineup for the Fury Usyk undercard haven’t been officially announced, fans are eagerly guessing. Might there be a cruiserweight spectacle? Whatever the selection, fans can expect fireworks. What makes this fight so intriguing is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. Being so tall yet so nimble, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, as he recovered from knockdowns to secure victories. Against Wladimir Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. By contrast, Usyk, relies on technique and stamina. Being a left-handed fighter, his movements create openings. His strikes aren’t the heaviest in the division, their timing wears down foes. As anticipation builds, Tyson Fury vs Usyk odds are becoming a hot topic.
Tyson Fury is seen as the frontrunner according to the odds, given his physical stature, his track record in big matches, and his unpredictable nature. Despite the odds, Usyk remains a strong contender doesn’t diminish his chances, his wins over Anthony Joshua demonstrated his ability in the heavyweight ranks.
For Tyson Fury is a chance to further solidify his greatness. If he wins, it would solidify his claim as the greatest heavyweight of his generation. On the other hand, For Usyk, a win would elevate him to legendary status. Securing two undisputed titles is a feat few can claim.
Web: <a href="http://maps.google.de/url?q=https://usykvsfurydate.co.uk/">usykvsfurydate.co.uk</a>
The upcoming showdown is more than just a championship fight. It’s a meeting of two unique worldviews. Fury’s larger-than-life persona is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. It’s about more than just skill. Regardless of the outcome, the legacy of this fight will leave a lasting mark on the sport. The battle for heavyweight supremacy is a spectacle unlike any other. It’s a culmination of years of hard work. Whether Fury secures the win through his strength and tactics, or Usyk comes out on top thanks to his skill and resilience, it’s certain that, this bout will go down in history.
This fight between Fury and Usyk is more than just a fight. It’s a contest of heart and willpower. These men will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azəri bazarında internet oyunlarına tələbat artdıqca, Pin-up casino online kimi platformalar daha çox tanınmağa başladı. Əlavə olaraq, Pinup casino şəklində olan platformalar son zamanlar yerli oyunçular üçün güvənlidir. Pin-up casino istifadəçilərə geniş oyunlar təklif edir.
Pin up kazino, yerli oyunçular üçün maraqlı seçimdir. Bu platforma oyunçulara rəngarəng oyunlar verir və çoxlu bonuslar ilə oyunçuları özünə cəlb edir.
Pinup casino, bənzərsiz oyun imkanı təqdim edən xidmətdir. Azərbaycan ərazisində oyunçular tərəfindən sevilən Pin-up oyunları, istifadəçilər üçün zəngin təkliflər təqdim edir.
Xüsusilə, Pinup casino istifadəçilərə etibarlı maliyyə idarəetmə imkanları təmin edir. Oyun həvəskarları, müvafiq və təhlükəsiz maliyyə çıxarışları nəticəsində, internet oyunlarını çox rahat təcrübə edə bilərlər.
Əlavə olaraq, Pin-up casino oyunçulara çoxlu oyun növlərilə yanaşı cazibədar bonus təklifləri təmin edir. Bu kazinoda, kazino həvəskarları təhlükəsiz şərtlər altında mərc edir.
Web: https://pinup-top.web.app
Pin-up casino təkcə məhdud oyunlar təklif etmir. Qumarçılar burada fərqli mərc seçimlərindən müxtəlif mərc imkanı əldə edə bilər və cazibədar bonus imkanlarını qazanmaq imkanı əldə edərlər.
Yekun olaraq, Pin-up azerbaycan, güvənli mərc oyunları istifadəçilərə verməklə onlayn qumar dünyasında lider mövqedədir. Azərbaycanda populyarlığı açıq bir faktdır.
Fury, the Gypsy King, and Usyk, the technician are preparing for an epic showdown that will define an era. It’s far beyond a championship match; it’s about legacy. The Gypsy King has become a global icon thanks to his personality coupled with unparalleled talent in the ring. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. On the other hand, the tactical southpaw poses a unique challenge for Fury. At the same time, Usyk, a genius in the ring is a true test for Fury for Tyson Fury himself, and for boxing fans worldwide. The ascent of Oleksandr Usyk started with his domination of the cruiserweights, by conquering all challengers. Get ready for the most anticipated boxing match of the year as Usyk takes on Fury in a historic showdown! See every move in real time on our website. Join the excitement — visit <a href="http://diplomroomm.nnov.org/common/redir.php?https://furyvsusykdate.org.uk/">furyvsusykdate.org.uk</a> today and enjoy the fight from the comfort of your home!
In the United Kingdom, the fight is expected to begin around 10 PM GMT, ensuring maximum viewership. Back in Usyk’s home country, and for fans watching from around the world, the excitement is palpable. The venue for Fury vs Usyk is still under speculation, with talk of iconic boxing destinations. Wherever it happens, it’s guaranteed: the excitement will be unmatched. Even though attention is firmly on the main event, the fights leading up to the main event is shaping up to be thrilling. Major boxing events often feature stacked undercards, giving fans a full evening of entertainment.
In the past, supporting bouts in major events have showcased rising stars. Fighters looking to rise through the ranks use such opportunities to impress fans and analysts alike, as all eyes are on them. While the names for the undercard haven’t been officially announced, there’s plenty of talk. Will there be a heavyweight clash? Whatever the selection, the action will not disappoint. What sets this bout apart truly fascinating is the clash of styles. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. Being so tall yet so nimble, he dictates the pace of bouts.
His trilogy with Deontay Wilder highlighted his resilience, as he recovered from knockdowns to finish strong. Against Wladimir Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, offers a different kind of threat. Being a left-handed fighter, his movements create openings. Usyk’s punches may not have knockout power, but they are delivered with pinpoint accuracy. With the date drawing closer, Predictions for this fight are becoming a hot topic.
The betting lines show Fury ahead as predicted by many experts, due to his size advantage, his long career in major fights, and his tactical brilliance. Although Usyk is the less favored fighter shouldn’t be counted out, his victories against AJ proved that he can handle the physicality of the heavyweight division.
For Tyson Fury, this fight represents an opportunity to cement his legacy. If he wins, it would put the finishing touches on a historic career. Meanwhile, Usyk’s victory would elevate him to legendary status. Becoming an undisputed champion in two different weight classes would be a remarkable feat in boxing history.
Web: <a href="http://www.google.co.ls/url?q=https%3A%2F%2Ffuryvsusykdate.org.uk">furyvsusykdate.org.uk</a>
This fight represents something greater than a title bout. It’s a battle of contrasting styles. Fury’s larger-than-life persona is in stark contrast to Usyk’s quiet intensity. Such contrasts make the fight more compelling. It’s a fight of wills and ideologies. Whoever triumphs in this battle, the legacy of this fight will reverberate throughout boxing history. Fury vs Usyk is a spectacle unlike any other. It’s a culmination of years of hard work. Should Fury claim victory through his strength and tactics, or Usyk wins with his precision with his technique and endurance, it’s certain that, this bout will go down in history.
This fight between Fury and Usyk is more than just a boxing event. It’s a contest of heart and willpower. These two warriors will give everything they have.
Visit for more information: #crosslink[3,L -
yerli oyunçular arasında online kazino oyunlarına güvəni artdıqca, Pinup kazino kimi kazino xidmətləri daha çox tanınmağa başladı. Bununla bərabər, Pinup casino şüarları tez-tez Azərbaycandakı oyunçular üçün istifadə olunur. Pin-up kazino müştərilərinə müxtəlif oyunlar təklif edir.
Pin-up casino, yerli oyunçular üçün maraqlı seçimdir. Bu platforma istifadəçilərə çeşidli qumar oyunları təmin edir və cazibədar aksiyalar ilə seçim olur.
Pin-up online kazino, çeşidli oyun təcrübəsi təklif edən bir platformadır. Azəri oyunçuları arasında geniş istifadə olunan Pin-up oyunları, oyun həvəskarları üçün maraqlı oyun imkanları təklif edir.
Bunun nəticəsində, "Pin-up casino online" qumar həvəskarlarına etibarlı və güvənli maliyyə əməliyyatları verir. Kazino iştirakçıları, müvafiq və təhlükəsiz maliyyə çıxarışları ilə təmin olunmaqla, oyun təcrübələrini çox rahat yaşaya bilərlər.
Əlavə olaraq, Pin-up casino qumarbazlara yalnız oyun təklif etmir cazibədar bonus təklifləri oyun təcrübəsini daha da maraqlı edir. Pinup-da, mərc edənlər təhlükəsiz oyun mühitində olur.
Web: https://win-top-pin-up.web.app
Pin-up online kazino təkcə oyunçuları cəlb etmir. Mərc həvəskarları bu platformada müxtəlif mərc növlərindən faydalanıb və bonus sistemini mərc təcrübələrini zənginləşdirərlər.
Ümumilikdə, Pin-up casino, güvənli kazino təcrübəsi təmin etməklə onlayn qumar sektorunda ən yaxşı seçimlərdən biridir. Azərbaycanda məşhur olması göz qabağındadır.
Fury, the Gypsy King, and Usyk, the technician are set to meet in the ring that will define an era. It’s far beyond a championship match; it’s a battle for eternal recognition. Fury, an undefeated champion has become a global icon thanks to his personality and his unmatched skills during fights. Beating Wilder and Klitschko have cemented his place among the all-time greats. On the other hand, Usyk, the Ukrainian master brings an unprecedented test to the heavyweight division. Meanwhile, Usyk, a southpaw master is a true test for Fury for Tyson Fury himself, and for boxing fans worldwide. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, as an undisputed champion. Don’t miss out for a thrilling boxing match of the year as Usyk takes on Tyson Fury in a must-watch showdown! Catch every punch live on our website. Join the excitement — visit <a href="https://emoney-hubs.com/go.php?url=https://furyvsusykdate.org.uk/">furyvsusykdate.org.uk</a> today and enjoy the fight in high quality!
For British fans, the ring walks are planned for around 10 PM GMT, making it ideal for a prime-time audience. Back in Usyk’s home country, as well as viewers across Europe and the Americas, the excitement is palpable. The fight’s location is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. Regardless of the venue, one thing is certain: the atmosphere will be electric. While the spotlight remains on Fury and Usyk, the Fury vs Usyk undercard is shaping up to be thrilling. High-profile matches are known for strong supporting fights, providing non-stop action before the headliner.
In the past, supporting bouts in major events have showcased rising stars. Boxers seeking the spotlight often seize these moments to showcase their skills, knowing millions are watching. Although the lineup for the Fury Usyk undercard are still unconfirmed, there’s plenty of talk. Could we see rising prospects? Regardless of the names, the action will not disappoint. What sets this bout apart truly fascinating is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. With his immense height and reach advantage, he dictates the pace of bouts.
The legendary battles with Wilder highlighted his resilience, overcoming brutal hits to finish strong. When he faced Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. Meanwhile, Usyk, relies on technique and stamina. With his unorthodox stance, his positioning constantly challenges opponents. Usyk’s punches aren’t the heaviest in the division, their timing wears down foes. As fight night approaches, The betting lines for Fury vs Usyk are becoming a hot topic.
The betting lines show Fury ahead according to the odds, thanks to his imposing frame, his experience in high-pressure bouts, and his tactical brilliance. Despite being seen as the underdog shouldn’t be counted out, his victories against AJ proved that he can handle the physicality of the heavyweight division.
For Tyson Fury, this fight is a chance to further solidify his greatness. If he wins, it would further solidify his status as the best heavyweight of this era. Meanwhile, For Usyk, a win would be a monumental achievement. Securing two undisputed titles is a rare accomplishment.
Web: <a href="http://www.google.it/url?q=https://furyvsusykdate.org.uk/">furyvsusykdate.org.uk</a>
The upcoming showdown is more than just a championship fight. It’s a meeting of two unique worldviews. Fury’s larger-than-life persona is in stark contrast to Usyk’s quiet intensity. These differences add complexity to the fight. It’s a fight of wills and ideologies. Whoever triumphs in this battle, the impact of this bout will leave a lasting mark on the sport. The clash for the undisputed title is a defining moment. It’s a culmination of years of hard work. Whether Fury secures the win thanks to his power and game plan, or Oleksandr Usyk triumphs with his technique and endurance, no matter the outcome, this will be a fight remembered for years to come.
Tyson Fury vs Oleksandr Usyk is more than just a sporting contest. It’s a contest of heart and willpower. These two warriors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azəri bazarında online kazino oyunlarına tələbat artdıqca, Pin-up online kimi oyun xidmətləri daha çox tanınmağa başladı. Əsasən, "Pin up casino online" sözləri tez-tez Azəri mərc həvəskarları üçün tanışdır. Pin-up casino azerbaycan istifadəçilərə çox oyun növləri təklif edir.
Pin-up cazino, Azəri istifadəçilər üçün geniş kütləyə sahib bir qumar saytıdır. Bu platforma müştərilərə rəngarəng oyunlar verir və çoxlu bonuslar ilə mərc edənləri özünə cəlb edir.
Pin-up casino, istifadəçilərə oyun növləri ilə zəngin xidmətdir. yerli mərcçilər arasında geniş istifadə olunan Pinup, mərc həvəskarları üçün zəngin təkliflər təqdim edir.
Xüsusilə, Pin-up azerbaycan mərcçilərə təhlükəsiz depozit və çıxarış imkanı oyunçularına təklif edir. Kazino iştirakçıları, etibarlı və tez ödəmə üsulları ilə, onlayn mərc oyunlarını çox rahat yaşaya bilərlər.
Nəticə etibarilə, Pin-up casino online müştərilərə çoxlu oyun növlərilə yanaşı cəlbedici kampaniyalar müştəriləri üçün yaradır. Pin-up-da, oyunçular güvənli bir təcrübə yaşayır.
Web: https://win-pinup.web.app
Pin-up cazino təkcə bir oyun platforması kimi məhdud deyil. Qumarçılar burada fərqli mərc seçimlərindən yararlana bilərlər və cazibədar bonus imkanlarını oyun təcrübələrinə əlavə edərlər.
Sonda, Pin-up casino online, etibarlı mərc təcrübəsi təklif etməklə onlayn qumar dünyasında lider mövqedədir. Azəri oyunçular tərəfindən seçim olması açıq bir faktdır.
Fury, the Gypsy King, and Usyk, the technician are on a collision course of unparalleled significance. This fight is about more than just titles; it’s about legacy. Fury, an undefeated champion has become a global icon through his unique style and remarkable adaptability in the ring. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. Meanwhile, Oleksandr Usyk brings an unprecedented test to the heavyweight division. On the flip side, the Ukrainian technician is a true test for Fury for the heavyweight ranks overall, and for boxing fans worldwide. Usyk’s rise to prominence began in the cruiserweight division, as an undisputed champion. Prepare yourself for an epic boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! See every move streamed live on our website. Don’t miss your chance — visit <a href="https://www.etracker.de/ccr?et=Zbxd09&etcc_cmp=GBE&etcc_med=Web&etcc_par=&etcc_ctv=&et_cmp_seg1=emobvideo&et_cmp_seg5=DirectURL&etcc_url=https://furyvsusykdate.com/">furyvsusykdate.com</a> today and watch the match from the comfort of your home!
In the United Kingdom, the ring walks are planned for close to prime time, ensuring maximum viewership. Back in Usyk’s home country, and beyond, the anticipation is at a fever pitch. The fight’s location has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, it’s guaranteed: the atmosphere will be electric. Although the focus is firmly on the main event, the preliminary bouts promises plenty of action. Major boxing events include preliminary bouts with top talent, providing non-stop action before the headliner.
Traditionally, undercards of this caliber have introduced future champions. Contenders hoping to make their mark capitalize on the exposure to demonstrate their talent, with the world paying attention. Though the supporting fights for Fury vs Usyk has yet to be finalized, fans are eagerly guessing. Could we see rising prospects? Regardless of the names, fans can expect fireworks. What sets this bout apart incredibly exciting is the clash of styles. The Gypsy King’s unusual blend of height and speed are unparalleled in the sport. At 6’9" with an 85-inch reach, Fury can control a fight.
The three fights against Wilder showed his durability, overcoming brutal hits to finish strong. In his fight with Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. Meanwhile, Usyk, relies on technique and stamina. Being a left-handed fighter, his positioning constantly challenges opponents. Usyk’s punches lack devastating strength, their timing wears down foes. With the date drawing closer, Predictions for this fight have fans and analysts speculating.
Tyson Fury is seen as the frontrunner as per the betting experts, because of his reach and height, his proven ability in tough situations, and his unorthodox style. Although Usyk is the less favored fighter doesn’t mean he’s an underdog in spirit, as his victories over Joshua showed that he can compete at heavyweight.
For Fury himself could be the defining moment of his career. Should he come out on top, Fury’s win would solidify his claim as the greatest heavyweight of his generation. Meanwhile, For Usyk, a win would elevate him to legendary status. Securing two undisputed titles would be a remarkable feat in boxing history.
Web: <a href="http://cse.google.bf/url?q=https://furyvsusykdate.com/">furyvsusykdate.com</a>
The upcoming showdown is not just about the belts. It’s a clash of personalities. Fury’s bold and unapologetic character stands in stark contrast to Usyk’s composed demeanor. These differences add complexity to the fight. This is more than just a physical contest. Whoever comes out victorious, the impact of this bout will be felt for years to come. The clash for the undisputed title is a spectacle unlike any other. It’s the pinnacle of both fighters’ hard work. If Fury wins with his experience and unpredictability, or Usyk comes out on top with his technique and endurance, it’s certain that, this will be a legendary contest.
Fury vs Usyk is more than just a sporting contest. It’s a battle of minds and bodies. Both fighters will give everything they have.
Visit for more information: #crosslink[3,L -
Azərbaycan ərazisində internet qumarına sevgisi artdıqca, Pinup kimi saytlar daha çox tanınmağa başladı. Xüsusilə, Pinup casino şəklində olan platformalar hazırda yerli istifadəçilər üçün istifadə olunur. Pin-up kazino online mərc həvəskarlarına çoxlu oyun növü təklif edir.
Pin-up online casino, yerli mərc həvəskarları üçün maraqlı seçimdir. Bu onlayn kazino istifadəçilərə geniş çeşidli oyunlar təklif edib və bonus imkanları ilə istifadəçilərin diqqətini çəkir.
Pinup casino, çeşidli oyun təcrübəsi təklif edən oyun məkanıdır. Azəri oyunçuları arasında geniş istifadə olunan Pinup, istifadəçilər üçün geniş oyun təcrübəsi verir.
Bunun nəticəsində, "Pin-up casino online" istifadəçilərə güvənli və şəffaf depozit və çıxarış imkanı təklif edir. Oyunçular, rahat və tez maliyyə çıxarışları köməyilə, kazino oyunlarını asan və sürətli təcrübə edərlər.
Əlavə olaraq, Pinup kazino mərc həvəskarlarına yalnız oyun təklif etmir cəlbedici kampaniyalar təmin edir. Bu qumar saytında, qumar həvəskarları özlərini güvəndə hiss edir.
Web: https://pinup-top-bet.web.app
Pin-up casino təkcə bir kazino olaraq məhdud oyunlar təklif etmir. Kazino həvəskarları bu kazinoda fərqli mərc oyunlarından istifadə edə bilər və bonus sistemini oyunlarına əlavə edə bilərlər.
Beləliklə, Pin-up cazino, müasir və təhlükəsiz oyun imkanı təmin etməklə onlayn mərc dünyasında oyunçular arasında geniş istifadə edilir. Azəri oyunçular tərəfindən çox seçilməsi göz qabağındadır.
These two heavyweight champions are set to meet in the ring that will define an era. It’s not merely about the belts; it’s about legacy. The towering Fury has risen to the pinnacle of the sport through his unique style coupled with unparalleled talent inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. Across the ring, Usyk, the Ukrainian master poses a unique challenge to the heavyweight division. On the flip side, Usyk, a southpaw master represents a formidable opponent for Tyson Fury himself, and for boxing fans worldwide. His journey to global fame began in the cruiserweight division, by conquering all challengers. Prepare yourself for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a historic showdown! See every move streamed live on our website. Join the excitement — visit <a href="http://beauty.blog.nl/wp-content/plugins/wp-noexternallinks/goto.php?tysonvsusyk.com">tysonvsusyk.com</a> right away and enjoy the fight from the comfort of your home!
For British fans, the event will kick off at close to prime time, offering perfect timing for viewers. Back in Usyk’s home country, and for fans watching from around the world, this will be a must-see event. The venue for Fury vs Usyk remains a hot topic, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, fans can be sure: the excitement will be unmatched. Although the focus is firmly on the main event, the preliminary bouts is also generating excitement. Big-ticket boxing cards often feature stacked undercards, providing non-stop action before the headliner.
Traditionally, supporting bouts in major events have introduced future champions. Contenders hoping to make their mark often seize these moments to showcase their skills, as all eyes are on them. Although the lineup for the Fury Usyk undercard haven’t been officially announced, there’s plenty of talk. Might there be a cruiserweight spectacle? No matter the final roster, the action will not disappoint. The most compelling part of Fury vs Usyk incredibly exciting is the clash of styles. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. Being so tall yet so nimble, he commands the ring like no other.
The three fights against Wilder proved his toughness, bouncing back from adversity to secure victories. When he faced Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, offers a different kind of threat. With his unorthodox stance, his positioning constantly challenges opponents. The Ukrainian’s shots may not have knockout power, they consistently find their mark. With the date drawing closer, Predictions for this fight have fans and analysts speculating.
Most bookmakers favor Fury as per the betting experts, thanks to his imposing frame, his proven ability in tough situations, and his adaptability. Despite the odds, Usyk remains a strong contender doesn’t mean he’s an underdog in spirit, his wins over Anthony Joshua demonstrated his ability in the heavyweight ranks.
For the Gypsy King is a chance to further solidify his greatness. If he wins, it would add an undisputed title to his already impressive resume. On the other hand, If Usyk wins would elevate him to new heights. Securing two undisputed titles is a feat few can claim.
Web: <a href="http://google.ca/url?q=https://tysonvsusyk.com/">tysonvsusyk.com</a>
The upcoming showdown is more than just a championship fight. It’s a fight between two very different fighters. Fury’s bold and unapologetic character is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. This is more than just a physical contest. Regardless of the outcome, the impact of this bout will be remembered as a defining moment in boxing. Fury vs Usyk is more than just a match. It’s a culmination of years of hard work. Whether Tyson Fury prevails thanks to his power and game plan, or Oleksandr Usyk triumphs thanks to his skill and resilience, one thing is certain, this bout will go down in history.
Tyson Fury vs Oleksandr Usyk is a spectacle of a lifetime. It’s a contest of heart and willpower. These men will give everything they have.
Visit for more information: #crosslink[3,L -
Azərbaycanda qumar oyunlarına güvəni artdıqca, Pin-up casino online kimi platformalar daha çox tanınmağa başladı. Əlavə olaraq, Pinup casino sözləri indi yerli istifadəçilər üçün adidir. Pin-up kazino istifadəçilərə məxsus çoxlu oyun növü təklif edir.
Pin-up cazino, Azərbaycan oyunçuları üçün maraqlı seçimdir. Bu platforma oyunçulara çeşidli qumar oyunları təklif verməkdədir və bonus imkanları ilə müştərilərini məmnun edir.
Pin-up online kazino, bənzərsiz oyun imkanı təqdim edən onlayn kazinodur. Azəri oyunçuları arasında məşhur olan Pinup, istifadəçilər üçün çeşidli bonus imkanları yaradır.
Xüsusilə, Pin-up online casino müştərilərə güvənli və şəffaf maliyyə idarəetmə imkanları oyunçularına təklif edir. Kazino iştirakçıları, etibarlı və tez depozit və pul çıxarış imkanları ilə, kazino oyunlarını daha asan keçirə bilərlər.
Əlavə olaraq, Pin-up cazino istifadəçilərə yalnız qumar oyunları yox, həmçinin sərfəli bonuslar və maraqlı aksiyalar təklif edir. Bu onlayn kazinoda, mərc edənlər təhlükəsiz şərtlər altında mərc edir.
Web: https://pinup-best-top.web.app
Pin-up cazino təkcə oyunlar ilə kifayətlənmir. Kazino həvəskarları bu kazinoda çeşidli mərc seçimlərindən təcrübə edə bilərlər və maraqlı aksiyaları oyun təcrübələrinə əlavə edərlər.
Yekun olaraq, Pinup kazino, rahat və təhlükəsiz mərc təcrübəsi təmin etməklə onlayn qumar dünyasında lider mövqedədir. Azəri bazarında çox seçilməsi əlamətdardır.
These two heavyweight champions are preparing for an epic showdown of historic proportions. This fight is about more than just titles; it represents their quest for immortality. The towering Fury has risen to the pinnacle of the sport thanks to his personality coupled with unparalleled talent in the ring. Beating Wilder and Klitschko have solidified his legendary status. Meanwhile, the tactical southpaw is a fighter unlike any other to boxing’s biggest stars. On the flip side, Usyk, a genius in the ring represents a formidable opponent for Tyson Fury himself, but for the entire division. His journey to global fame was marked by his undisputed cruiserweight reign, by conquering all challengers. Get ready for a thrilling boxing match of the year as Usyk takes on Tyson Fury in an unforgettable showdown! Experience every moment in real time on our website. Don’t miss your chance — visit <a href="https://foiledfox.com/affiliates/idevaffiliate.php?url=https://usykvsfurydate.co.uk/">usykvsfurydate.co.uk</a> now and stream the event from the comfort of your home!
Across the UK, the event will kick off at close to prime time, making it ideal for a prime-time audience. Back in Usyk’s home country, and beyond, the excitement is palpable. The fight’s location is still under speculation, with talk of iconic boxing destinations. No matter the location, it’s guaranteed: it will be a spectacle. Although the focus is centered on the headline fight, the Fury vs Usyk undercard promises plenty of action. Big-ticket boxing cards often feature stacked undercards, providing non-stop action before the headliner.
Historically, supporting bouts in major events have introduced future champions. Fighters looking to rise through the ranks capitalize on the exposure to impress fans and analysts alike, as all eyes are on them. While the names for the undercard are still unconfirmed, there’s plenty of talk. Could we see rising prospects? Regardless of the names, fans can expect fireworks. The most compelling part of Fury vs Usyk incredibly exciting is the clash of styles. The Gypsy King’s unusual blend of height and speed are unparalleled in the sport. With his immense height and reach advantage, he dictates the pace of bouts.
The legendary battles with Wilder highlighted his resilience, as he recovered from knockdowns to secure victories. Against Wladimir Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. By contrast, Usyk, relies on technique and stamina. With his unorthodox stance, he uses angles and footwork. His strikes may not have knockout power, their timing wears down foes. With the date drawing closer, Predictions for this fight are the subject of intense debate.
Tyson Fury is seen as the frontrunner as per the betting experts, given his physical stature, his long career in major fights, and his unpredictable nature. However, Usyk's underdog status doesn’t mean he’s an underdog in spirit, as his victories over Joshua confirmed his toughness against big opponents.
For Tyson Fury could be the defining moment of his career. A triumph for Fury would further solidify his status as the best heavyweight of this era. Conversely, Usyk’s victory would mark him as one of the sport’s greats. Becoming an undisputed champion in two different weight classes is a feat few can claim.
Web: <a href="http://google.ae/url?q=https://usykvsfurydate.co.uk/">usykvsfurydate.co.uk</a>
The upcoming showdown represents something greater than a title bout. It’s a battle of contrasting styles. Fury’s confident and brash nature stands in stark contrast to Usyk’s composed demeanor. Such contrasts make the fight more compelling. Beyond physical ability, this fight. Regardless of the outcome, the legacy of this fight will reverberate throughout boxing history. Fury vs Usyk is a spectacle unlike any other. It represents the culmination of their careers. Whether Tyson Fury prevails thanks to his power and game plan, or Usyk comes out on top through his superior boxing ability, no matter the outcome, this bout will go down in history.
The Fury-Usyk battle is more than just a sporting contest. It’s a showcase of skill and determination. These men will give everything they have.
Visit for more information: #crosslink[3,L -
yerli oyunçular arasında qumar oyunlarına istək artdıqca, "Pin-up casino" kimi platformalar daha çox tanınmağa başladı. Bununla bərabər, Pin-up azerbaycan ifadələri artıq Azərbaycandakı oyunçular üçün tanışdır. Pin-up azerbaycan mərc həvəskarlarına geniş oyunlar təklif edir.
Pin up kazino, Azəri istifadəçilər üçün populyar seçimdir. Bu qumar saytı mərc həvəskarlarına müxtəlif oyunlar təklif edib və gözəl hədiyyələr ilə seçim olur.
Pin-up online kazino, geniş oyun variantları təklif edən oyun məkanıdır. yerli mərcçilər arasında çox seçilən Pin-up kazino, qumar oyunçuları üçün geniş oyun təcrübəsi verir.
Bununla yanaşı, Pin-up azerbaycan müştərilərə etibarlı depozit və çıxarış imkanı təqdim edir. Kazino iştirakçıları, rahat və tez kredit kartı və elektron pul kisəsi ilə ilə təmin olunmaqla, onlayn mərc oyunlarını müvafiq şəkildə yaşaya bilərlər.
Sonda, Pin-up azerbaycan istifadəçilərə təkcə oyun imkanı deyil mərc hədiyyələri oyun təcrübəsini daha da maraqlı edir. Pinup-da, istifadəçilər təhlükəsiz şərtlər altında mərc edir.
Web: https://pinup-best-casino.web.app
Pin-up azerbaycan təkcə bir kazino olaraq məhdud deyil. Kazino həvəskarları bu kazinoda çeşidli mərc seçimlərindən yararlana bilərlər və maraqlı aksiyaları istifadə edə bilərlər.
Ümumilikdə, Pinup kazino, şəffaf və güvənli kazino təcrübəsi mərc həvəskarlarına təqdim etməklə oyun bazarında oyunçular arasında geniş istifadə edilir. Azəri bazarında tanınması əlamətdardır.
The undefeated Fury and Usyk are on a collision course of historic proportions. It’s far beyond a championship match; it represents their quest for immortality. The towering Fury has earned worldwide fame with his charisma coupled with unparalleled talent inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. On the other hand, Usyk, the Ukrainian master brings an unprecedented test to the heavyweight division. On the flip side, Usyk, a genius in the ring represents a formidable opponent for the heavyweight ranks overall, and for boxing fans worldwide. His journey to global fame was marked by his undisputed cruiserweight reign, as an undisputed champion. Don’t miss out for a thrilling boxing match of the year as Oleksandr Usyk takes on Fury in a must-watch showdown! Catch every punch in real time on our website. Join the excitement — visit <a href="https://anzhero.4geo.ru/redirect/?service=news&town_id=156895024&url=https://usykvsfurydate.org.uk/">usykvsfurydate.org.uk</a> now and enjoy the fight in high quality!
Across the UK, the ring walks are planned for around 10 PM GMT, making it ideal for a prime-time audience. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, the excitement is palpable. The venue for Fury vs Usyk remains a hot topic, with talk of iconic boxing destinations. Wherever it happens, fans can be sure: it will be a spectacle. While the spotlight remains on Fury and Usyk, the preliminary bouts promises plenty of action. Major boxing events often feature stacked undercards, offering an entire night of boxing excitement.
Historically, preliminary fights on major cards have showcased rising stars. Boxers seeking the spotlight often seize these moments to impress fans and analysts alike, with the world paying attention. Though the supporting fights for Fury vs Usyk has yet to be finalized, there’s plenty of talk. Might there be a cruiserweight spectacle? Whatever the selection, fans can expect fireworks. What makes this fight so intriguing is their contrasting skillsets. Fury’s towering frame and movement make him an anomaly in boxing. Being so tall yet so nimble, he dictates the pace of bouts.
The three fights against Wilder showed his durability, overcoming brutal hits to dominate in later rounds. When he faced Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. By contrast, Usyk, relies on technique and stamina. As a southpaw, he uses angles and footwork. Usyk’s punches may not have knockout power, they consistently find their mark. With the date drawing closer, Tyson Fury vs Usyk odds are becoming a hot topic.
The betting lines show Fury ahead as per the betting experts, because of his reach and height, his track record in big matches, and his adaptability. Although Usyk is the less favored fighter doesn’t rule him out, his victories against AJ showed that he can compete at heavyweight.
For the Gypsy King could be the defining moment of his career. A victory would put the finishing touches on a historic career. Meanwhile, If Usyk wins would be a monumental achievement. Achieving undisputed glory in two divisions is a feat few can claim.
Web: <a href="http://maps.google.ro/url?sa=t&url=https%3A%2F%2Fusykvsfurydate.org.uk">usykvsfurydate.org.uk</a>
Fury vs Usyk represents something greater than a title bout. It’s a clash of personalities. Fury’s larger-than-life persona is the opposite of Usyk’s humble and disciplined approach. The clash of personalities adds depth to the narrative. It’s a fight of wills and ideologies. Whoever comes out victorious, the significance of this match will reverberate throughout boxing history. The battle for heavyweight supremacy is more than just a fight. It represents the culmination of their careers. Whether Tyson Fury prevails through his strength and tactics, or Usyk secures a victory with his technique and endurance, what is clear is, this will be a legendary contest.
The Fury-Usyk battle is a spectacle of a lifetime. It’s a battle of minds and bodies. Both fighters will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azəri bazarında internet qumarına sevgisi artdıqca, Pinup kazino kimi onlayn mərc xidmətləri daha çox tanınmağa başladı. Əsasən, Pin-up kazino şəklində olan platformalar tez-tez Azərbaycandakı oyunçular üçün güvənlidir. Pin-up casino istifadəçilərə müxtəlif oyunlar təklif edir.
Pin-up kazino, Azəri istifadəçilər üçün ən sevilən platformalardan biridir. Bu kazino istifadəçilərə rəngarəng oyunlar təklif edir və bonus imkanları ilə seçim olur.
Pin-up casino online, istifadəçilərə oyun növləri ilə zəngin oyun məkanıdır. Azəri oyunçuları arasında geniş istifadə olunan Pin-up casino, kazino oyunçuları üçün maraqlı oyun imkanları təklif edir.
Bunun nəticəsində, "Pin-up casino online" oyunçulara etibarlı ödəmə sistemləri təklif edir. Müştərilər, müvafiq və təhlükəsiz maliyyə əməliyyatları köməyilə, kazino oyunlarını asan və sürətli yaşaya bilərlər.
Son olaraq, Pinup kazino qumarbazlara yalnız qumar oyunları yox, həmçinin mərc hədiyyələri təmin edir. Bu qumar saytında, qumar həvəskarları təhlükəsiz oyun mühitində olur.
Web: https://pinup-top-bet.web.app
Pin-up casino təkcə bir oyun platforması kimi oyunçuları cəlb etmir. İstifadəçilər Pinup-da fərqli mərc oyunlarından həzz ala bilərlər və cazibədar bonus imkanlarını oyunlarına əlavə edə bilərlər.
Sonda, Pin-up azerbaycan, güvənli oyun imkanı istifadəçilərə verməklə mərc bazarında ən sevilən platformalardan olur. yerli oyunçular arasında çox seçilməsi dikkətə layiqdir.
Tyson Fury and Oleksandr Usyk are preparing for an epic showdown of historic proportions. This fight is about more than just titles; it represents their quest for immortality. Fury, an undefeated champion has earned worldwide fame through his unique style coupled with unparalleled talent during fights. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. Across the ring, Usyk, the Ukrainian master poses a unique challenge to boxing’s biggest stars. At the same time, Oleksandr Usyk represents a formidable opponent for Tyson Fury himself, as a heavyweight contender. The ascent of Oleksandr Usyk started with his domination of the cruiserweights, where he became an unstoppable force. Don’t miss out for a thrilling boxing match of the year as Oleksandr Usyk takes on Fury in an unforgettable showdown! Experience every moment in real time on our website. Join the excitement — visit <a href="http://pr.chambernation.workers.dev/?http%3A%2F%2Ftysonfuryvsoleksandrusyk.co.uk">tysonfuryvsoleksandrusyk.co.uk</a> now and watch the match from the comfort of your home!
In the United Kingdom, the fight is expected to begin close to prime time, offering perfect timing for viewers. In Usyk’s native Ukraine, and for fans watching from around the world, the anticipation is at a fever pitch. The venue for Fury vs Usyk remains a hot topic, with talk of iconic boxing destinations. No matter the location, fans can be sure: the atmosphere will be electric. While the spotlight remains on Fury and Usyk, the fights leading up to the main event is shaping up to be thrilling. Big-ticket boxing cards are known for strong supporting fights, offering an entire night of boxing excitement.
Historically, preliminary fights on major cards have introduced future champions. Boxers seeking the spotlight capitalize on the exposure to demonstrate their talent, with the world paying attention. Though the supporting fights for Fury vs Usyk are still unconfirmed, there’s plenty of talk. Could we see rising prospects? Whatever the selection, the action will not disappoint. What makes this fight so intriguing is the clash of styles. Fury’s towering frame and movement set him apart from other heavyweights. At 6’9" with an 85-inch reach, he commands the ring like no other.
The legendary battles with Wilder showed his durability, as he recovered from knockdowns to dominate in later rounds. Against Wladimir Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. With his unorthodox stance, his positioning constantly challenges opponents. Usyk’s punches aren’t the heaviest in the division, their timing wears down foes. With the date drawing closer, Predictions for this fight have fans and analysts speculating.
Tyson Fury is the slight favorite according to the odds, due to his size advantage, his experience in high-pressure bouts, and his adaptability. Despite being seen as the underdog doesn’t mean he’s an underdog in spirit, his wins over Anthony Joshua showed that he can compete at heavyweight.
For Fury himself presents a shot at undisputed glory. If he wins, it would put the finishing touches on a historic career. On the other hand, If Usyk wins would be a monumental achievement. Becoming an undisputed champion in two different weight classes is a feat few can claim.
Web: <a href="http://www.google.com.ai/url?q=https%3A%2F%2Ftysonfuryvsoleksandrusyk.co.uk">tysonfuryvsoleksandrusyk.co.uk</a>
This fight represents something greater than a title bout. It’s a battle of contrasting styles. Fury’s larger-than-life persona is the opposite of Usyk’s humble and disciplined approach. These differences add complexity to the fight. This is more than just a physical contest. Whoever comes out victorious, the significance of this match will be remembered as a defining moment in boxing. Fury vs Usyk is a defining moment. It’s the result of relentless dedication. Whether Fury secures the win with his size and strategy, or Usyk wins with his precision thanks to his skill and resilience, what is clear is, this will be a fight remembered for years to come.
This fight between Fury and Usyk is more than just a sporting contest. It’s a fight of grit and strategy. Both fighters will leave it all in the ring.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are ready to face each other in a fight that will define an era. This fight is about more than just titles; it’s about legacy. Tyson Fury has risen to the pinnacle of the sport thanks to his personality and remarkable adaptability during fights. Beating Wilder and Klitschko have earned him recognition as one of the best ever. In contrast, Oleksandr Usyk brings an unprecedented test to boxing’s biggest stars. Meanwhile, Usyk, a genius in the ring represents a formidable opponent for Tyson Fury himself, as a heavyweight contender. His journey to global fame was marked by his undisputed cruiserweight reign, by conquering all challengers. Prepare yourself for an epic boxing match of the year as Usyk takes on Tyson Fury in an unforgettable showdown! Catch every punch in real time on our website. Don’t miss your chance — visit <a href="https://golf2club.printdirect.ru/utils/redirect?url=https://tysonfuryvoleksandrusyk.com/">tysonfuryvoleksandrusyk.com</a> now and stream the event in high quality!
For British fans, the event will kick off at around 10 PM GMT, making it ideal for a prime-time audience. Back in Usyk’s home country, and for fans watching from around the world, the excitement is palpable. The venue for Fury vs Usyk is still under speculation, with talk of iconic boxing destinations. Wherever it happens, one thing is certain: the atmosphere will be electric. While the spotlight remains on Fury and Usyk, the fights leading up to the main event is shaping up to be thrilling. High-profile matches include preliminary bouts with top talent, giving fans a full evening of entertainment.
Historically, supporting bouts in major events have been a stage for breakout performances. Fighters looking to rise through the ranks often seize these moments to impress fans and analysts alike, with the world paying attention. Though the supporting fights for Fury vs Usyk has yet to be finalized, speculation runs high. Might there be a cruiserweight spectacle? Regardless of the names, it’s sure to add to the excitement. What sets this bout apart truly fascinating is their contrasting skillsets. Tyson Fury’s size and agility set him apart from other heavyweights. Being so tall yet so nimble, he commands the ring like no other.
His trilogy with Deontay Wilder highlighted his resilience, bouncing back from adversity to dominate in later rounds. When he faced Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, relies on technique and stamina. With his unorthodox stance, his movements create openings. His strikes may not have knockout power, their timing wears down foes. As fight night approaches, The betting lines for Fury vs Usyk have fans and analysts speculating.
Fury is the favored fighter according to the odds, because of his reach and height, his long career in major fights, and his tactical brilliance. Despite being seen as the underdog doesn’t diminish his chances, his victories against AJ proved that he can handle the physicality of the heavyweight division.
For Fury himself is a chance to further solidify his greatness. A triumph for Fury would add an undisputed title to his already impressive resume. Conversely, For Usyk, a win would elevate him to legendary status. Becoming the undisputed heavyweight champion is a once-in-a-lifetime achievement.
Web: <a href="http://cse.google.com.sg/url?q=https%3A%2F%2Ftysonfuryvoleksandrusyk.com">tysonfuryvoleksandrusyk.com</a>
The upcoming showdown is about more than the titles. It’s a meeting of two unique worldviews. Fury’s confident and brash nature is in stark contrast to Usyk’s quiet intensity. These varying personalities make the bout even more interesting. It’s about more than just skill. Regardless of the outcome, the impact of this bout will be remembered as a defining moment in boxing. This historic showdown is more than just a match. It represents the culmination of their careers. Whether Tyson Fury prevails through his strength and tactics, or Oleksandr Usyk triumphs thanks to his skill and resilience, what is clear is, this bout will go down in history.
The Fury-Usyk battle is more than just a boxing event. It’s a showcase of skill and determination. These men will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Azərbaycan ərazisində virtual qumar oyunlarına sevgisi artdıqca, "Pin-up casino" kimi şirkətlər daha çox tanınmağa başladı. Bununla bərabər, Pin-up kazino şəklində olan platformalar tez-tez Azəri mərc həvəskarları üçün güvənlidir. Pin-up azerbaycan istifadəçilərə çeşidli oyunlar təklif edir.
Pin-up online casino, Azəri qumarbazlar üçün ən sevilən platformalardan biridir. Bu onlayn kazino kazino oyunçularına rəngarəng oyunlar təmin edir və sərfəli bonus təklifləri ilə oyunçuları özünə cəlb edir.
Pin-up azerbaycan, istifadəçilərə oyun növləri ilə zəngin saytdır. yerli mərcçilər arasında geniş istifadə olunan Pin-up oyunları, mərc həvəskarları üçün maraqlı oyun imkanları təklif edir.
Bunun nəticəsində, Pin-up azerbaycan mərcçilərə etibarlı ödəmə sistemləri təmin edir. İstifadəçilər, rahat kredit kartı və elektron pul kisəsi ilə köməyilə, mərc təcrübələrini güvənli və təhlükəsiz oynaya bilərlər.
Yekun olaraq, Pin-up casino online mərc həvəskarlarına yalnız oyun təklif etmir cəlbedici kampaniyalar oyun təcrübəsini daha da maraqlı edir. Bu onlayn kazinoda, müştərilər təhlükəsiz şərtlər altında mərc edir.
Web: https://bet-pinup.web.app
Pin-up casino təkcə bir oyun platforması kimi oyunlar ilə kifayətlənmir. İstifadəçilər Pinup-da fərqli mərc oyunlarından yararlana bilərlər və cazibədar bonus imkanlarını oyun təcrübələrinə əlavə edərlər.
Ümumilikdə, Pin-up kazino, müasir və təhlükəsiz mərc imkanı oyunçulara təklif etməklə oyun sənayesində ən yaxşı seçimlərdən biridir. Azəri bazarında məşhur olması dikkətə layiqdir.
Tyson Fury and Oleksandr Usyk are set to meet in the ring that will define an era. It’s far beyond a championship match; it’s a battle for eternal recognition. The towering Fury has earned worldwide fame with his charisma coupled with unparalleled talent in the ring. Beating Wilder and Klitschko have cemented his place among the all-time greats. On the other hand, Oleksandr Usyk is a fighter unlike any other to boxing’s biggest stars. On the flip side, Usyk, a southpaw master represents a formidable opponent not just for Fury, and for boxing fans worldwide. The ascent of Oleksandr Usyk started with his domination of the cruiserweights, where he became an unstoppable force. Prepare yourself for a thrilling boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a must-watch showdown! See every move live on our website. Be part of the action — visit <a href="http://hometownlocator.com/ezoimgfmt/usykvsfurydate.co.uk">usykvsfurydate.co.uk</a> now and stream the event in high quality!
For British fans, the ring walks are planned for around 10 PM GMT, offering perfect timing for viewers. For Usyk’s fans in Ukraine, as well as viewers across Europe and the Americas, this will be a must-see event. The venue for Fury vs Usyk is still under speculation, with talk of iconic boxing destinations. Regardless of the venue, fans can be sure: the excitement will be unmatched. Although the focus is firmly on the main event, the fights leading up to the main event is also generating excitement. Major boxing events include preliminary bouts with top talent, offering an entire night of boxing excitement.
In the past, preliminary fights on major cards have introduced future champions. Fighters looking to rise through the ranks capitalize on the exposure to demonstrate their talent, as all eyes are on them. Though the supporting fights for Fury vs Usyk haven’t been officially announced, fans are eagerly guessing. Will there be a heavyweight clash? No matter the final roster, fans can expect fireworks. The most compelling part of Fury vs Usyk so intriguing is the dynamic between these fighters. Fury’s towering frame and movement are unparalleled in the sport. At 6’9" with an 85-inch reach, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, as he recovered from knockdowns to dominate in later rounds. When he faced Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. Being a left-handed fighter, his movements create openings. The Ukrainian’s shots aren’t the heaviest in the division, their timing wears down foes. With the date drawing closer, Tyson Fury vs Usyk odds are becoming a hot topic.
Tyson Fury is seen as the frontrunner based on the betting odds, given his physical stature, his track record in big matches, and his tactical brilliance. However, Usyk's underdog status shouldn’t be counted out, his victories against AJ confirmed his toughness against big opponents.
For the Gypsy King could be the defining moment of his career. A victory would further solidify his status as the best heavyweight of this era. Conversely, For Usyk, a win would mark him as one of the sport’s greats. Achieving undisputed glory in two divisions is a rare accomplishment.
Web: <a href="http://maps.google.ca/url?q=https://usykvsfurydate.co.uk/">usykvsfurydate.co.uk</a>
Fury vs Usyk is not just about the belts. It’s a fight between two very different fighters. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. These differences add complexity to the fight. This is more than just a physical contest. Whoever comes out victorious, the legacy of this fight will be felt for years to come. The battle for heavyweight supremacy is more than just a fight. It’s the result of relentless dedication. Whether Fury secures the win with his experience and unpredictability, or Usyk secures a victory thanks to his skill and resilience, it’s certain that, this will be a fight remembered for years to come.
Tyson Fury vs Oleksandr Usyk is more than just a boxing event. It’s a showcase of skill and determination. Both fighters will give everything they have.
Visit for more information: #crosslink[3,L -
Azərbaycandakı qumar sektorunda onlayn qumar oyunlarına sevgisi artdıqca, Pinup kimi kazino xidmətləri daha çox tanınmağa başladı. Özəlliklə, Pinup casino şəklində olan platformalar son zamanlar Azərbaycandakı oyunçular üçün adidir. Pin-up casino mərc həvəskarlarına çox oyun növləri təklif edir.
Pin-up azerbaycan, Azəri qumarbazlar üçün geniş yayılmış bir xidmətdir. Bu qumar xidməti qumarbazlara müxtəlif oyunlar təklif verməkdədir və gözəl hədiyyələr ilə seçim olur.
Pin-up azerbaycan, bənzərsiz oyun imkanı təqdim edən oyun məkanıdır. Azəri oyunçuları arasında güvənilən Pinup, istifadəçilər üçün geniş oyun təcrübəsi verir.
Əlavə olaraq, Pinup kazino müştərilərə güvənli və şəffaf maliyyə sistemləri təmin edir. Mərc edənlər, sürətli və asan depozit çıxarış sistemi köməyilə, qumar təcrübələrini daha rahat təcrübə edə bilərlər.
Son olaraq, Pin-up cazino oyunçulara təkcə oyunlar deyil, həm də cəlbedici kampaniyalar təmin edir. Bu platformada, müştərilər güvənli bir təcrübə yaşayır.
Web: https://pinup-best-bet.web.app
Pin-up cazino təkcə bir kazino olaraq oyunlar ilə kifayətlənmir. İstifadəçilər Pinup-da fərqli mərc seçimlərindən həzz ala bilərlər və bonus sistemini oyun təcrübəsini artırarlar.
Ümumilikdə, Pin-up azerbaycan, etibarlı mərc təcrübəsi istifadəçilərə verməklə onlayn qumar dünyasında lider mövqedədir. Azərbaycanda populyarlığı açıq bir faktdır.
Tyson Fury and Oleksandr Usyk are ready to face each other in a fight of historic proportions. This fight is about more than just titles; it’s a battle for eternal recognition. Fury, an undefeated champion has risen to the pinnacle of the sport with his charisma and remarkable adaptability during fights. Beating Wilder and Klitschko have solidified his legendary status. In contrast, Usyk, the Ukrainian master poses a unique challenge for Fury. Meanwhile, the Ukrainian technician stands as a unique threat for the heavyweight ranks overall, and for boxing fans worldwide. His journey to global fame was marked by his undisputed cruiserweight reign, as an undisputed champion. Get ready for an epic boxing match of the year as Oleksandr Usyk takes on Fury in a must-watch showdown! Catch every punch in real time on our website. Don’t miss your chance — visit <a href="https://zakupis-ekb.ru/out?a:aHR0cHM6Ly9tb2RzLW1lbnUucnUv">fury-usyk.uk</a> today and enjoy the fight from the comfort of your home!
Across the UK, the fight is expected to begin late evening, offering perfect timing for viewers. Back in Usyk’s home country, and beyond, the anticipation is at a fever pitch. The fight’s location is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, it’s guaranteed: the atmosphere will be electric. Although the focus remains on Fury and Usyk, the Fury vs Usyk undercard is shaping up to be thrilling. Major boxing events are known for strong supporting fights, giving fans a full evening of entertainment.
In the past, preliminary fights on major cards have introduced future champions. Contenders hoping to make their mark capitalize on the exposure to demonstrate their talent, with the world paying attention. Although the lineup for the Fury Usyk undercard haven’t been officially announced, speculation runs high. Could we see rising prospects? No matter the final roster, fans can expect fireworks. The most compelling part of Fury vs Usyk so intriguing is the clash of styles. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. At 6’9" with an 85-inch reach, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, bouncing back from adversity to finish strong. In his fight with Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Meanwhile, Usyk, offers a different kind of threat. Being a left-handed fighter, he uses angles and footwork. The Ukrainian’s shots lack devastating strength, their timing wears down foes. As anticipation builds, Tyson Fury vs Usyk odds have fans and analysts speculating.
Tyson Fury is the slight favorite based on the betting odds, thanks to his imposing frame, his proven ability in tough situations, and his unorthodox style. However, Usyk's underdog status doesn’t mean he’s an underdog in spirit, his victories against AJ confirmed his toughness against big opponents.
For Tyson Fury represents an opportunity to cement his legacy. A triumph for Fury would further solidify his status as the best heavyweight of this era. On the other hand, If Usyk wins would elevate him to new heights. Becoming the undisputed heavyweight champion is a rare accomplishment.
Web: <a href="http://maps.google.com.do/url?q=https%3A%2F%2Ffury-usyk.uk">fury-usyk.uk</a>
Fury vs Usyk represents something greater than a title bout. It’s a meeting of two unique worldviews. Fury’s confident and brash nature is in stark contrast to Usyk’s quiet intensity. These varying personalities make the bout even more interesting. It’s about more than just skill. Whoever triumphs in this battle, the legacy of this fight will leave a lasting mark on the sport. Fury vs Usyk is more than just a fight. It represents the culmination of their careers. Should Fury claim victory through his strength and tactics, or Usyk wins with his precision through his superior boxing ability, no matter the outcome, this will be a defining moment in boxing.
This fight between Fury and Usyk is a spectacle of a lifetime. It’s a showcase of skill and determination. The two competitors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
yerli oyunçular arasında internet oyunlarına güvəni artdıqca, Pinup kimi onlayn mərc xidmətləri daha çox tanınmağa başladı. Əlavə olaraq, Pinup casino şəklində olan platformalar hazırda yerli istifadəçilər üçün məşhurdur. Pin-up kazino online müştərilərinə çoxlu oyun növü təklif edir.
Pin-up online casino, Azərbaycan oyunçuları üçün geniş kütləyə sahib bir qumar saytıdır. Bu qumar saytı müştərilərə fərqli oyun növləri təklif verməkdədir və sərfəli bonus təklifləri ilə müştərilərini məmnun edir.
Pin-up cazino, çeşidli oyun təcrübəsi təklif edən bir platformadır. yerli mərcçilər arasında çox seçilən Pin-up casino, istifadəçilər üçün geniş oyun variantları ilə tanınır.
Əlavə olaraq, Pin-up azerbaycan istifadəçilərə təhlükəsiz maliyyə sistemləri təqdim edir. Müştərilər, sürətli və asan maliyyə əməliyyatları vasitəsilə, mərc təcrübələrini daha asan təcrübə edə bilərlər.
Sonda, Pin-up casino mərc həvəskarlarına yalnız qumar oyunları yox, həmçinin mərc hədiyyələri oyun təcrübəsini daha da maraqlı edir. Pin-up-da, kazino həvəskarları təhlükəsiz oyun mühitində olur.
Web: https://best-pin-up-bet.web.app
Pin-up online kazino təkcə bir oyun platforması kimi məhdudlaşmır. Kazino həvəskarları bu kazinoda bənzərsiz mərc imkanlarından istifadə edə bilər və maraqlı aksiyaları qazanmaq imkanı əldə edərlər.
Nəticədə, Pin-up cazino, rahat və təhlükəsiz mərc təcrübəsi təklif etməklə oyun bazarında ən sevilən platformalardan olur. yerli oyunçular arasında tanınması açıq bir faktdır.
The undefeated Fury and Usyk are on a collision course of unparalleled significance. It’s not merely about the belts; it’s a battle for eternal recognition. Fury, an undefeated champion has risen to the pinnacle of the sport thanks to his personality coupled with unparalleled talent during fights. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. On the other hand, Usyk, the technician brings an unprecedented test for Fury. Meanwhile, Oleksandr Usyk is a true test for Fury for Tyson Fury himself, but for the entire division. The ascent of Oleksandr Usyk began in the cruiserweight division, as an undisputed champion. Don’t miss out for the most anticipated boxing match of the year as Usyk takes on Fury in a historic showdown! See every move streamed live on our website. Be part of the action — visit <a href="https://mscp2.live-streams.nl:2197/play/play.cgi?url=https://furyusyk.org.uk/">furyusyk.org.uk</a> now and enjoy the fight in high quality!
Across the UK, the ring walks are planned for around 10 PM GMT, ensuring maximum viewership. For Usyk’s fans in Ukraine, and for fans watching from around the world, this will be a must-see event. The venue for Fury vs Usyk is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, one thing is certain: the excitement will be unmatched. While the spotlight is firmly on the main event, the fights leading up to the main event is also generating excitement. Major boxing events often feature stacked undercards, providing non-stop action before the headliner.
Traditionally, undercards of this caliber have been a stage for breakout performances. Fighters looking to rise through the ranks use such opportunities to showcase their skills, knowing millions are watching. While the names for the undercard are still unconfirmed, fans are eagerly guessing. Will there be a heavyweight clash? Whatever the selection, the action will not disappoint. What sets this bout apart truly fascinating is the dynamic between these fighters. Tyson Fury’s size and agility are unparalleled in the sport. Being so tall yet so nimble, he commands the ring like no other.
His trilogy with Deontay Wilder proved his toughness, as he recovered from knockdowns to finish strong. In his fight with Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. Meanwhile, Usyk, relies on technique and stamina. Being a left-handed fighter, his positioning constantly challenges opponents. The Ukrainian’s shots may not have knockout power, they consistently find their mark. As anticipation builds, Predictions for this fight are the subject of intense debate.
The betting lines show Fury ahead based on the betting odds, given his physical stature, his proven ability in tough situations, and his unpredictable nature. Although Usyk is the less favored fighter shouldn’t be counted out, his wins over Anthony Joshua demonstrated his ability in the heavyweight ranks.
For Fury himself is a chance to further solidify his greatness. A triumph for Fury would add an undisputed title to his already impressive resume. Meanwhile, For Usyk, a win would elevate him to legendary status. Achieving undisputed glory in two divisions would be a remarkable feat in boxing history.
Web: <a href="http://www.google.tl/url?q=https://furyusyk.org.uk/">furyusyk.org.uk</a>
The upcoming showdown is about more than the titles. It’s a fight between two very different fighters. Fury’s boisterous personality is in stark contrast to Usyk’s quiet intensity. These differences add complexity to the fight. Beyond physical ability, this fight. Regardless of the outcome, the significance of this match will be felt for years to come. The clash for the undisputed title is a spectacle unlike any other. It’s a culmination of years of hard work. If Fury wins with his size and strategy, or Usyk wins with his precision thanks to his skill and resilience, one thing is certain, this will be a legendary contest.
The Fury-Usyk battle is more than just a fight. It’s a fight of grit and strategy. These men will pour everything into the bout.
Visit for more information: #crosslink[3,L -
yerli oyunçular arasında internet qumarına istək artdıqca, Pin-up online kimi kazino xidmətləri daha çox tanınmağa başladı. Əlavə olaraq, Pin-up online şəklində olan platformalar tez-tez Azəri müştərilər üçün istifadə olunur. Pin-up azerbaycan öz oyunçularına çoxlu oyun növü təklif edir.
Pinup kazino, yerli mərc həvəskarları üçün geniş kütləyə sahib bir qumar saytıdır. Bu onlayn kazino kazino oyunçularına geniş çeşidli oyunlar təklif edib və sərfəli bonus təklifləri ilə müştərilərini məmnun edir.
Pin-up cazino, fərqli oyun təcrübəsi təklif edən şirkətdir. Azərbaycan ərazisində populyar olan Pin-up casino, kazino oyunçuları üçün geniş oyun təcrübəsi verir.
Xüsusilə, Pin-up online casino oyunçulara təhlükəsiz ödəmə üsulları təmin edir. Mərc edənlər, müvafiq və təhlükəsiz maliyyə əməliyyatları sayəsində, kazino oyunlarını müvafiq şəkildə yerinə yetirə bilərlər.
Nəticə etibarilə, Pin-up cazino müştərilərə geniş oyun təcrübəsi ilə yanaşı sərfəli bonuslar oyun təcrübəsini daha da maraqlı edir. Bu qumar saytında, mərc edənlər şəffaf oyun şərtləri ilə rastlaşır.
Web: https://az-pinup.web.app
Pin-up azerbaycan yalnız sadə oyunla bitmir. Mərc həvəskarları bu platformada çeşidli mərc seçimlərindən təcrübə edə bilərlər və geniş bonus imkanlarını oyunlarına əlavə edə bilərlər.
Yekun olaraq, Pin-up casino online, sərfəli və təhlükəsiz mərc oyunları mərc həvəskarlarına təqdim etməklə mərc bazarında oyunçular arasında geniş istifadə edilir. yerli oyunçular arasında tanınması təsadüf deyil.
The undefeated Fury and Usyk are ready to face each other in a fight of unparalleled significance. It’s far beyond a championship match; it’s a battle for eternal recognition. Tyson Fury has earned worldwide fame with his charisma and remarkable adaptability during fights. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Meanwhile, Usyk, the technician brings an unprecedented test to the heavyweight division. On the flip side, Usyk, a genius in the ring stands as a unique threat for the heavyweight ranks overall, but for the entire division. The ascent of Oleksandr Usyk began in the cruiserweight division, as an undisputed champion. Prepare yourself for an epic boxing match of the year as Usyk takes on Tyson Fury in a must-watch showdown! Catch every punch streamed live on our website. Don’t miss your chance — visit <a href="https://www.weatheravenue.com/fr/https://tysonfuryvoleksandrusyk.com/">tysonfuryvoleksandrusyk.com</a> right away and stream the event with top-notch streaming!
Across the UK, the event will kick off at around 10 PM GMT, ensuring maximum viewership. Back in Usyk’s home country, and for fans watching from around the world, this will be a must-see event. The venue for Fury vs Usyk is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, one thing is certain: the atmosphere will be electric. While the spotlight is firmly on the main event, the fights leading up to the main event promises plenty of action. Major boxing events are known for strong supporting fights, offering an entire night of boxing excitement.
In the past, supporting bouts in major events have showcased rising stars. Fighters looking to rise through the ranks often seize these moments to demonstrate their talent, with the world paying attention. Although the lineup for the Fury Usyk undercard are still unconfirmed, speculation runs high. Will there be a heavyweight clash? Regardless of the names, the action will not disappoint. What makes this fight truly fascinating is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. With his immense height and reach advantage, he dictates the pace of bouts.
His trilogy with Deontay Wilder showed his durability, bouncing back from adversity to secure victories. When he faced Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. Meanwhile, Usyk, offers a different kind of threat. Being a left-handed fighter, his positioning constantly challenges opponents. His strikes lack devastating strength, their timing wears down foes. As fight night approaches, Tyson Fury vs Usyk odds have fans and analysts speculating.
Fury is the favored fighter according to the odds, given his physical stature, his track record in big matches, and his tactical brilliance. Despite the odds, Usyk remains a strong contender doesn’t diminish his chances, as his victories over Joshua showed that he can compete at heavyweight.
For Tyson Fury, this fight represents an opportunity to cement his legacy. Should he come out on top, Fury’s win would further solidify his status as the best heavyweight of this era. On the other hand, If Usyk wins would be a monumental achievement. Achieving undisputed glory in two divisions is a rare accomplishment.
Web: <a href="http://www.google.com/url?sa=t&source=web&url=https://tysonfuryvoleksandrusyk.com/">tysonfuryvoleksandrusyk.com</a>
The upcoming showdown is more than just a championship fight. It’s a meeting of two unique worldviews. Fury’s boisterous personality is in stark contrast to Usyk’s quiet intensity. Such contrasts make the fight more compelling. This is more than just a physical contest. Whoever comes out victorious, the significance of this match will be remembered as a defining moment in boxing. Fury vs Usyk is more than just a fight. It’s the pinnacle of both fighters’ hard work. Whether Tyson Fury prevails through his strength and tactics, or Usyk comes out on top with his technique and endurance, it’s certain that, this will be a fight remembered for years to come.
The Fury-Usyk battle is more than just a sporting contest. It’s a contest of heart and willpower. The two competitors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azərbaycan ərazisində qumar oyunlarına maraq artdıqca, "Pin-up casino" kimi platformalar daha çox tanınmağa başladı. Əlavə olaraq, Pin-up kazino adları artıq Azəri müştərilər üçün güvənlidir. Pin-up azerbaycan öz oyunçularına rəngarəng oyunlar təklif edir.
Pinup kazino, Azəri istifadəçilər üçün populyar seçimdir. Bu mərc platforması müştərilərə çeşidli qumar oyunları təklif verməkdədir və gözəl hədiyyələr ilə mərc edənləri özünə cəlb edir.
Pin-up azerbaycan, geniş oyun variantları təklif edən xidmətdir. Azəri bazarında oyunçular tərəfindən sevilən Pin-up kazino, kazino oyunçuları üçün geniş oyun variantları ilə tanınır.
Bunun nəticəsində, Pinup kazino mərcçilərə etibarlı maliyyə sistemləri təklif edir. Oyunçular, müvafiq və təhlükəsiz depozit və pul çıxarış imkanları ilə təmin olunmaqla, internet oyunlarını asan və sürətli oynaya bilərlər.
Nəticə etibarilə, Pin-up kazino qumarbazlara yalnız qumar oyunları yox, həmçinin sərfəli bonuslar oyunçularına verir. Bu kazinoda, müştərilər özlərini güvəndə hiss edir.
Web: https://bet-pinup.web.app
Pin-up azerbaycan yalnız məhdudlaşmır. Kazino həvəskarları bu kazinoda geniş mərc təcrübəsindən təcrübə edə bilərlər və geniş bonus imkanlarını oyun təcrübəsini artırarlar.
Bunun nəticəsində, Pin-up casino online, rahat və təhlükəsiz mərc təcrübəsi təklif etməklə onlayn qumar dünyasında ən sevilən platformalardan olur. yerli oyunçular arasında çox seçilməsi göz qabağındadır.
Tyson Fury and Oleksandr Usyk are preparing for an epic showdown of unparalleled significance. This fight is about more than just titles; it represents their quest for immortality. Tyson Fury has earned worldwide fame through his unique style and remarkable adaptability during fights. Triumphing against boxing legends like Wilder and Klitschko have solidified his legendary status. On the other hand, Oleksandr Usyk poses a unique challenge for Fury. At the same time, the Ukrainian technician stands as a unique threat for Tyson Fury himself, as a heavyweight contender. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Don’t miss out for the most anticipated boxing match of the year as Usyk takes on Fury in an unforgettable showdown! Catch every punch streamed live on our website. Join the excitement — visit <a href="https://ua.hit.gemius.pl/_sslredir/hitredir/id=pz.lpv9dzs6xxg7ra2qmsres7amw5hfzlkh0zycwagv.r7/fastid=cnjjilucryxjganvlekgwftdlmle/stparam=ypqkkvhkcq/url=https://usykvsfurydate.co.uk/">usykvsfurydate.co.uk</a> now and enjoy the fight with top-notch streaming!
In the United Kingdom, the event will kick off at late evening, offering perfect timing for viewers. In Usyk’s native Ukraine, and beyond, the excitement is palpable. The fight’s location remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, one thing is certain: the atmosphere will be electric. Although the focus remains on Fury and Usyk, the fights leading up to the main event promises plenty of action. High-profile matches include preliminary bouts with top talent, providing non-stop action before the headliner.
Traditionally, preliminary fights on major cards have showcased rising stars. Boxers seeking the spotlight capitalize on the exposure to showcase their skills, knowing millions are watching. Although the lineup for the Fury Usyk undercard are still unconfirmed, speculation runs high. Could we see rising prospects? No matter the final roster, the action will not disappoint. The most compelling part of Fury vs Usyk truly fascinating is the clash of styles. Fury’s towering frame and movement make him an anomaly in boxing. At 6’9" with an 85-inch reach, he commands the ring like no other.
His trilogy with Deontay Wilder proved his toughness, bouncing back from adversity to finish strong. In his fight with Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. By contrast, Usyk, offers a different kind of threat. Being a left-handed fighter, his movements create openings. Usyk’s punches may not have knockout power, they consistently find their mark. As anticipation builds, The betting lines for Fury vs Usyk are the subject of intense debate.
Most bookmakers favor Fury according to the odds, due to his size advantage, his proven ability in tough situations, and his unorthodox style. Despite being seen as the underdog shouldn’t be counted out, as his victories over Joshua showed that he can compete at heavyweight.
For the Gypsy King presents a shot at undisputed glory. A victory would further solidify his status as the best heavyweight of this era. On the other hand, Usyk’s victory would elevate him to new heights. Securing two undisputed titles is a feat few can claim.
Web: <a href="http://clients1.google.com.eg/url?q=https://usykvsfurydate.co.uk/">usykvsfurydate.co.uk</a>
The upcoming showdown represents something greater than a title bout. It’s a clash of personalities. Fury’s boisterous personality is in stark contrast to Usyk’s quiet intensity. These differences add complexity to the fight. It’s a fight of wills and ideologies. Whoever comes out victorious, the impact of this bout will be felt for years to come. The battle for heavyweight supremacy is a defining moment. It represents the culmination of their careers. Whether Tyson Fury prevails with his experience and unpredictability, or Usyk wins with his precision with his finesse and stamina, it’s certain that, this will be a defining moment in boxing.
Fury vs Usyk is more than just a sporting contest. It’s a showcase of skill and determination. These two warriors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azəri bazarında internet qumarına tələbat artdıqca, Pin-up casino online kimi şirkətlər daha çox tanınmağa başladı. Əsasən, Pinup azerbaycan sözləri çoxdan Azəri mərc həvəskarları üçün məşhurdur. Pin-up kazino öz oyunçularına çox oyun növləri təklif edir.
Pin-up kazino, Azəri istifadəçilər üçün güvənli bir qumar məkanıdır. Bu qumar saytı oyunçulara geniş çeşidli oyunlar təklif edir və gözəl hədiyyələr ilə istifadəçilərin diqqətini çəkir.
Pin-up azerbaycan, fərqli oyun təcrübəsi təklif edən şirkətdir. Azəri bazarında məşhur olan Pin-up oyunları, istifadəçilər üçün geniş oyun variantları ilə tanınır.
Bununla yanaşı, Pin-up azerbaycan mərc edənlərə təhlükəsiz ödəmə sistemləri təklif edir. Müştərilər, çox rahat kredit kartı və elektron pul kisəsi ilə vasitəsilə, qumar təcrübələrini çox rahat yerinə yetirə bilərlər.
Yekun olaraq, Pin-up cazino mərcçilərə təkcə oyunlar deyil, həm də bonus imkanı təmin edir. Pin-up-da, istifadəçilər özlərini güvəndə hiss edir.
Web: https://top-pinup.web.app
Pin-up online kazino təkcə bir oyun platforması kimi oyunçuları cəlb etmir. Oyunçular burada çeşidli mərc seçimlərindən yararlana bilərlər və bonus sistemini oyun təcrübəsini artırarlar.
Bunun nəticəsində, Pin-up cazino, müasir və təhlükəsiz mərc oyunları oyunçulara təklif etməklə onlayn qumar dünyasında ən sevilən platformalardan olur. Azərbaycanda məşhur olması dikkətə layiqdir.
These two heavyweight champions are ready to face each other in a fight of unparalleled significance. This fight is about more than just titles; it represents their quest for immortality. The Gypsy King has become a global icon with his charisma coupled with unparalleled talent during fights. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. In contrast, Usyk, the technician brings an unprecedented test for Fury. On the flip side, Usyk, a genius in the ring stands as a unique threat for the heavyweight ranks overall, but for the entire division. The ascent of Oleksandr Usyk began in the cruiserweight division, by conquering all challengers. Prepare yourself for an epic boxing match of the year as Usyk takes on Tyson Fury in a must-watch showdown! See every move in real time on our website. Be part of the action — visit <a href="https://www.clubgets.com/pursuit.php?a_cd=*****&b_cd=0018&link=https://furyusyk.org.uk/">furyusyk.org.uk</a> right away and stream the event from the comfort of your home!
In the United Kingdom, the event will kick off at late evening, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, and for fans watching from around the world, the excitement is palpable. The venue for Fury vs Usyk remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, it’s guaranteed: the atmosphere will be electric. Although the focus remains on Fury and Usyk, the preliminary bouts is also generating excitement. Major boxing events often feature stacked undercards, offering an entire night of boxing excitement.
Historically, preliminary fights on major cards have showcased rising stars. Boxers seeking the spotlight often seize these moments to demonstrate their talent, knowing millions are watching. Though the supporting fights for Fury vs Usyk has yet to be finalized, fans are eagerly guessing. Could we see rising prospects? Whatever the selection, the action will not disappoint. What sets this bout apart truly fascinating is the clash of styles. Fury’s towering frame and movement are unparalleled in the sport. At 6’9" with an 85-inch reach, he commands the ring like no other.
His trilogy with Deontay Wilder highlighted his resilience, overcoming brutal hits to finish strong. When he faced Klitschko, his strategic genius shone through, showing he’s both powerful and smart. Meanwhile, Usyk, offers a different kind of threat. As a southpaw, he uses angles and footwork. The Ukrainian’s shots lack devastating strength, they consistently find their mark. With the date drawing closer, Predictions for this fight have fans and analysts speculating.
Most bookmakers favor Fury as per the betting experts, given his physical stature, his track record in big matches, and his unpredictable nature. Although Usyk is the less favored fighter doesn’t diminish his chances, his victories against AJ showed that he can compete at heavyweight.
For Fury himself presents a shot at undisputed glory. A victory would add an undisputed title to his already impressive resume. On the other hand, For Usyk, a win would elevate him to legendary status. Achieving undisputed glory in two divisions would be a remarkable feat in boxing history.
Web: <a href="http://www.google.tt/url?q=https://furyusyk.org.uk/">furyusyk.org.uk</a>
This fight is not just about the belts. It’s a battle of contrasting styles. Fury’s larger-than-life persona is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. This is more than just a physical contest. Whoever triumphs in this battle, the legacy of this fight will reverberate throughout boxing history. Fury vs Usyk is a spectacle unlike any other. It’s the result of relentless dedication. Whether Fury secures the win through his strength and tactics, or Usyk secures a victory with his finesse and stamina, it’s certain that, this will be a fight remembered for years to come.
The Fury-Usyk battle is more than just a boxing event. It’s a fight of grit and strategy. Both fighters will leave it all in the ring.
Visit for more information: #crosslink[3,L -
yerli oyunçular arasında internet oyunlarına tələbat artdıqca, Pin-up kazino kimi oyun xidmətləri daha çox tanınmağa başladı. Bununla bərabər, Pin-up online adları tez-tez Azərbaycandakı oyunçular üçün adidir. Pin-up azerbaycan istifadəçilərə çoxlu oyun növü təklif edir.
Pin-up azerbaycan, Azərbaycandakı oyunçular üçün maraqlı seçimdir. Bu qumar saytı istifadəçilərə çoxlu oyun təklifləri verir və cəlbedici bonuslar ilə seçim olur.
Pin-up online kazino, geniş oyun variantları təklif edən bir platformadır. Azəri oyunçuları arasında güvənilən Pin-up oyunları, istifadəçilər üçün zəngin təkliflər təqdim edir.
Bu səbəbdən, "Pin-up casino online" qumar həvəskarlarına təhlükəsiz ödəmə üsulları təklif etməkdədir. Oyun həvəskarları, etibarlı və tez maliyyə çıxarışları nəticəsində, onlayn mərc oyunlarını asan və sürətli keçirə bilərlər.
Sonda, Pin-up cazino mərcçilərə təkcə oyun imkanı deyil sərfəli bonuslar oyun təcrübəsini daha da maraqlı edir. Bu onlayn kazinoda, istifadəçilər təhlükəsiz şərtlər altında mərc edir.
Web: https://win-pinup.web.app
Pin-up azerbaycan yalnız bir mərc saytı kimi oyunçuları cəlb etmir. İstifadəçilər Pinup-da müxtəlif mərc növlərindən faydalanıb və bonus sistemini oyun təcrübəsini artırarlar.
Yekun olaraq, Pin-up azerbaycan, sərfəli və təhlükəsiz mərc oyunları təqdim etməklə onlayn qumar sektorunda özünü doğruldur. yerli mərcçilər arasında məşhur olması göz qabağındadır.
Azərbaycanda mərc bazarında online kazino oyunlarına sevgisi artdıqca, Pinup kazino kimi platformalar daha çox tanınmağa başladı. Əsasən, Pin-up azerbaycan şüarları artıq Azəri oyunçuları üçün sevilir. Pin-up kazino online öz oyunçularına çoxlu oyun növü təklif edir.
Pin-up kazino, Azəri istifadəçilər üçün ən sevilən platformalardan biridir. Bu platforma oyunçulara fərqli oyun növləri təklif edib və gözəl hədiyyələr ilə istifadəçilərin diqqətini çəkir.
Pin-up casino online, fərqli oyun təcrübəsi təklif edən bir platformadır. Azəri oyunçuları arasında oyunçular tərəfindən sevilən Pinup, yerli oyunçular üçün fərqli oyun seçimləri ilə çıxış edir.
Bu səbəbdən, Pinup kazino mərc edənlərə etibarlı depozit və çıxarış imkanı verir. İstifadəçilər, etibarlı və tez depozit çıxarış sistemi ilə təmin olunmaqla, oyun təcrübələrini güvənli və təhlükəsiz təcrübə edə bilərlər.
Bununla yanaşı, Pin-up casino online mərcçilərə təkcə oyunlar deyil, həm də cəlbedici kampaniyalar və maraqlı aksiyalar təklif edir. Bu qumar saytında, qumar həvəskarları şəffaf oyun şərtləri ilə rastlaşır.
Web: https://win-top-pin-up.web.app
Pin-up casino təkcə oyunlar ilə kifayətlənmir. Qumarçılar burada fərqli mərc seçimlərindən faydalanıb və cazibədar bonus imkanlarını mərc təcrübələrini zənginləşdirərlər.
Sonda, Pin-up casino, etibarlı kazino təcrübəsi təmin etməklə mərc bazarında ən sevilən platformalardan olur. Azəri bazarında tanınması dikkətə layiqdir.
The undefeated Fury and Usyk are ready to face each other in a fight of historic proportions. It’s not merely about the belts; it’s about legacy. The towering Fury has earned worldwide fame with his charisma and remarkable adaptability during fights. His victories over Deontay Wilder and Wladimir Klitschko have cemented his place among the all-time greats. On the other hand, the tactical southpaw brings an unprecedented test for Fury. Meanwhile, the Ukrainian technician represents a formidable opponent for Tyson Fury himself, and for boxing fans worldwide. The ascent of Oleksandr Usyk began in the cruiserweight division, by conquering all challengers. Get ready for the most anticipated boxing match of the year as Oleksandr Usyk takes on Fury in an unforgettable showdown! See every move streamed live on our website. Join the excitement — visit <a href="http://nikolay-lavrentev-t.nnov.org/common/redir.php?https://tysonvsusyk.co.uk/">tysonvsusyk.co.uk</a> right away and enjoy the fight with top-notch streaming!
For British fans, the ring walks are planned for close to prime time, ensuring maximum viewership. Back in Usyk’s home country, and for fans watching from around the world, this will be a must-see event. The fight’s location is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, it’s guaranteed: the excitement will be unmatched. Even though attention is centered on the headline fight, the Fury vs Usyk undercard promises plenty of action. Major boxing events are known for strong supporting fights, providing non-stop action before the headliner.
In the past, undercards of this caliber have introduced future champions. Fighters looking to rise through the ranks often seize these moments to impress fans and analysts alike, knowing millions are watching. Though the supporting fights for Fury vs Usyk are still unconfirmed, speculation runs high. Will there be a heavyweight clash? No matter the final roster, the action will not disappoint. What makes this fight incredibly exciting is the clash of styles. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. With his immense height and reach advantage, he dictates the pace of bouts.
The legendary battles with Wilder showed his durability, as he recovered from knockdowns to finish strong. Against Wladimir Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Meanwhile, Usyk, relies on technique and stamina. As a southpaw, his movements create openings. Usyk’s punches lack devastating strength, they consistently find their mark. As anticipation builds, The betting lines for Fury vs Usyk have fans and analysts speculating.
The betting lines show Fury ahead as predicted by many experts, given his physical stature, his experience in high-pressure bouts, and his adaptability. Despite the odds, Usyk remains a strong contender doesn’t rule him out, his wins over Anthony Joshua showed that he can compete at heavyweight.
For the Gypsy King is a chance to further solidify his greatness. A triumph for Fury would put the finishing touches on a historic career. Meanwhile, For Usyk, a win would mark him as one of the sport’s greats. Becoming an undisputed champion in two different weight classes is a rare accomplishment.
Web: <a href="http://clients1.google.kz/url?q=https%3A%2F%2Ftysonvsusyk.co.uk">tysonvsusyk.co.uk</a>
The upcoming showdown is more than just a championship fight. It’s a battle of contrasting styles. Fury’s bold and unapologetic character is in stark contrast to Usyk’s quiet intensity. Such contrasts make the fight more compelling. It’s a fight of wills and ideologies. Whoever triumphs in this battle, the impact of this bout will be remembered as a defining moment in boxing. Fury vs Usyk is a defining moment. It represents the culmination of their careers. Whether Fury secures the win with his experience and unpredictability, or Usyk comes out on top through his superior boxing ability, it’s certain that, this will be a fight remembered for years to come.
This fight between Fury and Usyk is more than just a boxing event. It’s a fight of grit and strategy. These two warriors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında online kazino oyunlarına tələbat artdıqca, Pin-up kazino kimi oyun xidmətləri daha çox tanınmağa başladı. Əsasən, "Pin up casino online" ifadələri tez-tez Azəri oyunçuları üçün tanışdır. Pin-up casino azerbaycan istifadəçilərə geniş oyunlar təklif edir.
Pin-up online casino, yerli mərc həvəskarları üçün geniş kütləyə sahib bir qumar saytıdır. Bu platforma kazino oyunçularına çoxlu oyun təklifləri oyunçulara təqdim edir və cəlbedici bonuslar ilə oyunçuları özünə cəlb edir.
Pin-up azerbaycan, geniş oyun variantları təklif edən şirkətdir. Azəri bazarında güvənilən Pin-up casino, qumar oyunçuları üçün fərqli oyun seçimləri ilə çıxış edir.
Bununla yanaşı, Pin-up azerbaycan qumar həvəskarlarına güvənli maliyyə sistemləri verir. Mərc edənlər, çox rahat maliyyə əməliyyatları köməyilə, qumar təcrübələrini çox rahat yerinə yetirə bilərlər.
Yekun olaraq, Pin-up azerbaycan mərc həvəskarlarına yalnız oyun təklif etmir bonus imkanı müştəriləri üçün yaradır. Bu kazinoda, müştərilər təhlükəsiz şərtlər altında mərc edir.
Web: https://pinup-best-top.web.app
Pin-up cazino təkcə məhdudlaşmır. Oyunçular burada fərqli mərc oyunlarından faydalanıb və bonus sistemini oyun təcrübələrinə əlavə edərlər.
Beləliklə, Pin-up kazino, güvənli oyun imkanı təklif etməklə mərc bazarında oyunçular arasında geniş istifadə edilir. Azərbaycan mərcçiləri arasında çox seçilməsi dikkətə layiqdir.
Fury, the Gypsy King, and Usyk, the technician are preparing for an epic showdown of unparalleled significance. This fight is about more than just titles; it represents their quest for immortality. The Gypsy King has earned worldwide fame with his charisma coupled with unparalleled talent during fights. Beating Wilder and Klitschko have solidified his legendary status. On the other hand, Oleksandr Usyk poses a unique challenge for Fury. Meanwhile, Usyk, a southpaw master represents a formidable opponent for Tyson Fury himself, and for boxing fans worldwide. His journey to global fame began in the cruiserweight division, where he became an unstoppable force. Prepare yourself for a thrilling boxing match of the year as Oleksandr Usyk takes on Fury in an unforgettable showdown! Catch every punch in real time on our website. Don’t miss your chance — visit <a href="https://max-stroy.su/udata/emarket/basket/put/element/1435/?redirect-uri=https://tysonvsusyk.co.uk/">tysonvsusyk.co.uk</a> today and enjoy the fight in high quality!
In the United Kingdom, the event will kick off at around 10 PM GMT, making it ideal for a prime-time audience. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, this will be a must-see event. The fight’s location is still under speculation, with talk of iconic boxing destinations. No matter the location, one thing is certain: the excitement will be unmatched. Even though attention is centered on the headline fight, the preliminary bouts promises plenty of action. Major boxing events are known for strong supporting fights, giving fans a full evening of entertainment.
In the past, supporting bouts in major events have introduced future champions. Contenders hoping to make their mark capitalize on the exposure to impress fans and analysts alike, knowing millions are watching. While the names for the undercard has yet to be finalized, speculation runs high. Will there be a heavyweight clash? Regardless of the names, fans can expect fireworks. What sets this bout apart so intriguing is the clash of styles. Fury’s towering frame and movement set him apart from other heavyweights. With his immense height and reach advantage, he commands the ring like no other.
The three fights against Wilder showed his durability, bouncing back from adversity to secure victories. When he faced Klitschko, his strategic genius shone through, showing he’s both powerful and smart. Meanwhile, Usyk, relies on technique and stamina. Being a left-handed fighter, his movements create openings. Usyk’s punches may not have knockout power, they consistently find their mark. As anticipation builds, Predictions for this fight have fans and analysts speculating.
Tyson Fury is seen as the frontrunner as predicted by many experts, because of his reach and height, his track record in big matches, and his tactical brilliance. Although Usyk is the less favored fighter doesn’t rule him out, his dominance against Joshua proved that he can handle the physicality of the heavyweight division.
For Tyson Fury could be the defining moment of his career. Should he come out on top, Fury’s win would further solidify his status as the best heavyweight of this era. Meanwhile, Usyk’s victory would mark him as one of the sport’s greats. Becoming the undisputed heavyweight champion is a rare accomplishment.
Web: <a href="http://clients1.google.ac/url?q=https://tysonvsusyk.co.uk/">tysonvsusyk.co.uk</a>
The upcoming showdown is about more than the titles. It’s a fight between two very different fighters. Fury’s bold and unapologetic character contrasts with Usyk’s calm, focused demeanor. Such contrasts make the fight more compelling. It’s a fight of wills and ideologies. Regardless of the outcome, the legacy of this fight will reverberate throughout boxing history. The clash for the undisputed title is more than just a match. It’s the result of relentless dedication. If Fury wins through his strength and tactics, or Usyk comes out on top thanks to his skill and resilience, no matter the outcome, this bout will go down in history.
Fury vs Usyk is a spectacle of a lifetime. It’s a battle of minds and bodies. These two warriors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
yerli oyunçular arasında virtual qumar oyunlarına sevgisi artdıqca, "Pin-up casino" kimi onlayn mərc xidmətləri daha çox tanınmağa başladı. Əlavə olaraq, Pin-up kazino brendləri artıq Azərbaycandakı oyunçular üçün tanışdır. Pin-up azerbaycan istifadəçilərə rəngarəng oyunlar təklif edir.
Pin-up cazino, yerli mərc həvəskarları üçün populyar seçimdir. Bu qumar saytı istifadəçilərə rəngarəng oyunlar təklif verməkdədir və bonus imkanları ilə seçim olur.
Pin-up casino online, istifadəçilərə oyun növləri ilə zəngin onlayn kazinodur. Azərbaycan ərazisində məşhur olan Pin-up oyunları, kazino oyunçuları üçün fərqli oyun seçimləri ilə çıxış edir.
Əlavə olaraq, Pin-up online casino mərc edənlərə güvənli və şəffaf maliyyə idarəetmə imkanları oyunçularına təklif edir. Müştərilər, etibarlı və tez depozit çıxarış sistemi köməyilə, internet oyunlarını güvənli və təhlükəsiz yaşaya bilərlər.
Sonda, Pinup kazino mərcçilərə geniş oyun təcrübəsi ilə yanaşı cəlbedici kampaniyalar təmin edir. Bu platformada, oyunçular təhlükəsiz şərtlər altında mərc edir.
Web: https://top-pinup.web.app
Pin-up azerbaycan təkcə məhdud deyil. İstifadəçilər Pinup-da fərqli mərc oyunlarından yararlana bilərlər və maraqlı aksiyaları oyun təcrübəsini artırarlar.
Ümumilikdə, Pin-up casino online, şəffaf və güvənli qumar təcrübəsi istifadəçilərə verməklə onlayn mərc dünyasında oyunçular arasında geniş istifadə edilir. Azəri oyunçular tərəfindən geniş yayılması təsadüf deyil.
Fury, the Gypsy King, and Usyk, the technician are on a collision course that will define an era. This fight is about more than just titles; it’s a battle for eternal recognition. The Gypsy King has risen to the pinnacle of the sport through his unique style and remarkable adaptability during fights. His victories over Deontay Wilder and Wladimir Klitschko have cemented his place among the all-time greats. In contrast, Usyk, the Ukrainian master poses a unique challenge to the heavyweight division. On the flip side, the Ukrainian technician is a true test for Fury not just for Fury, as a heavyweight contender. His journey to global fame started with his domination of the cruiserweights, where he became an unstoppable force. Don’t miss out for a thrilling boxing match of the year as Oleksandr Usyk takes on Fury in an unforgettable showdown! See every move live on our website. Be part of the action — visit <a href="https://www.clubgets.com/pursuit.php?a_cd=*****&b_cd=0018&link=https://usykvsfurydate.co.uk/">usykvsfurydate.co.uk</a> now and stream the event in high quality!
For British fans, the event will kick off at around 10 PM GMT, making it ideal for a prime-time audience. Back in Usyk’s home country, as well as viewers across Europe and the Americas, this will be a must-see event. Where the bout will take place is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, it’s guaranteed: the excitement will be unmatched. Although the focus remains on Fury and Usyk, the preliminary bouts is shaping up to be thrilling. Major boxing events include preliminary bouts with top talent, giving fans a full evening of entertainment.
Traditionally, undercards of this caliber have showcased rising stars. Contenders hoping to make their mark often seize these moments to showcase their skills, knowing millions are watching. Though the supporting fights for Fury vs Usyk are still unconfirmed, speculation runs high. Will there be a heavyweight clash? No matter the final roster, fans can expect fireworks. What makes this fight incredibly exciting is the clash of styles. Fury’s towering frame and movement are unparalleled in the sport. With his immense height and reach advantage, he dictates the pace of bouts.
The three fights against Wilder proved his toughness, overcoming brutal hits to secure victories. In his fight with Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. By contrast, Usyk, brings speed, precision, and finesse. Being a left-handed fighter, his positioning constantly challenges opponents. Usyk’s punches lack devastating strength, their timing wears down foes. With the date drawing closer, Tyson Fury vs Usyk odds are becoming a hot topic.
Tyson Fury is seen as the frontrunner according to the odds, given his physical stature, his track record in big matches, and his unpredictable nature. However, Usyk's underdog status doesn’t rule him out, his victories against AJ showed that he can compete at heavyweight.
For Tyson Fury, this fight represents an opportunity to cement his legacy. Should he come out on top, Fury’s win would solidify his claim as the greatest heavyweight of his generation. On the other hand, If Usyk wins would elevate him to legendary status. Achieving undisputed glory in two divisions is a feat few can claim.
Web: <a href="http://www.google.tt/url?q=https://usykvsfurydate.co.uk/">usykvsfurydate.co.uk</a>
This fight represents something greater than a title bout. It’s a clash of personalities. Fury’s larger-than-life persona is in stark contrast to Usyk’s quiet intensity. Such contrasts make the fight more compelling. It’s a fight of wills and ideologies. Whoever triumphs in this battle, the significance of this match will leave a lasting mark on the sport. The battle for heavyweight supremacy is a defining moment. It’s the result of relentless dedication. Whether Fury secures the win with his size and strategy, or Usyk secures a victory with his finesse and stamina, one thing is certain, this will be a legendary contest.
Tyson Fury vs Oleksandr Usyk is a spectacle of a lifetime. It’s a showcase of skill and determination. These men will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Azərbaycan ərazisində online kazino oyunlarına sevgisi artdıqca, "Pin-up casino" kimi platformalar daha çox tanınmağa başladı. Özəlliklə, Pinup casino brendləri çoxdan yerli istifadəçilər üçün istifadə olunur. Pinup casino öz oyunçularına geniş oyunlar təklif edir.
Pin up kazino, Azərbaycan oyunçuları üçün geniş kütləyə sahib bir qumar saytıdır. Bu qumar xidməti oyunçulara çoxlu oyun təklifləri təklif edir və gözəl hədiyyələr ilə mərc edənləri özünə cəlb edir.
Pin-up casino online, oyun keyfiyyətini artıran xidmətdir. Azəri bazarında geniş istifadə olunan Pin-up oyunları, qumar oyunçuları üçün geniş oyun təcrübəsi verir.
Bununla yanaşı, "Pin-up casino online" müştərilərə güvənli ödəmə üsulları verir. Oyun həvəskarları, etibarlı və tez kredit kartı və elektron pul kisəsi ilə sayəsində, kazino oyunlarını daha rahat oynaya bilərlər.
Yekun olaraq, Pin-up cazino müştərilərə yalnız oyun təklif etmir cəlbedici kampaniyalar oyunçularına verir. Bu qumar saytında, kazino həvəskarları təhlükəsiz oyun mühitində olur.
Web: https://pinup-best-top.web.app
Pin-up online kazino təkcə oyunçuları cəlb etmir. Müştərilər burada çeşidli mərc seçimlərindən yararlana bilərlər və çoxlu bonusları oyun təcrübələrinə əlavə edərlər.
Ümumilikdə, Pin-up casino online, etibarlı oyun imkanı istifadəçilərə verməklə oyun sənayesində oyunçular arasında geniş istifadə edilir. Azəri bazarında məşhur olması göz qabağındadır.
These two heavyweight champions are set to meet in the ring of unparalleled significance. It’s not merely about the belts; it represents their quest for immortality. The Gypsy King has risen to the pinnacle of the sport with his charisma and remarkable adaptability inside the ropes. Beating Wilder and Klitschko have solidified his legendary status. Across the ring, the tactical southpaw brings an unprecedented test to boxing’s biggest stars. Meanwhile, the Ukrainian technician is a true test for Fury for Tyson Fury himself, and for boxing fans worldwide. Usyk’s rise to prominence started with his domination of the cruiserweights, where he became an unstoppable force. Prepare yourself for a thrilling boxing match of the year as Usyk takes on Fury in a must-watch showdown! Experience every moment live on our website. Join the excitement — visit <a href="https://www.muziekweb.nl/Muziekweb/ExternalLink/?ref=B00000000141&platform=twitter&target=https%3A%2F%2Ftysonfuryvsusyk.co.uk">tysonfuryvsusyk.co.uk</a> right away and enjoy the fight with top-notch streaming!
For British fans, the fight is expected to begin around 10 PM GMT, ensuring maximum viewership. In Usyk’s native Ukraine, and for fans watching from around the world, the excitement is palpable. The fight’s location is still under speculation, with talk of iconic boxing destinations. Regardless of the venue, it’s guaranteed: the excitement will be unmatched. While the spotlight remains on Fury and Usyk, the fights leading up to the main event is also generating excitement. Big-ticket boxing cards include preliminary bouts with top talent, offering an entire night of boxing excitement.
Traditionally, undercards of this caliber have showcased rising stars. Boxers seeking the spotlight capitalize on the exposure to demonstrate their talent, with the world paying attention. Though the supporting fights for Fury vs Usyk are still unconfirmed, speculation runs high. Could we see rising prospects? Regardless of the names, the action will not disappoint. The most compelling part of Fury vs Usyk truly fascinating is the dynamic between these fighters. Tyson Fury’s size and agility make him an anomaly in boxing. With his immense height and reach advantage, he commands the ring like no other.
His trilogy with Deontay Wilder showed his durability, bouncing back from adversity to dominate in later rounds. When he faced Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. By contrast, Usyk, brings speed, precision, and finesse. Being a left-handed fighter, he uses angles and footwork. The Ukrainian’s shots aren’t the heaviest in the division, their timing wears down foes. As anticipation builds, Predictions for this fight have fans and analysts speculating.
Fury is the favored fighter based on the betting odds, thanks to his imposing frame, his track record in big matches, and his unpredictable nature. However, Usyk's underdog status doesn’t rule him out, as his victories over Joshua confirmed his toughness against big opponents.
For Tyson Fury is a chance to further solidify his greatness. If he wins, it would add an undisputed title to his already impressive resume. Meanwhile, For Usyk, a win would mark him as one of the sport’s greats. Achieving undisputed glory in two divisions is a once-in-a-lifetime achievement.
Web: <a href="http://cse.google.md/url?q=https://tysonfuryvsusyk.co.uk/">tysonfuryvsusyk.co.uk</a>
Fury vs Usyk is not just about the belts. It’s a clash of personalities. Fury’s boisterous personality is in stark contrast to Usyk’s quiet intensity. These differences add complexity to the fight. It’s a fight of wills and ideologies. Whoever comes out victorious, the impact of this bout will leave a lasting mark on the sport. The clash for the undisputed title is more than just a fight. It’s the result of relentless dedication. Should Fury claim victory with his size and strategy, or Usyk secures a victory thanks to his skill and resilience, no matter the outcome, this will be a legendary contest.
Tyson Fury vs Oleksandr Usyk is more than just a sporting contest. It’s a battle of minds and bodies. These two warriors will give everything they have.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are ready to face each other in a fight that will define an era. It’s far beyond a championship match; it represents their quest for immortality. Fury, an undefeated champion has earned worldwide fame with his charisma coupled with unparalleled talent during fights. Beating Wilder and Klitschko have solidified his legendary status. In contrast, Oleksandr Usyk is a fighter unlike any other to boxing’s biggest stars. On the flip side, Usyk, a genius in the ring is a true test for Fury for the heavyweight ranks overall, and for boxing fans worldwide. Usyk’s rise to prominence started with his domination of the cruiserweights, as an undisputed champion. Prepare yourself for an epic boxing match of the year as Usyk takes on Fury in a must-watch showdown! See every move in real time on our website. Don’t miss your chance — visit <a href="https://www.undertow.club/redirector.php?url=https://tysonfuryvoleksandrusyk.com/">tysonfuryvoleksandrusyk.com</a> now and stream the event with top-notch streaming!
Across the UK, the event will kick off at around 10 PM GMT, ensuring maximum viewership. Back in Usyk’s home country, and beyond, the anticipation is at a fever pitch. The fight’s location is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, fans can be sure: it will be a spectacle. While the spotlight is firmly on the main event, the preliminary bouts is shaping up to be thrilling. Big-ticket boxing cards include preliminary bouts with top talent, offering an entire night of boxing excitement.
In the past, preliminary fights on major cards have introduced future champions. Fighters looking to rise through the ranks often seize these moments to showcase their skills, as all eyes are on them. Though the supporting fights for Fury vs Usyk are still unconfirmed, fans are eagerly guessing. Could we see rising prospects? No matter the final roster, it’s sure to add to the excitement. The most compelling part of Fury vs Usyk so intriguing is the clash of styles. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. With his immense height and reach advantage, Fury can control a fight.
The three fights against Wilder proved his toughness, bouncing back from adversity to secure victories. In his fight with Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, offers a different kind of threat. With his unorthodox stance, his positioning constantly challenges opponents. Usyk’s punches may not have knockout power, their timing wears down foes. As anticipation builds, Predictions for this fight are the subject of intense debate.
Tyson Fury is the slight favorite based on the betting odds, because of his reach and height, his long career in major fights, and his unorthodox style. However, Usyk's underdog status doesn’t mean he’s an underdog in spirit, as his victories over Joshua confirmed his toughness against big opponents.
For Tyson Fury presents a shot at undisputed glory. If he wins, it would solidify his claim as the greatest heavyweight of his generation. Meanwhile, If Usyk wins would elevate him to new heights. Securing two undisputed titles is a feat few can claim.
Web: <a href="http://www.google.sc/url?q=https://tysonfuryvoleksandrusyk.com/">tysonfuryvoleksandrusyk.com</a>
This fight is not just about the belts. It’s a fight between two very different fighters. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. These varying personalities make the bout even more interesting. This is more than just a physical contest. Whoever comes out victorious, the legacy of this fight will be remembered as a defining moment in boxing. The battle for heavyweight supremacy is a defining moment. It’s the pinnacle of both fighters’ hard work. Whether Fury secures the win with his size and strategy, or Usyk comes out on top through his superior boxing ability, one thing is certain, this bout will go down in history.
The Fury-Usyk battle is more than just a boxing event. It’s a fight of grit and strategy. Both fighters will give everything they have.
Visit for more information: #crosslink[3,L -
Azərbaycandakı qumar sektorunda qumar oyunlarına sevgisi artdıqca, Pin-up casino online kimi oyun xidmətləri daha çox tanınmağa başladı. Özəlliklə, Pin-up online şəklində olan platformalar artıq Azəri oyunçuları üçün sevilir. Pin-up kazino online öz oyunçularına geniş oyunlar təklif edir.
Pin-up casino, Azərbaycan oyunçuları üçün populyar seçimdir. Bu qumar xidməti oyunçulara rəngarəng oyunlar təklif edib və bonus imkanları ilə seçim olur.
Pin-up cazino, çeşidli oyun təcrübəsi təklif edən oyun məkanıdır. Azəri bazarında çox seçilən Pin-up online, yerli oyunçular üçün geniş oyun variantları ilə tanınır.
Bu səbəbdən, Pin-up azerbaycan mərc edənlərə güvənli və şəffaf ödəmə üsulları təmin edir. Oyun həvəskarları, rahat və tez kredit kartı və elektron pul kisəsi ilə nəticəsində, internet oyunlarını çox rahat oynaya bilərlər.
Son olaraq, Pin-up kazino müştərilərə təkcə oyun imkanı deyil bonuslar və aksiyalar təmin edir. Pin-up-da, müştərilər özlərini güvəndə hiss edir.
Web: https://top-pinup.web.app
Pin-up online kazino təkcə sadə oyunla bitmir. Kazino həvəskarları bu kazinoda fərqli mərc seçimlərindən faydalanıb və maraqlı aksiyaları qazanmaq imkanı əldə edərlər.
Ümumilikdə, Pinup kazino, rahat və təhlükəsiz qumar təcrübəsi təmin etməklə onlayn qumar sektorunda ən sevilən platformalardan olur. yerli oyunçular arasında məşhur olması göz qabağındadır.
Tyson Fury and Oleksandr Usyk are on a collision course of unparalleled significance. It’s not merely about the belts; it’s about legacy. The towering Fury has risen to the pinnacle of the sport with his charisma coupled with unparalleled talent in the ring. His victories over Deontay Wilder and Wladimir Klitschko have cemented his place among the all-time greats. Meanwhile, Usyk, the Ukrainian master brings an unprecedented test to the heavyweight division. At the same time, Usyk, a genius in the ring represents a formidable opponent not just for Fury, but for the entire division. His journey to global fame started with his domination of the cruiserweights, by conquering all challengers. Don’t miss out for the most anticipated boxing match of the year as Usyk takes on Fury in a historic showdown! See every move in real time on our website. Be part of the action — visit <a href="http://auto.nnov.org/common/redir.php?https://tysonvsusyk.com/">tysonvsusyk.com</a> today and stream the event with top-notch streaming!
In the United Kingdom, the event will kick off at around 10 PM GMT, making it ideal for a prime-time audience. Back in Usyk’s home country, and for fans watching from around the world, the anticipation is at a fever pitch. The fight’s location remains a hot topic, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, one thing is certain: the excitement will be unmatched. Although the focus is firmly on the main event, the Fury vs Usyk undercard is also generating excitement. Big-ticket boxing cards include preliminary bouts with top talent, giving fans a full evening of entertainment.
In the past, undercards of this caliber have been a stage for breakout performances. Contenders hoping to make their mark capitalize on the exposure to demonstrate their talent, as all eyes are on them. Though the supporting fights for Fury vs Usyk are still unconfirmed, speculation runs high. Could we see rising prospects? No matter the final roster, fans can expect fireworks. What makes this fight truly fascinating is the dynamic between these fighters. Fury’s towering frame and movement make him an anomaly in boxing. At 6’9" with an 85-inch reach, Fury can control a fight.
The legendary battles with Wilder proved his toughness, overcoming brutal hits to finish strong. In his fight with Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. With his unorthodox stance, his positioning constantly challenges opponents. His strikes aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. With the date drawing closer, Predictions for this fight have fans and analysts speculating.
Most bookmakers favor Fury as per the betting experts, thanks to his imposing frame, his long career in major fights, and his unpredictable nature. Despite being seen as the underdog doesn’t rule him out, his dominance against Joshua confirmed his toughness against big opponents.
For Tyson Fury, this fight could be the defining moment of his career. If he wins, it would add an undisputed title to his already impressive resume. Conversely, If Usyk wins would elevate him to legendary status. Becoming the undisputed heavyweight champion is a once-in-a-lifetime achievement.
Web: <a href="http://maps.google.com.bo/url?q=https%3A%2F%2Ftysonvsusyk.com">tysonvsusyk.com</a>
Fury vs Usyk represents something greater than a title bout. It’s a clash of personalities. Fury’s larger-than-life persona is in stark contrast to Usyk’s quiet intensity. Such contrasts make the fight more compelling. This is more than just a physical contest. Whoever triumphs in this battle, the impact of this bout will leave a lasting mark on the sport. Fury vs Usyk is more than just a match. It’s a culmination of years of hard work. Should Fury claim victory thanks to his power and game plan, or Usyk secures a victory with his finesse and stamina, one thing is certain, this will be a fight remembered for years to come.
The Fury-Usyk battle is more than just a boxing event. It’s a contest of heart and willpower. The two competitors will give everything they have.
Visit for more information: #crosslink[3,L -
yerli oyunçular arasında internet qumarına seçim artdıqca, Pinup kimi şirkətlər daha çox tanınmağa başladı. Əlavə olaraq, Pin-up online şüarları son zamanlar Azərbaycandakı oyunçular üçün güvənlidir. Pin-up kazino mərc həvəskarlarına geniş oyunlar təklif edir.
Pin up kazino, yerli mərc həvəskarları üçün güvənli bir qumar məkanıdır. Bu qumar saytı müştərilərə rəngarəng oyunlar təmin edir və gözəl hədiyyələr ilə seçim olur.
Pin-up online kazino, çeşidli oyun təcrübəsi təklif edən saytdır. Azərbaycanda çox seçilən Pin-up casino, mərc həvəskarları üçün geniş oyun təcrübəsi verir.
Bunun nəticəsində, Pin-up online casino qumar həvəskarlarına etibarlı və güvənli ödəmə üsulları təklif etməkdədir. Mərc edənlər, sürətli və asan maliyyə çıxarışları ilə, qumar təcrübələrini güvənli və təhlükəsiz yaşaya bilərlər.
Nəticə etibarilə, Pin-up casino online mərc həvəskarlarına çoxlu oyun növlərilə yanaşı bonus imkanı təmin edir. Bu kazinoda, oyunçular rahat və təhlükəsiz şəraitdə oynayır.
Web: https://pinup-top.web.app
Pin-up casino təkcə bir kazino olaraq məhdud oyunlar təklif etmir. Mərc həvəskarları bu platformada müxtəlif mərc növlərindən müxtəlif mərc imkanı əldə edə bilər və çoxlu bonusları oyunlarına əlavə edə bilərlər.
Sonda, Pin-up casino online, müasir və təhlükəsiz qumar təcrübəsi təmin etməklə oyun sənayesində özünü doğruldur. yerli mərcçilər arasında çox seçilməsi göz qabağındadır.
Fury, the Gypsy King, and Usyk, the technician are set to meet in the ring of historic proportions. It’s far beyond a championship match; it’s about legacy. The towering Fury has risen to the pinnacle of the sport through his unique style and his unmatched skills during fights. Triumphing against boxing legends like Wilder and Klitschko have solidified his legendary status. Meanwhile, the tactical southpaw is a fighter unlike any other to the heavyweight division. Meanwhile, the Ukrainian technician is a true test for Fury not just for Fury, but for the entire division. Usyk’s rise to prominence began in the cruiserweight division, as an undisputed champion. Prepare yourself for a thrilling boxing match of the year as Oleksandr Usyk takes on Fury in a must-watch showdown! Experience every moment in real time on our website. Join the excitement — visit <a href="http://mebeldoma72.ru/udata/emarket/basket/put/element/5696/?redirect-uri=https%3A%2F%2Ffuryvsusykdate.co.uk">furyvsusykdate.co.uk</a> now and stream the event with top-notch streaming!
For British fans, the fight is expected to begin late evening, offering perfect timing for viewers. For Usyk’s fans in Ukraine, and beyond, the anticipation is at a fever pitch. Where the bout will take place is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, fans can be sure: it will be a spectacle. Even though attention is centered on the headline fight, the Fury vs Usyk undercard promises plenty of action. High-profile matches are known for strong supporting fights, providing non-stop action before the headliner.
Historically, preliminary fights on major cards have showcased rising stars. Boxers seeking the spotlight use such opportunities to showcase their skills, knowing millions are watching. While the names for the undercard are still unconfirmed, there’s plenty of talk. Will there be a heavyweight clash? Whatever the selection, fans can expect fireworks. What makes this fight incredibly exciting is their contrasting skillsets. Tyson Fury’s size and agility are unparalleled in the sport. Being so tall yet so nimble, he dictates the pace of bouts.
The legendary battles with Wilder proved his toughness, overcoming brutal hits to finish strong. Against Wladimir Klitschko, his strategic genius shone through, showing he’s both powerful and smart. By contrast, Usyk, offers a different kind of threat. With his unorthodox stance, he uses angles and footwork. His strikes aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. With the date drawing closer, Predictions for this fight are the subject of intense debate.
The betting lines show Fury ahead based on the betting odds, given his physical stature, his long career in major fights, and his unpredictable nature. Despite the odds, Usyk remains a strong contender shouldn’t be counted out, as his victories over Joshua confirmed his toughness against big opponents.
For Tyson Fury is a chance to further solidify his greatness. Should he come out on top, Fury’s win would further solidify his status as the best heavyweight of this era. Meanwhile, For Usyk, a win would elevate him to legendary status. Securing two undisputed titles is a once-in-a-lifetime achievement.
Web: <a href="http://maps.google.cg/url?q=https://furyvsusykdate.co.uk/">furyvsusykdate.co.uk</a>
Fury vs Usyk is more than just a championship fight. It’s a meeting of two unique worldviews. Fury’s bold and unapologetic character contrasts with Usyk’s calm, focused demeanor. Such contrasts make the fight more compelling. It’s about more than just skill. Regardless of the outcome, the impact of this bout will be remembered as a defining moment in boxing. This historic showdown is a defining moment. It’s the pinnacle of both fighters’ hard work. Whether Tyson Fury prevails with his experience and unpredictability, or Usyk comes out on top through his superior boxing ability, what is clear is, this bout will go down in history.
This fight between Fury and Usyk is more than just a boxing event. It’s a contest of heart and willpower. The two competitors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azəri bazarında qumar oyunlarına sevgisi artdıqca, Pin-up casino online kimi oyun xidmətləri daha çox tanınmağa başladı. Əsasən, Pin-up azerbaycan brendləri artıq yerli istifadəçilər üçün adidir. Pin-up casino azerbaycan istifadəçilərə geniş oyunlar təklif edir.
Pinup kazino, yerli oyunçular üçün ən sevilən platformalardan biridir. Bu qumar xidməti müştərilərə fərqli oyun növləri təklif edir və cəlbedici bonuslar ilə qumarbazlar tərəfindən sevilir.
Pin-up casino, çeşidli oyun təcrübəsi təklif edən saytdır. Azəri bazarında populyar olan Pin-up kazino, yerli oyunçular üçün zəngin təkliflər təqdim edir.
Özəlliklə, "Pin-up casino online" oyunçulara güvənli ödəmə sistemləri təklif etməkdədir. İstifadəçilər, sürətli və asan depozit və pul çıxarış imkanları nəticəsində, internet oyunlarını müvafiq şəkildə yerinə yetirə bilərlər.
Son olaraq, Pin-up azerbaycan qumarbazlara təkcə oyun imkanı deyil bonuslar və aksiyalar və maraqlı aksiyalar təklif edir. Bu kazinoda, mərc edənlər rahat və təhlükəsiz şəraitdə oynayır.
Web: https://best-pin-up-bet.web.app
Pin-up online kazino yalnız bir mərc saytı kimi sadə oyunla bitmir. Kazino həvəskarları bu kazinoda geniş mərc təcrübəsindən həzz ala bilərlər və sərfəli bonus təkliflərini mərc təcrübələrini zənginləşdirərlər.
Beləliklə, Pinup kazino, sərfəli və təhlükəsiz qumar təcrübəsi təqdim etməklə onlayn mərc dünyasında özünü doğruldur. yerli oyunçular arasında məşhur olması açıq bir faktdır.
These two heavyweight champions are ready to face each other in a fight that will define an era. It’s far beyond a championship match; it’s a battle for eternal recognition. Tyson Fury has risen to the pinnacle of the sport through his unique style and his unmatched skills in the ring. Triumphing against boxing legends like Wilder and Klitschko have solidified his legendary status. On the other hand, Usyk, the Ukrainian master is a fighter unlike any other to the heavyweight division. At the same time, the Ukrainian technician stands as a unique threat for the heavyweight ranks overall, and for boxing fans worldwide. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, as an undisputed champion. Get ready for an epic boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! Catch every punch streamed live on our website. Join the excitement — visit <a href="https://padlet.pics/1/proxy?url=https://tysonfuryvsusyk.org.uk/">tysonfuryvsusyk.org.uk</a> today and stream the event with top-notch streaming!
For British fans, the event will kick off at close to prime time, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and beyond, the anticipation is at a fever pitch. The venue for Fury vs Usyk is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. Regardless of the venue, fans can be sure: it will be a spectacle. Even though attention is firmly on the main event, the preliminary bouts promises plenty of action. Major boxing events often feature stacked undercards, giving fans a full evening of entertainment.
In the past, undercards of this caliber have introduced future champions. Contenders hoping to make their mark capitalize on the exposure to showcase their skills, with the world paying attention. Though the supporting fights for Fury vs Usyk are still unconfirmed, fans are eagerly guessing. Might there be a cruiserweight spectacle? Whatever the selection, fans can expect fireworks. What makes this fight incredibly exciting is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. Being so tall yet so nimble, he commands the ring like no other.
His trilogy with Deontay Wilder highlighted his resilience, overcoming brutal hits to secure victories. Against Wladimir Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Meanwhile, Usyk, offers a different kind of threat. As a southpaw, his positioning constantly challenges opponents. His strikes lack devastating strength, their timing wears down foes. As anticipation builds, Tyson Fury vs Usyk odds are the subject of intense debate.
Tyson Fury is the slight favorite based on the betting odds, due to his size advantage, his long career in major fights, and his unorthodox style. Despite being seen as the underdog doesn’t rule him out, his wins over Anthony Joshua showed that he can compete at heavyweight.
For Tyson Fury presents a shot at undisputed glory. A triumph for Fury would put the finishing touches on a historic career. Conversely, Usyk’s victory would elevate him to legendary status. Becoming the undisputed heavyweight champion is a feat few can claim.
Web: <a href="http://www.google.cg/url?q=https://tysonfuryvsusyk.org.uk/">tysonfuryvsusyk.org.uk</a>
This fight is not just about the belts. It’s a clash of personalities. Fury’s larger-than-life persona is the opposite of Usyk’s humble and disciplined approach. The clash of personalities adds depth to the narrative. This is more than just a physical contest. Whoever triumphs in this battle, the significance of this match will reverberate throughout boxing history. Fury vs Usyk is a defining moment. It’s a culmination of years of hard work. Whether Fury secures the win with his size and strategy, or Usyk wins with his precision with his finesse and stamina, it’s certain that, this will be a legendary contest.
The Fury-Usyk battle is more than just a fight. It’s a battle of minds and bodies. These two warriors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azəri bazarında qumar oyunlarına seçim artdıqca, Pin-up online kimi onlayn mərc xidmətləri daha çox tanınmağa başladı. Özəlliklə, Pin-up azerbaycan ifadələri çoxdan Azəri oyunçuları üçün tanışdır. Pin-up kazino online mərc həvəskarlarına rəngarəng oyunlar təklif edir.
Pin-up cazino, Azəri istifadəçilər üçün ən sevilən platformalardan biridir. Bu onlayn kazino müştərilərə rəngarəng oyunlar təklif edir və gözəl hədiyyələr ilə qumarbazlar tərəfindən sevilir.
Pin-up cazino, bənzərsiz oyun imkanı təqdim edən onlayn kazinodur. Azəri bazarında populyar olan Pin-up casino, oyun həvəskarları üçün geniş oyun təcrübəsi verir.
Əlavə olaraq, Pinup casino müştərilərə təhlükəsiz maliyyə sistemləri təklif edir. Müştərilər, sürətli və asan depozit və pul çıxarış imkanları ilə təmin olunmaqla, qumar təcrübələrini çox rahat yerinə yetirə bilərlər.
Əlavə olaraq, Pin-up casino oyunçulara yalnız oyun təklif etmir cazibədar bonus təklifləri oyunçularına verir. Pin-up-da, istifadəçilər şəffaf oyun şərtləri ilə rastlaşır.
Web: https://win-pinup.web.app
Pin-up kazino sadəcə sadə oyunla bitmir. Mərc həvəskarları bu platformada fərqli mərc oyunlarından yararlana bilərlər və cazibədar bonus imkanlarını oyun təcrübəsini artırarlar.
Yekun olaraq, Pin-up casino, güvənli kazino təcrübəsi oyunçulara təklif etməklə oyun sənayesində lider mövqedədir. Azərbaycan mərcçiləri arasında populyarlığı təsadüf deyil.
These two heavyweight champions are set to meet in the ring that will define an era. This fight is about more than just titles; it’s a battle for eternal recognition. Tyson Fury has become a global icon with his charisma and his unmatched skills in the ring. Beating Wilder and Klitschko have earned him recognition as one of the best ever. Meanwhile, Usyk, the Ukrainian master is a fighter unlike any other to boxing’s biggest stars. Meanwhile, Usyk, a genius in the ring stands as a unique threat not just for Fury, as a heavyweight contender. The ascent of Oleksandr Usyk started with his domination of the cruiserweights, where he became an unstoppable force. Prepare yourself for the most anticipated boxing match of the year as Usyk takes on Tyson Fury in a must-watch showdown! Catch every punch streamed live on our website. Don’t miss your chance — visit <a href="https://pravda-mlm.ru/proxy.php?request=https%3A%2F%2Ffuryvsusykdate.com">furyvsusykdate.com</a> today and stream the event in high quality!
Across the UK, the ring walks are planned for close to prime time, ensuring maximum viewership. Back in Usyk’s home country, and beyond, the anticipation is at a fever pitch. Where the bout will take place remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, it’s guaranteed: the atmosphere will be electric. Even though attention is centered on the headline fight, the Fury vs Usyk undercard is also generating excitement. High-profile matches often feature stacked undercards, providing non-stop action before the headliner.
Traditionally, undercards of this caliber have introduced future champions. Fighters looking to rise through the ranks capitalize on the exposure to demonstrate their talent, knowing millions are watching. While the names for the undercard haven’t been officially announced, there’s plenty of talk. Might there be a cruiserweight spectacle? No matter the final roster, it’s sure to add to the excitement. What makes this fight truly fascinating is their contrasting skillsets. Tyson Fury’s size and agility make him an anomaly in boxing. At 6’9" with an 85-inch reach, Fury can control a fight.
The three fights against Wilder proved his toughness, as he recovered from knockdowns to dominate in later rounds. Against Wladimir Klitschko, his strategic genius shone through, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. As a southpaw, he uses angles and footwork. His strikes aren’t the heaviest in the division, they consistently find their mark. With the date drawing closer, Tyson Fury vs Usyk odds are the subject of intense debate.
Most bookmakers favor Fury according to the odds, thanks to his imposing frame, his proven ability in tough situations, and his unpredictable nature. However, Usyk's underdog status shouldn’t be counted out, his wins over Anthony Joshua proved that he can handle the physicality of the heavyweight division.
For Tyson Fury is a chance to further solidify his greatness. Should he come out on top, Fury’s win would further solidify his status as the best heavyweight of this era. Conversely, For Usyk, a win would elevate him to new heights. Securing two undisputed titles is a feat few can claim.
Web: <a href="http://www.google.tl/url?sa=t&url=http%3A%2F%2Fwww.magical-dream.com">furyvsusykdate.com</a>
This fight represents something greater than a title bout. It’s a fight between two very different fighters. Fury’s bold and unapologetic character is the opposite of Usyk’s humble and disciplined approach. The clash of personalities adds depth to the narrative. This is more than just a physical contest. No matter who wins, the legacy of this fight will reverberate throughout boxing history. The battle for heavyweight supremacy is a spectacle unlike any other. It’s the pinnacle of both fighters’ hard work. Whether Tyson Fury prevails through his strength and tactics, or Usyk wins with his precision with his finesse and stamina, no matter the outcome, this will be a fight remembered for years to come.
Tyson Fury vs Oleksandr Usyk is more than just a sporting contest. It’s a contest of heart and willpower. Both fighters will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azəri bazarında internet oyunlarına istək artdıqca, Pinup kimi platformalar daha çox tanınmağa başladı. Əlavə olaraq, "Pin up casino online" brendləri hazırda Azəri mərc həvəskarları üçün adidir. Pin-up kazino online istifadəçilərə geniş oyunlar təklif edir.
Pin-up cazino, yerli oyunçular üçün geniş yayılmış bir xidmətdir. Bu platforma oyunçulara çeşidli qumar oyunları təmin edir və çoxlu bonuslar ilə müştərilərini məmnun edir.
Pin-up cazino, fərqli oyun təcrübəsi təklif edən onlayn kazinodur. Azəri oyunçuları arasında populyar olan Pin-up online, oyun həvəskarları üçün fərqli oyun seçimləri ilə çıxış edir.
Özəlliklə, Pinup kazino mərc edənlərə etibarlı maliyyə əməliyyatları təklif etməkdədir. İstifadəçilər, rahat maliyyə çıxarışları ilə təmin olunmaqla, mərc təcrübələrini güvənli və təhlükəsiz təcrübə edə bilərlər.
Əlavə olaraq, Pin-up cazino oyunçulara çoxlu oyun növlərilə yanaşı mərc hədiyyələri oyunçularına verir. Bu onlayn kazinoda, mərc edənlər təhlükəsiz şərtlər altında mərc edir.
Web: https://bet-pinup.web.app
Pin-up casino online təkcə bir oyun platforması kimi məhdud oyunlar təklif etmir. Mərc həvəskarları bu platformada çeşidli mərc seçimlərindən təcrübə edə bilərlər və maraqlı aksiyaları mərc təcrübələrini zənginləşdirərlər.
Bunun nəticəsində, Pin-up casino online, güvənli mərc təcrübəsi təmin etməklə oyun bazarında ən sevilən platformalardan olur. Azərbaycanda çox seçilməsi əlamətdardır.
These two heavyweight champions are set to meet in the ring of historic proportions. This fight is about more than just titles; it’s about legacy. Fury, an undefeated champion has risen to the pinnacle of the sport thanks to his personality and his unmatched skills in the ring. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. On the other hand, Usyk, the Ukrainian master is a fighter unlike any other to boxing’s biggest stars. Meanwhile, Usyk, a genius in the ring stands as a unique threat for the heavyweight ranks overall, and for boxing fans worldwide. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, by conquering all challengers. Prepare yourself for a thrilling boxing match of the year as Oleksandr Usyk takes on Fury in a historic showdown! See every move live on our website. Be part of the action — visit <a href="http://hometownlocator.com/ezoimgfmt/furyvsusykdate.com">furyvsusykdate.com</a> now and watch the match from the comfort of your home!
For British fans, the fight is expected to begin around 10 PM GMT, ensuring maximum viewership. Back in Usyk’s home country, and for fans watching from around the world, the anticipation is at a fever pitch. Where the bout will take place has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, it’s guaranteed: the excitement will be unmatched. Although the focus remains on Fury and Usyk, the Fury vs Usyk undercard promises plenty of action. Major boxing events are known for strong supporting fights, offering an entire night of boxing excitement.
Historically, preliminary fights on major cards have introduced future champions. Boxers seeking the spotlight often seize these moments to showcase their skills, with the world paying attention. Although the lineup for the Fury Usyk undercard has yet to be finalized, there’s plenty of talk. Could we see rising prospects? Whatever the selection, it’s sure to add to the excitement. What sets this bout apart truly fascinating is the clash of styles. Tyson Fury’s size and agility make him an anomaly in boxing. With his immense height and reach advantage, he commands the ring like no other.
The legendary battles with Wilder proved his toughness, bouncing back from adversity to dominate in later rounds. When he faced Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, offers a different kind of threat. With his unorthodox stance, his positioning constantly challenges opponents. Usyk’s punches aren’t the heaviest in the division, their timing wears down foes. As fight night approaches, Predictions for this fight are becoming a hot topic.
The betting lines show Fury ahead based on the betting odds, due to his size advantage, his track record in big matches, and his tactical brilliance. However, Usyk's underdog status doesn’t mean he’s an underdog in spirit, his wins over Anthony Joshua showed that he can compete at heavyweight.
For Fury himself represents an opportunity to cement his legacy. A victory would put the finishing touches on a historic career. Conversely, Usyk’s victory would elevate him to new heights. Becoming an undisputed champion in two different weight classes is a rare accomplishment.
Web: <a href="http://maps.google.ca/url?q=https://furyvsusykdate.com/">furyvsusykdate.com</a>
Fury vs Usyk is about more than the titles. It’s a meeting of two unique worldviews. Fury’s boisterous personality is the opposite of Usyk’s humble and disciplined approach. The clash of personalities adds depth to the narrative. Beyond physical ability, this fight. Whoever comes out victorious, the impact of this bout will reverberate throughout boxing history. The battle for heavyweight supremacy is more than just a fight. It’s the result of relentless dedication. Whether Fury secures the win with his size and strategy, or Usyk comes out on top thanks to his skill and resilience, what is clear is, this will be a legendary contest.
Tyson Fury vs Oleksandr Usyk is more than just a fight. It’s a fight of grit and strategy. These two warriors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azərbaycanda onlayn qumar oyunlarına sevgisi artdıqca, Pinup kazino kimi kazino xidmətləri daha çox tanınmağa başladı. Əsasən, Pinup casino adları indi Azəri mərc həvəskarları üçün adidir. Pin-up casino azerbaycan öz oyunçularına geniş oyunlar təklif edir.
Pin-up cazino, Azərbaycandakı oyunçular üçün güvənli bir qumar məkanıdır. Bu platforma qumarbazlara geniş çeşidli oyunlar təklif edib və cəlbedici bonuslar ilə mərc edənləri özünə cəlb edir.
Pin-up casino, fərqli oyun təcrübəsi təklif edən oyun məkanıdır. yerli mərcçilər arasında çox seçilən Pin-up online, oyun həvəskarları üçün fərqli oyun seçimləri ilə çıxış edir.
Özəlliklə, Pinup kazino mərcçilərə təhlükəsiz maliyyə sistemləri təklif edir. Oyun həvəskarları, rahat maliyyə çıxarışları nəticəsində, qumar təcrübələrini daha rahat yerinə yetirə bilərlər.
Sonda, Pin-up cazino mərcçilərə təkcə oyun imkanı deyil sərfəli bonuslar oyunçularına verir. Pinup-da, istifadəçilər təhlükəsiz şərtlər altında mərc edir.
Web: https://bet-pinup.web.app
Pin-up online kazino yalnız bir mərc saytı kimi məhdudlaşmır. Oyunçular burada geniş mərc təcrübəsindən müxtəlif mərc imkanı əldə edə bilər və cazibədar bonus imkanlarını oyun təcrübələrinə əlavə edərlər.
Sonda, Pin-up kazino, etibarlı mərc təcrübəsi təmin etməklə onlayn qumar sektorunda özünü doğruldur. yerli oyunçular arasında seçim olması dikkətə layiqdir.
Tyson Fury and Oleksandr Usyk are set to meet in the ring that will define an era. It’s far beyond a championship match; it’s about legacy. Tyson Fury has risen to the pinnacle of the sport thanks to his personality and remarkable adaptability during fights. Beating Wilder and Klitschko have solidified his legendary status. In contrast, Oleksandr Usyk brings an unprecedented test for Fury. On the flip side, Oleksandr Usyk is a true test for Fury for Tyson Fury himself, and for boxing fans worldwide. His journey to global fame started with his domination of the cruiserweights, by conquering all challengers. Get ready for the most anticipated boxing match of the year as Oleksandr Usyk takes on Fury in a must-watch showdown! Catch every punch streamed live on our website. Don’t miss your chance — visit <a href="http://www.internettrafficreport.com/cgi-bin/cgirdir.exe?https://usykvsfurydate.com/">usykvsfurydate.com</a> today and enjoy the fight with top-notch streaming!
For British fans, the fight is expected to begin late evening, ensuring maximum viewership. In Usyk’s native Ukraine, and beyond, the excitement is palpable. The venue for Fury vs Usyk has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, fans can be sure: it will be a spectacle. While the spotlight is centered on the headline fight, the Fury vs Usyk undercard is shaping up to be thrilling. Major boxing events are known for strong supporting fights, giving fans a full evening of entertainment.
In the past, preliminary fights on major cards have showcased rising stars. Fighters looking to rise through the ranks capitalize on the exposure to demonstrate their talent, as all eyes are on them. Though the supporting fights for Fury vs Usyk haven’t been officially announced, there’s plenty of talk. Will there be a heavyweight clash? No matter the final roster, fans can expect fireworks. What sets this bout apart truly fascinating is the clash of styles. Tyson Fury’s size and agility make him an anomaly in boxing. With his immense height and reach advantage, Fury can control a fight.
The three fights against Wilder proved his toughness, bouncing back from adversity to finish strong. In his fight with Klitschko, his strategic genius shone through, showing he’s both powerful and smart. Meanwhile, Usyk, relies on technique and stamina. With his unorthodox stance, his movements create openings. Usyk’s punches may not have knockout power, but they are delivered with pinpoint accuracy. With the date drawing closer, Tyson Fury vs Usyk odds are becoming a hot topic.
The betting lines show Fury ahead as predicted by many experts, thanks to his imposing frame, his long career in major fights, and his adaptability. Despite being seen as the underdog doesn’t mean he’s an underdog in spirit, his victories against AJ showed that he can compete at heavyweight.
For Tyson Fury, this fight could be the defining moment of his career. Should he come out on top, Fury’s win would solidify his claim as the greatest heavyweight of his generation. On the other hand, For Usyk, a win would mark him as one of the sport’s greats. Becoming the undisputed heavyweight champion is a feat few can claim.
Web: <a href="http://google.com.my/url?q=https://usykvsfurydate.com/">usykvsfurydate.com</a>
The upcoming showdown is not just about the belts. It’s a meeting of two unique worldviews. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. These varying personalities make the bout even more interesting. This is more than just a physical contest. Regardless of the outcome, the legacy of this fight will be felt for years to come. Fury vs Usyk is more than just a match. It’s the result of relentless dedication. Should Fury claim victory through his strength and tactics, or Usyk secures a victory thanks to his skill and resilience, no matter the outcome, this will be a legendary contest.
Tyson Fury vs Oleksandr Usyk is a spectacle of a lifetime. It’s a battle of minds and bodies. The two competitors will give everything they have.
Visit for more information: #crosslink[3,L -
yerli oyunçular arasında internet qumarına güvəni artdıqca, Pin-up online kimi oyun xidmətləri daha çox tanınmağa başladı. Özəlliklə, Pinup casino ifadələri son zamanlar Azərbaycandakı oyunçular üçün tanışdır. Pin-up kazino müştərilərinə müxtəlif oyunlar təklif edir.
Pin-up casino, Azəri qumarbazlar üçün geniş yayılmış bir xidmətdir. Bu onlayn kazino oyunçulara çoxlu oyun təklifləri təklif edir və cazibədar aksiyalar ilə seçim olur.
Pinup casino, çeşidli oyun təcrübəsi təklif edən oyun məkanıdır. Azəri oyunçuları arasında çox seçilən Pin-up casino, mərc həvəskarları üçün maraqlı oyun imkanları təklif edir.
Xüsusilə, Pinup kazino istifadəçilərə etibarlı maliyyə əməliyyatları təklif etməkdədir. Müştərilər, etibarlı və tez depozit çıxarış sistemi sayəsində, internet oyunlarını çox rahat təcrübə edə bilərlər.
Əlavə olaraq, Pin-up cazino mərc həvəskarlarına çoxlu oyun növlərilə yanaşı bonus imkanı təqdim edir. Bu onlayn kazinoda, mərc edənlər özlərini güvəndə hiss edir.
Web: https://bet-on-pinup.web.app
Pin-up cazino yalnız bir mərc saytı kimi oyunçuları cəlb etmir. Mərc həvəskarları bu platformada geniş mərc təcrübəsindən müxtəlif mərc imkanı əldə edə bilər və cazibədar bonus imkanlarını mərc təcrübələrini zənginləşdirərlər.
Yekun olaraq, Pin-up azerbaycan, güvənli mərc təcrübəsi təqdim etməklə oyun bazarında özünü doğruldur. Azərbaycanda populyarlığı təsadüfi deyil.
Tyson Fury and Oleksandr Usyk are preparing for an epic showdown that will define an era. This fight is about more than just titles; it’s about legacy. Tyson Fury has risen to the pinnacle of the sport thanks to his personality and his unmatched skills in the ring. His victories over Deontay Wilder and Wladimir Klitschko have cemented his place among the all-time greats. In contrast, the tactical southpaw poses a unique challenge for Fury. Meanwhile, Oleksandr Usyk is a true test for Fury not just for Fury, as a heavyweight contender. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Don’t miss out for the most anticipated boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! Catch every punch in real time on our website. Be part of the action — visit <a href="https://golf2club.printdirect.ru/utils/redirect?url=https://usykvsfurydate.co.uk/">usykvsfurydate.co.uk</a> right away and watch the match in high quality!
Across the UK, the ring walks are planned for close to prime time, offering perfect timing for viewers. For Usyk’s fans in Ukraine, as well as viewers across Europe and the Americas, this will be a must-see event. Where the bout will take place remains a hot topic, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, fans can be sure: the atmosphere will be electric. While the spotlight remains on Fury and Usyk, the Fury vs Usyk undercard is also generating excitement. Big-ticket boxing cards include preliminary bouts with top talent, offering an entire night of boxing excitement.
Historically, supporting bouts in major events have been a stage for breakout performances. Contenders hoping to make their mark use such opportunities to demonstrate their talent, with the world paying attention. While the names for the undercard are still unconfirmed, fans are eagerly guessing. Will there be a heavyweight clash? Regardless of the names, fans can expect fireworks. What sets this bout apart truly fascinating is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed are unparalleled in the sport. With his immense height and reach advantage, he dictates the pace of bouts.
The three fights against Wilder proved his toughness, bouncing back from adversity to dominate in later rounds. In his fight with Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, offers a different kind of threat. Being a left-handed fighter, his positioning constantly challenges opponents. The Ukrainian’s shots may not have knockout power, but they are delivered with pinpoint accuracy. As fight night approaches, Predictions for this fight are the subject of intense debate.
Fury is the favored fighter as predicted by many experts, because of his reach and height, his experience in high-pressure bouts, and his tactical brilliance. Despite the odds, Usyk remains a strong contender doesn’t mean he’s an underdog in spirit, as his victories over Joshua proved that he can handle the physicality of the heavyweight division.
For Fury himself could be the defining moment of his career. A triumph for Fury would further solidify his status as the best heavyweight of this era. Meanwhile, Usyk’s victory would elevate him to new heights. Becoming the undisputed heavyweight champion would be a remarkable feat in boxing history.
Web: <a href="http://cse.google.com.sg/url?q=https%3A%2F%2Fusykvsfurydate.co.uk">usykvsfurydate.co.uk</a>
This fight is not just about the belts. It’s a battle of contrasting styles. Fury’s confident and brash nature is in stark contrast to Usyk’s quiet intensity. These differences add complexity to the fight. It’s about more than just skill. No matter who wins, the significance of this match will be remembered as a defining moment in boxing. This historic showdown is more than just a match. It’s the result of relentless dedication. Whether Tyson Fury prevails through his strength and tactics, or Usyk comes out on top thanks to his skill and resilience, what is clear is, this will be a defining moment in boxing.
The Fury-Usyk battle is more than just a boxing event. It’s a battle of minds and bodies. The two competitors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azərbaycanda internet qumarına maraq artdıqca, Pinup kimi onlayn mərc xidmətləri daha çox tanınmağa başladı. Bununla bərabər, Pinup casino ifadələri tez-tez Azərbaycandakı oyunçular üçün məşhurdur. Pin-up casino azerbaycan istifadəçilərə geniş oyunlar təklif edir.
Pin-up casino, Azəri qumarbazlar üçün geniş yayılmış bir xidmətdir. Bu qumar saytı istifadəçilərə çeşidli qumar oyunları oyunçulara təqdim edir və bonus imkanları ilə qumarbazlar tərəfindən sevilir.
Pin-up casino online, fərqli oyun təcrübəsi təklif edən onlayn kazinodur. Azəri bazarında oyunçular tərəfindən sevilən Pin-up online, qumar oyunçuları üçün geniş oyun variantları ilə tanınır.
Özəlliklə, Pin-up azerbaycan qumar həvəskarlarına güvənli ödəmə üsulları oyunçularına təklif edir. Müştərilər, etibarlı və tez depozit çıxarış sistemi sayəsində, onlayn mərc oyunlarını asan və sürətli təcrübə edərlər.
Nəticə etibarilə, Pin-up cazino mərcçilərə yalnız qumar oyunları yox, həmçinin bonuslar və aksiyalar təqdim edir. Bu platformada, kazino həvəskarları rahat və təhlükəsiz şəraitdə oynayır.
Web: https://top-pinup.web.app
Pin-up casino online yalnız bir mərc saytı kimi oyunlar ilə kifayətlənmir. İstifadəçilər Pinup-da çeşidli mərc seçimlərindən həzz ala bilərlər və maraqlı aksiyaları qazanmaq imkanı əldə edərlər.
Nəticədə, Pin-up casino, rahat və təhlükəsiz kazino təcrübəsi təmin etməklə oyun bazarında oyunçular arasında geniş istifadə edilir. yerli mərcçilər arasında tanınması təsadüfi deyil.
Tyson Fury and Oleksandr Usyk are preparing for an epic showdown of historic proportions. It’s far beyond a championship match; it’s a battle for eternal recognition. Tyson Fury has become a global icon with his charisma and his unmatched skills inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. Meanwhile, Oleksandr Usyk is a fighter unlike any other to the heavyweight division. At the same time, the Ukrainian technician represents a formidable opponent for the heavyweight ranks overall, and for boxing fans worldwide. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, as an undisputed champion. Prepare yourself for a thrilling boxing match of the year as Usyk takes on Tyson Fury in an unforgettable showdown! See every move live on our website. Don’t miss your chance — visit <a href="http://balvi.pilseta24.lv/linkredirect/?link=https%3A%2F%2Ftysonvsusyk.co.uk&referer=balvi.pilseta24.lv%2Fzina%3Fslug%3Deccal-briketes-un-apkures-granulas-ar-lielisku-kvalitati-pievilcigu-cenu-videi-draudzigs-un-izd-8c175fc171&additional_params=%7B%22company_orig_id%22%3A%22267661%22%2C%22object_country_id%22%3A%22lv%22%2C%22referer_layout_type%22%3A%22SR%22%2C%22bannerinfo%22%3A%22%7B%5C%22key%5C%22%3A%5C%22%5C%5C%5C%22Apbed%5C%5Cu012b%5C%5Cu0161anas+nams-krematorija%5C%5C%5C%22%2C+SIA%7C2020-09-11%7C2021-08-23%7Cbalvi+p24+lielais+baneris%7Chttps%3A%5C%5C%5C%2F%5C%5C%5C%2Fwww.krematorijariga.lv%5C%5C%5C%2F%7C%7Cupload%5C%5C%5C%2F267661%5C%5C%5C%2Fbaners%5C%5C%5C%2F1181_krematorija_980x90.gif%7Clva%7C267661%7C980%7C90%7C%7C0%7C0%7C%7C0%7C0%7C%5C%22%2C%5C%22doc_count%5C%22%3A1%2C%5C%22key0%5C%22%3A%5C%22%5C%5C%5C%22Apbed%5C%5Cu012b%5C%5Cu0161anas+nams-krematorija%5C%5C%5C%22%2C+SIA%5C%22%2C%5C%22key1%5C%22%3A%5C%222020-09-11%5C%22%2C%5C%22key2%5C%22%3A%5C%222021-08-23%5C%22%2C%5C%22key3%5C%22%3A%5C%22balvi+p24+lielais+baneris%5C%22%2C%5C%22key4%5C%22%3A%5C%22https%3A%5C%5C%5C%2F%5C%5C%5C%2Fwww.krematorijariga.lv%5C%5C%5C%2F%5C%22%2C%5C%22key5%5C%22%3A%5C%22%5C%22%2C%5C%22key6%5C%22%3A%5C%22upload%5C%5C%5C%2F267661%5C%5C%5C%2Fbaners%5C%5C%5C%2F1181_krematorija_980x90.gif%5C%22%2C%5C%22key7%5C%22%3A%5C%22lva%5C%22%2C%5C%22key8%5C%22%3A%5C%22267661%5C%22%2C%5C%22key9%5C%22%3A%5C%22980%5C%22%2C%5C%22key10%5C%22%3A%5C%2290%5C%22%2C%5C%22key11%5C%22%3A%5C%22%5C%22%2C%5C%22key12%5C%22%3A%5C%220%5C%22%2C%5C%22key13%5C%22%3A%5C%220%5C%22%2C%5C%22key14%5C%22%3A%5C%22%5C%22%2C%5C%22key15%5C%22%3A%5C%220%5C%22%2C%5C%22key16%5C%22%3A%5C%220%5C%22%2C%5C%22key17%5C%22%3A%5C%22%5C%22%7D%22%7D&control=8fd1d4b2ab0f24fc7e2c6cc1d2c0f7ca">tysonvsusyk.co.uk</a> now and watch the match with top-notch streaming!
In the United Kingdom, the ring walks are planned for close to prime time, ensuring maximum viewership. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. Where the bout will take place is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, it’s guaranteed: it will be a spectacle. Even though attention is firmly on the main event, the Fury vs Usyk undercard promises plenty of action. Big-ticket boxing cards are known for strong supporting fights, providing non-stop action before the headliner.
Historically, supporting bouts in major events have introduced future champions. Fighters looking to rise through the ranks capitalize on the exposure to demonstrate their talent, knowing millions are watching. While the names for the undercard haven’t been officially announced, there’s plenty of talk. Might there be a cruiserweight spectacle? Regardless of the names, fans can expect fireworks. What sets this bout apart incredibly exciting is the dynamic between these fighters. Fury’s towering frame and movement make him an anomaly in boxing. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
The three fights against Wilder highlighted his resilience, as he recovered from knockdowns to dominate in later rounds. Against Wladimir Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, offers a different kind of threat. With his unorthodox stance, his positioning constantly challenges opponents. The Ukrainian’s shots lack devastating strength, their timing wears down foes. As fight night approaches, The betting lines for Fury vs Usyk have fans and analysts speculating.
Tyson Fury is seen as the frontrunner based on the betting odds, because of his reach and height, his experience in high-pressure bouts, and his adaptability. Despite the odds, Usyk remains a strong contender doesn’t mean he’s an underdog in spirit, his wins over Anthony Joshua demonstrated his ability in the heavyweight ranks.
For Tyson Fury represents an opportunity to cement his legacy. A victory would further solidify his status as the best heavyweight of this era. On the other hand, Usyk’s victory would mark him as one of the sport’s greats. Securing two undisputed titles is a rare accomplishment.
Web: <a href="http://www.google.to/url?q=https://tysonvsusyk.co.uk/">tysonvsusyk.co.uk</a>
Fury vs Usyk is not just about the belts. It’s a fight between two very different fighters. Fury’s boisterous personality is in stark contrast to Usyk’s quiet intensity. These differences add complexity to the fight. It’s about more than just skill. Regardless of the outcome, the impact of this bout will be felt for years to come. The battle for heavyweight supremacy is more than just a fight. It represents the culmination of their careers. Whether Tyson Fury prevails with his size and strategy, or Usyk secures a victory with his finesse and stamina, it’s certain that, this bout will go down in history.
This fight between Fury and Usyk is more than just a sporting contest. It’s a fight of grit and strategy. Both fighters will give everything they have.
Visit for more information: #crosslink[3,L -
yerli oyunçular arasında qumar oyunlarına istək artdıqca, Pinup kimi platformalar daha çox tanınmağa başladı. Əsasən, Pin-up kazino ifadələri indi yerli istifadəçilər üçün adidir. Pin-up azerbaycan oyunçulara geniş oyunlar təklif edir.
Pin-up online casino, Azəri istifadəçilər üçün geniş kütləyə sahib bir qumar saytıdır. Bu onlayn kazino kazino oyunçularına fərqli oyun növləri təmin edir və sərfəli bonus təklifləri ilə istifadəçilərin diqqətini çəkir.
Pin-up casino online, çeşidli oyun təcrübəsi təklif edən xidmətdir. Azərbaycan ərazisində güvənilən Pin-up casino, istifadəçilər üçün zəngin təkliflər təqdim edir.
Bununla yanaşı, Pinup casino müştərilərə şəffaf və təhlükəsiz maliyyə əməliyyatları təmin edir. Kazino iştirakçıları, çox rahat depozit çıxarış sistemi ilə, mərc təcrübələrini daha asan təcrübə edə bilərlər.
Son olaraq, Pin-up azerbaycan mərc həvəskarlarına təkcə oyun imkanı deyil bonuslar və aksiyalar oyunçularına verir. Pin-up-da, müştərilər şəffaf oyun şərtləri ilə rastlaşır.
Web: https://win-pinup.web.app
Pin-up cazino yalnız məhdudlaşmır. Qumarçılar burada çeşidli mərc seçimlərindən yararlana bilərlər və bonus sistemini qazanmaq imkanı əldə edərlər.
Sonda, Pin-up casino, güvənli kazino təcrübəsi oyunçulara təklif etməklə oyun bazarında özünü doğruldur. yerli mərcçilər arasında məşhur olması təsadüf deyil.
These two heavyweight champions are set to meet in the ring of unparalleled significance. It’s far beyond a championship match; it’s about legacy. The towering Fury has become a global icon thanks to his personality and his unmatched skills during fights. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. On the other hand, Usyk, the Ukrainian master is a fighter unlike any other to the heavyweight division. Meanwhile, Oleksandr Usyk stands as a unique threat for the heavyweight ranks overall, but for the entire division. The ascent of Oleksandr Usyk began in the cruiserweight division, as an undisputed champion. Prepare yourself for a thrilling boxing match of the year as Usyk takes on Fury in a historic showdown! Experience every moment in real time on our website. Don’t miss your chance — visit <a href="https://www.jamonprive.com/idevaffiliate/idevaffiliate.php?id=102&url=http%3A%2F%2Ftysonvusyk.co.uk">tysonvusyk.co.uk</a> now and watch the match in high quality!
For British fans, the ring walks are planned for around 10 PM GMT, ensuring maximum viewership. In Usyk’s native Ukraine, and beyond, the excitement is palpable. The venue for Fury vs Usyk is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, one thing is certain: it will be a spectacle. Even though attention remains on Fury and Usyk, the preliminary bouts is shaping up to be thrilling. Big-ticket boxing cards include preliminary bouts with top talent, offering an entire night of boxing excitement.
Historically, supporting bouts in major events have introduced future champions. Fighters looking to rise through the ranks use such opportunities to impress fans and analysts alike, knowing millions are watching. Though the supporting fights for Fury vs Usyk has yet to be finalized, there’s plenty of talk. Will there be a heavyweight clash? Whatever the selection, the action will not disappoint. What makes this fight truly fascinating is their contrasting skillsets. Fury’s towering frame and movement set him apart from other heavyweights. Being so tall yet so nimble, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, overcoming brutal hits to finish strong. In his fight with Klitschko, his strategic genius shone through, showing he’s both powerful and smart. By contrast, Usyk, brings speed, precision, and finesse. Being a left-handed fighter, he uses angles and footwork. The Ukrainian’s shots may not have knockout power, but they are delivered with pinpoint accuracy. With the date drawing closer, The betting lines for Fury vs Usyk are becoming a hot topic.
Tyson Fury is the slight favorite based on the betting odds, because of his reach and height, his experience in high-pressure bouts, and his tactical brilliance. Although Usyk is the less favored fighter doesn’t rule him out, his dominance against Joshua confirmed his toughness against big opponents.
For Fury himself could be the defining moment of his career. If he wins, it would further solidify his status as the best heavyweight of this era. On the other hand, If Usyk wins would elevate him to legendary status. Becoming the undisputed heavyweight champion is a rare accomplishment.
Web: <a href="http://cse.google.ad/url?q=https://tysonvusyk.co.uk/">tysonvusyk.co.uk</a>
Fury vs Usyk represents something greater than a title bout. It’s a clash of personalities. Fury’s larger-than-life persona is the opposite of Usyk’s humble and disciplined approach. Such contrasts make the fight more compelling. It’s about more than just skill. Whoever triumphs in this battle, the impact of this bout will leave a lasting mark on the sport. The battle for heavyweight supremacy is more than just a fight. It represents the culmination of their careers. Should Fury claim victory with his size and strategy, or Usyk secures a victory with his finesse and stamina, one thing is certain, this will be a defining moment in boxing.
The Fury-Usyk battle is a spectacle of a lifetime. It’s a battle of minds and bodies. These men will give everything they have.
Visit for more information: #crosslink[3,L -
Azəri bazarında qumar oyunlarına seçim artdıqca, Pin-up online kimi oyun xidmətləri daha çox tanınmağa başladı. Bununla bərabər, Pin-up azerbaycan brendləri tez-tez yerli istifadəçilər üçün adidir. Pinup casino mərc həvəskarlarına çeşidli oyunlar təklif edir.
Pin-up cazino, yerli oyunçular üçün populyar seçimdir. Bu kazino istifadəçilərə çeşidli qumar oyunları təklif edir və çoxlu bonuslar ilə oyunçuları özünə cəlb edir.
Pinup casino, oyun keyfiyyətini artıran saytdır. Azərbaycanda geniş istifadə olunan Pin-up online, kazino oyunçuları üçün geniş oyun təcrübəsi verir.
Bununla yanaşı, Pinup casino istifadəçilərə etibarlı maliyyə əməliyyatları oyunçularına təklif edir. Oyun həvəskarları, müvafiq və təhlükəsiz depozit çıxarış sistemi ilə, qumar təcrübələrini müvafiq şəkildə oynaya bilərlər.
Bununla yanaşı, Pin-up casino online oyunçulara çoxlu oyun növlərilə yanaşı cazibədar bonus təklifləri təmin edir. Pinup-da, kazino həvəskarları təhlükəsiz şərtlər altında mərc edir.
Web: https://pinup-top-bet.web.app
Pin-up cazino sadəcə məhdud deyil. Kazino həvəskarları bu kazinoda geniş mərc təcrübəsindən istifadə edə bilər və maraqlı aksiyaları mərc təcrübələrini zənginləşdirərlər.
Beləliklə, Pin-up cazino, güvənli mərc imkanı təmin etməklə oyun sənayesində ən sevilən platformalardan olur. yerli mərcçilər arasında populyarlığı əlamətdardır.
Fury, the Gypsy King, and Usyk, the technician are preparing for an epic showdown that will define an era. It’s not merely about the belts; it represents their quest for immortality. The Gypsy King has become a global icon thanks to his personality and his unmatched skills during fights. Beating Wilder and Klitschko have cemented his place among the all-time greats. In contrast, Usyk, the Ukrainian master is a fighter unlike any other to the heavyweight division. On the flip side, Usyk, a genius in the ring is a true test for Fury for the heavyweight ranks overall, and for boxing fans worldwide. His journey to global fame began in the cruiserweight division, where he became an unstoppable force. Don’t miss out for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a must-watch showdown! Catch every punch streamed live on our website. Be part of the action — visit <a href="https://kolizeum.ru/click?redirect=https://usykvsfurydate.org.uk/">usykvsfurydate.org.uk</a> now and watch the match from the comfort of your home!
For British fans, the event will kick off at close to prime time, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and beyond, the anticipation is at a fever pitch. The fight’s location remains a hot topic, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, fans can be sure: it will be a spectacle. Even though attention remains on Fury and Usyk, the preliminary bouts is also generating excitement. High-profile matches often feature stacked undercards, offering an entire night of boxing excitement.
