Table of Contents
Multiple Regression
Introduction
Multiple regression is a method to build a model described by more than one variable. In many cases, the model you are interested in is linear, so you can think this as an extension of linear regression. But you can include non-linear terms if you want to. In this page, I only explain the procedure of linear multiple regression, but the procedure of the non-linear version is basically the same (well, if you have a term of the multiplication of two factors, things become different. For more details, see the Interaction section of this page).
Let's say you have four factors (Factor1, Factor2, Factor3, and Factor4), and your measurement (e.g., time or some performance scores). What you want to do in multiple regression is to find a model of the measurement described by all or the subset of the four factors. So, you end up having a model like:
;#; ## Y = a + b * Factor1 + c * Factor2 + d * Factor3 + e * Factor4, ## ;#;
or maybe
;#; ## Y = a + b * Factor1 + c * Factor3, ## ;#;
when Factor2 and Factor4 don't contribute the prediction of Y much. Or you can also think about a model like:
;#; ## Y = a + b * Factor1 + c * Factor1 * Factor1 + d * Factor2 + e * Factor2 * Factor2. ## ;#;
In this case, you have quadratic terms for Factor1 and Factor2.
One important thing you need to know in multiple regression is that you need to assume what your model will look like. You don't assume any kind of models and still want to find the best model? Unfortunately, it is impossible. Intuitively, if you don't assume any model, your search space for the model become infinite, and you cannot stop the search. This is like No-free lunch theorem in machine learning and optimization. You need to pay price (i.e., an assumption of the model) to get a lunch (i.e., a good model).
Thus, before starting multiple regression, you don't really know which factors you should use for your model. But you need to know what terms you will have (e.g., linear terms, quadratic terms, logarithmic terms, and interaction terms). In many cases, a linear model (a model with only linear terms) should work well. So, if you don't have any particular model in mind, try a linear model. In the example used in this page, we assume a linear model.
Another thing I should mention is whether you have any random effect. If so, you have to do multi-level linear regression. It is not kinda straightforward to define what a random effect is, but for example, if you factor is a within-subject factor, your grouping factor (e.g., participants) is usually treated as a random effect. I explain this in a separate page.
Model selection
Once you assume the model, you need to figure out which factors (independent variables) you include in your model. This is called model selection (I think it should be called variable selection though). In some cases, you already know what factors you want to include. In this case, you do not have to do any automatic way to choose the model (described below). In other cases, you want to find the optimal model under your assumption. In this case, there are several ways to do model selection.
One simple question you may have is why we just can't use all of the factors. This is totally fine, and in terms of the goodness of fit, this will be the best model in general. Intuitively, more independent variables or factors you have, more information you get, and more accurate your model becomes (for the data you have). This may be ok if you only have a small number of variables. But if you have many independent variables, your model may become too large and obscure important factors. And a large model (a model with many factors) is generally harder to interpret particularly when it contains many interaction terms. If you want to use the model created by multiple regression for prediction (predicting Y for new data), having too many variables might cause overfitting. Thus, the best model in multiple regression means a model which explains the measurement well with a smaller set of variables.
Comprehensibility
One subjective metric is whether each of the terms is really meaningful or not. Remember that the objective of multiple regression is to find a model that explains your Y. So, each term more or less should explain what it means in the context of the model. If you use a linear model, this shouldn't be a problem. But if you have other complicated terms, make sure you can explain them.
Comprehensibility should be used with AIC or cross validation explained later.
Akaike Information Criterion (AIC)
AIC is a common metric used in model selection. AIC is defined as follows:
AIC = -2 log (L) + 2 k,
where L is the likelihood of the model, and k is the number of variables in the model. If your model is far from the measurement (in other words, the goodness of fit is low), L becomes really small (e.g., log(L) becomes negative hundreds) , and AIC becomes large. If you have many variables, AIC becomes large too. The model whose AIC is the minimum among all the possible models is considered as the best model.
In many cases, AIC works well. In R, AIC is automatically calculated in model selection, and the best model will be automatically selected (see below for more details).
Cross Validation
Another common way to determine the best model is cross validation. This should be a familiar concept if you have some knowledge about machine learning. k-fold cross validation means that you split the data into k exclusive chunks of data (i.e., one data point only belongs to one chunk). We then build a model with k-1 chunks, and test the model with the rest of the data. We will repeat this until each chunk has been used for testing. In the testing phase, the error (i.e., the difference between the value predicted by the model and the real measurement) is calculated, and we pick up the model which shows the smallest errors as the best model.
Understanding fixed effects
Once you figure out the model, you need to examine how much each factor contributes to changes of the dependent variable. You can do this in two ways (both are technically the same though).
- Looking at the estimated coefficient for each factor and its t statistics and p value.
- Looking at the F statistics and p value for each factor by doing ANOVA.
Here, ANOVA is used to compare two different linear models (one is what you have built, and the other is a model only with the intercept). We will look into how to do these in the example below.