Historically, undercards of this caliber have been a stage for breakout performances. Fighters looking to rise through the ranks often seize these moments to demonstrate their talent, as all eyes are on them. While the names for the undercard haven’t been officially announced, fans are eagerly guessing. Could we see rising prospects? Regardless of the names, it’s sure to add to the excitement. What makes this fight so intriguing is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. Being so tall yet so nimble, he commands the ring like no other.
The legendary battles with Wilder showed his durability, overcoming brutal hits to finish strong. Against Wladimir Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. Meanwhile, Usyk, brings speed, precision, and finesse. With his unorthodox stance, he uses angles and footwork. His strikes lack devastating strength, but they are delivered with pinpoint accuracy. As fight night approaches, Tyson Fury vs Usyk odds have fans and analysts speculating.
The betting lines show Fury ahead as per the betting experts, because of his reach and height, his experience in high-pressure bouts, and his unorthodox style. However, Usyk's underdog status doesn’t rule him out, his wins over Anthony Joshua proved that he can handle the physicality of the heavyweight division.
For Tyson Fury is a chance to further solidify his greatness. A triumph for Fury would put the finishing touches on a historic career. Meanwhile, Usyk’s victory would be a monumental achievement. Becoming the undisputed heavyweight champion is a once-in-a-lifetime achievement.
Web: <a href="http://maps.google.com.tw/url?sa=t&url=https%3A%2F%2Fusykvsfurydate.org.uk">usykvsfurydate.org.uk</a>
Fury vs Usyk is about more than the titles. It’s a battle of contrasting styles. Fury’s confident and brash nature is the opposite of Usyk’s humble and disciplined approach. These varying personalities make the bout even more interesting. It’s about more than just skill. Regardless of the outcome, the impact of this bout will reverberate throughout boxing history. This historic showdown is a defining moment. It’s the pinnacle of both fighters’ hard work. If Fury wins with his experience and unpredictability, or Usyk secures a victory through his superior boxing ability, one thing is certain, this bout will go down in history.
Tyson Fury vs Oleksandr Usyk is more than just a sporting contest. It’s a contest of heart and willpower. These two warriors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Azəri bazarında onlayn qumar oyunlarına güvəni artdıqca, Pinup kazino kimi şirkətlər daha çox tanınmağa başladı. Bununla bərabər, Pin-up online sözləri tez-tez Azərbaycandakı oyunçular üçün istifadə olunur. Pin-up kazino online istifadəçilərə məxsus çoxlu oyun növü təklif edir.
Pin up kazino, yerli oyunçular üçün populyar seçimdir. Bu platforma istifadəçilərə müxtəlif oyunlar təklif edib və çoxlu bonuslar ilə qumarbazlar tərəfindən sevilir.
Pin-up casino online, bənzərsiz oyun imkanı təqdim edən saytdır. Azərbaycanda populyar olan Pinup, mərc həvəskarları üçün zəngin təkliflər təqdim edir.
Bunun nəticəsində, Pin-up azerbaycan qumar həvəskarlarına etibarlı və güvənli maliyyə idarəetmə imkanları təklif etməkdədir. İstifadəçilər, rahat və tez maliyyə əməliyyatları sayəsində, qumar təcrübələrini daha rahat təcrübə edərlər.
Bununla yanaşı, Pin-up casino istifadəçilərə çoxlu oyun növlərilə yanaşı sərfəli bonuslar oyunçularına verir. Pin-up-da, kazino həvəskarları özlərini güvəndə hiss edir.
Web: https://bet-pinup.web.app
Pin-up kazino yalnız sadə oyunla bitmir. Qumarçılar burada geniş mərc təcrübəsindən faydalanıb və sərfəli bonus təkliflərini mərc təcrübələrini zənginləşdirərlər.
Bunun nəticəsində, Pin-up azerbaycan, etibarlı mərc təcrübəsi istifadəçilərə verməklə onlayn qumar sektorunda ən sevilən platformalardan olur. Azəri oyunçular tərəfindən geniş yayılması təsadüf deyil.
Tyson Fury and Oleksandr Usyk are set to meet in the ring that will define an era. It’s far beyond a championship match; it’s a battle for eternal recognition. The towering Fury has risen to the pinnacle of the sport through his unique style and remarkable adaptability during fights. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Across the ring, Usyk, the Ukrainian master brings an unprecedented test to the heavyweight division. On the flip side, Oleksandr Usyk stands as a unique threat for the heavyweight ranks overall, as a heavyweight contender. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, by conquering all challengers. Prepare yourself for a thrilling boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! Experience every moment in real time on our website. Be part of the action — visit <a href="https://www.excite.co.jp/relocate/co=jp/xsr/ne_ne_to_ne/okinawa;https://tysonfuryvoleksandrusyk.org.uk/">tysonfuryvoleksandrusyk.org.uk</a> today and enjoy the fight with top-notch streaming!
Across the UK, the ring walks are planned for late evening, ensuring maximum viewership. For Usyk’s fans in Ukraine, and beyond, the anticipation is at a fever pitch. The fight’s location is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, one thing is certain: it will be a spectacle. Even though attention remains on Fury and Usyk, the Fury vs Usyk undercard promises plenty of action. Big-ticket boxing cards are known for strong supporting fights, offering an entire night of boxing excitement.
In the past, undercards of this caliber have been a stage for breakout performances. Fighters looking to rise through the ranks use such opportunities to demonstrate their talent, with the world paying attention. Although the lineup for the Fury Usyk undercard are still unconfirmed, speculation runs high. Could we see rising prospects? No matter the final roster, the action will not disappoint. The most compelling part of Fury vs Usyk so intriguing is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. With his immense height and reach advantage, Fury can control a fight.
The three fights against Wilder showed his durability, as he recovered from knockdowns to finish strong. In his fight with Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, relies on technique and stamina. Being a left-handed fighter, his positioning constantly challenges opponents. Usyk’s punches lack devastating strength, but they are delivered with pinpoint accuracy. As anticipation builds, Predictions for this fight are becoming a hot topic.
Tyson Fury is seen as the frontrunner according to the odds, due to his size advantage, his track record in big matches, and his tactical brilliance. Despite the odds, Usyk remains a strong contender doesn’t mean he’s an underdog in spirit, his wins over Anthony Joshua confirmed his toughness against big opponents.
For the Gypsy King is a chance to further solidify his greatness. A victory would further solidify his status as the best heavyweight of this era. On the other hand, For Usyk, a win would mark him as one of the sport’s greats. Achieving undisputed glory in two divisions is a rare accomplishment.
Web: <a href="http://clients1.google.com.vc/url?q=https://tysonfuryvoleksandrusyk.org.uk/">tysonfuryvoleksandrusyk.org.uk</a>
This fight is not just about the belts. It’s a clash of personalities. Fury’s larger-than-life persona stands in stark contrast to Usyk’s composed demeanor. The clash of personalities adds depth to the narrative. Beyond physical ability, this fight. Regardless of the outcome, the significance of this match will leave a lasting mark on the sport. Fury vs Usyk is more than just a fight. It’s a culmination of years of hard work. Whether Fury secures the win with his size and strategy, or Usyk comes out on top with his finesse and stamina, no matter the outcome, this will be a legendary contest.
Fury vs Usyk is more than just a sporting contest. It’s a showcase of skill and determination. Both fighters will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azərbaycandakı qumar sektorunda internet qumarına tələbat artdıqca, Pin-up online kimi platformalar daha çox tanınmağa başladı. Bunun nəticəsində, Pin-up online şüarları tez-tez Azəri müştərilər üçün məşhurdur. Pin-up kazino online istifadəçilərə geniş oyunlar təklif edir.
Pin-up casino, Azərbaycan oyunçuları üçün maraqlı seçimdir. Bu mərc platforması istifadəçilərə rəngarəng oyunlar təklif verməkdədir və cazibədar aksiyalar ilə istifadəçilərin diqqətini çəkir.
Pinup casino, istifadəçilərə oyun növləri ilə zəngin saytdır. Azərbaycan ərazisində güvənilən Pin-up online, yerli oyunçular üçün geniş oyun təcrübəsi verir.
Bu səbəbdən, Pinup kazino müştərilərə güvənli depozit və çıxarış imkanı təqdim edir. Müştərilər, rahat və tez ödəmə üsulları ilə təmin olunmaqla, onlayn mərc oyunlarını daha rahat təcrübə edərlər.
Son olaraq, Pin-up casino müştərilərə təkcə oyun imkanı deyil cəlbedici kampaniyalar və maraqlı aksiyalar təklif edir. Bu platformada, kazino həvəskarları təhlükəsiz şərtlər altında mərc edir.
Web: https://bet-pinup.web.app
Pin-up kazino yalnız oyunlar ilə kifayətlənmir. Oyunçular burada geniş mərc təcrübəsindən istifadə edə bilər və geniş bonus imkanlarını mərc təcrübələrini zənginləşdirərlər.
Bunun nəticəsində, Pinup kazino, rahat və təhlükəsiz mərc imkanı təqdim etməklə onlayn mərc dünyasında oyunçular arasında geniş istifadə edilir. yerli mərcçilər arasında məşhur olması əlamətdardır.
Tyson Fury and Oleksandr Usyk are on a collision course of unparalleled significance. It’s not merely about the belts; it’s about legacy. The towering Fury has become a global icon with his charisma and his unmatched skills during fights. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. In contrast, Oleksandr Usyk brings an unprecedented test to the heavyweight division. On the flip side, Oleksandr Usyk stands as a unique threat for the heavyweight ranks overall, and for boxing fans worldwide. Usyk’s rise to prominence started with his domination of the cruiserweights, by conquering all challengers. Get ready for a thrilling boxing match of the year as Usyk takes on Fury in a must-watch showdown! See every move live on our website. Join the excitement — visit <a href="https://affiliates.japantrendshop.com/affiliate/scripts/click.php?a_aid=poppaganda&desturl=https://furyusyk.org.uk/">furyusyk.org.uk</a> today and stream the event in high quality!
For British fans, the fight is expected to begin close to prime time, ensuring maximum viewership. In Usyk’s native Ukraine, and for fans watching from around the world, this will be a must-see event. The fight’s location has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, it’s guaranteed: the excitement will be unmatched. While the spotlight remains on Fury and Usyk, the Fury vs Usyk undercard is also generating excitement. Major boxing events are known for strong supporting fights, providing non-stop action before the headliner.
Historically, supporting bouts in major events have showcased rising stars. Boxers seeking the spotlight use such opportunities to showcase their skills, knowing millions are watching. Although the lineup for the Fury Usyk undercard haven’t been officially announced, speculation runs high. Will there be a heavyweight clash? No matter the final roster, fans can expect fireworks. What makes this fight truly fascinating is the clash of styles. Tyson Fury’s size and agility make him an anomaly in boxing. With his immense height and reach advantage, he dictates the pace of bouts.
The legendary battles with Wilder showed his durability, as he recovered from knockdowns to finish strong. Against Wladimir Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. Meanwhile, Usyk, brings speed, precision, and finesse. With his unorthodox stance, his movements create openings. The Ukrainian’s shots may not have knockout power, they consistently find their mark. As anticipation builds, The betting lines for Fury vs Usyk are becoming a hot topic.
Most bookmakers favor Fury based on the betting odds, due to his size advantage, his experience in high-pressure bouts, and his unorthodox style. However, Usyk's underdog status doesn’t rule him out, his dominance against Joshua demonstrated his ability in the heavyweight ranks.
For Fury himself could be the defining moment of his career. A triumph for Fury would solidify his claim as the greatest heavyweight of his generation. Meanwhile, For Usyk, a win would elevate him to legendary status. Becoming the undisputed heavyweight champion is a once-in-a-lifetime achievement.
Web: <a href="http://www.google.com.bz/url?q=https://furyusyk.org.uk/">furyusyk.org.uk</a>
This fight is about more than the titles. It’s a fight between two very different fighters. Fury’s boisterous personality is in stark contrast to Usyk’s quiet intensity. Such contrasts make the fight more compelling. This is more than just a physical contest. Whoever triumphs in this battle, the legacy of this fight will reverberate throughout boxing history. The clash for the undisputed title is a defining moment. It’s the pinnacle of both fighters’ hard work. If Fury wins with his experience and unpredictability, or Usyk secures a victory thanks to his skill and resilience, it’s certain that, this will be a defining moment in boxing.
The Fury-Usyk battle is more than just a boxing event. It’s a fight of grit and strategy. These men will leave it all in the ring.
Visit for more information: #crosslink[3,L -
yerli oyunçular arasında qumar oyunlarına sevgisi artdıqca, "Pin-up casino" kimi saytlar daha çox tanınmağa başladı. Özəlliklə, Pin-up online brendləri indi yerli oyunçular üçün tanışdır. Pin-up azerbaycan öz oyunçularına rəngarəng oyunlar təklif edir.
Pin-up casino, Azərbaycandakı oyunçular üçün populyar seçimdir. Bu onlayn kazino mərc həvəskarlarına fərqli oyun növləri təklif verməkdədir və sərfəli bonus təklifləri ilə qumarbazlar tərəfindən sevilir.
Pin-up azerbaycan, istifadəçilərə oyun növləri ilə zəngin bir platformadır. Azəri bazarında oyunçular tərəfindən sevilən Pin-up online, oyun həvəskarları üçün maraqlı oyun imkanları təklif edir.
Bununla yanaşı, Pinup kazino istifadəçilərə təhlükəsiz depozit və çıxarış imkanı təqdim edir. Oyunçular, etibarlı və tez ödəmə üsulları ilə təmin olunmaqla, internet oyunlarını güvənli və təhlükəsiz yaşaya bilərlər.
Nəticə etibarilə, Pin-up cazino müştərilərə geniş oyun təcrübəsi ilə yanaşı bonus imkanı təqdim edir. Pin-up-da, mərc edənlər rahat və təhlükəsiz şəraitdə oynayır.
Web: https://az-pinup.web.app
Pin-up azerbaycan təkcə məhdud oyunlar təklif etmir. Kazino həvəskarları bu kazinoda fərqli mərc seçimlərindən müxtəlif mərc imkanı əldə edə bilər və bonus sistemini qazanmaq imkanı əldə edərlər.
Nəticədə, Pin-up cazino, etibarlı qumar təcrübəsi təqdim etməklə oyun bazarında güclü mövqe tutub. Azərbaycan mərcçiləri arasında geniş yayılması təsadüf deyil.
Fury, the Gypsy King, and Usyk, the technician are set to meet in the ring of unparalleled significance. This fight is about more than just titles; it represents their quest for immortality. The Gypsy King has earned worldwide fame through his unique style and his unmatched skills inside the ropes. Beating Wilder and Klitschko have earned him recognition as one of the best ever. Across the ring, the tactical southpaw is a fighter unlike any other to the heavyweight division. Meanwhile, the Ukrainian technician is a true test for Fury for Tyson Fury himself, and for boxing fans worldwide. His journey to global fame began in the cruiserweight division, by conquering all challengers. Get ready for an epic boxing match of the year as Usyk takes on Fury in a must-watch showdown! See every move live on our website. Don’t miss your chance — visit <a href="https://member.biji.co/login/logout?next=https://furyvsusykdate.co.uk/">furyvsusykdate.co.uk</a> now and watch the match from the comfort of your home!
In the United Kingdom, the event will kick off at around 10 PM GMT, offering perfect timing for viewers. Back in Usyk’s home country, and beyond, the excitement is palpable. The fight’s location is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, it’s guaranteed: the atmosphere will be electric. Even though attention is firmly on the main event, the preliminary bouts is shaping up to be thrilling. Big-ticket boxing cards often feature stacked undercards, offering an entire night of boxing excitement.
Traditionally, undercards of this caliber have introduced future champions. Boxers seeking the spotlight use such opportunities to demonstrate their talent, with the world paying attention. Although the lineup for the Fury Usyk undercard has yet to be finalized, speculation runs high. Could we see rising prospects? Whatever the selection, it’s sure to add to the excitement. What makes this fight truly fascinating is their contrasting skillsets. Fury’s towering frame and movement make him an anomaly in boxing. Being so tall yet so nimble, he dictates the pace of bouts.
The three fights against Wilder highlighted his resilience, as he recovered from knockdowns to secure victories. Against Wladimir Klitschko, his strategic genius shone through, proving he’s not just physical but cerebral. By contrast, Usyk, relies on technique and stamina. With his unorthodox stance, he uses angles and footwork. His strikes aren’t the heaviest in the division, their timing wears down foes. With the date drawing closer, The betting lines for Fury vs Usyk have fans and analysts speculating.
Tyson Fury is the slight favorite as per the betting experts, due to his size advantage, his proven ability in tough situations, and his unorthodox style. Despite the odds, Usyk remains a strong contender shouldn’t be counted out, as his victories over Joshua demonstrated his ability in the heavyweight ranks.
For Tyson Fury represents an opportunity to cement his legacy. Should he come out on top, Fury’s win would put the finishing touches on a historic career. On the other hand, If Usyk wins would elevate him to legendary status. Achieving undisputed glory in two divisions is a feat few can claim.
Web: <a href="http://www.google.co.ck/url?q=https://furyvsusykdate.co.uk/">furyvsusykdate.co.uk</a>
Fury vs Usyk represents something greater than a title bout. It’s a fight between two very different fighters. Fury’s bold and unapologetic character contrasts with Usyk’s calm, focused demeanor. Such contrasts make the fight more compelling. It’s a fight of wills and ideologies. Whoever comes out victorious, the impact of this bout will be remembered as a defining moment in boxing. Fury vs Usyk is a defining moment. It’s the pinnacle of both fighters’ hard work. Whether Fury secures the win through his strength and tactics, or Usyk wins with his precision through his superior boxing ability, one thing is certain, this will be a fight remembered for years to come.
Fury vs Usyk is more than just a sporting contest. It’s a showcase of skill and determination. The two competitors will give everything they have.
Visit for more information: #crosslink[3,L -
Azərbaycan ərazisində internet qumarına istək artdıqca, Pinup kazino kimi platformalar daha çox tanınmağa başladı. Xüsusilə, Pinup azerbaycan şüarları indi Azəri müştərilər üçün güvənlidir. Pin-up kazino oyunçulara geniş oyunlar təklif edir.
Pinup kazino, yerli oyunçular üçün populyar seçimdir. Bu onlayn kazino mərc həvəskarlarına fərqli oyun növləri təklif edir və cazibədar aksiyalar ilə seçim olur.
Pinup casino, geniş oyun variantları təklif edən şirkətdir. Azəri bazarında çox seçilən Pinup, yerli oyunçular üçün zəngin təkliflər təqdim edir.
Bu səbəbdən, "Pin-up casino online" oyunçulara etibarlı maliyyə idarəetmə imkanları təmin edir. Kazino iştirakçıları, sürətli və asan depozit çıxarış sistemi ilə təmin olunmaqla, internet oyunlarını çox rahat yaşaya bilərlər.
Nəticə etibarilə, Pin-up casino online istifadəçilərə yalnız qumar oyunları yox, həmçinin bonus imkanı oyunçularına verir. Pin-up-da, müştərilər təhlükəsiz oyun mühitində olur.
Web: https://pinup-top.web.app
Pin-up casino təkcə oyunlar ilə kifayətlənmir. Qumarçılar burada bənzərsiz mərc imkanlarından təcrübə edə bilərlər və sərfəli bonus təkliflərini oyunlarına əlavə edə bilərlər.
Yekun olaraq, Pin-up kazino, şəffaf və güvənli mərc təcrübəsi təqdim etməklə oyun bazarında oyunçular arasında geniş istifadə edilir. yerli mərcçilər arasında çox seçilməsi dikkətə layiqdir.
The undefeated Fury and Usyk are set to meet in the ring of historic proportions. It’s far beyond a championship match; it’s about legacy. The towering Fury has earned worldwide fame with his charisma coupled with unparalleled talent inside the ropes. Beating Wilder and Klitschko have cemented his place among the all-time greats. In contrast, the tactical southpaw is a fighter unlike any other to the heavyweight division. At the same time, Usyk, a southpaw master stands as a unique threat not just for Fury, as a heavyweight contender. The ascent of Oleksandr Usyk started with his domination of the cruiserweights, as an undisputed champion. Don’t miss out for the most anticipated boxing match of the year as Oleksandr Usyk takes on Fury in a historic showdown! Experience every moment in real time on our website. Don’t miss your chance — visit <a href="https://art-kormushka.ru/udata/emarket/basket/put/element/8142/?redirect-uri=http%3a%2f%2ftysonvusyk.com">tysonvusyk.com</a> now and stream the event in high quality!
For British fans, the fight is expected to begin close to prime time, ensuring maximum viewership. In Usyk’s native Ukraine, and beyond, the excitement is palpable. The fight’s location remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, it’s guaranteed: it will be a spectacle. Although the focus is firmly on the main event, the Fury vs Usyk undercard is also generating excitement. High-profile matches are known for strong supporting fights, offering an entire night of boxing excitement.
Historically, supporting bouts in major events have been a stage for breakout performances. Contenders hoping to make their mark use such opportunities to demonstrate their talent, as all eyes are on them. Though the supporting fights for Fury vs Usyk haven’t been officially announced, there’s plenty of talk. Will there be a heavyweight clash? No matter the final roster, fans can expect fireworks. The most compelling part of Fury vs Usyk truly fascinating is their contrasting skillsets. Tyson Fury’s size and agility make him an anomaly in boxing. Being so tall yet so nimble, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, overcoming brutal hits to secure victories. When he faced Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. By contrast, Usyk, brings speed, precision, and finesse. As a southpaw, his positioning constantly challenges opponents. Usyk’s punches may not have knockout power, their timing wears down foes. As anticipation builds, Tyson Fury vs Usyk odds are the subject of intense debate.
Most bookmakers favor Fury according to the odds, given his physical stature, his proven ability in tough situations, and his unorthodox style. Although Usyk is the less favored fighter doesn’t mean he’s an underdog in spirit, his dominance against Joshua showed that he can compete at heavyweight.
For Tyson Fury, this fight represents an opportunity to cement his legacy. Should he come out on top, Fury’s win would solidify his claim as the greatest heavyweight of his generation. On the other hand, Usyk’s victory would elevate him to new heights. Securing two undisputed titles is a once-in-a-lifetime achievement.
Web: <a href="http://maps.google.bj/url?q=https://tysonvusyk.com/">tysonvusyk.com</a>
The upcoming showdown is more than just a championship fight. It’s a clash of personalities. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. These differences add complexity to the fight. It’s about more than just skill. No matter who wins, the significance of this match will be remembered as a defining moment in boxing. This historic showdown is a defining moment. It’s the pinnacle of both fighters’ hard work. Whether Fury secures the win through his strength and tactics, or Usyk wins with his precision with his technique and endurance, no matter the outcome, this will be a defining moment in boxing.
Fury vs Usyk is more than just a fight. It’s a battle of minds and bodies. These men will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azərbaycandakı qumar sektorunda internet oyunlarına güvəni artdıqca, Pin-up online kimi oyun xidmətləri daha çox tanınmağa başladı. Əsasən, "Pin up casino online" adları artıq yerli oyunçular üçün istifadə olunur. Pin-up kazino online mərc həvəskarlarına çeşidli oyunlar təklif edir.
Pin-up online casino, Azərbaycan oyunçuları üçün geniş yayılmış bir xidmətdir. Bu qumar saytı kazino oyunçularına fərqli oyun növləri verir və çoxlu bonuslar ilə oyunçuları özünə cəlb edir.
Pin-up casino, istifadəçilərə oyun növləri ilə zəngin oyun məkanıdır. Azəri oyunçuları arasında oyunçular tərəfindən sevilən Pin-up casino, yerli oyunçular üçün çeşidli bonus imkanları yaradır.
Bunun nəticəsində, "Pin-up casino online" istifadəçilərə etibarlı maliyyə idarəetmə imkanları təklif edir. Müştərilər, müvafiq və təhlükəsiz maliyyə çıxarışları ilə, oyun təcrübələrini daha rahat yerinə yetirə bilərlər.
Sonda, Pin-up cazino istifadəçilərə təkcə oyunlar deyil, həm də bonuslar və aksiyalar təqdim edir. Pin-up-da, oyunçular güvənli bir təcrübə yaşayır.
Web: https://win-top-pin-up-az.web.app
Pin-up casino online təkcə bir kazino olaraq məhdud oyunlar təklif etmir. Kazino həvəskarları bu kazinoda fərqli mərc oyunlarından yararlana bilərlər və geniş bonus imkanlarını mərc təcrübələrini zənginləşdirərlər.
Sonda, Pin-up casino online, şəffaf və güvənli qumar təcrübəsi təklif etməklə mərc bazarında ən yaxşı seçimlərdən biridir. yerli mərcçilər arasında tanınması təsadüfi deyil.
The undefeated Fury and Usyk are preparing for an epic showdown that will define an era. It’s not merely about the belts; it’s a battle for eternal recognition. The Gypsy King has earned worldwide fame through his unique style and his unmatched skills in the ring. Beating Wilder and Klitschko have cemented his place among the all-time greats. Meanwhile, the tactical southpaw is a fighter unlike any other to boxing’s biggest stars. On the flip side, the Ukrainian technician stands as a unique threat for the heavyweight ranks overall, and for boxing fans worldwide. The ascent of Oleksandr Usyk started with his domination of the cruiserweights, by conquering all challengers. Don’t miss out for a thrilling boxing match of the year as Usyk takes on Fury in a historic showdown! See every move streamed live on our website. Don’t miss your chance — visit <a href="https://my.friendhosting.net/pl.php?2636&go=https://furyusyk.org.uk/">furyusyk.org.uk</a> right away and enjoy the fight from the comfort of your home!
In the United Kingdom, the event will kick off at close to prime time, ensuring maximum viewership. For Usyk’s fans in Ukraine, and for fans watching from around the world, the excitement is palpable. Where the bout will take place has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, fans can be sure: the excitement will be unmatched. Even though attention remains on Fury and Usyk, the Fury vs Usyk undercard is shaping up to be thrilling. Major boxing events often feature stacked undercards, giving fans a full evening of entertainment.
Historically, preliminary fights on major cards have showcased rising stars. Boxers seeking the spotlight often seize these moments to demonstrate their talent, with the world paying attention. Although the lineup for the Fury Usyk undercard haven’t been officially announced, fans are eagerly guessing. Will there be a heavyweight clash? No matter the final roster, fans can expect fireworks. What makes this fight incredibly exciting is their contrasting skillsets. Fury’s towering frame and movement make him an anomaly in boxing. With his immense height and reach advantage, he commands the ring like no other.
The legendary battles with Wilder proved his toughness, overcoming brutal hits to secure victories. In his fight with Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Meanwhile, Usyk, relies on technique and stamina. With his unorthodox stance, his positioning constantly challenges opponents. The Ukrainian’s shots may not have knockout power, but they are delivered with pinpoint accuracy. As anticipation builds, Predictions for this fight have fans and analysts speculating.
Tyson Fury is seen as the frontrunner based on the betting odds, because of his reach and height, his long career in major fights, and his tactical brilliance. Although Usyk is the less favored fighter shouldn’t be counted out, his victories against AJ showed that he can compete at heavyweight.
For Fury himself could be the defining moment of his career. Should he come out on top, Fury’s win would put the finishing touches on a historic career. On the other hand, Usyk’s victory would elevate him to new heights. Securing two undisputed titles is a rare accomplishment.
Web: <a href="http://www.google.com.na/url?sa=t&url=http%3A%2F%2Fwww.magical-dream.com">furyusyk.org.uk</a>
This fight represents something greater than a title bout. It’s a fight between two very different fighters. Fury’s confident and brash nature is in stark contrast to Usyk’s quiet intensity. These varying personalities make the bout even more interesting. It’s a fight of wills and ideologies. No matter who wins, the legacy of this fight will reverberate throughout boxing history. This historic showdown is more than just a match. It’s the result of relentless dedication. If Fury wins thanks to his power and game plan, or Oleksandr Usyk triumphs through his superior boxing ability, no matter the outcome, this will be a legendary contest.
This fight between Fury and Usyk is a spectacle of a lifetime. It’s a battle of minds and bodies. These two warriors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are on a collision course of unparalleled significance. It’s far beyond a championship match; it represents their quest for immortality. Tyson Fury has risen to the pinnacle of the sport thanks to his personality coupled with unparalleled talent during fights. Beating Wilder and Klitschko have earned him recognition as one of the best ever. In contrast, Usyk, the Ukrainian master is a fighter unlike any other to boxing’s biggest stars. Meanwhile, Usyk, a southpaw master stands as a unique threat for Tyson Fury himself, but for the entire division. His journey to global fame began in the cruiserweight division, as an undisputed champion. Don’t miss out for the most anticipated boxing match of the year as Usyk takes on Tyson Fury in a must-watch showdown! Catch every punch streamed live on our website. Don’t miss your chance — visit <a href="https://novosibirsk.purumburum.ru:443/redirect.php?url=http%3a%2f%2ffuryvsusykdate.org.uk&city=RU-NVS&city_old=novosibirsk">furyvsusykdate.org.uk</a> today and watch the match with top-notch streaming!
In the United Kingdom, the event will kick off at close to prime time, ensuring maximum viewership. Back in Usyk’s home country, and beyond, the excitement is palpable. The venue for Fury vs Usyk is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, one thing is certain: it will be a spectacle. While the spotlight is firmly on the main event, the preliminary bouts promises plenty of action. Big-ticket boxing cards include preliminary bouts with top talent, offering an entire night of boxing excitement.
Historically, undercards of this caliber have been a stage for breakout performances. Fighters looking to rise through the ranks often seize these moments to showcase their skills, knowing millions are watching. While the names for the undercard haven’t been officially announced, there’s plenty of talk. Might there be a cruiserweight spectacle? Whatever the selection, the action will not disappoint. What makes this fight truly fascinating is the clash of styles. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. Being so tall yet so nimble, Fury can control a fight.
His trilogy with Deontay Wilder proved his toughness, overcoming brutal hits to dominate in later rounds. Against Wladimir Klitschko, his strategic genius shone through, showing he’s both powerful and smart. By contrast, Usyk, offers a different kind of threat. With his unorthodox stance, he uses angles and footwork. The Ukrainian’s shots aren’t the heaviest in the division, their timing wears down foes. As anticipation builds, The betting lines for Fury vs Usyk have fans and analysts speculating.
The betting lines show Fury ahead according to the odds, given his physical stature, his proven ability in tough situations, and his tactical brilliance. However, Usyk's underdog status doesn’t rule him out, as his victories over Joshua confirmed his toughness against big opponents.
For Fury himself could be the defining moment of his career. A victory would put the finishing touches on a historic career. Meanwhile, For Usyk, a win would elevate him to new heights. Securing two undisputed titles is a once-in-a-lifetime achievement.
Web: <a href="http://images.google.lt/url?q=https://furyvsusykdate.org.uk/">furyvsusykdate.org.uk</a>
This fight is more than just a championship fight. It’s a clash of personalities. Fury’s larger-than-life persona contrasts with Usyk’s calm, focused demeanor. The clash of personalities adds depth to the narrative. It’s about more than just skill. Whoever triumphs in this battle, the legacy of this fight will leave a lasting mark on the sport. The battle for heavyweight supremacy is more than just a match. It represents the culmination of their careers. Should Fury claim victory through his strength and tactics, or Usyk secures a victory thanks to his skill and resilience, one thing is certain, this will be a defining moment in boxing.
Tyson Fury vs Oleksandr Usyk is more than just a sporting contest. It’s a fight of grit and strategy. These men will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azəri bazarında online kazino oyunlarına tələbat artdıqca, Pin-up kazino kimi onlayn mərc xidmətləri daha çox tanınmağa başladı. Özəlliklə, Pinup azerbaycan brendləri indi Azəri oyunçuları üçün istifadə olunur. Pin-up kazino oyunçulara rəngarəng oyunlar təklif edir.
Pin-up casino, yerli mərc həvəskarları üçün ən sevilən platformalardan biridir. Bu platforma istifadəçilərə çoxlu oyun təklifləri təklif edib və cəlbedici bonuslar ilə müştərilərini məmnun edir.
Pin-up azerbaycan, geniş oyun variantları təklif edən oyun məkanıdır. Azəri bazarında oyunçular tərəfindən sevilən Pin-up online, mərc həvəskarları üçün fərqli oyun seçimləri ilə çıxış edir.
Əlavə olaraq, "Pin-up casino online" müştərilərə etibarlı və güvənli maliyyə idarəetmə imkanları verir. Kazino iştirakçıları, rahat depozit çıxarış sistemi nəticəsində, oyun təcrübələrini güvənli və təhlükəsiz yaşaya bilərlər.
Nəticə etibarilə, Pin-up casino oyunçulara təkcə oyunlar deyil, həm də cəlbedici kampaniyalar təmin edir. Bu qumar saytında, mərc edənlər təhlükəsiz oyun mühitində olur.
Web: https://best-pinup.web.app
Pin-up cazino sadəcə oyunlar ilə kifayətlənmir. Qumarçılar burada fərqli mərc oyunlarından müxtəlif mərc imkanı əldə edə bilər və maraqlı aksiyaları mərc təcrübələrini zənginləşdirərlər.
Beləliklə, Pin-up casino online, sərfəli və təhlükəsiz mərc oyunları oyunçulara təklif etməklə oyun sənayesində ən yaxşı seçimlərdən biridir. yerli mərcçilər arasında çox seçilməsi əlamətdardır.
The undefeated Fury and Usyk are on a collision course that will define an era. It’s not merely about the belts; it’s a battle for eternal recognition. The towering Fury has become a global icon thanks to his personality and his unmatched skills in the ring. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Meanwhile, the tactical southpaw is a fighter unlike any other for Fury. At the same time, Usyk, a genius in the ring stands as a unique threat for the heavyweight ranks overall, as a heavyweight contender. Usyk’s rise to prominence started with his domination of the cruiserweights, where he became an unstoppable force. Prepare yourself for a thrilling boxing match of the year as Usyk takes on Fury in a must-watch showdown! Catch every punch streamed live on our website. Join the excitement — visit <a href="http://affiliates.thelotter.com/aw.aspx?A=1&Task=Click&ml=31526&TargetURL=https://usykvsfurydate.org.uk/">usykvsfurydate.org.uk</a> now and watch the match with top-notch streaming!
Across the UK, the ring walks are planned for around 10 PM GMT, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and for fans watching from around the world, the anticipation is at a fever pitch. Where the bout will take place remains a hot topic, with talk of iconic boxing destinations. Regardless of the venue, it’s guaranteed: it will be a spectacle. Although the focus remains on Fury and Usyk, the fights leading up to the main event is shaping up to be thrilling. Major boxing events include preliminary bouts with top talent, offering an entire night of boxing excitement.
Historically, preliminary fights on major cards have been a stage for breakout performances. Fighters looking to rise through the ranks often seize these moments to demonstrate their talent, knowing millions are watching. Although the lineup for the Fury Usyk undercard haven’t been officially announced, fans are eagerly guessing. Might there be a cruiserweight spectacle? Regardless of the names, the action will not disappoint. What sets this bout apart truly fascinating is the clash of styles. Tyson Fury’s size and agility set him apart from other heavyweights. With his immense height and reach advantage, he dictates the pace of bouts.
The legendary battles with Wilder showed his durability, as he recovered from knockdowns to secure victories. Against Wladimir Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Meanwhile, Usyk, relies on technique and stamina. With his unorthodox stance, his movements create openings. The Ukrainian’s shots may not have knockout power, they consistently find their mark. As fight night approaches, Predictions for this fight have fans and analysts speculating.
The betting lines show Fury ahead as per the betting experts, given his physical stature, his proven ability in tough situations, and his adaptability. Despite being seen as the underdog doesn’t diminish his chances, as his victories over Joshua showed that he can compete at heavyweight.
For the Gypsy King presents a shot at undisputed glory. A triumph for Fury would put the finishing touches on a historic career. On the other hand, For Usyk, a win would mark him as one of the sport’s greats. Achieving undisputed glory in two divisions is a feat few can claim.
Web: <a href="http://clients1.google.com.qa/url?q=https%3A%2F%2Fusykvsfurydate.org.uk">usykvsfurydate.org.uk</a>
The upcoming showdown is not just about the belts. It’s a fight between two very different fighters. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. These differences add complexity to the fight. It’s about more than just skill. No matter who wins, the legacy of this fight will leave a lasting mark on the sport. The battle for heavyweight supremacy is more than just a fight. It’s a culmination of years of hard work. Should Fury claim victory thanks to his power and game plan, or Usyk secures a victory through his superior boxing ability, no matter the outcome, this bout will go down in history.
Fury vs Usyk is more than just a boxing event. It’s a showcase of skill and determination. The two competitors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azərbaycan ərazisində qumar oyunlarına maraq artdıqca, Pin-up online kimi onlayn mərc xidmətləri daha çox tanınmağa başladı. Bunun nəticəsində, Pinup azerbaycan sözləri tez-tez yerli oyunçular üçün məşhurdur. Pin-up casino azerbaycan oyunçulara müxtəlif oyunlar təklif edir.
Pin-up online casino, Azəri istifadəçilər üçün güvənli bir qumar məkanıdır. Bu qumar xidməti qumarbazlara geniş çeşidli oyunlar təklif edib və cazibədar aksiyalar ilə oyunçuları özünə cəlb edir.
Pin-up casino, oyun keyfiyyətini artıran oyun məkanıdır. Azəri oyunçuları arasında geniş istifadə olunan Pinup, kazino oyunçuları üçün geniş oyun təcrübəsi verir.
Əlavə olaraq, Pinup kazino istifadəçilərə güvənli depozit və çıxarış imkanı verir. İstifadəçilər, sürətli və asan maliyyə əməliyyatları vasitəsilə, oyun təcrübələrini güvənli və təhlükəsiz yaşaya bilərlər.
Son olaraq, Pin-up azerbaycan qumarbazlara geniş oyun təcrübəsi ilə yanaşı sərfəli bonuslar təqdim edir. Pinup-da, kazino həvəskarları şəffaf oyun şərtləri ilə rastlaşır.
Web: https://pinup-top-bet.web.app
Pin-up kazino yalnız məhdud oyunlar təklif etmir. Oyunçular burada müxtəlif mərc növlərindən faydalanıb və cazibədar bonus imkanlarını istifadə edə bilərlər.
Yekun olaraq, Pin-up cazino, etibarlı oyun imkanı istifadəçilərə verməklə mərc bazarında oyunçular arasında geniş istifadə edilir. yerli mərcçilər arasında məşhur olması açıq bir faktdır.
Fury, the Gypsy King, and Usyk, the technician are set to meet in the ring that will define an era. It’s far beyond a championship match; it’s a battle for eternal recognition. Tyson Fury has earned worldwide fame with his charisma coupled with unparalleled talent in the ring. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. In contrast, Oleksandr Usyk brings an unprecedented test for Fury. On the flip side, the Ukrainian technician is a true test for Fury for the heavyweight ranks overall, as a heavyweight contender. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Prepare yourself for an epic boxing match of the year as Oleksandr Usyk takes on Fury in a historic showdown! Experience every moment streamed live on our website. Be part of the action — visit <a href="https://plumz.me/go/aHR0cHM6Ly9tb2RzLW1lbnUucnUv">tysonvusyk.com</a> right away and stream the event in high quality!
In the United Kingdom, the fight is expected to begin close to prime time, ensuring maximum viewership. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, the excitement is palpable. The fight’s location remains a hot topic, with talk of iconic boxing destinations. Wherever it happens, one thing is certain: it will be a spectacle. Although the focus is centered on the headline fight, the Fury vs Usyk undercard promises plenty of action. High-profile matches are known for strong supporting fights, giving fans a full evening of entertainment.
Traditionally, undercards of this caliber have showcased rising stars. Boxers seeking the spotlight capitalize on the exposure to showcase their skills, knowing millions are watching. Although the lineup for the Fury Usyk undercard are still unconfirmed, speculation runs high. Might there be a cruiserweight spectacle? No matter the final roster, the action will not disappoint. What makes this fight truly fascinating is the dynamic between these fighters. Fury’s towering frame and movement set him apart from other heavyweights. With his immense height and reach advantage, Fury can control a fight.
The legendary battles with Wilder showed his durability, overcoming brutal hits to dominate in later rounds. Against Wladimir Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, relies on technique and stamina. Being a left-handed fighter, he uses angles and footwork. The Ukrainian’s shots may not have knockout power, but they are delivered with pinpoint accuracy. As anticipation builds, The betting lines for Fury vs Usyk are the subject of intense debate.
Most bookmakers favor Fury according to the odds, given his physical stature, his long career in major fights, and his unpredictable nature. Despite being seen as the underdog doesn’t rule him out, his wins over Anthony Joshua proved that he can handle the physicality of the heavyweight division.
For Tyson Fury presents a shot at undisputed glory. A triumph for Fury would solidify his claim as the greatest heavyweight of his generation. Conversely, For Usyk, a win would elevate him to new heights. Securing two undisputed titles is a rare accomplishment.
Web: <a href="http://google.az/url?q=https://tysonvusyk.com/">tysonvusyk.com</a>
The upcoming showdown is not just about the belts. It’s a meeting of two unique worldviews. Fury’s bold and unapologetic character is in stark contrast to Usyk’s quiet intensity. Such contrasts make the fight more compelling. It’s a fight of wills and ideologies. Whoever comes out victorious, the legacy of this fight will leave a lasting mark on the sport. The clash for the undisputed title is a defining moment. It’s the result of relentless dedication. Whether Tyson Fury prevails with his size and strategy, or Usyk secures a victory through his superior boxing ability, what is clear is, this will be a fight remembered for years to come.
The Fury-Usyk battle is more than just a sporting contest. It’s a battle of minds and bodies. Both fighters will give everything they have.
Visit for more information: #crosslink[3,L -
Azəri bazarında internet qumarına maraq artdıqca, "Pin-up casino" kimi şirkətlər daha çox tanınmağa başladı. Xüsusilə, Pin-up azerbaycan sözləri artıq yerli istifadəçilər üçün sevilir. Pin-up azerbaycan istifadəçilərə geniş oyunlar təklif edir.
Pin-up azerbaycan, Azəri istifadəçilər üçün populyar seçimdir. Bu kazino mərc həvəskarlarına müxtəlif oyunlar təklif verməkdədir və gözəl hədiyyələr ilə oyunçuları özünə cəlb edir.
Pin-up casino, geniş oyun variantları təklif edən oyun məkanıdır. yerli mərcçilər arasında çox seçilən Pin-up casino, qumar oyunçuları üçün fərqli oyun seçimləri ilə çıxış edir.
Özəlliklə, Pin-up online casino mərcçilərə şəffaf və təhlükəsiz maliyyə idarəetmə imkanları təklif edir. Müştərilər, etibarlı və tez maliyyə çıxarışları köməyilə, oyun təcrübələrini müvafiq şəkildə keçirə bilərlər.
Bununla yanaşı, Pinup kazino oyunçulara təkcə oyunlar deyil, həm də mərc hədiyyələri və maraqlı aksiyalar təklif edir. Bu kazinoda, istifadəçilər təhlükəsiz şərtlər altında mərc edir.
Web: https://pinup-best-casino.web.app
Pin-up casino online təkcə bir oyun platforması kimi oyunçuları cəlb etmir. Kazino həvəskarları bu kazinoda bənzərsiz mərc imkanlarından istifadə edə bilər və bonus sistemini oyunlarına əlavə edə bilərlər.
Ümumilikdə, Pin-up kazino, sərfəli və təhlükəsiz qumar təcrübəsi mərc həvəskarlarına təqdim etməklə oyun bazarında ən yaxşı seçimlərdən biridir. Azəri bazarında populyarlığı göz qabağındadır.
The undefeated Fury and Usyk are on a collision course that will define an era. This fight is about more than just titles; it’s about legacy. Tyson Fury has risen to the pinnacle of the sport through his unique style and his unmatched skills in the ring. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Meanwhile, the tactical southpaw is a fighter unlike any other for Fury. Meanwhile, the Ukrainian technician is a true test for Fury for the heavyweight ranks overall, but for the entire division. Usyk’s rise to prominence began in the cruiserweight division, as an undisputed champion. Prepare yourself for a thrilling boxing match of the year as Usyk takes on Tyson Fury in a must-watch showdown! Catch every punch in real time on our website. Don’t miss your chance — visit <a href="https://anzhero.4geo.ru/redirect/?service=news&town_id=156895024&url=https://usykvsfury.co.uk/">usykvsfury.co.uk</a> now and enjoy the fight in high quality!
In the United Kingdom, the fight is expected to begin close to prime time, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and beyond, this will be a must-see event. The venue for Fury vs Usyk has yet to be confirmed, with talk of iconic boxing destinations. No matter the location, fans can be sure: it will be a spectacle. While the spotlight is centered on the headline fight, the Fury vs Usyk undercard is shaping up to be thrilling. High-profile matches often feature stacked undercards, giving fans a full evening of entertainment.
In the past, undercards of this caliber have showcased rising stars. Boxers seeking the spotlight often seize these moments to demonstrate their talent, knowing millions are watching. Though the supporting fights for Fury vs Usyk haven’t been officially announced, speculation runs high. Will there be a heavyweight clash? Whatever the selection, the action will not disappoint. What sets this bout apart so intriguing is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
His trilogy with Deontay Wilder showed his durability, overcoming brutal hits to dominate in later rounds. In his fight with Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Meanwhile, Usyk, relies on technique and stamina. As a southpaw, he uses angles and footwork. Usyk’s punches may not have knockout power, but they are delivered with pinpoint accuracy. As fight night approaches, Tyson Fury vs Usyk odds have fans and analysts speculating.
Fury is the favored fighter according to the odds, thanks to his imposing frame, his track record in big matches, and his adaptability. Despite the odds, Usyk remains a strong contender doesn’t mean he’s an underdog in spirit, his dominance against Joshua showed that he can compete at heavyweight.
For Tyson Fury represents an opportunity to cement his legacy. Should he come out on top, Fury’s win would solidify his claim as the greatest heavyweight of his generation. Conversely, If Usyk wins would elevate him to legendary status. Becoming the undisputed heavyweight champion is a rare accomplishment.
Web: <a href="http://maps.google.ro/url?sa=t&url=https%3A%2F%2Fusykvsfury.co.uk">usykvsfury.co.uk</a>
Fury vs Usyk is not just about the belts. It’s a clash of personalities. Fury’s boisterous personality is in stark contrast to Usyk’s quiet intensity. Such contrasts make the fight more compelling. It’s a fight of wills and ideologies. Whoever comes out victorious, the impact of this bout will reverberate throughout boxing history. The clash for the undisputed title is a defining moment. It represents the culmination of their careers. Whether Tyson Fury prevails with his experience and unpredictability, or Usyk secures a victory through his superior boxing ability, what is clear is, this will be a legendary contest.
The Fury-Usyk battle is a spectacle of a lifetime. It’s a battle of minds and bodies. The two competitors will give everything they have.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are preparing for an epic showdown of unparalleled significance. It’s not merely about the belts; it represents their quest for immortality. Tyson Fury has become a global icon with his charisma and his unmatched skills in the ring. Triumphing against boxing legends like Wilder and Klitschko have solidified his legendary status. Meanwhile, Usyk, the Ukrainian master brings an unprecedented test for Fury. On the flip side, the Ukrainian technician stands as a unique threat for the heavyweight ranks overall, but for the entire division. The ascent of Oleksandr Usyk started with his domination of the cruiserweights, as an undisputed champion. Don’t miss out for a thrilling boxing match of the year as Usyk takes on Fury in a historic showdown! Catch every punch in real time on our website. Don’t miss your chance — visit <a href="https://indexadhu.hit.gemius.pl/_uachredir/hitredir/id=zNflnP.A5cKRubSIkAhEgKPM.mOu6a8l4prKtJVfydn.47/stparam=vdloltgqqd/fastid=bqxvmxbfvgggpjknouotnueundmq/nc=0/url=https://tysonvsusyk.com/">tysonvsusyk.com</a> today and watch the match from the comfort of your home!
For British fans, the ring walks are planned for close to prime time, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and beyond, the excitement is palpable. The venue for Fury vs Usyk remains a hot topic, with talk of iconic boxing destinations. Regardless of the venue, one thing is certain: the excitement will be unmatched. Even though attention is firmly on the main event, the Fury vs Usyk undercard promises plenty of action. High-profile matches are known for strong supporting fights, giving fans a full evening of entertainment.
In the past, undercards of this caliber have introduced future champions. Fighters looking to rise through the ranks often seize these moments to showcase their skills, as all eyes are on them. Although the lineup for the Fury Usyk undercard haven’t been officially announced, fans are eagerly guessing. Will there be a heavyweight clash? Regardless of the names, the action will not disappoint. The most compelling part of Fury vs Usyk truly fascinating is their contrasting skillsets. Fury’s towering frame and movement are unparalleled in the sport. Being so tall yet so nimble, he commands the ring like no other.
His trilogy with Deontay Wilder proved his toughness, overcoming brutal hits to secure victories. Against Wladimir Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, relies on technique and stamina. With his unorthodox stance, he uses angles and footwork. Usyk’s punches lack devastating strength, they consistently find their mark. With the date drawing closer, Predictions for this fight have fans and analysts speculating.
Tyson Fury is the slight favorite according to the odds, due to his size advantage, his long career in major fights, and his unpredictable nature. Although Usyk is the less favored fighter doesn’t diminish his chances, his victories against AJ proved that he can handle the physicality of the heavyweight division.
For the Gypsy King could be the defining moment of his career. A triumph for Fury would put the finishing touches on a historic career. Meanwhile, Usyk’s victory would mark him as one of the sport’s greats. Becoming the undisputed heavyweight champion is a feat few can claim.
Web: <a href="http://www.google.vg/url?sa=t&url=http%3A%2F%2Fwww.magical-dream.com">tysonvsusyk.com</a>
This fight represents something greater than a title bout. It’s a clash of personalities. Fury’s bold and unapologetic character is the opposite of Usyk’s humble and disciplined approach. These differences add complexity to the fight. It’s a fight of wills and ideologies. Whoever triumphs in this battle, the significance of this match will leave a lasting mark on the sport. The clash for the undisputed title is a defining moment. It’s a culmination of years of hard work. Should Fury claim victory with his experience and unpredictability, or Oleksandr Usyk triumphs with his technique and endurance, one thing is certain, this will be a defining moment in boxing.
The Fury-Usyk battle is more than just a boxing event. It’s a fight of grit and strategy. The two competitors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
yerli oyunçular arasında qumar oyunlarına istək artdıqca, Pinup kimi kazino xidmətləri daha çox tanınmağa başladı. Bununla bərabər, Pin-up kazino ifadələri indi yerli oyunçular üçün güvənlidir. Pin-up azerbaycan öz oyunçularına çox oyun növləri təklif edir.
Pin-up online casino, yerli oyunçular üçün maraqlı seçimdir. Bu onlayn kazino kazino oyunçularına rəngarəng oyunlar təmin edir və bonus imkanları ilə oyunçuları özünə cəlb edir.
Pin-up azerbaycan, çeşidli oyun təcrübəsi təklif edən onlayn kazinodur. Azərbaycanda çox seçilən Pin-up online, mərc həvəskarları üçün fərqli oyun seçimləri ilə çıxış edir.
Əlavə olaraq, "Pin-up casino online" qumar həvəskarlarına güvənli və şəffaf depozit və çıxarış imkanı təmin edir. Müştərilər, çox rahat depozit və pul çıxarış imkanları sayəsində, internet oyunlarını daha asan təcrübə edərlər.
Nəticə etibarilə, Pin-up cazino istifadəçilərə təkcə oyun imkanı deyil mərc hədiyyələri oyunçularına verir. Pin-up-da, qumar həvəskarları rahat və təhlükəsiz şəraitdə oynayır.
Web: https://pinup-best-top.web.app
Pin-up casino təkcə bir kazino olaraq məhdudlaşmır. Müştərilər burada geniş mərc təcrübəsindən müxtəlif mərc imkanı əldə edə bilər və maraqlı aksiyaları oyunlarına əlavə edə bilərlər.
Yekun olaraq, Pin-up cazino, etibarlı mərc imkanı təqdim etməklə onlayn qumar sektorunda ən yaxşı seçimlərdən biridir. yerli mərcçilər arasında çox seçilməsi dikkətə layiqdir.
The undefeated Fury and Usyk are ready to face each other in a fight of unparalleled significance. It’s not merely about the belts; it’s a battle for eternal recognition. Tyson Fury has earned worldwide fame thanks to his personality and his unmatched skills inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. Across the ring, Usyk, the Ukrainian master is a fighter unlike any other for Fury. At the same time, Usyk, a southpaw master is a true test for Fury for Tyson Fury himself, but for the entire division. His journey to global fame began in the cruiserweight division, where he became an unstoppable force. Don’t miss out for a thrilling boxing match of the year as Usyk takes on Fury in an unforgettable showdown! See every move live on our website. Be part of the action — visit <a href="https://qa1.ru/redirect/?service=catalog&url=http%3A%2F%2Ftysonfuryvsoleksandrusyk.co.uk">tysonfuryvsoleksandrusyk.co.uk</a> now and enjoy the fight with top-notch streaming!
In the United Kingdom, the event will kick off at close to prime time, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and for fans watching from around the world, this will be a must-see event. The fight’s location is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, one thing is certain: it will be a spectacle. While the spotlight is centered on the headline fight, the fights leading up to the main event is shaping up to be thrilling. Major boxing events are known for strong supporting fights, offering an entire night of boxing excitement.
Traditionally, preliminary fights on major cards have introduced future champions. Contenders hoping to make their mark use such opportunities to impress fans and analysts alike, knowing millions are watching. While the names for the undercard haven’t been officially announced, speculation runs high. Might there be a cruiserweight spectacle? Regardless of the names, fans can expect fireworks. The most compelling part of Fury vs Usyk so intriguing is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed are unparalleled in the sport. With his immense height and reach advantage, Fury can control a fight.
The legendary battles with Wilder showed his durability, as he recovered from knockdowns to secure victories. In his fight with Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. By contrast, Usyk, offers a different kind of threat. Being a left-handed fighter, he uses angles and footwork. Usyk’s punches may not have knockout power, but they are delivered with pinpoint accuracy. With the date drawing closer, The betting lines for Fury vs Usyk are the subject of intense debate.
Most bookmakers favor Fury as per the betting experts, thanks to his imposing frame, his proven ability in tough situations, and his tactical brilliance. Despite being seen as the underdog doesn’t rule him out, his victories against AJ showed that he can compete at heavyweight.
For the Gypsy King could be the defining moment of his career. A triumph for Fury would add an undisputed title to his already impressive resume. Conversely, Usyk’s victory would be a monumental achievement. Becoming an undisputed champion in two different weight classes is a once-in-a-lifetime achievement.
Web: <a href="http://www.google.com.kw/url?q=https://tysonfuryvsoleksandrusyk.co.uk/">tysonfuryvsoleksandrusyk.co.uk</a>
This fight is more than just a championship fight. It’s a fight between two very different fighters. Fury’s boisterous personality is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. This is more than just a physical contest. Regardless of the outcome, the significance of this match will leave a lasting mark on the sport. The clash for the undisputed title is more than just a fight. It’s the result of relentless dedication. Whether Tyson Fury prevails through his strength and tactics, or Oleksandr Usyk triumphs with his technique and endurance, no matter the outcome, this will be a fight remembered for years to come.
The Fury-Usyk battle is more than just a boxing event. It’s a fight of grit and strategy. These two warriors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında onlayn qumar oyunlarına tələbat artdıqca, Pinup kazino kimi kazino xidmətləri daha çox tanınmağa başladı. Xüsusilə, "Pin up casino online" ifadələri çoxdan yerli istifadəçilər üçün adidir. Pinup casino müştərilərinə çox oyun növləri təklif edir.
Pin-up kazino, Azəri qumarbazlar üçün populyar seçimdir. Bu mərc platforması oyunçulara çoxlu oyun təklifləri oyunçulara təqdim edir və sərfəli bonus təklifləri ilə seçim olur.
Pin-up casino online, fərqli oyun təcrübəsi təklif edən bir platformadır. Azəri bazarında populyar olan Pin-up online, oyun həvəskarları üçün geniş oyun təcrübəsi verir.
Xüsusilə, Pinup kazino müştərilərə təhlükəsiz maliyyə idarəetmə imkanları təqdim edir. Müştərilər, rahat maliyyə əməliyyatları nəticəsində, internet oyunlarını daha asan keçirə bilərlər.
Yekun olaraq, Pin-up azerbaycan oyunçulara çoxlu oyun növlərilə yanaşı bonuslar və aksiyalar və maraqlı aksiyalar təklif edir. Bu qumar saytında, oyunçular rahat və təhlükəsiz şəraitdə oynayır.
Web: https://best-pinup.web.app
Pin-up kazino təkcə bir kazino olaraq oyunçuları cəlb etmir. Kazino həvəskarları bu kazinoda çeşidli mərc seçimlərindən həzz ala bilərlər və geniş bonus imkanlarını oyun təcrübələrinə əlavə edərlər.
Ümumilikdə, Pin-up kazino, rahat və təhlükəsiz qumar təcrübəsi istifadəçilərə verməklə oyun bazarında ən yaxşı seçimlərdən biridir. yerli oyunçular arasında populyarlığı dikkətə layiqdir.
Fury, the Gypsy King, and Usyk, the technician are preparing for an epic showdown of historic proportions. It’s far beyond a championship match; it represents their quest for immortality. The towering Fury has earned worldwide fame with his charisma and remarkable adaptability inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. In contrast, Usyk, the Ukrainian master poses a unique challenge to boxing’s biggest stars. On the flip side, Usyk, a southpaw master is a true test for Fury not just for Fury, but for the entire division. His journey to global fame was marked by his undisputed cruiserweight reign, as an undisputed champion. Don’t miss out for the most anticipated boxing match of the year as Usyk takes on Fury in an unforgettable showdown! Catch every punch live on our website. Don’t miss your chance — visit <a href="https://www.jboss.org/downloading/?projectid=jbossas&url=https://tysonfuryvoleksandrusyk.com/">tysonfuryvoleksandrusyk.com</a> today and watch the match in high quality!
Across the UK, the ring walks are planned for close to prime time, making it ideal for a prime-time audience. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, this will be a must-see event. The fight’s location has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, fans can be sure: it will be a spectacle. While the spotlight remains on Fury and Usyk, the fights leading up to the main event is also generating excitement. High-profile matches are known for strong supporting fights, providing non-stop action before the headliner.
Historically, preliminary fights on major cards have showcased rising stars. Boxers seeking the spotlight capitalize on the exposure to showcase their skills, as all eyes are on them. Although the lineup for the Fury Usyk undercard are still unconfirmed, fans are eagerly guessing. Might there be a cruiserweight spectacle? No matter the final roster, fans can expect fireworks. What makes this fight so intriguing is the dynamic between these fighters. Tyson Fury’s size and agility are unparalleled in the sport. With his immense height and reach advantage, Fury can control a fight.
The legendary battles with Wilder proved his toughness, bouncing back from adversity to secure victories. Against Wladimir Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, offers a different kind of threat. With his unorthodox stance, he uses angles and footwork. Usyk’s punches aren’t the heaviest in the division, their timing wears down foes. With the date drawing closer, The betting lines for Fury vs Usyk have fans and analysts speculating.
Tyson Fury is the slight favorite according to the odds, given his physical stature, his proven ability in tough situations, and his tactical brilliance. Despite being seen as the underdog doesn’t mean he’s an underdog in spirit, his wins over Anthony Joshua demonstrated his ability in the heavyweight ranks.
For Tyson Fury presents a shot at undisputed glory. A triumph for Fury would solidify his claim as the greatest heavyweight of his generation. Conversely, Usyk’s victory would mark him as one of the sport’s greats. Securing two undisputed titles is a rare accomplishment.
Web: <a href="http://clients1.google.com.ar/url?q=https://tysonfuryvoleksandrusyk.com/">tysonfuryvoleksandrusyk.com</a>
The upcoming showdown is about more than the titles. It’s a clash of personalities. Fury’s larger-than-life persona stands in stark contrast to Usyk’s composed demeanor. The clash of personalities adds depth to the narrative. It’s a fight of wills and ideologies. No matter who wins, the legacy of this fight will be remembered as a defining moment in boxing. The battle for heavyweight supremacy is a defining moment. It’s the result of relentless dedication. Should Fury claim victory through his strength and tactics, or Oleksandr Usyk triumphs thanks to his skill and resilience, no matter the outcome, this bout will go down in history.
This fight between Fury and Usyk is more than just a fight. It’s a showcase of skill and determination. The two competitors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında qumar oyunlarına tələbat artdıqca, "Pin-up casino" kimi kazino xidmətləri daha çox tanınmağa başladı. Xüsusilə, Pinup casino sözləri hazırda Azəri oyunçuları üçün sevilir. Pin-up azerbaycan öz oyunçularına çoxlu oyun növü təklif edir.
Pin-up cazino, Azərbaycandakı oyunçular üçün geniş kütləyə sahib bir qumar saytıdır. Bu platforma istifadəçilərə fərqli oyun növləri təmin edir və cəlbedici bonuslar ilə qumarbazlar tərəfindən sevilir.
Pin-up azerbaycan, bənzərsiz oyun imkanı təqdim edən bir platformadır. yerli mərcçilər arasında çox seçilən Pin-up oyunları, qumar oyunçuları üçün çeşidli bonus imkanları yaradır.
Özəlliklə, Pinup casino qumar həvəskarlarına etibarlı ödəmə üsulları oyunçularına təklif edir. İstifadəçilər, rahat və tez maliyyə əməliyyatları ilə, oyun təcrübələrini daha asan yerinə yetirə bilərlər.
Bununla yanaşı, Pin-up casino online mərc həvəskarlarına yalnız oyun təklif etmir sərfəli bonuslar təmin edir. Bu qumar saytında, qumar həvəskarları güvənli bir təcrübə yaşayır.
Web: https://best-win-pinup.web.app
Pin-up kazino təkcə oyunçuları cəlb etmir. Müştərilər burada geniş mərc təcrübəsindən istifadə edə bilər və bonus sistemini oyun təcrübələrinə əlavə edərlər.
Yekun olaraq, Pin-up kazino, sərfəli və təhlükəsiz mərc oyunları təmin etməklə onlayn qumar sektorunda lider mövqedədir. yerli mərcçilər arasında populyarlığı təsadüf deyil.
Tyson Fury and Oleksandr Usyk are on a collision course of unparalleled significance. It’s far beyond a championship match; it represents their quest for immortality. The towering Fury has become a global icon through his unique style and remarkable adaptability during fights. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. In contrast, Usyk, the technician is a fighter unlike any other to boxing’s biggest stars. Meanwhile, Usyk, a genius in the ring stands as a unique threat for Tyson Fury himself, but for the entire division. His journey to global fame was marked by his undisputed cruiserweight reign, by conquering all challengers. Prepare yourself for the most anticipated boxing match of the year as Oleksandr Usyk takes on Fury in a historic showdown! Experience every moment streamed live on our website. Don’t miss your chance — visit <a href="https://mirdetstva.printdirect.ru/utils/redirect?url=https://tysonfuryvsusyk.co.uk/">tysonfuryvsusyk.co.uk</a> right away and watch the match from the comfort of your home!
In the United Kingdom, the fight is expected to begin late evening, ensuring maximum viewership. For Usyk’s fans in Ukraine, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. The fight’s location remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, fans can be sure: the atmosphere will be electric. While the spotlight is firmly on the main event, the Fury vs Usyk undercard is shaping up to be thrilling. Major boxing events are known for strong supporting fights, offering an entire night of boxing excitement.
In the past, supporting bouts in major events have introduced future champions. Boxers seeking the spotlight capitalize on the exposure to showcase their skills, as all eyes are on them. Though the supporting fights for Fury vs Usyk has yet to be finalized, speculation runs high. Could we see rising prospects? Whatever the selection, it’s sure to add to the excitement. The most compelling part of Fury vs Usyk so intriguing is their contrasting skillsets. Fury’s towering frame and movement make him an anomaly in boxing. Being so tall yet so nimble, he commands the ring like no other.
The legendary battles with Wilder highlighted his resilience, as he recovered from knockdowns to dominate in later rounds. When he faced Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. By contrast, Usyk, relies on technique and stamina. Being a left-handed fighter, his positioning constantly challenges opponents. His strikes lack devastating strength, they consistently find their mark. With the date drawing closer, Tyson Fury vs Usyk odds have fans and analysts speculating.
Tyson Fury is the slight favorite based on the betting odds, because of his reach and height, his proven ability in tough situations, and his unpredictable nature. Despite being seen as the underdog doesn’t diminish his chances, his dominance against Joshua showed that he can compete at heavyweight.
For Tyson Fury, this fight represents an opportunity to cement his legacy. A victory would further solidify his status as the best heavyweight of this era. Meanwhile, Usyk’s victory would be a monumental achievement. Becoming the undisputed heavyweight champion is a rare accomplishment.
Web: <a href="http://cse.google.com.sa/url?q=https%3A%2F%2Ftysonfuryvsusyk.co.uk">tysonfuryvsusyk.co.uk</a>
The upcoming showdown represents something greater than a title bout. It’s a meeting of two unique worldviews. Fury’s confident and brash nature stands in stark contrast to Usyk’s composed demeanor. Such contrasts make the fight more compelling. Beyond physical ability, this fight. Whoever triumphs in this battle, the significance of this match will be remembered as a defining moment in boxing. Fury vs Usyk is a spectacle unlike any other. It’s the pinnacle of both fighters’ hard work. Whether Fury secures the win through his strength and tactics, or Usyk comes out on top with his finesse and stamina, what is clear is, this will be a legendary contest.
Tyson Fury vs Oleksandr Usyk is more than just a boxing event. It’s a contest of heart and willpower. The two competitors will give everything they have.
Visit for more information: #crosslink[3,L -
Azərbaycan ərazisində internet qumarına seçim artdıqca, "Pin-up casino" kimi platformalar daha çox tanınmağa başladı. Əsasən, Pin-up azerbaycan brendləri hazırda Azəri oyunçuları üçün sevilir. Pin-up azerbaycan istifadəçilərə çox oyun növləri təklif edir.
Pin up kazino, yerli oyunçular üçün geniş kütləyə sahib bir qumar saytıdır. Bu kazino qumarbazlara rəngarəng oyunlar təklif edib və cazibədar aksiyalar ilə oyunçuları özünə cəlb edir.
Pin-up azerbaycan, geniş oyun variantları təklif edən xidmətdir. Azəri bazarında çox seçilən Pin-up oyunları, qumar oyunçuları üçün geniş oyun təcrübəsi verir.
Bununla yanaşı, Pinup casino istifadəçilərə şəffaf və təhlükəsiz depozit və çıxarış imkanı təqdim edir. Oyun həvəskarları, rahat depozit çıxarış sistemi ilə, mərc təcrübələrini çox rahat yerinə yetirə bilərlər.
Yekun olaraq, Pin-up cazino mərcçilərə təkcə oyunlar deyil, həm də bonuslar və aksiyalar oyun təcrübəsini daha da maraqlı edir. Bu kazinoda, oyunçular təhlükəsiz şərtlər altında mərc edir.
Web: https://win-pinup.web.app
Pin-up online kazino yalnız məhdud oyunlar təklif etmir. İstifadəçilər Pinup-da fərqli mərc seçimlərindən yararlana bilərlər və sərfəli bonus təkliflərini oyunlarına əlavə edə bilərlər.
Sonda, Pin-up cazino, müasir və təhlükəsiz qumar təcrübəsi mərc həvəskarlarına təqdim etməklə onlayn qumar dünyasında güclü mövqe tutub. Azərbaycan mərcçiləri arasında məşhur olması təsadüf deyil.
The undefeated Fury and Usyk are preparing for an epic showdown of unparalleled significance. It’s far beyond a championship match; it represents their quest for immortality. The Gypsy King has earned worldwide fame through his unique style coupled with unparalleled talent in the ring. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. In contrast, the tactical southpaw poses a unique challenge for Fury. At the same time, Oleksandr Usyk represents a formidable opponent for Tyson Fury himself, but for the entire division. His journey to global fame started with his domination of the cruiserweights, by conquering all challengers. Prepare yourself for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a must-watch showdown! Experience every moment in real time on our website. Be part of the action — visit <a href="http://feeds.osce.org/~/t/0/0/oscelatestnews/~https%3a%2f%2ffuryvsusykdate.co.uk">furyvsusykdate.co.uk</a> now and stream the event in high quality!
Across the UK, the event will kick off at close to prime time, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and for fans watching from around the world, the excitement is palpable. The fight’s location is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, one thing is certain: the excitement will be unmatched. Even though attention remains on Fury and Usyk, the fights leading up to the main event is also generating excitement. Big-ticket boxing cards are known for strong supporting fights, providing non-stop action before the headliner.
Traditionally, undercards of this caliber have been a stage for breakout performances. Contenders hoping to make their mark often seize these moments to impress fans and analysts alike, as all eyes are on them. While the names for the undercard haven’t been officially announced, there’s plenty of talk. Might there be a cruiserweight spectacle? Whatever the selection, the action will not disappoint. What makes this fight truly fascinating is the dynamic between these fighters. Tyson Fury’s size and agility set him apart from other heavyweights. At 6’9" with an 85-inch reach, Fury can control a fight.
His trilogy with Deontay Wilder proved his toughness, as he recovered from knockdowns to finish strong. When he faced Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. Meanwhile, Usyk, relies on technique and stamina. Being a left-handed fighter, he uses angles and footwork. His strikes lack devastating strength, they consistently find their mark. As fight night approaches, Predictions for this fight are the subject of intense debate.
The betting lines show Fury ahead as predicted by many experts, given his physical stature, his experience in high-pressure bouts, and his unorthodox style. Despite the odds, Usyk remains a strong contender doesn’t diminish his chances, as his victories over Joshua confirmed his toughness against big opponents.
For Tyson Fury is a chance to further solidify his greatness. A victory would solidify his claim as the greatest heavyweight of his generation. On the other hand, For Usyk, a win would mark him as one of the sport’s greats. Becoming an undisputed champion in two different weight classes is a rare accomplishment.
Web: <a href="http://clients1.google.tn/url?q=https%3A%2F%2Ffuryvsusykdate.co.uk">furyvsusykdate.co.uk</a>
The upcoming showdown is not just about the belts. It’s a fight between two very different fighters. Fury’s boisterous personality is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. It’s a fight of wills and ideologies. Regardless of the outcome, the legacy of this fight will be felt for years to come. Fury vs Usyk is a defining moment. It’s the pinnacle of both fighters’ hard work. Should Fury claim victory with his experience and unpredictability, or Usyk secures a victory with his technique and endurance, no matter the outcome, this will be a fight remembered for years to come.
Tyson Fury vs Oleksandr Usyk is more than just a boxing event. It’s a battle of minds and bodies. These two warriors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azərbaycan ərazisində internet qumarına sevgisi artdıqca, Pin-up online kimi oyun xidmətləri daha çox tanınmağa başladı. Əlavə olaraq, "Pin up casino online" şüarları hazırda Azərbaycandakı oyunçular üçün güvənlidir. Pin-up kazino online mərc həvəskarlarına çox oyun növləri təklif edir.
Pin-up azerbaycan, Azərbaycan oyunçuları üçün geniş kütləyə sahib bir qumar saytıdır. Bu kazino müştərilərə çeşidli qumar oyunları təklif edir və cəlbedici bonuslar ilə oyunçuları özünə cəlb edir.
Pin-up online kazino, fərqli oyun təcrübəsi təklif edən şirkətdir. Azəri bazarında geniş istifadə olunan Pin-up oyunları, mərc həvəskarları üçün zəngin təkliflər təqdim edir.
Bu səbəbdən, "Pin-up casino online" istifadəçilərə güvənli və şəffaf maliyyə idarəetmə imkanları təklif edir. İstifadəçilər, rahat və tez kredit kartı və elektron pul kisəsi ilə ilə təmin olunmaqla, kazino oyunlarını asan və sürətli oynaya bilərlər.
Son olaraq, Pin-up azerbaycan mərcçilərə yalnız qumar oyunları yox, həmçinin sərfəli bonuslar müştəriləri üçün yaradır. Bu qumar saytında, mərc edənlər təhlükəsiz oyun mühitində olur.
Web: https://pinup-best-bet.web.app
Pin-up azerbaycan yalnız oyunçuları cəlb etmir. Qumarçılar burada fərqli mərc seçimlərindən müxtəlif mərc imkanı əldə edə bilər və maraqlı aksiyaları mərc təcrübələrini zənginləşdirərlər.
Ümumilikdə, Pin-up azerbaycan, etibarlı mərc oyunları təqdim etməklə mərc bazarında özünü doğruldur. yerli oyunçular arasında geniş yayılması göz qabağındadır.
Fury, the Gypsy King, and Usyk, the technician are preparing for an epic showdown that will define an era. This fight is about more than just titles; it’s a battle for eternal recognition. The Gypsy King has become a global icon thanks to his personality and remarkable adaptability in the ring. Beating Wilder and Klitschko have solidified his legendary status. Meanwhile, Usyk, the technician brings an unprecedented test for Fury. At the same time, the Ukrainian technician is a true test for Fury for Tyson Fury himself, as a heavyweight contender. Usyk’s rise to prominence began in the cruiserweight division, by conquering all challengers. Don’t miss out for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! Experience every moment live on our website. Don’t miss your chance — visit <a href="https://japancar.ru/?wptouch_switch=desktop&redirect=https://usykvsfury.co.uk/">usykvsfury.co.uk</a> right away and enjoy the fight from the comfort of your home!
For British fans, the event will kick off at late evening, making it ideal for a prime-time audience. Back in Usyk’s home country, and beyond, the anticipation is at a fever pitch. The venue for Fury vs Usyk is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, fans can be sure: the excitement will be unmatched. While the spotlight remains on Fury and Usyk, the preliminary bouts is shaping up to be thrilling. Major boxing events are known for strong supporting fights, giving fans a full evening of entertainment.
In the past, preliminary fights on major cards have been a stage for breakout performances. Contenders hoping to make their mark use such opportunities to showcase their skills, with the world paying attention. Although the lineup for the Fury Usyk undercard has yet to be finalized, fans are eagerly guessing. Could we see rising prospects? Regardless of the names, the action will not disappoint. What sets this bout apart incredibly exciting is the clash of styles. Fury’s towering frame and movement are unparalleled in the sport. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
The three fights against Wilder proved his toughness, as he recovered from knockdowns to secure victories. When he faced Klitschko, his strategic genius shone through, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, offers a different kind of threat. With his unorthodox stance, his positioning constantly challenges opponents. The Ukrainian’s shots aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. As fight night approaches, The betting lines for Fury vs Usyk are the subject of intense debate.
Tyson Fury is seen as the frontrunner as per the betting experts, thanks to his imposing frame, his long career in major fights, and his unorthodox style. Despite being seen as the underdog shouldn’t be counted out, his victories against AJ confirmed his toughness against big opponents.
For the Gypsy King is a chance to further solidify his greatness. If he wins, it would put the finishing touches on a historic career. Conversely, If Usyk wins would elevate him to new heights. Becoming the undisputed heavyweight champion is a feat few can claim.
Web: <a href="http://www.google.com.au/url?q=https%3A%2F%2Fusykvsfury.co.uk">usykvsfury.co.uk</a>
Fury vs Usyk is about more than the titles. It’s a battle of contrasting styles. Fury’s larger-than-life persona is the opposite of Usyk’s humble and disciplined approach. Such contrasts make the fight more compelling. It’s about more than just skill. No matter who wins, the legacy of this fight will be remembered as a defining moment in boxing. Fury vs Usyk is more than just a fight. It’s the result of relentless dedication. If Fury wins through his strength and tactics, or Usyk comes out on top through his superior boxing ability, one thing is certain, this will be a defining moment in boxing.
This fight between Fury and Usyk is more than just a boxing event. It’s a fight of grit and strategy. The two competitors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında qumar oyunlarına güvəni artdıqca, Pin-up kazino kimi oyun xidmətləri daha çox tanınmağa başladı. Bununla bərabər, Pinup casino ifadələri çoxdan Azəri müştərilər üçün tanışdır. Pinup casino mərc həvəskarlarına rəngarəng oyunlar təklif edir.
Pinup kazino, Azərbaycandakı oyunçular üçün maraqlı seçimdir. Bu qumar saytı kazino oyunçularına geniş çeşidli oyunlar oyunçulara təqdim edir və cəlbedici bonuslar ilə seçim olur.
Pin-up online kazino, çeşidli oyun təcrübəsi təklif edən oyun məkanıdır. Azərbaycanda geniş istifadə olunan Pin-up kazino, kazino oyunçuları üçün geniş oyun variantları ilə tanınır.
Əlavə olaraq, Pin-up azerbaycan istifadəçilərə təhlükəsiz maliyyə sistemləri təklif edir. Mərc edənlər, etibarlı və tez maliyyə əməliyyatları nəticəsində, onlayn mərc oyunlarını müvafiq şəkildə təcrübə edərlər.
Sonda, Pin-up kazino oyunçulara geniş oyun təcrübəsi ilə yanaşı sərfəli bonuslar müştəriləri üçün yaradır. Pin-up-da, qumar həvəskarları rahat və təhlükəsiz şəraitdə oynayır.
Web: https://pinup-top-bet.web.app
Pin-up kazino sadəcə oyunlar ilə kifayətlənmir. İstifadəçilər Pinup-da fərqli mərc oyunlarından yararlana bilərlər və cazibədar bonus imkanlarını istifadə edə bilərlər.
Ümumilikdə, Pin-up casino online, şəffaf və güvənli kazino təcrübəsi mərc həvəskarlarına təqdim etməklə mərc bazarında özünü doğruldur. Azərbaycanda populyarlığı təsadüfi deyil.
Fury, the Gypsy King, and Usyk, the technician are set to meet in the ring of unparalleled significance. This fight is about more than just titles; it represents their quest for immortality. The towering Fury has risen to the pinnacle of the sport thanks to his personality and remarkable adaptability during fights. Beating Wilder and Klitschko have earned him recognition as one of the best ever. Meanwhile, Usyk, the Ukrainian master is a fighter unlike any other for Fury. On the flip side, Oleksandr Usyk is a true test for Fury not just for Fury, as a heavyweight contender. The ascent of Oleksandr Usyk began in the cruiserweight division, as an undisputed champion. Don’t miss out for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a historic showdown! Catch every punch in real time on our website. Join the excitement — visit <a href="http://pro.hit.gemius.pl/_sslredir/hitredir/id=aqvata_3kxzoqaqdqdv4tevfjw0d_m8oy5vq7zbltup.x7/url=furyvsusyk.org.uk">furyvsusyk.org.uk</a> right away and watch the match in high quality!
For British fans, the fight is expected to begin close to prime time, ensuring maximum viewership. In Usyk’s native Ukraine, and beyond, this will be a must-see event. The venue for Fury vs Usyk remains a hot topic, with talk of iconic boxing destinations. Wherever it happens, fans can be sure: it will be a spectacle. While the spotlight remains on Fury and Usyk, the Fury vs Usyk undercard is also generating excitement. Major boxing events are known for strong supporting fights, providing non-stop action before the headliner.
In the past, supporting bouts in major events have showcased rising stars. Fighters looking to rise through the ranks use such opportunities to impress fans and analysts alike, knowing millions are watching. Although the lineup for the Fury Usyk undercard are still unconfirmed, there’s plenty of talk. Could we see rising prospects? No matter the final roster, it’s sure to add to the excitement. What sets this bout apart so intriguing is the dynamic between these fighters. Fury’s towering frame and movement are unparalleled in the sport. Being so tall yet so nimble, he dictates the pace of bouts.
The legendary battles with Wilder proved his toughness, overcoming brutal hits to secure victories. In his fight with Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. By contrast, Usyk, offers a different kind of threat. As a southpaw, his positioning constantly challenges opponents. The Ukrainian’s shots lack devastating strength, they consistently find their mark. With the date drawing closer, Tyson Fury vs Usyk odds are the subject of intense debate.
Fury is the favored fighter as per the betting experts, due to his size advantage, his long career in major fights, and his unpredictable nature. Although Usyk is the less favored fighter doesn’t diminish his chances, his victories against AJ proved that he can handle the physicality of the heavyweight division.
For the Gypsy King could be the defining moment of his career. A victory would put the finishing touches on a historic career. Meanwhile, Usyk’s victory would mark him as one of the sport’s greats. Achieving undisputed glory in two divisions is a once-in-a-lifetime achievement.
Web: <a href="http://www.google.im/url?q=https%3A%2F%2Ffuryvsusyk.org.uk">furyvsusyk.org.uk</a>
This fight is more than just a championship fight. It’s a battle of contrasting styles. Fury’s boisterous personality is the opposite of Usyk’s humble and disciplined approach. These varying personalities make the bout even more interesting. It’s about more than just skill. Whoever triumphs in this battle, the impact of this bout will be remembered as a defining moment in boxing. This historic showdown is more than just a match. It represents the culmination of their careers. Whether Tyson Fury prevails thanks to his power and game plan, or Usyk wins with his precision with his finesse and stamina, it’s certain that, this will be a defining moment in boxing.
The Fury-Usyk battle is more than just a boxing event. It’s a showcase of skill and determination. These two warriors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Azərbaycandakı qumar sektorunda qumar oyunlarına tələbat artdıqca, Pinup kazino kimi platformalar daha çox tanınmağa başladı. Əsasən, Pin-up kazino şəklində olan platformalar indi Azərbaycandakı oyunçular üçün adidir. Pin-up casino azerbaycan oyunçulara müxtəlif oyunlar təklif edir.
Pin-up cazino, Azərbaycan oyunçuları üçün maraqlı seçimdir. Bu platforma qumarbazlara fərqli oyun növləri təklif verməkdədir və gözəl hədiyyələr ilə qumarbazlar tərəfindən sevilir.
Pinup casino, istifadəçilərə oyun növləri ilə zəngin saytdır. Azəri bazarında çox seçilən Pin-up online, oyun həvəskarları üçün çeşidli bonus imkanları yaradır.
Özəlliklə, Pin-up azerbaycan qumar həvəskarlarına güvənli ödəmə üsulları təklif etməkdədir. Oyunçular, müvafiq və təhlükəsiz depozit çıxarış sistemi sayəsində, mərc təcrübələrini çox rahat oynaya bilərlər.
Əlavə olaraq, Pin-up casino online qumarbazlara təkcə oyunlar deyil, həm də cəlbedici kampaniyalar müştəriləri üçün yaradır. Bu kazinoda, oyunçular təhlükəsiz şərtlər altında mərc edir.
Web: https://pinup-top.web.app
Pin-up cazino təkcə bir kazino olaraq məhdud deyil. Kazino həvəskarları bu kazinoda geniş mərc təcrübəsindən istifadə edə bilər və bonus sistemini mərc təcrübələrini zənginləşdirərlər.
Sonda, Pin-up casino, etibarlı mərc imkanı təmin etməklə onlayn qumar sektorunda lider mövqedədir. Azəri bazarında çox seçilməsi göz qabağındadır.
Tyson Fury and Oleksandr Usyk are preparing for an epic showdown that will define an era. This fight is about more than just titles; it’s about legacy. The Gypsy King has become a global icon with his charisma and his unmatched skills during fights. Beating Wilder and Klitschko have earned him recognition as one of the best ever. Across the ring, Usyk, the Ukrainian master is a fighter unlike any other to boxing’s biggest stars. On the flip side, Usyk, a genius in the ring stands as a unique threat for Tyson Fury himself, as a heavyweight contender. His journey to global fame began in the cruiserweight division, where he became an unstoppable force. Don’t miss out for the most anticipated boxing match of the year as Oleksandr Usyk takes on Fury in a must-watch showdown! See every move streamed live on our website. Join the excitement — visit <a href="https://indexadhu.hit.gemius.pl/_uachredir/hitredir/id=zNflnP.A5cKRubSIkAhEgKPM.mOu6a8l4prKtJVfydn.47/stparam=vdloltgqqd/fastid=bqxvmxbfvgggpjknouotnueundmq/nc=0/url=https://tysonfuryvoleksandrusyk.org.uk/">tysonfuryvoleksandrusyk.org.uk</a> right away and enjoy the fight in high quality!
In the United Kingdom, the ring walks are planned for close to prime time, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and for fans watching from around the world, the anticipation is at a fever pitch. Where the bout will take place remains a hot topic, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, one thing is certain: the atmosphere will be electric. Although the focus remains on Fury and Usyk, the fights leading up to the main event is shaping up to be thrilling. Major boxing events are known for strong supporting fights, providing non-stop action before the headliner.
In the past, supporting bouts in major events have been a stage for breakout performances. Fighters looking to rise through the ranks often seize these moments to impress fans and analysts alike, knowing millions are watching. Though the supporting fights for Fury vs Usyk are still unconfirmed, fans are eagerly guessing. Might there be a cruiserweight spectacle? Regardless of the names, the action will not disappoint. What sets this bout apart incredibly exciting is their contrasting skillsets. Tyson Fury’s size and agility make him an anomaly in boxing. Being so tall yet so nimble, he dictates the pace of bouts.
His trilogy with Deontay Wilder highlighted his resilience, as he recovered from knockdowns to finish strong. In his fight with Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, offers a different kind of threat. With his unorthodox stance, he uses angles and footwork. The Ukrainian’s shots may not have knockout power, but they are delivered with pinpoint accuracy. As anticipation builds, The betting lines for Fury vs Usyk are becoming a hot topic.
The betting lines show Fury ahead as predicted by many experts, thanks to his imposing frame, his track record in big matches, and his unorthodox style. However, Usyk's underdog status shouldn’t be counted out, as his victories over Joshua showed that he can compete at heavyweight.
For Tyson Fury, this fight presents a shot at undisputed glory. A victory would put the finishing touches on a historic career. Conversely, For Usyk, a win would mark him as one of the sport’s greats. Becoming an undisputed champion in two different weight classes is a rare accomplishment.
Web: <a href="http://www.google.vg/url?sa=t&url=http%3A%2F%2Fwww.magical-dream.com">tysonfuryvoleksandrusyk.org.uk</a>
Fury vs Usyk is more than just a championship fight. It’s a fight between two very different fighters. Fury’s confident and brash nature is the opposite of Usyk’s humble and disciplined approach. Such contrasts make the fight more compelling. This is more than just a physical contest. No matter who wins, the impact of this bout will be remembered as a defining moment in boxing. This historic showdown is more than just a match. It’s a culmination of years of hard work. Whether Tyson Fury prevails with his experience and unpredictability, or Oleksandr Usyk triumphs with his technique and endurance, it’s certain that, this will be a fight remembered for years to come.
This fight between Fury and Usyk is more than just a sporting contest. It’s a contest of heart and willpower. These men will give everything they have.
Visit for more information: #crosslink[3,L -
Azərbaycandakı qumar sektorunda online kazino oyunlarına maraq artdıqca, "Pin-up casino" kimi saytlar daha çox tanınmağa başladı. Əsasən, Pinup azerbaycan ifadələri hazırda Azəri oyunçuları üçün sevilir. Pinup casino istifadəçilərə çeşidli oyunlar təklif edir.
Pin-up cazino, Azərbaycandakı oyunçular üçün güvənli bir qumar məkanıdır. Bu mərc platforması kazino oyunçularına geniş çeşidli oyunlar təmin edir və çoxlu bonuslar ilə müştərilərini məmnun edir.
Pin-up azerbaycan, bənzərsiz oyun imkanı təqdim edən bir platformadır. Azəri bazarında çox seçilən Pin-up oyunları, oyun həvəskarları üçün fərqli oyun seçimləri ilə çıxış edir.
Xüsusilə, Pinup kazino qumar həvəskarlarına etibarlı maliyyə sistemləri təqdim edir. Oyun həvəskarları, müvafiq və təhlükəsiz maliyyə çıxarışları köməyilə, internet oyunlarını müvafiq şəkildə təcrübə edə bilərlər.
Əlavə olaraq, Pin-up cazino mərc həvəskarlarına çoxlu oyun növlərilə yanaşı bonuslar və aksiyalar müştəriləri üçün yaradır. Bu qumar saytında, qumar həvəskarları güvənli bir təcrübə yaşayır.
Web: https://top-pinup.web.app
Pin-up casino təkcə bir oyun platforması kimi məhdud deyil. Qumarçılar burada fərqli mərc seçimlərindən təcrübə edə bilərlər və geniş bonus imkanlarını istifadə edə bilərlər.
Nəticədə, Pin-up cazino, müasir və təhlükəsiz mərc təcrübəsi təqdim etməklə oyun sənayesində güclü mövqe tutub. Azərbaycanda məşhur olması təsadüfi deyil.
The undefeated Fury and Usyk are preparing for an epic showdown that will define an era. It’s far beyond a championship match; it’s about legacy. Tyson Fury has risen to the pinnacle of the sport with his charisma and remarkable adaptability inside the ropes. Beating Wilder and Klitschko have solidified his legendary status. On the other hand, the tactical southpaw brings an unprecedented test for Fury. Meanwhile, Usyk, a genius in the ring is a true test for Fury for Tyson Fury himself, and for boxing fans worldwide. Usyk’s rise to prominence began in the cruiserweight division, by conquering all challengers. Get ready for an epic boxing match of the year as Usyk takes on Fury in an unforgettable showdown! See every move in real time on our website. Join the excitement — visit <a href="https://polesie.spb.ru/udata/emarket/basket/put/element/2482/?redirect-uri=https://furyvsusykdate.co.uk/">furyvsusykdate.co.uk</a> right away and watch the match from the comfort of your home!
In the United Kingdom, the event will kick off at late evening, offering perfect timing for viewers. In Usyk’s native Ukraine, and beyond, the anticipation is at a fever pitch. Where the bout will take place is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, it’s guaranteed: the atmosphere will be electric. Even though attention is firmly on the main event, the preliminary bouts is also generating excitement. High-profile matches include preliminary bouts with top talent, offering an entire night of boxing excitement.
Traditionally, undercards of this caliber have been a stage for breakout performances. Contenders hoping to make their mark use such opportunities to demonstrate their talent, as all eyes are on them. While the names for the undercard has yet to be finalized, speculation runs high. Might there be a cruiserweight spectacle? Regardless of the names, the action will not disappoint. What makes this fight incredibly exciting is their contrasting skillsets. Fury’s towering frame and movement are unparalleled in the sport. At 6’9" with an 85-inch reach, he commands the ring like no other.
The legendary battles with Wilder highlighted his resilience, bouncing back from adversity to dominate in later rounds. In his fight with Klitschko, his strategic genius shone through, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, relies on technique and stamina. As a southpaw, he uses angles and footwork. His strikes may not have knockout power, their timing wears down foes. With the date drawing closer, Tyson Fury vs Usyk odds are the subject of intense debate.
Most bookmakers favor Fury based on the betting odds, thanks to his imposing frame, his experience in high-pressure bouts, and his adaptability. Although Usyk is the less favored fighter doesn’t mean he’s an underdog in spirit, his dominance against Joshua proved that he can handle the physicality of the heavyweight division.
For Fury himself is a chance to further solidify his greatness. A victory would add an undisputed title to his already impressive resume. On the other hand, If Usyk wins would mark him as one of the sport’s greats. Becoming the undisputed heavyweight champion is a rare accomplishment.
Web: <a href="http://www.google.je/url?q=https://furyvsusykdate.co.uk/">furyvsusykdate.co.uk</a>
This fight is about more than the titles. It’s a clash of personalities. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. These varying personalities make the bout even more interesting. Beyond physical ability, this fight. Whoever triumphs in this battle, the impact of this bout will be remembered as a defining moment in boxing. The clash for the undisputed title is a defining moment. It’s the result of relentless dedication. Whether Fury secures the win with his experience and unpredictability, or Usyk comes out on top thanks to his skill and resilience, it’s certain that, this will be a fight remembered for years to come.
This fight between Fury and Usyk is a spectacle of a lifetime. It’s a fight of grit and strategy. Both fighters will give everything they have.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are ready to face each other in a fight of historic proportions. It’s far beyond a championship match; it’s about legacy. Tyson Fury has earned worldwide fame through his unique style and remarkable adaptability inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. On the other hand, Usyk, the Ukrainian master poses a unique challenge for Fury. On the flip side, Usyk, a genius in the ring represents a formidable opponent not just for Fury, as a heavyweight contender. His journey to global fame was marked by his undisputed cruiserweight reign, as an undisputed champion. Get ready for the most anticipated boxing match of the year as Usyk takes on Tyson Fury in an unforgettable showdown! Catch every punch live on our website. Don’t miss your chance — visit <a href="http://rcde.ru/method/http//tysonvsusyk.com">tysonvsusyk.com</a> now and enjoy the fight from the comfort of your home!
In the United Kingdom, the ring walks are planned for around 10 PM GMT, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and for fans watching from around the world, the anticipation is at a fever pitch. Where the bout will take place is still under speculation, with talk of iconic boxing destinations. Regardless of the venue, fans can be sure: it will be a spectacle. While the spotlight is centered on the headline fight, the preliminary bouts promises plenty of action. High-profile matches include preliminary bouts with top talent, giving fans a full evening of entertainment.
Traditionally, preliminary fights on major cards have showcased rising stars. Boxers seeking the spotlight capitalize on the exposure to impress fans and analysts alike, with the world paying attention. Although the lineup for the Fury Usyk undercard has yet to be finalized, speculation runs high. Could we see rising prospects? No matter the final roster, it’s sure to add to the excitement. What sets this bout apart so intriguing is their contrasting skillsets. Fury’s towering frame and movement are unparalleled in the sport. Being so tall yet so nimble, he commands the ring like no other.
The legendary battles with Wilder proved his toughness, bouncing back from adversity to finish strong. When he faced Klitschko, his strategic genius shone through, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, relies on technique and stamina. As a southpaw, he uses angles and footwork. His strikes may not have knockout power, they consistently find their mark. With the date drawing closer, Tyson Fury vs Usyk odds are becoming a hot topic.
Most bookmakers favor Fury as predicted by many experts, due to his size advantage, his proven ability in tough situations, and his unpredictable nature. Despite being seen as the underdog doesn’t rule him out, his victories against AJ confirmed his toughness against big opponents.
For Tyson Fury represents an opportunity to cement his legacy. A triumph for Fury would add an undisputed title to his already impressive resume. On the other hand, If Usyk wins would be a monumental achievement. Achieving undisputed glory in two divisions is a rare accomplishment.
Web: <a href="http://images.google.co.ck/url?q=https://tysonvsusyk.com/">tysonvsusyk.com</a>
The upcoming showdown is not just about the belts. It’s a battle of contrasting styles. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. These differences add complexity to the fight. Beyond physical ability, this fight. No matter who wins, the impact of this bout will be felt for years to come. The clash for the undisputed title is more than just a match. It’s a culmination of years of hard work. Should Fury claim victory with his experience and unpredictability, or Usyk secures a victory with his technique and endurance, one thing is certain, this will be a fight remembered for years to come.
Fury vs Usyk is a spectacle of a lifetime. It’s a contest of heart and willpower. These two warriors will give everything they have.
Visit for more information: #crosslink[3,L -
Azərbaycan ərazisində virtual qumar oyunlarına istək artdıqca, Pinup kazino kimi şirkətlər daha çox tanınmağa başladı. Özəlliklə, "Pin up casino online" sözləri son zamanlar Azərbaycandakı oyunçular üçün adidir. Pin-up azerbaycan öz oyunçularına çoxlu oyun növü təklif edir.
Pin-up kazino, Azərbaycandakı oyunçular üçün geniş yayılmış bir xidmətdir. Bu qumar xidməti istifadəçilərə müxtəlif oyunlar təklif edib və bonus imkanları ilə qumarbazlar tərəfindən sevilir.
Pinup casino, istifadəçilərə oyun növləri ilə zəngin onlayn kazinodur. Azərbaycanda geniş istifadə olunan Pin-up kazino, istifadəçilər üçün geniş oyun variantları ilə tanınır.
Əlavə olaraq, Pin-up azerbaycan müştərilərə etibarlı və güvənli ödəmə sistemləri verir. Oyun həvəskarları, sürətli və asan maliyyə çıxarışları nəticəsində, qumar təcrübələrini asan və sürətli təcrübə edə bilərlər.
Əlavə olaraq, Pin-up casino online müştərilərə geniş oyun təcrübəsi ilə yanaşı cəlbedici kampaniyalar və maraqlı aksiyalar təklif edir. Pinup-da, oyunçular rahat və təhlükəsiz şəraitdə oynayır.
Web: https://pinup-best-bet.web.app
Pin-up cazino təkcə məhdud deyil. Kazino həvəskarları bu kazinoda fərqli mərc seçimlərindən faydalanıb və bonus sistemini istifadə edə bilərlər.
Beləliklə, Pin-up cazino, şəffaf və güvənli qumar təcrübəsi oyunçulara təklif etməklə oyun bazarında oyunçular arasında geniş istifadə edilir. Azərbaycanda seçim olması açıq bir faktdır.
These two heavyweight champions are set to meet in the ring of unparalleled significance. It’s far beyond a championship match; it represents their quest for immortality. The Gypsy King has risen to the pinnacle of the sport thanks to his personality coupled with unparalleled talent in the ring. His victories over Deontay Wilder and Wladimir Klitschko have cemented his place among the all-time greats. In contrast, Usyk, the technician brings an unprecedented test for Fury. On the flip side, Oleksandr Usyk stands as a unique threat not just for Fury, as a heavyweight contender. The ascent of Oleksandr Usyk began in the cruiserweight division, where he became an unstoppable force. Get ready for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! See every move in real time on our website. Join the excitement — visit <a href="http://sovermed.ru/?wptouch_switch=desktop&redirect=https://usykvsfurydate.com/">usykvsfurydate.com</a> now and enjoy the fight from the comfort of your home!
Across the UK, the ring walks are planned for late evening, making it ideal for a prime-time audience. Back in Usyk’s home country, and for fans watching from around the world, the anticipation is at a fever pitch. The venue for Fury vs Usyk is still under speculation, with talk of iconic boxing destinations. Regardless of the venue, fans can be sure: the atmosphere will be electric. Even though attention is centered on the headline fight, the fights leading up to the main event promises plenty of action. Major boxing events are known for strong supporting fights, providing non-stop action before the headliner.
Historically, undercards of this caliber have showcased rising stars. Contenders hoping to make their mark use such opportunities to demonstrate their talent, with the world paying attention. Although the lineup for the Fury Usyk undercard has yet to be finalized, speculation runs high. Might there be a cruiserweight spectacle? Whatever the selection, fans can expect fireworks. The most compelling part of Fury vs Usyk incredibly exciting is their contrasting skillsets. Tyson Fury’s size and agility are unparalleled in the sport. Being so tall yet so nimble, he dictates the pace of bouts.
The legendary battles with Wilder showed his durability, overcoming brutal hits to dominate in later rounds. In his fight with Klitschko, his strategic genius shone through, showing he’s both powerful and smart. By contrast, Usyk, relies on technique and stamina. With his unorthodox stance, his movements create openings. Usyk’s punches aren’t the heaviest in the division, they consistently find their mark. As fight night approaches, The betting lines for Fury vs Usyk are the subject of intense debate.
Most bookmakers favor Fury as per the betting experts, due to his size advantage, his proven ability in tough situations, and his unorthodox style. Despite the odds, Usyk remains a strong contender shouldn’t be counted out, as his victories over Joshua proved that he can handle the physicality of the heavyweight division.
For the Gypsy King represents an opportunity to cement his legacy. A victory would solidify his claim as the greatest heavyweight of his generation. Meanwhile, If Usyk wins would elevate him to legendary status. Becoming an undisputed champion in two different weight classes is a once-in-a-lifetime achievement.
Web: <a href="http://www.google.com.ua/url?sa=t&url=https%3A%2F%2Fusykvsfurydate.com">usykvsfurydate.com</a>
This fight is more than just a championship fight. It’s a clash of personalities. Fury’s boisterous personality is the opposite of Usyk’s humble and disciplined approach. These differences add complexity to the fight. Beyond physical ability, this fight. Whoever triumphs in this battle, the impact of this bout will be remembered as a defining moment in boxing. The clash for the undisputed title is more than just a match. It’s the result of relentless dedication. If Fury wins thanks to his power and game plan, or Oleksandr Usyk triumphs with his technique and endurance, one thing is certain, this will be a fight remembered for years to come.
Fury vs Usyk is more than just a boxing event. It’s a battle of minds and bodies. These two warriors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Azərbaycanda online kazino oyunlarına istək artdıqca, Pin-up kazino kimi kazino xidmətləri daha çox tanınmağa başladı. Özəlliklə, "Pin up casino online" sözləri artıq yerli oyunçular üçün güvənlidir. Pin-up casino azerbaycan öz oyunçularına müxtəlif oyunlar təklif edir.
Pin-up kazino, Azərbaycan oyunçuları üçün maraqlı seçimdir. Bu qumar xidməti kazino oyunçularına fərqli oyun növləri oyunçulara təqdim edir və sərfəli bonus təklifləri ilə seçim olur.
Pin-up online kazino, çeşidli oyun təcrübəsi təklif edən şirkətdir. yerli mərcçilər arasında oyunçular tərəfindən sevilən Pin-up kazino, qumar oyunçuları üçün geniş oyun variantları ilə tanınır.
Bu səbəbdən, Pin-up azerbaycan müştərilərə etibarlı və güvənli ödəmə üsulları təmin edir. İstifadəçilər, rahat və tez depozit çıxarış sistemi nəticəsində, qumar təcrübələrini müvafiq şəkildə təcrübə edərlər.
Əlavə olaraq, Pin-up kazino istifadəçilərə təkcə oyun imkanı deyil bonus imkanı oyunçularına verir. Bu platformada, müştərilər özlərini güvəndə hiss edir.
Web: https://win-pinup.web.app
Pin-up azerbaycan sadəcə sadə oyunla bitmir. Müştərilər burada bənzərsiz mərc imkanlarından həzz ala bilərlər və bonus sistemini mərc təcrübələrini zənginləşdirərlər.
Ümumilikdə, Pin-up azerbaycan, şəffaf və güvənli mərc oyunları təqdim etməklə onlayn mərc dünyasında lider mövqedədir. Azərbaycanda çox seçilməsi əlamətdardır.
The undefeated Fury and Usyk are ready to face each other in a fight that will define an era. It’s not merely about the belts; it’s about legacy. Tyson Fury has earned worldwide fame with his charisma and remarkable adaptability during fights. Beating Wilder and Klitschko have cemented his place among the all-time greats. Meanwhile, Usyk, the Ukrainian master poses a unique challenge to boxing’s biggest stars. Meanwhile, Usyk, a southpaw master represents a formidable opponent for Tyson Fury himself, and for boxing fans worldwide. The ascent of Oleksandr Usyk began in the cruiserweight division, as an undisputed champion. Don’t miss out for the most anticipated boxing match of the year as Usyk takes on Fury in a historic showdown! Experience every moment in real time on our website. Be part of the action — visit <a href="https://m.opt-union.ru/?no_mobail=1&url=https://usykvsfurydate.org.uk/">usykvsfurydate.org.uk</a> today and enjoy the fight from the comfort of your home!
For British fans, the fight is expected to begin close to prime time, ensuring maximum viewership. Back in Usyk’s home country, and beyond, the excitement is palpable. The venue for Fury vs Usyk is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, one thing is certain: the atmosphere will be electric. Even though attention is firmly on the main event, the preliminary bouts is shaping up to be thrilling. Major boxing events are known for strong supporting fights, providing non-stop action before the headliner.
Traditionally, undercards of this caliber have been a stage for breakout performances. Contenders hoping to make their mark use such opportunities to demonstrate their talent, knowing millions are watching. Although the lineup for the Fury Usyk undercard haven’t been officially announced, speculation runs high. Might there be a cruiserweight spectacle? No matter the final roster, fans can expect fireworks. What makes this fight so intriguing is the clash of styles. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. With his immense height and reach advantage, Fury can control a fight.
The legendary battles with Wilder proved his toughness, overcoming brutal hits to secure victories. When he faced Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. As a southpaw, he uses angles and footwork. The Ukrainian’s shots lack devastating strength, they consistently find their mark. As anticipation builds, Predictions for this fight are the subject of intense debate.
The betting lines show Fury ahead based on the betting odds, because of his reach and height, his long career in major fights, and his adaptability. Despite being seen as the underdog doesn’t mean he’s an underdog in spirit, his victories against AJ confirmed his toughness against big opponents.
For Fury himself could be the defining moment of his career. A triumph for Fury would put the finishing touches on a historic career. On the other hand, For Usyk, a win would elevate him to new heights. Becoming the undisputed heavyweight champion is a once-in-a-lifetime achievement.
Web: <a href="http://www.google.sh/url?sa=t&url=http%3A%2F%2Fwww.magical-dream.com">usykvsfurydate.org.uk</a>
This fight is more than just a championship fight. It’s a fight between two very different fighters. Fury’s confident and brash nature stands in stark contrast to Usyk’s composed demeanor. The clash of personalities adds depth to the narrative. It’s about more than just skill. Regardless of the outcome, the legacy of this fight will reverberate throughout boxing history. The battle for heavyweight supremacy is more than just a fight. It’s the result of relentless dedication. Should Fury claim victory through his strength and tactics, or Usyk wins with his precision thanks to his skill and resilience, no matter the outcome, this will be a fight remembered for years to come.
This fight between Fury and Usyk is more than just a sporting contest. It’s a contest of heart and willpower. These men will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azərbaycan ərazisində virtual qumar oyunlarına tələbat artdıqca, Pin-up online kimi onlayn mərc xidmətləri daha çox tanınmağa başladı. Özəlliklə, Pin-up azerbaycan adları hazırda Azərbaycandakı oyunçular üçün sevilir. Pin-up casino azerbaycan mərc həvəskarlarına çox oyun növləri təklif edir.
Pin-up online casino, Azərbaycan oyunçuları üçün ən sevilən platformalardan biridir. Bu qumar xidməti istifadəçilərə rəngarəng oyunlar təklif edir və gözəl hədiyyələr ilə mərc edənləri özünə cəlb edir.
Pinup casino, istifadəçilərə oyun növləri ilə zəngin xidmətdir. yerli mərcçilər arasında geniş istifadə olunan Pin-up kazino, oyun həvəskarları üçün geniş oyun təcrübəsi verir.
Bununla yanaşı, Pinup casino müştərilərə şəffaf və təhlükəsiz maliyyə sistemləri verir. Oyunçular, çox rahat depozit və pul çıxarış imkanları sayəsində, mərc təcrübələrini daha asan yerinə yetirə bilərlər.
Əlavə olaraq, Pin-up azerbaycan mərcçilərə yalnız qumar oyunları yox, həmçinin cəlbedici kampaniyalar təmin edir. Pin-up-da, kazino həvəskarları təhlükəsiz oyun mühitində olur.
Web: https://pinup-top-bet.web.app
Pin-up kazino təkcə oyunçuları cəlb etmir. Oyunçular burada fərqli mərc seçimlərindən həzz ala bilərlər və cazibədar bonus imkanlarını oyun təcrübələrinə əlavə edərlər.
Sonda, Pin-up kazino, etibarlı kazino təcrübəsi mərc həvəskarlarına təqdim etməklə onlayn qumar sektorunda güclü mövqe tutub. yerli mərcçilər arasında seçim olması dikkətə layiqdir.
These two heavyweight champions are preparing for an epic showdown of historic proportions. This fight is about more than just titles; it’s a battle for eternal recognition. The Gypsy King has risen to the pinnacle of the sport with his charisma and his unmatched skills inside the ropes. Beating Wilder and Klitschko have solidified his legendary status. Across the ring, Oleksandr Usyk poses a unique challenge for Fury. On the flip side, Usyk, a southpaw master represents a formidable opponent for the heavyweight ranks overall, as a heavyweight contender. Usyk’s rise to prominence started with his domination of the cruiserweights, by conquering all challengers. Prepare yourself for a thrilling boxing match of the year as Oleksandr Usyk takes on Fury in a must-watch showdown! See every move live on our website. Be part of the action — visit <a href="https://coop.theeroticreview.com/hit.php?s=1&p=2&w=101994&t=0&c=&u=https://tysonvsusyk.com/">tysonvsusyk.com</a> right away and stream the event in high quality!
Across the UK, the event will kick off at close to prime time, offering perfect timing for viewers. Back in Usyk’s home country, and for fans watching from around the world, the anticipation is at a fever pitch. The venue for Fury vs Usyk has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. Regardless of the venue, it’s guaranteed: the atmosphere will be electric. While the spotlight is firmly on the main event, the fights leading up to the main event is also generating excitement. Major boxing events include preliminary bouts with top talent, offering an entire night of boxing excitement.
In the past, undercards of this caliber have showcased rising stars. Boxers seeking the spotlight use such opportunities to showcase their skills, knowing millions are watching. Although the lineup for the Fury Usyk undercard are still unconfirmed, there’s plenty of talk. Will there be a heavyweight clash? Regardless of the names, the action will not disappoint. The most compelling part of Fury vs Usyk truly fascinating is the clash of styles. The Gypsy King’s unusual blend of height and speed are unparalleled in the sport. Being so tall yet so nimble, he dictates the pace of bouts.
The legendary battles with Wilder proved his toughness, as he recovered from knockdowns to finish strong. Against Wladimir Klitschko, his strategic genius shone through, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, offers a different kind of threat. Being a left-handed fighter, his positioning constantly challenges opponents. His strikes aren’t the heaviest in the division, their timing wears down foes. With the date drawing closer, Predictions for this fight are the subject of intense debate.
Tyson Fury is seen as the frontrunner according to the odds, given his physical stature, his long career in major fights, and his adaptability. Despite being seen as the underdog shouldn’t be counted out, as his victories over Joshua demonstrated his ability in the heavyweight ranks.
For Tyson Fury is a chance to further solidify his greatness. A victory would solidify his claim as the greatest heavyweight of his generation. Meanwhile, If Usyk wins would elevate him to new heights. Securing two undisputed titles is a feat few can claim.
Web: <a href="http://www.google.rw/url?q=https://tysonvsusyk.com/">tysonvsusyk.com</a>
Fury vs Usyk is not just about the belts. It’s a battle of contrasting styles. Fury’s boisterous personality is the opposite of Usyk’s humble and disciplined approach. The clash of personalities adds depth to the narrative. This is more than just a physical contest. Whoever triumphs in this battle, the legacy of this fight will leave a lasting mark on the sport. Fury vs Usyk is more than just a match. It’s the result of relentless dedication. Whether Fury secures the win with his experience and unpredictability, or Usyk wins with his precision with his finesse and stamina, no matter the outcome, this will be a fight remembered for years to come.
This fight between Fury and Usyk is more than just a boxing event. It’s a fight of grit and strategy. The two competitors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında online kazino oyunlarına seçim artdıqca, Pinup kazino kimi oyun xidmətləri daha çox tanınmağa başladı. Bununla bərabər, Pin-up azerbaycan sözləri indi Azəri oyunçuları üçün güvənlidir. Pin-up casino azerbaycan istifadəçilərə çeşidli oyunlar təklif edir.
Pin-up kazino, Azəri istifadəçilər üçün ən sevilən platformalardan biridir. Bu onlayn kazino qumarbazlara müxtəlif oyunlar verir və sərfəli bonus təklifləri ilə qumarbazlar tərəfindən sevilir.
Pin-up online kazino, bənzərsiz oyun imkanı təqdim edən şirkətdir. Azərbaycan ərazisində populyar olan Pinup, istifadəçilər üçün geniş oyun variantları ilə tanınır.
Xüsusilə, "Pin-up casino online" müştərilərə güvənli və şəffaf ödəmə üsulları verir. İstifadəçilər, çox rahat depozit çıxarış sistemi nəticəsində, onlayn mərc oyunlarını daha asan yerinə yetirə bilərlər.
Nəticə etibarilə, Pinup kazino müştərilərə təkcə oyunlar deyil, həm də bonuslar və aksiyalar oyun təcrübəsini daha da maraqlı edir. Pin-up-da, oyunçular güvənli bir təcrübə yaşayır.
Web: https://pinup-best-bet.web.app
Pin-up casino yalnız bir mərc saytı kimi sadə oyunla bitmir. İstifadəçilər Pinup-da müxtəlif mərc növlərindən müxtəlif mərc imkanı əldə edə bilər və bonus sistemini oyun təcrübəsini artırarlar.
Beləliklə, Pin-up kazino, rahat və təhlükəsiz oyun imkanı təmin etməklə oyun sənayesində özünü doğruldur. Azərbaycanda çox seçilməsi təsadüfi deyil.
These two heavyweight champions are preparing for an epic showdown of unparalleled significance. It’s far beyond a championship match; it represents their quest for immortality. The towering Fury has earned worldwide fame with his charisma coupled with unparalleled talent in the ring. Beating Wilder and Klitschko have cemented his place among the all-time greats. In contrast, Usyk, the technician is a fighter unlike any other to the heavyweight division. Meanwhile, Usyk, a genius in the ring represents a formidable opponent for the heavyweight ranks overall, as a heavyweight contender. His journey to global fame began in the cruiserweight division, by conquering all challengers. Get ready for a thrilling boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a historic showdown! Experience every moment streamed live on our website. Be part of the action — visit <a href="https://www.soft-major.ru/all?a:aHR0cHM6Ly9tb2RzLW1lbnUucnUv">usykvsfury.co.uk</a> right away and watch the match with top-notch streaming!
For British fans, the event will kick off at late evening, offering perfect timing for viewers. For Usyk’s fans in Ukraine, as well as viewers across Europe and the Americas, the excitement is palpable. The venue for Fury vs Usyk has yet to be confirmed, with talk of iconic boxing destinations. No matter the location, it’s guaranteed: the excitement will be unmatched. Although the focus is centered on the headline fight, the Fury vs Usyk undercard is shaping up to be thrilling. High-profile matches are known for strong supporting fights, providing non-stop action before the headliner.
Traditionally, undercards of this caliber have introduced future champions. Contenders hoping to make their mark capitalize on the exposure to impress fans and analysts alike, knowing millions are watching. Although the lineup for the Fury Usyk undercard are still unconfirmed, fans are eagerly guessing. Could we see rising prospects? Whatever the selection, fans can expect fireworks. What makes this fight truly fascinating is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed are unparalleled in the sport. At 6’9" with an 85-inch reach, Fury can control a fight.
His trilogy with Deontay Wilder highlighted his resilience, bouncing back from adversity to dominate in later rounds. When he faced Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Meanwhile, Usyk, brings speed, precision, and finesse. As a southpaw, his movements create openings. Usyk’s punches aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. As fight night approaches, The betting lines for Fury vs Usyk have fans and analysts speculating.
The betting lines show Fury ahead as predicted by many experts, thanks to his imposing frame, his proven ability in tough situations, and his adaptability. However, Usyk's underdog status shouldn’t be counted out, his victories against AJ confirmed his toughness against big opponents.
For Fury himself presents a shot at undisputed glory. A triumph for Fury would solidify his claim as the greatest heavyweight of his generation. Conversely, If Usyk wins would elevate him to new heights. Securing two undisputed titles is a rare accomplishment.
Web: <a href="http://google.com.kw/url?q=https://usykvsfury.co.uk/">usykvsfury.co.uk</a>
This fight is about more than the titles. It’s a battle of contrasting styles. Fury’s boisterous personality is in stark contrast to Usyk’s quiet intensity. These differences add complexity to the fight. Beyond physical ability, this fight. Whoever triumphs in this battle, the impact of this bout will be remembered as a defining moment in boxing. The battle for heavyweight supremacy is more than just a match. It’s a culmination of years of hard work. Whether Fury secures the win with his size and strategy, or Usyk secures a victory with his technique and endurance, one thing is certain, this will be a legendary contest.
This fight between Fury and Usyk is more than just a boxing event. It’s a battle of minds and bodies. These two warriors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azərbaycandakı qumar sektorunda internet qumarına maraq artdıqca, Pin-up online kimi şirkətlər daha çox tanınmağa başladı. Xüsusilə, Pin-up azerbaycan şüarları hazırda yerli istifadəçilər üçün adidir. Pin-up azerbaycan mərc həvəskarlarına çeşidli oyunlar təklif edir.
Pin-up cazino, Azərbaycan oyunçuları üçün populyar seçimdir. Bu qumar xidməti müştərilərə müxtəlif oyunlar təmin edir və bonus imkanları ilə istifadəçilərin diqqətini çəkir.
Pin-up azerbaycan, çeşidli oyun təcrübəsi təklif edən saytdır. yerli mərcçilər arasında oyunçular tərəfindən sevilən Pin-up kazino, kazino oyunçuları üçün geniş oyun təcrübəsi verir.
Xüsusilə, Pin-up azerbaycan oyunçulara güvənli maliyyə əməliyyatları təmin edir. Kazino iştirakçıları, sürətli və asan maliyyə əməliyyatları köməyilə, internet oyunlarını asan və sürətli oynaya bilərlər.
Bununla yanaşı, Pin-up casino müştərilərə təkcə oyun imkanı deyil sərfəli bonuslar təqdim edir. Bu onlayn kazinoda, mərc edənlər özlərini güvəndə hiss edir.
Web: https://pinup-best-bet.web.app
Pin-up azerbaycan təkcə bir oyun platforması kimi oyunlar ilə kifayətlənmir. Qumarçılar burada fərqli mərc oyunlarından müxtəlif mərc imkanı əldə edə bilər və maraqlı aksiyaları qazanmaq imkanı əldə edərlər.
Yekun olaraq, Pin-up azerbaycan, güvənli qumar təcrübəsi oyunçulara təklif etməklə mərc bazarında ən sevilən platformalardan olur. yerli mərcçilər arasında seçim olması təsadüfi deyil.
The undefeated Fury and Usyk are ready to face each other in a fight of unparalleled significance. It’s far beyond a championship match; it represents their quest for immortality. Fury, an undefeated champion has become a global icon with his charisma coupled with unparalleled talent inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. On the other hand, the tactical southpaw poses a unique challenge to the heavyweight division. Meanwhile, Usyk, a southpaw master is a true test for Fury for Tyson Fury himself, and for boxing fans worldwide. His journey to global fame started with his domination of the cruiserweights, by conquering all challengers. Get ready for a thrilling boxing match of the year as Usyk takes on Fury in a must-watch showdown! Experience every moment live on our website. Be part of the action — visit <a href="http://mahaleksmos.nnov.org/common/redir.php?https://tysonfuryvsoleksandrusyk.co.uk/">tysonfuryvsoleksandrusyk.co.uk</a> now and enjoy the fight with top-notch streaming!
In the United Kingdom, the fight is expected to begin late evening, ensuring maximum viewership. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, the excitement is palpable. The venue for Fury vs Usyk remains a hot topic, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, fans can be sure: the atmosphere will be electric. Even though attention is centered on the headline fight, the Fury vs Usyk undercard promises plenty of action. Major boxing events are known for strong supporting fights, giving fans a full evening of entertainment.
In the past, undercards of this caliber have been a stage for breakout performances. Contenders hoping to make their mark often seize these moments to showcase their skills, knowing millions are watching. Though the supporting fights for Fury vs Usyk has yet to be finalized, there’s plenty of talk. Could we see rising prospects? Whatever the selection, fans can expect fireworks. What makes this fight truly fascinating is the dynamic between these fighters. Fury’s towering frame and movement make him an anomaly in boxing. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
The three fights against Wilder showed his durability, overcoming brutal hits to secure victories. In his fight with Klitschko, his strategic genius shone through, demonstrating his mental sharpness. By contrast, Usyk, relies on technique and stamina. With his unorthodox stance, he uses angles and footwork. The Ukrainian’s shots aren’t the heaviest in the division, their timing wears down foes. As fight night approaches, Tyson Fury vs Usyk odds are becoming a hot topic.
The betting lines show Fury ahead as per the betting experts, thanks to his imposing frame, his track record in big matches, and his adaptability. However, Usyk's underdog status doesn’t rule him out, his wins over Anthony Joshua showed that he can compete at heavyweight.
For Fury himself presents a shot at undisputed glory. A victory would further solidify his status as the best heavyweight of this era. Conversely, For Usyk, a win would mark him as one of the sport’s greats. Becoming an undisputed champion in two different weight classes is a once-in-a-lifetime achievement.
Web: <a href="http://clients1.google.co.ck/url?q=https%3A%2F%2Ftysonfuryvsoleksandrusyk.co.uk">tysonfuryvsoleksandrusyk.co.uk</a>
This fight is more than just a championship fight. It’s a meeting of two unique worldviews. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. The clash of personalities adds depth to the narrative. This is more than just a physical contest. Whoever comes out victorious, the impact of this bout will be felt for years to come. The clash for the undisputed title is more than just a fight. It’s the result of relentless dedication. Should Fury claim victory thanks to his power and game plan, or Usyk secures a victory thanks to his skill and resilience, no matter the outcome, this will be a defining moment in boxing.
The Fury-Usyk battle is more than just a fight. It’s a showcase of skill and determination. The two competitors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azəri bazarında online kazino oyunlarına sevgisi artdıqca, Pin-up online kimi saytlar daha çox tanınmağa başladı. Özəlliklə, Pinup azerbaycan adları indi Azərbaycandakı oyunçular üçün məşhurdur. Pinup casino mərc həvəskarlarına geniş oyunlar təklif edir.
Pin-up kazino, Azəri qumarbazlar üçün geniş kütləyə sahib bir qumar saytıdır. Bu qumar xidməti kazino oyunçularına çoxlu oyun təklifləri təklif verməkdədir və sərfəli bonus təklifləri ilə qumarbazlar tərəfindən sevilir.
Pin-up online kazino, bənzərsiz oyun imkanı təqdim edən oyun məkanıdır. Azəri bazarında populyar olan Pin-up kazino, istifadəçilər üçün çeşidli bonus imkanları yaradır.
Bununla yanaşı, Pin-up azerbaycan qumar həvəskarlarına güvənli və şəffaf ödəmə sistemləri təqdim edir. Oyun həvəskarları, çox rahat kredit kartı və elektron pul kisəsi ilə vasitəsilə, mərc təcrübələrini daha asan keçirə bilərlər.
Son olaraq, Pin-up cazino oyunçulara yalnız oyun təklif etmir sərfəli bonuslar müştəriləri üçün yaradır. Bu platformada, mərc edənlər təhlükəsiz şərtlər altında mərc edir.
Web: https://win-top-pin-up.web.app
Pin-up online kazino təkcə bir kazino olaraq oyunlar ilə kifayətlənmir. Mərc həvəskarları bu platformada fərqli mərc oyunlarından həzz ala bilərlər və bonus sistemini qazanmaq imkanı əldə edərlər.
Beləliklə, Pin-up cazino, güvənli mərc oyunları mərc həvəskarlarına təqdim etməklə mərc bazarında güclü mövqe tutub. Azəri oyunçular tərəfindən məşhur olması göz qabağındadır.
Fury, the Gypsy King, and Usyk, the technician are ready to face each other in a fight of unparalleled significance. It’s not merely about the belts; it represents their quest for immortality. Fury, an undefeated champion has earned worldwide fame with his charisma coupled with unparalleled talent in the ring. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. In contrast, the tactical southpaw is a fighter unlike any other to boxing’s biggest stars. Meanwhile, Usyk, a southpaw master stands as a unique threat not just for Fury, and for boxing fans worldwide. The ascent of Oleksandr Usyk started with his domination of the cruiserweights, where he became an unstoppable force. Prepare yourself for a thrilling boxing match of the year as Usyk takes on Tyson Fury in an unforgettable showdown! Catch every punch in real time on our website. Be part of the action — visit <a href="https://nrns-games.com/proxy.php?request=https://tysonvsusyk.org.uk/">tysonvsusyk.org.uk</a> today and watch the match from the comfort of your home!
Across the UK, the fight is expected to begin close to prime time, ensuring maximum viewership. For Usyk’s fans in Ukraine, as well as viewers across Europe and the Americas, this will be a must-see event. The venue for Fury vs Usyk remains a hot topic, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, fans can be sure: it will be a spectacle. Although the focus is centered on the headline fight, the fights leading up to the main event is also generating excitement. High-profile matches include preliminary bouts with top talent, giving fans a full evening of entertainment.
In the past, undercards of this caliber have introduced future champions. Fighters looking to rise through the ranks use such opportunities to demonstrate their talent, as all eyes are on them. Though the supporting fights for Fury vs Usyk has yet to be finalized, speculation runs high. Might there be a cruiserweight spectacle? Regardless of the names, fans can expect fireworks. The most compelling part of Fury vs Usyk so intriguing is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. With his immense height and reach advantage, he commands the ring like no other.
The legendary battles with Wilder proved his toughness, as he recovered from knockdowns to secure victories. When he faced Klitschko, his strategic genius shone through, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, relies on technique and stamina. With his unorthodox stance, his positioning constantly challenges opponents. His strikes lack devastating strength, their timing wears down foes. As fight night approaches, Predictions for this fight have fans and analysts speculating.
The betting lines show Fury ahead as predicted by many experts, due to his size advantage, his track record in big matches, and his unpredictable nature. However, Usyk's underdog status doesn’t diminish his chances, his dominance against Joshua confirmed his toughness against big opponents.
For Fury himself is a chance to further solidify his greatness. A victory would solidify his claim as the greatest heavyweight of his generation. Conversely, If Usyk wins would mark him as one of the sport’s greats. Securing two undisputed titles would be a remarkable feat in boxing history.
Web: <a href="http://google.net/url?q=https://tysonvsusyk.org.uk/">tysonvsusyk.org.uk</a>
The upcoming showdown represents something greater than a title bout. It’s a clash of personalities. Fury’s boisterous personality is the opposite of Usyk’s humble and disciplined approach. The clash of personalities adds depth to the narrative. Beyond physical ability, this fight. Whoever comes out victorious, the legacy of this fight will reverberate throughout boxing history. The clash for the undisputed title is a defining moment. It’s the pinnacle of both fighters’ hard work. Whether Tyson Fury prevails with his experience and unpredictability, or Usyk wins with his precision with his technique and endurance, one thing is certain, this will be a defining moment in boxing.
Fury vs Usyk is a spectacle of a lifetime. It’s a fight of grit and strategy. The two competitors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında virtual qumar oyunlarına sevgisi artdıqca, "Pin-up casino" kimi platformalar daha çox tanınmağa başladı. Əlavə olaraq, Pin-up azerbaycan şəklində olan platformalar indi yerli oyunçular üçün adidir. Pin-up casino azerbaycan mərc həvəskarlarına çox oyun növləri təklif edir.
Pin-up kazino, Azəri istifadəçilər üçün ən sevilən platformalardan biridir. Bu qumar saytı istifadəçilərə geniş çeşidli oyunlar təklif edir və cazibədar aksiyalar ilə seçim olur.
Pin-up casino, oyun keyfiyyətini artıran bir platformadır. Azəri bazarında çox seçilən Pin-up casino, qumar oyunçuları üçün geniş oyun variantları ilə tanınır.
Əlavə olaraq, "Pin-up casino online" qumar həvəskarlarına təhlükəsiz ödəmə üsulları oyunçularına təklif edir. Oyunçular, çox rahat ödəmə üsulları ilə, qumar təcrübələrini müvafiq şəkildə yerinə yetirə bilərlər.
Əlavə olaraq, Pin-up cazino oyunçulara geniş oyun təcrübəsi ilə yanaşı bonuslar və aksiyalar təmin edir. Bu kazinoda, qumar həvəskarları özlərini güvəndə hiss edir.
Web: https://az-pinup.web.app
Pin-up kazino təkcə bir kazino olaraq məhdud oyunlar təklif etmir. Mərc həvəskarları bu platformada fərqli mərc seçimlərindən müxtəlif mərc imkanı əldə edə bilər və sərfəli bonus təkliflərini oyun təcrübələrinə əlavə edərlər.
Sonda, Pin-up cazino, etibarlı mərc oyunları oyunçulara təklif etməklə onlayn qumar sektorunda özünü doğruldur. Azərbaycan mərcçiləri arasında çox seçilməsi göz qabağındadır.
Tyson Fury and Oleksandr Usyk are ready to face each other in a fight of unparalleled significance. This fight is about more than just titles; it represents their quest for immortality. Fury, an undefeated champion has become a global icon through his unique style and his unmatched skills in the ring. Beating Wilder and Klitschko have cemented his place among the all-time greats. Across the ring, Usyk, the technician brings an unprecedented test for Fury. Meanwhile, Usyk, a genius in the ring represents a formidable opponent not just for Fury, and for boxing fans worldwide. His journey to global fame began in the cruiserweight division, where he became an unstoppable force. Prepare yourself for the most anticipated boxing match of the year as Usyk takes on Fury in a must-watch showdown! See every move live on our website. Be part of the action — visit <a href="https://ua.hit.gemius.pl/_sslredir/hitredir/id=pz.lpv9dzs6xxg7ra2qmsres7amw5hfzlkh0zycwagv.r7/fastid=cnjjilucryxjganvlekgwftdlmle/stparam=ypqkkvhkcq/url=https://furyvsusykdate.co.uk/">furyvsusykdate.co.uk</a> right away and watch the match from the comfort of your home!
In the United Kingdom, the event will kick off at around 10 PM GMT, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, and for fans watching from around the world, the anticipation is at a fever pitch. The venue for Fury vs Usyk is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, one thing is certain: the atmosphere will be electric. Although the focus is centered on the headline fight, the preliminary bouts promises plenty of action. Major boxing events include preliminary bouts with top talent, providing non-stop action before the headliner.
In the past, undercards of this caliber have showcased rising stars. Fighters looking to rise through the ranks capitalize on the exposure to showcase their skills, as all eyes are on them. Although the lineup for the Fury Usyk undercard haven’t been officially announced, speculation runs high. Will there be a heavyweight clash? No matter the final roster, fans can expect fireworks. What sets this bout apart so intriguing is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. At 6’9" with an 85-inch reach, Fury can control a fight.
The three fights against Wilder highlighted his resilience, as he recovered from knockdowns to secure victories. Against Wladimir Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Meanwhile, Usyk, brings speed, precision, and finesse. As a southpaw, his positioning constantly challenges opponents. The Ukrainian’s shots aren’t the heaviest in the division, they consistently find their mark. With the date drawing closer, Predictions for this fight have fans and analysts speculating.
The betting lines show Fury ahead as predicted by many experts, thanks to his imposing frame, his long career in major fights, and his unorthodox style. Despite the odds, Usyk remains a strong contender doesn’t rule him out, his victories against AJ proved that he can handle the physicality of the heavyweight division.
For Tyson Fury is a chance to further solidify his greatness. If he wins, it would put the finishing touches on a historic career. Conversely, If Usyk wins would be a monumental achievement. Becoming the undisputed heavyweight champion is a once-in-a-lifetime achievement.
Web: <a href="http://clients1.google.com.eg/url?q=https://furyvsusykdate.co.uk/">furyvsusykdate.co.uk</a>
The upcoming showdown is more than just a championship fight. It’s a fight between two very different fighters. Fury’s larger-than-life persona stands in stark contrast to Usyk’s composed demeanor. These differences add complexity to the fight. It’s about more than just skill. Whoever triumphs in this battle, the impact of this bout will be remembered as a defining moment in boxing. Fury vs Usyk is more than just a match. It represents the culmination of their careers. Whether Fury secures the win with his experience and unpredictability, or Usyk comes out on top with his finesse and stamina, it’s certain that, this will be a fight remembered for years to come.
Fury vs Usyk is more than just a sporting contest. It’s a contest of heart and willpower. The two competitors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında onlayn qumar oyunlarına tələbat artdıqca, Pin-up online kimi platformalar daha çox tanınmağa başladı. Əsasən, Pin-up online brendləri indi Azəri mərc həvəskarları üçün adidir. Pin-up azerbaycan istifadəçilərə çeşidli oyunlar təklif edir.
Pin up kazino, Azərbaycan oyunçuları üçün ən sevilən platformalardan biridir. Bu mərc platforması kazino oyunçularına geniş çeşidli oyunlar oyunçulara təqdim edir və cəlbedici bonuslar ilə oyunçuları özünə cəlb edir.
Pin-up casino online, geniş oyun variantları təklif edən onlayn kazinodur. Azəri oyunçuları arasında güvənilən Pin-up oyunları, kazino oyunçuları üçün geniş oyun variantları ilə tanınır.
Bununla yanaşı, Pin-up azerbaycan oyunçulara etibarlı maliyyə sistemləri təmin edir. Müştərilər, müvafiq və təhlükəsiz kredit kartı və elektron pul kisəsi ilə ilə, internet oyunlarını daha asan yerinə yetirə bilərlər.
Əlavə olaraq, Pin-up kazino mərcçilərə geniş oyun təcrübəsi ilə yanaşı sərfəli bonuslar və maraqlı aksiyalar təklif edir. Bu qumar saytında, istifadəçilər təhlükəsiz şərtlər altında mərc edir.
Web: https://pinup-top-bet.web.app
Pin-up online kazino təkcə oyunçuları cəlb etmir. İstifadəçilər Pinup-da müxtəlif mərc növlərindən istifadə edə bilər və bonus sistemini qazanmaq imkanı əldə edərlər.
Sonda, Pin-up casino, rahat və təhlükəsiz oyun imkanı oyunçulara təklif etməklə onlayn qumar dünyasında güclü mövqe tutub. Azəri oyunçular tərəfindən çox seçilməsi təsadüf deyil.
Fury, the Gypsy King, and Usyk, the technician are ready to face each other in a fight that will define an era. This fight is about more than just titles; it’s a battle for eternal recognition. The Gypsy King has earned worldwide fame through his unique style and remarkable adaptability in the ring. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. On the other hand, Oleksandr Usyk poses a unique challenge to boxing’s biggest stars. Meanwhile, Oleksandr Usyk is a true test for Fury for Tyson Fury himself, but for the entire division. His journey to global fame started with his domination of the cruiserweights, where he became an unstoppable force. Get ready for a thrilling boxing match of the year as Usyk takes on Fury in a must-watch showdown! Experience every moment in real time on our website. Join the excitement — visit <a href="https://cache.julialang.org/https://tysonfuryvsusyk.co.uk/">tysonfuryvsusyk.co.uk</a> right away and stream the event from the comfort of your home!
For British fans, the ring walks are planned for close to prime time, making it ideal for a prime-time audience. Back in Usyk’s home country, as well as viewers across Europe and the Americas, this will be a must-see event. Where the bout will take place has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, it’s guaranteed: the atmosphere will be electric. Even though attention is firmly on the main event, the Fury vs Usyk undercard is also generating excitement. Big-ticket boxing cards include preliminary bouts with top talent, giving fans a full evening of entertainment.
Historically, undercards of this caliber have been a stage for breakout performances. Contenders hoping to make their mark often seize these moments to impress fans and analysts alike, with the world paying attention. While the names for the undercard has yet to be finalized, fans are eagerly guessing. Could we see rising prospects? Regardless of the names, fans can expect fireworks. What sets this bout apart truly fascinating is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed are unparalleled in the sport. With his immense height and reach advantage, he commands the ring like no other.
His trilogy with Deontay Wilder showed his durability, overcoming brutal hits to dominate in later rounds. Against Wladimir Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, offers a different kind of threat. Being a left-handed fighter, his positioning constantly challenges opponents. The Ukrainian’s shots may not have knockout power, they consistently find their mark. With the date drawing closer, The betting lines for Fury vs Usyk have fans and analysts speculating.
Tyson Fury is the slight favorite based on the betting odds, because of his reach and height, his proven ability in tough situations, and his tactical brilliance. However, Usyk's underdog status doesn’t diminish his chances, as his victories over Joshua proved that he can handle the physicality of the heavyweight division.
For Tyson Fury presents a shot at undisputed glory. If he wins, it would solidify his claim as the greatest heavyweight of his generation. Meanwhile, If Usyk wins would mark him as one of the sport’s greats. Becoming the undisputed heavyweight champion would be a remarkable feat in boxing history.
Web: <a href="http://www.google.com.tr/url?sa=t&url=http%3A%2F%2Fwww.magical-dream.com">tysonfuryvsusyk.co.uk</a>
The upcoming showdown is more than just a championship fight. It’s a fight between two very different fighters. Fury’s larger-than-life persona is the opposite of Usyk’s humble and disciplined approach. The clash of personalities adds depth to the narrative. Beyond physical ability, this fight. Whoever triumphs in this battle, the legacy of this fight will leave a lasting mark on the sport. The battle for heavyweight supremacy is more than just a match. It’s the pinnacle of both fighters’ hard work. Whether Tyson Fury prevails through his strength and tactics, or Oleksandr Usyk triumphs with his technique and endurance, no matter the outcome, this will be a legendary contest.
This fight between Fury and Usyk is more than just a boxing event. It’s a showcase of skill and determination. The two competitors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
yerli oyunçular arasında internet qumarına seçim artdıqca, Pin-up kazino kimi oyun xidmətləri daha çox tanınmağa başladı. Xüsusilə, Pin-up kazino brendləri artıq Azəri oyunçuları üçün adidir. Pin-up casino azerbaycan mərc həvəskarlarına geniş oyunlar təklif edir.
Pin-up online casino, Azəri qumarbazlar üçün maraqlı seçimdir. Bu kazino kazino oyunçularına fərqli oyun növləri təmin edir və sərfəli bonus təklifləri ilə qumarbazlar tərəfindən sevilir.
Pin-up casino, çeşidli oyun təcrübəsi təklif edən saytdır. Azəri oyunçuları arasında geniş istifadə olunan Pin-up kazino, mərc həvəskarları üçün geniş oyun təcrübəsi verir.
Bu səbəbdən, Pinup kazino mərcçilərə şəffaf və təhlükəsiz maliyyə əməliyyatları təklif etməkdədir. İstifadəçilər, sürətli və asan depozit çıxarış sistemi sayəsində, qumar təcrübələrini çox rahat yaşaya bilərlər.
Sonda, Pin-up casino online mərc həvəskarlarına təkcə oyun imkanı deyil cəlbedici kampaniyalar təmin edir. Bu kazinoda, müştərilər güvənli bir təcrübə yaşayır.
Web: https://best-pinup.web.app
Pin-up cazino təkcə bir kazino olaraq məhdud deyil. Oyunçular burada fərqli mərc oyunlarından müxtəlif mərc imkanı əldə edə bilər və maraqlı aksiyaları qazanmaq imkanı əldə edərlər.
Yekun olaraq, Pin-up cazino, müasir və təhlükəsiz qumar təcrübəsi təklif etməklə mərc bazarında oyunçular arasında geniş istifadə edilir. Azərbaycan mərcçiləri arasında tanınması göz qabağındadır.
The undefeated Fury and Usyk are on a collision course that will define an era. It’s not merely about the belts; it’s about legacy. Tyson Fury has risen to the pinnacle of the sport thanks to his personality and remarkable adaptability in the ring. Beating Wilder and Klitschko have cemented his place among the all-time greats. Across the ring, Usyk, the technician poses a unique challenge to boxing’s biggest stars. On the flip side, Oleksandr Usyk stands as a unique threat for Tyson Fury himself, and for boxing fans worldwide. The ascent of Oleksandr Usyk began in the cruiserweight division, as an undisputed champion. Prepare yourself for a thrilling boxing match of the year as Usyk takes on Tyson Fury in an unforgettable showdown! See every move in real time on our website. Don’t miss your chance — visit <a href="http://sovermed.ru/?wptouch_switch=desktop&redirect=https://tysonfuryvoleksandrusyk.com/">tysonfuryvoleksandrusyk.com</a> right away and stream the event with top-notch streaming!
For British fans, the fight is expected to begin late evening, offering perfect timing for viewers. For Usyk’s fans in Ukraine, as well as viewers across Europe and the Americas, the excitement is palpable. The fight’s location is still under speculation, with talk of iconic boxing destinations. Regardless of the venue, one thing is certain: the excitement will be unmatched. Although the focus remains on Fury and Usyk, the preliminary bouts promises plenty of action. Major boxing events often feature stacked undercards, offering an entire night of boxing excitement.
In the past, supporting bouts in major events have showcased rising stars. Boxers seeking the spotlight use such opportunities to showcase their skills, knowing millions are watching. Though the supporting fights for Fury vs Usyk haven’t been officially announced, speculation runs high. Might there be a cruiserweight spectacle? Whatever the selection, fans can expect fireworks. The most compelling part of Fury vs Usyk truly fascinating is the clash of styles. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. Being so tall yet so nimble, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, bouncing back from adversity to dominate in later rounds. Against Wladimir Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. By contrast, Usyk, brings speed, precision, and finesse. Being a left-handed fighter, his positioning constantly challenges opponents. The Ukrainian’s shots may not have knockout power, they consistently find their mark. With the date drawing closer, The betting lines for Fury vs Usyk are the subject of intense debate.
Fury is the favored fighter as per the betting experts, because of his reach and height, his proven ability in tough situations, and his unpredictable nature. Despite being seen as the underdog shouldn’t be counted out, his wins over Anthony Joshua proved that he can handle the physicality of the heavyweight division.
For Tyson Fury represents an opportunity to cement his legacy. A victory would add an undisputed title to his already impressive resume. Conversely, If Usyk wins would elevate him to new heights. Becoming the undisputed heavyweight champion is a rare accomplishment.
Web: <a href="http://www.google.com.ua/url?sa=t&url=https%3A%2F%2Ftysonfuryvoleksandrusyk.com">tysonfuryvoleksandrusyk.com</a>
The upcoming showdown is about more than the titles. It’s a battle of contrasting styles. Fury’s larger-than-life persona stands in stark contrast to Usyk’s composed demeanor. The clash of personalities adds depth to the narrative. This is more than just a physical contest. Whoever comes out victorious, the significance of this match will reverberate throughout boxing history. This historic showdown is more than just a fight. It represents the culmination of their careers. Should Fury claim victory through his strength and tactics, or Oleksandr Usyk triumphs thanks to his skill and resilience, what is clear is, this will be a legendary contest.
This fight between Fury and Usyk is more than just a fight. It’s a fight of grit and strategy. Both fighters will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azəri bazarında qumar oyunlarına tələbat artdıqca, Pinup kazino kimi şirkətlər daha çox tanınmağa başladı. Əlavə olaraq, Pin-up azerbaycan sözləri tez-tez Azəri oyunçuları üçün məşhurdur. Pin-up azerbaycan istifadəçilərə məxsus rəngarəng oyunlar təklif edir.
Pin-up cazino, Azərbaycan oyunçuları üçün maraqlı seçimdir. Bu onlayn kazino istifadəçilərə müxtəlif oyunlar təmin edir və gözəl hədiyyələr ilə mərc edənləri özünə cəlb edir.
Pin-up online kazino, bənzərsiz oyun imkanı təqdim edən bir platformadır. Azərbaycan ərazisində populyar olan Pin-up casino, qumar oyunçuları üçün geniş oyun variantları ilə tanınır.
Xüsusilə, Pinup casino müştərilərə etibarlı və güvənli maliyyə idarəetmə imkanları təklif edir. Oyunçular, sürətli və asan maliyyə əməliyyatları vasitəsilə, onlayn mərc oyunlarını müvafiq şəkildə yaşaya bilərlər.
Yekun olaraq, Pin-up cazino müştərilərə yalnız qumar oyunları yox, həmçinin bonuslar və aksiyalar təmin edir. Bu qumar saytında, oyunçular rahat və təhlükəsiz şəraitdə oynayır.
Web: https://pinup-best-top.web.app
Pin-up cazino təkcə bir kazino olaraq məhdud deyil. Müştərilər burada fərqli mərc oyunlarından yararlana bilərlər və maraqlı aksiyaları qazanmaq imkanı əldə edərlər.
Ümumilikdə, Pin-up azerbaycan, müasir və təhlükəsiz mərc təcrübəsi mərc həvəskarlarına təqdim etməklə oyun sənayesində ən sevilən platformalardan olur. Azəri bazarında məşhur olması dikkətə layiqdir.
Fury, the Gypsy King, and Usyk, the technician are on a collision course of unparalleled significance. It’s far beyond a championship match; it’s a battle for eternal recognition. Fury, an undefeated champion has risen to the pinnacle of the sport thanks to his personality and remarkable adaptability during fights. His victories over Deontay Wilder and Wladimir Klitschko have cemented his place among the all-time greats. On the other hand, the tactical southpaw brings an unprecedented test to boxing’s biggest stars. At the same time, the Ukrainian technician represents a formidable opponent for the heavyweight ranks overall, as a heavyweight contender. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, as an undisputed champion. Get ready for a thrilling boxing match of the year as Usyk takes on Tyson Fury in a must-watch showdown! Experience every moment live on our website. Don’t miss your chance — visit <a href="https://nyashkult.printdirect.ru/utils/redirect?url=https://furyvsusykdate.org.uk/">furyvsusykdate.org.uk</a> now and watch the match in high quality!
For British fans, the fight is expected to begin close to prime time, ensuring maximum viewership. In Usyk’s native Ukraine, and for fans watching from around the world, the excitement is palpable. Where the bout will take place has yet to be confirmed, with talk of iconic boxing destinations. No matter the location, one thing is certain: the atmosphere will be electric. Although the focus remains on Fury and Usyk, the fights leading up to the main event is also generating excitement. Big-ticket boxing cards often feature stacked undercards, providing non-stop action before the headliner.
Traditionally, supporting bouts in major events have introduced future champions. Boxers seeking the spotlight use such opportunities to demonstrate their talent, as all eyes are on them. Although the lineup for the Fury Usyk undercard has yet to be finalized, fans are eagerly guessing. Might there be a cruiserweight spectacle? Whatever the selection, the action will not disappoint. What sets this bout apart so intriguing is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed are unparalleled in the sport. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
The three fights against Wilder proved his toughness, overcoming brutal hits to finish strong. In his fight with Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. By contrast, Usyk, brings speed, precision, and finesse. As a southpaw, his positioning constantly challenges opponents. Usyk’s punches lack devastating strength, their timing wears down foes. With the date drawing closer, Predictions for this fight have fans and analysts speculating.
The betting lines show Fury ahead based on the betting odds, given his physical stature, his experience in high-pressure bouts, and his tactical brilliance. Although Usyk is the less favored fighter doesn’t rule him out, his dominance against Joshua showed that he can compete at heavyweight.
For Fury himself could be the defining moment of his career. If he wins, it would add an undisputed title to his already impressive resume. Meanwhile, If Usyk wins would elevate him to new heights. Securing two undisputed titles is a rare accomplishment.
Web: <a href="http://www.google.com.ec/url?q=https%3A%2F%2Ffuryvsusykdate.org.uk">furyvsusykdate.org.uk</a>
Fury vs Usyk is about more than the titles. It’s a meeting of two unique worldviews. Fury’s larger-than-life persona contrasts with Usyk’s calm, focused demeanor. These varying personalities make the bout even more interesting. Beyond physical ability, this fight. Whoever comes out victorious, the impact of this bout will be remembered as a defining moment in boxing. This historic showdown is more than just a fight. It’s the pinnacle of both fighters’ hard work. If Fury wins with his size and strategy, or Usyk comes out on top with his technique and endurance, it’s certain that, this will be a fight remembered for years to come.
This fight between Fury and Usyk is a spectacle of a lifetime. It’s a showcase of skill and determination. These two warriors will give everything they have.
Visit for more information: #crosslink[3,L -
Azərbaycandakı qumar sektorunda internet oyunlarına istək artdıqca, "Pin-up casino" kimi oyun xidmətləri daha çox tanınmağa başladı. Əsasən, Pin-up kazino şüarları hazırda Azərbaycandakı oyunçular üçün məşhurdur. Pin-up casino istifadəçilərə məxsus rəngarəng oyunlar təklif edir.
Pin-up kazino, Azəri istifadəçilər üçün ən sevilən platformalardan biridir. Bu kazino mərc həvəskarlarına çeşidli qumar oyunları verir və cazibədar aksiyalar ilə oyunçuları özünə cəlb edir.
Pin-up cazino, çeşidli oyun təcrübəsi təklif edən bir platformadır. Azərbaycanda məşhur olan Pinup, yerli oyunçular üçün çeşidli bonus imkanları yaradır.
Bu səbəbdən, Pin-up online casino mərc edənlərə etibarlı maliyyə idarəetmə imkanları təklif etməkdədir. Müştərilər, sürətli və asan depozit çıxarış sistemi nəticəsində, kazino oyunlarını çox rahat təcrübə edərlər.
Nəticə etibarilə, Pin-up casino istifadəçilərə təkcə oyunlar deyil, həm də bonus imkanı oyunçularına verir. Bu kazinoda, müştərilər şəffaf oyun şərtləri ilə rastlaşır.
Web: https://pinup-best-top.web.app
Pin-up kazino yalnız bir mərc saytı kimi məhdud deyil. Qumarçılar burada fərqli mərc oyunlarından həzz ala bilərlər və sərfəli bonus təkliflərini istifadə edə bilərlər.
Nəticədə, Pin-up casino online, müasir və təhlükəsiz mərc təcrübəsi təklif etməklə mərc bazarında özünü doğruldur. Azərbaycanda tanınması təsadüf deyil.
Tyson Fury and Oleksandr Usyk are preparing for an epic showdown that will define an era. It’s not merely about the belts; it represents their quest for immortality. The Gypsy King has become a global icon thanks to his personality and his unmatched skills during fights. His victories over Deontay Wilder and Wladimir Klitschko have cemented his place among the all-time greats. Across the ring, Oleksandr Usyk brings an unprecedented test to boxing’s biggest stars. Meanwhile, Oleksandr Usyk represents a formidable opponent not just for Fury, but for the entire division. Usyk’s rise to prominence began in the cruiserweight division, as an undisputed champion. Don’t miss out for the most anticipated boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! See every move in real time on our website. Don’t miss your chance — visit <a href="https://craftcms.loyolapress.com/actions/loyola-press/redirects?env=production&uri=wp-content/plugins/translator/translator.php?l=is&u=https://tysonfuryvsoleksandrusyk.co.uk/">tysonfuryvsoleksandrusyk.co.uk</a> now and watch the match in high quality!
In the United Kingdom, the ring walks are planned for around 10 PM GMT, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and for fans watching from around the world, this will be a must-see event. The venue for Fury vs Usyk is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, one thing is certain: the excitement will be unmatched. While the spotlight is centered on the headline fight, the fights leading up to the main event is also generating excitement. Major boxing events include preliminary bouts with top talent, offering an entire night of boxing excitement.
In the past, preliminary fights on major cards have showcased rising stars. Fighters looking to rise through the ranks often seize these moments to demonstrate their talent, with the world paying attention. Though the supporting fights for Fury vs Usyk has yet to be finalized, there’s plenty of talk. Will there be a heavyweight clash? Regardless of the names, it’s sure to add to the excitement. What sets this bout apart truly fascinating is the clash of styles. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. Being so tall yet so nimble, Fury can control a fight.
The three fights against Wilder showed his durability, overcoming brutal hits to finish strong. In his fight with Klitschko, his strategic genius shone through, showing he’s both powerful and smart. Meanwhile, Usyk, brings speed, precision, and finesse. As a southpaw, his movements create openings. The Ukrainian’s shots aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. As anticipation builds, Tyson Fury vs Usyk odds have fans and analysts speculating.
Most bookmakers favor Fury according to the odds, because of his reach and height, his proven ability in tough situations, and his tactical brilliance. Despite being seen as the underdog doesn’t mean he’s an underdog in spirit, as his victories over Joshua showed that he can compete at heavyweight.
For Fury himself presents a shot at undisputed glory. A triumph for Fury would put the finishing touches on a historic career. Conversely, If Usyk wins would elevate him to legendary status. Becoming the undisputed heavyweight champion is a rare accomplishment.
Web: <a href="http://images.google.com.ng/url?sa=t&url=https://tysonfuryvsoleksandrusyk.co.uk/">tysonfuryvsoleksandrusyk.co.uk</a>
The upcoming showdown represents something greater than a title bout. It’s a meeting of two unique worldviews. Fury’s confident and brash nature is in stark contrast to Usyk’s quiet intensity. These varying personalities make the bout even more interesting. This is more than just a physical contest. Regardless of the outcome, the significance of this match will reverberate throughout boxing history. Fury vs Usyk is a defining moment. It’s the pinnacle of both fighters’ hard work. Whether Tyson Fury prevails thanks to his power and game plan, or Usyk secures a victory thanks to his skill and resilience, one thing is certain, this will be a fight remembered for years to come.
The Fury-Usyk battle is more than just a sporting contest. It’s a contest of heart and willpower. These men will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında qumar oyunlarına tələbat artdıqca, Pinup kazino kimi onlayn mərc xidmətləri daha çox tanınmağa başladı. Özəlliklə, Pinup azerbaycan ifadələri indi yerli oyunçular üçün adidir. Pin-up casino azerbaycan mərc həvəskarlarına rəngarəng oyunlar təklif edir.
Pin-up casino, yerli oyunçular üçün güvənli bir qumar məkanıdır. Bu platforma qumarbazlara fərqli oyun növləri oyunçulara təqdim edir və bonus imkanları ilə müştərilərini məmnun edir.
Pin-up azerbaycan, çeşidli oyun təcrübəsi təklif edən onlayn kazinodur. Azərbaycanda güvənilən Pin-up kazino, oyun həvəskarları üçün geniş oyun variantları ilə tanınır.
Özəlliklə, "Pin-up casino online" mərc edənlərə təhlükəsiz maliyyə sistemləri təqdim edir. Müştərilər, sürətli və asan depozit çıxarış sistemi nəticəsində, kazino oyunlarını çox rahat yerinə yetirə bilərlər.
Bununla yanaşı, Pin-up casino mərc həvəskarlarına təkcə oyun imkanı deyil cazibədar bonus təklifləri oyun təcrübəsini daha da maraqlı edir. Pin-up-da, kazino həvəskarları rahat və təhlükəsiz şəraitdə oynayır.
Web: https://az-pinup.web.app
Pin-up online kazino təkcə bir kazino olaraq oyunçuları cəlb etmir. İstifadəçilər Pinup-da fərqli mərc oyunlarından istifadə edə bilər və maraqlı aksiyaları oyunlarına əlavə edə bilərlər.
Yekun olaraq, Pin-up kazino, sərfəli və təhlükəsiz kazino təcrübəsi istifadəçilərə verməklə onlayn qumar sektorunda ən yaxşı seçimlərdən biridir. yerli mərcçilər arasında seçim olması təsadüf deyil.
Fury, the Gypsy King, and Usyk, the technician are ready to face each other in a fight of historic proportions. It’s far beyond a championship match; it’s about legacy. Tyson Fury has earned worldwide fame thanks to his personality and remarkable adaptability inside the ropes. Beating Wilder and Klitschko have earned him recognition as one of the best ever. Across the ring, Oleksandr Usyk poses a unique challenge to the heavyweight division. Meanwhile, Usyk, a genius in the ring represents a formidable opponent not just for Fury, as a heavyweight contender. Usyk’s rise to prominence began in the cruiserweight division, by conquering all challengers. Don’t miss out for the most anticipated boxing match of the year as Oleksandr Usyk takes on Fury in a historic showdown! Experience every moment live on our website. Don’t miss your chance — visit <a href="https://affiliate.webnode.com/scripts/9mckvo?a_aid=5ea1b216cd4f3&a_bid=e3d9c6bb&desturl=https://tysonvusyk.com/">tysonvusyk.com</a> today and watch the match in high quality!
For British fans, the fight is expected to begin late evening, offering perfect timing for viewers. Back in Usyk’s home country, and beyond, the excitement is palpable. The venue for Fury vs Usyk is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, one thing is certain: the atmosphere will be electric. While the spotlight is centered on the headline fight, the fights leading up to the main event promises plenty of action. Major boxing events include preliminary bouts with top talent, giving fans a full evening of entertainment.
Traditionally, supporting bouts in major events have showcased rising stars. Fighters looking to rise through the ranks capitalize on the exposure to demonstrate their talent, knowing millions are watching. While the names for the undercard has yet to be finalized, there’s plenty of talk. Could we see rising prospects? Whatever the selection, the action will not disappoint. The most compelling part of Fury vs Usyk truly fascinating is the dynamic between these fighters. Tyson Fury’s size and agility are unparalleled in the sport. With his immense height and reach advantage, he dictates the pace of bouts.
The three fights against Wilder highlighted his resilience, overcoming brutal hits to dominate in later rounds. In his fight with Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, relies on technique and stamina. With his unorthodox stance, his movements create openings. The Ukrainian’s shots may not have knockout power, but they are delivered with pinpoint accuracy. With the date drawing closer, The betting lines for Fury vs Usyk have fans and analysts speculating.
Tyson Fury is seen as the frontrunner based on the betting odds, given his physical stature, his experience in high-pressure bouts, and his tactical brilliance. However, Usyk's underdog status doesn’t diminish his chances, his victories against AJ showed that he can compete at heavyweight.
For Fury himself represents an opportunity to cement his legacy. A triumph for Fury would further solidify his status as the best heavyweight of this era. Meanwhile, Usyk’s victory would elevate him to legendary status. Becoming the undisputed heavyweight champion is a rare accomplishment.
Web: <a href="http://www.google.com/url?sa=t&url=http%3A%2F%2Fwww.magical-dream.com">tysonvusyk.com</a>
Fury vs Usyk represents something greater than a title bout. It’s a clash of personalities. Fury’s larger-than-life persona stands in stark contrast to Usyk’s composed demeanor. These differences add complexity to the fight. This is more than just a physical contest. Whoever triumphs in this battle, the significance of this match will be remembered as a defining moment in boxing. The battle for heavyweight supremacy is more than just a match. It’s the pinnacle of both fighters’ hard work. Should Fury claim victory with his experience and unpredictability, or Oleksandr Usyk triumphs thanks to his skill and resilience, what is clear is, this will be a legendary contest.
Fury vs Usyk is more than just a boxing event. It’s a showcase of skill and determination. Both fighters will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında online kazino oyunlarına sevgisi artdıqca, Pin-up online kimi oyun xidmətləri daha çox tanınmağa başladı. Xüsusilə, Pinup casino şüarları son zamanlar Azəri mərc həvəskarları üçün məşhurdur. Pin-up casino azerbaycan istifadəçilərə məxsus geniş oyunlar təklif edir.
Pin-up kazino, yerli oyunçular üçün geniş kütləyə sahib bir qumar saytıdır. Bu kazino oyunçulara çeşidli qumar oyunları təklif verməkdədir və cazibədar aksiyalar ilə seçim olur.
Pin-up casino, geniş oyun variantları təklif edən bir platformadır. Azəri oyunçuları arasında məşhur olan Pin-up oyunları, istifadəçilər üçün zəngin təkliflər təqdim edir.
Xüsusilə, Pin-up online casino oyunçulara təhlükəsiz maliyyə idarəetmə imkanları təqdim edir. İstifadəçilər, çox rahat ödəmə üsulları ilə təmin olunmaqla, oyun təcrübələrini çox rahat yerinə yetirə bilərlər.
Yekun olaraq, Pin-up kazino qumarbazlara geniş oyun təcrübəsi ilə yanaşı mərc hədiyyələri oyunçularına verir. Bu qumar saytında, qumar həvəskarları özlərini güvəndə hiss edir.
Web: https://bet-on-pinup.web.app
Pin-up casino yalnız bir mərc saytı kimi sadə oyunla bitmir. Qumarçılar burada çeşidli mərc seçimlərindən müxtəlif mərc imkanı əldə edə bilər və maraqlı aksiyaları mərc təcrübələrini zənginləşdirərlər.
Bunun nəticəsində, Pin-up azerbaycan, rahat və təhlükəsiz mərc oyunları istifadəçilərə verməklə onlayn qumar dünyasında ən yaxşı seçimlərdən biridir. yerli oyunçular arasında çox seçilməsi təsadüfi deyil.
These two heavyweight champions are ready to face each other in a fight that will define an era. It’s not merely about the belts; it’s about legacy. The towering Fury has risen to the pinnacle of the sport thanks to his personality coupled with unparalleled talent inside the ropes. Beating Wilder and Klitschko have solidified his legendary status. Across the ring, Usyk, the technician is a fighter unlike any other to boxing’s biggest stars. Meanwhile, Usyk, a genius in the ring is a true test for Fury not just for Fury, and for boxing fans worldwide. His journey to global fame began in the cruiserweight division, as an undisputed champion. Get ready for a thrilling boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a must-watch showdown! Catch every punch live on our website. Don’t miss your chance — visit <a href="https://pravda-mlm.ru/proxy.php?request=https%3A%2F%2Ftysonfuryvoleksandrusyk.org.uk">tysonfuryvoleksandrusyk.org.uk</a> today and watch the match from the comfort of your home!
For British fans, the fight is expected to begin late evening, ensuring maximum viewership. For Usyk’s fans in Ukraine, and for fans watching from around the world, this will be a must-see event. Where the bout will take place is still under speculation, with talk of iconic boxing destinations. No matter the location, it’s guaranteed: the excitement will be unmatched. Although the focus remains on Fury and Usyk, the Fury vs Usyk undercard is shaping up to be thrilling. High-profile matches are known for strong supporting fights, offering an entire night of boxing excitement.
Historically, preliminary fights on major cards have been a stage for breakout performances. Boxers seeking the spotlight use such opportunities to demonstrate their talent, knowing millions are watching. While the names for the undercard has yet to be finalized, fans are eagerly guessing. Might there be a cruiserweight spectacle? Whatever the selection, it’s sure to add to the excitement. What sets this bout apart incredibly exciting is the clash of styles. Tyson Fury’s size and agility are unparalleled in the sport. With his immense height and reach advantage, he commands the ring like no other.
His trilogy with Deontay Wilder showed his durability, bouncing back from adversity to finish strong. Against Wladimir Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. Being a left-handed fighter, his movements create openings. His strikes lack devastating strength, but they are delivered with pinpoint accuracy. As anticipation builds, Predictions for this fight have fans and analysts speculating.
Fury is the favored fighter based on the betting odds, given his physical stature, his proven ability in tough situations, and his unpredictable nature. Although Usyk is the less favored fighter doesn’t mean he’s an underdog in spirit, his victories against AJ proved that he can handle the physicality of the heavyweight division.
For the Gypsy King represents an opportunity to cement his legacy. Should he come out on top, Fury’s win would further solidify his status as the best heavyweight of this era. Conversely, For Usyk, a win would be a monumental achievement. Securing two undisputed titles is a once-in-a-lifetime achievement.
Web: <a href="http://www.google.tl/url?sa=t&url=http%3A%2F%2Fwww.magical-dream.com">tysonfuryvoleksandrusyk.org.uk</a>
This fight is about more than the titles. It’s a clash of personalities. Fury’s larger-than-life persona contrasts with Usyk’s calm, focused demeanor. These varying personalities make the bout even more interesting. Beyond physical ability, this fight. Regardless of the outcome, the significance of this match will reverberate throughout boxing history. The battle for heavyweight supremacy is more than just a fight. It’s the pinnacle of both fighters’ hard work. If Fury wins with his experience and unpredictability, or Usyk comes out on top thanks to his skill and resilience, one thing is certain, this will be a fight remembered for years to come.
Tyson Fury vs Oleksandr Usyk is more than just a fight. It’s a contest of heart and willpower. The two competitors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azərbaycan ərazisində onlayn qumar oyunlarına tələbat artdıqca, Pin-up online kimi onlayn mərc xidmətləri daha çox tanınmağa başladı. Bunun nəticəsində, Pin-up azerbaycan şüarları son zamanlar Azəri müştərilər üçün adidir. Pin-up kazino öz oyunçularına müxtəlif oyunlar təklif edir.
Pin up kazino, Azərbaycan oyunçuları üçün ən sevilən platformalardan biridir. Bu platforma oyunçulara müxtəlif oyunlar təklif edib və bonus imkanları ilə oyunçuları özünə cəlb edir.
Pin-up azerbaycan, geniş oyun variantları təklif edən onlayn kazinodur. yerli mərcçilər arasında populyar olan Pin-up online, istifadəçilər üçün geniş oyun təcrübəsi verir.
Bununla yanaşı, Pin-up azerbaycan müştərilərə etibarlı ödəmə üsulları təqdim edir. Müştərilər, rahat və tez maliyyə əməliyyatları ilə, internet oyunlarını asan və sürətli keçirə bilərlər.
Bununla yanaşı, Pin-up casino online qumarbazlara təkcə oyunlar deyil, həm də mərc hədiyyələri oyun təcrübəsini daha da maraqlı edir. Pin-up-da, oyunçular özlərini güvəndə hiss edir.
Web: https://win-top-pin-up.web.app
Pin-up azerbaycan yalnız bir mərc saytı kimi məhdud oyunlar təklif etmir. İstifadəçilər Pinup-da fərqli mərc oyunlarından istifadə edə bilər və maraqlı aksiyaları qazanmaq imkanı əldə edərlər.
Yekun olaraq, Pin-up azerbaycan, rahat və təhlükəsiz kazino təcrübəsi təmin etməklə onlayn qumar sektorunda ən sevilən platformalardan olur. yerli oyunçular arasında çox seçilməsi təsadüfi deyil.
Fury, the Gypsy King, and Usyk, the technician are on a collision course of unparalleled significance. It’s not merely about the belts; it’s about legacy. The towering Fury has become a global icon with his charisma coupled with unparalleled talent during fights. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. On the other hand, Usyk, the Ukrainian master is a fighter unlike any other for Fury. At the same time, the Ukrainian technician is a true test for Fury for the heavyweight ranks overall, and for boxing fans worldwide. Usyk’s rise to prominence started with his domination of the cruiserweights, where he became an unstoppable force. Prepare yourself for the most anticipated boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! Experience every moment live on our website. Don’t miss your chance — visit <a href="https://www.nn.printdirect.ru/utils/redirect?url=https://usykvsfurydate.org.uk/">usykvsfurydate.org.uk</a> today and enjoy the fight in high quality!
For British fans, the event will kick off at late evening, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, as well as viewers across Europe and the Americas, the excitement is palpable. Where the bout will take place is still under speculation, with talk of iconic boxing destinations. Wherever it happens, one thing is certain: the atmosphere will be electric. Even though attention is firmly on the main event, the preliminary bouts is also generating excitement. High-profile matches include preliminary bouts with top talent, giving fans a full evening of entertainment.
In the past, undercards of this caliber have introduced future champions. Boxers seeking the spotlight often seize these moments to impress fans and analysts alike, knowing millions are watching. Although the lineup for the Fury Usyk undercard haven’t been officially announced, there’s plenty of talk. Might there be a cruiserweight spectacle? No matter the final roster, the action will not disappoint. What sets this bout apart truly fascinating is their contrasting skillsets. Tyson Fury’s size and agility are unparalleled in the sport. Being so tall yet so nimble, Fury can control a fight.
The three fights against Wilder proved his toughness, overcoming brutal hits to secure victories. When he faced Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. Meanwhile, Usyk, offers a different kind of threat. With his unorthodox stance, his positioning constantly challenges opponents. Usyk’s punches aren’t the heaviest in the division, they consistently find their mark. As anticipation builds, Predictions for this fight have fans and analysts speculating.
Tyson Fury is the slight favorite as per the betting experts, thanks to his imposing frame, his long career in major fights, and his tactical brilliance. Despite being seen as the underdog doesn’t rule him out, his victories against AJ confirmed his toughness against big opponents.
For Tyson Fury presents a shot at undisputed glory. A victory would add an undisputed title to his already impressive resume. Meanwhile, For Usyk, a win would mark him as one of the sport’s greats. Becoming an undisputed champion in two different weight classes is a rare accomplishment.
Web: <a href="http://maps.google.by/url?q=https%3A%2F%2Fusykvsfurydate.org.uk">usykvsfurydate.org.uk</a>
This fight is about more than the titles. It’s a meeting of two unique worldviews. Fury’s bold and unapologetic character is in stark contrast to Usyk’s quiet intensity. These varying personalities make the bout even more interesting. Beyond physical ability, this fight. Whoever comes out victorious, the legacy of this fight will leave a lasting mark on the sport. The battle for heavyweight supremacy is a defining moment. It’s the pinnacle of both fighters’ hard work. Whether Fury secures the win with his experience and unpredictability, or Usyk comes out on top through his superior boxing ability, what is clear is, this bout will go down in history.
The Fury-Usyk battle is a spectacle of a lifetime. It’s a contest of heart and willpower. Both fighters will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında onlayn qumar oyunlarına seçim artdıqca, Pin-up casino online kimi platformalar daha çox tanınmağa başladı. Bununla bərabər, Pin-up azerbaycan şüarları artıq Azəri oyunçuları üçün istifadə olunur. Pin-up casino müştərilərinə rəngarəng oyunlar təklif edir.
Pin-up online casino, Azəri istifadəçilər üçün populyar seçimdir. Bu onlayn kazino qumarbazlara müxtəlif oyunlar verir və çoxlu bonuslar ilə müştərilərini məmnun edir.
Pin-up casino, çeşidli oyun təcrübəsi təklif edən saytdır. Azərbaycanda güvənilən Pin-up oyunları, kazino oyunçuları üçün maraqlı oyun imkanları təklif edir.
Xüsusilə, Pinup casino mərcçilərə etibarlı maliyyə idarəetmə imkanları təklif etməkdədir. Kazino iştirakçıları, sürətli və asan maliyyə çıxarışları sayəsində, kazino oyunlarını daha asan təcrübə edərlər.
Bununla yanaşı, Pin-up casino online mərc həvəskarlarına təkcə oyun imkanı deyil bonuslar və aksiyalar təmin edir. Bu qumar saytında, oyunçular rahat və təhlükəsiz şəraitdə oynayır.
Web: https://az-pinup.web.app
Pin-up casino yalnız bir mərc saytı kimi məhdud deyil. İstifadəçilər Pinup-da müxtəlif mərc növlərindən müxtəlif mərc imkanı əldə edə bilər və maraqlı aksiyaları oyun təcrübəsini artırarlar.
Nəticədə, Pin-up cazino, müasir və təhlükəsiz oyun imkanı istifadəçilərə verməklə onlayn qumar dünyasında ən yaxşı seçimlərdən biridir. yerli mərcçilər arasında populyarlığı əlamətdardır.
These two heavyweight champions are on a collision course that will define an era. This fight is about more than just titles; it’s a battle for eternal recognition. The Gypsy King has risen to the pinnacle of the sport through his unique style coupled with unparalleled talent during fights. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. On the other hand, Usyk, the Ukrainian master brings an unprecedented test to the heavyweight division. Meanwhile, Usyk, a genius in the ring is a true test for Fury for Tyson Fury himself, but for the entire division. His journey to global fame started with his domination of the cruiserweights, where he became an unstoppable force. Get ready for a thrilling boxing match of the year as Usyk takes on Tyson Fury in an unforgettable showdown! Catch every punch live on our website. Don’t miss your chance — visit <a href="https://rostov.metalloprokat.ru/statistic/redirect_site?source=products-list&object-id=12568824&object-kind=product&url=https://tysonfuryvoleksandrusyk.com/">tysonfuryvoleksandrusyk.com</a> today and enjoy the fight from the comfort of your home!
Across the UK, the ring walks are planned for late evening, offering perfect timing for viewers. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, this will be a must-see event. The venue for Fury vs Usyk is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, fans can be sure: the excitement will be unmatched. While the spotlight is firmly on the main event, the Fury vs Usyk undercard promises plenty of action. Major boxing events include preliminary bouts with top talent, offering an entire night of boxing excitement.
In the past, supporting bouts in major events have showcased rising stars. Fighters looking to rise through the ranks capitalize on the exposure to demonstrate their talent, with the world paying attention. While the names for the undercard are still unconfirmed, speculation runs high. Will there be a heavyweight clash? Regardless of the names, the action will not disappoint. The most compelling part of Fury vs Usyk so intriguing is the clash of styles. Fury’s towering frame and movement make him an anomaly in boxing. Being so tall yet so nimble, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, bouncing back from adversity to dominate in later rounds. Against Wladimir Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. Meanwhile, Usyk, offers a different kind of threat. As a southpaw, he uses angles and footwork. The Ukrainian’s shots aren’t the heaviest in the division, their timing wears down foes. As fight night approaches, Predictions for this fight are the subject of intense debate.
Tyson Fury is the slight favorite as predicted by many experts, given his physical stature, his proven ability in tough situations, and his unpredictable nature. Although Usyk is the less favored fighter shouldn’t be counted out, his wins over Anthony Joshua confirmed his toughness against big opponents.
For Fury himself could be the defining moment of his career. A triumph for Fury would solidify his claim as the greatest heavyweight of his generation. Meanwhile, For Usyk, a win would mark him as one of the sport’s greats. Becoming an undisputed champion in two different weight classes is a feat few can claim.
Web: <a href="http://clients1.google.lv/url?q=https%3A%2F%2Ftysonfuryvoleksandrusyk.com">tysonfuryvoleksandrusyk.com</a>
This fight is about more than the titles. It’s a battle of contrasting styles. Fury’s bold and unapologetic character contrasts with Usyk’s calm, focused demeanor. The clash of personalities adds depth to the narrative. This is more than just a physical contest. No matter who wins, the impact of this bout will be felt for years to come. This historic showdown is a defining moment. It’s the pinnacle of both fighters’ hard work. Whether Tyson Fury prevails thanks to his power and game plan, or Oleksandr Usyk triumphs with his finesse and stamina, one thing is certain, this will be a legendary contest.
This fight between Fury and Usyk is more than just a sporting contest. It’s a battle of minds and bodies. The two competitors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında internet qumarına tələbat artdıqca, Pinup kazino kimi kazino xidmətləri daha çox tanınmağa başladı. Özəlliklə, Pin-up online brendləri çoxdan yerli istifadəçilər üçün güvənlidir. Pin-up kazino online oyunçulara müxtəlif oyunlar təklif edir.
Pin-up kazino, Azəri qumarbazlar üçün güvənli bir qumar məkanıdır. Bu qumar xidməti mərc həvəskarlarına çeşidli qumar oyunları oyunçulara təqdim edir və çoxlu bonuslar ilə qumarbazlar tərəfindən sevilir.
Pinup casino, çeşidli oyun təcrübəsi təklif edən xidmətdir. Azərbaycan ərazisində güvənilən Pin-up online, istifadəçilər üçün çeşidli bonus imkanları yaradır.
Bununla yanaşı, Pinup kazino mərcçilərə güvənli maliyyə əməliyyatları təklif etməkdədir. Mərc edənlər, çox rahat maliyyə əməliyyatları köməyilə, onlayn mərc oyunlarını güvənli və təhlükəsiz yerinə yetirə bilərlər.
Son olaraq, Pin-up azerbaycan qumarbazlara yalnız oyun təklif etmir mərc hədiyyələri müştəriləri üçün yaradır. Bu platformada, müştərilər rahat və təhlükəsiz şəraitdə oynayır.
Web: https://pinup-best-bet.web.app
Pin-up casino təkcə bir oyun platforması kimi sadə oyunla bitmir. Oyunçular burada çeşidli mərc seçimlərindən istifadə edə bilər və sərfəli bonus təkliflərini mərc təcrübələrini zənginləşdirərlər.
Bunun nəticəsində, Pin-up cazino, müasir və təhlükəsiz oyun imkanı mərc həvəskarlarına təqdim etməklə mərc bazarında oyunçular arasında geniş istifadə edilir. yerli oyunçular arasında çox seçilməsi açıq bir faktdır.
These two heavyweight champions are ready to face each other in a fight of historic proportions. It’s far beyond a championship match; it represents their quest for immortality. Fury, an undefeated champion has risen to the pinnacle of the sport thanks to his personality and his unmatched skills during fights. Beating Wilder and Klitschko have earned him recognition as one of the best ever. Meanwhile, the tactical southpaw poses a unique challenge for Fury. On the flip side, the Ukrainian technician stands as a unique threat not just for Fury, but for the entire division. His journey to global fame started with his domination of the cruiserweights, where he became an unstoppable force. Prepare yourself for the most anticipated boxing match of the year as Oleksandr Usyk takes on Fury in a historic showdown! Catch every punch in real time on our website. Don’t miss your chance — visit <a href="http://traffic.shareaholic.com/e?a=1&u=http%3a%2f%2ftysonfuryvoleksandrusyk.com&r=1">tysonfuryvoleksandrusyk.com</a> now and stream the event in high quality!
In the United Kingdom, the ring walks are planned for close to prime time, ensuring maximum viewership. For Usyk’s fans in Ukraine, and beyond, the excitement is palpable. Where the bout will take place remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, it’s guaranteed: the excitement will be unmatched. While the spotlight is centered on the headline fight, the fights leading up to the main event is shaping up to be thrilling. High-profile matches include preliminary bouts with top talent, providing non-stop action before the headliner.
Traditionally, preliminary fights on major cards have been a stage for breakout performances. Contenders hoping to make their mark often seize these moments to demonstrate their talent, as all eyes are on them. While the names for the undercard has yet to be finalized, speculation runs high. Might there be a cruiserweight spectacle? Regardless of the names, fans can expect fireworks. What sets this bout apart so intriguing is the clash of styles. Tyson Fury’s size and agility make him an anomaly in boxing. At 6’9" with an 85-inch reach, Fury can control a fight.
The three fights against Wilder proved his toughness, bouncing back from adversity to secure victories. Against Wladimir Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, relies on technique and stamina. With his unorthodox stance, he uses angles and footwork. The Ukrainian’s shots lack devastating strength, but they are delivered with pinpoint accuracy. As fight night approaches, Tyson Fury vs Usyk odds are the subject of intense debate.
Fury is the favored fighter as per the betting experts, given his physical stature, his experience in high-pressure bouts, and his adaptability. Despite the odds, Usyk remains a strong contender doesn’t rule him out, as his victories over Joshua confirmed his toughness against big opponents.
For Tyson Fury could be the defining moment of his career. Should he come out on top, Fury’s win would solidify his claim as the greatest heavyweight of his generation. On the other hand, If Usyk wins would elevate him to new heights. Becoming the undisputed heavyweight champion would be a remarkable feat in boxing history.
Web: <a href="http://cse.google.co.ls/url?q=https://tysonfuryvoleksandrusyk.com/">tysonfuryvoleksandrusyk.com</a>
This fight represents something greater than a title bout. It’s a meeting of two unique worldviews. Fury’s bold and unapologetic character is the opposite of Usyk’s humble and disciplined approach. These varying personalities make the bout even more interesting. It’s a fight of wills and ideologies. Whoever triumphs in this battle, the impact of this bout will be remembered as a defining moment in boxing. Fury vs Usyk is more than just a fight. It represents the culmination of their careers. Should Fury claim victory with his experience and unpredictability, or Usyk wins with his precision with his finesse and stamina, one thing is certain, this will be a fight remembered for years to come.
Tyson Fury vs Oleksandr Usyk is more than just a sporting contest. It’s a contest of heart and willpower. These men will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında internet oyunlarına istək artdıqca, Pin-up kazino kimi saytlar daha çox tanınmağa başladı. Bununla bərabər, Pin-up kazino brendləri artıq yerli oyunçular üçün məşhurdur. Pin-up casino azerbaycan öz oyunçularına çeşidli oyunlar təklif edir.
Pinup kazino, yerli mərc həvəskarları üçün güvənli bir qumar məkanıdır. Bu kazino müştərilərə müxtəlif oyunlar oyunçulara təqdim edir və cəlbedici bonuslar ilə müştərilərini məmnun edir.
Pin-up online kazino, fərqli oyun təcrübəsi təklif edən onlayn kazinodur. yerli mərcçilər arasında güvənilən Pin-up online, mərc həvəskarları üçün geniş oyun variantları ilə tanınır.
Bununla yanaşı, Pinup casino qumar həvəskarlarına etibarlı və güvənli ödəmə sistemləri təklif etməkdədir. Mərc edənlər, çox rahat depozit çıxarış sistemi köməyilə, oyun təcrübələrini asan və sürətli təcrübə edə bilərlər.
Son olaraq, Pin-up casino qumarbazlara yalnız oyun təklif etmir sərfəli bonuslar və maraqlı aksiyalar təklif edir. Bu qumar saytında, müştərilər rahat və təhlükəsiz şəraitdə oynayır.
Web: https://win-top-pin-up-az.web.app
Pin-up online kazino təkcə sadə oyunla bitmir. Oyunçular burada bənzərsiz mərc imkanlarından istifadə edə bilər və çoxlu bonusları qazanmaq imkanı əldə edərlər.
Nəticədə, Pin-up casino, rahat və təhlükəsiz oyun imkanı təmin etməklə onlayn mərc dünyasında ən yaxşı seçimlərdən biridir. Azəri bazarında məşhur olması göz qabağındadır.
These two heavyweight champions are ready to face each other in a fight that will define an era. It’s not merely about the belts; it’s about legacy. The towering Fury has earned worldwide fame with his charisma and his unmatched skills in the ring. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. On the other hand, Oleksandr Usyk poses a unique challenge for Fury. Meanwhile, Oleksandr Usyk is a true test for Fury for the heavyweight ranks overall, but for the entire division. Usyk’s rise to prominence started with his domination of the cruiserweights, as an undisputed champion. Get ready for the most anticipated boxing match of the year as Oleksandr Usyk takes on Fury in a historic showdown! Catch every punch streamed live on our website. Join the excitement — visit <a href="http://www.comfortvps.com/openUrl.php?url=CURL-aHR0cHM6Ly9tb2RzLW1lbnUucnUv">tysonvusyk.com</a> today and stream the event from the comfort of your home!
In the United Kingdom, the event will kick off at late evening, ensuring maximum viewership. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. Where the bout will take place is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. Regardless of the venue, fans can be sure: the excitement will be unmatched. Although the focus is centered on the headline fight, the fights leading up to the main event is also generating excitement. Big-ticket boxing cards include preliminary bouts with top talent, providing non-stop action before the headliner.
In the past, preliminary fights on major cards have introduced future champions. Contenders hoping to make their mark often seize these moments to demonstrate their talent, with the world paying attention. Although the lineup for the Fury Usyk undercard has yet to be finalized, speculation runs high. Could we see rising prospects? Whatever the selection, the action will not disappoint. The most compelling part of Fury vs Usyk so intriguing is the clash of styles. Tyson Fury’s size and agility make him an anomaly in boxing. With his immense height and reach advantage, he commands the ring like no other.
His trilogy with Deontay Wilder highlighted his resilience, as he recovered from knockdowns to secure victories. When he faced Klitschko, his strategic genius shone through, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, offers a different kind of threat. With his unorthodox stance, his movements create openings. His strikes aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. As anticipation builds, Predictions for this fight are the subject of intense debate.
Most bookmakers favor Fury as per the betting experts, thanks to his imposing frame, his experience in high-pressure bouts, and his adaptability. Despite the odds, Usyk remains a strong contender shouldn’t be counted out, his dominance against Joshua showed that he can compete at heavyweight.
For Fury himself is a chance to further solidify his greatness. Should he come out on top, Fury’s win would put the finishing touches on a historic career. Conversely, For Usyk, a win would elevate him to new heights. Becoming the undisputed heavyweight champion is a once-in-a-lifetime achievement.
Web: <a href="http://images.google.co.ve/url?q=https://tysonvusyk.com/">tysonvusyk.com</a>
This fight is not just about the belts. It’s a fight between two very different fighters. Fury’s larger-than-life persona is the opposite of Usyk’s humble and disciplined approach. These differences add complexity to the fight. It’s a fight of wills and ideologies. No matter who wins, the significance of this match will be remembered as a defining moment in boxing. The clash for the undisputed title is a defining moment. It’s a culmination of years of hard work. Whether Tyson Fury prevails with his experience and unpredictability, or Usyk wins with his precision with his finesse and stamina, one thing is certain, this will be a fight remembered for years to come.
This fight between Fury and Usyk is a spectacle of a lifetime. It’s a contest of heart and willpower. These men will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azərbaycan ərazisində qumar oyunlarına istək artdıqca, Pinup kimi kazino xidmətləri daha çox tanınmağa başladı. Bunun nəticəsində, Pin-up kazino ifadələri çoxdan Azəri müştərilər üçün güvənlidir. Pin-up azerbaycan istifadəçilərə məxsus rəngarəng oyunlar təklif edir.
Pinup kazino, Azərbaycan oyunçuları üçün geniş yayılmış bir xidmətdir. Bu kazino oyunçulara fərqli oyun növləri təklif edir və çoxlu bonuslar ilə mərc edənləri özünə cəlb edir.
Pin-up azerbaycan, çeşidli oyun təcrübəsi təklif edən xidmətdir. Azəri oyunçuları arasında geniş istifadə olunan Pin-up oyunları, qumar oyunçuları üçün zəngin təkliflər təqdim edir.
Əlavə olaraq, Pin-up azerbaycan mərc edənlərə güvənli və şəffaf depozit və çıxarış imkanı verir. Müştərilər, sürətli və asan kredit kartı və elektron pul kisəsi ilə köməyilə, onlayn mərc oyunlarını çox rahat oynaya bilərlər.
Son olaraq, Pin-up kazino müştərilərə yalnız qumar oyunları yox, həmçinin cəlbedici kampaniyalar müştəriləri üçün yaradır. Pinup-da, istifadəçilər şəffaf oyun şərtləri ilə rastlaşır.
Web: https://best-pinup.web.app
Pin-up online kazino sadəcə oyunçuları cəlb etmir. Mərc həvəskarları bu platformada müxtəlif mərc növlərindən müxtəlif mərc imkanı əldə edə bilər və cazibədar bonus imkanlarını oyun təcrübələrinə əlavə edərlər.
Sonda, Pin-up casino, rahat və təhlükəsiz qumar təcrübəsi mərc həvəskarlarına təqdim etməklə oyun sənayesində ən yaxşı seçimlərdən biridir. Azəri bazarında məşhur olması təsadüf deyil.
Tyson Fury and Oleksandr Usyk are set to meet in the ring of historic proportions. This fight is about more than just titles; it represents their quest for immortality. Tyson Fury has earned worldwide fame through his unique style coupled with unparalleled talent in the ring. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Meanwhile, the tactical southpaw is a fighter unlike any other for Fury. At the same time, Usyk, a southpaw master stands as a unique threat for the heavyweight ranks overall, as a heavyweight contender. His journey to global fame began in the cruiserweight division, as an undisputed champion. Prepare yourself for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! Catch every punch in real time on our website. Join the excitement — visit <a href="https://ddlvid.com/redirect?url=https://fury-usyk.uk/">fury-usyk.uk</a> now and watch the match in high quality!
In the United Kingdom, the event will kick off at late evening, offering perfect timing for viewers. In Usyk’s native Ukraine, and beyond, the excitement is palpable. Where the bout will take place is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, fans can be sure: the excitement will be unmatched. Even though attention is firmly on the main event, the fights leading up to the main event promises plenty of action. High-profile matches are known for strong supporting fights, offering an entire night of boxing excitement.
In the past, supporting bouts in major events have showcased rising stars. Fighters looking to rise through the ranks capitalize on the exposure to impress fans and analysts alike, as all eyes are on them. Although the lineup for the Fury Usyk undercard has yet to be finalized, speculation runs high. Could we see rising prospects? Whatever the selection, fans can expect fireworks. The most compelling part of Fury vs Usyk truly fascinating is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. At 6’9" with an 85-inch reach, he commands the ring like no other.
The three fights against Wilder highlighted his resilience, as he recovered from knockdowns to secure victories. In his fight with Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, relies on technique and stamina. With his unorthodox stance, his movements create openings. The Ukrainian’s shots may not have knockout power, their timing wears down foes. As fight night approaches, Tyson Fury vs Usyk odds are the subject of intense debate.
Fury is the favored fighter as predicted by many experts, thanks to his imposing frame, his track record in big matches, and his tactical brilliance. Although Usyk is the less favored fighter doesn’t mean he’s an underdog in spirit, his dominance against Joshua showed that he can compete at heavyweight.
For Fury himself presents a shot at undisputed glory. A victory would further solidify his status as the best heavyweight of this era. On the other hand, If Usyk wins would elevate him to new heights. Achieving undisputed glory in two divisions is a rare accomplishment.
Web: <a href="http://images.google.ge/url?q=https://fury-usyk.uk/">fury-usyk.uk</a>
This fight is not just about the belts. It’s a fight between two very different fighters. Fury’s boisterous personality is the opposite of Usyk’s humble and disciplined approach. The clash of personalities adds depth to the narrative. Beyond physical ability, this fight. No matter who wins, the legacy of this fight will reverberate throughout boxing history. Fury vs Usyk is more than just a fight. It’s a culmination of years of hard work. Whether Fury secures the win with his size and strategy, or Oleksandr Usyk triumphs thanks to his skill and resilience, one thing is certain, this will be a defining moment in boxing.
This fight between Fury and Usyk is a spectacle of a lifetime. It’s a contest of heart and willpower. Both fighters will give everything they have.
Visit for more information: #crosslink[3,L -
yerli oyunçular arasında virtual qumar oyunlarına maraq artdıqca, Pin-up kazino kimi platformalar daha çox tanınmağa başladı. Özəlliklə, "Pin up casino online" şəklində olan platformalar son zamanlar Azəri oyunçuları üçün tanışdır. Pin-up kazino istifadəçilərə məxsus rəngarəng oyunlar təklif edir.
Pin up kazino, Azərbaycan oyunçuları üçün ən sevilən platformalardan biridir. Bu platforma istifadəçilərə rəngarəng oyunlar oyunçulara təqdim edir və sərfəli bonus təklifləri ilə seçim olur.
Pin-up azerbaycan, geniş oyun variantları təklif edən bir platformadır. Azərbaycan ərazisində geniş istifadə olunan Pin-up casino, qumar oyunçuları üçün geniş oyun təcrübəsi verir.
Bu səbəbdən, Pin-up online casino qumar həvəskarlarına güvənli və şəffaf maliyyə sistemləri təklif etməkdədir. Kazino iştirakçıları, çox rahat depozit çıxarış sistemi ilə təmin olunmaqla, kazino oyunlarını asan və sürətli təcrübə edə bilərlər.
Son olaraq, Pin-up kazino istifadəçilərə geniş oyun təcrübəsi ilə yanaşı mərc hədiyyələri və maraqlı aksiyalar təklif edir. Bu kazinoda, kazino həvəskarları təhlükəsiz oyun mühitində olur.
Web: https://win-top-pin-up-az.web.app
Pin-up casino yalnız oyunçuları cəlb etmir. Qumarçılar burada geniş mərc təcrübəsindən müxtəlif mərc imkanı əldə edə bilər və geniş bonus imkanlarını qazanmaq imkanı əldə edərlər.
Sonda, Pin-up casino online, sərfəli və təhlükəsiz qumar təcrübəsi təklif etməklə mərc bazarında özünü doğruldur. Azəri bazarında tanınması göz qabağındadır.
The undefeated Fury and Usyk are preparing for an epic showdown that will define an era. It’s not merely about the belts; it represents their quest for immortality. The towering Fury has risen to the pinnacle of the sport through his unique style and his unmatched skills in the ring. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. On the other hand, Usyk, the technician poses a unique challenge to boxing’s biggest stars. On the flip side, Usyk, a southpaw master stands as a unique threat for Tyson Fury himself, but for the entire division. The ascent of Oleksandr Usyk began in the cruiserweight division, where he became an unstoppable force. Get ready for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a historic showdown! See every move streamed live on our website. Join the excitement — visit <a href="https://polesie.spb.ru/udata/emarket/basket/put/element/2482/?redirect-uri=https://usykvsfurydate.org.uk/">usykvsfurydate.org.uk</a> today and stream the event in high quality!
For British fans, the event will kick off at around 10 PM GMT, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, and for fans watching from around the world, the anticipation is at a fever pitch. The fight’s location remains a hot topic, with talk of iconic boxing destinations. Regardless of the venue, it’s guaranteed: it will be a spectacle. Although the focus is centered on the headline fight, the Fury vs Usyk undercard promises plenty of action. High-profile matches are known for strong supporting fights, offering an entire night of boxing excitement.
Traditionally, preliminary fights on major cards have been a stage for breakout performances. Boxers seeking the spotlight capitalize on the exposure to demonstrate their talent, knowing millions are watching. While the names for the undercard are still unconfirmed, speculation runs high. Could we see rising prospects? Regardless of the names, fans can expect fireworks. What makes this fight so intriguing is the dynamic between these fighters. Fury’s towering frame and movement are unparalleled in the sport. Being so tall yet so nimble, he dictates the pace of bouts.
His trilogy with Deontay Wilder showed his durability, as he recovered from knockdowns to finish strong. In his fight with Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. By contrast, Usyk, offers a different kind of threat. Being a left-handed fighter, his movements create openings. The Ukrainian’s shots may not have knockout power, but they are delivered with pinpoint accuracy. As anticipation builds, Tyson Fury vs Usyk odds are becoming a hot topic.
Most bookmakers favor Fury based on the betting odds, given his physical stature, his experience in high-pressure bouts, and his unpredictable nature. Despite being seen as the underdog shouldn’t be counted out, his victories against AJ showed that he can compete at heavyweight.
For the Gypsy King presents a shot at undisputed glory. A triumph for Fury would put the finishing touches on a historic career. Conversely, Usyk’s victory would elevate him to new heights. Securing two undisputed titles would be a remarkable feat in boxing history.
Web: <a href="http://www.google.je/url?q=https://usykvsfurydate.org.uk/">usykvsfurydate.org.uk</a>
This fight represents something greater than a title bout. It’s a fight between two very different fighters. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. These differences add complexity to the fight. It’s about more than just skill. Whoever triumphs in this battle, the impact of this bout will be felt for years to come. This historic showdown is a defining moment. It’s a culmination of years of hard work. Whether Fury secures the win thanks to his power and game plan, or Usyk wins with his precision thanks to his skill and resilience, it’s certain that, this bout will go down in history.
Fury vs Usyk is more than just a sporting contest. It’s a fight of grit and strategy. These men will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Azərbaycandakı qumar sektorunda internet oyunlarına istək artdıqca, Pin-up online kimi platformalar daha çox tanınmağa başladı. Bunun nəticəsində, "Pin up casino online" sözləri artıq Azərbaycandakı oyunçular üçün güvənlidir. Pin-up kazino öz oyunçularına çeşidli oyunlar təklif edir.
Pin-up online casino, yerli mərc həvəskarları üçün ən sevilən platformalardan biridir. Bu platforma mərc həvəskarlarına çoxlu oyun təklifləri təklif edir və sərfəli bonus təklifləri ilə qumarbazlar tərəfindən sevilir.
Pin-up casino, istifadəçilərə oyun növləri ilə zəngin saytdır. Azəri bazarında çox seçilən Pin-up casino, oyun həvəskarları üçün zəngin təkliflər təqdim edir.
Bununla yanaşı, Pinup casino oyunçulara etibarlı və güvənli depozit və çıxarış imkanı verir. Oyunçular, müvafiq və təhlükəsiz depozit çıxarış sistemi ilə təmin olunmaqla, oyun təcrübələrini güvənli və təhlükəsiz keçirə bilərlər.
Əlavə olaraq, Pinup kazino qumarbazlara təkcə oyun imkanı deyil mərc hədiyyələri oyunçularına verir. Pinup-da, mərc edənlər təhlükəsiz şərtlər altında mərc edir.
Web: https://pinup-top-bet.web.app
Pin-up casino sadəcə sadə oyunla bitmir. Kazino həvəskarları bu kazinoda fərqli mərc oyunlarından müxtəlif mərc imkanı əldə edə bilər və çoxlu bonusları oyun təcrübələrinə əlavə edərlər.
Bunun nəticəsində, Pin-up kazino, şəffaf və güvənli qumar təcrübəsi mərc həvəskarlarına təqdim etməklə mərc bazarında özünü doğruldur. yerli oyunçular arasında tanınması əlamətdardır.
The undefeated Fury and Usyk are preparing for an epic showdown that will define an era. It’s not merely about the belts; it’s about legacy. Fury, an undefeated champion has become a global icon with his charisma coupled with unparalleled talent during fights. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. In contrast, Oleksandr Usyk brings an unprecedented test to the heavyweight division. Meanwhile, Oleksandr Usyk represents a formidable opponent for the heavyweight ranks overall, as a heavyweight contender. Usyk’s rise to prominence began in the cruiserweight division, where he became an unstoppable force. Prepare yourself for the most anticipated boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! Experience every moment in real time on our website. Don’t miss your chance — visit <a href="https://789.ru/go.php?url=https://tysonvusyk.co.uk/">tysonvusyk.co.uk</a> today and enjoy the fight with top-notch streaming!
Across the UK, the fight is expected to begin late evening, offering perfect timing for viewers. For Usyk’s fans in Ukraine, as well as viewers across Europe and the Americas, the excitement is palpable. The venue for Fury vs Usyk has yet to be confirmed, with talk of iconic boxing destinations. Regardless of the venue, it’s guaranteed: the atmosphere will be electric. While the spotlight is firmly on the main event, the preliminary bouts is also generating excitement. High-profile matches include preliminary bouts with top talent, giving fans a full evening of entertainment.
Historically, supporting bouts in major events have been a stage for breakout performances. Boxers seeking the spotlight capitalize on the exposure to impress fans and analysts alike, as all eyes are on them. Though the supporting fights for Fury vs Usyk are still unconfirmed, fans are eagerly guessing. Will there be a heavyweight clash? Regardless of the names, the action will not disappoint. The most compelling part of Fury vs Usyk incredibly exciting is their contrasting skillsets. Tyson Fury’s size and agility make him an anomaly in boxing. With his immense height and reach advantage, Fury can control a fight.
The three fights against Wilder proved his toughness, bouncing back from adversity to finish strong. Against Wladimir Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. By contrast, Usyk, brings speed, precision, and finesse. With his unorthodox stance, his movements create openings. Usyk’s punches aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. As fight night approaches, Predictions for this fight have fans and analysts speculating.
Tyson Fury is seen as the frontrunner as per the betting experts, because of his reach and height, his proven ability in tough situations, and his tactical brilliance. However, Usyk's underdog status doesn’t diminish his chances, his wins over Anthony Joshua proved that he can handle the physicality of the heavyweight division.
For Tyson Fury could be the defining moment of his career. If he wins, it would put the finishing touches on a historic career. Conversely, For Usyk, a win would elevate him to new heights. Becoming an undisputed champion in two different weight classes is a rare accomplishment.
Web: <a href="http://maps.google.co.uk/url?q=https://tysonvusyk.co.uk/">tysonvusyk.co.uk</a>
This fight is more than just a championship fight. It’s a clash of personalities. Fury’s larger-than-life persona stands in stark contrast to Usyk’s composed demeanor. These varying personalities make the bout even more interesting. Beyond physical ability, this fight. Regardless of the outcome, the legacy of this fight will reverberate throughout boxing history. The clash for the undisputed title is more than just a fight. It represents the culmination of their careers. Should Fury claim victory thanks to his power and game plan, or Oleksandr Usyk triumphs with his technique and endurance, one thing is certain, this will be a fight remembered for years to come.
Fury vs Usyk is more than just a fight. It’s a battle of minds and bodies. The two competitors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında qumar oyunlarına güvəni artdıqca, Pinup kimi platformalar daha çox tanınmağa başladı. Xüsusilə, "Pin up casino online" brendləri hazırda Azəri müştərilər üçün istifadə olunur. Pin-up casino azerbaycan istifadəçilərə müxtəlif oyunlar təklif edir.
Pin-up casino, yerli oyunçular üçün geniş yayılmış bir xidmətdir. Bu qumar xidməti istifadəçilərə çeşidli qumar oyunları təklif edir və çoxlu bonuslar ilə oyunçuları özünə cəlb edir.
Pin-up online kazino, oyun keyfiyyətini artıran xidmətdir. Azərbaycanda məşhur olan Pin-up kazino, yerli oyunçular üçün zəngin təkliflər təqdim edir.
Bunun nəticəsində, Pinup kazino müştərilərə güvənli ödəmə üsulları oyunçularına təklif edir. Müştərilər, etibarlı və tez maliyyə çıxarışları ilə, mərc təcrübələrini güvənli və təhlükəsiz təcrübə edərlər.
Bununla yanaşı, Pin-up cazino müştərilərə təkcə oyunlar deyil, həm də cəlbedici kampaniyalar oyunçularına verir. Bu kazinoda, müştərilər təhlükəsiz oyun mühitində olur.
Web: https://win-top-pin-up.web.app
Pin-up online kazino sadəcə məhdudlaşmır. Kazino həvəskarları bu kazinoda bənzərsiz mərc imkanlarından təcrübə edə bilərlər və maraqlı aksiyaları oyunlarına əlavə edə bilərlər.
Nəticədə, Pinup kazino, etibarlı mərc təcrübəsi təklif etməklə oyun sənayesində ən sevilən platformalardan olur. Azərbaycanda seçim olması açıq bir faktdır.
Fury, the Gypsy King, and Usyk, the technician are on a collision course that will define an era. It’s not merely about the belts; it’s a battle for eternal recognition. The towering Fury has earned worldwide fame with his charisma and his unmatched skills during fights. Beating Wilder and Klitschko have cemented his place among the all-time greats. In contrast, Usyk, the Ukrainian master poses a unique challenge to boxing’s biggest stars. On the flip side, Oleksandr Usyk represents a formidable opponent for the heavyweight ranks overall, and for boxing fans worldwide. His journey to global fame was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Get ready for an epic boxing match of the year as Usyk takes on Tyson Fury in a must-watch showdown! Experience every moment streamed live on our website. Don’t miss your chance — visit <a href="http://camxiaomifb.nnov.org/common/redir.php?https://usykvsfurydate.co.uk/">usykvsfurydate.co.uk</a> now and watch the match with top-notch streaming!
Across the UK, the fight is expected to begin close to prime time, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and beyond, the excitement is palpable. The venue for Fury vs Usyk remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, it’s guaranteed: it will be a spectacle. Although the focus is firmly on the main event, the Fury vs Usyk undercard promises plenty of action. Big-ticket boxing cards are known for strong supporting fights, offering an entire night of boxing excitement.
Traditionally, supporting bouts in major events have showcased rising stars. Fighters looking to rise through the ranks often seize these moments to demonstrate their talent, knowing millions are watching. While the names for the undercard haven’t been officially announced, there’s plenty of talk. Could we see rising prospects? No matter the final roster, the action will not disappoint. What makes this fight truly fascinating is the clash of styles. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
The three fights against Wilder showed his durability, bouncing back from adversity to finish strong. In his fight with Klitschko, his strategic genius shone through, demonstrating his mental sharpness. Meanwhile, Usyk, relies on technique and stamina. As a southpaw, he uses angles and footwork. His strikes may not have knockout power, but they are delivered with pinpoint accuracy. With the date drawing closer, The betting lines for Fury vs Usyk have fans and analysts speculating.
Most bookmakers favor Fury based on the betting odds, because of his reach and height, his long career in major fights, and his unorthodox style. Despite being seen as the underdog doesn’t diminish his chances, as his victories over Joshua confirmed his toughness against big opponents.
For Tyson Fury, this fight is a chance to further solidify his greatness. A triumph for Fury would add an undisputed title to his already impressive resume. On the other hand, If Usyk wins would elevate him to legendary status. Becoming the undisputed heavyweight champion is a feat few can claim.
Web: <a href="http://cse.google.com.af/url?q=https%3A%2F%2Fusykvsfurydate.co.uk">usykvsfurydate.co.uk</a>
This fight is about more than the titles. It’s a fight between two very different fighters. Fury’s boisterous personality is in stark contrast to Usyk’s quiet intensity. Such contrasts make the fight more compelling. It’s about more than just skill. No matter who wins, the significance of this match will be remembered as a defining moment in boxing. The clash for the undisputed title is more than just a fight. It’s the result of relentless dedication. If Fury wins thanks to his power and game plan, or Usyk secures a victory through his superior boxing ability, no matter the outcome, this bout will go down in history.
Fury vs Usyk is more than just a fight. It’s a battle of minds and bodies. The two competitors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
yerli oyunçular arasında virtual qumar oyunlarına maraq artdıqca, Pinup kazino kimi saytlar daha çox tanınmağa başladı. Əsasən, Pin-up kazino sözləri son zamanlar Azəri mərc həvəskarları üçün məşhurdur. Pin-up casino müştərilərinə rəngarəng oyunlar təklif edir.
Pin up kazino, Azəri istifadəçilər üçün populyar seçimdir. Bu kazino oyunçulara fərqli oyun növləri təklif edir və bonus imkanları ilə oyunçuları özünə cəlb edir.
Pin-up casino, oyun keyfiyyətini artıran xidmətdir. Azərbaycanda məşhur olan Pin-up online, yerli oyunçular üçün fərqli oyun seçimləri ilə çıxış edir.
Xüsusilə, Pinup kazino mərcçilərə etibarlı və güvənli ödəmə sistemləri təmin edir. Oyunçular, rahat və tez kredit kartı və elektron pul kisəsi ilə ilə, oyun təcrübələrini güvənli və təhlükəsiz təcrübə edərlər.
Nəticə etibarilə, Pin-up cazino mərc həvəskarlarına geniş oyun təcrübəsi ilə yanaşı bonuslar və aksiyalar oyunçularına verir. Pin-up-da, istifadəçilər güvənli bir təcrübə yaşayır.
Web: https://top-pinup.web.app
Pin-up casino online yalnız oyunçuları cəlb etmir. Oyunçular burada fərqli mərc oyunlarından faydalanıb və cazibədar bonus imkanlarını oyun təcrübəsini artırarlar.
Beləliklə, Pin-up azerbaycan, güvənli mərc imkanı təmin etməklə oyun bazarında özünü doğruldur. Azərbaycan mərcçiləri arasında populyarlığı əlamətdardır.
Tyson Fury and Oleksandr Usyk are on a collision course that will define an era. It’s not merely about the belts; it represents their quest for immortality. Tyson Fury has risen to the pinnacle of the sport through his unique style coupled with unparalleled talent inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. On the other hand, Usyk, the technician is a fighter unlike any other to boxing’s biggest stars. At the same time, Usyk, a genius in the ring stands as a unique threat not just for Fury, and for boxing fans worldwide. His journey to global fame began in the cruiserweight division, as an undisputed champion. Don’t miss out for a thrilling boxing match of the year as Usyk takes on Tyson Fury in a must-watch showdown! Experience every moment streamed live on our website. Don’t miss your chance — visit <a href="http://www.iwantbabes.com/out.php?site=https://furyusyk.org.uk/">furyusyk.org.uk</a> now and stream the event in high quality!
Across the UK, the ring walks are planned for late evening, ensuring maximum viewership. For Usyk’s fans in Ukraine, and beyond, this will be a must-see event. The fight’s location remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, one thing is certain: the excitement will be unmatched. While the spotlight is centered on the headline fight, the preliminary bouts is shaping up to be thrilling. Big-ticket boxing cards include preliminary bouts with top talent, offering an entire night of boxing excitement.
Traditionally, preliminary fights on major cards have introduced future champions. Fighters looking to rise through the ranks use such opportunities to demonstrate their talent, knowing millions are watching. Though the supporting fights for Fury vs Usyk has yet to be finalized, fans are eagerly guessing. Could we see rising prospects? No matter the final roster, the action will not disappoint. The most compelling part of Fury vs Usyk truly fascinating is their contrasting skillsets. Fury’s towering frame and movement make him an anomaly in boxing. Being so tall yet so nimble, he commands the ring like no other.
The legendary battles with Wilder highlighted his resilience, as he recovered from knockdowns to finish strong. When he faced Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Meanwhile, Usyk, relies on technique and stamina. Being a left-handed fighter, his positioning constantly challenges opponents. The Ukrainian’s shots lack devastating strength, but they are delivered with pinpoint accuracy. As anticipation builds, Tyson Fury vs Usyk odds are becoming a hot topic.
Fury is the favored fighter as per the betting experts, because of his reach and height, his proven ability in tough situations, and his adaptability. Although Usyk is the less favored fighter shouldn’t be counted out, as his victories over Joshua demonstrated his ability in the heavyweight ranks.
For the Gypsy King presents a shot at undisputed glory. A triumph for Fury would add an undisputed title to his already impressive resume. Meanwhile, For Usyk, a win would elevate him to legendary status. Becoming the undisputed heavyweight champion is a once-in-a-lifetime achievement.
Web: <a href="http://www.google.tk/url?q=https://furyusyk.org.uk/">furyusyk.org.uk</a>
The upcoming showdown is more than just a championship fight. It’s a clash of personalities. Fury’s larger-than-life persona contrasts with Usyk’s calm, focused demeanor. These varying personalities make the bout even more interesting. It’s a fight of wills and ideologies. Whoever comes out victorious, the impact of this bout will be remembered as a defining moment in boxing. The clash for the undisputed title is a defining moment. It’s the result of relentless dedication. If Fury wins with his size and strategy, or Usyk wins with his precision through his superior boxing ability, no matter the outcome, this bout will go down in history.
Tyson Fury vs Oleksandr Usyk is more than just a fight. It’s a battle of minds and bodies. These two warriors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında virtual qumar oyunlarına istək artdıqca, "Pin-up casino" kimi platformalar daha çox tanınmağa başladı. Özəlliklə, Pin-up online adları tez-tez Azəri mərc həvəskarları üçün güvənlidir. Pinup casino istifadəçilərə məxsus müxtəlif oyunlar təklif edir.
Pin-up cazino, yerli oyunçular üçün populyar seçimdir. Bu platforma kazino oyunçularına rəngarəng oyunlar təklif edib və çoxlu bonuslar ilə seçim olur.
Pin-up cazino, bənzərsiz oyun imkanı təqdim edən saytdır. Azərbaycanda çox seçilən Pin-up kazino, istifadəçilər üçün çeşidli bonus imkanları yaradır.
Xüsusilə, Pinup casino mərcçilərə təhlükəsiz ödəmə üsulları verir. İstifadəçilər, müvafiq və təhlükəsiz depozit çıxarış sistemi nəticəsində, internet oyunlarını müvafiq şəkildə yerinə yetirə bilərlər.
Son olaraq, Pin-up cazino müştərilərə təkcə oyunlar deyil, həm də sərfəli bonuslar təmin edir. Pin-up-da, mərc edənlər şəffaf oyun şərtləri ilə rastlaşır.
Web: https://pinup-best-bet.web.app
Pin-up casino online yalnız bir mərc saytı kimi məhdudlaşmır. Kazino həvəskarları bu kazinoda çeşidli mərc seçimlərindən təcrübə edə bilərlər və maraqlı aksiyaları oyun təcrübəsini artırarlar.
Bunun nəticəsində, Pin-up cazino, şəffaf və güvənli kazino təcrübəsi təmin etməklə onlayn qumar dünyasında oyunçular arasında geniş istifadə edilir. yerli mərcçilər arasında çox seçilməsi əlamətdardır.
Tyson Fury and Oleksandr Usyk are preparing for an epic showdown that will define an era. It’s not merely about the belts; it represents their quest for immortality. The Gypsy King has risen to the pinnacle of the sport through his unique style and remarkable adaptability during fights. Beating Wilder and Klitschko have earned him recognition as one of the best ever. In contrast, Usyk, the technician poses a unique challenge for Fury. On the flip side, Usyk, a genius in the ring represents a formidable opponent for the heavyweight ranks overall, as a heavyweight contender. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Prepare yourself for a thrilling boxing match of the year as Usyk takes on Fury in a must-watch showdown! Experience every moment live on our website. Join the excitement — visit <a href="https://www.clickgratis.com.br/download/url.php?url=aHR0cHM6Ly9tb2RzLW1lbnUucnUv">tysonvsusyk.com</a> today and enjoy the fight from the comfort of your home!
In the United Kingdom, the fight is expected to begin late evening, offering perfect timing for viewers. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, this will be a must-see event. The fight’s location remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, it’s guaranteed: it will be a spectacle. Although the focus is firmly on the main event, the preliminary bouts promises plenty of action. Major boxing events are known for strong supporting fights, giving fans a full evening of entertainment.
Traditionally, preliminary fights on major cards have been a stage for breakout performances. Boxers seeking the spotlight often seize these moments to demonstrate their talent, as all eyes are on them. Though the supporting fights for Fury vs Usyk haven’t been officially announced, speculation runs high. Will there be a heavyweight clash? Regardless of the names, fans can expect fireworks. The most compelling part of Fury vs Usyk so intriguing is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. Being so tall yet so nimble, Fury can control a fight.
The three fights against Wilder proved his toughness, bouncing back from adversity to finish strong. Against Wladimir Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. Meanwhile, Usyk, brings speed, precision, and finesse. With his unorthodox stance, he uses angles and footwork. His strikes lack devastating strength, they consistently find their mark. With the date drawing closer, The betting lines for Fury vs Usyk are becoming a hot topic.
Fury is the favored fighter as predicted by many experts, because of his reach and height, his experience in high-pressure bouts, and his adaptability. Although Usyk is the less favored fighter shouldn’t be counted out, his wins over Anthony Joshua showed that he can compete at heavyweight.
For Tyson Fury could be the defining moment of his career. A victory would add an undisputed title to his already impressive resume. Conversely, For Usyk, a win would elevate him to new heights. Becoming an undisputed champion in two different weight classes is a rare accomplishment.
Web: <a href="http://clients1.google.com.co/url?q=https://tysonvsusyk.com/">tysonvsusyk.com</a>
This fight is more than just a championship fight. It’s a clash of personalities. Fury’s confident and brash nature stands in stark contrast to Usyk’s composed demeanor. These varying personalities make the bout even more interesting. Beyond physical ability, this fight. No matter who wins, the impact of this bout will be remembered as a defining moment in boxing. The battle for heavyweight supremacy is more than just a fight. It’s the pinnacle of both fighters’ hard work. If Fury wins with his size and strategy, or Usyk secures a victory with his technique and endurance, no matter the outcome, this will be a legendary contest.
The Fury-Usyk battle is a spectacle of a lifetime. It’s a fight of grit and strategy. The two competitors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are preparing for an epic showdown of unparalleled significance. This fight is about more than just titles; it represents their quest for immortality. The Gypsy King has earned worldwide fame through his unique style and remarkable adaptability inside the ropes. Beating Wilder and Klitschko have cemented his place among the all-time greats. In contrast, Oleksandr Usyk brings an unprecedented test for Fury. On the flip side, the Ukrainian technician represents a formidable opponent for Tyson Fury himself, and for boxing fans worldwide. The ascent of Oleksandr Usyk began in the cruiserweight division, where he became an unstoppable force. Prepare yourself for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! Experience every moment live on our website. Be part of the action — visit <a href="http://cloudfront-eu-central-1.images.arcpublishing.com/goto/http:/usykvsfury.org.uk">usykvsfury.org.uk</a> now and watch the match with top-notch streaming!
Across the UK, the fight is expected to begin around 10 PM GMT, offering perfect timing for viewers. Back in Usyk’s home country, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. The venue for Fury vs Usyk is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, fans can be sure: the excitement will be unmatched. Even though attention is centered on the headline fight, the Fury vs Usyk undercard is shaping up to be thrilling. Major boxing events include preliminary bouts with top talent, providing non-stop action before the headliner.
In the past, preliminary fights on major cards have showcased rising stars. Fighters looking to rise through the ranks use such opportunities to demonstrate their talent, with the world paying attention. While the names for the undercard are still unconfirmed, there’s plenty of talk. Could we see rising prospects? Whatever the selection, the action will not disappoint. What makes this fight truly fascinating is the clash of styles. Fury’s towering frame and movement make him an anomaly in boxing. With his immense height and reach advantage, he commands the ring like no other.
The three fights against Wilder highlighted his resilience, bouncing back from adversity to secure victories. When he faced Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. Meanwhile, Usyk, brings speed, precision, and finesse. As a southpaw, his positioning constantly challenges opponents. The Ukrainian’s shots aren’t the heaviest in the division, their timing wears down foes. As fight night approaches, Predictions for this fight are the subject of intense debate.
Tyson Fury is the slight favorite as per the betting experts, due to his size advantage, his long career in major fights, and his unpredictable nature. Despite being seen as the underdog doesn’t rule him out, his dominance against Joshua showed that he can compete at heavyweight.
For Tyson Fury is a chance to further solidify his greatness. A triumph for Fury would put the finishing touches on a historic career. Meanwhile, For Usyk, a win would mark him as one of the sport’s greats. Achieving undisputed glory in two divisions is a feat few can claim.
Web: <a href="http://cse.google.com.kw/url?q=https%3A%2F%2Fusykvsfury.org.uk">usykvsfury.org.uk</a>
This fight is not just about the belts. It’s a clash of personalities. Fury’s larger-than-life persona contrasts with Usyk’s calm, focused demeanor. These differences add complexity to the fight. It’s a fight of wills and ideologies. Whoever comes out victorious, the impact of this bout will reverberate throughout boxing history. This historic showdown is a spectacle unlike any other. It’s the result of relentless dedication. Should Fury claim victory through his strength and tactics, or Usyk wins with his precision with his technique and endurance, what is clear is, this will be a defining moment in boxing.
The Fury-Usyk battle is a spectacle of a lifetime. It’s a contest of heart and willpower. The two competitors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are on a collision course of unparalleled significance. It’s not merely about the belts; it’s about legacy. The towering Fury has earned worldwide fame thanks to his personality coupled with unparalleled talent inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have cemented his place among the all-time greats. Across the ring, the tactical southpaw poses a unique challenge to the heavyweight division. Meanwhile, Oleksandr Usyk is a true test for Fury not just for Fury, and for boxing fans worldwide. His journey to global fame began in the cruiserweight division, as an undisputed champion. Prepare yourself for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a must-watch showdown! See every move streamed live on our website. Be part of the action — visit <a href="http://4geo.ru/redirect/?service=catalog&url=furyvsusyk.org.uk">furyvsusyk.org.uk</a> today and enjoy the fight from the comfort of your home!
Across the UK, the fight is expected to begin close to prime time, ensuring maximum viewership. Back in Usyk’s home country, and beyond, this will be a must-see event. The venue for Fury vs Usyk remains a hot topic, with talk of iconic boxing destinations. Regardless of the venue, one thing is certain: it will be a spectacle. Although the focus is firmly on the main event, the fights leading up to the main event is also generating excitement. Major boxing events often feature stacked undercards, giving fans a full evening of entertainment.
Historically, undercards of this caliber have been a stage for breakout performances. Boxers seeking the spotlight capitalize on the exposure to demonstrate their talent, with the world paying attention. While the names for the undercard has yet to be finalized, there’s plenty of talk. Could we see rising prospects? Whatever the selection, it’s sure to add to the excitement. The most compelling part of Fury vs Usyk so intriguing is the dynamic between these fighters. Fury’s towering frame and movement make him an anomaly in boxing. With his immense height and reach advantage, he commands the ring like no other.
The legendary battles with Wilder proved his toughness, as he recovered from knockdowns to secure victories. When he faced Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. By contrast, Usyk, relies on technique and stamina. With his unorthodox stance, he uses angles and footwork. Usyk’s punches lack devastating strength, their timing wears down foes. As fight night approaches, The betting lines for Fury vs Usyk are becoming a hot topic.
Most bookmakers favor Fury as per the betting experts, given his physical stature, his track record in big matches, and his tactical brilliance. However, Usyk's underdog status shouldn’t be counted out, as his victories over Joshua confirmed his toughness against big opponents.
For Tyson Fury presents a shot at undisputed glory. A triumph for Fury would further solidify his status as the best heavyweight of this era. Meanwhile, Usyk’s victory would mark him as one of the sport’s greats. Securing two undisputed titles is a feat few can claim.
Web: <a href="http://images.google.com.vn/url?sa=t&url=https%3A%2F%2Ffuryvsusyk.org.uk">furyvsusyk.org.uk</a>
Fury vs Usyk is more than just a championship fight. It’s a clash of personalities. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. The clash of personalities adds depth to the narrative. Beyond physical ability, this fight. No matter who wins, the impact of this bout will be remembered as a defining moment in boxing. The battle for heavyweight supremacy is a defining moment. It’s the result of relentless dedication. Whether Fury secures the win with his size and strategy, or Usyk comes out on top with his finesse and stamina, no matter the outcome, this bout will go down in history.
Fury vs Usyk is more than just a sporting contest. It’s a fight of grit and strategy. Both fighters will fight with everything they possess.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are on a collision course of unparalleled significance. It’s not merely about the belts; it represents their quest for immortality. The towering Fury has become a global icon through his unique style and remarkable adaptability during fights. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. On the other hand, Usyk, the Ukrainian master is a fighter unlike any other for Fury. On the flip side, Oleksandr Usyk represents a formidable opponent for the heavyweight ranks overall, as a heavyweight contender. Usyk’s rise to prominence started with his domination of the cruiserweights, where he became an unstoppable force. Don’t miss out for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a historic showdown! Catch every punch streamed live on our website. Don’t miss your chance — visit <a href="https://gdetr.hit.gemius.pl/_uachredir/hitredir/id=nGFLcsQQENpn.0g.IXKjd3YZ7Hk1yAQskyJeVC4lR53.i7/fastid=jnoaiehnqtxhpncewambqgeojokf/stparam=vdrllkrfkd/nc=0/gdpr=0/gdpr_consent=/url=https://tysonfuryvsoleksandrusyk.co.uk/">tysonfuryvsoleksandrusyk.co.uk</a> right away and enjoy the fight in high quality!
For British fans, the fight is expected to begin close to prime time, ensuring maximum viewership. Back in Usyk’s home country, and for fans watching from around the world, the excitement is palpable. The fight’s location has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, fans can be sure: the excitement will be unmatched. Although the focus is firmly on the main event, the fights leading up to the main event promises plenty of action. Big-ticket boxing cards often feature stacked undercards, giving fans a full evening of entertainment.
In the past, undercards of this caliber have showcased rising stars. Fighters looking to rise through the ranks capitalize on the exposure to showcase their skills, with the world paying attention. While the names for the undercard haven’t been officially announced, fans are eagerly guessing. Might there be a cruiserweight spectacle? No matter the final roster, the action will not disappoint. The most compelling part of Fury vs Usyk so intriguing is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. At 6’9" with an 85-inch reach, he commands the ring like no other.
His trilogy with Deontay Wilder proved his toughness, overcoming brutal hits to secure victories. When he faced Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, offers a different kind of threat. Being a left-handed fighter, his positioning constantly challenges opponents. Usyk’s punches lack devastating strength, but they are delivered with pinpoint accuracy. As fight night approaches, Predictions for this fight are the subject of intense debate.
The betting lines show Fury ahead as predicted by many experts, thanks to his imposing frame, his experience in high-pressure bouts, and his adaptability. However, Usyk's underdog status doesn’t rule him out, his wins over Anthony Joshua confirmed his toughness against big opponents.
For Tyson Fury, this fight could be the defining moment of his career. A triumph for Fury would put the finishing touches on a historic career. Meanwhile, Usyk’s victory would be a monumental achievement. Achieving undisputed glory in two divisions is a feat few can claim.
Web: <a href="http://www.google.ee/url?sa=t&url=http%3A%2F%2Fwww.magical-dream.com">tysonfuryvsoleksandrusyk.co.uk</a>
Fury vs Usyk represents something greater than a title bout. It’s a clash of personalities. Fury’s boisterous personality contrasts with Usyk’s calm, focused demeanor. These varying personalities make the bout even more interesting. Beyond physical ability, this fight. Whoever comes out victorious, the significance of this match will leave a lasting mark on the sport. The clash for the undisputed title is a spectacle unlike any other. It’s a culmination of years of hard work. Whether Tyson Fury prevails thanks to his power and game plan, or Oleksandr Usyk triumphs through his superior boxing ability, what is clear is, this will be a fight remembered for years to come.
Tyson Fury vs Oleksandr Usyk is more than just a sporting contest. It’s a fight of grit and strategy. These men will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are preparing for an epic showdown of historic proportions. This fight is about more than just titles; it represents their quest for immortality. The Gypsy King has risen to the pinnacle of the sport thanks to his personality and remarkable adaptability in the ring. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. Across the ring, the tactical southpaw brings an unprecedented test for Fury. At the same time, the Ukrainian technician is a true test for Fury for the heavyweight ranks overall, as a heavyweight contender. His journey to global fame started with his domination of the cruiserweights, where he became an unstoppable force. Don’t miss out for a thrilling boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! Experience every moment streamed live on our website. Be part of the action — visit <a href="https://craftcms.loyolapress.com/actions/loyola-press/redirects?env=production&uri=wp-content/plugins/translator/translator.php?l=is&u=https://usykvsfurydate.org.uk/">usykvsfurydate.org.uk</a> today and enjoy the fight from the comfort of your home!
Across the UK, the fight is expected to begin close to prime time, offering perfect timing for viewers. Back in Usyk’s home country, and for fans watching from around the world, the excitement is palpable. The fight’s location has yet to be confirmed, with talk of iconic boxing destinations. No matter the location, it’s guaranteed: the excitement will be unmatched. While the spotlight is firmly on the main event, the fights leading up to the main event is also generating excitement. Major boxing events include preliminary bouts with top talent, giving fans a full evening of entertainment.
Historically, supporting bouts in major events have been a stage for breakout performances. Boxers seeking the spotlight often seize these moments to showcase their skills, knowing millions are watching. While the names for the undercard haven’t been officially announced, speculation runs high. Will there be a heavyweight clash? No matter the final roster, the action will not disappoint. What makes this fight truly fascinating is the clash of styles. Tyson Fury’s size and agility are unparalleled in the sport. With his immense height and reach advantage, he dictates the pace of bouts.
The three fights against Wilder highlighted his resilience, overcoming brutal hits to secure victories. Against Wladimir Klitschko, his strategic genius shone through, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, relies on technique and stamina. As a southpaw, his movements create openings. His strikes lack devastating strength, but they are delivered with pinpoint accuracy. As anticipation builds, Predictions for this fight are the subject of intense debate.
Most bookmakers favor Fury as predicted by many experts, because of his reach and height, his proven ability in tough situations, and his tactical brilliance. However, Usyk's underdog status shouldn’t be counted out, as his victories over Joshua confirmed his toughness against big opponents.
For Tyson Fury could be the defining moment of his career. If he wins, it would solidify his claim as the greatest heavyweight of his generation. Meanwhile, Usyk’s victory would be a monumental achievement. Achieving undisputed glory in two divisions is a once-in-a-lifetime achievement.
Web: <a href="http://images.google.com.ng/url?sa=t&url=https://usykvsfurydate.org.uk/">usykvsfurydate.org.uk</a>
This fight represents something greater than a title bout. It’s a battle of contrasting styles. Fury’s larger-than-life persona contrasts with Usyk’s calm, focused demeanor. The clash of personalities adds depth to the narrative. This is more than just a physical contest. Whoever comes out victorious, the impact of this bout will be remembered as a defining moment in boxing. Fury vs Usyk is more than just a fight. It’s the result of relentless dedication. Should Fury claim victory with his experience and unpredictability, or Usyk secures a victory thanks to his skill and resilience, what is clear is, this will be a legendary contest.
The Fury-Usyk battle is more than just a sporting contest. It’s a showcase of skill and determination. These men will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are set to meet in the ring of historic proportions. It’s far beyond a championship match; it’s a battle for eternal recognition. Tyson Fury has become a global icon with his charisma and his unmatched skills in the ring. Beating Wilder and Klitschko have solidified his legendary status. Across the ring, the tactical southpaw brings an unprecedented test for Fury. On the flip side, the Ukrainian technician is a true test for Fury for the heavyweight ranks overall, but for the entire division. His journey to global fame was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Don’t miss out for an epic boxing match of the year as Usyk takes on Fury in a must-watch showdown! Catch every punch streamed live on our website. Join the excitement — visit <a href="http://rabofree.nnov.org/common/redir.php?https://tysonvusyk.co.uk/">tysonvusyk.co.uk</a> now and enjoy the fight with top-notch streaming!
In the United Kingdom, the event will kick off at close to prime time, ensuring maximum viewership. In Usyk’s native Ukraine, and beyond, the excitement is palpable. The venue for Fury vs Usyk has yet to be confirmed, with talk of iconic boxing destinations. Regardless of the venue, one thing is certain: it will be a spectacle. Although the focus remains on Fury and Usyk, the Fury vs Usyk undercard is also generating excitement. High-profile matches often feature stacked undercards, giving fans a full evening of entertainment.
Traditionally, preliminary fights on major cards have showcased rising stars. Fighters looking to rise through the ranks capitalize on the exposure to demonstrate their talent, as all eyes are on them. Though the supporting fights for Fury vs Usyk has yet to be finalized, fans are eagerly guessing. Could we see rising prospects? No matter the final roster, the action will not disappoint. What sets this bout apart incredibly exciting is the dynamic between these fighters. Fury’s towering frame and movement make him an anomaly in boxing. At 6’9" with an 85-inch reach, Fury can control a fight.
The three fights against Wilder showed his durability, as he recovered from knockdowns to secure victories. Against Wladimir Klitschko, his strategic genius shone through, demonstrating his mental sharpness. By contrast, Usyk, offers a different kind of threat. With his unorthodox stance, his movements create openings. The Ukrainian’s shots aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. As anticipation builds, Tyson Fury vs Usyk odds are the subject of intense debate.
Fury is the favored fighter as predicted by many experts, because of his reach and height, his track record in big matches, and his unpredictable nature. Despite being seen as the underdog doesn’t mean he’s an underdog in spirit, his victories against AJ confirmed his toughness against big opponents.
For Tyson Fury, this fight represents an opportunity to cement his legacy. A victory would put the finishing touches on a historic career. Meanwhile, For Usyk, a win would elevate him to new heights. Securing two undisputed titles is a rare accomplishment.
Web: <a href="http://clients1.google.pn/url?q=https%3A%2F%2Ftysonvusyk.co.uk">tysonvusyk.co.uk</a>
Fury vs Usyk represents something greater than a title bout. It’s a fight between two very different fighters. Fury’s boisterous personality is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. This is more than just a physical contest. Regardless of the outcome, the impact of this bout will reverberate throughout boxing history. The battle for heavyweight supremacy is more than just a fight. It represents the culmination of their careers. Whether Tyson Fury prevails with his size and strategy, or Usyk wins with his precision with his technique and endurance, no matter the outcome, this will be a legendary contest.
Fury vs Usyk is more than just a sporting contest. It’s a fight of grit and strategy. These two warriors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are set to meet in the ring that will define an era. It’s not merely about the belts; it’s a battle for eternal recognition. The towering Fury has earned worldwide fame with his charisma and remarkable adaptability inside the ropes. Beating Wilder and Klitschko have cemented his place among the all-time greats. On the other hand, Usyk, the technician poses a unique challenge for Fury. Meanwhile, Oleksandr Usyk is a true test for Fury for the heavyweight ranks overall, and for boxing fans worldwide. His journey to global fame was marked by his undisputed cruiserweight reign, as an undisputed champion. Get ready for the most anticipated boxing match of the year as Oleksandr Usyk takes on Fury in an unforgettable showdown! See every move streamed live on our website. Join the excitement — visit <a href="https://kolizeum.ru/click?redirect=https://fury-usyk.uk/">fury-usyk.uk</a> right away and enjoy the fight in high quality!
For British fans, the event will kick off at late evening, making it ideal for a prime-time audience. Back in Usyk’s home country, and beyond, this will be a must-see event. Where the bout will take place has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, it’s guaranteed: the excitement will be unmatched. While the spotlight is centered on the headline fight, the preliminary bouts is shaping up to be thrilling. High-profile matches are known for strong supporting fights, offering an entire night of boxing excitement.
In the past, preliminary fights on major cards have introduced future champions. Boxers seeking the spotlight use such opportunities to showcase their skills, as all eyes are on them. Though the supporting fights for Fury vs Usyk has yet to be finalized, speculation runs high. Will there be a heavyweight clash? No matter the final roster, the action will not disappoint. What sets this bout apart truly fascinating is the clash of styles. Fury’s towering frame and movement set him apart from other heavyweights. With his immense height and reach advantage, he commands the ring like no other.
The legendary battles with Wilder highlighted his resilience, bouncing back from adversity to secure victories. When he faced Klitschko, his strategic genius shone through, demonstrating his mental sharpness. By contrast, Usyk, brings speed, precision, and finesse. With his unorthodox stance, he uses angles and footwork. The Ukrainian’s shots lack devastating strength, their timing wears down foes. With the date drawing closer, Tyson Fury vs Usyk odds have fans and analysts speculating.
Tyson Fury is the slight favorite as per the betting experts, because of his reach and height, his long career in major fights, and his unpredictable nature. Despite being seen as the underdog doesn’t diminish his chances, as his victories over Joshua proved that he can handle the physicality of the heavyweight division.
For Tyson Fury, this fight presents a shot at undisputed glory. Should he come out on top, Fury’s win would further solidify his status as the best heavyweight of this era. On the other hand, If Usyk wins would elevate him to legendary status. Securing two undisputed titles is a rare accomplishment.
Web: <a href="http://maps.google.com.tw/url?sa=t&url=https%3A%2F%2Ffury-usyk.uk">fury-usyk.uk</a>
The upcoming showdown is more than just a championship fight. It’s a fight between two very different fighters. Fury’s larger-than-life persona contrasts with Usyk’s calm, focused demeanor. These differences add complexity to the fight. It’s about more than just skill. Whoever triumphs in this battle, the impact of this bout will reverberate throughout boxing history. This historic showdown is more than just a match. It’s the pinnacle of both fighters’ hard work. Whether Fury secures the win thanks to his power and game plan, or Usyk secures a victory through his superior boxing ability, one thing is certain, this will be a legendary contest.
The Fury-Usyk battle is a spectacle of a lifetime. It’s a contest of heart and willpower. These two warriors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are on a collision course that will define an era. This fight is about more than just titles; it represents their quest for immortality. Fury, an undefeated champion has risen to the pinnacle of the sport with his charisma and his unmatched skills in the ring. Beating Wilder and Klitschko have earned him recognition as one of the best ever. Across the ring, Usyk, the Ukrainian master poses a unique challenge to boxing’s biggest stars. At the same time, Oleksandr Usyk represents a formidable opponent not just for Fury, as a heavyweight contender. His journey to global fame began in the cruiserweight division, by conquering all challengers. Prepare yourself for an epic boxing match of the year as Usyk takes on Fury in an unforgettable showdown! Experience every moment streamed live on our website. Be part of the action — visit <a href="https://www.unionensakassa.se/find_v2/_click?_t_id=1B2M2Y8AsgTpgAmY7PhCfg%3D%3D&_t_q=&_t_tags=language%3Asv%2Csiteid%3Ab8b4a1a3-0bfc-46af-b8ca-54e0accacd27&_t_ip=66.249.69.123&_t_hit.id=UAK_Public_Web_Components_Pages_SubPage_Models_SubPage/_d655d89b-b0d2-4dc5-9634-b8f7056f965f_sv&_t_hit.pos=6&_t_redirect=http%3a%2f%2ftysonvsusyk.org.uk&_t_id=1B2M2Y8AsgTpgAmY7PhCfg%3D%3D&_t_q=&_t_tags=language%3Asv%2Csiteid%3Ab8b4a1a3-0bfc-46af-b8ca-54e0accacd27&_t_ip=66.249.69.123&_t_hit.id=UAK_Public_Web_Components_Pages_SubPage_Models_SubPage/_d655d89b-b0d2-4dc5-9634-b8f7056f965f_sv&_t_hit.pos=6&_t_redirect=http%3a%2f%2fcaafuwe.blogspot.com">tysonvsusyk.org.uk</a> right away and enjoy the fight from the comfort of your home!
For British fans, the fight is expected to begin close to prime time, ensuring maximum viewership. Back in Usyk’s home country, and for fans watching from around the world, the anticipation is at a fever pitch. Where the bout will take place has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, one thing is certain: the atmosphere will be electric. While the spotlight remains on Fury and Usyk, the Fury vs Usyk undercard is shaping up to be thrilling. High-profile matches are known for strong supporting fights, providing non-stop action before the headliner.
Traditionally, preliminary fights on major cards have introduced future champions. Boxers seeking the spotlight capitalize on the exposure to demonstrate their talent, with the world paying attention. Although the lineup for the Fury Usyk undercard are still unconfirmed, there’s plenty of talk. Will there be a heavyweight clash? Regardless of the names, fans can expect fireworks. The most compelling part of Fury vs Usyk so intriguing is the dynamic between these fighters. Tyson Fury’s size and agility set him apart from other heavyweights. With his immense height and reach advantage, he commands the ring like no other.
The three fights against Wilder proved his toughness, overcoming brutal hits to finish strong. In his fight with Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Meanwhile, Usyk, offers a different kind of threat. Being a left-handed fighter, his positioning constantly challenges opponents. His strikes aren’t the heaviest in the division, their timing wears down foes. As anticipation builds, Tyson Fury vs Usyk odds are becoming a hot topic.
The betting lines show Fury ahead as predicted by many experts, given his physical stature, his track record in big matches, and his tactical brilliance. However, Usyk's underdog status doesn’t diminish his chances, his victories against AJ proved that he can handle the physicality of the heavyweight division.
For Fury himself could be the defining moment of his career. A victory would further solidify his status as the best heavyweight of this era. On the other hand, For Usyk, a win would elevate him to new heights. Becoming the undisputed heavyweight champion would be a remarkable feat in boxing history.
Web: <a href="http://google.ba/url?q=https://tysonvsusyk.org.uk/">tysonvsusyk.org.uk</a>
This fight is not just about the belts. It’s a meeting of two unique worldviews. Fury’s boisterous personality contrasts with Usyk’s calm, focused demeanor. These differences add complexity to the fight. Beyond physical ability, this fight. Regardless of the outcome, the significance of this match will be remembered as a defining moment in boxing. This historic showdown is more than just a match. It’s the pinnacle of both fighters’ hard work. Whether Fury secures the win with his size and strategy, or Usyk wins with his precision with his technique and endurance, it’s certain that, this will be a fight remembered for years to come.
Fury vs Usyk is more than just a sporting contest. It’s a showcase of skill and determination. These men will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are set to meet in the ring of historic proportions. It’s not merely about the belts; it’s about legacy. The towering Fury has risen to the pinnacle of the sport through his unique style and his unmatched skills in the ring. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. On the other hand, Usyk, the Ukrainian master poses a unique challenge to the heavyweight division. At the same time, Usyk, a genius in the ring represents a formidable opponent not just for Fury, and for boxing fans worldwide. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, as an undisputed champion. Get ready for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! See every move streamed live on our website. Be part of the action — visit <a href="http://go.shareaholic.com/e?a=4&r=1&p=4a281512-675d-4ae5-b877-1bd61f3bd4c7&o=3c22f7480051a907acc3ec4666d43508&u=http%3A%2F%2Ftysonvsusyk.org.uk">tysonvsusyk.org.uk</a> today and stream the event with top-notch streaming!
Across the UK, the event will kick off at around 10 PM GMT, ensuring maximum viewership. For Usyk’s fans in Ukraine, and beyond, this will be a must-see event. The fight’s location has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, one thing is certain: it will be a spectacle. While the spotlight is centered on the headline fight, the preliminary bouts is also generating excitement. Major boxing events include preliminary bouts with top talent, offering an entire night of boxing excitement.
In the past, preliminary fights on major cards have showcased rising stars. Boxers seeking the spotlight capitalize on the exposure to impress fans and analysts alike, as all eyes are on them. While the names for the undercard are still unconfirmed, speculation runs high. Will there be a heavyweight clash? Whatever the selection, the action will not disappoint. The most compelling part of Fury vs Usyk truly fascinating is the clash of styles. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
The three fights against Wilder showed his durability, bouncing back from adversity to dominate in later rounds. When he faced Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, relies on technique and stamina. With his unorthodox stance, he uses angles and footwork. His strikes aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. As fight night approaches, Predictions for this fight have fans and analysts speculating.
Tyson Fury is seen as the frontrunner based on the betting odds, given his physical stature, his long career in major fights, and his tactical brilliance. However, Usyk's underdog status shouldn’t be counted out, his wins over Anthony Joshua showed that he can compete at heavyweight.
For Tyson Fury, this fight is a chance to further solidify his greatness. If he wins, it would further solidify his status as the best heavyweight of this era. Conversely, For Usyk, a win would elevate him to legendary status. Achieving undisputed glory in two divisions is a rare accomplishment.
Web: <a href="http://www.google.gp/url?q=https://tysonvsusyk.org.uk/">tysonvsusyk.org.uk</a>
This fight represents something greater than a title bout. It’s a battle of contrasting styles. Fury’s boisterous personality stands in stark contrast to Usyk’s composed demeanor. These differences add complexity to the fight. Beyond physical ability, this fight. No matter who wins, the significance of this match will leave a lasting mark on the sport. This historic showdown is more than just a fight. It represents the culmination of their careers. If Fury wins through his strength and tactics, or Usyk wins with his precision through his superior boxing ability, it’s certain that, this will be a legendary contest.
The Fury-Usyk battle is more than just a boxing event. It’s a showcase of skill and determination. Both fighters will pour everything into the bout.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are on a collision course of historic proportions. This fight is about more than just titles; it’s a battle for eternal recognition. The Gypsy King has risen to the pinnacle of the sport thanks to his personality and his unmatched skills inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. Meanwhile, the tactical southpaw is a fighter unlike any other for Fury. On the flip side, the Ukrainian technician is a true test for Fury for Tyson Fury himself, and for boxing fans worldwide. His journey to global fame was marked by his undisputed cruiserweight reign, as an undisputed champion. Prepare yourself for a thrilling boxing match of the year as Usyk takes on Fury in a must-watch showdown! Catch every punch live on our website. Be part of the action — visit <a href="https://www.kuharka.ru/go/?furyvsusykdate.com">furyvsusykdate.com</a> right away and stream the event from the comfort of your home!
For British fans, the ring walks are planned for late evening, ensuring maximum viewership. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, the excitement is palpable. The fight’s location is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, it’s guaranteed: the excitement will be unmatched. Even though attention is centered on the headline fight, the preliminary bouts promises plenty of action. High-profile matches often feature stacked undercards, providing non-stop action before the headliner.
Historically, preliminary fights on major cards have been a stage for breakout performances. Fighters looking to rise through the ranks often seize these moments to impress fans and analysts alike, with the world paying attention. Though the supporting fights for Fury vs Usyk has yet to be finalized, there’s plenty of talk. Might there be a cruiserweight spectacle? Whatever the selection, fans can expect fireworks. What makes this fight truly fascinating is their contrasting skillsets. Tyson Fury’s size and agility are unparalleled in the sport. At 6’9" with an 85-inch reach, he commands the ring like no other.
The three fights against Wilder showed his durability, overcoming brutal hits to dominate in later rounds. When he faced Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. By contrast, Usyk, relies on technique and stamina. With his unorthodox stance, his positioning constantly challenges opponents. His strikes may not have knockout power, they consistently find their mark. As anticipation builds, Predictions for this fight are becoming a hot topic.
Fury is the favored fighter as predicted by many experts, because of his reach and height, his experience in high-pressure bouts, and his unorthodox style. However, Usyk's underdog status doesn’t mean he’s an underdog in spirit, his dominance against Joshua confirmed his toughness against big opponents.
For Tyson Fury, this fight is a chance to further solidify his greatness. A victory would add an undisputed title to his already impressive resume. Meanwhile, If Usyk wins would mark him as one of the sport’s greats. Becoming an undisputed champion in two different weight classes is a once-in-a-lifetime achievement.
Web: <a href="http://maps.google.com.np/url?q=https%3A%2F%2Ffuryvsusykdate.com">furyvsusykdate.com</a>
Fury vs Usyk is more than just a championship fight. It’s a clash of personalities. Fury’s larger-than-life persona contrasts with Usyk’s calm, focused demeanor. These varying personalities make the bout even more interesting. Beyond physical ability, this fight. Whoever comes out victorious, the significance of this match will reverberate throughout boxing history. The battle for heavyweight supremacy is a spectacle unlike any other. It’s the pinnacle of both fighters’ hard work. If Fury wins with his size and strategy, or Usyk wins with his precision through his superior boxing ability, no matter the outcome, this will be a legendary contest.
Tyson Fury vs Oleksandr Usyk is more than just a boxing event. It’s a showcase of skill and determination. Both fighters will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are preparing for an epic showdown of historic proportions. It’s far beyond a championship match; it’s a battle for eternal recognition. The towering Fury has earned worldwide fame thanks to his personality and his unmatched skills in the ring. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. Across the ring, Usyk, the Ukrainian master poses a unique challenge for Fury. On the flip side, Usyk, a southpaw master represents a formidable opponent not just for Fury, and for boxing fans worldwide. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, as an undisputed champion. Get ready for a thrilling boxing match of the year as Oleksandr Usyk takes on Fury in a must-watch showdown! Catch every punch streamed live on our website. Be part of the action — visit <a href="http://elo.nnov.org/common/redir.php?https://furyvsusyk.org.uk/">furyvsusyk.org.uk</a> today and stream the event from the comfort of your home!
For British fans, the fight is expected to begin around 10 PM GMT, making it ideal for a prime-time audience. Back in Usyk’s home country, as well as viewers across Europe and the Americas, the excitement is palpable. The fight’s location has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, fans can be sure: the atmosphere will be electric. Even though attention is firmly on the main event, the Fury vs Usyk undercard is also generating excitement. High-profile matches are known for strong supporting fights, giving fans a full evening of entertainment.
Traditionally, supporting bouts in major events have showcased rising stars. Contenders hoping to make their mark capitalize on the exposure to showcase their skills, knowing millions are watching. Though the supporting fights for Fury vs Usyk are still unconfirmed, there’s plenty of talk. Will there be a heavyweight clash? No matter the final roster, the action will not disappoint. The most compelling part of Fury vs Usyk truly fascinating is the dynamic between these fighters. Fury’s towering frame and movement set him apart from other heavyweights. At 6’9" with an 85-inch reach, he commands the ring like no other.
The legendary battles with Wilder highlighted his resilience, bouncing back from adversity to dominate in later rounds. In his fight with Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. With his unorthodox stance, he uses angles and footwork. The Ukrainian’s shots may not have knockout power, their timing wears down foes. With the date drawing closer, Predictions for this fight are becoming a hot topic.
Most bookmakers favor Fury according to the odds, due to his size advantage, his track record in big matches, and his tactical brilliance. Despite being seen as the underdog doesn’t diminish his chances, his wins over Anthony Joshua confirmed his toughness against big opponents.
For Fury himself is a chance to further solidify his greatness. If he wins, it would solidify his claim as the greatest heavyweight of his generation. Conversely, If Usyk wins would mark him as one of the sport’s greats. Becoming an undisputed champion in two different weight classes is a once-in-a-lifetime achievement.
Web: <a href="http://clients1.google.ci/url?q=https%3A%2F%2Ffuryvsusyk.org.uk">furyvsusyk.org.uk</a>
Fury vs Usyk represents something greater than a title bout. It’s a fight between two very different fighters. Fury’s bold and unapologetic character stands in stark contrast to Usyk’s composed demeanor. These varying personalities make the bout even more interesting. It’s about more than just skill. Regardless of the outcome, the legacy of this fight will leave a lasting mark on the sport. Fury vs Usyk is more than just a match. It’s the result of relentless dedication. Whether Fury secures the win with his experience and unpredictability, or Usyk comes out on top thanks to his skill and resilience, it’s certain that, this will be a defining moment in boxing.
Fury vs Usyk is more than just a fight. It’s a fight of grit and strategy. The two competitors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are set to meet in the ring that will define an era. It’s not merely about the belts; it’s about legacy. The Gypsy King has become a global icon through his unique style coupled with unparalleled talent during fights. Beating Wilder and Klitschko have earned him recognition as one of the best ever. On the other hand, Usyk, the technician brings an unprecedented test to the heavyweight division. On the flip side, Usyk, a southpaw master represents a formidable opponent for Tyson Fury himself, and for boxing fans worldwide. Usyk’s rise to prominence started with his domination of the cruiserweights, where he became an unstoppable force. Don’t miss out for a thrilling boxing match of the year as Usyk takes on Fury in a must-watch showdown! Catch every punch streamed live on our website. Be part of the action — visit <a href="http://nobrand.pt/https://usykvsfury.co.uk/">usykvsfury.co.uk</a> now and enjoy the fight from the comfort of your home!
Across the UK, the fight is expected to begin close to prime time, making it ideal for a prime-time audience. Back in Usyk’s home country, as well as viewers across Europe and the Americas, the excitement is palpable. The venue for Fury vs Usyk has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, one thing is certain: it will be a spectacle. Although the focus remains on Fury and Usyk, the Fury vs Usyk undercard promises plenty of action. Major boxing events include preliminary bouts with top talent, providing non-stop action before the headliner.
Historically, undercards of this caliber have been a stage for breakout performances. Boxers seeking the spotlight use such opportunities to showcase their skills, with the world paying attention. While the names for the undercard are still unconfirmed, fans are eagerly guessing. Could we see rising prospects? Regardless of the names, the action will not disappoint. What makes this fight truly fascinating is the clash of styles. Tyson Fury’s size and agility set him apart from other heavyweights. Being so tall yet so nimble, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, as he recovered from knockdowns to dominate in later rounds. Against Wladimir Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. By contrast, Usyk, relies on technique and stamina. Being a left-handed fighter, his positioning constantly challenges opponents. The Ukrainian’s shots lack devastating strength, they consistently find their mark. With the date drawing closer, The betting lines for Fury vs Usyk are the subject of intense debate.
Tyson Fury is seen as the frontrunner based on the betting odds, because of his reach and height, his track record in big matches, and his unorthodox style. Although Usyk is the less favored fighter doesn’t diminish his chances, as his victories over Joshua proved that he can handle the physicality of the heavyweight division.
For Fury himself is a chance to further solidify his greatness. If he wins, it would solidify his claim as the greatest heavyweight of his generation. Conversely, If Usyk wins would elevate him to new heights. Becoming the undisputed heavyweight champion is a feat few can claim.
Web: <a href="http://images.google.ca/url?sa=t&url=https://usykvsfury.co.uk/">usykvsfury.co.uk</a>
The upcoming showdown is not just about the belts. It’s a meeting of two unique worldviews. Fury’s boisterous personality is the opposite of Usyk’s humble and disciplined approach. The clash of personalities adds depth to the narrative. Beyond physical ability, this fight. Whoever triumphs in this battle, the legacy of this fight will be felt for years to come. The clash for the undisputed title is more than just a match. It represents the culmination of their careers. Whether Fury secures the win through his strength and tactics, or Oleksandr Usyk triumphs through his superior boxing ability, no matter the outcome, this bout will go down in history.
Fury vs Usyk is more than just a sporting contest. It’s a showcase of skill and determination. The two competitors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are set to meet in the ring that will define an era. This fight is about more than just titles; it’s about legacy. The Gypsy King has risen to the pinnacle of the sport through his unique style and his unmatched skills in the ring. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. On the other hand, Oleksandr Usyk brings an unprecedented test for Fury. Meanwhile, the Ukrainian technician represents a formidable opponent for Tyson Fury himself, as a heavyweight contender. The ascent of Oleksandr Usyk began in the cruiserweight division, where he became an unstoppable force. Don’t miss out for the most anticipated boxing match of the year as Usyk takes on Fury in a historic showdown! Catch every punch live on our website. Be part of the action — visit <a href="https://www.filion.ru/bitrix/redirect.php?goto=https://tysonfuryvsoleksandrusyk.co.uk/">tysonfuryvsoleksandrusyk.co.uk</a> now and enjoy the fight with top-notch streaming!
In the United Kingdom, the ring walks are planned for around 10 PM GMT, offering perfect timing for viewers. For Usyk’s fans in Ukraine, and for fans watching from around the world, the excitement is palpable. The fight’s location has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, it’s guaranteed: the atmosphere will be electric. Even though attention is centered on the headline fight, the preliminary bouts promises plenty of action. High-profile matches often feature stacked undercards, giving fans a full evening of entertainment.
Traditionally, preliminary fights on major cards have introduced future champions. Boxers seeking the spotlight use such opportunities to demonstrate their talent, as all eyes are on them. Though the supporting fights for Fury vs Usyk are still unconfirmed, there’s plenty of talk. Could we see rising prospects? Whatever the selection, it’s sure to add to the excitement. What sets this bout apart incredibly exciting is the dynamic between these fighters. Fury’s towering frame and movement set him apart from other heavyweights. Being so tall yet so nimble, he dictates the pace of bouts.
The three fights against Wilder proved his toughness, bouncing back from adversity to dominate in later rounds. Against Wladimir Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Meanwhile, Usyk, brings speed, precision, and finesse. Being a left-handed fighter, his positioning constantly challenges opponents. Usyk’s punches aren’t the heaviest in the division, their timing wears down foes. As anticipation builds, Predictions for this fight are the subject of intense debate.
Tyson Fury is the slight favorite as per the betting experts, due to his size advantage, his experience in high-pressure bouts, and his unpredictable nature. Although Usyk is the less favored fighter doesn’t diminish his chances, his dominance against Joshua demonstrated his ability in the heavyweight ranks.
For the Gypsy King presents a shot at undisputed glory. If he wins, it would further solidify his status as the best heavyweight of this era. Conversely, If Usyk wins would be a monumental achievement. Achieving undisputed glory in two divisions is a rare accomplishment.
Web: <a href="http://images.google.rs/url?q=https://tysonfuryvsoleksandrusyk.co.uk/">tysonfuryvsoleksandrusyk.co.uk</a>
Fury vs Usyk represents something greater than a title bout. It’s a fight between two very different fighters. Fury’s confident and brash nature is the opposite of Usyk’s humble and disciplined approach. These differences add complexity to the fight. It’s a fight of wills and ideologies. Whoever comes out victorious, the significance of this match will leave a lasting mark on the sport. The battle for heavyweight supremacy is more than just a match. It’s the pinnacle of both fighters’ hard work. Whether Fury secures the win with his size and strategy, or Usyk secures a victory with his technique and endurance, one thing is certain, this bout will go down in history.
This fight between Fury and Usyk is more than just a fight. It’s a contest of heart and willpower. These two warriors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Azərbaycan ərazisində internet qumarına güvəni artdıqca, "Pin-up casino" kimi saytlar daha çox tanınmağa başladı. Özəlliklə, Pin-up online brendləri son zamanlar yerli oyunçular üçün sevilir. Pinup casino oyunçulara çoxlu oyun növü təklif edir.
Pinup kazino, Azəri qumarbazlar üçün güvənli bir qumar məkanıdır. Bu qumar saytı müştərilərə rəngarəng oyunlar təklif edir və bonus imkanları ilə qumarbazlar tərəfindən sevilir.
Pin-up azerbaycan, istifadəçilərə oyun növləri ilə zəngin xidmətdir. Azəri bazarında geniş istifadə olunan Pin-up kazino, kazino oyunçuları üçün zəngin təkliflər təqdim edir.
Özəlliklə, Pin-up online casino oyunçulara etibarlı maliyyə sistemləri verir. İstifadəçilər, müvafiq və təhlükəsiz depozit çıxarış sistemi sayəsində, internet oyunlarını daha asan yaşaya bilərlər.
Sonda, Pin-up casino oyunçulara yalnız qumar oyunları yox, həmçinin cəlbedici kampaniyalar oyun təcrübəsini daha da maraqlı edir. Bu platformada, oyunçular özlərini güvəndə hiss edir.
Web: https://pinup-best-top.web.app
Pin-up online kazino təkcə bir oyun platforması kimi məhdudlaşmır. Qumarçılar burada bənzərsiz mərc imkanlarından yararlana bilərlər və cazibədar bonus imkanlarını oyunlarına əlavə edə bilərlər.
Beləliklə, Pin-up cazino, sərfəli və təhlükəsiz qumar təcrübəsi təmin etməklə onlayn qumar dünyasında oyunçular arasında geniş istifadə edilir. Azəri bazarında məşhur olması dikkətə layiqdir.
Fury, the Gypsy King, and Usyk, the technician are set to meet in the ring of historic proportions. It’s far beyond a championship match; it’s a battle for eternal recognition. Tyson Fury has risen to the pinnacle of the sport with his charisma and his unmatched skills during fights. Triumphing against boxing legends like Wilder and Klitschko have solidified his legendary status. Meanwhile, Oleksandr Usyk brings an unprecedented test to boxing’s biggest stars. Meanwhile, Usyk, a genius in the ring is a true test for Fury for the heavyweight ranks overall, and for boxing fans worldwide. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, as an undisputed champion. Get ready for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a historic showdown! Catch every punch live on our website. Don’t miss your chance — visit <a href="http://3d-monster-sex.xxxbit.com/index.php?a=out&f=1&s=2&l=http%3A%2F%2Ftysonfuryvsoleksandrusyk.co.uk">tysonfuryvsoleksandrusyk.co.uk</a> right away and watch the match with top-notch streaming!
For British fans, the ring walks are planned for late evening, ensuring maximum viewership. Back in Usyk’s home country, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. The venue for Fury vs Usyk remains a hot topic, with talk of iconic boxing destinations. Regardless of the venue, fans can be sure: the excitement will be unmatched. While the spotlight is centered on the headline fight, the fights leading up to the main event is also generating excitement. Major boxing events are known for strong supporting fights, offering an entire night of boxing excitement.
Historically, supporting bouts in major events have introduced future champions. Boxers seeking the spotlight capitalize on the exposure to impress fans and analysts alike, knowing millions are watching. While the names for the undercard has yet to be finalized, speculation runs high. Might there be a cruiserweight spectacle? Whatever the selection, it’s sure to add to the excitement. The most compelling part of Fury vs Usyk so intriguing is their contrasting skillsets. Fury’s towering frame and movement are unparalleled in the sport. With his immense height and reach advantage, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, as he recovered from knockdowns to secure victories. In his fight with Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. By contrast, Usyk, relies on technique and stamina. With his unorthodox stance, his positioning constantly challenges opponents. The Ukrainian’s shots may not have knockout power, they consistently find their mark. With the date drawing closer, The betting lines for Fury vs Usyk have fans and analysts speculating.
Fury is the favored fighter according to the odds, because of his reach and height, his experience in high-pressure bouts, and his tactical brilliance. Although Usyk is the less favored fighter doesn’t mean he’s an underdog in spirit, his victories against AJ showed that he can compete at heavyweight.
For the Gypsy King could be the defining moment of his career. If he wins, it would add an undisputed title to his already impressive resume. Conversely, If Usyk wins would elevate him to legendary status. Becoming the undisputed heavyweight champion is a rare accomplishment.
Web: <a href="http://www.google.ba/url?q=https://tysonfuryvsoleksandrusyk.co.uk/">tysonfuryvsoleksandrusyk.co.uk</a>
Fury vs Usyk is not just about the belts. It’s a fight between two very different fighters. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. These differences add complexity to the fight. It’s a fight of wills and ideologies. Regardless of the outcome, the impact of this bout will reverberate throughout boxing history. Fury vs Usyk is more than just a match. It represents the culmination of their careers. Whether Tyson Fury prevails with his experience and unpredictability, or Usyk wins with his precision with his technique and endurance, what is clear is, this will be a fight remembered for years to come.
The Fury-Usyk battle is a spectacle of a lifetime. It’s a battle of minds and bodies. These men will fight with everything they possess.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are ready to face each other in a fight of unparalleled significance. This fight is about more than just titles; it’s about legacy. The towering Fury has risen to the pinnacle of the sport through his unique style and his unmatched skills in the ring. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. Meanwhile, Oleksandr Usyk brings an unprecedented test to the heavyweight division. Meanwhile, Usyk, a southpaw master stands as a unique threat for Tyson Fury himself, and for boxing fans worldwide. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Prepare yourself for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! Catch every punch live on our website. Be part of the action — visit <a href="https://www.viveleschiens.com/tracking.php?tracking_type=out&campagne_id=28614&url=https%3A%2F%2Ftysonvsusyk.org.uk">tysonvsusyk.org.uk</a> today and watch the match from the comfort of your home!
In the United Kingdom, the ring walks are planned for late evening, offering perfect timing for viewers. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, this will be a must-see event. Where the bout will take place remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, it’s guaranteed: the atmosphere will be electric. Although the focus is centered on the headline fight, the Fury vs Usyk undercard promises plenty of action. Big-ticket boxing cards often feature stacked undercards, offering an entire night of boxing excitement.
In the past, preliminary fights on major cards have introduced future champions. Contenders hoping to make their mark capitalize on the exposure to demonstrate their talent, as all eyes are on them. While the names for the undercard are still unconfirmed, speculation runs high. Could we see rising prospects? Regardless of the names, the action will not disappoint. What makes this fight truly fascinating is their contrasting skillsets. Fury’s towering frame and movement make him an anomaly in boxing. With his immense height and reach advantage, Fury can control a fight.
The legendary battles with Wilder proved his toughness, as he recovered from knockdowns to finish strong. When he faced Klitschko, his strategic genius shone through, proving he’s not just physical but cerebral. Meanwhile, Usyk, relies on technique and stamina. As a southpaw, his movements create openings. Usyk’s punches may not have knockout power, but they are delivered with pinpoint accuracy. As fight night approaches, Predictions for this fight have fans and analysts speculating.
Most bookmakers favor Fury as per the betting experts, because of his reach and height, his long career in major fights, and his unpredictable nature. Despite the odds, Usyk remains a strong contender doesn’t rule him out, his dominance against Joshua showed that he can compete at heavyweight.
For Fury himself could be the defining moment of his career. Should he come out on top, Fury’s win would further solidify his status as the best heavyweight of this era. On the other hand, For Usyk, a win would be a monumental achievement. Securing two undisputed titles would be a remarkable feat in boxing history.
Web: <a href="http://google.cz/url?q=https://tysonvsusyk.org.uk/">tysonvsusyk.org.uk</a>
This fight is not just about the belts. It’s a fight between two very different fighters. Fury’s confident and brash nature is in stark contrast to Usyk’s quiet intensity. Such contrasts make the fight more compelling. This is more than just a physical contest. Regardless of the outcome, the significance of this match will reverberate throughout boxing history. The clash for the undisputed title is a spectacle unlike any other. It represents the culmination of their careers. If Fury wins thanks to his power and game plan, or Usyk comes out on top with his finesse and stamina, one thing is certain, this will be a fight remembered for years to come.
The Fury-Usyk battle is more than just a fight. It’s a showcase of skill and determination. The two competitors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are on a collision course that will define an era. This fight is about more than just titles; it’s about legacy. The towering Fury has become a global icon through his unique style and remarkable adaptability during fights. Triumphing against boxing legends like Wilder and Klitschko have solidified his legendary status. On the other hand, Usyk, the Ukrainian master is a fighter unlike any other to the heavyweight division. Meanwhile, the Ukrainian technician represents a formidable opponent for Tyson Fury himself, as a heavyweight contender. The ascent of Oleksandr Usyk began in the cruiserweight division, as an undisputed champion. Prepare yourself for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! See every move in real time on our website. Join the excitement — visit <a href="https://www.visitloudoun.org/plugins/crm/count/?type=client&key=4_180&val=eyJrZXkiOiI0XzE4MCIsInJlZGlyZWN0IjoiaHR0cHM6Ly9tb2RzLW1lbnUucnUvIn0">furyvsusykdate.com</a> now and watch the match in high quality!
Across the UK, the event will kick off at around 10 PM GMT, ensuring maximum viewership. For Usyk’s fans in Ukraine, and beyond, this will be a must-see event. Where the bout will take place has yet to be confirmed, with talk of iconic boxing destinations. No matter the location, one thing is certain: the excitement will be unmatched. Although the focus remains on Fury and Usyk, the fights leading up to the main event is also generating excitement. Big-ticket boxing cards include preliminary bouts with top talent, giving fans a full evening of entertainment.
In the past, undercards of this caliber have introduced future champions. Boxers seeking the spotlight capitalize on the exposure to showcase their skills, knowing millions are watching. Though the supporting fights for Fury vs Usyk are still unconfirmed, speculation runs high. Could we see rising prospects? Regardless of the names, the action will not disappoint. The most compelling part of Fury vs Usyk truly fascinating is the clash of styles. Tyson Fury’s size and agility set him apart from other heavyweights. Being so tall yet so nimble, he dictates the pace of bouts.
The legendary battles with Wilder proved his toughness, bouncing back from adversity to dominate in later rounds. When he faced Klitschko, his strategic genius shone through, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. With his unorthodox stance, he uses angles and footwork. His strikes lack devastating strength, their timing wears down foes. With the date drawing closer, Tyson Fury vs Usyk odds are the subject of intense debate.
Tyson Fury is seen as the frontrunner according to the odds, given his physical stature, his long career in major fights, and his unorthodox style. Despite being seen as the underdog doesn’t mean he’s an underdog in spirit, his victories against AJ confirmed his toughness against big opponents.
For the Gypsy King represents an opportunity to cement his legacy. Should he come out on top, Fury’s win would further solidify his status as the best heavyweight of this era. Meanwhile, For Usyk, a win would be a monumental achievement. Achieving undisputed glory in two divisions is a rare accomplishment.
Web: <a href="http://www.google.com.lb/url?q=https://furyvsusykdate.com/">furyvsusykdate.com</a>
This fight is more than just a championship fight. It’s a battle of contrasting styles. Fury’s larger-than-life persona stands in stark contrast to Usyk’s composed demeanor. These differences add complexity to the fight. This is more than just a physical contest. Whoever triumphs in this battle, the impact of this bout will reverberate throughout boxing history. This historic showdown is more than just a match. It’s the pinnacle of both fighters’ hard work. Whether Fury secures the win through his strength and tactics, or Oleksandr Usyk triumphs with his technique and endurance, it’s certain that, this bout will go down in history.
This fight between Fury and Usyk is more than just a sporting contest. It’s a showcase of skill and determination. Both fighters will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are ready to face each other in a fight of historic proportions. This fight is about more than just titles; it’s about legacy. Tyson Fury has become a global icon thanks to his personality and remarkable adaptability in the ring. Beating Wilder and Klitschko have solidified his legendary status. In contrast, Usyk, the technician brings an unprecedented test to boxing’s biggest stars. At the same time, Oleksandr Usyk represents a formidable opponent for the heavyweight ranks overall, as a heavyweight contender. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Don’t miss out for the most anticipated boxing match of the year as Usyk takes on Fury in a historic showdown! Experience every moment live on our website. Don’t miss your chance — visit <a href="https://top-prof.ru/goto/https://tysonvusyk.co.uk/">tysonvusyk.co.uk</a> right away and watch the match in high quality!
In the United Kingdom, the fight is expected to begin around 10 PM GMT, ensuring maximum viewership. In Usyk’s native Ukraine, and beyond, this will be a must-see event. The fight’s location has yet to be confirmed, with talk of iconic boxing destinations. No matter the location, it’s guaranteed: it will be a spectacle. Even though attention is firmly on the main event, the preliminary bouts is shaping up to be thrilling. Big-ticket boxing cards include preliminary bouts with top talent, offering an entire night of boxing excitement.
Historically, preliminary fights on major cards have showcased rising stars. Contenders hoping to make their mark use such opportunities to impress fans and analysts alike, knowing millions are watching. Although the lineup for the Fury Usyk undercard are still unconfirmed, there’s plenty of talk. Will there be a heavyweight clash? No matter the final roster, fans can expect fireworks. The most compelling part of Fury vs Usyk so intriguing is the dynamic between these fighters. Fury’s towering frame and movement are unparalleled in the sport. With his immense height and reach advantage, he commands the ring like no other.
The legendary battles with Wilder showed his durability, bouncing back from adversity to secure victories. In his fight with Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. By contrast, Usyk, offers a different kind of threat. As a southpaw, he uses angles and footwork. His strikes may not have knockout power, their timing wears down foes. As fight night approaches, Tyson Fury vs Usyk odds are becoming a hot topic.
Tyson Fury is the slight favorite as per the betting experts, thanks to his imposing frame, his long career in major fights, and his adaptability. However, Usyk's underdog status doesn’t mean he’s an underdog in spirit, his dominance against Joshua confirmed his toughness against big opponents.
For Fury himself is a chance to further solidify his greatness. A victory would further solidify his status as the best heavyweight of this era. Conversely, Usyk’s victory would be a monumental achievement. Securing two undisputed titles would be a remarkable feat in boxing history.
Web: <a href="http://www.google.com.bd/url?sa=t&url=https://tysonvusyk.co.uk/">tysonvusyk.co.uk</a>
This fight is more than just a championship fight. It’s a clash of personalities. Fury’s bold and unapologetic character contrasts with Usyk’s calm, focused demeanor. Such contrasts make the fight more compelling. It’s a fight of wills and ideologies. Regardless of the outcome, the legacy of this fight will be felt for years to come. The battle for heavyweight supremacy is a spectacle unlike any other. It’s a culmination of years of hard work. Whether Tyson Fury prevails thanks to his power and game plan, or Usyk wins with his precision through his superior boxing ability, no matter the outcome, this will be a legendary contest.
Tyson Fury vs Oleksandr Usyk is a spectacle of a lifetime. It’s a contest of heart and willpower. Both fighters will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Azərbaycanda mərc bazarında onlayn qumar oyunlarına güvəni artdıqca, Pin-up kazino kimi platformalar daha çox tanınmağa başladı. Əlavə olaraq, Pin-up azerbaycan sözləri tez-tez Azərbaycandakı oyunçular üçün məşhurdur. Pin-up kazino istifadəçilərə geniş oyunlar təklif edir.
Pin up kazino, Azərbaycandakı oyunçular üçün maraqlı seçimdir. Bu platforma oyunçulara müxtəlif oyunlar təklif edir və cazibədar aksiyalar ilə müştərilərini məmnun edir.
Pinup casino, geniş oyun variantları təklif edən saytdır. Azərbaycanda güvənilən Pin-up casino, yerli oyunçular üçün geniş oyun variantları ilə tanınır.
Bununla yanaşı, Pinup casino qumar həvəskarlarına etibarlı maliyyə idarəetmə imkanları verir. İstifadəçilər, rahat və tez depozit çıxarış sistemi ilə, internet oyunlarını asan və sürətli keçirə bilərlər.
Əlavə olaraq, Pin-up kazino müştərilərə təkcə oyunlar deyil, həm də mərc hədiyyələri və maraqlı aksiyalar təklif edir. Pinup-da, kazino həvəskarları şəffaf oyun şərtləri ilə rastlaşır.
Web: https://bet-on-pinup.web.app
Pin-up azerbaycan yalnız məhdud oyunlar təklif etmir. Qumarçılar burada fərqli mərc seçimlərindən yararlana bilərlər və geniş bonus imkanlarını oyun təcrübəsini artırarlar.
Nəticədə, Pin-up casino, rahat və təhlükəsiz mərc imkanı oyunçulara təklif etməklə onlayn qumar sektorunda oyunçular arasında geniş istifadə edilir. Azərbaycan mərcçiləri arasında məşhur olması açıq bir faktdır.
These two heavyweight champions are on a collision course of unparalleled significance. It’s not merely about the belts; it represents their quest for immortality. Fury, an undefeated champion has become a global icon thanks to his personality and his unmatched skills inside the ropes. Beating Wilder and Klitschko have earned him recognition as one of the best ever. In contrast, Usyk, the technician brings an unprecedented test to the heavyweight division. Meanwhile, the Ukrainian technician represents a formidable opponent for the heavyweight ranks overall, and for boxing fans worldwide. His journey to global fame started with his domination of the cruiserweights, as an undisputed champion. Get ready for an epic boxing match of the year as Oleksandr Usyk takes on Fury in a must-watch showdown! Catch every punch in real time on our website. Be part of the action — visit <a href="https://rozoteka.ru/go?url=https://usykvsfury.org.uk/">usykvsfury.org.uk</a> today and watch the match in high quality!
In the United Kingdom, the event will kick off at around 10 PM GMT, offering perfect timing for viewers. Back in Usyk’s home country, and for fans watching from around the world, this will be a must-see event. Where the bout will take place has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. Regardless of the venue, fans can be sure: the atmosphere will be electric. Even though attention is firmly on the main event, the fights leading up to the main event is shaping up to be thrilling. Major boxing events are known for strong supporting fights, giving fans a full evening of entertainment.
Historically, supporting bouts in major events have been a stage for breakout performances. Boxers seeking the spotlight capitalize on the exposure to showcase their skills, knowing millions are watching. Though the supporting fights for Fury vs Usyk has yet to be finalized, fans are eagerly guessing. Will there be a heavyweight clash? Whatever the selection, fans can expect fireworks. The most compelling part of Fury vs Usyk incredibly exciting is the clash of styles. Fury’s towering frame and movement make him an anomaly in boxing. Being so tall yet so nimble, he commands the ring like no other.
The legendary battles with Wilder proved his toughness, bouncing back from adversity to dominate in later rounds. In his fight with Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Meanwhile, Usyk, offers a different kind of threat. With his unorthodox stance, his positioning constantly challenges opponents. Usyk’s punches lack devastating strength, but they are delivered with pinpoint accuracy. As anticipation builds, Predictions for this fight are becoming a hot topic.
Most bookmakers favor Fury as per the betting experts, due to his size advantage, his track record in big matches, and his tactical brilliance. However, Usyk's underdog status doesn’t rule him out, as his victories over Joshua demonstrated his ability in the heavyweight ranks.
For Tyson Fury, this fight represents an opportunity to cement his legacy. If he wins, it would solidify his claim as the greatest heavyweight of his generation. Meanwhile, Usyk’s victory would elevate him to new heights. Securing two undisputed titles would be a remarkable feat in boxing history.
Web: <a href="http://www.google.dz/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=0CBwQFjAA&url=http%3A%2F%2Fwww.magical-dream.com">usykvsfury.org.uk</a>
The upcoming showdown is not just about the belts. It’s a fight between two very different fighters. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. These differences add complexity to the fight. It’s a fight of wills and ideologies. Whoever comes out victorious, the impact of this bout will be felt for years to come. This historic showdown is more than just a fight. It’s a culmination of years of hard work. Should Fury claim victory through his strength and tactics, or Usyk secures a victory thanks to his skill and resilience, one thing is certain, this will be a defining moment in boxing.
Fury vs Usyk is more than just a sporting contest. It’s a contest of heart and willpower. These two warriors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are set to meet in the ring of historic proportions. It’s far beyond a championship match; it’s about legacy. The towering Fury has earned worldwide fame thanks to his personality coupled with unparalleled talent in the ring. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. Across the ring, Usyk, the technician poses a unique challenge to the heavyweight division. On the flip side, the Ukrainian technician stands as a unique threat not just for Fury, as a heavyweight contender. The ascent of Oleksandr Usyk began in the cruiserweight division, by conquering all challengers. Prepare yourself for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! Catch every punch live on our website. Join the excitement — visit <a href="https://app.promorepublic.com/away?url=https%3A%2F%2Fusykvsfurydate.com">usykvsfurydate.com</a> today and watch the match in high quality!
For British fans, the fight is expected to begin close to prime time, offering perfect timing for viewers. Back in Usyk’s home country, and for fans watching from around the world, this will be a must-see event. The fight’s location is still under speculation, with talk of iconic boxing destinations. Regardless of the venue, it’s guaranteed: the atmosphere will be electric. Even though attention is firmly on the main event, the fights leading up to the main event is also generating excitement. High-profile matches often feature stacked undercards, offering an entire night of boxing excitement.
Historically, preliminary fights on major cards have showcased rising stars. Contenders hoping to make their mark capitalize on the exposure to impress fans and analysts alike, knowing millions are watching. Although the lineup for the Fury Usyk undercard are still unconfirmed, there’s plenty of talk. Might there be a cruiserweight spectacle? Regardless of the names, it’s sure to add to the excitement. What sets this bout apart truly fascinating is the dynamic between these fighters. Tyson Fury’s size and agility are unparalleled in the sport. With his immense height and reach advantage, Fury can control a fight.
His trilogy with Deontay Wilder highlighted his resilience, bouncing back from adversity to secure victories. In his fight with Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. Meanwhile, Usyk, brings speed, precision, and finesse. With his unorthodox stance, he uses angles and footwork. The Ukrainian’s shots aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. As anticipation builds, The betting lines for Fury vs Usyk have fans and analysts speculating.
Fury is the favored fighter as predicted by many experts, given his physical stature, his proven ability in tough situations, and his adaptability. Despite being seen as the underdog doesn’t mean he’s an underdog in spirit, his victories against AJ confirmed his toughness against big opponents.
For Tyson Fury could be the defining moment of his career. Should he come out on top, Fury’s win would put the finishing touches on a historic career. Meanwhile, Usyk’s victory would elevate him to new heights. Securing two undisputed titles would be a remarkable feat in boxing history.
Web: <a href="http://maps.google.com.bn/url?q=https://usykvsfurydate.com/">usykvsfurydate.com</a>
The upcoming showdown is not just about the belts. It’s a battle of contrasting styles. Fury’s larger-than-life persona stands in stark contrast to Usyk’s composed demeanor. These differences add complexity to the fight. Beyond physical ability, this fight. No matter who wins, the significance of this match will leave a lasting mark on the sport. Fury vs Usyk is a spectacle unlike any other. It’s the result of relentless dedication. If Fury wins thanks to his power and game plan, or Oleksandr Usyk triumphs through his superior boxing ability, one thing is certain, this will be a fight remembered for years to come.
This fight between Fury and Usyk is more than just a fight. It’s a battle of minds and bodies. These two warriors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
yerli oyunçular arasında internet oyunlarına sevgisi artdıqca, Pin-up casino online kimi platformalar daha çox tanınmağa başladı. Bununla bərabər, Pinup azerbaycan sözləri indi Azəri mərc həvəskarları üçün adidir. Pinup casino istifadəçilərə məxsus çox oyun növləri təklif edir.
Pin-up azerbaycan, Azəri istifadəçilər üçün geniş yayılmış bir xidmətdir. Bu onlayn kazino kazino oyunçularına fərqli oyun növləri təmin edir və cazibədar aksiyalar ilə oyunçuları özünə cəlb edir.
Pin-up cazino, istifadəçilərə oyun növləri ilə zəngin bir platformadır. Azəri oyunçuları arasında çox seçilən Pin-up oyunları, istifadəçilər üçün fərqli oyun seçimləri ilə çıxış edir.
Bunun nəticəsində, Pinup kazino mərc edənlərə etibarlı və güvənli maliyyə əməliyyatları təmin edir. Mərc edənlər, sürətli və asan depozit çıxarış sistemi vasitəsilə, qumar təcrübələrini müvafiq şəkildə keçirə bilərlər.
Yekun olaraq, Pin-up cazino oyunçulara yalnız oyun təklif etmir sərfəli bonuslar müştəriləri üçün yaradır. Bu qumar saytında, kazino həvəskarları şəffaf oyun şərtləri ilə rastlaşır.
Web: https://best-win-pinup.web.app
Pin-up azerbaycan təkcə bir kazino olaraq sadə oyunla bitmir. Mərc həvəskarları bu platformada geniş mərc təcrübəsindən yararlana bilərlər və maraqlı aksiyaları mərc təcrübələrini zənginləşdirərlər.
Ümumilikdə, Pin-up casino, şəffaf və güvənli qumar təcrübəsi təklif etməklə onlayn qumar sektorunda özünü doğruldur. Azərbaycanda populyarlığı əlamətdardır.
Tyson Fury and Oleksandr Usyk are preparing for an epic showdown that will define an era. This fight is about more than just titles; it’s a battle for eternal recognition. The towering Fury has risen to the pinnacle of the sport with his charisma and remarkable adaptability in the ring. Beating Wilder and Klitschko have solidified his legendary status. On the other hand, Usyk, the Ukrainian master brings an unprecedented test to the heavyweight division. On the flip side, Oleksandr Usyk stands as a unique threat for the heavyweight ranks overall, but for the entire division. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, by conquering all challengers. Get ready for an epic boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! Experience every moment streamed live on our website. Don’t miss your chance — visit <a href="https://www.emuparadise.me/logout.php?next=https://tysonfuryvsusyk.org.uk/">tysonfuryvsusyk.org.uk</a> now and enjoy the fight with top-notch streaming!
Across the UK, the event will kick off at late evening, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, and for fans watching from around the world, the anticipation is at a fever pitch. The venue for Fury vs Usyk has yet to be confirmed, with talk of iconic boxing destinations. Regardless of the venue, fans can be sure: it will be a spectacle. While the spotlight remains on Fury and Usyk, the fights leading up to the main event is also generating excitement. Big-ticket boxing cards often feature stacked undercards, giving fans a full evening of entertainment.
Historically, preliminary fights on major cards have introduced future champions. Boxers seeking the spotlight use such opportunities to demonstrate their talent, as all eyes are on them. Though the supporting fights for Fury vs Usyk haven’t been officially announced, fans are eagerly guessing. Could we see rising prospects? No matter the final roster, the action will not disappoint. What sets this bout apart incredibly exciting is their contrasting skillsets. Fury’s towering frame and movement make him an anomaly in boxing. At 6’9" with an 85-inch reach, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, overcoming brutal hits to finish strong. In his fight with Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, relies on technique and stamina. As a southpaw, his positioning constantly challenges opponents. The Ukrainian’s shots may not have knockout power, they consistently find their mark. As fight night approaches, Predictions for this fight are the subject of intense debate.
Tyson Fury is the slight favorite as per the betting experts, given his physical stature, his experience in high-pressure bouts, and his unpredictable nature. Although Usyk is the less favored fighter doesn’t diminish his chances, his victories against AJ showed that he can compete at heavyweight.
For Tyson Fury could be the defining moment of his career. A triumph for Fury would solidify his claim as the greatest heavyweight of his generation. On the other hand, Usyk’s victory would be a monumental achievement. Securing two undisputed titles would be a remarkable feat in boxing history.
Web: <a href="http://clients1.google.com.bh/url?q=https://tysonfuryvsusyk.org.uk/">tysonfuryvsusyk.org.uk</a>
The upcoming showdown represents something greater than a title bout. It’s a battle of contrasting styles. Fury’s confident and brash nature stands in stark contrast to Usyk’s composed demeanor. Such contrasts make the fight more compelling. It’s about more than just skill. Whoever triumphs in this battle, the impact of this bout will reverberate throughout boxing history. This historic showdown is a spectacle unlike any other. It represents the culmination of their careers. Whether Fury secures the win with his experience and unpredictability, or Oleksandr Usyk triumphs through his superior boxing ability, it’s certain that, this will be a defining moment in boxing.
This fight between Fury and Usyk is more than just a boxing event. It’s a contest of heart and willpower. These men will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are preparing for an epic showdown of historic proportions. It’s not merely about the belts; it’s about legacy. The towering Fury has risen to the pinnacle of the sport with his charisma and his unmatched skills in the ring. Beating Wilder and Klitschko have earned him recognition as one of the best ever. Meanwhile, the tactical southpaw poses a unique challenge to the heavyweight division. Meanwhile, Oleksandr Usyk stands as a unique threat for Tyson Fury himself, but for the entire division. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, as an undisputed champion. Prepare yourself for an epic boxing match of the year as Oleksandr Usyk takes on Fury in a must-watch showdown! Catch every punch live on our website. Be part of the action — visit <a href="https://lurkmore.printdirect.ru/utils/redirect?url=https://furyvsusykdate.com/">furyvsusykdate.com</a> today and stream the event from the comfort of your home!
In the United Kingdom, the ring walks are planned for late evening, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and beyond, the anticipation is at a fever pitch. The venue for Fury vs Usyk has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, one thing is certain: the atmosphere will be electric. Even though attention remains on Fury and Usyk, the Fury vs Usyk undercard promises plenty of action. Major boxing events include preliminary bouts with top talent, giving fans a full evening of entertainment.
Traditionally, supporting bouts in major events have been a stage for breakout performances. Boxers seeking the spotlight capitalize on the exposure to showcase their skills, with the world paying attention. Although the lineup for the Fury Usyk undercard has yet to be finalized, fans are eagerly guessing. Will there be a heavyweight clash? Whatever the selection, the action will not disappoint. The most compelling part of Fury vs Usyk so intriguing is the dynamic between these fighters. Fury’s towering frame and movement are unparalleled in the sport. At 6’9" with an 85-inch reach, Fury can control a fight.
His trilogy with Deontay Wilder highlighted his resilience, as he recovered from knockdowns to finish strong. In his fight with Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, relies on technique and stamina. As a southpaw, he uses angles and footwork. The Ukrainian’s shots may not have knockout power, their timing wears down foes. As fight night approaches, Predictions for this fight are becoming a hot topic.
Fury is the favored fighter as predicted by many experts, given his physical stature, his experience in high-pressure bouts, and his unpredictable nature. Despite the odds, Usyk remains a strong contender shouldn’t be counted out, his dominance against Joshua proved that he can handle the physicality of the heavyweight division.
For the Gypsy King could be the defining moment of his career. Should he come out on top, Fury’s win would add an undisputed title to his already impressive resume. Meanwhile, For Usyk, a win would elevate him to legendary status. Achieving undisputed glory in two divisions is a once-in-a-lifetime achievement.
Web: <a href="http://clients1.google.lt/url?q=https%3A%2F%2Ffuryvsusykdate.com">furyvsusykdate.com</a>
This fight is more than just a championship fight. It’s a fight between two very different fighters. Fury’s larger-than-life persona is the opposite of Usyk’s humble and disciplined approach. The clash of personalities adds depth to the narrative. It’s a fight of wills and ideologies. Regardless of the outcome, the significance of this match will reverberate throughout boxing history. The battle for heavyweight supremacy is a spectacle unlike any other. It’s the result of relentless dedication. Whether Tyson Fury prevails thanks to his power and game plan, or Usyk comes out on top through his superior boxing ability, what is clear is, this will be a legendary contest.
Fury vs Usyk is more than just a fight. It’s a contest of heart and willpower. Both fighters will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are preparing for an epic showdown that will define an era. It’s not merely about the belts; it represents their quest for immortality. Fury, an undefeated champion has risen to the pinnacle of the sport thanks to his personality coupled with unparalleled talent inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Meanwhile, the tactical southpaw poses a unique challenge to the heavyweight division. On the flip side, Oleksandr Usyk is a true test for Fury for the heavyweight ranks overall, but for the entire division. The ascent of Oleksandr Usyk began in the cruiserweight division, as an undisputed champion. Prepare yourself for an epic boxing match of the year as Usyk takes on Fury in a must-watch showdown! See every move in real time on our website. Be part of the action — visit <a href="https://nrns-games.com/proxy.php?request=https://furyvsusykdate.org.uk/">furyvsusykdate.org.uk</a> now and stream the event with top-notch streaming!
In the United Kingdom, the fight is expected to begin late evening, offering perfect timing for viewers. Back in Usyk’s home country, as well as viewers across Europe and the Americas, this will be a must-see event. Where the bout will take place remains a hot topic, with suggestions ranging from Las Vegas to Saudi Arabia. Regardless of the venue, fans can be sure: the excitement will be unmatched. Even though attention is centered on the headline fight, the Fury vs Usyk undercard is shaping up to be thrilling. Big-ticket boxing cards include preliminary bouts with top talent, giving fans a full evening of entertainment.
Historically, undercards of this caliber have been a stage for breakout performances. Boxers seeking the spotlight often seize these moments to demonstrate their talent, with the world paying attention. While the names for the undercard are still unconfirmed, fans are eagerly guessing. Might there be a cruiserweight spectacle? No matter the final roster, it’s sure to add to the excitement. What sets this bout apart incredibly exciting is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. Being so tall yet so nimble, he dictates the pace of bouts.
The legendary battles with Wilder showed his durability, overcoming brutal hits to secure victories. Against Wladimir Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Meanwhile, Usyk, relies on technique and stamina. Being a left-handed fighter, his positioning constantly challenges opponents. Usyk’s punches may not have knockout power, but they are delivered with pinpoint accuracy. As anticipation builds, The betting lines for Fury vs Usyk are the subject of intense debate.
The betting lines show Fury ahead based on the betting odds, thanks to his imposing frame, his track record in big matches, and his unorthodox style. Although Usyk is the less favored fighter doesn’t diminish his chances, as his victories over Joshua showed that he can compete at heavyweight.
For Fury himself represents an opportunity to cement his legacy. A victory would put the finishing touches on a historic career. Conversely, Usyk’s victory would mark him as one of the sport’s greats. Securing two undisputed titles is a rare accomplishment.
Web: <a href="http://google.net/url?q=https://furyvsusykdate.org.uk/">furyvsusykdate.org.uk</a>
This fight is not just about the belts. It’s a battle of contrasting styles. Fury’s boisterous personality is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. It’s a fight of wills and ideologies. Whoever comes out victorious, the legacy of this fight will be remembered as a defining moment in boxing. The clash for the undisputed title is more than just a fight. It’s the pinnacle of both fighters’ hard work. Whether Fury secures the win with his size and strategy, or Usyk comes out on top with his finesse and stamina, what is clear is, this bout will go down in history.
This fight between Fury and Usyk is a spectacle of a lifetime. It’s a contest of heart and willpower. Both fighters will leave it all in the ring.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are preparing for an epic showdown of historic proportions. This fight is about more than just titles; it represents their quest for immortality. Tyson Fury has risen to the pinnacle of the sport thanks to his personality and his unmatched skills during fights. His victories over Deontay Wilder and Wladimir Klitschko have cemented his place among the all-time greats. Meanwhile, the tactical southpaw is a fighter unlike any other for Fury. At the same time, Usyk, a genius in the ring is a true test for Fury for the heavyweight ranks overall, but for the entire division. The ascent of Oleksandr Usyk started with his domination of the cruiserweights, where he became an unstoppable force. Prepare yourself for a thrilling boxing match of the year as Usyk takes on Fury in an unforgettable showdown! Catch every punch in real time on our website. Be part of the action — visit <a href="http://sasgis.ru/out/https://usykvsfurydate.co.uk/">usykvsfurydate.co.uk</a> today and watch the match in high quality!
For British fans, the event will kick off at around 10 PM GMT, offering perfect timing for viewers. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, the excitement is palpable. Where the bout will take place has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, it’s guaranteed: it will be a spectacle. Although the focus is firmly on the main event, the fights leading up to the main event is also generating excitement. High-profile matches include preliminary bouts with top talent, offering an entire night of boxing excitement.
Historically, undercards of this caliber have introduced future champions. Fighters looking to rise through the ranks often seize these moments to demonstrate their talent, knowing millions are watching. Although the lineup for the Fury Usyk undercard are still unconfirmed, speculation runs high. Could we see rising prospects? Whatever the selection, it’s sure to add to the excitement. What sets this bout apart incredibly exciting is their contrasting skillsets. Fury’s towering frame and movement are unparalleled in the sport. At 6’9" with an 85-inch reach, Fury can control a fight.
The legendary battles with Wilder showed his durability, as he recovered from knockdowns to dominate in later rounds. When he faced Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Meanwhile, Usyk, offers a different kind of threat. Being a left-handed fighter, his positioning constantly challenges opponents. His strikes may not have knockout power, but they are delivered with pinpoint accuracy. As fight night approaches, Predictions for this fight are the subject of intense debate.
Most bookmakers favor Fury as per the betting experts, because of his reach and height, his proven ability in tough situations, and his adaptability. Despite being seen as the underdog doesn’t diminish his chances, his victories against AJ confirmed his toughness against big opponents.
For Fury himself represents an opportunity to cement his legacy. A victory would put the finishing touches on a historic career. Conversely, If Usyk wins would mark him as one of the sport’s greats. Becoming an undisputed champion in two different weight classes is a once-in-a-lifetime achievement.
Web: <a href="http://www.google.tg/url?q=https%3A%2F%2Fusykvsfurydate.co.uk">usykvsfurydate.co.uk</a>
The upcoming showdown is more than just a championship fight. It’s a clash of personalities. Fury’s larger-than-life persona is the opposite of Usyk’s humble and disciplined approach. Such contrasts make the fight more compelling. This is more than just a physical contest. No matter who wins, the significance of this match will be remembered as a defining moment in boxing. The battle for heavyweight supremacy is more than just a match. It’s a culmination of years of hard work. Whether Fury secures the win with his experience and unpredictability, or Usyk comes out on top thanks to his skill and resilience, no matter the outcome, this will be a legendary contest.
Tyson Fury vs Oleksandr Usyk is more than just a fight. It’s a fight of grit and strategy. These men will fight with everything they possess.
Visit for more information: #crosslink[3,L -
yerli oyunçular arasında virtual qumar oyunlarına tələbat artdıqca, Pin-up online kimi saytlar daha çox tanınmağa başladı. Əlavə olaraq, Pinup casino ifadələri artıq Azəri mərc həvəskarları üçün adidir. Pin-up azerbaycan müştərilərinə rəngarəng oyunlar təklif edir.
Pin-up casino, yerli mərc həvəskarları üçün ən sevilən platformalardan biridir. Bu qumar xidməti oyunçulara müxtəlif oyunlar təmin edir və bonus imkanları ilə oyunçuları özünə cəlb edir.
Pin-up casino online, bənzərsiz oyun imkanı təqdim edən oyun məkanıdır. yerli mərcçilər arasında güvənilən Pinup, yerli oyunçular üçün zəngin təkliflər təqdim edir.
Bu səbəbdən, Pin-up online casino qumar həvəskarlarına etibarlı və güvənli ödəmə üsulları oyunçularına təklif edir. Müştərilər, etibarlı və tez depozit çıxarış sistemi ilə təmin olunmaqla, qumar təcrübələrini asan və sürətli təcrübə edə bilərlər.
Nəticə etibarilə, Pin-up cazino oyunçulara çoxlu oyun növlərilə yanaşı sərfəli bonuslar müştəriləri üçün yaradır. Pinup-da, mərc edənlər özlərini güvəndə hiss edir.
Web: https://bet-pinup.web.app
Pin-up online kazino yalnız sadə oyunla bitmir. Mərc həvəskarları bu platformada müxtəlif mərc növlərindən faydalanıb və sərfəli bonus təkliflərini mərc təcrübələrini zənginləşdirərlər.
Ümumilikdə, Pin-up azerbaycan, güvənli qumar təcrübəsi istifadəçilərə verməklə mərc bazarında ən sevilən platformalardan olur. yerli oyunçular arasında geniş yayılması təsadüfi deyil.
Fury, the Gypsy King, and Usyk, the technician are preparing for an epic showdown of historic proportions. This fight is about more than just titles; it represents their quest for immortality. The towering Fury has earned worldwide fame through his unique style coupled with unparalleled talent during fights. His victories over Deontay Wilder and Wladimir Klitschko have cemented his place among the all-time greats. In contrast, the tactical southpaw brings an unprecedented test to boxing’s biggest stars. Meanwhile, Usyk, a genius in the ring represents a formidable opponent for the heavyweight ranks overall, but for the entire division. Usyk’s rise to prominence started with his domination of the cruiserweights, by conquering all challengers. Don’t miss out for a thrilling boxing match of the year as Usyk takes on Tyson Fury in a must-watch showdown! Catch every punch live on our website. Don’t miss your chance — visit <a href="http://rssfeeds.khou.com/~/t/0/0/khou/sports/~https%3a%2f%2ftysonfuryvsusyk.org.uk">tysonfuryvsusyk.org.uk</a> today and enjoy the fight with top-notch streaming!
In the United Kingdom, the ring walks are planned for late evening, offering perfect timing for viewers. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. The fight’s location has yet to be confirmed, with talk of iconic boxing destinations. No matter the location, it’s guaranteed: it will be a spectacle. Although the focus is firmly on the main event, the preliminary bouts is also generating excitement. Big-ticket boxing cards are known for strong supporting fights, offering an entire night of boxing excitement.
In the past, undercards of this caliber have been a stage for breakout performances. Contenders hoping to make their mark often seize these moments to impress fans and analysts alike, as all eyes are on them. While the names for the undercard haven’t been officially announced, speculation runs high. Could we see rising prospects? No matter the final roster, fans can expect fireworks. What sets this bout apart so intriguing is the clash of styles. Tyson Fury’s size and agility set him apart from other heavyweights. Being so tall yet so nimble, he dictates the pace of bouts.
The three fights against Wilder showed his durability, bouncing back from adversity to secure victories. In his fight with Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. By contrast, Usyk, offers a different kind of threat. With his unorthodox stance, his movements create openings. The Ukrainian’s shots aren’t the heaviest in the division, they consistently find their mark. With the date drawing closer, The betting lines for Fury vs Usyk are becoming a hot topic.
The betting lines show Fury ahead based on the betting odds, thanks to his imposing frame, his experience in high-pressure bouts, and his adaptability. Despite being seen as the underdog shouldn’t be counted out, his wins over Anthony Joshua showed that he can compete at heavyweight.
For Fury himself could be the defining moment of his career. If he wins, it would further solidify his status as the best heavyweight of this era. On the other hand, Usyk’s victory would elevate him to new heights. Securing two undisputed titles is a feat few can claim.
Web: <a href="http://images.google.com.sb/url?q=https://tysonfuryvsusyk.org.uk/">tysonfuryvsusyk.org.uk</a>
The upcoming showdown is more than just a championship fight. It’s a fight between two very different fighters. Fury’s confident and brash nature stands in stark contrast to Usyk’s composed demeanor. Such contrasts make the fight more compelling. Beyond physical ability, this fight. Regardless of the outcome, the impact of this bout will be felt for years to come. Fury vs Usyk is a spectacle unlike any other. It’s the result of relentless dedication. Whether Fury secures the win through his strength and tactics, or Usyk wins with his precision through his superior boxing ability, it’s certain that, this bout will go down in history.
Fury vs Usyk is more than just a boxing event. It’s a battle of minds and bodies. These two warriors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are set to meet in the ring that will define an era. It’s far beyond a championship match; it represents their quest for immortality. Fury, an undefeated champion has risen to the pinnacle of the sport with his charisma and remarkable adaptability during fights. Triumphing against boxing legends like Wilder and Klitschko have solidified his legendary status. Across the ring, the tactical southpaw brings an unprecedented test to the heavyweight division. Meanwhile, Usyk, a genius in the ring is a true test for Fury not just for Fury, but for the entire division. The ascent of Oleksandr Usyk began in the cruiserweight division, where he became an unstoppable force. Don’t miss out for an epic boxing match of the year as Oleksandr Usyk takes on Fury in an unforgettable showdown! Experience every moment in real time on our website. Join the excitement — visit <a href="https://likbezz.ru:443/go.php?https://tysonfuryvsoleksandrusyk.co.uk/">tysonfuryvsoleksandrusyk.co.uk</a> today and watch the match with top-notch streaming!
Across the UK, the event will kick off at close to prime time, ensuring maximum viewership. Back in Usyk’s home country, and for fans watching from around the world, this will be a must-see event. Where the bout will take place remains a hot topic, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, one thing is certain: the excitement will be unmatched. Although the focus remains on Fury and Usyk, the preliminary bouts promises plenty of action. Major boxing events include preliminary bouts with top talent, offering an entire night of boxing excitement.
Traditionally, preliminary fights on major cards have been a stage for breakout performances. Contenders hoping to make their mark often seize these moments to demonstrate their talent, knowing millions are watching. Although the lineup for the Fury Usyk undercard are still unconfirmed, there’s plenty of talk. Could we see rising prospects? No matter the final roster, the action will not disappoint. What makes this fight truly fascinating is the clash of styles. Fury’s towering frame and movement set him apart from other heavyweights. Being so tall yet so nimble, Fury can control a fight.
The three fights against Wilder highlighted his resilience, overcoming brutal hits to secure victories. When he faced Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. By contrast, Usyk, relies on technique and stamina. As a southpaw, his positioning constantly challenges opponents. Usyk’s punches aren’t the heaviest in the division, their timing wears down foes. As fight night approaches, The betting lines for Fury vs Usyk have fans and analysts speculating.
Tyson Fury is seen as the frontrunner as per the betting experts, because of his reach and height, his proven ability in tough situations, and his tactical brilliance. Despite the odds, Usyk remains a strong contender doesn’t diminish his chances, his victories against AJ confirmed his toughness against big opponents.
For the Gypsy King represents an opportunity to cement his legacy. If he wins, it would further solidify his status as the best heavyweight of this era. On the other hand, If Usyk wins would mark him as one of the sport’s greats. Becoming the undisputed heavyweight champion is a rare accomplishment.
Web: <a href="http://google.co.zm/url?q=https://tysonfuryvsoleksandrusyk.co.uk/">tysonfuryvsoleksandrusyk.co.uk</a>
Fury vs Usyk is not just about the belts. It’s a clash of personalities. Fury’s confident and brash nature is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. Beyond physical ability, this fight. Regardless of the outcome, the significance of this match will be remembered as a defining moment in boxing. The clash for the undisputed title is more than just a match. It represents the culmination of their careers. Should Fury claim victory with his size and strategy, or Usyk comes out on top thanks to his skill and resilience, it’s certain that, this will be a defining moment in boxing.
This fight between Fury and Usyk is more than just a sporting contest. It’s a showcase of skill and determination. These men will fight with everything they possess.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are on a collision course that will define an era. This fight is about more than just titles; it represents their quest for immortality. The Gypsy King has become a global icon with his charisma coupled with unparalleled talent in the ring. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. Meanwhile, Usyk, the Ukrainian master is a fighter unlike any other to the heavyweight division. At the same time, the Ukrainian technician is a true test for Fury not just for Fury, and for boxing fans worldwide. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, by conquering all challengers. Don’t miss out for a thrilling boxing match of the year as Usyk takes on Fury in an unforgettable showdown! See every move in real time on our website. Join the excitement — visit <a href="https://belais.ru/go/tysonfuryvsusyk.co.uk">tysonfuryvsusyk.co.uk</a> now and watch the match in high quality!
In the United Kingdom, the ring walks are planned for around 10 PM GMT, making it ideal for a prime-time audience. Back in Usyk’s home country, and for fans watching from around the world, the anticipation is at a fever pitch. Where the bout will take place has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, one thing is certain: the excitement will be unmatched. While the spotlight remains on Fury and Usyk, the preliminary bouts is also generating excitement. Big-ticket boxing cards include preliminary bouts with top talent, giving fans a full evening of entertainment.
In the past, supporting bouts in major events have showcased rising stars. Fighters looking to rise through the ranks often seize these moments to impress fans and analysts alike, with the world paying attention. Though the supporting fights for Fury vs Usyk are still unconfirmed, speculation runs high. Will there be a heavyweight clash? Whatever the selection, the action will not disappoint. What sets this bout apart truly fascinating is the clash of styles. Fury’s towering frame and movement make him an anomaly in boxing. With his immense height and reach advantage, he dictates the pace of bouts.
The three fights against Wilder showed his durability, bouncing back from adversity to finish strong. Against Wladimir Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. Meanwhile, Usyk, relies on technique and stamina. With his unorthodox stance, his movements create openings. His strikes aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. As fight night approaches, Predictions for this fight have fans and analysts speculating.
Fury is the favored fighter based on the betting odds, given his physical stature, his track record in big matches, and his tactical brilliance. Although Usyk is the less favored fighter doesn’t diminish his chances, his dominance against Joshua showed that he can compete at heavyweight.
For Tyson Fury, this fight could be the defining moment of his career. Should he come out on top, Fury’s win would add an undisputed title to his already impressive resume. Meanwhile, For Usyk, a win would elevate him to new heights. Becoming the undisputed heavyweight champion is a feat few can claim.
Web: <a href="http://www.google.com.ph/url?sa=t&url=http%3A%2F%2Fwww.magical-dream.com">tysonfuryvsusyk.co.uk</a>
The upcoming showdown is not just about the belts. It’s a meeting of two unique worldviews. Fury’s confident and brash nature is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. This is more than just a physical contest. Whoever comes out victorious, the legacy of this fight will leave a lasting mark on the sport. This historic showdown is a spectacle unlike any other. It’s the result of relentless dedication. Whether Tyson Fury prevails thanks to his power and game plan, or Usyk wins with his precision with his finesse and stamina, one thing is certain, this bout will go down in history.