R code example
Model selection example
In this example, our goal is to find a linear model explained by multiple variables (i.e., a model which only includes linear terms). The procedure is basically the same even if you want to include quadratic or other kinds of non-linear terms.
We are going to use the example included in lm. (I couldn't come up with a good example of data. If you come with the data which look like what we will get in HCI research, let me know!)
You may have a pop-up window. Once you click the window, you will see some graphs. You don't really need to understand what those graphs are for this example. We are going to use the data named “swiss”. You can see what swiss looks like by doing this.
I omit the output because it is fairly long, but you will see that you have six values (Fertility, Agriculture, Examination, Education, Catholic, and Infant.Mortality). What we want to do here is to build a linear model for Fertility with using the other five variables. So let's create a linear model with using all of the five variables.
Now we move on to model selection. One way of model selection is backward. The backward model selection means that we are trying to find the best model by starting the model which includes all the variables and removing the least important variable (i.e., the variable which least contribute to explaining the variance of data) one by one. You can use step() function for this.
Let's take a look at the first part (from the line of “Start: AIC=190.69” and before the line of “Step: AIC=189.86”). The first line says that AIC for the model with all of the five variables is 190.69, and this is our starting point of the backward model selection. The line starting with “- Examination” says that if we remove the term of Examination, AIC becomes 189.86, which means the model becomes improved. The other lines also say the same thing: it shows AIC of the model if we remove the terms one by one. So, from this part of the results, we can remove Examination.
Now our model is Fertility ~ Agriculture + Education + Catholic + Infant.Mortality and AIC is 189.86. Let's try to remove one more variable from this new model. The results of this attempt is shown as the second part (from the line of “Step: AIC=189.86”). This time, AIC become increased if we remove any of the four variables, which means our model becomes worse if we remove any of the variables. Thus, we stop here, and the current model is the best model we can find through backward model selection. Now, take a look at more details of our model.
The adjusted R-squared is 0.67, which means that this model explains 67% of the variances that the data have. You can also see the coefficients for the model under “Estimate” column. Thus, the best model we have found is:
;#; ## Fertility = 62.1013 - 0.1546 * Agriculture - 0.9803 * Education + 0.1247 * Catholic + 1.0784 * Infant.Mortality. ## ;#;
You can also calculate the confidence interval for the effect size (R-squared) as follows.
N is the sample size, and K is the number of the factor, which is 4 in this case. You get the result like this.
Thus, the effect size is 0.67 with 95% CI = [0.44, 0.78].
If you want to try forward&backward model selection, you can change the option of step() funciton.
Generally, the backward model selection works well. But as you can see above, step() function doesn't really cover all possible models. If you want to look into the goodness of every possible model, you can use functions in wle package.
If you want to do model selection based on AIC, you can do this.
0 and 1 mean whether that term is used in the model. The results are already ordered by AIC, so the first one is the best model. It is Fertility ~ Agriculture + Education + Catholic + Infant.Mortality, which is the same results by step() function.
Or you can do model selection based on cross validation.
In this case, we still have Fertility ~ Agriculture + Education + Catholic + Infant.Mortality as the best model.
Interpreting the resulted model
Once you figure out what model is the best or you already know what model you want to use, the next step is to interpret the model you built. We use the example above to go through how to do this. First, let's review model2 again.
Again, we have four factors (Agriculture, Education, Catholic, and Infant.Mortality). This output is also telling us the estimated coefficient for each factor. However, this does not tell us how precise this estimation is. We first look at the standard error for each factor by doing functions in the arm package:
Or you can visualize this by using coefplot().
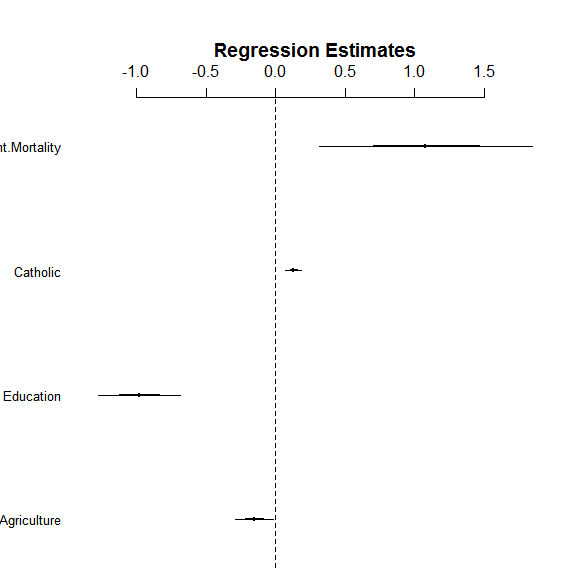
This coefplot gives you a very good understanding on how much each factor affects the dependent variable. A think line represents the 1SD range, and a thin line represents the 2SD range. In this example, Infant.Mortality has a positive effect on Fertility, but its effects can vary. On the other hand, Education shows a negative effect. Both Catholic and Agriculture show small effects, but their coefficients would not be likely to be zero (so likely to have some effects).