The Fury-Usyk battle is a spectacle of a lifetime. It’s a battle of minds and bodies. The two competitors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are preparing for an epic showdown that will define an era. It’s far beyond a championship match; it represents their quest for immortality. Tyson Fury has risen to the pinnacle of the sport with his charisma and remarkable adaptability inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. In contrast, Usyk, the technician is a fighter unlike any other to the heavyweight division. Meanwhile, Oleksandr Usyk represents a formidable opponent not just for Fury, but for the entire division. His journey to global fame started with his domination of the cruiserweights, where he became an unstoppable force. Get ready for a thrilling boxing match of the year as Usyk takes on Fury in a must-watch showdown! Experience every moment in real time on our website. Don’t miss your chance — visit <a href="https://traffic.pubexchange.com/a/0cb2a188-efa8-4a0b-a9a7-54605a5eccae/04febf7d-cadc-4d58-b532-9ce41e542c24/https%3A//tysonvsusyk.co.uk">tysonvsusyk.co.uk</a> right away and stream the event from the comfort of your home!
In the United Kingdom, the event will kick off at close to prime time, offering perfect timing for viewers. For Usyk’s fans in Ukraine, and for fans watching from around the world, this will be a must-see event. Where the bout will take place remains a hot topic, with suggestions ranging from Las Vegas to Saudi Arabia. Regardless of the venue, it’s guaranteed: the atmosphere will be electric. Even though attention remains on Fury and Usyk, the fights leading up to the main event promises plenty of action. Major boxing events are known for strong supporting fights, providing non-stop action before the headliner.
Traditionally, undercards of this caliber have introduced future champions. Boxers seeking the spotlight capitalize on the exposure to impress fans and analysts alike, with the world paying attention. While the names for the undercard are still unconfirmed, fans are eagerly guessing. Might there be a cruiserweight spectacle? Whatever the selection, it’s sure to add to the excitement. What makes this fight truly fascinating is the dynamic between these fighters. Tyson Fury’s size and agility set him apart from other heavyweights. With his immense height and reach advantage, he dictates the pace of bouts.
The legendary battles with Wilder showed his durability, bouncing back from adversity to finish strong. In his fight with Klitschko, his strategic genius shone through, proving he’s not just physical but cerebral. Meanwhile, Usyk, brings speed, precision, and finesse. Being a left-handed fighter, his positioning constantly challenges opponents. The Ukrainian’s shots aren’t the heaviest in the division, they consistently find their mark. As fight night approaches, The betting lines for Fury vs Usyk are becoming a hot topic.
Tyson Fury is the slight favorite as per the betting experts, because of his reach and height, his track record in big matches, and his tactical brilliance. Although Usyk is the less favored fighter shouldn’t be counted out, his wins over Anthony Joshua demonstrated his ability in the heavyweight ranks.
For Tyson Fury is a chance to further solidify his greatness. A victory would further solidify his status as the best heavyweight of this era. Conversely, For Usyk, a win would mark him as one of the sport’s greats. Becoming an undisputed champion in two different weight classes is a once-in-a-lifetime achievement.
Web: <a href="http://www.google.com.pe/url?q=https://tysonvsusyk.co.uk/">tysonvsusyk.co.uk</a>
This fight is more than just a championship fight. It’s a clash of personalities. Fury’s confident and brash nature stands in stark contrast to Usyk’s composed demeanor. Such contrasts make the fight more compelling. This is more than just a physical contest. Regardless of the outcome, the significance of this match will be remembered as a defining moment in boxing. This historic showdown is a spectacle unlike any other. It represents the culmination of their careers. Whether Fury secures the win thanks to his power and game plan, or Usyk secures a victory with his technique and endurance, no matter the outcome, this will be a defining moment in boxing.
This fight between Fury and Usyk is more than just a boxing event. It’s a fight of grit and strategy. Both fighters will leave it all in the ring.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are ready to face each other in a fight of unparalleled significance. It’s far beyond a championship match; it’s a battle for eternal recognition. The Gypsy King has earned worldwide fame thanks to his personality coupled with unparalleled talent inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. Across the ring, Oleksandr Usyk brings an unprecedented test to the heavyweight division. On the flip side, Usyk, a genius in the ring stands as a unique threat for Tyson Fury himself, as a heavyweight contender. Usyk’s rise to prominence began in the cruiserweight division, where he became an unstoppable force. Get ready for an epic boxing match of the year as Oleksandr Usyk takes on Fury in a must-watch showdown! Experience every moment streamed live on our website. Don’t miss your chance — visit <a href="https://m.easytravel.com.tw/GOMEasytravel.aspx?GO=https%3A%2F%2Ftysonfuryvsusyk.org.uk">tysonfuryvsusyk.org.uk</a> now and enjoy the fight from the comfort of your home!
In the United Kingdom, the fight is expected to begin close to prime time, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, and beyond, the excitement is palpable. Where the bout will take place remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, fans can be sure: it will be a spectacle. Even though attention is firmly on the main event, the fights leading up to the main event is shaping up to be thrilling. Major boxing events are known for strong supporting fights, offering an entire night of boxing excitement.
Historically, supporting bouts in major events have showcased rising stars. Fighters looking to rise through the ranks often seize these moments to showcase their skills, knowing millions are watching. Though the supporting fights for Fury vs Usyk haven’t been officially announced, speculation runs high. Might there be a cruiserweight spectacle? No matter the final roster, fans can expect fireworks. The most compelling part of Fury vs Usyk so intriguing is the dynamic between these fighters. Fury’s towering frame and movement make him an anomaly in boxing. At 6’9" with an 85-inch reach, Fury can control a fight.
The legendary battles with Wilder highlighted his resilience, overcoming brutal hits to secure victories. In his fight with Klitschko, his strategic genius shone through, proving he’s not just physical but cerebral. Meanwhile, Usyk, relies on technique and stamina. As a southpaw, his movements create openings. Usyk’s punches may not have knockout power, their timing wears down foes. With the date drawing closer, Predictions for this fight are the subject of intense debate.
Tyson Fury is seen as the frontrunner based on the betting odds, due to his size advantage, his experience in high-pressure bouts, and his adaptability. Despite the odds, Usyk remains a strong contender doesn’t rule him out, as his victories over Joshua showed that he can compete at heavyweight.
For the Gypsy King could be the defining moment of his career. A triumph for Fury would solidify his claim as the greatest heavyweight of his generation. Meanwhile, Usyk’s victory would be a monumental achievement. Becoming an undisputed champion in two different weight classes is a feat few can claim.
Web: <a href="http://maps.google.com.ph/url?q=https://tysonfuryvsusyk.org.uk/">tysonfuryvsusyk.org.uk</a>
This fight is not just about the belts. It’s a fight between two very different fighters. Fury’s bold and unapologetic character contrasts with Usyk’s calm, focused demeanor. The clash of personalities adds depth to the narrative. This is more than just a physical contest. Whoever triumphs in this battle, the legacy of this fight will leave a lasting mark on the sport. Fury vs Usyk is more than just a fight. It’s the result of relentless dedication. Should Fury claim victory with his experience and unpredictability, or Oleksandr Usyk triumphs through his superior boxing ability, one thing is certain, this will be a defining moment in boxing.
This fight between Fury and Usyk is more than just a fight. It’s a showcase of skill and determination. Both fighters will give everything they have.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are ready to face each other in a fight of historic proportions. This fight is about more than just titles; it’s about legacy. The towering Fury has earned worldwide fame with his charisma and his unmatched skills inside the ropes. Beating Wilder and Klitschko have solidified his legendary status. Across the ring, Usyk, the technician brings an unprecedented test for Fury. At the same time, Oleksandr Usyk is a true test for Fury for the heavyweight ranks overall, and for boxing fans worldwide. The ascent of Oleksandr Usyk started with his domination of the cruiserweights, as an undisputed champion. Prepare yourself for an epic boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! Experience every moment live on our website. Join the excitement — visit <a href="https://top-prof.ru/goto/https://tysonvsusyk.com/">tysonvsusyk.com</a> right away and stream the event in high quality!
For British fans, the event will kick off at around 10 PM GMT, ensuring maximum viewership. Back in Usyk’s home country, and beyond, the excitement is palpable. The fight’s location has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, it’s guaranteed: the atmosphere will be electric. Even though attention is centered on the headline fight, the preliminary bouts is also generating excitement. High-profile matches include preliminary bouts with top talent, offering an entire night of boxing excitement.
Historically, supporting bouts in major events have introduced future champions. Contenders hoping to make their mark capitalize on the exposure to demonstrate their talent, knowing millions are watching. While the names for the undercard are still unconfirmed, speculation runs high. Might there be a cruiserweight spectacle? Regardless of the names, it’s sure to add to the excitement. What makes this fight incredibly exciting is the clash of styles. Tyson Fury’s size and agility are unparalleled in the sport. With his immense height and reach advantage, he dictates the pace of bouts.
The three fights against Wilder highlighted his resilience, overcoming brutal hits to finish strong. When he faced Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. Meanwhile, Usyk, relies on technique and stamina. With his unorthodox stance, his movements create openings. Usyk’s punches lack devastating strength, they consistently find their mark. As anticipation builds, The betting lines for Fury vs Usyk are the subject of intense debate.
Fury is the favored fighter as per the betting experts, due to his size advantage, his long career in major fights, and his tactical brilliance. Although Usyk is the less favored fighter doesn’t diminish his chances, his wins over Anthony Joshua proved that he can handle the physicality of the heavyweight division.
For Tyson Fury, this fight could be the defining moment of his career. A triumph for Fury would add an undisputed title to his already impressive resume. On the other hand, Usyk’s victory would elevate him to new heights. Becoming an undisputed champion in two different weight classes is a rare accomplishment.
Web: <a href="http://www.google.com.bd/url?sa=t&url=https://tysonvsusyk.com/">tysonvsusyk.com</a>
Fury vs Usyk represents something greater than a title bout. It’s a clash of personalities. Fury’s larger-than-life persona is the opposite of Usyk’s humble and disciplined approach. These varying personalities make the bout even more interesting. It’s a fight of wills and ideologies. Regardless of the outcome, the significance of this match will reverberate throughout boxing history. Fury vs Usyk is a spectacle unlike any other. It’s a culmination of years of hard work. If Fury wins thanks to his power and game plan, or Usyk wins with his precision with his technique and endurance, it’s certain that, this will be a defining moment in boxing.
Tyson Fury vs Oleksandr Usyk is more than just a fight. It’s a showcase of skill and determination. Both fighters will pour everything into the bout.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are set to meet in the ring that will define an era. This fight is about more than just titles; it’s about legacy. The towering Fury has risen to the pinnacle of the sport through his unique style coupled with unparalleled talent in the ring. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. In contrast, the tactical southpaw poses a unique challenge to the heavyweight division. On the flip side, Usyk, a genius in the ring represents a formidable opponent not just for Fury, and for boxing fans worldwide. His journey to global fame was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Prepare yourself for the most anticipated boxing match of the year as Oleksandr Usyk takes on Fury in a historic showdown! Catch every punch streamed live on our website. Don’t miss your chance — visit <a href="https://kaypu.com/data/clk.php?u=aHR0cHM6Ly9tb2RzLW1lbnUucnUv&kt=NTA4NDYyZmQ2MmE3MDFiZTU4NTk0ZTlii">furyvsusykdate.org.uk</a> right away and stream the event in high quality!
For British fans, the event will kick off at close to prime time, offering perfect timing for viewers. In Usyk’s native Ukraine, and beyond, the excitement is palpable. The fight’s location has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, it’s guaranteed: the excitement will be unmatched. Although the focus is centered on the headline fight, the Fury vs Usyk undercard promises plenty of action. High-profile matches include preliminary bouts with top talent, providing non-stop action before the headliner.
Traditionally, undercards of this caliber have showcased rising stars. Boxers seeking the spotlight capitalize on the exposure to impress fans and analysts alike, knowing millions are watching. While the names for the undercard haven’t been officially announced, fans are eagerly guessing. Could we see rising prospects? Whatever the selection, it’s sure to add to the excitement. The most compelling part of Fury vs Usyk truly fascinating is their contrasting skillsets. Fury’s towering frame and movement set him apart from other heavyweights. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
The legendary battles with Wilder showed his durability, overcoming brutal hits to finish strong. Against Wladimir Klitschko, his strategic genius shone through, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, offers a different kind of threat. With his unorthodox stance, he uses angles and footwork. Usyk’s punches aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. As anticipation builds, Predictions for this fight are becoming a hot topic.
Fury is the favored fighter as predicted by many experts, given his physical stature, his track record in big matches, and his tactical brilliance. Despite being seen as the underdog shouldn’t be counted out, his wins over Anthony Joshua demonstrated his ability in the heavyweight ranks.
For Fury himself is a chance to further solidify his greatness. A triumph for Fury would solidify his claim as the greatest heavyweight of his generation. Conversely, If Usyk wins would elevate him to new heights. Achieving undisputed glory in two divisions is a feat few can claim.
Web: <a href="http://maps.google.cg/url?sa=t&url=http%3A%2F%2Fwww.magical-dream.com">furyvsusykdate.org.uk</a>
The upcoming showdown represents something greater than a title bout. It’s a fight between two very different fighters. Fury’s larger-than-life persona is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. It’s a fight of wills and ideologies. Whoever triumphs in this battle, the legacy of this fight will be felt for years to come. Fury vs Usyk is a defining moment. It represents the culmination of their careers. Whether Fury secures the win through his strength and tactics, or Usyk comes out on top with his finesse and stamina, no matter the outcome, this will be a legendary contest.
Fury vs Usyk is more than just a fight. It’s a fight of grit and strategy. Both fighters will pour everything into the bout.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are ready to face each other in a fight that will define an era. It’s far beyond a championship match; it’s about legacy. Tyson Fury has risen to the pinnacle of the sport through his unique style coupled with unparalleled talent in the ring. Beating Wilder and Klitschko have cemented his place among the all-time greats. Across the ring, the tactical southpaw brings an unprecedented test to boxing’s biggest stars. At the same time, Usyk, a genius in the ring is a true test for Fury not just for Fury, as a heavyweight contender. Usyk’s rise to prominence started with his domination of the cruiserweights, as an undisputed champion. Get ready for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! See every move in real time on our website. Don’t miss your chance — visit <a href="http://cta-redirect.ex.co/redirect?&web=https://furyvsusykdate.co.uk/">furyvsusykdate.co.uk</a> right away and enjoy the fight with top-notch streaming!
Across the UK, the ring walks are planned for late evening, ensuring maximum viewership. Back in Usyk’s home country, and beyond, the excitement is palpable. The venue for Fury vs Usyk is still under speculation, with talk of iconic boxing destinations. Wherever it happens, one thing is certain: the atmosphere will be electric. Although the focus remains on Fury and Usyk, the fights leading up to the main event promises plenty of action. Major boxing events often feature stacked undercards, providing non-stop action before the headliner.
In the past, supporting bouts in major events have been a stage for breakout performances. Contenders hoping to make their mark often seize these moments to impress fans and analysts alike, with the world paying attention. While the names for the undercard are still unconfirmed, fans are eagerly guessing. Will there be a heavyweight clash? No matter the final roster, fans can expect fireworks. What sets this bout apart so intriguing is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed are unparalleled in the sport. At 6’9" with an 85-inch reach, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, overcoming brutal hits to dominate in later rounds. Against Wladimir Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. By contrast, Usyk, brings speed, precision, and finesse. With his unorthodox stance, he uses angles and footwork. The Ukrainian’s shots aren’t the heaviest in the division, their timing wears down foes. With the date drawing closer, Tyson Fury vs Usyk odds are the subject of intense debate.
Most bookmakers favor Fury according to the odds, due to his size advantage, his proven ability in tough situations, and his unpredictable nature. However, Usyk's underdog status doesn’t rule him out, his dominance against Joshua demonstrated his ability in the heavyweight ranks.
For Fury himself could be the defining moment of his career. Should he come out on top, Fury’s win would put the finishing touches on a historic career. Meanwhile, For Usyk, a win would elevate him to legendary status. Securing two undisputed titles would be a remarkable feat in boxing history.
Web: <a href="http://www.google.cf/url?q=https://furyvsusykdate.co.uk/">furyvsusykdate.co.uk</a>
Fury vs Usyk is not just about the belts. It’s a clash of personalities. Fury’s bold and unapologetic character contrasts with Usyk’s calm, focused demeanor. Such contrasts make the fight more compelling. It’s about more than just skill. Whoever comes out victorious, the significance of this match will reverberate throughout boxing history. The clash for the undisputed title is more than just a match. It’s a culmination of years of hard work. Whether Fury secures the win thanks to his power and game plan, or Oleksandr Usyk triumphs with his finesse and stamina, no matter the outcome, this will be a legendary contest.
This fight between Fury and Usyk is more than just a fight. It’s a contest of heart and willpower. The two competitors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Azəri bazarında online kazino oyunlarına maraq artdıqca, Pin-up online kimi platformalar daha çox tanınmağa başladı. Əlavə olaraq, Pinup casino adları indi yerli istifadəçilər üçün tanışdır. Pin-up azerbaycan istifadəçilərə çoxlu oyun növü təklif edir.
Pinup kazino, Azəri istifadəçilər üçün geniş kütləyə sahib bir qumar saytıdır. Bu qumar saytı müştərilərə çoxlu oyun təklifləri təklif edir və gözəl hədiyyələr ilə qumarbazlar tərəfindən sevilir.
Pin-up casino, fərqli oyun təcrübəsi təklif edən saytdır. yerli mərcçilər arasında populyar olan Pin-up kazino, yerli oyunçular üçün fərqli oyun seçimləri ilə çıxış edir.
Özəlliklə, Pin-up azerbaycan oyunçulara güvənli depozit və çıxarış imkanı təklif edir. Kazino iştirakçıları, çox rahat depozit və pul çıxarış imkanları sayəsində, internet oyunlarını daha asan keçirə bilərlər.
Nəticə etibarilə, Pin-up azerbaycan mərcçilərə yalnız qumar oyunları yox, həmçinin cəlbedici kampaniyalar oyun təcrübəsini daha da maraqlı edir. Bu platformada, kazino həvəskarları təhlükəsiz şərtlər altında mərc edir.
Web: https://bet-on-pinup.web.app
Pin-up kazino yalnız bir mərc saytı kimi oyunlar ilə kifayətlənmir. Qumarçılar burada çeşidli mərc seçimlərindən istifadə edə bilər və sərfəli bonus təkliflərini oyun təcrübələrinə əlavə edərlər.
Bunun nəticəsində, Pin-up kazino, etibarlı qumar təcrübəsi təqdim etməklə onlayn qumar dünyasında lider mövqedədir. Azəri bazarında populyarlığı göz qabağındadır.
Azərbaycandakı qumar sektorunda qumar oyunlarına sevgisi artdıqca, Pinup kimi kazino xidmətləri daha çox tanınmağa başladı. Bununla bərabər, Pinup azerbaycan adları hazırda yerli istifadəçilər üçün tanışdır. Pin-up azerbaycan istifadəçilərə geniş oyunlar təklif edir.
Pin-up azerbaycan, yerli mərc həvəskarları üçün populyar seçimdir. Bu platforma qumarbazlara müxtəlif oyunlar verir və bonus imkanları ilə müştərilərini məmnun edir.
Pin-up online kazino, bənzərsiz oyun imkanı təqdim edən oyun məkanıdır. Azərbaycan ərazisində oyunçular tərəfindən sevilən Pin-up oyunları, oyun həvəskarları üçün geniş oyun variantları ilə tanınır.
Xüsusilə, Pin-up azerbaycan mərc edənlərə təhlükəsiz maliyyə əməliyyatları təklif etməkdədir. Müştərilər, sürətli və asan ödəmə üsulları vasitəsilə, onlayn mərc oyunlarını müvafiq şəkildə təcrübə edə bilərlər.
Sonda, Pin-up kazino müştərilərə təkcə oyun imkanı deyil cazibədar bonus təklifləri oyunçularına verir. Bu onlayn kazinoda, mərc edənlər təhlükəsiz oyun mühitində olur.
Web: https://win-top-pin-up.web.app
Pin-up azerbaycan yalnız oyunçuları cəlb etmir. Müştərilər burada bənzərsiz mərc imkanlarından yararlana bilərlər və cazibədar bonus imkanlarını qazanmaq imkanı əldə edərlər.
Sonda, Pinup kazino, müasir və təhlükəsiz oyun imkanı oyunçulara təklif etməklə onlayn qumar sektorunda ən sevilən platformalardan olur. Azəri bazarında geniş yayılması dikkətə layiqdir.
Azəri bazarında virtual qumar oyunlarına güvəni artdıqca, Pinup kazino kimi onlayn mərc xidmətləri daha çox tanınmağa başladı. Bununla bərabər, Pinup azerbaycan brendləri tez-tez Azəri oyunçuları üçün tanışdır. Pin-up casino azerbaycan oyunçulara geniş oyunlar təklif edir.
Pin-up online casino, Azərbaycandakı oyunçular üçün geniş kütləyə sahib bir qumar saytıdır. Bu platforma kazino oyunçularına çeşidli qumar oyunları təklif edib və sərfəli bonus təklifləri ilə mərc edənləri özünə cəlb edir.
Pin-up online kazino, bənzərsiz oyun imkanı təqdim edən xidmətdir. Azəri bazarında güvənilən Pinup, qumar oyunçuları üçün zəngin təkliflər təqdim edir.
Özəlliklə, Pinup casino oyunçulara təhlükəsiz ödəmə üsulları verir. Mərc edənlər, çox rahat maliyyə əməliyyatları ilə, oyun təcrübələrini daha asan təcrübə edərlər.
Yekun olaraq, Pin-up kazino qumarbazlara geniş oyun təcrübəsi ilə yanaşı cazibədar bonus təklifləri oyun təcrübəsini daha da maraqlı edir. Bu onlayn kazinoda, qumar həvəskarları özlərini güvəndə hiss edir.
Web: https://best-pin-up-bet.web.app
Pin-up cazino sadəcə məhdudlaşmır. Qumarçılar burada müxtəlif mərc növlərindən yararlana bilərlər və çoxlu bonusları oyunlarına əlavə edə bilərlər.
Sonda, Pin-up azerbaycan, sərfəli və təhlükəsiz mərc oyunları istifadəçilərə verməklə onlayn mərc dünyasında ən sevilən platformalardan olur. Azəri oyunçular tərəfindən seçim olması təsadüfi deyil.
Azərbaycanda mərc bazarında online kazino oyunlarına istək artdıqca, Pin-up online kimi saytlar daha çox tanınmağa başladı. Özəlliklə, Pinup casino ifadələri tez-tez yerli oyunçular üçün tanışdır. Pin-up kazino müştərilərinə çeşidli oyunlar təklif edir.
Pin-up azerbaycan, yerli mərc həvəskarları üçün populyar seçimdir. Bu qumar saytı mərc həvəskarlarına fərqli oyun növləri təmin edir və cazibədar aksiyalar ilə mərc edənləri özünə cəlb edir.
Pin-up casino, bənzərsiz oyun imkanı təqdim edən xidmətdir. yerli mərcçilər arasında geniş istifadə olunan Pin-up casino, mərc həvəskarları üçün zəngin təkliflər təqdim edir.
Bununla yanaşı, Pin-up azerbaycan istifadəçilərə etibarlı maliyyə sistemləri təklif etməkdədir. Oyunçular, rahat ödəmə üsulları nəticəsində, onlayn mərc oyunlarını daha rahat keçirə bilərlər.
Son olaraq, Pin-up casino istifadəçilərə çoxlu oyun növlərilə yanaşı mərc hədiyyələri və maraqlı aksiyalar təklif edir. Bu platformada, istifadəçilər şəffaf oyun şərtləri ilə rastlaşır.
Web: https://az-pinup.web.app
Pin-up casino online təkcə məhdud deyil. Qumarçılar burada müxtəlif mərc növlərindən həzz ala bilərlər və cazibədar bonus imkanlarını oyun təcrübəsini artırarlar.
Sonda, Pin-up cazino, rahat və təhlükəsiz mərc təcrübəsi təmin etməklə onlayn mərc dünyasında ən yaxşı seçimlərdən biridir. Azərbaycan mərcçiləri arasında çox seçilməsi təsadüf deyil.
Azərbaycandakı qumar sektorunda internet oyunlarına maraq artdıqca, Pin-up casino online kimi oyun xidmətləri daha çox tanınmağa başladı. Bunun nəticəsində, "Pin up casino online" ifadələri çoxdan Azəri müştərilər üçün tanışdır. Pin-up casino azerbaycan mərc həvəskarlarına rəngarəng oyunlar təklif edir.
Pin-up cazino, yerli mərc həvəskarları üçün geniş yayılmış bir xidmətdir. Bu kazino mərc həvəskarlarına çoxlu oyun təklifləri təklif edib və bonus imkanları ilə müştərilərini məmnun edir.
Pin-up online kazino, geniş oyun variantları təklif edən saytdır. Azəri bazarında oyunçular tərəfindən sevilən Pin-up casino, yerli oyunçular üçün maraqlı oyun imkanları təklif edir.
Xüsusilə, Pin-up azerbaycan qumar həvəskarlarına güvənli və şəffaf depozit və çıxarış imkanı təmin edir. Mərc edənlər, müvafiq və təhlükəsiz maliyyə əməliyyatları ilə təmin olunmaqla, internet oyunlarını müvafiq şəkildə təcrübə edə bilərlər.
Nəticə etibarilə, Pin-up casino online müştərilərə yalnız qumar oyunları yox, həmçinin bonuslar və aksiyalar müştəriləri üçün yaradır. Bu kazinoda, kazino həvəskarları təhlükəsiz şərtlər altında mərc edir.
Web: https://top-pinup.web.app
Pin-up casino online təkcə oyunçuları cəlb etmir. Mərc həvəskarları bu platformada bənzərsiz mərc imkanlarından müxtəlif mərc imkanı əldə edə bilər və bonus sistemini qazanmaq imkanı əldə edərlər.
Bunun nəticəsində, Pin-up kazino, etibarlı kazino təcrübəsi mərc həvəskarlarına təqdim etməklə mərc bazarında güclü mövqe tutub. Azərbaycanda tanınması təsadüfi deyil.
Azərbaycanda mərc bazarında online kazino oyunlarına güvəni artdıqca, Pin-up online kimi oyun xidmətləri daha çox tanınmağa başladı. Bununla bərabər, Pinup azerbaycan şəklində olan platformalar hazırda Azərbaycandakı oyunçular üçün sevilir. Pin-up azerbaycan istifadəçilərə məxsus çeşidli oyunlar təklif edir.
Pin-up azerbaycan, Azəri istifadəçilər üçün geniş kütləyə sahib bir qumar saytıdır. Bu kazino mərc həvəskarlarına çeşidli qumar oyunları təklif edir və cazibədar aksiyalar ilə seçim olur.
Pin-up azerbaycan, oyun keyfiyyətini artıran xidmətdir. yerli mərcçilər arasında məşhur olan Pin-up casino, kazino oyunçuları üçün maraqlı oyun imkanları təklif edir.
Bununla yanaşı, Pinup casino mərc edənlərə güvənli maliyyə idarəetmə imkanları oyunçularına təklif edir. Müştərilər, etibarlı və tez maliyyə çıxarışları vasitəsilə, qumar təcrübələrini asan və sürətli keçirə bilərlər.
Bununla yanaşı, Pin-up casino qumarbazlara təkcə oyun imkanı deyil cəlbedici kampaniyalar oyun təcrübəsini daha da maraqlı edir. Bu qumar saytında, oyunçular rahat və təhlükəsiz şəraitdə oynayır.
Web: https://win-top-pin-up-az.web.app
Pin-up kazino yalnız bir mərc saytı kimi oyunlar ilə kifayətlənmir. Müştərilər burada müxtəlif mərc növlərindən faydalanıb və çoxlu bonusları istifadə edə bilərlər.
Yekun olaraq, Pinup kazino, etibarlı mərc oyunları mərc həvəskarlarına təqdim etməklə mərc bazarında ən sevilən platformalardan olur. Azərbaycanda populyarlığı təsadüfi deyil.
Azəri bazarında qumar oyunlarına maraq artdıqca, Pin-up kazino kimi platformalar daha çox tanınmağa başladı. Özəlliklə, Pin-up kazino şəklində olan platformalar son zamanlar yerli istifadəçilər üçün məşhurdur. Pinup casino mərc həvəskarlarına rəngarəng oyunlar təklif edir.
Pin-up kazino, yerli mərc həvəskarları üçün geniş kütləyə sahib bir qumar saytıdır. Bu platforma qumarbazlara rəngarəng oyunlar verir və gözəl hədiyyələr ilə mərc edənləri özünə cəlb edir.
Pin-up casino online, geniş oyun variantları təklif edən bir platformadır. Azəri bazarında çox seçilən Pinup, qumar oyunçuları üçün zəngin təkliflər təqdim edir.
Bu səbəbdən, Pin-up azerbaycan istifadəçilərə şəffaf və təhlükəsiz ödəmə üsulları verir. Kazino iştirakçıları, sürətli və asan maliyyə çıxarışları ilə təmin olunmaqla, oyun təcrübələrini daha rahat oynaya bilərlər.
Bununla yanaşı, Pin-up casino qumarbazlara təkcə oyun imkanı deyil sərfəli bonuslar müştəriləri üçün yaradır. Pin-up-da, müştərilər özlərini güvəndə hiss edir.
Web: https://top-pinup.web.app
Pin-up online kazino təkcə bir oyun platforması kimi məhdudlaşmır. Oyunçular burada geniş mərc təcrübəsindən təcrübə edə bilərlər və cazibədar bonus imkanlarını oyunlarına əlavə edə bilərlər.
Ümumilikdə, Pin-up azerbaycan, güvənli mərc imkanı oyunçulara təklif etməklə onlayn qumar dünyasında güclü mövqe tutub. Azərbaycan mərcçiləri arasında tanınması əlamətdardır.
Azərbaycan ərazisində virtual qumar oyunlarına seçim artdıqca, "Pin-up casino" kimi şirkətlər daha çox tanınmağa başladı. Əlavə olaraq, Pin-up online brendləri hazırda Azərbaycandakı oyunçular üçün istifadə olunur. Pin-up kazino öz oyunçularına müxtəlif oyunlar təklif edir.
Pinup kazino, Azərbaycan oyunçuları üçün ən sevilən platformalardan biridir. Bu onlayn kazino istifadəçilərə rəngarəng oyunlar oyunçulara təqdim edir və gözəl hədiyyələr ilə seçim olur.
Pinup casino, oyun keyfiyyətini artıran saytdır. Azəri bazarında məşhur olan Pinup, oyun həvəskarları üçün çeşidli bonus imkanları yaradır.
Özəlliklə, Pin-up azerbaycan mərc edənlərə güvənli və şəffaf maliyyə sistemləri təmin edir. Müştərilər, çox rahat depozit və pul çıxarış imkanları sayəsində, mərc təcrübələrini müvafiq şəkildə yaşaya bilərlər.
Sonda, Pin-up casino online istifadəçilərə çoxlu oyun növlərilə yanaşı bonuslar və aksiyalar oyunçularına verir. Pinup-da, kazino həvəskarları güvənli bir təcrübə yaşayır.
Web: https://top-pinup.web.app
Pin-up casino yalnız bir mərc saytı kimi məhdud deyil. Kazino həvəskarları bu kazinoda geniş mərc təcrübəsindən təcrübə edə bilərlər və sərfəli bonus təkliflərini oyun təcrübəsini artırarlar.
Nəticədə, Pin-up casino, müasir və təhlükəsiz mərc oyunları oyunçulara təklif etməklə onlayn qumar dünyasında ən sevilən platformalardan olur. Azəri bazarında populyarlığı göz qabağındadır.
Azərbaycan ərazisində internet qumarına sevgisi artdıqca, Pin-up kazino kimi platformalar daha çox tanınmağa başladı. Əsasən, Pinup casino şəklində olan platformalar son zamanlar yerli oyunçular üçün sevilir. Pinup casino öz oyunçularına müxtəlif oyunlar təklif edir.
Pin-up online casino, Azəri qumarbazlar üçün maraqlı seçimdir. Bu qumar saytı qumarbazlara çeşidli qumar oyunları verir və çoxlu bonuslar ilə qumarbazlar tərəfindən sevilir.
Pin-up online kazino, bənzərsiz oyun imkanı təqdim edən şirkətdir. Azəri oyunçuları arasında güvənilən Pinup, qumar oyunçuları üçün maraqlı oyun imkanları təklif edir.
Bu səbəbdən, Pin-up online casino istifadəçilərə təhlükəsiz ödəmə sistemləri təklif edir. Mərc edənlər, rahat və tez kredit kartı və elektron pul kisəsi ilə sayəsində, qumar təcrübələrini müvafiq şəkildə yaşaya bilərlər.
Əlavə olaraq, Pin-up casino online qumarbazlara geniş oyun təcrübəsi ilə yanaşı sərfəli bonuslar və maraqlı aksiyalar təklif edir. Pinup-da, kazino həvəskarları rahat və təhlükəsiz şəraitdə oynayır.
Web: https://win-top-pin-up-az.web.app
Pin-up kazino yalnız məhdud deyil. İstifadəçilər Pinup-da çeşidli mərc seçimlərindən təcrübə edə bilərlər və sərfəli bonus təkliflərini qazanmaq imkanı əldə edərlər.
Ümumilikdə, Pin-up kazino, şəffaf və güvənli qumar təcrübəsi istifadəçilərə verməklə oyun bazarında lider mövqedədir. yerli oyunçular arasında məşhur olması açıq bir faktdır.
Azərbaycan ərazisində onlayn qumar oyunlarına maraq artdıqca, Pin-up online kimi onlayn mərc xidmətləri daha çox tanınmağa başladı. Bunun nəticəsində, Pin-up kazino adları tez-tez Azəri oyunçuları üçün məşhurdur. Pin-up kazino online istifadəçilərə məxsus çoxlu oyun növü təklif edir.
Pin-up kazino, Azərbaycandakı oyunçular üçün güvənli bir qumar məkanıdır. Bu platforma istifadəçilərə çeşidli qumar oyunları təklif edir və cəlbedici bonuslar ilə qumarbazlar tərəfindən sevilir.
Pin-up online kazino, geniş oyun variantları təklif edən saytdır. Azərbaycan ərazisində çox seçilən Pin-up kazino, yerli oyunçular üçün geniş oyun təcrübəsi verir.
Əlavə olaraq, Pin-up azerbaycan müştərilərə şəffaf və təhlükəsiz ödəmə üsulları təmin edir. Müştərilər, çox rahat maliyyə çıxarışları ilə təmin olunmaqla, onlayn mərc oyunlarını güvənli və təhlükəsiz yaşaya bilərlər.
Son olaraq, Pin-up azerbaycan mərc həvəskarlarına təkcə oyun imkanı deyil bonus imkanı təqdim edir. Bu kazinoda, oyunçular təhlükəsiz oyun mühitində olur.
Web: https://win-top-pin-up-az.web.app
Pin-up kazino yalnız sadə oyunla bitmir. Oyunçular burada çeşidli mərc seçimlərindən istifadə edə bilər və cazibədar bonus imkanlarını oyun təcrübələrinə əlavə edərlər.
Sonda, Pinup kazino, şəffaf və güvənli qumar təcrübəsi oyunçulara təklif etməklə oyun bazarında güclü mövqe tutub. yerli mərcçilər arasında çox seçilməsi dikkətə layiqdir.
Tyson Fury and Oleksandr Usyk are set to meet in the ring that will define an era. It’s far beyond a championship match; it’s about legacy. Tyson Fury has become a global icon thanks to his personality coupled with unparalleled talent during fights. Beating Wilder and Klitschko have cemented his place among the all-time greats. Meanwhile, the tactical southpaw is a fighter unlike any other to the heavyweight division. On the flip side, Oleksandr Usyk is a true test for Fury for Tyson Fury himself, but for the entire division. His journey to global fame began in the cruiserweight division, where he became an unstoppable force. Prepare yourself for an epic boxing match of the year as Usyk takes on Tyson Fury in an unforgettable showdown! Experience every moment streamed live on our website. Join the excitement — visit <a href="https://www.radiomaria.ro/2024/12/08/fury-vs-usyk-the-ultimate-heavyweight-showdown-142/">https://www.radiomaria.ro/2024/12/08/fury-vs-usyk-the-ultimate-heavyweight-showdown-142/</a> today and watch the match with top-notch streaming!
For British fans, the event will kick off at around 10 PM GMT, offering perfect timing for viewers. Back in Usyk’s home country, and beyond, the anticipation is at a fever pitch. Where the bout will take place has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, fans can be sure: it will be a spectacle. Even though attention is firmly on the main event, the fights leading up to the main event is shaping up to be thrilling. Big-ticket boxing cards often feature stacked undercards, offering an entire night of boxing excitement.
Historically, preliminary fights on major cards have showcased rising stars. Boxers seeking the spotlight use such opportunities to impress fans and analysts alike, knowing millions are watching. Though the supporting fights for Fury vs Usyk has yet to be finalized, speculation runs high. Could we see rising prospects? No matter the final roster, the action will not disappoint. What sets this bout apart incredibly exciting is their contrasting skillsets. Tyson Fury’s size and agility make him an anomaly in boxing. At 6’9" with an 85-inch reach, Fury can control a fight.
The three fights against Wilder highlighted his resilience, overcoming brutal hits to finish strong. Against Wladimir Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. With his unorthodox stance, he uses angles and footwork. His strikes aren’t the heaviest in the division, they consistently find their mark. As fight night approaches, Tyson Fury vs Usyk odds are the subject of intense debate.
Tyson Fury is the slight favorite according to the odds, given his physical stature, his long career in major fights, and his unpredictable nature. Despite the odds, Usyk remains a strong contender shouldn’t be counted out, as his victories over Joshua confirmed his toughness against big opponents.
For Tyson Fury, this fight is a chance to further solidify his greatness. If he wins, it would add an undisputed title to his already impressive resume. Meanwhile, For Usyk, a win would be a monumental achievement. Securing two undisputed titles is a feat few can claim.
Website: https://www.radiomaria.ro/2024/12/08/fury-vs-usyk-the-ultimate-heavyweight-showdown-142/
The upcoming showdown is about more than the titles. It’s a battle of contrasting styles. Fury’s bold and unapologetic character is in stark contrast to Usyk’s quiet intensity. These varying personalities make the bout even more interesting. This is more than just a physical contest. Regardless of the outcome, the legacy of this fight will reverberate throughout boxing history. Fury vs Usyk is more than just a fight. It represents the culmination of their careers. Whether Fury secures the win with his size and strategy, or Usyk comes out on top with his technique and endurance, no matter the outcome, this bout will go down in history.
Fury vs Usyk is more than just a fight. It’s a showcase of skill and determination. These two warriors will give everything they have.
Visit for more information: #crosslink[3,L -
Em ambientes virtuais de apostas, <a href="https://negociostorres.com/2024/08/04/fortune-tiger-jogue-com-dinheiro/">como jogar no tigrinho</a> ganha evidencia por ser agil e descomplicado. O padrao do tigrinho aposta e baseado na cultura chinesa, um aspecto que fascina ainda mais os participantes, ja que a tradicao e o simbolismo chines oferecem um ar enigmatico.
Quando falamos sobre uma casa de aposta chinesa tigrinho, nos referimos ao local onde esse jogo acontece. Essas locais de aposta sao frequentemente encontradas em plataformas virtuais que imitam os icones da cultura chinesa.
Os famosos tigres e dragoes da mitologia chinesa sao usados para guiar a tematica e o visual na mecanica do jogo tigrinho aposta.
A experiencia para o jogador fica mais imersiva, fazendo com que o jogador sinta que esta em uma experiencia rara, inusitado e distinto dos jogos comuns.
Web: https://negociostorres.com/2024/08/04/fortune-tiger-jogue-com-dinheiro/
Concluindo, o Tigrinho Aposta proporciona uma mistura envolvente de cultura e sorte, fornecendo a possibilidade de premiacoes atrativas.
O destaque do tigrinho jogo de aposta se deve a sua simplicidade, dinamismo e imersao. Com a popularidade dos sites de apostas online, esse tipo de jogo tem o potencial de crescer ainda mais, atraindo novos jogadores e se firmando entre os principais jogos.
These two heavyweight champions are set to meet in the ring of unparalleled significance. This fight is about more than just titles; it represents their quest for immortality. Tyson Fury has risen to the pinnacle of the sport through his unique style and remarkable adaptability inside the ropes. Beating Wilder and Klitschko have cemented his place among the all-time greats. In contrast, the tactical southpaw poses a unique challenge to the heavyweight division. At the same time, the Ukrainian technician represents a formidable opponent for the heavyweight ranks overall, and for boxing fans worldwide. Usyk’s rise to prominence began in the cruiserweight division, as an undisputed champion. Prepare yourself for the most anticipated boxing match of the year as Usyk takes on Fury in an unforgettable showdown! Experience every moment streamed live on our website. Be part of the action — visit <a href="https://backlinks-checker.com/share/2700947">https://backlinks-checker.com/share/2700947</a> right away and watch the match in high quality!
Across the UK, the fight is expected to begin close to prime time, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and for fans watching from around the world, this will be a must-see event. The fight’s location remains a hot topic, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, fans can be sure: it will be a spectacle. Even though attention remains on Fury and Usyk, the fights leading up to the main event is shaping up to be thrilling. High-profile matches are known for strong supporting fights, offering an entire night of boxing excitement.
In the past, undercards of this caliber have showcased rising stars. Contenders hoping to make their mark often seize these moments to showcase their skills, as all eyes are on them. Although the lineup for the Fury Usyk undercard are still unconfirmed, there’s plenty of talk. Could we see rising prospects? Regardless of the names, the action will not disappoint. What makes this fight so intriguing is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. Being so tall yet so nimble, he commands the ring like no other.
The legendary battles with Wilder proved his toughness, bouncing back from adversity to dominate in later rounds. When he faced Klitschko, his strategic genius shone through, showing he’s both powerful and smart. By contrast, Usyk, offers a different kind of threat. With his unorthodox stance, his movements create openings. Usyk’s punches aren’t the heaviest in the division, they consistently find their mark. As fight night approaches, The betting lines for Fury vs Usyk are the subject of intense debate.
The betting lines show Fury ahead according to the odds, given his physical stature, his long career in major fights, and his tactical brilliance. Despite the odds, Usyk remains a strong contender shouldn’t be counted out, his wins over Anthony Joshua confirmed his toughness against big opponents.
For Tyson Fury represents an opportunity to cement his legacy. A victory would add an undisputed title to his already impressive resume. Meanwhile, For Usyk, a win would mark him as one of the sport’s greats. Achieving undisputed glory in two divisions would be a remarkable feat in boxing history.
Website: https://backlinks-checker.com/share/2700947
This fight is more than just a championship fight. It’s a clash of personalities. Fury’s boisterous personality is the opposite of Usyk’s humble and disciplined approach. These differences add complexity to the fight. This is more than just a physical contest. Whoever comes out victorious, the impact of this bout will reverberate throughout boxing history. This historic showdown is more than just a match. It’s the result of relentless dedication. If Fury wins with his size and strategy, or Usyk secures a victory with his technique and endurance, it’s certain that, this bout will go down in history.
This fight between Fury and Usyk is a spectacle of a lifetime. It’s a showcase of skill and determination. These men will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Em sites de apostas online, <a href="https://www.tapyo.co/2024/08/25/jogue-fortune-tiger-jogo-do-tigre-da-pg-soft/">jogo tigrinho</a> atrai olhares pela sua facil jogabilidade e ritmo. O fundamento do jogo tigrinho se origina da cultura chinesa, um aspecto que fascina ainda mais os participantes, ja que a tradicao e o simbolismo chines carregam uma aura de misterio.
Quando falamos sobre uma casa de aposta chinesa tigrinho, estamos falando do lugar onde o jogo e oferecido. Essas plataformas digitais de apostas sao frequentemente encontradas em plataformas virtuais que imitam os icones da cultura chinesa.
Os figuras de tigres e dragoes orientam a estetica e as regras para a dinamica do jogo de aposta tigrinho.
A vivencia do apostador se torna mais envolvente, gerando uma sensacao de exclusividade e participacao, diferente das formas tradicionais de apostas.
Web: https://www.tapyo.co/2024/08/25/jogue-fortune-tiger-jogo-do-tigre-da-pg-soft/
Concluindo, o Jogo do Tigrinho proporciona uma mistura envolvente de cultura e sorte, com a chance de ganhar premios valiosos.
O sucesso do jogo tigrinho aposta se deve a mistura de jogabilidade agil e imersao profunda. Com o aumento das casas de apostas digitais, o tigrinho aposta tem todas as chances de continuar se expandindo, cativando novos adeptos e se consolidando entre os jogos favoritos.
Tyson Fury and Oleksandr Usyk are ready to face each other in a fight that will define an era. It’s far beyond a championship match; it represents their quest for immortality. Fury, an undefeated champion has become a global icon with his charisma and his unmatched skills inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. In contrast, Usyk, the technician brings an unprecedented test for Fury. Meanwhile, Oleksandr Usyk represents a formidable opponent for the heavyweight ranks overall, as a heavyweight contender. The ascent of Oleksandr Usyk began in the cruiserweight division, by conquering all challengers. Get ready for an epic boxing match of the year as Usyk takes on Tyson Fury in an unforgettable showdown! Catch every punch streamed live on our website. Join the excitement — visit <a href="https://www.lowesairduct.com/2024/12/08/usyk-vs-fury-the-ultimate-heavyweight-showdown-50/">https://www.lowesairduct.com/2024/12/08/usyk-vs-fury-the-ultimate-heavyweight-showdown-50/</a> now and enjoy the fight from the comfort of your home!
Across the UK, the fight is expected to begin close to prime time, ensuring maximum viewership. For Usyk’s fans in Ukraine, and for fans watching from around the world, the excitement is palpable. The venue for Fury vs Usyk remains a hot topic, with talk of iconic boxing destinations. Regardless of the venue, fans can be sure: it will be a spectacle. While the spotlight remains on Fury and Usyk, the Fury vs Usyk undercard is shaping up to be thrilling. Big-ticket boxing cards often feature stacked undercards, giving fans a full evening of entertainment.
In the past, supporting bouts in major events have introduced future champions. Boxers seeking the spotlight use such opportunities to showcase their skills, as all eyes are on them. Although the lineup for the Fury Usyk undercard has yet to be finalized, speculation runs high. Will there be a heavyweight clash? Whatever the selection, it’s sure to add to the excitement. What makes this fight incredibly exciting is the dynamic between these fighters. Fury’s towering frame and movement make him an anomaly in boxing. With his immense height and reach advantage, Fury can control a fight.
The legendary battles with Wilder highlighted his resilience, bouncing back from adversity to finish strong. Against Wladimir Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, relies on technique and stamina. As a southpaw, he uses angles and footwork. His strikes may not have knockout power, they consistently find their mark. As anticipation builds, The betting lines for Fury vs Usyk have fans and analysts speculating.
The betting lines show Fury ahead according to the odds, given his physical stature, his track record in big matches, and his adaptability. Despite the odds, Usyk remains a strong contender doesn’t rule him out, his wins over Anthony Joshua proved that he can handle the physicality of the heavyweight division.
For the Gypsy King presents a shot at undisputed glory. A triumph for Fury would further solidify his status as the best heavyweight of this era. Meanwhile, Usyk’s victory would elevate him to new heights. Becoming an undisputed champion in two different weight classes is a feat few can claim.
Website: https://www.lowesairduct.com/2024/12/08/usyk-vs-fury-the-ultimate-heavyweight-showdown-50/
Fury vs Usyk represents something greater than a title bout. It’s a meeting of two unique worldviews. Fury’s bold and unapologetic character is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. Beyond physical ability, this fight. Regardless of the outcome, the significance of this match will leave a lasting mark on the sport. The battle for heavyweight supremacy is more than just a match. It’s the result of relentless dedication. If Fury wins with his size and strategy, or Usyk secures a victory with his technique and endurance, one thing is certain, this bout will go down in history.
This fight between Fury and Usyk is more than just a sporting contest. It’s a showcase of skill and determination. The two competitors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Em plataformas online, <a href="https://classicmx.hu/fortune-tiger-jogo-do-tigrinho/">jogo tigre</a> se destaca por sua simplicidade e dinamismo. O significado do jogo de aposta tigrinho e baseado na cultura chinesa, o que desperta ainda mais curiosidade nos apostadores, ja que a rica tradicao chinesa trazem misticismo ao jogo.
Quando nos referimos a uma casa de apostas tigrinho, estamos falando do lugar onde o jogo e oferecido. Essas plataformas digitais de apostas costumam estar disponiveis em sites online que reproduzem a estetica e os simbolos tipicos da cultura oriental.
Os famosos tigres e dragoes da mitologia chinesa ajudam a construir a estetica e o funcionamento para a dinamica do jogo de aposta tigrinho.
A vivencia do apostador fica mais imersiva, fazendo com que o jogador se sinta parte de algo especial, diferente das formas tradicionais de apostas.
Web: https://classicmx.hu/fortune-tiger-jogo-do-tigrinho/
Em resumo, o Jogo do Tigrinho e uma forma de entretenimento que combina tradicao, sorte e emocao, trazendo aos apostadores a possibilidade de grandes premios.
O destaque do tigrinho jogo de aposta vem de sua facil jogabilidade, da adrenalina e da imersao proporcionada. Com a expansao das plataformas digitais, esse tipo de jogo tem o potencial de crescer ainda mais, cativando novos adeptos e se consolidando entre os jogos favoritos.
These two heavyweight champions are preparing for an epic showdown of historic proportions. It’s not merely about the belts; it represents their quest for immortality. The Gypsy King has earned worldwide fame through his unique style and his unmatched skills during fights. Beating Wilder and Klitschko have solidified his legendary status. On the other hand, Usyk, the technician brings an unprecedented test for Fury. At the same time, the Ukrainian technician is a true test for Fury for the heavyweight ranks overall, as a heavyweight contender. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, as an undisputed champion. Prepare yourself for an epic boxing match of the year as Usyk takes on Tyson Fury in an unforgettable showdown! See every move streamed live on our website. Join the excitement — visit <a href="https://www.myfirstproperty.co.uk/postcode-houseprices/ME1-3RH">https://www.myfirstproperty.co.uk/postcode-houseprices/ME1-3RH</a> now and stream the event from the comfort of your home!
For British fans, the event will kick off at close to prime time, ensuring maximum viewership. Back in Usyk’s home country, and for fans watching from around the world, this will be a must-see event. The venue for Fury vs Usyk has yet to be confirmed, with talk of iconic boxing destinations. Wherever it happens, fans can be sure: the excitement will be unmatched. While the spotlight is centered on the headline fight, the preliminary bouts is also generating excitement. Major boxing events often feature stacked undercards, offering an entire night of boxing excitement.
Historically, undercards of this caliber have been a stage for breakout performances. Fighters looking to rise through the ranks use such opportunities to impress fans and analysts alike, knowing millions are watching. Though the supporting fights for Fury vs Usyk has yet to be finalized, there’s plenty of talk. Might there be a cruiserweight spectacle? Whatever the selection, fans can expect fireworks. What makes this fight so intriguing is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. At 6’9" with an 85-inch reach, he commands the ring like no other.
The three fights against Wilder proved his toughness, bouncing back from adversity to secure victories. Against Wladimir Klitschko, his strategic genius shone through, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, offers a different kind of threat. As a southpaw, his movements create openings. The Ukrainian’s shots aren’t the heaviest in the division, their timing wears down foes. With the date drawing closer, Predictions for this fight have fans and analysts speculating.
The betting lines show Fury ahead based on the betting odds, due to his size advantage, his experience in high-pressure bouts, and his tactical brilliance. Although Usyk is the less favored fighter shouldn’t be counted out, his wins over Anthony Joshua confirmed his toughness against big opponents.
For Fury himself could be the defining moment of his career. A victory would solidify his claim as the greatest heavyweight of his generation. Conversely, For Usyk, a win would mark him as one of the sport’s greats. Achieving undisputed glory in two divisions is a feat few can claim.
Website: https://www.myfirstproperty.co.uk/postcode-houseprices/ME1-3RH
The upcoming showdown represents something greater than a title bout. It’s a battle of contrasting styles. Fury’s boisterous personality contrasts with Usyk’s calm, focused demeanor. These varying personalities make the bout even more interesting. Beyond physical ability, this fight. Whoever comes out victorious, the impact of this bout will be felt for years to come. The clash for the undisputed title is more than just a match. It’s the pinnacle of both fighters’ hard work. Whether Fury secures the win through his strength and tactics, or Usyk wins with his precision through his superior boxing ability, no matter the outcome, this bout will go down in history.
Fury vs Usyk is more than just a boxing event. It’s a fight of grit and strategy. These two warriors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Em plataformas online, <a href="https://www.ssaircons.com/jogue-fortune-tiger-jogo-do-tigre-da-pg-soft/">jogo do tigrinho</a> ganha evidencia por ser simples e dinamico. O fundamento do jogo tigrinho se apoia nas tradicoes orientais, o que desperta ainda mais curiosidade nos apostadores, ja que as tradicoes orientais agregam um toque de misterio e fascinio.
Quando pensamos em uma casa de aposta tigrinho, aludimos ao espaco onde o jogo e jogado. Essas casas de jogos podem ser encontradas online que imitam os icones da cultura chinesa.
Os famosos tigres e dragoes da mitologia chinesa sao utilizados tanto como representacao visual quanto como inspiracao na mecanica do jogo tigrinho aposta.
A jogabilidade fica mais intensa, fazendo com que o jogador sinta que esta em uma experiencia rara, original e distante dos jogos convencionais.
Web: https://www.ssaircons.com/jogue-fortune-tiger-jogo-do-tigre-da-pg-soft/
Em resumo, a Aposta no Tigrinho representa uma combinacao unica de tradicao, sorte e emocao, oferecendo a oportunidade de conquistar premios interessantes.
A fama do jogo de aposta tigrinho se explica pela juncao da jogabilidade facil com a intensa imersao. Com a popularidade dos sites de apostas online, esse tipo de aposta promete crescer ainda mais, ganhando mais fas e se posicionando como um dos favoritos.
These two heavyweight champions are preparing for an epic showdown that will define an era. It’s not merely about the belts; it’s about legacy. Fury, an undefeated champion has risen to the pinnacle of the sport with his charisma coupled with unparalleled talent in the ring. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. In contrast, Usyk, the Ukrainian master brings an unprecedented test to the heavyweight division. Meanwhile, Usyk, a southpaw master stands as a unique threat for the heavyweight ranks overall, and for boxing fans worldwide. The ascent of Oleksandr Usyk began in the cruiserweight division, as an undisputed champion. Prepare yourself for an epic boxing match of the year as Oleksandr Usyk takes on Fury in a must-watch showdown! Catch every punch live on our website. Join the excitement — visit <a href="https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7AY">https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7AY</a> now and watch the match with top-notch streaming!
For British fans, the fight is expected to begin late evening, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and beyond, this will be a must-see event. Where the bout will take place remains a hot topic, with talk of iconic boxing destinations. Wherever it happens, it’s guaranteed: the excitement will be unmatched. While the spotlight is centered on the headline fight, the Fury vs Usyk undercard is shaping up to be thrilling. Major boxing events often feature stacked undercards, providing non-stop action before the headliner.
Historically, supporting bouts in major events have showcased rising stars. Boxers seeking the spotlight capitalize on the exposure to demonstrate their talent, with the world paying attention. Although the lineup for the Fury Usyk undercard haven’t been officially announced, speculation runs high. Could we see rising prospects? Whatever the selection, it’s sure to add to the excitement. What makes this fight incredibly exciting is their contrasting skillsets. Tyson Fury’s size and agility set him apart from other heavyweights. Being so tall yet so nimble, Fury can control a fight.
The three fights against Wilder showed his durability, bouncing back from adversity to dominate in later rounds. Against Wladimir Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. By contrast, Usyk, relies on technique and stamina. Being a left-handed fighter, he uses angles and footwork. The Ukrainian’s shots aren’t the heaviest in the division, they consistently find their mark. As anticipation builds, Tyson Fury vs Usyk odds are the subject of intense debate.
Tyson Fury is the slight favorite according to the odds, thanks to his imposing frame, his long career in major fights, and his adaptability. Despite the odds, Usyk remains a strong contender doesn’t diminish his chances, his wins over Anthony Joshua showed that he can compete at heavyweight.
For Tyson Fury could be the defining moment of his career. If he wins, it would solidify his claim as the greatest heavyweight of his generation. Meanwhile, Usyk’s victory would elevate him to new heights. Becoming the undisputed heavyweight champion is a feat few can claim.
Website: https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7AY
Fury vs Usyk represents something greater than a title bout. It’s a meeting of two unique worldviews. Fury’s boisterous personality is in stark contrast to Usyk’s quiet intensity. These varying personalities make the bout even more interesting. Beyond physical ability, this fight. Regardless of the outcome, the significance of this match will reverberate throughout boxing history. The battle for heavyweight supremacy is a defining moment. It represents the culmination of their careers. Whether Fury secures the win through his strength and tactics, or Usyk secures a victory through his superior boxing ability, one thing is certain, this will be a fight remembered for years to come.
This fight between Fury and Usyk is a spectacle of a lifetime. It’s a contest of heart and willpower. These two warriors will give everything they have.
Visit for more information: #crosslink[3,L -
Em plataformas digitais, <a href="https://www.alkafhaj.com/fortune-tiger-jogo-do-tigre-online/">jogo do tigrinho fortune tiger</a> brilha pela facilidade e rapidez. O principio do aposta tigrinho se origina da cultura chinesa, um detalhe que aguca a curiosidade dos jogadores, ja que a rica tradicao chinesa trazem misticismo ao jogo.
Quando mencionamos uma casa de apostas tigrinho, significamos o lugar onde o jogo e realizado. Essas plataformas de apostas normalmente estao em plataformas digitais que imitam os icones da cultura chinesa.
Os famosos tigres e dragoes da mitologia chinesa orientam a estetica e as regras na jogabilidade do jogo do tigrinho aposta.
A experiencia para o jogador fica mais intensa, levando-o a sentir que esta em uma experiencia unica, diferente das formas tradicionais de apostas.
Web: https://www.alkafhaj.com/fortune-tiger-jogo-do-tigre-online/
Para concluir, o Tigrinho de Apostas se posiciona como um jogo que une sorte, adrenalina e a tradicao oriental, trazendo aos apostadores a possibilidade de grandes premios.
O destaque do tigrinho jogo de aposta se deve a mistura de jogabilidade agil e imersao profunda. Com o crescimento das plataformas de apostas digitais, o tigrinho aposta tem todas as chances de continuar se expandindo, ampliando sua base de jogadores e consolidando sua posicao no mercado.
Fury, the Gypsy King, and Usyk, the technician are preparing for an epic showdown that will define an era. This fight is about more than just titles; it’s a battle for eternal recognition. The Gypsy King has risen to the pinnacle of the sport with his charisma coupled with unparalleled talent inside the ropes. Beating Wilder and Klitschko have earned him recognition as one of the best ever. Meanwhile, Usyk, the technician is a fighter unlike any other for Fury. At the same time, Usyk, a genius in the ring stands as a unique threat not just for Fury, and for boxing fans worldwide. His journey to global fame started with his domination of the cruiserweights, by conquering all challengers. Get ready for the most anticipated boxing match of the year as Usyk takes on Fury in an unforgettable showdown! See every move streamed live on our website. Don’t miss your chance — visit <a href="https://backlinks-checker.com/share/2700947">https://backlinks-checker.com/share/2700947</a> now and watch the match with top-notch streaming!
For British fans, the event will kick off at around 10 PM GMT, offering perfect timing for viewers. For Usyk’s fans in Ukraine, and for fans watching from around the world, the anticipation is at a fever pitch. The venue for Fury vs Usyk remains a hot topic, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, fans can be sure: the excitement will be unmatched. Although the focus is centered on the headline fight, the fights leading up to the main event is shaping up to be thrilling. Big-ticket boxing cards often feature stacked undercards, providing non-stop action before the headliner.
Historically, preliminary fights on major cards have showcased rising stars. Contenders hoping to make their mark use such opportunities to showcase their skills, as all eyes are on them. Though the supporting fights for Fury vs Usyk are still unconfirmed, there’s plenty of talk. Will there be a heavyweight clash? Whatever the selection, the action will not disappoint. The most compelling part of Fury vs Usyk truly fascinating is the clash of styles. Tyson Fury’s size and agility are unparalleled in the sport. With his immense height and reach advantage, he dictates the pace of bouts.
The three fights against Wilder showed his durability, overcoming brutal hits to secure victories. Against Wladimir Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. By contrast, Usyk, offers a different kind of threat. With his unorthodox stance, his positioning constantly challenges opponents. Usyk’s punches aren’t the heaviest in the division, their timing wears down foes. As anticipation builds, Tyson Fury vs Usyk odds are becoming a hot topic.
Fury is the favored fighter based on the betting odds, thanks to his imposing frame, his experience in high-pressure bouts, and his tactical brilliance. Although Usyk is the less favored fighter shouldn’t be counted out, his dominance against Joshua proved that he can handle the physicality of the heavyweight division.
For Tyson Fury could be the defining moment of his career. A triumph for Fury would further solidify his status as the best heavyweight of this era. On the other hand, For Usyk, a win would elevate him to new heights. Becoming the undisputed heavyweight champion is a once-in-a-lifetime achievement.
Website: https://backlinks-checker.com/share/2700947
The upcoming showdown is more than just a championship fight. It’s a meeting of two unique worldviews. Fury’s boisterous personality stands in stark contrast to Usyk’s composed demeanor. Such contrasts make the fight more compelling. Beyond physical ability, this fight. Whoever triumphs in this battle, the legacy of this fight will leave a lasting mark on the sport. This historic showdown is a spectacle unlike any other. It’s a culmination of years of hard work. Whether Fury secures the win with his experience and unpredictability, or Usyk wins with his precision through his superior boxing ability, no matter the outcome, this will be a defining moment in boxing.
The Fury-Usyk battle is more than just a boxing event. It’s a battle of minds and bodies. These two warriors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Em casas de apostas digitais, <a href="https://www.gestinternational.com/fortune-tiger-slot-jogo-do-tigre-demo-de-graca-2/">joguinho do tigrinho</a> chama a atencao por sua simplicidade e dinamismo. O significado do jogo de aposta tigrinho e inspirado na tradicao chinesa, o que desperta ainda mais curiosidade nos apostadores, ja que os elementos misticos da cultura oriental agregam um toque de misterio e fascinio.
Quando pensamos em uma casa de aposta tigrinho, nos dirigimos ao espaco onde o jogo ocorre. Essas casas de apostas sao frequentemente encontradas em plataformas virtuais que imitam os icones da cultura chinesa.
Os simbolos tradicionais como tigres, dragoes e outros elementos miticos servem de inspiracao visual e tematica para a dinamica do jogo de aposta tigrinho.
A sensacao para o apostador fica mais intensa, fazendo com que o jogador sinta que esta em uma experiencia rara, inusitado e distinto dos jogos comuns.
Web: https://www.gestinternational.com/fortune-tiger-slot-jogo-do-tigre-demo-de-graca-2/
Para concluir, o Tigrinho de Apostas proporciona uma mistura envolvente de cultura e sorte, com a chance de ganhar premios valiosos.
O destaque do tigrinho jogo de aposta vem de sua facil jogabilidade, da adrenalina e da imersao proporcionada. Com o crescimento das plataformas de apostas digitais, essa modalidade tem tudo para continuar crescendo, atraindo novos jogadores e se firmando entre os principais jogos.
These two heavyweight champions are set to meet in the ring that will define an era. This fight is about more than just titles; it represents their quest for immortality. Fury, an undefeated champion has earned worldwide fame with his charisma and remarkable adaptability during fights. Beating Wilder and Klitschko have cemented his place among the all-time greats. On the other hand, Usyk, the Ukrainian master is a fighter unlike any other for Fury. On the flip side, Usyk, a southpaw master is a true test for Fury for the heavyweight ranks overall, as a heavyweight contender. The ascent of Oleksandr Usyk started with his domination of the cruiserweights, where he became an unstoppable force. Get ready for the most anticipated boxing match of the year as Usyk takes on Fury in a must-watch showdown! Experience every moment in real time on our website. Don’t miss your chance — visit <a href="https://primeboostseo.com/keyword-research-tips-primeboostseo-979/">https://primeboostseo.com/keyword-research-tips-primeboostseo-979/</a> now and enjoy the fight with top-notch streaming!
In the United Kingdom, the event will kick off at close to prime time, making it ideal for a prime-time audience. Back in Usyk’s home country, as well as viewers across Europe and the Americas, the excitement is palpable. Where the bout will take place has yet to be confirmed, with talk of iconic boxing destinations. Regardless of the venue, one thing is certain: the atmosphere will be electric. Although the focus is centered on the headline fight, the preliminary bouts is also generating excitement. Major boxing events often feature stacked undercards, providing non-stop action before the headliner.
Traditionally, supporting bouts in major events have introduced future champions. Boxers seeking the spotlight use such opportunities to demonstrate their talent, knowing millions are watching. Although the lineup for the Fury Usyk undercard are still unconfirmed, there’s plenty of talk. Will there be a heavyweight clash? Whatever the selection, fans can expect fireworks. What makes this fight so intriguing is the clash of styles. Tyson Fury’s size and agility make him an anomaly in boxing. Being so tall yet so nimble, he commands the ring like no other.
The three fights against Wilder proved his toughness, as he recovered from knockdowns to dominate in later rounds. In his fight with Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. As a southpaw, he uses angles and footwork. The Ukrainian’s shots may not have knockout power, they consistently find their mark. As anticipation builds, Predictions for this fight are the subject of intense debate.
The betting lines show Fury ahead as per the betting experts, thanks to his imposing frame, his proven ability in tough situations, and his unpredictable nature. However, Usyk's underdog status doesn’t diminish his chances, his wins over Anthony Joshua proved that he can handle the physicality of the heavyweight division.
For Tyson Fury is a chance to further solidify his greatness. A triumph for Fury would solidify his claim as the greatest heavyweight of his generation. Conversely, If Usyk wins would elevate him to new heights. Achieving undisputed glory in two divisions is a rare accomplishment.
Website: https://primeboostseo.com/keyword-research-tips-primeboostseo-979/
The upcoming showdown is about more than the titles. It’s a meeting of two unique worldviews. Fury’s boisterous personality is the opposite of Usyk’s humble and disciplined approach. Such contrasts make the fight more compelling. It’s about more than just skill. No matter who wins, the impact of this bout will reverberate throughout boxing history. Fury vs Usyk is more than just a fight. It represents the culmination of their careers. Whether Fury secures the win thanks to his power and game plan, or Usyk wins with his precision with his technique and endurance, what is clear is, this will be a defining moment in boxing.
Tyson Fury vs Oleksandr Usyk is more than just a boxing event. It’s a showcase of skill and determination. These two warriors will give everything they have.
Visit for more information: #crosslink[3,L -
Em plataformas online, <a href="https://signalsmatrix.com/2024/08/04/fortune-tiger-ganhe-ate-2500x-no-jogo-do-tigre/">tigrinho</a> ganha notoriedade por ser agil e descomplicado. O significado do jogo de aposta tigrinho se origina da cultura chinesa, o que desperta ainda mais curiosidade nos apostadores, ja que os elementos misticos da cultura oriental dao um charme especial ao jogo.
Quando nos referimos a uma casa de apostas tigrinho, nos dirigimos ao espaco onde o jogo ocorre. Essas casas de jogos normalmente estao em plataformas digitais que reproduzem a estetica e os simbolos tipicos da cultura oriental.
Os simbolos tradicionais como tigres, dragoes e outros elementos miticos servem de inspiracao visual e tematica para a dinamica do jogo de aposta tigrinho.
A imersao do jogador e muito mais imersiva, fazendo com que o apostador se sinta em algo exclusivo, e totalmente distinto das apostas tradicionais.
Web: https://signalsmatrix.com/2024/08/04/fortune-tiger-ganhe-ate-2500x-no-jogo-do-tigre/
Resumindo, o Tigrinho Aposta representa uma combinacao unica de tradicao, sorte e emocao, dando aos jogadores a chance de conquistar recompensas.
A fama do jogo de aposta tigrinho vem de sua facil jogabilidade, da adrenalina e da imersao proporcionada. Com a popularidade dos sites de apostas online, essa forma de aposta continuara se expandindo, ampliando sua base de jogadores e consolidando sua posicao no mercado.
The undefeated Fury and Usyk are preparing for an epic showdown of unparalleled significance. This fight is about more than just titles; it’s a battle for eternal recognition. Tyson Fury has become a global icon thanks to his personality coupled with unparalleled talent inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Meanwhile, the tactical southpaw poses a unique challenge for Fury. At the same time, Usyk, a genius in the ring stands as a unique threat for Tyson Fury himself, as a heavyweight contender. His journey to global fame was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Don’t miss out for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a must-watch showdown! Experience every moment streamed live on our website. Don’t miss your chance — visit <a href="https://fourpawswalkingandtraining.co.uk/top-live-streaming-options-for-fury-vs-usyk-fight/">https://fourpawswalkingandtraining.co.uk/top-live-streaming-options-for-fury-vs-usyk-fight/</a> right away and enjoy the fight with top-notch streaming!
Across the UK, the event will kick off at around 10 PM GMT, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, and beyond, this will be a must-see event. The venue for Fury vs Usyk has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, fans can be sure: the excitement will be unmatched. Although the focus is centered on the headline fight, the preliminary bouts is shaping up to be thrilling. Big-ticket boxing cards often feature stacked undercards, providing non-stop action before the headliner.
In the past, undercards of this caliber have been a stage for breakout performances. Contenders hoping to make their mark often seize these moments to showcase their skills, with the world paying attention. While the names for the undercard has yet to be finalized, fans are eagerly guessing. Might there be a cruiserweight spectacle? Regardless of the names, the action will not disappoint. What sets this bout apart so intriguing is the clash of styles. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. With his immense height and reach advantage, he commands the ring like no other.
The three fights against Wilder proved his toughness, overcoming brutal hits to secure victories. In his fight with Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. By contrast, Usyk, offers a different kind of threat. Being a left-handed fighter, he uses angles and footwork. Usyk’s punches aren’t the heaviest in the division, they consistently find their mark. As fight night approaches, Predictions for this fight are the subject of intense debate.
The betting lines show Fury ahead according to the odds, given his physical stature, his track record in big matches, and his adaptability. Despite the odds, Usyk remains a strong contender doesn’t rule him out, as his victories over Joshua confirmed his toughness against big opponents.
For Tyson Fury, this fight is a chance to further solidify his greatness. Should he come out on top, Fury’s win would solidify his claim as the greatest heavyweight of his generation. Conversely, For Usyk, a win would elevate him to legendary status. Securing two undisputed titles is a rare accomplishment.
Website: https://fourpawswalkingandtraining.co.uk/top-live-streaming-options-for-fury-vs-usyk-fight/
Fury vs Usyk is about more than the titles. It’s a meeting of two unique worldviews. Fury’s larger-than-life persona is the opposite of Usyk’s humble and disciplined approach. These differences add complexity to the fight. It’s a fight of wills and ideologies. Whoever triumphs in this battle, the legacy of this fight will reverberate throughout boxing history. The clash for the undisputed title is a defining moment. It represents the culmination of their careers. Whether Tyson Fury prevails with his size and strategy, or Usyk wins with his precision with his technique and endurance, no matter the outcome, this will be a defining moment in boxing.
This fight between Fury and Usyk is more than just a sporting contest. It’s a contest of heart and willpower. Both fighters will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are preparing for an epic showdown of historic proportions. This fight is about more than just titles; it represents their quest for immortality. The Gypsy King has risen to the pinnacle of the sport through his unique style coupled with unparalleled talent in the ring. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. Meanwhile, the tactical southpaw poses a unique challenge to the heavyweight division. On the flip side, Usyk, a genius in the ring is a true test for Fury for the heavyweight ranks overall, and for boxing fans worldwide. His journey to global fame began in the cruiserweight division, by conquering all challengers. Get ready for a thrilling boxing match of the year as Oleksandr Usyk takes on Fury in an unforgettable showdown! See every move live on our website. Join the excitement — visit <a href="https://test.afmlta.asn.au/category/1/page/9/">https://test.afmlta.asn.au/category/1/page/9/</a> today and watch the match from the comfort of your home!
For British fans, the ring walks are planned for late evening, making it ideal for a prime-time audience. Back in Usyk’s home country, and for fans watching from around the world, the excitement is palpable. Where the bout will take place remains a hot topic, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, it’s guaranteed: the atmosphere will be electric. Even though attention remains on Fury and Usyk, the Fury vs Usyk undercard is also generating excitement. Big-ticket boxing cards often feature stacked undercards, offering an entire night of boxing excitement.
In the past, preliminary fights on major cards have showcased rising stars. Boxers seeking the spotlight capitalize on the exposure to demonstrate their talent, as all eyes are on them. While the names for the undercard are still unconfirmed, fans are eagerly guessing. Might there be a cruiserweight spectacle? Whatever the selection, the action will not disappoint. What makes this fight so intriguing is the clash of styles. The Gypsy King’s unusual blend of height and speed are unparalleled in the sport. At 6’9" with an 85-inch reach, he commands the ring like no other.
The three fights against Wilder highlighted his resilience, as he recovered from knockdowns to secure victories. In his fight with Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. By contrast, Usyk, offers a different kind of threat. As a southpaw, he uses angles and footwork. His strikes may not have knockout power, their timing wears down foes. As anticipation builds, Tyson Fury vs Usyk odds are becoming a hot topic.
The betting lines show Fury ahead as per the betting experts, because of his reach and height, his long career in major fights, and his unpredictable nature. Although Usyk is the less favored fighter doesn’t mean he’s an underdog in spirit, his wins over Anthony Joshua proved that he can handle the physicality of the heavyweight division.
For Tyson Fury presents a shot at undisputed glory. If he wins, it would put the finishing touches on a historic career. Meanwhile, For Usyk, a win would elevate him to legendary status. Achieving undisputed glory in two divisions is a rare accomplishment.
Website: https://test.afmlta.asn.au/category/1/page/9/
The upcoming showdown is about more than the titles. It’s a fight between two very different fighters. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. The clash of personalities adds depth to the narrative. Beyond physical ability, this fight. Regardless of the outcome, the significance of this match will reverberate throughout boxing history. The battle for heavyweight supremacy is more than just a fight. It’s the pinnacle of both fighters’ hard work. Should Fury claim victory with his size and strategy, or Usyk secures a victory thanks to his skill and resilience, no matter the outcome, this bout will go down in history.
The Fury-Usyk battle is a spectacle of a lifetime. It’s a contest of heart and willpower. The two competitors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are set to meet in the ring of historic proportions. It’s far beyond a championship match; it’s a battle for eternal recognition. Tyson Fury has risen to the pinnacle of the sport through his unique style and his unmatched skills inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have solidified his legendary status. On the other hand, Usyk, the technician poses a unique challenge for Fury. On the flip side, Oleksandr Usyk stands as a unique threat for Tyson Fury himself, and for boxing fans worldwide. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Get ready for an epic boxing match of the year as Oleksandr Usyk takes on Fury in a must-watch showdown! Experience every moment live on our website. Don’t miss your chance — visit <a href="https://www.familyhomecaregivers.com/hundredofhooacademy-co-uk-new/tyson-fury-vs-usyk-the-ultimate-heavyweight-130/">https://www.familyhomecaregivers.com/hundredofhooacademy-co-uk-new/tyson-fury-vs-usyk-the-ultimate-heavyweight-130/</a> now and watch the match from the comfort of your home!
In the United Kingdom, the fight is expected to begin late evening, offering perfect timing for viewers. For Usyk’s fans in Ukraine, and for fans watching from around the world, the anticipation is at a fever pitch. Where the bout will take place has yet to be confirmed, with talk of iconic boxing destinations. Regardless of the venue, one thing is certain: the atmosphere will be electric. While the spotlight is firmly on the main event, the Fury vs Usyk undercard promises plenty of action. High-profile matches are known for strong supporting fights, offering an entire night of boxing excitement.
Traditionally, undercards of this caliber have introduced future champions. Contenders hoping to make their mark use such opportunities to demonstrate their talent, knowing millions are watching. Though the supporting fights for Fury vs Usyk are still unconfirmed, fans are eagerly guessing. Might there be a cruiserweight spectacle? No matter the final roster, the action will not disappoint. What makes this fight incredibly exciting is the dynamic between these fighters. Tyson Fury’s size and agility are unparalleled in the sport. At 6’9" with an 85-inch reach, he commands the ring like no other.
His trilogy with Deontay Wilder highlighted his resilience, as he recovered from knockdowns to finish strong. Against Wladimir Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. By contrast, Usyk, relies on technique and stamina. With his unorthodox stance, he uses angles and footwork. The Ukrainian’s shots aren’t the heaviest in the division, their timing wears down foes. With the date drawing closer, Tyson Fury vs Usyk odds have fans and analysts speculating.
Fury is the favored fighter according to the odds, given his physical stature, his long career in major fights, and his unorthodox style. Despite the odds, Usyk remains a strong contender doesn’t mean he’s an underdog in spirit, as his victories over Joshua proved that he can handle the physicality of the heavyweight division.
For the Gypsy King represents an opportunity to cement his legacy. A triumph for Fury would put the finishing touches on a historic career. On the other hand, Usyk’s victory would elevate him to legendary status. Achieving undisputed glory in two divisions would be a remarkable feat in boxing history.
Website: https://www.familyhomecaregivers.com/hundredofhooacademy-co-uk-new/tyson-fury-vs-usyk-the-ultimate-heavyweight-130/
This fight represents something greater than a title bout. It’s a fight between two very different fighters. Fury’s bold and unapologetic character is in stark contrast to Usyk’s quiet intensity. These varying personalities make the bout even more interesting. This is more than just a physical contest. Whoever triumphs in this battle, the legacy of this fight will leave a lasting mark on the sport. The clash for the undisputed title is a defining moment. It represents the culmination of their careers. Whether Fury secures the win with his experience and unpredictability, or Usyk wins with his precision thanks to his skill and resilience, it’s certain that, this will be a defining moment in boxing.
This fight between Fury and Usyk is more than just a boxing event. It’s a battle of minds and bodies. The two competitors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are set to meet in the ring that will define an era. It’s not merely about the belts; it represents their quest for immortality. Fury, an undefeated champion has become a global icon thanks to his personality and his unmatched skills in the ring. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. Meanwhile, Usyk, the technician is a fighter unlike any other to the heavyweight division. At the same time, Oleksandr Usyk stands as a unique threat not just for Fury, but for the entire division. The ascent of Oleksandr Usyk started with his domination of the cruiserweights, by conquering all challengers. Prepare yourself for an epic boxing match of the year as Usyk takes on Tyson Fury in a must-watch showdown! Catch every punch in real time on our website. Don’t miss your chance — visit <a href="https://websitehubs.com/masterings-multichannel-marketing/">https://websitehubs.com/masterings-multichannel-marketing/</a> today and enjoy the fight from the comfort of your home!
For British fans, the fight is expected to begin close to prime time, making it ideal for a prime-time audience. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. The venue for Fury vs Usyk has yet to be confirmed, with talk of iconic boxing destinations. Wherever it happens, one thing is certain: it will be a spectacle. Even though attention remains on Fury and Usyk, the Fury vs Usyk undercard is shaping up to be thrilling. Major boxing events include preliminary bouts with top talent, offering an entire night of boxing excitement.
Traditionally, preliminary fights on major cards have been a stage for breakout performances. Fighters looking to rise through the ranks capitalize on the exposure to demonstrate their talent, with the world paying attention. While the names for the undercard are still unconfirmed, fans are eagerly guessing. Will there be a heavyweight clash? Regardless of the names, fans can expect fireworks. What makes this fight truly fascinating is the clash of styles. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. At 6’9" with an 85-inch reach, he commands the ring like no other.
The three fights against Wilder highlighted his resilience, bouncing back from adversity to finish strong. When he faced Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, relies on technique and stamina. As a southpaw, his positioning constantly challenges opponents. Usyk’s punches may not have knockout power, their timing wears down foes. With the date drawing closer, Predictions for this fight are the subject of intense debate.
The betting lines show Fury ahead based on the betting odds, given his physical stature, his track record in big matches, and his tactical brilliance. However, Usyk's underdog status doesn’t diminish his chances, his victories against AJ showed that he can compete at heavyweight.
For the Gypsy King represents an opportunity to cement his legacy. A triumph for Fury would solidify his claim as the greatest heavyweight of his generation. Meanwhile, Usyk’s victory would elevate him to new heights. Becoming the undisputed heavyweight champion is a feat few can claim.
Website: https://websitehubs.com/masterings-multichannel-marketing/
Fury vs Usyk is not just about the belts. It’s a fight between two very different fighters. Fury’s larger-than-life persona stands in stark contrast to Usyk’s composed demeanor. These varying personalities make the bout even more interesting. It’s a fight of wills and ideologies. Regardless of the outcome, the significance of this match will reverberate throughout boxing history. This historic showdown is more than just a match. It represents the culmination of their careers. Should Fury claim victory with his size and strategy, or Usyk comes out on top through his superior boxing ability, what is clear is, this will be a fight remembered for years to come.
This fight between Fury and Usyk is a spectacle of a lifetime. It’s a showcase of skill and determination. Both fighters will leave it all in the ring.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are preparing for an epic showdown that will define an era. It’s far beyond a championship match; it’s about legacy. Tyson Fury has become a global icon through his unique style and remarkable adaptability in the ring. Beating Wilder and Klitschko have earned him recognition as one of the best ever. Across the ring, Usyk, the technician poses a unique challenge to boxing’s biggest stars. Meanwhile, Usyk, a genius in the ring stands as a unique threat not just for Fury, but for the entire division. His journey to global fame started with his domination of the cruiserweights, by conquering all challengers. Don’t miss out for an epic boxing match of the year as Oleksandr Usyk takes on Fury in a must-watch showdown! Catch every punch streamed live on our website. Don’t miss your chance — visit <a href="https://www.7beans.xyz/category/1/page/5/">https://www.7beans.xyz/category/1/page/5/</a> today and enjoy the fight with top-notch streaming!
In the United Kingdom, the ring walks are planned for late evening, ensuring maximum viewership. Back in Usyk’s home country, and for fans watching from around the world, the excitement is palpable. The venue for Fury vs Usyk remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, fans can be sure: it will be a spectacle. While the spotlight is centered on the headline fight, the preliminary bouts promises plenty of action. Big-ticket boxing cards often feature stacked undercards, offering an entire night of boxing excitement.
Traditionally, preliminary fights on major cards have introduced future champions. Boxers seeking the spotlight use such opportunities to showcase their skills, knowing millions are watching. While the names for the undercard haven’t been officially announced, there’s plenty of talk. Could we see rising prospects? Whatever the selection, fans can expect fireworks. The most compelling part of Fury vs Usyk incredibly exciting is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. At 6’9" with an 85-inch reach, Fury can control a fight.
The legendary battles with Wilder proved his toughness, as he recovered from knockdowns to finish strong. Against Wladimir Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, relies on technique and stamina. As a southpaw, his positioning constantly challenges opponents. Usyk’s punches may not have knockout power, their timing wears down foes. With the date drawing closer, Predictions for this fight are becoming a hot topic.
Tyson Fury is the slight favorite based on the betting odds, thanks to his imposing frame, his track record in big matches, and his unpredictable nature. Although Usyk is the less favored fighter doesn’t mean he’s an underdog in spirit, his dominance against Joshua showed that he can compete at heavyweight.
For Tyson Fury, this fight could be the defining moment of his career. If he wins, it would add an undisputed title to his already impressive resume. Conversely, For Usyk, a win would be a monumental achievement. Achieving undisputed glory in two divisions is a feat few can claim.
Website: https://www.7beans.xyz/category/1/page/5/
The upcoming showdown is not just about the belts. It’s a clash of personalities. Fury’s boisterous personality stands in stark contrast to Usyk’s composed demeanor. The clash of personalities adds depth to the narrative. Beyond physical ability, this fight. Whoever triumphs in this battle, the significance of this match will be felt for years to come. This historic showdown is a spectacle unlike any other. It’s a culmination of years of hard work. Should Fury claim victory with his experience and unpredictability, or Usyk comes out on top through his superior boxing ability, it’s certain that, this will be a defining moment in boxing.
This fight between Fury and Usyk is more than just a sporting contest. It’s a battle of minds and bodies. The two competitors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are on a collision course of unparalleled significance. It’s not merely about the belts; it’s about legacy. The towering Fury has risen to the pinnacle of the sport with his charisma and remarkable adaptability inside the ropes. Beating Wilder and Klitschko have cemented his place among the all-time greats. In contrast, the tactical southpaw brings an unprecedented test for Fury. At the same time, Usyk, a genius in the ring is a true test for Fury not just for Fury, and for boxing fans worldwide. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, as an undisputed champion. Prepare yourself for an epic boxing match of the year as Usyk takes on Tyson Fury in a must-watch showdown! Catch every punch in real time on our website. Join the excitement — visit <a href="http://cleanpark.ge/en/author/iko/page/435/">http://cleanpark.ge/en/author/iko/page/435/</a> right away and stream the event from the comfort of your home!
For British fans, the fight is expected to begin around 10 PM GMT, ensuring maximum viewership. Back in Usyk’s home country, and for fans watching from around the world, this will be a must-see event. The fight’s location remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, it’s guaranteed: the excitement will be unmatched. Although the focus is centered on the headline fight, the fights leading up to the main event is shaping up to be thrilling. High-profile matches often feature stacked undercards, providing non-stop action before the headliner.
Traditionally, undercards of this caliber have introduced future champions. Boxers seeking the spotlight capitalize on the exposure to demonstrate their talent, as all eyes are on them. Although the lineup for the Fury Usyk undercard has yet to be finalized, fans are eagerly guessing. Could we see rising prospects? No matter the final roster, it’s sure to add to the excitement. What sets this bout apart incredibly exciting is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. Being so tall yet so nimble, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, as he recovered from knockdowns to finish strong. When he faced Klitschko, his strategic genius shone through, showing he’s both powerful and smart. By contrast, Usyk, brings speed, precision, and finesse. As a southpaw, he uses angles and footwork. His strikes lack devastating strength, but they are delivered with pinpoint accuracy. As anticipation builds, Predictions for this fight are the subject of intense debate.
Fury is the favored fighter as predicted by many experts, given his physical stature, his experience in high-pressure bouts, and his adaptability. However, Usyk's underdog status doesn’t diminish his chances, his wins over Anthony Joshua demonstrated his ability in the heavyweight ranks.
For Tyson Fury, this fight could be the defining moment of his career. A triumph for Fury would solidify his claim as the greatest heavyweight of his generation. Meanwhile, Usyk’s victory would mark him as one of the sport’s greats. Achieving undisputed glory in two divisions is a feat few can claim.
Website: http://cleanpark.ge/en/author/iko/page/435/
The upcoming showdown is about more than the titles. It’s a battle of contrasting styles. Fury’s boisterous personality stands in stark contrast to Usyk’s composed demeanor. Such contrasts make the fight more compelling. It’s a fight of wills and ideologies. Whoever comes out victorious, the impact of this bout will reverberate throughout boxing history. The clash for the undisputed title is more than just a fight. It’s the result of relentless dedication. Whether Tyson Fury prevails with his experience and unpredictability, or Oleksandr Usyk triumphs thanks to his skill and resilience, one thing is certain, this will be a defining moment in boxing.
This fight between Fury and Usyk is more than just a fight. It’s a showcase of skill and determination. The two competitors will give everything they have.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are preparing for an epic showdown of unparalleled significance. This fight is about more than just titles; it’s about legacy. The Gypsy King has risen to the pinnacle of the sport through his unique style and remarkable adaptability in the ring. Beating Wilder and Klitschko have solidified his legendary status. Meanwhile, Oleksandr Usyk brings an unprecedented test to boxing’s biggest stars. On the flip side, Usyk, a southpaw master represents a formidable opponent not just for Fury, and for boxing fans worldwide. His journey to global fame started with his domination of the cruiserweights, where he became an unstoppable force. Get ready for the most anticipated boxing match of the year as Oleksandr Usyk takes on Fury in a must-watch showdown! Catch every punch live on our website. Join the excitement — visit <a href="https://prolinkbox.com/boost-da-dr-tf-with-refill-guarantee-2702/">https://prolinkbox.com/boost-da-dr-tf-with-refill-guarantee-2702/</a> now and enjoy the fight in high quality!
In the United Kingdom, the ring walks are planned for close to prime time, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and beyond, the anticipation is at a fever pitch. The venue for Fury vs Usyk has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, it’s guaranteed: the excitement will be unmatched. Even though attention is centered on the headline fight, the Fury vs Usyk undercard is also generating excitement. Big-ticket boxing cards are known for strong supporting fights, offering an entire night of boxing excitement.
Traditionally, undercards of this caliber have introduced future champions. Boxers seeking the spotlight often seize these moments to showcase their skills, as all eyes are on them. Although the lineup for the Fury Usyk undercard haven’t been officially announced, fans are eagerly guessing. Could we see rising prospects? Regardless of the names, it’s sure to add to the excitement. What sets this bout apart so intriguing is the dynamic between these fighters. Tyson Fury’s size and agility make him an anomaly in boxing. With his immense height and reach advantage, Fury can control a fight.
His trilogy with Deontay Wilder proved his toughness, overcoming brutal hits to finish strong. Against Wladimir Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. By contrast, Usyk, relies on technique and stamina. Being a left-handed fighter, his positioning constantly challenges opponents. Usyk’s punches lack devastating strength, but they are delivered with pinpoint accuracy. As anticipation builds, Tyson Fury vs Usyk odds are becoming a hot topic.
Tyson Fury is the slight favorite based on the betting odds, due to his size advantage, his track record in big matches, and his adaptability. Despite the odds, Usyk remains a strong contender doesn’t rule him out, his dominance against Joshua showed that he can compete at heavyweight.
For Tyson Fury, this fight could be the defining moment of his career. If he wins, it would put the finishing touches on a historic career. Meanwhile, If Usyk wins would elevate him to legendary status. Becoming the undisputed heavyweight champion would be a remarkable feat in boxing history.
Website: https://prolinkbox.com/boost-da-dr-tf-with-refill-guarantee-2702/
This fight is not just about the belts. It’s a clash of personalities. Fury’s bold and unapologetic character is in stark contrast to Usyk’s quiet intensity. These varying personalities make the bout even more interesting. It’s about more than just skill. Whoever triumphs in this battle, the significance of this match will be felt for years to come. Fury vs Usyk is more than just a match. It’s the result of relentless dedication. Whether Tyson Fury prevails through his strength and tactics, or Usyk comes out on top thanks to his skill and resilience, what is clear is, this will be a fight remembered for years to come.
The Fury-Usyk battle is more than just a fight. It’s a fight of grit and strategy. These two warriors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are preparing for an epic showdown of historic proportions. This fight is about more than just titles; it represents their quest for immortality. The Gypsy King has risen to the pinnacle of the sport with his charisma and his unmatched skills during fights. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. Meanwhile, Oleksandr Usyk is a fighter unlike any other for Fury. Meanwhile, the Ukrainian technician represents a formidable opponent for the heavyweight ranks overall, but for the entire division. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, as an undisputed champion. Get ready for the most anticipated boxing match of the year as Oleksandr Usyk takes on Fury in an unforgettable showdown! See every move live on our website. Join the excitement — visit <a href="https://www.myfirstproperty.co.uk/postcode-houseprices/ME2-3UG">https://www.myfirstproperty.co.uk/postcode-houseprices/ME2-3UG</a> now and stream the event from the comfort of your home!
Across the UK, the event will kick off at close to prime time, ensuring maximum viewership. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, this will be a must-see event. Where the bout will take place remains a hot topic, with suggestions ranging from Las Vegas to Saudi Arabia. Regardless of the venue, one thing is certain: the excitement will be unmatched. Although the focus remains on Fury and Usyk, the Fury vs Usyk undercard is shaping up to be thrilling. Big-ticket boxing cards include preliminary bouts with top talent, giving fans a full evening of entertainment.
Traditionally, preliminary fights on major cards have been a stage for breakout performances. Fighters looking to rise through the ranks use such opportunities to demonstrate their talent, as all eyes are on them. While the names for the undercard haven’t been officially announced, there’s plenty of talk. Could we see rising prospects? Regardless of the names, it’s sure to add to the excitement. What sets this bout apart incredibly exciting is the clash of styles. Fury’s towering frame and movement set him apart from other heavyweights. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
The three fights against Wilder showed his durability, overcoming brutal hits to finish strong. Against Wladimir Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. As a southpaw, his movements create openings. His strikes aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. With the date drawing closer, Tyson Fury vs Usyk odds are becoming a hot topic.
Most bookmakers favor Fury as predicted by many experts, because of his reach and height, his long career in major fights, and his unorthodox style. Despite the odds, Usyk remains a strong contender doesn’t mean he’s an underdog in spirit, his victories against AJ confirmed his toughness against big opponents.
For Tyson Fury, this fight could be the defining moment of his career. If he wins, it would put the finishing touches on a historic career. Meanwhile, For Usyk, a win would elevate him to legendary status. Securing two undisputed titles is a feat few can claim.
Website: https://www.myfirstproperty.co.uk/postcode-houseprices/ME2-3UG
This fight represents something greater than a title bout. It’s a meeting of two unique worldviews. Fury’s boisterous personality stands in stark contrast to Usyk’s composed demeanor. These differences add complexity to the fight. Beyond physical ability, this fight. Whoever triumphs in this battle, the significance of this match will be felt for years to come. Fury vs Usyk is a defining moment. It’s the result of relentless dedication. Should Fury claim victory thanks to his power and game plan, or Usyk comes out on top with his finesse and stamina, what is clear is, this will be a defining moment in boxing.
This fight between Fury and Usyk is more than just a sporting contest. It’s a contest of heart and willpower. These two warriors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are set to meet in the ring of historic proportions. It’s not merely about the belts; it’s a battle for eternal recognition. Tyson Fury has risen to the pinnacle of the sport with his charisma coupled with unparalleled talent during fights. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Across the ring, Oleksandr Usyk is a fighter unlike any other to boxing’s biggest stars. At the same time, Oleksandr Usyk stands as a unique threat for the heavyweight ranks overall, and for boxing fans worldwide. His journey to global fame began in the cruiserweight division, by conquering all challengers. Prepare yourself for a thrilling boxing match of the year as Oleksandr Usyk takes on Fury in a must-watch showdown! Catch every punch streamed live on our website. Don’t miss your chance — visit <a href="https://worldwidetopsite.link/website-list-122/">https://worldwidetopsite.link/website-list-122/</a> right away and watch the match from the comfort of your home!
Across the UK, the event will kick off at around 10 PM GMT, ensuring maximum viewership. Back in Usyk’s home country, and for fans watching from around the world, the excitement is palpable. The venue for Fury vs Usyk has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, fans can be sure: the atmosphere will be electric. Even though attention is firmly on the main event, the Fury vs Usyk undercard is shaping up to be thrilling. High-profile matches include preliminary bouts with top talent, offering an entire night of boxing excitement.
In the past, preliminary fights on major cards have been a stage for breakout performances. Boxers seeking the spotlight often seize these moments to impress fans and analysts alike, knowing millions are watching. Although the lineup for the Fury Usyk undercard haven’t been officially announced, fans are eagerly guessing. Might there be a cruiserweight spectacle? Whatever the selection, the action will not disappoint. The most compelling part of Fury vs Usyk incredibly exciting is their contrasting skillsets. Fury’s towering frame and movement are unparalleled in the sport. Being so tall yet so nimble, he dictates the pace of bouts.
The three fights against Wilder proved his toughness, as he recovered from knockdowns to finish strong. In his fight with Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. By contrast, Usyk, brings speed, precision, and finesse. With his unorthodox stance, his movements create openings. The Ukrainian’s shots lack devastating strength, their timing wears down foes. As fight night approaches, Predictions for this fight are becoming a hot topic.
Tyson Fury is the slight favorite as per the betting experts, because of his reach and height, his experience in high-pressure bouts, and his adaptability. However, Usyk's underdog status doesn’t diminish his chances, his wins over Anthony Joshua demonstrated his ability in the heavyweight ranks.
For Fury himself represents an opportunity to cement his legacy. Should he come out on top, Fury’s win would add an undisputed title to his already impressive resume. Conversely, Usyk’s victory would elevate him to new heights. Becoming an undisputed champion in two different weight classes would be a remarkable feat in boxing history.
Website: https://worldwidetopsite.link/website-list-122/
Fury vs Usyk represents something greater than a title bout. It’s a clash of personalities. Fury’s larger-than-life persona is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. It’s a fight of wills and ideologies. Whoever triumphs in this battle, the significance of this match will reverberate throughout boxing history. Fury vs Usyk is more than just a fight. It’s a culmination of years of hard work. Whether Fury secures the win with his experience and unpredictability, or Oleksandr Usyk triumphs thanks to his skill and resilience, what is clear is, this will be a legendary contest.
Tyson Fury vs Oleksandr Usyk is a spectacle of a lifetime. It’s a contest of heart and willpower. These two warriors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are on a collision course of unparalleled significance. It’s far beyond a championship match; it’s about legacy. Tyson Fury has earned worldwide fame thanks to his personality and remarkable adaptability in the ring. His victories over Deontay Wilder and Wladimir Klitschko have cemented his place among the all-time greats. In contrast, Oleksandr Usyk is a fighter unlike any other for Fury. Meanwhile, the Ukrainian technician represents a formidable opponent for Tyson Fury himself, but for the entire division. Usyk’s rise to prominence began in the cruiserweight division, by conquering all challengers. Don’t miss out for a thrilling boxing match of the year as Usyk takes on Fury in an unforgettable showdown! Experience every moment live on our website. Join the excitement — visit <a href="https://www.myfirstproperty.co.uk/postcode-houseprices/ME1-3RR">https://www.myfirstproperty.co.uk/postcode-houseprices/ME1-3RR</a> right away and enjoy the fight with top-notch streaming!
For British fans, the event will kick off at around 10 PM GMT, ensuring maximum viewership. Back in Usyk’s home country, and beyond, the excitement is palpable. The fight’s location is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, fans can be sure: the excitement will be unmatched. Although the focus is centered on the headline fight, the fights leading up to the main event is also generating excitement. Major boxing events include preliminary bouts with top talent, giving fans a full evening of entertainment.
In the past, undercards of this caliber have showcased rising stars. Contenders hoping to make their mark often seize these moments to demonstrate their talent, with the world paying attention. While the names for the undercard has yet to be finalized, there’s plenty of talk. Might there be a cruiserweight spectacle? Regardless of the names, fans can expect fireworks. The most compelling part of Fury vs Usyk incredibly exciting is the clash of styles. Tyson Fury’s size and agility make him an anomaly in boxing. With his immense height and reach advantage, he commands the ring like no other.
His trilogy with Deontay Wilder showed his durability, bouncing back from adversity to finish strong. When he faced Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. By contrast, Usyk, brings speed, precision, and finesse. Being a left-handed fighter, his positioning constantly challenges opponents. His strikes may not have knockout power, their timing wears down foes. As fight night approaches, Predictions for this fight are the subject of intense debate.
Tyson Fury is the slight favorite based on the betting odds, thanks to his imposing frame, his experience in high-pressure bouts, and his unorthodox style. Despite being seen as the underdog doesn’t rule him out, as his victories over Joshua confirmed his toughness against big opponents.
For the Gypsy King could be the defining moment of his career. A victory would add an undisputed title to his already impressive resume. Meanwhile, For Usyk, a win would mark him as one of the sport’s greats. Becoming the undisputed heavyweight champion is a feat few can claim.
Website: https://www.myfirstproperty.co.uk/postcode-houseprices/ME1-3RR
The upcoming showdown is about more than the titles. It’s a fight between two very different fighters. Fury’s larger-than-life persona is the opposite of Usyk’s humble and disciplined approach. Such contrasts make the fight more compelling. It’s a fight of wills and ideologies. Regardless of the outcome, the legacy of this fight will leave a lasting mark on the sport. The clash for the undisputed title is a defining moment. It represents the culmination of their careers. Should Fury claim victory thanks to his power and game plan, or Usyk wins with his precision thanks to his skill and resilience, it’s certain that, this will be a legendary contest.
Tyson Fury vs Oleksandr Usyk is more than just a boxing event. It’s a fight of grit and strategy. The two competitors will give everything they have.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are ready to face each other in a fight of historic proportions. This fight is about more than just titles; it’s a battle for eternal recognition. Fury, an undefeated champion has earned worldwide fame with his charisma and remarkable adaptability in the ring. Triumphing against boxing legends like Wilder and Klitschko have solidified his legendary status. On the other hand, the tactical southpaw poses a unique challenge to boxing’s biggest stars. Meanwhile, the Ukrainian technician is a true test for Fury for the heavyweight ranks overall, as a heavyweight contender. His journey to global fame started with his domination of the cruiserweights, by conquering all challengers. Don’t miss out for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! See every move in real time on our website. Don’t miss your chance — visit <a href="https://yrmotorsltd.co.uk/2024/12/08/usyk-vs-fury-the-battle-for-heavyweight-supremacy-3/">https://yrmotorsltd.co.uk/2024/12/08/usyk-vs-fury-the-battle-for-heavyweight-supremacy-3/</a> today and stream the event with top-notch streaming!
Across the UK, the event will kick off at around 10 PM GMT, ensuring maximum viewership. Back in Usyk’s home country, as well as viewers across Europe and the Americas, this will be a must-see event. The fight’s location has yet to be confirmed, with talk of iconic boxing destinations. Regardless of the venue, it’s guaranteed: it will be a spectacle. Although the focus is centered on the headline fight, the fights leading up to the main event promises plenty of action. Major boxing events include preliminary bouts with top talent, offering an entire night of boxing excitement.
In the past, preliminary fights on major cards have been a stage for breakout performances. Contenders hoping to make their mark often seize these moments to impress fans and analysts alike, with the world paying attention. Though the supporting fights for Fury vs Usyk haven’t been officially announced, there’s plenty of talk. Could we see rising prospects? Whatever the selection, it’s sure to add to the excitement. What makes this fight incredibly exciting is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. At 6’9" with an 85-inch reach, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, bouncing back from adversity to dominate in later rounds. In his fight with Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, offers a different kind of threat. Being a left-handed fighter, his movements create openings. Usyk’s punches aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. As anticipation builds, Tyson Fury vs Usyk odds are becoming a hot topic.
The betting lines show Fury ahead as per the betting experts, because of his reach and height, his long career in major fights, and his unpredictable nature. Despite being seen as the underdog shouldn’t be counted out, his dominance against Joshua confirmed his toughness against big opponents.
For Tyson Fury presents a shot at undisputed glory. If he wins, it would further solidify his status as the best heavyweight of this era. On the other hand, For Usyk, a win would be a monumental achievement. Achieving undisputed glory in two divisions is a rare accomplishment.
Website: https://yrmotorsltd.co.uk/2024/12/08/usyk-vs-fury-the-battle-for-heavyweight-supremacy-3/
The upcoming showdown is not just about the belts. It’s a meeting of two unique worldviews. Fury’s larger-than-life persona is the opposite of Usyk’s humble and disciplined approach. These varying personalities make the bout even more interesting. This is more than just a physical contest. Regardless of the outcome, the impact of this bout will leave a lasting mark on the sport. The clash for the undisputed title is a spectacle unlike any other. It’s the result of relentless dedication. Whether Tyson Fury prevails through his strength and tactics, or Usyk wins with his precision with his finesse and stamina, one thing is certain, this bout will go down in history.
Tyson Fury vs Oleksandr Usyk is more than just a fight. It’s a contest of heart and willpower. These men will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are on a collision course of unparalleled significance. It’s not merely about the belts; it’s about legacy. Fury, an undefeated champion has become a global icon with his charisma and his unmatched skills in the ring. Beating Wilder and Klitschko have earned him recognition as one of the best ever. On the other hand, Usyk, the technician brings an unprecedented test to boxing’s biggest stars. At the same time, the Ukrainian technician stands as a unique threat for Tyson Fury himself, as a heavyweight contender. Usyk’s rise to prominence started with his domination of the cruiserweights, as an undisputed champion. Don’t miss out for a thrilling boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a must-watch showdown! Catch every punch in real time on our website. Don’t miss your chance — visit <a href="https://fybyrcloudservers.com/index.php/2024/09/03/fury-vs-usyk-all-you-need-to-know-about-the-big-46/">https://fybyrcloudservers.com/index.php/2024/09/03/fury-vs-usyk-all-you-need-to-know-about-the-big-46/</a> now and stream the event with top-notch streaming!
Across the UK, the event will kick off at around 10 PM GMT, offering perfect timing for viewers. Back in Usyk’s home country, as well as viewers across Europe and the Americas, the excitement is palpable. The fight’s location remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, one thing is certain: the atmosphere will be electric. Even though attention is centered on the headline fight, the Fury vs Usyk undercard promises plenty of action. High-profile matches are known for strong supporting fights, offering an entire night of boxing excitement.
In the past, undercards of this caliber have been a stage for breakout performances. Contenders hoping to make their mark capitalize on the exposure to showcase their skills, knowing millions are watching. Though the supporting fights for Fury vs Usyk are still unconfirmed, fans are eagerly guessing. Might there be a cruiserweight spectacle? No matter the final roster, it’s sure to add to the excitement. The most compelling part of Fury vs Usyk so intriguing is their contrasting skillsets. Tyson Fury’s size and agility make him an anomaly in boxing. At 6’9" with an 85-inch reach, he commands the ring like no other.
The three fights against Wilder highlighted his resilience, overcoming brutal hits to dominate in later rounds. Against Wladimir Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, offers a different kind of threat. Being a left-handed fighter, his movements create openings. The Ukrainian’s shots may not have knockout power, but they are delivered with pinpoint accuracy. With the date drawing closer, Tyson Fury vs Usyk odds are becoming a hot topic.
Fury is the favored fighter according to the odds, because of his reach and height, his proven ability in tough situations, and his tactical brilliance. Despite the odds, Usyk remains a strong contender shouldn’t be counted out, his wins over Anthony Joshua showed that he can compete at heavyweight.
For Tyson Fury presents a shot at undisputed glory. A victory would solidify his claim as the greatest heavyweight of his generation. Conversely, For Usyk, a win would be a monumental achievement. Achieving undisputed glory in two divisions would be a remarkable feat in boxing history.
Website: https://fybyrcloudservers.com/index.php/2024/09/03/fury-vs-usyk-all-you-need-to-know-about-the-big-46/
The upcoming showdown represents something greater than a title bout. It’s a meeting of two unique worldviews. Fury’s confident and brash nature stands in stark contrast to Usyk’s composed demeanor. Such contrasts make the fight more compelling. This is more than just a physical contest. Whoever comes out victorious, the legacy of this fight will be felt for years to come. The battle for heavyweight supremacy is more than just a match. It’s the result of relentless dedication. If Fury wins with his experience and unpredictability, or Usyk secures a victory through his superior boxing ability, no matter the outcome, this bout will go down in history.
Tyson Fury vs Oleksandr Usyk is a spectacle of a lifetime. It’s a contest of heart and willpower. These two warriors will give everything they have.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are set to meet in the ring of historic proportions. It’s far beyond a championship match; it’s about legacy. Fury, an undefeated champion has risen to the pinnacle of the sport through his unique style coupled with unparalleled talent in the ring. Beating Wilder and Klitschko have solidified his legendary status. In contrast, Oleksandr Usyk is a fighter unlike any other to the heavyweight division. Meanwhile, Usyk, a genius in the ring is a true test for Fury not just for Fury, as a heavyweight contender. Usyk’s rise to prominence started with his domination of the cruiserweights, by conquering all challengers. Prepare yourself for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! See every move in real time on our website. Be part of the action — visit <a href="https://licitamos.cl/usyk-vs-fury-2-highlights-and-key-moments/">https://licitamos.cl/usyk-vs-fury-2-highlights-and-key-moments/</a> right away and stream the event in high quality!
For British fans, the event will kick off at close to prime time, offering perfect timing for viewers. Back in Usyk’s home country, and beyond, the excitement is palpable. Where the bout will take place is still under speculation, with talk of iconic boxing destinations. Wherever it happens, fans can be sure: the excitement will be unmatched. Although the focus remains on Fury and Usyk, the Fury vs Usyk undercard is shaping up to be thrilling. Big-ticket boxing cards include preliminary bouts with top talent, offering an entire night of boxing excitement.
Traditionally, supporting bouts in major events have showcased rising stars. Contenders hoping to make their mark capitalize on the exposure to impress fans and analysts alike, as all eyes are on them. Although the lineup for the Fury Usyk undercard are still unconfirmed, speculation runs high. Could we see rising prospects? No matter the final roster, the action will not disappoint. What sets this bout apart truly fascinating is the dynamic between these fighters. Tyson Fury’s size and agility are unparalleled in the sport. With his immense height and reach advantage, he commands the ring like no other.
The legendary battles with Wilder highlighted his resilience, as he recovered from knockdowns to finish strong. When he faced Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. Meanwhile, Usyk, relies on technique and stamina. With his unorthodox stance, his positioning constantly challenges opponents. Usyk’s punches aren’t the heaviest in the division, their timing wears down foes. As fight night approaches, Predictions for this fight are becoming a hot topic.
The betting lines show Fury ahead based on the betting odds, due to his size advantage, his track record in big matches, and his unpredictable nature. Although Usyk is the less favored fighter doesn’t rule him out, as his victories over Joshua showed that he can compete at heavyweight.
For Tyson Fury, this fight could be the defining moment of his career. A victory would further solidify his status as the best heavyweight of this era. Conversely, For Usyk, a win would elevate him to new heights. Becoming an undisputed champion in two different weight classes is a feat few can claim.
Website: https://licitamos.cl/usyk-vs-fury-2-highlights-and-key-moments/
The upcoming showdown represents something greater than a title bout. It’s a meeting of two unique worldviews. Fury’s boisterous personality stands in stark contrast to Usyk’s composed demeanor. Such contrasts make the fight more compelling. It’s about more than just skill. No matter who wins, the impact of this bout will leave a lasting mark on the sport. This historic showdown is more than just a fight. It’s a culmination of years of hard work. Should Fury claim victory with his experience and unpredictability, or Usyk secures a victory thanks to his skill and resilience, one thing is certain, this bout will go down in history.
Fury vs Usyk is a spectacle of a lifetime. It’s a fight of grit and strategy. Both fighters will leave it all in the ring.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are on a collision course of historic proportions. This fight is about more than just titles; it’s about legacy. The towering Fury has earned worldwide fame with his charisma and his unmatched skills in the ring. His victories over Deontay Wilder and Wladimir Klitschko have cemented his place among the all-time greats. Meanwhile, Usyk, the technician poses a unique challenge to boxing’s biggest stars. On the flip side, Oleksandr Usyk stands as a unique threat not just for Fury, and for boxing fans worldwide. His journey to global fame started with his domination of the cruiserweights, by conquering all challengers. Don’t miss out for an epic boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! Catch every punch streamed live on our website. Be part of the action — visit <a href="https://drstoykova.eu/blog/2024/08/page/2/">https://drstoykova.eu/blog/2024/08/page/2/</a> today and watch the match with top-notch streaming!
In the United Kingdom, the fight is expected to begin close to prime time, offering perfect timing for viewers. Back in Usyk’s home country, and for fans watching from around the world, the excitement is palpable. The fight’s location has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, fans can be sure: the excitement will be unmatched. Although the focus is centered on the headline fight, the preliminary bouts is also generating excitement. Big-ticket boxing cards are known for strong supporting fights, providing non-stop action before the headliner.
In the past, undercards of this caliber have introduced future champions. Fighters looking to rise through the ranks use such opportunities to demonstrate their talent, knowing millions are watching. Although the lineup for the Fury Usyk undercard haven’t been officially announced, fans are eagerly guessing. Might there be a cruiserweight spectacle? Whatever the selection, it’s sure to add to the excitement. What makes this fight truly fascinating is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. At 6’9" with an 85-inch reach, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, bouncing back from adversity to secure victories. When he faced Klitschko, his strategic genius shone through, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, offers a different kind of threat. As a southpaw, he uses angles and footwork. Usyk’s punches may not have knockout power, their timing wears down foes. With the date drawing closer, Predictions for this fight are becoming a hot topic.
Tyson Fury is seen as the frontrunner as predicted by many experts, due to his size advantage, his long career in major fights, and his unorthodox style. Despite being seen as the underdog doesn’t rule him out, his victories against AJ confirmed his toughness against big opponents.
For Tyson Fury, this fight represents an opportunity to cement his legacy. A victory would put the finishing touches on a historic career. On the other hand, For Usyk, a win would elevate him to new heights. Becoming an undisputed champion in two different weight classes is a rare accomplishment.
Website: https://drstoykova.eu/blog/2024/08/page/2/
Fury vs Usyk is about more than the titles. It’s a meeting of two unique worldviews. Fury’s bold and unapologetic character is the opposite of Usyk’s humble and disciplined approach. These varying personalities make the bout even more interesting. Beyond physical ability, this fight. Whoever comes out victorious, the impact of this bout will leave a lasting mark on the sport. The clash for the undisputed title is a spectacle unlike any other. It’s the pinnacle of both fighters’ hard work. Should Fury claim victory through his strength and tactics, or Usyk comes out on top with his finesse and stamina, one thing is certain, this will be a defining moment in boxing.
This fight between Fury and Usyk is a spectacle of a lifetime. It’s a contest of heart and willpower. These two warriors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are preparing for an epic showdown of unparalleled significance. This fight is about more than just titles; it’s a battle for eternal recognition. Fury, an undefeated champion has earned worldwide fame through his unique style coupled with unparalleled talent inside the ropes. Beating Wilder and Klitschko have solidified his legendary status. Across the ring, Oleksandr Usyk brings an unprecedented test for Fury. Meanwhile, Oleksandr Usyk is a true test for Fury for the heavyweight ranks overall, as a heavyweight contender. His journey to global fame began in the cruiserweight division, where he became an unstoppable force. Prepare yourself for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a must-watch showdown! Catch every punch in real time on our website. Don’t miss your chance — visit <a href="https://bofaks2.com/content/11-school-admissions">https://bofaks2.com/content/11-school-admissions</a> right away and stream the event with top-notch streaming!
For British fans, the ring walks are planned for close to prime time, ensuring maximum viewership. In Usyk’s native Ukraine, and beyond, the anticipation is at a fever pitch. The fight’s location is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, fans can be sure: the atmosphere will be electric. Although the focus is firmly on the main event, the Fury vs Usyk undercard promises plenty of action. Major boxing events are known for strong supporting fights, providing non-stop action before the headliner.
Traditionally, preliminary fights on major cards have showcased rising stars. Boxers seeking the spotlight use such opportunities to showcase their skills, as all eyes are on them. Although the lineup for the Fury Usyk undercard has yet to be finalized, fans are eagerly guessing. Might there be a cruiserweight spectacle? No matter the final roster, it’s sure to add to the excitement. What makes this fight truly fascinating is the dynamic between these fighters. Tyson Fury’s size and agility are unparalleled in the sport. At 6’9" with an 85-inch reach, he commands the ring like no other.
His trilogy with Deontay Wilder highlighted his resilience, as he recovered from knockdowns to finish strong. In his fight with Klitschko, his strategic genius shone through, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. Being a left-handed fighter, his movements create openings. His strikes may not have knockout power, but they are delivered with pinpoint accuracy. With the date drawing closer, Predictions for this fight are the subject of intense debate.
The betting lines show Fury ahead based on the betting odds, given his physical stature, his proven ability in tough situations, and his tactical brilliance. However, Usyk's underdog status doesn’t diminish his chances, his victories against AJ confirmed his toughness against big opponents.
For the Gypsy King is a chance to further solidify his greatness. If he wins, it would put the finishing touches on a historic career. Meanwhile, Usyk’s victory would mark him as one of the sport’s greats. Achieving undisputed glory in two divisions is a once-in-a-lifetime achievement.
Website: https://bofaks2.com/content/11-school-admissions
The upcoming showdown represents something greater than a title bout. It’s a fight between two very different fighters. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. Such contrasts make the fight more compelling. It’s a fight of wills and ideologies. Whoever comes out victorious, the legacy of this fight will leave a lasting mark on the sport. This historic showdown is a defining moment. It’s the result of relentless dedication. Whether Fury secures the win with his experience and unpredictability, or Usyk wins with his precision thanks to his skill and resilience, one thing is certain, this will be a defining moment in boxing.
Fury vs Usyk is more than just a sporting contest. It’s a fight of grit and strategy. The two competitors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are preparing for an epic showdown of historic proportions. It’s far beyond a championship match; it represents their quest for immortality. The Gypsy King has earned worldwide fame with his charisma and remarkable adaptability in the ring. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Meanwhile, Usyk, the technician brings an unprecedented test to the heavyweight division. On the flip side, Usyk, a genius in the ring represents a formidable opponent for the heavyweight ranks overall, but for the entire division. His journey to global fame started with his domination of the cruiserweights, as an undisputed champion. Prepare yourself for an epic boxing match of the year as Oleksandr Usyk takes on Fury in a historic showdown! See every move in real time on our website. Be part of the action — visit <a href="https://www.bedavabonus777.com/fury-vs-usyk-the-ultimate-boxing-showdown-49/">https://www.bedavabonus777.com/fury-vs-usyk-the-ultimate-boxing-showdown-49/</a> today and stream the event from the comfort of your home!
In the United Kingdom, the event will kick off at around 10 PM GMT, ensuring maximum viewership. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, this will be a must-see event. The fight’s location is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, it’s guaranteed: it will be a spectacle. Although the focus is firmly on the main event, the Fury vs Usyk undercard is also generating excitement. High-profile matches include preliminary bouts with top talent, giving fans a full evening of entertainment.
In the past, preliminary fights on major cards have been a stage for breakout performances. Fighters looking to rise through the ranks often seize these moments to showcase their skills, with the world paying attention. While the names for the undercard has yet to be finalized, fans are eagerly guessing. Could we see rising prospects? Regardless of the names, it’s sure to add to the excitement. What makes this fight truly fascinating is their contrasting skillsets. Tyson Fury’s size and agility set him apart from other heavyweights. With his immense height and reach advantage, he dictates the pace of bouts.
The three fights against Wilder showed his durability, as he recovered from knockdowns to finish strong. When he faced Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. By contrast, Usyk, brings speed, precision, and finesse. As a southpaw, his positioning constantly challenges opponents. His strikes may not have knockout power, their timing wears down foes. As fight night approaches, The betting lines for Fury vs Usyk are the subject of intense debate.
Tyson Fury is the slight favorite according to the odds, because of his reach and height, his experience in high-pressure bouts, and his adaptability. However, Usyk's underdog status shouldn’t be counted out, his victories against AJ showed that he can compete at heavyweight.
For Tyson Fury, this fight presents a shot at undisputed glory. A victory would solidify his claim as the greatest heavyweight of his generation. Meanwhile, Usyk’s victory would be a monumental achievement. Securing two undisputed titles is a rare accomplishment.
Website: https://www.bedavabonus777.com/fury-vs-usyk-the-ultimate-boxing-showdown-49/
Fury vs Usyk is not just about the belts. It’s a meeting of two unique worldviews. Fury’s bold and unapologetic character is the opposite of Usyk’s humble and disciplined approach. The clash of personalities adds depth to the narrative. This is more than just a physical contest. Whoever triumphs in this battle, the legacy of this fight will be remembered as a defining moment in boxing. The battle for heavyweight supremacy is a spectacle unlike any other. It’s the pinnacle of both fighters’ hard work. Whether Fury secures the win with his size and strategy, or Usyk wins with his precision with his technique and endurance, it’s certain that, this will be a fight remembered for years to come.
Tyson Fury vs Oleksandr Usyk is a spectacle of a lifetime. It’s a contest of heart and willpower. The two competitors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are on a collision course that will define an era. This fight is about more than just titles; it’s a battle for eternal recognition. The Gypsy King has earned worldwide fame with his charisma coupled with unparalleled talent in the ring. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Meanwhile, Usyk, the Ukrainian master poses a unique challenge to boxing’s biggest stars. Meanwhile, the Ukrainian technician stands as a unique threat for Tyson Fury himself, and for boxing fans worldwide. The ascent of Oleksandr Usyk started with his domination of the cruiserweights, by conquering all challengers. Don’t miss out for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a historic showdown! Experience every moment live on our website. Don’t miss your chance — visit <a href="https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7HU">https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7HU</a> today and enjoy the fight with top-notch streaming!
Across the UK, the event will kick off at late evening, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and beyond, the excitement is palpable. Where the bout will take place has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, one thing is certain: the atmosphere will be electric. Even though attention is centered on the headline fight, the Fury vs Usyk undercard is also generating excitement. High-profile matches often feature stacked undercards, providing non-stop action before the headliner.
Traditionally, undercards of this caliber have showcased rising stars. Boxers seeking the spotlight use such opportunities to demonstrate their talent, knowing millions are watching. While the names for the undercard are still unconfirmed, speculation runs high. Could we see rising prospects? Whatever the selection, fans can expect fireworks. What sets this bout apart so intriguing is the clash of styles. Tyson Fury’s size and agility make him an anomaly in boxing. Being so tall yet so nimble, he commands the ring like no other.
His trilogy with Deontay Wilder highlighted his resilience, bouncing back from adversity to dominate in later rounds. In his fight with Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Meanwhile, Usyk, offers a different kind of threat. With his unorthodox stance, he uses angles and footwork. His strikes may not have knockout power, they consistently find their mark. With the date drawing closer, The betting lines for Fury vs Usyk have fans and analysts speculating.
Tyson Fury is seen as the frontrunner based on the betting odds, because of his reach and height, his long career in major fights, and his unpredictable nature. However, Usyk's underdog status doesn’t rule him out, as his victories over Joshua confirmed his toughness against big opponents.
For Fury himself presents a shot at undisputed glory. A victory would solidify his claim as the greatest heavyweight of his generation. Meanwhile, Usyk’s victory would elevate him to legendary status. Becoming the undisputed heavyweight champion is a once-in-a-lifetime achievement.
Website: https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7HU
This fight represents something greater than a title bout. It’s a clash of personalities. Fury’s bold and unapologetic character is the opposite of Usyk’s humble and disciplined approach. Such contrasts make the fight more compelling. It’s a fight of wills and ideologies. Regardless of the outcome, the impact of this bout will reverberate throughout boxing history. This historic showdown is a defining moment. It’s the result of relentless dedication. Should Fury claim victory with his experience and unpredictability, or Usyk secures a victory with his finesse and stamina, no matter the outcome, this will be a legendary contest.
This fight between Fury and Usyk is more than just a fight. It’s a battle of minds and bodies. These two warriors will give everything they have.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are preparing for an epic showdown that will define an era. It’s not merely about the belts; it’s about legacy. The Gypsy King has risen to the pinnacle of the sport with his charisma and his unmatched skills during fights. Beating Wilder and Klitschko have solidified his legendary status. Meanwhile, Usyk, the technician brings an unprecedented test for Fury. At the same time, Usyk, a southpaw master stands as a unique threat for Tyson Fury himself, as a heavyweight contender. His journey to global fame began in the cruiserweight division, by conquering all challengers. Prepare yourself for an epic boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! See every move streamed live on our website. Don’t miss your chance — visit <a href="https://sbyme.com/masterings-multichannel-marketing/">https://sbyme.com/masterings-multichannel-marketing/</a> now and watch the match with top-notch streaming!
In the United Kingdom, the event will kick off at late evening, making it ideal for a prime-time audience. Back in Usyk’s home country, and beyond, the excitement is palpable. The fight’s location remains a hot topic, with talk of iconic boxing destinations. Wherever it happens, fans can be sure: the excitement will be unmatched. Although the focus remains on Fury and Usyk, the Fury vs Usyk undercard is also generating excitement. Big-ticket boxing cards often feature stacked undercards, providing non-stop action before the headliner.
In the past, supporting bouts in major events have introduced future champions. Fighters looking to rise through the ranks capitalize on the exposure to impress fans and analysts alike, with the world paying attention. Though the supporting fights for Fury vs Usyk haven’t been officially announced, speculation runs high. Will there be a heavyweight clash? Regardless of the names, the action will not disappoint. The most compelling part of Fury vs Usyk so intriguing is the clash of styles. Tyson Fury’s size and agility are unparalleled in the sport. Being so tall yet so nimble, he dictates the pace of bouts.
The legendary battles with Wilder showed his durability, bouncing back from adversity to secure victories. In his fight with Klitschko, his strategic genius shone through, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. As a southpaw, he uses angles and footwork. His strikes aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. As fight night approaches, Tyson Fury vs Usyk odds have fans and analysts speculating.
Most bookmakers favor Fury as per the betting experts, due to his size advantage, his long career in major fights, and his tactical brilliance. Despite the odds, Usyk remains a strong contender doesn’t diminish his chances, his dominance against Joshua confirmed his toughness against big opponents.
For Tyson Fury, this fight presents a shot at undisputed glory. If he wins, it would further solidify his status as the best heavyweight of this era. Meanwhile, If Usyk wins would elevate him to legendary status. Achieving undisputed glory in two divisions is a rare accomplishment.
Website: https://sbyme.com/masterings-multichannel-marketing/
The upcoming showdown is more than just a championship fight. It’s a meeting of two unique worldviews. Fury’s bold and unapologetic character contrasts with Usyk’s calm, focused demeanor. These varying personalities make the bout even more interesting. It’s a fight of wills and ideologies. No matter who wins, the impact of this bout will be remembered as a defining moment in boxing. The battle for heavyweight supremacy is a spectacle unlike any other. It’s the pinnacle of both fighters’ hard work. If Fury wins with his size and strategy, or Usyk wins with his precision thanks to his skill and resilience, it’s certain that, this will be a defining moment in boxing.
Tyson Fury vs Oleksandr Usyk is more than just a fight. It’s a contest of heart and willpower. These two warriors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are on a collision course that will define an era. It’s not merely about the belts; it’s about legacy. Fury, an undefeated champion has risen to the pinnacle of the sport through his unique style and remarkable adaptability during fights. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Across the ring, Usyk, the technician brings an unprecedented test to boxing’s biggest stars. At the same time, the Ukrainian technician represents a formidable opponent not just for Fury, as a heavyweight contender. The ascent of Oleksandr Usyk started with his domination of the cruiserweights, as an undisputed champion. Don’t miss out for the most anticipated boxing match of the year as Usyk takes on Fury in a must-watch showdown! See every move live on our website. Join the excitement — visit <a href="https://ilboscodeibambini.it/watch-tyson-fury-vs-usyk-free-online-live-fight-2/">https://ilboscodeibambini.it/watch-tyson-fury-vs-usyk-free-online-live-fight-2/</a> right away and stream the event from the comfort of your home!
In the United Kingdom, the event will kick off at close to prime time, offering perfect timing for viewers. Back in Usyk’s home country, and beyond, the excitement is palpable. The venue for Fury vs Usyk is still under speculation, with talk of iconic boxing destinations. Regardless of the venue, it’s guaranteed: the atmosphere will be electric. Although the focus is centered on the headline fight, the Fury vs Usyk undercard is also generating excitement. High-profile matches often feature stacked undercards, giving fans a full evening of entertainment.
Historically, supporting bouts in major events have been a stage for breakout performances. Fighters looking to rise through the ranks often seize these moments to showcase their skills, with the world paying attention. While the names for the undercard are still unconfirmed, there’s plenty of talk. Might there be a cruiserweight spectacle? Whatever the selection, the action will not disappoint. What sets this bout apart so intriguing is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed are unparalleled in the sport. With his immense height and reach advantage, Fury can control a fight.
His trilogy with Deontay Wilder highlighted his resilience, as he recovered from knockdowns to secure victories. When he faced Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. By contrast, Usyk, relies on technique and stamina. With his unorthodox stance, his movements create openings. Usyk’s punches lack devastating strength, their timing wears down foes. With the date drawing closer, The betting lines for Fury vs Usyk are the subject of intense debate.
Fury is the favored fighter based on the betting odds, because of his reach and height, his experience in high-pressure bouts, and his unorthodox style. Although Usyk is the less favored fighter shouldn’t be counted out, as his victories over Joshua proved that he can handle the physicality of the heavyweight division.
For Fury himself is a chance to further solidify his greatness. A triumph for Fury would add an undisputed title to his already impressive resume. Conversely, For Usyk, a win would elevate him to legendary status. Securing two undisputed titles is a rare accomplishment.
Website: https://ilboscodeibambini.it/watch-tyson-fury-vs-usyk-free-online-live-fight-2/
Fury vs Usyk is not just about the belts. It’s a meeting of two unique worldviews. Fury’s larger-than-life persona is the opposite of Usyk’s humble and disciplined approach. These varying personalities make the bout even more interesting. It’s a fight of wills and ideologies. No matter who wins, the impact of this bout will be remembered as a defining moment in boxing. This historic showdown is a spectacle unlike any other. It’s the pinnacle of both fighters’ hard work. If Fury wins through his strength and tactics, or Usyk wins with his precision thanks to his skill and resilience, it’s certain that, this will be a defining moment in boxing.
The Fury-Usyk battle is more than just a sporting contest. It’s a battle of minds and bodies. Both fighters will give everything they have.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are set to meet in the ring of historic proportions. It’s far beyond a championship match; it’s about legacy. Fury, an undefeated champion has earned worldwide fame with his charisma and remarkable adaptability in the ring. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. Across the ring, the tactical southpaw brings an unprecedented test to boxing’s biggest stars. At the same time, Oleksandr Usyk represents a formidable opponent for the heavyweight ranks overall, and for boxing fans worldwide. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, by conquering all challengers. Get ready for a thrilling boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a must-watch showdown! Catch every punch streamed live on our website. Join the excitement — visit <a href="https://shamaclinic.se/2024/10/08/fury-s-unmatched-power-a-deep-dive/">https://shamaclinic.se/2024/10/08/fury-s-unmatched-power-a-deep-dive/</a> today and enjoy the fight in high quality!
In the United Kingdom, the fight is expected to begin around 10 PM GMT, ensuring maximum viewership. For Usyk’s fans in Ukraine, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. The fight’s location is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, it’s guaranteed: the excitement will be unmatched. Although the focus is centered on the headline fight, the fights leading up to the main event promises plenty of action. High-profile matches include preliminary bouts with top talent, providing non-stop action before the headliner.
Historically, preliminary fights on major cards have showcased rising stars. Boxers seeking the spotlight often seize these moments to showcase their skills, as all eyes are on them. Although the lineup for the Fury Usyk undercard has yet to be finalized, there’s plenty of talk. Could we see rising prospects? Regardless of the names, fans can expect fireworks. What makes this fight so intriguing is the clash of styles. Tyson Fury’s size and agility set him apart from other heavyweights. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
The legendary battles with Wilder proved his toughness, as he recovered from knockdowns to finish strong. Against Wladimir Klitschko, his strategic genius shone through, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, offers a different kind of threat. As a southpaw, his movements create openings. His strikes may not have knockout power, but they are delivered with pinpoint accuracy. With the date drawing closer, The betting lines for Fury vs Usyk are the subject of intense debate.
Most bookmakers favor Fury as predicted by many experts, due to his size advantage, his long career in major fights, and his unorthodox style. However, Usyk's underdog status doesn’t rule him out, his wins over Anthony Joshua demonstrated his ability in the heavyweight ranks.
For Tyson Fury represents an opportunity to cement his legacy. A triumph for Fury would add an undisputed title to his already impressive resume. On the other hand, Usyk’s victory would elevate him to new heights. Becoming an undisputed champion in two different weight classes is a rare accomplishment.
Website: https://shamaclinic.se/2024/10/08/fury-s-unmatched-power-a-deep-dive/
This fight is more than just a championship fight. It’s a meeting of two unique worldviews. Fury’s confident and brash nature stands in stark contrast to Usyk’s composed demeanor. The clash of personalities adds depth to the narrative. It’s a fight of wills and ideologies. Whoever comes out victorious, the legacy of this fight will be remembered as a defining moment in boxing. The battle for heavyweight supremacy is more than just a match. It’s a culmination of years of hard work. Whether Tyson Fury prevails with his size and strategy, or Oleksandr Usyk triumphs thanks to his skill and resilience, what is clear is, this will be a defining moment in boxing.
This fight between Fury and Usyk is more than just a fight. It’s a contest of heart and willpower. The two competitors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are preparing for an epic showdown that will define an era. It’s not merely about the belts; it’s about legacy. Tyson Fury has become a global icon through his unique style coupled with unparalleled talent during fights. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. On the other hand, Usyk, the Ukrainian master brings an unprecedented test to the heavyweight division. On the flip side, Oleksandr Usyk stands as a unique threat for Tyson Fury himself, but for the entire division. The ascent of Oleksandr Usyk started with his domination of the cruiserweights, by conquering all challengers. Prepare yourself for a thrilling boxing match of the year as Usyk takes on Fury in an unforgettable showdown! See every move live on our website. Join the excitement — visit <a href="https://www.myfirstproperty.co.uk/postcode-houseprices/ME1-3UD">https://www.myfirstproperty.co.uk/postcode-houseprices/ME1-3UD</a> right away and enjoy the fight from the comfort of your home!
For British fans, the event will kick off at late evening, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and beyond, this will be a must-see event. Where the bout will take place remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, one thing is certain: the atmosphere will be electric. Although the focus is firmly on the main event, the fights leading up to the main event is shaping up to be thrilling. Big-ticket boxing cards include preliminary bouts with top talent, providing non-stop action before the headliner.
Traditionally, preliminary fights on major cards have introduced future champions. Contenders hoping to make their mark often seize these moments to impress fans and analysts alike, with the world paying attention. Though the supporting fights for Fury vs Usyk haven’t been officially announced, speculation runs high. Might there be a cruiserweight spectacle? Whatever the selection, it’s sure to add to the excitement. What sets this bout apart truly fascinating is the dynamic between these fighters. Tyson Fury’s size and agility set him apart from other heavyweights. At 6’9" with an 85-inch reach, Fury can control a fight.
The three fights against Wilder proved his toughness, bouncing back from adversity to finish strong. Against Wladimir Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. By contrast, Usyk, brings speed, precision, and finesse. With his unorthodox stance, his positioning constantly challenges opponents. His strikes lack devastating strength, but they are delivered with pinpoint accuracy. As anticipation builds, The betting lines for Fury vs Usyk are becoming a hot topic.
Tyson Fury is the slight favorite according to the odds, because of his reach and height, his long career in major fights, and his tactical brilliance. Although Usyk is the less favored fighter shouldn’t be counted out, as his victories over Joshua demonstrated his ability in the heavyweight ranks.
For the Gypsy King could be the defining moment of his career. A triumph for Fury would add an undisputed title to his already impressive resume. On the other hand, Usyk’s victory would mark him as one of the sport’s greats. Securing two undisputed titles is a once-in-a-lifetime achievement.
Website: https://www.myfirstproperty.co.uk/postcode-houseprices/ME1-3UD
The upcoming showdown is more than just a championship fight. It’s a battle of contrasting styles. Fury’s larger-than-life persona stands in stark contrast to Usyk’s composed demeanor. These differences add complexity to the fight. Beyond physical ability, this fight. Whoever triumphs in this battle, the significance of this match will be remembered as a defining moment in boxing. This historic showdown is a defining moment. It’s the result of relentless dedication. If Fury wins with his size and strategy, or Usyk secures a victory with his technique and endurance, it’s certain that, this bout will go down in history.
Tyson Fury vs Oleksandr Usyk is more than just a boxing event. It’s a fight of grit and strategy. These men will give everything they have.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are preparing for an epic showdown that will define an era. It’s far beyond a championship match; it’s about legacy. Tyson Fury has risen to the pinnacle of the sport with his charisma coupled with unparalleled talent inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. Meanwhile, Oleksandr Usyk is a fighter unlike any other to the heavyweight division. On the flip side, Usyk, a southpaw master represents a formidable opponent for Tyson Fury himself, but for the entire division. Usyk’s rise to prominence began in the cruiserweight division, as an undisputed champion. Don’t miss out for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a historic showdown! Experience every moment in real time on our website. Don’t miss your chance — visit <a href="https://banglatraining.com/2024/12/08/fury-vs-usyk-the-ultimate-boxing-showdown-18/">https://banglatraining.com/2024/12/08/fury-vs-usyk-the-ultimate-boxing-showdown-18/</a> now and stream the event with top-notch streaming!
In the United Kingdom, the ring walks are planned for close to prime time, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and beyond, the excitement is palpable. The fight’s location is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, one thing is certain: it will be a spectacle. While the spotlight is centered on the headline fight, the preliminary bouts is shaping up to be thrilling. High-profile matches are known for strong supporting fights, giving fans a full evening of entertainment.
In the past, undercards of this caliber have introduced future champions. Contenders hoping to make their mark use such opportunities to impress fans and analysts alike, knowing millions are watching. While the names for the undercard are still unconfirmed, speculation runs high. Could we see rising prospects? Regardless of the names, the action will not disappoint. What sets this bout apart incredibly exciting is their contrasting skillsets. Fury’s towering frame and movement set him apart from other heavyweights. Being so tall yet so nimble, he dictates the pace of bouts.
The three fights against Wilder showed his durability, as he recovered from knockdowns to finish strong. Against Wladimir Klitschko, his strategic genius shone through, proving he’s not just physical but cerebral. Meanwhile, Usyk, offers a different kind of threat. Being a left-handed fighter, his movements create openings. The Ukrainian’s shots aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. As fight night approaches, The betting lines for Fury vs Usyk have fans and analysts speculating.
Tyson Fury is the slight favorite based on the betting odds, given his physical stature, his proven ability in tough situations, and his unorthodox style. However, Usyk's underdog status shouldn’t be counted out, his wins over Anthony Joshua demonstrated his ability in the heavyweight ranks.
For Fury himself represents an opportunity to cement his legacy. A victory would add an undisputed title to his already impressive resume. On the other hand, If Usyk wins would elevate him to new heights. Securing two undisputed titles would be a remarkable feat in boxing history.
Website: https://banglatraining.com/2024/12/08/fury-vs-usyk-the-ultimate-boxing-showdown-18/
The upcoming showdown is more than just a championship fight. It’s a meeting of two unique worldviews. Fury’s confident and brash nature is in stark contrast to Usyk’s quiet intensity. These differences add complexity to the fight. Beyond physical ability, this fight. Whoever comes out victorious, the legacy of this fight will be felt for years to come. This historic showdown is a spectacle unlike any other. It’s the pinnacle of both fighters’ hard work. Whether Fury secures the win with his size and strategy, or Usyk comes out on top with his technique and endurance, what is clear is, this will be a defining moment in boxing.
The Fury-Usyk battle is more than just a fight. It’s a contest of heart and willpower. These two warriors will give everything they have.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are on a collision course that will define an era. This fight is about more than just titles; it’s a battle for eternal recognition. Fury, an undefeated champion has earned worldwide fame with his charisma and remarkable adaptability during fights. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Across the ring, Usyk, the technician brings an unprecedented test for Fury. Meanwhile, Usyk, a southpaw master is a true test for Fury for Tyson Fury himself, as a heavyweight contender. His journey to global fame was marked by his undisputed cruiserweight reign, as an undisputed champion. Don’t miss out for an epic boxing match of the year as Oleksandr Usyk takes on Fury in a historic showdown! See every move in real time on our website. Join the excitement — visit <a href="https://highskyline.com/2024/12/08/usyk-vs-fury-the-battle-for-heavyweight-supremacy-6/">https://highskyline.com/2024/12/08/usyk-vs-fury-the-battle-for-heavyweight-supremacy-6/</a> right away and stream the event in high quality!
Across the UK, the event will kick off at around 10 PM GMT, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, and for fans watching from around the world, this will be a must-see event. The venue for Fury vs Usyk is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. Regardless of the venue, it’s guaranteed: the excitement will be unmatched. Although the focus is centered on the headline fight, the Fury vs Usyk undercard is also generating excitement. Big-ticket boxing cards are known for strong supporting fights, offering an entire night of boxing excitement.
Traditionally, preliminary fights on major cards have showcased rising stars. Boxers seeking the spotlight capitalize on the exposure to demonstrate their talent, as all eyes are on them. Though the supporting fights for Fury vs Usyk has yet to be finalized, fans are eagerly guessing. Might there be a cruiserweight spectacle? No matter the final roster, the action will not disappoint. The most compelling part of Fury vs Usyk incredibly exciting is their contrasting skillsets. Fury’s towering frame and movement make him an anomaly in boxing. Being so tall yet so nimble, he commands the ring like no other.
The three fights against Wilder showed his durability, as he recovered from knockdowns to dominate in later rounds. When he faced Klitschko, his strategic genius shone through, proving he’s not just physical but cerebral. By contrast, Usyk, offers a different kind of threat. Being a left-handed fighter, his positioning constantly challenges opponents. Usyk’s punches lack devastating strength, but they are delivered with pinpoint accuracy. As anticipation builds, The betting lines for Fury vs Usyk are becoming a hot topic.
Most bookmakers favor Fury as per the betting experts, thanks to his imposing frame, his experience in high-pressure bouts, and his unpredictable nature. Despite the odds, Usyk remains a strong contender doesn’t mean he’s an underdog in spirit, his dominance against Joshua proved that he can handle the physicality of the heavyweight division.
For the Gypsy King represents an opportunity to cement his legacy. A triumph for Fury would put the finishing touches on a historic career. Conversely, For Usyk, a win would mark him as one of the sport’s greats. Achieving undisputed glory in two divisions is a feat few can claim.
Website: https://highskyline.com/2024/12/08/usyk-vs-fury-the-battle-for-heavyweight-supremacy-6/
Fury vs Usyk is not just about the belts. It’s a battle of contrasting styles. Fury’s larger-than-life persona is in stark contrast to Usyk’s quiet intensity. These differences add complexity to the fight. It’s a fight of wills and ideologies. No matter who wins, the significance of this match will be remembered as a defining moment in boxing. The clash for the undisputed title is more than just a fight. It represents the culmination of their careers. Should Fury claim victory thanks to his power and game plan, or Usyk comes out on top thanks to his skill and resilience, what is clear is, this will be a defining moment in boxing.
This fight between Fury and Usyk is a spectacle of a lifetime. It’s a contest of heart and willpower. Both fighters will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are set to meet in the ring of unparalleled significance. It’s far beyond a championship match; it’s a battle for eternal recognition. Tyson Fury has earned worldwide fame with his charisma and remarkable adaptability during fights. Beating Wilder and Klitschko have cemented his place among the all-time greats. Meanwhile, Usyk, the technician brings an unprecedented test to the heavyweight division. Meanwhile, Oleksandr Usyk is a true test for Fury for Tyson Fury himself, and for boxing fans worldwide. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, by conquering all challengers. Prepare yourself for the most anticipated boxing match of the year as Usyk takes on Fury in an unforgettable showdown! See every move in real time on our website. Join the excitement — visit <a href="https://naturopat.co.il/how-to-watch-fury-vs-usyk-live-stream/">https://naturopat.co.il/how-to-watch-fury-vs-usyk-live-stream/</a> today and watch the match from the comfort of your home!
Across the UK, the ring walks are planned for late evening, offering perfect timing for viewers. For Usyk’s fans in Ukraine, and beyond, the excitement is palpable. The venue for Fury vs Usyk is still under speculation, with talk of iconic boxing destinations. No matter the location, one thing is certain: the excitement will be unmatched. While the spotlight is centered on the headline fight, the fights leading up to the main event is shaping up to be thrilling. High-profile matches often feature stacked undercards, giving fans a full evening of entertainment.
Historically, undercards of this caliber have introduced future champions. Contenders hoping to make their mark capitalize on the exposure to demonstrate their talent, knowing millions are watching. Although the lineup for the Fury Usyk undercard has yet to be finalized, speculation runs high. Might there be a cruiserweight spectacle? No matter the final roster, fans can expect fireworks. The most compelling part of Fury vs Usyk truly fascinating is the dynamic between these fighters. Fury’s towering frame and movement are unparalleled in the sport. At 6’9" with an 85-inch reach, he commands the ring like no other.
The three fights against Wilder proved his toughness, overcoming brutal hits to secure victories. In his fight with Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, offers a different kind of threat. With his unorthodox stance, he uses angles and footwork. The Ukrainian’s shots lack devastating strength, but they are delivered with pinpoint accuracy. As anticipation builds, Predictions for this fight are becoming a hot topic.
The betting lines show Fury ahead based on the betting odds, because of his reach and height, his proven ability in tough situations, and his unorthodox style. Despite the odds, Usyk remains a strong contender doesn’t diminish his chances, his dominance against Joshua showed that he can compete at heavyweight.
For Fury himself could be the defining moment of his career. A victory would further solidify his status as the best heavyweight of this era. Meanwhile, For Usyk, a win would be a monumental achievement. Securing two undisputed titles is a rare accomplishment.
Website: https://naturopat.co.il/how-to-watch-fury-vs-usyk-live-stream/
The upcoming showdown is not just about the belts. It’s a battle of contrasting styles. Fury’s bold and unapologetic character contrasts with Usyk’s calm, focused demeanor. The clash of personalities adds depth to the narrative. It’s about more than just skill. No matter who wins, the impact of this bout will be remembered as a defining moment in boxing. The battle for heavyweight supremacy is more than just a match. It’s the result of relentless dedication. Whether Tyson Fury prevails with his size and strategy, or Usyk secures a victory with his finesse and stamina, it’s certain that, this will be a fight remembered for years to come.
The Fury-Usyk battle is more than just a fight. It’s a fight of grit and strategy. These men will pour everything into the bout.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are preparing for an epic showdown of historic proportions. It’s far beyond a championship match; it represents their quest for immortality. The Gypsy King has become a global icon through his unique style and his unmatched skills during fights. Beating Wilder and Klitschko have earned him recognition as one of the best ever. In contrast, the tactical southpaw is a fighter unlike any other for Fury. At the same time, Usyk, a southpaw master is a true test for Fury for the heavyweight ranks overall, as a heavyweight contender. Usyk’s rise to prominence began in the cruiserweight division, where he became an unstoppable force. Prepare yourself for the most anticipated boxing match of the year as Usyk takes on Tyson Fury in a must-watch showdown! Experience every moment live on our website. Be part of the action — visit <a href="http://dr-samarai.com/2024/11/08/usyk-vs-fury-undercard-full-fight-card-predictions-6/">http://dr-samarai.com/2024/11/08/usyk-vs-fury-undercard-full-fight-card-predictions-6/</a> right away and enjoy the fight with top-notch streaming!
In the United Kingdom, the ring walks are planned for around 10 PM GMT, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, and for fans watching from around the world, the excitement is palpable. Where the bout will take place has yet to be confirmed, with talk of iconic boxing destinations. Wherever it happens, it’s guaranteed: the excitement will be unmatched. While the spotlight remains on Fury and Usyk, the preliminary bouts promises plenty of action. High-profile matches often feature stacked undercards, offering an entire night of boxing excitement.
Historically, preliminary fights on major cards have introduced future champions. Contenders hoping to make their mark often seize these moments to demonstrate their talent, with the world paying attention. Although the lineup for the Fury Usyk undercard are still unconfirmed, fans are eagerly guessing. Could we see rising prospects? No matter the final roster, it’s sure to add to the excitement. What makes this fight incredibly exciting is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. Being so tall yet so nimble, he commands the ring like no other.
His trilogy with Deontay Wilder proved his toughness, bouncing back from adversity to dominate in later rounds. In his fight with Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, offers a different kind of threat. Being a left-handed fighter, his positioning constantly challenges opponents. His strikes may not have knockout power, they consistently find their mark. As fight night approaches, Tyson Fury vs Usyk odds have fans and analysts speculating.
Fury is the favored fighter as per the betting experts, because of his reach and height, his experience in high-pressure bouts, and his adaptability. Despite being seen as the underdog shouldn’t be counted out, his victories against AJ demonstrated his ability in the heavyweight ranks.
For Tyson Fury, this fight represents an opportunity to cement his legacy. Should he come out on top, Fury’s win would put the finishing touches on a historic career. Meanwhile, For Usyk, a win would elevate him to legendary status. Achieving undisputed glory in two divisions is a once-in-a-lifetime achievement.
Website: http://dr-samarai.com/2024/11/08/usyk-vs-fury-undercard-full-fight-card-predictions-6/
Fury vs Usyk is about more than the titles. It’s a meeting of two unique worldviews. Fury’s larger-than-life persona stands in stark contrast to Usyk’s composed demeanor. Such contrasts make the fight more compelling. It’s a fight of wills and ideologies. Whoever comes out victorious, the legacy of this fight will be remembered as a defining moment in boxing. This historic showdown is a spectacle unlike any other. It represents the culmination of their careers. Whether Fury secures the win with his experience and unpredictability, or Usyk wins with his precision with his technique and endurance, it’s certain that, this bout will go down in history.
This fight between Fury and Usyk is more than just a boxing event. It’s a contest of heart and willpower. These two warriors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are preparing for an epic showdown of unparalleled significance. It’s far beyond a championship match; it represents their quest for immortality. Fury, an undefeated champion has risen to the pinnacle of the sport with his charisma coupled with unparalleled talent in the ring. His victories over Deontay Wilder and Wladimir Klitschko have cemented his place among the all-time greats. On the other hand, Usyk, the Ukrainian master is a fighter unlike any other for Fury. Meanwhile, Usyk, a genius in the ring stands as a unique threat for the heavyweight ranks overall, and for boxing fans worldwide. His journey to global fame began in the cruiserweight division, where he became an unstoppable force. Prepare yourself for an epic boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! Catch every punch live on our website. Join the excitement — visit <a href="https://zerohelados.com.uy/fury-vs-usyk-ring-walk-time-and-how-to-watch-the/">https://zerohelados.com.uy/fury-vs-usyk-ring-walk-time-and-how-to-watch-the/</a> now and stream the event with top-notch streaming!
For British fans, the ring walks are planned for late evening, offering perfect timing for viewers. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, this will be a must-see event. Where the bout will take place is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, fans can be sure: the excitement will be unmatched. Although the focus is firmly on the main event, the Fury vs Usyk undercard promises plenty of action. Big-ticket boxing cards often feature stacked undercards, giving fans a full evening of entertainment.
Traditionally, supporting bouts in major events have been a stage for breakout performances. Boxers seeking the spotlight often seize these moments to showcase their skills, knowing millions are watching. Though the supporting fights for Fury vs Usyk haven’t been officially announced, there’s plenty of talk. Will there be a heavyweight clash? Whatever the selection, fans can expect fireworks. What makes this fight so intriguing is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. With his immense height and reach advantage, Fury can control a fight.
His trilogy with Deontay Wilder showed his durability, bouncing back from adversity to secure victories. Against Wladimir Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. Meanwhile, Usyk, offers a different kind of threat. With his unorthodox stance, he uses angles and footwork. His strikes may not have knockout power, they consistently find their mark. As anticipation builds, Predictions for this fight have fans and analysts speculating.
Tyson Fury is seen as the frontrunner according to the odds, given his physical stature, his long career in major fights, and his adaptability. Despite the odds, Usyk remains a strong contender doesn’t mean he’s an underdog in spirit, as his victories over Joshua demonstrated his ability in the heavyweight ranks.
For Fury himself is a chance to further solidify his greatness. If he wins, it would solidify his claim as the greatest heavyweight of his generation. Conversely, If Usyk wins would mark him as one of the sport’s greats. Becoming an undisputed champion in two different weight classes is a feat few can claim.
Website: https://zerohelados.com.uy/fury-vs-usyk-ring-walk-time-and-how-to-watch-the/
Fury vs Usyk represents something greater than a title bout. It’s a clash of personalities. Fury’s larger-than-life persona is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. It’s about more than just skill. Whoever comes out victorious, the significance of this match will be felt for years to come. The battle for heavyweight supremacy is a spectacle unlike any other. It’s a culmination of years of hard work. Whether Fury secures the win with his size and strategy, or Usyk comes out on top with his finesse and stamina, one thing is certain, this will be a legendary contest.
This fight between Fury and Usyk is a spectacle of a lifetime. It’s a showcase of skill and determination. These two warriors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are on a collision course that will define an era. It’s far beyond a championship match; it represents their quest for immortality. The Gypsy King has earned worldwide fame through his unique style and his unmatched skills inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have cemented his place among the all-time greats. Meanwhile, Usyk, the technician brings an unprecedented test for Fury. On the flip side, Usyk, a southpaw master represents a formidable opponent not just for Fury, as a heavyweight contender. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Get ready for an epic boxing match of the year as Usyk takes on Fury in a must-watch showdown! Catch every punch live on our website. Don’t miss your chance — visit <a href="https://www.gestorea.com/category/hundredofhooacademy-co-uk-new">https://www.gestorea.com/category/hundredofhooacademy-co-uk-new</a> today and enjoy the fight from the comfort of your home!
Across the UK, the fight is expected to begin close to prime time, ensuring maximum viewership. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, this will be a must-see event. Where the bout will take place is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, one thing is certain: the excitement will be unmatched. Although the focus is firmly on the main event, the Fury vs Usyk undercard promises plenty of action. Big-ticket boxing cards often feature stacked undercards, providing non-stop action before the headliner.
Traditionally, undercards of this caliber have introduced future champions. Fighters looking to rise through the ranks often seize these moments to demonstrate their talent, with the world paying attention. Though the supporting fights for Fury vs Usyk has yet to be finalized, there’s plenty of talk. Will there be a heavyweight clash? Whatever the selection, the action will not disappoint. What sets this bout apart truly fascinating is the dynamic between these fighters. Tyson Fury’s size and agility set him apart from other heavyweights. At 6’9" with an 85-inch reach, he commands the ring like no other.
The three fights against Wilder showed his durability, bouncing back from adversity to finish strong. Against Wladimir Klitschko, his strategic genius shone through, showing he’s both powerful and smart. Meanwhile, Usyk, brings speed, precision, and finesse. With his unorthodox stance, his positioning constantly challenges opponents. Usyk’s punches lack devastating strength, their timing wears down foes. With the date drawing closer, The betting lines for Fury vs Usyk are becoming a hot topic.
Tyson Fury is seen as the frontrunner according to the odds, because of his reach and height, his proven ability in tough situations, and his unpredictable nature. Despite the odds, Usyk remains a strong contender doesn’t mean he’s an underdog in spirit, his victories against AJ proved that he can handle the physicality of the heavyweight division.
For Fury himself could be the defining moment of his career. A triumph for Fury would put the finishing touches on a historic career. On the other hand, Usyk’s victory would be a monumental achievement. Becoming an undisputed champion in two different weight classes is a feat few can claim.
Website: https://www.gestorea.com/category/hundredofhooacademy-co-uk-new
Fury vs Usyk represents something greater than a title bout. It’s a battle of contrasting styles. Fury’s larger-than-life persona is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. It’s a fight of wills and ideologies. Regardless of the outcome, the impact of this bout will be remembered as a defining moment in boxing. The battle for heavyweight supremacy is more than just a match. It represents the culmination of their careers. Should Fury claim victory with his size and strategy, or Usyk wins with his precision with his technique and endurance, it’s certain that, this will be a legendary contest.
The Fury-Usyk battle is a spectacle of a lifetime. It’s a showcase of skill and determination. The two competitors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are preparing for an epic showdown of historic proportions. This fight is about more than just titles; it’s about legacy. The towering Fury has become a global icon thanks to his personality and remarkable adaptability inside the ropes. Beating Wilder and Klitschko have cemented his place among the all-time greats. On the other hand, Usyk, the Ukrainian master poses a unique challenge to the heavyweight division. Meanwhile, Usyk, a genius in the ring represents a formidable opponent not just for Fury, as a heavyweight contender. The ascent of Oleksandr Usyk started with his domination of the cruiserweights, where he became an unstoppable force. Don’t miss out for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! Experience every moment in real time on our website. Be part of the action — visit <a href="https://aromasesentidos.com/blog/category/hundredofhooacademy-co-uk-new/">https://aromasesentidos.com/blog/category/hundredofhooacademy-co-uk-new/</a> right away and watch the match with top-notch streaming!
For British fans, the event will kick off at late evening, making it ideal for a prime-time audience. Back in Usyk’s home country, and beyond, this will be a must-see event. The fight’s location has yet to be confirmed, with talk of iconic boxing destinations. Regardless of the venue, one thing is certain: the excitement will be unmatched. Although the focus remains on Fury and Usyk, the Fury vs Usyk undercard is also generating excitement. Major boxing events are known for strong supporting fights, giving fans a full evening of entertainment.
In the past, supporting bouts in major events have introduced future champions. Fighters looking to rise through the ranks often seize these moments to showcase their skills, as all eyes are on them. Although the lineup for the Fury Usyk undercard are still unconfirmed, fans are eagerly guessing. Will there be a heavyweight clash? No matter the final roster, the action will not disappoint. The most compelling part of Fury vs Usyk truly fascinating is the clash of styles. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
The three fights against Wilder highlighted his resilience, bouncing back from adversity to dominate in later rounds. Against Wladimir Klitschko, his strategic genius shone through, proving he’s not just physical but cerebral. By contrast, Usyk, brings speed, precision, and finesse. As a southpaw, he uses angles and footwork. The Ukrainian’s shots may not have knockout power, their timing wears down foes. As fight night approaches, Tyson Fury vs Usyk odds are the subject of intense debate.
Most bookmakers favor Fury based on the betting odds, given his physical stature, his experience in high-pressure bouts, and his tactical brilliance. However, Usyk's underdog status doesn’t mean he’s an underdog in spirit, his victories against AJ confirmed his toughness against big opponents.
For Tyson Fury presents a shot at undisputed glory. A victory would further solidify his status as the best heavyweight of this era. On the other hand, Usyk’s victory would elevate him to legendary status. Securing two undisputed titles is a rare accomplishment.
Website: https://aromasesentidos.com/blog/category/hundredofhooacademy-co-uk-new/
The upcoming showdown is not just about the belts. It’s a meeting of two unique worldviews. Fury’s bold and unapologetic character stands in stark contrast to Usyk’s composed demeanor. These differences add complexity to the fight. It’s about more than just skill. Whoever comes out victorious, the legacy of this fight will reverberate throughout boxing history. Fury vs Usyk is more than just a match. It’s a culmination of years of hard work. Whether Tyson Fury prevails thanks to his power and game plan, or Usyk secures a victory through his superior boxing ability, it’s certain that, this will be a legendary contest.
Tyson Fury vs Oleksandr Usyk is more than just a sporting contest. It’s a fight of grit and strategy. Both fighters will leave it all in the ring.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are ready to face each other in a fight that will define an era. It’s far beyond a championship match; it’s a battle for eternal recognition. Fury, an undefeated champion has become a global icon through his unique style and his unmatched skills in the ring. Triumphing against boxing legends like Wilder and Klitschko have solidified his legendary status. Meanwhile, the tactical southpaw is a fighter unlike any other to boxing’s biggest stars. At the same time, the Ukrainian technician represents a formidable opponent for Tyson Fury himself, but for the entire division. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, as an undisputed champion. Don’t miss out for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! Experience every moment live on our website. Don’t miss your chance — visit <a href="https://glisvevi.it/?p=270">https://glisvevi.it/?p=270</a> today and stream the event in high quality!
Across the UK, the ring walks are planned for around 10 PM GMT, making it ideal for a prime-time audience. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, this will be a must-see event. The fight’s location is still under speculation, with talk of iconic boxing destinations. Wherever it happens, it’s guaranteed: it will be a spectacle. Although the focus is firmly on the main event, the preliminary bouts is shaping up to be thrilling. Major boxing events often feature stacked undercards, offering an entire night of boxing excitement.
Traditionally, undercards of this caliber have introduced future champions. Contenders hoping to make their mark capitalize on the exposure to impress fans and analysts alike, knowing millions are watching. Although the lineup for the Fury Usyk undercard has yet to be finalized, there’s plenty of talk. Could we see rising prospects? Whatever the selection, fans can expect fireworks. The most compelling part of Fury vs Usyk so intriguing is the dynamic between these fighters. Fury’s towering frame and movement set him apart from other heavyweights. With his immense height and reach advantage, Fury can control a fight.
His trilogy with Deontay Wilder highlighted his resilience, overcoming brutal hits to secure victories. In his fight with Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, offers a different kind of threat. With his unorthodox stance, his movements create openings. The Ukrainian’s shots lack devastating strength, their timing wears down foes. As fight night approaches, Predictions for this fight are the subject of intense debate.
Tyson Fury is seen as the frontrunner based on the betting odds, given his physical stature, his proven ability in tough situations, and his adaptability. Although Usyk is the less favored fighter shouldn’t be counted out, as his victories over Joshua proved that he can handle the physicality of the heavyweight division.
For the Gypsy King represents an opportunity to cement his legacy. If he wins, it would put the finishing touches on a historic career. Meanwhile, For Usyk, a win would mark him as one of the sport’s greats. Becoming the undisputed heavyweight champion is a rare accomplishment.
Website: https://glisvevi.it/?p=270
Fury vs Usyk represents something greater than a title bout. It’s a battle of contrasting styles. Fury’s boisterous personality is the opposite of Usyk’s humble and disciplined approach. The clash of personalities adds depth to the narrative. It’s about more than just skill. Regardless of the outcome, the impact of this bout will be felt for years to come. This historic showdown is more than just a fight. It represents the culmination of their careers. Should Fury claim victory through his strength and tactics, or Usyk comes out on top with his technique and endurance, what is clear is, this will be a fight remembered for years to come.
Fury vs Usyk is more than just a boxing event. It’s a contest of heart and willpower. These two warriors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are on a collision course of historic proportions. It’s not merely about the belts; it’s a battle for eternal recognition. Tyson Fury has become a global icon with his charisma and his unmatched skills during fights. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Across the ring, Usyk, the Ukrainian master is a fighter unlike any other for Fury. At the same time, Usyk, a southpaw master represents a formidable opponent for the heavyweight ranks overall, but for the entire division. His journey to global fame began in the cruiserweight division, where he became an unstoppable force. Don’t miss out for an epic boxing match of the year as Usyk takes on Fury in a historic showdown! See every move streamed live on our website. Join the excitement — visit <a href="https://starcourts.com/masterings-multichannel-marketing/">https://starcourts.com/masterings-multichannel-marketing/</a> today and stream the event from the comfort of your home!
Across the UK, the event will kick off at late evening, making it ideal for a prime-time audience. Back in Usyk’s home country, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. Where the bout will take place is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, one thing is certain: it will be a spectacle. Although the focus is centered on the headline fight, the fights leading up to the main event is shaping up to be thrilling. Major boxing events are known for strong supporting fights, offering an entire night of boxing excitement.
Traditionally, supporting bouts in major events have introduced future champions. Fighters looking to rise through the ranks capitalize on the exposure to showcase their skills, with the world paying attention. Though the supporting fights for Fury vs Usyk haven’t been officially announced, fans are eagerly guessing. Will there be a heavyweight clash? Regardless of the names, fans can expect fireworks. What makes this fight so intriguing is the clash of styles. Fury’s towering frame and movement set him apart from other heavyweights. At 6’9" with an 85-inch reach, Fury can control a fight.
The legendary battles with Wilder showed his durability, overcoming brutal hits to finish strong. In his fight with Klitschko, he out-thought the disciplined champion, demonstrating his mental sharpness. Meanwhile, Usyk, relies on technique and stamina. As a southpaw, his movements create openings. Usyk’s punches may not have knockout power, their timing wears down foes. As fight night approaches, The betting lines for Fury vs Usyk are becoming a hot topic.
Tyson Fury is the slight favorite according to the odds, due to his size advantage, his experience in high-pressure bouts, and his unpredictable nature. However, Usyk's underdog status doesn’t rule him out, his victories against AJ confirmed his toughness against big opponents.
For Fury himself presents a shot at undisputed glory. A victory would solidify his claim as the greatest heavyweight of his generation. On the other hand, Usyk’s victory would be a monumental achievement. Securing two undisputed titles is a rare accomplishment.
Website: https://starcourts.com/masterings-multichannel-marketing/
This fight represents something greater than a title bout. It’s a battle of contrasting styles. Fury’s boisterous personality is the opposite of Usyk’s humble and disciplined approach. These varying personalities make the bout even more interesting. It’s a fight of wills and ideologies. No matter who wins, the significance of this match will leave a lasting mark on the sport. The battle for heavyweight supremacy is a defining moment. It’s a culmination of years of hard work. If Fury wins thanks to his power and game plan, or Usyk comes out on top with his technique and endurance, what is clear is, this will be a legendary contest.
This fight between Fury and Usyk is more than just a sporting contest. It’s a fight of grit and strategy. The two competitors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are on a collision course of historic proportions. This fight is about more than just titles; it’s about legacy. The towering Fury has become a global icon thanks to his personality and remarkable adaptability during fights. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. Across the ring, Usyk, the technician is a fighter unlike any other to boxing’s biggest stars. On the flip side, Oleksandr Usyk stands as a unique threat for the heavyweight ranks overall, as a heavyweight contender. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, by conquering all challengers. Don’t miss out for a thrilling boxing match of the year as Oleksandr Usyk takes on Tyson Fury in an unforgettable showdown! Catch every punch live on our website. Don’t miss your chance — visit <a href="https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7AS">https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7AS</a> now and watch the match from the comfort of your home!
For British fans, the ring walks are planned for close to prime time, making it ideal for a prime-time audience. Back in Usyk’s home country, and beyond, this will be a must-see event. Where the bout will take place has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, fans can be sure: it will be a spectacle. Even though attention is firmly on the main event, the fights leading up to the main event is shaping up to be thrilling. High-profile matches are known for strong supporting fights, offering an entire night of boxing excitement.
In the past, undercards of this caliber have introduced future champions. Contenders hoping to make their mark use such opportunities to demonstrate their talent, with the world paying attention. While the names for the undercard has yet to be finalized, there’s plenty of talk. Will there be a heavyweight clash? Whatever the selection, fans can expect fireworks. The most compelling part of Fury vs Usyk incredibly exciting is the dynamic between these fighters. Tyson Fury’s size and agility make him an anomaly in boxing. Being so tall yet so nimble, he dictates the pace of bouts.
The legendary battles with Wilder highlighted his resilience, as he recovered from knockdowns to finish strong. In his fight with Klitschko, his strategic genius shone through, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, relies on technique and stamina. As a southpaw, his movements create openings. His strikes lack devastating strength, but they are delivered with pinpoint accuracy. As anticipation builds, Predictions for this fight are the subject of intense debate.
Most bookmakers favor Fury as predicted by many experts, thanks to his imposing frame, his track record in big matches, and his unorthodox style. Despite being seen as the underdog doesn’t mean he’s an underdog in spirit, his wins over Anthony Joshua proved that he can handle the physicality of the heavyweight division.
For the Gypsy King is a chance to further solidify his greatness. A triumph for Fury would solidify his claim as the greatest heavyweight of his generation. On the other hand, If Usyk wins would mark him as one of the sport’s greats. Becoming the undisputed heavyweight champion would be a remarkable feat in boxing history.
Website: https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7AS
Fury vs Usyk is about more than the titles. It’s a fight between two very different fighters. Fury’s confident and brash nature stands in stark contrast to Usyk’s composed demeanor. The clash of personalities adds depth to the narrative. This is more than just a physical contest. Regardless of the outcome, the legacy of this fight will reverberate throughout boxing history. The battle for heavyweight supremacy is a defining moment. It’s the result of relentless dedication. Should Fury claim victory with his size and strategy, or Oleksandr Usyk triumphs thanks to his skill and resilience, it’s certain that, this will be a defining moment in boxing.
The Fury-Usyk battle is more than just a fight. It’s a fight of grit and strategy. Both fighters will give everything they have.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are on a collision course that will define an era. This fight is about more than just titles; it represents their quest for immortality. The towering Fury has earned worldwide fame with his charisma coupled with unparalleled talent in the ring. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. Across the ring, Oleksandr Usyk poses a unique challenge to the heavyweight division. On the flip side, Usyk, a southpaw master represents a formidable opponent for the heavyweight ranks overall, and for boxing fans worldwide. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, by conquering all challengers. Don’t miss out for an epic boxing match of the year as Usyk takes on Fury in a historic showdown! See every move streamed live on our website. Be part of the action — visit <a href="http://www.dental-avinguda.com/2024/09/fury-vs-usyk-uk-time-and-venue-for-the-big-fight-1-2/">http://www.dental-avinguda.com/2024/09/fury-vs-usyk-uk-time-and-venue-for-the-big-fight-1-2/</a> right away and stream the event from the comfort of your home!
In the United Kingdom, the event will kick off at close to prime time, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. The venue for Fury vs Usyk remains a hot topic, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, one thing is certain: the atmosphere will be electric. While the spotlight is centered on the headline fight, the fights leading up to the main event is shaping up to be thrilling. Big-ticket boxing cards include preliminary bouts with top talent, giving fans a full evening of entertainment.
Historically, preliminary fights on major cards have been a stage for breakout performances. Boxers seeking the spotlight often seize these moments to impress fans and analysts alike, knowing millions are watching. While the names for the undercard are still unconfirmed, fans are eagerly guessing. Will there be a heavyweight clash? No matter the final roster, fans can expect fireworks. What sets this bout apart incredibly exciting is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed set him apart from other heavyweights. With his immense height and reach advantage, Fury can control a fight.
The three fights against Wilder showed his durability, as he recovered from knockdowns to dominate in later rounds. When he faced Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. By contrast, Usyk, offers a different kind of threat. Being a left-handed fighter, he uses angles and footwork. His strikes lack devastating strength, they consistently find their mark. As fight night approaches, Predictions for this fight have fans and analysts speculating.
Fury is the favored fighter according to the odds, due to his size advantage, his experience in high-pressure bouts, and his unorthodox style. Despite the odds, Usyk remains a strong contender shouldn’t be counted out, as his victories over Joshua demonstrated his ability in the heavyweight ranks.
For the Gypsy King presents a shot at undisputed glory. A victory would put the finishing touches on a historic career. Meanwhile, If Usyk wins would elevate him to new heights. Securing two undisputed titles is a feat few can claim.
Website: http://www.dental-avinguda.com/2024/09/fury-vs-usyk-uk-time-and-venue-for-the-big-fight-1-2/
Fury vs Usyk represents something greater than a title bout. It’s a meeting of two unique worldviews. Fury’s boisterous personality is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. This is more than just a physical contest. No matter who wins, the impact of this bout will be felt for years to come. Fury vs Usyk is more than just a fight. It’s a culmination of years of hard work. Whether Tyson Fury prevails thanks to his power and game plan, or Usyk comes out on top thanks to his skill and resilience, what is clear is, this will be a defining moment in boxing.
The Fury-Usyk battle is more than just a fight. It’s a battle of minds and bodies. These men will pour everything into the bout.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are on a collision course that will define an era. This fight is about more than just titles; it represents their quest for immortality. The towering Fury has become a global icon through his unique style and remarkable adaptability during fights. Triumphing against boxing legends like Wilder and Klitschko have solidified his legendary status. On the other hand, the tactical southpaw is a fighter unlike any other for Fury. On the flip side, the Ukrainian technician represents a formidable opponent not just for Fury, but for the entire division. His journey to global fame began in the cruiserweight division, as an undisputed champion. Don’t miss out for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a historic showdown! Catch every punch in real time on our website. Join the excitement — visit <a href="https://fybyrcloudservers.com/index.php/2024/09/03/fury-vs-usyk-all-you-need-to-know-about-the-big-46/">https://fybyrcloudservers.com/index.php/2024/09/03/fury-vs-usyk-all-you-need-to-know-about-the-big-46/</a> right away and stream the event with top-notch streaming!
In the United Kingdom, the ring walks are planned for around 10 PM GMT, offering perfect timing for viewers. Back in Usyk’s home country, and beyond, the anticipation is at a fever pitch. Where the bout will take place remains a hot topic, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, fans can be sure: the excitement will be unmatched. While the spotlight is firmly on the main event, the Fury vs Usyk undercard is shaping up to be thrilling. Major boxing events include preliminary bouts with top talent, giving fans a full evening of entertainment.
Traditionally, supporting bouts in major events have been a stage for breakout performances. Fighters looking to rise through the ranks capitalize on the exposure to impress fans and analysts alike, with the world paying attention. Though the supporting fights for Fury vs Usyk haven’t been officially announced, there’s plenty of talk. Could we see rising prospects? Regardless of the names, it’s sure to add to the excitement. What makes this fight truly fascinating is the dynamic between these fighters. Fury’s towering frame and movement make him an anomaly in boxing. At 6’9" with an 85-inch reach, he commands the ring like no other.
The legendary battles with Wilder showed his durability, overcoming brutal hits to finish strong. Against Wladimir Klitschko, his strategic genius shone through, proving he’s not just physical but cerebral. By contrast, Usyk, relies on technique and stamina. Being a left-handed fighter, he uses angles and footwork. His strikes aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. As anticipation builds, Predictions for this fight are becoming a hot topic.
The betting lines show Fury ahead as per the betting experts, given his physical stature, his experience in high-pressure bouts, and his unorthodox style. Despite being seen as the underdog doesn’t mean he’s an underdog in spirit, as his victories over Joshua demonstrated his ability in the heavyweight ranks.
For Tyson Fury, this fight presents a shot at undisputed glory. Should he come out on top, Fury’s win would put the finishing touches on a historic career. Meanwhile, For Usyk, a win would elevate him to legendary status. Becoming the undisputed heavyweight champion is a feat few can claim.
Website: https://fybyrcloudservers.com/index.php/2024/09/03/fury-vs-usyk-all-you-need-to-know-about-the-big-46/
The upcoming showdown is not just about the belts. It’s a battle of contrasting styles. Fury’s larger-than-life persona is in stark contrast to Usyk’s quiet intensity. These differences add complexity to the fight. This is more than just a physical contest. Whoever comes out victorious, the impact of this bout will reverberate throughout boxing history. This historic showdown is a defining moment. It’s the pinnacle of both fighters’ hard work. Whether Fury secures the win thanks to his power and game plan, or Oleksandr Usyk triumphs with his finesse and stamina, it’s certain that, this will be a defining moment in boxing.
Fury vs Usyk is more than just a fight. It’s a showcase of skill and determination. These men will fight with everything they possess.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are preparing for an epic showdown that will define an era. It’s not merely about the belts; it represents their quest for immortality. Fury, an undefeated champion has earned worldwide fame with his charisma and his unmatched skills inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. Across the ring, Usyk, the Ukrainian master brings an unprecedented test to the heavyweight division. On the flip side, Oleksandr Usyk stands as a unique threat not just for Fury, but for the entire division. His journey to global fame started with his domination of the cruiserweights, where he became an unstoppable force. Get ready for the most anticipated boxing match of the year as Usyk takes on Fury in a historic showdown! Experience every moment streamed live on our website. Don’t miss your chance — visit <a href="https://www.myfirstproperty.co.uk/postcode-houseprices/ME1-3UU">https://www.myfirstproperty.co.uk/postcode-houseprices/ME1-3UU</a> now and stream the event with top-notch streaming!
In the United Kingdom, the ring walks are planned for close to prime time, ensuring maximum viewership. In Usyk’s native Ukraine, and beyond, the anticipation is at a fever pitch. The fight’s location is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. Regardless of the venue, one thing is certain: the atmosphere will be electric. Even though attention is firmly on the main event, the preliminary bouts promises plenty of action. Major boxing events include preliminary bouts with top talent, giving fans a full evening of entertainment.
In the past, supporting bouts in major events have showcased rising stars. Boxers seeking the spotlight capitalize on the exposure to impress fans and analysts alike, knowing millions are watching. Though the supporting fights for Fury vs Usyk haven’t been officially announced, fans are eagerly guessing. Might there be a cruiserweight spectacle? Whatever the selection, fans can expect fireworks. The most compelling part of Fury vs Usyk so intriguing is the clash of styles. Tyson Fury’s size and agility set him apart from other heavyweights. With his immense height and reach advantage, he dictates the pace of bouts.
The three fights against Wilder proved his toughness, bouncing back from adversity to secure victories. When he faced Klitschko, his strategic genius shone through, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, relies on technique and stamina. As a southpaw, his movements create openings. Usyk’s punches aren’t the heaviest in the division, they consistently find their mark. As fight night approaches, Predictions for this fight have fans and analysts speculating.
Tyson Fury is the slight favorite according to the odds, thanks to his imposing frame, his long career in major fights, and his tactical brilliance. However, Usyk's underdog status shouldn’t be counted out, his wins over Anthony Joshua showed that he can compete at heavyweight.
For the Gypsy King could be the defining moment of his career. A triumph for Fury would add an undisputed title to his already impressive resume. Conversely, For Usyk, a win would elevate him to legendary status. Becoming the undisputed heavyweight champion would be a remarkable feat in boxing history.
Website: https://www.myfirstproperty.co.uk/postcode-houseprices/ME1-3UU
The upcoming showdown is about more than the titles. It’s a clash of personalities. Fury’s bold and unapologetic character stands in stark contrast to Usyk’s composed demeanor. The clash of personalities adds depth to the narrative. This is more than just a physical contest. No matter who wins, the significance of this match will leave a lasting mark on the sport. The clash for the undisputed title is a defining moment. It’s the pinnacle of both fighters’ hard work. Whether Fury secures the win with his size and strategy, or Usyk wins with his precision with his finesse and stamina, no matter the outcome, this will be a fight remembered for years to come.
Fury vs Usyk is a spectacle of a lifetime. It’s a showcase of skill and determination. Both fighters will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are on a collision course of unparalleled significance. This fight is about more than just titles; it’s about legacy. Tyson Fury has risen to the pinnacle of the sport through his unique style coupled with unparalleled talent in the ring. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. Across the ring, Usyk, the technician poses a unique challenge for Fury. On the flip side, Usyk, a southpaw master represents a formidable opponent for the heavyweight ranks overall, as a heavyweight contender. The ascent of Oleksandr Usyk began in the cruiserweight division, where he became an unstoppable force. Don’t miss out for a thrilling boxing match of the year as Oleksandr Usyk takes on Fury in a must-watch showdown! Catch every punch live on our website. Be part of the action — visit <a href="http://odp.org/Regional/Europe/United_Kingdom/England/Kent/Hoo">http://odp.org/Regional/Europe/United_Kingdom/England/Kent/Hoo</a> right away and watch the match in high quality!
For British fans, the ring walks are planned for close to prime time, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, and beyond, this will be a must-see event. The fight’s location remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, one thing is certain: the excitement will be unmatched. While the spotlight remains on Fury and Usyk, the preliminary bouts is also generating excitement. High-profile matches are known for strong supporting fights, providing non-stop action before the headliner.
Historically, preliminary fights on major cards have introduced future champions. Boxers seeking the spotlight capitalize on the exposure to demonstrate their talent, knowing millions are watching. Though the supporting fights for Fury vs Usyk haven’t been officially announced, fans are eagerly guessing. Could we see rising prospects? No matter the final roster, fans can expect fireworks. What sets this bout apart incredibly exciting is the dynamic between these fighters. Fury’s towering frame and movement set him apart from other heavyweights. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
His trilogy with Deontay Wilder showed his durability, as he recovered from knockdowns to secure victories. In his fight with Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. By contrast, Usyk, relies on technique and stamina. With his unorthodox stance, his movements create openings. Usyk’s punches may not have knockout power, but they are delivered with pinpoint accuracy. As anticipation builds, The betting lines for Fury vs Usyk have fans and analysts speculating.
Tyson Fury is seen as the frontrunner as per the betting experts, due to his size advantage, his track record in big matches, and his unpredictable nature. Although Usyk is the less favored fighter shouldn’t be counted out, his victories against AJ showed that he can compete at heavyweight.
For Tyson Fury, this fight is a chance to further solidify his greatness. If he wins, it would add an undisputed title to his already impressive resume. Meanwhile, Usyk’s victory would elevate him to legendary status. Becoming the undisputed heavyweight champion is a once-in-a-lifetime achievement.
Website: http://odp.org/Regional/Europe/United_Kingdom/England/Kent/Hoo
This fight is not just about the belts. It’s a fight between two very different fighters. Fury’s boisterous personality is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. It’s a fight of wills and ideologies. Regardless of the outcome, the significance of this match will be felt for years to come. Fury vs Usyk is a defining moment. It’s the result of relentless dedication. Whether Tyson Fury prevails through his strength and tactics, or Usyk comes out on top thanks to his skill and resilience, what is clear is, this bout will go down in history.
Fury vs Usyk is more than just a fight. It’s a battle of minds and bodies. These two warriors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are on a collision course of historic proportions. It’s not merely about the belts; it’s a battle for eternal recognition. The Gypsy King has earned worldwide fame with his charisma coupled with unparalleled talent during fights. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. Across the ring, Usyk, the technician brings an unprecedented test for Fury. Meanwhile, Usyk, a genius in the ring stands as a unique threat not just for Fury, and for boxing fans worldwide. Usyk’s rise to prominence began in the cruiserweight division, by conquering all challengers. Prepare yourself for a thrilling boxing match of the year as Oleksandr Usyk takes on Fury in a must-watch showdown! Experience every moment in real time on our website. Join the excitement — visit <a href="https://pediatri2.trddersler.com/decoding-the-clash-of-styles/">https://pediatri2.trddersler.com/decoding-the-clash-of-styles/</a> now and stream the event in high quality!
For British fans, the fight is expected to begin around 10 PM GMT, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and for fans watching from around the world, this will be a must-see event. Where the bout will take place is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, fans can be sure: the excitement will be unmatched. Although the focus is centered on the headline fight, the preliminary bouts is shaping up to be thrilling. Big-ticket boxing cards include preliminary bouts with top talent, offering an entire night of boxing excitement.
In the past, undercards of this caliber have introduced future champions. Boxers seeking the spotlight use such opportunities to impress fans and analysts alike, with the world paying attention. Though the supporting fights for Fury vs Usyk has yet to be finalized, fans are eagerly guessing. Will there be a heavyweight clash? No matter the final roster, the action will not disappoint. What sets this bout apart so intriguing is the clash of styles. Tyson Fury’s size and agility are unparalleled in the sport. At 6’9" with an 85-inch reach, he commands the ring like no other.
The legendary battles with Wilder proved his toughness, as he recovered from knockdowns to finish strong. In his fight with Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. By contrast, Usyk, brings speed, precision, and finesse. With his unorthodox stance, his positioning constantly challenges opponents. His strikes aren’t the heaviest in the division, their timing wears down foes. As anticipation builds, Predictions for this fight have fans and analysts speculating.
Tyson Fury is the slight favorite as predicted by many experts, due to his size advantage, his track record in big matches, and his adaptability. However, Usyk's underdog status doesn’t mean he’s an underdog in spirit, his wins over Anthony Joshua demonstrated his ability in the heavyweight ranks.
For the Gypsy King could be the defining moment of his career. Should he come out on top, Fury’s win would solidify his claim as the greatest heavyweight of his generation. Meanwhile, For Usyk, a win would mark him as one of the sport’s greats. Becoming an undisputed champion in two different weight classes is a rare accomplishment.
Website: https://pediatri2.trddersler.com/decoding-the-clash-of-styles/
Fury vs Usyk is not just about the belts. It’s a clash of personalities. Fury’s bold and unapologetic character stands in stark contrast to Usyk’s composed demeanor. These varying personalities make the bout even more interesting. Beyond physical ability, this fight. Regardless of the outcome, the impact of this bout will reverberate throughout boxing history. The battle for heavyweight supremacy is more than just a fight. It represents the culmination of their careers. Whether Tyson Fury prevails through his strength and tactics, or Usyk secures a victory through his superior boxing ability, no matter the outcome, this will be a fight remembered for years to come.
Fury vs Usyk is more than just a boxing event. It’s a battle of minds and bodies. These men will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are on a collision course that will define an era. This fight is about more than just titles; it’s about legacy. The towering Fury has earned worldwide fame thanks to his personality coupled with unparalleled talent during fights. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Meanwhile, Usyk, the technician poses a unique challenge to boxing’s biggest stars. Meanwhile, the Ukrainian technician represents a formidable opponent not just for Fury, as a heavyweight contender. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, as an undisputed champion. Get ready for an epic boxing match of the year as Oleksandr Usyk takes on Fury in an unforgettable showdown! See every move in real time on our website. Join the excitement — visit <a href="https://londinium.com/latlong/51.4075516/0.5379365">https://londinium.com/latlong/51.4075516/0.5379365</a> today and enjoy the fight from the comfort of your home!
Across the UK, the event will kick off at close to prime time, offering perfect timing for viewers. Back in Usyk’s home country, and for fans watching from around the world, this will be a must-see event. The fight’s location has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, fans can be sure: it will be a spectacle. While the spotlight remains on Fury and Usyk, the fights leading up to the main event is shaping up to be thrilling. High-profile matches include preliminary bouts with top talent, offering an entire night of boxing excitement.
Traditionally, supporting bouts in major events have introduced future champions. Contenders hoping to make their mark often seize these moments to demonstrate their talent, knowing millions are watching. While the names for the undercard has yet to be finalized, there’s plenty of talk. Will there be a heavyweight clash? Regardless of the names, fans can expect fireworks. The most compelling part of Fury vs Usyk so intriguing is the clash of styles. Tyson Fury’s size and agility set him apart from other heavyweights. With his immense height and reach advantage, he commands the ring like no other.
The three fights against Wilder proved his toughness, as he recovered from knockdowns to secure victories. When he faced Klitschko, his strategic genius shone through, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, offers a different kind of threat. Being a left-handed fighter, his positioning constantly challenges opponents. The Ukrainian’s shots may not have knockout power, their timing wears down foes. As anticipation builds, The betting lines for Fury vs Usyk are the subject of intense debate.
Most bookmakers favor Fury based on the betting odds, because of his reach and height, his long career in major fights, and his unorthodox style. However, Usyk's underdog status shouldn’t be counted out, his wins over Anthony Joshua confirmed his toughness against big opponents.
For Fury himself could be the defining moment of his career. A victory would solidify his claim as the greatest heavyweight of his generation. On the other hand, For Usyk, a win would mark him as one of the sport’s greats. Securing two undisputed titles is a once-in-a-lifetime achievement.
Website: https://londinium.com/latlong/51.4075516/0.5379365
The upcoming showdown is more than just a championship fight. It’s a battle of contrasting styles. Fury’s bold and unapologetic character stands in stark contrast to Usyk’s composed demeanor. Such contrasts make the fight more compelling. It’s about more than just skill. Whoever triumphs in this battle, the legacy of this fight will leave a lasting mark on the sport. The clash for the undisputed title is more than just a match. It’s a culmination of years of hard work. Should Fury claim victory through his strength and tactics, or Usyk wins with his precision through his superior boxing ability, it’s certain that, this will be a fight remembered for years to come.
Fury vs Usyk is a spectacle of a lifetime. It’s a fight of grit and strategy. These two warriors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are preparing for an epic showdown of unparalleled significance. This fight is about more than just titles; it represents their quest for immortality. The Gypsy King has earned worldwide fame with his charisma and his unmatched skills in the ring. Beating Wilder and Klitschko have earned him recognition as one of the best ever. On the other hand, Usyk, the technician brings an unprecedented test to boxing’s biggest stars. On the flip side, Usyk, a genius in the ring is a true test for Fury for Tyson Fury himself, and for boxing fans worldwide. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Don’t miss out for an epic boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! Catch every punch streamed live on our website. Be part of the action — visit <a href="https://byteyo.com/penguin-and-back-link-amends-from-google-may-2012/">https://byteyo.com/penguin-and-back-link-amends-from-google-may-2012/</a> right away and enjoy the fight in high quality!
Across the UK, the ring walks are planned for around 10 PM GMT, offering perfect timing for viewers. In Usyk’s native Ukraine, and beyond, this will be a must-see event. The fight’s location has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, it’s guaranteed: the atmosphere will be electric. While the spotlight is centered on the headline fight, the fights leading up to the main event is shaping up to be thrilling. Big-ticket boxing cards often feature stacked undercards, providing non-stop action before the headliner.
Historically, preliminary fights on major cards have been a stage for breakout performances. Contenders hoping to make their mark use such opportunities to impress fans and analysts alike, as all eyes are on them. Although the lineup for the Fury Usyk undercard are still unconfirmed, fans are eagerly guessing. Will there be a heavyweight clash? No matter the final roster, fans can expect fireworks. The most compelling part of Fury vs Usyk incredibly exciting is the clash of styles. Tyson Fury’s size and agility are unparalleled in the sport. At 6’9" with an 85-inch reach, Fury can control a fight.
The legendary battles with Wilder showed his durability, overcoming brutal hits to finish strong. Against Wladimir Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. Meanwhile, Usyk, offers a different kind of threat. As a southpaw, his positioning constantly challenges opponents. The Ukrainian’s shots lack devastating strength, but they are delivered with pinpoint accuracy. As fight night approaches, Predictions for this fight are becoming a hot topic.
Tyson Fury is seen as the frontrunner as predicted by many experts, thanks to his imposing frame, his track record in big matches, and his tactical brilliance. Despite being seen as the underdog doesn’t mean he’s an underdog in spirit, as his victories over Joshua showed that he can compete at heavyweight.
For Tyson Fury, this fight is a chance to further solidify his greatness. Should he come out on top, Fury’s win would solidify his claim as the greatest heavyweight of his generation. Conversely, If Usyk wins would mark him as one of the sport’s greats. Securing two undisputed titles is a once-in-a-lifetime achievement.
Website: https://byteyo.com/penguin-and-back-link-amends-from-google-may-2012/
This fight is not just about the belts. It’s a meeting of two unique worldviews. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. Such contrasts make the fight more compelling. It’s about more than just skill. Whoever triumphs in this battle, the impact of this bout will leave a lasting mark on the sport. This historic showdown is more than just a match. It’s a culmination of years of hard work. Whether Tyson Fury prevails with his size and strategy, or Usyk comes out on top through his superior boxing ability, one thing is certain, this will be a fight remembered for years to come.
This fight between Fury and Usyk is more than just a fight. It’s a fight of grit and strategy. These men will leave it all in the ring.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are ready to face each other in a fight of historic proportions. It’s far beyond a championship match; it’s a battle for eternal recognition. Tyson Fury has become a global icon thanks to his personality and remarkable adaptability inside the ropes. Beating Wilder and Klitschko have earned him recognition as one of the best ever. Meanwhile, the tactical southpaw brings an unprecedented test to the heavyweight division. Meanwhile, Usyk, a southpaw master represents a formidable opponent for Tyson Fury himself, but for the entire division. His journey to global fame began in the cruiserweight division, as an undisputed champion. Get ready for a thrilling boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a historic showdown! See every move live on our website. Don’t miss your chance — visit <a href="https://global-rank.pages.dev/03/fIKnghwXNb">https://global-rank.pages.dev/03/fIKnghwXNb</a> right away and watch the match in high quality!
Across the UK, the event will kick off at around 10 PM GMT, making it ideal for a prime-time audience. For Usyk’s fans in Ukraine, and for fans watching from around the world, the excitement is palpable. The fight’s location is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, one thing is certain: the atmosphere will be electric. Even though attention remains on Fury and Usyk, the Fury vs Usyk undercard is also generating excitement. Big-ticket boxing cards often feature stacked undercards, offering an entire night of boxing excitement.
Traditionally, supporting bouts in major events have showcased rising stars. Contenders hoping to make their mark capitalize on the exposure to showcase their skills, knowing millions are watching. Although the lineup for the Fury Usyk undercard haven’t been officially announced, there’s plenty of talk. Could we see rising prospects? Whatever the selection, fans can expect fireworks. The most compelling part of Fury vs Usyk so intriguing is the dynamic between these fighters. Fury’s towering frame and movement are unparalleled in the sport. With his immense height and reach advantage, Fury can control a fight.
The three fights against Wilder proved his toughness, as he recovered from knockdowns to secure victories. Against Wladimir Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. By contrast, Usyk, brings speed, precision, and finesse. As a southpaw, his positioning constantly challenges opponents. The Ukrainian’s shots may not have knockout power, they consistently find their mark. As anticipation builds, The betting lines for Fury vs Usyk are the subject of intense debate.
Tyson Fury is the slight favorite as predicted by many experts, due to his size advantage, his long career in major fights, and his unpredictable nature. Despite the odds, Usyk remains a strong contender shouldn’t be counted out, his wins over Anthony Joshua proved that he can handle the physicality of the heavyweight division.
For the Gypsy King presents a shot at undisputed glory. If he wins, it would solidify his claim as the greatest heavyweight of his generation. Meanwhile, If Usyk wins would elevate him to new heights. Achieving undisputed glory in two divisions would be a remarkable feat in boxing history.
Website: https://global-rank.pages.dev/03/fIKnghwXNb
This fight represents something greater than a title bout. It’s a meeting of two unique worldviews. Fury’s larger-than-life persona contrasts with Usyk’s calm, focused demeanor. Such contrasts make the fight more compelling. It’s a fight of wills and ideologies. Regardless of the outcome, the legacy of this fight will leave a lasting mark on the sport. The battle for heavyweight supremacy is more than just a fight. It’s the pinnacle of both fighters’ hard work. Whether Fury secures the win with his size and strategy, or Usyk comes out on top with his finesse and stamina, one thing is certain, this bout will go down in history.
Fury vs Usyk is more than just a boxing event. It’s a battle of minds and bodies. These men will give everything they have.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are set to meet in the ring of historic proportions. It’s not merely about the belts; it represents their quest for immortality. The towering Fury has risen to the pinnacle of the sport through his unique style coupled with unparalleled talent inside the ropes. Beating Wilder and Klitschko have earned him recognition as one of the best ever. On the other hand, the tactical southpaw poses a unique challenge to the heavyweight division. On the flip side, Usyk, a southpaw master is a true test for Fury for Tyson Fury himself, and for boxing fans worldwide. The ascent of Oleksandr Usyk started with his domination of the cruiserweights, by conquering all challengers. Don’t miss out for a thrilling boxing match of the year as Usyk takes on Tyson Fury in an unforgettable showdown! Experience every moment in real time on our website. Join the excitement — visit <a href="https://wwii-enlistment.com/news/author/admin/page/43/">https://wwii-enlistment.com/news/author/admin/page/43/</a> now and stream the event with top-notch streaming!
Across the UK, the event will kick off at close to prime time, offering perfect timing for viewers. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, this will be a must-see event. The venue for Fury vs Usyk has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. Regardless of the venue, one thing is certain: the atmosphere will be electric. While the spotlight is firmly on the main event, the fights leading up to the main event is also generating excitement. Major boxing events often feature stacked undercards, giving fans a full evening of entertainment.
Traditionally, undercards of this caliber have showcased rising stars. Boxers seeking the spotlight often seize these moments to impress fans and analysts alike, as all eyes are on them. Although the lineup for the Fury Usyk undercard are still unconfirmed, there’s plenty of talk. Will there be a heavyweight clash? No matter the final roster, the action will not disappoint. The most compelling part of Fury vs Usyk truly fascinating is the clash of styles. Tyson Fury’s size and agility set him apart from other heavyweights. Being so tall yet so nimble, he dictates the pace of bouts.
The three fights against Wilder highlighted his resilience, bouncing back from adversity to finish strong. Against Wladimir Klitschko, his strategic genius shone through, showing he’s both powerful and smart. Meanwhile, Usyk, brings speed, precision, and finesse. Being a left-handed fighter, he uses angles and footwork. The Ukrainian’s shots may not have knockout power, they consistently find their mark. As fight night approaches, Predictions for this fight are the subject of intense debate.
The betting lines show Fury ahead as predicted by many experts, given his physical stature, his proven ability in tough situations, and his unorthodox style. However, Usyk's underdog status doesn’t diminish his chances, his dominance against Joshua proved that he can handle the physicality of the heavyweight division.
For Tyson Fury represents an opportunity to cement his legacy. Should he come out on top, Fury’s win would add an undisputed title to his already impressive resume. On the other hand, For Usyk, a win would elevate him to new heights. Securing two undisputed titles would be a remarkable feat in boxing history.
Website: https://wwii-enlistment.com/news/author/admin/page/43/
This fight is not just about the belts. It’s a clash of personalities. Fury’s boisterous personality is in stark contrast to Usyk’s quiet intensity. These differences add complexity to the fight. It’s a fight of wills and ideologies. No matter who wins, the significance of this match will reverberate throughout boxing history. The clash for the undisputed title is more than just a fight. It’s a culmination of years of hard work. Whether Tyson Fury prevails with his experience and unpredictability, or Usyk wins with his precision through his superior boxing ability, what is clear is, this will be a fight remembered for years to come.
Tyson Fury vs Oleksandr Usyk is more than just a boxing event. It’s a contest of heart and willpower. These two warriors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are ready to face each other in a fight of unparalleled significance. It’s far beyond a championship match; it represents their quest for immortality. The towering Fury has earned worldwide fame through his unique style and remarkable adaptability in the ring. Beating Wilder and Klitschko have earned him recognition as one of the best ever. On the other hand, Usyk, the Ukrainian master poses a unique challenge to boxing’s biggest stars. At the same time, Oleksandr Usyk stands as a unique threat for Tyson Fury himself, and for boxing fans worldwide. The ascent of Oleksandr Usyk began in the cruiserweight division, where he became an unstoppable force. Get ready for the most anticipated boxing match of the year as Usyk takes on Fury in a must-watch showdown! Catch every punch streamed live on our website. Be part of the action — visit <a href="https://www.myfirstproperty.co.uk/postcode-houseprices/ME2-3UE">https://www.myfirstproperty.co.uk/postcode-houseprices/ME2-3UE</a> right away and enjoy the fight in high quality!
For British fans, the fight is expected to begin late evening, offering perfect timing for viewers. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, this will be a must-see event. The venue for Fury vs Usyk has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, fans can be sure: it will be a spectacle. Even though attention is centered on the headline fight, the preliminary bouts is also generating excitement. Big-ticket boxing cards often feature stacked undercards, giving fans a full evening of entertainment.
Traditionally, preliminary fights on major cards have introduced future champions. Boxers seeking the spotlight use such opportunities to demonstrate their talent, with the world paying attention. Though the supporting fights for Fury vs Usyk haven’t been officially announced, fans are eagerly guessing. Could we see rising prospects? Regardless of the names, fans can expect fireworks. What sets this bout apart so intriguing is the clash of styles. Tyson Fury’s size and agility make him an anomaly in boxing. At 6’9" with an 85-inch reach, he commands the ring like no other.
His trilogy with Deontay Wilder proved his toughness, bouncing back from adversity to secure victories. When he faced Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Meanwhile, Usyk, relies on technique and stamina. Being a left-handed fighter, his movements create openings. Usyk’s punches aren’t the heaviest in the division, they consistently find their mark. With the date drawing closer, The betting lines for Fury vs Usyk are the subject of intense debate.
The betting lines show Fury ahead based on the betting odds, because of his reach and height, his long career in major fights, and his tactical brilliance. Despite the odds, Usyk remains a strong contender doesn’t rule him out, his victories against AJ confirmed his toughness against big opponents.
For Tyson Fury could be the defining moment of his career. If he wins, it would further solidify his status as the best heavyweight of this era. On the other hand, Usyk’s victory would mark him as one of the sport’s greats. Achieving undisputed glory in two divisions is a rare accomplishment.
Website: https://www.myfirstproperty.co.uk/postcode-houseprices/ME2-3UE
Fury vs Usyk represents something greater than a title bout. It’s a meeting of two unique worldviews. Fury’s bold and unapologetic character stands in stark contrast to Usyk’s composed demeanor. These varying personalities make the bout even more interesting. Beyond physical ability, this fight. Regardless of the outcome, the impact of this bout will reverberate throughout boxing history. The clash for the undisputed title is more than just a fight. It represents the culmination of their careers. Whether Fury secures the win with his experience and unpredictability, or Usyk wins with his precision thanks to his skill and resilience, what is clear is, this will be a defining moment in boxing.
Fury vs Usyk is more than just a sporting contest. It’s a contest of heart and willpower. Both fighters will give everything they have.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are set to meet in the ring that will define an era. It’s far beyond a championship match; it’s a battle for eternal recognition. The towering Fury has become a global icon with his charisma and remarkable adaptability during fights. Beating Wilder and Klitschko have cemented his place among the all-time greats. On the other hand, Usyk, the technician brings an unprecedented test to boxing’s biggest stars. At the same time, Oleksandr Usyk represents a formidable opponent for Tyson Fury himself, and for boxing fans worldwide. Usyk’s rise to prominence began in the cruiserweight division, by conquering all challengers. Prepare yourself for a thrilling boxing match of the year as Usyk takes on Tyson Fury in a must-watch showdown! Catch every punch streamed live on our website. Join the excitement — visit <a href="https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7NQ">https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7NQ</a> today and stream the event from the comfort of your home!
For British fans, the ring walks are planned for around 10 PM GMT, ensuring maximum viewership. In Usyk’s native Ukraine, and for fans watching from around the world, the excitement is palpable. Where the bout will take place has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, it’s guaranteed: the atmosphere will be electric. While the spotlight is firmly on the main event, the preliminary bouts is shaping up to be thrilling. Big-ticket boxing cards often feature stacked undercards, giving fans a full evening of entertainment.
In the past, supporting bouts in major events have been a stage for breakout performances. Contenders hoping to make their mark capitalize on the exposure to impress fans and analysts alike, as all eyes are on them. While the names for the undercard haven’t been officially announced, fans are eagerly guessing. Might there be a cruiserweight spectacle? No matter the final roster, it’s sure to add to the excitement. What sets this bout apart truly fascinating is the clash of styles. Fury’s towering frame and movement are unparalleled in the sport. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
The legendary battles with Wilder highlighted his resilience, as he recovered from knockdowns to secure victories. When he faced Klitschko, his strategic genius shone through, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, relies on technique and stamina. With his unorthodox stance, he uses angles and footwork. The Ukrainian’s shots aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. With the date drawing closer, Predictions for this fight are becoming a hot topic.
Tyson Fury is the slight favorite as per the betting experts, because of his reach and height, his proven ability in tough situations, and his adaptability. Although Usyk is the less favored fighter shouldn’t be counted out, as his victories over Joshua demonstrated his ability in the heavyweight ranks.
For Tyson Fury, this fight could be the defining moment of his career. A victory would add an undisputed title to his already impressive resume. Conversely, Usyk’s victory would elevate him to new heights. Becoming the undisputed heavyweight champion would be a remarkable feat in boxing history.
Website: https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7NQ
Fury vs Usyk is more than just a championship fight. It’s a fight between two very different fighters. Fury’s bold and unapologetic character stands in stark contrast to Usyk’s composed demeanor. These differences add complexity to the fight. Beyond physical ability, this fight. Whoever triumphs in this battle, the legacy of this fight will be felt for years to come. The clash for the undisputed title is a spectacle unlike any other. It’s the result of relentless dedication. If Fury wins thanks to his power and game plan, or Oleksandr Usyk triumphs with his technique and endurance, it’s certain that, this will be a defining moment in boxing.
This fight between Fury and Usyk is more than just a boxing event. It’s a battle of minds and bodies. Both fighters will give everything they have.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are on a collision course of unparalleled significance. It’s not merely about the belts; it’s a battle for eternal recognition. Fury, an undefeated champion has become a global icon with his charisma coupled with unparalleled talent inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. On the other hand, the tactical southpaw poses a unique challenge to the heavyweight division. At the same time, Usyk, a southpaw master stands as a unique threat for Tyson Fury himself, as a heavyweight contender. The ascent of Oleksandr Usyk started with his domination of the cruiserweights, where he became an unstoppable force. Don’t miss out for an epic boxing match of the year as Oleksandr Usyk takes on Fury in a historic showdown! Experience every moment streamed live on our website. Join the excitement — visit <a href="https://ilboscodeibambini.it/watch-tyson-fury-vs-usyk-free-online-live-fight-2/">https://ilboscodeibambini.it/watch-tyson-fury-vs-usyk-free-online-live-fight-2/</a> right away and stream the event from the comfort of your home!
Across the UK, the fight is expected to begin around 10 PM GMT, ensuring maximum viewership. Back in Usyk’s home country, and for fans watching from around the world, the anticipation is at a fever pitch. Where the bout will take place has yet to be confirmed, with talk of iconic boxing destinations. No matter the location, it’s guaranteed: it will be a spectacle. Although the focus is firmly on the main event, the fights leading up to the main event promises plenty of action. High-profile matches often feature stacked undercards, offering an entire night of boxing excitement.
Historically, undercards of this caliber have introduced future champions. Contenders hoping to make their mark capitalize on the exposure to demonstrate their talent, with the world paying attention. While the names for the undercard are still unconfirmed, speculation runs high. Could we see rising prospects? Regardless of the names, fans can expect fireworks. What sets this bout apart incredibly exciting is their contrasting skillsets. Fury’s towering frame and movement make him an anomaly in boxing. At 6’9" with an 85-inch reach, he commands the ring like no other.
The legendary battles with Wilder proved his toughness, bouncing back from adversity to dominate in later rounds. Against Wladimir Klitschko, he out-thought the disciplined champion, showing he’s both powerful and smart. Meanwhile, Usyk, offers a different kind of threat. With his unorthodox stance, he uses angles and footwork. The Ukrainian’s shots may not have knockout power, they consistently find their mark. With the date drawing closer, The betting lines for Fury vs Usyk have fans and analysts speculating.
The betting lines show Fury ahead according to the odds, because of his reach and height, his long career in major fights, and his adaptability. Although Usyk is the less favored fighter doesn’t diminish his chances, his wins over Anthony Joshua proved that he can handle the physicality of the heavyweight division.
For Fury himself represents an opportunity to cement his legacy. A victory would put the finishing touches on a historic career. Meanwhile, For Usyk, a win would elevate him to new heights. Achieving undisputed glory in two divisions is a once-in-a-lifetime achievement.
Website: https://ilboscodeibambini.it/watch-tyson-fury-vs-usyk-free-online-live-fight-2/
The upcoming showdown is more than just a championship fight. It’s a clash of personalities. Fury’s confident and brash nature stands in stark contrast to Usyk’s composed demeanor. These varying personalities make the bout even more interesting. It’s about more than just skill. Whoever comes out victorious, the significance of this match will reverberate throughout boxing history. The clash for the undisputed title is a defining moment. It’s a culmination of years of hard work. Whether Fury secures the win thanks to his power and game plan, or Usyk secures a victory thanks to his skill and resilience, it’s certain that, this bout will go down in history.
The Fury-Usyk battle is more than just a fight. It’s a battle of minds and bodies. These two warriors will leave it all in the ring.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are on a collision course of unparalleled significance. It’s far beyond a championship match; it’s about legacy. The Gypsy King has become a global icon with his charisma and his unmatched skills during fights. Beating Wilder and Klitschko have earned him recognition as one of the best ever. In contrast, Oleksandr Usyk is a fighter unlike any other for Fury. Meanwhile, the Ukrainian technician represents a formidable opponent for Tyson Fury himself, but for the entire division. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, as an undisputed champion. Don’t miss out for an epic boxing match of the year as Usyk takes on Fury in a historic showdown! See every move streamed live on our website. Be part of the action — visit <a href="https://bonusgate.org/?p=844">https://bonusgate.org/?p=844</a> today and enjoy the fight with top-notch streaming!
Across the UK, the fight is expected to begin around 10 PM GMT, offering perfect timing for viewers. Back in Usyk’s home country, and beyond, this will be a must-see event. The venue for Fury vs Usyk is still under speculation, with talk of iconic boxing destinations. No matter the location, fans can be sure: the excitement will be unmatched. While the spotlight remains on Fury and Usyk, the fights leading up to the main event is also generating excitement. High-profile matches include preliminary bouts with top talent, providing non-stop action before the headliner.
Historically, preliminary fights on major cards have been a stage for breakout performances. Contenders hoping to make their mark use such opportunities to showcase their skills, knowing millions are watching. While the names for the undercard haven’t been officially announced, speculation runs high. Could we see rising prospects? No matter the final roster, the action will not disappoint. The most compelling part of Fury vs Usyk incredibly exciting is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed are unparalleled in the sport. Being so tall yet so nimble, Fury can control a fight.
The legendary battles with Wilder proved his toughness, overcoming brutal hits to finish strong. When he faced Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Oleksandr Usyk, on the other hand, relies on technique and stamina. As a southpaw, his movements create openings. The Ukrainian’s shots aren’t the heaviest in the division, they consistently find their mark. As anticipation builds, The betting lines for Fury vs Usyk have fans and analysts speculating.
Tyson Fury is the slight favorite based on the betting odds, because of his reach and height, his long career in major fights, and his unpredictable nature. However, Usyk's underdog status shouldn’t be counted out, his dominance against Joshua confirmed his toughness against big opponents.
For the Gypsy King is a chance to further solidify his greatness. Should he come out on top, Fury’s win would further solidify his status as the best heavyweight of this era. Meanwhile, If Usyk wins would elevate him to new heights. Becoming an undisputed champion in two different weight classes is a rare accomplishment.
Website: https://bonusgate.org/?p=844
Fury vs Usyk represents something greater than a title bout. It’s a meeting of two unique worldviews. Fury’s bold and unapologetic character is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. Beyond physical ability, this fight. Whoever triumphs in this battle, the impact of this bout will reverberate throughout boxing history. This historic showdown is more than just a match. It’s a culmination of years of hard work. Should Fury claim victory thanks to his power and game plan, or Usyk secures a victory thanks to his skill and resilience, no matter the outcome, this will be a defining moment in boxing.
The Fury-Usyk battle is more than just a boxing event. It’s a contest of heart and willpower. These two warriors will give everything they have.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are on a collision course that will define an era. It’s far beyond a championship match; it’s about legacy. Tyson Fury has earned worldwide fame thanks to his personality and remarkable adaptability during fights. Triumphing against boxing legends like Wilder and Klitschko have earned him recognition as one of the best ever. On the other hand, the tactical southpaw brings an unprecedented test to boxing’s biggest stars. On the flip side, the Ukrainian technician stands as a unique threat for the heavyweight ranks overall, as a heavyweight contender. His journey to global fame was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Prepare yourself for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a must-watch showdown! Catch every punch streamed live on our website. Be part of the action — visit <a href="https://www.yukader.org/boxing-match-venue-and-location/">https://www.yukader.org/boxing-match-venue-and-location/</a> right away and enjoy the fight in high quality!
In the United Kingdom, the ring walks are planned for close to prime time, ensuring maximum viewership. Back in Usyk’s home country, and beyond, this will be a must-see event. Where the bout will take place has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, one thing is certain: it will be a spectacle. Even though attention is centered on the headline fight, the Fury vs Usyk undercard is also generating excitement. Major boxing events include preliminary bouts with top talent, giving fans a full evening of entertainment.
In the past, preliminary fights on major cards have showcased rising stars. Fighters looking to rise through the ranks capitalize on the exposure to showcase their skills, knowing millions are watching. While the names for the undercard haven’t been officially announced, fans are eagerly guessing. Might there be a cruiserweight spectacle? Whatever the selection, it’s sure to add to the excitement. What sets this bout apart incredibly exciting is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed are unparalleled in the sport. At 6’9" with an 85-inch reach, he commands the ring like no other.
The three fights against Wilder showed his durability, overcoming brutal hits to finish strong. In his fight with Klitschko, his strategic genius shone through, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. As a southpaw, his positioning constantly challenges opponents. The Ukrainian’s shots aren’t the heaviest in the division, their timing wears down foes. As fight night approaches, Predictions for this fight are the subject of intense debate.
The betting lines show Fury ahead based on the betting odds, thanks to his imposing frame, his proven ability in tough situations, and his tactical brilliance. However, Usyk's underdog status doesn’t mean he’s an underdog in spirit, his victories against AJ showed that he can compete at heavyweight.
For Tyson Fury could be the defining moment of his career. If he wins, it would further solidify his status as the best heavyweight of this era. Meanwhile, Usyk’s victory would elevate him to new heights. Becoming an undisputed champion in two different weight classes is a rare accomplishment.
Website: https://www.yukader.org/boxing-match-venue-and-location/
Fury vs Usyk is more than just a championship fight. It’s a clash of personalities. Fury’s bold and unapologetic character contrasts with Usyk’s calm, focused demeanor. These varying personalities make the bout even more interesting. It’s a fight of wills and ideologies. Whoever comes out victorious, the impact of this bout will reverberate throughout boxing history. The clash for the undisputed title is a defining moment. It’s the pinnacle of both fighters’ hard work. Should Fury claim victory with his size and strategy, or Oleksandr Usyk triumphs thanks to his skill and resilience, it’s certain that, this will be a legendary contest.
Tyson Fury vs Oleksandr Usyk is more than just a fight. It’s a fight of grit and strategy. These men will fight with everything they possess.
Visit for more information: #crosslink[3,L -
These two heavyweight champions are preparing for an epic showdown that will define an era. This fight is about more than just titles; it’s about legacy. Tyson Fury has become a global icon through his unique style and remarkable adaptability during fights. His victories over Deontay Wilder and Wladimir Klitschko have cemented his place among the all-time greats. In contrast, Usyk, the technician is a fighter unlike any other for Fury. On the flip side, the Ukrainian technician stands as a unique threat for Tyson Fury himself, and for boxing fans worldwide. His journey to global fame began in the cruiserweight division, as an undisputed champion. Don’t miss out for the most anticipated boxing match of the year as Usyk takes on Tyson Fury in an unforgettable showdown! Catch every punch live on our website. Join the excitement — visit <a href="https://shamaclinic.se/2024/10/page/63/">https://shamaclinic.se/2024/10/page/63/</a> right away and watch the match with top-notch streaming!
In the United Kingdom, the fight is expected to begin around 10 PM GMT, ensuring maximum viewership. In Usyk’s native Ukraine, and for fans watching from around the world, the anticipation is at a fever pitch. Where the bout will take place has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. No matter the location, it’s guaranteed: the excitement will be unmatched. Although the focus is firmly on the main event, the Fury vs Usyk undercard is also generating excitement. Major boxing events include preliminary bouts with top talent, giving fans a full evening of entertainment.
Traditionally, supporting bouts in major events have showcased rising stars. Contenders hoping to make their mark often seize these moments to impress fans and analysts alike, as all eyes are on them. Though the supporting fights for Fury vs Usyk are still unconfirmed, there’s plenty of talk. Could we see rising prospects? Whatever the selection, fans can expect fireworks. What sets this bout apart truly fascinating is their contrasting skillsets. Fury’s towering frame and movement make him an anomaly in boxing. Being so tall yet so nimble, he dictates the pace of bouts.
The legendary battles with Wilder proved his toughness, bouncing back from adversity to finish strong. In his fight with Klitschko, his strategic genius shone through, showing he’s both powerful and smart. By contrast, Usyk, offers a different kind of threat. Being a left-handed fighter, he uses angles and footwork. The Ukrainian’s shots aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. With the date drawing closer, Tyson Fury vs Usyk odds have fans and analysts speculating.
Tyson Fury is the slight favorite according to the odds, due to his size advantage, his track record in big matches, and his unorthodox style. Although Usyk is the less favored fighter doesn’t mean he’s an underdog in spirit, his victories against AJ demonstrated his ability in the heavyweight ranks.
For Tyson Fury presents a shot at undisputed glory. If he wins, it would add an undisputed title to his already impressive resume. Conversely, For Usyk, a win would elevate him to legendary status. Securing two undisputed titles is a rare accomplishment.
Website: https://shamaclinic.se/2024/10/page/63/
This fight is more than just a championship fight. It’s a meeting of two unique worldviews. Fury’s confident and brash nature contrasts with Usyk’s calm, focused demeanor. These differences add complexity to the fight. It’s about more than just skill. Whoever comes out victorious, the legacy of this fight will reverberate throughout boxing history. This historic showdown is more than just a fight. It’s the result of relentless dedication. Should Fury claim victory thanks to his power and game plan, or Usyk comes out on top through his superior boxing ability, one thing is certain, this will be a defining moment in boxing.
This fight between Fury and Usyk is a spectacle of a lifetime. It’s a showcase of skill and determination. The two competitors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are ready to face each other in a fight of unparalleled significance. It’s far beyond a championship match; it represents their quest for immortality. The Gypsy King has become a global icon thanks to his personality and his unmatched skills in the ring. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. Across the ring, Usyk, the Ukrainian master is a fighter unlike any other for Fury. At the same time, Oleksandr Usyk represents a formidable opponent not just for Fury, and for boxing fans worldwide. Usyk’s rise to prominence began in the cruiserweight division, as an undisputed champion. Get ready for a thrilling boxing match of the year as Usyk takes on Fury in a must-watch showdown! Catch every punch streamed live on our website. Don’t miss your chance — visit <a href="https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7AX">https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7AX</a> today and stream the event in high quality!
Across the UK, the fight is expected to begin late evening, ensuring maximum viewership. For Usyk’s fans in Ukraine, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. Where the bout will take place is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. Regardless of the venue, fans can be sure: it will be a spectacle. While the spotlight is centered on the headline fight, the preliminary bouts is shaping up to be thrilling. Major boxing events are known for strong supporting fights, giving fans a full evening of entertainment.
In the past, undercards of this caliber have been a stage for breakout performances. Fighters looking to rise through the ranks often seize these moments to demonstrate their talent, knowing millions are watching. Although the lineup for the Fury Usyk undercard are still unconfirmed, there’s plenty of talk. Might there be a cruiserweight spectacle? Whatever the selection, fans can expect fireworks. What makes this fight so intriguing is the clash of styles. Tyson Fury’s size and agility are unparalleled in the sport. With his immense height and reach advantage, he commands the ring like no other.
The legendary battles with Wilder highlighted his resilience, bouncing back from adversity to finish strong. In his fight with Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. Being a left-handed fighter, he uses angles and footwork. The Ukrainian’s shots lack devastating strength, they consistently find their mark. As anticipation builds, The betting lines for Fury vs Usyk have fans and analysts speculating.
The betting lines show Fury ahead according to the odds, thanks to his imposing frame, his proven ability in tough situations, and his adaptability. Despite the odds, Usyk remains a strong contender doesn’t diminish his chances, his dominance against Joshua proved that he can handle the physicality of the heavyweight division.
For Tyson Fury presents a shot at undisputed glory. If he wins, it would further solidify his status as the best heavyweight of this era. Conversely, For Usyk, a win would mark him as one of the sport’s greats. Becoming the undisputed heavyweight champion is a feat few can claim.
Website: https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7AX
Fury vs Usyk is about more than the titles. It’s a meeting of two unique worldviews. Fury’s confident and brash nature stands in stark contrast to Usyk’s composed demeanor. The clash of personalities adds depth to the narrative. It’s a fight of wills and ideologies. Whoever comes out victorious, the legacy of this fight will be remembered as a defining moment in boxing. This historic showdown is more than just a fight. It’s a culmination of years of hard work. Whether Fury secures the win thanks to his power and game plan, or Usyk comes out on top thanks to his skill and resilience, it’s certain that, this will be a defining moment in boxing.
This fight between Fury and Usyk is more than just a fight. It’s a fight of grit and strategy. The two competitors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are on a collision course of historic proportions. It’s not merely about the belts; it’s about legacy. Tyson Fury has become a global icon thanks to his personality and remarkable adaptability during fights. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. On the other hand, Usyk, the Ukrainian master poses a unique challenge for Fury. On the flip side, Usyk, a genius in the ring stands as a unique threat for Tyson Fury himself, and for boxing fans worldwide. The ascent of Oleksandr Usyk began in the cruiserweight division, as an undisputed champion. Don’t miss out for an epic boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! See every move streamed live on our website. Be part of the action — visit <a href="https://londinium.com/latlong/51.4291403/0.5402049">https://londinium.com/latlong/51.4291403/0.5402049</a> right away and stream the event from the comfort of your home!
In the United Kingdom, the fight is expected to begin around 10 PM GMT, offering perfect timing for viewers. In Usyk’s native Ukraine, and for fans watching from around the world, this will be a must-see event. The venue for Fury vs Usyk remains a hot topic, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, one thing is certain: the excitement will be unmatched. Even though attention is centered on the headline fight, the preliminary bouts is also generating excitement. High-profile matches include preliminary bouts with top talent, offering an entire night of boxing excitement.
Traditionally, preliminary fights on major cards have introduced future champions. Fighters looking to rise through the ranks capitalize on the exposure to showcase their skills, as all eyes are on them. Although the lineup for the Fury Usyk undercard haven’t been officially announced, there’s plenty of talk. Might there be a cruiserweight spectacle? Whatever the selection, fans can expect fireworks. What sets this bout apart incredibly exciting is their contrasting skillsets. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. Being so tall yet so nimble, Fury can control a fight.
The three fights against Wilder showed his durability, as he recovered from knockdowns to finish strong. In his fight with Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, relies on technique and stamina. With his unorthodox stance, his movements create openings. His strikes lack devastating strength, but they are delivered with pinpoint accuracy. As fight night approaches, Predictions for this fight are the subject of intense debate.
Fury is the favored fighter according to the odds, because of his reach and height, his long career in major fights, and his adaptability. However, Usyk's underdog status shouldn’t be counted out, his wins over Anthony Joshua confirmed his toughness against big opponents.
For Tyson Fury could be the defining moment of his career. If he wins, it would solidify his claim as the greatest heavyweight of his generation. Conversely, For Usyk, a win would mark him as one of the sport’s greats. Securing two undisputed titles would be a remarkable feat in boxing history.
Website: https://londinium.com/latlong/51.4291403/0.5402049
The upcoming showdown is about more than the titles. It’s a fight between two very different fighters. Fury’s bold and unapologetic character is the opposite of Usyk’s humble and disciplined approach. These varying personalities make the bout even more interesting. This is more than just a physical contest. Whoever triumphs in this battle, the significance of this match will reverberate throughout boxing history. The battle for heavyweight supremacy is more than just a match. It represents the culmination of their careers. Whether Tyson Fury prevails through his strength and tactics, or Usyk secures a victory with his technique and endurance, no matter the outcome, this will be a legendary contest.
Tyson Fury vs Oleksandr Usyk is more than just a fight. It’s a showcase of skill and determination. Both fighters will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are on a collision course of historic proportions. It’s not merely about the belts; it’s about legacy. Fury, an undefeated champion has risen to the pinnacle of the sport thanks to his personality and remarkable adaptability during fights. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. In contrast, Oleksandr Usyk brings an unprecedented test to boxing’s biggest stars. Meanwhile, Usyk, a genius in the ring is a true test for Fury for Tyson Fury himself, as a heavyweight contender. Usyk’s rise to prominence started with his domination of the cruiserweights, where he became an unstoppable force. Don’t miss out for an epic boxing match of the year as Usyk takes on Tyson Fury in an unforgettable showdown! See every move streamed live on our website. Join the excitement — visit <a href="https://www.london-11plus.co.uk/content/11-school-admissions">https://www.london-11plus.co.uk/content/11-school-admissions</a> today and enjoy the fight from the comfort of your home!
Across the UK, the event will kick off at late evening, making it ideal for a prime-time audience. Back in Usyk’s home country, as well as viewers across Europe and the Americas, the excitement is palpable. The venue for Fury vs Usyk remains a hot topic, with talk of iconic boxing destinations. Wherever it happens, fans can be sure: the atmosphere will be electric. Although the focus remains on Fury and Usyk, the fights leading up to the main event is shaping up to be thrilling. High-profile matches include preliminary bouts with top talent, giving fans a full evening of entertainment.
Historically, undercards of this caliber have showcased rising stars. Contenders hoping to make their mark use such opportunities to showcase their skills, with the world paying attention. Though the supporting fights for Fury vs Usyk has yet to be finalized, there’s plenty of talk. Might there be a cruiserweight spectacle? Regardless of the names, fans can expect fireworks. What makes this fight so intriguing is the clash of styles. Fury’s towering frame and movement make him an anomaly in boxing. Being so tall yet so nimble, Fury can control a fight.
His trilogy with Deontay Wilder proved his toughness, overcoming brutal hits to secure victories. Against Wladimir Klitschko, his strategic genius shone through, showing he’s both powerful and smart. By contrast, Usyk, brings speed, precision, and finesse. With his unorthodox stance, his movements create openings. His strikes may not have knockout power, their timing wears down foes. As anticipation builds, The betting lines for Fury vs Usyk are the subject of intense debate.
Tyson Fury is the slight favorite as per the betting experts, given his physical stature, his experience in high-pressure bouts, and his unorthodox style. Despite being seen as the underdog doesn’t rule him out, his victories against AJ demonstrated his ability in the heavyweight ranks.
For Tyson Fury, this fight could be the defining moment of his career. A triumph for Fury would put the finishing touches on a historic career. Conversely, Usyk’s victory would be a monumental achievement. Achieving undisputed glory in two divisions is a once-in-a-lifetime achievement.
Website: https://www.london-11plus.co.uk/content/11-school-admissions
Fury vs Usyk represents something greater than a title bout. It’s a fight between two very different fighters. Fury’s larger-than-life persona stands in stark contrast to Usyk’s composed demeanor. These varying personalities make the bout even more interesting. It’s a fight of wills and ideologies. Whoever comes out victorious, the impact of this bout will be remembered as a defining moment in boxing. Fury vs Usyk is more than just a match. It’s the pinnacle of both fighters’ hard work. Whether Fury secures the win through his strength and tactics, or Usyk comes out on top thanks to his skill and resilience, what is clear is, this bout will go down in history.
This fight between Fury and Usyk is more than just a fight. It’s a battle of minds and bodies. These men will give everything they have.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are ready to face each other in a fight of historic proportions. It’s not merely about the belts; it represents their quest for immortality. The Gypsy King has risen to the pinnacle of the sport with his charisma and his unmatched skills in the ring. His victories over Deontay Wilder and Wladimir Klitschko have cemented his place among the all-time greats. On the other hand, Oleksandr Usyk poses a unique challenge to boxing’s biggest stars. At the same time, Usyk, a genius in the ring stands as a unique threat not just for Fury, as a heavyweight contender. His journey to global fame began in the cruiserweight division, by conquering all challengers. Get ready for a thrilling boxing match of the year as Oleksandr Usyk takes on Fury in an unforgettable showdown! Experience every moment live on our website. Join the excitement — visit <a href="https://ssncdirect.com/fury-vs-usyk-betting-expert-tips-odds-and-13/">https://ssncdirect.com/fury-vs-usyk-betting-expert-tips-odds-and-13/</a> now and stream the event from the comfort of your home!
In the United Kingdom, the fight is expected to begin close to prime time, making it ideal for a prime-time audience. Back in Usyk’s home country, and beyond, the excitement is palpable. The fight’s location remains a hot topic, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, fans can be sure: it will be a spectacle. While the spotlight remains on Fury and Usyk, the fights leading up to the main event promises plenty of action. High-profile matches often feature stacked undercards, offering an entire night of boxing excitement.
Historically, undercards of this caliber have been a stage for breakout performances. Contenders hoping to make their mark use such opportunities to impress fans and analysts alike, as all eyes are on them. Although the lineup for the Fury Usyk undercard has yet to be finalized, speculation runs high. Might there be a cruiserweight spectacle? Regardless of the names, it’s sure to add to the excitement. The most compelling part of Fury vs Usyk truly fascinating is the dynamic between these fighters. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. Being so tall yet so nimble, he dictates the pace of bouts.
His trilogy with Deontay Wilder proved his toughness, as he recovered from knockdowns to secure victories. In his fight with Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. By contrast, Usyk, brings speed, precision, and finesse. With his unorthodox stance, his positioning constantly challenges opponents. His strikes may not have knockout power, but they are delivered with pinpoint accuracy. As fight night approaches, Predictions for this fight are the subject of intense debate.
The betting lines show Fury ahead according to the odds, given his physical stature, his experience in high-pressure bouts, and his unpredictable nature. However, Usyk's underdog status doesn’t rule him out, his dominance against Joshua demonstrated his ability in the heavyweight ranks.
For the Gypsy King represents an opportunity to cement his legacy. If he wins, it would further solidify his status as the best heavyweight of this era. On the other hand, If Usyk wins would elevate him to new heights. Securing two undisputed titles is a feat few can claim.
Website: https://ssncdirect.com/fury-vs-usyk-betting-expert-tips-odds-and-13/
The upcoming showdown is about more than the titles. It’s a fight between two very different fighters. Fury’s bold and unapologetic character is in stark contrast to Usyk’s quiet intensity. The clash of personalities adds depth to the narrative. Beyond physical ability, this fight. Whoever comes out victorious, the legacy of this fight will leave a lasting mark on the sport. Fury vs Usyk is more than just a match. It’s a culmination of years of hard work. Whether Tyson Fury prevails thanks to his power and game plan, or Usyk secures a victory with his finesse and stamina, one thing is certain, this will be a defining moment in boxing.
Fury vs Usyk is more than just a sporting contest. It’s a fight of grit and strategy. Both fighters will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are preparing for an epic showdown that will define an era. This fight is about more than just titles; it’s a battle for eternal recognition. Fury, an undefeated champion has risen to the pinnacle of the sport with his charisma and his unmatched skills during fights. Triumphing against boxing legends like Wilder and Klitschko have cemented his place among the all-time greats. Meanwhile, Usyk, the Ukrainian master poses a unique challenge to boxing’s biggest stars. On the flip side, Usyk, a southpaw master represents a formidable opponent for the heavyweight ranks overall, and for boxing fans worldwide. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, where he became an unstoppable force. Get ready for an epic boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a must-watch showdown! See every move in real time on our website. Join the excitement — visit <a href="http://www.alhuda.org.uk/hundredofhooacademy-co-uk-new/fury-vs-usyk-expert-predictions-and-betting-19">http://www.alhuda.org.uk/hundredofhooacademy-co-uk-new/fury-vs-usyk-expert-predictions-and-betting-19</a> right away and watch the match in high quality!
For British fans, the fight is expected to begin late evening, making it ideal for a prime-time audience. Back in Usyk’s home country, and for fans watching from around the world, this will be a must-see event. The venue for Fury vs Usyk has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. No matter the location, it’s guaranteed: the atmosphere will be electric. While the spotlight is centered on the headline fight, the Fury vs Usyk undercard promises plenty of action. Major boxing events include preliminary bouts with top talent, giving fans a full evening of entertainment.
In the past, undercards of this caliber have been a stage for breakout performances. Fighters looking to rise through the ranks often seize these moments to impress fans and analysts alike, knowing millions are watching. Though the supporting fights for Fury vs Usyk are still unconfirmed, fans are eagerly guessing. Might there be a cruiserweight spectacle? No matter the final roster, it’s sure to add to the excitement. The most compelling part of Fury vs Usyk truly fascinating is the dynamic between these fighters. Fury’s towering frame and movement are unparalleled in the sport. With his immense height and reach advantage, he dictates the pace of bouts.
The three fights against Wilder proved his toughness, as he recovered from knockdowns to dominate in later rounds. In his fight with Klitschko, his strategic genius shone through, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, brings speed, precision, and finesse. Being a left-handed fighter, he uses angles and footwork. His strikes may not have knockout power, their timing wears down foes. As fight night approaches, The betting lines for Fury vs Usyk are the subject of intense debate.
The betting lines show Fury ahead as per the betting experts, due to his size advantage, his proven ability in tough situations, and his unorthodox style. Despite the odds, Usyk remains a strong contender shouldn’t be counted out, his dominance against Joshua proved that he can handle the physicality of the heavyweight division.
For the Gypsy King represents an opportunity to cement his legacy. A triumph for Fury would further solidify his status as the best heavyweight of this era. Meanwhile, For Usyk, a win would elevate him to new heights. Achieving undisputed glory in two divisions is a once-in-a-lifetime achievement.
Website: http://www.alhuda.org.uk/hundredofhooacademy-co-uk-new/fury-vs-usyk-expert-predictions-and-betting-19
The upcoming showdown represents something greater than a title bout. It’s a meeting of two unique worldviews. Fury’s confident and brash nature stands in stark contrast to Usyk’s composed demeanor. Such contrasts make the fight more compelling. Beyond physical ability, this fight. Whoever comes out victorious, the legacy of this fight will be felt for years to come. This historic showdown is more than just a match. It represents the culmination of their careers. Whether Fury secures the win with his size and strategy, or Oleksandr Usyk triumphs with his technique and endurance, it’s certain that, this will be a defining moment in boxing.
This fight between Fury and Usyk is more than just a boxing event. It’s a battle of minds and bodies. These two warriors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are preparing for an epic showdown that will define an era. It’s not merely about the belts; it’s a battle for eternal recognition. The towering Fury has risen to the pinnacle of the sport with his charisma and his unmatched skills in the ring. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. Across the ring, Usyk, the Ukrainian master is a fighter unlike any other for Fury. Meanwhile, Usyk, a genius in the ring represents a formidable opponent for Tyson Fury himself, and for boxing fans worldwide. Usyk’s rise to prominence began in the cruiserweight division, by conquering all challengers. Prepare yourself for an epic boxing match of the year as Usyk takes on Tyson Fury in a must-watch showdown! Catch every punch in real time on our website. Don’t miss your chance — visit <a href="https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7AX">https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7AX</a> today and watch the match with top-notch streaming!
For British fans, the fight is expected to begin late evening, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and for fans watching from around the world, this will be a must-see event. The venue for Fury vs Usyk is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. Regardless of the venue, it’s guaranteed: the atmosphere will be electric. Even though attention remains on Fury and Usyk, the fights leading up to the main event is also generating excitement. Major boxing events are known for strong supporting fights, giving fans a full evening of entertainment.
In the past, undercards of this caliber have been a stage for breakout performances. Contenders hoping to make their mark use such opportunities to demonstrate their talent, as all eyes are on them. Although the lineup for the Fury Usyk undercard has yet to be finalized, fans are eagerly guessing. Could we see rising prospects? Whatever the selection, the action will not disappoint. The most compelling part of Fury vs Usyk truly fascinating is their contrasting skillsets. Tyson Fury’s size and agility are unparalleled in the sport. At 6’9" with an 85-inch reach, he commands the ring like no other.
The three fights against Wilder proved his toughness, as he recovered from knockdowns to finish strong. When he faced Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. Meanwhile, Usyk, offers a different kind of threat. As a southpaw, his positioning constantly challenges opponents. Usyk’s punches aren’t the heaviest in the division, they consistently find their mark. With the date drawing closer, Tyson Fury vs Usyk odds are the subject of intense debate.
Tyson Fury is the slight favorite as per the betting experts, given his physical stature, his track record in big matches, and his unpredictable nature. Despite being seen as the underdog shouldn’t be counted out, his victories against AJ demonstrated his ability in the heavyweight ranks.
For Fury himself presents a shot at undisputed glory. A triumph for Fury would solidify his claim as the greatest heavyweight of his generation. On the other hand, For Usyk, a win would be a monumental achievement. Achieving undisputed glory in two divisions is a feat few can claim.
Website: https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7AX
This fight represents something greater than a title bout. It’s a meeting of two unique worldviews. Fury’s confident and brash nature stands in stark contrast to Usyk’s composed demeanor. These differences add complexity to the fight. This is more than just a physical contest. Regardless of the outcome, the impact of this bout will leave a lasting mark on the sport. Fury vs Usyk is more than just a fight. It’s the result of relentless dedication. Whether Fury secures the win with his size and strategy, or Usyk wins with his precision with his technique and endurance, it’s certain that, this will be a fight remembered for years to come.
The Fury-Usyk battle is more than just a boxing event. It’s a showcase of skill and determination. The two competitors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are on a collision course of unparalleled significance. This fight is about more than just titles; it’s about legacy. Fury, an undefeated champion has earned worldwide fame through his unique style and his unmatched skills during fights. Beating Wilder and Klitschko have solidified his legendary status. Meanwhile, Usyk, the technician brings an unprecedented test to the heavyweight division. At the same time, the Ukrainian technician represents a formidable opponent for Tyson Fury himself, and for boxing fans worldwide. His journey to global fame was marked by his undisputed cruiserweight reign, by conquering all challengers. Prepare yourself for the most anticipated boxing match of the year as Usyk takes on Tyson Fury in a historic showdown! Experience every moment in real time on our website. Join the excitement — visit <a href="https://www.hopemediakenya.org/fury-vs-usyk-watch-the-heavyweight-showdown-live-4/">https://www.hopemediakenya.org/fury-vs-usyk-watch-the-heavyweight-showdown-live-4/</a> today and watch the match in high quality!
Across the UK, the event will kick off at around 10 PM GMT, making it ideal for a prime-time audience. Back in Usyk’s home country, and for fans watching from around the world, the excitement is palpable. The fight’s location has yet to be confirmed, with suggestions ranging from Las Vegas to Saudi Arabia. Regardless of the venue, one thing is certain: the excitement will be unmatched. Although the focus is centered on the headline fight, the preliminary bouts promises plenty of action. Big-ticket boxing cards often feature stacked undercards, giving fans a full evening of entertainment.
Historically, preliminary fights on major cards have been a stage for breakout performances. Fighters looking to rise through the ranks often seize these moments to demonstrate their talent, as all eyes are on them. While the names for the undercard haven’t been officially announced, there’s plenty of talk. Could we see rising prospects? Regardless of the names, fans can expect fireworks. What makes this fight so intriguing is the dynamic between these fighters. Fury’s towering frame and movement set him apart from other heavyweights. Being so tall yet so nimble, he dictates the pace of bouts.
The legendary battles with Wilder highlighted his resilience, bouncing back from adversity to secure victories. When he faced Klitschko, his strategic genius shone through, proving he’s not just physical but cerebral. Meanwhile, Usyk, offers a different kind of threat. Being a left-handed fighter, his positioning constantly challenges opponents. His strikes aren’t the heaviest in the division, their timing wears down foes. With the date drawing closer, Predictions for this fight are becoming a hot topic.
Tyson Fury is seen as the frontrunner as predicted by many experts, because of his reach and height, his proven ability in tough situations, and his unorthodox style. Despite being seen as the underdog doesn’t rule him out, his wins over Anthony Joshua demonstrated his ability in the heavyweight ranks.
For Tyson Fury, this fight could be the defining moment of his career. A victory would further solidify his status as the best heavyweight of this era. Conversely, If Usyk wins would elevate him to legendary status. Achieving undisputed glory in two divisions is a rare accomplishment.
Website: https://www.hopemediakenya.org/fury-vs-usyk-watch-the-heavyweight-showdown-live-4/
Fury vs Usyk is about more than the titles. It’s a fight between two very different fighters. Fury’s boisterous personality stands in stark contrast to Usyk’s composed demeanor. These varying personalities make the bout even more interesting. It’s a fight of wills and ideologies. Whoever comes out victorious, the significance of this match will reverberate throughout boxing history. The battle for heavyweight supremacy is more than just a match. It’s a culmination of years of hard work. Whether Tyson Fury prevails through his strength and tactics, or Oleksandr Usyk triumphs with his finesse and stamina, what is clear is, this will be a fight remembered for years to come.
Tyson Fury vs Oleksandr Usyk is a spectacle of a lifetime. It’s a showcase of skill and determination. The two competitors will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Fury, the Gypsy King, and Usyk, the technician are ready to face each other in a fight of unparalleled significance. This fight is about more than just titles; it’s a battle for eternal recognition. Tyson Fury has earned worldwide fame through his unique style and his unmatched skills inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. Meanwhile, the tactical southpaw poses a unique challenge to boxing’s biggest stars. Meanwhile, Oleksandr Usyk stands as a unique threat for Tyson Fury himself, but for the entire division. The ascent of Oleksandr Usyk began in the cruiserweight division, where he became an unstoppable force. Get ready for an epic boxing match of the year as Oleksandr Usyk takes on Fury in a historic showdown! Catch every punch live on our website. Join the excitement — visit <a href="https://naturopat.co.il/how-to-watch-fury-vs-usyk-live-stream/">https://naturopat.co.il/how-to-watch-fury-vs-usyk-live-stream/</a> now and watch the match with top-notch streaming!
In the United Kingdom, the event will kick off at around 10 PM GMT, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and for fans watching from around the world, the anticipation is at a fever pitch. Where the bout will take place has yet to be confirmed, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, it’s guaranteed: the excitement will be unmatched. Although the focus is centered on the headline fight, the Fury vs Usyk undercard is shaping up to be thrilling. High-profile matches often feature stacked undercards, providing non-stop action before the headliner.
In the past, supporting bouts in major events have introduced future champions. Contenders hoping to make their mark often seize these moments to impress fans and analysts alike, knowing millions are watching. Though the supporting fights for Fury vs Usyk has yet to be finalized, speculation runs high. Will there be a heavyweight clash? No matter the final roster, the action will not disappoint. The most compelling part of Fury vs Usyk incredibly exciting is the clash of styles. Tyson Fury’s size and agility make him an anomaly in boxing. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
The legendary battles with Wilder proved his toughness, as he recovered from knockdowns to secure victories. Against Wladimir Klitschko, he out-thought the disciplined champion, proving he’s not just physical but cerebral. By contrast, Usyk, offers a different kind of threat. Being a left-handed fighter, he uses angles and footwork. His strikes may not have knockout power, they consistently find their mark. With the date drawing closer, The betting lines for Fury vs Usyk have fans and analysts speculating.
Tyson Fury is the slight favorite as per the betting experts, because of his reach and height, his track record in big matches, and his unpredictable nature. Although Usyk is the less favored fighter doesn’t mean he’s an underdog in spirit, his dominance against Joshua showed that he can compete at heavyweight.
For Tyson Fury represents an opportunity to cement his legacy. Should he come out on top, Fury’s win would put the finishing touches on a historic career. Conversely, Usyk’s victory would elevate him to new heights. Securing two undisputed titles is a once-in-a-lifetime achievement.
Website: https://naturopat.co.il/how-to-watch-fury-vs-usyk-live-stream/
The upcoming showdown is about more than the titles. It’s a fight between two very different fighters. Fury’s boisterous personality stands in stark contrast to Usyk’s composed demeanor. These differences add complexity to the fight. It’s a fight of wills and ideologies. No matter who wins, the significance of this match will leave a lasting mark on the sport. The battle for heavyweight supremacy is more than just a match. It’s the pinnacle of both fighters’ hard work. Whether Tyson Fury prevails with his experience and unpredictability, or Oleksandr Usyk triumphs thanks to his skill and resilience, it’s certain that, this will be a legendary contest.
This fight between Fury and Usyk is more than just a boxing event. It’s a battle of minds and bodies. These men will leave it all in the ring.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are preparing for an epic showdown of historic proportions. This fight is about more than just titles; it’s a battle for eternal recognition. Tyson Fury has earned worldwide fame thanks to his personality and remarkable adaptability in the ring. His victories over Deontay Wilder and Wladimir Klitschko have solidified his legendary status. Across the ring, the tactical southpaw brings an unprecedented test to boxing’s biggest stars. At the same time, Oleksandr Usyk is a true test for Fury for the heavyweight ranks overall, as a heavyweight contender. His journey to global fame began in the cruiserweight division, by conquering all challengers. Prepare yourself for a thrilling boxing match of the year as Usyk takes on Fury in a historic showdown! Experience every moment streamed live on our website. Be part of the action — visit <a href="https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7JX">https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7JX</a> today and enjoy the fight with top-notch streaming!
Across the UK, the event will kick off at close to prime time, making it ideal for a prime-time audience. In Usyk’s native Ukraine, and beyond, the anticipation is at a fever pitch. The fight’s location remains a hot topic, with talk of iconic boxing destinations. Wherever it happens, fans can be sure: the atmosphere will be electric. Even though attention is centered on the headline fight, the fights leading up to the main event promises plenty of action. Major boxing events include preliminary bouts with top talent, providing non-stop action before the headliner.
Historically, preliminary fights on major cards have showcased rising stars. Contenders hoping to make their mark capitalize on the exposure to demonstrate their talent, knowing millions are watching. Though the supporting fights for Fury vs Usyk haven’t been officially announced, there’s plenty of talk. Could we see rising prospects? No matter the final roster, it’s sure to add to the excitement. What makes this fight incredibly exciting is the dynamic between these fighters. Fury’s towering frame and movement make him an anomaly in boxing. With his immense height and reach advantage, he dictates the pace of bouts.
His trilogy with Deontay Wilder showed his durability, as he recovered from knockdowns to finish strong. Against Wladimir Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Meanwhile, Usyk, relies on technique and stamina. As a southpaw, he uses angles and footwork. Usyk’s punches may not have knockout power, they consistently find their mark. As fight night approaches, The betting lines for Fury vs Usyk have fans and analysts speculating.
Most bookmakers favor Fury according to the odds, due to his size advantage, his experience in high-pressure bouts, and his unorthodox style. Although Usyk is the less favored fighter doesn’t rule him out, his dominance against Joshua confirmed his toughness against big opponents.
For the Gypsy King could be the defining moment of his career. A triumph for Fury would put the finishing touches on a historic career. Conversely, Usyk’s victory would elevate him to new heights. Becoming an undisputed champion in two different weight classes is a once-in-a-lifetime achievement.
Website: https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7JX
Fury vs Usyk represents something greater than a title bout. It’s a battle of contrasting styles. Fury’s bold and unapologetic character contrasts with Usyk’s calm, focused demeanor. These differences add complexity to the fight. It’s a fight of wills and ideologies. Whoever triumphs in this battle, the significance of this match will reverberate throughout boxing history. The battle for heavyweight supremacy is more than just a fight. It’s the result of relentless dedication. If Fury wins with his experience and unpredictability, or Usyk comes out on top thanks to his skill and resilience, no matter the outcome, this will be a fight remembered for years to come.
The Fury-Usyk battle is a spectacle of a lifetime. It’s a showcase of skill and determination. These men will give everything they have.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are on a collision course of historic proportions. This fight is about more than just titles; it’s a battle for eternal recognition. The Gypsy King has earned worldwide fame thanks to his personality coupled with unparalleled talent inside the ropes. Triumphing against boxing legends like Wilder and Klitschko have solidified his legendary status. In contrast, the tactical southpaw poses a unique challenge to boxing’s biggest stars. At the same time, Oleksandr Usyk is a true test for Fury for the heavyweight ranks overall, and for boxing fans worldwide. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, as an undisputed champion. Prepare yourself for the most anticipated boxing match of the year as Oleksandr Usyk takes on Tyson Fury in a historic showdown! Experience every moment streamed live on our website. Be part of the action — visit <a href="https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7EJ">https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7EJ</a> today and watch the match from the comfort of your home!
In the United Kingdom, the event will kick off at close to prime time, making it ideal for a prime-time audience. In Usyk’s native Ukraine, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. The venue for Fury vs Usyk has yet to be confirmed, with talk of iconic boxing destinations. Wherever it happens, fans can be sure: it will be a spectacle. Even though attention is centered on the headline fight, the Fury vs Usyk undercard promises plenty of action. Major boxing events are known for strong supporting fights, providing non-stop action before the headliner.
Traditionally, preliminary fights on major cards have introduced future champions. Contenders hoping to make their mark often seize these moments to impress fans and analysts alike, knowing millions are watching. Though the supporting fights for Fury vs Usyk haven’t been officially announced, fans are eagerly guessing. Could we see rising prospects? Regardless of the names, the action will not disappoint. What makes this fight so intriguing is the clash of styles. The Gypsy King’s unusual blend of height and speed make him an anomaly in boxing. At 6’9" with an 85-inch reach, he dictates the pace of bouts.
His trilogy with Deontay Wilder highlighted his resilience, as he recovered from knockdowns to finish strong. Against Wladimir Klitschko, his strategic genius shone through, showing he’s both powerful and smart. Oleksandr Usyk, on the other hand, offers a different kind of threat. As a southpaw, he uses angles and footwork. His strikes aren’t the heaviest in the division, but they are delivered with pinpoint accuracy. As fight night approaches, The betting lines for Fury vs Usyk are becoming a hot topic.
Tyson Fury is seen as the frontrunner as per the betting experts, because of his reach and height, his track record in big matches, and his tactical brilliance. Despite being seen as the underdog doesn’t diminish his chances, his wins over Anthony Joshua proved that he can handle the physicality of the heavyweight division.
For the Gypsy King is a chance to further solidify his greatness. If he wins, it would put the finishing touches on a historic career. Conversely, For Usyk, a win would be a monumental achievement. Achieving undisputed glory in two divisions is a rare accomplishment.
Website: https://www.myfirstproperty.co.uk/postcode-houseprices/ME3-7EJ
Fury vs Usyk is not just about the belts. It’s a clash of personalities. Fury’s boisterous personality is the opposite of Usyk’s humble and disciplined approach. These differences add complexity to the fight. It’s a fight of wills and ideologies. Regardless of the outcome, the legacy of this fight will leave a lasting mark on the sport. This historic showdown is a spectacle unlike any other. It represents the culmination of their careers. If Fury wins through his strength and tactics, or Usyk wins with his precision thanks to his skill and resilience, it’s certain that, this will be a legendary contest.
The Fury-Usyk battle is more than just a boxing event. It’s a contest of heart and willpower. Both fighters will give everything they have.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are preparing for an epic showdown of unparalleled significance. It’s far beyond a championship match; it’s a battle for eternal recognition. Tyson Fury has risen to the pinnacle of the sport through his unique style and remarkable adaptability inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have cemented his place among the all-time greats. On the other hand, Oleksandr Usyk is a fighter unlike any other to the heavyweight division. Meanwhile, Usyk, a genius in the ring is a true test for Fury for Tyson Fury himself, and for boxing fans worldwide. The ascent of Oleksandr Usyk began in the cruiserweight division, as an undisputed champion. Prepare yourself for a thrilling boxing match of the year as Usyk takes on Fury in an unforgettable showdown! Experience every moment in real time on our website. Join the excitement — visit <a href="https://prolinksdirectory.com/website-list-2387/">https://prolinksdirectory.com/website-list-2387/</a> today and enjoy the fight in high quality!
In the United Kingdom, the ring walks are planned for late evening, ensuring maximum viewership. Back in Usyk’s home country, as well as viewers across Europe and the Americas, this will be a must-see event. The venue for Fury vs Usyk is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, fans can be sure: the excitement will be unmatched. While the spotlight is firmly on the main event, the fights leading up to the main event is shaping up to be thrilling. Big-ticket boxing cards are known for strong supporting fights, providing non-stop action before the headliner.
In the past, undercards of this caliber have been a stage for breakout performances. Boxers seeking the spotlight use such opportunities to showcase their skills, as all eyes are on them. Although the lineup for the Fury Usyk undercard are still unconfirmed, fans are eagerly guessing. Will there be a heavyweight clash? No matter the final roster, fans can expect fireworks. What sets this bout apart truly fascinating is their contrasting skillsets. Fury’s towering frame and movement are unparalleled in the sport. With his immense height and reach advantage, he dictates the pace of bouts.
His trilogy with Deontay Wilder proved his toughness, bouncing back from adversity to finish strong. In his fight with Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. Meanwhile, Usyk, relies on technique and stamina. With his unorthodox stance, he uses angles and footwork. The Ukrainian’s shots lack devastating strength, but they are delivered with pinpoint accuracy. With the date drawing closer, Predictions for this fight are becoming a hot topic.
Tyson Fury is seen as the frontrunner as per the betting experts, thanks to his imposing frame, his track record in big matches, and his unpredictable nature. Despite the odds, Usyk remains a strong contender shouldn’t be counted out, his victories against AJ demonstrated his ability in the heavyweight ranks.
For Tyson Fury represents an opportunity to cement his legacy. Should he come out on top, Fury’s win would solidify his claim as the greatest heavyweight of his generation. Conversely, If Usyk wins would be a monumental achievement. Securing two undisputed titles is a once-in-a-lifetime achievement.
Website: https://prolinksdirectory.com/website-list-2387/
The upcoming showdown represents something greater than a title bout. It’s a battle of contrasting styles. Fury’s bold and unapologetic character is in stark contrast to Usyk’s quiet intensity. These varying personalities make the bout even more interesting. This is more than just a physical contest. Whoever comes out victorious, the impact of this bout will be felt for years to come. The clash for the undisputed title is a defining moment. It’s the pinnacle of both fighters’ hard work. Should Fury claim victory through his strength and tactics, or Usyk comes out on top thanks to his skill and resilience, one thing is certain, this will be a fight remembered for years to come.
Tyson Fury vs Oleksandr Usyk is a spectacle of a lifetime. It’s a showcase of skill and determination. The two competitors will pour everything into the bout.
Visit for more information: #crosslink[3,L -
The undefeated Fury and Usyk are set to meet in the ring of unparalleled significance. It’s far beyond a championship match; it represents their quest for immortality. Fury, an undefeated champion has become a global icon thanks to his personality and his unmatched skills during fights. Beating Wilder and Klitschko have earned him recognition as one of the best ever. Across the ring, Oleksandr Usyk poses a unique challenge for Fury. Meanwhile, Oleksandr Usyk represents a formidable opponent not just for Fury, but for the entire division. The ascent of Oleksandr Usyk was marked by his undisputed cruiserweight reign, by conquering all challengers. Get ready for a thrilling boxing match of the year as Oleksandr Usyk takes on Fury in a historic showdown! Experience every moment streamed live on our website. Join the excitement — visit <a href="http://cleanpark.ge/en/author/iko/page/435/">http://cleanpark.ge/en/author/iko/page/435/</a> right away and stream the event from the comfort of your home!
Across the UK, the event will kick off at around 10 PM GMT, ensuring maximum viewership. Back in Usyk’s home country, as well as viewers across Europe and the Americas, the excitement is palpable. The venue for Fury vs Usyk remains a hot topic, and potential hosts include Saudi Arabia or Las Vegas. Regardless of the venue, it’s guaranteed: the atmosphere will be electric. While the spotlight remains on Fury and Usyk, the fights leading up to the main event promises plenty of action. Big-ticket boxing cards are known for strong supporting fights, giving fans a full evening of entertainment.
Traditionally, preliminary fights on major cards have been a stage for breakout performances. Contenders hoping to make their mark often seize these moments to demonstrate their talent, with the world paying attention. While the names for the undercard are still unconfirmed, there’s plenty of talk. Will there be a heavyweight clash? Whatever the selection, the action will not disappoint. What makes this fight incredibly exciting is their contrasting skillsets. Tyson Fury’s size and agility are unparalleled in the sport. With his immense height and reach advantage, Fury can control a fight.
His trilogy with Deontay Wilder proved his toughness, bouncing back from adversity to dominate in later rounds. In his fight with Klitschko, Fury showcased his tactical brilliance, showing he’s both powerful and smart. By contrast, Usyk, offers a different kind of threat. As a southpaw, his positioning constantly challenges opponents. The Ukrainian’s shots lack devastating strength, their timing wears down foes. With the date drawing closer, Tyson Fury vs Usyk odds are becoming a hot topic.
Fury is the favored fighter based on the betting odds, because of his reach and height, his track record in big matches, and his tactical brilliance. However, Usyk's underdog status doesn’t diminish his chances, his wins over Anthony Joshua showed that he can compete at heavyweight.
For Fury himself is a chance to further solidify his greatness. If he wins, it would solidify his claim as the greatest heavyweight of his generation. On the other hand, Usyk’s victory would elevate him to legendary status. Securing two undisputed titles is a rare accomplishment.
Website: http://cleanpark.ge/en/author/iko/page/435/
Fury vs Usyk is more than just a championship fight. It’s a meeting of two unique worldviews. Fury’s larger-than-life persona contrasts with Usyk’s calm, focused demeanor. The clash of personalities adds depth to the narrative. It’s about more than just skill. Regardless of the outcome, the impact of this bout will leave a lasting mark on the sport. This historic showdown is a spectacle unlike any other. It’s the pinnacle of both fighters’ hard work. Should Fury claim victory with his experience and unpredictability, or Usyk secures a victory with his technique and endurance, no matter the outcome, this will be a defining moment in boxing.
Fury vs Usyk is more than just a sporting contest. It’s a fight of grit and strategy. Both fighters will leave it all in the ring.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are ready to face each other in a fight of unparalleled significance. It’s not merely about the belts; it’s a battle for eternal recognition. The Gypsy King has risen to the pinnacle of the sport thanks to his personality and his unmatched skills inside the ropes. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. In contrast, the tactical southpaw brings an unprecedented test to the heavyweight division. At the same time, Oleksandr Usyk represents a formidable opponent not just for Fury, as a heavyweight contender. Usyk’s rise to prominence was marked by his undisputed cruiserweight reign, as an undisputed champion. Prepare yourself for the most anticipated boxing match of the year as Oleksandr Usyk takes on Fury in an unforgettable showdown! Experience every moment live on our website. Don’t miss your chance — visit <a href="https://arkitechno.com/fury-vs-usyk-predicting-the-heavyweight-showdown-41/">https://arkitechno.com/fury-vs-usyk-predicting-the-heavyweight-showdown-41/</a> now and watch the match in high quality!
Across the UK, the event will kick off at around 10 PM GMT, offering perfect timing for viewers. Back in Usyk’s home country, as well as viewers across Europe and the Americas, the anticipation is at a fever pitch. Where the bout will take place is still under speculation, with suggestions ranging from Las Vegas to Saudi Arabia. Wherever it happens, fans can be sure: the excitement will be unmatched. Even though attention is firmly on the main event, the Fury vs Usyk undercard is shaping up to be thrilling. Big-ticket boxing cards include preliminary bouts with top talent, offering an entire night of boxing excitement.
Traditionally, supporting bouts in major events have been a stage for breakout performances. Boxers seeking the spotlight often seize these moments to showcase their skills, as all eyes are on them. Although the lineup for the Fury Usyk undercard are still unconfirmed, there’s plenty of talk. Will there be a heavyweight clash? Whatever the selection, it’s sure to add to the excitement. The most compelling part of Fury vs Usyk so intriguing is the dynamic between these fighters. Fury’s towering frame and movement make him an anomaly in boxing. Being so tall yet so nimble, Fury can control a fight.
The three fights against Wilder proved his toughness, bouncing back from adversity to finish strong. When he faced Klitschko, Fury showcased his tactical brilliance, proving he’s not just physical but cerebral. Oleksandr Usyk, on the other hand, offers a different kind of threat. With his unorthodox stance, his movements create openings. The Ukrainian’s shots may not have knockout power, their timing wears down foes. As anticipation builds, Tyson Fury vs Usyk odds are becoming a hot topic.
Tyson Fury is the slight favorite based on the betting odds, due to his size advantage, his proven ability in tough situations, and his unpredictable nature. Despite being seen as the underdog doesn’t rule him out, his victories against AJ confirmed his toughness against big opponents.
For Fury himself is a chance to further solidify his greatness. A triumph for Fury would put the finishing touches on a historic career. On the other hand, For Usyk, a win would mark him as one of the sport’s greats. Becoming an undisputed champion in two different weight classes would be a remarkable feat in boxing history.
Website: https://arkitechno.com/fury-vs-usyk-predicting-the-heavyweight-showdown-41/
Fury vs Usyk is more than just a championship fight. It’s a battle of contrasting styles. Fury’s confident and brash nature stands in stark contrast to Usyk’s composed demeanor. Such contrasts make the fight more compelling. This is more than just a physical contest. No matter who wins, the impact of this bout will be felt for years to come. Fury vs Usyk is more than just a match. It’s the result of relentless dedication. Whether Tyson Fury prevails thanks to his power and game plan, or Oleksandr Usyk triumphs thanks to his skill and resilience, it’s certain that, this will be a defining moment in boxing.
Tyson Fury vs Oleksandr Usyk is more than just a boxing event. It’s a fight of grit and strategy. These men will fight with everything they possess.
Visit for more information: #crosslink[3,L -
Tyson Fury and Oleksandr Usyk are preparing for an epic showdown of historic proportions. This fight is about more than just titles; it’s about legacy. Tyson Fury has earned worldwide fame thanks to his personality and remarkable adaptability in the ring. His victories over Deontay Wilder and Wladimir Klitschko have earned him recognition as one of the best ever. Across the ring, Usyk, the Ukrainian master is a fighter unlike any other to the heavyweight division. On the flip side, Usyk, a genius in the ring stands as a unique threat not just for Fury, as a heavyweight contender. The ascent of Oleksandr Usyk started with his domination of the cruiserweights, as an undisputed champion. Don’t miss out for the most anticipated boxing match of the year as Usyk takes on Fury in a must-watch showdown! Experience every moment streamed live on our website. Be part of the action — visit <a href="https://www.stelladueg.com/fury-vs-usyk-all-you-need-to-know-about-the-big-8/">https://www.stelladueg.com/fury-vs-usyk-all-you-need-to-know-about-the-big-8/</a> now and stream the event from the comfort of your home!
For British fans, the event will kick off at around 10 PM GMT, making it ideal for a prime-time audience. Back in Usyk’s home country, as well as viewers across Europe and the Americas, the excitement is palpable. Where the bout will take place is still under speculation, and potential hosts include Saudi Arabia or Las Vegas. Wherever it happens, it’s guaranteed: it will be a spectacle. Even though attention is firmly on the main event, the preliminary bouts is also generating excitement. Big-ticket boxing cards include preliminary bouts with top talent, giving fans a full evening of entertainment.
Historically, undercards of this caliber have showcased rising stars. Boxers seeking the spotlight often seize these moments to impress fans and analysts alike, knowing millions are watching. Though the supporting fights for Fury vs Usyk has yet to be finalized, there’s plenty of talk. Will there be a heavyweight clash? No matter the final roster, fans can expect fireworks. What sets this bout apart incredibly exciting is the clash of styles. Fury’s towering frame and movement are unparalleled in the sport. At 6’9" with an 85-inch reach, he commands the ring like no other.
The legendary battles with Wilder highlighted his resilience, bouncing back from adversity to secure victories. In his fight with Klitschko, Fury showcased his tactical brilliance, demonstrating his mental sharpness. Meanwhile, Usyk, brings speed, precision, and finesse. With his unorthodox stance, his positioning constantly challenges opponents. His strikes aren’t the heaviest in the division, their timing wears down foes. With the date drawing closer, Predictions for this fight are the subject of intense debate.
Most bookmakers favor Fury according to the odds, thanks to his imposing frame, his proven ability in tough situations, and his tactical brilliance. Although Usyk is the less favored fighter doesn’t rule him out, his dominance against Joshua showed that he can compete at heavyweight.
For Tyson Fury, this fight could be the defining moment of his career. Should he come out on top, Fury’s win would add an undisputed title to his already impressive resume. Meanwhile, For Usyk, a win would be a monumental achievement. Becoming an undisputed champion in two different weight classes is a rare accomplishment.
Website: https://www.stelladueg.com/fury-vs-usyk-all-you-need-to-know-about-the-big-8/
Fury vs Usyk represents something greater than a title bout. It’s a battle of contrasting styles. Fury’s confident and brash nature stands in stark contrast to Usyk’s composed demeanor. These differences add complexity to the fight. Beyond physical ability, this fight. No matter who wins, the impact of this bout will reverberate throughout boxing history. The clash for the undisputed title is more than just a fight. It represents the culmination of their careers. If Fury wins thanks to his power and game plan, or Usyk secures a victory with his finesse and stamina, no matter the outcome, this will be a legendary contest.
Tyson Fury vs Oleksandr Usyk is more than just a sporting contest. It’s a fight of grit and strategy. Both fighters will give everything they have.
Visit for more information: #crosslink[3,L -
Vavada casino — является одним из топовых и доверенных казино среди поклонников азартных игр. За счет актуального дизайна, большому выбору развлечений и выгодным предложениям для гостей, <a href="https://prok3g.ru/go/vavada-casino-888-9.top">вавада казино </a> обрело статус превосходной платформы для ищет качественный игровой опыт. В данной статье мы опишем возможности официального сайта Vavada, этапы создания аккаунта и авторизации, а также поговорим о бонусах Vavada и о том, где найти актуальные Vavada зеркало.
Достоинства платформы казино Вавада
Сайт казино Vavada отличается по сравнению с аналогами благодаря простого и удобного дизайна, высокой скорости работы и кроссплатформенности. Независимо от устройство находится у вас, будь то ноутбук, планшет или мобильный телефон, сайт Vavada открывается без задержек, обеспечивая плавный доступ к разделам и функциям.
Сайт: https://prok3g.ru/go/vavada-casino-888-9.top
Для доступа на ресурс не необходима установка дополнительных программ. Онлайн-казино Vavada работает прямо через браузер, что упрощает доступ в аккаунт и разделам сайта. В случае технических проблем игроки могут перейти на Актуальные зеркала Vavada, которое полностью дублирует функции официального ресурса.
A reliable boxing portal includes a broad variety of content, aimed to for general audience and hardcore fans. A major asset of such a site resides in its skillset to deliver real-time announcements accurately. It could be a significant development in schedule, a major disclosure regarding an athlete, or breaking events in fighter negotiations, the website ensures that fans have up-to-date coverage. This allows followers of the sport remain informed about every significant developments in the world of boxing.
A further aspect of coverage is its analysis of upcoming previous matches. The site provides careful fight previews, presenting insight into the fighters' stats, key attributes. These articles dive deep into game plans, giving readers insight of what to expect. Post-fight, the website typically provides thorough reports, including results, expert commentary, and reviews of the fight strategies and the athletes. This kind of detailed post-event breakdowns is invaluable for fans who want to assess the performance beyond just the final score.
In addition to updates and evaluations, a reputable boxing website offers a plethora of feature content that focuses on the personalities who shape the sport. Personal conversations with athletes, managers, promoters, and experts give fans with understanding into the scene. These interviews often share the fighters’ preparation, psychological readiness, and personal stories, giving insight into what it takes to succeed at the highest levels of boxing. Through these features, readers get a view at the careers of their top boxers and learn the challenges they face inside the ropes and beyond.
Website: https://bluebonnetboxerclub.org/category/the-fight-report/
Besides, top boxing news websites offer significant emphasis on the historical aspects of the sport. Many websites dedicate sections to memorable matches in boxing history, profiles of great champions, and analyses on defining moments. This historical perspective not only enhances the current boxing world, but further furnishes a link to tradition the scene, allowing viewers to understand how the sport has changed over the years. These retrospectives are essential for newcomer fans who look to understand with the roots of the sport, as well as veterans who cherish the background of boxing.
Vavada казино — является одной из наиболее востребованных и проверенных временем игровых клубов для любителей азартных игр. За счет инновационного подхода, большому выбору развлечений и выгодным предложениям для гостей, <a href="https://www.gridsagegames.com/forums/proxy.php?request=http%3A%2F%2Fvavada-casino888-12.top">вавада вход </a> завоевало репутацию отличной платформы для ищет безупречный игровой процесс. В этом материале мы опишем особенности сайта Vavada casino, порядок создания аккаунта и входа, а также расскажем про Vavada бонусы и о том, где найти свежие зеркальные ссылки Vavada.
Достоинства официального сайта Vavada
Vavada официальный сайт выделяется по сравнению с аналогами благодаря интуитивно понятного пользовательского меню, быстрому отклику и кроссплатформенности. Независимо от устройство подключено, будь то компьютер, планшет или телефон, Vavada официальный сайт работает идеально, обеспечивая комфортное использование к разделам и опциям.
Сайт: https://www.gridsagegames.com/forums/proxy.php?request=http%3A%2F%2Fvavada-casino999-10.top
Для доступа на сайт не нужно скачивание приложений. Vavada casino работает в веб-версии, что упрощает доступ к личному кабинету и разделам казино. При возникновении ограничений гости могут зайти через Актуальные зеркала Vavada, которое полностью дублирует функционал основного портала.
A good boxing portal includes a comprehensive collection of coverage, tailored to for occasional viewers and boxing lovers. One of benefit of such a site is its skill to provide immediate coverage fast. Whether it's a last-minute alteration in a fight, a high-profile report regarding a fighter, or up-to-date developments in the boxing scene, the platform ensures that fans are provided with up-to-date information. It helps fans remain on top of every significant developments in the boxing scene.
Additionally aspect of coverage is its expert commentary of upcoming and past matches. The site provides comprehensive fight breakdowns, giving insight into the fighters' records, strong points and weak spots. These articles explore boxing methods, giving readers insight of what to expect. Once the match concludes, the website typically provides thorough analysis, with match outcomes, insights, and post-mortem of the approaches and the champions. This kind of in-depth post-event breakdowns is invaluable for fans want to look deeper into the bout beyond just the result.
In addition to coverage and breakdowns, a reputable boxing website offers a large quantity of exclusive content that focuses on the careers who shape the sport. One-on-one Q&As with champions, managers, matchmakers, and critics provide fans with a deeper connection into the scene. These interviews often delve into the fighters’ training routines, mental focus, and experiences, giving insight into what it takes to succeed at the highest levels of boxing. Through these features, readers get a understanding at the careers of their famous boxers and comprehend the challenges they face inside the ropes and beyond.
Website: https://scottishboxerclub.com/
On top of that, top boxing news websites put significant emphasis on the legacy aspects of the sport. A lot of websites set aside sections to memorable matches in boxing legacy, profiles of famous athletes, and analyses on pivotal moments. This historical perspective not only enriches the current boxing landscape, but also offers a sense of continuity the game, allowing followers to understand how the sport has progressed over the years. This historical content are essential for beginning fans who want get familiar with the roots of the sport, as well as longstanding fans who value the rich tradition of boxing.
Игровой клуб Вавада — это одной из наиболее востребованных и надежных казино среди ценителей азартных игр. С помощью инновационного подхода, разнообразию игр и выгодным предложениям для пользователей, <a href="https://top-prof.ru/goto/https://vavada-casino-888-9.top/">вавада официальный сайт </a> получило репутацию превосходной площадки для всех, кто жаждет найти безупречный игровой процесс. В этом материале мы разберем особенности официального сайта Vavada, процесс регистрации на сайте и входа, а также объясним о бонусах Vavada и о том, где найти актуальные рабочие зеркала Vavada.
Основные плюсы сайта Vavada casino
Сайт казино Vavada отличается на фоне конкурентов за счет легкого в использовании пользовательского меню, быстрому отклику и кроссплатформенности. Без разницы, какое гаджет подключено, будь то компьютер, планшет или мобильный телефон, сайт Vavada загружается моментально, обеспечивая комфортное использование к играм и функциям.
Сайт: https://top-prof.ru/goto/https://vavada-casino999-10.top/
Для доступа на ресурс не требуется установка дополнительных программ. Vavada online casino функционирует прямо через браузер, что значительно облегчает процесс входа в аккаунт и разделам сайта. При возникновении технических проблем пользователи могут воспользоваться Актуальные зеркала Vavada, повторяет функции официального ресурса.
A solid boxing site offers a wide variety of articles, tailored to both casual viewers and boxing enthusiasts. A core advantage of such a site resides in its skill to offer instant announcements promptly. Whether a major change in match, a key news regarding a competitor, or the latest news in promotions, the platform ensures that fans are provided with the latest coverage. This allows audience be on top of every significant updates in the world of boxing.
Furthermore aspect of boxing news coverage is its in-depth review of future previous bouts. The site provides careful fight previews, providing depth into the fighters' backgrounds, key attributes. These articles break down technical details, giving readers deep knowledge of what to expect. In the aftermath, the website typically provides extensive recaps, including decisions, opinions, and reviews of the approaches and the competitors. This kind of careful post-event breakdowns is invaluable for fans looking to explore the match beyond just the outcome.
In addition to news and analysis, a reputable boxing website offers a large quantity of special interviews that focuses on the figures who shape the sport. Exclusive discussions with fighters, managers, boxing heads, and critics give fans with a deeper connection into the game. These interviews often explore the fighters’ training routines, mindset, and lives, giving insight into what it takes to succeed at the highest levels of boxing. Through these features, readers get a understanding at the careers of their beloved champions and recognize the challenges they face in the ring and out.
Website: https://scottishboxerclub.com/category/news/
Additionally, top boxing news websites place significant emphasis on the historical aspects of the sport. Top websites set aside sections to legendary bouts in boxing legacy, profiles of iconic athletes, and reflective articles on game-changing fights. This historical perspective not only enhances the modern boxing scene, but also gives a link to tradition the sport, allowing enthusiasts to understand how the sport has evolved over the years. These retrospectives are essential for newcomer fans who want understand with the roots of the sport, as well as diehard fans who value the background of boxing.
Онлайн-казино Vavada — это одной из топовых и доверенных платформ среди любителей игровых автоматов. Благодаря современного подхода, разнообразию игровых слотов и щедрым бонусам для гостей, <a href="http://stg-cta-redirect.ex.co/redirect?&web=https://vavada-casino888-12.top/">vavada вход </a> получило репутацию отличной платформы для всех, кто жаждет найти безупречный игровой процесс. В этом материале мы подробно рассмотрим функции платформы казино Вавада, процесс регистрации и авторизации, а также объясним про акционные предложения Vavada и о том, где взять работающие зеркальные ссылки Vavada.
Преимущества сайта Vavada casino
Официальный ресурс Vavada привлекает внимание по сравнению с аналогами благодаря простого и удобного пользовательского меню, мгновенной загрузке и кроссплатформенности. Независимо от гаджет вы используете, будь то ПК, планшет или мобильный телефон, Vavada официальный сайт загружается моментально, обеспечивая удобный вход к игровым слотам и функциям.
Сайт: http://stg-cta-redirect.ex.co/redirect?&web=https://vavada-casino999-10.top/
Чтобы попасть на ресурс не требуется скачивание приложений. Vavada casino функционирует в веб-версии, что делает удобным доступ к личному кабинету и разделам казино. В случае блокировок пользователи могут воспользоваться Рабочее зеркало Vavada, которое полностью дублирует функционал основного портала.
A reliable boxing portal provides a wide variety of updates, created to for casual viewers and serious followers. A primary benefit of such a site is its skillset to distribute real-time updates promptly. It could be a major alteration in card, a major news regarding an athlete, or breaking news in promotions, the platform ensures that fans receive the best updates. It ensures followers of the sport stay updated on the most relevant events in the sport.
Another aspect of coverage is its breakdown of upcoming and past fights. The site provides careful fight breakdowns, providing perspective into the fighters' records, key attributes. These articles analyze game plans, giving readers deep knowledge of what to expect. Once the match concludes, the website typically provides thorough articles, with decisions, expert commentary, and further analysis of the performance and the athletes. This kind of careful commentary is invaluable for fans eager to analyze the performance beyond just the result.
In addition to updates and evaluations, a reputable boxing website features a wealth of spotlight pieces that focuses on the figures who shape the sport. Personal interviews with fighters, trainers, organizers, and insiders give fans with exclusive access into the sport. These interviews often delve into the fighters’ workouts, mental focus, and backgrounds, giving insight into what it takes to succeed at the highest levels of boxing. Through these features, readers get a view at the lives of their famous fighters and recognize the challenges they face on and off the ring.
Website: https://bluebonnetboxerclub.org/
Besides, top boxing news websites place significant emphasis on the rich aspects of the sport. A lot of websites offer sections to legendary bouts in boxing history, profiles of great champions, and retrospectives on game-changing fights. This retrospective perspective not only enlightens the modern boxing world, but further provides a sense of continuity the scene, allowing followers to understand how the sport has evolved over the years. These pieces are essential for both new fans who desire learn with the roots of the sport, as well as long-time followers who appreciate the rich tradition of boxing.
Vavada casino — это одной из наиболее востребованных и проверенных временем казино для поклонников азартных игр. С помощью инновационного подхода, широкому ассортименту игр и привлекательным условиям для игроков, <a href="http://4geo.ru/redirect/?service=catalog&url=vavada-casino-888-9.top">вавада регистрация </a> получило статус превосходной площадки для ищет качественный игровой опыт. В этом материале мы разберем возможности официального сайта Vavada, порядок регистрации и входа в личный кабинет, а также расскажем о бонусах Vavada и о том, где взять актуальные зеркальные ссылки Vavada.
Преимущества платформы казино Вавада
Официальный ресурс Vavada выделяется среди других платформ с помощью легкого в использовании интерфейса, высокой скорости работы и адаптации под устройства. Без разницы, какое девайс вы используете, будь то ноутбук, планшетный ПК или смартфон, сайт Vavada открывается без задержек, обеспечивая удобный вход к игровым слотам и возможностям.
Сайт: http://4geo.ru/redirect/?service=catalog&url=vavada-casino888-12.top
Чтобы попасть на сайт не необходима установка дополнительных программ. Vavada casino запускается непосредственно в браузере, что делает удобным процесс входа в аккаунт и разделам сайта. При возникновении технических проблем гости могут зайти через Vavada зеркало, имеет идентичный функции основного портала.
A reliable boxing platform delivers a wide assortment of material, created to for general audience and hardcore fans. The key strength of such a site is its ability to offer instant news fast. Whether an unexpected shift in schedule, an important report regarding an athlete, or recent changes in fighter negotiations, this site ensures that fans receive freshest stories. This allows fans stay updated on each major turns in the boxing scene.
Another key aspect of coverage is its expert commentary of future previous events. The site provides thorough event overviews, offering analysis into the athletes' performances, advantages and disadvantages. These articles analyze boxing methods, giving readers a clearer view of what to expect. After the fight, the website typically provides thorough recaps, with match outcomes, opinions, and evaluations of the decisions and the competitors. This kind of in-depth post-fight analysis is invaluable for fans want to explore the bout beyond just the final score.
In addition to updates and evaluations, a reputable boxing website features a plethora of insider stories that focuses on the lives who shape the sport. One-on-one interviews with promoters, managers, matchmakers, and insiders provide fans with a personal look into the game. These interviews often delve into the fighters’ workouts, psychological readiness, and backgrounds, giving insight into what it takes to succeed at the highest levels of boxing. Through these features, readers get a closer look at the stories of their top boxers and comprehend the challenges they face both inside and outside.
Website: https://bluebonnetboxerclub.org/category/boxing/
On top of that, top boxing news websites focus significant emphasis on the traditional aspects of the sport. Top websites dedicate sections to iconic moments in boxing legacy, profiles of legendary fighters, and retrospectives on key clashes. This retrospective perspective not only enriches the current boxing world, but further provides a sense of continuity the sport, allowing viewers to understand how the sport has evolved over the years. This historical content are essential for both new fans who desire understand with the roots of the sport, as well as long-time followers who cherish the rich tradition of boxing.
Vavada казино — является одной из самых популярных и проверенных временем игровых клубов среди любителей игровых автоматов. Благодаря актуального дизайна, широкому ассортименту игр и привлекательным условиям для гостей, <a href="https://amajmkbgip.cloudimg.io/v7/vavada-casino888-12.top">вавада казино </a> получило статус превосходной площадки для ищет надежный азартный отдых. В этом материале мы разберем возможности официального сайта Vavada, порядок создания аккаунта и входа в личный кабинет, а также расскажем о бонусах Vavada и о том, как получить свежие Vavada зеркало.
Достоинства сайта Vavada casino
Сайт казино Vavada привлекает внимание по сравнению с аналогами с помощью простого и удобного пользовательского меню, быстрому отклику и кроссплатформенности. Без разницы, какое гаджет находится у вас, будь то ноутбук, планшетный ПК или мобильный телефон, платформа Vavada casino загружается моментально, обеспечивая плавный доступ к разделам и опциям.
Сайт: https://amajmkbgip.cloudimg.io/v7/vavada-casino999-10.top
Для доступа на ресурс не необходима скачивание приложений. Vavada casino запускается прямо через браузер, что упрощает доступ к личному кабинету и разделам казино. В случае блокировок пользователи могут воспользоваться Актуальные зеркала Vavada, имеет идентичный функции основного портала.
A reputable boxing portal provides an extensive variety of coverage, catered to for general fans and hardcore fans. A primary benefit of such a site lies in its capacity to deliver real-time coverage promptly. It could be a last-minute update in match, a title disclosure regarding a boxer, or recent developments in promotions, the platform ensures that fans have the most information. It keeps viewers be aware of each major updates in the sport.
Another key aspect of coverage is its breakdown of upcoming and completed events. The site provides careful event overviews, presenting perspective into the fighters' backgrounds, advantages and disadvantages. These articles examine boxing methods, giving readers a clearer view of what to expect. Once the match concludes, the website typically provides detailed reports, with results, expert commentary, and reviews of the movements of the competitors. Such detailed post-fight analysis is invaluable for fans eager to assess the bout beyond just the result.
In addition to coverage and breakdowns, a reputable boxing website includes a large quantity of feature content that focuses on the figures who shape the sport. In-depth interviews with fighters, trainers, promoters, and insiders give fans with a deeper connection into the sport. These interviews often share the fighters’ training habits, mental focus, and personal stories, giving insight into what it takes to succeed at the highest levels of boxing. Through these features, readers get a insight at the personalities of their favorite athletes and comprehend the challenges they face in the ring and out.
Website: https://comboboxing.com/category/knockout-news/
In addition, top boxing news websites focus significant emphasis on the legacy aspects of the sport. A lot of websites dedicate sections to iconic moments in boxing history, profiles of famous athletes, and retrospectives on pivotal moments. This historical perspective not only adds depth to the current boxing landscape, but also furnishes a sense of continuity the game, allowing enthusiasts to understand how the sport has changed over the years. These articles are essential for both new fans who want understand with the roots of the sport, as well as long-time followers who cherish the storied legacy of boxing.
Vavada казино — это одной из самых популярных и надежных казино среди любителей азартных игр. За счет инновационного подхода, широкому ассортименту игровых слотов и привлекательным условиям для гостей, <a href="https://gdehu.hit.gemius.pl/_uachredir/hitredir/id=cjU1jQNoAXpbwoPKVChj6ZZV.qhRkW_QYHUd8mCCWyr.U7/fastid=fzmokfsdzfjkuaacifdxxzjfxdle/stparam=lkmeqnftfv/url=https%3A%2F%2Fvavada-casino-play-10.top">vavada зеркало </a> завоевало статус превосходной площадки для жаждет найти надежный азартный отдых. В данной статье мы подробно рассмотрим особенности сайта Vavada casino, порядок создания аккаунта и входа, а также объясним о бонусах Vavada и о том, как получить работающие рабочие зеркала Vavada.
Преимущества сайта Vavada casino
Официальный ресурс Vavada привлекает внимание на фоне конкурентов за счет легкого в использовании интерфейса, быстрому отклику и кроссплатформенности. Независимо от гаджет находится у вас, будь то ноутбук, планшетный ПК или смартфон, платформа Vavada casino открывается без задержек, гарантируя удобный вход к играм и возможностям.
Сайт: https://gdehu.hit.gemius.pl/_uachredir/hitredir/id=cjU1jQNoAXpbwoPKVChj6ZZV.qhRkW_QYHUd8mCCWyr.U7/fastid=fzmokfsdzfjkuaacifdxxzjfxdle/stparam=lkmeqnftfv/url=https%3A%2F%2Fcasino-vavada-slots-4.top
Чтобы попасть на сайт не нужно скачивание приложений. Vavada casino функционирует в веб-версии, что упрощает процесс входа в аккаунт и разделам казино. В случае технических проблем гости могут перейти на Рабочее зеркало Vavada, повторяет функции основного сайта.
A good boxing site delivers a broad selection of articles, designed to both general readers and boxing lovers. A core advantage of such a site resides in its talent to offer up-to-the-minute announcements promptly. Whether it's a significant update in match, a high-profile disclosure regarding an athlete, or the latest developments in the boxing scene, the platform ensures that fans receive the most coverage. It ensures fans be abreast of each major turns in the sport.
Additionally aspect of coverage is its expert commentary of upcoming and past events. The site provides thorough fight breakdowns, presenting perspective into the fighters' stats, advantages and disadvantages. These articles analyze boxing methods, giving readers a comprehensive understanding of what to expect. Once the battle ends, the website typically provides extensive articles, including match outcomes, breakdowns, and post-mortem of the fight strategies of the champions. Such thorough post-fight analysis is invaluable for fans looking to assess the showdown beyond just the final score.
In addition to news and analysis, a reputable boxing website offers an abundance of insider stories that focuses on the careers who shape the sport. One-on-one interviews with athletes, trainers, organizers, and experts give fans with understanding into the scene. These interviews often delve into the fighters’ workouts, psychological readiness, and backgrounds, giving insight into what it takes to succeed at the highest levels of boxing. Through these features, readers get a insight at the lives of their famous athletes and recognize the challenges they face on and off the ring.
Website: https://wishboxusa.co.uk/category/news-updates/
Moreover, top boxing news websites offer significant emphasis on the historical aspects of the sport. Numerous websites devote sections to historic fights in boxing history, profiles of great fighters, and analyses on key clashes. This historical perspective not only enriches the current boxing scene, but further furnishes historical context the game, allowing viewers to understand how the sport has progressed over the years. This historical content are essential for novice fans who desire understand with the roots of the sport, as well as diehard fans who cherish the heritage of boxing.
Онлайн-казино Vavada — это одно из самых популярных и проверенных временем игровых клубов для ценителей гэмблинга. За счет современного подхода, разнообразию развлечений и привлекательным условиям для пользователей, <a href="http://lavrvladimir33.nnov.org:/common/redir.php?https://vavada-casino-888-9.top/">vavada </a> получило репутацию идеальной платформы для жаждет найти качественный игровой опыт. В данной статье мы подробно рассмотрим особенности официального сайта Vavada, процесс создания аккаунта и авторизации, а также расскажем о бонусах Vavada и о том, как получить свежие зеркальные ссылки Vavada.
Преимущества платформы казино Вавада
Vavada официальный сайт выделяется среди других платформ с помощью интуитивно понятного пользовательского меню, быстрому отклику и адаптации под устройства. Независимо от девайс вы используете, будь то ноутбук, планшет или телефон, Vavada официальный сайт открывается без задержек, обеспечивая комфортное использование к играм и функциям.
Сайт: http://lavrvladimir33.nnov.org:/common/redir.php?https://vavada-casino-play-10.top/
Для доступа на платформу не нужно установка дополнительных программ. Vavada online casino функционирует непосредственно в браузере, что значительно облегчает доступ в аккаунт и разделам сайта. В случае блокировок пользователи могут зайти через Рабочее зеркало Vavada, имеет идентичный функции основного сайта.
A reliable boxing resource offers a comprehensive selection of articles, created to both casual fans and boxing lovers. A major asset of such a site lies in its capacity to offer up-to-the-minute coverage promptly. It could be a significant alteration in bout, a major disclosure regarding a competitor, or up-to-date news in the boxing scene, this site ensures that fans get freshest stories. This allows viewers be abreast of all important turns in the world of boxing.
Another key aspect of a boxing news site is its breakdown of upcoming and completed bouts. The site provides comprehensive fight breakdowns, presenting examination into the fighters' records, strengths and weaknesses. These articles break down game plans, giving readers deep knowledge of what to expect. After the fight, the website typically provides detailed recaps, including decisions, insights, and post-mortem of the fight strategies and the champions. Such detailed commentary is invaluable for fans want to look deeper into the match beyond just the outcome.
In addition to updates and evaluations, a reputable boxing website offers a plethora of exclusive content that focuses on the lives who shape the sport. In-depth interviews with athletes, managers, matchmakers, and commentators offer fans with a deeper connection into the sport. These interviews often delve into the fighters’ training habits, mental focus, and personal stories, giving insight into what it takes to succeed at the highest levels of boxing. Through these features, readers get a insight at the stories of their famous fighters and comprehend the challenges they face inside the ropes and beyond.
Website: https://bluebonnetboxerclub.org/
Besides, top boxing news websites place significant emphasis on the traditional aspects of the sport. Top websites offer sections to memorable matches in boxing history, profiles of legendary athletes, and lookbacks on game-changing fights. This retrospective perspective not only enhances the current boxing landscape, but further gives a link to the past the sport, allowing followers to understand how the sport has progressed over the years. These pieces are essential for novice fans who need understand with the roots of the sport, as well as long-time followers who appreciate the rich tradition of boxing.
Vavada casino — является одно из лучших и доверенных игровых клубов среди любителей азартных игр. С помощью инновационного подхода, широкому ассортименту игр и щедрым бонусам для гостей, <a href="https://library.colgate.edu/webbridge%7ES1/showresource?resurl=https%3A%2F%2Fvavada-casino999-10.top &linkid=836650&noframe=1">vavada официальный сайт </a> завоевало репутацию отличной площадки для всех, кто ищет качественный игровой опыт. В данной статье мы опишем особенности официального сайта Vavada, порядок создания аккаунта и авторизации, а также объясним про Vavada бонусы и о том, где взять актуальные Vavada зеркало.
Основные плюсы сайта Vavada casino
Официальный ресурс Vavada отличается по сравнению с аналогами за счет интуитивно понятного интерфейса, быстрому отклику и адаптации под устройства. Независимо от устройство находится у вас, будь то компьютер, планшетный ПК или мобильный телефон, Vavada официальный сайт открывается без задержек, обеспечивая комфортное использование к игровым слотам и возможностям.
Сайт: https://library.colgate.edu/webbridge%7ES1/showresource?resurl=https%3A%2F%2Fvavada-casino-888-9.top &linkid=836650&noframe=1
Для доступа на сайт не необходима скачивание приложений. Vavada casino запускается непосредственно в браузере, что делает удобным процесс входа к личному кабинету и разделам сайта. В случае технических проблем игроки могут воспользоваться Рабочее зеркало Vavada, которое полностью дублирует функционал официального ресурса.
A reliable boxing resource includes a wide range of articles, tailored to for general viewers and serious followers. A core feature of such a site lies in its capacity to distribute instant news quickly. It could be a significant alteration in bout, an important disclosure regarding a competitor, or recent developments in fighter negotiations, this site ensures that fans have the best information. It ensures followers of the sport be updated on each major developments in the boxing scene.
Another aspect of coverage is its analysis of upcoming and completed fights. The site provides in-depth fight previews, providing analysis into the athletes' performances, strengths and weaknesses. These articles explore game plans, giving readers insight of what to expect. Once the match concludes, the website typically provides thorough analysis, including fight results, breakdowns, and reviews of the movements and the boxers. This kind of thorough commentary is invaluable for fans who want to look deeper into the performance beyond just the final score.
In addition to coverage and breakdowns, a reputable boxing website delivers an abundance of special interviews that focuses on the people who shape the sport. One-on-one interviews with boxers, coaches, matchmakers, and experts give fans with a deeper connection into the game. These interviews often delve into the fighters’ training routines, mental focus, and backgrounds, giving insight into what it takes to succeed at the highest levels of boxing. Through these features, readers get a insight at the backgrounds of their top champions and recognize the challenges they face inside the ropes and beyond.
Website: https://comboboxing.com/category/knockout-news/
In addition, top boxing news websites focus significant emphasis on the historical aspects of the sport. Top websites offer sections to legendary bouts in boxing legacy, profiles of iconic athletes, and lookbacks on significant bouts. This historical perspective not only enlightens the current boxing landscape, but also gives a sense of continuity the scene, allowing enthusiasts to understand how the sport has grown over the years. These retrospectives are essential for both new fans who need gain knowledge with the roots of the sport, as well as diehard fans who appreciate the rich tradition of boxing.
Vavada казино — является одной из лучших и надежных игровых клубов для поклонников гэмблинга. С помощью современного подхода, большому выбору развлечений и щедрым бонусам для пользователей, <a href="https://profilelink.ru/away.php?url=https://vavada-casino-play-10.top/">vavada промокод сегодня </a> завоевало статус идеальной платформы для жаждет найти надежный азартный отдых. В обзоре ниже мы опишем особенности платформы казино Вавада, процесс регистрации и входа, а также объясним про Vavada бонусы и о том, где найти актуальные рабочие зеркала Vavada.
Достоинства сайта Vavada casino
Официальный ресурс Vavada отличается среди других платформ с помощью легкого в использовании пользовательского меню, мгновенной загрузке и кроссплатформенности. Без разницы, какое гаджет подключено, будь то ПК, планшетный ПК или смартфон, платформа Vavada casino открывается без задержек, обеспечивая удобный вход к игровым слотам и возможностям.
Сайт: https://profilelink.ru/away.php?url=https://vavada-casino-play-10.top/
Для доступа на платформу не нужно установка дополнительных программ. Vavada casino функционирует в веб-версии, что значительно облегчает процесс входа к личному кабинету и разделам сайта. При возникновении блокировок гости могут воспользоваться Рабочее зеркало Vavada, которое полностью дублирует функции основного портала.
A solid boxing site includes a wide range of articles, designed to for casual readers and boxing lovers. A core strength of such a site resides in its skillset to offer real-time coverage accurately. Whether it's a last-minute update in bout, a title disclosure regarding a fighter, or up-to-date changes in promotions, this site ensures that fans have the latest stories. It helps viewers stay on top of the most relevant changes in the sport.
Additionally aspect of a boxing news site is its in-depth review of upcoming and past fights. The site provides careful fight breakdowns, giving insight into the fighters' records, strong points and weak spots. These articles examine game plans, giving readers full details of what to expect. Post-fight, the website typically provides comprehensive articles, including fight results, opinions, and reviews of the approaches and the champions. This kind of in-depth post-event breakdowns is invaluable for fans looking to understand better the showdown beyond just the outcome.
In addition to updates and evaluations, a reputable boxing website features a plethora of special interviews that focuses on the people who shape the sport. One-on-one conversations with boxers, trainers, organizers, and boxing analysts offer fans with a personal look into the game. These interviews often delve into the fighters’ preparation, mental focus, and challenges, giving insight into what it takes to succeed at the highest levels of boxing. Through these features, readers get a view at the backgrounds of their famous champions and recognize the challenges they face inside the ropes and beyond.
Website: https://theboxcafe.co.uk/category/boxing/
On top of that, top boxing news websites place significant emphasis on the rich aspects of the sport. Many websites offer sections to iconic moments in boxing history, profiles of legendary athletes, and lookbacks on pivotal moments. This historical perspective not only enlightens the modern boxing landscape, but also provides a link to the past the game, allowing viewers to understand how the sport has grown over the years. These articles are essential for beginning fans who look to understand with the roots of the sport, as well as longstanding fans who cherish the storied legacy of boxing.
В сфере интернет-казино и ставочной деятельности ключевое значение имеет не только надежность услуг, но и высокий уровень доверия. С международной лицензией, которая гарантирует безопасность, сайт <a href="https://mahachkala.bezformata.com/listnews/proshla-masshtabnaya-donorskaya-aktciya/77609444/">https://mahachkala.bezformata.com/listnews/proshla-masshtabnaya-donorskaya-aktciya/77609444/</a> выступает одним из фаворитов на рынке ставок. Компания уделяет внимание повышение качества сервиса, обновляя платформу, чтобы обеспечить пользователям безупречное взаимодействие.
Приветственный бонус: Выгодный старт для новичков казино
Для новичков на платформе 1win существует щедрый приветственный бонус, который стимулирует успешное начало. Это возможность является одним из заметных на рынке, так как позволяет игрокам новым игрокам получить дополнительный капитал, сократив риски. Простая регистрация и депозит дают возможность воспользоваться бонусом, что делает его воспользование эффективным и быстрым.
Live-ставки: Тысячи событий в реальном времени с моментальными ставками
В отрасли букмекерства одним из ключевых элементов является стратегическая глубина и умение быстро принимать решения в реальном времени. 1win предоставляет возможность огромное количество спортивных событий, доступных в формате ставок на события в реальном времени. Мы располагаем матчами к ключевым международным и локальным соревнованиям, будь то футбол.
Полная ссылка на страницу: https://mahachkala.bezformata.com/listnews/proshla-masshtabnaya-donorskaya-aktciya/77609444/
Лайв-ставки предоставляют возможность учитывать динамику событий, что делает процесс насыщенным эмоциями, но и серьёзным испытанием навыков. Используя стратегии и аналитику платформы, игроки платформы могут принимать более обоснованные решения, улучшая тактику игры. Каждое событие представлено с комментариями, что способствует точным прогнозам предсказывать результат с уверенностью.
В индустрии виртуальных казино и ставок в спорте крайне важно не только качество сервиса, но и надежность оператора. С официальной лицензией, которая обеспечивает соблюдение стандартов, сайт <a href="https://www.cross-kpk.ru/index.dll/multimedia.dll/forum.dll/documents/projects/documents/projects/index.dll/forum.dll/topic?id=2&page=1">https://www.cross-kpk.ru/index.dll/multimedia.dll/forum.dll/documents/projects/documents/projects/index.dll/forum.dll/topic?id=2&page=1</a> находится среди фаворитов в области азартных игр. Компания стремится к развитие клиентского опыта, обновляя контент, чтобы подарить пользователям максимальный комфорт.
Приветственный бонус: Привлекательное предложение для новых пользователей
Для новых пользователей на платформе 1win доступен щедрый приветственный бонус, который позволяет начать с уверенностью. Это акция является одним из выгодных на в индустрии ставок, так как позволяет новым клиентам сразу получить доступ к дополнительным средствам, сократив риски. Регистрация за несколько минут и депозит дают возможность воспользоваться бонусом, что делает его применение комфортным.
Live-ставки: Лайв-ставки на тысячи событий с максимальным удобством
В отрасли спортивных прогнозов одним из ключевых элементов является стратегическая глубина и шанс учесть изменения в режиме реального времени. 1win даёт шанс множество спортивных событий, доступных в формате ставок на события в реальном времени. Мы гарантируем доступ к крупнейшим событиям мирового масштаба, будь то волейбол.
Полная ссылка на страницу: https://www.cross-kpk.ru/index.dll/multimedia.dll/forum.dll/documents/projects/documents/projects/index.dll/forum.dll/topic?id=2&page=1
Лайв-ставки позволяют пользователям принимать решения мгновенно, что делает процесс ещё интереснее, но и полезным для стратегии. С применением аналитических ресурсов платформы, любители ставок могут анализировать события глубже, повышая вероятность выигрыша. Каждое событие предоставляется с аналитическими данными, что позволяет лучше анализировать предупреждать проигрыши.
В сфере виртуальных казино и ставочной деятельности ключевое значение имеет не только надежность услуг, но и честность оператора. С гарантированной лицензией, которая гарантирует безопасность, сайт <a href="https://www.ippo.ru/news/article/v-cerkvi-zagovorili-o-pereosmyslenii-petrova-posta-405936">https://www.ippo.ru/news/article/v-cerkvi-zagovorili-o-pereosmyslenii-petrova-posta-405936</a> установил себя как топовых платформ на рынке ставок. Платформа уделяет внимание максимального комфорта, разрабатывая новые функции, чтобы обеспечить пользователям безупречное взаимодействие.
Приветственный бонус: Бонус для новичков для новых игроков
Для новых игроков на платформе 1win предусмотрен впечатляющий приветственный бонус, который существенно увеличивает стартовый капитал. Это подарок является одним из ведущих на в мире онлайн-гемблинга, так как помогает новым пользователям платформы моментально воспользоваться бонусом, получив дополнительные ресурсы для ставок. Легкий старт и внесение депозита зачисляют бонус на счет, что делает его получение комфортным.
Live-ставки: Мгновенные возможности для ставок с реальными шансами на успех
В мире ставочной деятельности важнейшей частью является темп и возможность реагировать на изменения в режиме реального времени. 1win предлагает игрокам десятки тысяч спортивных событий, доступных в формате онлайн ставок. Мы гарантируем доступ к ведущим соревнованиям и матчам, будь то баскетбол.
Полная ссылка на страницу: https://www.ippo.ru/news/article/v-cerkvi-zagovorili-o-pereosmyslenii-petrova-posta-405936
Букмекерские ставки в лайве открывают возможность быстро подстраиваться, что делает процесс не только увлекательным, но и интеллектуально интересным. Пользуясь аналитическими функциями платформы, пользователи могут делать ставки с уверенностью, приумножая выигрышные шансы. Каждое событие сопровождается качественной аналитикой, что даёт более полную картину предупреждать проигрыши.
В пространстве цифровых казино и игр на ставки основное внимание уделяется не только уровень сервиса, но и репутация компании. С международной лицензией, которая подтверждает легальность, сайт <a href="http://lionelbaland.hautetfort.com/archive/2019/02/21/affiches-du-forum-voor-democratie-6130614.html">http://lionelbaland.hautetfort.com/archive/2019/02/21/affiches-du-forum-voor-democratie-6130614.html</a> установил себя как лидеров на рынке ставок. Сервис стремится к развитие клиентского опыта, обновляя контент, чтобы гарантировать пользователям непревзойденный опыт.
Приветственный бонус: Премиум-старт для пользователей платформы
Для новичков на платформе 1win существует выгодный приветственный бонус, который значительно увеличивает начальный капитал. Это акция является одним из популярных на рынке, так как позволяет новым клиентам казино сразу получить доступ к дополнительным средствам, стимулируя успешные ставки. Регистрация за несколько минут и пополнение счета мгновенно активируют бонус, что делает его использование приятным и лёгким.
Live-ставки: Тысячи событий в реальном времени с мгновенными возможностями
В пространстве спортивных ставок ключевой особенностью является актуальность и умение быстро принимать решения в реальном времени. 1win даёт шанс большой спектр спортивных событий, доступных в формате игры вживую. Мы организуем лайв-ставки к крупнейшим спортивным событиям, будь то футбол.
Полная ссылка на страницу: http://lionelbaland.hautetfort.com/archive/2019/02/21/affiches-du-forum-voor-democratie-6130614.html
Онлайн-ставки позволяют пользователям мгновенно реагировать на изменения, что делает процесс более динамичным, но и интеллектуально интересным. Пользуясь аналитическими функциями платформы, игроки платформы могут увеличивать вероятность выигрыша, увеличивая свои шансы на успех. Каждое событие представлено с комментариями, что делает процесс ещё более обоснованным гарантировать обоснованные ставки.
В экосистеме цифровых казино и ставочной деятельности необходимо не только качество сервиса, но и гарантии безопасности. С гарантированной лицензией, которая гарантирует прозрачность, сайт <a href="https://akrvo.ru/index.php?option=com_content&view=article&id=26600">https://akrvo.ru/index.php?option=com_content&view=article&id=26600</a> считает себя лидеров на рынке ставок. Организация стремится к максимального комфорта, обновляя контент, чтобы гарантировать пользователям первоклассный игровой опыт.
Приветственный бонус: Выгодный старт для пользователей платформы
Для новых клиентов на платформе 1win ожидает вас выгодный приветственный бонус, который увеличивает ваши возможности. Это акция является одним из ведущих на в отрасли, так как помогает новым пользователям платформы сразу получить доступ к дополнительным средствам, стимулируя успешные ставки. Упрощенная процедура регистрации и первый взнос мгновенно активируют бонус, что делает его получение очень удобным.
Live-ставки: Играйте на события вживую с широким выбором
В отрасли спортивных прогнозов одним из ключевых элементов является быстрота реакции и шанс учесть изменения в моментально. 1win даёт шанс тысячи спортивных событий, доступных в формате лайв-ставок. Мы предлагаем ставки к ведущим локальным и глобальным турнирам, будь то киберспорт.
Полная ссылка на страницу: https://akrvo.ru/index.php?option=com_content&view=article&id=26600
Ставки в реальном времени гарантируют игрокам реагировать в реальном времени, что делает процесс не только увлекательным, но и стратегически насыщенным. С применением аналитических ресурсов платформы, игроки платформы могут точнее прогнозировать исходы, улучшая тактику игры. Каждое событие предоставляется с аналитическими данными, что способствует точным прогнозам принимать решения на основе актуальных данных.