In a more numeric manner, you can use summary().
Important stats here are: Multiple R-squared (0.6993), Adjusted R-squared (0.6707), Estimate, and p values. The first two indicate the goodness of fit. The other two indicate whether each coefficient would be likely to be non-zero. For example, the above results show that all factors have significant effects (i.e., the coefficients of all factors are not non-zero) with 95% confidence. In this way, you can examine whether each factor has an effect in a more quantitative manner.
Another way to examine the effect of each factor is to run ANOVA. For example,
If you are knowledgeable about the relationship between t stats and F stats, you easily notice that this result is pretty much the same as what we got with summary() (the t stats is just the root square of the F stats because the degree of freedom is 1). But remember that ANOVA have different types of sum of squares. For example, you can use anova(model) (without capitalization) or Anova(model2, type=“II”) to use ANOVA with Type I SS or Type II SS, respectively. But here, I stick with Type III SS.
Multicollinearity
One important thing you should know before finishing up your analysis is multicollinearity. This means that one of the variables can be explained as a linear model of the other variables. In other words, One of the variables has a strong correlation with other variables. In the case of multicollinearity, when one of the variables increases, the effect by the other variables also get increased. This often causes unnecessary drastic changes on the prediction by the model.
You can calculate VIF (Variance Inflation Factor) to see whether any multicollinearlity exists. In R, calculating VIF is easy, but you need to include car package.
Generally, if VIF is larger than 10, it is considered that the variable has multicollinearity. So, you should consider removing that variable from your model. If VIF is larger than 2.5, you may need to be careful about that variable. If we do the same thing with the model including all the independent variables, the result is like this.
So, Examination is the first candidate to remove, and as we have seen, it doesn't really contribute to the prediction much. Thus, it should be removed.
Another way to examine multicollinearlity is to look at the correlation of the two of the independent variables. I wrote a code to do this quickly.
Copy the code above, and paste it into your R console. Then, run the following code.
You will get the following graph.
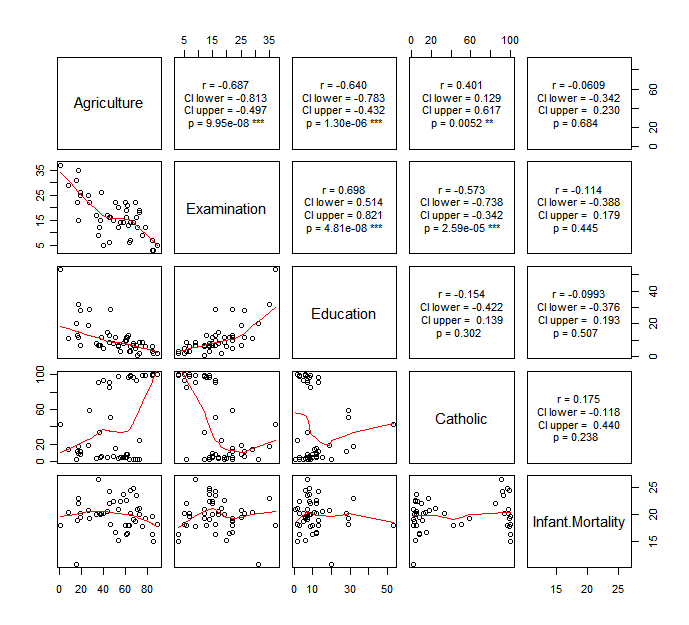
It is kinda hard to say which variable we should consider to remove from this, but I would say if you see any significant strong correlation, you probably should be careful about if it may cause multicollinearity. In this case, Agriculture and Examination are variables we may have to be careful about.
How to report
Once you are done with your analysis, you will have to report the following things:
- Your model,
- How you chose the model (either you just defined, you used AIC, or you used CV),
- Multiple R-squared and adjusted R-squared,
- Estimated value for each coefficient, and
- Significant effects with the t or F value and p value (if any).
For the last two items, you can say something like “Agriculture showed a significant effect (F(1, 44)=5.14, p<0.05). The estimated coefficient was -0.15 (SE=0.07).”
In some cases, it may be acceptable that you only report the direction of each significant effect (positive or negative) if you do not really care about the actual value of the coefficient. But I think you should report at least whether each significant effect contributes to the dependent variable in a positive or negative way.
Interaction effects in multiple regression
Another interesting thing (yet complicated thing) you can do in multiple regression is to include interaction effects in your model. Let's say you have two variables, Factor1 and Factor2. You can think about a model like this:
;#; ## Y = a + b * Factor1 + c * Factor2 + d * Factor1 * Factor2. ## ;#;
Like ANOVA, the term Factor1 * Factor2 is called an interaction effect. Including an interaction effect means that the effect by one variable changes depending on other variables. In the model above, if d is positive, Factor2's effect becomes larger as Factor1 becomes large (or vice versa). In R, you can express the model above like
or equivalently,