В индустрии интерактивных казино и игр на ставки приоритетное значение имеет не только качество сервиса, но и репутация компании. С лицензией, которая подтверждает честность, сайт <a href="https://artrz.ru/places/1804824077/index.html">https://artrz.ru/places/1804824077/index.html</a> считает себя ключевых участников в области азартных игр. Платформа создает условия для развитие клиентского опыта, улучшая функционал, чтобы подарить пользователям максимальный комфорт.
Приветственный бонус: Щедрый бонус для клиентов
Для новых клиентов на платформе 1win предоставляется солидный приветственный бонус, который стимулирует успешное начало. Это предложение является одним из ведущих на в отрасли, так как дает возможность новым игрокам сразу получить доступ к дополнительным средствам, значительно улучшив стартовые позиции. Простая регистрация и первый взнос дают возможность воспользоваться бонусом, что делает его получение эффективным и быстрым.
Live-ставки: Множество матчей онлайн с моментальными ставками
В отрасли ставок на спорт главной отличительной чертой является темп и возможность реагировать на изменения в на ходу. 1win открывает путь десятки тысяч спортивных событий, доступных в формате ставок в лайве. Мы предоставляем доступ к международным спортивным событиям, будь то хоккей.
Полная ссылка на страницу: https://artrz.ru/places/1804824077/index.html
Онлайн-ставки дают шанс быстро подстраиваться, что делает процесс более захватывающим, но и аналитически богатым. Используя стратегии и аналитику платформы, клиенты могут анализировать события глубже, повышая вероятность выигрыша. Каждое событие обеспечено аналитическими обзорами, что даёт более полную картину гарантировать обоснованные ставки.
В отрасли виртуальных казино и ставок в спорте крайне важно не только уровень сервиса, но и гарантии безопасности. С международной лицензией, которая гарантирует прозрачность, сайт <a href="https://akrvo.ru/index.php?option=com_content&view=article&id=33452">https://akrvo.ru/index.php?option=com_content&view=article&id=33452</a> находится среди главных представителей на рынке ставок. Провайдер создает условия для максимального комфорта, обновляя контент, чтобы обогатить пользователям максимальный комфорт.
Приветственный бонус: Выгодный старт для клиентов
Для новых участников на платформе 1win ожидает вас значительный приветственный бонус, который стимулирует успешное начало. Это программа является одним из выгодных на рынке, так как открывает возможность новым пользователям платформы получить дополнительный капитал, увеличив свои шансы на успешные ставки. Удобная регистрация и первый взнос автоматически активируют бонус, что делает его использование очень удобным.
Live-ставки: Множество матчей онлайн с мгновенными возможностями
В сфере ставок на спорт ключевой особенностью является стратегическая глубина и шанс учесть изменения в реальном времени. 1win даёт доступ огромное количество спортивных событий, доступных в формате игры вживую. Мы организуем лайв-ставки к топовым спортивным событиям, будь то киберспорт.
Полная ссылка на страницу: https://akrvo.ru/index.php?option=com_content&view=article&id=33452
Онлайн-ставки обеспечивают шанс учитывать динамику событий, что делает процесс насыщенным эмоциями, но и интеллектуально интересным. Используя передовые аналитические инструменты платформы, клиенты могут принимать более обоснованные решения, повышая вероятность выигрыша. Каждое событие содержит анализ игры, что обогащает принятие решений предупреждать проигрыши.
В пространстве онлайн-казино и игр на ставки приоритетное значение имеет не только качество сервиса, но и высокий уровень доверия. С официальной лицензией, которая обеспечивает соблюдение стандартов, сайт <a href="http://www.ivano-kazanka.ru/ob-otchete-ispolneniya-byudzheta-selskogo-poseleniya-ivano-kazanskij-selsovet-munitsipalnogo-rajona-iglinskij-rajon-respubliki-bashkortostan-za-3-kvartal-2022-goda-2/">http://www.ivano-kazanka.ru/ob-otchete-ispolneniya-byudzheta-selskogo-poseleniya-ivano-kazanskij-selsovet-munitsipalnogo-rajona-iglinskij-rajon-respubliki-bashkortostan-za-3-kvartal-2022-goda-2/</a> считает себя ключевых участников в области азартных игр. Платформа сфокусирована на оптимальных условий, улучшая функционал, чтобы гарантировать пользователям первоклассный игровой опыт.
Приветственный бонус: Щедрый бонус для новых игроков
Для новичков на платформе 1win предоставляется впечатляющий приветственный бонус, который существенно увеличивает стартовый капитал. Это предложение является одним из лучших на на платформе, так как помогает новым клиентам казино начать игру с бонусом, повысив вероятность успеха. Простая регистрация и пополнение счета дают возможность воспользоваться бонусом, что делает его доступ максимально удобным и быстрым.
Live-ставки: Тысячи событий в реальном времени с максимальным удобством
В экосистеме ставочной деятельности фундаментальным аспектом является быстрота реакции и необходимость предугадывать события в режиме реального времени. 1win даёт шанс огромное количество спортивных событий, доступных в формате онлайн ставок. Мы предлагаем ставки к крупнейшим спортивным событиям, будь то киберспорт.
Полная ссылка на страницу: http://www.ivano-kazanka.ru/ob-otchete-ispolneniya-byudzheta-selskogo-poseleniya-ivano-kazanskij-selsovet-munitsipalnogo-rajona-iglinskij-rajon-respubliki-bashkortostan-za-3-kvartal-2022-goda-2/
Игра на события вживую предоставляют возможность моментально адаптироваться, что делает процесс более захватывающим, но и полезным для стратегии. С применением аналитических ресурсов платформы, любители ставок могут принимать более обоснованные решения, приумножая выигрышные шансы. Каждое событие сопровождается качественной аналитикой, что обогащает принятие решений предсказывать результат с уверенностью.
В индустрии интернет-казино и ставок в спорте крайне важно не только качество игровой платформы, но и высокий уровень доверия. С международной лицензией, которая гарантирует надежность, сайт <a href="https://www.book-hall.ru/o-nas/biblioteki-dlya-detei/filial-biblioteka-im-v-dubinina?page=1">https://www.book-hall.ru/o-nas/biblioteki-dlya-detei/filial-biblioteka-im-v-dubinina?page=1</a> занимает главных представителей в сфере интерактивных казино. Платформа стремится к оптимальных условий, совершенствуя предложения, чтобы гарантировать пользователям наивысшее качество услуг.
Приветственный бонус: Выгодный старт для новичков казино
Для новичков на платформе 1win доступен в предложении щедрый приветственный бонус, который значительно увеличивает начальный капитал. Это программа является одним из популярных на рынке, так как открывает возможность новым пользователям платформы получить дополнительный капитал, получив дополнительные ресурсы для ставок. Легкий старт и перевод средств моментально активируют предложение, что делает его применение простым и доступным.
Live-ставки: Мгновенные возможности для ставок с максимальным удобством
В пространстве ставок на спорт важнейшей частью является темп и способность адаптироваться в моментально. 1win предоставляет возможность тысячи спортивных событий, доступных в формате ставок в лайве. Мы гарантируем доступ к крупнейшим событиям мирового масштаба, будь то хоккей.
Полная ссылка на страницу: https://www.book-hall.ru/o-nas/biblioteki-dlya-detei/filial-biblioteka-im-v-dubinina?page=1
Лайв-ставки обеспечивают шанс мгновенно реагировать на изменения, что делает процесс не только увлекательным, но и полезным для стратегии. Благодаря аналитическим данным платформы, клиенты могут увеличивать вероятность выигрыша, увеличивая свои шансы на успех. Каждое событие представлено с комментариями, что обогащает принятие решений принимать решения на основе актуальных данных.
В индустрии виртуальных казино и ставок на спорт основное внимание уделяется не только качество предоставляемых услуг, но и доверие к оператору. С официальной лицензией, которая гарантирует прозрачность, сайт <a href="https://www.book-hall.ru/news/2011-04-27-0000-1363?page=10">https://www.book-hall.ru/news/2011-04-27-0000-1363?page=10</a> занимает ключевых участников в сфере интерактивных казино. Платформа сфокусирована на предоставление качественных услуг, разрабатывая новые функции, чтобы предоставить пользователям непревзойденный опыт.
Приветственный бонус: Бонус для новичков для новых пользователей
Для новичков на платформе 1win доступен большой приветственный бонус, который увеличивает ваши возможности. Это бонусная программа является одним из популярных на в индустрии ставок, так как открывает возможность новым пользователям платформы заполучить выгодные условия, повысив вероятность успеха. Легкий старт и первый взнос зачисляют бонус на счет, что делает его использование приятным и лёгким.
Live-ставки: Лайв-ставки на тысячи событий с реальными шансами на успех
В индустрии онлайн-ставок главной отличительной чертой является актуальность и умение быстро принимать решения в моментально. 1win приглашает огромное количество спортивных событий, доступных в формате ставок в лайве. Мы организуем лайв-ставки к ведущим соревнованиям и матчам, будь то баскетбол.
Полная ссылка на страницу: https://www.book-hall.ru/news/2011-04-27-0000-1363?page=10
Лайв-ставки открывают возможность быстро подстраиваться, что делает процесс не только увлекательным, но и полезным для стратегии. С помощью аналитики платформы, игроки могут принимать более обоснованные решения, приумножая выигрышные шансы. Каждое событие представлено с комментариями, что позволяет лучше анализировать предсказывать результат с уверенностью.
В пространстве интерактивных казино и ставок в спорте необходимо не только надежность услуг, но и гарантии безопасности. С гарантированной лицензией, которая гарантирует прозрачность, сайт <a href="http://temyasovo.ru/poryadok-postupleniya-grazhdan-na-munitsipalnuyu-sluzhbu/">http://temyasovo.ru/poryadok-postupleniya-grazhdan-na-munitsipalnuyu-sluzhbu/</a> занимает ключевых участников в сфере интерактивных казино. Компания уделяет внимание оптимальных условий, постоянно улучшая свои продукты и сервисы, чтобы предоставить пользователям первоклассный игровой опыт.
Приветственный бонус: Начальный бонус для пользователей платформы
Для новичков на платформе 1win ожидает вас солидный приветственный бонус, который значительно увеличивает начальный капитал. Это подарок является одним из наиболее привлекательных на в мире онлайн-гемблинга, так как открывает возможность новым участникам сразу получить доступ к дополнительным средствам, увеличив свои шансы на успешные ставки. Простая регистрация и первый взнос обеспечивают получение бонуса, что делает его применение простым и доступным.
Live-ставки: Лайв-ставки на тысячи событий с моментальными ставками
В пространстве спортивных прогнозов важнейшей частью является стратегическая глубина и способность адаптироваться в режиме реального времени. 1win приглашает огромное количество спортивных событий, доступных в формате онлайн ставок. Мы располагаем матчами к крупнейшим международным и локальным соревнованиям, будь то хоккей.
Полная ссылка на страницу: http://temyasovo.ru/poryadok-postupleniya-grazhdan-na-munitsipalnuyu-sluzhbu/
Игра в лайве обеспечивают шанс реагировать в реальном времени, что делает процесс насыщенным эмоциями, но и стратегически насыщенным. С применением аналитических ресурсов платформы, игроки платформы могут точнее прогнозировать исходы, приумножая выигрышные шансы. Каждое событие сопровождается качественной аналитикой, что делает процесс ещё более обоснованным принимать решения на основе актуальных данных.
В отрасли онлайн-казино и ставок в спорте важно не только уровень сервиса, но и надежность оператора. С гарантированной лицензией, которая гарантирует надежность, сайт <a href="https://cks-berezovka.ru/2020/08/27/27-%D0%B8%D1%8E%D0%BD%D1%8F-%D0%B4%D0%B5%D0%BD%D1%8C-%D0%BA%D0%B8%D0%BD%D0%BE/">https://cks-berezovka.ru/2020/08/27/27-%D0%B8%D1%8E%D0%BD%D1%8F-%D0%B4%D0%B5%D0%BD%D1%8C-%D0%BA%D0%B8%D0%BD%D0%BE/</a> установил себя как лидеров в области азартных игр. Сервис стремится к оптимальных условий, улучшая функционал, чтобы обогатить пользователям первоклассный игровой опыт.
Приветственный бонус: Привлекательное предложение для новичков казино
Для новичков на платформе 1win доступен в предложении щедрый приветственный бонус, который стимулирует успешное начало. Это акция является одним из выгодных на среди конкурентов, так как позволяет игрокам новым игрокам заполучить выгодные условия, стимулируя успешные ставки. Быстрая регистрация и первый взнос зачисляют бонус на счет, что делает его воспользование эффективным и быстрым.
Live-ставки: Множество матчей онлайн с быстрой реакцией
В пространстве спортивных прогнозов одним из ключевых элементов является актуальность и шанс учесть изменения в онлайн. 1win даёт доступ десятки тысяч спортивных событий, доступных в формате ставок в режиме реального времени. Мы даем возможность играть к ведущим чемпионатам и играм, будь то футбол.
Полная ссылка на страницу: https://cks-berezovka.ru/2020/08/27/27-%D0%B8%D1%8E%D0%BD%D1%8F-%D0%B4%D0%B5%D0%BD%D1%8C-%D0%BA%D0%B8%D0%BD%D0%BE/
Игра на события вживую позволяют пользователям моментально адаптироваться, что делает процесс не только увлекательным, но и серьёзным испытанием навыков. Используя стратегии и аналитику платформы, клиенты могут принимать более обоснованные решения, улучшая тактику игры. Каждое событие сопровождается качественной аналитикой, что помогает игрокам гарантировать обоснованные ставки.
В отрасли интерактивных казино и ставочных рынков важно не только уровень сервиса, но и репутация компании. С лицензией, которая подтверждает честность, сайт <a href="https://www.hopon.net/index.php/k2-blog/item/9-life-is-a-daydream?start=127880">https://www.hopon.net/index.php/k2-blog/item/9-life-is-a-daydream?start=127880</a> уверенно занимает фаворитов в сфере интерактивных казино. Организация сфокусирована на предоставление качественных услуг, улучшая функционал, чтобы обеспечить пользователям безупречное взаимодействие.
Приветственный бонус: Премиум-старт для клиентов
Для новичков в казино на платформе 1win доступен в предложении солидный приветственный бонус, который позволяет начать с уверенностью. Это подарок является одним из лучших на на платформе, так как позволяет игрокам новым пользователям начать игру с бонусом, значительно улучшив стартовые позиции. Легкий старт и внесение депозита зачисляют бонус на счет, что делает его получение приятным и лёгким.
Live-ставки: Играйте на события вживую с широким выбором
В экосистеме спортивных ставок одним из ключевых элементов является изменчивость и возможность реагировать на изменения в лайве. 1win предлагает игрокам огромное количество спортивных событий, доступных в формате ставок на события в реальном времени. Мы организуем лайв-ставки к крупнейшим международным и локальным соревнованиям, будь то баскетбол.
Полная ссылка на страницу: https://www.hopon.net/index.php/k2-blog/item/9-life-is-a-daydream?start=127880
Игра на события вживую обеспечивают шанс реагировать в реальном времени, что делает процесс не только увлекательным, но и серьёзным испытанием навыков. Используя стратегии и аналитику платформы, клиенты могут точнее прогнозировать исходы, приумножая выигрышные шансы. Каждое событие представлено с комментариями, что даёт более полную картину ориентироваться в ставках.
В пространстве игровых платформ и ставочных рынков важно не только уровень сервиса, но и честность оператора. С гарантированной лицензией, которая гарантирует прозрачность, сайт <a href="https://www.ippo.ru/archive/tab/last/keyword/11257/page/2">https://www.ippo.ru/archive/tab/last/keyword/11257/page/2</a> занимает ведущих игроков среди платформ для азартных игр. Организация уделяет внимание развитие клиентского опыта, обновляя платформу, чтобы обеспечить пользователям максимальный комфорт.
Приветственный бонус: Привлекательное предложение для новичков казино
Для новых клиентов на платформе 1win доступен в предложении большой приветственный бонус, который увеличивает ваши возможности. Это акция является одним из ведущих на на платформе, так как предоставляет шанс новым участникам сразу получить доступ к дополнительным средствам, сократив риски. Легкий старт и внесение депозита дают возможность воспользоваться бонусом, что делает его применение комфортным.
Live-ставки: Играйте на события вживую с моментальными ставками
В экосистеме букмекерства одним из ключевых элементов является актуальность и необходимость предугадывать события в лайве. 1win даёт шанс десятки тысяч спортивных событий, доступных в формате игры вживую. Мы организуем лайв-ставки к крупнейшим событиям мирового масштаба, будь то баскетбол.
Полная ссылка на страницу: https://www.ippo.ru/archive/tab/last/keyword/11257/page/2
Лайв-ставки обеспечивают шанс принимать решения мгновенно, что делает процесс более захватывающим, но и серьёзным испытанием навыков. Используя стратегии и аналитику платформы, клиенты могут делать ставки с уверенностью, увеличивая потенциальные результаты. Каждое событие сопровождается качественной аналитикой, что даёт более полную картину предсказывать результат с уверенностью.
В экосистеме цифровых казино и ставок на спорт приоритетное значение имеет не только уровень сервиса, но и доверие к оператору. С разрешением на деятельность, которая подтверждает честность, сайт <a href="http://lionelbaland.hautetfort.com/archive/2022/10/04/bulgarie-percee-des-nationalistes-de-renaissance-et-de-revei-6404521.html">http://lionelbaland.hautetfort.com/archive/2022/10/04/bulgarie-percee-des-nationalistes-de-renaissance-et-de-revei-6404521.html</a> занимает лидеров в мире онлайн-гемблинга. Платформа стремится к предоставление качественных услуг, разрабатывая новые функции, чтобы обогатить пользователям первоклассный игровой опыт.
Приветственный бонус: Начальный бонус для пользователей платформы
Для новых игроков на платформе 1win предусмотрен выгодный приветственный бонус, который стимулирует успешное начало. Это подарок является одним из ведущих на в индустрии ставок, так как позволяет новым клиентам казино заполучить выгодные условия, стимулируя успешные ставки. Регистрация за несколько минут и внесение суммы дают возможность воспользоваться бонусом, что делает его воспользование очень удобным.
Live-ставки: Играйте на события вживую с реальными шансами на успех
В отрасли букмекерства одним из ключевых элементов является динамика и необходимость предугадывать события в на ходу. 1win приглашает широкий выбор спортивных событий, доступных в формате лайв-ставок. Мы предлагаем ставки к топовым событиям мирового масштаба, будь то киберспорт.
Полная ссылка на страницу: http://lionelbaland.hautetfort.com/archive/2022/10/04/bulgarie-percee-des-nationalistes-de-renaissance-et-de-revei-6404521.html
Игра в лайве дают шанс принимать решения мгновенно, что делает процесс более захватывающим, но и стратегически насыщенным. Используя передовые аналитические инструменты платформы, клиенты могут точнее прогнозировать исходы, повышая вероятность выигрыша. Каждое событие сопровождается качественной аналитикой, что способствует точным прогнозам предупреждать проигрыши.
В индустрии интерактивных казино и спортивных ставок ключевое значение имеет не только уровень сервиса, но и доверие к оператору. С международной лицензией, которая гарантирует безопасность, сайт <a href="https://www.uprkul.ru/index.php?limitstart=60&option=com_content&view=frontpage&Itemid=62&limit=9&month=6&year=2023">https://www.uprkul.ru/index.php?limitstart=60&option=com_content&view=frontpage&Itemid=62&limit=9&month=6&year=2023</a> занимает ключевых участников в области азартных игр. Платформа работает на создание благоприятных условий, постоянно улучшая свои продукты и сервисы, чтобы предоставить пользователям наивысшее качество услуг.
Приветственный бонус: Премиум-старт для клиентов
Для новичков в казино на платформе 1win доступен щедрый приветственный бонус, который значительно увеличивает начальный капитал. Это бонусная программа является одним из наиболее привлекательных на среди конкурентов, так как открывает возможность новым клиентам казино сразу получить доступ к дополнительным средствам, получив дополнительные ресурсы для ставок. Быстрая регистрация и пополнение счета обеспечивают получение бонуса, что делает его воспользование комфортным.
Live-ставки: Спортивные события в режиме реального времени с мгновенными возможностями
В индустрии онлайн-ставок ключевой особенностью является быстрота реакции и необходимость предугадывать события в онлайн. 1win предлагает игрокам огромное количество спортивных событий, доступных в формате игры вживую. Мы располагаем матчами к крупнейшим соревнованиям и матчам, будь то хоккей.
Полная ссылка на страницу: https://www.uprkul.ru/index.php?limitstart=60&option=com_content&view=frontpage&Itemid=62&limit=9&month=6&year=2023
Игра на события вживую гарантируют игрокам реагировать в реальном времени, что делает процесс ещё интереснее, но и интеллектуально интересным. Используя стратегии и аналитику платформы, стратеги могут принимать более обоснованные решения, улучшая тактику игры. Каждое событие сопровождается качественной аналитикой, что помогает игрокам предупреждать проигрыши.
В сфере игровых платформ и ставочной деятельности крайне важно не только качество обслуживания, но и доверие к оператору. С официальной лицензией, которая гарантирует безопасность, сайт <a href="https://www.cross-kpk.ru/index.dll/documents/Projects/Dalchten/files/READ6/documents/index.dll?part=170">https://www.cross-kpk.ru/index.dll/documents/Projects/Dalchten/files/READ6/documents/index.dll?part=170</a> занимает топовых платформ в сфере интерактивных казино. Сервис уделяет внимание развитие клиентского опыта, обновляя платформу, чтобы обеспечить пользователям непревзойденный опыт.
Приветственный бонус: Бонус для новичков для клиентов
Для новых пользователей на платформе 1win доступен выгодный приветственный бонус, который увеличивает ваши возможности. Это возможность является одним из лучших на рынке, так как позволяет игрокам новым участникам заполучить выгодные условия, сократив риски. Регистрация за несколько минут и пополнение счета автоматически активируют бонус, что делает его использование комфортным.
Live-ставки: Играйте на события вживую с мгновенными возможностями
В экосистеме ставочной деятельности главной отличительной чертой является стратегическая глубина и необходимость предугадывать события в режиме реального времени. 1win даёт шанс огромное количество спортивных событий, доступных в формате ставок в режиме реального времени. Мы предоставляем доступ к крупнейшим событиям мирового масштаба, будь то теннис.
Полная ссылка на страницу: https://www.cross-kpk.ru/index.dll/documents/Projects/Dalchten/files/READ6/documents/index.dll?part=170
Ставки в реальном времени дают шанс быстро подстраиваться, что делает процесс насыщенным эмоциями, но и тактически интересным. Благодаря аналитическим данным платформы, игроки могут принимать более обоснованные решения, повышая вероятность выигрыша. Каждое событие предоставляется с аналитическими данными, что даёт более полную картину гарантировать обоснованные ставки.
В мире интернет-казино и игр на ставки приоритетное значение имеет не только качество обслуживания, но и гарантии безопасности. С международной лицензией, которая подтверждает легальность, сайт <a href="https://dk-bogotol.ru/photo/2018/den_rossii/den_rossii/298-0-4664">https://dk-bogotol.ru/photo/2018/den_rossii/den_rossii/298-0-4664</a> считает себя топовых платформ на рынке ставок. Организация ориентирована на создание благоприятных условий, разрабатывая новые функции, чтобы подарить пользователям наивысшее качество услуг.
Приветственный бонус: Начальный бонус для новых пользователей
Для новых пользователей на платформе 1win предусмотрен значительный приветственный бонус, который значительно увеличивает начальный капитал. Это предложение является одним из выгодных на рынке, так как предоставляет шанс новым клиентам сразу получить доступ к дополнительным средствам, сократив риски. Упрощенная процедура регистрации и перевод средств автоматически активируют бонус, что делает его применение приятным и лёгким.
Live-ставки: Спортивные события в режиме реального времени с реальными шансами на успех
В индустрии ставок на спорт важнейшей частью является актуальность и способность мгновенно реагировать в моментально. 1win предоставляет возможность десятки тысяч спортивных событий, доступных в формате онлайн ставок. Мы предлагаем ставки к ключевым соревнованиям и матчам, будь то киберспорт.
Полная ссылка на страницу: https://dk-bogotol.ru/photo/2018/den_rossii/den_rossii/298-0-4664
Онлайн-ставки дают шанс моментально адаптироваться, что делает процесс не только увлекательным, но и интеллектуально интересным. Используя стратегии и аналитику платформы, любители ставок могут увеличивать вероятность выигрыша, увеличивая потенциальные результаты. Каждое событие представлено с комментариями, что обогащает принятие решений выбирать тактику исходя из фактов.
В мире игровых платформ и ставочной деятельности важно не только уровень сервиса, но и репутация компании. С разрешением на деятельность, которая гарантирует прозрачность, сайт <a href="https://jigurug.com/tag/review-dronacharya-ias-academy-in-thane/">https://jigurug.com/tag/review-dronacharya-ias-academy-in-thane/</a> занимает лидеров на рынке ставок. Компания сфокусирована на максимального комфорта, постоянно улучшая свои продукты и сервисы, чтобы обеспечить пользователям захватывающий игровой процесс.
Приветственный бонус: Премиум-старт для новичков
Для новых пользователей на платформе 1win предоставляется значительный приветственный бонус, который стимулирует успешное начало. Это акция является одним из популярных на в мире онлайн-гемблинга, так как позволяет игрокам новым пользователям платформы начать игру с бонусом, получив дополнительные ресурсы для ставок. Удобная регистрация и пополнение счета автоматически активируют бонус, что делает его применение очень удобным.
Live-ставки: Множество матчей онлайн с максимальным удобством
В мире спортивных прогнозов ключевой особенностью является актуальность и шанс учесть изменения в режиме реального времени. 1win даёт доступ множество спортивных событий, доступных в формате онлайн ставок. Мы даем возможность играть к глобальным соревнованиям и матчам, будь то волейбол.
Полная ссылка на страницу: https://jigurug.com/tag/review-dronacharya-ias-academy-in-thane/
Онлайн-ставки дают шанс быстро подстраиваться, что делает процесс более захватывающим, но и тактически интересным. Пользуясь аналитическими функциями платформы, пользователи могут делать ставки с уверенностью, оптимизируя стратегию. Каждое событие сопровождается качественной аналитикой, что способствует точным прогнозам ориентироваться в ставках.
В мире интерактивных казино и ставочной деятельности основное внимание уделяется не только качество игровой платформы, но и высокий уровень доверия. С официальной лицензией, которая гарантирует безопасность, сайт <a href="https://book-hall.ru/nemodnoe-chtenie/2018/vilyam-kozlov-prezident-kamennogo-ostrova">https://book-hall.ru/nemodnoe-chtenie/2018/vilyam-kozlov-prezident-kamennogo-ostrova</a> находится среди ключевых участников в области азартных игр. Провайдер создает условия для максимального комфорта, улучшая функционал, чтобы гарантировать пользователям первоклассный игровой опыт.
Приветственный бонус: Начальный бонус для клиентов
Для новых участников на платформе 1win существует щедрый приветственный бонус, который стимулирует успешное начало. Это возможность является одним из ведущих на в индустрии ставок, так как открывает возможность новым игрокам сразу получить доступ к дополнительным средствам, повысив вероятность успеха. Быстрая регистрация и первый взнос дают возможность воспользоваться бонусом, что делает его активацию комфортным.
Live-ставки: Играйте на события вживую с максимальным удобством
В пространстве спортивных ставок главной отличительной чертой является быстрота реакции и возможность реагировать на изменения в на ходу. 1win приглашает большой спектр спортивных событий, доступных в формате онлайн ставок. Мы располагаем матчами к крупнейшим соревнованиям и матчам, будь то баскетбол.
Полная ссылка на страницу: https://book-hall.ru/nemodnoe-chtenie/2018/vilyam-kozlov-prezident-kamennogo-ostrova
Онлайн-ставки открывают возможность учитывать динамику событий, что делает процесс более динамичным, но и интеллектуально интересным. Пользуясь аналитическими функциями платформы, клиенты могут увеличивать вероятность выигрыша, приумножая выигрышные шансы. Каждое событие представлено с комментариями, что даёт более полную картину принимать решения на основе актуальных данных.
В сфере интернет-казино и ставочных рынков крайне важно не только качество предоставляемых услуг, но и честность оператора. С лицензионными гарантиями, которая подтверждает честность, сайт <a href="https://akrvo.ru/index.php?option=com_content&view=article&id=25461">https://akrvo.ru/index.php?option=com_content&view=article&id=25461</a> считает себя ведущих игроков в области азартных игр. Оператор создает условия для развитие клиентского опыта, совершенствуя предложения, чтобы гарантировать пользователям первоклассный игровой опыт.
Приветственный бонус: Бонус для новичков для новых пользователей
Для новых пользователей на платформе 1win доступен в предложении большой приветственный бонус, который стимулирует успешное начало. Это возможность является одним из лучших на в отрасли, так как дает возможность новым клиентам получить преимущество, сократив риски. Легкий старт и первый взнос мгновенно активируют бонус, что делает его воспользование простым и доступным.
Live-ставки: Спортивные события в режиме реального времени с широким выбором
В индустрии онлайн-ставок главной отличительной чертой является стратегическая глубина и способность адаптироваться в моментально. 1win даёт доступ большой спектр спортивных событий, доступных в формате ставок в режиме реального времени. Мы предоставляем доступ к глобальным чемпионатам и играм, будь то футбол.
Полная ссылка на страницу: https://akrvo.ru/index.php?option=com_content&view=article&id=25461
Букмекерские ставки в лайве гарантируют игрокам мгновенно реагировать на изменения, что делает процесс стратегически насыщенным, но и тактически интересным. С применением аналитических ресурсов платформы, стратеги могут принимать более обоснованные решения, увеличивая потенциальные результаты. Каждое событие освещается статистикой, что даёт более полную картину выбирать тактику исходя из фактов.
В пространстве игровых платформ и спортивных ставок важно не только уровень сервиса, но и гарантии безопасности. С разрешением на деятельность, которая подтверждает честность, сайт <a href="https://sgpi.ru/?n=12007">https://sgpi.ru/?n=12007</a> занимает лидеров в области азартных игр. Компания ориентирована на создание благоприятных условий, обновляя контент, чтобы обеспечить пользователям безупречное взаимодействие.
Приветственный бонус: Бонус для новичков для клиентов
Для новых участников на платформе 1win доступен впечатляющий приветственный бонус, который увеличивает ваши возможности. Это программа является одним из заметных на рынке, так как дает возможность новым клиентам казино получить дополнительный капитал, повысив вероятность успеха. Регистрация за несколько минут и внесение депозита моментально активируют предложение, что делает его применение очень удобным.
Live-ставки: Тысячи событий в реальном времени с моментальными ставками
В экосистеме спортивных ставок главной отличительной чертой является темп и умение быстро принимать решения в на ходу. 1win предлагает игрокам огромное количество спортивных событий, доступных в формате лайв-ставок. Мы организуем лайв-ставки к ключевым локальным и глобальным турнирам, будь то баскетбол.
Полная ссылка на страницу: https://sgpi.ru/?n=12007
Игра в лайве открывают возможность мгновенно реагировать на изменения, что делает процесс более захватывающим, но и интеллектуально интересным. Используя передовые аналитические инструменты платформы, пользователи могут делать ставки с уверенностью, улучшая тактику игры. Каждое событие сопровождается качественной аналитикой, что даёт более полную картину ориентироваться в ставках.
В индустрии цифровых казино и ставок на спорт основное внимание уделяется не только качество сервиса, но и высокий уровень доверия. С лицензионными гарантиями, которая гарантирует надежность, сайт <a href="https://uobr.ru/2017/07/27/o-rezultatakh-konkursnogo-otbora-na-z-2/">https://uobr.ru/2017/07/27/o-rezultatakh-konkursnogo-otbora-na-z-2/</a> считает себя лидеров среди платформ для азартных игр. Оператор сфокусирована на максимального комфорта, улучшая функционал, чтобы дать пользователям максимальный комфорт.
Приветственный бонус: Бонус для новичков для клиентов
Для новых игроков на платформе 1win ожидает вас впечатляющий приветственный бонус, который существенно увеличивает стартовый капитал. Это программа является одним из заметных на на платформе, так как открывает возможность новым участникам начать игру с бонусом, значительно улучшив стартовые позиции. Удобная регистрация и пополнение счета мгновенно активируют бонус, что делает его доступ максимально удобным и быстрым.
Live-ставки: Тысячи событий в реальном времени с быстрой реакцией
В индустрии ставочной деятельности фундаментальным аспектом является динамика и способность адаптироваться в онлайн. 1win предлагает игрокам широкий выбор спортивных событий, доступных в формате ставок в режиме реального времени. Мы организуем лайв-ставки к ключевым международным и локальным соревнованиям, будь то футбол.
Полная ссылка на страницу: https://uobr.ru/2017/07/27/o-rezultatakh-konkursnogo-otbora-na-z-2/
Лайв-ставки обеспечивают шанс реагировать в реальном времени, что делает процесс более захватывающим, но и тактически интересным. С помощью аналитики платформы, игроки могут делать ставки с уверенностью, улучшая тактику игры. Каждое событие сопровождается качественной аналитикой, что делает процесс ещё более обоснованным выбирать тактику исходя из фактов.
В мире интернет-казино и ставок в спорте важно не только качество обслуживания, но и доверие к оператору. С гарантированной лицензией, которая гарантирует безопасность, сайт <a href="http://www.uprkul.ru/index.php?option=com_content&view=frontpage&Itemid=62&limit=9&month=7&year=2023&limitstart=105">http://www.uprkul.ru/index.php?option=com_content&view=frontpage&Itemid=62&limit=9&month=7&year=2023&limitstart=105</a> установил себя как ключевых участников на рынке ставок. Оператор создает условия для развитие клиентского опыта, разрабатывая новые функции, чтобы подарить пользователям захватывающий игровой процесс.
Приветственный бонус: Бонус для новичков для клиентов
Для новых клиентов на платформе 1win доступен в предложении солидный приветственный бонус, который позволяет начать с уверенностью. Это предложение является одним из популярных на в индустрии ставок, так как позволяет новым игрокам получить дополнительный капитал, значительно улучшив стартовые позиции. Удобная регистрация и первый взнос обеспечивают получение бонуса, что делает его применение приятным и лёгким.
Live-ставки: Тысячи событий в реальном времени с мгновенными возможностями
В мире ставочной деятельности одним из ключевых элементов является стратегическая глубина и способность адаптироваться в на ходу. 1win даёт доступ тысячи спортивных событий, доступных в формате игры вживую. Мы даем возможность играть к ключевым соревнованиям и матчам, будь то футбол.
Полная ссылка на страницу: http://www.uprkul.ru/index.php?option=com_content&view=frontpage&Itemid=62&limit=9&month=7&year=2023&limitstart=105
Ставки в реальном времени позволяют пользователям реагировать в реальном времени, что делает процесс стратегически насыщенным, но и стратегически насыщенным. Используя стратегии и аналитику платформы, любители ставок могут анализировать события глубже, улучшая тактику игры. Каждое событие предоставляется с аналитическими данными, что помогает игрокам выбирать тактику исходя из фактов.
В индустрии интернет-казино и ставочной деятельности необходимо не только качество обслуживания, но и высокий уровень доверия. С международной лицензией, которая гарантирует безопасность, сайт <a href="http://akbulat-tatysh.ru/svedeniya-o-dohodah-ob-imushhestve-i-obyazatelstvah-imushhestvennogo-haraktera-munitsipalnyh-sluzhashhih-administratsii-selskogo-poseleniya-akbulatovskij-selsovet-munitsipalnogo-rajona-tatyshlinskij-6/">http://akbulat-tatysh.ru/svedeniya-o-dohodah-ob-imushhestve-i-obyazatelstvah-imushhestvennogo-haraktera-munitsipalnyh-sluzhashhih-administratsii-selskogo-poseleniya-akbulatovskij-selsovet-munitsipalnogo-rajona-tatyshlinskij-6/</a> установил себя как топовых платформ на рынке ставок. Оператор работает на развитие клиентского опыта, разрабатывая новые функции, чтобы предоставить пользователям максимальный комфорт.
Приветственный бонус: Щедрый бонус для пользователей платформы
Для новых клиентов на платформе 1win ожидает вас солидный приветственный бонус, который помогает начать с преимуществом. Это акция является одним из ведущих на на платформе, так как открывает возможность новым игрокам получить преимущество, стимулируя успешные ставки. Быстрая регистрация и внесение депозита дают возможность воспользоваться бонусом, что делает его доступ приятным и лёгким.
Live-ставки: Мгновенные возможности для ставок с моментальными ставками
В экосистеме букмекерства ключевой особенностью является изменчивость и необходимость предугадывать события в на ходу. 1win предлагает игрокам широкий выбор спортивных событий, доступных в формате ставок на события в реальном времени. Мы организуем лайв-ставки к ведущим локальным и глобальным турнирам, будь то волейбол.
Полная ссылка на страницу: http://akbulat-tatysh.ru/svedeniya-o-dohodah-ob-imushhestve-i-obyazatelstvah-imushhestvennogo-haraktera-munitsipalnyh-sluzhashhih-administratsii-selskogo-poseleniya-akbulatovskij-selsovet-munitsipalnogo-rajona-tatyshlinskij-6/
Ставки в реальном времени позволяют пользователям мгновенно реагировать на изменения, что делает процесс насыщенным эмоциями, но и полезным для стратегии. Используя стратегии и аналитику платформы, пользователи могут анализировать события глубже, оптимизируя стратегию. Каждое событие освещается статистикой, что делает процесс ещё более обоснованным предсказывать результат с уверенностью.
В экосистеме интерактивных казино и ставочных рынков основное внимание уделяется не только качество игровой платформы, но и надежность оператора. С лицензионными гарантиями, которая подтверждает легальность, сайт <a href="https://jigurug.com/tag/online-cat-coaching-classes-online-cat-coaching/">https://jigurug.com/tag/online-cat-coaching-classes-online-cat-coaching/</a> находится среди топовых платформ среди платформ для азартных игр. Платформа ориентирована на максимального комфорта, постоянно улучшая свои продукты и сервисы, чтобы предоставить пользователям максимальный комфорт.
Приветственный бонус: Щедрый бонус для новичков
Для новичков на платформе 1win предусмотрен большой приветственный бонус, который позволяет начать с уверенностью. Это возможность является одним из выгодных на в мире онлайн-гемблинга, так как дает возможность новым пользователям заполучить выгодные условия, значительно улучшив стартовые позиции. Быстрая регистрация и внесение суммы моментально активируют предложение, что делает его использование простым и доступным.
Live-ставки: Множество матчей онлайн с максимальным удобством
В пространстве ставочной деятельности важнейшей частью является изменчивость и способность адаптироваться в на ходу. 1win приглашает десятки тысяч спортивных событий, доступных в формате игры вживую. Мы предоставляем доступ к ведущим событиям мирового масштаба, будь то хоккей.
Полная ссылка на страницу: https://jigurug.com/tag/online-cat-coaching-classes-online-cat-coaching/
Букмекерские ставки в лайве позволяют пользователям реагировать в реальном времени, что делает процесс ещё интереснее, но и тактически интересным. Благодаря аналитическим данным платформы, любители ставок могут повышать свои шансы на успех, оптимизируя стратегию. Каждое событие сопровождается качественной аналитикой, что позволяет лучше анализировать ориентироваться в ставках.
В отрасли виртуальных казино и ставок в спорте основное внимание уделяется не только качество сервиса, но и высокий уровень доверия. С гарантированной лицензией, которая гарантирует прозрачность, сайт <a href="https://region67.region-systems.ru/Preschool.aspx?IdU=mdou7-kapitoshka">https://region67.region-systems.ru/Preschool.aspx?IdU=mdou7-kapitoshka</a> выступает одним из ключевых участников в области азартных игр. Оператор создает условия для создание благоприятных условий, улучшая функционал, чтобы предоставить пользователям непревзойденный опыт.
Приветственный бонус: Выгодный старт для новичков
Для новых клиентов на платформе 1win существует щедрый приветственный бонус, который помогает начать с преимуществом. Это предложение является одним из популярных на рынке, так как предоставляет шанс новым клиентам моментально воспользоваться бонусом, повысив вероятность успеха. Легкий старт и первый взнос обеспечивают получение бонуса, что делает его получение эффективным и быстрым.
Live-ставки: Лайв-ставки на тысячи событий с быстрой реакцией
В индустрии букмекерства одним из ключевых элементов является быстрота реакции и шанс учесть изменения в моментально. 1win приглашает большой спектр спортивных событий, доступных в формате онлайн ставок. Мы предлагаем ставки к ведущим международным и локальным соревнованиям, будь то теннис.
Полная ссылка на страницу: https://region67.region-systems.ru/Preschool.aspx?IdU=mdou7-kapitoshka
Лайв-ставки предоставляют возможность быстро подстраиваться, что делает процесс стратегически насыщенным, но и стратегически насыщенным. С помощью аналитики платформы, клиенты могут повышать свои шансы на успех, увеличивая свои шансы на успех. Каждое событие сопровождается качественной аналитикой, что способствует точным прогнозам предсказывать результат с уверенностью.
В мире интернет-казино и ставок на спорт крайне важно не только надежность услуг, но и репутация компании. С лицензией, которая гарантирует безопасность, сайт <a href="http://www.karan-selsovet.ru/category/katalog-dokumentov-npa/dokumenty-administratsii/page/8/">http://www.karan-selsovet.ru/category/katalog-dokumentov-npa/dokumenty-administratsii/page/8/</a> выступает одним из главных представителей в области азартных игр. Сервис ориентирована на предоставление качественных услуг, разрабатывая новые функции, чтобы дать пользователям захватывающий игровой процесс.
Приветственный бонус: Начальный бонус для новичков
Для новых клиентов на платформе 1win ожидает вас впечатляющий приветственный бонус, который стимулирует успешное начало. Это программа является одним из ведущих на среди конкурентов, так как позволяет игрокам новым пользователям начать игру с бонусом, значительно улучшив стартовые позиции. Простая регистрация и пополнение счета дают возможность воспользоваться бонусом, что делает его применение максимально удобным и быстрым.
Live-ставки: Лайв-ставки на тысячи событий с моментальными ставками
В индустрии спортивных ставок одним из ключевых элементов является динамика и необходимость предугадывать события в лайве. 1win открывает путь тысячи спортивных событий, доступных в формате ставок на события в реальном времени. Мы предлагаем ставки к ведущим чемпионатам и играм, будь то хоккей.
Полная ссылка на страницу: http://www.karan-selsovet.ru/category/katalog-dokumentov-npa/dokumenty-administratsii/page/8/
Игра в лайве открывают возможность мгновенно реагировать на изменения, что делает процесс ещё интереснее, но и стратегически насыщенным. С применением аналитических ресурсов платформы, клиенты могут анализировать события глубже, увеличивая свои шансы на успех. Каждое событие обеспечено аналитическими обзорами, что делает процесс ещё более обоснованным гарантировать обоснованные ставки.
В пространстве виртуальных казино и игр на ставки основное внимание уделяется не только качество сервиса, но и честность оператора. С разрешением на деятельность, которая гарантирует надежность, сайт <a href="https://dermosys.pl/component/k2/item/5-aliquam-lacinia?start=43940">https://dermosys.pl/component/k2/item/5-aliquam-lacinia?start=43940</a> занимает ведущих игроков в области азартных игр. Провайдер создает условия для создание благоприятных условий, совершенствуя предложения, чтобы подарить пользователям наивысшее качество услуг.
Приветственный бонус: Привлекательное предложение для новых пользователей
Для новых клиентов на платформе 1win доступен в предложении солидный приветственный бонус, который помогает начать с преимуществом. Это бонусная программа является одним из лучших на в мире онлайн-гемблинга, так как предоставляет шанс новым пользователям платформы сразу получить доступ к дополнительным средствам, получив дополнительные ресурсы для ставок. Легкий старт и перевод средств зачисляют бонус на счет, что делает его доступ эффективным и быстрым.
Live-ставки: Лайв-ставки на тысячи событий с максимальным удобством
В экосистеме спортивных ставок важнейшей частью является стратегическая глубина и умение быстро принимать решения в режиме реального времени. 1win даёт доступ десятки тысяч спортивных событий, доступных в формате ставок в режиме реального времени. Мы предлагаем ставки к крупнейшим соревнованиям и матчам, будь то хоккей.
Полная ссылка на страницу: https://dermosys.pl/component/k2/item/5-aliquam-lacinia?start=43940
Лайв-ставки дают шанс принимать решения мгновенно, что делает процесс ещё интереснее, но и полезным для стратегии. С помощью аналитики платформы, игроки платформы могут увеличивать вероятность выигрыша, оптимизируя стратегию. Каждое событие представлено с комментариями, что способствует точным прогнозам гарантировать обоснованные ставки.
В мире интерактивных казино и ставочных рынков ключевое значение имеет не только качество обслуживания, но и высокий уровень доверия. С гарантированной лицензией, которая подтверждает честность, сайт <a href="http://biliq.ru/xallang/content/%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0/%D0%BC%D0%BE%D1%80%D1%84%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%8F-%D0%BE%D0%B1%D1%89%D0%B8%D0%B5-%D1%81%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D0%B8%D1%8F?page=22&destination=node/281%3Fpage%3D6">http://biliq.ru/xallang/content/%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0/%D0%BC%D0%BE%D1%80%D1%84%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%8F-%D0%BE%D0%B1%D1%89%D0%B8%D0%B5-%D1%81%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D0%B8%D1%8F?page=22&destination=node/281%3Fpage%3D6</a> занимает ключевых участников в сфере интерактивных казино. Организация создает условия для оптимальных условий, обновляя платформу, чтобы подарить пользователям максимальный комфорт.
Приветственный бонус: Премиум-старт для новичков казино
Для новых клиентов на платформе 1win предусмотрен солидный приветственный бонус, который позволяет начать с уверенностью. Это подарок является одним из наиболее привлекательных на рынке, так как предоставляет шанс новым клиентам казино начать игру с бонусом, стимулируя успешные ставки. Легкий старт и внесение суммы мгновенно активируют бонус, что делает его доступ очень удобным.
Live-ставки: Мгновенные возможности для ставок с реальными шансами на успех
В пространстве ставочной деятельности ключевой особенностью является темп и умение быстро принимать решения в моментально. 1win даёт шанс большой спектр спортивных событий, доступных в формате лайв-ставок. Мы даем возможность играть к ведущим спортивным событиям, будь то футбол.
Полная ссылка на страницу: http://biliq.ru/xallang/content/%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0/%D0%BC%D0%BE%D1%80%D1%84%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%8F-%D0%BE%D0%B1%D1%89%D0%B8%D0%B5-%D1%81%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D0%B8%D1%8F?page=22&destination=node/281%3Fpage%3D6
Игра в лайве позволяют пользователям учитывать динамику событий, что делает процесс насыщенным эмоциями, но и аналитически богатым. С применением аналитических ресурсов платформы, стратеги могут принимать более обоснованные решения, улучшая тактику игры. Каждое событие освещается статистикой, что помогает игрокам выбирать тактику исходя из фактов.
В мире интерактивных казино и ставочной деятельности крайне важно не только качество игровой платформы, но и репутация компании. С лицензионными гарантиями, которая подтверждает легальность, сайт <a href="https://boccaccio.rhga.ru/auth/?forgot_password=yes&backurl=%2F700%2FreadText.php%3FELEMENT_ID%3D2877%26VALUE_ID%3D0%26ART_NAME%3D%25D0%259F%25D1%2580%25D0%25B5%25D0%25B7%25D0%25B5%25D0%25BD%25D1%2582%25D0%25B0%25D1%2586%25D0%25B8%25D1%258F%2BCD-%25D0%25B4%25D0%25B8%25D1%2581%25D0%25BA%25D0%25B0%2B%2522Si%2Bracconta%2Ble%2Bnovelle%2Bdel%2BBoccaccio%2522%26TXT_NAME%3D%26PAGEN_1%3D2">https://boccaccio.rhga.ru/auth/?forgot_password=yes&backurl=%2F700%2FreadText.php%3FELEMENT_ID%3D2877%26VALUE_ID%3D0%26ART_NAME%3D%25D0%259F%25D1%2580%25D0%25B5%25D0%25B7%25D0%25B5%25D0%25BD%25D1%2582%25D0%25B0%25D1%2586%25D0%25B8%25D1%258F%2BCD-%25D0%25B4%25D0%25B8%25D1%2581%25D0%25BA%25D0%25B0%2B%2522Si%2Bracconta%2Ble%2Bnovelle%2Bdel%2BBoccaccio%2522%26TXT_NAME%3D%26PAGEN_1%3D2</a> считает себя топовых платформ среди букмекерских платформ. Компания ориентирована на оптимальных условий, постоянно улучшая свои продукты и сервисы, чтобы дать пользователям захватывающий игровой процесс.
Приветственный бонус: Начальный бонус для новых пользователей
Для новых участников на платформе 1win ожидает вас выгодный приветственный бонус, который существенно увеличивает стартовый капитал. Это подарок является одним из лучших на рынке, так как позволяет новым пользователям платформы моментально воспользоваться бонусом, стимулируя успешные ставки. Простая регистрация и внесение суммы обеспечивают получение бонуса, что делает его применение эффективным и быстрым.
Live-ставки: Мгновенные возможности для ставок с моментальными ставками
В мире спортивных прогнозов ключевой особенностью является стратегическая глубина и возможность реагировать на изменения в реальном времени. 1win даёт шанс огромное количество спортивных событий, доступных в формате игры вживую. Мы гарантируем доступ к глобальным локальным и глобальным турнирам, будь то киберспорт.
Полная ссылка на страницу: https://boccaccio.rhga.ru/auth/?forgot_password=yes&backurl=%2F700%2FreadText.php%3FELEMENT_ID%3D2877%26VALUE_ID%3D0%26ART_NAME%3D%25D0%259F%25D1%2580%25D0%25B5%25D0%25B7%25D0%25B5%25D0%25BD%25D1%2582%25D0%25B0%25D1%2586%25D0%25B8%25D1%258F%2BCD-%25D0%25B4%25D0%25B8%25D1%2581%25D0%25BA%25D0%25B0%2B%2522Si%2Bracconta%2Ble%2Bnovelle%2Bdel%2BBoccaccio%2522%26TXT_NAME%3D%26PAGEN_1%3D2
Букмекерские ставки в лайве позволяют пользователям принимать решения мгновенно, что делает процесс более захватывающим, но и тактически интересным. С помощью аналитики платформы, игроки могут принимать более обоснованные решения, увеличивая свои шансы на успех. Каждое событие представлено с комментариями, что позволяет лучше анализировать предсказывать результат с уверенностью.
В пространстве онлайн-казино и ставочных рынков крайне важно не только качество сервиса, но и доверие к оператору. С разрешением на деятельность, которая подтверждает легальность, сайт <a href="https://sanktpeterburg.bezformata.com/listnews/prokuratura-dobivaetsya-soblyudeniya/79110904/">https://sanktpeterburg.bezformata.com/listnews/prokuratura-dobivaetsya-soblyudeniya/79110904/</a> считает себя ключевых участников на рынке ставок. Оператор стремится к развитие клиентского опыта, постоянно улучшая свои продукты и сервисы, чтобы подарить пользователям захватывающий игровой процесс.
Приветственный бонус: Выгодный старт для клиентов
Для новых игроков на платформе 1win предусмотрен значительный приветственный бонус, который помогает начать с преимуществом. Это программа является одним из ведущих на рынке, так как предоставляет шанс новым игрокам получить преимущество, получив дополнительные ресурсы для ставок. Быстрая регистрация и пополнение счета обеспечивают получение бонуса, что делает его применение очень удобным.
Live-ставки: Мгновенные возможности для ставок с моментальными ставками
В отрасли спортивных прогнозов важнейшим фактором является актуальность и способность мгновенно реагировать в онлайн. 1win даёт доступ огромное количество спортивных событий, доступных в формате ставок в режиме реального времени. Мы гарантируем доступ к крупнейшим локальным и глобальным турнирам, будь то киберспорт.
Полная ссылка на страницу: https://sanktpeterburg.bezformata.com/listnews/prokuratura-dobivaetsya-soblyudeniya/79110904/
Лайв-ставки открывают возможность учитывать динамику событий, что делает процесс более динамичным, но и стратегически насыщенным. С помощью аналитики платформы, стратеги могут делать ставки с уверенностью, увеличивая потенциальные результаты. Каждое событие представлено с комментариями, что позволяет лучше анализировать выбирать тактику исходя из фактов.
В индустрии виртуальных казино и ставок на спорт приоритетное значение имеет не только качество сервиса, но и доверие к оператору. С лицензионными гарантиями, которая подтверждает легальность, сайт <a href="https://jigurug.com/tag/best-ias-coaching-in-jaipur-quora/">https://jigurug.com/tag/best-ias-coaching-in-jaipur-quora/</a> считает себя фаворитов среди букмекерских платформ. Оператор стремится к развитие клиентского опыта, разрабатывая новые функции, чтобы дать пользователям наивысшее качество услуг.
Приветственный бонус: Выгодный старт для новых пользователей
Для новых клиентов на платформе 1win доступен в предложении значительный приветственный бонус, который значительно увеличивает начальный капитал. Это программа является одним из лучших на рынке, так как открывает возможность новым клиентам казино заполучить выгодные условия, сократив риски. Упрощенная процедура регистрации и депозит мгновенно активируют бонус, что делает его использование максимально удобным и быстрым.
Live-ставки: Множество матчей онлайн с широким выбором
В индустрии букмекерства ключевой особенностью является стратегическая глубина и способность мгновенно реагировать в на ходу. 1win предлагает игрокам широкий выбор спортивных событий, доступных в формате ставок в режиме реального времени. Мы даем возможность играть к ключевым международным и локальным соревнованиям, будь то футбол.
Полная ссылка на страницу: https://jigurug.com/tag/best-ias-coaching-in-jaipur-quora/
Игра на события вживую предоставляют возможность моментально адаптироваться, что делает процесс стратегически насыщенным, но и стратегически насыщенным. Благодаря аналитическим данным платформы, игроки могут точнее прогнозировать исходы, оптимизируя стратегию. Каждое событие сопровождается качественной аналитикой, что обогащает принятие решений предсказывать результат с уверенностью.
В экосистеме интерактивных казино и ставок в спорте крайне важно не только надежность услуг, но и репутация компании. С лицензией, которая подтверждает легальность, сайт <a href="https://classictiles.ie/component/k2/item/38%20?start=954450">https://classictiles.ie/component/k2/item/38%20?start=954450</a> занимает ведущих игроков в сфере интерактивных казино. Платформа уделяет внимание повышение качества сервиса, разрабатывая новые функции, чтобы дать пользователям безупречное взаимодействие.
Приветственный бонус: Щедрый бонус для новичков казино
Для новичков на платформе 1win предоставляется солидный приветственный бонус, который позволяет начать с уверенностью. Это бонусная программа является одним из ведущих на в мире онлайн-гемблинга, так как предоставляет шанс новым клиентам казино заполучить выгодные условия, увеличив свои шансы на успешные ставки. Быстрая регистрация и внесение суммы зачисляют бонус на счет, что делает его применение очень удобным.
Live-ставки: Спортивные события в режиме реального времени с моментальными ставками
В отрасли онлайн-ставок главной отличительной чертой является стратегическая глубина и способность адаптироваться в онлайн. 1win даёт доступ тысячи спортивных событий, доступных в формате ставок в лайве. Мы гарантируем доступ к топовым локальным и глобальным турнирам, будь то хоккей.
Полная ссылка на страницу: https://classictiles.ie/component/k2/item/38%20?start=954450
Букмекерские ставки в лайве обеспечивают шанс быстро подстраиваться, что делает процесс более динамичным, но и серьёзным испытанием навыков. Благодаря аналитическим данным платформы, клиенты могут точнее прогнозировать исходы, приумножая выигрышные шансы. Каждое событие освещается статистикой, что обогащает принятие решений принимать решения на основе актуальных данных.
В мире игровых платформ и ставочных рынков крайне важно не только качество игровой платформы, но и репутация компании. С лицензией, которая гарантирует безопасность, сайт <a href="http://akrvo.ru/index.php?option=com_content&view=article&id=15556">http://akrvo.ru/index.php?option=com_content&view=article&id=15556</a> установил себя как топовых платформ в мире онлайн-гемблинга. Оператор стремится к повышение качества сервиса, постоянно улучшая свои продукты и сервисы, чтобы подарить пользователям наивысшее качество услуг.
Приветственный бонус: Выгодный старт для новичков
Для новых участников на платформе 1win ожидает вас большой приветственный бонус, который стимулирует успешное начало. Это программа является одним из популярных на среди конкурентов, так как позволяет новым клиентам моментально воспользоваться бонусом, увеличив свои шансы на успешные ставки. Простая регистрация и первый взнос дают возможность воспользоваться бонусом, что делает его получение комфортным.
Live-ставки: Мгновенные возможности для ставок с быстрой реакцией
В мире онлайн-ставок фундаментальным аспектом является изменчивость и способность адаптироваться в моментально. 1win даёт доступ множество спортивных событий, доступных в формате игры вживую. Мы гарантируем доступ к ключевым международным и локальным соревнованиям, будь то теннис.
Полная ссылка на страницу: http://akrvo.ru/index.php?option=com_content&view=article&id=15556
Ставки в реальном времени открывают возможность учитывать динамику событий, что делает процесс стратегически насыщенным, но и аналитически богатым. Используя стратегии и аналитику платформы, игроки платформы могут точнее прогнозировать исходы, приумножая выигрышные шансы. Каждое событие освещается статистикой, что обогащает принятие решений принимать решения на основе актуальных данных.
Vavada casino — это одним из самых популярных и доверенных платформ для любителей игровых автоматов. За счет актуального дизайна, большому выбору игровых слотов и выгодным предложениям для игроков, <a href="http://xenan.nnov.org/common/redir.php?https://vavada-casino888-12.top/">вавада казино </a> получило статус идеальной платформы для всех, кто ищет качественный игровой опыт. В обзоре ниже мы опишем функции платформы казино Вавада, процесс регистрации на сайте и входа в личный кабинет, а также объясним про Vavada бонусы и о том, где взять свежие зеркальные ссылки Vavada.
Основные плюсы сайта Vavada casino
Vavada официальный сайт выделяется на фоне конкурентов благодаря интуитивно понятного дизайна, мгновенной загрузке и адаптивному дизайну. Независимо от девайс вы используете, будь то ноутбук, планшетный ПК или смартфон, сайт Vavada загружается моментально, гарантируя плавный доступ к играм и функциям.
Сайт: http://xenan.nnov.org/common/redir.php?https://vavada-casino-888-9.top/
Для доступа на сайт не требуется загрузка ПО. Vavada online casino запускается прямо через браузер, что делает удобным доступ к личному кабинету и разделам казино. Если случаются технических проблем пользователи могут зайти через Рабочее зеркало Vavada, имеет идентичный функционал основного портала.
В мире онлайн-казино и игр на ставки приоритетное значение имеет не только качество игровой платформы, но и репутация компании. С международной лицензией, которая гарантирует надежность, сайт <a href="https://md-gazeta.ru/oficialno/61610">https://md-gazeta.ru/oficialno/61610</a> установил себя как фаворитов в области азартных игр. Сервис стремится к оптимальных условий, улучшая функционал, чтобы подарить пользователям наивысшее качество услуг.
Приветственный бонус: Премиум-старт для новых игроков
Для новичков на платформе 1win доступен значительный приветственный бонус, который позволяет начать с уверенностью. Это возможность является одним из выгодных на в индустрии ставок, так как открывает возможность новым клиентам казино начать игру с бонусом, стимулируя успешные ставки. Простая регистрация и перевод средств автоматически активируют бонус, что делает его применение простым и доступным.
Live-ставки: Играйте на события вживую с реальными шансами на успех
В отрасли ставок на спорт важнейшей частью является актуальность и способность мгновенно реагировать в лайве. 1win даёт шанс множество спортивных событий, доступных в формате игры вживую. Мы гарантируем доступ к ведущим соревнованиям и матчам, будь то киберспорт.
Полная ссылка на страницу: https://md-gazeta.ru/oficialno/61610
Ставки в реальном времени позволяют пользователям быстро подстраиваться, что делает процесс более динамичным, но и интеллектуально интересным. Благодаря аналитическим данным платформы, стратеги могут точнее прогнозировать исходы, приумножая выигрышные шансы. Каждое событие обеспечено аналитическими обзорами, что даёт более полную картину предсказывать результат с уверенностью.
Онлайн-казино Vavada — это одно из наиболее востребованных и доверенных платформ для поклонников гэмблинга. С помощью актуального дизайна, широкому ассортименту игровых слотов и привлекательным условиям для гостей, <a href="https://my.friendhosting.net/pl.php?2636&go=https://vavada-casino-888-9.top/">вавада вход </a> завоевало статус превосходной площадки для всех, кто хочет получить качественный игровой опыт. В данной статье мы подробно рассмотрим особенности сайта Vavada casino, порядок регистрации и входа в личный кабинет, а также расскажем про акционные предложения Vavada и о том, где найти свежие Vavada зеркало.
Преимущества официального сайта Vavada
Vavada официальный сайт отличается по сравнению с аналогами благодаря легкого в использовании пользовательского меню, мгновенной загрузке и адаптивному дизайну. Без разницы, какое девайс находится у вас, будь то ПК, планшет или телефон, Vavada официальный сайт загружается моментально, гарантируя удобный вход к игровым слотам и возможностям.
Сайт: https://my.friendhosting.net/pl.php?2636&go=https://vavada-casino999-10.top/
Чтобы попасть на сайт не требуется установка дополнительных программ. Vavada casino функционирует в веб-версии, что значительно облегчает процесс входа к личному кабинету и разделам казино. При возникновении блокировок гости могут зайти через Vavada зеркало, имеет идентичный функции основного сайта.
В мире интерактивных казино и ставок на спорт основное внимание уделяется не только качество сервиса, но и доверие к оператору. С гарантированной лицензией, которая обеспечивает соблюдение стандартов, сайт <a href="http://idramuzei.ru/index.php/vystavki?iccaldate=2026-09-1&start=8">http://idramuzei.ru/index.php/vystavki?iccaldate=2026-09-1&start=8</a> находится среди ведущих игроков в сфере интерактивных казино. Платформа создает условия для максимального комфорта, улучшая функционал, чтобы подарить пользователям первоклассный игровой опыт.
Приветственный бонус: Щедрый бонус для новых игроков
Для новых участников на платформе 1win ожидает вас выгодный приветственный бонус, который значительно увеличивает начальный капитал. Это бонусная программа является одним из заметных на в индустрии ставок, так как позволяет игрокам новым пользователям моментально воспользоваться бонусом, стимулируя успешные ставки. Быстрая регистрация и перевод средств зачисляют бонус на счет, что делает его применение простым и доступным.
Live-ставки: Играйте на события вживую с реальными шансами на успех
В отрасли онлайн-ставок важнейшим фактором является актуальность и возможность реагировать на изменения в реальном времени. 1win предоставляет возможность тысячи спортивных событий, доступных в формате ставок в режиме реального времени. Мы предоставляем доступ к крупнейшим локальным и глобальным турнирам, будь то баскетбол.
Полная ссылка на страницу: http://idramuzei.ru/index.php/vystavki?iccaldate=2026-09-1&start=8
Лайв-ставки позволяют пользователям учитывать динамику событий, что делает процесс насыщенным эмоциями, но и аналитически богатым. Пользуясь аналитическими функциями платформы, пользователи могут принимать более обоснованные решения, оптимизируя стратегию. Каждое событие представлено с комментариями, что даёт более полную картину принимать решения на основе актуальных данных.
Онлайн-казино Vavada — это одно из лучших и проверенных временем игровых клубов для любителей азартных игр. Благодаря инновационного подхода, широкому ассортименту игровых слотов и выгодным предложениям для пользователей, <a href="https://cm46.ru/udata/emarket/basket/put/element/2247/?redirect-uri=https://casino-vavada-slots-4.top/">вавада зеркало </a> обрело статус превосходной площадки для всех, кто ищет безупречный игровой процесс. В обзоре ниже мы опишем особенности официального сайта Vavada, процесс регистрации и входа в личный кабинет, а также поговорим про акционные предложения Vavada и о том, как получить актуальные Vavada зеркало.
Достоинства официального сайта Vavada
Сайт казино Vavada отличается на фоне конкурентов благодаря простого и удобного дизайна, высокой скорости работы и адаптивному дизайну. Независимо от гаджет подключено, будь то ПК, планшет или смартфон, платформа Vavada casino работает идеально, обеспечивая плавный доступ к играм и возможностям.
Сайт: https://cm46.ru/udata/emarket/basket/put/element/2247/?redirect-uri=https://vavada-casino888-12.top/
Для доступа на ресурс не необходима установка дополнительных программ. Онлайн-казино Vavada работает прямо через браузер, что упрощает процесс входа в аккаунт и игровым слотам. Если случаются технических проблем игроки могут зайти через Рабочее зеркало Vavada, которое полностью дублирует функционал основного портала.
В экосистеме игровых платформ и игр на ставки основное внимание уделяется не только качество обслуживания, но и высокий уровень доверия. С международной лицензией, которая гарантирует надежность, сайт <a href="http://uprkul.ru/index.php?option=com_content&view=frontpage&Itemid=62&limit=9&month=1&year=2023&limitstart=10">http://uprkul.ru/index.php?option=com_content&view=frontpage&Itemid=62&limit=9&month=1&year=2023&limitstart=10</a> установил себя как ключевых участников в мире онлайн-гемблинга. Организация работает на максимального комфорта, разрабатывая новые функции, чтобы предоставить пользователям максимальный комфорт.
Приветственный бонус: Щедрый бонус для новичков казино
Для новых игроков на платформе 1win предусмотрен солидный приветственный бонус, который стимулирует успешное начало. Это возможность является одним из заметных на рынке, так как позволяет игрокам новым клиентам моментально воспользоваться бонусом, стимулируя успешные ставки. Простая регистрация и внесение депозита обеспечивают получение бонуса, что делает его воспользование комфортным.
Live-ставки: Мгновенные возможности для ставок с максимальным удобством
В отрасли онлайн-ставок главной отличительной чертой является динамика и необходимость предугадывать события в моментально. 1win открывает путь широкий выбор спортивных событий, доступных в формате ставок на события в реальном времени. Мы организуем лайв-ставки к топовым международным и локальным соревнованиям, будь то киберспорт.
Полная ссылка на страницу: http://uprkul.ru/index.php?option=com_content&view=frontpage&Itemid=62&limit=9&month=1&year=2023&limitstart=10
Онлайн-ставки дают шанс моментально адаптироваться, что делает процесс более захватывающим, но и полезным для стратегии. Благодаря аналитическим данным платформы, клиенты могут точнее прогнозировать исходы, улучшая тактику игры. Каждое событие сопровождается качественной аналитикой, что позволяет лучше анализировать ориентироваться в ставках.
Онлайн-казино Vavada — является одно из самых популярных и доверенных игровых клубов для поклонников гэмблинга. За счет актуального дизайна, разнообразию игровых слотов и выгодным предложениям для пользователей, <a href="https://amajmkbgip.cloudimg.io/v7/vavada-casino-888-9.top">vavada промокод </a> завоевало статус отличной платформы для всех, кто хочет получить качественный игровой опыт. В обзоре ниже мы подробно рассмотрим функции платформы казино Вавада, этапы регистрации и авторизации, а также расскажем про акционные предложения Vavada и о том, где взять актуальные Vavada зеркало.
Основные плюсы платформы казино Вавада
Сайт казино Vavada отличается на фоне конкурентов с помощью простого и удобного пользовательского меню, мгновенной загрузке и адаптивному дизайну. Независимо от устройство вы используете, будь то компьютер, планшет или телефон, сайт Vavada работает идеально, обеспечивая удобный вход к разделам и опциям.
Сайт: https://amajmkbgip.cloudimg.io/v7/casino-vavada-slots-4.top
Для доступа на сайт не необходима установка дополнительных программ. Vavada casino запускается прямо через браузер, что упрощает доступ к личному кабинету и разделам казино. В случае технических проблем гости могут воспользоваться Vavada зеркало, имеет идентичный функционал официального ресурса.
В сфере интерактивных казино и ставок в спорте важно не только качество обслуживания, но и гарантии безопасности. С официальной лицензией, которая гарантирует прозрачность, сайт <a href="https://pvzrayon.ru/2023/03/20/vesna-idet-vesne-dorogu/">https://pvzrayon.ru/2023/03/20/vesna-idet-vesne-dorogu/</a> находится среди главных представителей в области азартных игр. Компания работает на предоставление качественных услуг, улучшая функционал, чтобы подарить пользователям непревзойденный опыт.
Приветственный бонус: Начальный бонус для новых игроков
Для новых пользователей на платформе 1win предоставляется солидный приветственный бонус, который стимулирует успешное начало. Это бонусная программа является одним из наиболее привлекательных на среди конкурентов, так как помогает новым игрокам получить преимущество, получив дополнительные ресурсы для ставок. Регистрация за несколько минут и депозит зачисляют бонус на счет, что делает его доступ максимально удобным и быстрым.
Live-ставки: Лайв-ставки на тысячи событий с быстрой реакцией
В экосистеме букмекерства одним из ключевых элементов является темп и возможность реагировать на изменения в реальном времени. 1win даёт шанс большой спектр спортивных событий, доступных в формате лайв-ставок. Мы гарантируем доступ к ключевым спортивным событиям, будь то хоккей.
Полная ссылка на страницу: https://pvzrayon.ru/2023/03/20/vesna-idet-vesne-dorogu/
Лайв-ставки гарантируют игрокам учитывать динамику событий, что делает процесс насыщенным эмоциями, но и интеллектуально интересным. Благодаря аналитическим данным платформы, игроки могут повышать свои шансы на успех, увеличивая свои шансы на успех. Каждое событие представлено с комментариями, что делает процесс ещё более обоснованным предупреждать проигрыши.
Vavada казино — является одной из лучших и доверенных платформ среди поклонников азартных игр. С помощью инновационного подхода, разнообразию игровых слотов и выгодным предложениям для гостей, <a href="https://jcboat.ru/page/2/?wptouch_switch=mobile&redirect=//vavada-casino-888-9.top">vavada casino официальный сайт </a> получило репутацию отличной платформы для хочет получить надежный азартный отдых. В обзоре ниже мы подробно рассмотрим особенности официального сайта Vavada, процесс создания аккаунта и входа в личный кабинет, а также объясним о бонусах Vavada и о том, как получить свежие рабочие зеркала Vavada.
Достоинства официального сайта Vavada
Официальный ресурс Vavada выделяется среди других платформ за счет интуитивно понятного пользовательского меню, высокой скорости работы и кроссплатформенности. Без разницы, какое девайс подключено, будь то ноутбук, планшет или смартфон, Vavada официальный сайт работает идеально, гарантируя удобный вход к разделам и возможностям.
Сайт: https://jcboat.ru/page/2/?wptouch_switch=mobile&redirect=//casino-vavada-slots-4.top
Для доступа на сайт не нужно скачивание приложений. Онлайн-казино Vavada запускается непосредственно в браузере, что значительно облегчает процесс входа к личному кабинету и разделам сайта. В случае блокировок пользователи могут воспользоваться Рабочее зеркало Vavada, которое полностью дублирует функции официального ресурса.
В отрасли интернет-казино и ставочных рынков необходимо не только качество обслуживания, но и честность оператора. С официальной лицензией, которая гарантирует безопасность, сайт <a href="https://www.cross-kpk.ru/index.dll/documents/Projects/Dalchten/files/index.dll/multimedia.dll/multimedia.dll/forum.dll/topic?id=44&page=1">https://www.cross-kpk.ru/index.dll/documents/Projects/Dalchten/files/index.dll/multimedia.dll/multimedia.dll/forum.dll/topic?id=44&page=1</a> находится среди лидеров на рынке ставок. Сервис создает условия для оптимальных условий, разрабатывая новые функции, чтобы подарить пользователям первоклассный игровой опыт.
Приветственный бонус: Премиум-старт для новых пользователей
Для новых игроков на платформе 1win предусмотрен значительный приветственный бонус, который стимулирует успешное начало. Это акция является одним из заметных на в мире онлайн-гемблинга, так как позволяет игрокам новым пользователям моментально воспользоваться бонусом, увеличив свои шансы на успешные ставки. Быстрая регистрация и внесение депозита зачисляют бонус на счет, что делает его воспользование приятным и лёгким.
Live-ставки: Тысячи событий в реальном времени с быстрой реакцией
В пространстве спортивных ставок важнейшей частью является динамика и возможность реагировать на изменения в реальном времени. 1win открывает путь большой спектр спортивных событий, доступных в формате онлайн ставок. Мы даем возможность играть к международным чемпионатам и играм, будь то футбол.
Полная ссылка на страницу: https://www.cross-kpk.ru/index.dll/documents/Projects/Dalchten/files/index.dll/multimedia.dll/multimedia.dll/forum.dll/topic?id=44&page=1
Онлайн-ставки гарантируют игрокам принимать решения мгновенно, что делает процесс более захватывающим, но и аналитически богатым. С применением аналитических ресурсов платформы, игроки могут делать ставки с уверенностью, приумножая выигрышные шансы. Каждое событие освещается статистикой, что способствует точным прогнозам выбирать тактику исходя из фактов.
Vavada casino — это одно из наиболее востребованных и доверенных казино среди ценителей гэмблинга. С помощью инновационного подхода, разнообразию развлечений и выгодным предложениям для пользователей, <a href="https://www.jboss.org/downloading/?projectid=jbossas&url=https://vavada-casino999-10.top/">вавада </a> обрело статус отличной платформы для ищет безупречный игровой процесс. В этом материале мы подробно рассмотрим особенности официального сайта Vavada, этапы регистрации на сайте и авторизации, а также поговорим про Vavada бонусы и о том, как получить актуальные зеркальные ссылки Vavada.
Достоинства официального сайта Vavada
Vavada официальный сайт отличается по сравнению с аналогами благодаря легкого в использовании интерфейса, быстрому отклику и кроссплатформенности. Без разницы, какое устройство подключено, будь то ноутбук, планшет или телефон, Vavada официальный сайт загружается моментально, гарантируя комфортное использование к игровым слотам и опциям.
Сайт: https://www.jboss.org/downloading/?projectid=jbossas&url=https://vavada-casino888-12.top/
Для доступа на сайт не требуется установка дополнительных программ. Vavada casino работает прямо через браузер, что значительно облегчает доступ к личному кабинету и игровым слотам. Если случаются ограничений игроки могут воспользоваться Рабочее зеркало Vavada, имеет идентичный функционал основного сайта.
В мире интернет-казино и ставок на спорт ключевое значение имеет не только качество обслуживания, но и доверие к оператору. С лицензионными гарантиями, которая подтверждает легальность, сайт <a href="https://krasn.pravo.ru/news/view/54531/">https://krasn.pravo.ru/news/view/54531/</a> занимает ключевых участников на рынке ставок. Платформа работает на создание благоприятных условий, обновляя платформу, чтобы обогатить пользователям наивысшее качество услуг.
Приветственный бонус: Щедрый бонус для клиентов
Для новых пользователей на платформе 1win предоставляется большой приветственный бонус, который значительно увеличивает начальный капитал. Это предложение является одним из ведущих на в индустрии ставок, так как позволяет игрокам новым игрокам получить дополнительный капитал, повысив вероятность успеха. Удобная регистрация и перевод средств зачисляют бонус на счет, что делает его получение очень удобным.
Live-ставки: Тысячи событий в реальном времени с реальными шансами на успех
В экосистеме ставочной деятельности главной отличительной чертой является изменчивость и необходимость предугадывать события в режиме реального времени. 1win даёт доступ огромное количество спортивных событий, доступных в формате ставок в лайве. Мы организуем лайв-ставки к глобальным событиям мирового масштаба, будь то баскетбол.
Полная ссылка на страницу: https://krasn.pravo.ru/news/view/54531/
Лайв-ставки предоставляют возможность учитывать динамику событий, что делает процесс стратегически насыщенным, но и тактически интересным. Используя передовые аналитические инструменты платформы, любители ставок могут точнее прогнозировать исходы, увеличивая потенциальные результаты. Каждое событие обеспечено аналитическими обзорами, что делает процесс ещё более обоснованным предсказывать результат с уверенностью.
Игровой клуб Вавада — является одним из наиболее востребованных и проверенных временем игровых клубов для ценителей игровых автоматов. Благодаря актуального дизайна, широкому ассортименту игр и выгодным предложениям для пользователей, <a href="http://stg-cta-redirect.ex.co/redirect?&web=https://vavada-casino888-12.top/">vavada зеркало </a> получило статус отличной площадки для ищет безупречный игровой процесс. В обзоре ниже мы опишем функции официального сайта Vavada, этапы регистрации и авторизации, а также расскажем про Vavada бонусы и о том, где взять работающие зеркальные ссылки Vavada.
Основные плюсы сайта Vavada casino
Сайт казино Vavada привлекает внимание на фоне конкурентов благодаря интуитивно понятного интерфейса, быстрому отклику и адаптивному дизайну. Независимо от устройство подключено, будь то ноутбук, планшетный ПК или смартфон, Vavada официальный сайт загружается моментально, обеспечивая плавный доступ к играм и функциям.
Сайт: http://stg-cta-redirect.ex.co/redirect?&web=https://vavada-casino888-12.top/
Чтобы попасть на платформу не необходима установка дополнительных программ. Vavada casino функционирует прямо через браузер, что делает удобным доступ в аккаунт и разделам сайта. В случае блокировок гости могут воспользоваться Актуальные зеркала Vavada, имеет идентичный функции основного сайта.
В экосистеме интерактивных казино и ставок в спорте важно не только надежность услуг, но и надежность оператора. С гарантированной лицензией, которая подтверждает легальность, сайт <a href="https://nbachati.ru/appeal/answer/?month=10&year=2021">https://nbachati.ru/appeal/answer/?month=10&year=2021</a> выступает одним из ведущих игроков в мире онлайн-гемблинга. Оператор создает условия для оптимальных условий, обновляя контент, чтобы обеспечить пользователям непревзойденный опыт.
Приветственный бонус: Выгодный старт для клиентов
Для новых игроков на платформе 1win предусмотрен щедрый приветственный бонус, который помогает начать с преимуществом. Это подарок является одним из лучших на среди конкурентов, так как предоставляет шанс новым игрокам заполучить выгодные условия, значительно улучшив стартовые позиции. Простая регистрация и депозит обеспечивают получение бонуса, что делает его использование эффективным и быстрым.
Live-ставки: Тысячи событий в реальном времени с быстрой реакцией
В индустрии ставочной деятельности ключевой особенностью является быстрота реакции и необходимость предугадывать события в онлайн. 1win предлагает игрокам большой спектр спортивных событий, доступных в формате игры вживую. Мы располагаем матчами к глобальным спортивным событиям, будь то киберспорт.
Полная ссылка на страницу: https://nbachati.ru/appeal/answer/?month=10&year=2021
Ставки в реальном времени предоставляют возможность быстро подстраиваться, что делает процесс ещё интереснее, но и полезным для стратегии. С помощью аналитики платформы, пользователи могут принимать более обоснованные решения, увеличивая потенциальные результаты. Каждое событие содержит анализ игры, что даёт более полную картину принимать решения на основе актуальных данных.
Vavada казино — это одной из топовых и доверенных казино для поклонников гэмблинга. Благодаря современного подхода, разнообразию развлечений и щедрым бонусам для гостей, <a href="https://pimg.danawa.com/proxy/vavada-casino888-12.top">вавада казино </a> обрело статус отличной платформы для всех, кто хочет получить качественный игровой опыт. В обзоре ниже мы опишем возможности платформы казино Вавада, порядок регистрации на сайте и входа в личный кабинет, а также расскажем про Vavada бонусы и о том, где найти свежие Vavada зеркало.
Достоинства сайта Vavada casino
Сайт казино Vavada выделяется среди других платформ с помощью интуитивно понятного пользовательского меню, мгновенной загрузке и кроссплатформенности. Без разницы, какое устройство подключено, будь то компьютер, планшетный ПК или смартфон, Vavada официальный сайт открывается без задержек, обеспечивая удобный вход к разделам и опциям.
Сайт: https://pimg.danawa.com/proxy/casino-vavada-slots-4.top
Для доступа на платформу не требуется загрузка ПО. Онлайн-казино Vavada работает непосредственно в браузере, что делает удобным доступ к личному кабинету и разделам сайта. При возникновении технических проблем игроки могут воспользоваться Рабочее зеркало Vavada, повторяет функции официального ресурса.
В экосистеме цифровых казино и игр на ставки приоритетное значение имеет не только качество игровой платформы, но и надежность оператора. С лицензионными гарантиями, которая подтверждает честность, сайт <a href="https://www.cross-kpk.ru/index.dll/documents/Projects/index.dll/forum.dll/documents/projects/Kristal/forum.dll/topic?id=44">https://www.cross-kpk.ru/index.dll/documents/Projects/index.dll/forum.dll/documents/projects/Kristal/forum.dll/topic?id=44</a> уверенно занимает топовых платформ среди платформ для азартных игр. Сервис стремится к развитие клиентского опыта, совершенствуя предложения, чтобы дать пользователям безупречное взаимодействие.
Приветственный бонус: Щедрый бонус для клиентов
Для новых участников на платформе 1win доступен в предложении выгодный приветственный бонус, который стимулирует успешное начало. Это акция является одним из ведущих на на платформе, так как дает возможность новым пользователям платформы сразу получить доступ к дополнительным средствам, значительно улучшив стартовые позиции. Упрощенная процедура регистрации и перевод средств мгновенно активируют бонус, что делает его применение простым и доступным.
Live-ставки: Лайв-ставки на тысячи событий с максимальным удобством
В пространстве спортивных ставок ключевой особенностью является изменчивость и возможность реагировать на изменения в онлайн. 1win открывает путь широкий выбор спортивных событий, доступных в формате лайв-ставок. Мы даем возможность играть к глобальным событиям мирового масштаба, будь то футбол.
Полная ссылка на страницу: https://www.cross-kpk.ru/index.dll/documents/Projects/index.dll/forum.dll/documents/projects/Kristal/forum.dll/topic?id=44
Онлайн-ставки открывают возможность быстро подстраиваться, что делает процесс более динамичным, но и интеллектуально интересным. Пользуясь аналитическими функциями платформы, клиенты могут повышать свои шансы на успех, увеличивая свои шансы на успех. Каждое событие представлено с комментариями, что обогащает принятие решений предсказывать результат с уверенностью.
Vavada казино — является одно из самых популярных и надежных игровых клубов среди любителей гэмблинга. Благодаря современного подхода, большому выбору игр и привлекательным условиям для игроков, <a href="https://top-prof.ru/goto/https://casino-vavada-slots-4.top/">вавада регистрация </a> завоевало статус идеальной площадки для всех, кто ищет качественный игровой опыт. В обзоре ниже мы опишем возможности сайта Vavada casino, этапы регистрации на сайте и входа в личный кабинет, а также объясним про Vavada бонусы и о том, где взять работающие рабочие зеркала Vavada.
Основные плюсы сайта Vavada casino
Сайт казино Vavada выделяется на фоне конкурентов с помощью простого и удобного интерфейса, высокой скорости работы и адаптации под устройства. Без разницы, какое гаджет вы используете, будь то ноутбук, планшетный ПК или мобильный телефон, Vavada официальный сайт открывается без задержек, обеспечивая плавный доступ к игровым слотам и опциям.
Сайт: https://top-prof.ru/goto/https://vavada-casino-888-9.top/
Для доступа на ресурс не необходима установка дополнительных программ. Vavada online casino работает прямо через браузер, что значительно облегчает процесс входа в аккаунт и игровым слотам. При возникновении ограничений гости могут зайти через Актуальные зеркала Vavada, имеет идентичный функции официального ресурса.
В пространстве онлайн-казино и спортивных ставок необходимо не только качество игровой платформы, но и репутация компании. С гарантированной лицензией, которая гарантирует прозрачность, сайт <a href="https://sgpi.ru/?n=7461">https://sgpi.ru/?n=7461</a> занимает ключевых участников в мире онлайн-гемблинга. Компания работает на предоставление качественных услуг, постоянно улучшая свои продукты и сервисы, чтобы гарантировать пользователям захватывающий игровой процесс.
Приветственный бонус: Бонус для новичков для клиентов
Для новых клиентов на платформе 1win доступен впечатляющий приветственный бонус, который существенно увеличивает стартовый капитал. Это возможность является одним из заметных на в отрасли, так как помогает новым участникам заполучить выгодные условия, стимулируя успешные ставки. Легкий старт и депозит моментально активируют предложение, что делает его воспользование максимально удобным и быстрым.
Live-ставки: Мгновенные возможности для ставок с мгновенными возможностями
В индустрии ставок на спорт главной отличительной чертой является стратегическая глубина и шанс учесть изменения в лайве. 1win даёт шанс широкий выбор спортивных событий, доступных в формате онлайн ставок. Мы предоставляем доступ к топовым событиям мирового масштаба, будь то волейбол.
Полная ссылка на страницу: https://sgpi.ru/?n=7461
Букмекерские ставки в лайве открывают возможность реагировать в реальном времени, что делает процесс не только увлекательным, но и аналитически богатым. С помощью аналитики платформы, любители ставок могут увеличивать вероятность выигрыша, увеличивая потенциальные результаты. Каждое событие освещается статистикой, что делает процесс ещё более обоснованным предсказывать результат с уверенностью.
Игровой клуб Вавада — является одним из самых популярных и надежных игровых клубов для любителей игровых автоматов. С помощью актуального дизайна, широкому ассортименту игр и привлекательным условиям для пользователей, <a href="http://www.ccg.org/_domain/vavada-casino-888-9.top/">вавада вход </a> обрело репутацию превосходной площадки для всех, кто жаждет найти безупречный игровой процесс. В обзоре ниже мы разберем функции официального сайта Vavada, процесс создания аккаунта и входа, а также объясним о бонусах Vavada и о том, как получить работающие Vavada зеркало.
Преимущества платформы казино Вавада
Vavada официальный сайт отличается среди других платформ с помощью простого и удобного пользовательского меню, высокой скорости работы и адаптации под устройства. Независимо от девайс подключено, будь то компьютер, планшет или мобильный телефон, Vavada официальный сайт загружается моментально, гарантируя комфортное использование к играм и опциям.
Сайт: http://www.ccg.org/_domain/vavada-casino-play-10.top/
Чтобы попасть на сайт не нужно загрузка ПО. Онлайн-казино Vavada запускается в веб-версии, что значительно облегчает доступ в аккаунт и разделам сайта. При возникновении блокировок гости могут зайти через Актуальные зеркала Vavada, имеет идентичный функционал основного портала.
В индустрии игровых платформ и ставок в спорте крайне важно не только качество сервиса, но и надежность оператора. С международной лицензией, которая подтверждает честность, сайт <a href="https://vpk.name/en/542565_russian-and-chinese-scientists-have-found-a-way-to-create-industrial-parts-without-defects.html">https://vpk.name/en/542565_russian-and-chinese-scientists-have-found-a-way-to-create-industrial-parts-without-defects.html</a> считает себя фаворитов в сфере интерактивных казино. Провайдер работает на повышение качества сервиса, обновляя контент, чтобы обогатить пользователям безупречное взаимодействие.
Приветственный бонус: Привлекательное предложение для пользователей платформы
Для новых клиентов на платформе 1win существует выгодный приветственный бонус, который значительно увеличивает начальный капитал. Это бонусная программа является одним из лучших на в отрасли, так как помогает новым участникам начать игру с бонусом, получив дополнительные ресурсы для ставок. Удобная регистрация и внесение суммы обеспечивают получение бонуса, что делает его применение эффективным и быстрым.
Live-ставки: Спортивные события в режиме реального времени с мгновенными возможностями
В экосистеме букмекерства важнейшим фактором является изменчивость и шанс учесть изменения в на ходу. 1win даёт доступ множество спортивных событий, доступных в формате ставок в режиме реального времени. Мы гарантируем доступ к крупнейшим международным и локальным соревнованиям, будь то теннис.
Полная ссылка на страницу: https://vpk.name/en/542565_russian-and-chinese-scientists-have-found-a-way-to-create-industrial-parts-without-defects.html
Лайв-ставки предоставляют возможность моментально адаптироваться, что делает процесс не только увлекательным, но и аналитически богатым. С применением аналитических ресурсов платформы, игроки платформы могут увеличивать вероятность выигрыша, увеличивая свои шансы на успех. Каждое событие предоставляется с аналитическими данными, что позволяет лучше анализировать принимать решения на основе актуальных данных.
Vavada casino — является одним из топовых и доверенных казино среди поклонников азартных игр. С помощью актуального дизайна, большому выбору игр и выгодным предложениям для пользователей, <a href="http://www.furninfo.com/absolutenm/templates/NewsFeed.asp?articleid=https://casino-vavada-slots-4.top/">vavada casino официальный сайт </a> обрело статус идеальной платформы для всех, кто хочет получить качественный игровой опыт. В этом материале мы опишем возможности официального сайта Vavada, процесс регистрации на сайте и авторизации, а также расскажем про акционные предложения Vavada и о том, как получить работающие Vavada зеркало.
Преимущества сайта Vavada casino
Официальный ресурс Vavada отличается по сравнению с аналогами за счет легкого в использовании пользовательского меню, высокой скорости работы и адаптивному дизайну. Независимо от гаджет находится у вас, будь то компьютер, планшет или телефон, платформа Vavada casino работает идеально, обеспечивая удобный вход к разделам и возможностям.
Сайт: http://www.furninfo.com/absolutenm/templates/NewsFeed.asp?articleid=https://vavada-casino-888-9.top/
Для доступа на платформу не нужно скачивание приложений. Онлайн-казино Vavada функционирует в веб-версии, что делает удобным процесс входа к личному кабинету и разделам казино. При возникновении ограничений гости могут перейти на Актуальные зеркала Vavada, повторяет функционал официального ресурса.
В отрасли онлайн-казино и ставок на спорт необходимо не только надежность услуг, но и доверие к оператору. С лицензией, которая обеспечивает соблюдение стандартов, сайт <a href="http://lionelbaland.hautetfort.com/archive/2012/09/26/chypre-ne-reconnaitra-pas-le-kosovo.html">http://lionelbaland.hautetfort.com/archive/2012/09/26/chypre-ne-reconnaitra-pas-le-kosovo.html</a> выступает одним из главных представителей на рынке ставок. Сервис сфокусирована на создание благоприятных условий, обновляя контент, чтобы дать пользователям непревзойденный опыт.
Приветственный бонус: Щедрый бонус для пользователей платформы
Для новых участников на платформе 1win предусмотрен выгодный приветственный бонус, который увеличивает ваши возможности. Это предложение является одним из наиболее привлекательных на среди конкурентов, так как позволяет новым пользователям платформы заполучить выгодные условия, стимулируя успешные ставки. Простая регистрация и первый взнос мгновенно активируют бонус, что делает его воспользование приятным и лёгким.
Live-ставки: Играйте на события вживую с широким выбором
В экосистеме ставок на спорт фундаментальным аспектом является стратегическая глубина и шанс учесть изменения в реальном времени. 1win даёт шанс огромное количество спортивных событий, доступных в формате ставок на события в реальном времени. Мы гарантируем доступ к глобальным спортивным событиям, будь то баскетбол.
Полная ссылка на страницу: http://lionelbaland.hautetfort.com/archive/2012/09/26/chypre-ne-reconnaitra-pas-le-kosovo.html
Онлайн-ставки предоставляют возможность реагировать в реальном времени, что делает процесс насыщенным эмоциями, но и интеллектуально интересным. Пользуясь аналитическими функциями платформы, игроки платформы могут повышать свои шансы на успех, оптимизируя стратегию. Каждое событие сопровождается качественной аналитикой, что делает процесс ещё более обоснованным предупреждать проигрыши.
Игровой клуб Вавада — это одно из лучших и доверенных игровых клубов среди ценителей азартных игр. За счет актуального дизайна, большому выбору игр и выгодным предложениям для гостей, <a href="https://www.fsegames.eu/forum/proxy.php?request=https%3A%2F%2Fcasino-vavada-slots-4.top &hash=6ab91069398bf3bd39dd2868f69c6558">vavada рабочее зеркало </a> завоевало статус превосходной площадки для ищет качественный игровой опыт. В обзоре ниже мы подробно рассмотрим возможности сайта Vavada casino, этапы регистрации на сайте и входа в личный кабинет, а также расскажем про Vavada бонусы и о том, где взять актуальные Vavada зеркало.
Достоинства сайта Vavada casino
Официальный ресурс Vavada привлекает внимание по сравнению с аналогами за счет легкого в использовании пользовательского меню, высокой скорости работы и адаптации под устройства. Без разницы, какое гаджет находится у вас, будь то компьютер, планшетный ПК или мобильный телефон, сайт Vavada работает идеально, гарантируя комфортное использование к играм и функциям.
Сайт: https://www.fsegames.eu/forum/proxy.php?request=https%3A%2F%2Fvavada-casino999-10.top &hash=6ab91069398bf3bd39dd2868f69c6558
Чтобы попасть на сайт не нужно загрузка ПО. Онлайн-казино Vavada работает в веб-версии, что упрощает доступ в аккаунт и разделам казино. В случае технических проблем гости могут зайти через Vavada зеркало, повторяет весь контент основного портала.
В индустрии интернет-казино и ставок в спорте основное внимание уделяется не только качество сервиса, но и честность оператора. С лицензионными гарантиями, которая гарантирует надежность, сайт <a href="https://book-hall.ru/news/2019-10-24-1521-6767?page=9">https://book-hall.ru/news/2019-10-24-1521-6767?page=9</a> считает себя лидеров в мире онлайн-гемблинга. Провайдер уделяет внимание создание благоприятных условий, совершенствуя предложения, чтобы подарить пользователям наивысшее качество услуг.
Приветственный бонус: Начальный бонус для новых пользователей
Для новичков на платформе 1win существует впечатляющий приветственный бонус, который позволяет начать с уверенностью. Это акция является одним из популярных на рынке, так как помогает новым клиентам получить дополнительный капитал, повысив вероятность успеха. Простая регистрация и внесение депозита автоматически активируют бонус, что делает его активацию очень удобным.
Live-ставки: Тысячи событий в реальном времени с моментальными ставками
В экосистеме спортивных прогнозов ключевой особенностью является актуальность и шанс учесть изменения в реальном времени. 1win предлагает игрокам большой спектр спортивных событий, доступных в формате ставок в режиме реального времени. Мы организуем лайв-ставки к топовым локальным и глобальным турнирам, будь то волейбол.
Полная ссылка на страницу: https://book-hall.ru/news/2019-10-24-1521-6767?page=9
Ставки в реальном времени предоставляют возможность моментально адаптироваться, что делает процесс стратегически насыщенным, но и полезным для стратегии. С применением аналитических ресурсов платформы, игроки платформы могут увеличивать вероятность выигрыша, увеличивая свои шансы на успех. Каждое событие представлено с комментариями, что делает процесс ещё более обоснованным гарантировать обоснованные ставки.
Игровой клуб Вавада — является одним из топовых и проверенных временем платформ среди поклонников азартных игр. За счет современного подхода, широкому ассортименту развлечений и привлекательным условиям для гостей, <a href="https://prok3g.ru/go/vavada-casino-play-10.top">vavada бонусы </a> завоевало репутацию превосходной платформы для всех, кто хочет получить качественный игровой опыт. В этом материале мы опишем возможности платформы казино Вавада, порядок создания аккаунта и входа, а также поговорим о бонусах Vavada и о том, где найти свежие рабочие зеркала Vavada.
Преимущества сайта Vavada casino
Официальный ресурс Vavada выделяется по сравнению с аналогами благодаря интуитивно понятного дизайна, высокой скорости работы и кроссплатформенности. Без разницы, какое устройство находится у вас, будь то ноутбук, планшетный ПК или смартфон, сайт Vavada загружается моментально, обеспечивая плавный доступ к игровым слотам и опциям.
Сайт: https://prok3g.ru/go/casino-vavada-slots-4.top
Для доступа на сайт не требуется скачивание приложений. Vavada casino запускается в веб-версии, что делает удобным доступ к личному кабинету и разделам казино. Если случаются ограничений гости могут воспользоваться Рабочее зеркало Vavada, повторяет функционал основного сайта.
В отрасли цифровых казино и спортивных ставок крайне важно не только надежность услуг, но и надежность оператора. С лицензией, которая гарантирует прозрачность, сайт <a href="https://www.cross-kpk.ru/index.dll/documents/Projects/multimedia.dll/documents/Projects/Dalchten/news.dll?detail=673">https://www.cross-kpk.ru/index.dll/documents/Projects/multimedia.dll/documents/Projects/Dalchten/news.dll?detail=673</a> считает себя топовых платформ на рынке ставок. Сервис стремится к развитие клиентского опыта, обновляя платформу, чтобы обеспечить пользователям максимальный комфорт.
Приветственный бонус: Премиум-старт для новичков
Для новичков в казино на платформе 1win ожидает вас щедрый приветственный бонус, который позволяет начать с уверенностью. Это акция является одним из ведущих на в отрасли, так как предоставляет шанс новым пользователям платформы получить преимущество, сократив риски. Легкий старт и депозит обеспечивают получение бонуса, что делает его применение максимально удобным и быстрым.
Live-ставки: Множество матчей онлайн с реальными шансами на успех
В мире онлайн-ставок ключевой особенностью является изменчивость и способность мгновенно реагировать в моментально. 1win даёт доступ множество спортивных событий, доступных в формате ставок в режиме реального времени. Мы предлагаем ставки к глобальным соревнованиям и матчам, будь то баскетбол.
Полная ссылка на страницу: https://www.cross-kpk.ru/index.dll/documents/Projects/multimedia.dll/documents/Projects/Dalchten/news.dll?detail=673
Онлайн-ставки обеспечивают шанс учитывать динамику событий, что делает процесс насыщенным эмоциями, но и аналитически богатым. С применением аналитических ресурсов платформы, любители ставок могут увеличивать вероятность выигрыша, увеличивая потенциальные результаты. Каждое событие предоставляется с аналитическими данными, что обогащает принятие решений предсказывать результат с уверенностью.
Vavada casino — это одной из топовых и доверенных игровых клубов среди ценителей гэмблинга. С помощью современного подхода, широкому ассортименту развлечений и привлекательным условиям для пользователей, <a href="https://www.jboss.org/downloading/?projectid=jbossas&url=https://vavada-casino-888-9.top/">vavada </a> получило статус превосходной площадки для ищет надежный азартный отдых. В этом материале мы разберем особенности сайта Vavada casino, этапы создания аккаунта и авторизации, а также расскажем про акционные предложения Vavada и о том, где найти свежие Vavada зеркало.
Преимущества сайта Vavada casino
Официальный ресурс Vavada привлекает внимание на фоне конкурентов за счет легкого в использовании пользовательского меню, быстрому отклику и адаптивному дизайну. Независимо от гаджет находится у вас, будь то ноутбук, планшетный ПК или смартфон, платформа Vavada casino загружается моментально, обеспечивая плавный доступ к разделам и возможностям.
Сайт: https://www.jboss.org/downloading/?projectid=jbossas&url=https://vavada-casino-play-10.top/
Для доступа на сайт не требуется скачивание приложений. Онлайн-казино Vavada запускается непосредственно в браузере, что значительно облегчает процесс входа в аккаунт и разделам казино. При возникновении блокировок игроки могут перейти на Рабочее зеркало Vavada, имеет идентичный функционал основного сайта.
В экосистеме виртуальных казино и ставочных рынков ключевое значение имеет не только надежность услуг, но и высокий уровень доверия. С официальной лицензией, которая обеспечивает соблюдение стандартов, сайт <a href="https://www.rcto-rd.ru/ob-uchrezhdenii/dokumenty/">https://www.rcto-rd.ru/ob-uchrezhdenii/dokumenty/</a> находится среди фаворитов в области азартных игр. Сервис уделяет внимание создание благоприятных условий, совершенствуя предложения, чтобы предоставить пользователям непревзойденный опыт.
Приветственный бонус: Привлекательное предложение для новичков казино
Для новичков в казино на платформе 1win доступен в предложении значительный приветственный бонус, который стимулирует успешное начало. Это возможность является одним из заметных на среди конкурентов, так как предоставляет шанс новым пользователям платформы начать игру с бонусом, значительно улучшив стартовые позиции. Простая регистрация и внесение суммы моментально активируют предложение, что делает его активацию приятным и лёгким.
Live-ставки: Тысячи событий в реальном времени с максимальным удобством
В сфере ставок на спорт важнейшей частью является актуальность и шанс учесть изменения в моментально. 1win даёт доступ тысячи спортивных событий, доступных в формате онлайн ставок. Мы даем возможность играть к международным локальным и глобальным турнирам, будь то теннис.
Полная ссылка на страницу: https://www.rcto-rd.ru/ob-uchrezhdenii/dokumenty/
Ставки в реальном времени гарантируют игрокам мгновенно реагировать на изменения, что делает процесс ещё интереснее, но и стратегически насыщенным. Используя передовые аналитические инструменты платформы, пользователи могут повышать свои шансы на успех, улучшая тактику игры. Каждое событие предоставляется с аналитическими данными, что способствует точным прогнозам ориентироваться в ставках.
Онлайн-казино Vavada — это одной из топовых и проверенных временем игровых клубов для любителей игровых автоматов. Благодаря инновационного подхода, разнообразию развлечений и выгодным предложениям для пользователей, <a href="https://www.clubgets.com/pursuit.php?a_cd=*****&b_cd=0018&link=https://casino-vavada-slots-4.top/">vavada </a> обрело статус идеальной площадки для ищет надежный азартный отдых. В обзоре ниже мы разберем функции сайта Vavada casino, процесс создания аккаунта и авторизации, а также поговорим о бонусах Vavada и о том, где найти работающие рабочие зеркала Vavada.
Преимущества официального сайта Vavada
Официальный ресурс Vavada выделяется среди других платформ за счет простого и удобного пользовательского меню, быстрому отклику и адаптивному дизайну. Независимо от устройство подключено, будь то компьютер, планшетный ПК или смартфон, платформа Vavada casino загружается моментально, обеспечивая комфортное использование к игровым слотам и опциям.
Сайт: https://www.clubgets.com/pursuit.php?a_cd=*****&b_cd=0018&link=https://casino-vavada-slots-4.top/
Чтобы попасть на ресурс не нужно установка дополнительных программ. Онлайн-казино Vavada работает в веб-версии, что значительно облегчает доступ к личному кабинету и игровым слотам. Если случаются ограничений пользователи могут перейти на Рабочее зеркало Vavada, которое полностью дублирует функции основного портала.
В сфере интернет-казино и игр на ставки необходимо не только качество предоставляемых услуг, но и гарантии безопасности. С лицензией, которая обеспечивает соблюдение стандартов, сайт <a href="https://classica.rhga.ru/section/russkiy-literaturnyy-kanon/tyutchev-v-poeticheskoy-kulture-russkogo-simvolizma-.html">https://classica.rhga.ru/section/russkiy-literaturnyy-kanon/tyutchev-v-poeticheskoy-kulture-russkogo-simvolizma-.html</a> установил себя как ключевых участников в сфере интерактивных казино. Организация ориентирована на оптимальных условий, обновляя платформу, чтобы гарантировать пользователям максимальный комфорт.
Приветственный бонус: Выгодный старт для новичков казино
Для новых пользователей на платформе 1win предоставляется солидный приветственный бонус, который увеличивает ваши возможности. Это акция является одним из выгодных на в мире онлайн-гемблинга, так как позволяет новым участникам получить дополнительный капитал, повысив вероятность успеха. Регистрация за несколько минут и депозит зачисляют бонус на счет, что делает его воспользование эффективным и быстрым.
Live-ставки: Лайв-ставки на тысячи событий с максимальным удобством
В отрасли букмекерства важнейшим фактором является динамика и возможность реагировать на изменения в лайве. 1win даёт шанс большой спектр спортивных событий, доступных в формате игры вживую. Мы предлагаем ставки к крупнейшим международным и локальным соревнованиям, будь то футбол.
Полная ссылка на страницу: https://classica.rhga.ru/section/russkiy-literaturnyy-kanon/tyutchev-v-poeticheskoy-kulture-russkogo-simvolizma-.html
Игра на события вживую обеспечивают шанс принимать решения мгновенно, что делает процесс более захватывающим, но и полезным для стратегии. Используя стратегии и аналитику платформы, стратеги могут анализировать события глубже, увеличивая потенциальные результаты. Каждое событие предоставляется с аналитическими данными, что обогащает принятие решений предупреждать проигрыши.
Vavada casino — это одно из топовых и надежных казино для любителей игровых автоматов. За счет современного подхода, широкому ассортименту игровых слотов и привлекательным условиям для гостей, <a href="https://gdehu.hit.gemius.pl/_uachredir/hitredir/id=cjU1jQNoAXpbwoPKVChj6ZZV.qhRkW_QYHUd8mCCWyr.U7/fastid=fzmokfsdzfjkuaacifdxxzjfxdle/stparam=lkmeqnftfv/url=https%3A%2F%2Fvavada-casino999-10.top">vavada зеркало </a> завоевало репутацию отличной платформы для жаждет найти безупречный игровой процесс. В обзоре ниже мы подробно рассмотрим функции официального сайта Vavada, процесс регистрации на сайте и авторизации, а также расскажем про Vavada бонусы и о том, как получить свежие Vavada зеркало.
Достоинства официального сайта Vavada
Vavada официальный сайт привлекает внимание среди других платформ за счет простого и удобного интерфейса, быстрому отклику и кроссплатформенности. Без разницы, какое девайс подключено, будь то компьютер, планшет или смартфон, платформа Vavada casino загружается моментально, гарантируя удобный вход к игровым слотам и возможностям.
Сайт: https://gdehu.hit.gemius.pl/_uachredir/hitredir/id=cjU1jQNoAXpbwoPKVChj6ZZV.qhRkW_QYHUd8mCCWyr.U7/fastid=fzmokfsdzfjkuaacifdxxzjfxdle/stparam=lkmeqnftfv/url=https%3A%2F%2Fvavada-casino-play-10.top
Для доступа на платформу не необходима установка дополнительных программ. Vavada online casino запускается непосредственно в браузере, что делает удобным процесс входа к личному кабинету и разделам казино. В случае технических проблем игроки могут воспользоваться Актуальные зеркала Vavada, повторяет функционал основного портала.
В пространстве виртуальных казино и игр на ставки ключевое значение имеет не только уровень сервиса, но и гарантии безопасности. С гарантированной лицензией, которая гарантирует прозрачность, сайт <a href="https://pvzrayon.ru/2021/03/30/besplatnye-konsultacii-projdut-v-obshhestvennoj-priemnoj-upravleniya-rosreestra-po-nizhegorodskoj-oblasti-13/">https://pvzrayon.ru/2021/03/30/besplatnye-konsultacii-projdut-v-obshhestvennoj-priemnoj-upravleniya-rosreestra-po-nizhegorodskoj-oblasti-13/</a> находится среди топовых платформ на рынке ставок. Оператор уделяет внимание повышение качества сервиса, обновляя контент, чтобы подарить пользователям наивысшее качество услуг.
Приветственный бонус: Начальный бонус для новых игроков
Для новых участников на платформе 1win ожидает вас значительный приветственный бонус, который существенно увеличивает стартовый капитал. Это акция является одним из выгодных на в отрасли, так как позволяет игрокам новым пользователям платформы начать игру с бонусом, значительно улучшив стартовые позиции. Удобная регистрация и пополнение счета моментально активируют предложение, что делает его доступ эффективным и быстрым.
Live-ставки: Мгновенные возможности для ставок с реальными шансами на успех
В мире спортивных прогнозов одним из ключевых элементов является темп и умение быстро принимать решения в на ходу. 1win даёт доступ широкий выбор спортивных событий, доступных в формате онлайн ставок. Мы предоставляем доступ к международным спортивным событиям, будь то волейбол.
Полная ссылка на страницу: https://pvzrayon.ru/2021/03/30/besplatnye-konsultacii-projdut-v-obshhestvennoj-priemnoj-upravleniya-rosreestra-po-nizhegorodskoj-oblasti-13/
Букмекерские ставки в лайве предоставляют возможность моментально адаптироваться, что делает процесс более динамичным, но и стратегически насыщенным. Используя стратегии и аналитику платформы, клиенты могут увеличивать вероятность выигрыша, увеличивая потенциальные результаты. Каждое событие содержит анализ игры, что помогает игрокам выбирать тактику исходя из фактов.
Онлайн-казино Vavada — является одним из самых популярных и доверенных казино для поклонников игровых автоматов. С помощью актуального дизайна, большому выбору игр и щедрым бонусам для пользователей, <a href="http://madona.pilseta24.lv/linkredirect/?link=https%3A%2F%2Fvavada-casino888-12.top &referer=madona.pilseta24.lv%2Fzinas%2F47%2F137787&additional_params=%7B%22company_orig_id%22%3A%22128682%22%2C%22object_country_id%22%3A%22lv%22%2C%22referer_layout_type%22%3A%22SR%22%2C%22bannerinfo%22%3A%22%7B%5C%22key%5C%22%3A%5C%22%5C%5C%5C%22CV-Online+Latvia%5C%5C%5C%22%2C+SIA%7C2021-03-01%7C2022-02-28%7Cmadona+p24+lielais+baneris%7Chttps%3A%5C%5C%5C%2F%5C%5C%5C%2Fwww.visidarbi.lv%5C%5C%5C%2F%3Futm_source%3Dpilseta24.lv%26amp%3Butm_medium%3Dbanner%7C%7Cupload%5C%5C%5C%2F128682%5C%5C%5C%2Fbaners%5C%5C%5C%2F1339_visi_darbi_980x90_08.gif%7Clva%7C128682%7C980%7C90%7C%7C0%7C0%7C%7C0%7C0%7C%5C%22%2C%5C%22doc_count%5C%22%3A1%2C%5C%22key0%5C%22%3A%5C%22%5C%5C%5C%22CV-Online+Latvia%5C%5C%5C%22%2C+SIA%5C%22%2C%5C%22key1%5C%22%3A%5C%222021-03-01%5C%22%2C%5C%22key2%5C%22%3A%5C%222022-02-28%5C%22%2C%5C%22key3%5C%22%3A%5C%22madona+p24+lielais+baneris%5C%22%2C%5C%22key4%5C%22%3A%5C%22https%3A%5C%5C%5C%2F%5C%5C%5C%2Fwww.visidarbi.lv%5C%5C%5C%2F%3Futm_source%3Dpilseta24.lv%26amp%3Butm_medium%3Dbanner%5C%22%2C%5C%22key5%5C%22%3A%5C%22%5C%22%2C%5C%22key6%5C%22%3A%5C%22upload%5C%5C%5C%2F128682%5C%5C%5C%2Fbaners%5C%5C%5C%2F1339_visi_darbi_980x90_08.gif%5C%22%2C%5C%22key7%5C%22%3A%5C%22lva%5C%22%2C%5C%22key8%5C%22%3A%5C%22128682%5C%22%2C%5C%22key9%5C%22%3A%5C%22980%5C%22%2C%5C%22key10%5C%22%3A%5C%2290%5C%22%2C%5C%22key11%5C%22%3A%5C%22%5C%22%2C%5C%22key12%5C%22%3A%5C%220%5C%22%2C%5C%22key13%5C%22%3A%5C%220%5C%22%2C%5C%22key14%5C%22%3A%5C%22%5C%22%2C%5C%22key15%5C%22%3A%5C%220%5C%22%2C%5C%22key16%5C%22%3A%5C%220%5C%22%2C%5C%22key17%5C%22%3A%5C%22%5C%22%7D%22%7D&control=9f28e99d3a4737aae057b8a038cc3d80">vavada вход </a> обрело статус отличной площадки для всех, кто хочет получить безупречный игровой процесс. В этом материале мы подробно рассмотрим особенности сайта Vavada casino, процесс регистрации на сайте и входа, а также объясним про Vavada бонусы и о том, где взять свежие зеркальные ссылки Vavada.
Преимущества официального сайта Vavada
Vavada официальный сайт отличается на фоне конкурентов с помощью интуитивно понятного пользовательского меню, высокой скорости работы и кроссплатформенности. Без разницы, какое девайс находится у вас, будь то ноутбук, планшет или смартфон, платформа Vavada casino загружается моментально, гарантируя удобный вход к играм и возможностям.
Сайт: http://madona.pilseta24.lv/linkredirect/?link=https%3A%2F%2Fvavada-casino999-10.top &referer=madona.pilseta24.lv%2Fzinas%2F47%2F137787&additional_params=%7B%22company_orig_id%22%3A%22128682%22%2C%22object_country_id%22%3A%22lv%22%2C%22referer_layout_type%22%3A%22SR%22%2C%22bannerinfo%22%3A%22%7B%5C%22key%5C%22%3A%5C%22%5C%5C%5C%22CV-Online+Latvia%5C%5C%5C%22%2C+SIA%7C2021-03-01%7C2022-02-28%7Cmadona+p24+lielais+baneris%7Chttps%3A%5C%5C%5C%2F%5C%5C%5C%2Fwww.visidarbi.lv%5C%5C%5C%2F%3Futm_source%3Dpilseta24.lv%26amp%3Butm_medium%3Dbanner%7C%7Cupload%5C%5C%5C%2F128682%5C%5C%5C%2Fbaners%5C%5C%5C%2F1339_visi_darbi_980x90_08.gif%7Clva%7C128682%7C980%7C90%7C%7C0%7C0%7C%7C0%7C0%7C%5C%22%2C%5C%22doc_count%5C%22%3A1%2C%5C%22key0%5C%22%3A%5C%22%5C%5C%5C%22CV-Online+Latvia%5C%5C%5C%22%2C+SIA%5C%22%2C%5C%22key1%5C%22%3A%5C%222021-03-01%5C%22%2C%5C%22key2%5C%22%3A%5C%222022-02-28%5C%22%2C%5C%22key3%5C%22%3A%5C%22madona+p24+lielais+baneris%5C%22%2C%5C%22key4%5C%22%3A%5C%22https%3A%5C%5C%5C%2F%5C%5C%5C%2Fwww.visidarbi.lv%5C%5C%5C%2F%3Futm_source%3Dpilseta24.lv%26amp%3Butm_medium%3Dbanner%5C%22%2C%5C%22key5%5C%22%3A%5C%22%5C%22%2C%5C%22key6%5C%22%3A%5C%22upload%5C%5C%5C%2F128682%5C%5C%5C%2Fbaners%5C%5C%5C%2F1339_visi_darbi_980x90_08.gif%5C%22%2C%5C%22key7%5C%22%3A%5C%22lva%5C%22%2C%5C%22key8%5C%22%3A%5C%22128682%5C%22%2C%5C%22key9%5C%22%3A%5C%22980%5C%22%2C%5C%22key10%5C%22%3A%5C%2290%5C%22%2C%5C%22key11%5C%22%3A%5C%22%5C%22%2C%5C%22key12%5C%22%3A%5C%220%5C%22%2C%5C%22key13%5C%22%3A%5C%220%5C%22%2C%5C%22key14%5C%22%3A%5C%22%5C%22%2C%5C%22key15%5C%22%3A%5C%220%5C%22%2C%5C%22key16%5C%22%3A%5C%220%5C%22%2C%5C%22key17%5C%22%3A%5C%22%5C%22%7D%22%7D&control=9f28e99d3a4737aae057b8a038cc3d80
Для доступа на платформу не требуется загрузка ПО. Онлайн-казино Vavada функционирует в веб-версии, что значительно облегчает доступ к личному кабинету и игровым слотам. Если случаются ограничений гости могут перейти на Актуальные зеркала Vavada, имеет идентичный функционал основного портала.
В отрасли интернет-казино и ставок на спорт основное внимание уделяется не только уровень сервиса, но и репутация компании. С международной лицензией, которая гарантирует безопасность, сайт <a href="http://biliq.ru/xallang/content/%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0/%D0%BC%D0%BE%D1%80%D1%84%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9-%D1%81%D0%BE%D1%81%D1%82%D0%B0%D0%B2-%D1%81%D0%BB%D0%BE%D0%B2%D0%B0?page=2&destination=node/278%3Fpage%3D21">http://biliq.ru/xallang/content/%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0/%D0%BC%D0%BE%D1%80%D1%84%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9-%D1%81%D0%BE%D1%81%D1%82%D0%B0%D0%B2-%D1%81%D0%BB%D0%BE%D0%B2%D0%B0?page=2&destination=node/278%3Fpage%3D21</a> выступает одним из лидеров на рынке ставок. Организация стремится к развитие клиентского опыта, улучшая функционал, чтобы обогатить пользователям наивысшее качество услуг.
Приветственный бонус: Премиум-старт для новичков казино
Для новичков в казино на платформе 1win предоставляется солидный приветственный бонус, который значительно увеличивает начальный капитал. Это возможность является одним из заметных на среди конкурентов, так как позволяет игрокам новым участникам заполучить выгодные условия, значительно улучшив стартовые позиции. Быстрая регистрация и внесение депозита зачисляют бонус на счет, что делает его применение простым и доступным.
Live-ставки: Мгновенные возможности для ставок с моментальными ставками
В экосистеме спортивных ставок важнейшей частью является быстрота реакции и возможность реагировать на изменения в на ходу. 1win приглашает тысячи спортивных событий, доступных в формате онлайн ставок. Мы гарантируем доступ к глобальным соревнованиям и матчам, будь то хоккей.
Полная ссылка на страницу: http://biliq.ru/xallang/content/%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0/%D0%BC%D0%BE%D1%80%D1%84%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9-%D1%81%D0%BE%D1%81%D1%82%D0%B0%D0%B2-%D1%81%D0%BB%D0%BE%D0%B2%D0%B0?page=2&destination=node/278%3Fpage%3D21
Игра в лайве обеспечивают шанс быстро подстраиваться, что делает процесс насыщенным эмоциями, но и интеллектуально интересным. Благодаря аналитическим данным платформы, клиенты могут анализировать события глубже, увеличивая потенциальные результаты. Каждое событие представлено с комментариями, что обогащает принятие решений ориентироваться в ставках.
Онлайн-казино Vavada — это одно из лучших и доверенных казино среди поклонников гэмблинга. За счет инновационного подхода, широкому ассортименту игр и щедрым бонусам для игроков, <a href="https://m.opt-union.ru/?no_mobail=1&url=https://vavada-casino-play-10.top/">vavada online casino </a> получило статус отличной платформы для всех, кто хочет получить надежный азартный отдых. В этом материале мы разберем особенности сайта Vavada casino, порядок создания аккаунта и входа, а также объясним о бонусах Vavada и о том, как получить работающие Vavada зеркало.
Достоинства официального сайта Vavada
Сайт казино Vavada отличается среди других платформ с помощью простого и удобного пользовательского меню, мгновенной загрузке и кроссплатформенности. Независимо от гаджет находится у вас, будь то ноутбук, планшет или мобильный телефон, Vavada официальный сайт работает идеально, гарантируя удобный вход к разделам и опциям.
Сайт: https://m.opt-union.ru/?no_mobail=1&url=https://vavada-casino888-12.top/
Чтобы попасть на ресурс не необходима скачивание приложений. Vavada casino работает прямо через браузер, что значительно облегчает доступ в аккаунт и разделам казино. При возникновении блокировок пользователи могут зайти через Vavada зеркало, повторяет весь контент основного портала.
В индустрии интерактивных казино и спортивных ставок важно не только качество обслуживания, но и надежность оператора. С лицензионными гарантиями, которая подтверждает легальность, сайт <a href="http://akrvo.ru/index.php?option=com_content&view=article&id=9075">http://akrvo.ru/index.php?option=com_content&view=article&id=9075</a> считает себя лидеров в области азартных игр. Организация уделяет внимание предоставление качественных услуг, разрабатывая новые функции, чтобы гарантировать пользователям первоклассный игровой опыт.
Приветственный бонус: Щедрый бонус для пользователей платформы
Для новичков в казино на платформе 1win предусмотрен солидный приветственный бонус, который значительно увеличивает начальный капитал. Это акция является одним из ведущих на рынке, так как позволяет новым пользователям заполучить выгодные условия, сократив риски. Легкий старт и пополнение счета моментально активируют предложение, что делает его использование приятным и лёгким.
Live-ставки: Лайв-ставки на тысячи событий с моментальными ставками
В мире букмекерства главной отличительной чертой является темп и возможность реагировать на изменения в лайве. 1win даёт доступ тысячи спортивных событий, доступных в формате лайв-ставок. Мы гарантируем доступ к международным чемпионатам и играм, будь то теннис.
Полная ссылка на страницу: http://akrvo.ru/index.php?option=com_content&view=article&id=9075
Онлайн-ставки гарантируют игрокам мгновенно реагировать на изменения, что делает процесс более захватывающим, но и аналитически богатым. Пользуясь аналитическими функциями платформы, стратеги могут анализировать события глубже, улучшая тактику игры. Каждое событие обеспечено аналитическими обзорами, что даёт более полную картину гарантировать обоснованные ставки.
Игровой клуб Вавада — является одной из лучших и надежных игровых клубов среди поклонников гэмблинга. Благодаря современного подхода, широкому ассортименту игр и щедрым бонусам для гостей, <a href="https://mirdetstva.printdirect.ru/utils/redirect?url=https://vavada-casino999-10.top/">vavada вход </a> завоевало статус отличной платформы для хочет получить качественный игровой опыт. В этом материале мы подробно рассмотрим возможности официального сайта Vavada, процесс регистрации на сайте и входа, а также поговорим про Vavada бонусы и о том, где найти работающие зеркальные ссылки Vavada.
Достоинства сайта Vavada casino
Vavada официальный сайт отличается среди других платформ благодаря простого и удобного пользовательского меню, мгновенной загрузке и кроссплатформенности. Без разницы, какое устройство вы используете, будь то ПК, планшет или телефон, платформа Vavada casino загружается моментально, гарантируя удобный вход к игровым слотам и возможностям.
Сайт: https://mirdetstva.printdirect.ru/utils/redirect?url=https://vavada-casino888-12.top/
Чтобы попасть на сайт не требуется загрузка ПО. Vavada online casino запускается в веб-версии, что значительно облегчает доступ к личному кабинету и разделам сайта. При возникновении технических проблем игроки могут воспользоваться Vavada зеркало, повторяет функции основного портала.
В пространстве интернет-казино и ставочных рынков основное внимание уделяется не только качество игровой платформы, но и гарантии безопасности. С лицензией, которая гарантирует надежность, сайт <a href="https://adm-ustug.ru/2020/04/22/%D0%B1%D0%B5%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BD%D1%8B%D0%B5-%D0%B6%D0%B8%D1%82%D0%B5%D0%BB%D0%B8-%D0%BA%D1%80%D0%B0%D1%8F-%D0%BF%D0%BE%D0%BB%D1%83%D1%87%D0%B0%D1%82-%D0%B2%D1%8B%D0%BF%D0%BB/">https://adm-ustug.ru/2020/04/22/%D0%B1%D0%B5%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BD%D1%8B%D0%B5-%D0%B6%D0%B8%D1%82%D0%B5%D0%BB%D0%B8-%D0%BA%D1%80%D0%B0%D1%8F-%D0%BF%D0%BE%D0%BB%D1%83%D1%87%D0%B0%D1%82-%D0%B2%D1%8B%D0%BF%D0%BB/</a> выступает одним из ключевых участников на рынке ставок. Организация работает на максимального комфорта, разрабатывая новые функции, чтобы гарантировать пользователям непревзойденный опыт.
Приветственный бонус: Бонус для новичков для новичков
Для новых игроков на платформе 1win ожидает вас впечатляющий приветственный бонус, который увеличивает ваши возможности. Это программа является одним из наиболее привлекательных на среди конкурентов, так как позволяет новым пользователям платформы получить дополнительный капитал, стимулируя успешные ставки. Регистрация за несколько минут и внесение суммы моментально активируют предложение, что делает его получение максимально удобным и быстрым.
Live-ставки: Играйте на события вживую с реальными шансами на успех
В пространстве онлайн-ставок одним из ключевых элементов является изменчивость и шанс учесть изменения в на ходу. 1win предоставляет возможность огромное количество спортивных событий, доступных в формате ставок на события в реальном времени. Мы гарантируем доступ к международным чемпионатам и играм, будь то киберспорт.
Полная ссылка на страницу: https://adm-ustug.ru/2020/04/22/%D0%B1%D0%B5%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BD%D1%8B%D0%B5-%D0%B6%D0%B8%D1%82%D0%B5%D0%BB%D0%B8-%D0%BA%D1%80%D0%B0%D1%8F-%D0%BF%D0%BE%D0%BB%D1%83%D1%87%D0%B0%D1%82-%D0%B2%D1%8B%D0%BF%D0%BB/
Ставки в реальном времени открывают возможность реагировать в реальном времени, что делает процесс ещё интереснее, но и стратегически насыщенным. С применением аналитических ресурсов платформы, игроки платформы могут повышать свои шансы на успех, улучшая тактику игры. Каждое событие представлено с комментариями, что способствует точным прогнозам принимать решения на основе актуальных данных.
Vavada казино — является одно из топовых и доверенных казино для любителей гэмблинга. Благодаря актуального дизайна, разнообразию развлечений и щедрым бонусам для игроков, <a href="https://vzh2010.printdirect.ru/utils/redirect?url=https://casino-vavada-slots-4.top/">vavada online casino </a> завоевало статус превосходной платформы для всех, кто жаждет найти безупречный игровой процесс. В данной статье мы разберем возможности сайта Vavada casino, процесс создания аккаунта и входа в личный кабинет, а также поговорим про акционные предложения Vavada и о том, где найти работающие зеркальные ссылки Vavada.
Основные плюсы официального сайта Vavada
Сайт казино Vavada выделяется среди других платформ с помощью интуитивно понятного дизайна, быстрому отклику и адаптивному дизайну. Независимо от устройство подключено, будь то ноутбук, планшетный ПК или телефон, Vavada официальный сайт загружается моментально, обеспечивая комфортное использование к играм и возможностям.
Сайт: https://vzh2010.printdirect.ru/utils/redirect?url=https://casino-vavada-slots-4.top/
Чтобы попасть на ресурс не нужно скачивание приложений. Vavada online casino функционирует прямо через браузер, что упрощает процесс входа к личному кабинету и разделам казино. В случае блокировок пользователи могут перейти на Актуальные зеркала Vavada, имеет идентичный функции основного сайта.
В мире онлайн-казино и ставок на спорт приоритетное значение имеет не только качество предоставляемых услуг, но и надежность оператора. С лицензионными гарантиями, которая гарантирует надежность, сайт <a href="http://www.temyasovo.ru/pravila-zemlepolzovaniya-i-zastrojki-v-novoj-redaktsii-selskogo-poseleniya-temyasovskij-selsovet-munitsipalnogo-rajona-bajmakskij-rajon-respubliki-bashkortostan/">http://www.temyasovo.ru/pravila-zemlepolzovaniya-i-zastrojki-v-novoj-redaktsii-selskogo-poseleniya-temyasovskij-selsovet-munitsipalnogo-rajona-bajmakskij-rajon-respubliki-bashkortostan/</a> установил себя как ведущих игроков в сфере интерактивных казино. Компания работает на предоставление качественных услуг, обновляя контент, чтобы предоставить пользователям первоклассный игровой опыт.
Приветственный бонус: Привлекательное предложение для новичков казино
Для новых пользователей на платформе 1win предусмотрен значительный приветственный бонус, который значительно увеличивает начальный капитал. Это подарок является одним из выгодных на на платформе, так как помогает новым клиентам моментально воспользоваться бонусом, получив дополнительные ресурсы для ставок. Легкий старт и внесение депозита зачисляют бонус на счет, что делает его использование простым и доступным.
Live-ставки: Тысячи событий в реальном времени с максимальным удобством
В отрасли онлайн-ставок фундаментальным аспектом является стратегическая глубина и способность мгновенно реагировать в реальном времени. 1win приглашает широкий выбор спортивных событий, доступных в формате ставок в режиме реального времени. Мы предлагаем ставки к топовым международным и локальным соревнованиям, будь то волейбол.
Полная ссылка на страницу: http://www.temyasovo.ru/pravila-zemlepolzovaniya-i-zastrojki-v-novoj-redaktsii-selskogo-poseleniya-temyasovskij-selsovet-munitsipalnogo-rajona-bajmakskij-rajon-respubliki-bashkortostan/
Онлайн-ставки предоставляют возможность моментально адаптироваться, что делает процесс более захватывающим, но и серьёзным испытанием навыков. Используя стратегии и аналитику платформы, клиенты могут точнее прогнозировать исходы, увеличивая потенциальные результаты. Каждое событие сопровождается качественной аналитикой, что обогащает принятие решений гарантировать обоснованные ставки.
В индустрии интернет-казино и ставок на спорт ключевое значение имеет не только качество игровой платформы, но и высокий уровень доверия. С разрешением на деятельность, которая гарантирует надежность, сайт <a href="http://lionelbaland.hautetfort.com/archive/2023/02/23/meloni-se-retrouve-seule-prise-en-etau-par-ses-allies-forza-6429834.html">http://lionelbaland.hautetfort.com/archive/2023/02/23/meloni-se-retrouve-seule-prise-en-etau-par-ses-allies-forza-6429834.html</a> занимает главных представителей в мире онлайн-гемблинга. Платформа уделяет внимание развитие клиентского опыта, разрабатывая новые функции, чтобы обогатить пользователям наивысшее качество услуг.
Приветственный бонус: Щедрый бонус для новых пользователей
Для новых участников на платформе 1win ожидает вас выгодный приветственный бонус, который помогает начать с преимуществом. Это подарок является одним из популярных на в индустрии ставок, так как открывает возможность новым пользователям получить преимущество, получив дополнительные ресурсы для ставок. Простая регистрация и перевод средств мгновенно активируют бонус, что делает его воспользование эффективным и быстрым.
Live-ставки: Множество матчей онлайн с моментальными ставками
В сфере ставочной деятельности важнейшей частью является стратегическая глубина и необходимость предугадывать события в онлайн. 1win даёт шанс большой спектр спортивных событий, доступных в формате игры вживую. Мы располагаем матчами к ведущим событиям мирового масштаба, будь то баскетбол.
Полная ссылка на страницу: http://lionelbaland.hautetfort.com/archive/2023/02/23/meloni-se-retrouve-seule-prise-en-etau-par-ses-allies-forza-6429834.html
Ставки в реальном времени предоставляют возможность реагировать в реальном времени, что делает процесс не только увлекательным, но и тактически интересным. С помощью аналитики платформы, игроки платформы могут повышать свои шансы на успех, увеличивая свои шансы на успех. Каждое событие освещается статистикой, что делает процесс ещё более обоснованным гарантировать обоснованные ставки.
Vavada casino — является одно из наиболее востребованных и надежных платформ для ценителей гэмблинга. Благодаря актуального дизайна, большому выбору игровых слотов и привлекательным условиям для гостей, <a href="http://o.nnov.org/common/redir.php?https://vavada-casino888-12.top/">казино вавада </a> завоевало репутацию отличной площадки для всех, кто ищет надежный азартный отдых. В этом материале мы опишем функции официального сайта Vavada, этапы регистрации на сайте и входа в личный кабинет, а также расскажем про Vavada бонусы и о том, как получить работающие зеркальные ссылки Vavada.
Достоинства сайта Vavada casino
Vavada официальный сайт выделяется по сравнению с аналогами благодаря интуитивно понятного дизайна, быстрому отклику и адаптации под устройства. Независимо от устройство находится у вас, будь то ПК, планшетный ПК или мобильный телефон, сайт Vavada загружается моментально, обеспечивая плавный доступ к разделам и опциям.
Сайт: http://o.nnov.org/common/redir.php?https://casino-vavada-slots-4.top/
Для доступа на сайт не необходима скачивание приложений. Онлайн-казино Vavada работает непосредственно в браузере, что упрощает процесс входа в аккаунт и разделам казино. При возникновении ограничений гости могут перейти на Рабочее зеркало Vavada, повторяет весь контент основного сайта.
В отрасли игровых платформ и спортивных ставок важно не только уровень сервиса, но и репутация компании. С лицензией, которая обеспечивает соблюдение стандартов, сайт <a href="https://www.cross-kpk.ru/index.dll/documents/documents/Projects/Dalchten/forum.dll/index.dll?part=400">https://www.cross-kpk.ru/index.dll/documents/documents/Projects/Dalchten/forum.dll/index.dll?part=400</a> считает себя ведущих игроков в области азартных игр. Оператор создает условия для предоставление качественных услуг, совершенствуя предложения, чтобы предоставить пользователям максимальный комфорт.
Приветственный бонус: Премиум-старт для клиентов
Для новых участников на платформе 1win существует впечатляющий приветственный бонус, который помогает начать с преимуществом. Это акция является одним из заметных на среди конкурентов, так как помогает новым клиентам моментально воспользоваться бонусом, получив дополнительные ресурсы для ставок. Легкий старт и пополнение счета зачисляют бонус на счет, что делает его доступ эффективным и быстрым.
Live-ставки: Лайв-ставки на тысячи событий с быстрой реакцией
В экосистеме букмекерства одним из ключевых элементов является стратегическая глубина и необходимость предугадывать события в онлайн. 1win предлагает игрокам большой спектр спортивных событий, доступных в формате игры вживую. Мы предлагаем ставки к ключевым международным и локальным соревнованиям, будь то хоккей.
Полная ссылка на страницу: https://www.cross-kpk.ru/index.dll/documents/documents/Projects/Dalchten/forum.dll/index.dll?part=400
Ставки в реальном времени дают шанс мгновенно реагировать на изменения, что делает процесс насыщенным эмоциями, но и полезным для стратегии. С применением аналитических ресурсов платформы, игроки могут анализировать события глубже, увеличивая свои шансы на успех. Каждое событие предоставляется с аналитическими данными, что способствует точным прогнозам выбирать тактику исходя из фактов.
Vavada casino — является одно из топовых и проверенных временем игровых клубов для любителей азартных игр. С помощью актуального дизайна, большому выбору развлечений и выгодным предложениям для пользователей, <a href="https://profilelink.ru/away.php?url=https://casino-vavada-slots-4.top/">вавада официальный сайт </a> получило статус отличной платформы для хочет получить надежный азартный отдых. В данной статье мы подробно рассмотрим особенности платформы казино Вавада, процесс создания аккаунта и авторизации, а также объясним про акционные предложения Vavada и о том, где взять свежие Vavada зеркало.
Достоинства официального сайта Vavada
Vavada официальный сайт выделяется на фоне конкурентов благодаря интуитивно понятного интерфейса, быстрому отклику и адаптации под устройства. Без разницы, какое девайс находится у вас, будь то компьютер, планшет или мобильный телефон, сайт Vavada открывается без задержек, обеспечивая плавный доступ к играм и возможностям.
Сайт: https://profilelink.ru/away.php?url=https://vavada-casino999-10.top/
Для доступа на платформу не необходима установка дополнительных программ. Vavada online casino функционирует в веб-версии, что значительно облегчает доступ в аккаунт и разделам сайта. Если случаются блокировок игроки могут зайти через Vavada зеркало, повторяет функционал основного портала.
В сфере цифровых казино и игр на ставки основное внимание уделяется не только качество игровой платформы, но и надежность оператора. С официальной лицензией, которая гарантирует надежность, сайт <a href="http://uprkul.ru/index.php?option=com_content&view=article&id=344:2018-06-28-10-29-58&catid=38:news&Itemid=62&month=7&year=2018">http://uprkul.ru/index.php?option=com_content&view=article&id=344:2018-06-28-10-29-58&catid=38:news&Itemid=62&month=7&year=2018</a> выступает одним из фаворитов в области азартных игр. Оператор ориентирована на создание благоприятных условий, совершенствуя предложения, чтобы обеспечить пользователям первоклассный игровой опыт.
Приветственный бонус: Щедрый бонус для клиентов
Для новых участников на платформе 1win предусмотрен значительный приветственный бонус, который позволяет начать с уверенностью. Это акция является одним из наиболее привлекательных на рынке, так как позволяет игрокам новым пользователям платформы начать игру с бонусом, сократив риски. Удобная регистрация и пополнение счета дают возможность воспользоваться бонусом, что делает его использование очень удобным.
Live-ставки: Мгновенные возможности для ставок с моментальными ставками
В сфере букмекерства фундаментальным аспектом является актуальность и способность адаптироваться в лайве. 1win даёт шанс десятки тысяч спортивных событий, доступных в формате онлайн ставок. Мы даем возможность играть к крупнейшим международным и локальным соревнованиям, будь то волейбол.
Полная ссылка на страницу: http://uprkul.ru/index.php?option=com_content&view=article&id=344:2018-06-28-10-29-58&catid=38:news&Itemid=62&month=7&year=2018
Ставки в реальном времени обеспечивают шанс принимать решения мгновенно, что делает процесс стратегически насыщенным, но и полезным для стратегии. С применением аналитических ресурсов платформы, клиенты могут точнее прогнозировать исходы, повышая вероятность выигрыша. Каждое событие представлено с комментариями, что способствует точным прогнозам предсказывать результат с уверенностью.
Онлайн-казино Vavada — это одним из топовых и надежных платформ среди ценителей гэмблинга. За счет актуального дизайна, большому выбору игровых слотов и выгодным предложениям для пользователей, <a href="https://remstroygarant.com/uz_redirect.php?url=https://vavada-casino999-10.top/">вавада рабочее зеркало </a> получило репутацию отличной платформы для всех, кто ищет безупречный игровой процесс. В данной статье мы разберем особенности сайта Vavada casino, процесс регистрации и входа в личный кабинет, а также поговорим про акционные предложения Vavada и о том, где найти работающие зеркальные ссылки Vavada.
Преимущества официального сайта Vavada
Vavada официальный сайт привлекает внимание среди других платформ благодаря простого и удобного дизайна, мгновенной загрузке и адаптации под устройства. Без разницы, какое девайс вы используете, будь то компьютер, планшет или мобильный телефон, сайт Vavada загружается моментально, обеспечивая комфортное использование к играм и возможностям.
Сайт: https://remstroygarant.com/uz_redirect.php?url=https://vavada-casino888-12.top/
Для доступа на сайт не требуется скачивание приложений. Vavada casino работает прямо через браузер, что значительно облегчает доступ в аккаунт и игровым слотам. При возникновении блокировок гости могут зайти через Актуальные зеркала Vavada, повторяет функции основного сайта.
В индустрии интернет-казино и ставочной деятельности основное внимание уделяется не только надежность услуг, но и доверие к оператору. С гарантированной лицензией, которая гарантирует надежность, сайт <a href="https://www.cross-kpk.ru/index.dll/documents/projects/Slavane/documents/projects/Kristal/multimedia.dll/multimedia.dll/news.dll?detail=621">https://www.cross-kpk.ru/index.dll/documents/projects/Slavane/documents/projects/Kristal/multimedia.dll/multimedia.dll/news.dll?detail=621</a> установил себя как ведущих игроков среди букмекерских платформ. Оператор ориентирована на предоставление качественных услуг, обновляя платформу, чтобы обеспечить пользователям безупречное взаимодействие.
Приветственный бонус: Выгодный старт для пользователей платформы
Для новых клиентов на платформе 1win предоставляется выгодный приветственный бонус, который существенно увеличивает стартовый капитал. Это акция является одним из ведущих на в мире онлайн-гемблинга, так как предоставляет шанс новым пользователям платформы получить преимущество, повысив вероятность успеха. Простая регистрация и внесение суммы обеспечивают получение бонуса, что делает его применение эффективным и быстрым.
Live-ставки: Тысячи событий в реальном времени с широким выбором
В экосистеме ставочной деятельности одним из ключевых элементов является темп и шанс учесть изменения в онлайн. 1win даёт доступ большой спектр спортивных событий, доступных в формате ставок на события в реальном времени. Мы гарантируем доступ к международным локальным и глобальным турнирам, будь то хоккей.
Полная ссылка на страницу: https://www.cross-kpk.ru/index.dll/documents/projects/Slavane/documents/projects/Kristal/multimedia.dll/multimedia.dll/news.dll?detail=621
Ставки в реальном времени гарантируют игрокам моментально адаптироваться, что делает процесс стратегически насыщенным, но и серьёзным испытанием навыков. Используя передовые аналитические инструменты платформы, клиенты могут увеличивать вероятность выигрыша, оптимизируя стратегию. Каждое событие обеспечено аналитическими обзорами, что обогащает принятие решений ориентироваться в ставках.
Онлайн-казино Vavada — это одним из самых популярных и доверенных казино среди поклонников игровых автоматов. За счет актуального дизайна, большому выбору игр и выгодным предложениям для игроков, <a href="https://api.linkr.bio/callbacks/go?url=https%3A%2F%2Fvavada-casino-play-10.top &hash=P8gzdZgE&type=1&id=w8oDvavR">вавада регистрация </a> получило статус идеальной площадки для жаждет найти надежный азартный отдых. В данной статье мы опишем функции сайта Vavada casino, процесс создания аккаунта и входа, а также поговорим о бонусах Vavada и о том, как получить актуальные зеркальные ссылки Vavada.
Основные плюсы платформы казино Вавада
Сайт казино Vavada отличается на фоне конкурентов с помощью интуитивно понятного интерфейса, высокой скорости работы и кроссплатформенности. Независимо от устройство находится у вас, будь то компьютер, планшетный ПК или смартфон, Vavada официальный сайт работает идеально, гарантируя плавный доступ к играм и возможностям.
Сайт: https://api.linkr.bio/callbacks/go?url=https%3A%2F%2Fvavada-casino-888-9.top &hash=P8gzdZgE&type=1&id=w8oDvavR
Чтобы попасть на ресурс не необходима скачивание приложений. Vavada online casino функционирует непосредственно в браузере, что значительно облегчает процесс входа к личному кабинету и игровым слотам. Если случаются блокировок игроки могут зайти через Рабочее зеркало Vavada, которое полностью дублирует весь контент официального ресурса.
В сфере цифровых казино и игр на ставки ключевое значение имеет не только качество обслуживания, но и гарантии безопасности. С разрешением на деятельность, которая подтверждает честность, сайт <a href="https://www.book-hall.ru/news/2019-09-07-1956-6726?page=13">https://www.book-hall.ru/news/2019-09-07-1956-6726?page=13</a> уверенно занимает лидеров на рынке ставок. Оператор уделяет внимание повышение качества сервиса, постоянно улучшая свои продукты и сервисы, чтобы предоставить пользователям захватывающий игровой процесс.
Приветственный бонус: Премиум-старт для новых игроков
Для новичков в казино на платформе 1win ожидает вас щедрый приветственный бонус, который стимулирует успешное начало. Это акция является одним из популярных на среди конкурентов, так как помогает новым клиентам казино получить преимущество, получив дополнительные ресурсы для ставок. Регистрация за несколько минут и пополнение счета мгновенно активируют бонус, что делает его доступ максимально удобным и быстрым.
Live-ставки: Играйте на события вживую с максимальным удобством
В экосистеме онлайн-ставок важнейшей частью является динамика и умение быстро принимать решения в на ходу. 1win даёт доступ тысячи спортивных событий, доступных в формате онлайн ставок. Мы даем возможность играть к крупнейшим событиям мирового масштаба, будь то хоккей.
Полная ссылка на страницу: https://www.book-hall.ru/news/2019-09-07-1956-6726?page=13
Букмекерские ставки в лайве обеспечивают шанс моментально адаптироваться, что делает процесс не только увлекательным, но и стратегически насыщенным. С применением аналитических ресурсов платформы, клиенты могут анализировать события глубже, повышая вероятность выигрыша. Каждое событие освещается статистикой, что делает процесс ещё более обоснованным принимать решения на основе актуальных данных.
Vavada casino — это одним из наиболее востребованных и доверенных платформ среди поклонников азартных игр. Благодаря современного подхода, большому выбору развлечений и выгодным предложениям для пользователей, <a href="https://mir-tabaka.su/redirect.php?action=url&goto=vavada-casino888-12.top">вавада регистрация </a> завоевало репутацию отличной площадки для всех, кто хочет получить качественный игровой опыт. В этом материале мы опишем особенности официального сайта Vavada, порядок регистрации и входа в личный кабинет, а также расскажем про акционные предложения Vavada и о том, как получить свежие зеркальные ссылки Vavada.
Основные плюсы сайта Vavada casino
Сайт казино Vavada отличается по сравнению с аналогами за счет простого и удобного интерфейса, мгновенной загрузке и адаптации под устройства. Без разницы, какое гаджет вы используете, будь то ПК, планшетный ПК или мобильный телефон, платформа Vavada casino загружается моментально, обеспечивая плавный доступ к играм и функциям.
Сайт: https://mir-tabaka.su/redirect.php?action=url&goto=vavada-casino888-12.top
Для доступа на сайт не нужно установка дополнительных программ. Vavada online casino запускается непосредственно в браузере, что упрощает процесс входа к личному кабинету и разделам казино. Если случаются ограничений пользователи могут воспользоваться Vavada зеркало, имеет идентичный функционал основного портала.
В индустрии виртуальных казино и ставочной деятельности необходимо не только надежность услуг, но и честность оператора. С международной лицензией, которая подтверждает легальность, сайт <a href="https://uprkul.ru/index.php?option=com_content&view=category&layout=blog&id=37&Itemid=30&limit=9&limitstart=10&month=9&year=2021">https://uprkul.ru/index.php?option=com_content&view=category&layout=blog&id=37&Itemid=30&limit=9&limitstart=10&month=9&year=2021</a> занимает ключевых участников в мире онлайн-гемблинга. Платформа уделяет внимание повышение качества сервиса, постоянно улучшая свои продукты и сервисы, чтобы подарить пользователям максимальный комфорт.
Приветственный бонус: Привлекательное предложение для новичков казино
Для новых игроков на платформе 1win ожидает вас щедрый приветственный бонус, который помогает начать с преимуществом. Это подарок является одним из выгодных на в мире онлайн-гемблинга, так как позволяет новым пользователям начать игру с бонусом, значительно улучшив стартовые позиции. Удобная регистрация и депозит автоматически активируют бонус, что делает его использование максимально удобным и быстрым.
Live-ставки: Спортивные события в режиме реального времени с моментальными ставками
В мире онлайн-ставок главной отличительной чертой является динамика и шанс учесть изменения в онлайн. 1win даёт шанс большой спектр спортивных событий, доступных в формате ставок в лайве. Мы предлагаем ставки к ведущим соревнованиям и матчам, будь то футбол.
Полная ссылка на страницу: https://uprkul.ru/index.php?option=com_content&view=category&layout=blog&id=37&Itemid=30&limit=9&limitstart=10&month=9&year=2021
Букмекерские ставки в лайве предоставляют возможность моментально адаптироваться, что делает процесс более динамичным, но и серьёзным испытанием навыков. С применением аналитических ресурсов платформы, игроки могут делать ставки с уверенностью, повышая вероятность выигрыша. Каждое событие освещается статистикой, что даёт более полную картину принимать решения на основе актуальных данных.
Игровой клуб Вавада — это одной из топовых и надежных казино среди ценителей игровых автоматов. С помощью актуального дизайна, большому выбору игровых слотов и выгодным предложениям для гостей, <a href="http://stg-cta-redirect.ex.co/redirect?&web=https://vavada-casino-play-10.top/">вавада вход </a> получило репутацию превосходной площадки для хочет получить надежный азартный отдых. В обзоре ниже мы опишем особенности сайта Vavada casino, этапы создания аккаунта и авторизации, а также расскажем про акционные предложения Vavada и о том, где взять свежие рабочие зеркала Vavada.
Преимущества официального сайта Vavada
Vavada официальный сайт отличается среди других платформ с помощью простого и удобного пользовательского меню, быстрому отклику и адаптации под устройства. Независимо от гаджет находится у вас, будь то компьютер, планшетный ПК или телефон, Vavada официальный сайт работает идеально, обеспечивая комфортное использование к играм и возможностям.
Сайт: http://stg-cta-redirect.ex.co/redirect?&web=https://vavada-casino999-10.top/
Чтобы попасть на платформу не необходима скачивание приложений. Онлайн-казино Vavada работает в веб-версии, что делает удобным процесс входа к личному кабинету и разделам сайта. Если случаются блокировок игроки могут воспользоваться Рабочее зеркало Vavada, которое полностью дублирует функционал официального ресурса.
В сфере виртуальных казино и ставочных рынков необходимо не только уровень сервиса, но и гарантии безопасности. С лицензией, которая обеспечивает соблюдение стандартов, сайт <a href="https://fomsrd.ru/news/?ELEMENT_ID=495&PAGEN_1=36">https://fomsrd.ru/news/?ELEMENT_ID=495&PAGEN_1=36</a> уверенно занимает фаворитов в мире онлайн-гемблинга. Компания уделяет внимание создание благоприятных условий, улучшая функционал, чтобы дать пользователям максимальный комфорт.
Приветственный бонус: Премиум-старт для клиентов
Для новичков в казино на платформе 1win ожидает вас выгодный приветственный бонус, который помогает начать с преимуществом. Это подарок является одним из наиболее привлекательных на на платформе, так как открывает возможность новым клиентам казино получить дополнительный капитал, значительно улучшив стартовые позиции. Легкий старт и депозит обеспечивают получение бонуса, что делает его получение простым и доступным.
Live-ставки: Множество матчей онлайн с мгновенными возможностями
В сфере ставок на спорт главной отличительной чертой является быстрота реакции и способность мгновенно реагировать в онлайн. 1win даёт шанс широкий выбор спортивных событий, доступных в формате онлайн ставок. Мы гарантируем доступ к глобальным локальным и глобальным турнирам, будь то теннис.
Полная ссылка на страницу: https://fomsrd.ru/news/?ELEMENT_ID=495&PAGEN_1=36
Лайв-ставки открывают возможность принимать решения мгновенно, что делает процесс ещё интереснее, но и полезным для стратегии. Используя стратегии и аналитику платформы, игроки платформы могут принимать более обоснованные решения, улучшая тактику игры. Каждое событие представлено с комментариями, что способствует точным прогнозам предсказывать результат с уверенностью.
Игровой клуб Вавада — является одним из топовых и проверенных временем платформ для поклонников азартных игр. Благодаря современного подхода, разнообразию игр и привлекательным условиям для игроков, <a href="https://mirdetstva.printdirect.ru/utils/redirect?url=https://vavada-casino-play-10.top/">vavada промокод сегодня </a> получило репутацию отличной площадки для всех, кто жаждет найти безупречный игровой процесс. В этом материале мы опишем возможности платформы казино Вавада, этапы создания аккаунта и входа в личный кабинет, а также расскажем про акционные предложения Vavada и о том, где взять актуальные рабочие зеркала Vavada.
Преимущества платформы казино Вавада
Vavada официальный сайт привлекает внимание среди других платформ за счет интуитивно понятного интерфейса, быстрому отклику и кроссплатформенности. Без разницы, какое девайс подключено, будь то компьютер, планшетный ПК или смартфон, платформа Vavada casino открывается без задержек, обеспечивая комфортное использование к разделам и функциям.
Сайт: https://mirdetstva.printdirect.ru/utils/redirect?url=https://vavada-casino999-10.top/
Чтобы попасть на ресурс не нужно загрузка ПО. Онлайн-казино Vavada работает непосредственно в браузере, что делает удобным доступ к личному кабинету и разделам казино. В случае блокировок игроки могут перейти на Актуальные зеркала Vavada, повторяет функционал основного портала.
В мире игровых платформ и ставочных рынков ключевое значение имеет не только качество предоставляемых услуг, но и репутация компании. С разрешением на деятельность, которая гарантирует безопасность, сайт <a href="https://www.book-hall.ru/nemodnoe-chtenie/2016/aleksandr-pushkin-dubrovskii?destination=node%2F5341">https://www.book-hall.ru/nemodnoe-chtenie/2016/aleksandr-pushkin-dubrovskii?destination=node%2F5341</a> занимает ключевых участников среди букмекерских платформ. Сервис работает на предоставление качественных услуг, обновляя контент, чтобы обогатить пользователям наивысшее качество услуг.
Приветственный бонус: Привлекательное предложение для новых игроков
Для новичков в казино на платформе 1win существует значительный приветственный бонус, который существенно увеличивает стартовый капитал. Это акция является одним из популярных на на платформе, так как позволяет новым участникам моментально воспользоваться бонусом, значительно улучшив стартовые позиции. Удобная регистрация и депозит дают возможность воспользоваться бонусом, что делает его получение очень удобным.
Live-ставки: Тысячи событий в реальном времени с мгновенными возможностями
В экосистеме ставок на спорт фундаментальным аспектом является темп и шанс учесть изменения в режиме реального времени. 1win приглашает огромное количество спортивных событий, доступных в формате ставок в режиме реального времени. Мы предоставляем доступ к ключевым спортивным событиям, будь то теннис.
Полная ссылка на страницу: https://www.book-hall.ru/nemodnoe-chtenie/2016/aleksandr-pushkin-dubrovskii?destination=node%2F5341
Онлайн-ставки гарантируют игрокам мгновенно реагировать на изменения, что делает процесс более динамичным, но и стратегически насыщенным. Благодаря аналитическим данным платформы, игроки могут анализировать события глубже, увеличивая свои шансы на успех. Каждое событие представлено с комментариями, что способствует точным прогнозам принимать решения на основе актуальных данных.
Vavada казино — это одной из лучших и проверенных временем игровых клубов среди любителей игровых автоматов. С помощью современного подхода, широкому ассортименту развлечений и выгодным предложениям для игроков, <a href="http://ussr.nnov.org/common/redir.php?https://vavada-casino888-12.top/">vavada регистрация </a> завоевало репутацию отличной площадки для ищет надежный азартный отдых. В этом материале мы подробно рассмотрим функции платформы казино Вавада, процесс создания аккаунта и входа, а также поговорим о бонусах Vavada и о том, как получить свежие Vavada зеркало.
Преимущества сайта Vavada casino
Сайт казино Vavada привлекает внимание среди других платформ благодаря легкого в использовании пользовательского меню, мгновенной загрузке и адаптации под устройства. Независимо от устройство подключено, будь то ПК, планшет или телефон, Vavada официальный сайт загружается моментально, обеспечивая плавный доступ к игровым слотам и опциям.
Сайт: http://ussr.nnov.org/common/redir.php?https://vavada-casino999-10.top/
Чтобы попасть на сайт не требуется загрузка ПО. Vavada online casino запускается в веб-версии, что значительно облегчает процесс входа в аккаунт и разделам сайта. В случае технических проблем гости могут перейти на Vavada зеркало, имеет идентичный весь контент основного портала.
В экосистеме игровых платформ и игр на ставки приоритетное значение имеет не только уровень сервиса, но и высокий уровень доверия. С разрешением на деятельность, которая подтверждает легальность, сайт <a href="https://www.cross-kpk.ru/index.dll/forum.dll/documents/projects/documents/projects/Kristal/forum.dll/topic?id=43">https://www.cross-kpk.ru/index.dll/forum.dll/documents/projects/documents/projects/Kristal/forum.dll/topic?id=43</a> занимает фаворитов в мире онлайн-гемблинга. Провайдер сфокусирована на предоставление качественных услуг, разрабатывая новые функции, чтобы обеспечить пользователям максимальный комфорт.
Приветственный бонус: Привлекательное предложение для новичков казино
Для новых игроков на платформе 1win доступен выгодный приветственный бонус, который существенно увеличивает стартовый капитал. Это программа является одним из выгодных на на платформе, так как открывает возможность новым пользователям платформы сразу получить доступ к дополнительным средствам, получив дополнительные ресурсы для ставок. Легкий старт и депозит моментально активируют предложение, что делает его доступ простым и доступным.
Live-ставки: Мгновенные возможности для ставок с быстрой реакцией
В отрасли ставок на спорт фундаментальным аспектом является темп и способность мгновенно реагировать в лайве. 1win предоставляет возможность большой спектр спортивных событий, доступных в формате ставок на события в реальном времени. Мы гарантируем доступ к международным локальным и глобальным турнирам, будь то баскетбол.
Полная ссылка на страницу: https://www.cross-kpk.ru/index.dll/forum.dll/documents/projects/documents/projects/Kristal/forum.dll/topic?id=43
Букмекерские ставки в лайве гарантируют игрокам реагировать в реальном времени, что делает процесс более захватывающим, но и аналитически богатым. С помощью аналитики платформы, стратеги могут увеличивать вероятность выигрыша, оптимизируя стратегию. Каждое событие сопровождается качественной аналитикой, что помогает игрокам принимать решения на основе актуальных данных.
Онлайн-казино Vavada — это одно из лучших и надежных казино для поклонников азартных игр. С помощью инновационного подхода, широкому ассортименту игр и щедрым бонусам для пользователей, <a href="http://adymrxvmro.cloudimg.io/v7/vavada-casino-play-10.top">vavada промокод </a> завоевало статус идеальной площадки для всех, кто хочет получить безупречный игровой процесс. В этом материале мы подробно рассмотрим функции сайта Vavada casino, этапы регистрации на сайте и входа в личный кабинет, а также объясним про Vavada бонусы и о том, где взять актуальные рабочие зеркала Vavada.
Преимущества официального сайта Vavada
Сайт казино Vavada выделяется на фоне конкурентов благодаря легкого в использовании пользовательского меню, мгновенной загрузке и адаптивному дизайну. Независимо от девайс подключено, будь то ПК, планшет или смартфон, сайт Vavada работает идеально, гарантируя комфортное использование к играм и опциям.
Сайт: http://adymrxvmro.cloudimg.io/v7/vavada-casino-play-10.top
Чтобы попасть на сайт не необходима загрузка ПО. Vavada online casino запускается прямо через браузер, что делает удобным доступ в аккаунт и разделам сайта. Если случаются блокировок гости могут воспользоваться Рабочее зеркало Vavada, повторяет весь контент основного сайта.
В отрасли цифровых казино и ставочной деятельности необходимо не только качество игровой платформы, но и надежность оператора. С лицензионными гарантиями, которая гарантирует прозрачность, сайт <a href="http://biliq.ru/xallang/content/%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0/%D1%84%D0%BE%D0%BD%D0%B5%D1%82%D0%B8%D0%BA%D0%B0-%D0%BE%D0%B1%D1%89%D0%B8%D0%B5-%D1%81%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D0%B8%D1%8F?page=14&destination=node/289%3Fpage%3D2">http://biliq.ru/xallang/content/%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0/%D1%84%D0%BE%D0%BD%D0%B5%D1%82%D0%B8%D0%BA%D0%B0-%D0%BE%D0%B1%D1%89%D0%B8%D0%B5-%D1%81%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D0%B8%D1%8F?page=14&destination=node/289%3Fpage%3D2</a> считает себя главных представителей в области азартных игр. Сервис стремится к повышение качества сервиса, обновляя контент, чтобы подарить пользователям первоклассный игровой опыт.
Приветственный бонус: Начальный бонус для новых игроков
Для новых игроков на платформе 1win существует значительный приветственный бонус, который позволяет начать с уверенностью. Это возможность является одним из наиболее привлекательных на среди конкурентов, так как позволяет новым игрокам сразу получить доступ к дополнительным средствам, значительно улучшив стартовые позиции. Удобная регистрация и внесение депозита зачисляют бонус на счет, что делает его активацию эффективным и быстрым.
Live-ставки: Лайв-ставки на тысячи событий с максимальным удобством
В пространстве спортивных ставок важнейшим фактором является актуальность и шанс учесть изменения в моментально. 1win даёт доступ большой спектр спортивных событий, доступных в формате лайв-ставок. Мы гарантируем доступ к ключевым соревнованиям и матчам, будь то футбол.
Полная ссылка на страницу: http://biliq.ru/xallang/content/%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0/%D1%84%D0%BE%D0%BD%D0%B5%D1%82%D0%B8%D0%BA%D0%B0-%D0%BE%D0%B1%D1%89%D0%B8%D0%B5-%D1%81%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D0%B8%D1%8F?page=14&destination=node/289%3Fpage%3D2
Лайв-ставки дают шанс быстро подстраиваться, что делает процесс насыщенным эмоциями, но и тактически интересным. Благодаря аналитическим данным платформы, пользователи могут анализировать события глубже, оптимизируя стратегию. Каждое событие представлено с комментариями, что делает процесс ещё более обоснованным принимать решения на основе актуальных данных.
Онлайн-казино Vavada — это одно из лучших и доверенных платформ среди поклонников гэмблинга. Благодаря современного подхода, широкому ассортименту игровых слотов и выгодным предложениям для пользователей, <a href="http://savanttools.com/ANON/vavada-casino999-10.top">вавада вход </a> завоевало статус идеальной платформы для всех, кто ищет безупречный игровой процесс. В данной статье мы разберем функции платформы казино Вавада, порядок регистрации и авторизации, а также поговорим о бонусах Vavada и о том, где найти актуальные рабочие зеркала Vavada.
Основные плюсы официального сайта Vavada
Официальный ресурс Vavada выделяется по сравнению с аналогами за счет простого и удобного дизайна, мгновенной загрузке и адаптивному дизайну. Независимо от гаджет подключено, будь то компьютер, планшетный ПК или смартфон, платформа Vavada casino открывается без задержек, гарантируя комфортное использование к игровым слотам и опциям.
Сайт: http://savanttools.com/ANON/vavada-casino888-12.top
Чтобы попасть на сайт не необходима скачивание приложений. Vavada casino работает прямо через браузер, что делает удобным процесс входа к личному кабинету и разделам казино. При возникновении блокировок пользователи могут воспользоваться Рабочее зеркало Vavada, имеет идентичный функции основного портала.
В мире игровых платформ и ставок в спорте ключевое значение имеет не только качество обслуживания, но и надежность оператора. С разрешением на деятельность, которая обеспечивает соблюдение стандартов, сайт <a href="http://www.yalangach.ru/prokuror-razyasnyaet-izmenili-pravila-medreabilitatsii-vzroslyh/">http://www.yalangach.ru/prokuror-razyasnyaet-izmenili-pravila-medreabilitatsii-vzroslyh/</a> уверенно занимает ведущих игроков в сфере интерактивных казино. Сервис работает на максимального комфорта, улучшая функционал, чтобы дать пользователям максимальный комфорт.
Приветственный бонус: Начальный бонус для клиентов
Для новых участников на платформе 1win существует впечатляющий приветственный бонус, который стимулирует успешное начало. Это предложение является одним из заметных на в мире онлайн-гемблинга, так как открывает возможность новым игрокам сразу получить доступ к дополнительным средствам, сократив риски. Упрощенная процедура регистрации и внесение суммы моментально активируют предложение, что делает его активацию простым и доступным.
Live-ставки: Лайв-ставки на тысячи событий с реальными шансами на успех
В отрасли спортивных прогнозов важнейшим фактором является быстрота реакции и шанс учесть изменения в онлайн. 1win приглашает множество спортивных событий, доступных в формате лайв-ставок. Мы предоставляем доступ к ключевым чемпионатам и играм, будь то хоккей.
Полная ссылка на страницу: http://www.yalangach.ru/prokuror-razyasnyaet-izmenili-pravila-medreabilitatsii-vzroslyh/
Букмекерские ставки в лайве обеспечивают шанс мгновенно реагировать на изменения, что делает процесс насыщенным эмоциями, но и серьёзным испытанием навыков. Пользуясь аналитическими функциями платформы, клиенты могут повышать свои шансы на успех, увеличивая свои шансы на успех. Каждое событие сопровождается качественной аналитикой, что способствует точным прогнозам выбирать тактику исходя из фактов.
Онлайн-казино Vavada — является одной из наиболее востребованных и проверенных временем игровых клубов среди поклонников азартных игр. За счет инновационного подхода, большому выбору развлечений и привлекательным условиям для пользователей, <a href="https://cm46.ru/udata/emarket/basket/put/element/2247/?redirect-uri=https://vavada-casino-888-9.top/">vavada зеркало </a> обрело статус отличной платформы для всех, кто ищет надежный азартный отдых. В данной статье мы подробно рассмотрим функции платформы казино Вавада, этапы создания аккаунта и входа в личный кабинет, а также расскажем о бонусах Vavada и о том, где найти актуальные рабочие зеркала Vavada.
Основные плюсы платформы казино Вавада
Официальный ресурс Vavada выделяется среди других платформ за счет легкого в использовании дизайна, мгновенной загрузке и адаптивному дизайну. Независимо от гаджет находится у вас, будь то ноутбук, планшет или смартфон, сайт Vavada загружается моментально, гарантируя удобный вход к игровым слотам и возможностям.
Сайт: https://cm46.ru/udata/emarket/basket/put/element/2247/?redirect-uri=https://casino-vavada-slots-4.top/
Чтобы попасть на платформу не требуется установка дополнительных программ. Vavada casino функционирует непосредственно в браузере, что делает удобным доступ в аккаунт и разделам казино. В случае ограничений пользователи могут перейти на Рабочее зеркало Vavada, имеет идентичный весь контент основного портала.
В отрасли онлайн-казино и ставочных рынков важно не только надежность услуг, но и надежность оператора. С лицензией, которая подтверждает легальность, сайт <a href="https://www.cross-kpk.ru/index.dll/documents/Projects/documents/Projects/forum.dll/news.dll?detail=624">https://www.cross-kpk.ru/index.dll/documents/Projects/documents/Projects/forum.dll/news.dll?detail=624</a> установил себя как лидеров в мире онлайн-гемблинга. Сервис сфокусирована на повышение качества сервиса, обновляя платформу, чтобы подарить пользователям максимальный комфорт.
Приветственный бонус: Премиум-старт для новых игроков
Для новых клиентов на платформе 1win существует впечатляющий приветственный бонус, который позволяет начать с уверенностью. Это акция является одним из наиболее привлекательных на среди конкурентов, так как позволяет игрокам новым игрокам моментально воспользоваться бонусом, стимулируя успешные ставки. Регистрация за несколько минут и депозит мгновенно активируют бонус, что делает его активацию приятным и лёгким.
Live-ставки: Лайв-ставки на тысячи событий с мгновенными возможностями
В экосистеме спортивных прогнозов фундаментальным аспектом является динамика и способность мгновенно реагировать в на ходу. 1win даёт шанс десятки тысяч спортивных событий, доступных в формате ставок в режиме реального времени. Мы гарантируем доступ к топовым соревнованиям и матчам, будь то киберспорт.
Полная ссылка на страницу: https://www.cross-kpk.ru/index.dll/documents/Projects/documents/Projects/forum.dll/news.dll?detail=624
Ставки в реальном времени гарантируют игрокам учитывать динамику событий, что делает процесс более динамичным, но и стратегически насыщенным. Используя передовые аналитические инструменты платформы, игроки могут анализировать события глубже, приумножая выигрышные шансы. Каждое событие содержит анализ игры, что способствует точным прогнозам ориентироваться в ставках.
Игровой клуб Вавада — является одной из топовых и проверенных временем казино для любителей азартных игр. Благодаря актуального дизайна, широкому ассортименту игровых слотов и выгодным предложениям для пользователей, <a href="https://www.fanatec.com/affiliate/scripts/click.php?a_aid=52726ff6553b8&a_bid=adbb7831&desturl=https://casino-vavada-slots-4.top/">vavada регистрация </a> обрело репутацию превосходной площадки для всех, кто жаждет найти безупречный игровой процесс. В этом материале мы разберем функции официального сайта Vavada, процесс регистрации на сайте и авторизации, а также поговорим про акционные предложения Vavada и о том, где взять работающие зеркальные ссылки Vavada.
Основные плюсы платформы казино Вавада
Официальный ресурс Vavada выделяется по сравнению с аналогами с помощью простого и удобного пользовательского меню, быстрому отклику и адаптации под устройства. Без разницы, какое устройство подключено, будь то ноутбук, планшетный ПК или смартфон, сайт Vavada работает идеально, обеспечивая комфортное использование к игровым слотам и опциям.
Сайт: https://www.fanatec.com/affiliate/scripts/click.php?a_aid=52726ff6553b8&a_bid=adbb7831&desturl=https://vavada-casino-888-9.top/
Для доступа на ресурс не требуется установка дополнительных программ. Онлайн-казино Vavada запускается прямо через браузер, что значительно облегчает доступ в аккаунт и разделам казино. Если случаются ограничений игроки могут зайти через Vavada зеркало, повторяет функции основного сайта.
В отрасли онлайн-казино и спортивных ставок важно не только качество предоставляемых услуг, но и репутация компании. С лицензионными гарантиями, которая обеспечивает соблюдение стандартов, сайт <a href="https://www.ippo.ru/predsedatel/page/101">https://www.ippo.ru/predsedatel/page/101</a> находится среди ключевых участников в мире онлайн-гемблинга. Сервис уделяет внимание оптимальных условий, разрабатывая новые функции, чтобы обеспечить пользователям первоклассный игровой опыт.
Приветственный бонус: Премиум-старт для пользователей платформы
Для новых участников на платформе 1win доступен в предложении значительный приветственный бонус, который помогает начать с преимуществом. Это подарок является одним из наиболее привлекательных на в мире онлайн-гемблинга, так как позволяет игрокам новым клиентам казино сразу получить доступ к дополнительным средствам, повысив вероятность успеха. Легкий старт и депозит автоматически активируют бонус, что делает его получение максимально удобным и быстрым.
Live-ставки: Множество матчей онлайн с моментальными ставками
В экосистеме спортивных ставок фундаментальным аспектом является актуальность и необходимость предугадывать события в на ходу. 1win даёт шанс широкий выбор спортивных событий, доступных в формате ставок в лайве. Мы даем возможность играть к международным событиям мирового масштаба, будь то баскетбол.
Полная ссылка на страницу: https://www.ippo.ru/predsedatel/page/101
Игра в лайве предоставляют возможность быстро подстраиваться, что делает процесс ещё интереснее, но и серьёзным испытанием навыков. С помощью аналитики платформы, пользователи могут делать ставки с уверенностью, оптимизируя стратегию. Каждое событие освещается статистикой, что обогащает принятие решений ориентироваться в ставках.
Игровой клуб Вавада — это одной из лучших и надежных игровых клубов для ценителей гэмблинга. С помощью актуального дизайна, разнообразию игровых слотов и выгодным предложениям для пользователей, <a href="https://top-prof.ru/goto/https://vavada-casino888-12.top/">vavada промокод сегодня </a> обрело статус превосходной платформы для всех, кто ищет надежный азартный отдых. В обзоре ниже мы подробно рассмотрим функции платформы казино Вавада, процесс регистрации и авторизации, а также объясним о бонусах Vavada и о том, где взять свежие зеркальные ссылки Vavada.
Достоинства сайта Vavada casino
Vavada официальный сайт привлекает внимание на фоне конкурентов за счет интуитивно понятного дизайна, мгновенной загрузке и адаптивному дизайну. Независимо от девайс подключено, будь то ПК, планшетный ПК или смартфон, Vavada официальный сайт работает идеально, гарантируя плавный доступ к разделам и возможностям.
Сайт: https://top-prof.ru/goto/https://vavada-casino999-10.top/
Для доступа на ресурс не необходима скачивание приложений. Онлайн-казино Vavada работает прямо через браузер, что значительно облегчает процесс входа к личному кабинету и игровым слотам. В случае блокировок пользователи могут воспользоваться Рабочее зеркало Vavada, которое полностью дублирует функции основного портала.
В отрасли интернет-казино и ставочной деятельности необходимо не только качество сервиса, но и высокий уровень доверия. С лицензионными гарантиями, которая гарантирует безопасность, сайт <a href="http://biliq.ru/xallang/content/%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0/%D0%BC%D0%BE%D1%80%D1%84%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%8F-%D0%BE%D0%B1%D1%89%D0%B8%D0%B5-%D1%81%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D0%B8%D1%8F?page=11&destination=node/281%3Fpage%3D18">http://biliq.ru/xallang/content/%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0/%D0%BC%D0%BE%D1%80%D1%84%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%8F-%D0%BE%D0%B1%D1%89%D0%B8%D0%B5-%D1%81%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D0%B8%D1%8F?page=11&destination=node/281%3Fpage%3D18</a> установил себя как главных представителей среди букмекерских платформ. Сервис стремится к максимального комфорта, разрабатывая новые функции, чтобы предоставить пользователям первоклассный игровой опыт.
Приветственный бонус: Премиум-старт для новичков
Для новых пользователей на платформе 1win предоставляется впечатляющий приветственный бонус, который существенно увеличивает стартовый капитал. Это подарок является одним из выгодных на в мире онлайн-гемблинга, так как позволяет игрокам новым игрокам получить дополнительный капитал, получив дополнительные ресурсы для ставок. Легкий старт и перевод средств обеспечивают получение бонуса, что делает его активацию простым и доступным.
Live-ставки: Тысячи событий в реальном времени с широким выбором
В сфере онлайн-ставок главной отличительной чертой является стратегическая глубина и необходимость предугадывать события в моментально. 1win предоставляет возможность большой спектр спортивных событий, доступных в формате игры вживую. Мы организуем лайв-ставки к крупнейшим событиям мирового масштаба, будь то хоккей.
Полная ссылка на страницу: http://biliq.ru/xallang/content/%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0/%D0%BC%D0%BE%D1%80%D1%84%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%8F-%D0%BE%D0%B1%D1%89%D0%B8%D0%B5-%D1%81%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D0%B8%D1%8F?page=11&destination=node/281%3Fpage%3D18
Игра на события вживую позволяют пользователям мгновенно реагировать на изменения, что делает процесс насыщенным эмоциями, но и стратегически насыщенным. С применением аналитических ресурсов платформы, стратеги могут принимать более обоснованные решения, приумножая выигрышные шансы. Каждое событие предоставляется с аналитическими данными, что даёт более полную картину предсказывать результат с уверенностью.
Vavada casino — это одной из самых популярных и проверенных временем игровых клубов среди поклонников гэмблинга. С помощью актуального дизайна, разнообразию игровых слотов и привлекательным условиям для пользователей, <a href="https://cm46.ru/udata/emarket/basket/put/element/2247/?redirect-uri=https://vavada-casino999-10.top/">вавада казино </a> получило репутацию превосходной платформы для всех, кто жаждет найти надежный азартный отдых. В этом материале мы разберем возможности платформы казино Вавада, этапы регистрации на сайте и авторизации, а также поговорим про Vavada бонусы и о том, где взять актуальные зеркальные ссылки Vavada.
Основные плюсы сайта Vavada casino
Сайт казино Vavada привлекает внимание на фоне конкурентов за счет простого и удобного пользовательского меню, быстрому отклику и адаптации под устройства. Независимо от гаджет вы используете, будь то ноутбук, планшет или смартфон, Vavada официальный сайт работает идеально, обеспечивая комфортное использование к игровым слотам и возможностям.
Сайт: https://cm46.ru/udata/emarket/basket/put/element/2247/?redirect-uri=https://casino-vavada-slots-4.top/
Для доступа на платформу не требуется скачивание приложений. Vavada casino функционирует непосредственно в браузере, что упрощает процесс входа к личному кабинету и игровым слотам. При возникновении блокировок игроки могут перейти на Vavada зеркало, имеет идентичный функции основного сайта.
В сфере интерактивных казино и ставок в спорте важно не только качество предоставляемых услуг, но и репутация компании. С лицензией, которая гарантирует прозрачность, сайт <a href="https://sgpi.ru/?n=3950">https://sgpi.ru/?n=3950</a> выступает одним из фаворитов среди букмекерских платформ. Платформа уделяет внимание повышение качества сервиса, постоянно улучшая свои продукты и сервисы, чтобы обеспечить пользователям наивысшее качество услуг.
Приветственный бонус: Щедрый бонус для новых игроков
Для новых участников на платформе 1win предусмотрен значительный приветственный бонус, который существенно увеличивает стартовый капитал. Это подарок является одним из наиболее привлекательных на рынке, так как помогает новым участникам начать игру с бонусом, увеличив свои шансы на успешные ставки. Упрощенная процедура регистрации и депозит дают возможность воспользоваться бонусом, что делает его активацию максимально удобным и быстрым.
Live-ставки: Мгновенные возможности для ставок с моментальными ставками
В мире ставочной деятельности одним из ключевых элементов является быстрота реакции и необходимость предугадывать события в режиме реального времени. 1win даёт шанс большой спектр спортивных событий, доступных в формате лайв-ставок. Мы гарантируем доступ к ведущим событиям мирового масштаба, будь то футбол.
Полная ссылка на страницу: https://sgpi.ru/?n=3950
Лайв-ставки дают шанс мгновенно реагировать на изменения, что делает процесс насыщенным эмоциями, но и тактически интересным. Благодаря аналитическим данным платформы, клиенты могут повышать свои шансы на успех, улучшая тактику игры. Каждое событие предоставляется с аналитическими данными, что делает процесс ещё более обоснованным принимать решения на основе актуальных данных.
Игровой клуб Вавада — это одной из топовых и надежных казино среди любителей азартных игр. За счет современного подхода, разнообразию развлечений и выгодным предложениям для гостей, <a href="http://intactadro.hit.gemius.pl/_sslredir/hitredir/id=ns.lntuw7vnfgpfowxhh79vqtmkbdsvhlgojhkt.meb.i7/stparam=valnhtgkcp/fastid=iohbdavhtvazduihqowcnvqsqzmp/sarg=nc/url=https://vavada-casino999-10.top/">vavada зеркало </a> получило репутацию отличной площадки для всех, кто хочет получить надежный азартный отдых. В этом материале мы опишем возможности сайта Vavada casino, этапы регистрации на сайте и авторизации, а также поговорим про акционные предложения Vavada и о том, где взять актуальные рабочие зеркала Vavada.
Преимущества платформы казино Вавада
Официальный ресурс Vavada привлекает внимание среди других платформ благодаря интуитивно понятного интерфейса, быстрому отклику и адаптивному дизайну. Независимо от гаджет вы используете, будь то ноутбук, планшетный ПК или смартфон, Vavada официальный сайт загружается моментально, обеспечивая удобный вход к играм и опциям.
Сайт: http://intactadro.hit.gemius.pl/_sslredir/hitredir/id=ns.lntuw7vnfgpfowxhh79vqtmkbdsvhlgojhkt.meb.i7/stparam=valnhtgkcp/fastid=iohbdavhtvazduihqowcnvqsqzmp/sarg=nc/url=https://vavada-casino999-10.top/
Для доступа на ресурс не необходима скачивание приложений. Онлайн-казино Vavada запускается непосредственно в браузере, что упрощает процесс входа к личному кабинету и разделам казино. Если случаются ограничений игроки могут перейти на Рабочее зеркало Vavada, повторяет функции официального ресурса.
В экосистеме интерактивных казино и ставок на спорт приоритетное значение имеет не только качество сервиса, но и честность оператора. С лицензией, которая подтверждает честность, сайт <a href="http://activelk.com/product/2925n/">http://activelk.com/product/2925n/</a> считает себя главных представителей среди букмекерских платформ. Сервис создает условия для повышение качества сервиса, разрабатывая новые функции, чтобы предоставить пользователям наивысшее качество услуг.
Приветственный бонус: Начальный бонус для новых пользователей
Для новичков в казино на платформе 1win существует большой приветственный бонус, который существенно увеличивает стартовый капитал. Это программа является одним из наиболее привлекательных на рынке, так как позволяет новым участникам начать игру с бонусом, сократив риски. Регистрация за несколько минут и первый взнос зачисляют бонус на счет, что делает его доступ комфортным.
Live-ставки: Лайв-ставки на тысячи событий с реальными шансами на успех
В отрасли ставок на спорт фундаментальным аспектом является актуальность и возможность реагировать на изменения в лайве. 1win предлагает игрокам широкий выбор спортивных событий, доступных в формате ставок в режиме реального времени. Мы гарантируем доступ к международным международным и локальным соревнованиям, будь то теннис.
Полная ссылка на страницу: http://activelk.com/product/2925n/
Лайв-ставки обеспечивают шанс реагировать в реальном времени, что делает процесс насыщенным эмоциями, но и аналитически богатым. Пользуясь аналитическими функциями платформы, игроки платформы могут анализировать события глубже, увеличивая свои шансы на успех. Каждое событие предоставляется с аналитическими данными, что способствует точным прогнозам принимать решения на основе актуальных данных.
Vavada казино — это одним из топовых и надежных казино среди ценителей азартных игр. За счет инновационного подхода, разнообразию развлечений и щедрым бонусам для гостей, <a href="http://feeds.gty.org/~/t/0/0/gtyblog/~vavada-casino-888-9.top">вавада рабочее зеркало </a> обрело статус идеальной площадки для хочет получить безупречный игровой процесс. В обзоре ниже мы разберем возможности официального сайта Vavada, порядок регистрации на сайте и входа в личный кабинет, а также поговорим про Vavada бонусы и о том, где взять работающие зеркальные ссылки Vavada.
Основные плюсы сайта Vavada casino
Сайт казино Vavada отличается по сравнению с аналогами благодаря простого и удобного интерфейса, быстрому отклику и кроссплатформенности. Независимо от девайс подключено, будь то ПК, планшет или мобильный телефон, платформа Vavada casino работает идеально, гарантируя удобный вход к игровым слотам и возможностям.
Сайт: http://feeds.gty.org/~/t/0/0/gtyblog/~vavada-casino888-12.top
Чтобы попасть на сайт не нужно скачивание приложений. Vavada casino запускается непосредственно в браузере, что значительно облегчает доступ к личному кабинету и игровым слотам. В случае технических проблем пользователи могут зайти через Vavada зеркало, повторяет весь контент основного сайта.
В сфере интерактивных казино и ставок на спорт приоритетное значение имеет не только надежность услуг, но и высокий уровень доверия. С международной лицензией, которая гарантирует надежность, сайт <a href="http://ivano-kazanka.ru/3079/">http://ivano-kazanka.ru/3079/</a> установил себя как топовых платформ в области азартных игр. Компания стремится к максимального комфорта, постоянно улучшая свои продукты и сервисы, чтобы обогатить пользователям непревзойденный опыт.
Приветственный бонус: Выгодный старт для новых игроков
Для новичков на платформе 1win доступен в предложении щедрый приветственный бонус, который существенно увеличивает стартовый капитал. Это бонусная программа является одним из популярных на рынке, так как позволяет новым игрокам моментально воспользоваться бонусом, стимулируя успешные ставки. Удобная регистрация и пополнение счета зачисляют бонус на счет, что делает его применение комфортным.
Live-ставки: Множество матчей онлайн с реальными шансами на успех
В индустрии ставочной деятельности ключевой особенностью является изменчивость и шанс учесть изменения в режиме реального времени. 1win предоставляет возможность огромное количество спортивных событий, доступных в формате игры вживую. Мы предлагаем ставки к ведущим событиям мирового масштаба, будь то киберспорт.
Полная ссылка на страницу: http://ivano-kazanka.ru/3079/
Онлайн-ставки гарантируют игрокам мгновенно реагировать на изменения, что делает процесс стратегически насыщенным, но и серьёзным испытанием навыков. Используя передовые аналитические инструменты платформы, клиенты могут делать ставки с уверенностью, повышая вероятность выигрыша. Каждое событие содержит анализ игры, что помогает игрокам ориентироваться в ставках.
Vavada казино — является одним из топовых и надежных платформ для ценителей азартных игр. С помощью современного подхода, широкому ассортименту игровых слотов и щедрым бонусам для игроков, <a href="http://b.nnov.org/common/redir.php?https://vavada-casino-888-9.top/">vavada бонусы </a> получило репутацию отличной платформы для жаждет найти надежный азартный отдых. В этом материале мы разберем функции платформы казино Вавада, этапы создания аккаунта и авторизации, а также расскажем про акционные предложения Vavada и о том, как получить актуальные рабочие зеркала Vavada.
Достоинства сайта Vavada casino
Vavada официальный сайт выделяется среди других платформ за счет интуитивно понятного пользовательского меню, мгновенной загрузке и адаптации под устройства. Без разницы, какое гаджет вы используете, будь то компьютер, планшетный ПК или мобильный телефон, платформа Vavada casino открывается без задержек, гарантируя комфортное использование к играм и опциям.
Сайт: http://b.nnov.org/common/redir.php?https://vavada-casino-888-9.top/
Чтобы попасть на платформу не требуется скачивание приложений. Онлайн-казино Vavada работает в веб-версии, что значительно облегчает процесс входа в аккаунт и разделам сайта. Если случаются ограничений пользователи могут воспользоваться Vavada зеркало, повторяет функционал основного портала.
В отрасли интерактивных казино и игр на ставки ключевое значение имеет не только качество обслуживания, но и честность оператора. С лицензией, которая обеспечивает соблюдение стандартов, сайт <a href="https://akrvo.ru/index.php?option=com_content&view=article&id=32971">https://akrvo.ru/index.php?option=com_content&view=article&id=32971</a> уверенно занимает главных представителей в области азартных игр. Компания работает на максимального комфорта, разрабатывая новые функции, чтобы обеспечить пользователям первоклассный игровой опыт.
Приветственный бонус: Начальный бонус для новых пользователей
Для новых пользователей на платформе 1win предоставляется щедрый приветственный бонус, который увеличивает ваши возможности. Это возможность является одним из ведущих на рынке, так как открывает возможность новым игрокам сразу получить доступ к дополнительным средствам, сократив риски. Легкий старт и перевод средств автоматически активируют бонус, что делает его получение комфортным.
Live-ставки: Спортивные события в режиме реального времени с широким выбором
В экосистеме ставочной деятельности главной отличительной чертой является темп и способность мгновенно реагировать в режиме реального времени. 1win предоставляет возможность огромное количество спортивных событий, доступных в формате лайв-ставок. Мы предлагаем ставки к топовым событиям мирового масштаба, будь то теннис.
Полная ссылка на страницу: https://akrvo.ru/index.php?option=com_content&view=article&id=32971
Игра на события вживую открывают возможность реагировать в реальном времени, что делает процесс стратегически насыщенным, но и тактически интересным. Благодаря аналитическим данным платформы, пользователи могут точнее прогнозировать исходы, увеличивая свои шансы на успех. Каждое событие освещается статистикой, что даёт более полную картину выбирать тактику исходя из фактов.
Онлайн-казино Vavada — является одно из лучших и доверенных платформ для ценителей гэмблинга. За счет современного подхода, разнообразию развлечений и выгодным предложениям для гостей, <a href="http://liveforums.ru/click/casino-vavada-slots-4.top">vavada casino официальный сайт </a> обрело статус превосходной платформы для всех, кто ищет безупречный игровой процесс. В данной статье мы опишем функции официального сайта Vavada, этапы создания аккаунта и авторизации, а также расскажем о бонусах Vavada и о том, как получить работающие рабочие зеркала Vavada.
Преимущества платформы казино Вавада
Официальный ресурс Vavada отличается среди других платформ с помощью простого и удобного пользовательского меню, высокой скорости работы и адаптивному дизайну. Без разницы, какое девайс находится у вас, будь то ПК, планшет или мобильный телефон, Vavada официальный сайт работает идеально, гарантируя удобный вход к игровым слотам и опциям.
Сайт: http://liveforums.ru/click/vavada-casino999-10.top
Чтобы попасть на платформу не нужно установка дополнительных программ. Онлайн-казино Vavada функционирует в веб-версии, что делает удобным доступ в аккаунт и разделам сайта. При возникновении технических проблем игроки могут зайти через Vavada зеркало, имеет идентичный функции официального ресурса.
В мире онлайн-казино и спортивных ставок крайне важно не только качество игровой платформы, но и честность оператора. С гарантированной лицензией, которая обеспечивает соблюдение стандартов, сайт <a href="https://zpu-journal.ru/e-zpu/2015/4/Lukov_Seliverstova_Biographical-Approach/">https://zpu-journal.ru/e-zpu/2015/4/Lukov_Seliverstova_Biographical-Approach/</a> уверенно занимает главных представителей среди платформ для азартных игр. Организация работает на создание благоприятных условий, совершенствуя предложения, чтобы обеспечить пользователям наивысшее качество услуг.
Приветственный бонус: Выгодный старт для новичков казино
Для новичков на платформе 1win предоставляется впечатляющий приветственный бонус, который позволяет начать с уверенностью. Это акция является одним из заметных на в индустрии ставок, так как открывает возможность новым клиентам моментально воспользоваться бонусом, значительно улучшив стартовые позиции. Быстрая регистрация и пополнение счета моментально активируют предложение, что делает его доступ комфортным.
Live-ставки: Мгновенные возможности для ставок с широким выбором
В пространстве онлайн-ставок одним из ключевых элементов является стратегическая глубина и способность мгновенно реагировать в онлайн. 1win предоставляет возможность широкий выбор спортивных событий, доступных в формате ставок в режиме реального времени. Мы гарантируем доступ к топовым спортивным событиям, будь то футбол.
Полная ссылка на страницу: https://zpu-journal.ru/e-zpu/2015/4/Lukov_Seliverstova_Biographical-Approach/
Букмекерские ставки в лайве предоставляют возможность моментально адаптироваться, что делает процесс более захватывающим, но и интеллектуально интересным. Используя передовые аналитические инструменты платформы, игроки платформы могут принимать более обоснованные решения, увеличивая свои шансы на успех. Каждое событие представлено с комментариями, что даёт более полную картину принимать решения на основе актуальных данных.
Игровой клуб Вавада — является одно из самых популярных и проверенных временем платформ для поклонников гэмблинга. Благодаря инновационного подхода, широкому ассортименту игр и привлекательным условиям для пользователей, <a href="http://liveforums.ru/click/vavada-casino999-10.top">vavada </a> обрело репутацию отличной площадки для всех, кто ищет надежный азартный отдых. В обзоре ниже мы подробно рассмотрим возможности официального сайта Vavada, процесс регистрации на сайте и входа в личный кабинет, а также объясним о бонусах Vavada и о том, где взять свежие Vavada зеркало.
Преимущества сайта Vavada casino
Vavada официальный сайт отличается на фоне конкурентов благодаря легкого в использовании пользовательского меню, быстрому отклику и адаптивному дизайну. Независимо от гаджет находится у вас, будь то компьютер, планшетный ПК или смартфон, платформа Vavada casino загружается моментально, обеспечивая удобный вход к игровым слотам и функциям.
Сайт: http://liveforums.ru/click/vavada-casino888-12.top
Для доступа на ресурс не требуется установка дополнительных программ. Онлайн-казино Vavada функционирует прямо через браузер, что делает удобным процесс входа в аккаунт и игровым слотам. Если случаются блокировок игроки могут воспользоваться Vavada зеркало, повторяет функции официального ресурса.
В индустрии интерактивных казино и ставок в спорте важно не только качество игровой платформы, но и честность оператора. С международной лицензией, которая гарантирует безопасность, сайт <a href="https://www.book-hall.ru/news/2016-06-07-1430-5292?page=1">https://www.book-hall.ru/news/2016-06-07-1430-5292?page=1</a> находится среди топовых платформ среди платформ для азартных игр. Провайдер создает условия для повышение качества сервиса, улучшая функционал, чтобы дать пользователям максимальный комфорт.
Приветственный бонус: Начальный бонус для новичков казино
Для новичков в казино на платформе 1win предусмотрен солидный приветственный бонус, который увеличивает ваши возможности. Это бонусная программа является одним из выгодных на в отрасли, так как помогает новым игрокам сразу получить доступ к дополнительным средствам, стимулируя успешные ставки. Упрощенная процедура регистрации и перевод средств обеспечивают получение бонуса, что делает его доступ комфортным.
Live-ставки: Мгновенные возможности для ставок с реальными шансами на успех
В индустрии ставок на спорт главной отличительной чертой является темп и способность адаптироваться в онлайн. 1win даёт доступ широкий выбор спортивных событий, доступных в формате лайв-ставок. Мы предлагаем ставки к ведущим чемпионатам и играм, будь то волейбол.
Полная ссылка на страницу: https://www.book-hall.ru/news/2016-06-07-1430-5292?page=1
Игра в лайве дают шанс реагировать в реальном времени, что делает процесс насыщенным эмоциями, но и полезным для стратегии. С применением аналитических ресурсов платформы, игроки платформы могут увеличивать вероятность выигрыша, приумножая выигрышные шансы. Каждое событие предоставляется с аналитическими данными, что обогащает принятие решений принимать решения на основе актуальных данных.
Vavada casino — это одно из наиболее востребованных и проверенных временем казино для любителей гэмблинга. Благодаря инновационного подхода, большому выбору игровых слотов и выгодным предложениям для пользователей, <a href="https://nn.purumburum.ru:443/redirect.php?url=https%3a%2f%2fvavada-casino-play-10.top &city=RU-NIZ&city_old=nn">vavada casino официальный сайт </a> получило статус отличной площадки для всех, кто хочет получить безупречный игровой процесс. В этом материале мы подробно рассмотрим функции платформы казино Вавада, процесс регистрации на сайте и авторизации, а также объясним о бонусах Vavada и о том, где найти актуальные Vavada зеркало.
Основные плюсы платформы казино Вавада
Сайт казино Vavada отличается на фоне конкурентов благодаря интуитивно понятного пользовательского меню, мгновенной загрузке и адаптивному дизайну. Без разницы, какое гаджет находится у вас, будь то компьютер, планшетный ПК или мобильный телефон, платформа Vavada casino открывается без задержек, обеспечивая комфортное использование к игровым слотам и опциям.
Сайт: https://nn.purumburum.ru:443/redirect.php?url=https%3a%2f%2fvavada-casino-play-10.top &city=RU-NIZ&city_old=nn
Чтобы попасть на ресурс не нужно скачивание приложений. Vavada casino функционирует в веб-версии, что упрощает доступ к личному кабинету и разделам сайта. При возникновении ограничений игроки могут перейти на Vavada зеркало, которое полностью дублирует функционал основного портала.
В индустрии интернет-казино и ставок на спорт приоритетное значение имеет не только качество обслуживания, но и честность оператора. С разрешением на деятельность, которая подтверждает легальность, сайт <a href="http://www.ci-kras.ru/izobrazitelnye-iskusstva/eksperty/">http://www.ci-kras.ru/izobrazitelnye-iskusstva/eksperty/</a> считает себя главных представителей в сфере интерактивных казино. Оператор создает условия для создание благоприятных условий, обновляя платформу, чтобы предоставить пользователям захватывающий игровой процесс.
Приветственный бонус: Щедрый бонус для клиентов
Для новых игроков на платформе 1win предусмотрен впечатляющий приветственный бонус, который существенно увеличивает стартовый капитал. Это бонусная программа является одним из лучших на среди конкурентов, так как дает возможность новым игрокам заполучить выгодные условия, значительно улучшив стартовые позиции. Легкий старт и внесение депозита мгновенно активируют бонус, что делает его использование максимально удобным и быстрым.
Live-ставки: Лайв-ставки на тысячи событий с широким выбором
В сфере спортивных ставок одним из ключевых элементов является динамика и необходимость предугадывать события в онлайн. 1win приглашает множество спортивных событий, доступных в формате лайв-ставок. Мы предоставляем доступ к международным соревнованиям и матчам, будь то баскетбол.
Полная ссылка на страницу: http://www.ci-kras.ru/izobrazitelnye-iskusstva/eksperty/
Игра на события вживую дают шанс реагировать в реальном времени, что делает процесс более динамичным, но и интеллектуально интересным. С помощью аналитики платформы, любители ставок могут делать ставки с уверенностью, увеличивая потенциальные результаты. Каждое событие представлено с комментариями, что даёт более полную картину гарантировать обоснованные ставки.
Онлайн-казино Vavada — это одним из самых популярных и надежных платформ для любителей гэмблинга. С помощью современного подхода, разнообразию игр и выгодным предложениям для пользователей, <a href="https://www.jboss.org/downloading/?projectid=jbossas&url=https://vavada-casino-play-10.top/">vavada регистрация </a> обрело репутацию идеальной платформы для ищет качественный игровой опыт. В данной статье мы опишем возможности платформы казино Вавада, этапы регистрации и входа в личный кабинет, а также расскажем про Vavada бонусы и о том, где найти актуальные зеркальные ссылки Vavada.
Достоинства официального сайта Vavada
Сайт казино Vavada привлекает внимание на фоне конкурентов благодаря легкого в использовании интерфейса, высокой скорости работы и адаптивному дизайну. Независимо от устройство вы используете, будь то ноутбук, планшет или смартфон, платформа Vavada casino работает идеально, гарантируя плавный доступ к игровым слотам и опциям.
Сайт: https://www.jboss.org/downloading/?projectid=jbossas&url=https://vavada-casino999-10.top/
Для доступа на сайт не нужно скачивание приложений. Vavada online casino запускается непосредственно в браузере, что делает удобным доступ в аккаунт и разделам сайта. В случае блокировок пользователи могут перейти на Рабочее зеркало Vavada, имеет идентичный функционал основного сайта.
В мире интернет-казино и ставок на спорт основное внимание уделяется не только качество предоставляемых услуг, но и доверие к оператору. С лицензионными гарантиями, которая гарантирует безопасность, сайт <a href="https://lexrus.ru/default.aspx?s=0&p=3198&0p2=140&0o2=2&0r2=DESC">https://lexrus.ru/default.aspx?s=0&p=3198&0p2=140&0o2=2&0r2=DESC</a> уверенно занимает ключевых участников среди платформ для азартных игр. Сервис ориентирована на развитие клиентского опыта, улучшая функционал, чтобы гарантировать пользователям максимальный комфорт.
Приветственный бонус: Премиум-старт для новых пользователей
Для новичков на платформе 1win доступен выгодный приветственный бонус, который стимулирует успешное начало. Это подарок является одним из лучших на среди конкурентов, так как предоставляет шанс новым игрокам начать игру с бонусом, увеличив свои шансы на успешные ставки. Регистрация за несколько минут и внесение депозита обеспечивают получение бонуса, что делает его применение приятным и лёгким.
Live-ставки: Тысячи событий в реальном времени с мгновенными возможностями
В пространстве спортивных прогнозов главной отличительной чертой является темп и умение быстро принимать решения в онлайн. 1win даёт шанс огромное количество спортивных событий, доступных в формате онлайн ставок. Мы даем возможность играть к глобальным чемпионатам и играм, будь то киберспорт.
Полная ссылка на страницу: https://lexrus.ru/default.aspx?s=0&p=3198&0p2=140&0o2=2&0r2=DESC
Ставки в реальном времени открывают возможность мгновенно реагировать на изменения, что делает процесс более динамичным, но и полезным для стратегии. С применением аналитических ресурсов платформы, любители ставок могут точнее прогнозировать исходы, увеличивая свои шансы на успех. Каждое событие обеспечено аналитическими обзорами, что обогащает принятие решений предупреждать проигрыши.
Vavada casino — это одно из наиболее востребованных и доверенных казино для ценителей гэмблинга. С помощью инновационного подхода, большому выбору развлечений и выгодным предложениям для пользователей, <a href="http://gosudar.com.ru/go.php?url=https://vavada-casino999-10.top/">vavada casino </a> завоевало статус идеальной платформы для всех, кто хочет получить безупречный игровой процесс. В этом материале мы опишем функции сайта Vavada casino, порядок создания аккаунта и входа, а также расскажем про акционные предложения Vavada и о том, где взять работающие Vavada зеркало.
Достоинства сайта Vavada casino
Сайт казино Vavada привлекает внимание на фоне конкурентов благодаря простого и удобного дизайна, высокой скорости работы и кроссплатформенности. Независимо от девайс подключено, будь то ноутбук, планшетный ПК или телефон, сайт Vavada открывается без задержек, обеспечивая комфортное использование к разделам и возможностям.
Сайт: http://gosudar.com.ru/go.php?url=https://vavada-casino999-10.top/
Чтобы попасть на ресурс не требуется скачивание приложений. Vavada casino работает непосредственно в браузере, что упрощает доступ в аккаунт и игровым слотам. Если случаются блокировок игроки могут перейти на Рабочее зеркало Vavada, повторяет функции основного сайта.
В индустрии интерактивных казино и ставочных рынков приоритетное значение имеет не только уровень сервиса, но и надежность оператора. С разрешением на деятельность, которая гарантирует надежность, сайт <a href="https://smallforbig.com/category/play/toybrands/page/10">https://smallforbig.com/category/play/toybrands/page/10</a> уверенно занимает ключевых участников среди платформ для азартных игр. Сервис ориентирована на повышение качества сервиса, улучшая функционал, чтобы обогатить пользователям непревзойденный опыт.
Приветственный бонус: Привлекательное предложение для новичков
Для новых игроков на платформе 1win существует щедрый приветственный бонус, который существенно увеличивает стартовый капитал. Это акция является одним из выгодных на на платформе, так как помогает новым пользователям получить преимущество, увеличив свои шансы на успешные ставки. Простая регистрация и депозит автоматически активируют бонус, что делает его доступ эффективным и быстрым.
Live-ставки: Мгновенные возможности для ставок с мгновенными возможностями
В сфере спортивных ставок важнейшей частью является динамика и способность адаптироваться в лайве. 1win приглашает множество спортивных событий, доступных в формате онлайн ставок. Мы предлагаем ставки к ключевым событиям мирового масштаба, будь то киберспорт.
Полная ссылка на страницу: https://smallforbig.com/category/play/toybrands/page/10
Ставки в реальном времени гарантируют игрокам мгновенно реагировать на изменения, что делает процесс более захватывающим, но и стратегически насыщенным. Благодаря аналитическим данным платформы, игроки могут точнее прогнозировать исходы, приумножая выигрышные шансы. Каждое событие сопровождается качественной аналитикой, что способствует точным прогнозам ориентироваться в ставках.
Vavada casino — это одним из самых популярных и доверенных платформ для поклонников азартных игр. С помощью актуального дизайна, широкому ассортименту игровых слотов и привлекательным условиям для пользователей, <a href="https://adocean-hu.hit.gemius.pl/_sslredir/hitredir/id=bVblbUNLCTKiT7enAqQT3dVrrmd1h48A9B9aUW5mU1b.U7/stparam=shkmiqmgeg/fastid=jaigammlgytixbnptugdafcqhdjo/url=vavada-casino999-10.top">vavada регистрация </a> завоевало репутацию отличной площадки для ищет качественный игровой опыт. В данной статье мы опишем функции официального сайта Vavada, процесс регистрации и входа в личный кабинет, а также объясним про акционные предложения Vavada и о том, как получить актуальные зеркальные ссылки Vavada.
Достоинства платформы казино Вавада
Vavada официальный сайт отличается по сравнению с аналогами за счет простого и удобного интерфейса, мгновенной загрузке и кроссплатформенности. Независимо от гаджет вы используете, будь то ноутбук, планшетный ПК или мобильный телефон, сайт Vavada загружается моментально, обеспечивая удобный вход к игровым слотам и опциям.
Сайт: https://adocean-hu.hit.gemius.pl/_sslredir/hitredir/id=bVblbUNLCTKiT7enAqQT3dVrrmd1h48A9B9aUW5mU1b.U7/stparam=shkmiqmgeg/fastid=jaigammlgytixbnptugdafcqhdjo/url=casino-vavada-slots-4.top
Чтобы попасть на платформу не нужно загрузка ПО. Онлайн-казино Vavada запускается в веб-версии, что делает удобным доступ в аккаунт и игровым слотам. При возникновении ограничений пользователи могут зайти через Vavada зеркало, которое полностью дублирует весь контент основного портала.
Игровой клуб Вавада — это одним из наиболее востребованных и надежных игровых клубов среди ценителей игровых автоматов. За счет инновационного подхода, разнообразию игровых слотов и привлекательным условиям для игроков, <a href="https://quanos.com/en/resources/repair-maintenance-servicing?externalUrl=https%3A%2F%2Fvavada-casino-play-10.top &library=114&type=1649858019">vavada online casino </a> обрело репутацию отличной площадки для всех, кто ищет безупречный игровой процесс. В обзоре ниже мы подробно рассмотрим возможности платформы казино Вавада, порядок создания аккаунта и входа в личный кабинет, а также объясним про Vavada бонусы и о том, где взять работающие Vavada зеркало.
Основные плюсы официального сайта Vavada
Сайт казино Vavada выделяется среди других платформ с помощью простого и удобного интерфейса, высокой скорости работы и адаптации под устройства. Без разницы, какое девайс находится у вас, будь то ПК, планшет или телефон, Vavada официальный сайт работает идеально, гарантируя плавный доступ к разделам и опциям.
Сайт: https://quanos.com/en/resources/repair-maintenance-servicing?externalUrl=https%3A%2F%2Fvavada-casino888-12.top &library=114&type=1649858019
Для доступа на ресурс не необходима загрузка ПО. Онлайн-казино Vavada функционирует непосредственно в браузере, что значительно облегчает процесс входа к личному кабинету и разделам казино. В случае ограничений пользователи могут перейти на Актуальные зеркала Vavada, повторяет весь контент основного портала.
В мире игровых платформ и ставочных рынков приоритетное значение имеет не только качество сервиса, но и гарантии безопасности. С лицензионными гарантиями, которая гарантирует надежность, сайт <a href="https://www.cross-kpk.ru/index.dll/documents/Projects/Dalchten/documents/projects/Zaranica/multimedia.dll/index.dll?part=22">https://www.cross-kpk.ru/index.dll/documents/Projects/Dalchten/documents/projects/Zaranica/multimedia.dll/index.dll?part=22</a> находится среди топовых платформ среди букмекерских платформ. Провайдер работает на развитие клиентского опыта, улучшая функционал, чтобы гарантировать пользователям максимальный комфорт.
Приветственный бонус: Начальный бонус для пользователей платформы
Для новых игроков на платформе 1win предусмотрен впечатляющий приветственный бонус, который позволяет начать с уверенностью. Это акция является одним из популярных на в отрасли, так как предоставляет шанс новым клиентам казино получить преимущество, стимулируя успешные ставки. Упрощенная процедура регистрации и первый взнос зачисляют бонус на счет, что делает его воспользование очень удобным.
Live-ставки: Спортивные события в режиме реального времени с моментальными ставками
В мире ставок на спорт ключевой особенностью является изменчивость и умение быстро принимать решения в на ходу. 1win предоставляет возможность множество спортивных событий, доступных в формате онлайн ставок. Мы располагаем матчами к международным международным и локальным соревнованиям, будь то баскетбол.
Полная ссылка на страницу: https://www.cross-kpk.ru/index.dll/documents/Projects/Dalchten/documents/projects/Zaranica/multimedia.dll/index.dll?part=22
Букмекерские ставки в лайве предоставляют возможность быстро подстраиваться, что делает процесс стратегически насыщенным, но и тактически интересным. С применением аналитических ресурсов платформы, игроки платформы могут принимать более обоснованные решения, улучшая тактику игры. Каждое событие содержит анализ игры, что помогает игрокам ориентироваться в ставках.
Игровой клуб Вавада — является одной из топовых и доверенных платформ среди любителей гэмблинга. За счет актуального дизайна, широкому ассортименту игр и щедрым бонусам для пользователей, <a href="https://gemadhu.hit.gemius.pl/_uachredir/hitredir/id=.W1FLyOnPRE8hyatrG5N19ULnBPNG5i.GLl6SoukFEb.77/stparam=wicmklenxg/fastid=jiwoniqjgjuaceinlzahegxxmkkw/nc=0/url=https%3A%2F%2Fvavada-casino-888-9.top">промокод вавада </a> получило статус отличной платформы для всех, кто хочет получить качественный игровой опыт. В этом материале мы подробно рассмотрим функции официального сайта Vavada, процесс создания аккаунта и входа в личный кабинет, а также расскажем про Vavada бонусы и о том, где найти свежие зеркальные ссылки Vavada.
Преимущества сайта Vavada casino
Официальный ресурс Vavada отличается среди других платформ с помощью легкого в использовании дизайна, быстрому отклику и адаптивному дизайну. Без разницы, какое девайс подключено, будь то ноутбук, планшетный ПК или мобильный телефон, платформа Vavada casino открывается без задержек, гарантируя плавный доступ к игровым слотам и функциям.
Сайт: https://gemadhu.hit.gemius.pl/_uachredir/hitredir/id=.W1FLyOnPRE8hyatrG5N19ULnBPNG5i.GLl6SoukFEb.77/stparam=wicmklenxg/fastid=jiwoniqjgjuaceinlzahegxxmkkw/nc=0/url=https%3A%2F%2Fvavada-casino-play-10.top
Чтобы попасть на ресурс не требуется установка дополнительных программ. Онлайн-казино Vavada работает в веб-версии, что упрощает процесс входа в аккаунт и игровым слотам. В случае технических проблем гости могут перейти на Рабочее зеркало Vavada, повторяет функции основного портала.
В экосистеме интерактивных казино и ставочной деятельности крайне важно не только надежность услуг, но и надежность оператора. С гарантированной лицензией, которая подтверждает честность, сайт <a href="https://naukaru.ru/en/nauka/article/12145/view">https://naukaru.ru/en/nauka/article/12145/view</a> уверенно занимает ключевых участников в сфере интерактивных казино. Компания уделяет внимание оптимальных условий, обновляя платформу, чтобы гарантировать пользователям безупречное взаимодействие.
Приветственный бонус: Бонус для новичков для клиентов
Для новых участников на платформе 1win доступен впечатляющий приветственный бонус, который увеличивает ваши возможности. Это акция является одним из ведущих на в индустрии ставок, так как открывает возможность новым клиентам получить преимущество, увеличив свои шансы на успешные ставки. Легкий старт и внесение суммы автоматически активируют бонус, что делает его воспользование максимально удобным и быстрым.
Live-ставки: Лайв-ставки на тысячи событий с реальными шансами на успех
В сфере спортивных прогнозов главной отличительной чертой является изменчивость и умение быстро принимать решения в режиме реального времени. 1win открывает путь большой спектр спортивных событий, доступных в формате ставок в лайве. Мы даем возможность играть к глобальным событиям мирового масштаба, будь то теннис.
Полная ссылка на страницу: https://naukaru.ru/en/nauka/article/12145/view
Лайв-ставки открывают возможность учитывать динамику событий, что делает процесс не только увлекательным, но и серьёзным испытанием навыков. Благодаря аналитическим данным платформы, игроки могут точнее прогнозировать исходы, оптимизируя стратегию. Каждое событие содержит анализ игры, что помогает игрокам ориентироваться в ставках.
Vavada casino — это одной из лучших и надежных казино для любителей азартных игр. За счет актуального дизайна, большому выбору игр и привлекательным условиям для пользователей, <a href="http://ir.shareaholic.com/e?a=1&u=https%3A%2F%2Fvavada-casino888-12.top &r=1">vavada промокод сегодня </a> получило репутацию превосходной платформы для жаждет найти надежный азартный отдых. В обзоре ниже мы разберем функции официального сайта Vavada, процесс создания аккаунта и входа, а также расскажем о бонусах Vavada и о том, где найти свежие зеркальные ссылки Vavada.
Преимущества официального сайта Vavada
Vavada официальный сайт выделяется по сравнению с аналогами благодаря простого и удобного дизайна, высокой скорости работы и адаптации под устройства. Без разницы, какое девайс вы используете, будь то ноутбук, планшет или смартфон, сайт Vavada открывается без задержек, гарантируя удобный вход к игровым слотам и опциям.
Сайт: http://ir.shareaholic.com/e?a=1&u=https%3A%2F%2Fvavada-casino999-10.top &r=1
Чтобы попасть на платформу не требуется загрузка ПО. Vavada casino работает прямо через браузер, что значительно облегчает процесс входа в аккаунт и разделам казино. Если случаются ограничений пользователи могут воспользоваться Рабочее зеркало Vavada, повторяет весь контент основного портала.
В индустрии виртуальных казино и ставок на спорт необходимо не только качество сервиса, но и высокий уровень доверия. С лицензионными гарантиями, которая гарантирует надежность, сайт <a href="https://cross-kpk.ru/news.dll?detail=469">https://cross-kpk.ru/news.dll?detail=469</a> считает себя фаворитов среди платформ для азартных игр. Оператор работает на максимального комфорта, обновляя контент, чтобы предоставить пользователям первоклассный игровой опыт.
Приветственный бонус: Щедрый бонус для новичков казино
Для новичков на платформе 1win предоставляется впечатляющий приветственный бонус, который увеличивает ваши возможности. Это возможность является одним из лучших на в индустрии ставок, так как помогает новым клиентам получить преимущество, значительно улучшив стартовые позиции. Упрощенная процедура регистрации и внесение суммы моментально активируют предложение, что делает его активацию простым и доступным.
Live-ставки: Мгновенные возможности для ставок с быстрой реакцией
В мире ставок на спорт ключевой особенностью является актуальность и способность мгновенно реагировать в режиме реального времени. 1win предлагает игрокам широкий выбор спортивных событий, доступных в формате ставок в лайве. Мы организуем лайв-ставки к топовым спортивным событиям, будь то баскетбол.
Полная ссылка на страницу: https://cross-kpk.ru/news.dll?detail=469
Букмекерские ставки в лайве обеспечивают шанс реагировать в реальном времени, что делает процесс насыщенным эмоциями, но и интеллектуально интересным. Благодаря аналитическим данным платформы, пользователи могут повышать свои шансы на успех, приумножая выигрышные шансы. Каждое событие содержит анализ игры, что способствует точным прогнозам предсказывать результат с уверенностью.
Игровой клуб Вавада — это одной из топовых и проверенных временем платформ среди любителей азартных игр. За счет современного подхода, большому выбору игровых слотов и щедрым бонусам для игроков, <a href="https://kaluga.doctora-mne.ru/redir.php?url=https://vavada-casino-play-10.top/">vavada промокод </a> завоевало репутацию отличной площадки для всех, кто жаждет найти надежный азартный отдых. В обзоре ниже мы разберем функции сайта Vavada casino, этапы регистрации на сайте и входа, а также объясним о бонусах Vavada и о том, где найти актуальные Vavada зеркало.
Достоинства платформы казино Вавада
Официальный ресурс Vavada выделяется на фоне конкурентов с помощью интуитивно понятного интерфейса, быстрому отклику и адаптации под устройства. Независимо от гаджет находится у вас, будь то компьютер, планшет или телефон, сайт Vavada загружается моментально, обеспечивая удобный вход к разделам и возможностям.
Сайт: https://kaluga.doctora-mne.ru/redir.php?url=https://casino-vavada-slots-4.top/
Для доступа на платформу не нужно загрузка ПО. Vavada online casino запускается в веб-версии, что делает удобным доступ в аккаунт и игровым слотам. Если случаются ограничений игроки могут зайти через Vavada зеркало, которое полностью дублирует весь контент основного сайта.
В пространстве виртуальных казино и игр на ставки важно не только качество обслуживания, но и надежность оператора. С официальной лицензией, которая подтверждает легальность, сайт <a href="https://www.ippo.ru/archive/tab/last/keyword/12851">https://www.ippo.ru/archive/tab/last/keyword/12851</a> занимает лидеров в области азартных игр. Провайдер стремится к максимального комфорта, улучшая функционал, чтобы дать пользователям максимальный комфорт.
Приветственный бонус: Выгодный старт для новичков казино
Для новых участников на платформе 1win предусмотрен большой приветственный бонус, который существенно увеличивает стартовый капитал. Это возможность является одним из выгодных на в отрасли, так как помогает новым клиентам заполучить выгодные условия, увеличив свои шансы на успешные ставки. Удобная регистрация и внесение суммы мгновенно активируют бонус, что делает его доступ комфортным.
Live-ставки: Мгновенные возможности для ставок с мгновенными возможностями
В экосистеме ставок на спорт фундаментальным аспектом является изменчивость и способность мгновенно реагировать в режиме реального времени. 1win приглашает десятки тысяч спортивных событий, доступных в формате лайв-ставок. Мы организуем лайв-ставки к международным международным и локальным соревнованиям, будь то футбол.
Полная ссылка на страницу: https://www.ippo.ru/archive/tab/last/keyword/12851
Онлайн-ставки обеспечивают шанс быстро подстраиваться, что делает процесс более динамичным, но и стратегически насыщенным. Используя передовые аналитические инструменты платформы, пользователи могут точнее прогнозировать исходы, приумножая выигрышные шансы. Каждое событие представлено с комментариями, что делает процесс ещё более обоснованным предупреждать проигрыши.
Vavada казино — это одним из самых популярных и проверенных временем игровых клубов среди любителей гэмблинга. Благодаря актуального дизайна, широкому ассортименту игровых слотов и привлекательным условиям для пользователей, <a href="http://talsi.pilseta24.lv/linkredirect/?link=https%3A%2F%2Fvavada-casino888-12.top &referer=talsi.pilseta24.lv%2Fzina%3Fslug%3Deccal-briketes-un-apkures-granulas-ar-lielisku-kvalitati-pievilcigu-cenu-videi-draudzigs-un-izd-8c175fc171&additional_params=%7B%22company_orig_id%22%3A%22291020%22%2C%22object_country_id%22%3A%22lv%22%2C%22referer_layout_type%22%3A%22SR%22%2C%22bannerinfo%22%3A%22%7B%5C%22key%5C%22%3A%5C%22%5C%5C%5C%22Talsu+riepas%5C%5C%5C%22%2C+autoserviss%7C2021-05-21%7C2022-05-20%7Ctalsi+p24+lielais+baneris%7Chttps%3A%5C%5C%5C%2F%5C%5C%5C%2Ftalsuriepas.lv%5C%5C%5C%2F%7C%7Cupload%5C%5C%5C%2F291020%5C%5C%5C%2Fbaners%5C%5C%5C%2F15_talsurie_1050x80_k.gif%7Clva%7C291020%7C980%7C90%7C%7C0%7C0%7C%7C0%7C0%7C%5C%22%2C%5C%22doc_count%5C%22%3A1%2C%5C%22key0%5C%22%3A%5C%22%5C%5C%5C%22Talsu+riepas%5C%5C%5C%22%2C+autoserviss%5C%22%2C%5C%22key1%5C%22%3A%5C%222021-05-21%5C%22%2C%5C%22key2%5C%22%3A%5C%222022-05-20%5C%22%2C%5C%22key3%5C%22%3A%5C%22talsi+p24+lielais+baneris%5C%22%2C%5C%22key4%5C%22%3A%5C%22https%3A%5C%5C%5C%2F%5C%5C%5C%2Ftalsuriepas.lv%5C%5C%5C%2F%5C%22%2C%5C%22key5%5C%22%3A%5C%22%5C%22%2C%5C%22key6%5C%22%3A%5C%22upload%5C%5C%5C%2F291020%5C%5C%5C%2Fbaners%5C%5C%5C%2F15_talsurie_1050x80_k.gif%5C%22%2C%5C%22key7%5C%22%3A%5C%22lva%5C%22%2C%5C%22key8%5C%22%3A%5C%22291020%5C%22%2C%5C%22key9%5C%22%3A%5C%22980%5C%22%2C%5C%22key10%5C%22%3A%5C%2290%5C%22%2C%5C%22key11%5C%22%3A%5C%22%5C%22%2C%5C%22key12%5C%22%3A%5C%220%5C%22%2C%5C%22key13%5C%22%3A%5C%220%5C%22%2C%5C%22key14%5C%22%3A%5C%22%5C%22%2C%5C%22key15%5C%22%3A%5C%220%5C%22%2C%5C%22key16%5C%22%3A%5C%220%5C%22%2C%5C%22key17%5C%22%3A%5C%22%5C%22%7D%22%7D&control=f1427842db246885719585c9a034ef46">vavada </a> получило репутацию отличной площадки для ищет безупречный игровой процесс. В данной статье мы опишем функции официального сайта Vavada, этапы создания аккаунта и авторизации, а также расскажем про акционные предложения Vavada и о том, как получить работающие Vavada зеркало.
Основные плюсы официального сайта Vavada
Vavada официальный сайт выделяется на фоне конкурентов благодаря простого и удобного дизайна, мгновенной загрузке и адаптации под устройства. Без разницы, какое гаджет находится у вас, будь то ноутбук, планшет или смартфон, платформа Vavada casino работает идеально, обеспечивая удобный вход к игровым слотам и опциям.
Сайт: http://talsi.pilseta24.lv/linkredirect/?link=https%3A%2F%2Fcasino-vavada-slots-4.top &referer=talsi.pilseta24.lv%2Fzina%3Fslug%3Deccal-briketes-un-apkures-granulas-ar-lielisku-kvalitati-pievilcigu-cenu-videi-draudzigs-un-izd-8c175fc171&additional_params=%7B%22company_orig_id%22%3A%22291020%22%2C%22object_country_id%22%3A%22lv%22%2C%22referer_layout_type%22%3A%22SR%22%2C%22bannerinfo%22%3A%22%7B%5C%22key%5C%22%3A%5C%22%5C%5C%5C%22Talsu+riepas%5C%5C%5C%22%2C+autoserviss%7C2021-05-21%7C2022-05-20%7Ctalsi+p24+lielais+baneris%7Chttps%3A%5C%5C%5C%2F%5C%5C%5C%2Ftalsuriepas.lv%5C%5C%5C%2F%7C%7Cupload%5C%5C%5C%2F291020%5C%5C%5C%2Fbaners%5C%5C%5C%2F15_talsurie_1050x80_k.gif%7Clva%7C291020%7C980%7C90%7C%7C0%7C0%7C%7C0%7C0%7C%5C%22%2C%5C%22doc_count%5C%22%3A1%2C%5C%22key0%5C%22%3A%5C%22%5C%5C%5C%22Talsu+riepas%5C%5C%5C%22%2C+autoserviss%5C%22%2C%5C%22key1%5C%22%3A%5C%222021-05-21%5C%22%2C%5C%22key2%5C%22%3A%5C%222022-05-20%5C%22%2C%5C%22key3%5C%22%3A%5C%22talsi+p24+lielais+baneris%5C%22%2C%5C%22key4%5C%22%3A%5C%22https%3A%5C%5C%5C%2F%5C%5C%5C%2Ftalsuriepas.lv%5C%5C%5C%2F%5C%22%2C%5C%22key5%5C%22%3A%5C%22%5C%22%2C%5C%22key6%5C%22%3A%5C%22upload%5C%5C%5C%2F291020%5C%5C%5C%2Fbaners%5C%5C%5C%2F15_talsurie_1050x80_k.gif%5C%22%2C%5C%22key7%5C%22%3A%5C%22lva%5C%22%2C%5C%22key8%5C%22%3A%5C%22291020%5C%22%2C%5C%22key9%5C%22%3A%5C%22980%5C%22%2C%5C%22key10%5C%22%3A%5C%2290%5C%22%2C%5C%22key11%5C%22%3A%5C%22%5C%22%2C%5C%22key12%5C%22%3A%5C%220%5C%22%2C%5C%22key13%5C%22%3A%5C%220%5C%22%2C%5C%22key14%5C%22%3A%5C%22%5C%22%2C%5C%22key15%5C%22%3A%5C%220%5C%22%2C%5C%22key16%5C%22%3A%5C%220%5C%22%2C%5C%22key17%5C%22%3A%5C%22%5C%22%7D%22%7D&control=f1427842db246885719585c9a034ef46
Для доступа на платформу не нужно скачивание приложений. Vavada casino запускается прямо через браузер, что делает удобным доступ к личному кабинету и разделам сайта. Если случаются технических проблем пользователи могут воспользоваться Актуальные зеркала Vavada, имеет идентичный функционал основного сайта.
В отрасли игровых платформ и спортивных ставок ключевое значение имеет не только качество сервиса, но и высокий уровень доверия. С лицензией, которая подтверждает легальность, сайт <a href="https://book-hall.ru/public/3402/5541?destination=node%2F5541">https://book-hall.ru/public/3402/5541?destination=node%2F5541</a> считает себя лидеров среди платформ для азартных игр. Сервис стремится к максимального комфорта, улучшая функционал, чтобы дать пользователям захватывающий игровой процесс.
Приветственный бонус: Выгодный старт для новых пользователей
Для новых клиентов на платформе 1win существует солидный приветственный бонус, который значительно увеличивает начальный капитал. Это подарок является одним из популярных на среди конкурентов, так как дает возможность новым клиентам получить дополнительный капитал, стимулируя успешные ставки. Регистрация за несколько минут и первый взнос моментально активируют предложение, что делает его воспользование очень удобным.
Live-ставки: Спортивные события в режиме реального времени с быстрой реакцией
В индустрии ставок на спорт ключевой особенностью является стратегическая глубина и необходимость предугадывать события в онлайн. 1win предоставляет возможность огромное количество спортивных событий, доступных в формате игры вживую. Мы предоставляем доступ к топовым спортивным событиям, будь то теннис.
Полная ссылка на страницу: https://book-hall.ru/public/3402/5541?destination=node%2F5541
Букмекерские ставки в лайве открывают возможность реагировать в реальном времени, что делает процесс более захватывающим, но и аналитически богатым. Благодаря аналитическим данным платформы, пользователи могут анализировать события глубже, увеличивая свои шансы на успех. Каждое событие содержит анализ игры, что помогает игрокам предупреждать проигрыши.
Игровой клуб Вавада — является одной из самых популярных и надежных платформ для любителей азартных игр. Благодаря актуального дизайна, большому выбору развлечений и щедрым бонусам для игроков, <a href="https://azrfmqghiq.cloudimg.io/vavada-casino-play-10.top">vavada зеркало </a> завоевало статус идеальной платформы для всех, кто ищет качественный игровой опыт. В обзоре ниже мы разберем функции официального сайта Vavada, порядок регистрации и входа, а также объясним про акционные предложения Vavada и о том, где взять свежие зеркальные ссылки Vavada.
Основные плюсы платформы казино Вавада
Vavada официальный сайт выделяется по сравнению с аналогами благодаря легкого в использовании пользовательского меню, мгновенной загрузке и кроссплатформенности. Независимо от девайс подключено, будь то ноутбук, планшетный ПК или телефон, Vavada официальный сайт открывается без задержек, гарантируя плавный доступ к игровым слотам и возможностям.
Сайт: https://azrfmqghiq.cloudimg.io/casino-vavada-slots-4.top
Для доступа на платформу не требуется загрузка ПО. Vavada casino работает непосредственно в браузере, что делает удобным процесс входа к личному кабинету и разделам казино. При возникновении технических проблем пользователи могут воспользоваться Рабочее зеркало Vavada, которое полностью дублирует весь контент основного сайта.
В мире интерактивных казино и ставочной деятельности основное внимание уделяется не только уровень сервиса, но и репутация компании. С разрешением на деятельность, которая гарантирует надежность, сайт <a href="http://activelk.com/2024/08/20/cevrimici-para-yatirmadan-kumarhane-tesviki-oyeblikket-norskespill-norsk-nettcasino-med-700-casinospill/">http://activelk.com/2024/08/20/cevrimici-para-yatirmadan-kumarhane-tesviki-oyeblikket-norskespill-norsk-nettcasino-med-700-casinospill/</a> выступает одним из фаворитов в сфере интерактивных казино. Платформа работает на максимального комфорта, совершенствуя предложения, чтобы предоставить пользователям непревзойденный опыт.
Приветственный бонус: Бонус для новичков для новичков казино
Для новичков в казино на платформе 1win доступен большой приветственный бонус, который стимулирует успешное начало. Это программа является одним из выгодных на на платформе, так как открывает возможность новым клиентам заполучить выгодные условия, получив дополнительные ресурсы для ставок. Удобная регистрация и первый взнос дают возможность воспользоваться бонусом, что делает его воспользование максимально удобным и быстрым.
Live-ставки: Лайв-ставки на тысячи событий с быстрой реакцией
В индустрии онлайн-ставок ключевой особенностью является быстрота реакции и возможность реагировать на изменения в на ходу. 1win предлагает игрокам тысячи спортивных событий, доступных в формате ставок на события в реальном времени. Мы организуем лайв-ставки к международным спортивным событиям, будь то баскетбол.
Полная ссылка на страницу: http://activelk.com/2024/08/20/cevrimici-para-yatirmadan-kumarhane-tesviki-oyeblikket-norskespill-norsk-nettcasino-med-700-casinospill/
Игра в лайве предоставляют возможность мгновенно реагировать на изменения, что делает процесс более захватывающим, но и интеллектуально интересным. Благодаря аналитическим данным платформы, пользователи могут повышать свои шансы на успех, увеличивая свои шансы на успех. Каждое событие представлено с комментариями, что способствует точным прогнозам предупреждать проигрыши.
Vavada казино — это одной из лучших и надежных казино для ценителей гэмблинга. Благодаря современного подхода, разнообразию игровых слотов и привлекательным условиям для игроков, <a href="http://gamerinfo.net/redirect.php?s=https%3A%2F%2Fvavada-casino-888-9.top">vavada casino </a> обрело репутацию отличной платформы для всех, кто ищет безупречный игровой процесс. В этом материале мы разберем возможности сайта Vavada casino, процесс регистрации на сайте и авторизации, а также расскажем о бонусах Vavada и о том, где взять актуальные зеркальные ссылки Vavada.
Преимущества платформы казино Вавада
Vavada официальный сайт отличается на фоне конкурентов благодаря простого и удобного дизайна, мгновенной загрузке и адаптации под устройства. Независимо от девайс подключено, будь то ПК, планшет или мобильный телефон, платформа Vavada casino загружается моментально, обеспечивая комфортное использование к разделам и функциям.
Сайт: http://gamerinfo.net/redirect.php?s=https%3A%2F%2Fvavada-casino999-10.top
Для доступа на ресурс не требуется скачивание приложений. Vavada online casino работает непосредственно в браузере, что упрощает доступ в аккаунт и игровым слотам. В случае блокировок игроки могут перейти на Vavada зеркало, имеет идентичный функции основного портала.
В пространстве интернет-казино и ставок в спорте крайне важно не только надежность услуг, но и надежность оператора. С лицензией, которая гарантирует безопасность, сайт <a href="https://ilanskdkzd.ru/news/uvazhaemye-zhiteli-ilanskogo-rajona/">https://ilanskdkzd.ru/news/uvazhaemye-zhiteli-ilanskogo-rajona/</a> считает себя лидеров в мире онлайн-гемблинга. Платформа стремится к развитие клиентского опыта, обновляя платформу, чтобы предоставить пользователям максимальный комфорт.
Приветственный бонус: Привлекательное предложение для новых пользователей
Для новичков на платформе 1win предусмотрен большой приветственный бонус, который увеличивает ваши возможности. Это возможность является одним из заметных на среди конкурентов, так как позволяет игрокам новым участникам начать игру с бонусом, стимулируя успешные ставки. Удобная регистрация и перевод средств обеспечивают получение бонуса, что делает его применение эффективным и быстрым.
Live-ставки: Мгновенные возможности для ставок с реальными шансами на успех
В сфере букмекерства важнейшей частью является стратегическая глубина и необходимость предугадывать события в реальном времени. 1win открывает путь огромное количество спортивных событий, доступных в формате ставок в режиме реального времени. Мы располагаем матчами к ведущим локальным и глобальным турнирам, будь то хоккей.
Полная ссылка на страницу: https://ilanskdkzd.ru/news/uvazhaemye-zhiteli-ilanskogo-rajona/
Лайв-ставки открывают возможность мгновенно реагировать на изменения, что делает процесс ещё интереснее, но и аналитически богатым. Пользуясь аналитическими функциями платформы, игроки могут точнее прогнозировать исходы, повышая вероятность выигрыша. Каждое событие обеспечено аналитическими обзорами, что позволяет лучше анализировать принимать решения на основе актуальных данных.
Vavada казино — является одной из лучших и доверенных платформ для поклонников гэмблинга. Благодаря актуального дизайна, большому выбору развлечений и привлекательным условиям для гостей, <a href="http://analogx.com/cgi-bin/cgirdir.exe?https://vavada-casino-888-9.top/">официальный сайт vavada </a> завоевало репутацию превосходной площадки для жаждет найти надежный азартный отдых. В обзоре ниже мы подробно рассмотрим возможности платформы казино Вавада, этапы регистрации на сайте и авторизации, а также расскажем о бонусах Vavada и о том, как получить работающие Vavada зеркало.
Достоинства официального сайта Vavada
Официальный ресурс Vavada привлекает внимание по сравнению с аналогами с помощью интуитивно понятного дизайна, высокой скорости работы и адаптации под устройства. Без разницы, какое девайс вы используете, будь то компьютер, планшетный ПК или мобильный телефон, Vavada официальный сайт загружается моментально, обеспечивая удобный вход к разделам и опциям.
Сайт: http://analogx.com/cgi-bin/cgirdir.exe?https://vavada-casino888-12.top/
Для доступа на платформу не необходима скачивание приложений. Онлайн-казино Vavada функционирует в веб-версии, что упрощает доступ в аккаунт и игровым слотам. Если случаются блокировок игроки могут воспользоваться Рабочее зеркало Vavada, имеет идентичный функции основного сайта.
В сфере онлайн-казино и спортивных ставок ключевое значение имеет не только качество сервиса, но и репутация компании. С лицензией, которая подтверждает честность, сайт <a href="https://jigurug.com/tag/coaching-for-online-sbi/">https://jigurug.com/tag/coaching-for-online-sbi/</a> считает себя ключевых участников среди букмекерских платформ. Компания стремится к максимального комфорта, постоянно улучшая свои продукты и сервисы, чтобы обогатить пользователям первоклассный игровой опыт.
Приветственный бонус: Начальный бонус для новичков казино
Для новичков в казино на платформе 1win доступен солидный приветственный бонус, который значительно увеличивает начальный капитал. Это предложение является одним из ведущих на в мире онлайн-гемблинга, так как помогает новым клиентам казино получить преимущество, стимулируя успешные ставки. Удобная регистрация и внесение суммы автоматически активируют бонус, что делает его воспользование эффективным и быстрым.
Live-ставки: Спортивные события в режиме реального времени с реальными шансами на успех
В сфере букмекерства одним из ключевых элементов является актуальность и необходимость предугадывать события в на ходу. 1win приглашает огромное количество спортивных событий, доступных в формате онлайн ставок. Мы располагаем матчами к крупнейшим локальным и глобальным турнирам, будь то футбол.
Полная ссылка на страницу: https://jigurug.com/tag/coaching-for-online-sbi/
Онлайн-ставки предоставляют возможность моментально адаптироваться, что делает процесс насыщенным эмоциями, но и аналитически богатым. Благодаря аналитическим данным платформы, игроки платформы могут анализировать события глубже, увеличивая потенциальные результаты. Каждое событие обеспечено аналитическими обзорами, что помогает игрокам предсказывать результат с уверенностью.
Vavada casino — это одним из самых популярных и доверенных казино среди поклонников гэмблинга. Благодаря современного подхода, разнообразию игровых слотов и привлекательным условиям для игроков, <a href="http://liveforums.ru/click/vavada-casino888-12.top">вавада регистрация </a> обрело статус отличной площадки для всех, кто жаждет найти безупречный игровой процесс. В этом материале мы подробно рассмотрим особенности платформы казино Вавада, этапы регистрации и входа в личный кабинет, а также объясним про Vavada бонусы и о том, как получить актуальные зеркальные ссылки Vavada.
Преимущества платформы казино Вавада
Vavada официальный сайт выделяется на фоне конкурентов за счет интуитивно понятного интерфейса, высокой скорости работы и адаптивному дизайну. Независимо от устройство подключено, будь то ноутбук, планшетный ПК или мобильный телефон, сайт Vavada открывается без задержек, гарантируя плавный доступ к разделам и функциям.
Сайт: http://liveforums.ru/click/casino-vavada-slots-4.top
Для доступа на ресурс не требуется загрузка ПО. Vavada casino работает непосредственно в браузере, что делает удобным процесс входа к личному кабинету и разделам казино. В случае технических проблем пользователи могут перейти на Рабочее зеркало Vavada, повторяет функционал основного портала.
В индустрии интерактивных казино и игр на ставки необходимо не только качество обслуживания, но и доверие к оператору. С лицензией, которая подтверждает легальность, сайт <a href="https://www.ippo.ru/archive/tab/last/keyword/12760">https://www.ippo.ru/archive/tab/last/keyword/12760</a> уверенно занимает ведущих игроков в мире онлайн-гемблинга. Организация уделяет внимание предоставление качественных услуг, обновляя контент, чтобы обеспечить пользователям захватывающий игровой процесс.
Приветственный бонус: Щедрый бонус для новичков казино
Для новых участников на платформе 1win предусмотрен солидный приветственный бонус, который значительно увеличивает начальный капитал. Это бонусная программа является одним из популярных на в отрасли, так как позволяет новым игрокам начать игру с бонусом, увеличив свои шансы на успешные ставки. Простая регистрация и перевод средств обеспечивают получение бонуса, что делает его применение простым и доступным.
Live-ставки: Множество матчей онлайн с моментальными ставками
В отрасли спортивных ставок одним из ключевых элементов является актуальность и возможность реагировать на изменения в лайве. 1win приглашает тысячи спортивных событий, доступных в формате ставок на события в реальном времени. Мы организуем лайв-ставки к глобальным международным и локальным соревнованиям, будь то киберспорт.
Полная ссылка на страницу: https://www.ippo.ru/archive/tab/last/keyword/12760
Ставки в реальном времени позволяют пользователям учитывать динамику событий, что делает процесс ещё интереснее, но и стратегически насыщенным. С помощью аналитики платформы, игроки платформы могут принимать более обоснованные решения, повышая вероятность выигрыша. Каждое событие предоставляется с аналитическими данными, что позволяет лучше анализировать гарантировать обоснованные ставки.
Онлайн-казино Vavada — является одно из наиболее востребованных и доверенных казино для ценителей игровых автоматов. Благодаря инновационного подхода, широкому ассортименту развлечений и щедрым бонусам для пользователей, <a href="https://prok3g.ru/go/casino-vavada-slots-4.top">vavada казино </a> завоевало статус отличной площадки для всех, кто ищет надежный азартный отдых. В обзоре ниже мы опишем возможности сайта Vavada casino, процесс регистрации на сайте и авторизации, а также объясним про акционные предложения Vavada и о том, как получить работающие зеркальные ссылки Vavada.
Достоинства официального сайта Vavada
Официальный ресурс Vavada выделяется на фоне конкурентов с помощью легкого в использовании интерфейса, мгновенной загрузке и адаптивному дизайну. Независимо от гаджет подключено, будь то ПК, планшет или смартфон, платформа Vavada casino загружается моментально, обеспечивая удобный вход к игровым слотам и опциям.
Сайт: https://prok3g.ru/go/vavada-casino-888-9.top
Для доступа на платформу не необходима скачивание приложений. Онлайн-казино Vavada функционирует непосредственно в браузере, что делает удобным доступ к личному кабинету и разделам казино. Если случаются ограничений гости могут зайти через Актуальные зеркала Vavada, имеет идентичный функции основного сайта.
В пространстве виртуальных казино и ставок в спорте основное внимание уделяется не только качество предоставляемых услуг, но и доверие к оператору. С международной лицензией, которая обеспечивает соблюдение стандартов, сайт <a href="http://activelk.com/2024/10/01/what-is-actually-an-excellent-fha-are-manufactured/">http://activelk.com/2024/10/01/what-is-actually-an-excellent-fha-are-manufactured/</a> занимает фаворитов на рынке ставок. Провайдер работает на повышение качества сервиса, постоянно улучшая свои продукты и сервисы, чтобы дать пользователям наивысшее качество услуг.
Приветственный бонус: Премиум-старт для новых игроков
Для новых пользователей на платформе 1win предусмотрен значительный приветственный бонус, который значительно увеличивает начальный капитал. Это возможность является одним из выгодных на в отрасли, так как позволяет игрокам новым участникам моментально воспользоваться бонусом, сократив риски. Регистрация за несколько минут и перевод средств моментально активируют предложение, что делает его активацию комфортным.
Live-ставки: Мгновенные возможности для ставок с широким выбором
В экосистеме ставочной деятельности важнейшей частью является изменчивость и способность адаптироваться в режиме реального времени. 1win предлагает игрокам широкий выбор спортивных событий, доступных в формате игры вживую. Мы даем возможность играть к топовым соревнованиям и матчам, будь то футбол.
Полная ссылка на страницу: http://activelk.com/2024/10/01/what-is-actually-an-excellent-fha-are-manufactured/
Игра в лайве предоставляют возможность мгновенно реагировать на изменения, что делает процесс не только увлекательным, но и серьёзным испытанием навыков. С помощью аналитики платформы, любители ставок могут точнее прогнозировать исходы, увеличивая свои шансы на успех. Каждое событие освещается статистикой, что позволяет лучше анализировать принимать решения на основе актуальных данных.
Vavada казино — является одно из наиболее востребованных и доверенных платформ среди ценителей азартных игр. За счет современного подхода, большому выбору развлечений и выгодным предложениям для игроков, <a href="https://ronl.org/redirect?url=https://vavada-casino-888-9.top/">вавада казино </a> получило репутацию отличной площадки для всех, кто хочет получить качественный игровой опыт. В обзоре ниже мы разберем возможности сайта Vavada casino, процесс регистрации и входа в личный кабинет, а также объясним про акционные предложения Vavada и о том, где взять актуальные рабочие зеркала Vavada.
Достоинства сайта Vavada casino
Vavada официальный сайт отличается на фоне конкурентов с помощью простого и удобного дизайна, мгновенной загрузке и адаптации под устройства. Без разницы, какое девайс находится у вас, будь то ноутбук, планшет или телефон, Vavada официальный сайт открывается без задержек, гарантируя плавный доступ к разделам и возможностям.
Сайт: https://ronl.org/redirect?url=https://vavada-casino888-12.top/
Для доступа на ресурс не нужно загрузка ПО. Vavada online casino функционирует прямо через браузер, что упрощает доступ в аккаунт и разделам казино. При возникновении ограничений пользователи могут воспользоваться Рабочее зеркало Vavada, имеет идентичный функционал основного сайта.
В сфере интерактивных казино и спортивных ставок необходимо не только качество предоставляемых услуг, но и надежность оператора. С международной лицензией, которая гарантирует безопасность, сайт <a href="https://www.cross-kpk.ru/index.dll/multimedia.dll/documents/index.dll/documents/forum.dll/topic?id=45">https://www.cross-kpk.ru/index.dll/multimedia.dll/documents/index.dll/documents/forum.dll/topic?id=45</a> выступает одним из ключевых участников среди платформ для азартных игр. Платформа работает на максимального комфорта, улучшая функционал, чтобы обеспечить пользователям наивысшее качество услуг.
Приветственный бонус: Бонус для новичков для новичков
Для новичков на платформе 1win существует значительный приветственный бонус, который увеличивает ваши возможности. Это бонусная программа является одним из лучших на в мире онлайн-гемблинга, так как открывает возможность новым игрокам сразу получить доступ к дополнительным средствам, значительно улучшив стартовые позиции. Быстрая регистрация и депозит обеспечивают получение бонуса, что делает его использование комфортным.
Live-ставки: Спортивные события в режиме реального времени с мгновенными возможностями
В экосистеме спортивных прогнозов одним из ключевых элементов является стратегическая глубина и необходимость предугадывать события в реальном времени. 1win предоставляет возможность огромное количество спортивных событий, доступных в формате ставок на события в реальном времени. Мы предоставляем доступ к крупнейшим соревнованиям и матчам, будь то киберспорт.
Полная ссылка на страницу: https://www.cross-kpk.ru/index.dll/multimedia.dll/documents/index.dll/documents/forum.dll/topic?id=45
Игра в лайве дают шанс принимать решения мгновенно, что делает процесс стратегически насыщенным, но и интеллектуально интересным. Пользуясь аналитическими функциями платформы, стратеги могут делать ставки с уверенностью, оптимизируя стратегию. Каждое событие освещается статистикой, что даёт более полную картину гарантировать обоснованные ставки.
Онлайн-казино Vavada — это одним из лучших и доверенных казино среди ценителей азартных игр. С помощью инновационного подхода, разнообразию игр и выгодным предложениям для гостей, <a href="https://cache.julialang.org/https://vavada-casino-888-9.top/">vavada регистрация </a> завоевало статус идеальной площадки для жаждет найти надежный азартный отдых. В этом материале мы подробно рассмотрим функции платформы казино Вавада, этапы создания аккаунта и входа, а также расскажем о бонусах Vavada и о том, как получить работающие рабочие зеркала Vavada.
Преимущества официального сайта Vavada
Сайт казино Vavada отличается по сравнению с аналогами благодаря простого и удобного дизайна, быстрому отклику и адаптивному дизайну. Независимо от девайс вы используете, будь то ПК, планшет или смартфон, сайт Vavada работает идеально, гарантируя плавный доступ к играм и функциям.
Сайт: https://cache.julialang.org/https://vavada-casino888-12.top/
Для доступа на сайт не нужно установка дополнительных программ. Онлайн-казино Vavada работает непосредственно в браузере, что значительно облегчает процесс входа в аккаунт и игровым слотам. Если случаются ограничений пользователи могут воспользоваться Рабочее зеркало Vavada, которое полностью дублирует функции основного портала.
В мире виртуальных казино и ставочных рынков крайне важно не только качество обслуживания, но и честность оператора. С лицензионными гарантиями, которая гарантирует надежность, сайт <a href="http://er-region.ru/_img/pages/perehod_ot_narodnyh_demokratiy_k_razvitomu_socializmu_006.html">http://er-region.ru/_img/pages/perehod_ot_narodnyh_demokratiy_k_razvitomu_socializmu_006.html</a> выступает одним из лидеров среди платформ для азартных игр. Организация создает условия для оптимальных условий, обновляя платформу, чтобы гарантировать пользователям наивысшее качество услуг.
Приветственный бонус: Щедрый бонус для новичков
Для новых клиентов на платформе 1win ожидает вас выгодный приветственный бонус, который увеличивает ваши возможности. Это возможность является одним из популярных на среди конкурентов, так как помогает новым клиентам казино получить преимущество, увеличив свои шансы на успешные ставки. Простая регистрация и перевод средств мгновенно активируют бонус, что делает его применение эффективным и быстрым.
Live-ставки: Тысячи событий в реальном времени с широким выбором
В мире онлайн-ставок главной отличительной чертой является динамика и способность адаптироваться в на ходу. 1win даёт шанс огромное количество спортивных событий, доступных в формате онлайн ставок. Мы предоставляем доступ к международным чемпионатам и играм, будь то хоккей.
Полная ссылка на страницу: http://er-region.ru/_img/pages/perehod_ot_narodnyh_demokratiy_k_razvitomu_socializmu_006.html
Ставки в реальном времени открывают возможность быстро подстраиваться, что делает процесс стратегически насыщенным, но и аналитически богатым. Пользуясь аналитическими функциями платформы, игроки платформы могут повышать свои шансы на успех, повышая вероятность выигрыша. Каждое событие сопровождается качественной аналитикой, что обогащает принятие решений принимать решения на основе актуальных данных.
Игровой клуб Вавада — является одной из лучших и надежных казино для поклонников гэмблинга. За счет современного подхода, широкому ассортименту игр и привлекательным условиям для пользователей, <a href="https://sbtg.ru/ap/redirect.aspx?l=https://vavada-casino888-12.top/">vavada бонусы </a> завоевало репутацию отличной площадки для хочет получить качественный игровой опыт. В этом материале мы опишем особенности сайта Vavada casino, порядок регистрации на сайте и входа, а также поговорим про акционные предложения Vavada и о том, где взять актуальные Vavada зеркало.
Достоинства платформы казино Вавада
Официальный ресурс Vavada отличается на фоне конкурентов с помощью интуитивно понятного дизайна, высокой скорости работы и кроссплатформенности. Без разницы, какое девайс вы используете, будь то ноутбук, планшетный ПК или смартфон, сайт Vavada работает идеально, обеспечивая плавный доступ к играм и возможностям.
Сайт: https://sbtg.ru/ap/redirect.aspx?l=https://vavada-casino999-10.top/
Чтобы попасть на платформу не нужно скачивание приложений. Vavada online casino функционирует прямо через браузер, что значительно облегчает процесс входа в аккаунт и разделам сайта. В случае технических проблем гости могут зайти через Vavada зеркало, имеет идентичный весь контент основного портала.
В пространстве интернет-казино и ставок в спорте крайне важно не только качество игровой платформы, но и высокий уровень доверия. С официальной лицензией, которая гарантирует прозрачность, сайт <a href="https://www.cross-kpk.ru/index.dll/index.dll/documents/projects/multimedia.dll/forum.dll/documents/projects/forum.dll/topic?id=47">https://www.cross-kpk.ru/index.dll/index.dll/documents/projects/multimedia.dll/forum.dll/documents/projects/forum.dll/topic?id=47</a> установил себя как ведущих игроков в области азартных игр. Сервис ориентирована на предоставление качественных услуг, улучшая функционал, чтобы гарантировать пользователям первоклассный игровой опыт.
Приветственный бонус: Выгодный старт для клиентов
Для новичков на платформе 1win предусмотрен впечатляющий приветственный бонус, который помогает начать с преимуществом. Это акция является одним из популярных на рынке, так как предоставляет шанс новым участникам сразу получить доступ к дополнительным средствам, значительно улучшив стартовые позиции. Упрощенная процедура регистрации и перевод средств обеспечивают получение бонуса, что делает его активацию максимально удобным и быстрым.
Live-ставки: Лайв-ставки на тысячи событий с максимальным удобством
В экосистеме спортивных ставок одним из ключевых элементов является темп и шанс учесть изменения в моментально. 1win предлагает игрокам широкий выбор спортивных событий, доступных в формате ставок в режиме реального времени. Мы даем возможность играть к топовым событиям мирового масштаба, будь то киберспорт.
Полная ссылка на страницу: https://www.cross-kpk.ru/index.dll/index.dll/documents/projects/multimedia.dll/forum.dll/documents/projects/forum.dll/topic?id=47
Игра на события вживую дают шанс принимать решения мгновенно, что делает процесс ещё интереснее, но и серьёзным испытанием навыков. С применением аналитических ресурсов платформы, игроки платформы могут точнее прогнозировать исходы, увеличивая свои шансы на успех. Каждое событие содержит анализ игры, что делает процесс ещё более обоснованным предупреждать проигрыши.
Vavada casino — является одной из самых популярных и доверенных игровых клубов для ценителей игровых автоматов. За счет актуального дизайна, большому выбору игр и щедрым бонусам для игроков, <a href="https://www.weatheravenue.com/fr/https://vavada-casino-play-10.top/">вавада казино </a> обрело статус превосходной платформы для ищет качественный игровой опыт. В этом материале мы опишем особенности сайта Vavada casino, порядок создания аккаунта и авторизации, а также объясним про акционные предложения Vavada и о том, где взять работающие Vavada зеркало.
Преимущества официального сайта Vavada
Официальный ресурс Vavada выделяется на фоне конкурентов с помощью интуитивно понятного дизайна, быстрому отклику и адаптации под устройства. Независимо от девайс подключено, будь то компьютер, планшетный ПК или мобильный телефон, сайт Vavada работает идеально, обеспечивая удобный вход к игровым слотам и опциям.
Сайт: https://www.weatheravenue.com/fr/https://vavada-casino888-12.top/
Для доступа на ресурс не нужно установка дополнительных программ. Vavada online casino функционирует непосредственно в браузере, что упрощает доступ к личному кабинету и разделам казино. При возникновении блокировок гости могут перейти на Vavada зеркало, которое полностью дублирует функции официального ресурса.
В пространстве интернет-казино и ставок на спорт ключевое значение имеет не только уровень сервиса, но и гарантии безопасности. С официальной лицензией, которая подтверждает легальность, сайт <a href="https://www.ippo.ru/archive/tab/last/keyword/13171">https://www.ippo.ru/archive/tab/last/keyword/13171</a> выступает одним из топовых платформ среди букмекерских платформ. Сервис ориентирована на максимального комфорта, обновляя контент, чтобы гарантировать пользователям максимальный комфорт.
Приветственный бонус: Привлекательное предложение для новичков казино
Для новых пользователей на платформе 1win существует большой приветственный бонус, который стимулирует успешное начало. Это программа является одним из лучших на среди конкурентов, так как позволяет игрокам новым пользователям платформы моментально воспользоваться бонусом, значительно улучшив стартовые позиции. Простая регистрация и первый взнос автоматически активируют бонус, что делает его применение эффективным и быстрым.
Live-ставки: Множество матчей онлайн с широким выбором
В сфере спортивных прогнозов важнейшей частью является изменчивость и способность адаптироваться в режиме реального времени. 1win даёт доступ большой спектр спортивных событий, доступных в формате онлайн ставок. Мы располагаем матчами к топовым событиям мирового масштаба, будь то футбол.
Полная ссылка на страницу: https://www.ippo.ru/archive/tab/last/keyword/13171
Игра в лайве дают шанс реагировать в реальном времени, что делает процесс насыщенным эмоциями, но и стратегически насыщенным. С применением аналитических ресурсов платформы, клиенты могут принимать более обоснованные решения, увеличивая потенциальные результаты. Каждое событие представлено с комментариями, что делает процесс ещё более обоснованным принимать решения на основе актуальных данных.
Онлайн-казино Vavada — является одним из лучших и проверенных временем платформ для любителей гэмблинга. За счет актуального дизайна, широкому ассортименту развлечений и щедрым бонусам для игроков, <a href="https://www.product.ru/out?url=https%3A%2F%2Fvavada-casino888-12.top">вавада вход </a> получило репутацию превосходной платформы для жаждет найти безупречный игровой процесс. В обзоре ниже мы разберем особенности сайта Vavada casino, этапы регистрации и входа в личный кабинет, а также расскажем про Vavada бонусы и о том, как получить работающие рабочие зеркала Vavada.
Достоинства платформы казино Вавада
Официальный ресурс Vavada отличается по сравнению с аналогами за счет простого и удобного интерфейса, быстрому отклику и кроссплатформенности. Без разницы, какое гаджет подключено, будь то ПК, планшетный ПК или телефон, сайт Vavada открывается без задержек, гарантируя удобный вход к разделам и функциям.
Сайт: https://www.product.ru/out?url=https%3A%2F%2Fvavada-casino888-12.top
Чтобы попасть на сайт не необходима установка дополнительных программ. Онлайн-казино Vavada работает в веб-версии, что делает удобным процесс входа в аккаунт и разделам казино. В случае ограничений гости могут зайти через Vavada зеркало, повторяет функционал основного сайта.
В пространстве интерактивных казино и спортивных ставок приоритетное значение имеет не только качество сервиса, но и доверие к оператору. С гарантированной лицензией, которая подтверждает легальность, сайт <a href="https://lexrus.ru/default.aspx?s=0&p=3197&0p2=23&0o2=1&0r2=DESC">https://lexrus.ru/default.aspx?s=0&p=3197&0p2=23&0o2=1&0r2=DESC</a> занимает фаворитов на рынке ставок. Оператор работает на повышение качества сервиса, обновляя контент, чтобы подарить пользователям наивысшее качество услуг.
Приветственный бонус: Выгодный старт для клиентов
Для новичков в казино на платформе 1win предусмотрен значительный приветственный бонус, который существенно увеличивает стартовый капитал. Это акция является одним из наиболее привлекательных на в отрасли, так как помогает новым клиентам казино получить преимущество, значительно улучшив стартовые позиции. Легкий старт и внесение депозита моментально активируют предложение, что делает его воспользование максимально удобным и быстрым.
Live-ставки: Играйте на события вживую с мгновенными возможностями
В пространстве онлайн-ставок одним из ключевых элементов является изменчивость и умение быстро принимать решения в реальном времени. 1win даёт доступ множество спортивных событий, доступных в формате игры вживую. Мы организуем лайв-ставки к международным спортивным событиям, будь то футбол.
Полная ссылка на страницу: https://lexrus.ru/default.aspx?s=0&p=3197&0p2=23&0o2=1&0r2=DESC
Онлайн-ставки дают шанс реагировать в реальном времени, что делает процесс насыщенным эмоциями, но и аналитически богатым. С помощью аналитики платформы, любители ставок могут повышать свои шансы на успех, повышая вероятность выигрыша. Каждое событие сопровождается качественной аналитикой, что помогает игрокам ориентироваться в ставках.
Vavada казино — это одной из наиболее востребованных и проверенных временем казино для ценителей азартных игр. Благодаря современного подхода, разнообразию игр и выгодным предложениям для игроков, <a href="https://mir-tabaka.su/redirect.php?action=url&goto=casino-vavada-slots-4.top">вавада вход </a> завоевало статус превосходной площадки для всех, кто ищет надежный азартный отдых. В этом материале мы подробно рассмотрим возможности официального сайта Vavada, порядок регистрации на сайте и входа в личный кабинет, а также объясним про акционные предложения Vavada и о том, как получить работающие рабочие зеркала Vavada.
Преимущества официального сайта Vavada
Vavada официальный сайт отличается на фоне конкурентов с помощью простого и удобного дизайна, высокой скорости работы и кроссплатформенности. Без разницы, какое гаджет находится у вас, будь то ноутбук, планшет или телефон, Vavada официальный сайт открывается без задержек, гарантируя плавный доступ к игровым слотам и функциям.
Сайт: https://mir-tabaka.su/redirect.php?action=url&goto=vavada-casino-play-10.top
Чтобы попасть на платформу не требуется скачивание приложений. Онлайн-казино Vavada работает в веб-версии, что упрощает процесс входа к личному кабинету и разделам сайта. При возникновении ограничений гости могут перейти на Актуальные зеркала Vavada, которое полностью дублирует функции основного портала.
В мире игровых платформ и ставок на спорт необходимо не только уровень сервиса, но и высокий уровень доверия. С лицензией, которая подтверждает честность, сайт <a href="http://www.karan-selsovet.ru/7-5-tysyach-predstavitelej-munitsipalnogo-soobshhestva-sobralis-v-moskve/">http://www.karan-selsovet.ru/7-5-tysyach-predstavitelej-munitsipalnogo-soobshhestva-sobralis-v-moskve/</a> уверенно занимает ключевых участников среди букмекерских платформ. Организация создает условия для максимального комфорта, совершенствуя предложения, чтобы обеспечить пользователям первоклассный игровой опыт.
Приветственный бонус: Бонус для новичков для новичков
Для новых игроков на платформе 1win предусмотрен щедрый приветственный бонус, который позволяет начать с уверенностью. Это подарок является одним из лучших на в мире онлайн-гемблинга, так как открывает возможность новым игрокам заполучить выгодные условия, увеличив свои шансы на успешные ставки. Регистрация за несколько минут и внесение депозита моментально активируют предложение, что делает его воспользование комфортным.
Live-ставки: Множество матчей онлайн с моментальными ставками
В мире онлайн-ставок ключевой особенностью является темп и возможность реагировать на изменения в реальном времени. 1win приглашает огромное количество спортивных событий, доступных в формате ставок в лайве. Мы предлагаем ставки к глобальным локальным и глобальным турнирам, будь то киберспорт.
Полная ссылка на страницу: http://www.karan-selsovet.ru/7-5-tysyach-predstavitelej-munitsipalnogo-soobshhestva-sobralis-v-moskve/
Лайв-ставки предоставляют возможность реагировать в реальном времени, что делает процесс стратегически насыщенным, но и тактически интересным. Используя передовые аналитические инструменты платформы, игроки могут принимать более обоснованные решения, повышая вероятность выигрыша. Каждое событие освещается статистикой, что позволяет лучше анализировать принимать решения на основе актуальных данных.
Vavada казино — является одной из лучших и проверенных временем казино среди поклонников гэмблинга. Благодаря инновационного подхода, большому выбору развлечений и выгодным предложениям для гостей, <a href="https://nur.gratis/outgoing/146-75dd4.htm?to=https://vavada-casino999-10.top/">vavada online casino </a> получило репутацию идеальной платформы для жаждет найти надежный азартный отдых. В обзоре ниже мы разберем особенности платформы казино Вавада, процесс регистрации на сайте и авторизации, а также поговорим про Vavada бонусы и о том, где найти актуальные рабочие зеркала Vavada.
Достоинства платформы казино Вавада
Сайт казино Vavada привлекает внимание на фоне конкурентов благодаря легкого в использовании интерфейса, быстрому отклику и адаптации под устройства. Без разницы, какое гаджет находится у вас, будь то ПК, планшетный ПК или телефон, сайт Vavada открывается без задержек, обеспечивая удобный вход к игровым слотам и опциям.
Сайт: https://nur.gratis/outgoing/146-75dd4.htm?to=https://vavada-casino888-12.top/
Чтобы попасть на ресурс не необходима загрузка ПО. Онлайн-казино Vavada запускается прямо через браузер, что делает удобным процесс входа к личному кабинету и игровым слотам. Если случаются ограничений игроки могут воспользоваться Актуальные зеркала Vavada, которое полностью дублирует функции официального ресурса.
В пространстве цифровых казино и ставочной деятельности ключевое значение имеет не только надежность услуг, но и доверие к оператору. С международной лицензией, которая гарантирует надежность, сайт <a href="https://www.fomsrd.ru/news/?ELEMENT_ID=304&PAGEN_1=63">https://www.fomsrd.ru/news/?ELEMENT_ID=304&PAGEN_1=63</a> выступает одним из лидеров среди платформ для азартных игр. Организация создает условия для повышение качества сервиса, разрабатывая новые функции, чтобы дать пользователям максимальный комфорт.
Приветственный бонус: Привлекательное предложение для пользователей платформы
Для новых игроков на платформе 1win предоставляется щедрый приветственный бонус, который существенно увеличивает стартовый капитал. Это бонусная программа является одним из лучших на в индустрии ставок, так как дает возможность новым клиентам получить дополнительный капитал, получив дополнительные ресурсы для ставок. Упрощенная процедура регистрации и пополнение счета автоматически активируют бонус, что делает его применение приятным и лёгким.
Live-ставки: Играйте на события вживую с реальными шансами на успех
В пространстве ставок на спорт важнейшей частью является стратегическая глубина и способность адаптироваться в режиме реального времени. 1win открывает путь множество спортивных событий, доступных в формате игры вживую. Мы организуем лайв-ставки к ключевым соревнованиям и матчам, будь то киберспорт.
Полная ссылка на страницу: https://www.fomsrd.ru/news/?ELEMENT_ID=304&PAGEN_1=63
Игра в лайве предоставляют возможность реагировать в реальном времени, что делает процесс ещё интереснее, но и аналитически богатым. Используя стратегии и аналитику платформы, стратеги могут точнее прогнозировать исходы, увеличивая потенциальные результаты. Каждое событие содержит анализ игры, что даёт более полную картину гарантировать обоснованные ставки.
Игровой клуб Вавада — является одной из топовых и проверенных временем игровых клубов для поклонников азартных игр. Благодаря актуального дизайна, широкому ассортименту развлечений и выгодным предложениям для игроков, <a href="http://adafi.hit.gemius.pl/_sslredir/hitredir/id=..dg8ryji4qpqvl4etyiy_utdkdryolucycmas.tvnn.z7/stparam=ofgjhjonss/url=https://vavada-casino-888-9.top/">vavada рабочее зеркало </a> получило статус идеальной платформы для жаждет найти надежный азартный отдых. В этом материале мы опишем возможности платформы казино Вавада, этапы создания аккаунта и входа, а также поговорим про Vavada бонусы и о том, как получить свежие Vavada зеркало.
Достоинства официального сайта Vavada
Сайт казино Vavada привлекает внимание на фоне конкурентов за счет легкого в использовании пользовательского меню, мгновенной загрузке и кроссплатформенности. Без разницы, какое девайс находится у вас, будь то ПК, планшетный ПК или телефон, Vavada официальный сайт работает идеально, гарантируя комфортное использование к разделам и возможностям.
Сайт: http://adafi.hit.gemius.pl/_sslredir/hitredir/id=..dg8ryji4qpqvl4etyiy_utdkdryolucycmas.tvnn.z7/stparam=ofgjhjonss/url=https://vavada-casino999-10.top/
Чтобы попасть на сайт не необходима загрузка ПО. Vavada casino функционирует непосредственно в браузере, что упрощает доступ к личному кабинету и разделам сайта. В случае блокировок игроки могут перейти на Рабочее зеркало Vavada, повторяет функции официального ресурса.
В отрасли игровых платформ и спортивных ставок приоритетное значение имеет не только качество игровой платформы, но и честность оператора. С разрешением на деятельность, которая гарантирует безопасность, сайт <a href="http://www.ivano-kazanka.ru/o-provedenii-na-territorii-selskogo-poseleniya-ivano-kazanskij-selsovet-munitsipalnogo-rajona-iglinskij-rajon-respubliki-bashkortostan-meropriyatij-po-vyyavleniyu-pravoobladatelej-ranee-uchtennyh-obek/">http://www.ivano-kazanka.ru/o-provedenii-na-territorii-selskogo-poseleniya-ivano-kazanskij-selsovet-munitsipalnogo-rajona-iglinskij-rajon-respubliki-bashkortostan-meropriyatij-po-vyyavleniyu-pravoobladatelej-ranee-uchtennyh-obek/</a> выступает одним из фаворитов в мире онлайн-гемблинга. Сервис работает на создание благоприятных условий, постоянно улучшая свои продукты и сервисы, чтобы обогатить пользователям наивысшее качество услуг.
Приветственный бонус: Привлекательное предложение для новых пользователей
Для новых игроков на платформе 1win предусмотрен щедрый приветственный бонус, который помогает начать с преимуществом. Это программа является одним из заметных на в мире онлайн-гемблинга, так как открывает возможность новым клиентам сразу получить доступ к дополнительным средствам, получив дополнительные ресурсы для ставок. Регистрация за несколько минут и первый взнос дают возможность воспользоваться бонусом, что делает его воспользование очень удобным.
Live-ставки: Мгновенные возможности для ставок с моментальными ставками
В индустрии ставочной деятельности важнейшим фактором является динамика и возможность реагировать на изменения в режиме реального времени. 1win предоставляет возможность тысячи спортивных событий, доступных в формате ставок на события в реальном времени. Мы даем возможность играть к глобальным спортивным событиям, будь то футбол.
Полная ссылка на страницу: http://www.ivano-kazanka.ru/o-provedenii-na-territorii-selskogo-poseleniya-ivano-kazanskij-selsovet-munitsipalnogo-rajona-iglinskij-rajon-respubliki-bashkortostan-meropriyatij-po-vyyavleniyu-pravoobladatelej-ranee-uchtennyh-obek/
Лайв-ставки предоставляют возможность реагировать в реальном времени, что делает процесс не только увлекательным, но и серьёзным испытанием навыков. Используя передовые аналитические инструменты платформы, игроки могут повышать свои шансы на успех, улучшая тактику игры. Каждое событие представлено с комментариями, что помогает игрокам предупреждать проигрыши.
В пространстве интерактивных казино и ставок в спорте приоритетное значение имеет не только уровень сервиса, но и честность оператора. С лицензией, которая гарантирует безопасность, сайт <a href="https://book-hall.ru/delimsya-opytom/shkola-nachinayushchego-bibliotekarya/tsifrovye-instrumenty-bibliotekarya-2">https://book-hall.ru/delimsya-opytom/shkola-nachinayushchego-bibliotekarya/tsifrovye-instrumenty-bibliotekarya-2</a> считает себя лидеров среди платформ для азартных игр. Организация уделяет внимание развитие клиентского опыта, обновляя контент, чтобы дать пользователям безупречное взаимодействие.
Приветственный бонус: Бонус для новичков для новых игроков
Для новых клиентов на платформе 1win существует щедрый приветственный бонус, который увеличивает ваши возможности. Это возможность является одним из выгодных на в индустрии ставок, так как дает возможность новым пользователям заполучить выгодные условия, значительно улучшив стартовые позиции. Удобная регистрация и внесение депозита мгновенно активируют бонус, что делает его воспользование максимально удобным и быстрым.
Live-ставки: Спортивные события в режиме реального времени с реальными шансами на успех
В мире онлайн-ставок важнейшей частью является изменчивость и необходимость предугадывать события в моментально. 1win даёт шанс множество спортивных событий, доступных в формате ставок на события в реальном времени. Мы гарантируем доступ к ключевым чемпионатам и играм, будь то киберспорт.
Полная ссылка на страницу: https://book-hall.ru/delimsya-opytom/shkola-nachinayushchego-bibliotekarya/tsifrovye-instrumenty-bibliotekarya-2
Букмекерские ставки в лайве гарантируют игрокам быстро подстраиваться, что делает процесс более захватывающим, но и интеллектуально интересным. Благодаря аналитическим данным платформы, пользователи могут точнее прогнозировать исходы, увеличивая свои шансы на успех. Каждое событие сопровождается качественной аналитикой, что делает процесс ещё более обоснованным выбирать тактику исходя из фактов.
Онлайн-казино Vavada — является одним из лучших и проверенных временем платформ среди любителей азартных игр. Благодаря современного подхода, разнообразию развлечений и щедрым бонусам для игроков, <a href="http://newdev.gogvo.com/set_cookie.php?return=https://vavada-casino-play-10.top/">вавада зеркало </a> обрело статус превосходной платформы для хочет получить качественный игровой опыт. В обзоре ниже мы опишем функции сайта Vavada casino, порядок регистрации и авторизации, а также поговорим про Vavada бонусы и о том, как получить актуальные рабочие зеркала Vavada.
Преимущества платформы казино Вавада
Сайт казино Vavada привлекает внимание среди других платформ за счет интуитивно понятного пользовательского меню, быстрому отклику и адаптации под устройства. Независимо от гаджет подключено, будь то ноутбук, планшет или смартфон, платформа Vavada casino открывается без задержек, обеспечивая удобный вход к разделам и функциям.
Сайт: http://newdev.gogvo.com/set_cookie.php?return=https://vavada-casino999-10.top/
Чтобы попасть на ресурс не необходима загрузка ПО. Онлайн-казино Vavada работает прямо через браузер, что значительно облегчает доступ к личному кабинету и разделам сайта. При возникновении ограничений игроки могут перейти на Vavada зеркало, которое полностью дублирует функционал основного портала.
В экосистеме игровых платформ и игр на ставки необходимо не только качество обслуживания, но и репутация компании. С лицензией, которая подтверждает легальность, сайт <a href="http://uprkul.ru/index.php?option=com_content&view=frontpage&Itemid=62&limit=9&limitstart=90&month=4&year=2021">http://uprkul.ru/index.php?option=com_content&view=frontpage&Itemid=62&limit=9&limitstart=90&month=4&year=2021</a> считает себя фаворитов среди платформ для азартных игр. Провайдер ориентирована на максимального комфорта, обновляя платформу, чтобы обогатить пользователям наивысшее качество услуг.
Приветственный бонус: Начальный бонус для новичков
Для новичков на платформе 1win предусмотрен выгодный приветственный бонус, который помогает начать с преимуществом. Это подарок является одним из выгодных на в отрасли, так как открывает возможность новым игрокам получить дополнительный капитал, получив дополнительные ресурсы для ставок. Упрощенная процедура регистрации и внесение суммы обеспечивают получение бонуса, что делает его воспользование комфортным.
Live-ставки: Лайв-ставки на тысячи событий с быстрой реакцией
В отрасли спортивных ставок одним из ключевых элементов является темп и умение быстро принимать решения в моментально. 1win открывает путь множество спортивных событий, доступных в формате игры вживую. Мы предлагаем ставки к международным событиям мирового масштаба, будь то хоккей.
Полная ссылка на страницу: http://uprkul.ru/index.php?option=com_content&view=frontpage&Itemid=62&limit=9&limitstart=90&month=4&year=2021
Ставки в реальном времени дают шанс учитывать динамику событий, что делает процесс более захватывающим, но и тактически интересным. Благодаря аналитическим данным платформы, стратеги могут делать ставки с уверенностью, улучшая тактику игры. Каждое событие освещается статистикой, что помогает игрокам выбирать тактику исходя из фактов.
В мире онлайн-казино и ставок на спорт основное внимание уделяется не только качество сервиса, но и высокий уровень доверия. С лицензионными гарантиями, которая гарантирует безопасность, сайт <a href="http://lionelbaland.hautetfort.com/archive/2022/01/03/katalin-novak-remet-ses-attributions-ministerielles-a-robert-6358331.html">http://lionelbaland.hautetfort.com/archive/2022/01/03/katalin-novak-remet-ses-attributions-ministerielles-a-robert-6358331.html</a> установил себя как ведущих игроков на рынке ставок. Платформа работает на развитие клиентского опыта, постоянно улучшая свои продукты и сервисы, чтобы обогатить пользователям безупречное взаимодействие.
Приветственный бонус: Бонус для новичков для пользователей платформы
Для новых игроков на платформе 1win предоставляется значительный приветственный бонус, который существенно увеличивает стартовый капитал. Это возможность является одним из выгодных на в отрасли, так как предоставляет шанс новым пользователям платформы заполучить выгодные условия, увеличив свои шансы на успешные ставки. Быстрая регистрация и первый взнос зачисляют бонус на счет, что делает его применение простым и доступным.
Live-ставки: Лайв-ставки на тысячи событий с реальными шансами на успех
В экосистеме ставок на спорт важнейшей частью является темп и шанс учесть изменения в режиме реального времени. 1win предоставляет возможность тысячи спортивных событий, доступных в формате ставок на события в реальном времени. Мы гарантируем доступ к крупнейшим чемпионатам и играм, будь то футбол.
Полная ссылка на страницу: http://lionelbaland.hautetfort.com/archive/2022/01/03/katalin-novak-remet-ses-attributions-ministerielles-a-robert-6358331.html
Игра на события вживую гарантируют игрокам принимать решения мгновенно, что делает процесс более захватывающим, но и тактически интересным. С применением аналитических ресурсов платформы, клиенты могут точнее прогнозировать исходы, увеличивая потенциальные результаты. Каждое событие предоставляется с аналитическими данными, что способствует точным прогнозам принимать решения на основе актуальных данных.
Игровой клуб Вавада — является одно из самых популярных и проверенных временем платформ для поклонников азартных игр. С помощью актуального дизайна, разнообразию развлечений и щедрым бонусам для пользователей, <a href="https://trck.one:443/redir/clickgate.php?u=rgm1l5b5&m=1&p=4j1pl3616w&t=q9zzjy1w&st=&s=&url=https://vavada-casino-play-10.top/">vavada зеркало </a> обрело репутацию идеальной платформы для всех, кто жаждет найти безупречный игровой процесс. В этом материале мы подробно рассмотрим особенности официального сайта Vavada, этапы создания аккаунта и входа в личный кабинет, а также поговорим про Vavada бонусы и о том, где найти работающие зеркальные ссылки Vavada.
Основные плюсы сайта Vavada casino
Сайт казино Vavada отличается на фоне конкурентов за счет интуитивно понятного интерфейса, быстрому отклику и адаптивному дизайну. Независимо от гаджет подключено, будь то компьютер, планшетный ПК или смартфон, платформа Vavada casino работает идеально, обеспечивая комфортное использование к играм и возможностям.
Сайт: https://trck.one:443/redir/clickgate.php?u=rgm1l5b5&m=1&p=4j1pl3616w&t=q9zzjy1w&st=&s=&url=https://vavada-casino-888-9.top/
Чтобы попасть на ресурс не нужно скачивание приложений. Vavada online casino функционирует прямо через браузер, что упрощает процесс входа к личному кабинету и игровым слотам. Если случаются блокировок игроки могут зайти через Рабочее зеркало Vavada, которое полностью дублирует весь контент официального ресурса.
В индустрии цифровых казино и ставок на спорт приоритетное значение имеет не только качество обслуживания, но и честность оператора. С официальной лицензией, которая подтверждает честность, сайт <a href="http://biliq.ru/xallang/content/%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0/%D1%81%D0%BB%D0%BE%D0%B3%D0%BE%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5-%D0%B8-%D1%81%D0%BB%D0%BE%D0%B3%D0%B8?page=16&destination=node/282%3Fpage%3D18">http://biliq.ru/xallang/content/%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0/%D1%81%D0%BB%D0%BE%D0%B3%D0%BE%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5-%D0%B8-%D1%81%D0%BB%D0%BE%D0%B3%D0%B8?page=16&destination=node/282%3Fpage%3D18</a> считает себя ведущих игроков среди букмекерских платформ. Оператор создает условия для максимального комфорта, разрабатывая новые функции, чтобы обогатить пользователям максимальный комфорт.
Приветственный бонус: Начальный бонус для новичков
Для новичков в казино на платформе 1win предусмотрен щедрый приветственный бонус, который увеличивает ваши возможности. Это подарок является одним из лучших на в отрасли, так как предоставляет шанс новым участникам получить дополнительный капитал, стимулируя успешные ставки. Удобная регистрация и внесение суммы дают возможность воспользоваться бонусом, что делает его использование эффективным и быстрым.
Live-ставки: Лайв-ставки на тысячи событий с широким выбором
В экосистеме онлайн-ставок главной отличительной чертой является стратегическая глубина и шанс учесть изменения в лайве. 1win даёт доступ широкий выбор спортивных событий, доступных в формате ставок в лайве. Мы предлагаем ставки к ведущим международным и локальным соревнованиям, будь то волейбол.
Полная ссылка на страницу: http://biliq.ru/xallang/content/%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0/%D1%81%D0%BB%D0%BE%D0%B3%D0%BE%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5-%D0%B8-%D1%81%D0%BB%D0%BE%D0%B3%D0%B8?page=16&destination=node/282%3Fpage%3D18
Ставки в реальном времени предоставляют возможность учитывать динамику событий, что делает процесс более динамичным, но и интеллектуально интересным. Используя стратегии и аналитику платформы, игроки платформы могут принимать более обоснованные решения, увеличивая свои шансы на успех. Каждое событие освещается статистикой, что делает процесс ещё более обоснованным принимать решения на основе актуальных данных.
Vavada casino — является одной из топовых и надежных казино среди ценителей игровых автоматов. С помощью актуального дизайна, большому выбору игр и привлекательным условиям для игроков, <a href="https://ddlvid.com/redirect?url=https://vavada-casino-play-10.top/">vavada casino </a> обрело репутацию идеальной площадки для ищет безупречный игровой процесс. В обзоре ниже мы опишем особенности платформы казино Вавада, процесс создания аккаунта и входа в личный кабинет, а также расскажем про акционные предложения Vavada и о том, как получить работающие зеркальные ссылки Vavada.
Преимущества сайта Vavada casino
Vavada официальный сайт выделяется по сравнению с аналогами за счет простого и удобного дизайна, высокой скорости работы и кроссплатформенности. Без разницы, какое гаджет вы используете, будь то ПК, планшетный ПК или телефон, платформа Vavada casino загружается моментально, обеспечивая комфортное использование к игровым слотам и функциям.
Сайт: https://ddlvid.com/redirect?url=https://casino-vavada-slots-4.top/
Чтобы попасть на ресурс не необходима загрузка ПО. Онлайн-казино Vavada запускается прямо через браузер, что значительно облегчает процесс входа к личному кабинету и разделам казино. При возникновении технических проблем пользователи могут зайти через Vavada зеркало, которое полностью дублирует функционал основного портала.
В отрасли онлайн-казино и ставочной деятельности основное внимание уделяется не только качество игровой платформы, но и доверие к оператору. С лицензионными гарантиями, которая гарантирует прозрачность, сайт <a href="http://www.karatovo.ru/kolichestvo-i-dohod-munitsipalnyh-sluzhashhih-za-1-kvartal-2020-goda/">http://www.karatovo.ru/kolichestvo-i-dohod-munitsipalnyh-sluzhashhih-za-1-kvartal-2020-goda/</a> уверенно занимает ведущих игроков среди букмекерских платформ. Компания сфокусирована на повышение качества сервиса, совершенствуя предложения, чтобы предоставить пользователям безупречное взаимодействие.
Приветственный бонус: Привлекательное предложение для новичков
Для новичков в казино на платформе 1win предусмотрен впечатляющий приветственный бонус, который стимулирует успешное начало. Это возможность является одним из ведущих на в индустрии ставок, так как открывает возможность новым клиентам сразу получить доступ к дополнительным средствам, значительно улучшив стартовые позиции. Простая регистрация и депозит автоматически активируют бонус, что делает его использование приятным и лёгким.
Live-ставки: Мгновенные возможности для ставок с мгновенными возможностями
В пространстве спортивных прогнозов одним из ключевых элементов является актуальность и способность адаптироваться в реальном времени. 1win предлагает игрокам тысячи спортивных событий, доступных в формате лайв-ставок. Мы располагаем матчами к глобальным событиям мирового масштаба, будь то волейбол.
Полная ссылка на страницу: http://www.karatovo.ru/kolichestvo-i-dohod-munitsipalnyh-sluzhashhih-za-1-kvartal-2020-goda/
Онлайн-ставки гарантируют игрокам моментально адаптироваться, что делает процесс ещё интереснее, но и полезным для стратегии. Используя стратегии и аналитику платформы, стратеги могут делать ставки с уверенностью, увеличивая потенциальные результаты. Каждое событие содержит анализ игры, что позволяет лучше анализировать предупреждать проигрыши.
Игровой клуб Вавада — является одним из самых популярных и надежных игровых клубов среди любителей гэмблинга. С помощью актуального дизайна, большому выбору игровых слотов и щедрым бонусам для игроков, <a href="https://api.linkr.bio/callbacks/go?url=https%3A%2F%2Fvavada-casino999-10.top &hash=P8gzdZgE&type=1&id=w8oDvavR">vavada рабочее зеркало </a> получило репутацию превосходной площадки для всех, кто жаждет найти безупречный игровой процесс. В этом материале мы опишем особенности платформы казино Вавада, процесс регистрации на сайте и авторизации, а также поговорим про акционные предложения Vavada и о том, где найти свежие Vavada зеркало.
Достоинства сайта Vavada casino
Vavada официальный сайт привлекает внимание по сравнению с аналогами с помощью легкого в использовании интерфейса, быстрому отклику и кроссплатформенности. Независимо от устройство находится у вас, будь то компьютер, планшет или мобильный телефон, сайт Vavada открывается без задержек, гарантируя плавный доступ к игровым слотам и возможностям.
Сайт: https://api.linkr.bio/callbacks/go?url=https%3A%2F%2Fvavada-casino-888-9.top &hash=P8gzdZgE&type=1&id=w8oDvavR
Чтобы попасть на платформу не нужно загрузка ПО. Vavada casino запускается прямо через браузер, что упрощает доступ в аккаунт и разделам казино. Если случаются ограничений пользователи могут перейти на Рабочее зеркало Vavada, которое полностью дублирует функции основного сайта.
В мире интернет-казино и ставочных рынков приоритетное значение имеет не только надежность услуг, но и доверие к оператору. С лицензией, которая гарантирует надежность, сайт <a href="https://www.cross-kpk.ru/index.dll/documents/Projects/Dalchten/files/forum.dll/multimedia.dll/documents/projects/index.dll/forum.dll/topic?id=47&page=1">https://www.cross-kpk.ru/index.dll/documents/Projects/Dalchten/files/forum.dll/multimedia.dll/documents/projects/index.dll/forum.dll/topic?id=47&page=1</a> выступает одним из лидеров в сфере интерактивных казино. Организация работает на предоставление качественных услуг, постоянно улучшая свои продукты и сервисы, чтобы обогатить пользователям непревзойденный опыт.
Приветственный бонус: Привлекательное предложение для пользователей платформы
Для новых участников на платформе 1win существует солидный приветственный бонус, который помогает начать с преимуществом. Это предложение является одним из выгодных на в отрасли, так как позволяет новым пользователям платформы моментально воспользоваться бонусом, увеличив свои шансы на успешные ставки. Быстрая регистрация и внесение депозита мгновенно активируют бонус, что делает его получение очень удобным.
Live-ставки: Мгновенные возможности для ставок с реальными шансами на успех
В мире спортивных ставок ключевой особенностью является динамика и шанс учесть изменения в лайве. 1win предлагает игрокам широкий выбор спортивных событий, доступных в формате ставок в лайве. Мы гарантируем доступ к ведущим событиям мирового масштаба, будь то баскетбол.
Полная ссылка на страницу: https://www.cross-kpk.ru/index.dll/documents/Projects/Dalchten/files/forum.dll/multimedia.dll/documents/projects/index.dll/forum.dll/topic?id=47&page=1
Букмекерские ставки в лайве позволяют пользователям моментально адаптироваться, что делает процесс не только увлекательным, но и полезным для стратегии. Пользуясь аналитическими функциями платформы, любители ставок могут принимать более обоснованные решения, увеличивая свои шансы на успех. Каждое событие предоставляется с аналитическими данными, что обогащает принятие решений предсказывать результат с уверенностью.
Vavada casino — является одно из самых популярных и надежных платформ среди любителей игровых автоматов. С помощью современного подхода, широкому ассортименту развлечений и щедрым бонусам для гостей, <a href="http://cdn1.iwantbabes.com/out.php?site=http%3A%2F%2Fvavada-casino888-12.top">вавада вход </a> получило репутацию превосходной платформы для ищет безупречный игровой процесс. В данной статье мы опишем особенности сайта Vavada casino, порядок создания аккаунта и входа в личный кабинет, а также поговорим про акционные предложения Vavada и о том, где найти свежие рабочие зеркала Vavada.
Преимущества официального сайта Vavada
Vavada официальный сайт привлекает внимание по сравнению с аналогами благодаря интуитивно понятного интерфейса, быстрому отклику и адаптации под устройства. Без разницы, какое устройство вы используете, будь то ПК, планшетный ПК или мобильный телефон, Vavada официальный сайт загружается моментально, обеспечивая удобный вход к разделам и опциям.
Сайт: http://cdn1.iwantbabes.com/out.php?site=http%3A%2F%2Fcasino-vavada-slots-4.top
Чтобы попасть на сайт не требуется установка дополнительных программ. Онлайн-казино Vavada работает прямо через браузер, что значительно облегчает доступ в аккаунт и разделам сайта. При возникновении технических проблем пользователи могут зайти через Vavada зеркало, повторяет функционал основного сайта.
В пространстве онлайн-казино и игр на ставки ключевое значение имеет не только качество игровой платформы, но и гарантии безопасности. С гарантированной лицензией, которая гарантирует надежность, сайт <a href="https://www.ippo.ru/archive/tab/last/keyword/11014">https://www.ippo.ru/archive/tab/last/keyword/11014</a> выступает одним из топовых платформ среди платформ для азартных игр. Компания работает на повышение качества сервиса, улучшая функционал, чтобы гарантировать пользователям первоклассный игровой опыт.
Приветственный бонус: Выгодный старт для клиентов
Для новых игроков на платформе 1win доступен щедрый приветственный бонус, который существенно увеличивает стартовый капитал. Это предложение является одним из выгодных на в мире онлайн-гемблинга, так как дает возможность новым клиентам получить дополнительный капитал, значительно улучшив стартовые позиции. Быстрая регистрация и пополнение счета мгновенно активируют бонус, что делает его доступ комфортным.
Live-ставки: Играйте на события вживую с максимальным удобством
В экосистеме букмекерства главной отличительной чертой является изменчивость и шанс учесть изменения в реальном времени. 1win даёт шанс тысячи спортивных событий, доступных в формате игры вживую. Мы организуем лайв-ставки к международным локальным и глобальным турнирам, будь то хоккей.
Полная ссылка на страницу: https://www.ippo.ru/archive/tab/last/keyword/11014
Букмекерские ставки в лайве гарантируют игрокам быстро подстраиваться, что делает процесс насыщенным эмоциями, но и серьёзным испытанием навыков. С помощью аналитики платформы, игроки могут увеличивать вероятность выигрыша, оптимизируя стратегию. Каждое событие содержит анализ игры, что способствует точным прогнозам предупреждать проигрыши.
Vavada казино — является одно из лучших и проверенных временем казино для ценителей азартных игр. За счет актуального дизайна, разнообразию игр и привлекательным условиям для гостей, <a href="http://bitreyd.nnov.org/common/redir.php?https://vavada-casino888-12.top/">vavada официальный сайт </a> завоевало репутацию отличной платформы для всех, кто жаждет найти безупречный игровой процесс. В этом материале мы опишем особенности официального сайта Vavada, процесс создания аккаунта и входа, а также расскажем про Vavada бонусы и о том, как получить актуальные рабочие зеркала Vavada.
Основные плюсы платформы казино Вавада
Сайт казино Vavada выделяется по сравнению с аналогами благодаря интуитивно понятного дизайна, мгновенной загрузке и адаптивному дизайну. Независимо от гаджет подключено, будь то компьютер, планшетный ПК или смартфон, платформа Vavada casino работает идеально, гарантируя удобный вход к игровым слотам и возможностям.
Сайт: http://bitreyd.nnov.org/common/redir.php?https://vavada-casino888-12.top/
Чтобы попасть на ресурс не необходима загрузка ПО. Онлайн-казино Vavada работает прямо через браузер, что значительно облегчает доступ к личному кабинету и разделам сайта. При возникновении блокировок гости могут перейти на Vavada зеркало, повторяет функции основного портала.
В экосистеме игровых платформ и ставок в спорте приоритетное значение имеет не только качество обслуживания, но и доверие к оператору. С лицензионными гарантиями, которая обеспечивает соблюдение стандартов, сайт <a href="https://www.dagcardiocenter.ru/news/radiochastotnaya-ablatsiya-rcha">https://www.dagcardiocenter.ru/news/radiochastotnaya-ablatsiya-rcha</a> находится среди ведущих игроков среди платформ для азартных игр. Платформа работает на повышение качества сервиса, разрабатывая новые функции, чтобы обеспечить пользователям максимальный комфорт.
Приветственный бонус: Выгодный старт для новых пользователей
Для новых пользователей на платформе 1win доступен в предложении солидный приветственный бонус, который существенно увеличивает стартовый капитал. Это предложение является одним из лучших на рынке, так как помогает новым пользователям моментально воспользоваться бонусом, сократив риски. Быстрая регистрация и пополнение счета моментально активируют предложение, что делает его применение простым и доступным.
Live-ставки: Играйте на события вживую с максимальным удобством
В пространстве спортивных ставок главной отличительной чертой является быстрота реакции и способность адаптироваться в режиме реального времени. 1win приглашает большой спектр спортивных событий, доступных в формате ставок в режиме реального времени. Мы предлагаем ставки к ключевым соревнованиям и матчам, будь то теннис.
Полная ссылка на страницу: https://www.dagcardiocenter.ru/news/radiochastotnaya-ablatsiya-rcha
Букмекерские ставки в лайве обеспечивают шанс реагировать в реальном времени, что делает процесс стратегически насыщенным, но и интеллектуально интересным. Благодаря аналитическим данным платформы, клиенты могут делать ставки с уверенностью, улучшая тактику игры. Каждое событие освещается статистикой, что делает процесс ещё более обоснованным предупреждать проигрыши.
Онлайн-казино Vavada — это одно из топовых и проверенных временем казино среди любителей игровых автоматов. С помощью современного подхода, разнообразию игр и привлекательным условиям для игроков, <a href="https://cache.julialang.org/https://vavada-casino888-12.top/">vavada вход </a> обрело статус идеальной площадки для всех, кто хочет получить надежный азартный отдых. В этом материале мы подробно рассмотрим функции официального сайта Vavada, этапы регистрации на сайте и авторизации, а также поговорим про Vavada бонусы и о том, где найти работающие Vavada зеркало.
Основные плюсы платформы казино Вавада
Сайт казино Vavada отличается по сравнению с аналогами благодаря интуитивно понятного интерфейса, высокой скорости работы и кроссплатформенности. Независимо от устройство находится у вас, будь то ноутбук, планшет или телефон, платформа Vavada casino загружается моментально, гарантируя плавный доступ к разделам и возможностям.
Сайт: https://cache.julialang.org/https://vavada-casino888-12.top/
Чтобы попасть на ресурс не нужно загрузка ПО. Vavada casino запускается прямо через браузер, что значительно облегчает доступ в аккаунт и разделам казино. В случае технических проблем гости могут воспользоваться Vavada зеркало, имеет идентичный весь контент основного портала.
В индустрии виртуальных казино и ставочной деятельности необходимо не только качество игровой платформы, но и высокий уровень доверия. С официальной лицензией, которая подтверждает легальность, сайт <a href="https://uprkul.ru/index.php?option=com_content&view=frontpage&Itemid=62&limit=9&limitstart=75&month=9&year=2021">https://uprkul.ru/index.php?option=com_content&view=frontpage&Itemid=62&limit=9&limitstart=75&month=9&year=2021</a> выступает одним из главных представителей в сфере интерактивных казино. Платформа создает условия для максимального комфорта, постоянно улучшая свои продукты и сервисы, чтобы гарантировать пользователям первоклассный игровой опыт.
Приветственный бонус: Бонус для новичков для новичков казино
Для новичков на платформе 1win предоставляется впечатляющий приветственный бонус, который существенно увеличивает стартовый капитал. Это акция является одним из популярных на в мире онлайн-гемблинга, так как дает возможность новым пользователям заполучить выгодные условия, повысив вероятность успеха. Удобная регистрация и внесение суммы обеспечивают получение бонуса, что делает его использование комфортным.
Live-ставки: Мгновенные возможности для ставок с мгновенными возможностями
В сфере спортивных прогнозов главной отличительной чертой является динамика и умение быстро принимать решения в лайве. 1win даёт доступ тысячи спортивных событий, доступных в формате ставок в лайве. Мы предлагаем ставки к топовым локальным и глобальным турнирам, будь то баскетбол.
Полная ссылка на страницу: https://uprkul.ru/index.php?option=com_content&view=frontpage&Itemid=62&limit=9&limitstart=75&month=9&year=2021
Игра на события вживую дают шанс мгновенно реагировать на изменения, что делает процесс ещё интереснее, но и стратегически насыщенным. Используя передовые аналитические инструменты платформы, игроки платформы могут анализировать события глубже, приумножая выигрышные шансы. Каждое событие предоставляется с аналитическими данными, что делает процесс ещё более обоснованным гарантировать обоснованные ставки.
Онлайн-казино Vavada — является одно из лучших и доверенных казино среди ценителей гэмблинга. С помощью инновационного подхода, широкому ассортименту развлечений и выгодным предложениям для гостей, <a href="http://3d-monster-sex.xxxbit.com/index.php?a=out&f=1&s=2&l=http%3A%2F%2Fvavada-casino-888-9.top">vavada промокод сегодня </a> завоевало статус превосходной площадки для жаждет найти качественный игровой опыт. В обзоре ниже мы опишем функции официального сайта Vavada, порядок регистрации и входа, а также поговорим о бонусах Vavada и о том, как получить работающие рабочие зеркала Vavada.
Преимущества платформы казино Вавада
Vavada официальный сайт отличается на фоне конкурентов с помощью легкого в использовании дизайна, высокой скорости работы и адаптации под устройства. Независимо от устройство находится у вас, будь то компьютер, планшетный ПК или телефон, платформа Vavada casino открывается без задержек, гарантируя комфортное использование к играм и функциям.
Сайт: http://3d-monster-sex.xxxbit.com/index.php?a=out&f=1&s=2&l=http%3A%2F%2Fvavada-casino-888-9.top
Чтобы попасть на платформу не требуется установка дополнительных программ. Vavada casino запускается в веб-версии, что значительно облегчает процесс входа в аккаунт и игровым слотам. Если случаются ограничений пользователи могут перейти на Vavada зеркало, имеет идентичный функционал основного сайта.
В сфере онлайн-казино и ставочной деятельности основное внимание уделяется не только качество предоставляемых услуг, но и доверие к оператору. С лицензией, которая подтверждает честность, сайт <a href="http://www.crb-kizlyar.ru/pedagogam">http://www.crb-kizlyar.ru/pedagogam</a> выступает одним из ведущих игроков среди букмекерских платформ. Платформа уделяет внимание развитие клиентского опыта, разрабатывая новые функции, чтобы дать пользователям первоклассный игровой опыт.
Приветственный бонус: Привлекательное предложение для новых игроков
Для новичков в казино на платформе 1win ожидает вас значительный приветственный бонус, который позволяет начать с уверенностью. Это бонусная программа является одним из наиболее привлекательных на на платформе, так как позволяет игрокам новым пользователям платформы сразу получить доступ к дополнительным средствам, стимулируя успешные ставки. Быстрая регистрация и внесение депозита моментально активируют предложение, что делает его воспользование комфортным.
Live-ставки: Тысячи событий в реальном времени с быстрой реакцией
В экосистеме спортивных прогнозов ключевой особенностью является актуальность и шанс учесть изменения в реальном времени. 1win приглашает большой спектр спортивных событий, доступных в формате лайв-ставок. Мы предлагаем ставки к крупнейшим соревнованиям и матчам, будь то хоккей.
Полная ссылка на страницу: http://www.crb-kizlyar.ru/pedagogam
Ставки в реальном времени открывают возможность мгновенно реагировать на изменения, что делает процесс стратегически насыщенным, но и стратегически насыщенным. С применением аналитических ресурсов платформы, игроки платформы могут принимать более обоснованные решения, улучшая тактику игры. Каждое событие представлено с комментариями, что даёт более полную картину принимать решения на основе актуальных данных.
Игровой клуб Вавада — это одно из топовых и доверенных казино для поклонников гэмблинга. Благодаря инновационного подхода, большому выбору развлечений и щедрым бонусам для игроков, <a href="https://www.consumersadvocate.org/p/atkins-diet-plans-review?url=https://casino-vavada-slots-4.top/">vavada online casino </a> завоевало статус отличной платформы для ищет безупречный игровой процесс. В данной статье мы опишем возможности сайта Vavada casino, этапы регистрации на сайте и входа, а также поговорим о бонусах Vavada и о том, где взять актуальные рабочие зеркала Vavada.
Преимущества официального сайта Vavada
Сайт казино Vavada выделяется на фоне конкурентов за счет легкого в использовании дизайна, высокой скорости работы и адаптации под устройства. Независимо от устройство вы используете, будь то ПК, планшетный ПК или смартфон, сайт Vavada загружается моментально, гарантируя комфортное использование к игровым слотам и функциям.
Сайт: https://www.consumersadvocate.org/p/atkins-diet-plans-review?url=https://vavada-casino-888-9.top/
Чтобы попасть на сайт не необходима установка дополнительных программ. Vavada casino запускается в веб-версии, что значительно облегчает процесс входа в аккаунт и разделам сайта. При возникновении блокировок игроки могут зайти через Актуальные зеркала Vavada, повторяет весь контент основного сайта.
В сфере игровых платформ и ставочных рынков необходимо не только надежность услуг, но и высокий уровень доверия. С разрешением на деятельность, которая гарантирует надежность, сайт <a href="https://maiantiemfood.com/kak-proizvesti-uspeshnuyu-registratsiyu-na-platforme-1win-i-poluchit-dostup-k-udivitelnomu-miru-onlayngemblinga/">https://maiantiemfood.com/kak-proizvesti-uspeshnuyu-registratsiyu-na-platforme-1win-i-poluchit-dostup-k-udivitelnomu-miru-onlayngemblinga/</a> выступает одним из главных представителей в мире онлайн-гемблинга. Организация создает условия для предоставление качественных услуг, совершенствуя предложения, чтобы обеспечить пользователям наивысшее качество услуг.
Приветственный бонус: Выгодный старт для новичков
Для новых игроков на платформе 1win предусмотрен солидный приветственный бонус, который позволяет начать с уверенностью. Это предложение является одним из выгодных на среди конкурентов, так как позволяет новым участникам начать игру с бонусом, стимулируя успешные ставки. Легкий старт и депозит автоматически активируют бонус, что делает его воспользование эффективным и быстрым.
Live-ставки: Лайв-ставки на тысячи событий с моментальными ставками
В индустрии спортивных ставок одним из ключевых элементов является динамика и умение быстро принимать решения в реальном времени. 1win предоставляет возможность десятки тысяч спортивных событий, доступных в формате лайв-ставок. Мы предоставляем доступ к глобальным чемпионатам и играм, будь то волейбол.
Полная ссылка на страницу: https://maiantiemfood.com/kak-proizvesti-uspeshnuyu-registratsiyu-na-platforme-1win-i-poluchit-dostup-k-udivitelnomu-miru-onlayngemblinga/
Ставки в реальном времени дают шанс быстро подстраиваться, что делает процесс насыщенным эмоциями, но и интеллектуально интересным. Пользуясь аналитическими функциями платформы, клиенты могут точнее прогнозировать исходы, увеличивая свои шансы на успех. Каждое событие сопровождается качественной аналитикой, что даёт более полную картину предупреждать проигрыши.
Vavada казино — является одно из лучших и проверенных временем платформ для любителей азартных игр. С помощью инновационного подхода, разнообразию развлечений и привлекательным условиям для пользователей, <a href="http://gosudar.com.ru/go.php?url=https://vavada-casino-888-9.top/">vavada промокод </a> обрело статус идеальной платформы для всех, кто ищет безупречный игровой процесс. В данной статье мы разберем возможности сайта Vavada casino, порядок регистрации и авторизации, а также расскажем про акционные предложения Vavada и о том, как получить свежие зеркальные ссылки Vavada.
Преимущества платформы казино Вавада
Сайт казино Vavada отличается на фоне конкурентов за счет интуитивно понятного дизайна, мгновенной загрузке и кроссплатформенности. Независимо от девайс подключено, будь то ПК, планшет или мобильный телефон, сайт Vavada загружается моментально, гарантируя удобный вход к разделам и возможностям.
Сайт: http://gosudar.com.ru/go.php?url=https://vavada-casino999-10.top/
Для доступа на платформу не нужно установка дополнительных программ. Vavada casino функционирует прямо через браузер, что упрощает доступ в аккаунт и игровым слотам. При возникновении блокировок гости могут перейти на Vavada зеркало, повторяет весь контент основного сайта.
В отрасли игровых платформ и игр на ставки крайне важно не только уровень сервиса, но и надежность оператора. С разрешением на деятельность, которая гарантирует безопасность, сайт <a href="https://www.cross-kpk.ru/index.dll/documents/forum.dll/documents/projects/news.dll?detail=686">https://www.cross-kpk.ru/index.dll/documents/forum.dll/documents/projects/news.dll?detail=686</a> установил себя как ведущих игроков в мире онлайн-гемблинга. Оператор стремится к максимального комфорта, обновляя контент, чтобы дать пользователям первоклассный игровой опыт.
Приветственный бонус: Бонус для новичков для новичков казино
Для новичков на платформе 1win доступен щедрый приветственный бонус, который стимулирует успешное начало. Это бонусная программа является одним из заметных на в индустрии ставок, так как дает возможность новым пользователям платформы получить дополнительный капитал, значительно улучшив стартовые позиции. Легкий старт и первый взнос мгновенно активируют бонус, что делает его использование очень удобным.
Live-ставки: Множество матчей онлайн с реальными шансами на успех
В индустрии спортивных ставок важнейшим фактором является динамика и шанс учесть изменения в лайве. 1win открывает путь множество спортивных событий, доступных в формате онлайн ставок. Мы гарантируем доступ к международным чемпионатам и играм, будь то киберспорт.
Полная ссылка на страницу: https://www.cross-kpk.ru/index.dll/documents/forum.dll/documents/projects/news.dll?detail=686
Лайв-ставки открывают возможность принимать решения мгновенно, что делает процесс более динамичным, но и серьёзным испытанием навыков. С помощью аналитики платформы, клиенты могут анализировать события глубже, увеличивая потенциальные результаты. Каждое событие обеспечено аналитическими обзорами, что способствует точным прогнозам ориентироваться в ставках.
Онлайн-казино Vavada — является одно из лучших и проверенных временем игровых клубов для поклонников азартных игр. Благодаря современного подхода, разнообразию игровых слотов и щедрым бонусам для пользователей, <a href="https://remstroygarant.com/uz_redirect.php?url=https://vavada-casino888-12.top/">официальный сайт vavada </a> завоевало репутацию отличной площадки для всех, кто хочет получить качественный игровой опыт. В данной статье мы разберем особенности платформы казино Вавада, этапы регистрации на сайте и входа, а также поговорим о бонусах Vavada и о том, где взять работающие Vavada зеркало.
Основные плюсы платформы казино Вавада
Официальный ресурс Vavada отличается среди других платформ с помощью легкого в использовании дизайна, высокой скорости работы и адаптивному дизайну. Без разницы, какое устройство вы используете, будь то ноутбук, планшетный ПК или телефон, сайт Vavada открывается без задержек, гарантируя комфортное использование к игровым слотам и возможностям.
Сайт: https://remstroygarant.com/uz_redirect.php?url=https://casino-vavada-slots-4.top/
Для доступа на платформу не нужно установка дополнительных программ. Vavada casino работает непосредственно в браузере, что упрощает доступ к личному кабинету и игровым слотам. В случае блокировок игроки могут воспользоваться Рабочее зеркало Vavada, имеет идентичный функции основного портала.
В индустрии онлайн-казино и спортивных ставок ключевое значение имеет не только качество игровой платформы, но и надежность оператора. С международной лицензией, которая гарантирует безопасность, сайт <a href="https://uprkul.ru/?option=com_content&view=frontpage&Itemid=62&limit=9&month=10&year=2021">https://uprkul.ru/?option=com_content&view=frontpage&Itemid=62&limit=9&month=10&year=2021</a> находится среди топовых платформ в сфере интерактивных казино. Сервис стремится к предоставление качественных услуг, обновляя контент, чтобы обогатить пользователям безупречное взаимодействие.
Приветственный бонус: Бонус для новичков для новичков
Для новичков на платформе 1win предусмотрен солидный приветственный бонус, который помогает начать с преимуществом. Это предложение является одним из заметных на в мире онлайн-гемблинга, так как открывает возможность новым клиентам получить преимущество, значительно улучшив стартовые позиции. Упрощенная процедура регистрации и первый взнос дают возможность воспользоваться бонусом, что делает его доступ приятным и лёгким.
Live-ставки: Тысячи событий в реальном времени с реальными шансами на успех
В пространстве спортивных прогнозов фундаментальным аспектом является стратегическая глубина и шанс учесть изменения в онлайн. 1win приглашает огромное количество спортивных событий, доступных в формате онлайн ставок. Мы гарантируем доступ к топовым локальным и глобальным турнирам, будь то баскетбол.
Полная ссылка на страницу: https://uprkul.ru/?option=com_content&view=frontpage&Itemid=62&limit=9&month=10&year=2021
Игра на события вживую предоставляют возможность быстро подстраиваться, что делает процесс более динамичным, но и тактически интересным. Пользуясь аналитическими функциями платформы, стратеги могут анализировать события глубже, увеличивая потенциальные результаты. Каждое событие содержит анализ игры, что делает процесс ещё более обоснованным гарантировать обоснованные ставки.
Vavada casino — является одним из лучших и надежных игровых клубов среди любителей азартных игр. Благодаря инновационного подхода, большому выбору игр и щедрым бонусам для пользователей, <a href="https://m.easytravel.com.tw/GOMEasytravel.aspx?GO=https%3A%2F%2Fvavada-casino888-12.top">vavada промокод </a> завоевало репутацию превосходной платформы для всех, кто ищет безупречный игровой процесс. В данной статье мы опишем особенности официального сайта Vavada, процесс создания аккаунта и входа, а также поговорим про акционные предложения Vavada и о том, где найти актуальные Vavada зеркало.
Основные плюсы сайта Vavada casino
Vavada официальный сайт выделяется по сравнению с аналогами благодаря простого и удобного пользовательского меню, высокой скорости работы и адаптации под устройства. Независимо от девайс находится у вас, будь то ПК, планшет или смартфон, платформа Vavada casino загружается моментально, обеспечивая комфортное использование к разделам и опциям.
Сайт: https://m.easytravel.com.tw/GOMEasytravel.aspx?GO=https%3A%2F%2Fvavada-casino888-12.top
Для доступа на платформу не нужно скачивание приложений. Vavada online casino работает в веб-версии, что делает удобным процесс входа в аккаунт и разделам сайта. Если случаются ограничений гости могут зайти через Рабочее зеркало Vavada, имеет идентичный функции официального ресурса.
В индустрии интернет-казино и ставок на спорт крайне важно не только качество предоставляемых услуг, но и гарантии безопасности. С официальной лицензией, которая гарантирует безопасность, сайт <a href="https://www.book-hall.ru/news/2014-12-23-1034-4325?page=4">https://www.book-hall.ru/news/2014-12-23-1034-4325?page=4</a> выступает одним из топовых платформ на рынке ставок. Платформа стремится к повышение качества сервиса, разрабатывая новые функции, чтобы гарантировать пользователям максимальный комфорт.
Приветственный бонус: Начальный бонус для новых пользователей
Для новых пользователей на платформе 1win существует впечатляющий приветственный бонус, который существенно увеличивает стартовый капитал. Это предложение является одним из наиболее привлекательных на в отрасли, так как дает возможность новым игрокам получить преимущество, стимулируя успешные ставки. Простая регистрация и перевод средств мгновенно активируют бонус, что делает его получение эффективным и быстрым.
Live-ставки: Множество матчей онлайн с моментальными ставками
В отрасли букмекерства главной отличительной чертой является изменчивость и необходимость предугадывать события в онлайн. 1win предлагает игрокам широкий выбор спортивных событий, доступных в формате ставок в лайве. Мы гарантируем доступ к крупнейшим событиям мирового масштаба, будь то баскетбол.
Полная ссылка на страницу: https://www.book-hall.ru/news/2014-12-23-1034-4325?page=4
Игра на события вживую позволяют пользователям принимать решения мгновенно, что делает процесс более захватывающим, но и тактически интересным. С применением аналитических ресурсов платформы, пользователи могут повышать свои шансы на успех, увеличивая потенциальные результаты. Каждое событие обеспечено аналитическими обзорами, что помогает игрокам предупреждать проигрыши.
В пространстве интернет-казино и ставочных рынков необходимо не только уровень сервиса, но и доверие к оператору. С официальной лицензией, которая гарантирует прозрачность, сайт <a href="https://revolution.rhga.ru/section/?section=sobitiya-revolucii%2F+&PAGEN_2=4&PAGEN_1=128">https://revolution.rhga.ru/section/?section=sobitiya-revolucii%2F+&PAGEN_2=4&PAGEN_1=128</a> считает себя топовых платформ на рынке ставок. Провайдер уделяет внимание предоставление качественных услуг, обновляя платформу, чтобы подарить пользователям непревзойденный опыт.
Приветственный бонус: Начальный бонус для новых игроков
Для новых пользователей на платформе 1win предусмотрен выгодный приветственный бонус, который помогает начать с преимуществом. Это возможность является одним из наиболее привлекательных на рынке, так как помогает новым клиентам казино получить преимущество, значительно улучшив стартовые позиции. Регистрация за несколько минут и перевод средств дают возможность воспользоваться бонусом, что делает его доступ приятным и лёгким.
Live-ставки: Играйте на события вживую с мгновенными возможностями
В сфере букмекерства важнейшей частью является быстрота реакции и способность мгновенно реагировать в лайве. 1win открывает путь большой спектр спортивных событий, доступных в формате лайв-ставок. Мы организуем лайв-ставки к ключевым локальным и глобальным турнирам, будь то футбол.
Полная ссылка на страницу: https://revolution.rhga.ru/section/?section=sobitiya-revolucii%2F+&PAGEN_2=4&PAGEN_1=128
Игра на события вживую обеспечивают шанс моментально адаптироваться, что делает процесс не только увлекательным, но и стратегически насыщенным. Используя передовые аналитические инструменты платформы, стратеги могут анализировать события глубже, оптимизируя стратегию. Каждое событие предоставляется с аналитическими данными, что способствует точным прогнозам гарантировать обоснованные ставки.
В экосистеме виртуальных казино и ставочной деятельности крайне важно не только качество обслуживания, но и надежность оператора. С лицензией, которая гарантирует надежность, сайт <a href="https://www.cross-kpk.ru/index.dll/multimedia.dll/documents/projects/Kristal/multimedia.dll/documents/index.dll?part=15">https://www.cross-kpk.ru/index.dll/multimedia.dll/documents/projects/Kristal/multimedia.dll/documents/index.dll?part=15</a> уверенно занимает главных представителей среди платформ для азартных игр. Компания ориентирована на развитие клиентского опыта, обновляя платформу, чтобы обогатить пользователям непревзойденный опыт.
Приветственный бонус: Привлекательное предложение для новичков
Для новичков в казино на платформе 1win ожидает вас выгодный приветственный бонус, который помогает начать с преимуществом. Это акция является одним из наиболее привлекательных на в отрасли, так как открывает возможность новым клиентам сразу получить доступ к дополнительным средствам, увеличив свои шансы на успешные ставки. Быстрая регистрация и первый взнос моментально активируют предложение, что делает его применение эффективным и быстрым.
Live-ставки: Мгновенные возможности для ставок с быстрой реакцией
В сфере ставочной деятельности ключевой особенностью является динамика и шанс учесть изменения в моментально. 1win даёт доступ огромное количество спортивных событий, доступных в формате ставок в режиме реального времени. Мы располагаем матчами к топовым соревнованиям и матчам, будь то теннис.
Полная ссылка на страницу: https://www.cross-kpk.ru/index.dll/multimedia.dll/documents/projects/Kristal/multimedia.dll/documents/index.dll?part=15
Игра в лайве гарантируют игрокам быстро подстраиваться, что делает процесс насыщенным эмоциями, но и тактически интересным. С помощью аналитики платформы, клиенты могут увеличивать вероятность выигрыша, увеличивая потенциальные результаты. Каждое событие предоставляется с аналитическими данными, что помогает игрокам предсказывать результат с уверенностью.
Vavada casino — это одной из лучших и надежных казино для любителей гэмблинга. Благодаря актуального дизайна, разнообразию развлечений и щедрым бонусам для гостей, <a href="https://www.undertow.club/redirector.php?url=https://vavada-casino-888-9.top/">vavada online casino </a> получило статус превосходной площадки для ищет безупречный игровой процесс. В этом материале мы подробно рассмотрим особенности платформы казино Вавада, этапы регистрации и входа, а также поговорим про акционные предложения Vavada и о том, где найти актуальные рабочие зеркала Vavada.
Основные плюсы платформы казино Вавада
Официальный ресурс Vavada привлекает внимание среди других платформ благодаря простого и удобного дизайна, быстрому отклику и кроссплатформенности. Без разницы, какое гаджет находится у вас, будь то компьютер, планшетный ПК или телефон, Vavada официальный сайт работает идеально, обеспечивая комфортное использование к игровым слотам и опциям.
Сайт: https://www.undertow.club/redirector.php?url=https://vavada-casino999-10.top/
Для доступа на ресурс не необходима скачивание приложений. Онлайн-казино Vavada работает непосредственно в браузере, что делает удобным доступ в аккаунт и разделам казино. В случае технических проблем гости могут воспользоваться Vavada зеркало, имеет идентичный весь контент официального ресурса.
В мире онлайн-казино и ставок в спорте ключевое значение имеет не только качество обслуживания, но и доверие к оператору. С лицензионными гарантиями, которая гарантирует надежность, сайт <a href="http://museum-bogotol.ru/news/741/">http://museum-bogotol.ru/news/741/</a> считает себя главных представителей среди платформ для азартных игр. Провайдер сфокусирована на создание благоприятных условий, совершенствуя предложения, чтобы подарить пользователям наивысшее качество услуг.
Приветственный бонус: Щедрый бонус для новичков казино
Для новичков на платформе 1win предусмотрен солидный приветственный бонус, который стимулирует успешное начало. Это бонусная программа является одним из популярных на в отрасли, так как помогает новым клиентам казино получить дополнительный капитал, повысив вероятность успеха. Упрощенная процедура регистрации и внесение суммы автоматически активируют бонус, что делает его активацию простым и доступным.
Live-ставки: Лайв-ставки на тысячи событий с мгновенными возможностями
В пространстве букмекерства фундаментальным аспектом является быстрота реакции и возможность реагировать на изменения в на ходу. 1win предлагает игрокам огромное количество спортивных событий, доступных в формате ставок на события в реальном времени. Мы организуем лайв-ставки к крупнейшим международным и локальным соревнованиям, будь то теннис.
Полная ссылка на страницу: http://museum-bogotol.ru/news/741/
Ставки в реальном времени дают шанс учитывать динамику событий, что делает процесс стратегически насыщенным, но и полезным для стратегии. Используя стратегии и аналитику платформы, игроки платформы могут увеличивать вероятность выигрыша, оптимизируя стратегию. Каждое событие представлено с комментариями, что даёт более полную картину выбирать тактику исходя из фактов.
Онлайн-казино Vavada — является одно из лучших и доверенных платформ для ценителей игровых автоматов. Благодаря инновационного подхода, разнообразию игр и выгодным предложениям для пользователей, <a href="https://www.kuharka.ru/go/?vavada-casino-play-10.top">vavada промокод сегодня </a> обрело репутацию отличной платформы для всех, кто ищет качественный игровой опыт. В обзоре ниже мы подробно рассмотрим особенности официального сайта Vavada, порядок регистрации на сайте и авторизации, а также объясним про акционные предложения Vavada и о том, как получить свежие рабочие зеркала Vavada.
Достоинства официального сайта Vavada
Vavada официальный сайт отличается среди других платформ с помощью простого и удобного интерфейса, мгновенной загрузке и адаптации под устройства. Без разницы, какое гаджет подключено, будь то компьютер, планшетный ПК или телефон, сайт Vavada работает идеально, обеспечивая плавный доступ к играм и возможностям.
Сайт: https://www.kuharka.ru/go/?vavada-casino999-10.top
Чтобы попасть на платформу не необходима установка дополнительных программ. Vavada online casino функционирует прямо через браузер, что делает удобным процесс входа в аккаунт и разделам сайта. При возникновении блокировок пользователи могут воспользоваться Рабочее зеркало Vavada, имеет идентичный функционал основного портала.
В мире интерактивных казино и ставок в спорте важно не только надежность услуг, но и гарантии безопасности. С официальной лицензией, которая гарантирует прозрачность, сайт <a href="http://viskatskoe.ru/otvetstvennost-za-nezakonnoe-iz-yatie-pasporta-grazhdanina-rossiyskoy-federatcii.html">http://viskatskoe.ru/otvetstvennost-za-nezakonnoe-iz-yatie-pasporta-grazhdanina-rossiyskoy-federatcii.html</a> считает себя ключевых участников в мире онлайн-гемблинга. Провайдер создает условия для предоставление качественных услуг, разрабатывая новые функции, чтобы предоставить пользователям первоклассный игровой опыт.
Приветственный бонус: Привлекательное предложение для новых игроков
Для новых игроков на платформе 1win существует солидный приветственный бонус, который увеличивает ваши возможности. Это программа является одним из популярных на в отрасли, так как дает возможность новым пользователям заполучить выгодные условия, значительно улучшив стартовые позиции. Регистрация за несколько минут и депозит обеспечивают получение бонуса, что делает его использование эффективным и быстрым.
Live-ставки: Мгновенные возможности для ставок с широким выбором
В экосистеме ставок на спорт важнейшей частью является быстрота реакции и способность адаптироваться в режиме реального времени. 1win приглашает тысячи спортивных событий, доступных в формате ставок на события в реальном времени. Мы предоставляем доступ к ведущим соревнованиям и матчам, будь то футбол.
Полная ссылка на страницу: http://viskatskoe.ru/otvetstvennost-za-nezakonnoe-iz-yatie-pasporta-grazhdanina-rossiyskoy-federatcii.html
Лайв-ставки гарантируют игрокам мгновенно реагировать на изменения, что делает процесс насыщенным эмоциями, но и тактически интересным. Пользуясь аналитическими функциями платформы, игроки могут точнее прогнозировать исходы, увеличивая свои шансы на успех. Каждое событие сопровождается качественной аналитикой, что способствует точным прогнозам предсказывать результат с уверенностью.
Vavada казино — это одной из топовых и проверенных временем игровых клубов для любителей игровых автоматов. За счет современного подхода, разнообразию игровых слотов и щедрым бонусам для игроков, <a href="https://mirdetstva.printdirect.ru/utils/redirect?url=https://vavada-casino888-12.top/">казино вавада </a> получило репутацию превосходной площадки для всех, кто хочет получить качественный игровой опыт. В данной статье мы подробно рассмотрим возможности сайта Vavada casino, процесс создания аккаунта и входа, а также расскажем о бонусах Vavada и о том, где найти свежие Vavada зеркало.
Основные плюсы официального сайта Vavada
Сайт казино Vavada выделяется по сравнению с аналогами за счет легкого в использовании интерфейса, мгновенной загрузке и адаптации под устройства. Независимо от устройство находится у вас, будь то ноутбук, планшет или смартфон, сайт Vavada работает идеально, обеспечивая комфортное использование к игровым слотам и опциям.
Сайт: https://mirdetstva.printdirect.ru/utils/redirect?url=https://vavada-casino888-12.top/
Чтобы попасть на платформу не нужно загрузка ПО. Онлайн-казино Vavada работает прямо через браузер, что значительно облегчает процесс входа к личному кабинету и разделам казино. Если случаются блокировок гости могут зайти через Рабочее зеркало Vavada, повторяет функции основного сайта.
В пространстве игровых платформ и игр на ставки важно не только качество игровой платформы, но и надежность оператора. С разрешением на деятельность, которая гарантирует прозрачность, сайт <a href="http://how-to-learn-any-language.com/forum/forum_posts.asp?TID=30554&PN=15&TPN=52">http://how-to-learn-any-language.com/forum/forum_posts.asp?TID=30554&PN=15&TPN=52</a> находится среди лидеров среди букмекерских платформ. Сервис уделяет внимание развитие клиентского опыта, совершенствуя предложения, чтобы дать пользователям захватывающий игровой процесс.
Приветственный бонус: Привлекательное предложение для новых пользователей
Для новых участников на платформе 1win существует значительный приветственный бонус, который существенно увеличивает стартовый капитал. Это программа является одним из заметных на в индустрии ставок, так как позволяет новым участникам получить дополнительный капитал, получив дополнительные ресурсы для ставок. Быстрая регистрация и перевод средств автоматически активируют бонус, что делает его применение комфортным.
Live-ставки: Спортивные события в режиме реального времени с реальными шансами на успех
В экосистеме онлайн-ставок важнейшей частью является изменчивость и способность адаптироваться в на ходу. 1win даёт доступ множество спортивных событий, доступных в формате игры вживую. Мы гарантируем доступ к глобальным событиям мирового масштаба, будь то хоккей.
Полная ссылка на страницу: http://how-to-learn-any-language.com/forum/forum_posts.asp?TID=30554&PN=15&TPN=52
Онлайн-ставки дают шанс быстро подстраиваться, что делает процесс более динамичным, но и интеллектуально интересным. С помощью аналитики платформы, игроки платформы могут делать ставки с уверенностью, приумножая выигрышные шансы. Каждое событие освещается статистикой, что способствует точным прогнозам ориентироваться в ставках.
Vavada казино — является одной из наиболее востребованных и проверенных временем платформ для поклонников игровых автоматов. С помощью инновационного подхода, широкому ассортименту развлечений и привлекательным условиям для гостей, <a href="https://vveb.ws/redirect.php?redirect=https://casino-vavada-slots-4.top/">вавада казино </a> обрело статус отличной платформы для всех, кто жаждет найти качественный игровой опыт. В данной статье мы разберем возможности официального сайта Vavada, порядок регистрации и входа, а также расскажем про Vavada бонусы и о том, где найти актуальные зеркальные ссылки Vavada.
Достоинства платформы казино Вавада
Vavada официальный сайт привлекает внимание среди других платформ за счет легкого в использовании интерфейса, высокой скорости работы и адаптации под устройства. Без разницы, какое устройство находится у вас, будь то компьютер, планшетный ПК или телефон, платформа Vavada casino загружается моментально, гарантируя плавный доступ к разделам и опциям.
Сайт: https://vveb.ws/redirect.php?redirect=https://vavada-casino-888-9.top/
Для доступа на платформу не требуется скачивание приложений. Vavada casino функционирует в веб-версии, что делает удобным процесс входа к личному кабинету и разделам сайта. При возникновении блокировок игроки могут зайти через Vavada зеркало, имеет идентичный весь контент основного сайта.
В индустрии интерактивных казино и ставок в спорте ключевое значение имеет не только надежность услуг, но и высокий уровень доверия. С лицензией, которая подтверждает честность, сайт <a href="https://www.uprkul.ru/index.php?option=com_content&view=frontpage&Itemid=62&limit=9&month=7&year=2024&limitstart=120">https://www.uprkul.ru/index.php?option=com_content&view=frontpage&Itemid=62&limit=9&month=7&year=2024&limitstart=120</a> находится среди ведущих игроков на рынке ставок. Сервис ориентирована на создание благоприятных условий, совершенствуя предложения, чтобы гарантировать пользователям безупречное взаимодействие.
Приветственный бонус: Щедрый бонус для новичков
Для новых клиентов на платформе 1win доступен в предложении щедрый приветственный бонус, который увеличивает ваши возможности. Это подарок является одним из заметных на в индустрии ставок, так как дает возможность новым клиентам казино получить преимущество, значительно улучшив стартовые позиции. Простая регистрация и внесение депозита дают возможность воспользоваться бонусом, что делает его воспользование комфортным.
Live-ставки: Множество матчей онлайн с широким выбором
В экосистеме спортивных прогнозов фундаментальным аспектом является стратегическая глубина и способность адаптироваться в режиме реального времени. 1win открывает путь широкий выбор спортивных событий, доступных в формате онлайн ставок. Мы организуем лайв-ставки к ключевым чемпионатам и играм, будь то теннис.
Полная ссылка на страницу: https://www.uprkul.ru/index.php?option=com_content&view=frontpage&Itemid=62&limit=9&month=7&year=2024&limitstart=120
Игра на события вживую обеспечивают шанс реагировать в реальном времени, что делает процесс не только увлекательным, но и полезным для стратегии. Используя передовые аналитические инструменты платформы, игроки платформы могут увеличивать вероятность выигрыша, приумножая выигрышные шансы. Каждое событие освещается статистикой, что позволяет лучше анализировать гарантировать обоснованные ставки.
Vavada казино — является одной из самых популярных и надежных платформ для поклонников гэмблинга. С помощью инновационного подхода, широкому ассортименту игровых слотов и привлекательным условиям для игроков, <a href="https://cache.julialang.org/https://vavada-casino-play-10.top/">vavada casino </a> получило репутацию превосходной площадки для всех, кто хочет получить надежный азартный отдых. В этом материале мы опишем функции платформы казино Вавада, порядок создания аккаунта и входа в личный кабинет, а также объясним про акционные предложения Vavada и о том, где найти работающие рабочие зеркала Vavada.
Основные плюсы сайта Vavada casino
Сайт казино Vavada привлекает внимание среди других платформ за счет легкого в использовании дизайна, высокой скорости работы и адаптации под устройства. Без разницы, какое гаджет вы используете, будь то ноутбук, планшет или мобильный телефон, Vavada официальный сайт загружается моментально, обеспечивая плавный доступ к играм и опциям.
Сайт: https://cache.julialang.org/https://vavada-casino888-12.top/
Для доступа на ресурс не нужно скачивание приложений. Онлайн-казино Vavada запускается в веб-версии, что значительно облегчает процесс входа в аккаунт и игровым слотам. В случае технических проблем пользователи могут перейти на Актуальные зеркала Vavada, повторяет функционал основного портала.
В экосистеме виртуальных казино и игр на ставки ключевое значение имеет не только качество сервиса, но и высокий уровень доверия. С лицензией, которая подтверждает легальность, сайт <a href="https://www.cross-kpk.ru/index.dll/documents/projects/multimedia.dll/multimedia.dll/documents/projects/news.dll?detail=585">https://www.cross-kpk.ru/index.dll/documents/projects/multimedia.dll/multimedia.dll/documents/projects/news.dll?detail=585</a> занимает топовых платформ на рынке ставок. Провайдер создает условия для развитие клиентского опыта, обновляя контент, чтобы гарантировать пользователям первоклассный игровой опыт.
Приветственный бонус: Бонус для новичков для новых пользователей
Для новых пользователей на платформе 1win доступен в предложении щедрый приветственный бонус, который существенно увеличивает стартовый капитал. Это предложение является одним из выгодных на на платформе, так как помогает новым участникам сразу получить доступ к дополнительным средствам, увеличив свои шансы на успешные ставки. Удобная регистрация и внесение суммы обеспечивают получение бонуса, что делает его активацию эффективным и быстрым.
Live-ставки: Мгновенные возможности для ставок с мгновенными возможностями
В пространстве спортивных ставок одним из ключевых элементов является актуальность и возможность реагировать на изменения в моментально. 1win предоставляет возможность десятки тысяч спортивных событий, доступных в формате ставок на события в реальном времени. Мы предлагаем ставки к крупнейшим соревнованиям и матчам, будь то футбол.
Полная ссылка на страницу: https://www.cross-kpk.ru/index.dll/documents/projects/multimedia.dll/multimedia.dll/documents/projects/news.dll?detail=585
Игра в лайве гарантируют игрокам учитывать динамику событий, что делает процесс не только увлекательным, но и аналитически богатым. Используя передовые аналитические инструменты платформы, стратеги могут делать ставки с уверенностью, увеличивая свои шансы на успех. Каждое событие предоставляется с аналитическими данными, что способствует точным прогнозам принимать решения на основе актуальных данных.
Vavada casino — является одним из топовых и проверенных временем платформ для поклонников азартных игр. С помощью современного подхода, разнообразию игровых слотов и выгодным предложениям для игроков, <a href="https://ddlvid.com/redirect?url=https://vavada-casino999-10.top/">vavada регистрация </a> завоевало статус превосходной платформы для всех, кто ищет надежный азартный отдых. В этом материале мы опишем возможности официального сайта Vavada, процесс создания аккаунта и авторизации, а также поговорим про акционные предложения Vavada и о том, где взять работающие зеркальные ссылки Vavada.
Основные плюсы официального сайта Vavada
Сайт казино Vavada привлекает внимание среди других платформ с помощью интуитивно понятного дизайна, быстрому отклику и адаптивному дизайну. Независимо от гаджет подключено, будь то компьютер, планшет или телефон, платформа Vavada casino открывается без задержек, гарантируя плавный доступ к разделам и возможностям.
Сайт: https://ddlvid.com/redirect?url=https://vavada-casino888-12.top/
Для доступа на платформу не нужно скачивание приложений. Онлайн-казино Vavada работает прямо через браузер, что делает удобным процесс входа в аккаунт и игровым слотам. При возникновении блокировок пользователи могут зайти через Рабочее зеркало Vavada, имеет идентичный функционал основного портала.
В отрасли интернет-казино и спортивных ставок важно не только качество игровой платформы, но и надежность оператора. С гарантированной лицензией, которая гарантирует безопасность, сайт <a href="https://www.cross-kpk.ru/index.dll/documents/projects/Kristal/forum.dll/multimedia.dll/documents/projects/index.dll?part=10">https://www.cross-kpk.ru/index.dll/documents/projects/Kristal/forum.dll/multimedia.dll/documents/projects/index.dll?part=10</a> находится среди топовых платформ среди букмекерских платформ. Организация создает условия для развитие клиентского опыта, совершенствуя предложения, чтобы дать пользователям первоклассный игровой опыт.
Приветственный бонус: Привлекательное предложение для новых игроков
Для новых пользователей на платформе 1win существует значительный приветственный бонус, который позволяет начать с уверенностью. Это программа является одним из наиболее привлекательных на среди конкурентов, так как предоставляет шанс новым клиентам казино получить преимущество, получив дополнительные ресурсы для ставок. Упрощенная процедура регистрации и перевод средств мгновенно активируют бонус, что делает его применение простым и доступным.
Live-ставки: Спортивные события в режиме реального времени с широким выбором
В экосистеме ставок на спорт важнейшим фактором является стратегическая глубина и возможность реагировать на изменения в на ходу. 1win приглашает множество спортивных событий, доступных в формате игры вживую. Мы предлагаем ставки к международным чемпионатам и играм, будь то хоккей.
Полная ссылка на страницу: https://www.cross-kpk.ru/index.dll/documents/projects/Kristal/forum.dll/multimedia.dll/documents/projects/index.dll?part=10
Игра на события вживую дают шанс учитывать динамику событий, что делает процесс более динамичным, но и стратегически насыщенным. Используя стратегии и аналитику платформы, любители ставок могут точнее прогнозировать исходы, приумножая выигрышные шансы. Каждое событие содержит анализ игры, что делает процесс ещё более обоснованным выбирать тактику исходя из фактов.
Vavada казино — это одной из топовых и доверенных казино среди поклонников гэмблинга. С помощью актуального дизайна, разнообразию развлечений и выгодным предложениям для гостей, <a href="https://www.consumersadvocate.org/p/atkins-diet-plans-review?url=https://vavada-casino888-12.top/">вавада вход </a> обрело статус идеальной площадки для хочет получить качественный игровой опыт. В этом материале мы подробно рассмотрим функции сайта Vavada casino, этапы регистрации и авторизации, а также объясним про Vavada бонусы и о том, где найти актуальные Vavada зеркало.
Достоинства платформы казино Вавада
Сайт казино Vavada выделяется среди других платформ с помощью простого и удобного интерфейса, мгновенной загрузке и адаптивному дизайну. Без разницы, какое девайс находится у вас, будь то компьютер, планшетный ПК или телефон, Vavada официальный сайт работает идеально, гарантируя плавный доступ к играм и опциям.
Сайт: https://www.consumersadvocate.org/p/atkins-diet-plans-review?url=https://vavada-casino999-10.top/
Чтобы попасть на ресурс не нужно установка дополнительных программ. Vavada online casino работает в веб-версии, что значительно облегчает доступ в аккаунт и игровым слотам. При возникновении технических проблем игроки могут перейти на Рабочее зеркало Vavada, имеет идентичный весь контент официального ресурса.
В экосистеме интерактивных казино и спортивных ставок ключевое значение имеет не только качество обслуживания, но и честность оператора. С официальной лицензией, которая подтверждает честность, сайт <a href="https://pvzrayon.ru/novosti/page/384/">https://pvzrayon.ru/novosti/page/384/</a> занимает ключевых участников среди платформ для азартных игр. Организация сфокусирована на повышение качества сервиса, обновляя платформу, чтобы гарантировать пользователям наивысшее качество услуг.
Приветственный бонус: Привлекательное предложение для новичков
Для новых клиентов на платформе 1win ожидает вас значительный приветственный бонус, который увеличивает ваши возможности. Это подарок является одним из выгодных на в мире онлайн-гемблинга, так как предоставляет шанс новым игрокам начать игру с бонусом, повысив вероятность успеха. Быстрая регистрация и пополнение счета автоматически активируют бонус, что делает его активацию приятным и лёгким.
Live-ставки: Множество матчей онлайн с быстрой реакцией
В отрасли ставочной деятельности ключевой особенностью является актуальность и способность мгновенно реагировать в лайве. 1win даёт доступ множество спортивных событий, доступных в формате ставок в режиме реального времени. Мы располагаем матчами к топовым соревнованиям и матчам, будь то теннис.
Полная ссылка на страницу: https://pvzrayon.ru/novosti/page/384/
Онлайн-ставки обеспечивают шанс быстро подстраиваться, что делает процесс стратегически насыщенным, но и серьёзным испытанием навыков. С помощью аналитики платформы, стратеги могут делать ставки с уверенностью, увеличивая потенциальные результаты. Каждое событие предоставляется с аналитическими данными, что способствует точным прогнозам предупреждать проигрыши.
Игровой клуб Вавада — это одним из самых популярных и надежных игровых клубов среди поклонников азартных игр. Благодаря современного подхода, большому выбору развлечений и выгодным предложениям для гостей, <a href="https://sbtg.ru/ap/redirect.aspx?l=https://vavada-casino-play-10.top/">vavada зеркало </a> завоевало репутацию отличной площадки для жаждет найти качественный игровой опыт. В обзоре ниже мы подробно рассмотрим особенности сайта Vavada casino, процесс создания аккаунта и входа в личный кабинет, а также поговорим о бонусах Vavada и о том, где взять актуальные зеркальные ссылки Vavada.
Преимущества платформы казино Вавада
Vavada официальный сайт выделяется по сравнению с аналогами благодаря легкого в использовании дизайна, мгновенной загрузке и адаптации под устройства. Без разницы, какое гаджет вы используете, будь то ПК, планшет или мобильный телефон, Vavada официальный сайт работает идеально, гарантируя комфортное использование к играм и функциям.
Сайт: https://sbtg.ru/ap/redirect.aspx?l=https://vavada-casino999-10.top/
Для доступа на платформу не требуется скачивание приложений. Vavada online casino работает прямо через браузер, что делает удобным процесс входа к личному кабинету и разделам сайта. При возникновении блокировок гости могут перейти на Рабочее зеркало Vavada, повторяет весь контент официального ресурса.
В отрасли цифровых казино и игр на ставки необходимо не только надежность услуг, но и надежность оператора. С лицензией, которая гарантирует безопасность, сайт <a href="https://book-hall.ru/news/2018-03-19-1242-6234">https://book-hall.ru/news/2018-03-19-1242-6234</a> находится среди лидеров на рынке ставок. Платформа создает условия для создание благоприятных условий, постоянно улучшая свои продукты и сервисы, чтобы гарантировать пользователям безупречное взаимодействие.
Приветственный бонус: Щедрый бонус для новичков
Для новых игроков на платформе 1win существует выгодный приветственный бонус, который увеличивает ваши возможности. Это бонусная программа является одним из популярных на в индустрии ставок, так как дает возможность новым пользователям платформы получить преимущество, стимулируя успешные ставки. Удобная регистрация и депозит зачисляют бонус на счет, что делает его воспользование комфортным.
Live-ставки: Играйте на события вживую с широким выбором
В пространстве онлайн-ставок фундаментальным аспектом является актуальность и шанс учесть изменения в лайве. 1win даёт доступ десятки тысяч спортивных событий, доступных в формате ставок на события в реальном времени. Мы даем возможность играть к глобальным международным и локальным соревнованиям, будь то баскетбол.
Полная ссылка на страницу: https://book-hall.ru/news/2018-03-19-1242-6234
Онлайн-ставки позволяют пользователям принимать решения мгновенно, что делает процесс стратегически насыщенным, но и серьёзным испытанием навыков. Используя стратегии и аналитику платформы, игроки платформы могут точнее прогнозировать исходы, повышая вероятность выигрыша. Каждое событие обеспечено аналитическими обзорами, что даёт более полную картину гарантировать обоснованные ставки.
Онлайн-казино Vavada — является одно из лучших и доверенных игровых клубов среди поклонников игровых автоматов. С помощью актуального дизайна, разнообразию игр и щедрым бонусам для игроков, <a href="https://api.my-samsung.com/api/profile/logoutuser?url=https%3A%2F%2Fcasino-vavada-slots-4.top">вавада рабочее зеркало </a> завоевало статус превосходной платформы для всех, кто ищет надежный азартный отдых. В обзоре ниже мы опишем особенности сайта Vavada casino, процесс регистрации на сайте и авторизации, а также расскажем про акционные предложения Vavada и о том, где найти работающие Vavada зеркало.
Достоинства официального сайта Vavada
Официальный ресурс Vavada отличается среди других платформ за счет простого и удобного пользовательского меню, мгновенной загрузке и кроссплатформенности. Независимо от гаджет вы используете, будь то ноутбук, планшетный ПК или смартфон, сайт Vavada загружается моментально, обеспечивая плавный доступ к разделам и функциям.
Сайт: https://api.my-samsung.com/api/profile/logoutuser?url=https%3A%2F%2Fvavada-casino-888-9.top
Для доступа на платформу не требуется установка дополнительных программ. Vavada casino запускается прямо через браузер, что упрощает процесс входа в аккаунт и разделам казино. Если случаются ограничений игроки могут перейти на Vavada зеркало, которое полностью дублирует функционал официального ресурса.
В индустрии интерактивных казино и ставок в спорте ключевое значение имеет не только уровень сервиса, но и высокий уровень доверия. С международной лицензией, которая гарантирует надежность, сайт <a href="http://temyasovo.ru/category/katalog-dokumentov-npa/dokumenty-administratsii/page/6/">http://temyasovo.ru/category/katalog-dokumentov-npa/dokumenty-administratsii/page/6/</a> считает себя лидеров в области азартных игр. Организация уделяет внимание создание благоприятных условий, совершенствуя предложения, чтобы обогатить пользователям захватывающий игровой процесс.
Приветственный бонус: Привлекательное предложение для новых пользователей
Для новых клиентов на платформе 1win предоставляется значительный приветственный бонус, который значительно увеличивает начальный капитал. Это подарок является одним из лучших на в отрасли, так как позволяет новым пользователям платформы получить преимущество, повысив вероятность успеха. Регистрация за несколько минут и первый взнос обеспечивают получение бонуса, что делает его применение очень удобным.
Live-ставки: Тысячи событий в реальном времени с быстрой реакцией
В мире букмекерства ключевой особенностью является актуальность и шанс учесть изменения в онлайн. 1win предоставляет возможность большой спектр спортивных событий, доступных в формате лайв-ставок. Мы предоставляем доступ к международным спортивным событиям, будь то баскетбол.
Полная ссылка на страницу: http://temyasovo.ru/category/katalog-dokumentov-npa/dokumenty-administratsii/page/6/
Игра на события вживую дают шанс реагировать в реальном времени, что делает процесс насыщенным эмоциями, но и полезным для стратегии. С применением аналитических ресурсов платформы, игроки могут делать ставки с уверенностью, повышая вероятность выигрыша. Каждое событие содержит анализ игры, что позволяет лучше анализировать предупреждать проигрыши.
Vavada casino — это одной из топовых и доверенных игровых клубов среди поклонников азартных игр. За счет актуального дизайна, разнообразию развлечений и щедрым бонусам для пользователей, <a href="http://www.mytokachi.jp/index.php?type=click&mode=sbm&code=2981&url=https://vavada-casino-888-9.top/">vavada вход </a> обрело статус отличной платформы для жаждет найти безупречный игровой процесс. В данной статье мы опишем особенности платформы казино Вавада, процесс регистрации и авторизации, а также объясним про акционные предложения Vavada и о том, как получить работающие зеркальные ссылки Vavada.
Преимущества платформы казино Вавада
Официальный ресурс Vavada отличается по сравнению с аналогами с помощью легкого в использовании дизайна, мгновенной загрузке и адаптации под устройства. Независимо от девайс подключено, будь то ПК, планшетный ПК или мобильный телефон, Vavada официальный сайт загружается моментально, гарантируя комфортное использование к разделам и возможностям.
Сайт: http://www.mytokachi.jp/index.php?type=click&mode=sbm&code=2981&url=https://vavada-casino-888-9.top/
Для доступа на сайт не необходима загрузка ПО. Vavada casino работает в веб-версии, что упрощает доступ к личному кабинету и разделам сайта. Если случаются блокировок пользователи могут воспользоваться Актуальные зеркала Vavada, повторяет функции официального ресурса.
В мире интерактивных казино и ставок в спорте важно не только качество обслуживания, но и гарантии безопасности. С гарантированной лицензией, которая обеспечивает соблюдение стандартов, сайт <a href="https://www.davidealgeri.com/disturbo-fobico-come-affrontarlo/">https://www.davidealgeri.com/disturbo-fobico-come-affrontarlo/</a> занимает лидеров в сфере интерактивных казино. Платформа уделяет внимание развитие клиентского опыта, улучшая функционал, чтобы предоставить пользователям непревзойденный опыт.
Приветственный бонус: Привлекательное предложение для пользователей платформы
Для новых клиентов на платформе 1win предусмотрен значительный приветственный бонус, который помогает начать с преимуществом. Это возможность является одним из ведущих на в отрасли, так как дает возможность новым клиентам казино получить преимущество, увеличив свои шансы на успешные ставки. Упрощенная процедура регистрации и внесение депозита зачисляют бонус на счет, что делает его использование эффективным и быстрым.
Live-ставки: Мгновенные возможности для ставок с широким выбором
В сфере спортивных прогнозов ключевой особенностью является стратегическая глубина и шанс учесть изменения в реальном времени. 1win приглашает множество спортивных событий, доступных в формате ставок в лайве. Мы организуем лайв-ставки к топовым локальным и глобальным турнирам, будь то футбол.
Полная ссылка на страницу: https://www.davidealgeri.com/disturbo-fobico-come-affrontarlo/
Букмекерские ставки в лайве предоставляют возможность реагировать в реальном времени, что делает процесс насыщенным эмоциями, но и полезным для стратегии. Благодаря аналитическим данным платформы, игроки платформы могут принимать более обоснованные решения, увеличивая потенциальные результаты. Каждое событие сопровождается качественной аналитикой, что обогащает принятие решений принимать решения на основе актуальных данных.
Онлайн-казино Vavada — это одно из лучших и доверенных платформ среди любителей азартных игр. Благодаря современного подхода, разнообразию игровых слотов и привлекательным условиям для пользователей, <a href="https://agajmtcknq.cloudimg.io/v7/vavada-casino-play-10.top">вавада казино </a> обрело репутацию идеальной платформы для жаждет найти надежный азартный отдых. В данной статье мы опишем особенности официального сайта Vavada, процесс регистрации и входа, а также поговорим про акционные предложения Vavada и о том, где найти работающие рабочие зеркала Vavada.
Достоинства платформы казино Вавада
Vavada официальный сайт выделяется на фоне конкурентов благодаря простого и удобного пользовательского меню, высокой скорости работы и адаптивному дизайну. Независимо от гаджет вы используете, будь то ноутбук, планшетный ПК или смартфон, платформа Vavada casino работает идеально, гарантируя плавный доступ к играм и опциям.
Сайт: https://agajmtcknq.cloudimg.io/v7/vavada-casino888-12.top
Для доступа на ресурс не нужно скачивание приложений. Vavada online casino запускается в веб-версии, что значительно облегчает доступ в аккаунт и игровым слотам. В случае блокировок игроки могут зайти через Рабочее зеркало Vavada, имеет идентичный весь контент основного портала.
В отрасли цифровых казино и спортивных ставок необходимо не только надежность услуг, но и репутация компании. С официальной лицензией, которая подтверждает честность, сайт <a href="http://dagdiag.ru/o-tsentre/novosti/v-subbotu-02122017g-s-900ch-do-1200ch-v-rdts-dlia-patsientov-organizovan-priem-na-hozraschetnoi-osnove">http://dagdiag.ru/o-tsentre/novosti/v-subbotu-02122017g-s-900ch-do-1200ch-v-rdts-dlia-patsientov-organizovan-priem-na-hozraschetnoi-osnove</a> выступает одним из ведущих игроков среди платформ для азартных игр. Компания стремится к максимального комфорта, совершенствуя предложения, чтобы гарантировать пользователям безупречное взаимодействие.
Приветственный бонус: Привлекательное предложение для новичков
Для новичков в казино на платформе 1win ожидает вас солидный приветственный бонус, который стимулирует успешное начало. Это возможность является одним из заметных на в мире онлайн-гемблинга, так как позволяет игрокам новым игрокам начать игру с бонусом, получив дополнительные ресурсы для ставок. Регистрация за несколько минут и пополнение счета обеспечивают получение бонуса, что делает его активацию максимально удобным и быстрым.
Live-ставки: Играйте на события вживую с реальными шансами на успех
В индустрии ставок на спорт важнейшим фактором является изменчивость и способность мгновенно реагировать в онлайн. 1win приглашает множество спортивных событий, доступных в формате игры вживую. Мы предоставляем доступ к глобальным чемпионатам и играм, будь то волейбол.
Полная ссылка на страницу: http://dagdiag.ru/o-tsentre/novosti/v-subbotu-02122017g-s-900ch-do-1200ch-v-rdts-dlia-patsientov-organizovan-priem-na-hozraschetnoi-osnove
Лайв-ставки позволяют пользователям мгновенно реагировать на изменения, что делает процесс более захватывающим, но и интеллектуально интересным. Используя передовые аналитические инструменты платформы, клиенты могут повышать свои шансы на успех, оптимизируя стратегию. Каждое событие обеспечено аналитическими обзорами, что даёт более полную картину выбирать тактику исходя из фактов.
Онлайн-казино Vavada — является одним из лучших и проверенных временем платформ для ценителей гэмблинга. За счет современного подхода, широкому ассортименту игр и щедрым бонусам для гостей, <a href="http://4geo.ru/redirect/?service=catalog&url=vavada-casino-play-10.top">vavada казино </a> получило репутацию отличной платформы для ищет надежный азартный отдых. В этом материале мы подробно рассмотрим возможности официального сайта Vavada, этапы создания аккаунта и входа в личный кабинет, а также поговорим про Vavada бонусы и о том, как получить свежие рабочие зеркала Vavada.
Преимущества официального сайта Vavada
Vavada официальный сайт привлекает внимание среди других платформ благодаря легкого в использовании интерфейса, быстрому отклику и адаптивному дизайну. Без разницы, какое гаджет вы используете, будь то компьютер, планшетный ПК или мобильный телефон, Vavada официальный сайт загружается моментально, обеспечивая плавный доступ к разделам и опциям.
Сайт: http://4geo.ru/redirect/?service=catalog&url=vavada-casino-888-9.top
Чтобы попасть на сайт не необходима установка дополнительных программ. Vavada casino функционирует в веб-версии, что делает удобным процесс входа к личному кабинету и игровым слотам. В случае технических проблем пользователи могут перейти на Актуальные зеркала Vavada, повторяет функционал основного портала.
В отрасли игровых платформ и игр на ставки приоритетное значение имеет не только надежность услуг, но и честность оператора. С лицензией, которая подтверждает честность, сайт <a href="https://www.cross-kpk.ru/index.dll/forum.dll/multimedia.dll/documents/projects/Zaranica/index.dll?part=5016">https://www.cross-kpk.ru/index.dll/forum.dll/multimedia.dll/documents/projects/Zaranica/index.dll?part=5016</a> уверенно занимает топовых платформ среди платформ для азартных игр. Оператор стремится к оптимальных условий, разрабатывая новые функции, чтобы гарантировать пользователям максимальный комфорт.
Приветственный бонус: Привлекательное предложение для новичков
Для новичков в казино на платформе 1win доступен в предложении большой приветственный бонус, который значительно увеличивает начальный капитал. Это бонусная программа является одним из лучших на в мире онлайн-гемблинга, так как дает возможность новым участникам получить дополнительный капитал, значительно улучшив стартовые позиции. Упрощенная процедура регистрации и пополнение счета обеспечивают получение бонуса, что делает его воспользование эффективным и быстрым.
Live-ставки: Тысячи событий в реальном времени с моментальными ставками
В сфере онлайн-ставок важнейшим фактором является быстрота реакции и способность мгновенно реагировать в лайве. 1win предлагает игрокам широкий выбор спортивных событий, доступных в формате ставок в режиме реального времени. Мы организуем лайв-ставки к ведущим локальным и глобальным турнирам, будь то киберспорт.
Полная ссылка на страницу: https://www.cross-kpk.ru/index.dll/forum.dll/multimedia.dll/documents/projects/Zaranica/index.dll?part=5016
Игра на события вживую предоставляют возможность реагировать в реальном времени, что делает процесс более динамичным, но и полезным для стратегии. Пользуясь аналитическими функциями платформы, игроки могут принимать более обоснованные решения, повышая вероятность выигрыша. Каждое событие содержит анализ игры, что позволяет лучше анализировать выбирать тактику исходя из фактов.
Vavada казино — является одним из лучших и проверенных временем игровых клубов среди ценителей гэмблинга. За счет современного подхода, разнообразию игр и выгодным предложениям для пользователей, <a href="https://golf2club.printdirect.ru/utils/redirect?url=https://vavada-casino-play-10.top/">vavada официальный сайт </a> завоевало репутацию идеальной площадки для всех, кто ищет надежный азартный отдых. В данной статье мы разберем возможности сайта Vavada casino, этапы регистрации на сайте и входа, а также поговорим о бонусах Vavada и о том, где найти свежие рабочие зеркала Vavada.
Основные плюсы сайта Vavada casino
Официальный ресурс Vavada выделяется на фоне конкурентов за счет простого и удобного дизайна, высокой скорости работы и адаптивному дизайну. Без разницы, какое устройство вы используете, будь то ПК, планшетный ПК или мобильный телефон, Vavada официальный сайт открывается без задержек, гарантируя плавный доступ к игровым слотам и функциям.
Сайт: https://golf2club.printdirect.ru/utils/redirect?url=https://vavada-casino999-10.top/
Для доступа на ресурс не требуется установка дополнительных программ. Vavada online casino работает непосредственно в браузере, что упрощает процесс входа в аккаунт и игровым слотам. В случае технических проблем гости могут зайти через Рабочее зеркало Vavada, повторяет функционал официального ресурса.
В мире виртуальных казино и ставочных рынков приоритетное значение имеет не только качество сервиса, но и надежность оператора. С лицензией, которая гарантирует прозрачность, сайт <a href="https://shkola4-vyksa.ru/blog-borba-s-korruptsiej/117-otsenka-korruptsionnykh-riskov">https://shkola4-vyksa.ru/blog-borba-s-korruptsiej/117-otsenka-korruptsionnykh-riskov</a> выступает одним из ведущих игроков в области азартных игр. Платформа сфокусирована на оптимальных условий, обновляя контент, чтобы обеспечить пользователям наивысшее качество услуг.
Приветственный бонус: Бонус для новичков для новых игроков
Для новичков в казино на платформе 1win ожидает вас большой приветственный бонус, который увеличивает ваши возможности. Это подарок является одним из выгодных на в индустрии ставок, так как позволяет игрокам новым пользователям сразу получить доступ к дополнительным средствам, получив дополнительные ресурсы для ставок. Удобная регистрация и первый взнос моментально активируют предложение, что делает его доступ очень удобным.
Live-ставки: Лайв-ставки на тысячи событий с широким выбором
В мире ставок на спорт главной отличительной чертой является изменчивость и умение быстро принимать решения в лайве. 1win даёт шанс большой спектр спортивных событий, доступных в формате игры вживую. Мы даем возможность играть к глобальным событиям мирового масштаба, будь то футбол.
Полная ссылка на страницу: https://shkola4-vyksa.ru/blog-borba-s-korruptsiej/117-otsenka-korruptsionnykh-riskov
Лайв-ставки открывают возможность мгновенно реагировать на изменения, что делает процесс более захватывающим, но и серьёзным испытанием навыков. Используя стратегии и аналитику платформы, игроки могут делать ставки с уверенностью, улучшая тактику игры. Каждое событие содержит анализ игры, что способствует точным прогнозам предсказывать результат с уверенностью.
В мире интерактивных казино и ставок на спорт необходимо не только качество обслуживания, но и честность оператора. С международной лицензией, которая гарантирует прозрачность, сайт <a href="https://www.cross-kpk.ru/news.dll?detail=518">https://www.cross-kpk.ru/news.dll?detail=518</a> выступает одним из топовых платформ в сфере интерактивных казино. Оператор работает на повышение качества сервиса, разрабатывая новые функции, чтобы гарантировать пользователям наивысшее качество услуг.
Приветственный бонус: Привлекательное предложение для новых пользователей
Для новых участников на платформе 1win предусмотрен щедрый приветственный бонус, который значительно увеличивает начальный капитал. Это возможность является одним из выгодных на на платформе, так как открывает возможность новым пользователям получить дополнительный капитал, увеличив свои шансы на успешные ставки. Простая регистрация и внесение депозита дают возможность воспользоваться бонусом, что делает его активацию простым и доступным.
Live-ставки: Множество матчей онлайн с моментальными ставками
В экосистеме ставочной деятельности важнейшей частью является быстрота реакции и способность мгновенно реагировать в режиме реального времени. 1win предоставляет возможность десятки тысяч спортивных событий, доступных в формате ставок в лайве. Мы гарантируем доступ к глобальным событиям мирового масштаба, будь то киберспорт.
Полная ссылка на страницу: https://www.cross-kpk.ru/news.dll?detail=518
Игра на события вживую позволяют пользователям быстро подстраиваться, что делает процесс более захватывающим, но и полезным для стратегии. Благодаря аналитическим данным платформы, клиенты могут повышать свои шансы на успех, увеличивая свои шансы на успех. Каждое событие предоставляется с аналитическими данными, что обогащает принятие решений принимать решения на основе актуальных данных.
Vavada казино — является одной из топовых и доверенных казино среди любителей гэмблинга. Благодаря современного подхода, большому выбору игр и привлекательным условиям для пользователей, <a href="http://intactadro.hit.gemius.pl/_sslredir/hitredir/id=ns.lntuw7vnfgpfowxhh79vqtmkbdsvhlgojhkt.meb.i7/stparam=valnhtgkcp/fastid=iohbdavhtvazduihqowcnvqsqzmp/sarg=nc/url=https://vavada-casino888-12.top/">vavada casino </a> обрело статус отличной площадки для всех, кто жаждет найти качественный игровой опыт. В данной статье мы разберем особенности платформы казино Вавада, процесс регистрации и входа, а также поговорим про Vavada бонусы и о том, где найти работающие рабочие зеркала Vavada.
Основные плюсы платформы казино Вавада
Сайт казино Vavada выделяется по сравнению с аналогами с помощью легкого в использовании дизайна, мгновенной загрузке и кроссплатформенности. Без разницы, какое девайс подключено, будь то компьютер, планшетный ПК или телефон, платформа Vavada casino загружается моментально, обеспечивая комфортное использование к разделам и опциям.
Сайт: http://intactadro.hit.gemius.pl/_sslredir/hitredir/id=ns.lntuw7vnfgpfowxhh79vqtmkbdsvhlgojhkt.meb.i7/stparam=valnhtgkcp/fastid=iohbdavhtvazduihqowcnvqsqzmp/sarg=nc/url=https://vavada-casino999-10.top/
Для доступа на платформу не нужно скачивание приложений. Онлайн-казино Vavada работает в веб-версии, что значительно облегчает процесс входа в аккаунт и разделам казино. Если случаются ограничений пользователи могут воспользоваться Рабочее зеркало Vavada, повторяет функции официального ресурса.
В мире интернет-казино и ставок на спорт основное внимание уделяется не только качество предоставляемых услуг, но и доверие к оператору. С гарантированной лицензией, которая подтверждает честность, сайт <a href="https://cross-kpk.ru/ims.dll?id=1664">https://cross-kpk.ru/ims.dll?id=1664</a> уверенно занимает фаворитов среди платформ для азартных игр. Сервис стремится к повышение качества сервиса, постоянно улучшая свои продукты и сервисы, чтобы дать пользователям захватывающий игровой процесс.
Приветственный бонус: Начальный бонус для новичков казино
Для новых участников на платформе 1win существует значительный приветственный бонус, который позволяет начать с уверенностью. Это возможность является одним из заметных на в мире онлайн-гемблинга, так как дает возможность новым игрокам получить дополнительный капитал, получив дополнительные ресурсы для ставок. Упрощенная процедура регистрации и внесение депозита моментально активируют предложение, что делает его применение эффективным и быстрым.
Live-ставки: Множество матчей онлайн с реальными шансами на успех
В сфере спортивных ставок главной отличительной чертой является темп и умение быстро принимать решения в моментально. 1win предлагает игрокам широкий выбор спортивных событий, доступных в формате лайв-ставок. Мы предлагаем ставки к крупнейшим международным и локальным соревнованиям, будь то футбол.
Полная ссылка на страницу: https://cross-kpk.ru/ims.dll?id=1664
Игра в лайве открывают возможность быстро подстраиваться, что делает процесс насыщенным эмоциями, но и полезным для стратегии. Используя передовые аналитические инструменты платформы, любители ставок могут точнее прогнозировать исходы, улучшая тактику игры. Каждое событие содержит анализ игры, что делает процесс ещё более обоснованным предупреждать проигрыши.
Vavada casino — это одной из лучших и проверенных временем платформ для любителей азартных игр. За счет современного подхода, разнообразию развлечений и выгодным предложениям для гостей, <a href="https://w0a4q94nk4.execute-api.eu-west-1.amazonaws.com/production/ref.php?url=https://vavada-casino-play-10.top/">вавада казино </a> обрело репутацию идеальной платформы для жаждет найти качественный игровой опыт. В этом материале мы разберем функции платформы казино Вавада, процесс регистрации и входа, а также расскажем про Vavada бонусы и о том, как получить актуальные Vavada зеркало.
Основные плюсы официального сайта Vavada
Vavada официальный сайт отличается среди других платформ за счет простого и удобного интерфейса, быстрому отклику и адаптации под устройства. Независимо от устройство подключено, будь то ноутбук, планшетный ПК или смартфон, платформа Vavada casino работает идеально, гарантируя комфортное использование к разделам и функциям.
Сайт: https://w0a4q94nk4.execute-api.eu-west-1.amazonaws.com/production/ref.php?url=https://vavada-casino888-12.top/
Для доступа на платформу не нужно загрузка ПО. Vavada casino работает непосредственно в браузере, что упрощает доступ к личному кабинету и разделам сайта. Если случаются блокировок пользователи могут зайти через Рабочее зеркало Vavada, повторяет функции основного портала.
В индустрии цифровых казино и спортивных ставок приоритетное значение имеет не только качество обслуживания, но и высокий уровень доверия. С разрешением на деятельность, которая гарантирует надежность, сайт <a href="https://nbachati.ru/appeal/answer/?month=07&year=2030">https://nbachati.ru/appeal/answer/?month=07&year=2030</a> уверенно занимает главных представителей в мире онлайн-гемблинга. Оператор уделяет внимание создание благоприятных условий, улучшая функционал, чтобы подарить пользователям захватывающий игровой процесс.
Приветственный бонус: Выгодный старт для новичков
Для новых игроков на платформе 1win доступен в предложении значительный приветственный бонус, который позволяет начать с уверенностью. Это подарок является одним из популярных на в индустрии ставок, так как дает возможность новым участникам моментально воспользоваться бонусом, значительно улучшив стартовые позиции. Регистрация за несколько минут и депозит дают возможность воспользоваться бонусом, что делает его активацию очень удобным.
Live-ставки: Тысячи событий в реальном времени с моментальными ставками
В индустрии ставок на спорт фундаментальным аспектом является изменчивость и умение быстро принимать решения в лайве. 1win предлагает игрокам множество спортивных событий, доступных в формате ставок на события в реальном времени. Мы организуем лайв-ставки к ключевым локальным и глобальным турнирам, будь то киберспорт.
Полная ссылка на страницу: https://nbachati.ru/appeal/answer/?month=07&year=2030
Игра на события вживую обеспечивают шанс принимать решения мгновенно, что делает процесс стратегически насыщенным, но и интеллектуально интересным. С применением аналитических ресурсов платформы, клиенты могут анализировать события глубже, увеличивая потенциальные результаты. Каждое событие обеспечено аналитическими обзорами, что помогает игрокам гарантировать обоснованные ставки.
Игровой клуб Вавада — является одной из наиболее востребованных и надежных казино среди поклонников игровых автоматов. За счет актуального дизайна, большому выбору развлечений и привлекательным условиям для гостей, <a href="https://www.fanatec.com/affiliate/scripts/click.php?a_aid=52726ff6553b8&a_bid=adbb7831&desturl=https://casino-vavada-slots-4.top/">официальный сайт vavada </a> получило статус идеальной площадки для ищет качественный игровой опыт. В обзоре ниже мы подробно рассмотрим особенности платформы казино Вавада, порядок регистрации и входа в личный кабинет, а также поговорим о бонусах Vavada и о том, как получить актуальные рабочие зеркала Vavada.
Достоинства платформы казино Вавада
Сайт казино Vavada привлекает внимание на фоне конкурентов благодаря легкого в использовании пользовательского меню, мгновенной загрузке и адаптивному дизайну. Без разницы, какое девайс вы используете, будь то ноутбук, планшет или телефон, Vavada официальный сайт работает идеально, обеспечивая удобный вход к разделам и функциям.
Сайт: https://www.fanatec.com/affiliate/scripts/click.php?a_aid=52726ff6553b8&a_bid=adbb7831&desturl=https://vavada-casino-888-9.top/
Чтобы попасть на сайт не требуется загрузка ПО. Vavada online casino запускается непосредственно в браузере, что делает удобным процесс входа в аккаунт и разделам сайта. Если случаются блокировок гости могут перейти на Актуальные зеркала Vavada, которое полностью дублирует функции основного портала.
В пространстве игровых платформ и ставок в спорте ключевое значение имеет не только качество обслуживания, но и гарантии безопасности. С лицензионными гарантиями, которая подтверждает честность, сайт <a href="https://book-hall.ru/delimsya-opytom/shkola-nachinayushchego-bibliotekarya/urok-7-sovremennye-zarubezhnye-pisateli-dlya-p?destination=node%2F5118">https://book-hall.ru/delimsya-opytom/shkola-nachinayushchego-bibliotekarya/urok-7-sovremennye-zarubezhnye-pisateli-dlya-p?destination=node%2F5118</a> занимает фаворитов среди букмекерских платформ. Сервис стремится к максимального комфорта, обновляя контент, чтобы подарить пользователям первоклассный игровой опыт.
Приветственный бонус: Выгодный старт для новичков казино
Для новичков в казино на платформе 1win существует солидный приветственный бонус, который помогает начать с преимуществом. Это предложение является одним из наиболее привлекательных на в отрасли, так как дает возможность новым клиентам казино получить дополнительный капитал, значительно улучшив стартовые позиции. Простая регистрация и первый взнос моментально активируют предложение, что делает его активацию приятным и лёгким.
Live-ставки: Множество матчей онлайн с быстрой реакцией
В отрасли спортивных прогнозов фундаментальным аспектом является актуальность и необходимость предугадывать события в моментально. 1win даёт шанс широкий выбор спортивных событий, доступных в формате игры вживую. Мы предоставляем доступ к ключевым чемпионатам и играм, будь то хоккей.
Полная ссылка на страницу: https://book-hall.ru/delimsya-opytom/shkola-nachinayushchego-bibliotekarya/urok-7-sovremennye-zarubezhnye-pisateli-dlya-p?destination=node%2F5118
Лайв-ставки предоставляют возможность принимать решения мгновенно, что делает процесс не только увлекательным, но и аналитически богатым. С применением аналитических ресурсов платформы, игроки платформы могут точнее прогнозировать исходы, увеличивая свои шансы на успех. Каждое событие обеспечено аналитическими обзорами, что даёт более полную картину предсказывать результат с уверенностью.
Онлайн-казино Vavada — является одно из лучших и надежных игровых клубов среди любителей игровых автоматов. С помощью современного подхода, широкому ассортименту игровых слотов и щедрым бонусам для пользователей, <a href="https://rarus-soft.ru/api/v1/url/redirect/?goto=https://vavada-casino-888-9.top/&goto=https://vavada-casino-888-9.top/">вавада вход </a> получило статус превосходной платформы для ищет надежный азартный отдых. В этом материале мы разберем функции платформы казино Вавада, этапы создания аккаунта и авторизации, а также расскажем о бонусах Vavada и о том, как получить свежие рабочие зеркала Vavada.
Достоинства официального сайта Vavada
Vavada официальный сайт отличается среди других платформ благодаря легкого в использовании интерфейса, высокой скорости работы и кроссплатформенности. Без разницы, какое гаджет вы используете, будь то компьютер, планшетный ПК или телефон, сайт Vavada работает идеально, обеспечивая комфортное использование к игровым слотам и опциям.
Сайт: https://rarus-soft.ru/api/v1/url/redirect/?goto=https://vavada-casino999-10.top/&goto=https://vavada-casino999-10.top/
Для доступа на сайт не необходима загрузка ПО. Онлайн-казино Vavada работает непосредственно в браузере, что значительно облегчает доступ в аккаунт и разделам сайта. Если случаются блокировок игроки могут перейти на Vavada зеркало, которое полностью дублирует функционал официального ресурса.
Vavada casino — это одной из самых популярных и проверенных временем платформ для поклонников азартных игр. За счет современного подхода, широкому ассортименту игр и выгодным предложениям для игроков, <a href="http://ozero-chany.ru/away.php?to=https://vavada-casino-888-9.top/">vavada бонусы </a> обрело репутацию превосходной платформы для жаждет найти надежный азартный отдых. В этом материале мы подробно рассмотрим особенности платформы казино Вавада, этапы регистрации и входа в личный кабинет, а также расскажем про Vavada бонусы и о том, где взять актуальные Vavada зеркало.
Достоинства официального сайта Vavada
Сайт казино Vavada отличается среди других платформ благодаря легкого в использовании интерфейса, мгновенной загрузке и кроссплатформенности. Независимо от девайс подключено, будь то ПК, планшет или смартфон, Vavada официальный сайт загружается моментально, гарантируя плавный доступ к играм и функциям.
Сайт: http://ozero-chany.ru/away.php?to=https://casino-vavada-slots-4.top/
Чтобы попасть на сайт не необходима установка дополнительных программ. Vavada casino работает прямо через браузер, что значительно облегчает процесс входа в аккаунт и игровым слотам. В случае блокировок игроки могут зайти через Vavada зеркало, повторяет весь контент основного портала.
В экосистеме интерактивных казино и ставочных рынков основное внимание уделяется не только качество игровой платформы, но и репутация компании. С лицензионными гарантиями, которая гарантирует безопасность, сайт <a href="https://moviediscopuntacana.com/2024/09/1win-skachat-na-android-i-ios-c-ofitsialnogo-sayta-1vin/">https://moviediscopuntacana.com/2024/09/1win-skachat-na-android-i-ios-c-ofitsialnogo-sayta-1vin/</a> считает себя лидеров в области азартных игр. Платформа уделяет внимание оптимальных условий, улучшая функционал, чтобы обеспечить пользователям первоклассный игровой опыт.
Приветственный бонус: Привлекательное предложение для новичков
Для новых пользователей на платформе 1win доступен выгодный приветственный бонус, который увеличивает ваши возможности. Это предложение является одним из наиболее привлекательных на среди конкурентов, так как позволяет новым пользователям платформы моментально воспользоваться бонусом, повысив вероятность успеха. Упрощенная процедура регистрации и пополнение счета мгновенно активируют бонус, что делает его использование очень удобным.
Live-ставки: Тысячи событий в реальном времени с широким выбором
В экосистеме букмекерства главной отличительной чертой является актуальность и возможность реагировать на изменения в режиме реального времени. 1win предлагает игрокам большой спектр спортивных событий, доступных в формате игры вживую. Мы располагаем матчами к топовым спортивным событиям, будь то хоккей.
Полная ссылка на страницу: https://moviediscopuntacana.com/2024/09/1win-skachat-na-android-i-ios-c-ofitsialnogo-sayta-1vin/
Игра в лайве позволяют пользователям учитывать динамику событий, что делает процесс стратегически насыщенным, но и стратегически насыщенным. С применением аналитических ресурсов платформы, любители ставок могут точнее прогнозировать исходы, улучшая тактику игры. Каждое событие обеспечено аналитическими обзорами, что даёт более полную картину выбирать тактику исходя из фактов.
Vavada казино — это одним из наиболее востребованных и проверенных временем платформ для поклонников азартных игр. За счет инновационного подхода, большому выбору развлечений и выгодным предложениям для пользователей, <a href="https://sportaladbg.hit.gemius.pl/_uachredir/hitredir/id=coKan4OmWxibEYKt5EFI1ady78yg5gOmmVP5TV9gnTj.v7/stparam=vmekjljulr/fastid=byhcxzhjuqsyzibchywhwbrbbumw/url=vavada-casino-888-9.top">vavada рабочее зеркало </a> обрело репутацию идеальной платформы для всех, кто ищет качественный игровой опыт. В данной статье мы разберем возможности официального сайта Vavada, процесс создания аккаунта и входа, а также поговорим про Vavada бонусы и о том, как получить свежие рабочие зеркала Vavada.
Достоинства сайта Vavada casino
Сайт казино Vavada отличается по сравнению с аналогами с помощью легкого в использовании пользовательского меню, высокой скорости работы и адаптации под устройства. Без разницы, какое девайс подключено, будь то компьютер, планшет или телефон, сайт Vavada работает идеально, гарантируя комфортное использование к играм и опциям.
Сайт: https://sportaladbg.hit.gemius.pl/_uachredir/hitredir/id=coKan4OmWxibEYKt5EFI1ady78yg5gOmmVP5TV9gnTj.v7/stparam=vmekjljulr/fastid=byhcxzhjuqsyzibchywhwbrbbumw/url=vavada-casino-888-9.top
Для доступа на платформу не требуется скачивание приложений. Онлайн-казино Vavada работает прямо через браузер, что упрощает процесс входа в аккаунт и игровым слотам. При возникновении блокировок игроки могут зайти через Vavada зеркало, имеет идентичный весь контент основного портала.
В индустрии игровых платформ и ставочной деятельности необходимо не только уровень сервиса, но и гарантии безопасности. С лицензией, которая гарантирует прозрачность, сайт <a href="http://akrvo.ru/index.php?option=com_content&view=article&id=29666">http://akrvo.ru/index.php?option=com_content&view=article&id=29666</a> занимает ведущих игроков среди платформ для азартных игр. Организация уделяет внимание повышение качества сервиса, улучшая функционал, чтобы гарантировать пользователям максимальный комфорт.
Приветственный бонус: Премиум-старт для новичков казино
Для новых пользователей на платформе 1win ожидает вас впечатляющий приветственный бонус, который помогает начать с преимуществом. Это программа является одним из выгодных на рынке, так как позволяет новым пользователям сразу получить доступ к дополнительным средствам, значительно улучшив стартовые позиции. Упрощенная процедура регистрации и внесение суммы моментально активируют предложение, что делает его доступ приятным и лёгким.
Live-ставки: Мгновенные возможности для ставок с широким выбором
В сфере онлайн-ставок одним из ключевых элементов является стратегическая глубина и шанс учесть изменения в на ходу. 1win даёт доступ множество спортивных событий, доступных в формате игры вживую. Мы предоставляем доступ к международным международным и локальным соревнованиям, будь то киберспорт.
Полная ссылка на страницу: http://akrvo.ru/index.php?option=com_content&view=article&id=29666
Ставки в реальном времени предоставляют возможность реагировать в реальном времени, что делает процесс ещё интереснее, но и серьёзным испытанием навыков. Используя передовые аналитические инструменты платформы, игроки могут точнее прогнозировать исходы, увеличивая потенциальные результаты. Каждое событие обеспечено аналитическими обзорами, что даёт более полную картину принимать решения на основе актуальных данных.
Игровой клуб Вавада — это одним из лучших и проверенных временем платформ для ценителей игровых автоматов. За счет актуального дизайна, разнообразию игровых слотов и привлекательным условиям для гостей, <a href="http://webloza.nnov.org/common/redir.php?https://vavada-casino999-10.top/">вавада регистрация </a> завоевало статус отличной платформы для всех, кто хочет получить качественный игровой опыт. В данной статье мы подробно рассмотрим возможности сайта Vavada casino, этапы создания аккаунта и авторизации, а также поговорим о бонусах Vavada и о том, как получить актуальные зеркальные ссылки Vavada.
Основные плюсы сайта Vavada casino
Официальный ресурс Vavada привлекает внимание среди других платформ за счет простого и удобного интерфейса, мгновенной загрузке и адаптивному дизайну. Независимо от устройство подключено, будь то ПК, планшет или телефон, сайт Vavada загружается моментально, гарантируя комфортное использование к игровым слотам и опциям.
Сайт: http://webloza.nnov.org/common/redir.php?https://vavada-casino888-12.top/
Для доступа на платформу не необходима установка дополнительных программ. Vavada casino запускается непосредственно в браузере, что значительно облегчает процесс входа в аккаунт и разделам сайта. Если случаются технических проблем игроки могут зайти через Рабочее зеркало Vavada, повторяет функционал официального ресурса.
В мире онлайн-казино и спортивных ставок крайне важно не только качество игровой платформы, но и репутация компании. С лицензией, которая гарантирует надежность, сайт <a href="http://www.gafurovskij.ru/zhitelyam-respubliki-bashkortostan-nuzhno-potoropitsya-s-registratsiej-prav-na-vremennye-zemelnye-uchastki/">http://www.gafurovskij.ru/zhitelyam-respubliki-bashkortostan-nuzhno-potoropitsya-s-registratsiej-prav-na-vremennye-zemelnye-uchastki/</a> занимает лидеров среди платформ для азартных игр. Компания уделяет внимание максимального комфорта, разрабатывая новые функции, чтобы предоставить пользователям первоклассный игровой опыт.
Приветственный бонус: Выгодный старт для новичков казино
Для новых пользователей на платформе 1win доступен впечатляющий приветственный бонус, который стимулирует успешное начало. Это бонусная программа является одним из популярных на среди конкурентов, так как позволяет новым клиентам казино моментально воспользоваться бонусом, значительно улучшив стартовые позиции. Регистрация за несколько минут и депозит автоматически активируют бонус, что делает его получение очень удобным.
Live-ставки: Спортивные события в режиме реального времени с мгновенными возможностями
В пространстве онлайн-ставок фундаментальным аспектом является темп и способность мгновенно реагировать в онлайн. 1win предоставляет возможность широкий выбор спортивных событий, доступных в формате игры вживую. Мы предлагаем ставки к ведущим чемпионатам и играм, будь то хоккей.
Полная ссылка на страницу: http://www.gafurovskij.ru/zhitelyam-respubliki-bashkortostan-nuzhno-potoropitsya-s-registratsiej-prav-na-vremennye-zemelnye-uchastki/
Лайв-ставки открывают возможность учитывать динамику событий, что делает процесс ещё интереснее, но и тактически интересным. С помощью аналитики платформы, игроки платформы могут делать ставки с уверенностью, оптимизируя стратегию. Каждое событие сопровождается качественной аналитикой, что даёт более полную картину предупреждать проигрыши.
Vavada casino — является одним из наиболее востребованных и доверенных платформ среди любителей игровых автоматов. Благодаря инновационного подхода, большому выбору развлечений и щедрым бонусам для игроков, <a href="https://city24adlv.hit.gemius.pl/_uachredir/hitredir/id=olVFz7bFGWnc86IWQU8Pqpci33mIj_8CRQzEPyQ2gTb.y7/stparam=snqjosqsli/fastid=aucpfktmcaqltglmdxytosdgmtlp/nc=0/url=vavada-casino999-10.top">вавада официальный сайт </a> получило репутацию отличной платформы для всех, кто хочет получить качественный игровой опыт. В обзоре ниже мы разберем возможности официального сайта Vavada, процесс создания аккаунта и входа в личный кабинет, а также поговорим про Vavada бонусы и о том, где взять работающие рабочие зеркала Vavada.
Преимущества платформы казино Вавада
Vavada официальный сайт выделяется на фоне конкурентов благодаря легкого в использовании интерфейса, высокой скорости работы и кроссплатформенности. Независимо от девайс находится у вас, будь то ноутбук, планшетный ПК или мобильный телефон, Vavada официальный сайт работает идеально, гарантируя комфортное использование к разделам и функциям.
Сайт: https://city24adlv.hit.gemius.pl/_uachredir/hitredir/id=olVFz7bFGWnc86IWQU8Pqpci33mIj_8CRQzEPyQ2gTb.y7/stparam=snqjosqsli/fastid=aucpfktmcaqltglmdxytosdgmtlp/nc=0/url=casino-vavada-slots-4.top
Для доступа на ресурс не необходима установка дополнительных программ. Vavada online casino запускается прямо через браузер, что упрощает процесс входа в аккаунт и разделам сайта. В случае технических проблем гости могут зайти через Рабочее зеркало Vavada, которое полностью дублирует функции основного сайта.
В экосистеме игровых платформ и игр на ставки основное внимание уделяется не только качество сервиса, но и надежность оператора. С лицензией, которая гарантирует прозрачность, сайт <a href="https://www.yantraharvest.com/1win-stavki-na-sport-unikalnye-vozmozhnosti-i-preimushchestva-vedushchey-platformy-v-mire-onlayngemblinga/">https://www.yantraharvest.com/1win-stavki-na-sport-unikalnye-vozmozhnosti-i-preimushchestva-vedushchey-platformy-v-mire-onlayngemblinga/</a> выступает одним из ведущих игроков в мире онлайн-гемблинга. Сервис ориентирована на повышение качества сервиса, улучшая функционал, чтобы предоставить пользователям захватывающий игровой процесс.
Приветственный бонус: Премиум-старт для новых игроков
Для новичков в казино на платформе 1win доступен значительный приветственный бонус, который помогает начать с преимуществом. Это возможность является одним из ведущих на рынке, так как помогает новым пользователям заполучить выгодные условия, сократив риски. Упрощенная процедура регистрации и внесение депозита автоматически активируют бонус, что делает его активацию приятным и лёгким.
Live-ставки: Лайв-ставки на тысячи событий с максимальным удобством
В мире ставок на спорт фундаментальным аспектом является быстрота реакции и возможность реагировать на изменения в реальном времени. 1win предоставляет возможность огромное количество спортивных событий, доступных в формате ставок на события в реальном времени. Мы предоставляем доступ к международным международным и локальным соревнованиям, будь то теннис.
Полная ссылка на страницу: https://www.yantraharvest.com/1win-stavki-na-sport-unikalnye-vozmozhnosti-i-preimushchestva-vedushchey-platformy-v-mire-onlayngemblinga/
Игра в лайве позволяют пользователям реагировать в реальном времени, что делает процесс более динамичным, но и интеллектуально интересным. Используя стратегии и аналитику платформы, клиенты могут точнее прогнозировать исходы, повышая вероятность выигрыша. Каждое событие предоставляется с аналитическими данными, что помогает игрокам выбирать тактику исходя из фактов.
Vavada casino — это одним из топовых и проверенных временем казино среди ценителей игровых автоматов. Благодаря современного подхода, разнообразию игр и щедрым бонусам для гостей, <a href="https://sbtg.ru/ap/redirect.aspx?l=https://vavada-casino-888-9.top/">vavada рабочее зеркало </a> завоевало статус превосходной площадки для всех, кто жаждет найти безупречный игровой процесс. В данной статье мы подробно рассмотрим функции сайта Vavada casino, процесс регистрации и входа в личный кабинет, а также расскажем про Vavada бонусы и о том, как получить актуальные зеркальные ссылки Vavada.
Преимущества сайта Vavada casino
Официальный ресурс Vavada выделяется на фоне конкурентов за счет легкого в использовании интерфейса, мгновенной загрузке и адаптации под устройства. Независимо от гаджет подключено, будь то компьютер, планшет или смартфон, Vavada официальный сайт загружается моментально, гарантируя удобный вход к играм и опциям.
Сайт: https://sbtg.ru/ap/redirect.aspx?l=https://vavada-casino-play-10.top/
Для доступа на сайт не необходима загрузка ПО. Онлайн-казино Vavada функционирует прямо через браузер, что делает удобным доступ к личному кабинету и игровым слотам. Если случаются блокировок пользователи могут воспользоваться Vavada зеркало, имеет идентичный функционал основного сайта.
В индустрии цифровых казино и ставок на спорт ключевое значение имеет не только качество игровой платформы, но и доверие к оператору. С разрешением на деятельность, которая подтверждает честность, сайт <a href="https://www.book-hall.ru/event/806?destination=node%2F806">https://www.book-hall.ru/event/806?destination=node%2F806</a> занимает ведущих игроков на рынке ставок. Платформа работает на максимального комфорта, разрабатывая новые функции, чтобы гарантировать пользователям максимальный комфорт.
Приветственный бонус: Щедрый бонус для новичков
Для новых клиентов на платформе 1win доступен в предложении выгодный приветственный бонус, который увеличивает ваши возможности. Это возможность является одним из популярных на в индустрии ставок, так как открывает возможность новым клиентам казино получить преимущество, получив дополнительные ресурсы для ставок. Регистрация за несколько минут и внесение депозита дают возможность воспользоваться бонусом, что делает его использование очень удобным.
Live-ставки: Играйте на события вживую с максимальным удобством
В мире спортивных прогнозов ключевой особенностью является темп и способность адаптироваться в режиме реального времени. 1win даёт шанс множество спортивных событий, доступных в формате ставок в лайве. Мы располагаем матчами к ведущим событиям мирового масштаба, будь то волейбол.
Полная ссылка на страницу: https://www.book-hall.ru/event/806?destination=node%2F806
Игра на события вживую дают шанс быстро подстраиваться, что делает процесс более захватывающим, но и тактически интересным. С помощью аналитики платформы, клиенты могут точнее прогнозировать исходы, увеличивая потенциальные результаты. Каждое событие сопровождается качественной аналитикой, что помогает игрокам гарантировать обоснованные ставки.
Vavada казино — является одно из топовых и надежных игровых клубов среди любителей гэмблинга. За счет современного подхода, разнообразию игровых слотов и щедрым бонусам для пользователей, <a href="https://nsk.metalloprokat.ru/statistic/redirect_site?object-id=8930934&object-kind=product&source=products-list&url=https%3A%2F%2Fvavada-casino999-10.top %2F">вавада рабочее зеркало </a> завоевало репутацию отличной платформы для всех, кто хочет получить безупречный игровой процесс. В этом материале мы разберем особенности сайта Vavada casino, процесс регистрации на сайте и входа, а также расскажем о бонусах Vavada и о том, где найти работающие зеркальные ссылки Vavada.
Преимущества платформы казино Вавада
Vavada официальный сайт отличается среди других платформ с помощью интуитивно понятного интерфейса, быстрому отклику и адаптации под устройства. Независимо от девайс находится у вас, будь то ПК, планшет или смартфон, платформа Vavada casino загружается моментально, гарантируя удобный вход к разделам и возможностям.
Сайт: https://nsk.metalloprokat.ru/statistic/redirect_site?object-id=8930934&object-kind=product&source=products-list&url=https%3A%2F%2Fcasino-vavada-slots-4.top %2F
Чтобы попасть на сайт не нужно установка дополнительных программ. Vavada casino запускается прямо через браузер, что делает удобным доступ в аккаунт и разделам казино. Если случаются ограничений пользователи могут перейти на Актуальные зеркала Vavada, повторяет функции основного портала.
В отрасли интерактивных казино и игр на ставки необходимо не только качество предоставляемых услуг, но и гарантии безопасности. С разрешением на деятельность, которая гарантирует надежность, сайт <a href="http://www.kundash.ru/beregite-les-ot-pozhara-pamyatka/">http://www.kundash.ru/beregite-les-ot-pozhara-pamyatka/</a> выступает одним из фаворитов в мире онлайн-гемблинга. Провайдер ориентирована на максимального комфорта, обновляя платформу, чтобы подарить пользователям наивысшее качество услуг.
Приветственный бонус: Выгодный старт для новичков
Для новых игроков на платформе 1win доступен впечатляющий приветственный бонус, который помогает начать с преимуществом. Это предложение является одним из заметных на в отрасли, так как помогает новым пользователям получить преимущество, увеличив свои шансы на успешные ставки. Простая регистрация и внесение депозита моментально активируют предложение, что делает его активацию простым и доступным.
Live-ставки: Играйте на события вживую с быстрой реакцией
В мире онлайн-ставок одним из ключевых элементов является быстрота реакции и способность мгновенно реагировать в на ходу. 1win даёт доступ множество спортивных событий, доступных в формате онлайн ставок. Мы располагаем матчами к ключевым спортивным событиям, будь то киберспорт.
Полная ссылка на страницу: http://www.kundash.ru/beregite-les-ot-pozhara-pamyatka/
Букмекерские ставки в лайве гарантируют игрокам быстро подстраиваться, что делает процесс более захватывающим, но и серьёзным испытанием навыков. Пользуясь аналитическими функциями платформы, игроки платформы могут точнее прогнозировать исходы, увеличивая свои шансы на успех. Каждое событие освещается статистикой, что способствует точным прогнозам выбирать тактику исходя из фактов.
Онлайн-казино Vavada — это одно из лучших и надежных казино для любителей гэмблинга. С помощью инновационного подхода, большому выбору развлечений и привлекательным условиям для игроков, <a href="https://www.voa-islam.com/l/73/https://vavada-casino-888-9.top/">промокод вавада </a> обрело репутацию превосходной платформы для ищет безупречный игровой процесс. В данной статье мы подробно рассмотрим возможности сайта Vavada casino, процесс регистрации и входа в личный кабинет, а также объясним про Vavada бонусы и о том, где взять работающие рабочие зеркала Vavada.
Достоинства платформы казино Вавада
Сайт казино Vavada привлекает внимание по сравнению с аналогами благодаря интуитивно понятного интерфейса, высокой скорости работы и адаптивному дизайну. Независимо от устройство вы используете, будь то компьютер, планшетный ПК или телефон, платформа Vavada casino открывается без задержек, обеспечивая плавный доступ к разделам и функциям.
Сайт: https://www.voa-islam.com/l/73/https://vavada-casino999-10.top/
Для доступа на ресурс не необходима установка дополнительных программ. Vavada casino работает непосредственно в браузере, что делает удобным процесс входа к личному кабинету и игровым слотам. В случае технических проблем пользователи могут зайти через Актуальные зеркала Vavada, имеет идентичный функционал основного портала.
В пространстве интерактивных казино и игр на ставки важно не только качество игровой платформы, но и честность оператора. С гарантированной лицензией, которая гарантирует безопасность, сайт <a href="https://www.cross-kpk.ru/index.dll/multimedia.dll/multimedia.dll/documents/projects/Kristal/documents/index.dll?part=506">https://www.cross-kpk.ru/index.dll/multimedia.dll/multimedia.dll/documents/projects/Kristal/documents/index.dll?part=506</a> находится среди главных представителей в мире онлайн-гемблинга. Провайдер ориентирована на создание благоприятных условий, совершенствуя предложения, чтобы предоставить пользователям максимальный комфорт.
Приветственный бонус: Щедрый бонус для новых пользователей
Для новых участников на платформе 1win ожидает вас большой приветственный бонус, который увеличивает ваши возможности. Это подарок является одним из ведущих на в мире онлайн-гемблинга, так как предоставляет шанс новым игрокам моментально воспользоваться бонусом, получив дополнительные ресурсы для ставок. Упрощенная процедура регистрации и депозит моментально активируют предложение, что делает его активацию комфортным.
Live-ставки: Мгновенные возможности для ставок с моментальными ставками
В пространстве спортивных ставок фундаментальным аспектом является изменчивость и шанс учесть изменения в онлайн. 1win открывает путь множество спортивных событий, доступных в формате ставок на события в реальном времени. Мы даем возможность играть к крупнейшим соревнованиям и матчам, будь то волейбол.
Полная ссылка на страницу: https://www.cross-kpk.ru/index.dll/multimedia.dll/multimedia.dll/documents/projects/Kristal/documents/index.dll?part=506
Игра на события вживую дают шанс мгновенно реагировать на изменения, что делает процесс стратегически насыщенным, но и интеллектуально интересным. С применением аналитических ресурсов платформы, любители ставок могут увеличивать вероятность выигрыша, улучшая тактику игры. Каждое событие сопровождается качественной аналитикой, что способствует точным прогнозам принимать решения на основе актуальных данных.
В пространстве интерактивных казино и ставок в спорте ключевое значение имеет не только качество обслуживания, но и высокий уровень доверия. С официальной лицензией, которая обеспечивает соблюдение стандартов, сайт <a href="https://cross-kpk.ru/ims.dll?id=2811">https://cross-kpk.ru/ims.dll?id=2811</a> выступает одним из лидеров на рынке ставок. Платформа уделяет внимание создание благоприятных условий, улучшая функционал, чтобы обеспечить пользователям максимальный комфорт.
Приветственный бонус: Бонус для новичков для новых пользователей
Для новых игроков на платформе 1win предусмотрен впечатляющий приветственный бонус, который увеличивает ваши возможности. Это возможность является одним из наиболее привлекательных на среди конкурентов, так как позволяет игрокам новым игрокам сразу получить доступ к дополнительным средствам, получив дополнительные ресурсы для ставок. Быстрая регистрация и внесение суммы обеспечивают получение бонуса, что делает его получение приятным и лёгким.
Live-ставки: Множество матчей онлайн с моментальными ставками
В сфере спортивных ставок ключевой особенностью является динамика и шанс учесть изменения в на ходу. 1win даёт доступ широкий выбор спортивных событий, доступных в формате игры вживую. Мы даем возможность играть к международным спортивным событиям, будь то футбол.
Полная ссылка на страницу: https://cross-kpk.ru/ims.dll?id=2811
Игра на события вживую предоставляют возможность моментально адаптироваться, что делает процесс ещё интереснее, но и полезным для стратегии. С помощью аналитики платформы, игроки платформы могут повышать свои шансы на успех, оптимизируя стратегию. Каждое событие обеспечено аналитическими обзорами, что даёт более полную картину гарантировать обоснованные ставки.
Онлайн-казино Vavada — это одним из лучших и проверенных временем платформ для поклонников игровых автоматов. За счет современного подхода, большому выбору игровых слотов и выгодным предложениям для игроков, <a href="http://savanttools.com/ANON/vavada-casino999-10.top">vavada официальный сайт </a> обрело репутацию превосходной площадки для всех, кто жаждет найти надежный азартный отдых. В этом материале мы подробно рассмотрим функции официального сайта Vavada, этапы создания аккаунта и входа в личный кабинет, а также поговорим о бонусах Vavada и о том, как получить актуальные рабочие зеркала Vavada.
Преимущества официального сайта Vavada
Vavada официальный сайт привлекает внимание среди других платформ с помощью простого и удобного пользовательского меню, быстрому отклику и кроссплатформенности. Независимо от устройство находится у вас, будь то ПК, планшет или мобильный телефон, сайт Vavada открывается без задержек, гарантируя комфортное использование к игровым слотам и функциям.
Сайт: http://savanttools.com/ANON/vavada-casino999-10.top
Для доступа на ресурс не требуется скачивание приложений. Vavada online casino работает в веб-версии, что делает удобным процесс входа в аккаунт и разделам казино. Если случаются блокировок игроки могут перейти на Актуальные зеркала Vavada, имеет идентичный функции официального ресурса.
В сфере цифровых казино и ставочных рынков ключевое значение имеет не только качество обслуживания, но и гарантии безопасности. С лицензией, которая гарантирует надежность, сайт <a href="https://www.cross-kpk.ru/index.dll/multimedia.dll/documents/projects/Kristal/forum.dll/multimedia.dll/forum.dll/topic?id=46&page=1">https://www.cross-kpk.ru/index.dll/multimedia.dll/documents/projects/Kristal/forum.dll/multimedia.dll/forum.dll/topic?id=46&page=1</a> уверенно занимает ведущих игроков среди букмекерских платформ. Платформа работает на максимального комфорта, обновляя контент, чтобы обеспечить пользователям непревзойденный опыт.
Приветственный бонус: Начальный бонус для новых пользователей
Для новых пользователей на платформе 1win существует выгодный приветственный бонус, который увеличивает ваши возможности. Это возможность является одним из лучших на рынке, так как открывает возможность новым пользователям платформы моментально воспользоваться бонусом, значительно улучшив стартовые позиции. Упрощенная процедура регистрации и первый взнос зачисляют бонус на счет, что делает его использование простым и доступным.
Live-ставки: Мгновенные возможности для ставок с моментальными ставками
В пространстве онлайн-ставок фундаментальным аспектом является изменчивость и умение быстро принимать решения в на ходу. 1win приглашает десятки тысяч спортивных событий, доступных в формате лайв-ставок. Мы организуем лайв-ставки к международным событиям мирового масштаба, будь то баскетбол.
Полная ссылка на страницу: https://www.cross-kpk.ru/index.dll/multimedia.dll/documents/projects/Kristal/forum.dll/multimedia.dll/forum.dll/topic?id=46&page=1
Онлайн-ставки позволяют пользователям учитывать динамику событий, что делает процесс насыщенным эмоциями, но и серьёзным испытанием навыков. Используя стратегии и аналитику платформы, игроки могут делать ставки с уверенностью, увеличивая потенциальные результаты. Каждое событие предоставляется с аналитическими данными, что даёт более полную картину принимать решения на основе актуальных данных.
Vavada casino — это одной из самых популярных и доверенных игровых клубов для любителей игровых автоматов. С помощью инновационного подхода, разнообразию игр и выгодным предложениям для пользователей, <a href="http://b.nnov.org/common/redir.php?https://casino-vavada-slots-4.top/">vavada казино </a> завоевало статус отличной платформы для ищет надежный азартный отдых. В обзоре ниже мы разберем возможности официального сайта Vavada, порядок регистрации и авторизации, а также объясним про Vavada бонусы и о том, где взять работающие рабочие зеркала Vavada.
Преимущества официального сайта Vavada
Сайт казино Vavada отличается на фоне конкурентов с помощью простого и удобного интерфейса, мгновенной загрузке и кроссплатформенности. Независимо от девайс подключено, будь то компьютер, планшет или телефон, сайт Vavada открывается без задержек, гарантируя плавный доступ к игровым слотам и возможностям.
Сайт: http://b.nnov.org/common/redir.php?https://vavada-casino-play-10.top/
Для доступа на платформу не нужно загрузка ПО. Vavada casino функционирует прямо через браузер, что делает удобным процесс входа к личному кабинету и разделам казино. В случае ограничений гости могут перейти на Рабочее зеркало Vavada, имеет идентичный функции основного портала.
В сфере виртуальных казино и ставок на спорт важно не только качество сервиса, но и гарантии безопасности. С гарантированной лицензией, которая подтверждает честность, сайт <a href="http://akrvo.ru/index.php?option=com_content&view=article&id=19515">http://akrvo.ru/index.php?option=com_content&view=article&id=19515</a> считает себя топовых платформ в области азартных игр. Оператор уделяет внимание повышение качества сервиса, разрабатывая новые функции, чтобы обеспечить пользователям максимальный комфорт.
Приветственный бонус: Щедрый бонус для новых игроков
Для новичков в казино на платформе 1win доступен щедрый приветственный бонус, который значительно увеличивает начальный капитал. Это подарок является одним из ведущих на в мире онлайн-гемблинга, так как позволяет новым клиентам получить дополнительный капитал, стимулируя успешные ставки. Легкий старт и внесение суммы мгновенно активируют бонус, что делает его использование очень удобным.
Live-ставки: Множество матчей онлайн с реальными шансами на успех
В экосистеме спортивных ставок важнейшей частью является динамика и способность мгновенно реагировать в на ходу. 1win даёт шанс множество спортивных событий, доступных в формате игры вживую. Мы предоставляем доступ к ведущим локальным и глобальным турнирам, будь то волейбол.
Полная ссылка на страницу: http://akrvo.ru/index.php?option=com_content&view=article&id=19515
Лайв-ставки обеспечивают шанс учитывать динамику событий, что делает процесс ещё интереснее, но и полезным для стратегии. Используя стратегии и аналитику платформы, стратеги могут принимать более обоснованные решения, оптимизируя стратегию. Каждое событие освещается статистикой, что обогащает принятие решений предсказывать результат с уверенностью.
Vavada casino — является одним из лучших и доверенных платформ для поклонников гэмблинга. За счет современного подхода, широкому ассортименту игр и привлекательным условиям для игроков, <a href="http://nikolay-lavrentev-t.nnov.org/common/redir.php?https://vavada-casino999-10.top/">vavada вход </a> получило репутацию отличной площадки для всех, кто ищет надежный азартный отдых. В данной статье мы опишем возможности сайта Vavada casino, этапы создания аккаунта и входа в личный кабинет, а также поговорим о бонусах Vavada и о том, где взять работающие рабочие зеркала Vavada.
Основные плюсы официального сайта Vavada
Vavada официальный сайт выделяется среди других платформ за счет интуитивно понятного пользовательского меню, быстрому отклику и кроссплатформенности. Независимо от гаджет вы используете, будь то ПК, планшет или телефон, Vavada официальный сайт загружается моментально, обеспечивая комфортное использование к игровым слотам и возможностям.
Сайт: http://nikolay-lavrentev-t.nnov.org/common/redir.php?https://casino-vavada-slots-4.top/
Для доступа на ресурс не требуется скачивание приложений. Vavada online casino работает в веб-версии, что упрощает процесс входа к личному кабинету и разделам казино. В случае блокировок игроки могут воспользоваться Рабочее зеркало Vavada, повторяет весь контент официального ресурса.
В индустрии виртуальных казино и ставочной деятельности основное внимание уделяется не только качество сервиса, но и честность оператора. С лицензией, которая подтверждает честность, сайт <a href="https://www.sendungsverfolgung24.org/forum/topic/dfdg234dsfsd/?part=2769">https://www.sendungsverfolgung24.org/forum/topic/dfdg234dsfsd/?part=2769</a> находится среди ключевых участников в области азартных игр. Организация стремится к повышение качества сервиса, совершенствуя предложения, чтобы предоставить пользователям наивысшее качество услуг.
Приветственный бонус: Бонус для новичков для новичков
Для новых участников на платформе 1win ожидает вас щедрый приветственный бонус, который увеличивает ваши возможности. Это возможность является одним из наиболее привлекательных на рынке, так как дает возможность новым клиентам казино начать игру с бонусом, увеличив свои шансы на успешные ставки. Легкий старт и перевод средств дают возможность воспользоваться бонусом, что делает его применение очень удобным.
Live-ставки: Мгновенные возможности для ставок с максимальным удобством
В отрасли спортивных прогнозов фундаментальным аспектом является быстрота реакции и возможность реагировать на изменения в реальном времени. 1win даёт шанс огромное количество спортивных событий, доступных в формате онлайн ставок. Мы организуем лайв-ставки к топовым спортивным событиям, будь то хоккей.
Полная ссылка на страницу: https://www.sendungsverfolgung24.org/forum/topic/dfdg234dsfsd/?part=2769
Игра в лайве позволяют пользователям моментально адаптироваться, что делает процесс не только увлекательным, но и интеллектуально интересным. Благодаря аналитическим данным платформы, любители ставок могут анализировать события глубже, увеличивая потенциальные результаты. Каждое событие содержит анализ игры, что даёт более полную картину гарантировать обоснованные ставки.
Vavada казино — является одним из наиболее востребованных и проверенных временем казино среди ценителей азартных игр. За счет современного подхода, большому выбору развлечений и выгодным предложениям для гостей, <a href="https://www.a3erf.com/article/[vavada-casino999-10.top - %E4%B9%B0%E7%90%83%E7%9B%98%E5%8F%A3%E8%AF%84%E7%BA%A7187">vavada рабочее зеркало </a> обрело репутацию превосходной площадки для всех, кто ищет качественный игровой опыт. В обзоре ниже мы разберем возможности официального сайта Vavada, процесс регистрации и входа, а также поговорим о бонусах Vavada и о том, как получить свежие зеркальные ссылки Vavada.
Достоинства платформы казино Вавада
Vavada официальный сайт привлекает внимание по сравнению с аналогами с помощью интуитивно понятного пользовательского меню, мгновенной загрузке и кроссплатформенности. Без разницы, какое устройство подключено, будь то компьютер, планшетный ПК или смартфон, сайт Vavada загружается моментально, обеспечивая комфортное использование к игровым слотам и возможностям.
Сайт: https://www.a3erf.com/article/[vavada-casino-888-9.top - %E4%B9%B0%E7%90%83%E7%9B%98%E5%8F%A3%E8%AF%84%E7%BA%A7187
Для доступа на сайт не нужно загрузка ПО. Онлайн-казино Vavada запускается прямо через браузер, что значительно облегчает доступ к личному кабинету и разделам сайта. При возникновении ограничений игроки могут перейти на Vavada зеркало, повторяет функционал официального ресурса.
В мире интерактивных казино и ставочной деятельности важно не только надежность услуг, но и гарантии безопасности. С лицензией, которая гарантирует надежность, сайт <a href="https://www.miassgrk.ru/support/page.php?table=settings&id=39">https://www.miassgrk.ru/support/page.php?table=settings&id=39</a> занимает ключевых участников среди платформ для азартных игр. Платформа ориентирована на создание благоприятных условий, совершенствуя предложения, чтобы обеспечить пользователям первоклассный игровой опыт.
Приветственный бонус: Бонус для новичков для пользователей платформы
Для новых клиентов на платформе 1win предоставляется солидный приветственный бонус, который помогает начать с преимуществом. Это бонусная программа является одним из ведущих на рынке, так как позволяет игрокам новым пользователям платформы сразу получить доступ к дополнительным средствам, получив дополнительные ресурсы для ставок. Упрощенная процедура регистрации и внесение суммы дают возможность воспользоваться бонусом, что делает его получение простым и доступным.
Live-ставки: Тысячи событий в реальном времени с максимальным удобством
В индустрии онлайн-ставок фундаментальным аспектом является динамика и способность мгновенно реагировать в режиме реального времени. 1win даёт доступ огромное количество спортивных событий, доступных в формате игры вживую. Мы организуем лайв-ставки к ключевым международным и локальным соревнованиям, будь то хоккей.
Полная ссылка на страницу: https://www.miassgrk.ru/support/page.php?table=settings&id=39
Ставки в реальном времени гарантируют игрокам моментально адаптироваться, что делает процесс ещё интереснее, но и серьёзным испытанием навыков. С применением аналитических ресурсов платформы, игроки могут увеличивать вероятность выигрыша, повышая вероятность выигрыша. Каждое событие представлено с комментариями, что позволяет лучше анализировать принимать решения на основе актуальных данных.
Vavada казино — является одной из лучших и проверенных временем игровых клубов среди поклонников игровых автоматов. За счет инновационного подхода, широкому ассортименту игровых слотов и привлекательным условиям для пользователей, <a href="https://padlet.pics/1/proxy?url=https://vavada-casino888-12.top/">vavada регистрация </a> обрело статус идеальной платформы для хочет получить надежный азартный отдых. В обзоре ниже мы подробно рассмотрим возможности сайта Vavada casino, этапы регистрации на сайте и входа, а также поговорим про акционные предложения Vavada и о том, где взять работающие Vavada зеркало.
Основные плюсы официального сайта Vavada
Официальный ресурс Vavada отличается среди других платформ с помощью легкого в использовании интерфейса, высокой скорости работы и адаптивному дизайну. Без разницы, какое девайс находится у вас, будь то ПК, планшетный ПК или мобильный телефон, платформа Vavada casino открывается без задержек, обеспечивая комфортное использование к разделам и опциям.
Сайт: https://padlet.pics/1/proxy?url=https://vavada-casino-888-9.top/
Чтобы попасть на платформу не нужно скачивание приложений. Vavada online casino запускается в веб-версии, что делает удобным доступ в аккаунт и игровым слотам. При возникновении ограничений гости могут зайти через Актуальные зеркала Vavada, имеет идентичный весь контент основного портала.
В мире онлайн-казино и ставочной деятельности необходимо не только качество игровой платформы, но и гарантии безопасности. С разрешением на деятельность, которая подтверждает легальность, сайт <a href="http://viskatskoe.ru/prinyat-zakon-ob-e-lektronnom-obzhalovanii-shtrafov-s-kamer-foto-i-videofiksatcii.html">http://viskatskoe.ru/prinyat-zakon-ob-e-lektronnom-obzhalovanii-shtrafov-s-kamer-foto-i-videofiksatcii.html</a> занимает ключевых участников в области азартных игр. Организация работает на создание благоприятных условий, обновляя контент, чтобы подарить пользователям безупречное взаимодействие.
Приветственный бонус: Бонус для новичков для новых игроков
Для новых игроков на платформе 1win предусмотрен выгодный приветственный бонус, который помогает начать с преимуществом. Это бонусная программа является одним из популярных на среди конкурентов, так как помогает новым пользователям платформы начать игру с бонусом, сократив риски. Удобная регистрация и первый взнос дают возможность воспользоваться бонусом, что делает его получение максимально удобным и быстрым.
Live-ставки: Играйте на события вживую с моментальными ставками
В сфере спортивных прогнозов важнейшим фактором является актуальность и шанс учесть изменения в лайве. 1win приглашает множество спортивных событий, доступных в формате ставок в режиме реального времени. Мы организуем лайв-ставки к глобальным локальным и глобальным турнирам, будь то волейбол.
Полная ссылка на страницу: http://viskatskoe.ru/prinyat-zakon-ob-e-lektronnom-obzhalovanii-shtrafov-s-kamer-foto-i-videofiksatcii.html
Игра на события вживую обеспечивают шанс принимать решения мгновенно, что делает процесс не только увлекательным, но и стратегически насыщенным. Благодаря аналитическим данным платформы, стратеги могут повышать свои шансы на успех, увеличивая потенциальные результаты. Каждое событие обеспечено аналитическими обзорами, что способствует точным прогнозам гарантировать обоснованные ставки.
Игровой клуб Вавада — это одной из наиболее востребованных и проверенных временем казино для ценителей азартных игр. Благодаря актуального дизайна, разнообразию игр и щедрым бонусам для пользователей, <a href="http://talsi.pilseta24.lv/linkredirect/?link=https%3A%2F%2Fvavada-casino999-10.top &referer=talsi.pilseta24.lv%2Fzina%3Fslug%3Deccal-briketes-un-apkures-granulas-ar-lielisku-kvalitati-pievilcigu-cenu-videi-draudzigs-un-izd-8c175fc171&additional_params=%7B%22company_orig_id%22%3A%22291020%22%2C%22object_country_id%22%3A%22lv%22%2C%22referer_layout_type%22%3A%22SR%22%2C%22bannerinfo%22%3A%22%7B%5C%22key%5C%22%3A%5C%22%5C%5C%5C%22Talsu+riepas%5C%5C%5C%22%2C+autoserviss%7C2021-05-21%7C2022-05-20%7Ctalsi+p24+lielais+baneris%7Chttps%3A%5C%5C%5C%2F%5C%5C%5C%2Ftalsuriepas.lv%5C%5C%5C%2F%7C%7Cupload%5C%5C%5C%2F291020%5C%5C%5C%2Fbaners%5C%5C%5C%2F15_talsurie_1050x80_k.gif%7Clva%7C291020%7C980%7C90%7C%7C0%7C0%7C%7C0%7C0%7C%5C%22%2C%5C%22doc_count%5C%22%3A1%2C%5C%22key0%5C%22%3A%5C%22%5C%5C%5C%22Talsu+riepas%5C%5C%5C%22%2C+autoserviss%5C%22%2C%5C%22key1%5C%22%3A%5C%222021-05-21%5C%22%2C%5C%22key2%5C%22%3A%5C%222022-05-20%5C%22%2C%5C%22key3%5C%22%3A%5C%22talsi+p24+lielais+baneris%5C%22%2C%5C%22key4%5C%22%3A%5C%22https%3A%5C%5C%5C%2F%5C%5C%5C%2Ftalsuriepas.lv%5C%5C%5C%2F%5C%22%2C%5C%22key5%5C%22%3A%5C%22%5C%22%2C%5C%22key6%5C%22%3A%5C%22upload%5C%5C%5C%2F291020%5C%5C%5C%2Fbaners%5C%5C%5C%2F15_talsurie_1050x80_k.gif%5C%22%2C%5C%22key7%5C%22%3A%5C%22lva%5C%22%2C%5C%22key8%5C%22%3A%5C%22291020%5C%22%2C%5C%22key9%5C%22%3A%5C%22980%5C%22%2C%5C%22key10%5C%22%3A%5C%2290%5C%22%2C%5C%22key11%5C%22%3A%5C%22%5C%22%2C%5C%22key12%5C%22%3A%5C%220%5C%22%2C%5C%22key13%5C%22%3A%5C%220%5C%22%2C%5C%22key14%5C%22%3A%5C%22%5C%22%2C%5C%22key15%5C%22%3A%5C%220%5C%22%2C%5C%22key16%5C%22%3A%5C%220%5C%22%2C%5C%22key17%5C%22%3A%5C%22%5C%22%7D%22%7D&control=f1427842db246885719585c9a034ef46">казино вавада </a> получило статус идеальной площадки для всех, кто жаждет найти надежный азартный отдых. В этом материале мы опишем возможности официального сайта Vavada, порядок регистрации и авторизации, а также расскажем про Vavada бонусы и о том, где взять свежие рабочие зеркала Vavada.
Достоинства сайта Vavada casino
Сайт казино Vavada выделяется по сравнению с аналогами благодаря простого и удобного интерфейса, быстрому отклику и кроссплатформенности. Без разницы, какое гаджет подключено, будь то ноутбук, планшетный ПК или мобильный телефон, сайт Vavada работает идеально, обеспечивая удобный вход к разделам и функциям.
Сайт: http://talsi.pilseta24.lv/linkredirect/?link=https%3A%2F%2Fvavada-casino-play-10.top &referer=talsi.pilseta24.lv%2Fzina%3Fslug%3Deccal-briketes-un-apkures-granulas-ar-lielisku-kvalitati-pievilcigu-cenu-videi-draudzigs-un-izd-8c175fc171&additional_params=%7B%22company_orig_id%22%3A%22291020%22%2C%22object_country_id%22%3A%22lv%22%2C%22referer_layout_type%22%3A%22SR%22%2C%22bannerinfo%22%3A%22%7B%5C%22key%5C%22%3A%5C%22%5C%5C%5C%22Talsu+riepas%5C%5C%5C%22%2C+autoserviss%7C2021-05-21%7C2022-05-20%7Ctalsi+p24+lielais+baneris%7Chttps%3A%5C%5C%5C%2F%5C%5C%5C%2Ftalsuriepas.lv%5C%5C%5C%2F%7C%7Cupload%5C%5C%5C%2F291020%5C%5C%5C%2Fbaners%5C%5C%5C%2F15_talsurie_1050x80_k.gif%7Clva%7C291020%7C980%7C90%7C%7C0%7C0%7C%7C0%7C0%7C%5C%22%2C%5C%22doc_count%5C%22%3A1%2C%5C%22key0%5C%22%3A%5C%22%5C%5C%5C%22Talsu+riepas%5C%5C%5C%22%2C+autoserviss%5C%22%2C%5C%22key1%5C%22%3A%5C%222021-05-21%5C%22%2C%5C%22key2%5C%22%3A%5C%222022-05-20%5C%22%2C%5C%22key3%5C%22%3A%5C%22talsi+p24+lielais+baneris%5C%22%2C%5C%22key4%5C%22%3A%5C%22https%3A%5C%5C%5C%2F%5C%5C%5C%2Ftalsuriepas.lv%5C%5C%5C%2F%5C%22%2C%5C%22key5%5C%22%3A%5C%22%5C%22%2C%5C%22key6%5C%22%3A%5C%22upload%5C%5C%5C%2F291020%5C%5C%5C%2Fbaners%5C%5C%5C%2F15_talsurie_1050x80_k.gif%5C%22%2C%5C%22key7%5C%22%3A%5C%22lva%5C%22%2C%5C%22key8%5C%22%3A%5C%22291020%5C%22%2C%5C%22key9%5C%22%3A%5C%22980%5C%22%2C%5C%22key10%5C%22%3A%5C%2290%5C%22%2C%5C%22key11%5C%22%3A%5C%22%5C%22%2C%5C%22key12%5C%22%3A%5C%220%5C%22%2C%5C%22key13%5C%22%3A%5C%220%5C%22%2C%5C%22key14%5C%22%3A%5C%22%5C%22%2C%5C%22key15%5C%22%3A%5C%220%5C%22%2C%5C%22key16%5C%22%3A%5C%220%5C%22%2C%5C%22key17%5C%22%3A%5C%22%5C%22%7D%22%7D&control=f1427842db246885719585c9a034ef46
Для доступа на ресурс не требуется скачивание приложений. Vavada casino работает в веб-версии, что значительно облегчает доступ к личному кабинету и игровым слотам. При возникновении технических проблем игроки могут зайти через Актуальные зеркала Vavada, которое полностью дублирует весь контент основного портала.
В экосистеме виртуальных казино и ставочной деятельности крайне важно не только качество сервиса, но и честность оператора. С лицензионными гарантиями, которая обеспечивает соблюдение стандартов, сайт <a href="https://admkir.ru/kal-kulyator-protcedur-infografika-buklety.html">https://admkir.ru/kal-kulyator-protcedur-infografika-buklety.html</a> установил себя как ведущих игроков в сфере интерактивных казино. Платформа уделяет внимание максимального комфорта, обновляя платформу, чтобы подарить пользователям первоклассный игровой опыт.
Приветственный бонус: Бонус для новичков для клиентов
Для новичков на платформе 1win существует щедрый приветственный бонус, который стимулирует успешное начало. Это программа является одним из популярных на среди конкурентов, так как позволяет игрокам новым клиентам казино начать игру с бонусом, повысив вероятность успеха. Упрощенная процедура регистрации и пополнение счета автоматически активируют бонус, что делает его получение приятным и лёгким.
Live-ставки: Спортивные события в режиме реального времени с широким выбором
В мире спортивных ставок ключевой особенностью является изменчивость и способность мгновенно реагировать в моментально. 1win даёт шанс огромное количество спортивных событий, доступных в формате ставок в режиме реального времени. Мы располагаем матчами к крупнейшим локальным и глобальным турнирам, будь то хоккей.
Полная ссылка на страницу: https://admkir.ru/kal-kulyator-protcedur-infografika-buklety.html
Игра на события вживую гарантируют игрокам учитывать динамику событий, что делает процесс стратегически насыщенным, но и полезным для стратегии. Пользуясь аналитическими функциями платформы, игроки могут увеличивать вероятность выигрыша, повышая вероятность выигрыша. Каждое событие предоставляется с аналитическими данными, что даёт более полную картину выбирать тактику исходя из фактов.
Онлайн-казино Vavada — является одной из лучших и проверенных временем платформ для поклонников гэмблинга. С помощью инновационного подхода, разнообразию развлечений и выгодным предложениям для пользователей, <a href="http://gosudar.com.ru/go.php?url=https://casino-vavada-slots-4.top/">vavada casino </a> завоевало статус превосходной площадки для всех, кто ищет безупречный игровой процесс. В этом материале мы опишем возможности сайта Vavada casino, этапы регистрации и входа, а также расскажем про акционные предложения Vavada и о том, как получить работающие рабочие зеркала Vavada.
Основные плюсы официального сайта Vavada
Официальный ресурс Vavada привлекает внимание среди других платформ благодаря легкого в использовании дизайна, высокой скорости работы и кроссплатформенности. Без разницы, какое устройство вы используете, будь то компьютер, планшетный ПК или телефон, сайт Vavada открывается без задержек, гарантируя комфортное использование к играм и функциям.
Сайт: http://gosudar.com.ru/go.php?url=https://vavada-casino999-10.top/
Чтобы попасть на ресурс не необходима установка дополнительных программ. Vavada online casino работает непосредственно в браузере, что делает удобным процесс входа в аккаунт и разделам сайта. Если случаются блокировок пользователи могут перейти на Vavada зеркало, повторяет весь контент основного сайта.
В пространстве цифровых казино и спортивных ставок ключевое значение имеет не только уровень сервиса, но и высокий уровень доверия. С разрешением на деятельность, которая подтверждает честность, сайт <a href="https://lekoboz.ru/component/content/article?id=6542:vrach-dolzhen-poluchat-dostojnuyu-zarabotnuyu-platu-rabotaya-na-odnu-stavku">https://lekoboz.ru/component/content/article?id=6542:vrach-dolzhen-poluchat-dostojnuyu-zarabotnuyu-platu-rabotaya-na-odnu-stavku</a> считает себя ведущих игроков в сфере интерактивных казино. Платформа ориентирована на создание благоприятных условий, совершенствуя предложения, чтобы подарить пользователям максимальный комфорт.
Приветственный бонус: Щедрый бонус для новых игроков
Для новых клиентов на платформе 1win предусмотрен щедрый приветственный бонус, который значительно увеличивает начальный капитал. Это подарок является одним из наиболее привлекательных на в мире онлайн-гемблинга, так как предоставляет шанс новым пользователям заполучить выгодные условия, увеличив свои шансы на успешные ставки. Простая регистрация и пополнение счета зачисляют бонус на счет, что делает его активацию эффективным и быстрым.
Live-ставки: Лайв-ставки на тысячи событий с широким выбором
В индустрии спортивных прогнозов важнейшим фактором является быстрота реакции и способность мгновенно реагировать в на ходу. 1win предлагает игрокам множество спортивных событий, доступных в формате лайв-ставок. Мы предлагаем ставки к топовым спортивным событиям, будь то киберспорт.
Полная ссылка на страницу: https://lekoboz.ru/component/content/article?id=6542:vrach-dolzhen-poluchat-dostojnuyu-zarabotnuyu-platu-rabotaya-na-odnu-stavku
Онлайн-ставки открывают возможность реагировать в реальном времени, что делает процесс более захватывающим, но и полезным для стратегии. С применением аналитических ресурсов платформы, стратеги могут делать ставки с уверенностью, улучшая тактику игры. Каждое событие освещается статистикой, что способствует точным прогнозам предупреждать проигрыши.
Онлайн-казино Vavada — является одним из наиболее востребованных и надежных казино среди любителей гэмблинга. Благодаря актуального дизайна, разнообразию развлечений и щедрым бонусам для гостей, <a href="http://local.allcorp.ru/go.php?c=49700&p=537085&url=http%3A%2F%2Fvavada-casino888-12.top">казино вавада </a> обрело репутацию отличной площадки для всех, кто жаждет найти безупречный игровой процесс. В обзоре ниже мы разберем функции платформы казино Вавада, процесс регистрации и авторизации, а также расскажем о бонусах Vavada и о том, где взять актуальные рабочие зеркала Vavada.
Основные плюсы официального сайта Vavada
Сайт казино Vavada отличается по сравнению с аналогами благодаря простого и удобного дизайна, мгновенной загрузке и кроссплатформенности. Без разницы, какое девайс подключено, будь то ПК, планшет или мобильный телефон, Vavada официальный сайт загружается моментально, гарантируя удобный вход к играм и функциям.
Сайт: http://local.allcorp.ru/go.php?c=49700&p=537085&url=http%3A%2F%2Fvavada-casino-888-9.top
Для доступа на сайт не требуется загрузка ПО. Онлайн-казино Vavada функционирует прямо через браузер, что упрощает процесс входа к личному кабинету и игровым слотам. В случае ограничений игроки могут воспользоваться Рабочее зеркало Vavada, имеет идентичный весь контент официального ресурса.
В мире онлайн-казино и ставочных рынков важно не только уровень сервиса, но и надежность оператора. С лицензией, которая подтверждает честность, сайт <a href="http://www.yalangach.ru/novelly-nalogovogo-zakonodatelstva-razyasneniya-zakona-prokuratura-baltachevskogo-rajona-informiruet/">http://www.yalangach.ru/novelly-nalogovogo-zakonodatelstva-razyasneniya-zakona-prokuratura-baltachevskogo-rajona-informiruet/</a> установил себя как топовых платформ среди платформ для азартных игр. Оператор работает на повышение качества сервиса, улучшая функционал, чтобы обеспечить пользователям непревзойденный опыт.
Приветственный бонус: Начальный бонус для новых игроков
Для новичков в казино на платформе 1win доступен щедрый приветственный бонус, который увеличивает ваши возможности. Это подарок является одним из ведущих на в отрасли, так как помогает новым участникам заполучить выгодные условия, стимулируя успешные ставки. Упрощенная процедура регистрации и депозит обеспечивают получение бонуса, что делает его активацию максимально удобным и быстрым.
Live-ставки: Играйте на события вживую с быстрой реакцией
В индустрии спортивных ставок ключевой особенностью является динамика и возможность реагировать на изменения в моментально. 1win предлагает игрокам огромное количество спортивных событий, доступных в формате ставок в лайве. Мы даем возможность играть к ключевым локальным и глобальным турнирам, будь то футбол.
Полная ссылка на страницу: http://www.yalangach.ru/novelly-nalogovogo-zakonodatelstva-razyasneniya-zakona-prokuratura-baltachevskogo-rajona-informiruet/
Букмекерские ставки в лайве открывают возможность учитывать динамику событий, что делает процесс стратегически насыщенным, но и тактически интересным. Пользуясь аналитическими функциями платформы, игроки могут точнее прогнозировать исходы, увеличивая потенциальные результаты. Каждое событие представлено с комментариями, что помогает игрокам ориентироваться в ставках.
Игровой клуб Вавада — является одной из наиболее востребованных и доверенных казино для любителей гэмблинга. С помощью актуального дизайна, большому выбору развлечений и привлекательным условиям для гостей, <a href="https://zoe.mediaworks.hu/zctc3/9/ORIGO/17616227/?redirect=https%3A%2F%2Fvavada-casino888-12.top">vavada промокод </a> завоевало статус отличной площадки для всех, кто хочет получить безупречный игровой процесс. В данной статье мы разберем функции сайта Vavada casino, порядок создания аккаунта и входа, а также объясним о бонусах Vavada и о том, где найти актуальные Vavada зеркало.
Достоинства официального сайта Vavada
Vavada официальный сайт отличается на фоне конкурентов благодаря легкого в использовании интерфейса, быстрому отклику и адаптивному дизайну. Независимо от устройство подключено, будь то ноутбук, планшет или смартфон, платформа Vavada casino открывается без задержек, обеспечивая комфортное использование к игровым слотам и функциям.
Сайт: https://zoe.mediaworks.hu/zctc3/9/ORIGO/17616227/?redirect=https%3A%2F%2Fcasino-vavada-slots-4.top
Для доступа на сайт не необходима загрузка ПО. Vavada online casino запускается непосредственно в браузере, что значительно облегчает доступ к личному кабинету и игровым слотам. При возникновении блокировок пользователи могут перейти на Актуальные зеркала Vavada, имеет идентичный функционал основного портала.
В экосистеме виртуальных казино и игр на ставки крайне важно не только надежность услуг, но и репутация компании. С международной лицензией, которая гарантирует прозрачность, сайт <a href="http://kilim-sp.ru/category/katalog-dokumentov-npa/page/17/">http://kilim-sp.ru/category/katalog-dokumentov-npa/page/17/</a> считает себя ведущих игроков на рынке ставок. Компания сфокусирована на повышение качества сервиса, обновляя контент, чтобы гарантировать пользователям безупречное взаимодействие.
Приветственный бонус: Привлекательное предложение для новых пользователей
Для новых участников на платформе 1win предусмотрен выгодный приветственный бонус, который увеличивает ваши возможности. Это подарок является одним из ведущих на на платформе, так как открывает возможность новым клиентам получить дополнительный капитал, получив дополнительные ресурсы для ставок. Быстрая регистрация и первый взнос автоматически активируют бонус, что делает его активацию приятным и лёгким.
Live-ставки: Спортивные события в режиме реального времени с широким выбором
В сфере спортивных прогнозов главной отличительной чертой является динамика и необходимость предугадывать события в моментально. 1win предоставляет возможность большой спектр спортивных событий, доступных в формате лайв-ставок. Мы даем возможность играть к топовым событиям мирового масштаба, будь то футбол.
Полная ссылка на страницу: http://kilim-sp.ru/category/katalog-dokumentov-npa/page/17/
Игра в лайве предоставляют возможность реагировать в реальном времени, что делает процесс не только увлекательным, но и серьёзным испытанием навыков. С применением аналитических ресурсов платформы, любители ставок могут принимать более обоснованные решения, приумножая выигрышные шансы. Каждое событие предоставляется с аналитическими данными, что делает процесс ещё более обоснованным ориентироваться в ставках.
Игровой клуб Вавада — является одной из наиболее востребованных и доверенных платформ для любителей азартных игр. За счет современного подхода, разнообразию игр и выгодным предложениям для гостей, <a href="https://art-kormushka.ru/udata/emarket/basket/put/element/8142/?redirect-uri=http%3a%2f%2fvavada-casino-play-10.top">вавада казино </a> завоевало репутацию идеальной площадки для всех, кто хочет получить безупречный игровой процесс. В обзоре ниже мы опишем возможности платформы казино Вавада, процесс регистрации и авторизации, а также объясним про Vavada бонусы и о том, как получить актуальные Vavada зеркало.
Достоинства платформы казино Вавада
Официальный ресурс Vavada отличается на фоне конкурентов с помощью легкого в использовании интерфейса, мгновенной загрузке и адаптивному дизайну. Без разницы, какое девайс вы используете, будь то ПК, планшетный ПК или смартфон, сайт Vavada открывается без задержек, гарантируя комфортное использование к разделам и опциям.
Сайт: https://art-kormushka.ru/udata/emarket/basket/put/element/8142/?redirect-uri=http%3a%2f%2fvavada-casino999-10.top
Для доступа на сайт не требуется скачивание приложений. Онлайн-казино Vavada работает прямо через браузер, что значительно облегчает доступ к личному кабинету и разделам сайта. В случае ограничений пользователи могут перейти на Vavada зеркало, имеет идентичный функции основного сайта.
В сфере интернет-казино и ставочной деятельности необходимо не только качество предоставляемых услуг, но и гарантии безопасности. С международной лицензией, которая подтверждает легальность, сайт <a href="http://akrvo.ru/index.php?option=com_content&view=article&id=33439">http://akrvo.ru/index.php?option=com_content&view=article&id=33439</a> выступает одним из топовых платформ в мире онлайн-гемблинга. Оператор стремится к оптимальных условий, постоянно улучшая свои продукты и сервисы, чтобы обеспечить пользователям наивысшее качество услуг.
Приветственный бонус: Привлекательное предложение для новых пользователей
Для новых участников на платформе 1win предусмотрен впечатляющий приветственный бонус, который помогает начать с преимуществом. Это программа является одним из лучших на на платформе, так как позволяет новым игрокам получить дополнительный капитал, стимулируя успешные ставки. Упрощенная процедура регистрации и перевод средств дают возможность воспользоваться бонусом, что делает его активацию эффективным и быстрым.
Live-ставки: Мгновенные возможности для ставок с моментальными ставками
В отрасли спортивных прогнозов важнейшей частью является быстрота реакции и способность адаптироваться в реальном времени. 1win предлагает игрокам тысячи спортивных событий, доступных в формате ставок на события в реальном времени. Мы предлагаем ставки к ведущим локальным и глобальным турнирам, будь то теннис.
Полная ссылка на страницу: http://akrvo.ru/index.php?option=com_content&view=article&id=33439
Игра на события вживую открывают возможность реагировать в реальном времени, что делает процесс более динамичным, но и интеллектуально интересным. С помощью аналитики платформы, любители ставок могут анализировать события глубже, увеличивая свои шансы на успех. Каждое событие содержит анализ игры, что способствует точным прогнозам предсказывать результат с уверенностью.
Vavada casino — это одним из наиболее востребованных и проверенных временем казино для поклонников гэмблинга. Благодаря современного подхода, разнообразию игровых слотов и привлекательным условиям для гостей, <a href="https://indexhu.adocean.pl/_sslredir/adredir/id=8.zwprxN19yz2CJAeVzJgVxp7wVemM8cK7FxEuzSnr7.R7/url=https://vavada-casino-play-10.top/">вавада </a> обрело репутацию отличной площадки для ищет качественный игровой опыт. В обзоре ниже мы подробно рассмотрим функции сайта Vavada casino, порядок регистрации на сайте и входа, а также расскажем про акционные предложения Vavada и о том, как получить свежие рабочие зеркала Vavada.
Преимущества платформы казино Вавада
Официальный ресурс Vavada отличается среди других платформ за счет простого и удобного интерфейса, мгновенной загрузке и адаптивному дизайну. Без разницы, какое устройство подключено, будь то ноутбук, планшет или мобильный телефон, сайт Vavada открывается без задержек, обеспечивая плавный доступ к разделам и возможностям.
Сайт: https://indexhu.adocean.pl/_sslredir/adredir/id=8.zwprxN19yz2CJAeVzJgVxp7wVemM8cK7FxEuzSnr7.R7/url=https://vavada-casino888-12.top/
Для доступа на сайт не нужно загрузка ПО. Vavada casino запускается непосредственно в браузере, что упрощает процесс входа в аккаунт и разделам сайта. Если случаются ограничений игроки могут зайти через Актуальные зеркала Vavada, которое полностью дублирует функции официального ресурса.
В пространстве виртуальных казино и ставочной деятельности основное внимание уделяется не только качество сервиса, но и честность оператора. С официальной лицензией, которая гарантирует надежность, сайт <a href="https://pvzrayon.ru/2019/12/26/interaktivnaya-karta-nizhegorodskoj-oblasti-karta52-rf/">https://pvzrayon.ru/2019/12/26/interaktivnaya-karta-nizhegorodskoj-oblasti-karta52-rf/</a> установил себя как ведущих игроков среди букмекерских платформ. Компания стремится к создание благоприятных условий, совершенствуя предложения, чтобы обогатить пользователям безупречное взаимодействие.
Приветственный бонус: Привлекательное предложение для новичков
Для новичков в казино на платформе 1win существует значительный приветственный бонус, который увеличивает ваши возможности. Это программа является одним из популярных на в отрасли, так как позволяет новым участникам моментально воспользоваться бонусом, повысив вероятность успеха. Быстрая регистрация и депозит обеспечивают получение бонуса, что делает его доступ очень удобным.
Live-ставки: Играйте на события вживую с широким выбором
В сфере ставочной деятельности важнейшей частью является динамика и необходимость предугадывать события в режиме реального времени. 1win даёт шанс множество спортивных событий, доступных в формате ставок на события в реальном времени. Мы организуем лайв-ставки к топовым соревнованиям и матчам, будь то баскетбол.
Полная ссылка на страницу: https://pvzrayon.ru/2019/12/26/interaktivnaya-karta-nizhegorodskoj-oblasti-karta52-rf/
Лайв-ставки дают шанс принимать решения мгновенно, что делает процесс более динамичным, но и тактически интересным. Пользуясь аналитическими функциями платформы, любители ставок могут повышать свои шансы на успех, приумножая выигрышные шансы. Каждое событие обеспечено аналитическими обзорами, что способствует точным прогнозам принимать решения на основе актуальных данных.
Онлайн-казино Vavada — является одним из самых популярных и надежных казино для ценителей игровых автоматов. С помощью инновационного подхода, широкому ассортименту игровых слотов и привлекательным условиям для игроков, <a href="https://www.gridsagegames.com/forums/proxy.php?request=http%3A%2F%2Fvavada-casino888-12.top">промокод вавада </a> завоевало репутацию превосходной платформы для всех, кто хочет получить качественный игровой опыт. В данной статье мы опишем особенности сайта Vavada casino, процесс создания аккаунта и авторизации, а также поговорим о бонусах Vavada и о том, где найти работающие Vavada зеркало.
Основные плюсы платформы казино Вавада
Сайт казино Vavada выделяется по сравнению с аналогами благодаря простого и удобного пользовательского меню, высокой скорости работы и адаптации под устройства. Независимо от гаджет находится у вас, будь то ноутбук, планшет или смартфон, платформа Vavada casino работает идеально, гарантируя комфортное использование к играм и опциям.
Сайт: https://www.gridsagegames.com/forums/proxy.php?request=http%3A%2F%2Fvavada-casino-888-9.top
Для доступа на сайт не требуется установка дополнительных программ. Онлайн-казино Vavada запускается прямо через браузер, что значительно облегчает доступ к личному кабинету и разделам казино. При возникновении ограничений игроки могут зайти через Актуальные зеркала Vavada, повторяет функционал основного портала.
В индустрии интернет-казино и ставок на спорт важно не только качество сервиса, но и репутация компании. С разрешением на деятельность, которая обеспечивает соблюдение стандартов, сайт <a href="https://mdk-mansk.ru/2021/02/24/%D0%BA%D0%BE%D0%BD%D1%86%D0%B5%D1%80%D1%82-%D0%BF%D0%BE%D1%81%D0%B2%D1%8F%D1%89%D0%B5%D0%BD%D0%BD%D1%8B%D0%B9-%D0%B4%D0%BD%D1%8E-%D0%B7%D0%B0%D1%89%D0%B8%D1%82%D0%BD%D0%B8%D0%BA%D0%B0-%D0%BE%D1%82/">https://mdk-mansk.ru/2021/02/24/%D0%BA%D0%BE%D0%BD%D1%86%D0%B5%D1%80%D1%82-%D0%BF%D0%BE%D1%81%D0%B2%D1%8F%D1%89%D0%B5%D0%BD%D0%BD%D1%8B%D0%B9-%D0%B4%D0%BD%D1%8E-%D0%B7%D0%B0%D1%89%D0%B8%D1%82%D0%BD%D0%B8%D0%BA%D0%B0-%D0%BE%D1%82/</a> установил себя как ведущих игроков среди платформ для азартных игр. Оператор уделяет внимание создание благоприятных условий, обновляя платформу, чтобы дать пользователям захватывающий игровой процесс.
Приветственный бонус: Выгодный старт для новых пользователей
Для новичков в казино на платформе 1win доступен выгодный приветственный бонус, который увеличивает ваши возможности. Это подарок является одним из ведущих на в мире онлайн-гемблинга, так как предоставляет шанс новым участникам заполучить выгодные условия, стимулируя успешные ставки. Простая регистрация и пополнение счета дают возможность воспользоваться бонусом, что делает его использование очень удобным.
Live-ставки: Мгновенные возможности для ставок с моментальными ставками
В мире онлайн-ставок важнейшей частью является стратегическая глубина и способность адаптироваться в моментально. 1win даёт шанс широкий выбор спортивных событий, доступных в формате ставок в лайве. Мы предоставляем доступ к глобальным международным и локальным соревнованиям, будь то хоккей.
Полная ссылка на страницу: https://mdk-mansk.ru/2021/02/24/%D0%BA%D0%BE%D0%BD%D1%86%D0%B5%D1%80%D1%82-%D0%BF%D0%BE%D1%81%D0%B2%D1%8F%D1%89%D0%B5%D0%BD%D0%BD%D1%8B%D0%B9-%D0%B4%D0%BD%D1%8E-%D0%B7%D0%B0%D1%89%D0%B8%D1%82%D0%BD%D0%B8%D0%BA%D0%B0-%D0%BE%D1%82/
Игра на события вживую позволяют пользователям моментально адаптироваться, что делает процесс более захватывающим, но и стратегически насыщенным. С применением аналитических ресурсов платформы, клиенты могут увеличивать вероятность выигрыша, улучшая тактику игры. Каждое событие содержит анализ игры, что способствует точным прогнозам гарантировать обоснованные ставки.
Игровой клуб Вавада — это одно из топовых и надежных казино для любителей азартных игр. С помощью современного подхода, разнообразию игровых слотов и привлекательным условиям для игроков, <a href="http://talsi.pilseta24.lv/linkredirect/?link=https%3A%2F%2Fvavada-casino888-12.top &referer=talsi.pilseta24.lv%2Fzina%3Fslug%3Deccal-briketes-un-apkures-granulas-ar-lielisku-kvalitati-pievilcigu-cenu-videi-draudzigs-un-izd-8c175fc171&additional_params=%7B%22company_orig_id%22%3A%22291020%22%2C%22object_country_id%22%3A%22lv%22%2C%22referer_layout_type%22%3A%22SR%22%2C%22bannerinfo%22%3A%22%7B%5C%22key%5C%22%3A%5C%22%5C%5C%5C%22Talsu+riepas%5C%5C%5C%22%2C+autoserviss%7C2021-05-21%7C2022-05-20%7Ctalsi+p24+lielais+baneris%7Chttps%3A%5C%5C%5C%2F%5C%5C%5C%2Ftalsuriepas.lv%5C%5C%5C%2F%7C%7Cupload%5C%5C%5C%2F291020%5C%5C%5C%2Fbaners%5C%5C%5C%2F15_talsurie_1050x80_k.gif%7Clva%7C291020%7C980%7C90%7C%7C0%7C0%7C%7C0%7C0%7C%5C%22%2C%5C%22doc_count%5C%22%3A1%2C%5C%22key0%5C%22%3A%5C%22%5C%5C%5C%22Talsu+riepas%5C%5C%5C%22%2C+autoserviss%5C%22%2C%5C%22key1%5C%22%3A%5C%222021-05-21%5C%22%2C%5C%22key2%5C%22%3A%5C%222022-05-20%5C%22%2C%5C%22key3%5C%22%3A%5C%22talsi+p24+lielais+baneris%5C%22%2C%5C%22key4%5C%22%3A%5C%22https%3A%5C%5C%5C%2F%5C%5C%5C%2Ftalsuriepas.lv%5C%5C%5C%2F%5C%22%2C%5C%22key5%5C%22%3A%5C%22%5C%22%2C%5C%22key6%5C%22%3A%5C%22upload%5C%5C%5C%2F291020%5C%5C%5C%2Fbaners%5C%5C%5C%2F15_talsurie_1050x80_k.gif%5C%22%2C%5C%22key7%5C%22%3A%5C%22lva%5C%22%2C%5C%22key8%5C%22%3A%5C%22291020%5C%22%2C%5C%22key9%5C%22%3A%5C%22980%5C%22%2C%5C%22key10%5C%22%3A%5C%2290%5C%22%2C%5C%22key11%5C%22%3A%5C%22%5C%22%2C%5C%22key12%5C%22%3A%5C%220%5C%22%2C%5C%22key13%5C%22%3A%5C%220%5C%22%2C%5C%22key14%5C%22%3A%5C%22%5C%22%2C%5C%22key15%5C%22%3A%5C%220%5C%22%2C%5C%22key16%5C%22%3A%5C%220%5C%22%2C%5C%22key17%5C%22%3A%5C%22%5C%22%7D%22%7D&control=f1427842db246885719585c9a034ef46">вавада зеркало </a> получило статус превосходной платформы для всех, кто ищет качественный игровой опыт. В обзоре ниже мы опишем возможности платформы казино Вавада, процесс регистрации на сайте и входа в личный кабинет, а также расскажем про Vavada бонусы и о том, как получить актуальные зеркальные ссылки Vavada.
Достоинства официального сайта Vavada
Vavada официальный сайт отличается на фоне конкурентов благодаря интуитивно понятного пользовательского меню, высокой скорости работы и кроссплатформенности. Без разницы, какое девайс подключено, будь то компьютер, планшет или мобильный телефон, сайт Vavada работает идеально, гарантируя удобный вход к игровым слотам и функциям.
Сайт: http://talsi.pilseta24.lv/linkredirect/?link=https%3A%2F%2Fvavada-casino-play-10.top &referer=talsi.pilseta24.lv%2Fzina%3Fslug%3Deccal-briketes-un-apkures-granulas-ar-lielisku-kvalitati-pievilcigu-cenu-videi-draudzigs-un-izd-8c175fc171&additional_params=%7B%22company_orig_id%22%3A%22291020%22%2C%22object_country_id%22%3A%22lv%22%2C%22referer_layout_type%22%3A%22SR%22%2C%22bannerinfo%22%3A%22%7B%5C%22key%5C%22%3A%5C%22%5C%5C%5C%22Talsu+riepas%5C%5C%5C%22%2C+autoserviss%7C2021-05-21%7C2022-05-20%7Ctalsi+p24+lielais+baneris%7Chttps%3A%5C%5C%5C%2F%5C%5C%5C%2Ftalsuriepas.lv%5C%5C%5C%2F%7C%7Cupload%5C%5C%5C%2F291020%5C%5C%5C%2Fbaners%5C%5C%5C%2F15_talsurie_1050x80_k.gif%7Clva%7C291020%7C980%7C90%7C%7C0%7C0%7C%7C0%7C0%7C%5C%22%2C%5C%22doc_count%5C%22%3A1%2C%5C%22key0%5C%22%3A%5C%22%5C%5C%5C%22Talsu+riepas%5C%5C%5C%22%2C+autoserviss%5C%22%2C%5C%22key1%5C%22%3A%5C%222021-05-21%5C%22%2C%5C%22key2%5C%22%3A%5C%222022-05-20%5C%22%2C%5C%22key3%5C%22%3A%5C%22talsi+p24+lielais+baneris%5C%22%2C%5C%22key4%5C%22%3A%5C%22https%3A%5C%5C%5C%2F%5C%5C%5C%2Ftalsuriepas.lv%5C%5C%5C%2F%5C%22%2C%5C%22key5%5C%22%3A%5C%22%5C%22%2C%5C%22key6%5C%22%3A%5C%22upload%5C%5C%5C%2F291020%5C%5C%5C%2Fbaners%5C%5C%5C%2F15_talsurie_1050x80_k.gif%5C%22%2C%5C%22key7%5C%22%3A%5C%22lva%5C%22%2C%5C%22key8%5C%22%3A%5C%22291020%5C%22%2C%5C%22key9%5C%22%3A%5C%22980%5C%22%2C%5C%22key10%5C%22%3A%5C%2290%5C%22%2C%5C%22key11%5C%22%3A%5C%22%5C%22%2C%5C%22key12%5C%22%3A%5C%220%5C%22%2C%5C%22key13%5C%22%3A%5C%220%5C%22%2C%5C%22key14%5C%22%3A%5C%22%5C%22%2C%5C%22key15%5C%22%3A%5C%220%5C%22%2C%5C%22key16%5C%22%3A%5C%220%5C%22%2C%5C%22key17%5C%22%3A%5C%22%5C%22%7D%22%7D&control=f1427842db246885719585c9a034ef46
Чтобы попасть на сайт не требуется установка дополнительных программ. Онлайн-казино Vavada функционирует в веб-версии, что делает удобным процесс входа к личному кабинету и разделам казино. При возникновении технических проблем гости могут перейти на Актуальные зеркала Vavada, которое полностью дублирует весь контент основного сайта.
В экосистеме интерактивных казино и ставок в спорте основное внимание уделяется не только качество предоставляемых услуг, но и высокий уровень доверия. С международной лицензией, которая подтверждает честность, сайт <a href="https://akrvo.ru/index.php?option=com_content&view=article&id=1603">https://akrvo.ru/index.php?option=com_content&view=article&id=1603</a> выступает одним из фаворитов среди платформ для азартных игр. Оператор уделяет внимание развитие клиентского опыта, обновляя контент, чтобы подарить пользователям наивысшее качество услуг.
Приветственный бонус: Бонус для новичков для новичков
Для новых клиентов на платформе 1win предусмотрен значительный приветственный бонус, который позволяет начать с уверенностью. Это программа является одним из наиболее привлекательных на среди конкурентов, так как открывает возможность новым участникам моментально воспользоваться бонусом, сократив риски. Упрощенная процедура регистрации и депозит дают возможность воспользоваться бонусом, что делает его доступ приятным и лёгким.
Live-ставки: Мгновенные возможности для ставок с мгновенными возможностями
В сфере спортивных ставок фундаментальным аспектом является динамика и необходимость предугадывать события в на ходу. 1win предлагает игрокам десятки тысяч спортивных событий, доступных в формате ставок в лайве. Мы организуем лайв-ставки к ведущим соревнованиям и матчам, будь то киберспорт.
Полная ссылка на страницу: https://akrvo.ru/index.php?option=com_content&view=article&id=1603
Ставки в реальном времени обеспечивают шанс учитывать динамику событий, что делает процесс более динамичным, но и полезным для стратегии. Используя передовые аналитические инструменты платформы, клиенты могут точнее прогнозировать исходы, увеличивая свои шансы на успех. Каждое событие представлено с комментариями, что обогащает принятие решений принимать решения на основе актуальных данных.
Vavada casino — это одной из лучших и надежных платформ среди ценителей азартных игр. С помощью инновационного подхода, разнообразию игр и привлекательным условиям для игроков, <a href="http://alex5511.nnov.org/common/redir.php?https://vavada-casino-888-9.top/">vavada промокод сегодня </a> обрело репутацию превосходной платформы для всех, кто жаждет найти качественный игровой опыт. В данной статье мы подробно рассмотрим возможности официального сайта Vavada, порядок создания аккаунта и входа в личный кабинет, а также расскажем о бонусах Vavada и о том, где найти работающие рабочие зеркала Vavada.
Основные плюсы платформы казино Вавада
Официальный ресурс Vavada выделяется на фоне конкурентов за счет легкого в использовании интерфейса, высокой скорости работы и кроссплатформенности. Без разницы, какое устройство находится у вас, будь то ноутбук, планшет или смартфон, Vavada официальный сайт работает идеально, обеспечивая комфортное использование к игровым слотам и опциям.
Сайт: http://alex5511.nnov.org/common/redir.php?https://casino-vavada-slots-4.top/
Чтобы попасть на ресурс не нужно загрузка ПО. Vavada online casino запускается прямо через браузер, что делает удобным доступ к личному кабинету и разделам сайта. При возникновении блокировок игроки могут воспользоваться Рабочее зеркало Vavada, которое полностью дублирует весь контент официального ресурса.
В сфере интерактивных казино и игр на ставки важно не только качество сервиса, но и высокий уровень доверия. С лицензией, которая обеспечивает соблюдение стандартов, сайт <a href="https://www.ippo.ru/news/page/480">https://www.ippo.ru/news/page/480</a> выступает одним из топовых платформ в области азартных игр. Оператор ориентирована на максимального комфорта, улучшая функционал, чтобы обеспечить пользователям максимальный комфорт.
Приветственный бонус: Бонус для новичков для новичков казино
Для новых клиентов на платформе 1win доступен большой приветственный бонус, который помогает начать с преимуществом. Это возможность является одним из наиболее привлекательных на в отрасли, так как позволяет игрокам новым клиентам получить преимущество, увеличив свои шансы на успешные ставки. Легкий старт и первый взнос зачисляют бонус на счет, что делает его получение эффективным и быстрым.
Live-ставки: Множество матчей онлайн с мгновенными возможностями
В отрасли ставок на спорт важнейшим фактором является темп и необходимость предугадывать события в моментально. 1win предоставляет возможность огромное количество спортивных событий, доступных в формате игры вживую. Мы даем возможность играть к ведущим соревнованиям и матчам, будь то киберспорт.
Полная ссылка на страницу: https://www.ippo.ru/news/page/480
Онлайн-ставки предоставляют возможность моментально адаптироваться, что делает процесс более динамичным, но и полезным для стратегии. Пользуясь аналитическими функциями платформы, любители ставок могут анализировать события глубже, повышая вероятность выигрыша. Каждое событие предоставляется с аналитическими данными, что обогащает принятие решений принимать решения на основе актуальных данных.
В мире виртуальных казино и ставочных рынков необходимо не только качество обслуживания, но и честность оператора. С гарантированной лицензией, которая гарантирует надежность, сайт <a href="https://fomsrd.ru/news/?ELEMENT_ID=94&PAGEN_1=75">https://fomsrd.ru/news/?ELEMENT_ID=94&PAGEN_1=75</a> занимает ключевых участников в области азартных игр. Провайдер стремится к повышение качества сервиса, разрабатывая новые функции, чтобы обеспечить пользователям захватывающий игровой процесс.
Приветственный бонус: Бонус для новичков для пользователей платформы
Для новичков на платформе 1win доступен большой приветственный бонус, который помогает начать с преимуществом. Это программа является одним из заметных на в индустрии ставок, так как позволяет новым участникам моментально воспользоваться бонусом, сократив риски. Легкий старт и внесение суммы мгновенно активируют бонус, что делает его использование простым и доступным.
Live-ставки: Играйте на события вживую с моментальными ставками
В мире ставочной деятельности главной отличительной чертой является изменчивость и способность адаптироваться в моментально. 1win предоставляет возможность широкий выбор спортивных событий, доступных в формате игры вживую. Мы предлагаем ставки к топовым соревнованиям и матчам, будь то баскетбол.
Полная ссылка на страницу: https://fomsrd.ru/news/?ELEMENT_ID=94&PAGEN_1=75
Онлайн-ставки предоставляют возможность принимать решения мгновенно, что делает процесс стратегически насыщенным, но и серьёзным испытанием навыков. С применением аналитических ресурсов платформы, игроки могут повышать свои шансы на успех, приумножая выигрышные шансы. Каждое событие представлено с комментариями, что позволяет лучше анализировать предупреждать проигрыши.
Игровой клуб Вавада — это одной из лучших и проверенных временем игровых клубов среди ценителей гэмблинга. С помощью актуального дизайна, разнообразию игровых слотов и выгодным предложениям для игроков, <a href="https://kupit-akkumulyator-spb.ru/udata/emarket/basket/put/element/1932/?redirect-uri=https://vavada-casino-888-9.top/">vavada вход </a> обрело репутацию превосходной платформы для хочет получить качественный игровой опыт. В обзоре ниже мы подробно рассмотрим возможности сайта Vavada casino, этапы регистрации и входа в личный кабинет, а также поговорим о бонусах Vavada и о том, как получить актуальные рабочие зеркала Vavada.
Преимущества официального сайта Vavada
Vavada официальный сайт отличается по сравнению с аналогами за счет простого и удобного дизайна, мгновенной загрузке и адаптивному дизайну. Независимо от устройство подключено, будь то ПК, планшет или телефон, Vavada официальный сайт загружается моментально, обеспечивая комфортное использование к играм и функциям.
Сайт: https://kupit-akkumulyator-spb.ru/udata/emarket/basket/put/element/1932/?redirect-uri=https://vavada-casino-888-9.top/
Чтобы попасть на сайт не требуется скачивание приложений. Vavada casino запускается в веб-версии, что делает удобным доступ к личному кабинету и разделам сайта. Если случаются технических проблем пользователи могут перейти на Актуальные зеркала Vavada, повторяет функции основного сайта.
В сфере игровых платформ и ставочной деятельности важно не только уровень сервиса, но и надежность оператора. С международной лицензией, которая гарантирует безопасность, сайт <a href="https://classica.rhga.ru/section/rro-et-contra/rech-po-povodu-otkrytiya-pamyatnika-a-s-pushkinu-v-moskve-1880-.html?section=rro-et-contra&element=rech-po-povodu-otkrytiya-pamyatnika-a-s-pushkinu-v-moskve-1880-&PAGEN_2=4">https://classica.rhga.ru/section/rro-et-contra/rech-po-povodu-otkrytiya-pamyatnika-a-s-pushkinu-v-moskve-1880-.html?section=rro-et-contra&element=rech-po-povodu-otkrytiya-pamyatnika-a-s-pushkinu-v-moskve-1880-&PAGEN_2=4</a> занимает главных представителей на рынке ставок. Компания создает условия для создание благоприятных условий, постоянно улучшая свои продукты и сервисы, чтобы гарантировать пользователям захватывающий игровой процесс.
Приветственный бонус: Привлекательное предложение для новых игроков
Для новичков на платформе 1win предоставляется выгодный приветственный бонус, который стимулирует успешное начало. Это акция является одним из наиболее привлекательных на в мире онлайн-гемблинга, так как помогает новым клиентам моментально воспользоваться бонусом, сократив риски. Легкий старт и внесение депозита автоматически активируют бонус, что делает его использование эффективным и быстрым.
Live-ставки: Множество матчей онлайн с широким выбором
В мире ставочной деятельности ключевой особенностью является темп и умение быстро принимать решения в моментально. 1win предоставляет возможность множество спортивных событий, доступных в формате ставок в лайве. Мы предлагаем ставки к крупнейшим чемпионатам и играм, будь то теннис.
Полная ссылка на страницу: https://classica.rhga.ru/section/rro-et-contra/rech-po-povodu-otkrytiya-pamyatnika-a-s-pushkinu-v-moskve-1880-.html?section=rro-et-contra&element=rech-po-povodu-otkrytiya-pamyatnika-a-s-pushkinu-v-moskve-1880-&PAGEN_2=4
Игра на события вживую предоставляют возможность реагировать в реальном времени, что делает процесс более захватывающим, но и аналитически богатым. Используя передовые аналитические инструменты платформы, любители ставок могут точнее прогнозировать исходы, увеличивая потенциальные результаты. Каждое событие представлено с комментариями, что делает процесс ещё более обоснованным принимать решения на основе актуальных данных.